Настоящее изобретение относится к кодированию аудиосигналов, и в частности к переключаемому кодированию аудиосигналов, где для различных частей аудиосигнала кодированный сигнал генерируется с использованием различных алгоритмов кодирования.
Известны переключаемые аудиокодеры, которые определяют различные алгоритмы кодирования для различных частей аудиосигнала. Как правило, переключаемые аудиокодеры предусматривают переключение между двумя различными режимами, то есть алгоритмами, такими как ACELP (линейное предсказание с возбуждением алгебраическим кодом) и TCX (возбуждение, кодируемое с преобразованием).
Режим LPD стандарта MPEG USAC (объединенное кодирование речевых аудиосигналов MPEG) основан на двух различных режимах ACELP и TCX. ACELP обеспечивает лучшее качество речеподобных сигналов и сигналов переходных процессов. TCX обеспечивает лучшее качество для музыкальных и шумоподобных сигналов. Кодер принимает решение, какой именно режим использовать, для каждого отдельного кадра. Решение, принятое кодером, является критическим для качества кодека. Единственное неправильное решение может сформировать сильный артефакт, особенно при низких скоростях передачи.
Наиболее прямым подходом для принятия решения, какой режим использовать, является выбор в режиме замкнутого цикла, то есть выполнение полного кодирования/декодирования в обоих режимах, затем вычисление критерия выбора (например, сегментного отношения сигнал/шум (SNR)) для обоих режимов на основе аудиосигнала и кодированного/декодированного аудиосигналов, и наконец выбор режима на основе критерия отбора. Этот подход обычно дает устойчивое и надежное решение. Однако, он также требует существенного количества сложности, потому что оба режима должны выполняться в каждом кадре.
Альтернативным подходом для уменьшения сложности является выбор режима с незамкнутым циклом. Выбор режима с незамкнутым циклом состоит не из выполнения полного кодирования/декодирования обоих режимов, а из выбора одного режима с использованием критерия отбора, вычисляемого с низкой сложностью. Сложность худшего случая тогда уменьшается на сложность наименее сложного режима (обычно TCX) минус сложность, необходимая для вычисления критерия выбора. Уменьшение сложности обычно является значительным, что делает этот подход привлекательным, когда сложность наихудшего случая в кодеке является ограниченной.
Стандарт AMR-WB+ (определенный в Международном стандарте 3GPP TS 26.290 V6.1.0 2004-12) включает в себя выбор режима с незамкнутым циклом, используемый для выбора между всеми комбинациями ACELP/TCX20/TCX40/TCX80 во кадре длиной 80 мс. Это описывается в разделе 5.2.4 стандарта 3GPP TS 26.290. Это также описано в трудах конференции «Low Complex Audio Encoding for Mobile, Multimedia, VTC 2006, Makinen et al.», а также в патентных документах US7747430 B2 и US 7739120 B2 того же самого автора.
Патентный документ US7747430 B2 раскрывает выбор режима с незамкнутым циклом на основе анализа параметров долгосрочного прогноза. Патентный документ US 7739120 B2 раскрывают выбор режима с незамкнутым циклом на основе характеристик сигнала, указывающих тип аудиоконтента в соответствующих секциях аудиосигнала, причем если такой выбор не является приемлемым, выбор дополнительно основывается на статистической оценке, выполняемой для соответствующих соседних секций.
Выбор режима с незамкнутым циклом в AMR-WB+ может быть описан двумя главными стадиями. На первой главной стадии вычисляются несколько особенностей аудиосигнала, таких как среднеквадратичное отклонение энергетических уровней, соотношение низкочастотной/высокочастотной энергии, полная энергия, расстояние ISP (спектральной пары иммитанса), задержки и коэффициенты усиления основного тона, спектральный наклон. Эти особенности затем используются для того, чтобы сделать выбор между ACELP и TCX, используя простой пороговый классификатор. Если TCX выбирается на первой главной стадии, то на второй главной стадии решение о выборе между возможными комбинациями TCX20/TCX40/TCX80 принимается в замкнутом цикле.
Международная патентная заявка WO 2012/110448 A1 раскрывает подход для выбора между двумя алгоритмами кодирования, имеющими различные характеристики, на основе результата переходного обнаружения и качества аудиосигнала. В дополнение к этому раскрывается применение гистерезиса, в котором гистерезис основывается на выборах, сделанных в прошлом, то есть для более ранних частей аудиосигнала.
В трудах конференции «Low Complex Audio Encoding for Mobile, Multimedia, VTC 2006, Makinen et al.» сравниваются выбор режима с незамкнутым циклом и выбор режима с замкнутым циклом для AMR-WB+. Тесты субъективного прослушивания показывают, что выбор режима с незамкнутым циклом дает значительно худшие результаты, чем выбор режима с замкнутым циклом. Однако также показано, что выбор режима с незамкнутым циклом уменьшает сложность наихудшего случая на 40%.
Задачей настоящего изобретения является предложить улучшенный подход, который обеспечивает выбор между первым алгоритмом кодирования и вторым алгоритмом кодирования с хорошим качеством и уменьшенной сложностью.
Эта задача решается с помощью устройства по п. 1 формулы изобретения, способа по п. 20 формулы изобретения, и компьютерной программы по п. 37 формулы изобретения.
Варианты осуществления настоящего изобретения предлагают устройство для выбора одного из первого алгоритма кодирования, имеющего первую характеристику, и второго алгоритма кодирования, имеющего вторую характеристику, для кодирования части аудиосигнала, чтобы получить кодированную версию части аудиосигнала, включающее в себя:
первый блок оценки для оценки первой меры качества для части аудиосигнала, которая связана с первым алгоритмом кодирования, без фактического кодирования и декодирования части аудиосигнала с использованием первого алгоритма кодирования;
второй блок оценки для оценки второй меры качества для части аудиосигнала, которая связана со вторым алгоритмом кодирования, без фактического кодирования и декодирования части аудиосигнала с использованием второго алгоритма кодирования; и
контроллер для выбора первого алгоритма кодирования или второго алгоритма кодирования на основе сравнения между первой мерой качества и второй мерой качества.
Варианты осуществления настоящего изобретения предлагают способ для выбора одного из первого алгоритма кодирования, имеющего первую характеристику, и второго алгоритма кодирования, имеющего вторую характеристику, для кодирования части аудиосигнала, чтобы получить кодированную версию части аудиосигнала, включающий в себя:
оценку первой меры качества для части аудиосигнала, которая связана с первым алгоритмом кодирования, без фактического кодирования и декодирования части аудиосигнала с использованием первого алгоритма кодирования;
оценку второй меры качества для части аудиосигнала, которая связана со вторым алгоритмом кодирования, без фактического кодирования и декодирования части аудиосигнала с использованием второго алгоритма кодирования; и
выбор первого алгоритма кодирования или второго алгоритма кодирования на основе сравнения между первой мерой качества и второй мерой качества.
Варианты осуществления настоящего изобретения основаны на осознании того, что выбор с незамкнутым циклом с улучшенным качеством может быть осуществлен путем оценки меры качества для каждого из первого и второго алгоритмов кодирования и выбора одного из алгоритмов кодирования на основе сравнения между первой и второй мерами качества. Меры качества оцениваются, то есть для того, чтобы получить меры качества, аудиосигнал фактически не кодируется и не декодируется. Таким образом, меры качества могут быть получены с уменьшенной сложностью. Затем может быть выполнен выбор режима с использованием оценок мер качества, сравнимый с выбором режима в замкнутом цикле.
В вариантах осуществления настоящего изобретения осуществляется выбор режима с незамкнутым циклом, где сначала оценивается с низкой сложностью сегментное отношение сигнал/шум для кодирования ACELP и TCX. Затем выполняется выбор режима с использованием этих оценок сегментного отношения сигнал/шум, как при выборе режима в замкнутом цикле.
Варианты осуществления настоящего изобретения не используют классический подход особенности+классификатор, как это делается при выборе режима с незамкнутым циклом в стандарте AMR-WB+. Вместо этого варианты осуществления настоящего изобретения пытаются оценить меру качества каждого режима и выбрать режим, который дает наилучшее качество.
Варианты осуществления настоящего изобретения будут теперь описаны более подробно со ссылками на сопроводительные чертежи, на которых:
Фиг. 1 показывает схематический вид одного варианта осуществления устройства для выбора одного из первого алгоритма кодирования и второго алгоритма кодирования;
Фиг. 2 показывает схематический вид одного варианта осуществления устройства для кодирования аудиосигнала;
Фиг. 3 показывает схематический вид одного варианта осуществления устройства для выбора одного из первого алгоритма кодирования и второго алгоритма кодирования;
Фиг. 4a и 4b представляют собой возможные представления SNR и сегментного SNR.
В последующем описании одинаковые элементы/стадии на различных чертежах обозначаются одинаковыми ссылочными цифрами. Следует отметить, что на этих чертежах особенности, такие как сигнальные соединения и т.п., которые не являются необходимыми для понимания настоящего изобретения, опущены.
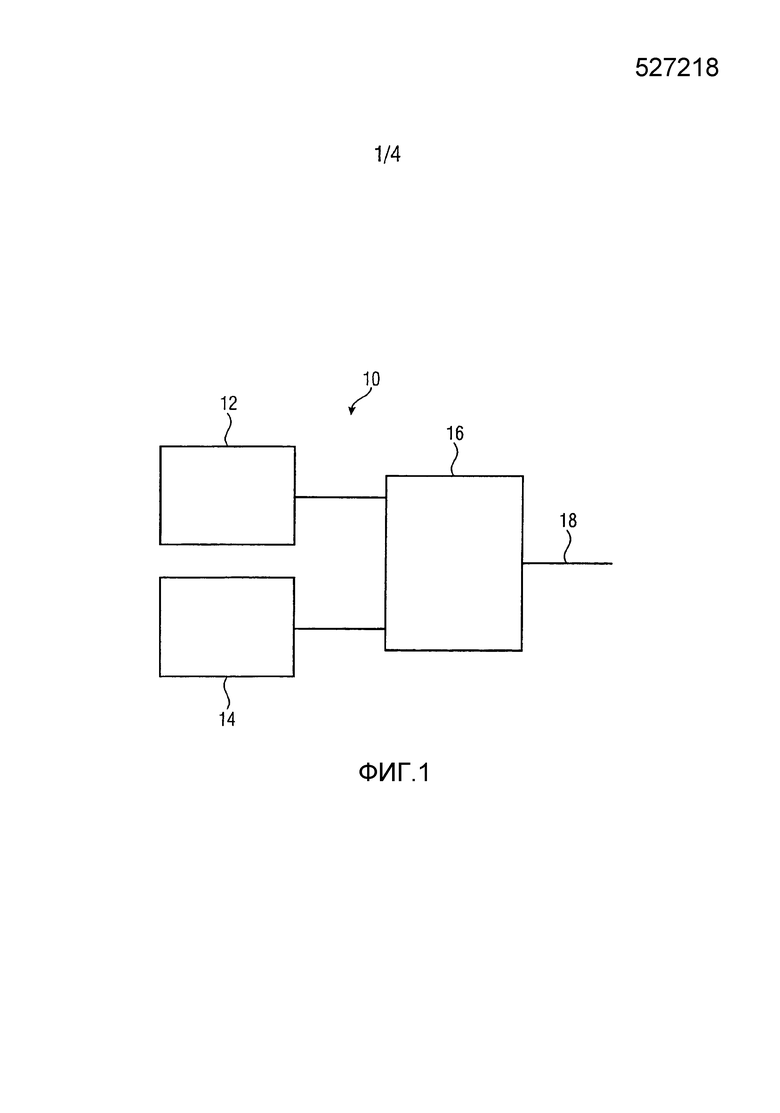
Фиг. 1 показывает устройство 10 для выбора одного из первого алгоритма кодирования, такого как алгоритм TCX, и второго алгоритма кодирования, такого как алгоритм ACELP, в качестве кодера для кодирования части аудиосигнала. Устройство 10 включает в себя первый блок 12 оценки для оценки первой меры качества для части сигнала. Первая мера качества связывается с первым алгоритмом кодирования. Другими словами, первый блок 12 оценки оценивает первую меру качества, которое часть аудиосигнала имела бы, если бы она кодировалась и декодировалась с использованием первого алгоритма кодирования, без фактического кодирования и декодирования части аудиосигнала с использованием первого алгоритма кодирования. Устройство 10 включает в себя второй блок 14 оценки для оценки второй меры качества для части сигнала. Вторая мера качества связывается со вторым алгоритмом кодирования. Другими словами, второй блок 14 оценки оценивает вторую меру качества, которое часть аудиосигнала имела бы, если бы она кодировалась и декодировалась с использованием второго алгоритма кодирования, без фактического кодирования и декодирования части аудиосигнала с использованием второго алгоритма кодирования. Кроме того, устройство 10 включает в себя контроллер 16 для выбора первого алгоритма кодирования или второго алгоритма кодирования на основе сравнения между первой мерой качества и второй мерой качества. Этот контроллер может включать в себя выход 18, указывающий выбранный алгоритм кодирования.
В одном варианте осуществления первая характеристика, связанная с первым алгоритмом кодирования, лучше подходит для музыкальных и шумоподобных сигналов, а вторая характеристика кодирования, связанная со вторым алгоритмом кодирования, лучше подходит для речеподобных и сигналов переходных процессов. В вариантах осуществления настоящего изобретения первый алгоритм кодирования является алгоритмом кодирования аудиосигналов, таким как алгоритм кодирования с преобразованием, например MDCT (модифицированным дискретным косинусным преобразованием), таким как алгоритм кодирования TCX (возбуждение, кодируемое с преобразованием). Другие алгоритмы кодирования с преобразованием могут быть основаны на быстром преобразовании Фурье (FFT), или на любом другом преобразовании, или на наборе фильтров. В вариантах осуществления настоящего изобретения второй алгоритм кодирования является алгоритмом кодирования речи, таким как алгоритм кодирования CELP (линейное предсказание с кодовым возбуждением), такой как алгоритм кодирования ACELP (линейное предсказание с возбуждением алгебраическим кодом).
В вариантах осуществления мера качества представляет перцепционную меру качества. Может быть вычислено единственное значение, которое является оценкой субъективного качества первого алгоритма кодирования, и единственное значение, которое является оценкой субъективного качества второго алгоритма кодирования. Алгоритм кодирования, который дает наилучшую оценку субъективного качества, может быть выбран на основе сравнения только этих двух значений. Это отличается от того, что делается в стандарте AMR-WB+, где вычисляется множество особенностей, представляющих различные характеристики сигнала, а затем применяется классификатор для того, чтобы принять решение, какой именно алгоритм выбрать.
В вариантах осуществления соответствующая мера качества оценивается на основе части взвешенного аудиосигнала, то есть взвешенной версии аудиосигнала. В вариантах осуществления взвешенный аудиосигнал может быть определен как аудиосигнал, фильтрованный функцией взвешивания, где функция взвешивания является взвешенным фильтром LPC A(z/g), где A(z) представляет собой фильтр LPC, а g является весовым коэффициентом в диапазоне от 0 до 1, таким как 0,68. Оказалось, что с помощью этого способа могут быть получены хорошие меры перцепционного качества. Следует отметить, что фильтр LPC A(z) и взвешенный фильтр LPC A(z/g) определяются на стадии предварительной обработки, и что они также используются в обоих алгоритмах кодирования. В других вариантах осуществления функция взвешивания может быть линейным фильтром, фильтром FIR или фильтром линейного предсказания.
В вариантах осуществления мерой качества является сегментное SNR (соотношение сигнал/шум) во взвешенном сигнальном домене. Оказалось, что сегментное SNR во взвешенном сигнальном домене представляет хорошую меру перцепционного качества, и поэтому может выгодным образом использоваться в качестве меры качества. Оно является также мерой качества, используемой как в алгоритме кодирования ACELP, так и в алгоритме кодирования TCX для того, чтобы оценить параметры кодирования.
Другой мерой качества может быть SNR во взвешенном сигнальном домене. Другими мерами качества могут быть сегментное SNR, SNR соответствующей части аудиосигнала в невзвешенном сигнальном домене, то есть не отфильтрованном (взвешенными) коэффициентами LPC. Другими мерами качества могут быть кепстральная дисторсия или отношение зашумления (NMR).
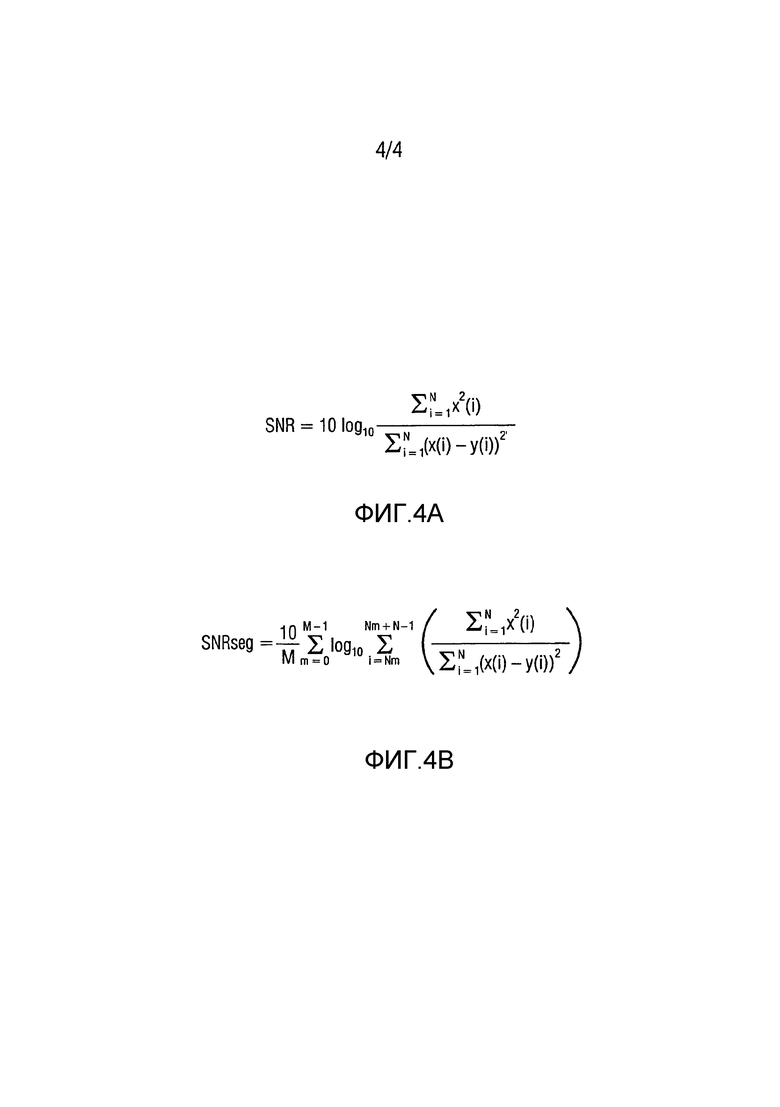
Обычно SNR сравнивает исходные и обработанные аудиосигналы (такие как речевые сигналы) образец за образцом. Цель заключается в том, чтобы измерить искажение волновых кодеров, которые воспроизводят входную волну. Значение SNR может быть вычислено как показано на Фиг. 4a, где x(i) и y(i) являются исходным и обработанным образцами, индексируемыми индексом i, а N является общим количеством образцов. Сегментное SNR, вместо того, чтобы обрабатывать весь сигнал, вычисляет среднее из значений SNR коротких сегментов, с длиной от 1 до 10 мс, например 5 мс. Значение SNR может быть вычислено как показано на Фиг. 4b, где N и М представляют собой длину сегмента и количество сегментов, соответственно.
В вариантах осуществления настоящего изобретения часть аудиосигнала представляет кадр аудиосигнала, который получается кадрированием аудиосигнала, и выбор подходящего алгоритма кодирования выполняется для множества последовательных кадров, получаемых кадрированием аудиосигнала. В последующем описании термины «часть» и «кадр» в отношении аудиосигнала используются взаимозаменяемым образом. В вариантах осуществления каждый кадр делится на подкадры, и сегментное SNR оценивается для каждого кадра путем вычисления SNR для каждого подкадра, преобразования в дБ и вычисления среднего из SNR подкадров в дБ.
Таким образом, в вариантах осуществления оценивается не (сегментное) SNR между входным аудиосигналом и декодированным аудиосигналом, а (сегментное) SNR между взвешенным входным аудиосигналом и взвешенным декодированным аудиосигналом. Относительно этого (сегментного) SNR может быть сделана ссылка на главу 5.2.3 стандарта AMR-WB+ (Международный стандарт 3GPP TS 26.290 V6.1.0 2004-12).
В вариантах осуществления настоящего изобретения соответствующая мера качества оценивается на основе энергии части взвешенного аудиосигнала и на основе оценки искажения, вводимого при кодировании части сигнала соответствующим алгоритмом, причем первый и второй блоки оценки выполнены с возможностью определения оценки искажений в зависимости от энергии взвешенного аудиосигнала.
В вариантах осуществления настоящего изобретения определяется оценка искажения АЦП, вносимого квантователем, используемым в первом алгоритме кодирования при оцифровке части аудиосигнала, и первая мера качества определяется на основе энергии части взвешенного аудиосигнала и оцененного искажения квантователя. В таких вариантах осуществления глобальное усиление для части аудиосигнала может быть оценено так, чтобы часть аудиосигнала производила бы заданную целевую скорость передачи при кодировании с квантователем и энтропийным кодером, используемым в первом алгоритме кодирования, причем оценка искажения квантователя определяется на основе оценки глобального усиления. В таких вариантах осуществления оценка искажения квантователя может быть определена на основе мощности оценки усиления. Когда квантователь, используемый в первом алгоритме кодирования, является однородным скалярным квантователем, первый блок оценки может быть выполнен с возможностью определения оценки искажения квантователя с использованием формулы D = G*G/12, в которой D является оценкой искажения квантователя, а G является оценкой глобального усиления. В случае, когда первый алгоритм кодирования использует другой квантователь, искажение квантователя может быть определено из глобального усиления другим способом.
Авторы настоящего изобретения установили, что мера качества, такая как сегментное SNR, которая была бы получена при кодировании и декодировании части аудиосигнала с использованием первого алгоритма кодирования, такого как алгоритм TCX, может быть оценена подходящим образом путем использования вышеупомянутых особенностей в любой их комбинации.
В вариантах осуществления настоящего изобретения первой мерой качества является сегментное SNR, и сегментное SNR оценивается путем вычисления оценки SNR, связанной с каждой из множества подчастей части аудиосигнала, на основе энергии соответствующей подчасти взвешенного аудиосигнала и оцененного искажения квантователя, и путем вычисления среднего значения всех SNR, связанных с подчастями части взвешенного аудиосигнала для того, чтобы получить оценку сегментного SNR для части взвешенного аудиосигнала.
В вариантах осуществления настоящего изобретения определяется оценка искажения адаптивной кодовой книги, вносимого адаптивной кодовой книгой, используемой во втором алгоритме кодирования при использовании адаптивной кодовой книги для кодирования части аудиосигнала, и вторая мера качества оценивается на основе энергии части взвешенного аудиосигнала и оцененного искажения адаптивной кодовой книги.
В таких вариантах осуществления для каждой из множества подчастей части аудиосигнала адаптивная кодовая книга может быть аппроксимирована на основе версии подчасти взвешенного аудиосигнала, сдвинутого назад на задержку основного тона, определенную на этапе предварительной обработки, усиление адаптивной кодовой книги может быть оценено так, что ошибка между подчастью части взвешенного аудиосигнала и аппроксимированной адаптивной кодовой книгой минимизируется, и оценка искажения адаптивной кодовой книги может быть определена на основе энергии ошибки между подчастью части взвешенного аудиосигнала и аппроксимированной адаптивной кодовой книгой, масштабированной усилением адаптивной кодовой книги.
В вариантах осуществления настоящего изобретения оценка искажения адаптивной кодовой книги, определенная для каждой подчасти части аудиосигнала, может быть уменьшена на постоянный множитель для того, чтобы учесть уменьшение искажения, которое достигается новой кодовой книгой во втором алгоритме кодирования.
В вариантах осуществления настоящего изобретения второй мерой качества является сегментное SNR, и сегментное SNR оценивается путем вычисления оценки SNR, связанной с каждой подчастью, на основе энергии соответствующей подчасти взвешенного аудиосигнала и оцененного искажения адаптивной кодовой книги, и путем вычисления среднего значения всех SNR, связанных с подчастями, для того, чтобы получить оценку сегментного SNR.
В вариантах осуществления настоящего изобретения адаптивная кодовая книга аппроксимируется на основе версии части взвешенного аудиосигнала, сдвинутого назад на задержку основного тона, определенную на этапе предварительной обработки, усиление адаптивной кодовой книги оценивается так, что ошибка между частью взвешенного аудиосигнала и аппроксимированной адаптивной кодовой книгой минимизируется, и оценка искажения адаптивной кодовой книги определяется на основе энергии между частью взвешенного аудиосигнала и аппроксимированной адаптивной кодовой книгой, масштабированной усилением адаптивной кодовой книги. Таким образом, оценка искажения адаптивной кодовой книги может быть определена с низкой сложностью.
Авторы настоящего изобретения установили, что мера качества, такая как сегментное SNR, которая была бы получена при кодировании и декодировании части аудиосигнала с использованием второго алгоритма кодирования, такого как алгоритм ACELP, может быть оценена подходящим образом путем использования вышеупомянутых особенностей в любой их комбинации.
В вариантах осуществления настоящего изобретения при сравнении оценок мер качества используется гистерезисный механизм. Это может сделать более устойчивым решение о том, какой алгоритм должен использоваться. Гистерезисный механизм может зависеть от оценок мер качества (таких как разность между ними) и других параметров, таких как статистика предыдущих решений, количество стационарных во времени кадров, переходные процессы во кадрах. В части таких гистерезисных механизмов может быть сделана ссылка, например, на международную патентную заявку WO 2012/110448 A1.
В вариантах осуществления настоящего изобретения кодер для кодирования аудиосигнала включает в себя устройство 10, стадию выполнения первого алгоритма кодирования и стадию выполнения второго алгоритма кодирования, причем кодер выполнен с возможностью кодировать часть аудиосигнала с использованием первого алгоритма кодирования или второго алгоритма кодирования в зависимости от выбора, сделанного контроллером 16. В вариантах осуществления настоящего изобретения система для кодирования и декодирования включает в себя кодер и декодер, выполненные с возможностью получения закодированной версии части аудиосигнала и указания алгоритма, использованного для кодирования данной части аудиосигнала, и декодирования закодированной версии части аудиосигнала с использованием указанного алгоритма.
Прежде, чем подробно описать вариант осуществления первого блока 12 оценки и второго блока 14 оценки со ссылками на Фиг. 3, описывается вариант осуществления кодера 20 со ссылками на Фиг. 2.
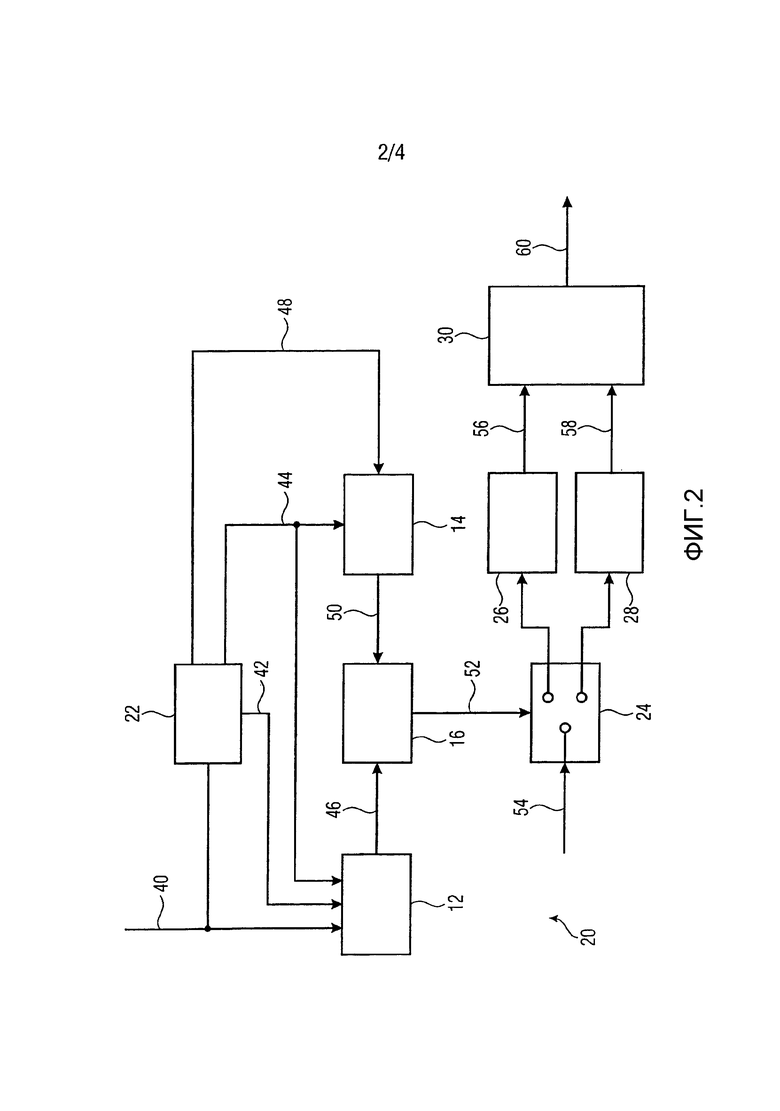
Кодер 20 включает в себя первый блок 12 оценки, второй блок 14 оценки, контроллер 16, блок 22 предварительной обработки, переключатель 24, первую стадию 26 кодера, выполненную с возможностью выполнения алгоритма TCX, вторую стадию 28 кодера, выполненную с возможностью выполнения алгоритма ACELP, и выходной интерфейс 30. Блок 22 предварительной обработки может быть частью общего кодера USAC и может быть выполнен с возможностью вывода коэффициентов LPC, взвешенных коэффициентов LPC, взвешенного аудиосигнала и набора задержек основного тона. Следует отметить, что все эти параметры используются в обоих алгоритмах кодирования, то есть и в алгоритме TCX, и в алгоритме ACELP. Таким образом, такие параметры не должны дополнительно вычисляться для принятия решения в режиме с незамкнутым циклом. Преимуществом использования уже вычисленных параметров при принятии решения в режиме с незамкнутым циклом является меньшая сложность.
Входной аудиосигнал 40 подается на входную линию. Входной аудиосигнал 40 подается на первый блок 12 оценки, блок 22 предварительной обработки и на обе стадии кодера 26, 28. Блок 22 предварительной обработки обрабатывает входной аудиосигнал обычным образом для того, чтобы вывести коэффициенты LPC и взвешенные коэффициенты 42 LPC и отфильтровать аудиосигнал 40 со взвешенными коэффициентами 42 LPC для того, чтобы получить взвешенный аудиосигнал 44. Блок 22 предварительной обработки выводит взвешенные коэффициенты 42 LPC, взвешенный аудиосигнал 44 и набор задержек 48 основного тона. Как будет понятно специалисту в данной области техники, взвешенные коэффициенты 42 LPC и взвешенный аудиосигнал 44 могут быть сегментированы на кадры или подкадры. Эта сегментация может быть получена путем кадрирования аудиосигнала подходящим образом.
В вариантах осуществления настоящего изобретения могут использоваться квантованные коэффициенты LPC или квантованные взвешенные коэффициенты LPC. Таким образом, следует понимать, что термин «коэффициенты LPC» охватывает также и термин «квантованные коэффициенты LPC», а термин «взвешенные коэффициенты LPC» охватывает также и термин «взвешенные квантованные коэффициенты LPC». В этой связи стоит заметить, что алгоритм TCX стандарта USAC использует квантованные взвешенные коэффициенты LPC для формирования спектра MCDT.
Первый блок 12 оценки получает аудиосигнал 40, взвешенные коэффициенты 42 LPC и взвешенный аудиосигнал 44, оценивает на их основе первую меру 46 качества и выводит первую меру качества на контроллер 16. Второй блок 16 оценки получает взвешенный аудиосигнал 44 и набор задержек 48 основного тона, оценивает на их основе вторую меру 50 качества и выводит вторую меру 50 качества на контроллер 16. Как известно специалисту в данной области техники, взвешенные коэффициенты 42 LPC, взвешенный аудиосигнал 44 и набор задержек 48 основного тона уже вычислены в предыдущем модуле (то есть в блоке 22 предварительной обработки) и поэтому являются доступными без дополнительных затрат.
Контроллер принимает решение о выборе алгоритма TCX или алгоритма ACELP на основе сравнения полученных мер качества. Как указано выше, контроллер может использовать гистерезисный механизм при принятии решения о том, какой алгоритм использовать. Выбор первой стадии 26 кодера или второй стадии 28 кодера схематично показан на Фиг. 2 посредством переключателя 24, который управляется управляющим сигналом 52, выводимым контроллером 16. Управляющий сигнал 52 указывает, должна ли использоваться первая стадия 26 кодера или вторая стадия 28 кодера. На основе управляющего сигнала 52 требуемые сигналы, схематично обозначенные стрелкой 54 на Фиг. 2 и по меньшей мере включающие в себя коэффициенты LPC, взвешенные коэффициенты LPC, аудиосигнал, взвешенный аудиосигнал и набор задержек основного тона, подаются либо на первую стадию 26 кодера, либо на вторую стадию 28 кодера. Выбранная стадия кодера применяет связанный с ней алгоритм кодирования и выводит кодированное представление 56 или 58 на выходной интерфейс 30. Выходной интерфейс 30 может быть выполнен с возможностью вывода кодированного аудиосигнала, который может включать в себя среди других данных кодированное представление 56 или 58 коэффициентов LPC или взвешенных коэффициентов LPC, параметров для выбранного алгоритма кодирования и информации о выбранном алгоритме кодирования.
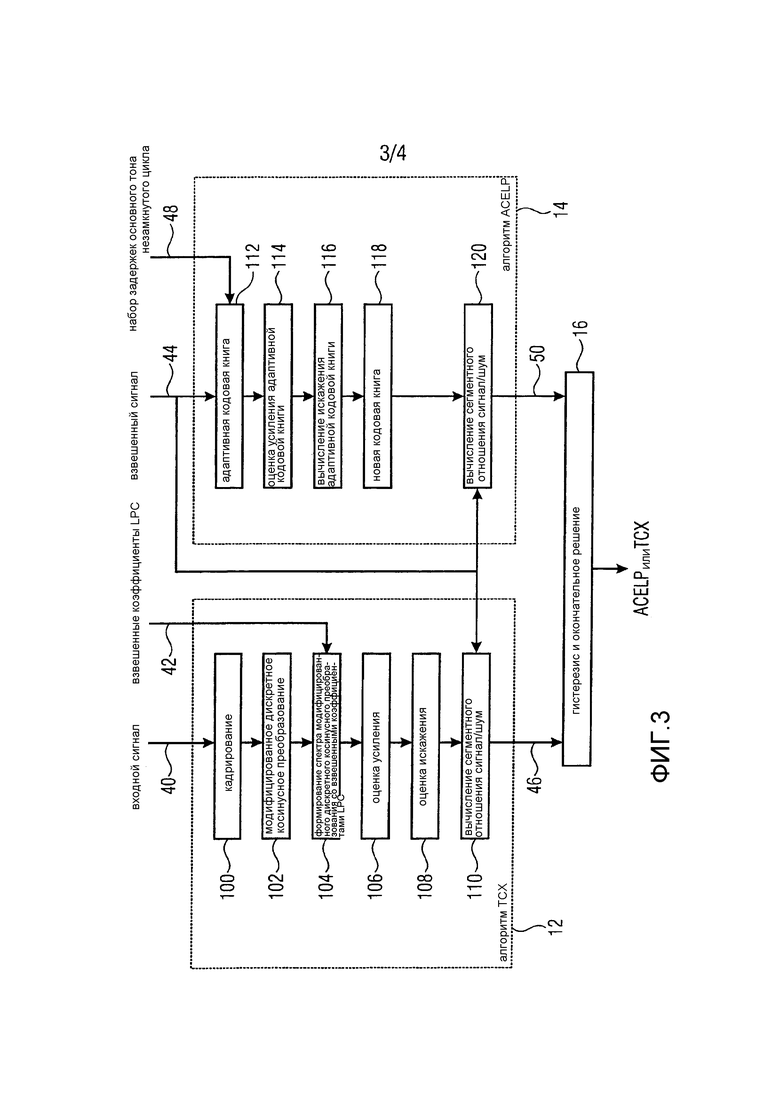
Далее со ссылками на Фиг. 3 описываются конкретные варианты осуществления для оценки первой и второй мер качества, в которых первая и вторая меры качества являются сегментными SNR в домене взвешенного сигнала. Фиг. 3 показывает первый блок 12 оценки и второй блок 14 оценки и их функциональность в форме блок-схем, показывающих соответствующую оценку шаг за шагом.
Оценка сегментного SNR алгоритма TCX
Первый блок оценки (TCX) получает аудиосигнал 40 (входной сигнал), взвешенные коэффициенты 42 LPC и взвешенный аудиосигнал 44 в качестве входов.
На стадии 100 аудиосигнал 40 кадрируется. Кадрирование может производиться с помощью 10-миллисекундного синусного окна с низким перекрытием. Когда предыдущий кадр является кадром ACELP, размер блока может быть увеличен на 5 мс, левая сторона окна может быть прямоугольной, и кадрированный нулевой импульсный отклик фильтра синтеза ACELP может быть удален из кадрированного входного сигнала. Это аналогично тому, что делается в алгоритме TCX. Кадр аудиосигнала 40, который представляет часть аудиосигнала, выводится на стадии 100.
На стадии 102 кадрированный аудиосигнал, то есть получающийся кадр, преобразуется с помощью MDCT (модифицированного дискретного косинусного преобразования). На стадии 104 выполняется формирование спектра путем формирования спектра MDCT со взвешенными коэффициентами LPC.
На стадии 106 глобальное усиление G оценивается так, чтобы взвешенный спектр, квантованный с усилением G, давал бы заданную цель R при кодировании энтропийным кодером, например арифметическим кодером. Термин «глобальное (общее) усиление» используется потому, что одно усиление определяется для всего кадра.
Далее объясняется пример реализации оценки глобального усиления. Следует отметить, что эта оценка глобального усиления является подходящей для тех вариантов осуществления, в которых алгоритм кодирования TCX использует скалярный квантователь с арифметическим кодером. Такой скалярный квантователь с арифметическим кодером принят в стандарте MPEG USAC.
Инициализация
Сначала переменные, используемые при оценке усиления, инициализируются следующим образом:
1. en[i]=9,0+10,0*log10(c[4*i+0]+c[4*i+1]+c[4*i+2]+c[4*i+3]),
где 0<=i<L/4, c[] является вектором коэффициентов для квантования, а L является длиной массива c[].
2. fac=128, offset=fac и target=любое значение (например 1000)
Итерация
Затем следующий блок операций выполняется NITER раз (например, здесь NITER = 10).
1. fac=fac/2
2. offset=offset-fac
3. ener=0
4. для каждого i, где 0<=i<L/4, выполнить следующее:
если en[i]-offset>3,0, тогда ener=ener+en[i]-offset
5. если ener>target, тогда offset=offset+fac
Результатом итерации является значение offset. После итерации глобальное усиление оценивается как G=10^(offset/20).
Конкретный способ, которым оценивается глобальное усиление, может меняться в зависимости от используемого квантователя и энтропийного кодера. В стандарте MPEG USAC принят скалярный квантователь с арифметическим кодером. Другие подходы TCX могут использовать другой квантователь, и специалисту в данной области техники будет понятно, как оценить глобальное усиление для используемого квантователя. Например, в стандарте AMR-WB+ предполагается использование решетчатого квантователя RE8. Для такого квантователя оценка глобального усиления может быть получена, как описано в главе 5.3.5.7 на странице 34 документа 3GPP TS 26.290 V6.1.0 2004-12, причем принимается фиксированная целевая скорость передачи.
После оценки глобального усиления на стадии 106 выполняется оценка искажения на стадии 108. Более конкретно, искажение квантователя аппроксимируется на основе оценки глобального усиления. В данном варианте осуществления предполагается, что используется однородный скалярный квантователь. Таким образом, искажение квантователя определяется с помощью простой формулы D=G*G/12, в которой D представляет определенное искажение квантователя, а G представляет оценку глобального усиления. Это соответствует быстрому приближению искажения однородного скалярного квантователя.
На основе определенного искажения квантователя вычисление сегментного SNR выполняется на стадии 110. Значение SNR в каждом подкадре кадра вычисляется как отношение взвешенной энергии аудиосигнала и искажения D, которое предполагается постоянным в подкадрах. Например, кадр разбивается на четыре последовательных подкадра (см. Фиг. 4). Значение сегментного SNR является тогда средним значением для SNR четырех подкадров, и может быть выражено в дБ.
Этот подход позволяет оценить значение первого сегментного SNR, которое было бы получено при фактическом кодировании и декодировании рассматриваемого кадра с использованием алгоритма TCX, однако без необходимости фактически кодировать и декодировать аудиосигнал, и, следовательно, со значительно уменьшенной сложностью и сокращенным временем вычислений.
Оценка сегментного SNR алгоритма ACELP
Второй блок 14 оценки получает взвешенный аудиосигнал 44 и набор задержек 48 основного тона, который уже был вычислен в блоке 22 предварительной обработки.
Как показано на стадии 112, в каждом подкадре адаптивная кодовая книга аппроксимируется путем простого использования взвешенного аудиосигнала и задержки T основного тона. Адаптивная кодовая книга аппроксимируется выражением
xw(n-T), n=0, …, N
где xw является взвешенным аудиосигналом, T является задержкой основного тона соответствующего подкадра, а N является длиной подкадра. Соответственно, адаптивная кодовая книга аппроксимируется путем использования версии подкадра, сдвинутого назад на T. Таким образом, в вариантах осуществления настоящего изобретения адаптивная кодовая книга аппроксимируется очень простым образом.
На стадии 114 определяется усиление адаптивной кодовой книги для каждого подкадра. Более конкретно, в каждом подкадре усиление G кодовой книги оценивается так, чтобы минимизировалась ошибка между взвешенным аудиосигналом и аппроксимированной адаптивной кодовой книгой. Это может быть сделано путем простого сравнения разности между обоими сигналами для каждого образца и нахождения такого усиления, чтобы сумма этих разностей была минимальной.
На стадии 116 определяется искажение адаптивной кодовой книги для каждого подкадра. В каждом подкадре искажение D, вносимое адаптивной кодовой книгой, является просто энергией ошибки между взвешенным аудиосигналом и аппроксимированной адаптивной кодовой книгой, масштабированной усилением G.
Искажения, определенные на стадии 116, могут быть скорректированы на дополнительной стадии 118 для того, чтобы принять во внимание новую кодовую книгу. Искажение новой кодовой книги, используемой в алгоритмах ACELP, может быть просто оценено как постоянное значение. В описанном варианте осуществления настоящего изобретения просто предполагается, что новая кодовая книга уменьшает искажение D на постоянный множитель. Таким образом, искажение, полученное на стадии 116 для каждого подкадра, может быть умножено на стадии 118 на постоянный множитель, такой как постоянный множитель в диапазоне от 0 до 1, такой как 0,055.
На стадии 120 выполняется вычисление значения сегментного SNR. В каждом подкадре значение SNR вычисляется как отношение взвешенной энергии аудиосигнала и искажения D. Значение сегментного SNR является тогда средним значением для SNR четырех подкадров, и может быть выражено в дБ.
Этот подход позволяет оценить значение второго сегментного SNR, которое было бы получено при фактическом кодировании и декодировании рассматриваемого кадра с использованием алгоритма ACELP, однако без необходимости фактически кодировать и декодировать аудиосигнал, и, следовательно, со значительно уменьшенной сложностью и сокращенным временем вычислений.
Первый и второй блоки 12 и 14 оценки выводят оценки сегментного SNR 46, 50 на контроллер 16, и контроллер 16 принимает решение, какой именно алгоритм должен использоваться для связанной части аудиосигнала, на основе оценок сегментного SNR 46, 50. Контроллер может опционально использовать гистерезисный механизм для более устойчивого принятия решения. Например, тот же самый гистерезисный механизм, что и при принятии решения в замкнутом цикле, может использоваться с немного отличающимися настроечными параметрами. Такой гистерезисный механизм может вычислять значение «dsnr», которое может зависеть от оценок сегментных SNR (таких как разность между ними) и других параметров, таких как статистика предыдущих решений, количество стационарных во времени кадров и переходные процессы в кадрах.
Без гистерезисного механизма контроллер может выбирать алгоритм кодирования, имеющий наиболее высокую оценку SNR, то есть выбирается алгоритм ACELP, если вторая оценка SNR выше первой оценки SNR, и выбирается алгоритм TCX, если первая оценка SNR выше второй оценки SNR. При использовании гистерезисного механизма контроллер может выбирать алгоритм кодирования в соответствии со следующим правилом, в котором acelp_snr является второй оценкой SNR, а tcx_snr является первой оценкой SNR:
если acelp_snr+dsnr>tcx_snr, тогда выбрать ACELP, иначе выбрать TCX.
Соответственно, варианты осуществления настоящего изобретения позволяют оценивать значения сегментного SNR и выбирать подходящий алгоритм кодирования простым и точным образом.
В вышеупомянутых вариантах осуществления значения сегментных SNR оцениваются путем вычисления среднего значения всех SNR, оцененных для соответствующих подкадров. В альтернативных вариантах осуществления SNR всего кадра может быть оценено без деления кадра на подкадры.
Варианты осуществления настоящего изобретения позволяют значительно сократить время вычислений по сравнению с выбором в замкнутом цикле, так как множество стадий, требуемых при отборе в замкнутом цикле, опускаются.
Соответственно, большое количество стадий и времени вычислений, связанных с ними, может быть сэкономлено с помощью подхода в соответствии с настоящим изобретением, обеспечивая при этом выбор подходящего алгоритма кодирования с хорошей эффективностью.
Хотя некоторые аспекты были описаны в контексте устройства, понятно, что эти аспекты также представляют описание соответствующего способа, где блок или устройство соответствуют стадии способа или особенности стадии способа. Аналогично, аспекты, описанные в контексте стадии способа также, представляют описание соответствующего блока или узла или особенности соответствующего устройства.
Варианты осуществления описанных в настоящем документе устройств и их особенности могут быть осуществлены компьютером, одним или более процессорами, одним или более микропроцессорами, программируемыми в условиях эксплуатации логическими матрицами (FPGA), специализированными интегральными схемами (ASIC) и т.п. или их комбинациями, которые конфигурируются или программируются для того, чтобы обеспечить описанную функциональность.
Некоторые или все стадии способа могут быть выполнены с помощью (или с использованием) аппаратного устройства, такого как, например, микропроцессор, программируемый компьютер или электронная схема. В некоторых вариантах осуществления какая-то одна или больше из наиболее важных стадий способа могут быть выполнены таким устройством.
В зависимости от определенных требований реализации варианты осуществления настоящего изобретения могут быть осуществлены в технических средствах или в программном обеспечении. Реализация может быть выполнена с использованием энергонезависимого носителя, такого как носитель цифрового накопителя, например гибкий диск, DVD, Blu-Ray, CD, ROM, PROM, EPROM, EEPROM или флэш-память, имеющего записанные на нем электронно читаемые управляющие сигналы, которые взаимодействуют (или способны взаимодействовать) с программируемой вычислительной системой таким образом, чтобы выполнялся соответствующий способ. Следовательно, носитель цифрового накопителя может быть машиночитаемым.
Некоторые варианты осуществления в соответствии с настоящим изобретением включают в себя носитель информации, имеющий записанные на нем электронно читаемые управляющие сигналы, которые способны взаимодействовать с программируемой вычислительной системой таким образом, чтобы выполнялся один из описанных в настоящем документе способов.
В целом варианты осуществления настоящего изобретения могут быть осуществлены как компьютерный программный продукт с программным кодом программы, использующимся для выполнения одного из способов, когда этот компьютерный программный продукт выполняется на компьютере. Программный код может быть, например, сохранен на машиночитаемом носителе.
Другие варианты осуществления включают в себя компьютерную программу для выполнения одного из способов, описанных в настоящем документе, сохраненную на машиночитаемом носителе.
Другими словами, один вариант осуществления способа в соответствии с настоящим изобретением является, следовательно, компьютерной программой, имеющей программный код для выполнения одного из описанных в настоящем документе способов, когда эта компьютерная программа выполняется на компьютере.
Дополнительный вариант осуществления способа в соответствии с настоящим изобретением является, следовательно, носителем информации (или носителем цифрового накопителя, или машиночитаемым носителем), содержащим записанную на нем компьютерную программу для выполнения одного из описанных в настоящем документе способов. Носитель информации, носитель цифрового накопителя или машиночитаемый носитель являются обычно материальными и/или энергонезависимыми.
Дополнительный вариант осуществления способа по настоящему изобретению является, следовательно, потоком данных или последовательностью сигналов, представляющих компьютерную программу для выполнения одного из описанных в настоящем документе способов. Поток данных или последовательность сигналов могут, например, быть выполнены с возможностью передачи через соединение передачи данных, например, через Интернет.
Дополнительный вариант осуществления включает в себя средство обработки, например, компьютер или программируемое логическое устройство, выполненное с возможностью или запрограммированное для выполнения одного из описанных в настоящем документе способов.
Дополнительный вариант осуществления включает в себя компьютер с установленной на нем компьютерной программой для выполнения одного из описанных в настоящем документе способов.
Дополнительный вариант осуществления в соответствии с настоящим изобретением включает в себя устройство или систему, выполненную с возможностью передачи получателю (например, электронно или оптически) компьютерной программы для выполнения одного из описанных в настоящем документе способов. Получатель может быть, например, компьютером, мобильным устройством, запоминающим устройством и т.п. Устройство или система могут, например, включать в себя файловый сервер для передачи компьютерной программы получателю.
В некоторых вариантах осуществления программируемое логическое устройство (например, логическая микросхема, программируемая в условиях эксплуатации) может использоваться для выполнения некоторой или всей функциональности описанных в настоящем документе способов. В некоторых вариантах осуществления логическая микросхема, программируемая в условиях эксплуатации может взаимодействовать с микропроцессором для того, чтобы выполнить один из описанных в настоящем документе способов. Обычно способы предпочтительно выполняются с использованием технических средств.
Вышеописанные варианты осуществления предназначены лишь для иллюстрации принципов настоящего изобретения. Подразумевается, что модификации и вариации описанных в настоящем документе компоновок деталей будут очевидны для специалистов в данной области техники. Следовательно, предполагается, что настоящее изобретение ограничено только областью охвата прилагаемой формулы изобретения, а не конкретными деталями, представленными путем описания и объяснения вариантов осуществления в настоящем документе.
| название | год | авторы | номер документа |
|---|---|---|---|
| УСТРОЙСТВО И СПОСОБ ВЫБОРА ОДНОГО ИЗ ПЕРВОГО АЛГОРИТМА КОДИРОВАНИЯ И ВТОРОГО АЛГОРИТМА КОДИРОВАНИЯ С ИСПОЛЬЗОВАНИЕМ УМЕНЬШЕНИЯ ГАРМОНИК | 2015 |
|
RU2632151C2 |
| АУДИОКОДЕР И СПОСОБ ДЛЯ КОДИРОВАНИЯ АУДИОСИГНАЛА | 2016 |
|
RU2707144C2 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ АУДИОСИГНАЛА С ИСПОЛЬЗОВАНИЕМ ВЫРОВНЕННОЙ ЧАСТИ ОПЕРЕЖАЮЩЕГО ПРОСМОТРА | 2012 |
|
RU2574849C2 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ КОДИРОВАНИЯ ЧАСТИ АУДИОСИГНАЛА С ИСПОЛЬЗОВАНИЕМ ОБНАРУЖЕНИЯ НЕУСТАНОВИВШЕГОСЯ СОСТОЯНИЯ И РЕЗУЛЬТАТА КАЧЕСТВА | 2012 |
|
RU2573231C2 |
| КОДЕР АУДИОСИГНАЛА, ДЕКОДЕР АУДИОСИГНАЛА, СПОСОБ КОДИРОВАНИЯ ИЛИ ДЕКОДИРОВАНИЯ АУДИОСИГНАЛА С УДАЛЕНИЕМ АЛИАСИНГА (НАЛОЖЕНИЯ СПЕКТРОВ) | 2010 |
|
RU2591011C2 |
| КОДЕР И ДЕКОДЕР АУДИОСИГНАЛА, ИСПОЛЬЗУЮЩИЕ ПРОЦЕССОР ЧАСТОТНОЙ ОБЛАСТИ, ПРОЦЕССОР ВРЕМЕННОЙ ОБЛАСТИ И КРОССПРОЦЕССОР ДЛЯ НЕПРЕРЫВНОЙ ИНИЦИАЛИЗАЦИИ | 2015 |
|
RU2668397C2 |
| КОДЕР И ДЕКОДЕР АУДИОСИГНАЛА, ИСПОЛЬЗУЮЩИЕ ПРОЦЕССОР ЧАСТОТНОЙ ОБЛАСТИ С ЗАПОЛНЕНИЕМ ПРОМЕЖУТКА В ПОЛНОЙ ПОЛОСЕ И ПРОЦЕССОР ВРЕМЕННОЙ ОБЛАСТИ | 2015 |
|
RU2671997C2 |
| СХЕМА КОДИРОВАНИЯ/ДЕКОДИРОВАНИЯ АУДИО СИГНАЛОВ С НИЗКИМ БИТРЕЙТОМ С ПРИМЕНЕНИЕМ КАСКАДНЫХ ПЕРЕКЛЮЧЕНИЙ | 2009 |
|
RU2485606C2 |
| КОДЕР, ДЕКОДЕР И СПОСОБ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ АУДИОКОНТЕНТА С ИСПОЛЬЗОВАНИЕМ ПАРАМЕТРОВ ДЛЯ УЛУЧШЕНИЯ МАСКИРОВАНИЯ | 2015 |
|
RU2701707C2 |
| СПОСОБЫ И УСТРОЙСТВА ДЛЯ ВВЕДЕНИЯ НИЗКОЧАСТОТНЫХ ПРЕДЫСКАЖЕНИЙ В ХОДЕ СЖАТИЯ ЗВУКА НА ОСНОВЕ ACELP/TCX | 2005 |
|
RU2389085C2 |
Изобретение относится к кодированию аудиосигналов, в частности к переключаемому кодированию аудиосигналов, где для различных частей аудиосигнала кодированный сигнал генерируется с использованием различных алгоритмов кодирования. Технический результат – обеспечение выбора алгоритма кодирования с хорошим качеством. Устройство для выбора одного из первого алгоритма кодирования, имеющего первую характеристику, и второго алгоритма кодирования, имеющего вторую характеристику, для кодирования части аудиосигнала для получения кодированной версии части аудиосигнала включает первый блок оценки для оценки для части аудиосигнала первой меры качества, которая связана с первым алгоритмом кодирования, без фактического кодирования и декодирования части аудиосигнала с использованием первого алгоритма кодирования, второй блок оценки предусматривается для оценки для части аудиосигнала второй меры качества, которая связана со вторым алгоритмом кодирования, без фактического кодирования и декодирования части аудиосигнала с использованием второго алгоритма кодирования, контроллер для выбора первого алгоритма кодирования или второго алгоритма кодирования на основе сравнения между первой мерой качества и второй мерой качества. 5 н. и 18 з.п. ф-лы, 5 ил.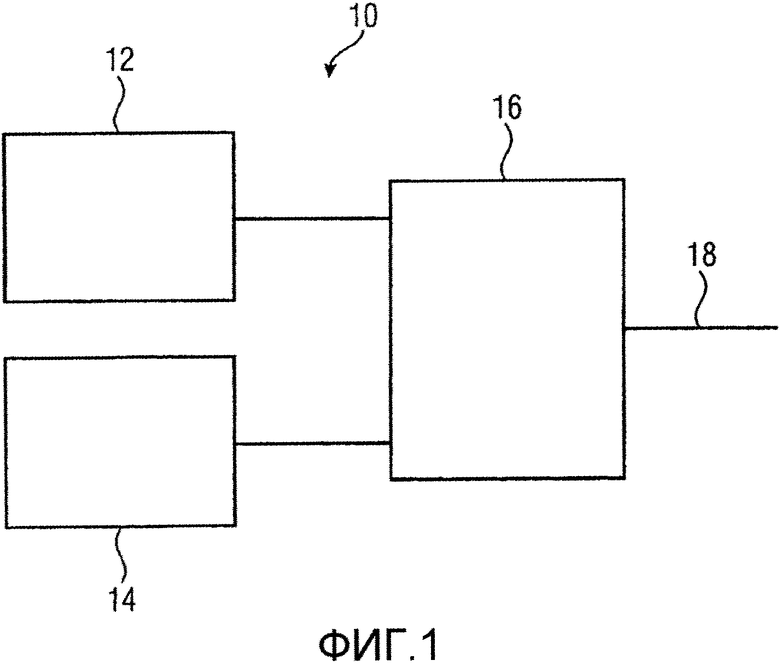
1. Устройство (10) для выбора одного из первого алгоритма кодирования, имеющего первую характеристику, и второго алгоритма кодирования, имеющего вторую характеристику, для кодирования части аудиосигнала (40), чтобы получить кодированную версию упомянутой части аудиосигнала (40), включающее в себя:
первый блок (12) оценки для оценки для упомянутой части аудиосигнала первой меры качества, которая связана с первым алгоритмом кодирования, без фактического кодирования и декодирования упомянутой части аудиосигнала с использованием первого алгоритма кодирования;
второй блок (14) оценки для оценки для упомянутой части аудиосигнала второй меры качества, которая связана со вторым алгоритмом кодирования, без фактического кодирования и декодирования упомянутой части аудиосигнала с использованием второго алгоритма кодирования; и
контроллер (16) для выбора первого алгоритма кодирования или второго алгоритма кодирования на основе сравнения между первой мерой качества и второй мерой качества,
причем первая и вторая меры качества являются значениями SNR (соотношения сигнал/шум) или значениями сегментного SNR соответствующей части взвешенной версии аудиосигнала.
2. Устройство (10) по п. 1, в котором первый алгоритм кодирования является алгоритмом кодирования с преобразованием, алгоритмом кодирования на основе модифицированного дискретного косинусного преобразования (MDCT), или алгоритмом кодирования на основе ТСХ (возбуждения, кодируемого с преобразованием), и в котором второй алгоритм кодирования является алгоритмом кодирования CELP (линейное предсказание с кодовым возбуждением) или ACELP (линейное предсказание с возбуждением алгебраическим кодом).
3. Устройство (10) по п. 1, в котором первый блок (12) оценки выполнен с возможностью определения оцененного искажения квантователя, которое внес бы при квантовании упомянутой части аудиосигнала квантователь, используемый в первом алгоритме кодирования, и оценки первой меры качества на основе энергии части взвешенной версии аудиосигнала и оцененного искажения квантователя.
4. Устройство (10) по п. 3, в котором первый блок (12) оценки выполнен с возможностью оценки глобального усиления для упомянутой части аудиосигнала таким образом, чтобы упомянутая часть аудиосигнала производила бы заданную целевую скорость передачи при кодировании с помощью квантователя и энтропийного кодера, используемых в первом алгоритме кодирования, в котором первый блок (12) оценки дополнительно выполнен с возможностью определения оцененного искажения квантователя на основе мощности оцененного глобального усиления, при этом квантователь, используемый в первом алгоритме кодирования, является однородным скалярным квантователем, и при этом первый блок (12) оценки выполнен с возможностью определения оцененного искажения квантователя с использованием формулы D=G*G/12, где D является оцененным искажением квантователя, a G является оцененным глобальным усилением.
5. Устройство (10) по п. 3, в котором первой мерой качества является сегментное SNR части взвешенного аудиосигнала, и в котором первый блок (12) оценки выполнен с возможностью оценки сегментного SNR путем вычисления оцененного SNR, связанного с каждой из множества подчастей упомянутой части взвешенного аудиосигнала, на основе энергии соответствующих подчастей взвешенного аудиосигнала и оцененного искажения квантователя, а также с возможностью вычисления среднего значения всех SNR, связанных с подчастями упомянутой части взвешенного аудиосигнала, для получения оцененного сегментного SNR для упомянутой части взвешенного аудиосигнала.
6. Устройство (10) по п. 1, в котором второй блок (14) оценки выполнен с возможностью определения оцененного искажения адаптивной кодовой книги, которое адаптивная кодовая книга, используемая во втором алгоритме кодирования, внесла бы при использовании адаптивной кодовой книги для кодирования упомянутой части аудиосигнала, и в котором второй блок (14) оценки выполнен с возможностью оценки второй меры качества на основе энергии части взвешенной версии аудиосигнала и оцененного искажения адаптивной кодовой книги, при этом для каждой из множества подчастей упомянутой части аудиосигнала второй блок (14) оценки выполнен с возможностью аппроксимировать адаптивную кодовую книгу на основе версии подчасти взвешенного аудиосигнала, сдвинутого назад на задержку основного тона, определенную на этапе предварительной обработки, оценивать усиление адаптивной кодовой книги так, чтобы ошибка между подчастью упомянутой части взвешенного аудиосигнала и аппроксимированной адаптивной кодовой книгой была минимальной, и определять оцененное искажение адаптивной кодовой книги на основе энергии ошибки между подчастью упомянутой части взвешенного аудиосигнала и аппроксимированной адаптивной кодовой книгой, масштабированной усилением адаптивной кодовой книги.
7. Устройство (10) по п. 6, в котором второй блок (14) оценки дополнительно выполнен с возможностью уменьшения оцененного искажения адаптивной кодовой книги, определенного для каждой подчасти упомянутой части аудиосигнала, на постоянный множитель.
8. Устройство (10) по п. 6, в котором второй мерой качества является сегментное SNR упомянутой части взвешенного аудиосигнала, и в котором второй блок (14) оценки выполнен с возможностью оценки сегментного SNR путем вычисления оцененного SNR, связанного с каждой подчастью, на основе энергии соответствующей подчасти взвешенного аудиосигнала и оцененного искажения адаптивной кодовой книги, а также с возможностью вычисления среднего значения всех SNR, связанных с подчастями, для получения оцененного сегментного SNR для упомянутой части взвешенного аудиосигнала.
9. Устройство (10) по п. 6, в котором второй блок (14) оценки выполнен с возможностью аппроксимировать адаптивную кодовую книгу на основе версии упомянутой части взвешенного аудиосигнала, сдвинутого назад на задержку основного тона, определенную на этапе предварительной обработки, оценивать усиление адаптивной кодовой книги так, чтобы ошибка между упомянутой частью взвешенного аудиосигнала и аппроксимированной адаптивной кодовой книгой была минимальной, и определять оцененное искажение адаптивной кодовой книги на основе энергии ошибки между упомянутой частью взвешенного аудиосигнала и аппроксимированной адаптивной кодовой книгой, масштабированной усилением адаптивной кодовой книги.
10. Устройство (10) по п. 1, в котором контроллер (16) выполнен с возможностью использовать гистерезис при сравнении оцененных мер качества.
11. Устройство (20) для кодирования части аудиосигнала, включающее в себя устройство (10) по п. 1, первую стадию (26) кодера для выполнения первого алгоритма кодирования и вторую стадию (28) кодера для выполнения второго алгоритма кодирования, причем устройство (20) для кодирования выполнено с возможностью кодирования упомянутой части аудиосигнала с использованием первого алгоритма кодирования или второго алгоритма кодирования в зависимости от выбора, сделанного контроллером (16).
12. Система для кодирования и декодирования, включающая в себя устройство (20) для кодирования по п. 11 и декодер, выполненный с возможностью получения закодированной версии упомянутой части аудиосигнала и указания алгоритма, использованного для кодирования упомянутой части аудиосигнала, и декодирования закодированной версии упомянутой части аудиосигнала с использованием указанного алгоритма.
13. Способ для выбора одного из первого алгоритма кодирования, имеющего первую характеристику, и второго алгоритма кодирования, имеющего вторую характеристику, для кодирования части аудиосигнала, чтобы получить кодированную версию упомянутой части аудиосигнала, включающий в себя:
оценку для упомянутой части аудиосигнала первой меры качества, которая связана с первым алгоритмом кодирования, без фактического кодирования и декодирования упомянутой части аудиосигнала с использованием первого алгоритма кодирования;
оценку для упомянутой части аудиосигнала второй меры качества, которая связана со вторым алгоритмом кодирования, без фактического кодирования и декодирования упомянутой части аудиосигнала с использованием второго алгоритма кодирования; и
выбор первого алгоритма кодирования или второго алгоритма кодирования на основе сравнения между первой мерой качества и второй мерой качества,
в котором первая и вторая меры качества являются значениями SNR (соотношения сигнал/шум) или значениями сегментного SNR соответствующей части взвешенной версии аудиосигнала.
14. Способ по п. 13, в котором первый алгоритм кодирования является алгоритмом кодирования с преобразованием, алгоритмом кодирования на основе модифицированного дискретного косинусного преобразования (MDCT), или алгоритмом кодирования на основе ТСХ (возбуждения, кодируемого с преобразованием), и в котором второй алгоритм кодирования является алгоритмом кодирования CELP (линейное предсказание с кодовым возбуждением) или ACELP (линейное предсказание с возбуждением алгебраическим кодом).
15. Способ по п. 13, включающий в себя определение (108) оцененного искажения квантователя, которое внес бы при квантовании упомянутой части аудиосигнала квантователь, используемый в первом алгоритме кодирования, а также определение меры качества на основе энергии части взвешенной версии аудиосигнала и оцененного искажения квантователя.
16. Способ по п. 15, включающий в себя оценку (106) глобального усиления для упомянутой части аудиосигнала так, что упомянутая часть аудиосигнала производила бы заданную целевую скорость передачи при кодировании с помощью квантователя и энтропийного кодера, используемых в первом алгоритме кодирования, и определение (108) оцененного искажения квантователя на основе мощности оцененного глобального усиления, при этом квантователь является однородным скалярным квантователем, при этом оцененное искажение квантователя определяется с использованием формулы D=G*G/12, где D является оцененным искажением квантователя, a G является оцененным глобальным усилением.
17. Способ по п. 15, в котором первой мерой качества является сегментное SNR фильтрованной LPC версии части взвешенного аудиосигнала, включающий в себя оценку первого сегментного SNR путем вычисления оцененного SNR, связанного с каждой из множества подчастей упомянутой части взвешенного аудиосигнала, на основе энергии соответствующих подчастей взвешенного аудиосигнала и оцененного искажения квантователя, а также путем вычисления среднего значения всех SNR, связанных с подчастями упомянутой части взвешенного аудиосигнала, для получения оцененного сегментного SNR для упомянутой части взвешенного аудиосигнала.
18. Способ по п. 13, включающий в себя определение оцененного искажения (116) адаптивной кодовой книги, которое адаптивная кодовая книга, используемая во втором алгоритме кодирования, внесла бы при использовании адаптивной кодовой книги для кодирования упомянутой части аудиосигнала, а также оценку второй меры качества на основе энергии части взвешенной версии аудиосигнала и оцененного искажения адаптивной кодовой книги, и
включающий в себя для каждой из множества подчастей упомянутой части аудиосигнала аппроксимацию (112) адаптивной кодовой книги на основе версии подчасти взвешенного аудиосигнала, сдвинутого назад на задержку основного тона, определенную на этапе предварительной обработки, оценку (114) усиления адаптивной кодовой книги так, чтобы ошибка между подчастью упомянутой части взвешенного аудиосигнала и аппроксимированной адаптивной кодовой книгой была минимальной, а также определение (116) оцененного искажения адаптивной кодовой книги на основе энергии ошибки между подчастью упомянутой части взвешенного аудиосигнала и аппроксимированной адаптивной кодовой книгой, масштабированной усилением адаптивной кодовой книги.
19. Способ по п. 18, включающий в себя уменьшение (118) оцененного искажения адаптивной кодовой книги, определенной для каждой подчасти упомянутой части аудиосигнала, на постоянный множитель.
20. Способ по п. 18, в котором второй мерой качества является сегментное SNR упомянутой части взвешенного аудиосигнала, включающий в себя оценку сегментного SNR путем вычисления оцененного SNR, связанного с каждой подчастью, на основе энергии соответствующей подчасти взвешенного аудиосигнала и оцененного искажения адаптивной кодовой книги, а также с возможностью вычисления среднего значения всех SNR, связанных с подчастями, для получения оцененного сегментного SNR для упомянутой части взвешенного аудиосигнала.
21. Способ по п. 18, включающий в себя аппроксимацию адаптивной кодовой книги на основе версии упомянутой части взвешенного аудиосигнала, сдвинутого назад на задержку основного тона, определенную на этапе предварительной обработки, оценку усиления адаптивной кодовой книги так, чтобы ошибка между упомянутой частью взвешенного аудиосигнала и аппроксимированной адаптивной кодовой книгой была минимальной, а также определение оцененного искажения адаптивной кодовой книги на основе энергии ошибки между упомянутой частью взвешенного аудиосигнала и аппроксимированной адаптивной кодовой книгой, масштабированной усилением адаптивной кодовой книги.
22. Способ по пп. 13-21, включающий в себя использование гистерезиса при сравнении оцененных мер качества.
23. Машиночитаемый носитель, содержащий компьютерную программу, содержащую программный код, который, при его выполнении на компьютере, выполняет способ по любому из пп. 13-22.
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| АУДИОКОДИРОВАНИЕ | 2005 |
|
RU2335809C2 |
| КОМБИНИРОВАННОЕ АУДИОКОДИРОВАНИЕ, МИНИМИЗИРУЮЩЕЕ ВОСПРИНИМАЕМОЕ ИСКАЖЕНИЕ | 2005 |
|
RU2393552C2 |
| US 7873511 B2, 18.01.2011 | |||
| US 7020615 B2, 28.03.2006 | |||
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| EP 1990799 A1, 12.11.2008. | |||

