Область техники
[0001] Настоящее изобретение направлено на способы определения профиля пользователя мобильного устройства на самом мобильном устройстве и системы демографического профилирования. Профиль пользователя мобильного устройства может включать в себя демографическую информацию пользователя, интересы пользователя (например, спорт, книги, покупки и т.д.), поведение пользователя и другую информацию о пользователе, представляющую интерес для поставщиков контента. Профиль пользователя может быть предоставлен поставщику контента. Затем поставщик контента может модифицировать взаимодействия с пользователем на основе предоставленного профиля пользователя.
Уровень техники
[0002] Учитывая значительное увеличение количества пользователей мобильных устройств ввиду их большей доступности и закономерный скачок в развитии сетей связи, технологии определения профилей пользователей мобильных устройств привлекают все больший интерес среди поставщиков контента и производителей мобильных устройств. Такие технологии позволяют им наблюдать за поведением пользователей на мобильных устройствах для определения информации, услуг, или товаров, к которым эти пользователи проявляют интерес, и на которые среди них имеется спрос. Ввиду этого, технологии определения профилей пользователей получили значительное освещение в уровне техники. Ниже приведены актуальные решения из уровня техники, которые являются наиболее близкими к настоящему изобретению.
[0003] Публикация патентной заявки США № US 2015/0356581 A1 (10.12.2015) раскрывает систему и способ определения демографического профиля пользователя мобильного терминала на основе сетевой оценки установленных мобильных приложений и шаблонов их использования. Для корректной работы данного технического решения предложена система (40) демографической классификации, которая расположена вне мобильного терминала пользователя. Данная система перехватывает весь сетевой трафик, исходящий из мобильного терминала пользователя, в точке (38), и анализирует его для оценки комбинации классов приложений, установленных на терминале, а также шаблонов их использования самим пользователем. Несмотря на то, что системой демографической классификации оценивается только обезличенная информация комбинаций классов приложений, и шаблонов их использования, исходящий сетевой трафик, который может включать в себя информацию конфиденциального характера, например, ФИО пользователя, доход пользователя, данные веб-форм, IMSI (международный идентификатор мобильного абонента), и другую информацию, обращение с которой должно быть особенно деликатным, перехватывается в полном объеме. Таким образом, основной проблемой данного решения является возможность утечки некоторой критичной информации при передаче сетевого трафика пользователя с его устройства в стороннюю систему, несмотря на то, что подавляющее большинство пользователей желает избежать каких-либо утечек критичной или конфиденциальной информации со своих мобильных устройств. Другой проблемой раскрытого в вышеупомянутой публикации решения является его непригодность к использованию на самом мобильном терминале ввиду его ограниченных ресурсов. В качестве примера, раскрытая в вышеуказанном источнике система (40) не может быть реализована на самом мобильном, поскольку для ее корректной работы на мобильном устройстве, мобильному устройству было бы необходимо обрабатывать весь исходящий трафик. Мобильное устройство просто не приспособлено к обработке такого большого объема данных. В этой ситуации, попытка реализация системы (40) на мобильном устройстве привела бы к неминуемому снижению его производительности, поскольку мобильное устройство было бы вынуждено тратить больше вычислительных и энергетических ресурсов на обработку и анализ такого большого объема информации. Вышеописанное решение является ближайшим аналогом.
[0004] Публикация другой патентной заявки США № US 2016/0182662 A1 (23.06.2016) раскрывает определение профиля использования сети пользователем с использованием модуля (142) обработки сетевого трафика и модуля (144) обработки пользовательских данных. Указанные модули расположены за пределами пользовательского устройства и осуществляют инспекцию пакетов данных для создания отчетов о действиях пользователей за интересующий период времени. Таким образом, аналогично вышеописанному ближайшему аналогу, основной проблемой данного решения является передача всего сетевого трафика пользователя сторонними модулями, несмотря на то, что подавляющее большинство пользователей желает избежать каких-либо утечек критичной или конфиденциальной информации со своих мобильных устройств. Другой проблемой раскрытого в публикации `662 решения является его непригодность к использованию на самом мобильном терминале ввиду его ограниченных ресурсов. Таким образом, это решение обладает аналогичными недостатками.
[0005] Кроме того, из уровня техники известны другие решения: патент США № US 8131271 B2 (06.03.2012), патент США № US 7162522 B2 (09.01.2007). Однако, эти решения также обладают аналогичными недостатками.
Задачи и проблемы, решаемые настоящим изобретением
[0006] Благодаря настоящему изобретению решается задача определения профиля пользователя на мобильном устройстве самого пользователя. Вследствие этого, никакая критичная или конфиденциальная информация не покидает мобильное устройство пользователя. Таким образом, в настоящем изобретении возможность утечки критичной или конфиденциальной информации пользователя при определении его профиля полностью исключена. Вследствие этого повышается защита конфиденциальной информации пользователя.
[0007] Кроме того, благодаря настоящему изобретению решается проблема непригодности самого мобильного устройства для реализации традиционно ресурсоемкого процесса определения профиля пользователя мобильного устройства. Для корректной работы настоящего изобретения обученными и экспортированными на мобильное устройство моделями обрабатывается текстовое содержимое веб-страниц, просматриваемых пользователем. Вследствие этого, настоящее изобретение снижает требования к вычислительным ресурсам мобильного устройства, поскольку необходимость обрабатывать и анализировать большой объем данных отсутствует. Кроме того, вследствие вышеупомянутого также снижается энергопотребление мобильного устройства. Дополнительно, обученные в соответствии с настоящим изобретением модели занимают лишь сотни килобайт в памяти мобильного устройства. Таким образом, настоящее изобретение дополнительно снижает требования к ресурсам памяти мобильного устройства.
[0008] Кроме того, в настоящем изобретении тематическая модель формируется на основе корпуса данных, который содержит тектовые данные, предобработанные и переведенные на представляющие интерес языки. Таким образом, настоящее изобретение обеспечивает мультиязычную тематическую модель. Благодаря этой мультиязычности нет необходимости создавать множество различных моделей для каждого конкретного языка. Мультиязычная тематическая модель производит корректную классификацию текстов на всех учтенных при ее обучении языках.
Сущность изобретения
Средства для решения задач и проблем
[0009] В первом аспекте настоящего изобретения предусмотрен способ определения демографического профиля пользователя мобильного устройства на самом мобильном устройстве, хранящем обученную мультиязычную тематическую модель и обученную демографическую модель, причем способ содержит этапы, на которых: собирают, на мобильном устройстве, содержимое веб-страниц, просмотренных пользователем на мобильном устройстве; осуществляют, на мобильном устройстве, предобработку содержимого веб-страниц для приспособления содержимого веб-страниц под тематическую модель; обрабатывают, на мобильном устройстве, предобработанное содержимое веб-страниц тематической моделью для получения векторов скрытых тем, ассоциированных с содержимым веб-страниц, просмотренных пользователем на своем мобильном устройстве; извлекают из полученного векторов скрытых тем вектор признаков пользователя; определяют, на мобильном устройстве, демографический профиль пользователя посредством обработки извлеченного вектора признаков пользователя демографической моделью.
[0010] Во втором аспекте настоящего изобретения предусмотрена система демографического профилирования, содержащая: внешнее вычислительное устройство, которое выполнено с возможностью обучения тематической модели и демографической модели; по меньшей мере одно мобильное устройство, которое выполнено с возможностью осуществления способа определения демографического профиля пользователя мобильного устройства на самом мобильном устройстве в соответствии с первым аспектом настоящего изобретения.
[0011] Благодаря настоящему изобретению решается задача определения профиля пользователя на мобильном устройстве самого пользователя. Вследствие этого, никакая критичная или конфиденциальная информация не покидает мобильное устройство пользователя. Таким образом, в настоящем изобретении возможность утечки критичной или конфиденциальной информации пользователя при определении его профиля полностью исключена. Вследствие этого повышается защита конфиденциальной информации пользователя. Другими словами, согласно настоящему изобретению “сырая” критическая и конфиденциальная информация пользователя используется лишь в ограниченном виде (только часть просмотренных веб-страниц участвует в определении профиля пользователя) и обрабатывается локально на самом мобильном устройстве без ее отправки и какого-либо опасного использования за пределами мобильного устройства легитимного пользователя. Кроме того, благодаря настоящему изобретению вычислительная сложность процесса определения профиля пользователя мобильного устройства снижается, делая данный процесс пригодным для реализации на самом мобильном устройстве, которое обладает ограниченными ресурсами. Это достигается за счет сокращения размера моделей и высокой разреженности данных в тематической и демографической моделях согласно настоящему изобретению.
[0012] Таким образом, благодаря настоящему изобретению повышается конфиденциальность сбора данных пользователя при его демографическом профилировании. Кроме того, получаемый в результате работы настоящего изобретения профиль ограничен лишь информацией о поле, возрасте, семейном положении и интересах пользователя. Таким образом, такой профиль может быть передан поставщику контента для модификации взаимодействий с пользователем на его основе без риска утечки конфиденциальной информации пользователя. Другими словами, поставщик контента имеет лишь информацию, ограниченную профилем, а не «сырые» критические и конфиденциальные данные, из которых можно получить любую персональную информацию, такую как имя, фамилия, место работы, место жительства, контакты родственников, номер банковского счета и т.д. Эти и другие особенности и преимущества настоящего изобретения будут подробно описаны ниже по тексту.
Краткое описание чертежей
[0013] Другие преимущества настоящего изобретения станут очевидны для специалиста в данной области техники после изучения нижеследующего подробного описания с обращением к чертежам, на которых:
[Фиг. 1] Фиг. 1 иллюстрирует последовательность этапов построения мультиязычной тематической модели и демографической модели на внешнем вычислительном устройстве, которое выполняется на первой стадии.
[Фиг. 2] Фиг. 2 иллюстрирует последовательность подэтапов этапа S103, на котором извлекают векторы признаков участников контрольной группы для обучения демографической модели.
[Фиг. 3] Фиг. 3 иллюстрирует последовательность этапов определения демографического профиля пользователя мобильного устройства на самом мобильном устройстве.
[Фиг. 4] Фиг. 4 иллюстрирует систему демографического профилирования пользователя мобильного устройства.
Подробное описание вариантов осуществления
[0014] Системы и способы согласно настоящему изобретению предполагают две основные стадии. Первая стадия представляет собой стадию машинного обучения (ML), на которой внешнее вычислительное устройство строит мультиязычную тематическую модель и демографическую модель. Вторая стадия представляет собой стадию определения профиля пользователя мобильного устройства на самом мобильном устройстве на основе построенных и экспортированных на мобильное устройство мультиязычной тематической модели и демографической модели. Мультиязычная тематическая модель – вероятностно-статистическая модель, построенная на основе набора текстовых документов, которая выполнена с возможностью определения того, к каким темам/категориям относится любой другой текстовый документ. Тематическая модель является универсальной для всех пользователей. Демографическая модель – модель, построенная на основе машинного обучения, которая выполнена с возможностью определения демографических характеристик пользователя (в предпочтительном варианте осуществления: пол, возраст, семейное положение) на основе содержимого веб-страниц, которые этот пользователь просматривает на своем мобильном устройстве.
[0015] Фиг. 1 иллюстрирует последовательность этапов построения тематической модели и демографической модели на внешнем вычислительном устройстве, которое выполняется на первой стадии. Как показано на фиг. 1 последовательность этапов построения мультиязычной тематической модели и демографической модели на вычислительном устройстве, которое является внешним относительно мобильного устройства пользователя, содержит следующие этапы, на которых:
[0016] На этапе S 100 – собирают, на внешнем вычислительном устройстве, данные для построения мультиязычной тематической модели. Далее по тексту собранные на данном этапе данные могут называться корпусом. Этот сбор может быть осуществлен любым известным из уровня техники способом. В предпочтительном варианте осуществления данные собираются с веб-страниц новостных интернет-порталов по категориям (например, но без ограничения, спорт, политика, технологии и т. д.) и являются текстовыми данными. Список этих категорий может быть задан поставщиком контента или определен согласно техническому заданию к требуемому профилю пользователя. Для построения мультиязычной тематической модели, корпус также должен быть мультиязычным. Таким образом, текстовые данные собираются для каждой из заданных категорий на каждом целевом языке. В предпочтительном варианте осуществления настоящего изобретения используются русский, английский, корейский целевые языки. Однако, настоящее изобретение может быть реализовано с любыми другими целевыми языками. Затем, эти языковые корпуса переводятся друг в друга. В качестве примера, для каждого английского текста получают русский и корейский. Тоже делают для русских и корейских текстов. Таким образом, в предпочтительном варианте осуществления настоящего изобретения данный этап S100 содержит подэтап, на котором языковые корпуса переводятся друг в друга. Для этого перевода может быть использована любая доступная для выбранных целевых языков система машинного перевода. Для целей настоящего изобретения качество перевода, обеспечиваемое системой машинного перевода, является достаточным, посколько для корректной работы настоящего изобретения достаточно лишь получить коллекцию слов на разных языках под каждую категорию. Эта коллекция слов может именоваться мультиязычным тематическим словарем. Данный подэтап перевода на целевой язык может быть выполнен с помощью любой известной из уровня техники системы автоматического машинного перевода, в качестве примера, но не ограничения, может использоваться Яндекс.Переводчик. Таким образом, в предпочтительном варианте настоящего изобретения собранные на данном этапе данные включают в себя следующую информацию: текстовое содержимое множества веб-страниц на каждом из выбранных целевых языков, и категорию, которая соответствует каждой веб-странице из упомянутого множества. В методе аддитивной регуляризации тематических моделей (ARTM) перечисленные выше типы информации называют модальностями. Таким образом, в предпочтительном варианте осуществления настоящего изобретения присутствуют четыре модальности: текстовые данные на русском, английском, корейском и категория. Данный метод позволят осуществить классификацию по выбранной модальности. За счет вышеупомянутого перевода собираемых языковых корпусов на выбранные языки при создании тематической модели обеспечивается ее мультиязычность. В предпочтительном варианте осуществления настоящего изобретения классификацию осуществляют по категориям. ARTM будет подробно описан ниже по тексту.
[0017] На этапе S101 – осуществляют, на внешнем вычислительном устройстве, предобработку содержимого веб-страниц. На данном этапе над содержимым веб-страниц осуществляется одно или более из удаления html-тегов и прочей служебной информации, не несущей никакой полезной информационной нагрузки для построения моделей, выделения основы слова – “стемминга”, удаления стоп-слов, перевода в нижний регистр, перевода на целевой язык. Указанные подэтапы предобработки содержимого веб-страниц могут быть выполнены любыми известными из уровня техники способами. В качестве примера, но не ограничения, удаление html-тегов может быть осуществлено средством синтаксического анализатора html-анализа jsoup, стемминг может быть осуществлен с использованием средства из библиотеки Lucene (Snowball Stemmer). В качестве примера, результатами выполнения стемминга над словами английского и русского языков “cars”, “сделать”, “сделаю” могут быть, соответственно, “car”, “сдела”, “сдела”. В качестве альтернативы, в другом варианте осуществления настоящего изобретения вместо стемминга может быть использована лемматизация – процесс приведения словоформы к лемме. Под стоп-словами понимаются высокочастотные слова языка, к которым могут быть отнесены предлоги, суффиксы, причастия, междометия, цифры, частицы и т. п., при этом для каждого языка можно выделить свой список стоп-слов. Наиболее простой способ удаления стоп-слов включает в себя удаление слова, если это слово содержится в списке предопределенных стоп-слов. Примерами стоп-слов в русском языке могут быть следующие стоп-слова: “а”, “в”, “для”, “ты”, “и”. Cтоп-слова удаляются, поскольку они не несут никакой полезной информационной нагрузки для построения моделей.
[0018] На этапе S102 – строят, на внешнем вычислительном устройстве, мультиязычную тематическую модель. Эта тематическая модель может осуществлять классификацию текстовых документов просмотренных пользователем по заданным заранее категориям. Из области техники Natural Language Processing (NLP) известно, что тематическое моделирование (например, с помощью Вероятностного латентного семантического анализа (PLSA) и Латентного размещения Дирихле (LDA)) — это представление наблюдаемого условного распределения 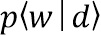 терминов (слов или словосочетаний)
терминов (слов или словосочетаний) 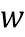 в документах
в документах 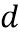 исследуемого корпуса:
исследуемого корпуса:
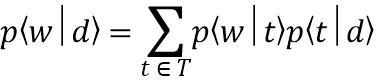 ,
,
где 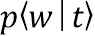 - вероятность слова в скрытой теме
- вероятность слова в скрытой теме 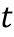
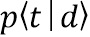 - вероятность скрытой темы в документе .
- вероятность скрытой темы в документе .
Параметры тематической модели находим путём решения задачи максимизации правдоподобия:
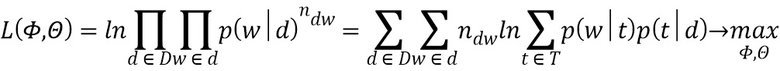 ,
,
где 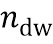 - количество появлений слова в документе .
- количество появлений слова в документе .
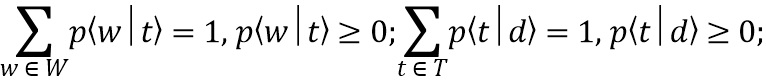
[0019] Оптимизацию параметров модели производим с помощью EM (Expectation-maximization) -алгоритма. Подробности использования этого алгоритма описаны в статьях [Воронцов К.В., Потапенко А.А. Регуляризация, робастность и разреженность вероятностных тематических моделей // Компьютерные исследования и моделирование: журнал. — 2012. — С. 693-706, Vorontsov, Konstantin, and Anna Potapenko. "Additive regularization of topic models." Machine Learning 101.1-3 (2015): 303-323,
Vorontsov, Konstantin, et al. "Non-bayesian additive regularization for multimodal topic modeling of large collections." Proceedings of the 2015 Workshop on Topic Models: Post-Processing and Applications. ACM, 2015].
[0020] В случае, когда в предпочтительном варианте осуществления настоящего изобретения наряду с правдоподобием необходимо максимизировать еще и  дополнительных критериев, может быть использован метод аддитивной регуляризации тематических моделей (ARTM). Для этого максимизируем линейную комбинацию критериев
дополнительных критериев, может быть использован метод аддитивной регуляризации тематических моделей (ARTM). Для этого максимизируем линейную комбинацию критериев  и
и
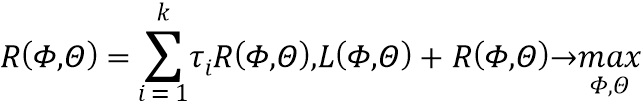 ,
,
где 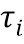 - коэффициент регуляризации,
- коэффициент регуляризации,
- фукционал регуляризации (далее называемый регуляризатором).
Для обучения тематической модели использовалась платформа BigARTM.
[0021] При обучении задают следующие регуляризаторы: разреживающий, сглаживающий и декоррелирующий распределения терминов в темах и документах. Здесь стоит отметить, что коэффициенты регуляризаторов подбирают таким образом, чтобы минимизировать размер тематической модели без потери качества классификации. Регуляризатор разреживания тем в документах приводит к появлению большого количества нулей в матрице весов, что позволяет оптимизировать размер модели для обеспечения возможности достижения одного из технических результатов настоящего изобретения. Таким образом, подбирают минимальное количество скрытых тем, коэффициенты регуляризации и веса модальностей. Эти величины в дальнейшем будут называться гиперпараметрами тематической модели. Подбор может быть осуществлен посредством случайного поиска. Затем экземпляр тематической модели с наилучшим качеством выбирают исходя из оценки качества классификации по заданным категориям по F1 мере. Тем самым решается задача мягкой кластеризации содержимого веб-страниц. В результате выполнения вышеупомянутых этапов строится тематическая модель, которая способна отображать содержимое веб-страницы в вектор скрытых тем, и параллельно с этим, отображать этот вектор скрытых тем в соответствующий вектор категорий, отражающий интересы участника. Данный вектор категорий в профиле пользователя будет соответствовать вектору интересов. Тут и далее под вектором скрытых тем понимается вектор вероятностей принадлежности веб-страницы к кластерам веб-страниц, которые являются близкими в семантическом смысле, а под вектором категорий веб-страницы понимается вектор вероятностей принадлежности веб-страницы к каждой из заданных категорий. Таким образом, далее по тексту, под классификатором тематической модели может пониматься средство отображения вектора скрытых тем произвольной веб-страницы в вектор категорий. Как было кратко указано выше, качество тематической модели может быть оценено, например, по F1 мере, на тестовом множестве данных, которое не участвовало в построении оцениваемой тематической модели. В качестве примера такого тестового множества данных может выступать произвольное содержимое других веб-страниц, категории которых известны или заданы заранее. Кроме того, из уровня техники известны другие способы оценки качества тематической модели [см., например, Кристофер Д. Маннинг, Прабхакар Рагхаван, Хайнрих Шютце, Введение в информационный поиск.: перевод с англ. – М.: ООО «И.Д. Вильямс», 2011 — 528 с.: пар 8.3 Оценка неранжированного поиска, стр. 168.]. В качестве примера оценки содержимое каждой веб-страницы из тестового множества данных может обрабатываться оцениваемой тематической моделью, которая в ответ на это генерирует вышеописанные векторы скрытых тем и соответствующие им векторы категорий. Затем для каждой веб-страницы из тестового множества данных оценивается правильность определения ее категории. Для этого предсказанная категория каждой веб-страницы, т.е. категория из сгенерированного вектора категорий с наибольшей вероятностью, сравнивается с соответствующей заранее известной или заданной категорией данной веб-страницы. Затем определяется точность оцениваемой тематической модели – доля правильно предсказанных оцениваемой тематической моделью категорий. Этот этап повторяется для всех построенных тематических моделей. В результате из всех построенных моделей выбирается модель с наивысшей точностью. Настоящее изобретение не ограничено использованием ARTM-метода, в качестве альтернативы могут быть использованы другие известные из уровня техники способы, такие как, например, LDA (Латентное размещение Дирихле).
[0022] На этапе S103 – извлекают, на внешнем вычислительном устройстве, векторы признаков участников контрольной группы для обучения демографической модели. Перед выполнением этого этапа собирают контрольную группу участников, анкетируют каждого участника контрольной группы, и собирают данные с мобильного устройства каждого участника, а результаты анкетирования и собранные данные передают на внешнее вычислительное устройство для их последующей обработки на подэтапах S103.1 – S103.10, которые будут подробно описаны ниже по тексту. Каждый из участников контрольной группы дает свое согласие на сбор данных с его мобильного устройства, на упомянутое анкетирование, и на другие указанные ниже действия. Способы анкетирования участников контрольной группы и сбора данных с их мобильных устройств известны из уровня техники. В качестве примера, они могут быть осуществлены с помощью приложения “Сазан”. В ходе анкетирования каждый из участников контрольной группы отвечает на ряд вопросов. Эти вопросы включают в себя, но без ограничения упомянутым: дату рождения; пол (мужской, женский); семейное положение (одинокие, в браке, в отношениях); состав домохозяйства (количество человек, 1, 2, 3, 4 и более); тип занятости (несовершеннолетний, студент/учащийся, рядовой работник, руководящий работник, не работающий); график работы (не учусь/не работаю, обычный рабочий день (5 дней в неделю), гибкий график, посменная работа, мобильная работа (транспорт и т.п.)); количество детей (0, 1, 2, 3, 4+); уровень дохода (не указано, низкий, средний, высокий). Для получения ответов на эти вопросы участнику контрольной группы может быть предложена форма для заполнения. После заполнения формы ответы на вопросы передаются на обработку вместе с идентификационной информацией, которая в дальнейшем позволяет идентифицировать мобильное устройство некоторого соответствующего участника контрольной группы. В качестве идентификационной информации может использоваться IMEI (международный идентификатор мобильного оборудования), IMSI, или любая другая информация, позволяющая идентифицировать мобильное устройство некоторого соответствующего участника контрольной группы.
[0023] Затем приложение, установленное на мобильное устройство участника, начинает сбор данных, формируемым при использовании участником своего мобильного устройства. Сбор проводится в фоновом режиме, чтобы не мешать использованию мобильного устройства участником. Собираемые данные включают в себя, но без ограничения упомянутым: активные приложения (длительность запуска приложения, название приложения, временную метку); основную информацию об устройстве, использование батареи, спаренные Bluetooth-устройства, историю браузера, закладки браузера, избранное браузера, текстовые данные просмотренных веб-страниц, историю поисковых запросов, предварительно шифруемые номера входящих и исходящих вызовов, длительность вызова, тип вызова входящий/исходящий, время вызова, данные об использовании сотовых вышек; месторасположение; данные светового сенсора; данные магнитного поля; данные гироскопа; данные о включении или выключении экрана, предварительно шифруемые номера входящих и исходящих смс-сообщений, размер смс-сообщений, тип смс-сообщений входящее/исходящее, время смс-сообщения, соседние Wi-Fi-устройства. Впоследствии, весь набор этих данных или, по меньшей мере, его часть может быть использован при построении демографической модели.
[0024] Фиг. 2 иллюстрирует последовательность подэтапов этапа S103, на котором извлекают векторы признаков участников контрольной группы для обучения демографической модели. Как показано на фиг. 2, последовательность содержит следующие подэтапы, на которых:
S103.1 – для каждого участника получают набор векторов скрытых тем;
S103.2 – для каждого участника получают временные метки каждой просмотренной им веб-страницы;
S103.3 – для каждого участника осуществляют эквализацию гитограммы всех его временных меток для получения вектора бинарных признаков временных меток.
S103.4 – для каждого набора векторов скрытых тем и векторов бинарных признаков временных меток вычисляют среднее, медиану и среднее квадратичное отклонение для получения, соответственно, вектора средних значений, вектора медианных значений и вектора значений среднего квадратичного отклонения;
S103.5 – для каждого участника преобразуют вектор средних значений, вектор медианных значений, вектор значений среднего квадратичного отклонения и вектор бинарных признаков временных меток в один вектор признаков участника;
S103.6 – строят набор обучающих данных; и
S103.7 – осуществляют анализ и чистку набора обучающих данных;
[0025] На подэтапе S103.1 для каждого участника получают набор векторов скрытых тем, при этом один вектор скрытых тем соответствует одной просмотренной участником веб-странице. Для этого просмотренные каждым участником веб-страницы обрабатывают построенной на этапе S102 тематической моделью. В ответ на это, тематическая модель генерирует набор векторов скрытых тем, где каждому вектору скрытых тем соответствует одна просмотренная соответствующим участником веб-страница. Таким образом, для всех участников получается множество наборов векторов скрытых тем.
[0026] На подэтапе S103.2 для каждого участника получают временные метки каждой просмотренной им веб-страницы. Временная метка характеризует момент времени первой загрузки веб-страницы – то есть момент, когда пользователь мог начать читать содержимое данной веб-страницы.
[0027] На подэтапе S103.3 для каждого участника осуществляют эквализацию гистограммы всех его временных меток. Для этого формируют упорядоченный список временных меток всех участников. Затем, этот список разбивают на N равных по количеству элементов частей. После этого заменяют каждую временную метку вектором длины N со значением 1 в компоненте с индексом того интервала, в который попадает данная временная метка, и 0 во всех остальных компонентах. Данный вектор называется вектором бинарных признаков временных меток.
[0028] На подэтапе S103.4 для каждого набора векторов скрытых тем и векторов бинарных признаков временных меток, полученных на подэтапе S103.3, вычисляют среднее, медиану и среднее квадратичное отклонение. Таким образом, получаются три вектора одинаковой длины: вектор средних значений, вектор медианных значений, вектор значений среднего квадратичного отклонения, причем длина каждого из этих векторов равна числу скрытых тем плюс число элементов в векторах бинарных признаков временных меток, полученных на подэтапе S103.3. Объединение этих векторов в дальнейшем называется вектором признаков.
[0029] На подэтапе S103.5 для каждого участника преобразуют векторы, полученные на подэтапе S103.4 в один вектор признаков участника. Вектор признаков участника содержит значения признаков, построенные для этого участника, и получается посредством конкатенации указанных векторов.
[0030] На подэтапе S103.6 строят набор обучающих данных. Для этого все полученные векторы признаков участников связывают с соответствующими им демографическими данными, которые были предоставленны участниками контрольной группы. Таким образом, каждому участнику ставится в соответствие описанный выше вектор признаков. Данный набор будет использоваться для обучения демографической модели методом обратного распространения ошибки.
[0031] На подэтапе S103.7 осуществляют анализ и чистку набора обучающих данных. В ходе анализа выделяются нерепрезентативные признаки, которые удаляют из набора обучающих данных. Признак, который может принимающий одно из двух значений: 0 или 1, называется бинарным. Примером бинарного признака в нашем случае является медиана элементов векторов признаков временных меток. Признак такого вида признается нерепрезентативным, если частота его присутствия в наборе обучающих данных ниже нижнего или выше верхнего предопределенных порогов отсечения. Индексы нерепрезентативных признаков сохраняются для того, чтобы иметь возможность последующего удаления таких признаков также и на мобильном устройстве пользователя (т.е. на второй стадии, на которой осуществляют определение демографического профиля произвольного пользователя на мобильном устройстве этого произвольного пользователя).
[0032] В результате выполнения этапа S103 на основе результата обработки истории браузера участников, посредством тематической модели, и их демографических данных формируется набор обучающих данных, пригодный для обучения демографической модели. Пример представления вышеупомянутых обучающих данных в табличной форме представлен в нижеследующей таблице 1, однако настоящее изобретение не следует ограничивать табличной формой представления этих данных:
Таблица 1
(вектор представлен в одном столбце)
(вектор представлен в одном столбце)
(вектор представлен в одном столбце)
[0033] Далее возвращаемся к подробному описанию фигуры 1, в частности к описанию этапа S104. На этапе S104 – строят, на внешнем вычислительном устройстве, демографическую модель. Этот этап выполняется с использованием обучающих данных с этапа S103. Под демографической моделью ниже понимается набор демографических классификаторов: демографического классификатора возраста, демографического классификатора пола, демографического классификатора семейного положения. Под обученной демографической моделью ниже понимается набор обученных демографических классификаторов: обученного демографического классификатора возраста, обученного демографического классификатора пола, обученного демографического классификатора семейного положения. Таким образом, в результате выполнения предыдущих этапов для каждого демографического классификатора есть свой набор обучающих данных, т.е. свой набор участников (наборы могут пересекаться). Например, если у участника есть метка пола, но нет остальных меток, то вектор признаков и метка пола этого участника будут присутствовать только в обучающих данных демографического классификатора пола.
[0034] В качестве демографического классификатора используется многослойный перцептрон. Для оптимизации параметров, включающих в себя один или более из: количества слоев, размера каждого слоя, функции активации, демографической модели в предпочтительном варианте осуществления настоящего изобретения используется генетический алгоритм. Кроме того, в варианте осуществления настоящего изобретения генетический алгоритм используется для оптимизации гиперпараметров обучения для каждого слоя, при это гиперпараметры представляют собой одно или более из: шага градиентного спуска, коэффициенты регуляризации, начального диапазона распределения весов, количества примеров за одну итерацию. Кроме того, в варианте осуществления настоящего изобретения генетический алгоритм используется для определения состава вектора входных параметров, т.е. того, какие элементы вектора признаков участника необходимо использовать в демографическом классификаторе). В процессе выполнения генетического алгоритма создается большое число экземпляров демографических классификаторов, которые отличаются перечисленными выше параметрами. Затем созданные демографические классификаторы обучаются методом обратного распространения ошибки. Далее, выбираются демографические классификаторы с наивысшим качеством классификации на основе оценки качества классификации, т.е. процента правильно определенных демографических признаков. После чего, на основе демографических классификаторов с наивысшим качеством классификации, методом скрещивания создаются новые демографические модели, обновляя популяцию классификаторов, при этом размер популяции подерживается постоянным путем удаления демографических классификаторов с худшим качеством. Затем, производят обучение новых классификаторов, скрещивание и формирование очередной популяции. Данный процесс продолжается до тех пор, пока наблюдается улучшение качества классификации. В результате, из всех построенных классификаторов выбирается демографический классификатор с наилучшей точностью, т.е. с наивысшим процентом правильно определенных демографических признаков.
[0035] Демографическая моделей построенная на основе найденных посредством генетического алгоритма классификаторов способна отображать вектор признаков пользователя в демографический профиль (возраст, пол, семейное положение) этого пользователя. Вектор признаков пользователя содержит значения признаков этого пользователя и может быть извлечен на самом мобильном устройстве пользователя по аналогии с извлечением вектора признаков участника контрольной группы, выполняемым на вышеописанном этапе S103. Для этого мультиязычная тематическая модель, обученная в соответствии с вышеописанным этапом S102, экспортируется на мобильное устройство пользователя, а далее соответствующая обработка выполняется непосредственно на самом мобильном устройстве. Более подробное описание этой второй стадии, реализуемой на самом мобильном устройстве произвольного пользователя, будет приведено ниже по тексту. Таким образом, далее по тексту, под демографическими классификаторами демографической модели понимается средство отображения вектора признаков пользователя в его демографический профиль. Качество демографической модели может быть оценено на тестовом множестве данных, которое не участвовало в построении оцениваемой демографической модели. В качестве примера такого тестового множества данных могут выступать векторы признаков пользователей, демографические профили которых известны или заданы заранее. Способы оценки качества демографической модели известны из уровня техники. В качестве примера, векторы признаков пользователей из тестового множества данных могут обрабатываться оцениваемой демографической моделью, которая в ответ на это генерирует их демографические профили. Затем для каждого вектора признаков пользователя оценивается правильность определения его демографического профиля. Для этого, предсказанный демографический профиль каждого пользователя сравнивается с соответствующим заранее известным демографическим профилем этого пользователя. Затем определяется точность оцениваемой демографической модели – процент правильно определенных демографических признаков. Этот этап повторяется для всех построенных демографических моделей. В результате, из всех построенных моделей выбирается модель с наивысшей точностью.
[0036] В качестве альтернативы генетическому алгоритму, который может итеративно подбирать оптимальные значения параметров демографических моделей, которые приводят в результате к получению демографической модели с наилучшей точностью, может быть использован перебор значений параметров демографических моделей. В результате выполнения этапа S104 получают обученную демографическую модель, которая способна отображать вектор признаков пользователя в демографический профиль этого пользователя с наивысшей точностью.
[0037] На этапе S105 – экспортируют, посредством внешнего вычислительного устройства, построенные и обученные на этапах S102 и S103 мультиязычную тематическую модель и демографическую модель на по меньшей мере одно мобильное устройство пользователя. В результате передачи этих моделей на мобильное устройство пользователя, само мобильное устройство наделяется возможностью определения интересов пользователя мобильного устройства на основе содержимого просмотренных им веб-страниц и предсказания демографического профиля пользователя. Нижеследующее описание относится к подробному описанию второй стадии, реализуемой на мобильном устройстве пользователя.
[0038] Фиг. 3 иллюстрирует последовательность этапов определения демографического профиля пользователя мобильного устройства на самом мобильном устройстве. Как показано на фиг. 3 последовательность этапов определения демографического профиля пользователя мобильного устройства на самом мобильном устройстве содержит следующие этапы, на которых:
S200 – сохраняют, на мобильном устройстве, обученную тематическую модель и обученную демографическую модель;
S201 – собирают, на мобильном устройстве, содержимое веб-страниц, просмотренных пользователем на мобильном устройстве;
S202 – осуществляют, на мобильном устройстве, предобработку содержимого веб-страниц для приспособления содержимого веб-страниц под тематическую модель;
S203 – обрабатывают, на мобильном устройстве, предобработанное содержимое веб-страниц тематической моделью для получения вектора скрытых тех, ассоциированного с содержимым веб-страниц, просмотренным пользователем на своем мобильном устройстве;
S204 – извлекают из полученного вектора скрытых тем вектор признаков пользователя;
S205 - определяют, на мобильном устройстве, демографический профиль пользователя посредством обработки извлеченного вектора признаков пользователя демографической моделью.
[0039] На этапе S200 – сохраняют, на мобильном устройстве, обученную тематическую модель и обученную демографическую модель. Этот этап не является обязательным. Раскрытый выше способ может начинаться с этапа S201 при условии, что мобильное устройство пользователя уже хранит обученную мультиязычную тематическую модель и демографическую модель. Указанные модели могут быть приняты от внешнего вычислительного устройства, который заранее выполнил их построение и обучение согласно способу, описанному выше со ссылкой на фигуры 1 и 2.
[0040] На этапе S201 собирают, на мобильном устройстве, содержимое веб-страниц, просмотренных пользователем на мобильном устройстве. Для получения истории загрузки веб-страниц производится поиск среди установленных на устройстве браузеров реализующих общедоступный интерфейс контент провайдера для доступа к истории браузера.
[0041] На этапе S202 – осуществляют, на мобильном устройстве, предобработку содержимого веб-страниц для приспособления содержимого веб-страниц под тематическую модель. Для этого на мобильном устройстве осуществляется предобработка, аналогичная предобработке, выполненной внешним вычислительным устройством и описанной подробно со ссылкой на этап S101 на фигуре 1. В целях краткости и ясности повторное описание этой предобработки тут не приводится.
[0042] На этапе S203 – обрабатывают, на мобильном устройстве, предобработанное содержимое веб-страниц тематической моделью для получения вектора скрытых тем, ассоциированного с содержимым веб-страниц, просмотренных пользователем на своем мобильном устройстве. Для этого предобработанное содержимое веб-страниц пользователя обрабатывается тематической моделью, которая возвращает векторы скрытых тем и векторы категорий, ассоциированные с веб-страницами. Усреднение значений векторов категорий для пользователя позволяет сформировать вектор его интересов.
[0043] На этапе S204 извлекают из полученного вектора скрытых тем вектор признаков пользователя. Для этого на мобильном устройстве осуществляют извлечение вектора признаков пользователя из полученного вектора скрытых тем. Это извлечение выполняется аналогично извлечению векторов признаков участников контрольной группы, которое описано со ссылкой на этап S103 на фигурах 1 и 2. В целях краткости и ясности повторное описание этого извлечения вектора признаков тут не приводится.
[0044] На этапе S205 - определяют, на мобильном устройстве, демографический профиль пользователя посредством обработки извлеченного вектора признаков пользователя демографической моделью.
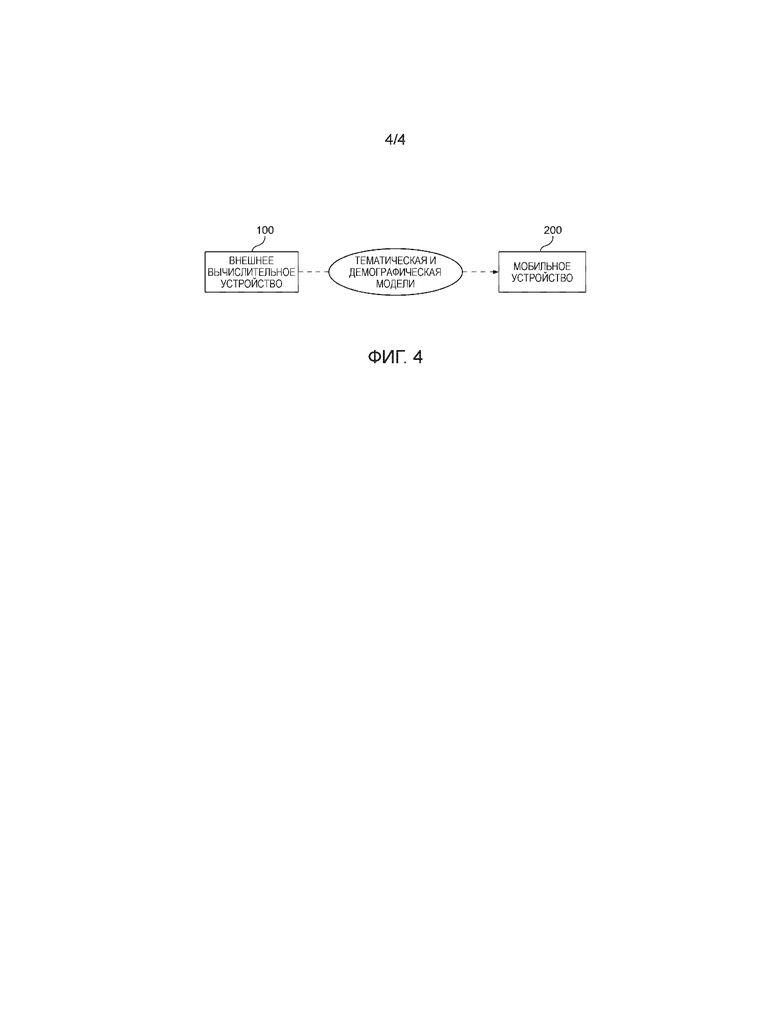
[0045] Настоящее изобретение также предусматривает систему демографического профилирования. Указанная система проиллюстрирована на фигуре 4. Как проиллюстрировано на фигуре 4 система содержит внешнее вычислительное устройство 100 и по меньшей мере одно мобильное устройство 200 пользователя. Согласно настоящему изобретению внешнее вычислительное устройство 100 выполнено с возможностью построения тематической модели и демографической модели согласно способу, описанному со ссылкой на фигуры 1 и 2, а мобильное устройство 200 выполнено с возможностью определения демографического профиля пользователя мобильного устройства на самом мобильном устройстве согласно способу, описанному со ссылкой на фигуру 3. Для выполнения этих способов каждое из внешнего вычислительного устройства 100 и мобильного устройства 200 оборудовано процессором (процессоры не показаны на фигуре 4). В целях краткости и ясности повторное описание упомянутых способов тут не приводится.
[0046] Таким образом, настоящее изобретение исключает возможность утечки конфиденциальной информации пользователя мобильного устройства в процессе определения его профиля, который отражает его интересы и демографию, поскольку при определении этого профиля никакая информация о пользователе не покидает мобильного устройства этого пользователя. Более того, фактическое содержимое просмотренных пользователем веб-страниц преобразуется в векторы скрытых тем, ассоциированные с этим содержимым, из которых нельзя получить конкретные просмотренные пользователем веб-страницы, поскольку вектор скрытых тем, ассоциированный с содержимым веб-страницы, характеризует лишь вероятности принадлежности просмотренной пользователем веб-страницы к кластерам веб-страниц, которые являются близкими в семантическом смысле.
[0047] Полученный с помощью настоящего изобретения профиль пользователя, характеризующий его интересы (например, музыка, путешествия, спорт, политика, покупки и т.д.) и демографию (например, возраст, пол, семейное положение), может быть применен для реализации, например, нижеследующего. На основании полученного профиля пользователя ему могут быть рекомендованы некоторые приложения. Кроме того, на основании пользовательских интересов пользователю может быть рекомендован некоторый контент. Например, в ответ на поисковый запрос некоторого пользователя об актере Тиме Роте, мобильное устройство этого пользователя или любое другое устройство пользователя, с которым мобильное устройство может осуществить синхронизацию, может рекомендовать к просмотру фильм «Бешеные Псы», в котором снимается Тим Рот. Кроме того, в зависимости от пользовательских интересов в мобильном устройстве пользователя имеющиеся закладки пользователя могут быть расширены или могут быть рекомендованы новые закладки. Однако, вышеуказанные сценарии применения получаемого настоящим изобретением профиля пользователя не ограничены вышеуказанными примерными сценариями, поскольку после ознакомления с настоящим описанием специалисту в данной области придут в голову другие сценарии использования профиля пользователя.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И СИСТЕМА РАНЖИРОВАНИЯ ЭЛЕМЕНТОВ СЕТЕВОГО РЕСУРСА ДЛЯ ПОЛЬЗОВАТЕЛЯ | 2013 |
|
RU2605039C2 |
| ОБНАРУЖЕНИЕ ОБЪЕКТОВ ИЗ ЗАПРОСОВ ВИЗУАЛЬНОГО ПОИСКА | 2017 |
|
RU2729956C2 |
| Система сбора и обработки данных для поведенческого таргетинга | 2022 |
|
RU2811670C2 |
| Способ и система определения положений элементов в ранжировании содержимого системой ранжирования | 2021 |
|
RU2831411C2 |
| АВТОМАТИЗИРОВАННОЕ ИЗВЛЕЧЕНИЕ ИНФОРМАЦИИ | 2016 |
|
RU2693193C1 |
| МНОЖЕСТВО ДЕЙСТВИЙ И ЗНАЧКОВ ДЛЯ РЕКЛАМЫ В МОБИЛЬНЫХ УСТРОЙСТВАХ | 2009 |
|
RU2467394C2 |
| Способ и система для формирования карточки объекта | 2018 |
|
RU2739554C1 |
| ФРЕЙМВОРК ПРИЕМА ВИДЕО ДЛЯ ПЛАТФОРМЫ ВИЗУАЛЬНОГО ПОИСКА | 2017 |
|
RU2720536C1 |
| СПОСОБ И СЕРВЕР ОПРЕДЕЛЕНИЯ ИСХОДНОЙ ССЫЛКИ НА ИСХОДНЫЙ ОБЪЕКТ | 2016 |
|
RU2660593C2 |
| ПРОСМОТР ИНФОРМАЦИИ СОЦИАЛЬНЫХ СЕТЕЙ | 2010 |
|
RU2571593C2 |



Изобретение относится к определению демографического профиля пользователя мобильного устройства на самом мобильном устройстве, хранящем обученную мультиязычную тематическую модель и обученную демографическую модель. Технический результат – повышение защиты конфиденциальных данных пользователя при определении его демографического профиля. Способ определения демографического профиля пользователя мобильного устройства на самом мобильном устройстве, хранящем обученную мультиязычную тематическую модель и обученную демографическую модель, содержит этапы, на которых собирают, на мобильном устройстве, содержимое веб-страниц, просмотренных пользователем на мобильном устройстве, осуществляют, на мобильном устройстве, предобработку содержимого веб-страниц для приспособления содержимого веб-страниц под тематическую модель, обрабатывают, на мобильном устройстве, предобработанное содержимое веб-страниц тематической моделью для получения векторов скрытых тем, ассоциированных с содержимым веб-страниц, просмотренных пользователем на своем мобильном устройстве, извлекают из полученных векторов скрытых тем вектор признаков пользователя; определяют, на мобильном устройстве, демографический профиль пользователя посредством обработки извлеченного вектора признаков пользователя демографической моделью. 2 н. и 17 з.п. ф-лы, 4 ил., 1 табл.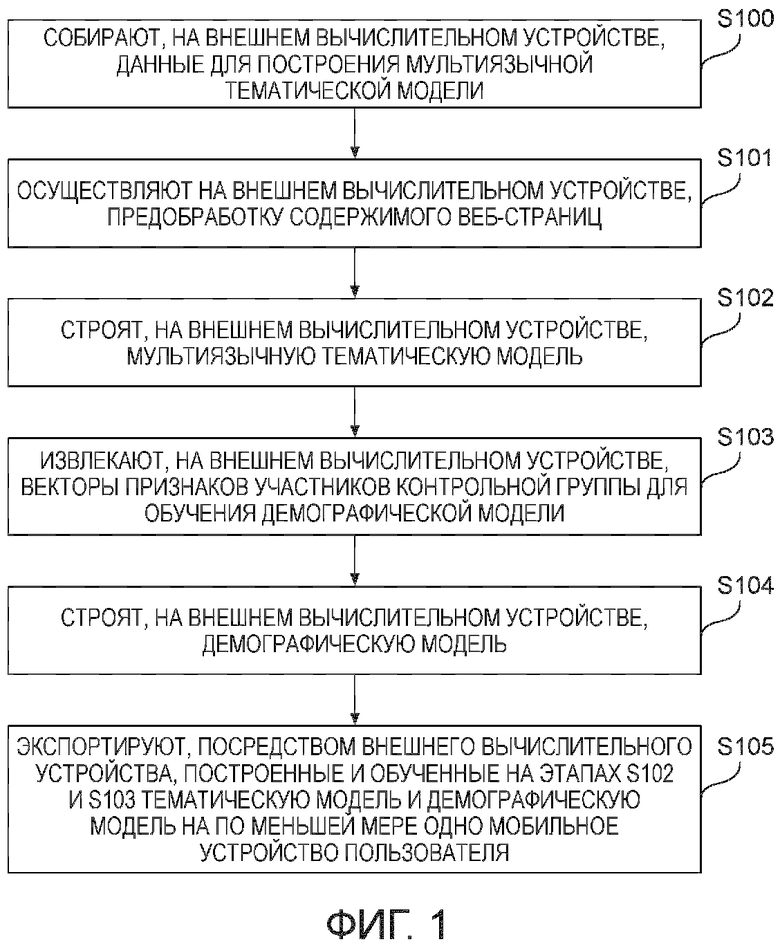
1. Способ определения демографического профиля пользователя мобильного устройства на самом мобильном устройстве, хранящем обученную мультиязычную тематическую модель и обученную демографическую модель, причем способ содержит этапы, на которых:
собирают, на мобильном устройстве, содержимое веб-страниц, просмотренных пользователем на мобильном устройстве;
осуществляют, на мобильном устройстве, предобработку содержимого веб-страниц для приспособления содержимого веб-страниц под тематическую модель;
обрабатывают, на мобильном устройстве, предобработанное содержимое веб-страниц тематической моделью для получения векторов скрытых тем, ассоциированных с содержимым веб-страниц, просмотренных пользователем на своем мобильном устройстве;
извлекают из полученных векторов скрытых тем вектор признаков пользователя;
определяют, на мобильном устройстве, демографический профиль пользователя посредством обработки извлеченного вектора признаков пользователя демографической моделью,
при этом вектор скрытых тем отражает вероятности принадлежности произвольной веб-страницы к кластерам веб-страниц, которые являются близкими в семантическом смысле, вектор признаков пользователя содержит значения признаков упомянутого пользователя, а демографическая модель содержит демографический классификатор возраста, демографический классификатор пола, демографический классификатор семейного положения,
причем извлечение векторов признаков пользователя из полученных векторов скрытых тем содержит подэтапы, на которых:
получают временные метки каждой просмотренной пользователем веб-страницы;
осуществляют эквализацию гистограммы всех временных меток просмотренных страниц пользователя для получения вектора бинарных признаков временных меток;
вычисляют вектор средних значений, вектор медианных значений и вектор значений среднего квадратичного отклонения упомянутых векторов скрытых тем и вектора бинарных признаков временных меток;
преобразуют вектор средних значений, вектор медианных значений, вектор значений среднего квадратичного отклонения и вектор бинарных признаков временных меток в вектор признаков пользователя путем конкатенации перечисленных векторов в один, при этом набор векторов признаков пользователей вместе с соответствующими метками является обучающим набором данных, посредством которых осуществляют обучение демографических классификаторов возраста, пола и семейного положения.
2. Способ по п. 1, при этом мультиязычную тематическую модель обучают на основе веб-страниц новостных интернет-порталов по категориям, которые произвольно заданы поставщиком контента, для этого:
собирают содержимое веб-страниц новостных интернет-порталов на по меньшей мере двух языках;
переводят с помощью системы машинного перевода собранное содержимое веб-страниц новостных интернет-порталов на каждом из упомянутых по меньшей мере двух языков на каждый другой из упомянутых по меньшей мере двух языков.
3. Способ по п. 2, при этом перед обучением тематической модели содержимое веб-страниц новостных интернет-порталов предобрабатывают, выполняя по меньшей мере один из этапов, на которых:
удаляют html-теги и служебную информацию из содержимого веб-страниц новостных интернет-порталов;
осуществляют стемминг содержимого веб-страниц новостных интернет-порталов;
осуществляют лемматизацию содержимого веб-страниц новостных интернет-порталов;
удаляют стоп-слова из содержимого веб-страниц новостных интернет-порталов; и
переводят в нижний регистр содержимое веб-страниц новостных интернет-порталов.
4. Способ по любому из пп. с 1 по 3, в котором тематическую модель обучают с помощью метода аддитивной регуляризации тематических моделей (ARTM) на основе содержимого веб-страниц новостных интернет порталов для того, чтобы получить обученную тематическую модель, которая способна отображать содержимое произвольной веб-страницы в вектор скрытых тем, и отображать этот вектор скрытых тем в вектор категорий, при этом каждый из вектора скрытых тем и вектора категории ассоциирован с содержимым упомянутой произвольной веб-страницы,
при этом вектор категорий отражает вероятности принадлежности этой произвольной веб-страницы к каждой из упомянутых категорий.
5. Способ по п. 4, в котором создают с помощью метода-ARTM множество экземпляров тематической модели, которые отличаются друг от друга значениями наборов гиперпараметров, оценивают точность каждого экземпляра, и выбирают тот экземпляр тематической модели, который обладает наивысшей точностью, при этом упомянутую оценку точности выполняют на основе тестового множества данных, которое не участвует в обучении тематической модели, и которое содержит содержимое произвольных веб-страниц, категории которых известны заранее, при этом упомянутая оценка точности состоит в выполнении следующих этапов, на которых:
содержимое каждой веб-страницы из тестового множества данных обрабатывают оцениваемым экземпляром тематической модели, который в ответ на это генерирует вектор скрытых тем и вектор категорий;
сравнивают предсказанную категорию упомянутой веб-страницы из тестового множества данных с соответствующей заранее известной категорией данной веб-страницы;
определяют долю правильно предсказанных оцениваемой тематической моделью категорий.
6. Способ по п. 5, в котором извлекают векторы признаков участников контрольной группы, при этом каждый из участников контрольной группы предоставляет информацию о своем, по меньшей мере, дне рождения, поле, семейном положении,
при этом извлечение векторов признаков участников контрольной группы содержит следующие этапы, на которых:
для каждого участника получают набор векторов скрытых тем, при этом один вектор скрытых тем соответствует одной просмотренной участником веб-странице;
для каждого участника получают временные метки каждой просмотренной им веб-страницы;
для каждого участника осуществляют эквализацию гистограммы всех его временных меток для получения вектора бинарных признаков временных меток;
для каждого набора векторов скрытых тем и векторов бинарных признаков временных меток вычисляют среднее, медиану и среднее квадратичное отклонение для получения, соответственно, вектора средних значений, вектора медианных значений и вектора значений среднего квадратичного отклонения;
для каждого участника преобразуют вектор средних значений, вектор медианных значений, вектор значений среднего квадратичного отклонения и вектор бинарных признаков временных меток в один вектор признаков участника;
строят набор обучающих данных посредством связывания каждого из полученных векторов признаков участников с демографическими данными, предоставленными соответствующим участником контрольной группы;
осуществляют анализ и чистку набора обучающих данных.
7. Способ по п. 6, обучают демографическую модель на основе набора обучающих данных с помощью алгоритма машинного обучения.
8. Способ по п. 7, в котором создают с помощью генетического алгоритма множество экземпляров демографической модели, которые отличаются друг от друга значениями наборов гиперпараметров, оценивают точность каждого экземпляра, и выбирают тот экземпляр демографической модели, который обладает наивысшей точностью, при этом упомянутую оценку точности выполняют на основе тестового множества данных, которое не участвует в обучении демографической модели, и которое содержит векторы признаков пользователей, демографические профили которых известны заранее, при этом упомянутая оценка точности состоит в выполнении следующих этапов, на которых:
каждый из векторов признаков пользователей из тестового множества данных обрабатывают оцениваемой демографической моделью, которая в ответ на это генерирует их демографические профили;
сравнивают предсказанный демографический профиль каждого пользователя с соответствующим заранее известным демографическим профилем этого пользователя;
определяют долю правильно предсказанных оцениваемой демографической моделью категорий.
9. Способ по п. 1, в котором обученную тематическую модель и обученную демографическую модель загружают на мобильное устройство с внешнего вычислительного устройства.
10. Способ по п. 1, при этом этап, на котором обрабатывают на мобильном устройстве содержимое веб-страниц для приспособления содержимого веб-страниц под тематическую модель, содержит следующие подэтапы, на которых:
удаляют html-теги и служебную информацию из содержимого веб-страниц, просмотренных пользователем мобильного устройства;
осуществляют стемминг содержимого веб-страниц, просмотренных пользователем мобильного устройства;
осуществляют лемматизацию содержимого веб-страниц, просмотренных пользователем мобильного устройства;
удаляют стоп-слова из содержимого веб-страниц, просмотренных пользователем мобильного устройства; и
переводят в нижний регистр содержимое веб-страниц, просмотренных пользователем мобильного устройства.
11. Система демографического профилирования, содержащая:
внешнее вычислительное устройство, которое выполнено с возможностью обучения тематической модели и демографической модели;
по меньшей мере одно мобильное устройство, которое выполнено с возможностью осуществления способа определения демографического профиля пользователя мобильного устройства на самом мобильном устройстве по п. 1.
12. Система по п. 11, в которой внешнее вычислительное устройство дополнительно выполнено с возможностью обучения мультиязычной тематической модели на основе веб-страниц новостных интернет-порталов по категориям, которые произвольно заданы поставщиком контента,
для этого внешнее вычислительное устройство выполнено с возможностью сбора содержимого веб-страниц новостных интернет-порталов на по меньшей мере двух языках;
перевода с помощью системы машинного перевода собранного содержимого веб-страниц новостных интернет-порталов на каждом из упомянутых по меньшей мере двух языков на каждый другой из упомянутых по меньшей мере двух языков.
13. Система по п. 12, в которой внешнее вычислительное устройство, перед обучением тематической модели, выполнено с возможностью предобработки содержимого веб-страниц новостных интернет-порталов, выполняя по меньшей мере одно из:
удаления html-тегов и служебной информации из содержимого веб-страниц новостных интернет-порталов;
стемминга содержимого веб-страниц новостных интернет-порталов;
лемматизации содержимого веб-страниц новостных интернет-порталов;
удаления стоп-слов из содержимого веб-страниц новостных интернет-порталов; и
перевода в нижний регистр содержимого веб-страниц новостных интернет-порталов.
14. Система по любому из пп. с 11 по 13, в которой внешнее вычислительное устройство выполнено с возможностью обучения тематической модели с помощью метода аддитивной регуляризации тематических моделей (ARTM) на основе содержимого веб-страниц новостных интернет порталов для того, чтобы получить обученную тематическую модель, которая способна отображать содержимое произвольной веб-страницы в вектор скрытых тем, и отображать этот вектор скрытых тем в вектор категорий, при этом каждый из вектора скрытых тем и вектора категории ассоциирован с содержимым упомянутой произвольной веб-страницы,
при этом вектор скрытых тем отражает вероятности принадлежности этой произвольной веб-страницы к кластерам веб-страниц, которые являются близкими в семантическом смысле,
при этом вектор категорий отражает вероятности принадлежности этой произвольной веб-страницы к каждой из упомянутых категорий.
15. Система по п. 14, в которой внешнее вычислительное устройство дополнительно выполнено с возможностью создания с помощью метода-ARTM множества экземпляров тематической модели, которые отличаются друг от друга значениями наборов гиперпараметров, оценки точности каждого экземпляра, и выбора того экземпляра тематической модели, который обладает наивысшей точностью, при этом упомянутую оценку точности внешнее вычислительное устройство выполняет на основе тестового множества данных, которое не участвует в обучении тематической модели, и которое содержит содержимое произвольных веб-страниц, категории которых известны заранее, при этом для упомянутой оценки точности внешнее вычислительное устройство дополнительно выполнено с возможностью:
обработки содержимого каждой веб-страницы из тестового множества данных оцениваемым экземпляром тематической модели, который в ответ на это генерирует вектор скрытых тем и вектор категорий;
сравнения предсказанной категории упомянутой веб-страницы из тестового множества данных с соответствующей заранее известной категорией данной веб-страницы;
определения доли правильно предсказанных оцениваемой тематической моделью категорий.
16. Система по п. 15, в которой внешнее вычислительное устройство дополнительно выполнено с возможностью извлечения векторов признаков участников контрольной группы, при этом каждый из участников контрольной группы предоставил информацию о своем, по меньшей мере, дне рождения, поле, семейном положении,
при этом для извлечения векторов признаков участников контрольной группы внешнее вычислительное устройство выполнено с возможностью:
для каждого участника получения набора векторов скрытых тем, при этом один вектор скрытых тем соответствует одной просмотренной участником веб-странице;
для каждого участника получения временной метки каждой просмотренной им веб-страницы;
для каждого участника эквализации гистограммы всех его временных меток для получения вектора бинарных признаков временных меток;
для каждого набора векторов скрытых тем и векторов бинарных признаков временных меток вычисления среднего, медианы и среднего квадратичного отклонения для получения, соответственно, вектора средних значений, вектора медианных значений и вектора значений среднего квадратичного отклонения;
для каждого участника преобразования вектора средних значений, вектора медианных значений, вектора значений среднего квадратичного отклонения и вектор бинарных признаков временных меток в один вектор признаков участника;
построения набора обучающих данных посредством связывания каждого из полученных векторов признаков участников с демографическими данными, предоставленными соответствующим участником контрольной группы;
осуществления анализа и чистки набора обучающих данных.
17. Система по п. 16, в которой внешнее вычислительное устройство выполнено с возможностью обучения демографической модели на основе набора обучающих данных с помощью алгоритма машинного обучения.
18. Система по п. 17, в котором внешнее вычислительное устройство выполнено с возможностью создания с помощью генетического алгоритма множества экземпляров демографической модели, которые отличаются друг от друга значениями наборов гиперпараметров, оценки точности каждого экземпляра, и выбора того экземпляра демографической модели, который обладает наивысшей точностью, при этом упомянутую оценку точности внешнее вычислительное устройство выполняет на основе тестового множества данных, которое не участвует в обучении демографической модели, и которое содержит векторы признаков пользователей, демографические профили которых известны заранее, при этом для упомянутой оценки точности внешнее вычислительное устройство выполнено с возможностью:
обработки каждого из векторов признаков пользователей из тестового множества данных оцениваемой демографической моделью, которая в ответ на это генерирует их демографические профили;
сравнения предсказанного демографического профиля каждого пользователя с соответствующим заранее известным демографическим профилем этого пользователя;
определения доли правильно предсказанных оцениваемой демографической моделью категорий.
19. Система по п. 11, в которой внешнее вычислительное устройство дополнительно выполнено с возможностью загрузки обученной тематической модели и обученной демографической модели на мобильное устройство.
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| ОСНОВАННОЕ НА ПРОФИЛЕ ИЗВЛЕЧЕНИЕ СОДЕРЖИМОГО ДЛЯ СИСТЕМ СРЕДСТВ ВЫДАЧИ РЕКОМЕНДАЦИЙ | 2011 |
|
RU2577189C2 |
| Способ промывки песчаных пробок в нефтяных скважинах | 1960 |
|
SU132591A1 |

