Область техники
Заявляемое изобретение обеспечивает реализацию декодера аудиосигнала (аудиодекодера), формирующего декодированное представление звуковых данных (аудиоконтента) на основе кодированного представления акустического материала.
Заявляемое изобретение обеспечивает реализацию кодера аудиосигнала, формирующего кодированное представление аудиоконтента, содержащее первый набор спектральных коэффициентов, представление сигнала возбуждения антиалиасинга (задающего сигнала устранения наложения спектров) и множество параметров области линейного предсказания на основе представления входящих звуковых данных.
В заявляемом изобретении предложен способ формирования декодированного представления аудиоконтента на основе кодированного представления акустического материала.
В заявляемом изобретении предложен способ формирования кодированного представления аудиоконтента на основе представления входящего звукового материала.
Частью предлагаемого изобретения является компьютерная программа для осуществления одного из указанных способов.
В предлагаемом изобретении сформулирована концепция унификации оконного взвешивания и переходов между фреймами для гибридного кодирования речи и звука (обозначаемого также аббревиатурой USAC),.
Уровень техники
Далее будут рассмотрены некоторые предпосылки к созданию изобретения, способствующие пониманию его технической сути и преимуществ.
В течение последних десяти лет значительные усилия были направлены на разработку технологий хранения и распространения фонограмм в цифровом виде. Одним из важных достижений на этом пути стало оформление Международного стандарта ISO/IEC 14496-3. Часть 3 этого стандарта касается кодирования и декодирования звукоданных, а подраздел 4 части 3 относится к общему кодированию звука. ISO/IEC 14496 в части 3, подразделе 4, определяет понятие кодирования и декодирования общих звуковых данных (общего аудиоконтента). В дополнение к этому были предложены другие усовершенствования, способствующие повышению качества и/или снижению объема задействуемого вычислительного ресурса. Более того, было установлено, что аудиокодеры, работающие в частотной области, не обеспечивают оптимальный результат при обработке звукового материала, содержащего речь. Недавно был предложен гибридный звуко-речевой кодек, который эффективно интегрировал в себе технологии обоих направлений - кодирование речи и кодирование звука. Подробнее смотри: «A Novel Scheme for Low Bitrate Unified Speech and Audio Coding - MPEG-RMO» [«Новейшая схема гибридного кодирования речи и звука с низким битрейтом - MPEG-RMO»] of M. Neuendorf et al. (presented at the 126th Convention of the Audio Engineering Society, May 7-10, 2009, Munich, Germany).
Такой аудиокодер кодирует часть аудиофреймов в частотной области, а часть аудиофреймов - в области значений линейного предсказания.
Однако, на практике переход между фреймами, закодированными в разных областях, трудно выполнить, не жертвуя значительным вычислительным ресурсом.
В сложившейся ситуации насущным стало создание концепции кодирования и декодирования звукового контента, содержащего как речь, так и общее звуковое наполнение, которая предусматривала бы оптимизацию переходов между фрагментами, закодированными в разных режимах.
Краткое описание изобретения
Заявляемое изобретение обеспечивает реализацию декодера аудиосигнала (аудиодекодера), формирующего декодированное представление аудиоконтента на основе кодированного представления аудиоконтента. В компоновку данного аудиодекодера включен тракт области трансформанты (например, тракт области линейного предсказания с возбуждением, управляемым кодом в трансформанте), в котором формируется представление во временной области звукоданных, закодированных в области трансформанты на базе первого набора спектральных коэффициентов с использованием представления сигнала стимуляции антиалиасинга и множества параметров области линейного предсказания (например, коэффициентов фильтра кодирования с линейным предсказанием). В тракт трансформанты введен спектральный процессор, предназначенный для приложения формы спектра к (первому) набору спектральных коэффициентов, исходя из, по меньшей мере, подмножества параметров области линейного предсказания с получением рассчитанного по форме спектра варианта первой последовательности спектральных коэффициентов. Кроме того, тракт области трансформанты включает в себя (первый) преобразователь из частотной области во временную область, формирующий представление аудиоконтента во временной области на базе рассчитанного по форме спектра варианта первой последовательности спектральных коэффициентов. Наряду с этим в тракт области трансформанты входит фильтр сигнала стимуляции антиалиасинга, рассчитанный на пропускание задающего сигнала компенсации наложения спектров (в виде представления), исходя из, по меньшей мере, некоторого подмножества параметров области линейного предсказания, с выведением из сигнала стимуляции антиалиасинга производного сигнала, синтезированного с устранением алиасинга. Тракт трансформанты также имеет в своем составе блок сведения представления аудиоконтента во временной области и сигнала безалиасингового синтеза или его доработанной постпроцессингом версии с генерацией во временной области сигнала с компенсированным наложением спектров (без алиасинга).
Предложенное конструктивное решение изобретения базируется на определении, что аудиодекодер, который формирует спектр первого набора спектральных коэффициентов в частотной области и который рассчитывает сигнал, синтезируемый с нейтрализацией алиасинга, посредством фильтрования во временной области сигнала стимуляции антиалиасинга, исходя в обоих случаях из параметров области линейного предсказания, надлежащим образом отвечает требованиям переходов между элементами (например, фреймами) аудиосигнала, закодированными с использованием разных видов формирования искажения, и переходов между фреймами, закодированными в разных областях. Таким образом, переходы (допустим, между перекрывающимися или неперекрывающимися фреймами) в структуре аудиосигнала, закодированные в разных режимах многорежимного кодирования звукового сигнала, могут быть реконструированы аудиодекодером с хорошим акустическим качеством при умеренном объеме оверхеда (протокольной информации).
В частности, моделирование спектра первого набора коэффициентов в частотной области позволяет кодировать переходы между фрагментами (фреймами) аудиоконтента, закодированными в разных режимах формирования шума в трансформанте, при этом антиалиасинг выполняется с достаточной эффективностью для переходов между разными элементами аудиоконтента, закодированными с применением разных механизмов формирования шума (например, на базе масштабных коэффициентов и на базе параметров области линейного предсказания). Наряду с этим, названные выше подходы предусматривают существенное сокращение артефактов спектрального наложения между составными частями (такими, как фреймы) аудиоконтента, закодированными в разных областях (предположим, одна - в области трансформанты, а другая - в области линейного предсказания с возбуждением алгебраическим кодом). Пропускание во временной области сигнала, стимулирующего антиалиасинг, дает возможность устранения алиасинга на переходах между фрагментами аудиоконтента, закодированными в режиме линейного предсказания с возбуждением алгебраическим кодом, даже если искажения в текущем фрагменте аудиоконтента (допустим, закодированном в режиме линейного предсказания с возбуждением кодом трансформанты) были компенсированы в частотной области, а не проходят фильтрацию во временной области.
Итак, из вышесказанного следует, что конструктивные решения по заявляемому изобретению предусматривают надлежащий баланс между объемом необходимой служебной информации и должным перцептуальным качеством переходов между участками аудиоконтента, кодированными с использованием трех разных алгоритмов (например, в частотной области, в режиме линейного предсказания с возбуждением кодом трансформанты и в режиме линейного предсказания с возбуждением алгебраическим кодом).
Предпочтительный вариант реализации декодера аудиосигнала представляет собой мультирежимный аудиодекодер, выполненный с возможностью коммутации между множеством режимов кодирования. В данном случае ветвь трансформанты характеризуется тем, что избирательно синтезирует сигнал с компенсацией алиасинга для того фрагмента аудиоконтента, который следует за фрагментом, или за которым следует фрагмент аудиоконтента, где не применим антиалиасинг посредством сложения наложением. Было установлено, что формирование искажения через построение формы спектра первой последовательности спектральных коэффициентов обеспечивает переход между элементами аудиоконтента, закодированными в области трансформанты, и позволяет использовать различные механизмы формирования искажений (в том числе алгоритмы ограничения шума с применением коэффициентов масштабирования и параметров области линейного предсказания) без задействования сигналов антиалиасинга, поскольку использование первого преобразователя сигнала из частотной области во временную область вслед за формированием спектра позволяет эффективно предотвращать наложение спектров последовательных фреймов, закодированных в спектральной области (в трансформанте), даже если для последовательности аудиофреймов используются разные способы формирования искажений. Таким образом, эффективность битрейта достигается за счет селективного пропускания сигнала безалиасингового синтеза только в случаях переходов между элементами аудиоконтента, закодированными не в трансформанте (а, например, в режиме линейного предсказания с управлением алгебраическим кодом).
В предпочтительной версии аудиодекодер выполнен с возможностью переключения с рабочего режима в области линейного предсказания с кодовым возбуждением из трансформанты, в котором используется информация о кодах возбуждения в трансформанте и о параметрах области линейного предсказания, на рабочий режим в частотной области, в котором используются данные спектральных коэффициентов и коэффициентов масштабирования. В этом случае тракт трансформанты выдает первый набор спектральных коэффициентов на основе информации о кодах возбуждения в трансформанте, и выводит параметры области линейного предсказания на основе информации о параметрах области линейного предсказания. Схема декодера аудиосигнала включает в себя тракт частотной области, предназначенный для образования во временной области представления аудиоконтента, закодированного в режиме частотной области с использованием набора спектральных коэффициентов частотной области, описанных в информации о спектральных коэффициентах, с учетом набора масштабных коэффициентов, описанных в информации о коэффициентах масштабирования. Тракт частотной области включает в себя спектральный процессор, предназначенный для приложения формы спектра к набору спектральных коэффициентов частотной области или к их предобработанной модификации с применением масштабных коэффициентов для получения рассчитанной по форме спектра последовательности спектральных коэффициентов в частотной области. Наряду с этим, тракт частотной области включает в себя частотно-временной преобразователь, формирующий представление аудиоконтента во временной области на базе сформированной по спектру последовательности спектральных коэффициентов в частотной области. Аудиодекодер характеризуется тем, что представления во временной области двух последовательных фрагментов аудиоконтента, один из которых закодирован в режиме линейного предсказания с возбуждением кодом из трансформанты, и второй из которых закодирован в частотной области, содержат перекрывание по времени, устраняющее алиасинг во временной области, возникающий в результате преобразования из частотной области во временную.
Как рассматривалось выше, реализуемая концепция изобретения хорошо применима в отношении переходов между фрагментами аудиоконтента, закодированными в режиме линейного предсказания с кодовым возбуждением из трансформанты и в режиме частотной области. Высокое качество антиалиасинга достигается за счет формирования спектра в частотной области в режиме линейного предсказания с кодовым возбуждением из трансформанты.
В предпочтительном конструктивном решении аудиодекодер предусматривает переключение между режимом работы в области линейного предсказания с кодированным в трансформанте возбуждением, где используется информация о кодах возбуждения в трансформанте и информация о параметрах области линейного предсказания, и режимом линейного предсказания с алгебраическим кодовым управлением, где используется информация о алгебраических кодах и информация о параметрах области линейного предсказания. При этом тракт трансформанты выстраивает первую последовательность спектральных коэффициентов на основе информации о кодах возбуждения в трансформанте и выводит параметры области линейного предсказания из информации о параметрах области линейного предсказания. В конструкцию аудиодекодера введен тракт линейного предсказания с алгебраическим кодовым возбуждением, предназначенный для формирования представления во временной области аудиоконтента, закодированного в режиме линейного предсказания с возбуждением алгебраическим кодом (далее обозначаемом сокращенно по-английски ACELP) на основе информации о алгебраических кодах возбуждения и информации о параметрах области линейного предсказания. В предлагаемой компоновке в тракт ACELP включены процессор возбуждения ACELP, генерирующий сигнал возбуждения во временной области на основе информации об алгебраических кодах возбуждения, и фильтр синтеза во временной области, обеспечивающие реконструкцию аудиосигнала на основе сигнала возбуждения во временной области и с использованием коэффициентов пропускания фильтра области линейного предсказания, выведенных из информации о параметрах области линейного предсказания. Тракт области трансформанты выполнен с возможностью избирательного синтеза безалиасингового сигнала для фрагмента аудиоконтента, закодированного в режиме линейного предсказания с возбуждением кодом из трансформанты, следующего за фрагментом аудиоконтента, закодированным в режиме ACELP, и для фрагмента аудиоконтента, закодированного в режиме линейного предсказания с кодовым возбуждением из трансформанты, предшествующего фрагменту аудиоконтента, закодированному в режиме ACELP. Установлено, что сигнал синтеза с нейтрализацией алиасинга оптимально подходит для переходов между сегментами (в частности, фреймами), закодированными в режиме области линейного предсказания с возбуждением кодами из трансформанты (далее обозначаемом английским акронимом TCX-LPD), и - в режиме ACELP.
В предпочтительном варианте исполнения аудиодекодера фильтр сигнала стимуляции антиалиасинга пропускает сигналы активации компенсации наложения спектров в зависимости от параметров фильтра области линейного предсказания, которые соответствуют левосторонней симметричной точке алиасинга первого частотно-временного преобразователя для фрагмента аудиоконтента, закодированного в режиме TCX-LPD, следующего за фрагментом аудиоконтента, закодированным в режиме ACELP. Фильтр сигнала стимуляции антиалиасинга рассчитан на пропускание сигнала возбуждения нейтрализации алиасинга в зависимости от параметров фильтра области линейного предсказания, которые соответствуют правосторонней симметричной точке алиасинга второго частотно-временного преобразователя для фрагмента аудиоконтента, закодированного в режиме TCX-LPD, предшествующего фрагменту аудиоконтента, закодированному в режиме ACELP. Благодаря применению параметров фильтра области линейного предсказания, соответствующих симметричным точкам зеркального наложения спектров, может быть достигнута чрезвычайно эффективная нейтрализация алиасинга. Более того, параметры фильтра области линейного предсказания, которые соответствуют зеркальным точкам алиасинга, как правило, легко доступны, поскольку эти симметричные точки зеркального наложения спектров часто находятся на переходе от одного фрейма к следующему, в силу чего передача названных параметров фильтра области линейного предсказания требуется постоянно. Следовательно, объем оверхеда (потока протокольных данных) сводится к необходимому минимуму.
Далее, декодер аудиосигнала выполняет функцию обнуления значений в памяти фильтра стимуляции антиалиасинга для выработки сигнала безалиасингового синтеза и функцию введения М отсчетов сигнала стимуляции антиалиасинга в фильтр стимуляции антиалиасинга для получения соответствующих отсчетов сигнала безалиасингового синтеза в качестве отклика на ненулевой входной сигнал и, далее, для получения множества отсчетов сигнала безалиасингового синтеза в качестве отклика на нулевой входной сигнал. Комбинатор [в составе аудиодекодера] преимущественно предназначен для сведения представления во временной области аудиоконтента с отсчетами отклика на ненулевой ввод и последующими отсчетами отклика на нулевой ввод с целью генерирования сигнала временной области с компенсированным алиасингом на переходе между фрагментом аудиоконтента, закодированным в режиме ACELP, и фрагментом аудиоконтента, закодированным в режиме TCX-LPD, следующим за фрагментом аудиоконтента, закодированным в режиме ACELP. Благодаря комбинированному использованию отсчетов отклика на ненулевое входящее значение и отсчетов отклика на нулевое входящее значение фильтр сигнала управления нейтрализацией наложения спектров может быть использован весьма эффективно. Кроме того, сигнал с устранением алиасинга может быть синтезирован очень сглаженным при условии сохранения максимально низкого числа требуемых отсчетов сигнала стимуляции антиалиасинга. Более того, было установлено, что при применении вышеуказанного подхода форма сигнала, синтезированного с устранением алиасинга, может быть очень хорошо адаптирована к типичным артефактам алиасинга. Таким образом достигается сбалансированное соотношение между эффективностью кодирования и компенсацией эффекта наложения спектров (алиасинга).
В предпочтительном варианте аудиодекодер выполнен с возможностью комбинирования оконной (взвешенной) и свернутой (симметрично сложенной) версии, по меньшей мере, одного сегмента представления во временной области, сгенерированного в режиме ACELP, с представлением во временной области следующего сегмента аудиоконтента, сгенерированного в режиме TCX-LPD, с целью, хотя бы, частичной нейтрализации алиасинга. Выявлено, что применение подобных механизмов предотвращения наложения спектров в дополнение к генерации сигнала безалиасингового синтеза обеспечивает возможность компенсации алиасинга при очень эффективном битрейте. В частности, требуемый сигнал активации антиалиасинга может быть закодирован с высокой эффективностью, если к сигналу, синтезируемому с устранением алиасинга, при нейтрализации алиасинга будет дополнительно применена оконно-взвешенная и симметрично свернутая версия, по крайней мере, одного фрагмента представления во временной области, полученного с использованием режима ACELP.
Предпочтительное конструктивное решение предусматривает способность аудиодекодера комбинировать взвешенную версию нулевой импульсной характеристики синтезирующего фильтра ветви ACELP с представлением во временной области следующего фрагмента аудиоконтента, сгенерированного в режиме TCX-LPD, с целью, как минимум, частично нейтрализовать алиасинг. Исследования показали, что использование такой нулевой импульсной характеристики может также помочь повысить эффективность кодирования сигнала стимуляции антиалиасинга, поскольку нулевая импульсная характеристика синтезирующего фильтра ветви ACELP обычно компенсирует, по меньшей мере, часть наложения спектров в сегменте аудиоконтента, кодированном в TCX-LPD. Соответственно, энергия сигнала безалиасингового синтеза снижается, что, в свою очередь, ведет к снижению энергии сигнала стимуляции антиалиасинга. Однако, кодирование сигналов с меньшим уровнем энергии, как правило, возможно при сниженных требованиях к скорости передачи данных.
В предпочтительном варианте исполнения аудиодекодер предусматривает переключение между режимом TCX-LPD, где используют частотно-временное преобразование «вершин» [Λ], и режимом частотной области, где используют частотно-временное преобразование «ветвей (/лучей)» [Λ], а также - режимом линейного предсказания с алгебраическим кодовым управлением. В этом случае аудиодекодер предусматривает возможность, по меньшей мере, частичной компенсации алиасинга на переходе от фрагмента аудиоконтента, закодированного в режиме TCX-LPD, к фрагменту аудиоконтента, закодированному в режиме частотной области путем выполнени операции наложения и сложения временных отсчетов последовательных перекрывающихся фрагментов аудиоконтента. Кроме того, аудиодекодер предусматривает возможность, по меньшей мере, частичной компенсации алиасинга на переходе от фрагмента аудиоконтента, закодированного в режиме TCX-LPD к фрагменту аудиоконтента, закодированному в режиме ACELP, с использованием сигнала безалиасингового синтеза. Установлено также, что декодер аудиосигнала полностью соответствует требованиям коммутации между различными рабочими режимами для эффективного устранения алиасинга.
В предпочтительной версии исполнения декодер аудиосигнала предусматривает использование общего коэффициента усиления для масштабного пересчета коэффициентов усиления представления во временной области, формируемого первым частотно-временным преобразователем в тракте трансформанты (например, в тракте TCX-LPD), и для масштабного пересчета коэффициентов усиления сигнала стимуляции антиалиасинга или сигнала безалиасингового синтеза. Расчеты показывают, что применение одного и того же общего коэффициента усиления как для масштабирования представления во временной области, выполняемого первым частотно-временным преобразователем, так и для масштабирования задающего сигнала компенсации наложения спектров или сигнала, синтезируемого с устранением наложения спектров, позволяет снизить скорость передачи данных на переходах между фрагментами аудиоконтента, закодированными в разных режимах. Это имеет очень большое значение, поскольку при кодировании сигнала активации антиалиасинга в условиях перехода между блоками аудиоконтента, закодированными в разных режимах, потребности в битрейте возрастают.
Предпочтительное конструктивное решение аудиодекодера предусматривает в дополнение к функции формирования спектра, выполняемой в зависимости от, по меньшей мере, подмножества параметров области линейного предсказания, применение функции «де-формировáния» (деконфигурирования) спектра в соответствии с, по меньшей мере, подмножеством первого набора спектральных коэффициентов. В такой ситуации аудиодекодер предусматривает де-формирование спектра, по крайней мере, того подмножества из набора спектральных коэффициентов антиалиасинга, которое является исходным для производного сигнала стимуляции антиалиасинга. Приложение функции деконфигурирования спектра одновременно к первому ряду коэффициентов спектрального разложения и к спектральным коэффициентам антиалиасинга, исходным для производного задающего сигнала антиалиасинга, обеспечивает гарантию, что сигнал, синтезированный с устранением алиасинга, будет адекватно адаптирован к «основному» сигналу аудиоконтента, генерируемому первым частотно-временным преобразователем. При этом вновь повышается эффективность кодирования сигнала стимуляции антиалиасинга.
В предпочтительной компоновке в схему декодера аудиосигнала введен второй частотно-временной преобразователь, генерирующий представление сигнала стимуляции антиалиасинга во временной области в зависимости от набора спектральных коэффициентов, представляющих сигнал стимуляции антиалиасинга. В этом случае первый частотно-временной преобразователь выполняет преобразование с перекрытием (наложением), в которое попадает алиасинг во временной области. Второй частотно-временной преобразователь выполняет преобразование без перекрытия. Соответственно, благодаря использованию преобразования с перекрытием при синтезе „главного» сигнала поддерживается надлежащая эффективность кодирования. Тем не менее, нейтрализация алиасинга достигается благодаря использованию дополнительного преобразования из частотной области во временную без перекрывания. И все же, установлено, что комбинированное преобразование из частотной области во временную с перекрыванием и без перекрывания обеспечивает более эффективное кодирование переходов, чем только частотно-временное преобразование без перекрывания.
Заявляемое изобретение включает в себя варианты реализации кодера аудиосигнала (аудиокодера), предназначенного для формирования кодированного представления звукового материала (аудиоконтента), которое включает в себя первую последовательность спектральных коэффициентов, представление сигнала стимуляции антиалиасинга и множество параметров области линейного предсказания на базе входящего представления аудиоконтента. В компоновку аудиокодера введен преобразователь из временной области в частотную область, выполняющий обработку входного представления массива акустических данных с формированием на выходе его представления в частотной области. В состав аудиокодера также введен спектральный процессор для приложения формы спектра к набору спектральных коэффициентов или к их предобработанной версии в зависимости от набора параметров области линейного предсказания для фрагмента аудиоконтента, который должен быть закодирован в области линейного предсказания, с формированием частотного представления, смоделированного по форме спектра аудиоконтента. Кроме того, в кодер аудиосигнала введен драйвер доступа к данным антиалиасинга, формирующий представление сигнала стимуляции антиалиасинга таким образом, чтобы в результате фильтрации сигнала стимуляции антиалиасинга в зависимости от, по меньшей мере, подмножества параметров области линейного предсказания был генерирован сигнал безалиасингового синтеза, обеспечивающий устранение артефактов алиасинга на стороне декодера аудиосигнала.
Обсуждаемый здесь кодер аудиосигнала полностью совместим с описанным выше декодером аудиосигнала. В частности, кодер аудиосигнала формирует такое представление звукового материала, которое позволяет удерживать в рационально низких пределах избыточность битрейта, которая необходима для нейтрализации алиасинга на переходах между фрагментами (например, фреймами или подфреймами) аудиоконтента, закодированными в разных режимах.
Еще одной составляющей заявляемого изобретения является способ формирования декодированного представления аудиоконтента и способ формирования кодированного представления звукового материала (аудиоконтента). Названные способы базируются на тех же принципах, что и рассмотренные выше аппаратные средства.
Заявляемое изобретение включает в себя создание компьютерных программ осуществления указанных способов. Компьютерные программы также основаны на представленной выше концепции.
Краткое описание фигур
Далее, варианты конструктивных решений заявляемого изобретения будут рассмотрены со ссылкой на прилагаемые фигуры, где: на фиг.1 показана принципиальная блочная схема реализации кодера аудиосигнала в соответствии с данным изобретением; на фиг.2А и 2B представлена принципиальная блочная схема реализации декодера аудиосигнала в соответствии с данным изобретением; на фиг.3А представлена принципиальная блочная схема образца декодера аудиосигнала согласно рабочей версии 4 проекта стандарта по «гибридному кодированию речи и звука» (USAC); на фиг.3B представлена принципиальная блочная схема другого варианта решения декодера аудиосигнала в соответствии с данным изобретением; на фиг.4 дано графическое представление образцов оконных переходов в соответствии с рабочей версией 4 проекта стандарта USAC; на фиг.5 схематически представлены возможные варианты оконных переходов при осуществлении кодирования аудиосигнала согласно изобретению; на фиг.6 представлена обзорная таблица всех типов окон, используемых аудиокодером или аудиодекодером, реализованными в соответствии с данным изобретением; на фиг.7 представлена таблица возможных оконных последовательностей, используемых аудиокодером или аудиодекодером, реализованными в соответствии с данным изобретением; на фиг.8А, 8B, 8C, 8D детализирована принципиальная блочная схема реализации кодера аудиосигнала в соответствии с изобретением; на фиг.9А, 9B, 9C, 9D детализирована принципиальная блочная схема реализации декодера аудиосигнала в соответствии с изобретением; на фиг.10 схематически представлены варианты операции декодирования переходов от и к ACELP с упреждающим антиалиасингом (РАС);на фиг.11 представлена схема вычисления кодером целевого РАС; на фиг.12 представлена схема квантования целевого РАС в контексте формирования искажения в частотной области (FDNS); в таблице 1дан перечень условий введения в битстрим вариантов фильтра LPC; на фиг.13 представлена принципиальная блочная схема обратного квантователя взвешенного алгебраического LPC-кодирования; в таблице 2 дан перечень возможных абсолютных и относительных видов квантования и соответствующей сигнализации „mode_lpc» в битстриме; в таблице 3 дан перечень режимов кодирования для номеров nk кодового словаря; в таблице 4 представлен нормирующий множитель (коэффициент нормализации) W для алгебраического векторного квантования (AVQ); в таблице 5 представлено построение кодовых соответствий средней энергии возбуждения 
Подробное техническое описание
1. Декодер аудиосигнала на фиг.1
На фиг.1 дана принципиальная блочная схема реализации кодера аудиосигнала (аудиокодера) 100 в соответствии с изобретением. Аудиокодер 100 принимает входное представление 110 аудиоконтента и на его базе генерирует кодированное представление 112 аудиоконтента. Кодированное представление 112 аудиоконтента включает в себя первый набор 112а спектральных коэффициентов, массив параметров области линейного предсказания 112b и представление 112 с сигнала стимуляции антиалиасинга.
В состав аудиокодера 100 входит преобразователь сигнала из временной области в частотную область (время-частотный преобразователь) 120, пересчитывающий входное представление 110 аудиоконтента (или его вариант, прошедший предварительную обработку - препроцессинг 110') в частотное представление 122 аудиоконтента (которое может иметь форму набора коэффициентов спектрального разложения).
Кроме того, аудиокодер 100 включает в свой состав спектральный процессор 130, который формирует спектр частотного представления 122 аудиоконтента, или его модификации 122' в результате препроцессинга, с учетом набора 140 параметров области линейного предсказания для фрагмента аудиоконтента, который подлежит кодированию в области линейного предсказания, с формированием в частотной области представления аудиоконтента, рассчитанного по форме спектра 132. Первый набор 112а спектральных коэффициентов может быть идентичен частотному представлению 132, рассчитанному по форме спектра аудиоконтента, или может быть выведен из него же.
Аудиокодер 100 также включает в себя драйвер доступа 150 к данным антиалиасинга, формирующий представление 112 с задающего сигнала антиалиасинга таким образом, что пропускание сигнала активации антиалиасинга в зависимости от, хотя бы, подмножества параметров области линейного предсказания 140 обеспечивает синтез безалиасингового сигнала 112b с устранением артефактов наложения спектров на стороне декодера аудиосигнала.
Следует обратить внимание на то, что параметры области линейного предсказания 112b могут, в том числе, быть идентичными параметрам области линейного предсказания 140.
Аудиокодер 100 формирует поток данных, полностью отвечающий требованиям реконструкции аудиоконтента, даже если разные фрагменты (допустим, фреймы или субфреймы) аудиоконтента закодированы в различных режимах. Например, для фрагмента аудиоконтента, закодированного в области линейного предсказания в режиме линейного предсказания с возбуждением кодом трансформанты, моделирование спектра, сопровождаемое формированием искажения, что обеспечивает квантование аудиоконтента с относительно невысоким битрейтом, осуществляют после преобразования из временной области в частотную область (время-частотного преобразования). Это дает возможность выполнять компенсирующее алиасинг сложение наложением фрагмента аудиоконтента, закодированного в области линейного предсказания, с предыдущим или последующим фрагментом аудиоконтента, закодированным в частотной области. Задействование параметров области линейного предсказания 140 способствует построению формы спектра, хорошо адаптированной к аудиоконтенту, подобному речи, обеспечивая высокую эффективность его кодирования. В дополнение к этому представление сигнала активации антиалиасинга обеспечивает действенную нейтрализацию эффекта наложения спектров (алиасинга) на переходах между фрагментами (например, фреймами или подфреймами) звукового контента, закодированными в режиме линейного предсказания с алгебраическим кодовым возбуждением. Благодаря учету параметров области линейного предсказания при формировании представления сигнала активации антиалиасинга такое представление является особенно эффективным и может быть декодировано на стороне декодера, учитывающего параметры области линейного предсказания, которые в любом случае присутствуют в декодере.
Исходя из сказанного, кодер аудиосигнала 100 характеризуется полным соответствием требованиям переходов между фрагментами аудиоконтента, закодированными в разных режимах кодирования, и возможностью предоставления антиалиасинговой информации в особо компактной форме.
2. Декодер аудиосигнала на фиг.2А и 2B
На фиг.2А и 2B отображена принципиальная блочная схема реализации декодера аудиосигнала (аудиодекодера) 200 в соответствии с изобретением. Аудиодекодер 200 служит для приема кодированного представления 210 аудиоконтента и формирования на его базе декодированного представления 212 аудиоконтента, например, в форме сигнала временной области с компенсированным алиасингом.
Аудиодекодер 200 включает в себя тракт области трансформанты (например, тракт области линейного предсказания с кодовым возбуждением в трансформанте), функцией которого является формирование представления во временной области 212 звукового материала, закодированного в трансформанте на базе первого набора 220 спектральных коэффициентов, представления 224 сигнала возбуждения антиалиасинга и множества параметров области линейного предсказания 222. В состав тракта трансформанты входит спектральный процессор 230, предназначенный для приложения формы спектра к (первому) набору 220 спектральных коэффициентов, исходя из, по меньшей мере, некоторого подмножества параметров области линейного предсказания 222 с получением рассчитанного по форме спектра варианта 232 первой последовательности 220 спектральных коэффициентов. Кроме того, тракт в области трансформанты включает в себя (первый) преобразователь из частотной области во временную область 240, формирующий представление аудиоконтента во временной области 242 на базе рассчитанного по форме спектра варианта первой последовательности 220 спектральных коэффициентов. Наряду с этим в схему тракта трансформанты входит фильтр сигнала активации антиалиасинга 250, рассчитанный на пропускание задающего сигнала компенсации наложения спектров (в виде представления 224), исходя из, по меньшей мере, некоторого подмножества параметров области линейного предсказания 222, с выведением из сигнала активации антиалиасинга сигнала, синтезированного с устранением алиасинга 252. Тракт области трансформанты также включает в свой состав комбинатор 260, выполняющий функцию сведения представления аудиоконтента во временной области 242 (или его варианта, прошедшего дополнительную завершающую обработку - построцессинг 242') и сигнала антиалиасингового синтеза 252 (или его варианта, прошедшего постпроцессинг 252') с выработкой сигнала с компенсированным алиасингом во временной области.
Аудиодекодер 200 может иметь в своем составе в качестве опции процессор 270, предусматривающий выведение из, по меньшей мере, некоторого набора параметров области линейного предсказания [222] рабочих характеристик спектрального процессора 230, который выполняет, например, масштабирование и/или формирование искажения в частотной области.
Кроме того, в схему аудиодекодера 200 в качестве вспомогательного элемента может быть включен процессор 280, предусматривающий выведение из, по меньшей мере, некоторой совокупности параметров области линейного предсказания 222 рабочих характеристик фильтра возбуждения антиалиасинга 250, который способен, например, выполнять функции синтезирующего фильтра, реконструирующего аудиосигнал с устранением алиасинга 252.
Аудиодекодер 200 выполнен с возможностью формирования сигнала во временной области с компенсацией алиасинга 212, одинаково хорошо совместимого как с сигналом временной области, представляющим аудиоконтент и сгенерированным в режиме частотной области, так и с сигналом временным области, представляющим аудиоконтент и закодированным в режиме ACELP. Особенно хорошо сочетаются при наложении и сложении фрагменты (например, фреймы) аудиоконтента, декодированные в режиме частотной области (с использованием тракта частотной области, не показанного на фиг.2А и 2B), и фрагменты (например, фреймы или субфреймы) аудиоконтента, декодированные с использованием тракта трансформанты на фиг.2А и 2B, поскольку спектральный процессор 230 формирует искажение в частотной области, то есть - до преобразования из частотной области во временную область 240. Кроме того, особенно эффективен антиалиасинг на переходах между сегментом (например, фреймом или подфреймом) аудиоконтента, декодируемьм с использованием тракта области трансформанты на фиг.2А и 2B, и сегментом (например, фреймом или подфреймом) аудиоконтента, декодируемого с использованием тракта декодирования ACELP, вследствие того, что сигнал с устранением алиасинга 252 синтезируется на основе фильтрации стимулирующего сигнала антиалиасинга в зависимости от параметров области линейного предсказания. Синтезируемый таким образом безалиасинговый сигнал 252, как правило, хорошо настроен на нейтрализацию артефактов алиасинга, возникающих на переходе между фрагментом аудиоконтента, закодированным в режиме [области линейного предсказания с кодовым возбуждением из трансформанты] TCX-LPD, и фрагментом аудиоконтента, закодированным в режиме [линейного предсказания с алгебраическим кодовым возбуждением] ACELP. Далее дана более глубокая детализация процесса декодирования аудиосигнала.
3. Коммутируемые аудиодекодеры на фиг.3А и 3B
Ниже для краткого обсуждения представлена концепция мультирежимного декодера аудиосигнала со ссылкой на фиг.3А и 3B.
3.1 Декодер аудиосигнала 300 на фиг.3А
Фиг 3А отображает принципиальную блочную схему стандартного мультирежимного декодера аудиосигнала (многорежимного аудиодекодера), на фиг.3B представлена принципиальная блочная схема конструктивного решения мультирежимного декодера аудиосигнала в соответствии с данным изобретением.
Говоря иначе, на фиг.3А показано прохождение сигнала в базовой стандартной системе декодирования (например, в соответствии с прототипом 4 проекта стандарта гибридного кодирования речи и звука USAC), а на фиг.3B показано прохождение сигнала в базовой модели декодера, технически решенной в соответствии с изобретением.
Сначала аудиодекодер 300 будет описан со ссылкой на фиг.3А. Аудиодекодер 300 включает в свой состав битовый мультиплексор 310, который принимает входной битстрим и распределяет информацию, содержащуюся в этом потоке двоичных данных, между целевыми процессорами соответствующих контуров преобразования. В схему аудиодекодера 300 входит тракт частотной области 320, куда поступает информация о коэффициентах масштабирования 322 и закодированная информация о спектральных коэффициентах 324, и где на базе этой информации для аудиофрейма, закодированного в режиме частотной области, формируется представление во временной области 326. В схему аудиодекодера 300 также входит тракт области линейного предсказания с возбуждением кодами в трансформанте 330, который принимает кодированную информацию о кодах возбуждения в трансформанте 332 и информацию о коэффициентах линейного предсказания 334 (также обозначаемую как данные кодирования с линейными предикторами или как информация области линейного предсказания или как параметры фильтра линейно-предиктивного кодирования [и mn], и на базе этой информации формирует представление во временной области аудиофрейма или аудиосубфрейма, закодированного в режиме области линейного предсказания с кодовьм возбуждением из трансформанты (в режиме TCX-LPD). Кроме того, схема аудиодекодера 300 включает в себя тракт линейного предсказания с алгебраическим кодовым возбуждением (тракт ACELP) 340, который принимает кодированные данные возбуждения 342 и данные линейно-предиктивного кодирования 344 (также обозначаемые как информация о коэффициентах линейного предсказания, или как данные области линейного предсказания, или кк параметры фильтра линейно-предиктивного кодирования) и на их базе формирует во временной области информацию о линейном предиктивном кодировании представления аудиофрейма или аудиосубфрейма, закодированного в режиме ACELP. Аудиодекодер 300 также включает в свою схему устройство оконного взвешивания переходов 350, предназначенное для приема представлений во временной области 326, 336, 346 фреймов или подфреймов аудиоконтента, закодированных в разных режимах, и компоновки представления во временной области с использованием оконного взвешивания переходов [между ними].
В тракт частотной области 320 введены: арифметический декодер 320а, декодирующий кодированное спектральное представление 324 с получением на выходе декодированного спектрального представления 320b, обратный квантователь 320с, генерирующий обратно проквантованное спектральное представление 320d на базе декодированного спектрального представления 320b, блок масштабирования 320е, пересчитывающий масштаб обратно проквантованного спектрального представления 320d на основании масштабных коэффициентов с получением на выходе масштабированного спектрального представления 320f, и блок (обратного) модифицированного дискретного косинусного преобразования (ОМДКП) 320g, генерирующий представление во временной области 326 на базе масштабированного спектрального представления 320f.
В тракт TCX-LPD 330 введены: арифметический декодер 330а, генерирующий декодированное спектральное представление 330b на базе кодированного спектрального представления 332, обратный квантователь 330с, генерирующий обратно квантованное спектральное представление 330d на базе декодированного спектрального представления 330b, блок (обратного) модифицированного дискретного косинусного преобразования 330е, генерирующий сигнал возбуждения 330f на основе обратно квантованного спектрального представления 330d, и синтезирующий фильтр линейно-предиктивного кодирования 330g, формирующий представление во временной области 336 на базе сигнала возбуждения 330f и коэффициентов фильтрации для кодирования с линейным предсказанием 334 (также называемых иногда коэффициентами пропускания фильтра области линейного предсказания).
В тракт ACELP 340 введены: процессор возбуждения ACELP 340а, генерирующий возбуждающий сигнал ACELP 340b на базе закодированного сигнала возбуждения 342, и синтезирующий фильтр линейно-предиктивного кодирования 340 с, генерирующий представление во временной области 346 на базе сигнала возбуждения ACELP 340b и коэффициентов фильтрации для кодирования с линейным предсказанием 344.
3.2 Оконное взвешивание переходов в соответствии с фиг.4
Теперь, обращаясь к фиг.4, более подробно рассмотрим оконное взвешивание переходов 350. Во-первых, обратим внимание на общий принцип разбиения на фреймы, используемый декодером аудиосигнала 300. При этом следует отметить, что очень похожий - с незначительными отличиями, или даже без таковых - принцип разделения на фреймы будет использован в других описываемых здесь аудиокодерах или аудиодекодерах. Принято, что аудиофреймы обычно имеют длину в N отсчетов, где N может достигать 2048. Последовательные фреймы аудиоконтента могут перекрываться примерно до 50%, например, числом N/2 аудиоотсчетов. Аудиофрейм может быть закодирован в частотной области таким образом, что N временных отсчетов аудиофрейма будут представлены набором, например, из N/2 спектральных коэффициентов. Или, N временных отсчетов аудиофрейма могут быть представлены последовательностью, допустим, из восьми наборов, скажем, по 128 спектральных коэффициентов. Таким образом может быть получена более высокая разрешающая способность по времени.
Если N временных отсчетов аудиофрейма закодированы в режиме частотной области с использованием одного набора спектральных коэффициентов, может быть применено одно окно, например, так называемое окно «STOP_START», так называемое окно «ААС Long», так называемое окно «AAC Start» или так называемое окно «AAC Stop» для оконного взвешивания временных отсчетов 326, полученных в результате обратного модифицированного дискретного косинусного преобразования 320g, И наоборот, может быть применено множество более коротких окон, скажем, типа «AAC Short», для оконного взвешивания представлений во временной области, полученных с использованием множества наборов спектральных коэффициентов, если N отсчетов аудиофрейма во временной области закодированы с использованием множества наборов спектральных коэффициентов. Например, отдельные короткие окна могут быть приложены к представлениям во временной области, полученным на основе индивидуальных наборов спектральных коэффициентов, связанных с одним аудиофреймом.
Аудиофрейм, закодированный в режиме линейного предсказания, может быть разбит на множество подфреймов, которые иногда называют «фреймами». Каждый из подфреймов может быть закодирован или в режиме TCX-LPD или в режиме ACELP. При этом в режиме TCX-LPD два или даже четыре субфрейма могут быть закодированы совокупно с использованием одного набора спектральных коэффициентов, описывающих возбуждение, кодированное в трансформанте.
Субфрейм (или группа из двух или четырех субфреймов), закодированный в режиме TCX-LPD, может быть представлен набором спектральных коэффициентов и одним или более наборов коэффициентов пропускания фильтра линейно-предиктивного кодирования. Подфрейм аудиоконтента, закодированный в области ACELP, может быть представлен кодированным сигналом возбуждения ACELP и одними или более наборами коэффициентов пропускания фильтра линейно-предиктивного кодирования.
Теперь, ссылаясь на фиг.4, рассмотрим выполнение переходов между фреймами или подфреймами. На графиках фиг.4 по осям абсцисс с 402а по 402i отложены временные аудиоотсчеты, а на осях ординат с 404а по 404i отображены окна и/или временные области, для которых сделана выборка временных отсчетов.
В ссылке под номером 410 показан переход между двумя взаимно перекрывающимися фреймами, закодированными в частотной области. Ссылка номер 420 отображает переход от субфрейма, закодированного в режиме ACELP, к фрейму, закодированному в режиме частотной области. В ссылке номер 430 представлен переход от фрейма (или подфрейма), закодированного в режиме TCX-LPD (также обозначаемом как режим «wLPT»), к фрейму, закодированному в режиме частотной области. На графике со ссылкой 440 продемонстрирован переход между фреймом, закодированным в режиме частотной области, и субфреймом, закодированным в режиме ACELP. В примере со ссылкой номер 450 проиллюстрирован переход между подфреймами, закодированными в режиме ACELP. В ссылке под номером 460 отображен переход от субфрейма, закодированного в режиме TCX-LPD, к субфрейму, закодированному в режиме ACELP. Под номером 470 дана ссылка на переход от фрейма, закодированного в режиме частотной области, к под фрейму, закодированному в режиме TCX-LPD. В ссылке номер 480 приведен пример перехода между подфреймом, закодированным в режиме ACELP, и подфреймом, закодированным в режиме TCX-LPD. Ссылка номер 490 дает образец перехода между подфреймами, закодированными в режиме TCX-LPD.
Заслуживает внимание, что переход от режима области TCX-LPD к режиму частотной области, показанный под номером ссылки 430, весьма неэффективен, вернее даже. очень неэффективно TCX-LPD в силу того, что часть информации, передаваемой декодеру, не учитывается. Подобно этому переходы между режимом ACELP и режимом TCX-LPD, показанные в ссылках 460 и 480, выполняются неэффективно вследствие того, что часть информации, передаваемой декодеру, теряется.
3.3 Декодер аудиосигнала 360 на фиг.3B
Далее будет описана реализация декодера аудиосигнала 360 в соответствии с изобретением.
Аудиодекодер 360 включает в свой состав битовый мультиплексор или анализатор синтаксиса битстрима 362, который принимает представление битового потока 361 аудиоконтента и на его основе распределяет элементы информации между различными трактами аудиодекодера 360.
Аудиодекодер 360 имеет в своем составе ветвь частотной области 370, куда поступает кодированная информация о коэффициентах масштабирования 372 и кодированные спектральные данные 374 от мультиплексора битстрима 362, и где на базе этой информации формируется представление во временной области 376 фрейма, закодированного в частотной области. Аудиодекодер 360 также включает в себя ветвь TCX-LPD 380, которая принимает кодированное спектральное представление 382 и кодированные коэффициенты пропускания фильтра линейно-предиктивного кодирования 384 и на их базе формирует представление во временной области 386 аудиофрейма или аудиосубфрейма, закодированного в области TCX-LPD.
Аудиодекодер 360 включает в свой состав ветвь ACELP 390, которая принимает кодированное возбуждение ACELP 392 и кодированные коэффициенты пропускания фильтра кодирования с линейным предсказанием 394 и на их базе формирует представление во временной области 396 аудиосубфрейма, закодированного в режиме ACELP.
Кроме этого, аудиодекодер 360 имеет в своем составе блок оконного взвешивания 398 переходов в представлениях во временной области 376, 386, 396 фреймов и субфреймов, закодированных в разных режимах, для получения непрерывного аудиосигнала.
Здесь следует отметить, что ветвь частотной области 370 по своим общим конструктивным и функциональным характеристикам может быть идентична тракту частотной области 320, даже при том, что ветвь частотной области 370 может содержать иные или дополнительные механизмы антиалиасинга. Кроме того, ветвь ACELP 390 по своей общей структуре и функциям может быть идентичной тракту ACELP 340, в силу чего к ней применимо описание, приведенное выше.
В то же время, ветвь TCX-LPD 380 отличается от тракта TCX-LPD 330 тем, что в тракте TCX-LPD 380 искажение формируют до выполнения обратного МДКП. Более того, в контур ветви TCX-LPD 380 введены дополнительные функциональные возможности нейтрализации алиасинга.
Ветвь TCX-LPD 380 включает в себя арифметический декодер 380а, который принимает кодированное спектральное представление 382 и на его базе формирует декодированное спектральное представление 380b. Ветвь TCX-LPD 380 включает в себя также обратный квантователь 380с, который принимает декодированное спектральное представление 380b и на его базе формирует обратно проквантованное спектральное представление 380d. Кроме того, ветвь TCX-LPD 380 включает в себя блок масштабирования и/или формирования искажения в частотной области 380е, который принимает обратно проквантованное спектральное представление 380d и параметры формирования спектра 380f и на их базе генерирует рассчитанное по форме спектра представление 380g для передачи в блок обратного модифицированного дискретного косинусного преобразования 380h, который формирует на базе представления 380g, рассчитанного по форме спектра, представление во временной области 386. Кроме названного, ветвь TCX-LPD 380 включает в себя преобразователь 380i коэффициентов линейного предсказания в частотную область, который рассчитывает данные спектрального масштабирования 380f на базе коэффициентов пропускания фильтра кодирования с линейным предсказанием 384.
Если рассматривать функции, выполняемые декодером аудиосигнала 360, то можно сказать, что ветвь частотной области 370 и ветвь области TCX-LPD 380 идентичны, так как в технологическую цепочку каждой из них включены арифметическое декодирование, обратное квантование, масштабирование спектра и обратное модифицированное дискретное косинусное преобразование в одной и той же последовательности. Соответственно, выходные сигналы 376, 386 из ветвей частотной 370 и TCX-LPD 380 областей очень похожи в силу того, что они оба могут представлять собой нефильтрованные (за исключением оконного взвешивания переходов) выходные сигналы обратных модифицированных дискретных косинусных преобразований. Следовательно, к сигналам временной области 376, 386 очень хорошо применима операция сложения наложением, с помощью которой достигается нейтрализация алиасинга во временной области. Благодаря этому переходы между аудиофреймом, закодированным в режиме частотной области, и аудиофреймом или аудиосубфреймом, закодированным в режиме TCX-LPD, могут быть эффективно выполнены с помощью простой операции сложения наложением без использования какой-либо дополнительной антиалиасинговой информации и без каких-либо потерь данных. Следовательно, достаточно минимального объема служебной информации.
Наряду с этим следует обратить внимание на то, что масштабирование обратно квантованного спектрального представления, выполняемое в тракте частотной области 370 на основании из информации о коэффициентах масштабирования, результативно способствует ограничению шума квантования, вносимого на стороне кодера при квантовании и на стороне декодера при обратном квантовании 320с, при этом подобный способ формирования искажения хорошо подходит для общеакустических сигналов, например, музыкальных. И наоборот, масштабирование и/или формирование искажения в частотной области 380е, выполняемое на основании коэффициентов пропускания фильтра линейно-предиктивного кодирования, результативно способствует ограничению шума квантования, вызванного квантованием на стороне кодера и обратным квантованием на стороне декодера 380с, что хорошо подходит для речеподобных звуковых сигналов. Из этого следует, что функции ветви частотной области 370 и ветви области TCX-LPD 380 различаются лишь формированием искажения в частотной области, когда использование ветви частотной области 370 обеспечивает особенно высокую эффективность кодирования (или качество звучания) общеакустических сигналов, а использование ветви TCX-LPD 380 обеспечивает особенно высокие эффективность кодирования или акустическое качество аудиосигналов, подобных звучанию речи.
Следует отметить, что ветвь TCX-LPD 380 предпочтительно включает в себя дополнительные механизмы антиалиасинга для переходов между аудиофреймами или аудиосубфреймами, закодированными в режиме TCX-LPD и в режиме ACELP. Детали рассмотрены ниже.
3.4 Оконное взвешивание переходов в соответствии с фиг.5
На фиг.5 схематически представлены графики типов оконного взвешивания, которые может выполнять аудиодекодер 360 или любые другие кодеры и декодеры аудиосигнала в соответствии с данным изобретением. На фиг.5 отображены алгоритмы оконного взвешивания возможных вариантов переходов между фреймами или подфреймами, закодированными в разных режимах. Абсциссы по осям с 502а по 502i отображают временные отсчеты аудиосигнала, а оси ординат с 504а по 504i обозначают окна или субфреймы, формирующие представление аудиоконтента во временной области.
График 510 отображает переход между последовательными фреймами, закодированными в частотной области. Как можно видеть, временные отсчеты первой, правой, половины фрейма (полученные, допустим, обратным модифицированным дискретным косинусным преобразованием (МДКП) 320g) ограничены правой половиной 512 окна, которое может быть, например, окном типа «AAC Long» или окном типа «ААС Stop». Аналогичным образом временные отсчеты левой половины следующего, второго, фрейма (полученные, допустим, в результате МДКП 320g) могут быть ограничены левой половиной 514 окна, которое может представлять собой, скажем, окно типа «ААС Long» или «ААС Stop». Правая половина 512, в частности, может включать в себя достаточно продолжительный правосторонний спад на переходе, а левая половина 514 следующего окна может включать в себя сравнительно длинный подъем на переходе. Взвешенный (с использованием правой половины окна 512) вариант представления во временной области первого аудиофрейма и взвешенный (с использованием левой половины окна 514) вариант представления во временной области следующего, второго, аудиофрейма могут быть суммированы наложением. Таким образом алиасинг, результирующий из МДКП, может быть эффективно нейтрализован.
График 520 отображает переход от субфрейма, закодированного в режиме ACELP, к фрейму, закодированному в частотной области. На подобном переходе для устранения артефактов алиасинга может быть применен прямой (упреждающий) антиалиасинг.
График 530 отображает переход от субфрейма, закодированного в режиме ТСХ-LPD, к фрейму, закодированному в частотной области. Как можно видеть, окно 532 приложено к временным отсчетам, полученным обратным МДКП 380h в тракте TCX-LPD, при этом окно 532 может являться, например, окном типа «ТСХ256», «ТСХ512» или «ТСХ1024». Окно 532 может включать в себя переход с правосторонним нисходящим фронтом 533 длиной в 128 временных отсчетов. Окно 534 приложено к отсчетам во временной области, полученным путем МДКП в тракте частотной области 370 для следующего аудиофрейма, закодированного в режиме частотной области. Окно 534 может представлять собой, например, окно типа «Stop Start» или «ААС Stop» и может включать в себя левосторонний восходящий фронт 535 на переходе длиной, допустим, 128 временных отсчетов. Временные отсчеты подфрейма области TCX-LPD, входящие в окно, ограниченное правосторонним спадом 533 на переходе, складывают наложением с временными отсчетами следующего аудиофрейма, кодированного в режиме частотной области, которые входят в окно, ограниченное левосторонним подъемом 535 на переходе. Спадающий 533 и нарастающий 535 фронты такого перехода от субфрейма, закодированного в режиме TCX-LPD, к следующему субфрейму, закодированному в режиме частотной области, согласованы таким образом, что алиасинг нейтрализуется. Нейтрализация алиасинга становится возможной благодаря масштабированию/формированию искажения в частотной области 380е до выполнения обратного МДКП 380h. Другими словами, антиалиасинг достигается за счет того, что как при обратном МДКП 320g тракта частотной области 370, так и при обратном МДКП 380h ветви TCX-LPD 380 вводят спектральные коэффициенты, для которых искажение уже сформировано (например, путем масштабирования на базе масштабных коэффициентов и масштабирования на базе коэффициентов пропускания фильтра линейно-предиктивного кодирования LPC).
График 540 отображает переход от аудиофрейма, закодированного в режиме частотной области, к субфрейму, закодированному в режиме ACELP. Как можно видеть, применение на этом переходе прямого антиалиасинга (FAC) обеспечивает частичное или даже полное устранение артефактов наложения спектров.
График 550 отображает переход от аудиосубфрейма с кодированием в режиме ACELP к другому аудиосубфрейму с кодированием в ACELP. При реализации специальные антиалиасинговые мероприятия не требуются.
График 560 отображает переход от субфрейма, кодированного в режиме TCX-LPD (также называемом режимом wLPT [преобразования со взвешенным линейным предсказанием]) к аудиосубфрейму с кодировкой в режиме ACELP. Можно видеть, что отсчеты временной области, полученные на выходе МДКП 380h ветви TCX-LPD 380 взвешены с помощью оконной функции 562, которая может иметь, в частности, форму окна «ТСХ256», «ТСХ512» или «ТСХ1024». Окно 562 включает в себя сравнительно короткий правосторонний спад 563 на переходе. Временные отсчеты следующего аудиосубфрейма, закодированного в режиме ACELP, имеют частичное временное наложение на аудиоотсчеты предшествующего аудиосубфрейма, закодированного в режиме TCX-LPD, которые находятся в пределах правого среза 563 окна 562. Временные аудиоотсчеты аудиосубфрейма, закодированного в режиме ACELP, показаны в блоке 564.
На графике видно, что введение сигнал прямого антиалиасинга 566 на переходе от аудиофрейма, закодированного в режиме TCX-LPD, к аудиофрейму, закодированному в режиме ACELP, обеспечивает частичное или даже полное устранение артефактов алиасинга. Детали введения антиалиасингового сигнала 566 будут описаны ниже.
График 570 отображает переход от фрейма, закодированного в режиме частотной области, к фрейму, закодированному в режиме TCX-LPD. Временные отсчеты, полученные обратным МДКП 320g ветви частотной области 370, могут быть взвешены оконной функцией 572, например, типа «Stop Start» или типа «AAC Start» с относительно коротким правосторонним спадом 573 на переходе. Представление во временной области, полученное обратным МДКП 380h ветви TCX-LPD 380 для следующего аудиосубфрейма, закодированного в режиме TCX-LPD, могут быть взвешены оконной функцией 574, такой, как «ТСХ256», «ТСХ512», или «ТСХ1024», с относительно коротким левосторонним подъемом 575 на переходе. Временные отсчеты, входящие в окно, ограниченное правосторонним нисходящим фронтом 573 на переходе, и временные отсчеты, входящие в окно, ограниченное левосторонним восходящим фронтом 575 на переходе складывают наложением путем оконного взвешивания перехода 398 с частичной компенсацией или даже полным подавлением артефактов алиасинга. Следовательно, для выполнения перехода от аудиофрейма, закодированного в частотной области, к аудиосубфрейму, закодированному в режиме области TCX-LPD, дополнительная служебная информация не требуется.
График 580 отображает переход от аудиофрейма с кодировкой в ACELP к аудиофрейму, кодированному в режиме TCX-LPD (он же - wLPT). Временные отсчеты на выходе ветви ACELP включены в интервал времени 582. К временным отсчетам на выходе обратного МДКП 380h ветви TCX-LPD 380 приложено окно 584. Окно 584 может относиться к типу «ТСХ256», «ТСХ512» или «ТСХ1024» и включать в себя сравнительно короткий левосторонний подъем 585. Левосторонний подъем 585 на переходе окна 584 частично перекрывает отсчеты временной области ветви ACELP, входящие в блок 582. В дополнение к этому вводят антиалиасинговый сигнал 586 для частичного или полного устранения артефактов наложения спектров, которые возникают на переходе от аудиосубфрейма, закодированного в режиме ACELP, к аудиосубфрейму, закодированному в режиме TCX-LPD. Подробно введение сигнала антиалиасинга 586 рассмотрено далее.
График 590 отображает переход между двумя аудиосубфреймами, закодированными в режиме TCX-LPD. Временные отсчеты первого аудиосубфрейма с кодировкой в TCX-LPD взвешены окном 592, например, типа «ТСХ256», «ТСХ512» или «ТСХ1024», которое может включать в себя относительно короткий правосторонний переходный уклон 593. Временные аудиоотсчеты второго аудиосубфрейма, закодированного в TCX-LPD, полученные обратным МДКП 380h ветви TCX-LPD 380, взвешиваются с помощью окна 594, например, типа «ТСХ256», «ТСХ512» или «ТСХ1024», которое может включать в себя относительно короткий левосторонний переходный подъем 595. Отсчеты временной области, входящие в окно, ограниченное правосторонним переходным уклоном 593, и отсчеты временной области, входящие в окно, ограниченное левосторонним переходным уклоном 595, складывают наложением при взвешивании перехода 398. Таким образом частично или полностью нейтрализуется алиасинг, результирующий из (обратного) МДКП 380h.
4. Обзор типов окон
Далее дан анализ всех типов окон. Для этого обратимся к фиг.6, где в виде таблицы графически представлены различные типы окон и их характеристики. В столбце 610 таблицы на фиг.6 даны длины левостороннего перекрывания, которые могут равняться длине левостороннего подъема на переходе. В столбце 612 даны длины преобразования, т.е. - количество спектральных коэффициентов, используемых для генерирования представления во временной области, взвешиваемого соответствующим окном. В столбце 614 даны длины правостороннего перекрывания, которое может равняться длине правостороннего спада на переходе. В столбце 616 даны названия типов окон. В столбце 618 дано графическое представление соответствующих оконных (взвешивающих) функций.
В первой строке 630 даны характеристики окна типа «AAC Short». Во второй строке 632 даны характеристики окна типа «ТСХ256». В третьей строке 634 даны характеристики окна типа «ТСХ512». В четвертой строке 636 даны характеристики окон типа «ТСХ1024» и «Stop Start». В пятой строке 638 даны характеристики окна типа «AAC Long». В шестой строке 640 даны характеристики окна типа «AAC Start», и в седьмой строке 642 даны характеристики окна типа «AAC Stop».
Примечательно, что у окон типов «ТСХ256», «ТСХ512» и «ТСХ1024» скосы на переходах адаптированы к правостороннему скату границы окна «AAC Start» и к левостороннему скату границы окна «AAC Stop», что обеспечивает нейтрализацию алиасинга во временной области путем сложения наложением временных представлений, взвешенных разными видами оконных функций. В предпочтительном варианте реализации левосторонние скосы (скаты на переходах) всех типов окон, имеющих одинаковые длины левостороннего участка наложения, могут быть идентичны, также и правосторонние скосы всех типов окон, имеющих одинаковые длины правостороннего участка наложения, могут быть идентичны. Кроме того, левосторонние переходные скосы и правосторонние переходные скосы, имеющие одинаковые длины участков наложения, могут быть подобраны так, чтобы обеспечивать нейтрализацию алиасинга, удовлетворяя требованиям антиалиасинга МДКП.
5. Допустимые последовательности окон
Далее, на фиг.7 в виде таблицы представлены возможные последовательности окон. Из таблицы на фиг.7 видно, что за аудиофреймом, закодированным в частотной области, чьи временные отсчеты взвешены окном типа «AAC Stop», может следовать аудиофрейм, закодированный в режиме частотной области, временные отсчеты которого взвешены окном типа «AAC Long» или окном типа «AAC Start».
За аудиофреймом с кодировкой в режиме частотной области, чьи временные отсчеты взвешены окном типа «AAC Long», может следовать аудиофрейм, закодированный в режиме частотной области, чьи временные отсчеты взвешены окном типа «AAC Long» или «AAC Start».
Аудиофреймы, закодированные в формате линейного предсказания, временные отсчеты которых взвешены с использованием окна типа «AAC Start», восьми окон типа «AAC Short» или окна типа «AAC StopStart», могут быть последовательно сменены аудиофреймом, закодированным в режиме частотной области, чьи временные отсчеты взвешены с использованием восьми окон типа «AAC Short», окна типа «AAC Short» или окна типа «AAC StopStart». В другом случае за аудиофреймами с кодировкой в режиме частотной области, чьи временные отсчеты взвешены окном типа «AAC Start», восемью окнами типа «AAC Short» или окном типа «AAC StopStart», может следовать аудиофрейм или субфрейм, закодированный в формате TCX-LPD (также обозначаемом LPD-TCX), или аудиофрейм или субфрейм, закодированный в формате ACELP (также обозначаемом LPD ACELP).
Аудиофрейм или аудиосубфрейм, закодированный в формате TCX-LPD, может быть последовательно замещен аудиофреймами с кодировкой в режиме частотной области, временные отсчеты которых взвешиваются с помощью восьми окон «AAC Short» и с помощью окна «AAC Stop» или с помощью окна «AAC StopStart», или аудиофреймом или аудиосубфреймом, закодированным в формате TCX-LPD, или аудиофреймом или аудиосубфреймом, закодированным в формате ACELP.
За аудиофреймом, закодированным в режиме ACELP, могут следовать аудиофреймы, кодированные в режиме частотной области, чьи временные отсчеты взвешиваются с использованием восьми окон «AAC Short», с использованием окна «AAC Stop», с использованием окна «AAC StopStart», аудиофрейм, с кодировкой в режиме TCX-LPD или аудиофрейм с кодировкой в режиме ACELP.
При переходах от аудиофрейма, закодированного в формате ACELP, к аудиофрейму, закодированному в режиме частотной области, или к аудиофрейму, закодированному в режиме TCX-LPD, выполняют так называемый прямой антиалиасинг (РАС).
Таким образом на подобном переходе между фреймами к представлению во временной области добавляют сигнал антиалиасингового синтеза, посредством чего редуцируют или купируют артефакты наложения спектров. Аналогичным образом FAC применяют при коммутации фрейма или субфрейма, кодированного в частотной области, или фрейма или субфрейма в формате TCX-LPD на фрейм или субфрейм с кодировкой в формате ACELP.
Детально FAC будет рассмотрен ниже.
6. Кодер аудиосигнала на фиг.8А, 8B, 8C, 8D
Далее дана детализация мультирежимного кодера аудиосигнала 800 со ссылкой на фиг.8А, 8B, 8C, 8D.
Аудиокодер 800 принимает входное представление 810 акустического материала и на его основе генерирует битовый поток 812 представления аудиоконтента. Аудиокодер 800 работает в различных режимах, в частности - в режиме частотной области, в режиме линейного предсказания с возбуждением, кодированным в трансформанте (TCX-LPD), и в режиме линейного предсказания с алгебраическим кодовым возбуждением (ACELP).B компоновку аудиокодера 800 введен контроллер кодирования 814, который выбирает один из режимов кодирования фрагмента аудиоконтента в зависимости от характеристик входного представления 810 аудиоконтента и/или в зависимости от достижимой эффективности кодирования или качества звучания.
Аудиокодер 800 включает в свою схему контур (ветвь) частотной области 820, генерирующий на базе входного представления 810 аудиоконтента кодированные спектральные коэффициенты 822, кодированные масштабные коэффициенты 824 и - факультативно-кодированные коэффициенты антиалиасинга 826. Далее, аудиокодер 800 включает в свою схему тракт (ветвь) TCX-LPD 850, генерирующий на базе входного представления 810 аудиоконтента кодированные спектральные коэффициенты 852, кодированные параметры области линейного предсказания 854 и кодированные коэффициенты антиалиасинга 856. Далее, аудиодекодер 800 включает в себя тракт (ветвь) ACELP 880, генерирующий на базе входного представления 810 аудиоконтента кодированное возбуждение ACELP 882 и кодированные параметры области линейного предсказания 884.
Ветвь частотной области 820 включает в себя преобразователь из временной области в частотную область (время-частотный преобразователь) 830, который принимает входное представление 810 аудиоконтента или его предварительно обработанную версию и на этой базе вырабатывает представление аудиоконтента в частотной области 832. Кроме этого, контур частотной области 820 включает в себя психоакустический анализатор 834, предназначенный для оценивания эффектов частотного маскирования и/или эффектов динамического маскирования звукоданных и для компоновки на базе этого информации, описывающей коэффициенты масштабирования 836. Контур частотной области 820 также включает в себя спектральный процессор 838, предназначенный для приема частотного представления 832 звукоданных и информации о коэффициентах масштабирования 836 и для применения частотно-зависимого и времязависимого масштабирования к спектральным коэффициентам представления в частотной области 832 на основе данных о масштабных коэффициентах 836 с целью формирования масштабированного представления в частотной области 840 аудиоконтента. Далее, ветвь частотной области 820 включает в себя блок квантования/кодирования 842, предназначенный для приема масштабированного частотного представления 840 и выполнения квантования и кодирования с целью выведения на основе масштабированного частотного представления 840 кодированных спектральных коэффициентов 822. Вместе с тем, в контур частотной области 820 введен блок квантования/кодирования 844, принимающий информацию о коэффициентах масштабирования 836 и компонующий на ее базе кодированную информацию о масштабных коэффициентах 824. В качестве опции в ветвь частотной области 820 может быть введен вычислитель 846 коэффициентов антиалиасинга 826.
Ветвь (тракт) TCX-LPD 850 включает в себя преобразователь из временной области в частотную область (время-частотный преобразователь) 860, выполненный с возможностью приема входного представления 810 звукоданных и формирования на его основе представления аудиоконтента в частотной области 861. Кроме того, тракт TCX-LPD 850 включает в себя вычислитель параметров области линейного предсказания 862, выполненный с возможностью приема входного представления 810 звукоданных или их предобработанной версии и выведения на его основе одного или более параметров области линейного предсказания (например, коэффициентов пропускания фильтра линейно-предиктивного кодирования) 863. Также, в тракт TCX-LPD 850 введен преобразователь 864 из области линейного предсказания в спектральную область, выполненный с возможностью приема параметров области линейного предсказания (таких как коэффициенты пропускания фильтра линейно-предиктивного кодирования) и формирования на их базе спектрального или частотного представления 865. Представление в спектральной области или представление в частотной области параметров области линейного предсказания может, например, отображать характеристики фильтра, описанного параметрами области линейного предсказания в частотной области или в спектральной области. Далее, ветвь TCX-LPD 850 содержит спектральный процессор 866, предназначенный для приема представления в частотной области 861 или его предобработанной версии 861' и представления в частотной области или представления в спектральной области параметров области линейного предсказания 863. Спектральный процессор 866 предназначен для построения формы спектра частотного представления 861 или его предобработанной версии 861', где частотное представление или спектральное представление 865 параметров области линейного предсказания 863 служит для настройки масштабирования различных спектральных коэффициентов частотного представления 861 или его предобработанной версии 861'. Таким образом, спектральный процессор 866 вырабатывает рассчитанную по форме спектра версию 867 частотного представления 861 или его предобработанной версии 861' на базе параметров области линейного предсказания 863. Помимо этого, ветвь TCX-LPD 850 включает в себя блок квантования/кодирования 868, предназначенный для приема рассчитанного по форме спектра представления в частотной области 867 и выработки на его базе кодированных спектральных коэффициентов 852. Одновременно, в ветвь TCX-LPD 850 введен другой блок квантования/кодирования 869, предназначенный для приема параметров области линейного предсказания 863 и формирования на их базе кодированных параметров области линейного предсказания 854.
Далее, в схемотехнику тракта TCX-LPD 850 включены средства вычисления коэффициентов антиалиасинга 856. В состав средств расчета антиалиасинговых коэффициентов входит вычислитель ошибок 870, формирующий данные искажений алиасинга 871 на основе кодированных спектральных коэффициентов и входного представления 810 звукоданных. При вычислении ошибок 870 произвольно могут учитываться данные 872 других дополнительно рассчитанных компонентов антиалиасинга. В средства вычисления коэффициентов антиалиасинга также входит вычислитель анализирующего фильтра 873, предоставляющий информацию 873а о фильтрации ошибок в зависимости от параметров области линейного предсказания 863. Кроме того, к средствам вычисления коэффициентов антиалиасинга относится фильтр анализа ошибок 874, который принимает информацию об ошибках алиасинга 871 и информацию о конфигурации фильтра анализа 873а и выполняет анализирующую фильтрацию ошибок, регулируемую с учетом данных анализирующей фильтрации 873а относительно информации об ошибках алиасинга 871 с выводом данных фильтрации ошибок алиасинга 874а. Помимо названного, к средствам вычисления коэффициентов антиалиасинга относится время-частотный преобразователь 875, который может выполнять дискретное косинусное преобразование IV типа, и который принимает данные фильтрации ошибок алиасинга 874а, формируя на их базе частотное представление 875а данных фильтрации искажений алиасинга 874а. Наряду с этим, в редства вычисления коэффициентов антиалиасинга входит блок квантования/кодирования 876, в который поступает частотное представление 875а для генерации на его базе кодированных коэффициентов антиалиасинга 856, которые содержат кодированное представление в частотной области 875а.
Дополнительно в средства вычисления коэффициентов антиалиасинга может быть включен вычислитель 877 взноса ACELP в антиалиасинг. Вычислитель 877 может выполнять расчет или оценивание взноса в нейтрализацию алиасинга аудиосубфрейма, закодированного в режиме ACELP, предшествующего аудиофрейму, закодированному в режиме TCX-LPD. В состав вычислителя доли ACELP в антиалиасинге могут быть введены устройства, выполняющие расчет синтеза после ACELP, оконное взвешивание синтеза после ACELP и свертывание взвешенного синтеза после ACELP с выводом информации 872 о дополнительных составляющих антиалиасинга, которые могут быть получены из предшествующего аудиосубфрейма, закодированного в режиме ACELP. Вместе с этим, или вместо этого, вычислитель 877 может включать в себя вычислитель отклика на нулевой входной сигнал фильтра, инициализированного декодированием предыдущего аудиосубфрейма, кодированного в режиме ACELP, и оконным взвешиванием указанного отклика на нулевой входной сигнал с выводом информации 872 о дополнительных компонентах антиалиасинга.
Ниже дан краткий обзор ветви (тракта) ACELP 880. Ветвь ACELP 880 включает в себя вычислитель 890 параметров области линейного предсказания 890а, выводимых на основе входного представления 810 звукоданных. Далее, ветвь ACELP 880 включает в свой состав вычислитель данных возбуждения ACELP 892 на основе входного представления 810 звукоданных и параметров области линейного предсказания 890а. Ветвь ACELP 880 содержит также кодер 894 данных возбуждения ACELP 892, генерирующий кодированное возбуждение ACELP 882. В дополнение к этому ветвь ACELP 880 содержит блок квантования/кодирования 896, в который вводят параметры области линейного предсказания 890а и на их базе получают кодированные параметры области линейного предсказания 884.
Декодер аудиосигнала 800 кроме перечисленного включает в свою компоновку форматер битстрима 898, который формирует поток двоичных данных 812 на базе кодированных спектральных коэффициентов 822, закодированной информации о коэффициентах масштабирования 824, антиалиасинговых коэффициентов 826, кодированных спектральных коэффициентов 852, кодированных параметров области линейного предсказания 852, кодированных антиалиасинговых коэффициентов 856, кодированного возбуждения ACELP 882, и кодированных параметров области линейного предсказания 884.
Детали выведения кодированных коэффициентов антиалиасинга 856 будут описаны дальше.
7. Декодер аудиосигнала на фиг.9А, 9B, 9C, 9D
Ниже, со ссылкой на фиг.9А, 9B, 9C, 9L рассматривается декодер аудиосигнала (аудиодекодер) 900.
Аудиодекодер 900 на фиг.9А однотипен с аудиодекодером 200 на фиг.2А, а также - с аудиодекодером 360 на фиг.3B, вследствие чего данные выше пояснения сохраняют силу.
Аудиодекодер 900 включает в свою конструкцию битовый мультиплексор 902, который принимает битовый поток и распределяет извлеченную из него информацию между соответствующими схемотехническим трактами (ветвями).
Аудиодекодер 900 включает в себя ветвь частотной области 910, в которую поступают закодированные спектральные коэффициенты 912 и закодированная информация о коэффициентах масштабирования 914. Кроме того, факультативно контур частотной области 910 может принимать антиалиасинговые коэффициенты, обеспечивающие выполнение так называемого прямого (упреждающего) антиалиасинга, например, при переходе между аудиофреймом, закодированным в режиме частотной области и аудиофреймом, закодированным в режиме ACELP. Тракт частотной области 910 формирует представление во временной области 918 звукового контента аудиофрейма, закодированного в режиме частотной области.
Аудиодекодер 900 включает в свою конфигурацию ветвь TCX-LPD 930, которая принимает кодированные спектральные коэффициенты 932, кодированные параметры области линейного предсказания 934 и кодированные коэффициенты антиалиасинга 936 и на их базе формирует представление во временной области звукового фрейма или субфрейма, закодированного в режиме TCX-LPD. Аудиодекодер 900 также включает в себя ветвь ACELP 980, в которую вводят кодированное возбуждение ACELP 982 и закодированные параметры области линейного предсказания 984, и которая на их базе формирует представление во временной области 986 аудиофрейма или аудиосубфрейма, закодированного в режиме ACELP.
7.1 Тракт частотной области
В этом разделе будут подробно рассмотрены элементы тракта частотной области 910. Заметим, что тракт частотной области 910 подобен тракту частотной области 320 аудиодекодера 300, что позволяет обратиться к описанию, данному ранее. Ветвь частотной области 910 включает в себя арифметический декодер 920, который принимает кодированные спектральные коэффициенты 912 и на их базе генерирует декодированные спектральные коэффициенты 920а, и обратный квантователь 921, который принимает декодированные спектральные коэффициенты 920а и на их базе генерирует обратно квантованные спектральные коэффициенты 921а. В состав ветви частотной области 910 также входит декодер масштабных коэффициентов 922, который принимает данные кодирования масштабных коэффициентов и на их базе генерирует декодированную информацию о коэффициентах масштабирования 922а. В ветвь частотной области включено устройство масштабирования 923, которое принимает на входе обратно квантованные спектральные коэффициенты 921а и масштабирует их в соответствии с масштабными коэффициентами 922а и генерирует на выходе спектральные коэффициенты в масштабном пересчете 923а. Допустим, множеству частотных полос присвоены масштабные множители 922а, тогда с каждой из множества полос частот будет соотнесен каждый из множества частотных дискретов со спектральным коэффициентом 921а. Соответственно, может быть выполнено масштабирование спектральных коэффициентов 923а для настройки диапазона частот. Поэтому количество масштабных коэффициентов, соотнесенных с аудиофреймом, как правило, меньше количества спектральных коэффициентов 921а, соотнесенных с ним. Ветвь частотной области 910 включает в себя также обратный преобразователь МДКП 924, который, принимая на входе масштабированные спектральные коэффициенты 923а, формирует из них представление звукоданных текущего аудиофрейма во временной области 924а. В качестве опции ветвь частотной области 910 может включать в себя комбинатор (блок сведения) 925 для совмещения представления во временной области 924а с сигналом антиалиасингового синтеза 929а с получением на выходе представления во временной области 918. При этом, возможны конструктивные решения, где комбинатор 925 опущен, и представление во временной области 924а выводится как представление аудиоконтента во временной области 918.
Для выработки сигнала безалиасингового синтеза 929а в тракт частотной области введены декодер 926а, генерирующий декодированные коэффициенты антиалиасинга 926b из кодированных коэффициентов антиалиасинга 916, и блок масштабирования 926 с коэффициентов антиалиасинга, генерирующий масштабированные антиалиасинговые коэффициенты 926d на базе декодированных коэффициентов антиалиасинга 926b. Наряду с названным, тракт частотной области включает в свою схему обратный дискретный косинусный преобразователь типа IV 927, который принимает масштабированные коэффициенты антиалиасинга 926d и на их базе генерирует сигнал стимуляции антиалиасинга 927а, вводимый в фильтр синтеза 927b. Фильтр синтеза 927b выполняет функцию синтезирующего фильтрования на базе стимулирующего сигнала антиалиасинга 927а и коэффициентов пропускания фильтра синтеза 927 с, генерируемых вычислителем фильтра синтеза 927d, с получением в результате синтез-фильтрования сигнала с компенсацией алиасинга 929а. Вычислитель фильтра синтеза 927d рассчитывает коэффициенты пропускания синтезирующего фильтра 927с на основе параметров области линейного предсказания, которые могут быть извлечены, например, из параметров области линейного предсказания, поступающих с битстримом для фрейма, закодированного в режиме TCX-LPD, или для фрейма, закодированного в режиме ACELP (или могут быть равнозначными этим параметрам области линейного предсказания).
Таким образом, с помощью синтез-фильтрования 927b может быть синтезирован сигнал без эффекта наложения спектров, (алиасинга) 929а, который может быть эквивалентным сигналу антиалиасингового синтеза 522 или 542 на фиг.5.
7.2 Тракт TCX-LPD
Далее, кратко обсудим тракт TCX-LPD 930 декодера аудиосигнала 900. Ниже даны дополнительные детали.
Тракт (контур) TCX-LPD 930 включает в себя блок синтеза основного сигнала 940, формирующий представление во временной области 940а звукоданных аудиофрейма или аудиосубфрейма на базе кодированных спектральных коэффициентов 932 и кодированных параметров области линейного предсказания 934. Ветвь TCX-LPD 930 также включает в себя блок антиалиасинговой обработки, описываемый ниже.
Синтезатор основного сигнала 940 имеет в своем составе арифметический декодер 941 спектральных коэффициентов, генерирующий декодированные спектральные коэффициенты 941а на базе кодированных спектральных коэффициентов 932. Синтезатор основного сигнала 940, кроме этого, имеет в своем составе обратный квантователь 942, генерирующий обратно квантованные спектральные коэффициенты 942а на базе декодированных спектральных коэффициентов 941а. К обратно квантованным спектральным коэффициентам 942а может быть применена обработка во вспомогательной цепи заполнения шумом 943 для получения спектральных коэффициентов с шумозаполнением. Обратно квантованный спектральный коэффициент с шумозаполнением 943а может быть обозначен как r[i]. К спектральным коэффициентам с обратным квантованием и шумозаполнением, r[i], 943a, может быть применено деконфигурирование спектра 944 с получением спектральных коэффициентов 944а деконфигурированного спектра, иногда обозначаемых r[i]. Блок масштабирования 945 может выполнять функцию формирования искажения в частотной области 945. В результате формирования искажения в частотной области 945 получают рассчитанный по форме спектра набор спектральных коэффициентов 945а, носящих еще обозначение rr[i]. При формировании искажения в частотной области 945 определяют доли спектральных коэффициентов де-формированного спектра 944а в спектральных коэффициентах, рассчитанных по форме спектра 945а, с помощью параметров формирования искажения в частотной области 945b, выводимых вычислителем параметров формирования искажения в частотной области, что будет рассматриваться ниже. Посредством формирования искажения в частотной области 945 набору спектральных коэффициентов деформированного спектра 944а присваивают относительно большие веса в случае, если частотная характеристика фильтра линейного предсказания, описанного параметрами области линейного предсказания 934, принимает сравнительно небольшое значение для частоты, соотнесенной с соответствующим конкретно взятым спектральным коэффициентом (из набора спектральных коэффициентов 944а. И наоборот, спектральному коэффициенту из набора спектральных коэффициентов 944а присваивают сравнительно больший вес при определении соответствующих спектральных коэффициентов в наборе 945а спектральных коэффициентов, рассчитанных по форме спектра, если частотная характеристика фильтра линейного предсказания, описанного параметрами области линейного предсказания 934, принимает сравнительно небольшое значение для частоты, соотнесенной с конкретным спектральным коэффициентом (из набора 944а). Таким образом, форму спектра, определяемую параметрами области линейного предсказания 934, применяют в частотной области при выведении рассчитанного по форме спектра спектрального коэффициента 945а из спектрального коэффициента де-формированного спектра 944а.
В блок синтеза основного сигнала 940 введен обратный МДКП-преобразователь 946, который принимает рассчитанные по форме спектра спектральные коэффициенты 945а и формирует на их основе представление во временной области 946а. После этого к представлению во временной области 946а применяют масштабный пересчет коэффициентов усиления 947, получая на выходе представление аудиоконтента во временной области 940а. Масштабирование усиления 947, выполняемое с применением коэффициента усиления g, представляет собой преимущественно частотно-независимую (не избирательную по частоте) операцию.
Процесс синтеза основного сигнала включает в себя процедуру обработки параметров формирования искажения в частотной области 945b, что описано далее. Для выработки параметров формирования искажения в частотной области 945b синтезатор основного сигнала 940 задействует декодер 950 кодированных параметров области линейного предсказания 934, генерирующий декодированные параметры области линейного предсказания 950а. Декодированные параметры области линейного предсказания могут, например, принять форму первого набора LPC1 декодированных параметров области линейного предсказания и второго набора LPC2 параметров области линейного предсказания. Первый набор параметров области линейного предсказания, LPC1, может быть соотнесен, например, с левосторонним переходом фрейма или аудиофрейма, закодированного в режиме TCX-LPD, а второй набор параметров области линейного предсказания, LPC2, может быть соотнесен с правосторонним переходом закодированного в TCX-LPD аудиофрейма или аудиосубфрейма. Декодированные параметры области линейного предсказания вводят в вычислитель спектра 951 для выработки представления в частотной области импульсной характеристики, определяемой параметрами области линейного предсказания 950а. В частности, первому, LPC1, и второму, LPC2, наборам декодированных параметров области линейного предсказания 950 могут быть приданы отдельные наборы коэффициентов частотной области Х0[k].
При расчете усиления 952 спектральные величины X0[k] преобразуются в значения коэффициентов усиления, при этом первый набор значений коэффициентов усиления g2[k] соотнесен с первым набором LPC1 спектральных коэффициентов, а второй набор значений коэффициентов усиления g2[k] соотнесен со вторым набором LPC2 спектральных коэффициентов. Например, значения коэффициентов усиления могут быть обратно пропорциональны величинам соответствующих спектральных коэффициентов. В вычислитель параметров фильтра 953 могут быть введены значения коэффициентов усиления 952а для расчета на их базе параметров фильтра 945b для формирования искажения в частотной области 945. Могут быть сгенерированы, скажем, параметры фильтра a[i] и b[i]. Параметры фильтра 945b обусловливают долю спектральных коэффициентов де-формированного спектра 944а среди спектрально-масштабированных спектральных коэффициентов 945а. Подробности возможного расчета параметров фильтра будут рассмотрены ниже.
В функции ветви TCX-LPD 930 входит расчет синтеза сигнала с применением прямого антиалиасинга, при этом выполнение расчета распределено между двумя контурами. Первый контур синтеза сигнала с (прямым) антиалиасингом включает в свой состав декодер 960, который принимает закодированные коэффициенты антиалиасинга 936 и на их основе выводит декодированные коэффициенты антиалиасинга 960а, которые затем проходят масштабирование 961 в зависимости от коэффициента усиления g с получением на выходе масштабированных коэффициентов антиалиасинга 961а. В некоторых реализациях один и тот же коэффициент усиления g может быть использован для масштабирования 961 коэффициентов антиалиасинга 960а и для масштабирования коэффициентов усиления 947 сигнала во временной области 946а, полученного обратным МДКП 946. Алгоритм синтеза безалиасингового сигнала включает в себя деформирование (деконфигурирование) спектра 962, которое может быть приложено к масштабированным коэффициентам антиалиасинга 961а с выведением масштабированных по усилению антиалиасинговых коэффициентов деконфигурированного спектра 962а. Деформирование спектра 962 может быть выполнено аналогично де-формированию спектра 944, что будет описано ниже. Масштабированные по усилению коэффициенты антиалиасинга деконфигурированного спектра 962а являются входными данными для обратного дискретного косинусного преобразования типа IV 963, результатом которого является задающий сигнал антиалиасинга 963а. Затем, сигнал стимуляции антиалиасинга 963а преобразуется в первый сигнал, синтезированный с применением прямого антиалиасинга 9б4а фильтром синтеза 964, сконфигурированным согласно коэффициентам фильтрации 9б5а, рассчитанным вычислителем 965 фильтра синтеза исходя из параметров области линейного предсказания LPC1, LPC2. Более подробно процедуры фильтрации синтеза 964 и расчета коэффициентов пропускания синтезирующего фильтра 9б5а описаны дальше. Из сказанного следует, что первый сигнал безалиасингового синтеза 9б4а строится на коэффициентах антиалиасинга 936 и на параметрах области линейного предсказания. Хорошая согласованность между сигналом антиалиасингового синтеза 9б4а и представлением аудиоконтента во временной области 940а достигается за счет применения при их формировании одного и того же масштабного коэффициента g, а также аналогичной или даже идентичной процедуры де-формирования спектра 944, 962. Далее, в функции ветви TCX-LPD 930 входит выработка дополнительных сигналов безалиасингового синтеза 973а, 976а в зависимости от предшествующего фрейма или субфрейма ACELP. Этот [«второй» в ветви TCX-LPD] контур 970 вычисления взноса ACELP в антиалиасинг предназначен для приема такой информации ACELP, как, например, сформированное трактом ACELP 980 представления во временной области 986 и/или данные синтезирующего фильтра ACELP. Контур вычисления 970 взноса ACELP в антиалиасинг выполняет такие операции, как расчет 971 синтеза после ACELP 971a, оконное взвешивание 972 при синтезе после ACELP 971а и свертывание 973 при синтезе после ACELP 972а. Следовательно, взвешенный и свернутый сигнал, синтезированный после ACELP 973а, сформирован путем свертывания взвешенного сигнала, синтезированного после ACELP 972а. Кроме того, контур вычисления 970 взноса ACELP в антиалиасинг выполняет расчет 975 отклика на нулевой входной сигнал (характеристик при отсутствии входного сигнала) фильтра синтеза представления во временной области предшествующего субфрейма ACELP при том, что исходное состояние указанного фильтра синтеза может совпадать с состоянием фильтра синтеза ACELP в конце предшествующего субфрейма ACELP. Таким образом определяют отклик на нулевой сигнал 975а, к которому применяют оконное взвешивание 976 для выведения взвешенного отклика на нулевой входной сигнал 976а. Дополнительные подробности вычисления взвешенного отклика на нулевой входной сигнал 976а будут даны позднее.
В завершение выполняется сведение 978 сигнала представления аудиоконтента во временной области 940а, первого сигнала, синтезированного с прямым антиалиасингом 964а, второго сигнала, синтезированного с прямым антиалиасингом 973а и третьего сигнала, синтезированного с прямым антиалиасингом 976а. В результате такого совмещения 978 строится представление во временной области 938 аудиофрейма или аудиосубфрейма, закодированного в режиме TCX-LPD, что более подробно будет описано в дальнейшем.
7.3 Тракт ACELP
Дальше кратко описана ветвь ACELP 980 аудиодекодера 900. Ветвь ACELP 980 включает в себя декодер 988 кодированного возбуждения ACELP 982 для генерирования декодированного сигнала возбуждения ACELP 988а. Затем, сигнал возбуждения проходит этап вычисления и постпроцессинга 989 с выводом модифицированного сигнала возбуждения 989а. Ветвь ACELP 980 включает в себя декодер 990 параметров области линейного предсказания 984 для генерирования декодированных параметров области линейного предсказания 990а. Модифицированный сигнал возбуждения 989а проходит синтезирующее фильтрование 991 с учетом параметров области линейного предсказания 990а, преобразуясь на выходе в синтезированный сигнал ACELP 991а. После этого синтезированный сигнал ACELP 991а проходит постпроцессинг 992 с формированием представления во временной области 986 аудиосубфрейма, закодированного в режиме ACELP.
7.4 Сведение сигнала
В завершение осуществляется сведение 996 сигналов представления во временной области 918 аудиофрейма, закодированного в режиме частотной области, представления во временной области 938 аудиофрейма, закодированного в режиме TCX-LPD, и представления во временной области 986 аудиофрейма, закодированного в режиме ACELP, с формированием на выходе представления во временной области 998 звуковых данных.
Дополнительные подробности представлены в дальнейшем.
8. Детализация кодера и декодера
8.1 Фильтр LPC
8.1.1 Описание инструментария
Далее представлены детали кодирования и декодирования с применением коэффициентов фильтрации линейно-предиктивного кодирования.
В режиме ACELP передаваемые данные содержат параметры фильтров LPC 984, индексы адаптивной и фиксированной кодовых таблиц 982, коэффициенты усиления адаптивной и фиксированной кодовых таблиц 982.
В режиме ТСХ поток данных включает в себя параметры фильтров LPC 934, параметры энергии и индексы квантования 932 коэффициентов МДКП. В этом подразделе описано декодирование фильтров LPC, например, с коэффициентами фильтрации LPC a1-a16 950a, 990a.
8.1.2 Определения
Ниже даны некоторые определения.
Показатель «nb_lpc» обозначает общее количество наборов параметров LPC, декодируемых в двоичном потоке.
Показатель битстрима «mode_lpc» обозначает режим кодирования следующего набора параметров LPC.
Показатель битстрима «lpc [k][x]» обозначает параметр LPC номер х из набора k.
Параметр битстрима «qn k» обозначает двоичный код, соотнесенных с соответствующими номерами nk кодовой таблицы.
8.1.3 Количество фильтров LPC
Фактическое количество „nb_lpc» фильтров LPC, закодированных в битовом потоке, зависит от комбинации режимов ACELP/TCX в суперфрейме, который может быть идентичен фрейму, состоящему из множества субфреймов. Данные о комбинации режимов ACELP/TCX получают из поля «lpd_mode», которое, в свою очередь, определяет режимы кодирования «mod[k]» при k=0-3 для каждого из 4 фреймов (субфреймов), составляющих суперфрейм. Режимы имеют следующие числовые значения: 0 для ACELP, 1 для короткого ТСХ (256 отсчетов), 2 для среднего ТСХ (512 отсчетов), 3 для длинного ТСХ (1024 отсчета). Здесь следует отметить, что показатель «lpd_mode» битстрима, который можно рассматривать как битовое поле «режим», определяет режимы кодирования для каждого из четырех фреймов внутри одного суперфрейма в потоке канала частотной области (который соответствует одному аудиофрейму частотной области, такому, например, как фрейм ААС (усовершенствованного алгоритма кодирования звука)). Режимы кодирования хранятся в памяти в виде матрицы «mod[]» со значениями от 0 до 3. Соответствие параметра битстрима «LPD_mode» матрице «mod[]» можно определить из таблицы 7.
Относительно матрицы «mod[0…3]» можно сказать, что матрица «mod[]» указывает на соответствующие режимы кодирования в каждом фрейме. Соответствие значений «mod[]» режимам кодирования во фрейме и элементам битстрима подробно показано в таблице 8.
В дополнение к фильтрам LPC 1-4 суперфрейма в пересылаемые данные включен добавочный LPC-фильтр LPCO для первого суперфрейма каждого фрагмента, закодированного с использованием корневого кодека LPD. В процедуре декодирования на основе линейного предсказания (LPC-декодирования) это индицируется флажком «first_lpd_flag», установленным на 1.
Обычный порядок нахождения фильтров LPC в битовом потоке: LPC4, добавочный LPC0, LPC2, LPC1 и LPC3. Условия наличия в битстриме конкретного фильтра LPC отображены в таблице 1.
Выполняется синтаксический анализ битстрима для выведения коэффициентов квантования, соответствующих каждому фильтру LPC, который требуется для данного сочетания режимов ACELP/TCX, Ниже описаны операции, выполняемые для декодирования одного из фильтров LPC.
8.1.4 Общий принцип действия обратного квантователя
Обратное квантование фильтра LPC, которое может потребоваться при декодировании 950 или при декодировании 990, выполняют согласно схеме на фиг.13. Фильтры LPC квантуют, применяя представление в виде частот линейчатого спектра (LSF). Сначала вычисляют первичную аппроксимацию, как описано в разделе 8.1.6. Затем, произвольно может быть выполнен расчет дополнительной оптимизации путем алгебраического векторного квантования (AVQ) 1330, как описано в разделе 8.1.7. Вектор квантования частот линейчатого спектра LSF реконструируют суммированием 1350 аппроксимации первой ступени и обратно взвешенного взноса алгебраического векторного квантования AVQ 1342. Применение оптимизации AVQ зависит от фактически используемого режима квантования фильтра LPC, как поясняется в разделе 8.1.5. После этого вектор обратного квантования LSF конвертируют в параметры вектора LSP (пары линейчатого спектра), которые впоследствии интерполируют и вновь преобразуют в параметры LPC.
8.1.5 Декодирование режима квантования LPC
Далее описывается операция декодирования режима квантования LPC, которая может входить в процедуру декодирования 950 или 990.
LPC4 всегда квантуют с применением метода абсолютного квантования. Другие фильтры LPC могут быть проквантованы как методом абсолютного квантования, так и одним из нескольких методов относительного квантования. В первую очередь для этих LPC-фильтров из битстрима извлекают информацию о режиме квантования. Такую информацию маркируют как «mode_lpc», и в битстриме она сигнализируется двоичным кодом переменной длины, как указано в последнем столбце таблицы 2.
8.1.6 Аппроксимация первой ступени
Для каждого фильтра LPC режим квантования определяет порядок вычисления аппроксимации первой ступени 1320 на фиг.13.
Для режима абсолютного квантования (mode_lpc=0) из битстрима извлекают 8-битовый индекс, соответствующий стохастической, прошедшей векторное квантование (VQ), первичной аппроксимации. Аппроксимацию первой ступени 1320 затем рассчитывают простой подстановкой по таблице.
Для методов относительного квантования аппроксимацию первой ступени вычисляют, используя уже инверсно проквантованные LPC-фильтры, как указано во втором столбце таблицы 2. Например, для LPC0 предусмотрен только один режим относительного квантования, для которого инверсно квантованный фильтр LPC4 является аппроксимацией первой ступени. Для LPC1 возможны два способа относительного квантования: первый - когда первичную аппроксимацию выполняет инверсно квантованный LPC2, второй - когда первичной аппроксимацией служит среднее между обратно квантованными фильтрами LPC0 и LPC2. Как и все операции, относящиеся к квантованию LPC, вычисление аппроксимации первой ступени осуществляют в области частот линейчатого спектра (LSF).
8.1.7 Оптимизация AVQ
8.1.7.1 Общие замечания
Следующей по очередности информацией, извлекаемой из битстрима, являются данные по оптимизации алгебраического векторного квантования AVQ, необходимые для построения вектора обратного квантования LSF. Единственное исключение представляет LPC1: для него битстрим не содержит данные оптимизации AVQ, когда этот фильтр закодирован относительно (LPC0+LPC2)/2.
Алгебраическое векторное квантование AVQ осуществляется с использованием 8-мерного RE8 решетчатого векторного квантователя для квантования спектра в режимах ТСХ в адаптивном многоскоростном широкополосном формате AMR-WB+. Декодирование фильтров LPC включает в себя декодирование двух 8-мерных субвекторов 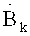
Данные AVQ для этих двух подвекторов извлекают из битстрима. Такая информация включает в себя два кодированных номера кодовой книги «qnl» и «qn2» и соответствующие индексы AVQ. Эти параметры декодируют следующим образом.
8.1.7.2 Декодирование номеров кодовой книги
Первыми параметрами, которые извлекают из битстрима для декодирования оптимизации AVQ, являются два номера кодовой книги nk, k=1 и 2, для каждого из двух названных выше субвекторов. Номера кодовой книги кодируют в зависимости от фильтра LPC (LPC0-LPC4) и режима его квантования (абсолютного или относительного). Как показано в таблице 3, существует четыре разных способа кодирования nk. Детализация кодов для nk приведена ниже.
Режимы nk 0 и 3. Номер nk кодовой книги закодирован как код переменный длины qnk следующим образом:
Q2 ® код для nk=00
Q3 ® код для nk=01
Q4 ® код для nk=10.
Другие: за кодом для nk=11 следуют:
Q5 ® 0
Q6 ® 10
Q0 ® 110
Q7 ® 1110
Q8 ® 11110
и т.д.
Режим nk 1.
Номер nk кодовой книги закодирован как унарный код qnk следующим образом:
Q0 ® унарный код для nk=0
Q2 ® унарный код для nk=10
Q3 ® унарный код для nk=110
Q4 ® унарный код для nk=1110
и т.д.
Режим nk 2.
Номер nk кодовой книги закодирован как код переменный длины qnk следующим образом:
Q2 ® код для nk=00
Q3 ® код для nk=01
Q4 ® код для nk=10.
Другие: за кодом для nk=11 следуют:
Q0 ® 0
Q5 ® 10
Q6 ® 110
и т.д.
8.1.7.3 Декодирование индексов AVQ
Декодирование фильтров LPC включает в себя декодирование параметров алгебраического векторного квантования AVQ, описывающих каждый квантованный субвектор
a) номер nk кодовой книги, который передают с использованием энтропийного кода «qnA», как описано выше;
b) ранг (уровень) Ik выбранного узла z решетки в так называемой базовой книге кодов, который указывает, какая перестановка необходима для данного заголовка массива, чтобы получить приближение к узлу z решетки;
c) и, если в базовой книге кодов отсутствует блок квантования
Затем, исходя из коэффициента масштабирования М, вектора ν расширения Вороного (узла решетки в RE8) и узла решетки z в базовой книге кодов (также узла решетки в RE8), каждый квантованный масштабированный блок 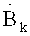
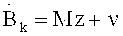
Когда расширение Вороного отсутствует (т.е. nk<5, М=1 и z=0), базовой кодовой книгой является книга кодов Q0, Q2, Q3 или Q4 из публикации М.Xie and J.-P.Adoul, «Embedded algebraic vector quantization (EAVQ) with application to wideband audio coding,» [«Встроенное алгебраическое векторное квантование (EAVQ) с применением к широкополосному кодированию звука»] «IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP),» Atlanta, GA, USA, vol.1, pp.240-243, 1996. В таком случае для передачи вектора k биты не требуются. В ином случае, когда применяется расширение Вороного из-за достаточно большого 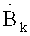
8.1.7.4 Расчет весов LSF
На стороне кодера веса, примененные к компонентам остаточного вектора LSF перед алгебраическим векторным квантованием AVQ, представляют собой:
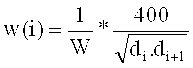
при:
d0=LSF1st[0]
d16=SF/2-LSF1st[15]
di=LSF1st[i]-LSF1st[i-1], i=1…15,
где LSF1st - первичная аппроксимация LSF, a W - масштабный коэффициент, зависящий от режима квантования (таблица 4).
На стороне декодера применяют соответствующий обратный порядок взвешивания 1340 для нахождения квантованного остаточного вектора LSF.
8.1.7.5 Реконструкция вектора обратного квантования LSF
Вектор обратного квантования LSF получают путем, сначала, сцепления двух субвекторов оптимизации AVQ, 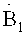

8.1.8 Переупорядочение квантованных LSF
Обратно квантованные частоты линейчатого фильтра LSF переупорядочивают, задавая перед использованием минимальный интервал между смежными LSF в 50 Гц.
8.1.9 Преобразование в параметры LSP
Процедура обратного квантования, описанная ранее, дает в результате набор характеристик LPC в области LSF. После этого частоты линейчатого фильтра LSF трансформируют в косинусоидальную область (в пары линейчатого спектра LSP), используя отношение qi=cos(wi), (i=1,…, 16, где wi - частоты линейчатого спектра (LSF).
8.1.10 Интерполяция параметров LSP
Несмотря на то, что пересылается только один LPC-фильтр, согласованный с концом фрейма, для каждого фрейма (или субфрейма) ACELP используют линейную интерполяцию с получением для каждого субфрейма (или сегмента субфрейма) отдельного фильтра (4 фильтра на фрейм или субфрейм ACELP). Интерполяцию выполняют между фильтром LPC, соответствующим концу предыдущего фрейма (или субфрейма), и фильтром LPC, соответствующим концу (текущего) фрейма ACELP. Пусть LSP(new) - новый вектор LSP, a LSF(old) - предшествующий вектор LSP. Интерполированные векторы LSP для субфреймов Nsfr=4 получаем с помощью
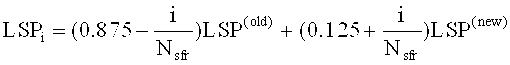
Интерполированные векторы LSP используют для вычисления отдельного фильтра линейного предсказания (LP//ЛП) в каждом подфрейме с использованием преобразования LSP в LP, описанного ниже.
8.1.11 Преобразование LSP в LP
Для каждого субфрейма интерполированные коэффициенты LSP трансформируют в коэффициенты фильтрации ЛП ak 950а, 990а, применяемые для синтеза в данном субфрейме восстановленного сигнала. По определению, пары линейчатого спектра LSP фильтра ЛП 16-го порядка представляют собой корни двух многочленов:
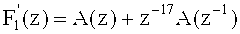
и
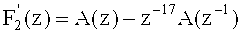
которые могут быть выражены как
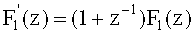
и
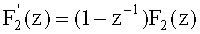
при
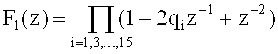
и
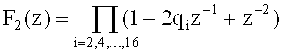
где qi, I=1,…, 16 - частоты LSF в косинусоидальной области, называемые также LSP (пары линейчатого спектра). Преобразование в область ЛП выполняют следующим образом. Коэффициенты F1(z) и F2(z) находят путем расширения приведенных выше уравнений за счет квантованных и интерполированных LSP. Следующее рекурсивное отношение используют для вычисления F1(z):
для i=1-8
f1(i)=-2q2i-1f1(i-1)+2f1(i-2)
j=i-1 до 1
f1(j)=f1(j)-2q2i-1f1(j-1)+f1(j-2)
конец
конец
при первоначальных значениях f1(0)=1 f1(-1)=0. Коэффициенты F2(z) рассчитывают аналогичным образом, заменяя q2i-1 на q2i.
Найдя коэффициенты F1(z) и F2(z), их умножают, соответственно, на 1+z-1 и 1-z-1, получая 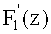
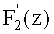
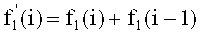
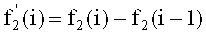
Наконец, из 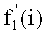
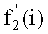
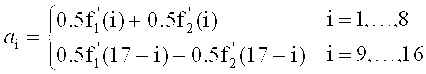
Это непосредственно вытекает из уравнения 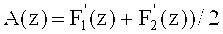
8.2. ACELP
Далее, более подробно рассматриваются процессы, осуществляемые ветвью ACELP 980 аудиодекодера 900, что облегчит понимание механизмов предотвращения эффекта наложения спектров, которые будут обсуждены позднее.
8.2.1 Определения
Дальше даны некоторые определения.
Элемент битстрима «mean_energy» описывает квантованную среднюю энергию возбуждения во фрейме. Элемент битстрима «acb_index[sfr]» указывает индекс адаптивного кодового словаря для каждого подфрейма.
Элемент битстрима «ltp_filtering_flag[sfr]» является флажком фильтрации возбуждения адаптивного кодового словаря. Элемент битстрима «lcb_index[sfr]» указывает индекс обновления кодового словаря для каждого подфрейма. Элемент битстрима «gains[sfr]» описывает квантованные коэффициенты усиления адаптивной кодовой книги и обновления кодовой книги относительно возбуждения.
Дополнительные подробности кодирования элемента битстрима «mean_energy» даны в таблице 5.
8.2.2 Настройка буфера возбуждения ACELP с использованием предшествовавшего синтеза частотной области (АВ/ЧО) и LPC0
Дальше говорится об опции инициализации буфера возбуждения ACELP, которая может выполняться блоком 990b.
В случае перехода из 40 в область ACELP до декодирования возбуждения ACELP обновляют предыдущий буфер возбуждения u(n) и буфер, содержащий предшествующий синтез с предыскажением 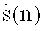
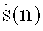
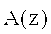
8.2.3 Декодирование возбуждения CELP
Если во фрейме текущим является режим CELP, возбуждение выполняется путем введения векторов масштабированной адаптивной кодовой книги и фиксированной кодовой книги. В каждом подфрейме возбуждение строится на повторении перечисленных ниже шагов.
Информация, необходимая для декодирования данных CELP, может рассматриваться как кодированное возбуждение ACELP 982. Также следует заметить, что декодирование возбуждения CELP может быть выполнено блоками 988, 989 ветви ACELP 980.
8.2.3.1 Декодирование возбуждения адаптивной кодовой книги с учетом элемента битстрима «асЬ index[]»
По полученному индексу основного тона (индексу адаптивной кодовой таблицы) ведется поиск целого числа и дробных частей запаздывания частоты основного тона.
Исходный вектор возбуждения в кодовой книге v'(n) находят путем интерполяции предшествующего возбуждения u(n) в момент задержки частоты основного тона и фазы (дробной части), используя интерполирующий фильтр КИХ.
Возбуждение по адаптивной кодовой книге вычисляют для субфрейма длиной в 64 отсчета. Полученный индекс адаптивного фильтра (ltp_filtering_flag[]) затем используют для принятия решения, является ли прошедшая фильтрование адаптивная кодовая книга v(n)=v'(n) или v(n)=0,18v'(n)+0,64v'(n-1)+0,18v'(n-2).
8.2.3.2 Декодирование возбуждения по обновляемой кодовой книге с использованием элемента битстрима «icb index[]»
Введенный индекс алгебраической кодовой книги используют для определения позиций и амплитуд (знаков) импульсов возбуждения и нахождения вектора алгебраического кода с(n). То есть
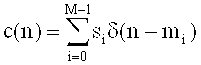
где mi и si - позиции импульса и знаки, а М - количество импульсов.
Вслед за декодированием вектора алгебраического кода с(n) выполняют процедуру заострения основного тона. Сначала с(n) фильтруют с помощью фильтра коррекции предыскажений, который задают так:
Femph(z)=1-0.3z-1
Фильтр коррекции предыскажений выполняет функцию ослабления энергии возбуждения в низких частотах. Затем, корректируют периодичность, используя адаптивный предварительный фильтр с передаточной функцией, определяемой как:
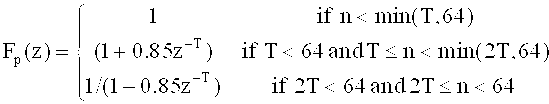
где n - индекс субфрейма (n=0,…, 63), и где Т - округленный вариант целочисленной части Т0 и дробной части T0,frac задержки частоты основного тона, который рассчитывают как:
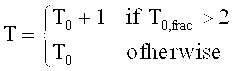
Адаптивный предварительный фильтр Fp(z) окрашивает спектр ослаблением межгармонических частот, раздражающих человеческое ухо при прохождении вокализованных сигналов.
8.2.3.3 Декодирование коэффициентов усиления адаптивной и обновляемой кодовой книги, описываемых элементом битстрима «gains[]»
Принимаемый 7-битовый индекс субфрейма напрямую обеспечивает коэффициент усиления адаптивной кодовой книги 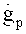
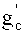
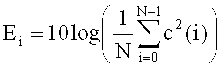
После этого рассчитывают ожидаемый коэффициент усиления 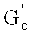
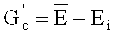
где 
Выигрыш от предсказания в линейной области дается как
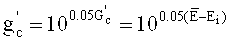
Квантованный коэффициент усиления фиксированной кодовой книги получают как
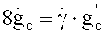
8.2.3.4 Расчет реконструированного возбуждения
Следующие шаги выполняют для n=0,…, 63. Полное возбуждение строится как:
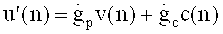
где с(n) - кодовый вектор из фиксированной кодовой таблицы после его фильтрации адаптивным предфильтром F(z). Сигнал возбуждения u'(n) используют для обновления содержимого адаптивной кодовой книги. Далее сигнал возбуждения u'(n) проходит постобработку, как описано в следующем разделе, с выводом постобработанного сигнала возбуждения и(п) для ввода в синтезирующий фильтр 
8.3 Постпроцессинг возбуждения
8.3.1 Общие указания
Далее описан постпроцессинг сигнала возбуждения, что может быть выполнено блоком 989. Другими словами, для синтеза сигнала может быть выполнена последующая доработка элементов возбуждения.
8.3.2 Сглаживание усиления для оптимизации шума
Для оптимизации возбуждения по искажениям применяют технику нелинейного сглаживания усиления 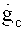
Коэффициент устойчивости q вычисляют, исходя из меры расстояния (/величины интервала) между смежными фильтрами ЛП. Здесь коэффициент q связан с величиной интервала ISF [иммитансных спектральных частот (immitance spectral frequencies/pairs=ISF/IS]. Интервал ISF определяют как
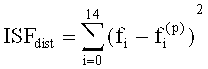
где fi - все ISF в текущем фрейме, 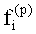
θ=1.25- ISFdist/1400000 в пределах 0≤θ≤1.
Мера расстояния между ISF уменьшается при стабильных сигналах. Поскольку значение q инверсно связано с величиной интервала ISF, то более стабильным сигналам соответствуют большие значения q. Коэффициент сглаживания усиления Sm рассчитывают как
Sm=λθ.
Значение Sm приближается к 1 для невокализованных и устойчивых сигналов, что характерно для стационарных сигналов фонового шума. Для чисто вокализованных сигналов или для неустойчивых сигналов значение Sm стремится к 0. Начальный модифицированный коэффициент усиления g0 вычисляют, сравнивая коэффициент усиления фиксированной кодовой книги 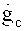
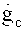
Наконец, усиление актуализируют с помощью значения коэффициента усиления следующим образом
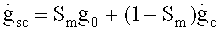
8.3.3 Оптимизатор основного тона
Схема оптимизатора основного тона видоизменяет полное возбуждение u'(n) путем фильтрации возбуждения фиксированной кодовой таблицы с помощью фильтра «инновации», частотные характеристики которого настроены на выделение верхних частот и редуцирование энергии низкочастотной компоненты «инновационного» кодового вектора, и коэффициенты которого соотнесены с периодичностью в сигнале. Фильтр формы
Finno(z)=-cреz+1-cpez-1
применяют, когда cре=0,125(1+rv) при показателе периодичности rv, найденном как rv=(Ev-Ec)/(Ev+Ec), что описано выше. Фильтрованный вектор фиксированной кодовой книги выводят с помощью
с'(n)=с(n)-cрe(с(n+1)+с(n-1)),
и обновленный, прошедший постпроцессинг, сигнал возбуждения получают как
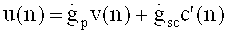
Описанная выше процедура может быть выполнена в один шаг путем обновления возбуждения 989а u(n) следующим образом:
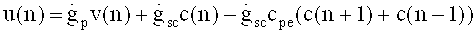
8.4 Синтез и постпроцессинг
В последующем описаны синтезирующая фильтрация 991 и постпроцессинг 992.
8.4.1 Общие замечания
Синтез линейного предсказания (ЛП/LP) выполняют посредством фильтрации постобработанного сигнала возбуждения 989а u(n) с помощью фильтра синтеза ЛП 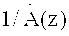
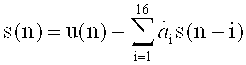
После этого выполняют компенсацию предыскажения синтезированного сигнала, пропуская его через фильтр 1/(1-0.68z-1) (фильтр, обратный фильтру коррекции предыскажений на входе кодера).
8.4.2 Постпроцессинг синтезированного сигнала
После LP-синтеза восстановленный сигнал проходит постобработку с оптимизацией основного тона в низких частотах. Двухполосную декомпозицию и адаптивную фильтрацию применяют только к нижней полосе частот. Результатом такого постпроцессинга является полная доработка частот, близких к первым гармоникам синтезируемого голосового сигнала.
Обработка сигнал проводится по двум ответвлениям. При фильтрации декодированного сигнала в верхней ветви используют фильтр верхних частот, генерирующий сигнал верхней полосы частот sH. При обработке в нижней ветви декодированный сигнал сначала проходит через адаптивный оптимизатор основного тона, а затем - через фильтр нижних частот с выводом доработанного сигнала нижней полосы частот sLEF. Постобработанный декодированный сигнал получают суммированием постобработанного сигнала полосы низких частот и сигнала полосы верхних частот. Целевая функция оптимизатора основного тона - ослабление межгармонического искажения в декодированном сигнале, что достигается в данном случае с помощью варьируемого во времени линейного фильтра с передаточной функцией
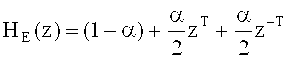
и описывается следующим уравнением:
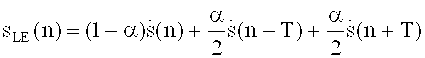
где а - коэффициент, управляющий межгармоническим затуханием, Т - период основного тона входного сигнала 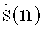
Для того, чтобы ограничить постпроцессинг низкочастотной областью, откорректированный сигнал sLE подвергают низкочастотной фильтрации с выведением сигнала sLEF, который суммируют с сигналом sH, прошедшим высокочастотную фильтрацию, с получением на выходе синтезированного, доработанного постпроцессингом сигнала sE.
Здесь может быть задействована другая процедура, подобная описанной выше, но освобождающая от необходимости высокочастотной фильтрации. Это достигается путем представления постобработанного сигнала sE(n) в области z
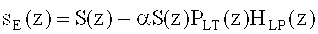
где PLT(z) - передаточная функция фильтра долгосрочного предиктора
PLT(z)=1-0.5zT-0.5z-T
и HLP(z) - передаточная функция фильтра низких частот.
Из этого следует, что постпроцессинг эквивалентен вычитанию масштабированного, прошедшего низкочастотную фильтрацию, сигнала с накопленной погрешностью из синтезированного сигнала 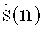
Значение Т получают из поступающего показателя задержки основного тона в замкнутом цикле в каждом субфрейме (дробная величина задержки основного тона, округленная до ближайшего целого числа). Выполняется простое отслеживание дублирования основного тона. Если нормализованная корреляция частоты основного тона при задержке Т/2 превышает 0,95, то значение Т/2 используют как новую величину задержки основного тона для постпроцессинга.
Коэффициент α имеем в виде
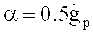
где 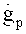
Следует указать на то, что в режиме ТСХ при кодировании в частотной области значение α устанавливают на нуль. Применен линейный фазовый НЧ-фильтр КИХ с 25 коэффициентами с частотой среза 5Fs/256 кГц (задержка фильтра - 12 отсчетов).
8.5 ТСХ на базе MDCT
Далее детализирована процедура кодирования возбуждения в трансформанте, ТСХ, на базе модифицированного дискретного косинусного преобразования, МДКП (MDCT), осуществляемая в процессе синтеза основного сигнала 940 в контуре ветви TXC-LPD 930.
8.5.1 Инструментарий
Когда переменная битстрима «core_mode» равна 1, что указывает на выполнение кодирования с использованием параметров области линейного предсказания, и когда выбран один или более из трех режимов ТСХ для кодирования «в области линейного предсказания», то есть - один из 4 матричных элементов mod[] больше 0, применяют инструмент ТСХ на базе MDCT. Для выполнения ТСХ на базе МДКП из арифметического декодера 941 вводятся квантованные спектральные коэффициенты 941 а. В первую очередь квантованные коэффициенты 941 а (или их инверсную разновидность 942а) дополняют комфортным шумом (заполнение шумом 943). Затем, к результирующим спектральным коэффициентам 943а (или их варианту для де-формированного спектра 944а) применяют формирование искажения в частотной области 945 на базе LPC и выполняют обратное МДКП 946 с синтезом сигнала временной области 94ба.
8.5.2 Определения
Дальше даны некоторые определения. Переменная «lg» описывает количество квантованных спектральных коэффициентов на выходе арифметического декодера. Элемент битстрима «noise_factor» описывает индекс квантования уровня шума. Переменная «noise_level» описывает уровень шума, внесенного в реконструированный спектр. Переменная «noise[]» описывает вектор генерируемого шума. Элемент битстрима «global_gain» описывает индекс квантования усиления при перемасштабировании. Переменная «g» обозначает коэффициент усиления при перемасштабировании. Переменная «rms» описывает квадратическое среднее синтезируемого сигнала х[] временной области. Переменная «х[]» синтезируемый сигнал временной области.
8.5.3 Процесс декодирования
Для выполнения ТСХ на базе МДКП у арифметического декодера 941 делается запрос набора квантованных спектральных коэффициентов lg, численный состав которого определяется величиной mod[]. Это значение (lg), кроме того, определяет длину и конфигурацию окна, которое будет применено для обратного МДКП. Окно, которое может быть применено в ходе или после ОМДКП 946, состоит из трех частей: часть левостороннего наложения L отсчетов, часть средних М отсчетов и часть правостороннего наложения R отсчетов. Для формирования окна МДКП длиной 2*lg добавляют ZL нолей слева и ZR нолей справа. В случае перехода от или к формату SHORT_WINDOW соответствующий участок наложения L или R может быть сокращен до 128 для адаптации к более короткому скосу окна SHORT_WINDOW. Соответственно, участок М и соответствующая область нулей ZL или ZR могут быть увеличены на 64 отсчета каждый.
Оконная функция МДКП, которая может быть применена в процессе ОМДКП 946 или вслед за ОМДКП 946, имеет вид
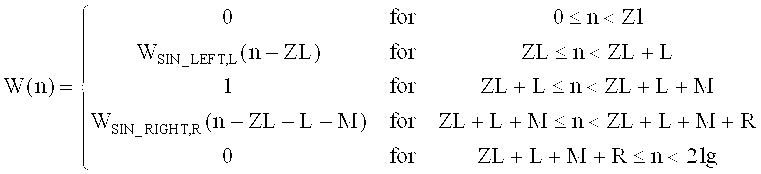
В таблице 6 можно видеть зависимость количества спектральных коэффициентов от значения mod[].
Квантованные спектральные коэффициенты quant[] 94 la, поступающие от арифметического декодера 941, или обратно квантованные спектральные коэффициенты 942а могут быть дополнены комфортным шумом (заполнение шумом 943). Уровень вносимого шума определяется декодированной переменной noise_factor следующим образом:
noise_level=0.0625*(8-noise_factor)
Затем вычисляют вектор шума noise[], используя случайную функцию random_sign(), дающую рандомизированное значение -1 или +1.
noise[i]=random_sign()*noise_level;
Векторы quant[] и noise[] комбинируют для формирования реконструированного вектора спектральных коэффициентов r[] 942а таким образом, что последовательности из 8 нолей в quant[] замещаются компонентами noise[]. Последовательность из 8 ненулевых значений определяют по формуле:
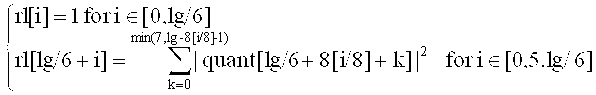
Реконструированный спектр 943а получают следующим образом:
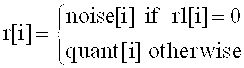
К реконструированному спектру 943а произвольно может быть применено деформирование спектра 944, включающее в себя следующие шаги:
1) вычисление энергии Em 8-мерного блока с индексом т для каждого 8-мерного блока первой четверти спектра;
2) вычисление отношения Rm=sqrt(Em/EI), где I - блочный индекс с максимальным значением из всех Em;
3) если Rm<0, 1, то Rm=0, 1;
4) если Rm<Rm-1, то Rm=Rm-1.
Каждый 8-мерный блок первой четверти спектра затем умножают на коэффициент Rm. Таким образом выводят коэффициенты де-формированного спектра 944а.
До применения обратного МДКП 946 восстанавливают (блок 950) два квантованных фильтра LPC - LPC1, LPC2 (каждый из которых может быть описан коэффициентами фильтрации a1-а10), соответствующие обеим краевым зонам блока МДКП (т.е. - левой и правой точкам свертывания), рассчитывают их взвешенные модификации, и вычисляют (блок 951) соответствующие децимированные (64 точки независимо от длины преобразования) спектры 951 а. Эти взвешенные спектры LPC 951 а вычисляют с применением НДПФ (нечетного дискретного преобразования Фурье) к коэффициентам фильтра LPC 950а. Перед вычислением НДПФ коэффициенты LPCC проходят комплексную модуляцию таким образом, чтобы частотные дискреты НДПФ (примененные при вычислении спектра 951) абсолютно совпадали с частотными дискретами МДКП (обратного МДКП 946). Например, взвешенный спектр LPC-синтеза 951 а конкретно взятого LPC-фильтра 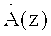
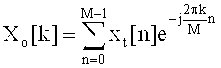
with
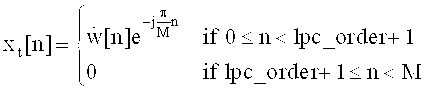
где 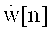
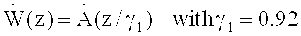
Коэффициент усиления g[k] 952a может быть вычислен из спектрального представления X0[k] 951a коэффициентов LPC-кодирования в соответствии с:
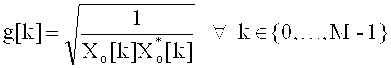
где М=64 обозначает количество полос, в которых применены выведенные коэффициенты усиления.
Пусть g1[k] и g2[k], k=0…63 - децимированные спектры LPC, соответствующие левой и правой точкам свертывания, вычисленным как объяснено выше. Операция обратного формирования искажения в частотной области, инверсного FDNS, 945 состоит в фильтровании реконструированного спектра r[i] 944a с использованием рекурсивного фильтра:
rr[i]=a[i]·r[i]+b[i]·rr[i-1], i=0…lg,
где a[i] и b[i] 945b выведены из левого и правого усиления g1[k], g2[k] 952a с использованием формул:
a[i]=2·g1[k]·g2[k]/(g1[k]+g2[k]),
b[i]=(g2[k]-gl[k])/(g1[k]+g2[k]).
Выше переменная k равна i/(lg/64), если учитывать, что LPC-кодированные спектры децимированы.
Реконструированный спектр rr[] 945а вводят для выполнения обратного МДКП 946. Не прошедший оконное взвешивание выходной сигнал х[] 946а ремасштабируют с применением коэффициента усиления g, полученного обратным квантованием декодированного индекса «global_gain»:
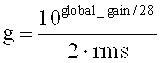
где среднеквадратичное значение rms рассчитывают как:
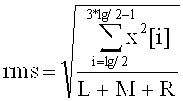
Перемасштабированный синтезированный во временной области сигнал 940а затем равен:
xw[i]=x[i]·g
После перемасштабирования выполняют оконное взвешивание и сложение наложением, например, в блоке 978.
После этого результат синтеза восстановленного ТСХ х(n) 938 дискреционно пропускают через фильтр коррекции предыскажений (1-0.68z-1). Результат синтеза предыскажения затем подвергают фильтрации анализа 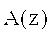
Кроме того, отметим, что длина синтезированного ТСХ вытекает из длины фрейма ТСХ (без перекрывания): 256, 512 или 1024 отсчета для mod[] 1, 2 или 3, соответственно.
8.6 Прямой антиалиасинг (FAC)
8.6.1 Описание инструментария прямого антиалиасинга
Далее описаны операции упреждающего устранения эффекта наложения спектров (прямого антиалиасинга) (FAC), которые выполняются на переходах между линейным предсказанием с управлением алгебраическим кодом ACELP и кодированием в трансформанте (ТС) (например, в режиме частотной области или в режиме TCX-LPD) с синтезом на выходе готового звукового сигнала. Задача FAC состоит в том, чтобы нейтрализовать алиасинг во временной области, который был внесен при ТС и который не может быть устранен предшествующим или последующим фреймом ACELP. Здесь в понятие ТС (кодирование в трансформанте/подполосовое кодирование) включены как МДКП длинных и коротких блоков (режим частотной области) так и ТСХ на базе МДКП (режим TCX-LPD).
На фиг.10 отображены разновидности промежуточных сигналов, рассчитываемых для синтезирования результирующего сигнала фрейма ТС. В приведенном примере фрейм ТС (предположим, фрейм 1020, закодированный в режиме частотной области или в режиме TCX-LPD) следует за и сменяется фреймом ACELP (фреймы 1010 и 1030). В других вариантах (когда за фреймом ACELP следуют несколько фреймов ТС, или за рядом фреймов ТС идет фрейм ACELP) вычисляются только заданные сигналы.
Теперь, обратившись к фиг.10, проанализируем алгоритм прямой компенсации алиасинга, в выполнении которого участвуют блоки 960, 961, 962, 963, 964, 965 и 970.
В графическом представлении операций декодирования упреждающего устранения алиасинга на фиг.10 абсциссы 1040а, 1040b, 1040с, 1040d обозначают дискреты времени аудиоотсчетов. Ось ординат 1042а отображает, например, амплитуду сигнала, синтезируемого с прямым антиалиасингом. Ось ординат 1042b отображает сигналы, представляющие кодированный аудиоконтент, например, синтезированный сигнал ACELP и выходной сигнал фрейма ТС. Ось ординат 1042с отображает взносы ACELP в антиалиасинг, такие как, например, взвешенную нулевую импульсную характеристику ACELP и взвешенный и свернутый синтезированный сигнал ACELP. Ось ординат 1042d отображает синтезированный сигнал в исходной области.
Как видно на графике, синтез сигнала с прямым антиалиасингом 1050 выполняется при переходе от аудиофрейма 1010, закодированного в режиме ACELP, к аудиофрейму 1020, закодированному в режиме TCX-LPD. Сигнал, синтезируемый с упреждающей компенсацией алиасинга (с прямым антиалиасингом) 1050, формируют посредством синтез-фильтрования 964 и сигнала стимуляции антиалиасинга 963а, полученного инверсным ДКП IV типа 963. Синтезирующее фильтрование 964 выполняют по коэффициентам пропускания синтезирующего фильтра 965а, выведенным из набора параметров области линейного предсказания или коэффициентов фильтра LPC. Как можно видеть на фиг.10, первая компонента 1050а (первого) сигнала, синтезируемого с прямым антиалиасингом 1050, может быть откликом фильтра синтеза 964 на ввод ненулевого задающего сигнала антиалиасинга 963а. Однако, сигнал, синтезируемый с прямым антиалиасингом 1050, наряду с этим содержит часть отклика на нулевой входной сигнал 1050b, который может быть сгенерирован фильтром синтеза 964 для нулевой составляющей сигнала стимуляции антиалиасинга 963а. Таким образом, сигнал, синтезируемый с упреждающей компенсацией алиасинга 1050, может включать в себя компоненту отклика на ненулевой входной сигнал 1050а и компоненту отклика на нулевой входной сигнал 1050b. Уточним, что синтезируемый с прямым антиалиасингом сигнал 1050 предпочтительно формируют на базе набора LPC1 параметров области линейного предсказания, соотнесенного с переходом между фреймом или субфреймом 1010 и фреймом или субфреймом 1020. Наряду с этим, другой сигнал, синтезируемый с прямым антиалиасингом 1054, формируют на переходе от фрейма или субфрейма 1020 к фрейму или субфрейму 1030. Синтез сигнала с прямым антиалиасингом 1054 может быть осуществлен синтезирующим фильтрованием 964 стимулирующего сигнала антиалиасинга 963а, полученного в результате обратного ДКП IV 963 на основе коэффициентов антиалиасинга. Следует учитывать, что синтезирование сигнала с прямым антиалиасингом 1054 может базироваться на наборе параметров области линейного предсказания LPC2, которые соотнесены с переходом между фреймом или субфреймом 1020 и последующим фреймом или субфреймом 1030.
Помимо этого, на переходе от фрейма или субфрейма ACELP 1010 к фрейму или субфрейму TXC-LPD 1020 будут сгенерированы дополнительные сигналы антиалиасингового синтеза 1060, 1062. Например, блоками 971, 972, 973 может быть сформирована взвешенная и свернутая версия 973а, 1060 синтезированного сигнала ACELP 986, 1056. Кроме того, например, блоки 975, 976 обеспечат взвешенный отклик на нулевой входной сигнал ACELP 976а, 1062. Так, взвешенный и свернутый синтезированный сигнал ACELP 973а, 1060 может быть получен путем оконного взвешивания синтезированного сигнала ACELP 986, 1056 и временного свертывания 973 результата оконного взвешивания, что более подробно будет описано ниже. Взвешенный отклик ACELP на нулевой входной сигнал 976а, 1062 может быть получен путем нулевого ввода в фильтр синтеза 975, который эквивалентен фильтру синтеза 991, генерирующему синтезированный сигнал ACELP 986, 1056, при том, что исходное состояние фильтра синтеза 975 идентично состоянию фильтра синтеза 991 при завершении формирования синтезированного сигнала ACELP 986, 1056 фрейма или субфрейма 1010. Следовательно, взвешенный и свернутый синтезированный сигнал ACELP 1060 может быть эквивалентным сигналу, синтезируемому с прямым антиалиасингом 973а, а взвешенный отклик ACELP на нулевой входной сигнал 1062 может быть эквивалентным сигналу, синтезируемому с прямым антиалиасингом 976а.
Наконец, фрейм с кодировкой в трансформанте образует на выходе сигнал 1050а, который может быть эквивалентен взвешенному варианту представления во временной области 940а, в комбинации с сигналами, синтезируемыми с прямым антиалиасингом 1052,1054, и дополнительными взносами ACELP 1060, 1062 в нейтрализацию алиасинга.
8.6.2 Определения
Дальше даны некоторые определения. Элемент битстрима «fac_gain» обозначает 7-битовый индекс коэффициента усиления. Элемент битстрима «nq[i]» обозначает номер в кодовой книге. Элемент синтаксиса «FAC[i]» обозначает данные прямого антиалиасинга. Переменная «fac_length» описывает длину прямого антиалиасинга как преобразования, которая может быть равна 64 для переходов от и к окну типа «EIGHT_SHORT_SEQUENCES» («восемь коротких последовательностей») и который может быть равна 128 в других случаях. Переменная «use_gain» указывает на использование конкретных параметров усиления.
8.6.3 Процесс декодирования
Ниже дан краткий обзор шагов алгоритма декодирования.
1. Декодировать параметры AVQ (блок 960)
- Информацию FAC кодируют с использованием того же инструментария алгебраического векторного квантования (AVQ), что и для кодирования фильтров LPC (см. раздел 8.1).
- При длине преобразования FAC i=0…: о номер кодовой книги nq[i] кодируют с использованием модифицированного унарного кода, о соответствующие данные FAC[i] кодируют с использованием 4*nq[i] битов;
- Соответственно, вектор FAC[i] для i=0,…, fac_length извлекают из битстрима.
2. Применить коэффициент усиления g к данным FAC (блок 961),
- Для переходов с ТСХ на базе МДКП (wLPT) используют коэффициент усиления соответствующего элемента «tcx_coding».
- Для других переходов из битстрима извлекают информацию «fac_gain» (закодированную 7-разрядным скалярным квантователем). Используя эту информацию, рассчитывают коэффициент усиления g=10fac_gain/28.
3. В случае перехода между ТСХ на базе MDCT и ACELP применить деформирование спектра 962 к первой четверти спектральных данных FAC 96 la. При деформировании применить коэффициенты усиления, вычисленные для соответствующего ТСХ на базе MDCT (для использования при де-формировании спектра 944) согласно пояснениям в разделе 8.5.3, в результате чего шум квантования FAC и ТСХ на базе МДКП имеет одинаковую форму.
4. Вычислить обратное ДКП-IV масштабированных по усилению данных FAC (блок 963).
- Длина преобразования FAC fac_length по умолчанию равна 128.
- Для переходов с короткими блоками эту длину сокращают до 64.
5. Применить (блок 964) взвешенный фильтр синтеза 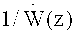
- Взвешенный фильтр синтеза строят на основе фильтра LPC, который соответствует точке свертывания (на фиг.10 обозначено как LPC1 для переходов от ACELP к TCX-LPD и как LPC2 для переходов от wLPD TC (TCX-LPD) к ACELP или LPCO для переходов от TC 40 (кодирование частотного кода в трансформанте) к ACELP).
- Тот же самый весовой множитель LPC используют для операций ACELP:
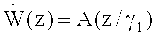
где γ1=0,92
- Перед вычислением синтеза сигнала FAC 964а исходную память взвешенного фильтра синтеза 964 устанавливают на 0.
- Для переходов от ACELP сигнал, синтезируемый с FAC 1050, расширяют далее, добавляя отклик на нулевой входной сигнал (ZIR) 1050b взвешенного фильтра синтеза (128 отсчетов).
6. В случае перехода от ACELP рассчитать взвешенный синтез сигнала после ACELP 972а, выполнить его свертывание (например, с получением сигнала 973а или сигнала 1060) и сложить его с взвешенным сигналом ZIR (например, с сигналом 976а или сигналом 1062). Отклик ZIR вычисляют, используя LPC1. Окно, прилагаемое к отсчетам fac_length, синтезируемым после ACELP, представляет собой:
sine [n+fac_length]*sine[fac_length-1-n], n=-fac_length…-1,
а окно, прилагаемое к ZIR:
1-sine[n+fac_length]2, n=0…fac_length-1,
где sine[n] - четверть цикла синуса [периода синусоиды]:
sine[n]=sin(n*π/(2*fac_length)), n=0…2*fac_length-1.
Результирующий сигнал схематически отображен на графике (с) на фиг.10 и обозначен как взнос ACELP (составляющие сигнала 1060, 1062).
7. Суммировать результат синтеза РАС 964а, 1050 (и взнос ACELP 973а, 976а, 1060, 1062 в случаях переходов от ACELP) с фреймом ТС (схематически отображенным на графике (b) на фиг.10) (или с взвешенным вариантом представления во временной области 940а) с выведением синтезированного сигнала 998 (отображенного линией на графике (d) на фиг.10).
8.7 Процесс кодирования прямого антиалиасинга (FAC)
Дальше описаны некоторые детали кодирования информации для прямого антиалиасинга, включая расчет и кодирование коэффициентов антиалиасинга 936.
На фиг.11 показаны шаги процесса, выполняемого на стороне кодера, когда фрейм 1120, закодированный в трансформанте (ТС), следует за и сменяется фреймом, закодированными в ACELP 1110, 1130. В данном случае понятие ТС (кодирование в трансформанте/подполосовое кодирование) включает в себя МДКП (модифицированное дискретное косинусное преобразование) длинных и коротких блоков, как в ААС (усовершенствованном методе аудиокодирования), а также ТСХ (кодирование возбуждения в области трансформанты) на базе МДКП (TCX-LPD). На фигуре 11 обозначены дискреты временной области 1140 и границы фреймов 1142, 1144. Вертикальные пунктирные линии обозначают начало 1142 и конец 1144 фрейма 1120, кодированного в ТС. LPC1 и LPC2 указывают на центр окна анализа для расчета двух LPC-фильтров: LPC1 - в начале 1142 фрейма 1120 с кодировкой в ТС, и LPC2 - в конце 1144 того же фрейма 1120. Подразумевается, что фрейм 1110 слева от указателя «LPC1» закодирован в ACELP. Предполагается, что фрейм 1130 справа от указателя «LPC2» также закодирован в ACELP.
На фиг.11 представлено четыре линии 1150, 1160, 1170, 1180, каждая из которых отображает ступень в вычислении кодером целевого РАС, и каждая из которых следует во времени за вышестоящей.
Линия 1 (1150) на фиг.11 отображает исходный звуковой сигнал, разделенный на фреймы 1110, 1120, ИЗО, как было сказано выше. Предположим, что средний фрейм 1120 закодирован в области МДКП с формированием искажения в частотной области, FDNS, и назовем его фреймом ТС (ТС-фреймом). Предположим, сигнал предшествующего фрейма 1110 имеет кодировку в режиме ACELP. Такая очередность режимов кодирования (ACELP - ТС - ACELP) выбрана для иллюстрации полного процесса преобразования прямого (упреждающего) антиалиасинга, РАС, который применим к обоим видам перехода (от ACELP к ТС и от ТС к ACELP).
Линия 2 (1160) на фиг.11 соответствует декодированным (синтезированным) сигналам каждого фрейма (которые могут быть заданы кодером, обладающим информацией об алгоритме декодирования). Верхняя дуга 1162, опирающаяся на начало и конец ТС-фрейма, отображает эффект оконного взвешивания (плоская в середине, но не в начале и конце). Эффект свертывания (зеркального отражения) отображен нижними кривыми 1164, 1166 в начале и конце сегмента (со знаком «-» в начале сегмента и знаком «+» в конце сегмента). Далее, для корректировки этих эффектов может быть применен РАС.
Линия 3 (1170) на фиг.11 отображена составляющая ACELP, внесенная в начало фрейма ТС для снижения нагрузки кодирования РАС. Этот взнос ACELP состоит из двух частей: 1) синтеза ACELP 877f, 1170 со взвешиванием и свертыванием конца предыдущего фрейма, и 2) взвешивания отклика на нулевой входной сигнал 877j, 1172 фильтра LPC1.
Здесь следует заметить, что взвешенный и свернутый синтезированный сегмент ACELP 1110 может быть эквивалентным взвешенному и свернутому сегменту синтеза ACELP 1060, и что взвешенный отклик на нулевой ввод 1172 может быть эквивалентным взвешенному отклику ACELP на нулевой ввод 1062. Иными словами, кодер аудиосигнала может оценить (или вычислить) результат синтеза 1162, 1164, 1166, 1170, 1172, который будет получен на стороне декодера аудиосигнала (блоки 869а и 877).
Ошибку ACELP, показанную на линии 4 (1180), в последующем находят простым вычитанием линии 2 (1160) и линии 3 (1170) из линии 1 (1150) (блок 870). Приближенная конфигурация ожидаемой огибающей ошибочного сигнала 871, 1182 во временной области показана на линии 4 (1180) на фиг.11. Ожидается, что ошибка во фрейме ACELP (1120) будет приблизительно плоской по амплитуде во временной области. Затем, ожидается, что за счет ошибки в ТС-фрейме (между маркерами LPC1 и LPC2) будет представлена общая конфигурация (огибающей во временной области), как отображено в сегменте 1182 на линии 4 (1180) на фиг.11.
Далее, согласно фиг.11 для эффективной компенсации эффектов оконного взвешивания и алиасинга во временной области в начале и в конце фрейма ТС на линии 4, учитывая, что для ТС-фрейма использовано FDNS, применяют FAC. Напомним, что на фиг.11 такое преобразование показано для обоих участков фрейма ТС - левостороннего (переход от ACELP к ТС) и правостороннего (переход от ТС к ACELP).
Итак, ошибка фрейма с кодировкой в трансформанте 871, 1182, представленная кодированными коэффициентами антиалиасинга 856, 936, выведена путем вычитания выхода фрейма ТС 1162, 1164, 1166 (характеризуемого, например, сигналом 869b) и составляющей ACELP 1170, 1172 (характеризуемой, например, сигналом 872) из сигнала 1152 в исходной области (т.е. - во временной области). Таким образом получают сигнал ошибки фрейма, закодированного в трансформанте 1182.
Рассмотрим процедуру кодирования ошибки фрейма, закодированного в трансформанте 871, 1182. Сначала из параметров фильтра LPC1 рассчитывают взвешивающий фильтр 874, 1210 W1(z). Дальше, сигнал ошибки 871, 1182а в начале фрейма ТС 1120 на линии 4 (1180) на фиг.11 (называемый также на фиг.11 и 12 целевым FAC) пропускают через фильтр W1(z), имеющий в качестве исходного состояния, иначе -содержащий в памяти фильтра, ошибку ACELP 871, 1182 в фрейме ACELP 1120 на линии 4 на фиг.11. На выходе фильтра 874, 1210 W1(z) в верхней части фиг, 12 формируется входной сигнал для ДКП-IV 875, 1220. Коэффициенты преобразования 875а, 1222 после ДКП-IV 875, 1220 квантуют и кодируют, применяя инструмент алгебраического векторного квантования AVQ 876 (обозначенный на схеме как Q 1230). Применяемое здесь AVQ идентично используемому при квантовании коэффициентов LPC. Эти закодированные коэффициенты пересылают на декодер. На выходе AVQ 1230 формируется входной сигнал для инверсного ДКП-IV 963, 1240, результатом которого станет сигнал временной области 963а, 1242. Этот сигнал временной области затем проходит через инверсный фильтр 964, 1250 1/W1(z), который имеет нулевую память (нулевое исходное состояние). Фильтрование с помощью 1/W1(z) расширяют за пределы длины целевого FAC путем использования нулевого ввода для отсчетов, выходящих за пределы цели РАС. На выходе 964а, 1252 фильтра 1250 1/W1(z) синтезирован FAC-сигнал (с компенсированным эффектом наложения спектров), представляющий собой корректировочный сигнал (например, сигнал 964а), который теперь может быть применен в начале фрейма ТС для компенсации искажений оконного взвешивания и алиасинга во временной области.
Теперь рассмотрим процедуру корректировки оконного взвешивания и алиасинга во временной области в конце фрейма ТС, обратившись к нижней части фиг.12. Сигнал ошибки 871, 1182b в конце фрейма ТС 1120 на линии 4 на фиг.11 (цель FAC) пропускают через фильтр 874, 1210; W2(z), имеющий в качестве исходного состояния, или содержащий в памяти фильтра, ошибку фрейма ТС 1120 на линии 4 на фиг.11. Все дальнейшие операции обработки совпадают с верхней частью фиг.12, относящейся к целевому РАС в начале фрейма ТС, за исключением расширения ZIR при синтезе РАС.
Следует обратить внимание на то, что преобразование в соответствии с фиг.12 целиком (слева направо) осуществляют на стороне кодера (при локальном РАС-синтезе), тогда как на стороне декодера такое преобразование задействуют только с момента приема декодированных коэффициентов ДКП-IV.
9. Битстрим
Для упрощения понимания концепции изобретения дальше изложены некоторые подробности относительно прохождения потока двоичных данных - битстрима. Следует принимать во внимание, что в битовый поток может быть включен значительный объем информации о конфигурации.
При этом звукоданные фрейма, закодированного в частотной области, главным образом представлены элементом битстрима «fd_channel_stream()». Этот элемент битстрима «fd_channel_stream()» содержит в себе информацию «global_gain», закодированные данные о масштабных коэффициентах «scale_factor_data()» и арифметически закодированные спектральные данные «ac_spectral_data». В дополнение к этому элемент битстрима «fd_channel_stream()» выборочно содержит данные прямого антиалиасинга, включая параметры усиления (обозначаемые также «fac_data(1)»), если (и только если) предыдущий фрейм (иногда обозначаемый как «суперфрейм») закодирован в режиме линейного предсказания, а последний субфрейм предыдущего фрейма закодирован в режиме ACELP. Другими словами, данные прямого антиалиасинга, включая информацию об усилении, избирательно формируются для аудиофрейма режима частотной области, если предшествующий фрейм или субфрейм был закодирован в режиме ACELP. Это является преимуществом, поскольку алиасинг может быть нейтрализован простьм наложением и сложением предшествующего аудиофрейма или аудиосубфрейма, закодированного в режиме TCX-LPD, и текущего аудиофрейма, закодированного в режиме частотной области, как пояснялось ранее.
Детализация синтаксиса элемента «fd_channel_stream()» дана на фиг.14, где показаны составляющие его информация о глобальном усилении «global_gain», данные коэффициентов масштабирования «scale_factor_data()», арифметически закодированные спектральные данные «ac_spectral_data()». Переменная «core_mode_last» описывает последний основной режим и задает нулевое значение для кодирования в частотной области на основе коэффициента масштабирования и задает единичное значение для кодирования на основе параметров области линейного предсказания (TCX-LPD или ACELP). Переменная «last_lpd_mode» описывает режим LPD последнего фрейма или субфрейма и задает нулевое значение для фрейма или субфрейма, закодированного в режиме ACELP.
Теперь, обращаясь к фиг 15А, 15B, опишем синтаксис элемента битстрима «lpd_channel_stream()», который кодирует информацию аудиофрейма («суперфрейма») в режиме линейного предсказания. Аудиофрейм («суперфрейм»), кодируемый в области линейного предсказания, может включать в себя множество подфреймов (иногда, например, в сочетании с термином «суперфрейм», называемых „фреймами»). Субфреймы (или «фреймы») могут быть разных видов, поскольку одни закодированц в области TCX-LPD, а другие - в режиме ACELP.
Переменная битстрима «acelp_core_mode» описывает схему распределения битов в случае применения ACELP. Элемент битстрима «lpd_mode» описан ранее. Переменной «first_tcx_flag» задается фактическое значение в начале каждого фрейма, закодированного в режиме LPD. Переменная «first_lpd_flag» служит флажком, маркирующим текущий фрейм или суперфрейм в качестве первого в последовательности фреймов или суперфреймов с кодированием в области линейного предсказания. Переменная «last_lpd» обновляется для описания режима (ACELP; ТСХ256; ТСХ512; ТСХ1024) кодирования последнего субфрейма (или фрейма). Из ссылки под номером 1510 можно видеть, что данные прямого антиалиасинга без информации об усилении («fac_data_(0)») вводят для подфрейма, закодированного в режиме TCX-LPD (mod[k]>0), если последний подфрейм был закодирован в режиме ACELP (last_lpd_mode=0), и для подфрейма, закодированного в режиме ACELP (mod[k]=0), если предыдущий подфрейм был закодирован в режиме TCX-LPD (last_lpd_mode>0).
И наоборот, если предшествующий фрейм был закодирован в режиме частотной области (core_mode_last=0), а первый субфрейм текущего фрейма закодирован в режиме ACELP (mod[0]=0), данные прямого антиалиасинга, включая параметры усиления («fac_data(l)»), будут содержаться в элементе битстрима «lpd_channel_stream».
Исходя из сказанного, данные прямого антиалиасинга, в том числе и целевое значение коэффициента усиления прямого антиалиасинга, включаются в битстрим при наличии прямого перехода между фреймом, закодированным в частотной области, и фреймом или субфреймом, закодированным в режиме ACELP. И наоборот, при наличии перехода между фреймом или субфреймом, закодированным в режиме TCX-LPD, и фреймом или субфреймом, закодированным в режиме ACELP, в битстрим включается информация прямого антиалиасинга без целевого значения коэффициента усиления прямого антиалиасинга.
Теперь обратимся к фиг.16 для разбора синтаксиса данных прямого антиалиасинга, описываемых элементом битстрима»fac_data()». Параметр «useGain» указывает на присутствие целевого элемента битстрима «fac_gain», содержащего значение коэффициента усиления прямого антиалиасинга, что обозначено номером ссылки 1610. В дополнение к этому элемент битстрима «fac_data» содержит множество элементов битстрима с номерами кодовой книги «nq[i]» и набор «fac_data» элементов битстрима «fac[i]».
Выше была описана процедура декодирования указанного номера по кодовой книге и указанных данных прямого антиалиасинга.
10. Альтернативные конструктивные решения
Несмотря на то, что здесь в основном рассматривается оборудование с точки зрения его технического устройства, понятно, что аспекты материальной части тесно связаны с описанием соответствующих способов ее применения, и какое-либо изделие или блок соответствуют особенностям метода или технологической операции. Аналогично, рассматриваемые технологии и рабочие операции непосредственно связаны с соответствующим машинным оборудованием и его элементной базой. Некоторые или все шаги предлагаемого способа могут быть выполнены с использованием аппаратных средств, таких, например, как микропроцессор, программируемый компьютер или электронная схема. В некоторых случаях осуществления одна или больше ответственных операций, составляющих данный способ, могут быть выполнены таким устройством.
Относящийся к изобретению кодированный аудиосигнал может быть сохранен в цифровой запоминающей среде или может быть транслирован в среде передачи информации, такой как беспроводная передающая среда или проводная передающая среда, например, Интернет.
В зависимости от конечного назначения и особенностей практического применения изобретение может быть реализовано в аппаратных или программных средствах. В реализации могу быть применены такие цифровые носители информации, как гибкий диск, DVD, «Блю-рей», CD, ПЗУ, ППЗУ, программируемое ПЗУ, СППЗУ или ФЛЭШ-память, содержащие электронно-считываемые управляющие сигналы, которые взаимодействуют (или совместимы) с программируемой компьютерной системой таким образом, что предлагаемый способ может быть осуществлен. Следовательно, цифровая среда хранения данных может быть читаемой компьютером.
Некоторые варианты конструкции согласно данному изобретению имеют в своем составе носитель информации, содержащий электронно считываемые сигналы управления, совместимый с программируемой компьютерной системой и способный участвовать в реализации одного из описанных здесь способов.
В целом данное изобретение может быть реализовано как компьютерный программный продукт с кодом программы, обеспечивающим осуществление одного из предлагаемых способов при условии, что компьютерный программный продукт используется с применением компьютера. Код программы может, например, храниться на машиночитаемом носителе.
Различные варианты реализации включают в себя компьютерную программу, хранящуюся на машиночитаемом носителе, для осуществления одного из описанных здесь способов
Таким образом, формулируя иначе, относящийся к изобретению способ осуществляется с помощью компьютерной программы, имеющей код программы, обеспечивающий реализацию одного из описанных здесь способов, если компьютерную программу выполняют с использованием компьютера.
Далее, следовательно, техническое исполнение изобретенного способа включает в себя носитель данных (либо цифровой накопитель информации, либо читаемую компьютером среду), содержащий записанную на нем компьютерную программу, предназначенную для осуществления одного из способов, описанных здесь. Носитель данных, цифровая среда хранения или средства записи информации, как правило, представляют собой материальные предметы и/или не подлежат передче средствами связи.
Отсюда следует, что реализация изобретения подразумевает наличие потока данных или последовательности сигналов, представляющих компьютерную программу для осуществления одного из описанных здесь способов. Поток данных или последовательность сигналов могут быть рассчитаны на передачу через средства связи, например, Интернет.
Кроме того, реализация включает в себя аппаратные средства, например, компьютер или программируемое логическое устройство, предназначенные или приспособленные для осуществления одного из описанных здесь способов.
Далее, для технического исполнения требуется компьютер с установленной на нем компьютерной программой для осуществления одного из описанных здесь способов.
Аппаратная версия заявляемого изобретения может быть дополнена средством или системой передачи (например, электронной или оптической) компьютерной программы осуществления одного из представленных здесь способов на удаленное принимающее устройство. Принимающее устройство может представлять собой, например, компьютер, мобильное устройство, ЗУ и тп. В подобное средство или систему могут быть введены, например, файловый сервер для пересылки компьютерной программы на приемник.
Некоторые версии конструкции для реализации одной или всех функциональных возможностей описанных здесь способов могут потребовать применения программируемого логического устройства (например, полевой программируемой матрицы логических элементов). В зависимости от назначения версии базовый матричный кристалл может сочетаться с микропроцессором с целью осуществления одного из описанных здесь способов. Как правило, описываемые способы могут быть реализованы с использованием любого аппаратного средства.
Описанные выше конструктивные решения являются только иллюстрациями основных принципов настоящего изобретения. Подразумевается, что для специалистов в данной области возможность внесения изменений и усовершенствований в компоновку и элементы описанной конструкции очевидна. В силу этого, представленные здесь описания и пояснения вариантов реализации изобретения ограничиваются только рамками патентных требований, а не конкретными деталями
11. Заключение
Подведем итоги обсуждения представленной концепции унификации алгоритмов оконного взвешивания и переходов между фреймами для интегрированного кодирования речи и звука (USAC).
Выводы предварим введением и информацией общего характера. Базовая конструкция (которую можно назвать стандартной компоновкой) устройства USAC состоит из или включает в себя три разных модуля кодирования. Для каждого сегмента аудиосигнала (например, фрейма или субфрейма) выбирают один модуль кодирования (или режим кодирования) для кодирования/декодирования этого сегмента в разных кодовых режимах. По мере того, как эти модули поочередно активируются, особое внимание требуют переходы из одного режима в другой. В прошлом для осуществления таких переходов предлагались разнообразные методики.
Конструктивные решения по настоящему изобретению предусматривают полную схему обеспечения оконного взвешивания и переходов. Описание прогресса, достигнутого на пути к созданию законченной версии такой схемы, представляет собой весьма убедительное и перспективное свидетельство постоянного совершенствования качества и оптимизации конструкции.
В настоящем документе обобщены предложения по изменению базовой разработки (рабочего проекта 4), направленные на создание более гибкой структуры гибридного кодирования речи и звука USAC, снижающей избыточность кодирования и упрощающей кодирование сегментов ко дека в области преобразования.
Для построения схемы оконного взвешивания без затратной некритической дискретизации (избыточного кодирования) необходимо наличие двух компонентов, которые для некоторых вариантов компоновки можно считать решающими: 1) окно прямого антиалиасинга (РАС); и 2) формирование искажения в частотной области (FDNS) для ветви кодирования в трансформанте корневого кодека LPD (ТСХ, также известного как TCX-LPD или wLPT [взвешенное линейное предиктивное преобразование]).
Комбинирование обеих техник позволяет задействовать схему оконного взвешивания, обеспечивающую очень гибкий выбор длины преобразования при минимальной потребности в битовом ресурсе.
Дальше рассмотрим основные проблемы, стоящие перед системами известного уровня техники, что упростит понимание преимуществ, предоставляемых заявляемым изобретением. Базовая концепция согласно рабочей версии 4 проекта стандарта USAC включает в себя коммутируемый корневой кодек, в который введены операции пред-/постпроцессинга с использованием модуля MPEG Surround и расширенного SBR. Ядро коммутации состоит из кодека частотной области (FD/40) и кодека области линейного предсказания (LPD). Последний включает в себя модуль ACELP и кодер области преобразования, работающий в области взвешенного сигнала („взвешенного линейно-предиктивного преобразования» (wLPT), также известного как возбуждение, управляемое кодом преобразования (ТСХ)). Признано, что в силу базовых различий в принципах кодирования построение переходов между режимами является объектом приложения наибольших усилий. Более того, значительного внимания требует эффективное совмещение разнородных режимов.
Рассмотрим проблемы, возникающие на переходах между временной и частотной областями (ACELP→-wLPT, ACELP→FD). Установлено, что переходы от кодирования во временной области к кодированию в области трансформанты осложнены, в частности, тем, что кодер в трансформанте базируется на свойстве устранения алиасинга в области трансформанты (TDAC) соседних блоков в МДКП. Как определено, блок, закодированный в частотной области, не может быть полностью декодирован без дополнительной информации из смежных с ним перекрывающихся блоков.
Далее обратимся к трудностям переходов из области сигнала в область линейного предсказания (FD→ACELP, FD→wLPT). Был сделан вывод, что переходы в и из линейно-предиктивной области предполагают совмещение различных парадигм формирования шумов квантования. Установлено, что в этих парадигмах задействованы разные подходы к передаче и приложению психоакустически мотивированной информации для формирования шума, что может приводить к нарушению однородности воспринимаемого качества в местах смены режимов кодирования.
Теперь, подробнее обсудим базовую стандартную матрицу перехода между фреймами, как она представлена в рабочей версии 4 проекта стандарта USAC. В силу гибридности базовой разработки USAC она может включать в себя массу оконных переходов. Таблица на фиг.4, содержащая 3х3 графиков, обзорно демонстрирует многообразие таких переходов, применяемых в настоящее время в соответствии с концепцией рабочей версии 4 проекта стандарта USAC.
Каждая из перечисленных выше составляющих относится к одному или более переходов, выделенных в таблице на фиг.4. Обратим внимание, что каждый из неоднородных переходов (расположенных не на основной диагонали) включает в себя различные специфические операции обработки, являющиеся результатом поиска компромисса между попыткой достичь критической дискретизации, предупреждением блокирующих артефактов, нахождением общей схемы оконного взвешивания и стремлением к компоновке кодера по замкнутому циклу. В некоторых случаях такой компромисс достигается за счет исключения закодированных и переданных отсчетов.
Далее, обсудим некоторые изменения, предложенные для внесения в систему. То есть рассмотрим усовершенствования базовой концепции рабочего проекта 4 стандарта USAC. Для решения указанных проблем оконных переходов в заявленном изобретении предложены два усовершенствования существующей системы, построенной на основе концепции рабочей версии 4 проекта стандарта USAC. Первое усовершенствование направлено на универсальную оптимизацию перехода из временной области в частотную область путем введения дополнительного окна прямого антиалиасинга. Второе усовершенствование обеспечивает совместимость операций обработки в областях сигнала и линейного предсказания благодаря введению ступени трансмутации коэффициентов LPC, после которой они могут быть применены в частотной области.
Перейдем к процедуре формирования искажения в частотной области (FDNS), которая позволяет использовать LPC в частотной области. Назначение этого инструмента (FDNS) - позволить кодерам МДКП, применяемым в разных доменах, выполнять операцию TDAC. В то время как МДКП в частотной области USAC выполняется в области сигнала, wLPT (или ТСХ) согласно базовой концепции действует в области взвешенного отфильтрованного сигнала. При замещении в базовой компоновке фильтра синтеза взвешенного LPC эквивалентной технологической операцией в частотной области МДКП обоих кодеров области трансформанты выполняется в одном и том же домене, и TDAC может быть осуществлено без внесения неоднородностей при формировании шума квантования.
Говоря иначе, фильтр синтеза взвешенного LPC 330g заменяют масштабированием/формированием искажения в частотной области 380е в комбинации с преобразованием LPC в частотную область 380i. Соответственно, МДКП 320g тракта частотной области и МДКП 380h ветви TCX-LPD выполняются в одном домене, обеспечивая антиалиасинг в трансформанте (TDAC).
Перейдем к некоторым деталям оконной функции прямого антиалиасинга (окна FAC). Понятие окна упреждающего устранения наложения спектров (FAC) уже было введено и описано. Эта дополнительная оконная функция компенсирует недостающую информацию TDAC, которая в непрерывном коде преобразования обычно вносится следующим или предыдущим окном. В силу того, что кодер ACELP во временной области не выполняет наложение смежных фреймов, FAC может компенсировать отсутствие необходимого перекрывания.
Выявлено, что благодаря применению фильтра LPC в частотной области в тракте кодирования области ЛП несколько ослабляется сглаживающее воздействие фильтрования посредством интерполированного LPC переходов между сегментами, закодированными в ACELP и wLPT (TCX-LPD. При этом было сделано заключение, что, поскольку FAC разработан для оптимизации перехода именно в этом месте, он может компенсировать также и этот эффект.
Благодаря введению окна прямого антиалиасинга FAC и формирования искажения в частотной области FDNS все возможные переходы могут быть выполнены без какого-либо вынужденного избыточного кодирования.
Ниже дано более подробное описание схемы оконного взвешивания.
Использование окна FAC для плавного перехода между ACELP и wLPT уже описано ранее. Для более подробного рассмотрения вопроса дается ссылка на следующую публикацию: ISO/IEC JTC1/SC29/WG11, MPEG2009/M 16688, June-July 2009, London, United Kingdom, «Alternatives for windowing in USAC».
В силу того, что формирование шумов в частотной области FDNS смещает взвешенное линейно-предиктивное преобразование wLPT в область сигнала, окно прямого антиалиасинга FAC теперь может быть приложено к обоим видам переходов -от/к ACELP к/от wLPT и от/к ACELP к/от 40 - одинаковым (или, по крайней мере, похожим) способом.
Так же и переходы, сформированные кодером в трансформанте на основе TDAC, которые ранее были возможны только между окнами 40 или только между окнами wLPT (т.е. из/в 40 в/из 40; или от/к wLPT к/от wLPT), теперь выполнимы также между частотной областью и wLPT в обоих направлениях. Таким образом, сочетание этих двух техник позволяет смещать 64 отсчета решетки фреймов ACELP вправо („позже» по оси времени). При таком подходе отпадает необходимость в выполнении сложения наложением 64 отсчетов на одном конце и в сверхдлинном окне преобразования в частотной области на другом конце. В обоих случаях в отличие от базовой концепции предлагаемые в заявленном изобретении технические решения позволяют избежать избыточного кодирования 64 отсчетов. Самое главное, что все остальные переходы остаются без изменения, не требуя никакие дальнейшие преобразования.
Дальше будет кратко рассмотрена новая матрица переходов между фреймами. Новая матрица переходов проиллюстрирована на фиг.5. Переходы на главной диагонали остаются такими же, как они были в рабочей версии 4 проекта стандарта USAC. Все остальные переходы могут быть выполнены с приложением окна FAC или прямым TDAC в области сигнала. В некоторых реализациях описанной выше схемы нужны только две длины перекрывания между соседними окнами области частотных преобразований (трансформанты), а именно - 1024 отсчета и 128 отсчетов, хотя другие длины участков наложения также применимы.
12. Субъективная оценка
Было проведено два теста прослушиванием, которые показали, что на текущем уровне технического исполнения предложенная новая технология не ставит качество под сомнение. Впоследствии варианты осуществления представленного изобретения обеспечат улучшение качества благодаря высвобождению битового пространства на участках, где ранее отсчеты прореживались. К дополнительным положительным эффектам можно отнести также ослабление контроля классификатора на входе кодера благодаря отсутствию искажающего воздействии некритической дискретизации на переходы между режимами.
13. Дополнительные замечания
Из сказанного можно сделать вывод, что в данном описании представлена предполагаемая схема оконного взвешивания и построения переходов для гибридного кодирования речи и звука USAC, которая обладает рядом преимуществ по сравнению с существующей концепцией, положенной в основу рабочей версии 4 проекта стандарта USAC. Предложенная схема оконного взвешивания и переходов поддерживает критическую (адаптивную) дискретизацию во всех закодированных в трансформанте фреймах освобождает от необходимости преобразований „не с показателем степени два» и должным образом выстраивает все закодированные в трансформанте фреймы. Предложение базируется на применении двух новых инструментов. Первый инструмент - прямой антиалиасинг (FAC) - описан в [М16688]. Второй инструмент - формирование искажения в частотной области (FDNS) - позволяет обрабатывать фреймы частотной области и фреймы wLPT в одном домене без введения неоднородностей при формировании шумов квантования. Таким образом, эти два базовых инструментальных средства позволяют управлять всеми переходами между режимами в системе USAC, обеспечивая согласованное оконное взвешивание во всех режимах кодирования в области частотных преобразований. Представленное описание обосновывается результатами субъективного тестирования, демонстрируя способность предложенного инструментария обеспечить равноценное или превосходящее качество по сравнению с базовым концептом в рабочей версия 4 проекта стандарта USAC.
Список литературы
[М16688] ISO/IEC JTC1/SC29/WG11, MPEG2009/M16688, June-July 2009, London, United Kingdom, «Alternatives for windowing in USAC»
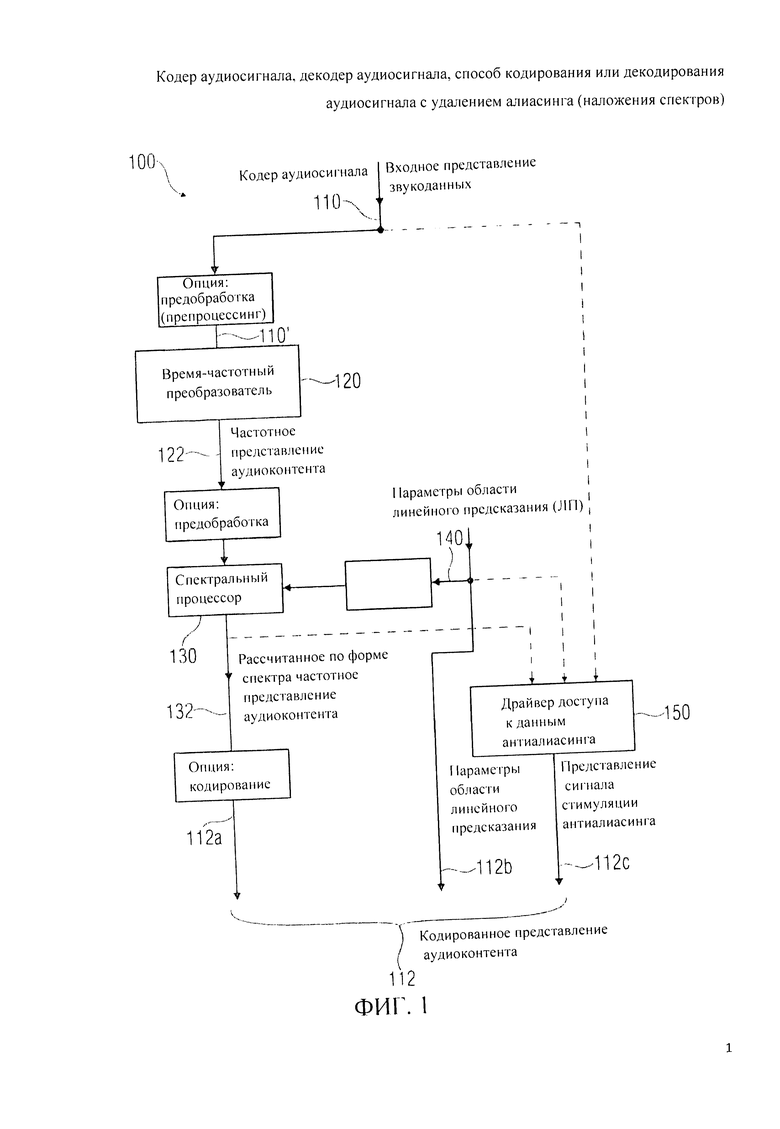
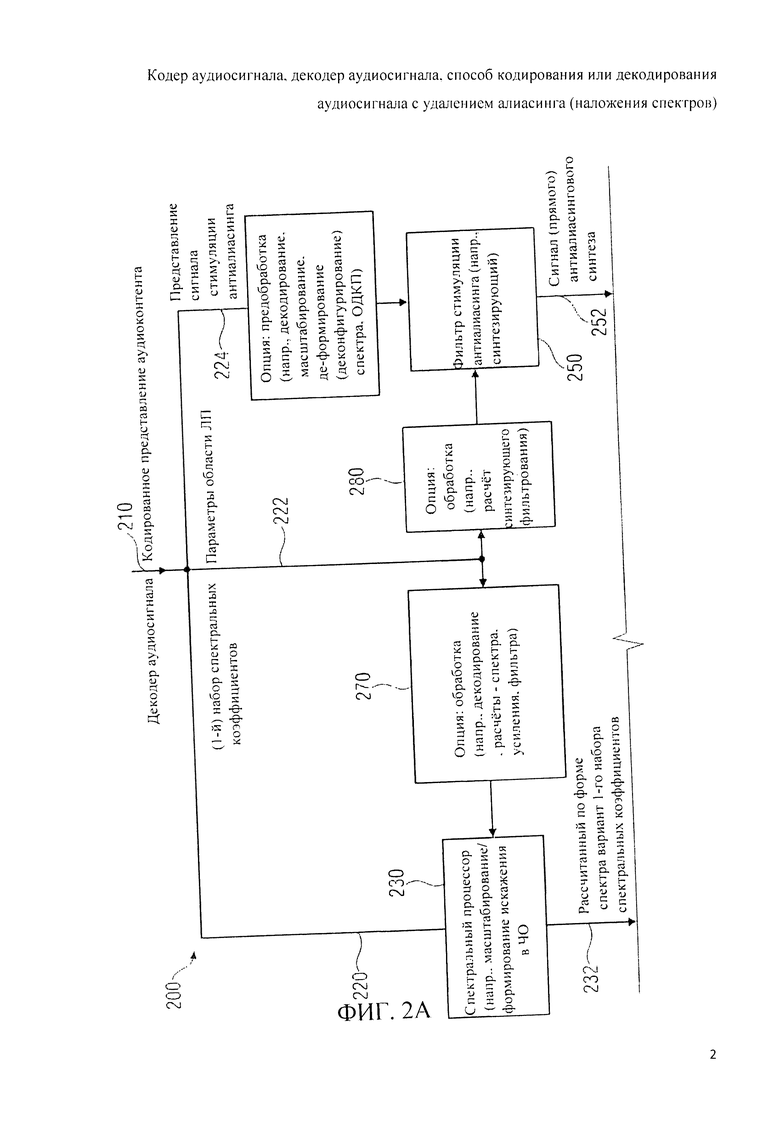
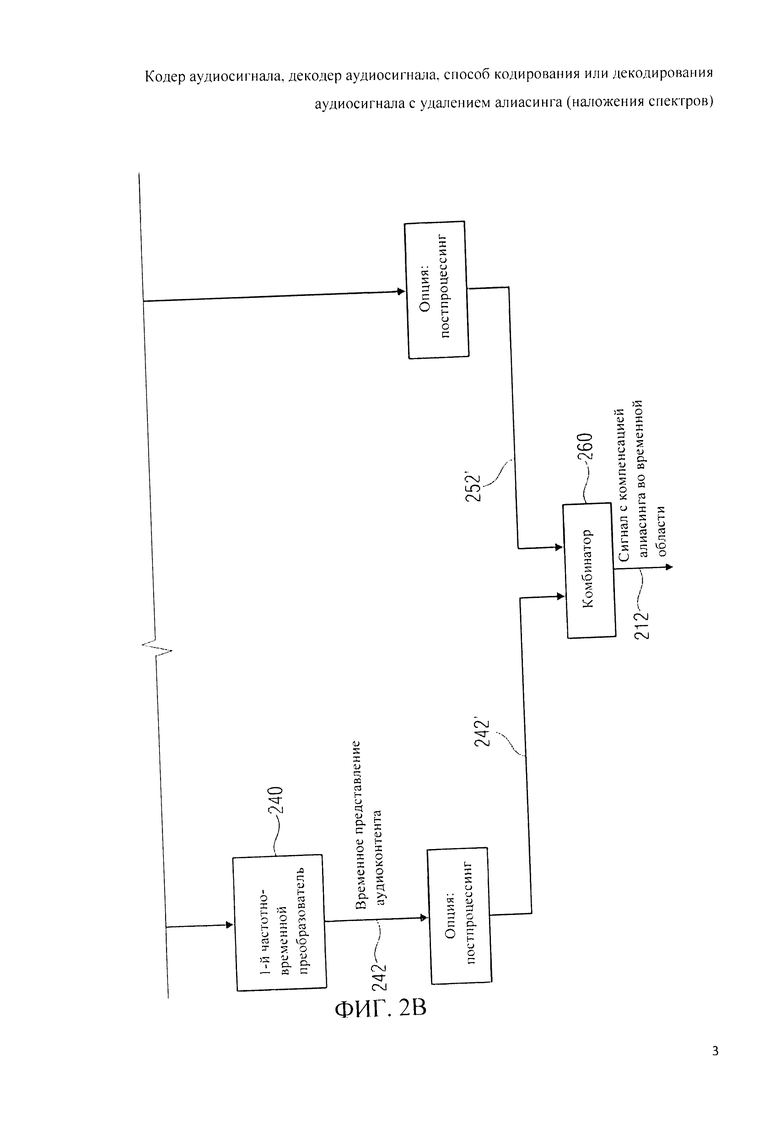
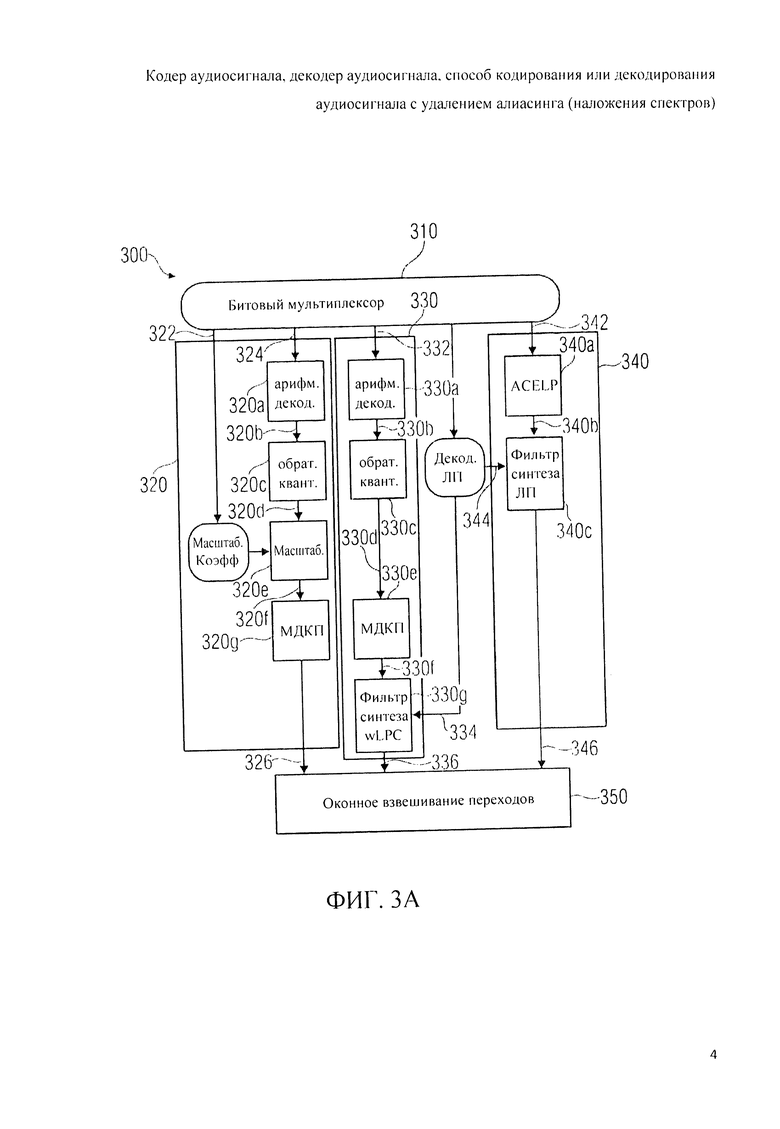
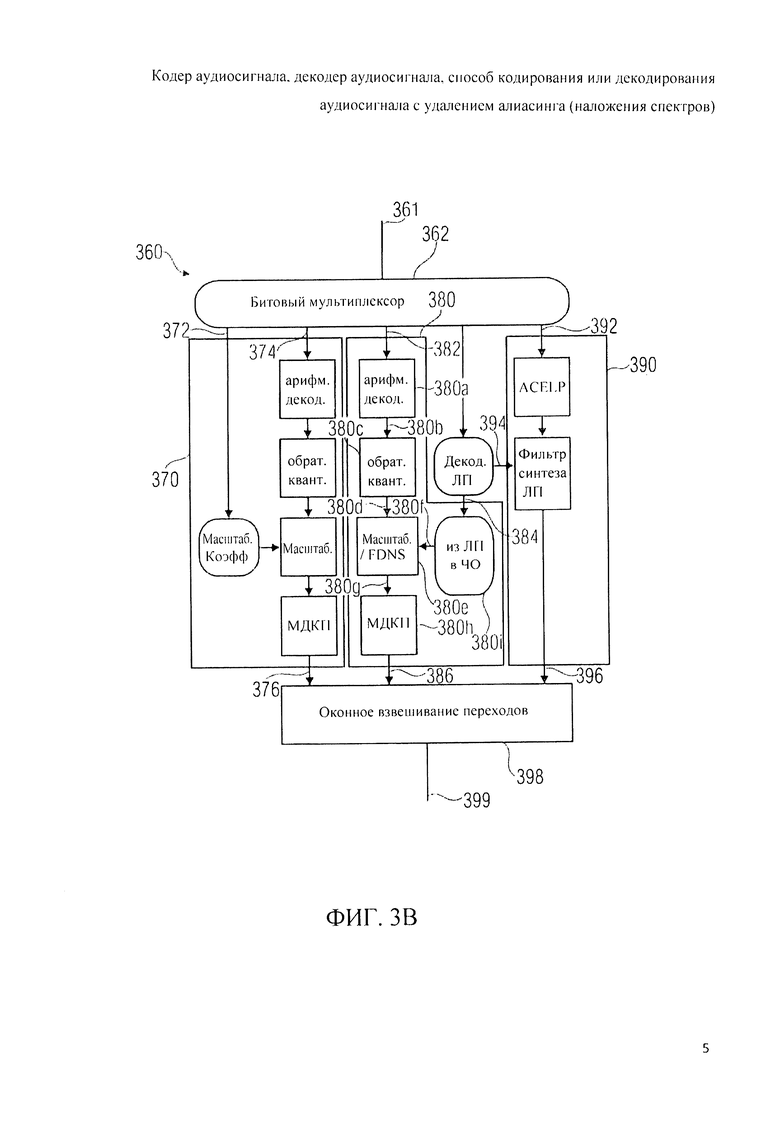
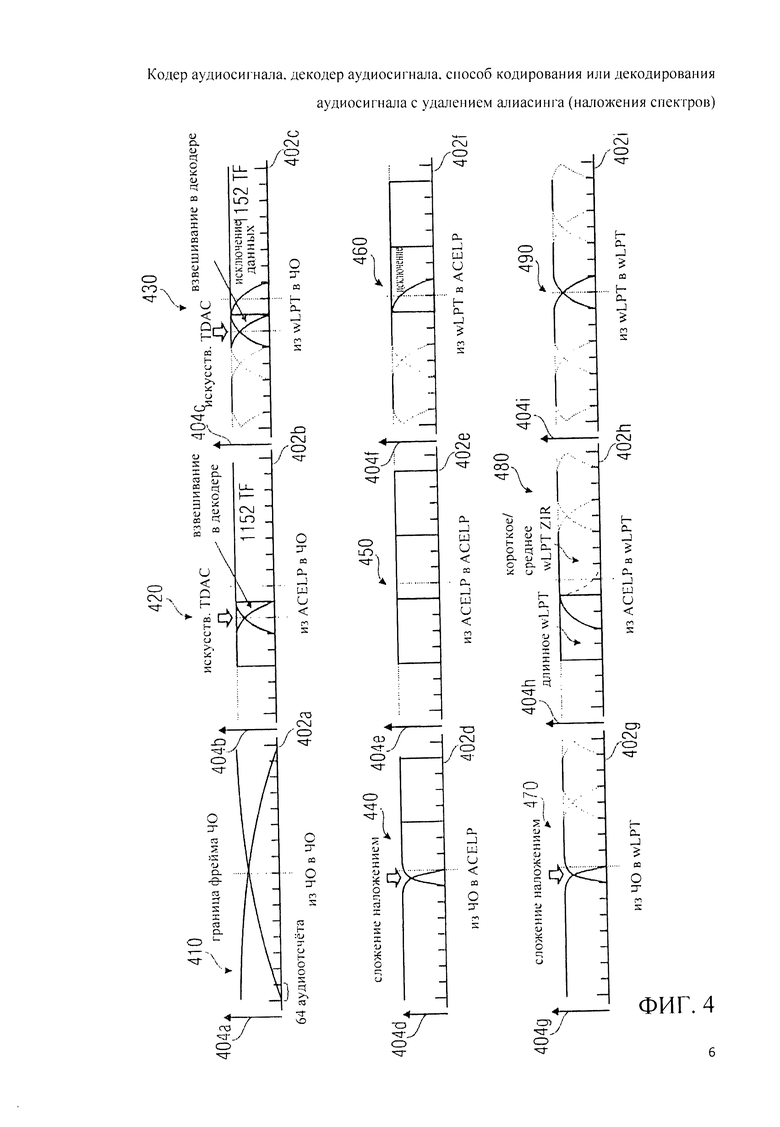
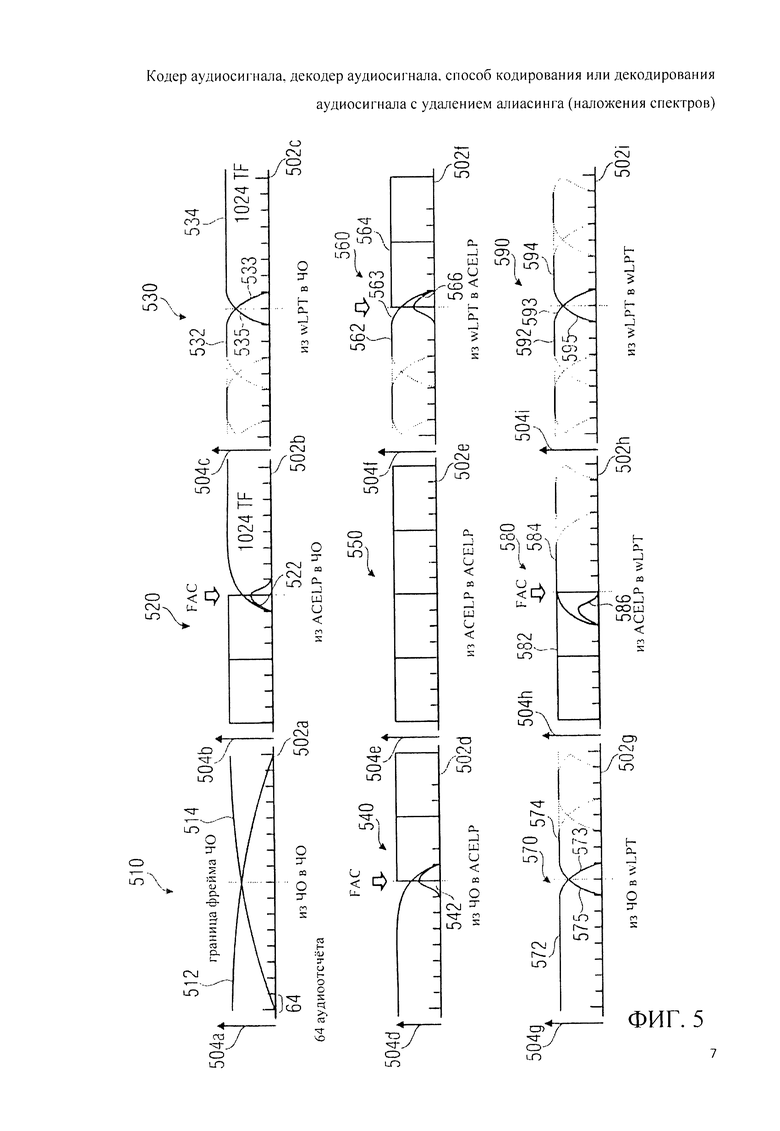
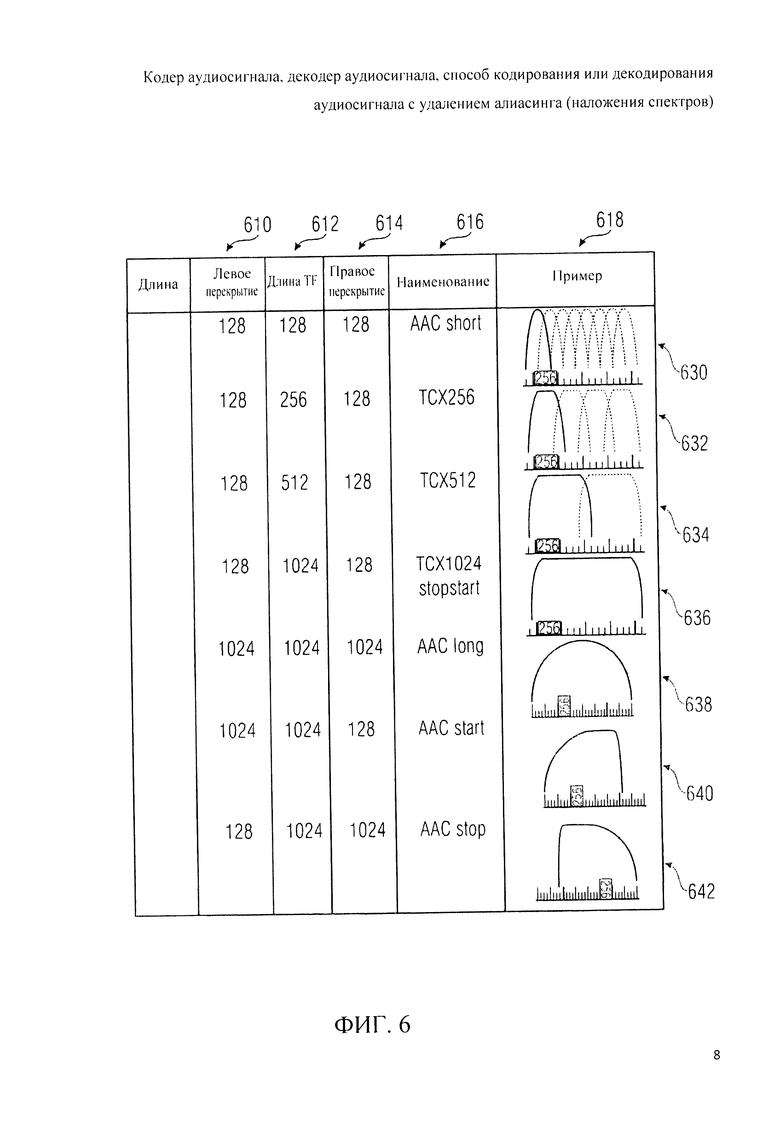
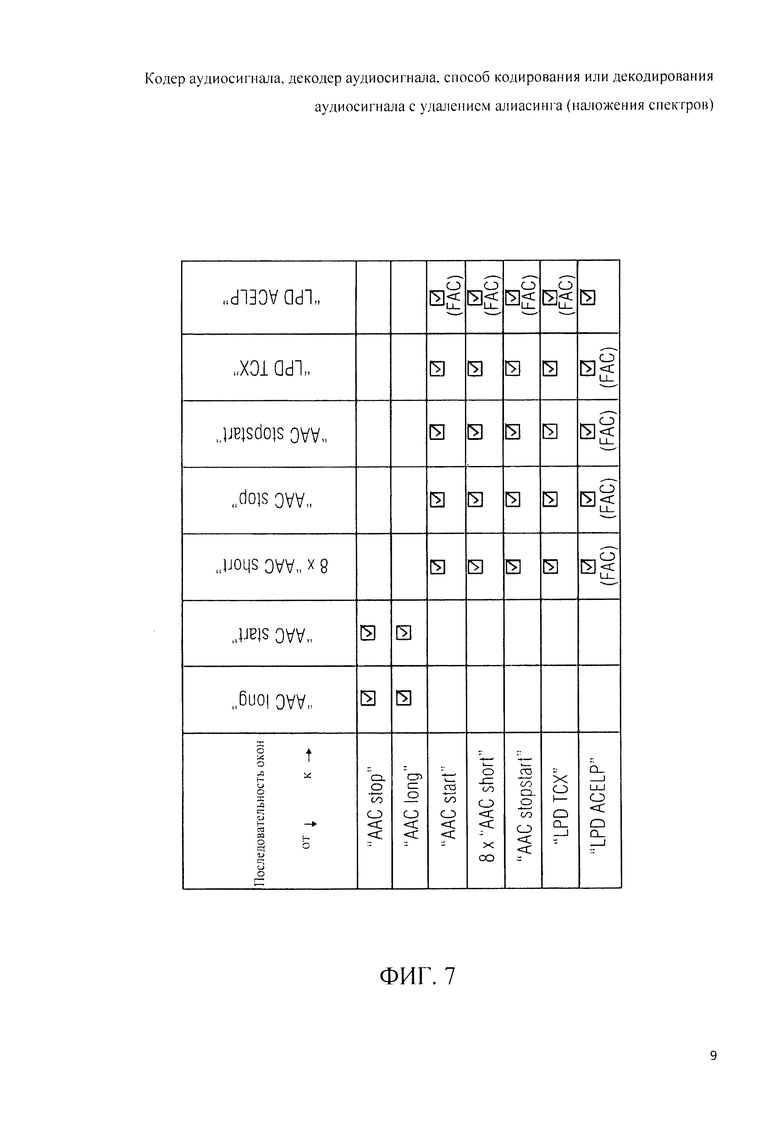
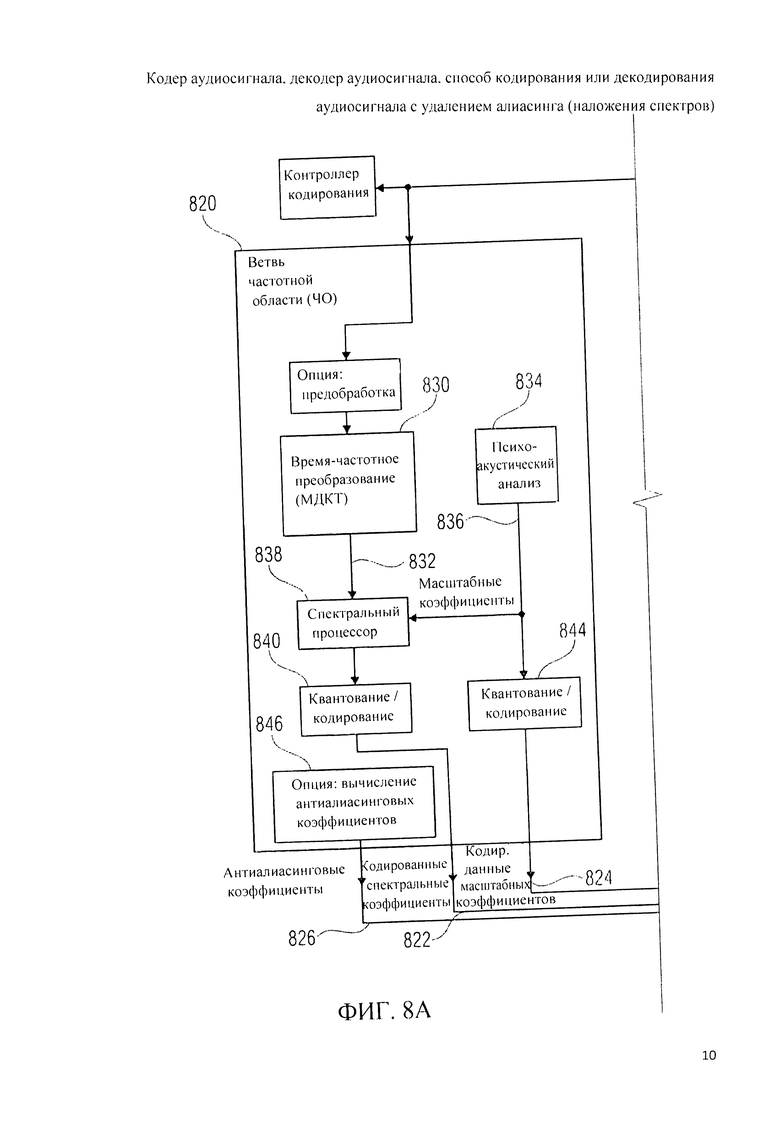
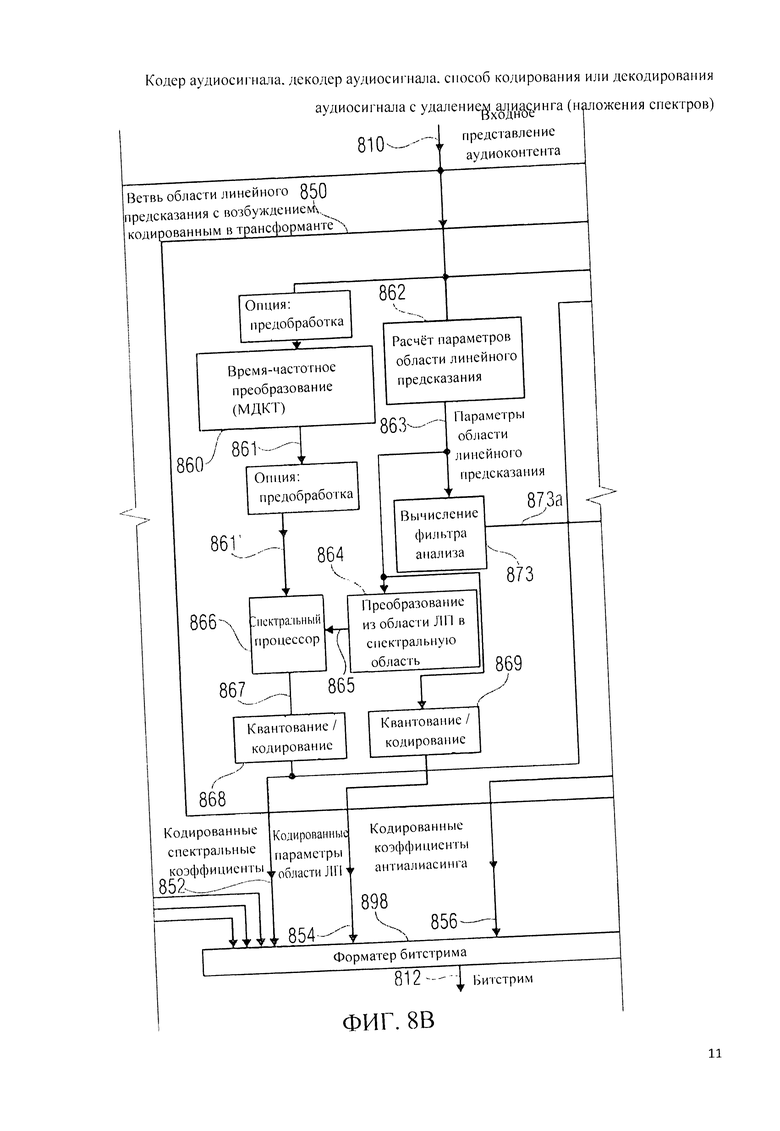
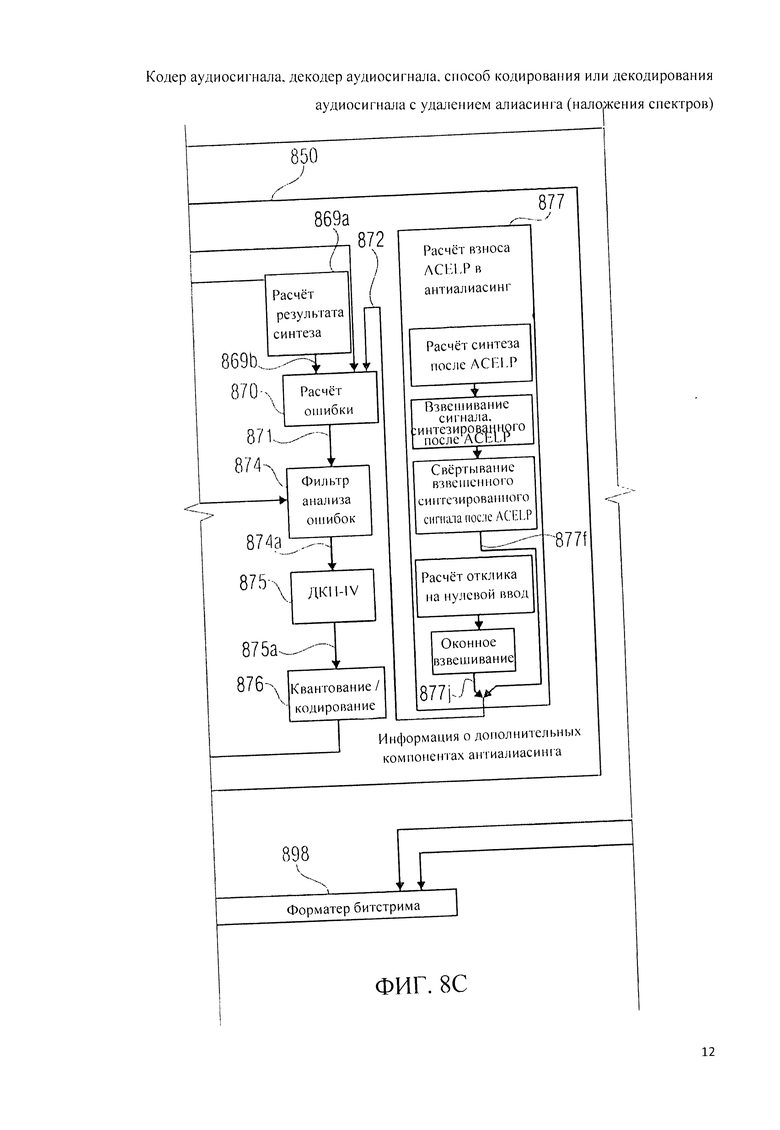
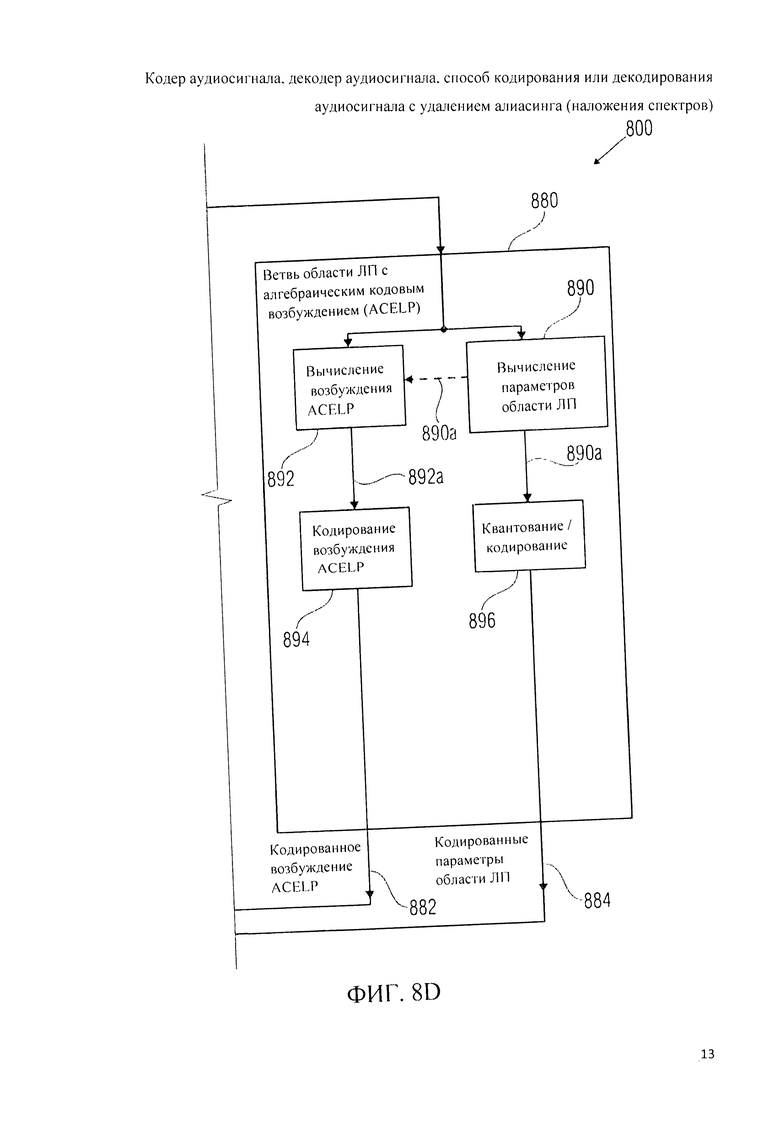
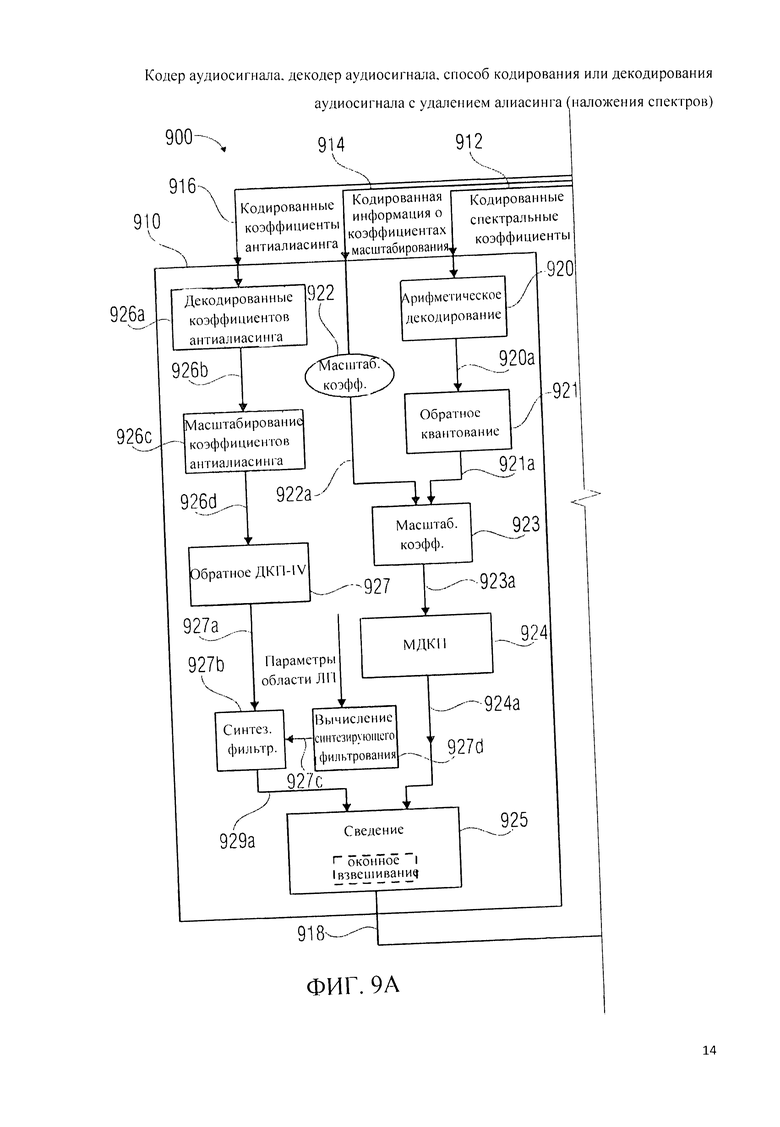
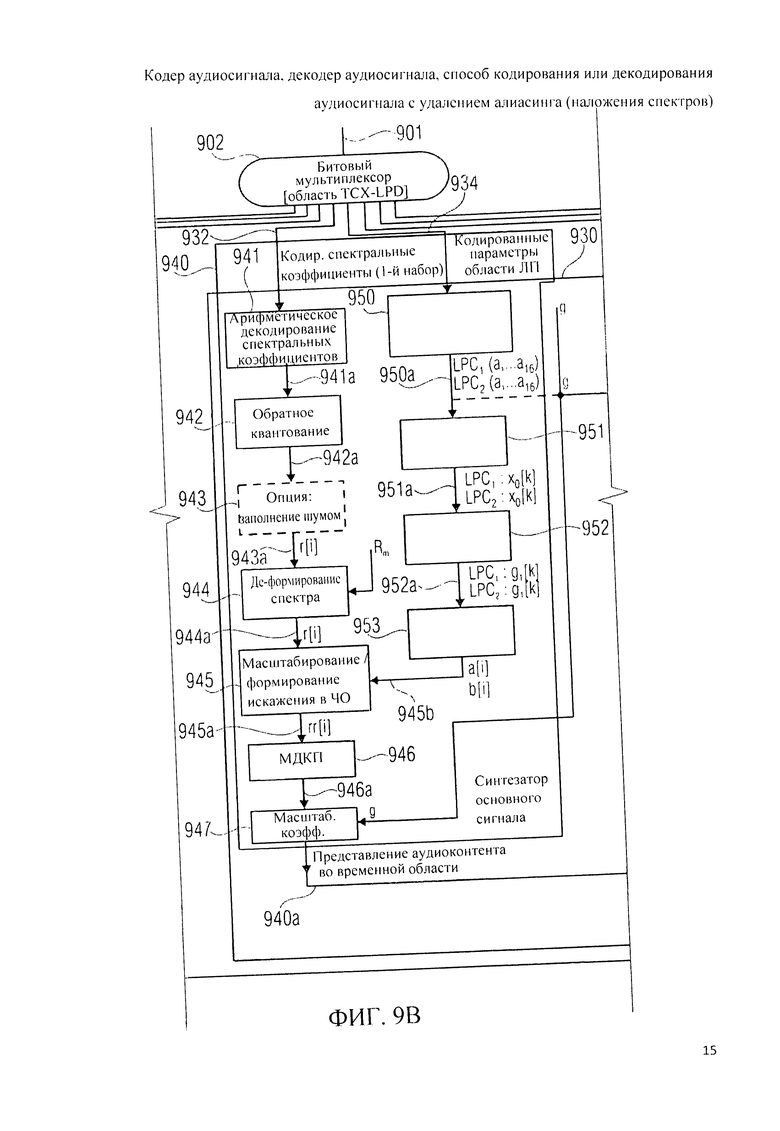
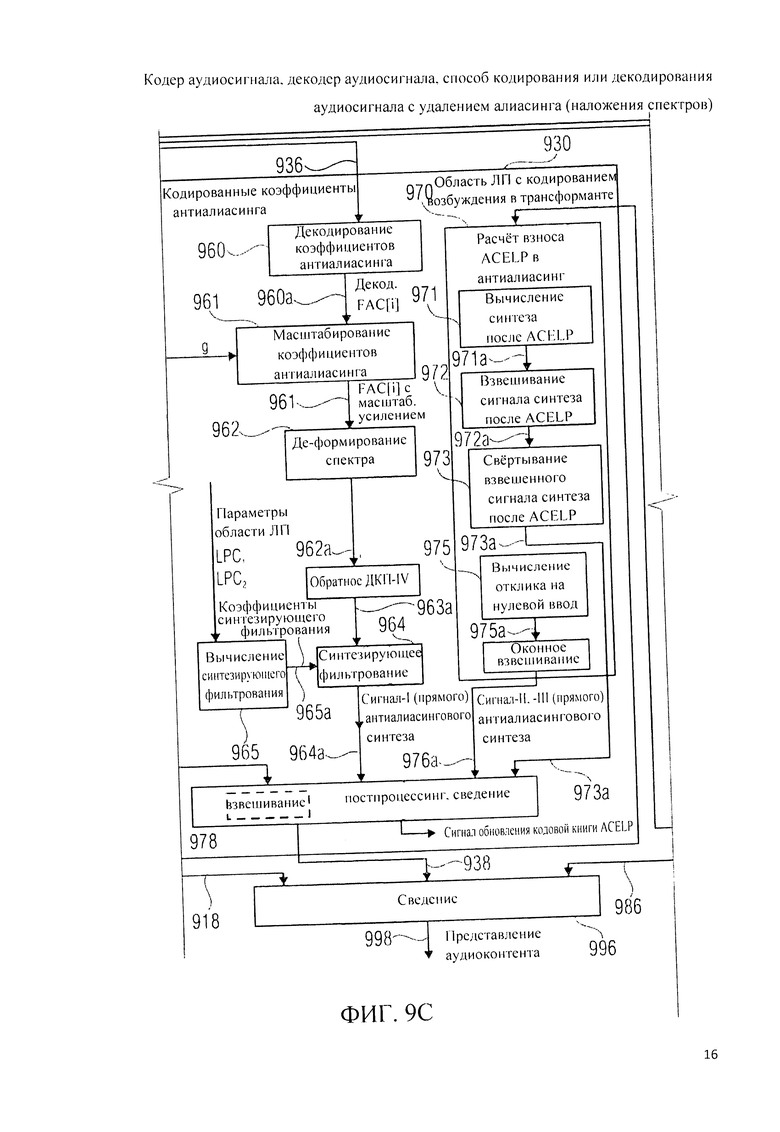
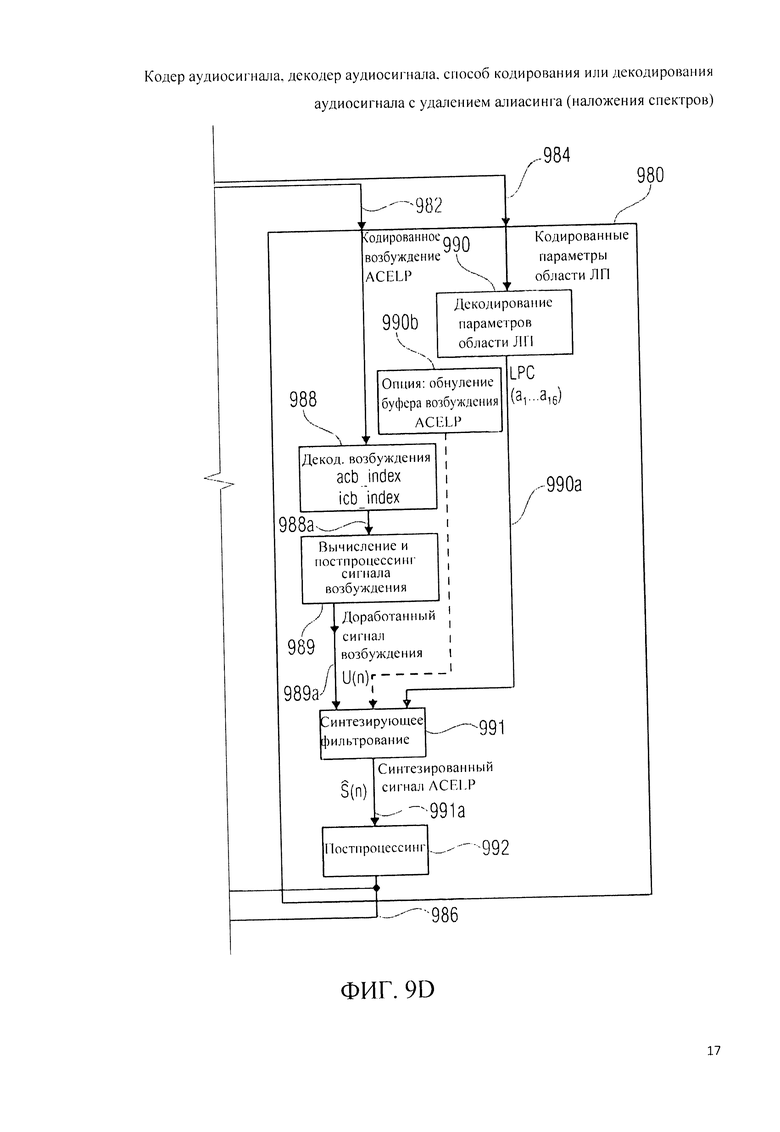
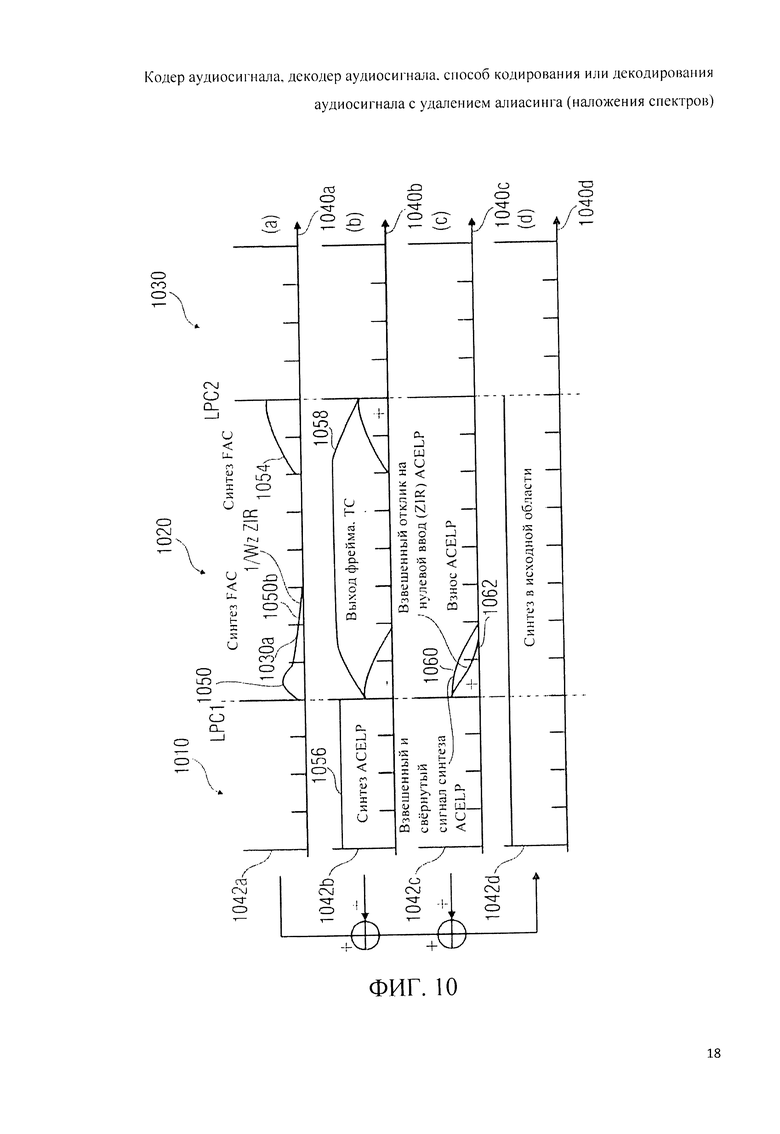
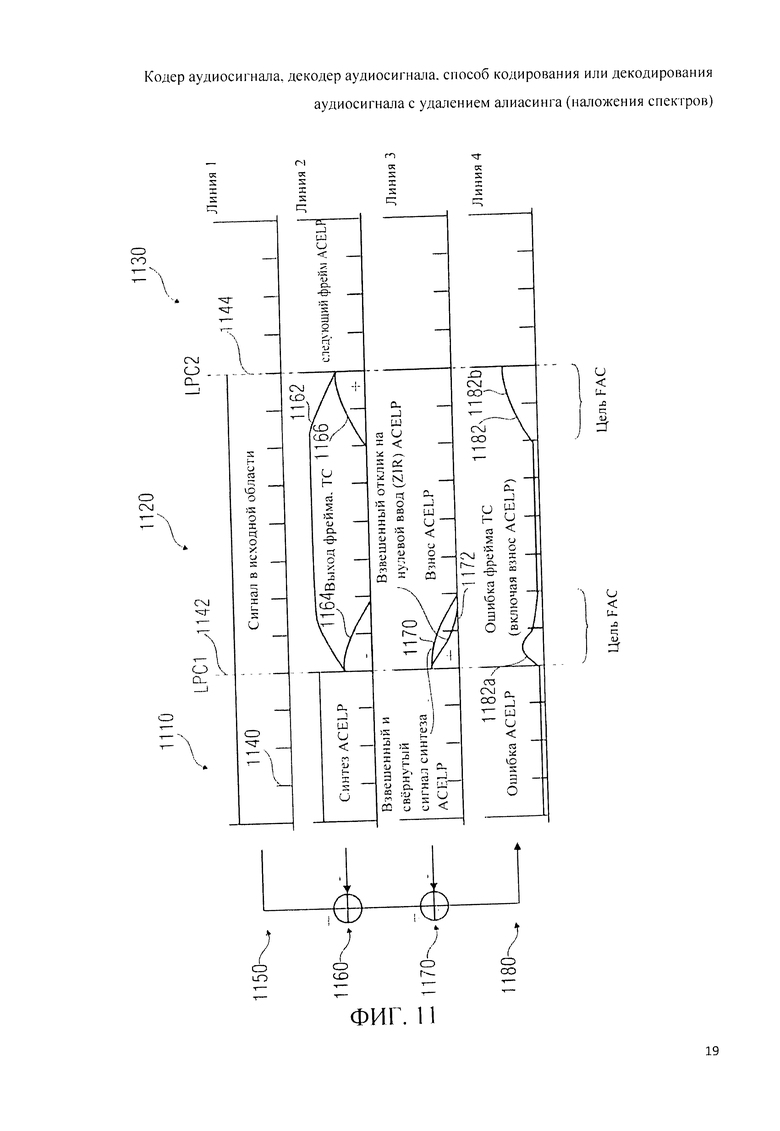
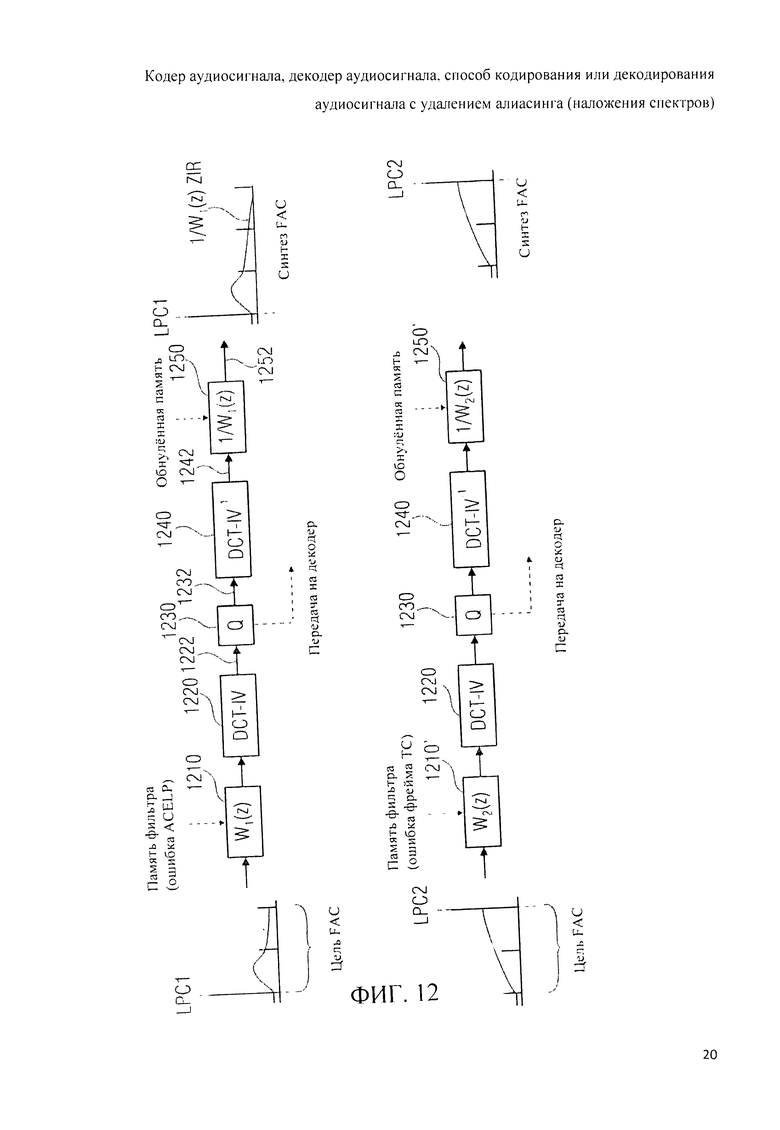
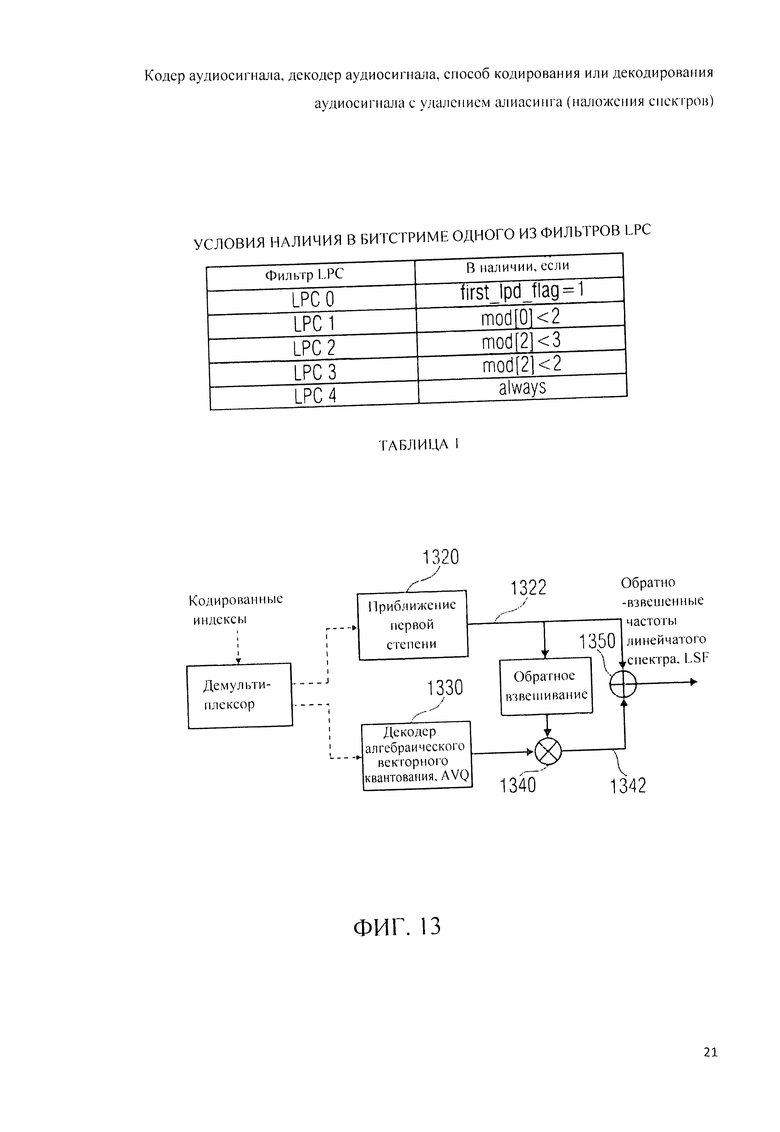
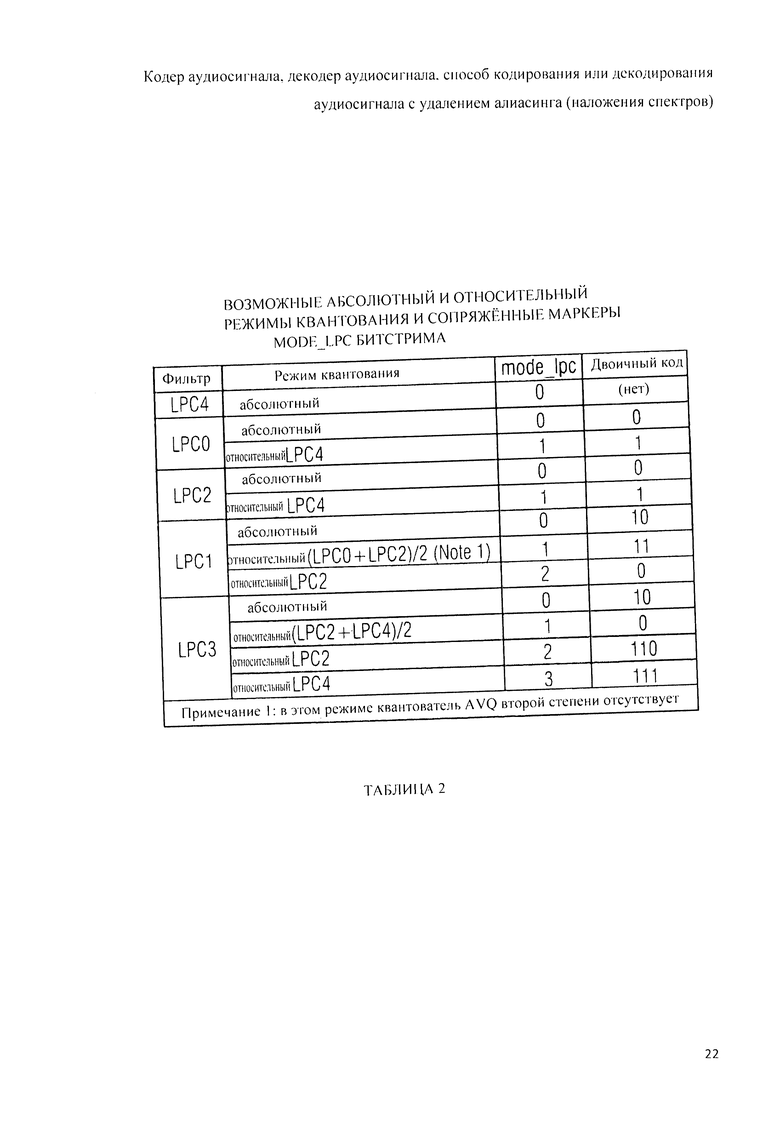

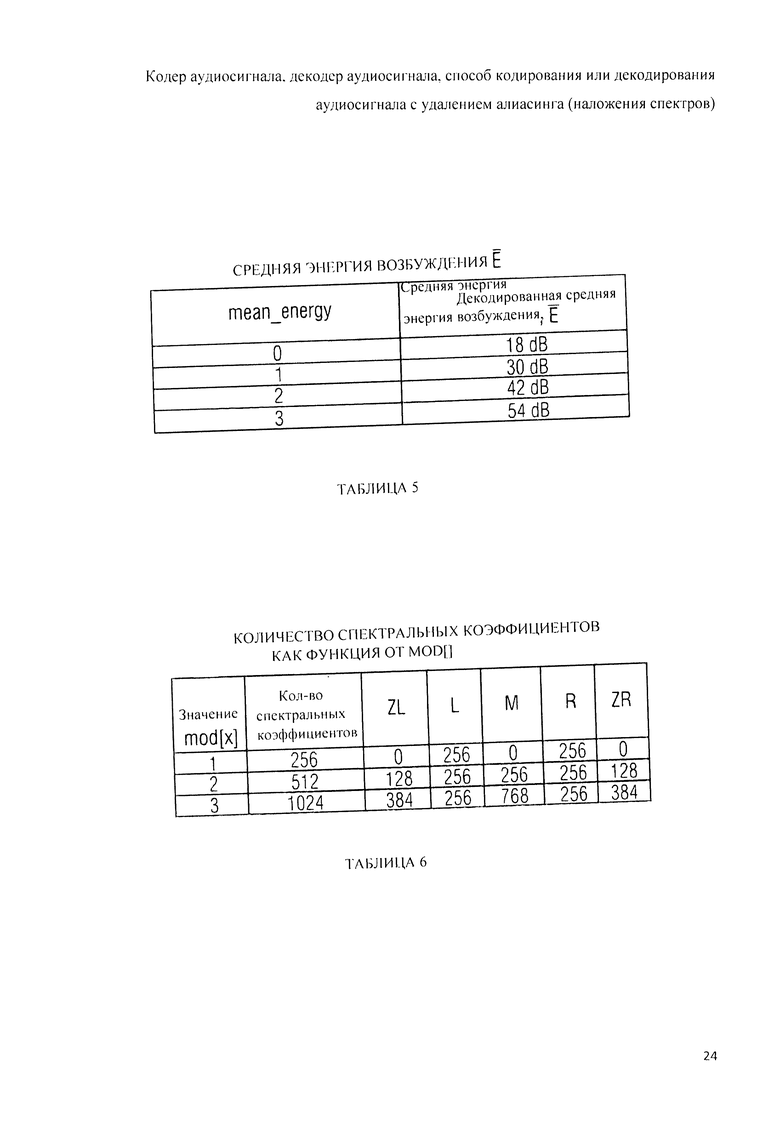
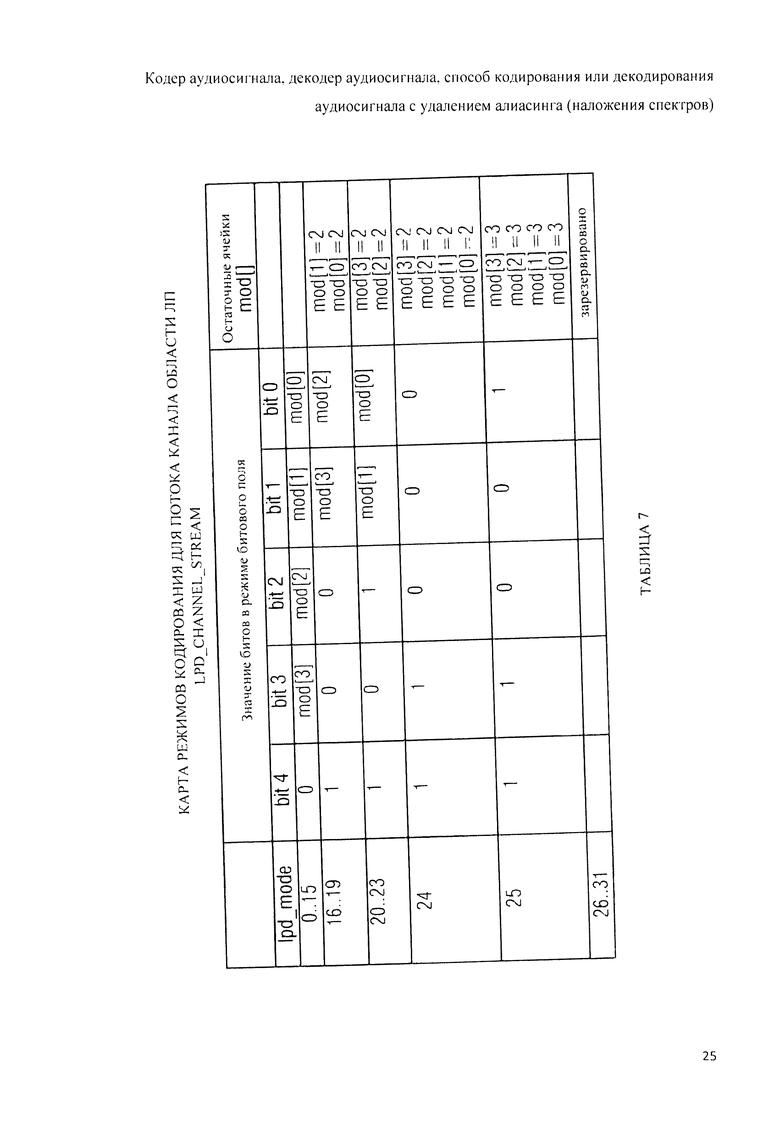


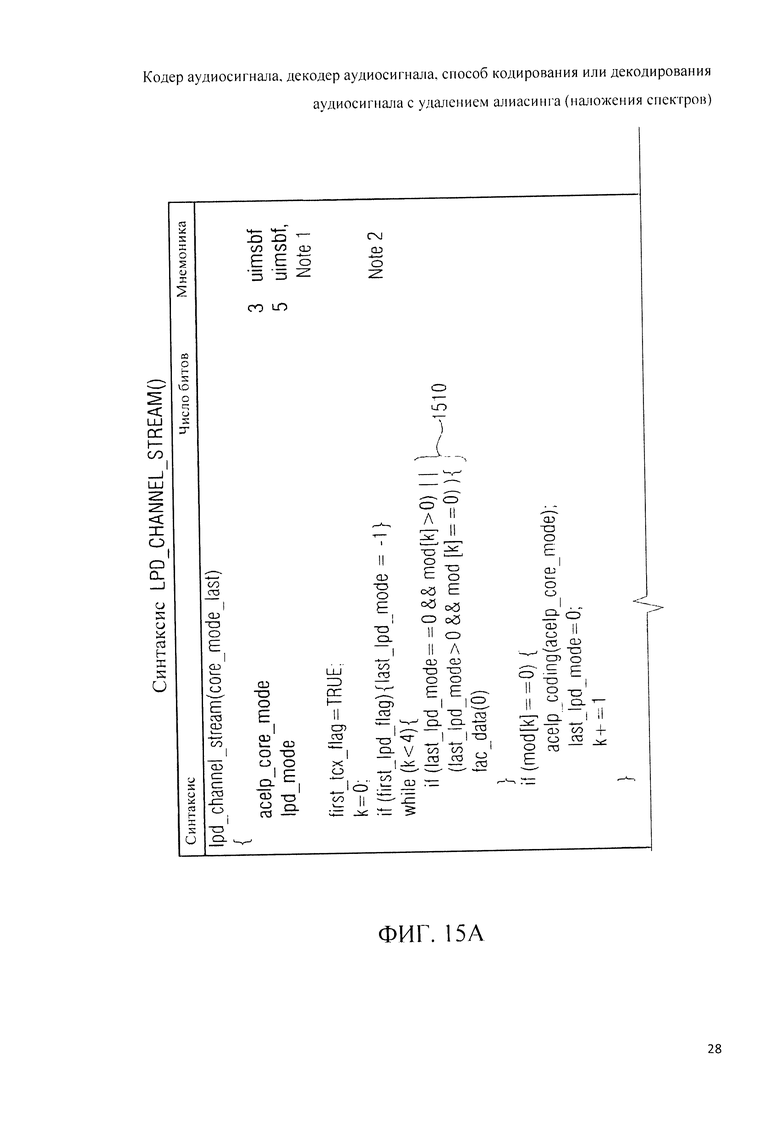


Группа изобретений относится к устройствам и способам кодирования и декодирования аудиосигнала с удалением алиасинга (наложения спектров). Техническим результатом является нейтрализация артефактов алиасинга при прохождении через декодер аудиосигнала. Способ включает этапы: преобразования из временной области в частотную область представления входных звуковых данных с формированием в частотной области представления аудиоконтента; формирования спектра частотного представления аудиоконтента или его предварительно обработанной модификации в зависимости от набора параметров области линейного предсказания для фрагмента аудиоконтента, кодируемого в области линейного предсказания, с получением частотного представления аудиоконтента, рассчитанного по форме спектра; и формирования представления сигнала стимуляции антиалиасинга с получением в результате фильтрации сигнала стимуляции антиалиасинга при учете, по меньшей мере, некоторого множества параметров области линейного предсказания сигнала безалиасингового синтеза с нейтрализацией артефактов наложения спектров (алиасинга) на стороне аудиодекодера. 6 н. и 12 з.п. ф-лы, 25 ил., 8 табл.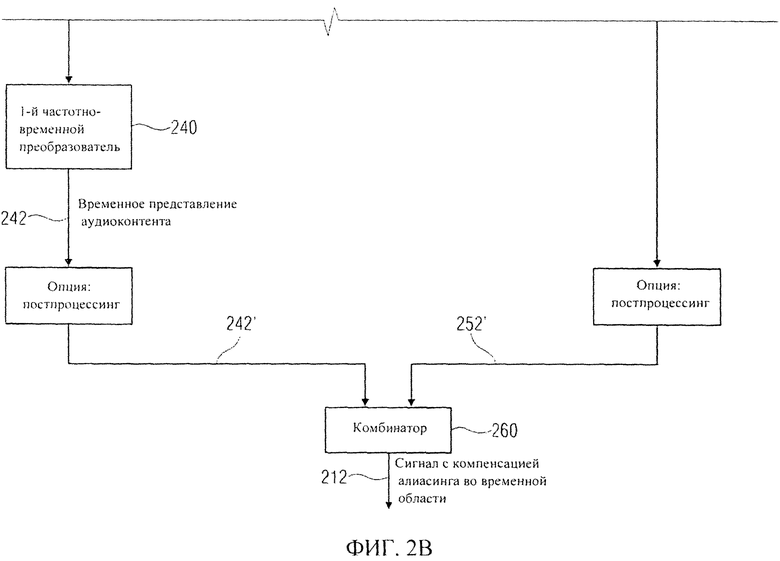
1. Декодер аудиосигнала (200; 360; 900), формирующий декодированное представление (212; 399; 998) аудиоконтента на основе кодированного представления (210; 361; 901) аудиоконтента, включающий в себя: тракт области линейного предсказания с кодовым возбуждением в трансформанте (230, 240, 242, 250, 260; 270, 280; 380; 930), формирующий представление во временной области (212; 386; 938) фрагмента аудиоконтента, закодированного в режиме предсказания с кодовым возбуждением в трансформанте на базе первого набора (220; 382; 944а) спектральных коэффициентов, представления (224; 936) сигнала стимуляции антиалиасинга и множества параметров области линейного предсказания (LPD) (222; 384; 950а); при этом тракт области линейного предсказания с кодовым возбуждением в трансформанте включает в себя спектральный процессор (230; 380е; 945), выполненный с возможностью применения операции формирования спектра к первому набору (944а) спектральных коэффициентов исходя из, по меньшей мере, подмножества параметров области линейного предсказания, с выведением рассчитанного по форме спектра варианта (232; 380g; 945а) первого набора спектральных коэффициентов; одновременно тракт области линейного предсказания с кодовым возбуждением в трансформанте включает в себя первый преобразователь из частотной области во временную область (240; 380h; 946), выполненный с возможностью формирования представления аудиоконтента во временной области на основе рассчитанного по форме спектра варианта первого набора спектральных коэффициентов; кроме того, тракт области линейного предсказания с кодовым возбуждением в трансформанте включает в себя фильтр сигнала стимуляции антиалиасинга (250; 964), генерирующий сигнал возбуждения компенсации наложения спектров (224; 963а) в зависимости от, по меньшей мере, подмножества параметров области линейного предсказания (222; 384; 934) с выводом сигнала, синтезированного без алиасинга (252; 964а), производного от сигнала, стимулирующего антиалиасинг; а также тракт области линейного предсказания с кодовым возбуждением в трансформанте включает в себя комбинатор (260; 978), предназначенный для сведения представления аудиоконтента во временной области (242; 940а) и сигнала, синтезированного с устранением алиасинга (252; 964), или его варианта, прошедшего построцессинг, с формированием на выходе сигнала временной области с компенсированным алиасингом.
2. Декодер аудиосигнала по п. 1, представляющий собой мультирежимный аудиодекодер, выполненный с возможностью коммутации между множеством режимов кодирования, в составе которого тракт области линейного предсказания с кодовым возбуждением в трансформанте (230; 240, 250, 260, 270, 280; 380; 930) скомпонован с возможностью селективного синтеза безалиасингового сигнала (252; 964а) для сегмента (1020) аудиоконтента, следующего за сегментом (1010) аудиоконтента, который не предусматривает возможность выполнения операции сложения наложением с нейтрализацией алиасинга, или для сегмента аудиоконтента, за которым следует очередной сегмент (1030) аудиоконтента, который не предусматривает операцию сложения наложением с нейтрализацией алиасинга.
3. Декодер аудиосигнала по п. 1, выполненный с возможностью коммутации между режимом области линейного предсказания с возбуждением, закодированным в трансформанте (TCX-LPD), для работы в котором используют информацию о кодах возбуждения в трансформанте (932) и информацию о параметрах области линейного предсказания (934), и режимом частотной области, для работы в котором используют информацию о спектральных коэффициентах (912) и информацию о коэффициентах масштабирования (914); при этом тракт области линейного предсказания с кодовым возбуждением в трансформанте (930) в составе декодера аудиосигнала формирует на основе информации о кодированном в трансформанте возбуждении (932) первый набор (944а) спектральных коэффициентов, и на основе информации о параметрах области линейного предсказания (934) выводит параметры области линейного предсказания (950а); кроме этого, декодер аудиосигнала включает в себя тракт частотной области (910), предназначенный для формирования представления во временной области (918) аудиоконтента, закодированного в режиме частотной области на основе набора спектральных коэффициентов в режиме частотной области (921а), описанных посредством информации о спектральных коэффициентах (912), и исходя из набора (922а) масштабных коэффициентов (922), описанных посредством информации о масштабных коэффициентах (914); при этом в тракт частотной области (910) введен спектральный процессор (923), предназначенный для приложения формы спектра к набору спектральных коэффициентов в режиме частотной области (921а) или к их предобработанной версии в зависимости от набора (922а) коэффициентов масштабирования с выведением рассчитанного по форме спектра набора (923а) спектральных коэффициентов в режиме частотной области, а кроме этого, в тракт частотной области (910) введен частотно-временной преобразователь (924а), предназначенный для формирования представления аудиоконтента во временной области (924) на основе рассчитанного по форме спектра набора спектральных коэффициентов в режиме частотной области (923а); при этом указанный декодер аудиосигнала формирует представления во временной области двух последовательных фрагментов аудиоконтента с временным наложением, которое нейтрализует во временной области алиасинг, возникающий при преобразовании из частотной области во временную область, причем один из двух названных последовательных фрагментов закодирован в режиме линейного предсказания с кодовым возбуждением из трансформанты (TCX-LPD), а второй фрагмент закодирован в режиме частотной области.
4. Декодер аудиосигнала по п. 1, выполненный с возможностью коммутации между режимом области линейного предсказания с возбуждением, закодированным в трансформанте, для работы в котором используют информацию о кодах возбуждения в трансформанте (932) и информацию о параметрах области линейного предсказания (934), и режимом линейного предсказания с возбуждением алгебраическим кодом (ACELP), для работы в котором используют информацию о возбуждении алгебраическим кодом (982) и информацию о параметрах области линейного предсказания (984); в составе которого тракт области линейного предсказания с кодовым возбуждением в трансформанте (930) выполнен с возможностью выведения первого набора (944а) спектральных коэффициентов на основе информации о кодах возбуждения в трансформанте (932) и извлечения параметров области линейного предсказания (950а) из информации о параметрах области линейного предсказания (934); кроме того, декодер аудиосигнала включает в свою схему тракт линейного предсказания с алгебраическим кодовым возбуждением (980), предназначенный для формирования представления во временной области (986) аудиоконтента, закодированного в режиме ACELP, на основе информации об алгебраических кодах возбуждения (982) и информации о параметрах области линейного предсказания (984); при этом тракт ACELP (980) имеет в своем составе процессор возбуждения ACELP (988, 989), генерирующий сигнал возбуждения во временной области (989а) на основе информации о алгебраических кодах возбуждения (982) и с использованием фильтра синтеза (991), вырабатывающего во временной области сигнал возбуждения во временной области для формирования реконструированного сигнала на основе сигнала возбуждения во временной области (989а) и с учетом коэффициентов пропускания фильтра области линейного предсказания (990а), рассчитанных исходя из информации о параметрах области линейного предсказания (984); далее, тракт области линейного предсказания с кодовым возбуждением в трансформанте (930) в составе декодера аудиосигнала выполнен с возможностью селективно синтезировать безалиасинговый сигнал (964) для фрагмента аудиоконтента, закодированного в режиме области линейного предсказания с кодовым возбуждением из трансформанты (TCX-LPD), следующего за фрагментом аудиоконтента, закодированным в режиме ACELP, и для фрагмента аудиоконтента, закодированного в режиме TCX-LPD, предшествующего фрагменту аудиоконтента, закодированному в режиме ACELP.
5. Декодер аудиосигнала по п. 4, в составе которого фильтр стимуляции антиалиасинга (964) генерирует задающий сигнал компенсации наложения спектров (963а) исходя из параметров фильтра области линейного предсказания (950а; LPC1), которые соответствуют левой точке свертывания алиасинга первого частотно-временного преобразователя (946), для фрагмента аудиоконтента, закодированного в режиме TCX-LPD, следующего за фрагментом аудиоконтента, закодированным в режиме ACELP; и в составе которого фильтр стимуляции антиалиасинга (964) генерирует сигналы активации нейтрализации алиасинга (963а) исходя из параметров фильтра области линейного предсказания (950а; LPC2), которые соответствуют правосторонней точке свертывания алиасинга первого частотно-временного преобразователя (946), для фрагмента аудиоконтента, закодированного в режиме TCX-LPD, предшествующего фрагменту аудиоконтента, закодированному в режиме ACELP.
6. Декодер аудиосигнала по п. 4, предусматривающий перезагрузку памяти фильтра стимуляции антиалиасинга (964) путем обнуления его значений для обеспечения синтеза безалиасингового сигнала, ввод М отсчетов сигнала стимуляции антиалиасинга в фильтр стимуляции антиалиасинга (964), получение соответствующего отклика на ненулевой ввод в виде отсчетов сигнала безалиасингового синтеза (964а) и последующее получение отклика на нулевой ввод в виде множества отсчетов сигнала безалиасингового синтеза; в составе которого комбинатор предназначен для сведения сигналов представления во временной области (940а) аудиоконтента, содержащего отсчеты отклика на ненулевой входной сигнал и последующие отсчеты отклика на нулевой входной сигнал с выведением сигнала временной области с компенсированным алиасингом на переходе от фрагмента аудиоконтента, закодированного в режиме ACELP, к последующему фрагменту аудиоконтента, закодированному в режиме TCX-LPD.
7. Декодер аудиосигнала по п. 4, предусматривающий совмещение взвешенного и свернутого варианта (973а; 1060), по меньшей мере, фрагмента представления во временной области, сформированного в режиме ACELP, с представлением во временной области (940; 1050а) следующего фрагмента аудиоконтена, сформированного в режиме TCX-LPD, с целью, по меньшей мере, частичной компенсации наложения спектров (алиасинга).
8. Декодер аудиосигнала по п. 4, предусматривающий совмещение взвешенного варианта (976а; 1062) отклика синтезирующего фильтра ветви ACELP на нулевой ввод и представления во временной области (940а; 1058) очередного фрагмента аудиоконтента, сформированного в режиме TCX-LPD, с целью, по меньшей мере, частичной компенсации алиасинга.
9. Декодер аудиосигнала по п. 4, выполняющий коммутацию между режимом области линейного предсказания с возбуждением, кодированным в трансформанте, в котором используют частотно-временное преобразование с перекрытием, режимом частотной области, в котором используют частотно-временное преобразование с перекрытием, и режимом линейного предсказания с алгебраическим кодовым возбуждением (ACELP), при этом декодер аудиосигнала, по меньшей мере, частично компенсирует алиасинг на переходе между сегментом аудиоконтента, закодированным в режиме TCX-LPD, и сегментом аудиоконтента, закодированным в режиме частотной области, выполняя операцию сложения наложением временных отсчетов последовательно перекрывающихся фрагментов аудиоконтента; и при этом декодер аудиосигнала, по меньшей мере, частично компенсирует алиасинг на переходе между сегментом аудиоконтента, закодированным в режиме TCX-LPD, и сегментом аудиоконтента, закодированным в режиме области ACELP, используя сигнал антиалиасингового синтеза (964а).
10. Декодер аудиосигнала по п. 1, предусматривающий применение общего значения коэффициента усиления (g) для масштабирования усиления (947) представления во временной области (946а), сформированного первым частотно-временным преобразователем (946) в составе тракта области линейного предсказания с кодовым возбуждением в трансформанте (930), и для масштабирования усиления (961) сигнала стимуляции антиалиасинга (963а) или сигнала безалиасингового синтеза (964а).
11. Декодер аудиосигнала по п. 1, предусматривающий в дополнение к формированию спектра в соответствии с, по меньшей мере, подмножеством параметров области линейного предсказания де-формирование спектра (944) в соответствии с, по меньшей мере, подмножеством из первого набора спектральных коэффициентов, при этом декодер аудиосигнала выполнен с возможностью применения де-формирования спектра (962), по меньшей мере, к подмножеству из набора антиалиасинговых спектральных коэффициентов, из которого формируется производный сигнал стимуляции антиалиасинга (963а).
12. Декодер аудиосигнала по п. 1, включающий в свой состав второй преобразователь из частотной области во временную область (963), предназначенный для формирования представления во временной области сигнала, стимулирующего антиалиасинг (963а) в зависимости от набора спектральных коэффициентов (960а), представляющих сигнал стимуляции антиалиасинга, при этом первый частотно-временной преобразователь выполняет преобразование с перекрытием, которое захватывает алиасинг во временной области, и при этом второй частотно-временной преобразователь выполняет преобразование без перекрытия.
13. Декодер аудиосигнала по п. 1, который предусматривает применение формирования спектра в отношении первого набора спектральных коэффициентов, исходя из тех же параметров области линейного предсказания, которые используют для настройки фильтрации сигнала стимуляции устранения эффекта наложения спектров (антиалиасинга).
14. Кодер аудиосигнала (100; 800), формирующий кодированное представление (112; 812) звуковых данных, которое включает в себя первый набор (112а; 852) спектральных коэффициентов, представление сигнала стимуляции антиалиасинга (112с; 856) и множество параметров области линейного предсказания (112b; 854) на основе входного представления (110; 810) звуковых данных, имеющий в своем составе: преобразователь из временной области в частотную область (время-частотный преобразователь) (120; 860), предназначенный для обработки представления входящих звуковых данных с формированием представления аудиоконтента в частотной области (112; 861); спектральный процессор (130; 866), предназначенный для применения операции формирования спектра к представлению аудиоконтента в частотной области или к его предварительно обработанной модификации исходя из набора параметров области линейного предсказания (140; 863) для фрагмента аудиоконтента, кодируемого в области линейного предсказания, с формированием частотного представления аудиоконтента, рассчитанного по форме спектра (132; 867); и драйвер доступа к данным антиалиасинга (150, 870, 874, 875, 876), предназначенный для формирования представления (112с; 856) сигнала стимуляции антиалиасинга таким образом, что в результате фильтрования сигнала стимуляции антиалиасинга в зависимости от, по меньшей мере, подмножества параметров области линейного предсказания синтезируется интиалиасинговый сигнал с устранением артефактов алиасинга на стороне декодера аудиосигнала.
15. Способ формирования декодированного представления аудиоконтента на основе кодированного представления аудиоконтента, включающий в себя: формирование представления во временной области фрагмента аудиоконтента, закодированного в режиме предсказания с кодовым возбуждением в трансформанте с использованием первого набора спектральных коэффициентов, представления сигнала стимуляции антиалиасинга и множества параметров области линейного предсказания, при этом первому набору спектральных коэффициентов задают форму спектра в зависимости от, по меньшей мере, подмножества параметров области линейного предсказания с получением рассчитанного по форме спектра варианта первого набора спектральных коэффициентов, и при этом представление аудиоконтента во временной области формируют, используя частотно-временное преобразование на основе рассчитанного по форме спектра варианта первого набора спектральных коэффициентов, и при этом сигнал стимуляции антиалиасинга фильтруют в зависимости, по меньшей мере, от подмножества параметров области линейного предсказания для синтеза антиалиасингового сигнала, производного от сигнала стимуляции антиалиасинга, и при этом представление аудиоконтента во временной области совмещают с сигналом антиалиасингового синтеза или с его постобработанной версией, получая на выходе сигнал временной области с компенсированным алиасингом.
16. Способ формирования кодированного представления аудиоконтента, состоящего из первого набора спектральных коэффициентов, представления сигнала стимуляции антиалиасинга и множества параметров области линейного предсказания, на основе представления входящих звуковых данных, включающий в себя: преобразование из временной области в частотную область представления входных звуковых данных с формированием в частотной области представления аудиоконтента; формирование спектра частотного представления аудиоконтента или его предварительно обработанной модификации в зависимости от набора параметров области линейного предсказания для фрагмента аудиоконтента, кодируемого в области линейного предсказания, с получением частотного представления аудиоконтента, рассчитанного по форме спектра; и формирование представления сигнала стимуляции антиалиасинга с получением в результате фильтрации сигнала стимуляции антиалиасинга при учете, по меньшей мере, некоторого множества параметров области линейного предсказания сигнала безалиасингового синтеза с нейтрализацией артефактов наложения спектров (алиасинга) на стороне аудиодекодера.
17. Машиночитаемый носитель информации с сохраненной на нем компьютерной программой для осуществления способа по п. 15 при условии ее выполнения на компьютере.
18. Машиночитаемый носитель информации с сохраненной на нем компьютерной программой для осуществления способа по п. 16 при условии ее выполнения на компьютере.
| Аппарат для очищения воды при помощи химических реактивов | 1917 |
|
SU2A1 |
| Аппарат для очищения воды при помощи химических реактивов | 1917 |
|
SU2A1 |
| Аппарат для очищения воды при помощи химических реактивов | 1917 |
|
SU2A1 |
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| Печь для непрерывного получения сернистого натрия | 1921 |
|
SU1A1 |

