Перекрестные ссылки на смежные заявки
Настоящая заявка испрашивает приоритет по предварительной заявке на патент США № 62/073,642, поданной 31 октября 2014 г., и предварительной заявке на патент США № 62/128,425, поданной 4 марта 2015 г., полное содержание каждой из которых включено в настоящую заявку путем ссылки.
Область техники
Описанное в настоящей заявке изобретение по существу относится к параметрическому кодированию и декодированию аудиосигналов и, в частности, к параметрическому кодированию и декодированию распределенных по каналам аудиосигналов.
Предпосылки создания изобретения
Для воспроизведения аудиоданных, представленных многоканальным аудиосигналом, часто используют системы воспроизведения аудио, содержащие множество громкоговорителей, причем соответствующие каналы многоканального аудиосигнала воспроизводят через соответствующие громкоговорители. Многоканальный аудиосигнал можно, например, записать с помощью множества акустических преобразователей или можно создать с помощью оборудования для создания аудио. Во многих случаях имеются ограничения по полосе пропускания при передаче аудиосигнала на оборудование для воспроизведения, и/или в компьютерном запоминающем устройстве или переносном устройстве для хранения данных ограничено пространство для хранения аудиосигнала. Существуют системы кодирования аудио для параметрического кодирования аудиосигналов с целью уменьшения полосы пропускания или размера для хранения данных. На стороне кодера эти системы обычно выполняют понижающее микширование многоканального аудиосигнала до сигнала понижающего микширования, который, как правило, представляет собой монофонический (одноканальный) или стереофонический (двухканальный) сигнал понижающего микширования, и извлекают дополнительную информацию, описывающую характеристики каналов посредством параметров, таких как разности уровней и взаимная корреляция. Сигнал понижающего микширования и дополнительную информацию затем кодируют и передают на сторону декодера. На стороне декодера по сигналу понижающего микширования с учетом параметров дополнительной информации выполняют реконструкцию, т. е. аппроксимацию, многоканального аудиосигнала.
Ввиду многообразия различных типов устройств и систем, подходящих для воспроизведения многоканальных аудиоданных, в том числе средств в недавно появившемся сегменте, ориентированном на бытовое применение конечными потребителями, актуальной является задача создания новых и альтернативных способов эффективного кодирования многоканальных аудиоданных, которые позволили бы снизить требования к полосе пропускания и/или к объему памяти для хранения, сделать более удобной реконструкцию многоканального аудиосигнала на стороне декодера и/или увеличить достоверность воспроизведения многоканального аудиосигнала, реконструированного на стороне декодера.
Краткое описание рисунков
Примеры осуществления будут более подробно описаны ниже и со ссылкой на сопроводительные рисунки, причем:
на Фиг. 1 и 2 представлены обобщенные структурные схемы секций кодирования для кодирования М-канальных аудиосигналов в виде двухканальных сигналов понижающего микширования и ассоциированных параметров повышающего микширования в соответствии с примерами осуществления;
на Фиг. 3 представлена обобщенная структурная схема системы кодирования аудио, содержащей секцию кодирования, показанную на Фиг. 1, в соответствии с примером осуществления;
на Фиг. 4 и 5 представлены блок-схемы способов кодирования аудио для кодирования М-канальных аудиосигналов в виде двухканальных сигналов понижающего микширования и ассоциированных параметров повышающего микширования в соответствии с примерами осуществления;
на Фиг. 6–8 представлены альтернативные способы разделения 11.1-канального (или 7.1 + 4-канального или 7.1.4-канального) аудиосигнала на группы каналов, представленные соответствующими каналами понижающего микширования, в соответствии с примерами осуществления;
на Фиг. 9 представлена обобщенная структурная схема секции декодирования для реконструкции М-канального аудиосигнала на основе двухканального сигнала понижающего микширования и ассоциированных параметров повышающего микширования в соответствии с примером осуществления;
на Фиг. 10 представлена обобщенная структурная схема системы декодирования аудио, содержащей секцию декодирования, показанную на Фиг. 9, в соответствии с примером осуществления;
на Фиг. 11 представлена обобщенная структурная схема секции микширования, содержащейся в секции декодирования, показанной на Фиг. 9, в соответствии с примером осуществления;
на Фиг. 12 представлена блок-схема способа декодирования аудио для реконструкции М-канального аудиосигнала на основе двухканального сигнала понижающего микширования и ассоциированных параметров повышающего микширования в соответствии с примером осуществления; и
на Фиг. 13 представлена обобщенная структурная схема секции декодирования для реконструкции 13.1-канального аудиосигнала на основе 5.1-канального сигнала и ассоциированных параметров повышающего микширования в соответствии с примером осуществления;
на Фиг. 14 представлена обобщенная структурная схема секции кодирования, выполненной с возможностью определения подходящего формата кодирования, который можно использовать для кодирования М-канального аудиосигнала (и возможных последующих каналов), и представления М-канального аудиосигнала в виде двухканального сигнала понижающего микширования и ассоциированных параметров повышающего микширования для выбранного формата;
на Фиг. 15 подробно представлена двухрежимная секция понижающего микширования в секции кодирования, показанной на Фиг. 14;
на Фиг. 16 подробно представлена двухрежимная секция анализа в секции кодирования, показанной на Фиг. 14; и
на Фиг. 17 представлена блок-схема способа кодирования аудио, который может быть реализован компонентами, показанными на Фиг. 14–16.
Все фигуры являются схематическими, и на них по существу показаны те части, которые необходимы для разъяснения сути изобретения, тогда как другие части могут быть опущены или просто подразумеваться.
Описание примеров осуществления
В настоящей заявке аудиосигнал может представлять собой отдельный аудиосигнал, аудиочасть аудиовизуального сигнала или мультимедийного сигнала или любой из таких сигналов в сочетании с метаданными. В настоящей заявке канал представляет собой аудиосигнал, связанный с заранее определенным/фиксированным пространственным положением/ориентацией или неопределенным пространственным положением, таким как «левый» или «правый».
I. Обзор. Сторона декодера
В соответствии с первым аспектом в примерах осуществления предложены системы декодирования аудио, способы декодирования аудио и связанные компьютерные программные продукты. Предлагаемые системы декодирования, способы и компьютерные программные продукты в соответствии с первым аспектом могут по существу иметь одни и те же общие возможности и преимущества.
В соответствии с примерами осуществления предложен способ декодирования аудио, который включает получение двухканального сигнала понижающего микширования и параметров повышающего микширования для параметрической реконструкции М-канального аудиосигнала на основе сигнала понижающего микширования, причем M ≥ 4. Способ декодирования аудио включает получение сигнализацию, указывающую на выбранный один из по меньшей мере двух форматов кодирования М-канального аудиосигнала, причем форматы кодирования сопоставлены с соответствующими различными разделениями каналов М-канального аудиосигнала на соответствующую первую и вторую группы одного или более каналов. В указанном формате кодирования первый канал сигнала понижающего микширования соответствует линейной комбинации первой группы одного или более каналов М-канального аудиосигнала, а второй канал сигнала понижающего микширования соответствует линейной комбинации второй группы одного или более каналов М-канального аудиосигнала. Способ декодирования аудио дополнительно включает определение набора преддекорреляционных коэффициентов на основе указанного формата кодирования; вычисление входного сигнала декорреляции как линейного отображения сигнала понижающего микширования, причем к сигналу понижающего микширования применяют набор преддекорреляционных коэффициентов; создание декоррелированного сигнала на основе входного сигнала декорреляции; определение наборов коэффициентов повышающего микширования первого типа, которые в настоящей заявке называются «влажными» коэффициентами повышающего микширования, и второго типа, которые в настоящей заявке называются «сухими» коэффициентами повышающего микширования, на основе полученных параметров повышающего микширования и указанного формата кодирования; вычисление сигнала повышающего микширования первого типа, который в настоящей заявке называется «сухим» сигналом повышающего микширования, как линейного отображения сигнала понижающего микширования, причем к сигналу понижающего микширования применяют набор «сухих» коэффициентов повышающего микширования; вычисление сигнала повышающего микширования второго типа, который в настоящей заявке называется «влажным» сигналом повышающего микширования, как линейного отображения декоррелированного сигнала, причем к декоррелированному сигналу применяют набор «влажных» коэффициентов повышающего микширования; и объединение «сухого» и «влажного» сигналов повышающего микширования для получения многомерного реконструированного сигнала, соответствующего подлежащему реконструкции М-канальному аудиосигналу.
В зависимости от аудиоданных М-канального аудиосигнала разные разделения каналов М-канального аудиосигнала на первую и вторую группы, при том что каждая группа вносит свой клад в канал сигнала понижающего микширования, могут подходить, например, для облегчения реконструкции М-канального аудиосигнала из сигнала понижающего микширования, в результате чего увеличивается (воспринимаемая) достоверность воспроизведения М-канального аудиосигнала, реконструированного из сигнала понижающего микширования, и/или повышается эффективность кодирования сигнала понижающего микширования. То, что способ декодирования аудио обеспечивает возможность получения сигнализации, указывающей на выбранный формат кодирования, и адаптации определения преддекорреляционных коэффициентов, а также «влажного» и «сухого» коэффициентов повышающего микширования для указанного формата кодирования, позволяет выбирать формат кодирования на стороне кодера, например, на основе аудиоданных М-канального аудиосигнала для использования сравнительных преимуществ применения этого конкретного формата кодирования для представления М-канального аудиосигнала.
В частности, определение преддекорреляционных коэффициентов на основе указанного формата кодирования может обеспечивать выбор канала или каналов сигнала понижающего микширования, из которых создается декоррелированный сигнал, и/или определять значимость такого канала или каналов на основе указанного формата кодирования до создания декоррелированного сигнала. Таким образом, то, что способ декодирования аудио обеспечивает возможность определения преддекорреляционных коэффициентов разным образом для разных форматов кодирования, может обеспечивать увеличение достоверности воспроизведения реконструированного М-канального аудиосигнала.
Первый канал сигнала понижающего микширования можно, например, сформировать на стороне кодера в виде линейной комбинации первой группы одного или более каналов в соответствии с указанным форматом кодирования. Аналогично второй канал сигнала понижающего микширования можно, например, сформировать на стороне кодера в виде линейной комбинации второй группы одного или более каналов в соответствии с указанным форматом кодирования.
Каналы М-канального аудиосигнала могут образовывать, например, поднабор большего количества каналов, что вместе представляет звуковое поле.
Декоррелированный сигнал служит для увеличения размерности аудиоданных сигнала понижающего микширования при восприятии слушателем. Создание декоррелированного сигнала может включать, например, применение линейного фильтра к входному сигналу декорреляции.
Под вычислением входного сигнала декорреляции как линейного отображения сигнала понижающего микширования подразумевается, что входной сигнал декорреляции получают путем первого линейного преобразования сигнала понижающего микширования. При первом линейном преобразовании в качестве входа берут два канала сигнала понижающего микширования, а в качестве выхода обеспечивают каналы входного сигнала декорреляции, а преддекорреляционные коэффициенты представляют собой коэффициенты, определяющие количественные характеристики этого первого линейного преобразования.
Под вычислением «сухого» сигнала повышающего микширования как линейного отображения сигнала понижающего микширования подразумевается, что «сухой» сигнал повышающего микширования получают путем второго линейного преобразования сигнала понижающего микширования. При втором линейном преобразовании в качестве входа берут два канала сигнала понижающего микширования, а в качестве выхода обеспечивают M каналов, а «сухие» коэффициенты повышающего микширования представляют собой коэффициенты, определяющие количественные характеристики этого второго линейного преобразования.
Под вычислением «влажного» сигнала повышающего микширования как линейного отображения декоррелированного сигнала подразумевается, что «влажный» сигнал повышающего микширования получают путем третьего линейного преобразования декоррелированного сигнала. При третьем линейном преобразовании в качестве входа берут каналы декоррелированного сигнала, а в качестве выхода обеспечивают M каналов, а «влажные» коэффициенты повышающего микширования представляют собой коэффициенты, определяющие количественные характеристики этого третьего линейного преобразования.
Объединение «сухого» и «влажного» сигналов повышающего микширования может включать добавление аудиоданных из соответствующих каналов «сухого» сигнала повышающего микширования к аудиоданным соответствующих каналов «влажного» сигнала повышающего микширования, например, путем использования аддитивного микширования по образцам или по коэффициентам преобразования.
Сигнализацию можно получить, например, вместе с сигналом понижающего микширования и/или параметрами повышающего микширования. Сигнал понижающего микширования, параметры повышающего микширования и сигнализацию можно, например, извлечь из битового потока.
В примере осуществления может присутствовать условие M = 5, т. е. М-канальный аудиосигнал может представлять собой пятиканальный аудиосигнал. Способ декодирования аудио в соответствии с настоящим примером осуществления можно использовать, например, для реконструкции пяти стандартных каналов в одном из актуальных установленных аудиоформатов 5.1 из двухканального сигнала понижающего микширования этих пяти каналов или для реконструкции пяти каналов на левой стороне или на правой стороне в 11.1-многоканальный аудиосигнал из двухканального сигнала понижающего микширования этих пяти каналов. В альтернативном варианте осуществления может присутствовать условие M = 4 или M ≥ 6.
В примере осуществления каждый из входного сигнала декорреляции и декоррелированного сигнала может содержать M–2 каналов. В настоящем примере осуществления канал декоррелированного сигнала можно создать на основе не более одного канала входного сигнала декорреляции. Например, каждый канал декоррелированного сигнала можно создать на основе не более одного канала входного сигнала декорреляции, но разные каналы декоррелированного сигнала, например, можно создать на основе разных каналов входного сигнала декорреляции.
В настоящем примере осуществления преддекорреляционные коэффициенты могут определяться так, чтобы в каждом из форматов кодирования канал входного сигнала декорреляции получал вклад от не более одного канала сигнала понижающего микширования. Например, преддекорреляционные коэффициенты могут определяться так, чтобы в каждом из форматов кодирования каждый канал входного сигнала декорреляции совпадал с каналом сигнала понижающего микширования. Однако следует понимать, что по меньшей мере некоторые из каналов входного сигнала декорреляции могут совпадать, например, с разными каналами сигнала понижающего микширования в конкретном формате кодирования и/или в разных форматах кодирования.
Поскольку в каждом конкретном формате кодирования два канала сигнала понижающего микширования представляют раздельные первую и вторую группы одного или более каналов, первую группу можно реконструировать из первого канала сигнала понижающего микширования с использованием, например, одного или более каналов декоррелированного сигнала, созданного на основе первого канала сигнала понижающего микширования, а вторую группу можно реконструировать из второго канала сигнала понижающего микширования с использованием, например, одного или более каналов декоррелированного сигнала, созданного на основе второго канала сигнала понижающего микширования В настоящем примере осуществления в каждом формате кодирования может не допускаться вклад от второй группы одного или более каналов в реконструированный вариант первой группы одного или более каналов посредством декоррелированного сигнала. Аналогично в каждом формате кодирования может не допускаться вклад от первой группы одного или более каналов в реконструированный вариант второй группы одного или более каналов посредством декоррелированного сигнала. Таким образом, в настоящем примере осуществления может быть предложено увеличение достоверности воспроизведения реконструированного М-канального аудиосигнала.
В примере осуществления преддекорреляционные коэффициенты могут определяться так, чтобы первый канал М-канального аудиосигнала вносил вклад в первый фиксированный канал входного сигнала декорреляции посредством сигнала понижающего микширования по меньшей мере в двух форматах кодирования. Другими словами, первый канал М-канального аудиосигнала может вносить вклад в один и тот же канал входного сигнала декорреляции посредством сигнала понижающего микширования в каждом из этих форматов кодирования. Следует понимать, что в настоящем примере осуществления в конкретном формате кодирования первый канал М-канального аудиосигнала может вносить вклад, например, в множество каналов входного сигнала декорреляции посредством сигнала понижающего микширования.
В настоящем примере осуществления при переключении указанного формата кодирования между двумя форматами кодирования остается по меньшей мере часть первого фиксированного канала входного сигнала декорреляции. Это может обеспечивать более плавный и/или менее резкий переход между форматами кодирования для восприятия слушателем во время воспроизведения реконструированного М-канального аудиосигнала. В частности, авторы изобретения установили, что поскольку декоррелированный сигнал можно, например, создать на основе части сигнала понижающего микширования, соответствующей нескольким временным интервалам, во время которых в сигнале понижающего микширования может происходить переключение между форматами кодирования, в результате переключения между форматами кодирования в декоррелированном сигнале потенциально могут возникать различимые на слух искажения. Даже если в результате переключения между форматами кодирования осуществляется интерполяция «влажных» и «сухих» коэффициентов повышающего микширования, в реконструированном М-канальном аудиосигнале все равно могут оставаться искажения, появившиеся в декоррелированном сигнале. Обеспечение входного сигнала декорреляции в соответствии с настоящим примером осуществления позволяет подавлять такие искажения в декоррелированном сигнале, которые вызываются переключением между форматами кодирования, что может увеличивать качество воспроизведения реконструированного М-канального аудиосигнала.
В примере осуществления преддекорреляционные коэффициенты могут определяться так, чтобы второй канал М-канального аудиосигнала дополнительно вносил вклад во второй фиксированный канал входного сигнала декорреляции посредством сигнала понижающего микширования по меньшей мере в двух форматах кодирования. Другими словами, второй канал М-канального аудиосигнала вносит вклад в один и тот же канал входного сигнала декорреляции посредством сигнала понижающего микширования в каждом из этих форматов кодирования. В настоящем примере осуществления при переключении указанного формата кодирования между двумя форматами кодирования остается по меньшей мере часть второго фиксированного входного сигнала декорреляции. Таким образом, переход между форматами кодирования оказывает влияние только на один вход декоррелятора. Это может обеспечивать более плавный и/или менее резкий переход между форматами кодирования для восприятия слушателем во время воспроизведения реконструированного М-канального аудиосигнала.
Первый и второй каналы М-канального аудиосигнала могут, например, отличаться друг от друга. Первый и второй фиксированные каналы входного сигнала декорреляции могут, например, отличаться друг от друга.
В примере осуществления полученная сигнализация может указывать на выбранный один из по меньшей мере трех форматов кодирования, а преддекорреляционные коэффициенты могут определяться так, чтобы первый канал М-канального аудиосигнала вносил вклад в первый фиксированный канал входного сигнала декорреляции посредством сигнала понижающего микширования по меньшей мере в трех форматах кодирования. Другими словами, первый канал М-канального аудиосигнала вносит вклад в один и тот же канал входного сигнала декорреляции посредством сигнала понижающего микширования в этих трех форматах кодирования. В настоящем примере осуществления при переключении указанного формата кодирования между любыми из трех форматов кодирования остается по меньшей мере часть первого фиксированного канала входного сигнала декорреляции, что обеспечивает более плавный и/или менее резкий переход между форматами кодирования для восприятия слушателем во время воспроизведения реконструированного М-канального аудиосигнала.
В примере осуществления преддекорреляционные коэффициенты могут определяться так, чтобы пара каналов М-канального аудиосигнала вносила вклад в третий фиксированный канал входного сигнала декорреляции посредством сигнала понижающего микширования по меньшей мере в двух форматах кодирования. Другими словами, пара каналов М-канального аудиосигнала вносит вклад в один и тот же канал входного сигнала декорреляции посредством сигнала понижающего микширования в каждом из этих форматов кодирования. В настоящем примере осуществления при переключении указанного формата кодирования между двумя форматами кодирования остается по меньшей мере часть третьего фиксированного канала входного сигнала декорреляции, что обеспечивает более плавный и/или менее резкий переход между форматами кодирования для восприятия слушателем во время воспроизведения реконструированного М-канального аудиосигнала.
Пара каналов может, например, отличаться от первого и второго каналов М-канального аудиосигнала. Третий фиксированный канал входного сигнала декорреляции может, например, отличаться от первого и второго фиксированных каналов входного сигнала декорреляции.
В примере осуществления способ декодирования аудио может дополнительно включать выполнение постепенного перехода от значений преддекорреляционных коэффициентов, связанных с первым форматом кодирования, к значениям преддекорреляционных коэффициентов, связанных со вторым форматом кодирования, в ответ на определение факта переключения указанного формата кодирования с первого формата кодирования на второй формат кодирования. Использование постепенного перехода между значениями преддекорреляционных коэффициентов при переключении между форматами кодирования обеспечивает более плавный и/или менее резкий переход между форматами кодирования для восприятия слушателем во время воспроизведения реконструированного М-канального аудиосигнала. В частности, авторы изобретения установили, что поскольку декоррелированный сигнал можно, например, создать на основе части сигнала понижающего микширования, соответствующей нескольким временным интервалам, во время которых в сигнале понижающего микширования может происходить переключение между форматами кодирования, в результате переключения между форматами кодирования в декоррелированном сигнале потенциально могут возникать различимые на слух искажения. Даже если в результате переключения между форматами кодирования осуществляется интерполяция «влажных» и «сухих» коэффициентов повышающего микширования, в реконструированном М-канальном аудиосигнале все равно могут оставаться искажения, появившиеся в декоррелированном сигнале. Обеспечение входного сигнала декорреляции в соответствии с настоящим примером осуществления позволяет подавлять такие искажения в декоррелированном сигнале, которые вызываются переключением между форматами кодирования, что может увеличивать качество воспроизведения реконструированного М-канального аудиосигнала.
Постепенный переход может быть выполнен, например, посредством линейной или непрерывной интерполяции. Постепенный переход может быть выполнен, например, посредством интерполяции с ограниченной скоростью изменения.
В примере осуществления способ декодирования аудио может дополнительно включать выполнение интерполяции от значений «влажных» и «сухих» коэффициентов повышающего микширования, включая коэффициенты с нулевыми значениями, связанных с первым форматом кодирования, к значениям «влажных» и «сухих» коэффициентов повышающего микширования, также включая коэффициенты с нулевыми значениями, связанных со вторым форматом кодирования, в ответ на определение факта переключения указанного формата кодирования с первого формата кодирования на второй формат кодирования. Следует понимать, что каналы понижающего микширования соответствуют разным комбинациями каналов из изначально кодированного М-канального аудиосигнала, так что коэффициент повышающего микширования с нулевым значением в первом формате кодирования необязательно будет иметь нулевое значение и во втором формате кодирования, и наоборот. Предпочтительно коэффициенты повышающего микширования подвержены действию интерполяции, а не компактного представления коэффициентов, например описанного ниже представления.
Линейную или непрерывную интерполяцию между значениями коэффициентов повышающего микширования можно использовать, например, для обеспечения более плавного перехода между форматами кодирования для восприятия слушателем во время воспроизведения реконструированного М-канального аудиосигнала.
Интерполяция с большим градиентом, при которой в определенный момент времени, связанный с переключением между форматами кодирования, прежние значения коэффициентов повышающего микширования заменяются новыми значениями коэффициентов повышающего микширования, может, например, увеличивать достоверность воспроизведения реконструированного М-канального аудиосигнала, например, в случаях быстрого изменения аудиоданных М-канального аудиосигнала и переключения формата кодирования на стороне кодера в ответ на эти изменения для увеличения достоверности воспроизведения реконструированного М-канального аудиосигнала.
В примере осуществления способ кодирования аудио может дополнительно включать получение сигнализации, указывающей на одну из множества интерполяционных схем, которую можно использовать для интерполяции «влажных» и «сухих» параметров повышающего микширования в рамках одного формата кодирования (т. е. при присвоении коэффициентам повышающего микширования новых значений в период времени, когда не происходит изменения формата кодирования), и использование указанной интерполяционной схемы. Сигнализацию, указывающую на одну из множества интерполяционных схем, можно получить, например, вместе с сигналом понижающего микширования и/или параметрами повышающего микширования. Предпочтительно интерполяционную схему, указанную сигнализацией, можно дополнительно использовать для перехода между форматами кодирования.
На стороне кодера, где доступен М-канальный аудиосигнал, можно, например, выбрать интерполяционные схемы, особенно подходящие для фактических аудиоданных М-канального аудиосигнала. Например, линейную или непрерывную интерполяцию можно использовать в случаях, когда для общего впечатления о реконструированном М-канальном аудиосигнале важно обеспечить плавное переключение, а интерполяцию с большим градиентом, т. е. интерполяцию, при которой в определенный момент времени, связанный с переходом между форматами кодирования, прежние значения коэффициентов повышающего микширования заменяются новыми значениями коэффициентов повышающего микширования, можно использовать в случаях, когда для общего впечатления о реконструированном М-канальном аудиосигнале важно обеспечить быстрое переключение.
В примере осуществления по меньшей мере два формата кодирования могут включать первый формат кодирования и второй формат кодирования. Существует коэффициент усиления, контролирующий в каждом формате кодирования вклад от канала М-канального аудиосигнала в одну из линейных комбинаций, которой соответствуют каналы сигнала понижающего микширования. В настоящем примере осуществления коэффициент усиления в первом формате кодирования может совпадать с коэффициентом усиления во втором формате кодирования, который контролирует вклад от того же канала М-канального аудиосигнала.
Использование одних и тех же коэффициентов усиления в первом и втором форматах кодирования может, например, увеличивать сходство между объединенными аудиоданными каналов сигнала понижающего микширования в первом формате кодирования и объединенными аудиоданными каналов сигнала понижающего микширования во втором формате кодирования. Поскольку каналы сигнала понижающего микширования используются для реконструкции М-канального сигнала понижающего микширования, это может способствовать более плавным переходам между этими двумя форматами кодирования для восприятия слушателем.
Использование одних и тех же коэффициентов усиления в первом и втором форматах кодирования может, например, способствовать увеличению сходства между аудиоданными первого и второго каналов соответственно сигнала понижающего микширования в первом формате кодирования и аудиоданными первого и второго каналов соответственно сигнала понижающего микширования во втором формате кодирования. Это может способствовать более плавным переходам между этими двумя форматами кодирования для восприятия слушателем.
В настоящем примере осуществления для разных каналов М-канального аудиосигнала можно, например, использовать разные коэффициенты усиления. В первом примере значения всех коэффициентов усиления в первом и втором форматах кодирования могут составлять 1. В первом примере первый и второй каналы сигнала понижающего микширования могут соответствовать невзвешенным суммам первой и второй групп соответственно как в первом, так и во втором форматах кодирования. Во втором примере значения по меньшей мере некоторых коэффициентов усиления могут быть отличными от 1. Во втором примере первый и второй каналы сигнала понижающего микширования могут соответствовать взвешенным суммам первой и второй групп соответственно.
В примере осуществления М-канальный аудиосигнал может содержать три канала, представляющих разные горизонтальные направления в среде воспроизведения для М-канального аудиосигнала, и два канала, представляющих направления, отделенные по вертикали от направлений вышеупомянутых трех каналов в среде воспроизведения. Другими словами, М-канальный аудиосигнал может содержать три канала, предназначенных для воспроизведения источниками звука, расположенными по существу на одной высоте со слушателем (или ушами слушателя) и/или распространяющими звук по существу горизонтально, и два канала, предназначенные для воспроизведения источниками звука, расположенными на другой высоте и/или распространяющими звук (по существу) негоризонтально. Два канала могут, например, представлять направления вверху.
В примере осуществления в первом формате кодирования вторая группа каналов может содержать два канала, представляющие направления, отделенные по вертикали от направлений вышеупомянутых трех каналов в среде воспроизведения. При наличии этих двух каналов во второй группе и использовании одного и того же канала сигнала понижающего микширования для представления этих двух каналов можно, например, увеличить достоверность воспроизведения реконструированного М-канального аудиосигнала в случаях, когда вертикальное измерение в среде воспроизведения важно для общего впечатления от М-канального аудиосигнала.
В примере осуществления в первом формате кодирования первая группа из одного или более каналов может содержать три канала, представляющих разные горизонтальные направления в среде воспроизведения М-канального аудиосигнала, а вторая группа из одного или более каналов может содержать два канала, представляющих направления, отделенные по вертикали от направлений вышеупомянутых трех каналов в среде воспроизведения. В настоящем примере осуществления первый формат кодирования позволяет представлять три канала посредством первого канала сигнала понижающего микширования и представлять два канала посредством второго канала сигнала понижающего микширования, в результате чего можно, например, увеличить достоверность воспроизведения реконструированного М-канального аудиосигнала в случаях, когда вертикальное измерение в среде воспроизведения важно для общего впечатления от М-канального аудиосигнала.
В примере осуществления во втором формате кодирования каждая из первой и второй группы может содержать один из двух каналов, представляющих направления, отделенные по вертикали от направлений вышеупомянутых трех каналов в среде воспроизведения М-канального аудиосигнала. При наличии этих двух каналов в разных группах и использовании разных каналов сигнала понижающего микширования для представления этих двух каналов можно, например, увеличить достоверность воспроизведения реконструированного М-канального аудиосигнала в случаях, когда вертикальное измерение в среде воспроизведения не столь важно для общего впечатления от М-канального аудиосигнала.
В примере осуществления в формате кодирования, который в настоящей заявке называется конкретным форматом кодирования, первая группа из одного или более каналов может состоять из N каналов, где N ≥ 3. В настоящем примере осуществления, если указанный формат кодирования является конкретным форматом кодирования, преддекорреляционные коэффициенты могут определяться так, чтобы на основе первого канала сигнала понижающего микширования было создано N − 1 каналов декоррелированного сигнала; а «сухие» и «влажные» коэффициенты повышающего микширования могут определяться так, чтобы первая группа из одного или более каналов была реконструирована как линейное отображение первого канала сигнала понижающего микширования и N − 1 каналов декоррелированного сигнала, причем к первому каналу сигнала понижающего микширования применяют поднабор «сухих» коэффициентов повышающего микширования, а к N − 1 каналам декоррелированного сигнала применяют поднабор «влажных» коэффициентов повышающего микширования.
Преддекорреляционные коэффициенты могут определяться, например, так, чтобы N − 1 каналов входного сигнала декорреляции совпадали с первым каналом сигнала понижающего микширования. N − 1 каналов декоррелированного сигнала можно создать, например, посредством обработки этих N − 1 каналов входного сигнала декорреляции.
Под реконструкцией первой группы одного или более каналов как линейного отображения первого канала сигнала понижающего микширования и N − 1 каналов декоррелированного сигнала понимается то, что реконструированный вариант первой группы одного или более каналов получают путем линейного преобразования первого канала сигнала понижающего микширования и N − 1 каналов декоррелированного сигнала. При этом линейном преобразовании N каналов берут в качестве входа и обеспечивают N каналов в качестве выхода, причем поднабор «сухих» коэффициентов повышающего микширования и поднабор «влажных» коэффициентов повышающего микширования вместе составляют коэффициенты, определяющие количественные характеристики этого линейного преобразования.
В примере осуществления полученные параметры повышающего микширования могут включать параметры повышающего микширования первого типа, называемые в настоящей заявке «влажными» параметрами повышающего микширования, и параметры повышающего микширования второго типа, называемые в настоящей заявке «сухими» параметрами повышающего микширования. В настоящем примере осуществления определение наборов «влажных» и «сухих» коэффициентов повышающего микширования в конкретном формате кодирования может включать определение поднабора «сухих» коэффициентов повышающего микширования на основе «сухих» параметров повышающего микширования; заполнение промежуточной матрицы, имеющей больше элементов, чем количество полученных «влажных» коэффициентов повышающего микширования, на основе полученных «влажных» коэффициентов повышающего микширования и наличия информации о том, что промежуточная матрица относится к классу заданных матриц; и получение поднабора «влажных» коэффициентов повышающего микширования путем умножения промежуточной матрицы на заданную матрицу, причем поднабор «влажных» коэффициентов повышающего микширования соответствует матрице, являющейся результатом умножения, и включает большее количество коэффициентов, чем количество элементов в промежуточной матрице.
В настоящем примере осуществления количество «влажных» коэффициентов повышающего микширования в поднаборе «влажных» коэффициентов повышающего микширования больше количества полученных «влажных» параметров повышающего микширования. Использование информации о заданной матрице и классе заданных матриц для получения поднабора «влажных» коэффициентов повышающего микширования из полученных «влажных» параметров повышающего микширования позволяет уменьшить количество информации, необходимой для параметрической реконструкции первой группы из одного или более каналов, что позволяет уменьшить количество метаданных, передаваемых вместе с сигналом понижающего микширования со стороны кодера. Уменьшение количества данных, необходимых для параметрической реконструкции, позволяет уменьшить требуемую полосу пропускания для передачи параметрического представления М-канального аудиосигнала и/или требуемое пространство для хранения такого представления.
Класс заданных матриц может быть связан с известными характеристиками по меньшей мере некоторых элементов матрицы, действительными для всех матриц в классе, такими как определенные взаимосвязи между некоторыми элементами матрицы или нулевые значения некоторых элементов матрицы. Наличие информации об этих характеристиках позволяет заполнять промежуточную матрицу на основе меньшего количества «влажных» параметров повышающего микширования по сравнению с полным количеством элементов матрицы в промежуточной матрице. На стороне кодера доступна информация по меньшей мере о характеристиках элементов, которые необходимы для вычисления всех элементов матрицы на основе меньшего количества «влажных» коэффициентов повышающего микширования, и о взаимосвязях между этими элементами.
Определение и использование заданной матрицы и класса заданных матриц более подробно описаны в предварительной заявке на патент США № 61/974,544 со строки 15 на странице 16 до строки 2 на странице 20; автор изобретения, чье имя указано первым: Lars Villemoes; дата подачи: 3 апреля 2014 г. В частности, в качестве примеров заданной матрицы см. выражение (9) в вышеупомянутом документе.
В примере осуществления полученные параметры повышающего микширования могут включать N(N − 1)/2 «влажных» параметров повышающего микширования. В настоящем примере осуществления заполнение промежуточной матрицы может включать получение значений для (N − 1)2 элементов матрицы на основе полученных N(N − 1)/2 «влажных» параметров повышающего микширования и наличия информации о принадлежности промежуточной матрицы к классу заданных матриц. Это может включать ввод значений «влажных» параметров повышающего микширования сразу как элементов матрицы или обработку «влажных» параметров повышающего микширования подходящим образом с целью получения значений для элементов матрицы. В настоящем примере осуществления заданная матрица может включать N(N − 1) элементов, а поднабор «влажных» параметров повышающего микширования может включать N(N − 1) коэффициентов. Например, полученные параметры повышающего микширования могут включать не более N(N − 1)/2 независимо присваиваемых «влажных» параметров повышающего микширования, и/или количество «влажных» параметров повышающего микширования может быть не больше половины количества «влажных» параметров повышающего микширования в поднаборе «влажных» параметров повышающего микширования.
В примере осуществления полученные параметры повышающего микширования могут включать (N − 1) «сухих» параметров повышающего микширования. В настоящем примере осуществления поднабор «сухих» параметров повышающего микширования может включать N коэффициентов, и поднабор «сухих» параметров повышающего микширования может определяться на основе полученных (N − 1) «сухих» параметров повышающего микширования и на основе заданной взаимосвязи между коэффициентами в поднаборе «сухих» параметров повышающего микширования. Например, полученные параметры повышающего микширования могут включать не более (N − 1) независимо присваиваемых «сухих» параметров повышающего микширования.
В примере осуществления класс заданных матриц может представлять собой один вариант верхних или нижних треугольных матриц, причем известные характеристики всех матриц в классе включают нулевые элементы заданной матрицы; симметричных матриц, причем известные характеристики всех матриц в классе включают равные элементы заданной матрицы (с обеих сторон главной диагонали); и произведения ортогональной матрицы и диагональной матрицы, причем известные характеристики всех матриц в классе включают известные взаимосвязи между элементами заданной матрицы. Другими словами, класс заданных матриц может быть классом нижних треугольных матриц, классом верхних треугольных матриц, классом симметричных матриц или классом произведений ортогональной матрицы и диагональной матрицы. Общим свойством для каждого из вышеупомянутых классов является то, что их размерность меньше полного количества элементов матрицы.
В примере осуществления заданная матрица и/или класс заданных матриц могут быть связаны с указанным форматом кодирования, за счет чего, например, обеспечивается возможность соответствующей адаптации определения набора «влажных» параметров повышающего микширования в рамках способа декодирования.
В соответствии с примерами осуществления предложен способ декодирования аудио, включающий получение сигнализации, указывающей на одну из по меньшей мере двух заданных конфигураций каналов; осуществление любого из способов декодирования аудио в соответствии с первым аспектом в ответ на обнаружение полученной сигнализации, указывающей на первую заданную конфигурацию каналов. Способ декодирования аудио в ответ на обнаружение полученной сигнализации, указывающей на вторую заданную конфигурацию каналов, может включать получение двухканального сигнала понижающего микширования и ассоциированных параметров повышающего микширования; выполнение параметрической реконструкции первого трехканального аудиосигнала на основе первого канала сигнала понижающего микширования и по меньшей мере некоторых из параметров повышающего микширования; и выполнение параметрической реконструкции второго трехканального аудиосигнала на основе второго канала сигнала понижающего микширования и по меньшей мере некоторых из параметров повышающего микширования.
Первая заданная конфигурация каналов может соответствовать М-канальному аудиосигналу, представленному полученным двухканальным сигналом понижающего микширования и ассоциированными параметрами повышающего микширования. Вторая заданная конфигурация каналов может соответствовать первому и второму трехканальным аудиосигналам, представленным первым и вторым каналами полученного сигнала понижающего микширования соответственно и ассоциированными параметрами повышающего микширования.
Возможность получения сигнализации, указывающей на одну из по меньшей мере двух заданных конфигураций каналов, и выполнения параметрической реконструкции на основе указанной конфигурации каналов может обеспечить использование общего формата для машиночитаемого носителя, содержащего параметрическое представление или М-канального аудиосигнала, или двух трехканальных аудиосигналов, со стороны кодера на стороне декодера.
В соответствии с примерами осуществления предложена система декодирования аудио, содержащая секцию декодирования, выполненную с возможностью реконструкции М-канального аудиосигнала на основе двухканального сигнала понижающего микширования и ассоциированных параметров повышающего микширования, причем M ≥ 4. Система декодирования аудио содержит секцию управления, выполненную с возможностью получения сигнализации, указывающей на выбранный формат из по меньшей мере двух форматов кодирования М-канального аудиосигнала. Форматы кодирования сопоставлены с соответствующими различными разделениями каналов М-канального аудиосигнала на соответствующие первую и вторую группы одного или более каналов. В указанном формате кодирования первый канал сигнала понижающего микширования соответствует линейной комбинации первой группы одного или более каналов М-канального аудиосигнала, а второй канал сигнала понижающего микширования соответствует линейной комбинации второй группы одного или более каналов М-канального аудиосигнала. Секция декодирования содержит секцию преддекорреляции, выполненную с возможностью определения набора преддекорреляционных коэффициентов на основе указанного формата кодирования и вычисления входного сигнала декорреляции как линейного отображения сигнала понижающего микширования, причем к сигналу понижающего микширования применяют набор преддекорреляционных коэффициентов; и секцию декорреляции, выполненную с возможностью создания декоррелированного сигнала на основе входного сигнала декорреляции. Секция декодирования содержит секцию микширования, выполненную с возможностью определения наборов «влажных» и «сухих» коэффициентов повышающего микширования на основе полученных параметров повышающего микширования и указанного формата кодирования; вычисления «сухого» сигнала повышающего микширования как линейного отображения сигнала понижающего микширования, причем к сигналу понижающего микширования применяют набор «сухих» коэффициентов повышающего микширования; вычисления «влажного» сигнала повышающего микширования как линейного отображения декоррелированного сигнала, причем к декоррелированному сигналу применяют набор «влажных» коэффициентов повышающего микширования; и сочетания «сухого» и «влажного» сигналов повышающего микширования для получения многомерного реконструированного сигнала, соответствующего подлежащему реконструкции М-канальному аудиосигналу.
В примере осуществления система декодирования аудио может дополнительно содержать дополнительную секцию декодирования, выполненную с возможностью реконструкции дополнительного М-канального аудиосигнала на основе дополнительного двухканального сигнала понижающего микширования и ассоциированных дополнительных параметров повышающего микширования. Система управления может быть выполнена с возможностью получения сигнализации, указывающей на выбранный формат из по меньшей мере двух форматов кодирования дополнительного М-канального аудиосигнала. Форматы кодирования дополнительного М-канального аудиосигнала могут быть сопоставлены с соответствующими различными разделениями каналов дополнительного М-канального аудиосигнала на соответствующие первую и вторую группы одного или более каналов. В указанном формате кодирования дополнительного М-канального аудиосигнала первый канал дополнительного сигнала понижающего микширования может соответствовать линейной комбинации первой группы одного или более каналов дополнительного М-канального аудиосигнала, а второй канал дополнительного сигнала понижающего микширования может соответствовать линейной комбинации второй группы одного или более каналов дополнительного М-канального аудиосигнала. Дополнительная секция декодирования может содержать дополнительную секцию преддекорреляции, выполненную с возможностью определения дополнительного набора преддекорреляционных коэффициентов на основе указанного формата кодирования дополнительного М-канального аудиосигнала и вычисления дополнительного входного сигнала декорреляции как линейного отображения дополнительного сигнала понижающего микширования, причем к дополнительному сигналу понижающего микширования применяют дополнительный набор преддекорреляционных коэффициентов; и дополнительную секцию декорреляции, выполненную с возможностью создания дополнительного декоррелированного сигнала на основе дополнительного входного сигнала декорреляции. Дополнительная секция декодирования может дополнительно содержать дополнительную секцию микширования, выполненную с возможностью определения дополнительных наборов «влажных» и «сухих» коэффициентов повышающего микширования на основе полученных дополнительных параметров повышающего микширования и указанного формата кодирования дополнительного М-канального аудиосигнала; вычисления дополнительного «сухого» сигнала повышающего микширования как линейного отображения дополнительного сигнала понижающего микширования, при этом к дополнительному сигналу понижающего микширования применяют дополнительный набор «сухих» коэффициентов повышающего микширования; вычисления дополнительного «влажного» сигнала повышающего микширования как линейного отображения дополнительного декоррелированного сигнала, при этом к дополнительному декоррелированному сигналу применяют дополнительный набор «влажных» коэффициентов повышающего микширования; и сочетания дополнительных «сухого» и «влажного» сигналов повышающего микширования для получения дополнительного многомерного реконструированного сигнала, соответствующего подлежащему реконструкции дополнительному М-канальному аудиосигналу.
В настоящем примере осуществления дополнительная секция декодирования, дополнительная секция преддекорреляции, дополнительная секция декорреляции и дополнительная секция микширования могут быть выполнены, например, с возможностью функционирования независимо от секции декодирования, секции преддекорреляции, секции декорреляции и секции микширования.
В настоящем примере осуществления дополнительная секция декодирования, дополнительная секция преддекорреляции, дополнительная секция декорреляции и дополнительная секция микширования могут быть, например, функционально эквивалентными секции декодирования, секции преддекорреляции, секции декорреляции и секции микширования соответственно (или выполненными по аналогии с ними). В альтернативном варианте осуществления по меньшей мере одна из дополнительной секции декодирования, дополнительной секции преддекорреляции, дополнительной секции декорреляции и дополнительной секции микширования могут быть выполнены, например, с возможностью осуществления по меньшей мере одного типа интерполяции, отличающегося от осуществляемого секцией декодирования, секцией преддекорреляции, секцией декорреляции и секцией микширования.
Например, полученная сигнализация может указывать на разные форматы кодирования для М-канального аудиосигнала и дополнительного М-канального аудиосигнала. В альтернативном варианте осуществления форматы кодирования М-канальных аудиосигналов могут, например, всегда совпадать, а полученная сигнализация может указывать на выбранный формат из по меньшей мере двух общих форматов кодирования для двух М-канальных аудиосигналов.
Интерполяционные схемы, используемые для постепенных переходов между преддекорреляционными коэффициентами в ответ на переключение между форматами кодирования М-канального аудиосигнала, могут совпадать с интерполяционными схемами, используемыми для постепенных переходов между дополнительными преддекорреляционными коэффициентами в ответ на переключение между форматами кодирования дополнительного М-канального аудиосигнала, или могут отличаться от этих схем.
Аналогично интерполяционные схемы, используемые для интерполяции значений «влажных» и «сухих» коэффициентов повышающего микширования в ответ на переключение между форматами кодирования М-канального аудиосигнала, могут совпадать с интерполяционными схемами, используемыми для интерполяции значений дополнительных «влажных» и «сухих» коэффициентов повышающего микширования в ответ на переключение между форматами кодирования дополнительного М-канального аудиосигнала, или могут отличаться от этих схем.
В примере осуществления система декодирования аудио может дополнительно содержать демультиплексор, выполненный с возможностью извлечения из битового потока сигнала понижающего микширования, параметров повышающего микширования, ассоциированных с сигналом понижающего микширования, и дискретно-кодированного аудиоканала. Система декодирования может дополнительно содержать одноканальную секцию декодирования, выполненную с возможностью декодирования дискретно-кодированного аудиоканала. Дискретно-кодированный аудиоканал может быть, например, кодированным в битовом потоке при помощи перцептуального аудиокодека, такого как Dolby Digital, MPEG AAC или их производных, а одноканальная секция декодирования может содержать, например, базовый декодер для декодирования дискретно-кодированного аудиоканала. Одноканальная секция декодирования может быть, например, выполнена с возможностью декодирования дискретно-кодированного аудиоканала независимо от секции декодирования.
В соответствии с примерами осуществления предложен компьютерный программный продукт, содержащий машиночитаемый носитель с командами, для осуществления любого из способов по первому аспекту.
II. Обзор. Сторона кодера
В соответствии со вторым аспектом в примерах осуществления предложены системы кодирования аудио, а также способы кодирования аудио и ассоциированные компьютерные программные продукты. Предлагаемые системы кодирования, способы и компьютерные программные продукты в соответствии со вторым аспектом могут по существу иметь одни и те же общие возможности и преимущества. Более того, представленные выше преимущества для признаков систем кодирования, способов и компьютерных программных продуктов в соответствии с первым аспектом могут быть по существу действительными и для соответствующих признаков систем кодирования, способов и компьютерных программных продуктов в соответствии со вторым аспектом.
В соответствии с примерами осуществления предложен способ кодирования аудио, включающий получение М-канального аудиосигнала, для которого M ≥ 4. Способ кодирования аудио включает повторяющийся выбор одного формата из по меньшей мере двух форматов кодирования на основе любого подходящего критерия выбора, например характеристик сигнала, загрузки системы, предпочтений пользователя, условий сети. Выбор можно повторять один раз для каждого временного интервала аудиосигнала или один раз для каждого n-го временного интервала, что может привести к выбору другого формата по сравнению с изначально выбранным; в альтернативном варианте осуществления выбор может управляться событиями. Форматы кодирования сопоставлены с соответствующими различными разделениями каналов М-канального аудиосигнала на соответствующие первую и вторую группы одного или более каналов. В каждом из форматов кодирования двухканальный сигнал понижающего микширования включает первый канал, образованный в виде линейной комбинации первой группы одного или более каналов М-канального аудиосигнала, и второй канал, образованный в виде линейной комбинации второй группы одного или более каналов М-канального аудиосигнала. Для выбранного формата кодирования канал понижающего микширования вычисляют на основе М-канального аудиосигнала. После вычисления сигнала понижающего микширования выбранного в данный момент формата кодирования осуществляют вывод сигнализации, указывающей выбранный в данный момент формат кодирования, и дополнительной информации, в результате чего обеспечивается возможность параметрической реконструкции М-канального аудиосигнала. Если выбор приводит к переключению первого выбранного формата кодирования на второй (отличающийся) выбранный формат кодирования, может быть запущен переход, в результате чего осуществляют вывод плавного перехода сигнала понижающего микширования в соответствии с первым выбранным форматом кодирования и сигнала понижающего микширования в соответствии со вторым выбранным форматом кодирования. В данном случае плавный переход может представлять собой линейную или нелинейную интерполяцию двух сигналов. Например, выражение
y(t) = tx1(t) + (1 − t)x2(t), t ∈ [0,1]
обеспечивает плавный переход y от функции x2 к функции x1 с линейной зависимостью от времени, причем x1, x2 могут представлять собой векторнозначные функции времени, представляющие сигналы понижающего микширования в соответствии с соответствующими форматами кодирования. Для упрощения изображения масштаб временного интервала, на котором осуществляется плавный переход, был изменен на [0, 1], где t = 0 представляет начало плавного перехода, а t = 1 представляет момент времени, когда плавный переход завершен.
Местоположение моментов t = 0 и t = 1 в физических единицах может быть важно для воспринимаемого выходного качества реконструированного аудио. В качестве рекомендации по расположению плавного перехода: его начало может находиться как можно раньше после определения необходимости изменения формата, и/или завершение плавного перехода может происходить за максимально возможно короткое время, чтобы это было незаметно для восприятия. Таким образом, для вариантов реализации, в которых выбор формата кодирования повторяют в каждый временной интервал, в соответствии с некоторыми примерами осуществления плавный переход начинают (t = 0) в начале временного интервала, а точку завершения плавного перехода (t = 1) располагают как можно ближе, но при этом достаточно далеко так, чтобы среднестатистический слушатель не смог различить искажения или ухудшения из-за перехода между двумя реконструкциями общего М-канального аудиосигнала (с обычным содержимым) на основе двух отличающихся форматов кодирования. В одном примере осуществления сигнал понижающего микширования, выводимый в рамках способа кодирования аудио, сегментируют на временные интервалы, и плавный переход может занимать один интервал. В другом примере осуществления сигнал понижающего микширования, выводимый в рамках способа кодирования аудио, сегментируют на перекрывающиеся временные интервалы, и длительность плавного перехода соответствует шагу от одного временного интервала до другого.
В примерах осуществления сигнализация, указывающая на выбранный в данный момент формат кодирования, может быть кодирована на основе следующих друг за другом временных интервалов. В альтернативном варианте осуществления сигнализация может быть дифференцирована по времени в том смысле, что такую сигнализацию можно не активировать на одном или более последовательных временных интервалах, если не происходит изменения выбранного формата кодирования. На стороне декодера такая последовательность временных интервалов может быть интерпретирована так, что выбранным остается самый недавний сигнализируемый формат кодирования.
В зависимости от аудиоданных М-канального аудиосигнала для захвата и эффективного кодирования М-канального аудиосигнала и сохранения достоверности при реконструкции этого сигнала из сигнала понижающего микширования и ассоциированных параметров повышающего микширования могут подходить различные разделения каналов М-канального аудиосигнала на первую и вторую группы, представленные соответствующими каналами сигнала понижающего микширования. Следовательно, достоверность реконструированного М-канального аудиосигнала можно повысить путем выбора подходящего формата кодирования, а именно — лучше всего подходящего из числа заданных форматов кодирования.
В примере осуществления дополнительная информация включает «сухие» и «влажные» коэффициенты повышающего микширования в том же смысле, как эти термины были употреблены в настоящей заявке выше. Если речь не идет о задачах особой реализации, обычно достаточно вычислить дополнительную информацию (в частности, «сухие» и «влажные» коэффициенты повышающего микширования) для выбранного в данный момент формата кодирования. В частности, набор «сухих» коэффициентов повышающего микширования (которые могут быть представлены в виде матрицы размерностью M × 2) может задавать линейное отображение соответствующего сигнала понижающего микширования, аппроксимирующего М-канальный аудиосигнал. Набор «влажных» коэффициентов повышающего микширования (которые могут быть представлены в виде матрицы размерностью M × P, где количество декорреляторов P может составлять P = M − 2) определяет линейное отображение декоррелированного сигнала, так что ковариация сигнала, полученного путем указанного линейного отображения декоррелированного сигнала, дополняет ковариацию М-канального аудиосигнала, аппроксимированного путем линейного отображения сигнала понижающего микширования выбранного формата кодирования. Отображение декоррелированного сигнала, который определяется набором «влажных» коэффициентов повышающего микширования, дополнит ковариацию М-канального (аппроксимированного) аудиосигнала в том смысле, что ковариация суммы М-канального аудиосигнала и отображения декоррелированного сигнала обычно ближе к ковариации полученного М-канального аудиосигнала. Эффект от введения дополнительной ковариации может заключаться в увеличении достоверности реконструированного сигнала на стороне декодера.
Линейное отображение сигнала понижающего микширования обеспечивает аппроксимацию М-канального аудиосигнала. При реконструкции М-канального аудиосигнала на стороне декодера декоррелированный сигнал используют для увеличения размерности аудиоданных сигнала понижающего микширования, и сигнал, полученный путем линейного отображения декоррелированного сигнала, объединяют с сигналом, полученным путем линейного отображения сигнала понижающего микширования, для увеличения достоверности аппроксимации М-канального аудиосигнала. Поскольку декоррелированный сигнал определяют на основе по меньшей мере одного канала сигнала понижающего микширования и декоррелированный сигнал не содержит каких-либо аудиоданных от М-канального аудиосигнала, который еще не доступен в сигнале понижающего микширования, разность между ковариацией полученного М-канального аудиосигнала и ковариацией М-канального аудиосигнала, аппроксимированного путем линейного отображения сигнала понижающего микширования, может указывать не только на достоверность М-канального аудиосигнала, аппроксимированного путем линейного отображения сигнала понижающего микширования, но и на достоверность М-канального аудиосигнала, реконструированного при помощи как сигнала понижающего микширования, так и декоррелированного сигнала. В частности, уменьшенная разность между ковариацией полученного М-канального аудиосигнала и ковариацией М-канального аудиосигнала, аппроксимированного путем линейного отображения сигнала понижающего микширования, может указывать на увеличенную достоверность реконструированного М-канального аудиосигнала. Отображение декоррелированного сигнала, который задается набором «влажных» коэффициентов повышающего микширования, дополняет ковариацию М-канального аудиосигнала (полученного из сигнала понижающего микширования) в том смысле, что ковариация суммы М-канального аудиосигнала и отображения декоррелированного сигнала ближе к ковариации полученного М-канального аудиосигнала. Следовательно, выбор одного из форматов кодирования на основе соответствующих вычисленных разностей позволяет увеличить достоверность реконструированного М-канального аудиосигнала.
Следует понимать, что формат кодирования можно выбрать, например, непосредственно на основе вычисленных разностей или на основе коэффициентов и/или значений, определенных на основе вычисленных разностей.
Кроме того, следует понимать, что формат кодирования можно выбрать, например, на основе соответствующих вычисленных «сухих» коэффициентов повышающего микширования дополнительно к соответствующим вычисленным разностям.
Набор «сухих» коэффициентов повышающего микширования может определяться, например, посредством аппроксимации по минимальной среднеквадратической ошибке при допущении, что для реконструкции доступен только сигнал понижающего микширования, т. е. при допущении, что для реконструкции не используется декоррелированный сигнал.
Вычисленные разности могут представлять собой, например, разности между полученной ковариационной матрицей М-канального аудиосигнала и ковариационными матрицами М-канального аудиосигнала, аппроксимированного путем соответствующих линейных отображений сигнала понижающего микширования разных форматов кодирования. Выбор одного из форматов кодирования может включать, например, вычисление матричных норм для соответствующих разностей между ковариационными матрицами и выбор одного из форматов кодирования на основе вычисленных матричных норм, например, выбор формата кодирования, связанного с минимальной из вычисленных матричных норм.
Декоррелированный сигнал может, например, включать по меньшей мере один канал и не более M − 2 каналов.
Под набором «сухих» коэффициентов повышающего микширования, определяющим линейное отображение сигнала понижающего микширования, аппроксимирующее М-канальный сигнал понижающего микширования, подразумевается, что аппроксимацию М-канального сигнала понижающего микширования осуществляют путем линейного преобразования сигнала понижающего микширования. При этом линейном преобразовании в качестве входа берут два канала сигнала понижающего микширования и обеспечивают M каналов в качестве выхода, а «сухие» коэффициенты повышающего микширования представляют собой коэффициенты, определяющие количественные характеристики этого линейного преобразования.
Аналогично «влажные» параметры повышающего микширования определяют количественные характеристики линейного преобразования, при котором каналы (-ы) декоррелированного сигнала берут в качестве входа и обеспечивают M каналов в качестве выхода.
В примере осуществления «влажные» параметры повышающего микширования могут определяться так, чтобы ковариация сигнала, полученного путем линейного отображения (которое задается «влажными» параметрами повышающего микширования) декоррелированного сигнала, аппроксимировала разность между ковариацией полученного М-канального аудиосигнала и ковариацией М-канального аудиосигнала, аппроксимированного путем линейного отображения сигнала понижающего микширования выбранного формата кодирования. Другими словами, ковариация суммы первого линейного отображения (определенного «сухими» параметрами повышающего микширования) сигнала понижающего микширования и второго линейного отображения (определенного «влажными» параметрами повышающего микширования, определенными в соответствии с этим примером осуществления) декоррелированного сигнала будет близка к ковариации М-канального аудиосигнала, выражающей входные данные для способа кодирования аудио, описанного выше в настоящей заявке. Определение «влажных» коэффициентов повышающего микширования в соответствии с настоящим примером осуществления может увеличить достоверность реконструированного М-канального аудиосигнала.
В альтернативном варианте осуществления «влажные» параметры повышающего микширования могут определяться так, чтобы ковариация сигнала, полученного путем линейного отображения декоррелированного сигнала, аппроксимировала часть разности между ковариацией полученного М-канального аудиосигнала и ковариацией М-канального аудиосигнала, аппроксимированного путем линейного отображения сигнала понижающего микширования выбранного формата кодирования. Если, например, на стороне декодера доступно ограниченное количество декорреляторов, полное восстановление ковариации полученного М-канального аудиосигнала может быть невозможно. В таком примере на стороне кодера могут определяться «влажные» параметры повышающего микширования, подходящие для частичной реконструкции ковариации М-канального аудиосигнала, с использованием меньшего количества декорреляторов.
В примере осуществления способ кодирования аудио может дополнительно включать для каждого из по меньшей мере двух форматов кодирования определение набора «влажных» коэффициентов повышающего микширования, которые вместе с «сухими» коэффициентами повышающего микширования (этого формата кодирования) позволяют осуществлять параметрическую реконструкцию М-канального аудиосигнала из сигнала понижающего микширования (этого формата кодирования) и из декоррелированного сигнала, определенного на основе сигнала понижающего микширования (этого формата), причем набор «влажных» коэффициентов повышающего микширования задает линейное отображение декоррелированного сигнала так, чтобы ковариация сигнала, полученного путем линейного отображения декоррелированного сигнала, аппроксимировала разность между ковариацией полученного М-канального аудиосигнала и ковариацией М-канального аудиосигнала, аппроксимированного путем линейного отображения сигнала понижающего микширования (этого формата). В настоящем примере осуществления выбранный формат кодирования можно выбирать на основе значений соответствующих определенных наборов «влажных» коэффициентов повышающего микширования.
Указание на достоверность реконструированного М-канального аудиосигнала можно получить, например, на основе определенных «влажных» коэффициентов повышающего микширования. Выбор формата кодирования может быть основан, например, на взвешенных или невзвешенных суммах определенных «влажных» коэффициентов повышающего микширования, на взвешенных или невзвешенных суммах модулей определенных «влажных» коэффициентов повышающего микширования и/или на взвешенных или невзвешенных суммах квадратов определенных «влажных» коэффициентов повышающего микширования, кроме того, например, на соответствующих суммах соответствующих вычисленных «сухих» коэффициентов повышающего микширования.
«Влажные» параметры повышающего микширования могут, например, вычисляться для множества полос частот М-канального сигнала, а выбор формата кодирования может быть основан, например, на значениях соответствующих определенных наборов «влажных» коэффициентов повышающего микширования в соответствующих полосах частот.
В примере осуществления переход между первым и вторым форматами кодирования включает вывод дискретных значений «сухих» и «влажных» коэффициентов повышающего микширования первого формата кодирования на одном временном интервале и второго формата кодирования — на последующем временном интервале. Функции декодера, в конечном итоге обеспечивающие реконструкцию М-канального сигнала, могут включать интерполяцию коэффициентов повышающего микширования между выводимыми дискретными значениями. Благодаря таким функциям на стороне декодера можно эффективно обеспечить плавный переход от первого формата кодирования ко второму. Как и в случае плавного перехода, используемого для сигнала понижающего микширования, как описано выше, такой плавный переход может приводить к меньшей вероятности восприятия перехода между форматами кодирования при реконструкции М-канального аудиосигнала.
Понятно, что коэффициенты, используемые для вычисления сигнала понижающего микширования на основе М-канального аудиосигнала, можно интерполировать, т. е. от значений, связанных с временным интервалом, на котором вычисляют сигнал понижающего микширования в соответствии с первым форматом кодирования, до значений, связанных с временным интервалом, на котором вычисляют сигнал понижающего микширования в соответствии со вторым форматом кодирования. По меньшей мере если понижающее микширование происходит во временной области, плавный переход понижающего микширования в результате интерполяции коэффициентов будет эквивалентен плавному переходу понижающего микширования в результате интерполяции коэффициентов, выполненной непосредственно в отношении соответствующих сигналов понижающего микширования. Следует понимать, что значения коэффициентов, использованные для вычисления сигнала понижающего микширования, обычно не зависят от сигналов, но могут задаваться для каждого из доступных форматов кодирования.
Если говорить о плавном переходе сигнала понижающего микширования и коэффициентах повышающего микширования, преимущество заключается в том, что обеспечивается синхронизация между двумя плавными переходами. Предпочтительно возможно совпадение соответствующих периодов переходов для сигнала понижающего микширования и коэффициентов повышающего микширования. В частности, средства, отвечающие за соответствующие плавные переходы, могут контролироваться общим потоком данных управления. Такие данные управления могут включать точки начала и точки завершения плавного перехода и необязательно кривую плавного перехода, такую как линейная, нелинейная кривая и т. д. Относительно коэффициентов повышающего микширования кривая плавного перехода может быть установлена заданным правилом интерполяции, которое определяет режим устройства декодирования; однако точки начала и завершения плавных переходов могут контролироваться опосредованно по положениям, в которых заданы и/или выведены дискретные значения коэффициентов повышающего микширования. Сходство временной зависимости двух процессов плавных переходов обеспечивает высокую степень соответствия между сигналом понижающего микширования и параметрами, обеспеченными для его реконструкции, что может привести к уменьшению искажений на стороне декодера.
В примере осуществления выбор формата кодирования основан на сравнении разности ковариаций полученного М-канального сигнала и реконструированного М-канального сигнала по сигналу понижающего микширования. В частности, реконструкция может совпадать с линейным отображением сигнала понижающего микширования, определенным только «сухими» коэффициентами повышающего микширования, т. е. без вклада от сигнала, определенного при помощи декорреляции (например, для увеличения размерности аудиоданных сигнала понижающего микширования). В частности, при сравнении не должен учитываться какой-либо вклад линейного отображения, определенного каким-либо набором «влажных» коэффициентов повышающего микширования. Другими словами, сравнение осуществляют при условии отсутствия доступа к декоррелированному сигналу. Этот принцип может способствовать выбору формата кодирования, который обеспечивает возможность более точного воспроизведения. После выполнения этого сравнения и принятия решения о выборе формата кодирования необязательно определяется набор «влажных» коэффициентов повышающего микширования. Связанное с этим процессом преимущество заключается в том, что не происходит двойного определения «влажных» коэффициентов повышающего микширования для конкретной части полученного М-канального аудиосигнала.
В соответствии с модификацией примера осуществления, описанного в предыдущем параграфе, «сухие» и «влажные» коэффициенты повышающего микширования вычисляют для всех форматов кодирования, а в качестве основы для выбора формата кодирования используют количественную меру «влажных» коэффициентов повышающего микширования. Действительно, количественная характеристика, вычисленная на основе определенных «влажных» коэффициентов повышающего микширования, может обеспечивать (инверсное) указание на достоверность реконструированного М-канального аудиосигнала. Выбор формата кодирования может быть основан, например, на взвешенных или невзвешенных суммах определенных «влажных» коэффициентов повышающего микширования, на взвешенных или невзвешенных суммах модулей определенных «влажных» коэффициентов повышающего микширования и/или на взвешенных или невзвешенных суммах квадратов определенных «влажных» коэффициентов повышающего микширования. Каждый из этих вариантов можно использовать в сочетании с соответствующими суммами соответствующих вычисленных «сухих» коэффициентов повышающего микширования. «Влажные» параметры повышающего микширования могут, например, вычисляться для множества полос частот М-канального сигнала, а выбор формата кодирования может быть основан, например, на значениях соответствующих определенных наборов «влажных» коэффициентов повышающего микширования в соответствующих полосах частот.
В примере осуществления способ кодирования аудио может дополнительно включать вычисление суммы квадратов соответствующих «влажных» коэффициентов повышающего микширования и суммы квадратов соответствующих «сухих» коэффициентов повышающего микширования для каждого из по меньшей мере двух форматов кодирования. В настоящем примере осуществления выбранный формат кодирования можно выбирать на основе сумм квадратов. Авторы изобретения обнаружили, что вычисленные суммы квадратов могут обеспечивать особенно точное указание на уменьшение достоверности при восприятии слушателем, которое будет происходить при реконструкции М-канального аудиосигнала на основе смешанного вклада сигналов при «влажных» и «сухих» параметрах.
Например, для каждого формата кодирования может создаваться отношение на основе вычисленных сумм квадратов для соответствующего формата кодирования, и выбранный формат может быть связан с минимальным или максимальным из созданных отношений. Создание отношения может включать, например, деление, с одной стороны, суммы квадратов «влажных» коэффициентов повышающего микширования на, с другой стороны, сумму суммы квадратов «сухих» коэффициентов повышающего микширования и суммы квадратов «влажных» коэффициентов повышающего микширования. В альтернативном варианте осуществления отношение может создаваться путем деления суммы квадратов «влажных» коэффициентов повышающего микширования на сумму квадратов «сухих» коэффициентов повышающего микширования.
В примере осуществления в способе предложено кодирование М-канального аудиосигнала и по меньшей мере одного связанного (M2-канального) аудиосигнала. Аудиосигналы могут быть связаны в том смысле, что могут описывать общие аудиоданные, например, когда записаны одновременно или сформированы в ходе одного и того же процесса создания аудиоданных. Аудиосигналы необязательно кодировать с помощью общего сигнала понижающего микширования, их можно кодировать с помощью отдельных процессов. При таких параметрах выбор одного из форматов кодирования дополнительно учитывает данные, относящиеся к указанному по меньшей мере одному дополнительному аудиоканалу, и формат кодирования, таким образом, выбирают с целью использования для кодирования как М-канального аудиосигнала, так и связанного (M2-канального) аудиосигнала.
В примере осуществления сигнал понижающего микширования, выводимый посредством способа кодирования аудио, можно сегментировать с разделением на временные интервалы, выбор формата кодирования может осуществляться один раз за временной интервал, и выбранный формат кодирования может поддерживаться для по меньшей мере заданного количества временных интервалов до выбора другого формата кодирования. Выбор формата кодирования для временного интервала может осуществляться любым из способов, например путем рассмотрения разностей между ковариациями, рассмотрения значений «влажных» коэффициентов повышающего микширования для доступных форматов кодирования и т. п. Поддерживание выбранного формата кодирования для минимального количества временных интервалов может позволить, например, избежать повторяющихся переключений между форматами кодирования. В настоящем примере осуществления можно, например, обеспечить улучшение качества воспроизведения реконструированного М-канального аудиосигнала при восприятии слушателем.
Минимальное количество временных интервалов может составлять, например, 10.
Полученный М-канальный аудиосигнал, например, можно буферизировать для минимального количества временных интервалов, а выбор формата кодирования может осуществляться, например, на основе мажоритарного решения по движущемуся окну, содержащему некоторое количество временных интервалов, выбранных с учетом указанного минимального количества временных интервалов, чтобы поддерживался выбранный формат кодирования. Реализация такой стабилизирующей функции может включать один из множества сглаживающих фильтров, в частности сглаживающие фильтры с конечной импульсной характеристикой, известные в области обработки цифровых сигналов. В качестве альтернативы этому подходу формат кодирования можно переключать на новый формат кодирования при обнаружении того, что для указанного минимального количества временных интервалов по порядку выбран новый формат кодирования. Для реализации этого критерия движущееся временное окно с минимальным количеством последовательных временных интервалов можно применить к прошлым выборам формата кодирования, например для буферизированных временных интервалов. Если после последовательности временных интервалов первого формата кодирования для каждого временного интервала в движущемся окне остался выбранным второй формат кодирования, то подтверждают переход ко второму формату кодирования, который вступает в действие от начала движущегося окна и далее. Реализация вышеупомянутой стабилизирующей функции может содержать конечный автомат.
В примере осуществления предложено компактное представление «сухих» и «влажных» параметров повышающего микширования, которое помимо прочего включает создание промежуточной матрицы, которая за счет принадлежности к классу заданных матриц уникальным образом определена меньшим количеством параметров по сравнению с количеством элементов в матрице. Аспекты этого компактного представления были описаны выше в настоящем описании и, в частности, со ссылкой на предварительную заявку на патент США № 61/974,544, автор, чье имя указано первым: Lars Villemoes; дата подачи: 3 апреля 2014 г.
В примере осуществления в выбранном формате кодирования первая группа из одного или более каналов М-канального аудиосигнала может состоять из N каналов, где N ≥ 3. Для первой группы из одного или более каналов может быть характерна возможность реконструкции из первого канала сигнала понижающего микширования и N − 1 каналов декоррелированного сигнала путем применения по меньшей мере «влажных» и «сухих» коэффициентов повышающего микширования.
В настоящем примере осуществления определение набора «сухих» коэффициентов повышающего микширования выбранного формата кодирования может включать определение поднабора «сухих» коэффициентов повышающего микширования выбранного формата кодирования для определения линейного отображения первого канала сигнала понижающего микширования выбранного формата кодирования для аппроксимации первой группы из одного или более каналов выбранного формата кодирования.
В настоящем примере осуществления определение набора «влажных» коэффициентов повышающего микширования выбранного формата кодирования может включать определение промежуточной матрицы на основе разности между ковариацией первой группы из полученных одного или более каналов выбранного формата кодирования и ковариацией первой группы из одного или более каналов выбранного формата кодирования, аппроксимированных путем линейного отображения первого канала сигнала понижающего микширования выбранного формата кодирования. Произведение промежуточной матрицы и заданной матрицы может соответствовать поднабору «влажных» коэффициентов повышающего микширования выбранного формата кодирования, в результате чего определяется линейное отображение N − 1 каналов декоррелированного сигнала как часть параметрической реконструкции первой группы из одного или более каналов выбранного формата кодирования. Поднабор «влажных» коэффициентов повышающего микширования выбранного формата кодирования может включать большее количество коэффициентов по сравнению с количеством элементов в промежуточной матрице.
В настоящем примере осуществления выходные параметры повышающего микширования могут включать набор параметров повышающего микширования первого типа, называемых в настоящей заявке «сухими» параметрами повышающего микширования, из которого можно выделить поднабор «сухих» параметров повышающего микширования, и набор параметров повышающего микширования второго типа, называемых в настоящей заявке «влажными» параметрами повышающего микширования, которые уникальным образом определяют промежуточную матрицу, при условии, что она принадлежит к классу заданных матриц. Промежуточная матрица может иметь больше элементов по сравнению с количеством элементов в поднаборе «влажных» параметров повышающего микширования выбранного формата кодирования.
В настоящем примере осуществления копия параметрической реконструкции первой группы из одного или более каналов на стороне декодера включает, в качестве одного вклада, «сухой» сигнал повышающего микширования, сформированный в результате линейного отображения первого канала сигнала понижающего микширования, и, в качестве дополнительного вклада, «влажный» сигнал повышающего микширования, сформированный в результате линейного отображения N − 1 каналов декоррелированного сигнала. Поднабор «сухих» коэффициентов повышающего микширования определяет линейное отображение первого канала сигнала понижающего микширования, а поднабор «влажных» коэффициентов повышающего микширования определяет линейное отображение декоррелированного сигнала. В результате выдачи «влажных» параметров повышающего микширования, количество которых меньше количества коэффициентов в поднаборе «влажных» коэффициентов повышающего микширования и из которых можно выделить поднабор «влажных» коэффициентов повышающего микширования на основе заданной матрицы и класса заданных матриц, можно уменьшить количество информации, переданной на сторону декодера для обеспечения возможности реконструкции М-канального аудиосигнала. Уменьшение количества данных, необходимых для параметрической реконструкции, позволяет уменьшить требуемую полосу пропускания для передачи параметрического представления М-канального аудиосигнала и/или требуемое пространство для хранения такого представления.
Промежуточную матрицу можно определить, например, так, чтобы ковариация сигнала, полученного путем линейного отображения N − 1 каналов декоррелированного сигнала, дополняла ковариацию первой группы из одного или более каналов, аппроксимированных путем линейного отображения первого канала сигнала понижающего микширования.
Определение и использование заданной матрицы и класса заданных матриц более подробно описаны в вышеупомянутой предварительной заявке на патент США № 61/974,544 со строки 15 на странице 16 до строки 2 на странице 20. В частности, в качестве примеров заданной матрицы см. выражение (9) в вышеупомянутом документе.
В примере осуществления определение промежуточной матрицы может включать такое определение промежуточной матрицы, при котором ковариация сигнала, полученного путем линейного отображения N − 1 каналов декоррелированного сигнала, определенного поднабором «влажных» коэффициентов повышающего микширования, аппроксимирует разность между ковариацией первой группы из полученных одного или более каналов и ковариацией первой группы из одного или более каналов, аппроксимированных путем линейного отображения первого канала сигнала понижающего микширования, или по существу совпадает с этой разностью. Другими словами, промежуточная матрица может определяться так, чтобы копия реконструкции первой группы из одного или более каналов, полученных как сумма «сухого» сигнала повышающего микширования, образованного путем линейного отображения первого канала сигнала понижающего микширования, и «влажного» сигнала повышающего микширования, образованного путем линейного отображения N − 1 каналов декоррелированного сигнала полностью или по меньшей мере приблизительно, восстанавливала ковариацию первой группы полученного одного или более каналов.
В примере осуществления «влажные» параметры повышающего микширования могут включать не более N(N − 1)/2 независимо присваиваемых «влажных» параметров повышающего микширования. В настоящем примере осуществления промежуточная матрица может иметь (N − 1)2 элементов матрицы и может уникальным образом определяться «влажными» параметрами повышающего микширования при условии, что промежуточная матрица относится к классу заданных матриц. В настоящем примере осуществления поднабор «влажных» коэффициентов повышающего микширования может включать N(N − 1) коэффициентов.
В примере осуществления поднабор «сухих» коэффициентов повышающего микширования может включать N коэффициентов. В настоящем примере осуществления «сухие» параметры повышающего микширования могут включать не более N − 1 «сухих» параметров повышающего микширования, а поднабор «сухих» коэффициентов повышающего микширования можно выделить из N − 1 «сухих» параметров повышающего микширования при помощи заданного правила.
В примере осуществления определенный поднабор «сухих» коэффициентов повышающего микширования может определять линейное отображение первого канала сигнала понижающего микширования, соответствующее аппроксимации по минимальной среднеквадратической ошибке первой группы из одного или более каналов, т. е. по набору линейных отображений первого канала сигнала понижающего микширования, причем определенный набор «сухих» коэффициентов повышающего микширования может определять линейное отображение, которое наилучшим образом аппроксимирует первую группу из одного или более каналов при минимальной среднеквадратической ошибке.
В примере осуществления предложена система кодирования аудио, содержащая секцию кодирования, выполненную с возможностью кодирования М-канального аудиосигнала в виде двухканального аудиосигнала и ассоциированных параметров повышающего микширования, причем M ≥ 4. Секция кодирования содержит секцию понижающего микширования, выполненную с возможностью вычисления двухканального сигнала понижающего микширования на основе М-канального аудиосигнала для по меньшей мере одного из по меньшей мере двух форматов кодирования, сопоставленных с различными разделениями каналов М-канального аудиосигнала на соответствующие первую и вторую группы из одного или более каналов, в соответствии с форматом кодирования. Первый канал сигнала понижающего микширования образован в виде линейной комбинации первой группы из одного или более каналов М-канального аудиосигнала, а второй канал сигнала понижающего микширования образован в виде линейной комбинации второй группы из одного или более каналов М-канального аудиосигнала.
Система кодирования аудио дополнительно содержит секцию управления, выполненную с возможностью выбора одного из форматов кодирования на основе любого подходящего критерия, например характеристик сигнала, загрузки системы, предпочтений пользователя, условий сети. Система кодирования аудио дополнительно содержит интерполятор понижающего микширования, выполненный с возможностью осуществления плавных переходов сигнала понижающего микширования между двумя форматами кодирования при запросе перехода со стороны секции управления. Во время такого перехода можно вычислить сигналы понижающего микширования для обоих форматов кодирования. Дополнительно к выдаче сигнала понижающего микширования или, когда применимо, к осуществлению его плавного перехода система кодирования аудио выполнена с возможностью выдачи по меньшей мере сигнализации, указывающей на выбранный в данный момент формат кодирования, и дополнительной информации, в результате чего обеспечивается возможность параметрической реконструкции М-канального аудиосигнала на основе сигнала понижающего микширования. Если система содержит множество секций кодирования, которые работают параллельно, например, для кодирования соответствующих групп аудиоканалов, то секция управления может быть реализована с возможностью независимой от каждой из них работы и может отвечать за выбор общего формата кодирования, который будет использоваться каждой из секций кодирования.
В примере осуществления предложен компьютерный программный продукт, содержащий машиночитаемый носитель с командами, для осуществления любого из способов, описанных в данном разделе.
III. Примеры осуществления
На Фиг. 6–8 представлены альтернативные варианты разделения 11.1-канального аудиосигнала на группы каналов для параметрического кодирования 11.1-канального аудиосигнала в виде 5.1-канального аудиосигнала. 11.1-канальный аудиосигнал содержит каналы L (левый), LS (левый боковой), LB (левый тыловой), TFL (верхний фронтальный левый), TBL (верхний тыловой левый), R (правый), RS (правый боковой), RB (правый тыловой), TFR (верхний фронтальный правый), TBR (верхний тыловой правый), C (центральный) и LFE (канал низкочастотных эффектов). Пять каналов L, LS, LB, TFL и TBL образуют пятиканальный аудиосигнал, представляющий в среде воспроизведения 11.1-канального аудиосигнала левую половину пространства. Три канала L, LS и LB представляют в среде воспроизведения разные горизонтальные направления, а два канала TFL и TBL представляют направления, отделенные по вертикали от трех каналов L, LS и LB. Два канала TFL и TBL могут быть предназначены, например, для воспроизведения в потолочных громкоговорителях. Аналогично пять каналов R, RS, RB, TFR и TBR образуют дополнительный пятиканальный аудиосигнал, представляющий в среде воспроизведения правую половину, причем три канала R, RS и RB представляют в среде воспроизведения разные горизонтальные направления, а два канала TFR и TBR представляют направления, отделенные по вертикали от трех каналов R, RS и RB.
Для представления 11.1-канального аудиосигнала в виде 5.1-канального аудиосигнала набор каналов L, LS, LB, TFL, TBL, R, RS, RB, TFR, TBR, C и LFE можно разделить на группы каналов, представленные соответствующими каналами понижающего микширования и ассоциированными параметрами повышающего микширования. Пятиканальный аудиосигнал L, LS, LB, TFL, TBL может быть представлен двухканальным сигналом понижающего микширования L1, L2 и ассоциированными параметрами повышающего микширования, а пятиканальный аудиосигнал R, RS, RB, TFR, TBR может быть представлен дополнительным двухканальным сигналом понижающего микширования R1, R2 и ассоциированными дополнительными параметрами повышающего микширования. Каналы C и LFE также можно разделить в 5.1-канальном представлении 11.1-канального аудиосигнала.
На Фиг. 6 представлен первый формат кодирования F1, в котором пятиканальный аудиосигнал L, LS, LB, TFL, TBL разделен на первую группу 601 каналов L, LS, LB и вторую группу 602 каналов TFL, TBL и в котором дополнительный пятиканальный аудиосигнал R, RS, RB, TFR, TBR разделен на дополнительную первую группу 603 каналов R, RS, RB и дополнительную вторую группу 604 каналов TFR, TBR. В первом формате кодирования F1 первая группа 601 каналов представлена первым каналом L1 двухканального сигнала понижающего микширования, а вторая группа 602 каналов представлена вторым каналом L2 двухканального сигнала понижающего микширования. Первый канал L1 сигнала понижающего микширования может соответствовать сумме каналов первой группы 601, т. е. L1 = L + LS + LB, а второй канал L2 сигнала понижающего микширования может соответствовать сумме каналов второй группы 602, т. е. L2 = TFL + TBL.
В примерах осуществления масштаб некоторых или всех каналов можно изменить до суммирования так, чтобы первый канал L1 сигнала понижающего микширования мог соответствовать линейной комбинации первой группы 601 каналов, т. е. L1 = c1 L + c2 LS + c3 LB, а второй канал L2 сигнала понижающего микширования мог соответствовать линейной комбинации второй группы 602 каналов, т. е. L2 = c4 TFL + c5 TBL. Коэффициенты усиления c2, c3, c4, c5, например, могут совпадать, а коэффициент усиления c1, например, может иметь другое значение; например, c1 может соответствовать полному отсутствию масштабирования. Например, можно использовать значения c1 = 1 и c2 = c3 = c4 = c5 = 1/√2. Если, например, коэффициенты усиления c1, ..., c5, действующие в отношении соответствующих каналов L, LS, LB, TFL, TBL в первом формате кодирования F1, совпадают с коэффициентами усиления, действующими в отношении этих каналов в других форматах кодирования F2 и F3, описанных ниже применительно к Фиг. 7 и 8, эти коэффициенты усиления не влияют на то, как сигнал понижающего микширования изменяется при переключении между разными форматами кодирования F1, F2, F3, а масштабированные каналы c1 L, c2 LS, c3 LB, c4 TFL, c5 TBL, следовательно, могут обрабатываться так же, как если бы они были исходными каналами L, LS, LB, TFL, TBL. С другой стороны, если для изменения масштаба тех же каналов в разных форматах кодирования действуют разные коэффициенты усиления, то переключение между этими форматами кодирования может приводить, например, к переходам между вариантами каналов L, LS, LB, TFL, TBL с разным масштабированием в сигнале понижающего микширования, что может приводить к различимым на слух искажениям на стороне декодера. Такие искажения, например, можно подавлять путем применения интерполяции от коэффициентов, используемых для создания сигнала понижающего микширования до переключения формата кодирования, до коэффициентов, используемых для создания сигнала понижающего микширования после переключения формата кодирования, и/или путем применения интерполяции преддекорреляционных коэффициентов, как описано ниже в связи с выражениями (3) и (4).
Аналогично дополнительная первая группа 603 каналов представлена первым каналом дополнительного сигнала понижающего микширования R1, а дополнительная вторая группа 604 каналов представлена вторым каналом дополнительного сигнала понижающего микширования R2.
Первый формат кодирования F1 обеспечивает каналы понижающего микширования L2 и R2, специально предназначенные для представления потолочных каналов TFL, TBL, TFR и TBR. Следовательно, использование первого формата кодирования F1 может обеспечивать возможность параметрической реконструкции 11.1-канального аудиосигнала с относительно высокой степенью достоверности в случаях, когда, например, в среде воспроизведения для общего восприятия 11.1-канального аудиосигнала важно вертикальное измерение.
На Фиг. 7 представлен второй формат кодирования F2, в котором пятиканальный аудиосигнал L, LS, LB, TFL, TBL разделен на первую группу 701 и вторую группу 702 каналов, которые представлены соответствующими каналами сигнала понижающего микширования L1, L2, причем каналы L1 и L2 соответствуют суммам соответствующих групп 701 и 702 каналов или линейным комбинациям соответствующих групп 701 и 702 каналов с применением тех же коэффициентов усиления c1, ..., c5 для изменения масштаба соответствующих каналов L, LS, LB, TFL, TBL, что и в первом формате кодирования F1. Аналогично дополнительный пятиканальный аудиосигнал R, RS, RB, TFR, TBR разделен на дополнительные первую группу 703 и вторую группу 704 каналов, которые представлены соответствующими каналами R1 и R2.
Второй формат кодирования F2 не обеспечивает каналы понижающего микширования, специально предназначенные для представления потолочных каналов TFL, TBL, TFR и TBR, но может обеспечивать возможность параметрической реконструкции 11.1-канального аудиосигнала с относительно высокой степенью достоверности в случаях, когда, например, в среде воспроизведения для общего впечатления от 11.1-канального аудиосигнала не столь важно вертикальное измерение.
На Фиг. 8 представлен третий формат кодирования F3, в котором пятиканальный аудиосигнал L, LS, LB, TFL, TBL разделен на первую группу 801 и вторую группу 802 из одного или более каналов, которые представлены соответствующими каналами L1 и L2 сигнала понижающего микширования, причем каналы L1 и L2 соответствуют суммам соответствующих групп 801 и 802 из одного или более каналов или линейным комбинациям соответствующих групп 801 и 802 из одного или более каналов с применением тех же коэффициентов c1, ..., c5 для изменения масштаба соответствующих каналов L, LS, LB, TFL, TBL, что и в первом формате кодирования F1. Аналогично дополнительный пятиканальный сигнал R, RS, RB, TFR, TBR разделен на дополнительные первую группу 803 и вторую группу 804 каналов, которые представлены соответствующими каналами R1 и R2. В третьем формате кодирования F3 только канал L представлен первым каналом L1 сигнала понижающего микширования, а четыре канала LS, LB, TFL и TBL представлены вторым каналом L2 сигнала понижающего микширования.
Как описано применительно к Фиг. 1–5, на стороне кодера вычисляют двухканальный сигнал понижающего микширования L1, L2 как линейное отображение пятиканального аудиосигнала X = [L LS LB TFL TBL]T в соответствии с выражением
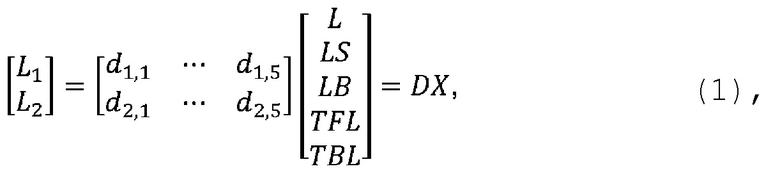
где dn,m, при n = 1, 2, m = 1…,5 — коэффициенты понижающего микширования, представленные матрицей понижающего микширования D. Как описано применительно к Фиг. 9–13, на стороне декодера выполняют параметрическую реконструкцию пятиканального аудиосигнала [L LS LB TFL TBL]T в соответствии с выражением
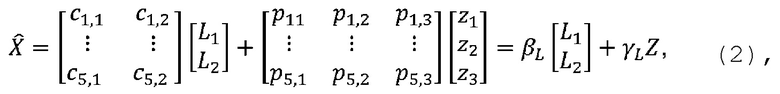
где cn,m, при n = 1, ..., 5, m = 1, 2 — «сухие» коэффициенты повышающего микширования, представленные «сухой» матрицей повышающего микширования βL, pn,k, при n = 1, ..., 5, k = 1, 2, 3 — «влажные» коэффициенты повышающего микширования, представленные «влажной» матрицей повышающего микширования γL, а zk, при k = 1, 2, 3 — каналы трехканального декоррелированного сигнала Z, созданного на основе сигнала понижающего микширования L1, L2.
На Фиг. 1 представлена обобщенная структурная схема секции 100 кодирования для кодирования М-канального аудиосигнала в виде двухканального сигнала понижающего микширования и ассоциированных параметров повышающего микширования в соответствии с примером осуществления.
В настоящей заявке пример М-канального аудиосигнала представляет собой пятиканальный аудиосигнал L, LS, LB, TFL и TBL, описанный применительно к Фиг. 6–8. Кроме того, могут быть предусмотрены примеры осуществления, в соответствии с которыми секция 100 кодирования выполнена с возможностью вычисления двухканального сигнала понижающего микширования на основе М-канального аудиосигнала, причем M = 4 или M ≥ 6.
Секция 100 кодирования содержит секцию 110 понижающего микширования и секцию 120 анализа. Для каждого из форматов кодирования F1, F2, F3, описанных применительно к Фиг. 6–8, в соответствии с форматом кодирования секция 110 понижающего микширования может вычислять двухканальный сигнал понижающего микширования L1, L2 на основе пятиканального аудиосигнала L, LS, LB, TFL, TBL. Например, в первом формате кодирования F1 первый канал L1 сигнала понижающего микширования сформирован в виде линейной комбинации (например, суммы) первой группы 601 каналов пятиканального аудиосигнала L, LS, LB, TFL, TBL, а второй канал L2 сигнала понижающего микширования сформирован в виде линейной комбинации (например, суммы) второй группы 602 каналов пятиканального аудиосигнала L, LS, LB, TFL, TBL. Действие, выполняемое секцией 110 понижающего микширования, может быть описано, например, выражением (1).
Для каждого из форматов кодирования F1, F2, F3 секция 120 анализа определяет набор «сухих» коэффициентов повышающего микширования βL, определяющих линейное отображение соответствующего сигнала понижающего микширования L1, L2, аппроксимирующее пятиканальный аудиосигнал L, LS, LB, TFL, TBL, и вычисляет разность между ковариацией полученного пятиканального аудиосигнала L, LS, LB, TFL, TBL и ковариацией пятиканального аудиосигнала, аппроксимированного путем соответствующего линейного отображения соответствующего сигнала понижающего микширования L1, L2. В настоящей заявке вычисленная разность проиллюстрирована на примере разности между ковариационной матрицей полученного пятиканального аудиосигнала L, LS, LB, TFL, TBL и ковариационной матрицей пятиканального аудиосигнала, аппроксимированного соответствующим линейным отображением соответствующего сигнала понижающего микширования L1, L2. Для каждого из форматов кодирования F1, F2, F3 секция 120 анализа определяет набор «влажных» коэффициентов повышающего микширования γL на основе соответствующей вычисленной разности, который вместе с «сухими» коэффициентами повышающего микширования βL обеспечивает возможность параметрической реконструкции в соответствии с выражением (2) пятиканального аудиосигнала L, LS, LB, TFL, TBL из сигнала понижающего микширования L1, L2 и из трехканального декоррелированного сигнала, определенного на стороне декодера на основе сигнала понижающего микширования L1, L2. Набор «влажных» коэффициентов повышающего микширования γL определяет линейное отображение декоррелированного сигнала, при котором ковариационная матрица сигнала, полученного путем линейного отображения декоррелированного сигнала, аппроксимирует разность между ковариационной матрицей полученного пятиканального аудиосигнала L, LS, LB, TFL, TBL и ковариационной матрицей пятиканального аудиосигнала, аппроксимированного путем линейного отображения сигнала понижающего микширования L1, L2.
Секция 110 понижающего микширования может, например, вычислять сигнал понижающего микширования L1, L2 во временной области, т. е. на основе представления во временной области пятиканального аудиосигнала L, LS, LB, TFL, TBL, или в частотной области, т. е. на основе представления в частотной области пятиканального аудиосигнала L, LS, LB, TFL, TBL.
Секция 120 анализа может, например, определять «сухие» коэффициенты повышающего микширования βL и «влажные» коэффициенты повышающего микширования γL на основе анализа в частотной области пятиканального аудиосигнала L, LS, LB, TFL, TBL. Секция 120 анализа может, например, получать сигнал понижающего микширования L1, L2, вычисленный секцией 110 понижающего микширования, или может вычислять собственный вариант сигнала понижающего микширования L1, L2 для определения «сухих» коэффициентов повышающего микширования βL и «влажных» коэффициентов повышающего микширования γL.
На Фиг. 3 представлена обобщенная структурная схема системы 300 кодирования аудио, содержащей секцию 100 кодирования, описанную применительно к Фиг. 1, в соответствии с одним примером осуществления. В настоящем примере осуществления аудиоданные, например, записанные одним или более акустическими преобразователями 301 или сгенерированные оборудованием 301 для создания аудио, представлены в форме 11.1-канального аудиосигнала, описанного применительно к Фиг. 6–8. Секция 302 анализа квадратурным зеркальным фильтром (QMF) (или банком фильтров) преобразует пятиканальный аудиосигнал L, LS, LB, TFL, TBL, один временной сегмент за другим, в область QMF для обработки секцией 100 анализа пятиканального аудиосигнала L, LS, LB, TFL, TBL, форма время-частотных плиток. (Как будет более подробно описано ниже, секция 302 QMF-анализа и противоположный элемент, секция 305 QMF-синтеза, являются необязательными). Система 300 кодирования аудио содержит дополнительную секцию 303 кодирования, аналогичную секции 100 кодирования и приспособленную для кодирования дополнительного пятиканального аудиосигнала R, RS, RB, TFR и TBR в виде дополнительного двухканального сигнала понижающего микширования R1, R2, и ассоциированных дополнительных «сухих» параметров повышающего микширования βR, и дополнительных «влажных» параметров повышающего микширования γR. Секция 302 QMF-анализа также преобразует дополнительный пятиканальный аудиосигнал R, RS, RB, TFR и TBR в QMF-область для обработки дополнительной секцией 303 кодирования.
Секция 304 управления выбирает один из форматов кодирования F1, F2, F3 на основе «влажных» и «сухих» коэффициентов повышающего микширования γL, γR и βL, βR, определенных секцией 100 кодирования и дополнительной секцией 303 кодирования для соответствующих форматов кодирования F1, F2, F3. Например, для каждого из форматов кодирования F1, F2, F3 секция 304 управления может вычислять соотношение
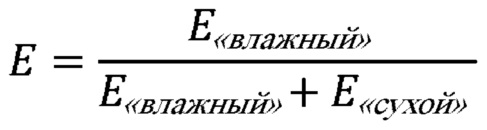 ,
,
где E«влажный» — сумма квадратов «влажных» коэффициентов повышающего микширования γL и γR, а E«сухой» — сумма квадратов «сухих» коэффициентов повышающего микширования βL, βR. Выбранный формат кодирования может быть связан с минимальным из соотношений E форматов кодирования F1, F2, F3, т. е. секция 304 управления может выбирать формат кодирования, соответствующий наименьшему отношению E. Авторы изобретения обнаружили, что сниженное значение соотношения E может быть показателем увеличенной достоверности воспроизведения 11.1-канального аудиосигнала, реконструированного из соответствующего формата кодирования.
В некоторых примерах осуществления сумма квадратов E«сухой» «сухих» коэффициентов повышающего микширования βL, βR может, например, включать дополнительный параметр со значением 1, соответствующий тому факту, что канал C передается на сторону декодера и может реконструироваться без декорреляции, например, с использованием лишь «сухого» коэффициента повышающего микширования со значением 1.
В некоторых примерах осуществления секция 304 управления может выбирать форматы кодирования для двух пятиканальных аудиосигналов L, LS, LB, TFL, TBL и R, RS, RB, TFR, TBR независимо один от другого на основе «влажных» и «сухих» коэффициентов повышающего микширования γL, βL и дополнительных «влажных» и «сухих» коэффициентов повышающего микширования γR, βR соответственно.
Система 300 кодирования аудио затем может вывести сигнал понижающего микширования L1, L2 и дополнительный сигнал понижающего микширования R1, R2 выбранного формата кодирования, параметры повышающего микширования α, из которых можно получить «сухие» и «влажные» коэффициенты повышающего микширования βL, γL и дополнительные «сухие» и «влажные» коэффициенты повышающего микширования βR, γR, связанные с выбранным форматом кодирования, и сигнализацию S, указывающую выбранный формат кодирования.
В настоящем примере осуществления секция 304 управления выводит сигнал понижающего микширования L1, L2 и дополнительный сигнал понижающего микширования R1, R2 выбранного формата кодирования, параметры повышающего микширования α, из которых можно получить «сухие» и «влажные» коэффициенты повышающего микширования βL, γL и дополнительные «сухие» и «влажные» коэффициенты повышающего микширования βR, γR, связанные с выбранным форматом кодирования, и сигнализацию S, показывающую выбранный формат кодирования. Сигнал понижающего микширования L1, L2 и дополнительный сигнал понижающего микширования R1, R2 преобразуются обратно из области QMF посредством секции 305 QMF-синтеза (или банка фильтров) и преобразуются в область модифицированного дискретного косинусного преобразования (МДКП) секцией 306 преобразования. Секция 307 квантования квантует параметры повышающего микширования α. Например, можно использовать равномерное квантование с размером шага 0,1 или 0,2 (безразмерное) с последующим энтропийным кодированием в виде кодирования Хаффмана. Более грубое квантование с размером шага 0,2 можно использовать, например, для экономии полосы пропускания при передаче, а более тонкое квантование с размером шага 0,1 можно использовать, например, для увеличения достоверности реконструкции на стороне декодера. Каналы C и LFE также преобразуются в область МДКП секцией 308 преобразования. Преобразованные МДКП сигналы понижающего микширования и каналы, квантованные параметры повышающего микширования и сигнализацию затем объединяют в битовый поток B мультиплексором 309 для передачи на сторону декодера. Система 300 кодирования аудио также может содержать базовый кодер (не показан на Фиг. 3), выполненный с возможностью кодирования сигнала понижающего микширования L1, L2, дополнительного сигнала понижающего микширования R1, R2 и каналов C и LFE с использованием перцептуального аудиокодека, такого как Dolby Digital, MPEG AAC или их производные, до передачи сигналов понижающего микширования и каналов C и LFE на мультиплексор 309. Коэффициент усиления, например, соответствующий –8,7 дБ, можно, например, применить к сигналу понижающего микширования L1, L2, дополнительному сигналу понижающего микширования R1, R2 и каналу C до формирования битового потока B. В альтернативном варианте осуществления, поскольку параметры не зависят от абсолютного уровня, коэффициенты усиления также можно применить ко всем входным каналам до формирования линейных комбинаций, соответствующих L1, L2.
Также могут быть предусмотрены варианты осуществления, в которых секция 304 управления получает только «влажные» и «сухие» коэффициенты повышающего микширования γL, γR, βL, βR для разных форматов кодирования F1, F2, F3 (или суммы квадратов «влажных» и «сухих» коэффициентов повышающего микширования для разных форматов кодирования) для выбора формата кодирования, т. е. секция 304 управления не должна обязательно получать сигналы понижающего микширования L1, L2 R1, R2 для разных форматов кодирования. В таких вариантах осуществления секция 304 управления может, например, управлять секциями 100, 303 кодирования для передачи сигналов понижающего микширования L1, L2, R1, R2, «сухих» коэффициентов повышающего микширования βL, βR и «влажных» коэффициентов повышающего микширования γL, γR для выбранного формата кодирования в качестве выхода системы 300 кодирования аудио или в качестве входа на мультиплексор 309.
Если происходит переключение выбранного формата кодирования, то можно, например, выполнить интерполяцию между значениями коэффициентов понижающего микширования, использованными до и после переключения формата кодирования, чтобы сформировать сигнал понижающего микширования в соответствии с уравнением (1). Это по существу эквивалентно интерполяции сигналов понижающего микширования, полученных в соответствии с соответствующими наборами значений коэффициентов понижающего микширования.
Хотя на Фиг. 3 показано, каким образом сигнал понижающего микширования можно получить в области QMF, а затем в дальнейшем преобразовать обратно во временную область, можно обеспечить альтернативный кодер, выполняющий те же функции без использования QMF-секций 302, 305, и тем самым он будет вычислять сигнал понижающего микширования непосредственно во временной области. Это возможно в ситуациях, в которых коэффициенты понижающего микширования не являются частотнозависимыми, как это обычно и бывает. При использовании альтернативного кодера переключения форматов кодирования можно обрабатывать либо путем плавного перехода между двумя сигналами понижающего микширования соответствующих форматов кодирования, либо путем интерполяции коэффициентов понижающего микширования (включая коэффициенты, которые имеют нулевые значения в одном из форматов), создающих сигналы понижающего микширования. Для такого альтернативного кодера может быть характерна меньшая задержка/латентность и/или меньшая вычислительная сложность.
На Фиг. 2 представлена обобщенная структурная схема секции 200 кодирования, сходной с секцией 100 кодирования, описанной применительно к Фиг. 1, в соответствии с одним примером осуществления. Секция 200 кодирования содержит секцию 210 понижающего микширования и секцию 220 анализа. Как и в секции 100 кодирования, описанной применительно к Фиг. 1, секция 210 понижающего микширования вычисляет двухканальный сигнал понижающего микширования L1, L2 на основе пятиканального аудиосигнала L, LS, LB, TFL, TBL для каждого из форматов кодирования F1, F2, F3, а секция 220 анализа определяет соответствующие наборы «сухих» коэффициентов повышающего микширования βL и вычисляет разности ΔL между ковариационной матрицей полученного пятиканального аудиосигнала L, LS, LB, TFL, TBL и ковариационными матрицами пятиканального аудиосигнала, аппроксимированными соответствующими линейными отображениями соответствующих сигналов понижающего микширования.
В отличие от секции 120 анализа в секции 100 кодирования, описанной применительно к Фиг. 1, секция 220 анализа не вычисляет «влажные» параметры повышающего микширования для всех форматов кодирования. Вместо этого в секцию 304 управления (см. Фиг. 3) передаются вычисленные разности ΔL для выбора формата кодирования. После выбора формата кодирования на основе вычисленных разностей ΔL секция 304 управления может определить «влажные» коэффициенты повышающего микширования (для включения в набор параметров повышающего микширования) для выбранного формата кодирования. В альтернативном варианте осуществления секция 304 управления отвечает за выбор формата кодирования на основе вычисленных разностей ΔL между вышеописанными ковариационными матрицами, но посредством сигнализации, направленной в обратную сторону, дает секции 220 анализа команду вычислить «влажные» коэффициенты повышающего микширования γL; в соответствии с этим альтернативным вариантом (не показан) секция 220 анализа способна выводить как разности, так и «влажные» коэффициенты повышающего микширования.
В настоящем примере осуществления набор «влажных» коэффициентов повышающего микширования определяют таким образом, чтобы ковариационная матрица сигнала, полученного путем линейного отображения декоррелированного сигнала, определяемого «влажными» коэффициентами повышающего микширования, дополняла ковариационную матрицу пятиканального аудиосигнала, аппроксимированного линейным отображением сигнала понижающего микширования выбранного формата кодирования. Иными словами, необязательно определять «влажные» параметры повышающего микширования, чтобы обеспечить полную ковариационную реконструкцию при реконструировании пятиканального аудиосигнала L, LS, LB, TFL, TBL на стороне декодера. «Влажные» параметры повышающего микширования можно определить, чтобы увеличить достоверность воспроизведения реконструированного пятиканального аудиосигнала, но если, например, количество декорреляторов на стороне декодера ограничено, то «влажные» параметры повышающего микширования можно определить, чтобы можно было максимально реконструировать ковариационную матрицу пятиканального аудиосигнала L, LS, LB, TFL, TBL.
Могут быть предусмотрены варианты осуществления, в которых системы кодирования аудио, сходные с системой 300 кодирования аудио, описанной применительно к Фиг. 3, содержат одну или более секций 200 кодирования того типа, который описан применительно к Фиг. 2.
На Фиг. 4 представлена блок-схема способа 400 кодирования аудио для кодирования М-канального аудиосигнала в двухканальный сигнал понижающего микширования и ассоциированные параметры повышающего микширования в соответствии с одним примером осуществления. Пример способа 400 кодирования аудио в настоящей заявке представляет собой способ, осуществляемый системой кодирования аудио, содержащей секцию 200 кодирования, описанную применительно к Фиг. 2.
Способ 400 кодирования аудио включает получение 410 пятиканального аудиосигнала L, LS, LB, TFL, TBL; вычисление 420 в соответствии с первым из форматов кодирования F1, F2, F3, описанным применительно к Фиг. 6–8, двухканального сигнала понижающего микширования L1, L2 на основе пятиканального аудиосигнала L, LS, LB, TFL, TBL; определение 430 набора «сухих» коэффициентов повышающего микширования βL в соответствии с форматом кодирования и вычисление 440 разности ΔL в соответствии с форматом кодирования. Способ 400 кодирования аудио включает определение 450 того, были ли вычислены разности ΔL для каждого из форматов кодирования F1, F2, F3. Если по меньшей мере для одного формата кодирования еще нужно определить разность ΔL, то способ 400 кодирования аудио возвращается к вычислению 420 сигнала понижающего микширования L1, L2 в соответствии со следующим по очереди форматом кодирования, как обозначено буквой N на блок-схеме.
Если разности ΔL вычислены для каждого из форматов кодирования F1, F2, F3, как обозначено буквой Y на блок-схеме, способ 400 переходит к выбору 460 одного из форматов кодирования F1, F2, F3 на основании соответствующих вычисленных разностей ΔL и определению 470 набора «влажных» коэффициентов повышающего микширования, которые в совокупности с «сухими» коэффициентами повышающего микширования βL выбранного формата кодирования позволяют осуществить параметрическую реконструкцию пятиканального аудиосигнала L, LS, LB, TFL, TBLM в соответствии с уравнением (2). Способ 400 кодирования аудио дополнительно включает вывод 480 сигнала понижающего микширования L1, L2 выбранного формата кодирования и параметров повышающего микширования, из которых можно получить «сухие» и «влажные» коэффициенты повышающего микширования, связанные с выбранным форматом кодирования; и вывод 490 сигнализации S, обозначающей выбранный формат кодирования.
На Фиг. 5 представлена блок-схема способа 500 кодирования аудио для кодирования М-канального аудиосигнала в двухканальный сигнал понижающего микширования и ассоциированные параметры повышающего микширования в соответствии с одним примером осуществления. Пример способа 500 кодирования аудио в настоящей заявке представляет собой способ, осуществляемый системой 300 кодирования аудио, описанной применительно к Фиг. 3.
Аналогично способу 400 кодирования аудио, описанному применительно к Фиг. 4, способ 500 кодирования аудио включает получение 410 пятиканального аудиосигнала L, LS, LB, TFL, TBL; вычисление 420 в соответствии с первым из форматов кодирования F1, F2, F3 двухканального сигнала понижающего микширования L1, L2 на основе пятиканального аудиосигнала L, LS, LB, TFL, TBL; определение 430 набора «сухих» коэффициентов повышающего микширования βL в соответствии с форматом кодирования; и вычисление 440 разности ΔL в соответствии с форматом кодирования. Способ 500 кодирования аудио дополнительно включает определение 560 набора «влажных» коэффициентов повышающего микширования γL, которые в совокупности с «сухими» коэффициентами повышающего микширования βL формата кодирования позволяют выполнить параметрическую реконструкцию М-канального аудиосигнала в соответствии с уравнением (2). Способ 500 кодирования аудио включает определение 550 того, были ли вычислены «влажные» и «сухие» коэффициенты повышающего микширования γL, βL для каждого из форматов кодирования F1, F2, F3. Если по меньшей мере для одного формата кодирования еще нужно вычислить «влажные» и «сухие» коэффициенты повышающего микширования γL, βL, то способ 500 кодирования аудио возвращается к вычислению 420 сигнала понижающего микширования L1, L2 в соответствии со следующим по очереди форматом кодирования, как обозначено буквой N на блок-схеме.
Если «влажные» и «сухие» коэффициенты повышающего микширования γL, βL вычислены для каждого из форматов кодирования F1, F2, F3, как обозначено буквой Y на блок-схеме, способ 500 кодирования аудио переходит к выбору 570 одного из форматов кодирования F1, F2, F3 на основании соответствующих вычисленных «влажных» и «сухих» коэффициентов повышающего микширования γL, βL; выводу 480 сигнала понижающего микширования L1, L2 выбранного формата кодирования и параметров повышающего микширования, из которых можно получить «сухие» и «влажные» коэффициенты повышающего микширования βL, γL, связанные с выбранным форматом кодирования; и выводу 490 сигнализации, обозначающей выбранный формат кодирования.
На Фиг. 9 представлена обобщенная структурная схема секции 900 декодирования для реконструкции М-канального аудиосигнала на основе двухканального сигнала понижающего микширования и ассоциированных параметров повышающего микширования αL в соответствии с одним примером осуществления.
В настоящем примере осуществления пример сигнала понижающего микширования представляет собой сигнал понижающего микширования L1, L2, который выводится секцией 100 кодирования, описанной применительно к Фиг. 1. В настоящем примере осуществления «сухие» и «влажные» коэффициенты повышающего микширования βL, γL, которые выводятся секцией 100 кодирования и которые приспособлены для параметрической реконструкции пятиканального аудиосигнала L, LS, LB, TFL, TBL, получают из параметров повышающего микширования αL. Однако также могут быть предусмотрены варианты осуществления, в которых параметры повышающего микширования αL приспособлены для параметрической реконструкции М-канального аудиосигнала, где М = 4 или М ≥ 6.
Секция 900 декодирования содержит секцию 910 преддекорреляции, секцию 920 декорреляции и секцию 930 микширования. Секция 910 преддекорреляции определяет набор преддекорреляционных коэффициентов на основе выбранного формата кодирования, использованного на стороне кодера для кодирования пятиканального аудиосигнала L, LS, LB, TFL, TBL. Как описано ниже применительно к Фиг. 10, выбранный формат кодирования может быть обозначен при помощи сигнализации со стороны кодера. Секция 910 преддекорреляции вычисляет входной сигнал декорреляции D1, D2, D3 как линейного отображения сигнала понижающего микширования L1, L2, где к сигналу понижающего микширования L1, L2 применяют набор преддекорреляционных коэффициентов.
Секция 920 декорреляции генерирует декоррелированный сигнал на основе входного сигнала декорреляции D1, D2, D3. В настоящем документе примером декоррелированного сигнала являются три канала, каждый из которых сгенерирован путем обработки одного из каналов входного сигнала декорреляции в декорреляторе 921–923 секции 920 декорреляции, например, включая применение линейных фильтров к соответствующим каналам входного сигнала декорреляции D1, D2, D3.
Секция 930 микширования определяет набор «влажных» и «сухих» коэффициентов повышающего микширования βL, γL на основе полученных параметров повышающего микширования αL и выбранного формата кодирования, использованного на стороне кодера для кодирования пятиканального аудиосигнала L, LS, LB, TFL, TBL. Секция 930 микширования выполняет параметрическую реконструкцию пятиканального аудиосигнала L, LS, LB, TFL, TBL в соответствии с уравнением (2), т. е. вычисляет «сухой» сигнал повышающего микширования как линейного отображения сигнала понижающего микширования L1, L2, причем к сигналу понижающего микширования L1, L2 применяют набор «сухих» коэффициентов повышающего микширования βL; вычисляет «влажный» сигнал повышающего микширования как линейного отображения декоррелированного сигнала, причем к декоррелированному сигналу применяют набор «влажных» коэффициентов повышающего микширования γL; и объединяет «сухой» и «влажный» сигналы повышающего микширования для получения многомерного реконструированного аудиосигнала 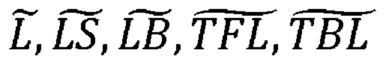 , соответствующего подлежащему реконструкции пятиканальному аудиосигналу L, LS, LB, TFL, TBL.
, соответствующего подлежащему реконструкции пятиканальному аудиосигналу L, LS, LB, TFL, TBL.
В некоторых примерах осуществления полученные параметры повышающего микширования αL могут включать сами «влажные» и «сухие» коэффициенты повышающего микширования βL, γL, или же они могут соответствовать более компактной форме, включающей меньшее количество параметров, чем количество «влажных» и «сухих» коэффициентов повышающего микширования βL, γL, из которых можно получать «влажные» и «сухие» коэффициенты повышающего микширования βL, γL на стороне декодера, зная используемую компактную форму.
На Фиг. 11 показана работа секции 930 микширования, описанной применительно к Фиг. 9, в одном примере сценария, в котором сигнал понижающего микширования L1, L2 представляет пятиканальный аудиосигнал L, LS, LB, TFL, TBL в соответствии с первым форматом кодирования F1, описанным применительно к Фиг. 6. Следует понимать, что в примерах сценариев, в которых сигнал понижающего микширования L1, L2 представляет пятиканальный аудиосигнал L, LS, LB, TFL, TBL в соответствии с любым из второго и третьего форматов кодирования F2, F3, работа секции 930 микширования может быть аналогичной. В частности, секция 930 микширования может временно активировать дополнительные экземпляры секций повышающего микширования и объединяющих секций, которые будут описаны далее, и обеспечивать плавный переход между двумя форматами кодирования, что может потребовать одновременной доступности вычисленных сигналов понижающего микширования.
В настоящем примере сценария первый канал L1 сигнала понижающего микширования представляет три канала L, LS, LB, а второй канал L2 сигнала понижающего микширования представляет два канала TFL, TBL. Секция 910 преддекорреляции определяет преддекорреляционные коэффициенты, чтобы генерировать два канала декоррелированного сигнала на основе первого канала L1 сигнала понижающего микширования и чтобы генерировать один канал декоррелированного сигнала на основе второго канала L2 сигнала понижающего микширования.
Первая «сухая» секция 931 повышающего микширования обеспечивает трехканальный «сухой» сигнал повышающего микширования X1 как линейного отображения первого канала L1 сигнала понижающего микширования, причем поднабор «сухих» коэффициентов повышающего микширования, которые можно получить из полученных параметров повышающего микширования αL, применяют к первому каналу L1 сигнала понижающего микширования. Первая «влажная» секция 932 повышающего микширования обеспечивает трехканальный «влажный» сигнал повышающего микширования Y1 как линейного отображения двух каналов декоррелированного сигнала, причем поднабор «влажных» коэффициентов повышающего микширования, которые можно получить из полученных параметров повышающего микширования αL, применяют к двум каналам декоррелированного сигнала. Первая объединяющая секция 933 объединяет первый «сухой» сигнал повышающего микширования X1 и первый «влажный» сигнал повышающего микширования Y1 в реконструированные варианты 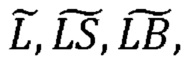 каналов L, LS, LB.
каналов L, LS, LB.
Аналогично вторая «сухая» секция 934 повышающего микширования обеспечивает двухканальный «сухой» сигнал повышающего микширования X2 как линейного отображения второго канала L2 сигнала понижающего микширования, а вторая «влажная» секция 935 повышающего микширования обеспечивает двухканальный «влажный» сигнал повышающего микширования Y2 в виде линейной комбинации одного канала декоррелированного сигнала. Вторая объединяющая секция 936 объединяет второй «сухой» сигнал повышающего микширования X2 и второй «влажный» сигнал повышающего микширования Y2 в реконструированные варианты 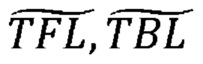 каналов TFL, TBL.
каналов TFL, TBL.
На Фиг. 10 представлена обобщенная структурная схема системы 1000 декодирования аудио, содержащей секцию 900 декодирования, описанную применительно к Фиг. 9, в соответствии с одним примером осуществления. Секция 1001 получения, например, включающая демультиплексор, получает битовый поток B, переданный от системы 300 кодирования аудио, описанной применительно к Фиг. 3, и извлекает сигнал понижающего микширования L1, L2, дополнительный сигнал понижающего микширования R1, R2 и параметры повышающего микширования α, а также каналы C и LFE из битового потока B. Параметры повышающего микширования α могут, например, содержать первый и второй поднаборы αL и αR, связанные с левой стороной и правой стороной соответственно 11.1-канального аудиосигнала L, LS, LB, TFL, TBL, R, RS, RB, TFR, TBR, C, LFE, который следует реконструировать.
Если сигнал понижающего микширования L1, L2, дополнительный сигнал понижающего микширования R1, R2 и/или каналы C и LFE закодированы в битовом потоке B с использованием перцептуального аудиокодека, такого как Dolby Digital, MPEG AAC или их производные, система 1000 декодирования аудио может содержать базовый декодер (не показан на Фиг. 10), выполненный с возможностью декодирования соответствующих сигналов и каналов при извлечении из битового потока B.
Секция 1002 преобразования преобразует сигнал понижающего микширования L1, L2 путем выполнения обратного МДКП, а секция 1003 QMF-анализа преобразует сигнал понижающего микширования L1, L2 в область QMF для обработки секцией 900 декодирования сигнала понижающего микширования L1, L2, форма время-частотных плиток. Секция 1004 деквантования деквантует первый поднабор параметров повышающего микширования αL, например, из формата энтропийного кодирования, перед его передачей в секцию 900 декодирования. Как описано применительно к Фиг. 3, квантование может быть выполнено с использованием одного из двух разных размеров шага, например 0,1 или 0,2. Реальный использованный размер шага можно предварительно задать или можно передать с помощью сигнализации в систему 1000 декодирования аудио со стороны кодера, например, через битовый поток B.
В настоящем примере осуществления система 1000 декодирования аудио содержит дополнительную секцию 1005 декодирования, аналогичную секции 900 декодирования. Дополнительная секция 1005 декодирования выполнена с возможностью получения дополнительного двухканального сигнала понижающего микширования R1, R2, описанного применительно к Фиг. 3, и второго поднабора αR параметров повышающего микширования и обеспечения реконструированного варианта 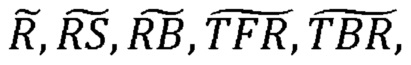 дополнительного пятиканального аудиосигнала R, RS, RB, TFR, TBR на основе дополнительного сигнала понижающего микширования R1, R2 и второго поднабора αR параметров повышающего микширования.
дополнительного пятиканального аудиосигнала R, RS, RB, TFR, TBR на основе дополнительного сигнала понижающего микширования R1, R2 и второго поднабора αR параметров повышающего микширования.
Секция 1006 преобразования преобразует дополнительный сигнал понижающего микширования R1, R2 путем выполнения обратного МДКП, а секция 1007 QMF-анализа преобразует дополнительный сигнал понижающего микширования R1, R2 в область QMF для обработки дополнительной секцией 1005 декодирования дополнительного сигнала понижающего микширования R1, R2, форма время-частотных плиток. Секция 1008 деквантования деквантует второй поднабор параметров повышающего микширования αR, например, из формата энтропийного кодирования, перед их передачей в дополнительную секцию 1005 декодирования.
В примерах осуществления, в которых коэффициент усиления применяли к сигналу понижающего микширования L1, L2, дополнительному сигналу понижающего микширования R1, R2 и каналу C на стороне кодера, соответствующий коэффициент, например, соответствующий 8,7 дБ, можно применить к этим сигналам в системе 1000 декодирования аудио для компенсации коэффициента усиления.
Секция 1009 управления получает сигнализацию S, указывающую формат, выбранный из форматов кодирования F1, F2, F3, использованный на стороне кодера для кодирования 11.1-канального аудиосигнала в сигнал понижающего микширования L1, L2, а также дополнительный сигнал понижающего микширования R1, R2 и ассоциированные параметры повышающего микширования α. Секция 1009 управления управляет секцией 900 декодирования (например, входящей в нее секцией 910 преддекорреляции и секцией 920 микширования) и дополнительной секцией (1005) декодирования и выполняет параметрическую реконструкцию в соответствии с указанным форматом кодирования.
В настоящем примере осуществления реконструированные варианты пятиканального аудиосигнала L, LS, LB, TFL, TBL и дополнительного пятиканального аудиосигнала R, RS, RB, TFL, TBL, выведенные секцией 900 декодирования и дополнительной секцией 1005 декодирования соответственно, преобразуются обратно из QMF-области посредством секции 1011 QMF-синтеза, а затем выводятся вместе с каналами C и LFE в качестве выхода системы 1000 декодирования аудио для воспроизведения на многоколоночной системе 1012. Секция 1010 преобразования преобразует каналы C и LFE во временную область посредством выполнения обратного МДКП, а затем эти каналы включаются в выход системы 1000 декодирования аудио.
Каналы C и LFE можно, например, извлечь из битового потока B в дискретно-кодированной форме, и система 1000 декодирования аудио может, например, содержать одноканальные секции декодирования (не показаны на Фиг. 10), выполненные с возможностью декодирования соответствующих дискретно-кодированных каналов. Одноканальные секции декодирования могут, например, включать базовые декодеры для декодирования аудиоданных, закодированных при помощи перцептуального аудиокодека, такого как Dolby Digital, MPEG AAC или их производные.
В настоящем примере осуществления преддекорреляционные коэффициенты определяются секцией 910 преддекорреляции таким образом, чтобы в каждом из форматов кодирования F1, F2, F3 каждый из каналов входного сигнала декорреляции D1, D2, D3 совпадал с каналом сигнала понижающего микширования L1, L2, в соответствии с таблицей 1.
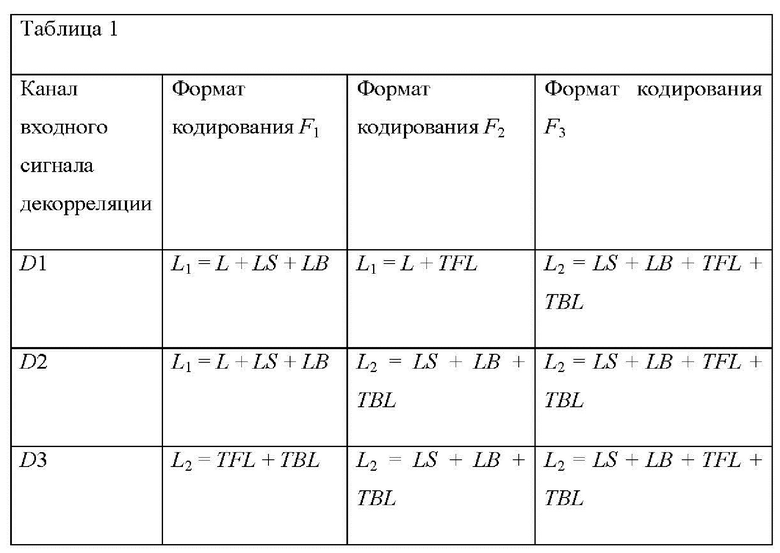
Как можно видеть в таблице 1, канал TBL вносит вклад через сигнал понижающего микширования L1, L2 в третий канал D3 входного сигнала декорреляции во всех трех форматах кодирования F1, F2, F3, тогда как каждая из пар каналов LS, LB и TFL, TBL вносит вклад через сигнал понижающего микширования L1, L2 в третий канал D3 входного сигнала декорреляции по меньшей мере в двух форматах кодирования соответственно.
В таблице 1 показано, что каждый из каналов L и TFL вносит вклад через сигнал понижающего микширования L1, L2 в первый канал D1 входного сигнала декорреляции в двух форматах кодирования соответственно, а пара каналов LS, LB вносит вклад через сигнал понижающего микширования L1, L2 в первый канал D1 входного сигнала декорреляции по меньшей мере в двух форматах кодирования.
В таблице 1 также показано, что три канала LS, LB, TBL вносят вклад через сигнал понижающего микширования L1, L2 во второй канал D2 входного сигнала декорреляции как во втором, так и в третьем формате кодирования F3, F3, тогда как пара каналов LS, LB вносит вклад через сигнал понижающего микширования L1, L2 во второй канал D2 входного сигнала декорреляции во всех трех форматах кодирования F1, F2, F3.
При переключении между разными форматами кодирования изменяется входной сигнал к декорреляторам 921–923. В настоящем примере осуществления по меньшей мере некоторые части входных сигналов декорреляции D1, D2, D3 при переключении сохранятся, т. е. по меньшей мере один канал пятиканального аудиосигнала L, LS, LB, TFL, TBL останется в каждом канале входного сигнала декорреляции D1, D2, D3 при любом переключении между двумя форматами кодирования F1, F2, F3, что позволит выполнить более плавный переход между форматами кодирования при восприятии слушателем при воспроизведении реконструированного М-канального аудиосигнала.
Авторы изобретения обнаружили, что поскольку декоррелированный сигнал может генерироваться на основе фрагмента сигнала понижающего микширования L1, L2, соответствующего нескольким временным интервалам, в течение которых может произойти переключение формата кодирования, потенциально возможно образование различимых на слух искажений в декоррелированном сигнале в результате переключения форматов кодирования. Даже если «влажные» и «сухие» коэффициенты повышающего микширования βL, γL интерполируются в ответ на переход между форматами кодирования, возникшие в декоррелированном сигнале искажения все равно могут присутствовать в реконструированном пятиканальном аудиосигнале L, LS, LB, TFL, TBL. Предоставление входного сигнала декорреляции D1, D2, D3 в соответствии с таблицей 1 может подавлять различимые на слух искажения в декоррелированном сигнале, вызванные переключением формата кодирования, и может улучшать качество воспроизведения реконструированного пятиканального аудиосигнала L, LS, LB, TFL, TBL.
Хотя таблица 1 выражается в терминах форматов кодирования F1, F2, F3, для которых каналы сигнала понижающего микширования L1, L2 генерируются в виде сумм первой и второй групп каналов соответственно, те же значения преддекорреляционных коэффициентов можно, например, использовать, когда каналы сигнала понижающего микширования сформированы в виде линейных комбинаций первой и второй групп каналов соответственно, так что каналы входного сигнала декорреляции D1, D2, D3 совпадают с каналами сигнала понижающего микширования L1, L2 в соответствии с таблицей 1. Следует понимать, что качество воспроизведения реконструированного пятиканального аудиосигнала таким способом можно также улучшить, если каналы сигнала понижающего микширования сформированы в виде линейных комбинаций первой и второй группы каналов соответственно.
Для дополнительного улучшения качества воспроизведения реконструированного пятиканального аудиосигнала можно, например, выполнить интерполяцию значений преддекорреляционных коэффициентов в ответ на переключение формата кодирования. В первом формате кодирования F1 входной сигнал декорреляции D1, D2, D3 можно определить следующим образом:
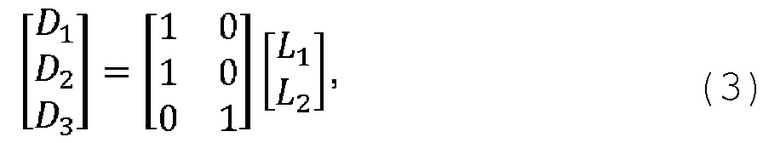
тогда как во втором формате кодирования F2 входной сигнал декорреляции D1, D2, D3 можно определить следующим образом:
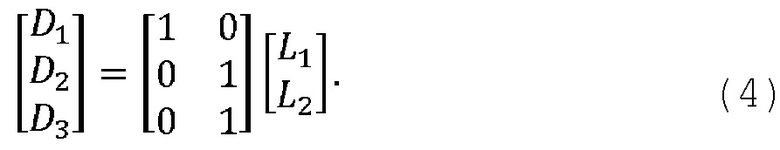
В ответ на переключение с первого формата кодирования F1 на второй формат кодирования F2 можно, например, выполнить непрерывную или линейную интерполяцию между преддекорреляционной матрицей в уравнении (3) и преддекорреляционной матрицей в уравнении (4).
Сигнал понижающего микширования L1, L2 в уравнениях (3) и (4) может, например, присутствовать в QMF-области, и при переключении между форматами кодирования коэффициенты понижающего микширования, примененные на стороне кодера для вычисления сигнала понижающего микширования L1, L2 согласно уравнению (1), можно интерполировать, например, на протяжении 32 QMF-интервалов. Интерполяцию преддекорреляционных коэффициентов (или матриц) можно, например, синхронизировать с интерполяцией коэффициентов понижающего микширования, например, ее можно выполнить на протяжении тех же 32 QMF-интервалов. Интерполяция преддекорреляционных коэффициентов может представлять собой, например, широкополосную интерполяцию, например, использованную для всех полос частот, декодированных системой 1000 декодирования аудио.
«Сухие» и «влажные» коэффициенты повышающего микширования βL, γL также можно интерполировать. Интерполяциями «сухих» и «влажных» коэффициентов повышающего микширования βL, γL можно, например, управлять при помощи сигнализации S со стороны кодера для улучшения обработки переходов. При переключении формата кодирования интерполяционная схема, выбранная на стороне кодера для интерполяции «сухих» и «влажных» коэффициентов повышающего микширования βL, γL на стороне декодера, может представлять собой, например, интерполяционную схему, подходящую для переключения формата кодирования, которая может отличаться от интерполяционных схем, применяемых для «сухих» и «влажных» коэффициентов повышающего микширования βL, γL при отсутствии переключений форматов кодирования.
В некоторых примерах осуществления в секции 900 декодирования может применяться по меньшей мере одна интерполяционная схема, отличающаяся от дополнительной секции 1005 декодирования.
На Фиг. 12 представлена блок-схема способа 1200 декодирования аудио для реконструкции М-канального аудиосигнала на основе двухканального сигнала понижающего микширования и ассоциированных параметров повышающего микширования в соответствии с одним примером осуществления. Пример способа 1200 декодирования в настоящей заявке представляет собой способ декодирования, который может быть реализован системой 1000 декодирования аудио, описанной применительно к Фиг. 10.
Способ 1200 декодирования аудио включает получение 1201 двухканального сигнала понижающего микширования L1, L2 и параметров повышающего микширования αL для параметрической реконструкции пятиканального аудиосигнала L, LS, LB, TFL, TBL, описанного применительно к Фиг. 6–8, на основе сигнала понижающего микширования L1, L2; получение 1202 сигнализации S, указывающий формат, выбранный из форматов кодирования F1, F2, F3, описанных применительно к Фиг. 6–8; и определение 1203 набора преддекорреляционных коэффициентов на основе указанного формата кодирования.
Способ 1200 декодирования аудио включает обнаружение 1204 того, происходит ли переключение с одного формата кодирования на другой. Если переключение не обнаружено, как обозначено на блок-схеме буквой N, то следующим этапом является вычисление 1205 входного сигнала декорреляции D1, D2, D3 как линейного отображения сигнала понижающего микширования L1, L2, причем к сигналу понижающего микширования применяют набор преддекорреляционных коэффициентов. С другой стороны, если обнаружено переключение формата кодирования, как обозначено буквой Y на блок-схеме, то вместо этого следующим шагом является выполнение 1206 интерполяции в форме постепенного перехода от значений преддекорреляционных коэффициентов одного формата кодирования к значениям преддекорреляционных коэффициентов другого формата кодирования, а затем вычисление 1205 входного сигнала декорреляции D1, D2, D3 с использованием интерполированных значений преддекорреляционных коэффициентов.
Способ 1200 декодирования аудио включает создание 1207 декоррелированного сигнала на основе входного сигнала декорреляции D1, D2, D3; и определение 1208 набора «влажных» и «сухих» коэффициентов повышающего микширования βL, γL на основе полученных параметров повышающего микширования и указанного формата кодирования.
Если переключение формата кодирования не обнаружено, как обозначено ветвью N от блока 1209 проверки условия, то способ 1200 переходит к вычислению 1210 «сухого» сигнала повышающего микширования как линейного отображения сигнала понижающего микширования, причем к сигналу понижающего микширования L1, L2 применяют набор «сухих» коэффициентов повышающего микширования βL; и вычислению 1211 «влажного» сигнала повышающего микширования как линейного отображения декоррелированного сигнала, причем к декоррелированному сигналу применяют набор «влажных» коэффициентов повышающего микширования γL. С другой стороны, если обнаружено переключение с одного формата кодирования на другой, как обозначено на блок-схеме ветвью Y от блока 1209 проверки условия, то способ вместо этого переходит к выполнению 1212 интерполяции от значений «сухих» и «влажных» коэффициентов повышающего микширования (включая нулевые значения коэффициентов), применимых к одному формату кодирования, к значениям «сухих» и «влажных» коэффициентов повышающего микширования (включая нулевые значения коэффициентов), применимых к другому формату кодирования; вычислению 1210 «сухого» сигнала повышающего микширования как линейного отображения сигнала понижающего микширования L1, L2, причем к сигналу понижающего микширования L1, L2 применяют интерполированный набор «сухих» коэффициентов повышающего микширования; и вычислению 1211 «влажного» сигнала повышающего микширования как линейного отображения декоррелированного сигнала, причем к декоррелированному сигналу применяют интерполированный набор «влажных» коэффициентов повышающего микширования. Способ также включает объединение 1213 «сухих» и «влажных» сигналов повышающего микширования для получения многомерного реконструированного аудиосигнала  , соответствующего подлежащему реконструкции пятиканальному аудиосигналу.
, соответствующего подлежащему реконструкции пятиканальному аудиосигналу.
На Фиг. 13 представлена обобщенная структурная схема секции 1300 декодирования для реконструкции 13.1-канального аудиосигнала на основе 5.1-канального аудиосигнала и ассоциированных параметров повышающего микширования α в соответствии с одним примером осуществления.
В настоящем примере осуществления примером 13.1-канального аудиосигнала являются каналы LW (левый широкий), LSCRN (левый экранный), TFL (верхний фронтальный левый), LS (левый боковой), LB (левый тыловой), TBL (верхний тыловой левый), RW (правый широкий), RSCRN (правый экранный), TFR (верхний фронтальный правый), RS (правый боковой), RB (правый тыловой), TBR (верхний тыловой правый), C (центральный) и LFE (канал низкочастотных эффектов). Данный 5.1-канальный сигнал включает сигнал понижающего микширования L1, L2, для которого первый канал L1 соответствует линейной комбинации каналов LW, LSCRN, TFL и для которого второй канал L2 соответствует линейной комбинации каналов LS, LB, TBL; и дополнительный сигнал понижающего микширования R1, R2, для которого первый канал R1 соответствует линейной комбинации каналов RW, RSCRN, TFR и для которого второй канал R2 соответствует линейной комбинации каналов RS, RB, TBR; и каналы C и LFE.
Первая секция 1310 повышающего микширования реконструирует каналы LW, LSCRN и TFL на основе первого канала L1 сигнала понижающего микширования под управлением по меньшей мере некоторых из параметров повышающего микширования α; вторая секция 1320 повышающего микширования реконструирует каналы LS, LB, TBL на основе второго канала L2 сигнала понижающего микширования под управлением по меньшей мере некоторых из параметров повышающего микширования α; третья секция 1330 повышающего микширования реконструирует каналы RW, RSCRN, TFR на основе первого канала R1 дополнительного сигнала понижающего микширования под управлением по меньшей мере некоторых из параметров повышающего микширования α; а четвертая секция 1340 повышающего микширования реконструирует каналы RS, RB, TBR на основе второго канала R2 сигнала понижающего микширования под управлением по меньшей мере некоторых из параметров повышающего микширования α. Реконструированный вариант  13.1-канального аудиосигнала может обеспечиваться в качестве выхода секции 1310 декодирования.
13.1-канального аудиосигнала может обеспечиваться в качестве выхода секции 1310 декодирования.
В примере осуществления система 1000 декодирования аудио, описанная применительно к Фиг. 10, может содержать секцию 1300 декодирования в дополнение к секциям 900 и 1005 декодирования или может по меньшей мере функционировать с возможностью реконструкции 13.1-канального сигнала способом, сходным с осуществляемым в секции 1300 декодирования. Сигнализация S, извлеченная из битового потока B может, например, показывать, представляет ли полученный 5.1-канальный аудиосигнал L1, L2, R1, R2, C, LFE и ассоциированные параметры повышающего микширования 11.1-канальный сигнал, как описано применительно к Фиг. 10, или же он представляет 13.1-канальный аудиосигнал, как описано применительно к Фиг. 13.
Секция 1009 управления может определять, обозначает ли полученная сигнализация S 11.1-канальную или 13.1-канальную конфигурацию, и может управлять другими секциями системы 1000 декодирования аудио при выполнении параметрической реконструкции либо 11.1-канального аудиосигнала, как описано применительно к Фиг. 10, либо 13.1-канального аудиосигнала, как описано применительно к Фиг. 13. Для 13.1-канальной конфигурации можно, например, использовать единственный формат кодирования вместо двух или трех форматов кодирования, используемых для 11.1-канальной конфигурации. Если сигнализация S обозначает 13.1-канальную конфигурацию, формат кодирования, таким образом, может быть указан неявно, и может отсутствовать необходимость в сигнализации S, явным образом указывающей выбранный формат кодирования.
Следует понимать, что хотя примеры осуществления, описанные применительно к Фиг. 1–5, изложены в терминах 11.1-канального аудиосигнала, описанного применительно к Фиг. 6–8, могут быть предусмотрены системы кодирования, которые могут включать любое количество секций кодирования и которые могут быть выполнены с возможностью кодирования любого количества М-канальных аудиосигналов, где M ≥ 4. Аналогично следует понимать, что хотя примеры осуществления, описанные применительно к Фиг. 9–12, изложены в терминах 11.1-канального аудиосигнала, описанного применительно к Фиг. 6–8, могут быть предусмотрены системы декодирования, которые могут включать любое количество секций декодирования и которые могут быть выполнены с возможностью реконструкции любого количества М-канальных аудиосигналов, где M ≥ 4.
В некоторых примерах осуществления сторона кодера может выбирать между тремя форматами кодирования F1, F2, F3. В других примерах осуществления сторона кодера может выбирать только между двумя форматами кодирования, например первым и вторым форматами кодирования F1, F2.
На Фиг. 14 представлена обобщенная структурная схема секции 1400 кодирования для кодирования М-канального аудиосигнала в виде двухканального сигнала понижающего микширования и ассоциированных «сухих» и «влажных» коэффициентов повышающего микширования в соответствии с одним примером осуществления. Секция 1400 кодирования может находиться в системе кодирования аудио типа, показанного на Фиг. 3. Более конкретно, она может быть расположена в месте, занимаемом секцией 100 кодирования. Как станет очевидно из описания внутренней работы показанных компонентов, секция 1400 кодирования может функционировать в двух разных форматах кодирования; однако можно реализовать сходные секции кодирования, не выходящие за рамки объема изобретения, которые способны работать в трех или более форматах кодирования.
Секция 1400 кодирования содержит секцию 1410 понижающего микширования и секцию 1420 анализа. По меньшей мере для одного выбранного формата (см. ниже описание секции управления 1430 из секции 1400 кодирования) из форматов кодирования F1, F2, который может представлять собой один из форматов, описанных применительно к Фиг. 6–7, или какой-либо из других форматов, секция 1410 понижающего микширования вычисляет в соответствии с форматом кодирования двухканальный сигнал понижающего микширования L1, L2 на основе пятиканального аудиосигнала L, LS, LB, TFL, TBL. Например, в первом формате кодирования F1 первый канал L1 сигнала понижающего микширования формируется в виде линейной комбинации (например, суммы) первой группы каналов пятиканального аудиосигнала L, LS, LB, TFL, TBL, а второй канал L2 сигнала понижающего микширования формируется в виде линейной комбинации (например, суммы) второй группы каналов пятиканального аудиосигнала L, LS, LB, TFL, TBL. Действие, выполняемое секцией 1410 понижающего микширования, может быть описано, например, выражением (1).
Для указанного по меньшей мере одного выбранного формата из форматов кодирования F1, F2 секция 1420 анализа определяет набор «сухих» коэффициентов повышающего микширования βL, определяющих линейное отображение соответствующего сигнала понижающего микширования L1, L2, аппроксимирующее пятиканальный аудиосигнал L, LS, LB, TFL, TBL. Для каждого из форматов кодирования F1, F2 секция 1420 анализа дополнительно определяет набор «влажных» коэффициентов повышающего микширования γL на основе соответствующей вычисленной разности, которые в сочетании с «сухими» коэффициентами повышающего микширования βL позволяют осуществить параметрическую реконструкцию согласно уравнению (2) пятиканального аудиосигнала L, LS, LB, TFL, TBL из сигнала понижающего микширования L1, L2 и из трехканального декоррелированного сигнала, определенного на стороне декодера на основе сигнала понижающего микширования L1, L2. Набор «влажных» коэффициентов повышающего микширования γL определяет линейное отображение декоррелированного сигнала, при котором ковариационная матрица сигнала, полученного путем линейного отображения декоррелированного сигнала, аппроксимирует разность между ковариационной матрицей полученного пятиканального аудиосигнала L, LS, LB, TFL, TBL и ковариационной матрицей пятиканального аудиосигнала, аппроксимированного путем линейного отображения сигнала понижающего микширования L1, L2.
Секция 1410 понижающего микширования может, например, вычислять сигнал понижающего микширования L1, L2 во временной области, т. е. на основе представления во временной области пятиканального аудиосигнала L, LS, LB, TFL, TBL, или в частотной области, т. е. на основе представления в частотной области пятиканального аудиосигнала L, LS, LB, TFL, TBL. Вычисление L1, L2 во временной области является возможным, по меньшей мере если выбор формата кодирования не является частотно-избирательным, и следовательно применимым ко всем частотным компонентам М-канального аудиосигнала; в настоящее время это является предпочтительным вариантом.
Секция 1420 анализа может, например, определять «сухие» коэффициенты повышающего микширования βL и «влажные» коэффициенты повышающего микширования γL на основе анализа в частотной области пятиканального аудиосигнала L, LS, LB, TFL, TBL. Анализ в частотной области можно выполнить на кадрированном участке М-канального аудиосигнала. Для кадрирования можно, например, использовать разъединенные прямоугольные или перекрывающиеся треугольные окна. Секция 1420 анализа может, например, получать сигнал понижающего микширования L1, L2, вычисленный секцией 1410 понижающего микширования (не показана на Фиг. 14), или может вычислять собственный вариант сигнала понижающего микширования L1, L2 для конкретной цели определения «сухих» коэффициентов повышающего микширования βL и «влажных» коэффициентов повышающего микширования γL.
Секция 1400 кодирования дополнительно содержит секцию 1430 управления, которая отвечает за выбор формата, используемого в данный момент. Нет необходимости в том, чтобы секция 1430 управления использовала определенный критерий или определенное основание при принятии решения о выборе формата кодирования. Значение сигнализации S, сгенерированное секцией 1430 управления, обозначает результат принятого секцией 1430 управления решения для рассмотренного в данный момент участка (например, временного интервала) М-канального аудиосигнала. Сигнализацию S можно включить в битовый поток B, генерируемый системой 300 кодирования, в которую входит секция 1400 кодирования, чтобы упростить реконструкцию закодированного аудиосигнала. Кроме того, сигнализация S передается и в каждую из секции 1410 понижающего микширования и секции 1420 анализа для информирования этих секций об используемом формате кодирования. Как и секция 1420 анализа, секция 1430 управления может рассматривать кадрированные участки М-канального сигнала. Для полноты следует отметить, что секция 1410 понижающего микширования может работать с задержкой в 1 или 2 кадра и, возможно, с дополнительным опережением относительно секции 1430 управления. Сигнализация S также может необязательно содержать информацию, относящуюся к обеспечению плавного перехода сигнала понижающего микширования, создаваемого секцией 1410 понижающего микширования, и/или информацию, относящуюся к интерполяции на стороне декодера дискретных значений «сухих» и «влажных» коэффициентов повышающего микширования, которую предоставляет секция 1420 анализа, для обеспечения синхронности на субкадровой временной шкале.
В качестве необязательного компонента секция 1400 кодирования может включать стабилизатор 1440, расположенный непосредственно после секции 1430 управления и воздействующий на ее выходной сигнал непосредственно перед его обработкой другими компонентами. На основе этого выходного сигнала стабилизатор 1440 предоставляет дополнительную информацию S последующим компонентам. Стабилизатор 1440 может обеспечивать достижение желаемой цели: не менять формат кодирования слишком часто. Для этой цели стабилизатор 1440 может учитывать количество выборов формата кодирования на протяжении прошедших временных интервалов М-канального аудиосигнала и обеспечивать, чтобы выбранный формат кодирования сохранялся по меньшей мере в течение заданного количества временных интервалов. В альтернативном варианте осуществления стабилизатор может применить усредняющий фильтр к некоторому количеству выполненных выборов формата кодирования (например, представленному дискретной переменной), что может создать эффект сглаживания. В еще одном варианте осуществления стабилизатор 1440 может содержать конечный автомат, выполненный с возможностью передачи дополнительной информации S для всех временных интервалов в движущемся временном окне, если конечный автомат определит, что выбор формата кодирования, выполненный секцией 1430 управления, остался неизменным на протяжении движущегося временного окна. Движущееся временное окно может соответствовать буферу, хранящему результаты выбора форматов кодирования для некоторого числа прошедших временных интервалов. Специалист, изучающий настоящее описание, легко поймет, что такие функции стабилизации, возможно, потребуется сопроводить увеличением операционной задержки между стабилизатором 1440, и по меньшей мере секцией 1410 понижающего микширования, и секцией 1420 анализа. Задержку можно реализовать при помощи секций буферизации М-канального аудиосигнала.
Как описано выше, Фиг. 14 представляет собой частичный вид системы кодирования, показанной на Фиг. 3. Хотя компоненты, показанные на Фиг. 14, относятся только к обработке левосторонних каналов L, LS, LB, TFL, TBL, система кодирования обрабатывает также по меньшей мере правосторонние каналы R, RS, RB, TFR, TBR. Например, дополнительный экземпляр (например, функционально эквивалентная копия) секции 1400 кодирования может работать параллельно, кодируя правосторонний сигнал, включая указанные каналы R, RS, RB, TFR, TBR. Хотя левосторонние и правосторонние каналы участвуют в двух отдельных сигналах понижающего микширования (или по меньшей мере в отдельных группах каналов общего сигнала понижающего микширования), для всех каналов предпочтительно использовать общий формат кодирования. Иными словами, секция 1430 управления в левосторонней секции 1400 кодирования может отвечать за принятие решения об общем формате кодирования для использования как левосторонними, так и правосторонними каналами; таким образом, предпочтительно, чтобы секция 1430 управления также имела доступ к правосторонним каналам R, RS, RB, TFR, TBR или к количественным показателям, полученным по этим сигналам, например, ковариации, сигналу понижающего микширования и т. п., и могла учитывать их при выборе используемого формата кодирования. Затем сигнализация S передается не только к секции 1410 понижающего микширования и секции 1420 анализа секции 1430 управления (левосторонней), но также и к эквивалентным секциям правосторонней секции кодирования (не показана). В альтернативном варианте осуществления можно достигнуть цели использования общего формата кодирования для всех каналов, если сама секция 1430 управления будет общей для левостороннего и правостороннего экземпляра секции 1400 управления. В схеме того типа, который показан на Фиг. 3, секция 1430 кодирования может быть выполнена вне как секции 100 кодирования, так и дополнительной секции 303 кодирования, отвечающих за левосторонние и правосторонние каналы соответственно, и может получать все левосторонние и правосторонние каналы L, LS, LB, TFL, TBL, R, RS, RB, TFR, TBR и выводить сигнализацию S, которая обозначает выбор формата кодирования и передается по меньшей мере к секции 100 кодирования и дополнительной секции 303 кодирования.
На Фиг. 15 схематично представлена возможная реализация секции 1410 понижающего микширования, выполненной с возможностью переключения в соответствии с сигнализацией S между двумя заданными форматами кодирования F1, F2 и обеспечения плавного перехода между ними. Секция 1410 понижающего микширования содержит две подсекции 1411, 1412 понижающего микширования, выполненные с возможностью получения М-канального аудиосигнала и вывода двухканального сигнала понижающего микширования. Две подсекции 1411, 1412 понижающего микширования могут быть функционально эквивалентными копиями одной схемы, хотя выполненными с разными параметрами понижающего микширования (например, значениями коэффициентов для получения сигнала понижающего микширования L1, L2 на основе М-канального аудиосигнала). При нормальной работе две подсекции 1411, 1412 понижающего микширования вместе обеспечивают один сигнал понижающего микширования L1(F1), L2(F1) в соответствии с первым форматом кодирования F1 и/или один сигнал понижающего микширования L1(F2), L2(F2) в соответствии со вторым форматом кодирования F2. После подсекций 1411, 1412 понижающего микширования расположены первая секция 1413 интерполяции понижающего микширования и вторая секция 1414 интерполяции понижающего микширования. Первая секция 1413 интерполяции понижающего микширования выполнена с возможностью интерполяции, в том числе обеспечения плавного перехода, первого канала L1 сигнала понижающего микширования, а вторая секция 1414 интерполяции понижающего микширования выполнена с возможностью интерполяции, в том числе обеспечения плавного перехода, второго канала L2 сигнала понижающего микширования. Первая секция 1413 интерполяции понижающего микширования может работать по меньшей мере в следующих состояниях:
a) только первый формат кодирования (L1 = L1(F1)) можно использовать при стабильной работе в первом формате кодирования;
b) только второй формат кодирования (L1 = L1(F2)) можно использовать при стабильной работе во втором формате кодирования; и
c) объединение каналов понижающего микширования в соответствии с обоими форматами кодирования (L1 = α1L1(F1) + α2L1(F2), причем 0 < α1 < 1 и 0 < α2 < 1) можно использовать при переходе от первого ко второму формату кодирования или наоборот.
Для состояния объединения (c) может быть необходимо, чтобы были доступны сигналы понижающего микширования как с первой, так и со второй подсекций понижающего микширования 1411, 1412. Предпочтительно первая секция 1413 интерполяции понижающего микширования может работать во множестве состояний объединения (c), чтобы был возможен переход мелкими подшагами или даже с псевдонепрерывным плавным переходом. Преимущество этого заключается в том, что плавный переход становится менее заметным. Например, в схеме интерполятора, где α1 + α2 = 1, возможен пятиступенчатый плавный переход, если определены следующие значения (α1, α2): (0,2; 0,8); (0,4; 0,6); (0,6; 0,4); (0,8; 0,2). Вторая секция 1414 интерполяции понижающего микширования может иметь идентичные или сходные возможности.
В одной версии вышеуказанного варианта осуществления секции 1410 понижающего микширования, указанной пунктирной линией на Фиг. 15, сигнализация S может также подаваться на первую и вторую подсекции 1411, 1412 понижающего микширования. Как описано выше, создание сигнала понижающего микширования, связанного с невыбранным форматом кодирования, далее может подавляться. Это может снизить среднюю вычислительную нагрузку.
В качестве дополнения или альтернативы этой версии плавный переход между сигналами понижающего микширования двух разных форматов кодирования можно осуществлять путем плавного перехода коэффициентов понижающего микширования. В первую подсекцию 1411 понижающего микширования затем можно передать коэффициенты понижающего микширования, генерируемые интерполятором коэффициентов (не показан), который хранит заданные значения коэффициентов понижающего микширования для использования в доступных форматах кодирования F1, F2 и получает в качестве входа сигнализацию S. В такой конфигурации всю вторую подсекцию 1412 понижающего микширования и первую и вторую подсекции 1413, 1414 интерполяции можно убрать или полностью деактивировать.
Сигнализация S, которую получает секция 1410 понижающего микширования, передается по меньшей мере к секциям 1413, 1414 интерполяции понижающего микширования, но не обязательно к подсекциям 1411, 1412 понижающего микширования. Необходимо передавать сигнализацию S к подсекциям 1411, 1412 понижающего микширования, если желательным является попеременное функционирование, т. е. если нужно уменьшить количество избыточного понижающего микширования вне переключений форматов кодирования. Сигнализация может представлять собой низкоуровневые команды, например, относящиеся к разным режимам работы секций 1413, 1414 интерполяции понижающего микширования, или она может быть связана с высокоуровневыми инструкциями, например, порядком выполнения заданной программы плавных переходов (например, последовательностью режимов работы, где каждый имеет заданную продолжительность) в заданной начальной точке.
На Фиг. 16 представлено возможное осуществление секции 1420 анализа, выполненной с возможностью попеременной работы, в соответствии с сигнализацией S, в двух заданных форматах кодирования F1, F2. Секция 1420 анализа содержит две подсекции 1421, 1422 анализа, выполненные с возможностью получения М-канального аудиосигнала и вывода «сухих» и «влажных» коэффициентов повышающего микширования. Эти две подсекции 1421, 1422 анализа могут представлять собой функционально эквивалентные копии одной схемы. При нормальной работе две подсекции 1421, 1422 анализа вместе обеспечивают один набор «сухих» и «влажных» коэффициентов повышающего микширования βL(F1), γL(F1) в соответствии с первым форматом кодирования F1 и/или один набор «сухих» и «влажных» коэффициентов повышающего микширования βL(F2), γL(F2) в соответствии со вторым форматом кодирования F2.
Как описано выше для секции 1420 анализа в целом, текущий сигнал понижающего микширования можно получать из секции 1410 понижающего микширования, или дубликат этого сигнала может генерироваться в секции 1420 анализа. Более точно, первая подсекция 1421 анализа может либо получать сигнал понижающего микширования L1(F1), L2(F1) в соответствии с первым форматом кодирования F1 от первой подсекции 1411 понижающего микширования секции 1410 понижающего микширования, либо может генерировать свой собственный дубликат. Аналогично вторая подсекция 1422 анализа может либо получать сигнал понижающего микширования L1(F2), L2(F2) в соответствии со вторым форматом кодирования F2 от второй подсекции 1412 понижающего микширования или может генерировать свой собственный дубликат этого сигнала.
После секций 1421, 1422 анализа расположены селектор 1423 «сухих» коэффициентов повышающего микширования и селектор 1424 «влажных» коэффициентов повышающего микширования. Селектор 1423 «сухих» коэффициентов повышающего микширования выполнен с возможностью перенаправления набора «сухих» коэффициентов повышающего микширования βL либо от первой, либо от второй подсекции 1421, 1422 анализа, а селектор 1424 «влажных» коэффициентов повышающего микширования выполнен с возможностью перенаправления набора «влажных» коэффициентов повышающего микширования γL либо от первой, либо от второй подсекции 1421, 1422 анализа. Селектор 1423 «сухих» коэффициентов повышающего микширования может работать по меньшей мере в состояниях (a) и (b), описанных выше применительно к первой секции 1413 интерполяции понижающего микширования. Однако если система кодирования, показанная на Фиг. 3, часть которой описана в данной части раздела, выполнена с возможностью совместной работы с системой декодирования, например, показанной на Фиг. 9, которая выполняет параметрическую реконструкцию на основе интерполированных дискретных значений полученных коэффициентов повышающего микширования, то нет необходимости настраивать состояние объединения, такое как (c), определенное для секций 1413, 1414 интерполяции понижающего микширования. Селектор 1424 «влажных» коэффициентов повышающего микширования может иметь сходные возможности.
Сигнализация S, которую получает секция 1420 анализа, передается по меньшей мере к селекторам 1423, 1424 «влажных» и «сухих» коэффициентов повышающего микширования. Нет необходимости в том, чтобы подсекции 1421, 1422 анализа получали сигнализацию, хотя выгодно избежать излишних вычислений коэффициентов повышающего микширования вне переходов. Сигнализация может представлять собой низкоуровневые команды, например, относящиеся к разным режимам работы селекторов 1423, 1424 «сухих» и «влажных» коэффициентов повышающего микширования, или она может быть связана с высокоуровневыми командами, такими как порядок перехода от одного формата кодирования к другому в конкретном временном интервале. Как описано выше, предпочтительно это включает операцию обеспечения плавного перехода, но может сводиться к определению значений коэффициентов повышающего микширования для подходящей временной точки или определению этих значений для применения в подходящий момент времени.
Далее будет описан способ 1700, который представляет собой вариант способа кодирования М-канального аудиосигнала в виде двухканального сигнала понижающего микширования в соответствии с одним примером осуществления, который схематически показан в виде блок-схемы на Фиг. 17. Приведенный в данной части раздела в качестве примера способ может осуществляться системой кодирования аудио, содержащей секцию 1400 кодирования, описанную выше применительно к Фиг. 14–16.
Способ 1700 кодирования аудио включает получение 1710 М-канального аудиосигнала L, LS, LB, TFL, TBL; выбор 1720 одного из по меньшей мере двух форматов кодирования F1, F2, F3, описанных применительно к Фиг. 6–8; вычисление 1730 для выбранного формата кодирования двухканального сигнала понижающего микширования L1, L2 на основе М-канального аудиосигнала L, LS, LB, TFL, TBL; вывод 1740 сигнала понижающего микширования L1, L2 выбранного формата кодирования и дополнительной информации α, позволяющей выполнить параметрическую реконструкцию М-канального аудиосигнала на основе сигнала понижающего микширования; и вывод 1750 сигнализации S, обозначающей выбранный формат кодирования. Способ повторяется, например, для каждого временного интервала М-канального аудиосигнала. Если выходной сигнал операции выбора 1720 имеет иной формат кодирования, чем тот, который был сразу выбран ранее, то сигнал понижающего микширования заменяется на подходящее время плавным переходом между сигналами понижающего микширования в соответствии с предыдущим и текущим форматами кодирования. Как уже описано выше, выполнение плавного перехода дополнительной информации, которую можно подвергнуть внутренней интерполяции на стороне декодера, является необязательным или невозможным.
Следует отметить, что способ, описанный в настоящем документе, можно реализовать без одного или более из четырех этапов 430, 440, 450 и 470, показанных на Фиг. 4.
IV. Эквиваленты, расширения, альтернативы и прочие положения
Хотя в настоящей заявке описаны и показаны конкретные примеры осуществления, изобретение не ограничивается этими конкретными примерами. В описанные выше примеры осуществления можно вносить модификации и изменения без выхода за рамки объема изобретения, который определяется только прилагаемой формулой изобретения.
В формуле изобретения слово «содержащий» не исключает других элементов или этапов, а использование единственного числа не исключает множество. Простой факт, что определенные измерения указаны во взаимно отличающихся зависимых пунктах формулы изобретения, не указывает на то, что при необходимости нельзя применить комбинацию этих измерений. Любые ссылочные позиции в формуле изобретения не должны считаться ограничивающими область изобретения.
Описанные выше устройства и способы могут быть реализованы в виде программного обеспечения, программно-аппаратного обеспечения, аппаратного обеспечения или их комбинации. В аппаратной реализации разделение задач между функциональными блоками, упомянутыми в описании выше, необязательно соответствует разделению на физические блоки; напротив, один физический компонент может иметь несколько функциональностей, и одна задача может выполняться распределенным образом несколькими физическими компонентами совместно. Определенные компоненты или все компоненты могут быть реализованы в виде программного обеспечения, исполняемого цифровым процессором, процессором сигналов или микропроцессором, или могут быть реализованы в виде аппаратного обеспечения или в виде специализированной интегральной микросхемы. Такое программное обеспечение может распространяться на машиночитаемых носителях, которые могут содержать компьютерные носители данных (или энергонезависимые носители) и средства коммуникации (или промежуточные носители). Как хорошо известно специалисту в данной области техники, термин «компьютерные носители данных» включает как энергозависимые, так и энергонезависимые, как съемные, так и несъемные носители данных, реализованные с помощью любого способа или технологии хранения информации, таких как машиночитаемые команды, структуры данных, программные модули или другие данные. Компьютерные носители данных включают, без ограничений, RAM, ROM, EEPROM, флэш-память или другие технологии памяти, CD-ROM, цифровые универсальные диски (DVD) или другие накопители на оптических дисках, магнитные кассеты, накопители на магнитной ленте, магнитных дисках, или другие магнитные устройства хранения, или любой другой носитель данных, который можно использовать для хранения нужной информации и к которому может получить доступ компьютер. Кроме того, специалисту в данной области хорошо известно, что средства коммуникации обычно реализуют машиночитаемые команды, структуры данных, программные модули или другие данные в виде модулированного сигнала данных, такого как несущая волна или другой механизм переноса, и включают какое-либо средство доставки информации.
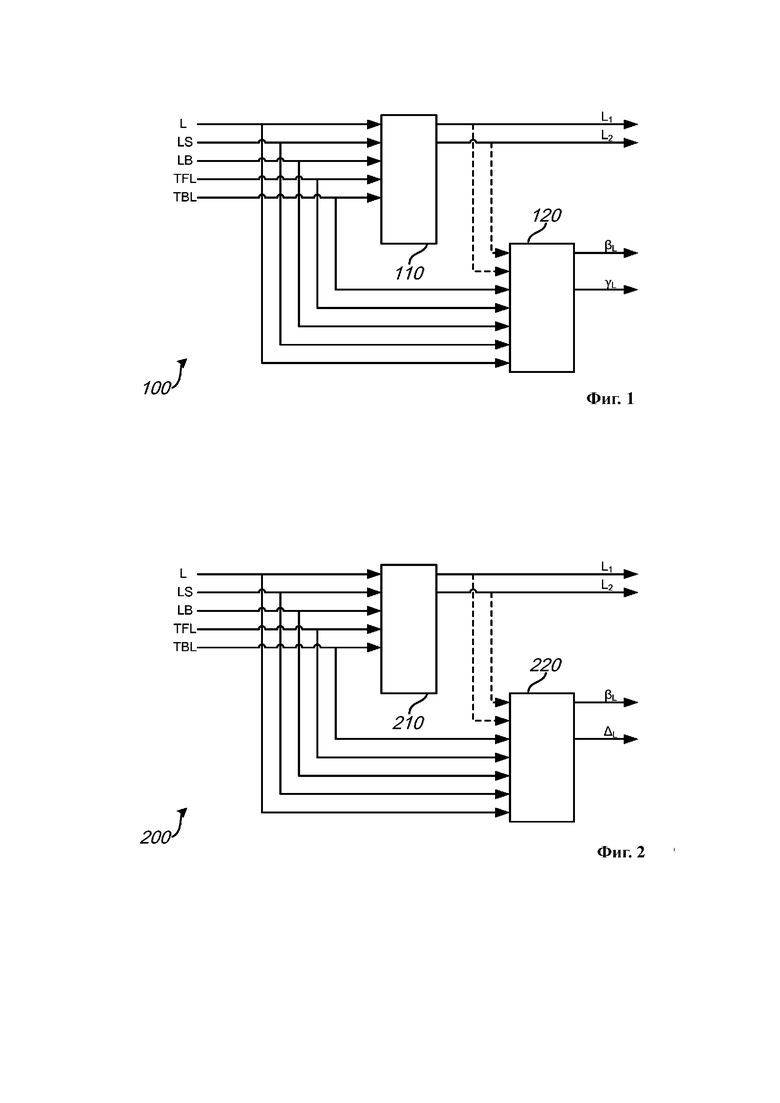
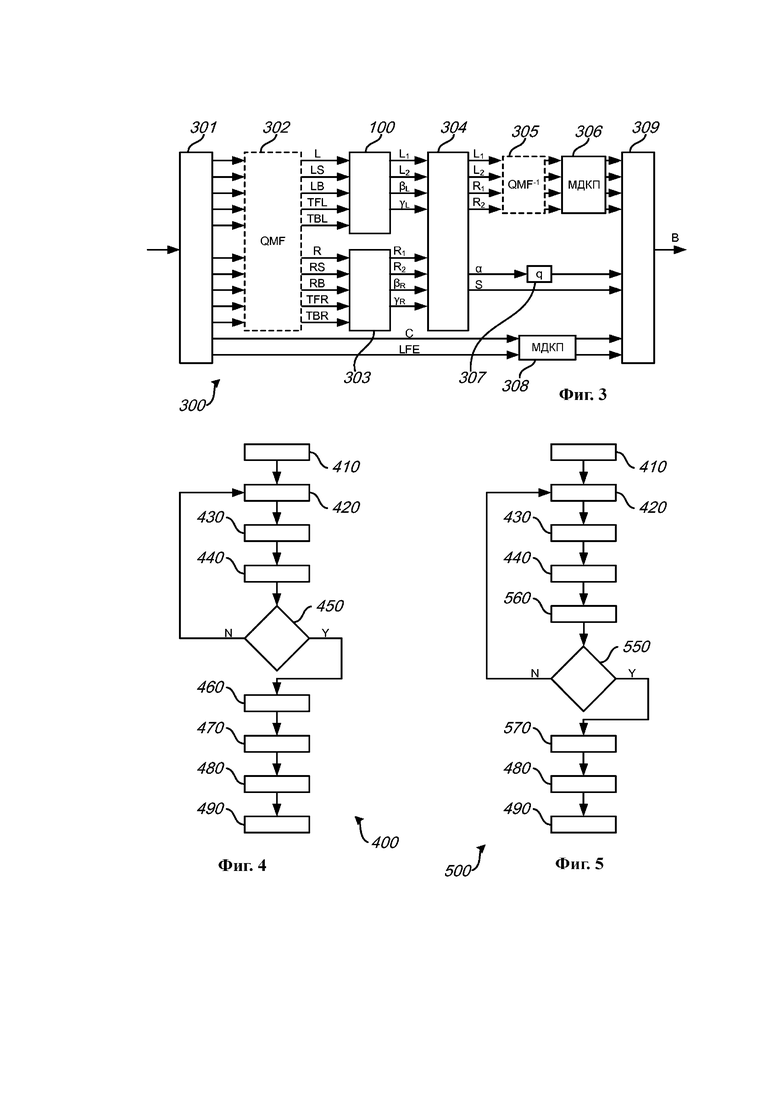
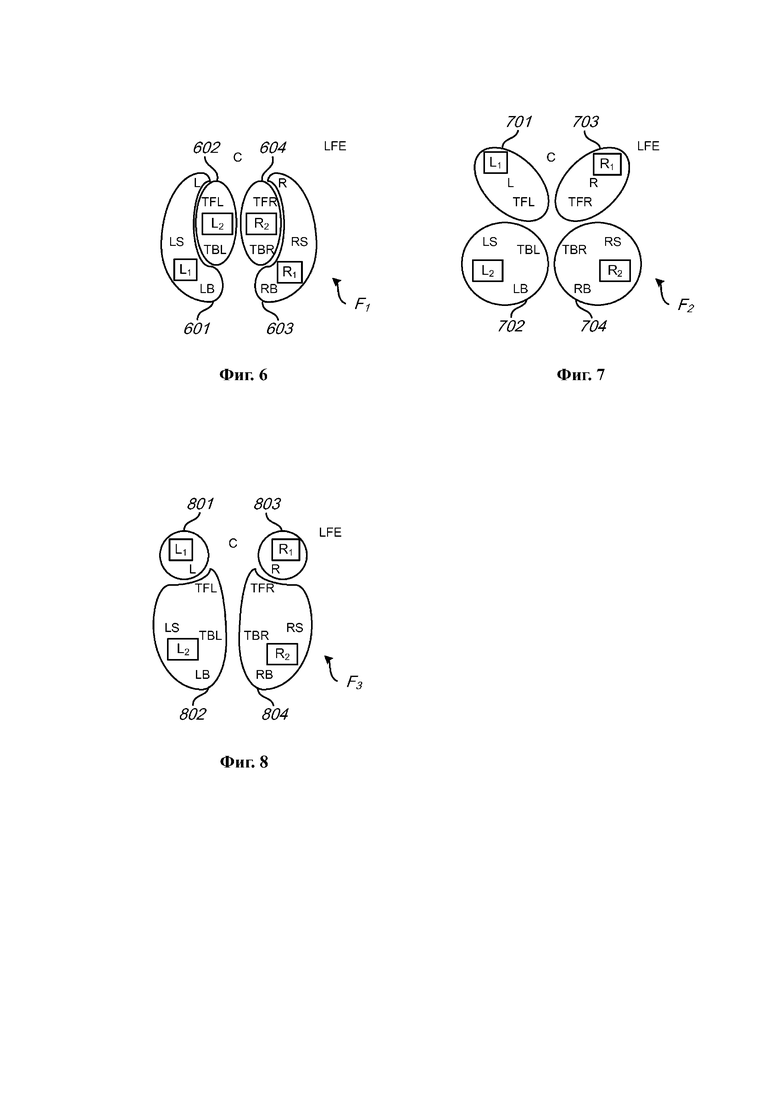
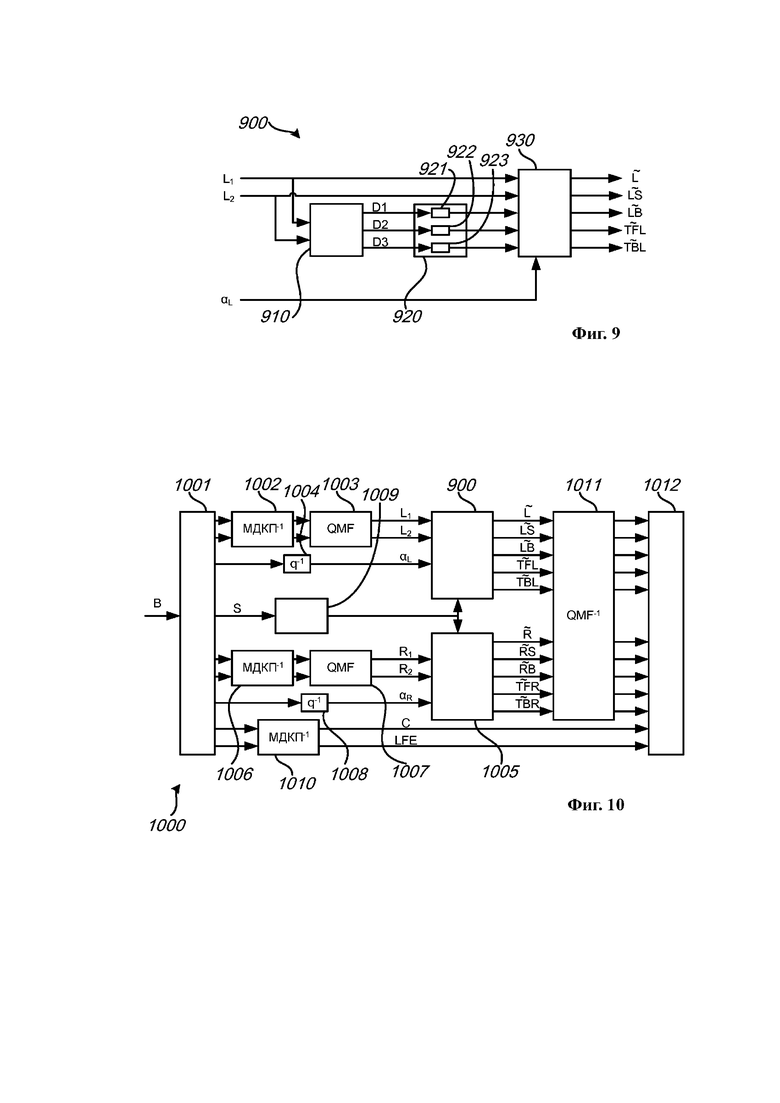
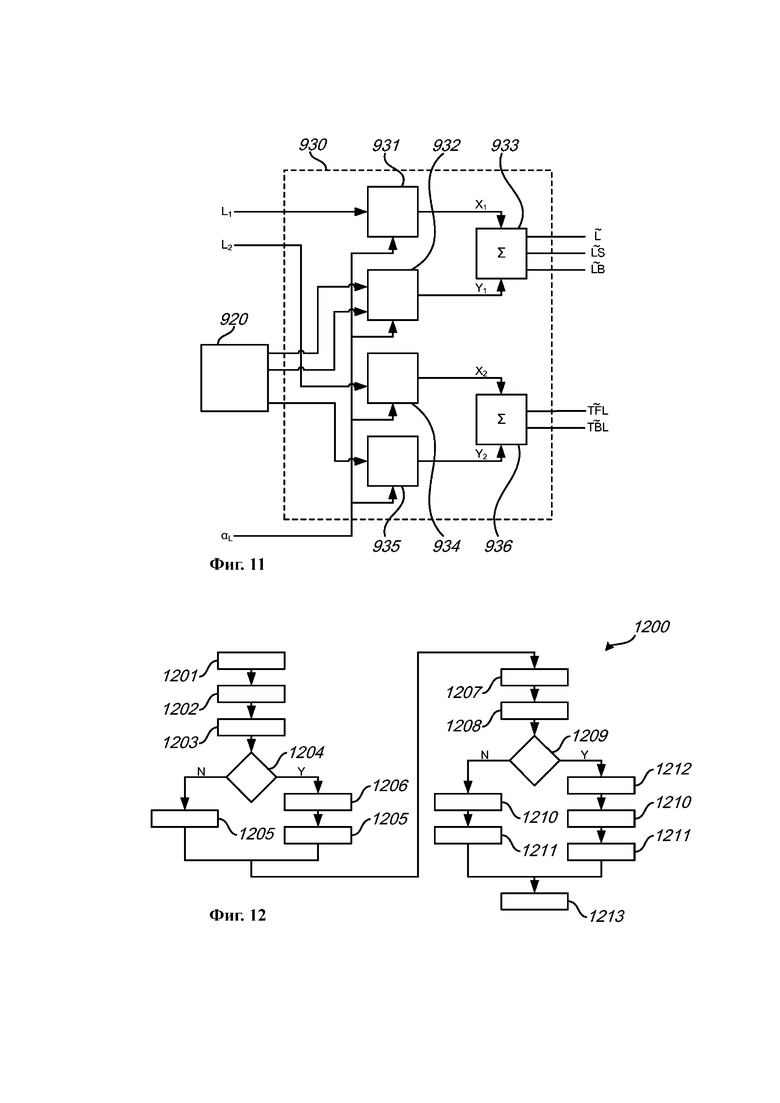
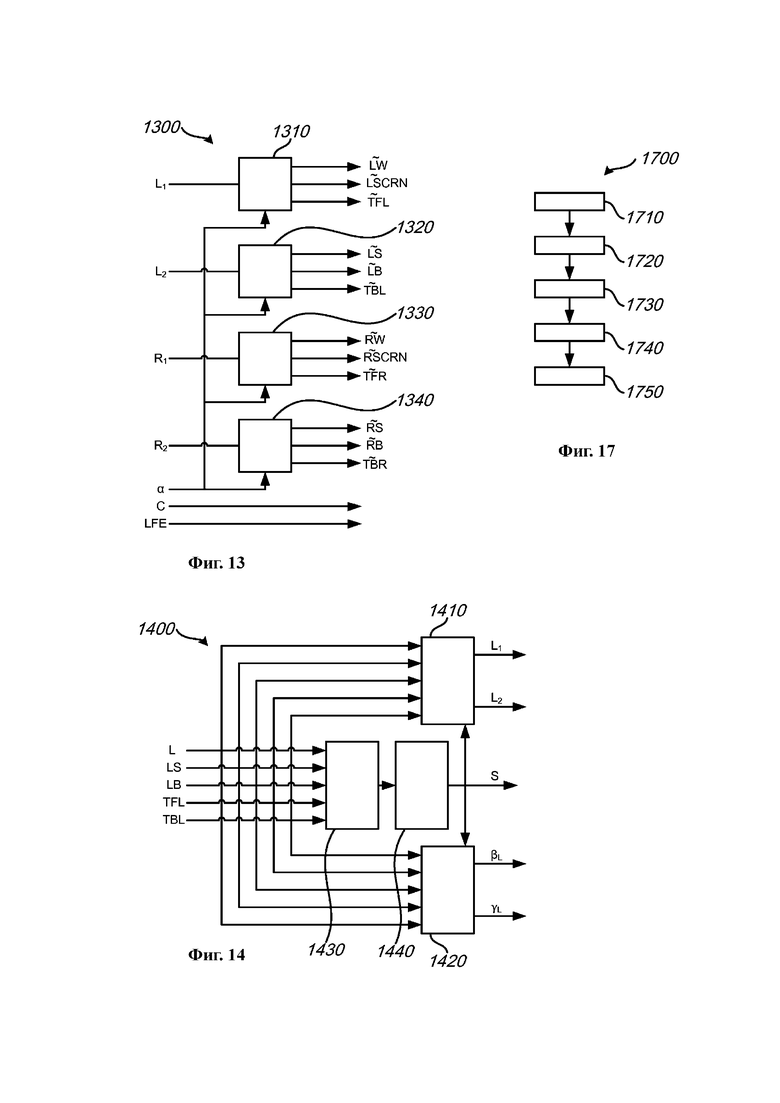
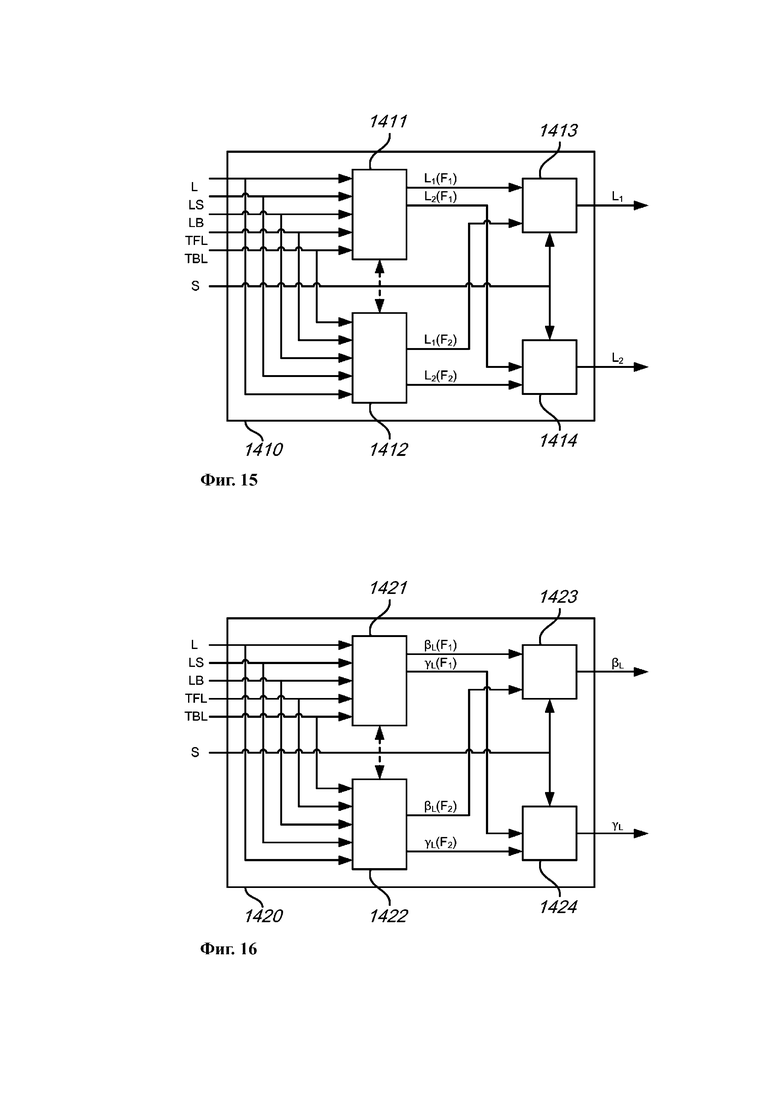
Изобретение относится к области вычислительной техники, а именно к кодированию аудиосигналов. Технический результат заключается в повышении достоверности при декодировании аудиосигнала. Способ декодирования звука, включающий, прием двухканального сигнала понижающего микширования и параметров повышающего микширования для восстановления M-канального звукового сигнала на основании сигнала понижающего микширования, прием сигнализации (S), указывающей на выбранный один из по меньшей мере двух форматов кодирования M-канального звукового сигнала, разделенным на соответствующие первую и вторую группы из одного или более каналов, вычисление первого сигнала повышающего микширования в качестве линейного отображения сигнала понижающего микширования, вычисление второго сигнала повышающего микширования в качестве линейного отображения сигнала понижающего микширования, и комбинирование первого и второго сигналов повышающего микширования с получением многомерного восстановленного сигнала, соответствующего M-канальному звуковому сигналу, при этом M-канальный звуковой сигнал имеет предварительно определенную конфигурацию канала, и указанный выбранный формат кодирования переключается между по меньшей мере двумя форматами кодирования. 2 н. и 16 з.п. ф-лы, 17 ил., 1 табл.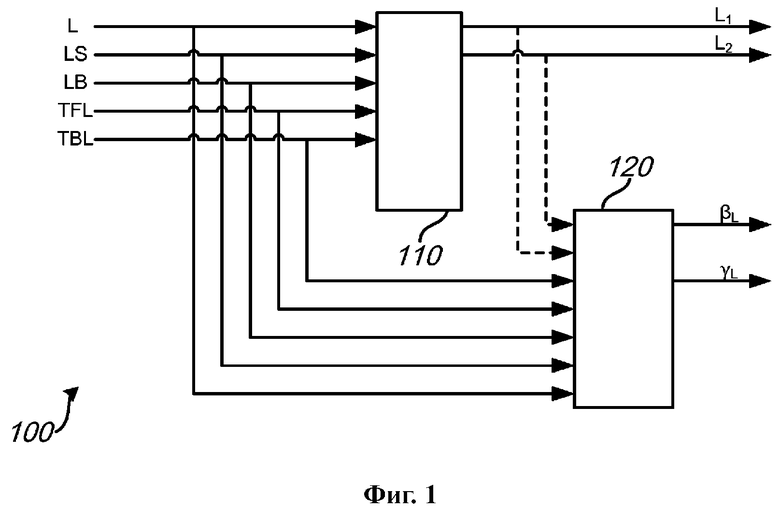
1. Способ (1200) декодирования звука, включающий:
прием (1201) двухканального сигнала понижающего микширования (L1, L2) и параметров повышающего микширования для восстановления М-канального звукового сигнала на основании сигнала понижающего микширования;
прием (1202) сигнализации (S), указывающей на выбранный один из по меньшей мере двух форматов кодирования М-канального звукового сигнала, причем форматы кодирования соответствуют каналам М-канального звукового сигнала, разделенным на соответствующие первую и вторую группы (601, 602) из одного или более каналов, причем в указанном формате кодирования первый канал сигнала понижающего микширования соответствует первой линейной комбинации одного или более каналов М-канального звукового сигнала, а второй канал сигнала понижающего микширования соответствует второй линейной комбинации одного или более каналов М-канального звукового сигнала;
вычисление первого сигнала повышающего микширования в качестве линейного отображения сигнала понижающего микширования, причем первый набор коэффициентов повышающего микширования применяют к сигналу понижающего микширования;
вычисление второго сигнала повышающего микширования в качестве линейного отображения сигнала понижающего микширования, причем второй набор коэффициентов повышающего микширования применяют к сигналу понижающего микширования; и
комбинирование (1213) первого и второго сигналов повышающего микширования с получением многомерного восстановленного сигнала, соответствующего М-канальному звуковому сигналу, подлежащему восстановлению,
отличающийся тем, что
М-канальный звуковой сигнал имеет предварительно определенную конфигурацию канала, и указанный выбранный формат кодирования переключается между по меньшей мере двумя форматами кодирования.
2. Способ декодирования звука по п. 1, отличающийся тем, что дополнительно включает определение существования набора коэффициентов на основании указанного формата кодирования.
3. Способ декодирования звука по любому из пп. 1, 2, отличающийся тем, что набор коэффициентов адаптирован на основании М-канального звукового сигнала.
4. Способ декодирования звука по любому из пп. 1-3, отличающийся тем, что дополнительно включает:
определение (1203) набора преддекорреляционных коэффициентов на основании указанного формата кодирования;
вычисление (1205) входного сигнала декорреляции (D1, D2, D3) в качестве линейного отображения сигнала понижающего микширования, причем набор преддекорреляционных коэффициентов применяют к сигналу понижающего микширования, причем преддекорреляционные коэффициенты определяют так, что первый канал (TBL) М-канального звукового сигнала делает вклад, посредством сигнала понижающего микширования, в первый фиксированный канал (D3) входного сигнала декорреляции в по меньшей мере двух форматах кодирования;
генерирование (1207) декоррелированного сигнала на основании входного сигнала декорреляции; и
определение второго сигнала повышающего микширования в качестве линейного отображения декоррелированного сигнала.
5. Способ декодирования звука по любому из пп. 1-4, отличающийся тем, что каждый из входного сигнала декорреляции и декоррелированного сигнала содержит М-2 канала, причем канал декоррелированного сигнала генерируют на основании не более чем одного канала входного сигнала декорреляции, и при этом преддекорреляционные коэффициенты определяют таким образом, что в каждом из форматов кодирования канал входного сигнала декорреляции принимает вклад не более чем одного канала сигнала понижающего микширования.
6. Способ декодирования звука по любому из пп. 1-5, отличающийся тем, что преддекорреляционные коэффициенты определяют таким образом, что дополнительно второй канал (L) М-канального звукового сигнала делает вклад посредством сигнала понижающего микширования во второй фиксированный канал (D1) входного сигнала декорреляции в по меньшей мере двух форматах кодирования; и/или при этом преддекорреляционные коэффициенты определяют таким образом, что пара каналов (LS, LB) М-канального звукового сигнала делает вклад посредством сигнала понижающего микширования в третий фиксированный канал (D2) входного сигнала декорреляции в по меньшей мере двух форматах кодирования.
7. Способ декодирования звука по любому из пп. 1-6, отличающийся тем, что дополнительно включает:
в ответ на обнаружение переключения указанного формата кодирования с первого формата кодирования на второй формат кодирования, выполнение (1206) постепенного перехода от значений преддекорреляционных коэффициентов, связанных с первым форматом кодирования, к значениям преддекорреляционных коэффициентов, связанных со вторым форматом кодирования.
8. Способ декодирования звука по любому из пп. 1-7, отличающийся тем, что в ответ на обнаружение принятой сигнализации, указывающей на первую предварительно определенную конфигурацию канала, дополнительно включает:
прием двухканального сигнала понижающего микширования (L1, L2) и связанных параметров повышающего микширования (α); и
выполнение параметрического восстановления первого звукового сигнала на основании первого канала (L1), сигнала понижающего микширования и по меньшей мере некоторых из параметров повышающего микширования.
9. Способ декодирования звука по любому из пп. 1-8, отличающийся тем, что в ответ на обнаружение принятой сигнализации, указывающей на первую предварительно определенную конфигурацию канала, дополнительно предусматривает выполнение параметрического восстановления второго звукового сигнала на основании второго канала (L2), сигнала понижающего микширования и по меньшей мере некоторых из параметров повышающего микширования.
10. Система (1000) декодирования звука, содержащая один или несколько компонентов, выполненных с возможностью выполнения способа по п. 1.
11. Система декодирования звука по п. 10, отличающаяся тем, что дополнительно предусматривает определение существования набора коэффициентов на основании указанного формата кодирования.
12. Система декодирования звука по любому из пп. 10, 11, отличающаяся тем, что набор коэффициентов адаптирован на основании М-канального звукового сигнала.
13. Система декодирования звука по любому из пп. 10-12, отличающаяся тем, что дополнительно предусматривает:
определение (1203) набора преддекорреляционных коэффициентов на основании указанного формата кодирования;
вычисление (1205) входного сигнала декорреляции (D1, D2, D3) в качестве линейного отображения сигнала понижающего микширования, причем набор преддекорреляционных коэффициентов применяют к сигналу понижающего микширования, причем преддекорреляционные коэффициенты определяют так, что первый канал (TBL) М-канального звукового сигнала делает вклад посредством сигнала понижающего микширования, в первый фиксированный канал (D3) входного сигнала декорреляции в по меньшей мере двух форматах кодирования;
генерирование (1207) декоррелированного сигнала на основании входного сигнала декорреляции; и
определение второго сигнала повышающего микширования в качестве линейного отображения декоррелированного сигнала.
14. Система декодирования звука по любому из пп. 10-13, отличающаяся тем, что каждый из входного сигнала декорреляции и декоррелированного сигнала содержит М-2 канала, причем канал декоррелированного сигнала генерируют на основании не более чем одного канала входного сигнала декорреляции, и при этом преддекорреляционные коэффициенты определяют таким образом, что в каждом из форматов кодирования канал входного сигнала декорреляции принимает вклад не более чем одного канала сигнала понижающего микширования.
15. Система декодирования звука по любому из пп. 10-14, отличающаяся тем, что преддекорреляционные коэффициенты определяют таким образом, что дополнительно второй канал (L) М-канального звукового сигнала делает вклад посредством сигнала понижающего микширования во второй фиксированный канал (D1) входного сигнала декорреляции в по меньшей мере двух форматах кодирования; и/или при этом преддекорреляционные коэффициенты определяют таким образом, что пара каналов (LS, LB) М-канального звукового сигнала делает вклад посредством сигнала понижающего микширования в третий фиксированный канал (D2) входного сигнала декорреляции в по меньшей мере двух форматах кодирования.
16. Система декодирования звука по любому из пп. 10-15, отличающаяся тем, что дополнительно предусматривает:
в ответ на обнаружение переключения указанного формата кодирования с первого формата кодирования на второй формат кодирования, выполнение (1206) постепенного перехода от значений преддекорреляционных коэффициентов, связанных с первым форматом кодирования, к значениям преддекорреляционных коэффициентов, связанных со вторым форматом кодирования.
17. Система декодирования звука по любому из пп. 10-16, отличающаяся тем, что в ответ на обнаружение принятой сигнализации, указывающей на первую предварительно определенную конфигурацию канала, дополнительно предусматривает:
прием двухканального сигнала понижающего микширования (L1, L2) и связанных параметров повышающего микширования (α); и
выполнение параметрического восстановления первого звукового сигнала на основании первого канала (L1), сигнала понижающего микширования и по меньшей мере некоторых из параметров повышающего микширования.
18. Система декодирования звука по любому из пп. 10-17, отличающаяся тем, что в ответ на обнаружение принятой сигнализации, указывающей на первую предварительно определенную конфигурацию канала, дополнительно предусматривает выполнение параметрического восстановления второго звукового сигнала на основании второго канала (L2), сигнала понижающего микширования и по меньшей мере некоторых из параметров повышающего микширования.
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ СИНТЕЗИРОВАНИЯ ВЫХОДНОГО СИГНАЛА | 2008 |
|
RU2439719C2 |
