ОБЛАСТЬ ТЕХНИКИ
Настоящее техническое решение относится к вычислительной технике, а в частности к способам распознавания текста на изображениях документов посредством методов машинного обучения.
УРОВЕНЬ ТЕХНИКИ
Из уровня техники известен источник информации US 8,897,563 В1, опубликованный 25.11.2014 года, раскрывающий способ и систему автоматической обработки документов. В данном решении система анализа документов, принимает и обрабатывает задания от множества пользователей, где каждое задание может содержать несколько электронных документов, для извлечения данных из них, посредством метода автоматической предварительной обработки каждого принятого электронного документа с использованием множества изображений. В решении предусмотрены алгоритмы преобразования для улучшения последующего извлечения данных из указанного документа. Указанный способ включает электронное разбиение каждой полученной страницы электронного документа на части; автоматическую обработку каждого фрагмента страницы принятого электронного документа с использованием каждого из множества алгоритмов предварительной обработки изображения для создания множества вариантов изображения каждого фрагмента, а также анализ результатов последующей обработки и извлечения данных для каждого из вариантов изображения частей, чтобы определить, какой результат лучше всего.
Из уровня техники также известен источник информации RU 2691214 С1, опубликованный 11.06.2019 года, раскрывающий способ распознавания текста с использованием искусственного интеллекта. Способ включает получение изображения текста, при этом текст на изображении содержит одно или более слов в одном или более предложениях; получение изображения текста в качестве первых исходных данных для набора обученных моделей машинного обучения, хранящего информацию о сочетаемости слов и частотности их совместного употребления в реальных предложениях; получение одного или более конечных выходных данных от набора обученных моделей машинного обучения, а также извлечение из одного или более конечных выходных данных одного или более предполагаемых предложений из текста на изображении. Каждое из одного или более предполагаемых предложений содержит вероятные последовательности слов.
Предлагаемое решение, отличается от известных из уровня техники решений тем, что после выделения области документа на изображении осуществляют классификацию типа документа с применением алгоритмов машинного обучения, а также осуществляют валидацию распознанного текста по набору правил относительно данных, содержащихся в полях, и ожидаемых форматов представления этих данных.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Технической задачей, на решение которой направлено заявленное решение, является разработка способа извлечения информации из изображений документов посредством методов машинного обучения, охарактеризованного в независимом пункте формулы изобретения. Дополнительные варианты реализации настоящего изобретения представлены в зависимых пунктах формулы изобретения.
Технический результат заключается в повышении точности извлечения информации из изображений документов. Дополнительным техническим результатом является повышение скорости распознавания текста на изображениях документов. Дополнительным техническим результатом является увеличение производительности вычислительной системы при решении поставленной задачи (т.е. позволяет производить обработку с получением результата (продукта) за меньшее количество времени), тем самым снижается нагрузка на центральный процессор вычислительного устройства, за счет уменьшения количества обрабатываемых запросов.
Заявленный технический результат достигается за счет работы компьютерно-реализуемого способа автоматического распознавания текста на изображении документа, способ выполняется на вычислительном устройстве, который содержит процессор и память, хранящую инструкции, исполняемые процессором и содержащие этапы, на которых:
на вычислительное устройство получают изображение документа;
посредством модуля локализации документа, осуществляют выделение области документа на изображении;
посредством модуля классификации типа документа, на основе выделенной области документа на изображении, осуществляют классификацию типа документа с применением сверточной нейронной сети;
посредством модуля бинаризации, осуществляют бинаризацию изображения определенного типа документа для отделения текста документа от фона;
посредством модуля сегментации, осуществляют сегментацию изображения документа, с определенным типом документа на этапе классификации, для определения текстовых полей, путем определения координат ограничивающих прямоугольников полей;
посредством модуля сопоставления, определяют тип найденных, на предыдущем этапе, текстовых полей с помощью структурных шаблонов документов;
посредством модуля распознавания текста, осуществляют распознавание текста на выявленных текстовых полях;
посредством модуля валидации, осуществляют валидацию распознанного текста на выявленных текстовых полях по набору правил относительно данных, содержащихся в полях, и ожидаемых форматов представления этих данных.
В частном варианте реализации предлагаемого способа, изображение получено посредством сканирования.
В другом частном варианте реализации предлагаемого способа, изображение получено посредством фотографирования.
В другом частном варианте реализации предлагаемого способа, выделение области документа на по меньшей мере одном изображении осуществляют с применением алгоритма поиска контура наибольшей площади или осуществляют выделение области посредством сегментации с помощью сверточной нейронной сети.
В другом частном варианте реализации предлагаемого способа, выделение области документа на изображении с применением алгоритма поиска контура наибольшей площади включает следующие этапы: сжатие размера полученного изображения документа до целевой высоты, зависящей от типа документа, преобразование многоканального изображения в одноканальное изображение, применение к преобразованному одноканальному изображению фильтра медианного размытия, выделение краев изображения, поиск контуров на изображении, выбор контура с наибольшей площадью, выделение ограничивающего прямоугольника для выбранного контура с наибольшей площадью и выравнивание области документа с помощью перспективной проекции с матрицей.
В другом частном варианте реализации предлагаемого способа, выделение области документа на изображении с применением сегментации с помощью сверточной нейронной сети включает следующие этапы: на вход обученной сверточной нейронной сети подают многоканальное изображение документа, на выходе получают бинарную маску размера входного изображения, где 1 - это область документа, 0 - это фон.
В другом частном варианте реализации предлагаемого способа, сверточная нейронная сеть обучается с помощью алгоритма стохастического градиентного спуска с минимизацией функции потерь.
В другом частном варианте реализации предлагаемого способа, под типом документа понимается документ, содержащий персональные данные.
В другом частном варианте реализации предлагаемого способа, документ, содержащий персональные данные, представляет собой: паспорт, СНИЛС, ИНН, страховой полис, водительское удостоверение, свидетельство о рождении, свидетельство о смерти, свидетельство о заключении брака, свидетельство о расторжении брака, документ об образовании, военный билет, трудовая книжка.
В другом частном варианте реализации предлагаемого способа, бинаризация выполняется путем анализа геометрических характеристик связанных компонент.
В другом частном варианте реализации предлагаемого способа, бинаризация выполняется на основе информации о цвете с применением цветовой модели HSV.
В другом частном варианте реализации предлагаемого способа, дополнительно, после этапа бинаризации, посредством модуля выравнивания, осуществляют выравнивание по меньшей мере одного изображения документа посредством распознавания линий текстовых строк.
В другом частном варианте реализации предлагаемого способа, распознавание линий, для осуществления выравнивания, осуществляют с применением алгоритма вероятностного преобразования Хафа.
В другом частном варианте реализации предлагаемого способа, для определения текстовых полей, путем определения координат ограничивающих прямоугольников полей, используют анализ гистограмм проекции профилей.
В другом частном варианте реализации предлагаемого способа, тип текстовых полей определяют на основе группировки по строкам, максимальной и минимальной ширины и высоты текстовых полей в шаблоне.
В другом частном варианте реализации предлагаемого способа, распознавание текста на выявленных текстовых полях осуществляется с помощью системы TesseractOCR.
ОПИСАНИЕ ЧЕРТЕЖЕЙ
Реализация изобретения будет описана в дальнейшем в соответствии с прилагаемыми чертежами, которые представлены для пояснения сути изобретения и никоим образом не ограничивают область изобретения. К заявке прилагаются следующие чертежи:
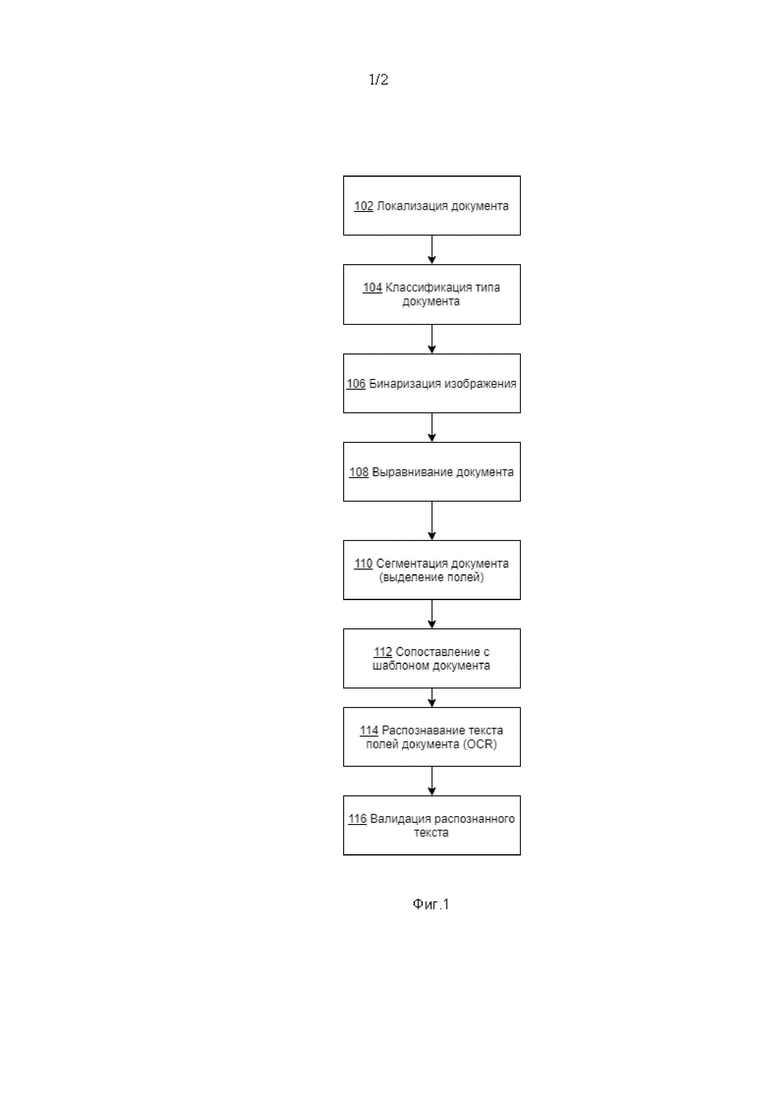
Фиг.1, иллюстрирует блок-схему работы предлагаемого компьютерно-реализуемого способа автоматического распознавания текста на по меньшей мере одном изображении документа.
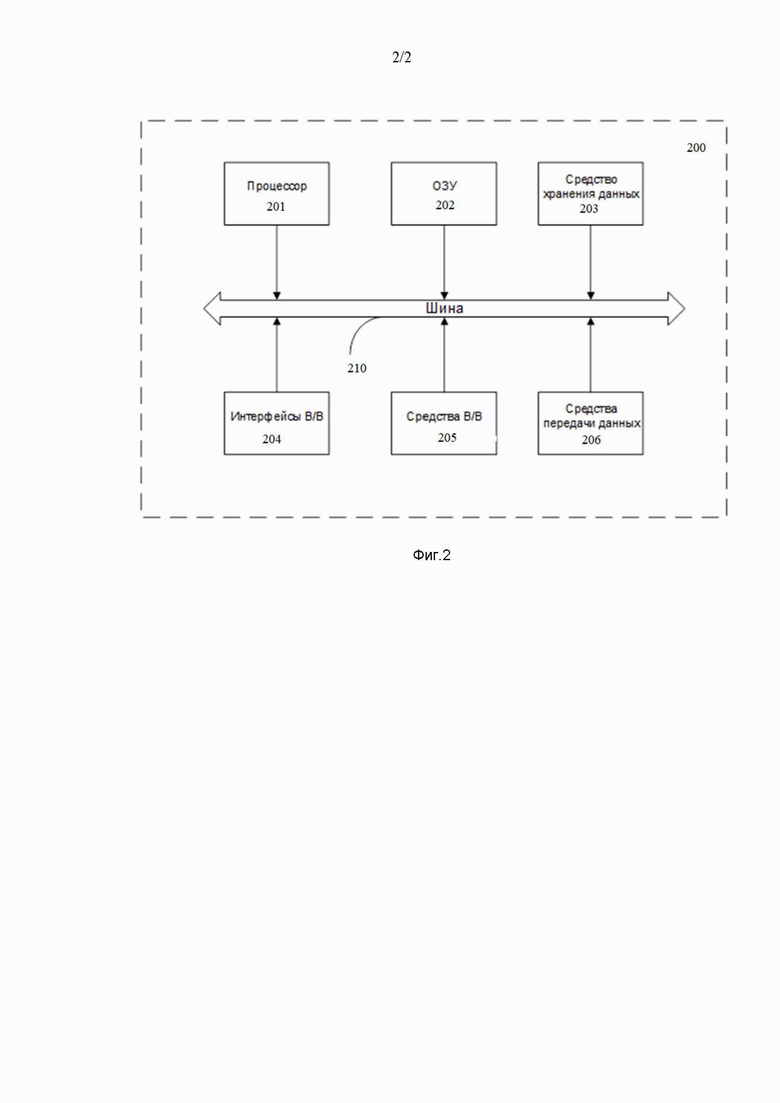
Фиг. 2, иллюстрирует пример схемы работы вычислительного устройства.
ДЕТАЛЬНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
В приведенном ниже подробном описании реализации изобретения приведены многочисленные детали реализации, призванные обеспечить отчетливое понимание настоящего изобретения. Однако, квалифицированному в предметной области специалисту, будет очевидно каким образом можно использовать настоящее изобретение, как с данными деталями реализации, так и без них. В других случаях хорошо известные методы, процедуры и компоненты не были описаны подробно, чтобы не затруднять излишне понимание особенностей настоящего изобретения.
Кроме того, из приведенного изложения будет ясно, что изобретение не ограничивается приведенной реализацией. Многочисленные возможные модификации, изменения, вариации и замены, сохраняющие суть и форму настоящего изобретения, будут очевидными для квалифицированных в предметной области специалистов.
Нижеуказанные термины и определения применяются в данной заявке, если иное явно не указано. Ссылки на методики, используемые при описании данного изобретения, относятся к хорошо известным методам, включая изменения этих методов и замену их эквивалентными методами, известными специалистам в данной области техники.
Под термином «тип документа» понимается вид документа, содержащий персональные данные. Тип документа может быть, но не ограничиваясь: паспорт (паспорт гражданина или заграничный паспорт), СНИЛС, ИНН, страховой полис, водительское удостоверение, свидетельство о рождении, свидетельство о смерти, свидетельство о заключении брака, свидетельство о расторжении брака, документ об образовании, военный билет, трудовая книжка.
На Фиг. 1 проиллюстрирована схема работы компьютерно-реализуемого способа автоматического распознавания текста на изображении документа.
На вычислительное устройство, посредством средств сетевого взаимодействия, получают изображение документа. Изображение документа может быть получено любым известным способом, например, посредством сканирования, фотографирования, а также может использоваться изображение созданного электронного документа.
На шаге 102, посредством модуля локализации документа, осуществляют выделение области документа на изображении с применением алгоритма поиска контура наибольшей площади или осуществляют выделение области посредством сегментации с помощью сверточной нейронной сети.
Выделение области документа на изображении с применением алгоритма поиска контура наибольшей площади включает следующие этапы.
1. Осуществляют масштабирование изображения, т.е. выполняют сжатие размера изображения до определенной целевой высоты, которая зависит от типа документа. Операция позволяет ускорить последующую обработку и исключить детали изображения, которые не требуются для локализации документа (например, фон).
2. Преобразовывают цветное RGB изображения документа в одноканальное изображение оттенков серого цвета.
3. Применяют фильтр медианного размытия для сглаживания деталей изображения документа таких как текст. Каждый пиксель изображения заменяется на медианное значение интенсивностей пикселей из окружающей области квадратной формы с размером равным характерной высоте текста документа на изображении.
4. Выделяют края с помощью алгоритма Кэнни, описанного в статье J. F. Canny, A computational approach to edge detection, IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 8, no. 6, pp.679-698, November 1986.
5. Осуществляют поиск контуров посредством способа, описанного в статье Satoshi Suzuki and others. Topological structural analysis of digitized binary images by border following. Computer Vision, Graphics, and Image Processing, 30(1):32-46, 1985.
6. Выбирают контур наибольшей площади, который принимается за границы документа на изображении.
7. Выделяют ограничивающий прямоугольник для выбранного контура максимальной площади.
8. Выравнивают область документа на изображении с помощью перспективной проекции с матрицей, которая определяется с применением алгоритма RANSAC к четырем точкам - углам выбранного прямоугольника.
В другом варианте реализации для выделения области документа на изображении применяется сегментация изображения с помощью сверточной нейронной сети U-Net, описанной в статье Ronneberger, Olaf; Fischer, Philipp; Brox, Thomas. U-Net: Convolutional Networks for Biomedical Image Segmentation. 2015.
На вход сверточной нейронной сети подают цветное сканированное или сфотографированное изображение, или изображение созданного электронного документа, на выходе получают бинарную маску размера входного изображения с элементами 1 для области документа и 0 для окружающего фона. Нейронная сеть обучается с помощью алгоритма стохастического градиентного спуска с минимизацией функции потерь на наборе размеченных примеров, которые представляют собой пары: вход - исходное изображение, выход - бинарная маска области документа.
На шаге 104, посредством модуля классификации типа документа, на основе выделенной области документа, на изображении документа осуществляют классификацию типа документа с применением сверточной нейронной сети ResNet описанной в статье Не et al. Deep Residual Learning for Image Recognition. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
На вход сверточной нейронной сети подают цветное или черно-белое изображение документа, на выходе получают вектор распределения вероятностей по возможным типам документов.
1. Полученное изображение преобразуют к размеру 224×224 пикселей.
2. Осуществляют нормализацию преобразованного изображения.
3. К нормализованному изображению применяется последовательность операций сверточной нейронной сети ResNet, а именно операции свертки, пулинг, softmax.
4. На выходе нейронной сети получают вектор распределения вероятностей по типам документов, например, [0.8, 0.1, 0.1].
5. В качестве результата принимается тип документа с наибольшей вероятностью. Наиболее вероятный тип документа определяется по индексу наибольшего элемента полученного ранее вектора, выраженного величиной сигнала на выходе нейронной сети. Модель нейронной сети содержит выходы для каждого типа документа, выбирается выход с наибольшим по значению сигналом. Сигналы вычисляются нейронной сетью на основе входного изображения посредством последовательности операций матричного умножения с параметрами, подобранными при обучении модели на наборе примеров, а также операций нелинейного преобразования (обнуление отрицательных значений) и пулинга (выбор максимального элемента из области). Для наглядности, выходные сигналы преобразуются в распределение вероятности (вектор положительных элементов такого же размера в сумме дающих значение 1) с помощью операции softmax.
Например, вектор распределения вероятностей представлен как [0.8, 0.1, 0.1]. Необходимо определить к какому типу документа относится данный вектор из трех возможных типов: паспорт, СНИЛС, ИНН, причем вектор относится к типу документа «паспорт», если первый элемент вектора имеет наибольшее значение [0.8, 0.1, 0.1], вектор относится к типу документа «СНИЛС», если второй элемент вектора имеет наибольшее значение [0.1, 0.8, 0.1], вектор относится к типу документа «ИНН», если третий элемент вектора имеет наибольшее значение [0.1, 0.1, 0.8]. Таким образом, нейронная сеть отнесет ранее полученный вектор распределения вероятностей [0.8, 0.1, 0.1] к типу документа «паспорт».
Параметры модели нейронной сети подбираются в процессе обучения по алгоритму стохастического градиентного спуска на наборе размеченных примеров. Примеры для обучения представляют собой пары: вход - изображение документа, выход - тип документа.
На этапе 106 посредством модуля бинаризации, осуществляют бинаризацию изображения определенного типа документа для отделения текста документа от фона. Значение каждого пикселя исходного изображения заменяется на 1, если пиксель относится к тексту поля документа, или 0 в противном случае.
В одном варианте реализации бинаризация выполняется на основе информации о цвете, что применимо для типов документов, в которых текст отличается от фона по цветовому признаку. Например, текст имеет черный цвет, а фон белый. В таком случае бинаризация может быть выполнена с использованием цветовой модели HSV, когда принимается что пиксели текста имеют значения в определенных, экспериментально подобранных путем анализа набора примеров, диапазонах каналов Hue и Value.
В другом варианте реализации бинаризация области изображения документа или отдельных подобластей изображения документа выполняется путем анализа геометрических характеристик связанных компонент по алгоритму:
1. Цветное изображение документа преобразуют в оттенки серого по формуле:
у=0.299⋅R+0.587⋅G+0.114⋅В
где R, G, В - интенсивности красного, зеленого и синего каналов соответственно,
у - получаемое в результате значение интенсивности пикселя в оттенках серого.
2. Выполняют бинаризацию изображения в оттенках серого с выбором порога по алгоритму Отцу, описанному в статье Nobuyuki Otsu. A threshold selection method from gray-level histograms. IEEE Trans. Sys. Man. Cyber. 9 (1): 62-66. doi:10.1109/TSMC. 1979.4310076, 1979. Для пикселей, интенсивность которых выше подобранного порогового значения, задается значение 1, для остальных - 0. В полученной бинарной маске выделены текстовые поля и отдельные, относительно яркие, элементы фона.
3. Выполняют склеивание отдельных символов текста с помощью морфологической операции замыкания, представляющей собой результат последовательного применения операций дилатации и эрозии с прямоугольным ядром размера W×1, где W - параметр наибольшего расстояния между символами в поле, который подбирается экспериментально на наборе примеров. В операции дилатации каждый пиксель заменяется на максимальное значение из окружающей области ядра, в операции эрозии - на минимальное значение.
4. Выделяют связанные компоненты - группы пикселей со значением 1, которые имеют среди окружающих 8-ми пикселей хотя бы один пиксель со значением 1. Для выделения связанных компонент применяется алгоритм, описанный в статье Kesheng Wu, Ekow Otoo, and Kenji Suzuki. Optimizing two-pass connected-component labeling algorithms. Pattern Analysis and Applications, 12(2): 117-135, Jun 2009. В результате получается маска изображения, где каждый пиксель имеет значение равное индексу компоненты, к которой он принадлежит.
5. Выбирают связанные компоненты с признаками, характерными для текстовых полей определенного типа документа. Например, в качестве критерия используется характерная высота текстового поля в документе. Например, при распознавании паспорта в качестве критерия отбора компонент, соответствующих распознаваемым текстовым полям, используется высота, поскольку текст полей имеет больший размер по сравнению с прочим текстом документа в рассматриваемых визуальных зонах. Пиксели компонент с высотой менее порогового значения относятся к фону (задается значение 0). Тем самым производится отделение текстовых полей от фона документа. Также могут быть использованы следующие геометрические характеристики: ширина, площадь, координаты центра, моменты инерции.
Дополнительно, на шаге 108, посредством модуля выравнивания, могут осуществлять выравнивание изображения документа посредством распознавания линий текстовых строк, если данное выравнивание не было осуществлено на этапе 102, по способу перспективной проекции.
В одном варианте реализации выравнивание производится по способу распознавания линий текстовых строк с применением алгоритма вероятностного преобразования Хафа, описанного в статье Jiri Matas, Charles Galambos, and Josef Kittler. Robust detection of lines using the progressive probabilistic hough transform. Computer Vision and Image Understanding, 78(1):119-137, 2000. Алгоритм выравнивания включает следующие шаги:
1. Цветное изображение преобразуют в оттенки серого.
2. Выполняют бинаризацию с выбором порога по алгоритму Отцу.
3. Применяют морфологическую операцию замыкания для склеивания символов текстовых полей.
4. Выделяют края с помощью алгоритма Кэнни.
5. Выполняют распознавание линий с помощью вероятностного преобразования Хафа.
6. Осуществляют кластеризацию линий по углу наклона к горизонтальной оси.
7. Угол с наибольшим числом представляющих его линий считается углом поворота документа.
8. Выравнивание документа осуществляется путем поворота на найденный угол.
На шаге 110 посредством модуля сегментации, осуществляют сегментацию изображения документа, с определенным типом документа на этапе классификации, для определения текстовых полей, путем определения координат ограничивающих прямоугольников полей. Сегментацию осуществляют с применением способа анализа гистограмм проекции профилей, который включает следующие шаги.
1. К бинарной маске текста полей применяют морфологическую операцию замыкания.
2. Строят гистограммы вертикальной проекции профилей: для каждой отметки по вертикальной оси подсчитывается количество пикселей со значением 1.
3. Посредством анализа выбросов на гистограмме вертикальной проекции профилей определяют вертикальные координаты границ строк текста на изображении документа. Значения на гистограмме сравниваются с экспериментально подобранным на наборе примеров порогом. Интервалы на гистограмме со значениями, превышающими порог считаются соответствующими строкам текста.
4. Для каждой выделенной на шаге 3 строки производят определение горизонтальных координат границ отдельных полей с помощью гистограммы горизонтальной проекции профилей (для каждой отметки по горизонтальной оси посчитывается количество пикселей со значением 1). Значения на гистограмме сравниваются с экспериментально подобранным порогом, значения, превышающие порог, считаются относящимися к полям документа.
5. Выполняют расширение найденных ограничивающих прямоугольников полей с некоторым экспериментально подобранным на наборе примеров масштабным коэффициентом.
На шаге 112 посредством модуля сопоставления, определяют тип найденных, на предыдущем этапе, текстовых полей с помощью структурных шаблонов документов.
Структурный шаблон документа представляет собой упорядоченный, по вертикальным координатам, список строк, где каждая строка состоит из упорядоченных, по горизонтальной координате, полей.
Например, паспорт, согласно структурному шаблону документа, содержит поля фамилии, имени, отчества в разных строках, пола и даты рождения в одной строке, 1-3 строки места рождения. Для полученной, посредством анализа гистограмм проекции профилей, структуры полей в виде разделения по строкам можно подобрать соответствие с типами полей в шаблоне.
Каждое поле в шаблоне характеризуется типом, максимальной и минимальной шириной и высотой. По способу автоматического перебора назначаются типы полей наилучшим образом соответствующие шаблону документа. Например, при распознавании зоны основной информации паспорта в результате сегментации получили 6 строк. В соответствии с шаблоном, строка 1 содержит тип поля «Фамилия», строка 2 - «Имя», строка 3 - «Отчество», строка 4 - поля «Пол» и «Дата рождения», строки 5, 6 - «Место рождения». Проверяется количество полей, сегментированных в строках, а также размеры полей на удовлетворение ограничений, заданных в шаблоне. В случае обнаружения несоответствий правилам шаблона, конкретная строка и относящиеся к ней поля считаются не распознанными. В описанном случае выполняется простой перебор строк шаблона.
На шаге 114 посредством модуля распознавания текста, осуществляют распознавание текста на выявленных текстовых полях с применением системы TesseractOCR, описанной в статье R. Smith An Overview of the Tesseract OCR Engine. Ninth International Conference on Document Analysis and Recognition (ICDAR 2007). 2007.
На шаге 116 посредством модуля валидации, осуществляют валидацию распознанного текста на выявленных текстовых полях по набору правил относительно данных, содержащихся в полях, и ожидаемых форматов представления этих данных.
Например, для поля «номер документа» проверяется, что все распознанные символы являются цифрами и количество символов равно количеству позиций номера в документе.
На Фиг. 2 далее будет представлена общая схема вычислительного устройства (200), обеспечивающего обработку данных, необходимую для реализации заявленного решения.
В общем случае устройство (200) содержит такие компоненты, как: один или более процессоров (201), по меньшей мере одну память (202), средство хранения данных (203), интерфейсы ввода/вывода (204), средство В/В (205), средства сетевого взаимодействия (206).
Процессор (201) устройства выполняет основные вычислительные операции, необходимые для функционирования устройства (200) или функциональности одного или более его компонентов. Процессор (201) исполняет необходимые машиночитаемые команды, содержащиеся в оперативной памяти (202).
Память (202), как правило, выполнена в виде ОЗУ и содержит необходимую программную логику, обеспечивающую требуемый функционал.
Средство хранения данных (203) может выполняться в виде HDD, SSD дисков, рейд массива, сетевого хранилища, флэш-памяти, оптических накопителей информации (CD, DVD, MD, Blue-Ray дисков) и т.п. Средство (203) позволяет выполнять долгосрочное хранение различного вида информации, например, вышеупомянутых файлов с наборами данных пользователей, базы данных, содержащих записи измеренных для каждого пользователя временных интервалов, идентификаторов пользователей и т.п.
Интерфейсы (204) представляют собой стандартные средства для подключения и работы с серверной частью, например, USB, RS232, RJ45, LPT, COM, HDMI, PS/2, Lightning, FireWire и т.п.
Выбор интерфейсов (204) зависит от конкретного исполнения устройства (200), которое может представлять собой персональный компьютер, мейнфрейм, серверный кластер, тонкий клиент, смартфон, ноутбук и т.п.
В качестве средств В/В данных (205) в любом воплощении системы, реализующей описываемый способ, может использоваться клавиатура. Аппаратное исполнение клавиатуры может быть любым известным: это может быть, как встроенная клавиатура, используемая на ноутбуке или нетбуке, так и обособленное устройство, подключенное к настольному компьютеру, серверу или иному компьютерному устройству. Подключение при этом может быть, как проводным, при котором соединительный кабель клавиатуры подключен к порту PS/2 или USB, расположенному на системном блоке настольного компьютера, так и беспроводным, при котором клавиатура осуществляет обмен данными по каналу беспроводной связи, например, радиоканалу, с базовой станцией, которая, в свою очередь, непосредственно подключена к системному блоку, например, к одному из USB-портов. Помимо клавиатуры, в составе средств В/В данных также может использоваться: джойстик, дисплей (сенсорный дисплей), проектор, тачпад, манипулятор мышь, трекбол, световое перо, динамики, микрофон и т.п.
Средства сетевого взаимодействия (206) выбираются из устройства, обеспечивающий сетевой прием и передачу данных, например, Ethernet карту, WLAN/Wi-Fi модуль, Bluetooth модуль, BLE модуль, NFC модуль, IrDa, RFID модуль, GSM модем и т.п. С помощью средств (205) обеспечивается организация обмена данными по проводному или беспроводному каналу передачи данных, например, WAN, PAN, ЛВС (LAN), Интранет, Интернет, WLAN, WMAN или GSM.
Компоненты устройства (200) сопряжены посредством общей шины передачи данных (210).
В настоящих материалах заявки было представлено предпочтительное раскрытие осуществление заявленного технического решения, которое не должно использоваться как ограничивающее иные, частные воплощения его реализации, которые не выходят за рамки испрашиваемого объема правовой охраны и являются очевидными для специалистов в соответствующей области техники.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ВЫЯВЛЕНИЯ ПОДДЕЛКИ ДОКУМЕНТОВ | 2023 |
|
RU2825085C1 |
| ОБНАРУЖЕНИЕ ТЕКСТОВЫХ ПОЛЕЙ С ИСПОЛЬЗОВАНИЕМ НЕЙРОННЫХ СЕТЕЙ | 2018 |
|
RU2699687C1 |
| СИСТЕМА РАСПОЗНАВАНИЯ ИЗОБРАЖЕНИЯ: BEORG SMART VISION | 2020 |
|
RU2777354C2 |
| РЕКОНСТРУКЦИЯ ДОКУМЕНТА ИЗ СЕРИИ ИЗОБРАЖЕНИЙ ДОКУМЕНТА | 2017 |
|
RU2659745C1 |
| ОБУЧЕНИЕ НЕЙРОННЫХ СЕТЕЙ ДЛЯ ОБРАБОТКИ ИЗОБРАЖЕНИЙ С ПОМОЩЬЮ СИНТЕТИЧЕСКИХ ФОТОРЕАЛИСТИЧНЫХ СОДЕРЖАЩИХ ЗНАКИ ИЗОБРАЖЕНИЙ | 2018 |
|
RU2709661C1 |
| ИЗВЛЕЧЕНИЕ НЕСКОЛЬКИХ ДОКУМЕНТОВ ИЗ ЕДИНОГО ИЗОБРАЖЕНИЯ | 2020 |
|
RU2764705C1 |
| РАСПОЗНАВАНИЕ РУКОПИСНОГО ТЕКСТА ПОСРЕДСТВОМ НЕЙРОННЫХ СЕТЕЙ | 2020 |
|
RU2757713C1 |
| СПОСОБ И СИСТЕМА ОБЕЗЛИЧИВАНИЯ ДОКУМЕНТОВ, СОДЕРЖАЩИХ ПЕРСОНАЛЬНЫЕ ДАННЫЕ | 2019 |
|
RU2793607C1 |
| ОПТИЧЕСКОЕ РАСПОЗНАВАНИЕ СИМВОЛОВ ПОСРЕДСТВОМ КОМБИНАЦИИ МОДЕЛЕЙ НЕЙРОННЫХ СЕТЕЙ | 2020 |
|
RU2768211C1 |
| Способ поиска машиночитаемой зоны документа на изображении с помощью ИНС, содержащей прямое и транспонированное преобразования Хафа | 2024 |
|
RU2833293C1 |
Изобретение относится к вычислительной технике. Технический результат заключается в повышении точности извлечения информации из изображений документов. Компьютерно-реализуемый способ автоматического распознавания текста на изображении документа, способ выполняется на вычислительном устройстве, содержащем процессор и память, хранящую инструкции, исполняемые процессором и содержащие этапы, на которых: получают изображение документа; осуществляют выделение области документа на изображении; на основе выделенной области документа на изображении осуществляют классификацию типа документа с применением сверточной нейронной сети; осуществляют бинаризацию изображения определенного типа документа для отделения текста документа от фона; осуществляют сегментацию изображения документа, с определенным типом документа, для определения текстовых полей, путем определения координат ограничивающих прямоугольников полей; определяют тип найденных текстовых полей с помощью структурных шаблонов документов; осуществляют распознавание текста на выявленных текстовых полях; осуществляют валидацию распознанного текста на выявленных текстовых полях по набору правил относительно данных, содержащихся в полях, и ожидаемых форматов представления этих данных. 15 з.п. ф-лы, 2 ил.
1. Компьютерно-реализуемый способ автоматического распознавания текста на изображении документа, способ выполняется на вычислительном устройстве, содержащем процессор и память, хранящую инструкции, исполняемые процессором и содержащие этапы, на которых:
на вычислительное устройство получают изображение документа;
посредством модуля локализации документа, осуществляют выделение области документа на изображении;
посредством модуля классификации типа документа, на основе выделенной области документа на изображении осуществляют классификацию типа документа с применением сверточной нейронной сети;
посредством модуля бинаризации, осуществляют бинаризацию изображения определенного типа документа для отделения текста документа от фона;
посредством модуля сегментации, осуществляют сегментацию изображения документа, с определенным типом документа на этапе классификации, для определения текстовых полей, путем определения координат ограничивающих прямоугольников полей;
посредством модуля сопоставления, определяют тип найденных, на предыдущем этапе, текстовых полей с помощью структурных шаблонов документов;
посредством модуля распознавания текста, осуществляют распознавание текста на выявленных текстовых полях;
посредством модуля валидации, осуществляют валидацию распознанного текста на выявленных текстовых полях по набору правил относительно данных, содержащихся в полях, и ожидаемых форматов представления этих данных.
2. Способ по п. 1, отличающийся тем, что изображение получено посредством сканирования.
3. Способ по п. 1, отличающийся тем, что изображение получено посредством фотографирования.
4. Способ по п. 1, отличающийся тем, что выделение области документа на изображении осуществляют с применением алгоритма поиска контура наибольшей площади или осуществляют выделение области посредством сегментации с помощью сверточной нейронной сети.
5. Способ по п. 4, отличающийся тем, что выделение области документа на изображении с применением алгоритма поиска контура наибольшей площади включает следующие этапы: сжатие размера полученного изображения документа до целевой высоты, зависящей от типа документа, преобразование многоканального изображения в одноканальное изображение, применение к преобразованному одноканальному изображению фильтра медианного размытия, выделение краев изображения, поиск контуров на изображении, выбор контура с наибольшей площадью, выделение ограничивающего прямоугольника для выбранного контура с наибольшей площадью и выравнивание области документа с помощью перспективной проекции с матрицей.
6. Способ по п. 4, отличающийся тем, что выделение области документа на изображении с применением сегментации с помощью сверточной нейронной сети включает следующие этапы: на вход обученной сверточной нейронной сети подают многоканальное изображение документа, на выходе получают бинарную маску размера входного изображения, где 1 - это область документа, 0 - это фон.
7. Способ по п. 6, отличающийся тем, что сверточная нейронная сеть обучается с помощью алгоритма стохастического градиентного спуска с минимизацией функции потерь.
8. Способ по п. 1, отличающийся тем, что под типом документа понимается документ, содержащий персональные данные.
9. Способ по п. 8, отличающийся тем, что документ, содержащий персональные данные, представляет собой: паспорт, СНИЛС, ИНН, страховой полис, водительское удостоверение, свидетельство о рождении, свидетельство о смерти, свидетельство о заключении брака, свидетельство о расторжении брака, документ об образовании, военный билет, трудовая книжка.
10. Способ по п. 1, отличающийся тем, что бинаризация выполняется путем анализа геометрических характеристик связанных компонент.
11. Способ по п. 1, отличающийся тем, что бинаризация выполняется на основе информации о цвете с применением цветовой модели HSV.
12. Способ по п. 1, отличающийся тем, что дополнительно, после этапа бинаризации, посредством модуля выравнивания, осуществляют выравнивание изображения документа посредством распознавания линий текстовых строк.
13. Способ по п. 12, отличающийся тем, что распознавание линий, для осуществления выравнивания, осуществляют с применением алгоритма вероятностного преобразования Хафа.
14. Способ по п. 1, отличающийся тем, что для определения текстовых полей, путем определения координат ограничивающих прямоугольников полей, используют анализ гистограмм проекции профилей.
15. Способ по п. 1, отличающийся тем, что тип текстовых полей определяют на основе группировки по строкам, максимальной и минимальной ширины и высоты текстовых полей в шаблоне.
16. Способ по п. 1, отличающийся тем, что распознавание текста на выявленных текстовых полях осуществляется с помощью системы TesseractOCR.

