Изобретение относится к технологиям распознавания речи, т.е. системам и способам перевода звукового сигнала, содержащего речь, в текст, состоящий из слов, входящих в лексический и произносительный словари системы распознавания речи.
Область применения изобретения: голосовое управление электронными приборами, автоматическая стенография, специальные программы для слабовидящих, голосовое управление движущимися средствами на расстоянии слышимости голоса.
Заявленное изобретение позволяет распознавать слитную непрерывную речь вне зависимости от индивидуальных особенностей говорящего на основе определения групп фонем по характеризующим их признакам и методе последовательного декодирования последовательностей символов, обозначающих группы фонем, в цепочку слов, составляющих высказывание (текст).
Известно техническое решение, характеризующее способ дикторонезависимого распознавания звуков речи, включающий в себя предварительную сегментацию речевого сигнала для определения временной длительности звуковых сегментов, определение периодичности каждого сегмента акустических составляющих речевого сигнала для соотнесения звукового сегмента по способу его образования к голосовому, шумному или шумно-голосовому виду звуков речи, определение амплитуды и частоты каждой из первых трех формант в спектре звукового сегмента в качестве информативных признаков звуков речи, интеграцию упомянутых информативных признаков для каждого звукового сегмента, фонемное распознавание каждого звукового сегмента путем сопоставления интегральных значений его информативных признаков с имеющимся банком данных отдельно для каждого вида звуков речи, принятие решения относительно распознаваемого звука речи и представление его в виде буквенного или транскрипционного обозначения. Основную сегментацию речевого сигнала выполняют по трем основным режимам в зависимости от ранее найденного вида звукового сегмента, при упомянутом фонемном распознавании сопоставляют интегральные значения информативных признаков каждого звукового сегмента как для каждого упомянутого вида звуков речи, так и для каждого типа в зависимости от числа формант в звуковом сегменте, затем устанавливают временные границы звуков речи в зависимости от изменения фонемной принадлежности звукового сегмента, после чего и принимают упомянутое решение относительно распознаваемого звука речи (патент на изобретение РФ 2234746, G10L 19/02, 30.10.2002). К числу недостатков данного решения следует отнести низкую различительную способность и скорость распознавания речи по формантам, поступательный характер распознавания, обуславливающие последовательное распознавание каждой форманты, а также необходимость обращаться в процессе распознавания к словарям и эталонным образцам.
Известно также техническое решение способа распознавания слов в слитной речи, состоящее в том, что с произнесением речевого высказывания периодически берут выборки акустического сигнала этого высказывания, оцифрованного с заданной частотой квантования, через фиксированные интервалы времени и по совокупности этих выборок вычисляют функционал, определяющий текущее акустическое состояние, при этом полученную последовательность текущих акустических состояний используют для восстановления последовательности слов (рабочей гипотезы), произнесенных в исходном речевом высказывании, для чего применяют сеть лексического декодирования, которая задает закономерности следования эталонных акустических состояний в языке. При этом проводится поиск рабочей гипотезы, являющийся оптимальным в смысле максимума степени ее совпадения с исходным речевым сигналом, что обеспечивается использованием алгоритма перемещаемого маркера, а восстанавливают рабочую гипотезу из маркера, который в этот момент времени находится в конечной вершине сети лексического декодирования (патент на изобретение РФ 2297676, G10L 15/02, 30.03.2005) Несмотря на то, что в данном способе различительная способность выше, чем в предыдущем способе, однако, аналогично с предыдущим известным способом распознавания речи к числу недостатков данного метода следует также отнести длительность процесса распознавания, обусловленного необходимостью обращения к эталонным образцам, а также поочередным распознаванем каждой форманты в слове.
Известны также способ и система распознавания речи, построенные с использованием методов фонемного анализа (патент США №5315689, МПК G10L 5/06, 1995), в котором применяется двухуровневая обработка речевого сигнала. Блок первого уровня осуществляет распознавание слова (команды) как звукового (слухового) образа в целом. Альтернативный блок второго уровня производит фонемное распознавание звукового сигнала. Недостатком этого способа является снижение степени вероятности правильного распознавания слов (фраз) при увеличении объема речевого фрагмента и распознавании слитной речи.
Известны также решения системы и способа распознавания речи (заявка на изобретение США US 2010332231 A1, G10L 15/04, 01.06.2010), заключающиеся в том, что из слитной речи на первом этапе определяют последовательность фонем, подлежащих распознаванию, которые затем сравнивают с хранящимся в памяти устройства списком слов, соответствующих отобранным фонемам, при этом далее осуществляют вероятностную оценку, по установленным ранее критериям на основании которой выбирают из ранее сформированного слова наиболее вероятные, а незнакомое слово вносят в словарь и определяют критерии для последующей вероятностной оценки. К числу недостатков данного способа можно отнести его чрезмерную сложность и высокие требования к ресурсам памяти устройства, осуществляющего распознавание речи в соответствии с данным способом, кроме того, решение не позволяет осуществлять распознавание слитной речи, так как распознавание идет слишком медленно и с достаточной степенью точности возможно лишь определение отдельных речевых команд, а не слитной речи.
Известно также решение системы распознавания речи (патент на изобретение США US 4624011 A, G10L 5/00 28.01.1983), в которой распознавание речи осуществляется сначала по определению частотных спектров речи, а затем по определению последовательности фонем и их акустических характеристик, выделяемых вспомогательным модулем, которые затем сравниваются с хранящимися в памяти эталонными характеристиками для вышеуказанных последовательностей, и вычисляется степень сходства, при этом при превышении предустановленного порога делается вывод о соответствии фонемы эталону, а при недостижении порогового значения - вносят новое слов в словарь. Недостатки данного способа распознавания речи и системы для его осуществления аналогичны предыдущему решению.
Известен способ и система распознавания речи, в которых (патент на изобретение США US 4696042, G10L 5/00, 03.11.1983) распознавание речи осуществляется по лингвистическим фонемам, предварительно распределенным по группам, соответствующим характеристическим особенностям произнесения звуков. Причем звук определяют в том числе по характерному созвучию со следующим звуком, что позволяет повысить различительную способность и качество распознавания, однако требует достаточно большого времени на последовательную обработку как отдельного звука, так и дифтонга.
Наиболее близким аналогом по совокупности существенных признаков, признанным в качестве прототипа, является решение системы и способа распознавания речи, известное из патента США US 4852170 (G10L 5/04, 18.12.1986), характеризующееся способом цифрового распознавания речи в режиме реального времени системой, включающей анализатор спектра, определяющий частную характеристику каждого сегмента речи заданной длительности, при этом каждый сегмент речи анализируется логически на наличие фонем и их принадлежность определенному классу, частью которого они являются, и затем частотный спектр сегмента анализируется на наличие особенностей, позволяющих распознать специфические фонемы в пределах типа. Последовательность фонем может быть сохранена в виде компактных групп и преобразована затем для синхронизации с голосом и логически переведена с одного языка на другой. К числу недостатков данного способа и системы распознавания речи следует отнести пофонемное распознание звуков в рамках выделенного речевого сегмента, что требует значительных временных затрат и существенного увеличения аппаратного ресурса и ресурса памяти для обеспечения требуемого быстродействия системы, невозможность реализации системы на базе компактных устройств. Необходимость ориентироваться на образцы произнесения речи разными возрастными категориями с учетом особенности их спектральных характеристик, выделяемых по различным признакам, как и в предыдущих случаях, либо приводит к потере качества, либо к существенному увеличению длительности распознавания.
Технической задачей заявленного изобретения является предложение способа, обеспечивающего дикторонезависимое распознавание слитной речи в режиме реального времени в сочетании с компактной системой его реализации.
Технический результат, достигаемый заявленным изобретением, заключается в сокращении длительности распознавания речи в сочетании с высокой точностью, обеспечиваемых вне зависимости от специфических особенностей разных языковых систем.
Заявленный технический результат достигается тем, что используют способ распознавания речи, включающий последовательно исполняемые этапы приема речевого сигнала на входе блока приема; обработки речевого сигнала блоком обработки информации, включающей его обработку аналого-цифровым преобразователем с предустановленной частотой дискретизации и разделением на сегменты, спектрального анализа сегментов речевого сигнала и нормализации спектра на высоких частотах; выделения в нормализованном спектре пауз, шумов и звуковых сигналов с последующим его распознаванием и преобразованием в текст с использованием предустановленного словаря. При этом отличается от прототипа тем, что на этапе распознавания на основе исходного речевого сигнала и нормализованного спектра в каждом сегменте определяют наличие/отсутствие акустических признаков речевого сигнала, комбинаторные наборы которых характеризуют группы фонем, параметры которых предустановленны в блоке памяти, и осуществляют сравнение определенных комбинаторных наборов акустических признаков сегмента с предустановленными параметрами групп фонем, с одновременным формированием последовательности символов, обозначающих группы фонем, соответствующие комбинаторным наборам акустических признаков каждого сегмента, преобразование которой в связный текст осуществляют последовательным декодированием комбинаторного сочетания символов групп фонем последовательности на основе словаря, размеченного по символам групп фонем.
В предпочтительном варианте изобретения определение комбинаторного набора акустических признаков сегмента речевого сигнала осуществляют параллельно и одномоментно.
В одном из вариантов изобретения на этапе разделения речевого сигнала на сегменты обрабатывают речевой сигнал короткими окнами одинаковой длины со смещением в два раза меньшей длины, с обеспечением возможности регистрации кратковременных характерных явлений внутри звуков речи и плавных переходов от одного звука в потоке речи к другому.
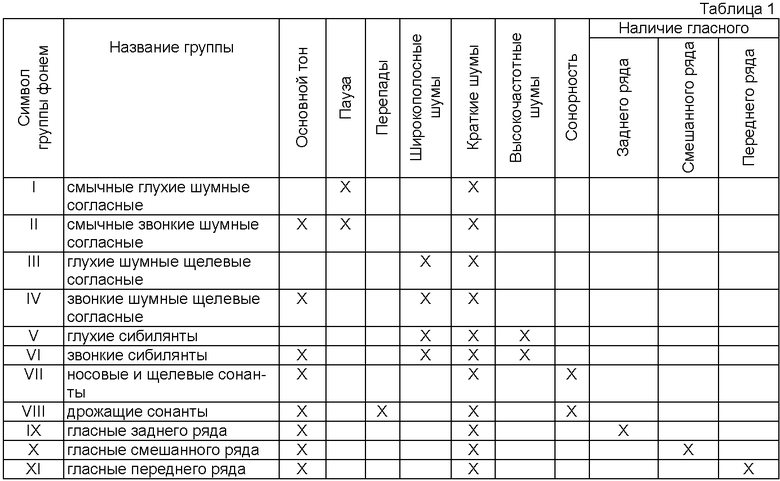
При классификации групп фонем используют комбинаторный набор акустических признаков, включающий определение наличия или отсутствия в речевом сигнале, по меньшей мере, основного тона, широкополосных шумов, перепада интенсивности речевого сигнала, высокочастотных шумов, сонорности, гласного, ряда гласного, комбинаторное сочетание которых формирует 11 групп фонем с неповторяемым набором акустических признаков: смычные глухие шумные согласные, смычные звонкие шумные согласные, глухие шумные щелевые согласные, звонкие шумные щелевые согласные, глухие сибилянты, звонкие сибилянты, носовые и щелевые сонанты, дрожащие сонанты, гласные переднего ряда, гласные смешанного ряда и гласные заднего ряда. А преобразование последовательности символов, обозначающих группы фонем, в текст осуществляют на основе последовательного метода декодирования, заключающегося в последовательном сокращении вариантов в выборке слов и словоформ из словаря, размеченного по символам групп фонем, формируемой по комбинаторной последовательности символов групп фонем от первого символа в сегменте до фрагмента последовательности, включающего комбинацию символов групп фонем, определяющую единственное слово из словаря, после которого осуществляют распознавание следующей входной последовательности, начиная с первого символа группы фонем после входящего в определенное ранее слово.
При этом, в одном из вариантов реализации заявленного изобретения, осуществляют формирование словаря на основе слов, написанных в транскрипции с вариантами произнесения, состоящих из размеченных по символам групп фонем.
Словарь может быть выполнен предустановленным в блок памяти, с обеспечением возможности его инициализации на этапе распознавания, так и дополнительно подгружаемым в блок памяти как файл со списком слов с соответствующими им транскрипциями, размеченными по символам групп фонем. На этапе декодирования последовательности символов, обозначающих группы фонем, в текст могут использовать один или группу предустановленных тематических словарей, размеченных по символам групп фонем, разных языковых систем. Тематический словарь или группа словарей, размеченных по символам групп фонем, может быть выбран из списка предустановленных тематических словарей на начальном этапе способа распознавания речи.
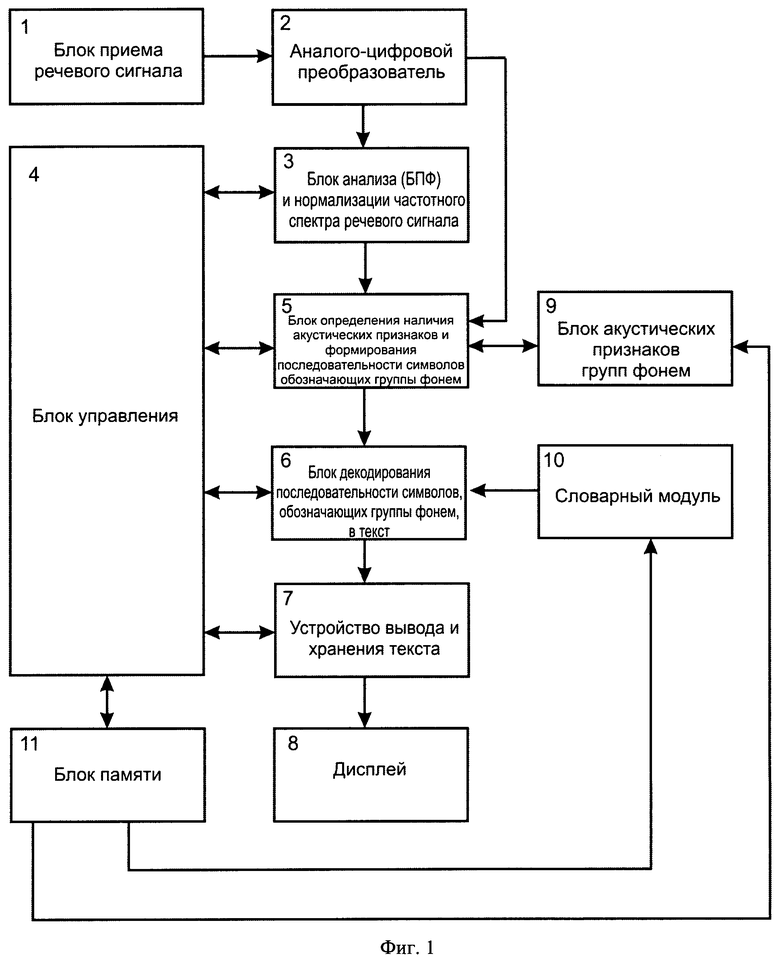
Заявленный технический результат достигается также тем, что для осуществления способа используют систему распознавания речи, включающую блок приема речевого сигнала, последовательно соединенный с аналого-цифровым преобразователем, выход которого соединен с блоком анализа и нормализации частотного спектра речевого сигнала, соединенного с блоком управления и блоком памяти, выполненной с обеспечением возможности записи и хранения распознанного речевого сигнала, хранения и вызова словаря. При этом система распознавания речи, согласно изобретению, отличается от прототипа тем, что дополнительно содержит последовательно соединенные блок определения наличия акустических признаков и формирования последовательности символов, обозначающих группы фонем, выполненный с обеспечением возможности формирования по текущим комбинаторным сочетаниям акустических признаков присутствующих в речевом сигнале соответствующей им последовательности символов, обозначающих группы фонем, блок декодирования последовательности символов, обозначающих группы фонем, в текст, по меньшей мере, один из входов которого соединен с блоком ввода предустановленного словаря, размеченного по символам групп фонем и вызываемого из блока памяти, выполненный с обеспечением возможности определения слов на основе словаря по комбинаторному сочетанию символов групп фонем текущей последовательности, а также устройство вывода и хранения текста, по меньшей мере, один вход/выход которых соединен с блоком управления, выполненным с обеспечением возможности управления режимами функционирования блоков, обмена данными между ними и взаимодействия с блоком памяти. При этом вход блока определения наличия акустических признаков и формирования последовательности символов, обозначающих группы фонем, соединен с выходом аналого-цифрового преобразователя, с обеспечением возможности ввода речевого сигнала, и выходом блока анализа и нормализации частного спектра речевого сигнала, с обеспечением возможности ввода нормализованного речевого сигнала, и блоком акустических признаков групп фонем, с обеспечением возможности сравнения текущего комбинаторного набора акустических признаков речевого сигнала с параметрами набора акустических признаков предустановленных групп фонем, и соединенный с блоком памяти. Устройство вывода и хранения текста дополнительно снабжено дисплеем для вывода и отображения распознанного текста на экран.
При этом в одном из вариантов выполнения изобретения блок акустических признаков групп фонем содержит комбинаторный набор акустических признаков 11 групп фонем: смычные глухие шумные согласные, смычные звонкие шумные согласные, глухие шумные щелевые согласные, звонкие шумные щелевые согласные, глухие сибилянты, звонкие сибилянты, носовые и щелевые сонанты, дрожащие сонанты, гласные переднего ряда, гласные смешанного ряда и гласные заднего ряда, включающий для каждой их групп фонем по меньшей мере характеристику наличия/отсутствия в окне основного тона, широкополосных шумов, перепада интенсивности речевого сигнала, высокочастотных шумов, сонорности, гласного, ряда гласного.
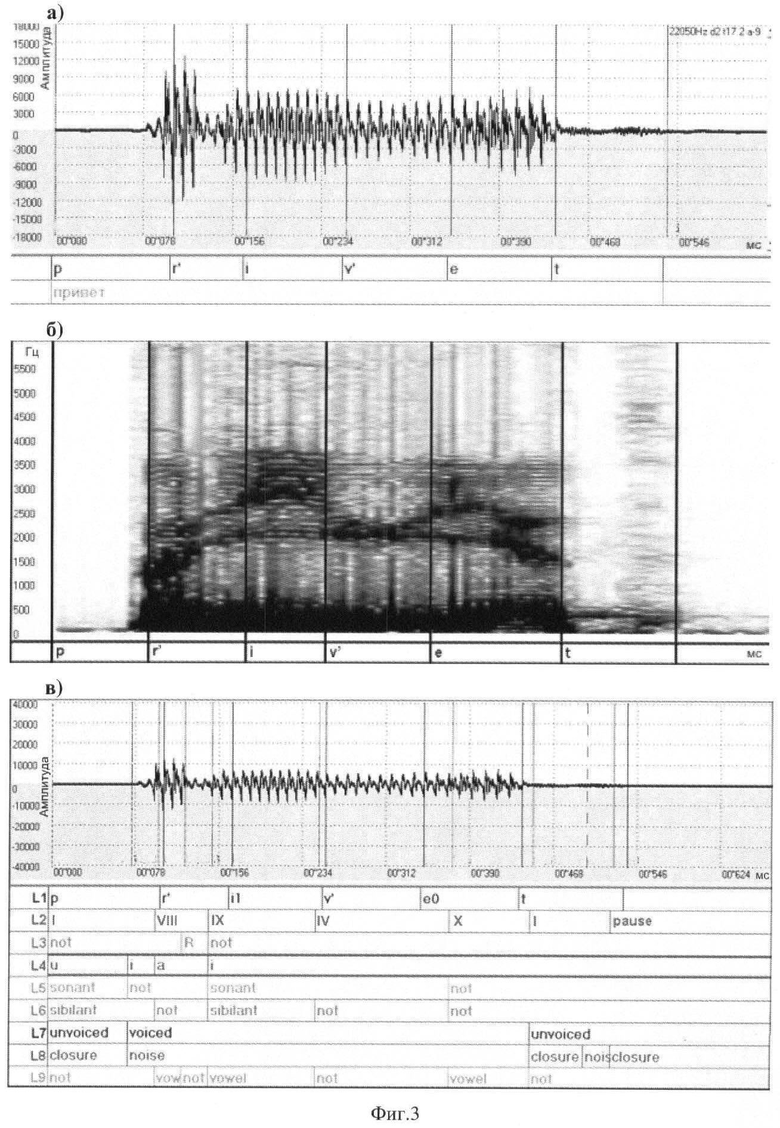
Заявленное изобретение поясняется чертежами, представленными на фиг.1-3, где фиг.1 - структурная схема системы распознавания речи, фиг.2 - функциональная схема распознавания речи, включая этапы определения акустических признаков, формирования последовательности символов, обозначающих группы фонем, и ее декодирования в текст, фиг.3 - пример формирования последовательности символов, определяющих группы фонем: 3а) - осциллограмма с разметкой речевого сигнала на аллофоны; 3б) - спектрограмма с разметкой на аллофоны; 3в) - иллюстрация определения на основе осциллограммы нормализованного речевого сигнала акустических признаков и формирования последовательности символов, определяющих группы фонем. Данный пример описывает частную реализацию системы и способа в соответствии с изобретением и не является исчерпывающим описанием их возможных реализаций.
В представленном примере реализации система распознавания речи согласно изобретению реализована на цифровом устройстве, представляющем архитектуру компьютера под управлением центрального микропроцессора с оперативным (ОЗУ) и постоянным (ПЗУ) запоминающими устройствами. Как следует из схемы, представленной на фиг.1, система распознавания речи содержит блок 1 приема речевого сигнала (приемник звука), в качестве которого может быть использован микрофон, как встроенный, так и внешний, любого известного из уровня техники типа и модели, последовательно соединенный с аналого-цифровым преобразователем 2 с частотой дискретизации не менее 22 кГц, осуществляющим преобразование речевого сигнала в цифровую форму. Блок 4 управления, выполненный на основе многоканального центрального микропроцессора, соединен по стандартным интерфейсным, мультиплексным каналам связи с последовательно соединенными друг с другом блоком 3 анализа и нормализации частотного спектра речевого сигнала, блоком 5 определения акустических признаков и формирования последовательности символов, обозначающих группы фонем, блоком 6 декодирования последовательности символов, обозначающих группы фонем, в текст и устройством 7 вывода и хранения текста, а также с блоком 11 памяти. Блок 5 определения наличия акустических признаков и формирования последовательности символов, обозначающих группы фонем, дополнительно соединен с выходом аналого-цифрового преобразователя 2, с обеспечением возможности передачи на вход бока 5 речевого сигнала, а также с блоком 9 акустических признаков групп фонем, с обеспечением возможности сравнения текущих комбинаций акустических признаков речевого сигнала с предустановленными комбинаторными наборами акустических признаков групп фонем. При этом блок 6 детектирования последовательности символов, обозначающих группы фонем, в текст соединен по каналам интерфейсной связи с выходом словарного модуля 10, вход которого соединен с блоком 11 памяти с обеспечением возможности вызова из блока памяти любого предустановленного тематического словаря или группы словарей, размеченных по символам групп фонем, и осуществления отбора слов соответствующих комбинациям символов групп фонем в текущей последовательности. Блок 11 памяти через блок 4 управления соединен с устройством 7 вывода и хранения текста, один выход которого соединен с устройством вывода распознанного текста, выполненного, например, в виде устройства 8 отображения - дисплея. В качестве устройства 7 вывода текста может быть использовано устройство печати и/или внешнее устройство хранения. В качестве устройства 8 отображения может быть использовано любое известное из уровня техники устройство, используемое в составе компьютерных или телекоммуникационных устройств. Блоки системы и функциональные связи между ними выполнены программно-аппаратным образом, с обеспечением возможности настройки конфигурации и ее адаптации к используемым компьютерным и мультимедийным средствам.
При этом система и способ распознавания речи согласно изобретению работают следующим образом.
Речевой сигнал в виде звукового потока данных поступает на вход блока приема речевого сигнала системы распознавания речи и передается далее на вход аналого-цифрового преобразователя, где осуществляют преобразование сигнала в цифровой вид. Полученный цифровой речевой сигнал передают на вход блока анализа и нормализации речевого сигнала, где осуществляют его сегментацию при обработке короткими окнами одинаковой длины и со смещением в два раза меньше длины, что позволяет выявлять как плавные переходы от одного звука в потоке речи к другому, так и кратковременные характерные явления внутри звуков речи, например, взрывы смычных согласных. Окна обработки выбирают по длине таким образом, чтобы получить наиболее оптимальные и сглаженные признаки групп фонем по времени их звучания в потоке речи. Эмпирически установлено, что длина окон в 25 мс дает оптимальный результат. Акустические признаки речевого сигнала, характерные для групп фонем, используемых в качестве базовых элементов для распознавания, определяют в рамках каждого окна (сегмента речевого сигнала) параллельно и одномоментно. При этом часть акустических признаков определяют напрямую из осциллограммы речевого сигнала, полученной от аналого-цифрового преобразователя, а часть - из спектра речевого сигнала, получаемого при обработке речевого сигнала в блоке анализа и нормализации при помощи быстрого преобразования Фурье. Полученный спектр нормализуется на высоких частотах в соответствии с нелинейным восприятием разных частот человеческой слуховой системой, что позволяет компенсировать более низкую интенсивность высоких частот по сравнению с низкими частотами в речевом сигнале.
Как указано выше, для определения акустических признаков речевого сигнала в каждом окне используют как исходный речевой сигнал, так и нормализованный спектр. На основе комбинаций значений акустических признаков определяется группа фонем, к которой относится речевой сигнал в рамках текущего окна обработки.
При этом процедура выделения акустических признаков, применяемых для определения групп фонем, из сигнала согласно изобретению осуществляется в рамках каждого окна (сегмента речевого сигнала) параллельно и одновременно, программно-аппаратным образом. Так как при классификации групп фонем используют следующий набор акустических признаков, позволяющих однозначно определить каждую из рассматриваемых в рамках изобретения 11 групп фонем: наличие/отсутствие основного тона, наличие/отсутствие широкополосных шумов, наличие/отсутствие перепада интенсивности речевого сигнала, наличие/отсутствие высокочастотных шумов, наличие/отсутствие сонорности, акустический признак присутствия/отсутствия гласного, акустический признак ряда гласного, то и анализ речевого сигнала в каждом окне осуществляют на наличие/отсутствие акустических признаков, присущих группам фонем в речевом сигнале или нормализованном спектре.
Одной из важнейших акустических характеристик является наличие основного тона в речевом сигнале. Отсутствие основного тона в сигнале свидетельствует о том, что в данный момент времени либо произносится глухой согласный, либо присутствует перерыв в речи (пауза). Присутствие основного тона определяют по высокой интенсивности частотных составляющих в низкочастотной области в диапазоне возможных значений частоты основного тона. Интенсивность частотных составляющих в текущем окне определяют относительного их максимальной интенсивности в речевом сигнале на протяжении сравнительно длинного отрезка речевого сигнала длинной около 5 секунд. Если в речевом сигнале в рамках предыдущего окна обработки было определено отсутствие основного тона и широкополосных шумов, а в речевом сигнале в текущем окне был определен один из других признаков, то данное окно дополнительно проверяется на наличие в нем широкополосных шумов, что является признаком, характеризующим группу смычные глухие шумные согласные или смычные звонкие шумные согласные.
Кратковременные перепады интенсивности речевого сигнала, свидетельствующие о присутствии в сигнале коротких смычек, характерных для дрожащих сонантов, определяют по соотношению интенсивности речевого сигнала в трех последовательно идущих окнах обработки. Интенсивность речевого сигнала в среднем окне существенно ниже интенсивности речевого сигнала в правом и левом окнах, в то время как интенсивность речевого сигнала в правом и левом окнах практически одинакова.
Наличие широкополосных шумов в речевом сигнале, связанных с произношением щелевых согласных или присутствием взрыва, происходящего во время размыкания смычки при произнесении смычных согласных, определяют по наличию интенсивных частотных составляющих в диапазоне выше возможных значений частоты основного тона и ее первой гармоники. Интенсивность частотных составляющих в текущем окне определяют относительного их максимальной интенсивности в речевом сигнале на протяжении сравнительно длинного отрезка речевого сигнала длинной около 5 секунд.
Наличие высокочастотных шумов в речевом сигнале, связанных с произношением щелевых сибилянтов, определяют в диапазоне выше возможных значений частоты основного тона и ее первой гармоники, по отношению интенсивности частотных составляющих в области средних частот и интенсивности частотных составляющих в области высоких частот. Интенсивность высокочастотных шумов существенно превосходит интенсивность средних частот в случае произнесения щелевых сибилянтов.
Сонорность речевого сигнала, характерную для произнесения сонантов и гласных, в противоположность шумным согласным, определяют по высокой интенсивности частотных составляющих в диапазоне средних частот выше низкочастотной области в диапазоне возможных значений частоты основного тона, но вмещающих в себя диапазон возможных значений частот формант сонантов. Интенсивность частотных составляющих в текущем окне считается относительно их максимальной интенсивности в речевом сигнале на протяжении сравнительно длинного отрезка речевого сигнала длинной около 5 секунд.
Еще одним акустическим признаком, используемым при распознавании речи и для характеристики групп фонем, является отсутствие или наличие гармонических составляющих в спектре в частотной области выше диапазона возможных значений частот формант сонантов. Отсутствие гармонических составляющих в области средних и верхних частот характерно для сонантов, а присутствие для гласных. Наличие или отсутствие гармонических составляющих определяется по отношению интенсивности частотных составляющих ниже и выше частотного порога.
Другой важной акустической характеристикой звуков речи является качество возможно произнесенного гласного, а именно ряд его произнесения, т.е. положения основной массы языка в полости рта в горизонтальном положении. Ряд произнесения гласного определяют по соотношению интенсивности гармонических составляющих в спектре речевого сигнала в области низких частот, области средних частот и области верхних частот. Отсутствие гармонических составляющих в спектре речевого сигнала в области средних частот и области верхних частот свидетельствует о произнесении гласного заднего ряда. Присутствие гармонических составляющих в спектре речевого сигнала в области средних частот свидетельствует о произнесении гласного среднего ряда. Одновременное присутствие гармонических составляющих в спектре речевого сигнала в области низких частот и области верхних частот и их отсутствие в области средних частот свидетельствует о произнесении гласного заднего ряда. Наличие или отсутствие гармонических составляющих определяют по отношению интенсивности частотных составляющих в области низких частот, области средних частот и области верхних частот.
В системе и способе согласно изобретению используют следующие группы фонем: смычные глухие шумные согласные (I), смычные звонкие шумные согласные (II), глухие шумные щелевые согласные (III), звонкие шумные щелевые согласные (IV), глухие сибилянты (V), звонкие сибилянты (VI), носовые и щелевые сонанты (VII), дрожащие сонанты (VIII), гласные переднего ряда (IX), гласные смешанного ряда (X) и гласные заднего ряда (XI). В скобках указан символ группы фонем, в соответствии с таблицей 1, однако в качестве символа групп фонем может быть использован любой машиночитаемый цифробуквенный или графический символ, который позволяет идентифицировать группу и осуществлять обработку речевого сигнала программно-аппаратным образом по признакам идентифицированных таким образом групп фонем.
Смычные глухие шумные согласные (I) определяются следующими акустическими признаками: отсутствием основного тона и широполосных шумов, и характеризуются смычкой, то есть фактическим отсутствием речевого сигнала, и последующими кратковременными широкополосными шумами. Смычные глухие шумные согласные отличаются от пауз между словами длиной смычки, которая значительно короче паузы между словами, и наличием последующего взрыва, характеризующегося кратковременными широкополосными шумами.
Смычные звонкие шумные согласные (II) однозначно определяются следующими акустическими признаками: наличием основного тона и отсутствием широполосных шумов на месте смычки, а также последующими кратковременными широкополосными шумами на месте взрыва.
Глухие шумные щелевые согласные (III) определяются следующими акустическими признаками: отсутствием основного тона, наличием широполосных шумов, отсутствием высокочастотных шумов, отсутствием сонорности.
Звонкие шумные щелевые согласные (IV) определяются следующими акустическими признаками: наличием основного тона, наличием широполосных шумов, отсутствием высокочастотных шумов, отсутствием сонорности.
Глухие сибилянты (V) определяются следующими акустическими признаками: отсутствием основного тона, наличием широполосных шумов, наличием высокочастотных шумов, отсутствием сонорности.
Звонкие сибилянты (VI) определяются следующими акустическими признаками: наличием основного тона, наличием широполосных шумов, наличием высокочастотных шумов, отсутствием сонорности.
Носовые и щелевые сонанты (VII) определяются следующими акустическими признаками: наличием основного тона, наличием сонорности, акустической характеристикой отсутствия гласного.
Дрожащие сонанты (VIII) определяются следующими акустическими признаками: наличием основного тона, наличием сонорности, наличием перепада интенсивности речевого сигнала.
Гласные заднего ряда (IX) определяются следующими акустическими признаками: наличием основного тона, наличием сонорности, акустической характеристикой присутствия гласного, акустической характеристикой заднего ряда гласного.
Гласные смешанного ряда (X) определяются следующими акустическими признаками: наличием основного тона, наличием сонорности, акустической характеристикой присутствия гласного, акустической характеристикой смешанного ряда гласного.
Гласные переднего ряда (XI) определяются следующими акустическими признаками: наличием основного тона, наличием сонорности, акустической характеристикой присутствия гласного, акустической характеристикой переднего ряда гласного.
Аффрикаты рассматриваются как последовательное произнесение соответствующих смычного и щелевого согласного, т.е. /с/ - это комбинация /t/ и /s/, a /ch/ - это комбинация /t/ и /sch'/, что отражается в транскрипции словаря блока 4.
Все признаки по группам фонем приведены в таблице 1.
Соответствие используемых групп фонем и фонем русского и английского языка приведены в таблице 2.
Соответствие используемых групп фонем и фонем русского и английского языка приведены в таблице 3.
Транскрипционные значки в таблице 3 приведены с использованием алфавита ARPAbet, стандартно применяемого во многих современных системах распознавания речи для английского языка.
Как видно из данных, представленных в таблицах 2 и 3, признаки групп фонем с одинаковой степенью достоверности позволяют идентифицировать звуки речи как для русского языка, так и для английского, что подтверждает универсальность заявленного способа распознавания речи вне зависимости от языковой системы.
Распознавание речи осуществляют на основе метода последовательного декодирования последовательностей символов, обозначающих группы фонем, в цепочку слов, составляющих высказывание (текст). Для определения слова по последовательности символов, обозначающих группы фонем, используется произносительный словарь, состоящий из списка слов и соответствующих им транскрипций, размеченный в символах групп фонем. Вначале этапа словарь загружают в оперативную память устройства и каждое слово кодируют в символах групп фонем по таблице соответствия. Разбор входной комбинации символов осуществляют на основании последовательного метода, который определяет варианты подходящих слов из словаря по последовательности символов фонем, пока варианты не приведут к единственному слову из словаря наибольшей длины (с наибольшим числом в составе из входной последовательности символов групп фонем). После этого начинается разбор следующей входной последовательности, начиная с первого символа группы фонем после входящего в определенное ранее слово.
Когда обработка входной последовательности символов групп доходит до самой краткой формы слова, имеющейся в словаре, проводится дальнейший выбор из вариантов этого слова с окончаниями и составными словами последовательности этой формы слова. Если следующий символ в последовательности не дает ни одного из вариантов продолжения этого слова, то это конечная форма слова, и происходит переход на определение нового слова. Если есть варианты окончания для этого слова по следующему символу, то выбирается этот вариант до конца. В случае, если выбранная наиболее длинная форма слова из словаря, соответствующая входной последовательности символов, приводит к неразборчивости последующей цепочки (не соответствию ни одному слову из словаря), проверяются варианты с другими формами (более короткими и не составными) этого слова. И если выбор более короткой формы приводит к разборчивости последующей последовательности, выбирается более короткий вариант слова.
Если входная последовательность символов не соответствует ни одному слову из словаря или его левой части (приводит к нулевому выбору слов из словаря), то она отсекается по одному символу из последовательности символов фонем, пока последующий разбор слов (справа от отсеченного) не окажется удачным.
Реализация способа согласно изобретению проиллюстрирована на нижеприведенном примере, дающем представление о работе способа и системы, но не являющемся исчерпывающим.
Пример распознавания на примере распознавания слова «ПРИВЕТ»
Слово «привет» и его транскрипции:
- орфографическая запись: привет;
- фонемная транскрипция: /р r' i v' e t/;
- символьная транскрипция на основе признаков групп фонем: /I VIII IX IV Х I/ в соответствии с таблицей 2.
На фиг.3в) обозначены следующие уровни сегментации:
L1 - разметка речевого сигнала на аллфоны.
L2 - определенные группы фонем.
L3 - уровень наличия перепада интенсивности речевого сигнала. Обозначения: R - наличие перепада интенсивности речевого сигнала, not - отсутствие перепада интенсивности речевого сигнала.
L4 - уровень акустического признака гласного. Обозначения: i - гласный переднего ряда, а - гласный смешанного ряда, u - гласный заднего ряда.
L5 - уровень наличия сонорности. Обозначения: sonant - наличие сонорности, not - отсутствие сонорности.
L6 - уровень наличия высокочастотных шумов. Обозначения: sibilant - наличие высокочастотных шумов, not - отсутствие высокочастотных шумов.
L7 - уровень наличия основного тона. Обозначения: voiced - наличие основного тона, unvoiced - отсутствие основного тона.
L8 - уровень наличия широполосных шумов. Обозначения: not - наличие широполосных шумов, closure - отсутствие широполосных шумов.
L9 - уровень наличия гласного. Обозначения: vowel - наличие гласного, not - отсутствие гласного.
Разбор последовательности символов в текст
Входной речевой (акустический) сигнал обрабатывают в блоке анализа и нормализации спектра. Длина речевого сигнала слова "привет" составляет около 700 мс. Речевой сигнал представляют в виде последовательности из 28 окон длиной в 25 мс. В каждом окне при помощи процедуры быстрого преобразования Фурье вычисляют спектр на частоте 0-7000 Гц. Полученный спектр нормализуют. Последовательность окон нормализованного сигнала поступает в блок определения наличия акустических признаков и формирования последовательности символов, обозначающих группы фонем, который определяет, что слово "привет" (в транскрипции pr'iv'et) соответствует последовательности I VIII IX IV Х I. Определение производилось на экспериментальном частотном словаре в 2400 словоформ. Минимальное слово, которое соответствует комбинации от первого символа, - I VIII IX выявляет предлог pr'i. В выборку этого слова входит 49 словоформ (слов, начинающихся с последовательности I VIII IX). Дальнейший выбор происходит только из данной выборки слов, помещенных в хэш-программы. Следующий символ группы сужает выборку до 12 слов, соответствующих словоформам - привет, прививка, включая привитый, прививать и др., приветствую, включая приветствует, приветствуют, приветствуем, приветливый и др. Выбор продолжают, так как все слова имеют большую длину по числу фонем относительно неразобранной последовательности. Четвертый символ в последовательности не сужает выбор, а пятый (X) сужает его на все словоформы слова "прививка". Шестой символ (I) не сужает выбор из оставшихся словоформ слова "привет" в символах групп, но это последний символ, и такой последовательности символов групп соответствует только одно слово - "привет". Как видно из представленного примера, система и способ распознавания речи не требует обращения к каким-либо образцам произнесения слов и не связан с характерными особенностями произношения, так как процесс распознавания основан на объективных акустических характеристиках речевого сигнала, являющихся дикторонезависимыми, и их сопоставлении с признаками групп фонем, и использовании произносительного словаря, размеченного в терминах групп фонем, с обеспечением возможности осуществления последовательно выборки слов из словаря по набору символов групп фонем с сужением выборки до единственного слова при последовательном добавлении символа справа от минимальной последовательности символов, определяющих обособленное слово из словаря и следующих за ним возможных словоформ, исключая последовательное пофонемное распознавание звуков, требующее учета особенностей речи диктора, с последующим распознаванием слов.
Таким образом, система и способ распознавания слитной речи в звуковом потоке согласно изобретению позволяет существенно сократить длительность распознавания речи в сочетании с высокой точностью за счет распознавания речи по цепочке символов групп фонем, исключая пофонемное распознавание, требующее больших временных затрат и значительных аппаратных ресурсов. Одновременное определение несколько основополагающих признаков звучащей речи, включающих в себя наличие или отсутствие основного тона, наличие или отсутствие широкополосных шумов, наличие или отсутствие перепада интенсивности речевого сигнала, наличие или отсутствие высокочастотных шумов, наличие или отсутствие сонорности, акустический признак присутствия или отсутствия гласного, акустический признак ряда гласного, позволяет классифицировать речевой сигнал в соответствии с признаками, являющимися независимыми от акустических характеристик разных дикторов, а также языка на котором, произносится речь.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ РАСПОЗНАВАНИЯ РЕЧИ НА ОСНОВЕ ДВУХУРОВНЕВОГО МОРФОФОНЕМНОГО ПРЕФИКСНОГО ГРАФА | 2015 |
|
RU2597498C1 |
| Способ и устройство классификации сегментов зашумленной речи с использованием полиспектрального анализа | 2014 |
|
RU2606566C2 |
| КОМПЬЮТЕРНОЕ УСТРОЙСТВО ДЛЯ ЧТЕНИЯ ПЛОСКОПЕЧАТНОГО ТЕКСТА | 1996 |
|
RU2113726C1 |
| СИСТЕМА И СПОСОБ ПЕРЕВОДА РЕЧЕВОГО СИГНАЛА В ТРАНСКРИПЦИОННОЕ ПРЕДСТАВЛЕНИЕ С МЕТАДАННЫМИ | 2014 |
|
RU2589851C2 |
| СПОСОБ РАСПОЗНАВАНИЯ ИЗОЛИРОВАННЫХ СЛОВ РЕЧИ С АДАПТАЦИЕЙ К ДИКТОРУ | 1994 |
|
RU2047912C1 |
| Устройство для обработки речевого сигнала | 2018 |
|
RU2701120C1 |
| СПОСОБ ВЕРИФИКАЦИИ ПОЛЬЗОВАТЕЛЯ В СИСТЕМАХ САНКЦИОНИРОВАНИЯ ДОСТУПА | 2007 |
|
RU2351023C2 |
| СПОСОБ ПРЕДВАРИТЕЛЬНОЙ ОБРАБОТКИ ТЕКСТА | 2007 |
|
RU2386178C2 |
| СПОСОБ ВЫДЕЛЕНИЯ ОСНОВНОГО ТОНА | 1998 |
|
RU2174714C2 |
| Способ дикторонезависимого распознавания фонемы в речевом сигнале | 2021 |
|
RU2763124C1 |
Изобретение относится к технологиям распознавания речи, т.е. системам и способам перевода звукового сигнала, содержащего речь, в текст, состоящий из слов, входящих в лексический и произносительный словари системы распознавания речи. Техническим результатом является сокращение длительности и высокая точность распознавания речи. Указанный результат достигается тем, что используют систему и способ распознавания речи, осуществляющие прием речевого сигнала на входе блока приема; обработку речевого сигнала блоком обработки информации, включающую его обработку аналого-цифровым преобразователем с предустановленной частотой дискретизации и разделением на сегменты, спектральный анализ сегментов речевого сигнала и нормализацию спектра на высоких частотах; выделение в нормализованном спектре пауз, шумов и звуковых сигналов. Далее определяют на основе исходного речевого сигнала и нормализованного спектра в каждом сегменте наличие/отсутствие акустических признаков речевого сигнала, комбинаторные наборы которых сравнивают с предустановленными в блоке памяти параметрами групп фонем, и по результатам сравнения осуществляют формирование последовательности символов, обозначающих группы фонем, соответствующих комбинаторным наборам акустических признаков каждого сегмента, преобразование которой в связный текст осуществляют последовательным декодированием комбинаторного сочетания символов групп фонем последовательности на основе словаря, размеченного по символам групп фонем. 2 н. и 17 з.п. ф-лы, 5 ил., 3 табл.
1. Способ распознавания речи, включающий последовательно исполняемые этапы приема речевого сигнала на входе блока приема; обработки речевого сигнала блоком обработки информации, включающей его обработку аналого-цифровым преобразователем с предустановленной частотой дискретизации и разделением на сегменты, спектрального анализа сегментов речевого сигнала и нормализации спектра на высоких частотах; выделения в нормализованном спектре пауз, шумов и звуковых сигналов с последующим его распознаванием и преобразованием в текст с использованием предустановленного словаря, отличающийся тем, что на этапе распознавания на основе исходного речевого сигнала и нормализованного спектра в каждом сегменте определяют наличие/отсутствие акустических признаков речевого сигнала, комбинаторные наборы которых характеризуют группы фонем, параметры которых предустановлены в блоке памяти, и осуществляют сравнение определенных комбинаторных наборов акустических признаков сегмента с предустановленными параметрами групп фонем, с одновременным формированием последовательности символов, обозначающих группы фонем, соответствующие комбинаторным наборам акустических признаков каждого сегмента, преобразование которой в связный текст осуществляют последовательным декодированием комбинаторного сочетания символов групп фонем последовательности на основе словаря, размеченного по символам групп фонем.
2. Способ распознавания по п.1, отличающийся тем, что при классификации групп фонем используют комбинаторный набор акустических признаков, включающий определение наличия или отсутствия в речевом сигнале, по меньшей мере, основного тона, широкополосных шумов, перепада интенсивности речевого сигнала, высокочастотных шумов, сонорности, гласного, ряда гласного, комбинаторное сочетание которых формирует 11 групп фонем с неповторяемым набором акустических признаков: смычные глухие шумные согласные, смычные звонкие шумные согласные, глухие шумные щелевые согласные, звонкие шумные щелевые согласные, глухие сибилянты, звонкие сибилянты, носовые и щелевые сонанты, дрожащие сонанты, гласные переднего ряда, гласные смешанного ряда и гласные заднего ряда.
3. Способ распознавания по п.1, отличающийся тем, что часть акустических признаков вычисляют из осциллограммы, а остальные - из спектра речевого сигнала, получаемого при помощи быстрого преобразования Фурье.
4. Способ распознавания по п.1, отличающийся тем, что определение комбинаторного набора акустических признаков сегмента речевого сигнала осуществляют параллельно и одномоментно.
5. Способ распознавания по п.1, отличающийся тем, что на этапе распознавания речи по последовательности символов, обозначающих группы фонем, используют предустановленный словарь, размеченный по символам групп фонем.
6. Способ распознавания по п.1 или 5, отличающийся тем, что преобразование последовательности символов, обозначающих группы фонем, в текст осуществляют на основе последовательного метода декодирования, заключающегося в последовательном сокращении выборки слов и словоформ из словаря, размеченного по символам групп фонем, формируемой по комбинаторной последовательности символов групп фонем от первого символа в сегменте до фрагмента последовательности, включающего комбинацию символов групп фонем, определяющую единственное слово из словаря, после которого осуществляют распознавание следующей входной последовательности.
7. Способ распознавания по п.2, отличающийся тем, что присутствие основного тона определяют по высокой интенсивности частотных составляющих в низкочастотной области в диапазоне возможных значений частоты основного тона, а интенсивность частотных составляющих в текущем окне определяют относительного их максимальной интенсивности в речевом сигнале на протяжении длинного отрезка речевого сигнала.
8. Способ распознавания по п.7, отличающийся тем, что интенсивность частотных составляющих в текущем окне определяют на протяжении отрезка речевого сигнала не менее 4 с.
9. Способ распознавания по п.2, отличающийся тем, что кратковременные перепады интенсивности определяют по соотношению интенсивности речевого сигнала в трех последовательно идущих окнах обработки.
10. Способ распознавания по п.2, отличающийся тем, что широкополосные шумы определяют по наличию интенсивных частотных составляющих в диапазоне выше возможных значений частоты основного тона и ее первой гармоники, при этом интенсивность частотных составляющих в текущем окне определяют относительно их максимальной интенсивности в речевом сигнале на протяжении сравнительно длинного отрезка речевого сигнала.
11. Способ распознавания по п.2, отличающийся тем, что высокочастотные шумы определяют в диапазоне выше возможных значений частоты основного тона и ее первой гармоники, по отношению интенсивности частотных составляющих в области средних частот и интенсивности частотных составляющих в области высоких частот.
12. Способ распознавания по п.2, отличающийся тем, что сонорность определяют по высокой интенсивности частотных составляющих в диапазоне средних частот выше низкочастотной области в диапазоне возможных значений частоты основного тона, но вмещающих в себя диапазон возможных значений частот формант сонантов.
13. Способ распознавания по п.2, отличающийся тем, что наличие гласных или сонант определяют по соответственно наличию/отсутствию гармонических составляющих в области средних и верхних частот.
14. Способ распознавания по п.2, отличающийся тем, что ряд произнесения гласного определяют по соотношению интенсивности гармонических составляющих в спектре речевого сигнала в области низких частот, области средних частот и области верхних частот.
15. Способ распознавания по п.1, отличающийся тем, что на этапе декодирования последовательности символов, обозначающих группы фонем, в текст используют один или группу предустановленных тематических словарей, размеченных по символам групп фонем, разных языковых систем, выбор которых осуществляют на начальном этапе распознавания речи.
16. Система распознавания речи, включающая блок приема речевого сигнала, последовательно соединенный с аналого-цифровым преобразователем, выход которого соединен с блоком анализа и нормализации частотного спектра речевого сигнала, соединенного с блоком управления и блоком памяти, выполненной с обеспечением возможности записи и хранения распознанного речевого сигнала, хранения и вызова словаря, отличающаяся тем, что дополнительно содержит последовательно соединенные блок определения наличия акустических признаков и формирования последовательности символов, обозначающих группы фонем, выполненный с обеспечением возможности формирования по текущим комбинаторным сочетаниям акустических признаков присутствующих в речевом сигнале соответствующей им последовательности символов, обозначающих группы фонем, блок декодирования последовательности символов, обозначающих группы фонем в текст, по меньшей мере, один из входов которого соединен с блоком ввода предустановленного словаря, размеченного по символам групп фонем и вызываемого из блока памяти, выполненный с обеспечением возможности определения слов на основе словаря по комбинаторному сочетанию символов групп фонем текущей последовательности, а также устройство вывода и хранения текста, по меньшей мере, один вход/выход которых соединен с блоком управления, выполненным с обеспечением возможности управления режимами функционирования блоков, обмена данными между ними и взаимодействия с блоком памяти.
17. Система распознавания по п.16, отличающаяся тем, что вход блока определения наличия акустических признаков и формирования последовательности символов, обозначающих группы фонем, соединен с выходом аналого-цифрового преобразователя с обеспечением возможности ввода речевого сигнала и выходом блока анализа и нормализации частного спектра речевого сигнала с обеспечением возможности ввода нормализованного речевого сигнала, и блоком акустических признаков групп фонем с обеспечением возможности сравнения текущего комбинаторного набора акустических признаков речевого сигнала с параметрами набора акустических признаков предустановленных групп фонем, и соединенный с блоком памяти.
18. Система распознавания по п.16, отличающаяся тем, что устройство вывода и хранения текста дополнительно снабжено дисплеем для вывода и отображения распознанного текста.
19. Система распознавания по любому из пп.16, 17 или 18, отличающаяся тем, что блок акустических признаков групп фонем содержит комбинаторный набор акустических признаков 11 групп фонем: смычные глухие шумные согласные, смычные звонкие шумные согласные, глухие шумные щелевые согласные, звонкие шумные щелевые согласные, глухие сибилянты, звонкие сибилянты, носовые и щелевые сонанты, дрожащие сонанты, гласные переднего ряда, гласные смешанного ряда и гласные заднего ряда, включающий для каждой из групп фонем по меньшей мере характеристику наличия/отсутствия в окне основного тона, широкополосных шумов, перепада интенсивности речевого сигнала, высокочастотных шумов, сонорности, гласного, ряда гласного.
| US 4852170 A, 25.07.1989 | |||
| Бесколесный шариковый ход для железнодорожных вагонов | 1917 |
|
SU97A1 |
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| Крышка для герметизации стеклянных банок в домашних условиях | 1959 |
|
SU128755A1 |
| СПОСОБ ДИКТОРОНЕЗАВИСИМОГО РАСПОЗНАВАНИЯ ЗВУКОВ РЕЧИ | 2002 |
|
RU2234746C2 |
| СПОСОБ РАСПОЗНАВАНИЯ ФОНЕМ РЕЧИ И УСТРОЙСТВО ДЛЯ РЕАЛИЗАЦИИ СПОСОБА | 2004 |
|
RU2268504C9 |

