ОБЛАСТЬ ТЕХНИКИ
Устройство относится к области сохранения данных и, в частности, к способу и устройству сохранения данных.
ПРЕДПОСЫЛКИ К СОЗДАНИЮ ИЗОБРЕТЕНИЯ
Технологии кодирования/декодирования каналов обычно применяются в стандартах связи для снижения частоты ошибок во время передачи данных. Коды с малой плотностью проверок на четность (LDPC-коды) были предложены Галлагером в 1962 и являются блоковыми линейными кодами, определенными разреженными проверочными матрицами, предусматривают простой итеративный декодирующий алгоритм, а также имеют характеристики, приближающиеся к границе Шеннона. С момента повторного открытия LDPC-кодов Маккеем и Нейлом в 1995 в теоретических исследованиях LDPC-кодов и соответствующем практическом применении имеет место значительный прогресс. В настоящее время LDPC-коды применяются в большом количестве стандартов систем связи, таких как DVB-S2, WiMAX, IEEE 802.3an и DMB-TH.
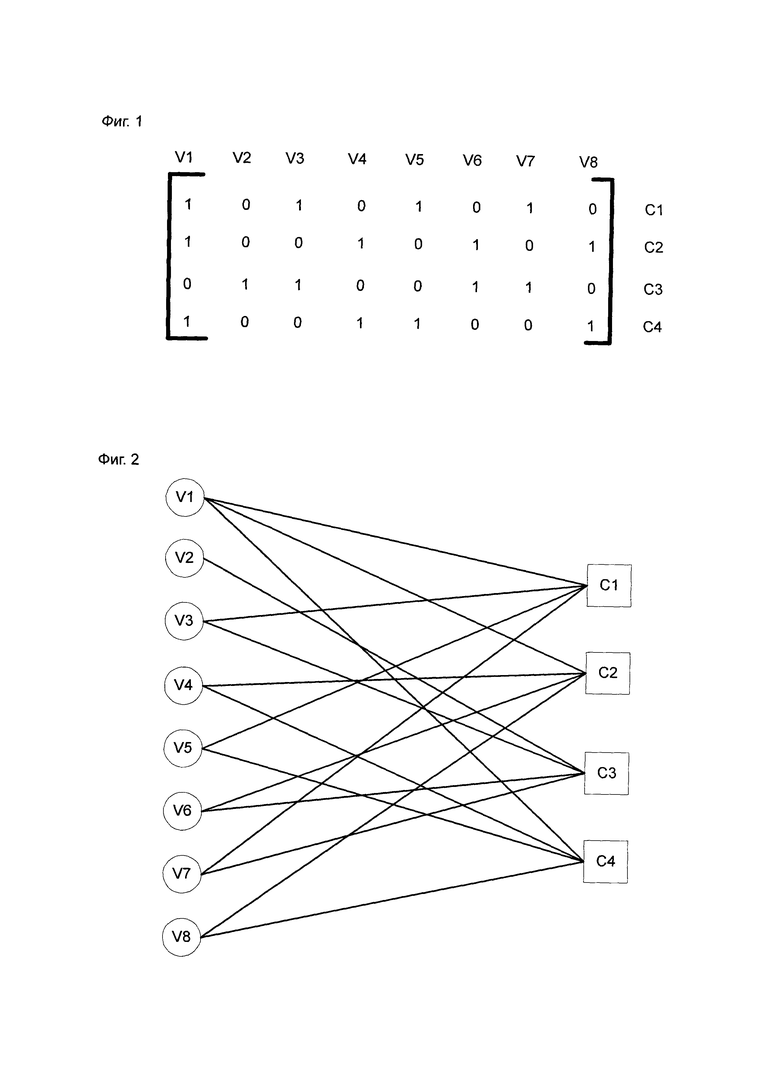
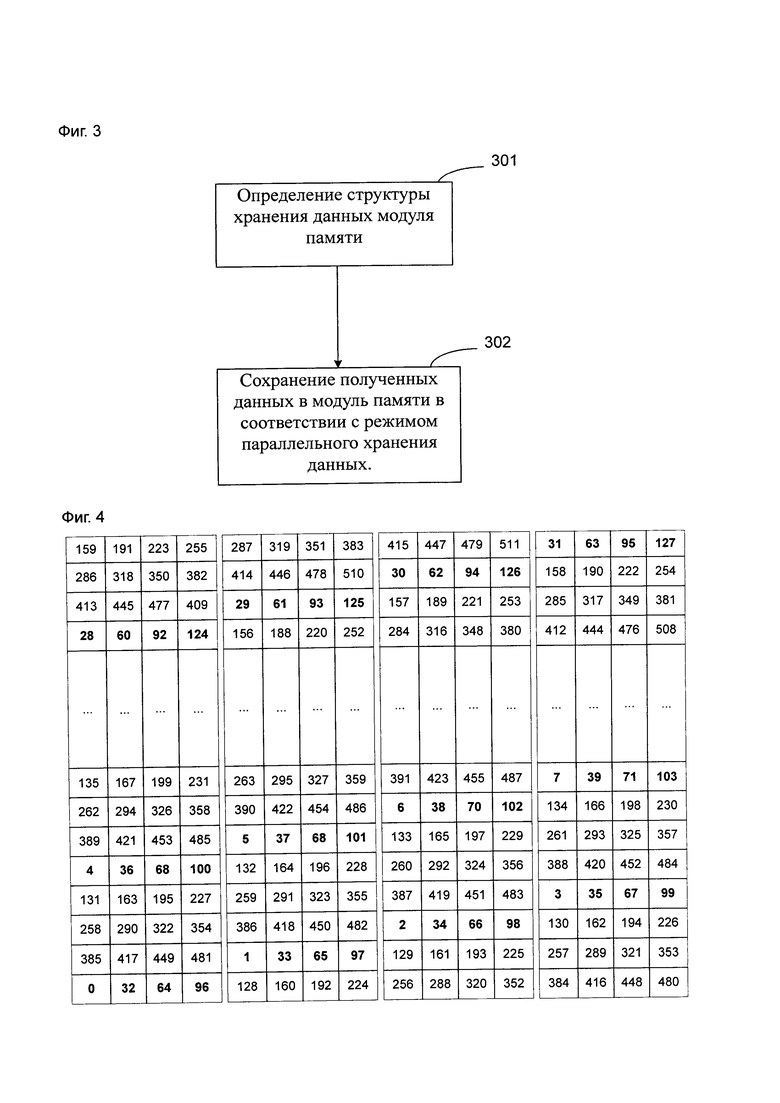
Матрица проверки четности LDPC-кодов представляет собой разреженную матрицу, которую можно наглядно представить посредством графа Таннера. Все LDPC-коды включают переменные узлы и проверочные узлы. В соответствии с отношением соединения между переменными узлами и проверочными узлами на графе Таннера LDPC-коды можно распределить по категориям на структурированные LDPC-коды и неструктурированные LDPC-коды, при этом структурированные LDPC-коды широко применяются в реальных продуктах благодаря таким преимуществам, как малая сложность и легкость в осуществлении аппаратным обеспечением. Для балансирования пропускной способности и издержек аппаратных ресурсов, как правило, в устройстве для декодирования структурированных LDPC-кодов применяется способ частично параллельного декодирования, т.е. осуществление каждый раз одновременного или неодновременного обновления определенного числа проверочных узлов или переменных узлов. В подобных технологиях проверочная матрица LDPC-кодов является такой, как показанная на фиг. 1, а соответствующий граф Таннера является таким, как показанный на фиг. 2, при этом переменный узел представлен Vi (i=1-8), а проверочный узел представлен Cj (j=1-4).
В большинстве случаев устройство для декодирования LDPC-кодов содержит элемент для сохранения, элемент для обработки, а также элемент для управления и вывода. Одной из ключевых технологий при реализации декодирующего устройства является сохранение декодированных кодов, в частности в случае LDPC-кодов, имеющих относительно большую кодовую длину, сохранение проверочной матрицы и сохранение промежуточных результатов, что во время итерации может привести к относительно высоким издержкам ресурсов и площади - в большинстве случаев занимается свыше 50% всей площади декодирующего устройства. Кроме того, один стандарт в области связи в большинстве случаев предусматривает несколько кодовых скоростей и кодовых длин для удовлетворения требований разных сценариев применения. Теоретически, для реализации декодирующего устройства, поддерживающего несколько кодовых скоростей, необходимо сохранять проверочные матрицы при нескольких кодовых скоростях, а поскольку проверочные узлы при разных кодовых скоростях имеют разные степени, в процессе декодирования имеет место нерегулярность сохранения промежуточных результатов, что, соответственно, приводит к повышению издержек площади декодирующего устройства.
В общем, в подобных технологиях сохранение зависимых данных в устройстве для декодирования LDPC-кодов осуществляется в основном с помощью операций сложения, что, таким образом, приводит к тому, что занято слишком много ресурсов и имеются относительно большие издержки; более того, поскольку в подобных технологиях данные сохраняются в последовательном режиме, возникает относительно большая задержка сохранения; кроме того, в подобных технологиях входные линии необходимо подсоединить к каждому запоминающему устройству, поэтому схема проводки является сложной и дорогой.
КРАТКОЕ ИЗЛОЖЕНИЕ СУЩНОСТИ ИЗОБРЕТЕНИЯ
С учетом всего вышесказанного в вариантах осуществления согласно изобретению представлены способ и устройство хранения данных, обеспечивающие возможность экономии ресурсов, снижения издержек, уменьшения длительности задержки сохранения, снижения сложности схемы проводки и экономии затрат.
С этой целью технические решения согласно изобретению реализуются следующим образом.
Способ сохранения данных, включающий:
определение структуры сохранения данных модуля памяти;
получение данных и сохранение полученных данных в модуль памяти в соответствии с режимом параллельного сохранения данных.
Модуль памяти может состоять из несколько ЗУПД.
Определение структуры сохранения данных модуля памяти может включать определение NR, что представляет собой число ЗУПД, RR, что представляет собой число строк в каждом ЗУПД, и RL, что представляет собой число столбцов RL в каждом ЗУПД.
Определение структуры сохранения данных модуля памяти может включать:
определение NR=BL*Max_NI, где BL представляет собой число столбцов основной матрицы, Max_NI представляет собой максимальный объем ввода данных; и
определение RR=Z/P, RL=Z/RR, где Z представляет собой коэффициент расширения, Р представляет собой показатель параллельности сохранения данных.
Сохранение полученных данных в модуль памяти в соответствии с режимом параллельного сохранения данных может включать:
определение адреса строки Ri и адреса столбца Li данных в модуле памяти;
сохранение данных в модуль памяти в соответствии с определенным адресом строки Ri и определенным адресом столбца Li,
при этом определение адреса строки Ri и адреса столбца Li данных в модуле памяти может включать:
определение Ri=imod(Z/P), и
определение Li=(IdivZ)+{[(imod4)*(16/P)+(imodZ)div(Z/P)]mod(64/P)},
где mod означает арифметику в остаточных классах, div представляет собой арифметику целочисленного деления, i представляет собой порядковый номер ввода данных, Z представляет собой коэффициент расширения и Р представляет собой показатель параллельности сохранения данных.
Величина Р может быть определена равной 4.
Устройство для сохранения данных содержит модуль памяти, модуль приема и модуль для осуществления сохранения, при этом
модуль памяти выполнен для хранения данных;
модуль приема выполнен для приема данных; и
модуль для осуществления сохранения выполнен для сохранения данных, полученных модулем приема, в модуль памяти в соответствии с режимом параллельного сохранения данных.
Модуль памяти может состоять из несколько ЗУПД.
Модуль для осуществления сохранения может быть выполнен специально для определения адреса строки Ri и адреса столбца Li данных в модуле памяти и сохранения данных в модуль памяти в соответствии с определенным адресом строки Ri и определенным адресом столбца Li, где Ri=imod(Z/P), Li=(idivZ)+{[(imod4)*(16/P)+(imodZ)div(Z/P)]mod(64/P)}, mod представляет собой арифметику в остаточных классах, div представляет собой арифметику целочисленного деления, i представляет собой порядковый номер ввода данных, Z представляет собой коэффициент расширения и Р представляет собой показатель параллельности сохранения данных.
В способе и устройстве сохранения данных, представленных в вариантах осуществления согласно изобретению, определяется структура сохранения данных модуля памяти; после того как данные были получены, полученные данные сохраняются в модуль памяти в соответствии с режимом параллельного сохранения данных. В решениях в соответствии с вариантами осуществления согласно изобретению, поскольку сохранение данных осуществляется в основном с помощью операций смещения и модулярных операций, используется меньше ресурсов, а издержки являются относительно малыми; более того, поскольку сохранение данных осуществляется в параллельном режиме, задержка сохранения является относительно короткой; кроме того, входные линии необходимо подключать лишь к части запоминающих устройств, что, таким образом, делает схему проводки простой и относительно недорогой.
КРАТКОЕ ОПИСАНИЕ ГРАФИЧЕСКИХ МАТЕРИАЛОВ
На фиг. 1 схематически представлена матрица проверки четности LDPC-кодов в соответствии с подобными технологиями.
На фиг. 2 представлен граф Таннера, соответствующий матрице проверки четности на фиг. 1.
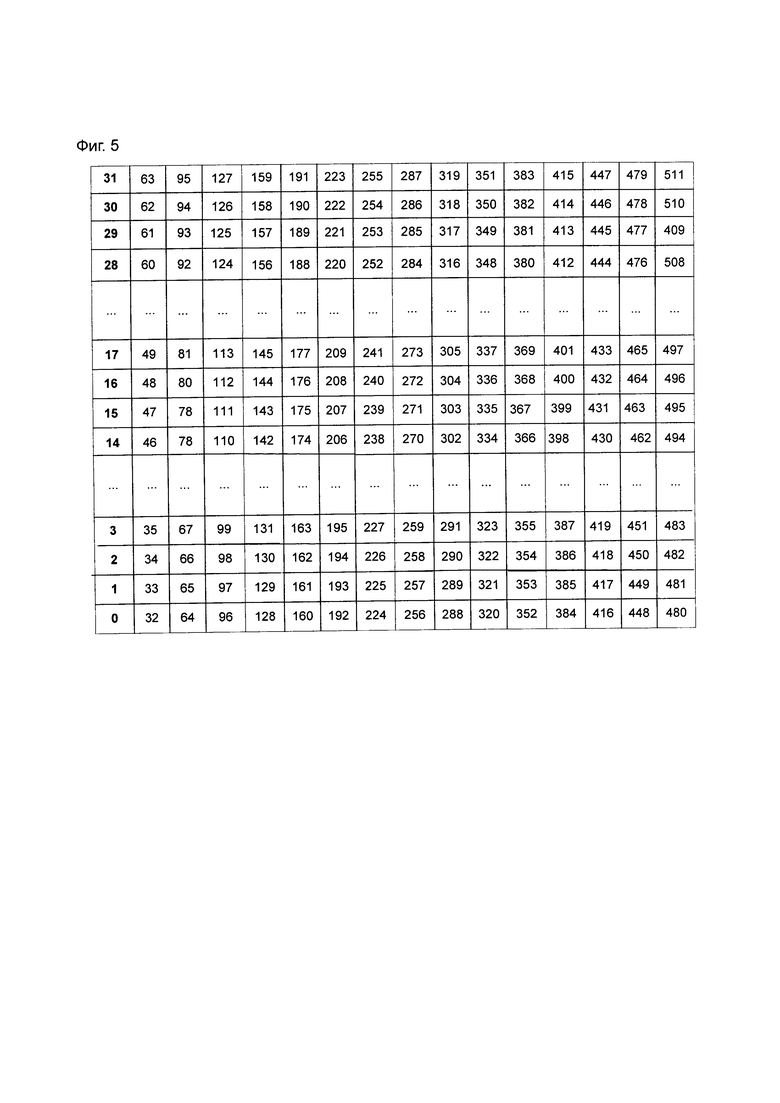
На фиг. 3 схематически представлена схема последовательности способа сохранения данных согласно одному варианту осуществления изобретения.
На фиг. 4 схематически представлена структура сохранения данных согласно одному варианту осуществления изобретения; и
На фиг. 5 схематически представлена структура сохранения данных в соответствии с подобными технологиями.
ПОДРОБНОЕ ОПИСАНИЕ
В вариантах осуществления изобретения представлен способ сохранения данных, при этом на фиг. 3 показана схематическая схема последовательности способа сохранения данных согласно одному варианту осуществления изобретения, и, как показано на фиг. 3, способ включает:
Этап 301, на котором определяют структуру хранения данных модуля памяти;
при необходимости, модуль памяти может состоять из нескольких запоминающих устройств с произвольным доступом (ЗУПД), и несколько ЗУПД в большинстве случаев выполнены одинакового размера.
Операцию на этом этапе может совершать вручную одно лицо.
При необходимости, определение структуры сохранения данных модуля памяти может включать определение NR, что означает число ЗУПД, RR, что означает число строк в каждом ЗУПД, и RL, что означает число столбцов в каждом ЗУПД.
При необходимости, определение структуры сохранения данных модуля памяти может включать:
определение NR=BL*Max_NI, где BL представляет собой число столбцов основной матрицы, Max_NI представляет собой максимальный объем ввода данных; и
определение RR=Z/P, RL=Z/RR, где Z представляет собой коэффициент расширения, Р представляет собой показатель параллельности сохранения данных.
В случае варианта осуществления, в котором число строк основной матрицы составляет 4, число столбцов основной матрицы составляет 32, коэффициент расширения составляет 512, а показатель параллельности сохранения данных составляет 16, структура сохранения данных одного ЗУПД представлена так, как показано на фиг. 4; можно видеть, что Z=512 и Р=16, поэтому ЗУПД имеет RR=512/16=32 строки и RL=512/32=16 столбцов; на фиг. 4 показана структура сохранения данных лишь одной группы ЗУПД; другие 32 группы ЗУПД обладают такой же структурой сохранения данных, что и текущая, то есть после того как данные были полностью сохранены в одной группе ЗУПД, оставшиеся данные последовательно сохраняются в следующей группе ЗУПД.
Этап 302, на котором после того как данные были получены, полученные данные сохраняют в модуль памяти в соответствии с режимом параллельного хранения данных.
При необходимости, на этом этапе сохранение полученных данных в модуль памяти в соответствии с режимом параллельного сохранения данных может включать:
определение адреса строки Ri и адреса столбца Li данных в модуле памяти;
сохранение данных в модуль памяти в соответствии с определенным адресом строки Ri и определенным адресом столбца Li.
При необходимости, определение адреса строки Ri и адрес столбца Li данных в модуле памяти может включать:
определение Ri=imod(Z/P), и
определение Li=(idivZ)+{[(imod4)*(16/P)+(imodZ)div(Z/P)]mod(64/P)},
где mod представляет собой арифметику в остаточных классах, div представляет собой арифметику целочисленного деления, i представляет собой порядковый номер вводимых данных, Z представляет собой коэффициент расширения, а Р представляет собой показатель параллельности сохранения данных.
Предпочтительно, значение Р может быть 4.
Как показано на фиг. 4, числа на фиг. 4 представляют собой порядковые номера ввода данных, и вводимые данные вводят параллельно в ЗУПД на основании соответствующих им порядковых номеров; при условии, что данные вводят в четырехпутевом параллельном режиме и вводимые данные имеют порядковый номер i, то в соответствии со способом сохранения согласно изобретению адрес строки и адрес столбца, где расположены данные, являются следующими:
Адрес строки Ri=imod32
Адрес столбца Li=(idiv512)+{[(imod4)*4+(imod512)div32]mod16}
Можно видеть, что по сравнению с декодирующей LDPC-код структурой сохранения данных ЗУПД в соответствии с подобными способами на фиг. 5, в которых для сохранения n данных необходимо n тактовых циклов, в варианте осуществления, как показано на фиг. 4, необходимо лишь n/4 тактовых циклов, что, таким образом, обеспечивает сокращение задержки сохранения без увеличения издержек.
Соответственно, в одном варианте осуществления изобретения представлено устройство для сохранения данных, при этом устройство содержит модуль памяти, модуль приема и модуль для осуществления сохранения, при этом
модуль памяти выполнен для хранения данных;
модуль приема выполнен для приема данных; и
модуль для осуществления сохранения выполнен для сохранения данных, полученных модулем приема, в модуль памяти в соответствии с режимом параллельного сохранения данных.
При необходимости, модуль памяти может содержать несколько ЗУПД.
При необходимости, модуль для осуществления сохранения может быть выполнен специально для определения адреса строки Ri и адреса столбца Li данных в модуле памяти и сохранения данных в модуль памяти в соответствии с определенным адресом строки Ri и определенным адресом столбца Li, при этом Ri=imod(Z/P), Li=(idivZ)+{[(imod4)*(16/P)+(imodZ)div(Z/P)]mod(64/P)}, mod представляет собой арифметику в остаточных классах, div представляет собой арифметику целочисленного деления, i представляет собой порядковый номер вводимых данных, Z представляет собой коэффициент расширения и Р представляет собой показатель параллельности сохранения данных.
Кроме того, следует отметить то, что у декодирующего LDPC-код устройства для сохранения в основном есть три функции: сохранение вводимых данных в декодирующее устройство для сохранения; чтение переменного узла, который необходимо декодировать, из декодирующего устройства для сохранения в процессе декодирования данных; и запись информации об обновленном переменном узле в декодирующее устройство для сохранения в процессе декодирования данных, при этом переменное обновление включает чтение последних итерированных переменных узлов и запись итерируемых в этот момент переменных узлов. Поскольку в способе доступа обновление переменного узла учитывается при вводе данных, то при обновлении переменного узла необходимо лишь вычислить адрес строки читаемого первым переменного узла в ЗУПД, а адреса строк читаемых следующими переменных узлов в ЗУПД затем можно получить путем последовательного приращения адреса на +1 и выполнения арифметики в остаточных классах в отношении величин адреса с приращением. Адрес строки читаемого первым переменного узла в ЗУПД является величиной, полученной путем выполнения арифметики в остаточных классах на основании порядкового номера первых достоверных данных в обрабатываемом в этот момент блоке кода и максимального адреса строки ЗУПД.
Логика при записи переменного узла является такой же, как и при чтении переменного узла, в отношении управления адресами. Между чтением переменного узла и обновлением переменного узла предусмотрена задержка времени обработки информации, а логика управления при чтении переменного узла является такой же, как и при записи переменного узла, поэтому при реализации на практике операции по чтению и записи можно выполнять одновременно на запоминающем устройстве, не опасаясь конфликта "чтение-запись". Следовательно, эффективность сохранения значительно повышается.
Таким образом, технические решения в соответствии с вариантами осуществления изобретения имеют следующие преимущества:
1. Относительно малые издержки, то есть имеет место недопущение издержек, возникающих вследствие применения стратегии "пространство ради времени" с целью увеличения скорости ввода данных.
2. Относительно высокий коэффициент использования запоминающего устройства (т.е. модуля памяти) и экономия энергии, то есть ввиду уменьшения ненужных издержек пространства коэффициент использования запоминающего устройства, следовательно, улучшается, в то время как логика управления упрощается, и, таким образом, происходит экономия потребляемой энергии.
3. Большая пропускная способность вводимых данных, то есть увеличение пропускной способности всего декодирования LDPC-кода.
4. Исключение сложных арифметических операций во время осуществления сохранения данных и, таким образом, легкость их осуществления аппаратным обеспечением: в большинстве случаев логика управления сохранением, применяемая в изобретении, применяется для выполнения модулярных операций, которые заключаются в смещении битов влево/вправо при осуществлении аппаратным обеспечением и являются относительно легкими в осуществлении; и
5. Снижение сложности последующей компоновки и схемы проводки: поскольку при декодировании LDPC-кода происходит частый обмен данными, ресурсы проводки являются достаточно сложными, однако в способе согласно изобретению ресурсы проводки можно уменьшить, таким образом, улучшая временную последовательность логики и уменьшая давление последующей компоновки и схемы проводки.
Все, что было описано, является лишь вариантами осуществления согласно изобретению и не предназначено для ограничения изобретения.
Изобретение относится к области сохранения данных и, в частности, к способу и устройству сохранения данных. Технический результат заключается в уменьшении длительности задержки сохранения данных. Технический результат достигается за счет определения адреса строки Ri и адреса столбца Li данных в модуле памяти, сохранения данных в модуль памяти в соответствии с определенным адресом строки Ri и определенным адресом столбца Li, при этом определение адреса строки Ri и адреса столбца Li данных в модуле памяти включает определение Ri=i mod (Z/P) и определение Li=(i div Z)+{[(i mod 4)*(16/P)+(i mod Z)div(Z/P)]mod(64/P)}, где mod означает арифметику в остаточных классах, div представляет собой арифметику целочисленного деления, i представляет собой порядковый номер ввода данных, Z представляет собой коэффициент расширения LDPC-кодов и Р представляет собой показатель параллельности сохранения данных для одной группы запоминающих устройств с произвольным доступом (ЗУПД). 2 н. и 1 з.п. ф-лы, 5 ил.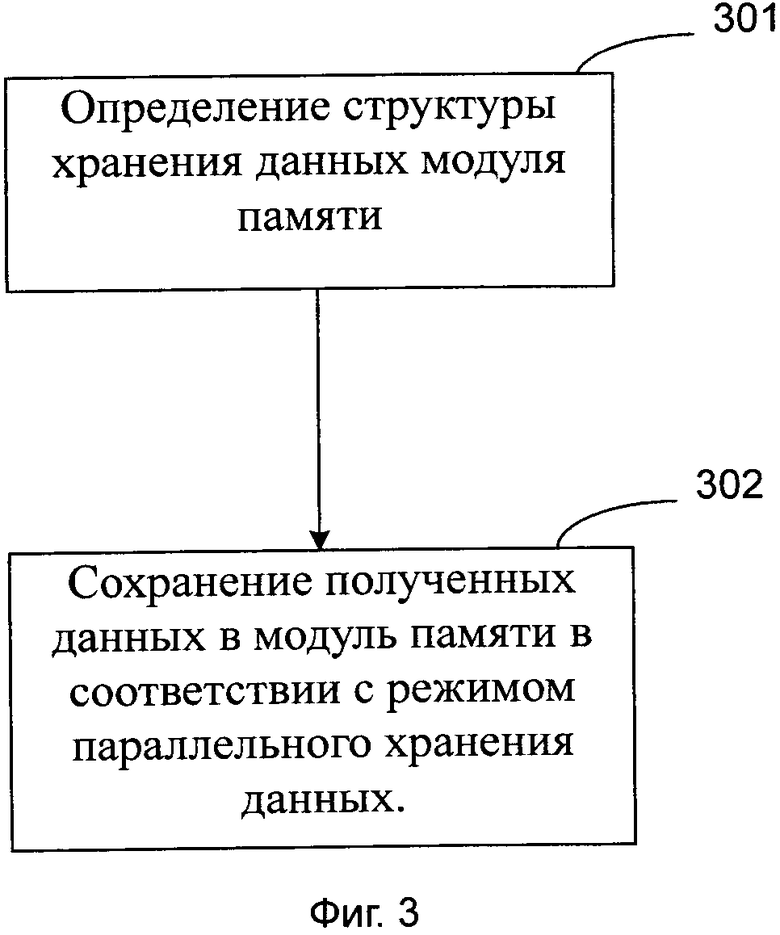
1. Способ сохранения данных, отличающийся тем, что способ включает:
определение структуры сохранения данных модуля памяти;
прием данных, которые служат в качестве вводимых данных кодов с малой плотностью проверок на четность (LDPC-кодов), и последующее сохранение полученных данных в модуль памяти в соответствии с режимом параллельного сохранения данных;
при этом сохранение полученных данных в модуль памяти в соответствии с режимом параллельного сохранения данных включает:
определение адреса строки Ri и адреса столбца Li данных в модуле памяти;
сохранение данных в модуль памяти в соответствии с определенным адресом строки Ri и определенным адресом столбца Li;
при этом определение адреса строки Ri и адреса столбца Li данных в модуле памяти включает:
определение Ri=i mod (Z/P) и
определение Li=(i div Z)+{[(i mod 4)*(16/P)+(i mod Z)div(Z/P)]mod(64/P)},
где mod означает арифметику в остаточных классах, div представляет собой арифметику целочисленного деления, i представляет собой порядковый номер ввода данных, Z представляет собой коэффициент расширения LDPC-кодов и Р представляет собой показатель параллельности сохранения данных для одной группы запоминающих устройств с произвольным доступом (ЗУПД).
2. Способ по п. 1, отличающийся тем, что Р определяют как величину, равную 4 или 16.
3. Устройство для сохранения данных, содержащее модуль памяти, модуль приема и модуль для осуществления сохранения, при этом
модуль памяти предусмотрен для хранения данных;
модуль приема предусмотрен для приема данных, которые служат в качестве вводимых данных кодов с малой плотностью проверок на четность (LDPC-кодов); и
модуль для осуществления сохранения предусмотрен для сохранения данных, полученных модулем приема, в модуль памяти в соответствии с режимом параллельного сохранения данных;
при этом модуль для осуществления сохранения выполнен с возможностью определения адреса строки Ri и адреса столбца Li данных в модуле памяти и сохранения данных в модуль памяти в соответствии с определенным адресом строки Ri и определенным адресом столбца Li, при этом Ri=i mod (Z/P), Li=(i div Z)+{[(i mod 4)*(16/P)+(i mod Z)div(Z/P)]mod(64/P)}, mod представляет собой арифметику в остаточных классах, div представляет собой арифметику целочисленного деления, i представляет собой порядковый номер вводимых данных, Z представляет собой коэффициент расширения LDPC-кодов и Р представляет собой показатель параллельности сохранения данных для одной группы запоминающих устройств с произвольным доступом (ЗУПД).
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| US 6724656 B2, 20.04.2004 | |||
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| СЕГНЕТОЭЛЕКТРИЧЕСКОЕ УСТРОЙСТВО ОБРАБОТКИ ДАННЫХ | 1998 |
|
RU2184400C2 |

