Область техники
Изобретение относится к области обработки данных, а именно к системам и способам определения похожих файлов.
Уровень техники
В настоящее время наряду с широким распространением компьютеров и подобных им устройств, таких как мобильные телефоны, имеет место рост количества компьютерных угроз. Под компьютерными угрозами в общем случае подразумевают объекты, способные нанести какой-либо вред компьютеру или пользователю компьютера, например: сетевые черви, клавиатурные шпионы, компьютерные вирусы.
Для защиты пользователя и его персонального компьютера от возможных компьютерных угроз применяются различные антивирусные технологии. В состав антивирусного программного обеспечения могут входить различные модули обнаружения компьютерных угроз. Частными случаями таких модулей являются модули сигнатурного и эвристического обнаружения. Однако возможны ситуации, когда указанные модули не являются эффективными - для создания современного вредоносного программного обеспечения зачастую используются методы, противодействующие эмуляции программного обеспечения (например: использование недокументированных функций, анализ результата выполнения функций, в том числе проверка установления определенных флагов процессора после выполнения функций или анализ возвращаемых кодов ошибок), а также полиморфные упаковщики. Под упаковкой исполняемого файла в данном случае подразумевается сжатие файла с добавлением к телу файла последовательности инструкций для распаковки. В случае использования полиморфного упаковщика на базе одного и того же вредоносного файла генерируется множество подобных ему файлов, идентичных по функционалу, но имеющих различную структуру. В таком случае эффективность сигнатурного обнаружения не будет большой, так как для каждого файла из множества полиморфных копий будет необходима уникальная сигнатура.
Существует альтернативный метод обнаружения вредоносного программного обеспечения посредством обнаружения похожих вредоносных файлов, в котором при анализе файла рассматриваются различные метаданные файла, которые могут варьироваться в зависимости от типа рассматриваемого файла и, например для исполняемого файла, могут выглядеть следующим образом: положение секций файла, размеры секций или иная информация из заголовка исполняемого файла, строковые данные, извлекаемые из файла. В качестве метаданных также могут рассматриваться и производные данные: информационная энтропия (мера неопределенности информации файла), частотные характеристики машинных инструкций или байт. При наличии достаточно большого набора файлов и признаков файлов формируется система классификации, которая, будучи обученной на множестве указанных файлов, умеет сопоставлять набор признаков, выделяемых из файла, некоторой категории файлов, например категории файлов вредоносного программного обеспечения.
В области техники существуют решения, реализующие подход обнаружения вредоносного программного обеспечения на основе метаданных, извлекаемых из файлов программного обеспечения, в том числе и такие методы, где из указанных метаданных файла формируют свертку (англ. convolution) - «гибкий» хэш файла (locality sensitive hash). Такой хэш, а именно способ вычисления, обладает важным свойством - для файлов, метаданные которых незначительно отличаются, значение хэшей будет совпадать.
Так, изобретение, описанное в заявке US 2009/0300761 A1, предлагает метод обнаружения файлов вредоносного программного обеспечения на основе анализа метаданных файла, в частности информации об упаковщике или уникальных строках. Также в описанном изобретении в качестве метаданных могут применяться генерируемые на основе файла последовательности инструкций псевдокода и частотные характеристики упомянутых инструкций. Из метаданных, выделенных из файла, формируется «intelligent hash» - свертка, представляющая собой строку, хранящую необходимый для обнаружения файлов вредоносного программного обеспечения набор признаков файла.
Изобретение, описанное в заявке US 2010/0192222 A1, предлагает в качестве метаданных дополнительно использовать результаты работы эмулятора и поведенческого анализатора.
Важным требованием, предъявляемым к существующим решениям для обнаружения файлов вредоносного программного обеспечения на основе выделения метаданных, является требование к качеству обнаружения, заключающееся в минимизации ложных срабатываний. В существующих решениях для обнаружения таких файлов вычисляется степень похожести файла на заранее сформированный набор файлов на основании всевозможных метрик расстояний между наборами метаданных файла и группы файлов. Данный подход создает значительную нагрузку на инфраструктуру компьютерной сети, реализующую связь между компьютером пользователя и базой данных метаданных файлов из заранее сформированных наборов файлов, в случае передачи большого набора метаданных анализируемого файла с использованием ресурсов упомянутой компьютерной сети.
Хотя рассмотренные подходы направлены на решение определенных задач в области защиты от компьютерных угроз, они обладают недостатком - желаемое качество обнаружения вредоносных файлов не достигается. Настоящее изобретение позволяет более эффективно решить задачу обнаружения вредоносных файлов на основе метаданных этих файлов.
Раскрытие изобретения
Настоящее изобретение предназначено для определения похожести файлов.
Технический результат настоящего изобретения заключается в определении похожих файлов, который достигается путем признания файла похожим на файлы из множества похожих файлов, имеющих одинаковую свертку, если свертка указанного файла совпадает со сверткой файла из указанного множества.
Способ определения похожести файлов, в котором: определяют множества изменяемых и неизменяемых признаков файлов, при этом файлы хранятся в базе данных файлов для обучения; при этом признак файла считают изменяемым, если для множества похожих файлов признак принимает различные значения; при этом признак файла считают неизменяемым, если для множества похожих файлов признак принимает одинаковое значение; выделяют множество признаков по меньшей мере из одного файла; разделяют множество выделенных признаков файла по меньшей мере на два подмножества: подмножество изменяемых признаков и подмножество неизменяемых признаков; при этом подмножество изменяемых признаков файла включает в себя по меньшей мере: размер файла, размер образа файла, количество секций файла, RVA (Relative Virtual Address) секций файла, RVA точки входа, частотные характеристики символов, множество строк файла и их количество, отфильтрованное множество строк файла и их количество; при этом подмножество неизменяемых признаков файла включает в себя по меньшей мере: тип использованного при создании файла компилятора, тип подсистемы, характеристики файла из COFF (Common Object File Format) заголовка; формируют свертку каждого из вышеописанных подмножеств признаков файла; при этом свертка подмножества неизменяемых признаков не является устойчивой к изменениям признаков подмножества; при этом свертка подмножества изменяемых признаков является устойчивой к изменениям признаков подмножества; формируют свертку файла как комбинацию сверток каждого из вышеописанных подмножеств признаков файла; сравнивают свертку по меньшей мере одного файла с набором заранее созданных сверток файлов; признают файл похожим на файлы из множества похожих файлов, имеющих одинаковую свертку, если при сравнении свертка указанного файла совпадает со сверткой файла из указанного множества.
Система определения похожести файлов, которая содержит: средство выделения признаков, предназначенное для выделения множества признаков из по меньшей мере одного файла и передающее выделенное множество признаков на вход средства разделения признаков; средство разделения признаков, предназначенное для формирования из множества выделенных признаков как минимум двух подмножеств: подмножества изменяемых признаков и подмножества неизменяемых признаков, и передающее сформированные подмножества признаков на вход средства формирования сверток признаков, а также для определения множества изменяемых и неизменяемых признаков файлов, при этом упомянутые файлы хранятся в базе данных файлов для обучения; при этом признак файла считают изменяемым, если для множества похожих файлов признак принимает различные значения; при этом признак файла считают неизменяемым, если для множества похожих файлов признак принимает одинаковое значение; при этом подмножество изменяемых признаков файла включает в себя по меньшей мере: размер файла, размер образа файла, количество секций файла, RVA секций файла, RVA точки входа, частотные характеристики символов, множество строк файла и их количество, отфильтрованное множество строк файла и их количество; при этом подмножество неизменяемых признаков файла включает в себя по меньшей мере: тип использованного при создании файла компилятора, тип подсистемы, характеристики файла из COFF заголовка; средство формирования сверток признаков, предназначенное для формирования свертки каждого из вышеописанных подмножеств признаков файла и передающее сформированные свертки подмножеств признаков на вход средства формирования свертки файла; при этом свертка подмножества неизменяемых признаков не является устойчивой к изменениям признаков подмножества; при этом свертка подмножества изменяемых признаков является устойчивой к изменениям признаков подмножества; средство формирования свертки файла, предназначенное для формирования свертки файла как комбинации сверток каждого из вышеописанных подмножеств признаков файла и передающее сформированную свертку файла на вход средства сравнения сверток файлов; базу данных сверток, предназначенную для хранения по меньшей мере одной свертки файла и соответствующей указанной свертке информации о вредоносности файла; базу данных файлов для обучения, предназначенную для хранения файлов, которые используются для определения множества изменяемых и неизменяемых признаков; средство сравнения сверток файлов, связанное с базой данных сверток и предназначенное для сравнения свертки по меньшей мере одного файла со свертками, присутствующими в базе данных сверток, и признания файла похожим на файлы из множества похожих файлов, имеющих одинаковую свертку, если при сравнении свертка указанного файла совпадает со сверткой файла из указанного множества.
Краткое описание чертежей
Дополнительные цели, признаки и преимущества настоящего изобретения будут очевидными из прочтения последующего описания осуществления изобретения со ссылкой на прилагаемые чертежи, на которых:
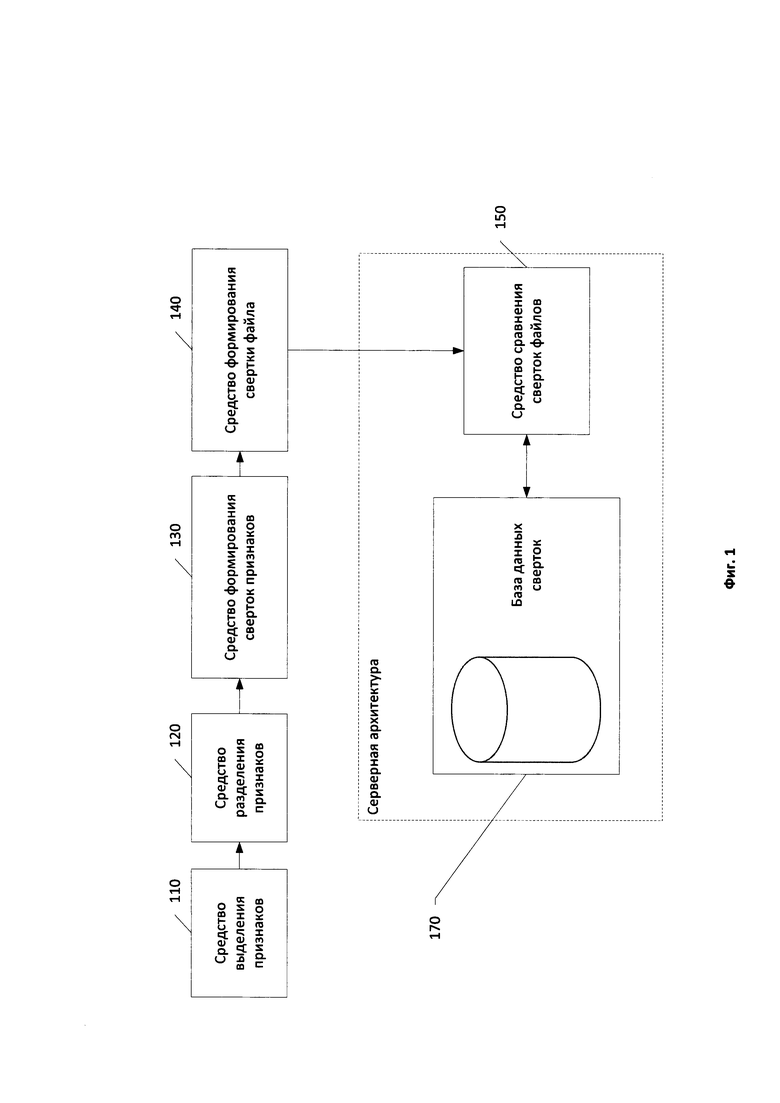
Фиг. 1 показывает структурную схему системы обнаружения вредоносного программного обеспечения.
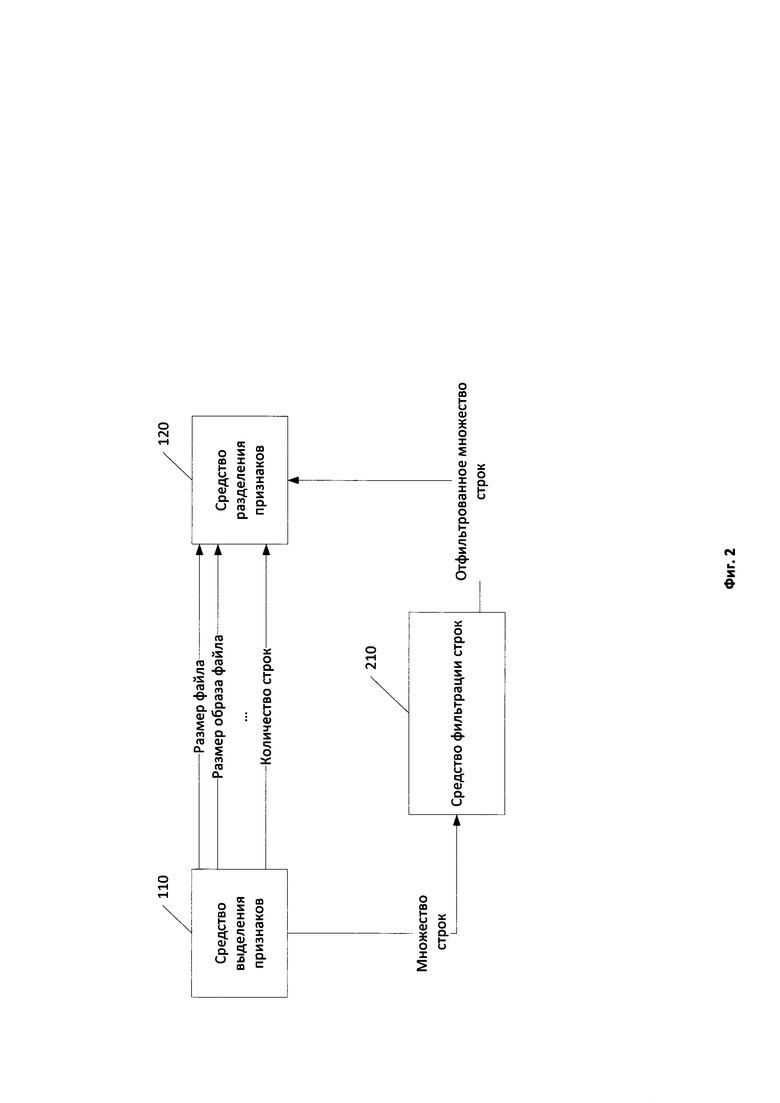
Фиг. 2 иллюстрирует вариант взаимодействия средства выделения признаков и средства разделения признаков.
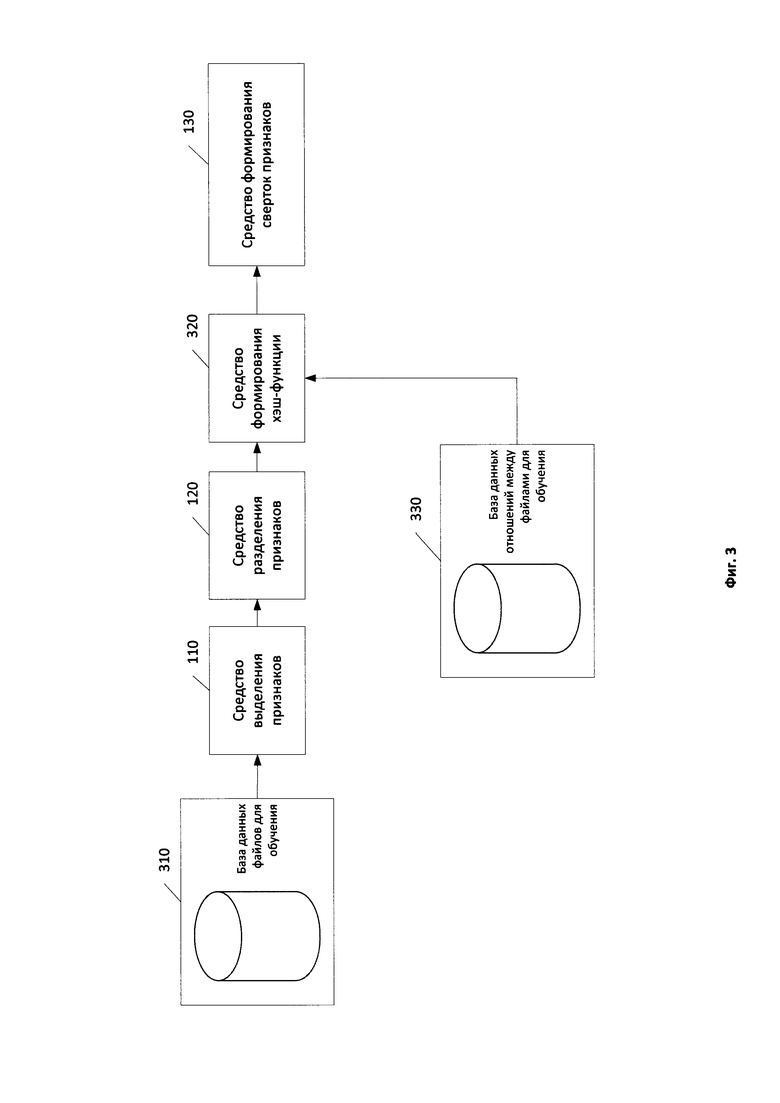
Фиг. 3 иллюстрирует структурную схему формирования хэш-функции на этапе обучения алгоритма SSH.
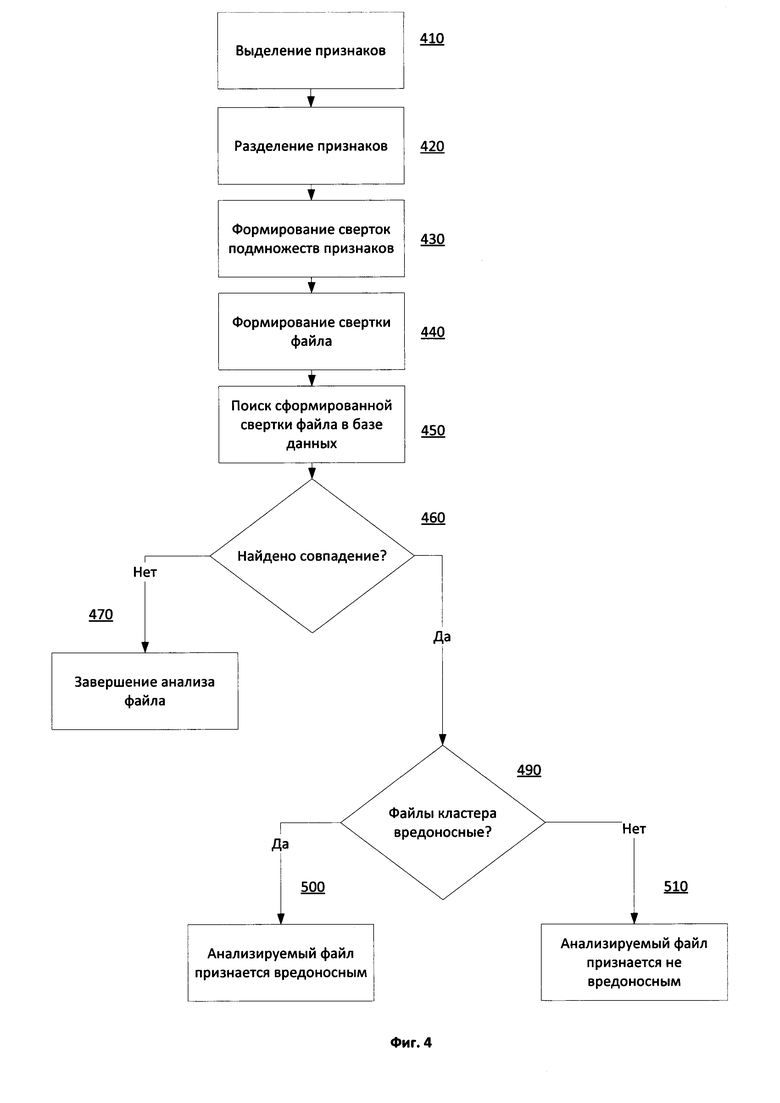
Фиг. 4 показывает примерную схему алгоритма работы одного из вариантов реализации системы обнаружения вредоносного программного обеспечения.
Фиг. 5 показывает пример компьютерной системы общего назначения.
Хотя изобретение может иметь различные модификации и альтернативные формы, характерные признаки, показанные в качестве примера на чертежах, будут описаны подробно. Следует понимать, однако, что цель описания заключается не в ограничении изобретения конкретным его воплощением. Наоборот, целью описания является охват всех изменений, модификаций, входящих в рамки данного изобретения, как это определено приложенной формуле.
Описание вариантов осуществления изобретения
Объекты и признаки настоящего изобретения, способы для достижения этих объектов и признаков станут очевидными посредством отсылки к примерным вариантам осуществления. Однако настоящее изобретение не ограничивается примерными вариантами осуществления, раскрытыми ниже, оно может воплощаться в различных видах. Сущность, приведенная в описании, является не чем иным, как конкретными деталями, необходимыми для помощи специалисту в области техники в исчерпывающем понимании изобретения, и настоящее изобретение определяется в объеме приложенной формулы.
На Фиг. 1 показана структурная схема системы обнаружения вредоносного программного обеспечения. В частном случае реализации источником файла для анализа является антивирусное программное обеспечение на компьютере, которое признало файл требующим дополнительного анализа. При анализе файла вышеупомянутой системой обнаружения средство выделения признаков 110 извлекает из файла множество признаков. Данное множество признаков варьируется в зависимости от типа файла. В частном случае реализации упомянутая система обнаружения анализирует исполняемые файлы формата РЕ (Portable Executable). В частном случае реализации изобретения множество признаков для упомянутого типа файлов включает в себя следующие признаки: размер файла, размер образа файла, количество секций файла, RVA (Related Virtual Address) секций файла, RVA точки входа, тип подсистемы, характеристики файла из COFF (Common Object File Format) заголовка, взаимное расположение объектов таблицы директорий, расположение объектов таблицы директорий по секциям файла, тип использованного при создании файла компилятора, частотные характеристики символов (в том числе печатных), множество строк файла и их количество. В частном случае реализации множество признаков файла для каждой секции файла включает в себя следующие признаки: информационная энтропия начала и конца секции, среднее значение ненулевых байт начала и конца секции, виртуальный размер секции, физический размер секции. В частном случае реализации изобретения средство выделения признаков выделяет множество строк для РЕ-файла из дампа, полученного при эмуляции процесса выполнения упомянутого файла.
Множество выделенных из файла признаков поступает на вход средства разделения признаков 120, которое разделяет множество признаков на по меньшей мере два подмножества. В частном случае реализации множество признаков разбивается на следующие подмножества: подмножество номинальных признаков, подмножество количественных признаков, подмножество порядковых признаков, подмножество бинарных признаков. В другом частном случае реализации множество признаков файла разделяется на следующие подмножества: подмножество признаков, содержащее как минимум один изменяемый признак, и подмножество признаков, содержащее как минимум один неизменяемый признак. Признак файла считается изменяемым, если для множества похожих файлов значение данного признака варьируется. Признак файла считается неизменяемым, если для множества похожих файлов значение признака остается неизменным. В свою очередь, файлы считаются похожими, если степень сходства между файлами превышает установленный порог. В частном случае реализации степень сходства между файлами определяют на основании степени сходства данных, хранящихся в файлах. В другом частном случае реализации степень сходства файлов определяют на основании степени сходства функционала файлов. В частном случае реализации в качестве функционала файла рассматривается журнал вызовов API-функций операционной системы при эмуляции исполнения файла. В частном случае реализации изобретения степень сходства определяют в соответствии с мерой Дайса, в другом частном случае реализации степень сходства определяют в соответствии с одной из метрик: Хэмминга, Левенштейна, Жаккара.
После разделения средством 120 выделенного из файла множества признаков на по меньшей мере два подмножества, одно из которых в частном случае реализации содержит как минимум один изменяемых признак, а другое - как минимум один неизменяемый, подмножества признаков поступают на вход средства формирования сверток признаков 130.
На Фиг. 2 показан вариант реализации взаимодействия средства выделения признаков 110 и средства разделения признаков 120. В частном случае реализации изобретения средство выделения признаков 110 передает множество выделенных строк на вход средству фильтрации строк 210. Средство фильтрации строк 210 осуществляет фильтрацию строк, считающихся сгенерированными случайным образом, например строк, генерируемых вредоносным программным обеспечением для формирования с их помощью пути для копирования файлов вредоносного программного обеспечения. Фильтрация осуществляется посредством определения вероятности принадлежности строки к естественному языку, заданному словарем. Строки и подстроки с малым (не превышающим установленный порог) значением указанной вероятности считаются неинформативными и фильтруются.
Принцип работы средства фильтрации строк 210 можно проиллюстрировать следующим примером. Пусть множество строк файла содержит следующие строки: «klnsdfjnjrmuiwenwefnuinwfui», «GetDriveType», «C:\lkjsdfjkh\windows.txt». При фильтрации указанного списка строк первая строка не попадет в результирующее отфильтрованное множество строк, вторая попадет в неизменном виде, а третья попадет в измененном виде - «*\*\windows.*». Отфильтрованное таким образом множество строк, а также информация о количестве строк из отфильтрованного множества поступают на вход средства разделения признаков 120 в качестве элементов множества признаков файла.
В частном варианте реализации изобретения для файла типа РЕ подмножество признаков, содержащее как минимум один изменяемый признак, включает в себя следующие признаки: размер файла, размер образа файла, количество секций файла, RVA секций файла, RVA точки входа, взаимное расположение объектов таблицы директорий, частотные характеристики символов (в том числе печатных), множество строк файла и их количество, отфильтрованное множество строк и их количество. В частном случае реализации упомянутое подмножество признаков для каждой секции файла включает в себя следующие признаки: информационная энтропия начала и конца секции, среднее значение ненулевых байт начала и конца секции, виртуальный размер секции, физический размер секции. В частном случае реализации изобретения множество строк файла выделяется в отдельное подмножество признаков, содержащее как минимум один изменяемый признак. В другом частном случае реализации изобретения отфильтрованное множество строк файла выделяется в отдельное подмножество признаков, содержащее как минимум один изменяемый признак.
В частном случае реализации изобретения для получения признаков файла типа РЕ, попадающих в подмножество признаков, содержащее как минимум один неизменяемый признак, из множества признаков файла выделяются признаки использованного при создании файла компилятора, тип подсистемы (NATIVE, WINDOWS_GUI, WINDOWS_CUI, OS2_CUI, POSIX_CUI, NATIVE_WINDOWS, WINDOWS_CE_GUI), характеристики файла из COFF заголовка, расположение объектов таблицы директорий по секциям файла.
Свертка подмножества признаков, содержащего как минимум один неизменяемый признак, далее именуемое как «подмножество неизменяемых признаков», формируется при помощи средства формирования сверток 130 таким образом, что она не является устойчивой к изменениям признаков подмножества.
В частном случае реализации изобретения свертка подмножества неизменяемых признаков представляет собой байтовую строку и формируется средством формирования сверток признаков 130 путем конкатенации строковых записей значения каждого из признаков, разделенных специальным символом, который в частном случае реализации представляет собой символ «*». Например, для консольного приложения, скомпилированного при помощи компилятора Microsoft Visual Studio 2008, свертка подмножества неизменяемых признаков будет выглядеть следующим образом: «WINDOWS_CUI*MSVS2008».
Свертка подмножества признаков, содержащего как минимум один изменяемый признак, далее именуемого как «подмножество изменяемых признаков», формируется при помощи средства формирования сверток признаков 130 таким образом, что свертка является устойчивой к изменениям признаков подмножества.
В частном случае реализации устойчивость сверток подмножеств изменяемых признаков достигается путем исключения из данных подмножеств набора признаков, значения которых варьируются в рамках множества похожих файлов. Таким образом, наборы изменяемых признаков для двух похожих файлов будут тождественны, и, независимо от способа формирования, свертки признаков будут также тождественны.
В другом частном случае реализации изобретения устойчивость сверток подмножеств изменяемых признаков достигается путем установления для каждого из признаков, характеризуемых значением одного или нескольких байт, числового окна, характеризующего минимальное и максимальное значение, принимаемое каждым байтом, характеризующим признак. В частном случае реализации изобретения свертка получается путем конкатенации байтового представления признаков с учетом установленного предела для каждого байта, характеризующего признак файла.
В другом частном случае реализации изобретения устойчивость сверток подмножеств изменяемых признаков достигается путем использования сверток, обладающих свойством locality sensitive hashing (lsh).
В частном случае реализации изобретения при выделении из подмножества изменяемых признаков множества строк (в том числе отфильтрованного множества строк) в отдельное подмножество, очевидно, возникает необходимость обеспечить устойчивость свертки упомянутого подмножества, состоящего из строк. В частном случае реализации изобретения для обеспечения устойчивости свертки подмножества строк файла используется косинусное хэширование, результатом которого является последовательность байт. Полученная таким образом свертка является сверткой подмножества признаков, состоящего из строк файла.
В одном из вариантов реализации изобретения для обеспечения устойчивости свертки подмножества изменяемых признаков средство формирования сверток признаков 130 реализует способ создания свертки подмножества изменяемых признаков, основанный на алгоритме Semi-Supervised Hashing (SSH). Преимущество использования данного алгоритма для решения lsh-задачи обусловлено формированием оптимальной хэш-функции для свертки подмножества изменяемых признаков в процессе обучения используемого алгоритма.
На Фиг. 3 показана структурная схема формирования хэш-функции в рамках этапа обучения SSH-алгоритма. Для всех файлов из базы данных файлов для обучения 310 средство выделения признаков 110 выделяет множество признаков. Наборы из множеств выделенных признаков для каждого файла из базы данных 310 поступают на вход средства разделения признаков 120. Средство разделения признаков 120 из каждого входного набора признаков выделяет подмножество изменяемых признаков. Наборы таких подмножеств признаков, соответствующие файлам из базы данных файлов для обучения 310, поступают средству формирования хэш-функции 320 в виде векторов байтовых значений признаков. Средству формирования хэш-функции 320 со стороны базы данных отношений между файлами для обучения 330 на вход поступает множество отношений похожести между файлами, которые хранятся в базе данных файлов для обучения 310. В частном случае реализации отношение похожести имеет вид кортежа, хранящего идентификаторы файлов из базы данных 310, между которыми рассматриваются отношения, и идентификатор отношения похожести между указанными файлами.
В частном случае реализации базы данных отношений между файлами для обучения 330 отношение похожести характеризуется одним из следующих значений: «похожи», «различны», «отношение неизвестно». Значение «похожи» применяется к паре похожих файлов. Для пар файлов, которые не являются похожими, устанавливается отношение похожести «различны». Если для пары файлов из базы данных файлов для обучения 310 отношение похожести не указано явным образом, отношение похожести устанавливается как «отношение неизвестно».
В частном случае реализации базы данных отношений между файлами для обучения 330 отношение похожести «различны» устанавливается между двумя файлами, один из которых является вредоносным, а другой не является таковым. В частном случае реализации отношение похожести «похожи» устанавливается между парами вредоносных похожих файлов. В другом частном случае реализации отношение похожести «похожи» устанавливается между парами похожих файлов, не являющихся вредоносными.
Получив информацию о векторах изменяемых признаков файлов и отношениях похожести между файлами, средство формирования хэш-функции 320 производит настраивание хэш-функции в соответствии с этапом обучения SHH-алгоритма. Множество векторов изменяемых признаков файлов рассматриваются как множество точек в n-мерном гиперпространстве, где n - количество признаков из множества изменяемых признаков. Средство формирования хэш-функции 320 на основании этапа обучения SSH-алгоритма разбивает указанное гиперпространство плоскостями таким образом, что файлы, для которых указано отношение похожести «похожи», остаются по одну сторону от плоскости, а файлы, для которых указано отношение похожести «различны», - по разные. Результатом обучения является вычисление коэффициентов, задающих плоскости разбиения гиперпространства. Коэффициенты представляются в виде матрицы. Средство формирования хэш-функции 320 подает указанную матрицу коэффициентов на вход средства формирования сверток признаков 130. В свою очередь, средство формирования сверток признаков 130, используя вышеописанную матрицу коэффициентов, для каждого входного сгруппированного в виде вектора набора признаков из подмножества изменяемых признаков формирует свертку подмножества изменяемых признаков, представляющую собой последовательность байт.
Особенностью описанного механизма формирования сверток является то, что для набора признаков двух файлов будет сгенерирована идентичная свертка, если для файлов, используемых для выделения указанных признаков, отношение похожести на этапе обучения SSH-алгоритма было установлено как «похожи». В то же время свертки наборов признаков двух файлов, отношение между которыми было установлено как «различны», будут различаться. Способ формирования хэш-функции для получения свертки подмножества изменяемых признаков гарантирует устойчивость свертки к изменениям признаков из подмножества изменяемых признаков. Это означает, что свертки наборов подмножества изменяемых признаков двух похожих файлов будут идентичны, даже если какие-либо признаки из подмножества изменяемых признаков указанных файлов будут иметь различные значения.
Средство формирования свертки файла 140 получает на вход со стороны средства формирования сверток признаков 130 свертки всех выделенных подмножеств признаков. Свертка каждого из подмножеств признаков представляет собой последовательность байт. Свертка файла формируется путем комбинации сверток подмножеств признаков файла. Будучи сформированной на основе устойчивых сверток подмножеств изменяемых признаков и сверток подмножеств неизменяемых признаков, свертка файла также обладает устойчивостью, принимая одинаковый, с точностью до байта, вид для множества похожих файлов.
В частном случае реализации средство формирования свертки файла 140 формирует свертку файла как конкатенацию байтового представления сверток подмножеств признаков.
В другом частном случае реализации средство формирования свертки файла 140 формирует свертку файла на основании косинусного хэширования, применяемого к сверткам подмножеств признаков файла.
В еще одном частном варианте реализации изобретения средство формирования свертки файла 140 после формирования свертки файла дополнительно вычисляет хэш-функцию от байтового представления свертки файла, после чего сверткой файла считается вычисленное значение упомянутой хэш-функции. В частном случае реализации средством формирования свертки файла 140 в качестве хэш-функции, применяемой к байтовому представлению свертки файла, используется MD5.
После вычисления свертки файла средство формирования свертки файла 140 передает сгенерированную свертку анализируемого файла средству сравнения сверток файлов 150. Средство сравнения сверток файлов 150 также связано с базой данных сверток 170.
Средство сравнения сверток файлов 150 сравнивает полученную от средства формирования свертки файла 140 свертку с множеством сверток файлов. Упомянутое множество сверток файлов хранится в базе данных сверток 170.
База данных сверток 170 помимо сверток файлов хранит идентификаторы соответствующих сверткам файлов, а также информацию о вредоносности файлов, свертки которых хранятся в базе данных. Свертки файлов, хранимые в базе данных сверток 170, заранее формируются в соответствии с вышеописанным способом формирования свертки файла. При формировании набора сверток для базы данных сверток 170 используются кластеры похожих файлов. В частном случае реализации как минимум один кластер файлов, используемый для формирования свертки, которая будет храниться в базе данных сверток 170, состоит из множества вредоносных файлов.
Если при сравнении свертки анализируемого файла, осуществляемом средством сравнения сверток файлов 150, упомянутое средство находит среди сверток, хранящихся в базе данных сверток 170, идентичную свертку, средство сравнения сверток файлов 150 признает анализируемый файл похожим на файлы из кластера похожих файлов, взятого за основу для формирования свертки в базе данных сверток 170.
В частном случае реализации средство сравнения сверток файлов 150 признает файл вредоносным, если он признан похожим на файлы кластера похожих файлов, которые являются вредоносными файлами. Информация о вредоносности файлов, используемых для формирования свертки, попадающей в базу данных сверток 170, задается при создании соответствующей записи в базе данных.
В частном случае реализации в качестве входных данных средства выделения признаков 110 используются файлы, анализируемые антивирусным программным обеспечением на компьютере пользователя. Результат анализа рассматриваемого файла с помощью описанных в рамках изобретения средств используется в сочетании с другими средствами защиты пользователя, предоставляемыми антивирусным программным обеспечением с целью повышения степени защищенности пользователя.
В частном случае реализации изобретения база данных сверток 170 и средство сравнения сверток файлов 150 являются частью серверной архитектуры, соединенной с персональным компьютером пользователя, на котором расположены средства, описанные в рамках изобретения и необходимые для формирования свертки файла. В другом частном случае реализации база данных сверток 170 и средство сравнения сверток файлов 150 располагаются непосредственно на персональном компьютере пользователя.
На Фиг. 4 изображена примерная схема алгоритма работы одного из вариантов реализации вышеописанной системы обнаружения вредоносного программного обеспечения. На этапе 410 средством выделения признаков 110 производится выделение множества признаков файла. Выделенное множество признаков передается средству разделения признаков 120, которое на этапе 420 разделяет множество выделенных признаков файла на как минимум одно подмножество, содержащее по меньшей мере один изменяемый признак, и как минимум одно подмножество, содержащее по меньшей мере один неизменяемый признак. Подмножества признаков поступают на средство формирования сверток подмножеств признаков 130, которое на этапе 430 осуществляет формирование сверток каждого из входных подмножеств признаков файла. На этапе 440 средство формирования свертки файла 140, получая от средства формирования сверток признаков 130 свертки каждого подмножества признаков файла, формирует свертку файла как конкатенацию сверток подмножеств признаков. Полученная на этапе 440 свертка файла поступает на вход средства сравнения сверток файлов 150, которое на этапе 450 производит поиск указанной свертки среди множества заранее сформированных сверток из базы данных сверток 170. В случае если на этапе 460 средством сравнения сверток файлов 150 будет выявлено совпадение свертки анализируемого файла и свертки из базы данных сверток 170, анализируемый файл будет признан похожим на файлы из кластера похожих файлов, которые были использованы для формирования свертки, совпавшей со сверткой анализируемого файла. Если на этапе 490 будет выяснено, что для формирования совпавшей свертки был использован кластер похожих вредоносных файлов, то анализируемый файл будет признан вредоносным на этапе 500. Если же на этапе 490 будет выяснено, что для формирования совпавшей свертки был использован кластер похожих файлов, которые не являются вредоносными, то анализируемый файл будет признан не вредоносным на этапе 510.
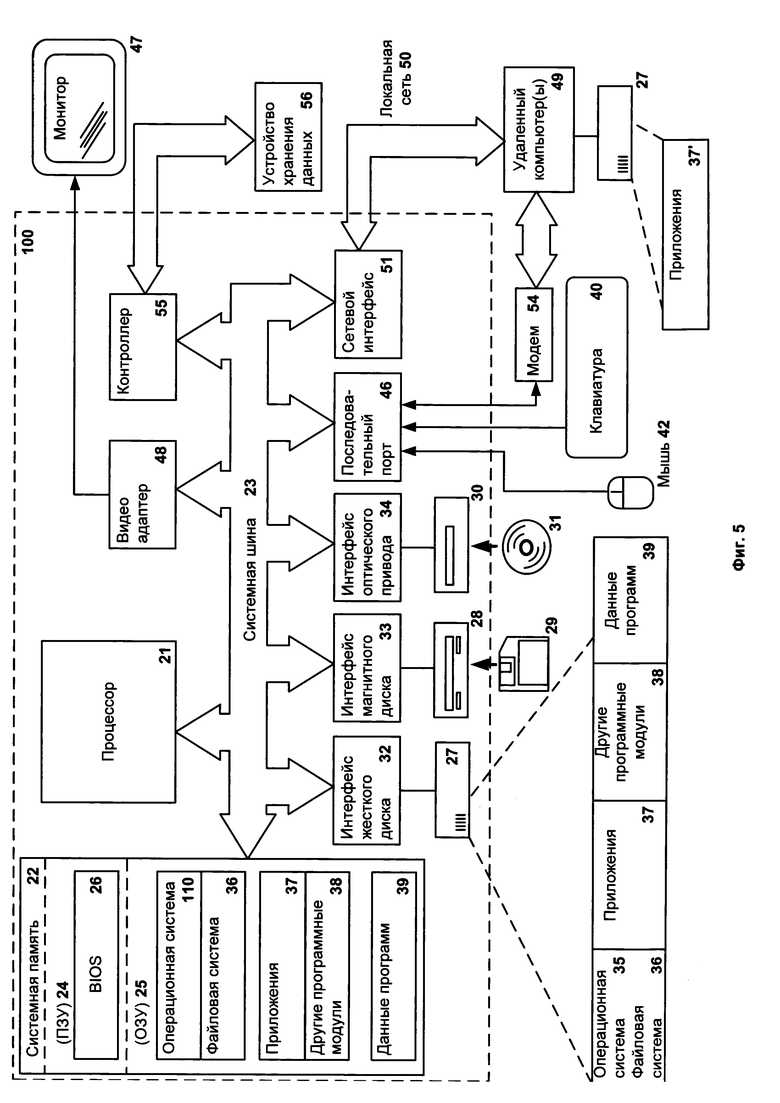
Фиг. 5 представляет пример компьютерной системы общего назначения, персональный компьютер или сервер 20, содержащий центральный процессор 21, системную память 22 и системную шину 23, которая содержит разные системные компоненты, в том числе память, связанную с центральным процессором 21. Системная шина 23 реализована, как любая известная из уровня техники шинная структура, содержащая в свою очередь память шины или контроллер памяти шины, периферийную шину и локальную шину, которая способна взаимодействовать с любой другой шинной архитектурой. Системная память содержит постоянное запоминающее устройство (ПЗУ) 24, память с произвольным доступом (ОЗУ) 25. Основная система ввода/вывода (BIOS) 26, содержит основные процедуры, которые обеспечивают передачу информации между элементами персонального компьютера 20, например, в момент загрузки операционной системы с использованием ПЗУ 24.
Персональный компьютер 20 в свою очередь содержит жесткий диск 27 для чтения и записи данных, привод магнитных дисков 28 для чтения и записи на сменные магнитные диски 29 и оптический привод 30 для чтения и записи на сменные оптические диски 31, такие как CD-ROM, DVD-ROM и иные оптические носители информации. Жесткий диск 27, привод магнитных дисков 28, оптический привод 30 соединены с системной шиной 23 через интерфейс жесткого диска 32, интерфейс магнитных дисков 33 и интерфейс оптического привода 34 соответственно. Приводы и соответствующие компьютерные носители информации представляют собой энергонезависимые средства хранения компьютерных инструкций, структур данных, программных модулей и прочих данных персонального компьютера 20.
Настоящее описание раскрывает реализацию системы, которая использует жесткий диск 27, сменный магнитный диск 29 и сменный оптический диск 31, но следует понимать, что возможно применение иных типов компьютерных носителей информации 56, которые способны хранить данные в доступной для чтения компьютером форме (твердотельные накопители, флеш-карты памяти, цифровые диски, память с произвольным доступом (ОЗУ) и т.п.), которые подключены к системной шине 23 через контроллер 55.
Компьютер 20 имеет файловую систему 36, где хранится записанная операционная система 35, а также дополнительные программные приложения 37, другие программные модули 38 и данные программ 39. Пользователь имеет возможность вводить команды и информацию в персональный компьютер 20 посредством устройств ввода (клавиатуры 40, манипулятора «мышь» 42). Могут использоваться другие устройства ввода (не отображены): микрофон, джойстик, игровая консоль, сканнер и т.п. Подобные устройства ввода по своему обычаю подключают к компьютерной системе 20 через последовательный порт 46, который в свою очередь подсоединен к системной шине, но могут быть подключены иным способом, например, при помощи параллельного порта, игрового порта или универсальной последовательной шины (USB). Монитор 47 или иной тип устройства отображения также подсоединен к системной шине 23 через интерфейс, такой как видеоадаптер 48. В дополнение к монитору 47, персональный компьютер может быть оснащен другими периферийными устройствами вывода (не отображены), например, колонками, принтером и т.п.
Персональный компьютер 20 способен работать в сетевом окружении, при этом используется сетевое соединение с другим или несколькими удаленными компьютерами 49. Удаленный компьютер (или компьютеры) 49 являются такими же персональными компьютерами или серверами, которые имеют большинство или все упомянутые элементы, отмеченные ранее при описании существа персонального компьютера 20, представленного на Фиг. 5. В вычислительной сети могут присутствовать также и другие устройства, например, маршрутизаторы, сетевые станции, пиринговые устройства или иные сетевые узлы.
Сетевые соединения могут образовывать локальную вычислительную сеть (LAN) 50 и глобальную вычислительную сеть (WAN). Такие сети применяются в корпоративных компьютерных сетях, внутренних сетях компаний и, как правило, имеют доступ к сети Интернет. В LAN- или WAN-сетях персональный компьютер 20 подключен к локальной сети 50 через сетевой адаптер или сетевой интерфейс 51. При использовании сетей персональный компьютер 20 может использовать модем 54 или иные средства обеспечения связи с глобальной вычислительной сетью, такой как Интернет. Модем 54, который является внутренним или внешним устройством, подключен к системной шине 23 посредством последовательного порта 46. Следует уточнить, что сетевые соединения являются лишь примерными и не обязаны отображать точную конфигурацию сети, т.е. в действительности существуют иные способы установления соединения техническими средствами связи одного компьютера с другим.
В заключение следует отметить, что приведенные в описании сведения являются примерами, которые не ограничивают объем настоящего изобретения, определенного формулой.
| название | год | авторы | номер документа |
|---|---|---|---|
| СИСТЕМА И СПОСОБ СОЗДАНИЯ ГИБКОЙ СВЕРТКИ ДЛЯ ОБНАРУЖЕНИЯ ВРЕДОНОСНЫХ ПРОГРАММ | 2013 |
|
RU2580036C2 |
| СПОСОБ И СИСТЕМА АНАЛИЗА РАБОТЫ ПРАВИЛ ОБНАРУЖЕНИЯ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ | 2013 |
|
RU2568285C2 |
| Система и способ классификации объектов вычислительной системы | 2018 |
|
RU2724710C1 |
| СИСТЕМА И СПОСОБ ОЦЕНКИ НАДЕЖНОСТИ ПРАВИЛА КАТЕГОРИЗАЦИИ | 2013 |
|
RU2587429C2 |
| МЕТОД ОТНЕСЕНИЯ РАНЕЕ НЕИЗВЕСТНОГО ФАЙЛА К КОЛЛЕКЦИИ ФАЙЛОВ В ЗАВИСИМОСТИ ОТ СТЕПЕНИ СХОЖЕСТИ | 2009 |
|
RU2420791C1 |
| Система и способ классификации объектов | 2017 |
|
RU2679785C1 |
| Система и способ обнаружения вредоносных файлов с использованием элементов статического анализа | 2017 |
|
RU2654146C1 |
| Система и способ управления вычислительными ресурсами для обнаружения вредоносных файлов | 2017 |
|
RU2659737C1 |
| Система и способ формирования набора антивирусных записей, используемых для обнаружения вредоносных файлов на компьютере пользователя | 2015 |
|
RU2617654C2 |
| Система и способ обнаружения вредоносного файла | 2018 |
|
RU2739865C2 |
Изобретение относится к вычислительной технике. Технический результат заключается в определении похожих файлов. Способ определения похожести файлов, в котором определяют множества изменяемых и неизменяемых признаков файлов; при этом признак файла считают изменяемым, если для множества похожих файлов признак принимает различные значения; при этом признак файла считают неизменяемым, если для множества похожих файлов признак принимает одинаковое значение; выделяют множество признаков по меньшей мере из одного файла; разделяют множество выделенных признаков файла по меньшей мере на два подмножества: подмножество изменяемых признаков и подмножество неизменяемых признаков; формируют свертку каждого из вышеописанных подмножеств признаков файла; формируют свертку файла как комбинацию сверток каждого из вышеописанных подмножеств признаков файла; сравнивают свертку по меньшей мере одного файла с набором заранее созданных сверток файлов; признают файл похожим на файлы из множества похожих файлов, имеющих одинаковую свертку, если при сравнении свертка указанного файла совпадает со сверткой файла из указанного множества. 2 н.п. ф-лы, 5 ил.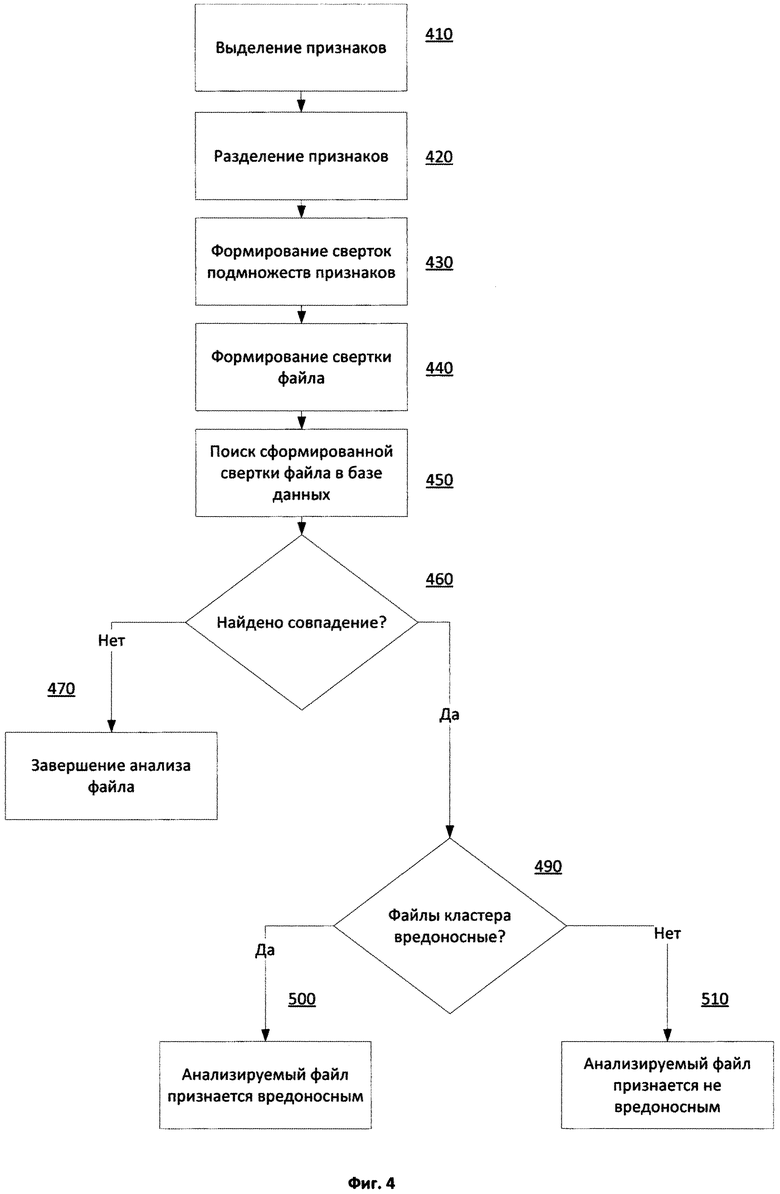
1. Способ определения похожести файлов, в котором:
а) определяют множества изменяемых и неизменяемых признаков файлов, при этом файлы хранятся в базе данных файлов для обучения;
при этом признак файла считают изменяемым, если для множества похожих файлов признак принимает различные значения;
при этом признак файла считают неизменяемым, если для множества похожих файлов признак принимает одинаковое значение;
б) выделяют множество признаков по меньшей мере из одного файла;
в) разделяют множество выделенных признаков файла по меньшей мере на два подмножества: подмножество изменяемых признаков и подмножество неизменяемых признаков;
при этом подмножество изменяемых признаков файла включает в себя по меньшей мере: размер файла, размер образа файла, количество секций файла, RVA (Relative Virtual Address) секций файла, RVA точки входа, частотные характеристики символов, множество строк файла и их количество, отфильтрованное множество строк файла и их количество;
при этом подмножество неизменяемых признаков файла включает в себя по меньшей мере: тип использованного при создании файла компилятора, тип подсистемы, характеристики файла из COFF (Common Object File Format) заголовка;
г) формируют свертку каждого из вышеописанных подмножеств признаков файла;
при этом свертка подмножества неизменяемых признаков не является устойчивой к изменениям признаков подмножества;
при этом свертка подмножества изменяемых признаков является устойчивой к изменениям признаков подмножества;
д) формируют свертку файла как комбинацию сверток каждого из вышеописанных подмножеств признаков файла;
е) сравнивают свертку по меньшей мере одного файла с набором заранее созданных сверток файлов;
ж) признают файл похожим на файлы из множества похожих файлов, имеющих одинаковую свертку, если при сравнении свертка указанного файла совпадает со сверткой файла из указанного множества.
2. Система определения похожести файлов, которая содержит:
а) средство выделения признаков, предназначенное для выделения множества признаков из по меньшей мере одного файла и передающее выделенное множество признаков на вход средства разделения признаков;
б) средство разделения признаков, предназначенное для формирования из множества выделенных признаков как минимум двух подмножеств: подмножества изменяемых признаков и подмножества неизменяемых признаков, и передающее сформированные подмножества признаков на вход средства формирования сверток признаков, а также для определения множества изменяемых и неизменяемых признаков файлов, при этом упомянутые файлы хранятся в базе данных файлов для обучения;
при этом признак файла считают изменяемым, если для множества похожих файлов признак принимает различные значения;
при этом признак файла считают неизменяемым, если для множества похожих файлов признак принимает одинаковое значение;
при этом подмножество изменяемых признаков файла включает в себя по меньшей мере: размер файла, размер образа файла, количество секций файла, RVA секций файла, RVA точки входа, частотные характеристики символов, множество строк файла и их количество, отфильтрованное множество строк файла и их количество;
при этом подмножество неизменяемых признаков файла включает в себя по меньшей мере: тип использованного при создании файла компилятора, тип подсистемы, характеристики файла из COFF заголовка;
в) средство формирования сверток признаков, предназначенное для формирования свертки каждого из вышеописанных подмножеств признаков файла и передающее сформированные свертки подмножеств признаков на вход средства формирования свертки файла;
при этом свертка подмножества неизменяемых признаков не является устойчивой к изменениям признаков подмножества;
при этом свертка подмножества изменяемых признаков является устойчивой к изменениям признаков подмножества;
г) средство формирования свертки файла, предназначенное для формирования свертки файла как комбинации сверток каждого из вышеописанных подмножеств признаков файла и передающее сформированную свертку файла на вход средства сравнения сверток файлов;
д) базу данных сверток, предназначенную для хранения по меньшей мере одной свертки файла и соответствующей указанной свертке информации о вредоносности файла;
е) базу данных файлов для обучения, предназначенную для хранения файлов, которые используются для определения множества изменяемых и неизменяемых признаков;
ж) средство сравнения сверток файлов, связанное с базой данных сверток и предназначенное для сравнения свертки по меньшей мере одного файла со свертками, присутствующими в базе данных сверток, и признания файла похожим на файлы из множества похожих файлов, имеющих одинаковую свертку, если при сравнении свертка указанного файла совпадает со сверткой файла из указанного множества.
| Колосоуборка | 1923 |
|
SU2009A1 |
| Мешалка для перемешивания вина в акратофоре | 1954 |
|
SU101223A1 |
| СИСТЕМА И СПОСОБ ПОВЫШЕНИЯ ЭФФЕКТИВНОСТИ ОБНАРУЖЕНИЯ НЕИЗВЕСТНЫХ ВРЕДОНОСНЫХ ОБЪЕКТОВ | 2010 |
|
RU2454714C1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |

