Перекрестная ссылка на родственные заявки
Настоящая заявка заявляет приоритет предыдущей заявки на патент США № 61/827288, поданной 24 мая 2013 г., содержание которой включено в настоящий документ посредством ссылки во всей полноте.
Область техники изобретения
Раскрытие, описанное в настоящем документе, относится, как правило, к звуковому кодированию. В частности, оно относится к применению и вычислению весовых коэффициентов для декорреляции звуковых объектов в системе кодирования звука.
Настоящее раскрытие является родственным предварительной заявке на патент США № 61/827246, поданной в тот же день, что и настоящая заявка, под названием «Coding of Audio Scenes», с указанием в качестве авторов изобретения Heiko Purnhagen и др. Указанная заявка включена в полном объеме в настоящую заявку посредством ссылки.
Уровень техники
В общепринятых звуковых системах применяется подход на основе каналов. Каждый канал может, например, представлять содержимое одного громкоговорителя или одного массива громкоговорителей. Возможные схемы кодирования для таких систем включают дискретное многоканальное кодирование или параметрическое кодирование, такое как MPEG Surround.
Совсем недавно был разработан новый подход. Этот подход является объектно-ориентированным. В системах, использующих объектно-ориентированный подход, трехмерная звуковая сцена представлена звуковыми объектами и связанными с ними метаданными положения. Данные звуковые объекты перемещаются по трехмерной сцене во время воспроизведения звукового сигнала. Система может дополнительно включать так называемые каналы платформы, которые могут быть описаны как стационарные звуковые объекты, которые непосредственно отображаются в местоположениях громкоговорителей, например, общепринятой звуковой системы, как описано выше. На декодирующей стороне такой системы объекты/каналы платформы могут восстанавливаться с применением сигналов понижающего микширования и матрицы повышающего микширования или восстановления, в которой объекты/каналы платформы восстанавливаются посредством формирования линейной комбинации сигналов понижающего микширования на основе значения соответствующих элементов в матрице восстановления. Проблемой, которая может возникнуть в объектно-ориентированной звуковой системе, особенно при низких целевых скоростях цифрового потока, является то, что корреляция между декодированными объектами/каналами платформы может быть больше, чем она была для кодированных исходных объектов/каналов платформы. Общим подходом для решения таких проблем, а также улучшения восстановления звуковых объектов, например, как в MPEG SAOC, является введение декорреляторов в декодирующее устройство. В MPEG SAOC внесенная декорреляция направлена на восстановление правильной корреляции между звуковыми объектами с учетом конкретного представления звуковых объектов, т.е. в зависимости от того, какой тип устройства воспроизведения подключается к звуковой системе.
Однако известные способы для объектно-ориентированных звуковых систем чувствительны к количеству сигналов понижающего микширования и количеству объектов/каналов платформы и могут дополнительно быть сложной операцией, которая зависит от представления звуковых объектов. Следовательно, в таких системах существует потребность в простых и гибких способах регулирования величины вносимой в декодирующее устройство декорреляции, что обеспечивает возможность улучшения восстановления звукового объекта.
Краткое описание чертежей
Далее приводится описание примерных вариантов осуществления со ссылками на прилагаемые чертежи, на которых:
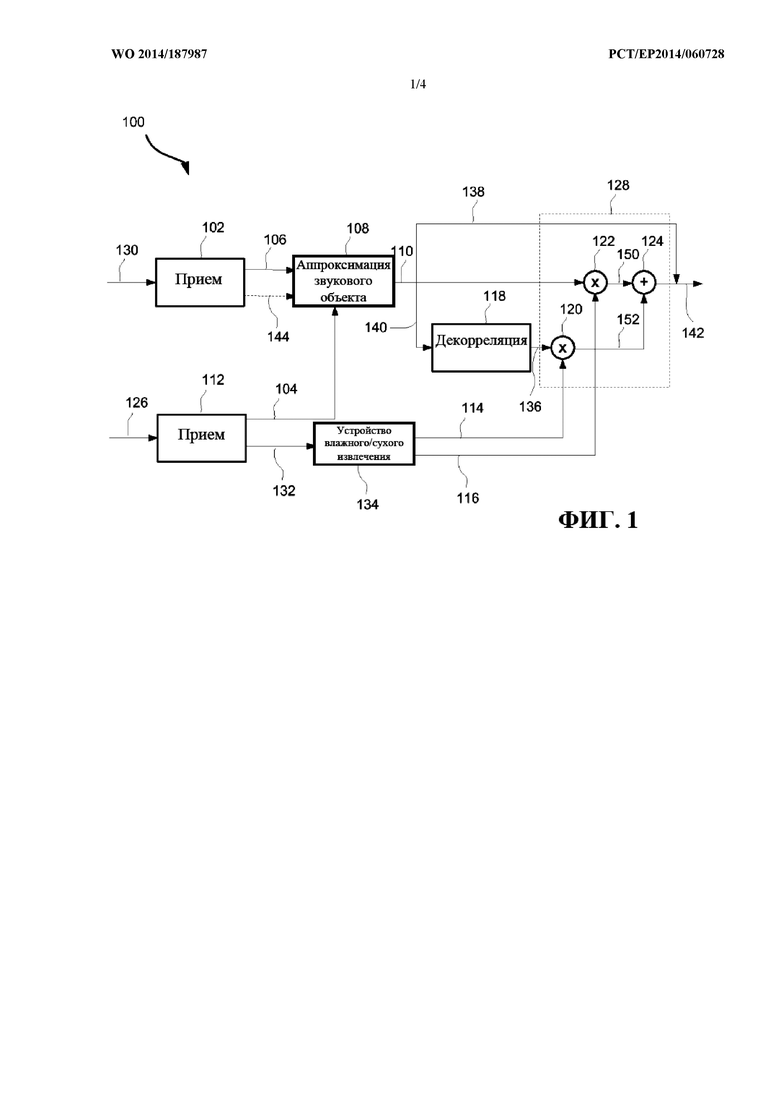
фиг. 1 представляет собой обобщенную блок-схему системы декодирования звука в соответствии с одним примерным вариантом осуществления;
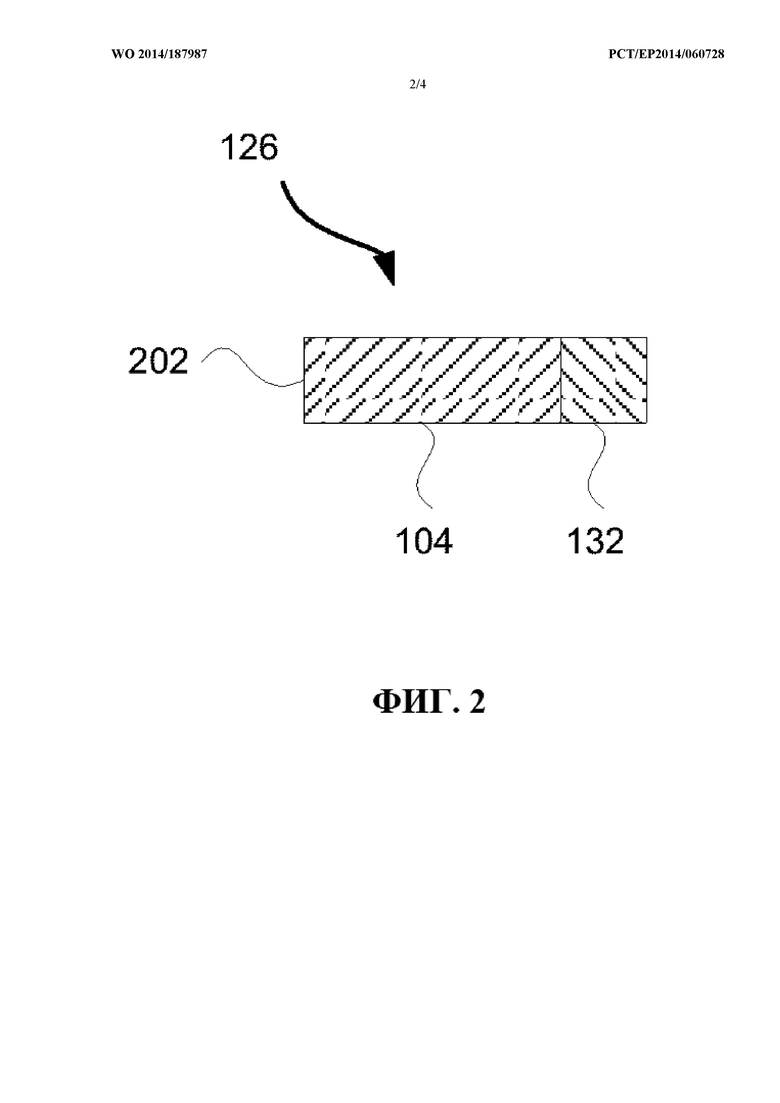
фиг. 2 в качестве примера показывает формат, в котором системой декодирования звука, показанной на фиг. 1, принимаются матрица восстановления и весовой параметр;
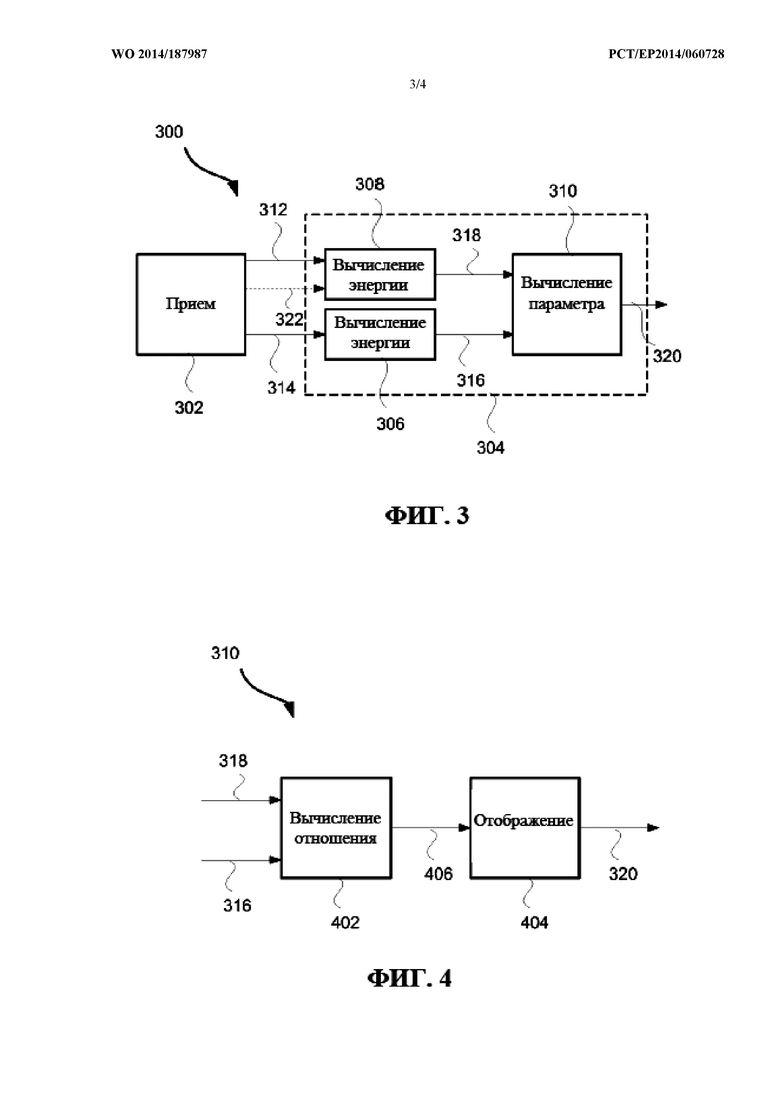
фиг. 3 представляет собой обобщенную блок-схему звукового кодирующего устройства для формирования по меньшей мере одного весового параметра для применения в процессе декорреляции в системе декодирования звука;
фиг. 4 в качестве примера показывает обобщенную блок-схему части кодирующего устройства, приведенного на фиг. 3, для формирования по меньшей мере одного весового параметра;
фиг. 5a-5c в качестве примера показывают отображающие функции, применяемые в части кодирующего устройства, приведенного на фиг. 4.
Все фигуры являются схематическими и, как правило, показывают лишь те части, которые необходимы для разъяснения раскрытия; другие части могут быть упущены или просто подразумеваться. Если не указано иное, подобные части на разных фигурах обозначены подобными позициями.
Подробное описание
В свете вышесказанного целью является предложение кодирующего устройства и декодирующего устройства и связанных с ними способов, которые обеспечивают менее сложное и более гибкое регулирование внесенной декорреляции, благодаря чему обеспечивается возможность улучшения восстановления звуковых объектов.
I. Обзор: декодирующее устройство
Согласно первому аспекту примерные варианты осуществления предлагают способы декодирования, декодирующие устройства и компьютерные программные продукты для декодирования. Предлагаемые способы, декодирующие устройства и компьютерные программные продукты могут, как правило, иметь одни и те же признаки и преимущества.
Согласно примерным вариантам осуществления предлагается способ восстановления частотно-временной мозаики N звуковых объектов. Способ включает этапы: приема М сигналов понижающего микширования; приема матрицы восстановления, обеспечивающей возможность восстановления аппроксимации N звуковых объектов из M сигналов понижающего микширования; применения матрицы восстановления к M сигналам понижающего микширования с целью формирования N аппроксимированных звуковых объектов; подвергания процессу декорреляции по меньшей мере подмножества N аппроксимированных звуковых объектов с целью формирования по меньшей мере одного декоррелированного звукового объекта, на основании чего каждый из по меньшей мере одного декоррелированного звукового объекта соответствует одному из N аппроксимированных звуковых объектов; восстановления частотно-временной мозаики звукового объекта посредством аппроксимированного звукового объекта для каждого из N аппроксимированных звуковых объектов, не имеющих соответствующий декоррелированный звуковой объект; и восстановления частотно-временной мозаики звукового объекта для каждого из N аппроксимированных звуковых объектов, имеющих соответствующий декоррелированный звуковой объект, посредством: приема по меньшей мере одного весового параметра, представляющего первый весовой коэффициент и второй весовой коэффициент, взвешивания аппроксимированного звукового объекта посредством первого весового коэффициента, взвешивания декоррелированного звукового объекта, соответствующего аппроксимированному звуковому объекту, посредством второго весового коэффициента и комбинирования взвешенного аппроксимированного звукового объекта с соответствующим взвешенным декоррелированным звуковым объектом.
Системы кодирования/декодирования звука, как правило, делят частотно-временное пространство на частотно-временные мозаики, например, путем применения подходящих банков фильтров для входных звуковых сигналов. Под частотно-временной мозаикой, как правило, подразумевается часть частотно-временного пространства, соответствующая временному интервалу и частотному поддиапазону. Временной интервал может обычно соответствовать длительности временного кадра, используемого в системе кодирования/декодирования звука. Частотный поддиапазон может, как правило, соответствовать одному или нескольким соседним частотным поддиапазонам, определенным банком фильтров, применяемым в системе кодирования/декодирования. В случае, если частотный поддиапазон соответствует нескольким соседним частотным поддиапазонам, определенным банком фильтров, это позволяет иметь неравномерные частотные поддиапазоны в процессе декодирования звукового сигнала, например, более широкие частотные поддиапазоны для верхних частот звукового сигнала. В случае широкого диапазона частот, когда система кодирования/декодирования звука работает во всем диапазоне частот, частотный поддиапазон частотно-временной мозаики может соответствовать всему диапазону частот. Описанный выше способ раскрывает этапы восстановления такой частотно-временной мозаики N звуковых объектов. Тем не менее, следует понимать, что способ может быть повторен для каждой частотно-временной мозаики системы декодирования звука. Также следует понимать, что несколько частотно-временных мозаик могут быть кодированы одновременно. Как правило, соседние частотно-временные мозаики могут немного перекрываться по времени и/или частоте. Например, перекрытие по времени может быть эквивалентно линейной интерполяции элементов матрицы восстановления во времени, то есть от одного временного интервала до следующего. Тем не менее, это раскрытие предназначается для прочих частей системы кодирования/декодирования, и любое перекрытие по времени и/или частоте между соседними частотно-временными мозаиками остается для реализации специалистом.
В данном контексте сигнал понижающего микширования является сигналом, который представляет собой комбинацию одного или нескольких каналов платформы и/или звуковых объектов.
Описанный выше способ обеспечивает гибкий и простой способ восстановления частотно-временной мозаики N звуковых объектов, где уменьшается любая нежелательная корреляция между аппроксимированными N звуковыми объектами. При использовании двух весовых коэффициентов, одного для аппроксимированного звукового объекта и одного для декоррелированного звукового объекта, достигается простая параметризация, которая позволяет обеспечить гибкое регулирование величины вносимой декорреляции.
Кроме того, простая параметризация в способе не зависит от того, какому типу представления подвергаются восстановленные звуковое объекты. Преимущество этого заключается в том, что такой же способ используется независимо от того, какой блок воспроизведения подключен к системе декодирования звука, реализующей данный способ, что приводит к менее сложной системе декодирования звука.
В соответствии с вариантом осуществления для каждого из N аппроксимированных звуковых объектов, имеющих соответствующий декоррелированный звуковой объект, по меньшей мере один весовой параметр содержит единственный весовой параметр, из которого выводятся первый весовой коэффициент и второй весовой коэффициент.
Преимущество этого заключается в том, что предлагается простая параметризация для управления величиной, вносимой в систему декодирования звука декорреляции. Этот подход использует единственный параметр, описывающий смесь «сухих» (не декоррелированных) и «влажных» (декоррелированных) вкладов для каждого объекта и частотно-временной мозаики. При использовании единственного параметра необходимая скорость цифрового потока может быть снижена по сравнению с использованием нескольких параметров, например, одного, описывающего влажный вклад, и одного, описывающего сухой вклад.
В соответствии с вариантом осуществления сумма квадратов первого весового коэффициента и второго весового коэффициента равна единице. В этом случае, единственный весовой параметр содержит либо первый весовой коэффициент, либо второй весовой коэффициент. Это может быть простой способ реализации единственного весового параметра для описания смешивания сухих и влажных вкладов для каждого объекта и частотно-временной мозаики. Кроме того, это означает, что восстановленный объект будет иметь такую же энергию, что и аппроксимированный объект.
В соответствии с вариантом осуществления этап подвергания процессу декорреляции по меньшей мере подмножества N аппроксимированных звуковых объектов включает подвергание процессу декорреляции каждого из N аппроксимированных звуковых объектов, на основании чего каждый из N аппроксимированных звуковых объектов соответствует декоррелированному звуковому объекту. Это может еще больше снизить любую нежелательную корреляцию между восстановленными звуковыми объектами, поскольку все восстановленные звуковые объекты основываются как на декоррелированном звуковом объекте, так и на аппроксимированном звуковом объекте.
В соответствии с вариантом осуществления первый и второй весовые коэффициенты являются переменными во времени и по частоте. Следовательно, гибкость системы декодирования звука может увеличиваться по той причине, что для разных частотно-временных мозаик может вноситься разная величина декорреляции. Это также может дополнительно снижать любую нежелательную корреляцию между восстановленными звуковыми объектами и улучшать качество восстановленных звуковых объектов.
В соответствии с вариантом осуществления матрица восстановления является переменной во времени и по частоте. Таким образом, гибкость системы декодирования звука увеличивается по той причине, что параметры, используемые для восстановления или аппроксимации звуковых объектов из сигналов понижающего микширования, могут отличаться для разных частотно-временных мозаик.
Согласно другому варианту осуществления матрица восстановления и по меньшей мере один весовой параметр после получения располагаются в кадре. Матрица восстановления расположена в первом поле кадра с применением первого формата, и по меньшей мере один весовой параметр расположен во втором поле кадра с применением второго формата, тем самым обеспечивая возможность декодирующему устройству, которое поддерживает только первый формат, декодировать матрицу восстановления в первом поле и отбрасывать по меньшей мере один весовой параметр во втором поле. Таким образом, может достигаться совместимость с декодирующим устройством, которое не реализует декорреляцию.
В соответствии с вариантом осуществления способ может дополнительно включать прием L дополнительных сигналов, при этом матрица восстановления дополнительно обеспечивает возможность восстановления аппроксимации N звуковых объектов из M сигналов понижающего микширования и L дополнительных сигналов, и при этом способ дополнительно включает применение матрицы восстановления к M сигналам понижающего микширования и L дополнительным сигналам для формирования N аппроксимированных звуковых объектов. L дополнительных сигналов могут, например, включать по меньшей мере один L дополнительный сигнал, который равен одному из восстанавливаемых N звуковых объектов. Это может улучшить качество конкретного восстановленного звукового объекта. Это может быть предпочтительным в случае, когда один из восстанавливаемых N звуковых объектов представляет собой часть звукового сигнала, которая имеет особое значение, например, звуковой объект, представляющий голос диктора в документальном кинофильме. В соответствии с вариантом осуществления по меньшей мере один из L дополнительных сигналов представляет собой комбинацию по меньшей мере двух из восстанавливаемых N звуковых объектов, тем самым обеспечивая компромисс между скоростью цифрового потока и качеством.
В соответствии с вариантом осуществления M сигналов понижающего микширования охватывают гиперплоскость, и при этом по меньшей мере один из L дополнительных сигналов не лежит в гиперплоскости, охватываемой М сигналами понижающего микширования. Таким образом, один или несколько из L дополнительных сигналов могут представлять размеры сигнала, которые не включены в любой из M сигналов понижающего микширования. Следовательно, качество восстановленных звуковых объектов может увеличиваться. В одном из вариантов осуществления по меньшей мере один из L дополнительных сигналов ортогонален гиперплоскости, охватываемой М сигналами понижающего микширования. Таким образом, весь полный сигнал одного или нескольких из L дополнительных сигналов представляет части звукового сигнала, не включенные ни в один из M сигналов понижающего микширования. Это может повысить качество восстановленных звуковых объектов и в то же время уменьшить требуемую скорость цифрового потока, поскольку по меньшей мере один из L дополнительных сигналов не содержит любую информацию, уже присутствующую в любом из M сигналов понижающего микширования.
Согласно примерным вариантам осуществления предлагается машиночитаемый носитель, содержащий команды машинного кода, предназначенные для выполнения любого способа согласно первому аспекту при выполнении на устройстве, имеющем возможность обработки.
Согласно примерным вариантам осуществления предлагается устройство для восстановления частотно-временной мозаики N звуковых объектов, содержащее: первый принимающий компонент, выполненный с возможностью приема M сигналов понижающего микширования; второй принимающий компонент, выполненный с возможностью приема матрицы восстановления, обеспечивающей возможность восстановления аппроксимации N звуковых объектов из M сигналов понижающего микширования; компонент аппроксимации звукового объекта, расположенный ниже по потоку от первого и второго принимающих компонентов и выполненный с возможностью применения матрицы восстановления к M сигналам понижающего микширования с целью формирования N аппроксимированных звуковых объектов; компонент декорреляции, расположенный ниже по потоку от компонента аппроксимации звукового объекта и выполненный с возможностью подвергать процессу декорреляции по меньшей мере подмножество N аппроксимированных звуковых объектов для формирования по меньшей мере одного декоррелированного звукового объекта, на основании чего каждый из по меньшей мере одного декоррелированного звукового объекта соответствует одному из N аппроксимированных звуковых объектов; при этом второй принимающий компонент дополнительно выполнен с возможностью приема для каждого из N аппроксимированных звуковых объектов, имеющих соответствующий декоррелированный звуковой объект, по меньшей мере одного весового параметра, представляющего первый весовой коэффициент и второй весовой коэффициент; и компонент восстановления звукового объекта, расположенный ниже по потоку от компонента аппроксимации звукового объекта, компонента декорреляции и второго принимающего компонента и выполненный с возможностью восстановления частотно-временной мозаики звукового объекта посредством аппроксимированного звукового объекта для каждого из N аппроксимированных звуковых объектов, не имеющих соответствующий декоррелированный звуковой объект; и восстановления частотно-временной мозаики звукового объекта для каждого из N аппроксимированных звуковых объектов, имеющих соответствующий декоррелированный звуковой объект, посредством: взвешивания аппроксимированного звукового объекта с помощью первого весового коэффициента; взвешивания декоррелированного звукового объекта, соответствующего аппроксимированному звуковому объекту, с помощью второго весового коэффициента; и комбинирования взвешенного аппроксимированного звукового объекта с соответствующим взвешенным декоррелированным звуковым объектом.
II. Обзор: кодирующее устройство
Согласно второму аспекту примерные варианты осуществления предлагают способы кодирования, кодирующие устройства и компьютерные программные продукты для кодирования. Предлагаемые способы, кодирующие устройства и компьютерные программные продукты могут, как правило, иметь одни и те же признаки и преимущества.
Согласно примерным вариантам осуществления предложен способ в кодирующем устройстве для формирования по меньшей мере одного весового параметра, при этом по меньшей мере один весовой параметр подлежит применению в декодирующем устройстве при восстановлении частотно-временной мозаики конкретного звукового объекта посредством комбинирования взвешенной аппроксимации конкретного звукового объекта на декодирующей стороне с соответствующей взвешенной декоррелированной версией аппроксимированного конкретного звукового объекта на декодирующей стороне, при этом способ включает этапы: приема М сигналов понижающего микширования, являющихся комбинациями по меньшей мере N звуковых объектов, включая конкретный звуковой объект; приема конкретного звукового объекта; вычисления первой величины, указывающей на уровень энергии конкретного звукового объекта; вычисления второй величины, указывающей на уровень энергии, соответствующий уровню энергии аппроксимации конкретного звукового объекта на кодирующей стороне, при этом аппроксимация на кодирующей стороне является комбинацией M сигналов понижающего микширования; вычисления по меньшей мере одного весового параметра на основе первой и второй величины.
Вышеописанный способ раскрывает этапы формирования по меньшей мере одного весового параметра для конкретного звукового объекта в ходе одной частотно-временной мозаики. Тем не менее, следует понимать, что способ может быть повторен для каждой частотно-временной мозаики системы кодирования/декодирования звука и для каждого звукового объекта.
Следует отметить, что мозаичное размещение, т.е. деление звукового сигнала/объекта на частотно-временные мозаики, в системе кодирования звука не должно быть таким же, как мозаичное размещение в системе декодирования звука.
Кроме того, также следует отметить, что аппроксимация конкретного звукового объекта на декодирующей стороне и аппроксимация конкретного звукового объекта на кодирующей стороне могут быть разными аппроксимациями, или они могут быть одинаковыми аппроксимациями.
С целью уменьшения требуемой скорости цифрового потока и уменьшения сложности по меньшей мере один весовой параметр может содержать единственный весовой параметр, из которого выводятся первый весовой коэффициент и второй весовой коэффициент, первый весовой коэффициент для взвешивания аппроксимации конкретного звукового объекта на декодирующей стороне, а второй весовой коэффициент для взвешивания декоррелированной версии аппроксимированного звукового объекта на декодирующей стороне.
С целью предотвращения добавления энергии к восстановленному звуковому объекту на декодирующей стороне восстановленный звуковой объект содержит аппроксимацию конкретного звукового объекта на декодирующей стороне и декоррелированную версию аппроксимированного звукового объекта на декодирующей стороне, сумма квадратов первого весового коэффициента и второго весового коэффициента может быть равна единице. В этом случае единственный весовой параметр может содержать либо первый весовой коэффициент, либо второй весовой коэффициент.
В соответствии с вариантом осуществления этап вычисления по меньшей мере одного весового параметра включает сравнение первой величины и второй величины. Например, могут сравниваться энергия аппроксимированного конкретного звукового объекта и энергия конкретного звукового объекта.
В соответствии с примерными вариантами осуществления сравнение первой величины и второй величины включает вычисление отношения второй величины к первой величине, возведение отношения в степень α и применение отношения, возведенного в степень α, для вычисления весового параметра. Это может повысить гибкость кодирующего устройства. Параметр α может быть равен двум.
В соответствии с примерными вариантами осуществления отношение, возведенное в степень α, подвергается действию возрастающей функции, которая отображает отношение, возведенное в степень α, по меньшей мере на один весовой параметр.
В соответствии с примерными вариантами осуществления первый и второй весовые коэффициенты являются переменными во времени и по частоте.
В соответствии с примерными вариантами осуществления вторая величина, указывающая на уровень энергии, соответствует уровню энергии аппроксимации конкретного звукового объекта на кодирующей стороне, при этом аппроксимация на кодирующей стороне является линейной комбинацией M сигналов понижающего микширования и L дополнительных сигналов, при этом сигналы понижающего микширования и дополнительные сигналы формируются из N звуковых объектов. С целью улучшения восстановления звукового объекта на декодирующей стороне в систему кодирования/декодирования звука могут быть включены дополнительные сигналы.
В соответствии с примерным вариантом осуществления по меньшей мере один из L дополнительных сигналов может соответствовать особо важным звуковым объектам, таким как звуковой объект, представляющий диалог. Таким образом, по меньшей мере один из L дополнительных сигналов может быть равным одному из N звуковых объектов. В соответствии с дополнительными вариантами осуществления по меньшей мере один из L дополнительных сигналов представляет собой комбинацию по меньшей мере двух из N звуковых объектов.
В соответствии с вариантами осуществления M сигналов понижающего микширования охватывают гиперплоскость, и при этом по меньшей мере один из L дополнительных сигналов не лежит в гиперплоскости, охваченной М сигналами понижающего микширования. Это означает, что по меньшей мере один из L дополнительных сигналов представляет размеры сигнала звуковых объектов, которые пропали в процессе формирования M сигналов понижающего микширования, которые могут улучшить восстановление звукового объекта на декодирующей стороне. В соответствии с дополнительными вариантами осуществления по меньшей мере один из L дополнительных сигналов ортогонален гиперплоскости, охватываемой М сигналами понижающего микширования.
Согласно примерным вариантам осуществления предлагается машиночитаемый носитель, содержащий команды машинного кода, предназначенные для выполнения любого способа согласно второму аспекту при выполнении на устройстве, имеющем возможность обработки.
В соответствии с вариантом осуществления предлагается кодирующее устройство для формирования по меньшей мере одного весового параметра, при этом по меньшей мере один весовой параметр подлежит применению в декодирующем устройстве при восстановлении частотно-временной мозаики конкретного звукового объекта посредством комбинирования взвешенной аппроксимации конкретного звукового объекта на декодирующей стороне с соответствующей взвешенной декоррелированной версией аппроксимированного конкретного звукового объекта на декодирующей стороне, при этом устройство содержит: принимающий компонент, выполненный с возможностью приема M сигналов понижающего микширования, являющихся комбинациями по меньшей мере N звуковых объектов, включая конкретный звуковой объект, при этом принимающий компонент дополнительно выполнен с возможностью приема конкретного звукового объекта; вычислительный блок, выполненный с возможностью вычисления первой величины, указывающей на уровень энергии конкретного звукового объекта; вычисления второй величины, указывающей на уровень энергии, соответствующий уровню энергии аппроксимации конкретного звукового объекта на кодирующей стороне, при этом аппроксимация на кодирующей стороне является комбинацией M сигналов понижающего микширования; вычисления по меньшей мере одного весового параметра на основе первой и второй величины.
Примерные варианты осуществления
На фиг. 1 показана обобщенная блок-схема системы 100 декодирования звука для восстановления N звуковых объектов. Система 100 декодирования звука выполняет обработку с частотно-временным разрешением, что означает, что она выполняется на отдельных частотно-временных мозаиках для восстановления N звуковых объектов. Далее описывается работа системы 100 для восстановления одной частотно-временной мозаики N звуковых объектов. N звуковых объектов могут представлять собой один или несколько звуковых объектов.
Система 100 содержит первый принимающий компонент 102, выполненный с возможностью приема М сигналов 106 понижающего микширования. M сигналов понижающего микширования могут представлять собой один или несколько сигналов понижающего микширования. M сигналов 106 понижающего микширования, например, могут представлять собой окружающий сигнал конфигурации 5.1 или 7.1, который является обратно совместимым с существующими системами декодирования звука, такими как Dolby Digital Plus, MPEG или AAC. В других вариантах осуществления М сигналов 106 понижающего микширования не являются обратно совместимыми. Входной сигнал первого принимающего компонента 102 может представлять собой битовый поток 130, из которого принимающий компонент может извлекать М сигналов 106 понижающего микширования.
Система 100 дополнительно содержит второй принимающий компонент 112, выполненный с возможностью приема матрицы 104 восстановления, обеспечивающей возможность восстановления аппроксимации N звуковых объектов из M сигналов 106 понижающего микширования. Матрица 104 восстановления может также называться матрицей повышающего микширования. Входной сигнал 126 второго принимающего компонента 112 может представлять собой битовый поток 126, из которого принимающий компонент может извлекать матрицу 104 восстановления или ее элементы и дополнительную информацию, которая будет более подробно описана ниже. В некоторых вариантах осуществления системы 100 декодирования звука первый принимающий компонент 102 и второй принимающий компонент 112 объединены в один принимающий компонент. В некоторых вариантах осуществления входные сигналы 130, 126 объединены в единый входной сигнал, который может представлять собой битовый поток с форматом, обеспечивающим возможность принимающим компонентам 102, 112 извлекать разную информацию из одного единого входного сигнала.
Система 100 может дополнительно содержать компонент 108 аппроксимации звукового объекта, расположенный ниже по потоку от первого 102 и второго 112 принимающих компонентов и выполненный с возможностью применения матрицы 104 восстановления к M сигналам 106 понижающего микширования для формирования N аппроксимированных звуковых объектов 110. Более конкретно, компонент 108 аппроксимации звукового объекта может выполнять матричную операцию, в которой матрица 104 восстановления умножается на вектор, содержащий M сигналов понижающего микширования. Матрица 104 восстановления может быть переменной во времени и по частоте, то есть значение элементов в матрице 104 восстановления может отличаться для каждой частотно-временной мозаики. Таким образом, элементы матрицы 104 восстановления зависят от того, какая частотно-временная мозаика в настоящее время обрабатывается.
Аппроксимированный 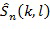 звуковой объект
звуковой объект 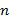 на частоте
на частоте 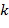 и временном интервале
и временном интервале 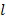 , т.е. частотно-временной мозаике, вычисляется, например, в компоненте 108 аппроксимации звукового объекта, например, посредством
, т.е. частотно-временной мозаике, вычисляется, например, в компоненте 108 аппроксимации звукового объекта, например, посредством 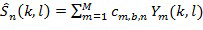 для всех частотных выборок в диапазоне частот
для всех частотных выборок в диапазоне частот 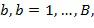 где
где 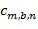 представляет собой коэффициент восстановления объекта в диапазоне частот
представляет собой коэффициент восстановления объекта в диапазоне частот 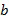 и связан с каналом понижающего микширования
и связан с каналом понижающего микширования 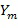 . Следует отметить, что коэффициент восстановления предполагается фиксированным на частотно-временной мозаике, но в дополнительных вариантах осуществления коэффициент может изменяться в ходе частотно-временной мозаики.
. Следует отметить, что коэффициент восстановления предполагается фиксированным на частотно-временной мозаике, но в дополнительных вариантах осуществления коэффициент может изменяться в ходе частотно-временной мозаики.
Система 100 дополнительно содержит компонент 118 декорреляции, расположенный ниже по потоку от компонента 108 аппроксимации звукового объекта. Компонент 118 декорреляции выполнен с возможностью подвергания процессу декорреляции по меньшей мере подмножества 140 N аппроксимированных звуковых объектов 110 для формирования по меньшей мере одного декоррелированного звукового объекта 136. Другими словами, все или только некоторые из N аппроксимированных звуковых объектов 110 подвергаются процессу декорреляции. Каждый из по меньшей мере одного декоррелированного звукового объекта 136 соответствует одному из N аппроксимированных звуковых объектов 110. Точнее, множество декоррелированных звуковых объектов 136 соответствует множеству 140 аппроксимированных звуковых объектов, которое вводится в процессе 118 декорреляции. Назначение по меньшей мере одного декоррелированного звукового объекта 136 заключается в том, чтобы уменьшить нежелательную корреляцию между N аппроксимированными звуковыми объектами 110. Эта нежелательная корреляция может появиться, в частности, при низких целевых скоростях цифрового потока звуковой системы, включающей систему 100 декодирования звука. При низких целевых скоростях цифрового потока матрица восстановления может быть разреженной. Это означает, что многие из элементов в матрице восстановления могут быть равны нулю. В этом случае определенный аппроксимированный звуковой объект 110 может основываться на единственном сигнале понижающего микширования или небольшом числе сигналов понижающего микширования из M сигналов 106 понижающего микширования, увеличивая, таким образом, риск нежелательного внесения корреляции между аппроксимированными звуковыми объектами 110. В соответствии с некоторыми вариантами осуществления каждый из N аппроксимированных звуковых объектов 110 подвергается процессу декорреляции посредством компонента 118 декорреляции, на основании чего каждый из N аппроксимированных звуковых объектов 110 соответствует декоррелированному звуковому объекту 136.
Каждый из N аппроксимированных звуковых объектов 110, подвергаемый процессу декорреляции посредством компонента 118 декорреляции, может подвергаться другому процессу декорреляции, например, посредством применения фильтра белого шума к декоррелируемому аппроксимированному звуковому объекту или посредством применения любого другого подходящего процесса декорреляции, такого как широкополосная фильтрация.
Примеры дополнительных процессов декорреляции могут быть найдены в инструментальном средстве параметрического стереокодирования MPEG (используемого в HE-AAC v2, как описано в стандарте ISO/IEC 14496-3 и в статье: J. 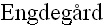 , H. Purnhagen, J.
, H. Purnhagen, J. 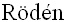 , L. Liljeryd, “Synthetic ambience in parametric stereo coding,” в AES 116th Convention, Berlin, DE, May 2004.), MPEG Surround (ISO/IEC 23003-1) и MPEG SAOC (ISO/IEC 23003-2).
, L. Liljeryd, “Synthetic ambience in parametric stereo coding,” в AES 116th Convention, Berlin, DE, May 2004.), MPEG Surround (ISO/IEC 23003-1) и MPEG SAOC (ISO/IEC 23003-2).
Чтобы не вносить нежелательную корреляцию, различные процессы декорреляции взаимно декоррелируются. Согласно другим вариантам осуществления несколько или все аппроксимированные звуковые объекты 110 подвергаются такому же процессу декорреляции.
Система 100 дополнительно содержит компонент 128 восстановления звукового объекта. Компонент 128 восстановления объекта расположен ниже по потоку от компонента 108 аппроксимации звукового объекта, компонента 118 декорреляции и второго принимающего компонента 112. Компонент 128 восстановления объекта выполнен с возможностью восстановления частотно-временной мозаики звукового объекта 142 для каждого из N аппроксимированных звуковых объектов 138, не имеющих соответствующий декоррелированный звуковой объект 136, посредством аппроксимированного звукового объекта 138. Другими словами, если определенный аппроксимированный звуковой объект 138 не подвергался процессу декорреляции, то он просто восстанавливается как аппроксимированный звуковой объект 110, предусмотренный компонентом 108 аппроксимации звукового объекта. Компонент 128 восстановления объекта дополнительно выполнен с возможностью восстановления частотно-временной мозаики звукового объекта для каждого из N аппроксимированных звуковых объектов 110, имеющих соответствующий декоррелированный звуковой объект 136, с применением как декоррелированного звукового объекта 136, так и соответствующего аппроксимированного звукового объекта 110.
Для облегчения данного процесса второй принимающий компонент 112 дополнительно выполнен с возможностью приема для каждого из N аппроксимированных звуковых объектов 110, имеющих соответствующий декоррелированный звуковой объект 136, по меньшей мере одного весового параметра 132. По меньшей мере один весовой параметр 132 представляет собой первый весовой коэффициент 116 и второй весовой коэффициент 114. Первый весовой коэффициент 116, также называемый сухим коэффициентом, и второй весовой коэффициент 114, также называемый влажным коэффициентом, получаются посредством устройства 134 сухого/влажного извлечения по меньшей мере из одного весового параметра 132. Первый и/или второй весовые коэффициенты 116, 114 могут быть переменными во времени и по частоте, то есть значение весовых коэффициентов 116, 114 может отличаться для каждой обрабатываемой частотно-временной мозаики.
В некоторых вариантах осуществления по меньшей мере один весовой параметр 132 содержит первый весовой коэффициент 116 и второй весовой коэффициент 114. В некоторых вариантах осуществления по меньшей мере один весовой параметр 132 содержит единственный весовой параметр. Если это так, устройство 134 влажного/сухого извлечения может получать первый и второй весовые коэффициенты 116, 114 из единственного весового параметра 132 . Например, первый и второй весовые коэффициенты 116, 114 могут удовлетворять определенным зависимостям, которые обеспечивают возможность получения одного из весовых коэффициентов, поскольку другой весовой коэффициент известен. Примером или такой зависимостью может быть то, что сумма квадратов первого весового коэффициента 116 и второго весового коэффициента 114 равна единице. Таким образом, если единственный весовой параметр 132 содержит первый весовой коэффициент 116, то второй весовой коэффициент 114 может получаться как квадратный корень из единицы минус квадрат первого весового коэффициента 116 и наоборот.
Первый весовой коэффициент 116 применяется для взвешивания 122, то есть для умножения, аппроксимированного звукового объекта 110. Второй весовой коэффициент 114 применяется для взвешивания 120, то есть для умножения, соответствующего декоррелированного звукового объекта 136. Компонент 128 восстановления звукового объекта дополнительно выполнен с возможностью комбинирования 124, например, посредством выполнения суммирования взвешенного аппроксимированного звукового объекта 150 с соответствующим взвешенным декоррелированным звуковым объектом 152 для восстановления частотно-временной мозаики соответствующего звукового объекта 142.
Другими словами, для каждого объекта и каждой частотно-временной мозаики величина декорреляции может регулироваться одним весовым параметром 132. В устройстве 134 влажного/сухого извлечения данный весовой параметр 132 преобразуется в весовой коэффициент 116 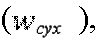 применяемый к аппроксимированному объекту 110, и весовой коэффициент 114
применяемый к аппроксимированному объекту 110, и весовой коэффициент 114 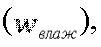 применяемый к декоррелированному объекту 136. Сумма квадратов данных весовых коэффициентов равна единице, т.е.
применяемый к декоррелированному объекту 136. Сумма квадратов данных весовых коэффициентов равна единице, т.е.
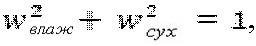
что означает, что окончательный объект 142, который является результатом суммирования 124, имеет ту же энергию, что и соответствующий аппроксимированный объект 110.
С целью обеспечения возможности декодирования входных сигналов 126, 130 посредством системы декодирования звука, которая не способна выполнять декорреляцию, то есть для сохранения обратной совместимости с таким устройством декодирования звука, входной сигнал 126 может располагаться в кадре 202, как изображено на фиг. 2. Согласно этому варианту осуществления матрица 104 восстановления располагается в первом поле кадра 202 с применением первого формата, и по меньшей мере один весовой параметр 132 располагается во втором поле кадра 202 с применением второго формата. Таким образом, декодирующее устройство, которое способно считывать первый формат, но не второй формат, может по-прежнему декодировать и использовать матрицу 104 восстановления для повышающего микширования сигнала 106 понижающего микширования любым общепринятым способом. Второе поле кадра 202 может в этом случае отбрасываться.
Согласно некоторым вариантам осуществления система 100 декодирования звука, приведенная на фиг. 1, может дополнительно принимать L дополнительных сигналов 144, например, в первый принимающий компонент 102. Таких дополнительных сигналов может быть один или несколько, т.е. 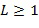 . Эти дополнительные сигналы 144 могут быть включены во входной сигнал 130. Дополнительные сигналы 144 могут быть включены во входной сигнал 130 таким образом, что сохраняется обратная совместимость в соответствии с описанием, приведенным выше, т.е. таким образом, что система декодирования, не способная обрабатывать дополнительные сигналы, по-прежнему может извлекать сигналы 106 понижающего микширования из входного сигнала 130. Матрица 104 восстановления может дополнительно обеспечивать возможность восстановления аппроксимации N звуковых объектов 110 из M сигналов 106 понижающего микширования и L дополнительных сигналов 144. Компонент 108 аппроксимации звукового объекта может, таким образом, быть выполненным с возможностью применения матрицы 104 восстановления к M сигналам 106 понижающего микширования и L дополнительным сигналам 144 с целью формирования N аппроксимированных звуковых объектов 110.
. Эти дополнительные сигналы 144 могут быть включены во входной сигнал 130. Дополнительные сигналы 144 могут быть включены во входной сигнал 130 таким образом, что сохраняется обратная совместимость в соответствии с описанием, приведенным выше, т.е. таким образом, что система декодирования, не способная обрабатывать дополнительные сигналы, по-прежнему может извлекать сигналы 106 понижающего микширования из входного сигнала 130. Матрица 104 восстановления может дополнительно обеспечивать возможность восстановления аппроксимации N звуковых объектов 110 из M сигналов 106 понижающего микширования и L дополнительных сигналов 144. Компонент 108 аппроксимации звукового объекта может, таким образом, быть выполненным с возможностью применения матрицы 104 восстановления к M сигналам 106 понижающего микширования и L дополнительным сигналам 144 с целью формирования N аппроксимированных звуковых объектов 110.
Роль дополнительных сигналов 144 заключается в том, чтобы улучшить аппроксимацию N звуковых объектов в компоненте 108 аппроксимации звукового объекта. Согласно одному примеру по меньшей мере один из дополнительных сигналов 144 равен одному из N восстанавливаемых звуковых объектов. В этом случае вектор в матрице 104 восстановления, используемый для восстановления конкретного звукового объекта, будет содержать только единственный ненулевой параметр, например, параметр со значением один (1). В соответствии с другими примерами по меньшей мере один из L дополнительных сигналов 144 представляет собой комбинацию по меньшей мере двух из N восстанавливаемых звуковых объектов.
В некоторых вариантах осуществления L дополнительных сигналов могут представлять размеры сигнала N звуковых объектов, которые были утерянной информацией в процессе формирования M сигналов 106 понижающего микширования из N звуковых объектов. Это можно объяснить тем, что M сигналов 106 понижающего микширования охватывают гиперплоскость в пространстве сигналов, и что L дополнительных сигналов 144 не лежат в этой гиперплоскости. Например, L дополнительных сигналов 144 могут быть ортогональными гиперплоскости, охватываемой М сигналами 106 понижающего микширования. На основании M сигналов 106 понижающего микширования самих по себе, могут восстанавливаться только сигналы, которые лежат в гиперплоскости, т.е. звуковые объекты, которые не лежат в гиперплоскости, будут аппроксимироваться посредством звукового сигнала в гиперплоскости. При дальнейшем использовании L дополнительных сигналов 144 для восстановления сигналы, которые не лежат в гиперплоскости, также могут быть восстановлены. В результате, аппроксимация звуковых объектов может улучшаться также посредством применения L дополнительных сигналов.
На фиг. 3 в качестве примера показана обобщенная блок-схема устройства 300 кодирования звука для формирования по меньшей мере одного весового параметра 320. По меньшей мере один весовой параметр 320 должен использоваться в декодирующем устройстве, например, системе 100 декодирования звука, описанной выше, при восстановлении частотно-временной мозаики конкретного звукового объекта посредством комбинирования (позиция 124 на фиг.1) взвешенной аппроксимации (позиция 150 на фиг. 1) конкретного звукового объекта на декодирующей стороне с соответствующей взвешенной декоррелированной версией (позиция 152 на фиг. 1) аппроксимированного конкретного звукового объекта на декодирующей стороне.
Кодирующее устройство 300 содержит принимающий компонент 302, выполненный с возможностью приема M сигналов 312 понижающего микширования, являющихся комбинациями по меньшей мере N звуковых объектов, включая конкретный звуковой объект. Принимающий компонент 302 дополнительно выполнен с возможностью приема конкретного звукового объекта 314. В некоторых вариантах осуществления принимающий компонент 302 дополнительно выполнен с возможностью приема сигналов L дополнительных сигналов 322. Как было рассмотрено выше, по меньшей мере один из L дополнительных сигналов 322 может быть равным одному из N звуковых объектов, по меньшей мере один из L дополнительных сигналов 322 может представлять собой комбинацию по меньшей мере двух из N звуковых объектов, и по меньшей мере один из L дополнительных сигналов 322 может содержать информацию, не присутствующую в любом из M сигналов понижающего микширования.
Кодирующее устройство 300 дополнительно содержит вычислительный блок 304. Вычислительный блок 304 выполнен с возможностью вычисления первой величины 316, указывающей на уровень энергии конкретного звукового объекта, например, в первом компоненте 306 вычисления энергии. Первая величина 316 может вычисляться в качестве нормы конкретного звукового объекта. Например, первая величина 316 может быть равна энергии конкретного звукового объекта и, таким образом, может быть вычислена посредством нормы по скалярному квадрату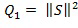 , где
, где 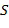 обозначает конкретный звуковой объект. Первая величина может альтернативно быть вычислена в качестве другой величины, которая указывает на энергию конкретного звукового объекта, например, как квадратный корень из энергии.
обозначает конкретный звуковой объект. Первая величина может альтернативно быть вычислена в качестве другой величины, которая указывает на энергию конкретного звукового объекта, например, как квадратный корень из энергии.
Вычислительный блок 304 дополнительно выполнен с возможностью вычисления второй величины 318, которая указывает на уровень энергии, соответствующий уровню энергии аппроксимации конкретного звукового объекта 314 на кодирующей стороне. Аппроксимация на кодирующей стороне может представлять собой, например, комбинацию, такую как линейная комбинация M сигналов 312 понижающего микширования. В альтернативном варианте аппроксимация на кодирующей стороне может представлять собой комбинацию, такую как линейная комбинация M сигналов 312 понижающего микширования и L дополнительных сигналов 322. Вторая величина может быть вычислена во втором компоненте 308 вычисления энергии.
Затем аппроксимация на кодирующей стороне может, например, быть вычислена посредством не энергетически согласованной матрицы повышающего микширования и M сигналов 312 понижающего микширования. Под термином "не энергетически согласованный" в контексте настоящего описания следует понимать, что аппроксимация конкретного звукового объекта не будет согласована по энергии с самим конкретным звуковым объектом, то есть аппроксимация будет иметь другой уровень энергии, часто ниже, по сравнению с конкретным звуковым объектом 314.
Не энергетически согласованная матрица повышающего микширования может формироваться с применением различных подходов. Например, может применяться прогнозирующий подход минимальной среднеквадратичной ошибки (MMSE), который берет по меньшей мере N звуковых объектов, а также M сигналов 312 понижающего микширования (и, возможно, L дополнительных сигналов 322) в качестве входных данных. Это может быть описано как итеративный подход, который направлен на нахождение матрицы повышающего микширования, которая сводит к минимуму среднеквадратичную ошибку аппроксимации N звуковых объектов. В частности, подход аппроксимирует N звуковых объектов посредством предварительной матрицы повышающего микширования, которая перемножается c M сигналами 312 понижающего микширования (и, возможно, L дополнительными сигналами 322) и сравнивает аппроксимацию с N звуковыми объектами с точки зрения среднеквадратичной ошибки. Предварительная матрица повышающего микширования, которая сводит к минимуму среднеквадратичную ошибку, выбирается в качестве матрицы повышающего микширования, которая применяется для определения аппроксимации конкретного звукового объекта на кодирующей стороне.
При использовании подхода MMSE ошибка прогнозирования e между конкретным звуковым объектом и аппроксимированным звуковым объектом 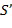 ортогональна . Это значит, что:
ортогональна . Это значит, что:
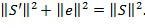
Другими словами, энергия звукового объекта равна сумме энергии аппроксимированного звукового объекта и энергии ошибки прогнозирования. В связи с вышеприведенным соотношением, энергия ошибки прогнозирования e, таким образом, дает показание энергии аппроксимации на кодирующей стороне 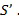
Следовательно, вторая величина 318 может быть вычислена с использованием либо аппроксимации конкретного звукового объекта , либо ошибки прогнозирования. Вторая величина может быть вычислена как норма аппроксимации конкретного звукового объекта или норма ошибки прогнозирования e. Например, вторая величина может быть вычислена как норма по скалярному квадрату, т.е. 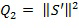 или
или 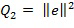 . Вторая величина может альтернативно быть вычислена как другая величина, которая указывает на энергию аппроксимированного конкретного звукового объекта, например, как корень квадратный из энергии аппроксимированного конкретного звукового объекта или корень квадратный из энергии ошибки прогнозирования.
. Вторая величина может альтернативно быть вычислена как другая величина, которая указывает на энергию аппроксимированного конкретного звукового объекта, например, как корень квадратный из энергии аппроксимированного конкретного звукового объекта или корень квадратный из энергии ошибки прогнозирования.
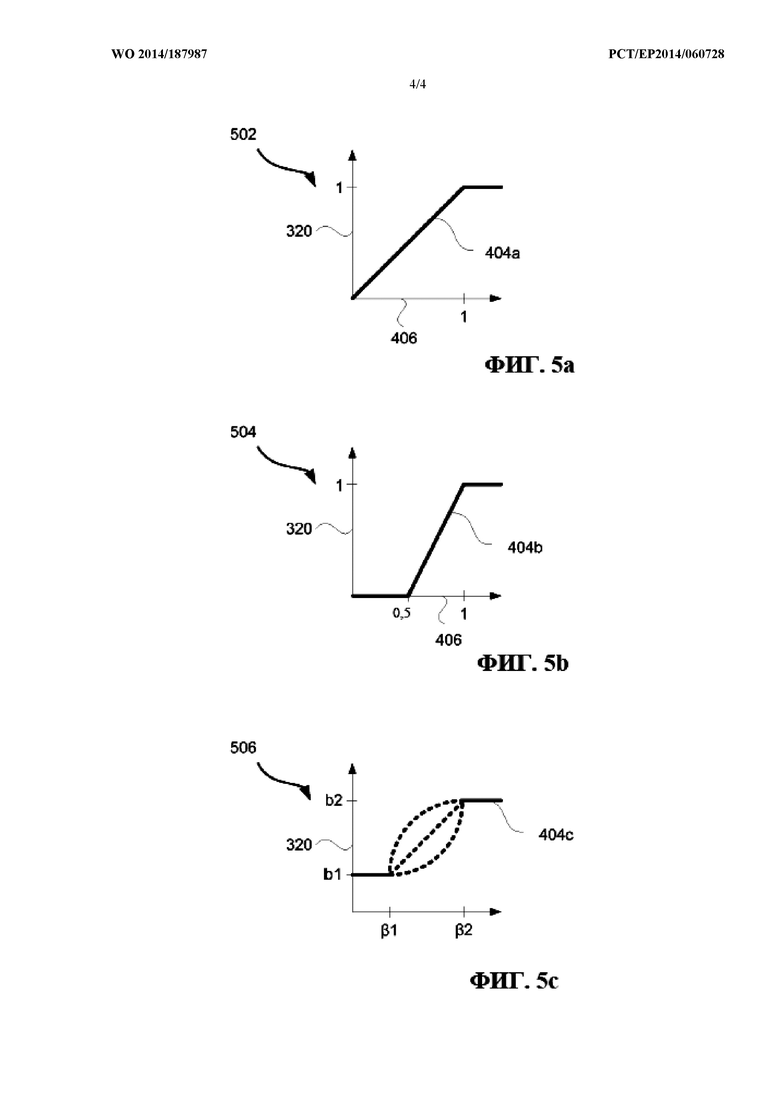
Вычислительный блок дополнительно выполнен с возможностью вычисления по меньшей мере одного весового параметра 320 на основе первой 316 и второй 318 величины, например, в компоненте 310 вычисления параметра. Компонент 310 вычисления параметра может, например, вычислять по меньшей мере один весовой параметр 320 посредством сравнения первой величины 316 и второй величины 318. Далее со ссылкой на фиг. 4 и фиг. 5а-с подробно описывается типовой компонент 310 вычисления параметра.
На фиг. 4 в качестве примера показана обобщенная блок-схема компонента 310 вычисления параметра для формирования по меньшей мере одного весового параметра 320. Компонент 310 вычисления параметра сравнивает первую величину 316 и вторую величину 318, например, в компоненте 402 вычисления отношения посредством вычисления отношения r второй 318 и первой 316 величин. Отношение затем возводится в степень α, т.е.
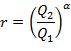 ,
,
где Q2 - вторая величина 318 и Q1 - первая величина 316. Согласно некоторым вариантам осуществления при 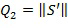 и
и 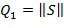 α равно 2, то есть отношение r представляет собой отношение энергии аппроксимированного конкретного звукового объекта и энергии конкретного звукового объекта. Отношение, возведенное в степень α 406, затем используется для вычисления по меньшей мере одного весового параметра 320, например, в отображающем компоненте 404. Отображающий компонент 404 подвергает r 406 воздействию возрастающей функции, отображающей r по меньшей мере на один весовой параметр 320. Такие возрастающие функции представлены в качестве примера на фиг. 5а-с. На фиг. 5а-с горизонтальная ось представляет величину r 406, а вертикальная ось представляет значение весового параметра 320. В этом примере весовой параметр 320 является единственным весовым параметром, который соответствует первому весовому коэффициенту 116 на фиг. 1.
α равно 2, то есть отношение r представляет собой отношение энергии аппроксимированного конкретного звукового объекта и энергии конкретного звукового объекта. Отношение, возведенное в степень α 406, затем используется для вычисления по меньшей мере одного весового параметра 320, например, в отображающем компоненте 404. Отображающий компонент 404 подвергает r 406 воздействию возрастающей функции, отображающей r по меньшей мере на один весовой параметр 320. Такие возрастающие функции представлены в качестве примера на фиг. 5а-с. На фиг. 5а-с горизонтальная ось представляет величину r 406, а вертикальная ось представляет значение весового параметра 320. В этом примере весовой параметр 320 является единственным весовым параметром, который соответствует первому весовому коэффициенту 116 на фиг. 1.
В целом, принцип для отображающей функции представляет собой:
Если Q2 << Q1, то первый весовой коэффициент приближается к 0, и если Q2 ≈ Q1, то первый весовой коэффициент приближается к 1.
На фиг. 5а показана отображающая функция 502, на которой для значений r 406 от 0 до 1 значение r будет таким же, как значение весового параметра 312. Для значений r выше 1 значение весового параметра 320 будет 1.
На фиг. 5b показана другая отображающая функция 504, в которой для значений r 406 от 0 до 0,5 значение весового параметра 320 будет 0. Для значений r выше 1 значение весового параметра 320 будет 1. Для значений r от 0,5 до 1 значение весового параметра 320 будет (r -0,5) * 2.
На фиг. 5c показана третья альтернативная отображающая функция 506, которая обобщает отображающие функции на фиг. 5a-b. Отображающая функция 506 определяется по меньшей мере посредством четырех параметров, b1, b2, β1 и β2, которые могут быть постоянными, настроенными для лучшего качества восприятия восстановленных звуковых объектов на декодирующей стороне. В целом, ограничение максимальной величины декорреляции в выходном звуковом сигнале может быть полезным, поскольку декоррелированный аппроксимированный звуковой объект часто имеет более низкое качество, чем аппроксимированный звуковой объект при прослушивании отдельно. Установка b1 больше нуля управляет этим непосредственно и, таким образом, может обеспечить то, что весовой параметр 320 (и, следовательно, первый весовой коэффициент 116 на фиг.1) будет больше нуля во всех случаях. Установка b2 меньше 1 имеет следствие, что всегда есть минимальный уровень энергии декорреляции на выходе из системы 100 декодирования звука. Другими словами, второй весовой коэффициент 114 на фиг. 1 всегда будет больше нуля. β1 неявно регулирует величину декорреляции, добавленной на выходе из системы 100 декодирования звука, но с разной предусмотренной динамикой (по сравнению с b1). Подобным образом β2 неявно регулирует величину декорреляции на выходе из системы 100 декодирования звука.
В случае криволинейной отображающей функции желательно, чтобы r принимало значения от β1 до β2, причем необходим по меньшей мере один дополнительный параметр, который может быть постоянным.
Эквиваленты, дополнения, альтернативы и прочее
Дополнительные варианты осуществления настоящего раскрытия будут очевидны для специалиста в данной области техники после изучения описания, приведенного выше. Несмотря на то что настоящее описание и графические материалы раскрывают варианты осуществления и примеры, раскрытие не ограничивается данными конкретными примерами. Возможны многочисленные модификации и изменения в пределах объема настоящего раскрытия, определенного прилагаемой формулой изобретения. Любые ссылочные позиции, встречающиеся в формуле изобретения, не должны рассматриваться как ограничивающие ее объем.
Кроме того, после изучения графических материалов, описания и прилагаемой формулы изобретения специалисту могут быть понятными изменения раскрытых вариантов осуществления и могут использоваться им при практической реализации раскрытия. В формуле изобретения слово «содержащий» не исключает другие элементы или этапы, и единственное число не исключает множественное. Сам факт, что некоторые признаки упоминаются во взаимно отличных зависимых пунктах формулы изобретения, не говорит о том, что не может быть использована с выгодой комбинация этих признаков.
Системы и способы, раскрытые выше, могут быть осуществлены в виде программного обеспечения, программно-аппаратного обеспечения, аппаратного обеспечения или их комбинации. При осуществлении в виде аппаратного обеспечения разделение задач между функциональными узлами, о которых говорилось в вышеприведенном описании, необязательно соответствует разделению на физические узлы; наоборот, один физический компонент может выполнять несколько функций, а одно задание может выполняться несколькими физическими компонентами во взаимодействии. Некоторые компоненты или все компоненты могут быть осуществлены в виде программного обеспечения, выполняемого процессором цифровых сигналов или микропроцессором, или быть осуществлены в виде аппаратного обеспечения или в виде зависимой от приложения интегральной микросхемы. Такое программное обеспечение может распространяться на машиночитаемых носителях, которые могут содержать компьютерные носители информации (или постоянные носители) и каналы передачи информации (или временные носители). Как хорошо известно специалисту в области техники, термин «компьютерные носители информации» включает энергозависимые и энергонезависимые, съемные и несъемные носители, реализованные любым способом или технологией для хранения информации, такой как машиночитаемые команды, структуры данных, программные модули или другие данные. Компьютерные носители информации включают, но не ограничиваются этим, ОЗУ, ПЗУ, ЭСППЗУ, флеш-память или другую технологию памяти, компакт-диски, компакт-диски формата DVD или другие оптические диски для хранения информации, магнитные кассеты, магнитную ленту, магнитный диск для хранения информации или другие магнитные устройства для хранения информации, или любой другой носитель, который может быть использован для хранения желаемой информации, и который может быть доступным с помощью компьютера. Дополнительно специалисту хорошо известно, что в каналах передачи информации, как правило, осуществлены машиночитаемые команды, структуры данных, программные модули или другие данные в виде модулированного сигнала данных, такого как несущая волна или другой механизм переноса, и включены любые средства для доставки информации.
| название | год | авторы | номер документа |
|---|---|---|---|
| КОДИРОВАНИЕ И ДЕКОДИРОВАНИЕ ЗВУКА | 2006 |
|
RU2418385C2 |
| КОДИРОВАНИЕ И ДЕКОДИРОВАНИЕ ЗВУКА | 2010 |
|
RU2461078C2 |
| КОДИРОВАНИЕ ЗВУКА С ИСПОЛЬЗОВАНИЕМ ДЕКОРРЕЛИРОВАННЫХ СИГНАЛОВ | 2005 |
|
RU2369982C2 |
| ПАРАМЕТРИЧЕСКОЕ КОДИРОВАНИЕ И ДЕКОДИРОВАНИЕ МНОГОКАНАЛЬНЫХ АУДИОСИГНАЛОВ | 2015 |
|
RU2798759C2 |
| ПАРАМЕТРИЧЕСКОЕ КОДИРОВАНИЕ И ДЕКОДИРОВАНИЕ МНОГОКАНАЛЬНЫХ АУДИОСИГНАЛОВ | 2015 |
|
RU2704266C2 |
| СТРУКТУРА ДЕКОРРЕЛЯТОРА ДЛЯ ПАРАМЕТРИЧЕСКОГО ВОССТАНОВЛЕНИЯ ЗВУКОВЫХ СИГНАЛОВ | 2014 |
|
RU2641463C2 |
| ПАРАМЕТРИЧЕСКОЕ КОДИРОВАНИЕ И ДЕКОДИРОВАНИЕ | 2010 |
|
RU2560790C2 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ КОДИРОВАНИЯ ПРОСТРАНСТВЕННОГО ЗВУКОВОГО ПРЕДСТАВЛЕНИЯ ИЛИ УСТРОЙСТВО И СПОСОБ ДЛЯ ДЕКОДИРОВАНИЯ ЗАКОДИРОВАННОГО АУДИОСИГНАЛА С ИСПОЛЬЗОВАНИЕМ ТРАНСПОРТНЫХ МЕТАДАННЫХ И СООТВЕТСТВУЮЩИЕ КОМПЬЮТЕРНЫЕ ПРОГРАММЫ | 2020 |
|
RU2792050C2 |
| МНОГОКАНАЛЬНОЕ КОДИРОВАНИЕ И ДЕКОДИРОВАНИЕ | 2005 |
|
RU2407068C2 |
| КОДИРОВАНИЕ И ДЕКОДИРОВАНИЕ АУДИО | 2006 |
|
RU2411594C2 |
Изобретение относится к кодированию и декодированию аудио сигналов. Технический результат – обеспечение возможности улучшения восстановления звукового объекта. Данная группа изобретений обеспечивает менее сложное и более гибкое регулирование внесенной в систему кодирования звука декорреляции. Согласно раскрытию это достигается посредством вычисления и применения двух весовых коэффициентов, одного для аппроксимированного звукового объекта и одного для декоррелированного звукового объекта, для внесения декорреляции звуковых объектов в систему кодирования звука. 6 н. и 22 з.п. ф-лы, 7 ил.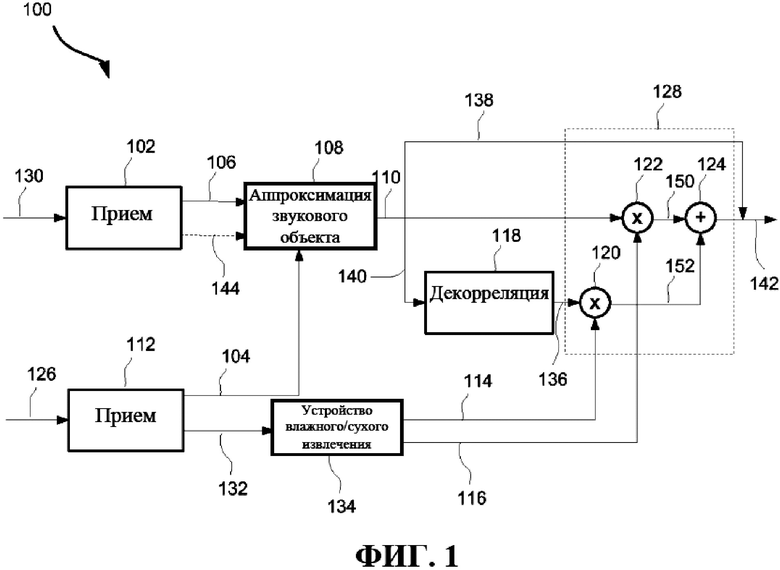
1. Способ восстановления частотно-временной мозаики N звуковых объектов, включающий этапы:
приема М сигналов понижающего микширования;
приема матрицы восстановления, обеспечивающей возможность восстановления аппроксимации N звуковых объектов из M сигналов понижающего микширования;
применения матрицы восстановления к M сигналам понижающего микширования для формирования N аппроксимированных звуковых объектов;
подвергания процессу декорреляции по меньшей мере подмножества N аппроксимированных звуковых объектов для формирования по меньшей мере одного декоррелированного звукового объекта, при этом каждый из по меньшей мере одного декоррелированного звукового объекта соответствует одному из N аппроксимированных звуковых объектов;
восстановления частотно-временной мозаики звукового объекта посредством аппроксимированного звукового объекта для каждого из N аппроксимированных звуковых объектов, не имеющих соответствующий декоррелированный звуковой объект; и
восстановления частотно-временной мозаики звукового объекта для каждого из N аппроксимированных звуковых объектов, имеющих соответствующий декоррелированный звуковой объект, посредством:
приема единственного весового параметра, из которого выводят первый весовой коэффициент и второй весовой коэффициент,
взвешивания аппроксимированного звукового объекта с помощью первого весового коэффициента,
взвешивания декоррелированного звукового объекта, соответствующего аппроксимированному звуковому объекту, с помощью второго весового коэффициента, и
комбинирования посредством осуществления суммирования взвешенного аппроксимированного звукового объекта с соответствующим взвешенным декоррелированным звуковым объектом для восстановления частотно-временной мозаики аппроксимированного звукового объекта, при этом уровень энергии восстановленной частотно-временной мозаики равен уровню энергии соответствующей частотно-временной мозаики аппроксимированного звукового объекта.
2. Способ по п. 1, в котором сумма квадратов первого весового коэффициента и второго весового коэффициента равна единице, и при этом единственный весовой параметр содержит либо первый весовой коэффициент, либо второй весовой коэффициент.
3. Способ по п. 1 или 2, в котором этап подвергания процессу декорреляции по меньшей мере подмножества N аппроксимированных звуковых объектов включает подвергание процессу декорреляции каждого из N аппроксимированных звуковых объектов, при этом каждый из N аппроксимированных звуковых объектов соответствует декоррелированному звуковому объекту.
4. Способ по п. 1 или 2, в котором первый и второй весовые коэффициенты являются переменными во времени и по частоте.
5. Способ по п. 1 или 2, в котором матрица восстановления является переменной во времени и по частоте.
6. Способ по п. 1 или 2, в котором матрица восстановления и по меньшей мере один весовой параметр при получении расположены в кадре, при этом матрица восстановления расположена в первом поле кадра с применением первого формата, и по меньшей мере один весовой параметр расположен во втором поле кадра с применением второго формата, тем самым обеспечивая возможность декодирующему устройству, которое поддерживает только первый формат, декодировать матрицу восстановления в первом поле и отбрасывать по меньшей мере один весовой параметр во втором поле.
7. Способ по п. 1 или 2, дополнительно включающий прием L дополнительных сигналов, при этом матрица восстановления дополнительно обеспечивает возможность восстановления аппроксимации N звуковых объектов из M сигналов понижающего микширования и L дополнительных сигналов, и при этом способ дополнительно включает применение матрицы восстановления к M сигналам понижающего микширования и L дополнительным сигналам для формирования N аппроксимированных звуковых объектов.
8. Способ по п. 7, в котором по меньшей мере один из L дополнительных сигналов равен одному из N восстанавливаемых звуковых объектов.
9. Способ по п. 7, в котором по меньшей мере один из L дополнительных сигналов представляет собой комбинацию по меньшей мере двух из N восстанавливаемых звуковых объектов.
10. Способ по п. 7, в котором M сигналов понижающего микширования охватывают гиперплоскость, и при этом по меньшей мере один из L дополнительных сигналов не лежит в гиперплоскости, охватываемой М сигналами понижающего микширования.
11. Способ по п. 10, в котором по меньшей мере один из L дополнительных сигналов ортогонален гиперплоскости, охватываемой М сигналами понижающего микширования.
12. Машиночитаемый носитель, содержащий команды машинного кода, предназначенные для выполнения способа по п. 1 или 2, при выполнении на устройстве, имеющем возможность обработки.
13. Устройство для восстановления частотно-временной мозаики N звуковых объектов, содержащее:
первый принимающий компонент, выполненный с возможностью приема M сигналов понижающего микширования;
второй принимающий компонент, выполненный с возможностью приема матрицы восстановления, обеспечивающей возможность восстановления аппроксимации N звуковых объектов из M сигналов понижающего микширования;
компонент аппроксимации звукового объекта, расположенный ниже по потоку от первого и второго принимающих компонентов и выполненный с возможностью применения матрицы восстановления к M сигналам понижающего микширования для формирования N аппроксимированных звуковых объектов;
компонент декорреляции, расположенный ниже по потоку от компонента аппроксимации звукового объекта и выполненный с возможностью подвергать процессу декорреляции по меньшей мере подмножество N аппроксимированных звуковых объектов для формирования по меньшей мере одного декоррелированного звукового объекта, при этом каждый из по меньшей мере одного декоррелированного звукового объекта соответствует одному из N аппроксимированных звуковых объектов;
при этом второй принимающий компонент дополнительно выполнен с возможностью приема для каждого из N аппроксимированных звуковых объектов, имеющих соответствующий декоррелированный звуковой объект, единственного весового параметра, из которого выводят первый весовой коэффициент и второй весовой коэффициент; и
компонент восстановления звукового объекта, расположенный ниже по потоку от компонента аппроксимации звукового объекта, компонента декорреляции и второго принимающего компонента и выполненный с возможностью:
восстановления частотно-временной мозаики звукового объекта посредством аппроксимированного звукового объекта для каждого из N аппроксимированных звуковых объектов, не имеющих соответствующий декоррелированный звуковой объект; и
восстановления частотно-временной мозаики звукового объекта для каждого из N аппроксимированных звуковых объектов, имеющих соответствующий декоррелированный звуковой объект, посредством:
взвешивания аппроксимированного звукового объекта с помощью первого весового коэффициента;
взвешивания декоррелированного звукового объекта, соответствующего аппроксимированному звуковому объекту, с помощью второго весового коэффициента; и
комбинирования посредством осуществления суммирования взвешенного аппроксимированного звукового объекта с соответствующим взвешенным декоррелированным звуковым объектом для восстановления частотно-временной мозаики аппроксимированного звукового объекта, при этом уровень энергии восстановленной частотно-временной мозаики равен уровню энергии соответствующей частотно-временной мозаики аппроксимированного звукового объекта.
14. Способ формирования в кодирующем устройстве по меньшей мере одного весового параметра, который подлежит применению при восстановлении частотно-временной мозаики конкретного звукового объекта, при этом способ включает этапы:
приема M сигналов понижающего микширования, являющихся комбинациями по меньшей мере N звуковых объектов, включая конкретный звуковой объект;
приема конкретного звукового объекта;
вычисления первой величины, указывающей на уровень энергии конкретного звукового объекта;
вычисления второй величины, указывающей на уровень энергии, соответствующий уровню энергии аппроксимации конкретного звукового объекта на кодирующей стороне, при этом аппроксимация на кодирующей стороне является комбинацией M сигналов понижающего микширования;
вычисления по меньшей мере одного весового параметра на основе первой и второй величины, при этом по меньшей мере один весовой параметр предназначен для взвешивания аппроксимации конкретного звукового объекта на декодирующей стороне и декоррелированной версии аппроксимации конкретного звукового объекта на декодирующей стороне.
15. Способ по п. 14, в котором по меньшей мере один весовой параметр содержит единственный весовой параметр, из которого выводят первый весовой коэффициент и второй весовой коэффициент, при этом первый весовой коэффициент предназначен для взвешивания аппроксимации конкретного звукового объекта на декодирующей стороне, а второй весовой коэффициент предназначен для взвешивания декоррелированной версии аппроксимированного звукового объекта на декодирующей стороне.
16. Способ по п. 15, в котором сумма квадратов первого весового коэффициента и второго весового коэффициента равна единице, и при этом единственный весовой параметр содержит либо первый весовой коэффициент, либо второй весовой коэффициент.
17. Способ по любому из пп. 14-16, в котором этап вычисления по меньшей мере одного весового параметра включает сравнение первой величины и второй величины.
18. Способ по п. 17, в котором сравнение первой величины и второй величины включает вычисление отношения второй и первой величины, возведение отношения в степень α и применение отношения, возведенного в степень α, для вычисления весового параметра.
19. Способ по п. 18, в котором α равно двум.
20. Способ по п. 18, в котором отношение, возведенное в степень α, подвергают действию возрастающей функции, отображающей отношение, возведенное в степень α, по меньшей мере на один весовой параметр.
21. Способ по любому из пп. 14-16, в котором первый и второй весовые коэффициенты являются переменными во времени и по частоте.
22. Способ по любому из пп. 14-16, в котором вторая величина, указывающая на уровень энергии, соответствует уровню энергии аппроксимации конкретного звукового объекта на кодирующей стороне, при этом аппроксимация на кодирующей стороне является линейной комбинацией M сигналов понижающего микширования и L дополнительных сигналов, при этом сигналы понижающего микширования и дополнительные сигналы сформированы из N звуковых объектов.
23. Способ по п. 22, в котором по меньшей мере один из L дополнительных сигналов равен одному из N звуковых объектов.
24. Способ по п. 22, в котором по меньшей мере один из L дополнительных сигналов представляет собой комбинацию по меньшей мере двух из N звуковых объектов.
25. Способ по п. 22, в котором M сигналов понижающего микширования охватывают гиперплоскость, и при этом по меньшей мере один из L дополнительных сигналов не лежит в гиперплоскости, охватываемой М сигналами понижающего микширования.
26. Способ по п. 25, в котором по меньшей мере один из L дополнительных сигналов ортогонален гиперплоскости, охватываемой М сигналами понижающего микширования.
27. Машиночитаемый носитель, содержащий команды машинного кода, предназначенные для выполнения способа по любому из пп. 14-16, при выполнении на устройстве, имеющем возможность обработки.
28. Кодирующее устройство для формирования по меньшей мере одного весового параметра, который подлежит применению при восстановлении частотно-временной мозаики конкретного звукового объекта, при этом устройство содержит:
принимающий компонент, выполненный с возможностью приема M сигналов понижающего микширования, являющихся комбинациями по меньшей мере N звуковых объектов, включая конкретный звуковой объект, при этом принимающий компонент дополнительно выполнен с возможностью приема конкретного звукового объекта;
вычислительный блок, выполненный с возможностью:
вычисления первой величины, указывающей на уровень энергии конкретного звукового объекта;
вычисления второй величины, указывающей на уровень энергии, соответствующий уровню энергии аппроксимации конкретного звукового объекта на кодирующей стороне, при этом аппроксимация на кодирующей стороне является комбинацией M сигналов понижающего микширования;
вычисления по меньшей мере одного весового параметра на основе первой и второй величин, при этом по меньшей мере один весовой параметр предназначен для взвешивания аппроксимации конкретного звукового объекта на декодирующей стороне и декоррелированной версии аппроксимации конкретного звукового объекта на декодирующей стороне.

