Варианты осуществления относятся к аудиокодеру для предоставления закодированного представления на основе аудиосигнала. Дополнительные варианты осуществления относятся к способу для предоставления закодированного представления на основе аудиосигнала. Некоторые варианты осуществления относятся к подавлению шумов с малой задержкой, с низкой сложностью, на дальнем конце применительно к перцепционным речевым и аудиокодекам.
Настоящая проблема речевых и аудиокодеков состоит в том, что они используются в неблагоприятных средах, где акустический входной сигнал искажается фоновым шумом и другими артефактами. Это вызывает ряд проблем. Поскольку теперь кодек должен кодировать как желательный сигнал, так и нежелательные искажения, проблема кодирования является более сложной, поскольку сигнал теперь состоит из двух источников, и это будет снижать качество кодирования. Но даже если мы можем кодировать комбинацию двух курсов с одинаковым качеством в качестве единого чистого сигнала, речевая часть по-прежнему будет более низкого качества, чем чистый сигнал. Потерянное качество кодирования является не только перцепционно раздражающим, но, что важно, оно также усиливает напряжение при прослушивании и, в наихудшем случае, уменьшает разборчивость или усиливает напряжение при прослушивании декодированного сигнала.
Документ WO 2005/031709 A1 показывает способ речевого кодирования, применяющий уменьшение шума посредством модифицирования коэффициента усиления кодовой книги. Подробнее, акустический сигнал, содержащий речевую составляющую и шумовую составляющую, кодируется посредством использования анализа посредством способа синтеза, при этом для кодирования акустического сигнала синтезированный сигнал сравнивается с акустическим сигналом на интервале времени, упомянутый синтезированный сигнал описан посредством использования фиксированной кодовой книги и ассоциированного фиксированного коэффициента усиления.
Документ US 2011/076968 A1 показывает устройство связи с уменьшенным по шуму речевым кодированием. Устройство связи включает в себя память, интерфейс ввода, модуль обработки, и передатчик. Модуль обработки принимает цифровой сигнал от интерфейса ввода, при этом цифровой сигнал включает в себя желательную составляющую цифрового сигнала и нежелательную составляющую цифрового сигнала. Модуль обработки идентифицирует одну из множества кодовых книг на основании нежелательной составляющей цифрового сигнала. Затем модуль обработки идентифицирует запись кодовой книги из одного из множества кодовых книг на основании желательной составляющей цифрового сигнала, чтобы создать выбранную запись кодовой книги. Затем модуль обработки генерирует кодированный сигнал на основании выбранной записи кодовой книги, при этом кодированный сигнал включает в себя, по существу, представление без затухания желательной составляющей цифрового сигнала и представление с затуханием нежелательной составляющей цифрового сигнала.
Документ US 2001/001140 A1 показывает модульный подход к повышению разборчивости речи с применением к речевому кодированию. Речевой кодер разделяет входную представленную в цифровой форме речь на составляющие части поинтервальным образом. Составляющие части включают в себя составляющие коэффициента усиления, составляющие спектра и составляющие сигнала возбуждения. Набор систем повышения разборчивости речи в речевом кодере обрабатывает составляющие части таким образом, что каждая составляющая часть имеет свой собственный процесс повышения разборчивости речи. Например, один процесс повышения разборчивости речи может быть применен для анализа составляющих спектра и другой процесс повышения разборчивости речи может быть использован для анализа составляющих сигнала возбуждения.
Документ US 5,680,508 A раскрывает улучшение речевого кодирования в фоновом шуме для низкоскоростного речевого кодера. Система кодирования речи использует измерения надежных признаков речевых кадров, чьи распределения сильно не затрагиваются шумом/уровнями, чтобы принять голосовые решения применительно к вводу речи, происходящему в шумной среде. Линейный программный анализ надежных признаков и соответствующих весов используются для того, чтобы определять оптимальную линейную комбинацию этих признаков. Входные речевые векторы сопоставляются со словарем кодовых слов для того, чтобы выбрать соответствующее, оптимально сопоставленное кодовое слово. Используется адаптивное векторное квантование, при котором словарь слов, полученный в тихой среде, обновляется на основании оценки шума у шумной среды, в которой происходит ввод речи, и затем осуществляется поиск в «шумном» словаре для наилучшего совпадения с входным речевым вектором. Соответствующий индекс чистого кодового слова затем выбирается для передачи и для синтеза на конце приемника.
Документ US 2006/116874 A1 показывает зависимую от шума пост-фильтрацию. Способ включает в себя предоставление фильтра, подходящего для уменьшения искажения, вызываемого речевым кодированием, оценку акустического шума в речевом сигнале, адаптацию фильтра в ответ на оцененный акустический шум, чтобы получать адаптированный фильтр, и применение адаптированного фильтра к речевому сигналу так, чтобы уменьшать акустический шум и искажение, вызываемые речевым кодированием в речевом сигнале.
Документ US 6,385,573 B1 показывает адаптивную компенсацию отклонения для синтезированного речевого остатка. Многоскоростной речевой кодек поддерживает множество режимов битовой скорости кодирования посредством адаптивного выбора режимов битовой скорости кодирования для сопоставления с ограничениями канала связи. При режимах кодирования с более высокой битовой скоростью, точное представление речи посредством CELP (линейное предсказание с кодовым возбуждением) и другие ассоциированные параметры моделирования, генерируются для декодирования и воспроизведения с более высоким качеством. Для достижения высокого качества при режимах кодирования с более низкой битовой скоростью, речевой кодер отступает от строгих критериев сопоставления формы волны у обычных кодеров CELP и пытается идентифицировать существенные перцепционные признаки входного сигнала.
Документ US 5,845,244 A относится к адаптации уровня маскирования шума в анализе-посредством-синтеза, использующем перцепционное взвешивание. В речевом кодере с анализом-посредством-синтеза, использующем перцепционный взвешивающий фильтр по короткому периоду, значения спектральных коэффициентов разложения адаптируются динамически на основе спектральных параметров, полученных во время анализа с линейным предсказанием по короткому периоду. Спектральные параметры, участвующие в данной адаптации, могут, в частности, содержать параметры, представляющие собой общую крутизну спектра речевого сигнала, и параметры, представляющие собой резонансный характер фильтра синтеза по короткому периоду.
Документ US 4,133,976 A показывает кодирование речевого сигнала с предсказанием с уменьшенными влияниями шума. Процессор речевого сигнала с предсказанием отличается адаптивным фильтром в цепи обратной связи вокруг квантователя. Адаптивный фильтр по существу объединяет сигнал ошибки квантования, сигналы параметра предсказания, связанного с формантой, и разностный сигнал, чтобы сконцентрировать шум ошибки квантования в спектральных пиках, соответствующих изменяющимся во времени участкам форманты речевого спектра так, что шум квантования маскируется формантами речевого сигнала.
Документ WO 9425959 A1 показывает использование слуховой модели, чтобы улучшать качество или уменьшать скорость передачи битов систем синтеза речи. Взвешивающий фильтр заменяется слуховой моделью, которая обеспечивает поиск оптимального вектора случайного кода в психоакустической области. Раскрывается алгоритм, который был назван PERCELP (от Перцепционно Улучшенное Произвольное Линейное Предсказание с Кодовым Возбуждением), который создает речь, которая значительно лучшего качества, чем получаемая с помощью взвешивающего фильтра.
Документ US 2008/312916 A1 показывает систему повышения разборчивости приемника, которая обрабатывает входной речевой сигнал, чтобы генерировать улучшенный разборчивый сигнал. В частотной области, FFT спектр речи, принимаемой от дальнего конца модифицируется в соответствии со спектром LPC у локального фонового шума, чтобы генерировать улучшенный разборчивый сигнал. Во временной области, речь модифицируется в соответствии с коэффициентами LPC у шума, чтобы генерировать улучшенный разборчивый сигнал.
Документ US 2013/030800 A1 показывает адаптивный процессор разборчивости голоса, который адаптивным образом идентифицирует и отслеживает местоположения форманты, тем самым обеспечивая выделение формант по мере того, как они меняются. В результате, эти системы и способы могут улучшать разборчивость на ближнем конце даже в шумных средах.
В документе [Atal, Bishnu S., and Manfred R. Schroeder. «Predictive coding of speech signals and subjective error criteria». Acoustics, Speech and Signal Processing, IEEE Transactions on 27,3 (1979): 247-254] описываются и оцениваются способы для уменьшения субъективного искажения в кодерах с предсказанием применительно к речевым сигналам. Улучшенное качество речи получается: 1) посредством эффективного удаления форманты и связанной с основным тоном избыточной структуры речи до квантования, и 2) посредством эффективного маскирования шума квантователя посредством речевого сигнала.
В документе [Chen, Juin-Hwey and Allen Gersho. «Real-time vector ARC speech coding at 4800 bps with adaptive postfiltering». Acoustics, Speech and Signal Processing, IEEE International Conference on ICASSP'87.. Том 12, IEEE, 1987] представляется улучшенный речевой кодер Векторного APC (VAPC), который объединяет APC с векторным квантованием и включает анализ-посредством-синтеза, перцепционное взвешивание шума, и адаптивную пост-фильтрацию.
Цель настоящего изобретения состоит в предоставлении концепции для уменьшения напряжения при прослушивании или улучшения качества сигнала или повышения разборчивости декодированного сигнала, когда акустический входной сигнал искажается фоновым шумом и другими артефактами.
Данная цель достигается независимыми пунктами формулы изобретения.
Преимущественные реализации рассматриваются в зависимых пунктах формулы изобретения.
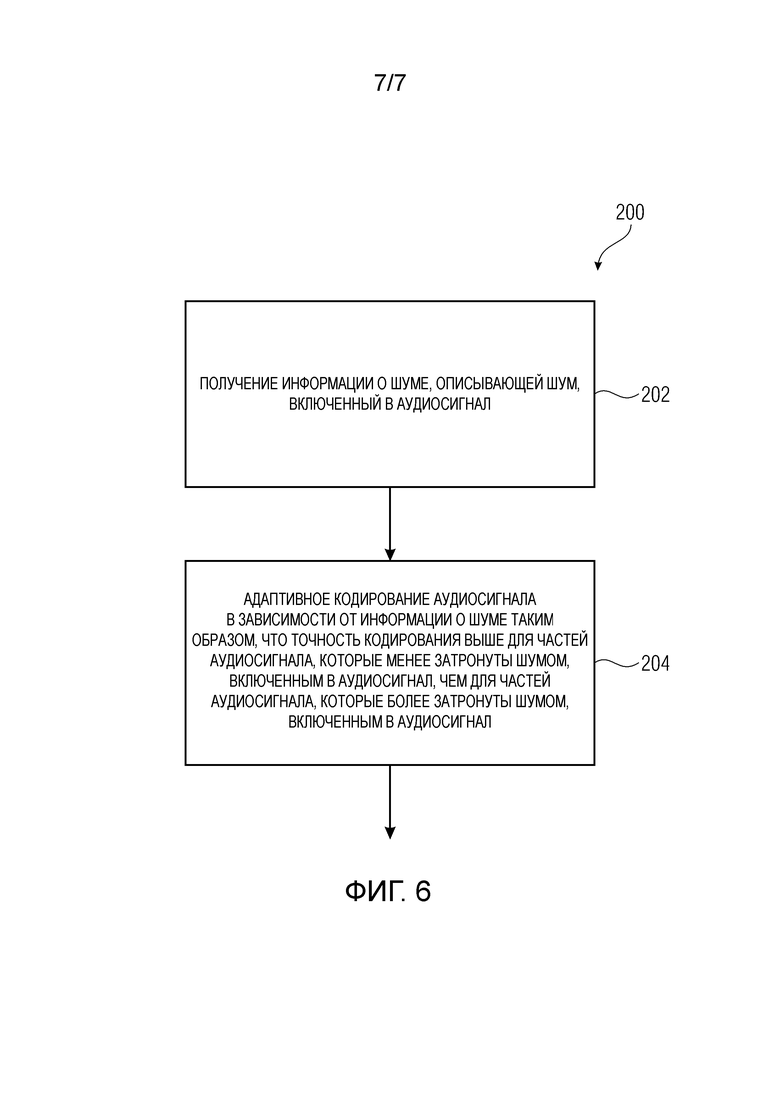
Варианты осуществления предоставляют аудиокодер для предоставления закодированного представления на основе аудиосигнала. Аудиокодер выполнен с возможностью получения информации о шуме, описывающей шум, включенный в аудиосигнал, при этом аудиокодер выполнен с возможностью адаптивного кодирования аудиосигнала в зависимости от информации о шуме таким образом, что точность кодирования выше для частей аудиосигнала, которые менее затронуты шумом, включенным в аудиосигнал, чем для частей аудиосигнала, которые более затронуты шумом, включенным в аудиосигнал.
В соответствии с концепцией настоящего изобретения, аудиокодер адаптивно кодирует аудиосигнал в зависимости от информации о шуме, описывающей шум, включенный в аудиосигнал для того, чтобы получать более высокую точность кодирования для тех частей аудиосигнала, которые менее затронуты шумом (например, которые имеют более высокое отношение сигнала-к-шуму), чем для частей аудиосигнала, которые более затронуты шумом (например, которые имеют более низкое отношение сигнала-к-шуму).
Кодеки связи часто работают в средах, где желательный сигнал искажается фоновым шумом. Варианты осуществления, раскрываемые в данном документе, направлены на ситуации, где сигнал стороны отправителя/кодера имеет фоновый шум еще до кодирования.
Например, в соответствии с некоторыми вариантами осуществления, посредством модифицирования перцепционной целевой функции кодера точность кодирования тех участков сигнала, которые имеют более высокое отношение сигнала-к-шуму (SNR) может быть увеличена, тем самым сохраняя качество свободных от шума участков сигнала. Посредством сохранения участков с высоким SNR у сигнала, разборчивость передаваемого сигнала может быть улучшена и напряжение при прослушивании может быть уменьшено. Тогда как традиционные алгоритмы подавления шума реализуются в качестве блока предварительной обработки для кодека, настоящий подход обладает двумя отличительными преимуществами. Во-первых, посредством совместного подавления шума и кодирования можно избежать тандемных эффектов подавления и кодирования. Во-вторых, поскольку предлагаемый алгоритм может быть реализован в качестве модификации перцепционной целевой функции, он имеет очень низкую вычислительную сложность. Более того, часто кодеки связи оценивают фоновый шум для генераторов комфортного шума и в любом случае, таким образом, оценка шума уже доступна в кодеке и она может быть использована (в качестве информации о шуме) без дополнительных вычислительных затрат.
Дополнительные варианты осуществления относятся к способу для предоставления закодированного представления на основе аудиосигнала. Способ содержит этапы, на которых получают информацию о шуме, описывающую шум, включенный в аудиосигнал, и адаптивно кодируют аудиосигнал в зависимости от информации о шуме таким образом, что точность кодирования выше для частей аудиосигнала, которые менее затронуты шумом, включенным в аудиосигнал, чем для частей аудиосигнала, которые больше затронуты шумом, включенным в аудиосигнал.
Дополнительные варианты осуществления относятся к потоку данных, несущему закодированное представление аудиосигнала, при этом закодированное представление аудиосигнала адаптивно кодирует аудиосигнал в зависимости от информации о шуме, описывающей шум, включенный в аудиосигнал таким образом, что точность кодирования выше для частей аудиосигнала, которые менее затронуты шумом, включенным в аудиосигнал, чем для частей аудиосигнала, которые более затронуты шумом, включенным в аудиосигнал.
Варианты осуществления настоящего изобретения описываются в данном документе со ссылкой на приложенные чертежи:
Фиг. 1 показывает принципиальную структурную схему аудиокодера для предоставления закодированного представления на основе аудиосигнала, в соответствии с вариантом осуществления;
Фиг. 2a показывает принципиальную структурную схему аудиокодера для предоставления закодированного представления на основе речевого сигнала, в соответствии с вариантом осуществления;
Фиг. 2b показывает принципиальную структурную схему средства определения записи кодовой книги, в соответствии с вариантом осуществления;
Фиг. 3 показывает на схеме амплитуду оценки шума и восстановленного спектра для шума, построенную по частоте;
Фиг. 4 показывает на схеме амплитуду соответствий линейного предсказания для шума для разных порядков предсказания, построенную по частоте;
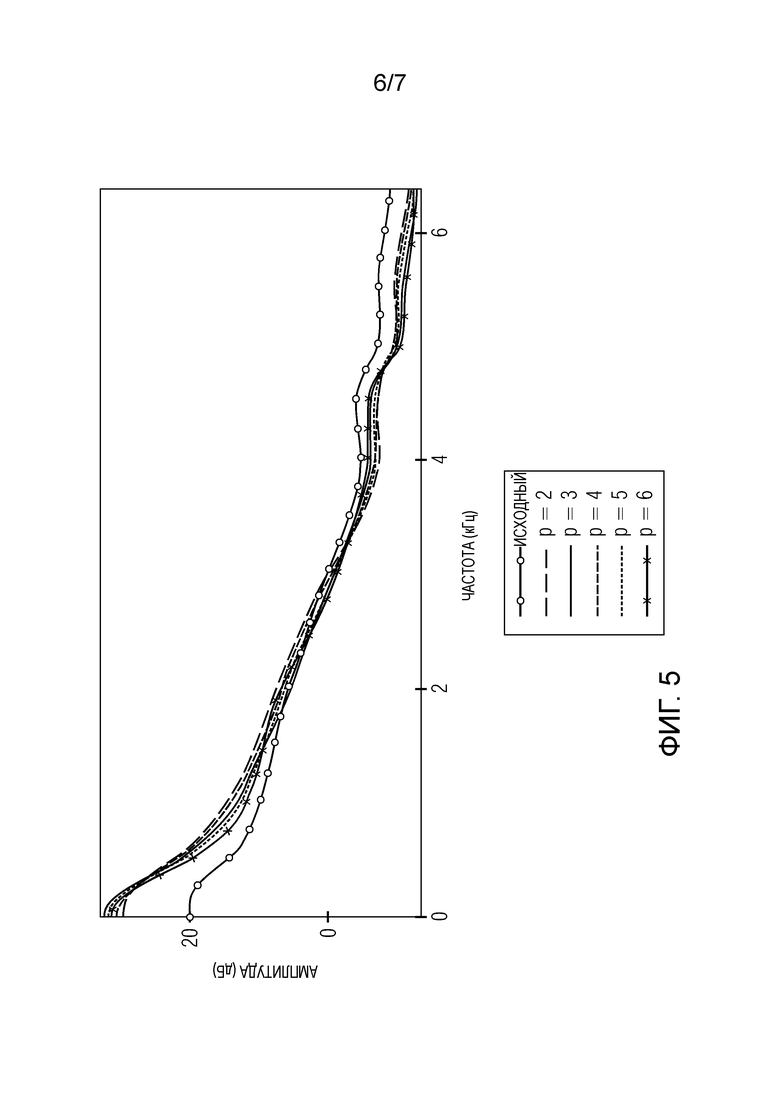
Фиг. 5 показывает на схеме амплитуду инверсии исходного взвешивающего фильтра и амплитуды инверсий предлагаемых взвешивающих фильтров, имеющих разные порядки предсказания, построенные по частоте; и
Фиг. 6 показывает блок-схему способа для предоставления закодированного представления на основе аудиосигнала, в соответствии с вариантом осуществления.
Равные или эквивалентные элементы или элементы с равной или эквивалентной функциональностью обозначаются в нижеследующем описании равными или эквивалентными цифровыми обозначениями.
В нижеследующем описании, множество подробностей излагается для того, чтобы предоставить более исчерпывающее объяснение вариантов осуществления настоящего изобретения. Тем не менее, специалисту в соответствующей области техники будет очевидно, что варианты осуществления настоящего изобретения могут быть реализованы на практике без этих конкретных подробностей. В других случаях, хорошо известные структуры и устройства показаны в форме структурной схемы, а не подробно для того, чтобы избежать затенения вариантов осуществления настоящего изобретения. В дополнение, признаки разных вариантов осуществления, описываемых далее, могут быть объединены друг с другом, при условии, что специально не отмечается иное.
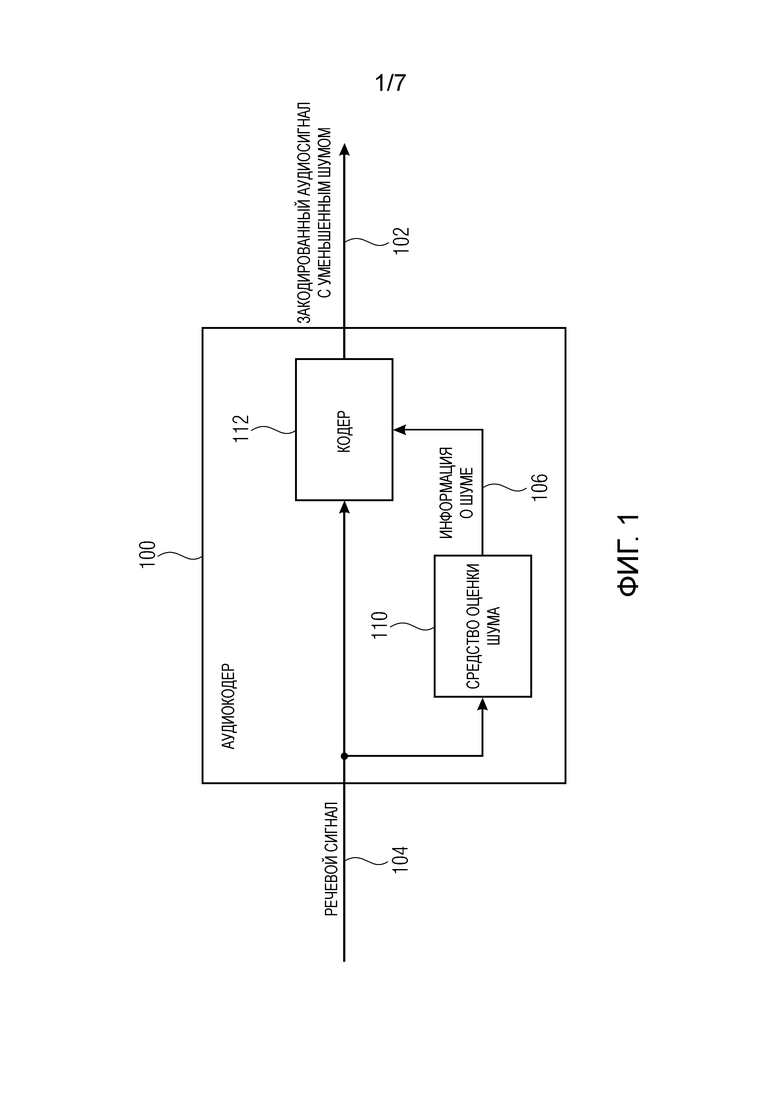
Фиг. 1 показывает принципиальную структурную схему аудиокодера 100 для предоставления закодированного представления 102 (или закодированного аудиосигнала) на основе аудиосигнала 104. Аудиокодер 100 выполнен с возможностью получения информации 106 о шуме, описывающей шум, включенный в аудиосигнал 104, и адаптивного кодирования аудиосигнала 104 в зависимости от информации 106 о шуме таким образом, что точность кодирования выше для частей аудиосигнала 104, который менее затронут шумом, включенным в аудиосигнал 104, чем для частей аудиосигнала, которые более затронуты шумом, включенным в аудиосигнал 104.
Например, аудиокодер 100 может содержать средство 110 оценки шума (или средство определения шума или средство анализа шума) и кодер 112. Средство 110 оценки шума может быть выполнено с возможностью получения информации 106 о шуме, описывающей шум, включенный в аудиосигнал 104. Кодер 112 может быть выполнен с возможностью адаптированного кодирования аудиосигнала 104 в зависимости от информации 106 о шуме таким образом, что точность кодирования выше для частей аудиосигнала 104, которые менее затронуты шумом, включенным в аудиосигнал 104, чем для частей аудиосигнала 104, которые более затронуты шумом, включенным в аудиосигнал 104.
Средство 110 оценки шума и кодер 112 могут быть реализованы посредством (или используя) устройства аппаратного обеспечения такого как, например, интегральная микросхема, программируемая вентильная матрица, микропроцессор, программируемый компьютер или электронная схема.
В вариантах осуществления, аудиокодер 100 может быть выполнен с возможностью одновременного кодирования аудиосигнала 104 и уменьшения шума в закодированной представлении 102 аудиосигнала 104 (или закодированном аудиосигнале) посредством адаптивного кодирования аудиосигнала 104 в зависимости от информации 106 о шуме.
В вариантах осуществления, аудиокодер 100 может быть выполнен с возможностью кодирования аудиосигнала 104, используя перцепционную целевую функцию. Перцепционная целевая функция может быть отрегулирована (или модифицирована) в зависимости от информации 106 о шуме, тем самым адаптивно кодируя аудиосигнал 104 в зависимости от информации 106 о шуме. Информация 106 о шуме может быть, например, отношением сигнала-к-шуму, или оцененной формой шума, включенного в аудиосигнал 104.
Варианты осуществления настоящего изобретения пытаются уменьшить напряжение при прослушивании или соответственно повысить разборчивость. Здесь важно отметить, что варианты осуществления, в целом, могут не предоставлять наиболее возможное точное представление входного сигнала, а пытаются передать такие части сигнала, которые являются оптимизированными по напряжению при прослушивании или разборчивости. В частности, варианты осуществления могут менять тембр сигнала, но таким образом, что передаваемый сигнал уменьшает напряжение при прослушивании или является лучше применительно к разборчивости, чем точно передаваемый сигнал.
В соответствии с некоторыми вариантами осуществления, модифицируется перцепционная целевая функция кодека. Другими словами, варианты осуществления явным образом не подавляют шум, а меняют цель таким образом, что точность выше в частях сигнала, где отношение сигнала к шуму наилучшее. Эквивалентным образом, варианты осуществления уменьшают искажение сигнала в тех частях, где SNR высокое. Слушатели тогда могут легко понимать сигнал. Те части сигнала, которые имеют низкое SNR, тем самым передаются с меньшей точностью, но поскольку они все равно содержат по большей части шум, то точное кодирование таких частей не является важным. Другими словами, фокусируя точность на частях высокого SNR, варианты осуществления косвенно улучшают SNR речевых частей, при этом уменьшая SNR частей шума.
Варианты осуществления могут быть реализованы или применяться в любом речевом или аудиокодеке, например, в таких кодеках, которые используют перцепционную модель. В сущности, в соответствии с некоторыми вариантами осуществления перцепционная взвешивающая функция может быть модифицирована (или отрегулирована) на основании характеристики шума. Например, средняя спектральная огибающая сигнала шума может быть оценена и использована, чтобы модифицировать перцепционную целевую функцию.
Описываемые в данном документе варианты осуществления предпочтительно применимы к речевым кодекам CELP-типа (CELP=линейное предсказание с кодовым возбуждением) или другим кодекам, в которых перцепционная модель может быть выражена посредством взвешивающего фильтра. Однако, варианты осуществления также могут быть использованы в кодеках TCX-типа (TCX=кодированное с преобразованием возбуждение), как, впрочем, и других кодеках частотной области. Дополнительно, предпочтительным случаем использования вариантов осуществления является речевое кодирование, но варианты осуществления также могут быть использованы в целом в любом речевом или аудиокодеке. Поскольку ACELP (ACELP=алгебраическое линейное предсказание с кодовым возбуждением) является типичным применением, применение вариантов осуществления в ACELP будет подробно описано ниже. Применение вариантов осуществления в других кодеках, включая кодеки частотной области, затем будет очевидно специалистам в соответствующей области техники.
Традиционный подход к подавлению шума в речевых или аудиокодеках состоит в применении его в качестве отдельного блока предварительной обработки с целью удаления шума до кодирования. Тем не менее, выделение его в отдельные блоки имеет два основных недостатка. Во-первых, поскольку средство подавления шума главным образом будет удалять не только шум, но также искажать желательный сигнал, кодек, таким образом, будет пытаться точно закодировать искаженный сигнал. Вследствие этого кодек будет иметь неверную цель и теряется эффективность и точность. Это также можно рассматривать как случай тандема, когда последующие блоки создают независимые ошибки, которые складываются. Посредством вариантов осуществления совместного подавления шума и кодирования избегают проблем тандема. Во-вторых, поскольку подавление шума традиционно реализуется в отдельном блоке предварительной обработки, высока вычислительная сложность и задержка. В противоположность этому, поскольку в соответствии с вариантами осуществления средство подавления шума реализуется в кодеке, оно может быть применено с очень низкой вычислительной сложностью и задержкой. Это в частности будет выгодно в недорогих устройствах, которые не обладают вычислительной емкостью для традиционного подавления шума.
Описание далее будет обсуждать применение в контексте кодека AMR-WB (AMR-WB=адаптивный многоскоростной широкополосный), так как на момент написания он является наиболее часто используемым речевым кодеком. Варианты осуществления также могут быть легко применены поверх других речевых кодеков, таких как 3GPP Улучшенные Голосовые Услуги или G.718. Следует отметить, что предпочтительным использованием вариантов осуществления является надстройка к существующим стандартам, поскольку варианты осуществления могут быть применены к кодекам без изменения формата битового потока.
Фиг. 2a показывает принципиальную структурную схему аудиокодера 100 для предоставления закодированного представления 102 на основе речевого сигнала 104, в соответствии с вариантами осуществления. Аудиокодер 100 может быть выполнен с возможностью извлечения остаточного сигнала 120 из речевого сигнала 104 и кодирования остаточного сигнала 120, используя кодовую книгу 122. Подробнее, аудиокодер 100 может быть выполнен с возможностью выбора записи кодовой книги из множества записей кодовой книги у кодовой книги 122 для кодирования остаточного сигнала 120 в зависимости от информации 106 о шуме. Например, аудиокодер 100 может содержать средство 124 определения записи кодовой книги, содержащее кодовую книгу 122, при этом средство 124 определения записи кодовой книги может быть выполнено с возможностью выбора записи кодовой книги из множества записей кодовой книги у кодовой книги 122 для кодирования остаточного сигнала 120 в зависимости от информации 106 о шуме, тем самым получая квантованный остаток 126.
Аудиокодер 100 может быть выполнен с возможностью оценки вклада голосового тракта в речевой сигнал 104 и удаления оцененного вклада голосового тракта из речевого сигнала 120 для того, чтобы получать остаточный сигнал 120. Например, аудиокодер 100 может содержать средство 130 оценки голосового тракта и средство 132 удаления голосового тракта. Средство 130 оценки голосового тракта может быть выполнено с возможностью приема речевого сигнала 104, чтобы оценивать вклад голосового тракта в речевой сигнал 104, и предоставления оцененного вклада голосового тракта 128 в речевой сигнал 104 средству 132 удаления голосового тракта. Средство 132 удаления голосового тракта может быть выполнено с возможностью удаления оцененного вклада голосового тракта 128 из речевого сигнала 104 для того, чтобы получать остаточный сигнал 120. Вклад голосового тракта в речевой сигнал 104 может быть оценен, например, используя линейное предсказание.
Аудиокодер 100 может быть выполнен с возможностью предоставления квантованного остатка 126 и оцененного вклада голосового тракта 128 (или параметров фильтра, описывающих оцененный вклад 128 голосового тракта 104) в качестве закодированного представления на основе речевого сигнала (или закодированного речевого сигнала).
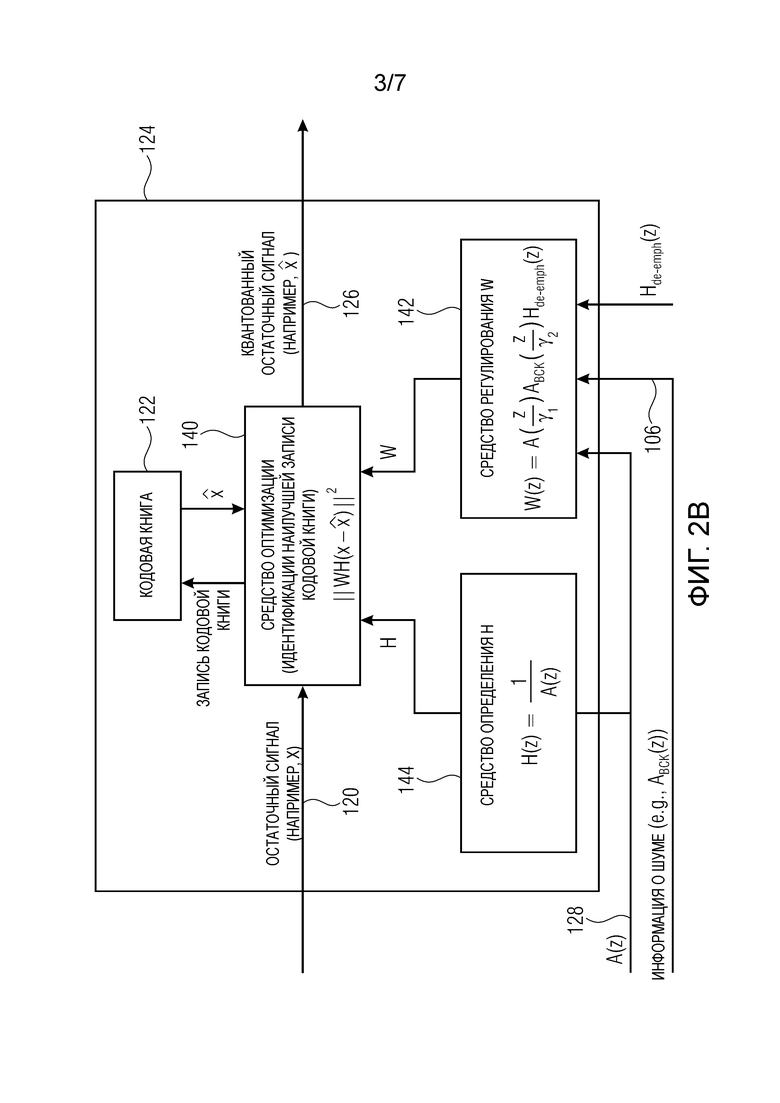
Фиг. 2b показывает принципиальную структурную схему средства 124 определения записи кодовой книги в соответствии с вариантом осуществления. Средство 124 определения записи кодовой книги может содержать средство 140 оптимизации, выполненное с возможностью выбора записи кодовой книги, используя перцепционный взвешивающий фильтр W. Например, средство 140 оптимизации может быть выполнено с возможностью выбора записи кодовой книги для остаточного сигнала 120 таким образом, что синтезированная взвешенная ошибка квантования остаточного сигнала 126, взвешенная с помощью перцепционного взвешивающего фильтра W, уменьшается (или минимизируется). Например, средство 130 оптимизации может быть выполнено с возможностью выбора записи кодовой книги, используя функцию расстояния:
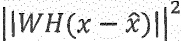
при этом 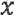 представляет собой остаточный сигнал, при этом
представляет собой остаточный сигнал, при этом 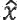 представляет собой квантованный остаточный сигнал, при этом
представляет собой квантованный остаточный сигнал, при этом 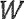 представляет собой перцепционный взвешивающий фильтр, и при этом
представляет собой перцепционный взвешивающий фильтр, и при этом 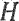 представляет собой фильтр синтеза квантованного голосового тракта. Таким образом, и могут быть сверточными матрицами.
представляет собой фильтр синтеза квантованного голосового тракта. Таким образом, и могут быть сверточными матрицами.
Средство 124 определения записи кодовой книги может содержать средство 144 определения фильтра синтеза квантованного голосового тракта, выполненного с возможностью определения фильтра синтеза квантованного голосового тракта из оцененного вклада голосового тракта A(z).
Кроме того, средство 124 определения записи кодовой книги может содержать средство 142 регулирования перцепционного взвешивающего фильтра, выполненного с возможностью регулирования перцепционного взвешивающего фильтра таким образом, что влияние шума на выбранную запись кодовой книги уменьшается. Например, перцепционный взвешивающий фильтр может быть отрегулирован таким образом, что части речевого сигнала, которые менее затронуты шумом, взвешиваются в большей степени для выбора записи кодовой книги, чем части речевого сигнала, которые более затронуты шумом. Кроме того (или в качестве альтернативы), перцепционный взвешивающий фильтр может быть отрегулирован таким образом, что ошибка между частями остаточного сигнала 120, которые менее затронуты шумом, и соответствующими частями квантованного остаточного сигнала 126, уменьшается.
Средство 142 регулирования перцепционного взвешивающего фильтра может быть выполнено с возможностью извлечения коэффициентов линейного предсказания из информации (106) о шуме, чтобы тем самым определять соответствие (A_BCK) линейного предсказания, и использования соответствия (A_BCK) линейного предсказания в перцепционном взвешивающем фильтре (W). Например, средство 142 регулирования перцепционного взвешивающего фильтра может быть выполнено с возможностью регулирования перцепционного взвешивающего фильтра W, используя формулу:
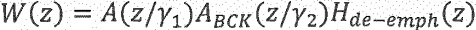
при этом 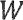 представляет собой перцепционный взвешивающий фильтр, при этом
представляет собой перцепционный взвешивающий фильтр, при этом 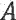 представляет собой модель голосового тракта,
представляет собой модель голосового тракта, 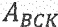 представляет собой соответствие линейного предсказания,
представляет собой соответствие линейного предсказания, 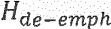 представляет собой фильтр устранения высокочастотных составляющих,
представляет собой фильтр устранения высокочастотных составляющих,  , и
, и 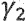 является параметром, с помощью которого может регулироваться величина подавления шума. Таким образом, может быть равно 1/(1-0,68z-1).
является параметром, с помощью которого может регулироваться величина подавления шума. Таким образом, может быть равно 1/(1-0,68z-1).
Другими словами, кодек AMR-WB использует алгебраическое линейное предсказание с кодовым возбуждением (ACELP) для параметризации речевого сигнала 104. Это означает, что сначала вклад голосового тракта, 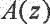 , оценивается с помощью линейного предсказания и удаляется, и затем осуществляется параметризация остаточного сигнала, используя алгебраическую кодовую книгу. Для нахождения наилучшей записи кодовой книги, перцепционное расстояние между исходным остатком и записями кодовой книги может быть минимизировано. Функция расстояния может быть записана как
, оценивается с помощью линейного предсказания и удаляется, и затем осуществляется параметризация остаточного сигнала, используя алгебраическую кодовую книгу. Для нахождения наилучшей записи кодовой книги, перцепционное расстояние между исходным остатком и записями кодовой книги может быть минимизировано. Функция расстояния может быть записана как 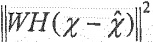 , где и являются исходным и квантованным остатками, и являются сверточными матрицами, соответствующими, соответственно,
, где и являются исходным и квантованным остатками, и являются сверточными матрицами, соответствующими, соответственно, 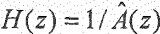 , фильтру синтеза квантованного голосового тракта и
, фильтру синтеза квантованного голосового тракта и 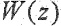 , и перцепционному взвешиванию, которое, как правило, выбирается как
, и перцепционному взвешиванию, которое, как правило, выбирается как 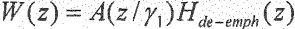 с . Остаток был вычислен с помощью фильтра анализа квантованного голосового тракта.
с . Остаток был вычислен с помощью фильтра анализа квантованного голосового тракта.
В сценарии применения, аддитивный шум на дальнем конце может присутствовать во входящем речевом сигнале. Таким образом, сигнал является y(t)=s(t)+n(t). В данном случае, как модель голосового тракта, A(z), так и исходный остаток содержат шум. Начиная с упрощения в виде игнорирования шума в модели голосового тракта и фокусирования на шуме в остатке, идея (в соответствии с вариантом осуществления) состоит в проведении перцепционного взвешивания таким образом, что влияния аддитивного шума уменьшаются в выборе остатка. Тогда как обычно ошибка между исходным и квантованным остатком должна походить на спектральную огибающую речи, в соответствии с вариантами осуществления уменьшается ошибка в области, которая считается более устойчивой к шуму. Другими словами, в соответствии с вариантами осуществления, частотные составляющие, которые менее искажены шумом, квантуются с меньшей ошибкой, тогда как составляющие с низкими амплитудами, которые вероятно содержат ошибки от шума, имеют более низкий вес в процессе квантования.
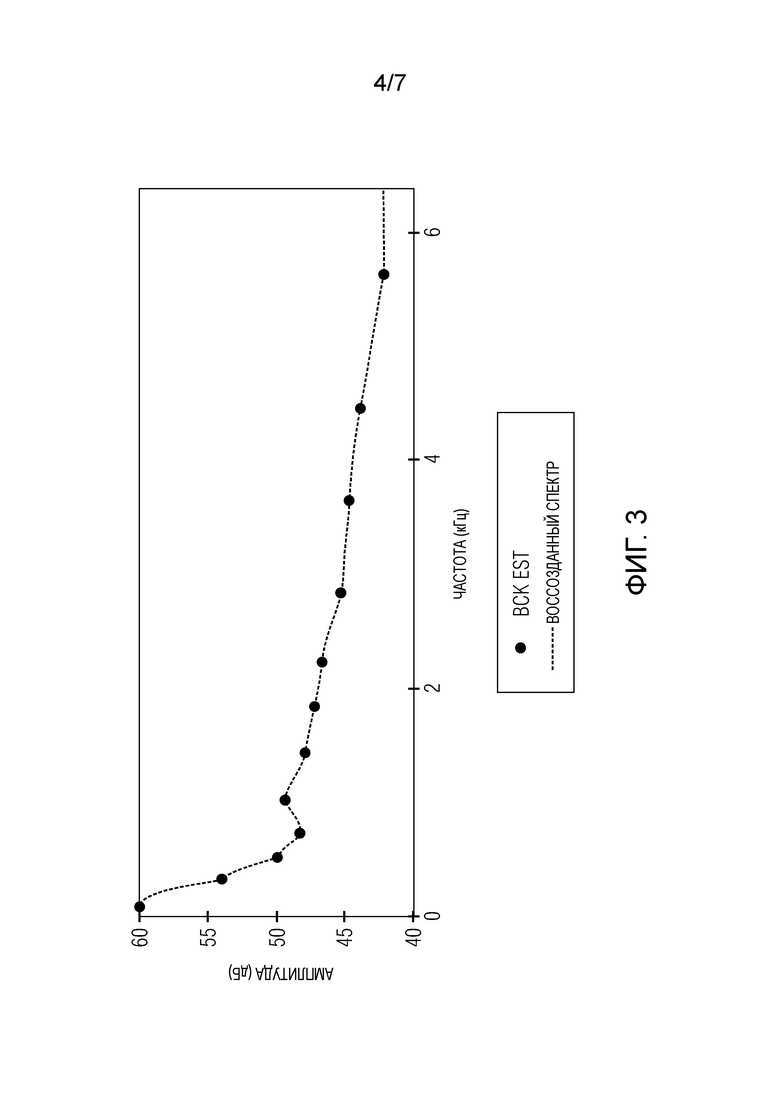
Для того, чтобы учитывать влияние шума на желательный сигнал, сначала требуется оценка сигнала шума. Оценка шума является классической задачей, для которой существует много способов. Некоторые варианты осуществления предоставляют способ с низкой сложностью, в соответствии с которым используется информация, которая уже существует в кодере. В предпочтительном подходе, может быть использована оценка формы фонового шума, которая сохраняется для обнаружения активности голоса (VAD). Данная оценка содержит уровень фонового шума в 12 полосах частот с увеличивающейся шириной. Спектр может быть построен из данной оценки посредством отображения ее по линейной шкале частоты с интерполяцией между исходными точками данных. Пример оценки исходного фона и воссозданный спектр показан на Фиг. 3. Подробнее, Фиг. 3 показывает оценку исходного фона и воссозданный спектр для шума автомобиля со средним SNR -10дБ. Из воссозданного спектра вычисляется автокорреляция и используется для извлечения коэффициентов линейного предсказания (LP) p-ого порядка с рекурсией Левинсона-Дарбина. Примеры полученных соответствий LP с p=2…6 показаны на Фиг. 4. Подробнее, Фиг. 4 показывает полученные соответствия линейного предсказания для фонового шума с разными порядками предсказания (p=2…6). Фоновый шум является шумом автомобиля со средним SNR -10дБ.
Полученное соответствие LP, ABCK(z) может быть использовано как часть взвешивающего фильтра таким образом, что может быть вычислен новый взвешивающий фильтр
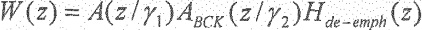
Здесь 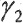 является параметром, с помощью которого может быть отрегулирована величина подавления шума. При
является параметром, с помощью которого может быть отрегулирована величина подавления шума. При 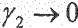 влияние небольшое, тогда как для
влияние небольшое, тогда как для 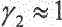 может быть получено высокое подавление шума.
может быть получено высокое подавление шума.
На Фиг. 5, показан пример инверсии исходного взвешивающего фильтра, как, впрочем, и инверсии предлагаемого взвешивающего фильтра с разными порядками предсказания. Применительно к фигуре, фильтр устранения высокочастотных составляющих не использовался. Другими словами, Фиг. 5 показывает амплитудно-частотные характеристики инверсии исходного и предлагаемого взвешивающих фильтров с разными порядками предсказания. Фоновый шум является шумом автомобиля со средним SNR -10дБ.
Фиг. 6 показывает блок-схему способа для предоставления закодированного представления на основе аудиосигнала. Способ содержит этап 202 получения информации о шуме, описывающей шум, включенный в аудиосигнал. Кроме того, способ 200 содержит этап 204 адаптивного кодирования аудиосигнала в зависимости от информации о шуме таким образом, что точность кодирования выше для частей аудиосигнала, которые менее затронуты шумом, включенным в аудиосигнал, чем частей аудиосигнала, которые более затронуты шумом, включенным в аудиосигнал.
Несмотря на то, что некоторые аспекты были описаны в контексте устройства, очевидно, что эти аспекты также представляют описание соответствующего способа, где блок или устройство соответствует этапу способа или признаку этапа способа. Аналогично, аспекты, описанные в контексте этапа способа также представляют собой описание соответствующего блока или элемента или признака соответствующего устройства. Некоторые или все из этапов способа могут быть исполнены посредством (или используя) устройство аппаратного обеспечения, подобное, например, микропроцессору, программируемому компьютеру или электронной схеме. В некоторых вариантах осуществления, один или более из наиболее важных этапов способа может быть исполнен таким устройством.
Закодированный аудиосигнал в соответствии с изобретением может быть сохранен на цифровом запоминающем носителе информации или может быть передан по средству передачи, такому как беспроводное средство передачи или проводное средство передачи, такое как Интернет.
В зависимости от определенных требований реализации, варианты осуществления изобретения могут быть реализованы в аппаратном обеспечении или в программном обеспечении. Реализация может быть выполнена, используя цифровой запоминающий носитель информации, например, гибкий диск, DVD, Blu-Ray, CD, ROM, PROM, EPROM, EEPROM или FLASH-память, с хранящимися на них электронно-читаемыми сигналами управления, которые взаимодействуют (или выполнены с возможностью взаимодействия) с программируемой компьютерной системой таким образом, что выполняется соответствующий способ. Вследствие этого, цифровой запоминающий носитель информации может быть машиночитаемым.
Некоторые варианты осуществления в соответствии с изобретением содержат носитель данных с электронно-читаемыми сигналами управления, которые выполнены с возможностью взаимодействия с программируемой компьютерной системой таким образом, что выполняется один из способов, описанный в данном документе.
В целом, варианты осуществления настоящего изобретения могут быть реализованы в качестве компьютерного программного продукта с программным кодом, при этом программный код работает для выполнения одного из способов, когда компьютерный программный продукт выполняется на компьютере. Программный код может, например, быть сохранен на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для выполнения одного из способов, описываемых в данном документе, хранящуюся на машиночитаемом носителе.
Другими словами, вариант осуществления способа в соответствии с изобретением является, вследствие этого, компьютерной программой с программным кодом для выполнения одного из способов, описываемых в данном документе, когда компьютерная программа выполняется на компьютере.
Дополнительным вариантом осуществления способов в соответствии с изобретением является, вследствие этого, носитель данных (или цифровой запоминающий носитель информации, или машиночитаемый носитель информации), содержащий, записанную на нем, компьютерную программу для выполнения одного из способов, описываемых в данном документе. Носитель данных, цифровой запоминающий носитель информации или записанный носитель информации, как правило, являются вещественными и/или не временными.
Дополнительным вариантом осуществления способа в соответствии с изобретением является, вследствие этого, поток данных или последовательность сигналов, представляющая собой компьютерную программу для выполнения одного из способов, описываемых в данном документе. Поток данных или последовательность сигналов может, например, быть выполнена с возможностью переноса через соединение связи для передачи данных, например, через Интернет.
Дополнительный вариант осуществления содержит средство обработки, например компьютер, или программируемое логическое устройство, сконфигурированное или выполненное с возможностью выполнения одного из способов, описываемых в данном документе.
Дополнительный вариант осуществления содержит компьютер с инсталлированной на нем компьютерной программой для выполнения одного из способов, описываемых в данном документе.
Дополнительный вариант осуществления в соответствии с изобретением содержит устройство или систему, выполненную с возможностью переноса (например, электронным образом или оптическим образом) компьютерной программы для выполнения одного из способов, описываемых в данном документе, к приемнику. Приемник может, например, быть компьютером, мобильным устройством, устройством памяти или подобным. Устройство или система могут, например, содержать файловый сервер для переноса компьютерной программы к приемнику.
В некоторых вариантах осуществления, программируемое логическое устройство (например, программируемая вентильная матрица) может быть использовано, чтобы выполнять некоторые или все из функциональных возможностей способов, описываемых в данном документе. В некоторых вариантах осуществления, программируемая вентильная матрица может взаимодействовать с микропроцессором для того, чтобы выполнять один из способов, описываемых в данном документе. В целом, способы предпочтительно выполняются посредством любого устройства аппаратного обеспечения.
Устройство, описываемое в данном документе, может быть реализовано, используя устройство аппаратного обеспечения, или используя компьютер, или используя комбинацию устройства аппаратного обеспечения и компьютера.
Способы, описываемые в данном документе, могут быть выполнены, используя устройство аппаратного обеспечения, или используя компьютер, или используя комбинацию устройства аппаратного обеспечения и компьютера.
Описанные выше варианты осуществления являются лишь иллюстративными для принципов настоящего изобретения. Следует понимать, что модификации и вариации компоновок и подробностей, описываемых в данном документе, будут очевидны специалистам в соответствующей области. Вследствие этого замысел ограничивается только объемом прилагаемой патентной формулы изобретения, а не конкретными подробностями, представленными в качестве описания и объяснения вариантов осуществления в данном документе.


Изобретение относится к средствам для кодирования аудиосигнала. Технический результат заключается в повышении разборчивости декодированного сигнала, когда акустический входной сигнал искажается фоновым шумом и другими артефактами. Получают информацию о шуме, описывающую шум, включенный в аудиосигнал. Адаптивно кодируют аудиосигнал в зависимости от информации о шуме таким образом, что точность кодирования выше для частей аудиосигнала, которые менее затронуты шумом, включенным в аудиосигнал, чем для частей аудиосигнала, которые больше затронуты шумом, включенным в аудиосигнал, при этом частотные составляющие, которые менее искажены шумом, квантуются с меньшей ошибкой, тогда как составляющие, которые вероятно содержат ошибки от шума, имеют более низкий вес в процессе квантования. 6 н. и 19 з.п. ф-лы, 7 ил.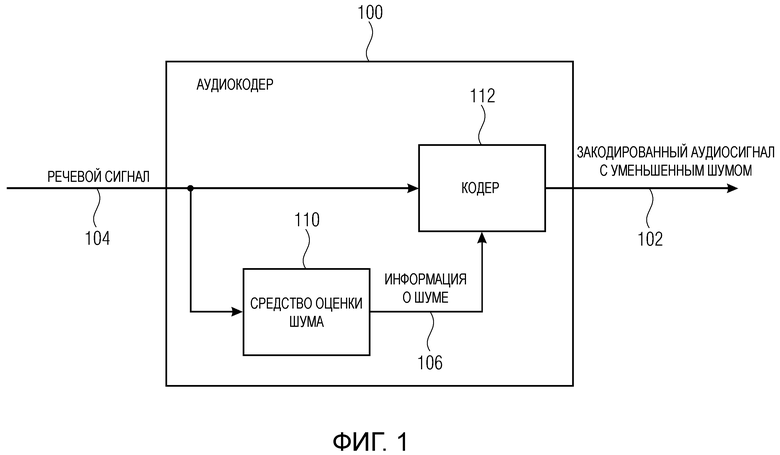
1. Аудиокодер (100) для предоставления закодированного представления (102) на основе аудиосигнала (104), при этом аудиокодер (100) выполнен с возможностью получения информации (106) о шуме, описывающей шум, включенный в аудиосигнал (104), и при этом аудиокодер (100) выполнен с возможностью адаптивного кодирования аудиосигнала (104) в зависимости от информации (106) о шуме таким образом, что точность кодирования выше для частей аудиосигнала (104), которые менее затронуты шумом, включенным в аудиосигнал (104), чем для частей аудиосигнала (104), которые более затронуты шумом, включенным в аудиосигнал (104);
при этом частотные составляющие, которые менее искажены шумом, квантуются с меньшей ошибкой, тогда как составляющие, которые вероятно содержат ошибки от шума, имеют более низкий вес в процессе квантования.
2. Аудиокодер (100) по п. 1, при этом аудиокодер (100) выполнен с возможностью адаптивного кодирования аудиосигнала (104) посредством регулирования перцепционной целевой функции, используемой для кодирования аудиосигнала (104) в зависимости от информации (106) о шуме.
3. Аудиокодер (100) по п. 1, при этом аудиокодер (100) выполнен с возможностью одновременного кодирования аудиосигнала (104) и уменьшения шума в закодированном представлении (102) аудиосигнала (104) посредством адаптивного кодирования аудиосигнала (104) в зависимости от информации (106) о шуме.
4. Аудиокодер (100) по п. 1, в котором информация (106) о шуме является отношением сигнала-к-шуму.
5. Аудиокодер (100) по п. 1, в котором информация (106) о шуме является оцененной формой шума, включенного в аудиосигнал (104).
6. Аудиокодер (100) по п. 1, в котором аудиосигнал (104) является речевым сигналом и при этом аудиокодер (100) выполнен с возможностью извлечения остаточного сигнала (120) из речевого сигнала (104) и кодирования остаточного сигнала (120), используя кодовую книгу (122);
при этом аудиокодер (100) выполнен с возможностью выбора записи кодовой книги из множества записей кодовой книги для кодовой книги (122) для кодирования остаточного сигнала (120) в зависимости от информации (106) о шуме.
7. Аудиокодер (100) по п. 6, при этом аудиокодер (100) выполнен с возможностью оценки вклада голосового тракта в речевой сигнал и удаления оцененного вклада голосового тракта из речевого сигнала (104) для того, чтобы получать остаточный сигнал (120).
8. Аудиокодер (100) по п. 7, при этом аудиокодер (100) выполнен с возможностью оценки вклада голосового тракта в речевой сигнал (104), используя линейное предсказание.
9. Аудиокодер (100) по п. 6, при этом аудиокодер (100) выполнен с возможностью выбора записи кодовой книги, используя перцепционный взвешивающий фильтр (W).
10. Аудиокодер (100) по п. 9, при этом аудиокодер выполнен с возможностью регулирования перцепционного взвешивающего фильтра (W) таким образом, что влияние шума на выбор записи кодовой книги уменьшается.
11. Аудиокодер (100) по п. 9, при этом аудиокодер (100) выполнен с возможностью регулирования перцепционного взвешивающего фильтра (W) таким образом, что части речевого сигнала (104), которые менее затронуты шумом, взвешиваются в большей степени для выбора записи кодовой книги, чем части речевого сигнала (104), которые более затронуты шумом.
12. Аудиокодер (100) по п. 9, при этом аудиокодер (100) выполнен с возможностью регулирования перцепционного взвешивающего фильтра (W) таким образом, что ошибка между частями остаточного сигнала (120), которые менее затронуты шумом, и соответствующими частями квантованного остаточного сигнала (126) уменьшается.
13. Аудиокодер (100) по п. 9, при этом аудиокодер (100) выполнен с возможностью выбора записи кодовой книги для остаточного сигнала (120,x) таким образом, что синтезированная взвешенная ошибка квантования остаточного сигнала, взвешенного с помощью перцепционного взвешивающего фильтра (W), уменьшается.
14. Аудиокодер (100) по п. 9, при этом аудиокодер (100) выполнен с возможностью выбора записи кодовой книги, используя функцию расстояния:
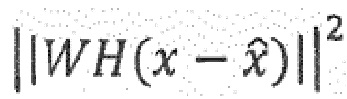 ,
,
при этом 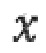 представляет собой остаточный сигнал, при этом
представляет собой остаточный сигнал, при этом 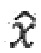 представляет собой квантованный остаточный сигнал, при этом
представляет собой квантованный остаточный сигнал, при этом 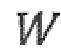 представляет собой перцепционный взвешивающий фильтр и при этом
представляет собой перцепционный взвешивающий фильтр и при этом 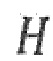 представляет собой фильтр синтеза квантованного голосового тракта.
представляет собой фильтр синтеза квантованного голосового тракта.
15. Аудиокодер (100) по п. 6, при этом аудиокодер выполнен с возможностью использования оценки формы шума, которая доступна в аудиокодере для обнаружения активности голоса, в качестве информации о шуме.
16. Аудиокодер (100) по п. 6, при этом аудиокодер (100) выполнен с возможностью извлечения коэффициентов линейного предсказания из информации (106) о шуме, чтобы тем самым определять соответствие линейного предсказания для упомянутого шума и чтобы использовать соответствие линейного предсказания в перцепционном взвешивающем фильтре (W).
17. Аудиокодер по п. 16, при этом аудиокодер выполнен с возможностью регулирования перцепционного взвешивающего фильтра, используя формулу:
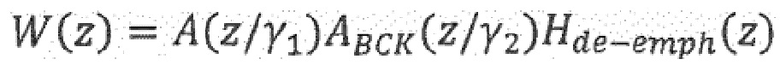 ,
,
при этом представляет собой перцепционный взвешивающий фильтр, при этом 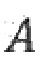 представляет собой модель голосового тракта,
представляет собой модель голосового тракта, 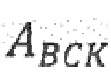 представляет собой соответствие линейного предсказания для упомянутого шума,
представляет собой соответствие линейного предсказания для упомянутого шума, 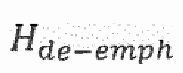 представляет собой фильтр синтеза квантованного голосового тракта,
представляет собой фильтр синтеза квантованного голосового тракта, 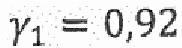 и
и 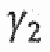 является параметром, с помощью которого может регулироваться величина подавления шума.
является параметром, с помощью которого может регулироваться величина подавления шума.
18. Способ для предоставления закодированного представления на основе аудиосигнала, при этом способ содержит этапы, на которых:
получают информацию о шуме, описывающую шум, включенный в аудиосигнал; и
адаптивно кодируют аудиосигнал в зависимости от информации о шуме таким образом, что точность кодирования выше для частей аудиосигнала, которые менее затронуты шумом, включенным в аудиосигнал, чем для частей аудиосигнала, которые больше затронуты шумом, включенным в аудиосигнал, при этом частотные составляющие, которые менее искажены шумом, квантуются с меньшей ошибкой, тогда как составляющие, которые вероятно содержат ошибки от шума, имеют более низкий вес в процессе квантования.
19. Машиночитаемый цифровой запоминающий носитель информации с хранящейся на нем компьютерной программой для выполнения способа по п. 18.
20. Аудиокодер (100) для предоставления закодированного представления (102) на основе аудиосигнала (104), при этом аудиокодер (100) выполнен с возможностью получения информации (106) о шуме, описывающей фоновый шум, и при этом аудиокодер (100) выполнен с возможностью адаптивного кодирования аудиосигнала (104) в зависимости от информации (106) о шуме посредством регулирования, в зависимости от информации о шуме, перцепционного взвешивающего фильтра, используемого для кодирования аудиосигнала (104);
причем аудиосигнал (104) является речевым сигналом и при этом аудиокодер (100) выполнен с возможностью извлечения остаточного сигнала (120) из речевого сигнала (104) и кодирования остаточного сигнала (120), используя кодовую книгу (122);
при этом аудиокодер (100) выполнен с возможностью выбора записи кодовой книги из множества записей кодовой книги для кодовой книги (122) для кодирования остаточного сигнала (120) в зависимости от информации (106) о шуме,
при этом аудиокодер (100) выполнен с возможностью регулирования перцепционного взвешивающего фильтра (W) таким образом, что части речевого сигнала (104), которые менее затронуты шумом, взвешиваются в большей степени для выбора записи кодовой книги, чем части речевого сигнала (104), которые более затронуты шумом;
при этом аудиокодер (100) выполнен с возможностью выбора записи кодовой книги для остаточного сигнала (120) таким образом, что синтезированная взвешенная ошибка квантования остаточного сигнала (126), взвешенная с помощью перцепционного взвешивающего фильтра W, уменьшается или минимизируется.
21. Аудиокодер (100) по п. 20, при этом аудиокодер (100) выполнен с возможностью выбора записи кодовой книги, используя функцию расстояния:
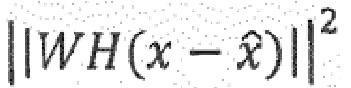 ,
,
при этом 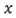 представляет собой остаточный сигнал, при этом представляет собой квантованный остаточный сигнал, при этом представляет собой перцепционный взвешивающий фильтр и при этом представляет собой фильтр синтеза квантованного голосового тракта.
представляет собой остаточный сигнал, при этом представляет собой квантованный остаточный сигнал, при этом представляет собой перцепционный взвешивающий фильтр и при этом представляет собой фильтр синтеза квантованного голосового тракта.
22. Аудиокодер (100) по п. 20, при этом аудиокодер (100) выполнен с возможностью извлечения коэффициентов линейного предсказания из информации (106) о шуме, чтобы тем самым определять соответствие линейного предсказания для упомянутого шума и чтобы использовать соответствие линейного предсказания в перцепционном взвешивающем фильтре (W).
23. Аудиокодер по п. 20, при этом аудиокодер выполнен с возможностью регулирования перцепционного взвешивающего фильтра, используя формулу:
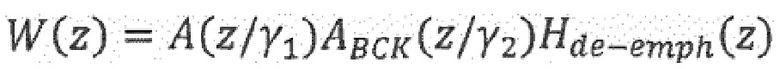 ,
,
при этом представляет собой перцепционный взвешивающий фильтр, при этом представляет собой модель голосового тракта, представляет собой соответствие линейного предсказания для упомянутого шума, представляет собой фильтр синтеза квантованного голосового тракта, и является параметром, с помощью которого может регулироваться величина подавления шума.
24. Аудиокодер (100) для предоставления закодированного представления (102) на основе аудиосигнала (104), при этом аудиокодер (100) выполнен с возможностью получения информации (106) о шуме, описывающей шум, включенный в аудиосигнал (104), и при этом аудиокодер (100) выполнен с возможностью адаптивного кодирования аудиосигнала (104) в зависимости от информации (106) о шуме таким образом, что точность кодирования выше для частей аудиосигнала (104), которые менее затронуты шумом, включенным в аудиосигнал (104), чем для частей аудиосигнала (104), которые более затронуты шумом, включенным в аудиосигнал (104);
при этом аудиосигнал (104) является речевым сигналом, и при этом аудиокодер (100) выполнен с возможностью извлечения остаточного сигнала (120) из речевого сигнала (104) и кодирования остаточного сигнала (120), используя кодовую книгу (122);
при этом аудиокодер (100) выполнен с возможностью выбора записи кодовой книги из множества записей кодовой книги для кодовой книги (122) для кодирования остаточного сигнала (120) в зависимости от информации (106) о шуме;
при этом аудиокодер (100) выполнен с возможностью выбора записи кодовой книги, используя перцепционный взвешивающий фильтр (W);
при этом аудиокодер (100) выполнен с возможностью регулирования перцепционного взвешивающего фильтра (W) таким образом, что части речевого сигнала (104), которые менее затронуты шумом взвешиваются в большей степени для выбора записи кодовой книги, чем части речевого сигнала (104), которые более затронуты шумом;
при этом аудиокодер (100) выполнен с возможностью выбора записи кодовой книги для остаточного сигнала (120) таким образом, что синтезированная взвешенная ошибка квантования остаточного сигнала (126), взвешенная с помощью перцепционного взвешивающего фильтра W, уменьшается или минимизируется.
25. Аудиокодер (100) для предоставления закодированного представления (102) на основе аудиосигнала (104), при этом аудиокодер (100) выполнен с возможностью получения информации (106) о шуме, описывающей шум, включенный в аудиосигнал (104), и при этом аудиокодер (100) выполнен с возможностью адаптивного кодирования аудиосигнала (104) в зависимости от информации (106) о шуме таким образом, что точность кодирования выше для частей аудиосигнала (104), которые менее затронуты шумом, включенным в аудиосигнал (104), чем для частей аудиосигнала (104), которые более затронуты шумом, включенным в аудиосигнал (104);
при этом аудиосигнал (104) является речевым сигналом и при этом аудиокодер (100) выполнен с возможностью извлечения остаточного сигнала (120) из речевого сигнала (104) и кодирования остаточного сигнала (120), используя кодовую книгу (122);
при этом аудиокодер (100) выполнен с возможностью выбора записи кодовой книги из множества записей кодовой книги у кодовой книги (122) для кодирования остаточного сигнала (120) в зависимости от информации (106) о шуме;
при этом аудиокодер (100) выполнен с возможностью извлечения коэффициентов линейного предсказания из информации (106) о шуме, чтобы тем самым определять соответствие линейного предсказания для упомянутого шума и чтобы использовать соответствие линейного предсказания в перцепционном взвешивающем фильтре (W); и
при этом аудиокодер выполнен с возможностью регулирования перцепционного взвешивающего фильтра, используя формулу:
,
при этом представляет собой перцепционный взвешивающий фильтр, при этом представляет собой модель голосового тракта, представляет собой соответствие линейного предсказания для упомянутого шума, представляет собой фильтр синтеза квантованного голосового тракта, и является параметром, с помощью которого может регулироваться величина подавления шума.
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| US 7392180 B1, 24.06.2008 | |||
| US 5680508 A1, 21.10.1997 | |||
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| US 6385573 B1, 07.05.2002 | |||
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ УПРАВЛЕНИЯ СГЛАЖИВАНИЕМ СТАЦИОНАРНОГО ФОНОВОГО ШУМА | 2008 |
|
RU2469419C2 |

