Изобретение относится к кодированию и/или декодированию аудио, в частности, но не исключительно, к кодированию и/или декодированию аудио, включающего бинауральный виртуальный пространственный сигнал.
Цифровое кодирование различных исходных сигналов стало в большей степени важным за последние десятилетия, так как цифровое представление и передача сигналов в большей степени заменили аналоговое представление и передачу. Например, распространение аудиовизуального контента, такого как видео и музыка, в большей степени основано на кодировании цифрового контента.
Более того, в последнее десятилетие была тенденция в направлении многоканального аудио и, особенно, в направлении пространственного аудио, выходящего за пределы традиционных стереосигналов. Например, традиционные стереозаписи содержат только два канала, тогда как современные развитые аудиосистемы типично используют пять или шесть каналов, как в популярных системах объемного звучания 5.1. Это предусматривает более вовлеченное впечатление от прослушивания, где пользователь может быть окружен источниками звука.
Различные технологии и стандарты были разработаны для передачи таких многоканальных сигналов. Например, шесть дискретных каналов, представляющие систему объемного звучания 5.1, могут передаваться в соответствии со стандартами, такими как стандарты расширенного кодирования аудио (AAC) или стандарты Dolby Digital.
Однако, для того чтобы обеспечить обратную совместимость, известно, что следует осуществлять понижающее микширование большего количества каналов в меньшее количество, и, более точно, это часто используется для понижающего микширования сигнала объемного звука 5.1 в стереосигнал с предоставлением стереосигналу возможности воспроизводиться (стерео) декодерами прежней системы, а сигналу 5.1 декодерами объемного звука.
Одним из примеров является обратно совместимый способ кодирования стандарта MPEG2. Многоканальный сигнал подвергается понижающему микшированию в стереосигнал. Дополнительные сигналы кодируются в порции служебных данных, предоставляя многоканальному декодеру MPEG2 возможность формировать представление многоканального сигнала. Декодер MPEG1 будет игнорировать служебные данные и, таким образом, декодировать только стереосигнал понижающего микширования. Основной недостаток способа кодирования, применяемого в MPEG2, состоит в том, что дополнительная скорость передачи данных, требуемая для дополнительных сигналов, находится в том же порядке величины, что и скорость передачи данных, требуемая для кодирования стереосигнала. Дополнительная скорость передачи данных для расширения стерео в многоканальное аудио, поэтому, является значительной.
Другие существующие способы для обратно совместимой многоканальной передачи без дополнительной многоканальной информации типично могут характеризоваться способами матрицированного заполнения. Примеры матричного кодирования объемного звука включают в себя способы, такие как Dolby Prologic II и Logic-7. Общий принцип этих способов заключается в том, что они матричным образом перемножают многочисленные каналы входного сигнала на подходящую неквадратную матрицу, тем самым формируя выходной сигнал с меньшим количеством каналов. Более точно, матричный кодировщик типично применяет фазовые сдвиги к объемным каналам перед микшированием их с фронтальными и центральным каналами.
Еще одной причиной для преобразования канала является эффективность кодирования. Было обнаружено, что, например, аудиосигналы объемного звука могут кодироваться как аудиосигналы стереоканалов, объединенные с параметрическим потоком битов, описывающим пространственные свойства аудиосигнала. Декодер может воспроизводить стерео аудиосигналы с весьма удовлетворительной степенью точности. Таким образом, могут быть получены существенные экономии битовой скорости передачи.
Есть несколько параметров, которые могут использоваться для описания пространственных свойств аудиосигналов. Одним из таких параметров является межканальная взаимная корреляция, такая как взаимная корреляция между левым каналом и правым каналом для стереосигналов. Еще одним параметром является отношение мощностей каналов. В так называемых (параметрических) пространственных кодировщиках аудио эти и другие параметры извлекаются из исходного аудиосигнала с тем, чтобы воспроизводить аудиосигнал, имеющий сокращенное количество каналов, например только один канал, плюс набор параметров, описывающих пространственные свойства исходного аудиосигнала. В так называемых (параметрических) пространственных декодерах аудио пространственные свойства в качестве описанных передаваемыми пространственными параметрами восстанавливаются.
Такое пространственное кодирование аудио предпочтительно использует каскадную или основанную на дереве иерархическую структуру, содержащую стандартные блоки в кодировщике и декодере. В кодировщике эти стандартные блоки могут быть понижающими микшерами, объединяющими каналы в меньшее количество каналов, такими как понижающие микшеры 2-в-1, 3-в-1, 3-в-2 и т.д., наряду с тем, что в декодере соответствующие стандартные блоки могут быть повышающими микшерами, расщепляющими каналы на большее количество каналов, такими как повышающие микшеры 1-в-2, 2-в-3.
Пример системы, в которой многоканальный сигнал подвергается понижающему микшированию в стереосигнал, который впоследствии подвергается постобработке с использованием пространственных параметров понижающего микширования, представлен в публикации WO 2005/098826A заявки на патент по Договору о патентном сотрудничестве. Пример устройства кодирования и декодирования аудиосигнала, способного к передаче аудиосигнала или аудиосигнала вместе с обработанным эффектами звукового поля аудиосигналом, приведен в публикации US2005/0273322A1 заявки на патент США.
3-мерное (3D) позиционирование источника звука в настоящее время приобретает интерес, особенно в мобильной области. Проигрывание музыки и звуковых эффектов в мобильных играх может добавить значительную ценность впечатлению потребителя, когда позиционируется в 3-х измерениях, эффективно создавая 3-мерный эффект 'вне головы'. Более точно, известно, что следует записывать и воспроизводить бинауральные аудиосигналы, которые содержат специфичную направлениям информацию, к которой чувствительно человеческое ухо. Бинауральные записи типично производятся с использованием двух микрофонов, установленных на имитатор головы человека, так что записанный звук соответствует звуку, улавливаемому человеческим ухом, и включает в себя любые влияния, обусловленные формой головы или ушей. Бинауральные записи отличаются от стерео (то есть стереофонических) записей тем, что воспроизведение бинауральной записи обычно предназначено для наушников или головных телефонов, тогда как стереозапись обычно производится для воспроизведения громкоговорителями. В то время как бинауральная запись предоставляет возможность воспроизведения всей пространственной информации с использованием только двух каналов, стереозапись не обеспечивала бы такого же пространственного восприятия. Обычные двухканальные (стереофонические) или многоканальные (например, 5.1) записи могут трансформироваться в бинауральные записи сверткой каждого обычного сигнала с набором передаточных функций восприятия. Такие передаточные функции восприятия моделируют влияние головы человека и, возможно, других объектов на сигнал. Широко известным типом передаточной функции пространственного восприятия является так называемая функция моделирования восприятия звука человеком (Head-Related Transfer Function, HRTF). Альтернативным типом передаточной функции пространственного восприятия, которая также учитывает отражения, вызванные стенами, потолком и полом помещения, является бинауральная импульсная характеристика помещения (BRIR).
Типично, алгоритмы 3-мерного позиционирования применяют HRTF, которые описывают передачу из некоторого местоположения источника звука на барабанные перепонки посредством импульсной характеристики. 3-мерное позиционирование источника звука может применяться к многоканальным сигналам посредством HRTF, тем самым предоставляя бинауральным сигналам возможность поставлять информацию пространственного звука пользователю, например, с использованием пары наушников.
Известно, что восприятие угла возвышения преимущественно облегчается определенными пиками и провалами в спектрах, приходящих в оба уха. С другой стороны, (воспринимаемый) курсовой угол источника звука улавливается в 'бинауральных' контрольных сигналах, таких как перепады уровня и разности времен поступления между сигналами на барабанных перепонках. Восприятие расстояния по большей части облегчается общим уровнем сигнала и, в случае реверберирующего окружения, соотношением направленной и реверберационной энергии. В большинстве случаев допускается, чтобы, особенно в последней конечной фазе реверберации, не было контрольных сигналов достоверного определения местоположения источника звука.
Контрольные сигналы восприятия для возвышения, курсового угла и расстояния могут улавливаться посредством (пары) импульсных характеристик: одна импульсная характеристика, чтобы описывать передачу из определенного положения источника звука в левое ухо; и одна для правого уха. Отсюда контрольные сигналы восприятия для возвышения, курсового угла и расстояния определяются соответствующими свойствами (пары) импульсных характеристик HRTF. В большинстве случаев, пара HRTF измеряется для большого набора местоположений источника звука; типично, с пространственным разрешением приблизительно в 5 градусов как по углу возвышения, так и курсовому углу.
Традиционный бинауральный 3-мерный синтез содержит фильтрацию (свертку) входного сигнала с парой HRTF для требуемого местоположения источника звука. Однако поскольку HRTF типично измеряются в безэховых условиях, восприятие 'расстояния' или определение местоположения 'вне головы' часто является отсутствующим. Хотя свертка сигнала с безэховыми HRTF не достаточна для 3-мерного синтеза звука, использование безэховых HRTF часто является предпочтительным с точки зрения сложности и гибкости. Эффект содержащей эхо среды (требуемый для создания восприятия расстояния) может добавляться на более поздней стадии, оставляя некоторую гибкость для конечного пользователя модифицировать акустические свойства помещения. Более того, поскольку часто предполагается, что реверберация однонаправленная (без контрольных сигналов направления), этот способ обработки часто более эффективен, чем свертка каждого источника звука с содержащей эхо парой HRTF. Более того, помимо аргументов сложности и гибкости для акустики помещения, использование безэховых HRTF также обладает преимуществом для синтеза сигналов (контрольных сигналов направления) 'с плоским звуком'.
Последнее исследование в области 3-мерного позиционирования показало, что частотное разрешение, которое представлено безэховыми импульсными характеристиками HRTF, во многих случаях выше, чем необходимо. Более точно, видится, что для обоих, фазового и амплитудного, спектров нелинейное частотное разрешение, которое предложено шкалой ERB, достаточно для синтеза 3-мерных источников звука с точностью, которая по восприятию не отличается от обработки с полными безэховыми HRTF. Другими словами, спектры безэховых HRTF не требуют спектрального разрешения, которое выше, чем частотное разрешение слуховой системы человека.
Традиционный алгоритм бинаурального синтеза очерчен на фиг.1. Набор входных каналов фильтруется набором HRTF. Каждый входной канал расщепляется на два сигнала (левую 'L' и правую 'R' составляющие); каждый из этих сигналов впоследствии фильтруется HRTF, соответствующей требуемому местоположению источника звука. Все сигналы левого уха впоследствии суммируются, чтобы сформировать левый бинауральный выходной сигнал, а сигналы правого уха суммируются, чтобы сформировать правый бинауральный выходной сигнал.
Свертка HRTF может выполняться во временной области, но часто предпочтительно выполнять фильтрацию в качестве произведения в частотной области. В таком случае, суммирование также может выполняться в частотной области.
Известны системы декодеров, которые могут принимать кодированный сигнал объемного звука и формировать впечатление объемного звука из бинаурального сигнала. Например, известны системы наушников, предоставляющие сигналу объемного звука возможность преобразовываться в бинауральный сигнал объемного звука для предоставления впечатления объемного звука пользователю наушников.
Фиг.2 иллюстрирует систему, в которой декодер объемного звучания MPEG принимает стереосигнал с пространственными параметрическими данными. Входной поток битов демультиплексируется, давая в результате пространственные параметры и поток битов понижающего микширования. Последний поток битов декодируется с использованием традиционного моно- или стереодекодера. Декодированный сигнал понижающего микширования декодируется пространственным декодером, который формирует многоканальный выходной сигнал на основании переданных пространственных параметров. В заключение, многоканальный выходной сигнал затем обрабатывается каскадом бинаурального синтеза (подобным таковому по фиг.1), давая в результате бинауральный выходной сигнал, дающий впечатление объемного звука пользователю.
Однако такой подход имеет некоторое количество недостатков.
Например, каскадное включение декодера пространственного звука и бинаурального синтеза включает в себя вычисление представления многоканального сигнала в качестве промежуточного этапа, сопровождаемое сверткой HRTF и понижающим микшированием на этапе бинаурального синтеза. Это может иметь следствием повышенную сложность и сниженную производительность.
К тому же, система очень сложна. Например, пространственные декодеры типично работают в области поддиапазонов (QMF). Свертка HRTF, с другой стороны, типично может быть реализована наиболее эффективно в области БПФ (FFT, быстрого преобразования Фурье). Поэтому необходимо каскадное включение многоканальной гребенки фильтров синтеза QMF, многоканального преобразования БПФ и стереопреобразования обратного БПФ, дающее в результате систему с высокими вычислительными потребностями.
Качество обеспечиваемого впечатления пользователя может снижаться. Например, артефакты кодирования, порождаемые пространственным декодером для создания многоканальной реконструкции, по-прежнему будут слышимы в (стерео) бинауральном выходном сигнале.
Более того, подход требует выделенных декодеров и сложной сигнальной обработки, которая должна выполняться индивидуальными пользовательскими устройствами. Это может замедлять приложение во многих ситуациях. Например, устройства прежних систем, которые способны только к декодированию стереопонижающего микширования, не будут способны обеспечивать пользовательское впечатление окружающего звука.
Отсюда было бы полезным улучшенное кодирование/декодирование аудиосигнала.
Соответственно, изобретение стремится предпочтительно смягчить, облегчить или устранить один или более из вышеупомянутых недостатков раздельно или в любом сочетании.
Согласно первому аспекту изобретения предложен кодировщик аудиосигнала, содержащий: средство для приема M-канального аудиосигнала, где M>2; средство понижающего микширования для понижающего микширования M-канального аудиосигнала в первый стереосигнал и связанные параметрические данные; средство формирования для модифицирования первого стереосигнала, чтобы формировать второй стереосигнал, в ответ на связанные параметрические данные и данные пространственных параметров для передаточной функции бинаурального восприятия, второй стереосигнал является бинауральным сигналом; средство для кодирования второго стереосигнала, чтобы формировать кодированные данные; и средство вывода для формирования выходного потока данных, содержащего кодированные данные и связанные параметрические данные.
Изобретение может предоставлять возможность улучшенного кодирования аудиосигнала. В частности, изобретение может предоставлять возможность эффективного стереокодирования многоканальных сигналов, наряду с предоставлением стереодекодерам прежних систем возможности обеспечивать усиленное пространственное впечатление. Более того, изобретение предоставляет возможность реверсировать процесс бинаурального виртуального пространственного синтеза в декодере, тем самым давая возможность высококачественного многоканального декодирования. Изобретение может предоставлять возможность кодировщика низкой сложности и, в частности, может давать возможность формирования бинаурального сигнала низкой сложности. Изобретение может предоставлять возможность облегченной реализации и повторного использования функциональных возможностей.
Изобретение, в частности, может обеспечивать основанное на параметрах определение бинаурального виртуального пространственного сигнала из многоканального сигнала.
Бинауральный сигнал, более точно, может быть бинауральным виртуальным пространственным сигналом, таким как виртуальный 3-мерный бинауральный стереосигнал. M-канальный аудиосигнал может быть сигналом объемного звучания, таким как сигнал объемного звучания 5.1 или 7.1. Бинауральный виртуальный пространственный сигнал может имитировать одно местоположение источника звука для каждого канала M-канального аудиосигнала. Данные пространственных параметров могут содержать данные, указывающие передаточную функцию из предполагаемого местоположения источника звука на барабанную перепонку предполагаемого пользователя.
Передаточная функция бинаурального восприятия, например, может быть функцией моделирования восприятия звука человеком (HRTF) или бинауральной импульсной характеристикой помещения (BRIR).
Согласно дополнительному признаку изобретения средство формирования выполнено с возможностью формировать второй стереосигнал посредством расчета значений данных поддиапазона для второго стереосигнала в ответ на связанные параметрические данные, данные пространственных параметров и значения данных поддиапазона для первого стереосигнала.
Это может предоставлять возможность улучшенного кодирования и/или облегченной реализации. Более точно, признак может давать пониженную сложность и/или сокращенные затраты вычислительных ресурсов. Интервалы частотных поддиапазонов первого стереосигнала, второго стереосигнала, связанных параметрических данных и данных пространственных параметров могут быть разными, либо некоторые или все поддиапазоны могут быть по существу идентичными для некоторых или всех из таковых.
Согласно дополнительному признаку изобретения средство формирования выполнено с возможностью формировать значения поддиапазона для первого поддиапазона второго стереосигнала в ответ на умножение соответствующих стереозначений поддиапазона для первого стереосигнала на матрицу первого поддиапазона; средство формирования дополнительно содержит средство параметров для определения значений данных для матрицы первого поддиапазона в ответ на связанные параметрические данные и данные пространственных параметров для первого поддиапазона.
Это может предоставлять возможность улучшенного кодирования и/или облегченной реализации. Более точно, признак может давать пониженную сложность и/или сокращенные затраты вычислительных ресурсов. Изобретение, в частности, может обеспечивать основанное на параметрах определение бинаурального виртуального пространственного сигнала из многоканального сигнала выполнением матричных операций над отдельными поддиапазонами. Значения матрицы первого поддиапазона могут отражать объединенный результат каскадного включения многоканального декодирования и фильтрации HRTF/BRIR результирующего множества каналов. Умножение матрицы поддиапазона может выполняться для всех поддиапазонов второго стереосигнала.
Согласно дополнительному признаку изобретения средство формирования дополнительно содержит средство для преобразования значения данных, по меньшей мере, одного из стереосигнала, связанных параметрических данных и данных пространственных параметров, связанных с поддиапазоном, содержащим интервал частот, отличный от интервала первого поддиапазона, в соответствующее значение данных для первого поддиапазона.
Это может предоставлять возможность улучшенного кодирования и/или облегченной реализации. Более точно, признак может давать пониженную сложность и/или сокращенные затраты вычислительных ресурсов. Более точно, изобретение может предоставлять разным процессам и алгоритмам возможность основываться на разделениях поддиапазонов, наиболее подходящих для индивидуального процесса.
Согласно дополнительному признаку изобретения средство формирования выполнено с возможностью определять стереозначения LB, RB поддиапазона для первого поддиапазона второго стереосигнала по существу в качестве:
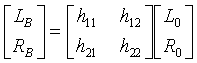 ,
,
при этом L0, R0 - соответствующие значения поддиапазона первого стереосигнала, а средство параметров выполнено с возможностью определять значения данных матрицы умножения по существу в качестве:
h 11 = m 11 H L(L)+m 21 H L(R)+m 31 H L(C)
h 12 = m 12 H L(L)+m 22 H L(R)+m 32 H L(C)
h 21 = m 11 H R(L)+m 21 H R(R)+m 31 H R(C)
h 22 = m 12 H R(L)+m 22 H R(R)+m 32 H R(C),
где mk,l - параметры, определенные в ответ на связанные параметрические данные для понижающего микширования средством понижающего микширования каналов L, R и C в первый стереосигнал; а HJ(X) определяется в ответ на данные пространственных параметров для канала X в отношении выходного стереоканала J второго стереосигнала.
Это может предоставлять возможность улучшенного кодирования и/или облегченной реализации. Более точно, признак может давать пониженную сложность и/или сокращенные затраты вычислительных ресурсов.
Согласно дополнительному признаку изобретения, по меньшей мере, один из каналов L и R соответствует понижающему микшированию, по меньшей мере, двух подвергнутых понижающему микшированию каналов, а средство параметров выполнено с возможностью определять HJ(X) в ответ на взвешенную комбинацию данных пространственных параметров для, по меньшей мере, двух подвергнутых понижающему микшированию каналов.
Это может предоставлять возможность улучшенного кодирования и/или облегченной реализации. Более точно, признак может давать пониженную сложность и/или сокращенные затраты вычислительных ресурсов.
Согласно дополнительному признаку изобретения средство параметров выполнено с возможностью определять взвешивание данных пространственных параметров для, по меньшей мере, двух подвергнутых понижающему микшированию каналов в ответ на относительную меру энергии для, по меньшей мере, двух подвергнутых понижающему микшированию каналов.
Это может предоставлять возможность улучшенного кодирования и/или облегченной реализации. Более точно, признак может давать пониженную сложность и/или сокращенные затраты вычислительных ресурсов.
Согласно дополнительному признаку изобретения данные пространственных параметров включают в себя, по меньшей мере, один параметр, выбранный из группы, состоящей из: параметра среднего уровня по поддиапазону; параметра среднего времени поступления; фазы, по меньшей мере, одного стереоканала; параметра временной привязки; параметра групповой задержки; фазы между стереоканалами; и параметра взаимной корреляции каналов.
Эти параметры могут обеспечивать в высокой степени преимущественное кодирование и, в частности, могут быть особенно пригодны для обработки поддиапазонов.
Согласно дополнительному признаку изобретения средство вывода выполнено с возможностью включать данные местоположения источника звука в выходной поток.
Это может предоставлять декодеру возможность определять подходящие данные пространственных параметров и/или может давать эффективный способ указания данных пространственных параметров с низкими непроизводительными затратами. Это может обеспечивать эффективный способ реверсирования процесса бинаурального виртуального пространственного синтеза в декодере, тем самым предоставляя возможность высококачественного многоканального декодирования. Признак, более того, может предоставлять возможность улучшенного впечатления пользователя и может давать возможность или облегчать реализацию бинаурального виртуального пространственного сигнала с движущимися источниками звука. Признак, в качестве альтернативы или дополнительно, может предоставлять возможность настройки пространственного синтеза в декодере, например, сначала реверсированием синтеза, выполняемого в кодировщике, сопровождаемым синтезом с использованием настроенной или индивидуализированной передаточной функции бинаурального восприятия.
Согласно дополнительному признаку изобретения средство вывода выполнено с возможностью включать, по меньшей мере, некоторые из данных пространственных параметров в выходной поток.
Это может обеспечивать эффективный способ реверсирования процесса бинаурального виртуального пространственного синтеза в декодере, тем самым предоставляя возможность высококачественного многоканального декодирования. Признак, более того, может предоставлять возможность улучшенного впечатления пользователя и может давать возможность или облегчать реализацию бинаурального виртуального пространственного сигнала с движущимися источниками звука. Данные пространственных параметров могут непосредственно или косвенно включаться в выходной поток, например, путем включения в состав информации, которая предоставляет декодеру возможность определять данные пространственных параметров. Признак, в качестве альтернативы или дополнительно, может предоставлять возможность настройки пространственного синтеза в декодере, например, сначала реверсированием синтеза, выполняемого в кодировщике, сопровождаемым синтезом с использованием настроенной или индивидуализированной передаточной функции бинаурального восприятия.
Согласно дополнительному признаку изобретения кодировщик дополнительно содержит средство для определения данных пространственных параметров в ответ на требуемые местоположения звукового сигнала.
Это может предоставлять возможность улучшенного кодирования и/или облегченной реализации. Требуемые местоположения звукового сигнала могут соответствовать местоположениям источников звука для отдельных каналов M-канального сигнала.
Согласно еще одному аспекту изобретения предложен декодер аудиосигнала, содержащий: средство для приема входных данных, содержащих первый стереосигнал и параметрические данные, связанные с подвергнутым понижающему микшированию стереосигналом M-канального аудиосигнала, где M>2, первый стереосигнал является бинауральным сигналом, соответствующим M-канальному аудиосигналу; и средство формирования для модифицирования первого стереосигнала, чтобы формировать подвергнутый понижающему микшированию стереосигнал, в ответ на параметрические данные и первые данные пространственных параметров для передаточной функции бинаурального восприятия, первые данные пространственных параметров являются связанными с первым стереосигналом.
Изобретение может предоставлять возможность улучшенного декодирования аудиосигнала. В частности, изобретение может предоставлять возможность высококачественного стереодекодирования и, более точно, может давать процессу бинаурального виртуального пространственного синтеза кодировщика возможность реверсироваться в декодере. Изобретение может предоставлять возможность выполнения декодера аудиосигнала низкой сложности. Изобретение может предоставлять возможность облегченной реализации и повторного использования функциональных возможностей.
Бинауральный сигнал, более точно, может быть бинауральным виртуальным пространственным сигналом, таким как виртуальный 3-мерный бинауральный стереосигнал. Данные пространственных параметров могут содержать данные, указывающие передаточную функцию из предполагаемого местоположения источника звука в ухо предполагаемого пользователя. Передаточная функция бинаурального восприятия, например, может быть функцией моделирования восприятия звука человеком (HRTF) или бинауральной импульсной характеристикой помещения (BRIR).
Согласно дополнительному признаку изобретения декодер аудиосигнала дополнительно содержит средство для формирования M-канального аудиосигнала в ответ на подвергнутый понижающему микшированию стереосигнал и параметрические данные.
Изобретение может предоставлять возможность улучшенного декодирования аудиосигнала. В частности, изобретение может предоставлять возможность высококачественного многоканального декодирования и, более точно, может давать процессу бинаурального виртуального пространственного синтеза кодировщика возможность реверсироваться в декодере. Изобретение может предоставлять возможность декодера аудиосигнала низкой сложности. Изобретение может предоставлять возможность облегченной реализации и повторного использования функциональных возможностей.
M-канальный аудиосигнал может быть сигналом объемного звучания, таким как сигнал объемного звучания 5.1 или 7.1. Бинауральный сигнал может быть виртуальным пространственным сигналом, который имитирует одно местоположение источника звука для каждого канала M-канального аудиосигнала.
Согласно дополнительному признаку изобретения средство формирования выполнено с возможностью формировать подвергнутый понижающему микшированию стереосигнал посредством расчета значений данных поддиапазона для подвергнутого понижающему микшированию стереосигнала в ответ на связанные параметрические данные, данные пространственных параметров и значения данных поддиапазона для первого стереосигнала.
Это может предоставлять возможность улучшенного декодирования и/или облегченной реализации. Более точно, признак может давать пониженную сложность и/или сокращенные затраты вычислительных ресурсов. Интервалы частотных поддиапазонов первого стереосигнала, подвергнутого понижающему микшированию стереосигнала, связанных параметрических данных и данных пространственных параметров могут быть разными, либо некоторые или все поддиапазоны могут быть по существу идентичными для некоторых или всех из таковых.
Согласно дополнительному признаку изобретения средство формирования выполнено с возможностью формировать значения поддиапазона для первого поддиапазона подвергнутого понижающему микшированию стереосигнала в ответ на умножение соответствующих стереозначений поддиапазона для первого стереосигнала на матрицу первого поддиапазона;
средство формирования дополнительно содержит средство параметров для определения значений данных для матрицы первого поддиапазона в ответ на параметрические данные и данные пространственных параметров для первого поддиапазона.
Это может предоставлять возможность улучшенного декодирования и/или облегченной реализации. Более точно, признак может давать пониженную сложность и/или сокращенные затраты вычислительных ресурсов. Значения матрицы первого поддиапазона могут отражать объединенный результат каскадного включения многоканального декодирования и фильтрации HRTF/BRIR результирующего множества каналов. Умножение матрицы поддиапазона может выполняться для всех поддиапазонов подвергнутого понижающему микшированию стереосигнала.
Согласно дополнительному признаку изобретения входные данные содержат, по меньшей мере, некоторые данные пространственных параметров.
Это может обеспечивать эффективный способ реверсирования процесса бинаурального виртуального пространственного синтеза, выполняемого в кодировщике, тем самым предоставляя возможность высококачественного многоканального декодирования. Признак, более того, может предоставлять возможность улучшенного впечатления пользователя и может давать возможность или облегчать реализацию бинаурального виртуального пространственного сигнала с движущимися источниками звука. Данные пространственных параметров могут непосредственно или косвенно включаться во входные данные, например они могут быть любой информацией, которая предоставляет декодеру возможность определять данные пространственных параметров.
Согласно дополнительному признаку изобретения входные данные содержат данные местоположения источника звука, и декодер содержит средство для определения данных пространственных параметров в ответ на данные местоположения источника звука.
Это может предоставлять возможность улучшенного кодирования и/или облегченной реализации. Требуемые местоположения звукового сигнала могут соответствовать местоположениям источников звука для отдельных каналов M-канального сигнала.
Декодер, например, может содержать хранилище данных, содержащее данные пространственных параметров HRTF, связанные с разными местоположениями источника звука, и может определять данные пространственных параметров для использования посредством извлечения данных параметров для указанных местоположений.
Согласно дополнительному признаку изобретения декодер аудиосигнала дополнительно содержит блок пространственного декодера для создания пары бинауральных выходных каналов модифицированием первого стереосигнала в ответ на связанные параметрические данные и вторые данные пространственных параметров для второй передаточной функции бинаурального восприятия, вторые данные пространственных параметров являются иными, чем первые данные пространственных параметров.
Признак может предоставлять возможность улучшенного пространственного синтеза и, в частности, может давать возможность индивидуального или настроенного пространственного синтезированного бинаурального сигнала, который является особенно подходящим для определенного пользователя. Это может достигаться по-прежнему, наряду с предоставлением стереодекодерам прежних систем возможности формировать пространственные бинауральные сигналы, не требуя пространственного синтеза в декодере. Отсюда может достигаться улучшенная аудиосистема. Вторая передаточная функция бинаурального восприятия, более точно, может быть иной, чем передаточная функция бинаурального восприятия первых пространственных данных. Вторая передаточная функция бинаурального восприятия и вторые пространственные данные, более точно, могут настраиваться для индивидуального пользователя декодера.
Согласно дополнительному признаку изобретения пространственный декодер содержит: блок преобразования параметров для преобразования параметрических данных в параметры бинаурального синтеза с использованием вторых данных пространственных параметров и блок пространственного синтеза для синтеза пары бинауральных каналов с использованием параметров бинаурального синтеза и первого стереосигнала.
Это может предоставлять возможность улучшенной производительности, и/или облегченной реализации, и/или пониженной сложности. Бинауральные параметры могут быть параметрами, которые могут перемножаться с образцами звучания поддиапазона первого стереосигнала и/или подвергнутого понижающему микшированию стереосигнала, чтобы формировать образцы звучания поддиапазона для бинауральных каналов. Умножение, например, может быть матричным умножением.
Согласно дополнительному признаку изобретения параметры бинаурального синтеза содержат коэффициенты матрицы для матрицы 2 на 2, определяющей отношение стереообразцов звучания подвергнутого понижающему микшированию стереосигнала к стереообразцам звучания пары бинауральных выходных каналов.
Это может предоставлять возможность улучшенной производительности, и/или облегченной реализации, и/или пониженной сложности. Стереообразцы звучания могут быть стереообразцами звучания поддиапазона, например частотных поддиапазонов преобразования QMF или Фурье.
Согласно дополнительному признаку изобретения параметры бинаурального синтеза содержат коэффициенты матрицы для матрицы 2 на 2, определяющей отношение стереообразцов звучания поддиапазона первого стереосигнала к стереообразцам звучания пары бинауральных выходных каналов.
Это может предоставлять возможность улучшенной производительности, и/или облегченной реализации, и/или пониженной сложности. Стереообразцы звучания могут быть стереообразцами звучания поддиапазона, например, частотных поддиапазонов преобразования QMF или Фурье.
Согласно еще одному аспекту изобретения предложен способ кодирования аудиосигнала, способ содержит: прием M-канального аудиосигнала, где M>2; понижающее микширование M-канального аудиосигнала в первый стереосигнал и связанные параметрические данные; модифицирование первого стереосигнала, чтобы сформировать второй стереосигнал, в ответ на связанные параметрические данные и данные пространственных параметров для передаточной функции бинаурального восприятия, второй стереосигнал является бинауральным сигналом; кодирование второго стереосигнала, чтобы сформировать кодированные данные; и формирование выходного потока данных, содержащего кодированные данные и связанные параметрические данные.
Согласно еще одному аспекту изобретения предложен способ декодирования аудиосигнала, способ содержит:
прием входных данных, содержащих первый стереосигнал и параметрические данные, связанные с подвергнутым понижающему микшированию стереосигналом M-канального аудиосигнала, где M>2, первый стереосигнал является бинауральным сигналом, соответствующим M-канальному аудиосигналу; и
модифицирование первого стереосигнала, чтобы сформировать подвергнутый понижающему микшированию стереосигнал, в ответ на параметрические данные и данные пространственных параметров для передаточной функции бинаурального восприятия, данные пространственных параметров являются связанными с первым стереосигналом.
Согласно еще одному аспекту изобретения предложен приемник для приема аудиосигнала, содержащий: средство для приема входных данных, содержащих первый стереосигнал и параметрические данные, связанные с подвергнутым понижающему микшированию стереосигналом M-канального аудиосигнала, где M>2, первый стереосигнал является бинауральным сигналом, соответствующим M-канальному аудиосигналу; и средство формирования для модифицирования первого стереосигнала, чтобы формировать подвергнутый понижающему микшированию стереосигнал, в ответ на параметрические данные и данные пространственных параметров для передаточной функции бинаурального восприятия, данные пространственных параметров являются связанными с первым стереосигналом.
Согласно еще одному аспекту изобретения предложен передатчик для передачи выходного потока данных, передатчик содержит: средство для приема M-канального аудиосигнала, где M>2; средство понижающего микширования для понижающего микширования M-канального аудиосигнала в первый стереосигнал и связанные параметрические данные; средство формирования для модифицирования первого стереосигнала, чтобы формировать второй стереосигнал, в ответ на связанные параметрические данные и данные пространственных параметров для передаточной функции бинаурального восприятия, второй стереосигнал является бинауральным сигналом; средство для кодирования второго стереосигнала, чтобы формировать кодированные данные; средство вывода для формирования выходного потока данных, содержащего кодированные данные и связанные параметрические данные; и средство для передачи выходного потока данных.
Согласно еще одному аспекту изобретения предложена система передачи для передачи аудиосигнала, система передачи содержит: передатчик, содержащий: средство для приема M-канального аудиосигнала, где M>2, средство понижающего микширования для понижающего микширования M-канального аудиосигнала в первый стереосигнал и связанные параметрические данные, средство формирования для модифицирования первого стереосигнала, чтобы формировать второй стереосигнал, в ответ на связанные параметрические данные и данные пространственных параметров для передаточной функции бинаурального восприятия, второй стереосигнал является бинауральным сигналом, средство для кодирования второго стереосигнала, чтобы формировать кодированные данные, средство вывода для формирования выходного потока данных аудио, содержащего кодированные данные и связанные параметрические данные, и средство для передачи выходного потока данных аудио; и приемник, содержащий: средство для приема выходного потока данных аудио и средство для модифицирования второго стереосигнала, чтобы формировать первый стереосигнал в ответ на параметрические данные и данные пространственных параметров.
Согласно еще одному аспекту изобретения предложен способ приема аудиосигнала, способ содержит: прием входных данных, содержащих первый стереосигнал и параметрические данные, связанные с подвергнутым понижающему микшированию стереосигналом M-канального аудиосигнала, где M>2, первый стереосигнал является бинауральным сигналом, соответствующим M-канальному аудиосигналу; и модифицирование первого стереосигнала, чтобы формировать подвергнутый понижающему микшированию стереосигнал, в ответ на параметрические данные и данные пространственных параметров для передаточной функции бинаурального восприятия, данные пространственных параметров являются связанными с первым стереосигналом.
Согласно еще одному аспекту изобретения предложен способ передачи выходного потока данных аудио, способ содержит: прием M-канального аудиосигнала, где M>2; понижающее микширование M-канального аудиосигнала в первый стереосигнал и связанные параметрические данные; модифицирование первого стереосигнала, чтобы формировать второй стереосигнал, в ответ на связанные параметрические данные и данные пространственных параметров для передаточной функции бинаурального восприятия, второй стереосигнал является бинауральным сигналом; кодирование второго стереосигнала, чтобы формировать кодированные данные; и формирование выходного потока данных аудио, содержащего кодированные данные и связанные параметрические данные; и передачу выходного потока данных аудио.
Согласно еще одному аспекту изобретения предложен способ передачи и приема аудиосигнала, способ содержит: прием M-канального аудиосигнала, где M>2; понижающее микширование M-канального аудиосигнала в первый стереосигнал и связанные параметрические данные; модифицирование первого стереосигнала, чтобы формировать второй стереосигнал, в ответ на связанные параметрические данные и данные пространственных параметров для передаточной функции бинаурального восприятия, второй стереосигнал является бинауральным сигналом; кодирование второго стереосигнала, чтобы формировать кодированные данные; и формирование выходного потока данных аудио, содержащего кодированные данные и связанные параметрические данные; передачу выходного потока данных аудио; прием выходного потока данных аудио; и модифицирование второго стереосигнала, чтобы формировать первый стереосигнал в ответ на параметрические данные и данные пространственных параметров.
Согласно еще одному аспекту изобретения предложен компьютерный программный продукт для выполнения любого из вышеописанных способов.
Согласно еще одному аспекту изобретения предложено устройство записи аудио, содержащее кодировщик согласно вышеописанному кодировщику.
Согласно еще одному аспекту изобретения предложено устройство воспроизведения аудио, содержащее декодер согласно вышеописанному декодеру.
Согласно еще одному аспекту изобретения предложен поток аудиоданных для аудиосигнала, содержащий первый стереосигнал; и параметрические данные, связанные с подвергнутым понижающему микшированию стереосигналом M-канального аудиосигнала, где M>2; при этом первый стереосигнал является бинауральным сигналом, соответствующим M-канальному аудиосигналу.
Согласно еще одному аспекту изобретения предложен запоминающий носитель, содержащий сохраненный на нем сигнал, как описанный выше.
Эти и другие аспекты, признаки и преимущества изобретения будут очевидны из и разъяснены со ссылкой на вариант(ы) осуществления, описанный ниже.
Варианты осуществления изобретения будут описаны только в качестве примера со ссылкой на чертежи, из которых
фиг.1 - иллюстрация бинаурального синтеза в соответствии с предшествующим уровнем техники;
фиг.2 - иллюстрация каскадного включения многоканального декодера и бинаурального синтеза;
фиг.3 иллюстрирует систему передачи для передачи аудиосигнала в соответствии с некоторыми вариантами осуществления изобретения;
фиг.4 иллюстрирует кодировщик в соответствии с некоторыми вариантами осуществления изобретения;
фиг.5 иллюстрирует кодировщик параметрического понижающего микширования объемного звучания;
фиг.6 иллюстрирует пример местоположения источника звука относительно пользователя;
фиг.7 иллюстрирует многоканальный декодер в соответствии с некоторыми вариантами осуществления изобретения;
фиг.8 иллюстрирует декодер в соответствии с некоторыми вариантами осуществления изобретения;
фиг.9 иллюстрирует декодер в соответствии с некоторыми вариантами осуществления изобретения;
фиг.10 иллюстрирует способ кодирования аудиосигнала в соответствии с некоторыми вариантами осуществления изобретения; и
фиг.11 иллюстрирует способ декодирования аудиосигнала в соответствии с некоторыми вариантами осуществления изобретения.
Фиг.3 иллюстрирует систему 300 передачи для передачи аудиосигнала в соответствии с некоторыми вариантами осуществления изобретения. Система 300 передачи содержит передатчик 301, который связан с приемником 303 через сеть 305, которая, более точно, может быть сетью Интернет.
В отдельном примере, передатчик 301 является устройством записи сигнала, а приемник является устройством 303 проигрывателя сигнала, но будет принято во внимание, что в других вариантах осуществления передатчик и приемник могут использоваться в других применениях и для других целей. Например, передатчик 301 и/или приемник 303 могут быть частью функциональных возможностей перекодировки и, например, могут предусматривать сопряжение с другими источниками или пунктами назначения сигналов.
В отдельном примере, где поддерживается функция записи сигнала, передатчик 301 содержит цифрователь 307, который принимает аналоговый сигнал, который преобразуется в цифровой сигнал PCM посредством осуществления выборки и аналого-цифрового преобразования. Цифрователь 307 осуществляет выборку множества сигналов, тем самым формируя многоканальный сигнал.
Передатчик 301 присоединен к кодировщику 309 по фиг.1, который кодирует многоканальный сигнал в соответствии с алгоритмом кодирования. Кодировщик 309 присоединен к сетевому передатчику 311, который принимает кодированный сигнал и служит средством связи с сетью 305 Интернет. Сетевой передатчик может передавать кодированный сигнал на приемник 303 через сеть 305 Интернет.
Приемник 303 содержит сетевой приемник 313, который служит средством связи с сетью 305 Интернет и который выполнен с возможностью принимать кодированный сигнал от передатчика 301.
Сетевой приемник 313 присоединен к декодеру 315. Декодер 315 принимает кодированный сигнал и декодирует его в соответствии с алгоритмом декодирования.
В отдельном примере, где поддерживается функция воспроизведения сигнала, приемник 303 дополнительно содержит проигрыватель 317 сигнала, который принимает декодированный аудиосигнал из декодера 315 и представляет таковой пользователю. Более точно, проигрыватель 317 сигнала может содержать цифроаналоговый преобразователь, усилители и громкоговорители, которые требуются для вывода декодированного аудиосигнала.
В отдельном примере, кодировщик 309 принимает пятиканальный сигнал объемного звука и осуществляет понижающее микширование такового в стереосигнал. Стереосигнал затем подвергается постобработке, чтобы сформировать бинауральный сигнал, который, более точно, является бинауральным виртуальным пространственным сигналом в виде 3-мерного бинаурального сигнала понижающего микширования. Посредством использования каскада 3-мерной постобработки, действующего на сигнал понижающего микширования после пространственного кодирования, 3-мерная обработка может инвертироваться в декодере 315. Как результат, многоканальный декодер для проигрывания через громкоговорители не будет показывать никакого значительного ухудшения качества, обусловленного модифицированным стереопонижающим микшированием, наряду с тем, что, одновременно, даже традиционные стереодекодеры будут синтезировать 3-мерный совместимый сигнал. Таким образом, кодировщик 309 может формировать сигнал, который предоставляет возможность высококачественного многоканального декодирования и, одновременно, дает возможность псевдопространственного впечатления от традиционного стереовыходного сигнала, например, такого как из традиционного декодера, питающего пару наушников.
Фиг.4 иллюстрирует кодировщик 309 более подробно.
Кодировщик 309 содержит многоканальный приемник 401, который принимает многоканальный аудиосигнал. Хотя описанные принципы будут применяться к многоканальному сигналу, содержащему любое количество каналов, больше двух, отдельный пример будет фокусироваться на пятиканальном сигнале, соответствующем стандартному сигналу объемного звука (для ясности и краткости низкочастотный канал, часто используемый для сигналов объемного звучания, будет игнорироваться. Однако специалисту в данной области техники будет ясно, что многоканальный сигнал может иметь дополнительный низкочастотный канал. Этот канал, например, может комбинироваться с центральным каналом процессором понижающего микширования).
Многоканальный приемник 401 присоединен к процессору 403 понижающего микширования, который выполнен с возможностью осуществлять понижающее микширование пятиканального аудиосигнала в первый стереосигнал. В дополнение, процессор 403 понижающего микширования формирует параметрические данные 405, связанные с первым стереосигналом и содержащие контрольные сигналы аудио и информацию, определяющую отношение первого стереосигнала к исходным каналам многоканального сигнала.
Процессор 403 понижающего микширования, например, может реализовывать многоканальный кодировщик объемного звучания MPEG. Пример такового проиллюстрирован на фиг.5. В примере, многоканальный входной сигнал состоит из каналов Lf (левого фронтального), Ls (левого объемного), C (центрального), Rf (правого фронтального) и Rs (правого объемного). Каналы Lf и Ls подаются в первый понижающий микшер 501 TTO (два в один), который формирует моносигнал понижающего микширования для левого (L) канала, а также параметры, устанавливающие отношение двух входных каналов Lf и Ls к выходному каналу L. Каналы Rf и Rs подаются во второй понижающий микшер 503 TTO, который формирует моносигнал понижающего микширования для правого (R) канала, а также параметры, устанавливающие отношение двух входных каналов Rf и Rs к выходному каналу R. Каналы R, L и C затем подаются в понижающий микшер 505 TTT (три в два), который комбинирует эти сигналы, чтобы сформировать стереосигнал понижающего микширования и дополнительные пространственные параметры.
Параметры, вытекающие из понижающего микшера 505 TTT, типично состоят из пары коэффициентов предсказания для каждого диапазона параметров, или пары перепадов уровня для описания соотношений энергии трех входных сигналов. Параметры понижающих микшеров 501, 503 TTO типично состоят из перепадов уровня и значений когерентности или взаимной корреляции между входными сигналами для каждой полосы частот.
Сформированный первый стереосигнал, таким образом, является стандартным традиционным стереосигналом, содержащим некоторое количество подвергнутых понижающему микшированию каналов. Многоканальный декодер может воссоздавать исходный многоканальный сигнал посредством повышающего микширования и применения связанных параметрических данных. Однако стандартный стереодекодер будет выдавать только стереосигнал, тем самым теряя пространственную информацию и создавая пониженное впечатление пользователя.
Однако в кодировщике 309 подвергнутый понижающему микшированию стереосигнал не кодируется и не передается непосредственно. Вернее, первый стереосигнал подается в пространственный процессор 407, в который также подаются связанные данные 405 параметров из процессора 403 понижающего микширования. Пространственный процессор 407, кроме того, присоединен к процессору 409 HRTF.
Процессор 409 HRTF формирует данные параметров функции моделирования восприятия звука человеком (HRTF), используемые пространственным процессором 407 для формирования 3-мерного бинаурального сигнала. Более точно, HRTF описывает передаточную функцию из заданного местоположения источника звука на барабанные перепонки посредством импульсной характеристики. Процессор 409 HRTF, более точно, формирует данные параметров HRTF, соответствующие значению требуемой функции HRTF в частотном поддиапазоне. Процессор 409 HRTF, например, может рассчитывать HRTF для местоположения источника звука одного из каналов многоканального сигнала. Эта передаточная функция может преобразовываться в подходящую область частотных поддиапазонов (такую как область поддиапазонов QMF или БПФ) и может определяться соответствующее значение параметра HRTF в каждом поддиапазоне.
Будет приниматься во внимание, что, хотя описание фокусируется на применении функций моделирования восприятия звука человеком, описанные подход и принципы равным образом хорошо применяются к другим передаточным функциям (пространственного) бинаурального восприятия, таким как функция бинауральной импульсной характеристики помещения (BRIR). Еще одним примером передаточной функции бинаурального восприятия является простое правило панорамирования амплитуды, которое описывает относительную величину уровня сигнала от одного входного канала до другого из бинауральных стереовыходных каналов.
В некоторых вариантах осуществления параметры HRTF могут рассчитываться динамически, тогда как в других вариантах осуществления они могут быть предопределены и храниться в пригодном складе данных. Например, параметры HRTF могут храниться в базе данных в качестве функции курсового угла, угла возвышения, расстояния и полосы частот. Надлежащие параметры HRTF для заданного частотного поддиапазона, в таком случае, могут просто извлекаться посредством выбора значений для требуемого пространственного положения источника звука.
Пространственный процессор 407 модифицирует первый стереосигнал, чтобы сформировать второй стереосигнал, в ответ на связанные параметрические данные и данные пространственных параметров HRTF. В противоположность первому стереосигналу, второй стереосигнал является бинауральным виртуальным пространственным сигналом, а более точно, 3-мерным бинауральным сигналом, который, когда представляется через традиционную стереофоническую систему (например, парой наушников), может давать расширенное пространственное впечатление, имитирующее наличие более чем двух источников звука в разных местоположениях источников звука.
Второй стереосигнал подается в процессор 411 кодирования, который присоединен к пространственному процессору 407 и который кодирует второй сигнал в поток данных, пригодный для передачи (например, с применением подходящих уровней квантования и т.п.). Процессор 411 кодирования присоединен к процессору 413 вывода, который формирует выходной поток, комбинируя, по меньшей мере, кодированные вторые данные стереосигнала и связанные данные 405 параметров, сформированные процессором 403 понижающего микширования.
Типично, синтез HRTF требует колебательные сигналы для всех индивидуальных источников звука (например, сигналов громкоговорителей в контексте сигнала объемного звука). Однако в кодировщике 309 пары HRTF подвергаются параметризации для частотных поддиапазонов, тем самым, например, предоставляя виртуальной установке громкоговорителей 5.1 возможность формироваться посредством постобработки с низкой сложностью сигнала понижающего микширования многоканального входного сигнала, с помощью пространственных параметров, которые извлекались во время последовательности операций кодирования (и понижающего микширования).
Пространственный процессор, более точно, может работать в области поддиапазонов, такой как область поддиапазонов QMF или БПФ. Предпочтительнее, чем декодирование подвергнутого понижающему микшированию первого стереосигнала для формирования исходного многоканального сигнала, сопровождаемого синтезом HRTF с использованием фильтрации HRTF, пространственный процессор 407 формирует значения параметров для каждого поддиапазона, соответствующего комбинированному результату декодирования подвергнутого понижающему микшированию первого стереосигнала в многоканальный сигнал, с последующим повторным кодированием многоканального сигнала в качестве 3-мерного бинаурального сигнала.
Более точно, изобретатели осознали, что 3-мерный бинауральный сигнал может формироваться применением умножения на матрицу 2×2 к значениям сигнала поддиапазона первого сигнала. Результирующие значения сигнала у второго сигнала близко соответствуют значениям сигнала, которые могут быть сформированы каскадным выполнением декодирования и синтеза HRTF. Таким образом, комбинированная сигнальная обработка многоканального кодирования и синтеза HRTF может комбинироваться в четыре значения параметров (коэффициента матрицы), которые могут просто применяться к значениям сигналов поддиапазона, чтобы формировать требуемые значения поддиапазона второго сигнала. Поскольку значения параметров матрицы отражают комбинированную последовательность операций декодирования многоканального сигнала и синтеза HRTF, значения параметров определяются в ответ на связанные параметрические данные из процессора 403 понижающего микширования, а также параметры HRTF.
В кодировщике 309 функции HRTF подвергаются параметризации для отдельных полос частот. Назначение параметризации HRTF состоит в том, чтобы зафиксировать наиболее важные контрольные сигналы для определения местоположения источника звука из каждой пары HRTF. Эти параметры могут включать в себя:
- (Средний) уровень на частотный поддиапазон для импульсной характеристики левого уха;
- (Средний) уровень на частотный поддиапазон для импульсной характеристики правого уха;
- (Среднее) время поступления или разность фаз между импульсными характеристиками левого уха и правого уха;
- (Средняя) абсолютная фаза или время (или групповая задержка) на частотный поддиапазон как для левой, так и для правой импульсных характеристик (в этом случае, время или разность фаз, в большинстве случаев становится абсолютным);
- Межканальная взаимная корреляция или когерентность на частотный поддиапазон между соответствующими импульсными характеристиками.
Параметры уровня на частотный поддиапазон могут облегчать синтез угла возвышения (благодаря специальным пикам и провалам в спектре), а также перепады уровня для курсового угла (определяемые по отношению параметров уровня для каждого поддиапазона).
Абсолютные значения фазы или значения разности фаз могут фиксировать разности времени поступления между обоими ушами, которые также являются важными контрольными сигналами для курсового угла источника звука. Значение когерентности могло добавляться для имитации перепадов тонкой структуры между обоими ушами, которые не могут быть привнесены в перепады уровня и/или разницы фаз, усредненные по диапазону (параметров).
В последующем, описан отдельный пример обработки пространственным процессором 407. В примере местоположение источника звука определяется относительно слушателя азимутальным углом α и расстоянием D, как показано на фиг.6. Источник звука, расположенный слева от слушателя, соответствует положительным азимутальным углам. Передаточная функция из местоположения источника звука в левое ухо обозначена H L, передаточная функция из местоположения источника звука в правое ухо - H R.
Передаточные функции H L и H R зависимы от азимутального угла α, расстояния D и угла ε возвышения (не показан на фиг.6). В параметрическом представлении передаточные функции могут быть описаны в качестве набора трех параметров на частотный поддиапазон b h HRTF. Этот набор параметров включает в себя средний уровень на полосу частот для левой передаточной функции, P l(α, ε, D, b h), средний уровень на полосу частот для правой передаточной функции, P r(α, ε, D, b h), среднюю разность фаз на полосу частот, ϕ(α, ε, D, b h). Возможное расширение этого набора должно включать в себя меру когерентности левой и правой передаточных функций на полосу частот HRTF, ρ(α, ε, D, b h). Эти параметры могут храниться в базе данных в качестве функции курсового угла, угла возвышения, расстояния и полосы частот и/или могут вычисляться с использованием некоторой аналитической функции. Например, параметры P l и P r могли бы храниться в качестве функции курсового угла или угла возвышения, наряду с тем, что влияние расстояния достигается делением этих значений на само расстояние (при условии соотношения 1/D между уровнем сигнала и расстоянием). В последующем, обозначение P l(Lf) обозначает пространственный параметр P l, соответствующий местоположению источника звука канала Lf.
Должно быть отмечено, что количество частотных поддиапазонов для параметризации (b h) HRTF и полоса пропускания для каждого поддиапазона не обязательно равны частотному разрешению гребенки (k) фильтров (QMF), используемой пространственным процессором 407, или разрешению пространственного параметра процессора 403 понижающего микширования и связанных диапазонов (b p) параметров. Например, гребенка гибридных фильтров QMF может иметь 71 канал, HRTF может подвергаться параметризации в 28 полосах частот, а пространственное кодирование может выполняться с использованием 10 диапазонов параметров. В таких случаях отображение из пространственных параметров и параметров HRTF в гибридный индекс QMF может применяться, например, с использованием справочной таблицы, либо функции интерполяции, или усреднения. Следующие индексы параметров будут использоваться в описании:
В отдельном примере пространственный процессор 407 разделяет первый стереосигнал на подходящие частотные поддиапазоны посредством фильтрации QMF. Для каждого поддиапазона значения LB, RB поддиапазона определяются в качестве:
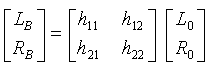 ,
,
где L0, R0 - соответствующие значения поддиапазона первого стереосигнала, а значения hj,k матрицы - параметры, которые определены из параметров HRTF и связанных с понижающим микшированием параметрических данных.
Коэффициенты матрицы нацелены на воспроизведение свойств понижающего микширования, как будто все отдельные каналы обрабатывались с помощью HRTF, соответствующих требуемому местоположению источника звука, и они включают в себя комбинированный результат декодирования многоканального сигнала и выполнения синтеза HRTF над таковым.
Более точно, со ссылкой на фиг.5 и ее описание, значения матрицы могут быть определены как:
h 11 = m 11 H L(L)+m 21 H L(R)+m 31 H L(C)
h 12 = m 12 H L(L)+m 22 H L(R)+m 32 H L(C)
h 21 = m 11 H R(L)+m 21 H R(R)+m 31 H R(C)
h 22 = m 12 H R(L)+m 22 H R(R)+m 32 H R(C),
где mk,l - параметры, определенные в ответ на параметрические данные, сформированные понижающим микшером 505 TTT.
Более точно, сигналы L, R и C формируются из стереосигнала L0, R0 понижающего микширования согласно:
 ,
,
где mk,l зависимы от двух коэффициентов c1 и c2 предсказания, которые являются частью переданных пространственных параметров:
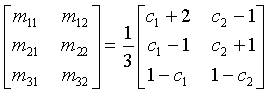 .
.
Значения HJ(X) определяются в ответ на данные параметров HRTF для канала X в отношении стерео выходного канала J второго стереосигнала, а также надлежащие параметры понижающего микширования.
Более точно, параметры HJ(X) относятся к левому (L) и правому (R) сигналам понижающего микширования, сформированным двумя понижающими микшерами 501, 503 TTO, и могут определяться в ответ на данные параметров HRTF для двух подвергнутых понижающему микшированию каналов. Более точно, может использоваться взвешенная комбинация параметров HRTF для двух отдельных левых (Lf и Ls) или правых (Rf и Rs) каналов. Отдельные параметры могут взвешиваться относительной энергией отдельных сигналов. В качестве отдельного примера следующие значения могут определяться для левого сигнала (L):
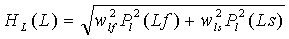 ,
,
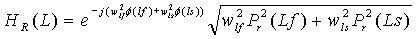 ,
,
где веса wx заданы согласно:
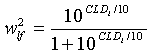 ,
,
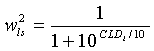 ,
,
а CLDl является 'перепадом уровней каналов' между левым фронтальным (Lf) и левым объемным (Ls), определенным в децибелах (каковой является частью потока битов пространственных параметров):
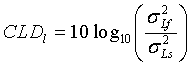 ,
,
с σ2 lf, мощностью в поддиапазоне параметров канала Lf, и σ2 ls, мощностью в соответствующем поддиапазоне канала Ls.
Подобным образом, следующие значения могут быть определены для правого сигнала (R):
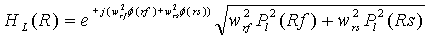 ,
,
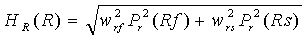 ,
,
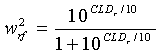 ,
,
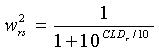
и для центрального (C) сигнала:
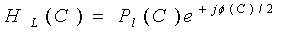
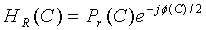 .
.
Таким образом, с использованием описанного подхода пространственная обработка с низкой сложностью может предоставлять бинауральному виртуальному пространственному сигналу возможность формироваться на основании подвергнутого понижающему микшированию многоканального сигнала.
Как упомянуто, преимущество описанного подхода состоит в том, что частотному поддиапазону связанных параметров понижающего микширования, пространственной обработке пространственным процессором 407 и параметрам HRTF не нужно быть теми же самыми. Например, может выполняться отображение между параметрами одного поддиапазона в поддиапазоны пространственной обработки. Например, если поддиапазон пространственной обработки покрывает интервал частот, соответствующий двум поддиапазонам параметров HRTF, пространственный процессор 407 может просто применять (индивидуальную) обработку к поддиапазонам параметров HRTF, используя один и тот же пространственный параметр для всех поддиапазонов параметров HRTF, которые соответствуют такому пространственному параметру.
В некоторых вариантах осуществления кодировщик 309 может быть выполнен с возможностью включать данные местоположения источника звука, которые предоставляют декодеру возможность идентифицировать требуемые данные местоположения одного или более источников звука, в выходной поток. Это предоставляет декодеру возможность определять параметры HRTF, примененные кодировщиком 309, тем самым давая ему возможность реверсировать операцию пространственного процессора 407. Дополнительно или в качестве альтернативы, кодировщик может быть выполнен с возможностью включать, по меньшей мере, некоторые из данных параметров HRTF в выходной поток.
Таким образом, по выбору, данные параметров HRTF и/или местоположения громкоговорителей могут быть включены в выходной поток. Это, например, может предоставить возможность динамического обновления данных местоположения громкоговорителя в качестве функции времени (в случае передачи местоположения громкоговорителя) или использования индивидуализированных данных HRTF (в случае передачи параметров HRTF).
В случае, когда параметры HRTF передаются в качестве части потока битов, по меньшей мере, параметры P l , P r и ϕ могут передаваться для каждой полосы частот и для каждого местоположения источника звука. Параметры P l, P r амплитуды могут квантоваться с использованием квантователя или могут квантоваться в логарифмической области. Фазовые углы ϕ могут квантоваться линейным образом. Индексы квантователя затем могут включаться в поток битов.
Более того, фазовые углы ϕ могут предполагаться нулевыми для частот, типично в окрестности 2,5 кГц, поскольку информация о (внутриушной) фазе неуместна в смысле восприятия для высоких частот.
После квантования различные схемы сжатия без потерь могут применяться к показателям квантователя параметров HRTF. Например, может применяться энтропийное кодирование, возможно, в сочетании с дифференциальным кодированием по полосам частот. В качестве альтернативы, параметры HRTF могут представляться в качестве разности относительно набора общих или средних параметров HRTF. Это поддерживается особенно для параметров амплитуды. В ином случае, фазовые параметры могут довольно точно аппроксимироваться простым кодированием угла возвышения и курсового угла. Посредством расчета разности времен поступления [типично разность времен поступления практически является частотно-зависимой; она главным образом зависит от курсового угла и угла возвышения], если задана разность траекторий до обоих ушей, могут выводиться соответствующие фазовые параметры. В дополнение к измерениям разности могут кодироваться дифференциальным образом в отношении предсказанных значений на основании значений курсового угла и угла возвышения.
К тому же, могут применяться схемы сжатия без потерь, такие как принципиальное разложение на составляющие, сопровождаемое передачей нескольких наиболее важных весов PCA.
Фиг.7 иллюстрирует пример многоканального декодера в соответствии с некоторыми вариантами осуществления изобретения. Декодер, более точно, может быть декодером 315 по фиг.3.
Декодер 315 содержит входной приемник 701, который принимает выходной поток из кодировщика 309. Входной приемник 701 демультиплексирует принятый поток данных и выдает уместные данные в надлежащие функциональные элементы.
Входной приемник 701 присоединен к процессору 703 декодирования, в который подаются кодированные данные второго стереосигнала. Процессор 703 декодирования декодирует эти данные, чтобы формировать бинауральный виртуальный пространственный сигнал, вырабатываемый пространственным процессором 407.
Процессор 703 декодирования присоединен к процессору 705 реверсирования, который выполнен с возможность реверсировать операцию, выполняемую пространственным процессором 407. Таким образом, процессор 705 реверсирования формирует подвергнутый понижающему микшированию стереосигнал, вырабатываемый процессором 403 понижающего микширования.
Более точно, процессор 705 реверсирования формирует стереосигнал понижающего микширования применением матричного умножения к значениям поддиапазона принятого бинаурального виртуального пространственного сигнала. Матричное умножение происходит посредством матрицы, соответствующей обратной матрице от используемой пространственным процессором 407, тем самым реверсируя эту операцию:
 .
.
Это матричное умножение также может быть описано в виде:
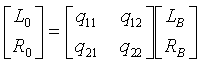 .
.
Коэффициенты qk,l матрицы определяются из параметрических данных, связанных с сигналом понижающего микширования (и принимаемых в потоке данных из кодировщика 309), а также данных параметров HRTF. Более точно, подход, описанный со ссылкой на кодировщик 309, также может использоваться процессором 409 HRTF для формирования коэффициентов hxy матрицы. Коэффициенты qxy матрицы, в таком случае, могут быть найдены стандартным обращением матрицы.
Процессор 705 реверсирования присоединен к процессору 707 параметров, который определяет данные параметров HRTF, которые должны использоваться. Параметры HRTF, в некоторых вариантах осуществления, могут быть включены в принимаемый поток данных и могут просто извлекаться из него. В других вариантах осуществления разные параметры HRTF, например, могут храниться в базе данных для разных местоположений источников звука, и процессор 707 параметров может определять параметры HRTF, извлекая значения, соответствующие требуемому местоположению источника сигнала. В некоторых вариантах осуществления требуемое местоположение(я) источника сигнала может включаться в поток данных из кодировщика 309. Процессор 707 параметров может извлекать эту информацию и использовать ее для определения параметров HRTF. Например, он может извлекать параметры HRTF, хранимые для указания местоположения(ий) источника звука.
В некоторых вариантах осуществления стереосигнал, сформированный процессором реверсирования, может выводиться непосредственно. Однако в других вариантах осуществления он может подаваться в многоканальный декодер 709, который может формировать M-канальный сигнал из стереосигнала понижающего микширования и принятых параметрических данных.
В примере, реверсирование 3-мерного бинаурального синтеза выполняется в области поддиапазонов, такой как в частотных поддиапазонах QMF или Фурье. Таким образом, процессор 703 декодирования может содержать гребенку фильтров QMF или быстрое преобразование Фурье (БПФ) для формирования образцов звучания поддиапазона, подаваемых в процессор 705 реверсирования. Подобным образом, процессор 705 реверсирования или многоканальный декодер 709 могут содержать гребенку фильтров обратного БПФ или QMF для преобразования сигналов обратно во временную область.
Формирование 3-мерного бинаурального сигнала на стороне кодировщика предусматривает, чтобы впечатление пространственного прослушивания обеспечивалось для пользователя наушников традиционным стереокодировщиком. Таким образом, описанный подход обладает преимуществом, что унаследованные стереоустройства могут воспроизводить 3-мерный бинауральный сигнал. По существу, для того чтобы воспроизводить 3-мерные бинауральные сигналы, не нужно применяться никакой дополнительной постобработке, имея следствием решение низкой сложности.
Однако при таком подходе типично используется обобщенная HRTF, каковая, в некоторых случаях, может приводить к субоптимальному пространственному формированию по сравнению с формированием 3-мерного бинаурального сигнала в декодере, использующем специализированные данные HRTF, оптимизированные для определенного пользователя.
Более точно, ограниченное восприятие расстояния и возможные погрешности определения местоположения источника звука иногда могут возникать из использования неиндивидуализированных HRTF (таких как импульсные характеристики, измеренные для имитатора головы или другой персоны). В принципе, HRTF отличаются от персоны к персоне вследствие различий в анатомической геометрии человеческого тела. Оптимальные результаты в показателях правильного определения местоположения источника звука, поэтому, могут лучше достигаться с данными индивидуализированной HRTF.
В некоторых вариантах осуществления декодер 315, кроме того, содержит функциональные возможности, сначала для реверсирования пространственной обработки кодировщика 309, сопровождаемой формированием 3-мерного бинаурального сигнала с использованием данных локальной HRTF, более точно, с использованием данных индивидуальной HRTF, оптимизированных для определенного пользователя. Таким образом, в этом варианте осуществления декодер 315 формирует пару бинауральных выходных каналов модифицированием подвергнутого понижающему микшированию стереосигнала с использованием связанных параметрических данных и данных параметров HRTF, которые являются иными, чем данные (HRTF), используемые в кодировщике 309. Отсюда при этом подходе предусмотрено сочетание 3-мерного синтеза на стороне кодировщика, обращения на стороне декодера, сопровождаемого еще одной стадией 3-мерного синтеза на стороне декодера.
Преимущество такого подхода состоит в том, что унаследованные стереоустройства будут иметь 3-мерные бинауральные сигналы в качестве выходных сигналов с обеспечением базового 3-мерного качества, наряду с тем, что усовершенствованные декодеры имеют возможность использовать персонифицированные HRTF, дающие возможность улучшенного 3-мерного качества. Таким образом, совместимый с унаследованным 3-мерный синтез, а также высококачественный специализированный 3-мерный синтез задействуются в одной и той же аудиосистеме.
Простой пример такой системы проиллюстрирован на фиг.8, которая показывает, каким образом дополнительный пространственный процессор 801 может быть добавлен в декодер по фиг.7, чтобы выдавать настроенный под требования заказчика 3-мерный бинауральный выходной сигнал. В некоторых вариантах осуществления пространственный процессор 801 может предусматривать только простой прямой 3-мерный бинауральный синтез с использованием индивидуальных функций HRTF для каждого из аудиоканалов. Таким образом, декодер может воссоздавать исходный многоканальный сигнал и преобразовывать таковой в 3-мерный бинауральный сигнал с использованием настроенной под требования заказчика фильтрации HRTF.
В других вариантах осуществления обращение синтеза кодировщика и синтеза декодера могут комбинироваться для обеспечения операции низкой сложности. Более точно, индивидуализированные HRTF, используемые для синтеза декодера, могут подвергаться параметризации и объединяться с (обращенными) параметрами, используемыми 3-мерным синтезом кодировщика.
Еще точнее, как описано ранее, синтез кодировщика включает в себя умножение стереообразцов звучания поддиапазона подвергнутых понижающему микшированию сигналов на матрицу 2×2:
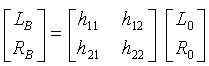 ,
,
где L0, R0 - соответствующие значения поддиапазона подвергнутого понижающему микшированию стереосигнала, а значения hj,k матрицы - параметры, которые определены из параметров HRTF и связанных с понижающим микшированием параметрических данных, как описано ранее.
Реверсирование, выполняемое процессором 705 реверсирования, в таком случае может быть задано посредством:
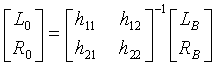 ,
,
где LB, RB - соответствующие значения поддиапазона подвергнутого понижающему микшированию декодером стереосигнала.
Чтобы гарантировать надлежащую последовательность операций обращения на стороне декодера, параметры HRTF, используемые в кодировщике для формирования 3-мерного бинаурального сигнала, и параметры HRTF, используемые для обращения 3-мерной бинауральной обработки, идентичны или в достаточной мере подобны. Поскольку один поток битов обычно обслуживает несколько декодеров, персонификация 3-мерного бинаурального понижающего микширования трудна для получения посредством синтеза кодировщика.
Однако, поскольку последовательность операций 3-мерного бинаурального синтеза обратима, процессор 705 реверсирования регенерирует подвергнутый понижающему микшированию стереосигнал, который затем используется для формирования 3-мерного бинаурального сигнала на основании индивидуализированных HRTF.
Более точно, по аналогии с операцией в кодировщике 309, 3-мерный бинауральный синтез в декодере 315 может формироваться простой, связанной с поддиапазонами матричной 2×2 операцией над сигналом L0, R0 понижающего микширования для формирования 3-мерного бинаурального сигнала LB', RB':
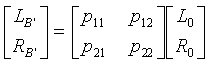 ,
,
где параметры px,y определяются на основании индивидуализированных HRTF таким же образом, как hx,y формируются кодировщиком 309 на основании общей HRTF. Более точно, в кодировщике 309 параметры hx,y определяются из многоканальных параметрических данных и общих HRTF. Так как многоканальные параметрические данные передаются в декодер 315, такой же подход может использоваться таковым для расчета px,y на основании индивидуальных HRTF.
Объединение этого с операцией процессора 705 реверсирования
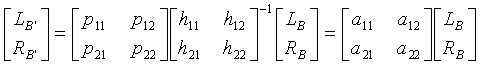 .
.
В этом уравнении элементы hx,y матрицы получены с использованием общего неиндивидуализированного набора HRTF, используемого в кодировщике, наряду с тем, что px,y получены с использованием другого и предпочтительно персонифицированного набора HRTF. Отсюда 3-мерный бинауральный входной сигнал LB, RB, сформированный с использованием данных неиндивидуализированных HRTF, преобразуется в альтернативный 3-мерный бинауральный выходной сигнал LB', RB' с использованием других данных персонифицированных HRTF.
Более того, как проиллюстрировано, комбинированный подход обращения синтеза кодировщика и синтеза декодера может достигаться простой матричной 2×2 операцией. Отсюда вычислительная сложность комбинированной последовательности операций, фактически, является такой же, как для простого 3-мерного бинаурального обращения.
Фиг.9 иллюстрирует пример декодера 315, работающего в соответствии с вышеописанными принципами. Более точно, стереообразцы звучания поддиапазона 3-мерного бинаурального стереосигнала понижающего микширования из кодировщика 309 подаются в процессор 705 реверсирования, который формирует исходные стереообразцы звучания понижающего микширования посредством матричной 2×2 операции.
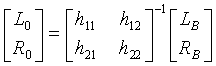 .
.
Результирующие образцы звучания поддиапазона подаются в блок 901 пространственного синтеза, который формирует индивидуализированный 3-мерный бинауральный сигнал умножением этих образцов звучания на матрицу 2×2.
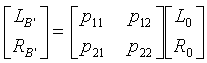 .
.
Коэффициенты матрицы формируются блоком (903) преобразования параметров, который формирует параметры на основании индивидуализированной HRTF и данных многоканального расширения, принятых из кодировщика 309.
Образцы LB', RB' звучания поддиапазона синтеза подаются на преобразование 905 из области поддиапазонов во временную область, которое формирует 3-мерные бинауральные сигналы во временной области, которые могут выдаваться пользователю.
Хотя фиг.9 иллюстрирует этапы 3-мерного обращения на основании неиндивидуализированных HRTF и 3-мерного синтеза на основании индивидуализированных HRTF в качестве последовательных операций посредством разных функциональных блоков, будет приниматься во внимание, что во многих вариантах осуществления эти операции применяются одновременно применением единственной матрицы. Более точно рассчитывается матрица 2×2
 ,
,
и выходные образцы звучания рассчитываются в виде
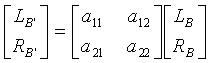 .
.
Будет приниматься во внимание, что описанная система предоставляет некоторое количество преимуществ, в том числе:
- никакого или несущественное ухудшение качества (восприятия) многоканальной реконструкции, так как пространственная стереофоническая обработка может реверсироваться в многоканальных декодерах;
- (3-мерное) бинауральное стереофоническое впечатление может обеспечиваться даже традиционными стереодекодерами;
- пониженная сложность по сравнению с существующими способами пространственного позиционирования. Сложность понижается некоторым количеством способов:
- эффективное хранение параметров HRTF. Вместо хранения импульсных характеристик HRTF, всего лишь ограниченное количество параметров используется, чтобы характеризовать HRTF;
- эффективная 3-мерная обработка. Поскольку HRTF характеризуются в качестве параметров при ограниченном частотном разрешении, и применение параметров HRTF выполняется в области (сильно дискретизированных с понижением частоты) параметров, стадия пространственного синтеза более эффективна, чем традиционные способы синтеза, основанные на полной свертке HRTF;
- требуемая обработка может выполняться, например, в области QMF, давая в результате меньшую вычислительную и относящуюся к памяти нагрузку, чем основанные на БПФ способы;
- эффективное повторное использование существующих блоков построения объемного звука (таких как стандартные функциональные возможности кодирования/декодирования объемного звука MPEG), предоставляющее возможность минимальной сложности реализации;
- возможность персонификации посредством модифицирования данных (параметризованной) HRTF, передаваемых кодировщиком;
- местоположения источников звука могут меняться на лету согласно передаваемой информации о местоположении.
Фиг.10 иллюстрирует способ кодирования аудиосигнала в соответствии с некоторыми вариантами осуществления изобретения.
Способ начинается на этапе 1001, на котором принимается M-канальный аудиосигнал (M>2).
Этап 1001 сопровождается этапом 1003, на котором M-канальный аудиосигнал подвергается понижающему микшированию в первый стереосигнал и связанные параметрические данные.
Этап 1003 сопровождается этапом 1005, на котором первый стереосигнал модифицируется, чтобы сформировать второй стереосигнал, в ответ на связанные параметрические данные и данные пространственных параметров функции моделирования восприятия звука человеком (HRTF). Второй стереосигнал является бинауральным виртуальным пространственным сигналом.
Этап 1005 сопровождается этапом 1007, на котором второй стереосигнал кодируется, чтобы сформировать кодированные данные.
Этап 1007 сопровождается этапом 1009, на котором формируется выходной поток данных, содержащий кодированные данные и связанные параметрические данные.
Фиг.11 иллюстрирует способ декодирования аудиосигнала в соответствии с некоторыми вариантами осуществления изобретения.
Способ начинается на этапе 1101, на котором декодер принимает входные данные, содержащие первый стереосигнал и параметрические данные, связанные с подвергнутым понижающему микшированию стереосигналом M-канального аудиосигнала, где M>2. Первый стереосигнал является бинауральным виртуальным пространственным сигналом.
Этап 1101 сопровождается этапом 1103, на котором первый стереосигнал модифицируется, чтобы сформировать подвергнутый понижающему микшированию стереосигнал, в ответ на параметрические данные и данные пространственных параметров функции моделирования восприятия звука человеком (HRTF), связанные с первым стереосигналом.
Этап 1103 сопровождается необязательным этапом 1105, на котором формируется M-канальный аудиосигнал в ответ на подвергнутый понижающему микшированию стереосигнал и параметрические данные.
Будет приниматься во внимание, что вышеприведенное описание, для ясности, описывало варианты осуществления изобретения со ссылкой на разные функциональный блоки и процессоры. Однако будет очевидно, что может использоваться любое подходящее распределение функциональных возможностей между разными функциональными блоками или процессорами, не умаляя изобретения. Например, функциональные возможности, проиллюстрированные выполняемыми отдельными процессорами или контроллерами, могут выполняться одним и тем же процессором или контроллерами. Отсюда ссылки на определенные функциональные блоки должны рассматриваться скорее только в качестве ссылок на пригодное средство для предоставления описанных функциональных возможностей, чем указывающими на строгую логическую или физическую структуру или организацию.
Изобретение может быть реализовано в любом пригодном виде, включая аппаратные средства, программное обеспечение, аппаратно-реализованное программное обеспечение или комбинацию таковых. Изобретение, по выбору, может быть реализовано, по меньшей мере частично, в качестве компьютерного программного обеспечения, работающего на одном или более процессоров данных и/или цифровых сигнальных процессоров. Элементы и компоненты варианта осуществления изобретения могут быть реализованы физически, функционально и логически любым подходящим образом. Действительно, функциональные возможности могут быть реализованы в одиночном блоке, множестве блоков или в качестве части других функциональных блоков. По существу, изобретение может быть реализовано в одиночном блоке, или может быть физически или функционально распределено между разными блоками и процессорами.
Хотя настоящее изобретение было описано в связи с некоторыми вариантами осуществления, оно не подразумевается ограниченным отдельными формами, изложенными в материалах настоящей заявки. Вернее, объем настоящего изобретения ограничен только прилагаемой формулой изобретения. Дополнительно, хотя признак может фигурировать описанным в связи с конкретными вариантами осуществления, специалист в данной области техники будет осознавать, что различные признаки описанных вариантов осуществления могут комбинироваться в соответствии с изобретением. В формуле изобретения термин 'содержит' не исключают присутствия других элементов или этапов.
Более того, хотя и перечислены в отдельности, множество средств, элементов или этапов способа могут быть реализованы, например, одиночным блоком или процессором. Дополнительно, хотя отдельные признаки могут быть включены в разные пункты формулы изобретения, таковые могут комбинироваться преимущественным образом, как только возможно, а включение в разные пункты формулы изобретения не подразумевает, что комбинация признаков не является выполнимой и/или полезной. К тому же, включение признака в одну категорию формулы изобретения не предполагает ограничения этой категорией, а скорее указывает, что признак равным образом применим к категориям другого пункта формулы изобретения надлежащим образом. Более того, очередность признаков в формуле изобретения не подразумевает никакого определенного порядка, в котором признаки должны обрабатываться, и, в частности, очередность отдельных этапов в пункте формулы изобретения о способе не подразумевает, что этапы должны выполняться в этой очередности. Вернее, этапы могут выполняться в любом подходящем порядке. В дополнение, упоминания в единственном числе не исключают множественности. Выражения единственного числа, 'первый', 'второй' и т.п. не устраняют множественности. Символы ссылок в пунктах формулы изобретения предусмотрены только в качестве проясняющих примеров, которые не должны трактоваться в качестве ограничивающих объем формулы изобретения каким бы то ни было образом.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И УСТРОЙСТВО ДЛЯ ГЕНЕРАЦИИ БИНАУРАЛЬНОГО АУДИОСИГНАЛА | 2008 |
|
RU2443075C2 |
| СПОСОБ, УСТРОЙСТВО, КОДИРУЮЩЕЕ УСТРОЙСТВО, ДЕКОДИРУЮЩЕЕ УСТРОЙСТВО И АУДИОСИСТЕМА | 2005 |
|
RU2396608C2 |
| СПОСОБЫ И УСТРОЙСТВА КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ ОБЪЕКТНО-ОРИЕНТИРОВАННЫХ АУДИОСИГНАЛОВ | 2007 |
|
RU2551797C2 |
| ДЕКОДИРОВАНИЕ БИНАУРАЛЬНЫХ АУДИОСИГНАЛОВ | 2007 |
|
RU2409911C2 |
| АУДИОДЕКОДИРОВАНИЕ | 2007 |
|
RU2420814C2 |
| СПОСОБЫ И УСТРОЙСТВА КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ ОБЪЕКТНО-ОРИЕНТИРОВАННЫХ АУДИОСИГНАЛОВ | 2010 |
|
RU2455708C2 |
| ДЕКОДИРОВАНИЕ БИНАУРАЛЬНЫХ АУДИОСИГНАЛОВ | 2007 |
|
RU2409912C9 |
| ГЕНЕРАЦИЯ ПРОСТРАНСТВЕННЫХ СИГНАЛОВ ПОНИЖАЮЩЕГО МИКШИРОВАНИЯ ИЗ ПАРАМЕТРИЧЕСКИХ ПРЕДСТАВЛЕНИЙ МУЛЬТИКАНАЛЬНЫХ СИГНАЛОВ | 2006 |
|
RU2407226C2 |
| МАНИПУЛИРОВАНИЕ ЗОНОЙ НАИЛУЧШЕГО ВОСПРИЯТИЯ ДЛЯ МНОГОКАНАЛЬНОГО СИГНАЛА | 2007 |
|
RU2454825C2 |
| ФОРМИРОВАНИЕ БИНАУРАЛЬНЫХ СИГНАЛОВ | 2009 |
|
RU2505941C2 |
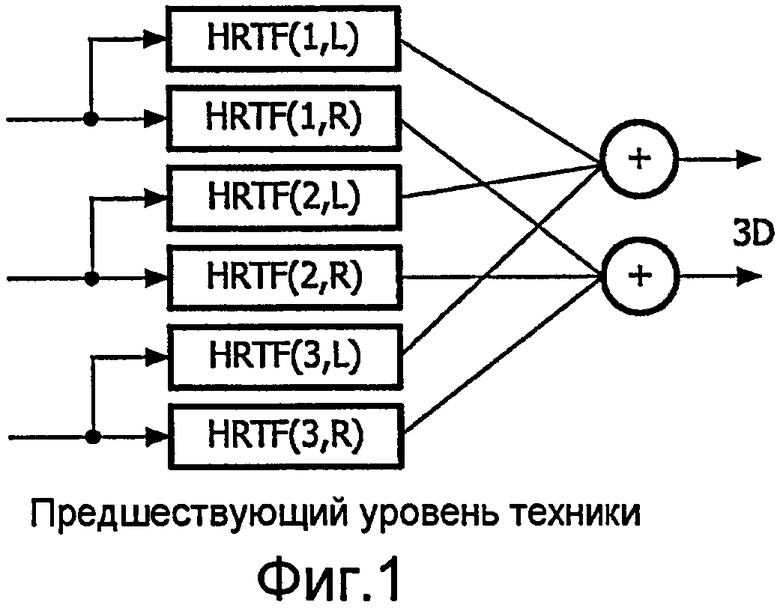
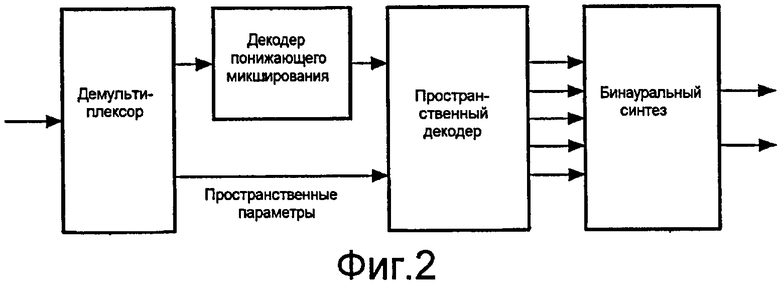
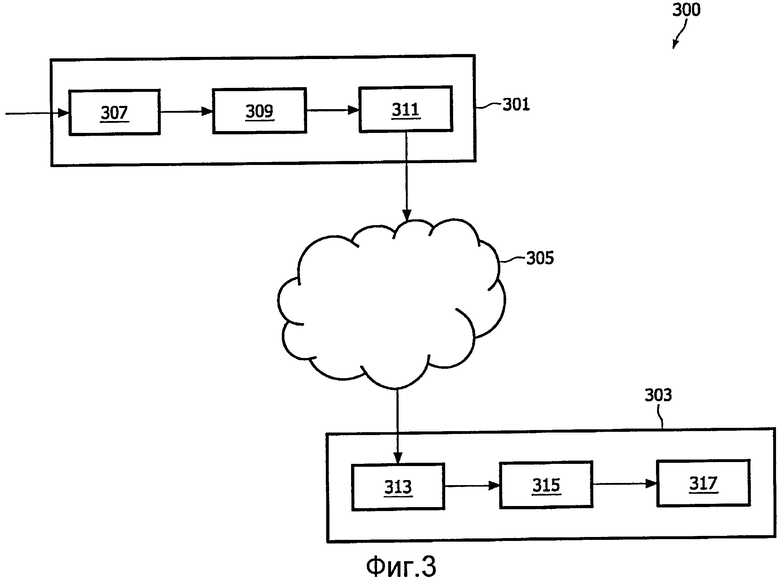
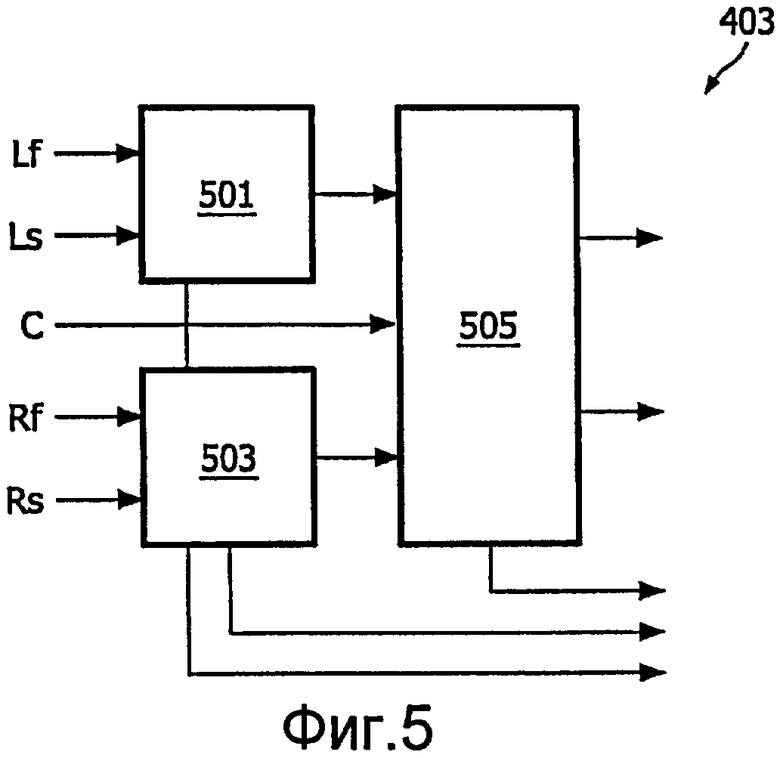
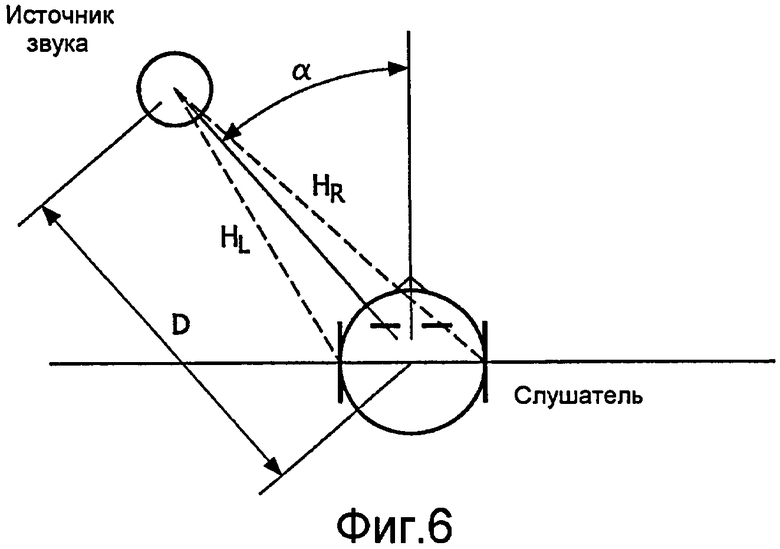
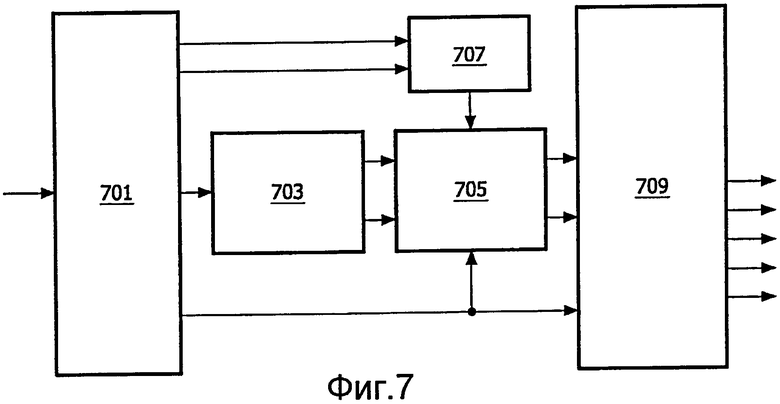
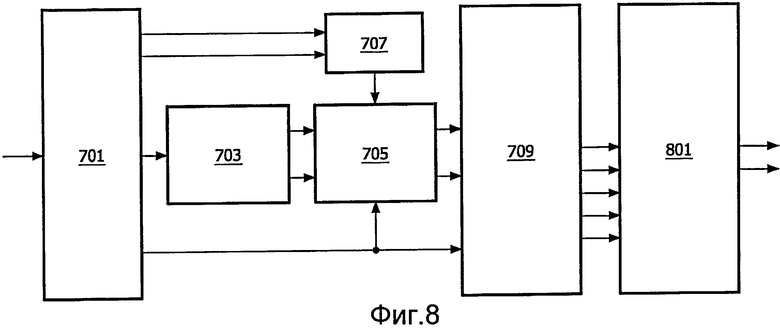
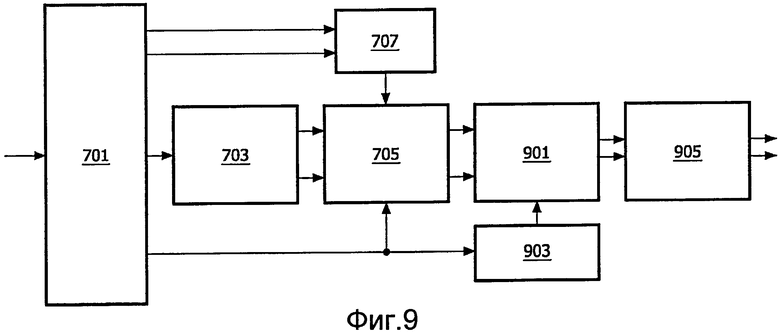
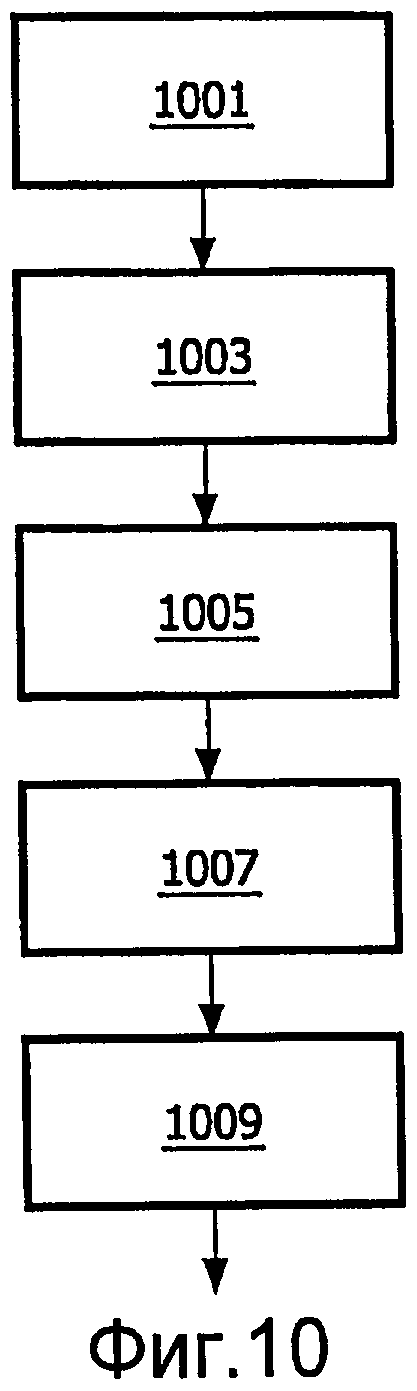
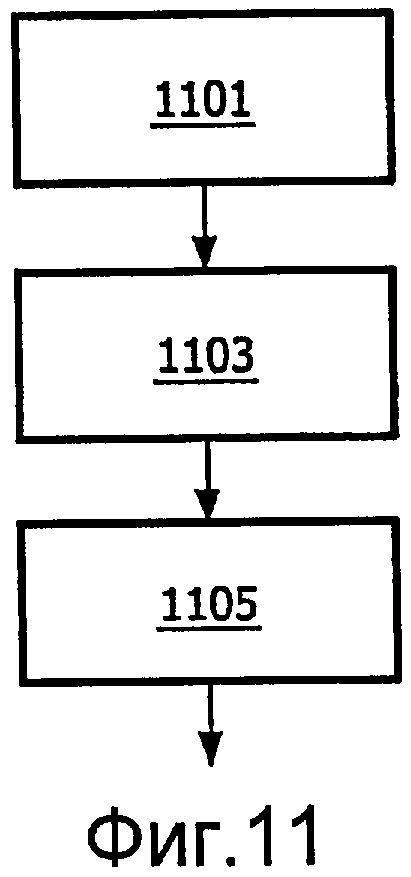
Изобретение относится к способам кодирования/декодирования аудио, в частности к кодированию/декодированию аудио, включающего бинауральный виртуальный пространственный сигнал. Техническим результатом является повышение эффективности стереокодирования многоканальных сигналов при снижении сложности кодирования. Указанный технический результат достигается тем, что кодер аудиосигнала содержит средство для приема М-канального аудиосигнала, где М>2, средство понижающего микширования для понижающего микширования М-канального аудиосигнала в первый стереосигнал и связанные параметрические данные, средство формирования для модифицирования первого стереосигнала с целью формирования второго стереосигнала в ответ на связанные параметрические данные и данные пространственных параметров, указывающие передаточную функцию бинаурального восприятия, причем второй стереосигнал является бинауральным сигналом, средство для кодирования второго стереосигнала с целью формирования кодированных данных и средство вывода для формирования выходного потока данных, содержащего кодированные данные и связанные параметрические данные. 16 н. и 19 з.п. ф-лы, 11 ил.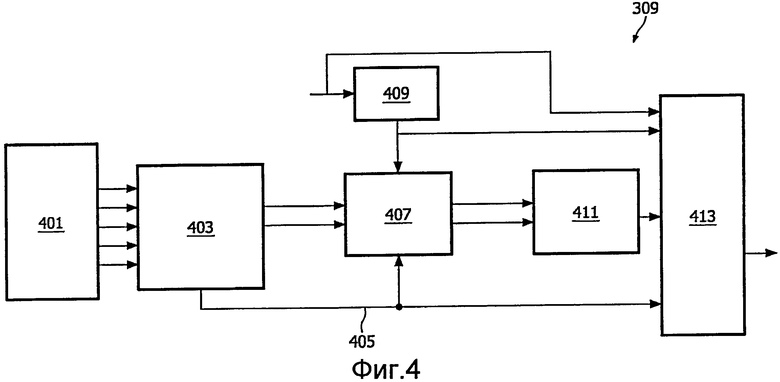
1. Кодер аудиосигнала, содержащий:
- средство (401) для приема М-канального аудиосигнала, где М>2;
- средство (403) понижающего микширования для понижающего микширования М-канального аудиосигнала в первый стереосигнал и связанные параметрические данные;
- средство (407) формирования для модифицирования первого стереосигнала с целью формирования второго стереосигнала в ответ на связанные параметрические данные и данные пространственных параметров, указывающие передаточную функцию бинаурального восприятия, причем второй стереосигнал является бинауральным сигналом;
- средство (411) для кодирования второго стереосигнала с целью формирования кодированных данных и
- средство (413) вывода для формирования выходного потока данных, содержащего кодированные данные и связанные параметрические данные.
2. Кодер по п.1, в котором средство (407) формирования выполнено с возможностью формировать второй стереосигнал посредством вычисления значений данных поддиапазона для второго стереосигнала в ответ на связанные параметрические данные, данные пространственных параметров и значения данных поддиапазона для первого стереосигнала.
3. Кодер по п.2, в котором средство (407) формирования выполнено с возможностью формировать значения поддиапазона для первого поддиапазона второго стереосигнала в ответ на умножение соответствующих стереозначений поддиапазона для первого стереосигнала на матрицу первого поддиапазона; причем средство (407) формирования дополнительно содержит средство параметров для определения значений данных матрицы первого поддиапазона в ответ на связанные параметрические данные и данные пространственных параметров для первого поддиапазона.
4. Кодер по п.3, в котором средство (407) формирования дополнительно содержит средство для преобразования значения данных, по меньшей мере, одного из первого стереосигнала, связанных параметрических данных и данных пространственных параметров, связанных с поддиапазоном, содержащим интервал частот, отличный от интервала первого поддиапазона, в соответствующее значение данных для первого поддиапазона.
5. Кодер по п.3, в котором средство (407) формирования выполнено с возможностью определять стереозначения LB, RB поддиапазона для первого поддиапазона второго стереосигнала по существу как:
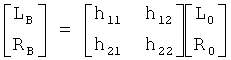 ,
,
при этом L0, R0 - соответствующие значения поддиапазона первого стереосигнала, а средство параметров выполнено с возможностью определять значения данных матрицы умножения по существу как:
h11=m11HL(L)+m21HL(R)+m31HL(C);
h12=m12HL(L)+m22HL(R)+m32HL(C);
h21=m11HR(L)+m21HR(R)+m31HR(C);
h22=m12HR(L)+m22HR(R)+m32HR(С),
где mk,l - параметры, определенные в ответ на связанные параметрические данные для понижающего микширования средством понижающего микширования каналов L, R и С в первый стереосигнал; a Hj(X) определяется в ответ на данные пространственных параметров для канала X в отношении выходного канала J второго стереосигнала.
6. Кодер по п.5, в котором, по меньшей мере, один из каналов L и R соответствует понижающему микшированию, по меньшей мере, двух подвергнутых понижающему микшированию каналов, а средство параметров выполнено с возможностью определять Hj(X) в ответ на взвешенную комбинацию данных пространственных параметров для, по меньшей мере, двух подвергнутых понижающему микшированию каналов.
7. Кодер по п.6, в котором средство параметров выполнено с возможностью определять взвешивание данных пространственных параметров для, по меньшей мере, двух подвергнутых понижающему микшированию каналов в ответ на относительную меру энергии для, по меньшей мере, двух подвергнутых понижающему микшированию каналов.
8. Кодер по п.1, в котором данные пространственных параметров включают в себя, по меньшей мере, один параметр, выбранный из группы, состоящей из:
- параметра среднего уровня по поддиапазону;
- параметра среднего времени поступления;
- фазы, по меньшей мере, одного стереоканала;
- параметра временной привязки;
- параметра групповой задержки;
- фазы между стереоканалами и
- параметра взаимной корреляции каналов.
9. Кодер по п.1, в котором средство (413) вывода выполнено с возможностью включать данные местоположения источника звука в выходной поток.
10. Кодер по п.1, в котором средство (413) вывода выполнено с возможностью включать в выходной поток, по меньшей мере, некоторые данные пространственных параметров.
11. Кодер по п.1, дополнительно содержащий средство (409) для определения данных пространственных параметров в ответ на требуемые местоположения звукового сигнала.
12. Декодер аудиосигнала, содержащий:
- средство (701, 703) для приема входных данных, содержащих первый стереосигнал и параметрические данные, связанные с подвергнутым понижающему микшированию стереосигналом М-канального аудиосигнала, где М>2, причем первый стереосигнал является бинауральным сигналом, соответствующим М-канальному аудиосигналу;
- средство (705) формирования для модифицирования первого стереосигнала с целью формирования подвергнутого понижающему микшированию стереосигнала в ответ на параметрические данные и первые данные пространственных параметров, указывающие передаточную функцию бинаурального восприятия, причем первые данные пространственных параметров связаны с первым стереосигналом.
13. Декодер по п.12, дополнительно содержащий средство (709) для формирования М-канального аудиосигнала в ответ на подвергнутый понижающему микшированию стереосигнал и параметрические данные.
14. Декодер по п.12, в котором средство (705) формирования выполнено с возможностью формировать подвергнутый понижающему микшированию стереосигнал посредством вычисления значений данных поддиапазона для подвергнутого понижающему микшированию стереосигнала в ответ на связанные параметрические данные, первые данные пространственных параметров и значения данных поддиапазона для первого стереосигнала.
15. Декодер по п.14, в котором средство (705) формирования выполнено с возможностью формировать значения поддиапазона для первого поддиапазона подвергнутого понижающему микшированию стереосигнала в ответ на умножение соответствующих стереозначений поддиапазона для первого стереосигнала на матрицу первого поддиапазона; причем средство (705) формирования дополнительно содержит средство параметров для определения значений данных матрицы первого поддиапазона в ответ на параметрические данные и данные параметров передаточной функции бинаурального восприятия для первого поддиапазона.
16. Декодер по п.12, в котором входные данные содержат, по меньшей мере, некоторые из первых данных пространственных параметров.
17. Декодер по п.12, в котором входные данные содержат данные местоположения источника звука и декодер содержит средство (707) для определения первых данных пространственных параметров в ответ на данные местоположения источника звука.
18. Декодер по п.12, дополнительно содержащий:
- блок (709, 801) пространственного декодера для создания пары бинауральных выходных каналов модифицированием первого стереосигнала в ответ на связанные параметрические данные и вторые данные пространственных параметров, указывающие вторую передаточную функцию бинаурального восприятия, причем вторые данные пространственных параметров отличаются от первых данных пространственных параметров.
19. Декодер по п.18, в котором блок (709, 801) пространственного декодера содержит:
- блок (903) преобразования параметров для преобразования параметрических данных в параметры бинаурального синтеза с использованием вторых данных пространственных параметров и
- блок (901) пространственного синтеза для синтеза пары бинауральных каналов с использованием параметров бинаурального синтеза и первого стереосигнала.
20. Декодер по п.19, в котором параметры бинаурального синтеза содержат коэффициенты матрицы для матрицы 2 на 2, определяющей отношение стереообразцов подвергнутого понижающему микшированию стереосигнала к стереообразцам пары бинауральных выходных каналов.
21. Декодер по п.19, в котором параметры бинаурального синтеза содержат коэффициенты матрицы для матрицы 2 на 2, определяющей отношение стереообразцов поддиапазона первого стереосигнала к стереообразцам пары бинауральных выходных каналов.
22. Способ кодирования аудиосигнала, при этом способ состоит в том, что:
- принимают (1001) М-канальный аудиосигнал, где М>2;
- осуществляют понижающее микширование (1003) М-канального аудиосигнала в первый стереосигнал и связанные параметрические данные;
- модифицируют (1005) первый стереосигнал для формирования второго стереосигнала в ответ на связанные параметрические данные и данные пространственных параметров, указывающие передаточную функцию бинаурального восприятия, причем второй стереосигнал является бинауральным сигналом;
- кодируют (1007) второй стереосигнал для формирования кодированных данных и
- формируют (1009) выходной поток данных, содержащий кодированные данные и связанные параметрические данные.
23. Способ декодирования аудиосигнала, при этом способ состоит в том, что:
- принимают (1101) входные данные, содержащие первый стереосигнал и параметрические данные, связанные с подвергнутым понижающему микшированию стереосигналом М-канального аудиосигнала, где М>2, причем первый стереосигнал является бинауральным сигналом, соответствующим М-канальному аудиосигналу; и
- модифицируют (1103) первый стереосигнал для формирования подвергнутого понижающему микшированию стереосигнала в ответ на параметрические данные и данные пространственных параметров, указывающие передаточную функцию бинаурального восприятия, причем данные пространственных параметров связаны с первым стереосигналом.
24. Приемник для приема аудиосигнала, содержащий:
- средство (701, 703) для приема входных данных, содержащих первый стереосигнал и параметрические данные, связанные с подвергнутым понижающему микшированию стереосигналом М-канального аудиосигнала, где М>2, причем первый стереосигнал является бинауральным сигналом, соответствующим М-канальному аудиосигналу; и
- средство (705) формирования для модифицирования первого стереосигнала с целью формирования подвергнутого понижающему микшированию стереосигнала в ответ на параметрические данные и данные пространственных параметров, указывающие передаточную функцию бинаурального восприятия, причем данные пространственных параметров связаны с первым стереосигналом.
25. Передатчик (1101) для передачи выходного потока данных, при этом передатчик содержит:
- средство (401) для приема М-канального аудиосигнала, где М>2;
- средство (403) понижающего микширования для понижающего микширования М-канального аудиосигнала в первый стереосигнал и связанные параметрические данные;
- средство (407) формирования для модифицирования первого стереосигнала с целью формирования второго стереосигнала в ответ на связанные параметрические данные и данные пространственных параметров, указывающие передаточную функцию бинаурального восприятия, причем второй стереосигнал является бинауральным сигналом;
- средство (411) для кодирования второго стереосигнала с целью формирования кодированных данных;
- средство (413) вывода для формирования выходного потока данных, содержащего кодированные данные и связанные параметрические данные; и
- средство (311) для передачи выходного потока данных.
26. Система передачи для передачи аудиосигнала, при этом система передачи содержит:
- передатчик, содержащий:
- средство (401) для приема М-канального аудиосигнала, где М>2,
- средство (403) понижающего микширования для понижающего микширования М-канального аудиосигнала в первый стереосигнал и связанные параметрические данные,
- средство (407) формирования для модифицирования первого стереосигнала с целью формирования второго стереосигнала в ответ на связанные параметрические данные и данные пространственных параметров, указывающие передаточную функцию бинаурального восприятия, причем второй стереосигнал является бинауральным сигналом,
- средство (411) для кодирования второго стереосигнала с целью формирования кодированных данных,
- средство (413) вывода для формирования выходного потока аудиоданных, содержащего кодированные данные и связанные параметрические данные, и
- средство (311) для передачи выходного потока аудиоданных; и
- приемник, содержащий:
- средство (701, 703) для приема выходного потока аудиоданных и
- средство (705) для модифицирования второго стереосигнала с целью формирования первого стереосигнала в ответ на параметрические данные и данные пространственных параметров.
27. Способ приема аудиосигнала, при этом способ состоит в том, что:
- принимают (1101) входные данные, содержащие первый стереосигнал и параметрические данные, связанные с подвергнутым понижающему микшированию стереосигналом М-канального аудиосигнала, где М>2, причем первый стереосигнал является бинауральным сигналом, соответствующим М-канальному аудиосигналу; и
- модифицируют (1103) первый стереосигнал для формирования подвергнутого понижающему микшированию стереосигнала в ответ на параметрические данные и данные пространственных параметров, указывающие передаточную функцию бинаурального восприятия, причем данные пространственных параметров связаны с первым стереосигналом.
28. Способ передачи выходного потока аудиоданных, при этом способ состоит в том, что:
- принимают (1001) М-канальный аудиосигнал, где М>2;
- осуществляют понижающее микширование (1003) М-канального аудиосигнала в первый стереосигнал и связанные параметрические данные;
- модифицируют (1005) первый стереосигнал для формирования второго стереосигнала в ответ на связанные параметрические данные и данные пространственных параметров, указывающие передаточную функцию бинаурального восприятия, причем второй стереосигнал является бинауральным сигналом;
- кодируют (1007) второй стереосигнал для формирования кодированных данных и
- формируют (1009) выходной поток аудиоданных, содержащий кодированные данные и связанные параметрические данные; и
- передают выходной поток аудиоданных.
29. Способ передачи и приема аудиосигнала, при этом способ состоит в том, что:
- принимают (1001) М-канальный аудиосигнал, где М>2;
- осуществляют понижающее микширование (1003) М-канального аудиосигнала в первый стереосигнал и связанные параметрические данные;
- модифицируют (1005) первый стереосигнал для формирования второго стереосигнала в ответ на связанные параметрические данные и данные пространственных параметров, указывающие передаточную функцию бинаурального восприятия, причем второй стереосигнал является бинауральным сигналом;
- кодируют (1007) второй стереосигнал для формирования кодированных данных и
- формируют (1009) выходной поток аудиоданных, содержащий кодированные данные и связанные параметрические данные;
- передают выходной поток аудиоданных;
- принимают (1101) выходной поток аудиоданных и
- модифицируют (1103) второй стереосигнал для формирования первого стереосигнала в ответ на параметрические данные и данные пространственных параметров.
30. Машиночитаемый носитель данных, на котором хранятся исполняемые компьютером команды, которые при исполнении процессором побуждают компьютер осуществлять способ по п.22.
31. Машиночитаемый носитель данных, на котором хранятся исполняемые компьютером команды, которые при исполнении процессором побуждают компьютер осуществлять способ по п.23.
32. Машиночитаемый носитель данных, на котором хранятся исполняемые компьютером команды, которые при исполнении процессором побуждают компьютер осуществлять способ по п.27.
33. Машиночитаемый носитель данных, на котором хранятся исполняемые компьютером команды, которые при исполнении процессором побуждают компьютер осуществлять способ по п.28.
34. Устройство аудиозаписи, содержащее кодер (309) по п.1.
35. Устройство аудиовоспроизведения, содержащее декодер (315) по п.12.
| WO 2005098826 А1, 20.10.2005 | |||
| US 2005273322 А1, 08.12.2005 | |||
| Способ определения родия | 1987 |
|
SU1545154A1 |
| KR 20040027015 А, 01.04.2004 | |||
| WO 2006008683 А1, 26.01.2006 | |||
| RU 2005103637 А, 10.07.2005. | |||

