Область техники, к которой относится изобретение
Настоящее изобретение относится к интернет-технологии, в частности к способу и системе формирования круга общения и устройству памяти.
Уровень техники
В связи с непрерывным развитием интернет-приложений, программ мгновенного обмена сообщениями и социальных сетей, играющих важную роль в обеспечении коммуникаций, которые широко используются пользователями в повседневной жизни и на работе. Посредством мгновенного обмена сообщениями и использования социальных сетей все больше и больше пользователей формируют цепочки коммуникаций путем обмена информацией и контактов, что приводит к созданию более широкого круга общения несколькими пользователями.
Каждый различный круг общения обычно формируется пользователями с похожими атрибутами, например наличием отношений между одноклассниками или коллегами, каждый круг общения имеет соответствующее имя, информационные теги и т.д., обозначающие информацию атрибута круга общения. В связи с тем что атрибуты участников круга общения часто отображаются в зависимости от сходства между отдельными пользователями, при возникновении изменений в информации атрибута, они должны быть отредактированы вручную, что не обеспечивает гибкость в использовании информации среди участников круга общения.
Сущность изобретения
В свете этого необходимо решить техническую задачу по предоставлению гибкости существующих способов, а также обеспечить способ формирования круга общения, который может осуществлять динамическое отображение информации круга общения.
Более того, необходимо также обеспечить систему для обработки информации в круге общения, которая может осуществлять динамическое отображение информации круга общения.
Кроме того, необходимо также обеспечить компьютерный носитель информации, который может осуществлять динамическое отображение информации круга общения.
Способ формирования круга общения включает в себя: получение информации подгрупп в пределах круга общения; извлечение атрибутов подгруппы из подгрупп, совместно используемых участниками круга общения; получение по меньшей мере одного результата распознавания посредством анализа атрибутов подгруппы, совместно используемых участниками круга общения; и отображение по меньшей мере одного результата распознавания для круга общения.
Система формирования круга общения включает в себя: модуль получения подгруппы, выполненный с возможностью получать подгруппы в пределах круга общения; модуль извлечения, выполненный с возможностью извлекать атрибуты группы из подгрупп, совместно используемые участниками круга общения; и модуль отображения, выполненный с возможностью получать по меньшей мере один результат распознавания на основе анализа атрибутов подгрупп, совместно используемых участниками круга общения, и сопоставить по меньшей мере один результат распознавания для круга общения.
Компьютерный носитель информации для хранения исполняемых компьютером команд, для выполнения способа формирования кругов общения, при этом способ содержит: получение подгрупп в пределах круга общения; извлечение атрибутов подгруппы из подгрупп, совместно используемых участниками круга общения; получение по меньшей мере одного результата распознавания посредством анализа атрибутов подгруппы, совместно используемых участниками круга общения; и отображение по меньшей мере одного результата распознавания для круга общения.
В соответствии с вышеупомянутым способом, системой и компьютерным носителем информации для формирования кругов общения извлекаются атрибуты, совместно используемые участниками круга общения, множества подгрупп, и затем результат распознавания атрибута получают из атрибутов подгруппы, совместно используемых участниками круга общения. И результат распознавания атрибута может быть сопоставлен с кругом общения. Таким образом, может быть реализовано динамическое сопоставление круга общения, тем самым обеспечивая способность адаптироваться кругу общения к динамическим изменениям во всех видах информации атрибутов участников круга общения, тем самым увеличивая гибкость при использовании.
Краткое описание чертежей
Фиг. 1 представляет собой блок-схему алгоритма, иллюстрирующую способ формирования круга общения в соответствии с вариантом осуществления настоящего изобретения;
фиг. 2 представляет собой блок-схему алгоритма, иллюстрирующую способ получения результата распознавания атрибута путем анализа атрибутов подгрупп, совместно используемых участниками круга общения, и отображение результата распознавания на круг общения в соответствии с вариантом осуществления настоящего изобретения;
фиг. 3 показывает результат распознавания атрибута, а также соответствующее весовое значение сопоставления, определяемое посредством сегментации слова атрибутов подгруппы, как показано на фиг. 2;
фиг. 4 показывает схему, иллюстрирующую блок-схему алгоритма способа получения результата распознавания атрибута посредством анализа атрибутов подгрупп, совместно используемых участниками круга общения, и отображение результатов распознавания на круг общения, согласно другому варианту осуществления настоящего изобретения;
фиг. 5 показывает блок-схему алгоритма способа, с помощью которого извлекается результат распознавания атрибута на основании сопоставления весовых значений и результата распознавания атрибута, и затем отображается на круг общения в соответствии с вариантом осуществления настоящего изобретения;
фиг. 6 показывает структурную схему системы формирования круга общения в соответствии с вариантом осуществления настоящего изобретения;
фиг. 7 показывает структурную схему модуля отображения в соответствии с вариантом осуществления настоящего изобретения; и
фиг. 8 изображает структурную схему блока распознавания в соответствии с вариантом осуществления настоящего изобретения.
Детальное описание
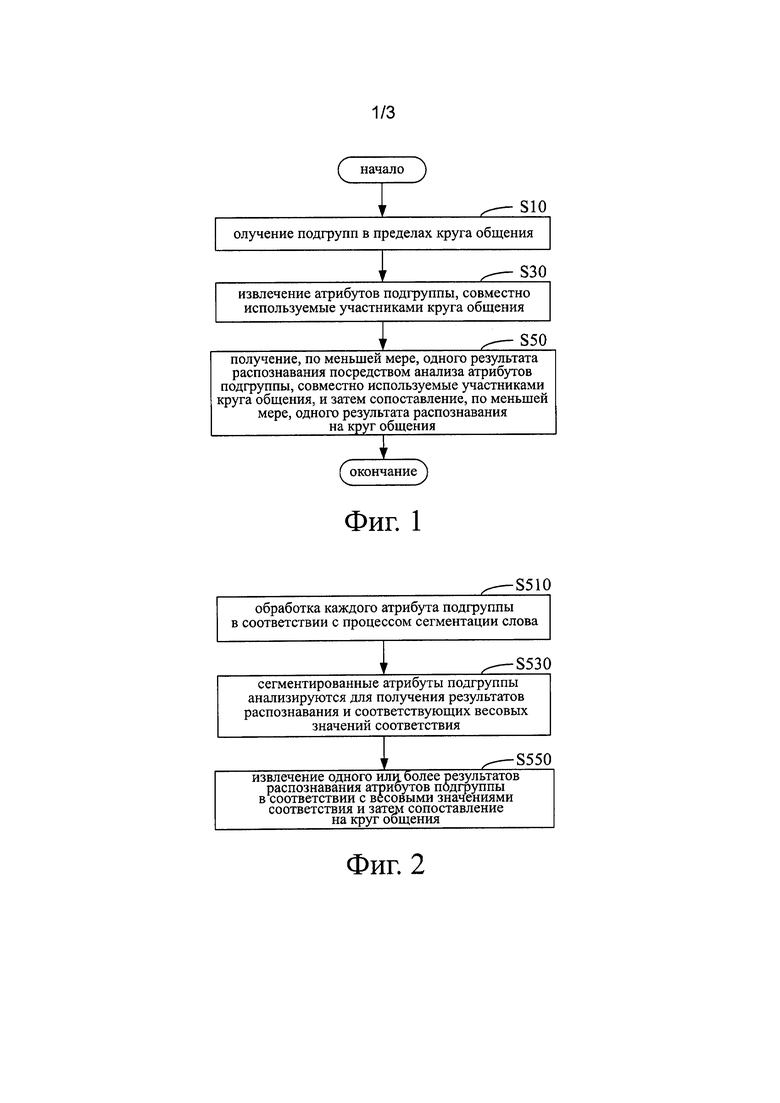
Как показано на фиг. 1, способ формирования круга общения в соответствии с вариантом осуществления настоящего изобретения включает в себя следующие этапы:
На этапе S10 получают подгруппы в пределах круга общения.
В этом варианте осуществления подгруппа состоит из конкретной категории пользователей. В предпочтительном варианте осуществления подгруппа может иметь форму цепочки обмена информацией. Например, круг общения может содержать группу пользователей, которые являются одноклассниками. Круг общения может также содержать группу пользователей, которые являются коллегами по работе. Участники круга общения могут образовывать любое количество цепочек для обмена информацией, например, круг общения может охватывать многих участников круга общения, например, как в случае наличия отношений между участником A и участником B, и отношений между участником B и участником C, что позволяет создать цепочку для обмена информацией, состоящую из отношений между участниками A и B и участниками B и C. Цепочка обмена информацией в пределах круга общения включает в себя цепочку обмена информацией, которая формируется из контактов службы мгновенных сообщений, а также цепочек обмена информацией, полученных из социальных веб-сайтов.
На этапе S30 извлекаются атрибуты подгруппы, которые совместно используются участниками круга общения.
В этом варианте осуществления, атрибуты подгруппы извлекаются из подгрупп. Указанные атрибуты подгруппы включают в себя имена и информацию о классификации подгрупп и т.д. Например, в цепочке обмена информацией между участником A и участником C мгновенное сообщение, посланное участником C, будет аффилировано с участником A атрибута подгруппы, обозначая их как одноклассников, в то время как мгновенное сообщение участника A участнику C будет аффилировано с подгруппой, которая идентифицирована как одноклассники колледжа. В цепочке обмена информацией, существующей между участником B и участником C, информация участника C в социальной сети будет аффилирована с участником B в подгруппе одноклассников колледжа. В социальной сети участника B участник C будет аффилирован с подгруппой студентов университета. В это время многие атрибуты подгруппы будут извлечены из подгрупп, охарактеризованных как «одноклассники», «одноклассники колледжа» и «студенты университета».
В другом варианте осуществления, существует высокая вероятность извлечения множества атрибутов подгруппы из существующих подгрупп круга общения. Для дальнейшего облегчения выполнения процедур атрибуты подгруппы и идентификация круга общения, а также идентификация пользователей могут быть коррелированы между собой. А именно, многие атрибуты подгруппы, извлеченные из различных подгрупп, идентификация круга общения и идентификация пользователя в круге общения имеют отображение отношений многие к одному между ними. Идентификация пользователя в круге общения осуществляется посредством отображения иконок.
На этапе S50, по меньшей мере, получается один результат распознавания, полученный посредством выполнения анализа атрибутов подгруппы, которые совместно используются участниками круга общения, и затем по меньшей мере один результат распознавания соотносится к кругу общения.
В этом варианте осуществления, атрибуты подгруппы, которые совместно используются участниками круга общения, представляют все вышеупомянутые общие атрибуты между участниками. Атрибуты круга общения могут быть проанализированы на основании атрибутов подгруппы и затем сопоставлены к кругу общения, таким образом устанавливая реляционное соотношение между результатом распознавания атрибута и кругом общения, добавляя соответствующее название, информацию об атрибутах и т.д. к информации круга общения. Посредством указанного выше способа может быть реализовано динамическое отображение информации круга общения, что позволяет адаптировать название и атрибут круга общения к динамическим изменениям информации об участниках, тем самым увеличивая гибкость при использовании.
Как показано на фиг. 2, в одном варианте осуществления конкретный процесс указанного выше этапа S50 включает в себя следующее.
На этапе S510, каждый атрибут подгруппы обрабатывается в соответствии с процессом сегментации слова.
Например, в этом варианте осуществления, посредством различных операций сегментации слова атрибутов подгруппы, соответствующие ключевые слова будут получены для каждой подгруппы. Например, атрибут «однокурсники университета» подгруппы содержит ключевые слова как "университет", так и "однокурсники". При выполнении процесса сегментации слова для атрибутов подгруппы, выполнение процедуры распознавания атрибутов подгруппы будет способствовать достижению более высокого уровня точности.
На этапе S530, сегментированные атрибуты подгруппы анализируются для получения результатов распознавания и соответствующих весовых значений сопоставления.
В этом варианте осуществления, множество ключевых слов, полученных с помощью сегментации слова атрибутов подгруппы, фильтруются для определения результатов распознавания круга общения и соответствующих весовых значений сопоставления. Вышеупомянутое весовое значение сопоставления используется для указания степени соответствия между результатом распознавания и соответствующим атрибутом подгруппы.
В одном варианте осуществления, конкретный процесс, выполняемый на указанном выше этапе S530, может включать в себя: дифференциации ключевых слов атрибутов подгруппы с помощью модели классификации и получение результатов распознавания атрибутов подгруппы, а также весовых значений сопоставления между результатами распознавания и атрибутами подгруппы.
В настоящем варианте осуществления, используется готовая модель классификации в качестве классификатора для различения атрибутов подгруппы, модель классификации служит для отличия общих характеристик и затем для получения результатов распознавания на основании вышеуказанных характеристик. Вышеупомянутая модель классификации выполнена с возможностью использовать различные типы априорной информации. Вышеупомянутая априорная информация включает в себя информацию об одноклассниках, коллегах, членах семьи и т.д. Соответствующие диагностические свойства модели классификации устанавливаются на основании различных типов предварительной информации. Модель классификации состоит из основных входных переменных и выходных переменных, среди которых входные переменные включают в себя атрибуты подгруппы, а также соответствующую идентификацию круга общения и индикаторы пользователей. Выходные переменные включают в себя результаты распознавания, весовые значения соответствия и соответствующую идентификацию круга общения и идентификацию пользователей.
Как видно на фиг. 3, в другом варианте осуществления, конкретный процесс, выполняемый на вышеупомянутом этапе S530, включает в себя следующее.
На этапе S531 вычисляется частота появления каждого из атрибутов подгруппы, а также количество участников, используя каждый из атрибутов подгруппы.
В этом варианте осуществления, в дополнение к модели классификации, которая реализует способ дифференциации за счет использования априорной информации, поскольку модель классификации имеет ограниченные возможности для определения результатов распознавания атрибутов, результаты распознавания могут быть определены с помощью логики агрегирования. Эти два способа также могут быть выполнены одновременно. Кроме того, поскольку логика агрегирования способна дифференцировать сравнительно широкий диапазон характеристик подгруппы, то можно непосредственно проводить анализ с помощью логики агрегирования, а не с помощью модели классификации.
В частности, для каждого атрибута подгруппы рассчитывается частота появления атрибута подгруппы, а также количество участников, используя атрибут подгруппы. Например, извлеченные атрибуты подгруппы круга общения включают в себя коллег, ТС, ТХ и т.д. с расчетной частотой появления всех атрибутов подгруппы в 200 раз, при этом количество участников, использующих все атрибуты подгруппы, равно 30. Среди этих вычисленных результатов частота появления «коллег» составляет 160 раз и 20 участников использовали атрибут подгруппы коллег; частота появления «ТС» равна 20 раз с двумя участниками, используя атрибут подгруппы ТС; и частота появления "ТХ" равна 2 раза с 8 участниками, используя атрибут подгруппу ТХ.
На этапе S533, на основании частоты появления атрибута группы и количества участников с помощью атрибута группы выполняется взвешенное агрегирование для получения информации о степени взвешенной агрегации атрибута подгруппы.
В этом варианте осуществления посредством использования взвешенного значения агрегации многочисленных данных в соответствии с атрибутами многих подгрупп круга общения могут быть получены атрибуты круга общения с вышеупомянутым атрибутом, указывающим отношения между участниками круга общения, а именно: их атрибуты отношений.
Во время выполнения процесса взвешивания значения агрегации вычисляется соответствующая степень взвешенного значения агрегации каждого атрибута подгруппы на основании частоты появления атрибута подгруппы, а также количество участников, используя атрибут подгруппы. Вышеупомянутая степень взвешенного значения агрегации атрибута подгруппы используется для показа, как часто атрибут подгруппы используется участниками круга общения. Например, в отношении атрибута подгрупп "коллеги" степень взвешенного значения агрегации равна a*(160/200)+b*(20/30), в котором a и b являются параметрами, полученными с помощью регрессионного анализа.
На этапе S535 один или более атрибутов подгруппы с их степенями взвешенного значения агрегации, превышающие пороговое значение, извлекаются как результаты распознавания атрибутов подгруппы. Извлеченная степень взвешенного значения агрегации атрибута подгруппы является соответствующим извлеченным весовым значением соответствия атрибута подгруппы.
В этом варианте осуществления, один или более атрибутов подгруппы с их степенями взвешенного значения агрегации, превышающие пороговое значение, извлекаются как результаты распознавания атрибутов подгруппы после вычисления степени взвешенного значения агрегации для каждого соответствующего атрибута подгруппы.
Как показано на фиг. 4, в другом варианте осуществления способ включает в себя следующие этапы до выполнения операции на указанном выше этапе S530.
На этапе S501 ключевые слова атрибутов подгруппы, полученные с помощью процесса сегментации слова, фильтруются один за другим с использованием базы данных шума.
В этом варианте осуществления, в извлеченных атрибутах подгрупп из подгрупп, где существует определенное количество шума. Вышеупомянутый шум включает в себя ненормативную лексику, строки, состоящие из простых символов, и отдельные символы с неопределенным значением. Необходимо проводить фильтрацию атрибутов подгрупп и устранить такой шум для получения отчетливых атрибутов подгруппы. Во-первых, для того чтобы получить точные атрибуты подгруппы, отдельные символы и символы будут исключены из атрибутов подгруппы. Отдельные символы и символы с неопределенным значением, неясные слова и ненормативная лексика сохранены в базе данных шума заранее. В этом способе, величина, характеризующая наличие шума, будет сравниваться с базой данных шума и исключена из атрибутов подгруппы.
На этапе S503 выполняется фильтрация неясных атрибутов из атрибутов подгруппы с помощью описанного выше процесса фильтрации.
В этом варианте осуществления будет использоваться предварительно установленная модель определения соответствия наличия неясных атрибутов, чтобы отфильтровать строки символов с неопределенным значением из атрибутов подгруппы. Могут быть выполнены процессы как фильтрации неясных атрибутов, так и фильтрации четких атрибутов в зависимости от необходимости, или может быть выполнена фильтрация либо неясных атрибутов, либо четких атрибутов. При реализации обоих процессов фильтрации неясных и четких атрибутов может быть выполнена фильтрация только четких атрибутов с целью повышения эффективности.
На этапе S550 один или несколько результатов распознавания атрибутов подгруппы извлекаются в соответствии с весовыми значениями соответствия и затем отображаются на круге общения.
В этом варианте осуществления один или несколько результатов распознавания атрибутов подгруппы извлекаются на основании величины весового значения соответствия. Таким образом, процесс извлечения результатов распознавания приводит к отображению соотношения между кругом общения и результатами распознавания.
Кроме того, информация, касающаяся деятельности в подгруппе, также может быть получена. Информация, касающаяся деятельности, также может способствовать получению точных результатов распознавания. В отношении деятельности упомянутая выше информация может состоять из степени активности, времени деятельности и т.д. Например, результаты распознавания могут включать в себя атрибуты подгруппы «одноклассники» и «коллеги», которые являются атрибутами подгруппы с наибольшими взвешенными значениями соответствия. И если время деятельности подгруппы является временем работы, то подгруппа «коллеги» будет извлечена в результате распознавания и затем будет отображаться на круге общения.
Как показано на фиг. 5, в одном варианте осуществления конкретный процесс, выполняемый на этапе S550, включает в себя следующее.
На этапе S551 осуществляется извлечение по меньшей мере одного атрибута подгруппы с наибольшим весовым значением соответствия как результат распознавания.
На этапе S553 выполняется сопоставление результата распознавания на круг общения как метка атрибута и/или наименование круга общения.
В этом варианте осуществления метка атрибута и/или наименование, полученное на основании результата распознавания, добавляется к информации круга общения и отображается пользователям. Таким образом, пользователи могут точно определить типы и атрибуты отношений участников круга общения.
Настоящее изобретение также предлагает компьютерный носитель информации, который может хранить исполняемые компьютером команды. Указанные исполняемые компьютером команды служат для выполнения вышеупомянутого способа формирования круга общения. Точный способ, с помощью которого команды, исполняемые компьютером, хранящиеся на компьютерном носителе информации, такой как выполнение способа формирования круга общения, не будет рассматриваться далее.
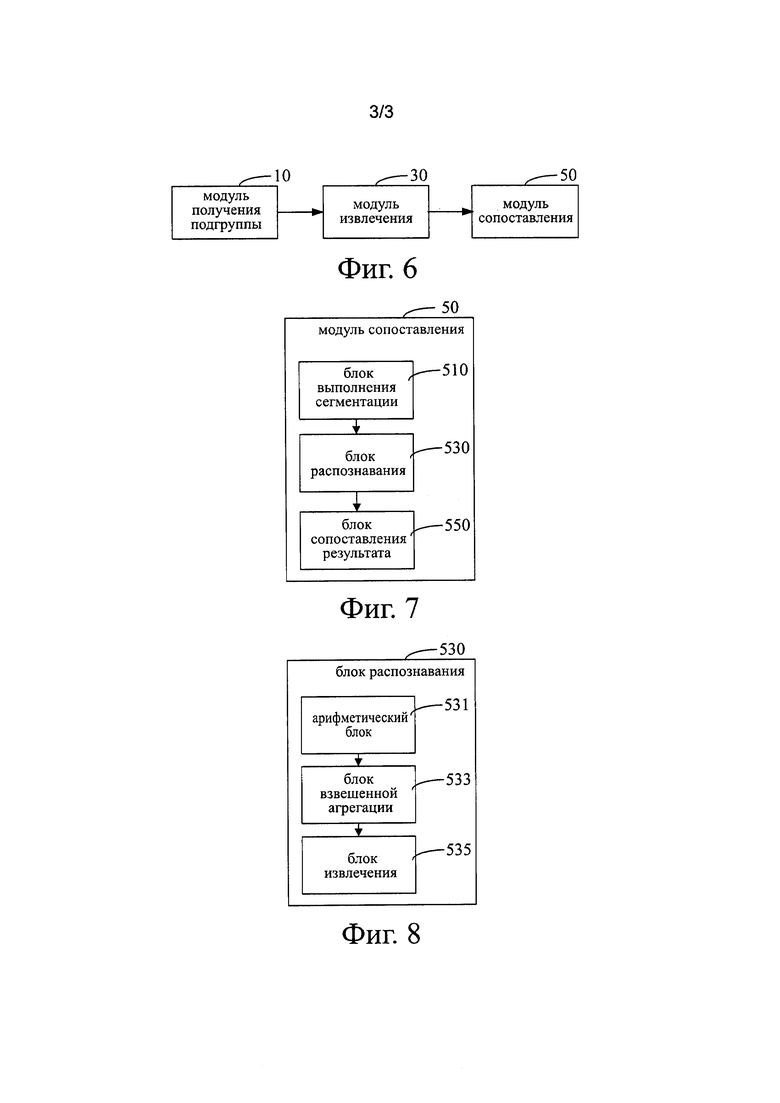
На фиг. 6 представлена система формирования круга общения, которая включает в себя модуль 10 получения подгруппы, модуль 30 извлечения и модуль 50 отображения.
Модуль 10 получения подгруппы служит для получения подгруппы внутри круга общения.
В этом варианте осуществления, подгруппа состоит из определенного типа пользователей. В предпочтительном варианте осуществления, подгруппа может быть образована виде цепочки отношений, например, круг общения может состоять из группы участников, являющихся одноклассниками, или группы участников, являющихся коллегами по работе. Определенное количество цепочек отношений существует между участниками круга общения. Например, среди многих участников круга общения участник A и участник B являются друзьями, и участники B и C дружат между собой и находятся в круге общения, таким образом, который включает в себя, по меньшей мере, цепочки отношений между участниками A и B и участниками B и C. Цепочка отношений в пределах круга общения включает в себя цепочку, которая использует службу передачи мгновенных сообщений, а также цепочки обмена информацией в социальных сетях.
Модуль 30 извлечения служит для извлечения атрибутов подгруппы, которые совместно используются участниками круга общения.
В этом варианте осуществления модуль 30 извлечения осуществляет извлечение атрибутов подгруппы, которые включают в себя имена и информацию классификации подгрупп и т.д. Например, в цепочке отношений между участниками A и C участник C аффилирован с атрибутом подгруппы "одноклассники" в сообщении участника A и участник A аффилирован атрибутом подгруппы "университетского однокурсника". В цепочке отношений между участниками B и C участник B аффилирован с атрибутом подгруппы "университетские однокурсники» в социальной сети участника C и с атрибутом участника B в социальной сети, участник C аффилирован с атрибутом подгруппы "университет".
В другом варианте осуществления, существует высокая вероятность наличия многих извлеченных атрибутов подгруппы из существующих подгрупп, в пределах круга общения посредством модуля 30 извлечения. Для дальнейшего облегчения выполнения процедур определения принадлежности атрибутов подгрупп будет выполняться идентификация круга общения и идентификации пользователей круга общения, а именно из существующих многие-ко-одному отношений между многими атрибутами подгруппы, идентификация круга общения и идентификация пользователей круга общения, извлеченных из различных подгрупп. Идентификация пользователя в круге общения осуществляется посредством отображения иконки.
Модуль 50 отображения используется для получения по меньшей мере одного результата распознавания с помощью анализа атрибутов подгруппы, совместно используемых участниками круга общения, и затем для отображения по меньшей мере одного результата распознавания на круг общения.
В этом варианте осуществления, атрибуты подгруппы, совместно используемые участниками круга общения, обозначены всеми вышеупомянутыми общими атрибутами между участниками. Соответственно, атрибуты круга общения могут быть проанализированы на основании атрибутов подгруппы, а затем отображены на круге общения модулем 50 отображения, тем самым создавая реляционное сопоставление результата распознавания атрибута и круга общения, и выполнено добавление соответствующего имени, информации об атрибутах и т.д. к информации о круге общения. Посредством указанного выше способа может быть реализовано динамическое отображение круга общения, что адаптирует наименование и атрибут круга общения к динамическим изменениям участников, тем самым увеличивая гибкость при использовании.
Как показано на фиг. 7, в одном варианте осуществления вышеупомянутый модуль 50 отображения включает в себя блок 510 обработки сегментации, блок 530 распознавания и блок 550 сопоставления результата.
Блок 510 обработки сегментации выполнен с возможностью осуществлять процесс сегментации атрибутов подгруппы.
В этом варианте осуществления, посредством различных операций сегментации слова, модуль 50 выполнения сегментации слова выполняет процесс сегментации слова каждого атрибута подгруппы соответственно, чтобы получить соответствующие ключевые слова. Например, атрибут подгруппы "университет однокурсники» содержит два ключевых слова "университет" и "однокурсники". Процесс сегментации слова атрибутов подгруппы позволяет повысить точность распознавания атрибут подгруппы.
Модуль 530 распознавания используется для получения одного или более результатов распознавания, а также весовых значений соответствия путем анализа ключевых слов атрибутов подгруппы, полученные с помощью процесса сегментации слова.
В этом варианте осуществления множество ключевых слов получены с помощью сегментации слова. Модуль 530 распознавания служит для фильтрации много ключевых слов и получения одного или нескольких результатов распознавания и весовых значений соответствия. Вышеупомянутое весовое значение используется для указания степени соответствия между результатом распознавания и соответствующим атрибутом подгруппы.
В одном варианте осуществления, модуль 530 распознавания также используется для различения атрибутов подгруппы с помощью модели классификации и получения одного или нескольких результатов распознавания атрибутов подгруппы, а также весовых значений соответствия между результатами распознавания и атрибутами подгруппы.
В этом варианте осуществления модуль 530 распознавания предварительно устанавливает модуль классификации, чтобы служить в качестве классификатора для различения атрибутов подгруппы, с помощью модели классификации, предназначенной для отличия общих характеристик, получают результаты распознавания, основанные на вышеуказанных характеристиках. Вышеупомянутая модель классификации построена на основе использования различных типов априорной информации. Вышеупомянутая априорная информация включает в себя информацию об одноклассниках, коллегах, членах семьи и т.д. Соответствующие диагностические свойства модели классификации устанавливаются на основании различных типов предварительной информации. Модель классификации состоит из основных входных переменных и выходных переменных, среди которых входные переменные включают в себя атрибуты подгруппы, а также соответствующую идентификацию круга общения и индикации пользователей. Выходные переменные включают в себя результаты распознавания, весовые значения соответствия и соответствующую идентификацию круга общения и идентификации пользователей.
Как показано на фиг. 8, в другом варианте осуществления, вышеупомянутый модуль 530 распознавания включает в себя арифметический блок 531, блок 533 взвешенной агрегации и блок 535 извлечения.
Арифметический блок 531 используется для вычисления частоты появления каждого из атрибутов подгруппы, а также количество участников с использованием каждого из атрибутов подгруппы.
В этом варианте осуществления, в дополнение к модели классификации, которая выполняет способ дифференциации за счет использования априорной информации, в связи с тем, что модель классификация имеет ограниченные возможности для определения результатов распознавания атрибутов, результаты распознавания могут быть определены с помощью логики агрегации. Эти два способа могут выполняться одновременно. Кроме того, в связи с тем, что возможности логики агрегации значительно расширены, то распознавание может осуществляться непосредственно через логику агрегации, без использования модели классификации.
В частности, арифметический блок 531 вычисляет частоту появления каждого отдельного атрибута подгруппы, а также количество участников, используя вышеупомянутый атрибут подгруппы. Например, извлекаемые атрибуты подгруппы круга общения могут включать в себя коллег, ТС, ТХ и т.д. Арифметический блок 531 вычисляет частоту появления всех атрибутов подгруппы, при появлении в общей сложности 200 раз, которые относятся ко всем атрибутам подгруппы 30 участников круга общения. Среди них, 160 появлений представляют собой «коллеги» с 20 участниками, использующие этот атрибут подгруппы; 20 представляют "ТС", атрибут подгруппы, используемый 2 участниками; и 20 представляют "ТХ", атрибут подгруппы, используемый 8 участниками.
В этом варианте осуществления блок 533 взвешенной агрегации осуществляет процесс взвешенной агрегации наибольшего количества данных, собранных в соответствии со многими атрибутами подгруппы в пределах круга общения с тем, чтобы проанализировать все атрибуты подгруппы, обработанные в круге общения, как упоминалось выше, таким образом, указывая атрибуты подгруппы, которые совместно используются участниками круга общения, а именно их атрибуты отношений.
На основании частоты появления атрибута подгруппы и количества участников с использованием рассчитанного атрибута подгруппы, блок 533 взвешенной агрегации определяет соответствующий уровень взвешенного значения агрегации каждого атрибута подгруппы. Вышеупомянутая степень взвешенного значения агрегации используется для указания частоты использования атрибута группы участниками круга общения. Например, в отношении атрибута подгруппы "коллеги" степень взвешенного значения агрегации равна a*(160/200)+b*(20/30), среди которых a и b являются параметрами, полученными с помощью регрессионного анализа.
Блок 535 извлечения используется для извлечения одного или более атрибутов подгруппы с их степенями взвешенного значения агрегации, превышающего пороговое значение, в качестве результатов распознавания атрибута, а также для извлечения степени агрегации взвешенного атрибута подгруппы, извлеченного в качестве соответствующего весового значения совпадения.
В этом варианте осуществления блок 535 извлечения извлекает один или более атрибутов подгруппы с их степенями взвешенного значения агрегации, превышающего заданное пороговое значение, как результаты распознавания атрибута после вычисления соответствующей степени взвешенного значения агрегации каждого атрибута подгруппы.
В другом варианте осуществления вышеупомянутый модуль 50 отображения также включает в себя фильтр. Вышеупомянутый фильтр используется для фильтрации символов в атрибутах подгрупп, полученных с помощью сегментации по отдельности на основе базы данных шума, и выполняет фильтрацию неясных атрибутов подгруппы, полученные в процессе фильтрации.
В этом варианте осуществления есть определенное количество шума, который существует в атрибутах подгрупп, выделенных из подгрупп. Вышеупомянутый шум включает в себя ненормативную лексику, строки простых символов и простые символы без четкого смысла и т.д. Необходимо выполнить фильтрацию шумов в атрибутах подгруппы для устранения шума и создания атрибутов простых атрибутов подгруппы. Фильтр сначала выполняет точную фильтрацию атрибутов подгруппы и устраняет одиночные символы. Словарь, состоящий из отдельных знаков, символов без четко выраженного значения и ненормативной лексики, сохранен в базе данных шума заранее. Шум в атрибутах подгруппы будет устранен путем сравнения с базой данных шума.
Модель поиска соответствия неясных символов будет предварительно установлена в базы данных шума для выполнения фильтрации и устранения строк слов без четко выраженного значения в атрибутах подгруппы. Точная фильтрация и нечеткая фильтрация могут одновременно выполняться в зависимости от необходимости выполнения только нечеткой фильтрации или только четкой фильтрации. Если необходимо выполнить как нечеткую, так и точную фильтрацию, нечеткая фильтрация должна происходить после выполнения точной фильтрации с целью повышения эффективности процесса.
Блок 550 сопоставления результата используется для извлечения одного или нескольких результатов распознавания в соответствии с весовыми значениями соответствия и для сопоставления извлеченного одного или нескольких результатов распознавания с кругом общения.
В этом варианте осуществления, блок 550 сопоставления результата извлекает один или несколько результатов распознавания атрибутов подгруппы на основании величины весового значения соответствия, и затем в соответствии с извлеченными результатами распознавания инициирует отображение между кругом общения и одним или более результатами распознавания.
В другом варианте осуществления, блок 550 сопоставления результата также используется для извлечения одного или более атрибута подгруппы с наибольшим значением весовой величины сопоставления и затем сопоставляет результаты распознавания одного или более результатов распознавания к кругу общения как атрибут отметок и/или наименования круга общения.
В этом варианте осуществления блок 550 сопоставления результата служит для добавления атрибута маркировки и/или наименований в информацию круга общения, соответственно, в то же время для отображения их пользователю, тем самым однозначно информируя пользователя обо всех вышеупомянутых соответствующих категориях и атрибутах отношений участников круга общения.
Специалистам в данной области техники понятно, что выполнением всего или части процесса в вышеупомянутом варианте осуществления и посредством использования компьютерной программы, можно обеспечить управление соответствующим аппаратным обеспечением для выполнения поставленной задачи. Упомянутая компьютерная программа может быть считана с машиночитаемого носителя данных. Такая программа может включать в себя вышеупомянутый вариант осуществления способа компьютерной программы. Среди которых упомянутый компьютерный носитель информации может представлять собой дискету, компакт-диск, постоянное запоминающее устройство (ROM) или память с произвольной выборкой (RAM) и т.д.
Вышеупомянутый способ и система, компьютерный носитель информации для формирования круга общения, а также процесс, при котором многочисленные совместно используемые участниками атрибуты извлекаются из общих подгрупп участников, и затем из которых результаты распознавания определяются, и способ, с помощью которого результаты отображаются на круг общения, реализуют динамическое отображение и обеспечивают возможность круга общения адаптироваться к различным типам изменений информации участников и информации об атрибутах, что обеспечивает повышение общей гибкости при использовании.
Упомянутый выше вариант осуществления иллюстрирует несколько способов, с помощью которых настоящее изобретение может быть реализовано, данное описание является относительно конкретным и подробным, тем не менее следует понимать, что это не накладывает ограничение на объем настоящего изобретения. Следует отметить, что специалистам в данной области техники, без отхода от концепции осуществления настоящего изобретения, понятно, что возможно внести дополнительные изменения и усовершенствования, которые попадают в объем защиты настоящего изобретения. Следовательно, объем патентной защиты настоящего изобретения, а также прилагаемая формула изобретения имеет преимущественную силу.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И СИСТЕМА ИЗВЛЕЧЕНИЯ ИМЕНОВАННЫХ СУЩНОСТЕЙ | 2021 |
|
RU2823914C2 |
| СИСТЕМА И ПРОЦЕСС ДЛЯ АНАЛИЗА, КВАЛИФИЦИРОВАНИЯ И ПРОГЛАТЫВАНИЯ ИСТОЧНИКОВ НЕСТРУКТУРИРОВАННЫХ ДАННЫХ ПОСРЕДСТВОМ ЭМПИРИЧЕСКОЙ АТРИБУЦИИ | 2015 |
|
RU2674331C2 |
| СПОСОБ, СИСТЕМА И УСТРОЙСТВО ДЛЯ БИОМЕТРИЧЕСКОГО РАСПОЗНАВАНИЯ РАДУЖНОЙ ОБОЛОЧКИ ГЛАЗА | 2016 |
|
RU2630742C1 |
| ОБНАРУЖЕНИЕ ОБЪЕКТОВ ИЗ ЗАПРОСОВ ВИЗУАЛЬНОГО ПОИСКА | 2017 |
|
RU2729956C2 |
| СПОСОБ ПОДГОТОВКИ РЕКОМЕНДАЦИЙ ДЛЯ ПРИНЯТИЯ РЕШЕНИЙ НА ОСНОВЕ КОМПЬЮТЕРИЗИРОВАННОЙ ОЦЕНКИ СПОСОБНОСТЕЙ ПОЛЬЗОВАТЕЛЕЙ | 2017 |
|
RU2672171C1 |
| Система классификации участников публичного мероприятия для целей поиска общих областей технологий разработки и обмена сообщениями между участниками | 2020 |
|
RU2738949C1 |
| ПРЕДЛОЖЕНИЕ РОДСТВЕННЫХ ТЕРМИНОВ ДЛЯ МНОГОСМЫСЛОВОГО ЗАПРОСА | 2005 |
|
RU2393533C2 |
| СИСТЕМЫ, УСТРОЙСТВА И СПОСОБЫ ИСПОЛЬЗОВАНИЯ КОНТЕКСТНОЙ ИНФОРМАЦИИ | 2009 |
|
RU2541890C2 |
| СПОСОБ СЕМАНТИЧЕСКОЙ ОБРАБОТКИ ЕСТЕСТВЕННОГО ЯЗЫКА С ИСПОЛЬЗОВАНИЕМ ГРАФИЧЕСКОГО ЯЗЫКА-ПОСРЕДНИКА | 2009 |
|
RU2509350C2 |
| РАСШИРЕНИЕ ИГРОВОГО ПРОЦЕССА С ИСПОЛЬЗОВАНИЕМ УСТРОЙСТВА ОТСЛЕЖИВАНИЯ ФИЗИЧЕСКОЙ АКТИВНОСТИ | 2014 |
|
RU2658282C2 |

Изобретение относится к Интернет-технологии, в частности к способу и системе формирования круга общения и устройству памяти. Технический результат заключается в обеспечении динамического формирования информации круга общения. Технический результат достигается за счет распознавания атрибутов подгруппы из круга общения, совместно используемых участниками круга общения, и сопоставление результата распознавания атрибутов подгруппы с кругом общения, выполнения процесса сегментации слова атрибутов подгруппы для сегментации атрибутов подгруппы на ключевые слова, получения по меньшей мере одного результата распознавания и соответствующих весовых значений соответствия атрибутов подгруппы посредством анализа сегментированных атрибутов подгруппы, извлечения результата распознавания атрибутов подгруппы в соответствии с соответствующим весовым значением соответствия атрибута подгруппы из по меньшей мере одного результата распознавания атрибутов подгруппы, и сопоставления извлеченного результата распознавания атрибутов подгруппы с кругом общения, в качестве информации атрибута круга общения. 3 н. и 14 з.п. ф-лы, 8 ил.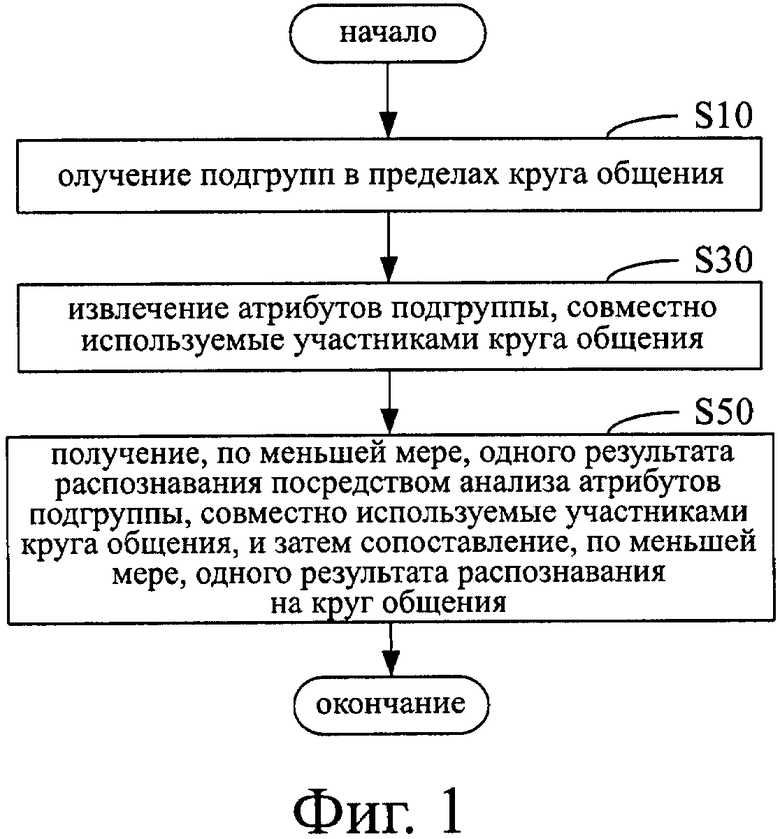
1. Реализуемый компьютером способ формирования круга общения, содержащий:
получение подгрупп из круга общения, содержащего пользователей услуги передачи мгновенных сообщений или пользователей социального веб-сайта;
извлечения атрибутов подгруппы, совместно используемых участниками круга общения, из подгрупп, при этом атрибуты подгруппы содержат, по меньшей мере, имена или информацию о классификации подгрупп;
получение результата распознавания атрибутов подгруппы, совместно используемых участниками круга общения; и
сопоставление результата распознавания атрибутов подгруппы с кругом общения, в котором получение результата распознавания атрибутов подгруппы, совместно используемых участниками круга общения, и сопоставление результата распознавания атрибутов подгруппы с кругом общения содержит:
выполнение процесса сегментации слова атрибутов подгруппы для сегментации атрибутов подгруппы на ключевые слова;
получение по меньшей мере одного результата распознавания и соответствующих весовых значений соответствия атрибутов подгруппы посредством анализа сегментированных атрибутов подгруппы;
извлечение результата распознавания атрибутов подгруппы в соответствии с соответствующим весовым значением соответствия атрибута подгруппы из по меньшей мере одного результата распознавания атрибутов подгруппы; и
сопоставление извлеченного результата распознавания атрибутов подгруппы с кругом общения в качестве информации атрибута круга общения.
2. Способ по п. 1, в котором подгруппа сформирована в виде цепочки отношений;
количество цепочек отношений существует между участниками круга общения; и цепочки отношений содержат цепочки отношений, существующие в услуге передачи мгновенных сообщений или социальном веб-сайте.
3. Способ по п. 1 дополнительно содержит до получения по меньшей мере одного
результата распознавания и соответствующих весовых значений соответствия атрибутов подгруппы путем анализа сегментированных атрибутов подгруппы:
фильтрацию каждого символа в сегментированных атрибутах подгруппы с использованием базы данных шума; и
выполнение фильтрации фильтруемых нечетких атрибутов подгруппы.
4. Способ по п. 1, в котором получение по меньшей мере одного результата распознавания и соответствующих весовых значений соответствия атрибутов подгруппы путем анализа сегментированных атрибутов подгруппы содержит:
дифференциацию атрибутов подгруппы, используя модель классификации для получения характеристик соответствия атрибутов подгруппы в модели классификации; и
получение по меньшей мере одного результата распознавания атрибутов подгруппы и соответствующего весового значения соответствия по меньшей мере одного результата распознавания атрибутов подгруппы и атрибутов подгруппы в соответствии с характеристиками.
5. Способ по п. 1 или 4, в котором получение по меньшей мере одного результата распознавания и соответствующих весовых значений соответствия атрибутов подгруппы путем анализа сегментированных атрибутов подгруппы содержит:
вычисление частоты появления каждого из атрибута подгруппы и количества участников с использованием каждого из атрибута подгруппы;
выполнение взвешенной агрегации для получения значения степени взвешенной агрегации для каждого из атрибутов подгруппы в зависимости от частоты появления каждого из атрибутов подгруппы и количества участников с помощью каждого из атрибутов подгруппы; и
извлечение одного или нескольких атрибутов подгруппы с их значениями степени взвешенной агрегации, превышающей пороговое значение, как по меньшей мере один результат распознавания атрибутов подгруппы, и
извлечение значений степени взвешенной агрегации одного или нескольких извлеченных атрибутов подгруппы в качестве соответствующих весовых значений соответствия атрибутов подгруппы.
6. Способ по п. 1, в котором извлечение результата распознавания атрибутов подгруппы в соответствии с соответствующим весовым значением соответствия атрибута подгруппы из по меньшей мере одного результата распознавания атрибутов подгруппы и сопоставление извлеченного результата распознавания атрибутов подгруппы с кругом общения в качестве информации атрибута круга общения содержит:
извлечение атрибута подгруппы с наибольшими весовым значением соответствия как результат распознавания атрибутов подгруппы; и
сопоставление результата распознавания атрибутов подгруппы с кругом общения как метка атрибута и/или название круга общения.
7. Способ по п. 6, в котором сопоставление результата распознавания атрибутов подгруппы с кругом общения как метка атрибута и/или название круга общения содержит:
добавление метки атрибута и/или названия круга общения на основании по меньшей мере одного сопоставленного результата распознавания; и
отображение метки атрибута и/или названия круга общения пользователям.
8. Способ по п. 1, в котором извлечение результата распознавания атрибутов подгруппы в соответствии с соответствующим весовым значением соответствия атрибута подгруппы из по меньшей мере одного результата распознавания атрибутов подгруппы и сопоставление извлеченного результата распознавания атрибутов подгруппы с кругом общения в качестве информации атрибута круга общения содержит:
получение информации о деятельности в подгруппах; и
извлечение результата распознавания, принимая информацию, касающуюся деятельности в подгруппах в качестве эталона.
9. Реализуемая компьютером система формирования круга общения, содержащая:
модуль получения подгруппы, выполненный с возможностью получать подгруппы в пределах круга общения, содержащие пользователей услуги передачи мгновенных сообщений или пользователей социального веб-сайта;
модуль извлечения, выполненный с возможностью извлекать атрибуты подгруппы, совместно используемые участниками круга общения, из подгрупп, при этом атрибуты подгруппы содержат, по меньшей мере, имена или информацию о классификации подгрупп; и
модуль сопоставления, выполненный с возможностью получать результат распознавания атрибутов подгруппы на основании анализа атрибутов подгруппы, совместно используемых участниками круга общения, и сопоставлять результат распознавания атрибутов подгруппы с кругом общения, в котором модуль сопоставления содержит:
блок сегментации слова, выполненный с возможностью выполнять процесс сегментации слова атрибутов подгруппы для сегментации атрибутов подгруппы на ключевые слова;
блок распознавания, выполненный с возможностью получать по меньшей мере один результат распознавания и соответствующие весовые значения соответствия атрибутов подгруппы путем анализа сегментированных атрибутов подгруппы; и
блок сопоставления результатов, выполненный с возможностью извлекать результат распознавания атрибутов подгруппы в соответствии с соответствующим весовым значением соответствия атрибута подгруппы из по меньшей мере одного результата распознавания атрибутов подгруппы и сопоставлять извлеченный результат распознавания атрибутов подгруппы с кругом общения в качестве информации атрибута круга общения.
10. Система по п. 9, в которой подгруппа в виде цепочки отношений; количество цепочек отношений существуют между участниками круга общения; и цепочки отношений содержат цепочки отношений, находящиеся в услуге передачи мгновенных сообщений или социальном веб-сайте.
11. Система по п. 9, дополнительно содержащая:
фильтр, выполненный с возможностью фильтровать каждый символ в сегментированных атрибутах подгруппы с использованием базы данных шума и выполнять фильтрацию нечетких сегментированных атрибутов подгруппы.
12. Система по п. 9, в которой блок распознавания дополнительно выполнен с возможностью различать атрибуты подгруппы с использованием модели классификации, чтобы получить характеристики, соответствующие атрибутам подгруппы в модели классификации, и получать по меньшей мере один результат распознавания атрибутов подгруппы и соответствующее весовое значение соответствия по меньшей мере одного результата распознавания атрибутов подгруппы и атрибутов подгруппы в соответствии с характеристиками.
13. Система по п. 9 или 12, в которой блок распознавания содержит:
арифметический блок, выполненный с возможностью вычислять частоту появления каждого атрибута подгруппы и количество участников, используя каждый атрибут подгруппы;
блок взвешенной агрегации, выполненный с возможностью выполнять взвешенную агрегацию для получения значения степени взвешенной агрегации для каждого из атрибутов подгруппы в зависимости от частоты появления каждого из атрибутов подгруппы и количества участников с помощью каждого из атрибутов подгруппы; и
блок извлечения, выполненный с возможностью извлекать один или более атрибутов подгруппы с их значениями степени взвешенной агрегации, превышающими пороговое значение, как по меньшей мере один результат распознавания атрибута подгруппы и извлекать значения степени взвешенной агрегации одного или нескольких извлеченных атрибутов подгруппы как соответствующие весовые значения соответствия атрибутов подгруппы.
14. Система по п. 9, в которой блок сопоставления результатов дополнительно выполнен с возможностью извлекать атрибут подгруппы с наибольшим весовым значением соответствия как результат распознавания атрибутов подгруппы и сопоставлять результат распознавания атрибутов подгруппы с кругом общения как метка атрибута и/или название круга общения.
15. Система по п. 14, в которой, блок сопоставления результатов дополнительно выполнен с возможностью добавлять метку атрибута и/или название круга общения на основании по меньшей мере одного сопоставленного результата распознавания и отображать метку атрибута и/или название круга общения для пользователей.
16. Система по п. 9, в которой блок сопоставления результатов дополнительно выполнен с возможностью получать информацию о деятельности в подгруппах и извлекать результат распознавания, принимая информацию о деятельности в подгруппах в качестве эталона.
17. Компьютерный носитель информации, содержащий одну или несколько программ,
в котором одна или несколько программ выполняются одним или более процессорами, для осуществления способа формирования круга общения; причем способ содержит этапы:
получение подгрупп из круга общения, содержащих пользователей услуги передачи мгновенных сообщений или пользователей социального веб-сайта;
извлечение атрибутов подгруппы, совместно используемых участниками круга общения, из подгрупп, при этом атрибуты подгруппы содержат, по меньшей мере, имена или информацию о классификации подгрупп;
получение результата распознавания атрибутов подгруппы, совместно используемых участниками круга общения; и
сопоставление результата распознавания атрибутов подгруппы с кругом общения, в котором получение по меньшей мере одного результата распознавания из атрибутов подгруппы, которые совместно используются участниками круга общения; и сопоставление по меньшей мере одного результата распознавания с кругом общения содержит:
выполнение процесса сегментации слова на атрибутах подгруппы для сегментации атрибутов подгруппы на ключевые слова;
получение по меньшей мере одного результата распознавания и соответствующих весовых значений соответствия атрибутов подгруппы посредством анализа сегментированных атрибутов подгруппы;
извлечение результата распознавания атрибутов подгруппы в соответствии с соответствующим весовым значением соответствия атрибута подгруппы из по меньшей мере одного результата распознавания атрибутов подгруппы; и
сопоставление извлеченного результата распознавания атрибутов подгруппы с кругом общения в качестве информации атрибута круга общения.
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| ОЧИСТИТЕЛЬ-УВЛАЖНИТЕЛЬ ГАЗА | 2006 |
|
RU2328334C1 |
| ПОЛЬЗОВАТЕЛЬСКИЙ ИНТЕРФЕЙС КОНТАКТОВ | 2003 |
|
RU2308076C2 |

