ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
Изобретение относится к ослаблению шума при передаче аудиосигналов и, в частности, но не только, к ослаблению шума для речевых сигналов.
УРОВЕНЬ ТЕХНИКИ
Ослабление шума в аудиосигналах требуется во множестве вариантов применения для того, чтобы дополнительно улучшать или выделять компонент полезного сигнала. Например, улучшение речи при наличии фонового шума привлекает большое внимание вследствие своей практической значимости. Очень перспективным вариантом применения является уменьшение уровня шума от одного микрофона в мобильной телефонной связи. Низкие затраты устройства с одним микрофоном приводят к его привлекательности на развивающихся рынках. С другой стороны, отсутствие нескольких микрофонов не позволяет решениям на основе формирователя диаграммы направленности подавлять высокие уровни шума, который может присутствовать.
Подход на основе одного микрофона, который хорошо работает в нестационарных условиях, в силу этого является коммерчески желательным. Алгоритмы ослабления шума от одного микрофона также являются значимыми в вариантах применения с несколькими микрофонами, в которых формирование диаграммы направленности аудио является непрактичным или предпочтительным либо в дополнение к такому формированию диаграммы направленности. Например, такие алгоритмы могут быть полезными для систем проведения аудио- и видеоконференций на основе громкой связи в реверберирующих и рассеянных нестационарных шумовых полях, либо когда присутствует ряд создающих помехи источников. Технологии пространственной фильтрации, к примеру, формирование диаграммы направленности, позволяют достигать только ограниченного успеха в таких сценариях, и дополнительное подавление шума должно быть выполнено для вывода модуля формирования диаграммы направленности на этапе постобработки.
Предложены различные алгоритмы ослабления шума, включающие в себя системы, которые основаны на знаниях или допущениях касательно характеристик компонента полезного сигнала. В частности, продемонстрировано, что основанные на знаниях способы улучшения речи, такие как схемы на базе таблиц кодирования, хорошо работают в нестационарных условиях шума, даже при управлении сигналом из одного микрофона. Примеры таких способов представляются в следующих работах: S. Srinivasan, J. Samuelsson и W. B. Kleijn, "Codebook driven short-term predictor parameter estimation for speech enhancement", IEEE Trans. Speech, Audio and Language Processing, издание 14, № 1, стр. 163-176, январь 2006 года, и S. Srinivasan, J. Samuelsson и W. B. Kleijn, "Codebook based Bayesian speech enhancement for non-stationary environments", IEEE Trans. Speech Audio Processing, издание 15, № 2, стр. 441-452, февраль 2007 года.
Эти способы основываются на обученных таблицах кодирования спектральных форм речи и шума, которые параметризуются, например, посредством линейных прогнозирующих (LP) коэффициентов. Использование таблицы кодирования речи является интуитивным и легко поддается практической реализации. Таблица кодирования речи может быть либо независимой от говорящего (обученной с использованием данных от нескольких говорящих), либо зависимой от говорящего. Второй случай является полезным, например, для приложений для мобильных телефонов, поскольку они чаще всего являются персональными и зачастую используются преимущественно одним говорящим. Тем не менее, использование таблиц кодирования шума в практической реализации является перспективным вследствие множества типов шума, которые могут встречаться на практике. Как результат, типично используется очень большая таблица кодирования шума.
Обычно такие алгоритмы на основе таблиц кодирования направлены на нахождение записи таблицы кодирования речи и записи таблицы кодирования шума, которые при комбинировании наиболее близко совпадают с захваченным сигналом. Когда надлежащие записи таблицы кодирования найдены, алгоритмы компенсируют принимаемый сигнал на основе записей таблицы кодирования. Тем не менее, чтобы идентифицировать надлежащие записи таблицы кодирования, поиск выполняется по всем возможным комбинациям записей таблицы кодирования речи и записей таблицы кодирования шума. Это приводит к очень ресурсоемкому в вычислительном отношении процессу, который зачастую является непрактичными для устройств с очень низкой сложностью. Кроме того, большие таблицы кодирования шума являются громоздкими при формировании и хранении, и большое число возможных вариантов шума может увеличивать риск ошибочной оценки, что приводит к неоптимальному ослаблению шума.
Следовательно, был бы желателен улучшенный подход к ослаблению шума, в частности был бы желателен подход, обеспечивающий повышенную гибкость, уменьшенные требования по объему вычислений, упрощенную реализацию и/или работу, сокращенные затраты и/или повышенную производительность.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Следовательно, изобретение предпочтительно нацелено на уменьшение, облегчение или устранение одного или более вышеуказанных недостатков по отдельности или в любой комбинации.
Согласно аспекту изобретения предусмотрено устройство ослабления шума, содержащее: приемное устройство для приема аудиосигнала, содержащего компонент полезного сигнала и компонент шумового сигнала; первую таблицу кодирования, содержащую множество возможных вариантов полезного сигнала для компонента полезного сигнала, причем каждый возможный вариант полезного сигнала представляет возможный компонент полезного сигнала; вторую таблицу кодирования, содержащую множество возможных вариантов долей шумового сигнала, причем каждый возможный вариант доли шумового сигнала представляет возможную долю шума для компонента шумового сигнала; модуль сегментации для сегментации аудиосигнала на временные сегменты; ослабитель шума, выполненный с возможностью для каждого временного сегмента выполнять этапы: формирования множества возможных вариантов оцененного сигнала посредством для каждого из возможных вариантов полезного сигнала первой таблицы кодирования формирования возможного варианта оцененного сигнала в качестве комбинации масштабированной версии возможного варианта полезного сигнала и взвешенной комбинации возможных вариантов долей шумового сигнала, причем масштабирование возможного варианта полезного сигнала и весовые коэффициенты взвешенной комбинации определяются таким образом, чтобы минимизировать функцию затрат, указывающую разность между возможным вариантом оцененного сигнала и аудиосигналом во временном сегменте, формирования возможного варианта сигнала для аудиосигнала во временном сегменте из возможных вариантов оцененного сигнала и ослабления шума аудиосигнала во временном сегменте в ответ на возможный вариант сигнала.
Изобретение позволяет предоставлять улучшенное и/или упрощенное ослабление шума. Во многих вариантах осуществления требуются существенно уменьшенные вычислительные ресурсы. Подход позволяет обеспечивать более эффективное ослабление шума во многих вариантах осуществления, которое может приводить к более быстрому ослаблению шума. Во многих сценариях подход может обеспечивать или давать возможность ослабления шума в реальном времени.
Существенно меньшая таблица кодирования шума (вторая таблица кодирования) может быть использована во многих вариантах осуществления по сравнению с традиционными подходами. Это позволяет уменьшать требования к запоминающему устройству.
Во многих вариантах осуществления множество возможных вариантов долей шумового сигнала может не отражать знания или допущение касательно характеристик компонента шумового сигнала. Возможные варианты долей шумового сигнала могут представлять собой общие возможные варианты долей шумового сигнала и, в частности, могут представлять собой фиксированные, предварительно определенные, статические, постоянные и/или необученные возможные варианты долей шумового сигнала. Это позволяет обеспечивать упрощенную работу и/или позволяет упрощать формирование и/или распределение второй таблицы кодирования. В частности, фаза обучения может исключаться во многих вариантах осуществления.
Каждый из возможных вариантов полезного сигнала может иметь длительность, соответствующую длительности временного сегмента. Каждый из возможных вариантов долей шумового сигнала может иметь длительность, соответствующую длительности временного сегмента.
Каждый из возможных вариантов полезного сигнала может быть представлен посредством набора параметров, который характеризует компонент сигнала. Например, каждый возможный вариант полезного сигнала может содержать набор коэффициентов линейного прогнозирования для модели линейного прогнозирования. Каждый возможный вариант полезного сигнала может содержать набор параметров, характеризующий спектральное распределение, такой как, например, спектральная плотность мощности (PSD).
Каждый из возможных вариантов долей шумового сигнала может быть представлен посредством набора параметров, который характеризует компонент сигнала. Например, каждый возможный вариант доли шумового сигнала может содержать набор параметров, характеризующий спектральное распределение, такой как, например, спектральная плотность мощности (PSD). Число параметров для возможных вариантов долей шумового сигнала может быть ниже числа параметров для возможных вариантов полезного сигнала.
Компонент шумового сигнала может соответствовать любому компоненту сигнала, не составляющему часть компонента полезного сигнала. Например, компонент шумового сигнала может включать в себя белый шум, цветной шум, детерминированный шум из источников нежелательного шума, шум от реализации и т.д. Компонент шумового сигнала может быть нестационарным шумом, который может изменяться для различных временных сегментов. Обработка каждого временного сегмента посредством ослабителя шума может быть независимой для каждого временного сегмента.
Ослабитель шума может, в частности, включать в себя процессор, схему, функциональный модуль или средство для формирования множества возможных вариантов оцененного сигнала посредством, для каждого из возможных вариантов полезного сигнала первой таблицы кодирования, формирования возможного варианта оцененного сигнала в качестве комбинации масштабированной версии возможного варианта полезного сигнала и взвешенной комбинации возможных вариантов долей шумового сигнала, причем масштабирование возможного варианта полезного сигнала и весовые коэффициенты взвешенной комбинации определяются таким образом, чтобы минимизировать функцию затрат, указывающую разность между возможным вариантом оцененного сигнала и аудиосигналом во временном сегменте; процессор, схему, функциональный модуль или средство для формирования возможного варианта сигнала для аудиосигнала во временном сегменте из возможных вариантов оцененного сигнала; и процессор, схему, функциональный модуль или средство для ослабления шума аудиосигнала во временном сегменте в ответ на возможный вариант сигнала.
В соответствии с необязательным признаком изобретения функция затрат является одной из функции затрат на основе максимального правдоподобия и функции затрат на основе минимальной среднеквадратической ошибки.
Это позволяет предоставлять очень эффективное и высокопроизводительное определение масштабирования и весовых коэффициентов.
В соответствии с необязательным признаком изобретения ослабитель шума выполнен с возможностью вычислять масштабирование и весовые коэффициенты из уравнений, отражающих производную функции затрат относительно масштабирования и весовых коэффициентов, равных нулю.
Это позволяет предоставлять очень эффективное и высокопроизводительное определение масштабирования и весовых коэффициентов. Во многих вариантах осуществления это позволяет обеспечивать работу, в которой масштабирование и весовые коэффициенты могут быть непосредственно вычислены из уравнений в замкнутой форме. Во многих вариантах осуществления это позволяет обеспечивать прямое вычисление масштабирования и весовых коэффициентов без необходимости рекурсивных итераций или операций поиска.
В соответствии с необязательным признаком изобретения возможные варианты полезного сигнала имеют более высокое частотное разрешение, чем взвешенная комбинация.
Это позволяет обеспечивать практическое ослабление шума с высокой производительностью. В частности, это позволяет обеспечивать выделение значимости возможного варианта полезного сигнала относительно значимости возможного варианта доли шумового сигнала при определении возможных вариантов оцененного сигнала.
Степени свободы при задании возможных вариантов полезного сигнала могут быть выше степеней свободы при формировании взвешенной комбинации. Число параметров, задающих возможные варианты полезного сигнала, может быть выше числа параметров, задающих возможные варианты долей шумового сигнала.
В соответствии с необязательным признаком изобретения множество возможных вариантов долей шумового сигнала покрывает частотный диапазон, при этом каждый возможный вариант доли шумового сигнала из группы возможных вариантов долей шумового сигнала предоставляет доли только в поддиапазоне частотного диапазона, причем поддиапазоны различных возможных вариантов долей шумового сигнала из группы возможных вариантов долей шумового сигнала отличаются.
Это позволяет обеспечивать упрощенную работу с меньшей сложностью и/или повышенную производительность в некоторых вариантах осуществления. В частности, это позволяет обеспечивать упрощенную и/или улучшенную адаптацию возможного варианта оцененного сигнала к аудиосигналу посредством регулирования весовых коэффициентов.
В соответствии с необязательным признаком изобретения поддиапазоны группы возможных вариантов долей шумового сигнала являются неперекрывающимися.
Это позволяет обеспечивать упрощенную работу с меньшей сложностью и/или повышенную производительность в некоторых вариантах осуществления.
В некоторых вариантах осуществления поддиапазоны группы возможных вариантов долей шумового сигнала могут быть перекрывающимися.
В соответствии с необязательным признаком изобретения поддиапазоны группы возможных вариантов долей шумового сигнала имеют неравные размеры.
Это позволяет обеспечивать упрощенную работу с меньшей сложностью и/или повышенную производительность в некоторых вариантах осуществления.
В соответствии с необязательным признаком изобретения каждый из возможных вариантов долей шумового сигнала из группы возможных вариантов долей шумового сигнала соответствует по существу плоскому частотному распределению.
Это позволяет обеспечивать упрощенную работу с меньшей сложностью и/или повышенную производительность в некоторых вариантах осуществления. В частности, это позволяет обеспечивать упрощенную и/или улучшенную адаптацию возможного варианта оцененного сигнала к аудиосигналу посредством регулирования весовых коэффициентов.
В соответствии с необязательным признаком изобретения устройство ослабления шума дополнительно содержит модуль оценки шума для формирования оценки шума для аудиосигнала во временном интервале, по меньшей мере, частично за пределами временного сегмента и для формирования, по меньшей мере, одного из возможных вариантов долей шумового сигнала в ответ на оценку шума.
Это позволяет обеспечивать упрощенную работу с меньшей сложностью и/или повышенную производительность в некоторых вариантах осуществления. В частности, во многих вариантах осуществления это может обеспечивать более точную оценку компонента шумового сигнала, в частности, для систем, в которых шум может иметь стационарный или медленно изменяющийся компонент. Оценка шума, например, может представлять собой оценку шума, сформированную из аудиосигнала в одном или более предыдущих временных сегментов.
В соответствии с необязательным признаком изобретения взвешенная комбинация представляет собой взвешенное суммирование.
Это позволяет предоставлять очень эффективную реализацию и может, в частности, уменьшать сложность и, например, обеспечивать упрощенное определение весовых коэффициентов для взвешенного суммирования.
В соответствии с необязательным признаком изобретения, по меньшей мере, один из возможных вариантов полезного сигнала первой таблицы кодирования и возможных вариантов долей шумового сигнала второй таблицы кодирования представляется посредством набора параметров, содержащего не более 20 параметров.
Это обеспечивает низкую сложность. Изобретение во многих вариантах осуществления и сценариях может обеспечивать эффективное ослабление шума даже для относительно приблизительных оценок сигнала и компонентов шумового сигнала.
В соответствии с необязательным признаком изобретения, по меньшей мере, один из возможных вариантов полезного сигнала первой таблицы кодирования и возможных вариантов долей шумового сигнала второй таблицы кодирования представляется посредством спектрального распределения.
Это позволяет предоставлять очень эффективную реализацию и может, в частности, уменьшать сложность.
В соответствии с необязательным признаком изобретения компонент полезного сигнала представляет собой компонент речевого сигнала.
Изобретение позволяет предоставлять преимущественный подход для улучшения речи.
Подход может быть, в частности, подходящим для улучшения речи. Возможные варианты полезного сигнала могут представлять компоненты сигнала, совместимые с речевой моделью.
Согласно аспекту изобретения предусмотрен способ ослабления шума, содержащий: прием аудиосигнала, содержащего компонент полезного сигнала и компонент шумового сигнала; предоставление первой таблицы кодирования, содержащей множество возможных вариантов полезного сигнала для компонента полезного сигнала, причем каждый возможный вариант полезного сигнала представляет возможный компонент полезного сигнала; предоставление второй таблицы кодирования, содержащей множество возможных вариантов долей шумового сигнала, причем каждый возможный вариант доли шумового сигнала представляет возможную долю шума для компонента шумового сигнала; сегментацию аудиосигнала на временные сегменты; и для каждого временного сегмента выполнение этапов: формирования множества возможных вариантов оцененного сигнала посредством для каждого из возможных вариантов полезного сигнала первой таблицы кодирования формирования возможного варианта оцененного сигнала в качестве комбинации масштабированной версии возможного варианта полезного сигнала и взвешенной комбинации возможных вариантов долей шумового сигнала, причем масштабирование возможного варианта полезного сигнала и весовые коэффициенты взвешенной комбинации определяются таким образом, чтобы минимизировать функцию затрат, указывающую разность между возможным вариантом оцененного сигнала и аудиосигналом во временном сегменте, формирования возможного варианта сигнала для временного сегмента из возможных вариантов оцененного сигнала и ослабления шума аудиосигнала во временном сегменте в ответ на возможный вариант сигнала.
Эти и другие аспекты, признаки и преимущества изобретения должны становиться очевидными и должны истолковываться со ссылкой на описанные далее варианты осуществления.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Варианты осуществления изобретения описаны далее только в качестве примера со ссылкой на чертежи, на которых:
Фиг. 1 является иллюстрацией примера элементов устройства ослабления шума в соответствии с некоторыми вариантами осуществления изобретения;
Фиг. 2 является иллюстрацией способа ослабления шума в соответствии с некоторыми вариантами осуществления изобретения; и
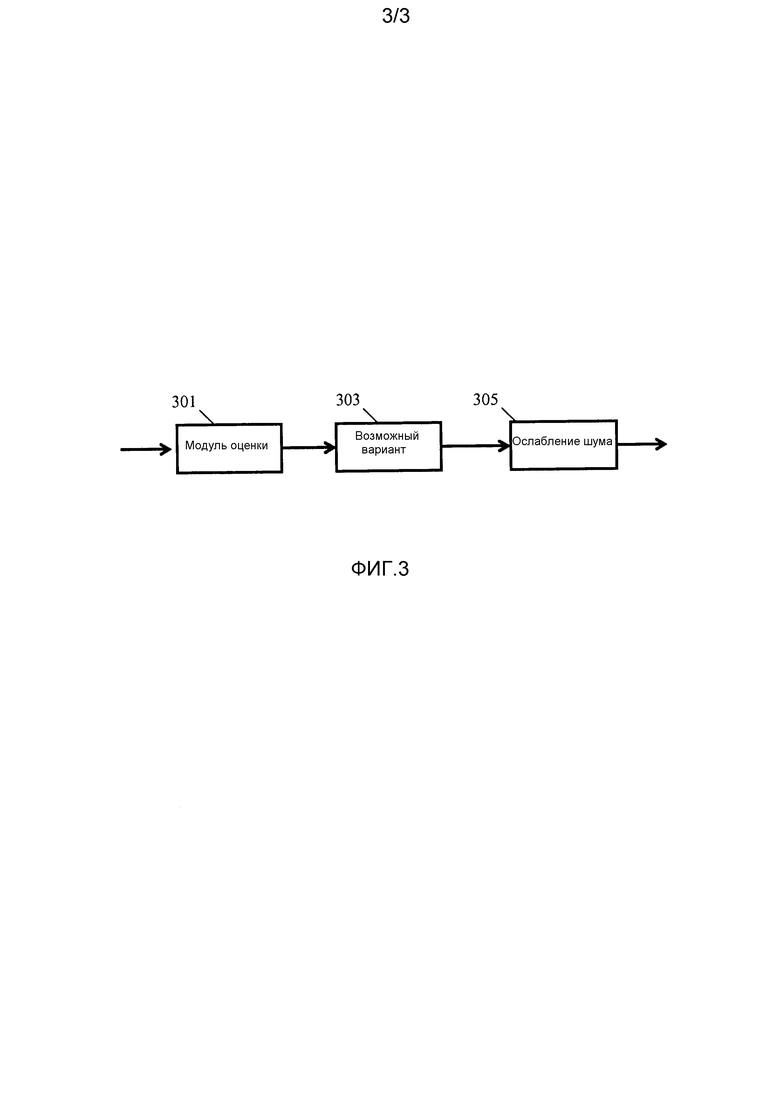
Фиг. 3 является иллюстрацией примера элементов ослабителя шума для устройства ослабления шума по фиг. 1.
ПОДРОБНОЕ ОПИСАНИЕ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ ИЗОБРЕТЕНИЯ
Нижеприведенное описание фокусируется на вариантах осуществления изобретения, применимых к улучшению речи посредством ослабления шума. Тем не менее, следует принимать во внимание, что изобретение не ограничено этим вариантом применения и может применяться ко многим другим сигналам.
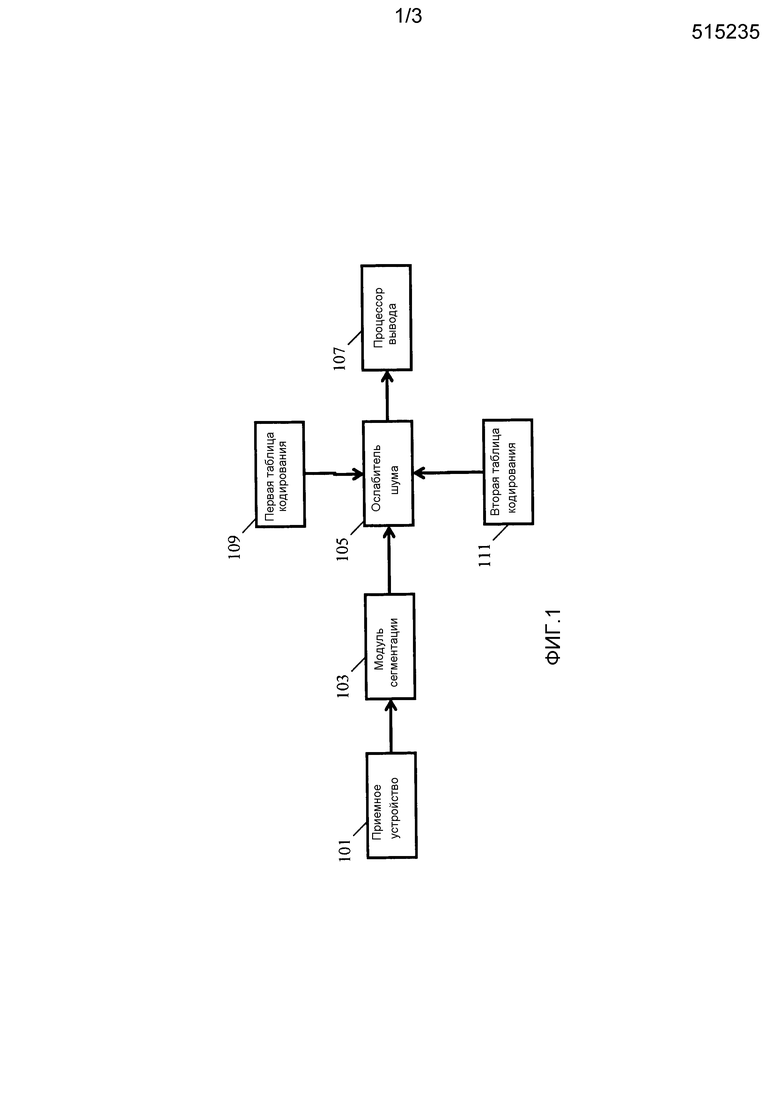
Фиг. 1 иллюстрирует пример ослабителя шума в соответствии с некоторыми вариантами осуществления изобретения.
Ослабитель шума содержит приемное устройство 101, которое принимает сигнал, который содержит как полезный компонент, так и неполезный компонент. Неполезный компонент упоминается в качестве шумового сигнала и может включать в себя любой компонент сигнала, не составляющий часть компонента полезного сигнала.
В системе по фиг. 1 сигнал представляет собой аудиосигнал, который, в частности, может быть сформирован из сигнала микрофона, захватывающего аудиосигнал в данном аудиоокружении. Нижеприведенное описание фокусируется на вариантах осуществления, в которых компонент полезного сигнала представляет собой речевой сигнал от требуемого говорящего. Компонент шумового сигнала может включать посторонний шум в окружении, аудио из нежелательных источников звука, шум от реализации и т.д.
Приемное устройство 101 соединяется с модулем 103 сегментации, который сегментирует аудиосигнал на временные сегменты. В некоторых вариантах осуществления временные сегменты могут быть неперекрывающимися, но в других вариантах осуществления временные сегменты могут быть перекрывающимися. Дополнительно, сегментация может быть выполнена посредством применения взвешивающей функции подходящей формы, и, в частности, устройство ослабления шума может использовать известную технологию суммирования с перекрытием для сегментации с использованием подходящей взвешивающей функции, к примеру, взвешивающей функции Хеннинга или Хэмминга. Длительность временного сегмента должна зависеть от конкретной реализации, но во многих вариантах осуществления должна составлять порядка 10-100 мс.
Модуль 103 сегментации подает результат в ослабитель 105 шума, который выполняет посегментное ослабление шума, чтобы выделять компонент полезного сигнала относительно неполезного компонента шумового сигнала. Результирующие сегменты после ослабления шума подаются в процессор 107 вывода, который предоставляет непрерывный аудиосигнал. Процессор вывода может, в частности, выполнять десегментацию, например, посредством выполнения функции суммирования с перекрытием. Следует принимать во внимание, что в других вариантах осуществления выходной сигнал может предоставляться в качестве сегментированного сигнала, например в вариантах осуществления, в которых дополнительная посегментная обработка сигналов выполняется для сигнала после ослабления шума.
Ослабление шума основано на подходе на основе таблиц кодирования, который использует отдельные таблицы кодирования, связанные с компонентом полезного сигнала и с компонентом шумового сигнала. Соответственно, ослабитель 105 шума соединяется с первой таблицей 109 кодирования, которая представляет собой таблицу кодирования полезных сигналов и в конкретном примере представляет собой таблицу кодирования речи. Ослабитель 105 шума дополнительно соединяется со второй таблицей 111 кодирования, которая представляет собой таблицу кодирования долей шумового сигнала.
Ослабитель 105 шума выполнен с возможностью выбирать записи таблицы кодирования из таблицы кодирования речи и таблицы кодирования шума, так что комбинация компонентов сигнала, соответствующих выбранным записям, наиболее близко напоминает аудиосигнал в этом временном сегменте. После того как надлежащие записи таблицы кодирования найдены (наряду с их масштабированием), они представляют оценку отдельного компонента речевого сигнала и компонента шумового сигнала в захваченном аудиосигнале. В частности, компонент сигнала, соответствующий выбранной записи таблицы кодирования речи, представляет собой оценку компонента речевого сигнала в захваченном аудиосигнале, и записи таблицы кодирования шума предоставляют оценку компонента шумового сигнала. Соответственно, подход использует подход на основе таблиц кодирования для того, чтобы оценивать компоненты речевого и шумового сигнала аудиосигнала, и после того, как эти оценки определены, они могут быть использованы для того, чтобы ослаблять компонент шумового сигнала относительно компонента речевого сигнала в аудиосигнале, поскольку оценки позволяют различать между ними.
Более конкретно, рассмотрим модель аддитивного шума, в которой речь и шум предположительно являются независимыми:
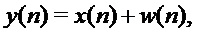
где y(n), x(n) и w(n) представляют дискретизированную зашумленную речь (входной аудиосигнал), чистую речь (компонент полезного речевого сигнала) и шум (компонент шумового сигнала) соответственно.
Подход на основе таблиц кодирования предшествующего уровня техники выполняет поиск в таблицах кодирования, чтобы находить запись таблицы кодирования для компонента сигнала и компонента шума, так что масштабированная комбинация наиболее близко напоминает захваченный сигнал, в силу этого предоставляя оценку PSD речи и шума для каждого кратковременного сегмента. Пусть Py(ω) обозначает PSD наблюдаемого зашумленного сигнала y(n), Px(ω) обозначает PSD компонента x(n) речевого сигнала и Pw(ω) обозначает PSD компонента шумового сигнала, в таком случае:
Py(ω)=Px(ω)+Pw(ω).
Пусть ^ обозначает оценку соответствующей PSD, традиционное ослабление шума на основе таблиц кодирования может сокращать шум посредством применения фильтра H(ω) Винера в частотной области к захваченному сигналу, т.е.:
Pna(ω)=Py(ω)H(ω),
где фильтр Винера задается следующим образом:
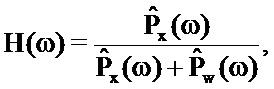
В подходе предшествующего уровня техники таблицы кодирования содержат возможные варианты речевого сигнала и возможные варианты шумового сигнала соответственно, и критически важная проблема состоит в том, чтобы идентифицировать самую подходящую пару возможных вариантов.
Оценка PSD речи и шума и, таким образом, выбор надлежащих возможных вариантов может следовать подходу на основе максимального правдоподобия (ML) или подходу на основе байесовской минимальной среднеквадратической ошибки (MMSE).
Отношение между вектором коэффициентов линейного прогнозирования и базовой PSD может быть определено посредством следующего:
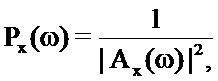
где 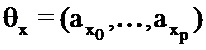
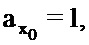
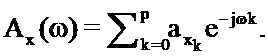
С использованием этого отношения оцененная PSD захваченного сигнала задается следующим образом:
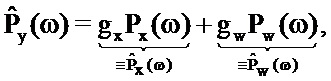
где gx и gw являются частотно-независимыми усилениями уровня, ассоциированными с PSD речи и шума. Эти усиления вводятся, чтобы учитывать изменение в уровне между PSD, сохраненными в таблице кодирования, и PSD, встречающимися во входном аудиосигнале.
Предшествующий уровень техники выполняет поиск по всем возможным спариваниям записи таблицы кодирования речи и записи таблицы кодирования шума, чтобы определять пару, которая максимизирует определенный показатель подобия между наблюдаемой зашумленной PSD и оцененной PSD, как описано ниже.
Рассмотрим пару PSD речи и шума, заданных посредством i-той PSD из таблицы кодирования речи и j-той PSD из таблицы кодирования шума. Зашумленная PSD, соответствующая этой паре, может быть записана следующим образом:
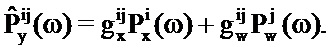
В этом уравнении PSD известны, тогда как усиления неизвестны. Таким образом, для каждой возможной пары PSD речи и шума должны определяться усиления. Это может осуществляться на базе подхода на основе максимального правдоподобия. Оценка по принципу максимального правдоподобия требуемых PSD речи и шума может быть получена в двухэтапной процедуре. Логарифм правдоподобия того, что данная пара 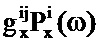
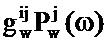
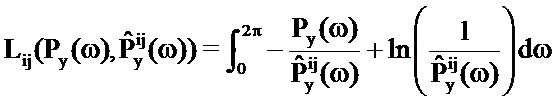
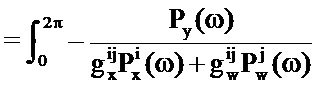
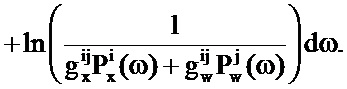
На первом этапе определяются неизвестные члены 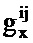
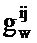
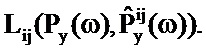
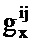
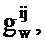
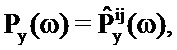
После того как члены уровня известны, может определяться значение 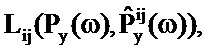
Пусть 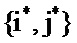
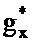
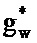
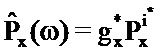
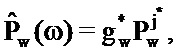
Таким образом, эти результаты задают фильтр Винера, который применяется к входному аудиосигналу для того, чтобы формировать сигнал после ослабления шума.
Таким образом, предшествующий уровень техники основан на нахождении подходящей записи таблицы кодирования полезных сигналов, которая является хорошей оценкой для компонента речевого сигнала, и подходящей записи таблицы кодирования шумового сигнала, которая является хорошей оценкой для компонента шумового сигнала. После того как они находятся, может применяться эффективное ослабление шума.
Тем не менее, подход является очень сложным и ресурсоемким. В частности, должны быть оценены все возможные комбинации записей таблицы кодирования шума и речи, чтобы находить наилучшее совпадение. Дополнительно, поскольку записи таблицы кодирования должны представлять большое множество возможных сигналов, это приводит к очень большим таблицам кодирования и в силу этого ко множеству возможных пар, которые должны быть оценены. В частности, компонент шумового сигнала зачастую может иметь большое изменение в возможных характеристиках, например, в зависимости от конкретных окружений использования и т.д. Следовательно, зачастую требуется очень большая таблица кодирования шума для того, чтобы обеспечивать достаточно близкую оценку. Это приводит к очень высокой вычислительной нагрузке, а также к значительным требованиям для хранения таблиц кодирования. Помимо этого формирование, в частности, таблицы кодирования шума может быть очень громоздким или трудным. Например, при использовании подхода на основе обучения набор обучающих выборок должен быть достаточно большим, чтобы в достаточной степени представлять возможный широкий спектр в шумовых сценариях. Это может приводить к очень затратному процессу.
В системе по фиг. 1 подход на основе таблиц кодирования не основан на выделенной таблице кодирования шума, которая задает возможные варианты для множества различных возможных компонентов шума. Наоборот, используется таблица кодирования шума, в которой записи таблицы кодирования считаются долями в компоненте шумового сигнала, вместо того чтобы обязательно быть прямыми оценками компонента шумового сигнала. Оценка компонента шумового сигнала затем формируется посредством взвешенной комбинации и, в частности, взвешенного суммирования записей таблицы кодирования долей шума. Таким образом, в системе по фиг. 1 оценка компонента шумового сигнала формируется посредством совместного рассмотрения множества записей таблицы кодирования, и фактически компонент оцененного шумового сигнала обычно задается в качестве линейной взвешенной комбинации или, в частности, суммирования записей таблицы кодирования шума.
В системе по фиг. 1 ослабитель 105 шума соединяется с таблицей 109 кодирования сигнала, которая содержит определенное число записей таблицы кодирования, каждая из которых содержит набор параметров, задающий возможный компонент полезного сигнала и, в конкретном примере, полезный речевой сигнал.
Таким образом, записи таблицы кодирования для компонента полезного сигнала соответствуют потенциальным возможным вариантам для компонентов полезного сигнала. Каждая запись содержит набор параметров, которые характеризуют возможный компонент полезного сигнала. В конкретном примере каждая запись содержит набор параметров, которые характеризуют возможный компонент речевого сигнала. Таким образом, сигнал, характеризуемый посредством записи таблицы кодирования, представляет собой сигнал, который имеет характеристики речевого сигнала, и в силу этого записи таблицы кодирования вводят знания речевых характеристик в оценку компонента речевого сигнала.
Записи таблицы кодирования для компонента полезного сигнала могут быть основаны на модели требуемого аудиоисточника либо дополнительно или альтернативно могут быть определены посредством процесса обучения. Например, записи таблицы кодирования могут представлять собой параметры для речевой модели, разработанной, чтобы представлять характеристики речи. В качестве другого примера, большое число речевых выборок может записываться и статистически обрабатываться, чтобы формировать подходящее число потенциальных возможных вариантов речи, которые сохраняются в таблице кодирования.
В частности, записи таблицы кодирования могут быть основаны на модели линейного прогнозирования. Фактически, в конкретном примере, каждая запись таблицы кодирования содержит набор параметров линейного прогнозирования. Записи таблицы кодирования, возможно, в частности, сформированы посредством процесса обучения, в котором параметры линейного прогнозирования сформированы посредством подгонки к большому числу речевых выборок.
Записи таблицы кодирования в некоторых вариантах осуществления могут представляться как частотное распределение и, в частности, как спектральная плотность мощности (PSD). PSD может соответствовать непосредственно параметрам линейного прогнозирования.
Число параметров для каждой записи таблицы кодирования типично является относительно небольшим. Фактически типично имеется не более 20 и зачастую не более 10 параметров, указывающих каждую запись таблицы кодирования. Таким образом, используется относительно приблизительная оценка компонента полезного сигнала. Это обеспечивает упрощенную обработку с меньшей сложностью, но при этом обнаружено, что это предоставляет эффективное ослабление шума в большинстве случаев.
Ослабитель 105 шума дополнительно соединяется с таблицей 111 кодирования долей шума. Тем не менее, в отличие от таблицы кодирования полезных сигналов, записи таблицы 109 кодирования долей шума, в общем, не задают компоненты шумового сигнала как таковые, а вместо этого задают возможные доли в оценке компонента шумового сигнала. Ослабитель 105 шума в силу этого формирует оценку для компонента шумового сигнала посредством комбинирования этих возможных долей.
Число параметров для каждой записи таблицы кодирования из таблицы 111 кодирования долей шума также типично является относительно небольшим. Фактически типично имеется не более 20 и зачастую не более 10 параметров, указывающих каждую запись таблицы кодирования. Таким образом, используется относительно приблизительная оценка компонента шумового сигнала. Это обеспечивает упрощенную обработку с меньшей сложностью, но при этом обнаружено, что это предоставляет эффективное ослабление шума в большинстве случаев. Дополнительно, число параметров, задающих записи таблицы кодирования долей шума, зачастую меньше числа параметров, задающих записи таблицы кодирования полезных сигналов.
В частности, для данной записи таблицы кодирования речи, обозначаемой посредством буквы i, ослабитель 105 шума формирует оценку аудиосигнала во временном сегменте следующим образом:
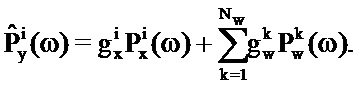
Где Nw является числом записей в таблице 111 кодирования долей шума, Pw(ω) является PSD записи и Px(ω) является PSD записи в таблице кодирования речи.
Для i-той записи таблицы кодирования речи ослабитель 105 шума в силу этого определяет наилучшую оценку для аудиосигнала посредством определения комбинации записей таблицы кодирования долей шума. Процесс затем повторяется для всех записей таблицы кодирования речи.
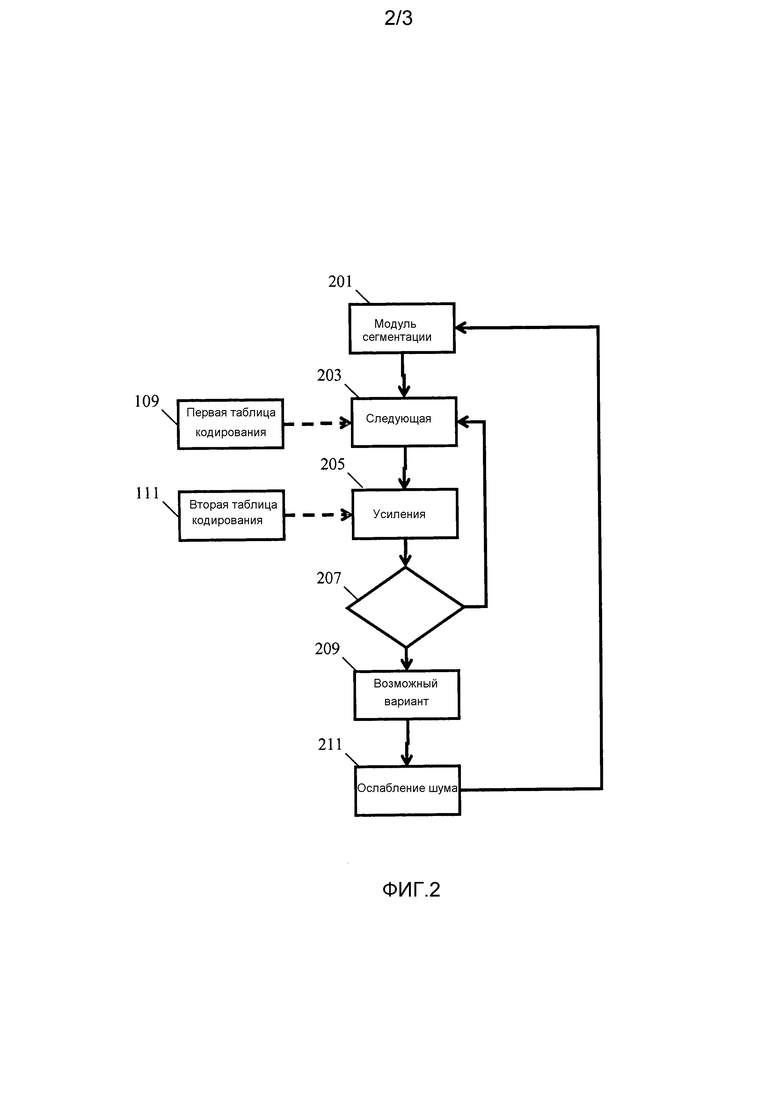
Фиг. 2 подробнее иллюстрирует процесс. Способ описывается со ссылкой на фиг. 3, который иллюстрирует элементы обработки ослабителя 105 шума. Способ начинается на этапе 201, на котором выбирается аудиосигнал в следующем сегменте.
Способ затем продолжается на этапе 203, на котором выбирается первая (следующая) запись таблицы кодирования речи из таблицы 109 кодирования речи.
После этапа 203 выполняется этап 205, на котором определяются весовые коэффициенты, применяемые к каждой записи таблицы кодирования из таблицы 111 кодирования долей шума, а также масштабирование записи таблицы кодирования речи. Таким образом, на этапе 205 gx и gw для каждого k определяются для записи таблицы кодирования речи.
Усиления (масштабирование/весовые коэффициенты), например, могут быть определены с использованием подхода на основе максимального правдоподобия, хотя следует принимать во внимание, что в других вариантах осуществления могут использоваться другие подходы и критерии, такие как, например, подход на основе минимальной среднеквадратической ошибки.
В качестве конкретного примера, логарифм правдоподобия того, что данная пара 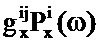
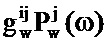
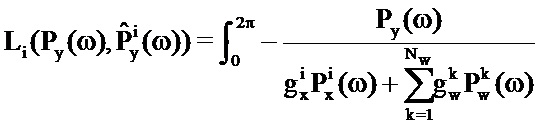
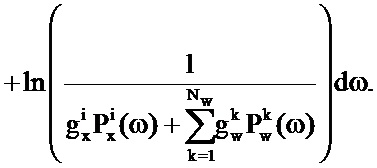
Функция логарифмического правдоподобия может рассматриваться как взаимно обратная функция затрат, т.е. чем больше значение, тем меньше разность (в смысле максимального правдоподобия) между возможным вариантом оцененного сигнала и входным аудиосигналом.
Определяются неизвестные значения 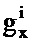
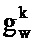
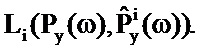
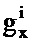
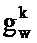
В частности, подход может быть основан на том факте, что правдоподобие максимизируется (и в силу этого соответствующая функция затрат минимизируется), когда 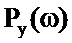
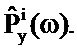
Во-первых, для удобства обозначения PSD речи и шума и члены усиления переименовываются следующим образом:
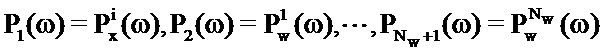
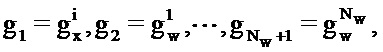
так что:
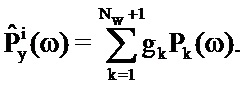
Функция затрат минимизируется посредством максимизации обратной функции затрат:
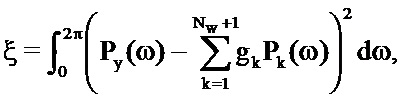
частная производная которой относительно gl (1<l≤Nw+1) может задаваться равной нулю, чтобы решать для членов усиления:
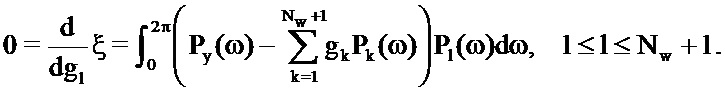
Это приводит к следующей линейной системе, решение которой дает в результате требуемые члены усиления:
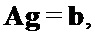
где:
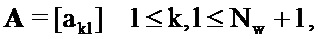
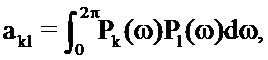
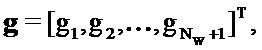
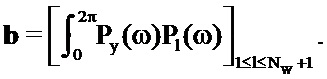
Следует отметить, что усиления, заданные посредством этих уравнений, могут быть отрицательными. Тем не менее, чтобы обеспечивать то, что рассматриваются только доли шума реального мира, усиления, возможно, должны быть положительными, например, посредством применения модифицированных условий Каруша-Куна-Таккера.
Таким образом, этап 205 продолжает формировать возможный вариант оцененного сигнала для обрабатываемой записи таблицы кодирования речи. Возможный вариант оцененного сигнала задается следующим образом:
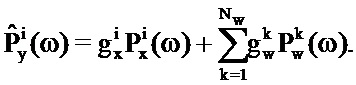
Где усиления вычислены так, как описано.
После этапа 205 способ переходит к этапу 207, на котором оценивается, обработаны или нет все речевые записи таблицы кодирования речи. Если нет, способ возвращается к этапу 203, на котором выбирается следующая запись таблицы кодирования речи. Это повторяется для всех записей таблицы кодирования речи.
Этапы 201-207 выполняются посредством модуля 301 оценки по фиг. 3. Таким образом, модуль 301 оценки является процессором, схемой или функциональным элементом, который определяет возможный вариант оцененного сигнала для каждой записи первой таблицы 109 кодирования.
Если выявлено, что все записи таблицы кодирования обработаны на этапе 207, способ переходит к этапу 209, на котором процессор 303 продолжает формировать возможный вариант сигнала для временного сегмента на основе возможных вариантов оцененного сигнала. Таким образом, возможный вариант сигнала формируется посредством рассмотрения 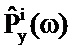
Этап 209 может, в частности, определять возможный вариант сигнала на основе определенных значений логарифмического правдоподобия. В качестве примера с низкой сложностью система может просто выбирать возможный вариант оцененного сигнала, имеющий наибольшее значение логарифмического правдоподобия. В более сложных вариантах осуществления возможный вариант сигнала может быть вычислен посредством взвешенной комбинации и, в частности, суммирования всех возможных вариантов оцененного сигнала, при этом взвешивание каждого возможного варианта оцененного сигнала зависит от значения логарифмического правдоподобия.
После этапа 209 выполняется этап 211, на котором модуль 303 ослабления шума продолжает компенсировать аудиосигнал на основе вычисленного возможного варианта сигнала. В частности, посредством фильтрации аудиосигнала с помощью фильтра Винера:
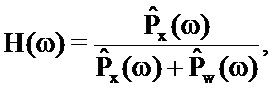
Следует принимать во внимание, что могут использоваться другие подходы для уменьшения шума на основе компонентов оцененного сигнала и шума. Например, система может просто вычитать оцененный возможный вариант шума из входного аудиосигнала.
Таким образом, этап 211 формирует выходной сигнал из входного сигнала во временном сегменте, в котором компонент шумового сигнала ослабляется относительно компонента речевого сигнала. Способ затем возвращается к этапу 201 и обрабатывает следующий сегмент.
Подход позволяет предоставлять очень эффективное ослабление шума при значительном уменьшении сложности. В частности, поскольку записи таблицы кодирования шума соответствуют долям шума, а не обязательно всему компоненту шумового сигнала, необходимо гораздо меньшее число записей. Большое изменение в возможных оценках шума является возможным посредством регулирования комбинации отдельных долей. Кроме того, ослабление шума может достигаться с существенно меньшей сложностью. Например, в отличие от традиционного подхода, который заключает в себе поиск по всем комбинациям записей таблицы кодирования речи и шума, подход по фиг. 1 включает в себя только один контур, а именно по записям таблицы кодирования речи.
Следует принимать во внимание, что таблица 111 кодирования долей шума может содержать различные записи, соответствующие различным возможным вариантам доли шума в различных вариантах осуществления.
В частности, в некоторых вариантах осуществления некоторые или все возможные варианты долей шумового сигнала могут совместно покрывать частотный диапазон, в котором выполняется ослабление шума, тогда как отдельные возможные варианты покрывают только поднабор этого диапазона. Например, группа записей может совместно покрывать частотный интервал, скажем, в 200 Гц - 4 кГц, но каждая запись набора содержит только поддиапазон (т.е. часть) этого частотного интервала. Таким образом, каждый возможный вариант может покрывать различные поддиапазоны. Фактически в некоторых вариантах осуществления каждая из записей может покрывать различный поддиапазон, т.е. поддиапазоны группы возможных вариантов долей шумового сигнала могут быть по существу неперекрывающимися. Например, спектральная плотность в частотном поддиапазоне одного возможного варианта может, по меньшей мере, на 6 дБ превышать спектральную плотность любого другого возможного варианта в этом поддиапазоне. Следует принимать во внимание, что в таких примерах поддиапазоны могут разделяться посредством переходных диапазонов. Такие переходные диапазоны предпочтительно могут быть меньше 10% полосы пропускания поддиапазонов.
В других вариантах осуществления некоторые или все возможные варианты долей шумового сигнала могут быть перекрывающимися, так что несколько возможных вариантов предоставляют значительную долю в интенсивности сигнала на данной частоте.
Также следует принимать во внимание, что спектральное распределение каждого возможного варианта может отличаться в различных вариантах осуществления. Тем не менее, во многих вариантах осуществления спектральное распределение каждого возможного варианта может быть по существу плоским в поддиапазоне. Например, амплитудное изменение может быть меньше 10%. Это позволяет упрощать работу во многих вариантах осуществления и может, в частности, обеспечивать обработку с меньшей сложностью и/или уменьшенными требованиями по хранению.
В качестве конкретного примера, каждый возможный вариант доли шумового сигнала может задавать сигнал с плоской спектральной плотностью в данном частотном диапазоне. Дополнительно, таблица 111 кодирования долей шума может содержать набор таких возможных вариантов (возможно в дополнение к другим возможным вариантам), которые покрывают весь требуемый частотный диапазон, в котором должна быть выполнена компенсация.
В частности, для поддиапазонов с равной шириной, записи таблицы 111 кодирования долей шума могут задаваться следующим образом:
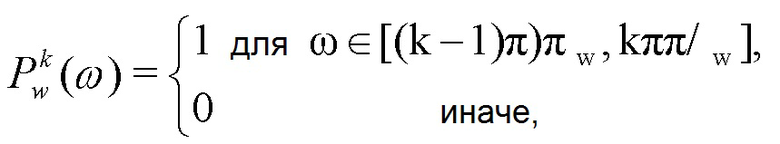
для 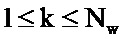
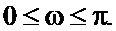
Таким образом, в некоторых подходах компонент шумового сигнала в этом случае моделируется в качестве взвешенной суммы плоских PSD с ограниченной полосой частот. Следует отметить, что в этом примере таблица 111 кодирования долей шума может быть реализована просто посредством линейного уравнения, задающего все записи, и нет необходимости в выделенном запоминающем устройстве таблиц кодирования, сохраняющем отдельные примеры сигналов.
Следует отметить, что такой подход на основе взвешенной суммы позволяет моделировать окрашенный шум. Частотное разрешение, с которым оценка шума может быть адаптирована к аудиосигналу, определяется посредством ширины каждого поддиапазона, который, в свою очередь, определяется посредством числа записей Nw таблицы кодирования. Тем не менее, возможные варианты долей шумового сигнала типично выполнены с возможностью иметь более низкое разрешение, чем частотное разрешение взвешенного суммирования (которое вытекает из регулирования весовых коэффициентов). Таким образом, степени свободы, доступные, чтобы совпадать с оценкой шума, меньше степеней свободы, доступных, чтобы задавать каждый возможный вариант полезного сигнала в таблице 109 кодирования полезных сигналов.
Это используется для того, чтобы обеспечивать, что оценка компонента полезного сигнала на основе таблицы кодирования полезных сигналов является центральной для оценки всего сигнала, и, в частности, снижать риск того, что ошибочный или неточный возможный вариант полезного сигнала выбирается вследствие подавления ошибок посредством адаптации взвешенного суммирования к аудиосигналу на основе неправильного возможного варианта полезного сигнала. Фактически, если свобода адаптации оценки компонента шума является слишком высокой, члены усиления могут регулироваться таким образом, что любая запись таблицы кодирования речи может приводить к одинаково высокой вероятности. Следовательно, приблизительное частотное разрешение (имеющее один член усиления для полосы элементов разрешения по частоте возможных вариантов полезного сигнала) в таблице кодирования шума обеспечивает то, что записи таблицы кодирования речи, которые являются близкими к базовой чистой речи, приводят к большему правдоподобию и наоборот.
В некоторых вариантах осуществления поддиапазоны преимущественно могут иметь неравные полосы пропускания. Например, полоса пропускания каждого возможного варианта может быть выбрана в соответствии с психоакустическими принципами. Например, каждый поддиапазон может быть выбран таким образом, что он соответствует полосе частот ERB или Барка.
Следует принимать во внимание, что подход с использованием таблицы 111 кодирования долей шума, содержащей определенное число неперекрывающихся PSD с ограниченной полосой частот равной полосы пропускания, представляет собой просто один пример и что альтернативно или дополнительно может использоваться определенное число других таблиц кодирования. Например, как упомянуто выше, могут рассматриваться неравная ширина и/или перекрывающиеся полосы пропускания для каждой записи таблицы кодирования. Кроме того, может использоваться комбинация перекрывающихся и неперекрывающихся полос пропускания. Например, таблица 111 кодирования долей шума может содержать набор записей, в котором интересующая полоса пропускания разделяется на первое число полос, и другой набор записей, в котором интересующая полоса пропускания разделяется на другое число полос.
В некоторых вариантах осуществления система может содержать модуль оценки шума, который формирует оценку шума для аудиосигнала, причем оценка шума формируется с учетом временного интервала, который, по меньшей мере, частично находится за пределами обрабатываемого временного сегмента. Например, оценка шума может быть сформирована на основе временного интервала, который существенно длительнее временного сегмента. Эта оценка шума затем может быть включена в качестве возможного варианта доли шумового сигнала в таблицу 111 кодирования долей шума при обработке временного интервала.
Это позволяет предоставлять в алгоритм запись таблицы кодирования, которая с большой вероятностью является близкой к более долговременному среднему компоненту шума, при предоставлении возможности адаптации с использованием других возможных вариантов, чтобы модифицировать ее для того, чтобы оценивать, чтобы следовать более кратковременным изменениям шума. Например, одна запись таблицы кодирования шума может выделяться для сохранения последней оценки PSD шума, полученной из другой оценки шума, как, например, в алгоритме, раскрытом в работе R. Martin "Noise power spectral density estimation based on optimal smoothing and minimum statistics" IEEE Trans. Speech and Audio Processing, издание 9, № 5, стр. 504-512, июль 2001 года. Таким образом, можно ожидать, что алгоритм должен работать, по меньшей мере, не хуже существующих алгоритмов и работать лучше в трудных условиях.
В качестве другого примера, система может усреднять результирующие оценки долей шума и сохранять более долговременное среднее в качестве записи в таблице 111 кодирования долей шума.
Система может быть использована во множестве различных вариантов применения, включающих в себя, например, варианты применения, которые требуют уменьшения уровня шума от одного микрофона, например мобильную телефонную связь и DECT-телефоны. В качестве другого примера, подход может быть использован в системах улучшения речи на основе нескольких микрофонов (например, слуховых аппаратах, матричных системах громкой связи и т.д.), которые обычно имеют одноканальный постпроцессор для дополнительного уменьшения уровня шума.
Следует принимать во внимание, что вышеприведенное описание для понятности описывает варианты осуществления со ссылкой на различные функциональные схемы, модули и процессоры. Тем не менее, должно быть очевидным, что любое надлежащее распределение функциональности между различными функциональными схемами, модулями или процессорами может быть использовано без отступления от изобретения. Например, функциональность, проиллюстрированная как выполняемая посредством отдельных процессоров или контроллеров, может быть выполнена посредством одного процессора или контроллера. Следовательно, ссылки на конкретные функциональные модули или схемы должны рассматриваться только как ссылки на надлежащее средство предоставления описанной функциональности, а не обозначать точную логическую или физическую структуру либо организацию.
Изобретение может быть реализовано в любой надлежащей форме, включающей в себя аппаратные средства, программное обеспечение, микропрограммное обеспечение или любую комбинацию вышеозначенного. Необязательно, изобретение может быть реализовано, по меньшей мере, частично как вычислительное программное обеспечение, выполняемое на одном или более процессоров данных и/или процессоров цифровых сигналов. Элементы и компоненты варианта осуществления изобретения могут быть физически, функционально и логически реализованы любым надлежащим образом. Фактически функциональность может быть реализована в одном модуле, во множестве модулей или как часть других функциональных модулей. По существу, изобретение может быть реализовано в одном модуле или может быть физически и функционально распределено между различными модулями, схемами и процессорами.
Хотя настоящее изобретение описано в связи с некоторыми вариантами осуществления, оно не имеет намерения быть ограниченным конкретной изложенной в данном документе формой. Вместо этого объем настоящего изобретения ограничен только посредством прилагаемой формулы изобретения. Дополнительно, хотя предположительно признак описывается в данном документе в связи с конкретными вариантами осуществления, специалисты в данной области техники должны признавать, что различные признаки описанных вариантов осуществления могут быть комбинированы в соответствии с изобретением. В формуле изобретения термин "содержащий" не исключает наличия других элементов или этапов.
Более того, хотя перечислены по отдельности, множество средств, элементов, схем или этапов способа может быть реализовано посредством, к примеру, одной схемы, модуля или процессора. Дополнительно, хотя отдельные признаки могут быть включены в различные пункты формулы изобретения, они могут быть преимущественно комбинированы, и их включение в различные пункты формулы изобретения не подразумевает, что комбинация признаков является невыполнимой и/или преимущественной. Также включение признака в одну категорию пунктов формулы изобретения не налагает ограничения на эту категорию, а вместо этого указывает то, что признак в равной степени применим к другим категориям пунктов формулы изобретения по мере необходимости. Более того, порядок признаков в пунктах формулы изобретения не налагает какой-либо конкретный порядок, в котором признаки должны осуществляться, и, в частности, порядок отдельных этапов в пункте формулы изобретения на способ не подразумевает, что этапы должны выполняться в этом порядке. Вместо этого этапы могут выполняться в любом надлежащем порядке. Кроме того, ссылки в единственном числе не исключают множественности. Таким образом, ссылки на "первый", "второй" и т.д. не исключают множественности. Цифровые позиционные обозначения в формуле изобретения предоставлены просто в качестве поясняющего примера, и они не должны истолковываться как каким-либо образом ограничивающие объем формулы изобретения.
Изобретение относится к области обработки речевых аудиосигналов. Технический результат заключается в обеспечении ослабления шума при приеме аудиосигналов. Технический результат достигается за счет обеспечения двух таблиц кодирования, которые содержат варианты полезного сигнала, представляющие возможный компонент полезного сигнала, и возможные варианты долей шумового сигнала, представляющие возможные доли шума, сегментации аудиосигнала на временные сегменты, и для каждого временного сегмента формирования возможных вариантов оцененного сигнала в качестве комбинации масштабированной версии возможного варианта полезного сигнала и взвешенной комбинации возможных вариантов долей шумового сигнала, минимизации функции затрат, указывающей разность между возможным вариантом оцененного сигнала и аудиосигналом во временном сегменте, определения варианта сигнала для временного сегмента из возможных вариантов оцененного сигнала и компенсации аудиосигнала шума на основе этого возможного варианта сигнала. 2 н. и 12 з.п. ф-лы, 3 ил.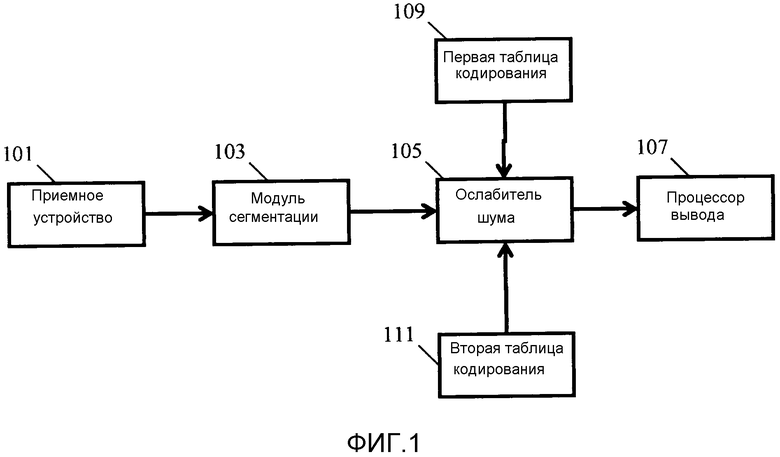
1. Устройство ослабления шума, содержащее:
- приемное устройство (101) для приема аудиосигнала, содержащего компонент полезного сигнала и компонент шумового сигнала;
- первую таблицу (109) кодирования, содержащую множество возможных вариантов полезного сигнала для компонента полезного сигнала, причем каждый возможный вариант полезного сигнала представляет возможный компонент полезного сигнала;
- вторую таблицу (111) кодирования, содержащую множество возможных вариантов долей шумового сигнала, причем каждый возможный вариант доли шумового сигнала представляет возможную долю шума для компонента шумового сигнала;
- модуль (103) сегментации для сегментации аудиосигнала на временные сегменты;
- ослабитель (105) шума, выполненный с возможностью для каждого временного сегмента выполнять этапы, на которых:
- формируют множество возможных вариантов оцененного сигнала посредством формирования, для каждого из возможных вариантов полезного сигнала первой таблицы кодирования, возможного варианта оцененного сигнала в качестве комбинации масштабированной версии возможного варианта полезного сигнала и взвешенной комбинации возможных вариантов долей шумового сигнала, причем масштабирование возможного варианта полезного сигнала и весовые коэффициенты взвешенной комбинации определяются таким образом, чтобы минимизировать функцию затрат, указывающую разность между возможным вариантом оцененного сигнала и аудиосигналом во временном сегменте,
- формируют возможный вариант сигнала для аудиосигнала во временном сегменте из возможных вариантов оцененного сигнала, и
- ослабляют шум аудиосигнала во временном сегменте в ответ на возможный вариант сигнала.
2. Устройство ослабления шума по п. 1, в котором функция затрат является одной из функции затрат на основе максимального правдоподобия и функции затрат на основе минимальной среднеквадратической ошибки.
3. Устройство ослабления шума по п. 1, в котором ослабитель (105) шума выполнен с возможностью вычислять масштабирование и весовые коэффициенты из уравнений, отражающих производную функции затрат относительно масштабирования и весовых коэффициентов, равных нулю.
4. Устройство ослабления шума по п. 1, в котором возможные варианты полезного сигнала имеют более высокое частотное разрешение, чем взвешенная комбинация.
5. Устройство ослабления шума по п. 1, в котором множество возможных вариантов долей шумового сигнала покрывает частотный диапазон, при этом каждый возможный вариант доли шумового сигнала из группы возможных вариантов долей шумового сигнала предоставляет доли только в поддиапазоне частотного диапазона, причем поддиапазоны различных возможных вариантов долей шумового сигнала из группы возможных вариантов долей шумового сигнала отличаются.
6. Устройство ослабления шума по п. 5, в котором поддиапазоны группы возможных вариантов долей шумового сигнала являются неперекрывающимися.
7. Устройство ослабления шума по п. 5, в котором поддиапазоны группы возможных вариантов долей шумового сигнала имеют неравные размеры.
8. Устройство ослабления шума по п. 5, в котором каждый из возможных вариантов долей шумового сигнала из группы возможных вариантов долей шумового сигнала соответствует по существу плоскому частотному распределению.
9. Устройство ослабления шума по п. 1, дополнительно содержащее модуль оценки шума для формирования оценки шума для аудиосигнала во временном интервале, по меньшей мере, частично за пределами временного сегмента и для формирования, по меньшей мере, одного из возможных вариантов долей шумового сигнала в ответ на оценку шума.
10. Устройство ослабления шума по п. 1, в котором взвешенная комбинация представляет собой взвешенное суммирование.
11. Устройство ослабления шума по п. 1, в котором, по меньшей мере, один из возможных вариантов полезного сигнала первой таблицы кодирования и возможных вариантов долей шумового сигнала второй таблицы кодирования представляется посредством набора параметров, содержащего не более 20 параметров.
12. Устройство ослабления шума по п. 1, в котором, по меньшей мере, один из возможных вариантов полезного сигнала первой таблицы кодирования и возможных вариантов долей шумового сигнала второй таблицы кодирования представляется посредством спектрального распределения.
13. Устройство ослабления шума по п. 1, в котором компонент полезного сигнала представляет собой компонент речевого сигнала.
14. Способ ослабления шума, содержащий этапы, на которых:
- принимают аудиосигнал, содержащий компонент полезного сигнала и компонент шумового сигнала;
- предоставляют первую таблицу (109) кодирования, содержащую множество возможных вариантов полезного сигнала для компонента полезного сигнала, причем каждый возможный вариант полезного сигнала представляет возможный компонент полезного сигнала;
- предоставляют вторую таблицу (111) кодирования, содержащую множество возможных вариантов долей шумового сигнала, причем каждый возможный вариант доли шумового сигнала представляет возможную долю шума для компонента шумового сигнала;
- сегментируют аудиосигнал на временные сегменты; и
- для каждого временного сегмента выполняют этапы, на которых:
- формируют множество возможных вариантов оцененного сигнала посредством формирования, для каждого из возможных вариантов полезного сигнала первой таблицы кодирования, возможного варианта оцененного сигнала в качестве комбинации масштабированной версии возможного варианта полезного сигнала и взвешенной комбинации возможных вариантов долей шумового сигнала, причем масштабирование возможного варианта полезного сигнала и весовые коэффициенты взвешенной комбинации определяются таким образом, чтобы минимизировать функцию затрат, указывающую разность между возможным вариантом оцененного сигнала и аудиосигналом во временном сегменте,
- формируют возможный вариант сигнала для временного сегмента из возможных вариантов оцененного сигнала, и
- ослабляют шум аудиосигнала во временном сегменте в ответ на возможный вариант сигнала.
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| КОДИРОВАНИЕ С МНОЖЕСТВОМ СКОРОСТЕЙ | 2004 |
|
RU2364958C2 |

