Область техники, к которой относится изобретение
Варианты осуществления настоящего изобретения относятся в основном к интерфейсам компьютерных систем. В частности, варианты осуществления изобретения относятся к нечувствительному к задержке буферу транзакций для протоколов связи с квитированием систем система-на-кристалле.
Уровень техники
Основные микросхемы процессоров, как высокопроизводительных, так и низкоэнергетических, все чаще выполняют дополнительные функции, например, графические, функции устройств отображения, функции модулей безопасности, функции PCIe ™ портов (т.е., портов в соответствии со спецификацией взаимного соединения периферийных компонентов (PCI Express ™ (PCIe ™)) базовой спецификации версии 2.0 (опубликована в 2007 г.) (далее упоминается как PCIe ™ спецификация) и других PCIe ™ на основе периферийных устройств, предоставляя при этом унаследованную поддержку устройствам, совместимых с PCI спецификацией, такой как спецификацией взаимного соединения периферийных компонентов (PCI) спецификации локальной шины, версия 3.0 (опубликована в 2002 г.) (здесь и далее, упоминается как PCI спецификация).
Такие конструкции высоко сегментированы из-за наличия различных спецификаций сервера, настольных, мобильных, встраиваемых, ультра мобильных и мобильных интернет устройств. Различные рынки стремятся использовать единую микросхему система-на-кристалле (SoC или SOC), сочетающая, по меньшей мере, некоторые из ядро процессора, контроллеров памяти, контроллеров ввода/вывода и других элементов сегмента удельного ускорения на одной микросхеме. Тем не менее, конструкции, которые аккумулируют эти признаки, не получили широкое распространение из-за трудностей интеграции различных компонентов (IP) архитектуры, охраняемые законом об авторском праве, или агентов на одном кристалле. Это особенно проявляется в том, что IP-блоки могут иметь различные спецификации и уникальную конструкцию, и могут потребовать использования множества специализированных проводов, коммуникационных протоколов и так далее, чтобы совместить их на SoC. В результате, каждая SoC или другое передовое полупроводниковое устройство, которое было разработано, имеет более сложную конструкцию и процедуру адаптации к специфическим требованиям для инкорпорирования различных IP-блоков в одном устройстве.
При использовании протокола связи с квитированием (и тому подобное) IP агент должен быть подключен к соединению (или структуре, шине) для получения права использования или прав доступа на взаимодействие, отправив сигнал с запросом (REQ) арбитру, и приняв сигнал (GNT) разрешения от арбитра, прежде чем будет осуществлена передача транзакции в соединение. Как правило, как показано на фиг. 1, устройство временного хранения информации (здесь и далее обозначается как буфер транзакций) реализуется как буфер транзакций или транзакции, относящейся к данным (извлекаемые из устройства хранения данных транзакций, например, регистры), для которых "REQ" уже был размещен на IO структуре подсистемы в качестве примера. Когда принимается "GNT", соответствующая транзакция извлекается из буфера транзакций и поставляется в IO структуры подсистемы, как показано на фиг. 1. В результате, глубина этого буфера транзакций зависит от латентности связи с квитированием для заданной полосы пропускания и устойчивости к задержке. Когда IP агент перемещается в пределах IO структуры подсистемы или меняет свои требования к латентности, то изменяется латентность связи с квитированием, что оказывает воздействие на глубину буфера транзакций.
Краткое описание чертежей
Варианты осуществления настоящего изобретения проиллюстрированы в качестве примера, и не ограничиваются описанием, приведенным на прилагаемых чертежах, на которых одинаковые ссылочные позиции указывают одинаковые элементы.
Фиг. 1 представляет собой схему, иллюстрирующую типичные транзакции узла.
Фиг. 2 представляет собой блок-схему, иллюстрирующую базовую архитектуру межкомпонентного соединения в соответствии с вариантом осуществления.
Фиг. 3 представляет собой блок-схему алгоритма, иллюстрирующую процесс обработки протокола связи с квитированием согласно одному варианту осуществления.
Фиг. 4 представляет собой блок-схему алгоритма, иллюстрирующую механизм обработки транзакции в соответствии с другим вариантом осуществления.
Фиг. 5 представляет собой блок-схему алгоритма, иллюстрирующую способ обработки транзакции протоколов связи с квитированием согласно одному варианту осуществления.
Фиг. 6А и 6В показывают блок-схемы, иллюстрирующие систему система-на-кристалле в соответствии с одним вариантом осуществления.
Фиг. 7А иллюстрирует примерный формат команд расширения системы команд (AVX) в соответствии с одним вариантом осуществления настоящего изобретения.
Фиг. 7В иллюстрирует примерный формат команд расширения системы команд (AVX) в соответствии с другим вариантом осуществления настоящего изобретения.
Фиг. 7С иллюстрирует примерный формат команд расширения системы команд (AVX) в соответствии с другим вариантом осуществления настоящего изобретения.
Фиг. 8А представляет собой блок-схему, иллюстрирующую общий формат векторных команд и их шаблоны команд класса А, в соответствии с вариантами осуществления изобретения.
Фиг. 8В показывает блок-схему, иллюстрирующую общий формат векторных команд и их шаблоны команд класса В, в соответствии с вариантами осуществления изобретения.
Фиг. 9А показывает блок-схему, иллюстрирующую примерный конкретный формат векторных команд, в соответствии с одним вариантом осуществления изобретения.
Фиг. 9В изображает блок-схему, иллюстрирующую общий формат векторных команд, в соответствии с другим вариантом осуществления изобретения.
Фиг. 9С показывает блок-схему, иллюстрирующую общий формат векторных команд, в соответствии с другим вариантом осуществления изобретения.
Фиг. 9D представляет собой блок-схему, иллюстрирующую общий формат векторных команд, в соответствии с другим вариантом осуществления изобретения.
Фиг. 10 представляет собой блок-схему архитектуры регистра в соответствии с одним вариантом осуществления настоящего изобретения.
Фиг. 11а представляет собой блок-схему, иллюстрирующую пример упорядоченного конвейера и пример переименования регистра конвейером с изменением последовательности выполнения команд в соответствии с вариантами осуществления изобретения.
Фиг. 11В представляет собой блок-схему, иллюстрирующую пример варианта осуществления архитектуры ядра с логикой последовательного выполнения команд и пример переименования регистра архитектурой ядра с логикой изменения последовательности выполнения команд, включенного в состав процессора, в соответствии с вариантами осуществления изобретения.
Фиг. 12А показывает блок-схему ядра процессора в соответствии с одним вариантом осуществления настоящего изобретения.
Фиг. 12В показывает блок-схему ядра процессора в соответствии с другим вариантом осуществления настоящего изобретения.
Фиг. 13 представляет собой блок-схему процессора согласно вариантам осуществления настоящего изобретения.
Фиг. 14 представляет собой блок-схему системы в соответствии с одним вариантом осуществления настоящего изобретения.
Фиг. 15 представляет собой блок-схему более конкретного примера системы в соответствии с вариантом осуществления настоящего изобретения.
Фиг. 16 показывает блок-схему более конкретного примера системы в соответствии с другим вариантом осуществления настоящего изобретения.
Фиг. 17 показывает блок-схему SoC в соответствии с вариантом осуществления настоящего изобретения.
Фиг. 18 представляет собой блок-схему, которая иллюстрирует пример контрастного использования преобразователя команд программного обеспечения для преобразования двоичных команд в наборе команд источника в двоичные команды в целевом наборе команд в соответствии с вариантами осуществления изобретения.
Описание вариантов осуществления
Различные варианты осуществления и аспекты изобретения будут описаны со ссылкой на подробное приведенное ниже описание и на прилагаемые чертежи, которые иллюстрируют различные варианты осуществления. Нижеследующее описание и чертежи иллюстрируют изобретение и не должны быть истолкованы как ограничивающие изобретение. Многочисленные конкретные подробности описаны ниже для обеспечения полного понимания различных вариантов осуществления настоящего изобретения. Тем не менее, в некоторых случаях, хорошо известные или типовые детали не описаны с целью обеспечения более краткого описания вариантов осуществления настоящего изобретения.
Ссылка в описании на "один вариант осуществления" или "вариант осуществления" означает, что конкретный признак, структура или характеристика, описанные в связи с вариантом осуществления, могут быть включены в состав, по меньшей мере, одного из вариантов осуществления изобретения. Употребление фразы "в одном из вариантов" в различных местах описания, не обязательно все относится к одному и тому же варианту осуществления.
Варианты осуществления, описанные здесь, могут быть использованы во многих различных типах систем. В качестве примеров реализации, описанные здесь, могут быть использованы с применением полупроводниковых приборов, таких как процессоры или другие полупроводниковые устройства, которые могут быть изготовлены на одном полупроводниковом кристалле. В конкретной реализации, устройство может представлять собой систему-на-кристалле (SoC) или другой усовершенствованный процессор, который включает в себя различные однородные и/или гетерогенные агенты обработки и дополнительные компоненты, такие как сетевые компоненты, например, маршрутизаторы, контроллеры, мосты, память и так далее.
Некоторые варианты реализации могут быть использованы в полупроводниковом устройстве, которое реализовано в соответствии с заданной спецификацией, такой как спецификация структуры интегрированной системы на кристалле (IOSF), разработанной Intel® Corporation, изготовленной производителем полупроводника, чтобы обеспечить стандартизированный протокол межкомпонентного соединения на кристалле для установки компонентов архитектуры (IP), защищенных авторским правом, внутри SoC или другой микросхемы. Такие ЕР блоки могут представлять собой различные компоненты, включающие в себя универсальные процессоры с логикой последовательного выполнения команд и ядро с логикой изменения последовательности выполнения команд, блоки фиксированных функций, графические процессоры, контроллеры и многих другие. Благодаря стандартизации протокола межкомпонентного взаимодействия, инфраструктура, таким образом, реализуется для широкого использования ЕР агентов в различных типах микросхем. Соответственно, изготовитель полупроводниковых устройств может не только эффективно проектировать различные типы микросхем для различных клиентов, но может также с помощью спецификации предоставлять возможность третьим сторонам разрабатывать логические устройства, такие как IP агенты, которые будут включены в структуру таких микросхем. И, кроме того, путем предоставления нескольких вариантов различных аспектов протокола межкомпонентного соединения, повторным использованием конструкций, можно добиться наличия эффективной компоновки. Хотя варианты осуществления описаны здесь с использованием IOSF спецификации, очевидно, что объем настоящего изобретения не ограничивается в этом отношении, и варианты осуществления могут быть использованы во многих различных типах систем.
Согласно некоторым вариантам осуществления, предусматривается новый подход, который полностью устраняет зависимость буфера транзакции от латентности связи с квитированием. В этом подходе, глубина буфера транзакций зависит от латентности доступа для чтения набора регистров, из которого извлекаются транзакции. Буфер транзакций используется только для хранения фиксированного числа первоначально приостановленных транзакций (например, соответствующие запросы были отправлены, но соответствующие подтверждения не были приняты от арбитра). Когда буфер транзакций заполнен, запросы (REQ) новых транзакций отправляются независимо и ведется подсчет таких приостановленных запросов. Поскольку гарантируется, что сигнал (GNT) разрешения поступит в порядке, в котором были сделаны запросы (для данного класса потока/виртуального канала (FC/VC) канал), то будет обеспечена надлежащая сохранность только первоначальных транзакции в буфере транзакций на FC/VC канале. Каждый раз, прием GNT предохраняет буфер транзакций от переполнения, если не подтвержденный REQ был отправлен без сохранения соответствующей транзакции внутри буфера транзакций, то такие транзакции извлекаются из набора регистров для пополнения буфера транзакций.
Фиг. 2 представляет собой блок-схему, иллюстрирующую базовую архитектуру межкомпонентного соединения в соответствии с вариантом осуществления. Как показано на фиг. 2, система 100 может быть частью системы-на-кристалле или другого полупроводникового устройства, и включает в себя систему 120 коммутации, которая действует в качестве межкомпонентного соединения между различными компонентами. В примере, как показано, эти компоненты включают в себя IP агенты 130 и 140, которые могут быть независимыми IP блоками для обеспечения различных функциональных возможностей, таких как вычислительных, графических и так далее. Эти IP агенты являются, таким образом, IP блоками или логическими устройствами, имеющие интерфейс, совместимый со спецификацией IOSF, в одном варианте осуществления. Как далее видно, сеть 120 также взаимодействует с мостом 150, который также может быть IP агентом. Хотя это не показано для простоты иллюстрации в варианте на фиг. 1, мост 150 может работать в качестве интерфейса с другими компонентами системы, например, на той же микросхеме или на одной или нескольких различных микросхемах. Например, мост 150 может представлять собой любое из устройств сопряжения в системе, такое как мосты 920 и 985, показанные на фиг. 6А и 6В.
Как будет описано дополнительно ниже, каждый из элементов, показанный на фиг. 2, а именно сеть 120, IP агенты 130 и 140, мост 150 могут включать в себя один или несколько интерфейсов для осуществления обработки различных коммуникационных сигналов. Эти интерфейсы могут быть определены в соответствии со спецификацией IOSF, которая определяет коммуникационные сигналы на этих интерфейсах, протоколы, используемые для обмена информацией между агентами, арбитраж и механизмы управления потоком, используемые для инициирования и организации обмена информацией, поддержанные декодированием адреса и возможностями преобразования, обмен сообщениями при полосной или внеполосной коммуникации, управление мощностью, тестирование, проверку достоверности и отладку.
Как описано выше, когда IP агент, такой как IP агент 150, пытается отправить данные в систему 120 коммутации, IP агент 150 должен послать REQ сигнал (например, устанавливая REQ линию, ассоциированную с IP агентом) арбитру 110 и ждать GNT сигнал, принятый от арбитра 110 (который одобрен арбитром 110). После приема GNT от арбитра 110, IP агент 150 должен послать транзакцию в последующем цикле в систему 120 коммутации. После того, как IP агент 150 послал REQ арбитру 110 и ожидает GNT сигнал от арбитра 110, новые данные транзакции могут быть приняты и сохранены в блоке хранения транзакций, таком как регистры, IP агентом 150. В обычной системе IP агент 150 буферизует новые данные транзакции в буфере транзакции в ожидании GNT от арбитра, что может занять длительный период времени. В результате, буфер транзакций может потребовать большей емкости хранения для удержания всех приостановленных транзакций. Данная величина емкости хранения напрямую зависит от латентности связи с квитированием.
Согласно одному варианту осуществления, по меньшей мере, один из ЕР агентов 130, 140 и 150, в этом примере, IP агент 150 включает в себя буфер 162 транзакций фиксированного размера, который хранит только фиксированное количество данных приостановленных транзакций, в то время как остальные данные транзакций могут по-прежнему удерживаться в блоке 161 хранения данных транзакций. В одном варианте осуществления, со ссылкой на фиг. 2 и фиг. 3, в качестве примера, когда IP агент 150 принимает новые данные транзакции, которые становятся доступными в блоке 162 хранения данных транзакций, которые должны быть переданы в систему 120 коммутации, логическое устройство 165 транзакций посылает REQ в адрес арбитра 110 (через тракт 301). Логическое устройство 165 транзакций посылает новый REQ арбитру 110 независимо от того, был ли принят GNT от арбитра 110.
Кроме того, в соответствии с одним вариантом осуществления, логическое устройство 165 транзакций определяет, имеет ли буфер 161 транзакций достаточно места для буферизации новых данных о транзакции. Если буфер 161 транзакции имеет достаточно места для буферизации новых данных, то логическое устройство 165 транзакций извлекает новые данные транзакций из блока 162 хранения данных транзакций и сохраняет извлеченные данные в буфер 161 транзакций (через тракт 302В). Если буфер 161 транзакции не имеет достаточного места для буферизации новых данных, то логическое устройство 165 транзакций обновляет логическое устройство 170 отслеживания. Логическое устройство 170 отслеживания выполнено с возможностью отслеживать число не подтвержденных REQs, чьи данные не были буферизованы в буфер 161 транзакций. В частности, в соответствии с одним вариантом осуществления, логическое устройство 165 транзакций увеличивает значение счетчика 170 (через тракт 302А), оставляя новые данные транзакций в блоке 162 хранения данных транзакций. Указанное счетчиком 170 значение представляет число не подтвержденного или приостановленного REQs, чьи данные транзакций не были буферизованы в буфер 161 транзакций. То есть, значение счетчика 170 представляет собой число транзакций, которые соответствует отправленным REQs, но их ассоциированные данные транзакций не были буферизованы в буфер 161 транзакций (например, до сих пор хранятся в блоке 162 хранения данных транзакций). Следует отметить, что данные транзакции, сохраненные в буфере 161 транзакций, могут быть обновлены посредством тракта 302В или логического устройства 170 отслеживания (например, соответствующее значение счетчика увеличивается), прежде чем его REQ подается в тракт 301.
Впоследствии, когда GNT принимается от арбитра 110 (по тракту 303), который может быть асинхронным или параллельным по отношению к операциям в трактах 302А и 302В, в одном варианте осуществления, логическое устройство 165 транзакций извлекает следующие данные транзакций соответственно (если существуют) из буфера 161 транзакций и помещает извлеченные данные в систему 120 коммутации (через тракт 304). Кроме того, логическое устройство 165 транзакций определяет, имеется ли какой-либо не подтвержденный или приостановленный REQ посредством проверки значения счетчика 170. Если значение счетчика 170 больше, чем заданное пороговое значение, такое как ноль, то это означает, что существует, по меньшей мере, один неподтвержденный REQ. В такой ситуации, логическое устройство 165 транзакций извлекает следующие данные транзакции соответственно из блока 162 хранения данных транзакций и помещает их в буфер 161 транзакций (по тракту 305), и уменьшает показания счетчика 170 (по тракту 306). В результате, размер буфера 161 может поддерживаться на относительно небольшой величине, с обеспечением достаточной степени латентности доступа к блоку 162 хранения данных транзакций.
Фиг. 4 представляет собой блок-схему алгоритма, иллюстрирующую механизм обработки транзакции в соответствии с другим вариантом осуществления. Как показано на фиг. 4, в этом варианте осуществления, способы, описанные выше, могут быть применены к ситуации, в которой данные нескольких каналов/полос (например, виртуальные каналы/полосы) с множеством классов (например, классы потоков), передаются по межкомпонентному соединению или систему коммутаций. Каждый канал может дополнительно нести несколько различных классов данных. Согласно одному варианту осуществления, буфер (например, буферы 161А - 161N) поддерживается для буферизации данных каждой из комбинации канала/полосы и класса (канал /класс). Для каждого канала/класса, конкретный счетчик (например, счетчики 170) и указатель отсчета (например, указатели 404 отсчета) поддерживаются логическим устройством 403 пополнения буфера, где логическое устройство 403 пополнения буфера осуществляет извлечение соответствующих данных конкретного канала/класса из местоположения, на которое указывает соответствующий указатель отсчета, и размещает извлеченные данные в одном из буферов 161А - 161N, в соответствии с этим конкретным каналом/классом. То есть, для каждой комбинации канал/класс, существует соответствующий указатель отсчета и счетчик. Указатель отсчета указывает на место хранения блока 162 хранения транзакции, в котором в следующие имеющиеся данные соответствующего канала/класса, сохраняются, в то время как соответствующий счетчик сохраняет значение, представляющее номер неподтвержденного REQs этой конкретной комбинации канал/класс.
Когда GNT принят от арбитра 110, арбитр 402 транзакции определяет, какая из комбинаций канал/класс соответствует принятому GNT сигналу, и информирует логическое устройство 403 пополнения буфера о необходимости загрузить данные, ассоциированные с этим конкретным каналом/классом из блока 162 хранения и поместить данные в соответствующий один из буферов 161А - 161N. Арбитр 402 транзакции может поддерживать информацию, идентифицирующую неподтвержденные запросы, и информация может быть использована для ассоциирования принятых GNTs с неподтвержденными REQs. В ответ на это, логическое устройство 403 пополнения буфера проверяет значение счетчика, соответствующее принятому GNT, и извлекает следующие доступные данные транзакций из места хранения, на которое ссылается соответствующий указатель отсчета. В результате, большое количество данных конкретного канала/класса не будет блокировать данные другого канала/класса.
Фиг. 5 представляет собой блок-схему алгоритма, иллюстрирующую способ обработки транзакции протоколов связи с квитированием, согласно одному варианту осуществления. Способ 500 может быть выполнен путем обработки логическим устройством, которое может включать в себя программное обеспечение, аппаратные средства или их сочетание. Способ 500 может быть выполнен IP агентом, как описано выше. Как показано на фиг. 5, на этапе 501, в ответ на данные транзакции, которые будут передаваться посредством межкомпонентного соединения (например, система коммутации, шина), данные транзакции буферизуются в буфер транзакции, если буфер имеет достаточно места. На этапе 502, REQ представляется арбитру, который ассоциирован с межкомпонентным соединением. На этапе 503, в ответ на прием GNT от арбитра, данные транзакции затем извлекаются из буфера транзакции и передаются на межкомпонентное соединение. На этапе 504, логическое устройство обработки определяет, имеется ли какой-либо неподтвержденный REQ, например, путем проверки значения счетчика, который показывает число неподтвержденного REQ. Если это так, то на этапе 505, логическое устройство пополнения буфера осуществляет обработку данных, извлеченных из блока хранения транзакции (например, регистры) и, возможно, уменьшает показания счетчика, если это необходимо.
Фиг. 6А показывает блок-схему, иллюстрирующую систему система-на-кристалле в соответствии с одним вариантом осуществления. Как показано на фиг. 6А, SoC 900 может включать в себя различные компоненты, все из которых могут быть интегрированы на одном полупроводниковом кристалле для обеспечения различных возможностей обработки при высоких скоростях и малой мощности, занимая сравнительно небольшое пространство. SoC 900 включает в себя процессор или центральный процессор (CPU) 901, имеющий один или несколько процессорных ядер 905А и 906В. В различных вариантах осуществления, ядра 905 могут быть относительно простыми ядрами с логикой последовательного выполнения команд или более сложными ядрами с логикой выполнением команд с изменением их очередности. Или может быть использовано объединение простого и сложного ядер на одном SoC. Как видно, ядра 905 могут быть соединены с помощью когерентного межкомпонентного соединения 915, которое дополнительно подключает память 910, например, общий кэш последнего уровня (LLC). Хотя объем вариантов осуществления настоящего изобретения не ограничивается в этом отношении, в одном варианте осуществления когерентное межкомпонентное соединение 915 может быть реализовано в соответствии со спецификацией последовательной кэш-когерентной шиной типа точка-точка (QPI) ™, разработанной Intel Corporation, Santa Clara, California.
Согласно одному варианту осуществления, когерентное межкомпонентное соединение 915 может устанавливать связь через мост 920 с системой 950 коммутаций, которая может быть IOSF системой. Когерентное межкомпонентное соединение 915 дополнительно может устанавливать связь посредством интегрированного контроллера памяти с памятью вне кристалла (не показано для простоты иллюстрации варианта осуществления). Различные компоненты могут соединяться с системой 950 коммутации, которая включает в себя модуль 940 обработки контента (СРМ), который может использоваться для выполнения различных операций, таких как выполнение функций безопасности, криптографических функций и так далее. Кроме того, процессор 945 дисплея может быть частью конвейера обработки медиа информации для воспроизведения видео на ассоциированном дисплее.
Как дополнительно показано, система 950 коммутаций может дополнительно подключаться к другим IP агентам. Кроме того, для обеспечения связи с другими устройствами на кристалле, система 950 коммутации может дополнительно осуществлять связь с контроллером 960 PCIe ™ и контроллером 965 универсальной последовательной шины (USB), оба из которых могут взаимодействовать с различными устройствами в соответствии с этими протоколами. Наконец, как показано в варианте осуществления, мост 970, который может быть использован для связи с дополнительными компонентами других протоколов, такими как протокол открытого ядра (ОСР) или расширенная шинная архитектура микроконтроллеров (AMBA) ARM протокола. Хотя вариант осуществления показан с конкретными компонентами, следует понимать, что объем настоящего изобретения не ограничивается этим, и в различных вариантах осуществления могут применяться дополнительные или другие компоненты.
Более того, следует понимать, что хотя вариант реализации показан в виде одного кристалла SoC, варианты осуществления могут быть дополнительно реализованы в системе, в которой множество микросхем устанавливают связь друг с другом через иной, чем IOSF интерфейс. На фиг. 6В показана блок-схема системы в соответствии с другим вариантом осуществления настоящего изобретения. Как показано на фиг. 6В, SoC 925 включает в себя северный комплекс 902 и южный комплекс 903. Северный комплекс 902 может включать в себя множество компонентов, аналогичные тем, которые обсуждались выше, и дополнительный интерфейс вне кристалла. Соответственно, северный комплекс 902 может осуществлять связь с другой микросхемой 903, которая может включать в себя различные функциональные возможности для обеспечения связи между этими двумя микросхемами, а также с различными устройствами вне кристалла, такими как различные периферийные устройства, в соответствии с одним или более различными характеристиками. В частности, вторая микросхема 903 показана, как включающая в себя интерфейс вне кристалла, чтобы обеспечить связь с микросхемой 902 и который, в свою очередь, взаимодействует с системой 980 коммутации, которая может быть ОСР системой коммутации в соответствии с вариантом осуществления. Как видно, система 980 коммутации дополнительно может быть соединена с различными контроллерами для установления связи с устройствами вне кристалла, включающие в себя контроллер 960 PCIe ™, контроллер 965 USB и мост 985. Мост 958 может быть соединен с другой ОСР системой коммутации и т.д.
Различные IP блоки или агенты, описанные выше, представляют компоненты или функциональные блоки (то есть функциональные блоки), обычно используемые в SoC конструкциях, включающие в себя, но не ограничиваясь ядрами процессора, компонентами кэш-памяти и агентами, контроллерами памяти, I/O контроллерами и интерфейсами, периферийными устройствами и периферийными интерфейсами, видео и аудио компонентами и интерфейсами, компонентами платформы управления и т.д.
Системы межкомпонентного соединения, такие как описаны выше, поддерживают связь между IP блоками с использованием соответствующей проводки и протоколов. Обычно структура данной системы межкомпонентного соединения может содержать матричную "сетку", свободно наполненную систему коммутации, содержащую множество соединений типа точка-точка, общую шинную архитектуру или кольцевую топологию. В одном варианте осуществления, SoC архитектура обобщается таким образом, что каждая система коммутации может быть сконфигурирована в любой из этих топологий. Кроме того, конкретная структура межкомпонентного соединения и протоколы также обобщены в SoC архитектуре так, что различные системы коммутации могут использовать одни и те же или различные структуры межкомпонентного соединения и протоколы. Например, может быть желательно использовать межкомпонентное соединение, которое поддерживает протокол поддержки когерентности кэшей (например, QPI), для связи между ядрами процессора и кэш-памятью IP блоков, в то время как другие структуры и протоколы, такие как ОСР, могут быть использованы для других систем коммутации в архитектуре. Возможно, один протокол может быть использован для всей архитектуры или структуры системы коммутации могут представлять собой часть SoC.
Протокол открытого ядра определяет интерфейс точка-точка между двумя взаимодействующими объектами, такими как IP ядра и модули шинных интерфейсов (оболочки интерфейса шины), также называемые здесь как агенты. Один объект выступает как ОСР ведущий, например, и другие, как ведомые. Только ведущий может представить команды и управлять объектом. Ведомый отвечает на поступившие команды, либо принимая данные от ведущего, либо представляя данные ведущему. Для двух объектов, которые устанавливают одноранговую связь, необходимо иметь два экземпляра ОСР, соединяющий их, где первый объект является ведущим и тот, где первый объект является ведомым.
Характеристики IP ядра определяют, нуждается ли ядро в ведомом, ведущем или в обеих сторонах ОСР; модули оболочки интерфейса должны работать как дополнительная сторона ОСР для каждого подключенного объекта. Передача по этой системе происходит следующим образом. Системный инициатор (как ОСР ведущий) осуществляет передачу команды управления и, возможно, данных в адрес подключенного ведомого (модуль оболочки шинного интерфейса). Модуль интерфейса передает запрос через систему шин на кристалле. ОСР не указывает на функциональность встроенной шины. Вместо этого структура интерфейса преобразует ОСР запрос во встроенную шину обмена. Принимающий модуль оболочки шинного интерфейса (в качестве ОСР ведущего) преобразует операцию встроенной шины в нормативную ОСР команду. Целевая система (ОСР ведомого) принимает команду и осуществляет требуемое действие.
Каждый экземпляр ОСР выполнен (выбором сигналов или битовой шириной конкретного сигнала) на основе требований подключенного объекта, и не зависит от других. Например, системные инициаторы могут потребовать дополнительные адресные биты в их ОСР экземплярах для определения системных целей; дополнительные адресные биты могут быть использованы встроенной шиной для выбора целевой шины, к которой обращается системный инициатор.
ОСР является гибким. Есть несколько полезных моделей для обеспечения коммуникации IP ядер друг с другом. Некоторые используют конвейер для улучшения пропускной способности и характеристик латентности. Другие используют модели многотактового доступа, где сигналы удерживаются статически в течение нескольких тактов, чтобы упростить временной анализ и уменьшить область применения. Поддержка этого шаблона поведения может оказываться путем использования синхронных сигналов квитирования, которые позволяют как ведущему, так и ведомому осуществлять управления, когда сигналы могут быть изменены.
Согласно одному варианту осуществления устройство включает в себя блок хранения данных транзакций для хранения данных транзакций, подлежащих передаче по межкомпонентному соединению системы обработки данных; буфер транзакций, соединенный с блоком хранения данных транзакций для буферизации, по меньшей мере, части данных транзакций и логическое устройство транзакции, соединенное с блоком хранения данных транзакций и буфером транзакций для передачи сигнала с запросом (REQ) в адрес арбитра, ассоциированного с межкомпонентным соединением, в ответ на первые данные транзакции, которые становятся доступными в блоке хранения данных транзакций, в ответ на принятый сигнал разрешения (GNT) от арбитра, извлечение вторых данных транзакции из буфера транзакций и передачу вторых данных транзакции в межкомпонентное соединение и пополнение буфера транзакций с третьими данными транзакций, извлеченными из блока хранения данных транзакций, после того, как вторые данные транзакций были переданы на межкомпонентное соединение. Буфер транзакций буферизует заранее определенное фиксированное количество данных транзакций. Логическое устройство транзакций определяет факт заполнения буфера транзакции в ответ на первые данные транзакций и буферизует первые данные транзакций в буфере транзакций, если буфер транзакций не заполнен. Логическое устройство транзакций увеличивает значение счетчика в ответ на определение, что буфер транзакций заполнен, после того, как REQ был передан. Счетчик показывает количество REQs, которые приостановлены и их ассоциированные данные транзакций не были буферизованы в буфере транзакций. Третьи данные транзакции буферизуются в буфер транзакций, только если значение счетчика превышает нулевое значение. Логическое устройство транзакций уменьшает значение счетчика после того, как вторые данные транзакции была переданы на межкомпонентное соединение.
Набор команд или архитектура системы команд (ISA) является частью компьютерной архитектуры, относящейся к программированию, и может включать в себя собственные данные, команды, регистровую архитектуру, способы адресации, архитектуру памяти, обработку прерываний и исключений и внешний ввод и вывод (I/O). Термин команда, как правило, относится здесь к макрокоманде - это команды, которые поставляются в процессор (или преобразователь команды, который преобразовывает (например, с помощью статического двоичного преобразования, динамического бинарного преобразования, включающее в себя динамическую компиляцию), трансформирует, эмулирует или иным образом преобразовывает команду из одной или более других команд, которые будут обрабатываться процессором) для выполнения - в отличие от микрокоманд или микроопераций (микрокоманды) - что является результатом декодирования макрокоманд декодером процессора.
ISA отличается от микроархитектуры, которая является внутренней структурой процессора, реализующей набор команд. Процессоры с различными микроархитектурами могут совместно использовать общий набор команд. Например, процессоры Intel® Pentium 4, процессоры Intel® Core ™ и процессоры Advanced Micro Devices, Inc. Sunnyvale CA реализовывают почти идентичные версии х86 набора команд (с некоторыми расширениями, которые были добавлены в более новых версиях), но имеют различные внутренние структуры. Например, та же архитектура регистра ISA может быть реализована по-разному в разных микроархитектурах с использованием хорошо известных способов, включающие в себя выделенные физические регистры, один или несколько динамически выделенных физических регистров, используя механизм переименования регистров (например, использование Таблицы псевдонимов регистров (RAT), Буфера переупорядочивания (ROB) и глобального внутрисхемного регистра процессорной логики; использование множества карт и пула регистров) и т.д. Если не указано иное, фразы архитектура регистров, набор регистров и регистр используются здесь для обозначения того, что доступно для программного обеспечения/программиста и способ, в котором команды определяют регистры. Там, где желательно указать на специфичность, будут использоваться прилагательные логическое, архитектурное представление или программное обеспечение для обозначения регистров/наборов в архитектуре регистров, в то время, как различные прилагательные будет использоваться для определения регистров в заданной микроархитектуре (например, физический регистр, буфер переупорядочения, глобальный внутрисхемный регистр процессорной логики, пул регистров).
Набор команд включает в себя один или несколько форматов команд. Данный формат команд определяет различные поля (число битов, расположение битов), чтобы указать, среди прочего, операцию, которая должна быть выполнена (код операции) и операнд (ы), по которым операция должна быть выполнена. Некоторые форматы команд дополнительно будут разбиты посредством определения шаблонов команд (или субформаты). Например, шаблоны команд заданного формата команд могут быть определены, чтобы иметь различные подмножества полей формата команд (включенные в состав поля, как правило, в том же порядке, но, по меньшей мере, у некоторых есть разные позиции битов, потому что включены в состав меньших полей) и/или определены, чтобы иметь заданное поле, что интерпретируется по-разному. Таким образом, каждая команда ISA выражается с помощью заданного формата команд (и, если определено, в заданном одном из шаблонов команд этого формата команд) и включает в себя поля для указания операции и операндов. Например, примерная команда ADD имеет специфический операнд и формат команд, который включает в себя поле операнда, чтобы указать поля кода операций и операнда для выбора операнда (источник 1/получатель и источник 2); и появление этой ADD команды в потоке команд будет иметь конкретный контент в полях операндов, которые выбирают конкретные операнды.
Научные, финансовые, общего назначения, RMS (понимание, выемка и синтез), визуальные и мультимедийные приложения (например, 2D/3D графика, обработка изображений, сжатие видео/распаковка, алгоритмы распознавания голоса и аудио манипуляции) часто требуют выполнения однотипных операций обработки большого количества элементов данных (именуемые как "параллелизм на уровне данных"). Один поток команд - много потоков данных (SIMD) относится к типу команд, который вызывает процессор выполнить операцию обработки множества элементов данных. SIMD технология особенно подходит для процессоров, которые могут логически разделять биты в регистре на количество элементов данных фиксированного размера, каждое из которых представляет собой отдельное значение. Например, биты в 256 - битовом регистре могут быть заданы как исходный операнд для обработки как четырех отдельных 64-битовых упакованных элементов данных (счетверенное слово (Q) размера элементов данных), восемь отдельных 32-битовых упакованных элементов данных (сдвоенное слово (D) размера элементов данных), шестнадцать отдельных 16-битовых упакованных элементов данных (слово (W) размера данных) или тридцать два отдельных 8-битовых элементов данных (байт (В) размера элементов данных). Этот тип данных упоминается как тип упакованных данных или тип данных вектора, и операнды этого типа данных, называются как операнды упакованных данных или вектор-операнд. Другими словами, элемент упакованных данных или вектор относится к последовательности элементов упакованных данных, и операнд упакованных данных или вектор-операнд является исходным или конечным операндом SIMD команды (также известная как команда упакованных данных или векторная команда).
В качестве примера, один тип SIMD команды определяет одновекторную операцию, которая должна быть выполнена на двух исходных вектор-операндах вертикально для генерации вектор-операнда получателя (также называемый как вектор-операнд результат) того же размера, с таким же количеством элементов данных и в том же порядке элемента данных. Элементы данных в исходном вектор-операнде называются элементами данных источника, в то время как элементы данных в вектор-операнде получателя называются элементами данных получателя или результата. Эти вектор-операнды источника имеют тот же самый размер и содержат элементы данных одной и той же ширины и, таким образом, они содержат одинаковое количество элементов данных. Элементы данных источника в одних и тех же позициях битов в двух вектор-операндах источника образуют пары элементов данных (также упоминаемые как соответствующие элементы данных, то есть, элемент данных в позиции 0 элемента данных каждого исходного операнда соответствуют, элементу данных в позиции 1 элемента данных каждого исходного операнда и так далее). Операция, определенная данной SIMD командой выполняется отдельно на каждой из этих пар элементов данных источника, чтобы генерировать соответствующий ряд элементов данных результата и, таким образом, каждая пара элементов данных источника имеет соответствующий элемент данных результата. Поскольку операция является вертикальной и вектор-операнд результат имеет такой же размер, имеется такое же число элементов данных и результирующие элементы данных хранятся в том же порядке элемента данных как вектор-операнды источника, элементы данных результата находятся на тех же битовых позициях вектор-операнда результата, как их соответствующие пары элементов данных источника в вектор-операндах источника. В дополнение к этому примерному типу SIMD команд, существует множество других типов SIMD команд (например, есть только один или более чем два вектор-операндов источника, которые работают горизонтально, что генерирует вектор-операнд результата, имеющий другой размер, различные размеры элементов данных и/или другой порядок элементов данных). Следует иметь в виду, что вектор-операнд получателя (или операнд получатель) определяется как непосредственный результат выполнения операции, указанной командой, включающий в себя сохранение операнда получателя на позиции (будь то регистр или адрес памяти, указанный этой командой) так, что она может быть доступна в качестве операнда источника посредством другой команды (с указанием той же позиции другой командой).
Технология SIMD, как, например, используемая процессорами Intel® Core ™, имеющая набор команд, включающая в себя х86, ММХ ™, потоковые SIMD расширения (SSE), SSE2, SSE3, SSE4.1 и SSE4.2 команды, что позволяет существенно улучшить производительность приложений. Описание дополнительного набора SIMD расширений, относящиеся к Расширению системы команд (AVX) (AVX1 и AVX2) и используя схему кодирования вектора расширений (VEX), было опубликовано (например, см Intel® 64 и IA-32 Руководство архитектуры разработчиков программного обеспечения, октябрь 2011; и см. Intel® Справочник по программированию систем команд расширения, июнь 2011).
Варианты осуществления команды, описанные в данном документе, могут быть реализованы в различных форматах. Кроме того, ниже приведено подробное описание примерных систем, архитектур и конвейеров. Варианты осуществления команды могут быть реализованы на таких системах, архитектурах и конвейерах, но не ограничиваются подробно описанными ниже.
VEX кодирование позволяет командам иметь более, чем два операнда и позволяет SIMD векторным регистрам иметь длину больше, чем 128 бит. Использование префикса VEX предусматривается для трехоперандного (или более) синтаксиса. Например, предыдущие двухоперандные команды выполняют операции, такие как А=А+В, которые перезаписывают исходный операнд. Использование VEX префикса позволяет операндам выполнить неразрушающие операции, такие как А=В+С.
Фиг. 7А показывает примерный формат команд AVX, включающий в себя VEX префикс 2102, вещественное поле 2130 кода операции, Mod R/M байт 2140, SEB байт 2150, поле 2162 смещения и IMM8 2172. Фиг. 7В иллюстрирует, какие поля, показанные на фиг. 7А, составляют полное поле 2174 кода операции и поле 2142 базовой операции. Фиг. 7С иллюстрирует, какие поля, показанные на фиг. 7А, составляют поле 2144 индексного регистра.
VEX префикс (байты 0-2) 2102 кодируется как три байта. Первый байт является форматом поля 2140 (VEX байт 0, биты [7:0]), который содержит эксплицитное значение байта С4 (уникальный значение, используемое для различения формата команд С4).
Второй-третий байты (VEX байты 1-2) включают в себя ряд битовых полей, обеспечивающих специфическую способность. В частности, REX поле 2105 (VEX байт 1, биты [7-5]) состоит из VEX.R битового поля (VEX байт 1, бит [7] - R), битовое поле VEX.X (VEX байт 1, бит [6] - X) и битовое поле VEX. B (VEX байт 1, бит [5] - В). Другие поля команд кодирования ниже трех бит индексов регистра, как известно в данной области техники, (rrr, ххх и bbb), так что Rrrr, Хххх и Bbbb могут быть образованы путем добавления VEX.R, VEX.X и VEX.B. Поле 2115 карты кода операции (VEX байт 1, бит [4:0] - mmmmm) включает в себя контент, чтобы закодировать подразумеваемый начальный байт кода операции. W поле 2164 (VEX байт 2, бит [7] - W) - представлено нотацией VEX.W и предоставляет различные функции в зависимости от команды. Роль VEX.vvvv 2120 (VEX байт 2, бит [6:3] -vvvv) может включать в себя следующее: 1) VEX.vvvv кодирует первый регистровый операнд источника, указанный в перевернутой (1S дополнение) форме и действует для команд с 2 или более исходными операндами; 2) VEX.vvvv кодирует регистровый операнд получателя, указанный в 1s форме дополнения для некоторых векторных сдвигов; или 3) VEX.vvvv не кодирует любой операнд, поле зарезервировано и должно содержать 1111b. Если VEX.L 2168 размер поля (VEX байт 2, бит [2] -L)=0, то это указывает на 128 битовый вектор; если VEX.L=1 указывает на 256 битовый вектор. Префикс кодирования поля 2125 (VEX байт 2, бит [1:0] -рр) предоставляет дополнительные биты для поля базовой операции.
Вещественное поле 2130 кода операции (байт 3) также известно как байт-код операции. Часть кода операции указывается в этом поле. MOD R / М поле 2140 (байт 4) включает в себя MOD поле 2142 (биты [7-6]), Reg поле 2144 (биты [5-3]) и R / М поле 2146 (биты [2-0]). Роль Reg поля 2144 может включать в себя следующее: кодирование либо регистрового операнда получателя или регистрового операнда источника (rrr из Rrrr) или рассматриваться как расширение кода операции и не используется для кодирования любого операнда команды. Роль R / М поля 2146 может включать в себя следующее: кодирование операнда команды, который ссылается на адрес памяти, или кодирование либо регистрового операнда получателя, либо регистрового операнда источника.
Масштаб, индекс, база (SIB) - контент поля 2150 масштаба (байт 5) включает в себя SS2152 (биты [7-6]), которое используется для генерации адреса памяти. Контент SIB.xxx 2154 (биты [5-3]) и SIB.bbb 2156 (биты [2-0]) были ранее упомянуты в связи с регистровыми индексами Хххх и Bbbb. Поле 2162 смещения и непосредственное поле (IMM8) 2172 содержат адресные данные.
Формат векторных команд представляет собой формат команд, который подходит для векторных команд (например, существуют определенные поля, специфичные для векторных операций). Хотя варианты осуществления описаны, где обе векторные и скалярные операции поддерживаются форматом векторных команд, альтернативные варианты осуществления используют только векторные операции формата векторных команд.
Фиг. 8А, 8В и 8С являются блок-схемами, иллюстрирующие общий формат векторных команд и их шаблоны команд в соответствии с вариантами осуществления изобретения. На фиг. 8А представлена блок-схема, иллюстрирующая общий формат векторных команд и класс А их шаблонов команд в соответствии с вариантами осуществления изобретения; на фиг. 8В изображается блок-схема, иллюстрирующая общий формат векторных команд и класс В их шаблонов команд в соответствии с вариантами осуществления изобретения. В частности, общий формат 2200 векторных команд, который определяется шаблонами команд класса А и класса В, оба из которых не включают в себя шаблоны команд доступа 2205 к памяти и шаблоны команд доступа 2220 к памяти. Термин общий в контексте формата векторных команд относится к формату команды, который не связан с каким-либо конкретным набором команд.
Хотя варианты осуществления настоящего изобретения будут описаны для случая, в котором формат векторных команд поддерживает следующие: 64 байтовую длину вектор-операнда (или размер) с 32 битами (4 байта) или 64 бит (8 байт) ширины элемента данных (или размеры) (и, следовательно, 64 байт вектор состоит из либо 16 элементов сдвоенного размера или, альтернативно, 8 элементов счетверенного слова); 64 байтовую длину вектор-операнда (или размер) с 16 бит (2 байта) или 8 бит (1 байт) элемента данных ширины (или размеров); 32 байт длина вектор-операнда (или размер) с 32 бит (4 байта), 64 бит (8 байт), 16 бит (2 байта) или 8 бит (1 байт) элемента данных ширины (или размеров); и 16 байтовую длину вектор-операнда (или размер) с 32 бит (4 байта) 64 бит (8 байт), 16 бит (2 байта) или 8 бит (1 байт) элемента данных ширины (или размеров); альтернативные варианты осуществления могут поддерживать больше, меньше и/или различные размеры вектор-операндов (например, 256 байт вектор-операнды) с больше, меньше или различной шириной элементов данных (например, 128 бит (16 байт) шириной элементов данных).
Шаблоны команд класс А на фиг. 8А включают в себя: 1) в пределах шаблонов команд без доступа 2205 к памяти показаны без доступа к памяти, шаблон команды всего цикла управления 2210 и без доступа к памяти, шаблон команды операции 2215 преобразования данных; и 2) в пределах шаблонов команд доступа 2220 к памяти, как показано с доступом к памяти, шаблон команд временного 2225 шаблон доступа к памяти, шаблон команд невременного 2230 доступа к памяти. Шаблоны команд класса В на фиг. 8В включают в себя: 1) в пределах шаблонов команд без доступа 2205 к памяти показаны без доступа к памяти, управление маски записи, шаблон команды частичного цикла управления 2210 и без доступа к памяти, управление маски записи, шаблон команды типа vsize операции 2217; и 2) в пределах шаблонов команд доступа 2220 к памяти, как показано с доступом к памяти, управление 2227 маски записи.
Общий формат 2200 векторных команд включает в себя следующие поля, перечисленные ниже в порядке, показанном на фиг. 8А и фиг. 8В. Поле 2240 формата представляет собой конкретное значение (значение идентификатора формата команды) в данном поле, которое однозначно идентифицирует формат векторной команды и, таким образом, вхождения команд формат векторных команд в потоках команд. Таким образом, это поле является возможным, в том смысле, что оно не нужно для набора команд, который имеет только общий формат векторных команд. Поле 2242 базовой операции определяет контент, который отличает разные базовые операции.
Поле 2244 регистрового индекса, контент которого, напрямую или через генерацию адресов, определяет местоположения операндов источника и получателя, будь то в регистрах или в памяти. Они включают в себя достаточное количество битов для выбора N регистров из Р×Q (например, 32×512, 16×128, 32×1024, 64×1024) набора регистров. Хотя в одном варианте осуществления N может иметь до трех регистров источника и одного регистра получателя, альтернативные варианты осуществления могут поддерживать больше или меньше регистров источника и получателя (например, может поддерживать до двух источников, где один из этих источников также действует как получатель, может поддерживать до для трех источников, где один из этих источников также выступает в качестве получателя, может поддерживать до двух источников и одного получателя).
Поле 2246 модификатора, контент которого отличает вхождение команд в общий формат векторных команд, который определяет доступ к памяти от тех, которые этого доступа не имеют; то есть, между шаблонами команд без доступа 2205 и шаблонами команд с доступом 2220 к памяти. Операции доступа к памяти считывают и/или записывают в иерархии памяти (в некоторых случаях с указанием адресов источника и/или получателя с помощью значений в регистрах) в то время, как операции без доступа к памяти не делают этого (например, источник и получатель являются регистрами). В то время, как в одном варианте осуществления данное поле также выбирает между тремя различными способами выполнения вычислений адреса памяти, альтернативные варианты осуществления могут поддерживать больше, меньше или различные способы для выполнения расчетов адреса памяти.
Поле 2250 дополнительного действия, контент которого отличает одну из множества различных операций, подлежащих выполнению в дополнение к базовой операции. Это поле является конкретным условием. В одном варианте осуществления настоящего изобретения, данное поле разделено на поле 2268 класса, альфа поле 2252 и бета поле 2254. Поле 2250 дополнительного действия позволяет общим группам операций быть выполненными в одной команде, а не посредством 2, 3 или 4 команд. Поле 2260 масштаба, контент которого позволяет выполнить масштабирование контента поля индекса для генерации адресов памяти (например, для генерации адресов, которые использует 2scale * Индекс + База).
Поле 2262А смещения, контент которого используется как часть генерации адресов памяти (например, для генерации адресов, которые используют 2scale * Индекс + База + Смещение). Поле 2262В коэффициента сдвига (обратите внимание, что размещение рядом поля 2262А смещения прямо над полем 2262В коэффициента сдвига указывает на используемый один или другой), контент которого используется как часть генерации адресов; что определяет коэффициент сдвига, который должен быть масштабирован размером доступа (N) к памяти - где N это количество байтов в доступе к памяти (например, для генерации адресов, которые использует 2scale * Индекс + База + масштабированное смещение). Избыточные младшие биты игнорируются и, следовательно, контент поля коэффициента сдвига умножается на общий размер (N) операндов памяти в целях получения окончательного смещения, которое будет использоваться при расчете эффективного адреса. Значение N определяется аппаратными средствами процессора во время работы на основании поля 2274 полного кода операции (описано ниже) и поля 2254С манипулирования данными. Поле 2262А смещения и поле 2262В коэффициента сдвига являются возможными, в том смысле, что они не используются для шаблонов команд без доступа 2205 к памяти и/или различные варианты осуществления могут реализовать только один или ни одного из двух.
Поле 2264 ширины элемента данных, контент которого отличает, которая одна из множества значений ширины элементов данных должна быть использована (в некоторых вариантах осуществления для всех команд, в других вариантах осуществления для только некоторых команд). Это поле является возможным, в том смысле, что оно не нужно, если поддерживается только одна ширина элемента данных и/или ширины элементов данных поддерживаются с помощью некоторого аспекта кода операции.
Поле 2270 маски записи, контент которого управляет на позиции каждого элемента данных, отражает ли эта позиция элемента данных в вектор-операнде получателя результат базовой операции и операции дополнения. Шаблоны команд класс А поддерживает слияния-маскировку бита на предоставление права доступа на запись, в то время как шаблоны команд класса В поддерживают как слияние-обнуление-маскировку бита на предоставление права доступа на запись. При слиянии, векторные маски позволяют любому набору элементов получателя быть защищенными от обновления во время выполнения какой-либо операции (указанной базовой операцией и операцией дополнения); в другом варианте осуществления сохраняется прежнее значение каждого элемента получателя, где соответствующая битовая маска имеет 0. В отличие от этого, когда обнуление векторных масок позволяет любому набору элементов получателя быть обнуленным во время выполнения какой-либо операции (указанной базовой операцией и операцией дополнения); в одном варианте осуществления, элемент получателя установлен на 0, когда соответствующая битовая маска имеет значение 0. Подмножество этой функциональности предоставляет возможность контролировать длину вектора выполняемой операции (то есть, диапазон элементов модифицируется от первого до последнего); тем не менее, это является возможным, что элементы, которые модифицированы, являются последовательными. Таким образом, поле 2270 маски записи позволяет выполнить частичные векторные операций, включающие в себя загрузку, хранение, арифметическое вычисление, логическое вычисление и т.д. Хотя варианты осуществления настоящего изобретения описаны, где контент поля 2270 маскировки бита на предоставление права доступа на запись выбирает один из нескольких регистров маскировки, который содержит маскировку бита на предоставление права доступа на запись, которые будут использоваться (и, таким образом, контент поля 2270 маскировки бита на предоставление права доступа на запись косвенно идентифицирует, что маскировка должна быть выполнена), альтернативные варианты осуществления вместо этого или дополнительно позволяют, чтобы контент поля 2270 маскировки бита на предоставление права доступа на запись непосредственно указывал на выполнение маскировки.
Непосредственное поле 2272, контент которого указывает на непосредственную спецификацию. Это поле не является обязательным, в том смысле, что отсутствует в варианте реализации общего формата вектора, который не поддерживает непосредственную операцию, и его нет в командах, которые не используются немедленно. Поле 2268 класса, контент которого различает различные классы команд. На фиг. 8А и 8В, контент этого поля выбирает команды класса А и класса В. На фиг. 8А и фиг. 8В, закругленные угловые квадраты используются для обозначения конкретного значения в поле (например, класс А 2268А и класс В 2268В для поля 2268 класса соответственно на фиг. 8А и фиг. 8В).
В случае шаблонов команд без доступа 2205 к памяти класса А, альфа поле 2252 интерпретируется как RS поле 2252А, контент которого отличает один из различных типов операций дополнения, который должен быть выполнен (например, шаблоны команд округления 2252А.1 и преобразования 2252А.2 данных соответственно, указано без доступа к памяти, операция 2210 округления и без доступа к памяти, операция 2215 преобразования данных), в то время как бета поле 2254 отличает, какая из операций указанного типа выполняться. В шаблонах команд без доступа 2205 к памяти, поле 2260 масштаба, поле 2262А смещения и поле 2262В смещения масштаба отсутствуют.
В шаблоне команды операции 2210 управления полным округлением без доступа к памяти, бета поле 2254 интерпретируется, как поле 2254А управления округлением, контент которого обеспечивает статическое округление. Хотя в описанных вариантах осуществления изобретения поле 2254А управления округлением включает в себя поле 2256 подавления всех исключений с плавающей запятой (SAE) и поле 2258 управления округлением, альтернативные варианты осуществления могут поддерживать кодирование в соответствии с данными концепциями в том же поле или только иметь одну или другую из этих концепций/полей (например, может иметь только поле 2258 управления округлением).
SAE поле 2256, контент которого отличает, сообщать или нет о событии исключения; когда контент SAE поля 2256 указывает, что функция подавления активна, то данная команде не сообщает каким-либо флагом исключений с плавающей запятой и не активирует обработчик исключений с плавающей запятой.
Поле 2258 управления операцией округления, контент которого отличает, какая из групп операций округления выполняется (например, округление с повышением, округление с понижением, округление к нулю и округление к ближнему). Таким образом, поле 2258 управление операцией округления позволяет изменить режим округления по предписанию. В одном из вариантов осуществления изобретения, где процессор включает в себя регистр управления для указания режимов округления, контент поля 2250 управления округлением замещает значение регистра.
В шаблоне команды типа операции 2215 преобразования данных без доступа к памяти, бета поле 2254 интерпретируется как поле 2254В преобразования данных, контент которого отличает один из ряда данных преобразований, который должен быть выполнен (например, без преобразования данных, выборка, трансляция).
В случае шаблона команды с доступом 2220 к памяти класса А, альфа поле 2252 интерпретируется как поле 2252В маркера замещения, контент которого отличает которой один из маркеров замещения будет использоваться (на фиг. 8А, временной 2252В.1 и невременной 2252В.2 соответственно, указанный для доступа к памяти, временной 2225 шаблон команды и доступ к памяти, невременной 2230 шаблон команд), в то время как бета поле 2254 интерпретируется как поле 2254С манипулирования данными, контент которого отличает, которая одна из ряда операций манипулирования данными (также известные как примитивы) должна быть выполнена (например, нет манипуляции; вещание; преобразование с повышением источника; и преобразование с понижением). Шаблоны команд доступа 2220 к памяти включают в себя поле 2260 масштаба и, возможно, поле 2262А смещения или поле 2262В смещения масштаба.
Команды вектора памяти выполняют загрузку вектора из и хранение вектора в памяти, с поддержкой преобразования. Как и в случае обычных векторных команд, команды вектора памяти передачи данных из/в память поэлементным образом, элементами, которые фактически переданы, указываются контентом векторной маски, который выбирается, как маска предоставления права доступа на запись.
Временные данные представляют собой данные, вероятно, которые будут повторно использоваться достаточно скоро, чтобы извлечь выгоду из кэширования. Это, однако, подсказка, и разные процессоры могут реализовать его по-разному, в том числе полностью игнорируя подсказку. Невременные данные представляют собой данные, которые вряд ли будут повторно использоваться достаточно скоро, чтобы извлечь выгоду из кэширования в кэше первого уровня, и должен быть отдан приоритет для согласования. Это, однако, является подсказкой, и разные процессоры могут реализовать его по-разному, в том числе полностью игнорируя подсказку.
В случае шаблонов команд класса В, альфа поле 2252 интерпретируется как поле 2252С управления (Z) маскировки бита на предоставление права доступа на запись, контент которого определяет факт того, что управление маскировкой бита на предоставление права доступа на запись посредством поля 2270 маскировки бита на предоставление права доступа на запись должно являться слиянием или обнулением.
В случае шаблонов команд без доступа 2205 к памяти класса В, часть бета поля 2254 интерпретируется как RL поле 2257А, контент которого отличает которой один из различных типов дополнительных операций должен быть выполнен (например, округление 2257А 0,1 и длина вектора (VSIZE) 2257А.2 соответственно, указанная для без доступа к памяти, управление маскировкой бита на предоставление права доступа на запись, шаблон команды типа операции 2212 управления частичного округления и без доступа к памяти, управление маскировкой бита на предоставление права доступа на запись, шаблон команды типа операции 2217 VSIZE), в то время как остальная часть бета поля 2254 отличает, какая из операций указанного типа должна быть выполнена. В шаблонах команд без доступа 2205 к памяти, поле 2260 масштаба, поле 2262А смещения и поле 2262В масштаба смещения не представлены.
Без доступа к памяти, управление маскировкой бита на предоставление права доступа на запись, шаблон команд типа операции 2210 управления частичным округлением, остальная часть бета поля 2254 интерпретируются как поле 2259А операции округления и функция отчетности события исключения отключена (данная команда не сообщает о каком-либо флаге исключения с плавающей запятой и не инициирует обработчик исключений с плавающей запятой).
Поле 2259А управления действием округления, являясь просто полем 2258 управления операцией округления, контент которого определяет какая из групп округления выполняется (например, округление с повышением, округление с понижением, округление к нулю и округление к ближнему). Таким образом, поле 2259А управления действием округления позволяет изменить режим округления по указанию. В одном из вариантов осуществления изобретения, где процессор включает в себя регистр управления для указания режимов округления, контент поля 2250 управления операцией округления замещает значение регистра.
В шаблоне команд типа операции 2217 VSIZE управление маскировкой бита на предоставление права доступа на запись без доступа к памяти, остальная часть бета поля 2254 интерпретируются как поле 2259В вектора длины, контент которого отличает, которая одна из ряда данных векторных длин должна быть выполнена (например, 128,256 или 512 байт).
В случае шаблона команды доступа 2220 к памяти класса В, часть бета поля 2254 интерпретируется как поле 2257 В вещания, контент которого отличает будет или нет выполняться операция манипулирования данными типа вещания, в то время как остальная часть бета поля 2254 интерпретируется поле 2259В векторной длины. Шаблоны команд доступа 2220 к памяти включают в себя поле 2260 масштаба и, возможно, поле 2262А смещения или поле 2262В масштаба смещения.
Что касается общего формата 2200 векторных команд, поле 2274 всего кода операции показана, включающее в себя поле 2240 формата, поле 2242 базовой операции и поле 2264 ширины элемента данных. В то время, как один из вариантов осуществления, где показана поле 2274 всего кода операции включает в себя все эти поля, поле 2274 всего кода операции включает в себя менее, чем все эти поля в вариантах осуществления, которые не поддерживают их все. Поле 2274 всего кода операции предоставляет код операции (код операции).
Поле 2250 дополнительного действия, поле 2264 ширины элемента данных и поле 2270 маскировки бита на предоставление права доступа на запись позволяют указать эти признаки в каждой команде в общем формате векторных команд. Объединение поля маскировки бита на предоставление права доступа на запись маски и поля ширины элемента данных создают типовые команды, которые позволяют применить маску, основанную на различных значениях ширины элементов данных.
Различные шаблоны команд, находящиеся в классе А и классе В, полезны в различных ситуациях. В некоторых вариантах осуществления изобретения, разные процессоры или различные ядра процессора, могут поддерживать только класс А, только класс В или оба класса. Например, высокая производительность ядра общего назначения с логикой изменения последовательности команд, предназначенное для универсальных вычислений, может поддерживать только класс В, ядро, предназначенное в первую очередь для работы с графикой и/или научными вычислениями может поддерживать только класса А, и ядро, предназначенное для обоих может поддерживать оба типа (конечно, ядро, которое имеет некоторое сочетание шаблонов и команд обоих классов, но не все шаблоны и команды обоих классов находится в компетенции данного изобретения). Кроме того, один процессор может содержать несколько ядер, каждое из которых поддерживают тот же класс или в котором разные ядра поддерживают различные классы. Например, в процессоре с отдельным графическим и универсальным ядрами, одно из графических ядер, предназначенное, главным образом, для графики и/или научных вычислений, может поддерживать только класса А, в то время как одно или более из ядер общего назначения может иметь высокую производительность ядра общего назначения с выполнением с изменением последовательности команд и переименованием регистров, предназначен для универсальных вычислений, которые поддерживают только класса В. Другой процессор, который не имеет отдельного графического ядра, может включать в себя еще одно универсальное упорядоченное ядро или с логикой изменения последовательности выполнения команд, которые поддерживают оба класс А и класс В. Конечно, признаки одного класса также могут быть реализованы в другом классе в различных вариантах осуществления изобретения. Программы, написанные на языке высокого уровня, будут поставлены (например, точно скомпилированы или статически скомпилированы) в разнообразных исполняемых формах, включающие в себя: 1) форму, имеющую только команды класса(ов), поддержанные целевым процессором для выполнения; или 2) форму, имеющую альтернативные процедуры, написанные с использованием различных комбинаций команд всех классов и имеющие код управления потоком, который выбирает подпрограммы для выполнения на основании команд, поддерживаемых процессором, который в настоящее время выполняет код.
На фиг. 9 показана блок-схема, иллюстрирующая примерный конкретный формат векторных команд в соответствии с вариантами осуществления изобретения. На фиг. 9 показан конкретный формат 2300 векторных команд, который является конкретным, в том смысле, что он определяет местоположение, размер, интерпретацию и порядок полей, а также значения для некоторых из этих полей. Конкретный формат 2300 векторных команд может быть использован для расширения х86 набора команд и, таким образом, некоторые поля могут быть одинаковыми или используются в существующем х86 наборе команд и их расширения (например, AVX). Этот формат по-прежнему соответствует полю префикса кодирования, вещественному полю кода операции, MOD R / М полю, SIB полю, полю смещения и непосредственным полям существующего х86 набора команд с расширениями. Проиллюстрированы поля, показанные на фиг. 8, в которые, поля, показанные на фиг. 9, сопоставлены.
Следует понимать, что, хотя варианты осуществления настоящего изобретения описаны со ссылкой на конкретный формат 2300 векторных команд в контексте общего формата 2200 векторных команд для иллюстративных целей, и что изобретение не ограничено конкретным форматом 2300 векторных команд, за исключением формулы изобретения. Например, общий формат 2200 векторных команд предусматривает целый ряд возможных размеров для различных полей, в то время как конкретный формат 2300 векторных команд показан как имеющий поля конкретных размеров. В качестве конкретного примера, в то время как поле 2264 ширины элемента данных показано как одно битовое поле в конкретном формате 2300 векторных команд, но изобретение не ограничено таким образом, (то есть, общий формат 2200 векторных команд) предусматривает другие размеры поля 2264 ширины элемента данных).
Общий формат 2200 векторных команд включает в себя следующие поля, перечисленные ниже в порядке, показанном на фиг. 9А. EVEX префикс (Байты 0-3) 2302 - кодируется в форме четырех байт. Поле 2240 формата (EVEX Байт 0, биты [7:0]) - первый байт (EVEX байт 0) является полем 2240 формата и содержит 0×62 (уникальное значение, используемое для различения формата векторной команды в одном варианте осуществления изобретения). Второй - четвертый байты (EVEX байты 1-3) включают в себя ряд битовых полей, обеспечиваюпшх определенную возможность.
REX поле 2305 (EVEX Байт 1, биты [7-5]) - состоит из EVEX. R битового поля (EVEX байт 1, бит [7] - R), EVEX. X битовое поле (EVEX байт 1, бит [6] - X) и 2257 ВЕХ байт 1, бит [5] - В). Битовые поля EVEX. R, EVEX. X и EVEX. B обеспечивают ту же функциональность, что и соответствующие битовые поля VEX, и закодированы с 1 с дополнительную форму, т.е. ZMM0 кодируется как 1111b, ZMM15 кодируется как 0000В. Другие поля команд кодируют нижние три бита регистра индексов, как известно в данной области техники (rrr, ххх и bbb), так что Rrrr, Хххх и Bbbb могут быть образованы путем добавления EVEX. R, EVEX. X и EVEX. B.
REX′ поле 2210 - первая часть REX′ поля 2210 является EVEX.R′ битовым полем (EVEX Байт 1, бит [4] - R′), которая используется для кодирования либо верхнего 16 или нижнего 16 расширенного 32 набора регистра. В одном варианте осуществления настоящего изобретения, этот бит, наряду с другими, как указано ниже, хранится в битовой перевернутом формате, чтобы отличить (в известного х86 32-битного режима) от BOUND команды, реальный опкод составляет 62, что но не учитывается MOD R / М (об этом ниже) полем значение 11 в MOD поле; альтернативные варианты осуществления изобретения не сохраняют этот и другие указанные биты в перевернутом формате. Значение 1 используется для кодирования нижних 16 регистров. Другими словами, R′Rrrr формируется путем объединения EVEX.R′, EVEX.R и других RRR из других полей.
Поле 2315 опкода (EVEX байт 1, биты [3:0] - mmmm) - контент которого кодирует применяемый первоначальный байт опкода (OF, OF 38 или OF 3). Поле 2264 ширины элемента данных (EVEX байт 2, бит [7] - W) представлено нотацией EVEX. W. EVEX. W используется для определения степени детализации (размера) типа данных (либо 32-битных элементов данных или 64-битовых элементов данных). EVEX.vvvv 2320 (EVEX байт 2, биты [6:3] - vvvv) роль EVEX.vvvv может включать в себя следующее: 1) EVEX.vvvv кодирует первый операнд регистра источника, указанный в перевернутой (1 с дополнения) форме и действует для команд с 2 или более операндами источника; 2) EVEX.vvvv кодирует операнд регистра получателя, указанный в Is форме дополнения для некоторых векторных сдвигов; или 3) EVEX.vvvv не кодирует любой операнд, поле зарезервировано и должно содержать 11 lib. Таким образом, поле 2320 EVEX.vvvv кодирует 4 бита нижнего разряда первого спецификатора регистра источника, хранящиеся в перевернутой (1S дополнительной) форме. В зависимости от команды, используется дополнительное EVEX битное поле для расширения размера спецификатора до 32 регистров. EVEX.U 2268 класс поле (EVEX байт 2, бит [2] -U) - если EVEX.U=0, то это означает класс А или EVEX.U0; если EVEX.U=1, то это означает класс В или EVEX.U1.
Поле 2325 префикса кодирования (EVEX байт 2, бит [1:0] -рр) - предоставляет дополнительные биты для поля базовой операции. В дополнение к предоставлению поддержки для унаследованных SSE команд в формате EVEX префикса также имеет преимущество при уплотнении SIMD префикса (не требуя байт для выражения SIMD префикса, EVEX префикс требует только 2 бита). В одном варианте осуществления для поддержки унаследованных SSE команд, которые используют SIMD префикс (66Н, F2H, F3H), как в традиционном формате, так и в формате EVEX префикса, унаследованные SIMD префиксы кодируются в поле кодирования SIMD префикса; и во время выполнения расширения в унаследованный SIMD префикс перед предоставлением в декодер PLA (так как PLA может выполнять как унаследованный, так и EVEX формат этих унаследованных команд без изменений). Хотя новые команды могут использовать контент поля кодирования EVEX префикса непосредственно как расширение опкода, определенные варианты осуществления расширяют таким же образом последовательности, но обеспечивают различные значения для определения этих унаследованных SIMD префиксов. Альтернативный вариант осуществления может переформатировать PLA для поддержки кодирования 2 битового SIMD префикса и, таким образом, не требует расширения.
Альфа поле 2252 (EVEX байт 3, бит [7] - ЕН; также известное как EVEX.EH, EVEX.rs, EVEX.RL, EVEX управление маской предоставления права доступа на запись, и EVEX. N; также обозначено α) - как было описано ранее, это поле является конкретным контекстом. Бета поле 2254 (EVEX байт 3, биты [6:4] -SSS, также известное как EVEX.s2-0, EVEX.r2-0, EVEX.rr1, EVEX.LLO, EVEX.LLB; также обозначено βββ) - как описано выше, это поле является конкретным контекстом.
REX′ поле 2210 - это остаток от REX′ поля и EVEX.V′ битового поля (EVEX байт 3, бит [3] - V′), которые могут быть использованы для кодирования либо верхних 16 или нижних 16 расширенного 32 набора регистра. Этот бит сохранен в битовом перевернутом формате. Значение 1 используется для кодирования нижних 16 регистров. Другими словами, V′VVVV формируется путем объединения EVEX.V′, EVEX.vvvv.
Поле 2270 маскировки бита на предоставление права доступа на запись (EVEX байт 3, биты [2:0] -kkk) - контент которого определяет индекс регистра в регистрах маскировки бита на предоставление права доступа на запись, как описано выше. В одном варианте осуществления настоящего изобретения, конкретное значение EVEX.kkk=000 имеет конкретное поведение, не применяя маскировку бита на предоставление права доступа на запись для конкретной команды (это может быть реализовано в различных формах, включающие в себя использование проводной записи маски ко всем из них или аппаратные средства, которые обходят аппаратные средства маскировки).
Поле 2330 реального опкода (Байт 4) также известен как байт опкода. Часть опкода указывается в данном поле. MOD R/M поле 2340 (Байт 5) включает в себя MOD поле 2342, Reg поле 2344 и R/M поле 2346. Как ранее описано, контент MOD поля 2342 различает операции с доступом к памяти и операций без доступа к памяти. Роль Reg поля 2344 можно описать для двух ситуаций: кодирование либо операнда регистра получателя, или операнда регистра источника, или рассматриваться как опкод расширения и не используется для кодирования любого операнда команды. Роль R/M поля 2346 может включать в себя следующее: кодирование операнда команды, который ссылается на адрес памяти, или кодирование либо операнда регистра получателя, или операнда регистра источника.
Масштаб, индекс, база (SIB) байт (байт 6) - как было описано ранее, контент поля 2250 масштаба используется для генерации адресов памяти. SIB.xxx 2354 и SIB.bbb 2356 - контент этих полей были ранее упоминались в связи с индексами регистров Хххх и Bbbb. Поле 2262А смещения (байты 7-10) - когда MOD поле 2342 содержит 10, байты 7-10 являются полем 2262А смещения и работает так же, как унаследованное 32-битное смещение (disp32) и работает на байтовой детализации.
Поле 2262В коэффициента смещения (байт 7) - когда MOD поле 2342 содержит 01, байт 7 является полем 2262В коэффициента смещения. Расположение этого поля является таким же, что унаследованный х86 набор команд 8-битного смещения (disp8), который работает на байтовой детализации. Так disp8 является знаком расширения, возможно обратиться только между 128 и 127 байтами смещения; с точки зрения строк 64 байтового кэша, disp8 использует 8 битов, которые могут быть установлены только на четыре действительных значениях -128, -64, 0 и 64; так как более большой диапазон часто необходим, то disp32 используется; однако, disp32 требует 4 байта. В отличие от disp8 и disp32, поле 2262 В коэффициента смещения является интерпретацией disp8; при использовании поля 2262 В коэффициента смещения, фактическое смещение определяется контентом поля коэффициента смещения, умноженного на размер операнда доступа (N) к памяти. Этот тип смещения упоминается как disp8 * N. Это уменьшает среднюю длину команд (один байт используется для смещения, но с гораздо большим диапазоном). Такое сжатое смещение основано на предположении, что эффективное смещение является кратным детализированному значению доступа к памяти и, следовательно, не требуется кодирование избыточных битов младшего разряда адреса смещения. Другими словами, поле 262В коэффициента смещения заменяет унаследованный х86 набор команд 8-битного смещения. Таким образом, поле 2262В коэффициента смещения кодируется так же, как х86 набор команд 8-битного смещения (так что нет изменений в правилах кодирования ModRM/SIB), с той лишь разницей, что disp8 увеличен посредством disp8 * N. Другими словами, нет никаких изменений в правилах кодирования или длины кодирования, но только в интерпретации значения смещения посредством аппаратных средств (который должен масштабировать смещение по размеру операнда памяти, чтобы получить побайтовый адрес смещения). Непосредственное поле 2272 работает, как описано выше.
Фиг. 9В показывает блок-схему, иллюстрирующую поля конкретного формата 2300 векторных команд, которые составляют поле 2274 полного опкода в соответствии с одним вариантом осуществления настоящего изобретения. В частности, поле 2274 полного опкода включает в себя поле 2240 формата, поле 2242 базовой операции и поле 2264 ширины (W) элемента данных. Поле 2242 базовой операции включает в себя поле 2325 кодирования префикса, поле 2315 карты опкода и поле 2330 реального опкода.
Фиг. 9С показывает блок-схему, иллюстрирующую поля конкретного формата 2300 векторных команд, которые составляют поле 2244 индекса регистра в соответствии с одним вариантом осуществления настоящего изобретения. В частности, поле 2244 индекса регистра включает в себя поле REX 2305, поле REX′ 2310, ModR/M.reg поле 2344, MODR/M.r/m поле 2346, VVVV поле 2320, ххх поле 2354 и bbb поле 2356.
Фиг. 9D является блок-схемой, иллюстрирующей поля конкретного формата 2300 векторных команд, которые составляют поле 2250 дополнительной операции согласно одному варианту осуществления настоящего изобретения. Когда поле 2268 класса (U) содержит 0, это означает EVEX.U0 (класс А 2268А); когда содержит 1, то это означает EVEX.U1 (класс 2268 В В). При U=0 и MOD поле 2342 содержит 11 (означая операцию без доступа к памяти), альфа поле 2252 (EVEX байт 3, бит [7] - ЕН) интерпретируется как rs поле 2252А. Когда rs поле 2252А содержит 1 (округление 2252А.1), бета поле 2254 (EVEX байт 3, биты [6:4]- SSS) интерпретируется как поле 2254А управления округлением. Поле 2254А управления округлением включает в себя однобитное SAE поле 2256 и двухбитное поле 2258 управления округлением. Когда rs поле 2252А содержит 0 (преобразование 2252А.2 данных), бета поле 2254 (EVEX байт 3, разряды [6:4] - SSS) интерпретируется как трехбайтное поле 2254 В преобразования данных. При U=0 и MOD поле 2342 содержит 00, 01 или 10 (что означает операцию доступа к памяти), альфа поле 2252 (EVEX байт 3, бит [7] - ЕН) интерпретируется как поле 2252В подсказки (ЕН) на удаление и бета поле 2254 (EVEX байт 3, биты [6:4]- SSS) интерпретируется как трехбайтное поле 254С манипуляции данных.
При U=1, альфа поле 2252 (EVEX байт 3, бит [7] - ЕН) интерпретируется как поле 2252С управления (Z) маскировкой предоставления права доступа на запись. При U=1 и MOD поле 2342 содержит 11 (означающий операцию без доступа к памяти), часть бета поля 2254 (EVEX байт 3, бит [4] - S0) интерпретируется как RL поле 2257А; когда содержит 1 (округление 2257А.1) остальная часть бета поля 2254 (EVEX байт 3, бит [6-5] - S2-1) интерпретируется как поле 2259А операции округления, в то время как когда RL поле 2257А содержит 0 (VSIZE 2257.А2), остальная часть бета поля 2254 (EVEX байт 3, бит [6-5] - S2-1) интерпретируется как поле 2259В длины вектора (EVEX байт 3, бит [6-5] - L1-0). При U=1 и поле MOD 2342 содержит 00, 01 или 10 (что означает операцию доступа к памяти), бета поле 2254 (EVEX байт 3, разряды [6:4]- SSS) интерпретируется как поле 2259В длины вектора (EVEX байт 3, бит [6-5] - L1-0) и поле 2257В вещания (EVEX байт 3, бит [4] - В).
Фиг. 10 представляет собой блок-схему архитектуры 2400 регистра в соответствии с одним вариантом осуществления настоящего изобретения. В показанном варианте, есть 32 векторных регистров 2410, которые имеют 512 битовую ширину; эти регистры ссылаются как zmm0 через zmm31. Нижний разряд 256 бит нижних 16 регистров ZMM накладываются на регистры ymm0-16. Нижний разряд 128 бит нижних 16 регистров ZMM (нижний разряд 128 битовых регистров YMM) накладываются на регистры xmm0-15. Конкретный формат 2300 векторных команд работает на эти перекрытые файлы регистров, как показано в таблицах ниже.

Другими словами, поле 2259В длины вектора выбирает между максимальной длиной и одной или несколькими другими более короткими длинами, где каждая такая короткая длина составляет половину длины предшествующей длины; и шаблоны команд без поля 2259В вектора длины имеют максимальную векторную длину. Дополнительно, в одном варианте осуществления, шаблоны команд класса В конкретного формата 2300 векторных команд работают с упакованными данными или скалярными данными одинарной/двойной точности с плавающей точкой и упакованными или скалярными целочисленными данными. Скалярные операции представляют собой операции, выполненные на низком разряде элемента данных в zmm/ymm/xmm регистре; позиции высокого порядка элемента данных либо остаются такими же, как они были до обработки или обнуляются в зависимости от варианта осуществления.
Регистры 2415, содержащие маску записи в показанном варианте осуществления, имеют 8 регистров, содержащие маску записи (k0 - k7), каждый имеет 64-битовый размер. В альтернативном варианте осуществления, регистры 2415, содержащие маску записи являются 16-битовыми. Как описано выше, в одном варианте осуществления настоящего изобретения, регистр k0 вектора маски не может быть использован как маска записи; когда кодирование, как правило, указывает k0, то используется для записи маски, то выбирается проводная маска записи из 0xFFFF, эффективно отключая маскировку бита предоставления права доступа на запись для этой команды.
Регистры 2425 общего назначения, в показанном варианте осуществления, имеют шестнадцать 64- битных регистров общего назначения, которые используются наряду с существующими х86 режимами адресации для указания адреса операндов памяти. Эти регистры ссылаются по именам RAX, RBX, RCX, RDX, RBP, RSI, RDI, RSP и с R8 по R15.
Набор (х 87 стек) 2445 регистров стека математического сопроцессора, операции над скалярными числами с плавающей запятой, с которым совместно используется ММХ набор 2450 регистров для работы с упакованными целыми числами, а показанном варианте осуществления х87 стек является восьмиэлементным стеком, используемый для выполнения операций над скалярными числами с плавающей запятой 32/64/80- бит данных с плавающей запятой, используя х87 набор команд математического сопроцессора; в то время, как регистры ММХ используются для выполнения операций над 64-битными упакованными целыми числами, так и для временного хранения результатов некоторых операций, выполняемых между набором команд ММХ и ХММ.
Альтернативные варианты осуществления изобретения могут использовать многоразрядные и малоразрядные регистры. Кроме того, альтернативные варианты осуществления изобретения могут использовать больше, меньше или различные наборы регистров и регистры.
Ядра процессора могут быть реализованы различными способами для различных целей и в разных процессорах. Например, варианты реализаций таких ядер могут включать в себя: 1) ядро общего назначения с логикой последовательного выполнения операций, предназначенное для вычислений общего назначения; 2) высокопроизводительное ядро общего назначения с логикой изменения последовательности выполнения команд, предназначенное для вычислений общего назначения; 3) ядро специального назначения, предназначенное, в первую очередь, для работы с графикой и/или для научных вычислений. Варианты реализации различных процессоров могут включать в себя: 1) CPU, включающий в себя одно или более ядер общего назначения с логикой последовательного выполнения команд, предназначенное для вычислений общего назначения, и/или одно или более ядер общего назначения с логикой изменения последовательности выполнения команд, предназначенное для вычислений общего назначения; и 2) сопроцессор, включающий в себя одно или несколько специальных ядер, предназначенных, в первую очередь, для работы с графикой и/или для научных вычислений. Такие разные процессоры взывают необходимость построения различных архитектур вычислительных систем, которые могут включать в себя: 1) сопроцессор на отдельной от процессора микросхеме; 2) сопроцессор на отдельном кристалле в том же пакете, что и CPU; 3) сопроцессор на одном кристалле как CPU (в этом случае, например, сопроцессор иногда называют как логический специального назначения, такой как интегральный графический и/или научный логический или ядрами специального назначения); и 4) систему на кристалле, которая могут включать в себя на одном кристалле с описанным CPU (иногда упоминается как ядро (а) приложений или процессор (ы) приложений), описанным выше сопроцессором с дополнительной функциональностью. Далее приводится описание примеров архитектур ядра, с последующим описанием примерных процессоров и компьютерных архитектур.
На фиг. 11а представлена блок-схема, иллюстрирующая примерный упорядоченный конвейер и пример переименования регистров конвейером с изменением последовательности выполнения команд в соответствии с вариантами осуществления изобретения. Фиг. 11В показывает блок-схему, иллюстрирующую примерный вариант осуществления архитектуры ядра с логикой последовательного выполнения команд и пример переименования регистров архитектуры ядра с логикой изменения последовательности выполнения команд, которые должны быть включены в состав процессора согласно вариантам осуществления настоящего изобретения. Квадраты, очерченные сплошной линией, иллюстрируют упорядоченный конвейер и ядро с логикой последовательного выполнения команд, в то время как возможные добавленные квадраты, очерченные пунктирными линиями, иллюстрируют переименование регистров конвейера и ядра с логикой изменения последовательности выполнения команд. Учитывая тот факт, что аспект последовательного выполнения команд представляет собой подмножество аспекта алгоритма выполнения с изменением последовательности команд, то будет описан аспект выполнения с изменением последовательности команд.
Как показано на фиг. 11А, процессор конвейера 2500 включает в себя этап 2502 выборки, этап 2504 длины декодирования, этап 2506 декодирования, этап 2508 распределения, этап 2510 переименования и этап 2512 планирования (также известный как отправка или выпуск), этап 2514 чтения регистра чтение/память, этап 2516 выполнения, этап 2518 записи перезапись/память, этап 2522 обработки исключений, этап 2524 завершения.
Фиг. 11В показывает ядро 2590 процессора, включающее в себя блок 2530 периферийного оборудования, соединенное с исполнительным блоком 2550, и оба соединены с блоком 2570 памяти. Ядро 2590 может быть ядром компьютера с сокращенным набором команд (RISC), ядром компьютера с полным набором команд (CISC), ядром архитектуры процессора со сверхдлинным командным словом (VLIW) или гибридным или альтернативным типом ядра. В качестве еще одного варианта осуществления, ядро 2590 может быть ядром специального назначения, таким как, например, сетевым или коммуникационным ядром, сжатия, ядром сопроцессора, ядром графического процессора общего назначения (GPGPU), графическим ядром или т.п.
Блок 2530 периферийного оборудования включает в себя блок 2532 предсказания ветвлений, который соединен с блоком 2534 кэш команд, который соединен с буфером (TLB) 2536 быстрого преобразования адреса команды, который соединен с блоком 2538 выборки команды, который соединен с блоком 2540 декодирования. Блок 2540 декодирования (или декодер) может декодировать команды и генерировать выходной сигнал как одну или нескольких микроопераций, пункты входа набора микрокоманд, микрокоманды, другие команды или другие управляющие сигналы, которые декодируются, или которые иным образом отражаются, или выводятся из оригинальных команд. Блок 2540 декодирования может быть реализован с использованием различных механизмов. Примеры подходящих механизмов включают в себя, но не ограничиваются ими, таблицы перекодировки, аппаратные средства, программируемые логические матрицы (PLAs), набор микрокоманд постоянного запоминающего устройства (ROM) и т.п. В одном варианте осуществления ядро 2590 включает в себя набор микрокоманд постоянного запоминающего устройства (ROM) или другой носитель, который хранит микрокод для некоторых макрокоманд (например, в блоке 2540 декодирования или иначе в блоке 2530 периферийных устройств). Блок 2540 декодирования соединен с блоком 2552 переименования/распределения в исполнительном блоке 2550.
Исполнительный блок 2550 включает в себя блок 2552 переименования/распределения, соединенный с блоком 2554 процессорной логики и набором из одного или более блока (ов) 2556 планировщика. Блок (и) 2556 планировщика представляет собой любое количество различных планировщиков, включающее в себя станции резервации, центральное окно команд и т.д. Блок (и) 2556 планировщика соединен с блоком (ми) 2558 набора физических регистров. Каждый из блоков 2558 набора физических регистров представляет собой один или несколько наборов физических регистров, которые отличаются тем, что могут хранить один или несколько различных типов данных, таких как скалярное целое число, скалярное число с плавающей запятой, упакованные целые числа, упакованные числа с плавающей запятой, векторное целое число, векторное число плавающей запятой, статус (например, указатель команд, который также является адресом следующей выполняемой команды) и т.д.
В одном варианте осуществления блок (и) 2558 набора физических регистров включает в себя блок векторных регистров, блок регистров маски записи и блок регистров скалярного числа. Эти блоки регистров могут обеспечить архитектурные векторные регистры, регистры векторной маски и регистры общего назначения. Блок (и) 2558 набора физических регистров перекрывается блоком 2554 процессорной логики, чтобы проиллюстрировать различные способы, в которых может быть выполнено переименование регистров и выполнение с изменением последовательности команд (например, с использованием буфера (ов) переупорядочивания и набора (ов) невостребованных регистров, с использованием набора планируемых операций, буфера (ов) предшествующих операций и набора (ов) невостребованных регистров; используя битовые карты регистров и пула регистров; и т.д.). Блок 2554 процессорной логики и блок (и) 2558 набора физических регистров соединены с исполнительным блоком (и) 2560.
Исполнительный блок (и) 2560 включает в себя набор из одного или нескольких исполнительных блоков 2562 и набор из одного или нескольких блоков 2564 доступа к памяти. Исполнительные блоки 2562 могут выполнять различные операции (например, сдвиг, сложение, вычитание, умножение) с различными типами данных (например, скалярным числом с плавающей запятой, упакованным целым числом, упакованным числом с плавающей запятой, векторным целым числом, векторным числом с плавающей запятой). В то время как некоторые варианты осуществления могут включать в себя ряд исполнительных блоков, предназначенных для выполнения конкретных функций или наборов функций, другие варианты осуществления могут включать в себя только один исполнительный блок или несколько исполнительных блоков, которые все выполняют все функции.
Блок (и) 2556 планировщика, блок (и) 2558 набора физических регистров и исполнительный блок (и) 2560, показаны, как имеющие возможность иметь множественное число, поскольку некоторые варианты осуществления определяют отдельные конвейеры для отдельных видов данных/операций (например, конвейер скалярного целого числа, скалярного числа с плавающей запятой/упакованного целого числа/упакованного числа с плавающей запятой/векторного целого числа/векторного числа с плавающей точкой и/или конвейер доступа к памяти, что у каждого есть свой собственный блок планировщика, блок набора (ов) физических регистров и/или исполнительный блок (и), и в случае использования отдельного конвейера доступа к памяти, некоторые варианты осуществления реализуются, где только исполнительный блок данного конвейера имеет блок (и) 2564 доступа к памяти). Следует также понимать, что там, где используются отдельные конвейеры, один или несколько из этих конвейеров могут быть конвейерами выполнения с изменением последовательности команд и остальные являются упорядоченными конвейерами.
Набор блоков 2564 доступа к памяти соединен с блоком 2570 памяти, который включает в себя блок 2572 данных TLB, соединенный с блоком 2574 кэша данных, соединенный с блоком 2576 кэш уровня 2 (L2). В одном примерном варианте осуществления, блоки 2564 доступа к памяти могут включать в себя блок нагрузки, блок хранения адреса и блок хранения данных, каждый из которых соединен с блоком 2572 данных TLB в блоке 2570 памяти. Блок 2534 кэш команд дополнительно соединен с блоком 2576 кэш уровня 2 (L2) в блоке 2570 памяти. Блок 2576 кэш уровня 2 (L2) соединен с одним или более других уровней кэш-памяти и, в конечном счете, с основной памятью.
В качестве примера, примерный вариант архитектуры ядра с логикой переименования регистров изменения последовательности выполнения команд, может реализовать конвейер 2500 следующим образом: 1) блок 2538 выборки команды выполняет выборку и выполняется процесс этапа 2502 выборки и этап 2504 длины декодирования; 2) блок 2540 декодирования выполняет этап 2506 декодирования; 3) блок 2552 переименования/распределения выполняет этап 2508 распределения и этап 2510 переименования; 4) блок (и) 2556 планировщика выполняет этап 2512 планирования; 5) блок (и) 2558 набора (ов) физических регистров и блок 2570 памяти выполняют этап 2514 чтения регистра чтение/память; исполнительный блок 2560 выполняет этап 2516 выполнения; блок 2570 памяти и блок (и) 2558 набора (ов) физических регистров выполняют этап 2518 записи перезапись/память; 7) различные блоки могут быть вовлечены в выполнение операций на этапе 2522 обработки исключений; и 8) блок 2554 процессорной логики и блок (и) 2558 набора (ов) физических регистров выполняют этап 2524 завершения.
Ядро 2590 может поддерживать один или более наборов команд (например, х86 набор команд (с некоторыми расширениями, которые были добавлены в более новых версиях); MIPS набор команд MIPS Technologies of Sunnyvale, CA; ARM набор команд (с возможными дополнительными расширениями, такими как NEON) ARM Holdings of Sunnyvale, CA), включающие в себя команду (ы), описанную в данном документе. В одном варианте осуществления, ядро 2590 включает в себя логику для поддержки выполнения набора команд упакованных данных (например, AVX1, AVX2 и/или некоторых форм общего формата векторных команд (U=0 и/или U=1), как описано ранее), тем самым обеспечивая выполнение операций, посредством разнообразных мультимедийных приложений с использованием упакованных данных.
Следует иметь в виду, что ядро может поддерживать многопоточность (выполняя два или более параллельных набора операций или потоков) и может выполнить операции различными способами, включающими в себя многопотоковый режим обработки с квантованием по времени, одновременную многопотоковую обработку (где одно физическое ядро обеспечивает ядро с логикой для каждого из потоков, где физическое ядро выполняет одновременную многопотоковую обработку) или их комбинацией (например, выборку с квантованием по времени и декодирование и затем одновременную многопотоковую обработку, например, согласно Intel® гиперпотоковой технологии).
В то время как переименование регистров описывается в контексте логики изменения последовательности выполнения команд, следует понимать, что переименование регистров может быть использовано в архитектуре с логикой последовательного выполнения команд. В то время, как показанный вариант осуществления процессора также включает в себя отдельные команды и блоки 2534/2574 кэша данных и блок 2576 кэша уровня L2, альтернативные варианты осуществления могут иметь один внутренний кэш, как для команд, так и для данных, таких как, например, внутренний кэш уровня 1 (L1) или внутренний кэш несколько уровней. В некоторых вариантах осуществления система может включать в себя комбинацию внутреннего кэша и внешнего кэша, который является внешним по отношению к ядру и/или процессору. В качестве альтернативы, кэш может быть внешним по отношению к ядру и/или процессору.
Фиг. 12А и фиг. 12В иллюстрируют блок-схему более конкретного примера архитектуры ядра с логикой последовательного выполнения команд, где ядро будет одним из нескольких логических блоков (включающее в себя другие ядра одного типа и/или различных типов) в микросхеме. Логические блоки устанавливают связь посредством межкомпонентного соединения сети с высокой пропускной способностью (например, сетевое кольцо) с некоторой фиксированной функцией логики, интерфейсами I/O памяти и другими I/O логическими боками, в зависимости от приложения.
На фиг. 12А показана блок-схема одноядерного процессора, а также его соединение с межкомпонентным соединением на кристалле сети 2602 и с его локальным подмножеством кэша 2604 уровня 2 (L2), в соответствии с вариантами осуществления изобретения. В одном варианте осуществления, декодер 2600 команд поддерживает х86 набор команд с расширенным набором команд упакованных данных. Кэш 2606 L1 обеспечивает низколатентный доступ к кэш-памяти в скалярных и векторных блоках. В то время как в одном из вариантов осуществления (для упрощения конструкции), скалярный блок 2608 и блок 2610 вектора используют отдельные наборы регистров (соответственно, скалярные регистры 2612 и векторные регистры 2614) и данные, передаваемые между ними, записываются в память, и затем перезаписываются из кэш 2606 уровня 1 (L1), альтернативные варианты осуществления изобретения могут использовать другой подход (например, использовать единый набор регистров или включать в себя канал связи, что позволяет передавать данные между двумя наборами регистров без записи и прочтения).
Локальное подмножество кэша 2604 L2 является частью глобального кэш L2, который разделен на отдельные локальные подмножества, по одному на ядро процессора. Каждое ядро процессора имеет прямой путь доступа к собственному локальному подмножеству кэша 2604 L2. Данные, считанные ядром процессора, хранятся в его подмножестве кэша 2604 L2 и могут быть быстро получены, параллельно с другими процессорными ядрами, имеющие доступ к их собственному локальному подмножеству кэш L2. Данные, записанные процессорным ядром, хранятся на собственном подмножестве кэша 2604 L2 и имеют доступ из других подмножеств, если это необходимо. Сетевое кольцо обеспечивает согласованность для общих данных. Сетевое кольцо является двунаправленным, что позволяет агентам, таким как ядра процессора, кэш L2 и другим логическим блокам взаимодействовать друг с другом в пределах микросхемы. Каждый кольцевой тракт передачи данных имеет 1012 бит в каждом направлении.
Фиг. 12В представляет собой увеличенный вид части ядра процессора, показанного на фиг. 12А, в соответствии с вариантами осуществления изобретения. Фиг. 12В включает в себя кэш 2606А данных L1 часть кэша 2604 L1, а также более подробное пояснение блока 2610 вектора и векторных регистров 2614. В частности, блок 2610 вектора является блоком обработки 16-ти разрядного вектора (VPU) (см 16 - разрядный ALU 2628), который выполняет одну или несколько целой, одинарной точностью с плавающей запятой и двойной точностью с плавающей запятой команд. VPU поддерживает свизлинг входов регистров блоком 2620 выборки, числовое преобразование посредством блоков 2622А-В числового преобразования и репликацию блоком 2624 репликации на входе памяти. Регистры 2626 битовой маски записи позволяют записывать результирующий предсказывающий вектор.
Фиг. 13 представляет собой блок-схему процессора 2700, который может иметь более, чем одно ядро, может иметь встроенный контроллер памяти и может иметь интегрированную графику в соответствии с вариантами осуществления изобретения. Квадраты, обрамленные сплошной линией, как показано на фиг. 13, иллюстрируют процессор 2700 с одним ядром 2702А, агентом 2710 системы, набором из одного или нескольких блоков 2716 контроллера шины, однако возможно использование дополнительных квадратов, которые обозначены пунктирными линиями, иллюстрирующие альтернативный процессор 2700 с несколькими ядрами 2702A-N, набором из одной или более блока (ов) 2714 контроллера памяти, интегрированного в блок 2710 агента системы, и логическим блоком 2708 специального назначения.
Таким образом, различные варианты реализации процессора 2700 могут включать в себя: 1) CPU с логический блоком 2708 специального назначения, будучи интегрированным в блок графики и/или специальный блок логической обработки (которые могут включать в себя одно или несколько ядер), и ядра 2702А-N, являющиеся одним или более ядрами общего назначения (например, ядрами с логикой последовательного выполнения команд общего назначения, ядрами выполнения с изменением последовательности команд, сочетание этих двух); 2) сопроцессор с ядрами 2702A-N, представляющее собой большое количество ядер специального назначения, предназначенных в первую очередь для работы с графикой и/или научно-техническими данными; и 3) сопроцессор с ядрами 2702A-N представляет собой большое количество ядер с логикой последовательного выполнения команд общего назначения. Таким образом, процессор 2700 может быть процессором общего назначения, сопроцессором или процессором специального назначения, как, например, сетевым или коммуникационным процессором, сжатия, графическим процессором GPGPU (графический процессор общего назначения), высокопроизводительным специализированным многократноядерным (MIC) сопроцессором (включающий в себя 30 или более ядер), встроенным процессором или тому подобное. Процессор может быть реализован на одной или более микросхеме. Процессор 2700 может быть частью и/или может быть реализован на одной или более подложек с использованием любого из ряда технологических процессов, таких как, например, BiCMOS, CMOS или NMOS.
Иерархия памяти включает в себя один или несколько уровней кэша в пределах ядер, набор или один или более общих блоков 2706 кэша и внешнюю память (не показана), соединенные с набором интегрированных блоков 2714 контроллеров памяти. Набор общих блоков 2706 кэша может включать в себя один или несколько кэшей среднего уровня, таких как уровень 2 (L2), уровень 3 (L3), уровень 4 (L4) или другие уровни кэш, кэш последнего уровня (LLC) и/или их комбинации. В то время, как в одном варианте осуществления, который основан на кольце, блок 2712 межкомпонентного соединения соединяет интегрированный графический логический блок 2708, набор общих блоков 2706 кэша и блок 2710 агента системы/встроенный блок (и) 2714 контроллера памяти, альтернативные варианты осуществления могут использовать любое количество хорошо известных способов для межкомпонентного соединения таких блоков. В одном варианте осуществления, когерентность поддерживается между одним или несколькими блоками 2706 кэша и ядрами 2702A-N.
В некоторых вариантах осуществления, одно или более ядер 2702A-N способны выполнить многопоточность. Агент 2710 системы включает в себя такие компоненты для координации и функционирования ядер 2702А - N. Блок 2710 агента системы может включать в себя, например, блок (PCU) управления электропотреблением и блок отображения. (PCU) может быть или включать в себя логические блоки и компоненты, необходимые для регулирования уровня мощности ядер 2702A-N и интегрированного графического логического блока 2708. Блок отображения предназначен для управления одним или несколькими внешне подключенными дисплеями.
Ядра 2702А - N могут быть однородными или гетерогенными с точки зрения архитектуры набора команд; то есть, два или более ядра 2702А -N могут выполнить тот же набор команд, в то время как другие могут быть способны выполнять только подмножество этого набора команд или иной набор команд.
Фиг. 14 до фиг. 18 показывают блок-схемы примерных компьютерных архитектур. Также могут быть использованы другие системы и конфигурации, известные в данной области техники, ноутбуков, настольных, карманных PCs, персональных цифровых помощников, инженерных рабочих станций, серверов, сетевых устройств, сетевых концентраторов, коммутаторов, встроенных процессоров, процессоров (DSP) цифровой обработки сигналов, графических устройств, игровых устройств, телевизионных приставок, микроконтроллеров, сотовых телефонов, портативных медиа-плееров, переносных устройств и различны других электронных устройств. В общем, огромное разнообразие систем или электронных устройств, использующие встроенный процессор и/или другую логику выполнения, как описано здесь, обычно применяются.
Обратимся теперь к фиг. 14, где показана блок-схема системы 2800 в соответствии с одним вариантом осуществления настоящего изобретения. Система 2800 может включать в себя один или несколько процессоров 2810, 2815, которые соединены с контроллер-концентратором 2820. В одном варианте осуществления контроллер-концентратор 2820 включает в себя контроллер-концентратор (GMCH) 2890 графической и оперативной памяти и контроллер-концентратор (IOН) 2850 ввода/вывода (который может быть выполнен на отдельных микросхемах); GMCH 2890 включает в себя контроллеры графической и оперативной памяти, к которым подключены память 2840 и сопроцессор 2845; IOH 2850 соединяет (I/O) устройства 2860 ввода/вывода с GMCH 2890. Альтернативно, один или оба контроллеров-концентраторов графической и оперативной памяти интегрированы в процессоре (как описано здесь), память 2840 и сопроцессор 2845 соединены с процессором 2810 непосредственно, и контроллер-концентратор 2820 находится с IOH 2850 на одной микросхеме.
Факультативный характер дополнительных процессоров 2815 обозначается на фиг. 14 пунктирными линиями. Каждый процессор 2810, 2815 может включать в себя один или более ядер обработки, как описано здесь, и может представлять собой некоторый вариант процессора 2700.
Память 2840 может быть, например, динамическим оперативным запоминающим устройством (DRAM), памятью на фазовых переходах (РСМ) или комбинацией из двух. По меньшей мере, в одном варианте осуществления контроллер-концентратор 2820 взаимодействует с процессором (ми) 2810, 2815 по многоточечной шине, такой как внешняя шина (FSB), посредством двухточечного интерфейса, таким как последовательная кэш-когерентная шина типа точка-точка (QPI) или аналогичным соединением 2895.
В одном варианте осуществления, сопроцессор 2845 является процессором специального назначения, таким как, например, высокопроизводительный MIC процессор, сетевой или коммуникационный процессор, сжатия, графический процессор, GPGPU, встроенный процессор или тому подобное. В одном варианте осуществления контроллер-концентратор 2820 может включать в себя интегрированный графический ускоритель.
Может существовать множество различий между физическими ресурсами 2810, 2815 с точки зрения спектра характеристик, включающие в себя архитектурные, микроархитектурные, термальные, характеристики энергопотребления и тому подобное.
В одном варианте осуществления процессор 2810 выполняет команды, которые управляют операциями обработки данных общего типа. Команды сопроцессора могут быть встроены в набор команд. Процессор 2810 распознает эти команды сопроцессора как тип команд, которые должны быть выполнены прилагаемым сопроцессором 2845. Соответственно, процессор 2810 направляет эти команды сопроцессора (или управляющие сигналы, представляющие команды сопроцессора) на шину сопроцессора или другое межкомпонентное соединение на сопроцессор 2845. Сопроцессор (ы) 2845 принимает и выполняет принятые команды сопроцессора.
На фиг. 15 показана блок-схема первого более конкретного примера системы 2900 в соответствии с вариантом осуществления настоящего изобретения. Как показано на фиг. 15, многопроцессорная система 2900 представляет собой систему межкомпонентных соединений точка-точка и включает в себя первый процессор 2970 и второй процессор 2980, соединенные через межкомпонентное соединение 2950 типа точка-точка. Каждый из процессоров 2970 и 2980 могут являться некоторыми версиями процессора 2700. В одном варианте осуществления настоящего изобретения, процессоры 2970 и 2980 являются соответственно процессорами 2810 и 2815, в то время как сопроцессор 2938 является сопроцессором 2845. В другом варианте осуществления, процессоры 2970 и 2980 являются соответственно процессором 2810 и сопроцессором 2845.
Процессоры 2970 и 2980 показаны, включающие в себя интегрированные блоки 2972 и 2982 контроллера памяти (ГМС), соответственно. Процессор 2970 также включает в себя как часть блоков контроллера шины интерфейсов 2976 и 2978 (Р-Р) точка-точка; Аналогично, второй процессор 2980 включает РР интерфейсы 2986 и 2988. Процессоры 2970, 2980 могут обмениваться информацией через интерфейс 2950 (Р-Р) точка-точка с помощью Р-Р интерфейсных схем 2978, 2988. Как показано на фиг. 15, IMCs 2972 и 2982 подключают процессоры к соответствующим блокам памяти, а именно, памяти 2932 и памяти 2934, которые могут быть частями основной памяти, локально прикрепленные к соответствующим процессорам.
Процессоры 2970, 2980 могут каждый обмениваться информацией с набором 2990 микросхем через отдельные Р-Р интерфейсы 2952, 2954 с использованием интерфейсных схем 2976, 2994, 2986, 2998 типа точка-точка. Набор 2990 микросхем может возможно обмениваться информацией с сопроцессором 2938 через интерфейс 2939 высокой производительности. В одном варианте осуществления, сопроцессор 2938 является процессором специального назначения, таким как, например, MIC процессор высокой пропускной способности, сетевой или коммуникационный процессор, сжатия, графический процессор, GPGPU, встроенный процессор или тому подобное.
Общая кэш-память (не показана) может быть включена в состав либо процессора, либо находится вне обоих процессоров, но быть подключенной к процессорами через Р-Р межкомпонентное соединение, так что информация кэша локального процессора может быть сохранена в общей кэш-памяти, если процессор находится в режиме пониженного энергопотребления. Набор 2990 микросхем может быть соединен с первой шиной 2916 через интерфейс 2996. В одном варианте осуществления, первая шина 2916 может быть шиной взаимодействия периферийных компонентов (PCI) или шиной, такой как шина PCI Express или шиной межкомпонентного соединения I/O третьего поколения, хотя объем настоящего изобретения не ограничивается этим.
Как показано на фиг. 15, различные устройства 2914 ввода/вывода могут быть соединены с первой шиной 2916, наряду с блоком 2918 связи с внутренней шиной, который соединяет первую шину 2916 со второй шиной 2920. В одном варианте осуществления, один или более дополнительный процессор (ы) 2915, такие как сопроцессоры высокой пропускной способности MIC процессоров, GPGPU, ускорители (как, например, графические ускорители и блоки обработки цифровых сигналов (DSP)), программируемая вентильная матрица или любой другой процессор, подсоединены к первой шине 2916. В одном варианте осуществления, вторая шина 2920 может быть шиной с малым числом выводов (LPC). Различные устройства могут быть соединены со второй шиной 2920, включающие в себя, например, клавиатуру и/или мышь 2922, коммуникационные устройства 2927 и блок 2928 хранения, такой как диск или другое запоминающее устройство, которое может хранить команды/код и данные 2930, в одном варианте осуществления. Дополнительно, блок 2924 аудио ввода/вывода может быть соединен со второй шиной 2920. Следует отметить, что возможны другие архитектуры. Например, вместо архитектуры точка-точка, показанной на фиг.15, система может использовать многоточечную шину или другую подобную архитектуру.
На фиг. 16 показана блок-схема второго более конкретного примера системы 3000 в соответствии с вариантом осуществления настоящего изобретения. Аналогичные элементы на фиг. 16 и на фиг. 17 обозначены одинаковыми ссылочными номерами, и некоторые аспекты, показанные на фиг. 15 были не проиллюстрированы на фиг. 16 для более четкого пояснения других аспектов, показанных на фиг. 16. Фиг. 16 показывает, что процессоры 2970, 2980 могут включать в себя интегрированную память 2972 и логический блок и 2982 управления I/O ("CL"). Таким образом, CL 2972, 2982 включают в себя интегрированные блоки контроллера памяти и включают в себя блок управления I/O. Фиг. 16 показывает, что не только блоки 2932, 2934 памяти соединены с CL 2972, 2982, но и устройства 3014 ввода/вывода также соединены с логическими блоками 2972, 2982 управления. Унаследованные устройства 3015 I/O соединены с набором 2990 микросхем.
На фиг. 17 показана блок-схема SoC 3100 в соответствии с вариантом осуществления настоящего изобретения. Одинаковые элементы, показанные на фиг. 13, имеют одинаковые ссылочные позиции. Кроме того, квадраты, обрамленные пунктирной линией, представляют возможные признаки более усовершенствованных SoCs. На фиг. 17 блок (и) 3102 межкомпонентного соединения соединяется с: процессором 3110 приложений, который включает в себя набор из одного или более ядер 202А - N и общий блок (и) 2706 кэша; блок 2710 агента системы; блок (и) 2716 контроллера шины; блок (и) 2714 контроллера интегрированной памяти; набор или один или несколько сопроцессоров 3120, который может включать в себя интегрированный логический блок графики, процессор изображения, аудио процессор и видеопроцессор; блок 3130 статического оперативного запоминающего устройства (SRAM); блок 3132 прямого доступа к памяти (DMA); и блок 3140 отображения для соединения с одним или более внешними дисплеями. В одном варианте осуществления, сопроцессор (ы) 3120 включает в себя процессор специального назначения, такой как, например, сетевой или коммуникационный процессор, обработки сжатия, GPGPU, высокопроизводительный процессор MIC, встроенный процессор или тому подобное.
Механизмы вариантов осуществления, раскрытые здесь, могут быть реализованы в аппаратных средствах, программном обеспечении, встроенном программном обеспечении или комбинации таких подходов реализации. Варианты осуществления изобретения могут быть реализованы в виде компьютерных программ или программного кода на программируемых исполняющих системах, содержащих, по меньшей мере, один процессор, систему хранения (включая энергозависимую и энергонезависимую память и/или запоминающие элементы), по меньшей мере, одно устройство ввода и, по меньшей мере, одно устройство вывода.
Программный код, например, код 2930, показанный на фиг. 15, может быть применим к входным командам для реализации функций, описанных в данном документе, и генерируют выходную информацию. Выходная информация может быть применена к одному или более устройств вывода, известным способом. Для целей настоящего изобретения, система обработки включает в себя любую систему, которая имеет процессор, такой как, например, процессор обработки цифрового сигнала (DSP), микроконтроллер, специализированную заказную интегральную схему (ASIC) или микропроцессор.
Программный код может быть реализован на высокоуровневом процедурном или объектно ориентированном языке программирования, чтобы обмениваться данными с системой обработки. Программный код также может быть реализован на языке ассемблера или машинном языке, если это желательно. В самом деле, механизмы, описанные здесь, не ограничены каким-либо конкретным языком программирования. В любом случае, язык может быть транслируемым или интерпретируемым языком.
Один или более аспектов, по меньшей мере, одного из вариантов осуществления, могут быть реализованы с помощью репрезентативных команд, сохраненных на машиночитаемом носителе, который представляет собой различную логику в процессоре, который при считывании машиной, вызывает машину выстроить логику для выполнения способов, описанных в данном документе. Такие представления, известные как «IP ядра», могут храниться на материальном, машиночитаемом носителе и поставляться различным клиентам или производственным предприятиям для загрузки в оборудование, что на самом деле, выполняет логика или процессор.
Такие машиночитаемые носители данных могут включать в себя, без ограничения, невременные, материальные схемы изделий, изготовленные или образованные оборудованием или устройством, включающие в себя устройства хранения информации, такие как жесткие диски, любой другой тип диска, включающие в себя дискеты, оптические диски, компактные диски памяти только для чтения (CD-ROM), компакт-диск с возможностью перезаписи (CD-RW) и магнитооптические диски, полупроводниковые приборы, такие как постоянно запоминающие устройства (ROMs), оперативные запоминающие устройства (RAMs), таких как динамические запоминающие устройства (DRAMs), статические оперативные запоминающие устройства (SRAMs), стираемые программируемые постоянные запоминающие устройства (EPROMs), флэш-память, электрически стираемые программируемые постоянные запоминающие устройства (EEPROMs), память на фазовых переходах (РСМ), магнитные или оптические карты или любой другой тип носителя информации, подходящий для хранения электронных команд.
Соответственно, варианты осуществления изобретения также включают в себя невременные материальные машиночитаемые носители информации, содержащие команды или содержащие проектные данные, такие как язык описания аппаратных средств (HDL), который определяет структуры, схемы, устройства, процессоры и/или системные признаки, описанные в данном документе. Такие варианты осуществления также могут быть отнесены к программным продуктам.
В некоторых случаях, преобразователь команд может быть использован для преобразования команды из набора команд источника в целевой набор команд. Например, преобразователь команд может преобразовать (например, с помощью статического двоичного преобразования, динамического двоичного преобразования, включающее в себя динамическую компиляцию), превратить, эмулировать или иным образом преобразовать команду в одну или несколько других команд, обрабатываемых ядром. Преобразователь команд может быть реализован в программном обеспечении, аппаратными средствами, микропрограммным обеспечением или их комбинациями. Преобразователь команд может быть на процессоре, вне процессора или частично на и частично вне процессора.
Фиг. 18 представляет собой блок-схему, на которой показан вариант противопоставления использования программного обеспечения преобразователя команды для преобразования двоичных команд в наборе команд источника в двоичные команды целевого набора команд, в соответствии с вариантами осуществления изобретения. В показанном варианте осуществления, преобразователь команд является программным обеспечением преобразователя команды, хотя, в качестве альтернативы, преобразователь команд может быть реализован в программном обеспечении, встроенном программном обеспечении, аппаратных средствах или различных их комбинациях. Фиг. 18 показывает программу, написанную языком 3202 высокого уровня, которая может быть выполнена с использованием х86 компилятора 3204, генерированием х86 бинарного кода 3206, что может быть изначально выполнено процессором, по меньшей мере, одного набора команд х86 ядром 3216. Процессор, по меньшей мере, с одним х86 набор команд ядра 3216, представляет любой процессор, который может, по существу, выполнять те же функции, что и процессор Intel, по меньшей мере, с одним х86 набором команд ядра посредством совместимого выполнения или иной обработки (1) значительной части набора команд Intel х86 набора команд ядра или (2) объектного кода версий приложений или другого целевого программного обеспечения для работы на процессоре Intel, по меньшей мере, с одним х86 набором команд ядра, чтобы, по существу, достичь того же результата, что и процессор Intel, по меньшей мере, с одним х86 набором команд ядра. х86 компилятор 3204 представляет собой компилятор, который выполнен с возможностью генерировать х86 двоичный код 3206 (например, объектный код), который может, с или без дополнительного процесса соединения, для выполнения на процессоре, по меньшей мере, с одним х86 набором команд ядра 3216. Аналогично, фиг.18 показывает программу на языке 3202 высокого уровня, которая может быть составлена с использованием альтернативного набора команд компилятора 3208, чтобы генерировать альтернативный набор команд двоичного кода 3210, который может изначально выполняться процессором без, по меньшей мере, одного х86 набора команд ядра 3214 (например, процессор с ядрами, которые выполняют набор команд MIPS MIPS Technologies of Sunnyvale, CA и/или которые выполняют набор команд ARM ARM Holdings of Sunnyvale, CA). Преобразователь 3212 команд используется для преобразования х86 двоичного кода 3206 в код, который может изначально выполняться процессором без х86 набора команд ядра 3214. Этот преобразованный код, вероятно, не будет таким же, как альтернативный набор команд двоичного кода 3210, потому что преобразователь команд не способен сделать это; однако, преобразованный код будет выполнять общую операцию и может быть составлен командами из альтернативного набора команд. Таким образом, преобразователь 3212 команд представляет программное обеспечение, прошивку, аппаратные средства или их комбинацию посредством эмуляции, моделирования или любым другим процессом, позволяет процессору или другому электронному устройству, которое не имеет х86 набора команд процессора или ядра, выполнить х86 двоичный код 3206.
Некоторые части предыдущих подробных описаний были представлены в терминах алгоритмов и символических представлений операций над битами данных в памяти компьютера. Эти алгоритмические описания и представления являются способами, используемые специалистами в данной области обработки данных, чтобы наиболее эффективно передать сущность их работы другим специалистам в данной области техники. Описанные алгоритмы представляют собой самосогласованную последовательность операций, ведущая к желаемому результату. Операции требуют физических манипуляций физическими величинами.
Следует иметь в виду, однако, что все эти и подобные термины должны быть ассоциированы с соответствующими физическими величинами и просто обозначать данные величины. Если специально не указано иное, как видно из приведенного выше обсуждения, следует понимать, что использованные в описании таких терминов, как указанные в приведенной ниже формуле изобретения, относятся к действиям и процессам компьютерной системы или подобного электронного вычислительного устройства, которое манипулирует и преобразует данные, представленные в виде физических (электронных) величин в регистрах и памяти компьютерной системы в другие данные, аналогично представленные в виде физических величин в памяти компьютерной системы или регистрах или других таких носителей информации, устройствах передачи или устройствах отображения.
Способы, показанные на чертежах, могут быть реализованы с использованием кода и данных, хранящиеся и исполняемые на одном или нескольких электронных устройств. Такие электронные устройства хранения и передачи (внутренней и/или с другими электронными устройствами в сети) кода и данных, используя машиночитаемые носители, такие как невременные машиночитаемые носители информации (например, магнитные диски; оптические диски, память с произвольным доступом; постоянное запоминающее устройство; устройства флэш-памяти; память на фазовых переходах) и временные машиночитаемые носители информации (например, электрические, оптические, акустические или иные носители информации, которая передается посредством передачи сигналов, таких как несущая высокочастотного сигнала, инфракрасные сигналы, цифровые сигналы).
Процессы или способы, описанные посредством чертежей, могут быть выполнены посредством логики, которые содержит аппаратные средства (например, схему, специализированную логическую схему и т.д.), встроенные программы, программное обеспечение (например, встроенной на невременном машиночитаемом носителе информации) или их комбинацию. Хотя эти процессы или способы описаны выше в терминах некоторых последовательных операций, следует понимать, что некоторые из описанных операций могут быть выполнены в другом порядке. Кроме того, некоторые операции могут выполняться параллельно, а не последовательно.
В приведенном выше описании, варианты осуществления настоящего изобретения были описаны со ссылкой на конкретные примерные варианты его осуществления. Но очевидно, что различные модификации могут быть сделаны в нем без отступления от объема и сущности изобретения, как изложено в нижеследующей формуле изобретения. Описание и чертежи, соответственно, следует рассматривать в иллюстративном смысле, а не в ограничительном смысле.
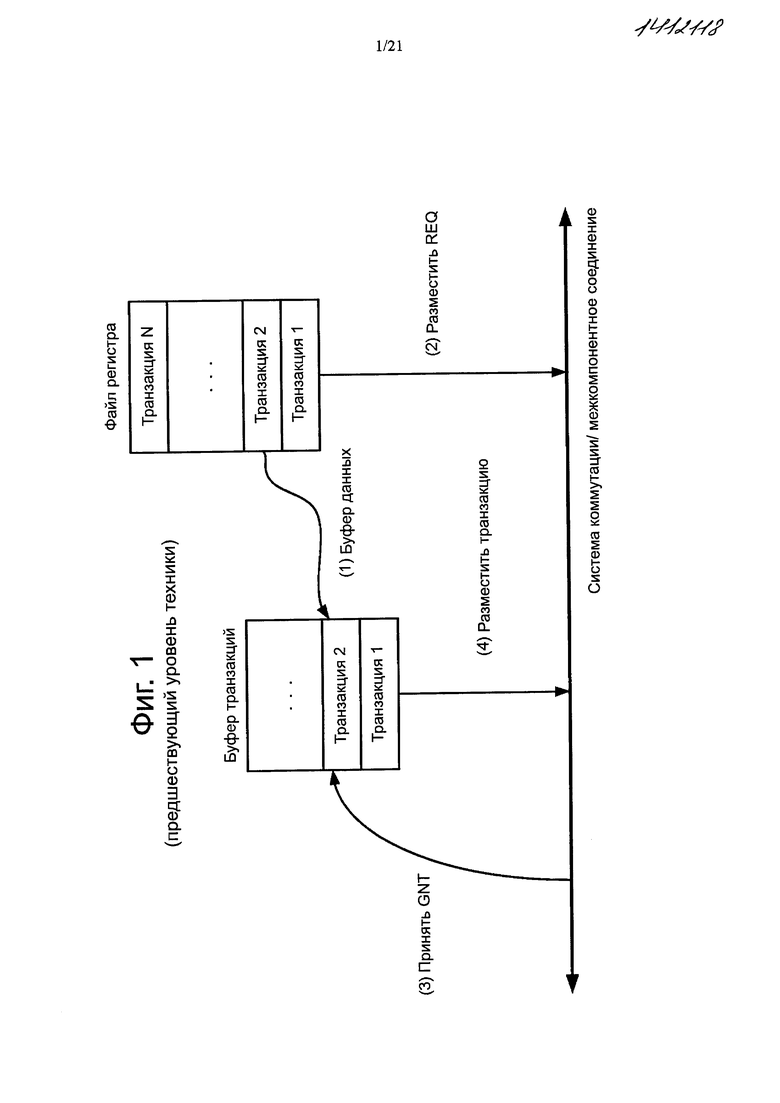
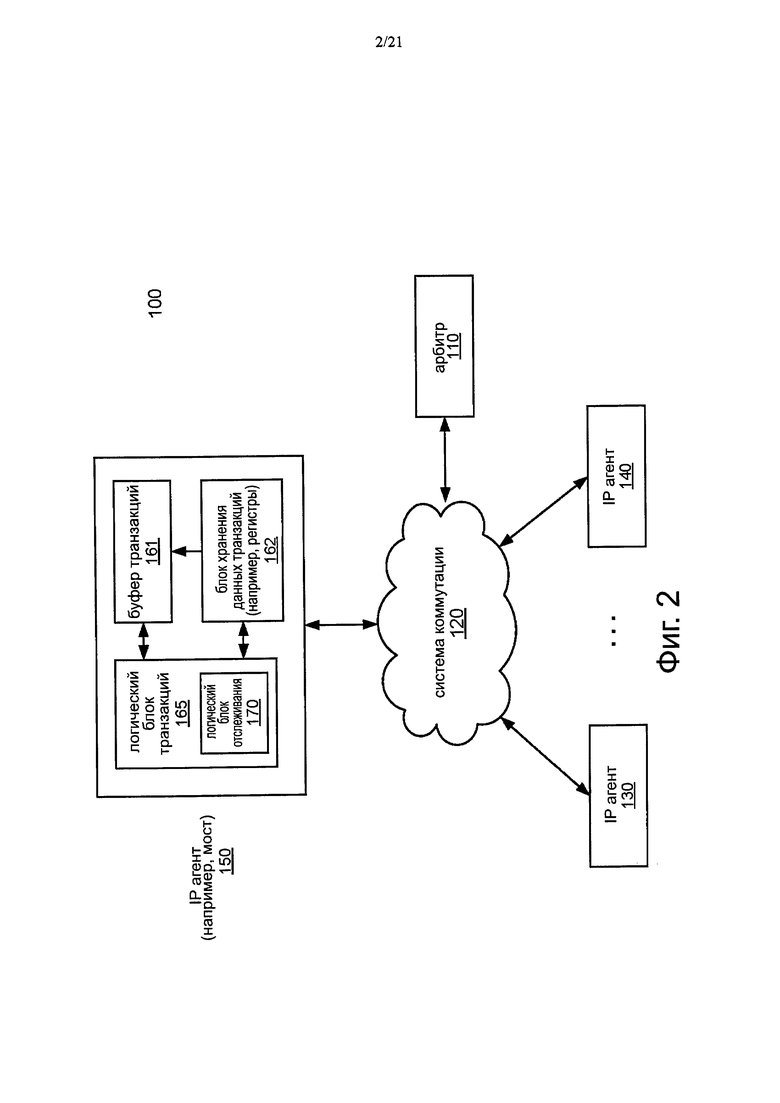
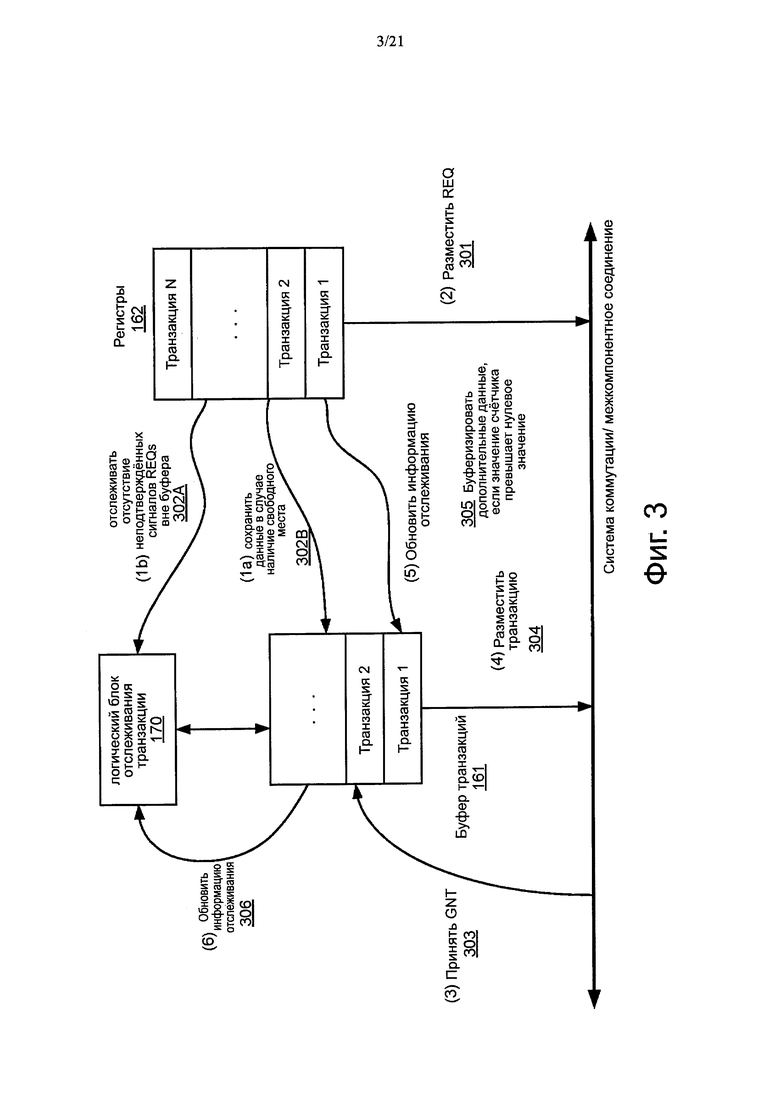


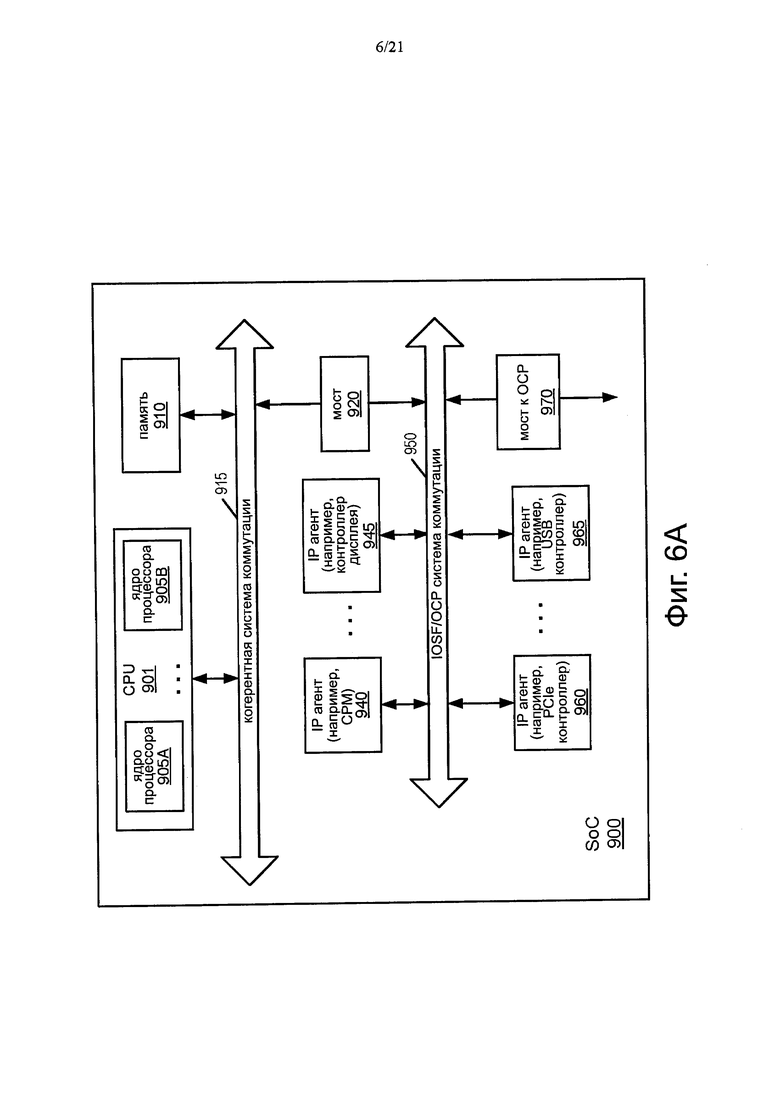

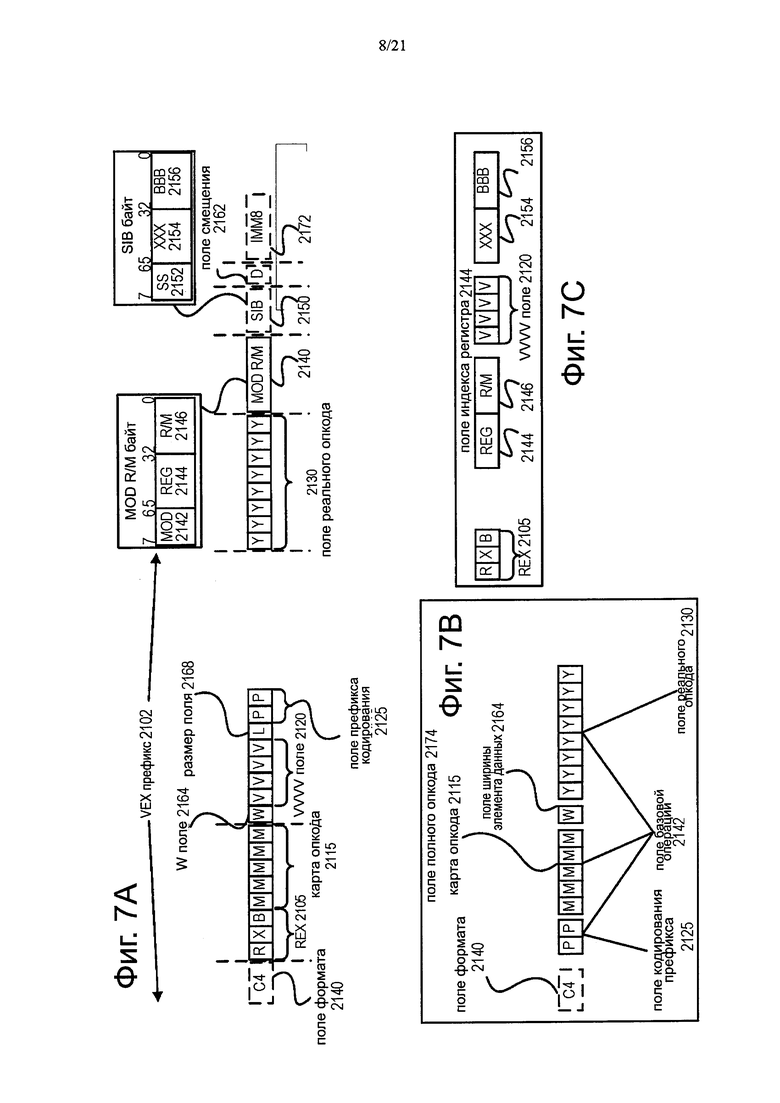
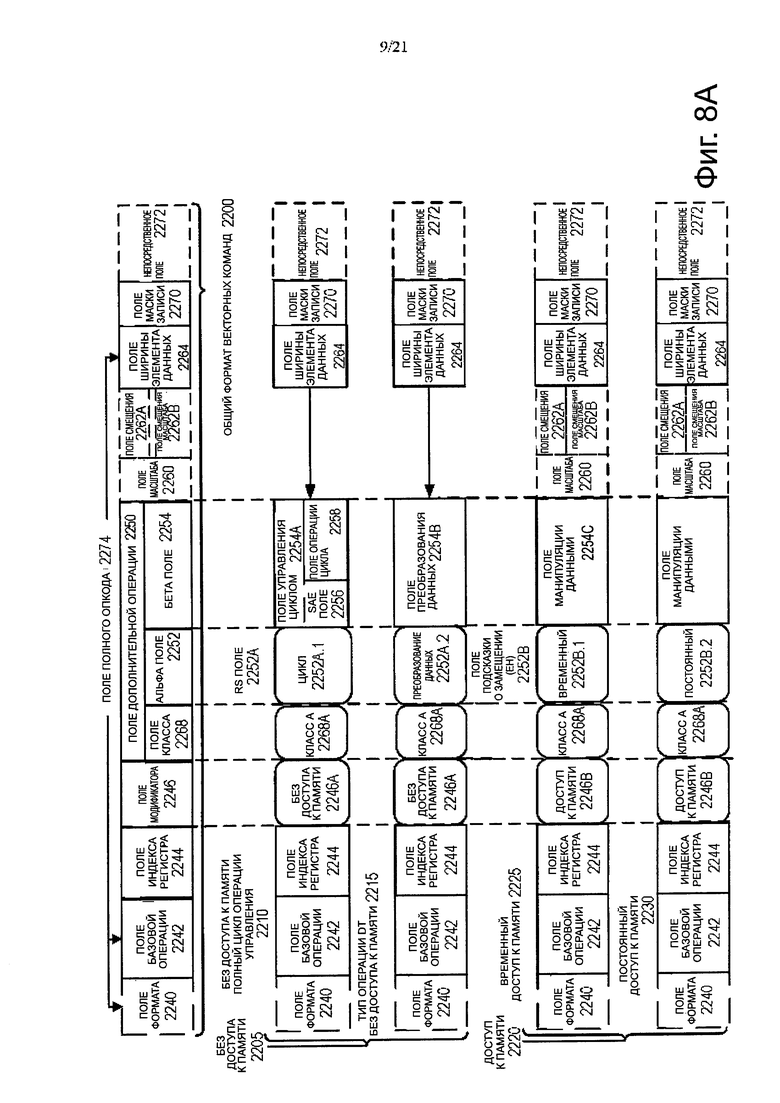

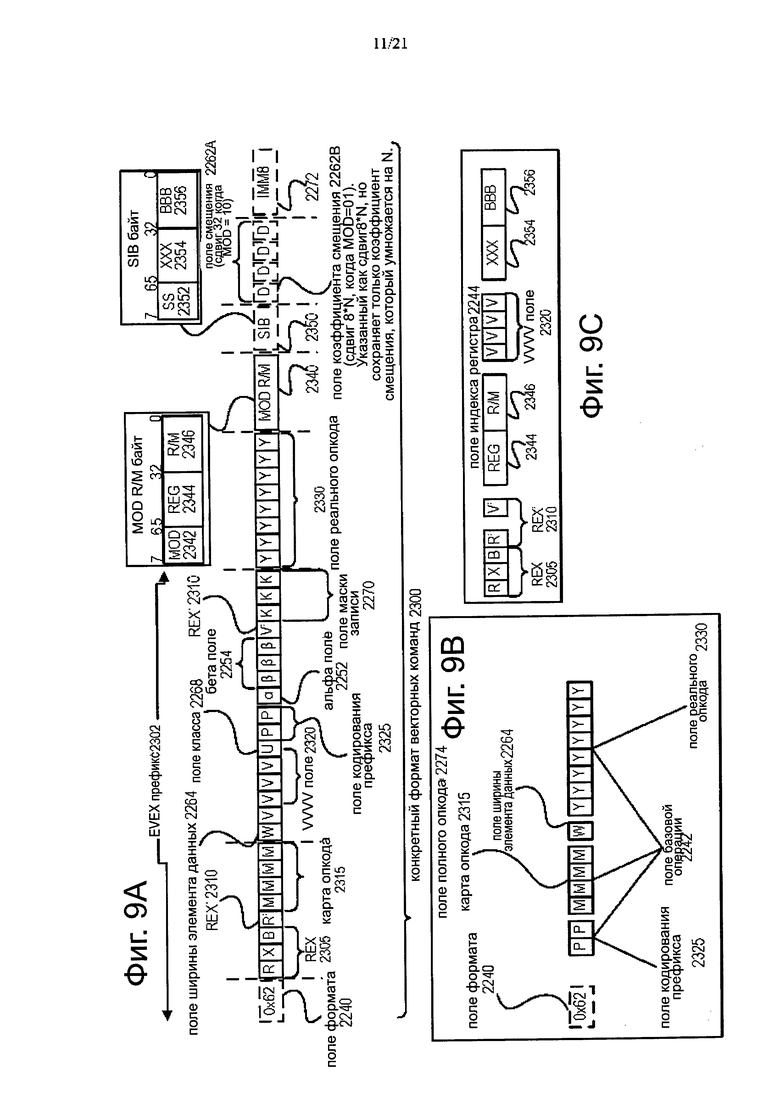
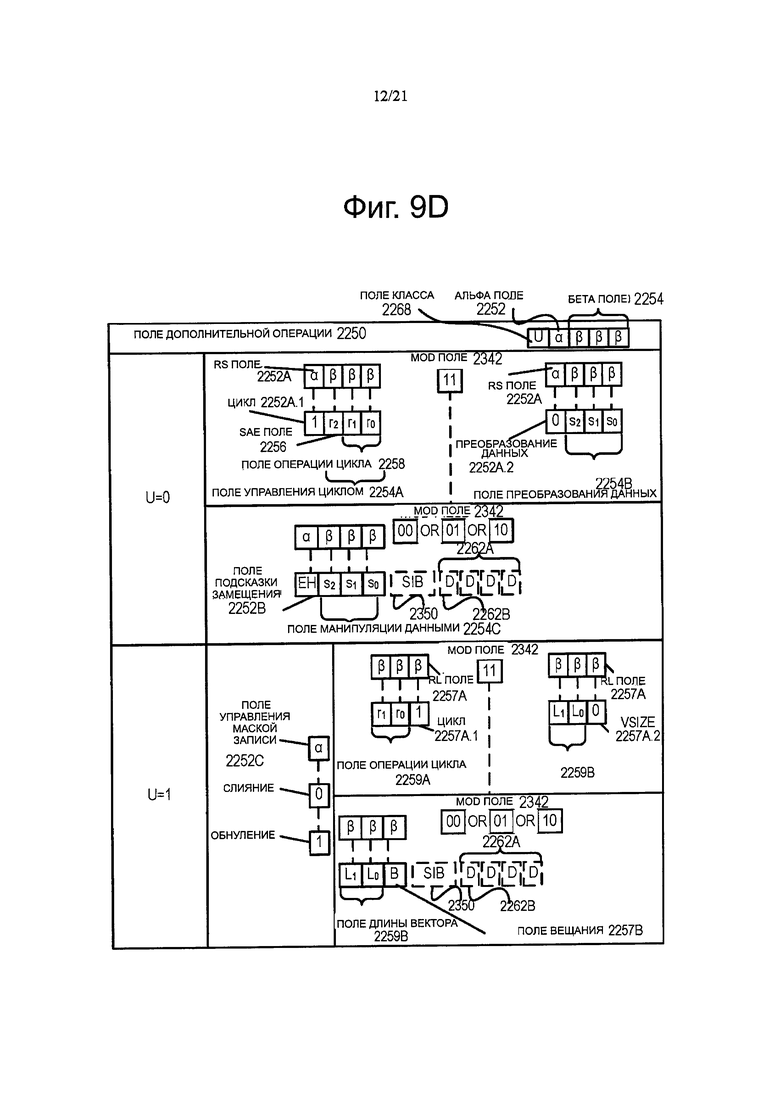

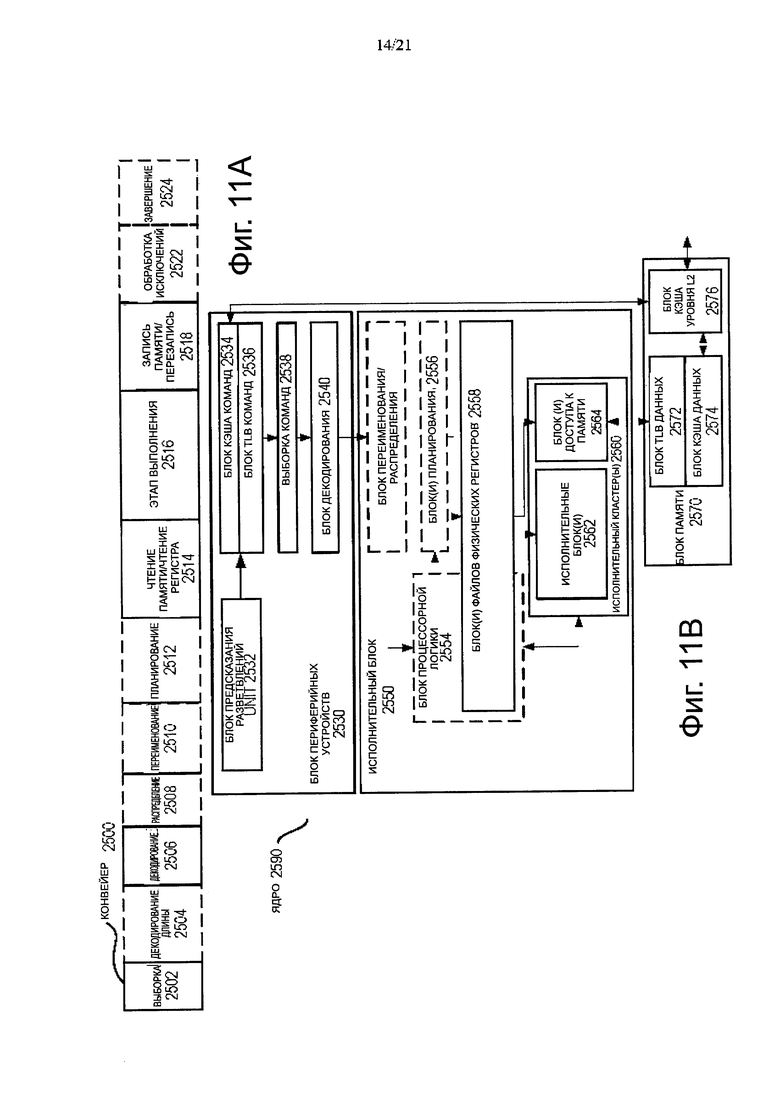

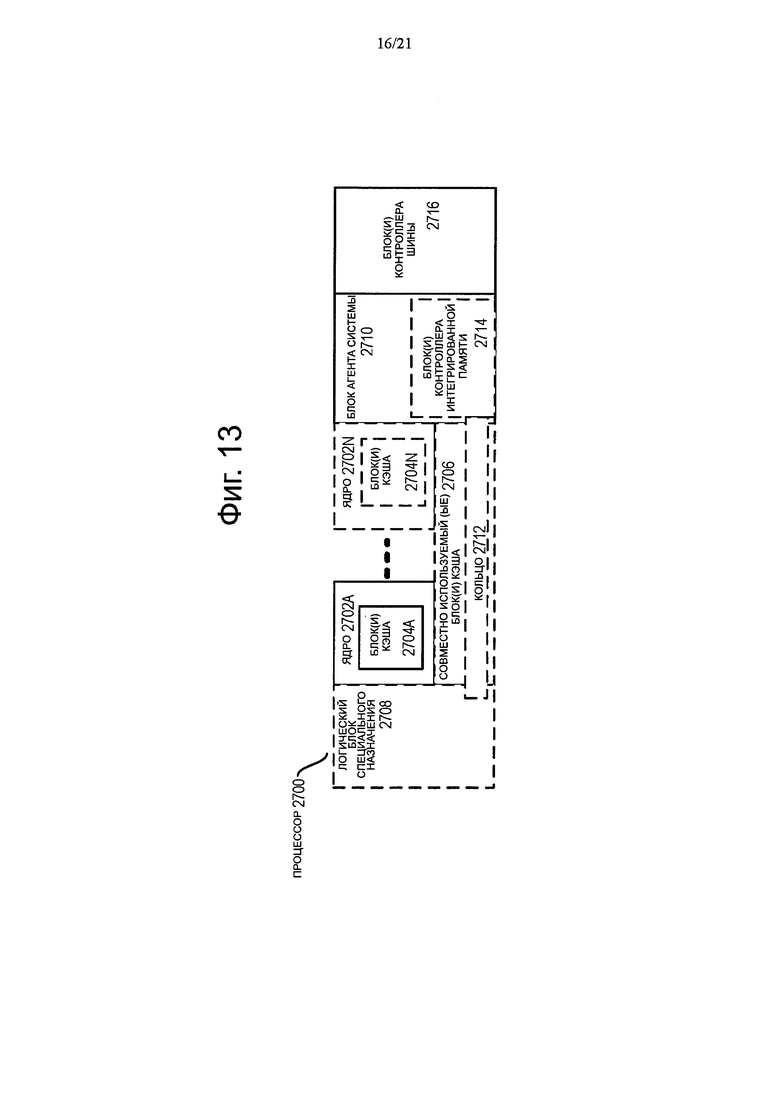



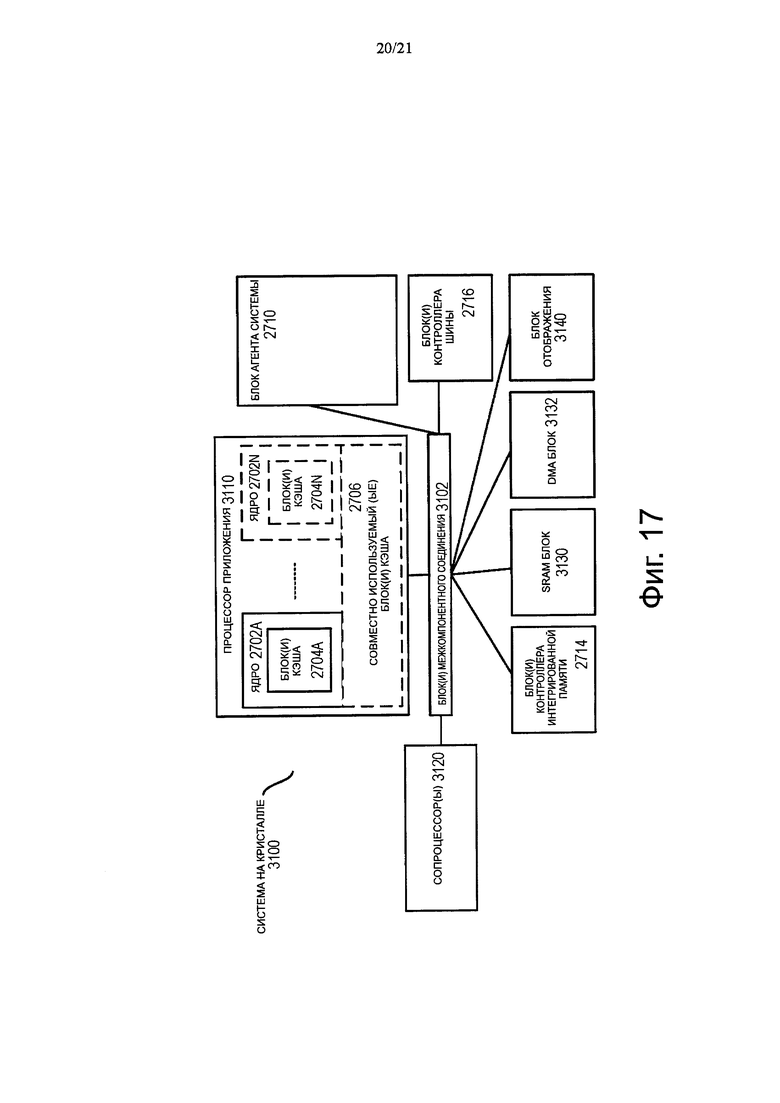

Изобретение относится к вычислительной технике. Технический результат заключается в уменьшении зависимости глубины буфера транзакций от латентности связи с квитированием. Устройство для обработки транзакций содержит блок хранения данных транзакций для хранения данных транзакций, подлежащих передаче по межкомпонентному соединению; буфер транзакций для буферизации части данных транзакций и логический блок транзакций для передачи сигнала с запросом (REQ) арбитру в ответ на первые данные транзакций, которые становятся доступными в блоке хранения данных транзакций, извлечения в ответ на сигнал разрешения (GNT), принимаемый от арбитра, вторых данных транзакций из буфера транзакций и передачи вторых данных транзакций на межкомпонентное соединение и пополнения буфера транзакций третьими данными транзакций, извлекаемыми из блока хранения данных транзакций, после передачи вторых данных транзакций на межкомпонентное соединение, при этом логический блок транзакций выполнен с возможностью увеличения значения счетчика в ответ на определение, что буфер транзакций заполнен после передачи сигнала REQ, причем значение счетчика представляет собой число сигналов REQ, на которые не поступил ответ и чьи ассоциированные данные транзакций не были буферизованы в буфере транзакций. 3 н. и 11 з.п. ф-лы, 27 ил., 1 табл.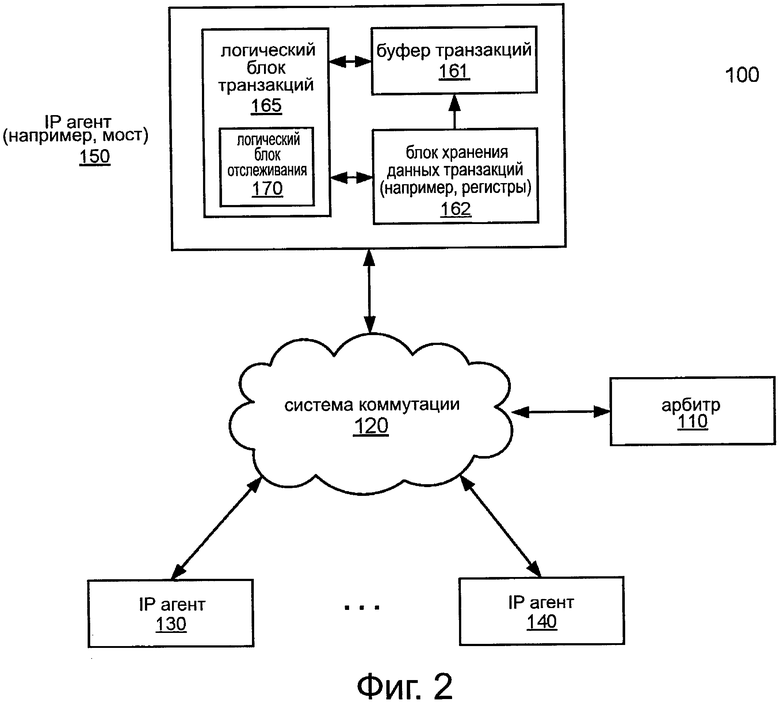
1. Устройство, содержащее:
блок хранения данных транзакций для хранения данных транзакций, подлежащих передаче по межкомпонентному соединению системы обработки данных;
буфер транзакций, соединенный с блоком хранения данных транзакций, для буферизации по меньшей мере части данных транзакций; и
логический блок транзакций, соединенный с блоком хранения данных транзакций и буфером транзакций, выполненный с возможностью передачи сигнала с запросом (REQ) арбитру, связанному с межкомпонентным соединением, в ответ на первые данные транзакций, которые становятся доступными в блоке хранения данных транзакций,
извлечения в ответ на сигнал (GNT) разрешения, принимаемый от арбитра, вторых данных транзакций из буфера транзакций и передачи вторых данных транзакций на межкомпонентное соединение, и
пополнение буфера транзакций третьими данными транзакций, извлекаемыми из блока хранения данных транзакций, после передачи вторых данных транзакций на межкомпонентное соединение.
2. Устройство по п. 1, в котором буфер транзакций выполнен с возможностью буферизации заданного фиксированного объема данных транзакций.
3. Устройство по п. 1, в котором логический блок транзакций выполнен с возможностью определения, заполнен ли буфер транзакций, в ответ на первые данные транзакций и буферизации первых данных транзакций в буфере транзакций, если буфер транзакций не заполнен.
4. Устройство по п. 3, в котором логический блок транзакций выполнен с возможностью увеличения значения счетчика в ответ на определение, что буфер транзакций заполнен после передачи REQ.
5. Устройство по п. 4, в котором значения счетчика представляют собой число сигналов REQ, на которые не поступил ответ и чьи ассоциированные данные транзакций не были буферизованы в буфере транзакций.
6. Устройство по п. 4, в котором третьи данные транзакций буферизуются в буфере транзакций, только если значение счетчика превышает нулевое значение.
7. Устройство по п. 4, в котором логический блок транзакций уменьшает значение счетчика после передачи вторых данных транзакций на межкомпонентное соединение.
8. Способ, содержащий этапы, на которых:
передают посредством логического блока транзакций сигнал с запросом (REQ) арбитру, связанному с межкомпонентным соединением, в ответ на первые данные транзакций, которые становятся доступными в блоке хранения данных транзакций, причем блок хранения данных транзакций выполнен с возможностью хранения данных транзакций, подлежащих передаче по межкомпонентному соединению системы обработки данных;
в ответ на сигнал (GNT) разрешения, принятый от арбитра, извлекают вторые данные транзакций из буфера транзакций и передают вторые данные транзакций на межкомпонентное соединение, причем буфер транзакций выполнен с возможностью буферизации по меньшей мере части данных транзакций из блока хранения данных транзакций; и
пополняют посредством логического блока транзакций буфер транзакций третьими данными транзакций, извлеченными из блока хранения данных транзакций, после передачи вторых данных транзакций на межкомпонентное соединение.
9. Способ по п. 8, в котором буфер транзакций выполнен с возможностью буферизации заданного фиксированного объема данных транзакций.
10. Способ по п. 8, дополнительно содержащий этап, на котором определяют, заполнен ли буфер транзакций в ответ на первые данные транзакций, и буферизуют первые данные транзакций в буфере транзакций, если буфер транзакций не заполнен.
11. Способ по п. 10, дополнительно содержащий этап, на котором увеличивают значение счетчика в ответ на определение, что буфер транзакций заполнен после передачи REQ.
12. Способ по п. 11, в котором, значение счетчика представляет собой число сигналов REQ, на которые не поступил ответ и чьи ассоциированные данные транзакций не были буферизованы в буфере транзакций.
13. Способ по п. 11, в котором буферизируют третьи данные транзакций в буфере транзакций, только если значение счетчика больше нулевого значения.
14. Способ по п. 11, дополнительно содержащий этап, на котором уменьшают значение счетчика после передачи вторых данных транзакций на межкомпонентное соединение.
15. Система, содержащая:
межкомпонентное соединение;
арбитр для разрешения доступа к межкомпонентному соединению и
множество агентов интеллектуальной собственности (IP), соединенных с межкомпонентным соединением для обеспечения связи друг с другом, причем по меньшей мере один из IP-агентов включает в себя:
блок хранения данных транзакций для хранения данных транзакций, подлежащих передаче по межкомпонентному соединению,
буфер транзакций, соединенный с блоком хранения данных транзакций, для буферизации по меньшей мере части данных транзакций и
логический блок транзакций, соединенный с блоком хранения данных транзакций и буфером транзакций, выполненный с возможностью передачи сигнала с запросом (REQ) арбитру в ответ на первые данные транзакций, которые становятся доступными в блоке хранения данных транзакций,
извлечения в ответ на сигнал (GNT) разрешения, принятый от арбитра, вторых данных транзакций из буфера транзакций и передачи вторых данных транзакций на межкомпонентное соединение и
пополнения буфера транзакций третьими данными транзакций, извлекаемыми из блока хранения данных транзакций, после передачи вторых данных транзакций на межкомпонентное соединение.
16. Система по п. 15, в которой буфер транзакций выполнен с возможностью буферизации заданного фиксированного объема данных транзакций.
17. Система по п. 15, в которой логический блок транзакций выполнен с возможностью определения, заполнен ли буфер транзакций в ответ на первые данные транзакций, и буферизации первых данных транзакций в буфере транзакций, если буфер транзакций не заполнен.
18. Система по п. 17, в которой логический блок транзакций выполнен с возможностью увеличения значения счетчика в ответ на определение, что буфер транзакций заполнен после передачи REQ.
19. Система по п. 18, в которой значение счетчика представляет собой число сигналов REQ, на которые не поступил ответ и чьи ассоциированные данные транзакций не были буферизованы в буфере транзакций.
20. Система по п. 18, в которой третьи данные транзакций буферизуются в буфер транзакций, только если значение счетчика больше нуля.
21. Система по п. 18, в которой логический блок транзакций выполнен с возможностью уменьшения значения счетчика после передачи вторых данных транзакций на межкомпонентное соединение.
| US 5761464 A, 02.06.1998 | |||
| US 5951635 A, 14.09.1999 | |||
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Прибор, замыкающий сигнальную цепь при повышении температуры | 1918 |
|
SU99A1 |
| АРХИТЕКТУРА ПРОЦЕССОРА ВВОДА-ВЫВОДА, КОТОРЫЙ ОБЪЕДИНЯЕТ МОСТ МЕЖСОЕДИНЕНИЯ ПЕРВИЧНЫХ КОМПОНЕНТ | 1996 |
|
RU2157000C2 |

