Область техники
Изобретение относится к компьютерной безопасности, а именно к способам хеширования файлов в системах класса DLP (data loss prevention), и может быть использовано для быстрого поиска дубликатов файлов, в том числе для предотвращения утечки данных.
Уровень техники
DLP системы обрабатывают значительное количество теневых копий оригиналов файлов, которые, например, были загружены на USB-носители, в облачные хранилища, отправлены по электронной почте или через другие каналы связи. Для данных теневых копий требуется осуществлять быстрый поиск с возможностью поиска конкретного файла, находить копии данного файла в файловых системах или в корпоративных архивах сохраненных сообщений (история переписки в электронной почте, корпоративном мессенджере) и во многих других случаях.
Для этого DLP системы используют хеширование для обеспечения целостности данных и выявления возможных нарушений. С помощью хеширования создается уникальный идентификатор для каждого файла, который можно сравнить с эталонным значением для обнаружения дубликатов или возможных изменений. В случае обнаружения дубликатов или изменений DLP система может предпринять определенные действия, например, уведомить администратора или заблокировать доступ к файлу.
На сегодняшний день из уровня техники известны различные алгоритмы, выполняющие хеширование\контрольное суммирование файла до единого значения (CRC 8/16/32 и их аналоги, линейка алгоритмов MD2/4/5/6, алгоритмы SHA и алгоритмы стандарта ГОСТ 34.11-94), однако их применение влияет на вычислительные ресурсы ЦПУ, более того, что еще критичнее, существенно влияет на производительность систем хранения данных. Данные алгоритмы хеширования являются довольно точными, но весьма ресурсоемкими. Данная точность является для прикладных задач избыточной, поскольку DLP системы хранят пусть и большой, но все же не бесконечный архив файлов.
Один из известных способов сравнения массивов бинарных данных раскрыт в патенте РФ на изобретение №2601191, где осуществляют автоматизированное сравнение массивов бинарных данных путем получения наборов идентификационных данных, состоящих из последовательно расположенных минимальных значений для каждой хэш-функции в виде набора идентификационных данных анализируемых документов, а также получения наборов идентификационных данных для эталонных документов, с выявлением совпадений между этими наборами. При этом последовательность бинарных данных в данном способе разбивают на подблоки заданной длины с перекрытием на один символ данных.
Однако перекрытие подблоков бинарных данных может привести к снижению точности хеширования, поскольку одни и те же данные будут хешироваться несколько раз. Это может увеличить вероятность коллизий, когда два разных входных данных дают один и тот же хеш. Кроме того, данный способ является достаточно ресурсоемким.
Раскрытие сущности изобретения
Настоящее изобретение направлено на достижение технических результатов, заключающихся в повышении быстродействия и точности поиска дубликатов файлов, и снижении нагрузки на ЦПУ и систему хранения данных.
Заявленные технические результаты обеспечивает способ хеширования файлов для быстрого поиска дубликатов, содержащий следующие этапы:
1) парсер протокола получает оригиналы файлов и их метаданные от внешних источников;
2) метаданные и оригиналы файлов сохраняются в базу данных;
3) по базе данных проводится сканирование файлов, хеш для которых еще не рассчитан;
4) файл, хеш для которого еще не рассчитан, подвергается хешированию, при этом, если такой файл менее заданного размера, то он хешируется полностью, а если размер файла больше заданного размера, то хешируются его первый или последний блоки заданного размера;
5) к полученному хешу добавляется размер файла, и полученный хеш сохраняется в базу данных с привязкой к файлу;
6) выборка конкретных файлов по базе данных в соответствии с их хешами и поиск дубликатов.
Краткое описание чертежей
Заявляемое изобретение поясняется изображением:
на чертеже - блок-схема способа хеширования файлов для быстрого поиска дубликатов.
Осуществление изобретения
Используемые термины в настоящем изобретении:
Хеширование - преобразование произвольного массива данных в строку фиксированной длины, состоящую из цифр и букв.
Метаданные - данные о данных, которые включают информацию об их составе, содержании, статусе, происхождении, местонахождении, качестве, форматах, объеме, условиях доступа, авторских правах и т.п.
Парсер протокола - программа или часть программного кода, реализующая синтаксический разбор каких-либо входных данных.
Обфускация - приведение исходного кода или исполняемого кода программы к виду, сохраняющему ее функциональность, но затрудняющему анализ, понимание алгоритмов работы и модификацию при декомпиляции.
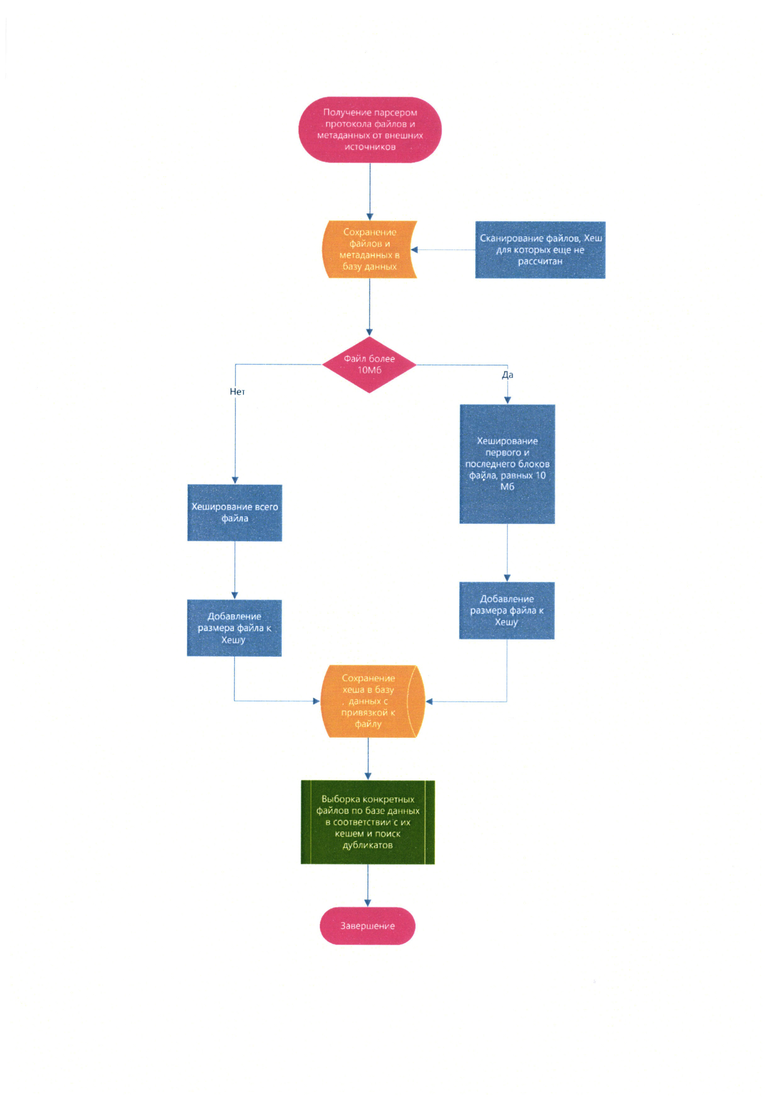
На чертеже представлена блок-схема способа хеширования файлов для быстрого поиска дубликатов.
Как видно из вышеуказанной блок-схемы, парсер протокола (какой это конкретно протокол\канал связи не важно) получает данные от внешних источников, например из сетевых коммуникаций - переписок в почте, мессенджерах, передачи браузерного траффика, сетевыми папками, из коммуникаций с устройствами - записи на USB, печати на принтере и т.д.
Парсер протокола выделяет сетевую часть, фильтрует служебный траффик и выделяет из траффика метаданные и файлы.
Метаданные - например, отправитель, получатель, время, ПК и т.д., и оригинал файла сохраняются в базу данных.
По базе данных проводится сканирование файлов, хеш для которых еще не рассчитан. Эти файлы подвергаются хешированию, при этом если файл менее заданного размера, например, 10 Мб, то файл хешируется полностью, а если размер файла больше заданного размера, например, 10 Мб, то хешируются его первый и/или последний блоки заданного размера, например по 10 Мб.
Так как в DLP систему в большинстве случаев поступают офисные документы и файлы относительно небольшого размера, то для таких файлов можно рассчитать хеш всего объема документа, зачастую такие файлы не превышают размер в 10Мб.
Расчет хеша для первого и/или последнего блока файла сокращает время необходимое на хеширование и способствует в том числе обфускации.
К полученному хешу добавляется размер файла, и полученный хеш сохраняется в базу данных с привязкой к файлу. Добавление размера файла к хешу влияет на безопасность системы, так как это уменьшает вероятность коллизий и улучшает защиту от атак на основе подбора хешей.
Далее по базе данных происходит выборка конкретных файлов при помощи интерфейса пользователя DLP системы, либо при автоматизированных проверках в DLP системе происходит быстрая выгрузка файлов по их хешам. При выборе файла из базы данных вычисляется его хеш и сравнивается с хешами других файлов. Соответственно, файлы с одинаковым хешем являются дубликатами по отношению друг к другу.
Изобретение относится к области вычислительной техники. Технический результат заключается в повышении быстродействия и точности поиска дубликатов файлов и снижении нагрузки на ЦПУ и систему хранения данных. Технический результат достигается за счет способа хеширования файлов для быстрого поиска дубликатов, который состоит из следующих этапов: парсер протокола получает оригиналы файлов и их метаданные от внешних источников; метаданные и оригиналы файлов сохраняются в базу данных; по базе данных проводится сканирование файлов, хеш для которых еще не рассчитан; файл, хеш для которого еще не рассчитан, подвергается хешированию, при этом если такой файл менее заданного размера, то файл хешируется полностью, а если размер файла больше заданного размера, то хешируются его первый или последний блоки заданного размера; к полученному хешу добавляется размер файла, и полученный хеш сохраняется в базу данных с привязкой к файлу; выборка конкретных файлов по базе данных в соответствии с их хешами и поиск дубликатов. 2 з.п. ф-лы, 1 ил.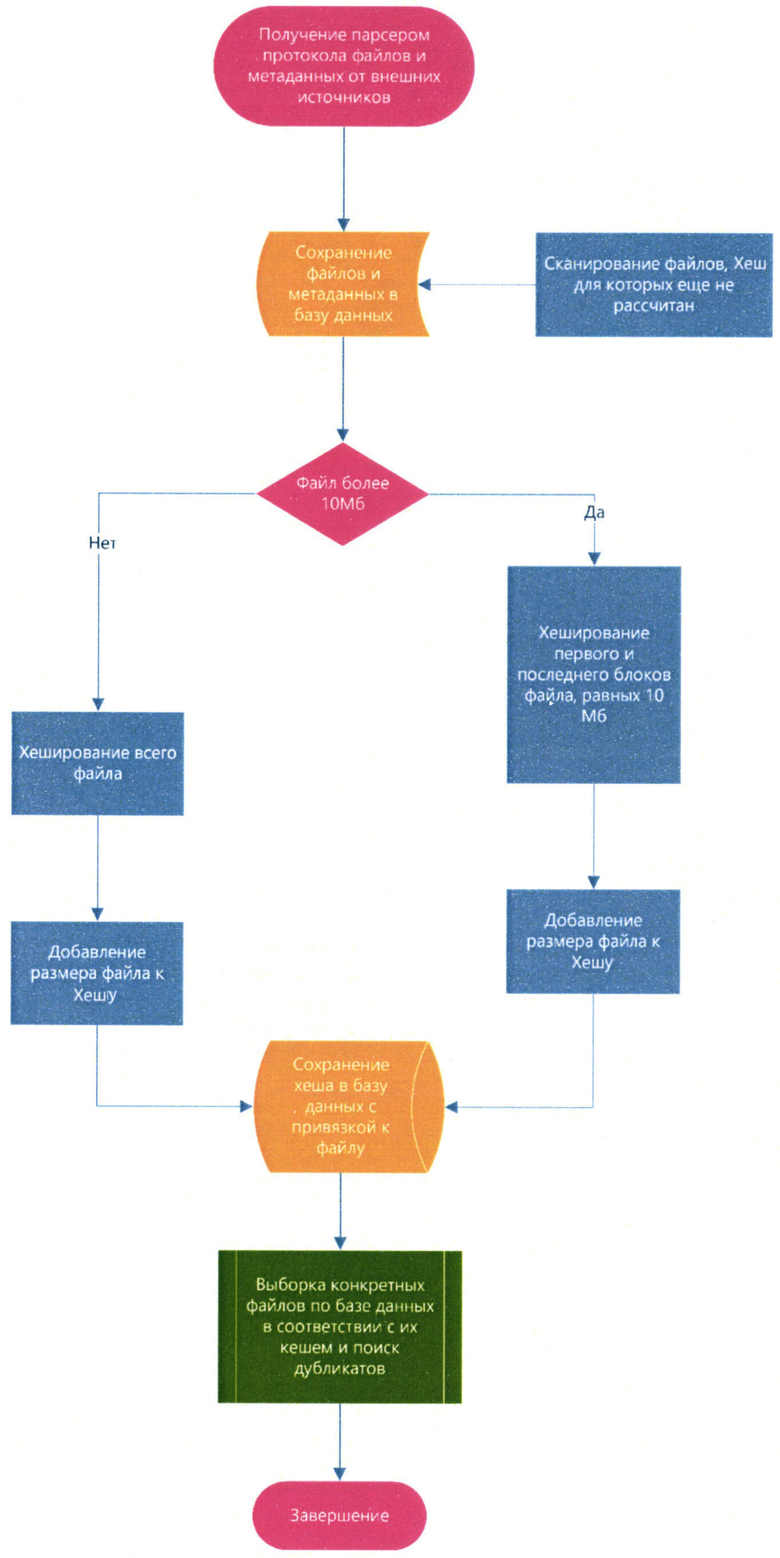
1. Способ хеширования файлов для быстрого поиска дубликатов, содержащий следующие этапы:
1) парсер протокола получает оригиналы файлов и их метаданные от внешних источников;
2) метаданные и оригиналы файлов сохраняются в базу данных;
3) по базе данных проводится сканирование файлов, хеш для которых еще не рассчитан;
4) файл, хеш для которого еще не рассчитан, подвергается хешированию, при этом если такой файл менее заданного размера, то он хешируется полностью, а если размер файла больше заданного размера, то хешируются его первый или последний блоки заданного размера;
5) к полученному хешу добавляется размер файла, и полученный хеш сохраняется в базу данных с привязкой к файлу;
6) выборка конкретных файлов по базе данных в соответствии с их хешами и поиск дубликатов.
2. Способ хеширования файлов для быстрого поиска дубликатов по п. 1, отличающийся тем, что если размер файла больше заданного размера, то хешируются его первый и последний блоки заданного размера.
3. Способ хеширования файлов для быстрого поиска дубликатов по п. 1, отличающийся тем, что если файл менее 10 Мб, то он хешируется полностью, а если размер файла больше 10 Мб размера, то хешируются его первый или последний блоки по 10 Мб.
| Колосоуборка | 1923 |
|
SU2009A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| СПОСОБ ХЕШИРОВАНИЯ ИНФОРМАЦИИ | 2020 |
|
RU2747517C1 |

