ОБЛАСТЬ ТЕХНИКИ
Настоящее изобретение относится к способу и системе для обнаружения текста в графических изображениях.
УРОВЕНЬ ТЕХНИКИ
Обнаружение текста в изображениях имеет множество применений, таких как индексация изображений для помощи в поиске мультимедийного контента и автоматической навигации для слабовидящих пользователей, роботизированная навигация в городских средах и многие другие. Как правило, подходы к обнаружению текста затрагивают два класса изображений: изображения документов и изображения натуральных сцен. Различие между классами делается на основе свойств анализируемого изображения. Когда используется в данном документе, обнаружение текста относится к процессу определения присутствия текста в данном изображении. Текст - это выравнивание по линии символов, которые включают в себя буквы или символы из набора знаков.
Изображения документов - это образы документов (например, рукописного, машинописного, с напечатанным текстом). Изображения документов типично предполагают включение в себя символов темного цвета (например, черного) с высокой контрастностью по сравнению с фоном, который однороден по цвету. Дополнительно, изображения документов имеют свойство наличия больших сегментов текста и простые и структурированные макеты страниц. Одним способом обработки изображений документов является оптическое распознавание символов (OCR). OCR-процесс - это компьютерный перевод изображения текста в цифровую форму в виде машиноредактируемого текста, как правило, в стандартной схеме кодирования.
В противоположность изображениям документов, изображения сцен имеют гораздо меньше текста со сложными фонами и текстом, который изменяется по размеру шрифта, цвету шрифта и ориентации линии текста.
КРАТКОЕ ИЗЛОЖЕНИЕ СУЩЕСТВА ИЗОБРЕТЕНИЯ
Согласно одному аспекту изобретения предложен способ обнаружения текста, содержащий этапы, на которых: принимают, посредством компьютера, входное изображение; выполняют обнаружение контуров во входном изображении; формируют контурную карту на основе входного изображения; формируют бинарную контурную карту; определяют набор связанных компонентов в бинарной контурной карте; для каждого связанного компонента в наборе связанных компонентов определяют ограничивающую область; определяют набор областей входного изображения на основе ограничивающей области; классифицируют каждую область в наборе областей; нормализуют набор областей на основе классификации; объединяют нормализованный набор областей; и обнаруживают и распознают текст в объединенном нормализованном наборе областей.
Согласно одному варианту осуществления способа входное изображение является изображением графического пользовательского интерфейса.
Согласно другому варианту осуществления способ дополнительно содержит этап, на котором удаляют длинную горизонтальную линию и длинные вертикальные линии из бинарной контурной карты.
Согласно другому варианту осуществления способа область классифицируется как одна из области белого текста, области черного текста и нетекстовой области.
Согласно другому варианту осуществления способа классификация каждой области основана, по меньшей мере, на одном из изменения ширины штриха для белых пикселов, изменения ширины штриха для черных пикселов, отношения белых пикселов к черным пикселам в области, и отношения белых пикселов к черным пикселам вдоль границы области.
Согласно другому варианту осуществления способа нормализация содержит этапы, на которых: определяют классификацию области в наборе областей; и инвертируют пикселы в упомянутой области на основе классификации.
Согласно другому варианту осуществления способа нормализация содержит этапы, на которых: определяют то, что область в наборе областей классифицирована как область черного текста; и инвертируют пикселы в упомянутой области.
Согласно другому варианту осуществления способа каждая ограничивающая область соответствует области входного изображения.
Согласно другому варианту осуществления способ дополнительно содержит этап, на котором для каждой области в наборе областей формируют бинарное изображение с помощью адаптивного порогового значения.
Согласно другому варианту осуществления способа ограничивающая область является ограничивающим прямоугольником.
Согласно другому варианту осуществления способ дополнительно содержит этапы, на которых: определяют то, что область в наборе областей классифицирована как нетекстовая область; отфильтровывают упомянутую область из набора областей.
Согласно другому варианту осуществления способа бинарная контурная карта формируется с помощью глобального порогового значения.
Согласно еще одному аспекту изобретения предложен энергонезависимый машиночитаемый носитель, хранящий множество инструкций, чтобы управлять обнаружением текста процессором данных, при этом упомянутое множество инструкций включает в себя инструкции, которые предписывают процессору данных: принимать изображение графического пользовательского интерфейса (GUI); выполнять обнаружение контуров изображения GUI; формировать контурную карту на основе изображения GUI; формировать бинарную контурную карту; определять набор связанных компонентов в бинарной контурной карте; для каждого связанного компонента в наборе связанных компонентов определять ограничивающую область; определять набор областей входного изображения на основе ограничивающей области; классифицировать каждую область в наборе областей; нормализовывать набор областей на основе классификации; объединять нормализованный набор областей в бинарное изображение; и обнаруживать и распознавать текст в бинарном изображении.
Согласно одному варианту осуществления машиночитаемого носителя область классифицируется как одна из области белого текста, области черного текста и нетекстовой области.
Согласно другому варианту осуществления машиночитаемого носителя классификация каждой области основана, по меньшей мере, на одном из изменения ширины штриха для белых пикселов, изменения ширины штриха для черных пикселов, отношения белых пикселов к черным пикселам в области, и отношения белых пикселов к черным пикселам вдоль границы области.
Согласно другому варианту осуществления машиночитаемого носителя инструкции, которые предписывают процессору данных нормализовать набор областей, включают в себя: инструкции, которые предписывают процессору данных определять классификацию области в наборе областей; и инструкции, которые предписывают процессору данных инвертировать пикселы в упомянутой области на основе классификации.
Согласно другому варианту осуществления машиночитаемого носителя инструкции, которые предписывают процессору данных нормализовать набор областей, включают в себя: инструкции, которые предписывают процессору данных определять то, что область в наборе областей классифицирована как область черного текста; и инструкции, которые предписывают процессору данных инвертировать пикселы в упомянутой области.
Согласно еще одному аспекту изобретения предложена система обнаружения текста, содержащая: процессор; и память, соединенную с процессором; при этом процессор выполнен с возможностью: принимать изображение графического пользовательского интерфейса (GUI); определять набор связанных компонентов в изображении GUI; для каждого связанного компонента в наборе связанных компонентов определять ограничивающую область; определять набор областей изображения GUI на основе ограничивающей области; классифицировать каждую область в наборе областей; определять область в наборе областей, которая классифицирована как область черного текста; инвертировать пикселы в упомянутой области; объединять нормализованный набор областей в бинарное изображение; и обнаруживать и распознавать текст в бинарном изображении.
Согласно одному варианту осуществления системы классификация каждой области основана, по меньшей мере, на одном из изменения ширины штриха для белых пикселов, изменения ширины штриха для черных пикселов, отношения белых пикселов к черным пикселам в области и отношения белых пикселов к черным пикселам вдоль границы области.
Согласно другому варианту осуществления системы область классифицируется как одна из области белого текста, области черного текста и нетекстовой области.
Технический результат, достигаемый настоящим изобретением заключается в оптимизации обнаружения текста в изображениях экрана GUI, в частности, в улучшении точности и производительности обнаружения и распознавания текста в изображениях экрана GUI.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Настоящее раскрытие может быть лучше понято, и его многочисленные признаки и преимущества будут более очевидными, посредством ссылки к сопроводительным чертежам.
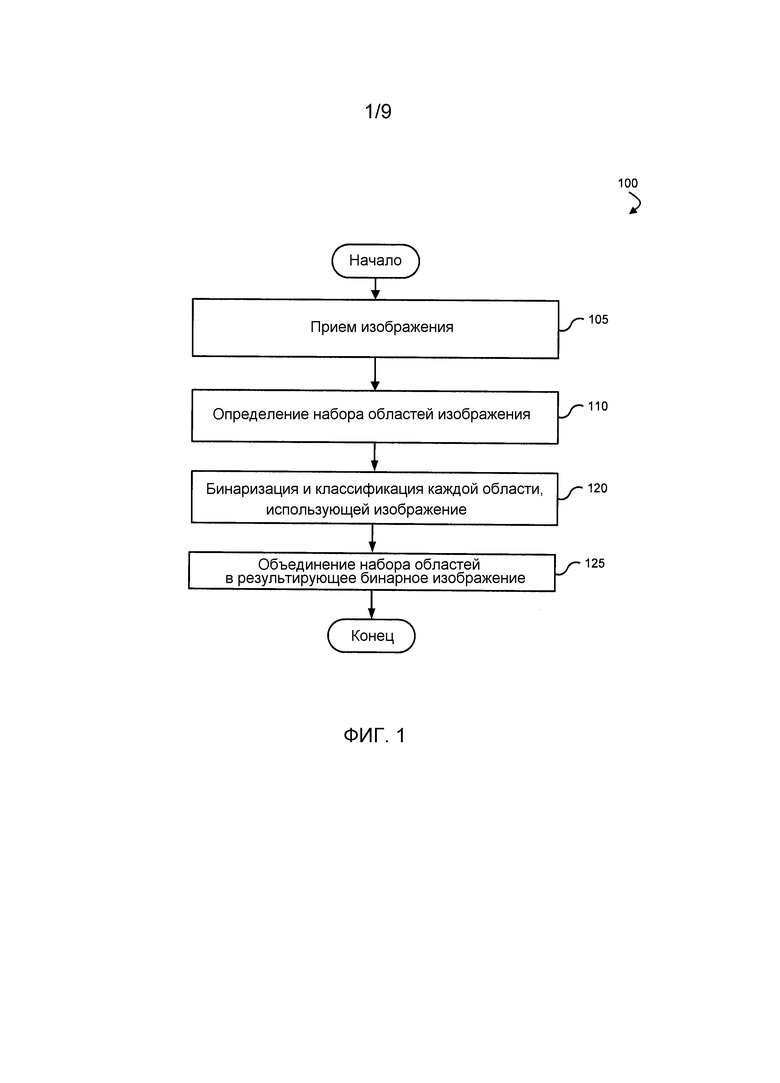
Фиг. 1 - это блок-схема последовательности операций процесса обработки изображения в соответствии с вариантом осуществления.
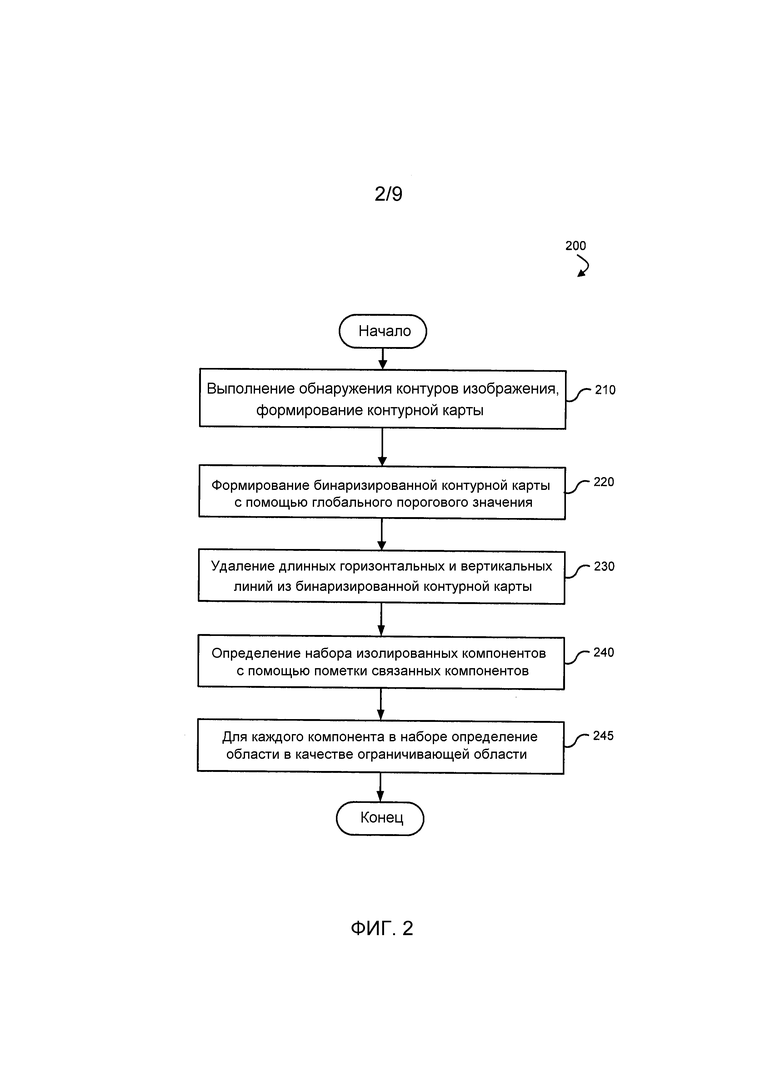
Фиг. 2 - это блок-схема последовательности операций процесса определения набора областей изображения в соответствии с вариантом осуществления.
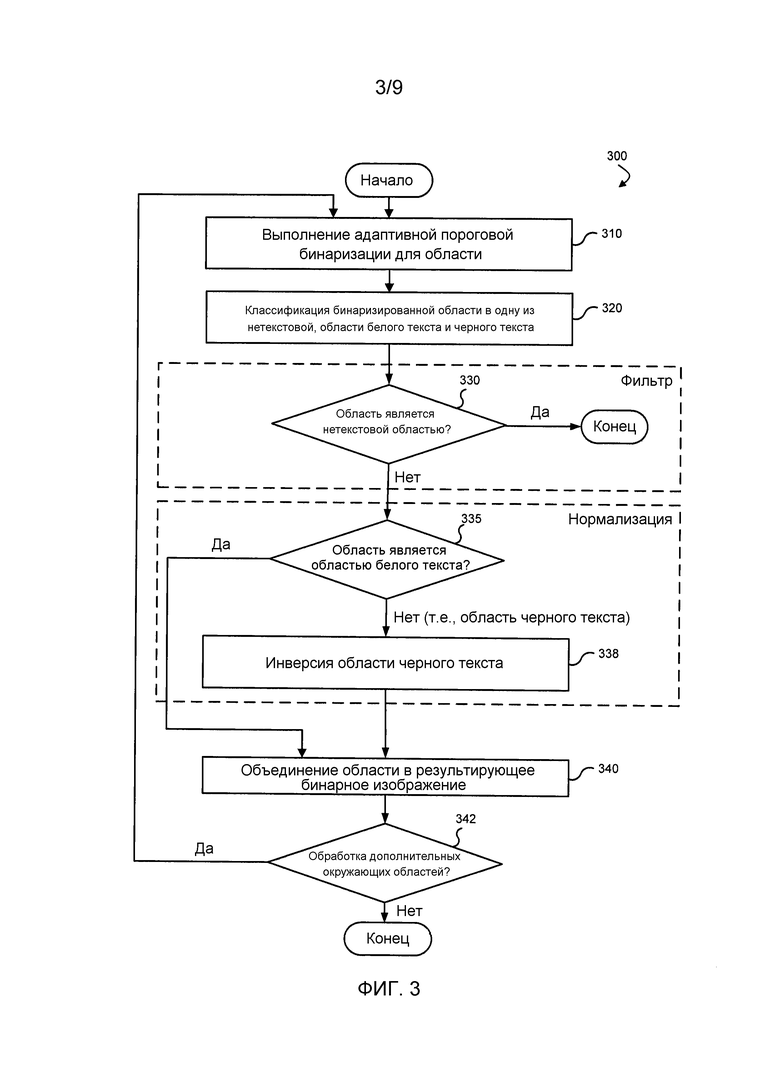
Фиг. 3 - это блок-схема последовательности операций процесса бинаризации и классификации областей изображения в соответствии с вариантом осуществления.
Фиг. 4 - это изображение графического пользовательского интерфейса в соответствии с вариантом осуществления.
Фиг. 5 - это изображение графического пользовательского интерфейса после обнаружения контуров в соответствии с вариантом осуществления.
Фиг. 6 - это изображение графического пользовательского интерфейса после обнаружения контуров и глобальной бинаризации контурной карты в соответствии с вариантом осуществления.
Фиг. 7 - это бинарная контурная карта изображения графического пользовательского интерфейса после удаления длинных линий в соответствии с вариантом осуществления.
Фиг. 8 - это бинарная контурная карта изображения графического пользовательского интерфейса после пометки связанных компонентов в соответствии с вариантом осуществления.
Фиг. 9 - это бинарная контурная карта изображения частичного графического пользовательского интерфейса, показывающая рабочие ограничивающие прямоугольники в соответствии с вариантом осуществления.
Фиг. 10 - это бинарная контурная карта изображения графического пользовательского интерфейса, показывающая ограничивающие прямоугольники, отфильтрованные по размеру в соответствии с вариантом осуществления.
Фиг. 11 - это бинарная контурная карта изображения графического пользовательского интерфейса, показывающая ограничивающие прямоугольники, отфильтрованные по размеру и включению в себя других прямоугольников в соответствии с вариантом осуществления.
Фиг. 12 - это изображение графического пользовательского интерфейса после бинаризации в соответствии с вариантом осуществления.
Фиг. 13 - это результирующее изображение графического пользовательского интерфейса после обнаружения текста в соответствии с вариантом осуществления.
Фиг. 14 иллюстрирует компьютерную систему, в которой вариант осуществления может быть реализован.
ПОДРОБНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
Графические пользовательские интерфейсы (GUI), в качестве захваченных на экране изображений, имеют свойства, отличные от изображений документов и натуральных сцен. В частности, этот тип экранного изображения (т.е. GUI в качестве захваченного на экране изображения), как правило, имеет текстовые записи, которые включают в себя несколько слов и символов и изменяются по размеру и цвету шрифта, в противоположность изображениям документов. По существу, изображения экрана GUI трудно обрабатывать посредством типичных технологий обработки документа. Кроме того, изображения экрана GUI могут иметь резкие границы и/или цветовые переходы и имеют текст, который легче обнаруживать, как противоположность изображениям натуральных сцен. По существу, вычислительно сложные технологии обработки натуральных сцен неэффективны для обработки изображений экрана GUI.
В данном документе описывается обработка третьего класса изображения, т.е. изображений экрана GUI. В частности, обработка графических пользовательских интерфейсов (GUI) как захваченных на экране изображений подразумевает структурный анализ этих изображений без знания внутреннего представления GUI-объектов. В результате такой обработки, которая независима от технологии, которая использовалась для построения самого GUI, текст может быть обнаружен и извлечен из изображений.
Обнаружение текста в изображениях экрана GUI может допускать обнаружение элементов управления GUI и типов этих элементов управления. Кроме того, точность и производительность оптического распознавания символов (OCR) текстового содержимого в изображениях экрана GUI может быть значительно улучшена.
Предоставляются системы и способы обнаружения текста. Изображение принимается, и определяется набор связанных компонентов в контурной карте изображения. Для каждого связанного компонента в наборе определяется ограничивающая область. Набор областей изображения определяется на основе ограничивающей области. Каждая область в наборе областей классифицируется (например, как одна из области белого текста, области черного текста и нетекстовой области) и нормализуется на основе классификации. Нормализованный набор областей объединяется в бинарное изображение.
Фиг. 1 - это блок-схема последовательности операций процесса обработки изображения в соответствии с вариантом осуществления. Изображенная последовательность 100 операций процесса может выполняться посредством выполнения последовательностей исполняемых инструкций. В другом варианте осуществления различные части последовательности 100 операций процесса выполняются компонентами механизма обнаружения символов, схемой аппаратной логики, например, специализированной интегральной микросхемой (ASIC) и т.д. Например, блоки последовательности 100 операций процесса могут выполняться посредством исполнения последовательностей исполняемых инструкций в модуле обнаружения текста.
На этапе 105 изображение принимается в качестве входных данных. В одном варианте осуществления изображение является изображением экрана графического пользовательского интерфейса (GUI), хотя другие изображения с похожими свойствами могут быть приняты и обработаны, как описано в данном документе.
Когда используется в данном документе, входное изображение является электронным моментальным снимком (например, снимком экрана), взятым из GUI или другого субъекта с похожими свойствами, как ранее описано. Входное изображение дискретизируется и преобразуется как сетка точек или пикселов. Каждому пикселу назначается тональное значение (черный, белый, оттенки серого или цветной), которое представлено в двоичном коде (нули и единицы). Двоичные биты для каждого пиксела сохраняются в последовательность и могут быть уменьшены до математического представления, например, когда сжаты.
Набор областей изображения определяется на этапе 110. В одном варианте осуществления выполняется пометка связанных компонентов, где связанные компоненты во входном изображении уникально помечаются. Различные технологии для пометки связанных компонентов или обнаружения пятен (например, двухпроходные и т.д.) могут быть использованы. Ограничивающая область определяется для каждого из связанных компонентов. Каждая ограничивающая область соответствует области в изображении. Координаты ограничивающих областей используются поверх первоначального входного изображения, чтобы определять область исходного входного изображения, которая охвачена ограничивающей областью. Дополнительные подробности определения областей описываются относительно Фиг. 2.
Используя входное изображение, адаптивная пороговая бинаризация и классификация выполняется по каждой из областей в наборе, на этапе 120. Обычно, предполагается, что текст в GUI легко читается пользователем, и, по существу, существует резкий контраст между символами и фоном в GUI и в соответствующем изображении экрана GUI. Кроме того, типично нет шума или недостаточного освещения в этом типе изображения. Адаптивная пороговая бинаризация обеспечивает быстрый и эффективный способ отделения текста от фона, когда применяется локально к конкретным областям.
Когда описывается в данном документе, бинаризация - это процесс создания бинарного изображения посредством преобразования пиксела в изображении в одно из двух возможных значений, т.е. 1 или 0. Все пикселы преобразуются либо в черные, либо в белые. Результатом будет либо белый текст на черном фоне, либо черный текст на белом фоне, в зависимости от цвета фона и переднего плана в каждой области во входном изображении.
Классификатор, такой как наивный байесовский классификатор, используется, чтобы идентифицировать нетекстовые области и, во время обработки изображения, отфильтровывать те области, которые идентифицированы как нетекстовые области. Кроме того, классификатор может использоваться, чтобы нормализовать области, так что текст во всех областях в наборе является единообразным в цветовом представлении. Например, изображение, которое обрабатывается к настоящему времени, может включать в себя заголовок веб-страницы с темным текстом на белом фоне, тогда как тело может изображать содержимое белым текстом на темном фоне. Классификатор унифицирует текст и фон каждой области либо в белый текст на темном фоне, либо в темный текст на белом фоне. Дополнительные подробности процесса адаптивной бинаризации и классификации предоставляются относительно Фиг. 3. В одном варианте осуществления классификатор позволяет отфильтровывать нетекстовые области и нормализовать текст и фон в один проход.
На этапе 125 набор областей объединяется в результирующее бинарное изображение, которое имеет разделенные текст и фон и очищено (или большей частью очищено) от нетекстовых областей. Объединение выполняется с помощью координат ограничивающих областей. В этот момент может быть использована любая стандартная схема распознавания символов, чтобы преобразовывать изображение текста в машинокодированный текст.
Фиг. 2 - это блок-схема последовательности операций процесса определения набора областей изображения в соответствии с вариантом осуществления. Изображенная последовательность 200 операций процесса может выполняться посредством выполнения последовательностей исполняемых инструкций. В другом варианте осуществления различные части последовательности 200 операций процесса выполняются компонентами механизма обнаружения символов, схемой аппаратной логики, например, специализированной интегральной микросхемой (ASIC) и т.д. Например, блоки последовательности 200 операций процесса могут выполняться посредством исполнения последовательностей исполняемых инструкций в модуле обнаружения текста.
В одном варианте осуществления последовательность 200 операций процесса предусматривает дополнительные подробности этапа 110 на Фиг. 1. На этапе 210 обнаружение контуров выполняется по входному изображению. Контур - это значительное местное изменение насыщенности цвета в изображении. Контуры типично появляются на границе (например, границе объекта, границе поверхности и т.д.) между двумя различными областями в изображении, например, между символом и фоном. Целью обнаружения контуров является создание штрихового рисунка из изображения. Различные технологии обнаружения краев могут быть применены. Например, могут быть использованы градиентные или лапласовские технологии. Результатом обнаружения контуров является контурная карта входного изображения.
На этапе 220 создается бинарная контурная карта, например, с помощью глобального порогового значения для всего контурного изображения (например, контурной карты). Глобальное пороговое значение используется, чтобы разделять пикселы изображения и фоновые пикселы изображения объектов. Контурная карта изображения может включать в себя пикселы, которые являются черными, белыми и/или оттенками серого. Бинаризация на этой стадии модифицирует пикселы с оттенками серого в двоичную форму (например, все черные или белые пикселы).
Длинные горизонтальные и вертикальные линии удаляются из бинарной контурной карты на этапе 230. Эти линии типично указывают границы между различными участками входного изображения (например, участками изображения экрана GUI) и вряд ли должны быть текстом. По существу, такие длинные горизонтальные и вертикальные линии могут быть отброшены. Различные способы идентификации линий могут быть использованы. В одном варианте осуществления этап 230 может быть пропущен, если он не является релевантным для типа изображения.
На этапе 240 набор изолированных компонентов бинарной контурной карты (с удаленными длинными линиями) определяются с помощью пометки связанных компонентов. На верхнем уровне группа пикселов идентифицируется как область, где существует достаточная связанность между пикселами. Например, текущий пиксел во входном изображении может быть проверен относительно различных условий, таких как, является ли другой пиксел такой же насыщенности (или тонального значения, например, такой же черный или такой же белый) 8-связанным соседом, т.е. соседом на сервер, юг, восток, запад и по диагоналям.
Если эти условия удовлетворяются, соседний пиксел и текущий пиксел считаются частью одного и того же компонента. Каждый из идентифицированных компонентов формирует отдельное пятно. Компоненты могут использоваться, чтобы идентифицировать букву(ы), число(а), слово(а), другие текстовые элементы и нетекстовые элементы в изображении. Компонент может включать в себя слово, например, когда размер шрифта небольшой, и контуры символа соединяются с соседними символами. Компонент может включать в себя символ, например, когда размер шрифта большой. Компонент может включать в себя нетекстовые пятна высокой контрастности.
На этапе 245, для каждого компонента в наборе, определяется область в качестве ограничивающей области (например, ограничивающий прямоугольник). Ограничивающие прямоугольники являются координатами прямоугольной рамки, которая полностью окружает компонент. Различные другие ограничивающие формы могут быть применены. Координаты ограничивающих областей используются поверх первоначального входного изображения, чтобы определять область исходного входного изображения, которая охвачена ограничивающей областью.
Различные технологии могут быть использованы, чтобы идентифицировать подходящие области для бинаризации. Например, могут быть использованы технологии сегментации, требующие больших вычислительных затрат. В другом варианте осуществления могут быть выбраны области фиксированного размера (например, половина изображения или треть изображения).
В одном варианте осуществления фильтрация ограничивающих областей выполняется для того, чтобы оптимизировать производительность, например, уменьшая число ограничивающих прямоугольников, которые позже бинаризируются и классифицируются. Когда используется в этом контексте, фильтрация подразумевает выборочное удаление определенных ограничивающих прямоугольников из набора ограничивающих прямоугольников для изображения.
В одном примере фильтрация основана на размере ограничивающего прямоугольника. Если ограничивающий прямоугольник очень небольшой или тонкий (например, один пиксел в ширину), он считается нарушившим минимальное ограничение по размеру и отбрасывается. Аналогично, может быть наложено максимальное ограничение по размеру, так что если ограничивающий прямоугольник слишком большой (например, половина всего изображения), он считается нарушившим максимальное ограничение по размеру и отбрасывается.
В другом примере перекрывающиеся ограничивающие прямоугольники являются кандидатами для фильтрации. Когда используются в данном документе, перекрывающиеся ограничивающие прямоугольники - это те, которые имеют общую область изображения. Вложенный ограничивающий прямоугольник является одним примером. Чтобы выбирать, какие перекрывающиеся ограничивающие прямоугольники удалять, ограничивающие прямоугольники могут быть отсортированы по своей площади от наибольшей к наименьшей. Затем, для каждого ограничивающего прямоугольника, определяется число того, сколько меньших или перекрывающихся прямоугольников совместно используют одну и ту же область изображения. На основе этого подсчета решается, отбрасывать ли внешний (или, иначе, больший) ограничивающий прямоугольник или отбрасывать внутренние (или, иначе, меньшие) ограничивающие прямоугольники. Когда существует не слишком много внутренних ограничивающих прямоугольников, внешний прямоугольник сохраняется, а внутренние прямоугольники отбрасываются. С другой стороны, когда число внутренних ограничивающих прямоугольников слишком большое, внешний прямоугольник отбрасывается, оставляя меньшие внутренние прямоугольники в наборе ограничивающих прямоугольников. Предположим, что многие внутренние ограничивающие прямоугольники могут указывать множество различных цветовых схем в этой части изображения, которые могут функционировать, чтобы правильно отличать символы от фона.
Фиг. 3 - это блок-схема последовательности операций процесса бинаризации и классификации областей изображения в соответствии с вариантом осуществления. Изображенная последовательность 300 операций процесса может выполняться посредством выполнения последовательностей исполняемых инструкций. В другом варианте осуществления различные части последовательности 300 операций процесса выполняются компонентами механизма обнаружения символов, схемой аппаратной логики, например, специализированной интегральной микросхемой (ASIC) и т.д. Например, блоки последовательности 300 операций процесса могут выполняться посредством исполнения последовательностей исполняемых инструкций в модуле обнаружения текста.
В одном варианте осуществления последовательность 300 операций процесса предусматривает дополнительные подробности этапа 120 на Фиг. 1. На этап 310 адаптивная пороговая бинаризация предпочтительно выполняется для области с использованием входного изображения, а не применяется ко всему изображению. Адаптивное определение границ основано на конкретной статистике изображения для каждой отдельной области изображения, соответствующей ограничивающей области. Например, во время процесса определения границы индивидуальные пикселы в области изображения помечаются как пикселы "объекта", если их значение больше, чем некоторое пороговое значение (предполагая, что объект ярче, чем фон), и как пикселы "фона" в ином случае. Бинаризация адаптивна в том, что пороговое значение может изменяться от одной ограничивающей области к другой в зависимости от статистики изображения для конкретной ограничивающей области. Существует множество подходов к определению границы, например, срединный (0,5 (max+min)), итерационный и т.д. В одном варианте осуществления граница определяется посредством формул:
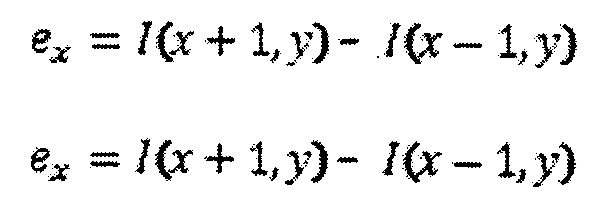
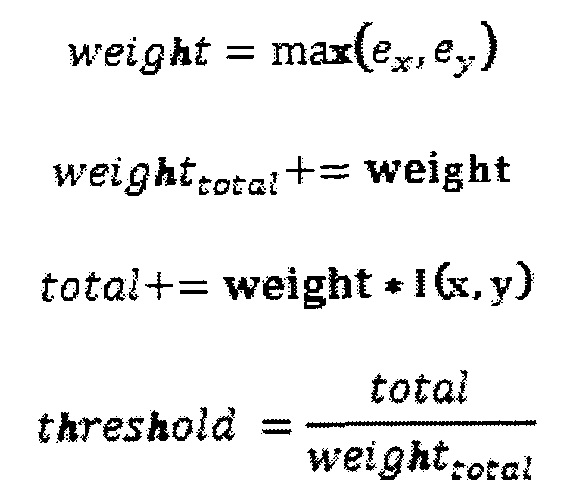
Результатом будет либо белый текст на черном фоне, либо черный текст на белом фоне, в зависимости от цвета фона и переднего плана в каждой области в качестве ограничивающей области во входном изображении.
Как ранее описано, классификатор используется, чтобы идентифицировать нетекстовые области и, во время обработки изображения, отфильтровывать те области, которые идентифицированы как нетекстовые области. На этапе 320 бинаризированная область, соответствующая ограничивающей области, классифицируется. В одном варианте осуществления наивный байесовский классификатор используется, чтобы идентифицировать область как одну из трех групп: нетекстовые, области белого текста и области черного текста. Признаки каждой области, соответствующей ограничивающей области, могут быть использованы, чтобы выполнять классификацию.
Для белых пикселов изучается изменение ширины штриха. Более конкретно, для белого пиксела в ограничивающей области соседи изучаются, чтобы идентифицировать минимальное расстояние до следующего черного пиксела. Предположим, что ширина штриха символа(ов) в ограничивающей области должна быть более или менее однообразной, т.е. с небольшим изменением. По существу, если изменение большое, ограничивающая область может не быть должным образом классифицирована как белый текст.
Аналогично, для черных пикселов изучается изменение ширины штриха. Более конкретно, для черного пиксела в области соседи изучаются, чтобы идентифицировать минимальное расстояние до следующего белого пиксела. Предположим, что ширина штриха символа(ов) в ограничивающей области должна быть более или менее однообразной, т.е. с небольшим изменением. По существу, если изменение большое, область может не быть должным образом классифицирована как черный текст.
Изучается отношение белых пикселов к черным пикселам в области. Предположим здесь, что, когда существует текст, типично, существует приблизительно 30-40% фона, а оставшиеся пикселы являются передним планом. Чем больше удалено соотношение от этого значения, тем более вероятно, что область не включает в себя текст, а вместо этого более вероятно должна быть нетекстовой.
Изучается отношение белых пикселов к черным пикселам вдоль границы области. На основе способа, которым выбираются области, ограничивающий прямоугольник обычно находится вокруг символа(ов). Граница области наиболее вероятно должна включать в себя предпочтительно пикселы фона, а не переднего плана. Предположим, что большинство пикселов вдоль границы области являются фоновыми. Если это не так, маловероятно, что область является текстовой областью, а, вместо этого, более вероятно должна быть нетекстовой. Граница является ограничивающим прямоугольником без внутренней области.
Вышеупомянутые признаки используются, чтобы классифицировать область, соответствующую ограничивающей области. Могут быть использованы другие классификаторы, такие как деревья решений (например, такие как С4,5) и метод опорных векторов (SVM).
После того как ограничивающая область классифицирована, классификация может использоваться, чтобы отфильтровывать нетекстовые области в изображении и/или нормализовать области, так что текст во всех областях в наборе является однообразным в цветовом представлении. На этапе 330 определяется, классифицирована ли область как нетекстовая область. Если так, область отфильтровывается или иначе не включается в набор областей, которые позже объединяются, чтобы формировать результирующее бинарное изображение, на этапе 340.
Классификация может также быть использована, чтобы нормализовать текст и фон каждой области (например, ограничивающей области), чтобы они были либо белым текстом на темном фоне, либо темным текстом на белом фоне. В одном варианте осуществления области нормализуются, чтобы показывать белый текст на темном фоне. Например, на этапе 335, определяется, является ли область областью белого текста. Когда это так, эта область объединяется в результирующее бинарное изображение на этапе 340. Изображение может считаться разбитым на составляющие части (т.е. области), и каждая из частей анализируется отдельно. Процесс объединения берет составляющие части (области, которые не были отброшены из набора областей) и составляет их вместе, используя координаты каждой области (например, координаты ограничивающей области).
Когда ограничивающая область не является областью белого текста, определяется, что она является областью черного текста, и инвертируется на этапе 338. Операция инверсии создает область белого текста с темным фоном, которая затем объединяется в результирующее бинарное изображение на этапе 340. Хотя нормализация в белый текст показана на Фиг. 3, нормализация в черный текст может также быть реализована. В одном варианте осуществления, части изображения, которые не имеют каких-либо ограничивающих областей, считаются не имеющими какого-либо текста и изображаются фоновым цветом в конечном изображении.
Как изображено циклом 310-342, каждая область в наборе может быть повторена, применяя процессы адаптивной пороговой бинаризации, классификации, фильтрации и нормализации. Как ранее описано, классификатор позволяет отфильтровывать нетекстовые области и нормализовать текст и фон за один проход.
Фиг. 4 - это изображение графического пользовательского интерфейса в соответствии с вариантом осуществления. В частности, изображение 410 является входным изображением GUI веб-сайта магазина. Цвет в изображении 410 показан в оттенках серого, однако, изображение может быть обработано в своей истиной цветной форме.
Фиг. 5 - это изображение графического пользовательского интерфейса после обнаружения контуров в соответствии с вариантом осуществления. Изображение 510 является результатом выполнения обнаружения контуров изображения 410 на Фиг. 4. Изображение 510 -это контурная карта. Пикселам в контурной карте назначено тональное значение белого и оттенков серого. Текст 515 представлен в оттенках серого, тогда как текст 520 представлен белым цветом.
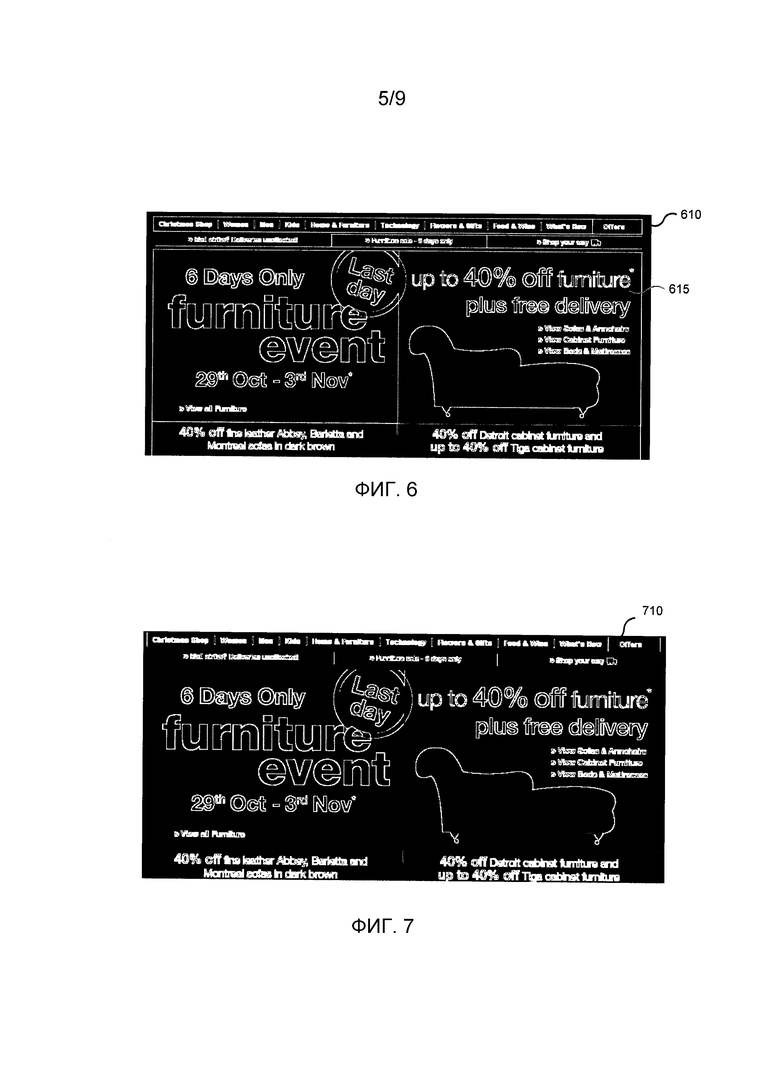
Фиг. 6 - это изображение графического пользовательского интерфейса после обнаружения контуров и глобальной бинаризации контурной карты в соответствии с вариантом осуществления Изображение 610 является результатом выполнения глобальной пороговой бинаризации изображения 510 на Фиг. 5. Изображение 610 - это бинарная контурная карта. Текст 615 был ранее представлен в оттенке серого, но был модифицирован в бинарную форму, т.е. белый. Следует понимать, что каждый пиксел в бинарной контурной карте существует в двоичной форме.
Фиг. 7 - это бинарная контурная карта изображения графического пользовательского интерфейса после удаления длинных линий в соответствии с вариантом осуществления. Изображение 710 является результатом удаления длинных горизонтальных и вертикальных линий в изображении 610 на Фиг. 6.
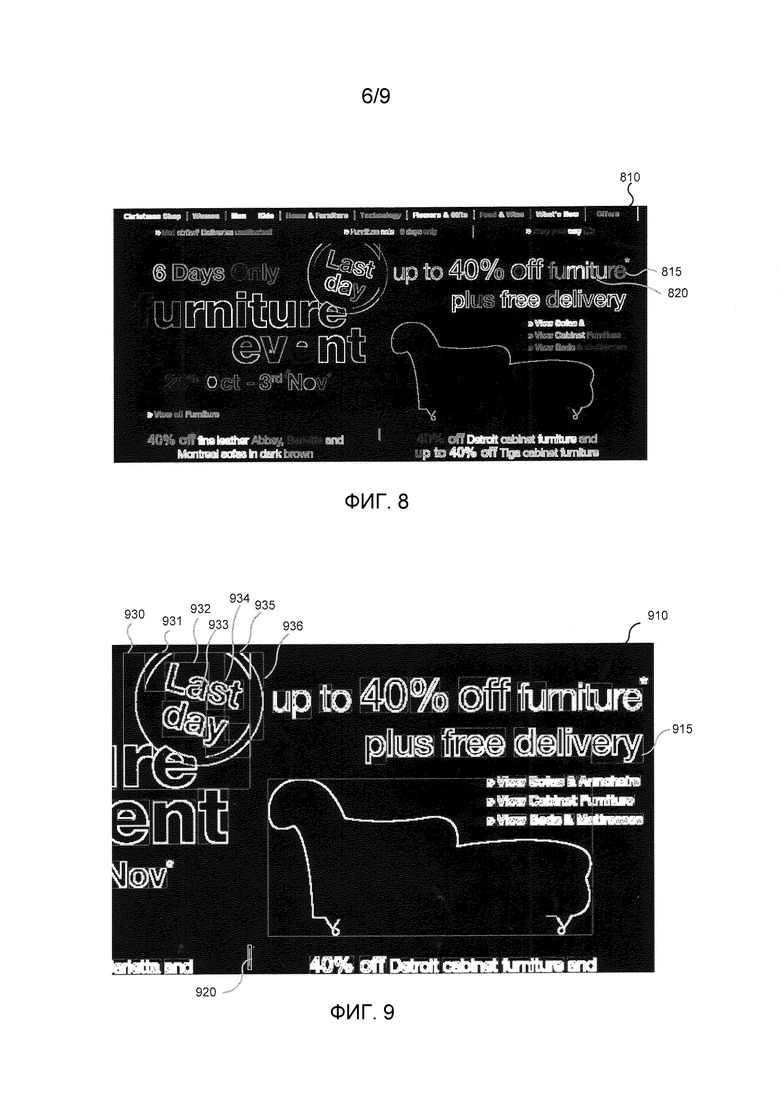
Фиг. 8 - это бинарная контурная карта изображения графического пользовательского интерфейса после пометки связанных компонентов в соответствии с вариантом осуществления. Изображение 810 является результатом пометки связанных компонентов в изображении 710 на Фиг. 7. В целях иллюстрации, каждый связанный компонент в изображении представляется в оттенках серого, т.е., изменяющейся насыщенности. Как показано, связанный компонент 815 состоит из букв "re" в слове "furniture". Другой связанный компонент 820 (показан с более светлой насыщенностью серого) состоит из букв "itu" в том же слове. В итоге, слово "furniture" состоит из четырех отдельных компонентов.
Фиг. 9 - это бинарная контурная карта изображения частичного графического пользовательского интерфейса, показывающая ограничивающие прямоугольники в соответствии с вариантом осуществления. Изображение 910 - это увеличенная часть результата формирования ограничивающих прямоугольников в изображении 810 на Фиг. 8. Как показано, ограничивающий прямоугольник 915 окружает буквы "ery" в слове "delivery" изображения 910, так как буквы "ery" являются связанными компонентами, а буква "v" не связана с буквой "е".
Фиг. 10 - это бинарная контурная карта изображения частичного графического пользовательского интерфейса, показывающая ограничивающие прямоугольники, отфильтрованные по размеру в соответствии с вариантом осуществления. Изображение 1001 является увеличенной частью результата фильтрации ограничивающих прямоугольников в изображении 910 на Фиг. 9 на основе размера. Обращаясь к Фиг. 9, короткий отрезок 920 линии показан как включающий в себя тонкий ограничивающий прямоугольник 920. В отличие от этого, обращаясь снова к Фиг. 10, ограничивающий прямоугольник не показывается вокруг короткого отрезка 1002 линии. Как ранее описано, ограничивающие прямоугольники, которые не удовлетворяют минимальному ограничению по размеру, отбрасываются.
Фиг. 11 - это бинарная контурная карта изображения графического пользовательского интерфейса, показывающая ограничивающие прямоугольники, отфильтрованные по размеру и включению в себя других прямоугольников в соответствии с вариантом осуществления. Изображение 1101 - это увеличенная часть результата фильтрации ограничивающих прямоугольников в изображении 910 на Фиг. 9 на основе размера и включения в себя других прямоугольников. Обращаясь к Фиг. 9, показаны множество перекрывающихся ограничивающих прямоугольников 930-936. В частности, ограничивающие прямоугольники 931-934, среди прочих, являются вложенными относительно ограничивающего прямоугольника 930. В отличие от этого, обращаясь снова к Фиг. 11, множество из перекрывающихся ограничивающих прямоугольников было отброшены, при этом остались ограничивающие прямоугольники 930, 935 и 936.
Фиг. 12 - это изображение графического пользовательского интерфейса после бинаризации в соответствии с вариантом осуществления. Изображение 1210 является результатом адаптивной пороговой бинаризации и фильтрации нетекстовых областей в изображении 410 на Фиг. 4. Следует понимать, что софа 420 из Фиг. 4 больше не появляется в изображении 1210. Так как софа классифицирована как нетекстовая область, она удалена из результирующего изображения. В другом варианте осуществления софа 420 отфильтровывается на основе максимального ограничения по размеру ограничивающего прямоугольника.
Фиг. 13 - это результирующее изображение графического пользовательского интерфейса после обнаружения текста в соответствии с вариантом осуществления. Изображение 1310 является результатом нормализации текста и фона в изображении 1210 (в белый текст, темный фон) на Фиг. 12 и объединения областей в наборе.
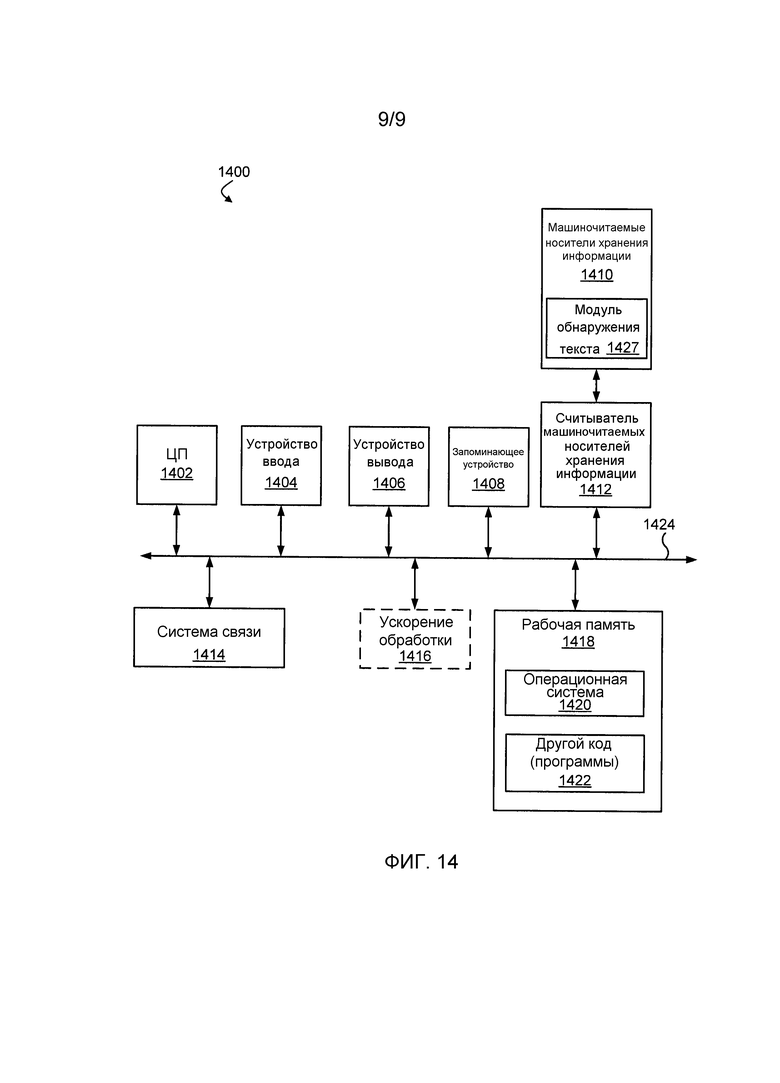
Фиг. 14 иллюстрирует компьютерную систему, в которой вариант осуществления может быть реализован. Система 1400 может быть использована, чтобы реализовывать любую из компьютерных систем, описанных выше. Компьютерная система 1400 показана содержащей аппаратные элементы, которые могут быть электрически связаны через шину 1424. Аппаратные элементы могут включать в себя, по меньшей мере, один центральный процессор (CPU) 1402, по меньшей мере, одно устройство 1404 ввода и, по меньшей мере, одно устройство 1406 вывода. Компьютерная система 1400 может также включать в себя, по меньшей мере, одно запоминающее устройство 1408. В качестве примера, запоминающее устройство 1408 может включать в себя устройства, такие как дисковые накопители,оптические запоминающие устройства, твердотельное запоминающее устройство, такое как оперативное запоминающее устройство ("RAM") и/или постоянное запоминающее устройство ("ROM"), которые могут быть программируемыми, флэш-обновляемыми и/или т.п.
Компьютерная система 1400 может дополнительно включать в себя считыватель 1412 машиночитаемых носителей хранения информации, систему 1414 связи (например, модем, сетевую карту (беспроводную или проводную), устройство инфракрасной связи и т.д.) и рабочую память 1418, которая может включать в себя устройства RAM и ROM, которые описаны выше. В некоторых вариантах осуществления компьютерная система 14 00 может также включать в себя блок 1416 ускорения обработки, который может включать в себя цифровой сигнальный процессор (DSP), специализированный процессор и/или т.п.
Считыватель 1412 машиночитаемых носителей хранения информации может быть дополнительно связан с машиночитаемым носителем 1410 хранения информации, вместе (и в комбинации с запоминающим устройством 1408 в одном варианте осуществления) всесторонне представляя удаленные, локальные, несъемные и/или съемные запоминающие устройства плюс любые материальные энергонезависимые носители хранения информации для временного и/или более постоянного содержания, хранения, передачи и извлечения машиночитаемой информации (например, инструкций и данных). Машиночитаемый носитель 1410 хранения может быть энергонезависимым, таким как аппаратные запоминающие устройства (например, RAM, ROM, EPROM (стираемое программируемое ROM), EEPROM (электрически стираемое программируемое ROM), жесткие диски и флэш-память). Система 1414 связи может разрешать обмениваться данными с сетью и/или любым другим компьютером, описанным выше относительно системы 1400. Машиночитаемый носитель 1410 хранения информации включает в себя модуль 1427 обнаружения текста.
Компьютерная система 1400 может также содержать элементы программного обеспечения, которые являются машиночитаемыми инструкциями, показанными как расположенные в настоящий момент в рабочей памяти 1418, включающей в себя операционную систему 1420 и/или другой код 1422, такой как прикладная программа (которая может быть клиентским приложением, веб-браузером, приложением среднего уровня и т.д.). Следует понимать, что альтернативные варианты осуществления компьютерной системы 1400 могут иметь многочисленные отличия от описанной выше. Например, специальные аппаратные средства могут также быть использованы, и/или отдельные элементы могут быть реализованы в аппаратных средствах, программном обеспечении (включающем в себя машинонезависимое программное обеспечение, такое как апплеты) или и в том, и в другом. Дополнительно, соединение с другими вычислительными устройствами, такими как сетевые устройства ввода/вывода, может быть применено.
Следовательно, подробное описание и чертежи должны рассматриваться в иллюстративном, а не в ограничительном смысле. Будет, однако, очевидно, что различные модификации и изменения могут быть выполнены.
Каждый признак, раскрытый в этой спецификации (включающий в себя любые сопровождающие формулу изобретения, реферат и чертежи), может быть заменен альтернативными признаками, служащими той же, эквивалентной или похожей цели, пока явно не установлено иное. Таким образом, пока явно не установлено иное, каждый раскрытый признак является одним примером характерной серии эквивалентных или похожих признаков.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И СИСТЕМА ПРЕОБРАЗОВАНИЯ МОМЕНТАЛЬНОГО СНИМКА ЭКРАНА В МЕТАФАЙЛ | 2013 |
|
RU2534005C2 |
| СПОСОБ РАСПОЗНАВАНИЯ ТЕКСТА НА ИЗОБРАЖЕНИЯХ ДОКУМЕНТОВ | 2021 |
|
RU2768544C1 |
| СПОСОБ И СИСТЕМА УЛУЧШЕНИЯ ТЕКСТА ПРИ ЦИФРОВОМ КОПИРОВАНИИ ПЕЧАТНЫХ ДОКУМЕНТОВ | 2012 |
|
RU2520407C1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ОПРЕДЕЛЕНИЯ ПРИГОДНОСТИ ДОКУМЕНТА ДЛЯ ОПТИЧЕСКОГО РАСПОЗНАВАНИЯ СИМВОЛОВ (OCR) | 2016 |
|
RU2634195C1 |
| УЛУЧШЕНИЕ КОНТРАСТА И СНИЖЕНИЕ ШУМА НА ИЗОБРАЖЕНИЯХ, ПОЛУЧЕННЫХ С КАМЕР | 2017 |
|
RU2721188C2 |
| СПОСОБ РЕДАКТИРОВАНИЯ СТАТИЧЕСКИХ ЦИФРОВЫХ КОМБИНИРОВАННЫХ ИЗОБРАЖЕНИЙ, ВКЛЮЧАЮЩИХ В СЕБЯ ИЗОБРАЖЕНИЯ НЕСКОЛЬКИХ ОБЪЕКТОВ | 2011 |
|
RU2458396C1 |
| ВЫЯВЛЕНИЕ СНИМКОВ ЭКРАНА НА ИЗОБРАЖЕНИЯХ ДОКУМЕНТОВ | 2014 |
|
RU2595557C2 |
| СИСТЕМА И СПОСОБ ОБРАБОТКИ ИЗОБРАЖЕНИЙ С ИСПОЛЬЗОВАНИЕМ ГЛУБИННЫХ НЕЙРОННЫХ СЕТЕЙ | 2018 |
|
RU2743931C1 |
| КЛАССИФИКАЦИЯ ИЗОБРАЖЕНИЙ ДОКУМЕНТОВ НА ОСНОВЕ ПАРАМЕТРОВ ЦВЕТОВЫХ СЛОЕВ | 2015 |
|
RU2603495C1 |
| РЕКОНСТРУКЦИЯ ДОКУМЕНТА ИЗ СЕРИИ ИЗОБРАЖЕНИЙ ДОКУМЕНТА | 2017 |
|
RU2659745C1 |



Изобретение относится к способу и системе для обнаружения текста в графических изображениях. Техническим результатом является оптимизация обнаружения текста в изображениях экрана GUI, в частности улучшение точности и производительности обнаружения и распознавания текста в изображениях экрана GUI. В способе обнаружения текста изображение принимается, и определяется набор связанных компонентов в изображении. Для каждого связанного компонента в наборе определяется ограничивающая область. Набор областей изображения определяется на основе ограничивающей области. Каждая область в наборе областей классифицируется и нормализуется на основе классификации. Нормализованный набор областей объединяется в бинарное изображение. В объединенном нормализованном наборе областей обнаруживают и распознают текст. 3 н. и 17 з.п. ф-лы, 14 ил.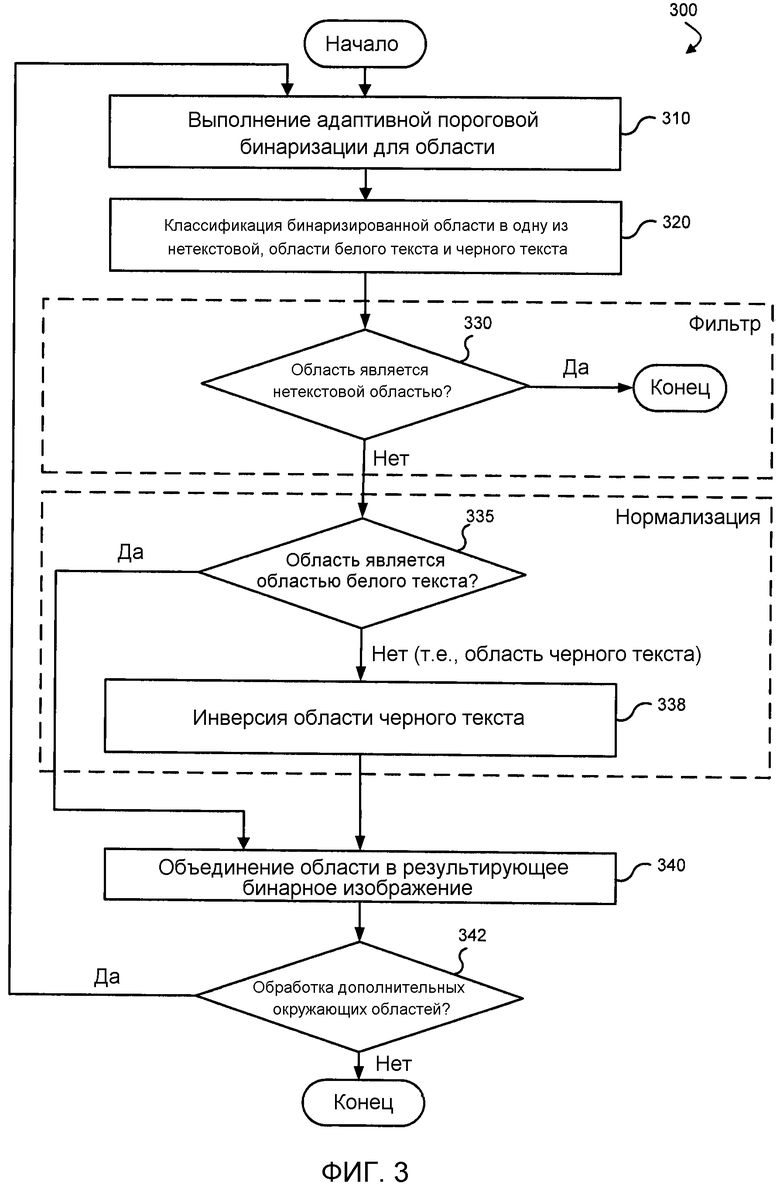
1. Способ обнаружения текста, содержащий этапы, на которых:
- принимают, посредством компьютера, входное изображение;
- выполняют обнаружение контуров во входном изображении;
- формируют контурную карту на основе входного изображения;
- формируют бинарную контурную карту;
- определяют набор связанных компонентов в бинарной контурной карте;
- для каждого связанного компонента в наборе связанных компонентов определяют ограничивающую область;
- определяют набор областей входного изображения на основе ограничивающей области;
- классифицируют каждую область в наборе областей;
- нормализуют набор областей на основе классификации;
- объединяют нормализованный набор областей; и
- обнаруживают и распознают текст в объединенном нормализованном наборе областей.
2. Способ по п. 1, в котором входное изображение является изображением графического пользовательского интерфейса.
3. Способ по п. 1, дополнительно содержащий этап, на котором: удаляют длинную горизонтальную линию и длинные вертикальные линии из бинарной контурной карты.
4. Способ по п. 1, в котором область классифицируется как одна из области белого текста, области черного текста и нетекстовой области.
5. Способ по п. 1, в котором классификация каждой области основана, по меньшей мере, на одном из изменения ширины штриха для белых пикселов, изменения ширины штриха для черных пикселов, отношения белых пикселов к черным пикселам в области, и отношения белых пикселов к черным пикселам вдоль границы области.
6. Способ по п. 1, в котором нормализация содержит этапы, на которых:
- определяют классификацию области в наборе областей; и
- инвертируют пикселы в упомянутой области на основе классификации.
7. Способ по п. 1, в котором нормализация содержит этапы, на которых:
- определяют то, что область в наборе областей классифицирована как область черного текста; и
- инвертируют пикселы в упомянутой области.
8. Способ по п. 1, в котором каждая ограничивающая область соответствует области входного изображения.
9. Способ по п. 1, дополнительно содержащий этап, на котором: для каждой области в наборе областей формируют бинарное изображение с помощью адаптивного порогового значения.
10. Способ по п. 1, в котором ограничивающая область является ограничивающим прямоугольником.
11. Способ по п. 1, дополнительно содержащий этапы, на которых:
- определяют то, что область в наборе областей классифицирована как нетекстовая область;
- отфильтровывают упомянутую область из набора областей.
12. Способ по п. 1, в котором бинарная контурная карта формируется с помощью глобального порогового значения.
13. Энергонезависимый машиночитаемый носитель, хранящий множество инструкций, чтобы управлять обнаружением текста процессором данных, при этом упомянутое множество инструкций включает в себя инструкции, которые предписывают процессору данных:
- принимать изображение графического пользовательского интерфейса (GUI);
- выполнять обнаружение контуров изображения GUI;
- формировать контурную карту на основе изображения GUI;
- формировать бинарную контурную карту;
- определять набор связанных компонентов в бинарной контурной карте;
- для каждого связанного компонента в наборе связанных компонентов определять ограничивающую область;
- определять набор областей входного изображения на основе ограничивающей области;
- классифицировать каждую область в наборе областей;
- нормализовывать набор областей на основе классификации;
- объединять нормализованный набор областей в бинарное изображение; и
- обнаруживать и распознавать текст в бинарном изображении.
14. Энергонезависимый машиночитаемый носитель по п. 13, при этом область классифицируется как одна из области белого текста, области черного текста и нетекстовой области.
15. Энергонезависимый машиночитаемый носитель по п. 13, при этом классификация каждой области основана, по меньшей мере, на одном из изменения ширины штриха для белых пикселов, изменения ширины штриха для черных пикселов, отношения белых пикселов к черным пикселам в области и отношения белых пикселов к черным пикселам вдоль границы области.
16. Энергонезависимый машиночитаемый носитель по п. 13, при этом инструкции, которые предписывают процессору данных нормализовать набор областей, включают в себя:
- инструкции, которые предписывают процессору данных определять классификацию области в наборе областей; и
- инструкции, которые предписывают процессору данных инвертировать пикселы в упомянутой области на основе классификации.
17. Энергонезависимый машиночитаемый носитель по п. 13, при этом инструкции, которые предписывают процессору данных нормализовать набор областей, включают в себя:
- инструкции, которые предписывают процессору данных определять то, что область в наборе областей классифицирована как область черного текста; и
- инструкции, которые предписывают процессору данных инвертировать пикселы в упомянутой области.
18. Система обнаружения текста, содержащая:
- процессор; и
- память, соединенную с процессором;
при этом процессор выполнен с возможностью:
- принимать изображение графического пользовательского интерфейса (GUI);
- определять набор связанных компонентов в изображении GUI;
- для каждого связанного компонента в наборе связанных компонентов определять ограничивающую область;
- определять набор областей изображения GUI на основе ограничивающей области;
- классифицировать каждую область в наборе областей;
- определять область в наборе областей, которая классифицирована как область черного текста;
- инвертировать пикселы в упомянутой области;
- объединять нормализованный набор областей в бинарное изображение; и
- обнаруживать и распознавать текст в бинарном изображении.
19. Система по п. 18, в которой классификация каждой области основана, по меньшей мере, на одном из изменения ширины штриха для белых пикселов, изменения ширины штриха для черных пикселов, отношения белых пикселов к черным пикселам в области и отношения белых пикселов к черным пикселам вдоль границы области.
20. Система по п. 18, в которой область классифицируется как одна из области белого текста, области черного текста и нетекстовой области.
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| US 6519362 B1, 11.02.2003 | |||
| US 6026177 A, 15.02.2000 | |||
| Колосоуборка | 1923 |
|
SU2009A1 |
| РАСПОЗНАВАНИЕ НАПИСАННЫХ ЗНАКОВ НА ПОЛЬЗОВАТЕЛЬСКОМ ИНТЕРФЕЙСЕ | 2004 |
|
RU2314563C1 |

