По данной заявке испрашивается приоритет патентной заявки Великобритании №1121033.3, поданной 07 декабря 2011 г., и предварительной патентной заявки США №61/568188, поданной 08 декабря 2011 г., при этом обе из них во всей своей полноте включены в настоящее описание посредством ссылки.
ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
Настоящее изобретение, в целом, относится к области электронных документов и, в частности, относится к аннотированию электронных документов.
ПРЕДПОСЫЛКИ СОЗДАНИЯ ИЗОБРЕТЕНИЯ
Типичный поиск, осуществляемый посредством использования поисковой машины по «Всемирной Паутине» (Web) создает множество результатов поиска (например, электронные документы, включающие в себя новостные текстовые блоки, web-страницы, содержимое социальных средств общения и подобное). Тем не менее, по меньшей мере, часть результатов поиска часто не имеет отношения к поиску. Более того, содержимое даже релевантных результатов поиска может отличаться от документа к документу.
Дополнительно, социальные средства общения позволяют пользователям рекомендовать различные электронные документы другим пользователям. Тем не менее, сталкиваясь лишь с унифицированным указателем ресурса (URL) или названием, может быть сложным сказать, является ли вероятнее всего связанный электронный документ интересующим.
Таким образом, нахождение документа, чье содержимое действительно является релевантным или интересующим, приводит к некоторым попыткам и ошибкам, поскольку пользователь должен отсортировать множество документов по очереди при небольших предварительных знаниях об их содержимом. Это может быть трудоемким заданием, в частности, если какой-либо из документов обширный (например, как в случае с книгами или некоторыми новостными статьями). При исполнении на мобильном устройстве (например, смартфоне) просмотр различных документов по очереди может занимать еще больше времени, поскольку документам может потребоваться больше времени для считывания и загрузки на устройство.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Один вариант осуществления способа аннотирования электронного документа включает в себя этапы, на которых: разбивают электронный документ на множество частей, при этом каждая из множества частей связан с соответствующей длиной, соответствующим баллом информативности, и соответствующим баллом согласованности; автоматически выбирают подмножество из множества частей таким образом, что совокупный балл информативности этого подмножества является максимальным, тогда как совокупная длина данного подмножества меньше или равна максимальной длине; и компонуют упомянутое подмножество в качестве аннотации к электронному документу.
В дополнительных вариантах осуществления: упомянутое подмножество содержит меньше чем все из множества частей; по меньшей мере, одна из частей содержит предложение; соответствующий балл информативности для заданной части из множества частей присваивается в соответствии с методикой выставления баллов, которая является независимой от языка; методика выставления баллов присваивает весовые коэффициенты множеству признаков заданной части в соответствии с набором программируемых вручную правил; соответствующий балл информативности для заданной части из множества частей присваивается в соответствии с методикой выставления баллов, которая является зависимой от языка; методика выставления баллов является методикой контролируемого машинного обучения, которая использует статистический классификатор; статистический классификатор соответствует методу опорных векторов; методика выставления баллов является методикой неконтролируемого машинного обучения, которая представляет заданную часть в качестве взвешенного узла в ориентированном графе; соответствующий балл информативности для каждой из множества частей является, по меньшей мере, равным пороговому значению; соответствующие баллы согласованности каждой из множества частей являются, по меньшей мере, равными пороговому значению; способ дополнительно содержит этап, на котором: усекают каждую из множества частей вслед за разбиением, но перед этапом, на котором выполняют автоматический выбор; при этом этап, на котором выполняют автоматический выбор, выполняется при помощи блока комбинаторной оптимизации; этап, на котором выполняют автоматический выбор, содержит этап, на котором оценивают каждую из множества частей по отдельности для включения в упомянутое подмножество; этап, на котором оценивают, содержит этап, на котором исключают из включения в подмножество тех из множества частей, чьи соответствующие длины превышают текущую совокупную длину подмножества; этап, на котором оценивают, содержит, для заданной части из множества частей, этапы, на которых: вычисляют первую сумму, при этом первая сумма является суммой соответствующих баллов информативности, связанных с наиболее информативным подмножеством из множества частей, которое исключает заданную часть, и имеет совокупную длину меньше или равную максимальной длине; вычисляют вторую сумму, при этом вторая сумма является суммой первого значения и второго значения, при этом первое значение равно первой сумме минус соответствующая длина заданной части, а второе значение является соответствующим баллом информативности заданной части; и определяют, включить ли заданную часть в упомянутое подмножество, на основании сравнения первой суммы и второй суммы; этап, на котором определяют, содержит этапы, на которых: включают заданную часть в подмножество, когда вторая сумма больше первой суммы, и исключают заданную часть из подмножества, когда первая сумма больше второй суммы; множество частей компонуется в соответствии с очередностью, в которой каждая из множества частей появляется в электронном документе; способ дополнительно содержит этап, на котором определяют, перед этапом, на котором разбивают, автоматически выбирают, и компонуют, что электронный документ может быть представлен в виде аннотации; этап, на котором определяют, содержит этапы, на которых: генерируют вектор признаков для электронного документа, при этом вектор признаков содержит множество признаков электронного документа; присваивают весовой коэффициент каждому из множества признаков; и назначают балл электронному документу в соответствии с весовым коэффициентом, присвоенным каждому из множества признаков, при этом балл указывает на то, является ли электронный документ документом, который допускает аннотирование; весовой коэффициент изучается автоматически; этап, на котором присваивают весовой коэффициент, содержит, для заданного признака из множества признаков, этапы, на которых: повышают весовой коэффициент, когда заданный признак возникает, по меньшей мере, с определенной частотой в наборе обучающих примеров, содержащих документы, которые допускают аннотирование, и понижают весовой коэффициент, когда заданный признак возникает, по меньшей мере, с определенной частотой в наборе обучающих примеров, содержащих документы, которые не могут быть аннотированы; и этапы, на которых присваивают весовой коэффициент и присваивают балл, выполняются таким образом, который является специфичным для языка, на котором написан электронный документ.
Один вариант осуществления вещественного машиночитаемого носителя информации, содержащего исполняемую программу для аннотирования электронного документа, включает в себя программу, которая выполняет операции, включающие в себя: разбиение электронного документа на множество частей, при этом каждая из множества частей связана с соответствующей длиной, соответствующим баллом информативности и соответствующем баллом согласованности; автоматический выбор подмножества из множества частей таким образом, что совокупный балл информативности этого подмножества является максимальным, в то время как совокупная длина данного подмножества меньше или равна максимальной длине; и компонование упомянутого подмножества в качестве аннотации к электронному документу.
Один вариант осуществления системы для аннотирования электронного документа включает в себя процессор и машиночитаемый носитель информации, содержащий исполняемую программу, которая предписывает процессору выполнять операции, включающие в себя: разбиение электронного документа на множество частей, при этом каждая из множества частей связана с соответствующей длиной, соответствующим баллом информативности и соответствующем баллом согласованности; автоматический выбор подмножества из множества частей таким образом, что совокупный балл информативности этого подмножества является максимальным, в то время как совокупная длина данного подмножества меньше или равна максимальной длине; и компонование упомянутого подмножества в качестве аннотации к электронному документу.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Идеи настоящего изобретения могут быть легко поняты посредством рассмотрения нижеследующего подробного описания совместно с сопроводительными чертежами, на которых:
Фиг. 1 является структурной схемой, изображающей один пример сети связи, внутри которой могут быть развернуты варианты осуществления настоящего изобретения;
Фиг. 2 является структурной схемой, изображающей более подробно вариант осуществления сервера приложений, иллюстрируемого на Фиг. 1;
Фиг. 3 является логической блок-схемой, иллюстрирующей один вариант осуществления способа извлечения содержимого из электронного документа, в соответствии с настоящим изобретением;
Фиг. 4 является логической блок-схемой, иллюстрирующей один вариант осуществления способа определения того, может ли электронный документ быть аннотирован, в соответствии с настоящим изобретением;
Фиг. 5 является логической блок-схемой, иллюстрирующей один вариант осуществления способа аннотирования электронного документа, в соответствии с настоящим изобретением;
Фиг. 6 является логической блок-схемой, иллюстрирующей один вариант осуществления способа выбора набора предложений для формирования аннотации к документу, в соответствии с настоящим изобретением; и
Фиг. 7 является высокоуровневой структурной схемой настоящего изобретения, реализованного при помощи вычислительного устройства общего назначения.
ПОДРОБНОЕ ОПИСАНИЕ
В одном варианте осуществления, настоящее изобретение является способом и устройством для автоматического аннотирования содержимого электронных документов. Варианты осуществления изобретения способствуют согласованному и эффективному потреблению содержимого посредством аннотирования содержимого электронных документов, не требуя загрузки электронных документов на устройство. В одном варианте осуществления, изобретение реализовано в качестве приложения для мобильного устройства, такого как смартфон или планшетный компьютер, где мобильное устройство взаимодействует с удаленным сервером через сеть.
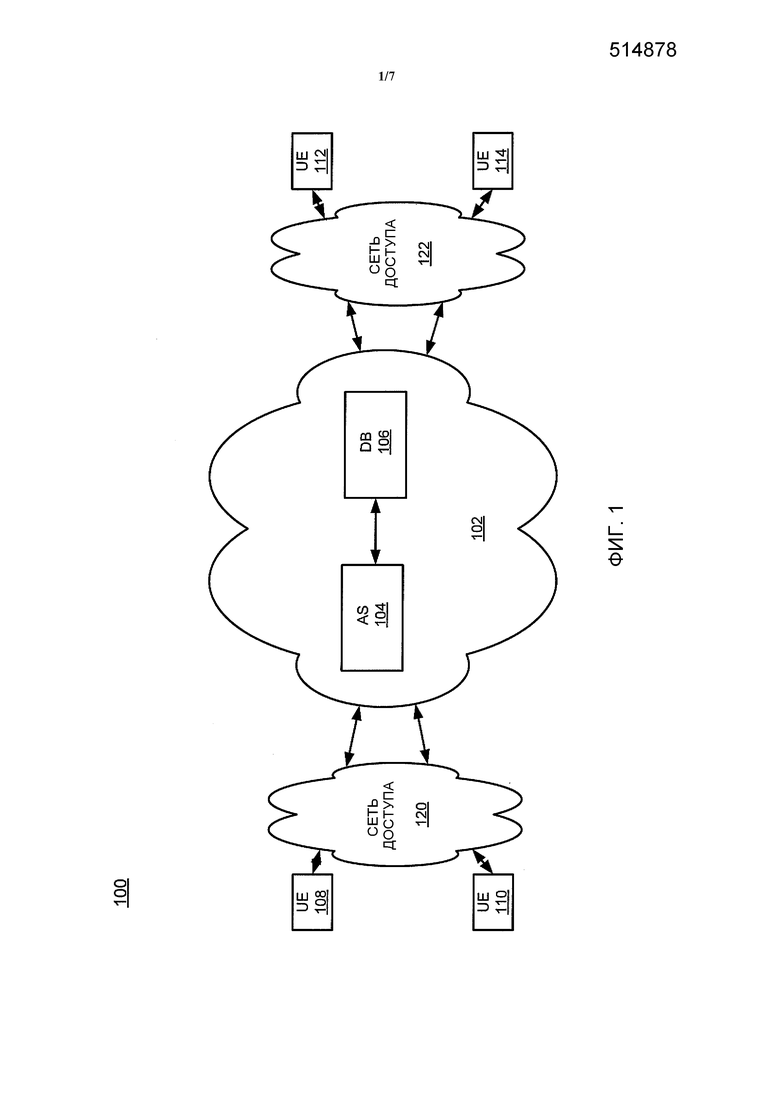
Фиг. 1 является структурной схемой, изображающей один пример сети 100 связи, внутри которой могут быть развернуты варианты осуществления настоящего изобретения. Сеть 100 связи может быть любым типом сети связи, такой как, например, традиционная сеть с коммутацией каналов (например, телефонная коммутируемая сеть общего пользования (PSTN)) или сеть Интернет Протокола (IP) (например, сеть Мультимедийной Подсистемы на Базе Протокола IP (IMS), сеть режима асинхронной передачи (ATM), беспроводная сеть, сотовая сеть (например, 2G, 3G и подобная), сеть долгосрочного развития (LTE), и подобная), относящейся к текущему раскрытию. Следует отметить, что IP сеть в широком смысле определяется как сеть, которая использует Интернет Протокол для осуществления обмена пакетами данных. Дополнительные примерные IP сети включают в себя сети передачи Голоса по IP (VoIP), сети Услуги по IP (SoIP) и подобные.
В одном варианте осуществления сеть 100 может содержать базовую сеть 102. Базовая сеть 102 может осуществлять связь с одной или более сетями 120 и 122 доступа. Сети 120 и 122 доступа могут включать в себя сеть беспроводного доступа (например, сеть WiFi и подобную), сеть сотового доступа, сеть PSTN доступа, сеть кабельного доступа, сеть проводного доступа и подобную. В одном варианте осуществления сети 120 и 122 доступа все могут быть сетями доступа разных типов, все могут быть сетью доступа одного типа, или некоторые сети доступа могут быть сетью доступ одного типа, а другие могут быть сетями доступа других типов. Базовая сеть 102 и сети 120 и 122 доступа могут эксплуатироваться разными поставщиками услуг, одним и тем же поставщиком услуг или их сочетанием.
В одном варианте осуществления базовая сеть 102 может включать в себя сервер 104 приложений (AS) и базу 106 данных (DB). Несмотря на то, что проиллюстрирован только один AS 104 и одна DB 106, следует отметить, что любое количество серверов 104 приложений и баз 106 данных может быть развернуто. Например, базовая сеть 102 может содержать часть облачной среды, в которой услуги и приложения поддерживаются высоко распределенным образом.
В одном варианте осуществления AS 104 может быть выполнен в виде компьютера общего назначения, как иллюстрируется на Фиг. 7 и рассматривается ниже. В одном варианте осуществления AS 104 может выполнять способы и алгоритмы, рассматриваемые ниже в отношении аннотирования содержимого электронных документов.
В одном варианте осуществления DB 106 хранит аннотации к электронным документам, которые были собраны и аннотированы посредством AS 104. В дополнительном варианте осуществления, DB 106 опционально может хранить профили для пользователей сети 100. Например, DB 106 может хранить номера сотовых телефонов, адреса электронной почты, профили социальных средств общения, и подобное для каждого пользователя. Данная персональная информация может храниться в зашифрованном виде для того, чтобы защитить конфиденциальность пользователя. Кроме того, может потребоваться авторизация пользователя для того, чтобы DB 106 сохранила любую персональную информацию. В дополнение, DB 106 может хранить предпочтения пользователя в отношении типов содержимого, в которых они заинтересованы (например, новостные статьи, связанные с развлечением, спортом, наукой и т.д.).
В одном варианте осуществления сеть 120 доступа может осуществлять связь с одним или более оконечными устройствами 108 и 110 пользователя (также именуемыми как «оконечные устройства» или «UE»). В одном варианте осуществления, сеть 122 доступа может осуществлять связь с одним или более оконечными устройствами 112 и 114 пользователя.
В одном варианте осуществления оконечные устройства 108, 110, 112 и 114 пользователя могут быть любым типом оконечного устройства, таким как настольный компьютер или мобильное оконечное устройство, такое как сотовый телефон, интеллектуальный телефон, планшетный компьютер, компьютер класса лэптоп, нетбук, ультрабук, портативное мультимедийное устройство (например, проигрыватель МРЗ), игровая консоль, портативное игровое устройство, и подобное. Следует отметить, что, несмотря на то, что лишь четыре оконечных устройства пользователя иллюстрируются на Фиг. 1, любое количество оконечных устройств пользователя может быть развернуто. В одном варианте осуществления, любое из оконечных устройств пользователя может иметь один или более встроенные в них датчики. Эти датчики могут включать в себя, например, датчики местоположения, климатические датчики, акустические датчики, датчики положения, оптические датчики, датчики давления, датчики близости и им подобные. AS 104 может подписаться на выходные данные с этих датчиков, как более подробно рассматривается ниже.
Следует отметить, что сеть 100 была упрощена. Например, сеть 100 может включать в себя другие сетевые элементы (не показаны), такие как элементы границы, маршрутизаторы, коммутаторы, серверы политики, устройства безопасности, сеть распространения информационного наполнения (CDN) и подобное.
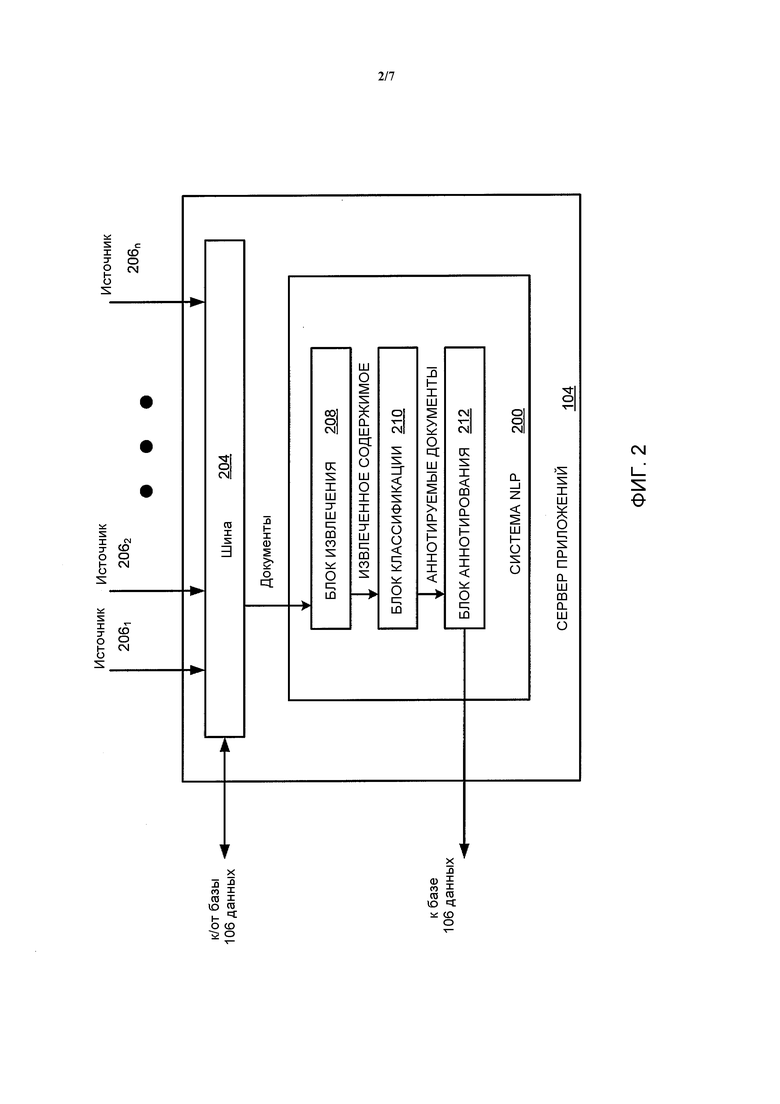
Фиг. 2 является структурной схемой, изображающей более подробно вариант осуществления сервера 104 приложений, иллюстрируемого на Фиг. 1. Как иллюстрируется, AS 104 в целом содержит систему 200 обработки данных на естественном языке (NLP) и шину 204.
Шина 204 получает электронные документы от множества источников 2061-206n (далее вместе именуемых как «источники 206»). В одном варианте осуществления, шина 204 вытягивает эти документы из источников 206. Таким образом, документы могут включать в себя, например, web-каналы (например, каналы исчерпывающей аннотации сайта (RSS), каналы Atom и т.д.) и Web-страницы (например, новостные сайты, сайты социальных средств общения и т.д.). Шина 204 переадресует полученные документы системе 200 NLP для дальнейшей обработки и аннотирования, как рассматривается более подробно ниже. В одном примерном варианте осуществления, шина 206 является сервисной шиной предприятия (ESB) Mule.
Система 200 NLP в целом содержит блок 208 извлечения, блок 210 классификации и блок 212 аннотирования. Блок 208 извлечения содержит первый фильтр, который принимает полученные документы от шины 204 и извлекает содержимое из документов. В одном варианте осуществления извлеченное содержимое содержит одно или более из следующего: текст, изображения, видео. Извлеченное содержимое может быть представлено на любом языке. В одном варианте осуществления блок 208 извлечения использует эвристический подход для извлечения содержимого.
Блок 210 классификации содержит второй фильтр, который принимает, по меньшей мере, некоторое из извлеченного содержимого от блока 208 извлечения и определяет, на основании извлеченного содержимого, может ли быть исходный документ представлен в виде аннотации. В одном варианте осуществления блок 210 классификации является блоком статистической классификации, который использует полученные в результате обучения (например, контролируемые) модели языка. Например, в одном конкретном варианте осуществления, блок 210 классификации является классификатором на основе линейной регрессии.
Блок 212 аннотирования принимает исходные документы, которые определены блоком классификации как документы, которые допускают аннотирование, и аннотирует эти документы. В одном варианте осуществления блок 212 аннотирования создает, по меньшей мере, две аннотации разных длин. Например, блок 212 аннотирования может создавать «короткую аннотацию и «длинную аннотацию, где длинная аннотация приблизительно от тридцати трех до пятидесяти процентов длиннее короткой аннотации (например, короткая аннотация может быть ограничена приблизительно 390 знаками, тогда как длинная аннотация ограничивается приблизительно 590 знаками). Блок 212 аннотирования выводит аннотацию или аннотации в базу 106 данных для сохранения. База 106 данных может, в свою очередь, без запроса рассылать аннотации одному или более оконечным устройствам 108, 110, 112 и 114 пользователя, как рассматривается более подробно ниже.
Фиг. 3 является блок-схемой, иллюстрирующей один вариант осуществления способа 300 извлечения содержимого из электронного документа, в соответствии с настоящим изобретением. Способ 300 может быть реализован, например, на сервере 104 приложений, иллюстрируемом на Фиг. 1 и 2. По существу, при рассмотрении способа 300 упоминаются различные элементы, иллюстрируемые на Фиг. 2. Тем не менее, следует иметь в виду, что способ 300 не ограничивается реализацией с помощью конфигурации сервера, иллюстрируемой на Фиг. 2, и что такое упоминание главным образом выполняется, чтобы способствовать объяснению.
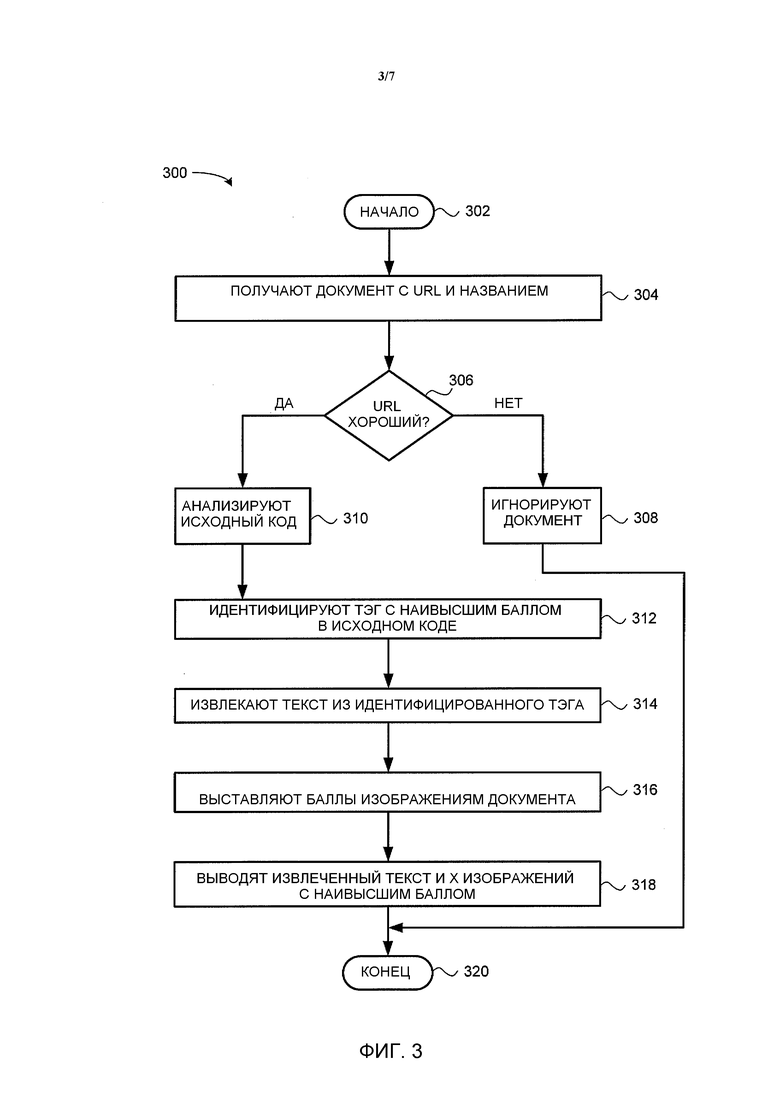
Способ 300 начинается на этапе 302. На этапе 304 шина 205 получает электронный документ с URL и названием. Как рассмотрено выше, шина 204 может получать документ из сети 100 по запросу. В одном варианте осуществления, документ является web-каналом или web-страницей.
На этапе 306 блок 208 извлечения определяет, является ли URL хорошим (т.е. содержит содержимое, которое подходит для аннотирования). Например, некоторые документы, такие как письма, дискуссии, рекламные объявления, адреса контактов или подобное, могу не подходить для аннотирования. В одном варианте осуществления, данное определение выполняется в соответствии с одним или более предварительно указанными шаблонами. Например, шаблоны, такие как текстовый блок|запись|страница|содержимое| текст|тело или подобное могут указывать содержимое, которое подходит для аннотирования, тогда как шаблоны, такие как виртуальная визитка|рекламирование|баннерная лента|титульные данные или подобное, может указывать содержимое, которое не подходит для аннотирования. Если блок 208 извлечения решает на этапе 306, что URL не является хорошим, тогда блок 208 извлечения игнорирует документ на этапе 308 перед тем, как способ 300 завершается на этапе 320.
В качестве альтернативы, если блок 208 извлечения решает на этапе 306, что URL хороший, тогда способ 300 переходит к этапу 310. На этапе 310, блок 208 извлечения анализирует исходный код документа (например, код языка гипертекстовой разметки (HTTP)). В одном варианте осуществления, анализ исходного кода включает в себя сбор списка всех абзацев в дереве объектной модели документа (DOM), где абзацы включают в себя любые элементы, которые размечены тэгом абзаца (т.е. <p>) или тэгом заголовка (например, <h1>). Каждому такому абзацу присваивается исходный (по умолчанию) балл, и наиболее близкому релевантному структурному тэгу присваивается балл, который является суммой баллов абзацев, связанных с тэгом. В одном варианте осуществления, структурный тэг рассматривается как релевантный абзацу, если структурный тэг является тегом <div> с атрибутом класса или ID, указывающим на то, что он имеет текстовое содержимое.
На этапе 312 блок 208 извлечения идентифицирует тэг в исходном коде с наивысшим баллом, где балл основан на вышеописанной схеме приращения. Данный тэг представляет собой узел DOM, содержащий наиболее релевантное содержимое.
На этапе 314 блок 208 извлечения извлекает текст из идентифицированного исходного кода тэга. В одном варианте осуществления блок 208 извлечения использует методику извлечения, которая исключает текст в узлах, которые вероятно содержат нерелевантный материал (например, подписи изображений, навигационные ссылки, авторские строки и ссылки на сайты социальных средств общения).
На этапе 316 блок 208 извлечения выставляет баллы набору всех изображений, упоминаемых в документе. Выставление баллов идентифицирует изображения, которые наиболее вероятно будут релевантными (т.е. непосредственно относятся к содержимому, которое аннотируется). Релевантные изображения могут включать в себя, например: изображения, которые имеют признаки, такие как располагаются непосредственно в основном содержимом документа; изображения, которые больше определенного минимального размера (например, большие изображения наиболее вероятно являются релевантными для документа); изображения формата Объединенной группы экспертов в области фотографии (JPEG) (например, нерелевантные изображения, такие как пиктограммы и логотипы имеют тенденцию быть представленными в других форматах, таких как форматы переносимой сетевой графики (PNG) и формата обмена графическими данными (GIF)); и изображения, которые проистекают из того же источника, что и документ (например, рекламные изображения часто импортируются из внешних источников). Нерелевантные изображения, могут включать в себя, например, пиктограммы, логотипы, элементы навигации, рекламные изображения, или подобное.
В одном варианте осуществления, методика выставления баллов является взвешенной методикой, где весовые коэффициенты основаны на различных признаках изображения. Эти признаки могут включать в себя метаданные, касающиеся изображений, как впрочем, и содержимое изображения (например, полученное посредством методики обработки изображения). Например, признаки могут включать в себя: является ли заданное изображение правильного размера, или в каком типе формата сохранено изображение. Затем линейная комбинация весовых коэффициентов суммируется и масштабируется (например, в масштабе от 0 до единицы). Например, один взвешенный алгоритм для выставления баллов изображению может быть определен следующим образом:
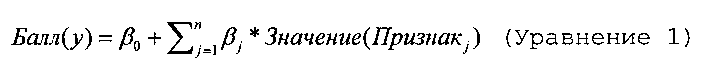
В случае Уравнения 1, признак изображения обозначается как j (j={1,…,n}), и балл изображения равен постоянному весовому коэффициенту, β0, добавленному к сумме произведения каждого весового коэффициента признака, βj, и значения. В целом, блок 208 извлечения рассматривает каждый признак либо как присутствующий (и в этом случае значение равно единице), либо как отсутствующий (и в этом случае значение равно 0). Тем не менее, в одном варианте осуществления, где Уравнение 1 используется при аннотировании содержимого, значением признака является число, отражающее то, сколько раз признак возникает в документе.
На этапе 318 блок 208 извлечения выводит (например, на блок 210 классификации) извлеченный текст и x изображений с наибольшим баллом (в одном варианте осуществления, x=3). В одном варианте осуществления x изображений с наибольшим баллом должны иметь баллы выше определенного порогового значения, θ (в одном варианте осуществления, θ=0,67), для того чтобы быть выведенными блоком 208 извлечения. В одном варианте осуществления, баллы для x изображений с наибольшим баллом также выводятся блоком 208 извлечения.
Затем способ 300 завершается на этапе 320.
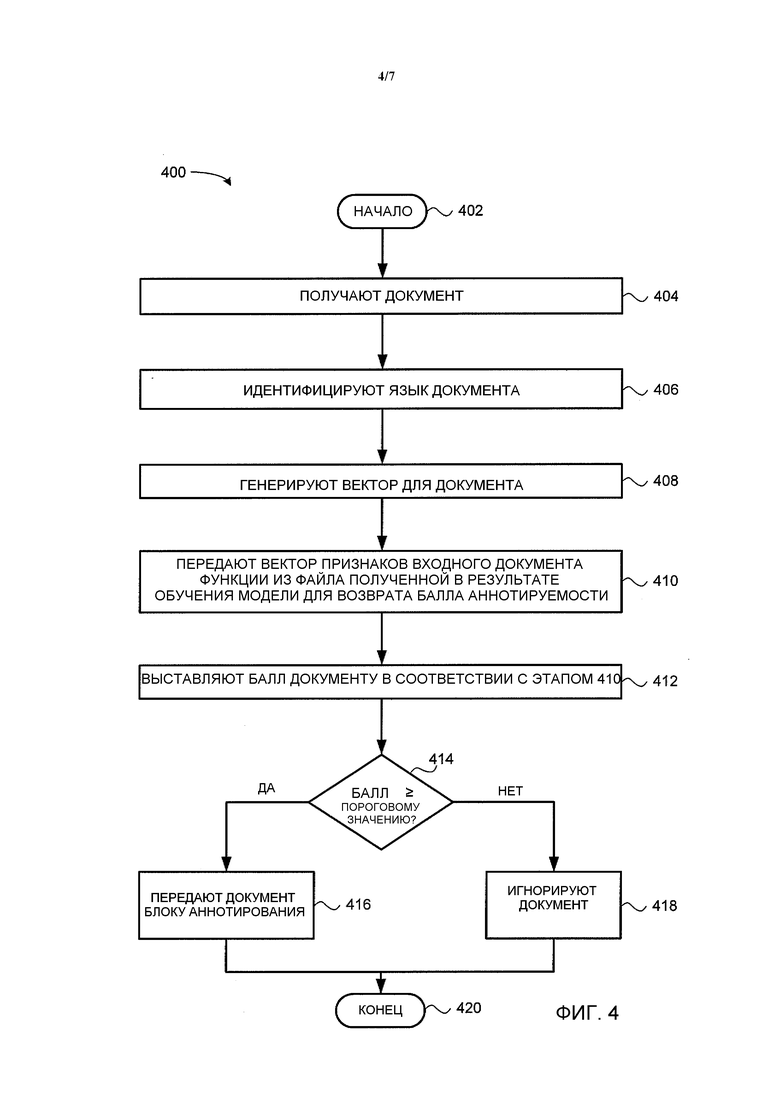
Фиг. 4 является блок-схемой, иллюстрирующей один вариант осуществления способа 400 определения того, может ли электронный документ быть аннотирован, в соответствии с настоящим изобретением. Способ 400 может быть реализован, например, на сервере 104 приложений, иллюстрируемом на Фиг. 1 и 2. По существу, при рассмотрении способа 400 упоминаются различные элементы, иллюстрируемые на Фиг. 2. Тем не менее, следует иметь в виду, что способ 400 не ограничивается реализацией с помощью конфигурации сервера, иллюстрируемой на Фиг. 2, и что такое упоминание главным образом выполняется, чтобы способствовать объяснению.
Способ 400 начинается с этапа 402. На этапе 404 блок 210 классификации получает электронный документ (например, от шины 204). На этапе 406 блок 210 классификации идентифицирует язык документа. В одном варианте осуществления язык определяется, принимая во внимание код языка или идентификатор, связанный с документом. Тем не менее, в альтернативном варианте осуществления блок 210 классификации дополнительно включает в себя компонент идентификации языка, который идентифицирует язык путем анализа содержимого документа. В одном варианте осуществления настоящее изобретение является независимым от языка, что означает, что раскрываемые здесь системы и способы (такие как оставшиеся этапы способа 400) применимы независимо от языка, на котором написан исходный документ.
На этапе 408 блок 210 классификации формирует вектор признаков для документа. В одном варианте осуществления векторы признаков разработаны таким образом, чтобы быть устойчивыми к вариациям языка, жанру, длине документа и подобному и включают в себя счетчики признаков (например, для букв, цифр, букв прописных и строчных, символов пробела и знаков пунктуации, слов, наиболее употребляемых m слов, наиболее употребляемых y знаков, уникальных слов, и т.д.)
На этапе 410 блок 210 классификации передает вектор признаков документа в функцию для идентифицированного языка, хранящуюся в (скомпилированном) файле «модели», для того чтобы получить балл аннотируемости. В одном варианте осуществления хранящаяся функция имеет вид Уравнения 1, где y теперь представляет собой балл аннотируемости документа, а примерными признаками являются признаки, описанные выше в связи с этапом 408. Весовые коэффициенты β изучаются автоматически во время фазы обучения блока классификации, перед развертыванием системы. Например, в программе машинного обучения, положительные примеры обучения (например, в папке документов с возможностью аннотирования) приводят к повышению весовых коэффициентов для признаков, которые относительно распространены (например, возникают, по меньшей мере, с определенной частотой) в положительных примерах, тогда как отрицательные примеры обучения (например, в папке неаннотируемых документов) приводят к понижению весовых коэффициентов для признаков, которые относительно распространены (например, возникают, по меньшей мере, с определенной частотой) в отрицательных примерах. В одном варианте осуществления, блок классификации хранит множество папок для каждого языка, который сервер 104 приложений может обработать. Первая папка содержит множество примерных документов, которые могут быть аннотированы (т.е. положительные примеры обучения, как рассмотрено выше), тогда как вторая папка содержит множество примерных документов, которые не могут быть аннотированы (т.е. отрицательные примеры обучения, как рассмотрено выше). В одном варианте осуществления, типы документов, которые не могут быть аннотированы, включают в себя: письма редактору, статьи редакционного мнения и художественные произведения; другие типы документов являются потенциально с возможностью представления в виде аннотации.
На этапе 412 блок 210 классификации выставляет баллы документу в соответствии с вычислением, выполненным на этапе 410. В одном варианте осуществления, вектор признаков, построенный из входного документа, передается в функцию, основанную на Уравнении 1, чьи коэффициенты изучены автоматически во время обучающей фазы предварительного развертывания, как рассмотрено выше.
На этапе 414 классификатор 210 определяет, является ли балл документа (как сгенерировано на этапе 412) большим или равным определенному пороговому значению. Если блок 210 классификации решает на этапе 414, что балл документа больше или равен пороговому значению, тогда это указывает на то, что документ может быть аннотирован. Раз так, то способ 400 переходит к этапу 416, и блок 210 классификации передает документ в блок 212 аннотирования для аннотирования.
В качестве альтернативы, если блок 210 классификации решает на этапе 414, что балл документа меньше порогового значения, тогда это указывает на то, что документ не может быть аннотирован. Раз так, то способ 400 переходит к этапу 418, и документ игнорируется.
Как только документ либо был передан блоку аннотирования (в соответствии с этапом 416) или проигнорирован (в соответствии с этапом 418), способ 400 завершается на этапе 420.
Как рассмотрено выше, блок 210 классификации использует модель, полученную в результате обучения по примерным документам, чтобы взвешивать признаки вектора признаков документа. В одном варианте осуществления, примерные документы могут быть промаркированы оператором-человеком как аннотируемые или как неаннотируемые. В альтернативном варианте осуществления, маркирование самонастраивается либо посредством использования предварительно существующих корпусов текста, которые были промаркированы для некоторой другой задачи, либо посредством использования статистики по непромаркированной коллекции документов, для того чтобы определить, является или нет заданный документ в коллекции с аннотируемым. В последнем случае, релевантной статистикой может быть, например, длина текста (например, где документы, которые слишком короткие или слишком длинные относительно распределения длинны, могут быть промаркированы как не являющиеся аннотируемыми). Как также рассматривалось выше, блок 210 классификации может использовать множество моделей для разных языков.
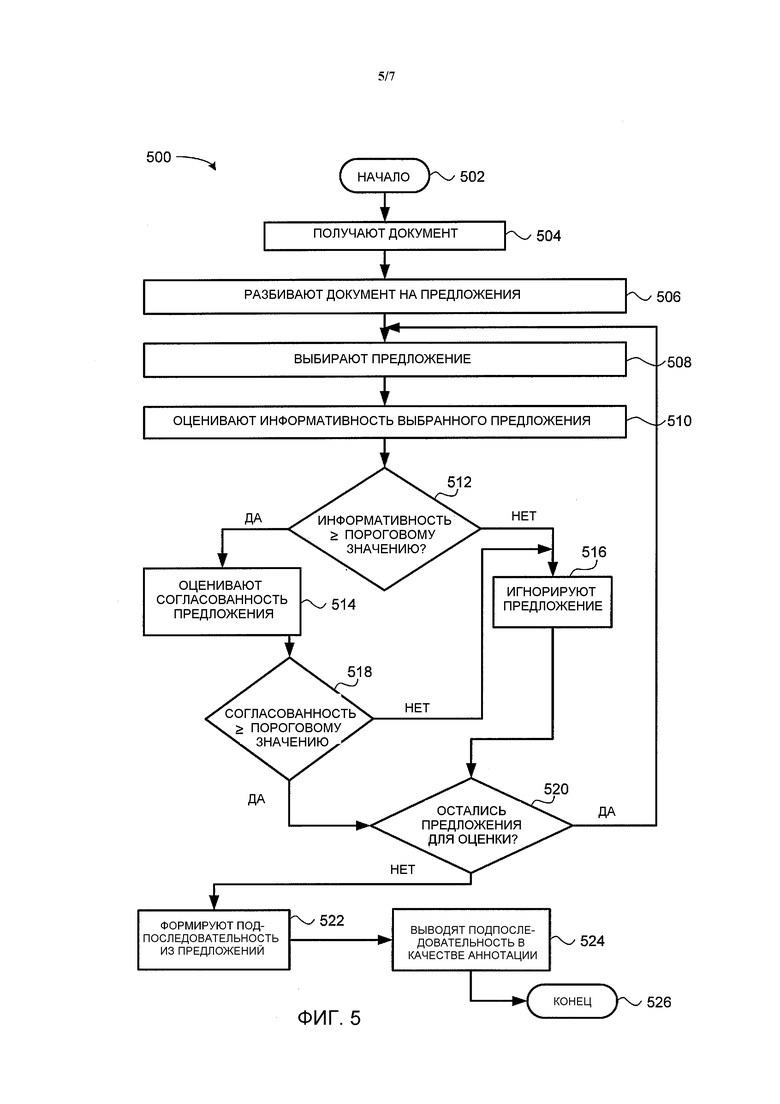
Фиг. 5 является блок-схемой, иллюстрирующей один вариант осуществления способа 500 аннотирования электронного документа, в соответствии с настоящим изобретением. Способ 500 может быть реализован, например, на сервере 104 приложений, иллюстрируемом на Фиг. 1 и 2. По существу, при рассмотрении способа 500 упоминаются различные элементы, иллюстрируемые на Фиг. 2. Тем не менее, следует иметь в виду, что способ 500 не ограничивается реализацией с помощью конфигурации сервера, иллюстрируемой на Фиг. 2, и что такое упоминание главным образом выполняется, чтобы способствовать объяснению.
Способ 500 начинается на этапе 502. На этапе 504 блок 212 аннотирования получает электронный документ (например, от шины 204).
На этапе 506 блок 212 аннотирования разбивает документ на множество предложений. Несмотря на то, что предложения используются для простоты объяснения, следует иметь в виду, что документ также может быть разбит на другие единицы текста, такие как фразы, клаузлы, абзацы или блоки, или комбинации разных типов единиц текста. В одном варианте осуществления разбиение сопровождается использованием блока разбиения на предложения, который разбивает текст на предложения (или другие единицы текста) на основании полученной в результате обучения модели языка. В дополнительном варианте осуществления блок разбиения сконфигурирован для языка, на котором написан документ.
На этапе 508 блок 212 аннотирования выбирает одно из предложений для оценки. В одном варианте осуществления, предложения оцениваются в очередности, в которой они появляются в документе.
На этапе 510 блок 212 аннотирования оценивает информативность предложения. В одном варианте осуществления, информативность оценивается в соответствии с одним из множества доступных алгоритмов. Например, в одном варианте осуществления, используются три алгоритма: (1) первый алгоритм, который всегда используется для коротких аннотаций (например, короче приблизительно 390 знаков); (2) второй алгоритм, который всегда используется для длинных аннотаций (например, которые на от тридцати трех до пятидесяти процентов длиннее коротких аннотаций) и когда требуется полученная в результате англоязычного обучения модель, основанная на эталонных аннотациях; и (3) третий неконтролируемый алгоритм, который используется во всех других случаях.
В одном варианте осуществления, первый алгоритм использует набор программируемых вручную правил, основанных на множестве независимых от языка признаков. Эти признаки могут включать в себя, например: позицию предложения внутри документа или длину предложения. В одном варианте осуществления, эти признаки трансформируются в логические признаки (например, «это предложение появляется в первых x предложениях документа?» или «длина предложения короче/длиннее у знаков?») и затем взвешиваются образом, подобным взвешиванию, рассмотренному выше со ссылкой на Уравнение 1. Выходными данными первого алгоритма является массив баллов информативности каждого предложения.
В одном варианте осуществления, второй алгоритм является методикой контролируемого машинного обучения, обучение которой осуществляется на созданных человеком эталонных аннотациях. Второй алгоритм пытается максимизировать функцию, основанную на известной метрике Ориентированное на Релевантность Дублирование для Оценки Выделения Сути (ROUGE), как раскрывается в документе под авторством Chin-Yew Lin ROUGE: A Package for Automatic Evaluation of Summaries Proceedings of the Workshop on text Summarization Branches Out (WAS 2004), Барселона, Испания, 25-26 июля 2004 г. ROUGE измеряет точность системы как функцию пропорции слов в эталонной аннотации, которые присутствуют в созданной системой аннотации, и может быть определена, как:
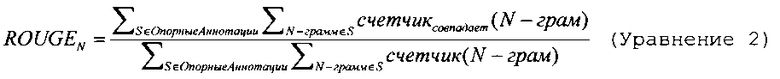
где 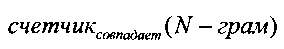 является максимальным количеством N-грам (групп из N последовательных символов), одновременно встречающихся как в эталонных, так и сгенерированных системой аннотациях, а счетчик(N-грам) является общим количеством N-грам, встречающихся в эталонных аннотациях.
является максимальным количеством N-грам (групп из N последовательных символов), одновременно встречающихся как в эталонных, так и сгенерированных системой аннотациях, а счетчик(N-грам) является общим количеством N-грам, встречающихся в эталонных аннотациях.
Второй алгоритм рассматривает каждое предложение в качестве экземпляра классификации, и затем наделяет признаками каждый экземпляр с помощью стандартного набора признаков, обычно используемых для аннотирования. В одном варианте осуществления, эти признаки включают в себя одно или более из следующего: позиция предложения внутри документа (например, посредством номера предложения и общей позиции), наличие чисел в предложении, наличие местоимений в предложении, наличие слов из заглавных букв в предложении, и размер предложения. В одном варианте осуществления, блок классификации использует обучающую последовательность, в которой предложения с наивысшими баллами ROUGE1 промаркированы как положительные (т.е. включать в аннотацию), а оставшиеся предложения промаркированы как отрицательные (т.е. не включать в аннотацию).
В одном варианте осуществления, второй алгоритм использует метод опорных векторов (SVM) в качестве статистического классификатора. SVM может быть определена в соответствии с документом под авторством Hsu и других (A Practical Guide to Support Vector Classification Department of Computer Science, National Taiwan University), как:
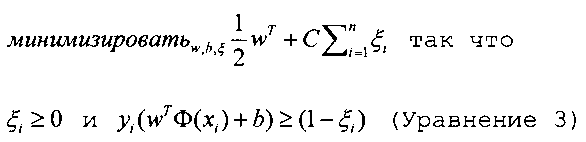
в котором каждое предложение i представлено в качестве вектора признака 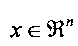 , с маркером y∈{-1,+1}n. Функция Ф отображает обучающие векторы в пространстве признаков более высокой размерности. В данном случае, w является вектором нормали к гиперплоскости, b является размером допустимого отклонения (т.е. расстоянием до ближайших обучающих примеров или вспомогательных векторов от оптимальной гиперплоскости, разделяющей положительные и отрицательные классы), С>0 является параметром регуляризации, который представляет ухудшение в виде вектора ошибок, и ξi≥0 является фиктивной переменной, которая измеряет степень ошибочной классификации х. SVM находит оптимальную гиперплоскость с максимальным допустимым отклонением в данном гиперпространстве. Выходными данными SVM является массив баллов для каждого предложения. В одном варианте осуществления полученная в результате обучения модель обеспечивается для англоязычных документов на основании данных из Конференции по Вопросам Автоматического Аннотирования (DUC).
, с маркером y∈{-1,+1}n. Функция Ф отображает обучающие векторы в пространстве признаков более высокой размерности. В данном случае, w является вектором нормали к гиперплоскости, b является размером допустимого отклонения (т.е. расстоянием до ближайших обучающих примеров или вспомогательных векторов от оптимальной гиперплоскости, разделяющей положительные и отрицательные классы), С>0 является параметром регуляризации, который представляет ухудшение в виде вектора ошибок, и ξi≥0 является фиктивной переменной, которая измеряет степень ошибочной классификации х. SVM находит оптимальную гиперплоскость с максимальным допустимым отклонением в данном гиперпространстве. Выходными данными SVM является массив баллов для каждого предложения. В одном варианте осуществления полученная в результате обучения модель обеспечивается для англоязычных документов на основании данных из Конференции по Вопросам Автоматического Аннотирования (DUC).
В одном варианте осуществления, третий алгоритм является методикой неконтролируемого машинного обучения, которая идентифицирует характерные узлы в ориентированном графе посредством случайного блуждания по графу (например, методика ранжирования страниц). В конкретном варианте осуществления, третий алгоритм рассматривает задачу выбора предложений как проблему оптимизации, основанную на графе. В частности, третий алгоритм представляет предложения в качестве узлов в ориентированном графе, и ребра между узлами связывают предложения, которые встречаются позже в документе с предложениями, которые встречаются раньше в документе. Узлы взвешиваются, и исходно взвешиваются в соответствии с позицией соответствующего предложения в документе (например, предложениям, встречающимся раньше в документе, присваивается более тяжелые весовые коэффициенты, и весовые коэффициенты уменьшаются экспоненциально по мере того, как попадаются предложения, встречающиеся позже в документе). Исходные вестовые коэффициенты регулируются на основе связей между соответствующими узлами, где весовой коэффициент wxy связи, которая соединяет узлы x и y, вычисляется как балл модифицированного косинус сходства в соответствии с:
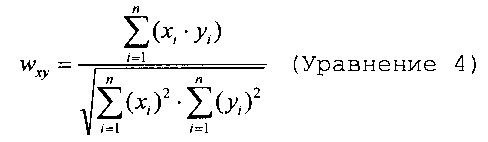
где части (например, слова) в предложении пронумерованы от 1 до n, и весовой коэффициент части i в предложении x представлен как xi. В одном варианте осуществления, весовой коэффициент части является частотой части в соответствующем предложении, деленной на количество предложений в документе, которые содержат часть.
Как рассмотрено выше, в одном варианте осуществления, третий алгоритм использует методику ранжирования страниц, которая идентифицирует характерные узлы в ориентированном графе. Одна конкретная методика ранжирования страниц, которая может быть реализована в качестве третьего алгоритма, рассматривается в документе под авторством Brin и других The Anatomy of a Large-Scale Hypertextual Websearch Engine, Computer Networks and ISDN Systems, 30, 1-7 (1998); и документе под авторством Mihalcea Graph-Based Ranking Algorithms for Sentence Extraction, Applied to Text Summarization, Proceedings of the 42nd Annual Meeting of the Association for Computational Linguistics (ACL 2004), Барселона, Испания. В одном конкретном варианте осуществления каждый узел графа взвешен на основании весовых коэффициентов входящих связей от более поздних узлов, которые указывают на рассматриваемый узел, нормируемых с помощью весовых коэффициентов исходящих связей на которые указывает рассматриваемый узел. По существу, методика ранжирования страниц используется для идентификации доминирующих узлов, получаемых при случайном блуждании. Таким образом, весовой коэффициент (или балл) узла может быть вычислен как:
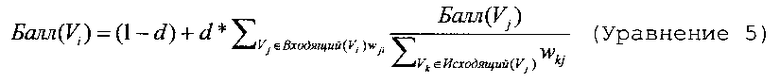
Весовые коэффициенты ребер из узла повторно нормируются для представления вероятности перехода. Выходными данными является массив баллов, один для каждого предложения. Данный подход имеет склонность придавать более высокий вес первым упоминаниям, что приводит к разбросу весовых коэффициентов по темам, где предложение, включающее в себя первое упоминание темы, рассматривается как представитель темы.
Как только предложению был выставлен балл в отношении информативности в соответствии с соответствующим алгоритмом, способ переходит к этапу 512. На этапе 512 блок 212 аннотирования определяет, является ли информативность предложения больше или равной первому определенному пороговому значению. Если блок 212 аннотирования решает на этапе 512, что информативность предложения меньше первого определенного порогового значения, тогда блок 212 аннотирования игнорирует предложение на этапе 516. Способ 500 затем переходит к этапу 520, где блок 212 аннотирования определяет, остались ли еще предложения для оценки.
В качестве альтернативы, если блок 212 аннотирования решает на этапе 512, что информативность предложения больше или равна первому определенному пороговому значению, тогда способ 500 переходит к этапу 514. На этапе 514 блок 212 аннотирования оценивает согласованность предложения; таким образом, этап 514 предназначен для сохранения читаемости каждого предложения аннотации, которая в конечном счете создается. В одном варианте осуществления, выставление баллов согласованности предложения осуществляется посредством присвоения весовых коэффициентов предложению на основании различных логических признаков, чье наличие делает предложение более или менее читаемым (например, находится ли предложение между кавычками, включает ли предложение вопрос, включает ли предложение местоимение, кажется ли что в предложении отсутствует кавычка, длина предложения, среди прочих признаков).
На этапе 518 блок 212 аннотирования определяет, является ли согласованность предложения большей или равной второму определенному пороговому значению. Если блок 212 аннотирования решает на этапе 518, что согласованность предложения меньше второго определенного порогового значения, тогда способ 500 переходит к этапу 516, и блок 212 аннотирования игнорирует предложение, как рассмотрено выше.
В качестве альтернативы, если блок 212 аннотирования решает на этапе 518, что согласованность предложения больше или равна второму определенному пороговому значению, тогда способ 500 переходит к этапу 520.
На этапе 520 блок 212 аннотирования определяет, есть ли еще предложения, оставшиеся для оценки. Если блок 212 аннотирования решает на этапе 520, что присутствуют предложения, оставшиеся для оценки, тогда способ 500 возвращается к этапу 508, и блок 212 аннотирования переходит, как описано выше, к выбору и оценке следующего предложения из документа.
В качестве альтернативы, если блок 212 аннотирования решает на этапе 520, что отсутствуют предложения, оставшиеся для оценки, тогда способ 500 переходит к этапу 522. В другом варианте осуществления, могут присутствовать предложения, которые не были оценены, но блок 212 аннотирования может принять решение о том, чтобы не оценивать дальше документ в любом случае (например, блок аннотирования может уже получить достаточное количество предложений) и просто продолжить. На этапе 522 блок 212 аннотирования генерирует подпоследовательность усеченных предложений. В одном варианте осуществления, подпоследовательность генерируется, используя блок комбинаторной оптимизации.
В одном варианте осуществления, блок комбинаторной оптимизации использует методику динамического программирования, которая решает классическую задачу о ранце 0/1, как утверждается в документе под авторством Goddard «Dynamic Programming: 0-1 Knapsack Problem (2012, www.cse.unl.edu/~goddard/Courses/ CSCE310J), которая определяется следующим образом: для заданного набора из i элементов, где каждый элемент имеет весовой коэффициент и значение определяют, какие элементы поместить в ранец таким образом, чтобы весовой коэффициент был меньше или равен пределу и таким образом, чтобы суммарное значение было максимальным. Сформулированная с точки зрения аннотирования, проблема может быть выражена следующим образом:
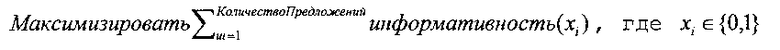 таким образом, чтобы
таким образом, чтобы 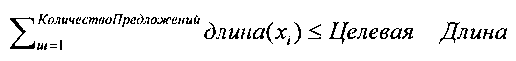 (Уравнение 6)
(Уравнение 6)
При помощи стандартного решения динамического программирования для задачи о ранце 0/1, наиболее информативная подпоследовательность из предложений с 1 по i, которая имеет общую длину p, будет либо содержать предложение i, или она не будет содержать предложение i. Если длина предложения i больше p, тогда предложение i исключается, и блок 212 аннотирования выбирает наиболее информативную подпоследовательность из предложений с 1 по i-1. В противном случае, значением наиболее информативной подпоследовательности из предложений с 1 по i является максимум из двух чисел: (1) значение наиболее информативной подпоследовательности предложения с 1 по i-1, общая длина которой равна p; и сумма (а)+(b), где а является значением наиболее информативной подпоследовательности из предложений с 1 по i-1, общая длина которой равна p-длина(предложение i), и b является информативностью предложения i. Если условие (2) больше, тогда предложение i выбирается для включения в аннотацию; в противном случае, предложение i не выбирается.
Таким образом, при аннотировании, блоку оптимизации на этапе 522 предоставляется целевая длина подпоследовательности, наряду со всеми усеченными предложениями и их баллами информативности. Блок оптимизации затем возвращает наилучшую подпоследовательность предложений на основании целевой длины и информативности предложений. В одном варианте осуществления, очередность предложений в подпоследовательности соответствует очередности, в которой они появляются в документе.
На этапе 524 блок 212 аннотирования выводит подпоследовательность в качестве аннотации к документу (например, на оконечное устройство 108, 110, 112 или 114 пользователя, либо в базу 106 данных). Способ 500 затем завершается на этапе 526.
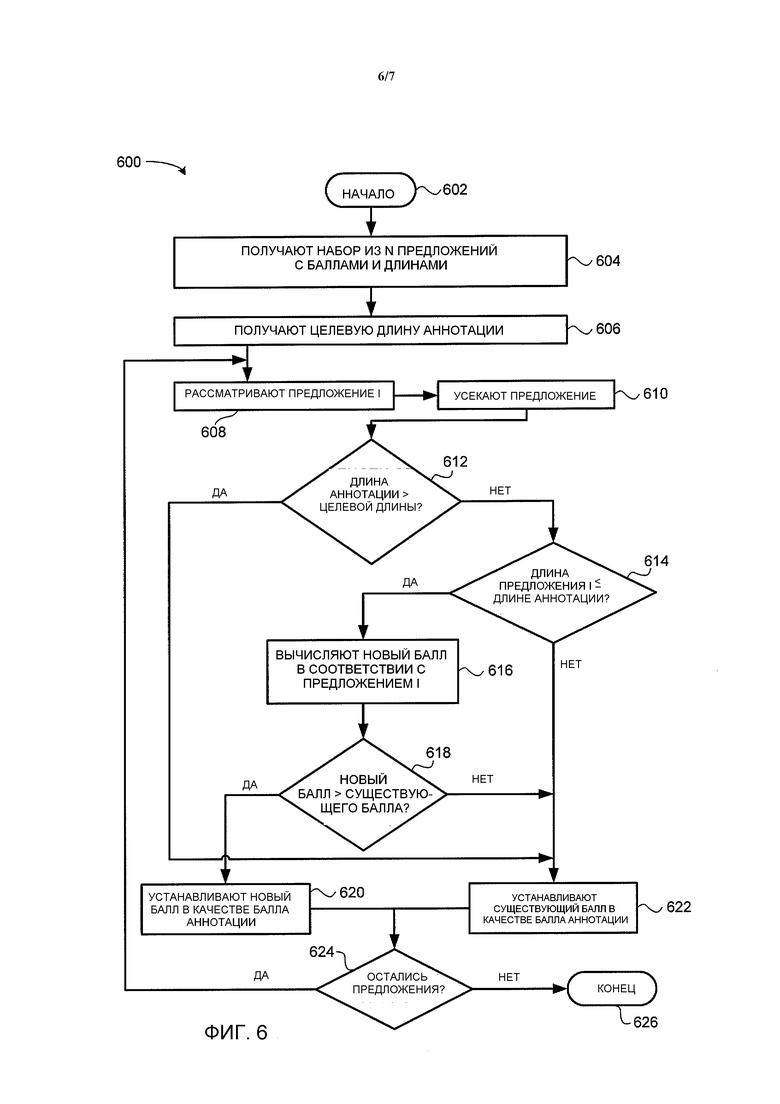
Фиг. 6 является блок-схемой, иллюстрирующей один вариант осуществления способа 600 выбора набора предложений для формирования аннотации к документу, в соответствии с настоящим изобретением. Способ 600 может быть реализован, например, в соответствии с этапом 522 способа 500 и на сервере 104 приложений, иллюстрируемом на Фиг. 1 и 2. По существу, при рассмотрении способа 600 упоминаются различные элементы, иллюстрируемые на Фиг. 2. Тем не менее, следует иметь в виду, что способ 600 не ограничивается реализацией с помощью конфигурации сервера, иллюстрируемой на Фиг. 2, и что такое упоминание главным образом выполняется, чтобы способствовать объяснению.
Способ 600 строит аннотацию по мере того, как он оценивает набор предложений предложение за предложением. Таким образом, аннотация может развиваться и меняться по мере того, как способ 600 проделывает свою работу над набором предложений.
Способ 600 начинается на этапе 602. На этапе 604 блок 212 аннотирования получает набор из N предложений, где каждое предложение было обработано в соответствии со способом 500, как описано выше. В дополнение, каждое предложение связано с баллом информативности, как описано выше, и длиной предложения.
На этапе 606 блок 212 аннотирования получает целевую длину аннотации. Целевая длина может быть длиной по умолчанию или может быть определена пользователем.
На этапе 608 блок 212 аннотирования рассматривает предложение i из набора из N предложений. В одном варианте осуществления, предложения выбираются из набора в очередности, в которой они появляются в исходном документе.
На этапе 610 блок 212 аннотирования усекает предложение. В одном варианте осуществления, усечение предложения задействует одно или более сокращений, которые исключают материал из предложений. В одном варианте осуществления, некоторые типы материала могут быть исключены или сокращены независимо от языка, на котором написано предложение (например, строки данных, префиксы жирного шрифта, материал, заключенный в скобки). Предложение усекается таким образом, чтобы не повлиять на согласованность предложения, несмотря на то, что усечение может повлиять на информативность предложения.
В другом варианте осуществления, некоторые типы материала, которые могут быть исключены или сокращены, являются специфичными для конкретных языков. Например, в одном специфичном для английского языка варианте осуществления, этап 610 может задействовать удаление англоязычного понятия «который» (which is). В качестве альтернативы, этап 610 может задействовать замену англоязычного понятия «который имеет» (which have) на англоязычное понятие «с» (with), или замену понятия «который [глагол]» на «[глагол]щий» (например, «который идет», становится «идущий»). В дополнительном варианте осуществления, этап 610 может задействовать понижение согласованности пары англоязычных клаузул с перекрестно ссылающимися объектами до их пар глаголов (например, «Вредоносная компьютерная программа разрушала данные в течение периода в пять месяцев, и программа инфицировала почти сто компьютеров» становится «Вредоносная компьютерная программа разрушала данные в течение периода в пять месяцев, и инфицировала почти сто компьютеров»). В еще одном дополнительном варианте осуществления, этап 610 может задействовать предположение перекрестно ссылающегося компонента, который разрешает ссылки на именные группы, местоимения и/или имена собственные.
На этапе 612 блок 212 аннотирования определяет, является ли текущая длинна аннотации больше целевой длины. Если блок 212 аннотирования решает на этапе 612, что текущая длина аннотации больше целевой длины, тогда блок 212 аннотирования устанавливает существующий балл в качестве балла аннотации на этапе 622, и предложение i не включается в аннотацию. В одном варианте осуществления, балл инициализируется в начале способа 600 как равный нулю и увеличивается в соответствии с баллами предложений, которые выбираются для включения в аннотацию.
Альтернативно, если блок 212 аннотирования решает на этапе 612, что текущая длина аннотации не больше целевой длинны, тогда способ 600 переходит к этапу 614. На этапе 614 блок 212 аннотирования определяет, является ли длина выбранного предложения i меньшей или равной длине текущей аннотации. В одном варианте осуществления, аннотация инициализируется в качестве пустого набора, состав которого увеличивается по мере того, как предложения выбираются для включения в аннотацию.
Если блок 212 аннотирования решает на этапе 614, что длина выбранного предложения i больше длины текущей аннотации, тогда блок 212 аннотирования устанавливает существующий балл в качестве балла аннотации на этапе 622, и предложение i не включается в аннотацию, как рассматривается выше.
В качестве альтернативы, если блок 212 аннотирования решает на этапе 614, что длина выбранного предложения i меньше или равна длине текущей аннотации, то способ 600 переходит к этапу 616. На этапе 616, блок 212 аннотирования вычисляет новый балл для аннотации, который учитывает включение предложения i. Как рассматривается выше, новый балл является максимальным из двух чисел: (1) значения наиболее информативной подпоследовательности из предложений с 1 по i-1, общая длина которой равна p; и (2) суммы (а)+(b), где а является значением наиболее информативной подпоследовательности из предложений с 1 по i-1, общая длина которой равна p-длина (предложения i), a b является информативностью предложения i. В одном варианте осуществления, если предложение не было усечено, то балл (b) информативности предложения был уже вычислен блоком 212 аннотирования (например, в соответствии со способом 500).
На этапе 618 блок 212 аннотирования определяет, больше ли новый балл существующего балла. Если блок 212 аннотирования решает на этапе 618, что новый балл не больше существующего балла, тогда блок 212 аннотирования устанавливает существующий балл в качестве балла аннотации на этапе 622, и предложение i не включается в аннотацию, как рассматривается выше.
В качестве альтернативы, если блок 212 аннотирования решает на этапе 618, что новый балл больше существующего балла, тогда блок аннотирования устанавливает новый балл в качестве балла аннотации на этапе 620. В данном случае, предложение i может быть включено в аннотацию. Если предложение i является первым предложением, которое будет добавлено в аннотацию, тогда предложение i включается безусловно. Если предложение i не является первым предложением, которое будет добавлено в аннотацию, тогда в одном варианте осуществления, предложение i включается безусловно. Тем не менее, в другом варианте осуществления, предложение i включается, если оно относится к аннотации, которая составлена до этого. Относится ли предложение i к аннотации, может определяться посредством вычисления наложения слов, содержащихся в предложении i, со словами, содержащимися в составленной до этого аннотации, и определения того, удовлетворяет ли наложение пороговому значению.
Как только балл аннотации был установлен в соответствии либо с этапом 620, либо этапом 622, способ 600 переходит к этапу 624, и блок аннотирования определяет, есть ли еще предложения в наборе из N предложений, оставшиеся для оценки. Если блок 212 аннотирования решает на этапе 624, что есть еще предложения, оставшиеся для оценки, тогда способ 600 возвращается к этапу 608, и блок 212 аннотирования рассматривает новое предложение для оценки, как рассматривается выше.
В качестве альтернативы, если блок 212 аннотирования решает на этапе 624, что нет предложений оставшихся для оценки, тогда способ 600 завершается на этапе 626.
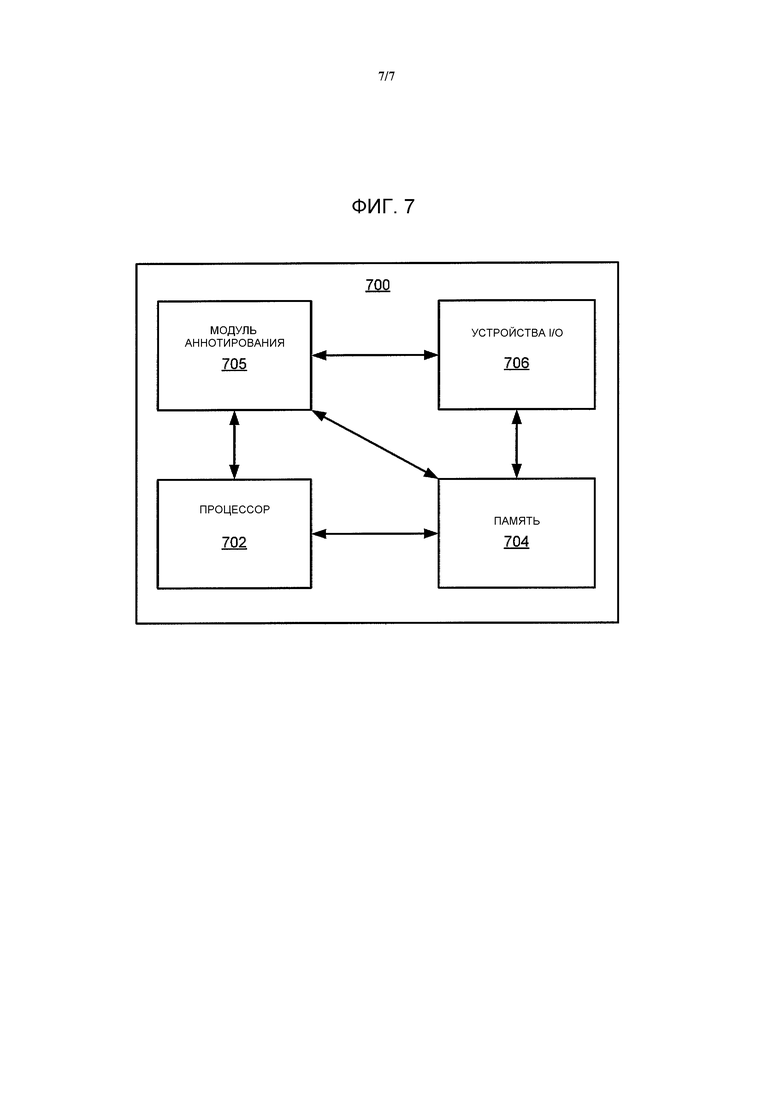
Фиг. 7 является высокоуровневой структурной схемой настоящего изобретения, реализованного при помощи вычислительного устройства 700 общего назначения. В одном варианте осуществления, вычислительное устройство 700 общего назначения развернуто в качестве сервера приложений, такого как AS 104, иллюстрируемый на Фиг. 1. Следует понимать, что варианты осуществления изобретения могут быть реализованы в качестве физического устройства или подсистемы, которая соединена с процессором посредством канала связи. Вследствие этого, в одном варианте осуществления, вычислительное устройство 700 общего назначения содержит процессор 702, память 704, модуль 705 аннотирования, и различные устройства 706 ввода/вывода (I/O), такие как дисплей, клавиатура, манипулятор типа мышь, модем, микрофон, громкоговорители, сенсорный экран, адаптируемое устройство I/O и подобное. В одном варианте осуществления, по меньшей мере, одно устройство I/O является запоминающим устройством (например, дисковым накопителем, накопителем на оптическом диске, накопителем на гибком диске).
В качестве альтернативы, варианты осуществления настоящего изобретения (например, модуль 705 аннотирования) могут быть представлены посредством одного или более приложений программного обеспечения (или даже комбинации программного и аппаратного обеспечения, например, используя Проблемно Ориентированные Интегральные Микросхемы (ASIC)), где программное обеспечение загружается с запоминающего носителя информации (например, устройств 706 I/O) и исполняется процессором 702 в памяти 704 вычислительного устройства 700 общего назначения. Таким образом, в одном варианте осуществления, модуль 705 аннотирования для описываемого здесь автоматического аннотирования электронного документа со ссылкой на предшествующие Фигуры, может храниться на не временном машиночитаемом носителе информации (например, RAM, магнитном или оптическом накопителе или дискете, и подобном).
Следует отметить, что несмотря на то, что явным образом не указано, один или более этапы описываемых здесь способов могут включать в себя этап сохранения, отображения и/или вывода, как того требуется для конкретного применения. Другими словами, любые данные, записи, поля, и/или промежуточные результаты, рассмотренные в способах, могут быть сохранены, отображены, и/или выведены на другое устройство, как того требуется для конкретного применения. Кроме того, для этапов или блоков на сопроводительных Фигурах, в которых размещаются операция определения или задействуют принятие решения, не обязательно требуется, чтобы на практике были реализованы обе ветви операции определения. Другими словами, одна из ветвей операции определения может быть считаться опциональным этапом.
Несмотря на то, что здесь были показаны и описаны подробно различные варианты осуществления, которые включают в себя идеи настоящего изобретения, специалистам в соответствующей области будут легко очевидны многие другие измененные варианты осуществления, которые также включают в себя эти идеи.
Изобретение относится к средствам аннотирования электронного документа. Технический результат заключается в повышении релевантности нахождения документов. Генерируют вектор признаков для электронного документа, при этом вектор признаков содержит множество признаков электронного документа. Присваивают весовой коэффициент каждому из множества признаков. Назначают балл аннотируемости электронному документу в соответствии с весовым коэффициентом, присвоенным каждому из множества признаков, при этом балл аннотируемости указывает, является ли электронный документ аннотируемым. Определяют, что электронный документ является аннотируемым. Разбивают электронный документ на множество частей, при этом каждая из множества частей связана с соответствующей длиной, соответствующим баллом информативности и соответствующим баллом согласованности. Автоматически выбирают подмножество из множества частей таким образом, что совокупный балл информативности этого подмножества является максимальным, тогда как совокупная длина данного подмножества меньше или равна максимальной длине. Компонуют упомянутое подмножество в качестве аннотации к электронному документу. 3 н. и 20 з.п. ф-лы, 7 ил.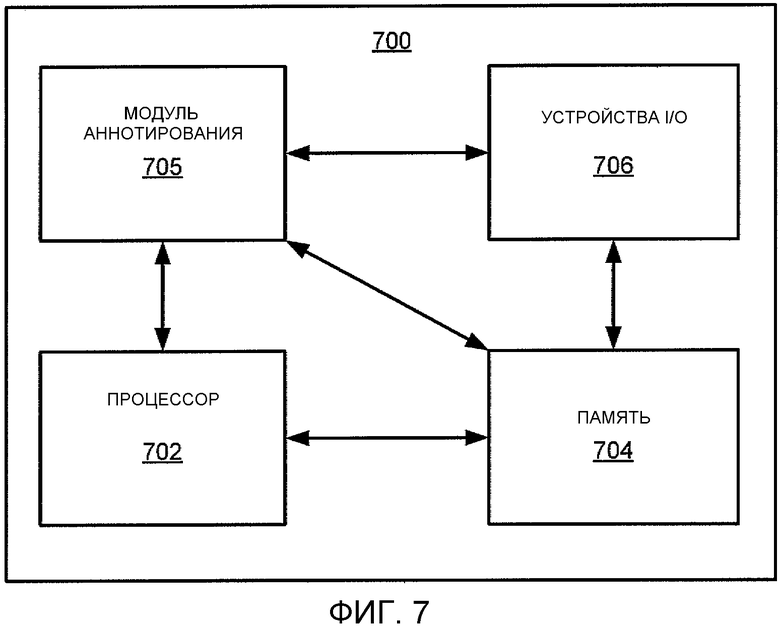
1. Способ аннотирования электронного документа, содержащий этапы, на которых:
генерируют вектор признаков для электронного документа, при этом вектор признаков содержит множество признаков электронного документа;
присваивают весовой коэффициент каждому из множества признаков;
назначают балл аннотируемости электронному документу в соответствии с весовым коэффициентом, присвоенным каждому из множества признаков, при этом балл аннотируемости указывает, является ли электронный документ аннотируемым;
определяют, что электронный документ является аннотируемым;
разбивают электронный документ на множество частей, при этом каждая из множества частей связана с соответствующей длиной, соответствующим баллом информативности и соответствующим баллом согласованности;
автоматически выбирают подмножество из множества частей таким образом, что совокупный балл информативности этого подмножества является максимальным, тогда как совокупная длина данного подмножества меньше или равна максимальной длине; и
компонуют упомянутое подмножество в качестве аннотации к электронному документу.
2. Способ по п. 1, в котором упомянутое подмножество содержит меньше, чем все из множества частей.
3. Способ по п. 1, в котором по меньшей мере одна из частей представляет собой предложение.
4. Способ по п. 1, в котором соответствующий балл информативности для заданной части из множества частей присваивается в соответствии с методикой выставления баллов, которая является независимой от языка.
5. Способ по п. 4, в котором методика выставления баллов присваивает весовые коэффициенты множеству признаков заданной части в соответствии с набором программируемых вручную правил.
6. Способ по п. 1, в котором соответствующий балл информативности для заданной части из множества частей присваивается в соответствии с методикой выставления баллов, которая является зависимой от языка.
7. Способ по п. 6, в котором методика выставления баллов является методикой контролируемого машинного обучения, которая использует статистический классификатор.
8. Способ по п. 7, в котором статистический классификатор соответствует методу опорных векторов.
9. Способ по п. 6, в котором методика выставления баллов является методикой неконтролируемого машинного обучения, которая представляет заданную часть в качестве взвешенного узла в ориентированном графе.
10. Способ по п. 1, в котором соответствующий балл информативности для каждой из множества частей является, по меньшей мере, равным пороговому значению.
11. Способ по п. 1, в котором соответствующие баллы согласованности каждой из множества частей являются, по меньшей мере, равными пороговому значению.
12. Способ по п. 1, дополнительно содержащий этап, на котором усекают каждую из множества частей вслед за этапом разбиения, но перед этапом автоматического выбора.
13. Способ по п. 1, в котором этап автоматического выбора выполняется при помощи блока комбинаторной оптимизации.
14. Способ по п. 1, в котором этап автоматического выбора содержит этап, на котором оценивают каждую из множества частей по отдельности для включения в упомянутое подмножество.
15. Способ по п. 14, в котором этап оценивания содержит этап, на котором исключают из включения в упомянутое подмножество те из множества частей, соответствующие длины которых превышают текущую совокупную длину упомянутого подмножества.
16. Способ по п. 14, в котором этап оценивания содержит, для заданной части из множества частей, этапы, на которых:
вычисляют первую сумму, при этом первая сумма является суммой соответствующих баллов информативности, связанных с наиболее информативным подмножеством из множества частей, которое исключает заданную часть и имеет совокупную длину, меньшую или равную максимальной длине; и
вычисляют вторую сумму, при этом вторая сумма является суммой первого значения и второго значения, причем первое значение равно первой сумме минус соответствующая длина заданной части, а второе значение является соответствующим баллом информативности заданной части; и
определяют, включить ли заданную часть в упомянутое подмножество, на основе сравнения первой суммы и второй суммы.
17. Способ по п. 16, в котором этап определения содержит этапы, на которых:
включают заданную часть в упомянутое подмножество, когда вторая сумма больше первой суммы; и
исключают заданную часть из данного подмножества, когда первая сумма больше второй суммы.
18. Способ по п. 1, в котором множество частей компонуется в соответствии с очередностью, в которой каждая из множества частей появляется в электронном документе.
19. Способ по п. 1, в котором весовой коэффициент выясняется автоматически.
20. Способ по п. 19, в котором этап присваивания весового коэффициента содержит, для заданного признака из множества признаков, этапы, на которых:
повышают весовой коэффициент, когда заданный признак возникает, по меньшей мере, с определенной частотой в наборе обучающих примеров, содержащих документы, которые являются аннотируемыми; и
понижают весовой коэффициент, когда заданный признак возникает, по меньшей мере, с определенной частотой в наборе обучающих примеров, содержащих документы, которые не являются аннотируемыми.
21. Способ по п. 1, в котором этапы присваивания весового коэффициента и назначения балла аннотируемости выполняются таким образом, который является характерным для языка, на котором написан электронный документ.
22. Вещественный машиночитаемый носитель информации, содержащий исполняемую программу для аннотирования электронного документа, при этом программа выполняет операции, содержащие:
генерирование вектора признаков для электронного документа, при этом вектор признаков содержит множество признаков электронного документа;
присваивание весового коэффициента каждому из множества признаков;
назначение балла аннотируемости электронному документу в соответствии с весовым коэффициентом, присвоенным каждому из множества признаков, при этом балл аннотируемости указывает, является ли электронный документ аннотируемым;
определение того, что электронный документ является аннотируемым;
разбиение электронного документа на множество частей, при этом каждая из множества частей связана с соответствующей длиной, соответствующим баллом информативности и соответствующим баллом согласованности;
автоматический выбор подмножества из множества частей таким образом, что совокупный балл информативности этого подмножества является максимальным, тогда как совокупная длина данного подмножества меньше или равна максимальной длине; и
компонование упомянутого подмножества в качестве аннотации к электронному документу.
23. Система для аннотирования электронного документа, содержащая:
процессор; и
машиночитаемый носитель информации, содержащий исполняемую программу, которая предписывает процессору выполнять операции, содержащие:
генерирование вектора признаков для электронного документа, при этом вектор признаков содержит множество признаков электронного документа;
присваивание весового коэффициента каждому из множества признаков;
назначение балла аннотируемости электронному документу в соответствии с весовым коэффициентом, присвоенным каждому из множества признаков, при этом балл аннотируемости указывает, является ли электронный документ аннотируемым;
определение того, что электронный документ является аннотируемым;
разбиение электронного документа на множество частей, при этом каждая из множества частей связана с соответствующей длиной, соответствующим баллом информативности и соответствующим баллом согласованности;
автоматический выбор подмножества из множества частей таким образом, что совокупный балл информативности этого подмножества является максимальным, тогда как совокупная длина данного подмножества меньше или равна максимальной длине; и
компонование упомянутого подмножества в качестве аннотации к электронному документу.
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |
| Дроссельное устройство фурменного прибора доменной печи | 1980 |
|
SU933712A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| АННОТИРОВАНИЕ ДОКУМЕНТОВ В СОВМЕСТНО РАБОТАЮЩИХ ПРИЛОЖЕНИЯХ ДАННЫМИ В РАЗРОЗНЕННЫХ ИНФОРМАЦИОННЫХ СИСТЕМАХ | 2006 |
|
RU2427896C2 |

