ОБЛАСТЬ ИЗОБРЕТЕНИЯ
УРОВЕНЬ ТЕХНИКИ
[001] Во многих естественных языках есть омонимы, т.е. слова, имеющие несколько значений. Когда человек находит такое слово в тексте, он может безошибочно выбрать правильное значение в зависимости от контекста и интуиции. Совсем другая ситуация - когда текст анализируется с помощью компьютерной системы. Существующие системы для разрешения неоднозначности в тексте в основном базируются на лексических ресурсах, таких как словари. Для конкретного слова такие способы извлекают из лексического ресурса все возможные значения этого слова. После этого могут применяться различные способы определения того, какое из этих значений слова является релевантным. Большинство таких способов являются статистическими, т.е. основанными на анализе больших корпусов текста, в то время как некоторые другие основаны на использовании информации из словаря (например, учитывающих степень "пересечения" между толкованием в словаре и локальным контекстом, в котором используется слово). Для конкретного слова, для которого должна быть разрешена неоднозначность, такие способы, как правило, основаны на решении задачи классификации (т.е. возможные значения слова рассматриваются в качестве категорий, и слово должно быть отнесено к одной из них).
[002] Существующие способы решают проблему разрешения неоднозначности многозначных слов и омонимов, считая многозначными словами и омонимами те слова, которые появляются несколько раз в используемом реестре значений. Ни один из способов не работает со словами, которые вообще не появляются в используемом лексическом ресурсе. Реестры значений, используемые существующими способами, не позволяют вносить изменения и не отражают изменения, происходящие в языке. Есть только несколько способов, которые основаны на использовании значений из Википедии, но эти способы не вносят никаких изменений в реестр значений.
[003] В настоящее время мир быстро меняется, появляется много новых технологий и продуктов, при этом соответственно изменяется и язык. Появляются новые слова для обозначения новых понятий, а также появляются новые значения для некоторых существующих слов. Поэтому способы устранения неоднозначности текста - обеспечивать возможность эффективно обрабатывать новые слова, которые отсутствуют в используемом реестре значений, добавлять эти понятия в реестр значений и использовать их во время дальнейшего анализа.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[004] Пример осуществления относится к способу. Способ включает в себя получение вычислительным устройством неизвестного слова. Способ дополнительно включает в себя определение процессором вычислительного устройства множества потенциальных семантических классов для назначения неизвестному слову. Способ дополнительно включает построение процессором с использованием корпусов текстов классификатора для неизвестного слова. Способ дополнительно включает классификацию неизвестного слова, основанную по меньшей мере частично на встроенном классификаторе, с помощью по меньшей мере одного семантического класса из множества потенциальных семантических классов. Способ дополнительно включает в себя добавление неизвестного слова в семантическую иерархию в качестве экземпляра по меньшей мере одного семантического класса.
[005] Другой пример осуществления относится к системе. Система включает в себя один или более процессоров данных. Система дополнительно включает в себя одно или более устройств хранения, хранящих инструкции, которые, будучи исполненными одним или более процессорами данных, воздействуют на один или более процессоров данных для выполнения операций, содержащих получение вычислительным устройством неизвестного слова. Операции дополнительно содержат определение процессором вычислительного устройства множества потенциальных семантических классов для назначения неизвестному слову. Операции дополнительно содержат построение процессором с использованием корпусов текстов классификатора для неизвестного слова. Операции дополнительно содержат классификацию неизвестного слова, основанную по меньшей мере частично на встроенном классификаторе, с помощью по меньшей мере одного семантического класса из множества потенциальных семантических классов. Операции дополнительно содержат добавление неизвестного слова в семантическую иерархию в качестве экземпляра по меньшей мере одного семантического класса.
[006] Еще один пример осуществления относится к машиночитаемому носителю данных, имеющему хранящиеся на нем машинные инструкции, причем процессор исполняет инструкции для выполнения операций, содержащих получение вычислительным устройством неизвестного слова. Операции дополнительно содержат определение процессором вычислительного устройства множества потенциальных семантических классов для назначения неизвестному слову. Операции дополнительно содержат построение процессором с использованием корпусов текстов классификатора для неизвестного слова. Операции дополнительно содержат классификацию неизвестного слова, основанную по меньшей мере частично на встроенном классификаторе, с помощью по меньшей мере одного семантического класса из множества потенциальных семантических классов. Операции дополнительно содержат добавление неизвестного слова в семантическую иерархию в качестве экземпляра по меньшей мере одного семантического класса.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[007] Описания одного или более вариантов реализации изложены в сопутствующих рисунках и представленном ниже описании. Другие отличительные признаки, аспекты и преимущества описания предмета изобретения станут очевидны из описания, рисунков и формулы изобретения, где:
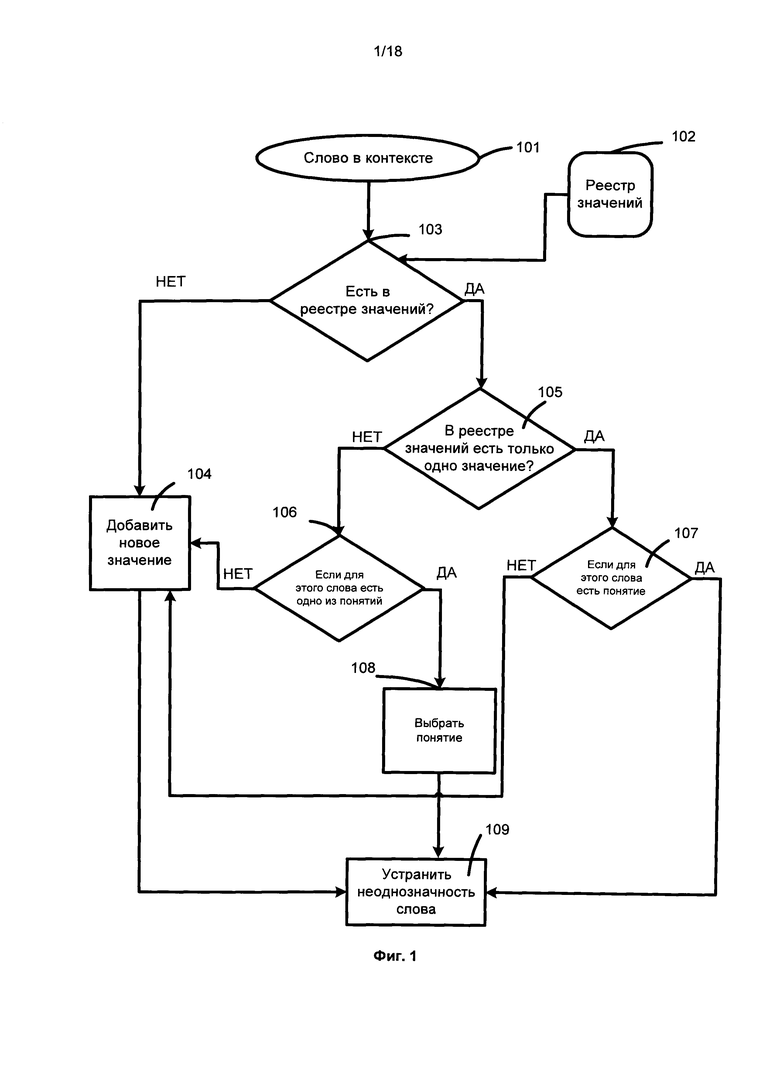
[008] на Фиг. 1 представлена блок-схема способа разрешения семантической неоднозначности в соответствии с одним или более вариантами реализации;
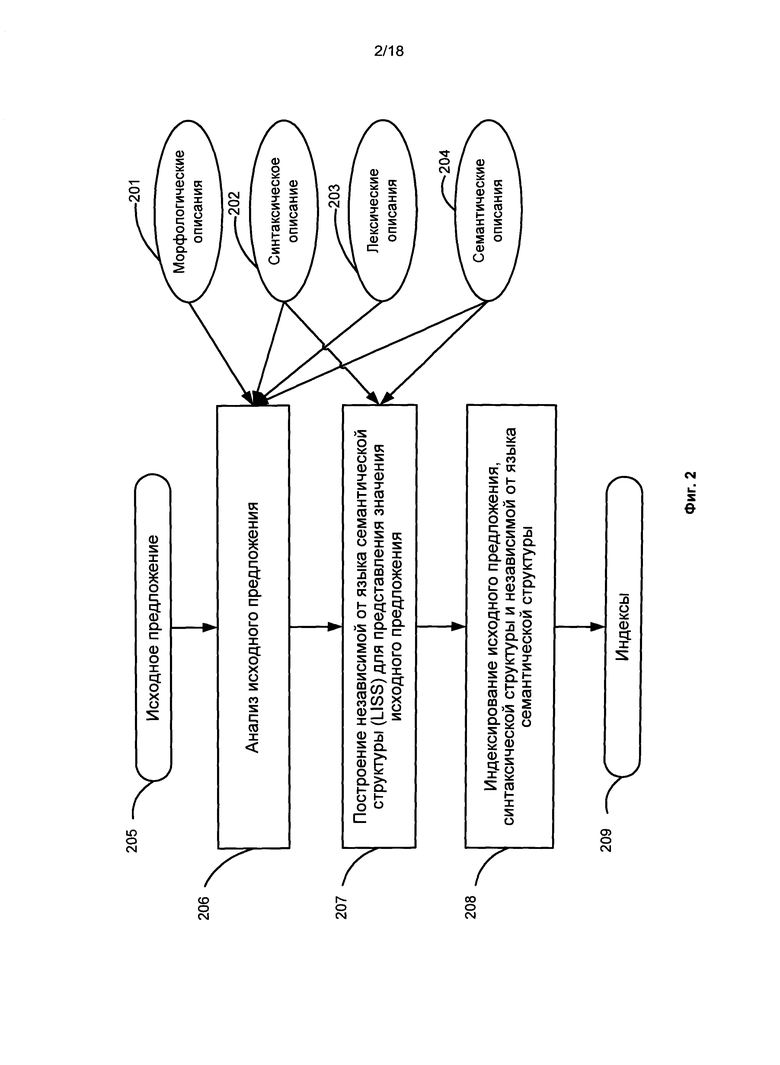
[009] на Фиг. 2 представлена блок-схема способа исчерпывающего анализа в соответствии с одним или более вариантами реализации;
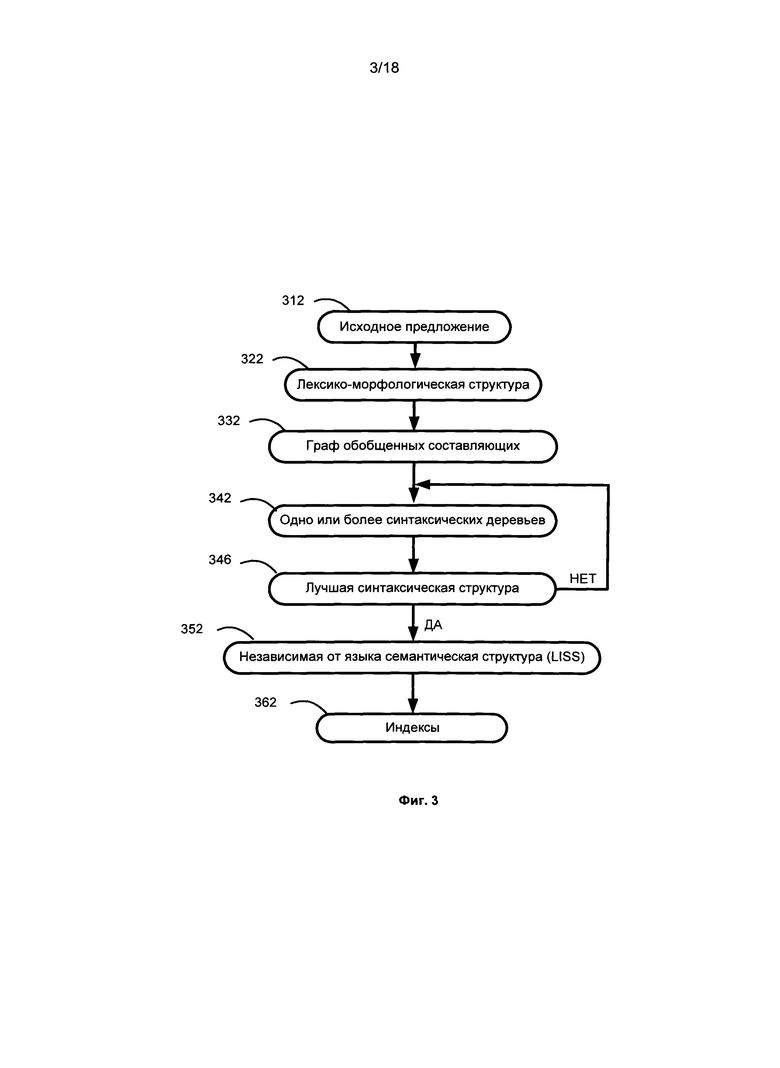
[010] на Фиг. 3 представлена блок-схема анализа предложения в соответствии с одним или более вариантами реализации;
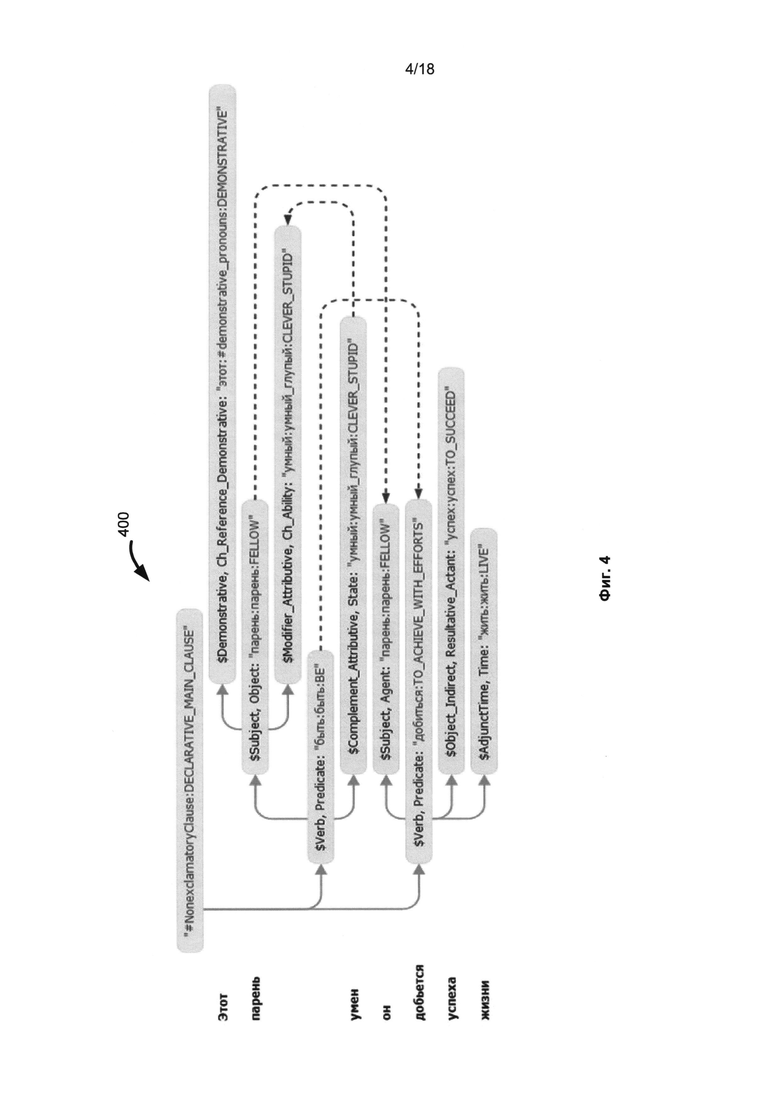
[011] на Фиг. 4 представлен пример семантической структуры, полученной для примера предложения;
[012] на Фиг. 5A-5D представлены фрагменты или части семантической иерархии;
[013] на Фиг. 6 представлена диаграмма, демонстрирующая описания языка в соответствии с одним примером реализации;
[014] на Фиг. 7 представлена диаграмма, демонстрирующая морфологические описания в соответствии с одним или более вариантами реализации;
[015] на Фиг. 8 представлена диаграмма, демонстрирующая синтаксические описания в соответствии с одним или более вариантами реализации;
[016] на Фиг. 9 представлена диаграмма, демонстрирующая семантические описания в соответствии с одним или более примерами реализации;
[017] на Фиг. 10 представлена диаграмма, демонстрирующая лексические описания в соответствии с одним или более вариантами реализации;
[018] на Фиг. 11 представлена блок-схема способа разрешения семантической неоднозначности с использованием параллельных текстов в соответствии с одним или более вариантами реализации;
[019] на Фиг. 12A-B представлены семантические структуры совмещенных предложений в соответствии с одним или более вариантами реализации;
[020] на Фиг. 13 представлена блок-схема способа разрешения семантической неоднозначности с использованием методик классификации в соответствии с одним или более вариантами реализации; и
[021] на Фиг. 14 представлен пример аппаратного обеспечения для реализации компьютерной системы в соответствии с одним вариантом реализации.
[022] Аналогичные номера и обозначения на различных рисунках указывают на аналогичные элементы.
ПОДРОБНОЕ ОПИСАНИЕ
[023] В последующем описании для целей пояснения изложено множество конкретных деталей реализации, чтобы обеспечить глубокое понимание понятий, лежащих в основе описанных вариантов реализации изобретения. Однако для специалистов в данной области будет очевидно, что описанные варианты реализации могут быть реализованы на практике без некоторых или всех из этих конкретных особенностей. В других случаях структуры и устройства показаны только в виде блок-схемы во избежание затруднения понимания описанных вариантов реализации. Некоторые этапы процесса не описаны подробно во избежание затруднения понимания лежащего в основе понятия.
[024] В соответствии с различными вариантами реализации изобретения, описанными в настоящем документе, предложены способ и система для разрешения семантической неоднозначности в тексте, основанные на использовании реестра значений с иерархической структурой, или семантической иерархии, а также способ добавления понятий к семантической иерархии. Семантические классы (как часть лингвистических описаний) группируются в семантическую иерархию, в которой существуют связи «родительский объект - дочерний объект». Как правило, дочерний семантический класс наследует многие или большинство свойств своего непосредственного родительского класса и всех унаследованных семантических классов. Например, семантический класс SUBSTANCE является дочерним классом семантического класса ENTITY, но в то же время он является родительским классом для семантических классов GAS, LIQUID, METAL, WOOD_MATERIAL и т.д.
[025] Каждый семантический класс в семантической иерархии сопровождается глубинной моделью. Глубинная модель семантического класса представляет собой набор глубинных позиций. Глубинные позиции отражают семантические роли дочерних составляющих в различных предложениях с объектами данного семантического класса в качестве ядра и возможных семантических классов в качестве заполнителей глубинных позиций. Глубинные позиции выражают семантические отношения между составляющими, включающими, например, такие составляющие, как «агент», «адресат», «инструмент», «количество» и т.д. Дочерний семантический класс наследует и уточняет глубинную модель своего непосредственного родительского семантического класса.
[026] По меньшей мере, некоторые из вариантов реализации используют технологию исчерпывающего анализа текста, которая использует широкий спектр лингвистических описаний, представленных в патенте США №8,078,450. Анализ включает в себя лексико-морфологический, синтаксический и семантический анализ, в результате создаются независимые от языка семантические структуры, в которых каждое слово сопоставлено с соответствующим семантическим классом.
[027] На Фиг. 1 представлена блок-схема способа разрешения семантической неоднозначности в соответствии с одним или более вариантами реализации. Для данного текста и реестра значений 102 с иерархической структурой для каждого слова 101 в тексте в данном способе выполняются следующие шаги. Если слово появляется только один раз в реестре значений (105), способ проверяет (107), является ли такое вхождение экземпляром значения данного слова. Это может быть сделано с помощью одного из существующих статистических способов: если контекст слова аналогичен контексту слов в этом значении в корпусах, а также если контексты аналогичны, то слову в тексте назначается (109) соответствующее понятие из реестра. Если не найдено слово, которое является экземпляром этого объекта в реестре значений, в реестр значений вводится новое понятие (104) и слово, связанное с этим новым понятием. Родительский объект понятия, которое должно быть введено, может быть выявлен путем статистического анализа каждого уровня иерархии, начиная от корня и выбора наиболее вероятного узла на каждом этапе. Вероятность каждого узла, который должен быть связан со словом, основана на анализе корпусов текстов.
[028] Если слово встречается два или более раз в реестре значений, принимается решение (106), какое из значений, если они есть, является правильным для слова 101. Это может быть сделано путем применения любого существующего способа разрешения неоднозначности слова. Если оказывается, что одно из значений является правильным для слова, то это слово отождествляется с соответствующим понятием из реестра значений 108. В ином случае новое значение добавляется в реестр значений 104. Родительский объект значения, которое должно быть введено, может быть выявлен путем статистического анализа каждого уровня иерархии, начиная от корня и выбора наиболее вероятного узла на каждом этапе. Вероятность каждого узла основана на анализе корпусов текстов.
[029] Если слово совсем не появляется в реестре значений, соответствующее значение вставляется в реестр значений 104. Родительский объект значения, которое должно быть введено, может быть выявлен путем статистического анализа каждого уровня иерархии, начиная от корня и выбора наиболее вероятного узла на каждом этапе. Вероятность каждого узла основана на корпусах текстов. В другом варианте реализации способ может устранить неоднозначность только для одного слова или для нескольких слов в контексте, в то время как другие слова рассматриваются только в качестве контекста, и для них не требуется снимать неоднозначность.
[030] В одном варианте реализации могут использоваться способы исчерпывающего анализа. На Фиг. 2 представлена блок-схема способа исчерпывающего анализа в соответствии с одним или более вариантами реализации. Как показано на Фиг. 2, лингвистические описания могут включать в себя лексические описания 203, морфологические описания 201, синтаксические описания 202 и семантические описания 204. Каждый из этих компонентов лингвистических описаний показан либо как воздействующий, либо как используемый в качестве входных данных на этапах, показанных на блок-схеме 200. Способ включает в себя получение исходного предложения 205. Исходное предложение 205 анализируется (206), как показано более подробно на Фиг. 3. Затем формируется независимая от языка семантическая структура (Language-Independent Semantic Structure - LISS) (207). LISS представляет смысл исходного. Затем индексируются исходное предложение, синтаксическая структура и LISS (208). Результатом является набор полученных индексов 209.
[031] Индекс может содержать таблицу или может быть представлен в виде таблицы, в которой каждое значение элемента (например, слова, выражения или фразы) в документе сопровождается списком номеров или адресов его вхождения в этом документе. В некоторых вариантах реализации морфологические, синтаксические, лексические и семантические признаки могут быть проиндексированы таким же способом, как индексируется каждое слово в документе. В одном варианте реализации индексы могут быть получены для индексации всех или, по меньшей мере, одного значения морфологических, синтаксических, лексических и семантических признаков (параметров). Эти параметры или значения генерируются в процессе двухступенчатого семантического анализа, описанного ниже более подробно. Индекс можно использовать для упрощения таких операций обработки естественного языка, как устранение неоднозначности слов в документах.
[032] На Фиг. 3 представлена блок-схема анализа предложения в соответствии с одним или более вариантами реализации. Как показано на Фиг. 2 и Фиг. 3, при анализе (206) значения исходного предложения 205 определяется лексико-морфологическая структура 322. Затем выполняется синтаксический анализ, реализованный по алгоритму двухэтапного анализа (например, «грубого» синтаксического анализа и «точного» синтаксического анализа), с использованием лингвистических моделей и знаний на различных уровнях для вычисления оценок вероятности и создания наиболее вероятной синтаксической структуры, например, наилучшей синтаксической структуры.
[033] Таким образом, проводится грубый синтаксический анализ исходного предложения для создания графа 332 обобщенных составляющих, используемого для дальнейшего синтаксического анализа. Применяются все возможные поверхностные синтаксические модели для каждого элемента лексико-морфологической структуры, а также формируются и обобщаются все возможные составляющие для представления всех возможных вариантов синтаксического разбора предложения.
[034] После грубого синтаксического анализа выполняется точный синтаксический анализ на графе обобщенных составляющих для получения одного или более синтаксических деревьев 342, представляющих исходное предложение. В одном варианте реализации создание одного или более синтаксических деревьев 342 включает в себя выбор между лексическими значениями и выбор между отношениями из графов. Многие априорные и статистические оценки могут быть использованы в процессе выбора между лексическими вариантами, а также при выборе между отношениями из графа. Априорные и статистические оценки также могут быть использованы для оценки частей созданного дерева и всего дерева. В одном варианте реализации одно или более синтаксических деревьев могут быть созданы или упорядочены в порядке убывания оценки. Таким образом, в первую очередь может создаваться наилучшее синтаксическое дерево 346. В это время также может выполняться проверка и установление недревесных связей для каждого синтаксического дерева. Если не удается выбрать первое созданное синтаксическое дерево, например, из-за невозможности установления недревесных связей, в качестве лучшего может быть выбрано второе синтаксическое дерево и т.д.
[035] На этапах анализа могут извлекаться многие лексические, грамматические, синтаксические, прагматические и семантические характеристики. Например, система может извлекать и хранить лексическую информацию и информацию о лексических единицах, принадлежащих к семантическим классам, информацию о грамматических формах и линейном порядке, о синтаксических отношениях и поверхностных позициях, об использовании синтформ, аспектность, признаки тональности, такие как положительная или отрицательная тональность, глубинные позиции, недревесные связи, семантемы и т.д. Как показано на фиг. 3, такой двухэтапный подход к синтаксическому анализу обеспечивает, предтавление значения исходного предложения наилучшей синтаксической структурой 346, выбранной из одного или более синтаксических деревьев. Такой двухэтапный анализ следует принципу целостного и целенаправленного распознавания, т.е. гипотезы о структуре части предложения проверяются с помощью всех доступных лингвистических описаний в рамках гипотезы о структуре всего предложения. Такой подход позволяет избежать необходимости анализа множества заведомо бесперспективных вариантов разбора предложения. В некоторых ситуациях такой подход снижает объем вычислительных ресурсов, необходимым для обработки предложения.
[036] Способы анализа обеспечивают достижение максимальной точности при передаче или понимании смысла предложения. На Фиг. 4 представлен пример семантической структуры, полученной для предложения «This boy is smart, he′ll succeed in life.». Как показано на Фиг. 4, эта структура содержит всю синтаксическую и семантическую информацию, такую как семантические классы, семантемы, семантические отношения (глубинные позиции), недревовидные ссылки и т.д. Независимая от языка семантическая структура (LISS) 352 (сформированная в блоке 207 на Фиг. 2) предложения может быть представлена в виде ациклического графа (дерева, дополненного недревесными связями), в котором каждое слово конкретного языка замещено его универсальными (независимыми от языка) семантическими понятиями или семантическими объектами, называемыми в настоящем документе «семантическими классами». Семантический класс является семантическим признаком, который может быть извлечен и использован для задач классификации, кластеризации и фильтрации текстовых документов, написанных на одном или множестве языков. Другими признаками, используемыми для такой задачи, могут быть семантемы, так как они могут отражать не только семантические, но и синтаксические, грамматические и другие особенности конкретного языка в независимых от языка структурах.
[037] На Фиг. 4 представлен пример синтаксического дерева 400, полученного в результате точного синтаксического анализа предложения «This boy is smart, he′ll succeed in life». Это дерево содержит полную или по существу полную семантическую информацию, такую как лексические значения, части речи, синтаксические роли, грамматические значения, синтаксические отношения (позиции), синтаксические модели, типы недревовидных ссылок и т.д. Например, установлено, что «he» относится к «boy» как субъект анафорической модели 410. Установлено, что «boy» является субъектом 420 глагола «be», «he» - субъектом 430 «succeed», a «smart» относится к «парень» с помощью «управления-дополнения» 440.
[038] На Фиг. 5A-5D представлены фрагменты семантической иерархии в соответствии с одним вариантом реализации. Как показано, наиболее распространенные понятия находятся на верхних уровнях иерархии. Например, в отношении типов документов, как показано на Фиг. 5 В и 5С, семантические классы PRINTED_MATTER (502), SCINTIFIC_AND_LITERARY_WORK (504), TEXT_AS_PART OF_CREATIVE WORK (505) и другие являются дочерними классами семантического класса TEXT_OBJECTS_AND_DOCUMENTS (501), a PRINTED_MATTER (502) в свою очередь является родительским классом для семантического класса EDITION_AS_TEXT(503), который включает в себя классы PERIODICAL и NONPERIODICAL, причем PERIODICAL в свою очередь является родительским классом для ISSUE, MAGAZINE, NEWSPAPER и других классов. Для деления на классы можно использовать различные подходы. В некоторых вариантах реализации при определении классов в первую очередь учитывается семантика использования понятий, которая является неизменной для всех языков.
[039] Каждый семантический класс в семантической иерархии может сопровождаться глубинной моделью. Глубинная модель семантического класса представляет собой набор глубинных позиций. Глубинные позиции отражают семантические роли дочерних компонентов в различных предложениях с объектами семантического класса в качестве основы родительского компонента и возможных семантических классов в качестве заполнителей глубинных позиций. Глубинные позиции выражают семантические отношения между компонентами, включающими в себя, например, «агент», «адресат», «инструмент», «количество» и т.д. Дочерний семантический класс наследует и регулирует глубинную модель своего непосредственного родительского семантического класса.
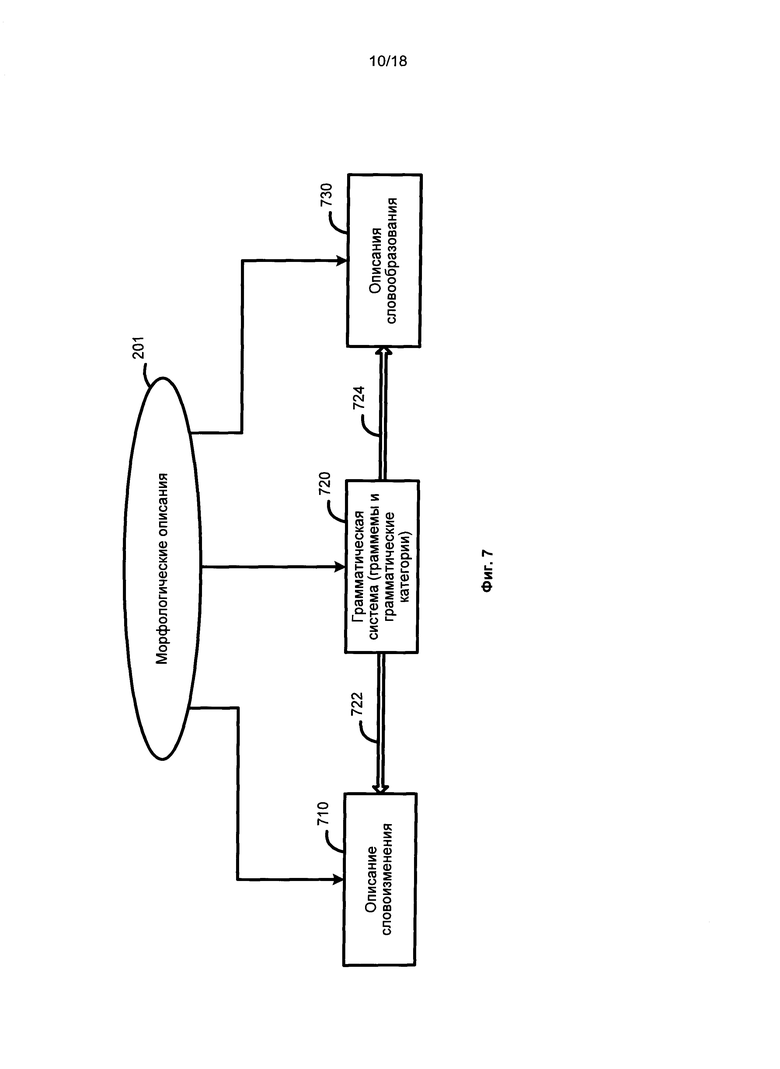
[040] На Фиг. 6 представлена диаграмма описания языка 610 согласно одному примеру реализации. Как показано на Фиг. 6, описания языка 610 включают в себя морфологические описания 201, синтаксические описания 202, лексические описания 203 и семантические описания 204. Описания языка 610 объединены в одно общее понятие. На Фиг. 7 представлены морфологические описания 201, а на Фиг. 8 представлены синтаксические описания 202. На Фиг. 9 представлены семантические описания 204.
[041] Как показано на Фиг. 6 и Фиг. 9, семантическая иерархия 910, являясь частью семантических описаний 204, представляет собой элемент описаний языка 610, который соединяет независимые от языка семантические описания 204 и лексические описания конкретного языка 203, как показано двойной стрелкой 623, морфологические описания 201 и синтаксические описания 202, как показано двойной стрелкой 624. Семантическая иерархия может быть создана один раз, а затем ее можно заполнить данными для каждого конкретного языка. Семантический класс для конкретного языка включает в себя лексические значения с их моделями.
[042] Семантические описания 204 не зависят от языка. Семантические описания 204 могут обеспечить описания глубинных компонентов, а также могут содержать семантическую иерархию, описания глубинных позиций, систему семантем и прагматические описания.
[043] Как показано на Фиг. 6, морфологические описания 201, лексические описания 203, синтаксические описания 202, а также семантические описания 204 могут быть связаны. Лексическое значение может иметь одну или более поверхностных (синтаксических) моделей, которые могут сопровождаться семантемами и прагматическими характеристиками. Синтаксические описания 202 и семантические описания 204 также могут быть связаны. Например, диатезы синтаксического описания 202 можно рассматривать как «интерфейс» между поверхностными моделями конкретного языка и независимыми от языка глубинными моделями семантического описания 204.
[044] На Фиг. 7 представлен пример морфологических описаний 201. Как показано, компоненты морфологических описаний 201 включают в себя, без ограничений, описание словоизменения 710, грамматическую систему (например, граммемы) 720 и описание словообразования 730. В одном варианте реализации грамматическая система 720 включает в себя набор грамматических категорий, таких как «часть речи», «падеж», «род», «число», «одушевленность», «возвратность», «время», «аспект» и т.д., а также их значения, далее именуемые «граммемы». Например, граммемы частей речи могут включать в себя «прилагательное», «существительное», «глагол» и т.д.; граммемы падежей могут включать в себя «именительный», «винительный», «родительный» и т.д.; а граммемы категории рода могут включать в себя «женский», «мужской», «средний» и т.д.
[045] Как показано на Фиг. 7, описание словоизменения 710 может описывать, как может изменяться основная форма слова в соответствии с его падежом, родом, числом, временем и т.д., и включает в себя практически все возможные формы данного слова. Описание словообразования 730 может описывать, какие новые слова могут быть созданы с использованием данного слова. Граммемы являются единицами грамматических систем 720 и, как показано ссылкой 722 и ссылкой 724, граммемы могут использоваться для построения описания изменения формы слова 710, а также описания словообразования 730.
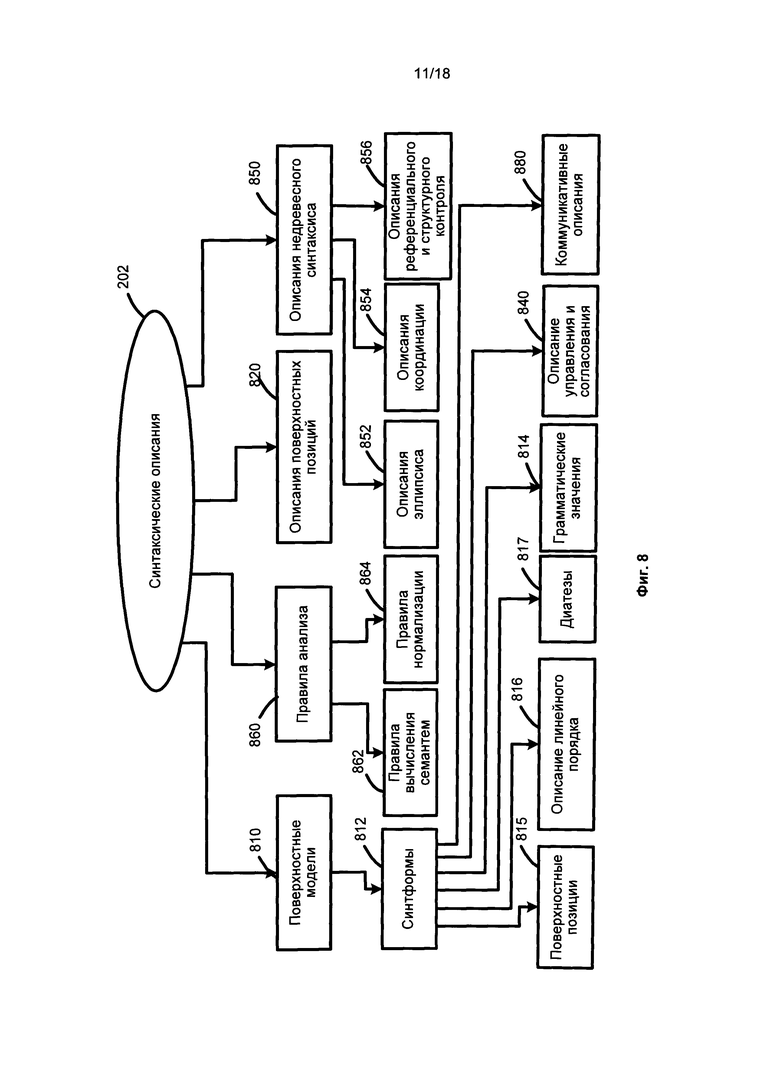
[046] На Фиг. 8 представлен пример синтаксических описаний 202. Компоненты синтаксических описаний 202 могут включать поверхностные модели 810, описания поверхностных позиций 820, описания референциального и структурного контроля 856, описания управления и согласования 840, описания недревесного синтаксиса 850 и правила анализа 860. Синтаксические описания 202 используются для создания возможных синтаксических структур предложения на данном исходном языке с учетом свободного линейного порядка слов, недревовидного синтаксического явления (например, согласования, эллипсиса и т.д.), референтных отношений, а также других факторов. Все эти компоненты используются в процессе синтаксического анализа, который может быть выполнен в соответствии с технологией исчерпывающего анализа языка, подробно описанной в патенте США №8,078,450.
[047] Поверхностные модели 810 представляют собой наборы из одной или более синтаксических форм («синтформ» 812) для описания возможных синтаксических структур предложений, как показано в синтаксическом описании 102. В общем случае, лексическое значение языка связано с его поверхностными (синтаксическими) моделями 810, которые представляют возможные составляющие с данным лексическом значением в качестве ядра и, помимо прочего, включают в себя набор поверхностных позиций дочерних элементов, описание линейного порядка, диатезы.
[048] Поверхностные модели 810 представлены синтформами 812. Каждая синтформа 812 может включать в себя определенное лексическое значение, которое функционирует в качестве ядра составляющей и может дополнительно включать в себя набор поверхностных позиций 815 своих дочерних компонентов, описание линейного порядка 816, диатезы 817, грамматические значения 814, описания управления и согласования 840, коммуникативные описания 880, в том числе в связи с ядром составляющей.
[049] Описания поверхностных позиций 820 как части синтаксических описаний 102 используются для задания общих свойств поверхностных позиций 815, которые используются в поверхностных моделях 810 различных лексических значений в исходном языке. Поверхностные позиции 815 используются для выражения синтаксических отношений между компонентами предложения. Примеры поверхностных позиций 815 могут включать в себя, помимо прочего, «субъект», «прямое_дополнение», «косвенное_дополнение», «определительное придаточное предложение».
[050] При синтаксическом анализе модель составляющих использует множество поверхностных позиций 815 дочерних компонентов и их описания линейного порядка 816, а также описывает грамматические значения 814 возможных заполнителей этих поверхностных позиций 815. Диатезы 817 представляют соответствия между поверхностными позициями 815 и глубинными позициями 514 (как показано на рисунке 5). Диатезы 817 представлены связью 624 между синтаксическими описаниями 202 и семантическими описаниями 204. Коммуникативные описания 880 описывают коммуникативный порядок в предложении.
[051] Синтаксические формы (синтформы) 812 представляют собой набор поверхностных позиций 815, связанных с описанием линейного порядка 816. Одна или более составляющих, возможных для лексического значения словоформы в исходном предложении, могут быть представлены поверхностными синтаксическими моделями, такими как поверхностные модели 810. Каждая составляющая рассматривается как реализация некоторой модели составляющей путем выбора соответствующей синтформы 812. Выбранные синтаксические формы (синтформы) 812 представляют собой наборы поверхностных позиций 815 с указанным линейным порядком. Каждая поверхностная позиция в синтформе может иметь грамматические и семантические ограничения для своих заполнителей.
[052] Описание линейного порядка 816 представлено в виде выражений линейного порядка, которые представляют последовательность, в которой различные поверхностные позиции 815 могут встречаться в предложении. Выражения линейного порядка могут включать имена переменных, имена поверхностных позиций, скобки, граммемы, оценки, а также оператор «или» и т.д. Например, описание линейного порядка простого предложения «Boys play football» может быть представлено в виде «Subject Core Object_Direct» (т.е. «Субъект Ядро Прямое_дополнение»), где « Subject, Object_Direct» представляют собой имена поверхностных позиций 815, соответствующих порядку слов. Заполнители поверхностных позиций 815, указанные символами элементов предложения, присутствуют в том же порядке для элементов выражений линейного порядка.
[053] Различные поверхностные позиции 815 могут находиться в отношении строгого и/или нестрогого порядка в синтформе 812. Например, скобки можно использовать для построения выражений линейного порядка и описывать отношения строгого линейного порядка между различными поверхностными позициями 815. SurfaceSlot1 SurfaceSlot2 или (SurfaceSlot1 SurfaceSlot2) означает, что обе поверхностных позиции расположены в том же выражении линейного порядка, но возможен только один порядок следования этих поверхностных позиций относительно друг друга, при котором SurfaceSlot2 следует за SurfaceSlot1.
[054] В другом примере можно использовать квадратные скобки для построения выражений линейного порядка и описания отношения нестрогого линейного порядка между различными поверхностными позициями 815 синтформ 812. Таким образом, [SurfaceSlot1 SurfaceSlot2] указывает, что обе поверхностных позиции принадлежат той же переменной линейного порядка, а их порядок относительно друг друга не имеет значения.
[055] Выражения линейного порядка в описании линейного порядка 816 могут содержать грамматические значения 814, выраженные граммемами, которым соответствуют дочерние компоненты. Кроме того, два выражения линейного порядка могут быть объединены оператором | (т.е. «ИЛИ»). Например: (Subject Core Object) | [Subject Core Object].
[056] Коммуникативные описания 880 описывают порядок слов в синтформе 812 с точки зрения коммуникативных актов, которые необходимо представить в виде выражений коммуникативного порядка, которые аналогичны выражениям линейного порядка. Описание подчиненности и согласования 840 содержит правила и ограничения грамматических значений окружающих компонентов, которые используются в процессе синтаксического анализа.
[057] Описания недревесного синтаксиса 850 связаны с обработкой различных лингвистических явлений, таких как эллипсис и координация, и используются в трансформациях синтаксических структур, которые создаются на различных этапах анализа в соответствии с вариантами реализации настоящего изобретения. Описания недревесного синтаксиса 850 включают в себя, помимо прочего, описание эллипсиса 852, описание координации 854, а также описания референциального и структурного контроля 830.
[058] Правила анализа 860 (как часть синтаксических описаний 202) могут включать в себя, без ограничений, правила вычисления семантем 862 и правила нормализации 864. Хотя правила анализа 860 используются на этапе семантического анализа 150, правила анализа 860, как правило, описывают свойства конкретного языка и связаны с синтаксическими описаниями 102. Правила нормализации 864 по существу используются в виде правил преобразования для описания трансформаций семантических структур, которые могут быть различными в разных языках.
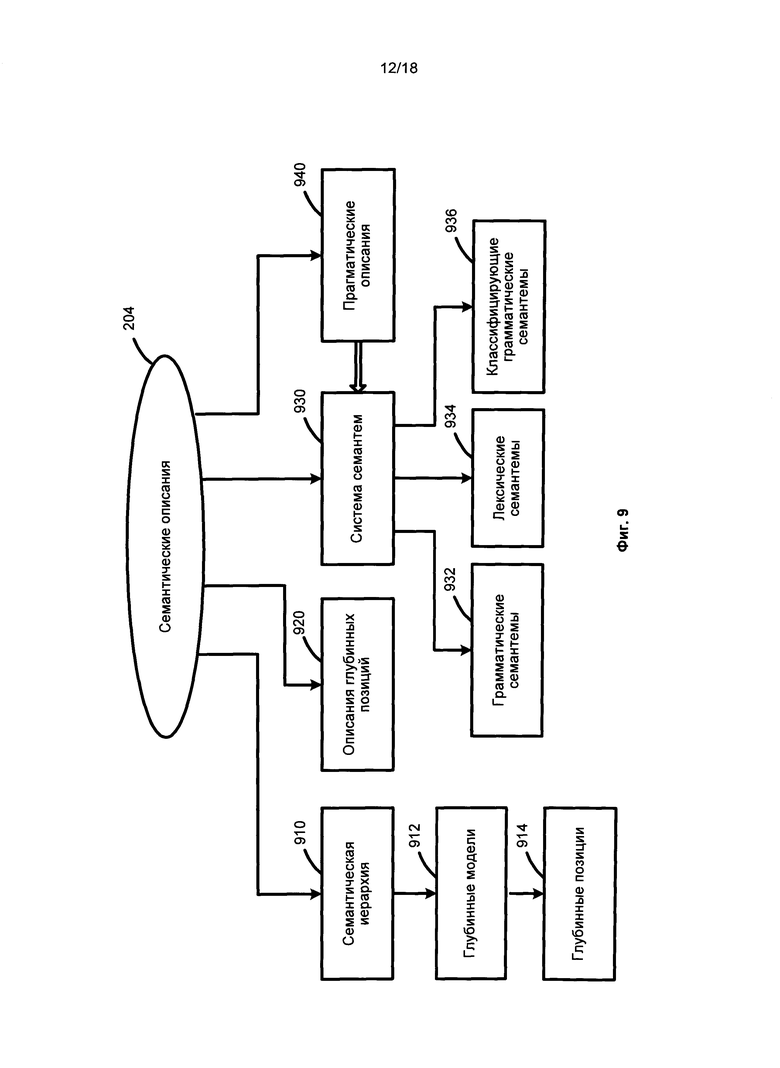
[059] На Фиг. 9 представлен пример семантических описаний. Компоненты семантических описаний 204 не зависят от языка и могут включать в себя, без ограничений, семантическую иерархию 910, описание глубинных позиций 920, систему семантем 930 и прагматические описания 940.
[060] Семантическая иерархия 910 состоит из смысловых понятий (семантических объектов), называемых семантическими классами, организованных в соответствии с иерархическими отношениями «родительский объект - дочерний объект», которые аналогичны дереву. Как правило, дочерний семантический класс наследует большинство свойств своего непосредственного родителя и все унаследованные семантические классы. Например, семантический класс SUBSTANCE является дочерним классом семантического класса ENTITY и родителем семантических классов GAS, LIQUID, METAL, WOOD_MATERIAL и т.д.
[061] Каждый семантический класс в семантической иерархии 910 сопровождается глубинной моделью 912. Глубинная модель 912 семантического класса представляет собой набор глубинных позиций 914, которые отражают семантические роли дочерних составляющих в различных предложениях с объектами семантического класса в качестве ядра родительской составляющей и возможных семантических классов в качестве заполнителей глубинных позиций. Глубинные позиции 914 выражают семантические отношения, включающие, например, «агент», «адресат», «инструмент», «количество» и т.д. Дочерний семантический класс наследует и уточняет глубинную модель 912 своего непосредственного родительского семантического класса.
[062] Описание глубинных позиций 920 используется для описания общих свойств глубинных позиций 914 и отражает семантические роли дочерних составляющих в глубинных моделях 912. Описание глубинных позиций 920 также содержит грамматические и семантические ограничения для заполнителей глубинных позиций 914. Свойства и ограничения для глубинных позиций 914 и их возможных заполнителей очень похожи и часто идентичны для различных языков. Таким образом, глубинные позиции 914 являются независимыми от языка.
[063] Система семантем 930 представляет набор семантических категорий и семантем, которые представляют значения семантических категорий. Например, семантическая категория Degree Of Comparison может использоваться для описания степени сравнения, и ее семантемами, помимо прочего, могут быть, например, Positive (т.е. положительная степень,), Comparative Higher Degree (сравнительная степень,), Superlative Highest Degree (превосходная степень,). В качестве другого примера, семантическая категория Relation To Reference Point может использоваться для описания нахождения как до, так и после референта, а ее семантемы могут быть Previous и Subsequent, соответственно, при этом порядок может анализироваться в пространстве или времени в широком смысле этих слов. В качестве еще одного примера семантическая категория Evaluation Objective может использоваться для описания объективной оценки, например. Bad, Good и т.д.
[064] Система семантем 930 включает независимые от языка семантические атрибуты, которые выражают не только семантические характеристики, но и стилистические, прагматические и коммуникативные характеристики. Некоторые семантемы можно использовать для выражения единичного значения, которое находит регулярное грамматическое и/или лексическое выражение в языке. По своему назначению и использованию система семантем 930 может быть разделена на различные типы, включающие в себя, без ограничений, грамматические семантемы 932, лексические семантемы 934 и классифицирующие грамматические (дифференцирующие) семантемы 936.
[065] Грамматические семантемы 932 используются для кодирования грамматических свойств составляющих при преобразовании синтаксического дерева в семантическую структуру. Лексические семантемы 934 описывают конкретные свойства объектов (например, «быть плоским» или «быть жидким») и используются при описании глубинных позиций 920 в качестве ограничения для заполнителей глубинных позиций (например, для глаголов «облицовывать» и «заливать» соответственно). Классифицирующие грамматические (дифференцирующие) семантемы 936 выражают дифференцирующие свойства объектов в пределах одного семантического класса, например, в семантическом классе HAIRDRESSER семантеме «Related To Men» назначено лексическое значение «цирюльник», в отличие от других лексических значений, которые также относятся к этому классу, например «парикмахер», «стилист по прическам» и т.д.
[066] Прагматическое описание 940 позволяет системе назначить соответствующую тему, стиль или жанр для текстов и объектов семантической иерархии 910. Например, «Экономическая политика», «Внешняя политика», «Юстиция», «Законодательство», «Торговля», «Финансы» и т.д. Прагматические свойства также может быть выражены семантемами. Например, прагматический контекст может учитываться в процессе семантического анализа.
[067] На Фиг. 10 представлена диаграмма, иллюстрирующая лексические описания 203 в соответствии с одним примером реализации. Как показано, лексические описания 203 включают в себя лексико-семантический словарь 1004, который включает в себя набор лексических значений 1012, организованный с их семантическими классами в семантическую иерархию, в которой каждое лексическое значение может включать, без ограничений, свою глубинную модель 912, поверхностную модель 810, грамматическое значение 1008 и семантическое значение 1010. Лексическое значение может объединять различные производные (например, слова, выражения, фразы), которые выражают смысл с помощью разных частей речи или разных словоформ, например, однокоренных слов. В свою очередь семантический класс объединяет лексические значения слов или выражений в разных языках с очень близкой семантикой.
[068] Кроме того, любой элемент описания языка 610 может быть извлечен в процессе исчерпывающего анализа текстов, и любой элемент может быть проиндексирован (создан индекс для признака). Индексы или указатели могут быть сохранены и использованы для решения задач классификации, кластеризации и фильтрации текстовых документов, написанных на одном или более языках. Индексация семантических классов важна и востребована для решения этих задач. Синтаксические структуры и семантические структуры также могут быть проиндексированы и сохранены для использования при семантическом поиске, классификации, кластеризации и фильтрации.
[069] Описанные методики включают в себя способы добавления новых понятий в семантическую иерархию. Это может быть необходимо для обработки конкретной терминологии, которая не включена в иерархию. Например, семантическую иерархию можно использовать для машинного перевода технических текстов, которые включают конкретные редкие термины. В этом примере может быть целесообразно добавить эти термины в иерархию перед ее использованием в переводе.
[070] В одном варианте реализации процесс добавления термина в иерархию может осуществляться вручную, т.е. опытному пользователю может быть разрешено вводить термин в конкретном месте и необязательно указывать грамматические свойства введенного термина. Это может осуществляться, например, путем указания родительского семантического класса термина. Например, когда может потребоваться добавить новое слово Netangin, которое представляет собой препарат для лечения тонзиллита, в иерархию, пользователь может указать MEDICINE в качестве родительского семантического класса. В некоторых случаях слова могут быть добавлены в несколько семантических классов. Например, некоторые препараты могут быть добавлены в класс MEDICINE, а также в класс SUBSTANCE, так как их названия могут относиться к препаратам или к соответствующим активным веществам.
[071] В одном варианте реализации пользователю может быть предоставлен графический интерфейс пользователя для упрощения процесса добавления новых терминов. Такой графический интерфейс пользователя может предоставлять пользователю список возможных родительских семантических классов для нового термина. Такой предоставляемый список может быть или создан заранее, или может создаваться для данного слова путем поиска наиболее вероятных семантических классов для такого нового термина. Такой поиск возможных семантических классов может выполняться путем анализа структуры слова. В одном варианте реализации анализ структуры слова может предполагать создание символьного представления n-грамм слов и/или вычисления сходства слов. Символьная n-грамма представляет собой последовательность n символов, например, слово Netangin может быть представлено в виде следующего набора двойных символов (биграмм): [Ne, et, ta, an, ng, gi, in]. В другом варианте реализации анализ структуры слова может включать в себя выявление морфем слова (например, его окончание, префиксы и суффиксы). Например, окончание "-in" является общим для препаратов и русских фамилий. Поэтому в указанном списке могут быть, по меньшей мере, два семантических класса, соответствующих этим двум понятиям.
[072] В одном варианте реализации указанный интерфейс может позволять пользователю выбирать слова, аналогичные тому, которое необходимо добавить. Это может быть сделано для упрощения процесса добавления новых понятий. Пользователь может видеть некоторые списки известных экземпляров семантических классов. В некоторых случаях список понятий может представлять семантический класс лучше, чем его название. Например, пользователь, читающий предложение «Petrov was born in Moscow in 1971 (т.е. Петров родился в Москве в 1971 году)», возможно, не знает, что «-ов» является типичным окончанием русских фамилий у мужчин. Кроме того, он может не знать, является «Иванов» именем или фамилией человека. Пользователю может быть предоставлен список, включающий слова «Иванов», «Сидоров», «Болыпов», которые представлены фамилиями, а также список имен, которые не имеют одинаковых окончаний, при этом пользователю будет легче принять правильное решение.
[073] В одном варианте реализации пользователю может быть предоставлен графический интерфейс пользователя, позволяющий добавлять новые понятия непосредственно в иерархию. Пользователь может просматривать иерархию и с помощью графического интерфейса пользователя может определять места, в которые необходимо добавить понятия. В другом варианте реализации пользователю может быть предложено выбрать дочерний узел узла иерархии, начиная от корня, пока не будет найден правильный узел.
[074] В одном варианте реализации семантическая иерархия имеет ряд семантических классов, позволяющих вставлять новые понятия. Это может быть либо целая иерархия (т.е. все семантические классы, которые в нее входят), либо подмножество понятий. Список обновляемых семантических классов может быть либо заранее определенным (например, список возможных типов именованных объектов, например PERSON, ORGANIZATION и т.д.), либо он может создаваться в соответствии со словом, которое необходимо добавить. В одном варианте реализации пользователю может быть предоставлен графический интерфейс пользователя, спрашивающий пользователя о том, является ли добавляемое слово экземпляром конкретного семантического класса.
[075] В одном варианте реализации семантическая иерархия имеет ряд семантических классов, позволяющих вставлять новые понятия. Это может быть либо целая иерархия (т.е. все семантические классы, которые в нее входят), либо подмножество понятий. Список обновляемых семантических классов может быть либо заранее определенным (например, список возможных типов именованных объектов, например PERSON, ORGANIZATION и т.д.), либо он может создаваться в соответствии со словом, которое необходимо добавить.
[076] Добавляемые термины могут быть сохранены в дополнительном файле, который затем пользователь может добавить в семантическую иерархию. В другом варианте реализации эти термины могут отображаться как часть иерархии.
[077] Поскольку семантическая иерархия может не зависеть от языка, описанные методики позволяют обрабатывать слова и тексты на одном или множестве языков.
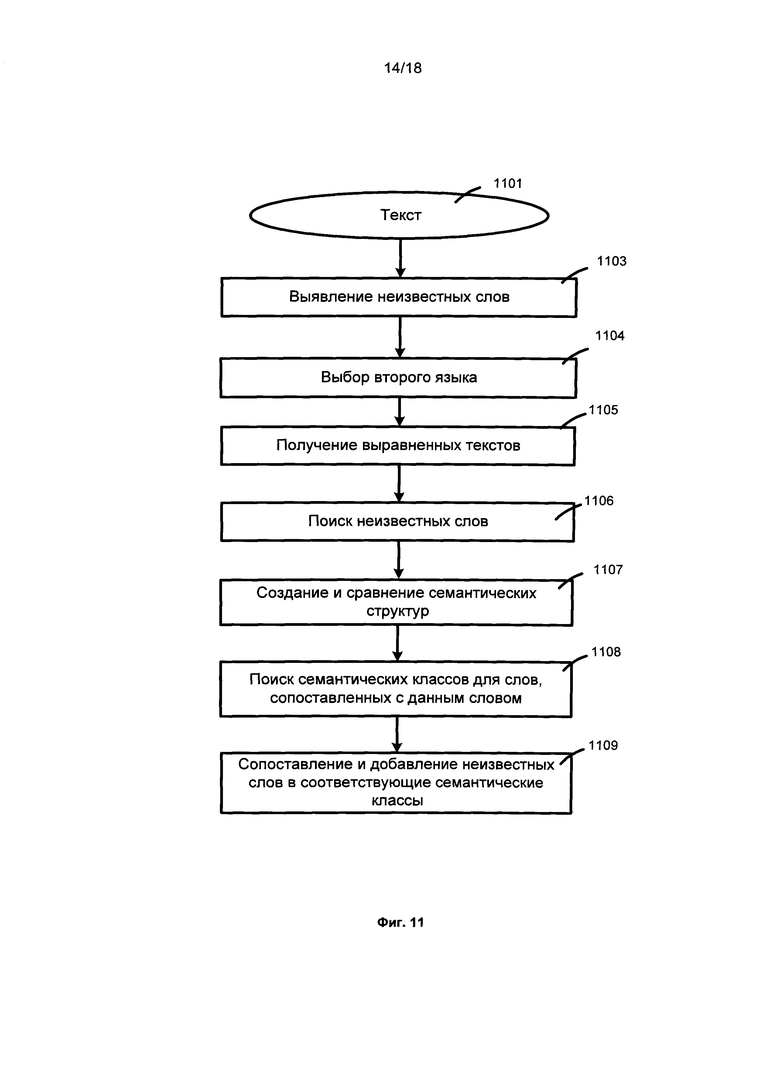
[078] На Фиг. 11 представлена блок-схема способа разрешения семантической неоднозначности на основе корпусов параллельных или сравнимых текстов (т.е. корпусов с, по меньшей мере, частичным выравниванием) в соответствии с одним вариантом реализации. В одном варианте реализации способ включает в себя: рассматривается текст 1101 с, по меньшей мере, одним неизвестным словом, при этом выявляются (1103) все неизвестные слова (т.е. слова, которые отсутствуют в реестре значений). Текст 1101 может быть на любом языке, который может быть проанализирован с помощью вышеуказанного анализатора, основанного на технологии исчерпывающего анализа текста, который использует лингвистические описания, описанные в патенте США 8,078,450. Анализ включает в себя лексико-морфологический, синтаксический и семантический анализ. Это означает, что система может использовать для анализа все необходимые независимые от языка и отражающие специфику конкретного языка лингвистические описания в соответствии с Фиг. 6, 7, 8, 9, 10. Но часть, отражающая специфику языка, связанная с первым языком указанной семантической иерархии, может быть неполной. Например, в лексиконе могут быть пробелы, т.е. некоторые лексические значения могут отсутствовать. Таким образом, некоторые слова не могут быть найдены в семантической иерархии и для них нет соответствующих лексических и синтаксических моделей.
[079] Поскольку, по меньшей мере, одно неизвестное слово в первом языке было обнаружено на этапе 1104, выбирается параллельный корпус. Выбирается, по меньшей мере, один второй язык, отличающийся от первого языка (1104). Параллельный корпус должен быть корпусом или текстами на этих двух языках и быть, по меньшей мере, частично выравненным. Выравнивание может быть выполнено на уровне предложений, то есть каждому предложению на первом языке соответствует предложение на втором языке. Это может быть, например, память переводов (translation memory, TM) или другие ресурсы. Выравненные параллельные тексты могут быть получены любым способом выравнивания, например, путем использования двуязычного словаря или путем использования способа, описанного в заявке на патент США №13/464,447. В некоторых вариантах реализации единственным требованием к выбору второго языка может быть то, что второй язык также может быть проанализирован с помощью вышеуказанного анализатора, основанного на технологии исчерпывающего анализа текстов, благодаря чему существуют и могут быть использованы для анализа все необходимые и отражающие специфику конкретного языка лингвистические описания в соответствии с Фиг. 6, 7, 8, 9, 10.
[080] Для каждого второго языка получена пара текстов с, по меньшей мере, частичным выравниванием (1105). Указанные ранее найденные неизвестные слова ищутся (1106) в части текстов на первом языке. Для предложений, содержащих неизвестные слова и совмещенных с ними предложений на других языках, создаются и сравниваются (1107) независимые языковые семантические структуры. Независимая от языка семантическая структура (LISS) предложения представлена ациклическим графом (деревом, дополненным недревовидными связями), в котором каждое слово на конкретном языке замещено его универсальными (независимыми от языка) семантическими понятиями, т.е. семантическими объектами, которые в настоящем документе именуются «семантическими классами». Кроме того, отношения между членами предложения отражены с помощью независимых от языка понятий - глубинных позиций 914. Семантическая структура, построенная в результате исчерпывающего синтаксического и семантического анализа, также подробно описана в патенте США №8,078,450. Таким образом, например, если два предложения на двух разных языках имеют тот же смысл (значение), то они являются результатом точного и тщательного перевода друг друга, поэтому их семантические структуры должно быть идентичными или очень похожими.
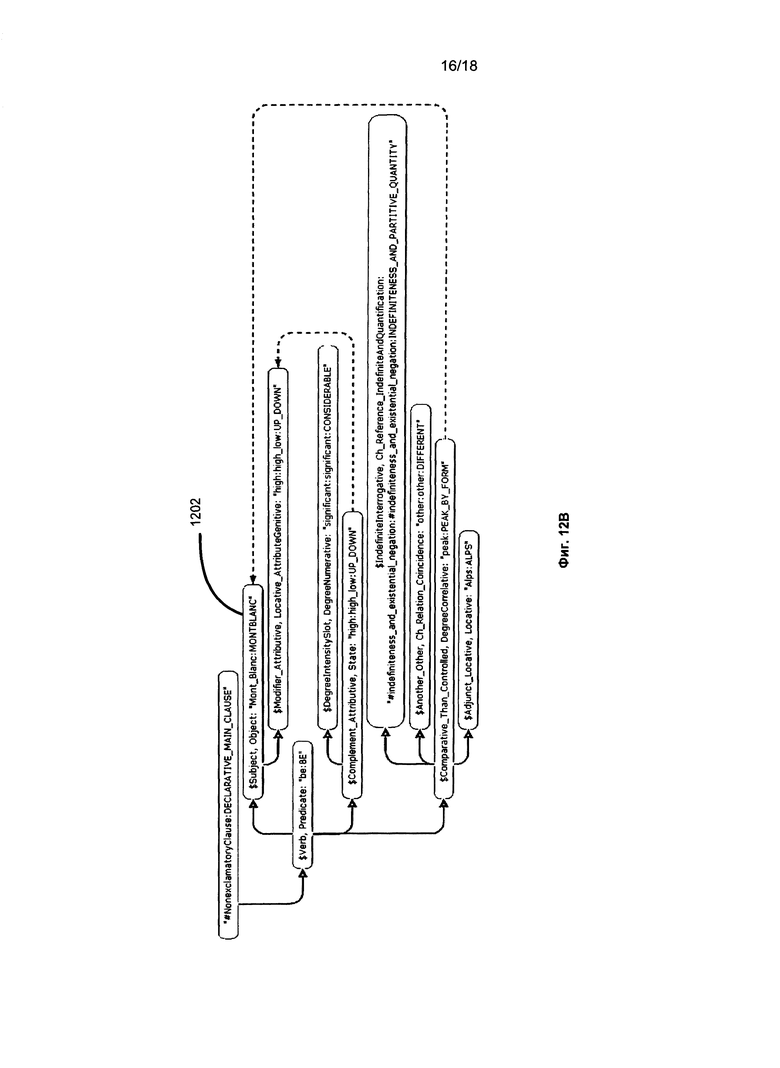
[081] На Фиг. 12A-12B представлены примеры предложений, которые могут присутствовать в выравненных текстах. На Фиг. 12A представлена семантическая структура предложения на русском языке «Монблан значительно выше, чем любой другой пик в Альпах», где слово «Монблан» определено как неизвестное понятие. Это предложение соответствует следующему предложению на английском языке: «Mont Blanc is significantly higher than any other peak in Alps». Его семантическая структура представлена на Фиг. 12B.
[082] Считается, что семантические структуры найденных пар предложений идентичны, если они имеют одинаковую конфигурацию с одинаковыми семантическими классами в узлах, за исключением узлов, соответствующих неизвестным словам, и с теми же глубинными позициями в качестве дуг.
[083] Для каждого неизвестного слова находят один или более семантических классов слова (слов), с которыми оно сопоставлено (1108). Как показано на Фиг. 12A и 12B, так как семантические структуры имеют одинаковую конфигурацию и узлы, за исключением 1201 и 1202, в которых слово «Монблан» в русскоязычной части показано на Фиг. 12A как #Unknown_word: UNKNOWN_SUBSTANTIVE, имеют одинаковые семантические классы, узлы 1201 и 1202 сравниваются и сопоставляются.
[084] Таким способом для всех неизвестных слов находятся (1109) соответствующие семантические классы. Если такое соответствие установлено, становится возможным сопоставить и добавить неизвестное слово в соответствующий семантический класс с семантическими свойствами, которые могут быть извлечены из соответствующего лексического значения на другом языке. Это означает, что лексическое значение «Монблан» будет добавлено в русскоязычную часть семантической иерархии 910 в семантический класс MONTBLANC, поскольку оно соответствует англоязычному лексическому значению «Mont Blanc» и унаследует синтаксическую модель и другие атрибуты его родительского семантического класса MOUNTAIN.
[085] Как также показано на Фиг. 11, при наличии сопоставленных предложений 1101 на двух или более языках, в которых все слова в одном предложении имеют соответствующие лексические классы в иерархии, а некоторые другие предложения содержат неизвестные слова, описанный способ сопоставляет неизвестные слова с семантическими классами, соответствующими словам, сопоставленных с ними.
[086] На Фиг. 12A-12B представлены примеры предложений, которые могут присутствовать в выравненных текстах. На Фиг. 12A представлена семантическая структура предложения на русском языке «Монблан значительно выше, чем любой другой пик в Альпах», в котором слово «Монблан» является неизвестным. Это предложение совмещено со следующим предложением на английском языке: «Mont Blanc is significantly higher than any other peak in Alps.» Его семантическая структура представлена на Фиг. 12B. В результате сравнения семантической структуры русскоязычного предложения на Фиг. 12A с семантической структурой англоязычного предложения на Фиг. 12B, которые могут иметь одинаковые структуры, как показано, можно сделать вывод о соответствии слова «Монблан» на русском языке слову (группе слов) «Mont Blanc» на английском языке. В этом случае сопоставленным с русским словом «Монблан» будет слово «Mont Blanc», и существует соответствующий объект семантической иерархии. Следовательно, русское слово «Монблан» можно сопоставить с тем же семантическим классом MONTBLANC и можно добавить в качестве русскоязычного лексического класса с такими же семантическими свойствами, что и «Mont Blanc» в английском языке.
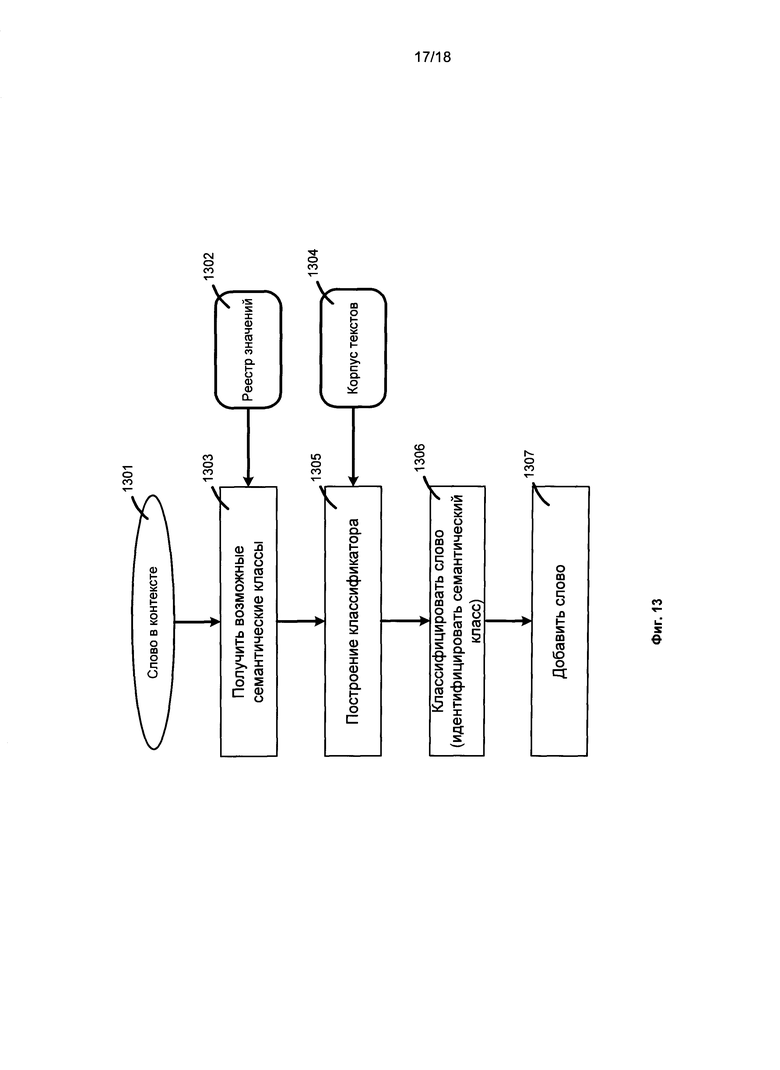
[087] На Фиг. 13 представлена блок-схема способа разрешения семантической неоднозначности на основе методик машинного обучения в соответствии с одним или более вариантами реализации. В одном варианте реализации проблема разрешения семантической неоднозначности может быть решена как задача "обучения с учителем" (например, классификация). Получено слово в контексте 1301. Для определения семантического класса слова в описанном способе сначала получают все возможные семантические классы 1303 из реестра значений 1302, которые могут быть назначены для данного слова 1301.
[088] Список семантических классов может быть задан заранее. Например, новые понятия могут быть допустимы только в семантических классах PERSON, LOCATION и ORGANIZATION. В данном примере эти семантические классы являются категориями. Список семантических классов может быть создан способом, который выбирает наиболее вероятные классы из всех классов в семантической иерархии, что, в свою очередь, может быть выполнено с использованием методик машинного обучения. Классы могут быть ранжированы по вероятности того, что заданное слово является экземпляром такого класса. Ранжирование может проводиться управляемым способом на основе корпусов текстов. Затем выбирается top-k, где k может представлять собой значение, заданное пользователем, или оптимальное значение, найденное статистическими способами. Эти заранее заданные или найденные семантические классы представляют категории, одной или многим из которых должно быть назначено слово. Затем строится классификатор (1305) с использованием корпусов текстов 1304 (например. Naive Bayes классификатор). Слово классифицируют (1306) в одну или более возможных категорий (т.е. семантических классов 1303). Наконец, слово добавляют (1307) в иерархию как экземпляр найденного семантического класса (классов).
[089] В одном варианте реализации разрешение неоднозначности может осуществляться в форме проверки гипотезы. Во-первых, для заданного неизвестного слова все семантические классы могут быть ранжированы по вероятности того, что данное неизвестное слово является объектом этого семантического класса. Затем выдвигается гипотеза о том, что неизвестное слово является экземпляром первого ранжированного семантического класса. Затем эту гипотезу проверяют путем статистического анализа корпусов текстов. Это возможно выполнить с помощью индексов 209. Если гипотеза отклонена, может быть сформулирована новая гипотеза о том, что неизвестное слово является экземпляром второго ранжированного семантического класса. И так далее до тех пор, пока гипотеза не будет принята. В другом варианте реализации семантический класс для слова может быть выбран с использованием существующих методик разрешения неоднозначности значений слов.
[090] На Фиг. 14 представлен пример аппаратного обеспечения для реализации методик и систем, описанных в настоящем документе, в соответствии с одним вариантом реализации настоящего описания. Как показано на Фиг. 14, пример аппаратного обеспечения 1400 включает, по меньшей мере, один процессор 1402, связанный с памятью 1404. Процессор 1402 может представлять собой один или более процессоров (например, микропроцессоров), а память 1404 может представлять собой оперативные запоминающие устройства (ОЗУ), представляющее собой главное устройство памяти аппаратного обеспечения 1400, а также любые дополнительные уровни памяти (например, кэш-память, энергонезависимую память или резервные запоминающие устройства, такие как программируемая или флэш-память) ПЗУ и т.п. Кроме того, память 1404 может включать в себя запоминающие устройства, физически расположенные в другом месте аппаратного обеспечения 1400, например любая кэш-память в процессоре 1402, а также любые запоминающие устройства, используемые в качестве виртуальной памяти, например съемные запоминающие устройства 1410.
[091] Аппаратное обеспечение 1400 может иметь ряд входов и выходов для обмена информацией с внешними устройствами. Для работы с пользователем или оператором аппаратное обеспечение 1400 может включать в себя одно или более устройств пользовательского ввода 1406 (например, клавиатуру, мышь, устройство, формирующее изображения, сканер, микрофон и т.п.) и одно или более устройств вывода 1408 (например, жидкокристаллический дисплей (ЖКД), устройство воспроизведения звука (динамик)). Для реализации настоящего изобретения аппаратное обеспечение 1400 может включать по меньшей мере одно устройство с экраном.
[092] В качестве дополнительного устройства памяти аппаратное обеспечение 1400 также может включать одно или более съемных запоминающих устройств 1410, например, помимо прочего, накопитель на гибких магнитных или иных съемных дисках, накопитель на жестком магнитном диске, устройство хранения с прямым доступом (DASD), оптический привод (например, привод компакт-дисков (CD), компакт-дисков в формате DVD) и/или ленточный накопитель. Более того, аппаратное обеспечение 1400 может включать в себя интерфейс для взаимодействия с одной или более сетями 1412 (например, помимо прочего, локальной сетью (LAN), глобальной сетью (WAN), беспроводной сетью и/или Интернетом) для обеспечения обмена информацией с другими компьютерами, подключенными к сетям. Следует принимать во внимание, что аппаратное обеспечение 1400, как правило, включает в себя подходящие аналоговые и/или цифровые интерфейсы между процессором 1402 и каждым из компонентов 1404, 1406, 1408 и 1412, что хорошо известно специалистам в данной области.
[093] Аппаратное обеспечение 1400 работает под управлением операционной системы 1414, и на нем выполняются различные компьютерные программные приложения, компоненты, программы, объекты, модули и т.п., с целью реализации вышеописанных методик. Более того, различные приложения, компоненты, программы, объекты и т.п. в совокупности указанные как прикладное ПО 1416 на Фиг. 14, также могут выполняться на одном или более процессорах другого компьютера, соединенного с аппаратным обеспечением 1400 через сеть 1412, например, в среде распределенных вычислений, причем вычисления, необходимые для реализации функций компьютерной программы, могут быть распределены по множеству компьютеров в сети.
[094] Как правило, подпрограммы, выполняемые для реализации вариантов реализации настоящего описания, могут быть реализованы в виде части операционной системы или конкретного приложения, компонента, программы, объекта, модуля или последовательности инструкций, именуемых «компьютерной программой». Компьютерная программа, как правило, содержит один или более наборов инструкций, которые находятся в разное время в различных устройствах памяти и хранения в компьютере, и которые, при считывании и исполнении одним или более процессорами компьютера, воздействуют на компьютер для выполнения операций, необходимых для исполнения элементов, вовлекающих различные аспекты изобретения. Более того, поскольку настоящее изобретение описано в контексте полностью функциональных компьютеров и компьютерных систем, и специалистам в данной области будет понятно, что различные варианты реализации настоящего изобретения можно распространять в виде программного продукта в различных формах, а также что настоящее изобретение в равной мере применяется для фактического воздействия на распространение независимо от конкретного типа используемого машиночитаемого носителя. Примеры машиночитаемых носителей включают в себя, без ограничений, носители с возможностью записи, такие как, помимо прочего, устройства оперативной и энергонезависимой памяти, накопители на гибких магнитных и других съемных дисках, накопители на жестких магнитных дисках, оптические диски (например, ПЗУ на компакт-дисках (CD-ROM), компакт-диски в формате DVD, флэш-память и т.п.). Также можно применять другие типы распространения, такие как загрузка из сети Интернет.
[095] Хотя некоторые примеры реализации описаны и представлены на прилагаемых рисунках, следует понимать, что такие варианты реализации являются лишь иллюстрирующими, но не ограничивающими, и что настоящее описание не ограничено конкретными показанными и описанными схемами и комбинациями, поскольку обычному специалисту в данной области после изучения настоящего описания будут очевидны и различные другие модификации. В подобной технологической области, где рост происходит быстро, и дальнейшие улучшения предвидеть непросто, описанные варианты реализации можно легко подвергать модификациям или перегруппировке по одной или более особенностям, чему будут способствовать технологические достижения, и это не будет считаться отклонением от принципов настоящего описания.
[096] Варианты реализации объекта изобретения и операций, изложенных в настоящем описании, могут быть реализованы в цифровой электронной схеме, компьютерном программном обеспечении, встроенном программном обеспечении или аппаратном обеспечении, включая структуры, изложенные в настоящем описании, а также их структурные эквиваленты, или в комбинации одного или более из них. Варианты реализации объекта изобретения, изложенные в настоящем описании, могут быть реализованы в виде одной или более компьютерных программ, т.е. одного или более модулей с инструкциями компьютерной программы, закодированных на одном или более компьютерных носителях данных для исполнения на устройстве для обработки данных или для управления работой такого аппарата. Альтернативно или дополнительно программные инструкции могут быть закодированы в искусственном сгенерированном распространяющемся сигнале, например, машиногенерируемом электрическом, оптическом или электромагнитном сигнале, который генерируется для кодирования информации с целью ее передачи в подходящий аппарат приема для исполнения аппаратом для обработки данных. Компьютерный носитель данных может представлять собой или может входить в состав машиночитаемого устройства хранения, машиночитаемого субстрата хранения, массива или устройства памяти со случайным или последовательным доступом или комбинации одного или более из них. Более того, хотя компьютерный носитель данных не является распространяемым сигналом, компьютерный носитель данных может быть источником или пунктом назначения для инструкций компьютерной программы, закодированных в искусственно сгенерированном распространяемом сигнале. Компьютерный носитель данных также может представлять собой или может входить в состав одного или более компонентов или носителей (например, множества CD, дисков или иных устройств хранения). Соответственно, компьютерный носитель данных может быть вещественным и не носящим временного характера.
[097] Операции, изложенные в настоящем описании, могут быть реализованы в виде операций, выполняемых устройством для обработки данных, применительно к данным, хранящимся на одном или более машиночитаемых устройствах хранения или полученных из других источников.
[098] Термин «клиент» или «сервер» включает различные аппараты, устройства и машины для обработки данных, включая, в качестве примера, программируемый процессор, компьютер, систему на микросхеме или множество вышеописанных устройств или их комбинаций. Аппарат может включать в себя логическую схему особого назначения, например ППВМ (программируемая пользователем вентильная матрица) или СИС (специализированная интегральная схема). Аппарат также может включать, в дополнение к аппаратному обеспечению, код, создающий среду для выполнения необходимой компьютерной программы, например, код, представляющий встроенное программное обеспечение процессора, стек протоколов, систему управления базами данных, операционную систему, межплатформенную среду исполнения, виртуальную машину или комбинацию одной или более из них. В аппарате и среде исполнения могут быть реализованы различные инфраструктуры модели вычисления, такие как веб-службы, инфраструктура распределенных и сетевых распределенных вычислений.
[099] Компьютерная программа (также именуемая программой, программным обеспечением, программным приложением, скриптом или кодом) может быть написана на любой форме языка программирования, включая компилируемые или интерпретируемые языки, декларативные или процедурные языки, и может быть установлена в любой форме, включая в виде автономной программы или в виде модуля, компонента, подпрограммы, объекта или любой другой единицы, подходящей для использования в вычислительной среде. Компьютерная программа может, но не должна, соответствовать файлу в файловой системе. Программа может храниться в части файла, в котором хранятся другие программы или данные (например, один или более скриптов, хранящихся в документе на языке разметки), в отдельном файле, предназначенном для требуемой программы, или во множестве скоординированных файлов (например, в файлах, хранящих один или более модулей, подпрограмм или частей кода). Компьютерная программа может быть исполнена на одном компьютере или на множестве компьютеров, расположенных в одном месте или распределенных по множеству мест и взаимосвязанных сетью передачи данных.
[0100] Процессы и логические схемы, изложенные в настоящем описании, могут исполняться одним или более программируемыми процессорами, исполняющими одну или более компьютерных программ для выполнения действий путем работы с входными данными и создания выходных данных. Процессы и логические схемы также могут выполняться при помощи логической схемы особого назначения, и аппарат может быть реализован в виде логической схемы особого назначения, например, ППВМ (программируемой пользователем вентильной матрицы) или СИС (специализированной интегральной схемы).
[0101] К процессорам, подходящим для исполнения компьютерной программы, относятся, для примера, микропроцессоры общего и особого назначения и один или более процессоров цифрового компьютера любого типа. Как правило, процессор принимает инструкции и данные из постоянного запоминающего устройства, оперативного запоминающего устройства или обоих. Важными элементами компьютера являются процессор для выполнения действий в соответствии с инструкциями и одно или более устройств памяти для хранения инструкций и данных. Как правило, компьютер также включает в себя или функционально связан с одним или более съемных запоминающих устройств для хранения данных, например магнитными, магнитооптическими или оптическими дисками, для приема с них данных, передачи на них данных или обоих. Однако наличие таких устройств в компьютере не обязательно. Более того, компьютер может быть встроен в другое устройство, например, мобильный телефон, карманный компьютер (PDA), мобильный аудио- или видеоплеер, игровую консоль или портативное устройство хранения (например, флэш-накопитель на основе универсальной последовательной шины (USB)). Устройства, подходящие для хранения инструкций компьютерной программы и данных, включают в себя все формы энергонезависимой памяти, носителей и устройств памяти, включая, для примера, полупроводниковые устройства памяти, например ЭППЗУ, ЭСППЗУ и устройства флэш-памяти; магнитные диски, например внутренние жесткие диски или съемные диски; магнитооптические диски; а также диски CD-ROM и DVD-ROM. Процессор и память могут быть оснащены или могут иметь встроенные логические схемы особого назначения.
[0102] Для обеспечения взаимодействия с пользователем варианты реализации объекта изобретения, изложенные в настоящем описании, могут быть реализованы на компьютере, имеющем устройство отображения, например, на основе ЭЛТ (электронной-лучевой трубки), ЖКД (жидкокристаллического дисплея), ОСД (органического светодиода), ТПТ (тонкопленочного транзистора), плазменной или другой гибкой конфигурации, или любой другой монитор для отображения информации для пользователя и клавиатуру, указательное устройство, например, мышь, трекбол и т.п., или сенсорный экран, тачпад и т.п., при помощи которого пользователь может вводить информацию в компьютер. Для взаимодействия с пользователем также могут использоваться другие типы устройств. Например, обратная связь, предоставляемая пользователю, может иметь любую осязаемую форму, например, визуальная обратная связь, слуховая обратная связь или тактильная обратная связь, а также вводимая пользователем информация может получаться в любой форме, включая в виде акустического, речевого или тактильного ввода. Кроме того, компьютер может взаимодействовать с пользователем путем отправки документов и приема документов от устройства, используемого пользователем. Например, путем отправки веб-страниц веб-браузеру на клиентском устройстве пользователя в ответ на запросы, получаемые от веб-браузера.
[0103] Варианты реализации объекта изобретения, изложенные в настоящем описании, могут быть реализованы в компьютерной системе, которая включает дополнительный компонент, например сервер данных, или которая включает компонент промежуточного программного обеспечения, например сервер приложений, или которая включает компонент предварительной обработки данных, например клиентский компьютер с графическим интерфейсом пользователя или веб-браузер, с помощью которого пользователь может взаимодействовать с вариантом реализации объекта изобретения, изложенным в настоящем описании, или любую комбинацию одного или более таких дополнительных, промежуточных компонентов или компонентов предварительной обработки данных. Компоненты системы могут быть взаимосвязаны любой формой или средой для цифровой передачи данных, например, сетью передачи данных. Примеры сетей передачи данных включают в себя локальную сеть (LAN), глобальную сеть (WAN), объединенную сеть (например, Интернет) и одноранговые сети (например, специальные одноранговые сети).
[0104] Хотя данное описание содержит много конкретных аспектов реализации, их не следует расценивать как ограничения сферы действия любых изобретений и пунктов формулы изобретения, но следует считать описаниями особенностей, которые являются специфичными для конкретных вариантов реализации конкретных изобретений. Некоторые особенности, изложенные в настоящем описании в контексте отдельных вариантов реализации, также могут быть реализованы в комбинации в одном варианте реализации. Напротив, различные особенности, описанные в контексте одного варианта реализации, также могут быть реализованы во множество вариантов реализации по отдельности или в любой подходящей подкомбинации. Более того, хотя особенности могут быть описаны выше как работающие в некоторых комбинациях или даже исходно заявляемые в таковом качестве, одна или более особенностей из заявленной комбинации могут в некоторых случаях быть извлечены из комбинации, а заявленная комбинация может быть направлена на подкомбинацию или вариант подкомбинации.
[0105] Аналогично, хотя операции на рисунках представлены в конкретном порядке, не следует считать, что такие операции должны выполняться в данном конкретном показанном порядке, в последовательном порядке, или что для достижения желаемых результатов требуется выполнить все представленные операции. В некоторых обстоятельствах благоприятной является многозадачная и параллельная обработка. Более того, разделение различных компонентов системы в вышеописанных вариантах реализации не следует считать обязательным для всех вариантов реализации, а следует считать, что описанные программные компоненты и системы могут быть по существу интегрированы вместе в один программный продукт или могут входить в пакеты множества программных продуктов.
[0106] Таким образом, описаны конкретные варианты реализации объекта изобретения. Другие варианты реализации входят в сферу действия приведенной ниже формулы изобретения. В некоторых случаях действия, перечисленные в пунктах формулы изобретения, могут выполняться в другом порядке и при этом достигать желаемых результатов. Кроме того, для достижения желаемых результатов процессы, показанные на прилагаемых рисунках, не обязательно должны выполняться в показанном конкретном порядке или в последовательном порядке. В некоторых вариантах реализации можно использовать многозадачность или параллельную обработку.








Изобретение относится к компьютерной технике, а именно к анализу текстов. Технический результат - эффективная обработка новых слов, отсутствующих в используемом реестре значений, добавление этих понятий в реестр значений и использование их во время дальнейшего анализа. Способ выявления семантического значения неизвестного слова в задачах автоматической обработки естественного языка, содержащий: получение вычислительным устройством неизвестного слова; определение процессором вычислительного устройства множества потенциальных семантических классов для назначения неизвестному слову; построение процессором с использованием корпусов текстов классификатора для неизвестного слова; классификацию неизвестного слова, основанную, по меньшей мере частично, на встроенном классификаторе, с помощью по меньшей мере одного семантического класса из множества потенциальных семантических классов; и добавление неизвестного слова в семантическую иерархию в качестве экземпляра по меньшей мере одного семантического класса. 3 н. и 18 з.п. ф-лы, 18 ил.
1. Способ выявления семантического значения неизвестного слова в задачах автоматической обработки естественного языка, содержащий:
получение вычислительным устройством неизвестного слова;
определение процессором вычислительного устройства множества потенциальных семантических классов для назначения неизвестному слову;
построение процессором с использованием корпусов текстов классификатора для неизвестного слова;
классификацию неизвестного слова, основанную, по меньшей мере частично, на встроенном классификаторе, с помощью по меньшей мере одного семантического класса из множества потенциальных семантических классов; и
добавление неизвестного слова в семантическую иерархию в качестве экземпляра по меньшей мере одного семантического класса.
2. Способ по п. 1, дополнительно содержащий упорядочение множества потенциальных семантических классов в соответствии с вероятностью того, что неизвестное слово должно быть классифицировано к каждому из множества потенциальных семантических классов.
3. Способ по п. 1, дополнительно содержащий формирование гипотезы о том, что неизвестное слово является экземпляром потенциального семантического класса из числа упорядоченных потенциальных семантических классов, причем классификация неизвестного слова содержит проверку гипотезы путем статистического анализа корпусов текстов.
4. Способ по п. 3, в котором гипотеза проверяется в отношении упорядоченных потенциальных семантических классов в порядке от наиболее вероятного потенциального семантического класса до наименее вероятного потенциального семантического класса, причем гипотеза проверяется до тех пор, пока она не будет принята.
5. Способ по п. 2, дополнительно содержащий выбор подмножества из всех семантических классов семантической иерархии, причем множество потенциальных семантических классов содержит такое подмножество.
6. Способ по п. 5, в котором подмножество семантических классов заранее определено.
7. Способ по п. 5, дополнительно содержащий выявление подмножества семантических классов в качестве оптимального подмножества на основе статистического анализа.
8. Система для выявления семантического значения неизвестного слова в задачах автоматической обработки естественного языка, содержащая:
один или более процессоров данных; и
одно или более устройств хранения, хранящих инструкции, которые, будучи исполненными одним или более процессорами данных, воздействуют на один или более процессоров данных для выполнения операций, содержащих:
получение вычислительным устройством неизвестного слова;
определение процессором вычислительного устройства множества потенциальных семантических классов для назначения неизвестному слову;
построение процессором с использованием корпусов текстов классификатора для неизвестного слова;
классификацию неизвестного слова, основанную, по меньшей мере частично, на встроенном классификаторе, с помощью по меньшей мере одного семантического класса из множества потенциальных семантических классов; и
добавление неизвестного слова в семантическую иерархию в качестве экземпляра по меньшей мере одного семантического класса.
9. Система по п. 8, дополнительно содержащая упорядочение множества потенциальных семантических классов в соответствии с вероятностью того, что неизвестное слово должно быть классифицировано к каждому из множества потенциальных семантических классов.
10. Система по п. 8, в которой операции дополнительно содержат формирование гипотезы о том, что неизвестное слово является экземпляром потенциального семантического класса из упорядоченных потенциальных семантических классов, причем классификация неизвестного слова содержит проверку гипотезы путем статистического анализа корпусов текстов.
11. Система по п. 10, в которой гипотеза проверяется в отношении упорядоченных потенциальных семантических классов в порядке от наиболее вероятного потенциального семантического класса до наименее вероятного потенциального семантического класса, причем гипотеза проверяется до тех пор, пока она не будет принята.
12. Система по п. 9, в которой операции дополнительно содержат выбор подмножества из всех семантических классов семантической иерархии, причем множество потенциальных семантических классов содержит такое подмножество.
13. Система по п. 12, в которой подмножество семантических классов заранее определено.
14. Система по п. 12, в которой операции дополнительно содержат выявление подмножества семантических классов в качестве оптимального подмножества на основе статистического анализа.
15. Машиночитаемый носитель данных, имеющий хранящиеся на нем машинные инструкции, причем процессор исполняет инструкции для выполнения операций по выявлению семантического значения неизвестного слова в задачах автоматической обработки естественного языка, содержащих:
получение вычислительным устройством неизвестного слова;
определение процессором вычислительного устройства множества потенциальных семантических классов для назначения неизвестному слову;
построение процессором с использованием корпусов текстов классификатора для неизвестного слова;
классификацию неизвестного слова, основанную по меньшей мере частично, на встроенном классификаторе, с помощью по меньшей мере одного семантического класса из множества потенциальных семантических классов; и
добавление неизвестного слова в семантическую иерархию в качестве экземпляра по меньшей мере одного семантического класса.
16. Машиночитаемый носитель данных по п. 15, в котором операции дополнительно содержат упорядочение множества потенциальных семантических классов в соответствии с вероятностью того, что неизвестное слово должно быть классифицировано к каждому из множества потенциальных семантических классов.
17. Машиночитаемый носитель данных по п. 15, в котором операции дополнительно содержат формирование гипотезы о том, что неизвестное слово является экземпляром потенциального семантического класса из упорядоченных потенциальных семантических классов, причем классификация неизвестного слова содержит проверку гипотезы путем статистического анализа корпусов текстов.
18. Машиночитаемый носитель данных по п. 17, в котором гипотеза проверяется в отношении упорядоченных потенциальных семантических классов в порядке от наиболее вероятного потенциального семантического класса до наименее вероятного потенциального семантического класса, и причем гипотеза проверяется до тех пор, пока она не будет принята.
19. Машиночитаемый носитель данных по п. 16, в котором операции дополнительно содержат выбор подмножества из всех семантических классов семантической иерархии, причем множество потенциальных семантических классов содержит такое подмножество.
20. Машиночитаемый носитель данных по п. 19, в котором подмножество семантических классов заранее определено.
21. Машиночитаемый носитель данных по п. 19, в котором операции дополнительно содержат выявление подмножества семантических классов в качестве оптимального подмножества на основе статистического анализа.
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| CN 102902665 A, 30.01.2013. | |||

