ПРЕДПОСЫЛКИ СОЗДАНИЯ ИЗОБРЕТЕНИЯ
[0001] Известны два общих подхода к работе с документами в различных форматах в процессе разработки систем обработки естественного языка (NLP), например, при машинном переводе. Первый подход основан на интеграции с приложениями, использующими различные форматы. При таком подходе внешние программы (например, Internet Explorer и Microsoft Word) и их API (интерфейсы прикладного программирования), которые включают коллекцию стандартных процедур (функций и методов), используются при разработке прикладного программного обеспечения для работы с данными, имеющими конкретные форматы. API определяет некий уровень абстракции, который позволяет работать с семейством родственных форматов, поддерживаемых одним приложением. В этом случае можно использовать конкретное приложение или библиотеку для работы с конкретным форматом. Например, если необходимо поддерживать формат *.DOC, то можно использовать Microsoft Word™. Microsoft Word™ предоставляет программный интерфейс, поэтому программное обеспечение может читать документы Microsoft Word™ и вносить изменения в них. Однако он не позволяет преобразовать исходные тексты из формата одного редактора в формат другого редактора.
[0002] Этому первому подходу присущи по меньшей мере следующие недостатки:
- невозможность использовать его для любого формата и любого приложения;
- ему требуется внешнее «родное» приложение;
- обработка в автоматическом режиме, например, на сервере, затруднена или невозможна;
- затруднено или невозможно добавление дополнительных функций в редактор, например, динамическое выделение вариантов переводов в системе машинного перевода, и
- преобразование в другой формат невозможно или ограничено различными поддерживаемыми форматами.
[0003] Другое ограничение первого подхода заключается в том, что если исходный формат, например, формат PDF, невозможно редактировать, то пользователь или система не могут что-либо добавить в документ или что-либо изменить в нем.
[0004] Можно не использовать внешнее приложение, если собственная библиотека способна работать с конкретным форматом. Однако для этого должна быть доступна спецификация формата. Поддержка возможности редактирования с сохранением данных является очень трудоемкой. Общий недостаток этого подхода состоит в том, что для каждого формата необходимо индивидуальное решение. Это неудобно как для разработчика, так и для конечного пользователя.
[0005] Другой подход заключается в представлении первичных документов в виде текста, содержащего теги. Такой подход используется в формате XLIFF. Этот подход также используется при разработке продуктов NLP. При нем документы различных форматов преобразуются в единое представление в виде размеченного тегами текста. Состав и содержание тегов определяются исходным форматом документа. Теги содержат данные, требуемые для восстановления документа. Теги могут содержать данные форматирования или структурирования данных. Некоторые теги невозможно изменить, однако другие теги можно редактировать вместе с текстом, который соответствует этому тегу. Обычно изменение производится в полуавтоматическом режиме. Пользователь вручную отслеживает и корректирует содержащий теги текст. По сравнению с предыдущим подходом преимущество состоит в том, что это решение является единым для всех форматов. Один из недостатков заключается в том, что возможности редактирования документа существенно ограничены. Автоматическое изменение является трудоемким, а ручное исправление текста неудобно.
[0006] Примером такого формата является формат XLIFF (https://www.oasis-open.org/committees/xlin7faq.php#WhatIsXLIFF). XLIFF представляет собой открытый стандарт описания документов (с использованием XML). Однако проблема преобразования из одного конкретного формата в другой конкретный формат им не решается. Также стандарт XLIFF не обеспечивает возможность отображения и редактирования документов в режиме WYSIWYG (режиме полного соответствия вывода на экран и при печати). Таким образом, можно отметить как минимум следующие индивидуальные и общие недостатки второго подхода:
- недостаточный выбор инструментов редактирования, отсутствие режима WYSIWYG;
- в некоторых случаях документ невозможно преобразовать в другой формат;
- подход хорошо подходит для форматов, в которых используются теги (например, HTML или XML), но малопригоден для двоичных форматов, таких как формат DOC.
[0007] Для открывания и сохранения файлов в различных форматах можно использовать такие текстовые редакторы, как Microsoft Office™ или OpenOffice™.
[0008] Каждое приложение для редактирования поддерживает один конкретный тип документа. Например, если в качестве «type» (типа) выступает «text document)) (текстовый документ), то используются форматы Microsoft Word™, расширенный текстовый формат (rtf) и формат OpenDocument Text. Эти форматы поддерживаются различными приложениями, такими как Microsoft Word™, OpenOffice™ и AbiWord™. Некоторые приложения ограничиваются только возможностью открывать документы конкретных форматов. Например, невозможно открыть файлы презентации (Power Point) в приложении Microsoft Word™. Даже если документ одного и того же типа открывается различными приложениями для редактирования, то этот документ может отображаться по-разному. Например, элементы форматирования и элементы данных могут быть частично утрачены или искажены.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
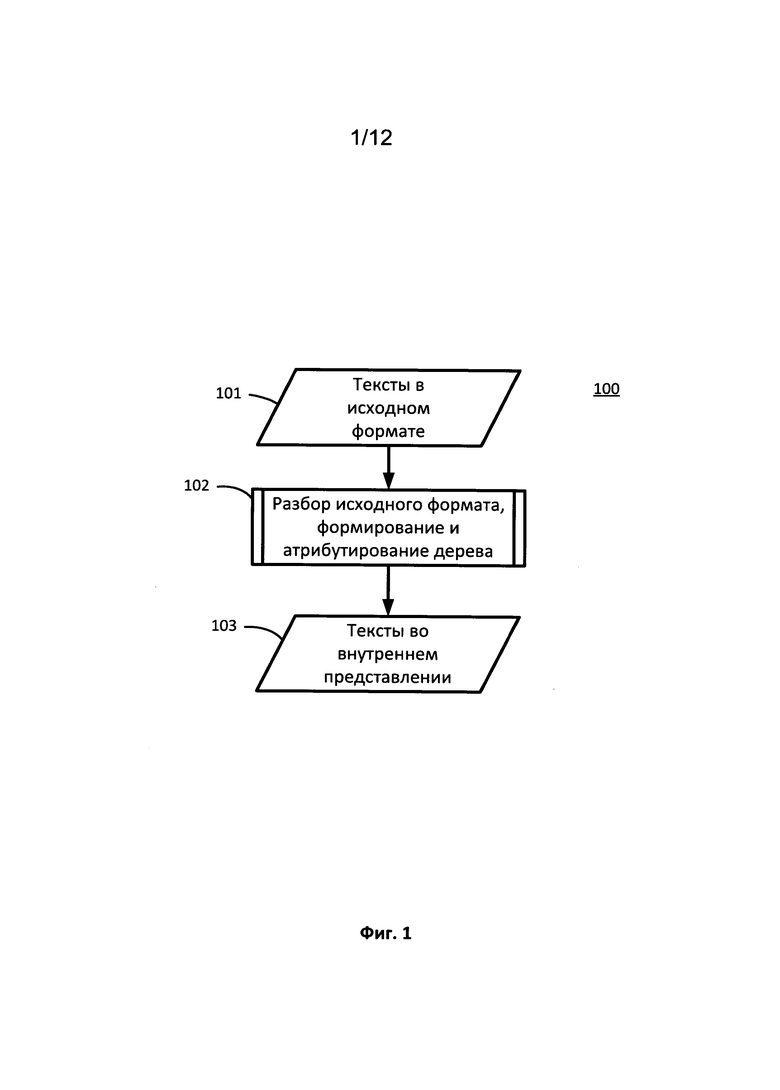
[0009] На Фиг. 1 приведена блок-схема последовательности операций для получения универсального представления текстов в любом формате.
[0010] На Фиг. 2 показана блок-схема последовательности операций, выполняющих дальнейшие действия с использованием текстового представления документа согласно одной из возможных реализаций изобретения.
[0011] На Фиг. 3A приведен пример исходного текста в веб-браузере.
[0012] На Фиг. 3В показаны объекты, выделяемые в тексте согласно одной из возможных реализаций изобретения.
[0013] На Фиг. 3С представлен исходный HTML-код, соответствующий этому тексту.
[0014] На Фиг. 4 приведено схематическое разбиение представленного на фигуре 3А текста на фрагменты, полученные при его импорте согласно одной из возможных реализаций изобретения.
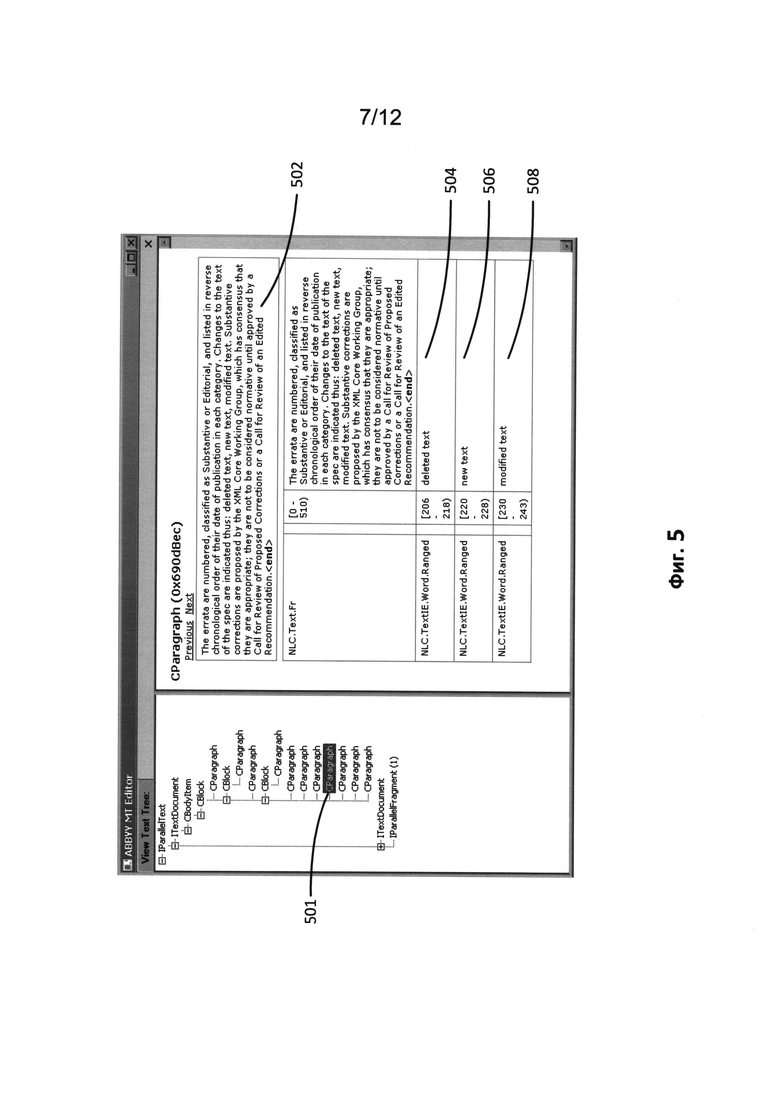
[0015] На Фиг. 5 показано текстовое представление документа в окне отладки текстовой подсистемы согласно одной из возможных реализаций изобретения.
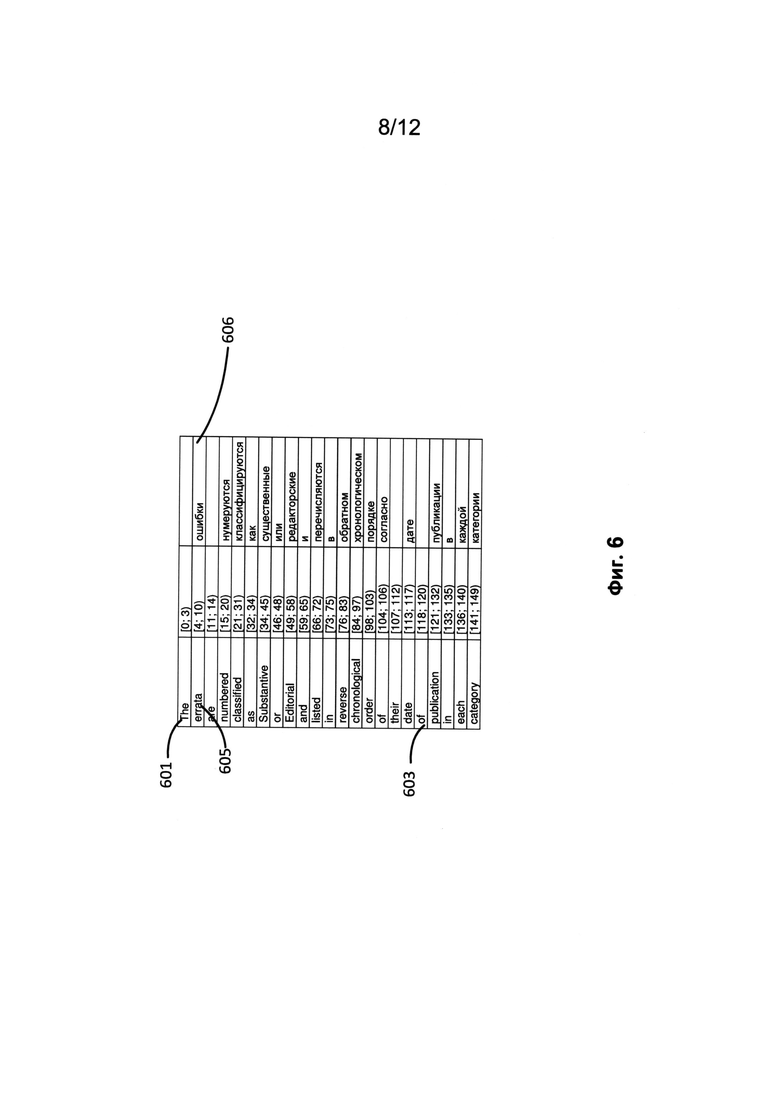
[0016] Фиг. 6 содержит пример таблицы переводов «текст→текст» согласно одной из возможных реализаций изобретения.
[0017] На Фиг. 7 показан пример интерфейса текстовой подсистемы, который позволяет пользователю видеть исходный текст и текст перевода на другой язык в двух одновременно открытых окнах согласно одной из возможных реализаций изобретения.
[0018] На Фиг. 8 приведен пример перевода исходного документа, представленного на Фиг. 3А, экспортированного в Internet Explorer точно в том же формате, что и исходный текст, согласно одной из возможных реализаций изобретения.
[0019] На Фиг. 9 показан пример HTML-кода перевода, приведенного на Фиг. 9, согласно одной из возможных реализаций изобретения.
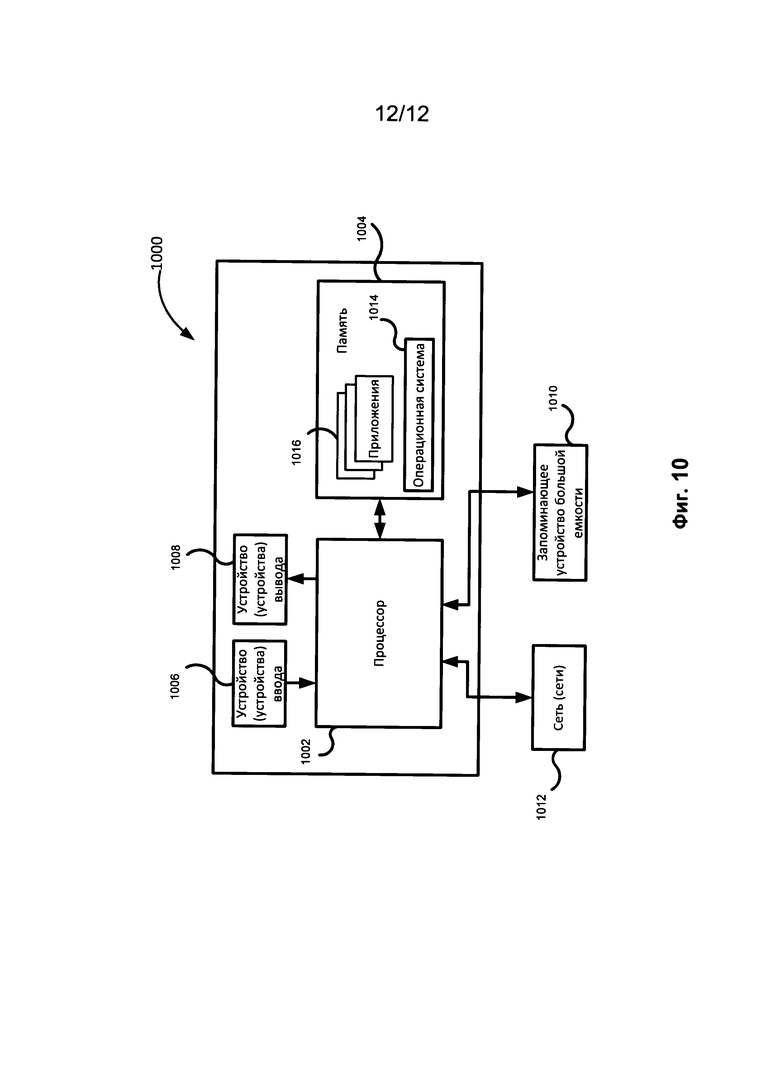
[0020] На Фиг. 10 показан пример вычислительного средства, которое можно использовать согласно одной из возможных реализаций изобретения.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[0021] Раскрываются системы, машиночитаемые носители данных и методы представления текста. Содержащий текст документ получают в первом формате. Универсальное текстовое представление документа создается с использованием первого фильтра, связанного с первым форматом. Универсальное текстовое представление отображает текст и поддерживаемые нетекстовые данные, оно сохраняет неподдерживаемые данные с привязкой к поддерживаемым данным. Текст в универсальном текстовом представлении может модифицироваться пользователем при помощи программы в режиме WYSIWYG (в режиме полного соответствия вывода на экран и при печати). Измененное универсальное текстовое представление может экспортироваться с помощью второго фильтра, связанного со вторым форматом, при этом экспортируются поддерживаемые и неподдерживаемые нетекстовые данные. Технический результат состоит в получении возможности интеграции разных приложений для обработки текста на основе унификации представления текстовой информации, включая также информацию о структуре, формате и оформлении документа (шрифты, форматирование и т.п.), за счет того, что универсальное текстовое представление представляет текст и поддерживаемые нетекстовые данные и сохраняет неподдерживаемые данные с привязкой к поддерживаемым данным.
ПОДРОБНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
[0022] В настоящем документе приведено описание систем и способов универсального представления документов, которые пригодны для использования в различных редакторах и в прикладном программном обеспечении, особенно если это представление необходимо изменять, например, если его требуется перевести на другой язык. Документы, например, файлы, содержащиеся в запоминающем устройстве, могут содержать текстовые данные, а также нетекстовые данные. В некоторых вариантах осуществления универсальное представление обеспечивается путем создания и поддержки соответствующего представления текстовых данных и нетекстовых данных для всех форматов, которые поддерживают исходные данные при редактировании, но свободны от некоторых или всех указанных выше недостатков. Эти варианты осуществления мот представлять собой текстовую подсистему - инструмент, предназначенный для хранения текстовых данных. Универсальное представление пригодно для хранения, редактирования и восстановления данных из любого текстового формата, форматирования текста и любых атрибутов, характеризующих этот текст.
[0023] Текстовые данные могут представлять текстовые документы в различных форматах. Формат является бинарным представлением текстовых данных и нетекстовых данных. Например, форматы html, docx и xls являются примерами бинарных форматов. Необычными возможными примерами являются и исполняемые файлы (ехе) и файлы ресурсов (rc). Редактор позволяет отредактировать и экспортировать эти документы в исходном формате, сохраняя все данные. Возможно автоматизированное редактирование,
а также ручное редактирование в WYSIWYG-редакторе. Варианты осуществления допускают анализ и изменение документов в различных форматах без потери данных. С этой проблемой сталкиваются программы машинного перевода.
[0024] В одном варианте осуществления текстовый документ в специальном формате можно преобразовать в универсальное текстовое представление документа. Универсальное текстовое представление представляет собой модель данных. Модель определяет способ представления документа включая его текстовые и нетекстовые данные, а также способы редактирования и изменения этих данных. Упомянутая текстовая подсистема и ее интерфейс ITextDocument являются примером реализации такой модели. В этом варианте осуществления текст (текстовые данные) рассматривается как простая строка символов. Нетекстовые данные представляют собой другие данные, которые могут быть связаны с текстом. В другом случае нетекстовые данные не относятся к тексту. Примерами нетекстовых данных являются элементы форматирования, структуры, изображения и т.д. В случае исполняемых файлов код представляет собой нетекстовые данные. Нетекстовые данные могут поддерживаться текстовой подсистемой, если они определены в универсальном текстовом представлении. Например, текстовая подсистема поддерживает основные свойства форматирования, стили, таблицы, списки, гиперссылки в тексте и т.д. Неподдерживаемые данные представляют собой данные, которые не определены в универсальном текстовом представлении, например, это более сложные свойства форматирования (например, тип подчеркивания), обновляемые поля, формулы электронных таблиц и т.д.
[0025] Для преобразования исходного документа в универсальное представление текстового документа можно использовать фильтры. Фильтр формата представляет собой инструмент преобразования документа в формат универсального представления документа и обратно. Например, фильтр может проанализировать исходный документ и создать соответствующие элементы универсального представления текстового документа. Кроме того, фильтры могут перевести универсальное представление в различные форматы. Соответственно, поддержка нового формата файлов может обеспечиваться путем создания фильтра, поддерживающего новый формат файла. При универсальном представлении текстового документа можно использовать внешние приложения, такие как анализаторы формата. В одном варианте осуществления документ может быть структурирован в виде дерева. Элементы текстового документа в универсальном представлении могут включать элементы и соответствующие атрибуты. Примеры элементов могут включать следующее:
- элементы структуры: таблицы, списки и абзацы;
- элементы форматирования: абзацы, таблицы, символы, поддержка иерархии стилей и
- элементы текстовых объектов: гиперссылки, закладки и рисунки.
[0026] Для поддержки всех данных в исходном документе данные преобразуются в соответствующие элементы универсального представления текстового документа. Универсальное представление может содержать стандартные элементы, поддерживаемые всеми фильтрами. Для тех данных, для которых отсутствует однозначное соответствие со стандартными элементами, и для которых атрибуты универсального представления не могут быть установлены, могут использоваться произвольные атрибуты. Эти атрибуты содержат произвольные данные и связаны с подходящими стандартными элементами, такими как весь документ, структурные элементы, диапазон текста или стиль. Фильтр специального формата может определить произвольные атрибуты.
[0027] При редактировании документа и пользователь, и программа-переводчик могут вносить изменения и работать только со стандартными элементами. Нестандартные атрибуты остаются невидимыми. Так как редактируются только стандартные элементы, целостность документа поддерживается автоматически. При экспорте в исходный формат с использованием соответствующего исходному формату фильтра все данные (стандартные и нестандартные) распознаются и восстанавливаются с помощью фильтра.
[0028] В ходе редактирования могут возникнуть проблемы относительно ассоциативности данного атрибута. Например, при переводе фразы, которой был присвоен атрибут, одна фраза в тексте перевода может быть разбита на две фразы в разных местах текста. Если такое происходит, то атрибут может быть привязан к обоим диапазонам или только к первому, чтобы показать, как эту фразу можно разбить на две фразы. Желаемое поведение зависит от того, какие данные и какого формата представляет этот атрибут. Подобное поведение может произойти при привязке атрибута.
[0029] Преимущество описываемых вариантов осуществления заключается в том, что для просмотра и редактирования всех поддерживаемых форматов можно использовать один общий редактор. Кроме того, этот общий редактор может поддерживать режим WYSIWYG. Также можно обеспечить преобразование между различными поддерживаемыми форматами, используя стандартный набор элементов и атрибутов.
[0030] В различных вариантах осуществления документ переводится из исходного формата в универсальное представление. Текстовые документы могут храниться в различных форматах, таких как формат HTML, Microsoft Word™, PowerPoint™, InDesign™ и т.д. В соответствии с различными вариантами осуществления текстовые документы, хранящиеся в различных исходных форматах, могут быть преобразованы в универсальное представление. Универсальное представление документа включает текстовую информацию, форматирование и структуры данных: списки, таблицы, стили, иллюстрации и т.д. Эти элементы могут быть изменены в рамках универсального представления, например, возможно изменение текста, форматирования и структур. Такое изменение может производиться автоматически с помощью программного обеспечения или пользователем с помощью WYSIWYG-редактора.
[0031] После изменения универсального представления его можно экспортировать в исходный формат или в другие форматы. В связи с большим разнообразием исходных форматов исходный документ может включать данные, которые непосредственно не поддерживаются редактором или заданными элементами универсального представления текста.. Например, могут не поддерживаться дополнительные свойства форматирования, такие как сложное подчеркивание, таблицы и списки, структура заголовков, макросы, сложные текстовые поля, метаданные и т.д. Для воссоздания исходного документа из универсального представления эти данные могут сохраняться внутри универсального представления. Например, когда документ модифицируется и конвертируется, все дополнительные данные формата, такие как все ссылки на атрибуты исходного элемента, переносятся на соответствующий элемент в модифицированном документе.
[0032] Если универсальное представление документа не модифицировалось, то исходный документ может быть воссоздан из универсального представления. В одном варианте осуществления воссозданный документ выглядит точно так, как исходный документ.
Если документ модифицировался и воссоздан из универсального представления, то воссозданный документ выглядит так, как будто он был изменен своим «родным» приложением. Кроме того, универсальное представление может экспортироваться в любой поддерживаемый формат, такой как универсальный текстовый формат HTML или RTF. Однако обычно дополнительные данные, которые не поддерживаются конкретным форматом, будут утеряны. Например, если представление не поддерживает сложные списки Microsoft Word™, то такие сложные списки будут некорректно отображаться в таком представлении. И наоборот, списки, созданные во внешнем редакторе, будет выглядеть иначе в Microsoft Word™. Дополнительный пример: двойное подчеркивание может превратиться в одинарное подчеркивание; вместо текущего поля даты используется текст даты во время сохранения исходного документа, а ключевые слова, сноски и комментарии могут быть отброшены. Однако если универсальное представление экспортируется в исходном формате, то эти атрибуты могут сохраняться во время импорта, а затем восстанавливаться при экспорте в том же формате.
[0033] Различные варианты осуществления включают по меньшей мере следующие возможности:
1. Универсальный текстовый процессор.
2. Программно доступное универсальное представление.
3. WYSIWYG-редактор.
4. Документ может быть изменен с сохранением неподдерживаемых данных.
5. Преобразование универсального представления в различные форматы.
[0034] В то время как неподдерживаемые данные могут сохраняться в универсальном представлении, преобразование документа в форматы, отличные от исходного формата, может привести к потере данных в преобразованном документе. Например, невозможно преобразовать исходный формат RTF в формат HTML, не потеряв часть структуры и форматирования. Отмеченные выше особенности можно осуществить без необходимости доступа к исходному приложения, в котором документ был создан.
[0035] Универсальное представление может использоваться в системе машинного перевода. Другие системы, которые требуют обработки и модификации документов в документы в различные форматы, также могут использовать универсальное представление. Например,
- проверка, которая выделяет и исправляет ошибки, или
- предотвращение потери данных.
[0036] Другие области применения могут включать следующее:
- импорт, поиск и сравнение документов;
- только экспорт, генерация отчетов;
- программы просмотра/редактирования; и
- конверторы формата.
[0037] В одном варианте осуществления универсальное представление близко к общепринятому представлению, например, к модели DOM. Однако в дополнение к стандартным элементам и атрибутам (поддерживаемыми текстовым представлением, редактором и программами экспорта в «универсальный» формат), универсальное представление может содержать элементы и атрибуты, специфичные для конкретного формата. Как правило, такие данные, связанные с конкретным форматом, «распознаются» только теми программами, которые осуществляют экспорт в этот конкретный формат. В большинстве других случаев эти данные безвозвратно теряются при преобразовании в формат, отличающийся от исходного формата.
[0038] Элементы и атрибуты, специфичные для конкретного формата, связаны с соответствующими стандартными элементами документа в универсальном представлении. После изменения универсального представления данные и атрибуты остаются связанными с соответствующими элементами документа, даже если последние были заменены или модифицированы.
[0039] Поведение элементов в универсальном представлении может быть связано с элементами. Если текст изменяется, то поведение разных элементов, связанных с измененным текстом, может различаться. Необходимо решить, как должно обрабатываться поведение этих элементов. Например, определенный фрагмент текста (диапазон текста) может быть связан с определенным элементом, таким как гиперссылка. После перевода этот фрагмент может оказаться разбитым на две различные части. Должен ли элемент гиперссылки оставаться связанным с одним неразрывным фрагментом или необходимо создавать копию? Например, закладки являются уникальными, но гиперссылки не являются уникальными. Следовательно, гиперссылка может копироваться, а закладку копировать нельзя. Другой пример: диапазон текста можно вырезать и вставить в окно в другом документе. Элементы, связанные с вставленным текстом, также могут копироваться или не копироваться. Например, возможно копирование элементов, которые связанны с чертежом, однако связанные со сценариями элементы не должны копироваться. Обычно сценарии связаны с контекстом конкретного документа, поэтому они не должны копироваться в другой документ.
[0040] Элементы в универсальном представлении могут быть помечены «только для чтения», а возможности их изменения могут быть ограничены. Это может оказаться полезным при работе с определенными конкретными форматами. Например, если в настоящее время ведется работа с листом Excel™, то содержание этой таблицы находится в единой таблице (весь текст должен располагаться в единой таблице). Пользователь может редактировать текстовые ячейки, однако универсальное представление может показывать, что ячейки числового типа и таблица не могут быть изменены. В этом случае редактор универсального представления может запретить любые изменения этих элементов.
[0041] В некоторых вариантах осуществления можно сохранить идентификатор, показывающий местоположение элемента в исходном документе. Этот идентификатор можно сохранить в качестве специального атрибута, связанного с форматом элемента. Например, элемент «text range» (диапазон текста) может иметь идентификатор, который определяет расположение текстового диапазона в исходном документе. Элемент «text range» (диапазон текста) может содержать фактические данные диапазона текста. В другом варианте осуществления элемент «text range» (диапазон текста) не содержит фактические данные диапазона текста. В этом варианте осуществления данные из исходного документа могут храниться в элементе данных со связанным форматом. Используя идентификатор диапазона текста, данные диапазона текста могут быть получены из элемента данных исходного документа. Например, при работе с презентацией PowerPoint™ нет необходимости импортировать всю сложную структуру слайда. Вместо этого можно извлечь текстовую часть и расположение текста. Затем эти данные затем можно использовать для возвращения текста именно в то место, которое было указано в ходе экспорта после обработки или изменения.
[0042] Можно создать фильтры для извлечения данных, которые поддерживают большинство известных форматов, включая форматы Microsoft Office™ (бинарные и на основе XML), OpenOffice™, Adobe InDesign™, FrameMaker™, HTML, RTF и другие. Можно добавить поддержку новых форматов. Кроме того, можно добавить поддержку новых свойств в существующих форматах (например, поддержку верхних и нижних колонтитулов или текстовых полей).
[0043] В различных вариантах осуществления текстовая подсистема хранит документы в универсальном представлении, которое пригодно для хранения. Кроме того, текстовая подсистема может создавать документы в различных форматах с помощью универсального представления. Редактор для форматирования и редактирования универсального представления также может являться частью текстовой подсистемы.
[0044] На Фиг. 1 показана блок-схема операций (100) для получения универсального представления текстов в произвольном формате (101). Сначала исходный формат разбирается и создается дерево блоков (102). Например, в тексте производится поиск заголовков уровня 1, уровня 2 и т.д. При этом можно извлекать главы, абзацы, сноски и комментарии, ссылки, врезки, рисунки, таблицы, списки и т.д. Также можно извлекать ключевые слова верхнего уровня и нижнего уровня, нумерацию страниц и другие функции. Структура всего текста организована в виде текстового дерева. В качестве конкретного примера HTML-фильтр может создать узел дерева с одним или несколькими HTML-тегами. Например, каждый HTML-тег может использоваться для создания узла дерева. В другом примере документы для обработки слов можно разбить на разделы, абзацы и таблицы. В еще одном примере слайды из документа презентации можно использовать в качестве узлов первого уровня дерева. Узлы, расположенные под узлами первого уровня, могут содержать текст или текстовое поле (которое может содержать один или несколько абзацев) из слайдов. Такое дерево может содержать узлы различных типов, таких как перечисленные ниже, не ограничиваясь ими: корневой узел текстового потока, таблицу, ячейку, список, элемент списка, узел в общей форме (фрагмент текста) и т.д.
[0045] Текстовое дерево представляет собой дерево блоков. Блок является единицей логической структуры документа. Например, абзац или кадр может быть блоком. Однако в текстовой подсистеме блок является элементом, который сам своим размером и расположением определяет свои собственные размеры и размещение в документе, а также правила, согласно которым этот текст должен включаться в данный документ. Например, абзац может быть блоком. Блоки абзацев могут включаться в родительский блок. Родительский блок может иметь атрибуты, которые используются при размещении дочерних блоков. Например, абзац не имеет фиксированного размера. При отображении абзаца в редакторе размер и местоположение абзаца могут определяться элементами фиксированной разметки родителя. Рамки и таблицы являются иллюстрационными элементами фиксированной разметки в текстовой подсистеме. Элементы фиксированной разметки могут определять конкретные области в документе.
[0046] Блоки текстовой системы могут образовать дерево, описывающее порядок следования текста в документе и относительное размещение частей текста.
[0047] На Фиг. 3A приведен пример исходного текста в веб-браузере. На Фиг. 3B показаны извлеченные из текста объекты. Этот текст разобран на блоки (301, 302, 303, 304 и 305). Извлеченные объекты также содержать связи (311, 312, 313 и 314), выделенный текст (321 и 322) и перечеркнутый текст (331). Могут быть извлечены и другие объекты, которые не показаны. Например, можно извлекать полужирный текст, курсив и т.д. На Фиг. 3C показан исходный HTML-код, соответствующий этому тексту.
[0048] Любой блок в текстовой подсистеме может иметь атрибуты форматирования. Кроме того, текст внутри блока может иметь атрибуты форматирования. В одном варианте осуществления весь текст документа распределен по параграфам в дереве. Текстовое дерево может включать корневой блок текста, который содержит текст документа. Этот корневой блок текста может содержать блоки параграфов, каждый из которых содержит текст одного параграфа. Поэтому блока считается, что корневой блок текста содержит текст всего документа через текст внутри всех дочерних параграфов этого блока. В другом примере блок параграфа может содержать блоки предложений, фраз и/или слов. Текст блока параграфа можно извлекать из блоков текста предложения, фразы, и/или слова.
[0049] На Фиг. 4 показано схематическое разбиение текста, показанного на Фиг. 3 в блоках, полученных при импорте текста согласно одному из вариантов осуществления описываемой текстовой системы. Это схематическое представление не содержит свойства форматирования и не связывает атрибуты с диапазонами текста. Если деревья блоков не содержат фиксированных элементов разметки, то содержание дерева может быть записано в любом месте в документе в зависимости от формата назначения. Например, при записи текстового документа из исходного HTML-документа текст абзацев может выглядеть не абсолютно одинаково в текстовом документе и в исходном HTML-документе. Это является следствием того, что средство просмотра HTML-страниц изменит размер абзаца при визуализации HTML на основе содержимого HTML. Другими словами, отсутствует определенное положение в визуализированном HTML-документе, где должен располагаться текст. То же самое верно и для текстовой версии HTML-документа. Поэтому HTML-документ и текстовая версия HTML-документа будут содержать один и тот же текст, но он может быть отформатирован не абсолютно одинаково.
[0050] Текстовое дерево может иметь атрибуты, основанные на соответствующих признаках исходного документа. Кроме того, блоки могут также иметь атрибуты, основанные на исходном документе. Текстовое дерево сохраняет всю информацию из исходного формата, например, тип шрифта, стиль, жирность и размер. После завершения построения текстового дерева оно является внутренним представлением исходного документа (103 на Фиг. 1).
[0051] На Фиг. 5 показано текстовое представление документа в окне отладки текстовой подсистемы согласно одной из возможных реализаций изобретения. Извлеченный абзац (501) слева соответствует диапазону текста, который включает текст (502), расположенный в этом документе в диапазоне символов (0-510). Для каждого фрагмента текста с форматированием или с атрибутами, отличающимися от атрибутов всего фрагмента в целом, существует соответствующий диапазон символов. Например, диапазон символов [206-218] означает «удаленный текст» (504), диапазон символов [220-228] означает «новый текст» (506), а диапазон символов [230-243] указывает на «измененный текст» (508).
[0052] Текст во внутреннем представлении приложения представляет собой текстовое дерево, которое имеет существенные отличия по сравнению с представлением текста в формате HTML (XML). В текстовом дереве показаны древовидная структура HTML-тегов для разметки физической структуры (макета) и параграфов, в то время как все другие теги, например, теги форматирования, показаны в атрибутах текста, поэтому их можно восстановить после завершения обработки. Кроме того, не все теги исходных документов и не всех атрибуты отображаются в текстовом дереве. Поскольку варианты осуществления позволяют представить произвольный текстовый документ в любом внешнем формате в виде текстового дерева документа, постольку текстовое дерево может включать произвольные свойства. Эти произвольные свойства не должны отображаться в редакторе. Кроме того, пользователи могут создавать произвольные свойства в текстовом дереве. Любое приложение может создавать, добавлять и/или читать эти произвольные свойства. Например, программа-переводчик может создавать произвольные свойства.
[0053] Для отображения тегов и атрибутов текста в текстовом дереве имеется механизм "пользовательских объектов". Текстовое дерево может хранить все теги импортированного документа в виде набора пользовательских объектов, например, атрибутов. В одном варианте осуществления теги импортируемого документа обрабатываются следующим образом:
1) тег порождает пользовательский объект с полным описанием, которое включает, все атрибуты этого тега;
2) если имеется соответствующее описание тега и его атрибутов в текстовом дереве (например, в виде признаков форматирования или сущностей в виде картинок, ссылок и т.д.), то этот тег и его атрибуты отображаются указанным образом;
3) пользовательский объект связывается с узлом, порожденным этим тегом или связанным с содержащимся в теге текстом или, если текст отсутствует, то связанным со специально добавляемым символом, и
4) этот тег анализируется для определения наличия вспомогательного текста (например, сносок, всплывающих подсказок, вырезок и т.д.).
[0054] Форматирование является одним из наиболее заметных атрибутов текста. Форматирование представляет собой набор атрибутов, который обеспечивают особые признаки изображения символа текста (полужирный, курсив и т.д.) и маску, которая предоставляет атрибуты, указанные в форматировании. Стиль представляет собой именованное форматирование, он обладает рядом дополнительных свойств. Свойства стиля могут быть основаны на предках стиля. Полное форматирование стиля представляет собой сумму форматов стиля и всех его предков, оно имеет полную маску для атрибутов. Если форматы объединяются в стиль, то подчиненные атрибуты имеют приоритет над родительскими атрибутами.
[0055] Кроме символа, форматирование и/или стиль могут быть связаны с любым узлом в текстовом дереве. Форматирование плюс стиль в каждом узле обеспечивают полное форматирование данного узла. Однако полное форматирование символов в тексте состоит из суммы полного форматирования всех родительских узлов содержащего текст абзаца и собственного форматирования символов.
[0056] Различные варианты осуществления текстовой подсистемы могут обеспечивать такой механизм сериализации объектов-атрибутов текстового дерева, что при наличии нескольких ссылок на один и тот же объект из разных частей документа, после восстановления из текстового дерева объект будет так же один и тот же (не несколько совпадающих признаков, а именно точно такой же).
[0057] Дополнительные атрибуты, связанные с диапазоном текста, могут быть реализованы с помощью интерфейса ITextAttribute. Реализация этого интерфейса позволяет объекту атрибута управлять своим поведением при изменении текста, например, при вставке и переносе атрибутов с помощью шаблонов. Например, если атрибут вставляется в текст, текстовой подсистемой вызывается метод IsEqual вместе с его атрибутом, который имеет такое же название в текстовой подсистеме.. Если этот метод возвращает значение «true» (истина), то считается, что вставляется точно такой же атрибут, что и атрибут, присутствующий в настоящее время в тексте, и он полностью совпадает с атрибутом, который будет вставлен в рассматриваемый диапазон. Это позволяет вставлять объекты с одним и тем же именем из буфера обмена при наличии таких же объектов в тексте. Например, можно объединять атрибуты, связанные с атрибутами текста. В частности, два тега, которые относятся к диапазону символов, могут задавать цвет текста для этого диапазона. Если диапазоны символов расположены рядом друг с другом, то эти два тега могут быть объединены в единый тег, который охватывает объединенные диапазоны исходных тегов. Однако можно объединять не все тэги.
Например, связанные с изображениями теги невозможно объединять, поскольку два рисунка невозможно объединить, даже если они находятся рядом друг с другом.
[0058] Кроме того, интерфейс ITextAttribute позволяет определять поведение атрибута при операциях замены. Если в этом случае имеются атрибуты с одинаковыми названиями, но с разными значениями в заменяемом диапазоне, то текстовая подсистема запрашивает атрибут, который находится в пределах измененного текста, вызывая виртуальный метод ITextAttribute::GetReplaceValue. Когда они копируются, атрибуты с одинаковыми именами могут объединяться.
[0059] Кроме того, документ может быть модифицирован, в результате чего все атрибуты и свойства документа сохраняются в итоговом документе. Получение универсального представления текстового документа (например, (103) на Фиг. 1) может стать отправной точкой для нескольких сценариев работы с этим документом. На Фиг. 2 показана блок-схема последовательности дальнейших действий с использованием текстового представления документа согласно одной из возможных реализаций изобретения, если документ должен быть изменен, например, переведен на другой язык.
[0060] Например, можно создать копии документа, часть документа может быть извлечена в отдельный документ, несколько документов могут быть «склеены» в один документ или часть одного документа может быть « вклеена» в другой документ в виде врезки, сноски, комментария или иным образом. В одном из вариантов осуществления документ может быть переведен на другой язык с помощью системы машинного перевода или вручную. При этом необходимо, чтобы документ на другом языке имел аналогичное или такое же форматирование, как исходный документ, например, имел те же атрибуты, стили, форматирование, ссылки и гиперссылки.
[0061] Вернемся к Фиг. 2; на этапе (204) производится перевод документа. Для перевода можно использовать любую систему машинного перевода, которая вместе с переводом возвращает таблицу соответствия между переведенными словами. Поскольку фрагменты текста и диапазоны текста являются элементами дерева, их можно разделить на блоки текстового дерева и рассматривать их независимо друг от друга. В других вариантах осуществления может рассматриваться весь текст документа.
[0062] Кроме того, поскольку система машинного перевода может рекомендовать различные переводы слова или диапазона текста, то если выбраны определенные пользовательские режимы, система может предлагать создать таблицу переводов «текст→текст» (205), которая включает один или несколько вариантов перевода фрагментов (и слов) исходного текста. Таблица переводов «текст→текст» (205) также может использоваться как отправная точка для различных сценариев при дальнейшей работе с документом..
[0063] Чтобы создать документ с переводом на другой язык, на этапе 206 создается копия текстового дерева, и таблица переводов «текст→текст» (205) применяется к узлам этого дерева. На Фиг. 6 показан пример таблицы переводов «текст→текст» для параграфа, который начинается с предложения "The errata are numbered, classified as substantive or editorial and listed in reverse chronological order of their date of publication in each category." (Ошибки нумеруются, классифицируются как существенные или редакционные, а также составляется их список в обратном хронологическом порядке даты их опубликования в каждой категории.) Левая колонка таблицы содержит список слов исходного текста на исходном языке. Вторая колонка содержит диапазон символов, используемых в этом слове. Правая колонка содержит слово на целевом языке, которое должно заменить слово на исходном языке и которое должно быть вставлено вместо указанного набора символов. Некоторые слова в исходном (английском) языке, например, артикли (601), не имеют соответствия в языке перевода (русском языке). Предлог “of” (603) также часто не отражается в переводе предложения, поэтому места таких слов не заполняются, и правая колонка остается пустой. Если порядок слов меняется в процессе перевода, то в диапазон символов добавляется ссылка, которая заменяет это слово. Атрибуты и данные замененного слова присваиваются тому слову на целевом языке, которое заменяет исходное слово. Например, если слово «errata» (605) было набрано курсивом в этом предложении исходного документа, то слово, соответствующее ему в переводе «ошибки» (606), также будет иметь этот атрибут. При этом гарантируется, что переведенная версия документа будет иметь форматирование, которое напоминает форматирование исходного документа или совпадает с ним.
[0064] Внутреннее представление (207) нового документа в виде текстового дерева также может быть отправным пунктом для различных сценариев дальнейшей работы с документом. Чтобы создать документ с переводом без участия пользователя в автоматическом режиме, можно выбрать такие слова в новом языке, которые соответствуют словам и/или предложениям на исходном языке. Возможно, что некоторые слова и/или предложения на исходном языке могут переводиться разными словами и/или предложениями в новом языке. При учете таких элементов, как контекст предложения, некоторые слова и/или фразы обеспечат повышение качества перевода. Каждый вариант перевода может иметь оценку, которая отражает воспринимаемую правильность перевода. Вариант перевода с наилучшей оценкой может быть выбран для каждого слова и/или предложения текста.
[0065] В другом варианте осуществления пользователь имеет возможность выбирать в интерактивном режиме подходящий вариант перевода из нескольких возможностей для отдельных слов и/или фраз. Кроме того, пользователь может вручную изменить стиль или форматирование, или он может выполнять другие операции редактирования документа, такие как объединение или разделение абзацев, изменение нумерации частей текста, применение новой нумерацию страниц, переделка или добавление заголовков и т.д. Можно создать «окончательный» документ с переводом на другой язык, имеющий такой же формат и такой же макет, как исходный документ. Для этого итогового документа все атрибуты текстового дерева исходного текста передаются в текстовое дерево для нового документа.
[0066] Передача атрибутов между различными документами может быть затруднена. Например, если текст исходного документа набран полужирным шрифтом или курсивом, то соответствующий фрагмент в тексте перевода должен быть помечен этим атрибутом для сохранения форматирования. Связанные с текстом объекты (например, ссылки, гиперссылки, комментарии и т.д.) передаются в новый документ. Однако эталон атрибута может использоваться только в пределах одного документа, поэтому первый экземпляр исходного документа (206) имеет атрибуты, а затем перевод производится в пределах этой копии.
[0067] При работе с уникальными атрибутами необходимо учитывать некоторые особенности. Поскольку эти атрибуты не могут располагаться внутри более чем одного непрерывного диапазона текста, эталон атрибута не может использоваться до тех пор, пока старые атрибуты не будут удалены. В противном случае эти атрибуты не используются. Поэтому можно сначала создать эталон и найти перевод нужного фрагмента текста. После этого старый текст может быть удален вместе с его атрибутами, а затем перевод должен быть вставлен и его атрибуты должны быть изменены соответствующим образом. Например, вставленные атрибуты могут быть изменены на основании удаленных атрибутов.
[0068] В еще одном варианте осуществления текстовая подсистема включает поддержку двуязычного текста. Двуязычный текст включает два различных документа и обеспечивает связь между частями этих документов. В качестве соединительного механизма может использоваться параллельный фрагмент. Параллельный фрагмент представляет собой объект, который связывает соответствующий текст в обоих документах. Все фрагменты могут располагаться в линейном порядке. Таким образом, исходные документы могут рассматриваться как два параллельных текстовых потока, разделенные на последовательные парные части. Для любого фрагмента можно запросить фрагменты, расположенные до него и после него. Кроме того, параллельные фрагменты можно использовать для обозначения фрагментов в одном документе, которые соответствуют фрагментам во втором документе.
[0069] Двуязычный документ может представлять собой структуру данных, которая хранит два одноязычных документа и обеспечивает доступ к фрагментам этих документов. В свою очередь, эти фрагменты привязаны к текстовому представлению объектами, хранящими атрибуты и данные, которые отмечают фрагменты текста. Разметка начинается с создания начального фрагмента дерева, которое включает одноязычные документы. Затем этот фрагмент может быть разбит на более мелкие фрагменты. При создании документа он инициализируется с использованием пустых документов и разметки. При упорядочении двуязычного документа атрибуты, общие для обоих текстов, упорядочиваются как один атрибут. При этом после восстановления имеется один экземпляр в обоих текстах.
[0070] Текстовая подсистема может иметь интерфейс редактирования, позволяющий пользователю видеть в двух параллельно открытых окнах исходный текст и текст перевода на другом языке. Пример такого интерфейса приведен на Фиг. 7. Возвратимся к блок-схеме, показанной на Фиг. 2; перевод может редактироваться на этапе 208.
[0071] Затем новый документ можно экспортировать в исходный формат или в другой указанный формат (209). Перевод исходного документа, приведенного на Фиг. 3, показан на Фиг. 8 в точно таком же формате, что и исходный текст, а его HTML-код показан на Фиг. 9.
[0072] На Фиг. 10 приведен возможный пример вычислительного средства (1000), которое можно использовать для реализации описанных вариантов осуществления. Вычислительное средство (1000) содержит по меньшей мере один процессор (1002), подключенный к памяти (1004). Процессор (1002) может представлять собой один или несколько процессоров, он может содержать одно, два или больше вычислительных ядер. Память (1004) может представлять собой оперативную память (RAM), она может также содержать любые другие виды или виды памяти, прежде всего энергонезависимые запоминающие устройства (например, флэш-накопители) или постоянные запоминающие устройства, такие как накопители на жестких дисках и так далее. Кроме того, можно рассмотреть компоновку, в которой запоминающее устройство (1004) включает носители данных, которые физически расположены в другом месте внутри вычислительного средства (1000), такие как кэш-память в процессоре (1002), и память, используемую в качестве виртуальной памяти, расположенную во внешнем или внутреннем постоянном запоминающем устройстве (1010).
[0073] Обычно вычислительное средство (1000) также имеет определенное количество входных и выходных портов для передачи информации и приема информации. Для взаимодействия с пользователем вычислительное средство (1000) может использовать одно или несколько устройств ввода (например, клавиатуру, мышь, сканер и др.) и устройство отображения (1008) (например, жидкокристаллический дисплей). Вычислительное средство (1000) также может иметь одно или несколько постоянных запоминающих устройств (1010), таких как привод оптических дисков (формата CD, DVD или другого формата), накопитель на жестком диске и др. Кроме того, вычислительное средство (1000) может иметь интерфейс с одной или с несколькими сетями (1012), которые обеспечивают связь с другими сетями и компьютерным оборудованием. В частности, это может быть локальная сеть (LAN), беспроводная сеть Wi-Fi, которая может быть подключена к сети Интернет, а может быть не подключена к ней. Разумеется, вычислительное средство (1000) имеет соответствующие аналоговые и/или цифровые интерфейсы между процессором (1002) и каждым из компонентов (1004, 1006, 1008, 1010 и 1012).
[0074] Вычислительное средство (1000) управляется операционной системой (1014), оно содержит различные приложения, компоненты, программы, модули и другие объекты, совместно обозначенные числом 1016.
[0075] В целом программы, используемые для реализации раскрытых вариантов осуществления, могут быть частью операционной системы, либо они могут представлять собой специализированное приложение, компоненту, программу, динамически подключаемую библиотеку, модуль, сценарий или их сочетание.
[0076] Настоящее описание демонстрирует основной изобретательский замысел, который не может быть ограничен упомянутыми выше аппаратными средствами. Следует отметить, что аппаратные средства в первую очередь предназначены для решения узкой проблемы. С течением времени и по мере развития технологии такая задача становится более сложной или она развивается. Возникают новые инструменты, способные удовлетворять новым требованиям. В этом смысле уместно рассматривать аппаратные средства с точки зрения класса технических задач, которые они способны решать, а не просто как техническую реализацию на основе некоторых элементов.








Изобретение относится к методам представления текста. Технический результат состоит в получении возможности интеграции разных приложений для обработки текста на основе унификации представления текстовой информации, включая также информацию о структуре, формате и оформлении документа (шрифты, форматирование и т.п.). Для этого содержащий текст документ получают в первом формате. Универсальное текстовое представление документа создается с использованием первого фильтра, связанного с первым форматом. Универсальное текстовое представление отображает текст и поддерживаемые нетекстовые данные, оно сохраняет неподдерживаемые данные с привязкой к поддерживаемым данным. Универсальное текстовое представление изменяется на основании действий пользователя при помощи программы в режиме полного соответствия вывода на экран и при печати (режим WYSIWYG). Пользователь видит расположение поддерживаемых и неподдерживаемых данных. Затем модифицированное универсальное текстовое представление экспортируется с помощью второго фильтра, связанного со вторым форматом. Также экспортируются поддерживаемые и неподдерживаемые нетекстовые данные. 3 н. и 19 з.п. ф-лы, 12 ил.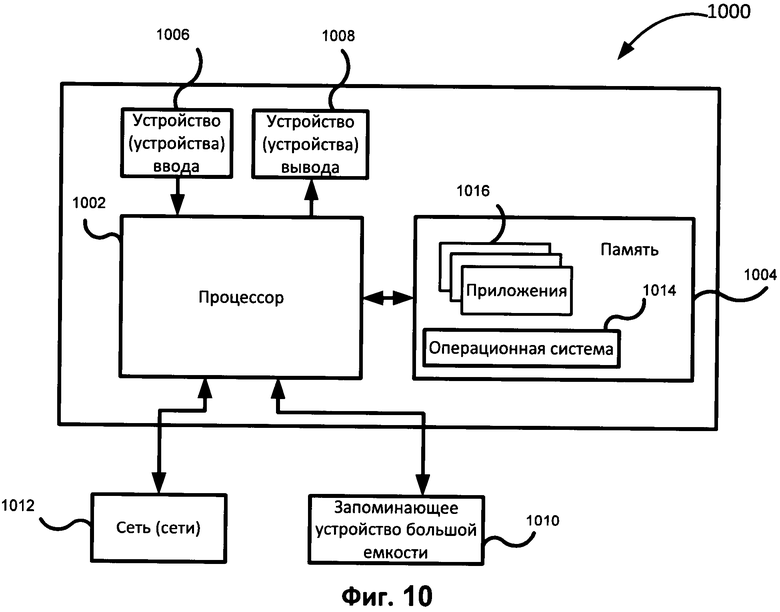
1. Реализуемый с помощью компьютера способ представления текста, который включает:
получение документа в первом формате, при этом этот документ содержит текст;
создание с использованием первого фильтра, связанного с первым форматом, универсального текстового представления документа, отличающегося тем, что это универсальное текстовое представление представляет текст и поддерживаемые нетекстовые данные и сохраняет неподдерживаемые данные с привязкой к поддерживаемым данным;
модификация универсального текстового представления, основанная на действиях пользователя с помощью программы, поддерживающей режим полного соответствия вывода на экран и при печати (режим WYSIWYG), так, что пользователь может видеть местоположение поддерживаемых данных и неподдерживаемых данных, и
экспорт, с использованием процессора, модифицированного универсального текстового представления с использованием второго фильтра, связанного со вторым форматом, при этом экспортируются как поддерживаемые, так и неподдерживаемые нетекстовые данные.
2. Способ по п. 1, отличающийся тем, что универсальное текстовое представление содержит текстовое дерево, причем это текстовое дерево имеет узлы, содержащие одно или несколько слов и месторасположение этих слов, и в котором один или несколько узлов содержат атрибуты, связанные с форматированием одного или нескольких слов.
3. Способ по п. 2, дополнительно содержащий:
определение текстовых диапазонов двух атрибутов узла, расположенных рядом друг с другом;
определение двух атрибутов, которые могут быть объединены, и объединение этих двух атрибутов в один атрибут, который охватывает текстовые диапазоны этих двух атрибутов.
4. Способ по п. 1, отличающийся тем, что первый формат совпадает со вторым форматом, и в котором первый фильтр совпадает со вторым фильтром.
5. Способ по п. 1, отличающийся тем, что первый формат отличается от второго формата, и в котором первый фильтр отличается от второго фильтра.
6. Способ по п. 5, отличающийся тем, что второй фильтр экспортирует все поддерживаемые данные.
7. Способ по п. 1, отличающийся тем, что привязка неподдерживаемых данных к поддерживаемым данным включает описание желаемого поведения неподдерживаемых данных.
8. Способ по п. 2, отличающийся тем, что изменение универсального текстового представления включает перевод текстовых данных, представленных в универсальном текстовом представлении, с первого языка на второй (другой) язык.
9. Способ по п. 8, в котором перевод текстовых данных дополнительно содержит
получение таблицы переводов, отличающейся тем, что таблица переводов содержит соответствие между словами на первом языке и переведенными словами на втором языке;
создание копии текстового дерева, отличающейся тем, что копия текстового дерева сохраняет форматирование текста, и
замену в каждом узле дерева скопированного текста одного или нескольких слов на первом языке переведенным словом или переведенными словами, основанными на таблице перевода.
10. Способ по п. 9, дополнительно содержащий:
получение правок переводов и
обновление скопированного текстового дерева на основании этих правок.
11. Способ по п. 9, дополнительно содержащий этап создания параллельных фрагментов текста для текстового дерева и скопированного дерева, представляющего текст в текстовом дереве, который соответствует тексту в скопированном дереве.
12. Способ по п. 11, дополнительно содержащий:
отображение текста на первом языке в виде текстового дерева, и
одновременное отображение текста скопированного дерева на втором языке.
13. Система для представления текста, которая содержит:
один или несколько электронных процессоров, настроенных на:
получение документа в первом формате, при этом этот документ содержит текст;
создание с использованием первого фильтра, связанного с первым форматом, универсального текстового представления документа, отличающегося тем, что это универсальное текстовое представление представляет этот текст и поддерживаемые нетекстовые данные и сохраняет неподдерживаемые данные с привязкой к поддерживаемым данным;
модификацию универсального текстового представления, основанную на действиях пользователя с помощью программы, поддерживающей режим полного соответствия вывода на экран и при печати (режим WYSIWYG) так, что этот пользователь может видеть местоположение поддерживаемых данные и неподдерживаемых данных, и
экспорт модифицированного универсального текстового представления с использованием второго фильтра, связанного со вторым форматом, при этом экспортируются как поддерживаемые, так и неподдерживаемые нетекстовые данные.
14. Система по п. 13, отличающаяся тем, что универсальное текстовое представление содержит текстовое дерево, отличающаяся тем, что текстовое дерево включает узлы, которые содержат одно или несколько слов и расположение этих слов, и отличающаяся тем, что один или несколько узлов включают атрибуты, связанные с форматированием одного или нескольких слов.
15. Система по п. 14, отличающаяся тем, что один или несколько процессоров дополнительно сконфигурированы на:
определение текстовых диапазонов двух атрибутов узла, расположенных рядом друг с другом;
определение двух атрибутов, которые могут быть объединены, и объединение двух атрибутов в один атрибут, который охватывает текстовые диапазоны двух атрибутов.
16. Система по п. 14, отличающаяся тем, что для изменения универсального текстового представления один или несколько процессоров настроены на перевод с первого языка на второй (другой) язык текстовых данных, представленные в универсальном текстовом представлении.
17. Система по п. 16, отличающаяся тем, что для перевода текстовых данных один или несколько процессоров дополнительно настроены на:
получение таблицы переводов, отличающейся тем, что таблица перевода содержит соответствие между словами на первом языке и переведенными словами на втором языке;
создание копии текстового дерева, отличающейся тем, что копия текстового дерева сохраняет форматирование текста, и
для каждого узла в тексте скопированного дерева замену одного или нескольких слов на первом языке переведенным одним или несколькими словами на основании таблицы перевода.
18. Машиночитаемый носитель информации, в котором записаны команды, причем эти команды включают:
команды для получения документа в первом формате, при этом этот документ содержит текст;
команды для создания, используя первый фильтр, связанный с первым форматом, универсального текстового представления документа, отличающегося тем, что универсальное текстовое представление представляет этот текст и поддерживаемые нетекстовые данные и сохраняет неподдерживаемые данные с привязкой к поддерживаемым данным;
команды для модификации универсального текстового представления на основании ввода пользователя в программе в режиме полного соответствия вывода на экран и при печати (режим WYSIWYG) так, что пользователь может видеть местоположение, в котором хранятся поддерживаемые данные и неподдерживаемые данные и
команды для экспорта измененного универсального текстового представления с использованием второго фильтра, связанного со вторым форматом, при этом экспортируются как поддерживаемые, так и неподдерживаемые нетекстовые данные.
19. Машиночитаемый носитель информации по п. 18, отличающийся тем, что универсальное текстовое представление содержит текстовое дерево, отличающееся тем, что текстовое дерево включает узлы, содержащие одно или несколько слов и расположение этих слов, и отличающееся тем, что один или несколько узлов включают атрибуты, связанные с форматированием из одного или нескольких слов.
20. Машиночитаемый носитель информации по п. 19, отличающийся тем, что эти команды дополнительно содержат:
команды для определения текстовых диапазонов двух атрибутов узла, находящихся рядом друг с другом;
команды для определения двух атрибутов, которые могут быть объединены, а также
команды для объединения двух атрибутов в один атрибут, который охватывает текстовые диапазоны двух атрибутов.
21. Машиночитаемый носитель информации по п. 19, отличающийся тем, что команды для изменения универсального текстового представления содержат команды для перевода текстовых данных, представленных в универсальном текстовом представлении, с первого языка на второй (другой) язык.
22. Машиночитаемый носитель по п. 21, отличающийся тем, что команды для перевода текстовых данных дополнительно включают:
команды для получения таблицы переводов, отличающейся тем, что эта таблица переводов содержит соответствие между словами на первом языке и переведенными словами на втором языке;
команды для создания копии текстового дерева, отличающейся тем, что эта копия текстового дерева сохраняет форматирование текста, а также
команды для замены в каждом узле скопированного текстового дерева одного или нескольких слов на первом языке переведенными одним или несколькими словам на основании таблицы перевода.
| Початкоотделяющий аппарат кукурузоуборочного комбайна | 1983 |
|
SU1132833A1 |
| EA 007776 B1, 27.02.2007 | |||
| US 5626846 A1, 13.05.1997 | |||
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| US 6812941 B1, 02.11.2004. | |||

