Область техники, к которой относится изобретение
Настоящая технология относится к устройству и способу распределения потоковой передачи данных, к устройству и способу приема потоковой передачи данных, системе потоковой передачи данных, программе и носителю записи, и, в частности, к устройству и способу распределения потоковой передачи данных, устройству и способу приема потоковой передачи данных, системе потоковой передачи данных, программе и носителю записи, которые позволяют уменьшить нагрузку на обработку для отображения субтитров при потоковой передаче данных.
Уровень техники
В настоящее время выполняется стандартизация при потоковой передаче данных через Интернет, такой как IPTV и т.п., для распределения движущихся изображений, используя IP (протокол Интернет). Например, выполняется стандартизация систем, применяемая для потоковой передачи для VoD (видео по запросу) на основе потоковой передачи HTTP (протокол передачи гипертекста) и потоковой передачи прямой трансляции. В ходе работ по внедрению таких стандартов рассматривается использование формата файла МР4, в качестве формата, используемого на уровне контейнера.
Кроме того, в случае, когда присутствуют субтитры, как составляющий элемент потоковой передачи HTTP, часто используют TTML (Язык временной разметки текста), определенный в соответствии с W3C (Консорциум всемирной сети). TTML также применяется другими группами стандартизации, и привлекает внимание в качестве доминирующего формата.
TTML преимущественно разделяют на два типа в соответствии с классификациями экземпляров документа. Один из экземпляров документа, называется "экземпляром документа инициализации", который представляет собой, например, экземпляр, формируемый, в соответствии с описанием, устанавливающим цвет, вид шрифта, положение отображения и т.п. для знаков, отображаемых в субтитрах. Другой представляет собой экземпляр документа, называемый "экземпляр основного документа", который представляет собой экземпляр, формируемый в результате описания, такой как строка знаков, фактически отображаемая, как субтитры.
Когда используется TTML, строки символов, описанные в "экземплярах основного документа", могут отображаться в последовательности, в соответствии с цветом, шрифтом, положением отображения и т.п. знаков, причем цвет, шрифт, положение отображения и т.п. описаны, например, в "экземпляре документа инициализации".
В частности, приемник для приема потока и выполнения отображения может быть выполнен с возможностью первоначального анализа "экземпляра документа инициализации", после чего идентификация цвета, шрифта, положения отображения и т.п. знаков, и после этого отображает строку знаков, полученную в результате анализа "экземпляра основного документа." Таким образом, приемнику не требуется каждый раз анализировать отображаемый контекст, как определяющий информацию, такую как цвет, шрифт, положение отображения и т.п. знаков, таким образом, что нагрузка при обработке, относящаяся к отображения субтитров, может быть уменьшена.
Кроме того, было предложено устройство приема потока, выполненное с возможностью реализации эффективного управления полосой и эффективной обработки переключения каналов на стороне приемника в формате организации, в которой 2-D программа и 3-D программа смешаны друг с другом (см., например, Патентную Литературу 1).
Список литературы
Патентная литература
Патентная литература 1 - JP 2011-097227 А
Раскрытие изобретения
Техническая задача
В отличие от содержания кинофильмов, драм и т.п., в случае, когда субтитры требуется вставить в изображение содержания, передаваемого в режиме прямой передачи, такого как новости, спортивные передачи и т.п., например, строки знаков субтитров не могут быть определены заранее. Таким образом, необходима обработка по вставке строки знаков субтитров во время широковещательной передачи (потоковой передачи) на основе потребности. В таком случае желательно обеспечить для приемника возможность принимать "экземпляр документа инициализации" в TTML и анализировать получаемое содержание, и после этого принимать "экземпляр основного документа" на основе необходимости.
Кроме того, возникает, например, случай, в котором предоставляемое содержание требуется изменить, в соответствии с содержанием строки знаков, отображаемой в качестве субтитров (текст, который требуется выделить, текст, выражающий эмоции, обозначающий удивление или растерянность и т.п.). В таком случае также возможно заранее определить множество видов контекста отображения с использованием "экземпляра документа инициализации" в TTML, и после этого устанавливать контекст представления, который должен использоваться в "экземпляре основного документа".
Однако формат файла МР4 не определяет способ для сохранения экземпляра TTML с распознанным типом экземпляра TTML, и поэтому приемник не может идентифицировать тип экземпляра TTML. Таким образом, ожидается, что нагрузка на обработку, относящаяся к анализу представления контекста, будет уменьшаться при отображении субтитров при потоковой передаче по Интернет, такой как IPTV и т.п.
Настоящая технология раскрыта с учетом такой ситуации и позволяет уменьшить нагрузку на обработку, относящуюся к отображению субтитров при потоковой передаче данных.
Решение задачи
В соответствии с первым аспектом настоящей технологии, предложено устройство распределения потоковой передачи данных, включающее в себя: блок генерирования фрагмента содержания, выполненный с возможностью генерирования данных хранения фрагмента содержания, предназначенного для потокового распределения, фрагмент определяется в соответствии с форматом файла МР4; и блок генерирования фрагмента субтитров, выполненный с возможностью генерирования фрагмента, содержащего экземпляр документа TTML (язык временной разметки текста), относящийся к субтитрам, предназначенным для отображения в содержании, при этом фрагмент определяется по формату файла МР4. В устройстве распределения потоковой передачи данных блок генерирования фрагмента субтитров добавляет к информации заголовка фрагмента информацию распознавания классификации экземпляра для определения, является ли экземпляр документа TTML, хранящийся во фрагменте, экземпляром документа TTML, определяющим контекст отображения, относящийся к субтитрам.
Блок генерирования фрагмента субтитров может сохранять во фрагменте образец, в котором описан экземпляр документа TTML, вместе с информацией идентификации содержания описания для индивидуальной идентификации описания содержания экземпляра документа TTML, относящегося к субтитрам.
Устройство распределения потоковой передачи данных может дополнительно включать в себя блок генерирования заголовка кинофильма, выполненный с возможностью добавлять, в информацию заголовка кинофильма, включающего в себя множество фрагментов, информацию распознавания классификации фрагмента для обозначения того, что кинофильм включает в себя фрагмент, содержащий экземпляр документа TTML.
Устройство распределения потоковой передачи данных может дополнительно включать в себя блок генерирования заголовка кинофильма, выполненный с возможностью добавлять в информацию заголовка кинофильма, включающего в себя множество фрагментов, информацию распознавания классификации фрагмента для обозначения того, что кинофильм включает в себя фрагмент, содержащий экземпляр документа TTML. В блоке генерирования заголовка кинофильма содержится экземпляр документа TTML, устанавливающий предоставляемое содержание, относящееся к субтитрам, в информации о распознавании классификации фрагмента, и информация о распознавании классификации экземпляра не добавляется к информации заголовка фрагмента.
В соответствии с первым аспектом настоящего изобретения, предусмотрен способ распределения потоковой передачи данных, включающий в себя этапы, на которых: генерируют с помощью блока генерирования фрагмента содержания фрагмент содержания, предназначенный для распределения, путем потоковой передачи, фрагмента, определяемого форматом файла МР4; генерируют с помощью блока генерирования фрагмента субтитрово фрагмент, содержащий экземпляр документа TTML (язык временной разметки текста), относящийся к субтитрам, которые должны отображаться в содержании, фрагмент, определяемый форматом файла МР4; и добавляют с помощью блока генерирования фрагмента субтитров к информации заголовка фрагмента, информацию распознавания классификации экземпляра для различия, является ли экземпляр документа TTML, сохраненный во фрагменте, экземпляром документа TTML, определяющим представление содержания, относящегося к субтитрам.
В соответствии с первым аспектом настоящего изобретения предусмотрена программа для выполнения компьютером функции устройства распределения потоковой передачи данных, устройство распределения потоковой передачи данных, включающее в себя: блок генерирования фрагмента содержания, выполненный с возможностью генерирования фрагмента, сохраняет данные содержания, предназначенного для распределения в результате выполнения потоковой передачи данных, при этом фрагмент определен форматом файла МР4; и блок генерирования фрагмента субтитров, выполненный с возможностью генерирования фрагмента, содержащего экземпляр документа TTML (язык временной разметки текста), относящийся к субтитрам, отображаемым в содержании, при этом фрагмент определен форматом файла МР4. В устройстве распределения потоковой передачи блок генерирования фрагмента субтитров добавляет к информации заголовка фрагмента информацию распознавании классификации экземпляра для определения, является ли экземпляр документа TTML, сохраненный во фрагменте, экземпляром документа TTML, определяющим контекст отображения, относящийся к субтитрам.
В первом аспекте настоящего изобретения генерируют данные сохранения фрагмента содержания, которые должны распределяться при выполнении потоковой передачи данных, причем фрагмент, определяемый форматом файла МР4, генерируют фрагмент, содержащий экземпляр документа TTML (язык временной разметки текста), относящийся к субтитрам, предназначен для отображения в содержании, фрагмент, определенный форматом файла МР4, и информацию распознавания классификации экземпляра, для определения, является ли экземпляр документа TTML, сохраненный во фрагменте, экземпляром документа TTML, определяющим контекст отображения, относящийся к субтитрам, добавляют к информации заголовка фрагмента.
В соответствии со вторым аспектом настоящего изобретения, предусмотрено устройство приема потоковой передачи данных, включающее в себя: блок приема кинофильма, выполненный с возможностью приема данных кинофильма, включающих в себя множество фрагментов, при этом фрагменты определены форматом файла МР4; блок определения TTML (язык временной разметки текста), выполненный с возможностью определения, включает ли в себя кинофильм фрагмент, содержащий экземпляр документа TTML на основе информации распознавания классификации фрагмента, указывающей, что кинофильм включает в себя фрагмент, содержащий экземпляр документа TTML, информацию распознавания классификации фрагмента добавляют к информации заголовка кинофильма; и блок декодирования TTML, выполненный с возможностью выделения и декодирования фрагмента, содержащего экземпляр документа TTML, когда определяют, что кинофильм включает в себя фрагмент, содержащий экземпляр документа TTML.
Блок декодирования TTML может различать классификацию экземпляра документа TTML, сохраненного во фрагменте на основе информации распознавания классификации экземпляра для определения, является ли экземпляр документа TTML, сохраненный во фрагменте, экземпляром документа TTML, определяющим отображаемое содержание, относящееся к субтитрам, информация распознавании классификации экземпляра включена в информацию заголовка фрагмента, и декодирует экземпляр документа TTML.
Блок декодирования TTML может распознавать классификацию экземпляра документа TTML, сохраненного во фрагменте, на основе информации различения классификации экземпляра, для определения, является ли экземпляр документа TTML, сохраненный во фрагменте, экземпляром документа TTML, определяющим получение содержания, относящегося к субтитрам, при этом информация распознавания классификации экземпляра включена в информацию заголовка фрагмента, и устройство приема потоковой передачи данных может дополнительно включать в себя блок определения декодирования, выполненный с возможностью определения, следует ли декодировать экземпляр документа TTML на основе информации, идентифицирующей содержание описания, для индивидуальной идентификации содержания описания экземпляра документа TTML, относящегося к субтитрам в образце, сохраненном во фрагменте, когда экземпляр документа TTML, сохраненный во фрагменте, будет распознан, как представляющий собой экземпляр документа TTML, устанавливающий содержание представления, относящееся к субтитрам.
Когда определяют, что кинофильм включает в себя фрагмент, содержащий экземпляр документа TTML, блок декодирования TTML может декодировать экземпляр документа TTML, определяющий содержание представления, относящееся к субтитрам, экземпляр документа TTML, определяющий содержание представления, относящееся к субтитрам, включенным в информацию распознавания классификации фрагмента.
В соответствии со вторым аспектом настоящего изобретения, предложен способ приема потоковой передачи данных, включающий в себя этапы, на которых: принимают с помощью блока приема кинофильма данные кинофильма, включающие в себя множество фрагментов, при этом фрагменты определены форматом файла МР4; определяют с помощью блока определения TTML, включает ли в себя кинофильм фрагмент, содержащий экземпляр документа TTML, на основе информации различения определения классификации фрагмента, указывающей, что кинофильм включает в себя фрагмент, содержащий экземпляр документа TTML, информацию различения классификации фрагмента добавляют к информации заголовка кинофильма; и выделяют и декодируют с помощью блока декодирования TTML фрагмент, содержащий экземпляр документа TTML, когда определяют, что кинофильм включает в себя фрагмент, содержащий экземпляр документа TTML.
В соответствии со вторым аспектом настоящего изобретения, предложена программа, вызывающая выполнение компьютером функции устройства приема потоковой передачи данных, при этом устройство приема потоковой передачи данных включает в себя: блок приема кинофильма выполненный с возможностью приема данных кинофильма, включающих в себя множество фрагментов, при этом фрагменты определены форматом файла МР4; блок определения TTML выполненный с возможностью определения, включает ли в себя кинофильм фрагмент, содержащий экземпляр документа TTML, на основе информации различения определения классификации фрагмента, указывающей, что кинофильм включает в себя фрагмент, содержащий экземпляр документа TTML, информацию различения классификации фрагмента добавляют к информации заголовка кинофильма; и блок декодирования TTML выполненный с возможностью выделения и декодирования фрагмента, содержащего экземпляр документа TTML, когда определяют, что кинофильм включает в себя фрагмент, содержащий экземпляр документа TTML.
Во втором аспекте настоящего изобретения принимают данные кинофильма, включающие в себя множество фрагментов, причем эти фрагменты определены в соответствии с форматом файла МР4, определяют, содержит ли кинофильм фрагмент, содержащий экземпляр документа TTML, на основе информации определения классификации фрагмента, указывающей, что кинофильм включает в себя фрагмент, содержащий экземпляр документа TTML, информацию определения классификации фрагмента добавляют к информации заголовка кинофильма, и когда определяют, что кинофильм включает в себя фрагмент, содержащий экземпляр документа TTML, фрагмент, содержащий экземпляр документа TTML, выделяют и декодируют.
В соответствии с третьим аспектом настоящего изобретения, предусмотрена система потоковой передачи данных, включающая в себя: устройство распределения потоковой передачи данных, включающее в себя блок генерирования фрагмента содержания, выполненный с возможностью генерирования данных, содержащих фрагмент содержания, предназначенный для распределения, путем выполнения потоковой передачи данных, при этом фрагмент определен форматом файла МР4, и блок генерирования фрагмента субтитров, выполненный с возможностью генерирования фрагмента, содержащего экземпляр документа TTML (язык временной разметки текста), относящийся к субтитрам, которые должны быть отображены в содержании, причем фрагмент определен форматом файла МР4. В устройстве распределения потоковой передачи данных блок генерирования фрагмента субтитров выполнен с возможностью добавления к информации заголовка фрагмента информации, определяющей классификацию экземпляра, для определения, является ли экземпляр документа TTML содержащийся во фрагменте, экземпляром документа TTML, определяющим представление контекста, относящегося к субтитрам. Система потоковой передачи данных дополнительно включает в себя устройство приема потоковой передачи данных, включающее в себя блок приема кинофильма, выполненный с возможностью приема данных кинофильма, включающего в себя множество фрагментов, при этом фрагменты определены форматом файла МР4, блок определения TTML, выполненный возможностью определения, включает ли кинофильм в себя фрагмент, содержащий экземпляр документа TTML, на основе информации определения классификации фрагмента, указывающей, что кинофильм включает в себя фрагмент, содержащий экземпляр документа TTML, информация, определяющая классификацию фрагмента, добавлена к информации заголовка кинофильма, и блок декодирования TTML выполнен с возможностью выделения и декодирования фрагмента, содержащего экземпляр документа TTML, когда определяют, что кинофильм включает в себя фрагмент, содержащий экземпляр документа TTML.
В третьем аспекте настоящего изобретения, генерируют фрагмент, содержащий данные содержания, предназначенного для распределения при потоковой передачи данных, фрагмент определен форматом файла МР4, фрагмент, содержащий экземпляр документа TTML (язык временной разметки текста), относящийся к субтитрам, предназначенным для отображения в содержании, генерируют фрагмент, определенный форматом файла МР4, и информацию определения классификации экземпляра для определения, является ли экземпляр документа TTML, сохраненный во фрагменте, экземпляром документа TTML, определяющим отображение контекста, относящегося к субтитрам, добавляют к информации заголовка фрагмента. Кроме того, принимают данные кинофильма, включающие в себя множество фрагментов, причем фрагменты определены форматом файла МР4, определяют, включает ли в себя кинофильм фрагмент, содержащий экземпляр документа TTML, на основе информации определения классификации фрагмента, указывающей, что кинофильм включает в себя фрагмент, содержащий экземпляр документа TTML, причем информацию определения классификации фрагмента добавляют к информации заголовка кинофильма, и когда определяют, что кинофильм включает в себя фрагмент, содержащий экземпляр документа TTML, этот фрагмент, содержащий экземпляр документа TTML, выделяют и декодируют.
Полезный эффект изобретения
В соответствии с существующей технологией, возможно уменьшить нагрузку при обработке, относящейся к отображению субтитров при потоковой передаче данных.
Краткое описание чертежей
На фиг. 1 показана схема для помощи при пояснении конфигурации TTML.
На фиг. 2 показана схема, представляющая конфигурацию "BOX" в формате файла МР4.
На фиг. 3 показана схема для помощи при пояснении иерархической структуры "BOX".
На фиг. 4 показана схема для помощи при пояснении потоковой передачи данных, используя формат файла МР4.
На фиг. 5 показана схема для помощи при пояснении конфигурации "Movie".
На фиг. 6 показана схема для помощи при пояснении структуры "BOX" в "Movie".
На фиг. 7 показана схема для помощи при пояснении конфигурации "не фрагментированного Movie."
На фиг. 8 показана схема для помощи при пояснении конфигурации "Фрагментированного Movie."
На фиг. 9 показана схема для помощи при пояснении конфигурации "BOX" "moov".
На фиг. 10 показана схема, представляющая конфигурацию "BOX" "moof" в случае "экземпляра документа инициализации."
На фиг. 11 показана схема, представляющая конфигурацию "BOX" "moof в случае " экземпляра основного документа."
На фиг. 12 показана схема для помощи при пояснении формата описания "Sample" "mdat", когда сохраняется экземпляр документа TTML.
На фиг. 13 показана блок-схема, представляющая пример конфигурации системы потоковой передачи данных в соответствии с вариантом осуществления настоящей технологии.
На фиг. 14 показана схема, представляющая пример описания "экземпляра документа инициализации."
На фиг. 15 показана схема, представляющая пример описания "экземпляра основного документа."
На фиг. 16 показана схема, представляющая субтитры, отображаемые на основе "экземпляра основного документа" по фиг.15.
На фиг. 17 показана схема, представляющая другой пример описания "экземпляра основного документа."
На фиг. 18 показана схема, представляющая субтитры, отображаемые на основе "экземпляра основного документа" по фиг. 17.
На фиг. 19 показана схема для помощи при пояснении примера отображения субтитров.
На фиг. 20 показана блок-схема последовательности операций для помощи при пояснении примера процесса распределения потоковой передачи данных.
На фиг. 21 показана блок-схема последовательности операций для помощи при пояснении примера процесса вставки данных субтитров.
На фиг. 22 показана блок-схема последовательности операций для помощи при пояснении примера процесса воспроизведения содержания.
На фиг. 23 показана блок-схема последовательности операций для помощи при пояснении примера процесса декодирования ТТ.
На фиг. 24 показана схема для помощи при пояснении другой конфигурации "BOX" "moov".
На фиг. 25 показана схема для помощи при пояснении примера отображения субтитров, соответствующих фиг. 24.
На фиг. 26 показана блок-схема, представляющая пример конфигурации персонального компьютера.
Осуществление изобретения
Предпочтительные варианты осуществления раскрытой здесь технологии будут описаны ниже со ссылкой на чертежи.
Вначале будет представлено описание TTML (язык временной разметки текста). TTML представляет собой язык разметки, определенный W3C (консорциум всемирной сети), и может устанавливать положение отображения (компоновку), временные характеристики отображения и т.п. текста.
Например, когда информацию, описанную в TTML, передают из сервера, и клиент ее анализирует, заданная строка знаков может отображаться в определенное время, с указанным шрифтом и в определенной области на устройстве отображения устройства клиента. Когда информация, описанная в TTML, используется таким образом, легко осуществляется, например, отображение субтитров синхронно с изображением и звуком содержания.
TTML формируют путем объединения текстов, которые называются здесь экземплярами документа. Экземпляры документа преимущественно классифицируют на два типа. Один представляет собой экземпляр документа, называемый "экземпляром документа инициализации", который представляет собой экземпляр, формируемый путем описания, которое устанавливает, например, цвет, шрифт, положение отображения и т.п. знаков, отображаемых, как субтитры. Другой представляет собой экземпляр документа, называемый "экземпляром основного документа", который представляет собой экземпляр, формируемый путем описания, такого как строка знаков, фактически отображаемая как субтитры.
На фиг. 1 показана схема, предназначенная для помощи при пояснении конфигурации TTML.
Экземпляр 21, показанный на фиг. 1, представляет собой "экземпляр документа инициализации". Теги, такие как "head" (заголовок), "styling" (стилизация), "layout" (компоновка)... описаны в этом экземпляре 21. Такие теги, как "styling" и "layout" устанавливают представление содержания, такое как цвет, шрифт, положение отображения и т.п. знаков, отображаемых, как субтитры.
Кроме того, в этом примере, представляемое содержание "s1" определено путем описания "<region xml:id="subtitleArea"style="sl"…" Множество видов представления контекста, таких как "s1", "s2" … может быть определено, например, в одном "экземпляре инициализации документа".
Экземпляр 22 на фиг. 1 представляет собой "экземпляр основного документа". Теги, такие как "body" (тело), "div", "p"... описаны в этом экземпляре 22. Например, описание "<р xml:id=…>" устанавливает строку знаков субтитров, а также время начала отображения и время окончания отображения строки знаков.
Таким образом, TTML представляет собой описание, имеющее иерархическую структуру, формируемую путем комбинирования экземпляра 21 и экземпляра 22. Иерархическая структура, формируемая комбинацией экземпляра 21 и экземпляра 22, показана с левой стороны от экземпляра 22 на фиг. 1.
Например, в результате настройки приемника для приема и отображения потока, приема и анализа TTML, показанного на фиг. 1, заданная строка знаков может отображаться в заданный период времени в содержании. Таким образом, отображение субтитров изменяется на устройстве отображения приемника, соответственно, на основе строки знаков, времени начала отображения и времени окончания отображения, которые определены тегом "p" в экземпляре 22. В примере, показанном на фиг. 1, строка F1 знаков, строка F2 знаков …, установленные тегами "p" в экземпляре 22, выбирают и отображают с течением времени.
В частности, детали TTML раскрыты в языке временной разметки текста (TTML) 1.0 и т.п.
Описание будет далее представлено для формата файла МР4. Формат файла МР4 предлагает высокую степень свободы, и определен таким образом, что файл МР4 формируют путем сбора данных различных размеров, называемых "BOX" (коробка). Существуют различные виды "BOX", которые можно свободно увеличивать.
На фиг. 2 показана конфигурация "BOX " в формате файла МР4. Размер и тип (вид) рассматриваемой "BOX" описаны в областях, показанных, как "размер BOX" и "тип BOX". В области, показанной, как "данные BOX", сохраняют, например, кодированные видеоданные, аудиоданные, данные субтитров и т.п.
Кроме того, формат файла МР4 определен таким образом, что описанная выше "BOX" имеет иерархическую структуру. В частности, как показано на фиг. 3, "BOX" на нижнем уровне может быть сохранен в области "данные BOX" для "BOX" на более высоком уровне.
В формате файла МР4 данные модуля содержания, предназначенные для передачи, такого как модуль декодирования аудиоданных и один фрейм видеоданных, например, называются "Sample" (выборка). Множество выборок формируют "Chunk" (фрагмент). Например, как показано на фиг. 4, "Chunk" аудиоданных и "Chunk" видеоданных формируют потоковую передачу.
В формате файла МР4 объединение последовательности "Chunk" видеоданных или объединение последовательности "Chunk" аудиоданных, например, называется "Track" (дорожкой). Данные, формируемые путем объединения множества дорожек, называются "Movie" (кинофильм).
На фиг. 5 показана схема для помощи при пояснении конфигурации "Movie". В примере на фиг. 5, видео "Tracks" и аудио "Tracks" формирует один "Movie".
"Movie" имеет структуру "BOX", как описано выше. На фиг. 6 показана схема, предназначенная для помощи при пояснении структуры "BOX" "Movie". В примере на фиг. 6 показана "коробка метаданных кинофильма" и "коробка данных кинофильма" сохранена в "BOX" для "Movie".
"Коробка метаданных кинофильма" представляет собой "BOX", описывающую информацию (такую как "adrs=1000" и т.п.), относящуюся к положению сохранения каждой выборки "Sample", содержащейся в "Коробке данных кинофильма" и информацию (такую как "Λt=10" и т.п.), относящуюся к времени воспроизведения и длительности воспроизведения. "Коробка метаданных кинофильма" также описывает параметр кодека и т.п., в соответствии с требованиями. "Коробка данных кинофильма" представляет собой "BOX", содержащую каждую "Sample". В частности, в стандартах формата файла МР4, "Коробка метаданных кинофильма" называются "moov", и "Коробка данных кинофильма" называется "mdat".
Когда "Movie", как показано на фиг.6, принимают и анализируют с помощью приемника. Sample 1, Sample 2, Sample 3 … могут быть воспроизведены в момент времени t0, момент времени t10, момент времени t20 …, соответственно.
Кроме того, "Movie" приблизительно классифицируются на два типа. Один называется "нефрагментированный Movie", который пригоден для передачи содержания, такого, как, например, кинофильмы, драмы и т.п.. Другой называется "фрагментированным Movie", который пригоден для передач прямой трансляции, таких как новости, спортивные передачи и т.п.
На фиг. 7 показана схема для помощи при пояснении конфигурации "нефрагментированного Movie".
Как показано на фиг.7, "BOX", относящаяся к "типу файла (ftyp)", расположена в заголовке "нефрагментированного Movie". "Тип файла (fiyp)" представляет собой "BOX", содержащую тип файла, информацию о совместимости и т.п.
После "(ftyp)" расположены "moov" и "mdat", описанные выше. Как указано выше, "moov" описывает параметр кодека, информацию о положении сохранения, информацию времени воспроизведения и т.п. "moov" представляет собой, своего рода информацию заголовка для "Movie". Кроме того, как описано выше, "mdat" содержит выборки "Sample", формируемые модулем декодирования аудиоданных, один фрейм видеоданных и т.п.
В "нефрагментированном Movie" "moov" определяет получение содержания в целом "Movie". В частности, в случае содержания, такого как кинофильмы, драмы и т.п., моменты времени, в которые можно воспроизвести изображения, аудиоданные и субтитры, известны заранее, и, поэтому, представляемый контекст всего "Movie" может быть определен до того, как будет принята каждая выборка "Sample".
В случае прямой трансляции содержания, такой как новости, спортивные передачи и т.п., моменты времени, в которые необходимо воспроизводить изображения, звук и субтитры, не известны заранее. Таким образом, "фрагментированный кинофильм" используется для передачи прямых трансляций.
На фиг. 8 показана схема, предназначенная для помощи при пояснении конфигурации "фрагментированного Movie".
Как показано на фиг. 8, "фрагментированный Movie" имеет типы "ftyp" и "moov", как и в случае "нефрагментированного Movie". Однако, после "ftyp" и "moov" следует множество "BOX", называемых "Fragment". "Fragment" включает в себя "BOX", называемый "Movie Fragment (moof)" и "mdat".
Как показано на фиг. 8, каждый "Fragment" имеет "moof, и "moof представляет собой, так сказать, информацию заголовка "Chunk", "moot описывает информацию о положении сохранения, информацию о времени воспроизведения и т.п., относящиеся к "Sample" "mdat", сохраненной в рассматриваемом "Fragment". Таким образом, в "фрагментированном Movie", в отличие от "нефрагментированного Movie", получение контекста каждого "Fragment" определяют в каждом "Fragment".
В частности, "произвольный доступ к фрагменту кинофильма (mfra)", показанный на фиг. 8, представляет собой "BOX", вставленный в конце "фрагментированного Movie", и "произвольный доступ к фрагментам кинофильма (mfra)" содержит информацию для случайного доступа и т.п.
В частности, примеры, представленные на фиг.7 и на фиг. 8, представляют конфигурации "Movie", как формат файла МР4. Когда выполняется потоковая передача данных через Интернет и т.п., например, данные, описанные выше со ссылкой на фиг. 7 и фиг. 8, распределяются в заданном формате передачи. В таком формате передачи, например, "moov", показанный на фиг. 8, вставляют между "Fragment", и многократно распределяют множество раз.
В последнее время выполняется стандартизация при потоковой передаче в Интернет, такой как IPTV и т.п. для распределения движущихся изображений, используя IP (протокол Интернет). Например, стандартизация систем, применяемых для потоковой передачи VoD (Видео по запросу) на основе потоковой передачи HTTP (Протокол передачи HyperText), и выполняется потоковая передача при прямой трансляции. В ходе работы для такой стандартизации уделяют внимание использованию формата файла МР4, как формата, используемого на уровне контейнера.
Кроме того, когда присутствуют субтитры, как составляющий элемент потоковой передачи, часто используется TTML, и стандартизация при потоковой передаче также привлекает внимание.
Например, когда субтитры должны быть вставлены в изображения содержания прямой трансляции, такого как новости, спортивные передачи и т.п., строку знаков субтитров необходимо определять заранее. Таким образом, требуется процесс вставки строки знаков субтитров во время широковещательной передачи (потоковой передачи) на основе необходимости. В таком случае желательно, например, обеспечить прием приемником "экземпляра документа инициализации" в TTML и анализировать предоставление содержания, и затем принимать "экземпляр основного документа", в соответствии с необходимостью.
Кроме того, возникает, например, случай, в котором требуется представить содержание, которое изменяется в соответствии с содержанием строки знаков, отображаемой, как субтитры (текст, который требуется выделить, текст, передающий эмоциональное выражение, указывающий удивление или недоумение и т.п.), даже при одном и том же содержании. В таком случае также возможно заранее определить множество видов предоставляемого содержания с помощью "экземпляра документа инициализации" в TTML, и после того установить предоставляемое содержание, которое должно использоваться в "экземпляре основного документа".
Однако формат файла МР4 не определяет способ для сохранения экземпляра TTML с определенным типом экземпляра TTML, и, поэтому, приемник обязательно идентифицирует тип экземпляра TTML. Таким образом, в прошлом при потоковой передаче данных через Интернет, такой, как IPTV и т.п., передаваемой в формате файла МР4, не было другого варианта выбора, кроме необходимости анализировать предоставляемое содержание каждый раз, вместе со строкой знаков, предназначенной для отображения, например, в качестве субтитров. В этой ситуации ожидалось, что нагрузка при обработке, относящаяся к анализу предоставляемого содержания, могла бы быть уменьшена при отображении субтитров, при потоковой передаче через Интернет, такой как IPTV и т.п.
В соответствии с этим, настоящей технологией стало возможным сохранять экземпляр TTML с типами экземпляров TTML, определенными, используя формат файла МР4, следующим образом.
Предполагается, что настоящая технология применяется для случая вставки субтитров в содержание, передаваемое, как "фрагментированный Movie". Затем экземпляр документа TTML сохраняют и передают, как "Выборку" "mdat" в "Fragment". Таким образом, экземпляр 21 или экземпляр 22 на фиг. 1 и т.п. сохраняются соответствующим образом, как "Sample" "mdat" в "Fragment" 1, для отображения субтитров, которые должны быть вставлены в содержании, для которого выполняется потоковая передача данных.
Вначале существующая технология позволяет идентифицировать потоковую передачу через Интернет, как обозначающую информацию, описанную в TTML на основе информации, описанной в "BOX" для "moov". В частности, настоящая технология позволяет предоставить описание "moov.trak.mdia.minf.stbl.stsd", и это описание указывает, что включена информация, описанная в TTML.
На фиг. 9 показана схема для помощи при пояснении конфигурации "BOX" для "moov". Как описано выше, в "BOX" используется иерархическая структура. "BOX", называемый "stsd", представлен, как "BOX" на более низком уровне, чем "BOX" для "moov" (описанный как "moov.trak.mdia.minf.stbl.stsd")". stsd" представляет собой "BOX" для сохранения информация заголовка, для воспроизведения данных дорожки.
В настоящей технологии, когда включена информация, описанная в TTML, 4СС (four_character_code) "ttml" описан, как "sampleEntry" "stsd." В частности, стандарты, применявшиеся в прошлом, устанавливают, что в "stsd" содержатся 4СС, указывающие аудиоданные "МР4А", 4СС, указывающие видеоданные "MP4V", и т.п.
Кроме того, когда включена информация, описанная в TTML, описание "text" предусматривают в "HandlerType" для "moov.trak.mdia.hdlr".
Кроме того, настоящая технология позволяет различать, является ли экземпляр документа TTML, сохраненный, как "Sample" для "mdat" в рассматриваемом "Fragment", "экземпляром документа инициализации" или "экземпляром основного документа" на основе информации, описанной в "BOX" для "moof.
В частности, "BOX", называемый здесь "ttsd", вновь представлен, как "BOX" на более нижнем уровне, чем "BOX", называемый "traf" в "BOX" для "moof. Когда "initFlag" для "ttsd" описан как "true", это означает, что экземпляр документа TTML, сохраняемый в рассматриваемом "Fragment", представляет собой "экземпляр документа инициализации". Кроме того, когда "initFlag" "ttsd" описан, как "false", это означает, что экземпляр документа TTML, сохраненный в данном "Fragment", представляет собой "экземпляр основного документа".
На фиг. 10 показана схема, представляющая конфигурацию "BOX" для "moof, когда экземпляр документа TTML, сохраненный в данном "Fragment", представляет собой "экземпляр документа инициализации". Как показано на фиг. 10, "traf представлен на более низком уровне, чем "moof, и "ttsd" представлен, как "BOX" на еще более низком уровне. Описание "initFlag: "true" предусмотрено, как информация, сохраненная в "ttsd".
На фиг. 11 показана схема, представляющая конфигурацию "BOX" для "moof, когда экземпляр документа TTML, сохраненный в данном "Fragment", представляет собой "экземпляр основного документа". Как показано на фиг.11, "traf представлен на более нижнем уровне, чем "moof, и "ttsd" предусмотрен, как "BOX", на еще более нижнем уровне. Описание "initFlag: "false" предоставлено, как информация, сохраненная в "ttsd".
Далее, настоящая технология позволяет для приемника определять, изменилось ли (было обновлено) содержание описания экземпляра документа TTML, переданного в приемник. В частности, формат описания "Sample" для "mdat", когда экземпляр документа TTML сохранен, определен, как показано, например, на фиг. 12.
В настоящей технологии, поле "неподписанный id (16) id документа;", показанное на фиг. 12, предоставлено, как новое. Идентификатор для идентификации экземпляра документа TTML, описанного в данном "Sample", описан в поле "неподписанный id (16) id документа;". Этот идентификатор представляет собой, например, ID или версию, предоставленную для каждого экземпляра документа. Естественно, когда изменяется экземпляр документа, описанный выше идентификатор также изменяется. Таким образом, приемник может определять, изменился ли экземпляр документа или нет.
Кроме того, поле "неиспользуемый интервал (16) длина текста;", показанный на фиг.12, содержит длину текста для текста, сохраненного в поле "неиспользуемый интервал (8) текст [длина текста];". Экземпляр документа TTML сохраняют в поле "неподписанный интервал (8) текст [длина текста]", показанном на фиг. 12.
Когда содержание передают в режиме широковещательной передачи, используя потоковую передачу данных по множеству каналов, например, неизвестно, какой канал выбирает зритель и в какое время, поэтому информация определения предоставляемого содержания (то есть, "экземпляра документа инициализации") должна передаваться периодически. В этом случае нагрузка на обработку в приемнике увеличивается, когда приемник выполнен с возможностью анализа "экземпляра документа инициализации" каждый раз, когда приемник принимает "экземпляр документа инициализации", и поэтому желательно, чтобы контекст, предоставляющий содержание, был определен на основе однократно проанализированного "экземпляра документа инициализации".
Однако, когда содержание "экземпляра документа инициализации" обновляют, изменяется предоставляемое содержание. Поэтому необходимо, чтобы приемник вновь выполнял анализ. Таким образом, как описано выше, настоящая технология позволяет приемнику определять, изменилось ли содержание описания переданного экземпляра документа TTML (было обновлено) или нет.
Подводя итог всему сказанному выше, в настоящей технологии, "ttml" предоставляют, как новый 4СС (four_character_code), описанный в "sampleEntry" для "stsd" в "moov". Затем стало возможным определить, что экземпляр документа TTML сохраняется в "Fragment" путем ссылки на описание "stsd" в "moov".
Кроме того, в настоящей технологии, "ttsd" предусмотрен как "BOX" на более нижнем уровне, чем "moof" каждого "Fragment". Затем "initFlag: ‘true’" или "initFlag: ‘false’" описаны, как информация, сохраненная в "ttsd", для того, чтобы сделать возможным определять, являются ли данные TTML, сохраненные в "Fragment", "экземпляром документа инициализации" или "экземпляром основного документа".
Кроме того, в настоящей технологии предусмотрено поле "непродписанный id (16) id документа;" в "Sample" "mdat". Затем стало возможным определять, изменилось ли описание содержания экземпляра документа TTML (обновлено) или нет на основе идентификатора, сохраненного в этом поле.
Таким образом, когда экземпляр документа TTML передают, используя формат файла МР4, экземпляр TTML может быть сохранен с распознанным типом экземпляра TTML, и обновление содержания описания может быть легко идентифицировано. Таким образом, в соответствии с настоящей технологией, становится возможным, например, уменьшить нагрузку, связанную с обработкой, относящейся к отображению субтитров при потоковой передаче, такой как IPTV и т.п.
На фиг. 13 показана блок-схема, представляющая пример конфигурации системы потоковой передачи данных, в соответствии с вариантом осуществления настоящей технологии. Система 100 потоковой передачи данных, показанная на фиг. 13, включает в себя сервер 121 ТТ (текст с временной разметкой), сервер 122 IPTV и клиент 123 IPTV.
Сервер 122 IPTV, показанный на фиг. 13, например, выполнен, как передатчик для широковещательной передачи потоковых данных содержания. Клиент 123 IPTV, показанный на фиг. 13, выполнен, например, как приемник, для приема широковещательной передачи потоковых данных. Сервер 121 ТТ представляет собой, например, устройство для генерирования данных, относящихся к субтитрам, которые вставляют в содержание, предназначенное для широковещательной передачи, используя широковещательную передачу потоковых данных.
Сервер 121 ТТ включает в себя блок 141 генерирования фрагмента ТТ (текст с временной разметкой) и блок 142 вставки выборки.
Блок 141 генерирования фрагмента ТТ описывает 4СС "ttml" в "sampleEntry" для "stsd" в "moov", и описывает "text" в "HandlerType" для "moov.trak.mdia.hdlr". (Этот процесс является менее частым, чем генерирование "Fragment", который будет описан ниже). Кроме того, блок 141 генерирования фрагмента ТТ генерирует данные "Fragment", в которых экземпляр документа TTML сохраняют, как описано выше, со ссылкой на фиг. 8. В это время блок 141 генерирования фрагмента ТТ предоставляет "ttsd", как "BOX", на более нижнем уровне, чем "moof". Затем блок 141 генерирования фрагмента ТТ описывает "initFlag: ‘true’" или "initFlag: ‘false’", как информацию, сохраненную в "ttsd", в соответствии с типом генерируемого экземпляра документа.
Например, когда экземпляр документа TTML, сохраненный в данном "Fragment", представляет собой "экземпляр документа инициализации", "initFlag: ‘true’" описан, как информация, сохраненная в "ttsd". Кроме того, например, когда экземпляр документа TTML, сохраненный в данном "Fragment", представляет собой "экземпляр основного документа," "initFlag: ‘false’" описан как информация, сохраненная в "ttsd".
Блок 142 вставки выборки генерирует экземпляр документа TTML, и вставляет этот экземпляр документа TTML, как "Выборку" для "mdat" в "Fragment", генерируемый блоком 141 генерирования фрагмента ТТ.
В это время, как описано выше со ссылкой на фиг.12, блок 142 вставки выборки обеспечивает поле "неподписанный id (16) id документа;". Затем, блок 142 вставки выборки описывает идентификатор, для идентификации экземпляра документа TTML, описанного в данной выборке "Sample", в поле "неподписанный id (16) id документа." В частности, когда меняется экземпляр документа, описанный выше идентификатор также меняется.
Кроме того, временной штамп, генерируемый блоком 151 генерирования NTP синхронизированного временного штампа подают в блок 141 генерирования фрагмента ТТ и в блок 142 вставки выборки, соответственно.
Сервер 122 IPTV включает в себя блок 161 выборки содержания, мультиплексор 162 фрагмента, и блок 163 распределения фрагмента.
Блок 161 генерирования выборки содержания, например, кодирует звуковые данные и данные изображения, и т.п., формируя содержание, и генерирует аудиоданные, и видеоданные, и т.п. Затем, на основе аудиоданных и видеоданных и т.п., блок 161 генерирования выборки содержания генерирует данные выборки "Sample".
Мультиплексор 162 фрагмента генерирует "Fragment", "mdat" которого включает в себя данные "Sample", генерируемые блоком 161 генерирования выборки содержания. Мультиплексор 162 фрагмента затем мультиплексирует "Fragment", генерируемый сервером 121 ТТ, и "Fragment", генерируемый самим мультиплексором 162 фрагмента. Таким образом, мультиплексируют "Fragment", содержащий видеоданные, аудиоданные и т.п., и "Fragment", содержащий экземпляр документа TTML.
Блок 163 распределения фрагмента распределяет "фрагментированный Movie", включающий в себя "Fragment", мультиплексированные мультиплексором 162 фрагмента, через сеть и т.п. Таким образом, содержание распределяется путем потоковой передачи данных.
В частности, временной штамп, генерируемый блоком 151 генерирования NTP синхронизированного временного штампа, подают в блок 161 генерирования выборки содержания и в мультиплексор 162 фрагмента, соответственно.
Клиент 123 IPTV включает в себя блок 181 синхронизации, демультиплексор 182 фрагмента, декодер 183 ТТ (текста с временной разметкой), декодер 184 содержания и блок 185 управления отображением.
Блок 181 синхронизации подает NTP-синхронизированную информацию времени в каждую часть.
Демультиплексор 182 фрагмента принимает "фрагментированный Movie", переданный сервером 122 IPTV через сеть и т.п., и выделяет каждый "Fragment", формирующий "фрагментированный Movie". Затем демультиплексор 182 фрагмента анализирует описание "sampleEntry" для "stsd" в "moov", для определения, имеется ли "Fragment", содержащий экземпляр документа TTML в данном "фрагментированном Movie". Таким образом, когда описание "sampleEntry" в "moov" представляет собой "stsd", "ttml" определяет, что имеется "Fragment", содержащий экземпляр документа TTML в данном "фрагментированном Movie".
Когда определяют, что имеется "Fragment", содержащий экземпляр документа TTML, демультиплексор 182 фрагмента проверяет "ttsd" в "moof" каждого "Fragment", для определения, содержит ли данный "Fragment" экземпляр документа TTML. Таким образом, "Fragment", имеющий "ttsd", предусмотренный на более низком уровне, чем "moof, определяют, как "Fragment", содержащий экземпляр документа TTML, и подают в декодер 183 ТТ. С другой стороны, "Fragment", в котором не содержится "ttsd" в "moof, определяют, как "Fragment", не содержащий экземпляр документа TTML ("Fragment" аудиоданных, видеоданных и т.п.), и подают на декодер 184 содержания.
Декодер 183 ТТ представляет собой функциональный блок для декодирования данных выборки "Sample", содержащей экземпляр документа TTML. В частности, декодирование в декодере 183 ТТ преимущественно означает анализ экземпляра документа TTML.
На основе описания "ttsd" в "moof" для каждого "Fragment" декодер 183 ТТ определяет тип экземпляра документа TTML, сохраненного в данном "Fragment". Таким образом, когда описание "ttsd" представляет собой "initFlag: ‘true’", определяют, что данный "Fragment" содержит "экземпляр документа инициализации". Когда описание "ttsd" представляет собой "initFlag: ‘false’", с другой стороны, определяют, что данный "Fragment" содержит "экземпляр основного документа".
При определении, что "экземпляр документа инициализации" сохранен, декодер 183 ТТ сохраняет идентификатор, описанный в поле "неиспользованный id (16) id документа;" "Sample" для "mdat" в "Fragment". Затем декодер 183 ТТ анализирует описание "экземпляра документа инициализации", содержащегося в "Sample" "mdat,", и устанавливает отображение содержания.
Декодер 183 ТТ после этого сравнивает идентификатор, описанный в поле "неподписанный id (16) id документа;" с идентификатором, сохраненным заранее, для определения, изменился ли "экземпляр документа инициализации". Только при определении, что "экземпляр документа инициализации" изменился, декодер 183 ТТ анализирует описание "экземпляра документа инициализации", сохраненного в "Sample" "mdat", и снова устанавливает отображение содержания.
Кроме того, при определении, что "экземпляр основного документа" сохранен, декодер 183 ТТ анализирует " экземпляр основного документа", сохраненный в "Sample" "mdat", и генерирует данные отображения субтитров. Данные отображения субтитров, генерируемые в декодере 183 ТТ, поступают в блок 185 управления устройством отображения, вместе с информацией, относящейся к времени отображения.
Декодер 184 содержания декодирует аудиоданные и видеоданные, и т.п., сохраненные в "Sample" "mdat", и генерирует данные отображения изображения и выходные данные звука и т.п. Данные отображения изображения и выходные данные звука, и т.п., генерируемые в декодере 184 содержания, поступают в блок 185 управления устройством отображения, вместе с информацией, относящейся к времени отображения и времени вывода, и т.п.
Блок 185 управления устройством отображения генерирует сигнал изображения для отображения субтитров в состоянии, когда они наложены на изображение содержания, на основе информации, относящейся к времени отображения и т.п. Блок 185 управления устройством отображения подает данные изображения на устройство отображения, которое не показано на чертеже и т.п. Кроме того, блок 185 управления устройством отображения генерирует звуковой сигнал для вывода звука содержания на основе информации, относящейся к выходному времени и т.п. Блок 185 управления устройством отображения подает звуковой сигнал в громкоговоритель, который не показан на чертеже и т.п.
Такая система 100 потоковой передачи данных может, например, управлять отображением субтитров следующим образом,
Например, сервер 121 ТТ сохраняет экземпляр документа TTML, как показано на фиг. 14 в "Fragment", и распределяют его от сервера 122 IPTV. На фиг. 14 показан пример описания "экземпляра документа инициализации".
Затем сервер 121 ТТ сохраняет экземпляр документа TTML, показанный на фиг. 15, в "Fragment", и распределяет из сервера 122 IPTV. На фиг. 15 показан пример описания "экземпляра основного документа".
Когда строка знаков, установленная описанием на фиг. 15, отображается в отображаемом контексте в соответствии с описанием на фиг. 14, могут отображаться субтитры, как показано, например, на фиг. 16.
После этого сервер 121 ТТ сохраняет экземпляр документа TTML, как показано на фиг. 17, в "Fragment", и распределяет из сервера 122 IPTV. На фиг.17 показан другой пример описания "экземпляра основного документа".
Когда строка знаков, установленная описанием на фиг. 17, отображается в наборе контекста для представления, в соответствии с описанием на фиг. 14, могут отображаться субтитры, например, как показано на фиг. 18.
В частности, строки знаков, установленные тегом "<р>" "экземпляра основного документа", представляют собой строки знаков субтитров. Когда время установлено в теге "<р>," строка знаков отображается в соответствии с установленным временем. Когда спецификация времени отсутствует, или когда установлен только период отображения (длительность), отображением управляют так, чтобы оно начиналось во время воспроизведения, идентифицированного, как "decodingTime" в данной выборке "Sample".
В частности, как показано на фиг. 19, экземпляры документа TTML, сохраненные, как "Sample" "mdat" в соответствующих "Fragment", то есть, Fragment0, Fragment1 и Fragment2 анализируют и отображают субтитры.
В этом случае предположим, что "экземпляр документа инициализации" (экземпляр Init), показанный на фиг. 14, сохраняют в mdatO в FragmentO. Кроме того, предположим, что "экземпляр основного документа" (Body instancel), показанный на фиг. 15, сохраняют в mdati Fragment1. Далее, предположим, что "экземпляр основного документа" (Body instance1), показанный на фиг. 17, сохраняют в mdat2 Fragment1.
В примере по фиг. 19 представление содержания устанавливают на основе экземпляра Init, сохраненного в Sample0 mdat0 в Fragment0. После этого, в момент времени t1, субтитры, такие, как показаны на фиг.16, отображаются на основе Body instancel, сохраненного в выборке 1 mdat1 в Fragment1. Кроме того, ниже, в момент времени t2, субтитры, такие, как показано на фиг. 18, отображаются на основе Body instance1, сохраненного в Sample1 mdat2 в Fragment2.
В частности, момент времени t1 и момент времени t2, описанные выше, рассчитывают на следующей основе moov.trak.mdia.minf.stbl.stts или "времени декодирования" первых выборок "Sample", сохраненных в первом mdat, соответствующем moors, с момента времени декодирования, которые описаны в moof.traf.tfdt.
Таким образом, для идентификации времени отображения строки знаков, описанной в экземпляре документа TTML, используется время представления файла МР4 "Sample", содержащего экземпляр документа.
Пример процесса потокового распределения сервером 122 IPTV на фиг. 13 поясняется ниже со ссылкой на блок-схему последовательности операций по фиг. 20. Этот процесс, например, выполняют в случае распределения передаваемого в режиме прямой трансляции содержания, как "фрагментированный Movie", через сеть и т.п. с субтитрами, вставленными в содержание, передаваемое в режиме прямой трансляции.
На этапе S21, сервер 122 IPTV получает данные содержания. В это время, например, получают данные звука и данные изображения и т.п., формирующие содержание.
На этапе S22, блок 161 генерирования выборки содержания, например, кодирует данные звука и данные изображения, и т.п., формирующие содержание, и генерирует аудиоданные и видеоданные и т.п. Затем, на основе аудиоданных и видеоданных, и т.п., блок 161 генерирования выборки содержания генерирует данные "Sample".
На этапе S23 мультиплексор 162 фрагмента генерирует "Fragment", "mdat" которого включает в себя данные выборки "Sample", сгенерированной на этапе S22.
На этапе S24, сервер 121 ТТ выполняет процесс вставки данных субтитров, который будет описан ниже со ссылкой на фиг. 21. Данные, относящиеся к субтитрам, таким образом, вставляют в данные содержания, которое должно быть распределено путем потоковой передачи данных.
Подробный пример процесса вставки данных субтитров на этапе S24, показанный на фиг. 20, будет описан ниже со ссылкой на блок-схему последовательности операций на фиг. 21.
На этапе S41 генерируют текст TTML.
На этапе S42, блок 141 генерирования фрагмента ТТ описывает 4СС "ttml" в "sampleEntry" для "stsd" в "moov", и описывает "text" в "HandlerType" для "moov.trak.mdia.hdlr". (Этот процесс выполняется менее часто, чем генерирование "Fragment", который будет описан ниже). Кроме того, блок 141 генерирования фрагмента ТТ генерирует данные "Fragment", в которых содержится экземпляр документа TTML. В это время блок 141 генерирования фрагмента ТТ предоставляет "ttsd", как "BOX", на более низком уровне, чем "moof". Затем блок 141 генерирования фрагмента ТТ описывает "initFlag: ‘true’" или "initFlag: ‘false’", как информацию, содержащуюся в "ttsd", в соответствии с типом генерируемого экземпляра документа.
Например, когда экземпляр документа TTML, сохраненный в данном "Fragment", представляет собой "экземпляр документа инициализации", "initFlag: ‘true’" описан, как информация, содержащаяся в "ttsd". Кроме того, например, когда экземпляр документа TTML, сохраненный в данном "Fragment", представляет собой "экземпляр основного документа," "initFlag: ‘false’" описан, как информация, содержащаяся в "ttsd".
На этапе S43, блок 142 вставки образца генерирует экземпляр документа TTML
на основе текста TTML, генерируемого на этапе S41, и вставляет экземпляр документа TTML, как выборку "Sample" "mdat" в "Fragment", генерируемый на этапе S42.
В это время, как описано выше со ссылкой на фиг.12, блок 142 вставки образца обеспечивает поле "неподписанный id (16) id документа;". Затем блок 142 вставки образца описывает идентификатор для идентификации типа экземпляра документа TTML, описанного в данной выборке "Sample", в поле "неподписанный id (16) id документа;", В частности, когда экземпляр документа изменяется, описанный выше идентификатор также изменяется.
На этапе S44, блок 142 вставки образца выводит "Fragment", в которые вставлен экземпляр документа TTML, используя процесс по этапу S43. Данные "Fragment", таким образом, поступает в мультиплексор 162 фрагмента в сервере 122 IPTV.
В частности, временной штамп, генерируемый блоком 151 генерирования NTP синхронизированного временного штампа, поступает в блок 141 генерирования фрагмента ТТ и в блок 142 вставки образца, соответственно.
Как показано на фиг. 20, после процесса на этапе S24 мультиплексора 162 фрагмента на этапе S25 мультиплексируют "Fragment", генерируемый в процессе на этапе S41, на фиг.21, и "Fragment", генерируемый в процессе на этапе S23. Таким образом, видеоданные, аудиоданные и т.п. содержат "Fragment", и мультиплексируют "Fragment" сохранения экземпляра документа TTML.
На этапе S26 мультиплексор 162 фрагмента генерирует данные "фрагментированного Movie".
На этапе S27 блок 163 распределения фрагмента распределяет "фрагментированный Movie", генерируемый в процессе на этапе S26 через сеть и т.п.
Таким образом, выполняется процесс распределения потоковой передачи данных.
Пример процесса воспроизведения содержания с помощью клиента 123 IPTV на фиг. 13 поясняется ниже со ссылкой на блок-схему последовательности операций на фиг. 22.
На этапе S61 демультиплексор 182 фрагмента клиента 123 IPTV принимает "фрагментированный Movie", распределяемый процессом на этапе S27, на фиг. 20.
На этапе S62 демультиплексор 182 фрагмента анализирует описание "sampleEntry" для "stsd" в "moov" "фрагментированного Movie", принятого на этапе S61.
На этапе S63 демультиплексор 182 фрагмента выделяет каждый "Fragment", формирующий "фрагментированный Movie", полученный на этапе S61.
На этапе S64 демультиплексор 182 фрагмента определяет, имеется ли "Fragment", содержащий экземпляр документа TTML в данном "фрагментированном Movie", на основе результата анализа в процессе на этапе S62. В это время, когда при описании "sampleEntry" для "stsd" в "moov" представляет собой "ttml", определяют, что присутствует "Fragment", содержащий экземпляр документа TTML в данном "фрагментированном Movie".
Когда на этапе S64 определяют, что имеется "Fragment", содержащий экземпляр документа TTML в данном "фрагментированном Movie", обработка переходит на этап S65.
На этапе S65, демультиплексор 182 фрагмента и декодер 183 ТТ выполняют обработку декодирования ТТ, которая будет описана ниже со ссылкой на блок-схему последовательности операций на фиг. 23.
Подробный пример процесса декодирования ТТ на этапе S65 на фиг. 22 будет описан ниже со ссылкой на блок-схему последовательности операций на фиг. 23.
На этапе S81 демультиплексор 182 фрагмента проверяет "ttsd" в "moof" каждого "Fragment".
На этапе S82, демультиплексор 182 фрагмента определяет, содержит ли рассматриваемый "Fragment" экземпляр документа TTML. В это время "Fragment", имеющий "ttsd", предусмотренный на более низком уровне, чем "moof, определяют, как "Fragment", содержащий экземпляр документа TTML. С другой стороны, "Fragment", в котором не предусмотрен "ttsd" в "moof, определяют, как "Fragment", не содержащий экземпляр документа TTML ("Fragment" аудиоданных, видеоданных и т.п.).
Когда на этапе S82 определяют, что данный "Fragment" содержит экземпляр документа TTML, обработка переходит на этап S83.
На этапе S83, декодер 183 ТТ определяет тип экземпляра документа TTML, сохраненного в данном "Fragment", на основе описания "ttsd" в "moot "Fragment". В это время, когда описание "ttsd" представляет собой "initFlag: ‘true’," определяют, что данный "Fragment" содержит "экземпляр документа инициализации". С другой стороны, когда описание "ttsd" представляет собой "initFlag: ‘false’", определяют, что данный "Fragment" содержит "экземпляр основного документа".
Когда в процессе на этапе S83 определяют, что "экземпляр документа инициализации" сохранен, обработка переходит на этап S84.
На этапе S84 декодер ТТ 183 получает идентификатор, описанный в поле "неподписанный id (16) id документа;".
На этапе S85, декодер 183 ТТ сравнивает идентификатор, полученный на этапе S84, с идентификатором, сохраненным заранее, для определения, изменился ли "экземпляр документа инициализации". В частности, когда "экземпляр документа инициализации" буде принят в первый раз, определяют, что "экземпляр документа инициализации" изменился.
Когда на этапе S85 определяют, что "экземпляр документа инициализации" изменился, обработка переходит на этап S86.
На этапе S86, декодер 183 ТТ сохраняет ID, описанный в поле "неподписанный id (16) id документа;" выборки "Sample" "mdat" в "Fragment." В частности, когда содержание передают в режиме широковещательной передачи путем потоковой передачи данных по множеству каналов, например, данный идентификатор сохраняется в ассоциации с каналом.
На этапе S87, декодер 183 ТТ анализирует (декодирует) описание "экземпляра документа инициализации", сохраненного в "Sample" "mdat".
На этапе S88, декодер 183 ТТ устанавливает содержание для представления на основе результатов анализа на этапе S87.
В частности, когда на этапе S85 определяют, что "экземпляр документа инициализации" не изменился, обработку на этапах S86 - S88 пропускают.
С другой стороны, когда определяют при обработке на этапе S83, что "экземпляр основного документа" сохранен, обработка переходит на этап S89.
На этапе S89, декодер 183 ТТ анализирует (декодирует) " экземпляр основного документа", сохраненный в "Sample" "mdat".
На этапе S90 декодер 183 ТТ генерирует данные отображения субтитров на основе результата анализа на этапе S89. Данные отображения субтитров, сгенерированные на этапе S90, выводят в блок 185 управления устройством отображения, вместе с информацией, относящейся к времени отображения.
Когда на этапе S82 определяют, что данный "Fragment" не содержит экземпляр документа TTML, обработка переходит на этап S66, на фиг. 22.
Обработка декодирования ТТ выполняется таким образом.
Возвращаясь к описанию на фиг. 22, когда на этапе S64 определяют, что отсутствует "Fragment", содержащий экземпляр документа TTML в данном "фрагментированном Movie", обработка переходит на этап S66.
На этапе S66, декодер 184 содержания декодирует аудиоданные и видеоданные, и т.п., сохраненные в "Sample" "mdat".
На этапе S67, декодер 184 данных содержания выводит данные отображения изображения и выходные данные звука, и т.п., полученные в результате обработки на этапе S66. Данные отображения изображения и выходные данные звука, и т.п. генерируемые на этапе S67, подают в блок 185 управления устройством отображения вместе с информацией, относящейся к времени отображения и времени выхода, и т.п.
На этапе S68 блок 185 управления устройством отображения генерирует сигнал изображения, для отображения субтитров в состоянии с наложением на изображении содержания, на основе информации, относящейся к времени отображения и т.п. Блок 185 управления устройством отображения подает сигнал изображения на устройство отображения, которое не показано на чертеже, и т.п. Кроме того, блок 185 управления устройством отображения генерирует звуковой сигнал для вывода звука содержания на основе информации, относящейся к выходному времени, и т.п. Блок 185 управления устройством отображения подает звуковой сигнал в громкоговоритель, который не показан на чертеже, и т.п.
Таким образом, данные отображения изображения и данные вывода звука, генерируемые в процессе на этапе S67 на фиг. 22, и данные отображения субтитров, генерируемые в процессе на этапе S90 на фиг. 23, отображают или выводят синхронно друг с другом.
На этапе S69 определяют, закончился или нет "фрагментированный Movie". Например, когда принимают "Случайный доступ к фрагменту кинофильма (mfra)", показанному на фиг. 8, определяют, что "фрагментированный Movie" закончился. Кроме того, например, когда пользователь подает команду на остановку воспроизведения, определяют, что "фрагментированный Movie" закончен.
Когда на этапе S69 определяют, что "фрагментированный Movie" еще не окончился, обработка возвращается на этап S63. Когда на этапе S69 определяют, что "фрагментированный Movie" закончился, с другой стороны, процесс заканчивается.
Таким образом, выполняют процесс воспроизведения содержания,.
Как описано выше со ссылкой на фиг. 9, 4СС "ttml" описан в "sampleEntry" "moov.trak.mdia.minf.stbl.stsd", когда включена информация, описанная в TTML. Однако, "экземпляр документа инициализации" может быть дополнительно сохранен в "moov.trak.mdia.minf.stbl.stsd".
На фиг. 24 показана схема для помощи при пояснении конфигурации "BOX" в "moov", в котором содержится "экземпляр документа инициализации". Как показано на фиг.24, как и в случае фиг.9, 4СС "ttml" описан в "sampleEntry" "moov.trak.mdia.minf.stbl.stsd", и после этого в 4СС "ttml" следует описание "TTconfig {…"
Поле "неподписанный id (16) id документа;" предусмотрено в описании "TTconfig {…" на фиг. 24. Как и в случае, описанном со ссылкой на фиг.12, оно представляет собой поле, в котором описан идентификатор для идентификации экземпляра документа TTML. Этот идентификатор не является, например, ID или версией, заданной для каждого экземпляра документа. Естественно, что когда экземпляр документа меняется, указанный выше идентификатор также меняется. Таким образом, приемник может определять, изменился ли экземпляр документа или нет.
Кроме того, поле "неподписанный int (16) длина - текста;" показанное на фиг. 24, содержит длину текста для текста, содержащегося в поле "неподписанный int (8) текст [длина текста];", экземпляр документа TTML сохраняется в поле "неподписанный int (8) текст [длина текста];" показан на фиг.24. В примере на фиг.24 содержится только "экземпляр документа инициализации" сохраняется в поле "неподписанный интервал (8) текст [длина текста];" и "экземпляр основного документа" не содержится в поле "неподписанный int (8) текст [длина текста]."
Кроме того, в случае, когда "moov" выполнен так, как показано на фиг. 24, "initFlag: ‘true’" или "initFlag: ‘false’" не требуется описывать (может быть описано, но представляет собой бессмысленную информацию) в "ttsd", как "BOX" на более низком уровне, чем "traf" для "moof. Таким образом, в данном случае, экземпляры документа TTML, содержащиеся, как "Sample" "mdat" в каждом "Fragment", представляют собой только "экземпляры основного документа". Поэтому, нет необходимости указать, что экземпляр документа TTML, сохраненный в данном "Fragment", представляет собой "экземпляр документа инициализации" или "экземпляр основного документа".
Далее, в случае, когда "moov" выполнен, как показано на фиг.24, когда блок 141 генерирования фрагмента ТТ сервера 122 IPTV генерирует, например, данные "фрагментированного Movie", блок 141 генерирования фрагмента ТТ описывает 4СС "ttml" в "sampleEntry" для "stsd" в "moov", и описывает "text" в "HandlerType" для "moov.trak.mdia.hdlr". Кроме того, блок 141 генерирования фрагмента ТТ добавляет описание "TTconfig {…" на фиг.24 к "stsd" в "moov". В частности, в этом случае, "экземпляр документа инициализации" сохраняется в поле "неподписанный int (8) text [длина текста];."
В случае, когда "moov" выполнен, как показано на фиг.24, демультиплексор 182 фрагмента клиента 123 IPTV анализируют описание "sampleEntry" в "stsd", в "moov" "фрагментированного Movie", для определения, присутствует ли здесь "Fragment", содержащий экземпляр рассматриваемого документа TTML в "фрагментированном Movie". В этом случае, когда определяют, что присутствует "Fragment", содержащий экземпляр документа TTML (то есть, когда 4СС "ttml" описан в "sampleEntry" в "stsd"), описание "TTconfig {…" поступает в декодер 183 ТТ.
Затем декодер 183 ТТ получает идентификатор, описанный в поле "неподписанный id (16) id документа;" и сравнивает идентификатор, описанный в поле "неподписанный id (16) id документа;" с идентификатором, сохраненным заранее, для определения, изменился или нет "экземпляр документа инициализации". Когда определяют, что "экземпляр документа инициализации" изменился, декодер 183 ТТ сохраняет идентификатор, описанный в поле "неподписанный id (16) id документа;." В частности, когда содержание передают в режиме широковещательной передачи путем потоковой передачи по множеству каналов, например, рассматриваемый идентификатор сохраняют в ассоциации с каналом.
Далее, декодер 183 ТТ анализирует (декодирует) описание "экземпляра документа инициализации", сохраненного в поле "неподписанный int (8) text [длина текста];." Затем содержание для отображения устанавливают на основе результата анализа.
В случае, когда "moov" выполнен, как показано на фиг. 24, как показано на фиг.25, экземпляры документа TTML, сохраненные, как "Sample" "mdat" в соответствующих фрагментах "Fragment", то есть Fragmenti и Fragment2, анализируют, и отображают субтитры.
В этом примере, предположим, что "экземпляр основного документа" (Body instance1), показанный на фиг. 15, сохранен в mdat1 Fragment1. Кроме того, предположим, что "экземпляр основного документа" (Body instance2), показанный на фиг. 17, сохранен в mdat2 Fragment2.
В примере на фиг. 25 предоставляемое содержание установлено на основе "экземпляра документа инициализации (экземпляр Init)", сохраненного в "stsd" в "moov". После этого, в момент времени t1, субтитры, как показано на фиг. 16, отображают на основе Body instancel, сохраненного в Samplel mdati в Fragmenti. Кроме того, после этого, в момент времени t2, субтитры, как показано на фиг. 18, отображают на основе Body instance2, сохраненного в Sample2 mdat2 в Fragment2.
В частности, момент времени t1 и момент времени t2, описанные выше, вычисляют на основе moov.trak.mdia.minf.stbl.stts или на основе "временных характеристик декодирования" первых выборок "Sample", сохраненных в первом, соответствующем mdat moofs, временные характеристики декодирования которых описаны в moof.traf.tfdt.
Таким образом, "экземпляр документа инициализации" может быть дополнительно сохранен в "moov.trak.mdia.minf.stbl.stsd".
Следует отметить, что последовательности обработки, описанные выше, могут осуществляться не только с использованием аппаратных средств, но также и с использованием программного средства. Когда последовательность обработки, описанная выше, должна быть выполнена с помощью программных средств, программу, составляющую программное средство, устанавливают из сети или с носителя записи в компьютер, в который встроены специализированные аппаратные средства или, например, в персональный компьютер 700 общего назначения, как показано на фиг. 26, и этот персональный компьютер может выполнять различные функции, в результате установки в нем различных программ.
На фиг. 26 CPU (центральное процессорное устройство) 701 выполняет различную обработку, в соответствии с программой, сохраненной в ROM (постоянное запоминающее устройство) 702 или программой, загружаемой из блока 708 накопителя в RAM (оперативное запоминающее устройство) 703. RAM 703 также содержит данные, необходимые для выполнения CPU 701 различной обработки и т.п., соответственно.
CPU 701, ROM 702 и RAM 703 взаимно соединены через шину 704. Шина 704 также соединена с интерфейсом 705 ввода/вывода.
Интерфейс 705 ввода/вывода соединен со входным блоком 706, состоящим из клавиатуры, "мыши" и т.п., и выходным блоком 707, состоящим из устройства отображения, сформированного LCD ("жидкокристаллический устройство отображения) и т.п., громкоговорителя и т.п., блока 708 хранения, состоящего из жесткого диска и т.п., и блока 709 связи, состоящего из модема и карты сетевого интерфейса, такой как карта LAN и т.п.Блок 709 связи выполняет обработку передачи данных через сеть, включающую в себя Интернет.
Интерфейс 705 ввода/вывода также соединяют с приводом 710, в соответствии с необходимостью. Съемные носители 711, такие как магнитный диск, оптический диск, магнитооптический диск, полупроводниковое запоминающее устройство и т.п. загружают в привод 710, в соответствии с необходимостью. Компьютерную программу, считываемую с этих съемных носителей информации, устанавливают в блоке 708 накопителя, в соответствии с необходимостью.
Когда последовательность обработки, описанная выше, должна быть выполнена с помощью программного обеспечения, программу, составляющую программное обеспечение, устанавливают из сети, такой как Интернет и т.п., или с носителя записи, такого как съемный носитель 711 записи и т.п.
В частности, носитель записи не только формируется съемными носителями 711, показанным на фиг. 26, съемные носители 711 записи, имеющие программу, записанную на них, распределяется между пользователями для распространения программы отдельно от конкретного устройства, и съемный носитель 711 записи, включающий в себя магнитный диск (включающий в себя гибкий диск (зарегистрированный товарный знак)), оптический диск (включающий в себя CD-ROM (постоянное запоминающее устройство на компакт-диске) и DVD (цифровой универсальный диск)), магнитооптический диск (включающий в себя MD (минидиск) (зарегистрированный товарный знак)), полупроводниковое запоминающее устройство и т.п., но также сформированный ROM 702, жестким диском, включенным в состав блока 708 накопителя, и т.п. на котором записана программа и который распределяет пользователь в состоянии, заранее встроенном в соответствующее устройство.
Следует отметить, что последовательность обработки, описанная выше в настоящем описании, включает в себя не только процессы, выполняемые во временной последовательности, в описанном порядке, но также и процессы, которые необязательно должны выполняться в этой временной последовательности, но могут быть выполнены параллельно или отдельно.
Кроме того, варианты осуществления настоящей технологии не ограничены упомянутыми выше вариантами осуществления, но различные изменения могут быть выполнены, без выхода за пределы сущности настоящей технологии.
Следует отметить, что в настоящей технологии также могут применяться следующие составы.
(1) Устройство распределения потоковой передачи данных, включающее в себя:
блок генерирования фрагмента содержания, выполненный с возможностью генерирования фрагмента хранящихся данных содержания, подлежащего потоковому распределению, при этом фрагмент определяется в соответствии с форматом файла МР4; и
блок генерирования фрагмента субтитров, выполненный с возможностью генерирования фрагмента, содержащего экземпляр документа TTML (язык временной разметки текста), относящегося к субтитрам, подлежащим отображению в содержании, при этом фрагмент определяется по формату файла МР4, причем
блок генерирования фрагмента субтитров выполнен с возможностью добавления к информации заголовка фрагмента информацию распознавания классификации экземпляра для определения, является ли экземпляр документа TTML, хранящийся во фрагменте, экземпляром документа TTML, определяющего контекст отображения, относящийся к субтитрам.
(2) Устройство распределения потоковой передачи данных по п.(1), в котором блок генерирования фрагмента субтитров выполнен с возможностью сохранения, во фрагменте, образца, содержащего описание экземпляра документа TTML, вместе с информацией идентификации содержания описания для индивидуальной идентификации описания содержания экземпляра документа TTML, относящегося к субтитрам.
(3) Устройство распределения потоковой передачи данных по пп. (1) или (2), дополнительно включающее в себя
блок генерирования заголовка кинофильма, выполненный с возможностью добавления, в информацию заголовка кинофильма, включающего в себя множество фрагментов, информации распознавания классификации фрагмента для указания того, что кинофильм включает в себя фрагмент, содержащий экземпляр документа TTML.
(4) Устройство распределения потоковой передачи данных по пп. (1) или (2), дополнительно включающее в себя
блок генерирования заголовка кинофильма, выполненный с возможностью добавления, в информацию заголовка кинофильма, включающего в себя множество фрагментов, информации распознавания классификации фрагмента для указания того, что кинофильм включает в себя фрагмент, содержащий экземпляр документа TTML, при этом
в блоке генерирования заголовка кинофильма содержится экземпляр документа TTML, устанавливающий предоставляемое содержание, относящееся к субтитрам, в информации о распознавании классификации фрагмента, а
информация о распознавании классификации экземпляра не добавляется к информации заголовка фрагмента.
(5) Способ распределения потоковой передачи данных, включающий в себя этапы, на которых:
генерируют с помощью блока генерирования фрагмента содержания фрагмент содержания, подлежащий распределению, путем потоковой передачи, фрагмента, определяемого форматом файла МР4;
генерируют с помощью блока генерирования фрагмента субтитров фрагмент, содержащий экземпляр документа TTML (язык временной разметки текста), относящийся к субтитрам, подлежащим отображению в содержании, при этом фрагмент определяется форматом файла МР4; и
добавляют с помощью блока генерирования фрагмента субтитров к информации заголовка фрагмента, информации распознавании классификации экземпляра для различия, является ли экземпляр документа TTML, сохраненный во фрагменте, экземпляром документа TTML, определяющим представление содержания, относящегося к субтитрам.
(6) Программа, вызывающая выполнение компьютером функции устройства распределения потоковой передачи данных, при этом устройство распределения потоковой передачи данных, содержит:
блок генерирования фрагмента содержания, выполненный с возможностью генерирования фрагмента сохраняющихся данных содержания, подлежащего распределению в результате выполнения потоковой передачи данных, при этом фрагмент определен форматом файла МР4; и
блок генерирования фрагмента субтитров, выполненный с возможностью генерирования фрагмента, содержащего экземпляр документа TTML (язык временной разметки текста), относящийся к субтитрам, отображаемым в содержании, при этом фрагмент определен форматом файла МР4, при этом
блок генерирования фрагмента субтитров выполнен с возможностью добавления к информации заголовка фрагмента информации распознавания классификации экземпляра для определения, является ли экземпляр документа TTML, сохраненный во фрагменте, экземпляром документа TTML, определяющим контекст отображения, относящийся к субтитрам.
(7) Носитель записи, хранящий программу по п. (6).
(8) Устройство приема потоковой передачи данных, содержащее:
блок приема кинофильма, выполненный с возможностью приема данных кинофильма, включающих в себя множество фрагментов, при этом фрагменты определены форматом файла МР4;
блок определения TTML (язык временной разметки текста), выполненный с возможностью определения, включает ли в себя кинофильм фрагмент, содержащий экземпляр документа TTML на основе информации распознавания классификации фрагмента, указывающей, что кинофильм включает в себя фрагмент, содержащий экземпляр документа TTML, при этом информацию распознавания классификации фрагмента добавляют к информации заголовка кинофильма; а
блок декодирования TTML выполнен с возможностью выделения и декодирования
фрагмента, содержащего экземпляр документа TTML, при определении того, что кинофильм включает в себя фрагмент, содержащий экземпляр документа TTML.
(9) Устройство приема потоковой передачи данных по п. (8), в котором блок декодирования TTML выполнен с возможностью различения классификации экземпляра документа TTML, сохраненного во фрагменте на основе информации распознавания классификации экземпляра для определения, является ли экземпляр документа TTML, сохраненный во фрагменте, экземпляром документа TTML, определяющим отображаемое содержание, относящееся к субтитрам, при этом информация распознавании классификации экземпляра включена в информацию заголовка фрагмента, и декодирования экземпляра документа TTML.
(10) Устройство приема потоковой передачи данных по п. (8) или (9), в котором
блок декодирования TTML выполнен с возможностью распознавания классификации экземпляра документа TTML, сохраненного во фрагменте, на основе информации различения классификации экземпляра, для определения, является ли экземпляр документа TTML, сохраненный во фрагменте, экземпляром документа TTML, определяющим получение содержания, относящегося к субтитрам, при этом информация распознавания классификации экземпляра включена в информацию заголовка фрагмента, и
устройство приема потоковой передачи данных дополнительно включает в себя блок определения декодирования, выполненный с возможностью определения, следует ли декодировать экземпляр документа TTML на основе информации, идентифицирующей содержание описания, для индивидуальной идентификации содержания описания экземпляра документа TTML, относящегося к субтитрам в образце, сохраненном во фрагменте, при распознавании экземпляра документа TTML, сохраненного во фрагменте, в качестве представляющего собой экземпляр документа TTML, устанавливающий содержание представления, относящееся к субтитрам.
(11) Устройство приема потоковой передачи данных по п. (8) или (9), в котором при определении, что кинофильм включает себя в себя фрагмент, содержащий экземпляр документа TTML, блок декодирования TTML выполнен с возможностью декодирования экземпляра документа TTML, определяющего содержание представления, относящегося к субтитрам, экземпляр документа TTML, определяющий содержание представления, относящееся к субтитрам, включенным в информацию распознавания классификации фрагмента.
(12) Способ приема потоковой передачи данных, включающий в себя этапы, на которых:
принимают с помощью блока приема кинофильма данные кинофильма, включающие в себя множество фрагментов, при этом фрагменты определены форматом файла МР4;
определяют с помощью блока определения TTML, включает ли в себя кинофильм фрагмент, содержащий экземпляр документа TTML, на основе информации различения определения классификации фрагмента, указывающей, что кинофильм включает в себя фрагмент, содержащий экземпляр документа TTML, информацию различения классификации фрагмента добавляют к информации заголовка кинофильма; и
выделяют и декодируют с помощью блока декодирования TTML фрагмент, содержащий экземпляр документа TTML, при определении, что кинофильм включает в себя фрагмент, содержащий экземпляр документа TTML.
(13) Программа, вызывающая выполнение компьютером функции устройства приема потоковой передачи данных, при этом устройство приема потоковой передачи данных включает в себя:
блок приема кинофильма выполненный с возможностью приема данных кинофильма, включающие в себя множество фрагментов, при этом фрагменты определены форматом файла МР4;
блок определения TTML выполненный с возможностью определения, включает ли в себя кинофильм фрагмент, содержащий экземпляр документа TTML, на основе информации различения определения классификации фрагмента, указывающей, что кинофильм включает в себя фрагмент, содержащий экземпляр документа TTML, информацию различения классификации фрагмента добавляют к информации заголовка кинофильма; и
блок декодирования TTML выполненный с возможностью выделения и декодирования фрагмента, содержащего экземпляр документа TTML, при определении, что кинофильм включает в себя фрагмент, содержащий экземпляр документа TTML.
(14) Носитель записи, хранящий программу по п. (13).
(15) Система потоковой передачи данных, включающая в себя:
устройство распределения потоковой передачи данных, содержащее:
блок генерирования фрагмента содержания, выполненный с возможностью генерирования фрагмента сохраненных данных содержания, предназначенного для потокового распределения, при этом фрагмент определяется в соответствии с форматом файла МР4; и
блок генерирования фрагмента субтитров, выполненный с возможностью генерирования фрагмента, содержащего экземпляр документа TTML (язык временной разметки текста), относящийся к субтитрам, предназначенным для отображения в содержании, при этом фрагмент определяется по формату файла МР4,
блок генерирования фрагмента субтитров, выполненный с возможностью добавления к информации заголовка фрагмента информацию распознавания классификации экземпляра для определения, является ли экземпляр документа TTML, сохраненный во фрагменте, экземпляром документа TTML, определяющим контекст отображения, относящийся к субтитрам; и
устройство приема потоковой передачи данных, содержащее
блок приема кинофильма, выполненный с возможностью приема данных кинофильма, включающих в себя множество фрагментов, фрагменты определены форматом файла МР4;
блок определения TTML, выполненный с возможностью определения, включает ли в себя кинофильм фрагмент, содержащий экземпляр документа TTML на основе информации распознавания классификации фрагмента, указывающей, что кинофильм включает в себя фрагмент, содержащий экземпляр документа TTML, при этом информацию распознавания классификации фрагмента добавляют к информации заголовка кинофильма; и
блок декодирования TTML, выполненный с возможностью выделения и декодирования фрагмента, содержащего экземпляр документа TTML, при. определении, что кинофильм включает в себя фрагмент, содержащий экземпляр документа TTML.
Список номеров ссылочных позиций
100 Система потоковой передачи данных
121 сервер ТТ
122 сервер IPTV
123 клиент IPTV
141 блок генерирования фрагмента ТТ
142 Блок вставки образца
151 Блок генерирования временного штампа
161 Блок генерирования образца содержания
162 Мультиплексор фрагмента
163 Блок распределения фрагмента
181 Блок синхронизации
182 Демультиплексор фрагмента
183 Декодер ТТ
184 Декодер содержания
185 Блок управления устройством отображения.

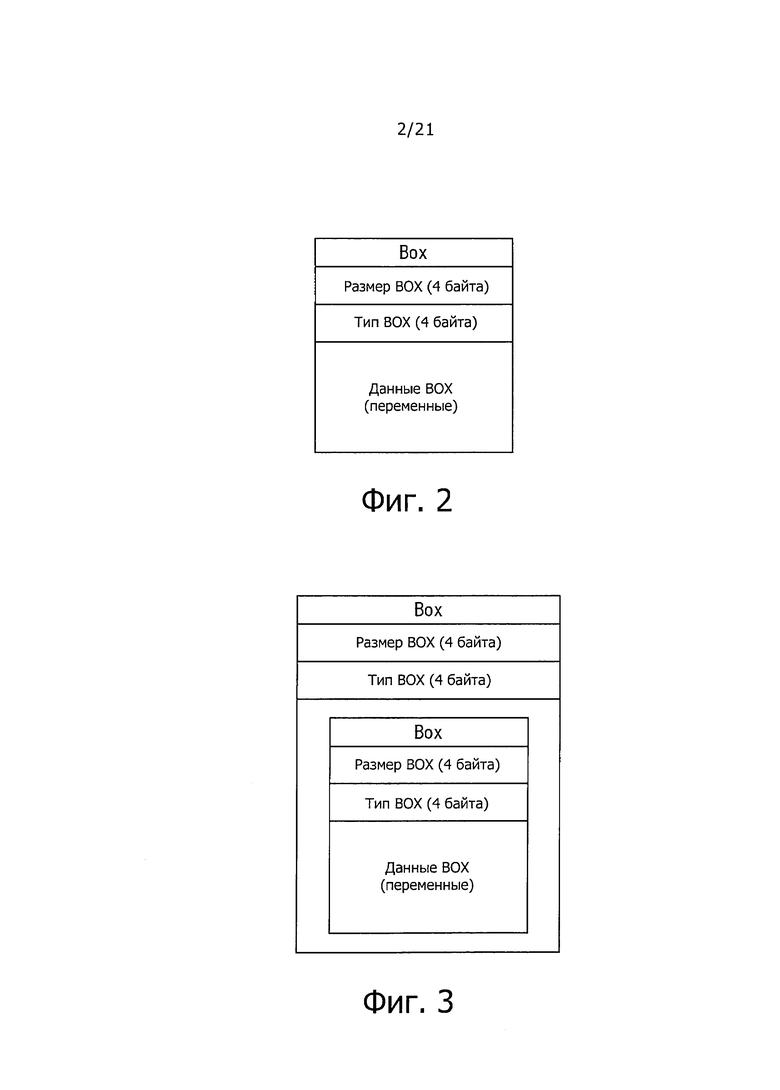
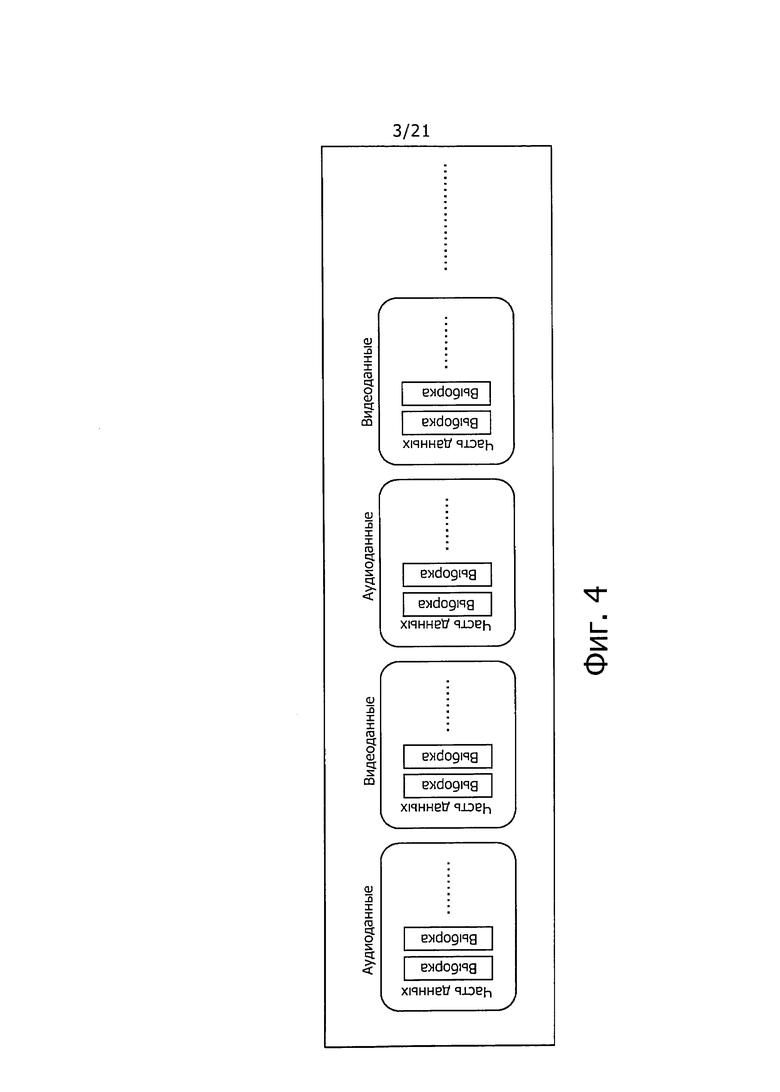
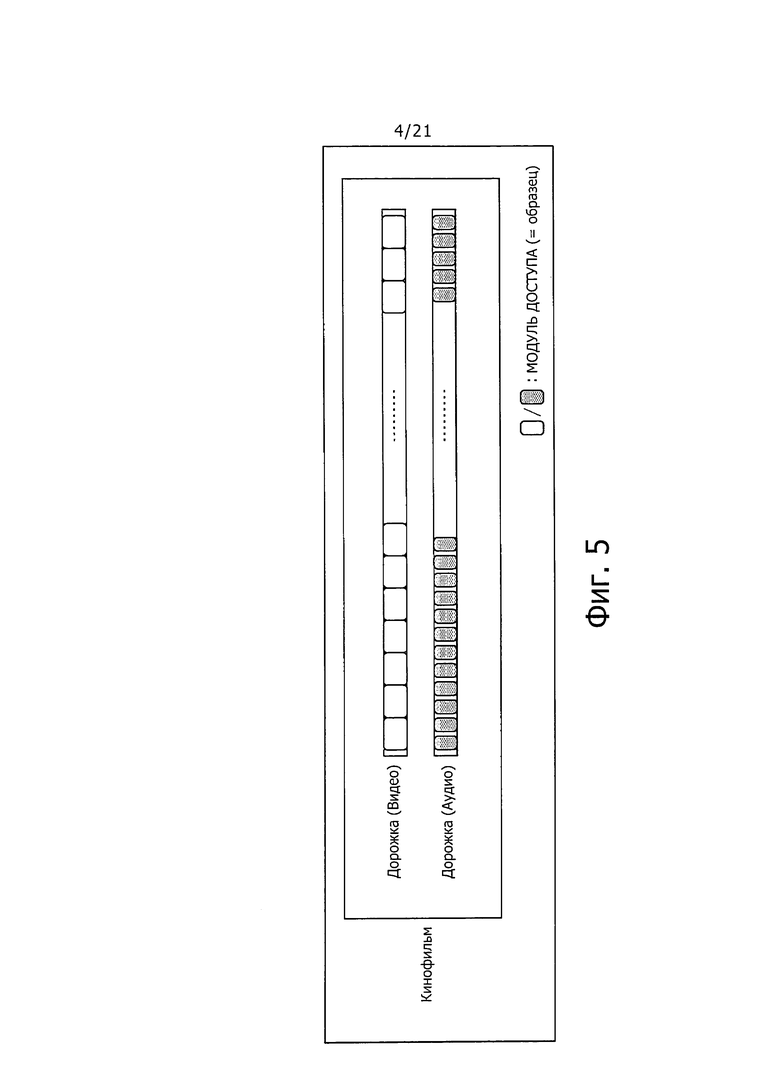
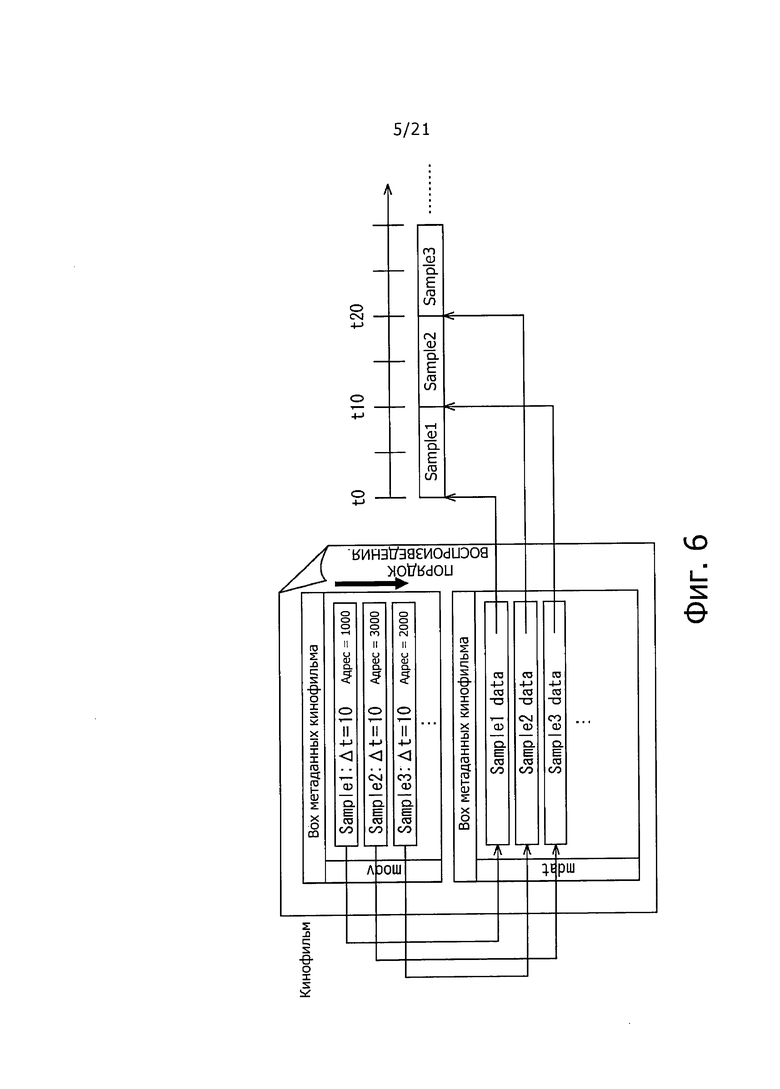
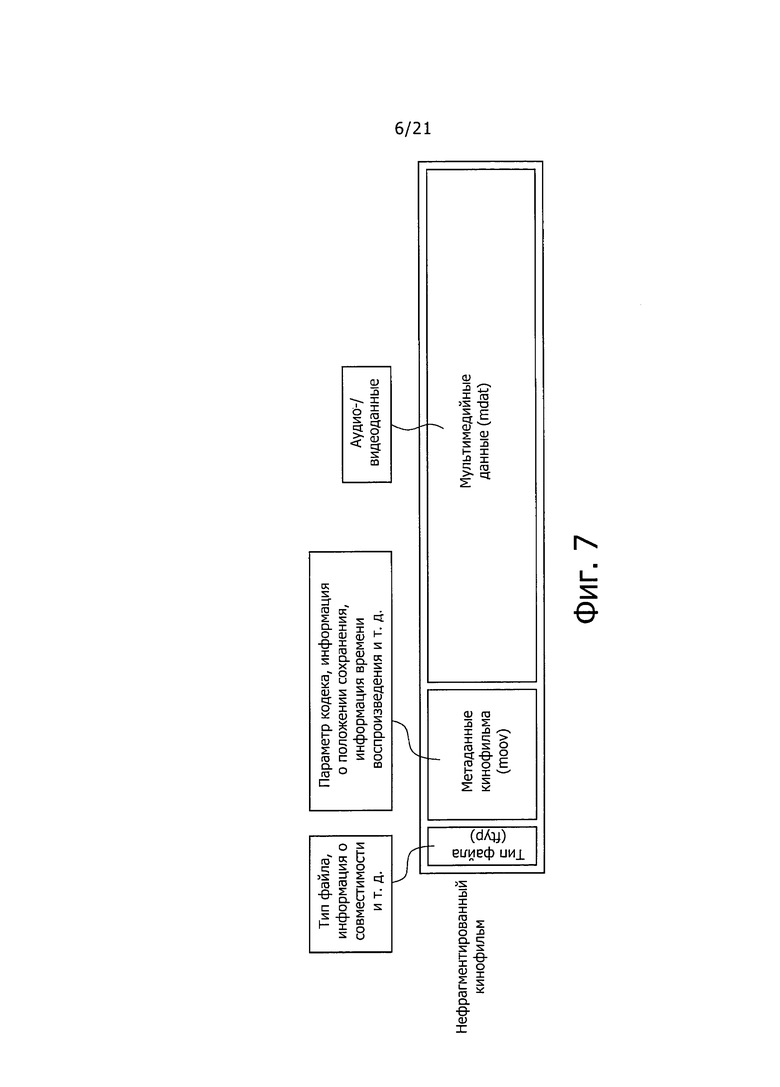
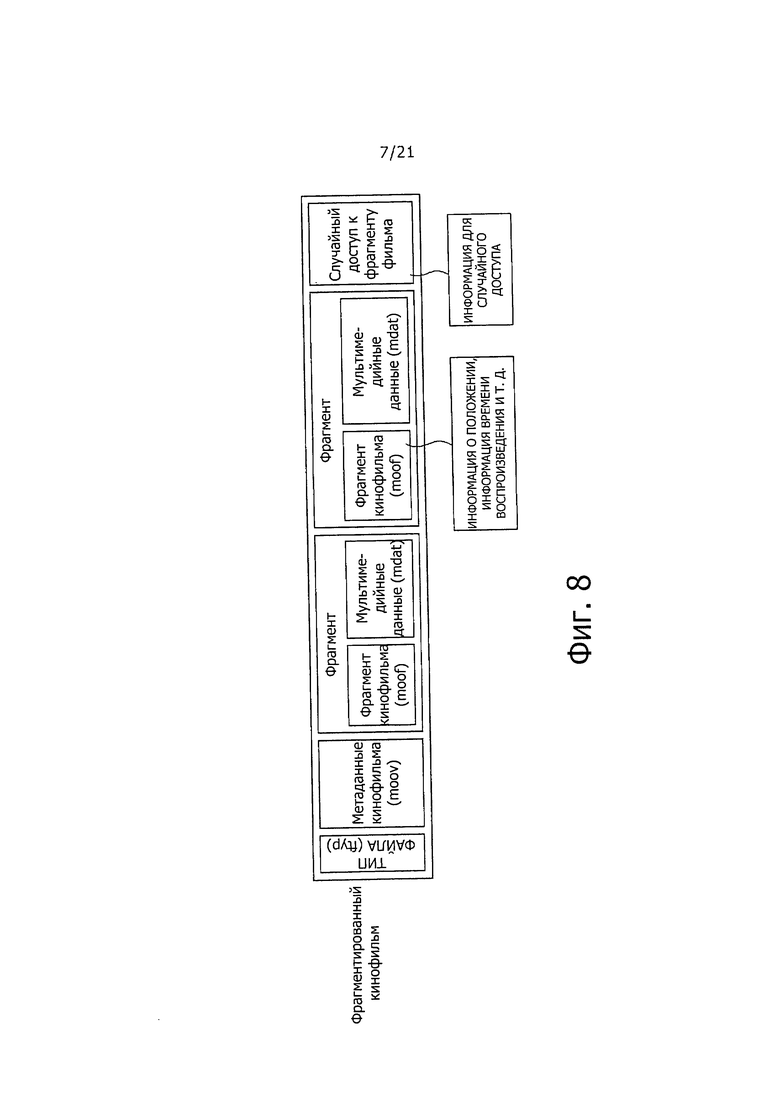
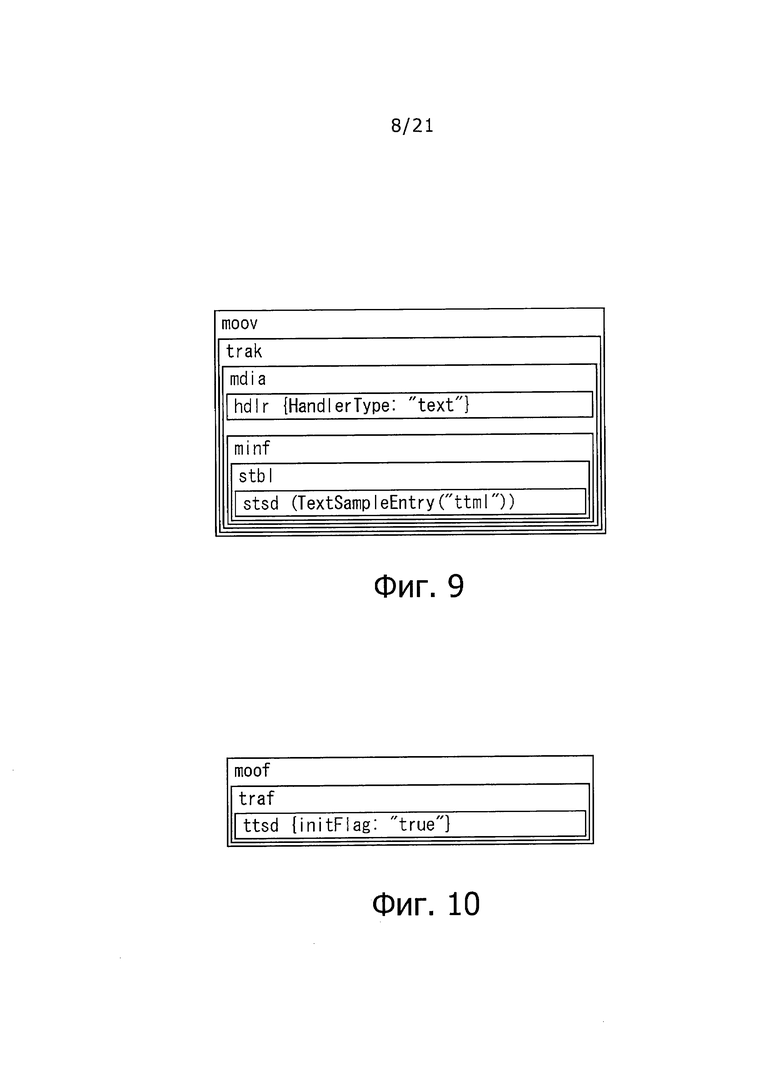
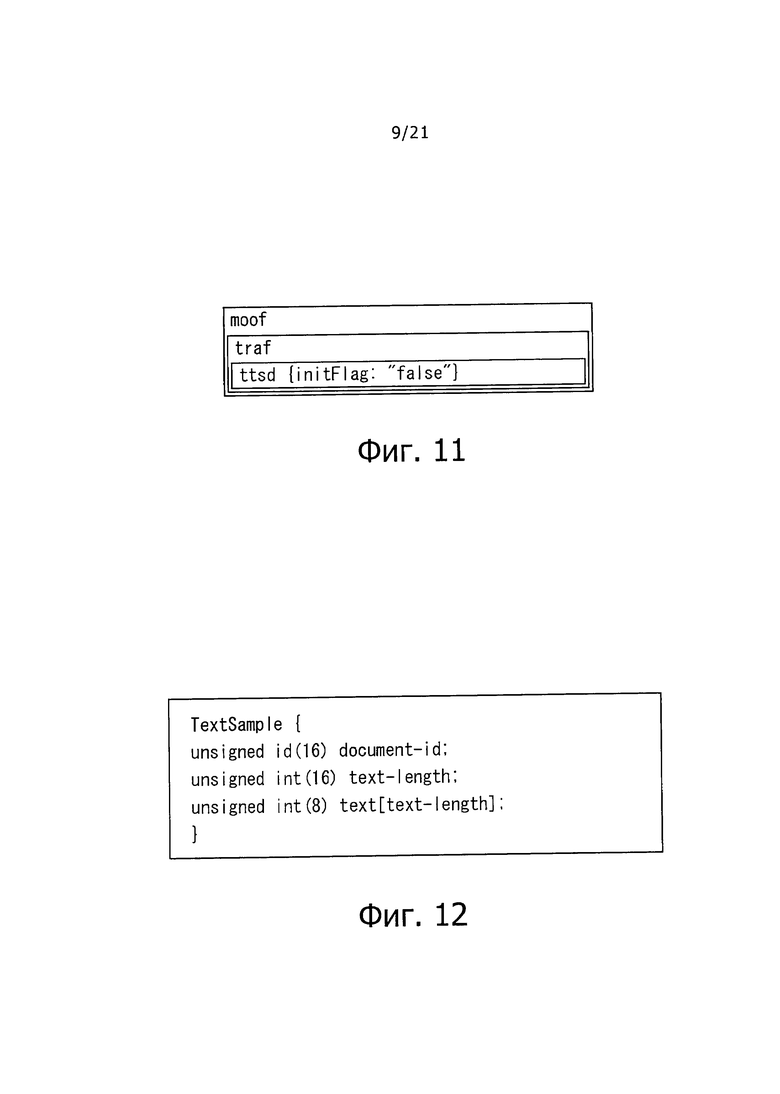
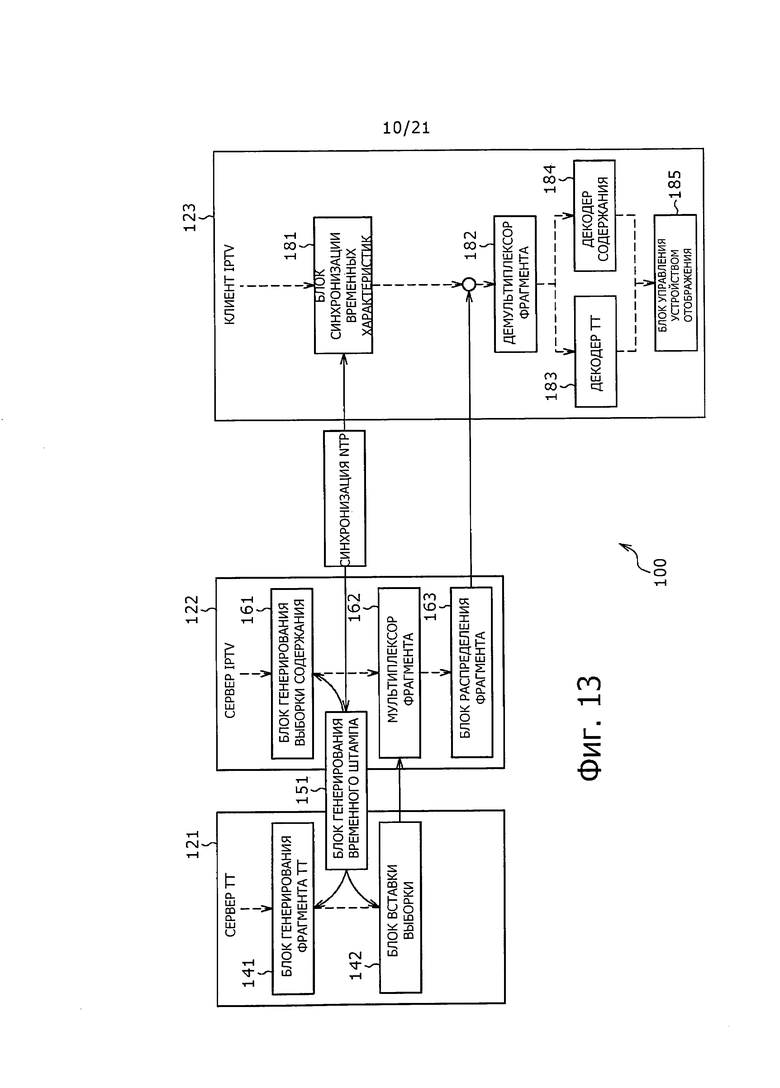

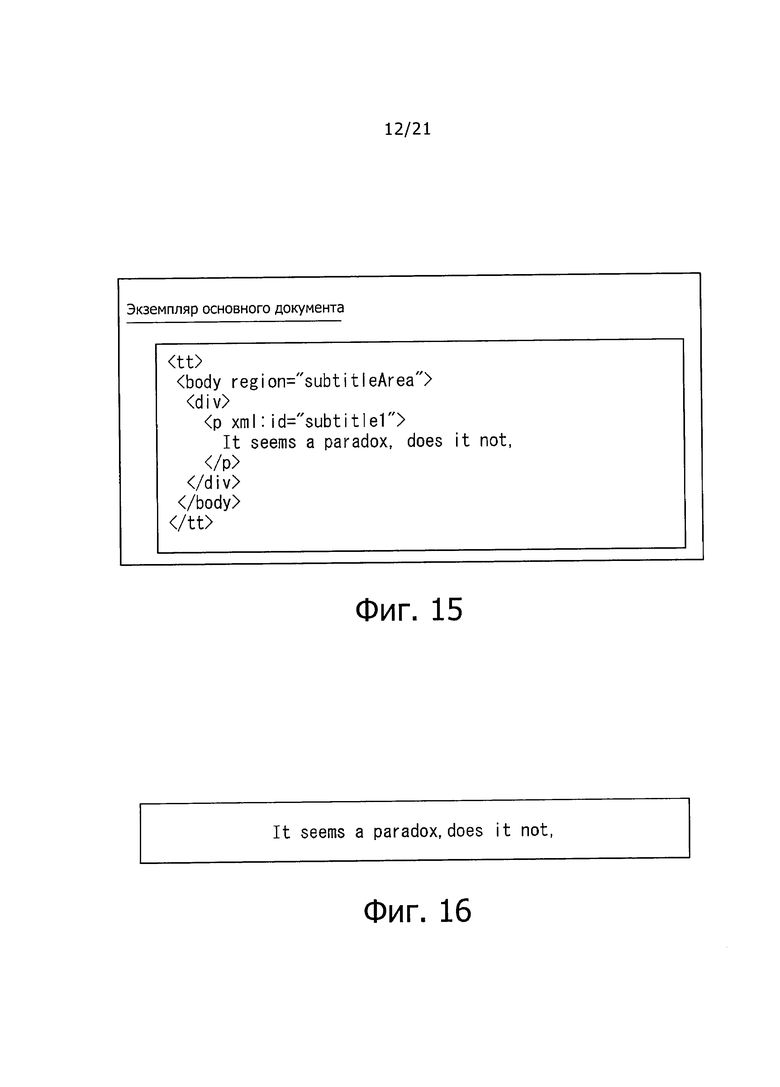

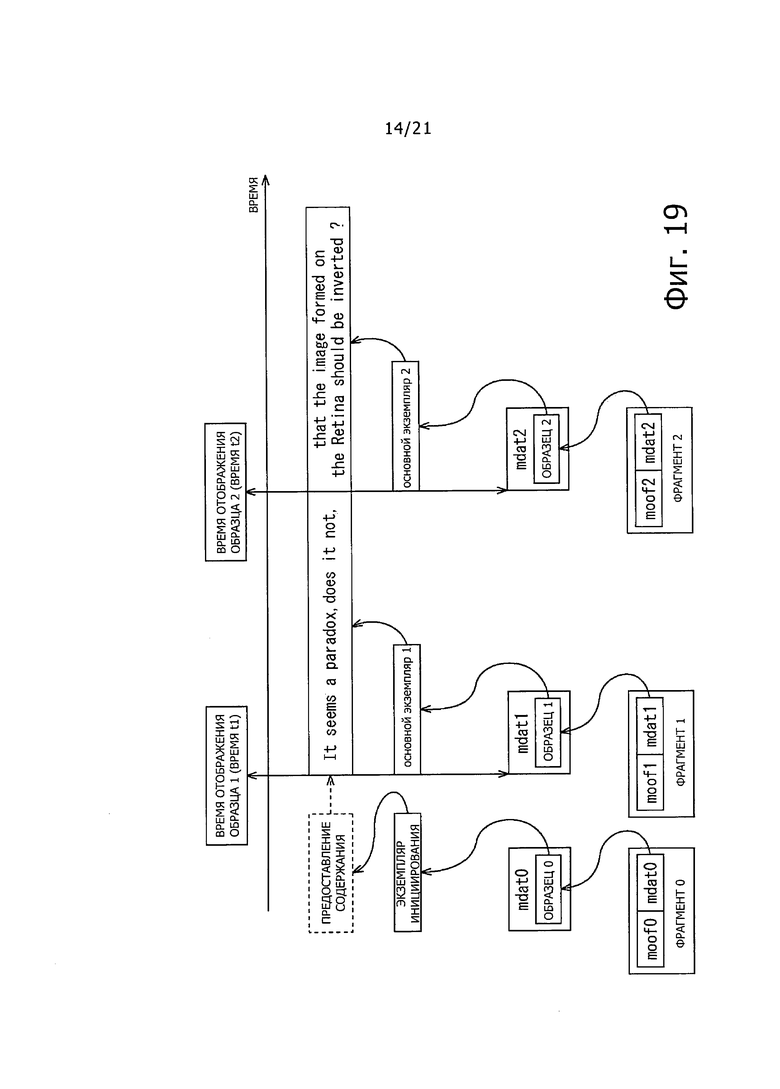
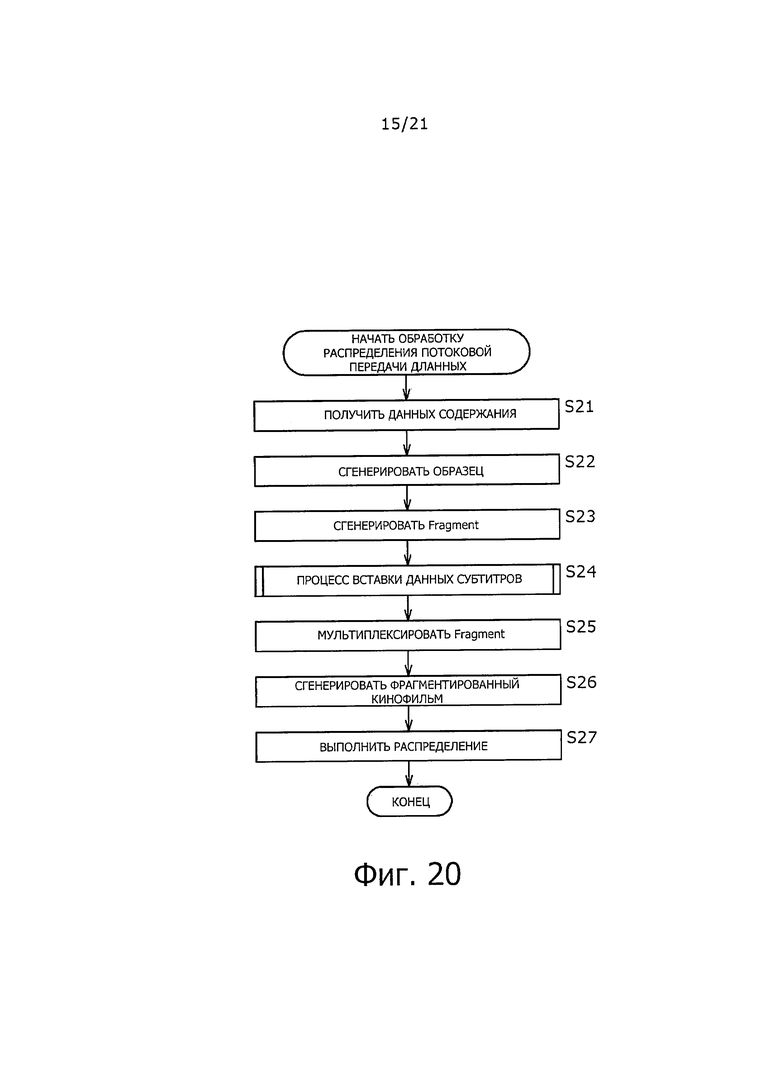
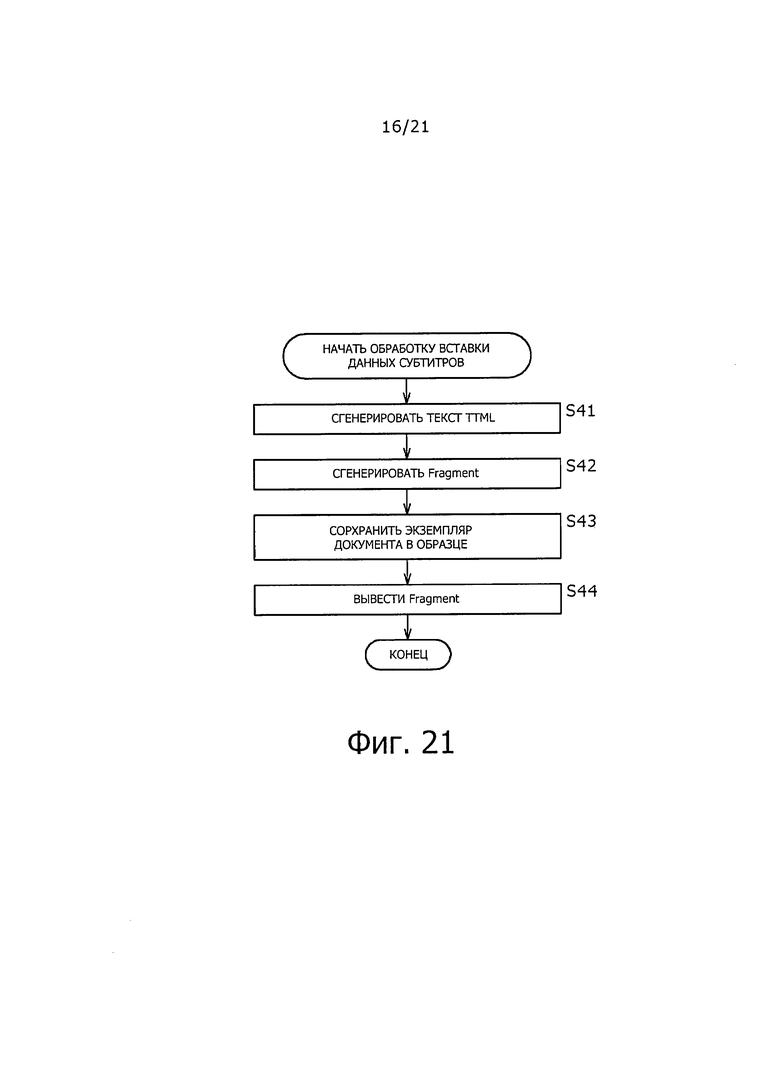
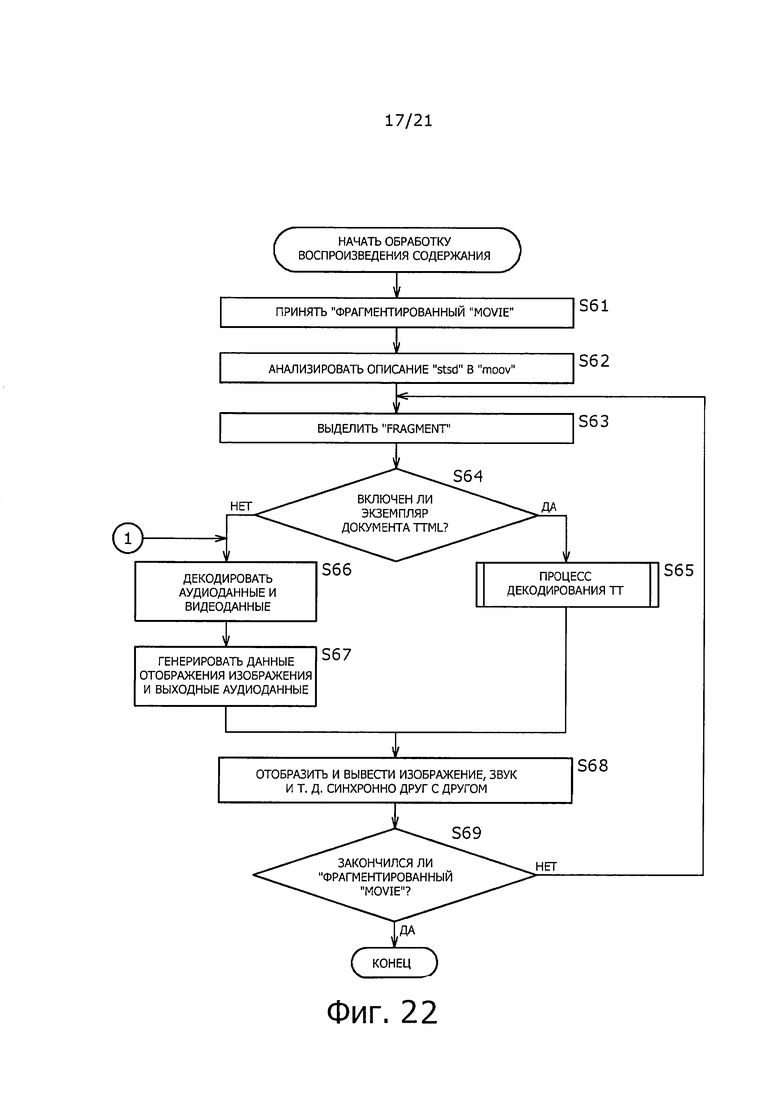
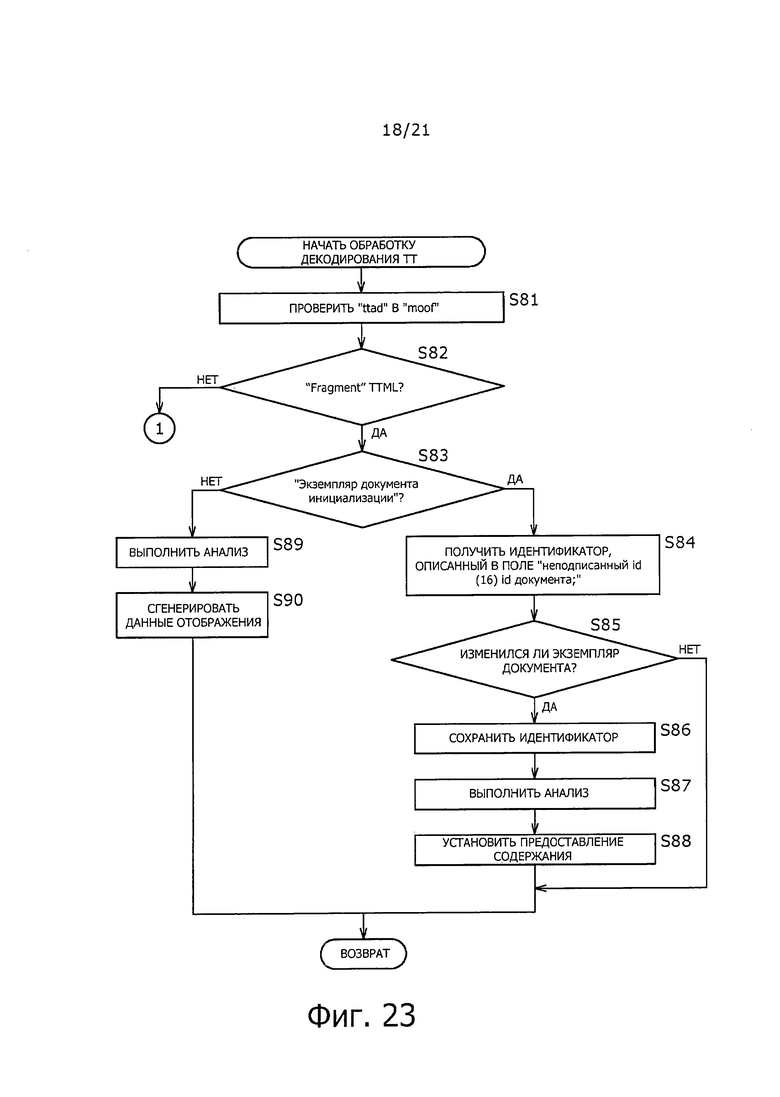

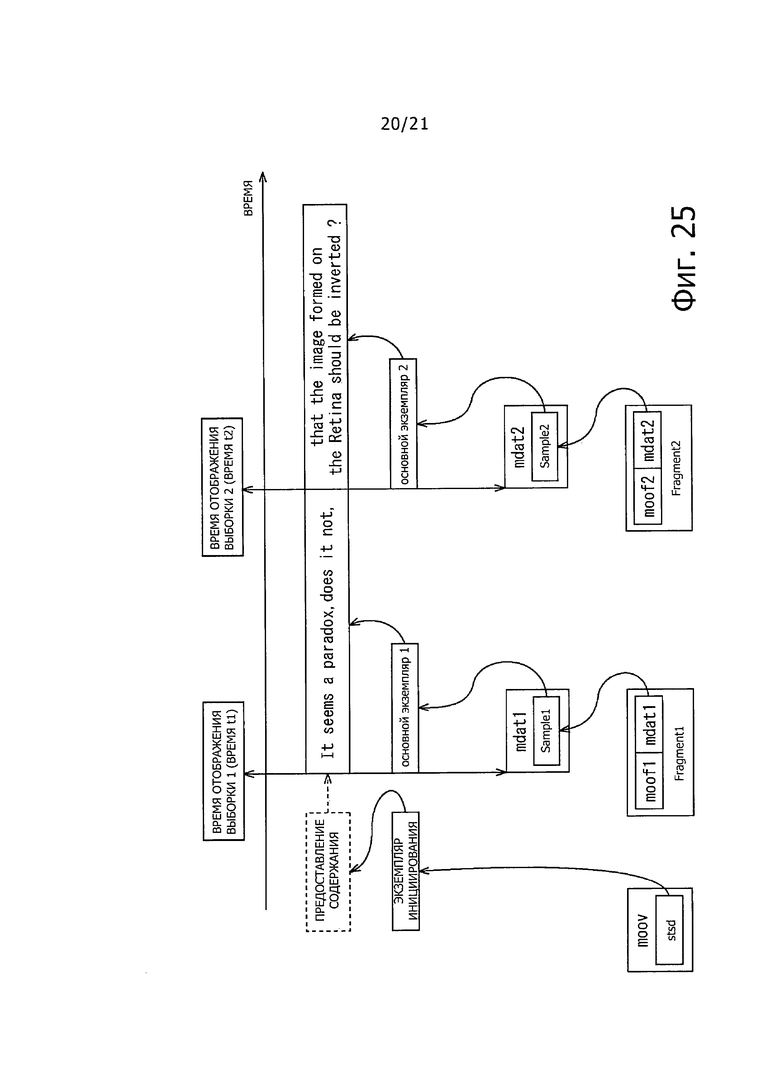
Изобретение относится к средствам распределения потоковой передачи данных. Технический результат заключается в уменьшении нагрузки на обработку для отображения субтитров при потоковой передаче данных. Генерируют первый фрагмент, хранящий данные содержания, подлежащего распределению посредством потоковой передачи. Генерируют второй фрагмент, хранящий экземпляр документа TTML (язык временной разметки текста), относящийся к субтитрам, подлежащим отображению в указанном содержании. Добавляют к информации заголовка второго фрагмента информацию распознавания классификации экземпляра для различения, является ли экземпляр документа TTML, хранящийся в указанном втором фрагменте, экземпляром документа TTML, определяющим представление содержания, относящегося к субтитрам. Сохраняют в указанном втором фрагменте образец, содержащий описание экземпляра документа TTML, вместе с информацией идентификации описания содержания для идентификации описания содержания указанного экземпляра документа TTML, относящегося к субтитрам, для определения, является ли указанный экземпляр документа TTML экземпляром документа инициализации или экземпляром основного документа. 7 н. и 3 з.п. ф-лы, 26 ил.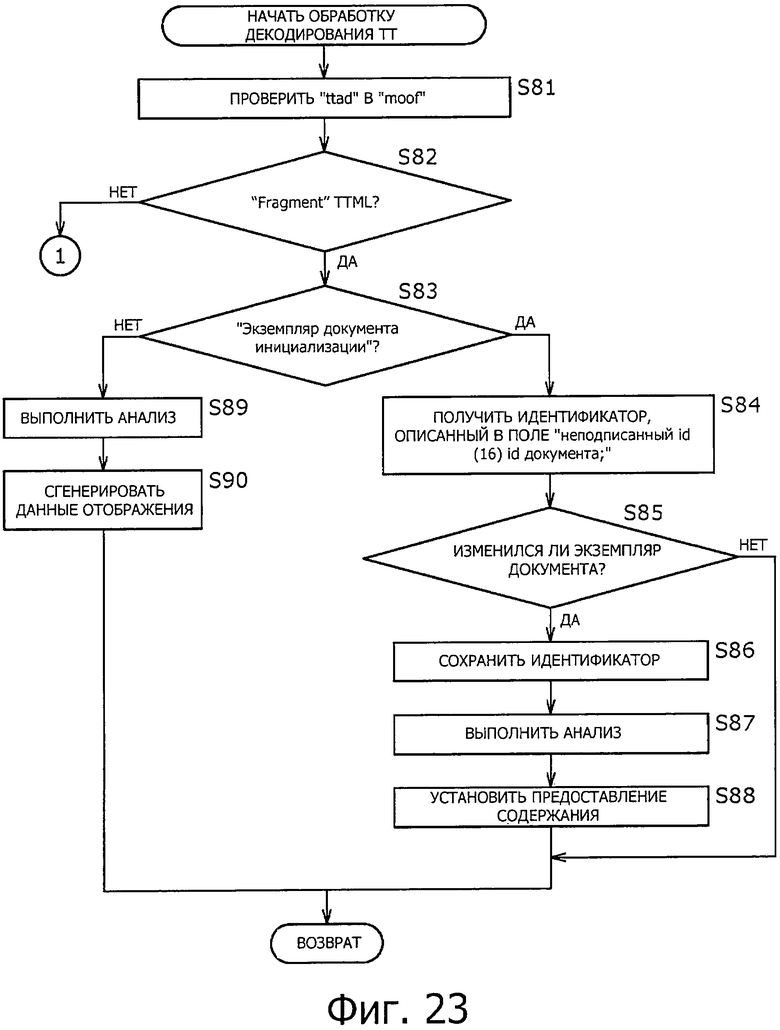
1. Устройство распределения потоковой передачи данных, для распределения потоков содержания прямой трансляции, содержащее:
блок генерирования фрагмента содержания, выполненный с возможностью генерирования первого фрагмента хранения данных содержания, подлежащего потоковому распределению; и
блок генерирования фрагмента субтитров, выполненный с возможностью генерирования второго фрагмента, хранящего экземпляр документа TTML (язык временной разметки текста), относящийся к субтитрам, подлежащим отображению в содержании; при этом
блок генерирования фрагмента субтитров выполнен с возможностью добавления к информации заголовка указанного второго фрагмента, информации распознавания классификации экземпляра для определения, является ли экземпляр документа TTML, хранящийся в указанном втором фрагменте, экземпляром документа TTML, определяющим представления содержания, относящегося к субтитрам; причем
блок генерирования фрагмента субтитров выполнен с возможностью хранения, в указанном втором фрагменте, образца, содержащего описание экземпляра документа TTML, вместе с информацией идентификации описания содержания для индивидуальной идентификации описания содержания экземпляра документа TTML, относящегося к субтитрам, для определения, является ли указанный экземпляр документа TTML экземпляром документа инициализации или экземпляром основного документа; при этом
только когда указанный экземпляр документа TTML является экземпляром документа инициализации, образец включает в себя идентификатор, указывающий изменен ли экземпляр документа инициализации после генерирования указанного экземпляра документа инициализации.
2. Устройство распределения потоковой передачи данных по п. 1, дополнительно содержащее
блок генерирования заголовка кинофильма, выполненный с возможностью добавления в информацию заголовка кинофильма, включающего в себя множество указанных вторых фрагментов, информации распознавания классификации фрагмента для указания того, что кинофильм включает в себя указанный второй фрагмент, содержащий экземпляр документа TTML.
3. Устройство распределения потоковой передачи данных по п. 1, дополнительно содержащее
блок генерирования заголовка кинофильма, выполненный с возможностью добавления в информацию заголовка кинофильма, включающего в себя множество указанных вторых фрагментов, информации распознавания классификации фрагмента для указания того, что кинофильм включает в себя указанный второй фрагмент, содержащий экземпляр документа TTML, при этом
блок генерирования заголовка кинофильма выполнен с возможностью хранения экземпляра документа TTML, определяющего представление содержания, относящегося к субтитрам, в информации о распознавании классификации фрагмента, причем
указанную информацию о распознавании классификации экземпляра не добавляют к информации заголовка указанного второго фрагмента.
4. Способ распределения потоковой передачи данных для распределения потоков содержания прямой трансляции, содержащий этапы, на которых:
генерируют, с помощью блока генерирования фрагмента, первый фрагмент, хранящий данные содержания, подлежащего распределению посредством потоковой передачи;
генерируют, с помощью блока генерирования фрагмента субтитров, второй фрагмент, хранящий экземпляр документа TTML (язык временной разметки текста), относящийся к субтитрам, подлежащим отображению в указанном содержании; и
добавляют, с помощью блока генерирования фрагмента субтитров, к информации заголовка второго фрагмента, информацию распознавания классификации экземпляра для различения, является ли экземпляр документа TTML, хранящийся в указанном втором фрагменте, экземпляром документа TTML, определяющим представление содержания, относящегося к субтитрам; и
сохраняют, с помощью блока генерирования фрагмента субтитров, в указанном втором фрагменте, образец, содержащий описание экземпляра документа TTML, вместе с информацией идентификации описания содержания для индивидуальной идентификации описания содержания указанного экземпляра документа TTML, относящегося к субтитрам, для определения, является ли указанный экземпляр документа TTML экземпляром документа инициализации или экземпляром основного документа; при этом
только когда указанный экземпляр документа TTML является экземпляром документа инициализации, образец включает в себя идентификатор, указывающий, изменен ли экземпляр документа инициализации после генерирования указанного экземпляра документа инициализации.
5. Носитель записи, хранящий программу, вызывающую выполнение компьютером функции устройства распределения потоковой передачи данных, для распределения потоков содержания прямой трансляции, содержащего:
блок генерирования фрагмента содержания, выполненный с возможностью генерирования первого фрагмента хранения данных содержания, подлежащего потоковому распределению; и
блок генерирования фрагмента субтитров, выполненный с возможностью генерирования второго фрагмента, хранящего экземпляр документа TTML (язык временной разметки текста), относящийся к субтитрам, подлежащим отображению в содержании; при этом
блок генерирования фрагмента субтитров выполнен с возможностью добавления к информации заголовка указанного второго фрагмента, информации распознавания классификации экземпляра для определения, является ли экземпляр документа TTML, хранящийся в указанном втором фрагменте, экземпляром документа TTML, определяющим представления содержания, относящегося к субтитрам; причем
блок генерирования фрагмента субтитров выполнен с возможностью хранения в указанном втором фрагменте образца, содержащего описание экземпляра документа TTML, вместе с информацией идентификации описания содержания для индивидуальной идентификации описания содержания экземпляра документа TTML, относящегося к субтитрам, для определения, является ли указанный экземпляр документа TTML экземпляром документа инициализации или экземпляром основного документа; при этом
только когда указанный экземпляр документа TTML является экземпляром документа инициализации, образец включает в себя идентификатор, указывающий, изменен ли экземпляр документа инициализации после генерирования указанного экземпляра документа инициализации.
6. Устройство приема потоковой передачи данных для приема потоков содержания прямой трансляции, содержащее:
блок приема кинофильма, выполненный с возможностью приема данных кинофильма, содержащего множество фрагментов;
блок определения TTML, выполненный с возможностью определения, содержит ли кинофильм фрагмент, хранящий экземпляр документа TTML на основе информации распознавания классификации фрагмента, указывающей, что кинофильм включает в себя фрагмент, хранящий указанный экземпляр документа TTML, при этом информация распознавания классификации фрагмента добавлена к информации заголовка кинофильма;
блок декодирования TTML, выполненный с возможностью выделения и декодирования фрагмента, содержащего экземпляр документа TTML, при определении того, что кинофильм включает в себя фрагмент, содержащий экземпляр документа TTML; при этом
блок декодирования TTML выполнен с возможностью различения классификации указанного экземпляра документа TTML, сохраненного в указанном фрагменте на основе информации распознавания классификации экземпляра для определения, является ли экземпляр документа TTML, сохраненный в указанном фрагменте, экземпляром документа TTML, определяющим представление содержания, относящегося к субтитрам, при этом информация распознавания классификации экземпляра включена в информацию заголовка указанного фрагмента; и
блок определения декодирования, выполненный с возможностью определения, следует ли декодировать экземпляр документа TTML на основе информации идентификации описания содержания, индивидуально идентифицирующей описание содержания указанного экземпляра документа TTML, относящегося к указанным субтитрам, для определения, является ли указанный экземпляр документа TTML экземпляром документа инициализации или экземпляром основного документа, в образце, хранящемся в указанном фрагменте, при распознавании экземпляра документа TTML, хранящегося в указанном фрагменте, в качестве представляющего собой экземпляр документа TTML, определяющий представление содержания, относящегося к субтитрам; при этом
образец содержит идентификатор, указывающий, изменен ли экземпляр документа инициализации, а блок декодирования TTML выполнен с возможностью анализа описания экземпляра документа инициализации, только при определении блоком определения декодирования, что указанный экземпляр документа TTML является экземпляром документа инициализации, и что идентификатор указывает, что экземпляр документа инициализации был изменен после того, как указанный экземпляр документа инициализации был сгенерирован.
7. Устройство приема потоковой передачи данных по п. 6, в котором, при определении, что кинофильм включает себя в себя фрагмент, содержащий экземпляр документа TTML, блок декодирования TTML выполнен с возможностью декодирования экземпляра документа TTML, определяющего представление содержания, относящегося к субтитрам, при этом экземпляр документа TTML определяет представление содержания, относящегося к субтитрам, включенным в информацию распознавания классификации фрагмента.
8. Способ приема потоковой передачи данных, для приема потоков содержания прямой трансляции, содержащий этапы, на которых:
принимают с помощью блока приема кинофильма данные кинофильма, включающие в себя множество фрагментов;
определяют с помощью блока определения TTML, включает ли в себя кинофильм фрагмент, хранящий экземпляр документа TTML, на основе информации распознавания классификации фрагмента, указывающей, что кинофильм включает в себя фрагмент, содержащий экземпляр документа TTML, при этом информация распознавания классификации фрагмента добавлена к информации заголовка кинофильма;
выделяют и декодируют с помощью блока декодирования TTML указанный фрагмент, хранящий экземпляр документа TTML, при определении, что кинофильм включает в себя фрагмент, содержащий экземпляр документа TTML;
различают, с помощью блока декодирования TTML, классификацию указанного экземпляра документа TTML, сохраненного в указанном фрагменте на основе информации распознавания классификации экземпляра для определения, является ли экземпляр документа TTML, сохраненный в указанном фрагменте, экземпляром документа TTML, определяющим представление содержания, относящегося к субтитрам, при этом информация распознавания классификации экземпляра включена в информацию заголовка указанного фрагмента; и
определяют, с помощью блока определения декодирования, следует ли декодировать экземпляр документа TTML на основе информации идентификации описания содержания, индивидуально идентифицирующей описание содержания указанного экземпляра документа TTML, относящегося к указанным субтитрам, для определения, является ли указанный экземпляр документа TTML экземпляром документа инициализации или экземпляром основного документа, в образце, хранящемся в указанном фрагменте, при распознавании экземпляра документа TTML, хранящегося в указанном фрагменте, в качестве представляющего собой экземпляр документа TTML, определяющий представление содержания, относящегося к субтитрам; при этом образец содержит идентификатор, указывающий, изменен ли экземпляр документа инициализации; и
осуществляют анализ, с помощью блока декодирования TTML, описания экземпляра документа инициализации, только при определении блоком определения декодирования, что указанный экземпляр документа TTML является экземпляром документа инициализации, и что идентификатор указывает, что экземпляр документа инициализации был изменен после того, как указанный экземпляр документа инициализации был сгенерирован.
9. Носитель записи, хранящий программу, вызывающую выполнение компьютером функции устройства приема потоковой передачи данных, для приема потоков содержания прямой трансляции, содержащего:
блок приема кинофильма, выполненный с возможностью приема данных кинофильма, содержащего множество фрагментов;
блок определения TTML, выполненный с возможностью определения, содержит ли кинофильм фрагмент, хранящий экземпляр документа TTML на основе информации распознавания классификации фрагмента, указывающей, что кинофильм включает в себя фрагмент, хранящий указанный экземпляр документа TTML, при этом информация распознавания классификации фрагмента добавлена к информации заголовка кинофильма;
блок декодирования TTML, выполненный с возможностью выделения и декодирования фрагмента, содержащего экземпляр документа TTML, при определении того, что кинофильм включает в себя фрагмент, содержащий экземпляр документа TTML; при этом
блок декодирования TTML выполнен с возможностью различения классификации указанного экземпляра документа TTML, сохраненного в указанном фрагменте на основе информации распознавания классификации экземпляра для определения, является ли экземпляр документа TTML, сохраненный в указанном фрагменте, экземпляром документа TTML, определяющим представление содержания, относящегося к субтитрам, при этом информация распознавания классификации экземпляра включена в информацию заголовка указанного фрагмента; и
блок определения декодирования, выполненный с возможностью определения, следует ли декодировать экземпляр документа TTML на основе информации идентификации описания содержания, индивидуально идентифицирующей описание содержания указанного экземпляра документа TTML, относящегося к указанным субтитрам, для определения, является ли указанный экземпляр документа TTML экземпляром документа инициализации или экземпляром основного документа, в образце, хранящемся в указанном фрагменте, при распознавании экземпляра документа TTML, хранящегося в указанном фрагменте, в качестве представляющего собой экземпляр документа TTML, определяющий представление содержания, относящегося к субтитрам; при этом
образец содержит идентификатор, указывающий, изменен ли экземпляр документа инициализации, а блок декодирования TTML выполнен с возможностью анализа описания экземпляра документа инициализации, только при определении блоком определения декодирования, что указанный экземпляр документа TTML является экземпляром документа инициализации, и что идентификатор указывает, что экземпляр документа инициализации был изменен после того, как указанный экземпляр документа инициализации был сгенерирован.
10. Система передачи и приема потоков содержания прямой трансляции, содержащая:
устройство распределения потоковой передачи данных по п. 1; и
устройство приема потоковой передачи данных по п. 6.
| Колосоуборка | 1923 |
|
SU2009A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| RU 200914864 A, 10.08.2010. | |||

