Настоящая технология относится к приемному устройству и способу управления приемным устройством, устройству распределения и способу распределения, программе, и системе распределения и, в частности, к приемному устройству и способу управления приемным устройством, устройству распределения и способу распределения, программе, и системе распределения, которые позволяют отображать фрагментированную текстовую информацию, для которой следует продолжение.
Уровень техники
В результате распространения Интернет в последние годы предоставляют различные услуги, относящиеся к потоковой передаче через Интернет, такие как IPTV (телевидение через Протокол Интернет) для распределения видеосодержания, например, используя IP (Протокол Интернет). В качестве шага в направлении стандартизации в потоковой передаче через Интернет, были стандартизованы способы, применяемые для потоковой передачи VOD (видеоданные по запросу) и потоковой передачи прямых трансляций, используя HTTP (Протокол потоковой передачи гипертекста). Файл формата МР4 представляет собой чрезвычайно перспективный формат для уровней контейнера.
Когда данные субтитров сохраняют, как компонент потока, субтитры отображают на основе файла, который содержит данные субтитров (например, см. Патентную литературу 1).
Используя TTML (Язык разметки текста с ярлыками), который был стандартизирован W3C (World Wide Web Консорциум), становится стандартом для отображения субтитров. TTML W3C все чаще применяется другими организациями по стандартизации, и на него обратили внимание, как на перспективный формат на основе текста с ярлыками.
Говорят, что TTML представляет собой документ XML (Расширенный язык разметки), и, таким образом, он требует относительно длительного времени для обработки. Таким образом, когда документ XML применяют для потоковой передачи в прямом эфире разделенные на куски экземпляры документа TTML, которые непрерывно генерируют, как фрагменты, в течение короткого времени, которые должны быть обработаны в режиме реального времени, и, таким образом, должна быть воплощена идея в отношении формата или системы обработки. По этой причине, в настоящее время рассматривается, что способ сохранения TTML, для обеспечения обработки в режиме реального времени будет необходим в DASH (Динамическая адаптивная потоковая передача через HTTP), которая представляет собой соответствующий стандарт для формата адаптивной потоковой передачи и в МР4, который представляет собой основной формат файла для потоковой передачи.
Список литературы
Патентная литература
Патентная литература 1: JP 2009-301605А
Сущность изобретения
Техническая задача
Что касается структуры, TTML разделяют на следующие типы: экземпляр документа инициализации, который устанавливает атрибут компоновки или стиля, и экземпляр основного документа, который состоит из строки знаков, предназначенных для отображения. При этом описание представлено в TTML и уже определено, как Информативное Приложение.
Возможно комбинировать документы TTML, имеющие эти два типа описания в один документ для распределения. Однако анализ всех документов XML на стороне приема для каждого распределения может привести к чрезмерному увеличению объема служебных сигналов в системе обработки. При этом достаточно уведомлять сторону приема только один раз об атрибутах, относящихся к формату отображения, таких как атрибут стиля и атрибут компоновки TTML во время предоставления инициализации контекста. Приемная сторона может быть уведомлена о фактическом разбиении текста TTML (строка знаков, предназначенная для отображения), по отдельности, последовательно для описания, необходимого для установки получения контекста.
Однако отображение фрагментированной текстовой информации, переданной по отдельности, таким образом, не может быть продолжено, когда последующий фрагмент получают в то время как информация текста находится на дисплее. В частности, в случае широковещательной передачи в режиме прямого вещания, заранее неизвестна текстовая информация, по которой должен отображаться субтитр и в какое время, и, таким образом, отображение текстовой информации, находящейся в настоящее время на дисплее, не может быть продолжено.
По этой причине требуется установить технический способ, который позволил бы отображать фрагментированную текстовую информацию, требующую продолжения.
Настоящая технология была разработана с учетом такой ситуации и позволяет отображать фрагментированную текстовую информацию, для которой требуется продолжение.
Решение задачи
Первым вариантом осуществления настоящей технологии, предусмотрено приемное устройство, включающее в себя приемный модуль, выполненный с возможностью приема потока содержания, предназначенного для распространения в прямом эфире, и модуль анализа, выполненный с возможностью анализа фрагментированной текстовой информации, соответствующей данным субтитров, включенным в принимаемый поток, и модуль управления, выполненный с возможностью управления отображением первой текстовой информации, так, чтобы обеспечить возможность продолжения отображения, когда вторая текстовая информация из текстовой информации отображается на основе результата анализа, при этом отображение второй текстовой информации начинается по времени после отображения первой текстовой информации.
Текстовая информация включает в себя структурированный документ, который описывает содержание, и документ определения отображения, который определяет формат отображения, который применяют для структурированного документа. Время, обозначающее начало отображения первой текстовой информации, описано в первом структурированном документе, который описывает содержание первой текстовой информации. Время, обозначающее конец отображения первой текстовой информации, и время, обозначающее начало отображения второй текстовой информации, описано во втором структурированном документе, который описывает содержание второй текстовой информации. Модуль управления начинает отображение первой текстовой информации, временем, обозначенным началом отображения первой текстовой информации, описанным в первом структурированном документе, и затем заканчивает отображение первой текстовой информации на дисплее, временем, обозначающим конец отображения первой текстовой информации, описанной во втором структурированном документе, на основе результата анализа.
Время, обозначающее начало отображения второй текстовой информации, описанное во втором структурированном документе, по времени находиться перед временем, обозначающим конец отображения первой текстовой информации, и модуль управления начинает отображение второй текстовой информации, временем, обозначающим начало отображения второй текстовой информации, описанной во втором структурированном документе, на основе результата анализа.
Время, обозначающее конец отображения второй текстовой информации, дополнительно описано во втором структурированном документе, и модуль управления заканчивает отображение второй текстовой информации, в соответствии со временем, обозначающим конец отображения второй текстовой информации, описанной во втором структурированном документе, на основе результата анализа.
Время, обозначающее конец отображения второй текстовой информации, описанное во втором структурированном документе, по времени установлено после времени, обозначающего конец отображения первой текстовой информации.
Тот же документ определения отображения применяется для структурированного документа, до тех пор, пока содержание определения формата отображения не будет модифицировано.
Поток представляет собой данные с форматом, который соответствует формату файла МР4, и данные субтитров соответствуют стандарту языка разметки текста с ярлыками (TTML).
Способ управления и программа, первый аспект настоящей технологии, соответствуют приемному устройству, первому аспекту описанной выше настоящей технологии.
В приемном устройстве, способе управления и программе, первый аспект настоящей технологии, принимают поток содержания, предназначенный для распределения в режиме реального времени, анализируют фрагментированную текстовую информацию, соответствующую данным субтитров, включенным в принятый поток, и отображением первой текстовой информации управляют таким образом, чтобы обеспечить возможность отображения с продолжением, когда вторую текстовую информацию из текстовой информации отображают на основе результата анализа, при этом начало второй текстовой информации по времени начинается после отображения первой текстовой информации.
Вторым вариантом осуществления настоящей технологии, предусмотрено устройство распределения, включающее в себя модуль генерирования содержания, выполненный с возможностью генерирования потока содержания для распределения в режиме реального времени, модуль получения текстовой информации, выполненный с возможностью получения фрагментированной текстовой информации, для обеспечения возможности продолжения отображения первой текстовой информации, когда вторая текстовая информация отображается, как текстовая информация, соответствующая данным субтитров содержания, при этом отображение второй текстовой информации начинается по времени после отображения первой текстовой информации, и модуль распределения, выполненный с возможностью распределения потока содержания, включающего в себя данные субтитров в режиме реального времени.
Способ распределения и программа, второй аспект настоящей технологии, соответствуют устройству распределения, второму аспекту описанной выше настоящей технологии.
В устройстве распределения, способе распределения и программе, второй аспект настоящей технологии, генерируют поток содержания для распределения в режиме реального времени, фрагментированную текстовую информацию получают так, чтобы обеспечить возможность продолжения отображения первой текстовой информации, когда отображается вторая текстовая информация, как текстовая информация, соответствующая данным субтитров содержания, при этом отображение второй текстовой информации начинается по времени после отображения первой текстовой информации, и поток содержания, включающий в себя данные субтитров, распределяют в режиме реального времени.
Вторым вариантом осуществления настоящей технологии, предусмотрена система распространения, включающая в себя устройство распределения и приемное устройство. Устройство распределения включает в себя модуль генерирования содержания, выполненный с возможностью генерирования потока содержания для распределения в режиме реального времени, модуль получения текстовой информации, выполненный с возможностью получения фрагментированной текстовой информации для обеспечения возможности продолжения отображения первой текстовой информации, когда вторую текстовую информацию отображают, как текстовую информацию, соответствующую данным субтитров содержания, отображение второй текстовой информации начинается по времени после отображения первой текстовой информации, и модуль распределения, выполненный с возможностью распределения потока содержания, включающего в себя данные субтитров, в режиме реального времени. Приемное устройство включает в себя приемный модуль, выполненный с возможностью приема потока содержания, модуль анализа, выполненный с возможностью анализа фрагментированной текстовой информации, соответствующей данным субтитров, включенным в принятый поток, и модуль управления, выполненный с возможностью управления отображением первой текстовой информации, с тем, чтобы обеспечить возможность продолжения отображения, когда вторая текстовая информация из текстовой информации отображается на основе результата анализа.
Устройство распределения и приемное устройство каждое может представлять собой независимое устройство, или каждое может представлять собой блок, включенный в одно устройство.
В системе распространения, третий аспект настоящей технологии, с помощью системы распределения, генерируют поток содержания для распределения в режиме реального времени, получают информацию фрагментированного текста для обеспечения возможности продолжения отображения первой текстовой информации, когда отображается вторая текстовая информация в качестве текстовой информации, соответствующей данным субтитров содержания, при этом отображение второй текстовой информации начинается по времени после отображения первой текстовой информации, и поток содержания, включающий в себя данные субтитров, распределяют в режиме реального времени; и с помощью приемного устройства, принимают поток содержания, текстовую информацию, фрагментированную данными субтитров, включенными в принимаемый поток, анализируют, и отображением первой текстовой информации управляют для обеспечения возможности отображения с продолжением, когда вторая текстовая информация после первой текстовой информации отображается на основе результата анализа.
Предпочтительные эффекты изобретения
Первым - третьим аспектами настоящей технологии можно продолжить отображение фрагментированной текстовой информации.
Краткое описание чертежей
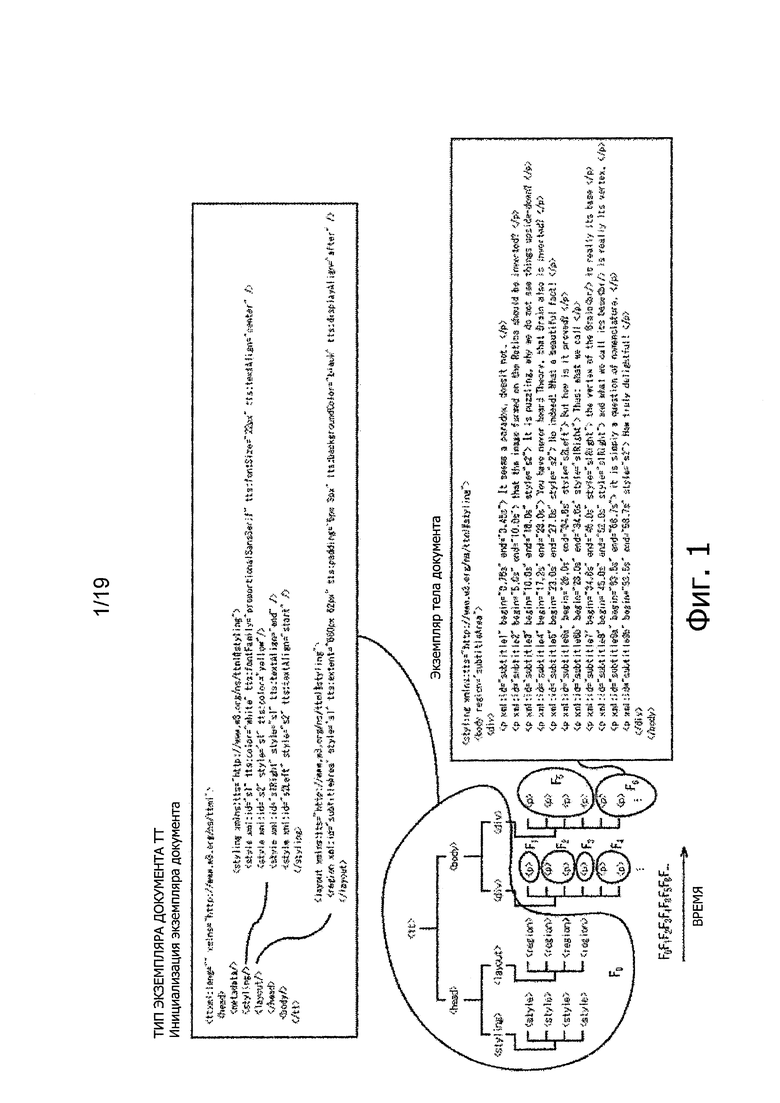
На фиг. 1 представлена схема, иллюстрирующая конфигурацию TTML.
На фиг. 2 представлена схема, иллюстрирующая конфигурацию блока BOX в формате файла МР4.
На фиг. 3 представлена схема, иллюстрирующая иерархическую структуру блока BOX.
На фиг. 4 представлена схема, иллюстрирующая потоковую передачу, используя формат файла МР4.
На фиг. 5 представлена схема, иллюстрирующая конфигурацию фильма Movie.
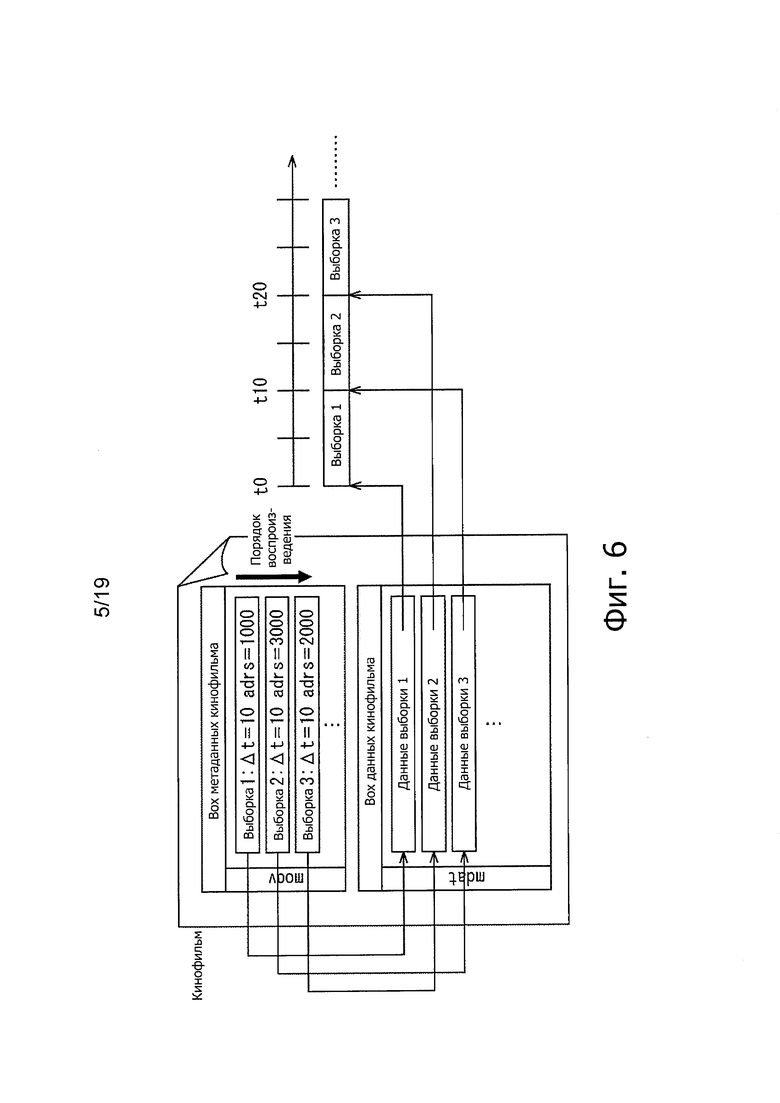
На фиг. 6 представлена схема, иллюстрирующая блочную структуру фильма Movie.
На фиг. 7 представлена схема, иллюстрирующая конфигурацию нефрагментированого фильма Movie.
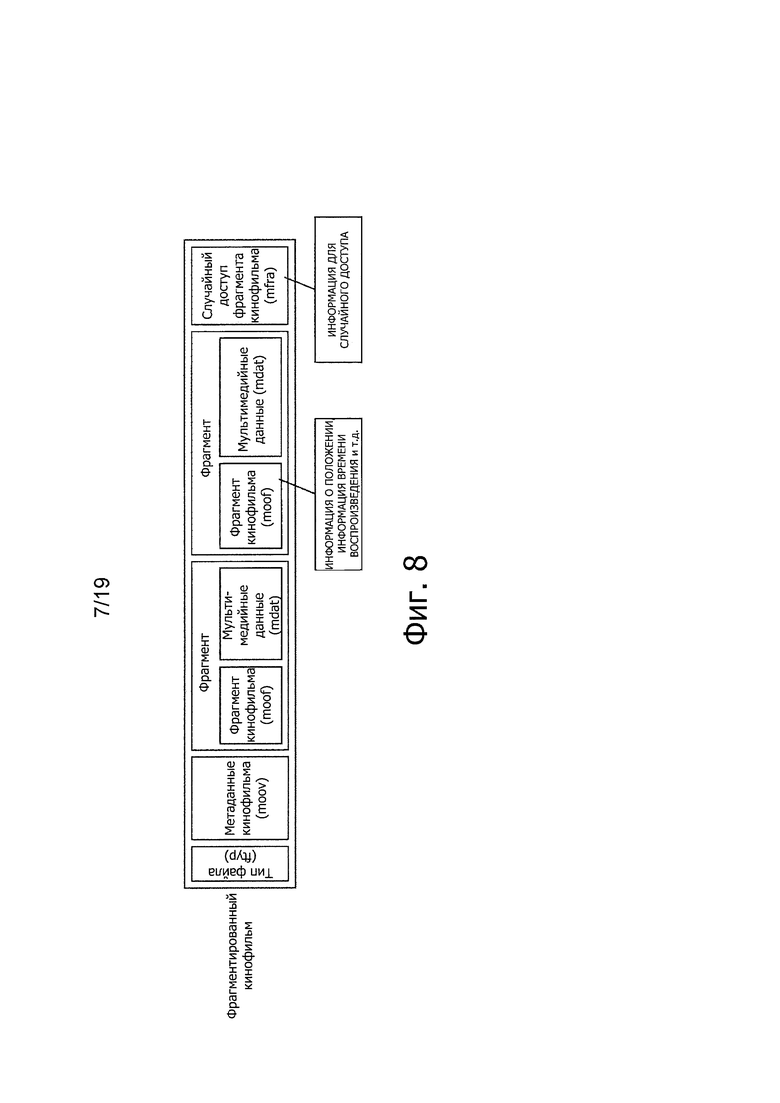
На фиг. 8 представлена схема, иллюстрирующая конфигурацию фрагментированного фильма Movie.
На фиг. 9 представлена схема, иллюстрирующая пример конфигурации потоковой передачи системы распространения вариантом осуществления существующей технологии.
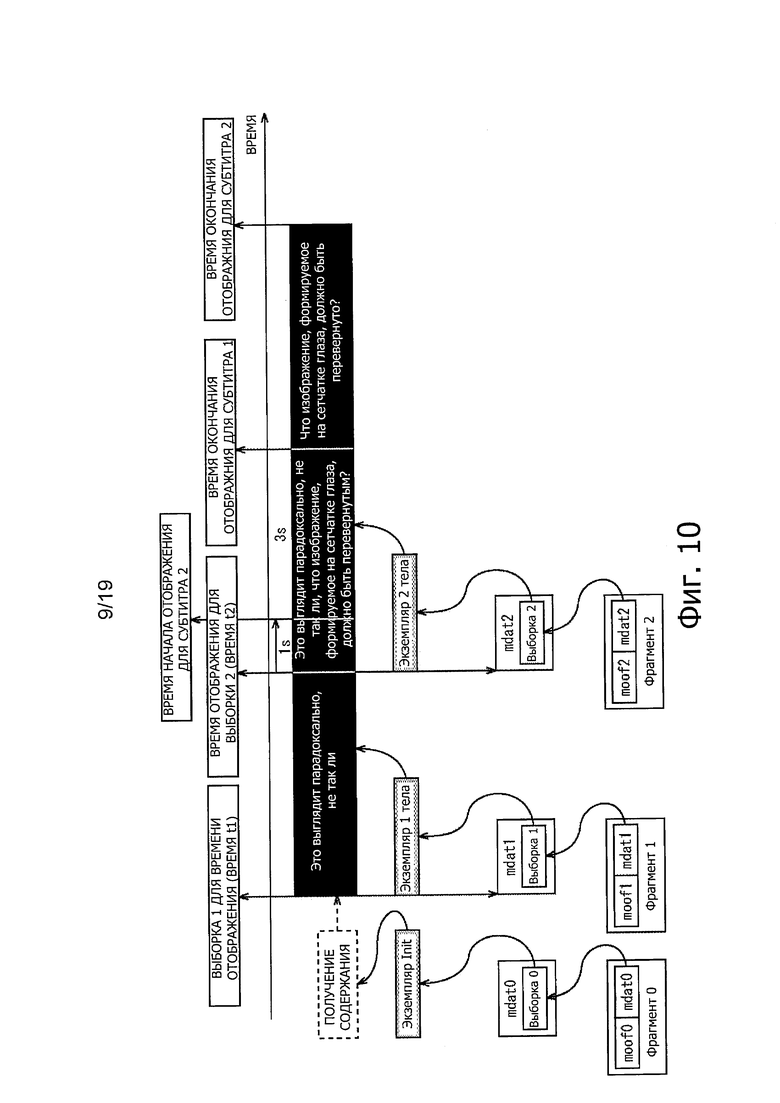
На фиг. 10 представлена схема, иллюстрирующая субтитры, которые накладывают и отображают на видеоизображение во временной последовательности, в клиенте IPTV.
На фиг. 11 показана фигура, поясняющая пример описания для экземпляра Документа Инициализации.
На фиг. 12 показана фигура, поясняющая пример описания для экземпляра тела документа.
На фиг. 13 показана фигура, поясняющая пример отображения субтитров.
На фиг. 14 показана фигура, поясняющая пример описания для экземпляра тела документа.
На фиг. 15 показана фигура, поясняющая пример отображения субтитров.
На фиг. 16 показана фигура, поясняющая пример отображения субтитров.
На фиг. 17 показана фигура, поясняющая пример отображения субтитров.
На фиг. 18 представлена иллюстрация блок-схемы последовательности операций обработки распределения потоковой передачи.
На фиг. 19 представлена блок-схема последовательности операций, поясняющая обработку вставки данных субтитров.
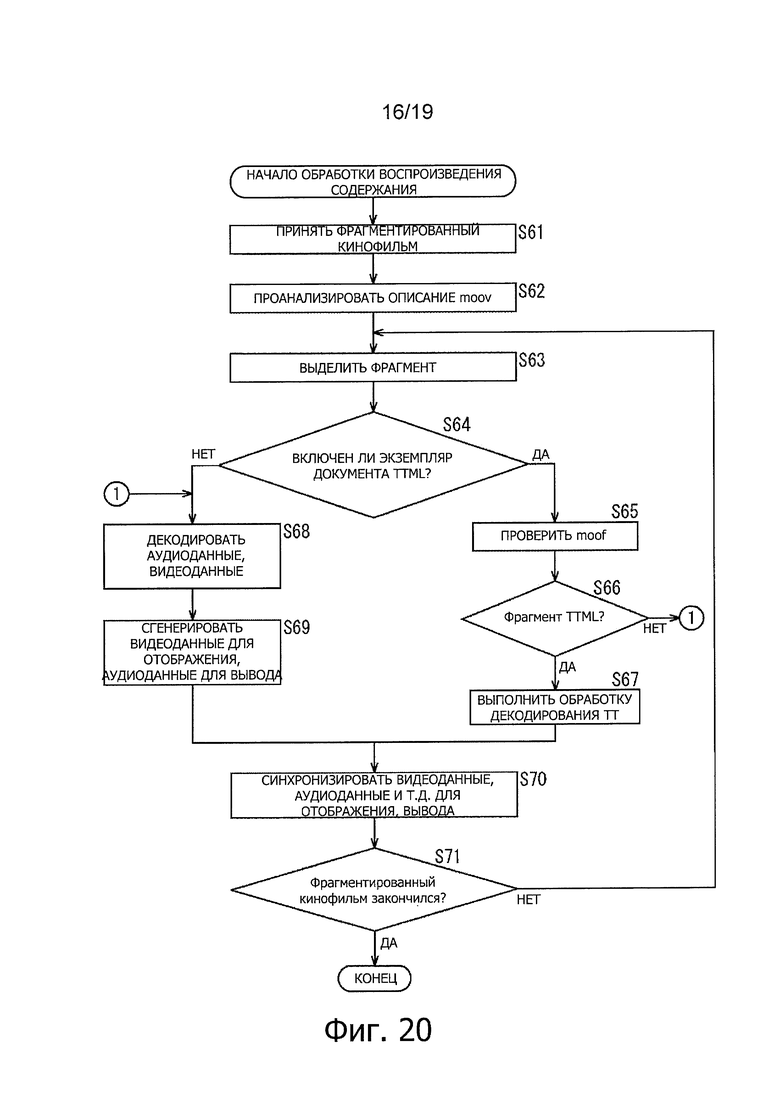
На фиг. 20 представлена блок-схема последовательности операций, поясняющая обработку воспроизведения содержания.
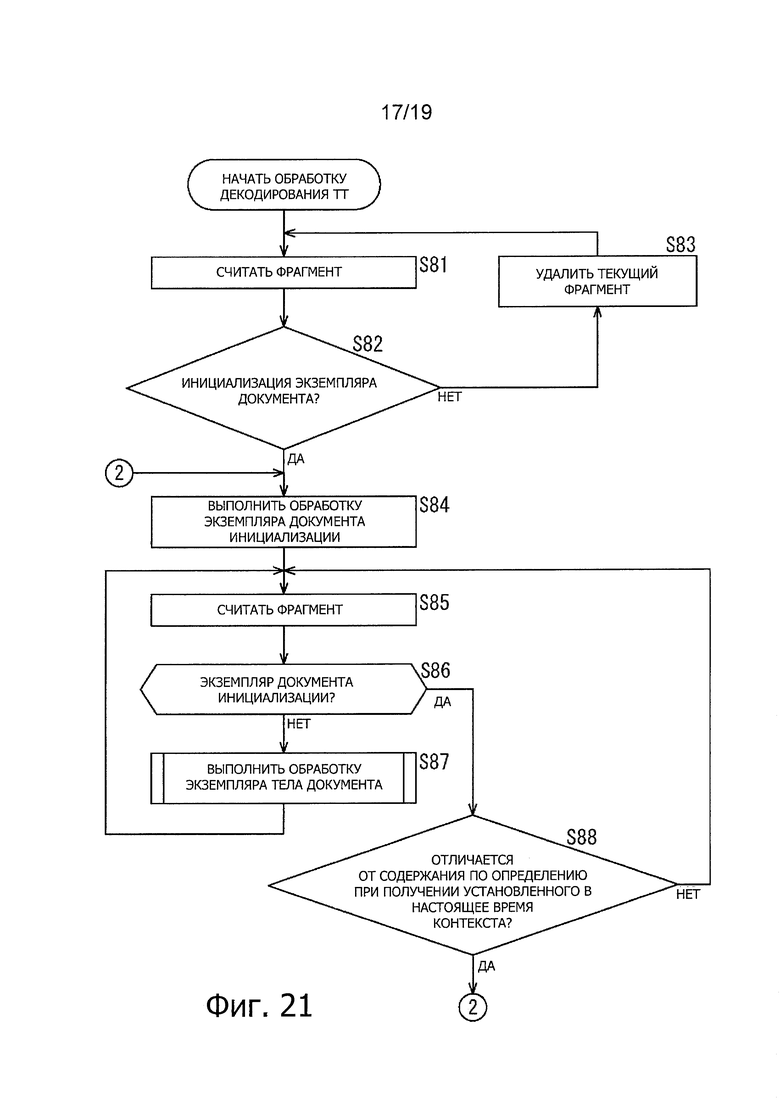
На фиг. 21 показана блок-схема последовательности операций, иллюстрирующая обработку ТТ декодирования.
На фиг. 22 показана блок-схема последовательности операций, поясняющая обработку для случая тела документа.
На фиг. 23 представлена схема, иллюстрирующая пример конфигурации компьютера.
Подробное описание изобретения Далее, со ссылкой на чертежи будет описан вариант осуществления настоящей технологии.
Вначале будет описан TTML. TTML представляет собой язык разметки, определенный W3C, и выполненный с возможностью установления положения отображения (компоновки) текста, временных характеристик отображения и т.п.
Например, информацию, описанную в TTML, передают из сервера и анализируют с помощью клиента, и заданная строка знаков, таким образом, может отображаться на дисплее клиента в установленное время, с установленным шрифтом и в установленной области. Используя информацию, описанную в TTML, таким образом, могут отображаться субтитры синхронно с, например, видеоданными или аудиоданными в содержании.
TTML включает в себя набор текстов, каждый из которых называется экземпляром документа. Экземпляр документа, в основном, классифицируется на два типа. Один из экземпляра документа называется экземпляром документа инициализации, который включает в себя описание, которое определяет, например, цвет, шрифт, положение отображения и т.п. знаков, которые должны отображаться, как субтитры. Другой из экземпляра документа, называемый экземпляром документа, который включает в себя описание строки знаков и т.п., фактически отображается, как субтитры.
В следующем описании, экземпляр документа инициализации может быть сокращенно обозначен, как экземпляр Init. Кроме того, экземпляр основного документа может быть сокращенно обозначен, как основной экземпляр.
Конфигурация TTML
На фиг. 1 показана схема, иллюстрирующая конфигурацию TTML.
Как представлено на фиг. 1, в экземпляре документа инициализации, установлено получение контекста, такого как цвет, шрифт и положение отображения знаков, которые должны отображаться, как субтитры, с помощью элемента, такого как элемент стилизации и элемент компоновки.
В этом примере получаемое содержание s1 определяется по описанию "<region xml:id="subtitleArea" style="s1"…>", которое представляет собой элемент компоновки. Например, множество типов получаемого содержания, таких как s1, s2… также может быть определено в одном экземпляре документа инициализации.
Элемент, такой как p-элемент, описан в экземпляре основного документа. Например, строка знаков в субтитрах и атрибутах, такая как время начала отображения и время окончания отображения, установлена по описанию "<p xml:id=…>", которое представляет собой p-элемент.
Таким образом, TTML обеспечивает описание, имеющее иерархическую структуру, включающую в себя комбинацию экземпляра описания и инициализации документа, и экземпляра основного документа. Иерархическая структура, включающая в себя эти экземпляры, представлена в нижней левой области на фиг. 1.
Например, в приемнике, который принимает и отображает поток, заданная текстовая информация (строка знаков) может отображаться в заданный интервал времени в содержании, в результате обеспечения приема приемником и анализа TTML, иллюстрируемого на фиг. 1. Таким образом, отображение субтитров меняется, соответственно, в дисплее приемника на основе строки знаков и атрибутов, обозначающих время начала отображения, время окончания отображения и т.п., которые установлены p-элементами экземпляра документа. В примере на фиг. 1 строка F1 знаков, строка F2 знаков…, установленные p-элементами экземпляра основного документа, отображаются с переключением, с течением времени.
Деталь TTML раскрыта, например, в публикации "Timed Text Markup Language (TTML) 1.0" W3C Recommendation 18, November 2010.
Подробное описание формата файла МР4
Далее будет описан формат файла МР4. Формат файла МР4 представляет собой формат файла с высокой степенью гибкости, и определен так, что файл МР4 состоит из набора данных, называемых блоком BOX с различными размерами. BOX имеет различные типы и может быть расширяться произвольно.
Конфигурация BOX формате файла МР4 иллюстрируется на фиг. 2. На фиг. 2 размер и тип (вид) BOX описаны в областях, отображаемых, как Размер BOX и Тип BOX. Например, видеоданные, аудиоданные, данные субтитров и т.п., которые были кодированы, сохраняют в области, отображенной, как данные BOX.
В формате файла МР4 описанный выше BOX определен, как имеющий иерархическую структуру. Таким образом, как показано на фиг. 3, BOX на нижнем уровне иерархии может быть сохранен в области данных BOX относительно BOX более высокой иерархии.
В формате файла МР4, единичные данные переданного содержания, например, модуль декодирования аудиоданных, или одни из данных кадра и видеоданных называются выборкой. Множество выборок затем формируют отрезок данных. Например, как представлено на фиг. 4, отрезки аудиоданных и отрезки видеоданных формируют потоковую передачу.
В формате файла МР4, например, набор отрезков в последовательности видеоданных, и набор отрезков в последовательности аудиоданных каждый называется дорожкой. Данные, которые формируют путем интеграции множества дорожек, называются кинофильмом.
На фиг. 5 показана схема, иллюстрирующая конфигурацию кинофильма. В примере на фиг. 5, кинофильм сформирован видео дорожкой и аудиодорожкой. Как описано выше, кинофильм имеет структуру BOX. На фиг. 6 показана схема, иллюстрирующая структуру BOX в кинофильме. В примере на фиг. 6, BOX метаданных кинофильма и BOX данных кинофильма сохранены в BOX кинофильма.
BOX метаданных кинофильма представляет собой BOX, в котором описана информация, относящаяся к положению сохранения каждой выборки, сохраненная в BOX данных кинофильма, и информация, относящаяся ко времени воспроизведения и временному интервалу воспроизведения,. Например, adrs=1000 и т.п. описана, как информация, относящаяся к положению сохранения каждой выборки, и Δt=10 и т.п., описана, как информация, относящаяся ко времени воспроизведения и временному интервалу воспроизведения. Параметр кодека и т.п. описан по п. необходимостью. BOX данных кинофильма представляет собой BOX, в котором сохраняется каждая выборка. Спецификацией формата файла МР4, BOX метаданных кинофильма называется moov, и BOX данных кинофильма называется mdat.
Выборка 1, Выборка 2, Выборка 3… могут быть воспроизведены во время t0, t10, t20…, путем приема и анализа кинофильма, как представлено на фиг. 6 с помощью приемника.
Кинофильм, в общем, классифицируется на два типа. Один называется нефрагментированным кинофильмом, который пригоден, например, для передачи содержания, такого как кинофильм или драма. Другой называется фрагментированным кинофильмом, который пригоден, например, для передачи содержания, такого как новости или спортивная широковещательная передача.
На фиг. 7 показана схема, иллюстрирующая конфигурацию нефрагментированного кинофильма.
Как представлено на фиг. 7, BOX, называемый типом файла (ftyp), расположен в заголовке нефрагментированного кинофильма, ftyp представляет собой BOX, в котором содержится тип файла, информацию о совместимости и т.п. Описанные выше moov и mdat расположены далее после ftyp. Как описано выше, в moov описаны параметр кодека, информация о положении сохранения, информация о времени воспроизведения и т.п. Как описано выше, в mdat, сохранены выборки, включающие в себя модуль декодирования аудиоданных и один кадр видеоданных.
В нефрагментированном кинофильме получение контекста всего кинофильма определяется по moov. Таким образом, в случае содержания, такого как кинофильм или драма, заранее известно, какие видеоданные, какие аудиоданные и какие субтитры требуется воспроизвести, и в какие моменты данные, и, таким образом, может быть определено получение контекста всего кинофильма перед приемом каждой выборки.
С другой стороны, в случае содержания, передаваемого в прямом эфире, такого как новости или спортивная широковещательная передача, заранее неизвестно, какие видеоданные, какие аудиоданные и какие субтитры должны быть воспроизведены и в какие моменты времени. По этой причине фрагментированный кинофильм принят для передачи содержания с возможностью прямой передачи.
На фиг. 8 показана схема, иллюстрирующая конфигурацию фрагментированного кинофильма.
Как представлено на фиг. 8, аналогично случаю нефрагментированного кинофильма, ftyp и moov расположены во фрагментированном кинофильме, однако, множество BOX, называемых фрагментами, расположено после ftyp и moov. Фрагмент включает в себя BOX, называемый фрагментом кинофильма (moof) и mdat. В примере на фиг. 8 каждый фрагмент включает в себя moof, который, если можно так выразиться, представляет собой информацию заголовка фрагмента. В moof описаны информация о положении сохранения, информация о времени воспроизведения и т.п. в отношении выборки в mdat, содержащемся во фрагменте. Таким образом, в отличие от случая нефрагментированного кинофильма, получение содержания для каждого фрагмента определено в каждом фрагменте во фрагментированном кинофильме.
Фрагмент случайного доступа для кинофильма (mfra), представленный на фиг. 8, представляет собой BOX, который вставляются в конце фрагментированного кинофильма и который содержит информацию для случайного доступа и т.п.
Примеры, представленные на фиг. 7 и 8, каждый иллюстрирует конфигурацию кинофильма, как формат файла МР4, и, например, когда выполняют потоковую передачу через Интернет и т.п., описанные выше данные распределяют в заданном формате передачи, как можно видеть на фиг. 7 и 8. В заданном формате передачи, например, moov, представленный на фиг. 8, вставляют между фрагментами и распределяют с повторением множество раз.
С другой стороны, как описано выше, для стандартизации потоковой передачи через Интернет, такой как IPTV, обсуждается, следует ли использовать формат файла МР4, как формат, который должен быть принят на уровнях контейнеров. Когда субтитры включены, как компонент потоковой передачи, TTML часто используют и привлекают внимание при стандартизации потоковой передачи.
Например, когда субтитры вставляют в видеоданные содержания, получаемого при прямой трансляции, такого как новости, строка знаков (текстовая информация) для субтитров не может быть определена заранее. По этой причине необходимо выполнять обработку вставки строки знаков для субтитров, необходимостью, во время потоковой передачи при широковещательной передаче. В таком случае предпочтительно, например, чтобы приемник принимал экземпляр документа инициализации TTML и анализировал получаемое содержание, с тем, чтобы затем принимать экземпляр тела документа, по п. необходимостью.
Однако фрагментированные части текстовой информации, которые передают отдельно от одного экземпляра тела документа в другой, таким образом, не зависят от одного экземпляр тела документа до другого. Поэтому, когда предпринимают попытку отображения следующей части текстовой информации в то время, как отображают определенную фрагментированную часть текстовой информации, отображение предыдущей части текстовой информации не может продолжаться. В частности, в содержании прямой передачи, такой как новости, заранее неизвестно, какие видеоданные, какие аудиоданные и какие субтитры должны быть воспроизведены, и в какое время, и не может быть установлен технический способ для продолжения отображения отображаемой в настоящее время текстовой информации.
Таким образом, в настоящей технологии, когда текстовую информацию субтитров вставляют в содержание, которое передают, как фрагментированный кинофильм, обеспечивается возможность непрерывного отображения фрагментированной текстовой информации.
Система распределения потоковой передачи
На фиг. 9 показана схема, иллюстрирующая пример конфигурации системы распределения потоковой передачи вариантом осуществления настоящей технологии. Система 10 распределения потоковой передачи, представленная на фиг. 9, включает в себя сервер 20 ТТ, сервер 30 IPTV и клиент 40 IPTV.
Сервер 30 IPTV сформирован, например, как передатчик, который выполняет широковещательную передачу содержание, используя потоковую передачу, и клиент 40 IPTV сформирован, например, как приемник, который принимает широковещательную передачу, используя потоковую передачу. Сервер 20 ТТ представляет собой устройство, которое генерирует данные, относящиеся к субтитрам, которые должны быть вставлены в содержание, для которого выполняют широковещательную передачу, через потоковую передачу.
Сервер 20 ТТ включает в себя модуль 21 генерирования фрагмента ТТ и модуль 22 вставки выборки.
Модуль 21 генерирования фрагмента ТТ генерирует данные фрагмента, в которых содержится экземпляр документа TTML, и подает эти фрагментированные данные в модуль 22 вставки выборки. Здесь, со ссылкой на фиг. 8, генерируют фрагментированные данные, в которых содержится экземпляр документа TTML, как описано выше.
Модуль 22 вставки выборки генерирует экземпляр документа TTML. Модуль 22 вставки выборки вставляет сгенерированный экземпляр документа TTML, как выборку mdat в данных фрагмента из модуля 21 генерирования фрагмента ТТ. Модуль 22 вставки выборки выводит данные фрагмента в сервер 30 IPTV, в данные фрагмента вставлен экземпляр документа TTML.
Штамп синхронизированного времени NTP, генерируемый модулем 25 генерирования штампа времени, соответствующим образом поступает в модуль 21 генерирования фрагмента ТТ и в модуль 22 вставки выборки.
Сервер 30 IPTV включает в себя модуль 31 генерирования выборки содержания, мультиплексор 32 фрагмента и модуль 33 распределения фрагмента.
Модуль 31 генерирования выборки содержания кодирует, например, данные, такие как аудиоданные или видеоданные, включенные в содержание, и генерирует аудиоданные, видеоданные и т.п. Модуль 31 генерирования выборки содержания генерирует выборку на основе таких аудиоданных, видеоданных и т.п., и подает эту выборку в мультиплексор 32 фрагмента.
Данные фрагмента из модуля 22 вставки выборки сервера 20 ТТ и данные выборки из модуля 31 генерирования выборки содержания поступают в мультиплексор 32 фрагмента. Мультиплексор 32 фрагмента генерирует фрагмент, имеющий mdat, в котором содержат данные выборки из модуля 31 генерирования выборки содержания.
Мультиплексор 32 фрагмента мультиплексирует генерируемые данные фрагмента и данные фрагмента из модуля 32 вставки выборки. Таким образом, фрагмент, в котором содержатся аудиоданные, видеоданные, и фрагмент, в котором содержится экземпляр документа TTML, мультиплексируют. Мультиплексор 32 фрагмента передает мультиплексированные данные фрагмента в модуль 33 распределения фрагмента.
Модуль 33 распределения фрагмента распределяет мультиплексированные данные фрагмента из мультиплексора 32 фрагмента через сеть и т.п. Таким образом, содержание распределяют, используя потоковую передачу.
Синхронизированный временной штамп NTP, генерируемый модулем 25 генерирования временного штампа, соответствующим образом подают в модуль 31 генерирования выборки содержания и в мультиплексор 32 фрагмента.
Клиент 40 IPTV включает в себя модуль 41 часов для времени, приемный модуль 42, демультиплексор 43 фрагмента, декодер 44 ТТ, декодер 45 содержания и модуль 46 управления дисплеем.
Модуль 41 часов для времени подает синхронизированную информацию о времени NTP в каждый модуль 40 клиента IPTV.
Приемный модуль 42 принимает фрагментированный кинофильм, переданный из сервера 30 IPTV через сеть, и подает этот фрагментированный кинофильм в демультиплексор 43 фрагмента.
Демультиплексор 43 фрагмента получает фрагментированный кинофильм из приемного модуля 42 и выделяет каждый фрагмент, включенный во фрагментированный кинофильм. Демультиплексор 43 фрагмента анализирует описание moov для определения, включает в себя или нет фрагментированный кинофильм фрагмент, в котором содержится экземпляр документа TTML.
Когда определяют, что включен фрагмент, в котором содержится экземпляр документа TTML, демультиплексор 43 фрагмента подает данные фрагмента в декодер 44 ТТ. С другой стороны, когда определяют, что фрагмент, в котором содержится экземпляр документа TTML не включен, демультиплексор 43 фрагмента подает данные фрагмента в декодер 45 содержания.
Данные фрагмента, в которых содержится экземпляр документа TTML из демультиплексора 43 фрагмента, подают в декодер 44 ТТ. Декодер 44 ТТ декодирует данные выборки, в которой содержится экземпляр документа TTML. Декодирование с использованием декодера 44 ТТ, в основном, означает синтаксический анализ экземпляра документа TTML.
Декодер 44 ТТ анализирует описание moof во фрагменте для определения типа экземпляра документа TTML, сохраненного во фрагменте. Когда определяют, что тип экземпляра документа TTML представляет собой экземпляр документа инициализации, декодер 44 ТТ 44 анализирует описание экземпляра документа инициализации, сохраненного в выборке mdat, и устанавливает контекст получения.
После того, как контекст получения будет однажды установлен, только в случае, когда определяют, что экземпляр документа инициализации был модифицирован, декодер 44 ТТ анализирует описание экземпляра документа инициализации, сохраненного в выборке mdat, и снова устанавливает контекст получения.
Когда определяют, что тип экземпляра документа TTML представляет собой экземпляр тела документа, декодер 44 ТТ анализирует экземпляр тела документа, сохраненный в выборке mdat, и генерирует данные отображения субтитров. Данные отображения субтитров, генерируемые здесь, вместе с информацией, относящейся ко времени отображения, подают в модуль 46 управления дисплеем.
Данные фрагмента, в котором не содержится экземпляр документа TTML из демультиплексора 43 фрагмента, подают в декодер 45 содержания. Декодер 45 содержания декодирует аудиоданные, видеоданные и т.п., которые сохраняются в выборке mdat, и генерирует данные отображения видеоизображения, данные аудиовыхода и т.п. Данные отображения видеоизображения, данные аудиовыхода и т.п., генерируемые здесь вместе с информацией, относящейся к времени отображения, времени вывода и т.п., поступают в модуль 46 управления дисплеем.
Информацию из декодера 44 ТТ, относящуюся к данным отображения и времени отображения субтитров, или информацию, относящуюся к данным отображения видеоизображения и времени отображения, и информацию, относящуюся к выводу данные аудиовыхода и времени вывода из декодера 45 содержания, подают в модуль 46 управления дисплеем.
Модуль 46 управления дисплеем генерирует видеосигналы для наложения и отображения субтитров на видеоданные содержания на основе информации, относящейся к времени отображения, и передает эти видеосигналы в дисплей (не показан) на последующем этапе. Кроме того, модуль 46 управления дисплеем генерирует аудиосигналы для вывода аудиоданных содержания на основе информации, относящейся к времени вывода, и подает эти аудиосигналы в громкоговоритель (не показан) на последующем этапе.
Система 10 распределения потоковой передачи сформирована, как описано выше.
Пример отображения субтитров
С помощью системы 10 распределения потоковой передачи по фиг. 9, можно управлять, например, отображением субтитров, как показано ниже. На фиг. 10 представлена схема, иллюстрирующая субтитры во временной последовательности, которые накладываются и отображаются на видеоданные содержания в клиенте 40 IPTV, который принимает содержание, распределяемое в прямом эфире, как фрагментированный кинофильм.
Например, когда экземпляр документа TTML (экземпляр Init), как показано на фиг. 11, сохраняют в фрагменте с помощью сервера 20 ТТ и распределяют из сервера 30 IPTV, данные Fragment0, распределяемые фрагментированным кинофильмом, принимают с помощью клиента 40 IPTV.
На фиг. 11 показан пример описания экземпляра документа инициализации. В примере на фиг. 11, описание записано для определения цвета, шрифта и т.п. знаков субтитров, и "subtitleArea1" и "subtitleArea2" описаны, как положение отображения субтитров.
Возвращаясь к фиг. 10, когда Fragment0, в котором содержится выборка (Sample0) в mdat0, получают с помощью клиента 40 IPTV, выборку, содержащую экземпляр документа инициализации по фиг. 11, представляющую контексты, такие как цвет, шрифт и положение отображения знаков текстовой информации, предназначенной для отображения, устанавливают в качестве субтитров.
Когда в фрагменте сохраняют экземпляр документа TTML (экземпляр 1 тела), как представлено на фиг. 12 в фрагменте с помощью сервера 20 ТТ и распределяют из сервера 30 IPTV, данные Fragment1, распределяемые, как фрагментированный кинофильм, принимают с помощью клиента 40 IPTV.
На фиг. 12 показан пример описания экземпляра тела документа. В примере на фиг. 12 строка знаков "Это выглядит парадоксально, не так ли", установлена начальной меткой и конечной меткой p-элемента строки знаков в субтитре. Кроме того, атрибут ID, атрибут начала, атрибут области установлены, как атрибуты p-элемента. Для атрибута ID устанавливают ID для идентификации субтитров. В качестве атрибута начала устанавливают время начала отображения субтитров. Для атрибута области устанавливают строку знаков, для установления положения дисплея субтитров.
Возвращаясь к фиг. 10, когда Fragment1, в котором сохранена выборка (Выборка 1) в mdat1, получают с помощью клиента 40 IPTV, выборка, содержащая экземпляр тела документа (экземпляр 1 тела) по фиг. 12, строка знаков в субтитрах, определенная при описании на фиг. 12, отображается на основе предоставления контекста, который устанавливают описанием на фиг. 11. Таким образом, "0,1 s" устанавливают, как начальный атрибут экземпляра тела документа по фиг. 12, и, таким образом, строку знаков "Это выглядит парадоксально, не так ли", как представлено на фиг. 13, отображают с помощью клиента 40 IPTV по прошествии 0,1 секунды после получения элемента тела документа.
В примере на фиг. 12, "субтитр " устанавливают, как атрибут ID, и, таким образом, строку знаков в субтитрах идентифицируют по "субтитру 1". Кроме того, "область 1 субтитра" установлена, как атрибут области, и, таким образом, строка знаков в субтитрах отображается в положении отображения, установленном в "области 1 субтитра" по фиг. 11.
Далее, когда экземпляр документа TTML (экземпляр 2 тела), как показано на фиг. 14, сохраняют во фрагменте с помощью сервера 20 ТТ и распределяют из сервера 30 IPTV, данные фрагмента 2, распределяемые, как фрагментированный кинофильм, принимают в клиенте 40 IPTV.
На фиг. 14 показан пример описания экземпляра тела документа. В примере на фиг. 14, строка знаков в субтитрах формируется из строки знаков "Это выглядит парадоксально, не так ли", идентифицированной "субтитром 1", который представляет собой атрибут ID p-элемента в верхней строке, и строка знаков "что изображение, сформированное на сетчатке, должно быть перевернуто?" идентифицирована "субтитром 2", который представляет собой атрибут ID p-элемента в нижнем ряду. Для p-элемента в верхнем ряду "3 с" установлены, как конец атрибута для установления времени окончания отображения субтитров, и "область 1 субтитра" определена, как атрибут области. Кроме того, для p-элемента в нижнем ряду, "1 с", "5 с", "область 2 субтитра" определены, как начальный атрибут, конечный атрибут, атрибут области, соответственно.
Возвращаясь к фиг. 10, когда Fragment2, в котором сохраняют выборку (Sample2) в mdat2, получают с помощью клиента 40 IPTV, выборка, содержащая экземпляр тела документа (экземпляр 2 тела) по фиг. 14, строка знаков в субтитрах, установленная описанием на фиг. 14, отображается на основе получения контекста, который устанавливают описанием фиг. 11. Таким образом, "1 с" устанавливается в экземпляре тела документа по фиг. 14, как начальный атрибут строки знаков в субтитром, идентифицированном "субтитр 2", и, таким образом, только строка знаков "Это выглядит парадоксально, не так ли", которая идентифицирована по субтитру 1, как представлено на фиг. 15, отображается с помощью клиента 40 IPTV по прошествии 1 секунды после получения экземпляра тела документа.
Далее, когда 1 секунда, которая установлена начальным атрибутом "субтитра 2", пройдет после экземпляра тела документа на фиг. 14, будет получено "что изображение, сформированное на сетчатке, должно быть перевернуто?" для "субтитра 2" отображается, как представлено на фиг. 16 в нижнем ряду строки знаков "Это выглядит парадоксально, не так ли", которая определена по "субтитру 1". Поскольку "область 2 субтитра 2" установлена, как атрибут области, строка знаков субтитров для "субтитра 2" отображается в положении отображения, установленном "областью 2 субтитра 2" на фиг. 11.
Строка знаков в субтитрах, идентифицированных "субтитром 1" и "субтитром 2" на фиг. 16, продолжает отображаться в верхнем и нижнем рядах в течение интервала от времени, установленного начальным атрибутом строки знаков субтитра, идентифицированного по "субтитру 2", до времени, установленного конечным атрибутом строки знаков в субтитре, идентифицированном в "субтитре 1". Когда 3 секунды, которые установлены конечным атрибутом "субтитра 1", проходят после экземпляра тела документа (экземпляр 2 тела) на фиг. 14, отображение строки знаков в субтитрах для "субтитра 1" стирают, и только строку знаков в субтитре для "субтитра 2" отображают, как представлено на фиг. 17.
Возвращаясь к фиг. 10, далее только строку знаков в субтитре, идентифицированную "субтитром 2" на фиг. 17, продолжают отображать в течение интервала от времени, определенного конечным атрибутом конца строки знаков в субтитре, идентифицированном "субтитром 1" до времени, определенным конечным атрибутом в строке знаков в субтитре, идентифицированном в "субтитре 2". Когда проходят 5 секунд, которые установлены конечным атрибутом "субтитра 2", после получения экземпляра тела документа (экземпляр 2 тела) на фиг. 14, отображение строки знаков в субтитре для "субтитра 2" стирают, и отображение субтитров прекращают.
Таким образом, например, когда экземпляр тела документа (экземпляр 2 тела) по фиг. 14 получают после экземпляра тела документа (экземпляр 1 тела) на фиг. 12, атрибут начала строки знаков в субтитре, таком как "субтитр 1", устанавливают с помощью экземпляра 1 тела, и его конечный атрибут устанавливают экземпляром 2 тела. Следовательно, даже если получают экземпляр 2 тела, разрешают продолжить отображение строки знаков в субтитре "субтитр 1".
Обработка распределения потоковой передачи
Далее будут описаны детали обработки, выполняемой каждым устройством, включенным в систему 10 распределения потоковой передачи на фиг. 9.
Вначале, со ссылкой на блок-схему последовательности операций на фиг. 18, описана обработка распределения потоковой передачи, выполняемая сервером 30 IPTV. Обработку выполняют, например, когда субтитры вставляют в живое содержание и распределяют, как фрагментированный кинофильм, через сеть и т.п.
На этапе S21, сервер 30 IPTV получает данные содержания. В этой точке, например, получают данные и т.п., такие как аудиоданные и видеоданные, включенные в содержание.
На этапе S22, модуль 31 генерирования выборки содержания кодирует, например, данные, такие как аудиоданные и видеоданные, включенные в содержание, и генерирует аудиоданные, видеоданные и т.п. Модуль 31 генерирования выборки содержания затем генерирует данные выборки на основе аудиоданных и видеоданных.
На этапе S23, мультиплексор 32 фрагмента генерирует фрагмент, который сохраняет данные выборки, сгенерированные на этапе S22, в mdat.
На этапе S24 сервер 20 ТТ выполняет обработку вставки данных субтитров. Таким образом, данные, относящиеся к субтитрам, вставляют в данные содержания для распределения через потоковую передачу.
Здесь, со ссылкой на блок-схему последовательности операций на фиг. 19, будет подробно описана обработка вставки данных субтитров, соответствующая этапу S24 на фиг. 18.
На этапе S41, генерируют последовательность TTML.
На этапе S42, модуль 21 генерирования фрагмента ТТ генерирует данные фрагмента, в котором сохраняют экземпляр документа TTML.
На этапе S43, модуль 22 вставки выборки генерирует экземпляр документа TTML на основе последовательности TTML, генерируемой на этапе S41, и вставляет экземпляр документа TTML, как выборку mdat, в фрагмент, сгенерированный на этапе S42.
На этапе S44, модуль 22 вставки выборки выводит фрагмент, в котором экземпляр документа TTML был вставлен в результате обработки на этапе S43. Далее фрагмент подают в мультиплексор 32 фрагмента из сервера IPTV 30.
Временной штамп синхронизированной NTP, сгенерированный с помощью модуля 25 генерирования временного штампа 25, соответствующим образом подают в модуль 21 генерирования фрагмента ТТ и в модуль 22 вставки выборки.
Возвращаясь к блок-схеме последовательности операций на фиг. 18, после обработки на этапе S24, на этапе S25, мультиплексор 32 фрагмента умножает фрагмент, сгенерированный на этапе S42 на фиг. 19, и фрагмент, сгенерированный на этапе S23. Таким образом, здесь фрагмент, в котором сохраняют аудиоданные и видеоданные, и т.п., и фрагмент, в котором сохраняют экземпляр документа TTML, мультиплексируют.
На этапе S26, мультиплексор 32 фрагмента генерирует данные кинофильма фрагмента.
На этапе S27 модуль 33 распределения фрагмента распределяет кинофильм фрагмента, сгенерированный на этапе S26, через сеть и т.п.
Обработку распределения потоковой передачи выполняют, как описано выше.
Далее будет описана обработка воспроизведения содержания, выполняемая клиентом 40 IPTV, со ссылкой на блок-схему последовательности операций на фиг. 20.
На этапе S61, приемный модуль 42 принимает кинофильм фрагмента, распределенный на этапе S27 по фиг. 18.
На этапе S62, демультиплексор 43 фрагмента анализирует описание для moov для кинофильма фрагмента, принятое на этапе S61.
На этапе S63, демультиплексор 43 фрагмента выделяет фрагменты, включенные в кинофильм фрагмента, принятый на этапе S61.
На этапе S64, демультиплексор 43 фрагмента определяет, включает ли в себя или нет кинофильм фрагмента фрагмент, в котором экземпляр документа TTML сохранен на основе результата анализа, на этапе S62.
На этапе S64, когда определяют, что кинофильм фрагмента включает в себя фрагмент, в котором содержится экземпляр документа TTML, обработка переходит к этапу S65.
На этапе S65, демультиплексор 43 фрагмента проверяет описание moof в каждом фрагменте.
На этапе S66 демультиплексор 43 фрагмента определяет, сохранен или нет экземпляр документа TTML во фрагменте.
На этапе S66, когда определяют, что экземпляр документа TTML не сохранен во фрагменте, обработка переходит на этап S68, описанный ниже. С другой стороны, на этапе S66, когда демультиплексор 43 фрагмента определяет, что экземпляр документа TTML сохранен во фрагменте, обработка переходит на этап S67.
На этапе S67, декодер 44 ТТ выполняет обработку декодирования ТТ.
При обработке декодирования ТТ, когда результат анализа описания moof во фрагменте обозначает, что тип экземпляра документа TTML представляет собой экземпляр документа инициализации, описание экземпляра документа инициализации, сохраненного в выборке mdat, анализируют, и устанавливают получение контекста. Когда тип экземпляра документа TTML представляет собой экземпляр тела документа, экземпляр тела документа, сохраненный в выборке mdat, анализируют, и генерируют данные отображения субтитров. Данные отображения субтитров, вместе с информацией, относящейся к времени отображения, устанавливающей начало отображения и/или конец отображения, подают в модуль 46 управления дисплеем.
Детали обработки декодирования ТТ будут описаны ниже со ссылкой на фиг. 21 и 22.
С другой стороны, на этапе S64, когда определяют, что фрагмент кинофильм не включает в себя какой-либо фрагмент, в котором содержится экземпляр документа TTML, обработка переходит на этап S68.
На этапе S68, декодер 45 содержания декодирует аудиоданные, видеоданные и т.п., сохраненные в выборке mdat.
На этапе S69, декодер 45 содержания выводит данные отображения видеоизображения, данные вывода звука и т.п., которые были получены, как результат обработки на этапе S68. Данные отображения видеоизображения, данные вывода звука и т.п., генерируемые здесь вместе с информацией, относящейся ко времени отображения, времени вывода и т.п., подают в модуль 46 управления дисплеем.
На этапе S70, модуль 46 управления дисплеем генерирует видеосигналы для наложения и отображения субтитров на видеоданные содержания на основе информации, относящейся к времени отображения, устанавливающему начало отображения и/или конец отображения, и передает эти видеосигналы в дисплей (не показан) на последующем этапе. Кроме того, модуль 46 управления дисплеем генерирует аудиосигналы для вывода адуиоданных для содержания на основе информации, относящейся к времени вывода и т.п., и подает аудиосигналы в громкоговоритель (не показан) на последующем этапе.
Таким образом, данные отображения видеоизображения, данные вывода звука, сгенерированные на этапе S69 на фиг. 20, и данные отображения субтитров, генерируемые на этапе S105, на фиг. 22, описанные ниже, синхронизируют и отображают или выводят.
На этапе S71 определяют, закончился или нет фрагмент кинофильма. Например, когда принимают случайный доступ фрагмента кинофильма (mfra), иллюстрируемый на фиг. 8, определяют, что фрагмент кинофильма закончился. Когда пользователь вырабатывает команду на остановку приема, определяют, что фрагмент кинофильма закончился.
На этапе S71, когда определяют, что фрагмент кинофильма еще не закончился, обработка возвращается на этап S63, и последующая обработка повторяется. С другой стороны, на этапе S71, когда определяют, что фрагмент кинофильма закончился, обработка воспроизведения содержания на фиг. 20 заканчивается.
Обработку воспроизведения содержания выполняют, как описано выше.
Далее будут описаны подробности обработки декодирования ТТ, соответствующие этапу S67 на фиг. 20, со ссылкой на блок-схему последовательности операций на фиг. 21.
На этапе S81, декодер 44 ТТ считывает фрагмент из демультиплексора 43 фрагмента.
На этапе S82 декодер 44 ТТ анализирует описание moof во фрагменте, и определяет, является или нет экземпляр документа TTML экземпляром документа инициализации.
На этапе S82, когда определяют, что тип экземпляра документа TTML не является экземпляром документа инициализации, обработка переходит на этап S83. На этапе S83, декодер 44 ТТ удаляет текущий фрагмент. Обработка затем возвращается на этап S81 и последующая обработка повторяется.
С другой стороны, на этапе S82, когда определяют, что тип экземпляра документа TTML представляет собой экземпляр документа инициализации, обработка переходит на этап S84. На этапе S84, декодер 44 ТТ выполняет обработку экземпляра документа инициализации, анализирует описание экземпляра документа инициализации в выборке mdat, и устанавливает получение содержания.
Когда установка получения содержания заканчивается на этапе S84, обработка переходит на этап S85. На этапе S85, декодер 44 ТТ считывает фрагмент из демультиплексора 43 фрагмента.
На этапе S86, декодер 44 ТТ анализирует описание moof во фрагменте, и определяет, является или нет тип экземпляра документа TTML экземпляром документа инициализации.
На этапе S86, когда определяют, что тип экземпляра документа TTML не является экземпляром документа инициализации, тип должен представлять собой экземпляр тела документа, и, таким образом, обработка переходит на этап S87. На этапе S87, декодер 44 ТТ выполняет обработку экземпляра тела документа.
Здесь обработка экземпляра тела документа, соответствующая этапу S87 на фиг. 21, будет описана со ссылкой на блок-схему последовательности операций на фиг. 22.
На этапе S101, декодер 44 ТТ выполняет обработку синтаксического анализатора XML, и выделяет элементы, включенные в экземпляр тела документа. Декодер 44 ТТ выполняет обработку на этапе S102 и затем последовательно для каждого одного из множества элементов, которые были выделены.
На этапе S102, декодер 44 ТТ определяет, является или нет выделенный элемент p-элементом. На этапе S102, когда определяют, что выделенный элемент не является p-элементом, обработка переходит на этап S103. На этапе S103, декодер 44 ТТ обрабатывает другие элементы, кроме p-элемента.
Когда обработка на этапе S103 будет закончена, обработка переходит на этап S108. На этапе S108, декодер 44 ТТ определяет, закончена или нет обработка для всех элементов.
На этапе S108, когда определяют, что обработка для всех элементов не закончена, обработка возвращается на этап S102, и выполняется обработка определения на этапе S102. На этапе S102, когда определяют, что выделенный элемент представляет собой p-элемент, обработка переходит на этап S104. На этапе S104, декодер 44 ТТ определяет, включен или нет атрибут начала в p-элемент.
На этапе S104, когда определяют, что атрибут начала включен в p-элемент, обработка переходит на этап S105. На этапе S105, декодер 44 ТТ выполняет нормальный p-элемент.
Например, когда выполняют обработку анализатора XML для экземпляра тела документа по фиг. 12, выполняется нормальная обработка для p-элемента, поскольку атрибут начала включен в p-элемент, и, таким образом генерируют, данные отображения субтитров, содержащие строку знаков "Это выглядит парадоксально, не так ли". Генерируемые данные отображения субтитров, вместе с информацией, относящейся ко времени отображения, устанавливающему начало отображения по прошествии 0,1 секунды, подают в модуль 46 управления дисплеем.
С другой стороны, на этапе S104, когда определяют, что атрибут начала не включен в p-элемент, обработка переходит на этап S106. На этапе S106, декодер 44 ТТ определяет, отображается ли уже или нет тот же самый субтитр, на основе результата анализа ID атрибута p-элемента.
На этапе S106, когда определяют, что тот же субтитр уже отображают, обработка переходит на этап S107. На этапе S107, декодер 44 ТТ обеспечивает постоянное отображение субтитра на дисплее.
Например, когда выполняют обработку анализатора XML для экземпляра тела документа по фиг. 14, выполняется обработка на этапе S107, поскольку атрибут начала не включен в p-элемент верхнего ряда, и, кроме того, субтитр, имеющий атрибут ID "субтитр 1", уже отображается в экземпляре тела документа на фиг. 12. Таким образом, декодер 44 ТТ подает информацию, относящуюся ко времени отображения, обозначающую, например, конец отображения по истечении 3 секунд, установленных оконечным атрибутом, так, что субтитр на дисплее, имеющий ID атрибута для "субтитра 1", продолжает отображаться.
Например, атрибут начала включен в p-элемент в нижнем ряду экземпляра тела документа на фиг. 14, и, таким образом, выполняется обработка на этапе S105. Таким образом, декодер 44 ТТ генерирует данные отображения субтитра, составляющего строку знаков "субтитра 2", которая представляет собой, "что изображение, сформированное на сетчатке должно ли быть перевернуто?". Сгенерированные данные субтитров, вместе с информацией, относящейся к времени отображения, устанавливающей начало отображения по истечении 1 секунды и окончания отображения после истечения 5 секунд, подают в модуль 46 управления дисплеем.
Когда обработка на этапе S105 или S107 заканчивается, выполняется обработка определения на этапе S108. На этапе S108, когда определяют, что обработка для всех элементов была закончена, обработка возвращается на этап S87 по фиг. 21, и последующая обработка повторяется.
Таким образом, фрагмент считывают, и определяют, является или нет тип экземпляра документа TTML экземпляром документа инициализации (этап S86). При обработке определения на этапе S86 определяют, что тип 1 не является экземпляром документа инициализации, снова выполняют обработку экземпляра тела документа (этап S 87). С другой стороны, когда при обработке определения на этапе S 86 определяют, что тип 1 представляет собой экземпляр документа инициализации, обработка переходит на этап S88.
На этапе S88, декодер 44 ТТ определяет, отличается или нет содержание определения формата отображения для экземпляра документа инициализации, сохраненного в считываемом фрагменте, от содержания определения контекста предоставления, установленного в данное время.
На этапе S88, когда определяют, что содержание определения формата отображения отличается от содержания определения для контекста предоставления, обработка переходит на этап S84, и последующую обработку повторяют. Таким образом, обработку экземпляра документа инициализации снова выполняют, и снова устанавливают получение содержания (этап S84). С другой стороны, на этапе S88, когда определяют, что содержание определения формата отображения является таким же, как содержание определения контекста предоставления, обработка возвращается на этап S85, и последующая обработка повторяется. Таким образом, в этом случае, контекст предоставления не устанавливают снова, и фрагмент снова считывают из демультиплексора 43 фрагмента.
На этапе S71, на фиг. 20, обработку декодирования ТТ на фиг. 21 многократно выполняют, пока это не будет определено, что кинофильм фрагмента закончился и, таким образом, обработка воспроизведения содержания по фиг. 20 закончилась.
Таким образом, обработка декодирования ТТ была описана со ссылкой на фиг. 21 и 22.
Как описано выше, атрибут сначала прикреплен к субтитру, который описан в экземпляре тела документа, сохраненном в первом считанном фрагменте, и атрибут конца прикреплен к тому же субтитру, который описан в экземпляре тела документа, сохраненном в считываемом в последующем фрагменте, обеспечивая, таким образом, возможность продолжения отображения субтитра первого считанного фрагмента даже после считывания последующего фрагмента.
Пример конфигурации компьютера, в котором применяется настоящая технология Последовательность обработки, описанная выше, может быть исполняться аппаратным обеспечением, но также может исполняться программным обеспечением. Когда последовательность обработки исполняется программным обеспечением, программу, которая строит такое программное обеспечение, устанавливают в компьютер. Здесь выражение "компьютер" включает в себя компьютер, в который встроены специализированные аппаратные средства, и персональный компьютер общего назначения и т.п., который выполнен с возможностью исполнения различных функций, когда устанавливают различные программы.
На фиг. 23 показана блок-схема, представляющая пример конфигурации аппаратных средств компьютера, который выполняет описанную выше последовательность обработки, используя программы.
В компьютере 100 центральное процессорное устройство (CPU) 101, постоянное запоминающее устройство (ROM) 102 и оперативное запоминающее устройство (RAM) 103 взаимно соединены через шину 104.
Интерфейс 105 ввода/вывода также соединен с шиной 104. Модуль 106 ввода, модуль 107 вывода, модуль 108 сохранения, модуль 109 передачи данных и привод ПО соединены с интерфейсом 105 ввода/вывода.
Модуль 106 ввода выполнен из клавиатуры, мыши, микрофона и т.п. Модуль 107 вывода выполнен из дисплея, громкоговорителя и т.п. Модуль 108 сохранения выполнен из жесткого диска, энергонезависимого запоминающего устройства и т.п. Модуль 109 передачи данных выполнен из сетевого интерфейса и т.п. Привод ПО выполняет привод съемного носителя 111, такого как магнитный диск, оптический диск, магнитооптический диск, полупроводниковое запоминающее устройство и т.п.
В компьютере 100, выполненном, как описано выше, CPU 101 загружает программу, которая сохранена, например, в модуле 108 сохранения в RAM 103, через интерфейс 105 ввода/вывода и шину 104, и выполняет эту программу. Таким образом, выполняется описанная выше последовательность обработки.
Программы, предназначенные для исполнения компьютером 100 (CPU 101), предоставляют в записанном виде на съемном носителе 111, который представляет собой упакованный носитель и т.п. Кроме того, программы могут быть предоставлены через проводную или беспроводную среду передачи данных, такую как локальная вычислительная сеть, Интернет или широковещательная цифровая спутниковая передача.
В компьютере 100, путем вставки съемного носителя 111 в привод 110, программа может быть установлена в модуль 108 сохранения через интерфейс 105 ввода/вывода. Далее программа может быть принята модулем 109 передачи данных через проводную или беспроводную среды передачи и может быть установлена в модуле 108 сохранения. Кроме того, программа может быть заранее установлена в ROM 102 или в модуле 108 сохранения.
Следует отметить, что программа, исполняемая компьютером 100, может представлять собой программу, которую обрабатывают во временной последовательности, последовательностью, описанной в данном описании, или программу, которую обрабатывают параллельно или в необходимые моменты времени, такие как по вызову.
Описанный здесь этап обработки для описания программы, которая обеспечивает выполнение компьютером 100 различной обработки, не обязательно должен быть обработан хронологически в порядке, описанном в блок-схеме последовательности операций. Он также включает в себя обработку, выполняемую параллельно или по отдельности (например, параллельная обработка или обработка по объектам).
Программа может быть обработана с помощью одного компьютера или множества компьютеров распределенным образом. Кроме того, программа может выполняться после ее передачи в удаленный компьютер.
Кроме того, в настоящем раскрытии, система имеет значение набора множества сконфигурированных элементов (таких как устройство или модуль (часть)), и при этом не учитывается, находятся или нет все элементы конфигурации в одном и том же кожухе. Поэтому, система может быть выполнена либо из множества устройств, сохранена в отдельном кожухе, и соединена через сеть или множество модулей в пределах одного кожуха.
Вариант осуществления раскрытия не ограничен описанными выше вариантами осуществления, и различные изменения, и модификации могут быть выполнены без выхода за пределы объема раскрытия.
Например, настоящее раскрытие может принимать конфигурацию облачных вычислений, которые обрабатываются путем выделения и соединения одной функции с помощью множества устройств через сеть.
Далее, каждый этап, описанный со ссылкой на упомянутые выше блок-схемы последовательности операций, может быть выполнен одним устройством или путем выделения множества устройств.
Кроме того, в случае, когда множество процессов включено в один этап, множество таких процессов, включенных в этот один этап, может быть выполнено одним устройством или путем выделения множества устройств.
Кроме того, настоящая технология также может быть выполнена, как описано ниже.
(1) Приемное устройство, включающее в себя:
приемный модуль, выполненный с возможностью приема потока содержания, предназначенного для распространения в прямом эфире;
модуль анализа, выполненный с возможностью анализа фрагментированной текстовой информации, соответствующей данным субтитров, включенным в принимаемый поток; и
модуль управления, выполненный с возможностью управления отображением первой текстовой информации, так, чтобы обеспечить возможность продолжения отображения, когда вторая текстовая информация из текстовой информации отображается на основе результата анализа, при этом отображение второй текстовой информации начинается по времени после отображения первой текстовой информации.
(2) Приемное устройство по п. (1),
в котором текстовая информация включает в себя структурированный документ, который описывает содержание, и документ определения отображения, который определяет формат отображения, который применяют для структурированного документа;
в котором время, обозначающее начало отображения первой текстовой информации, описано в первом структурированном документе, который описывает содержание первой текстовой информации;
в котором время, обозначающее конец отображения первой текстовой информации, и время, обозначающее начало отображения второй текстовой информации, описано во втором структурированном документе, который описывает содержание второй текстовой информации; и
в котором модуль управления начинает отображение первой текстовой информации, временем, обозначенным началом отображения первой текстовой информации, описанным в первом структурированном документе, и затем заканчивает отображение первой текстовой информации на дисплее, временем, обозначающим конец отображения первой текстовой информации, описанной во втором структурированном документе, на основе результата анализа.
(3) Приемное устройство по п. (2),
в котором время, обозначающее начало отображения второй текстовой информации, описанное во втором структурированном документе, по времени находится перед временем, обозначающим конец отображения первой текстовой информации; и
модуль управления начинает отображение второй текстовой информации, временем, обозначающим начало отображения второй текстовой информации, описанной во втором структурированном документе, на основе результата анализа.
(4) Приемное устройство по п. (2) или (3),
в котором время, обозначающее конец отображения второй текстовой информации, дополнительно описано во втором структурированном документе; и
в котором модуль управления заканчивает отображение второй текстовой информации, в соответствии со временем, обозначающим конец отображения второй текстовой информации, описанной во втором структурированном документе, на основе результата анализа.
(5) Приемное устройство по п. (4),
в котором время, обозначающее конец отображения второй текстовой информации, описанное во втором структурированном документе, по времени установлено после времени, обозначающего конец отображения первой текстовой информации.
(6) Приемное устройство по любому из пп. (2)-(5),
в котором тот же документ определения отображения применяется для структурированного документа, до тех пор, пока содержание определения формата отображения не будет модифицировано.
(7) Приемное устройство по любому из пп. (1)-(6),
в котором поток представляет собой данные с форматом, который соответствует формату файла МР4, и
данные субтитров соответствуют стандарту языка разметки текста с ярлыками (TTML).
(8) Способ управления, выполняемый приемным устройством, способ управления, включающий в себя следующие этапы:
принимают поток содержания, предназначенный для распределения в режиме реального времени;
анализируют фрагментированную текстовую информацию, соответствующую данным субтитров, включенным в принятый поток; и
управляют отображением первой текстовой информации таким образом, чтобы обеспечить возможность отображения с продолжением, когда вторую текстовую информацию из текстовой информации отображают на основе результата анализа, при этом начало второй текстовой информации по времени начинается после отображения первой текстовой информации.
(9) Программа для обеспечения выполнения компьютером следующей функции: приемного модуля, выполненного с возможностью приема потока содержания,
предназначенного для распространения в прямом эфире;
модуля анализа, выполненного с возможностью анализа фрагментированной текстовой информации, соответствующей данным субтитров, включенным в принимаемый поток; и
модуля управления, выполненного с возможностью управления отображением первой текстовой информации, так, чтобы обеспечить возможность продолжения отображения, когда вторая текстовая информация из текстовой информации отображается на основе результата анализа, при этом отображение второй текстовой информации начинается по времени после отображения первой текстовой информации.
(10) Устройство распределения, включающее в себя:
модуль генерирования содержания, выполненный с возможностью генерирования потока содержания для распределения в режиме реального времени;
модуль получения текстовой информации, выполненный с возможностью получения фрагментированной текстовой информации, для обеспечения возможности продолжения отображения первой текстовой информации, когда вторая текстовая информация отображается, как текстовая информация, соответствующая данным субтитров содержания, при этом отображение второй текстовой информации начинается по времени после отображения первой текстовой информации; и
модуль распределения, выполненный с возможностью распределения потока содержания, включающего в себя данные субтитров в режиме реального времени.
(11) Способ распределения, выполняемый устройством распределения, способ распределения, включающий в себя этапы:
генерируют поток содержания для распределения в режиме реального времени;
получают фрагментированную текстовую информацию так, чтобы обеспечить возможность продолжения отображения первой текстовой информации, когда отображается вторая текстовая информация, как текстовая информация, соответствующая данным субтитров содержания, при этом отображение второй текстовой информации начинается по времени после отображения первой текстовой информации; и
распределяют поток содержания, включающий в себя данные субтитров, в режиме реального времени.
(12) Программа для обеспечения выполнения компьютером следующих функций: модуля генерирования содержания, выполненного с возможностью генерирования
потока содержания для распределения в режиме реального времени;
модуля получения текстовой информации, выполненного с возможностью получения фрагментированной текстовой информации, для обеспечения возможности продолжения отображения первой текстовой информации, когда вторая текстовая информация отображается, как текстовая информация, соответствующая данным субтитров содержания, при этом отображение второй текстовой информации начинается по времени после отображения первой текстовой информации; и
модуля распределения, выполненного с возможностью распределения потока содержания, включающего в себя данные субтитров в режиме реального времени.
(13) Система распространения, включающая в себя:
устройство распределения; и
приемное устройство,
в котором устройство распределения включает в себя
модуль генерирования содержания, выполненный с возможностью генерирования потока содержания для распределения в режиме реального времени;
модуль получения текстовой информации, выполненный с возможностью получения фрагментированной текстовой информации для обеспечения возможности продолжения отображения первой текстовой информации, когда вторую текстовую информацию отображают, как текстовую информацию, соответствующую данным субтитров содержания, отображение второй текстовой информации начинается по времени после отображения первой текстовой информации; и
модуль распределения, выполненный с возможностью распределения потока содержания, включающего в себя данные субтитров, в режиме реального времени, и
в котором приемное устройство включает в себя
приемный модуль, выполненный с возможностью приема потока содержания;
модуль анализа, выполненный с возможностью анализа фрагментированной текстовой информации, соответствующей данным субтитров, включенным в принятый поток;и
модуль управления, выполненный с возможностью управления отображением первой текстовой информации, с тем, чтобы обеспечить возможность продолжения отображения, когда вторая текстовая информация из текстовой информации отображается на основе результата анализа.
Список номеров ссылочных позиций
10 система распределения потоковой передачи
20 ТТ сервер
21 модуль генерирования ТТ фрагмента
22 модуль вставки выборки
25 модуль генерирования временного штампа
30 сервер IPTV
31 модуль генерирования выборки содержания
32 мультиплексор фрагмента
33 модуль распределения фрагмента
40 клиент IPTV
41 модуль часов для измерения времени
42 приемный модуль
43 демультиплексор фрагмента
44 декодер ТТ
45 декодер содержания
46 модуль управления дисплеем
100 компьютер
101 CPU













Изобретение относится к области отображения текстовой информации. Техническим результатом является возможность отображать фрагментированную текстовую информацию, требующую продолжения. Устройство приема контента, включающее в себя приемный модуль, выполненный с возможностью принимать поток содержания, предназначенного для распределения в прямом эфире, модуль анализа, выполненный с возможностью анализировать фрагментированную текстовую информацию, соответствующую данным субтитра, включенным в принимаемый поток, и модуль управления, выполненный с возможностью управления отображением первой информации текста для обеспечения продолжения отображения второй информации текста из информации текста, отображаемой на основе результата анализа, вторая информация текста начинает временно отображаться после отображения первой информации текста. 7 н. и 7 з.п. ф-лы, 23 ил.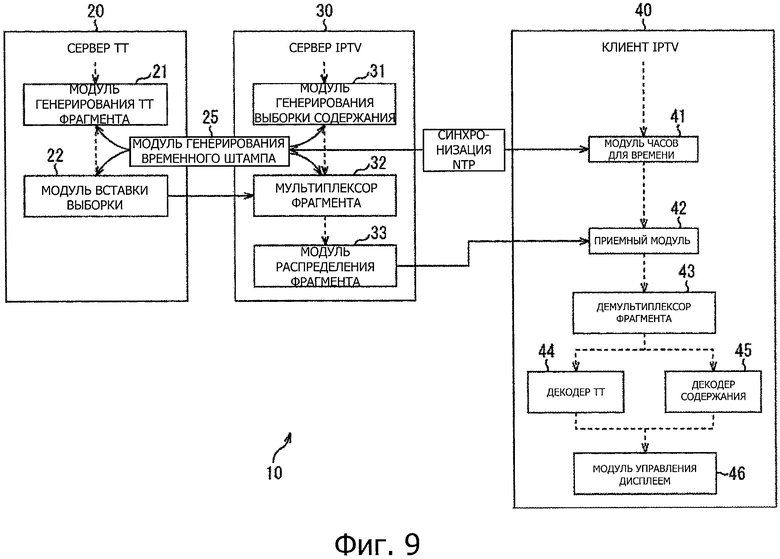
1. Устройство приема контента, содержащее:
схему, выполненную с возможностью
приема потока контента;
анализа фрагментированной текстовой информации, соответствующей данным субтитров, включенным в принимаемый поток; и
управления отображением первой текстовой информации, полученной в первый момент времени и включающей в себя первую строку знаков, так чтобы продолжить отображать первую строку знаков, когда вторая текстовая информация, полученная во второй момент времени после первого момента времени и включающая в себя вторую строку знаков, отображается на основе результата анализа, при этом отображение второй строки знаков начинается по времени после отображения первой строки знаков,
в котором текстовая информация включает в себя структурированный документ, который описывает контент, и документ определения отображения, который определяет формат отображения, который применяют для структурированного документа,
первая текстовая информация, полученная в первый момент времени, включает в себя первый структурированный документ, который описывает первую строку знаков и время, обозначающее начало отображения первой строки знаков, при этом первая текстовая информация не включает в себя время, обозначающее конец отображения первой строки знаков,
вторая текстовая информация, полученная во второй момент времени после первого момента времени, включает в себя второй структурированный документ, который описывает вторую строку знаков, время, обозначающее конец отображения первой строки знаков, и время, обозначающее начало отображения второй строки знаков, и
схема выполнена с возможностью
начала отображения первой строки знаков во время, обозначающее начало отображения первой строки знаков, описанное в первом структурированном документе, полученном в первый момент времени, и последующего окончания отображения первой строки знаков во время, обозначающее конец отображения первой строки знаков, описанной во втором структурированном документе, полученном во второй момент времени после первого момента времени, на основе результата анализа.
2. Устройство по п. 1,
в котором время, обозначающее начало отображения второй текстовой информации, описанное во втором структурированном документе, по времени находится перед временем, обозначающим конец отображения первой текстовой информации; и
схема начинает отображение второй текстовой информации в соответствии со временем, обозначающим начало отображения второй текстовой информации, описанной во втором структурированном документе, на основе результата анализа.
3. Устройство по п. 2,
в котором время, обозначающее конец отображения второй текстовой информации, дополнительно описано во втором структурированном документе; и
в котором схема заканчивает отображение второй текстовой информации в соответствии со временем, обозначающим конец отображения второй текстовой информации, описанной во втором структурированном документе, на основе результата анализа.
4. Устройство по п. 3,
в котором время, обозначающее конец отображения второй текстовой информации, описанное во втором структурированном документе, по времени установлено после времени, обозначающего конец отображения первой текстовой информации.
5. Устройство по любому из пп. 1-4,
в котором тот же документ определения отображения применяется для структурированного документа, до тех пор пока содержание определения формата отображения не будет модифицировано.
6. Устройство по любому из пп. 1-4,
в котором поток представляет собой данные с форматом, который соответствует формату файла МР4, и
данные субтитров соответствуют стандарту языка разметки текста с ярлыками (TTML).
7. Устройство по любому из пп. 1-4, в котором контент включает телевизионный контент.
8. Способ управления контентом, выполняемый устройством приема контента, при этом способ включает в себя следующие этапы:
принимают поток контента;
анализируют фрагментированную текстовую информацию, соответствующую данным субтитров, включенным в принятый поток; и
управляют, используя схему, отображением первой текстовой информации, полученной в первый момент времени и включающей в себя первую строку знаков, так чтобы продолжить отображать первую строку знаков, когда вторую текстовую информацию, полученную во второй момент времени после первого момента времени и включающую в себя вторую строку знаков, отображают на основе результата анализа, при этом отображение второй строки знаков начинается по времени после отображения первой строки знаков,
в котором текстовая информация включает в себя структурированный документ, который описывает контент, и документ определения отображения, который определяет формат отображения, который применяют для структурированного документа,
первая текстовая информация, полученная в первый момент времени, включает в себя первый структурированный документ, который описывает первую строку знаков и время, обозначающее начало отображения первой строки знаков, при этом первая текстовая информация не включает в себя время, обозначающее конец отображения первой строки знаков,
вторая текстовая информация, полученная во второй момент времени после первого момента времени, включает в себя второй структурированный документ, который описывает вторую строку знаков, время, обозначающее конец отображения первой строки знаков, и время, обозначающее начало отображения второй строки знаков, и
управление включает в себя начало отображения первой строки знаков во время, обозначающее начало отображения первой строки знаков, описанное в первом структурированном документе, полученном в первый момент времени, и последующее окончание отображения первой строки знаков во время, обозначающее конец отображения первой строки знаков, описанной во втором структурированном документе, полученном во второй момент времени после первого момента времени, на основе результата анализа.
9. Способ по п. 8, в котором контент включает телевизионный контент.
10. Съемный носитель, содержащий записанную на нем программу для обеспечения выполнения компьютером следующей функции:
приема потока контента;
анализа фрагментированной текстовой информации, соответствующей данным субтитров, включенным в принимаемый поток; и
управления отображением первой текстовой информации, полученной в первый момент времени и включающей в себя первую строку знаков, так чтобы продолжить отображать первую строку знаков, когда вторая текстовая информация, полученная во второй момент времени после первого момента времени и включающая в себя вторую строку знаков, отображается на основе результата анализа, при этом отображение второй строки знаков начинается по времени после отображения первой строки знаков,
в котором текстовая информация включает в себя структурированный документ, который описывает контент, и документ определения отображения, который определяет формат отображения, который применяют для структурированного документа,
первая текстовая информация, полученная в первый момент времени, включает в себя первый структурированный документ, который описывает первую строку знаков и время, обозначающее начало отображения первой строки знаков, при этом первая текстовая информация не включает в себя время, обозначающее конец отображения первой строки знаков,
вторая текстовая информация, полученная во второй момент времени после первого момента времени, включает в себя второй структурированный документ, который описывает вторую строку знаков, время, обозначающее конец отображения первой строки знаков, и время, обозначающее начало отображения второй строки знаков, и
управление включает в себя начало отображения первой строки знаков во время, обозначающее начало отображения первой строки знаков, описанное в первом структурированном документе, полученном в первый момент времени, и последующее окончание отображения первой строки знаков во время, обозначающее конец отображения первой строки знаков, описанной во втором структурированном документе, полученном во второй момент времени после первого момента времени, на основе результата анализа.
11. Устройство распределения контента, включающее в себя:
схему, выполненную с возможностью
генерирования потока контента;
получения фрагментированной текстовой информации, так чтобы продолжить отображать первую текстовую информацию, включающую в себя первую строку знаков, когда отображается вторая текстовая информация, включающая в себя вторую строку знаков, при этом первая текстовая информация и вторая текстовая информация соответствуют данным субтитров контента, а отображение второй строки знаков начинается по времени после отображения первой строки знаков; и
распределения потока контента, включающего в себя данные субтитров, при этом первую текстовую информацию распределяют в первый момент времени и вторую текстовую информацию распределяют во второй момент времени после первого момента времени,
в котором текстовая информация включает в себя структурированный документ, который описывает контент, и документ определения отображения, который определяет формат отображения, который применяют для структурированного документа, первая текстовая информация, полученная в первый момент времени, включает в себя первый структурированный документ, который описывает первую строку знаков и время, обозначающее начало отображения первой строки знаков, при этом первая текстовая информация не включает в себя время, обозначающее конец отображения первой строки знаков,
вторая текстовая информация, полученная во второй момент времени после первого момента времени, включает в себя второй структурированный документ, который описывает вторую строку знаков, время, обозначающее конец отображения первой строки знаков, и время, обозначающее начало отображения второй строки знаков, и
первая текстовая информация и вторая текстовая информация предназначены для использования устройством приема контента, получающим первую текстовую информацию и вторую текстовую информацию, так чтобы устройство приема контента начинало отображать первую строку знаков во время, обозначающее начало отображения первой строки знаков, описанное в первом структурированном документе, полученном в первый момент времени, и затем заканчивало отображение первой строки знаков во время, обозначающее конец отображения первой строки знаков, описанной во втором структурированном документе, полученном во второй момент времени после первого момента времени.
12. Способ распределения контента, выполняемый устройством распределения контента, при этом способ включает в себя следующие этапы:
генерируют, используя схему, поток контента;
получают фрагментированную текстовую информацию, так чтобы продолжить отображать первую текстовую информацию, включающую в себя первую строку знаков, когда отображается вторая текстовая информация, включающая в себя вторую строку знаков, при этом первая текстовая информация и вторая текстовая информация соответствуют данным субтитров контента, а отображение второй строки знаков начинается по времени после отображения первой строки знаков; и
распределяют поток контента, включающий в себя данные субтитров, при этом первую текстовую информацию распределяют в первый момент времени и вторую текстовую информацию распределяют во второй момент времени после первого момента времени,
в котором текстовая информация включает в себя структурированный документ, который описывает контент, и документ определения отображения, который определяет формат отображения, который применяют для структурированного документа,
первая текстовая информация, полученная в первый момент времени, включает в себя первый структурированный документ, который описывает первую строку знаков и время, обозначающее начало отображения первой строки знаков, при этом первая текстовая информация не включает в себя время, обозначающее конец отображения первой строки знаков,
вторая текстовая информация, полученная во второй момент времени после первого момента времени, включает в себя второй структурированный документ, который описывает вторую строку знаков, время, обозначающее конец отображения первой строки знаков, и время, обозначающее начало отображения второй строки знаков, и
первая текстовая информация и вторая текстовая информация предназначены для использования устройством приема контента, получающим первую текстовую информацию и вторую текстовую информацию, так чтобы устройство приема контента начинало отображать первую строку знаков во время, обозначающее начало отображения первой строки знаков, описанное в первом структурированном документе, полученном в первый момент времени, и затем заканчивало отображение первой строки знаков во время, обозначающее конец отображения первой строки знаков, описанной во втором структурированном документе, полученном во второй момент времени после первого момента времени.
13. Съемный носитель, содержащий записанную на нем программу для обеспечения выполнения компьютером следующих функций:
генерирования потока контента;
получения фрагментированной текстовой информации, так чтобы продолжить отображать первую текстовую информацию, включающую в себя первую строку знаков, когда отображается вторая текстовая информация, включающая в себя вторую строку знаков, при этом первая текстовая информация и вторая текстовая информация соответствуют данным субтитров контента, а отображение второй строки знаков начинается по времени после отображения первой строки знаков; и
распределения потока содержания, включающего в себя данные субтитров в режиме реального времени, при этом первую текстовую информацию распределяют в первый момент времени и вторую текстовую информацию распределяют во второй момент времени после первого момента времени,
в котором текстовая информация включает в себя структурированный документ, который описывает контент, и документ определения отображения, который определяет формат отображения, который применяют для структурированного документа,
первая текстовая информация, полученная в первый момент времени, включает в себя первый структурированный документ, который описывает первую строку знаков и время, обозначающее начало отображения первой строки знаков, при этом первая текстовая информация не включает в себя время, обозначающее конец отображения первой строки знаков,
вторая текстовая информация, полученная во второй момент времени после первого момента времени, включает в себя второй структурированный документ, который описывает вторую строку знаков, время, обозначающее конец отображения первой строки знаков, и время, обозначающее начало отображения второй строки знаков, и
первая текстовая информация и вторая текстовая информация предназначены для использования устройством приема контента, получающим первую текстовую информацию и вторую текстовую информацию, так чтобы устройство приема контента начинало отображать первую строку знаков во время, обозначающее начало отображения первой строки знаков, описанное в первом структурированном документе, полученном в первый момент времени, и затем заканчивало отображение первой строки знаков во время, обозначающее конец отображения первой строки знаков, описанной во втором структурированном документе, полученном во второй момент времени после первого момента времени.
14. Система распространения контента, включающая в себя:
устройство распределения; и
приемное устройство,
в котором устройство распределения включает в себя
схему, выполненную с возможностью:
генерирования потока контента;
получения фрагментированной текстовой информации, так чтобы продолжить отображать первую текстовую информацию, включающую в себя первую строку знаков, когда отображают вторую текстовую информацию, включающую в себя вторую строку знаков, при этом первая текстовая информация и вторая текстовая информация соответствуют данным субтитров контента, а отображение второй строки знаков начинается по времени после отображения первой строки знаков; и
распределения потока контента, включающего в себя данные субтитров, при этом первую текстовую информацию распределяют в первый момент времени и вторую текстовую информацию распределяют во второй момент времени после первого момента времени,
в котором текстовая информация включает в себя структурированный документ, который описывает контент, и документ определения отображения, который определяет формат отображения, который применяют для структурированного документа,
первая текстовая информация, полученная в первый момент времени, включает в себя первый структурированный документ, который описывает первую строку знаков и время, обозначающее начало отображения первой строки знаков, при этом первая текстовая информация не включает в себя время, обозначающее конец отображения первой строки знаков,
вторая текстовая информация, полученная во второй момент времени после первого момента времени, включает в себя второй структурированный документ, который описывает вторую строку знаков, время, обозначающее конец отображения первой строки знаков, и время, обозначающее начало отображения второй строки знаков, и
в котором приемное устройство включает в себя
схему, выполненную с возможностью
приема потока контента;
анализа фрагментированной текстовой информации, соответствующей данным субтитров, включенным в принятый поток; и
управления отображением первой строкой знаков, включенной в первую текстовую информацию, полученную в первый момент времени, так чтобы продолжить отображать первую строку знаков, когда вторая строка знаков, включенная во вторую текстовую информацию, полученную во второй момент времени после первого момента времени, отображается на основе результата анализа путем отображения первой строки знаков во время, обозначающее начало отображения первой строки знаков, описанное в первом структурированном документе, полученном в первый момент времени, и последующее окончание отображения первой строки знаков во время, обозначающее конец отображения первой строки знаков, описанной во втором структурированном документе, полученном во второй момент времени после первого момента времени, на основе результата анализа.
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Аппарат для очищения воды при помощи химических реактивов | 1917 |
|
SU2A1 |
| Аппарат для очищения воды при помощи химических реактивов | 1917 |
|
SU2A1 |

