ОБЛАСТЬ ТЕХНИКИ
Настоящее изобретение относится к способу получения карты глубины изображения повышенного качества, в частности используя данные автоматического расчета карты глубины 2D изображения.
УРОВЕНЬ ТЕХНИКИ
В настоящее время потребителю доступны технологии стереоскопического отображения 3D изображений. В то же время количество доступных устройств, позволяющих потребителям использовать содержание 3D изображений, по-прежнему крайне ограничено из-за высокой стоимости получения и обработки стереоскопического содержания. Компании в области бытовой электроники, как мы видим, имеют большой спрос на технологию, которая может автоматически преобразовывать существующие 2D изображения в стереоскопические 3D в режиме реального времени или близко к реальному времени через потребительские устройства воспроизведения, такие как телевизоры, Blu-Ray плееры или телеприставки.
Существует значительное число фундаментальных исследований, сосредоточенных на извлечении 3D информации из одного или нескольких 2D изображений в видеопоследовательности. Такой процесс является практичным в различных областях деятельности, таких как автономная навигация робота, и является центральным понятием в области компьютерной визуализации. Однако требования для таких приложений, как автономная навигация робота и компьютерная визуализация, отличаются от требований по использованию в устройствах 3D-развлечений. В компьютерной визуализации акцент делается на извлечении физически точного измерения расстояния, тогда как в приложениях для 3D-развлечений акцент делается на извлечении информации о глубине, что обеспечивает получение визуально привлекательной 3D модели, которая согласуется с оптическими сигналами 2D изображения. Настоящее изобретение относится к последней категории.
Основная проблема, стоящая перед способами преобразования 2D в 3D, заключается в некорректном убеждении, что с учетом информации 2D изображения можно получить несколько различных конфигураций 3D. В частности, автоматизированные алгоритмы преобразования 2D в 3D действуют на основе характеристик изображения, таких как цвет, положение, форма, фокус, градация оттенков и движение. Они не воспринимают "объекты" в рамках сцены, как это делает человеческий глаз. Для извлечения 3D информации из 2D изображений был разработан ряд способов; обзор этих способов можно найти в исследовательском отчете ХР-002469656TU Delft, сделанном Квинквином Веем в декабре 2005 года. Оптический анализ движения обеспечивает наиболее перспективные методы анализа видеоизображений, которые привели к развитию методик "структура-из-движения", лучше всего представлены в справочнике "Различные геометрические планы при компьютерном распознавании" Ричарда Хартли и Андрея Циссермана, Кембридж Юниверсити Пресс, 2000 г.
Одним из способов преодоления некорректного преобразования 2D в 3D является попытка совместить информацию о глубине из нескольких изображений методом анализа. Такие способы получения глубины путем слияния могут заключаться в комбинировании «глубины-из-фокуса» с сегментированием движения. Из предшествующего уровня техники известны несколько приемов, в частности, в публикации "Изучаем глубину в одном монокулярном изображении", А. Саксена и др., 2005, МИТ Пресс, описан способ использования вероятностной модели при получении комбинированной информации о глубине от смежных изображений. Другой подход описан в публикации "Получение карты глубины по классификатору изображений" С. Баттиато и др. Материалы СПАйИ, 2004 г. При этом подходе применяют классификацию изображения (например, внутри/снаружи), чтобы определить, каким источником информации о глубине следует воспользоваться. Наконец, в публикации "Приоритеты слияния глубины для системы преобразования 2D в 3D", Юн-Лин Чанг и др. Материалы СПАйИ, 2008 г. описан способ приоритетного слияния глубины по результатам оценки движения такими методами, как геометрическая глубина.
Эти примеры из уровня техники страдают от нескольких проблем. Например, способ комбинирования нескольких источников глубины не обеспечивает последовательный диапазон глубин. В целом большинство, если не все процессы преобразования 2D в 3D не дают удовлетворительный стереоскопический эффект. Настоящее изобретение направлено на получение усовершенствованной карты глубины или лучшего качества, которая была бы пригодной для использования в индустрии развлечений, а также для других отраслей промышленности.
КРАТКОЕ ИЗЛОЖЕНИЕ СУЩНОСТИ ИЗОБРЕТЕНИЯ
В широком смысле предлагается способ повышения или улучшения качества карты глубины на основе анализа объектов изображения.
Другой аспект относится к системе повышения качества карты глубины 2D изображения, в которой:
детектор распознавания лица выполнен с возможностью анализа 2D изображения с целью определения положения лица на этом 2D изображении,
система выполнена с возможностью получать модель глубины на основе положения лица, и
модель глубины в комбинации с картой глубины предназначена для получения карты глубины изображения повышенного качества.
2D изображение может представлять собой фотокадр или 2D фотографию. Как вариант, 2D изображение может представлять собой кадр видеоряда. Система может применяться для нескольких кадров видеоряда, чтобы тем самым обеспечить стереоскопический видеоряд.
Следующий аспект настоящего изобретения относится к способу получения карты глубины повышенного качества, который включает следующие операции:
получение 2D изображения и соответствующей карты глубины;
использование детектора распознавания лица с целью определения положения лица на этом 2D изображении;
получение модели глубины на основе положения лица, и
комбинирование модели глубины с картой глубины для получения карты глубины изображения повышенного качества.
Следующий аспект настоящего изобретения относится к способу получения карты глубины повышенного качества, который включает следующие операции:
получение 2D изображения;
создание оригинальной карты глубины, относящейся к этому 2D изображению;
использование детектора распознавания лица с целью определения положения лица на этом 2D изображении;
получение модели глубины на основе положения лица, и
комбинирование модели глубины с оригинальной картой глубины для получения карты глубины изображения повышенного качества.
В предпочтительном варианте осуществления система также определяет правдоподобие третьего лица на 2D изображении на основе положения лица.
В предпочтительном варианте осуществления система предусматривает субдискретизацию 2D изображения перед использованием детектора распознавания лица с тем, чтобы сократить количество технических условий компьютерной обработки. Для определения положения лица на 2D изображении с использованием детектора распознавания лица предпочтительно комбинировать обработку основного изображения с методиками геометрической обработки.
Модель глубины может быть получена путем определения глубины объектов на изображении, а также геометрии объектов. В конкретном случае, лицо человека.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Иллюстрации вариантов осуществления настоящего изобретения сопровождаются ссылкой на прилагаемые чертежи. Существенные признаки и преимущества изобретения будут очевидны из приведенного описания.
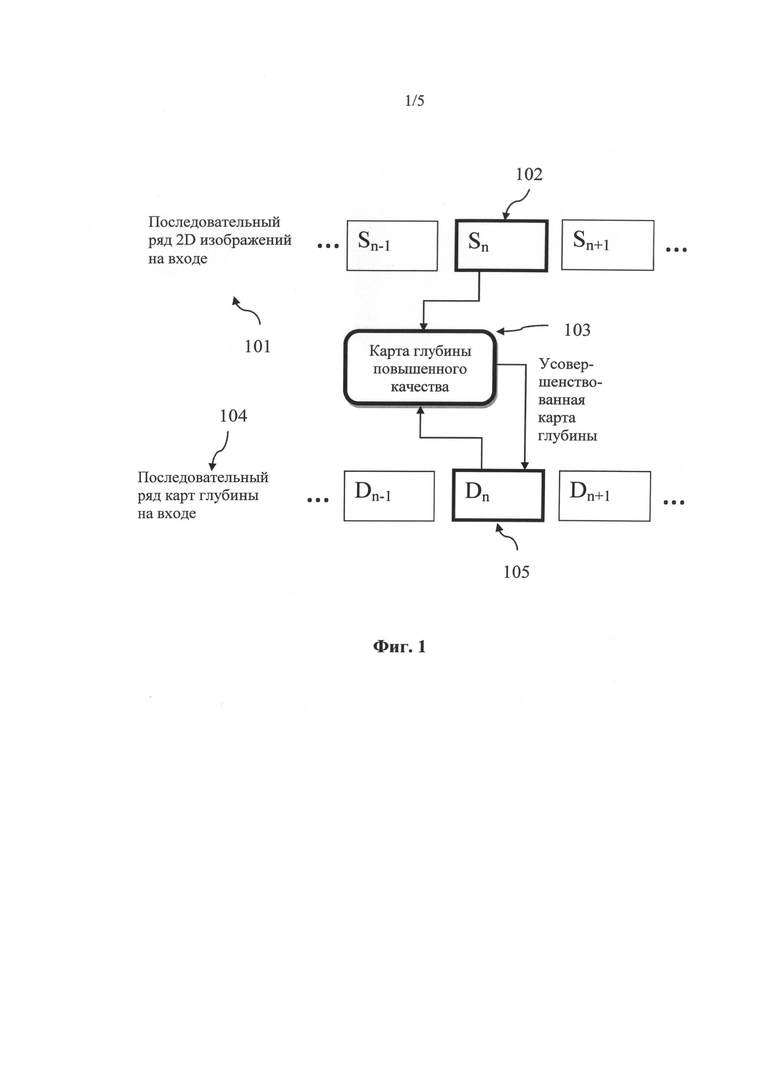
На Фиг.1 представлена общая схема обработки согласно одному варианту осуществления настоящего изобретения.
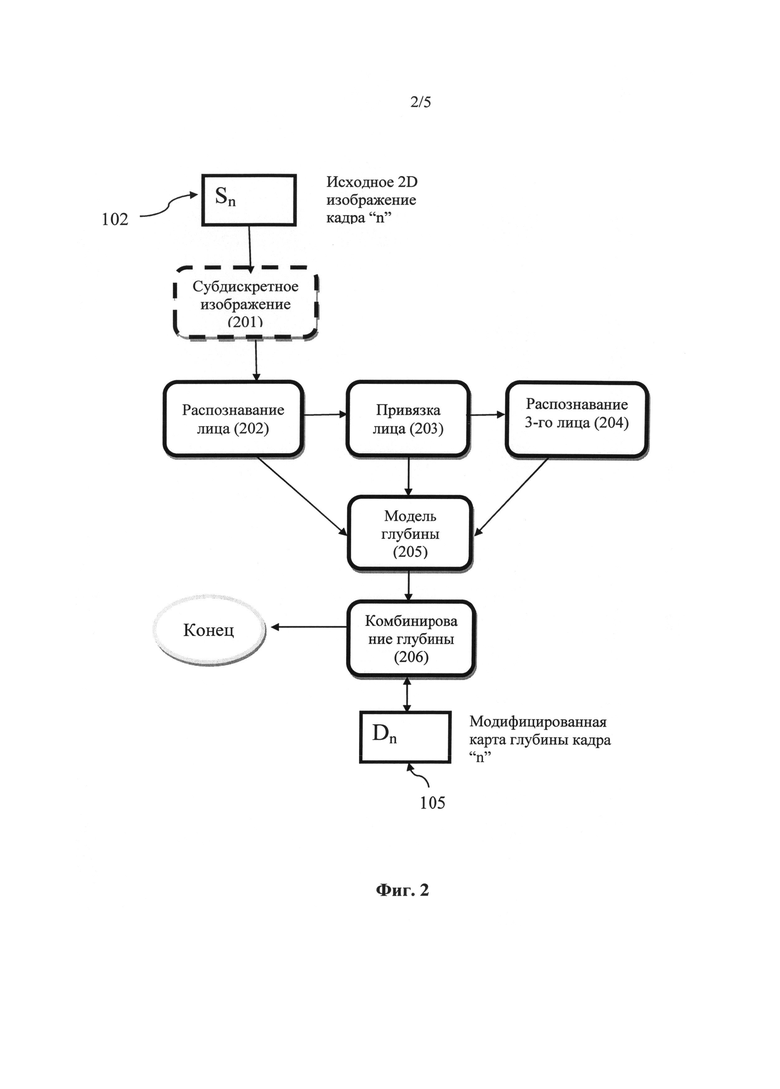
На Фиг.2 представлена схема процесса усовершенствованной обработки, представленной на Фиг.1.
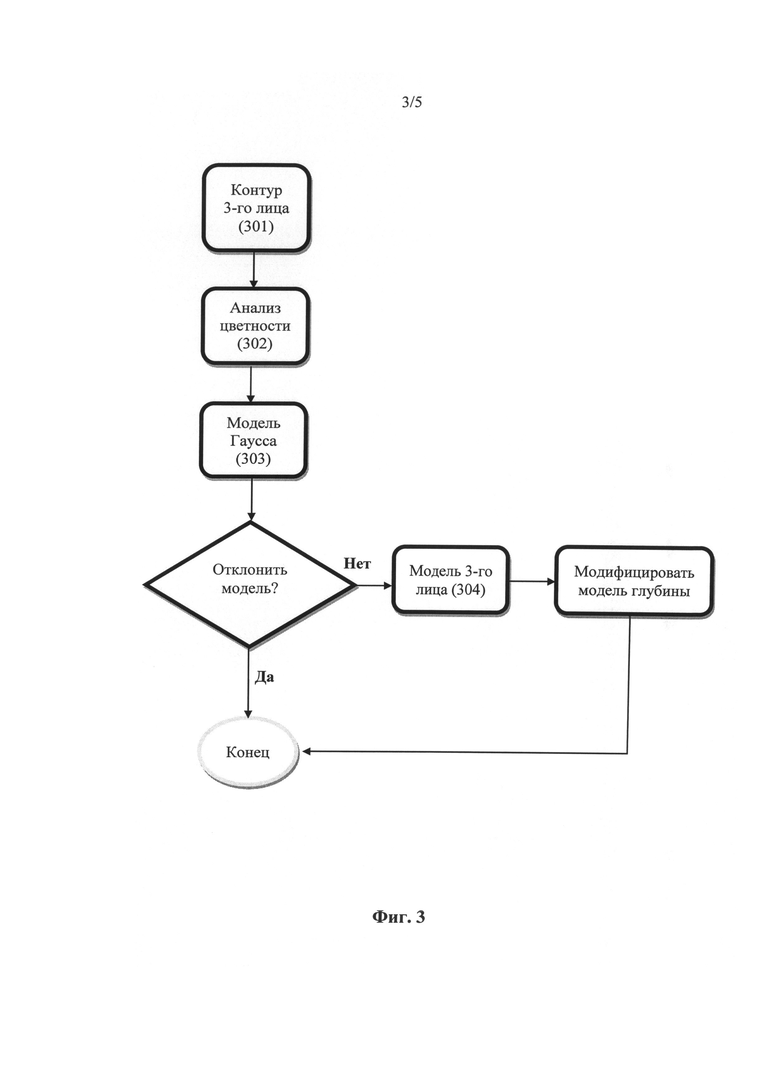
На Фиг.3 представлена схема процесса по отношению к объекту обнаружения.
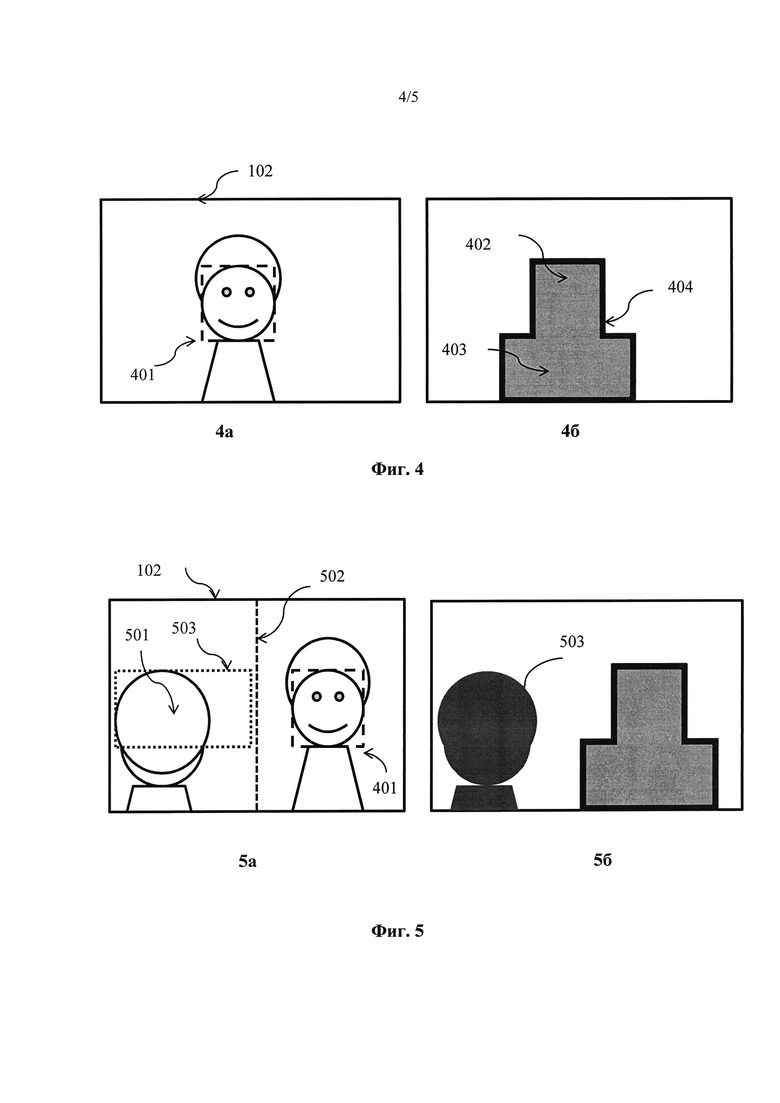
На Фиг.4а представлен пример с лицом, а на Фиг.4б представлена модель глубины, рассчитанная по ограничительному прямоугольнику на Фиг.4а.
На Фиг.5а представлен пример кадра, выполненного через плечо, с функцией распознавания лица на правой стороне изображения, а на Фиг.5б модель глубины модели, полученной с помощью изображения на Фиг.5а.
Фиг.6 иллюстрирует полученное изображение и возможные усовершенствования согласно настоящему изобретению.
ПОДРОБНОЕ ОПИСАНИЕ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ
Следующее описание представлено с возможностью для любого специалиста в данной области осуществить изобретение в контексте конкретного выполнения с учетом требований. Различные усовершенствования вариантов осуществления будут очевидны специалистам в данной области техники, а общие принципы, изложенные в данном документе, могут быть применены к другим вариантам осуществления без отхода от сущности и объема правовой охраны настоящего изобретения. Таким образом, настоящее изобретение не ограничивается вариантами осуществления, а должно соответствовать самому широкому объему, согласно принципам и в соответствии с существенными признаками, раскрытыми в данном документе.
Настоящее изобретение описывает способ позиционирования лица, выбранного в качестве главного объекта. Такую информацию используют для дальнейшего анализа какого-нибудь изображения и повышения качества его карты глубины, что позволяет повысить качество преобразования 2D в 3D в режиме реального времени. Предпочтительный вариант системы в целом обеспечивает способ обработки последовательности одного или более 2D изображений и связанных с ними карт глубины. Хотя настоящее изобретение сфокусировано на последовательности кадров, как на кинопленке, следует понимать, что настоящее изобретение также может быть использовано для неподвижных изображений. Ссылки на один кадр или кадры сделаны для пояснения настоящего изобретения. Следует иметь в виду, что можно использовать неподвижное изображение или один 2D кадр. Также следует иметь в виду, что согласно настоящему изобретению может быть использовано несколько кадров видеопоследовательности как, например, в 3D кино.
На Фиг.1 представлена общая схема обработки последовательности, когда качество карт глубины повышают за счет анализа кадров последовательности 2D изображения и улучшения Dn карты глубины, относящейся к 2D изображению кадра Sn. To есть каждый исходный кадр 102 анализируют и используют для повышения качества соответствующей карты глубины 105. Существующие карты глубины могут быть созданы с использованием другой системы преобразования 2D в 3D или системы опознавания. В качестве альтернативной системы сначала, до применения настоящего изобретения, может быть использована существующая технология по созданию карты глубины из 2D изображения. Таким же образом настоящее изобретение может быть использовано, когда карты глубины еще нет. Настоящее изобретение может быть реализовано с помощью процессора, подключенного к памяти. Процессор получает 2D изображение 102 через устройство ввода/вывода или другие средства связи. Им может быть, например, беспроводное устройство. 2D изображение 102 может быть сохранено в памяти. В идеале карта глубины 2D изображения уже существует.
Для получения модели глубины 2D изображения используют процессор, который анализирует 2D изображение. Процесс также может включать использование способов распознавания лиц, чтобы найти лицо на изображении, а затем оценить вероятность нахождения третьего лица на 2D изображении. Для получения карты глубины повышенного качества процессор комбинирует модель глубины с оригинальной картой глубины. Карту глубины повышенного качества можно также сохранять в памяти. В зависимости от варианта стереоскопического изображения, созданного процессором, в качестве альтернативы карта глубины повышенного качества может быть передана вместе с 2D изображением на внешнее устройство для создания и отображения стереоскопических изображений.
Карта глубины повышенного качества может быть передана на дисплей через устройство ввода/вывода. На дисплей стереоскопические изображения могут быть выведены как в виде оригинальных 2D изображений, так и в виде карт глубины повышенного качества.
Настоящее изобретение может быть реализовано в современных стереоскопических 3D телевизорах за счет добавления интегральной схемы (ASIC) для обработки изображения согласно настоящему изобретению. ASIC может быть подключена к видеодекодеру или ТВ-тюнеру на входе и модулю 3D визуализации на выходе.
Последовательность несжатых изображений передают от видеодекодера через регулярные промежутки времени (в зависимости от частоты кадров) на входные порты прикладной микросхемы ASIC. ASIC включает в себя как логические элементы и внутреннюю память, необходимые для обработки 2D, так и информацию о глубине на входе для получения конечной карты глубины повышенного качества. Кроме того, в ASIC можно применять внешнюю общую память для хранения временных результатов, таких как субдискретное изображение (201).
Как вариант, вместо прикладной микросхемы ASIC может быть использована одно кристаллическая (SoC) или программируемая логическая интегральная схема (FPGA), в зависимости от рабочих характеристик и других параметров, таких как объем.
Кроме того, изобретение может быть реализовано на других мультимедийных платформах, таких как персональный компьютер (ПК), мобильное устройство (телефон, планшет) или компьютерная приставка к телевизору (STB). Применительно к работе однокристальной схемы SoC, компьютера или мобильного устройства изобретение может быть реализовано в комбинации процессоров общего назначения (х86 или ARM) или программируемых подсистем графики типовых графических процессоров (GPU).
Настоящее изобретение предназначено для повышения качества имеющейся карты глубины на основе семантической информации, заложенной в 2D изображении. Предполагается, что после повышения качества 103 карты глубины до визуализации стереоскопического изображения, при работе с картой глубины и 2D изображением могут быть использованы дополнительные аксессуары.
Сам процесс повышения качества более подробно проиллюстрирован на Фиг.2, где представлена общая схема процесса поэтапной обработки, включая анализ 2D изображения в кадре "n" и повышение качества соответствующей карты глубины, создание модели лица и комбинирование ее с существующей картой глубины. Первый этап относится к получению 2D изображения 102 заданного кадра "n". В предпочтительном варианте 2D изображение является субдискретным 201, в идеале с использованием стандартного алгоритма, такого как билинейная интерполяция. Распознавание лиц может быть затратным с точки зрения вычислений и зависеть от количества пикселей в изображении. За счет уменьшения количества пикселей, которые необходимо проанализировать, можно увеличить скорость распознавания лица. Кроме того, процесс субдискретизации эффективно выравнивает изображение за счет билинейной интерполяции, а это может повысить точность распознавания лица за счет удаления искажений на изображении. Степень субдискретизации может варьироваться в зависимости от общего количества пикселей в изображении и характеристик системы. В идеале для анализа глубины изображение дискретизируют до четверти от общего количества пикселей исходного изображения. Тем не менее, этот этап в основном применяют для увеличения производительности и в некоторых вариантах его можно пропустить.
В предпочтительном варианте 2D изображение 102 или субдискретное изображение 201 затем изучают с целью распознавания лица 202. Процесс распознавания лица, сам по себе, известен из уровня техники. В настоящем изобретении может быть использован детектор лица, выполненный с возможностью распознавания одного или нескольких лиц на одном 2D изображении и формирования ограничительного прямоугольника, соответствующего метке лица. Задача детектора распознавания лиц заключается в максимальном выявлении таких объектов с минимальным уровнем ложных идентификаций. Типовые алгоритмы распознавания лица основаны либо на способах анализа изображения, либо на основе методов измерения площадей построением треугольников или других простых фигур, либо их комбинированием. Способы анализа изображения основаны на использовании набора примеров уже известных изображений лица и анализе подмножества текущего изображения для выявления сходства с изучаемым изображением. Геометрические методы обработки направлены непосредственно на выявление конкретных геометрических особенностей типичного лица, таких, как расстояние между глазами.
Удобнее всего выполнять распознавание лица с учетом настоящего изобретения, при котором эффективно сочетают способ анализа изображения с геометрическим подходом. Такое сочетание включает два этапа: этап подготовки и этап распознавания. На этапе распознавания последовательный ряд исходного 2D изображения сопоставляют с результатами, полученными на этапе подготовки. В процессе сопоставления используют признаки Хаара в масштабируемых подмножествах изображения. Признаки Хаара представляют собой не что иное, как комбинацию смежных пикселей, которые были признаны эффективными при выполнении распознавания изображений. Метку на изображении для конкретного подмножества выполняют на основе различий между средней интенсивностью пикселей каждого признака Хаара.
В дополнение к признакам Хаара используют дополнительный признак, относящийся к цветности. Функцией такого признака является устранение подобности лица там, где цветность вряд ли относится к лицу. На этапе подготовки формируют таблицу поиска цветности с целью соотнесения каждого цвета с вероятностью распознавания лица. На этапе подготовки для всех цветовых оттенков лица создают единую гистограмму. Хотя в теории при определенных условиях освещения лицо может иметь любой цвет, функцией цветового признака является задача максимально быстро отсечь любые зоны, которые не относятся к лицу. Признак цветности рассматривается как единый итоговый прямоугольник локализованной цветовой тональности, согласно которому принимают или отклоняют распознавание лица на основе итоговой суммы значения цветности, равной или превышающей порог отсечения.
На этапе подготовки можно использовать стандартный алгоритм машинного обучения (AdaBoostalgorithm) в отношении двух подготовленных изображений:
один с лицами, а другой без них. Алгоритм машинного обучения используют для того, чтобы определить, какая комбинация функций являются наиболее эффективной при сопоставлении этих двух изображений. На этапе подготовки алгоритм AdaBoost для каждого признака назначает количественное значение, которое означает эффективность каждого признака в процессе распознавания лиц.
На этапе распознавания лица комбинируют количественное значение каждого признака, рассчитанного на подготовительном этапе, с метками текущего подмножества и получают достоверную метку текущего подмножества. Используя эмпирические методы, итоговая метка может быть между 0 и 1 с вероятностью того, что подмножество данного изображения включает в себя лицо. Такую достоверную метку лица впоследствии используют при построении модели глубины.
Модель глубины
На Фиг.4 представлено изображение 102 с лицом. Используя методику, описанную выше, ограничительный прямоугольник 401 (обозначен пунктирной линией) обозначил лицо. Это используется для формирования модели глубины (205). Модель глубины, представленная на Фиг.4б, указывает на удаленность каждого пикселя на изображении от камеры или наблюдателя. Для удобства темные цвета представляют пиксели, расположенные ближе к экрану, а светлые цвета дальше. Для получения модели глубины распознаваемого лица система определяет две характеристики: глубину объектов в модели и геометрию объектов. Глубину можно определить по следующей формуле:
Глубина=Метка лица∗(0.5+0.5∗ Пропорциональный размер изображения)
То есть расстояние от лица до камеры пропорционально размеру ограничительного прямоугольника 401 вокруг лица с определенной уверенностью в том, что такое лицо обнаружено. Метку лица изменяют от 0 до 1, где 0 означает полное отсутствие определенности, а 1 означает полную уверенность. Размер ограничительного прямоугольника берется в процентах от размера изображения. Например, если ширина ограничительного прямоугольника составляет 10, а размер рамки изображения, на котором распознано лицо, составляет 100, то Пропорциональный размер изображения составляет 10/100=10%. При этом наложение лиц перекрывает максимальную глубину в каждой точке.
В предпочтительном варианте, для каждого лица, распознаваемого в кадре изображения, геометрию модели выстраивают из двух отдельных прямоугольников. Положение этих прямоугольников размещают относительно ограничительных прямоугольников распознанных лиц. Первый прямоугольник определяет голову, а второй прямоугольник тело. Схематично это представлено на Фиг.4, где прямоугольник 402 представляет голову Фиг.4а, а прямоугольник 403 представляет тело. Положение этих прямоугольников рассчитывают на основе координат изображения Х0, Y0 ограничительного прямоугольника распознания лица. Положение головы соответствует положению и размеру ограничительного прямоугольника. Предполагаемый прямоугольник тела 403 в два раза больше по ширине и наполовину по высоте чем прямоугольник головы и расположен симметрично ниже лица. Модель может быть обрезана по краям границы изображения.
В каждом из этих случаев два прямоугольника модели глубины в идеале включают "размытую" зону 404 по краю модели плавно интегрируя объект в модель глубины. В предпочтительном варианте используют 4-пиксельный градиент для придания формы прямоугольникам глубины на заднем плане.
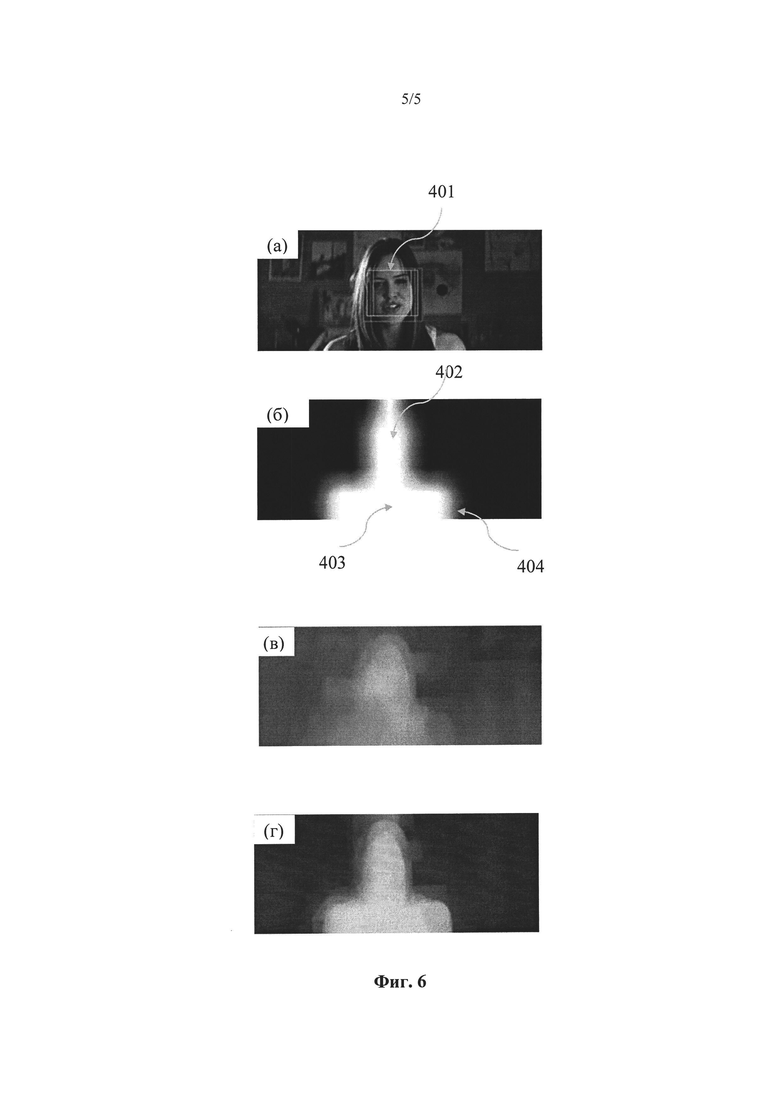
Этот процесс проиллюстрирован на Фиг.6, где представлен пример распознавания лица 6 (а) и процесс обработки модели глубины 6 (б). Фиг.6 (в) иллюстрирует карту глубины, полученную в процессе преобразования 2D в 3D, которая не относится к настоящему изобретению. Оттенки серого характеризуют относительные расстояния каждого пикселя 2D изображения с точки зрения наблюдателя: светлые тона характеризуют близкие расстояния, темные тона характеризуют удаленно расположенные объекты. Как видно на Фиг.6 (в), карта глубины содержит несколько ошибок, в частности, большие зоны стены находятся на таком же расстоянии от камеры, как и человек на переднем плане. Как только применим модель глубины, получим значительное повышение качества карты глубины в плане разделения объектов на передние и задние, что приводит к значительному улучшению стереоскопического эффекта. По мере того, как показано на Фиг.6, используют примерные карты глубины и модели глубины, становится понятным, что точные представления таких карт глубины и моделей глубины могут отличаться от тех, которые представлены на Фиг.6. На Фиг.6 приводится лишь пример для того, чтобы лучше проиллюстрировать настоящее изобретение.
Целевое распознавание объекта
Один аспект настоящего изобретения относится к возможности использования идентификации одного объекта для предположения и нацеливания на распознавание дополнительных объектов. В частности, если какое-либо лицо распознано с некоторыми ограничениями по размеру и положению, система может предположить и проверить наличие других объектов, которые могут быть в контенте.
На практике, обычным для режиссеров является кадр, снятый в необычной конфигурации. Одной из таких необычных конфигураций является третье лицо или кадр, «выполненный через плечо» (OTS). Такие кадры характеризуются тем, что съемку камерой выполняют из-за или через плечо третьего лица таким образом, что у третьего лица через камеру видно спину, а лица не видно. Такая типичная сцена представлена на Фиг.5, где 501 иллюстрирует затылок 3-го лица. Учитывая, что третье лицо не смотрит в камеру, трудно использовать функцию распознавания лица для распознания такого объекта. Однако если лицо в кадре распознано 202, система может использовать положение распознанного лица, чтобы сузить поиск 3-го лица 204.
Первый этап заключается в определении вероятности того, что кадр выполнен через плечо (OTS) в отношении распознаваемого лица. В предпочтительном варианте в процессе сужения поиска лица используют два критерия (203).
1. Ограничительный прямоугольник самого крупного распознанного лица 401 составляет 1/8-ю ширины кадра 102.
2. Ограничительный прямоугольник такого лица 401 является стороной центра изображения 1/20-й ширины кадра 102
Следует отметить, что эти конкретные правила могут варьироваться в зависимости от типа контента, и что другие характеристики могут быть использованы, не изменяя сущности изобретения. Например, некий режиссер или представитель киноиндустрии может отобрать крупный план кадра, выполненного через плечо. В этом случае в ограничительном прямоугольнике самое крупное распознанное лицо 401 лицо может быть увеличено до 1/5-й ширины кадра.
Если согласиться с такими условиями, то сцену определяют как возможный кадр, выполненный через плечо (OTS), и приступают к процессу распознавания 3-го лица, приведенному на Фиг.3.
Распознавание третьего лица
Модель 3-го лица может быть выстроена с использованием смешанной модели Гаусса, которая известна специалистам в данной области в качестве метода кластеризации данных. Смешанная модель Гаусса характеризуется аппроксимацией исходной модели, которая многократно обновляется на основе данных, найденных на изображении. Исходную модель конфигурируют в зависимости от положения и цветности объекта. Чтобы распознать лицо на изображении необходимо инициировать процесс распознавание кадра, выполненного через плечо. Пространственная протяженность 3-го лица настроена так, чтобы быть на "другой" стороне изображения. Например, если лицо, соответствующее критерию распознавания, обнаружено с правой стороны со смещением от осевой линии 502, то 3-е лицо будет находиться на левой стороне кадра 102. Исходную пространственную протяженность 3-го лица 301 устанавливают соответствующей координате Х ограничительного прямоугольника 401 распознаваемого лица. Координату Х задают от центральной линии 502 к краю кадра 102. Проиллюстрировано пунктирной линией прямоугольника 503 на Фиг.5. Исходное распределение цветности модели может быть задано по средней цветности ограничительного прямоугольника 401.
Для определения цветности 302 исходной модели используют наиболее часто встречающиеся цвета в целевой зоне 503. В предпочтительном варианте гистограмма состоит из цветов, а наиболее часто встречающийся цвет выбирают для исходной модели.
Используя стандартные методы 303 построения смешанной модели Гаусса модель обрабатывают несколько раз до получения сходства. Модель отклоняют, если после получения сходства пространственные протяженности модифицированной модели доходят до или перекрывают ограничительный прямоугольник 401 распознаваемого лица. По сути это означает, что объект со стороны экрана выходит за пределы средней линии и, следовательно, скорее всего, не представляют собой дискретный компонент 3-го лица на краю экрана, а фактически является частью фона. Модель также может быть отклонена, если цветовая вариативность 2D изображения в целевой зоне слишком высока. Данный критерий основан на том наблюдении, что в информации об изображении в зоне присутствия 3-го лица, как правило, преобладает один или два цвета. Предполагается, что вокруг сцены, предполагающей присутствие третьего лица, 60-90% целевой зоны составляет один или два цвета. Если цветовая вариативность в целевой зоне, предполагающей присутствие 3-го лица, слишком велика, то модель Гаусса будет включать в себя расширенный диапазон цветности. Это позволяет увеличить степень сведения модели, а затем она будет отклонена на основании ее пространственной протяженности, как описано ранее.
Способ разработки модели глубины 304 для 3-го лица отличается от описанного выше подхода по распознаванию лица. В предпочтительном варианте присутствие 3-го лица моделируют на основе цветовой смешанной модели Гаусса. Для каждого пикселя пространственной протяженности сведенной смешанной модели Гаусса глубину определяют как функцию пиксельной цветности изображения относительно модели. Если пиксельная цветность изображения соответствует среднему значению цветности смешанной модели Гаусса, то модель глубины определяют как передний план (255). Край определяют линейно так, что когда цветность отличается на 10% от общей цветовой гаммы, то она становится фоновым значением (0).
Следует отметить, что приведенный выше пример является лишь одним из возможных вариантов и это же изобретение может быть использовано для моделирования сцен с различными вариантами. Например, если сцена снималась через плечи двух человек с обеих сторон, то было бы очевидным распознать такую расстановку и включить дополнительный этап распознавания и моделирования за плечом второго человека.
Комбинирование глубины
Модель глубины, полученную из анализа исходного 2D изображения 102, используют для повышения качества ранее существовавшей карты глубины 105. Этого достигают по следующей формуле:
Повышение качества глубины(х,у)=Фиксация(Глубины(х,у)+(Модели(х,у)-Среднее значение Модели)).
По сути, глубину каждого пикселя в точке х, у видоизменяют за счет применения насыщенной добавки с нулевым значением, включая существующую глубину по х, у и модель глубины по х, у. Среднее значение Модели представляет собой среднюю глубину модели. Функция Фиксации просто гарантирует, что значение видоизменения глубины находится в пределах 0 и 255. Если значение превышает 255, его устанавливают на 255, а если значение меньше 0, то его устанавливают на 0. Преимуществом такого подхода является то, что он гарантирует, что итоговая карта глубины будет иметь достаточную контрастность глубины для изготовления высококачественных стереоскопических 3D изображений.
Настоящее изобретение обеспечивает карту глубины повышенного качества за счет анализа последовательности изображений и ориентации на конкретные семантические объекты и с помощью такого анализа позволяет получить модель глубины повышенного качества, которая в сочетании с имеющимися данными глубины позволяет повысить качество стереоскопической 3D-визуализации. Повышение качества можно увидеть на примере изображения, представленного на Фиг.6. На Фиг.6а представлено наложение на 2D изображение ограничительного прямоугольника для распознавания лица. Видно, что лицо на изображении выделено как объект для распознавания. Как показано на Фиг.6 определение карты глубины выполняют с использованием процесса преобразования 2D в 3D.
Видно, что в процессе создания карты глубины на изображении выделяют как основной предмет, так и другие объекты. Например, не были выявлены картины на задней стенке. В этом случае итоговые стереоскопические изображения, созданные с помощью карты глубины на Фиг.6б, не будут видны, так как зритель подсознательно ожидает каждое из изображений с такой же глубиной, как задняя стена. Стереоскопические изображения позволяют проецировать картины, как будто они находятся за стеной.
Настоящее изобретение применимо как к исходному изображению на Фиг.6а, так и к карте глубины на Фиг.6б как к исходным ресурсам, в результате чего создают карту глубины повышенного качества. Как было описано ранее, в настоящем изобретении используют распознавание лица и создание модели глубины, основанной на расположении лица. Модель глубины, созданная из изображения Фиг.6а, представлена на Фиг.6в. На Фиг.6в положение головы и плеч выделяются на общем фоне, а оставшиеся на изображении в значительной степени игнорируются. На Фиг.6в также представлены размытые очертания, которые идеально включены в модель по краям головы и плеч.
Когда модель глубины сливают с картой глубины, как описано в настоящем изобретении, создают карту глубины повышенного качества, как показано на Фиг.6г. Видно, что карта глубины повышенного качества обеспечивает более близкое представление об идеальной карте глубины. В конкретном случае большинство фотографий на задней стенке в стереоскопическом изображении будут правильно расположены на стене, а не за стеной.
В практическом плане карта глубины повышенного качества, которая создает стереоскопическое изображение, представляется более реалистичной или жизненной для наблюдателя. То улучшение, которое представлено на Фиг.6, легко оценить, для некоторых изображений трудно определить, как разные наблюдатели будут иметь разную степень резкости, когда речь пойдет о стереовидении. В таких случаях цель процесса повышения качества глубины больше напоминает реальную физическую карту глубины, которая была получена с использованием камеры карты глубины, предназначенной для захвата расстояния. Процесс преобразования 2D в 3D может не в полной мере идентифицировать человека в качестве объекта, поскольку он состоит из нескольких компонентов (волосы, лицо, тело) с разной цветностью и характеристиками телодвижения, которые сложно отнести к одному объекту, используя традиционную обработку изображений и способы сегментации изображений. Настоящее изобретение направлено на распознавание лица, и, по мере распознавания, на создание моделей глубины соответствующих частей, которые предполагается присоединять к такому лицу. Полученную модель глубины затем сливают с картой глубины, чтобы компенсировать недостатки текущей карты глубины, как описано в предшествующем уровне техники.
Фиг.6 наглядно иллюстрирует преимущества согласно настоящему изобретению. Если система позволяет распознать лицо и отталкиваясь от лица вывести тело, то настоящее изобретение позволяет улучшить выделение женщины на переднем плане от стены на заднем фоне. На Фиг.6б, используя традиционные средства получения карты глубины без распознавания лица мы не в состоянии отличить детали стены позади женщин от их лиц/тел. Но с явно распознанным лицом, как описано здесь, настоящее изобретение обеспечивает повышенный контраст глубины между передним и задним планом. Этот улучшенный результат, как показано на Фиг.6г, будет ближе к результатам камеры карты глубины в отличие от традиционных процессов преобразования.
Известные из уровня техники процессы преобразования 2D в 3D не приводили к точному воспроизведению стереоскопических эффектов, потому что они были не в состоянии обнаружить цель и конкретные объекты, такие как лицо, и создать модель глубины. Этот недостаток приводил к неточностям в картах глубины и снижал эффективность стереоскопического 3D изображения.
Настоящее изобретение включает в себя способ накопления информации о глубине из нескольких источников, что обеспечивает контрастность глубины и последовательность методик преобразования 2D в 3D в режиме реального времени по сравнению с известным уровнем техники. Кроме того, из уровня техники преобразования 2D в 3D в режиме реального времени не известен способ распознавания и осмысления объектов на сцене, визуально важный для наблюдателя.
Ссылка в данном описании на "один из вариантов осуществления", или "вариант осуществления" означает, что конкретный существенный признак, структура или характеристика, описанные в связи с вариантом осуществления, включены, по меньшей мере, в один из вариантов осуществления настоящего изобретения. Таким образом, фраза «в одном варианте осуществления» или «в варианте осуществления» в различных местах настоящего описания, не обязательно относится к такому же варианту.
Кроме того, конкретные существенные признаки, процессы или характеристики могут быть объединены в любом подходящем способе в одной или нескольких комбинациях. Следует иметь в виду, что специалисты в данной области могут реализовать настоящее изобретение разными способами, описанными выше, а вариации могут быть выполнены без отхода от его сущности и объема.
Любое обсуждение документов, процессов, действий или знаний в данном описании приведены для объяснения содержания изобретения. Не следует воспринимать это как признание того, что любой материал является частью известного уровня техники или общеизвестных знаний в данной области, в любой стране, или до даты подачи заявки на патент, к которой относится данное описание.
| название | год | авторы | номер документа |
|---|---|---|---|
| ОБЪЕДИНЕНИЕ ДАННЫХ 3D ИЗОБРАЖЕНИЯ И ГРАФИЧЕСКИХ ДАННЫХ | 2010 |
|
RU2538335C2 |
| ТЕЛЕВИЗИОННЫЙ МНОГОРАКУРСНЫЙ СПОСОБ ПОЛУЧЕНИЯ, ПЕРЕДАЧИ И ПРИЕМА СТЕРЕОИНФОРМАЦИИ О НАБЛЮДАЕМОМ ПРОСТРАНСТВЕ С ЕГО АВТОМАТИЧЕСКИМ ИЗМЕРЕНИЕМ. СИСТЕМА "ТРЕТИЙ ГЛАЗ" | 2013 |
|
RU2543549C2 |
| ОСНОВАННОЕ НА ЗНАЧИМОСТИ ОТОБРАЖЕНИЕ ДИСПАРАТНОСТИ | 2012 |
|
RU2580439C2 |
| СИСТЕМА И СПОСОБ ОТСЛЕЖИВАНИЯ ОБЪЕКТА | 2004 |
|
RU2370817C2 |
| УСТРОЙСТВО ВОСПРОИЗВЕДЕНИЯ, СПОСОБ ЗАПИСИ, СИСТЕМА ВОСПРОИЗВЕДЕНИЯ НОСИТЕЛЯ ЗАПИСИ | 2010 |
|
RU2522304C2 |
| СПОСОБ, ТЕРМИНАЛ И СИСТЕМА ДЛЯ БИОМЕТРИЧЕСКОЙ ИДЕНТИФИКАЦИИ | 2023 |
|
RU2815689C1 |
| СПОСОБ МНОГОМОДАЛЬНОГО БЕСКОНТАКТНОГО УПРАВЛЕНИЯ МОБИЛЬНЫМ ИНФОРМАЦИОННЫМ РОБОТОМ | 2020 |
|
RU2737231C1 |
| СПОСОБ, ТЕРМИНАЛ И СИСТЕМА ДЛЯ БИОМЕТРИЧЕСКОЙ ИДЕНТИФИКАЦИИ | 2022 |
|
RU2798179C1 |
| КОМБИНИРОВАНИЕ 3D ВИДЕО И ВСПОМОГАТЕЛЬНЫХ ДАННЫХ | 2010 |
|
RU2554465C2 |
| СПОСОБ КОДИРОВАНИЯ СИГНАЛА ВИДЕОДАННЫХ ДЛЯ ИСПОЛЬЗОВАНИЯ С МНОГОВИДОВЫМ УСТРОЙСТВОМ ВИЗУАЛИЗАЦИИ | 2014 |
|
RU2667605C2 |
Изобретение относится к способу получения карты глубины изображения повышенного качества, в частности используя данные автоматического расчета карты глубины 2D изображения. Технический результат - повышение качества карты глубины 2D изображения. Система повышения качества карты глубины 2D изображения содержит детектор распознавания лица, анализирующий 2D изображения с целью выявления лица на этом 2D изображении и определяющий положение такого выявленного лица на этом 2D изображении. Система, на основе положения лица, получает модель глубины, которая включает как минимум одну добавленную в модель глубины в ответ на выявление лица определенную форму в положении, соответствующем положению выявленного лица, являющуюся характерной для выявленного лица и комбинирует модель глубины с картой глубины для получения карты глубины изображения повышенного качества посредством модификации информации о глубине в карте глубины в месте, соответствующем положению указанной определенной формы в модели глубины, с информацией о глубине, связанной с указанной формой в модели глубины. 3 н. и 31 з.п. ф-лы, 11 ил.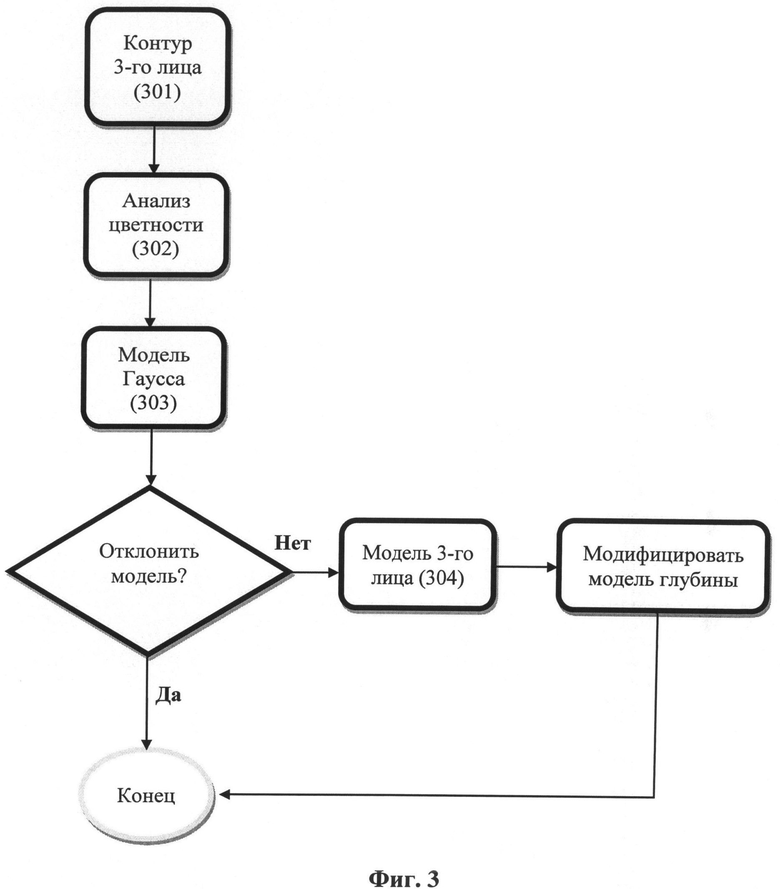
1. Система повышения качества карты глубины 2D изображения, содержащая детектор распознавания лица, выполненный с возможностью анализа 2D изображения с целью выявления лица на этом 2D изображении и определения положения такого выявленного лица на этом 2D изображении, при этом указанная система выполнена с возможностью
получения на основе положения лица модели глубины, которая включает, как минимум, одну добавленную в модель глубины в ответ на выявление лица определенную форму в положении, соответствующем положению выявленного лица, являющуюся характерной для выявленного лица;
и комбинирования модели глубины с картой глубины для получения карты глубины изображения повышенного качества посредством модификации информации о глубине в карте глубины в месте, соответствующем положению указанной определенной формы в модели глубины, с информацией о глубине, связанной с указанной формой в модели глубины.
2. Система по п. 1, отличающаяся тем, что 2D изображение представляет собой кадр видеоряда.
3. Система по п. 1, отличающаяся тем, что детектор распознавания лица выполнен с возможностью формирования ограничительного прямоугольника и метки лица, указывающей на то, что лицо правильно выявлено детектором распознавания лица.
4. Система по п. 2, отличающаяся тем, что глубину лица определяют путем слияния метки лица с пропорциональным размером ограничительного прямоугольника 2D изображения.
5. Система по п. 2, отличающаяся тем, что глубину лица определяют по формуле:
Глубина = Метка лица * (0.5+0.5 * Пропорциональный размер изображения), где Пропорциональный размер изображения пропорционален размеру ограничительного прямоугольника 2D изображения, а метка лица указывает на то, что лицо правильно выявлено детектором распознавания лица.
6. Система по п. 1, отличающаяся тем, что, как минимум, одна определенная форма включает первый прямоугольник или квадрат.
7. Система по п. 6, отличающаяся тем, что модель дополнительно содержит второй прямоугольник, представляющий собой плечи человека, при этом второй прямоугольник в два раза больше по ширине и наполовину по высоте первого прямоугольника.
8. Система по п. 7, отличающаяся тем, что первый и второй прямоугольники включают размытую зону у краев первого и второго прямоугольника для беспрепятственного включения объекта в модель глубины.
9. Система по п. 1, отличающаяся тем, что система определяет вероятность того, что третье лицо находится на 2D изображении, на основе положения распознанного лица на 2D изображении.
10. Система по п. 9, отличающаяся тем, что вероятность того, что третье лицо находится на 2D изображении определяют из расчета либо ширины ограничительного прямоугольника в пределах 1/8 и 1/5 ширины 2D изображения, либо ширины ограничительного прямоугольника, расположенного со смещением от осевой линии 2D изображения примерно на 1/20 ширины кадра 2D изображения.
11. Система по п. 9, отличающаяся тем, что модель третьего лица проверяют с использованием смешанной модели Гаусса по цветности и положению третьего лица.
12. Система по п. 11, отличающаяся тем, что модель отклоняют, если она перекрывает или затрагивает пространство ограничительного прямоугольника.
13. Система по п. 11, отличающаяся тем, что она выполнена с возможностью определения зоны расположения третьего лица и отклонения модели, если в зоне расположения третьего лица не доминирует один цвет.
14. Система по п. 11, отличающаяся тем, что она выполнена с возможностью определения зоны расположения третьего лица и выявления сходства модели с зоной расположения третьего лица по глубине пикселей 2D изображения.
15. Система по п. 1, отличающаяся тем, что она выполнена с возможностью слияния модели глубины и карты глубины по формуле:
Повышение качества глубины (x, y) = Фиксация (Глубины (x, y) + (Модели (x, y) - Среднее значение Модели)),
где 'Фиксация' является функцией, которая обеспечивает такое положение, когда модифицированная характеристика глубины остается в определенном диапазоне характеристик, 'Глубина (х, y)' является глубиной пикселя при положении (х, y), а 'Среднее значение модели' представляет собой среднее значение глубины модели глубины.
16. Система по п. 1, отличающаяся тем, что 2D изображение является субдискретным, а указанный детектор лица выполнен с возможностью анализа указанного субдискретного 2D изображения.
17. Система по п. 16, отличающаяся тем, что 2D изображение является субдискретным до четверти от общего количества пикселей исходного 2D изображения.
18. Способ получения карты глубины повышенного качества, включающий:
получение 2D изображения и соответствующей карты глубины;
использование детектора распознавания лица с целью выявления присутствия лица на указанном 2D изображении и определения положения выявленного лица на этом 2D изображении;
получение на основе положения лица модели глубины, которая включает как минимум одну добавленную в модель глубины в ответ на выявление лица определенную форму в положении, соответствующем положению выявленного лица, являющуюся характерной для выявленного лица; и
комбинирование модели глубины с картой глубины для получения карты глубины изображения повышенного качества посредством модификации информации о глубине в карте глубины в месте, соответствующем положению указанной определенной формы в модели глубины, с информацией о глубине, связанной с указанной формой в модели глубины.
19. Способ по п. 18, отличающийся тем, что 2D изображение является кадром видеоряда.
20. Способ по п. 18, отличающийся тем, что дополнительно включает формирование ограничительного прямоугольника вокруг лица и расчет метки лица, указывающей на то, что лицо правильно выявлено детектором распознавания лица.
21. Способ по п. 20, отличающийся тем, что дополнительно включает расчет пропорционального соотношения ограничительного прямоугольника и 2D изображения и пропорциональное слияние с меткой лица для определения глубины выявленного лица.
22. Способ по п. 21, отличающийся тем, что пропорциональное слияние с меткой лица выполняют по формуле:
Глубина = Метка лица * (0.5+0.5 * Пропорциональный размер изображения) где Пропорциональный размер изображения относится к пропорциональному соотношению размера ограничительного прямоугольника и 2D изображения, а метка лица указывает на то, что лицо правильно выявлено детектором распознавания лица.
23. Способ по п. 18, отличающийся тем, что определенная форма включает первый прямоугольник или квадрат.
24. Способ по п. 23, отличающийся тем, что дополнительно включает действие по определению второго прямоугольника, представляющего собой плечи человека, при этом второй прямоугольник в два раза больше по ширине и наполовину по высоте первого прямоугольника.
25. Способ по п. 23, отличающийся тем, что дополнительно включает действие по добавлению размытой области около 4 пикселей для беспрепятственного включения объекта в модель глубины.
26. Способ по п. 18, отличающийся тем, что дополнительно включает:
формирование ограничительного прямоугольника;
расчет ширины указанного ограничительного прямоугольника;
размещение ограничительного прямоугольника между 1/8 и 1/5 ширины 2D изображения, и
размещение ограничительного прямоугольника со смещением от осевой линии 2D изображения примерно на 1/20 ширины 2D изображения.
27. Способ по п. 26, отличающийся тем, что дополнительно включает определение вероятности того, что третье лицо присутствует на 2D изображении на основании положения выявленного лица по отношению к 2D изображению, и использование смешанной модели Гаусса и цветовой модели зоны расположения третьего лица для создания модели третьего лица.
28. Способ по п. 27, отличающийся тем, что дополнительно включает отклонение модели, если модель перекрывает или затрагивает пространство ограничительного прямоугольника.
29. Способ по п. 27, отличающийся тем, что дополнительно включает:
определение зоны расположения третьего лица;
анализ цветности пикселей в упомянутой зоне, и
отклонение упомянутой модели, если в упомянутой зоне расположения третьего лица не доминирует один цвет.
30. Способ по п. 27, отличающийся тем, что дополнительно включает:
определение зоны расположения третьего лица;
сопоставление цветности пикселей в упомянутой зоне с моделью, и
установление пиксельной глубины на основе сходства пикселей с моделью.
31. Способ по п. 18, отличающийся тем, что слияние модели глубины с картой глубины выполняют по формуле:
Повышение качества глубины (х, y) = Фиксация (Глубины (х, y) + (Модели (х, y) - Среднее значение Модели)),
где 'Фиксация' является функцией, которая обеспечивает такое положение, когда модифицированная характеристика глубины остается в определенном диапазоне характеристик, 'Глубина (х, y)' является глубиной пикселя при положении (х, y), 'Модель (х, y)' является моделью глубины при положении (х, y), а 'Среднее значение модели' представляет собой среднее значение глубины модели глубины.
32. Способ по п. 18, отличающийся тем, что дополнительно включает субдискретизацию 2D изображения, при этом детектор распознавания лица выполняет анализ субдискретного 2D изображения.
33. Способ по п. 32, отличающийся тем, что 2D изображение субдискретизируют до четверти от общего количества пикселей исходного 2D изображения.
34. Система повышения качества карты глубины для ряда последовательности одного или более 2D изображений, содержащая детектор распознавания объекта, выполненный с возможностью анализа 2D изображения с целью выявления объекта в 2D изображении и определения положения такого объекта, при этом указанная система выполнена с возможностью
получения на основе положения лица модели глубины, которая включает как минимум одну добавленную в модель глубины в ответ на выявление объекта определенную форму в положении, соответствующем положению выявленного лица, являющуюся характерной для выявленного объекта и указывающую на глубину объекта, представленного этой формой; и
комбинирования модели глубины с картой глубины для получения карты глубины изображения повышенного качества посредством модификации информации о глубине в карте глубины в месте, соответствующем положению указанной определенной формы в модели глубины, с информацией о глубине, связанной с указанной формой в модели глубины.
| Колосоуборка | 1923 |
|
SU2009A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| Печь для непрерывного получения сернистого натрия | 1921 |
|
SU1A1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ОБРАБОТКИ КАРТЫ ГЛУБИНЫ | 2008 |
|
RU2497196C2 |
| RU 2002131792 A, 10.07.2004. | |||

