Изобретение относится к области электроники, в частности к технике для реализации общения людей, говорящих на разных языках, в частности, но не исключительно, к системам, которые преобразуют входной речевой аудиосигнал на входном языке в выходной речевой аудиосигнал или текст на выходном языке.
Далее по тексту описания принято называть входной речевой аудиосигнал на входном языке А участника разговора А, а выходной речевой аудиосигнал на выходном языке Б участника разговора Б, терминальные устройства, используемые участниками разговора: первый (передающий) терминал А и второй (принимающий) терминал Б, которые используют языки А и Б соответственно.
Известен способ связи разноязычных собеседников, включающий центр переводов и средство в виде терминала мобильной связи для осуществления собеседниками передачи друг другу информации через центр переводов, терминал мобильной радиосвязи содержит громкоговорящий элемент (RU №31288).
Недостатком данного устройства является сложность системы связей, предусматривающей обращение в промежуточный центр переводов, чем обусловлена ограниченность области применения и низкая надежность.
Известен способ связи разноязычных собеседников и синхронного перевода речевой информации с одного языка на другой, в котором запоминающее устройство, коммутационно связанное с аналого-цифровым преобразователем /АЦП/ 1-го терминала связи электронной системы (функционально являющегося в данном рассмотрении передающим), вводят входящий аналоговый аудиосигнал в речевой форме на входном языке. Затем посредством АЦП осуществляют аналого-цифровую обработку и преобразование речевой формы аналогового аудиосигнала в кодовую текстовую форму на 1-м, входном, языке, В процессе обмена информационными - кодовыми сигналами (в текстовой форме) между 1-м терминалом связи и вторым (принимающим) терминалом, обеспечивают электронный перевод кодовой текстовой формы на 1-м, входном, языке передающего 1-го терминала в кодовую текстовую форму на 3-м, выходном, языке 2-го (принимающего) терминала. На конечном этапе приемопередачи преобразуют кодовую форму текста на 3-м, выходном, языке 2-го терминала в аналоговый аудиосигнал в речевой форме на 3-м, выходном, языке этого 2-го терминала, посредством синтезатора речи и выводят речевую форму аналогового аудиосигнала на 3-м, выходном, языке через динамик 2-го терминала связи, функционально являющегося в рассматриваемом случае принимающим (RU №2419142).
Недостатком прототипа являются сложность аппаратной схемы и сложность преобразования аудиосигнала, в частности с учетом необходимости перевода кодовой текстовой формы входного аудиосигнала на промежуточный язык, длительность перевода, не обеспечивающая на практике реального синхронного перевода.
Известен способ обеспечения общения людей, говорящих на разных языках, электронная приемо-передающая система реализующая синхронный перевод устной речи с одного языка на другой, включающая по меньшей мере один приемо-передающий терминал связи входящего аналогового аудиосигнала в речевой форме, который содержит: энергонезависимое запоминающее устройство, преимущественно флэш-память; средства ввода речевой формы аналогового аудиосигнала на входном языке в терминал связи, функционально являющийся передающим; средства аналого-цифрового преобразования и обработки речевой формы аналогового аудиосигнала в кодовую текстовую форму на входном языке; средства перевода кодовой формы текста на входном языке в кодовую форму текста на выходном языке; средства цифроаналогового преобразования и обработки кодовой формы текста на выходном языке в аналоговый аудиосигнал на этом же языке в речевой форме, а также средства вывода речевой формы аналогового аудиосигнала на выходном языке через терминал связи, функционально являющийся принимающим (RU №2070734, прототип).
К недостаткам данного известного из уровня техники решения следует отнести относительно низкие функциональные и технические характеристики вследствие значительных погрешностей преобразования речевой формы вводимого в передающий терминал аудиосигнала в кодовую текстовую форму.
В целом, в настоящее время существуют системы распознавания речи и машинного перевода достаточно высокого качества. Такие системы требуют значительных вычислительных ресурсов. Для этого используется распределенная обработка на серверах в сети Интернет или облачных структурах. Такой подход имеет как плюсы (возможность обеспечить высокое качество), так и минусы (работы только при доступе к Интернету и полный контроль со стороны провайдера сервиса). Системы компаний Google и Apple (Siri) обеспечивают высокое качество распознавания речи при использовании большого словаря и сетевых облачных ресурсов. Локальные версии этих систем обеспечивают хорошее качество лишь для сравнительно небольших задач, например голосового ввода записей телефонной книжки.
Локальные системы распознавания речи и машинного перевода ограничены в своих возможностях вычислительными ресурсами терминалов (компьютеров или смартфонов). Главной причиной этого является большой размер словарей (до нескольких сот тысяч слов), языковых моделей и сложность таких систем. Однако при сужении тематики разговора сложность задачи распознавания речи и перевода значительно снижается. Для хорошего покрытия текста на заданную тему (например, бизнес, путешествия, спорт и т.д.) достаточно словаря размером 10-20 тысяч слов. Современные системы распознавания речи и машинного перевода способны решать такую задачу в несколько раз быстрее реального времени (времени произнесения фразы).
Технической задачей полезной модели является создание эффективного способа обеспечения общения людей, говорящих на разных языках, и расширение арсенала способов обеспечения общения людей, говорящих на разных языках.
Техническим результатом изобретения является обеспечение высокой точности перевода и возможности гибкого использования мобильных терминалов без привлечения сетевых ресурсов с одновременным расширением возможностей, реализуемых посредством заявленного изобретения, в частности: возможность высококачественного распознавания речи и машинного перевода на терминале без доступа к сетевым ресурсам за счет использования тематических языковых моделей; возможность использования для организации общения людей, говорящих на разных языках, различных, в том числе маломощных, терминалов за счет гибкого распределения стадий конвейера обработки информации между терминалами; возможность управления набором используемых акустических и языковых моделей, в том числе загрузка моделей из облачного сервиса, адаптация моделей к речи участника разговора и тематике разговора, сохранение моделей в облачном сервисе.
Для достижения технического результата в данном изобретении предлагается использовать набор тематических языковых моделей сравнительно небольшого размера для систем распознавания речи и машинного перевода, функционирующих на терминалах участников разговора. Средний объем таких моделей составляет от 5 до 20 мегабайт, что позволяет хранить набор моделей в постоянной памяти терминала. Участники разговора могут выбирать используемую модель в зависимости от тематики разговора.
В данном изобретении также предлагается возможность использования дополнительных сервисов, в частности сервиса распространения и хранения моделей в облаке и сервиса обучения акустических и языковых моделей. Пользователи предлагаемой системы могут получать доступ к акустическим и языковым моделям, хранящимся в облачном сервисе, и устанавливать их на свой терминал. На терминал могут быть установлены модели для нескольких языков и/или тематик. Речевой сигнал участника разговора может быть использован для обучения акустической модели, адаптированной к голосу этого участника разговора. Речевой сигнал участника разговора в виде текста может быть использован для обучения тематических языковых моделей. Обученные модели сохраняются в локальном запоминающем устройстве или в облачном сервисе хранения моделей.
Сущность изобретения заключается в том, что представлен способ обеспечения общения людей, говорящих на разных языках, согласно которому в первый терминал А вводится входной аналоговый речевой аудиосигнал на входном языке А; речевой сигнал преобразуется в цифровую форму, цифровой речевой сигнал на языке А при помощи программного средства распознавания речи, использующего только локальные ресурсы терминала А, в том числе тематическую языковую модель, расположенную в запоминающем устройстве терминала А, преобразуется в текст на языке А, текст на языке А при помощи программного средства машинного перевода речи, использующего только локальные ресурсы терминала А, в том числе тематическую языковую модель, расположенную в запоминающем устройстве терминала А, преобразуется в текст на выходном языке Б, и текст на языке Б передается по каналу связи второму терминалу Б, текст ответного сообщения на языке Б принимается терминалом А по каналу связи и передается программному средству синтеза речи на языке Б, формирующему цифровой аудиосигнал на языке Б, преобразуемый средством вывода речи в аналоговый аудиосигнал, который воспроизводится терминалом А. При этом терминал Б функционирует аналогично с точностью до замены языка А на язык Б и обратно.
При этом средство распознавания речи, и/или средство машинного перевода, и/или средство синтеза речи имеют аппаратную или аппаратно-программную реализацию.
В частных случаях реализации средство синтеза речи на языке Б функционирует на терминале А, средство синтеза речи на языке А функционирует на терминале Б, и по каналу связи передается речевой сигнал или кодированный речевой сигнал. При этом терминал Б функционирует аналогично с точностью до замены языка А на язык Б и обратно.
При этом средство распознавания речи, и/или машинного перевода, и/или средство синтеза речи имеют аппаратную или аппаратно-программную реализацию.
Кроме того, средство машинного перевода с языка Б на язык А и средство машинного перевода с языка А на язык Б функционируют на терминале А.
При этом средство распознавания речи и/или средство машинного перевода и/или средство синтеза речи имеют аппаратную или аппаратно-программную реализацию.
В частных случаях реализации средство синтеза речи на языке Б, средство машинного перевода с языка Б на язык А и средство синтеза речи на языке Б функционируют на терминале А, а в качестве терминала Б используется устройство с малой вычислительной мощностью (стационарный телефон или маломощный).
При этом средство распознавания речи и/или машинного перевода и/или средство синтеза речи имеют аппаратную или аппаратно-программную реализацию.
В частных случаях реализации в качестве терминалов связи используются мобильные электронные устройства, соединенные по протоколу Bluetooth 2.0/4.0 и не использующие сотовую связь для организации разговора.
При этом средство распознавания речи и/или машинного перевода и/или средство синтеза речи имеют аппаратную или аппаратно-программную реализацию.
В частных случаях реализации в качестве терминалов связи используются мобильные электронные устройства, соединенные по протоколу NFC и не использующие сотовую связь для организации разговора.
При этом средство распознавания речи и/или машинного перевода и/или средство синтеза речи имеют аппаратную или аппаратно-программную реализацию.
В частных случаях реализации в качестве первого и второго терминала функционально используют один и тот же терминал связи.
Предпочтительно, способ предусматривает обучение акустических и языковых моделей, ориентированных на конкретного пользователя и/или тематику разговора, и сохранение обученных моделей в облачном сервисе и их загрузку из облачного сервиса.
Предпочтительно, способ предусматривает загрузку из облачного сервиса акустических и языковых моделей, ориентированных на различные языки и тематики разговора.
На фиг.1 приведена общая схема аппаратной части терминала, на фиг.2 - общая схема программного обеспечения терминала, на фиг.3 - блок-схема процесса общения, когда участник А говорит, а участник Б слушает, на фиг.4 - блок-схема процесса, при котором используется перевод на промежуточный более распространенный язык В, на фиг.5-6 - блок-схемы терминалов А и Б при симметричном распределении стадий конвейера обработки информации и передаче текстовой информации между терминалами, на фиг.7-8 - блок-схемы терминалов А и Б при симметричном распределении стадий конвейера обработки информации и передаче кодированного речевого сигнала (например, по стандарту GSM) между терминалами, на фиг.9-10 - блок-схемы терминалов А и Б при условии, что терминал А обладает большей вычислительной мощностью, чем терминал Б, и передаче текстовой информации между терминалами, на фиг.11 - блок-схема терминала А при условии, что терминал Б является стационарным телефоном или маломощным сотовым телефонами и передаче кодированного речевого сигнала (например, по стандарту GSM) между терминалами, на фиг.12 - блок-схема терминала А при условии, что терминал Б является пейджером или другим устройством, допускающим ввод/вывод текстовой информации.
Конструктивно терминал (сотовый мобильный телефон, смартфон, персональный компьютер) представляет собой корпус 9 (изображен условно), в котором размещен процессор 1. К процессору 1 подключены запоминающее устройство 2, монитор 3, микрофон 4, динамик 5, клавиатура 6, блок питания 7, приемо-передающее устройство 8 (приемопередатчик GSM/GPRS/Wi-Fi, сетевая карта, гибридный Bluetooth 2.0/4.0, NFC и т.д.). Общая схема аппаратной части терминала приведена на фиг.1.
Программное обеспечение терминала включает следующие компоненты:
управляющая система 10, средство 11 ввода речи, средство 12 вывода речи, средство 13 кодирования речи, средство 14 распознавания речи, средство 15 синтеза речи, средство 16 машинного перевода, средство 17 обучения акустических моделей, средство 18 обучения языковых моделей, средство 19 взаимодействия с облачным сервисом 20. Используемые акустические и языковые модели для систем обработки речи хранятся в запоминающем устройстве 2. На фиг.2. обозначены:
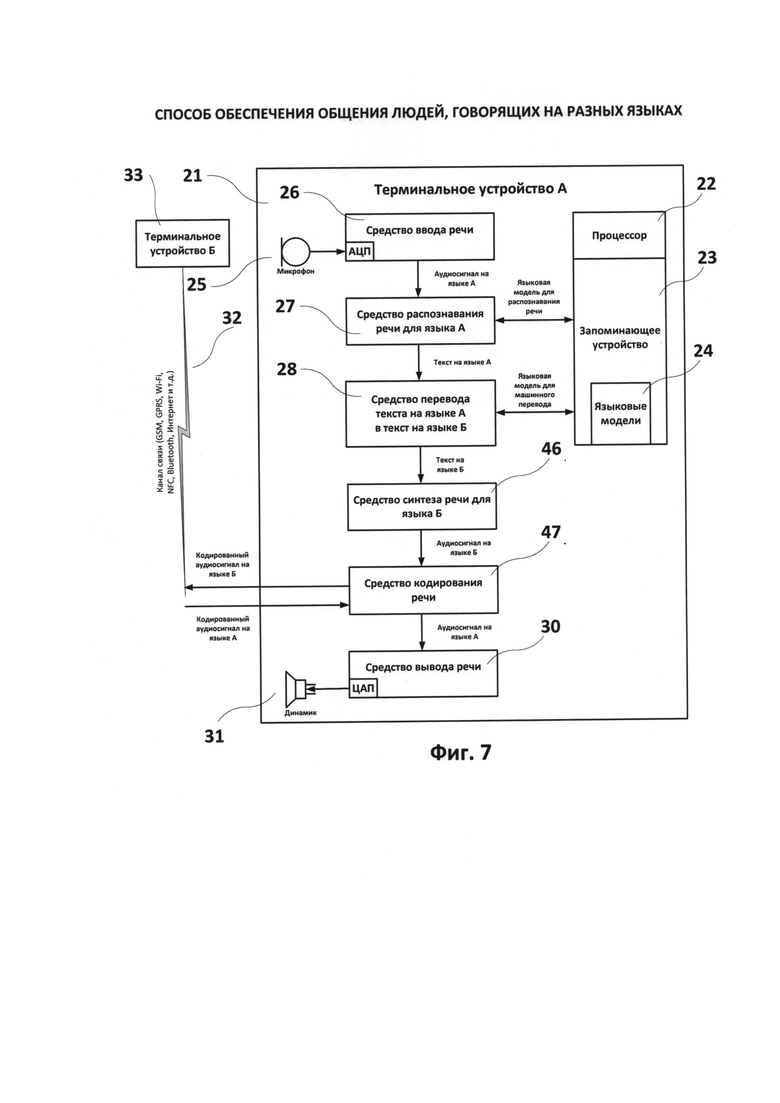
21 - первый (передающий) терминал А;
22 - процессор (на терминале А);
23 - запоминающее устройство (на терминале А);
24 - языковые модели, хранящиеся в запоминающем устройстве (на терминале А);
25 - микрофон (на терминале А);
26 - средство ввода речевой информации (на терминале А);
27 - средство распознавания речи для входного языка А (на терминале А);
28 - средство перевода текста на языке А в текст на языке Б (на терминале А);
29 - средство синтеза речи для языка А (на терминале А);
30 - средство вывода речевой информации (на терминале А);
31 - динамик (на терминале А);
32 - канал передачи информации между терминалами А и Б;
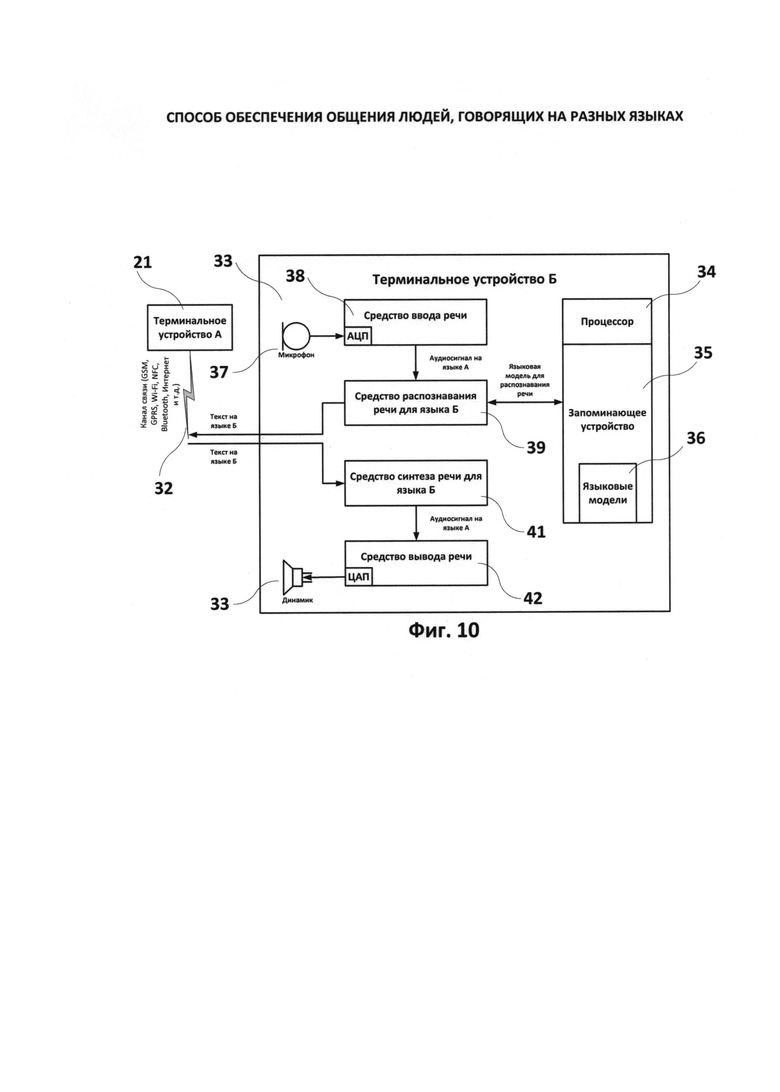
33 - второй (принимающий) терминал Б;
34 - процессор (на терминале Б);
35 - запоминающее устройство (на терминале Б);
36 - языковые модели, хранящиеся в запоминающем устройстве (на терминале Б);
37 - микрофон (на терминале Б);
38 - средство ввода речевой информации (на терминале Б);
39 - средство распознавания речи для языка Б (на терминале Б);
40 - средство перевода текста на языке Б в текст на языке А (на терминале
Б);
41 - средство синтеза речи для языка Б (на терминале Б);
42 - средство вывода речевой информации (на терминале Б);
43 - динамик (на терминале Б);
44 - средство перевода текста на языке Б в текст на языке А (на терминале А);
45 - средство синтеза речи для языка А (на терминале А);
46 - средство синтеза речи для языка Б (на терминале А);
47 - средство кодирования речи (на терминале А);
48 - средство кодирования речи (на терминале Б);
49 - средство распознавания речи для языка Б (на терминале А);
На фиг.5-12 некоторые существенные блоки и средства коммуникации (такие как экран, клавиатура, блок питания и т.д.) не показаны, поскольку они являются общеизвестными, и их функциональная принадлежность к рассматриваемым терминалам неоспорима, и они не являются принципиальными объектами заявленных изобретений.
Управляющая система 10 отвечает за координацию работы всех компонентов программного обеспечения терминала и управление режимами работы терминала. Средство 11 ввода речи отвечает за ввод речевого сигнала с микрофона. Средство 12 вывода речи отвечает за вывод речевого сигнала на динамик или другое устройство воспроизведения звука. Средство 13 кодирования речи выполняет преобразование речевого сигнала в набор кодовых векторов при распознавании речи и передаче на другой терминал. Средство 14 распознавания речи выполняет преобразование речевого акустического сигнала в текстовую форму. Средство 15 синтеза речи выполняет преобразование текста в речевой акустический сигнал. Средство 16 машинного перевода преобразует текст на одном языке в текст на другом языке. Средство 17 обучения акустических моделей накапливает информацию о речевом сигнале пользователя терминала и адаптирует акустические модели к специфическим особенностям речи данного пользователя. Средство 18 обучения языковых моделей накапливает информацию о фразах, произносимых пользователем терминала, и адаптирует языковые модели к специфическим особенностям речи данного пользователя на заданную тему. Средство 19 взаимодействия с облачным сервисом 20 отвечает за загрузку акустических и языковых моделей из облака и их сохранение в облаке.
Процесс общения людей, говорящих на разных языках, естественным образом разбивается на несколько стадий, фиг.3 иллюстрирует процесс, когда участник А говорит, а участник Б слушает:
a) ввод речи на языке А;
b) перевод речи на языке А в текст на языке А (распознавание речи);
c) перевод текста на языке А в текст на языке Б (машинный перевод);
d) перевод текста на языке Б в речь на языке Б (синтез речи);
e) вывод речи на языке Б.
Стадии a-e образуют конвейер обработки информации при общении людей, говорящих на разных языках. Стадии а и е могут, в принципе, выполняться на терминале, не имеющем вычислительной мощности, например стационарном телефоне или маломощном сотовом телефоне. Выполнение стадий b-d требует существенной вычислительной мощности. В качестве терминала, на котором выполняются эти задачи, может выступать, например, смартфон или ноутбук. Поскольку стадия а выполняется на терминале А, а стадия e - на терминале Б, в промежутке между этими стадиями информация должна быть передана с терминала А на терминал Б.
В данном изобретении предлагается дать участникам разговора возможность распределения стадий работы конвейера между терминалами А и Б, например в случае использования однотипных терминалов А и Б стадии a-с могут выполняться на терминале А, а стадии d-e - на терминале Б. Если терминал Б является стационарным телефоном, стадии a-d будут выполняться на терминале А, а стадия е - на терминале Б. Распределение работ между терминалами А и Б может задаваться автоматически, полуавтоматически или вручную в зависимости от вычислительной мощности терминалов А и Б, наличия языковых моделей на этих терминалах и/или выбора участников разговора.
Тип информации, передаваемой между терминалами А и Б, определяется распределением стадий конвейера между терминалами. Например, если на терминале А выполняются стадии а-с, будет передаваться текст на языке Б. Если же на терминале А выполняются стадии a-d, будет передаваться речевой сигнал (кодированный речевой сигнал). Передача текста является предпочтительной в силу меньшего объема и облегчения защиты передаваемых данных, но не обязательной.
Приведенный выше конвейер обработки информации не является единственно возможным. Например, при отсутствии средств перевода с языка А на язык Б может использоваться перевод на промежуточный более распространенный язык В (см. фиг.4). Реализация способа иллюстрируемыми чертежами:
Фиг.5-6 - блок-схемы терминалов А и Б при симметричном распределении стадий конвейера обработки информации и передаче текстовой информации между терминалами.
Фиг.7-8 - блок-схемы терминалов А и Б при симметричном распределении стадий конвейера обработки информации и передаче кодированного речевого сигнала (например, по стандарту GSM) между терминалами.
Фиг.9-10 - блок-схемы терминалов А и Б при условии, что терминал А обладает большей вычислительной мощностью, чем терминал Б, и передаче текстовой информации между терминалами.
Фиг.11 - блок-схема терминала А при условии, что терминал Б является стационарным телефоном или маломощным сотовым телефонами, и передаче кодированного речевого сигнала (например, по стандарту GSM), между терминалами.
Фиг.12 - блок-схема терминала А при условии, что терминал Б является пейджером или другим устройством, допускающим ввод/вывод текстовой информации.
Согласно заявленному способу в терминал А 21 (фиг.5-6), вводится входной аналоговый речевой сигнал на языке А через микрофон 25. Затем посредством АЦП, входящего в состав средства 26 ввода речи, осуществляется преобразование аналогового речевого сигнала в цифровой речевой сигнал на языке А. Речевой сигнал в цифровой форме поступает на вход средства 27 распознавания речи, использующего одну из языковых моделей 24, хранящихся в запоминающем устройстве 23. Средство 27 распознавания речи преобразует речевой сигнал на языке А в текстовую форму (текст на языке А) и передает его к средство 28 машинного перевода на язык Б. Средство 28 машинного перевода использует одну из языковых моделей 24, хранящихся в запоминающем устройстве 23, и преобразует текст на языке А в текст на языке Б, и передает его по каналу связи 32 терминалу Б 33. Ответ от терминала Б 33 в виде текста на языке А приходит по каналу передачи данных 32 и поступает на вход средства синтеза речи на языке А 29. Средство 29 синтеза речи на языке преобразует текст на языке А в цифровой речевой сигнал на языке А и передает его средству 30 вывода речи. Средство 30 вывода речи посредством входящего в его состав ЦАП преобразует цифровой речевой сигнал в аналоговый речевой сигнал и выводит его через динамик 31. Средства 27 распознавания речи, средства 28 машинного перевода и средства 29 синтеза речи на языке А, функционирующие на терминале А 21, используют процессор 22 и могут иметь программную, программно-аппаратную или аппаратную реализацию.
Изложенная выше схема иллюстрирует вариант реализации изобретения, представленный на фиг.5-6, и не является исчерпывающей или единственно возможной.
Особенностями заявленного способа является следующее.
При организации синхронного перевода устной речи используются только локальные вычислительные ресурсы терминалов и не используются сетевые ресурсы (в сети «Интернет», в облаке и т.д.).
Для преобразования входного речевого аудиосигнала в текст на языке А используются локальная система распознавания речи с языковой моделью, ориентированной на конкретную область (например, путешествия, бизнес, быт и т.д.), что позволяет повысить точность распознавания и снизить требования к вычислительной мощности терминала.
Для перевода текста на языке А в текст на языке Б или В используется локальная система машинного перевода с моделью языка, ориентированной на конкретную область (например, путешествия, бизнес, быт и т.д.), что позволяет повысить точность распознавания и снизить требования к вычислительной мощности терминала.
При организации синхронного перевода устной речи формируется конвейер передачи информации от одного участника разговора к другому.
Конвейер передачи информации от участника разговора А к участнику разговора Б включает следующие стадии: ввод речи на языке А, преобразование речи в текст на языке А, перевод текста с языка А на язык Б, синтез речи на языке Б, вывод речи на языке Б.
При отсутствии системы машинного перевода с языка А на язык Б конвейер передачи информации от участника разговора А к участнику разговора Б включает следующие стадии: ввод речи на языке А, преобразование речи в текст на языке А, перевод текста с языка А на язык В, перевод текста с языка В на язык Б, синтез речи на языке Б, вывод речи на языке Б.
Конвейер передачи информации от участника разговора Б к участнику разговора А формируется аналогично (язык А заменяется на язык Б и обратно).
Допускаются различные способы распределения стадий конвейера обработки информации между терминалами А и Б. После завершения работы последней стадии конвейера обработки информации на терминале А (Б) происходит передача информации (аудиосигнала, кодированного аудиосигнала или текста) терминалу Б (А), на котором выполняются оставшиеся стадии конвейера обработки информации.
Терминалы А и Б при установлении связи осуществляют распределения стадий конвейера обработки информации в зависимости от вычислительных возможностей терминалов и предварительных установок, заданных участниками разговора А и Б.
В качестве терминалов А и Б могут использоваться устройства, соединенные посредством системы мобильной связи (например, стандарта GSM или CDMA) или сети «Интернет». Также в качестве терминалов А и Б могут использоваться (в том числе для обеспечения конфиденциальности) устройства, соединенные посредством протоколов Bluetooth или NFC и не использующие сотовую связь.
Предлагаемая система позволяет обучать используемые акустические и языковые модели к конкретному пользователю и/или тематике разговора. Обученные модели могут быть сохранены в облачном сервисе и впоследствии использованы на этом или другом терминале данного пользователя. Кроме того, облачный сервис используется для распространения акустических и языковых моделей для других языков или тематик разговора.
Одним из конкретных частных приложений технической реализации заявленного способа является электронная приемо-передающая система с функцией синхронного перевода устной речи с языка А на язык Б между двумя терминалами А и Б при симметричном распределении стадий конвейера обработки информации и передаче текстовой информации между терминалами (фиг.5-6).
Еще одним из конкретных частных приложений технической реализации заявленного способа является электронная приемо-передающая система с функцией синхронного перевода устной речи с языка А на язык Б между двумя терминалами А и Б при симметричном распределении стадий конвейера обработки информации передаче кодированного речевого сигнала (например, по стандарту GSM) между терминалами (фиг.7-8).
Еще одним из конкретных частных приложений технической реализации заявленного способа является электронная приемо-передающая система с функцией синхронного перевода устной речи с языка А на язык Б между двумя терминалами А и Б при условии, что терминал А обладает большей вычислительной мощностью, чем терминал Б, и передаче текстовой информации между терминалами (фиг.9-10).
Еще одним из конкретных частных приложений технической реализации заявленного способа является электронная приемо-передающая система с функцией синхронного перевода устной речи с языка А на язык Б между двумя терминалами А и Б при условии, что терминал Б является стационарным телефоном или маломощным сотовым телефоном (фиг.11).
Еще одним из конкретных частных приложений технической реализации заявленного способа является электронная приемо-передающая система с функцией синхронного перевода устной речи с языка А на язык Б между двумя терминалами А и Б при условии, что терминал Б является пейджером или другим устройством, допускающим ввод/вывод текстовой информации (фиг.12).
В результате реализации настоящего изобретения обеспечиваются:
- возможность высококачественного распознавания речи и машинного перевода на терминале без доступа к сетевым ресурсам за счет использования тематических языковых моделей;
- возможность использования для организации общения людей, говорящих на разных языках, различных, в том числе маломощных, терминалов за счет гибкого распределения стадий конвейера обработки информации между терминалами;
- возможность управления набором используемых акустических и языковых моделей, в том числе загрузка моделей из облачного сервиса, адаптация моделей к речи участника разговора и тематике разговора, сохранение моделей в облачном сервисе.










Изобретение относится к области электроники, в частности к средствам приема и передачи речи абонентов, говорящих на разных языках. Техническим результатом является обеспечение защиты передаваемой и принимаемой речи от несанкционированного доступа, повышение точности передачи речи, повышение надежности приема и передачи речи. На мобильном терминале используются языковые модели, настроенные на заданную тему (например, туризм, бизнес, быт и т.д.). Это позволяет достигать высокого качества на устройствах с небольшой вычислительной мощностью (например, смартфонах). Для общения людей, говорящих на языках А и Б, организуется конвейер обработки информации, включающий следующие стадии: ввод речи на языке А, преобразование речи в текст на языке А, перевод текста на язык Б, синтез речи на языке Б, вывод речи на языке Б. Система позволяет также обучать акустические и языковые модели, ориентированные на конкретного пользователя и/или тематику разговора, и сохранять их в облачном сервисе. Гибкость работы обеспечивается возможностью локализации разных стадий конвейера обработки информации на терминалах участников разговора, а также возможностью загрузки используемых моделей из облачного сервиса. 11 з.п. ф-лы, 12 ил.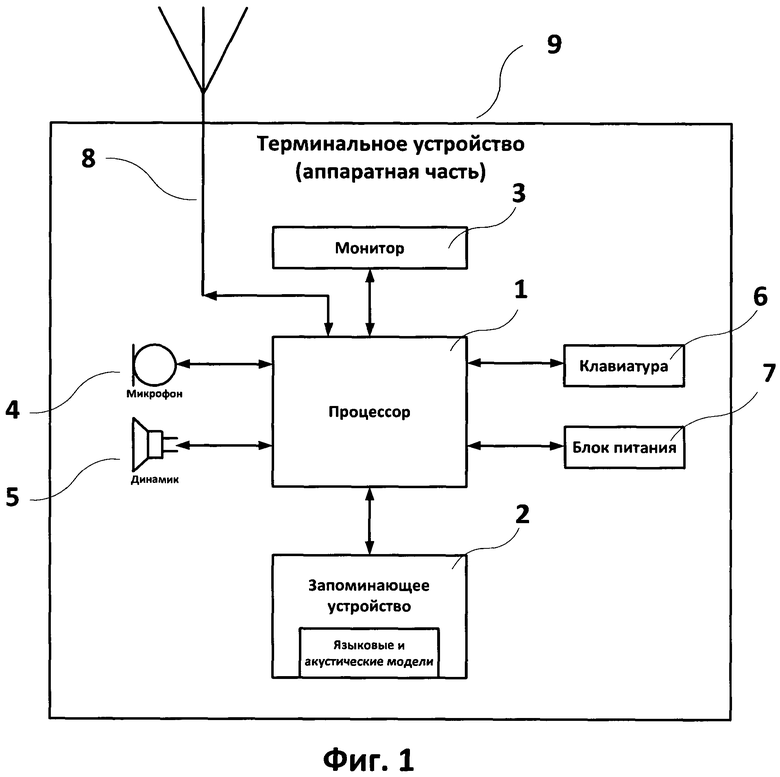
1. Способ передачи и приема речи абонентов, говорящих на разных языках, согласно которому между двумя терминалами связи устанавливается канал связи и при помощи локальных вычислительных ресурсов терминалов, в которых предусмотрены акустические и языковые тематические модели, формируется изолированный от сетевых ресурсов конвейер обработки аудиосигналов, в котором одним из терминалов принимается входной аналоговый речевой аудиосигнал на входном языке, при помощи локальных вычислительных ресурсов терминалов осуществляются распознавание речи и ее перевод в кодированный текст на входном языке, а затем с помощью акустических и языковых тематических моделей - машинный перевод этого текста в кодированный текст на выходном языке с последующим преобразованием переведенного кодированного текста для синтеза аналогового речевого аудиосигнала на выходном языке, который выводится другим терминалом.
2. Способ по п. 1, отличающийся тем, что одним из терминалов принимается входной аналоговый речевой аудиосигнал на входном языке и тем же терминалом при помощи его локальных вычислительных ресурсов, в которых предусмотрены акустические и языковые тематические модели, осуществляются распознавание речи и ее перевод в кодированный текст на входном языке, машинный перевод этого текста в кодированный текст на выходном языке с последующим преобразованием переведенного текста для синтеза аналогового речевого аудиосигнала на выходном языке, передаваемого для вывода по каналу связи другому терминалу.
3. Способ по п. 1, отличающийся тем, что одним из терминалов принимается входной аналоговый речевой аудиосигнал на входном языке, передаваемый по каналу связи другому терминалу, которым при помощи его локальных вычислительных ресурсов, в которых предусмотрены акустические и языковые тематические модели, осуществляются распознавание речи и ее перевод в кодированный текст на входном языке, машинный перевод этого текста в кодированный текст на выходном языке с последующим преобразованием переведенного текста для синтеза аналогового речевого аудиосигнала на выходном языке, который выводится этим же терминалом.
4. Способ по п. 1, отличающийся тем, что одним из терминалов принимается входной аналоговый речевой аудиосигнал на входном языке и при помощи его локальных вычислительных ресурсов, в которых предусмотрены акустические и языковые тематические модели, осуществляются распознавание речи и ее перевод в кодированный текст на входном языке, передаваемый по каналу связи другому терминалу, которым при помощи его локальных вычислительных ресурсов, в которых предусмотрены акустические и языковые тематические модели, осуществляется машинный перевод этого текста в кодированный текст на выходном языке с последующим преобразованием переведенного текста для синтеза аналогового речевого аудиосигнала на выходном языке, который выводится другим терминалом.
5. Способ по любому из п.п. 1-4, отличающийся тем, что аналоговый речевой аудиосигнал ответного сообщения на входном или выходном языке принимается соответствующим терминалом с последующим формированием конвейера обработки информации для синтеза аналогового речевого аудиосигнала на выходном или входном языке, соответственно, который выводится другим терминалом.
6. Способ по п. 5, отличающийся тем, что осуществляют реверсивную передачу входного и выходного речевых сигналов с помощью двух соединенных каналом связи терминалов, выполненных с возможностью формирования конвейера обработки информации для преобразования входного и выходного речевых сигналов, как в направлении от одного терминала другому, так и в обратном направлении.
7. Способ по любому из п.п. 2, 3, отличающийся тем, что в качестве одного из терминалов используется устройство из группы: стационарный телефон, мобильный телефон, использующие проводную или сотовую связь для организации разговора.
8. Способ по любому из пп. 1-4, 6, отличающийся тем, что, по меньшей мере одно из средств распознавания речи, машинного перевода, синтеза речи имеет аппаратную или аппаратно-программную реализацию.
9. Способ по любому из пп. 1-4, 6, отличающийся тем, что в качестве терминалов связи используются мобильные электронные устройства, соединенные беспроводным каналом связи по протоколу из группы: Bluetooth, NFC.
10. Способ по любому из пп. 1-4, 6, отличающийся тем, что канал связи для общения на разных языках устанавливают с образованием двух терминалов связи средствами одного и того же реверсивного терминального устройства.
11. Способ по любому из пп. 1-4, 6, отличающийся тем, что формируют тематические акустические и языковые модели, которые сохраняют в постоянной памяти по меньшей мере одного терминала или в облачном сервисе с возможностью их загрузки в терминалы связи при необходимости.
12. Способ по п. 11, отличающийся тем, что на по меньшей мере одном терминале используют тематические акустические и языковые модели на различных языках.
| Золотниковый парораспределительный механизм | 1929 |
|
SU31288A1 |
| СПОСОБ ОРГАНИЗАЦИИ СИНХРОННОГО ПЕРЕВОДА УСТНОЙ РЕЧИ С ОДНОГО ЯЗЫКА НА ДРУГОЙ ПОСРЕДСТВОМ ЭЛЕКТРОННОЙ ПРИЕМОПЕРЕДАЮЩЕЙ СИСТЕМЫ | 2008 |
|
RU2419142C2 |
| RU 2070734 C1, 20.12.1996 | |||
| US 4597056 A, 24.06.1986 | |||
| Способ получения смазочного и пропитывающего для набивок материала | 1934 |
|
SU45374A1 |
| US 5490061 A, 06.02.1996. | |||

