ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
Настоящее изобретение относится к области человеко-машинного взаимодействия и, в частности, к голосовой связи на естественном языке между человеком и устройством, в частности, но не ограничиваясь, при взаимодействии между пользователем-человеком и мобильным устройством или телевизионной (ТВ) панелью.
УРОВЕНЬ ТЕХНИКИ
В последнее время был достигнут значительный прогресс в разработке голосовых интерфейсов для мобильных устройств или ТВ-панелей. Современные системы теперь могут обеспечивать достаточно качественные службы распознавания и формирования речи. Это обеспечивает возможность развития сложных систем, отвечающих на вопросы, для мобильных устройств и ТВ-панелей таким образом, что связь осуществляется посредством устной речи. Например, поиск содержимого в службе видео по запросу (VOD) или запрос отображения программы телевещания у ТВ-панели, осуществляемые голосовым способом, могут быть более естественными, чем использование пульта дистанционного управления телевизором или клавиатуры.
В настоящее время такие системы становятся все более распространенными. Тем не менее для используемых архитектур характерно игнорирование некоторых особых свойств морфологически богатых языков, таких как гибкий порядок слов и большое число возможных форм слова. В частности, модули понимания естественных языков часто основаны на бесконтекстных грамматиках (CFG) и их модификациях (например, рекурсивных сетях переходов). Известно, что такие синтаксические модели не подходят для языков с гибким порядком слов и богатой морфологией (Jurafsky, D. & Martin, J.H. (2000). Speech & Language Processing. Pearson Education). Распространенными примерами являются чешский, русский, турецкий и арабский языки. Результатом разработки CFG для этих языков может стать лавинообразное увеличение числа грамматических правил при том, что подсчет всех возможных вариантов является нецелесообразным из-за изменчивости порядка слов.
В качестве альтернативного подхода может быть предложена модель «набора слов», но она полностью игнорирует применимую грамматическую информацию (Manning, C. D. (1999). Foundations of statistical natural language processing. H. Schütze (Ed.). MIT press.)
В US 20100114944 A1 раскрыты способ и система для обеспечения голосового интерфейса. Описанный компонент обработки естественного языка основан на CFG и таким образом его недостаток заключается в лавинообразном увеличении числа грамматических правил.
В US 8301438 B2 описан способ обработки вопросов на естественном языке и устройство для его осуществления. Основной способ основан на извлечении именованных объектов и ключевых слов и не имеет развитого синтаксического модуля. Недостаток данного подхода состоит в игнорировании применимой синтаксической информации.
В WO 1997041521 A1 раскрыты способ и устройство для выполнения человеко-машинного диалога в виде двусторонней речи для осуществления управляемого машиной диалога для назначения визитов. Оно не имеет компонента, отвечающего на вопросы. Фактически роль системы в диалоге сводится к исполнению голосовых команд.
В US 5754736 A описаны система и способ вывода голосовой информации в ответ на входные голосовые сигналы. В этом подходе используется вероятностная бесконтекстная грамматика (PCFG) и таким образом его недостаток состоит в лавинообразном увеличении числа грамматических правил.
В EP 0895396 A2 описан компонент обработки естественного языка, основанный на CFG, недостатком которого также является лавинообразное увеличение числа грамматических правил.
В WO 2006036328 A1 модуль обработки естественного языка основан на синтаксическом анализе зависимостей, но полученное дерево преобразуют в XML-кодированную структуру признаков и затем в семантические логические формы. Данный подход предполагает использование дополнительного уровня с правилами преобразования на основе шаблонов, отображающими представление дерева в итоговый запрос к базе данных или команду к аппаратным средствам в случае голосовой команды. Однако данный способ плохо подходит для случаев диалоговой речи, которая обладает большой изменчивостью в морфологически богатых языках.
Документ WO 2006036328 A1 может рассматриваться в качестве ближайшего аналога предлагаемого изобретения. Все приведенные источники настоящим включены в настоящий документ путем ссылки в полном объеме там, где это применимо.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
Как следует из вышеприведенного описания уровня техники, в уровне техники известны в общем два подхода к обработке естественных языков: подход на основе правил (или на основе грамматики) и статистический подход. Применительно к языкам с богатой морфологией способам на основе правил присуща проблема неуправляемого роста числа правил. Авторы настоящего изобретения предлагают избегать использования способов на основе правил в обработке и понимании естественных языков и заменить их статистическим подходом.
Авторы настоящего изобретения предлагают использовать синтаксическую обработку зависимостей в качестве промежуточной процедуры. Среди способов статистической синтаксической обработки существует группа алгоритмов, которые основаны на конечных автоматах и сильно зависят от порядка слов в предложении. Эти способы едва ли способны обработать так называемое явление непроективности, когда некоторые ветви дерева синтаксического анализа пересекаются. Авторы настоящего изобретения предлагают эффективное решение данной проблемы путем использования алгоритмов статистического синтаксического анализа на основе графов, которые работают одинаково хорошо с проективными и непроективными деревьями.
Кроме того, в способе согласно изобретению применяется статистический модуль для прямого отображения между синтаксическим деревом и структурой зависимостей понятий. Набор понятий должен соответствовать структуре базы данных таким образом, чтобы формирование запроса к базе данных с использованием структуры понятий стало тривиальной процедурой.
Такой подход обладает следующими преимуществами:
- он сохраняет синтаксическую информацию в виде синтаксического дерева;
- он заменяет сложные грамматические правила, основанные на конкретном порядке слов, процедурой статистического синтаксического анализа, независимой от порядка слов;
- он обеспечивает гибкое статистическое отображение с синтаксического дерева в запрос к базе данных.
Одна задача настоящего изобретения состоит в создании способа обработки голосового ввода и формирования ответа на естественном языке, который имеет следующие преимущества по отношению к уровню техники:
- сохранение синтаксической информации до конца процедуры обработки;
- поддержка гибкого порядка слов без увеличения числа вариантов и соответствующих вычислительных затрат.
Таким образом, способ и устройство согласно изобретению имеют преимущество по отношению к уровню техники в том, что они обеспечивают возможность эффективной обработки голосовых вводов пользователя в морфологически богатых языках без вычислительно затратных операций, которые обычно связаны с большим числом применимых правил. Кроме того, устройство и способ согласно настоящему изобретению обеспечивают устойчивость к несовершенному вводу из модуля преобразования речи в текст и к особенностям голосовых вводов пользователя-человека, включая, например, вводы с неполным упоминанием частичных имен собственных или необходимость корректировки распознанной текстовой строки на основании таких голосовых вводов (восстановление предлогов и т.п.).
В общем случае изобретение обеспечивает способ, основанный на синтаксическом анализе зависимостей для распознанного голосового ввода, за которым следует отображение дерева зависимостей, направленное на идентификацию ключевых понятий, которые должны использоваться при формировании запроса к базе данных. Модуль распознавания речи может быть размещен на сервере, принимающем сигнал, записанный посредством микрофона, и возвращающем наиболее вероятную гипотезу относительно фрагмента речи. Затем приводятся в действие модули предварительной обработки, которые включают в себя модули лексемизации, нормализации, извлечения выражений времени и именованных объектов. Входную текстовую строку обрабатывают посредством модуля морфологического анализа. Затем выполняется синтаксическая обработка зависимостей распознанного и предварительно обработанного фрагмента речи. Затем выполняется статистический вывод для извлечения ключевых понятий. Для этого вывода используется предварительно обученная модель понятий и их связь, обусловленная субдеревьями зависимостей. Затем извлеченные понятия используют для формирования запроса к базе данных, в частности на языке запросов SQL. В соответствии с ответом базы данных выбирают подходящий шаблон ответа и формируют текстовую строку ответа с использованием модуля флективности. Затем текстовую строку ответа вводят в модуль преобразования текста в речь и преобразуют в голосовой сигнал, «читающий» упомянутую правильно обработанную текстовую строку ответа в виде голосового ответа на пользовательский ввод.
Таким образом, примерная диалоговая система, реализованная в устройстве и/или способе согласно изобретению, понимает вопросы и голосовые команды, которые в естественной речи, как правило, являются разнообразными, в особенности во флективных языках. Примерная диалоговая система выполняет глубокий синтаксический анализ введенного словосочетания, обнаруживая не только основные структуры вопроса и команды, но также и важные грамматические свойства, такие как время, вид и наклонение.
В одном аспекте изобретение относится к способу обработки голосового ввода и формирования ответа на естественном языке, причем способ содержит этапы, на которых: принимают голосовой ввод и формируют входной голосовой сигнал; обрабатывают входной голосовой сигнал для получения распознанной входной текстовой строки; нормализуют распознанную входную текстовую строку, обнаруживают лексемы, именованные объекты и выражения времени в распознанной входной текстовой строке; выполняют морфологический анализ с разрешением неоднозначностей по основным формам слов и обнаружением морфологических признаков; выполняют синтаксический анализ зависимостей для распознанной входной текстовой строки посредством статистического синтаксического анализа для формирования дерева зависимостей, причем для поддержки гибкости порядка слов используются алгоритмы статистического синтаксического анализа на основе графов с обработкой непроективных деревьев; выполняют статистическую обработку дерева зависимостей для обнаружения ключевых понятий и их зависимостей для формирования синтаксического дерева; преобразуют синтаксическое дерево в SQL-запрос; отправляют SQL-запрос в базу данных и принимают данные, относящиеся к SQL-запросу; преобразуют принятые данные в текстовую строку ответа на естественном языке; и синтезируют голосовой сигнал ответа в соответствии с текстовой строкой ответа.
В варианте выполнения статистическая модель, обусловленная субдеревьями зависимостей, используется в упомянутой статистической обработке дерева зависимостей для обнаружения ключевых понятий и их зависимостей. Упомянутое преобразование принятых данных в ответ на естественном языке может дополнительно содержать этап, на котором используют шаблоны для формирования ответа таким образом, что поля данных, получаемых из базы данных, замещаются в шаблоне в установленной грамматической форме. Упомянутое преобразование принятых данных в текстовую строку ответа на естественном языке может также дополнительно содержать этап, на котором используют алгоритмы склонения именных словосочетаний для постановки именного словосочетания в установленную форму.
В другом аспекте изобретение относится к устройству для обработки голосового ввода и формирования ответа на естественном языке, причем устройство содержит: принимающий модуль, выполненный с возможностью приема голосового ввода и формирования голосового сигнала; модуль преобразования речи в текст, выполненный с возможностью обработки голосового сигнала для выполнения распознавания речи в голосовом сигнале; модуль предварительной обработки входной текстовой строки, выполненный с возможностью нормализации распознанной входной текстовой строки для выполнения предварительной обработки распознанного запроса и извлечения лексем, именованных объектов и выражений времени; модуль морфологического анализа, выполненный с возможностью выполнения разрешения неоднозначностей по основным формам слов и обнаружения морфологических признаков во входной текстовой строке; модуль синтаксического анализа зависимостей, выполненный с возможностью формирования дерева зависимостей путем выполнения статистического морфологического и синтаксического анализа входной текстовой строки, причем для поддержки гибкости порядка слов используются алгоритмы статистического синтаксического анализа на основе графов с обработкой непроективных деревьев; модуль извлечения, выполненный с возможностью извлечения ключевых понятий из дерева зависимостей, причем упомянутый модуль извлечения использует шаблоны для обнаружения субдеревьев, соответствующих понятиям, и их зависимостей для формирования синтаксического дерева; модуль SQL-запросов, выполненный с возможностью формирования SQL-запроса в базу данных путем преобразования синтаксического дерева в SQL-запрос; клиент базы данных, выполненный с возможностью отправки SQL-запроса в базу данных и приема данных, относящихся к SQL-запросу; модуль формирования текстовой строки ответа, выполненный с возможностью замещения словосочетаний, полученных из данных, принятых в ответ на упомянутый SQL-запрос, в шаблонах для формирования текстовой строки ответа на естественном языке, причем словосочетания ставят в надлежащую грамматическую форму, и модуль преобразования текста в речь, выполненный с возможностью синтезирования голосового сигнала ответа в соответствии с текстовой строкой ответа.
В варианте выполнения для извлечения ключевых понятий и грамматических признаков из дерева зависимостей используется статистическая модель. Вышеупомянутый модуль формирования текстовой строки ответа дополнительно содержит модуль склонения, который использует алгоритмы склонения именных словосочетаний для постановки именного словосочетания в установленную форму, причем упомянутый модуль склонения обнаруживает объекты склонения и ставит их в надлежащую форму на основании словаря склонений. При необходимости устройство может дополнительно использовать модуль службы преобразования текста в речь (TTS) для формирования голосового сигнала ответа в соответствии с текстовой строкой ответа. В варианте выполнения устройство дополнительно содержит по меньшей мере один громкоговоритель, выполненный с возможностью выдачи голосового сигнала ответа пользователю.
Специалисту в данной области техники будет понятно, что помимо охарактеризованных выше аспектов настоящее изобретение может также принимать другие формы, в частности, в зависимости от фактического применения, оно может быть реализовано в компьютерной программе, компьютерном программном продукте, интегрированной или распределенной компьютерной системе, одном или более процессорах и т.п.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Теперь аспекты изобретения будут описаны более подробно в качестве иллюстративного примера с обращением к чертежам, на которых:
Фиг.1 - блок-схема, изображающая основные части предлагаемой диалоговой системы, реализованной в способе и устройстве согласно изобретению.
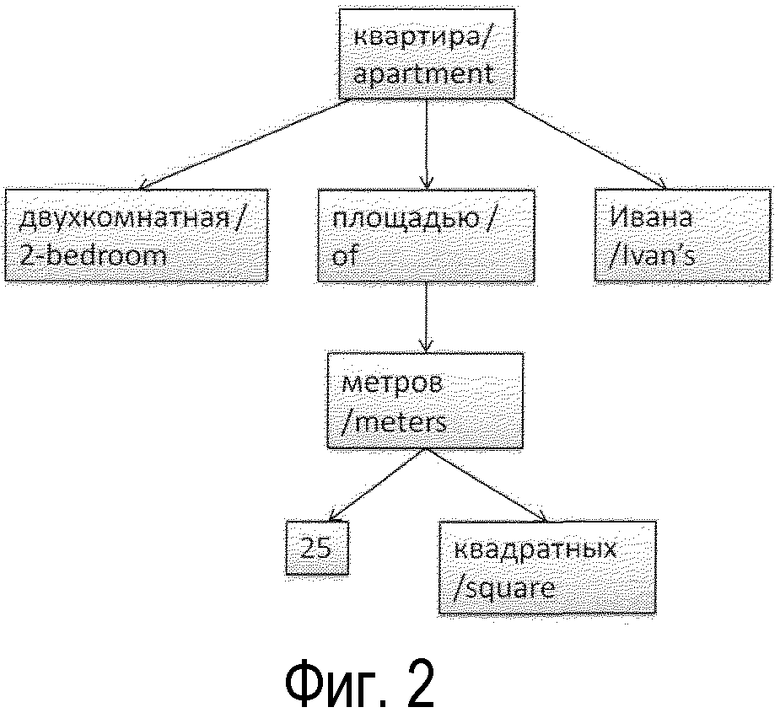
Фиг.2 иллюстрирует примерный результат синтаксической обработки зависимостей входной строки в дерево зависимости словосочетаний (синтаксическое).
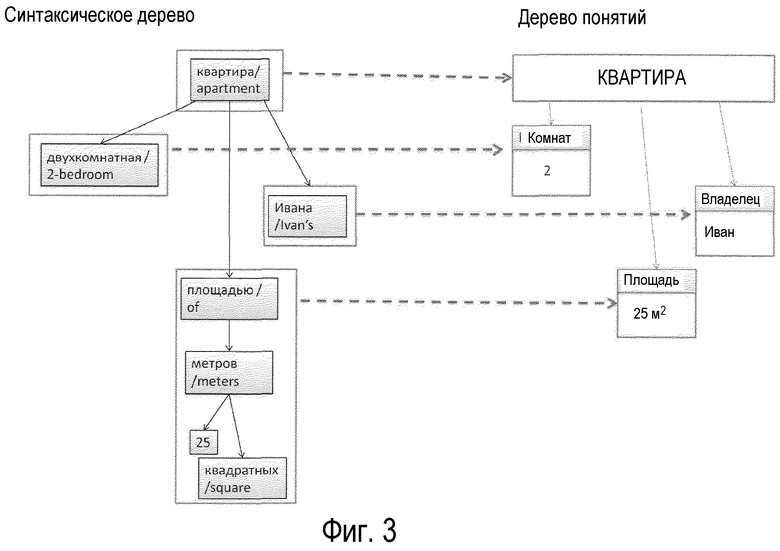
Фиг.3 иллюстрирует пример отображения с дерева зависимости словосочетаний (синтаксического) в структуру зависимости понятий (дерево понятий).
Следует отметить, что чертежи приведены лишь в качестве вспомогательного средства для понимания подробного описания изобретения и не предназначены для определения или ограничения объема заявленных изобретений каким-либо образом.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
Как видно на Фиг.1, диалоговая система для голосовой связи на естественном языке, которая обеспечивает человекомашинное взаимодействие посредством голосового диалога и реализована в устройстве и способе согласно изобретению, может рассматриваться как состоящая в основном из следующих трех главных частей, функции которых определяют способ работы устройства согласно изобретению и соответствующие этапы способа согласно изобретению:
1) Часть, преобразующая речь в текст: преобразует звуковой (голосовой) ввод в текст;
- модуль автоматического распознавания речи является основным компонентом этой части.
2) Часть для обработки естественного языка: извлекает лингвистическую информацию из входного словосочетания;
- модуль предварительной обработки - этот модуль преобразует текст в стандартную форму, включая дексемизацию, нормализацию чисел, извлечение общепринятых сокращений, распознавание именованных объектов и т.п.
Пример:
Ввод
Ivan's 2-bedroom apartment of 25 sqm
Предварительная обработка
<PN>Ivan</PN> ' s two bedroom apartment of twenty five square meters
Комментарий:
1. “Ivan's” лексемизировано как “Ivan ' s”. “2-bedroom” лексемизировано как “2 bedroom”.
2. “Ivan” отмечено как имя собственное: <PN>Ivan</PN>
3. Число “25” нормализовано как “twenty five”. Число “2” нормализовано как “two”.
4. Сокращение “sqm” расшифровано как “square meters”
- модуль морфологического анализа - этот модуль обнаруживает морфологические признаки для каждой лексемы, такие как падеж, число, род, и находит основную форму слова (исходную форму) для каждого слова.
Пример:
Ввод
<PN>Ivan</PN> ' s two bedroom apartment of twenty five square meters
Квартира <PN>Ивана</PN> площадью двадцать пять квадратных метров
Вывод
Квартира Ивана площадью двадцать пять квадратных метров
основная форма: квартира СУЩ - ед - ж - им - неодуш
основная форма: иван СУЩ - ед - м - род - одуш
основная форма: площадь СУЩ - ед - ж - твор - неодуш
основная форма: двадцать ЧИС - им
основная форма: пять ЧИС - им
основная форма: квадратный ПРИЛ - мн - род
основная форма: метр СУЩ - мн - м - род - неодуш
- модуль синтаксического анализа зависимостей: этот модуль обнаруживает структуру зависимостей для словосочетания (см. Фиг.2).
3) Часть для понимания естественного языка: извлекает полезную информацию и преобразует ее в определенный машинный код;
- модуль анализа понятий - этот модуль извлекает понятия для базы данных, формируя отображение из структуры дерева зависимостей словосочетания в структуру зависимости понятий
Пример:
Понятия
КВАРТИРА
Владелец: Имя=«Иван»
Площадь: Значение=25
Комнаты: число=2
(см. Фиг.3)
4) Часть для формирования ответа: обнаруживает запрашиваемую информацию и формирует ответ;
- генератор запросов к базе данных - формирует запрос к базе данных с использованием извлеченной структуры понятий;
- клиент базы данных - обрабатывает сформированный запрос и выдает ответ;
- модуль формирования естественного языка - формирует ответ в виде текстового словосочетания с использованием ответа из базы данных;
- модуль преобразования текста в речь - преобразует текстовый вывод в звук.
Таким образом, после описания общего принципа работы и компонентов заявленного изобретения обратимся теперь к конкретному примерному варианту выполнения заявленного изобретения. Однако следует понимать, что этот вариант выполнения приведен лишь в качестве примера для иллюстрации изобретательского замысла и не должен рассматриваться как определяющий и/или ограничивающий объем заявленного изобретения каким-либо образом. После внимательного прочтения и понимания подробного описания, приведенного ниже с обращением к чертежам, которые также образуют часть описания настоящей заявки, специалисту в данной области техники могут стать очевидными другие модификации, варианты и эквивалентные замены.
Прежде всего, следует понимать, что определенные выше функциональные модули, которые обеспечивают работу предложенного изобретения, могут быть реализованы посредством различных сочетаний аппаратных и программных средств. В общем случае изобретение реализуется одним или более процессорами, выполненными с возможностью выполнения программных модулей. В свою очередь, упомянутые программные модули могут быть представлены любым надлежащим числом компьютерных программных модулей и могут использовать любое надлежащее число библиотек, оболочек, приложений, программных пакетов в зависимости от конкретной функции или этапа способа, реализуемых определенным модулем. Компьютерные программные модули могут быть реализованы в виде машинного кода или в виде текста программы на языке программирования, таком как C, C++, C#, Java, Python, Perl, Ruby и т.п. Более подробное описание средств и способов реализации функциональных модулей, относящихся к обработке естественных языков, можно найти, например, в источнике Jurafsky, D. & Martin, J.H. (2000). Speech & Language Processing. Pearson Education.
Способ обработки голосового ввода и формирования ответа на естественном языке, рассматриваемый в общем случае, содержит следующие этапы. Сначала принимают пользовательский голосовой ввод, например посредством микрофона. Из принятого пользовательского голосового ввода формируют входной голосовой сигнал. Входной голосовой сигнал обрабатывают для получения распознанной входной текстовой строки. Распознанную входную текстовую строку нормализуют для обнаружения лексем, именованных объектов и выражений времени. После этого выполняют морфологический анализ в отношении распознанной и нормализованной входной текстовой строки, который включает в себя, в частности, разрешение неоднозначностей по основным формам слов и обнаружение морфологических признаков. Затем выполняют синтаксическую обработку зависимостей для распознанной входной текстовой строки посредством статистического синтаксического анализа для формирования дерева зависимостей, причем используются алгоритмы статистического синтаксического анализа на основе графов с обработкой непроективных деревьев для поддержки гибкости порядка слов. Затем выполняют статистическую обработку дерева зависимостей для обнаружения ключевых понятий и их зависимостей таким образом, чтобы сформировать синтаксическое дерево. Синтаксическое дерево преобразуют в запрос к базе данных на соответствующем языке запросов к базе данных, обычно в форме SQL-запроса. SQL-запрос отправляют в базу данных, и принимают ответ на запрос посредством клиента базы данных, причем ответ содержит данные, которые соответствуют SQL-запросу. Текстовая строка ответа на естественном языке составляется модулем формирования текстовой строки ответа на основе данных, обеспечиваемых клиентом базы данных, в ответ на упомянутый SQL-запрос к базе данных. При этом может быть использован модуль флективности в случае морфологически богатых языков для формирования правильно грамматически сформулированной текстовой строки ответа. Модуль флективности использует алгоритмы склонения для именных словосочетаний для постановки именного словосочетания в установленную форму. Кроме того, модуль флективности при необходимости обнаруживает объекты склонения и ставит их в надлежащую форму на основании словаря склонений. Наконец, голосовой сигнал ответа синтезируется посредством модуля преобразования текста в речь в соответствии с текстовой строкой ответа, и выдается голосовой сигнал в качестве ответа на пользовательский голосовой ввод посредством любого подходящего средства, в частности посредством по меньшей мере одного громкоговорителя.
Обращаясь теперь к Фиг.1, в устройстве согласно изобретению голосовой сигнал принимается посредством принимающего модуля, например записывается посредством микрофона 101, включенного в устройство (например, ТВ-панель или мобильный телефон), с которым взаимодействует пользователь. Затем сигнал передается в модуль 102 преобразования речи в текст, который может быть реализован либо в виде встроенного устройства (интегрированного с устройством) или в виде внешней (основанной на сервере) службы, подобной модулю 110 преобразования речи в текст, который будет описан ниже. При этом модуль преобразования речи в текст может использовать устройство автоматического распознавания речи (ASR) (также обозначенного как служба ASR на Фиг.1). Вывод модуля 102 преобразования речи в текст представляет собой распознанную последовательность слов в форме текста (также называемую в настоящем документе «входной текстовой строкой»).
Затем распознанную текстовую строку передают в модуль 103 предварительной обработки входной текстовой строки, который предназначен для преобразования некоторых конкретных объектов в стандартизированную форму: например, для отделения знаков препинания от слов; для группирования символов, которые должны быть обработаны вместе; для стандартизации чисел; для извлечения именованных объектов (имен собственных, географических названий, наименований организаций и т.п.) и выражений времени. Задача этой работы модуля 103 предварительной обработки входной текстовой строки состоит в упрощении последующего морфологического и синтаксического анализа, который выполняется далее в модуле 104 морфологического анализа и модуле 105 синтаксического анализа зависимостей.
Морфологический анализ выполняется в модуле 104 морфологического анализа. Морфологический анализ может быть стохастическим. Например, он может быть основан на механизмах условных случайных полей или Марковской модели максимальной энтропии. Результаты работы модуля 104 используются для синтаксического анализа 105 зависимостей.
Синтаксическую обработку зависимостей выполняют с использованием обнаруженных морфологических признаков и основных форм (исходных форм слов). В варианте выполнения процедура синтаксического анализа может использовать статистический метод на основе графов, который одинаково хорошо работает как с проективной, так и с непроективной структурой дерева.
Полученное дерево синтаксического анализа затем передается в модуль 106 извлечения для извлечения ключевых понятий из дерева зависимостей, который также может быть в общем назван модулем 106 анализа понятий, как показано Фиг.1, и который предназначен для извлечения ключевых понятий и их зависимостей. Эта задача выполняется по существу путем выполнения отображения из структуры зависимости словосочетаний, обеспеченной посредством синтаксического анализа зависимостей, как упомянуто выше, в структуру зависимости понятий, сформированную таким образом для входной текстовой строки. Для этого отображения используется статистический метод: субдеревья отображаются в понятия в соответствии со статистической моделью. Кроме того, на данном этапе определяется вид фрагмента речи пользователя, например вопрос, команда и т.п. Каждое понятие сопоставляется с соответствующим вложенным предложением запроса к базе данных. Это выполняется в модуле 107 SQL-запросов (который также называется в настоящем документе генератором запросов). Известно, что запросы являются основным механизмом для получения информации из базы данных и состоят из вопросов, представляемых в базу данных в заданном формате. Многие различные системы управления базами данных используют стандартный формат запросов структурированного языка запросов (SQL). При этом следует понимать, что SQL в контексте настоящего изобретения является лишь примерным форматом запросов, который может быть использован в предпочтительном варианте выполнения заявленного изобретения. Специалисту в данной области техники может быть очевидно использование в настоящем способе и устройстве других подходящих форматов языков запросов к базе данных.
Вместе вложенные предложения формируют действительный запрос, который передается в клиент 108 базы данных, осуществляющий связь с базой 112 данных, причем упомянутый клиент 108 базы данных передает SQL-запрос в базу данных и принимает данные, соответствующие SQL-запросу, из базы данных. База данных может быть реализована в виде стандартной базы данных SQL. В данном случае вложенные предложения запроса соответствуют вложенным предложениям SQL-запроса.
Эту информацию передают в модуль 109 формирования текстовой строки ответа (также называемого генератором текста ответа, см. Фиг.1), который замещает словосочетания, получаемые из данных, принятых в ответ на упомянутый SQL-запрос, в шаблоны для формирования текстовой строки ответа на естественном языке, причем словосочетания ставятся в правильную грамматическую форму. Модуль 109 формирования текстовой строки ответа также в общем называется в настоящем документе модулем формирования естественного языка. Модуль 109 формирования текстовой строки ответа может быть основан на шаблонах: его основная функция состоит в замещении соответствующих полей шаблона ответа информацией, получаемой из базы данных посредством клиента 108 базы данных. Шаблон ответа может содержать шаблоны для ответов с интервалами, которые должны быть заполнены информацией, полученной из базы данных, или определенными частями входной текстовой строки. Для морфологически богатых языков этот модуль должен также быть выполнен с возможностью выполнения склонения определенного словосочетания, заполняющего интервал, в определенную форму. В предпочтительном варианте выполнения модуль флективности, который использует алгоритмы склонения именных словосочетаний для постановки именного словосочетания в установленную форму, причем упомянутый модуль флективности обнаруживает объекты склонения и ставит их в правильную форму на основании словаря склонений, дополняет упомянутый модуль формирования естественного языка для обеспечения лингвистически правильной текстовой строки ответа с учетом конкретных грамматических форм соответствующих слов, включенных в упомянутую текстовую строку ответа.
Пример:
Запрос: Найти дешевую пятикомнатную квартиру с хорошим ремонтом. -- “Find cheap 5-bedroom apartment with good finishes”
Ответ 1: К сожалению, в нашей базе нет пятикомнатных квартир с хорошим ремонтом. - “Unfortunately, in our database there is no cheap 5-bedroom apartments with good finishes”
Шаблон: К сожалению, в нашей базе нет <интервал> -- Unfortunately in our database there is no <интервал>
Целевая форма для интервала: множественное число, родительный падеж
Ответ 2: Я могу предложить вам дешевую пятикомнатную квартиру с хорошим ремонтом. - I can suggest you cheap 5-bedroom apartments with good finishes
Шаблон: Я могу предложить вам <интервал> -- I can suggest you <интервал>
Целевая форма для интервала: единственное число, винительный падеж
Как указано выше, этот модуль флективности должен включать в себя словарь склонений для выполнения склонения одиночных слов. Однако для склонения именных словосочетаний этого не достаточно, поскольку в каждом именном словосочетании некоторые слова склоняются, а некоторые - нет. Все склоняемые слова имеют ту же форму, что и главное слово в словосочетании (главное слово в словосочетании); другие слова могут иметь различные формы.
Для обнаружения схем склонения определенного словосочетания может быть использована статистическая модель, основанная на условных случайных полях на линейной цепи.
Пример:
дешевая пятикомнатная квартира с хорошим ремонтом→
дешевых[i] пятикомнатных[i] квартир[h] с[f] хорошим[f] ремонтом[f]
Комментарий: здесь [h] обозначает главное слово в словосочетании; [i] - слова, которые должны склоняться с главным словом; [f] - слова, которые имеют неизменную форму в словосочетании. Эти метки формируют схемы склонений в словосочетании.
Вывод модуля 109 формирования текстовой строки ответа, который при необходимости использует вышеупомянутый модуль флективности, затем передается в модуль 110 преобразования текста в речь, который, хотя это и не является необходимым, может дополнительно использовать внешний модуль 111 службы преобразования текста в речь. Модуль 110 преобразования текста в речь предназначен для «прочтения» итоговой текстовой строки ответа, выданной модулем 109 формирования текстовой строки ответа, посредством синтезатора речи, и проигрывания голосового ответа на естественном языке пользователю посредством по меньшей мере одного громкоговорителя 115 устройства обработки голосового ввода и формирования ответа на естественном языке согласно изобретению. Упомянутый по меньшей мере один громкоговоритель 115 устройства согласно изобретению выполнен с возможностью выдачи пользователю голосового сигнала ответа.
Устройство согласно изобретению может использоваться в качестве встроенной подсистемы человеко-машинного интерфейса в ТВ-панели, мобильном телефоне, платежных или информационных терминалах или в любых других устройствах, которые поддерживают голосовые команды или голосовой диалог с пользователем.
При том, что изобретение было описано выше с точки зрения устройства для обработки голосового ввода и формирования ответа на естественном языке и посредством его соответствующих элементов и их функциональных взаимодействий, специалисту в данной области техники будет очевидно, что заявленное изобретение может также принимать другие формы. Определенные модули устройства и/или этапы способа согласно изобретению могут быть реализованы посредством различных сочетаний компонентов аппаратного обеспечения, программного обеспечения, микропрограммного обеспечения или выполнены в виде компьютерной программы, компьютерного программного кода или команд, компьютерных программных элементов или тому подобного. Упомянутая компьютерная программа или компьютерные программные элементы могут быть использованы для инструктирования соответствующих компонентов заявленного устройства выполнять соответствующие этапы способа согласно изобретению. Упомянутая компьютерная программа или компьютерные программные элементы могут быть реализованы на машиночитаемом носителе, который может быть постоянным машиночитаемым носителем, таким как оптический или магнитный носитель данных, или упомянутая компьютерная программа или компьютерные программные элементы могут быть переданы в устройство согласно изобретению посредством внешнего носителя, например сервера, посредством временного носителя через компьютерную сеть, локальную сеть (LAN), беспроводную локальную сеть (WLAN) или тому подобное. Кроме того, сетевые соединения в проводных и/или беспроводных сетях, беспроводные сетевые соединения и т.п. могут быть использованы для передачи данных между различными модулями устройства согласно изобретению и/или внешними серверами, в частности между клиентом базы данных и базой данных. Кроме того, определенные модули устройства согласно изобретению могут быть размещены вместе, в то время как некоторые другие модули могут быть размещены удаленно по отношению к устройству согласно изобретению. Все модули, которые составляют устройство согласно изобретению и выполняют этапы способа согласно изобретению, реализуются посредством одного или более блоков обработки, в частности одного или более центральных процессоров (CPU), которые могут быть реализованы в виде одного интегрированного устройства или распределены по сети. Упомянутые блоки обработки выполняют соответствующие функции под управлением программных модулей, таких как компьютерные программы, компьютерные программные элементы и т.п., реализованные на языке или языках программирования, таких как C, C++, C#, Java, Python, Perl, Ruby и т.п., и могут включать в себя подходящие и/или необходимые библиотеки, оболочки, приложения базы данных, программные пакеты и т.п. для выполнения своих конкретных задач. Различные архитектуры, охватывающие конкретные программные/аппаратные модули, выполненные с возможностью выполнения соответствующих функций способа и устройства согласно изобретению, могут быть очевидны специалисту в данной области техники, при этом вышеописанные варианты выполнения устройства и способа согласно изобретению являются лишь конкретными практическими примерами, которые не предназначены для определения или ограничения объема изобретения.
Все такие возможные варианты выполнения очевидны специалисту в данной области техники и предполагаются включенными в объем настоящего изобретения.
Также следует понимать, что конфигурация модулей устройства и этапов способа, перечисленных в настоящем документе, является лишь примерной; на практике по меньшей мере один из модулей, упомянутых в настоящем документе, могут быть интегрированы в один или более других функциональных модулей, охарактеризованных в настоящем изобретении. Все такие конфигурации очевидны специалисту в данной области техники. Определенные модули или этапы способа, описанные в настоящем документе, могут быть реализованы посредством компьютера общего назначения или специализированного блока обработки данных, посредством процессора или множества процессоров, интегрированной схемы, программируемой вентильной матрицы (FPGA), конечного автомата и т.п.
При том, что выше приведено подробное описание вариантов выполнения с обращением к чертежам, следует понимать, что вышеупомянутые варианты выполнения приведены лишь с целью иллюстрации и не должны использоваться для определения или ограничения масштаба настоящего изобретения каким-либо образом. Объем настоящего изобретения должен определяться только приложенной формулой изобретения и ее эквивалентами.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ СИНТЕЗА САМООБУЧАЮЩЕЙСЯ СИСТЕМЫ ИЗВЛЕЧЕНИЯ ЗНАНИЙ ИЗ ТЕКСТОВЫХ ДОКУМЕНТОВ ДЛЯ ПОИСКОВЫХ СИСТЕМ | 2002 |
|
RU2273879C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ВЫСТРАИВАНИЯ ДИАЛОГА С ПОЛЬЗОВАТЕЛЕМ В УДОБНОМ ДЛЯ ПОЛЬЗОВАТЕЛЯ КАНАЛЕ | 2018 |
|
RU2688758C1 |
| РАСШИРЕНИЕ ВОЗМОЖНОСТЕЙ ИНФОРМАЦИОННОГО ПОИСКА | 2015 |
|
RU2618375C2 |
| СПОСОБ КЛАСТЕРИЗАЦИИ РЕЗУЛЬТАТОВ ПОИСКА В ЗАВИСИМОСТИ ОТ СЕМАНТИКИ | 2014 |
|
RU2564629C1 |
| СПОСОБ ОЦЕНКИ СТЕПЕНИ РАСКРЫТИЯ ПОНЯТИЯ В ТЕКСТЕ, ОСНОВАННЫЙ НА КОНТЕКСТАХ, ДЛЯ ПОИСКОВЫХ СИСТЕМ | 2007 |
|
RU2348072C1 |
| СИСТЕМА И МЕТОД СЕМАНТИЧЕСКОГО ПОИСКА | 2013 |
|
RU2563148C2 |
| СИСТЕМА И СПОСОБ СОЗДАНИЯ И ИСПОЛЬЗОВАНИЯ ПОЛЬЗОВАТЕЛЬСКИХ ОНТОЛОГИЧЕСКИХ МОДЕЛЕЙ ДЛЯ ОБРАБОТКИ ПОЛЬЗОВАТЕЛЬСКОГО ТЕКСТА НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2015 |
|
RU2596599C2 |
| СИСТЕМА И СПОСОБ СОЗДАНИЯ И ИСПОЛЬЗОВАНИЯ ПОЛЬЗОВАТЕЛЬСКИХ СЕМАНТИЧЕСКИХ СЛОВАРЕЙ ДЛЯ ОБРАБОТКИ ПОЛЬЗОВАТЕЛЬСКОГО ТЕКСТА НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2015 |
|
RU2584457C1 |
| МАШИННОЕ ОБУЧЕНИЕ | 2005 |
|
RU2391791C2 |
| СПОСОБ И СИСТЕМА СЕМАНТИЧЕСКОЙ ОБРАБОТКИ ТЕКСТОВЫХ ДОКУМЕНТОВ | 2016 |
|
RU2630427C2 |
Изобретение относится к области человеко-машинного взаимодействия, а именно к голосовой связи на естественном языке между человеком и устройством. Технический результат состоит в обеспечении обработки пользовательских голосовых вводов на морфологически богатых языках без вычислительно затратных операций, связанных с большим количеством применимых правил. Для этого обработка голосового ввода и формирование ответа на естественном языке содержит этапы, на которых: принимают голосовой ввод и формируют входной голосовой сигнал; обрабатывают входной голосовой сигнал для получения распознанной входной текстовой строки, нормализуют распознанную входную текстовую строку, обнаруживают лексемы, именованные объекты и выражения времени в распознанной входной текстовой строке. Затем выполняют морфологический анализ с разрешением неоднозначностей по основным формам слов и обнаружением морфологических признаков и синтаксический анализ зависимостей для распознанной входной текстовой строки посредством статистического синтаксического анализа для формирования дерева зависимостей. Причем для поддержки гибкости порядка слов используются алгоритмы статистического синтаксического анализа на основе графов с обработкой непроективных деревьев. Кроме того, выполняют статистическую обработку дерева зависимостей для обнаружения ключевых понятий и их зависимостей для формирования синтаксического дерева, преобразуют синтаксическое дерево в SQL-запрос, отправляют SQL-запрос в базу данных и принимают данные, относящиеся к SQL-запросу, преобразуют принятые данные в текстовую строку ответа на естественном языке и синтезируют голосовой сигнал ответа в соответствии с текстовой строкой ответа. 2 н. и 7 з.п. ф-лы, 3 ил.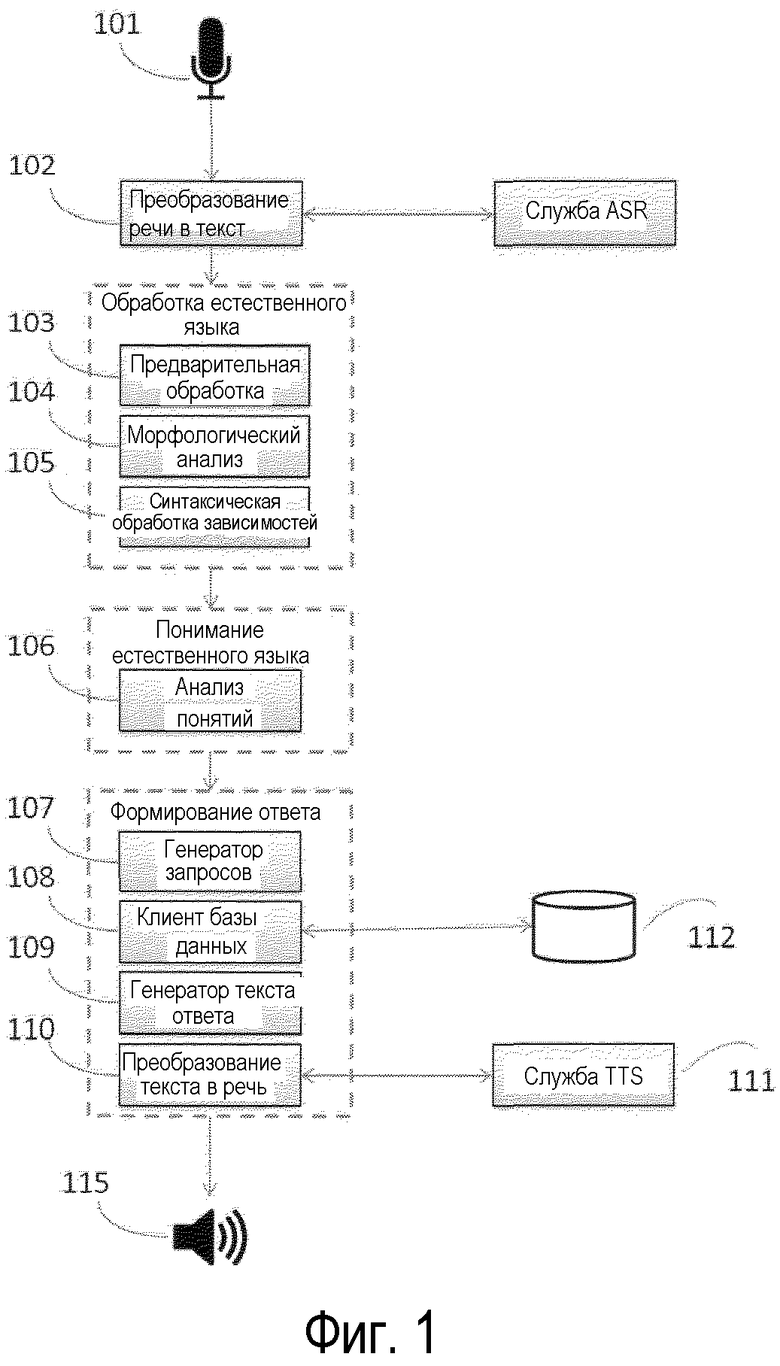
1. Способ обработки голосового ввода и формирования ответа на естественном языке, причем способ содержит этапы, на которых:
принимают голосовой ввод и формируют входной голосовой сигнал;
обрабатывают входной голосовой сигнал для получения распознанной входной текстовой строки;
нормализуют распознанную входную текстовую строку, обнаруживают лексемы, именованные объекты и выражения времени в распознанной входной текстовой строке;
выполняют морфологический анализ с разрешением неоднозначностей по основным формам слов и обнаружением морфологических признаков;
выполняют синтаксический анализ зависимостей для распознанной входной текстовой строки посредством статистического синтаксического анализа для формирования дерева зависимостей, причем для поддержки гибкости порядка слов используются алгоритмы статистического синтаксического анализа на основе графов с обработкой непроективных деревьев;
выполняют статистическую обработку дерева зависимостей для обнаружения ключевых понятий и их зависимостей для формирования синтаксического дерева;
преобразуют синтаксическое дерево в SQL-запрос;
отправляют SQL-запрос в базу данных и принимают данные, относящиеся к SQL-запросу;
преобразуют принятые данные в текстовую строку ответа на естественном языке; и
синтезируют голосовой сигнал ответа в соответствии с текстовой строкой ответа.
2. Способ по п. 1, в котором статистическая модель, обусловленная субдеревьями зависимостей, используется в упомянутой статистической обработке дерева зависимостей для обнаружения ключевых понятий и их зависимостей.
3. Способ по п. 1, в котором упомянутое преобразование принятых данных в ответ на естественном языке дополнительно содержит этап, на котором используют шаблоны для формирования ответа таким образом, что поля данных, получаемых из базы данных, замещаются в шаблоне в установленной грамматической форме.
4. Способ по п. 1, в котором упомянутое преобразование принятых данных в текстовую строку ответа на естественном языке дополнительно содержит этап, на котором используют алгоритмы склонения именных словосочетаний для постановки именного словосочетания в установленную форму.
5. Устройство для обработки голосового ввода и формирования ответа на естественном языке, причем устройство содержит:
принимающий модуль, выполненный с возможностью приема голосового ввода и формирования голосового сигнала;
модуль преобразования речи в текст, выполненный с возможностью обработки голосового сигнала для выполнения распознавания речи в голосовом сигнале;
модуль предварительной обработки входной текстовой строки, выполненный с возможностью нормализации распознанной входной текстовой строки для выполнения предварительной обработки распознанного запроса и извлечения лексем, именованных объектов и выражений времени;
модуль морфологического анализа, выполненный с возможностью выполнения разрешения неоднозначностей по основным формам слов и обнаружения морфологических признаков во входной текстовой строке;
модуль синтаксического анализа зависимостей, выполненный с возможностью формирования дерева зависимостей путем выполнения статистического морфологического и синтаксического анализа входной текстовой строки, причем для поддержки гибкости порядка слов используются алгоритмы статистического синтаксического анализа на основе графов с обработкой непроективных деревьев;
модуль извлечения, выполненный с возможностью извлечения ключевых понятий из дерева зависимостей, причем упомянутый модуль извлечения использует шаблоны для обнаружения субдеревьев, соответствующих понятиям, и их зависимостей для формирования синтаксического дерева;
модуль SQL-запросов, выполненный с возможностью
формирования SQL-запроса в базу данных путем преобразования синтаксического дерева в SQL-запрос;
клиент базы данных, выполненный с возможностью отправки SQL-запроса в базу данных и приема данных, относящихся к SQL-запросу;
модуль формирования текстовой строки ответа, выполненный с возможностью замещения словосочетаний, полученных из данных, принятых в ответ на упомянутый SQL-запрос, в шаблонах для формирования текстовой строки ответа на естественном языке, причем словосочетания ставят в надлежащую грамматическую форму, и
модуль преобразования текста в речь, выполненный с возможностью синтезирования голосового сигнала ответа в соответствии с текстовой строкой ответа.
6. Устройство по п. 5, в котором для извлечения ключевых понятий и грамматических признаков из дерева зависимостей используется статистическая модель.
7. Устройство по п. 5, в котором упомянутый модуль формирования текстовой строки ответа дополнительно содержит модуль склонения, который использует алгоритмы склонения именных словосочетаний для постановки именного словосочетания в установленную форму, причем упомянутый модуль склонения обнаруживает объекты склонения и ставит их в надлежащую форму на основании словаря склонений.
8. Устройство по п. 5, в котором устройство дополнительно использует модуль службы преобразования текста в речь (TTS) для формирования голосового сигнала ответа в соответствии с текстовой строкой ответа.
9. Устройство по п. 5, причем устройство дополнительно содержит по меньшей мере один громкоговоритель, выполненный с возможностью выдачи голосового сигнала ответа пользователю.
| EA 4079 B1, 25.12.2003 | |||
| ДЕТЕКТИРОВАНИЕ АВТООТВЕТЧИКА ПУТЕМ РАСПОЗНАВАНИЯ РЕЧИ | 2007 |
|
RU2439716C2 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| . | |||

