Ссылка на родственные заявки
[1] Согласно настоящей заявке испрашивается в отношении США внутренний приоритет, а в отношении других юрисдикционных систем конвенционный приоритет в соответствии со следующими заявками: 1) предварительная заявка на выдачу патента США №62/576,180, поданная 24 октября 2017 года под названием «А System and Method for Video Hair Coloration Using Deep Neural Networks»; и 2) предварительная заявка на выдачу патента США №62/597,494, поданная 12 декабря 2017 года под названием «А System and Method for Real-time Deep Hair Matting on Mobile Devices», при этом содержание каждой заявки включено посредством ссылки для любой юрисдикционной системы, где допускается такое включение.
Область техники, к которой относится настоящее изобретение
[2] Настоящая заявка относится к обработке изображений для формирования нового изображения из исходного изображения и, в частности, для обработки изображения с использованием глубинных нейронных сетей, таких как сверточная нейронная сеть (CNN).
Предшествующий уровень техники настоящего изобретения
[3] Существует множество сценариев, в которых обработка изображений полезна для анализа исходного изображения, чтобы идентифицировать в нем определенный объект, и по меньшей мере в подмножестве этих сценариев для внесения исправлений или других изменений, чтобы создать новое изображение. Обработка изображений может использоваться для классификации объекта, представленного на изображении, и/или идентификации местоположения объекта на изображении. Кроме того, обработка изображений может использоваться для корректировки или изменений атрибутов (например, соответствующего значения пикселя) изображения, например, для изменений цвета, текстуры, освещения, яркости, контраста и других атрибутов. К другим изменениям могут относиться добавление или вычитание объектов изображения, изменения форм объектов и т.п.
[4] Согласно одному примеру обработка изображений может быть использована для окрашивания волос субъекта на исходном изображении, чтобы получить изображение окрашенных волос.
[5] Обработка изображений обычно требует значительных ресурсов от вычислительных устройств, в частности, таких распространенных мобильных устройств, как смартфоны, планшетные компьютеры и подобные устройства. Это становится особенно актуальным при обработке в режиме реального времени видео, содержащего группу изображений.
Краткое раскрытие настоящего изобретения
[6] Приведенное ниже описание относится к реализации глубинного обучения и, в частности, к реализации глубинного обучения на мобильном устройстве. Целью настоящего изобретения является создание среды глубинного обучения для обработки видео в реальном масштабе времени («живого» видео), например, для сегментации объекта, такого как волосы, и смены цвета волос. Специалисту в данной области техники будет понятно, что могут быть обнаружены объекты, отличающиеся от волос, или могут быть изменены цвет или другие соответствующие атрибуты. Видеоизображения (например, кадры) могут обрабатываться с использованием глубинной нейронной сети для определения соответствующей маски волос (например, выделения объекта) из пикселей волос (например, пикселей объекта) на основе каждого видеоизображения. Соответствующие маски объектов могут быть использованы для определения того, какой из пикселей должен быть подвергнут изменению при корректировке атрибута видеоизображения, такого как цвет, освещение, текстура и т.п. Согласно одному примеру для окрашивания волос нейронную сеть глубинного обучения, например сверточную нейронную сеть, выполняют с возможностью классификации пикселей исходного изображения, чтобы определить, является ли каждый пиксель пикселем волос, и определить выделение волос. Затем выделение используют для изменения атрибута исходного изображения для создания нового изображения. CNN может включать в себя предварительно обученную сеть для классификации изображения, адаптированную для получения выделения сегментации. CNN может быть дополнительно обучена с использованием грубых данных сегментации и для сведения к минимуму потери совместимости градиентов выделения и изображения при обучении. CNN может дополнительно использовать скип-соединения между соответствующими слоями ступени кодера и ступени декодера, при этом менее глубокие слои в кодере, которые содержат обладающие высоким разрешением, но слабые признаки, объединяются с обладающими низким разрешением, но мощными признаками, из более глубоких слоев в декодере.
[7] Такое выделение может использоваться, чтобы непосредственно или опосредованно различать другие объекты. Выделение волос может определять границы или края человека, причем предметом, находящимся за пределами выделения волос, может быть, например, фон. К другим объектам, которые могут быть обнаружены, относится кожа и т.п.
[8] Предлагается вычислительное устройство для обработки изображения, содержащее: запоминающий блок для хранения и предоставления сверточной нейронной сети (CNN), выполненной с возможностью классификации пикселей изображения для определения того, является ли каждый из пикселей пикселем объекта или нет, чтобы определить выделение сегментации объекта для объекта на изображении, причем CNN включает в себя предварительно обученную сеть для классификации изображения, адаптированную для определения выделения сегментации объекта, и CNN дополнительно обучена с использованием данных сегментации; и блок обработки данных, связанный с запоминающим блоком и выполненный с возможностью обработки изображения с использованием CNN для генерирования выделения сегментации объекта для определения нового изображения.
[9] CNN может быть адаптирована для сведения к минимуму потерь совместимости градиентов выделения и изображения при обучении с использованием данных сегментации.
[10] CNN может быть дополнительно адаптирована к использованию скип-соединений между слоями в ступени кодера и соответствующими слоями в ступени декодера, чтобы объединить обладающие низким разрешением, но мощные признаки и обладающие высоким разрешением, но слабые признаки при повышающей дискретизации в ступени декодера для определения выделения сегментации объекта.
[11] Потеря Lc совместимости градиентов выделения и изображения может быть определена следующим образом:
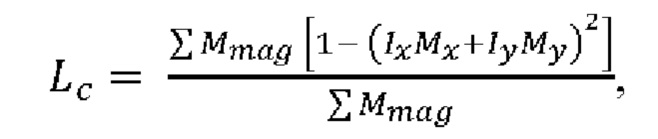
где Ix, Iy представляют собой нормализованный градиент изображения; Mx, My представляют собой нормализованный градиент выделения; и Mmag представляет собой величину градиента выделения.
[12] Потеря совместимости градиентов выделения и изображения может быть объединена с потерей бинарной перекрестной энтропии с весом w, чтобы свести к минимуму суммарные потери L при обучении, где L определяется как L=LM+wLC.
[13] CNN может быть обучена с использованием зашумленных и грубых данных сегментации. Данные сегментации могут представлять собой краудсорсинговые данные сегментации.
[14] Объектом могут быть волосы. Блок обработки данных может быть выполнен с возможностью определения нового изображения на основе изображения путем применения изменения к пикселям на изображении, выбранным с использованием выделения сегментации объекта. Изменение может представлять собой изменение цвета (например, когда объект представляет собой волосы для имитации изменения цвета волос).
[15] CNN может включать в себя обученную сеть, выполненную с возможностью исполнения на мобильном устройстве с ограниченной вычислительной мощностью для создания нового изображения в качестве видеоизображения в режиме реального времени.
[16] Блок обработки данных может быть выполнен с возможностью предоставления интерактивного графического пользовательского интерфейса (GUI) для отображения изображения и нового изображения. Интерактивный GUI может быть выполнен таким образом, чтобы принимать входные данные для определения изменения для выдачи нового изображения. Блок обработки данных может быть выполнен с возможностью анализа пикселей объекта на изображении с использованием выделения сегментации объекта, чтобы определить одного или более кандидатов для изменения. Интерактивный GUI может быть выполнен с возможностью представления одного или более кандидатов для получения входных данных с целью выбора одного из кандидатов для применения в качестве изменения.
[17] Изображение может представлять собой селфи-видео.
[18] Предлагается вычислительное устройство для обработки изображения, содержащее: запоминающий блок для хранения и предоставления сверточной нейронной сети (CNN), выполненной с возможностью классификации пикселей изображения для определения того, является ли каждый из пикселей пикселем волос или нет, при этом CNN обучена для сведения к минимуму потери совместимости градиентов выделения и изображения при обучении с использованием данных сегментации для определения выделения сегментации волос; и блок обработки данных, связанный с запоминающим блоком, при этом блок обработки данных выполнен с возможностью определения и представления изображения окрашенных волос путем применения нового цвета волос к пикселям волос на изображении с использованием выделения сегментации волос.
[19] Предлагается вычислительное устройство для обработки изображения, содержащее: блок обработки данных, запоминающий блок, связанный с блоком обработки данных, и устройство ввода, связанное по меньшей мере с одним из блока обработки данных и запоминающего блока, при этом в запоминающем блоке хранятся команды, которые при выполнении блоком обработки данных конфигурируют вычислительное устройство для следующих действий: прием изображения посредством устройства ввода; определение выделения сегментации волос, которое идентифицирует пиксели волос на изображении; определение изображения окрашенных волос путем применения нового цвета к пикселям волос на изображении с использованием выделения сегментации волос; и предоставление изображения окрашенных волос для выдачи в устройство отображения; и при этом выделение сегментации волос определяется посредством следующего: обработка изображения с использованием сверточной нейронной сети (CNN), хранящейся в запоминающем блоке, для применения множества сверточных фильтров (фильтров свертки) в последовательности слоев свертки, чтобы выполнить обнаружение соответствующих признаков, где первый набор слоев свертки в последовательности предоставляет выходные данные, которые понижают разрешение изображения от первого разрешения изображения до минимального разрешения, и второй набор слоев свертки в последовательности повышает разрешение выходных данных обратно до первого разрешения изображения, и CNN обучена для сведения к минимуму потерь совместимости градиентов выделения и изображения, чтобы определить выделение сегментации волос.
[20] Предлагается вычислительное устройство, выполненное с возможностью генерирования сверточной нейронной сети (CNN), обученной для обработки изображений, чтобы определить выделение сегментации объекта, причем указанное вычислительное устройство содержит: запоминающий блок для приема CNN, выполненной с возможностью классификации изображения и выполненной с возможностью исполнения на исполнительном вычислительном устройстве, характеризующемся ограниченной вычислительной мощностью; блок обработки данных, выполненный с возможностью предоставления интерактивного интерфейса для приема входных данных и отображения выходных данных, при этом блок обработки данных выполнен с возможностью следующего: прием входных данных для адаптации CNN для определения выделения сегментации объекта и сохранение CNN после адаптации в запоминающем блоке; и прием входных данных для обучения CNN после адаптации с использованием обучающих данных сегментации, помеченных для сегментации объекта, чтобы генерировать CNN для обработки изображений для определения выделения сегментации объекта. Блок обработки данных может быть выполнен с возможностью приема входных данных для адаптации CNN по меньше мере к одному из следующего: применение функции потери совместимости градиентов выделения и изображения, определенной для сведения к минимуму потери совместимости градиентов выделения и изображения при обучении; и применение скип-соединений между слоями в ступени кодера и соответствующими слоями в ступени декодера, чтобы объединить обладающие низким разрешением, но мощные признаки и обладающие высоким разрешением, но слабые признаки при повышающей дискретизации в ступени декодера; и сохранение CNN после адаптации в запоминающем блоке.
[21] Предлагается способ генерирования сверточной нейронной сети (CNN), обученной для обработки изображений, чтобы определить выделение сегментации объекта. Способ предусматривает: получение CNN, выполненной с возможностью классификации изображения и выполненной с возможностью исполнения на вычислительном устройстве, характеризующемся ограниченной вычислительной мощностью; адаптацию CNN для определения выделения сегментации объекта; и обучение CNN после адаптации с использованием обучающих данных сегментации, помеченных для сегментации объекта, чтобы определить выделение сегментации объекта. CNN может быть обучена с использованием функции потери совместимости градиентов выделения и изображения, определенной для сведения к минимуму потери совместимости градиентов выделения и изображения, чтобы генерировать CNN для обработки изображений для определения выделения сегментации объекта.
[22] CNN может быть предварительно обучена для классификации изображения, и на стадии обучения осуществляется дополнительное обучение CNN после предварительного обучения. Обучающие данные сегментации могут представлять собой зашумленные и грубые обучающие данные сегментации (например, определенные на основе краудсорсинговых данных).
[23] Способ может предусматривать адаптацию CNN к использованию скип-соединений между слоями в ступени кодера и соответствующими слоями в ступени декодера, чтобы объединить обладающие низким разрешением, но мощные признаки и обладающие высоким разрешением, но слабые признаки при повышающей дискретизации в ступени декодера.
[24] Функция потери совместимости градиентов выделения и изображения может быть объединена с функцией потери бинарной перекрестной энтропии для сведения к минимуму общей потери. Способ может предусматривать предоставление CNN для обработки изображений, чтобы определить выделение сегментации объекта, для сохранения на мобильном устройстве.
[25] Предлагается способ, предусматривающий: сохранение в запоминающем блоке, входящем в состав вычислительного устройства, сверточной нейронной сети (CNN), выполненной с возможностью классификации пикселей изображения для определения того, является ли каждый из пикселей пикселем объекта или нет, чтобы определить выделение сегментации объекта для объекта на изображении, при этом CNN включает в себя предварительно обученную сеть для классификации изображения, адаптированную для определения выделения сегментации объекта и обученную с использованием данных сегментации.
[26] CNN может быть дополнительно обучена для сведения к минимуму потери совместимости градиентов выделения и изображения при обучении с использованием данных сегментации; и способ предусматривает обработку изображения посредством блока обработки данных, входящего в состав вычислительного устройства, с использованием CNN для генерирования выделения сегментации объекта для определения нового изображения.
[27] Предлагается способ обработки изображения. Способ предусматривает: сохранение в запоминающем блоке, входящем в состав вычислительного устройства, сверточной нейронной сети (CNN), выполненной с возможностью классификации пикселей изображения для определения того, является ли каждый из пикселей пикселем волос или нет, при этом CNN обучают для сведения к минимуму потери совместимости градиентов выделения и изображения при обучении с использованием данных сегментации для определения выделения сегментации волос; и определение и представление посредством блока обработки данных, входящего в состав вычислительного устройства и связанного с запоминающим блоком, изображения окрашенных волос путем применения нового цвета волос к пикселям волос на изображении с использованием выделения сегментации волос.
[28] Предлагается способ обработки изображения, предусматривающий: прием изображения посредством блока обработки данных; определение выделения сегментации волос, которое идентифицирует пиксели волос на изображении, посредством блока обработки данных; определение посредством блока обработки данных изображения окрашенных волос путем применения нового цвета волос к пикселям волос на изображении с использованием выделения сегментации волос; и предоставление посредством блока обработки данных изображения окрашенных волос для выдачи на устройство отображения. Выделение сегментации волос ограничивают посредством следующего: обработка изображения с использованием сверточной нейронной сети (CNN), сохраненной посредством запоминающего блока, связанного с блоком обработки данных, для применения множества сверточных фильтров (фильтров свертки) в последовательности слоев свертки, чтобы выполнить обнаружение соответствующих признаков, и CNN обучена с использованием зашумленных и грубых данных сегментации и для сведения к минимуму потери совместимости градиентов выделения и изображения для определения выделения сегментации волос.
[29] Первый набор слоев свертки в последовательности может предоставлять выходные данные, которые понижают разрешение изображения от первого разрешения изображения до минимального разрешения, и второй набор слоев свертки в последовательности повышает разрешение выходных данных обратно до первого разрешения изображения, при этом CNN использует скип-соединения между соответствующими слоями свертки из первого набора и второго набора.
[30] CNN может предусматривать функцию повышающей дискретизации, вставленную перед исходным слоем второго набора слоев свертки и перед соответствующими последующими слоями второго набора слоев свертки для повышения разрешения выходных данных до первого разрешения изображения.
[31] Функция повышающей дискретизации может использовать соответствующие скип-соединения, где каждое из соответствующих скип-соединений объединяет: первую карту активации, которая выдана из соседнего слоя свертки в последовательности в качестве входных данных для следующего слоя свертки второго набора слоев свертки; и вторую карту активации, которая выдана из более раннего слоя свертки в первом наборе слоев свертки, где вторая карта активации имеет большее разрешение изображения, чем первая карта активации. Каждое из соответствующих скип-соединений может быть задано для сложения выходных данных фильтра свертки 1×1, применяемого ко второй карте активации, с выходными данными функции повышающей дискретизации, применяемой к первой карте активации, чтобы повысить разрешение первой карты активации до более высокого разрешения изображения.
[32] Способ может предусматривать представление посредством блока обработки данных графического пользовательского интерфейса (GUI) на устройстве отображения, при этом GUI содержит первую часть для просмотра изображения и вторую часть для одновременного просмотра изображения окрашенных волос.
[33] Способ может предусматривать применение обработки с использованием условий освещения к новому цвету волос на изображении окрашенных волос, чтобы показать новый цвет волос при другом условии освещения.
[34] Новый цвет волос может быть первым новым цветом волос, и изображение окрашенных волос может быть первым изображением окрашенных волос. В этом случае способ может предусматривать: определение и представление посредством блока обработки данных второго изображения окрашенных волос путем применения второго нового цвета волос к пикселям волос на изображении с использованием выделения сегментации волос и путем предоставления второго изображения окрашенных волос для выдачи в устройство отображения. Способ может предусматривать представление посредством блока обработки данных GUI с двумя новыми цветами на устройстве отображения, при этом GUI с двумя новыми цветами содержит первую часть с новым цветом для просмотра первого изображения окрашенных волос и вторую часть с новым цветом для одновременного просмотра второго изображения окрашенных волос.
[35] Способ может предусматривать: анализ посредством блока обработки данных изображения на предмет цвета, включая текущий цвет пикселей волос на изображении; определение одного или более предлагаемых новых цветов волос; и представление предлагаемых новых цветов волос посредством интерактивной части GUI для выбора нового цвета волос, чтобы определить изображение окрашенных волос.
[36] Блок обработки данных может включать в себя графический процессор (GPU) для выполнения CNN, при этом блок обработки данных и запоминающий блок могут быть предоставлены посредством вычислительного устройства, включающего в себя одно из смартфона и планшетного компьютера. Согласно указанному способу изображение может быть одним из множества видеоизображений, входящих в состав видео, при этом указанный способ может предусматривать обработку посредством блока обработки данных множества видеоизображений для изменения цвета волос.
[37] CNN может содержать модель на основе MobileNet, адаптированную для классификации пикселей изображения для определения, является ли каждый из пикселей пикселем волос.CNN может быть сконфигурирована в качестве нейронной сети на основе раздельных сверток по глубине, содержащей свертки, в которых отдельные стандартные свертки факторизированы на свертку по глубине и поточечную свертку, причем свертка по глубине ограничена применением одного фильтра к каждому входному каналу, и поточечная свертка ограничена объединением выходных данных свертки по глубине.
[38] Специалисту в данной области техники будут очевидны эти и другие аспекты, включая аспекты, относящиеся к компьютерным программным продуктам, в которых (энергонезависимый) запоминающий блок хранит команды, которые при выполнении блоком обработки данных конфигурируют операции вычислительного устройства для осуществления любого из описанных в настоящем документе аспектов, относящихся к реализуемым компьютером способам.
Краткое описание фигур
[39] На фиг. 1 представлено схематическое изображение применения классификатора на основе комитета деревьев принятия решений (алгоритма случайного леса) для классификации пикселей изображения в соответствии с приведенным в настоящем документе примером.
[40] На фиг. 2 представлена иллюстрация архитектуры глубинной нейронной сети в соответствии с моделью MobileNet от компании Google Inc.
[41] На фиг. 3 представлена иллюстрация архитектуры глубинной нейронной сети, выполненной с возможностью обработки изображения и получения в качестве выходных данных выделения изображения, в соответствии с приведенным в настоящем документе примером.
[42] На фиг. 4 представлена иллюстрация архитектуры глубинной нейронной сети, выполненной с возможностью применения скип-соединений (дополнительных соединений между узлами для пропуска одного или нескольких слоев), чтобы обработать изображение и получить в качестве выходных данных выделение изображения, в соответствии с приведенным в настоящем документе примером.
[43] На фиг. 5 представлена иллюстрация архитектуры глубинной нейронной сети, выполненной с возможностью применения скип-соединений с обучением на основе показателя потери совместимости градиентов выделения и изображения, чтобы обработать изображение и получить в качестве выходных данных выделение изображения, в соответствии с приведенным в настоящем документе примером.
[44] На фиг. 6 представлена таблица с изображениями качественных результатов для моделей нейронных сетей, показанных на фиг. 3-5.
[45] На фиг. 7 представлена таблица с изображениями качественных результатов для моделей нейронных сетей, показанных на фиг. 3 и 5.
[46] На фиг. 8 представлена блок-схема вычислительного устройства, сконфигурированного с глубинной нейронной сетью для обработки изображений, в соответствии с приведенным в настоящем документе примером.
[47] На фиг. 9 представлена принципиальная схема операций вычислительного устройства, показанного на фиг. 8, в соответствии с приведенным в настоящем документе примером.
[48] На фиг. 10 представлена принципиальная схема стадий для определения иллюстративной CNN в соответствии с приведенными в настоящем документе идеями.
[49] Идея настоящего изобретения лучше всего описывается на примере его конкретных вариантов осуществления, которые описываются в настоящем документе со ссылкой на прилагаемые фигуры, где одинаковые позиции относятся к одинаковым признакам. Следует понимать, что термин «изобретение», в случае его использования в настоящем документе, предназначен для обозначения идеи изобретения, лежащей в основе описанных ниже вариантов осуществления, а не только самих вариантов осуществления. Кроме того, следует понимать, что общая идея изобретения не ограничивается иллюстративными вариантами осуществления, описанными ниже, и этот принцип должен использоваться при прочтении приведенного ниже описания.
[50] Дополнительно, слово «иллюстративный» следует понимать как «служащий в качестве примера, образца или иллюстрации». Любой вариант осуществления структуры, процесса, конструкции, технологии и т.п., обозначенный в настоящем документе в качестве иллюстративного, не обязательно должен рассматриваться в качестве предпочтительного или преимущественного по сравнению с другими такими вариантами осуществления. Не предполагается и не следует делать вывод о конкретном качестве или пригодности примеров, обозначенных в настоящем документе в качестве иллюстративных.
Подробное раскрытие настоящего изобретения
Глубинное обучение и сегментация
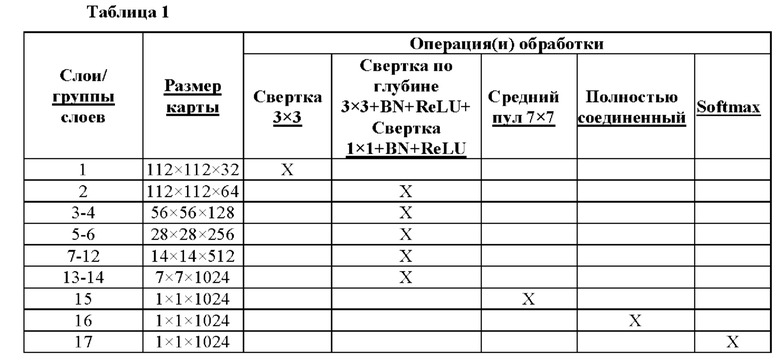
[51] Сегментация изображения в режиме реального времени является одной из важных проблем, присущих машинному зрению во множестве программных приложений. В частности, речь идет о сегментации волос для усиления их живого цвета в косметических программных приложениях. Однако этому случаю применения присущи дополнительные сложности. Во-первых, в отличие от многих объектов, имеющих простую форму, волосы характеризуются очень сложной структурой. Для создания реалистичного усиления цвета не достаточно грубого выделения сегментации волос. Вместо этого необходима маска волос. Во-вторых, множество косметических программных приложений выполняются на мобильных устройствах или веб-браузерах, где не имеется значительных вычислительных ресурсов. Это усложняет функционирование в режиме реального времени. В настоящем документе описываются система, способ и подобные объекты для точного сегментирования волос со скоростью более 30 кадров в секунду на мобильном устройстве.
[52] Система и способ сегментирования волос основаны на сверточных нейронных сетях (CNN). Большинство современных CNN не могут работать в режиме реального времени даже на мощных GPU (графических процессорах) и могут занимать большой объем памяти. Целью, поставленной в настоящем документе перед системой и способами, является функционирование в режиме реального времени на мобильном устройстве. В качестве первого способствующего фактора показано, как адаптировать для сегментации волос недавно предложенную архитектуру MobileNets™ компании Google Inc., которая является достаточно быстрой и компактной для использования на мобильном устройстве. Подробности, относящиеся к MobileNets, могут быть найдены в документе «MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications» of Howard et al., arXiv:1704.04861v1 [cs:CV], 17 апреля 2017 года, который посредством ссылки включается в настоящий документ.
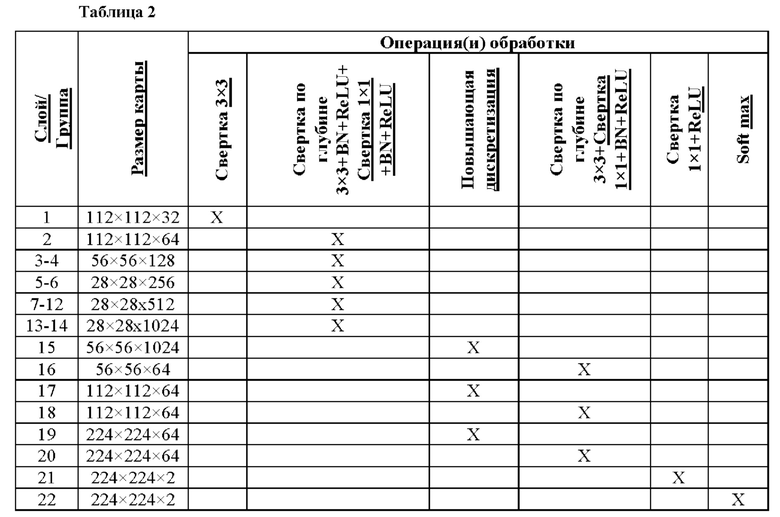
[53] При отсутствии истинных данных подробной сегментации волос сеть обучается на зашумленных и грубых краудсорсинговых данных (грубых данных сегментации, где разметка не является особо точной на уровне пикселей). При этом результат грубой сегментации не является привлекательным с эстетический точки зрения для усиления цвета волос. Более точная цветовая маска дает улучшенные результаты для создания реалистичного усиления цвета волос. В качестве второго способствующего фактора предлагается способ получения более точных масок волос в режиме реального времени без необходимости в точных обучающих данных для маски волос. Во-первых, показано, как изменить базовую архитектуру сети для обеспечения возможности захватывать более мелкие детали. Во-вторых, посредством добавления вторичной функции потерь, которая способствует получению привлекательных для восприятия результатов маскирования, показано, что сеть может быть обучена для получения подробных масок волос с использованием только грубых обучающих данных сегментации волос. Мы сравниваем этот подход с постобработкой с использованием простого управляемого фильтра (сохраняющего края фильтра с линейной сложностью выполнения относительно размера изображения) и показываем, что он дает более точные и четкие результаты.
[54] Прежде чем преступить к подробному описанию глубинного обучения и сегментации, следует отметить, что заявителем были предприняты и проанализированы более ранние попытки по разработке решения по окраске волосы на видео на мобильных устройствах. Например, был разработан классификатор, включающий модель случайного леса (RF) на основе признаков цветовой гистограммы, положения и градиентных факторов. Классификатор последовательно обрабатывал пиксели, постепенно перемещая фильтр или ядро вокруг изображения, что хорошо известно, для определения, является ли центральный пиксель пикселем волос или нет. На фиг. 1 представлено схематическое изображение, где изображение 100 обрабатывают путем сканирования фильтра 102 поверх изображения для последовательной обработки пикселей с использованием классификатора RF 104, который выдает, является ли центральный пиксель 106 фильтра 102 пикселем волос или нет. Выходные данные 108 могут быть использованы для определения маски волос (не показана), при этом выходные данные являются значением соответствующего пикселя в маске волос. Следует понимать, что на схематическом изображении, показанном на фиг. 1, фильтр 102, центральный пиксель 106 и показанный путь изображены без соблюдения масштаба. Результаты не были обнадеживающими ни с точки зрения скорости, ни с точки зрения правильности, поэтому этот подход отвергли в пользу глубинного обучения.
[55] Причина, по которой глубинное обучение не было выбрано в первую очередь, заключается в том, что по-прежнему сложно обеспечить его работу на мобильных устройствах в режиме реального времени. Большинство архитектур алгоритма глубинного обучения не работают в режиме реального времени даже на мощных GPU. Первоначальный подход адаптировал архитектуру нейронной сети Visual Group Geometry, а именно VGG16. Классификационная сеть на основе VGG16, предварительно обученная с помощью ImageNet (большая база данных для воспроизведения визуальной обстановки (общедоступный набор данных), разработанная для использования совместно с исследованием программного обеспечения для распознания объектов), была адаптирована посредством удаления последних 3 слоев (например, полностью соединенных слоев и выходного слоя) и преобразования в сеть семантической сегментации путем добавления нескольких транспонированных сверточных слоев (часто сокращенно именуемых «слоями свертки»). Хотя результат (выходные данные) были довольно хорошими, обработка занимала много времени, в частности, на мобильном устройстве (более секунды на каждый кадр). Таким образом, подход был изменен для нахождения более подходящей архитектуры, которая характеризуется меньшим размером и выполняет меньшее количество операций, чтобы повысить скорость обработки и т.п.
Архитектура MobileNet
[56] Архитектура MobileNet компании Google Inc. представляет собой легкую, предварительно обученную архитектуру нейронной сети глубинного обучения, реализованную для мобильных устройств. На фиг. 2 показана схематическая иллюстрация сети MobileNet 200, которая демонстрирует исходное изображение 100 в качестве входных данных, слои/группы 202 слоев сети в соответствии с предварительно обученной сверточной нейронной сетью MobileNet и классификационные метки 204 в качестве выходных данных сети MobileNet 200. Входные изображения, обработанные посредством MobileNet, имеют разрешение 224×224 пикселей с 3-я цветовыми значениями (т.е. 224×224×3).
[57] Архитектура MobileNet использует раздельные свертки по глубине (форма факторизованных сверток) для сведения к минимуму операций обработки данных (т.е. операций с плавающей запятой, умножения и/или сложения и подобных операций). Раздельные свертки по глубине факторизируют (например, разделяют функции) стандартную свертку на свертку по глубине и свертку 1×1 (также называемой «поточечной сверткой») с целью ускорения обработки путем уменьшения или сведения к минимуму требуемого количества операций. Свертка по глубине применяет одиночный фильтр к каждому входному каналу. Затем поточечная свертка применяет свертку 1×1 для объединения выходных данных глубинной свертки, в результате чего функции/операции фильтрации и объединения разделяются на две стадии, вместо одной операции фильтрации и объединения, выполняемой стандартными свертками. Таким образом, структуры в архитектуре 200 могут включать в себя два слоя свертки на каждую структуру - один слой свертки по глубине и один слой поточечной свертки - для определения или иллюстрации «группы слоев».
[58] В Таблице 1 представлена информация о размере карты активации и информация об операции(ях) обработки для каждого из 17 слоев/групп 202 слоев, начиная слева направо и заканчивая операцией Softmax. Строго говоря, MobileNet имеет 28 слоев свертки от своего первого полного слоя свертки и своего полностью соединенного слоя.
[59] В Таблице 1 BN представляет функцию пакетной нормализации (batchnorm) для нормализации входных данных (для последующей операции) путем регулировки и масштабирования активаций (например, индивидуальных значений в карте активации, предоставляемых от одного слоя/операций следующим). ReLU является выпрямителем и представляет функцию блоков линейной ректификации (например, максимальную функцию (X, 0) для ввода X, так что все отрицательные значения X приравнены 0). Понижающая дискретизация обрабатывается посредством шагающей свертки в свертках по глубине, а также в первом слое. В итоговом понижении разрешения по среднему пулу 7×7 используется функция понижающей дискретизации на основе усредняющих значений в массиве 7×7. Softmax, или нормализованная экспоненциальная функция, «сдавливает» K-мерный вектор z произвольных действительных значений с образованием K-мерного вектора σ (z) действительных значений, где каждый показатель находится в диапазоне (0, 1), и все показатели составляют в сумме 1 (например, функция масштабирования и нормализации). Полезно, что выходные данные могут использоваться для представления распределения по категориям вероятностного распределения по K различным возможным результатам (категориям или классам), и, следовательно, часто используются с классификаторами нейронных сетей, классифицирующими по K классам. На фиг. 2 соответствующие 17 слоев кодируются оттенками серого и рисунком посредством операции(й) обработки.
[60] На фиг. 3 представлена иллюстрация, показывающая адаптированную сеть 300 глубинного обучения со слоями/группами 302 слоев. Сеть 300 также получает исходное изображение 100 в качестве входных данных для обработки. Сеть 300 (например, ее слои/группы 302 слоев) адаптирована для выдачи выделения 304 волос. В Таблице 2 представлена информация о размере карты активации и информация об операции(ях) обработки для каждого из 22 слоев/групп 302 слоев, начиная слева направо.
[61] Сеть 300 подобна сети 200, но адаптирована. Понижающая дискретизация до разрешения 14×14, а затем до разрешения 7×7 сети 200 устраняется, и минимальное разрешение в слоях 5-14 составляет 28×28. Конечные три слоя удаляют (т.е. два полностью соединенных слоя и слой Softmax, хотя также используется конечный Softmax). Для того чтобы сохранить мелкие детали, выходное разрешение признаков увеличивается путем изменения размера шага последних двух слоев с 2 до 1. Благодаря использованию предварительно обученных весов на ImageNet, включенную в базовую архитектуру MobileNet, ядра для слоев с обновленным разрешением расширяются посредством своего коэффициента масштабирования относительно их исходного разрешения. В частности, ядра для слоев, которые увеличились в 2 раза, расширены в 2 раза, а ядра для слоев, которые увеличились в 4 раза, расширены в 4 раза. Это дает конечное минимальное разрешение 28×28 в ступени кодера. Слои/группы слоев 15 и далее могут задавать ступень декодера.
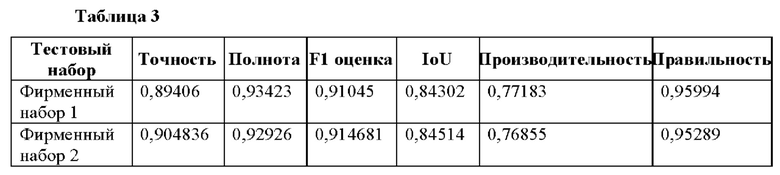
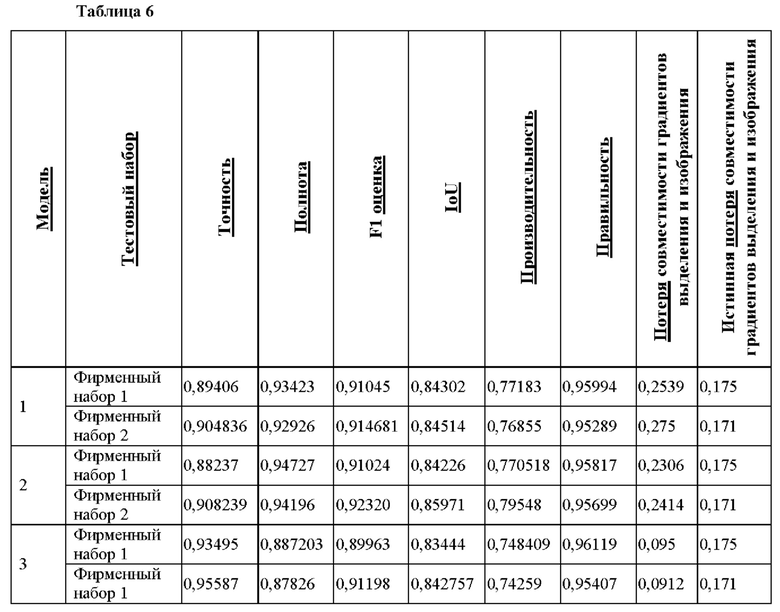
[62] Слои 2-14, 16, 18 и 20 включают в себя раздельные свертки по глубине - факторизированные стандартные свертки, где свертка по глубине применяет один фильтр к каждому входному каналу, и поточечная свертка объединяет выходные данные свертки по глубине. Раздельные свертки по глубине уменьшают объем вычислений и размер модели, что полезно для обработки данных в среде мобильных устройств.
[63] Фаза декодирования берет вышеуказанные признаки CNN из фазы кодирования в качестве входных данных и увеличивает их разрешение до выделения волос с исходным разрешением 224×224. Повышающая дискретизация осуществляется в слоях 15, 17 и 19, чередуясь с дополнительным анализом признаков в слоях 16, 18 и 20. Повышающая дискретизация выполняется посредством упрощенной версии инвертированной архитектуры MobileNet. На каждой ступени операции выполняют повышение разрешения предыдущего уровня в 2 раза путем репликации каждого пикселя в окрестности 2×2. Затем применяют разделительную свертку по глубине, за которой следуют поточечные свертки 1×1 с 64 фильтрами, а затем ReLU, как показано в Таблице 2. Операции завершаются в слое/группе слоев 21 путем добавления свертки 1×1 с активацией Softmax и 2 выходными каналами для волос/отсутствия волос.
[64] Хотя это не показано, сеть обучается путем сведения к минимуму потери LM бинарной перекрестной энтропии между прогнозируемыми и истинными выделениями. Бинарная перекрестная энтропия будет рассматриваться ниже со ссылкой на фиг. 5.
[65] Следовательно, на фиг. 3 показана полностью сверточная архитектура MobileNet для сегментации волос. Модель, созданная и обученная подобным образом, применяет множество сверточных фильтров (фильтров свертки) в последовательности слоев свертки для обнаружения соответствующих признаков, где первый набор слоев свертки в последовательности предоставляет выходные данные, которые понижают разрешение (и кодируют) изображения от первого разрешения изображения до минимального разрешения, и второй набор слоев свертки в последовательности повышает разрешение выходных данных обратно до первого разрешения изображения. Модель характеризуется наличием операций повышающей дискретизации, вставленных перед исходным слоем второго набора слоев свертки и перед соответствующими последующими слоями второго набора слоев свертки для повышения разрешения выходных данных до первого разрешения изображения. Первый набор может задавать ступень кодера, и второй набор - ступень декодера.
[66] Обучение глубинных нейронных сетей требует большого объема данных. Хотя имеются большие наборы данных для общей семантической сегментации, эти наборы данных гораздо менее популярны в случае сегментации волос. Более того, в отличие от таких объектов, как автомобили, которым присуща относительно простая форма, форма волос очень сложна. Таким образом, получение точной истинной сегментации для волос является еще более сложной задачей.
[67] Для решения этой проблемы была использована сеть, предварительно обученная на ImageNet. Она была дополнительно подстроена на данные сегментации волос. Тем не менее, все еще необходимы несколько тысяч обучающих изображений. Данные были получены посредством краудсорсинга с использованием программного приложения для окрашивания волос, где пользователи должны вручную пометить свои волосы. Хотя получение этих данных является недорогим, результирующие отметки сегментации волос являются очень зашумленными и грубыми. Этот источник данных может быть вручную очищен путем сохранения только изображений человеческих лиц с достаточно хорошими выделениями волос. Это значительно быстрее, чем отметить границы волос с нуля или исправить неправильные сегментации. Два фирменных (предназначенных для внутреннего использования) набора тестовых данных были аналогичным образом определены.
[68] Вышеуказанная сеть 300 была реализована на устройстве Apple iPad Pro 12.9 (2015), включающем библиотеку Core ML™ от компании Apple Corporation. Библиотека Core ML автоматически генерирует класс MobileNet из модели MobileNet и может быть адаптирована, как описано. Для того чтобы получить преимущество распараллеливания, модель была обработана с использованием графического процессора (GPU) iPad и связанной с ним памяти. Следует отметить, что в случае некоторых реализаций для достижения желаемой обработки CNN может быть обработана (например, выполнена) при помощи GPU, при этом в других реализациях может быть достаточно обработки с использованием центрального процессора (CPU) вычислительного устройства.
[69] Благодаря компактности архитектуры (300) и использованию библиотеки Core ML, прямой прогон для одного изображения занимает только 60 мс. Сеть также была реализована с использованием Tensorflow™ (общедоступная программная библиотека для высокопроизводительных численных вычислений с поддержкой машинного обучения и глубинного обучения, первоначально разработанная компанией Google Inc.). Сравнимая обработка была медленней, составляя приблизительно 300 мс. Хотя Tensorflow имеет оптимизации NEON™ (технология NEON представляет собой усовершенствование в развитии архитектуры с одним потоком команд и многими потоками данных (SLMD) для некоторых процессоров компании Arm Limited), она не оптимизирована для обработки графики. Общеизвестно, что GPU на современных телефонах и планшетных компьютерах обладают значительной мощностью.
[70] Эта модель на данном этапе показывает очень хорошие качественные и количественные результаты, как показано в Таблице 3, где фирменный набор 1 содержит 350 обрезанных изображений лиц. Он имеет введенные вручную аннотации на основе краудсорсинговых данных и подобен используемым обучающим данным. Фирменный набор 2 представляет собой 108 изображений лиц в формате 3:4 (из исходного устройства ввода) и имеет ручную разметку. Фирменный набор 1 имеет более грубую ручную разметку, тогда как фирменный набор 2 имеет более точную ручную разметку, при этом ни один из наборов не имеет точной разметки.
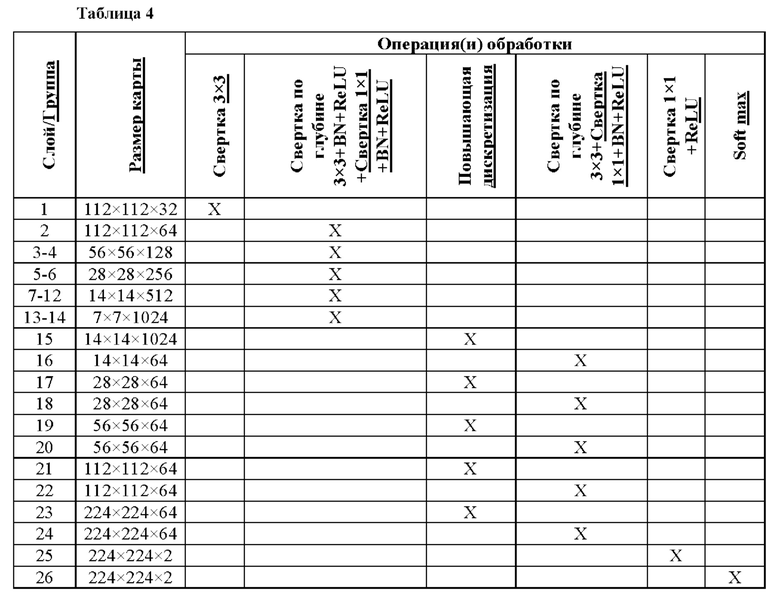
[71] Однако этот подход по-прежнему не захватывает все волосы и обеспечивает только грубое и нечеткое выделение, а не точную альфа-маску. Постобработка результирующего выделения при помощи управляемой фильтрации, чтобы сделать ее более привлекательной с визуальной точки зрения, исправляет только незначительные ошибки, как дополнительно описано ниже.
[72] Существует необходимость улучшить результаты для получения более истинного (и предпочтительно истинного) маскирования при помощи CNN. В плане вышесказанного существуют две проблемы, а именно CNN 300 довольно сильно снизила разрешение изображения на ступени кодера, и, следовательно, нельзя ожидать, что полученные в результате выделения будут содержать детали с очень высоким разрешением. Кроме того, как упоминалось выше, ни обучающие данные, ни тестовые данные не доступны с надлежащей правильностью для обучения и оценки способа маскирования.
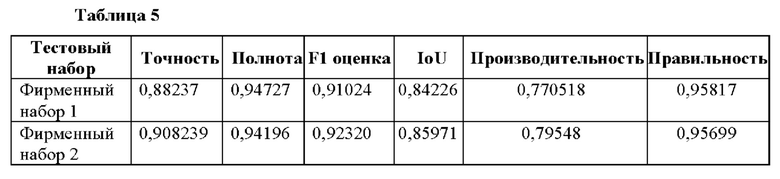
[73] Для решения первой проблемы понижающей дискретизации скип-соединения добавлены в архитектуру, чтобы повторно определить операции повышающей дискретизации. Путем добавления скип-соединений мощные, но обладающие низким разрешением признаки объединяют с более слабыми, но обладающими высоким разрешением признаками. Отметим, что архитектура вернулась к исходной архитектуре кодера, вплоть до разрешения 7×7, поскольку из-за добавления скип-соединений больше нет необходимости ограничивать понижающую дискретизацию. Меньшее количество скип-соединений будет использоваться, если архитектура, показанная на фиг. 3, адаптирована и разрешение остановлено, например, на значении 28×28. Таким образом, менее глубокие слои в кодере, которые содержат обладающие высоким разрешением, но слабые признаки, объединяются с обладающими низким разрешением, но мощными признаками из более глубоких слоев. Слои объединяют путем применения к входящим слоям кодера сначала свертки 1×1, чтобы сделать выходную глубину совместимой с входящими слоями декодера (64 для трех внешних скип-соединений и 1024 для внутреннего скип-соединения), а затем слияния этих слоев при помощи сложения. Для каждого разрешения самый глубокий слой кодера с этим разрешением берется для скип-соединения.
[74] На фиг. 4 представлена иллюстрация, показывающая адаптированную сеть 400 глубинного обучения со слоями/группами 402 слоев. Сеть 400 также получает исходное изображение 100 в качестве входных данных для обработки. Сеть 400 (например, ее слои/группы 402) адаптирована для выдачи выделения 404 волос.
[75] В Таблице 4 представлена информация о размере карты активации и информация об операции(ях) обработки для каждого из 26 слоев/групп 402 слоев, начиная слева направо.
[76] В моделях сети 300 и сети 400 каждый из множества фильтров свертки генерирует карту активации, и карта активации, генерируемая одним слоем свертки, выдается для предоставления входных данных для следующего слоя свертки в последовательности. Множество фильтров свертки содержит первый набор фильтров свертки и второй набор фильтров свертки, при этом первый набор фильтров свертки обрабатывает изображение в первом наборе слоев (например, в слоях 2- 14 сети 400), чтобы, например, включать в себя кодер; и второй набор фильтров свертки обрабатывает изображение во втором наборе слоев (например, в слоях 16, 18, 20, 22 и 24 сети 400), чтобы, например, включать в себя декодер. Выделение сегментации волос определяется на основе конечной карты активации, выданной из конечного слоя свертки (например, из слоя 25) из последовательности.
[77] Модель сети 300 или сеть 400 может содержать функцию нормализации и функцию выпрямителя, последовательно перемежающиеся с первым набором фильтров свертки, для нормализации и линейного выпрямления выходных данных. Модель может содержать функцию выпрямителя, перемежающуюся со вторым набором фильтров свертки, для линейного выпрямления выходных данных. В модели сети 300 или сети 400 первый набор слоев содержит: исходный слой, заданный исходным фильтром свертки 3×3; и множество последовательных раздельных сверток по глубине, каждая из которых последовательно задана посредством соответствующего фильтра свертки по глубине 3×3, функции пакетной нормализации и функции блоков линейной ректификации, а также фильтра свертки 1×1, за которым следуют функция пакетной нормализации и функция блоков линейной ректификации.
[78] В модели сети 300 или сети 400 второй набор слоев содержит: множество исходных слоев с последовательным расположением, каждый из которых задан посредством соответствующего фильтра свертки по глубине 3×3, фильтра свертки 1×1 и функции блоков линейной ректификации; и конечный слой, ограниченный конечным фильтром свертки 1×1 и функцией блоков линейной ректификации.
[79] На фиг. 4 показаны операции повышающей дискретизации на слоях 15, 17, 19, 21 и 23. Повышающая дискретизация в слоях 15, 17, 19 и 21 включает в себя выполнение скип-соединения с выходной картой предыдущего слоя. Карта из предыдущего слоя имеет разрешение, равное целевому разрешению. Функция повышающей дискретизации на этих уровнях осуществляет операцию свертки 1×1 на карте более раннего соответствующего уровня ступени кодера, чтобы объединить информацию канала, и осуществляет операцию повышающей дискретизации (например, 2×2, как описано) на карте активации соседнего уровня, обычно предоставляемой в качестве входных данных для соответствующего слоя, так что она имеет то же разрешение, что и карта из более раннего слоя. Выходные данные операции свертки 1×1 и операции повышающей дискретизации складываются.
[80] Таким образом, функция повышающей дискретизации использует соответствующее скип-соединение, при этом каждое из соответствующих скип-соединений объединяет первую карту активации, выданную из соседнего слоя свертки в последовательности в качестве входных данных для следующего слоя свертки второго набора слоев свертки; и вторую карту активации, выданную из более раннего слоя свертки в первом наборе слоев свертки, где вторая карта активации имеет большее разрешение изображения, чем первая карта активации. Каждое из соответствующих скип-соединений задано для сложения выходных данных фильтра свертки 1×1, применяемого ко второй карте активации, с выходными данными функции повышающей дискретизации, применяемой к первой карте активации, чтобы повысить разрешение первой карты активации до более высокого разрешения изображения. Наконец, карту сегментации волос определяют путем применения Softmax (нормализованной экспоненциальной функции) к конечной карте активации для определения значений от 0 до 1 для каждого пикселя карты сегментации волос.
[81] Количественные результаты этого подхода показаны в Таблице 5:
[82] Более того, из-за уменьшения конечного разрешения кодера вышеуказанная архитектура является более быстрой, даже если она содержит дополнительные уровни декодера. Прямой прогон с использованием Core ML для одного изображения занимает 30 мс на устройстве Apple iPad Pro 12.9 (2015).
[83] С точки зрения правильности, хотя во втором наборе она лучше, чем в модели без скип-соединений, результаты первого набора являются неубедительными. Это иллюстрирует вышеуказанный второй аспект, который заключается в том, что грубые данные сегментации имеют ограниченную правильность, и это не только препятствует обучению, но также и тестированию.
[84] Утверждается, что количественная оценка с такими данными в целом достигла своего предела при текущем уровне производительности. Однако качественно эта архитектура также кажется лишь незначительно лучше. Одно из возможных объяснений состоит в том, что, хотя архитектура скип-соединений теперь способна изучать более мелкие детали, эти детали не присутствуют в наших текущих обучающих данных, что делает выдаваемые в результате сетью выделения такими же грубыми, как и в обучающем наборе.
Оценка и сведение к минимуму потери совместимости градиентов выделения и изображения
[85] Принимая во внимание доступные обучающие и тестовые данные, CNN ограничивается изучением создания маски волос с использованием только грубых обучающих данных сегментации. На основании информации, приведенной в работе Rhemann et al., добавлен основанный на восприятии показатель корректности выделения. Для этого добавлен показатель совместимости между градиентами выделения и изображений. Показатель расстояния (потери) заключается в следующем.
[86] Потеря совместимости градиентов выделения и изображения показана в Уравнении 1:
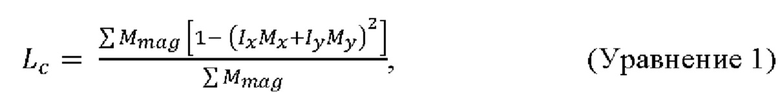
[87] где Ix,Iy представляют собой нормализованный градиент изображения; Мх,Му представляют собой нормализованный градиент выделения; и Mmag представляет собой величину градиента выделения. Значение потери (Lc) является небольшим, когда имеется совпадение между градиентами изображения и выделения. Эта потеря добавляется к первоначальной потери бинарной перекрестной энтропии с весом w, в результате чего суммарная потеря имеет следующий вид

[88] Сочетание двух потерь поддерживает баланс между истинностью обучающих выделений, при этом генерируются выделения, которые придерживаются краев изображений. Этот показатель потери совместимости градиентов выделения и изображения используют как для оценки существующих моделей, так и для обучения новой модели, где показатель (потери) бинарной перекрестной энтропии объединяется с новым показателем из Уравнения 1, как указано в Уравнении 2.
[89] Потеря перекрестной энтропии или логистическая функция измеряют производительность модели классификации, выходные данные которой представляют собой значение вероятности от 0 до 1. Потеря перекрестной энтропии увеличивается при отклонении прогнозируемой вероятности от фактической (истиной) метки. В представленном примере модель классифицирует каждый пиксель в соответствующих наблюдениях о как один из двух классов с - волосы или не волосы, так что потеря LM бинарной перекрестной энтропии может быть вычислена как в Уравнении 3:
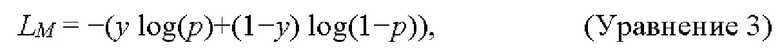
[90] где у представляют собой бинарную метку (0 или 1) для правильной классификации для наблюдения о; и р представляет собой прогнозируемую вероятность того, что наблюдение о относится к классу с.
[91] На фиг. 5 показана обучающая архитектура, включающая в себя сеть 500 со скип-соединениями, которая принимает изображение 100 (I) и создает выделение 504 (М). Сеть 500 сопоставима по структуре с сетью 400, но обучается с использованием рассмотренных показателей потерь.
[92] Кроме того, показаны входные дынные 502, содержащие Ix, Iy (нормализованный градиент изображения) из изображения 100, и входные данные 506, содержащие Мх, Му (нормализованный градиент выделения), в компонент 508 определения потери совместимости градиентов выделения и изображения для обучения. Также показан компонент 510 определения потери бинарной перекрестной энтропии. Потеря LC совместимости градиентов выделения и изображения и потеря LM бинарной перекрестной энтропии объединяются (не показано), чтобы определить параметр потери L для обучения сети 500, как описано выше.
[93] Таким образом, сеть 500 представляет собой CNN, которая содержит предварительно обученную сеть для классификации изображения, такую как сеть, которая предварительно обучена с использованием общедоступных обучающих данных изображения. Предварительно обученная сеть адаптирована для определения выделения сегментации объекта, такого как выделение сегментации волос, а не для классификации изображения как такового. CNN дополнительно обучается для сведения к минимуму потерь совместимости градиентов выделения и изображения при обучении, и подобное обучение может осуществляться с использованием грубых данных сегментации. Эта потеря совместимости градиентов выделения и изображения может быть объединена с потерей бинарной перекрестной энтропии. CNN дополнительно адаптирована к использованию скип-соединений между слоями в ступени кодера и соответствующими слоями в ступени декодера, чтобы объединить обладающие низким разрешением, но мощные признаки и обладающие высоким разрешением, но слабые признаки при повышающей дискретизации в ступени декодера для определения выделения сегментации объекта.
[94] Полученные в результате выделения намного больше напоминают маски и являются более детализированными. На фиг. 6 представлена Таблица 600 с изображениями, в которой отображаются качественные результаты. На фигуре показано изображение 602 для обработки (пример изображения 100), а также соответствующие выделения (примеры выделений 304, 404 и 504), полученные с использованием моделей, показанных соответственно на фиг. 3-5. Выделение 604 было получено с использованием модели без скип-соединений (Модель 1) согласно фиг. 3, выделение 606 было получено с использованием модели со скип-соединениям (Модель 2) согласно фиг. 4, и выделение 608 было получено с использованием модели со скип-соединениями и потерей совместимости градиентов выделения и изображения после обучения (Модель 3) согласно фиг. 5.
[95] В количественном отношении этот способ функционирует лучше в соответствии с новым показателем совместимости, но несколько хуже по другим показателям (сходство с истинными данными). Однако, как указывалось ранее, принимая во внимание текущую доступную правильность истинных данных, может быть нежелательным максимально увеличивать согласование прогноза с истинными данными выше определенного уровня. В Таблице 6 показаны качественные результаты всех моделей с использованием одинаковых наборов тестовых данных:
[96] Выходные данные маски из Модели 3 архитектуры, показанной на фиг.5, сравнили с выходными данными грубого выделения из Модели 1 архитектуры, показанной на фиг. 3, а также с выходными данными из Модели 1 с добавлением управляемого фильтра. Управляемый фильтр является сохраняющим края фильтром и имеет линейную сложность выполнения относительно размера изображения. Обработка изображения 224×224 на iPad Pro занимает всего 5 мс. На фиг. 7 представлена Таблица 700 с изображениями, в которой отображаются качественные результаты моделей, показанных на фиг. 3 и 5. Показано изображение 702 для обработки (пример изображения 100). Изображение 704 представляет собой выделение из Модели 1, показанной на фиг. 3, без постобработки с использованием управляемого фильтра. Изображение 706 представляет собой выделение из Модели 1 с добавлением постобработки с использованием управляемого фильтра. Изображение 708 представляет собой выходные данные выделения (или маски) из Модели 3, показанной на фиг. 5. Как указано выше, Модель 3 использует скип-соединения и обучается с зашумленными и грубыми данными сегментации из краудсорсинговых данных, а также обучается с использованием функции потери совместимости градиентов выделения и изображения.
[97] Изображение 706, в котором используется управляемый фильтр, демонстрирует захват большего количества деталей, при этом становятся заметными отдельные пряди волос. Однако управляемый фильтр добавляет детали лишь локально возле краев выделения. Более того, края уточненных выделений имеют вокруг себя видимое сияние (ореол), который становится более очевидным, когда цвет волос является менее контрастным по сравнению с окружающей средой. Это сияние вызывает появление хроматической аберрации в процессе изменения цвета волос. Архитектура, показанная на фиг. 5, дает более острые края (как показано на изображении 708) и захватывает более длинные пряди волос без образования нежелательного эффекта сияния, наблюдаемого при постобработке с использованием управляемого фильтра.
[98] В качестве дополнительно преимущества архитектура, показанная на фиг. 5, работает в два раза быстрее по сравнению с архитектурой, показанной на фиг. 4, используя только 30 мс на один кадр при функционировании на мобильном устройстве, при этом отсутствует необходимость в дополнительной маскирующей стадии постобработки. Благодаря использованию скип-соединений, которые помогают захватывать детали с высоким разрешением, архитектура, показанная на фиг. 5, поддерживает исходную структуру кодера MobileNet с самыми глубокими слоями, имеющими разрешение 7×7. Эти слои имеют множество глубоких каналов (1024) и требуют очень больших вычислительных мощностей для обработки с повышенным разрешением. Использование разрешения 7×7 делает обработку более быстрой по сравнению с разрешением 28x28 в архитектуре, показанной на фиг. 4.
Эксперименты
[99] Способ оценивали на основе трех наборов данных. Первым является краудсорсинговый набор данных, состоящий из 9000 обучающих, 380 контрольных и 282 тестовых изображений. Все эти поднаборы включают в себя исходные изображения и их зеркально отраженные версии. Поскольку целью является маскирование волос на мобильном устройстве, предварительная обработка данных выполняется путем обнаружения лица и обрезки области вокруг него на основе масштаба, ожидаемого для типичных селфи.
[100] Для того чтобы сравнить этот способ с существующими подходами, оцениваются два публичных набора данных: набор данных от LFW Parts, Kae et al., и набор данных волос от Guo и Aarabi. Первый из наборов состоит из 2927 изображений 250x250, в которые входят 1500 обучающих, 500 контрольных и 927 тестовых изображений. Пиксели делятся на три категории, такие как волосы, кожа и фон, которые генерируются на уровне суперпикселей. Последний из наборов состоит из 115 изображений высокого разрешения. Поскольку он содержит слишком мало изображений для обучения, мы используем наши краудсорсинговые обучающие данные при оценке этого набора. Для того чтобы согласовать этот набор данных с нашими обучающими данными, осуществляется аналогичная предварительная обработка (с использованием обнаружения лица и обрезки), а также добавляются зеркально отраженные изображения. Поскольку в некоторых случаях лица не были обнаружены, итоговый набор данных состоит из 212 изображений.
[101] Обучение проводится с использованием пакета размером 4 посредством способа Adadelta (Adadelta: an adaptive learning rate method,» arXiv preprint arXiv:1212.5701, 2012) в Keras (F. Chollet et al., https://github.com/keras-team/keras, 2015), при этом скорость обучения составляет 1:0, ρ=0:95 и ε=1е - 7. Регуляризация L2 используется с весом 2×10-5 только для слоев свертки. Слои свертки по глубине и последний слой свертки не регуляризируются. Вес компенсации потерь устанавливается равным ω=0:5 (Уравнение 3).
[102] В данных LFW из трех классов только класс волос вносит вклад в потери совместимости градиентов выделения и изображения. Модель обучена в течение 50 периодов, и период с наилучшими показателями выбран с использованием контрольных данных. Обучение с использованием краудсорсингового набора данных занимает 5 часов на графическом процессоре Nvidia GeForce GTX 1080 Ti ™ (Nvidia, GeForce и GTX 1080 Ti являются товарными марками компании Nvidia Corporation), при этом обучение с использованием LFW Parts занимает менее часа из-за гораздо меньшего размера обучающего набора.
А. Количественная оценка
[103] Для количественного анализа производительности измеряются оценка F1, Производительность, IoU и Правильность, усредненные по всем тестовым изображениям. Для измерения совместимости краев изображения и выделения волос также сообщается потеря совместимости градиентов выделения и изображения (Уравнение 1). Напомним, что во время очистки краудсорсинговых изображений (данных изображений) в ручном режиме, изображения только фильтровались, а не корректировались относительно выделений. В результате этого качество аннотации волос все еще оставляет желать лучшего. Таким образом, перед оценкой краудсорсинговых данных была предпринята коррекция тестовых выделений в ручном режиме, занимающая не более 2-х минут на одну аннотацию. Это дало немного лучшие истинные данные. Эти варианты способа (Модель 1, Модель 1 с управляемым фильтрованием и Модель 3) оцениваются по этим повторно размеченным данным. Все эти способы работают аналогично в отношении показателей сравнения с истинными данными, при этом Модель 3 является явным победителем в категории потерь совместимости градиентов, что указывает на то, что ее выделения намного лучше прилегают к краям изображения.
[104] По набору данных LFW Parts сообщается о равной производительности с наиболее эффективным способом в Qin et al., но это достигается в режиме реального времени на мобильном устройстве. Для оценки используется только показатель правильности, так как это единственный показатель, используемый в Qin et al. Можно утверждать, что поскольку набор LFW Parts имел аннотации на уровне суперпикселей, истинные данные в нем могут оказаться недостаточно хорошими для анализа с высокой степенью правильности. По набору данных Guo и Aarabi сообщается, что оценка F1 составляет 0:9376 и Производительность составляет 0:8253. HNN повторно запустили на этом повторно обработанном наборе данных, при этом была получена производительность, аналогичная сообщенной авторами, с оценкой F1 0:7673 и Производительностью 0:4674.
В. Качественная оценка
[105] Способ оценивают на общедоступных селфи изображениях для количественного анализа. Модель 1 дает хорошие, но грубые выделения. Модель 1 с управляемым фильтром дает лучшие выделения, но они имеют нежелательное размытие на границах волос. Наиболее точные и резкие результаты достигаются Моделью 3. Состоянием отказа как постобработки с использованием управляемого фильтра, так и Модели 3 является присущая им недостаточная сегментация похожих на волосы объектов вблизи волос, таких как брови, в случае темных волос или яркого фона для светлых волос.
[106] Кроме того, блики на волосах могут привести к тому, что выделение волос, полученное при помощи Модели 3, будет неравномерным.
С. Эксперименты с архитектурой сети
[107] Были проведены эксперименты с множеством каналов слоев декодера, в которых использовались контрольные данные, однако было отмечено, что это не оказывает большого влияния на правильность, принимая во внимание 64 канала, дающих наилучшие результаты в соответствии с большинством измерений. Эти эксперименты были проведены с использованием архитектуры со скип-соединениями, показанной на фиг. 4, без использования потери совместимости градиентов.
[108] Согласно данным Howard et al. известно, что MobileNets работают лучше, принимая во внимание более высокое разрешение изображения. Принимая во внимание цель точного маскирования волос, были проведены эксперименты с использованием нашей Модели 3, при этом разрешение было увеличено выше 224×224, что является самым высоким разрешением для MobileNet при обучении на ImageNet. Качественное сравнение выделений, полученных с использованием Модели 3 из изображений 224x224 и изображений 480x480, показало, что результаты 480×480 выглядят более точными по краям волос, при этом захватываются более длинные пряди, включая пряди, проходящие по лицу (например, на носу). Однако проблемы, упомянутые в предыдущем разделе, также имеют место: выделение волос больше заходит в области, которые не относятся к волосам, и внутренняя часть выделения становится неравномерной из-за бликов на волосах. Кроме того, обработка большего изображения является значительно более затратной с точки зрения вычислительных ресурсов.
[109] Как отмечено выше, CNN выполнена с возможностью оперативного исполнения на вычислительном устройстве пользователя, таком как мобильное устройство. Она может быть сконфигурирована таким образом, что выполнение CNN происходит по меньшей мере частично в GPU такого устройства, чтобы получить преимущество обработки (например, распараллеливание в таких GPU). Согласно некоторым реализациям выполнение может происходить в CPU. Следует понимать, что среды обучения для получения обученной сети с использованием грубых данных сегментации (обучающих данных) могут варьировать в зависимости от сред выполнения. Среды обучения могут иметь более высокие возможности обработки данных и/или больше памяти для ускорения обучающих операций.
[110] На фиг. 8 представлена блок-схема иллюстративного вычислительного устройства 800 в соответствии с одним или более аспектами настоящего изобретения, такого как карманное мобильное устройство (например, смартфон или планшетный компьютер). Однако вычислительное устройство может быть другим устройством, таким как портативный компьютер, настольный компьютер, рабочая станция и т.п. Как отмечалось выше, целью усилий по исследованию и разработке является предоставление глубинной нейронной сети для работы в карманном мобильном устройстве с ограниченными ресурсами, чтобы эффективно и продуктивно получать обработанные изображения (например, видео).
[111] Вычислительное устройство 800 содержит пользовательское устройство, например, для сбора одного или более изображений, таких как видео, и обработки изображений, чтобы изменить один или более атрибутов и представить новые изображения. Согласно одному примеру изображения обрабатывают для изменения цвета волос на изображениях. Вычислительное устройство 800 содержит один или более процессоров 802, одно или более устройств 804 ввода, устройство 806 ввода-вывода на основе жестов, один или более коммуникационных блоков 808 и одно или более устройств 810 вывода. Вычислительное устройство 800 также содержит одно или более запоминающих устройств 812, в которых хранятся один или более модулей и/или элементов данных. Модули могут включать в себя модуль 814 глубинной нейронной сети, программное приложение 816, имеющее компоненты для графического пользовательского интерфейса (GUI 818), прогнозирования 820 цвета и получения 822 изображений. Данные могут включать в себя одно или более изображений для обработки (например, изображение 824), одно или более выделений, генерированных на основе одно или более изображений (например, выделение 826, генерированное на основе изображения 824), и одно или более новых изображений, генерированных с использованием одного или более выделений и одного или более изображений (например, новое изображение 828).
[112] Программное приложение 816 предоставляет функциональность для сбора одного или более изображений, таких как видео, и обработки изображений, чтобы изменить один или более атрибутов и представить новые изображения. Согласно одному примеру изображения обрабатывают для изменения цвета волос на изображениях. Программное приложение осуществляет обработку изображений с использованием глубинной нейронной сети, предоставляемой моделью 814 нейронной сети. Модель сети может быть сконфигурирована подобно любой из моделей, показанных на фиг. 3, 4 и 5.
[113] Программное приложение 816 может быть связано с определенными данными атрибутов, такими как цветовые данные 830, для изменения одного или более атрибутов изображения. Изменение атрибутов относится к изменению значений пикселей для создания нового изображения. Следует понимать, что связанные с изображениями данные (например, для хранения, печати и/или отображения изображений) могут быть представлены с использованием различных цветовых моделей и форматов данных, и программное приложение 816 может быть сконфигурировано соответствующим образом. Согласно другим примерам данные атрибутов могут относиться к изменению такого эффекта, как условия освещения, текстура, форма и т.п. Программное приложение 816 может быть сконфигурировано с одной или более функциями для изменения атрибута(ов) (не показаны), например, для накладывания эффекта на изображение в желаемом месте (например, на объект или его часть, которые представляют интерес на изображении, идентифицированном посредством глубинной нейронной сети).
[114] Запоминающее(ие) устройство(а) 212 может(могут) хранить дополнительные модули, такие как операционная система 832 и другие модули (не показаны), включая коммуникационные модули; модули графической обработки (например, для GPU процессоров 802); модуль карты; модуль контактов; модуль календаря; модуль фотографий/галереи; редактор фотографий (изображений/медиа); медиаплеер и/или потоковый модуль; программные приложения для социальных сетей; модуль браузера; и т.п. Запоминающие устройства могут именоваться в настоящем документе запоминающими блоками.
[115] Коммуникационные каналы 838 могут коммуникационно, физически и/или оперативно соединять каждый из компонентов 802, 804, 806, 808, 810, 812 и любые модули 814, 816 и 826 для обеспечения межкомпонентной связи. Согласно некоторым примерам коммуникационные каналы 838 могут включать в себя системную шину, сетевое соединение, структуру данных для межпроцессного взаимодействия или любой другой способ передачи данных.
[116] Один или более процессоров 802 могут реализовать функциональность и/или выполнять команды внутри вычислительного устройства 800. Например, процессоры 802 могут быть выполнены с возможностью приема команд и/или данных из запоминающих устройств 812 для выполнения, кроме прочего, функциональности модулей, показанных на фиг. 8 (например, операционной системы, программных приложений и т.п.). Вычислительное устройство 800 может хранить данные/информацию для запоминающих устройств 812. Некоторая часть функциональности описана ниже в настоящем документе. Следует понимать, что операции могут не совпадать точно с модулями 814, 816 и 826, показанными на фиг. 8, при этом один модуль может способствовать функциональности другого.
[117] Компьютерный программный код для осуществления операций может быть написан на любом сочетании одного или более языков программирования, например, объектно-ориентированном языке программирования, таком как Java, Smalltalk, С++ или тому подобное, или обычном процедурном языке программирования, таком как язык программирования «С» или аналогичные языки программирования.
[118] Вычислительное устройство 800 может генерировать выходные данные для отображения на экране устройства 806 ввода-вывода на основе жестов или в некоторых примерах для отображения проектором, монитором или другим устройством отображения. Следует понимать, что устройство 806 ввода-вывода на основе жестов может быть сконфигурировано с использованием различных технологий (например, в отношении возможностей ввода: высокоомный сенсорный экран, сенсорный экран на поверхностно-акустических волнах, емкостной сенсорный экран, проекционно-емкостной сенсорный экран, чувствительный к давлению экран, сенсорный экран с распознаванием акустических импульсов или другая чувствительная к присутствию технология; и в отношении возможностей вывода: жидкокристаллический дисплей (LCD), дисплей на светодиодах (LED), дисплей на органических светодиодах (OLED), точечно-матричный дисплей, дисплей на основе электронных чернил или аналойный монохромный или цветной дисплей).
[119] В примерах, описанных в настоящем документе, устройство 806 ввода-вывода на основе жестов включает в себя устройство на основе сенсорного экрана, способное принимать в качестве ввода тактильное взаимодействие или жесты от пользователя, взаимодействующего с сенсорным экраном. Такие жесты могут включать в себя жесты касания, жесты перетаскивания или смахивания, жесты щелчка, жесты приостановки (например, когда пользователь прикасается к одному и тому же месту на дисплее в течение по меньшей мере порогового периода времени), когда пользователь касается одного или более мест на устройстве 806 ввода-вывода на основе жестов или указывает на них. Устройство 806 ввода-вывода на основе жестов может также предусматривать использование жестов без касания. Устройство 806 ввода-вывода на основе жестов может выдавать или отображать пользователю информацию, такую как графический пользовательский интерфейс. Устройство 806 ввода-вывода на основе жестов может представлять различные программные приложения, функции и возможности вычислительного устройства 800, включая, кроме прочего, например, программное приложение 818 для просмотра изображений, обработки изображений и отображения новых изображений, программные приложения для обмена сообщениями, программные приложения для телефонной связи, контактов и календаря, программные приложения для просмотра веб-страниц, игровые программные приложения, программные приложения для чтения электронных книг, финансовые программные приложения, платежные программные приложения и другие программные приложения и функции.
[120] Хотя в настоящем раскрытии иллюстрируется и обсуждается устройство 806 ввода-вывода на основе жестов по существу в форме устройства с экраном дисплея, которое обладает возможностями ввода/вывода (например, сенсорный экран), могут быть использованы и другие примеры устройств ввода-вывода на основе жестов, которые могут обнаруживать движение и которые могут не иметь экрана как такового. В этом случае вычислительное устройство 800 включает в себя экран дисплея или связано с устройством отображения для представления новых изображений. Вычислительное устройство 800 может принимать входные данные на основе жестов от трекпада/сенсорной панели, одной или более камер или другого чувствительного к присутствию жестам устройства ввода, при этом присутствие означает присутствие аспектов пользователя, включая, например, движение всего пользователя или его части.
[121] Один или более коммуникационных блоков 808 могут обмениваться данными с внешними устройствами (не показаны), например, для приема новых данных атрибутов или функциональности программного приложения, а также для совместного использования новых изображений с другим вычислительным устройством, устройством печати или устройством отображения (ни одно не показано) посредством одной или более коммуникационных сетей (не показаны) путем передачи и/или приема сетевых сигналов в одной или более сетей. Коммуникационные блоки могут включать в себя различные антенны и/или сетевые интерфейсные карты, чипы (например, глобальной спутниковой навигационной (GPS) системы) и подобное оборудование для беспроводной и/или проводной связи.
[122] Устройства 804 ввода и устройства 810 вывода могут включать в себя любое из одной или более кнопок, переключателей, указательных устройств, камер, клавиатуры, микрофона, одного или более датчиков (например, биометрических датчиков и т.п.), громкоговорителя, звонка, одного или более световых устройств, тактильного (вибрирующего) устройства и подобных устройств. Одно или более из них могут быть подключены через универсальную последовательную шину (USB) или другой коммуникационный канал (например, 838). Камера (устройство 804 ввода) может быть фронтально ориентированной (т.е. на одной и той же стороне), чтобы позволить пользователю захватывать изображение(я) с использованием камеры, когда он смотрит на устройство 806 ввода/вывода на основе жестов, чтобы сделать «селфи».
[123] Одно или более запоминающих устройств 812 могут принимать различные формы и/или конфигурации, например, в виде кратковременной памяти или долговременной памяти. Запоминающие устройства 812 могут быть выполнены с возможностью кратковременного хранения информации в виде энергозависимой памяти, которая не сохраняет свое содержимое при отключении питания. Примеры энергозависимой памяти включают в себя память с произвольным доступом (RAM), динамическую память с произвольным доступом (DRAM), статическую память с произвольным доступом (SRAM) и подобные устройства. В некоторых примерах запоминающие устройства 812 также включают в себя одну или более машиночитаемых сред хранения данных, например, для хранения больших объемов информации по сравнению с энергозависимой памятью и/или хранения такой информации в течение долгого времени, сохраняя информацию при отключении питания. Примеры энергозависимой памяти включают в себя магнитные жесткие диски, оптические диски, дискеты, флэш-память или формы электрически программируемой памяти (EPROM) или электрически стираемой и программируемой (EEPROM) памяти.
[124] Хотя это не показано, вычислительное устройство может быть сконфигурировано в качестве среды обучения для обучения модели 814 нейронной сети, например, с использованием сети, показанной на фиг. 5, наряду с соответствующими обучающими и/или тестовыми данными.
[125] Вычислительное устройство 800 содержит блок обработки данных и запоминающий блок, связанный с блоком обработки данных. Запоминающий блок хранит команды, которые при выполнении блоком обработки данных конфигурируют вычислительное устройство для хранения и предоставления модели сети нейронной глубинного обучения (например, содержащей сверточную нейронную сеть), выполненной с возможностью классификации пикселей изображения, чтобы определить, является ли каждый из пикселей членом представляющего интерес объекта (например, пикселем волос); и определения и представления нового изображения (например, изображения окрашенных волос) путем изменения одного или более атрибутов пикселей, которые являются членами представляющего интерес объекта. В операциях изменения используется выделение, определенное на основе изображения с использованием модели глубинной нейронной сети. Согласно одному примеру представляющий интерес объект представляет собой волосы, а атрибут представляет собой цвет. Таким образом, в результате изменения одного или более атрибутов новый цвет волос применяется к пикселям волос на изображении с использованием выделения сегментации волос.
[126] Глубинная нейронная сеть адаптирована к легкой архитектуре, предназначенной для вычислительного устройства, которое представляет собой мобильное устройство (например, смартфон или планшетный компьютер), имеющее меньше вычислительных ресурсов, чем «более крупное» устройство, такое как портативный компьютер, настольный компьютер, рабочая станция, сервер или другое вычислительное устройство сопоставимого поколения.
[127] Модель глубинной нейронной сети может быть сконфигурирована в качестве нейронной сети на основе раздельных сверток по глубине, содержащей свертки, в которых отдельные стандартные свертки факторизированы в свертку по глубине и поточечную свертку. Свертка по глубине ограничена применением одного фильтра к каждому входному каналу, и поточечная свертка ограничена объединением выходных данных свертки по глубине.
[128] Модель глубинной нейронной сети может быть дополнительно сконфигурирована таким образом, чтобы включать в себя операции для реализации скип-соединений между слоями в кодере и соответствующими слоями в декодере, например при повышающей дискретизации.
[129] Модель глубинной нейронной сети может обучаться с использованием показателя потери совместимости градиентов выделения и изображения, при этом потеря совместимости градиентов выделения и изображения определяется относительно обработанного изображения и генерированного выделения, и используемый показатель потери обучает модель. Потеря совместимости градиентов выделения и изображения может быть определена согласно Уравнению 1.
[130] На фиг. 9 представлена принципиальная схема операций 900 вычислительного устройства 800 в соответствии с одним примером. Операции 900 относятся к пользователю вычислительного устройства 800, который использует программное приложение, такое как программное приложение 816, для создания селфи, содержащего видео, содержащее видеокадры, задающие изображения головы пользователя с волосами, выбирает новый цвет волос и просматривает видео, на котором цвет волос пользователя изменен на новый. В ходе операции 902 получают изображение посредством устройства или блока ввода, такого как камера, что может предусматривать вызов GUI 818 и компонента 822 получения изображений. Изображение направляется для отображения (904), например, в устройство 806 ввода-вывода на основе жестов или другое устройство отображения. Для того чтобы способствовать обработке волос на мобильных устройствах, изображения (данные) могут быть предварительно обработаны (не показано). Изображения могут быть предварительно обработаны путем обнаружения лица и обрезки области вокруг него исходя из масштаба, ожидаемого для типичных селфи.
[131] В ходе операции 906 входные данные принимают посредством устройства 806 ввода-вывода на основе жестов и GUI 818 (интерактивного GUI), чтобы осуществить выбор нового цвета волос.GUI 818 может быть выполнен с возможностью представления данных цвета волос посредством интерактивного интерфейса для осуществления выбора. Согласно некоторым примерам программное приложение 816 может быть выполнено с возможностью предложения цвета. Хотя это и не показано, операции могут предусматривать определение существующего или текущего цвета волос на основе полученного изображения и необязательно другого цвета (например, цвета кожи) или информации об освещении, и т.п. Предпочтения пользователя, представленные в виде данных (не показаны), могут запрашиваться посредством GUI 818. Операции могут дополнительно предусматривать предоставление этой информации компоненту 820 прогнозирования цвета. Компонент 820 прогнозирования цвета может иметь функцию предложения соответствующего цвета (например, одного или более кандидатов для новых цветов из данных 830 цвета) с учетом одного или более из существующего цвета волос, цвета кожи или другого цвета и/или информации об освещении, предпочтений пользователя, трендов и т.п.
[132] В ходе операции 908 принимают второе изображение для обработки, чтобы применить новый атрибут, а именно новый цвет волос, к пикселям волос на втором изображении, которые идентифицированы моделью 814 глубинной нейронной сети, как описано в настоящем документе. Поскольку камера производит непрерывную съемку изображений, первое изображение, используемое для определения существующего цвета волос, больше не является текущим.
[133] В ходе операции 910 определяют выделение сегментации волос, которое идентифицирует пиксели волос на (втором) изображении, с помощью модели 814. В ходе операции 912 создают новое изображение (например, изображение окрашенных волос) посредством применения нового цвета волос к пикселям волос на изображении с использованием выделения сегментации волос. В ходе операции 914 предоставляют новое изображение для вывода в устройство 806 ввода-вывода на основе жестов на GUI, предоставляемом компонентом 818 GUI. При получении дополнительных изображений из камеры определяют соответствующие выделения, а также определяют и представляют дополнительные соответствующие новые изображения с окрашенными волосами.
[134] Дополнительные или альтернативные GUI или функции GUI могут предоставляться для облегчения внесения других изменений атрибутов, сравнения в режиме реального времени существующих и новых цветов волос или двух новых цветов волос или сохранения неподвижных изображений или видео сегментов, показывающих новый цвет волос. Операции могут представлять GUI посредством устройства ввода-вывода на основе жестов, при этом GUI содержит первую часть для просмотра изображения и вторую часть для одновременного просмотра изображения окрашенных волос, например, в случае компоновки с разделением экрана.
[135] Операции могут предусматривать применение обработки с использованием условий освещения к цвету волос (существующему или новому цвету), чтобы показать цвет при другом условии освещения. Операции могут быть сконфигурированы для показа первого нового цвета волос и второго нового цвета волос на соответствующих новых изображениях. Одно выделение может быть создано и предусмотрено для двух отдельных операций окрашивания, чтобы применить два новых цвета волос. Соответствующие новые цветные изображения для первого и второго цветов могут предоставляться последовательно или одновременно.
[136] Дополнительно к любым опциям или элементам управления GUI, рассматриваемым в настоящем документе, или альтернативно им могут быть предусмотрены активируемые голосом элементы управления.
[137] Другие легкие архитектуры могут адаптироваться аналогичным образом для создания выделения сегментации волос путем использования скип-соединений между соответствующими слоями кодера и декодера и обучаться с использованием функции потерь совместимости градиентов выделения и изображения. Одним из примеров такой архитектуры является решение ShuffleNet™, которое представляет собой эффективную в отношении вычислений CNN, разработанную специально для мобильных устройств с очень ограниченной вычислительной мощностью (например, 10-150 мегафлоп) с использованием поточечной групповой свертки и перетасовки каналов, от Zhang et al. и компании Megvii Technology Limited. Подробная информация о ShuffleNet представлена в документе ShuffleNet: An Extremely Efficient Convolutional Neural Network for Moble Devices of Zhang et al. arXiv:1707.01083v2 [cs:CV], 7 декабря 2017 года, который посредством ссылки включается в настоящий документ.
[138] На фиг. 10 представлена принципиальная схема стадий 1000 для задания иллюстративной CNN в соответствии с приведенным в настоящем документе примером. На стадии 1002 получают CNN, предварительно обученную для классификации изображения и выполненную с возможностью исполнения на вычислительном устройстве, характеризующемся ограниченной вычислительной мощностью (например, MobileNet, ShuffleNet и т.п.).
[139] На стадии 1004 выполняется адаптацию CNN для определения выделения сегментации объекта, например, удаление полностью соединенных слоев, определение операций повышающей дискретизация и т.п. На стадии 1006 выполняется адаптацию CNN к использованию скип-соединений между слоями в ступени кодера и соответствующими слоями в ступени декодера, чтобы объединить обладающие низким разрешением, но мощные признаки и обладающие высоким разрешением, но слабые признаки при повышающей дискретизации в ступени декодера. Стадию 1008 осуществляют для получения обучающих данных сегментации, содержащих помеченные данные для сегментации объекта. Как уже отмечалось, это могут быть краудсорсинговые, а также зашумленные и грубые данные сегментации, в которых выделение сегментации объекта (разметка) не является точным.
[140] Стадию 1010 осуществляют для определения функции потерь совместимости градиентов выделения и изображения в качестве параметра для сведения к минимуму при обучении. Стадию 1012 осуществляют для дополнительного обучения предварительно обученной CNN после адаптации с использованием обучающих данных сегментации и функции потери совместимости градиентов выделения и изображения для сведения к минимуму потери совместимости градиентов выделения и изображения, чтобы создать дополнительно обученную CNN. На стадии 1014 дополнительно обученная CNN тестируется с использованием тестовых данных сегментации, содержащих помеченные данные для сегментации объекта. Очевидно, что некоторые из стадий, показанных на фиг. 10, являются необязательными. Например, кроме прочего, адаптация к использованию скип-соединений может быть необязательной. Адаптация для сведения к минимуму потери совместимости градиентов (и, следовательно, аналогичное обучение для такой потери) может быть необязательной. Обучающие данные могут представлять собой зашумленные и грубые данные сегментации (например, без точной разметки), например, полученные на основе краудсорсинговых данных.
[141] Обученная подобным образом CNN может быть предоставлена для хранения и использования на мобильном устройстве, как описано выше.
[142] Специалисту в данной области техники будет понятно, что в дополнение к аспектам, относящимся к вычислительному устройству, раскрываются аспекты, относящиеся к компьютерному программному продукту, в которых команды хранятся в энергонезависимом запоминающем устройстве (например, памяти, CD-ROM, DVD-ROM, диске и т.п.) для настройки вычислительного устройства для выполнению любого из раскрытых аспектов, относящихся к способу.
[143] Конкретная реализация может включать в себя любые или все описанные в настоящем документе признаки. Эти и другие аспекты, признаки и различные сочетания могут быть выражены в качестве способов, устройств, систем, средств для осуществления функций, программных продуктов и другими путями, которые объединяют описанные в настоящем документе признаки. Описано множество вариантов осуществления. Тем не менее, следует понимать, что различные модификации могут быть сделаны без отклонения от сути и объема описанных в настоящем документе процессов и технологий. Кроме того, другие стадии могут быть предусмотрены в описанных процессах, при этом существующие стадии могут быть удалены из них, и другие компоненты могут быть добавлены в описанные системы, при этом существующие компоненты могут быть удалены из них. Соответственно, другие варианты осуществления также находятся в пределах объема приведенной ниже формулы изобретения.
[144] По всему описанию и формуле изобретения слова «содержит» и «включает в себя» и их варианты означают «включает в себя, кроме прочего», и они не предназначены для исключения других компонентов, целых чисел или стадий (и не исключают их). По всему описанию единственное число охватывает множественное число, если из контекста явным образом не следует противоположное. В частности, в случае использования единственного числа, следует понимать, что множественное число не исключается и подразумевается в дополнении к единственному числу, если из контекста явным образом не следует противоположное.
[145] Следует понимать, что признаки, целые числа, характеристики, соединения, химические фрагменты или группы, описанные в связи с конкретным аспектом, вариантом осуществления или примером настоящего изобретения, могут быть применены к любому другому аспекту, варианту осуществления или примеру, кроме случаев, когда они являются несовместимыми. Все признаки, раскрытые в настоящем описании (включая прилагаемую формулу, реферат и фигуры) и(или) все стадии любого раскрытого способа и процесса могут быть объединены в любом сочетании, кроме сочетаний, в которых по меньше мере некоторые из этих признаков и(или) стадий являются взаимоисключающими. Настоящее изобретение не ограничивается деталями любого из вышеописанных примеров или вариантов осуществления. Настоящее изобретение распространяется на любой новый признак или любое новое сочетание признаков, раскрытых в настоящем описании (включая прилагаемую формулу, реферат и фигуры), или любую новую стадию или любое новое сочетание стадий любого раскрытого способа или процесса.
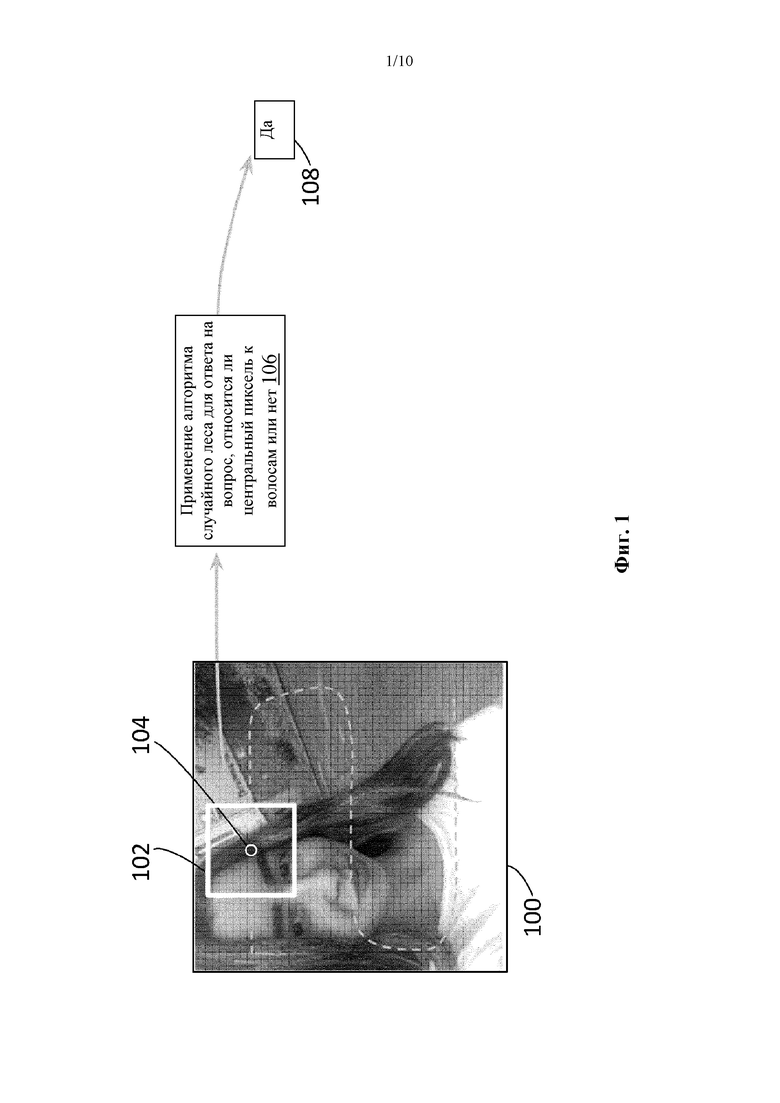
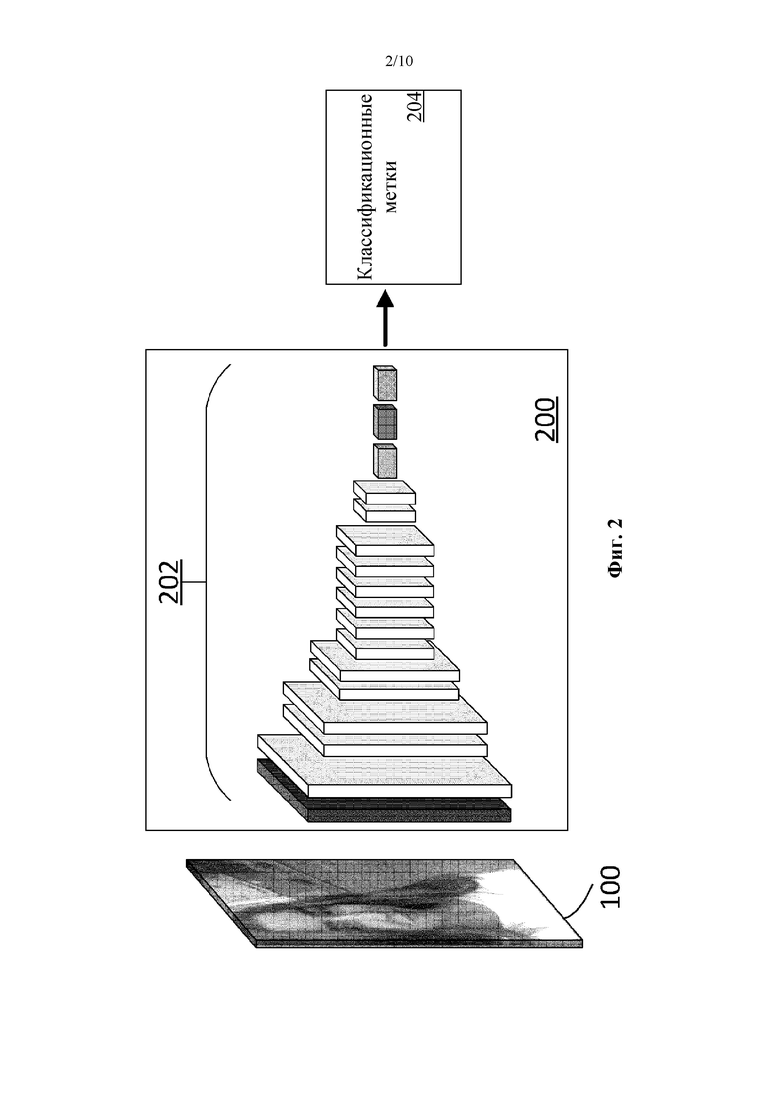
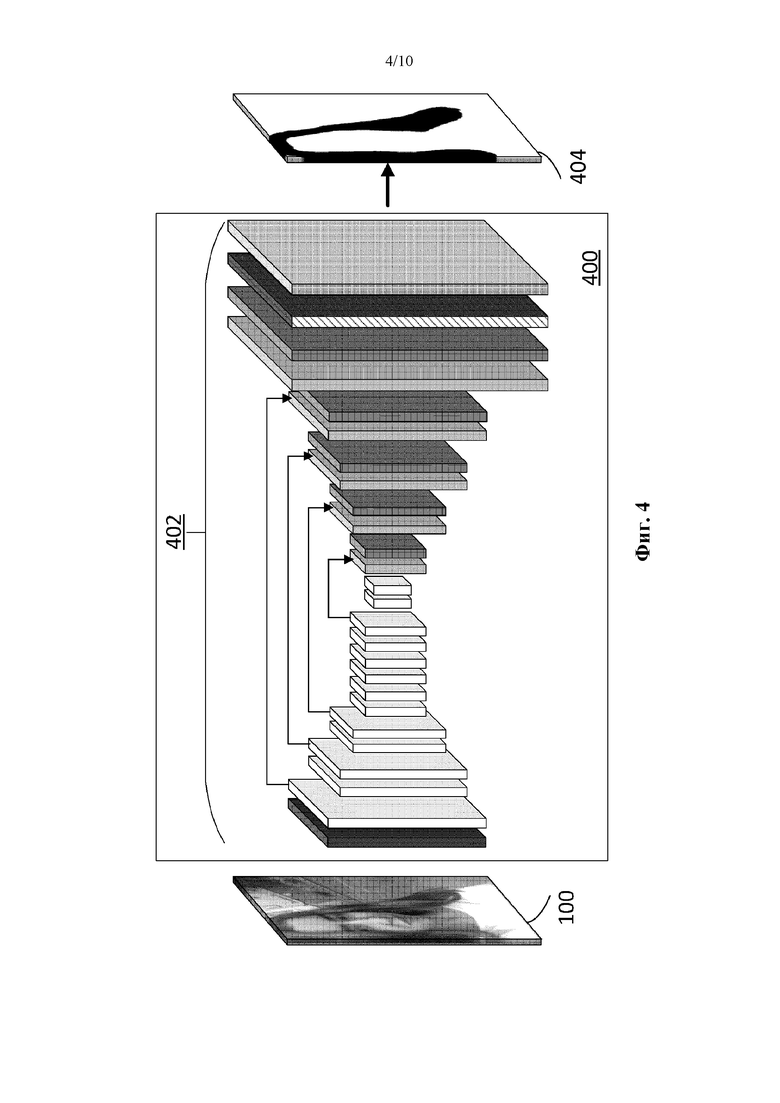
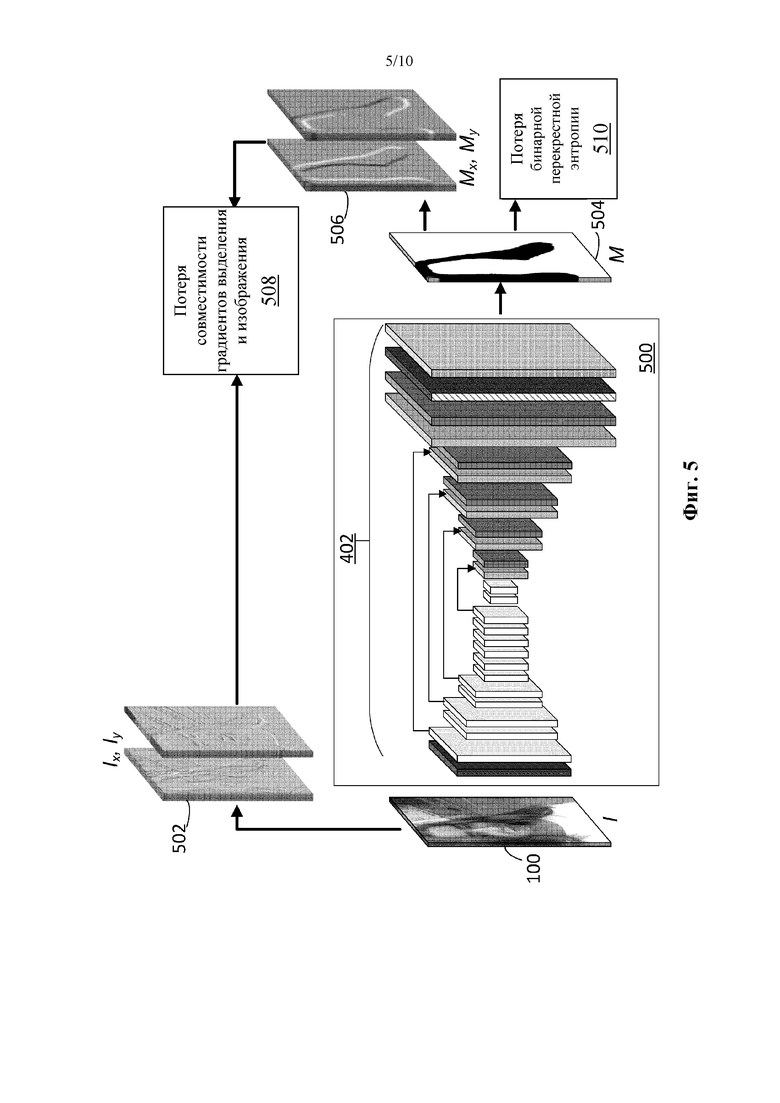
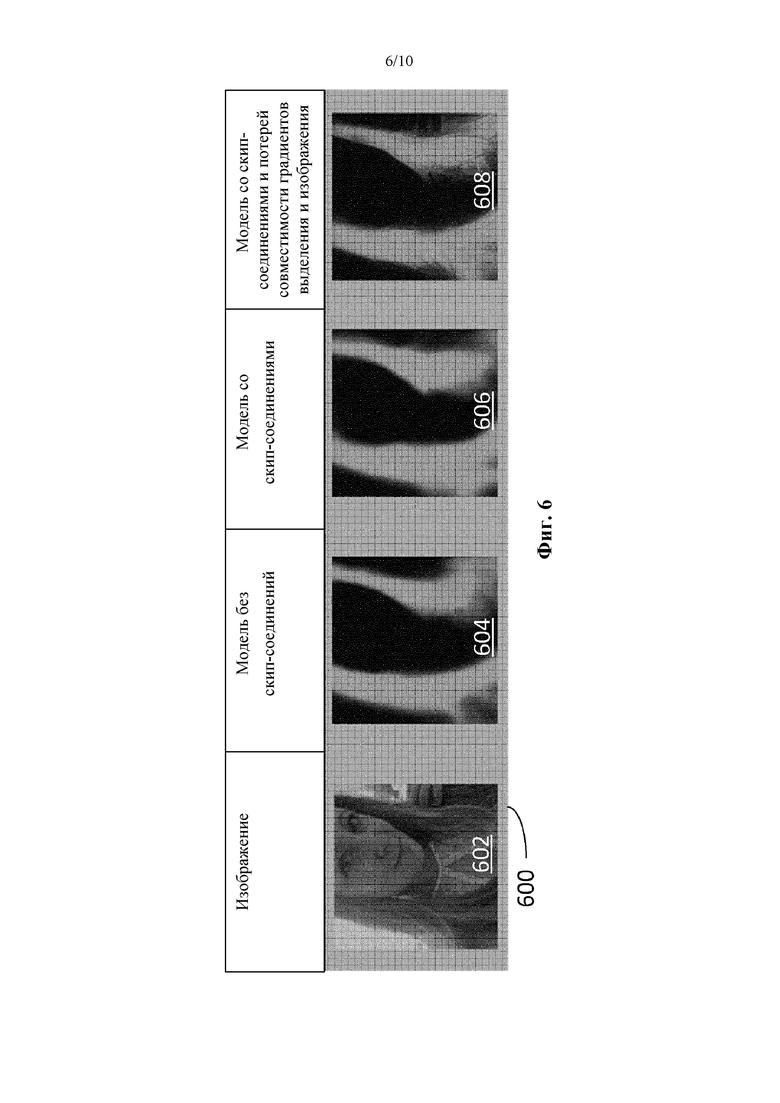

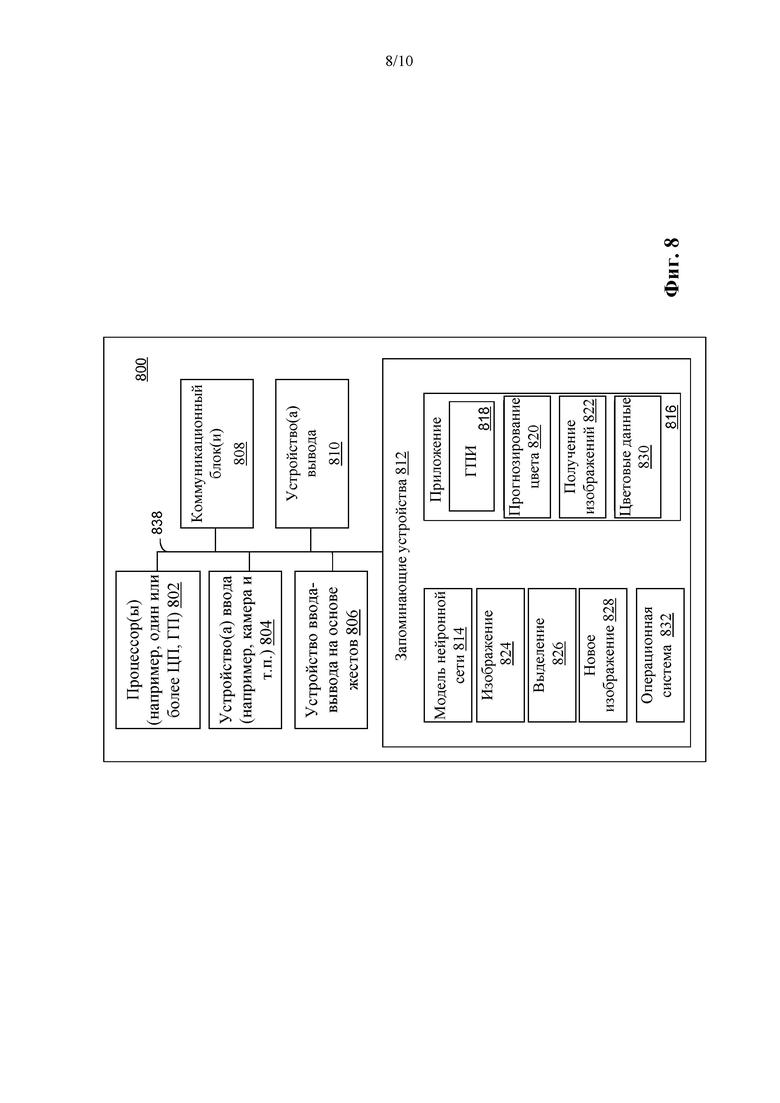
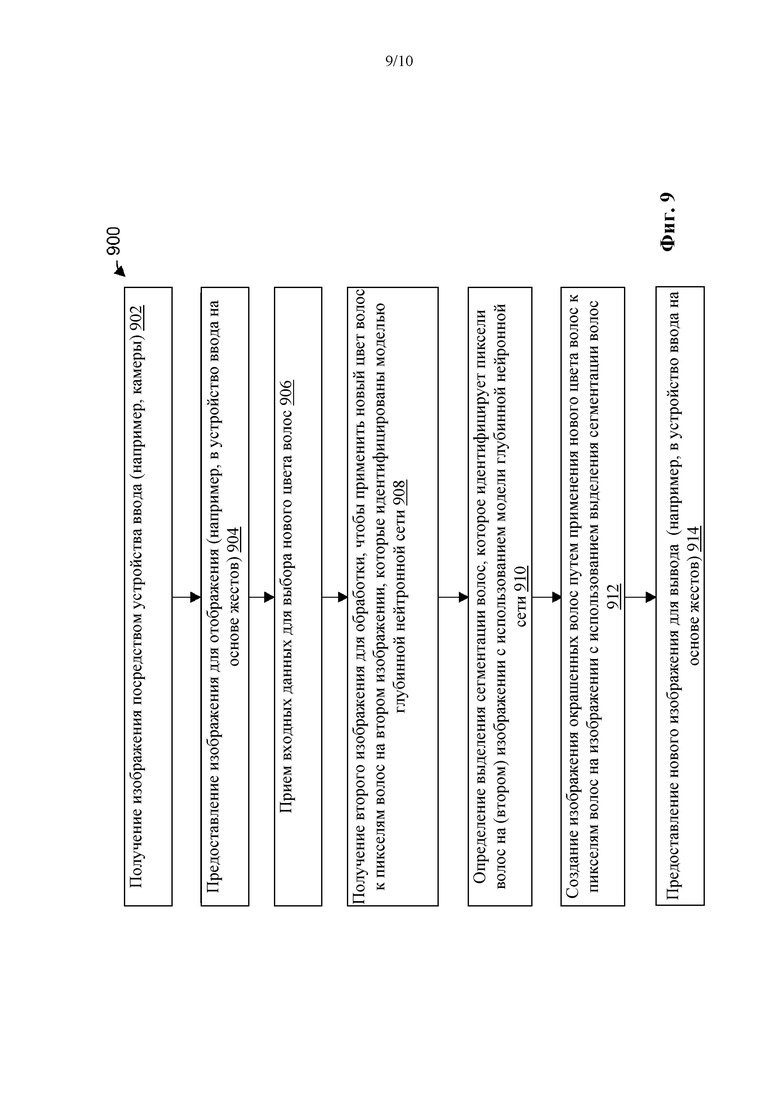
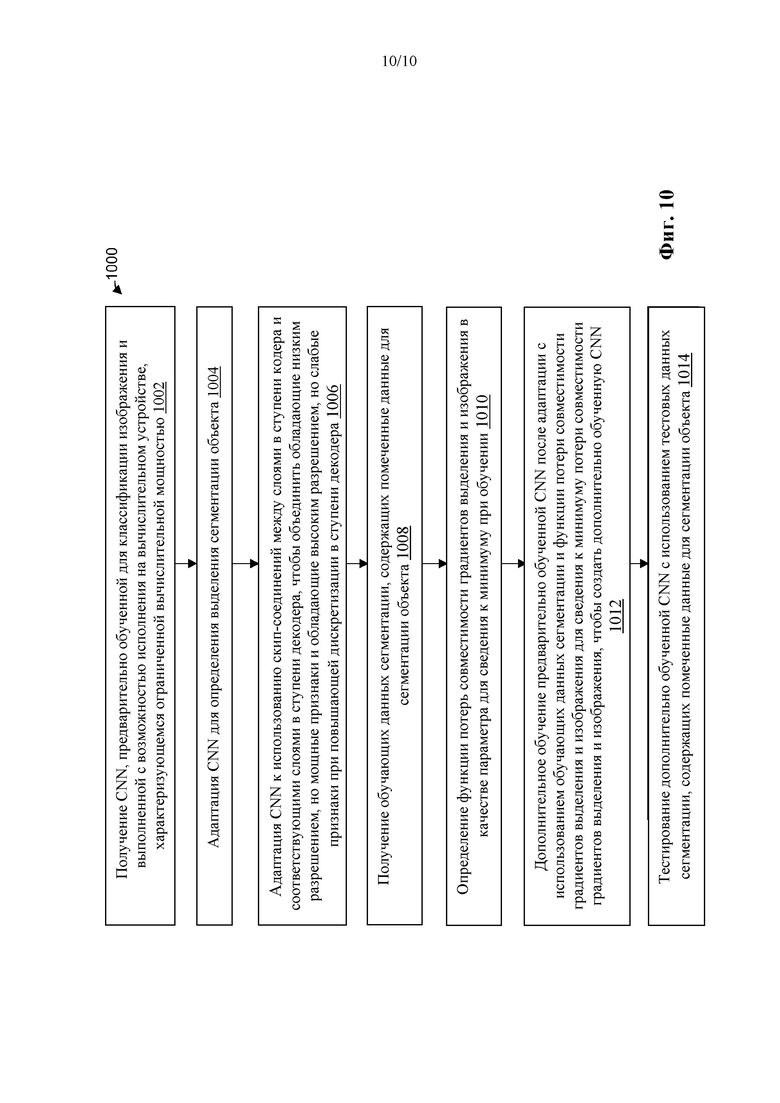
Изобретение относится к области вычислительной техники для обработки изображений. Технический результат заключается в повышении разрешения выходных данных изображения. Система и способ реализуют глубинное обучение на мобильном устройстве, чтобы создать сверточную нейронную сеть (CNN) для обработки видео в режиме реального времени, например для окрашивания волос. Изображения обрабатываются с использованием CNN для определения соответствующей маски пикселей волос. Соответствующие маски объектов могут быть использованы для определения того, какой пиксель необходимо изменить при корректировке параметров пикселей, например для изменения цвета, освещения, текстуры и т.п. CNN может включать в себя (предварительно обученную) сеть для классификации изображения, адаптированную для получения выделения сегментации. CNN может быть обучена для сегментации изображения (например, с использованием грубых данных сегментации), чтобы свести к минимуму потерю совместимости градиентов выделения и изображения. CNN может дополнительно использовать скип-соединения между соответствующими слоями ступени кодера и ступени декодера. 8 н. и 74 з.п. ф-лы, 6 табл., 10 ил.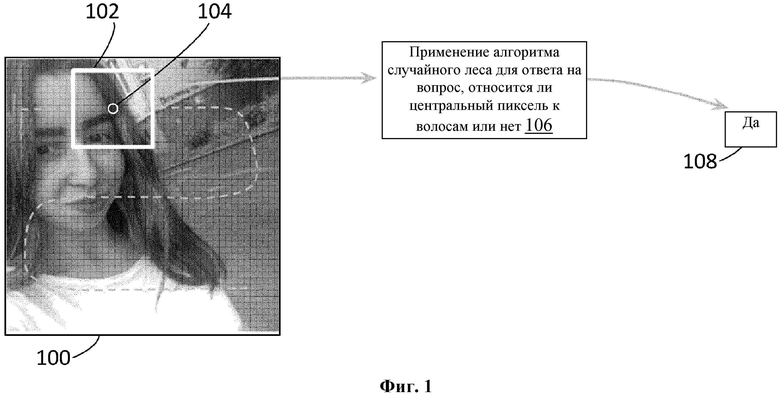
1. Вычислительное устройство для обработки изображения, содержащее:
запоминающий блок для хранения и предоставления сверточной нейронной сети (CNN), выполненной с возможностью классификации пикселей изображения для определения того, является ли каждый из пикселей пикселем объекта или нет, чтобы определить выделение сегментации объекта для объекта на изображении, причем CNN включает в себя предварительно обученную сеть для классификации изображения, адаптированную для определения выделения сегментации объекта, и CNN дополнительно обучена с использованием данных сегментации; и
блок обработки данных, связанный с запоминающим блоком и выполненный с возможностью обработки изображения с использованием CNN для генерирования выделения сегментации объекта для определения нового изображения.
2. Вычислительное устройство по п. 1, где CNN дополнительно обучена для сведения к минимуму потери совместимости градиентов выделения и изображения.
3. Вычислительное устройство по одному из пп. 1 и 2, при этом потеря LC совместимости градиентов выделения и изображения определяется как
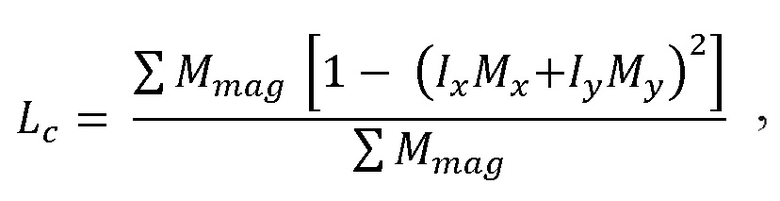
где Ix, Iy представляют собой нормализованный градиент изображения; Mx, My представляют собой нормализованный градиент выделения; и Mmag представляет собой величину градиента выделения.
4. Вычислительное устройство по п. 3, где потеря LC совместимости градиентов выделения и изображения объединяется с потерей бинарной LM перекрестной энтропии с весом w, чтобы свести к минимуму суммарные потери L при обучении, где L определяется как L = LM + wLC.
5. Вычислительное устройство по любому из пп. 1-4, где данные сегментации являются зашумленными и грубыми данными сегментации.
6. Вычислительное устройство по любому из пп. 1-5, где данные сегментации являются краудсорсинговыми данными сегментации.
7. Вычислительное устройство по любому из пп. 1-4, адаптированное к использованию скип-соединений между слоями в ступени кодера и соответствующими слоями в ступени декодера, чтобы объединить обладающие низким разрешением, но мощные признаки и обладающие высоким разрешением, но слабые признаки при повышающей дискретизации в ступени декодера для определения выделения сегментации объекта.
8. Вычислительное устройство по любому из пп. 1-7, где объект является волосами.
9. Вычислительное устройство по любому из пп. 1-8, где блок обработки данных выполнен с возможностью определения нового изображения на основе указанного изображения путем применения изменения к пикселям на указанном изображении, выбранным с использованием выделения сегментации объекта.
10. Вычислительное устройство по п. 9, где изменение является изменением цвета.
11. Вычислительное устройство по одному из пп. 9 и 10, где CNN включает в себя обученную сеть, выполненную с возможностью исполнения на мобильном устройстве с ограниченной вычислительной мощностью для создания нового изображения в качестве видеоизображения в режиме реального времени.
12. Вычислительное устройство по любому из пп. 9-11, в котором блок обработки данных выполнен с возможностью предоставления интерактивного графического пользовательского интерфейса (GUI) для отображения указанного изображения и нового изображения, при этом указанный интерактивный GUI выполнен с возможностью получения входных данных для определения изменения с целью получения нового изображения.
13. Вычислительное устройство по п. 12, в котором блок обработки данных выполнен с возможностью анализа пикселей объекта на изображении с использованием выделения сегментации объекта, чтобы определить одного или более кандидатов для изменения, и интерактивный GUI выполнен с возможностью представления одного или более кандидатов для получения входных данных с целью выбора одного из кандидатов для применения в качестве изменения.
14. Вычислительное устройство по любому из пп. 1-13, где изображение представляет собой селфи-видео.
15. Вычислительное устройство для обработки изображения, содержащее:
запоминающий блок для хранения и предоставления сверточной нейронной сети (CNN), выполненной с возможностью классификации пикселей изображения для определения того, является ли каждый из пикселей пикселем волос или нет, при этом CNN обучена для сведения к минимуму потери совместимости градиентов выделения и изображения при обучении с использованием данных сегментации для определения выделения сегментации волос; и
блок обработки данных, связанный с запоминающим блоком, при этом блок обработки данных выполнен с возможностью определения и представления изображения окрашенных волос путем применения нового цвета волос к пикселям волос на изображении с использованием выделения сегментации волос.
16. Вычислительное устройство по п. 15, где CNN включает в себя обученную сеть, выполненную с возможностью исполнения на мобильном устройстве с ограниченной вычислительной мощностью для создания изображения окрашенных волос в качестве видеоизображения в режиме реального времени.
17. Вычислительное устройство по одному из пп. 15 и 16, где CNN включает в себя предварительно обученную сеть для классификации изображения, адаптированную для создания выделения сегментации волос, при этом указанная предварительно обученная сеть адаптирована к использованию скип-соединений между слоями в ступени кодера и соответствующими слоями в ступени декодера, чтобы объединить обладающие низким разрешением, но мощные признаки и обладающие высоким разрешением, но слабые признаки при повышающей дискретизации в ступени декодера.
18. Вычислительное устройство по п. 17, где слой с более низким разрешением из ступени кодера обрабатывается путем применения сначала поточечной свертки, чтобы сделать выходную глубину совместимой с входящим слоем более высокого изображения из ступени декодера.
19. Вычислительное устройство по любому из пп. 15-18, где CNN адаптирована для объединения обладающих низким разрешением, но мощных признаков и обладающих высоким разрешением, но слабых признаков из соответствующих уровней при осуществлении повышающей дискретизации в ступени декодера.
20. Вычислительное устройство по любому из пп. 15-19, где CNN обучена с использованием грубых данных сегментации для сведения к минимуму потери совместимости градиентов выделения и изображения.
21. Вычислительное устройство по любому из пп. 15-20, при этом потеря LC совместимости градиентов выделения и изображения определяется как
где Ix, Iy представляют собой нормализованный градиент изображения; Mx, My представляют собой нормализованный градиент выделения; и Mmag представляет собой величину градиента выделения.
22. Вычислительное устройство по одному из пп. 20 и 21, где потеря LC совместимости градиентов выделения и изображения объединяется с потерей LM бинарной перекрестной энтропии с весом w, чтобы свести к минимуму суммарные потери L при обучении, и L определяется как L = LM + wLC.
23. Вычислительное устройство по любому из пп. 1-22, где CNN выполнена с возможностью использования раздельной свертки по глубине, содержащей свертку по глубине и поточечную свертку, чтобы свести к минимуму операции обработки и обеспечить возможность исполнения CNN на мобильном устройстве, имеющем ограниченную вычислительную мощность.
24. Вычислительное устройство для обработки изображения, содержащее:
блок обработки данных, запоминающий блок, связанный с блоком обработки данных, и устройство ввода, связанное по меньшей мере с одним из блока обработки данных и запоминающего блока, при этом в запоминающем блоке хранятся команды, которые при выполнении блоком обработки данных конфигурируют вычислительное устройство для следующих действий:
прием изображения посредством устройства ввода;
определение выделения сегментации волос, которое идентифицирует пиксели волос на изображении;
определение изображения окрашенных волос путем применения нового цвета к пикселям волос на изображении с использованием выделения сегментации волос; и
предоставление изображения окрашенных волос для выдачи в устройство отображения; и
при этом выделение сегментации волос определяется посредством следующего:
обработка изображения с использованием сверточной нейронной сети (CNN), хранящейся в запоминающем блоке, для применения множества сверточных фильтров (фильтров свертки) в последовательности слоев свертки, чтобы выполнить обнаружение соответствующих признаков, где первый набор слоев свертки в последовательности предоставляет выходные данные, которые понижают разрешение изображения от первого разрешения изображения до минимального разрешения, и второй набор слоев свертки в последовательности повышает разрешение выходных данных обратно до первого разрешения изображения, и CNN обучена для сведения к минимуму потери совместимости градиентов выделения и изображения, чтобы определить выделение сегментации волос.
25. Вычислительное устройство по п. 24, где CNN адаптирована для применения скип-соединений между соответствующими слоями свертки из первого набора и второго набора.
26. Вычислительное устройство по одному из пп. 24 и 25, где CNN содержит функцию повышающей дискретизации, вставленную перед исходным слоем второго набора слоев свертки и перед соответствующими последующими слоями второго набора слоев свертки для повышения разрешения выходных данных до первого разрешения изображения.
27. Вычислительное устройство по п. 26, где функция повышающей дискретизации использует соответствующие скип-соединения, при этом каждое из соответствующих скип-соединений объединяет:
первую карту активации, которая выдана из соседнего слоя свертки в последовательности в качестве входных данных для следующего слоя свертки второго набора слоев свертки; и
вторую карту активации, которая выдана из более раннего слоя свертки в первом наборе слоев свертки, при этом вторая карта активации имеет большее разрешение изображения, чем первая карта активации.
28. Вычислительное устройство по п. 27, где каждое из соответствующих скип-соединений задано для сложения выходных данных фильтра свертки 1×1, применяемого ко второй карте активации, с выходными данными функции повышающей дискретизации, применяемой к первой карте активации, чтобы повысить разрешение первой карты активации до более высокого разрешения изображения.
29. Вычислительное устройство по любому из пп. 24-28, где команды конфигурируют вычислительное устройство для представления графического пользовательского интерфейса (GUI) посредством устройства отображения, при этом GUI содержит первую часть для просмотра изображения и вторую часть для одновременного просмотра изображения окрашенных волос.
30. Вычислительное устройство по п. 29, при этом команды конфигурируют указанное вычислительное устройство для применения обработки с использованием условий освещения к новому цвету волос на изображении окрашенных волос, чтобы показать новый цвет волос при другом условии освещения.
31. Вычислительное устройство по любому из пп. 24-30, где новый цвет волос является первым цветом волос, а изображение окрашенных волос является первым изображением окрашенных волос, при этом команды конфигурируют вычислительное устройство для следующего:
определение и представление второго изображения окрашенных волос путем применения второго нового цвета волос к пикселям волос на изображении с использованием выделения сегментации волос и путем предоставления второго изображения окрашенных волос для выдачи в устройство отображения.
32. Вычислительное устройство по п. 31, где команды конфигурируют вычислительное устройство для представления GUI с двумя новыми цветами посредством устройства отображения, при этом GUI с двумя новыми цветами содержит первую часть с новым цветом для просмотра первого изображения окрашенных волос и вторую часть с новым цветом для одновременного просмотра второго изображения окрашенных волос.
33. Вычислительное устройство по любому из пп. 24-32, где команды конфигурируют вычислительное устройство для следующего:
анализ изображения на предмет цвета, включая текущий цвет пикселей волос на изображении;
определение одного или более предлагаемых новых цветов волос; и
представление предлагаемых новых цветов волос посредством интерактивной части GUI для выбора нового цвета волос, чтобы определить изображение окрашенных волос.
34. Вычислительное устройство по любому из пп. 24-33, в котором блок обработки данных включает в себя графический процессор (GPU) для выполнения CNN и указанное вычислительное устройство включает в себя одно из смартфона и планшетного компьютера.
35. Вычислительное устройство по любому из пп. 24-34, при этом изображение является одним из множества видеоизображений, входящих в состав видео, и команды конфигурируют вычислительное устройство для обработки множества видеоизображений для изменения цвета волос.
36. Вычислительное устройство по любому из пп. 24-35, где CNN включает в себя модель на основе MobileNet, адаптированную для классификации пикселей изображения для определения, является ли каждый из пикселей пикселем волос.
37. Вычислительное устройство по любому из пп. 24-36, где CNN сконфигурирована в качестве нейронной сети на основе раздельных сверток по глубине, содержащей свертки, в которых отдельные стандартные свертки факторизированы на свертку по глубине и поточечную свертку, причем свертка по глубине ограничена применением одного фильтра к каждому входному каналу и поточечная свертка ограничена объединением выходных данных свертки по глубине.
38. Вычислительное устройство по любому из пп. 24-37, при этом потеря 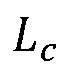 совместимости градиентов выделения и изображения определяется как
совместимости градиентов выделения и изображения определяется как
где Ix, Iy представляют собой нормализованный градиент изображения; Mx, My представляют собой нормализованный градиент выделения; и Mmag представляет собой величину градиента выделения.
39. Вычислительное устройство, выполненное с возможностью генерирования сверточной нейронной сети (CNN), обученной для обработки изображений, чтобы определить выделение сегментации объекта, причем указанное вычислительное устройство содержит:
запоминающий блок для приема CNN, выполненной с возможностью классификации изображения и выполненной с возможностью исполнения на исполнительном вычислительном устройстве, характеризующемся ограниченной вычислительной мощностью;
блок обработки данных, выполненный с возможностью предоставления интерактивного интерфейса для приема входных данных и отображения выходных данных, при этом блок обработки данных выполнен с возможностью следующего:
прием входных данных для адаптации CNN для определения выделения сегментации объекта и сохранение CNN после адаптации в запоминающем блоке; и
прием входных данных для обучения CNN после адаптации с использованием обучающих данных сегментации, помеченных для сегментации объекта, чтобы генерировать CNN для обработки изображений для определения выделения сегментации объекта.
40. Вычислительное устройство по п. 39, в котором блок обработки данных выполнен с возможностью приема входных данных для адаптации CNN по меньшей мере к одному из следующего:
применение функции потери совместимости градиентов выделения и изображения, определенной для сведения к минимуму потери совместимости градиентов выделения и изображения при обучении; и
применение скип-соединений между слоями в ступени кодера и соответствующими слоями в ступени декодера, чтобы объединить обладающие низким разрешением, но мощные признаки и обладающие высоким разрешением, но слабые признаки при повышающей дискретизации в ступени декодера; и
сохранение CNN после адаптации в запоминающем блоке.
41. Способ генерирования сверточной нейронной сети (CNN), обученной для обработки изображений, чтобы определить выделение сегментации объекта, причем указанный способ предусматривает:
получение CNN, выполненной с возможностью классификации изображения и выполненной с возможностью исполнения на вычислительном устройстве, характеризующемся ограниченной вычислительной мощностью;
адаптацию CNN для определения выделения сегментации объекта; и
обучение CNN после адаптации с использованием обучающих данных сегментации, помеченных для сегментации объекта, чтобы определить выделение сегментации объекта.
42. Способ по п. 41, в котором CNN предварительно обучают для классификации изображения и на стадии обучения осуществляют дополнительное обучение CNN после предварительного обучения.
43. Способ по одному из пп. 41 и 42, предусматривающий адаптацию CNN к использованию функции потери совместимости градиентов выделения и изображения, определенной для сведения к минимуму потери совместимости градиентов выделения и изображения, чтобы генерировать CNN для обработки изображений.
44. Способ по любому из пп. 41-43, где обучающие данные сегментации являются зашумленными и грубыми обучающими данными сегментации, определенными на основе краудсорсинговых данных.
45. Способ по любому из пп. 41-44, предусматривающий адаптацию CNN к использованию скип-соединений между слоями в ступени кодера и соответствующими слоями в ступени декодера, чтобы объединить обладающие низким разрешением, но мощные признаки и обладающие высоким разрешением, но слабые признаки при повышающей дискретизации в ступени декодера.
46. Способ по любому из пп. 41-45, где функцию потери совместимости градиентов выделения и изображения объединяют с функцией потери бинарной перекрестной энтропии для сведения к минимуму общей потери.
47. Способ по любому из пп. 41-46, в котором потерю совместимости градиентов выделения и изображения определяют как
где Ix, Iy представляют собой нормализованный градиент изображения; Mx, My представляют собой нормализованный градиент выделения; и Mmag представляет собой величину градиента выделения.
48. Способ по любому из пп. 41-47, предусматривающий предоставление CNN для обработки изображений, чтобы определить выделение сегментации объекта, для сохранения на мобильном устройстве.
49. Способ обработки изображений, предусматривающий:
сохранение в запоминающем блоке, входящем в состав вычислительного устройства, сверточной нейронной сети (CNN), выполненной с возможностью классификации пикселей изображения для определения того, является ли каждый из пикселей пикселем объекта или нет, чтобы определить выделение сегментации объекта для объекта на изображении; и
обработку изображения посредством блока обработки данных, входящего в состав вычислительного устройства, с использованием CNN для генерирования выделения сегментации объекта для определения нового изображения; и
при этом CNN включает в себя предварительно обученную сеть для классификации изображения, адаптированную для определения выделения сегментации объекта и обученную с использованием данных сегментации.
50. Способ по п. 49, в котором CNN адаптируют по меньшей мере к одному из следующего:
применение функции потери совместимости градиентов выделения и изображения для сведения к минимуму потери совместимости градиентов выделения и изображения при обучении с использованием данных сегментации; и
применение скип-соединений между слоями в ступени кодера и соответствующими слоями в ступени декодера, чтобы объединить обладающие низким разрешением, но мощные признаки и обладающие высоким разрешением, но слабые признаки при повышающей дискретизации в ступени декодера для определения выделения сегментации объекта.
51. Способ по п. 50, в котором потерю совместимости градиентов выделения и изображения определяют как
где Ix, Iy представляют собой нормализованный градиент изображения; Mx, My представляют собой нормализованный градиент выделения; и Mmag представляет собой величину градиента выделения.
52. Способ по п. 51, в котором потерю совместимости градиентов выделения и изображения объединяют с потерей бинарной перекрестной энтропии с весом w, чтобы свести к минимуму суммарные потери L при обучении, где L определяют как L = LM + wLC.
53. Способ по любому из пп. 49-52, в котором объект является волосами.
54. Способ по любому из пп. 49-53, предусматривающий определение посредством блока обработки данных нового изображения на основе указанного изображения путем применения изменения к пикселям на изображении, выбранным с использованием выделения сегментации объекта.
55. Способ по п. 54, где изменение является изменением цвета.
56. Способ по одному из пп. 54 и 55, в котором CNN включает в себя обученную сеть, выполненную с возможностью исполнения на мобильном устройстве с ограниченной вычислительной мощностью для создания нового изображения в качестве видеоизображения в режиме реального времени.
57. Способ по любому из пп. 54-56, в котором блок обработки данных выполняют с возможностью предоставления интерактивного графического пользовательского интерфейса (GUI) для отображения указанного изображения и нового изображения, при этом указанный интерактивный GUI выполнен с возможностью получения входных данных для определения изменения с целью получения нового изображения.
58. Способ по п. 57, предусматривающий анализ посредством блока обработки данных пикселей объекта на изображении с использованием выделения сегментации объекта, чтобы определить одного или более кандидатов для изменения, и интерактивный GUI выполняют с возможностью представления одного или более кандидатов для получения входных данных с целью выбора одного из кандидатов для применения в качестве изменения.
59. Способ по любому из пп. 49-58, в котором изображение представляет собой селфи-видео.
60. Способ обработки изображения, предусматривающий:
сохранение в запоминающем блоке, входящем в состав вычислительного устройства, сверточной нейронной сети (CNN), выполненной с возможностью классификации пикселей изображения для определения того, является ли каждый из пикселей пикселем волос или нет, при этом CNN обучают для сведения к минимуму потери совместимости градиентов выделения и изображения при обучении с использованием данных сегментации для определения выделения сегментации волос; и
определение и представление посредством блока обработки данных, входящего в состав вычислительного устройства и связанного с запоминающим блоком, изображения окрашенных волос путем применения нового цвета волос к пикселям волос на изображении с использованием выделения сегментации волос.
61. Способ по п. 60, где CNN включает в себя обученную сеть, выполненную с возможностью исполнения на мобильном устройстве с ограниченной вычислительной мощностью для создания изображения окрашенных волос в качестве видеоизображения в режиме реального времени.
62. Способ по одному из пп. 60 и 61, где CNN включает в себя предварительно обученную сеть для классификации изображений, адаптированную для создания выделения сегментации волос, при этом указанная предварительно обученная сеть адаптирована к использованию скип-соединений между слоями в ступени кодера и соответствующими слоями в ступени декодера, чтобы объединить обладающие низким разрешением, но мощные признаки и обладающие высоким разрешением, но слабые признаки при повышающей дискретизации в ступени декодера.
63. Способ по п. 62, где слой с более низким разрешением из ступени кодера обрабатывают путем применения сначала поточечной свертки, чтобы сделать выходную глубину совместимой с входящим слоем более высокого изображения из ступени декодера.
64. Способ по любому из пп. 60-63, где CNN обучают с использованием грубых данных сегментации для сведения к минимуму потери совместимости градиентов выделения и изображения.
65. Способ по любому из пп. 60-64, при этом потерю совместимости градиентов выделения и изображения определяют как
где Ix, Iy представляют собой нормализованный градиент изображения; Mx, My представляют собой нормализованный градиент выделения; и Mmag представляет собой величину градиента выделения.
66. Способ по одному из пп. 64 и 65, где потерю LC совместимости градиентов выделения и изображения объединяют с потерей LM бинарной перекрестной энтропии с весом w, чтобы свести к минимуму суммарные потери L при обучении, и L определяют как L = LM + wLC.
67. Способ по любому из пп. 41-66, где CNN выполняют с возможностью использования раздельной свертки по глубине, содержащей свертку по глубине и поточечную свертку, чтобы свести к минимуму операции обработки и обеспечить возможность исполнения CNN на мобильном устройстве, имеющем ограниченную вычислительную мощность.
68. Способ обработки изображения, предусматривающий:
прием изображения посредством блока обработки данных;
определение выделения сегментации волос, которое идентифицирует пиксели волос на изображении, посредством блока обработки данных;
определение посредством блока обработки данных изображения окрашенных волос путем применения нового цвета волос к пикселям волос на изображении с использованием выделения сегментации волос; и
предоставление посредством блока обработки данных изображения окрашенных волос для выдачи на устройство отображения; и
при этом выделение сегментации волос определяют посредством следующего:
обработка изображения с использованием сверточной нейронной сети (CNN), сохраненной посредством запоминающего блока, связанного с блоком обработки данных, для применения множества сверточных фильтров (фильтров свертки) в последовательности слоев свертки, чтобы выполнить обнаружение соответствующих признаков, и CNN обучена с использованием зашумленных и грубых данных сегментации и для сведения к минимуму потери совместимости градиентов выделения и изображения для определения выделения сегментации волос.
69. Способ по п. 68, где первый набор слоев свертки в последовательности предоставляет выходные данные, которые понижают разрешение изображения от первого разрешения изображения до минимального разрешения, и второй набор слоев свертки в последовательности повышает разрешение выходных данных обратно до первого разрешения изображения, при этом CNN использует скип-соединения между соответствующими слоями свертки из первого набора и второго набора.
70. Способ по п. 69, где CNN включает в себя функцию повышающей дискретизации, вставленную перед исходным слоем второго набора слоев свертки и перед соответствующими последующими слоями второго набора слоев свертки для повышения разрешения выходных данных до первого разрешения изображения.
71. Способ по п. 70, в котором функция повышающей дискретизации использует соответствующие скип-соединения, при этом каждое из соответствующих скип-соединений объединяет:
первую карту активации, которая выдана из соседнего слоя свертки в последовательности в качестве входных данных для следующего слоя свертки второго набора слоев свертки; и
вторую карту активации, которая выдана из более раннего слоя свертки в первом наборе слоев свертки, при этом вторая карта активации имеет большее разрешение изображения, чем первая карта активации.
72. Способ по п. 71, где каждое из соответствующих скип-соединений задают для сложения выходных данных фильтра свертки 1×1, применяемого ко второй карте активации, с выходными данными функции повышающей дискретизации, применяемой к первой карте активации, чтобы повысить разрешение первой карты активации до более высокого разрешения изображения.
73. Способ по любому из пп. 68-72, предусматривающий представление посредством блока обработки данных графического пользовательского интерфейса (GUI) на устройстве отображения, при этом GUI содержит первую часть для просмотра изображения и вторую часть для одновременного просмотра изображения окрашенных волос.
74. Способ по п. 73, предусматривающий применение обработки с использованием условий освещения к новому цвету волос на изображении окрашенных волос, чтобы показать новый цвет волос при другом условии освещения.
75. Способ по любому из пп. 68-74, где новый цвет волос является первым новым цветом волос, а изображение окрашенных волос является первым изображением окрашенных волос, при этом способ предусматривает
определение и представление посредством блока обработки данных второго изображения окрашенных волос путем применения второго нового цвета волос к пикселям волос на изображении с использованием выделения сегментации волос и путем предоставления второго изображения окрашенных волос для выдачи в устройство отображения.
76. Способ по п. 75, предусматривающий представление посредством блока обработки данных GUI с двумя новыми цветами на устройстве отображения, при этом GUI с двумя новыми цветами содержит первую часть с новым цветом для просмотра первого изображения окрашенных волос и вторую часть с новым цветом для одновременного просмотра второго изображения окрашенных волос.
77. Способ по любому из пп. 68-76, дополнительно предусматривающий:
анализ посредством блока обработки данных изображения на предмет цвета, включая текущий цвет пикселей волос на изображении;
определение одного или более предлагаемых новых цветов волос; и
представление предлагаемых новых цветов волос посредством интерактивной части GUI для выбора нового цвета волос, чтобы определить изображение окрашенных волос.
78. Способ по любому из пп. 68-77, где блок обработки данных включает в себя графический процессор (GPU) для выполнения CNN, при этом блок обработки данных и запоминающий блок предоставляют посредством вычислительного устройства, включающего в себя одно из смартфона и планшетного компьютера.
79. Способ по любому из пп. 68-78, где изображение является одним из множества видеоизображений, входящих в состав видео, при этом указанный способ предусматривает обработку посредством блока обработки данных множества видеоизображений для изменения цвета волос.
80. Способ по любому из пп. 68-79, где CNN включает в себя модель на основе MobileNet, адаптированную для классификации пикселей изображения для определения, является ли каждый из пикселей пикселем волос.
81. Способ по любому из пп. 68-80, где CNN конфигурируют в качестве нейронной сети на основе раздельных сверток по глубине, содержащей свертки, в которых отдельные стандартные свертки факторизированы на свертку по глубине и поточечную свертку, причем свертка по глубине ограничена применением одного фильтра к каждому входному каналу и поточечная свертка ограничена объединением выходных данных свертки по глубине.
82. Способ по любому из пп. 68-81, где потерю совместимости градиентов выделения и изображения определяют как
где Ix, Iy представляют собой нормализованный градиент изображения; Mx, My представляют собой нормализованный градиент выделения; и Mmag представляет собой величину градиента выделения.
| Токарный резец | 1924 |
|
SU2016A1 |
| US 8965112 B1, 24.02.2015 | |||
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| CN 104966093 A, 07.10.2015 | |||
| RU 2012135476 A, 27.02.2014. | |||

