Область техники
Изобретение относится к области защиты от компьютерных угроз, а именно к системам и способам оценки надежности правила категоризации.
Уровень техники
В настоящее время наряду с широким распространением компьютеров и подобных им устройств, таких как мобильные телефоны, имеет место рост количества компьютерных угроз. Под компьютерными угрозами в общем случае подразумевают объекты, способные нанести какой-либо вред компьютеру или пользователю компьютера, например: сетевые черви, клавиатурные шпионы, компьютерные вирусы.
Для защиты пользователя и его персонального компьютера от возможных компьютерных угроз применяются различные антивирусные технологии. В состав антивирусного программного обеспечения могут входить различные модули обнаружения компьютерных угроз. Частными случаями таких модулей являются модули сигнатурного и эвристического обнаружения. Ввиду большого роста количества вредоносных программ эффективность указанных модулей зависит от количества сигнатур и эвристических правил, используемых модулями. В настоящее время созданием новых эвристических правил и сигнатур занимаются эксперты и разработанные для этих целей автоматизированные системы создания сигнатур. В результате экстенсивной работы экспертов и автоматизированных систем создается большое количество эвристических правил и сигнатур для обнаружения компьютерных угроз. Большое количество созданных эвристических правил и сигнатур, далее правил обнаружения, зачастую ведет за собой увеличение количества ложных срабатываний при работе модулей обнаружения угроз. Появляется потребность в системах оценки надежности созданных правил обнаружения.
Существуют системы проверки правил обнаружения на основе проверки указанных правил с использованием коллекции безопасных файлов. При использовании таких систем правило обнаружения проходит проверку на коллекции безопасных файлов и попадает в распоряжение антивирусного программного обеспечения пользователей только после обновления баз антивирусного модуля.
Но коллекция безопасных файлов, имеющаяся у производителей антивирусного программного обеспечения, не может покрыть все разнообразие файлов, встречающееся у пользователей, поэтому очень часто используется обратная связь от правила обнаружения, когда оно уже работает у пользователя. Антивирусное приложение, которое использует правило обнаружения, посылает разработчикам уведомления о том, на каких файлах сработало правило, и разработчики на своей стороне анализируют эту информацию. В патенте US 8356354 описывается система выпуска обновлений антивирусных баз, один из вариантов которой предполагает отправку уведомлений антивирусным приложением информации разработчикам о файлах, на которых сработало правило. Полученная информация анализируется на предмет ложных срабатываний указанного правила.
Но и совместное использование коллекции заведомо безопасных файлов и заведомо вредоносных файлов, с обратной связью от пользователей, не может гарантировать эффективность правила обнаружения по причине неполноты коллекции и очевидной невозможности проверить правило на файлах, которые расположены на персональных компьютерах без установленного антивирусного программного обеспечения. А также существенный недостаток в ограниченности используемого сегодня метода обратной связи: как правило для обратной связи используется не сам файл, а его хэш контрольной суммы, и если файл из коллекции будет хоть немного отличаться от файла, на котором сработало правило, с большой вероятностью хэши не совпадут и ложное срабатывание обнаружено не будет.
Хотя рассмотренные подходы направлены на решение определенных задач в области защиты от компьютерных угроз, они обладают недостатком - желаемое качество выбора надежных правил обнаружения (использование которых не повлечет за собой появление ложных срабатываний) не достигается. Настоящее изобретение позволяет более эффективно решить задачу выявления надежных правил обнаружения.
Раскрытие изобретения
Настоящее изобретение предназначено для оценки надежности правил категоризации.
Технический результат настоящего изобретения заключается в автоматизации анализа надежности правила категоризации на основании сравнения комбинации степеней надежности правила категоризации с установленным числовым порогом.
Способ признания правила категоризации надежным, в котором: создают при помощи средства создания правила категоризации правило категоризации, применение которого к файлу позволяет определить принадлежность рассматриваемого файла к одной из определенных в рамках правила категорий файлов; собирают при помощи средства сбора статистики статистку использования по меньшей мере одного созданного правила категоризации, при этом статистика использования правила категоризации представляет собой информацию о множестве файлов, принадлежащих к каждой из категорий, которые определены в рамках упомянутого правила категоризации; определяют при помощи средства определения надежности степень надежности правила категоризации на основании статистики использования правила категоризации с использованием по меньшей мере одного алгоритма интеллектуального анализа данных; признают при помощи средства определения надежности правило категоризации надежным, если комбинация степеней надежности правила, определенных ранее, превышает установленный числовой порог.
В частном случае реализации способа правило категоризации применяют к результатам обработки файла.
В другом частном случае реализации способа обработкой файла является эмуляция процесса выполнения файла.
Еще в одном частном случае реализации способа обработкой файла является вычисление свертки файла.
В другом частном случае реализации способа правилом категоризации является правило для обнаружения вредоносного программного обеспечения.
Еще в одном частном случае реализации способа правилом категоризации является свертка файла, которая определяет, входил ли файл в категорию файлов с совпадающим значением свертки.
В другом частном случае реализации способа предварительно осуществляется обучение алгоритмов интеллектуального анализа данных.
Еще в одном частном случае реализации способа для обучения используется множество файлов для обучения, а также статистика использования правил, применение которых к множеству файлов для обучения разбивает указанное множество файлов на категории таким образом, что хотя бы одна категория файлов в соответствии с правилом категоризации представляла собой однородное множество файлов, которое состоит только из похожих файлов.
В другом частном случае реализации способа похожими файлами считают файлы, степень сходства между которыми превышает заранее установленный порог.
Еще в одном частном случае реализации способа степень сходства между файлами определяют на основании степени сходства данных, хранящихся в файлах.
Еще в одном частном случае реализации способа степень сходства между файлами определяют на основании степени сходства функционала файлов.
В другом частном случае реализации способа в качестве функционала файла используют журнал вызовов API-функций операционной системы при эмуляции исполнения файла.
В другом частном случае реализации способа степень сходства определяют в соответствии с одной из метрик: Хэмминга, Левенштейна, Жаккара, Дайса.
Еще в одном частном случае реализации способа в качестве алгоритма интеллектуального анализа данных используется один из алгоритмов иерархической кластеризации, нечеткой кластеризации, алгоритм минимально покрывающего дерева.
Система признания правила категоризации надежным, которая содержит: средство создания правила категоризации, предназначенное для создания правил категоризации; применение правила категоризации к файлу позволяет определить принадлежность рассматриваемого файла к одной из определенных в рамках правила категорий файлов; средство сбора статистики, связанное со средством создания правил категоризации и предназначенное для сбора статистики использования по меньшей мере одного правила категоризации, при этом статистика использования правила категоризации представляет собой информацию о множестве файлов, принадлежащих к каждой из категорий, определенных в рамках упомянутого правила категоризации; базу данных файлов, связанную со средством сбора статистики и предназначенную для хранения файлов, которые использует средство сбора статистики для получения статистики использования правил категоризации; средство определения надежности, связанное со средством сбора статистики и предназначенное для определения степени надежности правила категоризации на основании статистики использования правила категоризации, полученной от средства сбора статистики, при помощи по меньшей мере одного алгоритма интеллектуального анализа данных, а также признания правила категоризации надежным, если комбинация указанных степеней надежности превышает установленный числовой порог.
В частном случае реализации системы средство сбора статистики применяет правило категоризации к результатам обработки файла.
В другом частном случае реализации системы обработкой файла является эмуляция процесса выполнения файла.
Еще в одном частном случае реализации системы обработкой файла является вычисление свертка файла.
В другом частном случае реализации системы правилом категоризации является правило для обнаружения вредоносного программного обеспечения.
Еще в одном частном случае реализации системы правилом категоризации является свертка файла, которая определяет, входил ли файл в категорию файлов с совпадающим значением свертки.
В другом частном случае реализации системы дополнительно используется средство обучения алгоритмов, связанное со средством определения надежности и предназначенное для обучения алгоритмов интеллектуального анализа данных, используемых средством определения надежности.
Еще в одном частном случае реализации системы для обучения алгоритмов интеллектуального анализа данных используется множество файлов для обучения, а также статистика использования правил, применение которых к множеству файлов для обучения разбивает указанное множество файлов на категории таким образом, что хотя бы одна категория файлов в соответствии с правилом категоризации представляет собой однородное множество файлов, которое состоит только из похожих файлов.
В другом частном случае реализации системы похожими файлами считают файлы, степень сходства между которыми превышает заранее установленный порог.
Еще в одном частном случае реализации системы степень сходства между файлами определяют на основании степени сходства данных, хранящихся в файлах.
В другом частном случае реализации системы степень сходства между файлами определяют на основании степени сходства функционала файлов.
Еще в одном частном случае реализации системы в качестве функционала файла используют журнал вызовов API-функций операционной системы при эмуляции исполнения файла.
Еще в одном частном случае реализации системы степень сходства определяют в соответствии с одной из метрик: Хэмминга, Левенштейна, Жаккара, Дайса.
В другом частном случае реализации системы средство определения надежности для определения степени надежности правила категоризации использует алгоритмы иерархической кластеризации, нечеткой кластеризации, алгоритм минимально покрывающего дерева.
Краткое описание чертежей
Дополнительные цели, признаки и преимущества настоящего изобретения будут очевидными из прочтения последующего описания осуществления изобретения со ссылкой на прилагаемые чертежи, на которых
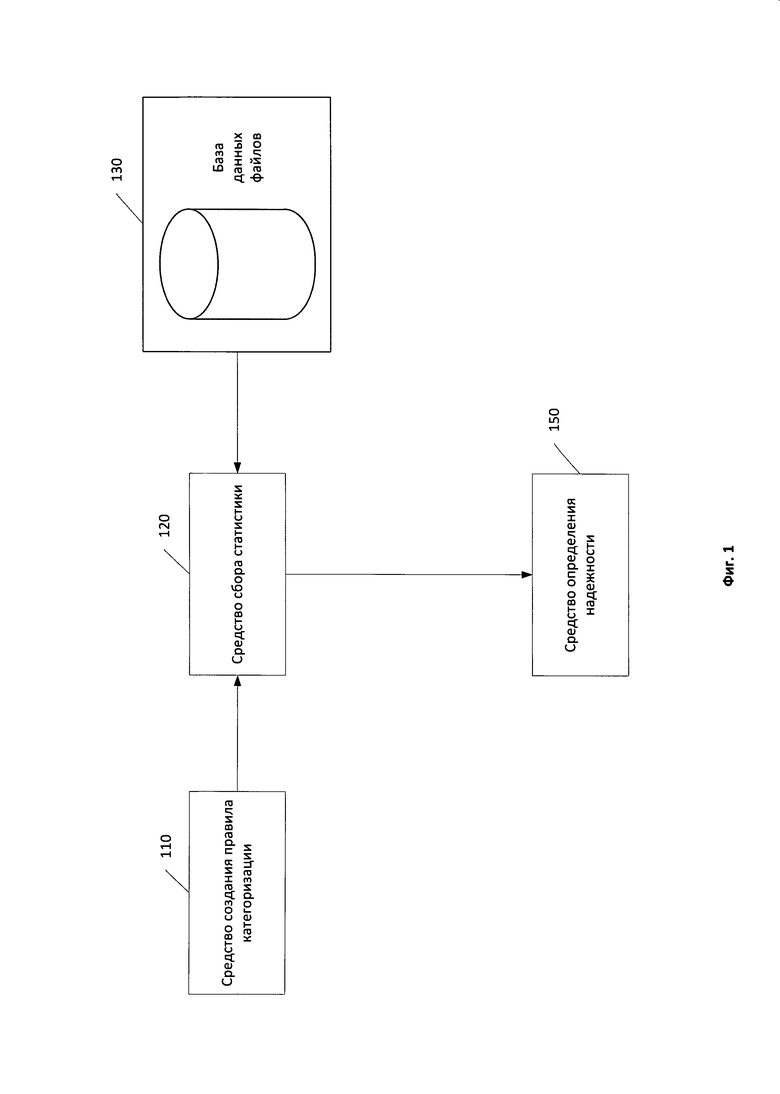
Фиг.1 показывает структурную схему системы определения надежности правила категоризации.
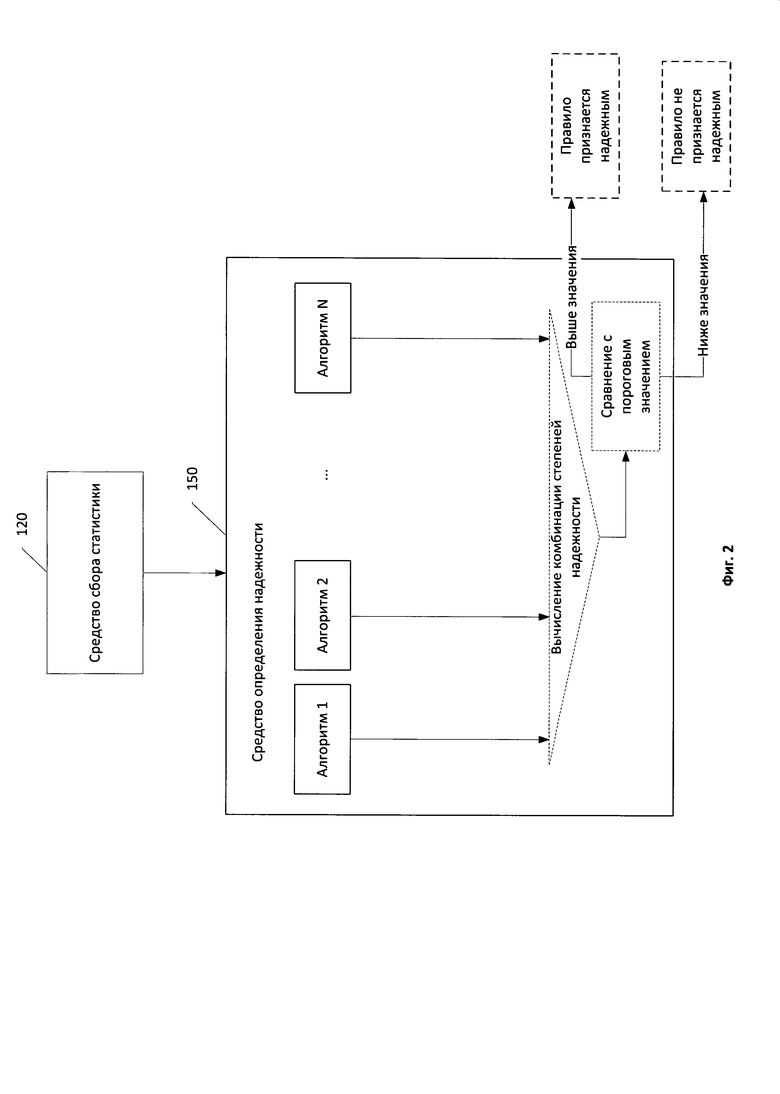
Фиг.2 иллюстрирует типовую схему определения надежности правила категоризации.
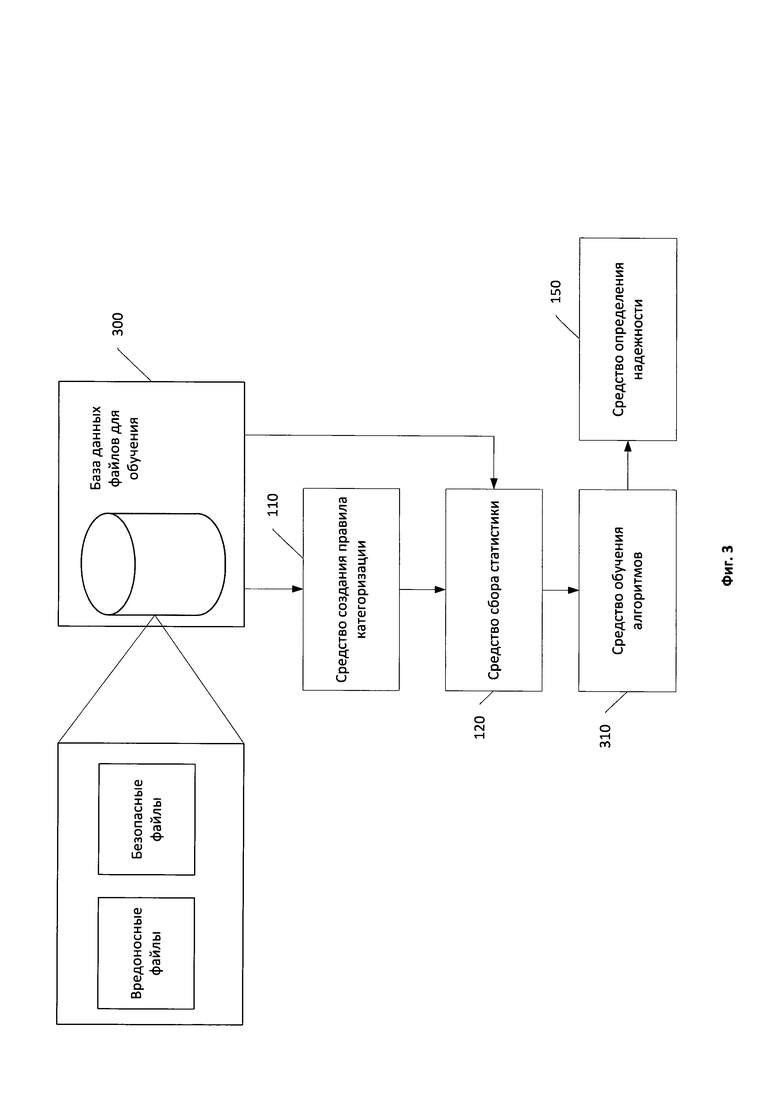
Фиг.3 иллюстрирует структурную схему обучения средства определения надежности.
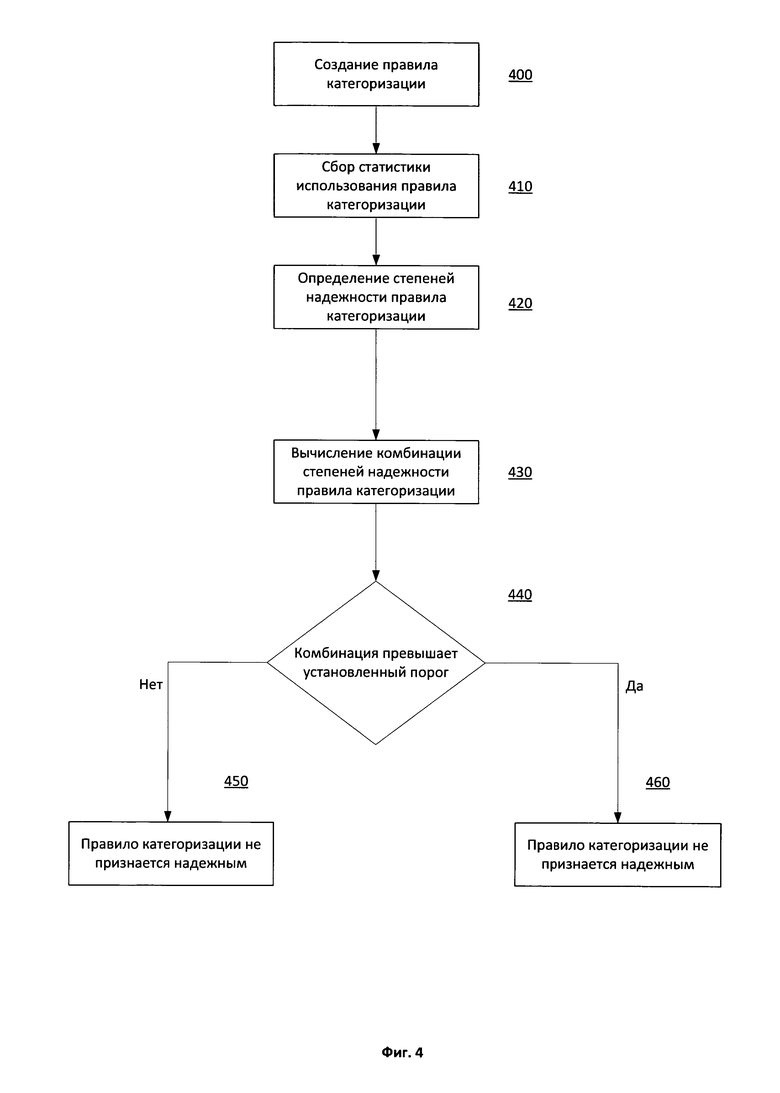
Фиг.4 показывает примерную схему алгоритма работы одного из вариантов реализации системы определения надежности правила категоризации.
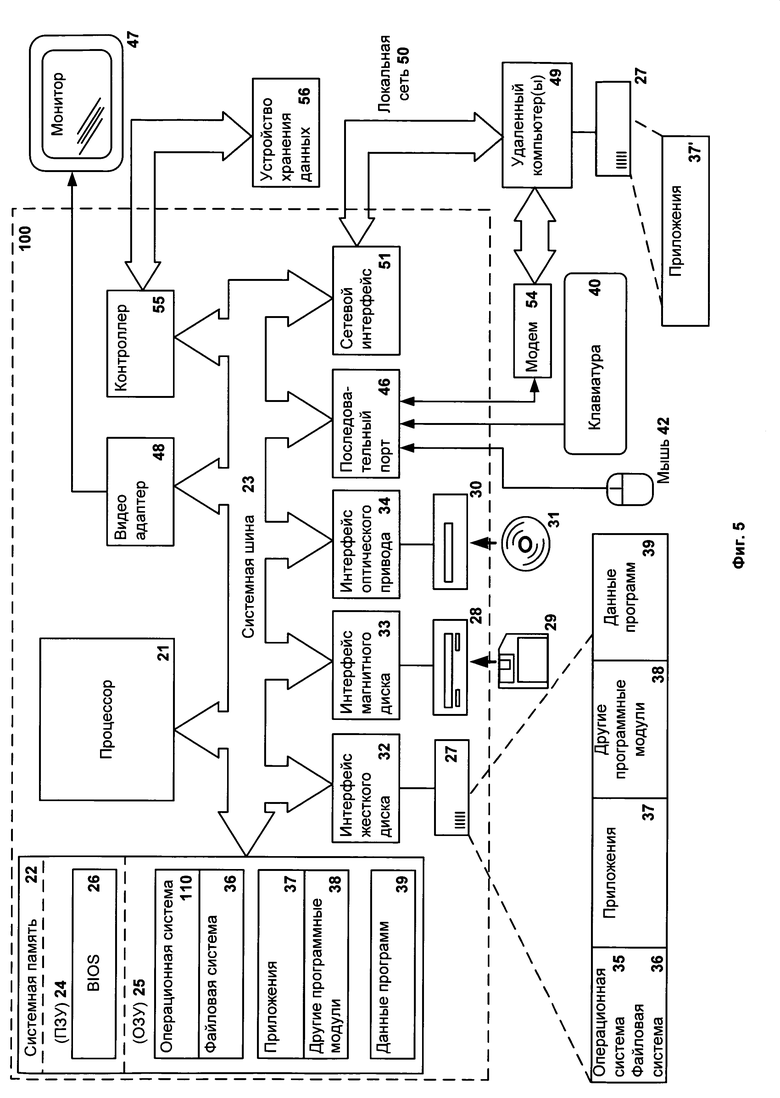
Фиг.5 показывает пример компьютерной системы общего назначения.
Хотя изобретение может иметь различные модификации и альтернативные формы, характерные признаки, показанные в качестве примера на чертежах, будут описаны подробно. Следует понимать, однако, что цель описания заключается не в ограничении изобретения конкретным его воплощением. Наоборот, целью описания является охват всех изменений, модификаций, входящих в рамки данного изобретения, как это определено приложенной формуле.
Описание изобретения
Объекты и признаки настоящего изобретения, способы для достижения этих объектов и признаков станут очевидными посредством отсылки к примерным вариантам осуществления. Однако настоящее изобретение не ограничивается примерными вариантами осуществления, раскрытыми ниже, оно может воплощаться в различных видах. Сущность, приведенная в описании, является не чем иным, как конкретными деталями, необходимыми для помощи специалисту в области техники в исчерпывающем понимании изобретения, и настоящее изобретение определяется в объеме приложенной формулы.
На Фиг.1 показана структурная схема работы системы определения надежности правила категоризации. Правилом категоризации в общем случае считают правило, применение которого к файлу позволяет определить принадлежность рассматриваемого файла к одной из определенных в рамках правила категорий файлов. Правила категоризации также могут быть применимы к результатам обработки файла, например к результатам эмуляции процесса выполнения файла или к результатам вычисления свертки файла. Примером правила категоризации может быть правило для обнаружения вредоносного программного обеспечения, которое определяет, входит ли файл в определенную категорию файлов вредоносного программного обеспечения - правило, разделяющее множество файлов, к которым применяется правило, на, например, файлы, относящиеся к категории вредоносного программного обеспечения Trojan.Win32, и файлы, не относящиеся к указанной категории или свертка файла, которая определяет, входит ли файл в категорию файлов с совпадающим значением свертки.
Средство создания правила категоризации 110 предназначено для создания правил категоризации. В частном случае реализации для создания правила категоризации упомянутым средством используются данные одного файла. В другом частном случае реализации при создании правила категоризации используется кластер похожих файлов. В свою очередь, файлы считаются похожими, если степень сходства между ними превышает установленный порог. В частном случае реализации степень сходства между файлами определяют на основании степени сходства данных, хранящихся в файлах. В другом частном случае реализации степень сходства файлов определяют на основании степени сходства функционала файлов. В частном случае реализации в качестве функционала файла рассматривается журнал вызовов API-функций операционной системы при эмуляции исполнения файла. В частном случае реализации изобретения степень сходства определяют в соответствии с мерой Дайса, в другом частном случае реализации степень сходства определяют в соответствии с одной из метрик: Хэмминга, Левенштейна, Жаккара и других применимых. В частном случае реализации средство создания правила категоризации 110 создает сигнатуры для обнаружения вредоносного программного обеспечения с использованием кластера вредоносных файлов. Для каждого кластера похожих вредоносных файлов средство создания правила категоризации 110 выделяет общие для файлов из кластера участки данных и создает сигнатуру для обнаружения как конкатенацию блоков общих байт с указанием смещений каждого блока относительно начала файла. После создания правила категоризации средство создания правила категоризации 110 передает полученную сигнатуру на вход средства сбора статистики 120.
Средство сбора статистики 120 предназначено для сбора статистики использования правила категоризации. Статистика использования правила категоризации представляет собой информацию о множестве файлов, принадлежащих к каждой из категорий, определенных в рамках упомянутого правила категоризации. Для получения статистики использования правила категоризации средство сбора статистики 120 использует множество файлов. В частном случае реализации упомянутое множество файлов хранится в базе данных файлов 130. В другом частном случае реализации файлы, используемые для получения статистики, распределены по вычислительным системам, соединенным при помощи сети. Средство сбора статистики 120 применяет правило категоризации к множеству файлов из базы данных файлов 130. Применение правила категоризации позволяет разделить файлы из базы данных файлов 130 на категории, определенные в рамках правила категоризации (например, на файлы, относящиеся к категории вредоносного программного обеспечения Trojan.Win32, и файлы, не относящиеся к указанной категории). Из каждого множества файлов, соответствующих категориям правила, средство сбора статистики 120 выделят множество признаков файлов. В частном случае реализации такими признаками являются: время с момента первого применения правила категоризации; количество файлов, которые были отнесены правилом категоризации к одной из определенных в рамках правила категорий; среднее, минимальное и максимальное значения размеров файлов, которые были отнесены правилом категоризации к одной из определенных в рамках правила категорий; количество уникальных компиляторов, использованных для создания упомянутых файлов; количество используемых в файлах уникальных упаковщиков. Под упаковкой исполняемого файла в данном случае подразумевается сжатие файла с добавлением к телу файла последовательности инструкций для распаковки. Средство сбора статистики 120 формирует статистику использования правила категоризации на основании признаков, выделенных для каждой категории файлов, на которые разбивается множество файлов из базы данных файлов 130 при применении правила категоризации. В частном случае реализации статистика использования правила категоризации может содержать в себе признаки, производные от набора вышеописанных параметров. Полученную описанным образом статистику использования правила категоризации средство сбора статистики 120 передает на вход средства определения надежности 150.
Средство определения надежности 150 предназначено для признания правила категоризации надежным. Работу указанного средства можно разделить на два этапа. На первом этапе средство определения надежности 150 определяет степени надежности правила категоризации. Степень надежности представляет собой числовое значение, в частном случае реализации действительное число, например 1.4. Детальная схема упомянутого средства изображена на Фиг.2. Для определения степени надежности используется по меньшей мере один алгоритм алгоритма интеллектуального анализа данных. Цель использования алгоритма интеллектуального анализа данных - по входному набору данных, представляющих собой статистику использования правила категоризации, вычислить степень надежности правила категоризации.
В частном случае реализации для определения степени надежности в качестве алгоритма интеллектуального анализа данных используется дерево принятия решения, которое на основе статистики использования назначает правилу категоризации численное значение степени надежности. Каждому правилу категоризации, к которому применяется дерево принятия решения для определения степени надежности, назначается некоторое число - степень надежности. Каждой вершине дерева назначается анализируемый параметр статистики использования, например «количество компиляторов, использованных для создания файлов, которые попадают в одну из категорий файлов в соответствии с правилом категоризации». Указанная вершина связанна со следующими вершинами, соответствующими другим условиям проверки, посредством ребер, соответствующих одной из возможных оценок параметра статистики использования. Переход по каждому из ребер (в соответствии с применением дерева принятия решения к статистике использования правила категоризации) сопровождается изменением степени надежности.
Применение дерева принятия решений для оценки полного списка параметров из статистики использования правила категоризации формирует итоговую степень надежности правила категоризации. Вариант использования дерева принятия решения при определении степени надежности можно пояснить следующим примером. Пусть при сборе статистики использования правила категоризации учитываются следующие параметры статистики: время с момента первого применения правила категоризации (параметр 1); отношение максимального и минимального значения к среднему значению размера файлов, которые были отнесены правилом категоризации к каждой из определенных в рамках правила категорий (параметр 2 и параметр 3 для каждой категории); количество уникальных компиляторов, использованных для создания упомянутых файлов (параметр 4); количество используемых в файлах уникальных упаковщиков (параметр 5). Пусть требуется проанализировать правило, применение которого к множеству файлов разбивает множество на три категории: категория «А», категория «В», категория «С», где, например, в соответствии с логикой правила категоризации, в категорию «С» попадают все файлы из вышеописанного множества, которые не попали в категорию «А» и «В». Пусть была получена следующая статистика использования указанного правила:
- параметр 1-10 часов;
- параметр 2A (параметр 2 для категории «А») - 1.2;
- параметр 2B (параметр 2 для категории «В») - 1.7;
- параметр 2C (параметр 2 для категории «С») - 5;
- параметр 3A (параметр 3 для категории «А») - 0.9;
- параметр 3B (параметр 3 для категории «В») - 0.8;
- параметр 3C (параметр 3 для категории «С») - 0.5;
- параметр 4-1;
- параметр 5-2.
Пусть изначально каждому оцениваемому правилу категоризации назначается степень надежности, равная числу 10. Пусть схема используемого для определения степени надежности дерева принятия решений выглядит следующим образом:
- если параметр 1 меньше 24 часов, вычесть из степени надежности число 2, иначе прибавить 1;
- если параметр 2A больше 1.3, вычесть из степени надежности число 1.5, иначе прибавить 1.2;
- если параметр 2B больше 1.3, вычесть из степени надежности число 1.5, иначе прибавить 1.2;
- если параметр 2C больше 20, вычесть из степени надежности число 0.01, иначе прибавить 0.01;
- если параметр 3A меньше 0.8, вычесть из степени надежности число 2, иначе прибавить 1.1;
- если параметр 3B меньше 0.8, вычесть из степени надежности число 2, иначе прибавить 1.1;
- если параметр 3C меньше 0.3, вычесть из степени надежности число 0.005, иначе прибавить 0.002;
- если параметр 4 больше 1, вычесть из степени надежности число 5, иначе прибавить 2;
- если параметр 5 меньше 3, вычесть из степени надежности число 0.5, иначе прибавить 0.3.
В соответствии с вышеописанными условиями после применения дерева принятия решений степень надежности анализируемого правила категоризации будет равняться 11.412.
Возможны ситуации, где необходимо оценивать правила категоризации, которые разделяют множество файлов на разное количество категорий. В частном случае реализации для применения одного и того же дерева принятия решений для оценки таких правил категоризации можно сгруппировать категории правил для применения к ним одинаковых оценок и изменений степени надежности и дополнительно выделить отдельную категорию для оценки - в нее будут входить файлы, которые в соответствии с применением правила не вошли ни в одну из категорий, которые были ранее сгруппированы.
В другом частном случае реализации в дополнение к упомянутому дереву принятия решений средство определения надежности 150 вычисляет еще одну степень надежности правила категоризации при помощи регрессионного анализа. В еще одном частном случае реализации в дополнение к упомянутым алгоритмам интеллектуального анализа данных средство определения надежности 150 вычисляет дополнительную степень надежности правила категоризации при помощи наивного байесовского классификатора. В частном случае реализации дополнительные степени надежности вычисляются средством определения надежности 150 для повышения точности определения надежности правила категоризации. Каждая степень надежности правила категоризации, вычисленная при помощи всех используемых алгоритмов интеллектуального анализа данных средством определения надежности 150 на основании статистики использования правила категоризации, используется упомянутым средством на втором этапе работы.
На втором этапе работы средство определения надежности 150 вычисляет комбинацию степеней надежности и сравнивает полученное значение с установленным пороговым значением. В частном случае реализации в качестве комбинации степеней надежности вычисляется среднее значение степеней надежности. В другом частном варианте реализации в качестве комбинации степеней надежности вычисляется среднее квадратичное значение степеней надежности. Если комбинация степеней надежности правила категоризации превышает пороговое значение, то средство определения надежности 150 признает правило категоризации надежным, в противном случае средство определения надежности 150 не признает правило категоризации надежным.
Пусть, например, с помощью нескольких алгоритмов интеллектуального анализа данных были получены следующие степени надежности: 10.5, 11, 15, 17.3. И для вычислении комбинации степеней используется среднее значение степеней надежности. В таком случае комбинация степеней надежности примет значение 13.45. Если для признания правила категоризации надежным установлено пороговое значение комбинации степеней надежности, например число 12, то средство определения надежности 150 признает оцениваемое правило надежным.
На Фиг.3 изображена схема обучения используемых средством определения надежности 150 алгоритмов интеллектуального анализа данных. Для обучения всех используемых упомянутым средством алгоритмов используется база данных файлов для обучения 300, которая в частном случае реализации содержит в себе как вредоносные, так и безопасные файлы. Указанные файлы используются средством создания правила категоризации 110 для создания правила категоризации. Созданное средством создания правила категоризации 110 правило категоризации, которое в частном случае реализации является сигнатурой для обнаружения вредоносного программного обеспечения, поступает на вход средства сбора статистики 120. Средство сбора статистики 120 использует файлы из базы данных файлов для обучения 300 для получения статистики использования правила категоризации, созданного при помощи средства создания правила категоризации 110. Для обучения алгоритмов интеллектуального анализа данных используется статистика использования множества правил категоризации. Статистика использования каждого правила категоризации формируется средством сбора статистики 120 в соответствии с вышеописанной схемой и поступает на вход средству обучения алгоритмов 310.
Средство обучения алгоритмов 310 предназначено для обучения используемых средством определения надежности 150 алгоритмов интеллектуального анализа данных. Для обучения алгоритмов интеллектуального анализа данных средством обучения алгоритмов 310 используется машинное обучение. В частном случае реализации средство обучения алгоритмов 310 использует статистику использования множества правил категоризации для формирования дерева принятия решения, которое используется средством определения надежности 150. В другом частном случае результатом работы средства обучения алгоритмов 310 является обучение алгоритма регрессивного анализа и байесовского классификатора. Результаты обучения алгоритмов передаются средством обучения алгоритмов 310 на вход средства определения надежности 150. Указанные результаты обучения алгоритмов используются средством определения надежности 150 для определения надежности правила категоризации при помощи каждого из используемых алгоритмов интеллектуального анализа данных.
В частном случае реализации для повышения качества обучения алгоритмов интеллектуального анализа данных, а следовательно, и определения надежности правил категоризации к каждому анализируемому правилу категоризации предъявляется требование: хотя бы одна категория файлов, на которые разбивается множество файлов в соответствии с применением правила категоризации, является однородным множеством файлов. В свою очередь множество файлов является однородным, если оно содержит только похожие файлы (определение похожих файлов приведено выше). С учетом упомянутого требования при обучении алгоритмов интеллектуального анализа данных применяется фильтрация правил категоризации. При фильтрации для получения статистики использования правил категоризации применяются только такие правила, применение которых к множеству файлов из базы данных файлов для обучения 300 разбивает указанное множество на категории файлов (определенные в рамках правила) таким образом, что хотя бы одна категория файлов представляет собой однородное множество файлов.
На Фиг.4 изображена примерная схема алгоритма работы одного из вариантов реализации вышеописанной системы признания правила категоризации надежным. На этапе 400 средством создания правила категоризации 110 создается правило категоризации. Созданное на этапе 400 правило категоризации поступает на вход средства сбора статистики 120. Средство сбора статистики 120, используя полученное со стороны средства создания правила категоризации 110 и файлы из базы данных файлов 130, формирует статистику использования правила категоризации на этапе 410. Сформированная на этапе 410 статистика использования правила категоризации поступает на вход средства определения надежности 150. Средство определения надежности, используя по меньшей мере один алгоритм интеллектуального анализа данных, вычисляет степень надежности правила категоризации на этапе 420. Средство определения надежности 150 вычисляет на этапе 430 комбинацию степеней надежности правила категоризации, полученных на этапе 420. Полученная на этапе 430 комбинация степеней надежности сравнивается с установленным пороговым значением в соответствии с этапом 440 при помощи средства определения надежности 150. Если комбинация степеней надежности не превышает установленное пороговое значение, то средство определения надежности 150 не признает правило категоризации надежным в соответствии с этапом 450. При превышении установленного порогового значения средство определения надежности 150 признает правило категоризации надежным в соответствии с этапом 460.
Фиг.5 представляет пример компьютерной системы общего назначения, персональный компьютер или сервер 20, содержащий центральный процессор 21, системную память 22 и системную шину 23, которая содержит разные системные компоненты, в том числе память, связанную с центральным процессором 21. Системная шина 23 реализована, как любая известная из уровня техники шинная структура, содержащая в свою очередь память шины или контроллер памяти шины, периферийную шину и локальную шину, которая способна взаимодействовать с любой другой шинной архитектурой. Системная память содержит постоянное запоминающее устройство (ПЗУ) 24, память с произвольным доступом (ОЗУ) 25. Основная система ввода/вывода (BIOS) 26 содержит основные процедуры, которые обеспечивают передачу информации между элементами персонального компьютера 20, например, в момент загрузки операционной системы с использованием ПЗУ 24.
Персональный компьютер 20 в свою очередь содержит жесткий диск 27 для чтения и записи данных, привод магнитных дисков 28 для чтения и записи на сменные магнитные диски 29 и оптический привод 30 для чтения и записи на сменные оптические диски 31, такие как CD-ROM, DVD-ROM и иные оптические носители информации. Жесткий диск 27, привод магнитных дисков 28, оптический привод 30 соединены с системной шиной 23 через интерфейс жесткого диска 32, интерфейс магнитных дисков 33 и интерфейс оптического привода 34 соответственно. Приводы и соответствующие компьютерные носители информации представляют собой энергонезависимые средства хранения компьютерных инструкций, структур данных, программных модулей и прочих данных персонального компьютера 20.
Настоящее описание раскрывает реализацию системы, которая использует жесткий диск 27, сменный магнитный диск 29 и сменный оптический диск 31, но следует понимать, что возможно применение иных типов компьютерных носителей информации 56, которые способны хранить данные в доступной для чтения компьютером форме (твердотельные накопители, флеш карты памяти, цифровые диски, память с произвольным доступом (ОЗУ) и т.п.), которые подключены к системной шине 23 через контроллер 55.
Компьютер 20 имеет файловую систему 36, где хранится записанная операционная система 35, а также дополнительные программные приложения 37, другие программные модули 38 и данные программ 39. Пользователь имеет возможность вводить команды и информацию в персональный компьютер 20 посредством устройств ввода (клавиатуры 40, манипулятора «мышь» 42). Могут использоваться другие устройства ввода (не отображены): микрофон, джойстик, игровая консоль, сканнер и т.п. Подобные устройства ввода по своему обычаю подключают к компьютерной системе 20 через последовательный порт 46, который в свою очередь подсоединен к системной шине, но могут быть подключены иным способом, например при помощи параллельного порта, игрового порта или универсальной последовательной шины (USB). Монитор 47 или иной тип устройства отображения также подсоединен к системной шине 23 через интерфейс, такой как видеоадаптер 48. В дополнение к монитору 47 персональный компьютер может быть оснащен другими периферийными устройствами вывода (не отображены), например колонками, принтером и т.п.
Персональный компьютер 20 способен работать в сетевом окружении, при этом используется сетевое соединение с другим или несколькими удаленными компьютерами 49. Удаленный компьютер (или компьютеры) 49 являются такими же персональными компьютерами или серверами, которые имеют большинство или все упомянутые элементы, отмеченные ранее при описании существа персонального компьютера 20, представленного на Фиг.5. В вычислительной сети могут присутствовать также и другие устройства, например маршрутизаторы, сетевые станции, пиринговые устройства или иные сетевые узлы.
Сетевые соединения могут образовывать локальную вычислительную сеть (LAN) 50 и глобальную вычислительную сеть (WAN). Такие сети применяются в корпоративных компьютерных сетях, внутренних сетях компаний и, как правило, имеют доступ к сети Интернет. В LAN- или WAN-сетях персональный компьютер 20 подключен к локальной сети 50 через сетевой адаптер или сетевой интерфейс 51. При использовании сетей персональный компьютер 20 может использовать модем 54 или иные средства обеспечения связи с глобальной вычислительной сетью, такой как Интернет. Модем 54, который является внутренним или внешним устройством, подключен к системной шине 23 посредством последовательного порта 46. Следует уточнить, что сетевые соединения являются лишь примерными и не обязаны отображать точную конфигурацию сети, т.е. в действительности существуют иные способы установления соединения техническими средствами связи одного компьютера с другим.
В заключение следует отметить, что приведенные в описании сведения являются примерами, которые не ограничивают объем настоящего изобретения, определенного формулой.
| название | год | авторы | номер документа |
|---|---|---|---|
| Система и способ двухэтапной классификации файлов | 2018 |
|
RU2708356C1 |
| СИСТЕМА И СПОСОБ СОЗДАНИЯ ГИБКОЙ СВЕРТКИ ДЛЯ ОБНАРУЖЕНИЯ ВРЕДОНОСНЫХ ПРОГРАММ | 2013 |
|
RU2580036C2 |
| Система и способ определения похожих файлов | 2015 |
|
RU2614561C1 |
| Система и способ снижения количества ложных срабатываний классифицирующих алгоритмов | 2018 |
|
RU2706883C1 |
| СИСТЕМА И СПОСОБ ОБНАРУЖЕНИЯ НАПРАВЛЕННЫХ АТАК НА КОРПОРАТИВНУЮ ИНФРАСТРУКТУРУ | 2013 |
|
RU2587426C2 |
| СПОСОБ КОНТРОЛЯ ПРИЛОЖЕНИЙ | 2015 |
|
RU2587424C1 |
| Система и способ классификации объектов вычислительной системы | 2018 |
|
RU2724710C1 |
| СПОСОБ И СИСТЕМА АНАЛИЗА РАБОТЫ ПРАВИЛ ОБНАРУЖЕНИЯ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ | 2013 |
|
RU2568285C2 |
| СИСТЕМА И СПОСОБ ОПТИМИЗАЦИИ ИСПОЛЬЗОВАНИЯ РЕСУРСОВ КОМПЬЮТЕРА | 2011 |
|
RU2475819C1 |
| Система и способ категоризации приложения на вычислительном устройстве | 2019 |
|
RU2747514C2 |
Изобретение относится к области защиты от компьютерных угроз, а именно к системам и способам оценки надежности правила категоризации. Технический результат настоящего изобретения заключается в автоматизации анализа надежности правила категоризации на основании сравнения комбинации степеней надежности правила категоризации с установленным числовым порогом. Способ признания правила категоризации надежным содержит этапы, на которых: а) создают при помощи средства создания правила категоризации по меньшей мере одно правило категоризации, которое используется для обучения по меньшей мере одного алгоритма интеллектуального анализа данных; при этом для создания правил категоризации используются файлы из базы данных для обучения; при этом правило категоризации позволяет определить принадлежность файла, к которому оно применяется, к одной из определенных в рамках правила категорий файлов; б) фильтруют при помощи средства обучения алгоритмов по меньшей мере одно созданное на этапе ранее правило категоризации, которое используется для обучения по меньшей мере одного алгоритма интеллектуального анализа данных; при этом результатом фильтрации является выделение набора правил категоризации, каждое из которых разбивает множество файлов для обучения на подмножества файлов, соответствующие определенным в рамках правила категориям файлов, таким образом, что хотя бы одно такое подмножество, соответствующее категории файлов, представляет собой однородное множество файлов; при этом однородное множество файлов содержит только похожие файлы; в) обучают при помощи средства обучения алгоритмов по меньшей мере один алгоритм интеллектуального анализа данных для последующего определения степени надежности правила категоризации с использованием выделенного на этапе ранее набора правил категоризации и множества файлов для обучения, в состав которого входит по меньшей мере одно множество похожих файлов; г) создают при помощи средства создания правила категоризации по меньшей мере одно правило категоризации; д) собирают при помощи средства сбора статистики статистку использования по меньшей мере одного созданного правила категоризации; при этом статистика использования правила категоризации представляет собой информацию о множестве файлов, принадлежащих к каждой из категорий, которые определены в рамках упомянутого правила категоризации; е) определяют при помощи средства определения надежности по меньшей мере одну степень надежности правила категоризации на основании статистики использования правила категоризации с использованием одного из алгоритмов интеллектуального анализа данных; ж) признают при помощи средства определения надежности правило категоризации надежным, если комбинация степеней надежности правила, определенных на этапе г), превышает установленный числовой порог. 2 н. и 10 з.п. ф-лы, 5 ил.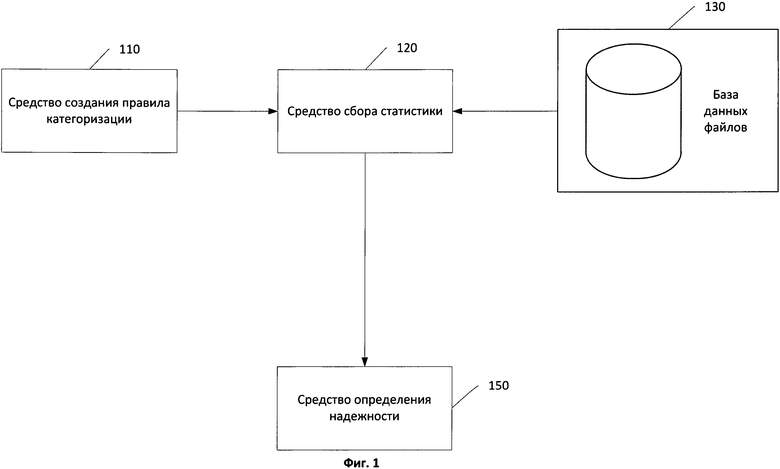
1. Способ признания правила категоризации надежным, в котором:
а) создают при помощи средства создания правила категоризации по меньшей мере одно правило категоризации, которое используется для обучения по меньшей мере одного алгоритма интеллектуального анализа данных;
при этом для создания правил категоризации используются файлы из базы данных для обучения;
при этом правило категоризации позволяет определить принадлежность файла, к которому оно применяется, к одной из определенных в рамках правила категорий файлов;
б) фильтруют при помощи средства обучения алгоритмов по меньшей мере одно созданное на этапе ранее правило категоризации, которое используется для обучения по меньшей мере одного алгоритма интеллектуального анализа данных;
при этом результатом фильтрации является выделение набора правил категоризации, каждое из которых разбивает множество файлов для обучения на подмножества файлов, соответствующие определенным в рамках правила категориям файлов, таким образом, что хотя бы одно такое подмножество, соответствующее категории файлов, представляет собой однородное множество файлов;
при этом однородное множество файлов содержит только похожие файлы;
в) обучают при помощи средства обучения алгоритмов по меньшей мере один алгоритм интеллектуального анализа данных для последующего определения степени надежности правила категоризации с использованием выделенного на этапе ранее набора правил категоризации и множества файлов для обучения, в состав которого входит по меньшей мере одно множество похожих файлов;
г) создают при помощи средства создания правила категоризации по меньшей мере одно правило категоризации;
д) собирают при помощи средства сбора статистики статистку использования по меньшей мере одного созданного правила категоризации;
при этом статистика использования правила категоризации представляет собой информацию о множестве файлов, принадлежащих к каждой из категорий, которые определены в рамках упомянутого правила категоризации;
е) определяют при помощи средства определения надежности по меньшей мере одну степень надежности правила категоризации на основании статистики использования правила категоризации с использованием одного из алгоритмов интеллектуального анализа данных;
ж) признают при помощи средства определения надежности правило категоризации надежным, если комбинация степеней надежности правила, определенных на этапе г), превышает установленный числовой порог.
2. Способ по п. 1, в котором похожими файлами считают файлы, степень сходства между которыми превышает заранее установленный порог.
3. Способ по п. 2, в котором степень сходства между файлами определяют на основании степени сходства данных, хранящихся в файлах.
4. Способ по п. 2, в котором степень сходства между файлами определяют на основании степени сходства функционала файлов.
5. Способ по п. 4, в котором в качестве функционала файла используют журнал вызовов API-функций операционной системы при эмуляции исполнения файла.
6. Способ по п. 2, в котором степень сходства определяют в соответствии с одной из метрик: Хэмминга, Левенштейна, Жаккара, Дайса.
7. Система признания правила категоризации надежным, которая содержит:
а) средство создания правила категоризации, предназначенное для создания правил категоризации; применение правила категоризации к файлу позволяет определить принадлежность рассматриваемого файла к одной из определенных в рамках правила категорий файлов;
б) средство сбора статистики, связанное со средством создания правил категоризации и предназначенное для сбора статистики использования по меньшей мере одного правила категоризации;
при этом статистика использования правила категоризации представляет собой информацию о множестве файлов, принадлежащих к каждой из категорий, определенных в рамках упомянутого правила категоризации;
в) базу данных файлов, связанную со средством сбора статистики и предназначенную для хранения файлов, которые использует средство сбора статистики для получения статистики использования правил категоризации;
г) средство определения надежности, связанное со средством сбора статистики и предназначенное для определения по меньшей мере одной степени надежности правила категоризации на основании статистики использования правила категоризации, полученной от средства сбора статистики, при помощи одного из алгоритмов интеллектуального анализа данных, а также признания правила категоризации надежным, если комбинация указанных степеней надежности превышает установленный числовой порог;
д) средство обучения алгоритмов, связанное со средством определения надежности и предназначенное для фильтрации правил категоризации, которые используются для обучения по меньшей мере одного алгоритма интеллектуального анализа данных, а также для обучения по меньшей мере одного алгоритма интеллектуального анализа данных с целью последующего определения степени надежности правила;
при этом результатом фильтрации является выделение набора правил категоризации, каждое из которых разбивает множество файлов для обучения на подмножества файлов, соответствующие определенным в рамках правила категориям файлов, таким образом, что хотя бы одно такое подмножество, соответствующее категории файлов, представляет собой однородное множество файлов;
при этом однородное множество файлов содержит только похожие файлы;
е) базу данных файлов для обучения, связанную со средством создания правила категоризации и предназначенную для хранения файлов, которые используются для обучения по меньшей мере одного алгоритма интеллектуального анализа данных.
8. Система по п. 7, в которой похожими файлами считают файлы, степень сходства между которыми превышает заранее установленный порог.
9. Система по п. 8, в которой степень сходства между файлами определяют на основании степени сходства данных, хранящихся в файлах.
10. Система по п. 8, в которой степень сходства между файлами определяют на основании степени сходства функционала файлов.
11. Система по п. 10, в которой в качестве функционала файла используют журнал вызовов API-функций операционной системы при эмуляции исполнения файла.
12. Система по п. 8, в которой степень сходства определяют в соответствии с одной из метрик: Хэмминга, Левенштейна, Жаккара, Дайса.
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| СИСТЕМА И СПОСОБ УМЕНЬШЕНИЯ ЛОЖНЫХ СРАБАТЫВАНИЙ ПРИ ОПРЕДЕЛЕНИИ СЕТЕВОЙ АТАКИ | 2011 |
|
RU2480937C2 |
| СИСТЕМА И СПОСОБ ДИНАМИЧЕСКОЙ АДАПТАЦИИ ФУНКЦИОНАЛА АНТИВИРУСНОГО ПРИЛОЖЕНИЯ НА ОСНОВЕ КОНФИГУРАЦИИ УСТРОЙСТВА | 2012 |
|
RU2477520C1 |

