Настоящее изобретение согласно одной из его особенностей относится в целом к поддержанию связи в коммуникационной среде, точнее, к облегчению обмена данными между изолированными областями памяти коммуникационной среды.
Для обмена данными между изолированными областями памяти коммуникационной среды обычно применяются сетевые технические средства и протоколы. В частности, данные могут передаваться от одной изолированной области памяти другой изолированной области памяти с использованием протокола управления передачей/протокола IP (TCP/IP) по каналу сети Ethernet. Существующие сетевые технические средства позволяют передавать данные синхронно или асинхронно. Выбор осуществляется исключительно отправителем.
При синхронной пересылке данных работа отправителя приостанавливается до завершения пересылки данных. С другой стороны, при асинхронной пересылке данных отправитель может продолжать действовать.
Преодоление недостатков известного уровня техники и достижение преимуществ обеспечивается в способе обеспечения связи в коммуникационной среде, включающему: получение процессором коммуникационной среды от отправителя коммуникационной среды предварительного разрешения на преобразование синхронной пересылки данных в асинхронную пересылку данных, причем предварительное разрешение включает получение указания блока памяти для слежения за асинхронной пересылкой данных; получение процессором от отправителя запроса на передачу данных получателю коммуникационной среды; инициирование процессором передачи данных получателю, выполняемой с использованием синхронной пересылки данных; установление процессором необходимости преобразования синхронной пересылки данных в асинхронную пересылку данных; и выполняемое при указанном установлении автоматическое преобразование процессором синхронной пересылки данных в асинхронную пересылку данных для завершения передачи данных получателю, при этом автоматическое преобразование является независимым от любых действий отправителя, кроме предварительного разрешения.
Объектами изобретения являются также компьютерная система, сконфигурированная для осуществления описанного выше способа, а также энергонезависимый машиночитаемый носитель данных, в котором хранятся команды, считываемые и выполняемые устройством обработки данных для осуществления описанного выше способа.
Технический результат, достигаемый при осуществлении изобретения, заключается в облегчении передачи данных в коммуникационной среде за счет указания блока памяти для слежения за асинхронной пересылкой данных, что, в частности, позволяет отправителю регулировать максимальное число не выполненных запросов асинхронной пересылки и автоматизирует асинхронную пересылку данных.
Дополнительные признаки и преимущества изобретения реализованы посредством приемов, раскрытых в описанных вариантах осуществления. В описании подробно рассмотрены другие варианты осуществления и особенности, считающиеся частью заявленного изобретения.
Одна или несколько особенностей настоящего изобретения конкретно охарактеризованы и отдельно заявлены в формуле изобретения, следующей за описанием. Перечисленные выше и другие задачи, признаки и преимущества изобретения станут ясны из следующего далее подробного описания в сочетании с сопровождающими его чего чертежами, на которых:
на фиг. 1 проиллюстрирован один из примеров коммуникационной среды, в которой содержится и/или используется одна или несколько особенностей настоящего изобретения,
на фиг. 2 - примеры областей памяти, связанных с проиллюстрированными на фиг. 1 логическими разделами согласно одной из особенностей настоящего изобретения,
на фиг. 3 - один из примеров исходящей синхронной пересылки данных, используемой согласно одной из особенностей настоящего изобретения,
на фиг. 4 - примеры структур управления, используемых для автоматического преобразования синхронной пересылки данных в асинхронную пересылку данных, согласно одной из особенностей настоящего изобретения,
на фиг. 5А - один из вариантов осуществления логики автоматического преобразования синхронной пересылки данных в асинхронную пересылку данных согласно одной из особенностей настоящего изобретения;
на фиг. 5Б - один из наглядных примеров успешного завершения асинхронной пересылки данных согласно одной из особенностей настоящего изобретения;
на фиг. 6 - один из вариантов осуществления компьютерного программного продукта, в котором содержится одна или несколько особенностей настоящего изобретения,
на фиг. 7 - один из вариантов осуществления главной компьютерной системы, в которой содержится и используется одна или несколько особенностей настоящего изобретения,
на фиг. 8 - дополнительный пример компьютерной системы, в которой содержится и используется одна или несколько особенностей настоящего изобретения,
на фиг. 9 - другой пример компьютерной системы, содержащей компьютерную сеть, в которой содержится и используется одна или несколько особенностей настоящего изобретения,
на фиг. 10 - один из вариантов осуществления различных элементов компьютерной системы, в которой содержится и используется одна или несколько особенностей настоящего изобретения,
на фиг. 11А - один из вариантов осуществления блока выполнения проиллюстрированной на фиг. 10 компьютерной системы, в которой содержится и используется одна или несколько особенностей настоящего изобретения,
на фиг. 11Б - один из вариантов осуществления блока выполнения команд перехода проиллюстрированной на фиг. 10 компьютерной системы, в которой содержится и используется одна или несколько особенностей настоящего изобретения,
на фиг. 11В - один из вариантов осуществления блока выполнения команд загрузки/сохранения проиллюстрированной на фиг. 10 компьютерной системы, в которой содержится и используется одна или несколько особенностей настоящего изобретения, и
на фиг. 12 - один из вариантов осуществления главной компьютерной системы эмуляции, в которой содержится и используется одна или несколько особенностей настоящего изобретения.
Согласно одной из особенностей настоящего изобретения предложено средство автоматического преобразования синхронной пересылки данных в асинхронную пересылку данных. Например, синхронная пересылка данных автоматически преобразуется в асинхронную пересылку данных, если определено, что завершение пересылки данных задерживается, например, получатель данных не способен принять данные во время пересылки. Преобразование синхронной пересылки данных в асинхронную пересылку данных является автоматическим в том смысле, что оно осуществляется не по запросу отправителя (или получателя), а отправителю (или получателю) не известно о преобразовании в момент его инициации. Кроме того, в момент преобразования отправителю (или получателю) не требуется предпринимать какое-либо действие или вмешиваться в преобразование.
Один из вариантов осуществления коммуникационной среды, в которой содержится и/или используется одна или несколько особенностей настоящего изобретения, описан со ссылкой на фиг.1. В одном из примеров коммуникационная среда 100 содержит комплекс 102 центральных процессоров (CPC), который основан на системе z/Architecture®, предлагаемой International Business Machines Corporation (IBM®). Особенности системы z/Architecture® описаны в публикации № SA 22-7832-08 "IBM® z/Architecture Principles of Operation" (август 2010 г.), которая в порядке ссылки во всей полноте включена в настоящую заявку. Одной из систем, в которых может содержаться комплекс 102 центральных процессоров, является система zEnterprise 196 (z196), предлагаемая International Business Machines Corporation (Армонк, штат Нью-Йорк, США). IBM® и z/Architecture® являются зарегистрированными товарными знаками, а zEnterprise 196 и z196 являются товарными знаками International Business Machines Corporation (Армонк, штат Нью-Йорк, США). Названия других продуктов, используемые в описании, могут являться зарегистрированными товарными знаками, товарными знаками или названиями продуктов International Business Machines Corporation или других компаний.
Комплекс 102 центральных процессоров содержит, например, один или несколько разделов 104, гипервизор 106, один или несколько центральных процессоров 108 и один или несколько компонентов подсистемы 110 ввода-вывода. В этом примере одним или несколькими разделами 104 являются логические разделы (также известные как LPAR), в которых содержится набор аппаратных ресурсов системы в форме отдельной виртуальной системы.
Каждый логический раздел 104 способен функционировать как отдельная система. Иными словами, каждый логический раздел может независимо возвращаться в исходное состояние, если желательно, в него может осуществляться начальная загрузка операционной системы 120, и он может оперировать различными программами. Операционная система или прикладная программа, выполняемая в логическом разделе, выглядит как имеющая доступ ко всей системе в целом, но, в действительности, для нее доступна только ее часть. За счет сочетания аппаратного обеспечения и лицензионного внутреннего кода (LIC) также называемого аппаратно-программным обеспечением, предотвращается взаимное влияние программы в одном логическом разделе и программы в другом логическом разделе. Это позволяет нескольким различным логическим разделам использовать один или множество физических процессоров в режиме квантования времени. В этом примере несколько логических разделов имеют резидентную операционную систему 120, которая может различаться в одном или нескольких логических разделах. В одном из вариантов осуществления операционной системой 120 является операционная система z/OS®, предлагаемая компанией International Business Machines Corporation (Армонк, штат Нью-Йорк, США).
В контексте настоящего изобретения аппаратно-программное обеспечение содержит, например, микрокод, милликод и/или макрокод процессора. Оно содержит, например, команды аппаратного уровня и/или структуры данных, используемые при реализации высокоуровневого машинного кода. В одном из вариантов осуществления оно содержит, например, собственный код, который обычно представляет собой микрокод, содержащий выверенное программное обеспечение или характерный для базового аппаратного обеспечения и управляющий доступом операционной системы к аппаратному обеспечению системы.
Логическими разделами 104 управляет гипервизор 106, который реализован посредством аппаратно-программного, обеспечения действующего в центральных процессорах 108. Одним из примеров гипервизора 106 является администратор ресурсов процессора/системы (Processor Resource/Systems Manager (PR/SM™)), предлагаемый компанией International Business Machines Corporation (Армонк, штат Нью-Йорк, США).
Центральные процессоры 108 являются физическими ресурсами процессора, которые выделяются логическим разделам. Например, логический раздел 104 содержит один или несколько логических процессоров, при этом каждый из них отображает все или часть физических ресурсов 108 процессора, выделенных разделу. Логические процессоры конкретного раздела 104 могут быть закреплены за разделом, и в этом случае ресурсы базового процессора резервируются за этим разделом; или могут использоваться совместно с другим разделом, и в этом случае ресурсы базового процессора потенциально доступны для другого раздела.
Логические разделы 104 и гипервизор 106 в каждом случае могут содержать одну или несколько программ, постоянно хранящихся в соответствующих частях основной памяти 150, связанной с центральными процессорами. В одном из примеров каждому логическому разделу выделена часть основной памяти, именуемая областью памяти, как подробнее описано далее со ссылкой на фиг.2.
Как показано на фиг.2, в одном из вариантов осуществления основная память 150 содержит множество областей памяти, каждая из которых имеет диапазон адресов в основной памяти. Область памяти может быть выделена какому-либо объекту, такому как логический раздел, или другому объекту. В примере, проиллюстрированном на фиг.2, две области памяти выделены, соответственно, двум логическим разделам. Одна область памяти именуется областью 202 памяти отправителя, а другая область памяти именуется областью 204 памяти получателя, поскольку далее дополнительно описана связь между отправителем и получателем. В области 202 памяти отправителя содержится, например, одна или несколько входных очередей 210, одна или несколько выходных очередей 212 и один или несколько буферов 214. Аналогичным образом, в области 204 памяти получателя одна или несколько входных очередей 220, одна или несколько выходных очередей 222 и один или несколько буферов 224. Использование очередей и буферов дополнительно описано далее.
Отдельные области памяти являются изолированными друг от друга в том смысле, что данные не могут записываться непосредственно из одной области памяти в другую область памяти без контроля со стороны аппаратно-программного обеспечения. В одном из примеров для пересылки данных из одной области памяти в другую область памяти применяется сетевая пересылка с использованием, например, протокола TCP/IP по каналам сети Ethernet. В одном из конкретных примеров для осуществления пересылки применяется предлагаемая компанией International Business Machines Corporation технология под названием HiperSockets™.
HiperSockets™ обеспечивает возможность установления высокоскоростной связи по протоколу TCP/IP в комплексе центральных процессоров. При этом исключается потребность в какой-либо физической кабельной сети или внешних сетевых соединениях между серверами, действующими в различных логических разделах. Вместо этого связь осуществляется посредством системной памяти процессора. HiperSockets™ реализована на основе протокола OSA-Express прямого ввода-вывода с организацией очередей (QDIO). Аппаратно-программное обеспечение эмулирует уровень управления каналом интерфейса OSA-Express QDIO.
Пересылка данных из одной области памяти в другую область памяти с использованием сетевых технических средств является, например, синхронным, и в этом случае после инициации пересылки данных работа отправителя приостанавливается до завершения пересылки. Один из примеров синхронной пересылки данных из одной области памяти в другую описан ссылкой на фиг.3.
Как показано на фиг.3, отправитель 300, такой как стек протоколов TCP/IP или программа, действующая в области памяти отправителя, инициирует запрос на передачу данных получателю 310, такому как другой стек протоколов TCP/IP или программа, например в области памяти получателя. Поскольку в этом примере область памяти получателя изолирована от области памяти отправителя, для осуществления синхронной передачи данных от отправителя получателю используется протокол сетевой связи. Использование синхронной пересылки данных обеспечивает канал высокоскоростной прямой связи с малым временем ожидания между отправителем и получателем путем пересылки данных из одной области памяти в другую под управлением аппаратно-программного обеспечения. В одном из примеров пересылка данных из одной области памяти в другую осуществляется посредством HiperSockets™. Этот механизм пересылки является очень эффективным, поскольку получатель может принимать данные с той же или более высокой скоростью, чем скорость передачи данных отправителем.
Для пересылки данных отправитель извлекает данные, которые содержатся в выбранном буфере 320 данных, и помещает их в выходную очередь 330 отправителя (OUTQ). Например, в выходную очередь помещается указатель 332 выбранного буфера данных. Затем отправитель 300 передает процессору сигнал 340 осуществления пересылки данных получателю 310. В одном из примеров сигнал передается аппаратно-программному обеспечению 350 процессора, которое собирается осуществлять пересылку; тем не менее, в других примерах сигнал передается не аппаратно-программному обеспечению, а другому коду и/или аппаратному обеспечению процессора.
В ответ на прием сигнала с запросом пересылки данных от отправителя получателю аппаратно-программное обеспечение копирует данные из выходной очереди отправителя и помещает их во входную очередь 360 получателя (INQ). Например, данные копируются в пустой буфер 370, а указатель 372 этих данных помещается во входную очередь 360. После завершения пересылки данных аппаратно-программное обеспечение передает отправителю сигнал завершения пересылки. Пока отправитель не примет этот сигнал завершения, его работа приостанавливается, и он не может выполнять какие-либо другие операции.
В качестве одного из конкретных примеров, чтобы передать сигнал процессору, отправитель передает команду адаптера сигналов (SIGA, от английского - Signal Adapter) с указанием функции записи (SIGA-w), которая сообщает процессору о том, что в одной или нескольких выходных очередях содержатся данные для передачи получателю. Функция записи задана в виде кода функции, содержащегося в первом общем регистре общего назначения, используемом командой, а во втором регистре общего назначения, используемом командой, указан адрес сетевого соединения (например, идентификатор подсистемы) функции записи. Кроме того, в еще одном, третьем регистре общего назначения, используемом командой, заданы выходные очереди.
В этом конкретном примере очереди реализованы в виде очередей прямого доступа с организацией очередей (QDIO), при этом каждая очередь имеет множество связанных с ней буферов, а также различную управляющую информацию. В одном из вариантов осуществления очередь QDIO содержит структуры данных, описывающие очередь, а также блоки буферных запоминающих устройств, которые используются для пересылки данных. В качестве одного из примеров, структуры данных множества запоминающих устройств, называемые компонентами очереди, которые собирательно описывают характеристики очереди и обеспечивают средства управления для обмена данными, включают, например:
блок информации очереди (QIB), в котором содержится информация о совокупности входных и выходных очередей QDIO. В QIB содержится адрес блока информации из списка запоминающих устройств (SLIB) для входных очередей и адрес SLIB для выходных очередей.
Для каждой очереди существует один SLIB, и в каждом SLIB содержится информация об очереди и о каждом буфере очереди. Каждый SLIB имеет заголовок и один или несколько элементов, называемых элементами блока информации из списка запоминающих устройств (SLIBE), в которых содержится информация о каждом из буферов очереди. В одном из примеров каждый блок информации из списка запоминающих устройств содержит адрес следующего блока информации из списка запоминающих устройств, адрес списка запоминающих устройств (SL) и адрес блока состояния списка запоминающих устройств (SLSB).
Для каждой очереди определен один список запоминающих устройств, который содержит, например, 128 записей, по одной на каждый из буферов очереди. Список запоминающих устройств содержит информацию о местоположениях буферов ввода-вывода в основной памяти. В каждой записи содержится абсолютный адрес списка адресов блоков запоминающих устройств (SBAL). Каждый список адресов блоков запоминающих устройств содержит список абсолютных адресов блоков запоминающих устройств, которые в совокупности образуют один из буферов данных, связанных с каждой очередью.
В состав каждого SBAL входит запись из списка блоков запоминающих устройств (SBALE). В каждом SBALE содержится абсолютный адрес блока запоминающего устройства. В совокупности блоки запоминающих устройств, адресуемые всеми записями отдельного SBAL, образуют один из множества возможных буферов QDIO очереди QDIO. В одном из примеров очередь QDIO может содержать 128 связанных с ней буферов QDIO.
В SLSB содержатся индикаторы состояния, которые обеспечивают информацию о состоянии буферов, которые образуют очередь.
Дополнительные подробности, касающиеся SIGA, очередей QDIO и соответствующих структур управления, описаны в патенте US 6332171 B1 под названием "Self-Contained Queues With Associated Control Information For Receipt And Transfer Of Incoming And Outgoing Data Using A Queued Direct Input-Output Device" на имя Baskey и др., выданном 18 декабря 2001 г.; патенте US 6345241 B1 под названием "Method And Apparatus For Simulation Of Data In a Virtual Environment Using A Queued Direct Input-Output Device" на имя Brice и др., выданном 5 февраля 2002 г.; патенте US 6519645 B2 под названием "Method And Apparatus For Providing Configuration Information Using A Queued Direct Input-Output Device" на имя Markos и др., выданном 11 февраля 2003 г.; и патенте US 7941799 B2 под названием "Interpreting I/O Operation Requests From Pageable Guests Without Host Intervention" на имя Easton и др., выданном 10 мая 2011 г.
Когда при описанной обработке получатель не способен использовать пустые буферы с такой же скоростью, с которой отправитель передает данные, на стороне отправителя увеличивается время ожидания и затраты ресурсов ЦП в силу синхронной природы протокола. Когда пустой буфер недоступен для получателя, у отправителя существует два варианта. Он может пойти на затраты ресурсов на постановку в очередь невыполненной операции и последующую повторную передачу данных тому же получателю или отбросить данные, чтобы протокол связи более высокого уровня, такой как TCP/IP, мог снова привести в действие операцию. Сложности постановки в очередь и повторной передачи данных заключаются в том, что для этого не только требуется восстановление дополнительных циклов ЦП, но потенциально могут блокироваться или задерживаться последующие передачи отправителем данных другим адресатам, которые могут быть способны принимать поступающие данные.
В виртуальных средах, в которых множество серверов (например, отправители, получатели) могут совместно использовать ресурсы ЦП, с большей вероятностью возникают ситуации, в которых получатель может быть не способен поддерживать скорость, с которой различные отправителю передают ему данные. Это обычно происходит, когда гипервизор, такой как PR/SM управляет диспетчеризацией серверов в различных доступных совместно используемых процессорах. Задача решается, когда между отправителем и совместно используемым ресурсом ЦП имеются гипервизоры множества уровней. Это имеет место, например, когда отправитель действует в виртуальной машине под управлением z/VM®, которая также действует в логическом разделе. В данном случае два гипервизора должны осуществлять диспетчеризацию сервера таким образом, чтобы он своевременно восполнял пустые буферы.
Своевременная диспетчеризация получателя не создает затруднений при наличии достаточных доступных ресурсов ЦП. Синхронная пересылка данных прерывается только при ограниченности ресурсов ЦП в течение короткого или длительного времени. Так, согласно одной из особенностей настоящего изобретения отправитель способен использовать синхронную передачу данных с малым временем ожидания в среде без ограничения ресурсов ЦП с одновременным устранением сопутствующих трудностей и затрат, когда ресурсы ЦП становятся ограниченными. Это достигается путем преобразования протокола синхронного обмена в протокол асинхронного обмена, когда получатель не способен поддерживать скорость передачи данных отправителем. В одном из вариантов осуществления протокол синхронного обмена преобразуется в протокол асинхронного обмена автоматически без какого-либо уведомления отправителя (т.е. отправителю не требуется совершать какое-либо действие в момент преобразования). Тем самым отправитель освобождается от необходимости выполнять восстановление какого-либо типа или блокировать или замедлять передачу данных другим получателям, когда ресурсы ЦП становятся ограниченными для конкретного получателя. Кроме того, синхронная передача данных получателю с ранее ограниченными ресурсами может возобновляться автоматически.
Согласно одной из особенностей настоящего изобретения предложено средство организации отправителем очереди данных в своей памяти, пока получатель не обеспечит пустые буферы, которые могут принять данные. С целью облегчения этого используется одна или несколько структур управления, описанных со ссылкой на фиг.4. Например, отправитель выделяет пустой блок 400 в своей каждой незавершенной асихронной пересылке. В одном из примеров число этих блоков в любой момент времени может составлять X, при этом X является зависящей от модели и конфигурируемой величиной. X отображает число одновременных запросов асинхронной пересылки, разрешенных отправителем. Этот блок памяти, именуемый блоком асинхронных операций QDIO (прямого ввода-вывода с организацией очередей) (QAOB), используется, чтобы следить за асинхронной пересылкой данных, пока аппаратно-программное обеспечение не завершит операцию. В этом примере в QAOB содержится только управляющая информация, а не сами данные. Отправитель использует этот блок при инициировании пересылки данных для запросов, которые он асинхронное выполнение которых он необязательно разрешит; в противном случае ему не требуется обеспечивать блок управления. Это позволяет отправителю регулировать максимальное число не выполненных запросов асинхронной пересылки. QAOB как таковой используется и инициализируется только аппаратно-программным обеспечением, когда оно определяет, что пересылка данных должна осуществляться асинхронно. От отправителя не требуется каких-либо действий для пересылки данных помимо обеспечения памяти для QAOB, если пересылка данных должна осуществляться асинхронно.
В одном из конкретных примеров QAOB включен в команду SIGA, в которой содержится запрос. Отправитель передает команду записи SIGA с QAOB (SIGA-wq) с указанием выбранного кода функции в первом регистре общего назначения, в котором указана функция записи с QAOB. В четвертом регистре общего назначения, используемом командой, указан адрес QAOB. Этот регистр общего назначения имеет значение 0, когда QAOB не указан, или содержит абсолютный адрес QAOB (например, 256-байтового QAOB). В ответ на заданный код функция записи с QAOB аппаратно-программное обеспечение определяет, указан ли в четвертом регистре общего назначения QAOB, который может использоваться при асинхронной пересылке данных.
Когда аппаратно-программное обеспечение изменяет протокол пересылки данных на асинхронный, оно использует QAOB для слежения за данными, постоянно хранящимися в памяти отправителя, связанной с пересылкой исходящих данных. В примере, в котором для передачи используется HiperSockets™, QAOB следит за адресами и средствами управления, указанными отправителем в списке адресов блоков запоминающих устройств (SBAL), связанном с пересылкой данных. Примеры полей, извлекаемых из SBAL и помещаемых в QAOB, включают, например:
все значащие SBALE из SBAL (например, первый SBALE для SBALE с установленным разрядом последней записи). Они содержат абсолютный адрес буфера данных и счет байтов;
номер выходной очереди SBAL,
номер буфера (например, 1-27) SBAL, инициирующего запрос,
число значащих записей SBALE и
ключ хранения, используемый для доступа к блокам запоминающего устройства, указанным каждым значащим SBALE.
Помимо QAOB используется другая управляющая структура, именуемая очередью 410 завершения (CQ). Иными словами, в одном из примеров помимо обеспечения QAOB отправитель также выделяет в своей памяти очередь нового типа, а именно, очередь завершения при формировании очереди передаваемых данных. В случае HiperSockets™ ей является входная очередь QDIO с SBAL, но без буферов, связанных с SBALE. Эта новая входная очередь используется не для пересылки данных, а используется аппаратно-программным обеспечением для сообщения о событиях завершения, чтобы уведомить отправителя о завершении асинхронной пересылки данных. Когда поступление в очередь помечается как "входящее", информация о событии завершения находится в самих SBALE, которые включены в очередь завершения. Аппаратно-программное обеспечение сообщает адрес QAOB, связанного с завершенной асинхронной пересылкой данных в CQ, и при необходимости генерирует прерывание, чтобы уведомить отправителя о завершенной пересылке данных. На этом этапе отправитель может повторно использовать в других целях память, связанную с завершенной операцией. (В одном из вариантов осуществления для сообщения об одном событии завершения используется SBALE. Поскольку SBAL содержит, например, 16 SBALE, аппаратно-программное обеспечение может сообщать о вплоть до 16 событиях завершения (QAOB) в одном SBAL.)
Кроме того, в одном из вариантов осуществления аппаратно-программное обеспечение формирует для предполагаемого получателя другую очередь TPQ 420, которая используется, чтобы запоминать, что имеется невыполненный запрос пересылки данных.
Дополнительные подробности преобразования синхронной пересылки данных в асинхронную пересылку данных описаны со ссылкой на фиг.5А-5Б. На фиг.5А проиллюстрирован один из вариантов осуществления логики, используемой аппаратно-программным обеспечением для выполнения преобразования, а на фиг.5Б наглядно проиллюстрирован один из примеров преобразования. Обе фигуры рассмотрены далее в описании.
Как показано на фиг.5А-5Б, сначала на шаге 500 аппаратно-программное обеспечение 350 принимает указание QAOB (например, адрес блока запоминающего устройства, который может использоваться для асинхронной пересылки данных). Соответственно, ему известно, что при необходимости (или при желании) оно может асинхронно выполнить запрошенную пересылку данных. В одном из вариантов осуществления аппаратно-программное обеспечение может принимать множество QAOB, указывающих, что оно может выполнить вплоть до указанного числа асинхронных пересылок данных. Предоставление QAOB отправителем является предварительным разрешением аппаратно-программному обеспечению на выполнение асинхронной пересылки данных, если она выбрана аппаратно-программным обеспечением.
В одном из конкретных примеров QAOB включен в состав запроса пересылки данных, который аппаратно-программное обеспечение принимает на шаге 502 от отправителя 300. В ответ на прием запроса пересылки данных на шаге 504 аппаратно-программное обеспечение пытается передать данные получателю. Если на шаге 506 запроса установлено, что получатель способен принять данные (например, у получателя имеется пустой буфер), данные синхронно пересылаются на шаге 508, и пересылка данных завершается. После этого, отправитель может выполнить другую пересылку данных, а, если отправителем разрешена асинхронная обработка, он может включить QAOB в новый запрос.
Тем не менее, если получатель не способен в данный момент принять данные (например, как определено состоянием буферов, у получателя отсутствует пустой буфер, и, соответственно, прием данных получателем задерживается), запрос пересылки данных автоматически преобразуется аппаратно-программным обеспечением из синхронного в асинхронный при условии, что в запросе содержится QAOB. Запрос сохраняется в QAOB на шаге 510, и QAOB помещается в очередь TPQ 420 планируемого пункта назначения, например, путем помещения указателя QAOB в TPQ на шаге 512. Теперь в QAOB входит содержимое SBAL, и, соответственно, SBAL может использоваться для другой обработки.
В одном из вариантов осуществления, если QAOB не указан, запрос не выполняется или ожидает возможности синхронной передачи.
В одном из примеров в ответ на постановку QAOB в очередь управление передается серверу-отправителю с указанием того, что для этой асинхронной пересылки данных используется заданный QAOB. Затем сервер-отправитель может немедленно настроиться на свою следующую пересылку данных и необязательно выделить другой QAOB, если он необходим для следующей пересылки данных.
Затем на шаге 514 запроса определяется, способен ли получатель принять данные. Например, определяется, приняло ли аппаратно-программное обеспечение от получателя сигнал, указывающий, что получатель в настоящее время способен принять данные (например, имеются доступные пустые буферы), или установило ли аппаратно-программное обеспечение, что имеется доступный буфер путем проверки состояния буферов. В одном из конкретных примеров получатель использует команду SIGA для передачи аппаратно-программному обеспечению сигнала, указывающего, что получатель поместил пустые буферы в свои входные очереди. В первом регистре общего назначения указан код функции чтения SIGA (SIGA-r). Функция чтения SIGA побуждает аппаратно-программное обеспечение к пересылке любых ожидающих пакетов из очереди TPQ получателя во входные буферы целевого объекта.
Если получатель не способен принять данные, аппаратно-программное обеспечение переходит к ожиданию. В противном случае, если получатель способен принять данные (например, имеется по меньшей мере один пустой буфер), аппаратно-программное обеспечение на шаге 518 запроса определяет, имеет ли оно указатель QAOB в очереди TPQ получателя. Если это не так, обработка завершается. В противном случае аппаратно-программное обеспечение использует QAOB для пересылки данных. В частности, оно пересылает получателю данные, указанные QAOB, помещая данные в пустой буфер и помещая указатель теперь заполненного буфера во входную очередь получателя.
После этого аппаратно-программное обеспечение на шаге 520 указывает отправителю, что пересылка данных завершена. В одном из примеров в этом указании сообщается адрес QAOB, связанного с завершенной асинхронной пересылкой данных, в очереди 410 завершения (фиг.5Б) отправителя, и при необходимости генерируется прерывание 550, чтобы сообщить отправителю о завершенной пересылке данных. На этом этапе отправитель может повторно использовать в других целях память, связанную с завершенной операцией. QAOB, указанный в CQ, содержит информацию, касающуюся асинхронной обработки, включая, например, информацию о состоянии, коды завершения, коды ошибок и т.д.
В одном из конкретных примеров, когда в поступлении в очередь завершения указан адрес QAOB (т.е. адрес QAOB включен в SBALE в одно из поступлений в очередь завершения), аппаратно-программное обеспечение возвращает программе в QAOB следующую информацию, например:
код причин, отражающий результаты асинхронной операции ввода-вывода,
состояние буферов: "состояние очереди - буфера N (SQBN)" для асинхронной пересылки данных. Оно имеет такое же значение, которое было бы помещено в SLSB для синхронной пересылки данных. В SQBN содержится значение, указывающее текущее состояние QAOB. Значение переменной состояния содержит, например, две части: в первой части указано, принадлежит ли буфер аппаратно-программному обеспечению, а во второй части, указано текущее состояние процесса QAOB.
Хотя конкретный запрос выполняется асинхронно, другие запросы отправителя, адресованные другим получателям, могут выполняться синхронно, если только, например, прием данных конкретным получателем не задерживается. Кроме того, другие запросы, адресованные получателю отправителем, автоматически преобразуются в синхронные, если только снова не установлено, что прием данных получателем задерживается. Например, аппаратно-программное обеспечение пытается передать данные получателю, как описано выше, и, если получатель способен принять данные, они передаются синхронно. В одном из вариантов осуществления даже при взаимном преобразовании синхронной и асинхронной передачи, обработка данных осуществляется в порядке поступления как при передаче. Аппаратно-программное обеспечение переносит все ожидающие обслуживания QAOB в очередь TPQ 420 получателя до приема каких-либо будущих синхронных запросов от этого или любого другого отправителя. При попытке другой синхронной пересылки данных получателю, у которого QAOB уже помещены в его TPQ 420, она будет автоматически преобразована в асинхронный запрос аппаратно-программным обеспечением (если это разрешено отправителем) или окажется неудачной, и будет получен ответ "отсутствуют доступные буферы". Сохранение порядка позволяет избегать дорогостоящей обработки с целью переупорядочения, повышать эффективность стека протоколов TCP/IP получателя и общего использования ЦП.
Выше было подробное описано средство автоматического преобразования синхронной пересылки данных в асинхронную пересылку данных в ответ на установление процессором (например, аппаратно-программным обеспечением) того, что такое преобразование должно произойти. Например, преобразование осуществляется, если задерживается прием данных получателем (например, из-за отсутствия доступного буфера, медленного реагирования и т.д.). Кроме того, средство автоматически позволяет синхронно осуществлять другие пересылки данных тому же получателю.
Одна или несколько особенностей этого средства позволяет настраиваться на транзитную или более долговременную передачу данных без дорогостоящих повторных передач с поддержанием связи с целевым адресатом и минимальным или отсутствующим влиянием на других действующих адресатов в сети. Согласно одной из особенностей предложено средство переключения между синхронной и асинхронной пересылкой данных без уведомления программы-отправителя. В одном из конкретных примеров с использованием очереди завершения (CQ) на основе HiperSockets драйвер устройства не приостанавливает операцию ввода-вывода (SIGA не блокирует процесс). При использовании CQ процесс записи не прерывается, и отправитель может продолжать передавать дополнительные команды записи (SIGA) тому же адресату или другим адресатам, при этом некоторые из них могут выполняться синхронно, а другие - асинхронно. Это отсутствие блокирования делает CQ асинхронной.
Согласно одной из особенностей настоящего изобретения данные копируются только один раз от отправителя получателю (без внутреннего буфера) независимо от того, является ли пересылка синхронной или асинхронной.
Как учтут специалисты в данной области техники, одна или несколько особенностей настоящего изобретения могут быть воплощены в виде системы, способа или компьютерного программного продукта. Соответственно, одна или несколько особенностей настоящего изобретения могут принимать форму целиком аппаратного варианта осуществления, целиком программного варианта осуществления (содержащего аппаратно-программное обеспечение, резидентное программное обеспечение, микрокод и т.д.) или варианта осуществления, сочетающего программные и аппаратные особенности, которые все могут в целом именоваться в описании "схемой", "модулем" или "системой". Кроме того, одна или несколько особенностей настоящего изобретения могут принимать форму компьютерного программного продукта, воплощенного в одной или нескольких машиночитаемых средах, в которых записан машиночитаемый программный код.
Может использоваться любое сочетание одной или нескольких постоянных машиночитаемых сред. Машиночитаемой средой может являться машиночитаемая запоминающая среда. Машиночитаемой запоминающей средой может являться, например, без ограничения электронная, магнитная, оптическая, электромагнитная, инфракрасная или полупроводниковая система, устройство или прибор или любое применимое сочетание перечисленного. Более конкретные примеры (неисчерпывающий список) машиночитаемой запоминающей среды включают: электрическое соединение, содержащее один или несколько проводов, портативный компьютерный диск, жесткий диск, оперативное запоминающее устройство (ОЗУ), постоянное запоминающее устройство (ПЗУ), стираемое программируемое постоянное запоминающее устройство (СППЗУ или флэш-память), оптическое волокно, портативное постоянное запоминающее устройство на компакт-диске (CD-ROM), оптическое запоминающее устройство, магнитное запоминающее устройство или любое применимое сочетание перечисленного. В контексте настоящего документа машиночитаемой запоминающей средой может являться любая материальная среда, в которой может содержаться или храниться программа для использования системой выполнения команд, устройством или прибором или применительно к ним.
Как показано на фиг.6, в одном из примеров компьютерный программный продукт 600 содержит, например, одну или несколько постоянных машиночитаемых запоминающих сред 602 для хранения в них машиночитаемого программного кода или логики 604 для обеспечения и реализации одной или нескольких особенностей настоящего изобретения.
Программный код, воплощенный в машиночитаемой среде, может передаваться с использованием соответствующей среды, включая без ограничения беспроводную, проводную среду, оптоволоконный кабель, ВЧ-среду и т.д. или любое применимое сочетание перечисленного.
Компьютерный программный код для выполнения операций, обеспечивающих особенности настоящего изобретения, может быть записан на одном или нескольких языках программирования в любом сочетании, включая объектно-ориентированный язык программирования, такой как Java, Smalltalk, C++ и т.п., и традиционных процедурных языках программирования, таких как "C" и языки ассемблера или аналогичные языки программирования. Программный код может целиком выполняться в пользовательском компьютере, частично в пользовательском компьютере, в качестве автономного пакета программного обеспечения, частично в пользовательском компьютере и частично в удаленном компьютере или целиком в удаленном компьютере или сервере. В случае последнего сценария удаленный компьютер может быть соединен с пользовательским компьютером посредством сети любого типа, включая локальную вычислительную сеть (ЛВС) или глобальную вычислительную сеть (ГВС), или может быть установлено соединение с внешним компьютером (например, по сети Интернет с использованием поставщика услуг Интернет).
Особенности настоящего изобретения описаны со ссылкой на структурные схемы и/или блок-схемы способов, оборудования (систем) и компьютерных программных продуктов согласно вариантам осуществления изобретения. Подразумевается, что каждый блок на структурных схемах и/или блок-схемах и сочетания блоков на структурных схемах и/или блок-схемах могут быть реализованы посредством команд управления компьютерной программой. Эти команды управления компьютерной программой могут передаваться процессору универсального компьютера, специализированного компьютера или другой программируемого устройства для обработки данных с целью формирования механизма, в котором команды, выполняемые посредством процессора компьютера или другого программируемого оборудования обработки данных, создают средство реализации функций/действий, обозначенных блоком или блоками на структурных схемах и/или блок-схемах.
Эти команды управления компьютерной программой также могут храниться в машиночитаемой среде, которая способна предписывать компьютеру, другому программируемому оборудованию обработки данных или другим устройствам действовать конкретным способом, в результате чего команды, хранящиеся на машиночитаемом носителе, формируют продукт, содержащий команды, в которых реализуется функция/действие, обозначенное блоком или блоками на структурных схемах и/или блок-схемах.
Команды управления компьютерной программой также могут загружаться в компьютер, другое программируемое оборудование обработки данных или другие устройства, чтобы инициировать выполнение последовательности оперативных шагов компьютером, другим программируемым оборудованием или другими устройствами с целью формирования реализованного в компьютере процесса, при этом команды, выполняемые компьютером или другим программируемым оборудованием, обеспечивают процессы реализации функций/действий, обозначенных блоком или блоками на структурных схемах и/или блок-схемах.
Приведенные на чертежах структурные схемы и блок-схемы иллюстрируют архитектуру, функциональные возможности и действие возможных вариантов реализации систем, способов и компьютерных программных продуктов согласно различным вариантам осуществления одной или нескольких особенностей настоящего изобретения. В связи с этим каждым блоком на структурных схемах или блок-схемах может быть представлен определенный модуль, сегмент или часть кода, которая содержит одну или несколько выполняемых команд для реализации заданной логической функции(-й). Следует также отметить, что в некоторых альтернативных вариантах реализации указанные в блоке функции могут выполняться не в том порядке, в котором они представлены на чертежах. Например, функции, указанные двумя последовательно показанными блоками, в действительности, могут выполняться преимущественно одновременно, или функции иногда могут выполняться в обратном порядке в зависимости от соответствующих функциональных возможностей. Следует также отметить, что каждый блок на блок-схемах и/или структурных схемах и сочетания блоков на блок-схемах и/или структурных схемах могут быть реализованы посредством специализированных аппаратных систем, выполняющих заданные функции или действия, или посредством сочетаний специализированных аппаратных систем и компьютерных команд.
Помимо вышесказанного, одна или несколько особенностей настоящего изобретения может обеспечиваться, предлагаться, применяться, координироваться, обслуживаться и т.д. поставщиком услуг, который предлагает управление пользовательскими средами. Например, поставщик услуг способен создавать, вести, поддерживать и т.д. для одного или нескольких пользователей машинный код и/или вычислительную инфраструктуру, в которой выполняется одна или несколько особенностей настоящего изобретения. В ответ поставщик услуг может получать оплату от пользователя на основании соглашения о подписке и/или абонентской плате в качестве примеров. Дополнительно или в качестве альтернативы, поставщик услуг может получать плату за рекламное содержание, продаваемое одному или нескольким третьим лицам.
Согласно одной из особенностей настоящего изобретения для выполнения одной или нескольких особенностей настоящего изобретения может быть развернуто приложение. В качестве одного из примеров, развертывание приложения включает использование вычислительной инфраструктуры, способной выполнять одну или несколько особенностей настоящего изобретения.
В качестве одной из дополнительных особенностей настоящего изобретения развертывание вычислительной инфраструктуры может включать интегрирование машиночитаемого кода в вычислительную систему, при этом код в сочетании с вычислительной системой способен выполнять одну или несколько особенностей особенности настоящего изобретения.
В качестве еще одной дополнительной особенности настоящего изобретения может быть предложен способ интегрирования вычислительной инфраструктуры, включающий интегрирование машиночитаемого кода в компьютерную систему. Компьютерная система содержит машиночитаемую среду, содержащую одну или несколько особенностей настоящего изобретения. Код в сочетании с компьютерной системой способен выполнять одну или несколько особенностей настоящего изобретения.
Хотя выше описаны различные варианты осуществления, они являются лишь примерами. Например, одна или несколько особенностей настоящего изобретения могут содержаться и использоваться в вычислительных средах других архитектур. В качестве примера, одна или несколько особенностей настоящего изобретения могут содержаться, использоваться и/или выгодно применяться в серверах помимо серверов zEnterprise. Кроме того, при преобразовании синхронной передачи в асинхронную передачу могут учитываться другие критерии помимо того, доступен ли буфер. Помимо этого, одна или несколько особенностей настоящего изобретения могут использоваться для любых пересылок данных из одной изолированной области памяти в другую. Также возможно множество других разновидностей.
Кроме того, одна или несколько особенностей настоящего изобретения могут выгодно применяться в вычислительных средах других типов. В качестве примера, может использоваться система обработки данных, применимая для хранения и/или выполнения программного кода и содержащая по меньшей мере два процессора, прямо или косвенно связанных со средствами памяти посредством системной шины. Элементы памяти включают, например, локальную память, применяемую во время фактического выполнения программного кода, массовую память и кэш-память, которая обеспечивает временное хранение по меньшей мере части программного кода для уменьшения необходимого числа случаев извлечения кода из массовой памяти во время выполнения.
С системой прямой или косвенно посредством промежуточных контроллеров ввода-вывода могут быть связаны устройства ввода-вывода (включая без ограничения, клавиатуры, дисплеи, координатно-указательные устройства, ЗУПД, накопители на магнитной ленте, на компакт-дисках, на многоцелевых компакт-дисках, портативные миниатюрные накопители на жестких дисках и другие запоминающие среды и т.д.). С системой также могут быть связаны сетевые адаптеры, позволяющие системе обработки данных устанавливать связь с другими системами обработки данных или удаленными принтерами или запоминающими устройствами посредством промежуточной частных или общедоступных сетей. Модемы, кабельные модемы и сетевые карты Ethernet являются лишь несколькими из сетевых адаптеров доступных типов.
Рассмотрим фиг.7, на которой представлены характерные компоненты главной компьютерной системы 5000 для реализации одной или нескольких особенностей настоящего изобретения. Характерный главный компьютер 5000 содержит один или несколько ЦП 5001, поддерживающих связь с памятью (т.е. центральной памятью) 5002 компьютера, а также интерфейсы ввода-вывода с запоминающими устройствами 5011 и сетями 5010 для связи с другими компьютерами или SAN и т.п. ЦП 5001 совместим с архитектурой, содержащей структурированный набор команд и структурированные функциональные возможности. ЦП 5001 может выполнять динамическую трансляцию 5003 адреса (DAT) для трансляции адресов программ (виртуальных адресов) в действительные адреса памяти. DAT обычно содержит буфер 5007 быстрого преобразования адреса (TLB) для кэширования трансляций, чтобы при последующих доступах к блоку памяти 5002 компьютера не требовалась задержка трансляции адреса. Обычно между памятью 5002 компьютера и процессором 5001 используется кэш-память 5009. Кэш-память 5009 может являться иерархической и состоящей из кэша большой емкости, доступного для нескольких ЦП, и более быстродействующих кэшей (низкого уровня) меньшей емкости между кэшем большой емкости и каждым ЦП. В некоторых случаях реализации кэши низкого уровня разделены на отдельные кэши низкого уровня для выборки команд и доступа к данным. В одном из вариантов осуществления блок 5004 выборки команд вызывает из памяти 5002 команду посредством кэш-памяти 5009. Команда декодируется в блоке 5006 декодирования команд и отправляется (с другими командами в некоторых вариантах осуществления) в блок или блоки 5008 выполнения команд. Обычно используется несколько блоков 5008 выполнения команд, например, блок выполнения арифметических команд, блок выполнения команд с плавающей точкой и блок выполнения команд перехода. Команда выполняется блоком, который в зависимости от необходимости осуществляет доступ к операндам из определяемых командами регистров или памяти. Если доступ (загрузка или сохранение) к операнду должен осуществляться из памяти 5002, блок 5005 загрузки/сохранения обычно обрабатывает процедуру доступа под управлением выполняемой команды. Команды могут выполняться в аппаратных схемах или во внутреннем микрокоде (аппаратно-программном обеспечении) или с использованием сочетания того и другого.
Как было отмечено, в локальном (или основном) запоминающем устройстве компьютерной системы хранится информация, а также адресные, защитные, контрольные и корректирующие записи. Некоторые особенности адресации включают формат адресов, концепцию адресных пространств, различные типы адресов и то, каким образом адрес одного типа транслируется в адрес другого типа. Некоторые из основных запоминающих устройств имеют постоянно абонированные ячейки. Основное запоминающее устройство обеспечивает систему запоминающим устройством с прямой адресацией и быстрой выборкой данных. В основное запоминающее устройство должны загружаться (из устройств ввода) как данные, так и программы, после чего они могут обрабатываться.
Основное запоминающее устройство может содержать одно или несколько буферных запоминающих устройств меньшей емкости с более быстрой выборкой, иногда называемых кэшами. Кэш обычно физически связан с ЦП или процессором ввода-вывода. Физическая конструкция и использование различных запоминающих сред в целом не сказывается на программе за исключением производительности.
Для команд и операндов, хранимых в памяти, могу быть предусмотрены раздельные кэши. Информация содержится в кэше в форме непрерывных байтов на целочисленной границе, называемой блоком или строкой данных кэша (или для краткости строкой). Согласно одной из моделей может быть предусмотрена команда извлечения атрибута кэша (EXTRACT CACHE ATTRIBUTE), которая выдает размер строки кэша в байтах. Согласно одной из моделей также может быть предусмотрена команда упреждающей выборки данных (PREFETCH DATA) и команда упреждающей выборки данных относительно большой длины (PREFETCH DATA RELATIVE LONG) для упреждающей выборки данных из запоминающего устройства в кэш данных или команд или для высвобождения данных из кэша.
Запоминающее устройство рассматривается как длинная горизонтальная битовая строка. В случае большинства операций доступ к запоминающему устройству последовательно осуществляется слева направо. Битовая строка подразделяется на блоки из восьми разрядов. Восьмиразрядный блок называется байтом и является базовым конструктивным блоком всех форматов представления информации. Местоположение каждого байта в запоминающем устройстве идентифицируется однозначно определяемым неотрицательным целым числом, которое является адресом местоположения этого байта или просто адресом байта. Соседние местоположения байтов имеют идущие подряд адреса, начинающиеся слева с 0 и последовательно следующие слева направо. Адреса представляют собой двоичные целые числа без знака, содержащие 24, 31 или 64 разряда.
Обмен информацией между запоминающим устройством и ЦП или канальной подсистемой осуществляется путем передачи одного байта или группы байтов за один раз. Если не оговорено иное, например, в системе z/Architecture® хранящаяся группа байтов адресуется посредством крайнего левого байта из группы. Число байтов в группе подразумевается или прямо оговаривается выполняемой операцией. Используемая в работе ЦП группа байтов называется полем. Разряды в каждой группе байтов, например, в системе z/Architecture® последовательно нумеруются слева направо. Крайние левые разряды в z/Architecture® иногда именуются "старшими" разрядами, а крайние правые разряды - "младшими" разрядами. Тем не менее, номера разрядов не являются адресами ячеек запоминающего устройства. Возможна только адресация байтов. Чтобы оперировать с отдельными разрядами хранящегося байта, осуществляется доступ ко всему байту. Разряды в байте пронумерованы слева направо от 0 до 7 (например, в системе z/Architecture®). Разряды в адресе могут быть пронумерованы от 8 до 31 или от 40 до 63 в случае 24-разрядных адресов или от 1 до 31 или от 33 до 63 в случае 31-разрядных адресов и от 0 до 63 в случае 64-разрядных адресов. В любом другом имеющем фиксированную длину формате из множества байтов разряды, образующие формат, последовательно пронумерованы, начиная с 0. В целях обнаружения ошибок и предпочтительно их исправления с каждым байтом или группой байтов может передаваться один или несколько контрольных разрядов. Такие контрольные разряды генерируются автоматически машиной и не могут непосредственно управляться программой. Емкость запоминающего устройства выражается в числе байтов. Когда кодом операций команды подразумевается длина хранящегося поля операнда, считается, что поле имеет фиксированную длину, которая может составлять 1, 2, 4, 8 или 16 байтов. Для некоторых команд могут подразумеваться более длинные поля. Когда длина хранящегося поля операнда не подразумевается, а прямо указывается, считается, что поле имеет переменную длину. Операнды переменной длины могут различаться по длине с шагом в 1 байт (или в случае некоторых команд с шагом в 2 байта и другими шагами). При сохранении информации в запоминающем устройстве замещается содержимое местоположений только тех байтов, которые включены в указанное поле, несмотря на то, что ширина физического пути доступа к запоминающему устройству может превышать длину сохраняемого поля.
Некоторые хранящиеся единицы информации должны находиться на целочисленной границе. Применительно к единице информации граница называется целочисленной, когда адрес ее ячейки запоминающего устройства кратен длине единицы информации в байтах. Полям длиной 2, 4, 8 и 16 байтам на целочисленной границе даются особые названия. Полуслово является группой из 2 идущих подряд байтов на двухбайтовой границе и представляет собой базовый конструктивный блок команд. Слово является группой из 4 идущих подряд байтов на четырехбайтовой границе. Двойное слово является группой из 8 идущих подряд байтов на 8-байтовой границе. Учетверенное слово является группой из 16 идущих подряд байтов на 16-байтовой границе. Когда в адресах ячеек запоминающего устройства указаны полуслова, слова, двойные слова и учетверенные слова, в двоичном представлении адреса содержится один, два, три или четыре крайних правых нулевых разряда, соответственно. Команды должны находиться на двухбайтовых целочисленных границах. Хранящиеся операнды большинства команд не содержат требования размещения на границах.
В устройствах, в которых реализованы раздельные кэши для команд и операндов, хранимых в памяти, могут происходить значительные задержки, если программа сохраняется в строке кэша, из которой впоследствии осуществляется выборка команд, независимо от того, изменяются ли при сохранении команды, выборка которых впоследствии осуществляется.
В одном из вариантов осуществления изобретение может быть реализовано на практике посредством программного обеспечения (иногда называемого лицензионным внутренним кодом, аппаратно-программным обеспечением, микрокодом, милликодом, пикокодом и т.п., что во всех случаях согласуется с настоящим изобретением). Как показано на фиг.7, обычно процессор 5001 главной системы 5000, получает доступ к программному коду системы программного обеспечения, в котором воплощено настоящее изобретение, посредством долговременных запоминающих сред 5011, таких как ПЗУ на компакт-дисках, накопитель на магнитной ленте или накопитель на жестких дисках. Программный код системы программного обеспечения может быть воплощен в любой из разнообразных известных сред для применения с системой обработки данных, такой как дискета, накопитель на жестких дисках или ПЗУ на компакт-дисках. Код может распределяться в таких средах или может распределяться пользователям из памяти 5002 компьютера или запоминающего устройства одной компьютерной системы по сети 5010 другим компьютерным системам для применения пользователями таких других систем.
Программный код включает операционную систему, которая управляет функцией и взаимодействием различных узлов вычислительной машины и одной или нескольких прикладных программ. Обычно подкачка страниц программного кода осуществляется из запоминающей среды 5011 в относительно быстродействующее запоминающее устройство 5002, в котором он доступен для обработки процессором 5001. Методы и способы воплощения программного кода системы программного обеспечения в памяти, в физических средах и/или распределения программного кода посредством сетей хорошо известны и не будут дополнительно рассматриваться в описании. Программный код, созданный и хранящийся в материальной среде (включая без ограничения модули электронной памяти (ОЗУ), флэш-память, компакт-диски, универсальные цифровые диски, магнитную ленту и т.п.) часто именуется "компьютерным программным продуктом". Содержащая компьютерный программный продукт среда обычно может считываться устройством обработки данных предпочтительно в компьютерной системе для выполнения устройством обработки данных.
На фиг.8 проиллюстрирована характерная рабочая станция или аппаратная серверная система, в которой может быть на практике реализовано настоящее изобретение. В показанную на фиг.8 систему 5020 входит характерная базовая компьютерная система 5021, такая как персональный компьютер, рабочая станция или сервер, включая необязательные периферийные устройства. Базовая компьютерная система 5021 имеет один или несколько процессоров 5026 и шину для соединения процессора(-ов) 5026 и других компонентов системы 5021 и обеспечения связи между ними известными способами. Шина соединяет процессор 5026 с памятью 5025 и долговременным запоминающим устройством 5027, которое может содержать накопитель на жестких дисках (например, включая любое из следующего: магнитный носитель, компакт-диск, универсальный цифровой диск и флэш-память) или, например, накопитель на магнитной ленте. В систему 5021 также может входить адаптер пользовательского интерфейса, который посредством шины соединяет микропроцессор 5026 с одним или несколькими устройствами сопряжения, такими как клавиатура 5024, мышь 5023, принтер/сканер 5030 и/или другие устройства сопряжения, которыми могут являться любое пользовательское устройство сопряжения, такое как сенсорный экран, дополнительная цифровая клавиатура и т.д. Шина посредством дисплейного адаптера также соединяет дисплей 5022, такой как ЖК-дисплей или монитор с микропроцессором 5026.
Система 5021 может поддерживать связь с другими компьютерами или компьютерными сетями посредством сетевого адаптера, способного поддерживать связь 5028 с сетью 5029. Примерами сетевых адаптеров являются каналы связи, кольцевая сеть с эстафетным доступом, сеть Ethernet или модемы. В качестве альтернативы, система 5021 может поддерживать связь с использованием беспроводного интерфейса, такого как карта CDPD (сотовой системы передачи пакетов цифровых данных). Система 5021 может быть связана с другими такими компьютерами в локальной вычислительной сети (ЛВС) или глобальной вычислительной сети (ГВС), или системой 5021 может являться клиент, связанный отношениями клиент/сервер с другим компьютером и т.д. Все эти конфигурации, а также соответствующее коммуникационное оборудование и программное обеспечение известны из техники.
На фиг.9 проиллюстрирована сеть 5040 обработки данных, в которой может быть реализовано на практике настоящее изобретение. В сеть 5040 обработки данных может входить множество отдельных сетей, таких как беспроводная сеть и проводная сеть, в каждую из которых может входить множество отдельных рабочих станций 5041, 5042, 5043, 5044. Кроме того, как известно специалистам в данной области техники, в нее может входить одна или несколько ЛВС, в которую может входить множество интеллектуальных рабочих станций, связанных с главным процессором.
На фиг.9 также показано, что в сети также могут входить мэйнфреймы или серверы, такие как шлюз (клиент-сервер 5046) или сервер приложений (удаленный сервер 5048, который может осуществлять доступ к хранилищу данных, а также может быть доступен непосредственно с рабочей станции 5045). Шлюз 5046 служит точкой входа в каждую отдельную сеть. Шлюз необходим при подсоединении одного сетевого протокола к другому. Шлюз 5046 предпочтительно может быть связан с другой сетью (например, сетью Интернет 5047) линией связи. Шлюз 5046 также может быть непосредственно связан с одной или несколькими рабочими станциями 5041, 5042, 5043, 5044 с использованием линии связи. Шлюз может быть реализован с использованием сервера IBM eServer™ System z® производства International Business Machines Corporation.
Как показано на фиг.8 и 9, доступ к программному коду системы программного обеспечения, в котором может быть воплощено настоящее изобретение, может осуществлять процессор 5026 системы 5020 посредством долговременных запоминающих сред 5027, таких как ПЗУ на компакт-дисках, или накопитель на жестких дисках. Программный код системы программного обеспечения может быть воплощен в любой из разнообразных известных сред для применения с системой обработки данных, такой как дискета, накопитель на жестких дисках или ПЗУ на компакт-дисках. Код может распределяться в таких средах или может распределяться пользователям 5050, 5051 из памяти компьютера или запоминающего устройства одной компьютерной системы по сети другим компьютерным системам для применения пользователями таких других систем.
В качестве альтернативы, программный код может быть воплощен в памяти 5025 с возможностью доступа к нему для процессора 5026 с использованием процессорной шины. В таком программном коде реализована операционная система, которая управляет функцией и взаимодействием различных узлов вычислительной машины и одной или нескольких прикладных программ 5032. Обычно подкачка страниц программного кода осуществляется из запоминающих сред 5027 в быстродействующее запоминающее устройство 5025, в котором он доступен для обработки процессором 5026. Методы и способы воплощения программного кода системы программного обеспечения в памяти, в физических средах и/или распределения программного кода посредством сетей хорошо известны и не будут дополнительно рассматриваться в описании. Программный код, созданный и хранящийся в материальной среде (включая без ограничения модули электронной памяти (ОЗУ), флэш-память, компакт-диски, универсальные цифровые диски, магнитную ленту и т.п.) часто именуется "компьютерным программным продуктом". Содержащая компьютерный программный продукт среда обычно может считываться устройством обработки данных предпочтительно в компьютерной системе для выполнения устройством обработки данных.
Кэш, который является наиболее легкодоступным для процессора (обычно более быстродействующим и менее объемным, чем другие кэши процессора), представляет собой кэш низшего уровня (L1 или уровня 1), а основное запоминающее устройство (основная память) представляет собой кэш высшего уровня (L3 в случае 3 уровней). Кэш низшего уровня часто поделен кэш команд (I-кэш), в котором хранятся машинные команды для выполнения, и кэш данных (D-кэш), в котором хранятся операнды, хранимые в памяти.
На фиг.10 проиллюстрирован один из примеров осуществления процессора 5026. Обычно с целью помещения в буфер блоков памяти и повышения производительности процессора используется один или несколько уровней кэша 5053. Кэш 5053 представляет собой высокоскоростной буфер, в котором в строках данных кэша хранятся данные в памяти, которые вероятно будут использоваться. Типичные строки данных кэша содержат 64, 128 или 256 байтов данных в памяти. Для кэширования команд и для кэширования данных часто используются раздельные кэши. Согласованность кэшей (синхронизация копий строк в памяти и в кэшах) часто обеспечивается различными алгоритмами слежения ("snoop"), хорошо известными из техники. Основное запоминающее устройство 5025 процессорной системы часто называют кэшем. В процессорной системе, имеющей уровня 4 кэша 5053, основное запоминающее устройство 5025 иногда называют кэшем уровня 5 (L5), поскольку оно обычно является более быстродействующими и представляет собой лишь часть энергонезависимого запоминающего устройство (ЗУПД, ЗУ на ленте и т.д.), которое доступно для компьютерной системы. Основное запоминающее устройство 5025 "кэширует" страницы данных, которые подкачиваются в основное запоминающее устройство 5025 и откачиваются из него операционной системой.
Программный счетчик (счетчик команд) 5061 отслеживает адрес текущей команды для выполнения. Счетчиком команд в процессоре на основе z/Architecture является 64-разрядным, при этом он может быть усечен до 31 или 24 разрядов с целью поддержки ранее существовавших ограничений адресации. Поскольку счетчик команд обычно воплощен в слове состояния программы (PSW) компьютера, оно сохраняется при переключении контекста. Соответственно, выполняемая программа с показанием счетчика команд может прерываться, например, операционной системой (при переключении контекста из программной среды в среду операционной системы). PSW программы поддерживает показание счетчика команд, пока программа неактивна, а во время выполнения операционной системы используется счетчик команд (в PSW) операционной системы. Обычно показание счетчика команд приращивается на величину, равную числу байтов текущей команды. RISC-команды (на основе вычислений с сокращенным набором команд) обычно имеют фиксированную длину, тогда как CISC-команды (на основе вычислений с полным набором команд) обычно имеют переменную длину. Команды, используемые в системе IBM z/Architecture, являются CISC-командами, имеющими длину 2, 4 или 6 байтов. Показание счетчика 5061 команд изменяется, например, в результате операции переключения контекста или операции выбранного перехода согласно команде перехода. При операции переключения контекста в слове состояния программы сохраняется текущее показание счетчика команд вместе с другой информацией о состоянии выполняемой программы (такой как коды условий), и загружается новое показание счетчика команд, указывающее на команду нового программного модуля для выполнения. Операция выбранного перехода выполняется, чтобы позволить программе принимать решения, или чтобы выполнять программный цикл путем загрузки в счетчик 5061 команд результата команды перехода.
Обычно для выборки команд от имени процессора 5026 применяется блок 5055 выборки команд. Блок выборки осуществляет выборку "очередных последовательных команд", целевых команд из команд выбранного перехода или первых команд программы, следующей за переключением контекста. В современных блоках выборки команд часто применяют методы выборки с целью предварительной выборки команд по предположению, исходя из вероятности использования команд, предварительная выборка которых была осуществлена. Например, блок выборки может осуществлять выборку 16 байтов команды, содержащих очередную последовательную команду, и дополнительных байтов следующих далее команд.
Затем вызванные команды выполняются процессором 5026. В одном из вариантов осуществления вызванная команда(-ы) передаются блоку 5056 диспетчеризации блока выборки. Блок диспетчеризации декодирует команду(-ы) и пересылает информацию о декодированной команде(-ах) соответствующим блокам 5057, 5058, 5060. Блок 5057 выполнения обычно принимает информацию о декодированных арифметических командах от блока 5055 выборки команд и выполняет арифметические операции с операндами в соответствии с содержащимся в команде кодом операции. Операнды предоставляются блоку 5057 выполнения предпочтительно из памяти 5025, структурированных регистров 5059 или из непосредственного поля выполняемой команды. Сохраненные результаты выполнения хранятся в памяти 5025, регистрах 5059 или в другом машинном аппаратном обеспечении (таком как управляющие регистры, регистры PSW и т.п.).
Процессор 5026 обычно имеет один или несколько блоков 5057, 5058, 5060, выполнения функции команды. Как показано на фиг.11А, блок 5057 выполнения посредством интерфейсной логической схемы 5071 может поддерживать связь со структурированными общими регистрами 5059, блоком 5056 декодирования/диспетчеризации, блоком 5060 загрузки/сохранения и другими процессорными блоками 5065. В блоке 5057 выполнения может применяться несколько регистровых схем 5067, 5068, 5069 для хранения информации, с которой будет работать арифметическое логическое устройство (АЛУ) 5066. АЛУ выполняет арифметические операции, такие как сложение, вычитание, умножение и деление, а также логические функции, такие как И, ИЛИ и исключающее ИЛИ, поворот и смещение. АЛУ предпочтительно поддерживает зависящие от конструкции специализированные операции. В других схемах могут обеспечиваться другие структурированные средства 5072, включающие, например, коды условия и логическую схему поддержки восстановления. Обычно результат операции АЛУ хранится в схеме 5070 выходного регистра, из которой он может пересылаться целому ряду других функций обработки. Хотя существует множество конструкций процессоров, настоящее описание имеет целью лишь обеспечить понимание одного из вариантов осуществления.
Например, команда сложения выполняется блоком 5057 выполнения, обладающим арифметическими и логическими функциональными возможностями, а, например, команда с плавающей точкой выполняется блоком вычислений с плавающей точкой, обладающим специализированными возможностями работы с плавающей точкой. Блок выполнения предпочтительно работает с указанными командой операндами путем выполнения заданной кодом операции функции применительно к операндам. Например, команда сложения может выполняться блоком 5057 выполнения применительно к операндам, обнаруженным в двух регистрах 5059, указанных в регистровых полях команды.
Блок 5057 выполнения выполняет арифметическое сложение двух операндов и сохраняет результат в третьем операнде, которым может являться третий регистр или один из двух исходных регистров. Блок выполнения предпочтительно использует арифметическое логическое устройство (АЛУ) 5066, способное выполнять ряд логических функций, таких как смещение, поворот. И, ИЛИ и исключающее ИЛИ, а также ряд алгебраических функций, включая любые из следующих функций: сложение, вычитание, умножение, деление. Некоторые АЛУ 5066 рассчитаны на скалярные операции, а некоторые - на операции с плавающей точкой. В зависимости от архитектуры данные могут иметь обратный порядок следования байтов (когда наименьший значимый байт соответствует старшему байтовому адресу) или прямой порядок следования байтов (когда наименьший значимый байт соответствует младшему байтовому адресу). В системе IBM z/Architecture используется обратный порядок следования байтов. В зависимости от архитектуры поля чисел со знаком могут быть представлены в виде прямого кода, дополнения до единицы или дополнения до двух. Число в форме дополнения до двух выгодно в том смысле, что АЛУ не требуется поддерживать возможность вычитания, поскольку при отрицательной или положительной величине дополнения до двух в АЛУ требуется только сложение. Числа обычно описаны в сокращенном виде, в котором 12-разрядное поле определяет адрес блока из 4096 байтов и обычно описано, например, в виде 4-х килобайтового блока.
Как показано на фиг.11Б, содержащаяся в команде перехода информация для выполнения команды перехода обычно передается блоку 5058 перехода, в котором часто применяется алгоритм предсказания переходов, такой как таблица 5082 предыстории переходов (ТПП), для предсказания исхода перехода до завершения других условных операций. Целевой объект текущей команды перехода вызывается и выполняется по предположению до завершения условных операций. Когда условные операции завершены, выполненные по предположению команды перехода завершаются или отбрасываются, исходя из условной операции и предположенного исхода. Типичная команда перехода может предусматривать проверку кодов условий и переход к целевому адресу, если коды условий отвечают требованию команды перехода, при этом целевой адрес может вычисляться на основании нескольких чисел, включая, например, числа из регистровых полей или непосредственного поля команды. В блоке 5058 перехода может применяться АЛУ 5074, имеющее множество схем 5075, 5076, 5077 входных регистров и схему 5080 выходного регистра. Блок 5058 перехода, например, может поддерживать связь с общими регистрами 5059, декодировать блок 5056 диспетчеризации или другие схемы 5073.
Выполнение группы команд может прерываться по ряду причин, включая, например, переключение контекста, инициированное операционной системой, исключительную ситуацию или ошибку в процессе выполнения программы, приводящую к переключению контекста, сигнал прерывания ввода-вывода, приводящий к переключению контекста, или многопоточный режим работы множества программ (в многопоточной среде). Переключение контекста предпочтительно служит для сохранения информации о состоянии выполняемой в данный момент программы и затем для загрузки информации о состоянии другой вызываемой программы. Информация о состоянии может сохраняться, например, в аппаратных регистрах или в памяти. Информация о состоянии предпочтительно содержит показание счетчика команд, указывающее очередную команду для выполнения, коды условий, сведения о преобразовании данных памяти и содержимое структурированного регистра. Переключение контекста может осуществляться аппаратными схемами, прикладными программами, программами операционной системы или аппаратно-программным кодом (микрокодом, пикокодом или лицензионным внутренним кодом (LIC) по отдельности или в сочетании).
Процессор осуществляет доступ к операндам в соответствии с определенными командами способами. Команда может содержать непосредственный операнд, в котором используется значение части команды, может содержать одно или несколько регистровых полей, прямо указывающих регистры общего назначения или регистры особо назначения (например, регистры с плавающей точкой). В команде могут использоваться подразумеваемые регистры, обозначаемые полем кода операции как операнды. В команде могут использоваться ячейки памяти для операндов. Ячейка памяти для операнда может обеспечиваться регистром, непосредственным полем или сочетанием регистров и непосредственного поля, примером чего является средство дальнего смещения на основе системы z/Architecture, в котором команда определяет базовый регистр, индексный регистр и непосредственное поле (поле смещения), которые суммируются с целью получения, например, адреса операнда в памяти. Под ячейкой в данном случае подразумевается ячейка основной памяти (основного запоминающего устройства), если не указано иное.
Как показано на фиг.11В, процессор осуществляет доступ к памяти с использованием блока 5060 загрузки/сохранения. Блок 5060 загрузки/сохранения может выполнять операцию загрузки путем получения адреса целевого операнда в памяти 5053 и загрузки операнда в регистр 5059 или другую ячейку памяти 5053, или может выполнять операцию сохранения путем получения адреса целевого операнда в памяти 5053 и сохранения данных, полученных из регистра 5059 или другой ячейки памяти 5053, в ячейке целевого операнда в памяти 5053. Блок 5060 загрузки/сохранения может действовать по предположению и осуществлять доступ к памяти в последовательности, которая не соответствует последовательности команд, тем не менее, блок 5060 загрузки/сохранения должен обеспечивать для программ видимость выполнения команды по порядку. Блок 5060 загрузки/сохранения может поддерживать связь с общими регистрами 5059, блоком 5056 декодирования/диспетчеризации, интерфейсом 5053 кэша/памяти или другими элементами 5083 и содержит различные регистровые схемы, АЛУ 5085 и управляющую логику 5090 для вычисления адресов ячеек запоминающего устройства и обеспечения последовательного потока для сохранения порядка следования операций. Некоторые операции могут выполняться не по порядку, но блок загрузки/сохранения обеспечивает функциональные возможности для того, чтобы выполняемые не по порядку операции выглядели для программы выполненными по порядку, как хорошо известно из техники.
Адреса, которые "видит" прикладная программа, предпочтительно часто именуются виртуальными адресами. Иногда виртуальные адреса именуются "логическими адресами" и "исполнительными адресами". Эти виртуальные адреса являются виртуальными в том смысле, что их перенаправляют в ячейку физической памяти посредством одной из ряда технологий динамической трансляции адреса (DAT), включая без ограничения простое приписывание величины смещения к виртуальному адресу, трансляцию виртуального адреса посредством одной или нескольких таблиц трансляции, которые предпочтительно содержат по меньшей мере таблицу сегментов и таблицу страниц по отдельности или в сочетании, предпочтительно таблицу сегментов, содержащую запись с указанием таблицы страниц. В системе z/Architecture предусмотрена иерархия трансляции, в которую входит первая таблица региона, вторая таблица региона, третья таблица региона, таблица сегментов и необязательная таблица страниц. Эффективность трансляции адресов часто повышается за счет использования буфера быстрого преобразования адреса (TLB), который содержит записи, отображающие виртуальный адрес соответствующей ячейки физической памяти. Записи создаются, когда DAT транслирует виртуальный адрес с использованием таблиц перевода. Затем при последующем использовании виртуального адреса может использоваться запись из быстродействующего TLB вместо доступа к таблицам медленной последовательной трансляции. Содержимым TLB может управлять ряд алгоритмов замещения, включая алгоритм замещения наиболее давней по использованию страницы (LRU).
В том случае, когда процессором является процессор мультипроцессорной системы, каждый процессор отвечает за сохранение совместно используемых ресурсов, таких как средства ввода-вывода, кэши, TLB и память, взаимно заблокированных для обеспечения непротиворечивости. Обычно для поддержания непротиворечивости кэшей используются технологии "слежения". Для облегчения совместного использования каждая строка кэша может помечаться в среде слежения как находящаяся в одном из следующих состояний, включающих состояние совместного использования, состояние монопольного использования, измененное состояние, недействительное состояние и т.п.
Блоки 5054 ввода-вывода (фиг.10) обеспечивают процессор средствами подключения к периферийным устройствам, включая, например, накопители на магнитной ленте, накопители на дисках, принтеры, дисплеи и сети. Блоки ввода-вывода представлены в компьютерной программе программными драйверами. В мэйнфреймах, таких как System z® производства IBM®, блоки ввода-вывода мэйнфрейма являются адаптерами каналов и адаптерами открытых систем и обеспечивают связь между операционной системой и периферийными устройствами.
Кроме того, одна или несколько особенностей настоящего изобретения могут выгодно применяться в вычислительных средах других типов. В качестве примера, среда может содержать эмулятор (например, программные или другие механизмы эмуляции), в которых эмулируется конкретная архитектура (включая, например, выполнение команд, структурированные функции, такие как трансляция адреса, и структурированные регистры) или ее сокращенная версия (например, в собственной компьютерной системе, имеющей процессор и память). В такой среде за счет одной или нескольких эмулирующих функций эмулятора может быть реализована одна или несколько особенностей настоящего изобретения, несмотря на то, что компьютер, в котором выполняется эмулятор, может иметь архитектуру, отличающуюся от эмулируемых возможностей. В качестве одного из примеров в режиме эмуляции декодируется конкретная эмулируемая команда или операция, и создается соответствующая эмулирующая функция с целью реализации отдельной команды или операции.
В эмулирующей среде главный компьютер содержит, например, память для хранения команд и данных; блок выборки команд для выборки команд из памяти и необязательно локальной буферизации выбранных команд; блок декодирования команд для приема команд от блока выборки команд и определения типа команд, которые были выбраны; и блок выполнения команд для выполнения команд. Выполнение может предусматривать загрузку данных из памяти в регистр; сохранение данных из регистра в памяти; или выполнение арифметической или логической операции какого-либо типа, определяемой блоком декодирования. В одном из примеров каждый блок реализован посредством программного обеспечения. Например, выполняемые блоками операции реализованы в виде одной или нескольких подпрограмм в программном обеспечении эмулятора.
В частности, в мэйнфрейме структурированные машинные команды используются программаторами, обычно современными программаторами на языке "C" посредством компилирующего приложения. Эти команды, хранящиеся в запоминающей среде, могут выполняться в собственной системе команд сервера IBM® на основе z/Architectwe® или в качестве альтернативы в машинах на основе других архитектур. Они могут эмулироваться в существующих и будущих серверах на основе мэйнфреймов IBM® и в других машинах IBM® (например, серверах Power Systems и серверах System x®). Они могут выполняться в операционной системе Linux разнообразными машинами, использующими аппаратное обеспечение производства IBM®, Intel®, AMD™ и других компаний. Помимо выполнения этим аппаратным обеспечением на основе Z/Architecture®, может использоваться Linux, а также машины, использующие эмуляцию Hercules, UMX или FSI (Fundamental Software, Inc), когда выполнение обычно происходит в режиме эмуляции. В режиме эмуляции эмулирующее программное обеспечение выполняется собственным процессором, эмулирующим архитектуру эмулируемого процессора.
Собственный процессор обычно выполняет эмулирующее программное обеспечение, представляющее собой аппаратно-программное обеспечение или собственную операционную систему для эмуляции эмулируемого процессора. Эмулирующее программное обеспечение отвечает за выборку и выполнение команд архитектуры эмулируемого процессора. Эмулирующее программное обеспечение поддерживает счетчик эмулируемых команд для слежения за границами команд. Эмулирующее программное обеспечение может осуществлять выборку одной или нескольких эмулируемых машинных команд за один раз и преобразование одной или нескольких эмулируемых машинных команд в соответствующую группу собственных машинных команд для выполнения собственным процессором. Эти преобразованные команды могут помещаться в кэш, что позволяет ускорять преобразование. Тем не менее, эмулирующее программное обеспечение должно поддерживать правила архитектуры эмулируемого процессора с тем, чтобы обеспечивать правильную работу операционных систем и приложений, написанных для эмулируемого процессора. Кроме того, эмулирующее программное обеспечение должно обеспечивать ресурсы, указанные архитектурой эмулируемого процессора, включая без ограничения управляющие регистры, регистры общего назначения, регистры с плавающей точкой, функцию динамической трансляции адреса, включая таблицы сегментов и таблицы страниц, например, механизмы прерывания, механизмы переключения контекста, часы истинного времени (TOD) и структурированные интерфейсы с подсистемами ввода-вывода с тем, чтобы операционная система или прикладная программа, рассчитанная на работу в эмулируемом процессоре, могла быть запущена в собственном процессоре, имеющем эмулирующее программное обеспечение.
Конкретная эмулируемая команда декодируется, и вызывается подпрограмма для выполнения функции отдельной команды. Функция эмулирующего программного обеспечения, эмулирующая функцию эмулируемого процессора, реализуется, в подпрограмме или драйвере на языке "С" или каким-либо другим способом обеспечения драйвера для конкретного аппаратного обеспечения, доступным для специалистов в данной области техники, ознакомившихся в описанием предпочтительного варианта осуществления. В различных патентах, в которых предложена эмуляция программного и аппаратного обеспечения, включая без ограничения патент US 5551013 под названием "Multiprocessor for hardware emulation", выданный на имя Beausoleil и др., патент US 6009261 под названием "Preprocessing of stored target routines for emulating incompatible instructions on a target processor", выданный на имя Scalzi и др.; патент US 5574873 под названием "Decoding guest instruction to directly access emulation routines that emulate the guest instructions", выданный на имя Davidian и др.; патент US 6308255 под названием "Symmetrical multiprocessing bus and chipset used for coprocessor support allowing non-native code to run in a system", выданный на имя Gorishek и др.; патент US 6463582 под названием "Dynamic optimizing object code translator for architecture emulation and dynamic optimizing object code translation method", выданный на имя Lethin и др.; патент US 5790825 под названием "Method for emulating guest instructions on a host computer through dynamic recompilation of host instructions", выданный на имя Eric Traut; и многие другие, проиллюстрированы разнообразные известные способы эмуляции формата команд, структурированного для отличающейся машины, в целевой машине, доступные для специалистов в данной области техники.
На фиг.12 проиллюстрирован один из примеров известной из техники эмулирующей главной компьютерной системы 5092, которая эмулирует главную компьютерную систему 5000′, имеющую главную архитектуру. Главным процессором (ЦП) 5091 в главной компьютерной системе 5092 эмуляции является главный процессор (или виртуальный главный процессор) эмуляции, представляющий собой процессор 5093 эмуляции со структурой собственных команд, отличающейся от структуры команд процессора 5091 главного компьютера 5000'. Главная компьютерная система 5092 эмуляции имеет память 5094, доступную для процессора 5093 эмуляции. В примере осуществления память 5094 разделена на память 5096 главного компьютера и память 5097 программ эмуляции. Память 5096 главного компьютера доступна для программ эмулируемого главного компьютера 5092 в зависимости от архитектуры главного компьютера. Процессор 5093 эмуляции выполняет собственные команды структурированной системы команд, структура которых отличается от структуры команд эмулируемого процессора 5091 и которые извлекаются из памяти 5097 программ эмуляции, и может осуществлять выборку главной команды для выполнения из программы в памяти 5096 главного компьютера путем применения одной или нескольких команд из программы контроля последовательности и выборки/декодирования, которая может декодировать выбранную главную команду(-ы) и определять программу выполнения собственных команд эмуляции функции выбранной главной команды. Другие средства, которые предусмотрены в архитектуре главной компьютерной системы 5000', могут эмулироваться программами структурированных средств, включая такие средства, как, например, регистры общего назначения, управляющие регистры, поддержка подсистемы динамической трансляции адреса и ввода-вывода и кэш-память процессора. Программы эмуляции также могут использовать функции, доступные в процессоре 5093 эмуляции (такие как общие регистры и динамическое преобразование виртуальных адресов) для повышения производительности программ эмуляции. Также может быть предусмотрено особое программное обеспечение и механизмы разгрузки, облегчающие процессору 5093 эмуляцию функции главного компьютера 5000′.
Используемая в описании терминология имеет целью описание лишь частных вариантов осуществления, а не ограничение изобретения. Подразумевается, что используемые в описании формы единственного числа включают также формы множественного числа, если из контекста ясно не следует иное. Дополнительно подразумевается, что термины "содержит" и/или "содержащий", используемые в описании, означают присутствие указанных признаков, чисел, шагов, операций, элементов и/или компонентов, но не исключают присутствие или добавление одного или нескольких других признаков, чисел, шагов, операций, элементов, компонентов и/или их групп.
Подразумевается, что соответствующие структуры, материалы, действия и эквиваленты всех элементов "средство или шаг плюс функция" следующей далее формулы изобретения, если таковые существуют, включают любую структуру, материал или действие для выполнения функции в сочетании с другими конкретно заявленными средствами. Описание одной или нескольких особенностей настоящего изобретения представлено в качестве иллюстрации и не имеет целью исчерпать или ограничить изобретение раскрытой формой. Для специалистов в данной области техники бесспорны многочисленные модификации и разновидности, не выходящие за пределы объема и существа изобретения. Выбранный и описанный вариант осуществления имеет целью наилучшим образом пояснить принципы изобретения и его практическое применение, а также позволить специалистам в данной области техники понять изобретение, поскольку предусмотрены различные варианты осуществления с различными модификациями, рассчитанными на конкретное применение.
| название | год | авторы | номер документа |
|---|---|---|---|
| ПРЕОБРАЗОВАНИЕ ИНИЦИИРУЕМОГО СООБЩЕНИЯМИ ПРЕРЫВАНИЯ В УВЕДОМЛЕНИЕ О ГЕНЕРИРОВАННОМ АДАПТЕРОМ ВВОДА-ВЫВОДА СОБЫТИИ | 2010 |
|
RU2546561C2 |
| УПРАВЛЕНИЕ СКОРОСТЬЮ, С КОТОРОЙ ОБРАБАТЫВАЮТСЯ ЗАПРОСЫ НА ПРЕРЫВАНИЕ, ФОРМИРУЕМЫЕ АДАПТЕРАМИ | 2010 |
|
RU2526287C2 |
| СПОСОБ И КОМПЬЮТЕРНАЯ СИСТЕМА ДЛЯ ВЫПОЛНЕНИЯ КОМАНДЫ ЗАПУСКА СУБКАНАЛА В ВЫЧИСЛИТЕЛЬНОЙ СРЕДЕ | 2012 |
|
RU2556419C2 |
| НЕЧУВСТВИТЕЛЬНЫЙ К ЗАДЕРЖКЕ БУФЕР ТРАНЗАКЦИИ ДЛЯ СВЯЗИ С КВИТИРОВАНИЕМ | 2014 |
|
RU2598594C2 |
| РАСШИРЕНИЕ СОГЛАСУЮЩЕГО ПРОТОКОЛА ДЛЯ ИНДИКАЦИИ СОСТОЯНИЯ ТРАНЗАКЦИИ | 2015 |
|
RU2665306C2 |
| СПОСОБ И СИСТЕМА ДЛЯ УПРАВЛЕНИЯ ВЫПОЛНЕНИЕМ ВНУТРИ ВЫЧИСЛИТЕЛЬНОЙ СРЕДЫ | 2012 |
|
RU2577487C2 |
| АКТИВАЦИЯ/ДЕАКТИВАЦИЯ АДАПТЕРОВ ВЫЧИСЛИТЕЛЬНОЙ СРЕДЫ | 2010 |
|
RU2562372C2 |
| КОМАНДЫ СОХРАНЕНИЯ/СОХРАНЕНИЯ БЛОКА ДАННЫХ ДЛЯ СВЯЗИ С АДАПТЕРАМИ | 2010 |
|
RU2522314C1 |
| СРЕДСТВО ДЛЯ УСТАНОВКИ КЛЮЧА БЕЗ ПЕРЕВОДА В ПАССИВНОЕ СОСТОЯНИЕ | 2010 |
|
RU2542953C2 |
| КОМАНДА КОНФИГУРИРОВАНИЯ ТВЕРДОТЕЛЬНОГО ЗАПОМИНАЮЩЕГО УСТРОЙСТВА | 2012 |
|
RU2571392C2 |
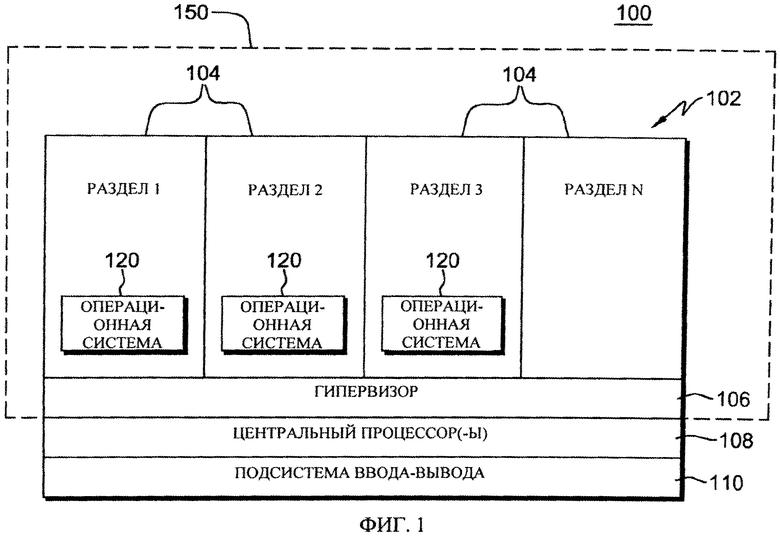
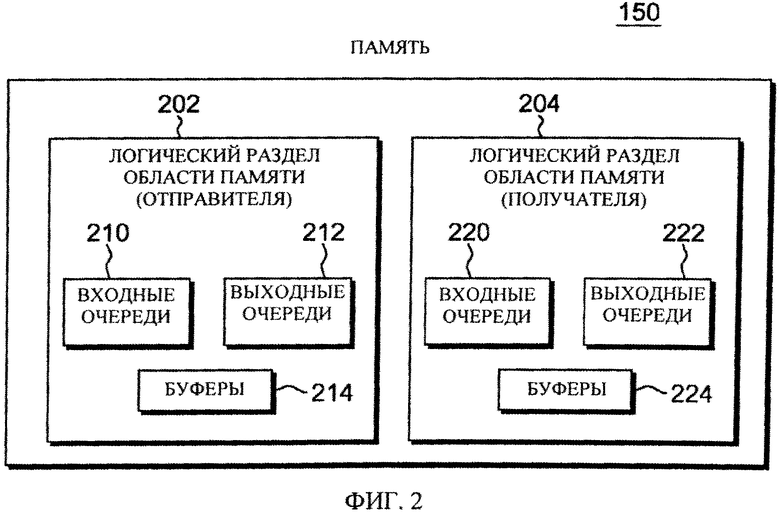
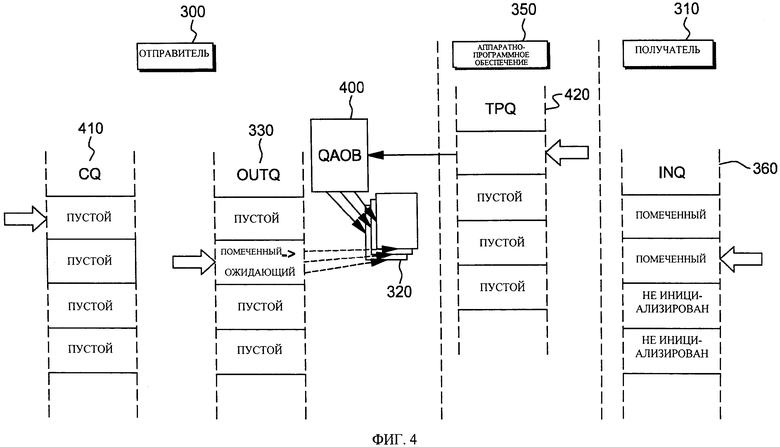
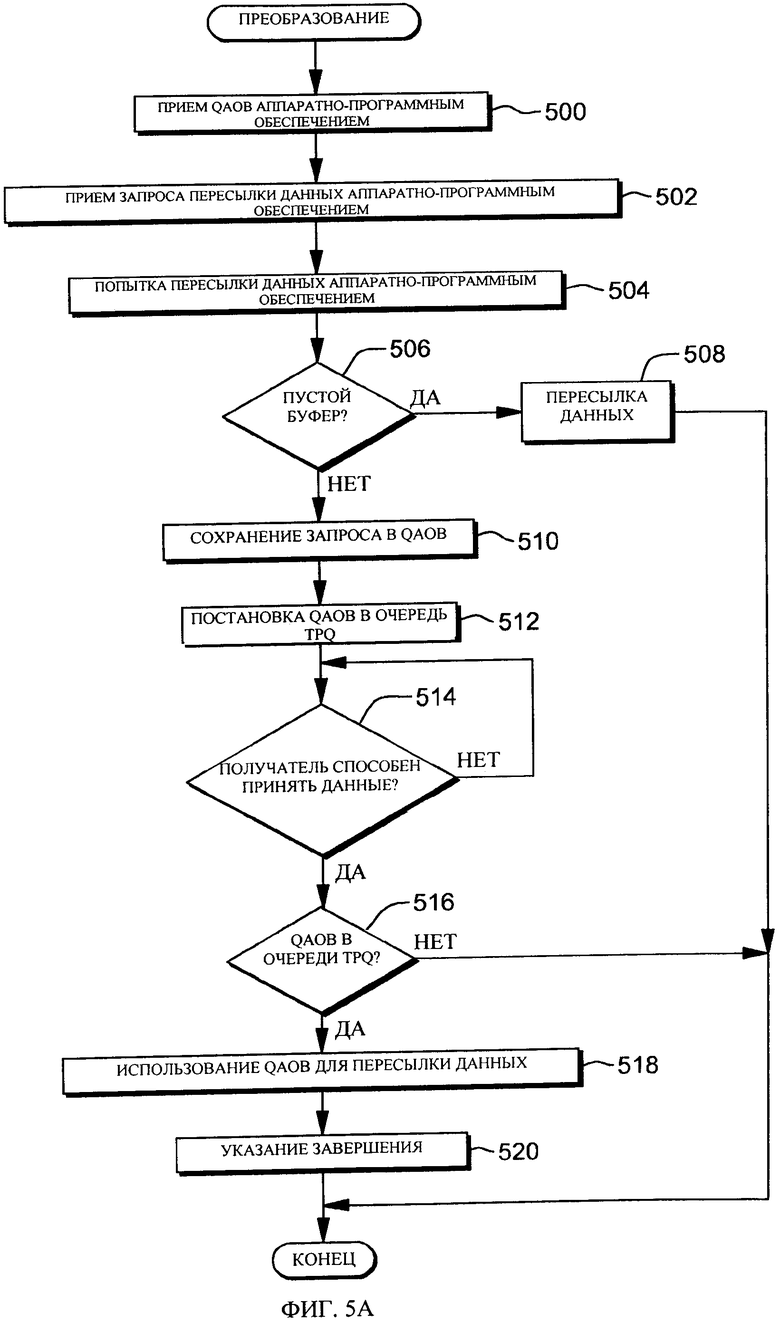
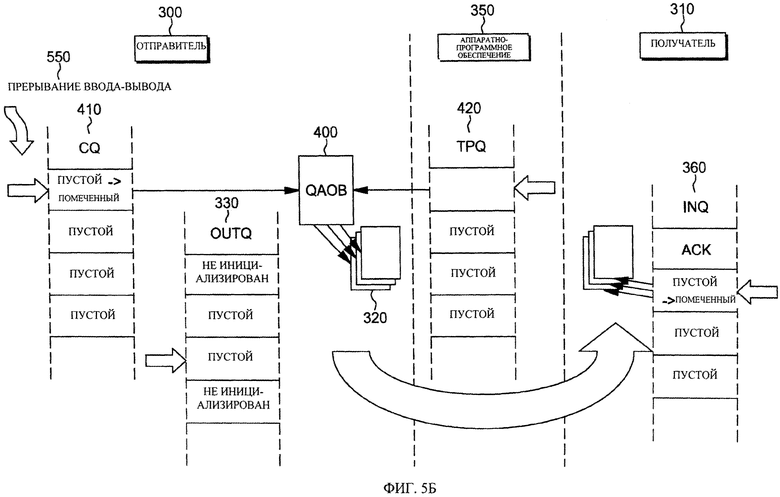
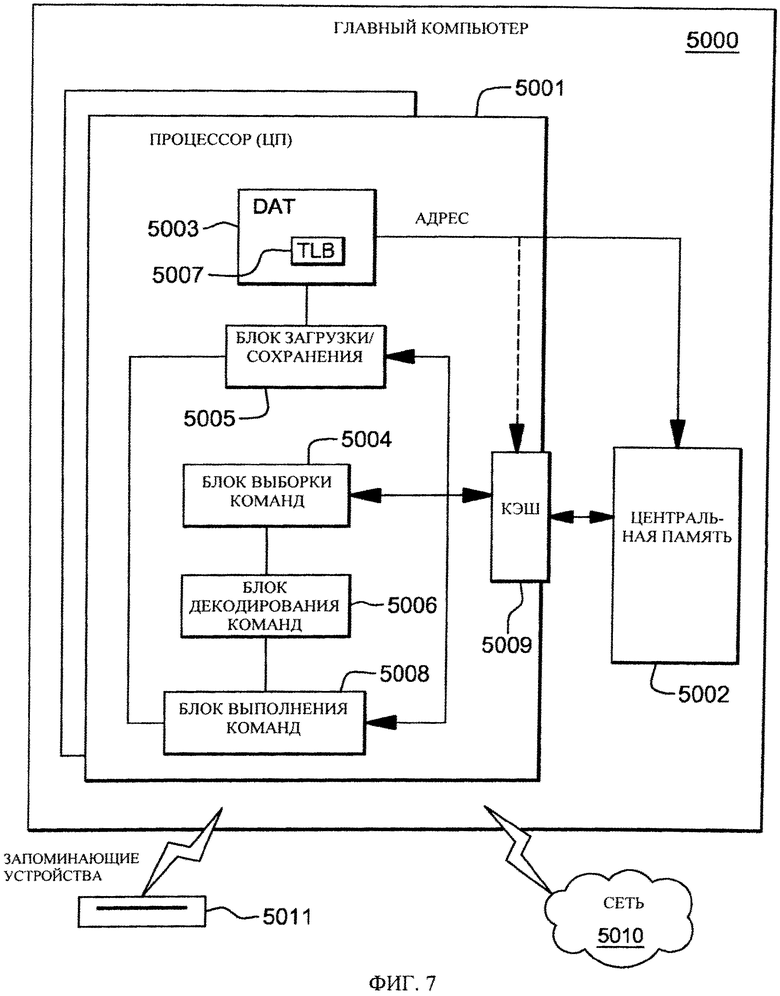
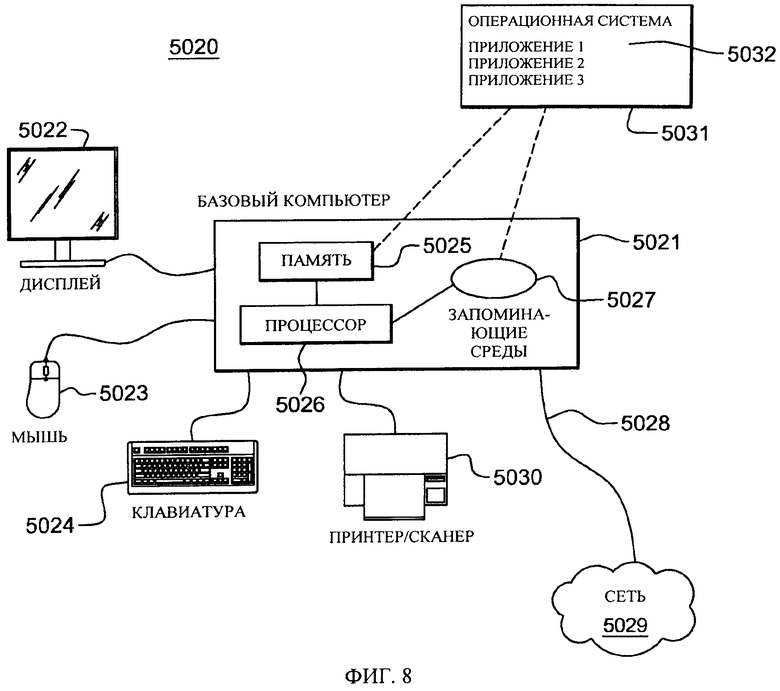
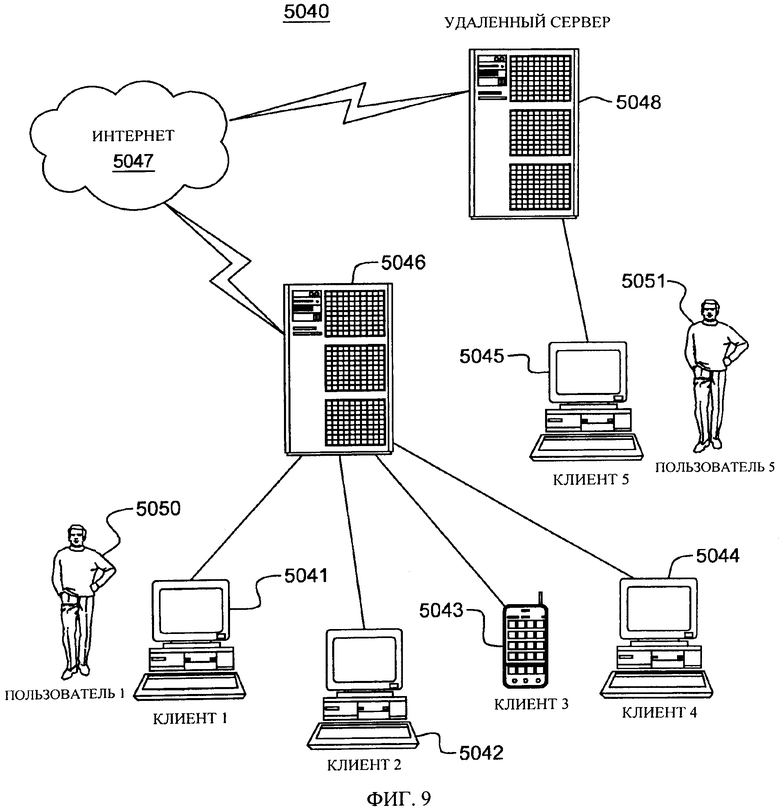
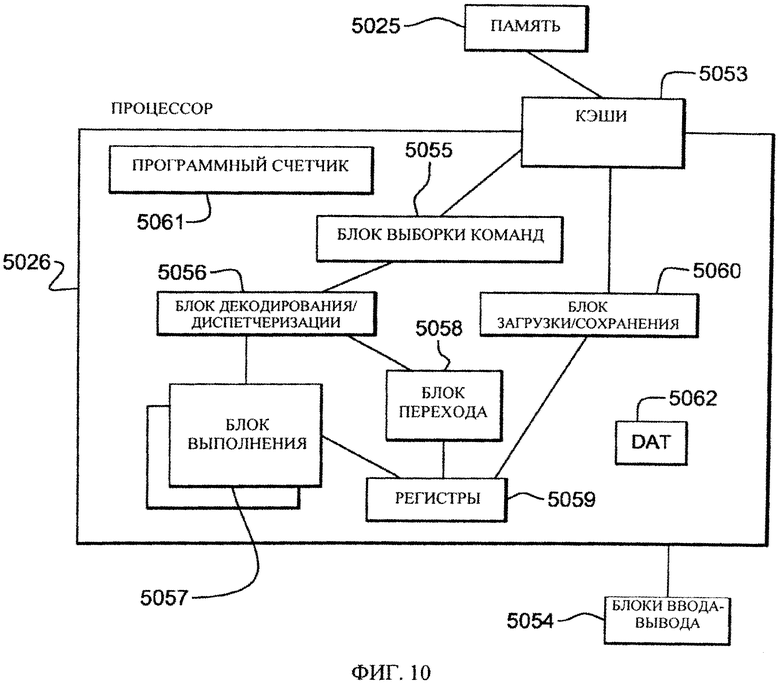
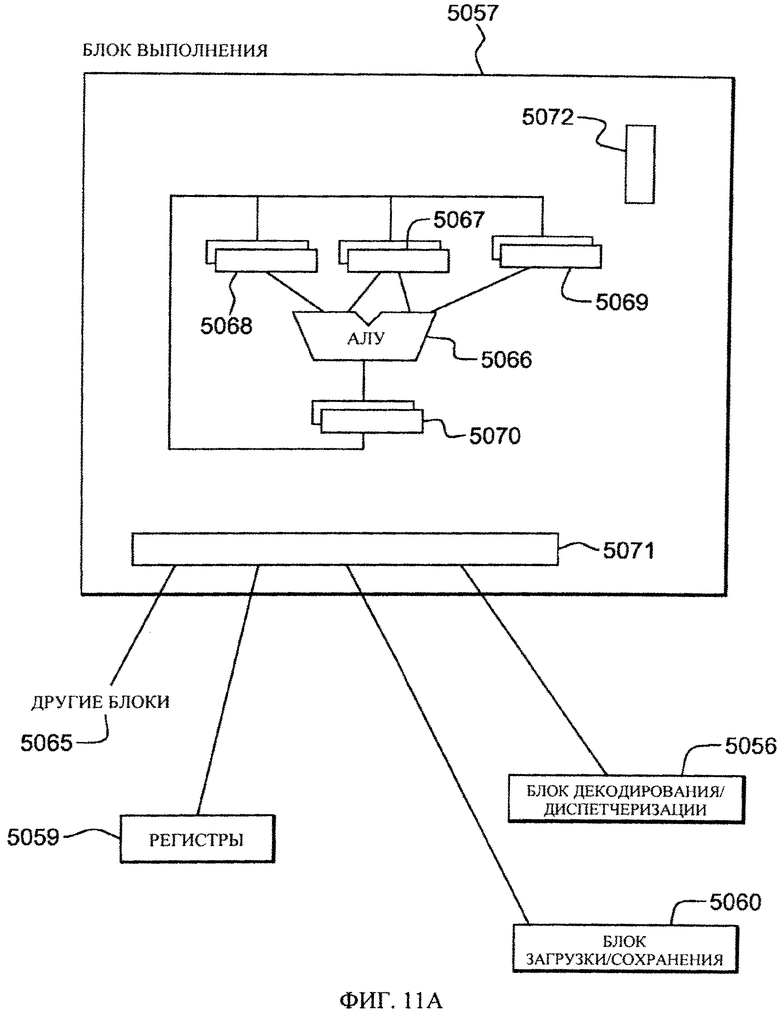
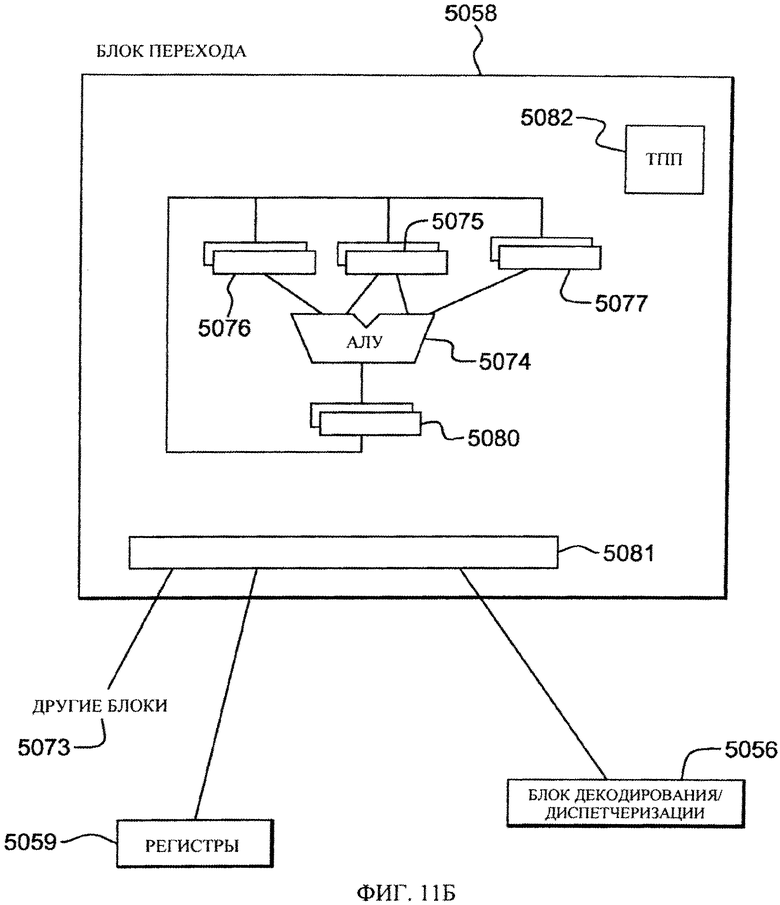
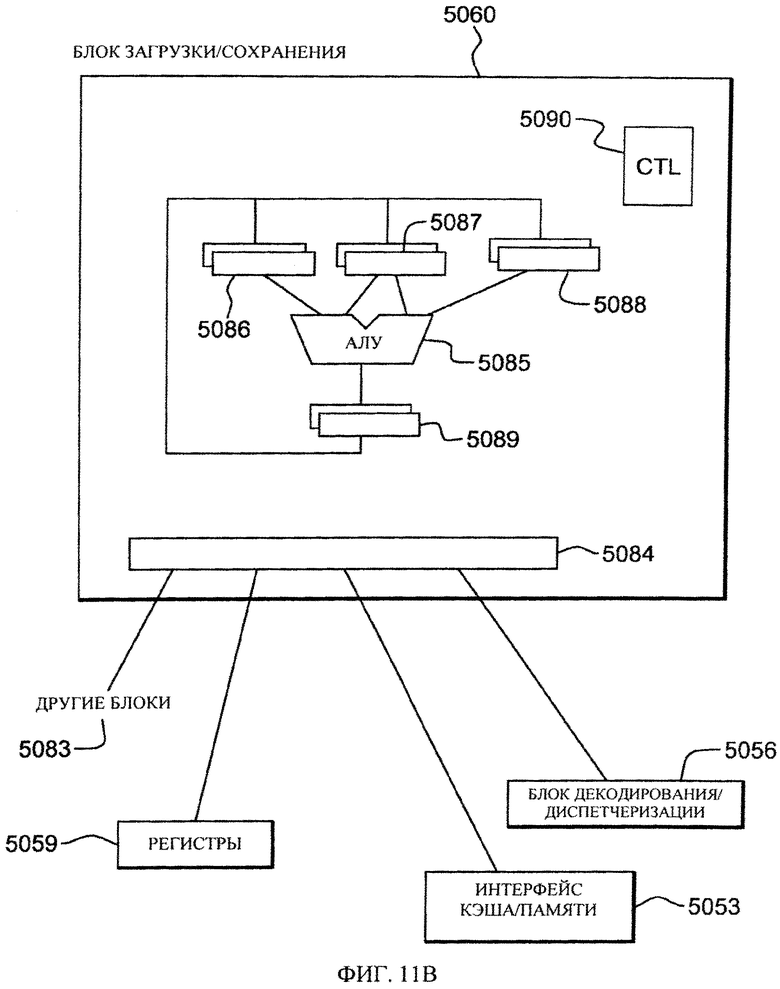
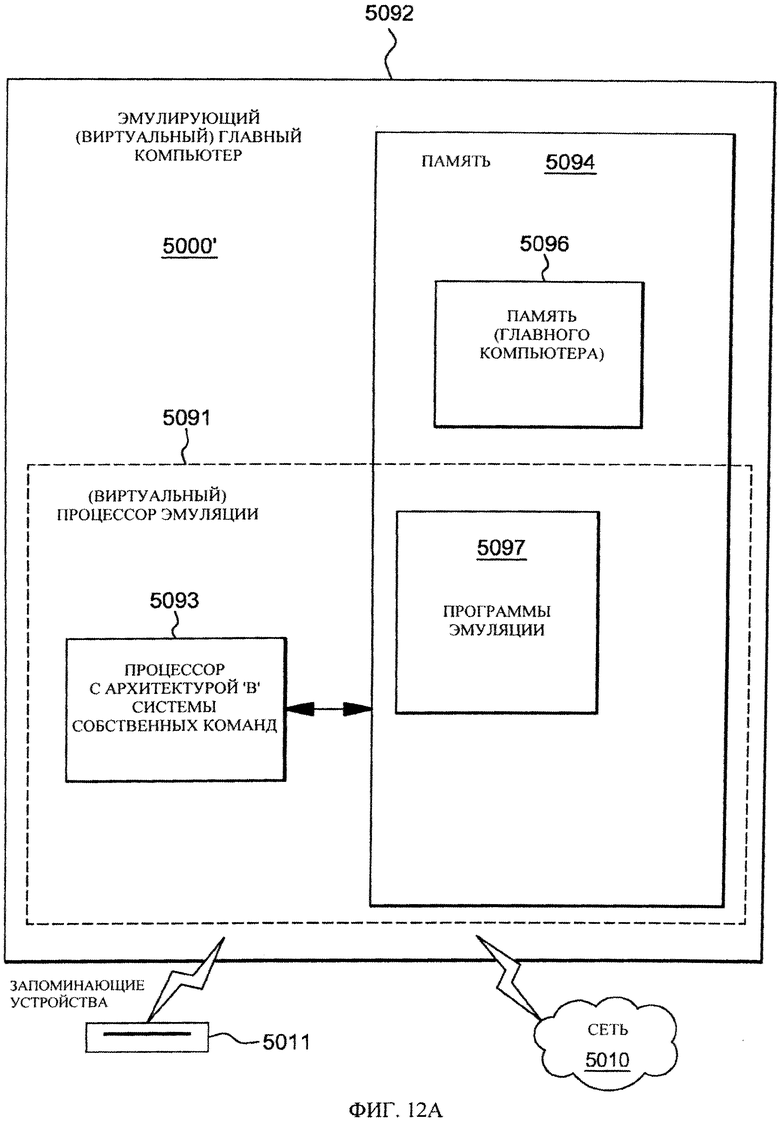
Изобретение относится к области связи в коммуникационной среде. Техническим результатом является повышение эффективности передачи данных в коммуникационной среде. Раскрыт способ обеспечения связи в коммуникационной среде, включающий: получение процессором коммуникационной среды от отправителя коммуникационной среды предварительного разрешения на преобразование синхронной пересылки данных в асинхронную пересылку данных, причем предварительное разрешение включает получение указания блока памяти для слежения за асинхронной пересылкой данных; получение процессором от отправителя запроса на передачу данных получателю коммуникационной среды; инициирование процессором передачи данных получателю, выполняемой с использованием синхронной пересылки данных; установление процессором необходимости преобразования синхронной пересылки данных в асинхронную пересылку данных; и выполняемое при указанном установлении автоматическое преобразование процессором синхронной пересылки данных в асинхронную пересылку данных для завершения передачи данных получателю, при этом автоматическое преобразование является независимым от любых действий отправителя, кроме предварительного разрешения. 3 н. и 28 з.п. ф-лы, 15 ил.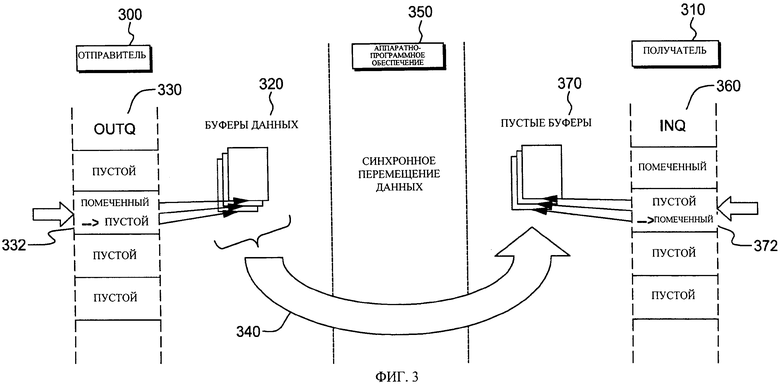
1. Энергонезависимый машиночитаемый носитель данных, в котором хранятся команды, считываемые и выполняемые устройством обработки данных для осуществления способа обеспечения связи в коммуникационной среде, включающего:
получение процессором коммуникационной среды от отправителя коммуникационной среды предварительного разрешения на преобразование синхронной пересылки данных в асинхронную пересылку данных, причем предварительное разрешение включает получение указания блока памяти для слежения за асинхронной пересылкой данных,
получение процессором от отправителя запроса на передачу данных получателю коммуникационной среды,
инициирование процессором передачи данных получателю, выполняемой с использованием синхронной пересылки данных,
установление процессором необходимости преобразования синхронной пересылки данных в асинхронную пересылку данных, и
выполняемое при указанном установлении автоматическое преобразование процессором синхронной пересылки данных в асинхронную пересылку данных для завершения передачи данных получателю, при этом автоматическое преобразование является независимым от любых действий отправителя, кроме предварительного разрешения.
2. Машиночитаемый носитель данных по п. 1, в котором указанное установление включает установление задержки приема данных получателем в то время, когда данные передаются, и выполняемое в этом случае автоматическое преобразование синхронной пересылки данных в асинхронную пересылку данных для завершения передачи данных в то время, когда получатель способен принять данные.
3. Машиночитаемый носитель данных по п. 2, в котором автоматическое преобразование включает:
сохранение запроса в блоке памяти,
постановку блока памяти в очередь получателя,
установление способности получателя принять данные, и
передачу данных получателю с использованием блока памяти.
4. Машиночитаемый носитель данных по п. 3, в котором установление способности получателя принять данные включает установление наличия у получателя пустого буфера для приема данных.
5. Машиночитаемый носитель данных по п. 3, в котором способ дополнительно включает уведомление отправителя о завершении передачи.
6. Машиночитаемый носитель данных по п. 5, в котором уведомление о завершении передачи включает сообщение адреса блока памяти в очереди завершения в памяти, доступной для отправителя.
7. Машиночитаемый носитель данных по п. 6, в котором способ дополнительно включает генерирование прерывания для отправителя при сообщении адреса в очереди завершения.
8. Машиночитаемый носитель данных по п. 2, в котором установление задержки приема данных получателем включает установление недоступности приемного буфера для приема данных.
9. Машиночитаемый носитель данных по п. 1, в котором способ дополнительно включает получение другого запроса от отправителя, при этом другой запрос подлежит синхронной передаче другому получателю до завершения асинхронной передачи запроса получателю.
10. Машиночитаемый носитель данных по п. 1, в котором способ дополнительно включает прием одного или нескольких дополнительных запросов от отправителя до завершения асинхронной передачи данных получателю, при этом данные одного или нескольких дополнительных запросов могут передаваться синхронно или асинхронно одному или нескольким получателям.
11. Машиночитаемый носитель данных по п. 1, в котором способ дополнительно включает поддержание порядка поступления данных получателю при преобразовании синхронной пересылки данных в асинхронную пересылку данных.
12. Компьютерная система для обеспечения связи в коммуникационной среде, содержащая память и процессор, поддерживающий связь с памятью, при этом компьютерная система сконфигурирована для осуществления способа, включающего:
получение процессором коммуникационной среды от отправителя коммуникационной среды предварительного разрешения на преобразование синхронной пересылки данных в асинхронную пересылку данных, причем предварительное разрешение включает получение указания блока памяти для слежения за асинхронной пересылкой данных,
получение процессором от отправителя запроса на передачу данных получателю коммуникационной среды,
инициирование процессором передачи данных получателю, выполняемой с использованием синхронной пересылки данных,
установление процессором необходимости преобразования синхронной пересылки данных в асинхронную пересылку данных, и
выполняемое при указанном установлении автоматическое преобразование процессором синхронной пересылки данных в асинхронную пересылку данных для завершения передачи данных получателю, при этом автоматическое преобразование является независимым от любых действий отправителя, кроме предварительного разрешения.
13. Компьютерная система по п. 12, в которой указанное установление включает установление задержки приема данных получателем в то время, когда данные передаются, и выполняемое в этом случае автоматическое преобразование синхронной пересылки данных в асинхронную пересылку данных для завершения передачи данных в то время, когда получатель способен принять данные.
14. Компьютерная система по п. 13, в которой автоматическое преобразование включает:
сохранение запроса в блоке памяти, постановку блока памяти в очередь получателя, установление способности получателя принять данные, и передачу данных получателю с использованием блока памяти.
15. Компьютерная система по п. 14, в которой установление способности получателя принять данные включает установление наличия у получателя пустого буфера для приема данных.
16. Компьютерная система по п. 14, в которой способ дополнительно включает уведомление отправителя о завершении передачи.
17. Компьютерная система по п. 16, в которой уведомление о завершении передачи включает сообщение адреса блока памяти в очереди завершения в памяти, доступной для отправителя.
18. Компьютерная система по п. 17, в которой способ дополнительно включает генерирование прерывания для отправителя при сообщении адреса в очереди завершения.
19. Компьютерная система по п. 12, в которой способ дополнительно включает получение другого запроса от отправителя, при этом другой запрос подлежит синхронной передаче другому получателю до завершения асинхронной передачи запроса получателю.
20. Компьютерная система по п. 12, в которой способ дополнительно включает прием одного или нескольких дополнительных запросов от отправителя до завершения асинхронной передачи данных получателю, при этом данные одного или нескольких дополнительных запросов могут передаваться синхронно или асинхронно одному или нескольким получателям.
21. Способ обеспечения связи в коммуникационной среде, включающий:
получение процессором коммуникационной среды от отправителя коммуникационной среды предварительного разрешения на преобразование синхронной пересылки данных в асинхронную пересылку данных, причем предварительное разрешение включает получение указания блока памяти для слежения за асинхронной пересылкой данных,
получение процессором от отправителя запроса на передачу данных получателю коммуникационной среды,
инициирование процессором передачи данных получателю, выполняемой с использованием синхронной пересылки данных,
установление процессором необходимости преобразования синхронной пересылки данных в асинхронную пересылку данных, и
выполняемое при указанном установлении автоматическое преобразование процессором синхронной пересылки данных в асинхронную пересылку данных для завершения передачи данных получателю, при этом автоматическое преобразование является независимым от любых действий отправителя, кроме предварительного разрешения.
22. Способ по п. 21, в котором указанное установление включает установление задержки приема данных получателем в то время, когда данные передаются, и выполняемое в этом случае автоматическое преобразование синхронной пересылки данных в асинхронную пересылку данных для завершения передачи данных в то время, когда получатель способен принять данные.
23. Способ по п. 22, в котором автоматическое преобразование включает:
сохранение запроса в блоке памяти,
постановку блока памяти в очередь получателя, установление способности получателя принять данные, и
передачу данных получателю с использованием блока памяти.
24. Способ по п. 23, в котором установление способности получателя принять данные включает установление наличия у получателя пустого буфера для приема данных.
25. Способ по п. 23, дополнительно включающий уведомление отправителя о завершении передачи.
26. Способ по п. 25, в котором уведомление о завершении передачи включает сообщение адреса блока памяти в очереди завершения в памяти, доступной для отправителя.
27. Способ по п. 26, дополнительно включающий генерирование прерывания для отправителя при сообщении адреса в очереди завершения.
28. Способ по п. 22, в котором установление задержки приема данных получателем включает установление недоступности приемного буфера для приема данных.
29. Способ по п. 21, дополнительно включающий получение другого запроса от отправителя, при этом другой запрос подлежит синхронной передаче другому получателю до завершения асинхронной передачи запроса получателю.
30. Способ по п. 21, дополнительно включающий прием одного или нескольких дополнительных запросов от отправителя до завершения асинхронной передачи данных получателю, при этом данные одного или нескольких дополнительных запросов могут передаваться синхронно или асинхронно одному или нескольким получателям.
31. Способ по п. 21, дополнительно включающий поддержание порядка поступления данных получателю при преобразовании синхронной пересылки данных в асинхронную пересылку данных.
| US 7739351 B2, 15.06.2010 | |||
| US 6625637 B1, 23.09.2003 | |||
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Способ и приспособление для нагревания хлебопекарных камер | 1923 |
|
SU2003A1 |
| ИНТЕРФЕЙС ВЫСОКОСКОРОСТНОЙ ПЕРЕДАЧИ ДАННЫХ | 2004 |
|
RU2369033C2 |

