ОБЛАСТЬ ТЕХНИКИ
Изобретение относится к системе и способу для генерации аудиосигнала и, в частности, к системе и способу для генерации аудиосигнала, представляющего речь пользователя, из аудиосигнала, полученного с использованием контактного датчика, например, костнопроводного или контактного микрофона.
УРОВЕНЬ ТЕХНИКИ
Мобильные устройства часто используются в акустически неблагоприятных условиях (т.е. в условиях с высоким уровнем фонового шума). Помимо проблем с тем, что пользователь мобильного устройства способен слышать удаленную сторону при осуществлении двусторонней связи, трудно получить 'чистый' (т.е. не содержащий шум или, по существу, очищенный от шума) аудиосигнал, представляющий речь пользователя. В условиях низкого отношения сигнал/шум (SNR) входного сигнала, традиционные алгоритмы обработки речи могут осуществлять шумоподавление лишь частично до того, как речевой сигнал ближней стороны (т.е. полученный микрофоном в мобильном устройстве) сможет исказиться артефактами в виде 'музыкальных тонов'.
Известно, что аудиосигналы, полученные с использованием контактного датчика, например, костнопроводного (BC) или контактного микрофона (т.е. микрофона в физическом контакте с объектом, издающим звук) относительно слабо подвержены фоновому шуму по сравнению с аудиосигналами, полученными с использованием воздухопроводного (AC) датчика, например, микрофона (т.е. микрофона, который отделен от объекта, издающего звук, воздухом), поскольку звуковые колебания, измеренные BC-микрофоном, прошли через тело пользователя, а не через воздух, как в случае нормального AC-микрофона, который, помимо улавливания полезного аудиосигнала, также воспринимает фоновый шум. Кроме того, интенсивность аудиосигналов, полученных с использованием BC-микрофона, в общем случае, гораздо выше, чем интенсивность аудиосигналов, полученных с использованием AC-микрофона. Поэтому считается, что BC-микрофоны пригодны для использования в устройствах, которые подлежат использованию в зашумленных средах. Фиг. 1 иллюстрирует свойства высокого SNR аудиосигнала, полученного с использованием BC-микрофона, по сравнению с аудиосигналом, полученным с использованием AC-микрофона в одной и той же зашумленной среде.
Однако проблема с речью, полученной с использованием BC-микрофона, состоит в том, что ее качество и разборчивость обычно гораздо ниже, чем у речи, полученной с использованием AC-микрофона. Это снижение разборчивости, в общем случае, обусловлены фильтрационными свойствами кости и ткани, которые могут сильно ослаблять высокочастотные компоненты аудиосигнала.
Качество и разборчивость речи, полученной с использованием BC-микрофона, зависит от его конкретного положения на пользователе. Чем ближе микрофон располагается к гортани и голосовым связкам в районе горла или шеи, тем выше результирующее качество и интенсивность BC-аудиосигнала. Кроме того, поскольку BC-микрофон находится в физическом контакте с объектом, издающим звук, результирующий сигнал имеет более высокое SNR по сравнению с AC-аудиосигналом, который также воспринимает фоновый шум.
Однако, хотя речь, полученная с использованием BC-микрофона, размещенного в или вокруг области шеи, будет иметь значительно более высокую интенсивность, разборчивость сигнала останется весьма низкой, что объясняется фильтрацией глоттального сигнала через кости и мягкую ткань в и вокруг области шеи и недостатком передаточной функции речевого тракта.
Характеристики аудиосигнала, полученного с использованием BC-микрофона, также зависят от корпуса BC-микрофона, т.е. его экранирования от фонового шума в среде, а также давления, прилагаемого к BC-микрофону для установления контакта с телом пользователя.
Существуют способы фильтрации или улучшении речи, нацеленные на повышение разборчивости речи, полученной от BC-микрофона, но эти способы требуют либо присутствие чистого опорного речевого сигнала для построения корректирующего фильтра для применения к аудиосигналу от BC-микрофона, либо обучение зависящих от пользователя моделей с использованием чистого аудиосигнала от AC-микрофона. В результате, эти способы не пригодны для применения в реальных условиях, где чистый опорный речевой сигнал не всегда доступен (например, в зашумленных средах), или где любой из нескольких разных пользователей может использовать конкретное устройство.
Поэтому существует необходимость в альтернативных системе и способе для генерации аудиосигнала, представляющего речь пользователя, из аудиосигнала, полученного с использованием BC-микрофона, которые можно использовать в зашумленных средах и которые не требуют от пользователя обучать алгоритм до использования.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
Согласно первому аспекту изобретения, предусмотрен способ генерации сигнала, представляющего речь пользователя, причем способ содержит этапы, на которых получают первый аудиосигнал, представляющий речь пользователя, с использованием датчика, находящегося в контакте с пользователем; получают второй аудиосигнал с использованием воздухопроводного датчика, причем второй аудиосигнал представляет речь пользователя и включает в себя шум из среды, окружающей пользователя; выявляют периоды речи в первом аудиосигнале; применяют алгоритм улучшения речи ко второму аудиосигналу для снижения шума во втором аудиосигнале, причем алгоритм улучшения речи использует выявленные периоды речи в первом аудиосигнале; корректируют первый аудиосигнал с использованием очищенного от шума второго аудиосигнала для генерации выходного аудиосигнала, представляющего речь пользователя.
Преимущество этого способа состоит в том, что, хотя очищенный от шума AC-аудиосигнал все же может содержать шум и/или артефакты, его можно использовать для улучшения частотных характеристик BC-аудиосигнала (который, в общем случае, не содержит речевых артефактов), чтобы он звучал более разборчиво.
Предпочтительно, этап выявления периодов речи в первом аудиосигнале содержит выявление частей первого аудиосигнала, где амплитуда аудиосигнала превышает пороговое значение.
Предпочтительно, этап применения алгоритма улучшения речи содержит применение спектральной обработки ко второму аудиосигналу.
В предпочтительном варианте осуществления, этап применения алгоритма улучшения речи для снижения шума во втором аудиосигнале содержит использование выявленных периодов речи в первом аудиосигнале для оценивания минимальных уровней шума в спектральной области второго аудиосигнала.
В предпочтительных вариантах осуществления, этап коррекции первого аудиосигнала содержит осуществление анализа с линейным прогнозированием на первом аудиосигнале и очищенном от шума втором аудиосигнале для построения корректирующего фильтра.
В частности, этап осуществления анализа с линейным прогнозированием предпочтительно содержит: (i) оценивание коэффициентов линейного прогнозирования для первого аудиосигнала и очищенного от шума второго аудиосигнала; (ii) использование коэффициентов линейного прогнозирования для первого аудиосигнала для генерации сигнала возбуждения для первого аудиосигнала; (iii) использование коэффициентов линейного прогнозирования для очищенного от шума второго аудиосигнала для построения огибающей в частотной области; и (iv) коррекцию сигнала возбуждения для первого аудиосигнала с использованием огибающей в частотной области.
Альтернативно, этап коррекции первого аудиосигнала содержит (i) использование долговременных спектральных способов для построения корректирующего фильтра, или (ii) использование первого аудиосигнала в качестве входного сигнала адаптивного фильтра, который минимизирует среднеквадратическую ошибку между выходным сигналом фильтра и очищенным от шума вторым аудиосигналом.
В некоторых вариантах осуществления, до этапа коррекции, способ дополнительно содержит этап применения алгоритма улучшения речи к первому аудиосигналу для снижения шума в первом аудиосигнале, причем алгоритм улучшения речи использует выявленные периоды речи в первом аудиосигнале, и этап коррекции содержит коррекцию очищенного от шума первого аудиосигнала с использованием очищенного от шума второго аудиосигнала для генерации выходного аудиосигнала, представляющего речь пользователя.
В конкретных вариантах осуществления, способ дополнительно содержит этапы, на которых получают третий аудиосигнал с использованием второго воздухопроводного датчика, причем третий аудиосигнал, представляет речь пользователя и включает в себя шум из среды, окружающей пользователя; и используют способ формирования диаграммы направленности для объединения второго аудиосигнала и третьего аудиосигнала и генерации объединенного аудиосигнала; при этом этап применения алгоритма улучшения речи содержит применение алгоритма улучшения речи к объединенному аудиосигналу для снижения шума в объединенном аудиосигнале, причем алгоритм улучшения речи использует выявленные периоды речи в первом аудиосигнале.
В конкретных вариантах осуществления, способ дополнительно содержит этапы, на которых получают четвертый аудиосигнал, представляющий речь пользователя, с использованием второго датчика, находящегося в контакте с пользователем; и используют способ формирования диаграммы направленности для объединения первого аудиосигнала и четвертого аудиосигнала и генерации второго объединенного аудиосигнала; при этом этап выявления периодов речи содержит выявление периодов речи во втором объединенном аудиосигнале.
Согласно второму аспекту изобретения, предусмотрено устройство для использования при генерации аудиосигнала, представляющего речь пользователя, причем устройство содержит схему обработки, которая сконфигурирована для приема первого аудиосигнала, представляющего речь пользователя, от датчика, находящегося в контакте с пользователем; приема второго аудиосигнала от воздухопроводного датчика, причем второй аудиосигнал, представляет речь пользователя и включает в себя шум из среды, окружающей пользователя; выявления периодов речи в первом аудиосигнале; применения алгоритма улучшения речи ко второму аудиосигналу для снижения шума во втором аудиосигнале, причем алгоритм улучшения речи использует выявленные периоды речи в первом аудиосигнале; и коррекции первого аудиосигнала с использованием очищенного от шума второго аудиосигнала для генерации выходного аудиосигнала, представляющего речь пользователя.
В предпочтительных вариантах осуществления, схема обработки сконфигурирована для коррекции первого аудиосигнала путем осуществления анализа с линейным прогнозированием на первом аудиосигнале и очищенном от шума втором аудиосигнале для построения корректирующего фильтра.
В предпочтительных вариантах осуществления, схема обработки сконфигурирована для осуществления анализа с линейным прогнозированием посредством: (i) оценивания коэффициентов линейного прогнозирования для первого аудиосигнала и очищенного от шума второго аудиосигнала; (ii) использования коэффициентов линейного прогнозирования для первого аудиосигнала для генерации сигнала возбуждения для первого аудиосигнала; (iii) использования коэффициентов линейного прогнозирования для очищенного от шума аудиосигнала для построения огибающей в частотной области; и (iv) коррекции сигнала возбуждения для первого аудиосигнала с использованием огибающей в частотной области.
Предпочтительно, устройство дополнительно содержит контактный датчик, который сконфигурирован контактировать с телом пользователя, когда устройство используется, и для генерации первого аудиосигнала; и воздухопроводный датчик, который сконфигурирован для генерации второго аудиосигнала.
Согласно третьему аспекту изобретения, предусмотрен компьютерный программный продукт, содержащий машиночитаемый код, который сконфигурирован таким образом, что при выполнении машиночитаемого кода подходящим компьютером или процессором, компьютер или процессор осуществляет вышеописанный способ.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Ниже будут описаны примерные варианты осуществления изобретения, исключительно в качестве примера, со ссылкой на нижеследующие чертежи, в которых:
фиг. 1 иллюстрирует свойства высокого SNR аудиосигнала, полученного с использованием BC-микрофона, по сравнению с аудиосигналом, полученным с использованием AC-микрофона в одной и той же зашумленной среде;
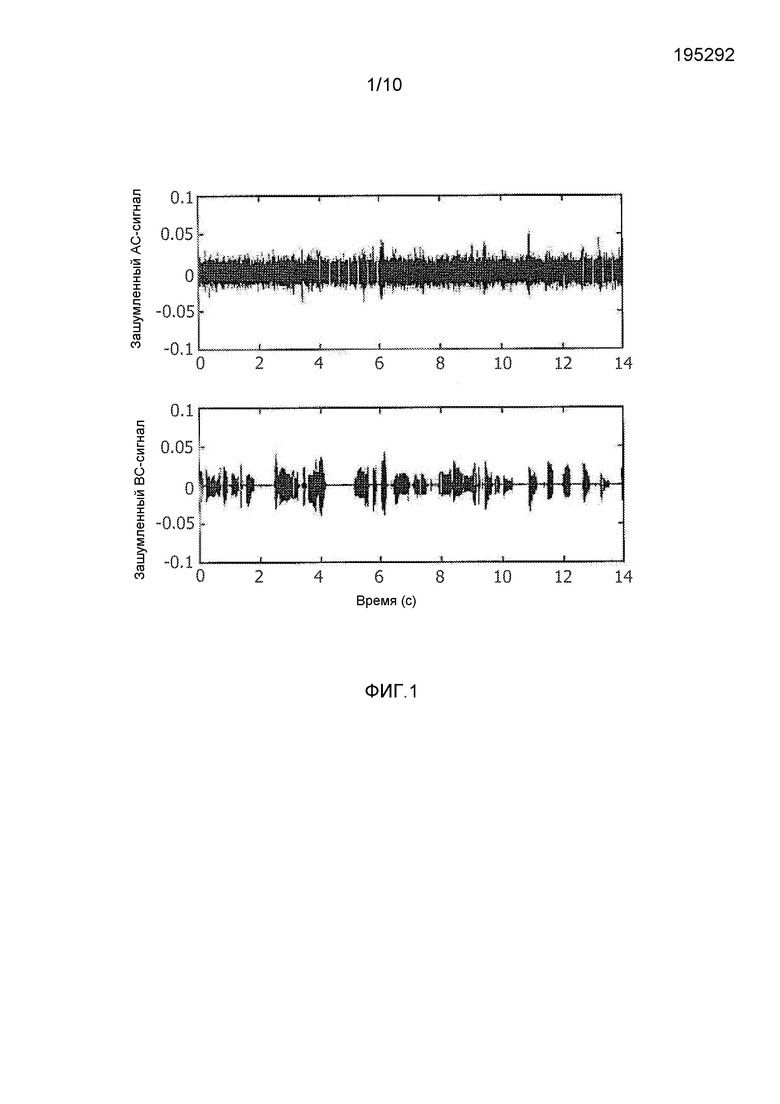
фиг. 2 - блок-схема устройства, включающего в себя схему обработки согласно первому варианту осуществления изобретения;
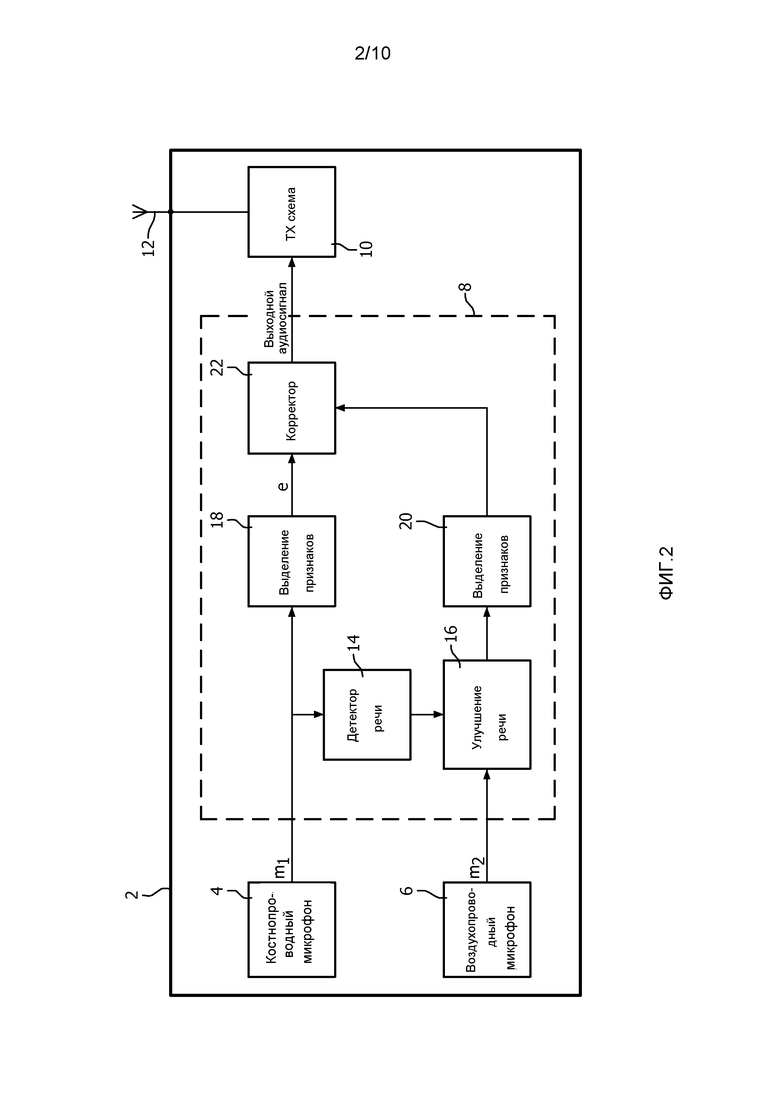
фиг. 3 - блок-схема последовательности операций способа обработки аудиосигнала от BC-микрофона согласно изобретению;
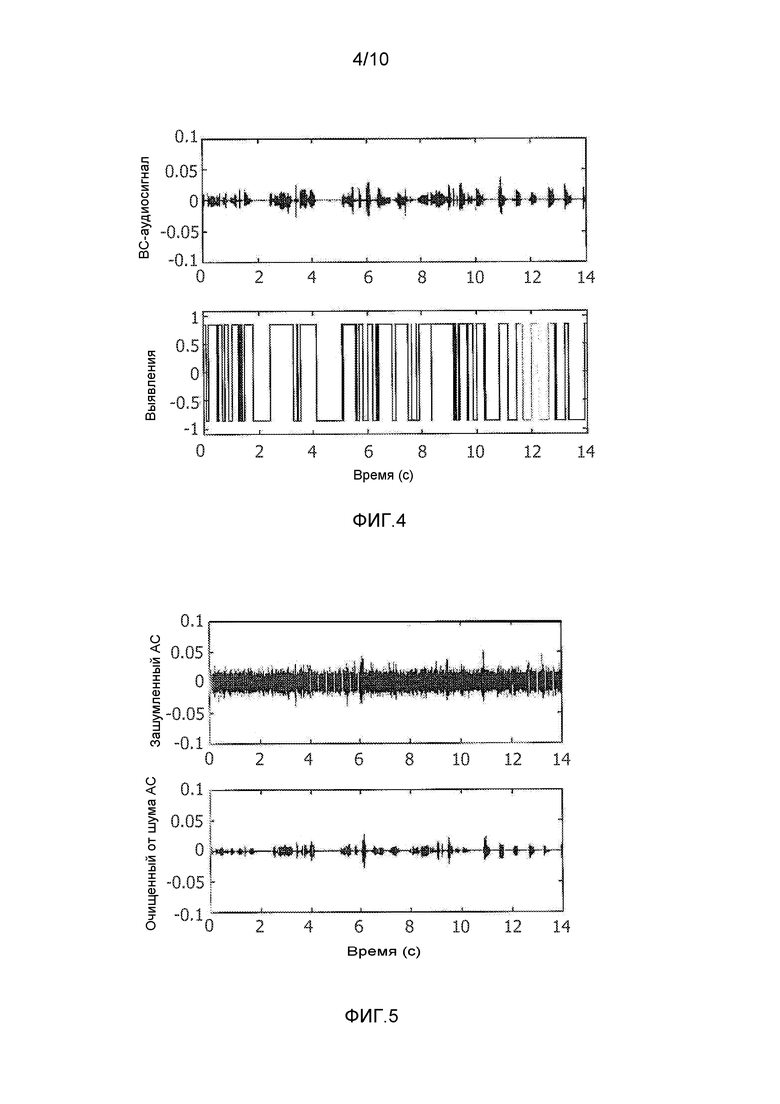
фиг. 4 - график, демонстрирующий результат выявления речи, осуществляемого на сигнале, полученном с использованием BC-микрофона;
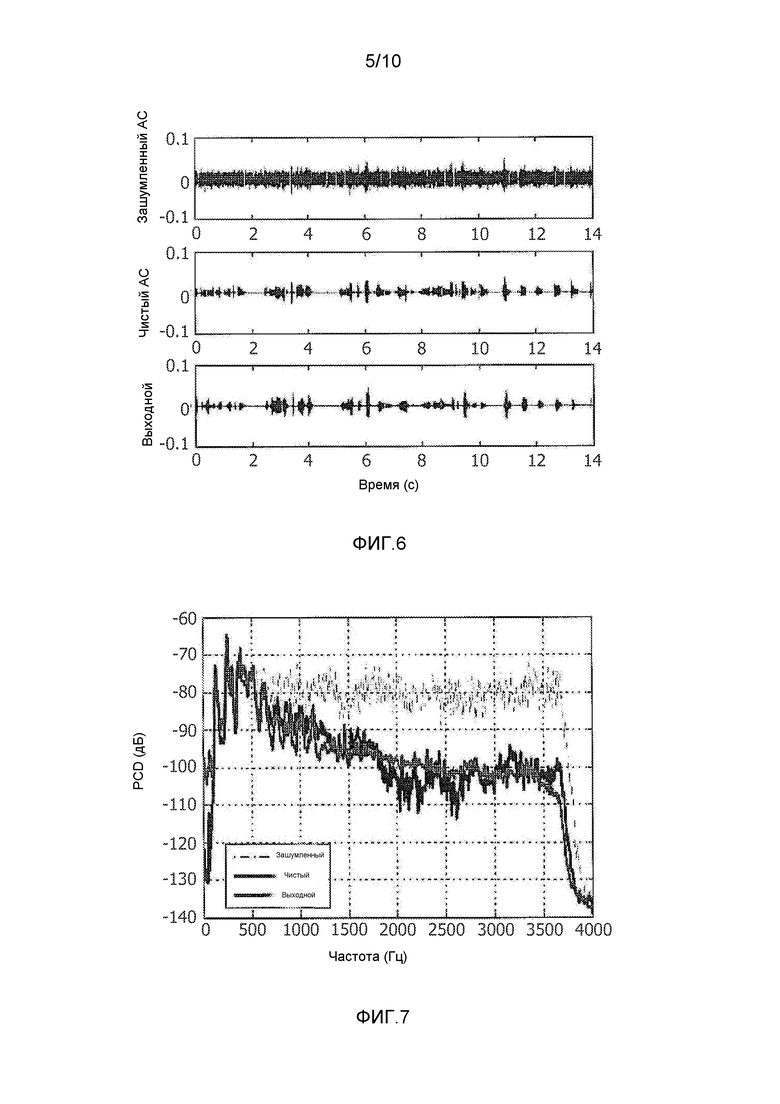
фиг. 5 - график, демонстрирующий результат применения алгоритма улучшения речи к сигналу, полученному с использованием AC-микрофона;
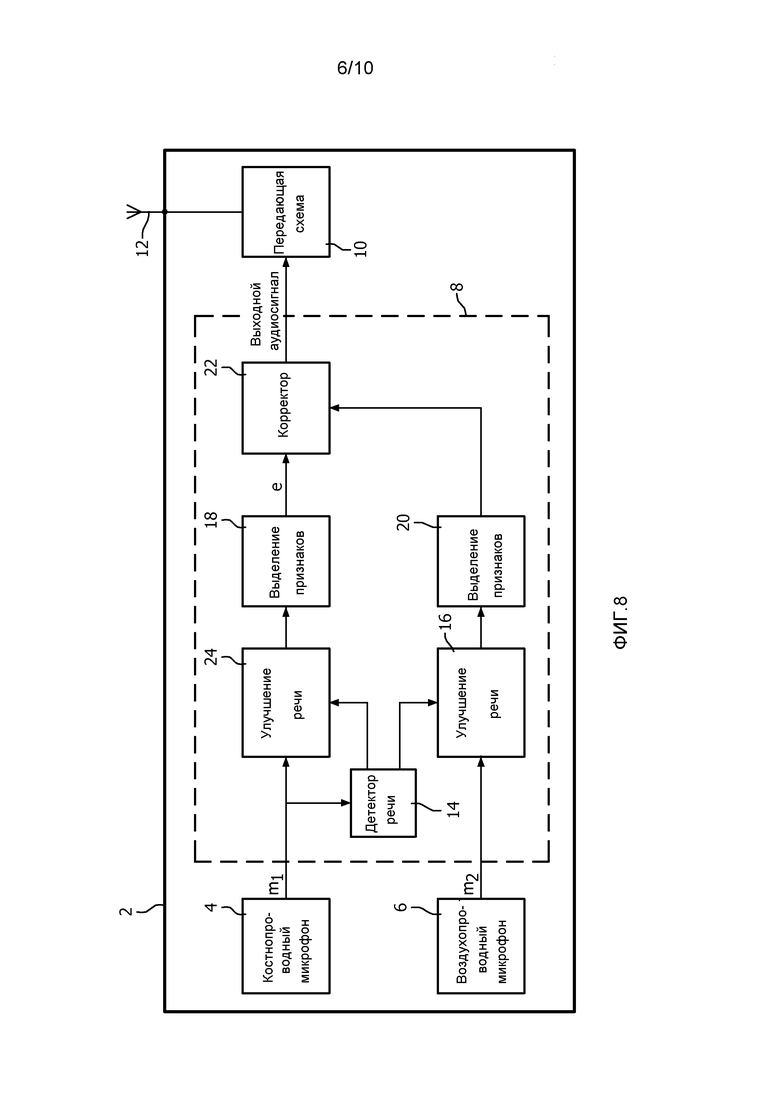
фиг. 6 - график, демонстрирующий сравнение между сигналами, полученными с использованием AC-микрофона в зашумленной и чистой среде и выходным сигналом способа согласно изобретению;
фиг. 7 - график, демонстрирующий сравнение между спектральными плотностями мощности трех сигналов, показанных на фиг. 6;
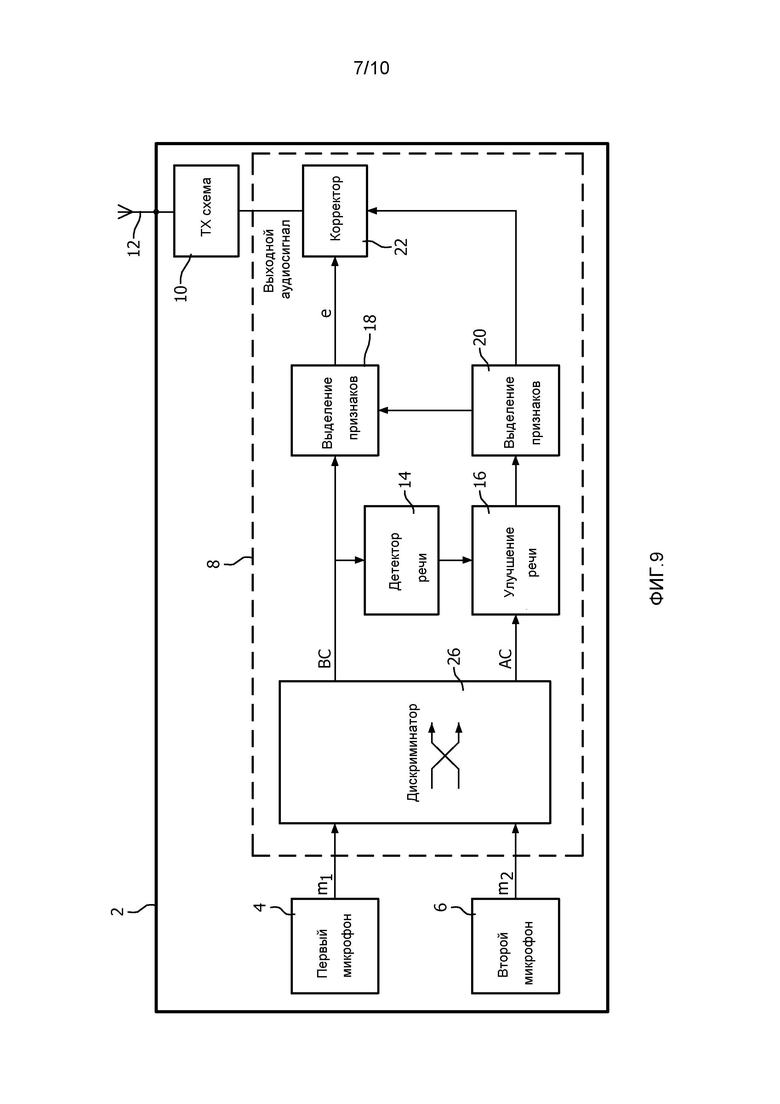
фиг. 8 - блок-схема устройства, включающего в себя схему обработки согласно второму варианту осуществления изобретения;
фиг. 9 - блок-схема устройства, включающего в себя схему обработки согласно третьему варианту осуществления изобретения;
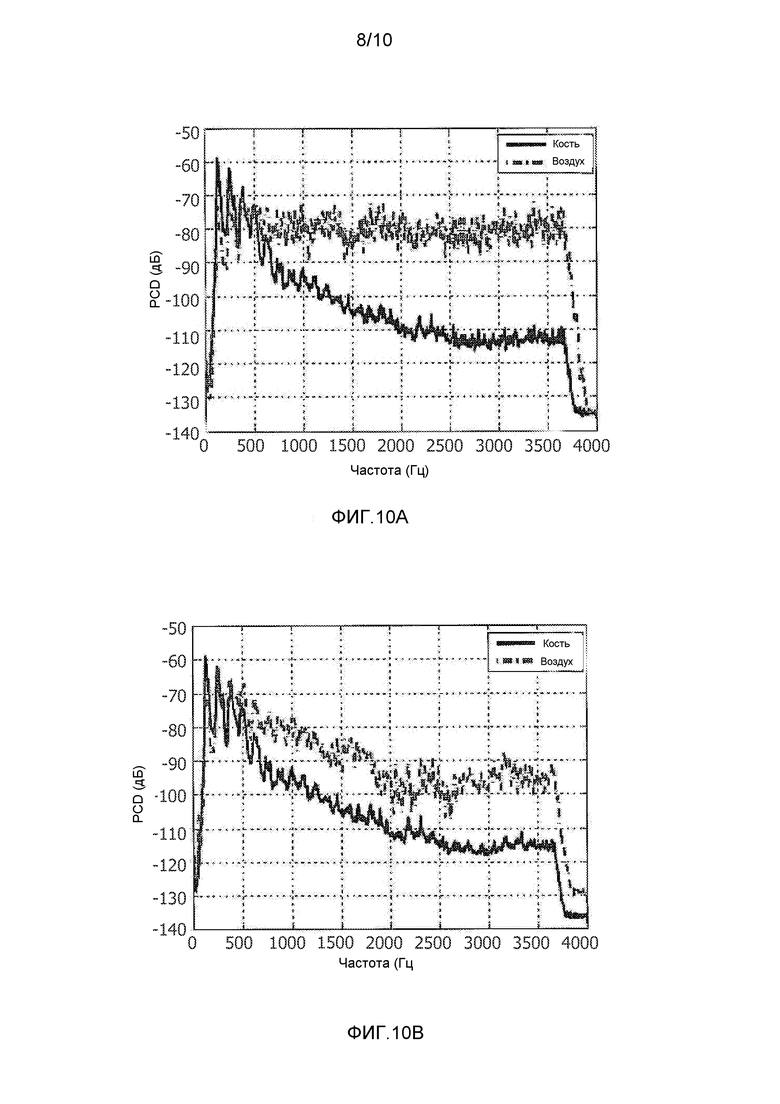
фиг. 10A и 10B - графики, демонстрирующие сравнение между спектральными плотностями мощности между сигналами, полученными от BC-микрофона и AC-микрофона с фоновым шумом и без него, соответственно;
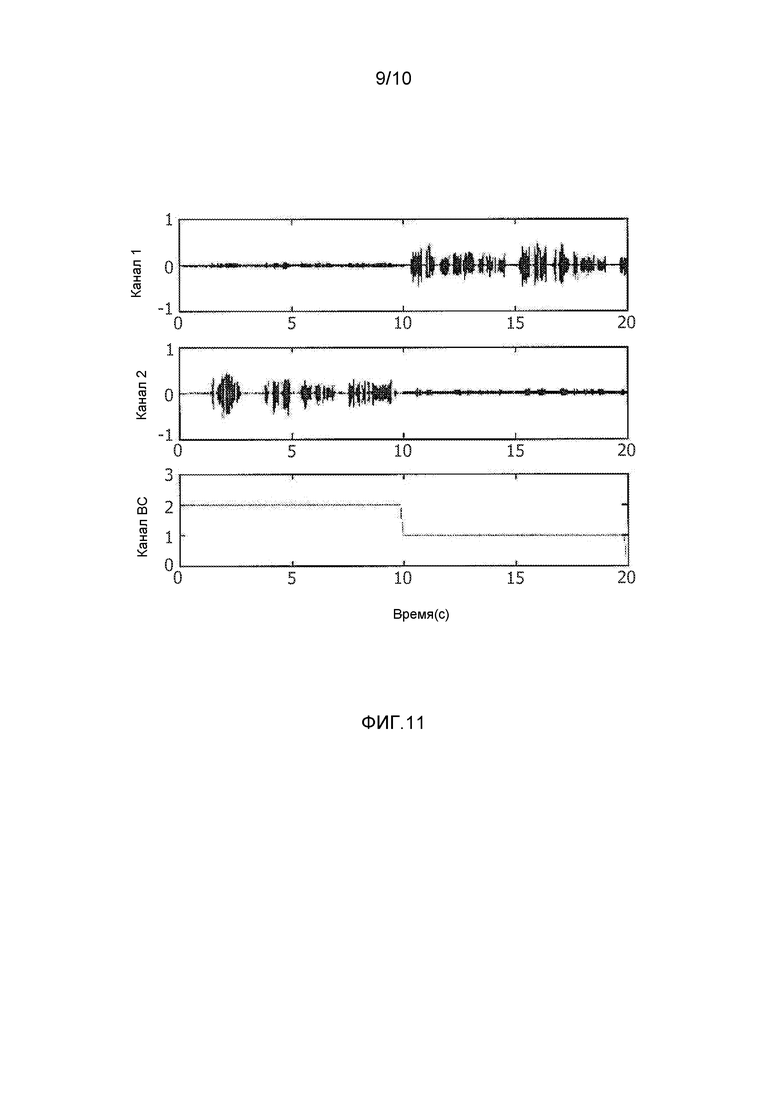
фиг. 11 - график, демонстрирующий результат действия модуля различения BC/AC в схеме обработки согласно третьему варианту осуществления; и
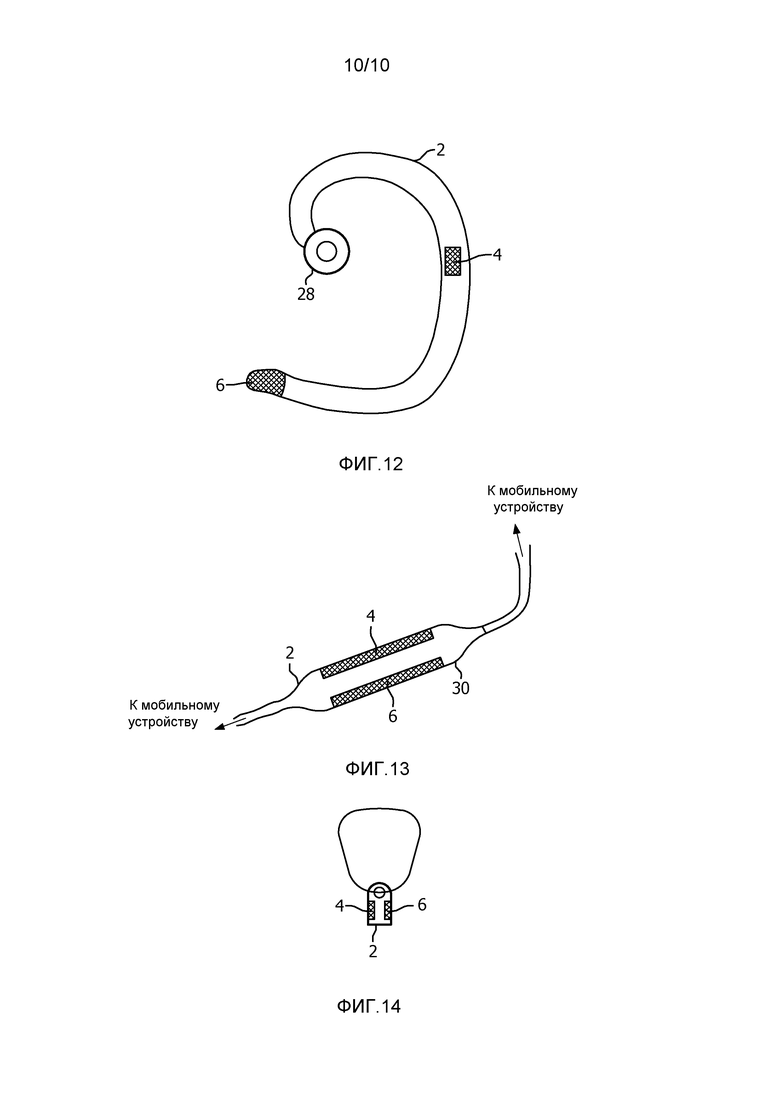
фиг. 12-14 демонстрируют примерные устройства включающие в себя два микрофона, которые можно использовать со схемой обработки согласно изобретению.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
Как описано выше, изобретение решает проблему обеспечения чистого (или, по меньшей мере, разборчивого) речевого аудиосигнала из неблагоприятной акустической среды, где качество речи ухудшено за счет сильного шума или реверберации.
Существующие алгоритмы, разработанные для коррекции аудиосигналов, полученных с использованием BC-микрофона или контактного датчика (для придания речи более натурального звучания) опираются на использование чистого опорного сигнала или предварительного обучения модели, зависящей от пользователя, однако изобретение обеспечивает усовершенствованные систему и способ для генерации аудиосигнала, представляющего речь пользователя, из аудиосигнала, полученного от BC или контактного микрофона, которые можно использовать в зашумленных средах и которые не требуют от пользователя обучать алгоритм до использования.
Устройство 2, включающее в себя схему обработки согласно первому варианту осуществления изобретения, показано на фиг. 1. Устройство 2 может быть портативным или мобильным устройством, например, мобильным телефоном, смартфоном или КПК, или вспомогательным приспособлением для такого мобильного устройства, например, беспроводной или проводной гарнитурой.
Устройство 2 содержит два датчика 4, 6 для генерации соответствующих аудиосигналов, представляющих речь пользователя. Первый датчик 4 представляет собой костнопроводный или контактный датчик, который располагается в устройстве 2, находясь в контакте с частью пользователя устройства 2, когда устройство 2 используется, и второй датчик 6 представляет собой воздухопроводный датчик, который, в общем случае, не находится в непосредственном физическом контакте с пользователем. В проиллюстрированных вариантах осуществления, первый датчик 4 представляет собой костнопроводный или контактный микрофон, и второй датчик представляет собой воздухопроводный микрофон. В альтернативных вариантах осуществления, первый датчик 4 может представлять собой акселерометр, который вырабатывает электрический сигнал, который представляет ускорения, обусловленные вибрацией тела пользователя, когда пользователь говорит. Специалистам в данной области техники очевидно, что первый и/или второй датчики 4, 6 можно реализовать с использованием других типов датчика или преобразователя.
BC-микрофон 4 и AC-микрофон 6 действуют одновременно (т.е. регистрируют одну и ту же речь в одно и то же время) для генерации костнопроводного и воздухопроводного аудиосигнала соответственно.
Аудиосигнал от BC-микрофона 4 (именуемый ниже “BC-аудиосигналом” и обозначенный “m1” на фиг. 2) и аудиосигнал от AC-микрофона 6 (именуемый ниже “AC-аудиосигналом” и обозначенный “m2” на фиг. 2) поступают на схему 8 обработки, которая осуществляет обработку аудиосигналов согласно изобретению.
Выходной сигнал схемы 8 обработки является чистым (или, по меньшей мере, улучшенным) аудиосигналом, представляющим речь пользователя, который поступает на схему 10 передатчика для передачи через антенну 12 на другое электронное устройство.
Схема 8 обработки содержит блок 14 выявления речи, который принимает BC-аудиосигнал, блок 16 улучшения речи, который принимает AC-аудиосигнал и выходной сигнал блока 14 выявления речи, блок 18 выделения первого признака, который принимает BC-аудиосигнал, блок 20 выделения второго признака, который принимает выходной сигнал блока 16 улучшения речи, и корректор 22, который принимает выходной сигнал блока 18 выделения первого признака и выходной сигнал блока 20 выделения второго признака и генерирует выходной аудиосигнал схемы 8 обработки.
Работа схемы 8 обработки и функции различных блоков, упомянутых выше, будут описаны ниже более подробно со ссылкой на фиг. 3, которая является блок-схемой последовательности операций способа обработки сигнала согласно изобретению.
Кратко, способ согласно изобретению содержит использование свойств или признаков BC-аудиосигнала и алгоритм улучшения речи для снижения величины шума в AC-аудиосигнале, и затем использование очищенного от шума AC-аудиосигнала для коррекции BC-аудиосигнала. Преимущество этого способа состоит в том, что, хотя очищенный от шума AC-аудиосигнал все же может содержать шум и/или артефакты, его можно использовать для улучшения частотных характеристик BC-аудиосигнала (который, в общем случае, не содержит речевых артефактов), чтобы он звучал более разборчиво.
Таким образом, на этапе 101 на фиг. 3, соответствующие аудиосигналы получаются одновременно с использованием BC-микрофона 4 и AC-микрофона 6, и сигналы поступают на схему 8 обработки. В дальнейшем, предполагается, что соответствующие аудиосигналы от BC-микрофона 4 и AC-микрофона 6 синхронизируются с использованием надлежащих задержек по времени до дополнительной обработки аудиосигналов, описанной ниже.
Блок 14 выявления речи обрабатывает принятый BC-аудиосигнал для идентификации частей BC-аудиосигнала, которые представляют речь, пользователем устройства 2 (этап 103 на фиг. 3). Использование BC-аудиосигнала для выявления речи является преимущественным, вследствие относительной невосприимчивости BC-микрофона 4 к фоновому шуму и высокому SNR.
Блок 14 выявления речи может осуществлять выявление речи путем применения простого способа сравнения с порогом к BC-аудиосигналу, посредством которого выявляются периоды речи, в течение которых амплитуда BC-аудиосигнала превышает пороговое значение.
В дополнительных вариантах осуществления изобретения (не проиллюстрированных на фигурах), можно подавлять шум в BC-аудиосигнале на основании минимальной статистики и/или способов формирования диаграммы направленности (в случае наличия более одного BC-аудиосигнала) до осуществления выявления речи.
Графики на фиг. 4 демонстрируют результат работы блока 14 выявления речи на BC-аудиосигнале.
Как описано выше, выходной сигнал блока 14 выявления речи (показанный в нижней части фиг. 4) поступает на блок 16 улучшения речи совместно с AC-аудиосигналом. По сравнению с BC-аудиосигналом, AC-аудиосигнал содержит стационарные и нестационарные источники фонового шума, поэтому улучшение речи осуществляется на AC-аудиосигнале (этап 105), что позволяет использовать его как эталон для дальнейшего улучшения (коррекции) BC-аудиосигнала. Одним эффектом блока 16 улучшения речи является снижение величины шума в AC-аудиосигнале.
Известны многие разные типы алгоритмов улучшения речи, которые могут применяться к AC-аудиосигналу блоком 16, и конкретный используемый алгоритм может зависеть от конфигурации микрофонов 4, 6 в устройстве 2, а также от предназначения устройства 2.
В конкретных вариантах осуществления, блок 16 улучшения речи применяет ту или иную форму спектральной обработки к AC-аудиосигналу. Например, блок 16 улучшения речи может использовать выходной сигнал блока 14 выявления речи для оценивания характеристик минимального уровня шума в спектральной области AC-аудиосигнала в течение периодов отсутствия речи, определенных блоком 14 выявления речи. Оценки минимального уровня шума обновляются всякий раз, когда речь не выявляется. В альтернативном варианте осуществления, блок 16 улучшения речи отфильтровывает неречевые части AC-аудиосигнала с использованием неречевых частей, указанных в выходном сигнале блока 14 выявления речи.
В вариантах осуществления, где устройство 2 содержит более чем один AC-датчик (микрофон) 6, блок 16 улучшения речи также может применять ту или иную форму формирования диаграммы направленности микрофона.
Верхний график на фиг. 5 демонстрирует AC-аудиосигнал полученный от AC-микрофона 6, и нижний график на фиг. 5 демонстрирует результат применения алгоритма улучшения речи к AC-аудиосигналу с использованием выходного сигнала блока 14 выявления речи. Можно видеть, что уровень фонового шума в AC-аудиосигнале достаточен для генерации SNR приблизительно 0 дБ, и блок 16 улучшения речи применяет коэффициент усиления к AC-аудиосигналу для подавления фонового шума почти на 30 дБ. Однако также можно видеть, что, хотя величина шума в AC-аудиосигнале значительно снижена, некоторые артефакты остаются.
Поэтому, как описано выше, очищенный от шума AC-аудиосигнал используется в качестве опорного сигнала для повышения разборчивости (т.е. улучшения) BC-аудиосигнала (этап 107).
В некоторых вариантах осуществления изобретения, можно использовать долговременные спектральные способы для построения корректирующего фильтра, или альтернативно, BC-аудиосигнал можно использовать в качестве входного сигнала адаптивного фильтра, который минимизирует среднеквадратическую ошибку между выходным сигналом фильтра и улучшенным AC-аудиосигналом, при этом на выходе фильтра образуется скорректированный BC-аудиосигнал. Еще одна альтернатива основана на предположении о том, что конечная импульсная характеристика может моделировать передаточную функцию между BC-аудиосигналом и улучшенным AC-аудиосигналом. В этих вариантах осуществления, очевидно, что блок 22 коррекции требует исходный BC-аудиосигнал помимо признаков, выделенных из BC-аудиосигнала блоком 18 выделения признаков. В этом случае, будет дополнительное соединение между линией ввода BC-аудиосигнала и блоком 22 коррекции в схеме 8 обработки, показанной на фиг. 2.
Однако способы на основе линейного прогнозирования могут быть более пригодны для повышения разборчивости речи в BC-аудиосигнале, поэтому, в предпочтительных вариантах осуществления изобретения, блоки 18, 20 выделения признаков являются блоками линейного прогнозирования, которые выделяют коэффициенты линейного прогнозирования из обоих BC-аудиосигнала и очищенного от шума AC-аудиосигнала, которые используются для построения корректирующего фильтра, что дополнительно описано ниже.
Линейное прогнозирование (LP) является инструментом речевого анализа, который основан на модели источника-фильтра генерации речи, где источник и фильтр соответствуют глоттальному возбуждению, порождаемому голосовыми связками, и формой речевого тракта, соответственно. Предполагается, что фильтр является полностью полюсным. Таким образом, LP-анализ обеспечивает сигнал возбуждения и огибающую в частотной области, представленную полностью полюсной моделью, которая связана со свойствами речевого тракта в ходе генерации речи.
Модель задана в виде
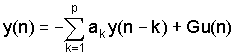
где y(n) и y(n-k) соответствуют настоящей и предыдущей выборкам сигнала для анализируемого сигнала, u(n) - сигнал возбуждения с коэффициентом усиления G, ak представляет коэффициенты предсказателя, и p - порядок полностью полюсной модели.
Целью LP-анализа является оценивание значений коэффициентов предсказателя для данных речевых выборок, для минимизации ошибки прогнозирования
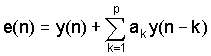
где ошибка фактически соответствует источнику возбуждения в модели источника-фильтра. e(n) это часть сигнала, которую не может прогнозировать модель, поскольку эта модель может прогнозировать лишь спектральную огибающую, и фактически соответствует импульсам, генерируемым голосовой щелью в гортани (возбуждением голосовых связок).
Известно, что аддитивный белый шум сильно влияет на оценивание коэффициентов LP, и что присутствие одного или более дополнительных источников в y(n) приводит к оцениванию сигнала возбуждения, который включает в себя вклады от этих источников. Поэтому важно получать аудиосигнал, не содержащий шума, который содержит только полезный исходный сигнал для оценивания правильного сигнала возбуждения.
Таким сигналом является BC-аудиосигнал. Вследствие своего высокого SNR, источник возбуждения e можно точно оценивать с использованием LP-анализа, осуществляемого блоком 18 линейного прогнозирования. Затем этот сигнал возбуждения e можно фильтровать с использованием результирующей полностью полюсной модели, оцененной путем анализа очищенного от шума AC-аудиосигнала. Поскольку полностью полюсный фильтр представляет гладкую спектральную огибающую очищенного от шума AC-аудиосигнала, он более устойчив к артефактам, возникающим в результате процесса улучшения.
Как показано на фиг. 2, анализ с линейным прогнозированием осуществляется как на BC-аудиосигнале (с использованием блока 18 линейного прогнозирования), так и на очищенном от шума AC-аудиосигнале (с использованием блока 20 линейного прогнозирования). Линейное прогнозирование осуществляется для каждого блока выборок аудиосигнала длиной 32 мс с перекрытием в 16 мс. Фильтр предыскажений также можно применять к одному или обоим из сигналов до анализа с линейным прогнозированием. Для повышения производительности анализа с линейным прогнозированием и последующей коррекции BC-аудиосигнала, очищенный от шума AC-аудиосигнал и BC-сигнал можно сначала синхронизировать (не показано) путем введения надлежащей задержки по времени в тот или иной аудиосигнал. Эту задержку по времени можно определять адаптивно с использованием способов кросс-корреляции.
В течение текущего блока выборки, предыдущий, настоящий и будущий коэффициенты предсказателя оцениваются, преобразуются в линейные спектральные частоты (LSF), сглаживаются и преобразуются обратно в коэффициенты линейного предсказателя. LSF используются, поскольку представление спектральной огибающей коэффициентами линейного прогнозирования не подвергается сглаживанию. Сглаживание применяется для ослабления переходных эффектов в ходе операции синтеза.
Коэффициенты LP, полученные для BC-аудиосигнала, используются для генерации BC-сигнала возбуждения e. Затем этот сигнал фильтруются (корректируются) блоком 22 коррекции, который просто использует полностью полюсный фильтр, оцененный и сглаженный из очищенного от шума AC-аудиосигнала
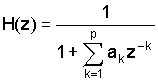
Дополнительное формирование с использованием LSF полностью полюсного фильтра можно применять к полностью полюсному фильтру AC для предотвращения ненужных всплесков в эффективном спектре.
Если фильтр предыскажений применяется к сигналам до LP-анализа, фильтр высоких частот можно применять к выходному сигналу H(z). Широкополосный коэффициент усиления также можно применять к выходному сигналу для компенсации широкополосного усиления или ослабления, порожденного фильтрами высоких частот.
Таким образом, выходной аудиосигнал выводится путем фильтрации 'чистого' сигнала возбуждения e, полученного из LP-анализа BC-аудиосигнала с использованием полностью полюсной модели, оцененный посредством LP-анализа очищенного от шума AC-аудиосигнала.
Фиг. 6 демонстрирует сравнение между сигналом AC-микрофона в зашумленной и чистой среде и выходным сигналом способа согласно изобретению при использовании линейного прогнозирования. Таким образом, можно видеть, что выходной аудиосигнал содержит значительно меньше артефактов, чем зашумленный AC-аудиосигнал, и больше напоминает чистый AC-аудиосигнал.
Фиг. 7 демонстрирует сравнение между спектральными плотностями мощности трех сигналов, показанных на фиг. 6. Также здесь можно видеть, что спектр выходного аудиосигнала в большей степени совпадает с AC-аудиосигналом в чистой среде.
Устройство 2, содержащее схему 8 обработки согласно второму варианту осуществления изобретения, показано на фиг. 8. Устройство 2 и схема 8 обработки в общем случае соответствует тому, что найдено в первом варианте осуществления изобретения, с признаками, общими для обоих вариантах осуществления, обозначенными одинаковыми ссылочными позициями.
Во втором варианте осуществления, предусмотрен второй блок 24 улучшения речи для улучшения (снижения шума) BC-аудиосигнала, выдаваемого BC-микрофоном 4 до осуществления линейного прогнозирования. Как и первый блок 16 улучшения речи, второй блок 24 улучшения речи принимает выходной сигнал блока 14 выявления речи. Второй блок 24 улучшения речи используется для применения умеренного улучшения речи к BC-аудиосигналу для удаления любого шума, который может примешиваться к сигналу микрофона. Хотя алгоритмы, выполняемые первым и вторым блоками 16, 24 улучшения речи могут быть одинаковыми, фактическая степень применяемого шумоподавления/улучшения речи, будет разной для AC- и BC-аудиосигналов.
Устройство 2, содержащее схему 8 обработки согласно третьему варианту осуществления изобретения, показано на фиг. 9. Устройство 2 и схема 8 обработки, в общем случае, соответствует тому, что найдено в первом варианте осуществления изобретения, с признаками, общими для обоих вариантов осуществления, обозначенными одинаковыми ссылочными позициями.
Этот вариант осуществления изобретения можно использовать в устройствах 2, где датчики/микрофоны 4, 6 размещены в устройстве 2 таким образом, чтобы любой из двух датчиков/микрофонов 4, 6 мог контактировать с пользователем (и, таким образом, действовать как BC или контактный датчик или микрофон), а другой датчик мог контактировать с воздухом (и, таким образом, действовать как AC-датчик или микрофон). Примером такого устройства является подвеска, где датчики размещаются на противоположных сторонах подвески, благодаря чему, один из датчиков находится в контакте с пользователем, независимо от ориентации подвески. В общем случае, в этих устройствах 2 датчики 4, 6 относятся к одному и тому же типу, находясь в контакте с пользователем или воздухом.
В этом случае, схема 8 обработки должна определять, какой, если имеется, из аудиосигналов от первого микрофона 4 и второго микрофона 6 соответствует BC-аудиосигналу и AC-аудиосигналу.
Таким образом, схема 8 обработки снабжена блоком 26 различения, который принимает аудиосигналы от первого микрофона 4 и второго микрофона 6, анализирует аудиосигналы для определения, какой, если имеется, из аудиосигналов является BC-аудиосигналом и выводит аудиосигналы на соответствующие ветви схемы 8 обработки. Если блок 26 различения определяет, что ни один из микрофонов 4, 6 не контактирует с телом пользователя, то блок 26 различения может выводить один или оба AC-аудиосигнала на схему (не показана на фиг. 9), которая осуществляет традиционное улучшение речи (например, формирование диаграммы направленности) для генерации выходного аудиосигнала.
Известно, что высокочастотные компоненты речи в BC-аудиосигнале ослабляются средой распространения (например, частоты свыше 1 кГц), что показывают графики на фиг. 9, которые демонстрируют сравнение спектральных плотностей мощности BC- и AC-аудиосигналов в присутствии фонового рассеянного белого шума (фиг. 10A) в отсутствие фонового шума (фиг. 10B). Это свойство можно использовать для различения между BC- и AC-аудиосигналами, и в одном варианте осуществления блока 26 различения, спектральные свойства каждого из аудиосигналов анализируются для определения, какой, если имеется, микрофон 4, 6 находится в контакте с телом.
Однако проблема связана с тем, что два микрофона 4, 6 могут быть не откалиброваны, т.е. частотные характеристики двух микрофонов 4, 6 могут отличаться друг от друга. В этом случае к одному из микрофонов можно применять калибровочный фильтр до перехода к блоку 26 различения (не показан на фигурах). Таким образом, в дальнейшем, можно предполагать, что характеристики совпадают в широкой полосе коэффициента усиления, т.е. частотные характеристики двух микрофонов имеют одинаковую форму.
В ходе дальнейшей работы блок 26 различения сравнивает спектры аудиосигналов от двух микрофонов 4, 6 для определения, какой аудиосигнал, при наличии, является BC-аудиосигналом. Если микрофоны 4, 6 имеют разные частотные характеристики, это можно исправить с помощью калибровочного фильтра при изготовлении устройства 2, чтобы различия в характеристиках микрофона не влияли на сравнения, осуществляемые блоком 26 различения.
Даже при использовании этого калибровочного фильтра, необходимо учитывать некоторые различия в коэффициенте усиления между AC- и BC-аудиосигналами ввиду различия в интенсивности AC- и BC-аудиосигналов, помимо их спектральных характеристик (в частности, на частотах свыше 1 кГц).
Таким образом, блок 26 различения нормализует спектры двух аудиосигналов выше пороговой частоты (исключительно в целях различения) на основании глобальных пиков, найденных ниже пороговой частоты, и сравнивает спектры выше пороговой частоты для определения, который из них, при наличии, является BC-аудиосигналом. Если эта нормализация не осуществляется, то, вследствие высокой интенсивности BC-аудиосигнала, можно определить, что мощность на более высоких частотах все же выше в BC-аудиосигнале, чем в AC-аудиосигнале, что не соответствует действительности.
В дальнейшем, предполагается, что любая калибровка, необходимая для учета различий в частотной характеристике микрофонов 4, 6 была осуществлена. На первом этапе блок 26 различения применяет N-точечное быстрое преобразование Фурье (FFT) к аудиосигналам от каждого микрофона 4, 6 следующим образом:


создавая N частотных бинов между 
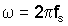
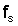
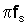
Затем блок 26 различения находит значение максимального пика спектра мощности среди частотных бинов ниже пороговой частоты ωc:
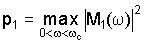
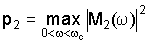
и использует максимальные пики для нормализации спектров мощности аудиосигналов выше пороговой частоты ωc. Пороговая частота ωc выбирается как частота, выше которой спектр BC-аудиосигнала, в общем случае, ослабляется относительно AC-аудиосигнала. Пороговая частота ωc может быть равна, например, 1 кГц. Каждый частотный бин содержит единственное значение, которое, для спектра мощности, равно квадрату величины частотной характеристики в этом бине.
Альтернативно, блок 26 различения может находить суммарный спектр мощности ниже ωc для каждого сигнала, т.е.
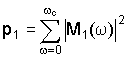
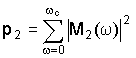
и может нормализовать спектры мощности аудиосигналов выше пороговой частоты ωc с использованием суммарных спектров мощности.
Поскольку низкочастотные бины AC-аудиосигнала и BC-аудиосигнала должны содержать примерно одинаковую низкочастотную информацию, значения p1 и p2 используются для нормализации спектров сигналов от двух микрофонов 4, 6, что позволяет сравнивать высокочастотные бины для обоих аудиосигналов (где ожидается наличие расхождений между BC-аудиосигналом и AC-аудиосигналом) и потенциальный идентифицированный BC-аудиосигнал.
Затем блок 26 различения сравнивает мощность между спектром сигнала от первого микрофона 4 и спектром сигнала от нормализованного второго микрофона 6 в верхних частотных бинах
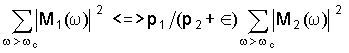
где є - малая константа для предотвращения деления на нуль, и p1/(p2+є) представляет нормализацию спектров второго аудиосигнала (хотя очевидно, что нормализацию можно альтернативно применять к первому аудиосигналу).
При условии, что разность между мощностями двух аудиосигналов превышает заранее определенную величину, которая зависит от положения костнопроводного датчика и может быть определена экспериментальным путем, аудиосигнал с наибольшей мощностью в нормализованном спектре выше ωc является аудиосигналом от AC-микрофона, и аудиосигнал с наименьшей мощностью является аудиосигналом от BC-микрофона. Затем блок 26 различения выводит аудиосигнал, определенный как BC-аудиосигнал, в верхнее ответвление схемы 8 обработки (т.е. ответвление, которое включает в себя блок 14 выявления речи и блок 18 выделения признаков) и аудиосигнал, определенный как AC-аудиосигнал, в нижнее ответвление схемы 8 обработки (т.е. ответвление, которое включает в себя блок 16 улучшения речи).
Однако, если разность между мощностями двух аудиосигналов меньше заранее определенной величины, то невозможно утверждать, что какой-либо из аудиосигналов является BC-аудиосигналом (и может оказаться, что ни один из микрофонов 4, 6 не контактирует с телом пользователя). В этом случае схема 8 обработки может рассматривать оба аудиосигнала как AC-аудиосигналы и обрабатывать их с использованием традиционных способов, например, объединяя AC-аудиосигналы с использованием способов формирования диаграммы направленности.
Очевидно, что, вместо вычисления квадратов модулей в вышеприведенных уравнениях, можно вычислять значения модулей.
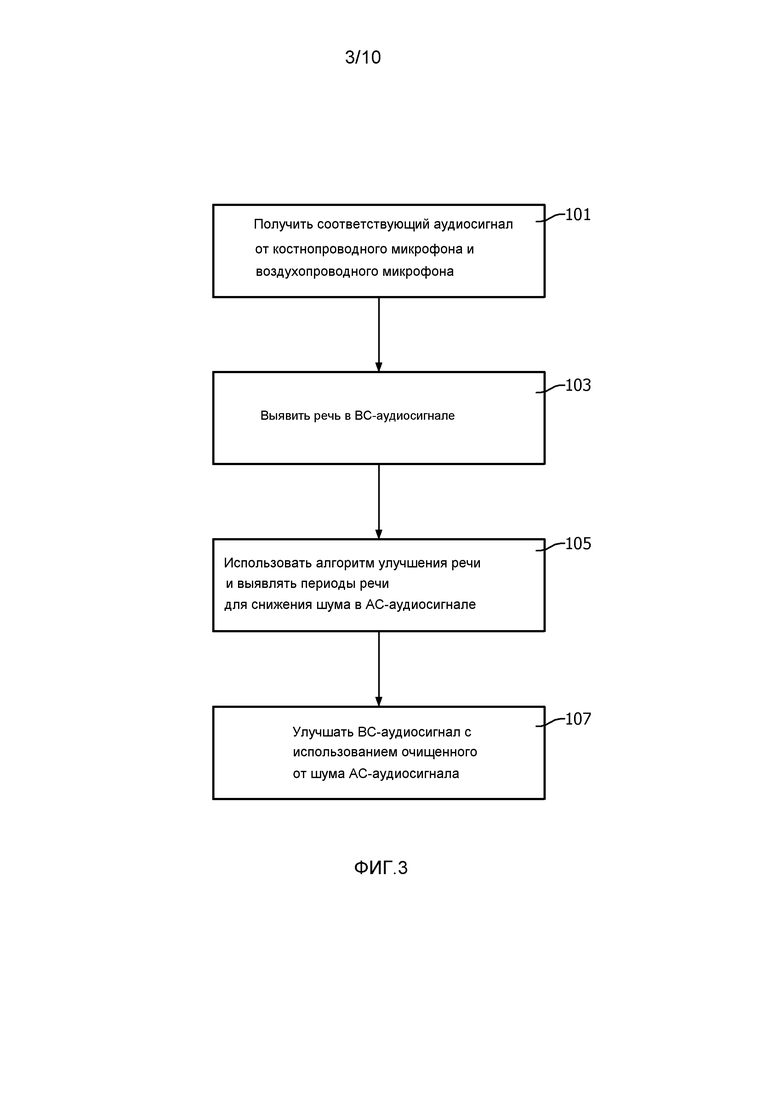
Также очевидно, что альтернативные сравнения между мощностью двух сигналов можно производить с использованием ограниченного отношения, что позволяет учитывать неопределенности при принятии решения. Например, ограниченное отношение мощностей на частотах выше пороговой частоты можно определить как:
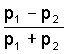
где отношение заключено между -1 и 1, причем значения, близкие к 0, указывают неопределенность, с которой микрофон, при наличии, является BC-микрофоном.
График на фиг. 11 иллюстрирует работу вышеописанного блока 26 различения в ходе процедуры тестирования. В частности, в течение первых 10 секунд теста, второй микрофон находится в контакте с пользователем (т.е. выдает BC-аудиосигнал), что точно идентифицируется блоком 26 различения (что показано на нижнем графике). В течение следующих 10 секунд теста, в контакте с пользователем находится первый микрофон (т.е. теперь он выдает BC-аудиосигнал) и это, опять же, точно идентифицируется блоком 26 различения.
Фиг. 12-14 демонстрируют примерные устройства 2, включающие в себя два микрофона, которые можно использовать со схемой 8 обработки согласно изобретению.
Устройство 2, показанное на фиг. 12, является беспроводной гарнитурой, которую можно использовать с мобильным телефоном для обеспечения функциональности громкой связи (со свободными руками). Беспроводной гарнитуре придана форма, позволяющая ей располагаться вокруг уха пользователя, и она содержит наушник 28 для передачи звуков пользователю, AC-микрофон 6, подлежащий размещению вблизи рта или щеки пользователя для обеспечения AC-аудиосигнала, и BC-микрофон 4 размещенный в устройстве 2 таким образом, чтобы контактировать с головой пользователя (предпочтительно где-то в районе уха) и обеспечивать BC-аудиосигнал.
Фиг. 13 демонстрирует устройство 2 в форме проводного комплекта громкой связи (со свободными руками), который может быть подключен к мобильному телефону для обеспечения функциональности громкой связи. Устройство 2 содержит наушник (не показан) и микрофонную часть 30, содержащую два микрофона 4, 6 которые, при эксплуатации, располагается вблизи рота или шеи пользователя. Микрофонная часть сконфигурирована таким образом, что любой из двух микрофонов 4, 6 может находиться в контакте с шеей пользователя, и это означает, что вышеописанный третий вариант осуществления схемы 8 обработки, который включает в себя блок 26 различения, особенно полезный в этом устройстве 2.
Фиг. 14 демонстрирует устройство 2 в форме подвески, которую пользователь носит на шее. Такая подвеска подлежат использованию в устройстве мобильной персональной системы чрезвычайных мер по оказанию помощи (MPERS), которое позволяет пользователю осуществлять связь с поставщиком медицинских услуг или службой экстренной помощи.
Два микрофона 4, 6 в подвеске 2 размещены таким образом, что подвеска является двусторонней (т.е. они располагаются на противоположных сторонах подвески 2), и это означает, что один из микрофонов 4, 6 должен контактировать с шеей или грудной клеткой пользователя. Таким образом, подвеска 2 требует использования схемы 8 обработки согласно вышеописанному третьему варианту осуществления, который включает в себя блок 26 различения для успешной работы.
Очевидно, что любое из вышеописанных примерных устройств 2 можно расширить, включив в него более двух микрофонов (например, подвеска 2 может иметь треугольное (требующее трех микрофонов, по одному на каждой грани) или квадратное (требующее четырех микрофонов, по одному на каждой грани)) поперечное сечение. Устройство 2 также может быть сконфигурировано таким образом, чтобы более чем один микрофон мог получать BC-аудиосигнал. В этом случае, можно объединять аудиосигналы от нескольких AC (или BC) микрофонов до ввода в схему 8 обработки с использованием, например, способов формирования диаграммы направленности, для генерации AC (или BC) аудиосигнала с повышенным SNR. Это может способствовать дополнительному повышению качества и разборчивости аудиосигнала, выводимого схемой 8 обработки.
Специалистам в данной области техники известно, какие микрофоны пригодны для использования в качестве AC-микрофонов и BC-микрофонов. Например, один или более микрофонов может быть выполнен на основе технологии MEMS.
Очевидно, что схему 8 обработки, показанную на фиг. 2, 8 и 9 можно реализовать как единичный процессор или как множество соединенных друг с другом специализированных блоков обработки. Альтернативно, очевидно, что функциональные возможности схемы 8 обработки можно реализовать в форме компьютерной программы, которая выполняется процессором или процессорами общего назначения в устройстве. Кроме того, очевидно, что схему 8 обработки можно реализовать в устройстве, отдельном от устройства корпусных BC и/или AC-микрофонов 4, 6, с возможностью обмена аудиосигналами между этими устройствами.
Также очевидно, что схема 8 обработки (и блок 26 различения, при реализации в конкретном варианте осуществления), может обрабатывать аудиосигналы на поблочной основе (т.е. обрабатывать единомоментно один блок выборок аудиосигнала). Например, в блоке 26 различения, аудиосигналы могут делиться на блоки из N выборок аудиосигнала до применения FFT. Последующая обработка, осуществляемая блоком 26 различения, затем осуществляется на каждом блоке из N преобразованных выборок аудиосигнала. Блоки 18, 20 выделения признаков могут действовать аналогичным образом.
Таким образом, обеспечены система и способ для генерации аудиосигнала, представляющего речь пользователя, из аудиосигнала, полученного с использованием BC-микрофона, которые можно использовать в зашумленных средах и которые не требуют от пользователя обучать алгоритм до использования.
Хотя изобретение подробно проиллюстрировано и описано в чертежах и вышеприведенном описании, такие иллюстрация и описание следует рассматривать как иллюстративные или примерные, но не как ограничительные; изобретение не ограничивается раскрытыми вариантами осуществления.
Специалисты в данной области техники могут внести и реализовать изменения в раскрытые варианты осуществления при практическом осуществлении заявленного изобретение, изучая чертежи, раскрытие и нижеследующую формулу изобретения. В формуле изобретения, слово "содержащий" не исключает наличия других элементов или этапов, и их упоминание в единственном числе не исключает наличия их во множественном числе. Единичный процессор или другой блок может выполнять функции нескольких элементов, указанных в формуле изобретения. Лишь тот факт, что определенные меры упомянуты во взаимно различных зависимых пунктах, не говорит о том, что нельзя выгодно использовать комбинацию этих мер. Компьютерная программа может храниться/распространяться на подходящем носителе, например, на оптическом носителе или твердотельном носителе, поставляемом совместно с или в составе другого оборудования, но также может распространяться в других формах, например через интернет или другие проводные или беспроводные системы электросвязи. Никакие ссылочные позиции в формуле изобретения не следует рассматривать в порядке ограничения объема.
Изобретение относится к средствам генерации аудиосигнала. Технический результат заключается в уменьшении шумовых составляющих в речевом аудиосигнале. Получают первый аудиосигнал, представляющий речь пользователя, с использованием датчика, находящегося в контакте с пользователем. Получают второй аудиосигнал с использованием воздухопроводного датчика, причем второй аудиосигнал представляет речь пользователя и включает в себя шум из среды, окружающей пользователя. Выявляют периоды речи в первом аудиосигнале. Применяют алгоритм улучшения речи ко второму аудиосигналу для снижения шума во втором аудиосигнале, причем алгоритм улучшения речи использует выявленные периоды речи в первом аудиосигнале. Корректируют первый аудиосигнал с использованием очищенного от шума второго аудиосигнала для генерации выходного аудиосигнала, представляющего речь пользователя. 3 н. и 12 з.п. ф-лы, 14 ил.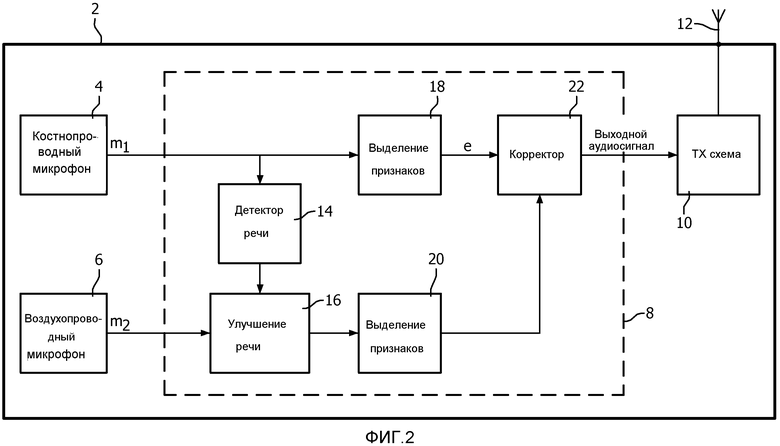
1. Способ генерации сигнала, представляющего речь пользователя, причем способ содержит этапы, на которых:
получают (101) первый аудиосигнал, представляющий речь пользователя, с использованием датчика, находящегося в контакте с пользователем,
получают (101) второй аудиосигнал с использованием воздухопроводного датчика, причем второй аудиосигнал
представляет речь пользователя и включает в себя шум из среды, окружающей пользователя,
выявляют (10 3) периоды речи в первом аудиосигнале,
применяют (105) ко второму аудиосигналу алгоритм улучшения речи для снижения величины шума во втором аудиосигнале, причем алгоритм улучшения речи для снижения величины шума использует выявленные периоды речи в первом аудиосигнале,
корректируют (107) первый аудиосигнал с использованием очищенного от шума второго аудиосигнала для генерации выходного аудиосигнала, представляющего речь пользователя.
2. Способ по п. 1, в котором этап (103) выявления периодов речи в первом аудиосигнале содержит выявление частей первого аудиосигнала, где амплитуда аудиосигнала превышает пороговое значение.
3. Способ по п. 1 или 2, в котором этап (105) применения алгоритма улучшения речи для снижения величины шума во втором аудиосигнале содержит применение спектральной обработки ко второму аудиосигналу.
4. Способ по п. 1 или 2, в котором этап (105) применения алгоритма улучшения речи для снижения величины шума во втором аудиосигнале содержит использование выявленных периодов речи в первом аудиосигнале для оценивания минимальных уровней шума в спектральной области второго аудиосигнала.
5. Способ по п. 1 или 2, в котором этап (107) коррекции первого аудиосигнала содержит осуществление анализа с линейным прогнозированием на первом аудиосигнале и очищенном от шума втором аудиосигнале для построения корректирующего фильтра.
6. Способ по п. 5, в котором осуществление анализа с линейным прогнозированием содержит этапы, на которых:
(i) оценивают коэффициенты линейного прогнозирования для первого аудиосигнала и очищенного от шума второго аудиосигнала,
(ii) используют коэффициенты линейного прогнозирования для первого аудиосигнала для генерации сигнала возбуждения для первого аудиосигнала,
(iii) используют коэффициенты линейного прогнозирования для очищенного от шума второго аудиосигнала для построения огибающей в частотной области, и
(iv) корректируют сигнал возбуждения для первого аудиосигнала с использованием огибающей в частотной области.
7. Способ по п. 1 или 2, в котором этап (107) коррекции первого аудиосигнала содержит (i) использование долговременных спектральных способов для построения корректирующего фильтра, или (ii) использование первого аудиосигнала в качестве входного сигнала адаптивного фильтра, который минимизирует среднеквадратическую ошибку между выходным сигналом фильтра и очищенным от шума вторым аудиосигналом.
8. Способ по п. 1 или 2, в котором до этапа коррекции (107) способ дополнительно содержит этап применения к первому аудиосигналу алгоритма улучшения речи для снижения величины шума в первом аудиосигнале, причем алгоритм улучшения речи для снижения величины шума использует выявленные периоды речи в первом аудиосигнале, и этап коррекции содержит коррекцию очищенного от шума первого аудиосигнала с использованием очищенного от шума второго аудиосигнала для генерации выходного аудиосигнала, представляющего речь пользователя.
9. Способ по п. 1 или 2, дополнительно содержащий этапы, на которых:
получают третий аудиосигнал с использованием второго воздухопроводного датчика, причем третий аудиосигнал представляет речь пользователя и включает в себя шум из среды, окружающей пользователя, и
используют способ формирования диаграммы направленности для объединения второго аудиосигнала и третьего аудиосигнала и генерации объединенного аудиосигнала,
причем этап (105) применения алгоритма улучшения речи для снижения величины шума содержит применение к объединенному аудиосигналу алгоритма улучшения речи для снижения величины шума в объединенном аудиосигнале, причем алгоритм улучшения речи для снижения величины шума использует выявленные периоды речи в первом аудиосигнале.
10. Способ по п. 1 или 2, дополнительно содержащий этапы, на которых:
получают четвертый аудиосигнал, представляющий речь пользователя, с использованием второго датчика, находящегося в контакте с пользователем, и
используют способ формирования диаграммы направленности для объединения первого аудиосигнала и четвертого аудиосигнала и генерации второго объединенного аудиосигнала,
причем этап (103) выявления периодов речи содержит выявление периодов речи во втором объединенном аудиосигнале.
11. Устройство (2) для использования при генерации аудиосигнала, представляющего речь пользователя, причем устройство (2) содержит:
схему (8) обработки, которая сконфигурирована с возможностью:
приема первого аудиосигнала, представляющего речь пользователя, от датчика (4), находящегося в контакте с пользователем,
приема второго аудиосигнала от воздухопроводного датчика (6), причем второй аудиосигнал представляет речь пользователя и включает в себя шум из среды, окружающей пользователя,
выявления периодов речи в первом аудиосигнале,
применения ко второму аудиосигналу алгоритма улучшения речи для снижения величины шума во втором аудиосигнале, причем алгоритм улучшения речи для снижения величины шума использует выявленные периоды речи в первом аудиосигнале, и
коррекции первого аудиосигнала с использованием очищенного от шума второго аудиосигнала для генерации выходного аудиосигнала, представляющего речь пользователя.
12. Устройство (2) по п. 11, в котором схема (8) обработки сконфигурирована с возможностью коррекции первого аудиосигнала путем осуществления анализа с линейным прогнозированием на первом аудиосигнале и очищенном от шума втором аудиосигнале для построения корректирующего фильтра.
13. Устройство (2) по п. 11 или 12, в котором схема (8) обработки сконфигурирована с возможностью осуществления анализа с линейным прогнозированием посредством:
(i) оценивания коэффициентов линейного прогнозирования для первого аудиосигнала и очищенного от шума второго аудиосигнала,
(ii) использования коэффициентов линейного прогнозирования для первого аудиосигнала для генерации сигнала возбуждения для первого аудиосигнала,
(iii) использования коэффициентов линейного прогнозирования для очищенного от шума аудиосигнала для построения огибающей в частотной области, и
(iv) коррекции сигнала возбуждения для первого аудиосигнала с использованием огибающей в частотной области.
14. Устройство (2) по п. 11 или 12, причем устройство (2) дополнительно содержит:
контактный датчик (4), который сконфигурирован с возможностью контактировать с телом пользователя, когда устройство (2) используется, и с возможностью генерации первого аудиосигнала, и
воздухопроводный датчик (6), который сконфигурирован с возможностью генерации второго аудиосигнала.
15. Носитель информации, хранящий компьютерный программный продукт, причем программный продукт содержит машиночитаемый код, который сконфигурирован таким образом, что при выполнении машиночитаемого кода подходящим компьютером или процессором компьютер или процессор осуществляет способ по п. 1 или 2.
| Печь для непрерывного получения сернистого натрия | 1921 |
|
SU1A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| Печь для непрерывного получения сернистого натрия | 1921 |
|
SU1A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| Аппарат для очищения воды при помощи химических реактивов | 1917 |
|
SU2A1 |
| Аппарат для очищения воды при помощи химических реактивов | 1917 |
|
SU2A1 |

