Область техники
Настоящее изобретение относится к области обработки аудиосигнала с целью создания улучшенного акустического окружения, в частности, для прослушивания при помощи наушников.
Предшествующий уровень техники
Способ и система для виртуализации преобразования звуковой последовательности, описанные в международной патентной заявке WO/2006/024850, известны из предшествующего уровня техники. Согласно этому известному решению, слушатель может прослушивать звук виртуальных громкоговорителей с помощью наушников с уровнем реализма, при котором этот звук трудно отличить от реальных громкоговорителей. Наборы персонализированных пространственных импульсных характеристик (ППИХ) получают для звуковых источников громкоговорителей для ограниченного количества положений головы слушателя. Персонализированные пространственные импульсные характеристики используются при преобразовании аудиосигнала, предназначенного для громкоговорителей, на виртуализированном выходе на наушники. Основывая преобразование на положении головы слушателя, система может регулировать преобразование таким образом, что кажется, что виртуальные громкоговорители не двигаются, когда слушатель поворачивает голову.
Недостаток предшествующего уровня техники
Решение, предложенное в предшествующем уровне техники, недостаточно приемлемо, поскольку оно не позволяет персонализировать эталонное акустическое окружение, не позволяет изменять тип акустического окружения по отношению к типу последовательности, которая должна быть воспроизведена.
Кроме того, использование решения из предшествующего уровня техники приводит к значительной продолжительности захвата образа звука с использованием затратной компьютерной обработки данных, требующей больших вычислительных ресурсов. Кроме того, это известное решение не позволяет ослабить стереосигнал на N каналах и не предусматривает генерацию каналов, которые исходно не существуют.
Решение, изложенное в изобретении
Настоящее изобретение преследует цель предоставить решение этой проблемы. В частности, способ, который раскрывается в настоящем изобретении, позволяет преобразовывать 2D-звук в 3D-звук либо с использованием стереофайла, либо с использованием многоканальных файлов, позволяет генерировать звуковой 3D-стереосигнал посредством виртуализации с возможностью выбора конкретного звукового фона.
С этой целью в изобретении рассматривается, в соответствии с наиболее общим смыслом, способ обработки исходного аудиосигнала с N.x каналов, где N - больше 1, х - больше или равно 0, включающий стадию многоканальной обработки указанного входного аудиосигнала посредством многоканальной свертки с заранее заданным образом, причем вышеуказанный образ создается путем захвата эталонного звука с помощью набора громкоговорителей, расположенных в базовом пространстве, и при этом он включает дополнительную стадию выбора по меньшей мере одного из множества образов, ранее созданных на различных звуковых фонах.
Это решение, основанное на частотной фильтрации, разности между левым и правым каналом, с тем чтобы сформировать центральный канал и дифференциацию фаз, позволяет создать из стереосигнала множество стереоканалов, где каждый виртуальный громкоговоритель является стереофайлом.
Это позволяет применить другой образ для каждого из виртуальных каналов и создать путем рекомбинации каналов новый конечный стереоаудиофайл, содержащий 3D-образ каждого виртуального громкоговорителя.
Преимущественно способ согласно изобретению включает стадию создания нового образа путем обработки по меньшей мере одного ранее созданного образа.
В соответствии с одним вариантом воплощения способ дополнительно включает стадию рекомбинации М.х каналов, соответственно обрабатываемых с целью получения выходного сигнала М.у каналов, где N.x отличается от М.у, М - больше 1, у - больше или равно 0.
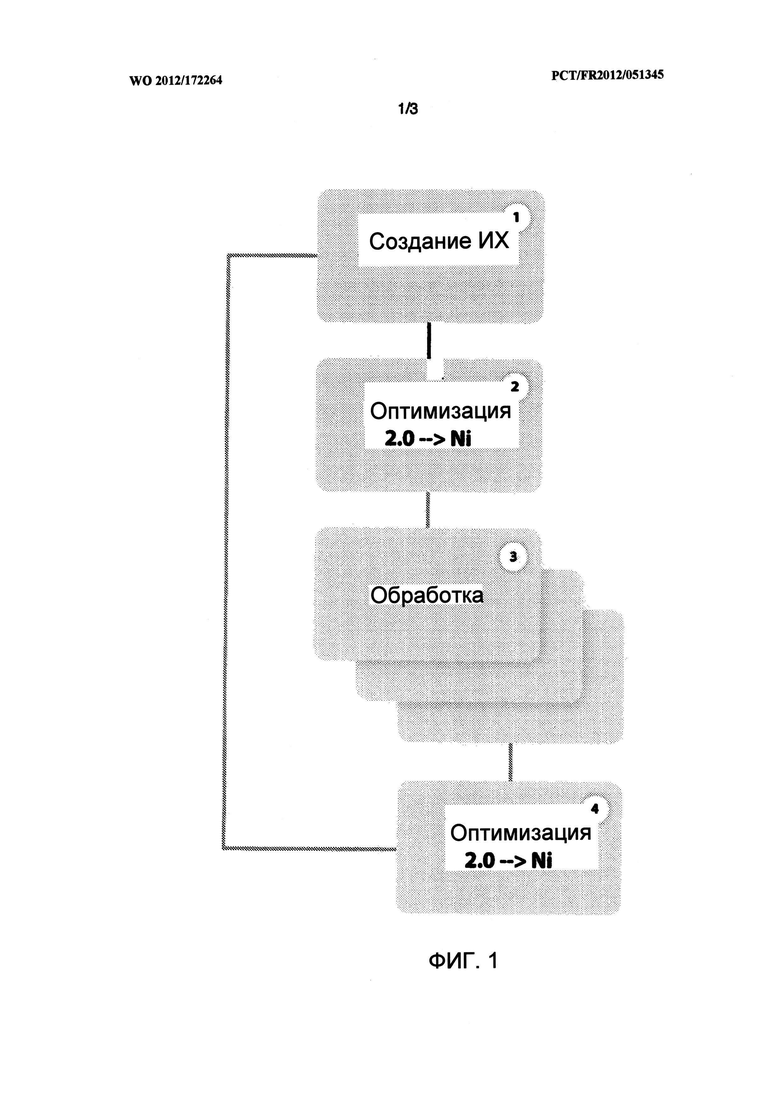
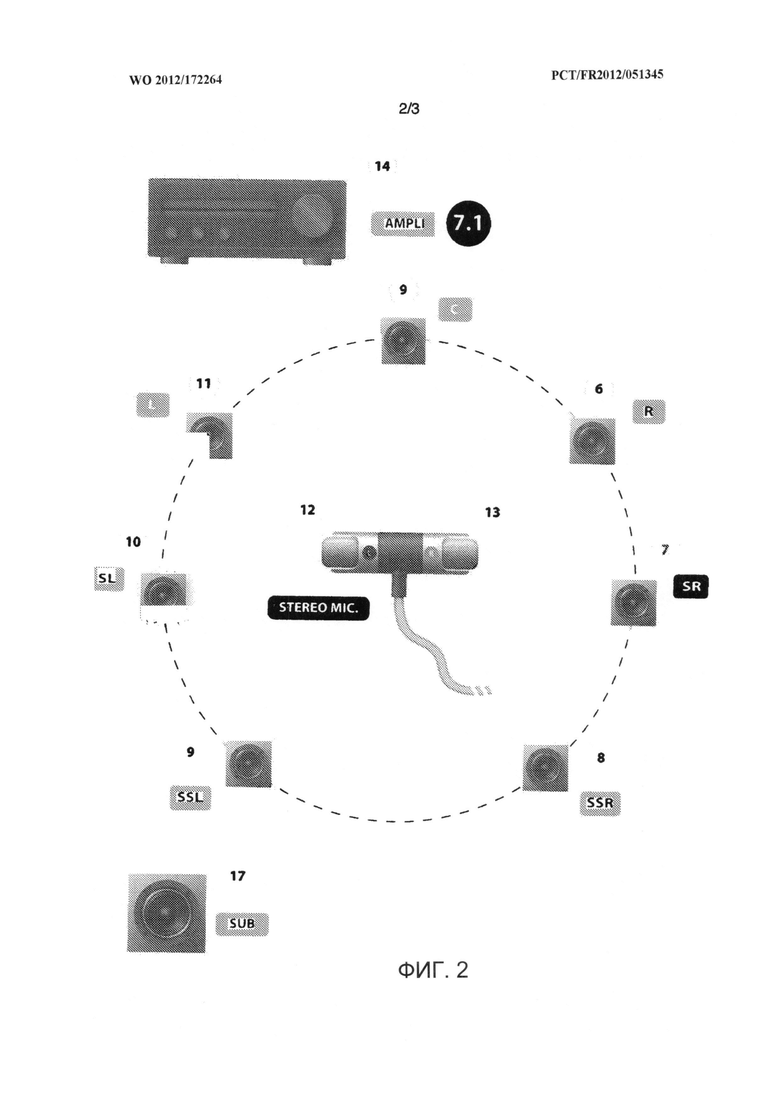
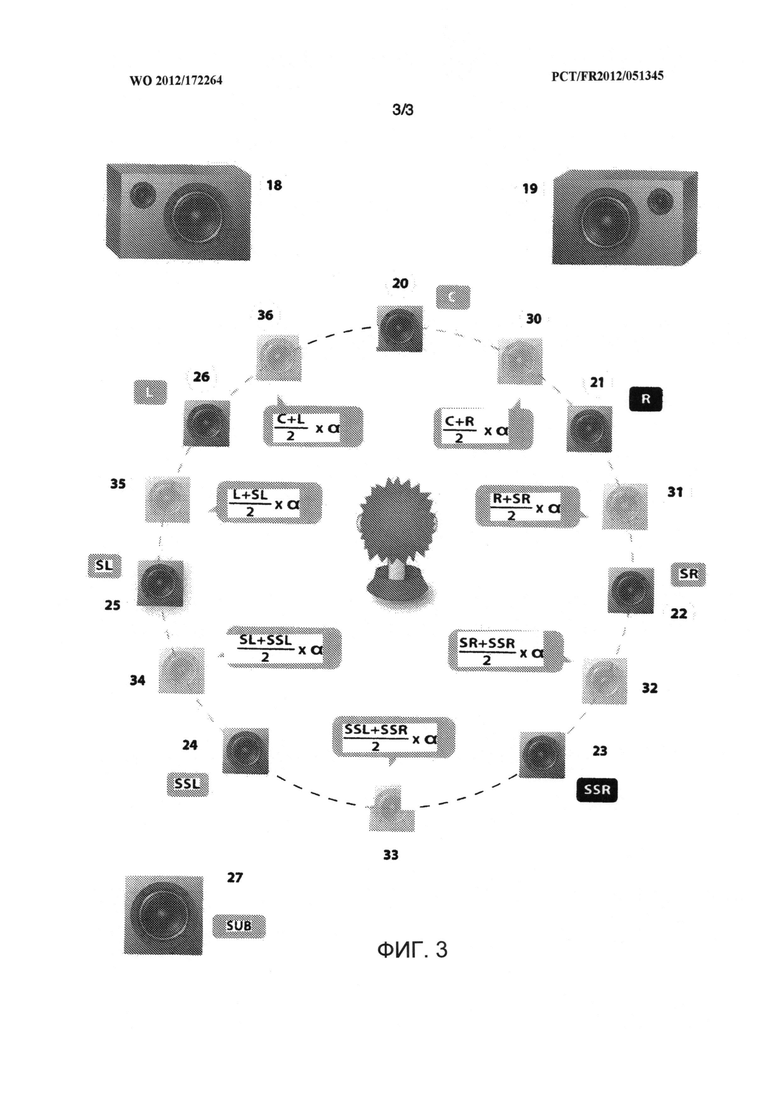
Изобретение поясняется фигурами, где показано: на фиг.1 - последовательность основных действий способа, на фиг.2 - используемое оборудование, на фиг.3 - сочетание громкоговорителей и их образов.
Подробное описание примерного варианта воплощения изобретения
Способ в соответствии с изобретением разбивается на последовательность стадий:
- создание нескольких последовательностей звуковых образов
- создание последовательности виртуализированных образов путем комбинирования из библиотеки образов
- объединение дорожек исходного звукового сигнала с последовательностью виртуализированных образов.
1 - Создание образа
Получение сигнала
Создание звукового образа состоит из размещения в определенной окружающей среде, например концертном зале, большом помещении или даже в природной среде (пещера, открытое пространство и т.д.) набора акустических образов, сгруппированных в N×M звуковых точках. Например, простая пара "правого-левого" громкоговорителей или наборы 5.1, 7.1, или 11.1 громкоговорителей, воспроизводящих эталонный звуковой сигнал известным способом.
Пара микрофонов размещается, например, на искусственной голове, или применяются всенаправленные HRTF микрофоны, которые улавливают звук громкоговорителей в рассматриваемой окружающей среде. Сигналы, вырабатываемые парой микрофонов, записываются после дискретизации на высокой частоте, например 192 кГц, 24 бит.
Эта цифровая запись позволяет захватить сигнал, отображающий данное звуковое окружение.
Эта стадия не ограничивается захватом звукового сигнала, вырабатываемого громкоговорителями. Захват может быть также произведен из сигнала, вырабатываемого наушниками, расположенными на искусственной голове. Этот вариант позволяет воссоздать звуковое окружение данных наушников при воспроизведении на другом наборе наушников.
2 - Вычисление образа
Этот сигнал затем подвергается обработке, состоящей из приложения разности между эталонным сигналом, подаваемым на громкоговорители, оцифрованным с теми же условиями, и сигналом, захваченным микрофонами. Эта разность создается с помощью компьютера, получающего в качестве входных данных файлы .vaw или аудиофайлы, относительно эталонного сигнала, подаваемого на каждый из громкоговорителей, с одной стороны, и захваченного сигнала, с другой стороны, для того чтобы создать сигнал "ИХ - Импульсная характеристика" для каждого из громкоговорителей, которые были использованы для создания эталонного сигнала. Эта обработка применяется к каждому из входных сигналов каждого из громкоговорителей, с которых собираются данные.
При такой обработке создается набор файлов, каждый из которых соответствует образу одного из громкоговорителей в определенной окружающей среде.
Представление семейства образов
Вышеупомянутая стадия воспроизводится для различных звуковых окружений и/или различных вариантов расположения громкоговорителей. Для каждого из новых вариантов расположения стадия получения, а затем обработки выполняется с целью создания новой последовательности образов, представляющих новую картину расстановки звука.
Таким образом, создается библиотека последовательностей звуковых образов, представляющих данные известные звуковые окружения.
Создание виртуального окружения
Вышеупомянутая библиотека используется для создания новой последовательности образов, представляющей виртуальное окружение, путем комбинирования нескольких последовательностей образов и добавления файлов, соответствующих выбранным образам с тем, чтобы уменьшить зоны, где звуковое окружение не содержало звука громкоговорителей во время вышеупомянутой стадии получения.
Эта стадия создания виртуального окружения позволяет повысить согласованность и динамический диапазон звука в результате применения к конкретной записи, в частности, благодаря лучшему трехмерному заполнению звукового пространства.
Это эквивалентно использованию искусственного окружения с очень большим числом громкоговорителей.
Результатом этой стадии является получение нового виртуализированного образа зала, который может быть применен к любой звуковой последовательности для улучшения воспроизведения.
Обработка звуковой последовательности
Далее выбирается существующая аудиопоследовательность, дискретизируемая с теми же предпочтительными условиями.
В противном случае, виртуализированный образ модифицируется так, чтобы уменьшить частоту и выполнить дискретизацию аудиосигнала, подлежащего обработке.
Известным сигналом является, например, стереосигнал. Он является объектом частотной нарезки и нарезки, основанной на разности фаз между правым и левым сигналами.
Из этого сигнала извлекаются N дорожки путем применения одного из виртуализированных образов к комбинациям этих нарезок.
Таким образом, можно создавать различное количество дорожек, комбинируя результаты нарезки и применяя один из образов к каждой из дорожек, так чтобы создать N×M треки, причем N и М не обязательно равны количеству каналов, используемых на стадии создания образа. Это возможно, например, для создания большего количества дорожек для более динамичного воспроизведения или меньшего количества, например, для воспроизведения через наушники.
Результат этой стадии представляет собой последовательность аудиосигналов, которые затем преобразуются в обычный стереосигнал для возможности воспроизведения на стандартном оборудовании.
Естественно, можно также применять и операции обработки, такие как чередование фаз сигнала.
Стадия обработки звуковой последовательности может быть выполнена в отсроченном режиме с целью получения записей, которые могут быть переданы в любой момент.
Она также может быть выполнена в реальном времени, так чтобы обрабатывать аудиопоток одновременно с его созданием. Этот вариант особенно подходит для преобразования звука в режиме реального времени, получаемого в потоковой передаче, в расширенный звуковой сигнал для воспроизведения с лучшим динамическим диапазоном.
В соответствии с вариантом воплощения такая обработка позволяет создать сигнал, производя повышение каких-либо колебаний около основного звукового сигнала, которые человеческий мозг может "представить" по ошибке сзади, в то время как это передний сигнал. Для этой цели выполняется горизонтальное движение, чтобы перенастроить мозг, а затем повторно выполнить центрирование. Эта стадия состоит из незначительного увеличения уровня или близости к центру переднего виртуального громкоговорителя.
Эта стадия применяется, когда звуковой сигнал преимущественно центрирован, что часто происходит с "голосовой" частью музыкальной записи. Это приближение-усиление обработки применяется временно, предпочтительно когда появляется центрированная аудиопоследовательность.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ТРАНСАУРАЛЬНОГО СИНТЕЗА ДЛЯ ПРИДАНИЯ ЗВУКУ ПРОСТРАНСТВЕННОЙ ФОРМЫ | 2013 |
|
RU2639955C2 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ ФОРМИРОВАНИЯ ЗАКОДИРОВАННОГО СТЕРЕОСИГНАЛА АУДИОЧАСТИ ИЛИ ПОТОКА ДАННЫХ АУДИО | 2006 |
|
RU2376726C2 |
| УСТРОЙСТВО И СПОСОБ СИНТЕЗИРОВАНИЯ ТРЕХ ВЫХОДНЫХ КАНАЛОВ, ИСПОЛЬЗУЯ ДВА ВХОДНЫХ КАНАЛА | 2005 |
|
RU2384973C1 |
| ПРОЦЕССОР АУДИОСИГНАЛОВ ДЛЯ ОБРАБОТКИ КОДИРОВАННЫХ МНОГОКАНАЛЬНЫХ АУДИОСИГНАЛОВ И СПОСОБ ДЛЯ ЭТОГО | 2012 |
|
RU2595910C2 |
| АУДИОСИСТЕМА И СПОСОБ ОПЕРИРОВАНИЯ ЕЮ | 2012 |
|
RU2595943C2 |
| РЕНДЕРИНГ ОТРАЖЕННОГО ЗВУКА ДЛЯ ОБЪЕКТНО-ОРИЕНТИРОВАННОЙ АУДИОИНФОРМАЦИИ | 2013 |
|
RU2602346C2 |
| КОДИРОВАНИЕ И ДЕКОДИРОВАНИЕ АУДИО | 2007 |
|
RU2427978C2 |
| ФОРМИРОВАНИЕ БИНАУРАЛЬНЫХ СИГНАЛОВ | 2009 |
|
RU2505941C2 |
| ДЕКОДИРОВАНИЕ БИНАУРАЛЬНЫХ АУДИОСИГНАЛОВ | 2007 |
|
RU2409911C2 |
| МАНИПУЛИРОВАНИЕ ЗОНОЙ НАИЛУЧШЕГО ВОСПРИЯТИЯ ДЛЯ МНОГОКАНАЛЬНОГО СИГНАЛА | 2007 |
|
RU2454825C2 |
Настоящее изобретение относится к средствам обработки аудиосигнала. Технический результат заключается в улучшении качества звукового пространства при малом количестве регистраций за счет улучшения согласованности и динамического диапазона звука. Обрабатывают исходный аудиосигнал с N.х каналами, где N больше 1, а х больше или равно 0, включая стадию многоканальной обработки вышеупомянутого входного аудиосигнала посредством многоканальной свертки с заранее заданным образом. Вышеупомянутый образ создается путем захвата эталонного звука с помощью набора акустических экранов, расположенных в базовом пространстве. Дополнительно выбирают по меньшей мере один образ из множества образов, ранее созданных на различных звуковых фонах. 3 з.п. ф-лы, 3 ил.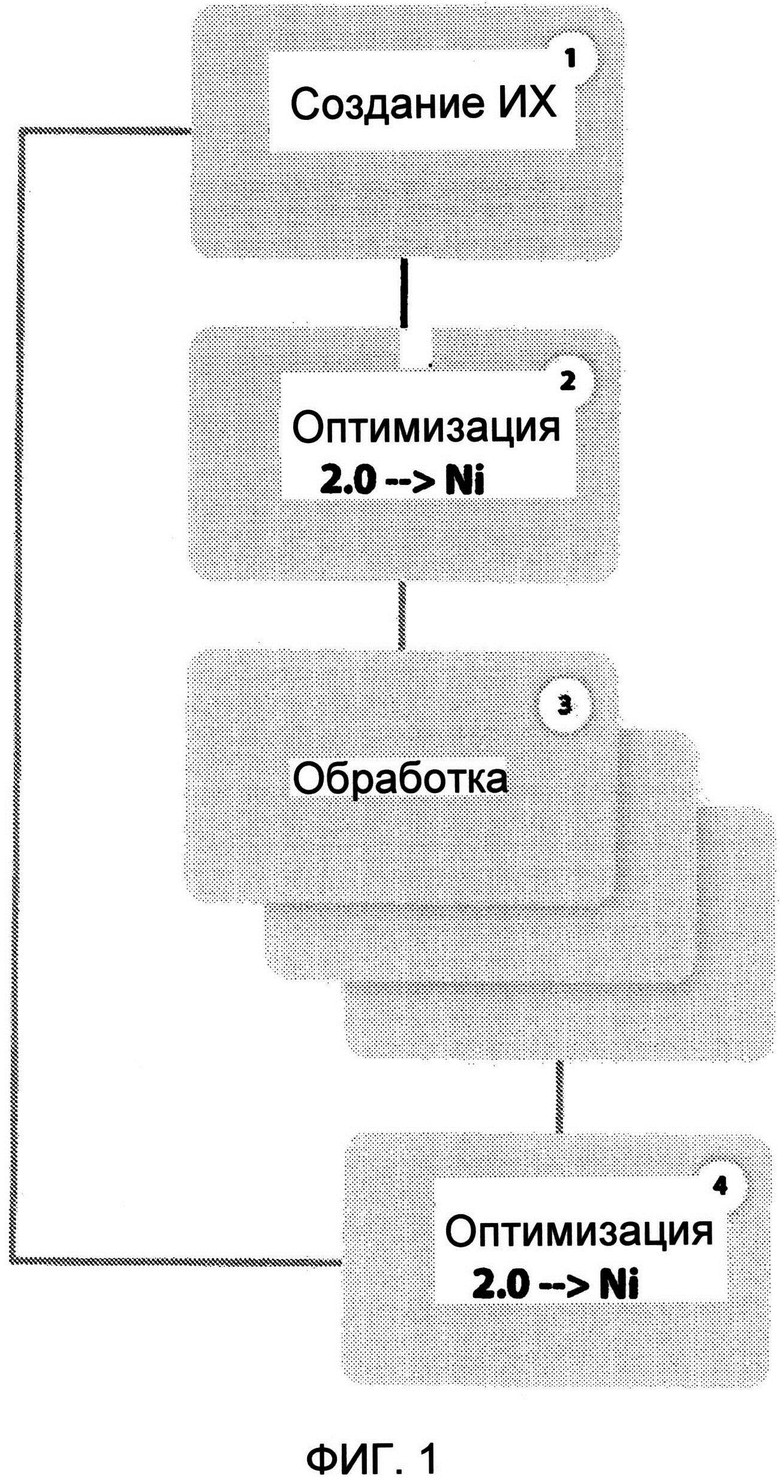
1. Способ обработки исходного аудиосигнала с N.x каналов, где N больше 1 и х больше или равно 0, включающий стадию многоканальной обработки входного аудиосигнала посредством многоканальной свертки с заранее заданным образом, причем вышеупомянутый образ создают путем захвата эталонного звука с использованием набора громкоговорителей, расположенных в базовом пространстве, и при этом он дополнительно включает дополнительную стадию выбора по меньшей мере одного из множества образов, ранее созданных на различных звуковых фонах посредством добавления файлов, соответствующих выбранным образам, и комбинирования нескольких последовательностей образов для создания новой последовательности образов, представляющей виртуальное окружение.
2. Способ по п. 1, отличающийся тем, что дополнительно включает стадию создания нового образа путем обработки по меньшей мере одного ранее созданного образа.
3. Способ по пп. 1 или 2, отличающийся тем, что дополнительно включает стадию рекомбинации N.x каналов, соответственно обрабатываемых с целью получения выходного сигнала М.у каналов, при этом N.x отличается от М.у, М имеет значение больше 1, у имеет значение больше или равное 0.
4. Способ по пп. 1 или 2, отличающийся тем, что дополнительно включает стадию, состоящую из временного увеличения уровня эффекта присутствия центрального переднего виртуального громкоговорителя, когда звуковой сигнал центрирован.
| Колосоуборка | 1923 |
|
SU2009A1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Прибор, замыкающий сигнальную цепь при повышении температуры | 1918 |
|
SU99A1 |
| МНОГОСТУПЕНЧАТЫЙ ЛОПАСТНОЙ НАСОС ДЛЯ РАБОТЫ НА ГАЗОЖИДКОСТНОЙ СМЕСИ С ПОВЫШЕННЫМ ГАЗОСОДЕРЖАНИЕМ (ВАРИАНТЫ) | 2011 |
|
RU2471089C1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Бесколесный шариковый ход для железнодорожных вагонов | 1917 |
|
SU97A1 |
| HENRIK MOLLER: "Fundamentals of binaural technology", 1992, pages 171-218 | |||
| УСТРОЙСТВО И СПОСОБ ДЛЯ ФОРМИРОВАНИЯ ЗАКОДИРОВАННОГО СТЕРЕОСИГНАЛА АУДИОЧАСТИ ИЛИ ПОТОКА ДАННЫХ АУДИО | 2006 |
|
RU2376726C2 |

