Область техники, к которой относится изобретение
Настоящее изобретение касается области информационных технологий и, в частности, способа и устройства обработки объекта данных.
Уровень техники
Дедупликация данных, также называемая устранением дублирования данных, представляет собой процесс идентификации и устранения дублирования содержимого в наборе данных или потоке данных с целью улучшения эффективности хранения данных и/или передачи данных и для краткости называется дедупликацией или устранением дублирования. В общем, в технологии дедупликации набор данных или поток данных разделяют на ряды блоков данных и сохраняют только один блок данных, который является дублирующимся, тем самым уменьшают затраты памяти в процессе хранения данных или на потребление полосы пропускания в процессе передачи данных.
Ключевой вопрос, который необходимо решить, заключается в том, как делить объект данных на блоки данных, где дублирующееся содержимое может быть легко идентифицировано. После деления объекта данных на блоки данных, в качестве контрольной суммы можно вычислить значение 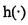 хэш-функции фрагмента данных и блоки данных с одинаковой контрольной суммой считают дублирующимися данными. В уровне техники обычно используемым блоком данных для устранения дублирования является файл, блок фиксированной длины (Блок), определяемый содержимым фрагмент (Фрагмент) переменной длины и подобное. В определяемом содержимым способе деления на фрагменты (Определяемое содержимым деление на фрагменты, CDC) используют скользящее окно для просмотра данных и идентификации строки байтов, которая соответствует заранее заданной характеристике, и маркировки положения строки байтов как границы фрагмента, для того, чтобы разделить набор данных или поток данных на последовательности фрагментов переменной длины. В этом способе границу фрагмента выбирают на основе характеристики содержимого данных, и граница фрагмента может более точно идентифицировать блок данных, присутствующий в похожих файлах или потоках данных, и, следовательно, этот способ широко применим в различных решениях дедупликации данных. Согласно исследованию, когда определяемый содержимым способ деления на фрагменты используют для деления набора данных или потока данных, более мелкая гранулярность при делении на фрагменты означает более высокую вероятность идентификации дублирующихся данных и лучший результат дедупликации. Тем не менее, более мелкая гранулярность при делении на фрагменты означает большее количество фрагментов, на которые делят заданный набор данных, тем самым означает увеличение затрат на индексирование и увеличение сложности поиска дублирующихся данных. В результате уменьшается временная эффективность дедупликации данных.
хэш-функции фрагмента данных и блоки данных с одинаковой контрольной суммой считают дублирующимися данными. В уровне техники обычно используемым блоком данных для устранения дублирования является файл, блок фиксированной длины (Блок), определяемый содержимым фрагмент (Фрагмент) переменной длины и подобное. В определяемом содержимым способе деления на фрагменты (Определяемое содержимым деление на фрагменты, CDC) используют скользящее окно для просмотра данных и идентификации строки байтов, которая соответствует заранее заданной характеристике, и маркировки положения строки байтов как границы фрагмента, для того, чтобы разделить набор данных или поток данных на последовательности фрагментов переменной длины. В этом способе границу фрагмента выбирают на основе характеристики содержимого данных, и граница фрагмента может более точно идентифицировать блок данных, присутствующий в похожих файлах или потоках данных, и, следовательно, этот способ широко применим в различных решениях дедупликации данных. Согласно исследованию, когда определяемый содержимым способ деления на фрагменты используют для деления набора данных или потока данных, более мелкая гранулярность при делении на фрагменты означает более высокую вероятность идентификации дублирующихся данных и лучший результат дедупликации. Тем не менее, более мелкая гранулярность при делении на фрагменты означает большее количество фрагментов, на которые делят заданный набор данных, тем самым означает увеличение затрат на индексирование и увеличение сложности поиска дублирующихся данных. В результате уменьшается временная эффективность дедупликации данных.
Предполагаемая длина является ключевым параметром определяемого содержимым способа деления на фрагменты (Определяемое содержимым деление на фрагменты, CDC) для управления гранулярностью при делении на фрагменты. В общем, способ CDC подает на выход последовательность фрагментов переменной длины для конкретного объекта данных, при этом длины различных фрагментов статистически подчиняются закону нормального распределения и предполагаемую длину используют для регулировки среднего значения нормального распределения. В общем, среднее значение нормального распределения представлено средней длиной фрагмента. Так как случайная величина принимает среднее значение с наибольшей вероятностью при нормальном распределении, среднюю длину фрагмента также называют пиковой длиной, и она может быть равна предполагаемой длине в идеальных условиях. Например, в CDC способе контрольную сумму f (w байт) данных в скользящем окне вычисляют в реальном времени. Когда определенные биты f (w байт) соответствуют заранее заданному значению, позицию скользящего окна выбирают как границу фрагмента. Так как обновление содержимого данных может привести к случайному изменению контрольной суммы, если условие f(w байт) & 0×FFF=0 установлено как условие соответствия, где & является операцией побитового И в двоичном поле, a 0×FFF является шестнадцатеричным представлением 4095, одно соответствие контрольной сумме может теоретически произойти в 4096 случайных изменениях f(w байт), то есть граница фрагмента может быть найдена каждый раз при перемещении вперед скользящего окна на 4КБ (4096 байт). Длина фрагмента при идеальных обстоятельствах является предполагаемой длиной фрагмента (Предполагаемая длина фрагмента) в CDC способе и для краткости называется предполагаемой длиной.
Для насколько возможно большого уменьшения количества фрагментов при поддержании эффективного использования памяти при дедупликации, в уровне техники предложен определяемый содержимым двухуровневый способ деления на фрагменты. Центральная идея определяемого содержимым двухуровневого способа деления на фрагменты состоит в том, чтобы приспособить режим деления на фрагменты переменной длины к двум различным предполагаемым длинам: при делении файла на фрагменты данных, определяют дублирование потенциального фрагмента путем запроса в систему хранения процесса дедупликации и применяют режим малых фрагментов в области перехода между дублирующимися данными и недублирующимися данными и применяют режим больших фрагментов в непереходной области.
Тем не менее, технология не может работать независимо и при определении того, как объект данных делить на фрагменты, вычислительное устройство фрагментов должно часто запрашивать контрольную сумму фрагмента данных, существующего в устройстве хранения процесса дедупликации, при этом фрагмент данных сохраняют в устройстве хранения процесса дедупликации, когда осуществили дедупликацию данных, определяют в соответствии с дублированием потенциальных фрагментов, существует ли область перехода между дублирующимися данными и недублирующимися данными, и далее определяют, какой применять режим деления на фрагменты в конечном счете. Следовательно, уровень техники приводит к загрузке запросами устройства хранения процесса дедупликации.
Раскрытие изобретения
В вариантах осуществления настоящего изобретения предложена технология обработки объекта данных, с помощью которой можно делить объект данных на фрагменты данных.
В соответствии с первым аспектом, в варианте осуществления настоящего изобретения предложен способ обработки объекта данных, при этом способ включает в себя следующее: делят объект данных на один или более блоков; вычисляют выборочный коэффициент сжатия для каждого блока, агрегируют в один сегмент данных последовательные блоки с одинаковой характеристикой коэффициента сжатия и получают выборочный коэффициент сжатия для каждого из сегментов данных; выбирают, в соответствии с диапазоном длин, которому принадлежит длина каждого сегмента данных, и диапазоном коэффициентов сжатия, которому принадлежит выборочный коэффициент сжатия каждого из сегментов данных, предполагаемую длину для деления сегмента данных на фрагменты данных, при этом выборочный коэффициент сжатия для каждого из сегментов данных однозначно принадлежит одному из диапазонов коэффициентов сжатия, и длина каждого из сегментов данных однозначно принадлежит одному из диапазонов длин.
В соответствии со вторым аспектом, в варианте осуществления настоящего изобретения предложено устройство обработки объекта данных, при этом устройство содержит: модуль деления на блоки, выполненный для деления объекта данных на один или более блоков; модуль выработки сегментов данных, выполненный для вычисления выборочного коэффициента сжатия для каждого блока, агрегирования в один сегмент данных последовательных блоков с одинаковой характеристикой коэффициента сжатия и получения выборочного коэффициента сжатия для каждого из сегментов данных; и модуль выработки фрагментов данных, выполненный для выбора, в соответствии с диапазоном длин, которому принадлежит длина каждого сегмента данных, и диапазоном коэффициентов сжатия, которому принадлежит выборочный коэффициент сжатия каждого сегмента данных, предполагаемой длины для деления сегмента данных на фрагменты данных, при этом выборочный коэффициент сжатия для каждого из сегментов данных однозначно принадлежит одному из диапазонов коэффициентов сжатия, и длина каждого из сегментов данных однозначно принадлежит одному из диапазонов длин.
При реализации вариантов осуществления настоящего изобретения объект данных делят на блоки, блоки агрегируют в сегмент данных в соответствии с коэффициентом сжатия каждого блока и далее сегмент данных делят на фрагменты данных, в результате получаем деление объекта данных на фрагменты данных.
Краткое описание чертежей
Для более понятного описания технических решений в вариантах осуществления настоящего изобретения или в уровне техники, ниже кратко описаны прилагаемые чертежи, нужные для описания вариантов осуществления изобретения или уровня техники. На приложенных чертежах и в последующем описании просто проиллюстрированы некоторые варианты осуществления настоящего изобретения, при этом из приложенных чертежей могут быть получены другие чертежи.
Фиг. 1 - вид, показывающий блок-схему варианта осуществления способа обработки объекта данных;
фиг. 2 - вид, показывающий блок-схему варианта осуществления способа обработки объекта данных;
фиг. 3 - вид, показывающий блок-схему варианта осуществления способа обработки объекта данных;
фиг. 4 - вид, показывающий блок-схему варианта осуществления способа обработки объекта данных;
фиг. 5 - вид, показывающий блок-схему варианта осуществления способа обработки объекта данных; и
фиг. 6 - вид, показывающий блок-схему варианта осуществления устройства обработки объекта данных.
Осуществление изобретения
Ниже со ссылками на приложенные чертежи в вариантах осуществления настоящего изобретения приведено ясное и полное описание технических решений настоящего изобретения. Ясно, что описанные варианты осуществления изобретения являются некоторыми, а не всеми вариантами осуществления настоящего изобретения. Все другие варианты осуществления изобретения, основанные на упомянутых вариантах осуществления настоящего изобретения, должны находиться в пределах объема охраны настоящего изобретения.
Уменьшение предполагаемой длины фрагмента данных способствует получению более высокой степени дедупликации, но также может увеличить количество фрагментов данных и соответствующих индексов, тем самым увеличить сложность поиска дублирующихся фрагментов данных и ограничить эффективность дедупликации.
В уровне техники мелкую гранулярность деления на фрагменты применяют в области перехода между дублирующимся содержимым и недублирующимся содержимым, при этом крупную гранулярность деления на фрагменты применяют в других областях, тем самым формируют двухуровневый способ деления на фрагменты. Тем не менее, в этом способе нужно часто запрашивать о дублировании потенциальных фрагментов в процессе деления на фрагменты и, следовательно, это приводит к загрузке запросами системы хранения процесса дедупликации. Кроме того, результат деления на фрагменты для этого способа основан на порядке передачи многоверсионных данных и, следовательно, способ не является стабильным.
В одном варианте осуществления настоящего изобретения предложен определяемый содержимым многоуровневый способ дедупликации данных с делением на фрагменты, который обеспечивает способность к сжатию и может делить объект данных на фрагменты данных. Более конкретно, при реализации вариантов осуществления настоящего изобретения, объект данных делят на блоки, блоки агрегируют в сегмент данных в соответствии с коэффициентом сжатия каждого блока и далее предполагаемую длину выбирают в соответствии с длинами и выборочными коэффициентами сжатия сегментов данных, что делают с целью деления каждого сегмента данных на фрагменты данных, в результате получают деление объекта данных на последовательности фрагменты данных с многоуровневым распределением длин.
В варианте осуществления настоящего изобретения объектом данных называют сегмент рабочих данных, например, файл или поток данных. Таблицу соответствия политики деления на фрагменты используют для поддержания отношения соответствия для диапазона коэффициентов сжатия, диапазона длин и предполагаемой длины фрагмента, при этом предполагаемая длина фрагмента сегмента данных становится больше при увеличении коэффициента сжатия и длины сегмента данных.
В способе, предложенном в варианте осуществления настоящего изобретения, объект данных может быть разделен на фрагменты данных, а фрагменты данных, полученные после деления, могут быть использованы как блоки дедупликации данных, так что объект данных может быть сохранен или передан по назначению, при этом без потери данных уменьшается использование памяти для хранения. Конечно, фрагмент данных, выработанный при делении, может быть в дальнейшем использован для целей, отличных от дедупликации данных. Вариант осуществления настоящего изобретения включают в себя следующее: этап (а), вводят объект данных (Объект данных) в устройство деления на фрагменты, при этом объект данных может поступать из памяти, находящейся как в устройстве деления на фрагменты, так и вне указанного устройства, например, объект данных может быть файлом или потоком данных, при условии удовлетворения требованию операции дедупликации, которое не ограничено в варианте осуществления настоящего изобретения; этап (б), делят объект данных на один или более блоков (Блоки), оценивают коэффициент сжатия каждого блока путем использования способа взятия выборок, делают запрос в таблицу соответствия политики деления на фрагменты и агрегируют в один сегмент (Сегмент) данных соседние последовательные блоки, коэффициенты сжатия которых принадлежат одному и тому же диапазону коэффициентов сжатия, при этом выборочный коэффициент сжатия является мерой сжимаемости фрагмента данных и выборочный коэффициент сжатия совпадает с коэффициентом сжатия блока, когда взятие выборок осуществляют на всем блоке; этап (в), делают запрос в таблицу соответствия политики деления на фрагменты для каждого сегмента данных, выбирают предполагаемую длину в соответствии с диапазоном коэффициентов сжатия и диапазоном длин, которые соответствуют сегменту данных, и делят сегмент данных на последовательности фрагментов (Фрагмент) в соответствии с выбранной предполагаемой длиной, что делают с использованием определяемого содержимым способа деления на фрагменты; и этап (г), сращивают соседние фрагменты, которые находятся на разных сегментах данных, и вычисляют значение хэш-функции для каждого фрагмента для дедупликации данных, при этом этап сращивания не является обязательным и значение хэш-функции может быть вычислено непосредственно без сращивания. На этапе (б) объект данных снова делят на последовательности сегментов данных с использованием информации о выборочном коэффициенте сжатия последовательности блоков. Может присутствовать несколько способов деления, например, в другом способе реализации: на этапе (б) можно ссылаться не на диапазон коэффициентов сжатия, а вместо этого объединять в один сегмент данных соседние последовательные блоки, для которых разница между значениями выборочных коэффициентов сжатия меньше заданного порога.
Вариант 1 осуществления изобретения
Как показано на фиг. 1, ниже используются конкретные этапы для подробного описания способа обработки объекта данных по некоторому варианту осуществления настоящего изобретения.
Этап 11: Делят объект данных, который должен пройти дедупликацию, на один или более блоков, вычисляют выборочный коэффициент сжатия для каждого блока, агрегируют в один сегмент данных соседние последовательные блоки с одинаковыми характеристиками коэффициента сжатия и получают выборочный коэффициент сжатия для каждого из сегментов данных. Каждый блок может иметь или фиксированную или переменную длину. В случае, когда блок имеет переменную длину, случайная длина в определенном диапазоне может быть выбрана как длина блока; или объект данных может быть просмотрен с целью подачи на выход нескольких групп кандидатов на границы фрагментов с разными предполагаемыми длинами, и одну из нескольких групп кандидатов на границы фрагментов используют для деления объекта данных на один или более блоков переменной длины.
Коэффициент сжатия используют для измерения степени, до которой могут быть сжаты данные, и коэффициент сжатия вычисляют следующим образом: коэффициент сжатия = объем сжатых данных/исходный объем данных. Способ оценки коэффициента сжатия следующий: извлекают сегмент выборочных данных для каждого блока, что делают на основе доли S выборки, сжимают выборочные данные с использованием некоторого алгоритма сжатия данных, например, алгоритма LZ сжатия без потерь и алгоритма RLE кодирования, вычисляют коэффициент сжатия, и используют коэффициент сжатия для выборки в качестве коэффициента сжатия блока, из которого делали выборку. Более высокая доля выборки означает, что коэффициент сжатия выборки будет ближе к фактическому коэффициенту сжатия блока, из которого делали выборку.
Для сжимаемого сегмента данных его коэффициент сжатия в общем меньше 1; для несжимаемого сегмента данных, из-за добавления служебных символов метаданных, таких как поле описания, длина сегмента данных после сжимающего кодирования может быть больше исходной длины данных, в результате чего коэффициент сжатия может быть больше 1. Ввод коэффициента сжатия включает в себя ряд диапазонов коэффициентов сжатия, при этом пересечение различных диапазонов коэффициентов сжатия пусто и объединение всех диапазонов коэффициентов сжатия представляет собой полный диапазон значений коэффициента сжатия [0, ∞).
Термин «характеристика коэффициента сжатия» относится к использованию коэффициента сжатия как параметра для агрегации блоков. Если коэффициент сжатия или значение, полученное после операции над коэффициентом сжатия блока, удовлетворяет заранее заданному условию, блок соответствует характеристике коэффициента сжатия. Более конкретно, характеристика коэффициента сжатия может быть диапазоном коэффициентов сжатия, а именно, диапазоном для коэффициента сжатия, и также может быть порогом разности между значениями коэффициентов сжатия соседних блоков. Как ясно из таблицы 1, в качестве характеристики коэффициента сжатия используют диапазон коэффициентов сжатия. Объект данных делят на семь блоков: блоки от 1 до 7. Благодаря взятию выборки для каждого блока и оценке их коэффициентов сжатия, получают выборочный коэффициент сжатия, например, выборочный коэффициент сжатия блока 1 равен 0,4, а выборочный коэффициент сжатия блока 2 равен 0,42; каждый выборочный коэффициент сжатия принадлежит одному диапазону коэффициентов сжатия, например, коэффициент сжатия, равный 0,4, принадлежит диапазону [0, 0,5) коэффициентов сжатия, а коэффициент сжатия, равный 0,61, принадлежит диапазону [0,5, 0,8) коэффициентов сжатия. Так как каждый блок соответствует одному выборочному коэффициенту сжатия, то также можно считать, что каждый блок принадлежит одному диапазону коэффициентов сжатия; блоки, которые принадлежат одному диапазону коэффициентов сжатия агрегируют в один сегмент данных и, следовательно, блок 1 и блок 2 могут быть агрегированы в сегмент 1 данных, блок 3, блок 4 и блок 5 могут быть агрегированы в сегмент 2 данных, а блок 6 и блок 7 могут быть агрегированы в сегмент 3 данных.
Этап 12: Выбирают, в соответствии с диапазоном длин, которому принадлежит длина каждого сегмента данных, и диапазоном коэффициентов сжатия, которому принадлежит выборочный коэффициент сжатия каждого сегмента данных, предполагаемую длину для деления сегмента данных на фрагменты данных. Диапазон значений длины сегмента данных относят, по меньшей мере, к одному из диапазонов длин, где длина каждого из сегментов данных однозначно принадлежит одному из диапазонов длин и выборочный коэффициент сжатия каждого из сегментов данных однозначно принадлежит одному из диапазонов коэффициентов сжатия.
Разные диапазоны коэффициентов сжатия не пересекаются, разные диапазоны длин не пересекаются, и каждая комбинация диапазона коэффициентов сжатия и диапазона длин соответствует одной предполагаемой длине. Выборочный коэффициент сжатия каждого сегмента данных однозначно принадлежит одному диапазону коэффициентов сжатия, и длина каждого сегмента данных однозначно принадлежит одному диапазону длин. Выборочный коэффициент сжатия сегмента данных можно получить путем осуществления выборки и сжатия сегмента данных; или путем вычисления среднего значение выборочных коэффициентов сжатия блоков, которые образуют сегмент данных, при этом среднее значение может быть средним арифметическим; или путем вычисления взвешенного среднего выборочных коэффициентов сжатия блоков на основе длины каждого блока, при этом конкретный способ заключается в следующем: вычисляют взвешенное среднее выборочных коэффициентов сжатия блоков, при этом выборочные коэффициенты сжатия блоков, которые образуют сегмент данных, используют как усредняемые значения, а длины блоков используют как веса.
При делении сегмента данных на фрагменты данных, необходимо найти границу фрагмента данных. Фрагмент данных находится между соседними границами.
Если на этапе 11 используют следующий способ деления на блоки: вычисляют несколько групп кандидатов на границы фрагментов с разными предполагаемыми длинами и делят объект данных на один или более блоков переменной длины с использованием одной из нескольких групп кандидатов на границы фрагментов, на этапе 12 могут выбирать, в соответствии с выбранной предполагаемой длиной и из нескольких групп кандидатов на границы фрагментов, границы фрагментов с одной и той же предполагаемой длиной для деления сегмента данных на фрагменты данных, то есть выбирают соответствующие границы фрагментов из нескольких групп кандидатов на границы фрагментов, полученных в ходе просмотра на этапе 11, вместо повторного просмотра сегмента данных. Если на этапе 11 для деления на блоки используют другой способ, например, способ использования блоков фиксированной длины, то на этапе 12 могут выбрать предполагаемую длину и далее найти границу каждого блока с помощью просмотра сегмента данных, что делают для деления сегмента данных на фрагменты данных. По сравнению со способом вычисления нескольких групп кандидатов на границы фрагментов с разными предполагаемыми длинами, последний способ обладает одним дополнительным этапом поиска границ фрагментов данных с помощью просмотра сегмента данных.
Как ясно из примера таблицы 2, диапазон значений коэффициентов сжатия разделен на три диапазона коэффициентов сжатия: [0, 0,5), [0,5, 0,8) и [0,8, ∞). Эти диапазоны коэффициентов сжатия не пересекаются и выборочный коэффициент сжатия каждого сегмента данных принадлежит одному диапазону коэффициентов сжатия, что также можно понимать как то, что каждый сегмент данных соответствует одному диапазону коэффициентов сжатия. Кроме того, диапазон значений длин сегмента данных поделен, по меньшей мере, на один диапазон длин. Эти диапазоны длин не пересекаются и, следовательно, каждый сегмент данных соответствует одному диапазону длин. Диапазон длин и диапазон коэффициентов сжатия совместно определяют предполагаемую длину сегмента данных. Например, если диапазон длин сегмента А данных составляет [0 МБ, 10 МБ), выборочный коэффициент сжатия сегмента А данных находится в диапазоне [0, 0,5) коэффициентов сжатия и предполагаемая длина, совместно определенная диапазоном [0 МБ, 10 МБ) длин и диапазоном [0, 0,5) коэффициентов сжатия, равна 32 КБ, то предполагаемая длина сегмента А данных равна 32 КБ. Аналогично, в соответствии с диапазоном длин, которому принадлежит длина сегмента В данных, и диапазоном коэффициентов сжатия, которому принадлежит выборочный коэффициент сжатия сегмента В данных, может быть получена предполагаемая длина сегмента В, равная 256 КБ. После получения предполагаемой длины, каждый сегмент данных может быть поделен на фрагменты данных в соответствии с предполагаемыми длинами. Например, сегмент А данных делят на фрагменты данных в соответствии с предполагаемой длиной, равной 32 КБ, а сегмент В данных делят на фрагменты данных в соответствии с предполагаемой длиной, равной 256 КБ, при этом «Б» в КБ является сокращением для байта (Байт), 1 КБ=1024 Байт и 1 МБ=1024 КБ.
Так как предполагаемая длина является теоретическим значением, фактические длины фрагментов данных могут быть другими, то есть фрагменты данных имеют переменную длину. Тем не менее, средняя длина фрагмента данных, полученного делением сегмента А данных, близка к предполагаемой длине 32 КБ и, следовательно, велика вероятность того, что значения длин этих фрагментов данных переменной длины будут равны 32 КБ и 32 КБ также является пиковой длиной. В этом варианте осуществления настоящего изобретения каждая предполагаемая длина соответствует одной пиковой длине и, следовательно, в этом варианте осуществления настоящего изобретения предложен способ деления на фрагменты данных и дедупликации, в котором существует несколько пиковых длин.
В этом варианте осуществления изобретения предполагаемая длина может быть получена с использованием эмпирического значения или с помощью аналитической статистики. Как показано в таблице 2, необязательное правило определения предполагаемой длины заключается в следующем: если диапазоны коэффициентов сжатия одинаковы, соответствующая предполагаемая длина увеличивается при увеличении нижнего предела диапазона длин; а если диапазоны длин одинаковы, соответствующая предполагаемая длина в таблице соответствия также увеличивается при увеличении нижнего предела диапазона коэффициентов сжатия. Предполагаемая длина фрагмента для сегмента данных положительно коррелирует с нижней границей диапазона коэффициентов сжатия, которому принадлежит выборочный коэффициент сжатия сегмента данных, и с нижней границей диапазона длин, которому принадлежит длина сегмента данных. В некоторых случаях коэффициент дедупликации большого объекта данных и объекта данных, который трудно сжать, не чувствителен к гранулярности деления на фрагменты и способ деления на фрагменты, использующий предполагаемую длину, может быстро уменьшить количество фрагментов без быстрого ухудшения коэффициента дедупликации.
На основе расположений фрагментов данных в сегменте данных, фрагменты данных, полученные делением сегмента данных, находятся в некотором порядке, где фрагменты данных в порядке образуют последовательность фрагментов данных, которая также может быть названа подпоследовательностью фрагментов. Этап 12 также может включать в себя сращивание подпоследовательностей фрагментов, выработанных разными фрагментами данных, полученными при делении, что делают с целью формирования последовательности деления на фрагменты объекта данных, при этом порядок фрагментов в последовательности деления на фрагменты совпадает с порядком фрагментов данных в объекте данных.
Этап 13: Сращивают в некоторый фрагмент данных, для соседних сегментов данных, концевой фрагмент данных предыдущего сегмента данных и начальный фрагмент данных следующего сегмента данных, при этом сформированный после сращивания фрагмент данных может быть назван сращенным фрагментом данных. Этап 13 не является обязательным этапом. Например, если граница сегмента данных на этапе 11 является границей блока фиксированной длины, этап 13 может быть использован и сращивание может исключить использование границы блока фиксированной длины как границы фрагмента, что может достичь лучшего эффекта дедупликации.
Кроме того, для сращенного фрагмента данных, выработанного в области перехода между двумя сегментами данных, соседние фрагменты данных на двух сторонах сращенного фрагмента данных соответствуют разным предполагаемым длинам соответственно. При желании меньшее значение из двух предполагаемых длин может быть применено для деления сращенного фрагмента данных на фрагменты данных с целью получения более мелкой гранулярности, так что дублирующееся содержимое в области перехода между двумя сегментами данных может быть идентифицировано лучшим образом, что улучшит эффект дедупликации при одновременном небольшом увеличении общего количества фрагментов данных. В других вариантах осуществления изобретения предполагаемая длина, которая меньше меньшего значения из двух предполагаемых длин, также может быть применена для деления сращенного фрагмента данных на фрагменты данных еще более мелкой гранулярности.
Когда этап 12 содержит этап сращивания подпоследовательностей фрагментов, этап 13 могут осуществить до сращивания подпоследовательностей фрагментов, и также его могут осуществить после сращивания подпоследовательностей фрагментов.
Этап 14: Вычисляют контрольную сумму каждого из сегментов данных, определяют, с использованием контрольной суммы, хранится ли каждый из фрагментов данных в устройстве хранения, и посылают в устройство хранения фрагмент данных, который не хранится в устройстве хранения, вместе с контрольной суммой и выборочным коэффициентом сжатия, которые соответствуют фрагменту данных, который не хранится в устройстве хранения.
Контрольную сумму используют для однозначной идентификации фрагмента данных и фрагмент данных и контрольная сумма, соответствующая фрагменту данных, взаимно-однозначно соответствуют друг другу. Способ вычисления контрольной суммы заключается в вычислении значения хэш-функции (Хэш) фрагмента данных как контрольной суммы.
Этап 15: В устройстве хранения хранят принятый фрагмент данных и контрольную сумму фрагмента данных. Во время хранения, в устройстве хранения могут определить, соответствует ли выборочный коэффициент сжатия принятого фрагмента данных порогу коэффициентов сжатия; и сжимают и далее сохраняют фрагмент данных, который соответствует порогу коэффициентов сжатия, что делают для экономии памяти для хранения, и непосредственно, без сжатия, сохраняют данные, которые не соответствуют порогу коэффициентов сжатия. Например, если порог коэффициентов сжатия меньше или равен 0,7, фрагмент данных, коэффициент сжатия которого меньше или равен 0,7, может быть сохранен после сжатия, а фрагмент данных, выборочный коэффициент сжатия которого, больше 0,7 сохраняют непосредственно без сжатия.
Заметим, что на этапе 11 может быть использовано более одного способа деления на сегменты. Например, в другом варианте реализации, политика сегментации, используемая на этапе 11, может быть модифицирована следующим образом: агрегируют в один сегмент данных соседние последовательные блоки, для который разница значений выборочных коэффициентов сжатия меньше заданного порога. Другими словами, то, что разница значений выборочных коэффициентов сжатия меньше заданного порога, является характеристикой коэффициента сжатия. По-прежнему будем использовать таблицу 1 в качестве примера, где предполагается, что разницу значений выборочных коэффициентов сжатия, которая меньше значения 0,1, используют в качестве порога. Тогда 0,42-0,4<0,1 и, следовательно, блок 1 и блок 2 располагают в одном сегменте данных; и 0,53-0,42>0,1, и, следовательно, блок 3 и блок 2 не располагают в одном сегменте данных. По аналогии блок 1 и блок 2 располагают в первом сегменте данных, блок 3 и блок 4 располагают во втором сегменте данных, а блок 5, блок 6 и блок 7 располагают в третьем сегменте данных.
Вариант 2 осуществления изобретения
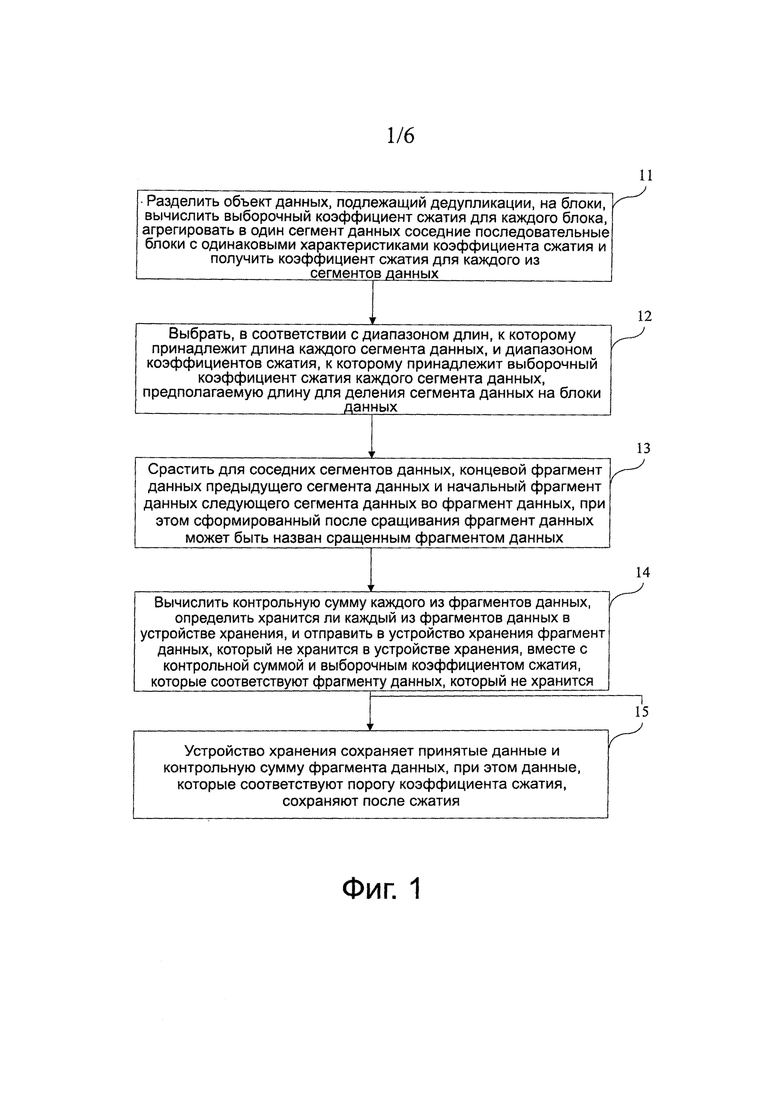
Как показано на фиг. 2, вариант 2 осуществления изобретения описан подробно и способ обработки объекта данных по этому варианту осуществления изобретения включает в себя следующие этапы:
21: Загружают таблицу соответствия политики деления на фрагменты. Как показано в таблицах 1 и 2, в таблицу соответствия политики деления на фрагменты записывают, какие коэффициенты сжатия обладают одинаковой характеристикой коэффициентов сжатия; кроме того, в таблицу соответствия политики деления на фрагменты дополнительно записывают диапазон длин, которому принадлежит длина сегмента данных, диапазон коэффициентов сжатия, которому принадлежит коэффициент сжатия сегмента данных, и предполагаемую длину, которая совместно определена диапазоном длин и диапазоном коэффициентов сжатия. Предполагаемую длину используют для деления сегмента данных на фрагменты данных. Этот этап также могут осуществлять в дальнейшем, при условии загрузки таблицы соответствия политики деления на фрагменты, до возникновения необходимости в ее использовании.
22: Вводят объект данных, который нужно обработать в устройстве, реализующим способ. Другими словами, получают объект данных, который нужно обработать, при этом источник получения объекта данных может являться устройством реализации способа, и также может быть внешним устройством, соединенным с устройством реализации способа.
23: Делят объект данных с использованием фиксированной длины. В конкретной реализации, на этом этапе объект данных нужно просмотреть для получения границы каждого блока фиксированной длины, при этом данные между двумя соседними границами представляют собой блок.
24: Осуществляют выборку и сжатие данных каждого блока, и используют коэффициент сжатия, полученный благодаря выборке и сжатию, как выборочный коэффициент сжатия данных всего блока.
25: Агрегируют в сегмент данных последовательные блоки с одинаковой характеристикой коэффициента сжатия в соответствии с таблицей соответствия политики деления на фрагменты.
26: Делят каждый сегмент данных на фрагменты данных заданной предполагаемой длины в соответствии с таблицей соответствия политики деления на фрагменты. В конкретной реализации на этом этапе каждый сегмент данных нужно просмотреть с целью поиска границ фрагментов данных и сегмент данных делят с использованием границ с целью формирования ряда фрагментов данных.
В этом варианте осуществления изобретения после осуществления этапа 26, обработка объекта данных завершена и достигнут эффект деления объекта данных на фрагменты данных. Последующие этапы 27, 28 и 29 являются дополнительным расширением способа обработки объекта данных.
27: Сращивают подпоследовательности фрагментов, выработанные для каждого сегмента данных. Фрагменты данных, сформированные делением каждого сегмента данных, находятся в некотором порядке, который совпадает с расположением фрагментов данных в сегменте данных, и фрагменты данных, находящиеся в порядке, также можно назвать подпоследовательностями фрагментов. На этом этапе способ сращивания заключается в следующем: для любых двух соседних сегментов данных сращивают концевой фрагмент данных предыдущего сегмента данных и начальный фрагмент данных следующего сегмента данных в некоторый фрагмент данных, так что устраняют границу между сегментами данных, объединяют несколько подпоследовательностей фрагментов и образуют последовательности фрагментов данных всего объекта данных; при желании фрагмент данных, сращенный на этом этапе, может быть разделен на фрагменты данных более мелкой гранулярности, что улучшит эффект дедупликации. Другой способ сращивания заключается в следующем: при сохранении неизменными фрагментов данных, сортируют, в соответствии с порядком сегментов данных в объекте данных, при этом начальный фрагмент данных следующего сегмента данных расположен после конечного фрагмента данных предыдущего сегмента данных, подпоследовательности фрагментов каждого сегмента данных с целью формирования последовательностей фрагментов данных всего объекта данных.
28: Вычисляют в качестве контрольных сумм значения хэш-функций фрагментов.
29: Подают на выход фрагменты и контрольные суммы каждого фрагмента и, при желании, также могут быть поданы на выход выборочные коэффициенты сжатия каждого фрагмента. Выборочные коэффициенты сжатия фрагментов могут быть получены с помощью вычисления с использованием выборочного коэффициента сжатия сегмента, которому принадлежат фрагменты, и один способ заключается в непосредственном использовании выборочного коэффициента сжатия сегмента в качестве выборочного коэффициента сжатия фрагментов в сегменте.
Когда присутствует более одного объекта данных, этапы 22-29 повторяют до тех пор, пока не обработаны все объекты данных.
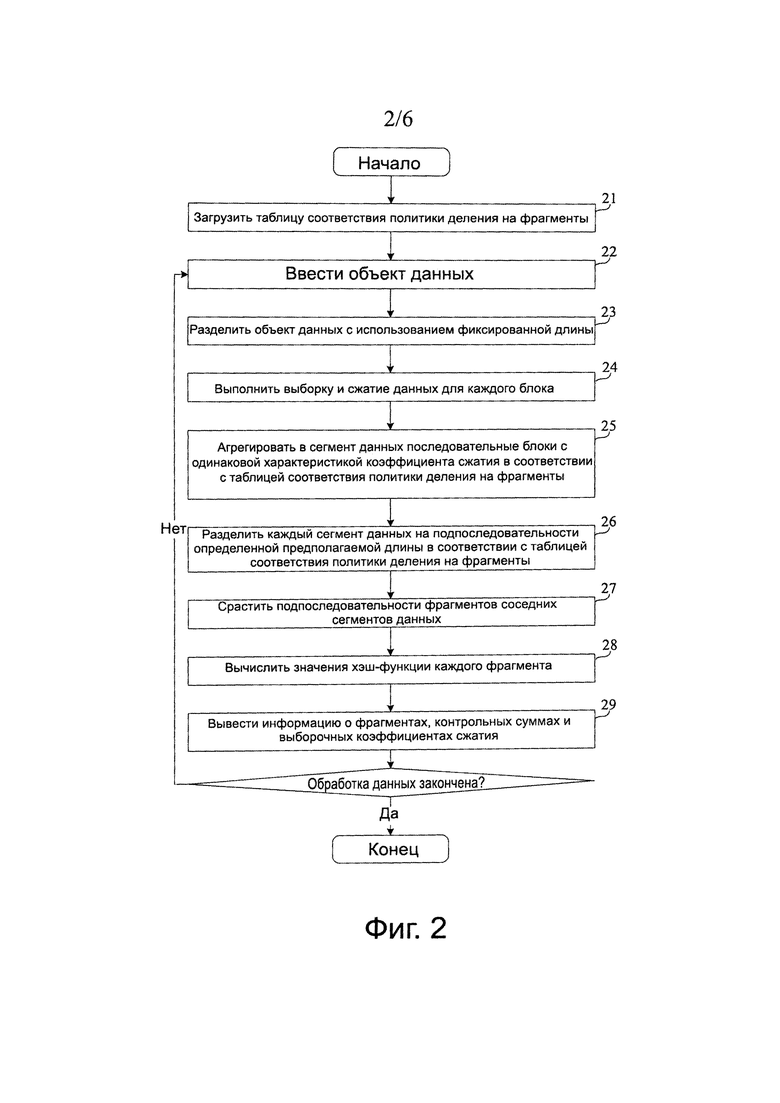
Конкретный способ реализации упомянутых выше этапов заключается в следующем: просматривают объект данных с использованием скользящего окна в w байт, и повторно вычисляют контрольную сумму f (w байт) данных, расположенных в окне, путем применения алгоритма быстрого хэширования для каждого перемещения вперед на 1 байт; если предполагаемая длина текущего сегмента данных равна Е, определяют, удовлетворяет ли текущая контрольная сумма критерию фильтрации границы фрагмента, что делают на основе справедливости выражения Соответствие(f(w байт), Е)=D, где целое D∈[0, Е) является заданным заранее собственным значением и функцию 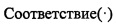 используют для отображения f(w байт) в диапазон [0, Е). Так как хэш-функция
используют для отображения f(w байт) в диапазон [0, Е). Так как хэш-функция 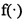 является случайной, то критерий фильтрации может подавать на выход ряд фрагментов, пиковая длина которых равна Е. Когда процесс достигает нового сегмента данных, предполагаемая длина Е нового сегмента данных изменяется и, следовательно, подают на выход подпоследовательность фрагментов с новой пиковой длиной. Когда осуществляют деление на фрагменты для соседней области двух сегментов данных, бывшая граница фрагмента данных определена предполагаемой длиной предыдущего сегмента данных и последняя граница определена предполагаемой длиной следующего сегмента данных и, следовательно, предыдущая и последующая границы фрагмента данных находятся соответственно в двух сегментах, что эквивалентно тому, что подпоследовательности фрагментов между соседними сегментами сращивают автоматически, так что процесс не использует границу сегмента в качестве границы фрагмента.
является случайной, то критерий фильтрации может подавать на выход ряд фрагментов, пиковая длина которых равна Е. Когда процесс достигает нового сегмента данных, предполагаемая длина Е нового сегмента данных изменяется и, следовательно, подают на выход подпоследовательность фрагментов с новой пиковой длиной. Когда осуществляют деление на фрагменты для соседней области двух сегментов данных, бывшая граница фрагмента данных определена предполагаемой длиной предыдущего сегмента данных и последняя граница определена предполагаемой длиной следующего сегмента данных и, следовательно, предыдущая и последующая границы фрагмента данных находятся соответственно в двух сегментах, что эквивалентно тому, что подпоследовательности фрагментов между соседними сегментами сращивают автоматически, так что процесс не использует границу сегмента в качестве границы фрагмента.
Для лучшего понимания, в варианте 2 осуществления изобретения дополнительно предложена блок-схема, показанная на фиг. 3, где состоящий из этапов процесс последовательно заключается в следующем: 3а, вводят объект данных, для которого необходимо выполнить способ обработки объекта данных, при этом объект данных может быть временно сохранен в буфере до выполнения обработки объекта данных; 3б, осуществляют деление блока, выборку и оценку коэффициента сжатия для объекта данных, где L, М и Н представляют соответственно три различных диапазона коэффициентов сжатия; 3в, агрегируют в сегмент данных последовательные блоки с одинаковой характеристикой коэффициента сжатия; 3г, выбирают предполагаемую длину в соответствии с характеристикой коэффициента сжатия и длины для каждого сегмента данных и вычисляют границу фрагмента и делят каждый сегмент данных на фрагменты данных в соответствии с вычисленной границей фрагмента, при этом фрагменты данных, полученные делением каждого сегмента данных, образуют подпоследовательность фрагментов; и 3д, сращивают последовательности фрагментов сегментов данных и вычисляют контрольную сумму фрагментов.
Вариант 3 осуществления изобретения
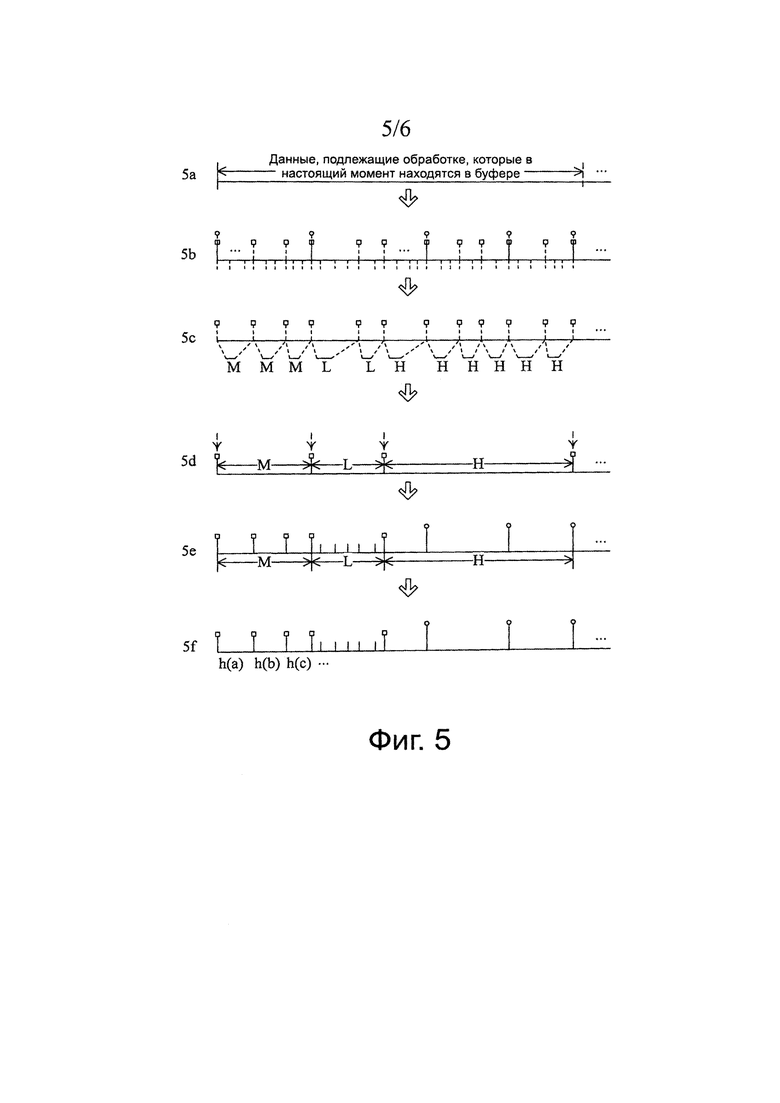
В варианте 2 осуществления изобретения объект данных, который должен пройти дедупликацию, делят на несколько блоков фиксированной длины. Тем не менее, в варианте 3 осуществления изобретения с объектом данных, который должен пройти дедупликацию, осуществляют предварительное деление на фрагменты с использованием предполагаемой длины. Более конкретно, объект данных (файл/поток данных) просматривают с использованием определяемого содержимым способа деления на фрагменты и вырабатывают несколько групп кандидатов на границы фрагментов с различными предполагаемыми длинами, при этом каждая группа кандидатов на границы фрагментов соответствует одному кандидату на последовательность фрагментов объекта данных и последовательность фрагментов также можно понимать как решение для фрагментов в объекте данных. Одно из решений предварительного деления на фрагменты используют для деления объекта данных на блоки, при этом выборку и сжатие осуществляют для блоков и определяют способ деления сегментов данных и на последующем этапе деления сегмента данных на фрагменты данных соответствующий кандидат на границу фрагмента выбирают для деления фрагмента данных в соответствии с предполагаемой длиной.
Следовательно, в варианте 2 осуществления изобретения объект данных нужно просмотреть, когда объект данных делят на блоки, и когда сегмент данных делят на фрагменты данных. В этом варианте осуществления изобретения объект данных необходимо просматривать только один раз, таким образом, экономят ресурсы системы и улучшают эффективность обработки объекта данных. Кроме того, так как граница или блока или фрагмента данных в варианте 3 осуществления изобретения основана на кандидате на границу фрагмента, граница сегмента, выработанная при агрегации блоков, не оказывает отрицательного воздействия на дедупликацию, что означает, что нет необходимости осуществлять операцию для устранения границы сегмента для фрагмента данных и, другими словами, нет необходимости в сращивании, для соседних сегментов данных, конечного фрагмента данных предыдущего сегмента данных и начального фрагмента данных следующего сегмента данных с целью формирования фрагмента данных.
Меньшая предполагаемая длина означает более мелкую среднюю гранулярность фрагментов, и меньшая предполагаемая длина лучше способствует восприятию изменения частичного коэффициента сжатия данных; и большая предполагаемая длина означает более крупную среднюю гранулярность фрагментов.
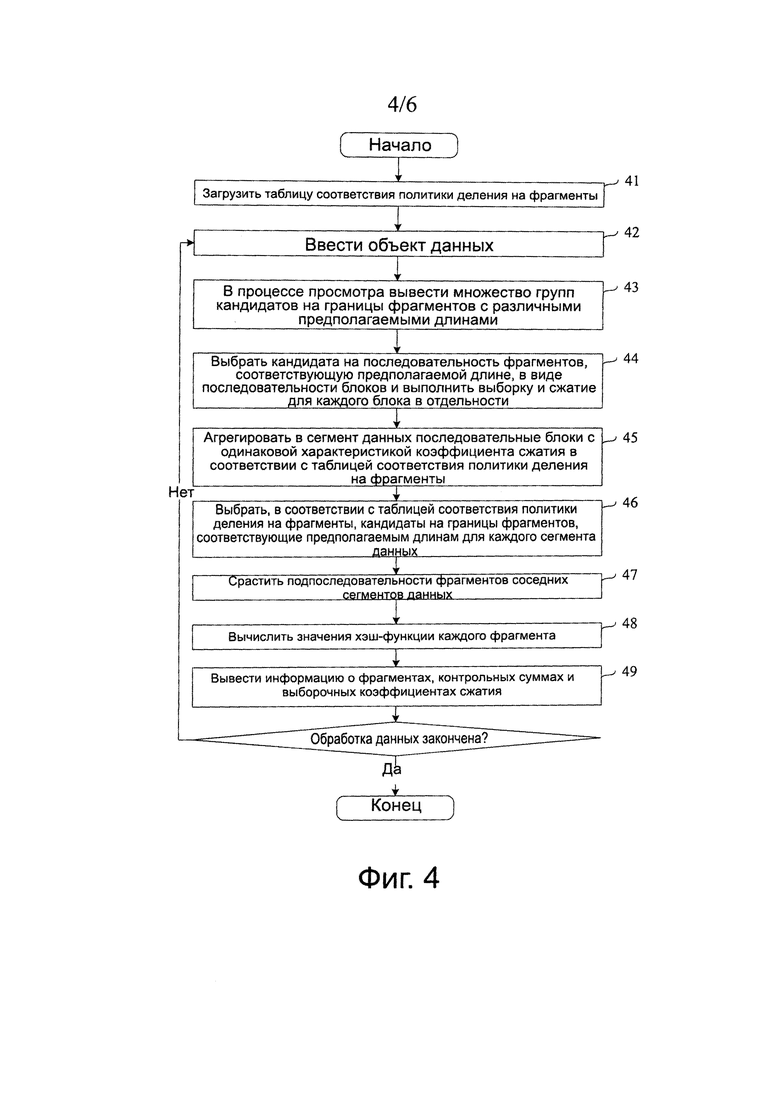
Как показано на фиг. 4, способ обработки объекта данных, предложенный в этом варианте осуществления изобретения, может более конкретно включать в себя следующие этапы:
41: Загружают таблицу соответствия политики деления на фрагменты. Как показано в таблицах 1 и 2, в таблицу соответствия политики деления на фрагменты записывают, какие коэффициенты сжатия обладают одинаковой характеристикой коэффициентов сжатия; кроме того, в таблицу соответствия политики деления на фрагменты дополнительно записывают диапазон длин, которому принадлежит длина сегмента данных, диапазон коэффициентов сжатия, которому принадлежит коэффициент сжатия сегмента данных, и предполагаемую длину, которая совместно определена диапазоном длин и диапазоном коэффициентов сжатия, при этом предполагаемую длину используют для деления сегмента данных на фрагменты данных. Этот этап также могут осуществлять в дальнейшем, пока не загрузят таблицу соответствия политики деления на фрагменты, до возникновения необходимости в ее использовании.
42: Вводят объект данных, который нужно обработать в устройстве, реализующем способ. Другими словами, получают объект данных, который нужно обработать, при этом источник получения объекта данных может являться устройством реализации способа, и также может быть внешним устройством, соединенным с устройством реализации способа.
43: В процессе просмотра, подают на выход несколько групп кандидатов на границы фрагментов, где каждая группа кандидатов на границы фрагментов и предполагаемая длина взаимно-однозначно соответствуют друг другу. Эти предполагаемые длины включают в себя предполагаемые длины, соответствующие сегментам данных на последующих этапах.
44: Выбирают одну группу кандидатов на границы фрагментов из нескольких групп кандидатов на границы фрагментов с этапа 43 и осуществляют выборку и сжатие для кандидата на последовательность фрагментов, образованного с помощью выбранной группы кандидатов на границы. Этот этап заключается в делении объекта данных на блоки, где предполагаемая длина блока является одной из нескольких предполагаемых длин, используемых на этапе 43. Когда деление на блоки осуществляют в соответствии с предполагаемой длиной, объект данных не нужно снова просматривать, а его непосредственно делят на блоки в соответствии с кандидатами на границы фрагментов, которые соответствуют предполагаемой длине. Далее осуществляют выборку и сжатие данных каждого блока, и используют коэффициент сжатия, полученный благодаря выборке и сжатию, как выборочный коэффициент сжатия всего блока данных.
45: Агрегируют в сегмент данных последовательные блоки с одинаковой характеристикой коэффициента сжатия в соответствии с таблицей соответствия политики деления на фрагменты.
46: Выбирают в соответствии с таблицей соответствия политики деления на фрагменты, кандидатов на границы фрагментов, которые соответствуют предполагаемым длинам для каждого сегмента данных. Граница фрагмента данных определяет длину и расположение фрагмента данных и, следовательно, этот этап заключается в делении сегмента данных на фрагменты данных. Как описано выше, кандидаты на границы фрагментов этапа 46 приходят с этапа 43, так что объект данных не нужно снова просматривать, когда сегмент данных делят на фрагменты данных, тем самым экономят ресурсы системы.
В этом варианте осуществления изобретения после осуществления этапа 46, обработка объекта данных завершена и достигнут эффект деления объекта данных на фрагменты данных. Последующие этапы 47, 48 и 49 являются дополнительным расширением способа обработки объекта данных.
47: Сращивают подпоследовательности фрагментов соседних сегментов данных. Сортируют подпоследовательности каждого сегмента данных в соответствии с порядком сегментов данных в объекте данных с целью формирования последовательность фрагментов данных объекта данных. Фрагмент данных также можно называть фрагментом.
48: Вычисляют в качестве контрольных сумм значения хэш-функций фрагментов данных.
49: Подают на выход фрагменты и контрольные суммы фрагментов и, при желании, также могут быть поданы на выход выборочные коэффициенты сжатия фрагментов. Выборочные коэффициенты сжатия фрагментов могут быть получены с помощью вычисления с использованием выборочного коэффициента сжатия сегмента, которому принадлежат фрагменты, и один способ заключается в непосредственном использовании выборочного коэффициента сжатия сегмента в качестве выборочного коэффициента сжатия фрагментов в сегменте.
Когда сохраняют фрагмент данных, определяют в соответствии с выборочным коэффициентом сжатия, нужно ли сжимать фрагмент данных перед сохранением.
Когда обработка данных не завершена, то есть когда присутствует более одного объекта данных, этапы 42-49 осуществляют последовательно для остающихся объектов до тех пор, пока не обработаны все объекты данных.
Конкретный способ реализации упомянутого выше этапа 43 заключается в следующем: в ходе процесса строят все предполагаемые длины Ei и соответствующие собственные значения Di в таблице соответствия политики деления на фрагменты, которая показана в Таблице 2, как список параметров, и определяют путем последовательного использования различных параметров <Ei, Di>, удовлетворяет ли каждая контрольная сумма f(w байт), подаваемая на выход скользящим окном, условию соответствия Соответствие(f(w байт), Ei)=Di, и если контрольная сумма удовлетворяет условию соответствия, выбирают кандидата на границу фрагмента, соответствующего текущему окну Ei. Эффективность соответствия контрольной суммы может быть улучшена с помощью оптимизации параметра <Ei, Di>. Например, когда определено Соответствие(f(w байт), Ei)=f(w байт) mod Ei, и выбраны Е0=212 Б=4 КБ, E1=215 Б=32 КБ, D0=D1=0, если f(w байт) mod E0≠D0, то ясно, что имеет место f(w байт) mod E1≠D1. То есть, если одна контрольная сумма не удовлетворяет критерию фильтрации, соответствующему предполагаемой длине 4 КБ, нет необходимости продолжать проверять, удовлетворяет ли контрольная сумма критерию фильтрации, соответствующему предполагаемой длине 32 КБ.
Для лучшего понимания, в варианте 3 осуществления изобретения дополнительно предложена блок-схема, показанная на фиг.5. Этапы на фиг. 5 следующие: 5а, подают на выход объект данных, для которого необходимо выполнить способ обработки объекта, данных, при этом объект данных может быть временно сохранен в буфере до выполнения обработки объекта данных; 5б, определяют несколько групп кандидатов на границы фрагментов данных с использованием различных предполагаемых длин; 5в, выбирают среди нескольких групп кандидатов на границы фрагментов, которые определены на этапе 5б, группу кандидата на последовательность фрагментов для деления объекта данных и осуществляют выборку и оценку коэффициента сжатия для фрагментов, полученных после деления; 5г, агрегируют в сегмент данных последовательные кандидаты на блоки с одинаковой характеристикой коэффициента сжатия; 5д, выбирают предполагаемую длину и соответствующую границу фрагментов в соответствии с характеристикой коэффициента сжатия и длины для каждого сегмента данных, при этом фрагменты данных, полученные делением из каждого сегмента данных в соответствии с соответствующей границей фрагментов, образуют подпоследовательность фрагментов; и 5е, сращивают подпоследовательности фрагментов сегментов данных и вычисляют контрольную сумму фрагментов.
Вариант 4 осуществления изобретения
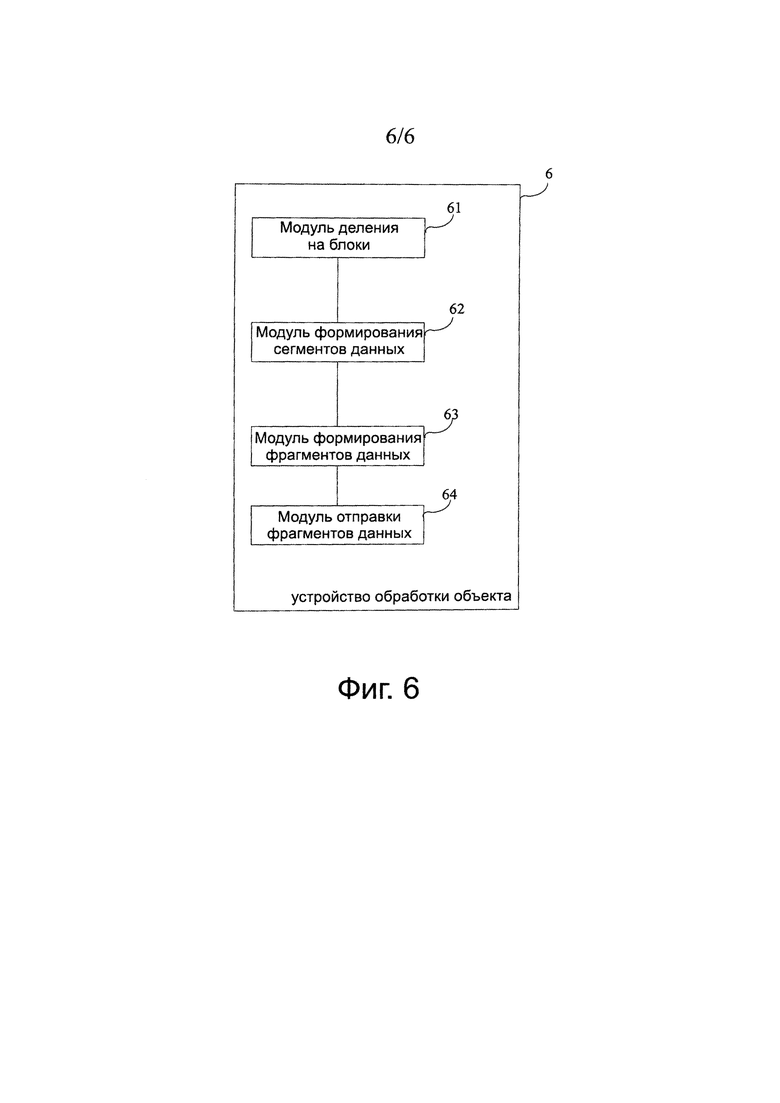
Как показано на фиг.6, в этом варианте осуществления изобретения описано устройство 6 обработки объекта данных, к которому применимы способы, предложенные в варианте 1, варианте 2 и варианте 3 осуществления изобретения. Устройство 6 обработки объекта данных содержит: модуль 61 деления на блоки, модуль 62 выработки сегментов данных и модуль 63 выработки фрагментов данных.
В устройстве 6 обработки объекта данных, модуль 61 деления на блоки выполнен для деления объекта данных на один или более блоков; модуль 62 выработки сегментов данных выполнен для вычисления выборочного коэффициента сжатия для каждого блока, агрегирования в один сегмент данных последовательных блоков с одинаковой характеристикой коэффициента сжатия и получения выборочного коэффициента сжатия для каждого сегмента данных; и модуль 63 выработки фрагментов данных выполнен для выбора, в соответствии с диапазоном длин, которому принадлежит длина каждого сегмента данных, и диапазоном коэффициентов сжатия, которому принадлежит выборочный коэффициент сжатия каждого сегмента данных, предполагаемой длины для деления сегмента данных на фрагменты данных, при этом выборочный коэффициент сжатия для каждого из сегментов данных однозначно принадлежит одному из диапазонов коэффициентов сжатия, и длина каждого из сегментов данных однозначно принадлежит одному из диапазонов длин.
Более конкретно, модуль 61 деления на блоки может быть выполнен для деления объекта данных на один или более блоков фиксированной длины; и также может быть выполнен для вычисления нескольких групп кандидатов на границы фрагментов с различными предполагаемыми длинами и для деления объекта данных на один или более блоков переменной длины с использованием нескольких групп кандидатов на границы фрагментов.
Модуль 62 выработки сегментов данных более конкретно выполнен для вычисления выборочного коэффициента сжатия для каждого блока, агрегирования в один сегмент данных соседних последовательных блоков, для которых выборочные коэффициенты сжатия принадлежат одному диапазону выборочных коэффициентов сжатия, и получения выборочного коэффициента сжатия для каждого сегмента данных.
Модуль 62 выработки сегментов данных дополнительно более конкретно выполнен для вычисления выборочного коэффициента сжатия для каждого блока, агрегирования в один сегмент данных соседних последовательных блоков, для которых разность значений выборочных коэффициентов сжатия меньше заданного порога, и получения выборочного коэффициента сжатия для каждого сегмента данных.
В различных возможных реализациях устройства 6 обработки объекта данных функция модуля 63 выработки фрагментов данных по выбору предполагаемой длины для деления сегмента данных на фрагменты данных может более конкретно заключаться в следующем: выбирают в соответствии с выбранной предполагаемой длиной и из нескольких групп кандидатов на границы фрагментов, вычисленных модулем деления на блоки, границы фрагментов с одной предполагаемой длиной для деления сегмента данных на фрагменты данных.
Модуль 63 выработки фрагментов данных может быть дополнительно выполнен для сращивания, для соседних сегментов данных, концевого фрагмента данных предыдущего сегмента данных и начального фрагмента данных следующего сегмента данных в некоторый сращенный фрагмент данных. Далее модуль 63 выработки фрагментов данных может быть дополнительно выполнен для деления сращенного фрагмента данных на несколько фрагментов данных, при этом предполагаемая длина, используемая для деления, меньше или равна предполагаемой длины, соответствующей предыдущему сегменту данных, и предполагаемая длина, используемая для деления, меньше или равна предполагаемой длины, соответствующей следующему сегменту данных.
Кроме того, устройство 6 обработки объекта данных может дополнительно содержать модуль 64 посылки фрагментов данных. Модуль 64 посылки фрагментов данных выполнен для следующего: вычисляют контрольную сумму каждого из сегментов данных, определяют, с использованием контрольной суммы, хранится ли каждый из фрагментов данных в устройстве хранения, и посылают в устройство хранения фрагмент данных, который не хранится в устройстве хранения, вместе с контрольной суммой и выборочным коэффициентом сжатия, которые соответствуют фрагменту данных, который не хранится в устройстве хранения. В устройстве хранения сохраняют контрольную сумму принятого фрагмента данных, определяют, соответствует ли выборочный коэффициент сжатия принятого фрагмента данных порогу для коэффициентов сжатия, и сжимают и затем сохраняют фрагмент данных, который соответствует порогу для коэффициентов сжатия.
Устройство 6 обработки объекта данных также можно рассматривать как устройство, образованное ЦП и памятью, при этом в памяти сохраняют программы, а в ЦП осуществляют способы, предложенные в варианте 1, варианте 2 и варианте 3 осуществления изобретения, в соответствии с программами из памяти. Устройство 6 обработки объекта данных может дополнительно содержать интерфейс, при этом интерфейс используют для соединения с устройством хранения. Например, функция интерфейса может заключаться в посылке в устройство хранения фрагмента данных, выработанного после обработки с помощью ЦП.
На основе приведенных выше описаний вариантов осуществления изобретения специалист в рассматриваемой области может ясно понять, что настоящее изобретение может быть реализовано с помощью программного обеспечения, помимо необходимого многоцелевого аппаратного обеспечения, или с помощью только аппаратного обеспечения. В большинстве обстоятельств последнее является предпочтительным путем реализации. На основе такого понимания, технические решения настоящего изобретения, которые вносят существенный или частичный вклад в уровень техники, могут быть реализованы в форме программного продукта. Компьютерный программный продукт сохраняют на считываемый носитель информации, такой как флоппи-диск, накопитель на жестких дисках или оптических дисках компьютера, и компьютерный программный продукт содержит несколько команд для управления вычислительным устройством (которое может быть персональным компьютером, сервером, сетевым устройством или подобным устройством) с целью осуществления способов, описанных в вариантах осуществления настоящего изобретения.
В упомянутых выше конкретных вариантах реализации подробно описаны цели, технические решения и полезные эффекты настоящего изобретения, но они не ограничивают объем правовой охраны настоящего изобретения. Любое изменение или замена, легко получаемая специалистом в рассматриваемой области из технического описания настоящего изобретения, должна находиться в границах объема правовой охраны настоящего изобретения. Следовательно, объем правовой охраны настоящего изобретения должен представлять собой объект правовой охраны формулы изобретения.

Изобретение относится области информационных технологий и, в частности, к обработке объекта данных. Техническим результатом является повышение эффективности хранения обработанных данных. В способе обработки объекта данных делят объект данных на блоки. Вычисляют выборочный коэффициент сжатия каждого блока и агрегируют в один сегмент данных соседние последовательные блоки с одинаковой характеристикой выборочного коэффициента сжатия. Получают выборочный коэффициент сжатия каждого сегмента данных и выбирают, в соответствии с диапазоном длин, к которому принадлежит длина каждого сегмента данных, и диапазоном коэффициентов сжатия, к которому принадлежит выборочный коэффициент сжатия каждого сегмента данных, предполагаемую длину для деления сегмента данных на фрагменты данных. При этом выборочный коэффициент сжатия каждого сегмента данных однозначно принадлежит одному диапазону коэффициентов сжатия, а длина каждого сегмента данных однозначно принадлежит одному диапазону длин обработанных данных. 2 н. и 18 з.п. ф-лы, 2 табл., 6 ил.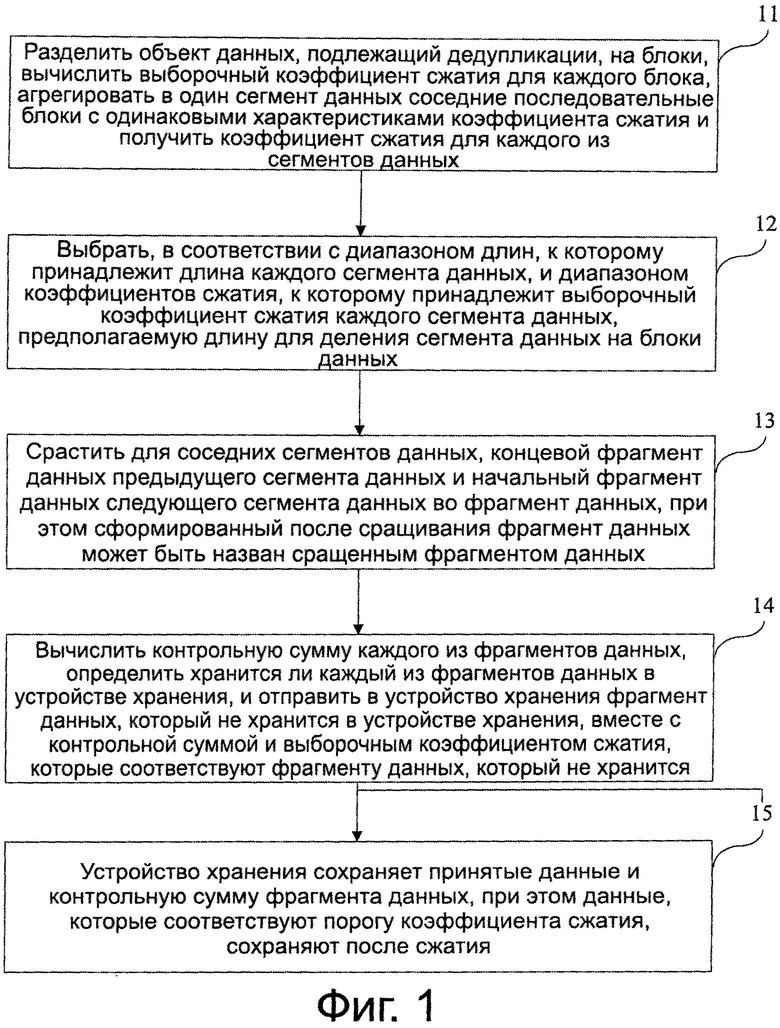
1. Способ обработки объекта данных, содержащий этапы, на которых:
делят объект данных на один или более блоков;
вычисляют выборочный коэффициент сжатия для каждого блока, агрегируют в один сегмент данных последовательные блоки с одинаковой характеристикой выборочного коэффициента сжатия и получают выборочный коэффициент сжатия для каждого из сегментов данных; и
выбирают, в соответствии с диапазоном длин, к которому принадлежит длина каждого сегмента данных, и диапазоном коэффициентов сжатия, к которому принадлежит выборочный коэффициент сжатия каждого из сегментов данных, предполагаемую длину для деления сегмента данных на фрагменты данных, при этом выборочный коэффициент сжатия для каждого из сегментов данных однозначно принадлежит к одному из диапазонов коэффициентов сжатия, а длина каждого из сегментов данных однозначно принадлежит к одному из диапазонов длин.
2. Способ по п. 1, в котором на этапе деления объекта данных на один или более блоков:
делят объект данных на один или более блоков фиксированной длины.
3. Способ по п. 1, дополнительно содержащий этап, на котором:
сращивают, для соседних сегментов данных, концевой фрагмент данных предыдущего сегмента данных и начальный фрагмент данных следующего сегмента данных в сращенный фрагмент данных.
4. Способ по п. 3, дополнительно содержащий этап, на котором:
делят сращенный фрагмент данных на множество фрагментов данных, при этом предполагаемая длина, используемая для деления, меньше или равна предполагаемой длины, соответствующей предыдущему сегменту данных, и предполагаемая длина, используемая для деления, меньше или равна предполагаемой длины, соответствующей следующему сегменту данных.
5. Способ по п. 1, в котором на этапе деления объекта данных на один или более блоков:
вычисляют множество групп кандидатов на границы фрагментов с разными предполагаемыми длинами и делят объект данных на один или более блоков переменной длины с использованием одной из нескольких групп кандидатов на границы фрагментов.
6. Способ по п. 1 или 5, в котором на этапе выбора предполагаемой длины для деления сегмента данных:
выбирают, в соответствии с выбранной предполагаемой длиной и из указанного множества групп кандидатов на границы фрагментов, границы фрагментов с одинаковой предполагаемой длиной для деления сегмента данных на фрагменты данных.
7. Способ по п. 1, в котором на этапе агрегирования в один сегмент данных последовательных блоков с одинаковой характеристикой выборочного коэффициента сжатия:
агрегируют в один сегмент данных соседние последовательные блоки, для которых выборочные коэффициенты сжатия принадлежат к одному диапазону выборочных коэффициентов сжатия.
8. Способ по п. 1, в котором на этапе агрегирования в один сегмент данных последовательных блоков с одинаковой характеристикой выборочного коэффициента сжатия:
агрегируют в один сегмент данных соседние последовательные блоки, для которых разность значений выборочных коэффициентов сжатия меньше заданного порога.
9. Способ по п. 1 или 3, дополнительно содержащий этапы, на которых:
вычисляют контрольную сумму каждого из фрагментов данных, определяют, с использованием контрольной суммы, хранится ли каждый из фрагментов данных в устройстве хранения, и посылают в устройство хранения фрагмент данных, не хранящийся в устройстве хранения, вместе с контрольной суммой и выборочным коэффициентом сжатия, которые соответствуют фрагменту данных, не хранящемуся в устройстве хранения; и
сохраняют, с помощью устройства хранения, контрольную сумму принятого фрагмента данных, определяют, соответствует ли выборочный коэффициент сжатия принятого фрагмента данных порогу для коэффициентов сжатия, и сжимают, а затем сохраняют фрагмент данных, соответствующий порогу для коэффициентов сжатия.
10. Способ по п. 9, в котором:
выборочный коэффициент сжатия сегмента, из которого получен фрагмент данных, используют в качестве выборочного коэффициента сжатия фрагмента данных.
11. Способ по п. 1, в котором на этапе вычисления выборочного коэффициента сжатия сегмента данных:
вычисляют среднее арифметическое выборочных коэффициентов сжатия блоков, образующих сегмент данных; или
вычисляют взвешенное среднее выборочных коэффициентов сжатия блоков посредством использования выборочных коэффициентов сжатия блоков, образующих сегмент данных, в качестве флаговых значений, а длины блоков - в качестве весов.
12. Устройство обработки объекта данных, содержащее:
модуль деления на блоки, выполненный с возможностью деления объекта данных на один или более блоков;
модуль формирования сегментов данных, выполненный с возможностью вычисления выборочного коэффициента сжатия для каждого блока, агрегирования в один сегмент данных последовательных блоков с одинаковой характеристикой коэффициента сжатия и получения выборочного коэффициента сжатия для каждого из сегментов данных; и
модуль формирования фрагментов данных, выполненный с возможностью выбора, в соответствии с диапазоном длин, к которому принадлежит длина каждого сегмента данных, и диапазоном коэффициентов сжатия, к которому принадлежит выборочный коэффициент сжатия каждого сегмента данных, предполагаемой длины для деления сегмента данных на фрагменты данных, при этом выборочный коэффициент сжатия для каждого из сегментов данных однозначно принадлежит одному из диапазонов коэффициентов сжатия, а длина каждого из сегментов данных однозначно принадлежит одному из диапазонов длин.
13. Устройство по п. 12, в котором модуль деления на блоки выполнен с возможностью:
деления объекта данных на один или более блоков фиксированной длины.
14. Устройство по п. 12, в котором модуль формирования фрагментов данных выполнен с возможностью:
сращивания, для соседних сегментов данных, концевого фрагмента данных предыдущего сегмента данных и начального фрагмента данных следующего сегмента данных в сращенный фрагмент данных.
15. Устройство по п. 14, в котором модуль формирования фрагментов данных выполнен с возможностью:
деления сращенного фрагмента данных на множество фрагментов данных, при этом предполагаемая длина, используемая для деления, меньше или равна предполагаемой длины, соответствующей предыдущему сегменту данных, и предполагаемая длина, используемая для деления, меньше или равна предполагаемой длины, соответствующей следующему сегменту данных.
16. Устройство по п. 12, в котором модуль деления на блоки дополнительно выполнен с возможностью:
вычисления множества групп кандидатов на границы фрагментов с разными предполагаемыми длинами и деления объекта данных на один или более блоков переменной длины с использованием одной из нескольких групп кандидатов на границы фрагментов.
17. Устройство по п. 12 или 16, в котором модуль формирования фрагментов данных выполнен с возможностью:
выбора, в соответствии с выбранной предполагаемой длиной и из указанного множества групп кандидатов на границы фрагментов, границ фрагментов с одинаковой предполагаемой длиной для деления сегмента данных на фрагменты данных.
18. Устройство по п. 12, в котором модуль формирования сегментов данных выполнен с возможностью:
вычисления выборочного коэффициента сжатия для каждого блока, агрегирования в один сегмент данных соседних последовательных блоков, выборочные коэффициенты сжатия которых принадлежат к одному диапазону коэффициентов сжатия, и получения выборочного коэффициента сжатия для каждого из сегментов данных.
19. Устройство по п. 12, в котором модуль формирования сегментов данных выполнен с возможностью:
вычисления выборочного коэффициента сжатия для каждого блока, агрегирования в один сегмент данных соседних последовательных блоков, для которых разность значений выборочных коэффициентов сжатия меньше заданного порога, и получения выборочного коэффициента сжатия для каждого сегмента данных.
20. Устройство по п. 12, дополнительно содержащее:
модуль отправки фрагментов данных, выполненный с возможностью вычисления контрольной суммы каждого из фрагментов данных, определения, с использованием контрольной суммы, хранится ли каждый из фрагментов данных в устройстве хранения, и отправки в устройство хранения фрагмента данных, не хранящегося в устройстве хранения, вместе с контрольной суммой и выборочным коэффициентом сжатия, которые соответствуют фрагменту данных, не хранящемуся в устройстве хранения;
при этом устройство хранения выполнено с возможностью хранения контрольной суммы принятого фрагмента данных, определения, соответствует ли выборочный коэффициент сжатия принятого фрагмента данных порогу для коэффициентов сжатия, и сжатия, а затем сохранения фрагмента данных, соответствующего порогу для коэффициентов сжатия.
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| CN 101706825 A, 12.05.2010 | |||
| US 5430556 A, 04.07.1995 | |||
| СПОСОБ И УСТРОЙСТВО СЖАТИЯ ВИДЕОИНФОРМАЦИИ | 1997 |
|
RU2209527C2 |
| СПОСОБ СЖАТИЯ ЦИФРОВОГО ПОТОКА ВИДЕОСИГНАЛА В ТЕЛЕВИЗИОННОМ КАНАЛЕ СВЯЗИ | 2010 |
|
RU2467499C2 |

