Область техники
Настоящее изобретение относится к системам и способам антивирусной защиты на мобильных устройствах, а более конкретно к системе и способу обнаружения вредоносных файлов на мобильном устройстве.
Уровень техники
На сегодняшний день мобильное вычислительное устройство (далее - мобильное устройство) стало неотъемлемой частью жизни человека (пользователя). Примерами таких устройств являются мобильные телефоны, смартфоны, коммуникаторы (КПК), планшетные компьютеры и нетбуки. При этом большинство мобильных устройств содержат, как правило, различные данные пользователя, требующиеся для повседневной жизни человека. Такими данными могут являться личные (например, фотографии и видео), персональные (например, ФИО (фамилия, имя, отчество), год рождения, номера телефонов) и конфиденциальные (например, логин и пароль к сайту банка, номер кредитной карты) данные.
Одной из наиболее популярных мобильных платформ, использующихся на мобильных устройствах, является операционная система Google Android (далее - ОС Android). В первую очередь популярность ОС Android завоевала из-за своей открытости и бесплатности, что повлекло ее распространения на различных аппаратных платформах и, как следствие, огромное количество разработанных различных приложений всеми желающими под данную ОС Android. На сегодняшний день для ОС Android уже созданы несколько миллионов приложений, которые были установлены на более чем одном миллиарде мобильных устройств по всему миру. В то же время стали все активнее создаваться и вредоносные программы для мобильных устройств, использующих ОС Android. Под вредоносными программами для мобильных устройств понимается любое программное обеспечение, предназначенное для получения несанкционированного доступа к вычислительным ресурсам мобильных устройств или к информации, хранимой на них, с целью несанкционированного использования ресурсов или причинения вреда (нанесения ущерба) владельцам мобильных устройств путем копирования, искажения, удаления или подмены информации. Под информацией могут пониматься информация из адресной книги телефона или о кредитных картах, о доступе к различным приложениям и сайтам. Под несанкционированным использованием моут пониматься, например, проведения нежелательных платежей, передачи сообщений, содержащих спам, и вызов международных звонков. Поэтому, поскольку установленные приложения на мобильных устройствах в том или ином виде имеют доступ к «важным» данным пользователей, стало важно защитить мобильные устройства и их приложения от вредоносных программ.
Большинство существующих подходов, применяемых для защиты мобильных устройств, являются, по сути, адаптированными антивирусными технологиями с персональных компьютеров, использующих операционную систему Windows. Такие антивирусные программы сталкиваются с рядом сложностей при их применении на мобильных устройствах. Во-первых, вредоносные действия на мобильном устройстве и на ПК отличны, что требует соответствующей адаптации технологий антивирусных программ. Во-вторых, на мобильном устройстве действия, совершаемые вредоносными программами, как правило, реализуются через API-функции, а так как у каждой мобильной платформы (например, ОС на ядре Linux, ОС Android, ОС Apple (IOS) или ОС Bada) свои API-функции, то и оптимизация требуется для каждой платформы соответствующая, что может привезти к усложнению работы антивирусной программы. Следовательно, это также необходимо учитывать при поиске вредоносных файлов и проведения антивирусной проверки. В-третьих, антивирусные программы, предназначенные для мобильных устройств, имеют ограничения в использовании системных ресурсов мобильных устройств, такие как батарея, центральный процессор (ЦП) и память, т.е. сама ОС ограничивает доступ к ресурсам. Для решения приведенных сложностей желательна антивирусная программа, которая будет учитывать изначально (при ее создании) особенности мобильных платформ.
Так, например, в патенте US 8370931 B1 описан метод выявления вредоносного кода за счет контроля процессов и динамического сопоставления поведения (действий пользователя) с помощью перечня правил. Также в патенте приведен алгоритм сбора поведенческих характеристик пользователей.
В патенте US 8266698 B1 описан метод обнаружения в приложениях вредоносной угрозы за счет анализа поведения приложений. Во время анализа производится сбор особенностей (свойств) действий клиента и действий приложения, на основании которых формируется так называемый «вектор свойств» (совокупность действий пользователя и приложения) для последующего анализа.
Кроме того, вредоносные программы тоже не стоят на месте. В настоящее время все больше и больше появляется программ для мобильных платформ, в частности троянские программы, использующих технологии полиморфизма (добавление/изменение инструкций в файле без изменения самого функционала), метаморфизма (полное изменение тела вируса без изменения его функциональности, гораздо более усложненная форма полиморфизма) и обфускации программного кода. Под обфускацией понимается приведение исходного текста или исполняемого кода программы к виду, сохраняющему ее функциональность, но затрудняющему анализ, понимание алгоритмов работы и модификацию при декомпиляции. Данные технологии позволяют скрыть и привести исполняемый код приложения к виду, сохраняющему функциональность кода, но затрудняющему анализ и понимание алгоритмов работы. Также в ОС Android одним из основных способов исполнения приложений является виртуальная машина Dalvik. Особенность же исполняемых файлов формата Dalvik executable (далее - файл DEX) такова, что код в файле можно менять местами без потери логики выполнения. Стоит отметить, что еще одним способом исполнения приложений является Android Runtime, которому также присущи вышеуказанные особенности. Таким образом, технологии, использующие классические методы поиска похожести (например, через образцы строк или анализ поведения приложений), малоэффективны против таких вредоносных файлов и представленные выше подходы не позволяют выявлять такие вредоносные программы (файлы). Поэтому требуется более эффективный способ определения похожести файлов.
Один из вариантов выявления метаморфных вредоносных программ описан в патентной заявке US 20120072988, где раскрывается способ определения и извлечения вредоносного кода во время контроля исполнения кода, который включает анализ потока данных в исполняемом коде. Особенностью способа является создание новой техники «суперблок» для более надежного формирования граф-схем исполнения кода, которые отражают шаги исполнения кода для последующего анализа. В качестве недостатка предложенного подхода можно отметить отсутствие возможности обучения и формирования базы образцов для последующего поиска похожести вредоносных программ.
Таким образом, требуется новый принцип анализа и выявления вредоносных программ, который был бы адаптирован к мобильным платформам, в частности, к мобильной платформе Android, и в то же время не зависел от технологий полиморфизма и обфускации программного кода.
Соответственно, существует потребность в способе и системе обнаружения вредоносных файлов для мобильных устройств, использующих тип ОС Android.
Раскрытие изобретения
Настоящее изобретение предназначено для выявления вредоносных файлов на мобильных устройствах, использующих операционную систему Android.
Технический результат настоящего изобретения заключается в повышении безопасности или предотвращении совершения вредоносных действий на мобильных устройствах, содержащих операционную систему Android. Указанный технический результат достигается за счет обнаружения вредоносных файлов на упомянутых мобильных устройствах.
Стоит отметить, что особенностью технического решения в заявленном изобретении от уровня техники является обнаружение вредоносных файлов на основании анализа и определения похожести непосредственно по байт-коду файлов.
В качестве одного из вариантов исполнения предлагается система обнаружения вредоносных файлов среди исполняемых файлов формата DEX на мобильном устройстве, использующем операционную систему Android, которая включает в себя: средство анализа, предназначенное для выявления классов и методов, содержащихся в упомянутых классах, содержащихся в проверяемом файле, выявления байт-кода для каждого выявленного метода проверяемого файла, определения инструкций, содержащихся в каждом выявленном методе, путем выявления соответствующего кода операции из байт-кода, принадлежащего соответствующему выявленному методу проверяемого файла, и передачи определенных методов и инструкций с соответствующим кодом операции средству создания векторов; средство создания векторов, предназначенное для разделения всех определенных инструкций для каждого метода по крайней мере на две группы, где разделение на группы производится на основании определения принадлежности кода операции инструкции заданным группам, формирования для каждого метода вектора на основании результата разделения инструкций по группам и передачи сформированных векторов методов средству сравнения; средство сравнения, предназначенное для сравнения сформированных векторов методов проверяемого файла с векторами вредоносных файлов, содержащихся в средстве хранения базы векторов, определения степени похожести между сравниваемыми файлами, и вынесения вердикта о вредоносности проверяемого файла при превышении заданного порога; средство хранения базы векторов, предназначенное для хранения векторов методов вредоносных файлов и представления указанных векторов средству сравнения.
В другом варианте исполнения системы все указанные средства могут быть размещены как на одном устройстве, так и быть распределены между мобильным устройством и удаленным антивирусным сервером.
В еще одном варианте исполнения системы связь между мобильным устройством и удаленным антивирусным сервером производится с помощью сети Интернет.
В другом варианте исполнения системы группы задаются на основании семантических значений байт-кода.
В еще одном варианте исполнения системы группы разделяются по крайней мере на группы, описывающие инструкции, которые: не имеют никакого логического смысла, работают с константами, работают с полями, относятся к вызовам или перехватам.
В другом варианте исполнения системы система включает в себя средство оптимизации, предназначенное для повышения точности определения степени похожести указанных файлов.
В еще одном варианте исполнения системы повышение точности определения степени похожести осуществляется одним из следующих вариантов:
- путем исключения из проверки классов и методов, относящихся к стандартным библиотечным пакетам;
- путем исключения классов, не содержащих ни одного метода;
- путем исключения методов, содержащих две и менее инструкций;
- путем исключения файлов, векторы которых хранятся в средстве хранения базы векторов, из дальнейшего анализа, если сравнение суммарного количества классов и методов указанных файлов с суммарным количеством классов и методов проверяемого файла отличается более чем на 25%;
- путем исключения классов или методов сравниваемых файлов из дальнейшего сравнения, если размер сравниваемых классов или методов отличается более чем на 25%;
- путем сравнения векторов методов, только содержащихся в одном классе.
В качестве другого варианта исполнения предлагается способ обнаружения вредоносных файлов среди исполняемых файлов формата DEX на мобильном устройстве, использующем операционную систему Android, который включает в себя этапы, на которых: выявляют классы и методы, содержащиеся в упомянутых классах проверяемого файла, выявляют байт-код для каждого выявленного метода проверяемого файла, определяют инструкции, содержащиеся в каждом выявленном методе, путем выявления соответствующего кода операции из байт-кода, принадлежащего соответствующему выявленному методу проверяемого файла, разделяют все определенные инструкций для каждого метода по крайней мере на две группы, где разделение на группы производится на основании определения принадлежности кода операции инструкции заданным группам, формируют для каждого метода векторы на основании результатов разделения инструкций по группам, сравнивают сформированные векторы методов проверяемого файла с векторами вредоносных файлов, содержащихся в средстве хранения базы векторов, для определения степени похожести между сравниваемыми файлами, и выносят вердикт о вредоносности проверяемого файла при превышении заданного порога.
В другом варианте исполнения способа группы задаются на основании семантических значений байт-кода.
В еще одном варианте исполнения способа группы разделяются по крайней мере на группы, описывающие инструкции, которые: не имеют никакого логического смысла, работают с константами, работают с полями, относятся к вызовам или перехватам.
В другом варианте исполнения способа при сравнении файлов производят повышения точности определения степени похожести указанных файлов.
В еще одном варианте исполнения способа повышение точности определения степени похожести осуществляется одним из следующих вариантов:
- путем исключения из проверки классов и методов, относящихся к стандартным библиотечным пакетам;
- путем исключения классов, не содержащих ни одного метода;
- путем исключения методов, содержащих две и менее инструкций;
- путем исключения файлов, векторы которых хранятся в средстве хранения базы векторов, из дальнейшего сравнения, если сравнение суммарного количества классов и методов указанных файлов с суммарным количеством классов и методов проверяемого файла отличается более чем на 25%;
- путем исключения классов или методов сравниваемых файлов из дальнейшего сравнения, если размер сравниваемых классов или методов отличается более чем на 25%;
- путем сравнения векторов методов, только содержащихся в одном классе.
Краткое описание чертежей
Дополнительные цели, признаки и преимущества настоящего изобретения будут очевидными из прочтения последующего описания осуществления изобретения со ссылкой на прилагаемые чертежи, на которых:
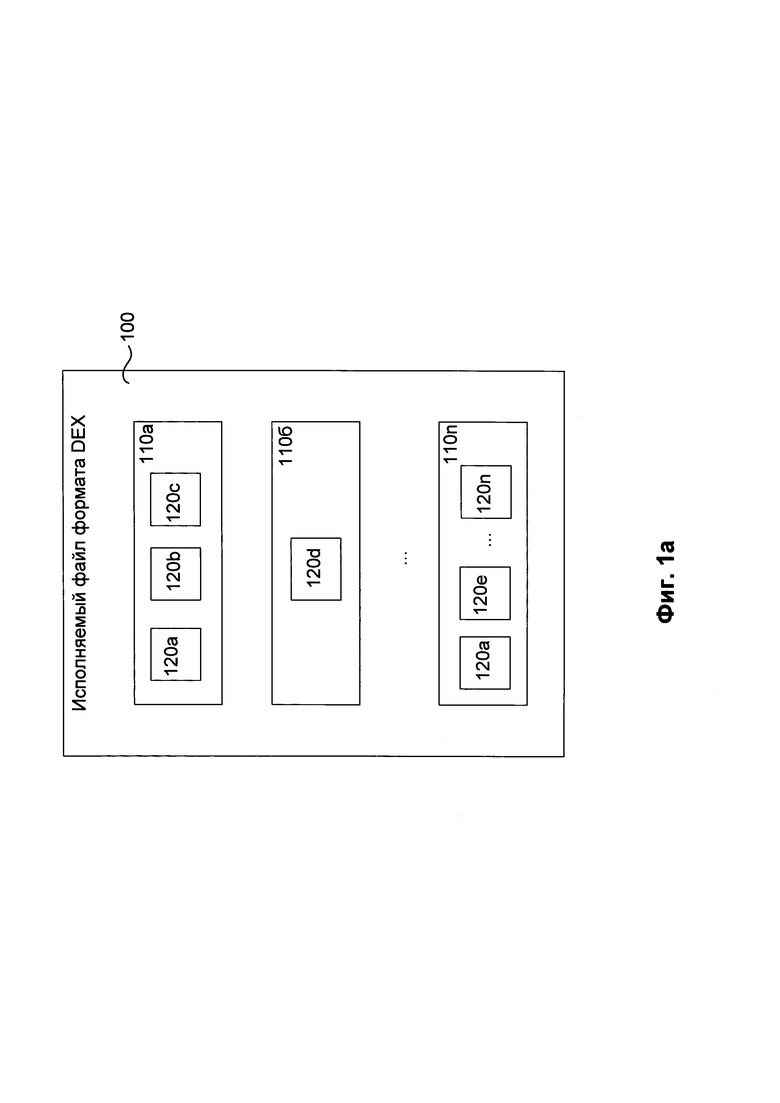
На Фиг. 1а представлена структурная схема исполняемого файла формата DEX.
На Фиг. 1б представлен пример исполняемого файла формата DEX.
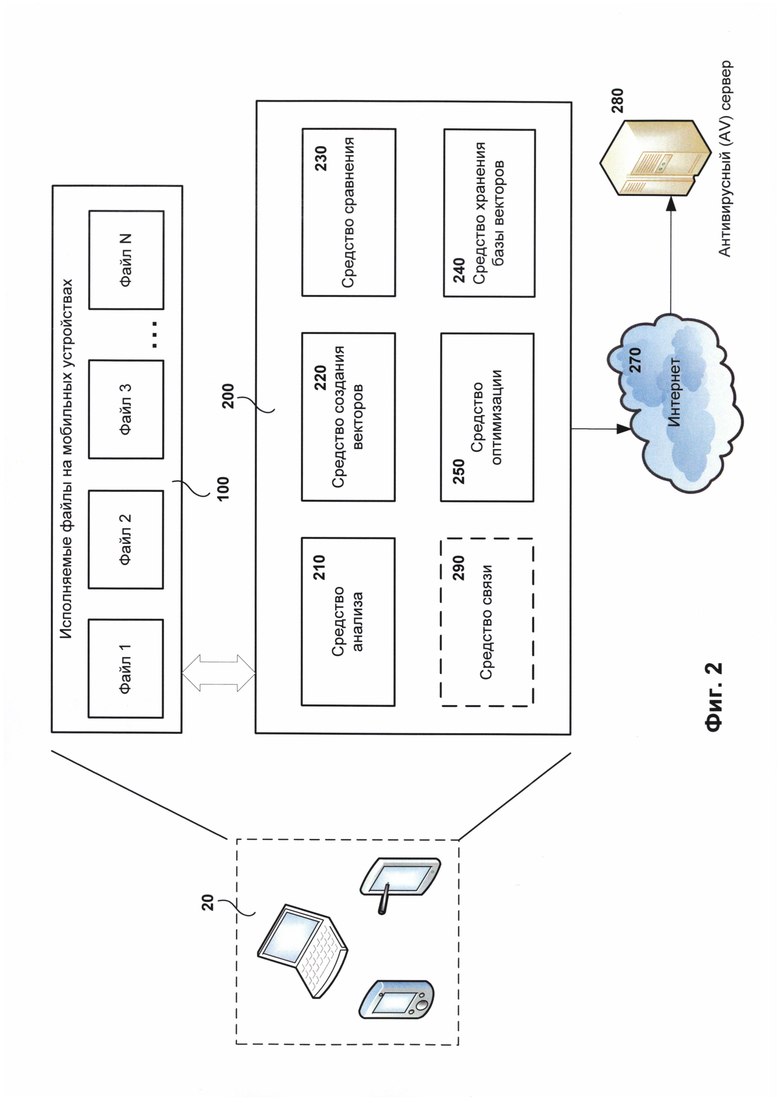
На Фиг. 2 представлена система обнаружения вредоносного файла на мобильных устройствах, использующих тип ОС Android.
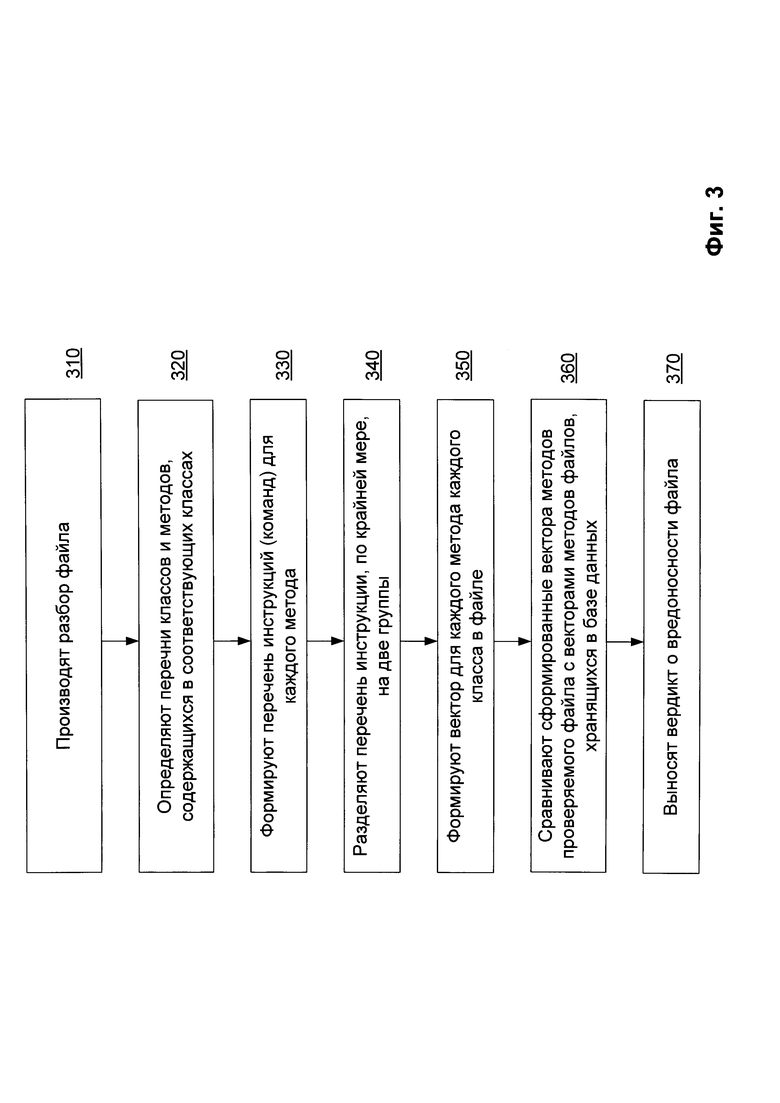
Фиг. 3 иллюстрирует алгоритм обнаружения вредоносных файлов среди исполняемых файлов формата DEX на мобильных устройствах.
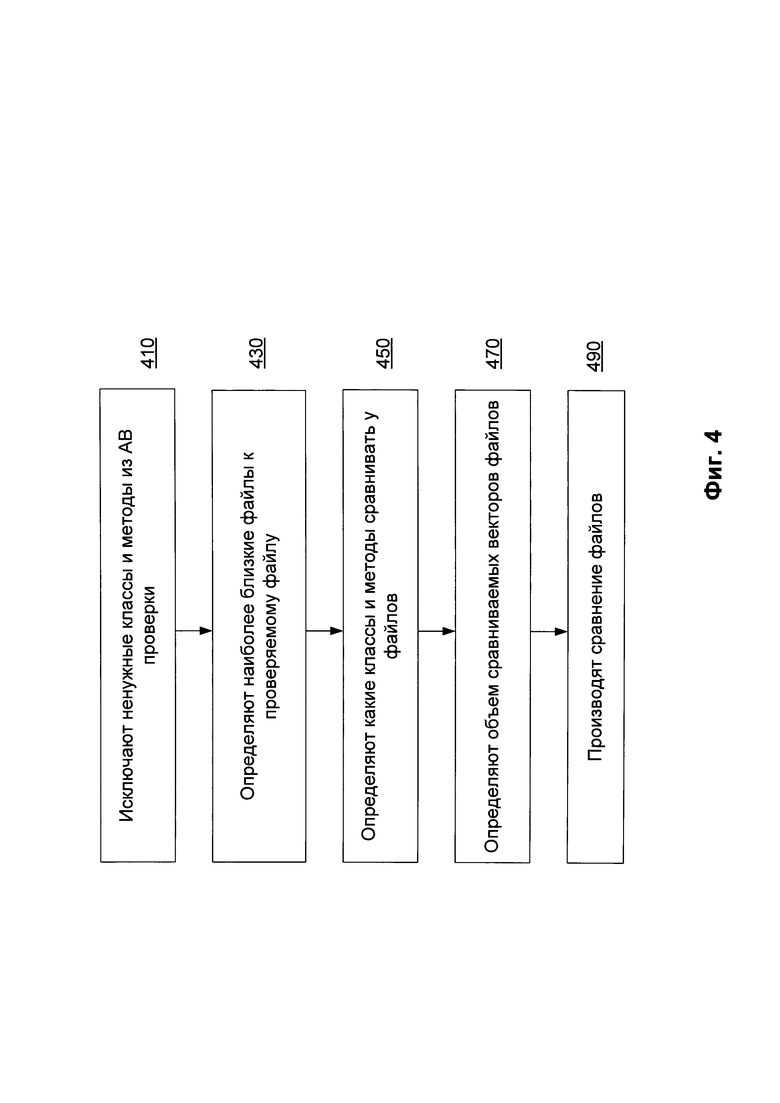
Фиг. 4 иллюстрирует алгоритм одного из вариантов повышения точности определения степени похожести файлов.
Фиг. 5 показывает пример компьютерной системы общего назначения, на которой может быть реализовано данное изобретение.
Хотя изобретение может иметь различные модификации и альтернативные формы, характерные признаки, показанные в качестве примера на чертежах, будут описаны подробно. Следует понимать, однако, что цель описания заключается не в ограничении изобретения конкретным его воплощением. Наоборот, целью описания является охват всех изменений, модификаций, входящих в рамки данного изобретения, как это определено в приложенной формуле.
Описание вариантов осуществления изобретения
Объекты и признаки настоящего изобретения, способы для достижения этих объектов и признаков станут очевидными посредством отсылки к примерным вариантам осуществления. Однако настоящее изобретение не ограничивается примерными вариантами осуществления, раскрытыми ниже, оно может воплощаться в различных видах. Сущность, приведенная в описании, является ничем иным, как конкретными деталями, необходимыми для помощи специалисту в области техники в исчерпывающем понимании изобретения, и настоящее изобретение определяется в объеме приложенной формулы.
В начале рассмотрим особенности приложений, исполняющихся в ОС Android. При создании каждого приложения для ОС Android формируется файл формата Android Pack (далее - apk-файл), который является, по сути, архивом. Архив, как правило, содержит следующие файлы: каталог «МЕТА-INF», каталог «res», файл «AndroidManifest.xml», файл «classes.dex» и файл «resources.arsc».
Каталог META-INF в свою очередь содержит файл CERT.RSA, который является сертификатом приложения, файл CERT.SF, который содержит контрольные суммы файлов ресурсов (например, картинок, звуков и т.д.), и файл MANIFEST.MF, который содержит служебную информацию, описывающую сам apk-файл. Другими словами, данная папка содержит файлы-подписи приложения, удостоверяющие упомянутое приложение компанией-разработчиком.
Папка «res» содержит различные файлы-ресурсы, которые, например, позволяют отображать интерфейс и картинки и воспроизводить мелодии приложения.
Файл «AndroidManifest.xml» является так называемым «паспортом apk-приложения». Данный файл содержит общие сведения о приложении, включающие служебную информацию, необходимую для работы приложения, например, информацию о доступе к сети или доступе к телефонной книге.
Файл «resources.arsc» является таблицей ресурсов. В файле содержится описания всех ресурсов в виде гипертекста XML (от англ. Extensible Markup Language).
Файл «classes.dex» является исполняемым файлом формата Dalvik Executable (далее - DEX), который содержит байт-код и служебную информацию, необходимую для работы в виртуальной машине Dalvik (далее - ВМД). Стоит отметить, что ВМД является основным способом исполнения приложений в ОС Android. Особенности формата DEX таковы, что представляется возможным получить полную информацию о структурных элементах программы (классах, методах, полях, обработчиках исключений и т.д.), а также ассоциировать с этими элементами байт-код, определяющий их поведение.
На Фиг. 1a представлена структурная схема файла DEX 100, на которой изображены части структурных элементов файла. Указанные элементы требуются для дальнейшей работы заявленного изобретения. Файл формата DEX 100 состоит из классов 110a…110n. В объектно-ориентированном программировании под классом понимаются разновидность абстрактного типа данных, характеризуемым способом своего построения. В свою очередь, под абстрактным типом данных понимается тип данных, который предоставляет для работы с элементами соответствующего типа определенный набор методов 120a…120n, а также возможность устанавливать (формировать) элементы этого типа при помощи специальных (других) методов. Количество классов 110 и методов 120 для каждого файла формата DEX 100 варьируется от целей и задач соответствующего приложения. Каждый метод содержит в себе инструкции ВМД. Формат инструкции ВМД может быть представлен в следующем виде:

Как видно, инструкция делится на две части, где первая часть содержит «OPCODE» инструкции, под которым понимается код операции. Вторая часть содержит аргументы инструкции и определяет используемые инструкцией регистры и другие параметры (например, значения для регистров). Пример исходного текста (кода) исполняемого файла формата DEX представлен на Фиг. 1б. На Фиг. 1б можно видеть пакет «com.soft.android.appinstaller», из исходного кода которого будет построен файл формата DEX, у которого классы представлены в виде древовидной структуры (ActivityTexts, FinishActivity и т.д.). Кроме того, инструкции класса «MessageSender» представлены на Фиг. 1б справа. Стоит отметить, что каждый метод, по сути, содержит некоторое количество команд для выполнения своего назначения и имеет набор входных аргументов. Поэтому для каждого метода класса в файле формата DEX может быть определен соответствующий массив байт-кода (набор инструкций).
Заявленное изобретение позволяет осуществить сравнение файлов формата DEX на основании сравнения функциональности структурных элементов программ (например, методов и классов), содержащихся в указанных файлах. Подобный подход позволят избавиться от недостатков бинарного и строкового сравнения файлов для файлов формата DEX. Одним из недостатков является то, что бинарное сравнение, которое подразумевает один порядок байт-кода, обходится за счет изменения порядка массива байт-кода. Другим недостатком является то, что строковое сравнение является неактуальным при шифровании строк равного размера.
На Фиг. 2 представлена система обнаружения вредоносного файла на мобильных устройствах, использующих ОС Android (далее - система обнаружения). Как видно на Фиг. 2 система обнаружения 200 установлена на мобильном устройстве 20 для выполнения своего предназначения. Стоит отметить, что мобильное устройство является частным случаем компьютерной системы, описанной на Фиг. 5. В качестве мобильного устройства 20 могут пониматься любые устройства, в том числе мобильные телефоны, смартфоны, КПК или планшетные компьютеры, которые используют в своей работе ОС Android. Соответственно, исполняемые файлы на мобильных устройствах, которые требуют антивирусной проверки, как правило, являются исполняемыми файлами формата DEX 100, например, файл 1, файл 2, файл 3 и файл N, каждый из которых является файлом 100. Соответственно, перед запуском каждого файла 100 производится их антивирусная проверка с помощью системы обнаружения 200.
Система обнаружения 200 содержит по крайней мере средство анализа 210, средство создания векторов 220, средство сравнения 230 и средство хранения базы векторов 240. Также в одном из частных случаев реализации система обнаружения 200 содержит средство оптимизации 250. Кроме того, средство обнаружения 200 может иметь связь с удаленным сервером, например, антивирусным сервером 280. Связь с сервером 280 будет производиться, например, через сеть Интернет 270. Антивирусный сервер 280 может иметь различные назначения, в том числе в одном из вариантов реализации быть средством анализа 210, средством создания векторов 220 и средством сравнения 230. В этом случае средство анализа 210, средство создания векторов 220 и средство сравнения 230 могут частично или полностью перенаправлять возложенные на них задачи к антивирусному серверу 280. Тогда средство анализа 210, средство создания векторов 220 и средство сравнения 230 будут являться контролирующими средствами, которые передают и получают необходимую информации для работы системы обнаружения 200. В еще одном частном случае ранее упомянутые средства, а именно средства 210, 220, 230, 240 и 250, могут быть размещены на удаленном сервере 280, тогда средство связи 290 выполняет задачу по взаимодействию упомянутых средств с мобильным устройством 20. Например, средство связи 290 производит передачу файлов, над которыми необходимо провести антивирусную проверку, или данные о файле, которых достаточно для проведения антивирусной проверки (например, хеш-сумму файла). Таким образом, система обнаружения 200 в одном из вариантов реализации может являться распределенной системой обнаружения.
Итак, средство анализа 210 производит анализ проверяемого файла 100 с целью выявления информации о содержимом файла, в частности о классах и методах, содержащихся в выявленных классах. В одном из вариантов реализации под анализом понимается разбор файла путем дизассемблирования файла, которое предназначено для преобразования исполняемого кода файла в исходный текст программы. После чего производится определение содержимого (структуры) файла, а именно информация о методах и классах. Для дизассемблирования файла средство 210 может являться или содержать в себе функционал дизассемблера файлов. В другом варианте реализации разбор файла может производиться путем декомпиляции файла. Для декомпиляции файла средство анализа 210 может являться или содержать в себе функционал декомпилятора (от англ. decompiler) файлов, предназначенного для разбора файлов формата DEX, например, декомпилятор «ApkTool». Далее средство анализа 210 для каждого выявленного метода класса определяет соответствующий массив байт-кода (последовательный набор инструкций). По сути массив байт-кода является представлением того или иного метода в кодах виртуальной машины. Определив массив байт-кода средство анализа 210 производит разбиение указанного массива на инструкции (команды), во время которого производится определение для каждой инструкции своего байт-кода. Таким образом формируется «функциональная карта» для каждого метода каждого класса анализируемого файла. Можно говорить о том, что в случае, когда средство анализа 210 производит разбиение массива на инструкции и определения байт-кода, средство 210 выполняет функцию дизассемблера длин для приложений (файлов) формата DEX. Далее выявленную информацию, а именно методы и принадлежащие им инструкции с соответствующим байт-кодом, средство анализа 210 предоставляет средству создания векторов 220. Стоит отметить, что, например, в случае определения в классе отсутствия по крайней мере одного метода, класс может считаться несуществующим. В еще одном варианте реализации, если метод будет содержать менее двух инструкций (команд), то такой метод также может считаться несуществующим. Стоит отметить, что в случае определения класса или метода как несуществующего, это означает, что они исключаются из дальнейшего анализа. Данная оптимизация позволяет повысить скорость дальнейшего анализа и уменьшить уровень ложных срабатываний (ошибку первого рода).
Средство создания векторов 220 предназначено для формирования вектора для каждого метода (в том числе и для методов проверяемого файла) на основании полученной информации от средства анализа 210, а именно на основании анализа байт-кода каждого метода. Принцип формирования вектора рассмотрим на примере формирования вектора для метода «onReceive». Код метода «onReceive», разбитый по строкам, представлен в Таблице 1.
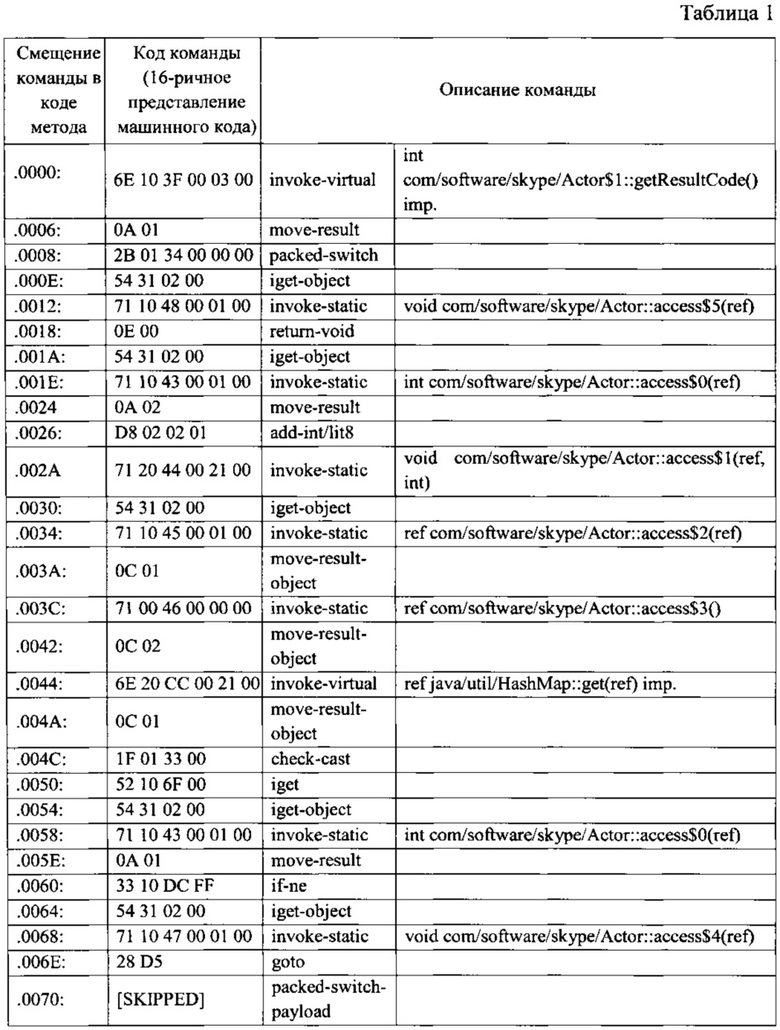
Как видно из Таблицы 1, каждая строчка представляет из себя код инструкции для ВМД по соответствующему смещению со своими аргументами и регистрами. При формировании вектора для метода средство формирования векторов 220 выбирает только первые байты инструкции, которые определяют выполняемое инструкцией действие. Другими словами, выбираем «OPCODE» (в переводе с англ. «код операции» и для упрощения использования далее - опкод) инструкции, который характеризуется, как правило, первым байтом кода. Согласно Таблице 1 первым байтом будут являться первые две цифры машинного кода, а именно для первой строки по смещению 0000 - это 6Е, для второй по смещению 0006 - 0А и т.д. Таким образом будут выбраны следующие байты: 6Е, 0A, 2В, 54, 71, 0Е, 54, 71, 0А, D8, 71, 54, 71, 0С, 71, 0С, 6Е, 0С, 1F, 52, 54, 71, 0А, 33, 54, 71 и 28.
Далее средство формирования векторов 220 подсчитывает количество инструкций, принадлежащих той или иной функциональной группе. Определение принадлежности той или иной инструкции, соответствующей функциональной группе (далее - группа), может проводится, например, с помощью таблицы соответствия, примером которой является Таблица 2. Согласно Таблице 2 принадлежность инструкции к какой-либо группе может определяться по опкоду инструкции.

Например, для метода «onReceive» в группу передачи управления (другими словами, группу вызовов «invoke») или группу 1 входят опкоды инструкций, как 6Е и 71. Таким образом, средство формирования векторов 220 разбивает все множество инструкций на n-групп. Стоит отметить, что группы, по которым затем будет произведено распределение инструкций (команд), могут быть созданы как автоматически, так и заранее заданы с помощью пользователя. Так, например, группы могут быть созданы согласно семантическим значениям опкода. Примерами таких групп могут являться следующие группы: группа, описывающая инструкции, не имеющие никакого логического смысла (например, инструкция передачи данных между регистрами), группа, описывающая инструкции для работы с постоянными (константами), группа работы с полями, группа вызовов и/или группа передачи управления. После разбиения на группы средство формирования векторов 220, например, может представить каждый метод в виде вектора (точки) в n-мерном евклидовом пространстве:
F(M)={x0, x1, …, xk}, k=dim(M), где x∈OPCODE
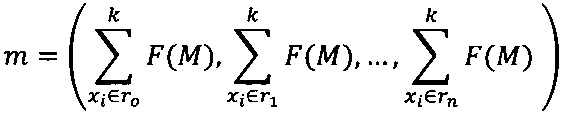 ,
,
где М - метод,
F(M) - функциональная карта метода,
m - точка в n-мерном пространстве соответствующая методу,
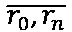 - разбиение опкодов по смысловому значению в соответствии с заданными группами.
- разбиение опкодов по смысловому значению в соответствии с заданными группами.
Другими словами, при формировании вектора количество команд в группе определяют координату вектора по соответствующей оси. Сформированные векторы методов всех определенных классов анализируемого файла средство формирования векторов 220 передает средству сравнения 230.
В одном из вариантов реализации средство создания векторов 220 перед формированием непосредственно векторов выявляет и исключает из дальнейшей проверки классы и методы, которые относятся к стандартным библиотечным пакетам, т.е. входят в состав комплекта средств разработки приложений (от англ. software development kit (SDK)). Например, на основании определения принадлежности байт-кода (опкода) методов и/или классов к стандартным библиотечным пакетам.
Средство сравнения 230 в свою очередь производит сравнения файлов с помощью сформированных векторов методов проверяемого файла с векторами методов файлов, хранящимися в средстве хранения базы векторов 240. С помощью полученного представления векторов методов файлов средство сравнения 230 производит подсчет (представление) меры отличия между двумя ближайшими методами сравниваемых файлов как расстояние между двумя ассоциированными с ними точками в n-мерном евклидовом пространстве. Другими словами, от каждой точки находится ближайшая точка от другого метода другого файла, и определяется расстояние. В частном случае реализации для сравнения средство сравнения 230 может использовать алгоритм Левенштейна или любой аналогичный ему алгоритм.
Так, например, для методов р и q расстояние может быть вычислено с помощью формулы:
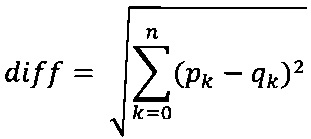 ,
,
где diff - расстояние между двумя ассоциированными точками.
Таким образом, определяется некое расстояния diff (мера отличия), которое затем нормализуется по длине (по суммарному количеству команд) сформированного вектора. Сравниваемые методы считаются тем больше похожими, чем меньше их нормализованная мера отличия. Мера отличия принадлежит интервалу от нуля до единицы. Далее средство сравнения 230 выносит вердикт о похожести проверяемого файла формата DEX 100 с файлами, векторы которых хранятся в средстве хранения базы векторов 240. После чего средство сравнения 230 определяет, является ли проверяемый файл формата DEX 100 вредоносным с помощью выявленного наиболее похожего файла. В том случае, если наиболее похожий файл является вредоносным файлом, то и проверяемый файл признается вредоносным. В противном случае, если наиболее похожий файл является чистым (не вредоносным) файлом, то и проверяемый файл признается чистым. Информация о вредоносности того или иного файла также храниться в средстве 240. Стоит отметить, что коэффициент похожести, после превышения (или наоборот) которого может быть вынесено решение о вредоносности файла, определяется (или назначается) в зависимости от уровня требуемой безопасности на мобильном устройстве 20.
Тем не менее, стоит отметить, что при определении степени похожести файлов сначала производится сравнение их методов, затем сравнение их классов и вынесения окончательного решения. Так, в частном случае реализации, если методы похожи между собой менее чем на 50%, то будет считаться, что методы совсем не похожи. В данном случае похожесть методов будет определяться по сумме содержащихся в них инструкций (опкодов). Следовательно, чем больше одинаковых опкодов, тем больше методы будут похожи. Также если классы отличаются более чем на 10%, то классы будут являться различными. В данном случае похожесть классов будет определяться по сумме (количеству) содержащихся в них методов.
Нормализованная мера отличия может быть вычислена согласно формуле:
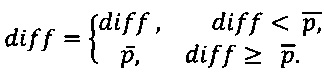
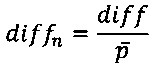
Кроме того, с целью повышения точности определения степени похожести файлов в различных вариантах реализации может производится адаптация как векторов методов, хранящихся в средстве хранения базы векторов 240, перед их сравнением с векторами методов проверяемого файла, так и адаптация непосредственно в момент сравнения двух файлов. Данная адаптация может быть произведена, например, с помощью средства оптимизации 250.
Одним из вариантов адаптации является то, что производится сравнение не всех методов (точнее их векторов) друг с другом, а самых близких. Для это будет произведена сортировка методов по возрастанию. Сортировка может быть осуществлена в соответствии с количеством (суммой) инструкций каждого метода.
Другим вариантом адаптации является то, что при сравнении будет производиться сравнение методов, например, только внутри похожих классов. Соответственно, перед сравнением методов будет производиться и сравнение классов. Например, если классы будут удовлетворять заданному для них коэффициенту похожести, то будут сравниваться методы соответствующих классов. Коэффициент похожести классов может быть рассчитан, например, путем сравнения количества (суммы) методов, содержащихся в каждом классе. Кроме того, производить выбор, какие классы сравнивать между собой и какие методы внутри классов также сравнивать между собой, можно на сравнении размеров (сумм) соответствующих методов и классов. Размер, как упоминалось ранее, может определяться с помощью суммирования числа методов для классов и суммирования числа инструкций для методов. Таким образом, например, если при сравнении классов или методов их размер отличается более чем на 25%, то дальнейший их анализ не будет производиться. В противном случае, если отличается менее чем на 25%, то сравниваются. Также может быть осуществлено предварительное сравнение файлов перед полным сравнением. В этом случае будет сравниваться суммарное количество классов и методов каждого файла. Если файл из средства хранения базы векторов 240 отличается от текущего проверяемого файла не более чем на 25% в любую сторону, то будет произведено дальнейшее сравнение файлов. В противном случае средство сравнения 230 вынесет вердикт о том, что файлы отличны друг от друга.
Еще одним вариантом адаптации является ограничение количества сравниваемых векторов (точек). Например, ограничение может быть установлено определенным диапазоном в n-мерном евклидовом пространстве, согласно которому будут сравниваться только векторы (точки), которые попали в данный диапазон. В частном случае реализации диапазон определяется на основании суммы координат всех точек.
Стоит отметить, что упомянутая предварительная адаптация позволяет повысить скорость сравнения файлов и соответственно проверки файлов 100 и обнаружения среди них вредоносных файлов.
На Фиг. 3 представлен способ обнаружения вредоносного файла на мобильных устройствах. Во время проведения антивирусной проверки исполняемого файла на мобильном устройстве 20 производится его сравнение с известными вредоносными файлами. Для этого на этапе 310 производится разбор файла, например, с помощью упомянутого ранее средства анализа 210. Во время декомпиляции на этапе 320 выявляется информация о структуре файла, в частности, перечни классов и методов, содержащихся в выявленных классах. На этапе 330 формируется перечень инструкций (команд) для каждого выявленного метода с помощью того же средства анализа 210. Для этого определяется соответствующий массив байт-кода (набор команд) каждому выявленному методу. Стоит отметить, что под массивом байт-кода понимается представление того или иного метода в машинном коде. Подобрав массив байт-кода для каждого метода, производится разбиение указанного массива на отдельные инструкции (команды) со своим байт-кодом. Таким образом формируется функциональная карта для каждого метода каждого класса анализируемого файла, содержащая перечень инструкций с соответствующим байт-кодом.
На этапе 340, например, с помощью средства создания векторов 220 производится разделение перечня инструкций по крайней мере на две группы. Стоит отметить, что количество и особенность определения типа групп могут быть как заранее заданы, так и созданы автоматически. Так, например, группы могут быть созданы согласно семантическим значениям опкода. Примерами таких групп могут являться следующие группы: группа, описывающая инструкции, не имеющие никакого логического смысла (например, инструкция передачи данных между регистрами), группа, описывающая инструкции для работы с постоянными (константами), группа работы с полями, группа вызовов и/или группа переходов. Принцип разделения на группы основан на том, что производится анализ байт-кода каждой инструкции, во время которого производится извлечение первых байт, относящихся к опкоду инструкции. Пример принципа разделения приведен при описании Фиг. 2. После разбиения на группы, на этапе 350, с помощью все того же средства формирования векторов 220 формируется вектор для каждого метода. Так, при формировании вектора количество команд в каждой группе определяет координату вектора по соответствующей оси. Таким образом, каждый метод представляется в виде вектора (точки) в n-мерном евклидовом пространстве, где размерность пространства равняется количеству групп.
На этапе 360, например, с помощью средства сравнения 230 производится сравнение файлов с помощью сформированных векторов проверяемого файла с векторами файлов, хранящихся в средстве хранения базы векторов 240. При сравнении производится расчет меры отличия между двумя ближайшими методами сравниваемых файлов как расстояние между двумя ассоциированными с ними точками в n-мерном евклидовом пространстве. Другими словами, от каждой точки находится ближайшая точка от другого метода другого файла, и определяется расстояние между точками. Пример вычисления расстояния приведен при описании Фиг. 2. Таким образом, определяется расстояние, которое затем нормализуется по длине (по суммарному количеству команд) сформированного вектора. Пример расчета нормализованной меры отличия приведен при описании Фиг. 2. Сравниваемые методы считаются тем больше похожими, чем меньше их нормализованная мера отличия. Мера отличия принадлежит интервалу от нуля до единицы. Далее, на этапе 370, выносится вердикт о похожести файлов проверяемого файла формата DEX 100 с файлами, векторы которых хранятся в средстве хранения базы векторов 240. После чего определяется, является ли проверяемый файл 100 вредоносным с помощью выявленного наиболее похожего файла, как указано при описании Фиг. 2. Стоит отметить, что коэффициент похожести, после превышения (или наоборот) которого может быть вынесен вердикт о вредоносности файла, определяется (или назначается) в зависимости от уровня требуемой безопасности на мобильном устройстве 20.
Тем не менее, порядок определения степени похожести файлов может иметь вид: сначала производится сравнение методов, затем сравнение классов и потом окончательное решение о похожести. Сравнение методов производится путем подсчета суммы инструкций, содержащихся в каждом методе, а сравнение классов производится на основании подсчета суммы методов, содержащихся в каждом классе. В частном случае реализации способа, если методы похожи менее чем на 50%, то будет считаться, что методы совсем не похожи. Если классы отличаются более чем на 10%, то классы будут являться различными.
На Фиг. 4 представлен алгоритм одного из вариантов повышения точности определения степени похожести файлов. Для повышения точности определения степени похожести файлов может производится адаптация как базы векторов методов, хранящихся в средстве хранения базы векторов 240, перед их сравнением с векторами методов проверяемого файла, так и адаптация непосредственно в момент сравнения двух файлов.
Так, на этапе 410 перед формированием непосредственно векторов для проверяемого файла выявляют и исключают из дальнейшей проверки классы и методы, которые относятся к стандартным библиотечным пакетам, т.е. входят в состав комплекта средств разработки приложений (от англ. software development kit (SDK)). Кроме того, в случае определения в каком-либо классе по крайней мере одного несуществующего метода, класс будет считаться несуществующим. Также, если метод будет содержать менее двух инструкций (команд), то такой метод будет считаться несуществующим.
Далее, во время сравнения файлов производится адаптация сравниваемых файлов так, чтобы производилось сравнение только самых близких файлов и их методов. Соответственно, на этапе 430 определяются файлы, которые являются наиболее близкими к проверяемому файлу. Для этого сравнивается суммарное количество классов и методов каждого файла. Если файл из средства хранения базы векторов 240 отличается от текущего проверяемого файла не более чем на 25% в любую сторону, то с таким файлом будет произведено дальнейшее сравнение. В противном случае файл будет определен как отличный от проверяемого файла.
Далее, на этапе 450, производится оптимизация классов и методов определенного файла на этапе 430 для последующего сравнения с проверяемым файлом. Под оптимизацией понимается определения классов и методов, которые будут сравниваться в файлах. Так, выбор, какие классы сравнивать и какие методы внутри классов также сравнивать между собой, производится путем сравнения их размеров. Например, размер может определяться с помощью суммирования методов для классов и суммирования инструкций для методов. Таким образом, если при сравнении классов или методов их размер отличается более чем на 25%, то дальнейший их анализ не производится. В противном случае, если отличается менее чем на 25%, то сравниваются.
Кроме того, на этапе 470 при непосредственном сравнении определенных на этапе 450 векторов (методов в соответствующих классах) файлов производится ограничение количества сравниваемых векторов (точек). Например, ограничение может быть установлено определенным диапазоном в пространстве, согласно которому будут сравниваться только векторы (точки), который попали в данный диапазон. После чего производится окончательное сравнение файлов на этапе 490.
На Фиг. 5 показана компьютерная система, на которой может быть использовано описанное изобретение.
Фиг. 5 представляет пример компьютерной системы общего назначения (может быть как персональным компьютером, так и сервером) 20, содержащий центральный процессор 21, системную память 22 и системную шину 23, которая содержит разные системные компоненты, в том числе память, связанную с центральным процессором 21. Системная шина 23 реализована, как любая известная из уровня техники шинная структура, содержащая в свою очередь память шины или контроллер памяти шины, периферийную шину и локальную шину, которая способна взаимодействовать с любой другой шинной архитектурой. Системная память содержит постоянное запоминающее устройство (ПЗУ) 24, память с произвольным доступом (ОЗУ) 25. Основная система ввода/вывода (BIOS) 26 содержит основные процедуры, которые обеспечивают передачу информации между элементами персонального компьютера 20, например, в момент загрузки операционной системы с использованием ПЗУ 24.
Персональный компьютер 20 в свою очередь содержит жесткий диск 27 для чтения и записи данных, привод магнитных дисков 28 для чтения и записи на сменные магнитные диски 29 и оптический привод 30 для чтения и записи на сменные оптические диски 31, такие как CD-ROM, DVD-ROM и иные оптические носители информации. Жесткий диск 27, привод магнитных дисков 28, оптический привод 30 соединены с системной шиной 23 через интерфейс жесткого диска 32, интерфейс магнитных дисков 33 и интерфейс оптического привода 34 соответственно. Приводы и соответствующие компьютерные носители информации представляют собой энергонезависимые средства хранения компьютерных инструкций, структур данных, программных модулей и прочих данных персонального компьютера 20.
Настоящее описание раскрывает реализацию системы, которая использует жесткий диск 27, сменный магнитный диск 29 и сменный оптический диск 31, но следует понимать, что возможно применение иных типов компьютерных носителей информации 56, которые способны хранить данные в доступной для чтения компьютером форме (твердотельные накопители, флэш-карты памяти, цифровые диски, память с произвольным доступом (ОЗУ) и т.п.), которые подключены к системной шине 23 через контроллер 55.
Компьютер 20 имеет файловую систему 36, где хранится записанная операционная система 35, а также дополнительные программные приложения 37, другие программные модули 38 и данные программ 39. Пользователь имеет возможность вводить команды и информацию в персональный компьютер 20 посредством устройств ввода (клавиатуры 40, манипулятора «мышь» 42). Могут использоваться другие устройства ввода (не отображены): микрофон, джойстик, игровая консоль, сканнер и т.п. Подобные устройства ввода по своему обычаю подключают к компьютерной системе 20 через последовательный порт 46, который в свою очередь подсоединен к системной шине, но могут быть подключены иным способом, например, при помощи параллельного порта, игрового порта или универсальной последовательной шины (USB). Монитор 47 или иной тип устройства отображения также подсоединен к системной шине 23 через интерфейс, такой как видеоадаптер 48. В дополнение к монитору 47, персональный компьютер может быть оснащен другими периферийными устройствами вывода (не отображены), например, колонками, принтером и т.п.
Персональный компьютер 20 способен работать в сетевом окружении, при этом используется сетевое соединение с другим или несколькими удаленными компьютерами 49. Удаленный компьютер (или компьютеры) 49 являются такими же персональными компьютерами или серверами, которые имеют большинство или все упомянутые элементы, отмеченные ранее при описании существа персонального компьютера 20, представленного на Фиг. 5. В вычислительной сети могут присутствовать также и другие устройства, например маршрутизаторы, сетевые станции, пиринговые устройства или иные сетевые узлы.
Сетевые соединения могут образовывать локальную вычислительную сеть (LAN) 50 и глобальную вычислительную сеть (WAN). Такие сети применяются в корпоративных компьютерных сетях, внутренних сетях компаний и, как правило, имеют доступ к сети Интернет. В LAN- или WAN-сетях персональный компьютер 20 подключен к локальной сети 50 через сетевой адаптер или сетевой интерфейс 51. При использовании сетей персональный компьютер 20 может использовать модем 54 или иные средства обеспечения связи с глобальной вычислительной сетью, такой как Интернет. Модем 54, который является внутренним или внешним устройством, подключен к системной шине 23 посредством последовательного порта 46. Следует уточнить, что сетевые соединения являются лишь примерными и не обязаны отображать точную конфигурацию сети, т.е. в действительности существуют иные способы установления соединения техническими средствами связи одного компьютера с другим.
В заключение следует отметить, что приведенные в описании сведения являются примерами, которые не ограничивают объем настоящего изобретения, определенного формулой.
| название | год | авторы | номер документа |
|---|---|---|---|
| СИСТЕМА И СПОСОБ АВТОМАТИЧЕСКОЙ МОДИФИКАЦИИ АНТИВИРУСНОЙ БАЗЫ ДАННЫХ | 2012 |
|
RU2536664C2 |
| Способ ускорения полной антивирусной проверки файлов на мобильном устройстве | 2019 |
|
RU2726878C1 |
| Способ выборочного повторного антивирусного сканирования файлов на мобильном устройстве | 2019 |
|
RU2726877C1 |
| СПОСОБ И СИСТЕМА ВЫЯВЛЕНИЯ ВРЕДОНОСНЫХ ФАЙЛОВ В НЕИЗОЛИРОВАННОЙ СРЕДЕ | 2020 |
|
RU2722692C1 |
| Система и способ определения похожих файлов | 2015 |
|
RU2614561C1 |
| СПОСОБ ОБНАРУЖЕНИЯ КОДОВ ВРЕДОНОСНЫХ КОМПЬЮТЕРНЫХ ПРОГРАММ В ТРАФИКЕ СЕТИ ПЕРЕДАЧИ ДАННЫХ, В ТОМ ЧИСЛЕ ПОДВЕРГНУТЫХ КОМБИНАЦИЯМ ПОЛИМОРФНЫХ ПРЕОБРАЗОВАНИЙ | 2016 |
|
RU2615317C1 |
| Система и способ снижения нагрузки на сервис обнаружения вредоносных приложений | 2019 |
|
RU2739833C1 |
| СИСТЕМА И СПОСОБ ОБНАРУЖЕНИЯ ВРЕДОНОСНОГО ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ ПУТЕМ СОЗДАНИЯ ИЗОЛИРОВАННОЙ СРЕДЫ | 2012 |
|
RU2535175C2 |
| Система и способ категоризации приложения на вычислительном устройстве | 2019 |
|
RU2747514C2 |
| СИСТЕМА И СПОСОБ СОЗДАНИЯ ГИБКОЙ СВЕРТКИ ДЛЯ ОБНАРУЖЕНИЯ ВРЕДОНОСНЫХ ПРОГРАММ | 2013 |
|
RU2580036C2 |

Изобретение относится к обеспечению безопасности мобильных устройств. Технический результат заключается в предотвращении совершения вредоносных действий на мобильных устройствах, содержащих операционную систему Android. Система включает средство анализа для выявления классов и методов в проверяемом исполняемом файле формата DEX, выявления байт-кода для каждого метода, определения инструкций в каждом методе путем выявления соответствующего опкода инструкции из байт-кода, передачи определенных методов и инструкций с соответствующим опкодом инструкции средству создания векторов; средство создания векторов для разделения всех определенных инструкций для каждого метода на функциональные группы, которые заранее заданы, подсчета количества инструкций, принадлежащих каждой функциональной группе, соответствующего метода, представления каждого метода в виде вектора на основании количества инструкций в упомянутой группе, передачи сформированных векторов методов средству сравнения; средство сравнения для сравнения сформированных векторов методов проверяемого файла с векторами вредоносных файлов, вынесения вердикта о вредоносности проверяемого файла; средство хранения базы векторов методов вредоносных файлов. 2 н. и 10 з.п. ф-лы, 6 ил., 2 табл.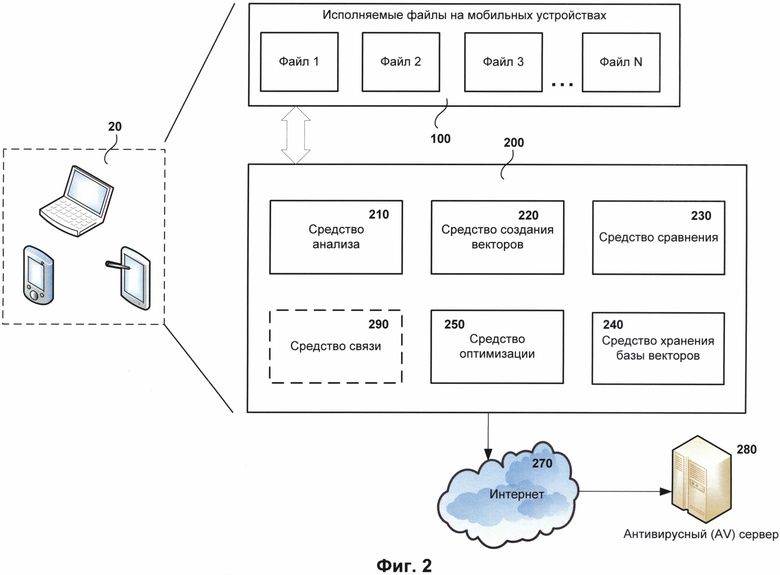
1. Система обнаружения вредоносных файлов среди исполняемых файлов формата DEX на мобильном устройстве, использующем операционную систему Android, которая включает в себя:
а) средство анализа, предназначенное для:
- выявления классов и методов, содержащихся в упомянутых классах, содержащихся в проверяемом исполняемом файле формата DEX,
- выявления байт-кода для каждого выявленного метода проверяемого файла,
- определения инструкций, содержащихся в каждом выявленном методе, путем выявления соответствующего опкода инструкции из байт-кода, принадлежащего соответствующему выявленному методу проверяемого файла,
- передачи определенных методов и инструкций с соответствующим опкодом инструкции средству создания векторов;
б) средство создания векторов, предназначенное для:
- разделения всех определенных инструкций для каждого метода по крайней мере на две функциональные группы, которые заранее заданы, при этом разделение заключается в определение принадлежности опкода инструкции, которые были получены от средства анализа для каждого метода, одной из заданных групп,
- подсчета количества инструкций, принадлежащих каждой функциональной группе, соответствующего метода,
- представления каждого метода в виде вектора на основании количества инструкций в упомянутой группе,
- передачи сформированных векторов методов средству сравнения;
в) средство сравнения, предназначенное для:
- сравнения сформированных векторов методов проверяемого файла с векторами вредоносных файлов, содержащихся в средстве хранения базы векторов,
- определения степени похожести между сравниваемыми файлами,
- вынесения вердикта о вредоносности проверяемого файла при превышении заданного порога;
г) средство хранения базы векторов, предназначенное для хранения векторов методов вредоносных файлов и представления указанных векторов средству сравнения.
2. Система по п. 1, в которой все указанные средства могут быть размещены как на одном устройстве, так и быть распределены между мобильным устройством и удаленным антивирусным сервером.
3. Система по п. 2, в которой связь между мобильным устройством и удаленным антивирусным сервером производится с помощью сети Интернет.
4. Система по п. 1, в которой группы задаются на основании семантических значений байт-кода.
5. Система по п. 1, в которой группы разделяются по крайней мере на группы, описывающие инструкции, которые: передают данные между регистрами, работают с константами, работают с полями, относятся к вызовам или перехватам.
6. Система по п. 1, которая включает в себя средство оптимизации, предназначенное для повышения точности определения степени похожести указанных файлов.
7. Система по п. 6, в которой повышение точности определения степени похожести осуществляется одним из следующих вариантов:
- путем исключения из проверки классов и методов, относящихся к стандартным библиотечным пакетам;
- путем исключения классов, не содержащих ни одного метода;
- путем исключения методов, содержащих две и менее инструкций;
- путем исключения файлов, вектора которых хранятся в средстве хранения базы векторов, из дальнейшего анализа, если сравнение суммарного количества классов и методов указанных файлов с суммарным количеством классов и методов проверяемого файла отличается более чем на 25%;
- путем исключения классов или методов сравниваемых файлов из дальнейшего сравнения, если размер сравниваемых классов или методов отличается более чем на 25%;
- путем сравнения векторов методов, только содержащихся в одном классе.
8. Способ обнаружения вредоносных файлов среди исполняемых файлов формата DEX на мобильном устройстве, использующем операционную систему Android, который включает в себя этапы, на которых:
а) выявляют классы и методы, содержащиеся в упомянутых классах, проверяемого исполняемого файла формата DEX,
б) выявляют байт-код для каждого выявленного метода проверяемого файла,
в) определяют инструкции, содержащиеся в каждом выявленном методе, путем выявления соответствующего опкода инструкции из байт-кода, принадлежащего соответствующему выявленному методу проверяемого файла,
г) разделяют все определенные инструкций для каждого метода по крайней мере на две функциональные группы, которые заранее заданы, при этом разделение заключается в определение принадлежности опкода инструкции, которые были получены от средства анализа для каждого метода, одной из заданных групп;
д) подсчитывают количество инструкций, принадлежащих каждой функциональной группе, соответствующего метода,
е) представляют каждый метод в виде вектора в n-мерном евклидовом пространстве на основании количества инструкций в упомянутой группе,
ж) сравнивают сформированные векторы методов проверяемого файла с векторами вредоносных файлов, содержащихся в средстве хранения базы векторов, для определения степени похожести между сравниваемыми файлами,
з) выносят вердикт о вредоносности проверяемого файла при превышении заданного порога.
9. Способ по п. 8, в котором группы задаются на основании семантических значений байт-кода.
10. Способ по п. 8, в котором группы разделяются, по крайней мере, на группы, описывающие инструкции, которые: передают данные между регистрами, работают с константами, работают с полями, относятся к вызовам или перехватам.
11. Способ по п. 8, в котором при сравнении файлов производят повышения точности определения степени похожести указанных файлов.
12. Способ по п. 8, в котором повышение точности определения степени похожести осуществляется одним из следующих вариантов:
- путем исключения из проверки классов и методов, относящихся к стандартным библиотечным пакетам;
- путем исключения классов, не содержащих ни одного метода;
- путем исключения методов, содержащих две и менее инструкций;
- путем исключения файлов, векторы которых хранятся в средстве хранения базы векторов, из дальнейшего сравнения, если сравнение суммарного количества классов и методов указанных файлов с суммарным количеством классов и методов проверяемого файла отличается более чем на 25%;
- путем исключения классов или методов сравниваемых файлов из дальнейшего сравнения, если размер сравниваемых классов или методов отличается более чем на 25%;
- путем сравнения векторов методов, только содержащихся в одном классе.
| СИСТЕМА И СПОСОБ ОБНАРУЖЕНИЯ ВРЕДОНОСНОГО ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ ПУТЕМ СОЗДАНИЯ ИЗОЛИРОВАННОЙ СРЕДЫ | 2012 |
|
RU2535175C2 |
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| US 8826439 B1, 02.09.2014 | |||
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |

