Данная заявка имеет отношение к звуковому кодированию, использующему понижающее микширование сигналов.
Было предложено много алгоритмов звукового кодирования, чтобы эффективно закодировать или сжать звуковые данные одного канала, то есть монозвуковые сигналы. Используя психоакустику, звуковые образцы соответственно масштабированы, квантованы или даже установлены на ноль, чтобы удалить ненужное из, например, РСМ (импульсно-кодовая модуляция) закодированного звукового сигнала. Выполняется также удаление избыточности.
В качестве следующего шага используется подобие между левым и правым каналом звуковых стереосигналов, чтобы эффективно кодировать/сжимать звуковые стереосигналы.
Однако поступающие заявки излагают дальнейшие требования к алгоритмам звукового кодирования. Например, в телеконференциях, компьютерных играх, исполнении музыки и т.п. несколько звуковых сигналов, которые частично или даже полностью некоррелированные, должны быть переданы параллельно. Чтобы поддерживать необходимую скорость передачи битов для кодирования этих звуковых сигналов достаточно низкой, чтобы соответствовать требованиям низкоскоростной битовой передачи, недавно были предложены звуковые кодер-декодеры, которые микшируют с понижением многократные входные звуковые сигналы в сигнал понижающего микширования, такой как стерео- или даже моносигнал понижающего микширования. Например, MPEG (Экспертная группа по кинематографии) Стандарт объемного звучания микширует с понижением входные каналы в сигнал понижающего микширования способом, предписанным стандартом. Понижающее микширование выполняется при помощи так называемого ОТТ-1 (один-к-двум) и ТТТ-1 (два-к-трем) блока для понижающего микширования двух сигналов в один и трех сигналов в два соответственно. Чтобы микшировать с понижением более трех сигналов, используется иерархическая структура этих блоков. Каждый блок ОТТ-1, помимо моносигнала понижающего микширования, выводит разность уровней каналов между двумя входными каналами, так же как межканальные параметры когерентной/взаимной корреляции, представляющие когерентную или взаимную корреляцию между двумя входными каналами. Параметры выводятся наряду с сигналом понижающего микширования MPEG кодера объемного звучания в пределах MPEG объемного потока данных. Точно так же каждый блок ТТТ-1 передает коэффициенты предсказания канала, позволяющие восстановить три входных канала из получающегося стереосигнала понижающего микширования. Коэффициенты предсказания канала также передаются как дополнительная информация в пределах MPEG объемного потока данных. MPEG декодер объемного звучания микширует с повышением сигнал понижающего микширования при помощи переданной дополнительной информации и восстанавливает его; оригинальные каналы входят в MPEG кодирующее устройство объемного звучания.
Однако MPEG объемное звучание, к сожалению, не отвечает всем требованиям, изложенным во многих заявках. Например, MPEG декодер объемного звучания предназначен для повышающего микширования сигнала понижающего микширования MPEG кодирующего устройства объемного звучания таким образом, что входные каналы MPEG кодирующего устройства объемного звучания восстанавливаются, как они есть. Другими словами, MPEG объемный поток данных предназначен для его воспроизведения при помощи конфигурации громкоговорителя, используемой для кодирования.
Однако согласно некоторым выводам было бы полезно, если бы конфигурация громкоговорителя могла бы быть изменена на стороне декодера.
Чтобы соответствовать последним требованиям, в настоящее время разрабатывается кодирующий стандарт пространственного звукового объекта (SAOC). Каждый канал рассматривается как индивидуальный объект, и все объекты микшируются с понижением в сигнал понижающего микширования. Однако, кроме того, индивидуальные объекты могут также включать индивидуальные звуковые источники, например инструменты или речевые каналы. Однако в отличие от MPEG декодера объемного звучания декодер SAOC способен индивидуально микшировать с повышением сигнал понижающего микширования, чтобы воспроизводить индивидуальные объекты на любой конфигурации громкоговорителя. Чтобы позволить декодеру SAOC восстанавливать закодированные индивидуальные объекты в потоке данных SAOC, различия уровней объекта и для объектов, создающих вместе стерео (или многоканальный) сигнал, параметры межобъектной взаимной корреляции передаются как дополнительная информация в пределах SAOC битового потока. Помимо этого, SAOC декодер/транскодер обеспечивается информацией о том, как индивидуальные объекты были понижающее микшированы в сигнал понижающего микширования. Таким образом, на стороне декодера можно восстанавливать индивидуальные каналы SAOC и выводить эти сигналы на любую конфигурацию громкоговорителя, используя предоставляемую информацию, контролируемую пользователем.
Однако, хотя кодер-декодер SAOC был разработан для индивидуального управления звуковыми объектами, некоторые заявки предъявляют более высокие требования. Например, применение для режима Караоке требует полного отделения фонового звукового сигнала от звукового сигнала переднего плана или звуковых сигналов переднего плана. Наоборот, в сольном режиме объекты переднего плана должны быть отделены от фоновых объектов. Однако вследствие равной обработки индивидуальных звуковых объектов было невозможно полностью удалить фоновые объекты или объекты переднего плана соответственно из сигнала понижающего микширования.
Таким образом, цель данного изобретения - обеспечить звуковой кодер-декодер, используя понижающее микширование звуковых сигналов таким образом, чтобы достигнуть наилучшего разделения индивидуальных объектов, таких как, например, применимые в режиме Караоке/соло.
Эта цель достигается посредством звукового декодера по п.1, звукового кодирующего устройства по п.18, способа декодирования по п.20, способа кодирования по п.21 и многообъектного звукового сигнала по п.23.
Со ссылкой на чертежи предпочтительные осуществления данного применения описаны более подробно.
Фиг.1 показывает блок-схему компоновки кодирующего устройства/декодера SAOC, в которой могут быть реализованы осуществления данного изобретения;
Фиг.2 показывает схематическую и иллюстративную диаграмму спектрального представления монозвукового сигнала;
Фиг.3 показывает блок-схему звукового декодера согласно осуществлению данного изобретения;
Фиг.4 показывает блок-схему звукового кодирующего устройства согласно осуществлению данного изобретения;
Фиг.5 показывает блок-схему компоновки звукового кодирующего устройства/декодера для использования в режиме Караоке/соло, как сравнительное осуществление;
Фиг.6 показывает блок-схему компоновки звукового кодирующего устройства/декодера для применения в режиме Караоке/соло согласно осуществлению;
Фиг.7а показывает блок-схему звукового кодирующего устройства для применения в режиме Караоке/соло согласно сравнительному осуществлению;
Фиг.7b показывает блок-схему звукового кодирующего устройства для применения в режиме Караоке/соло согласно осуществлению;
Фиг.8а и b показывают графики результатов качественных измерений;
Фиг.9 показывает блок-схему компоновки звукового кодирующего устройства /декодера для применения в режиме Караоке/соло в целях сравнения;
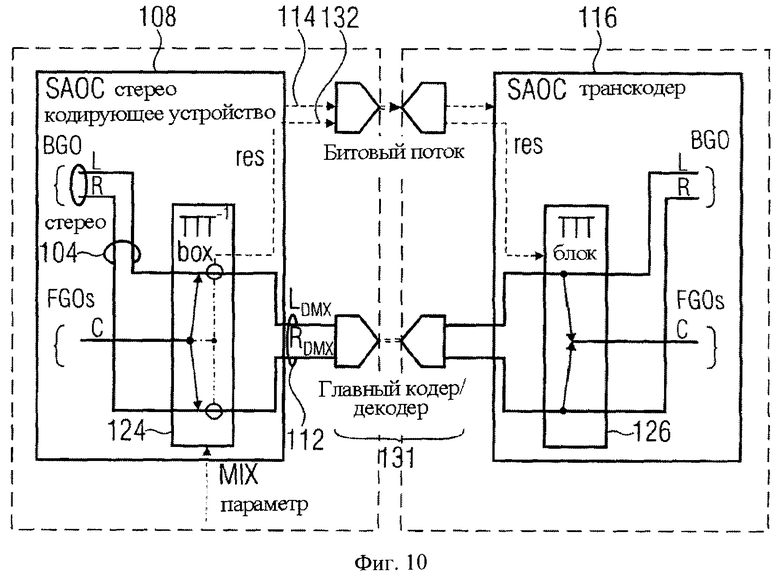
Фиг.10 показывает блок-схему компоновки звукового кодирующего устройства/декодера для применения в режиме Караоке/соло согласно осуществлению;
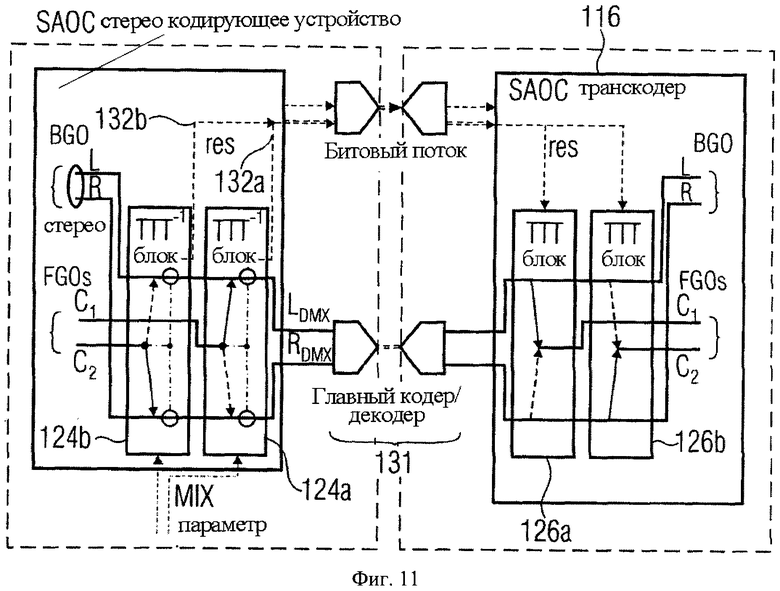
Фиг.11 показывает блок-схему компоновки звукового кодирующего устройства/декодера для применения в режиме Караоке/соло согласно дальнейшему осуществлению;
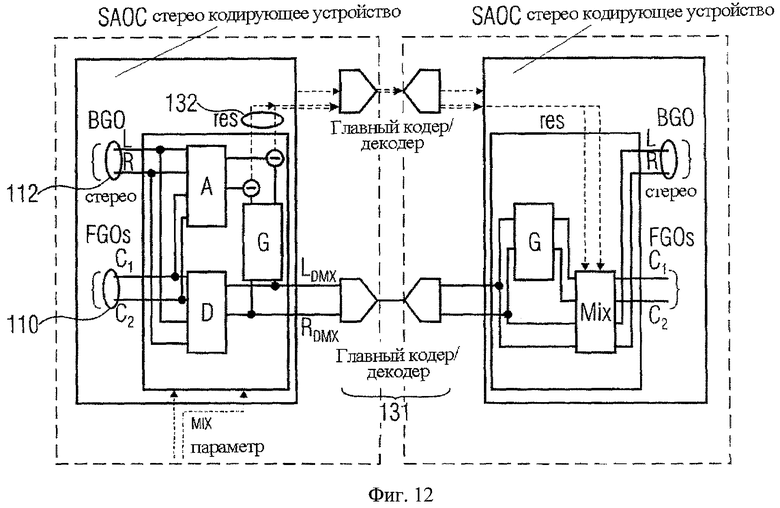
Фиг.12 показывает блок-схему компоновки звукового кодирующего устройства/декодера для применения в режиме Караоке/соло согласно дальнейшему осуществлению;
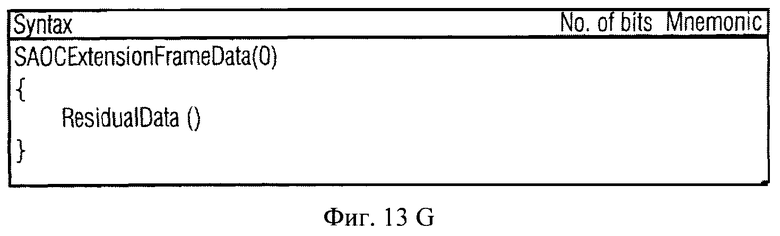
Фиг.13a-h показывает таблицы, отражающие возможный синтаксис для SOAC битового потока согласно осуществлению данного изобретения;
Фиг.14 показывает блок-схему звукового декодера для применения в режиме Караоке/соло согласно осуществлению; и
Фиг.15 показывает таблицу, отражающую возможный синтаксис для передачи информации о количестве данных, потраченных на передачу остаточного сигнала.
Прежде чем осуществления данного изобретения будут описаны более подробно, предоставляются кодер-декодер SAOC и параметры SAOC, переданные в SAOC битовый поток, чтобы облегчить понимание определенных осуществлений, более детально обрисованных в дальнейшем.
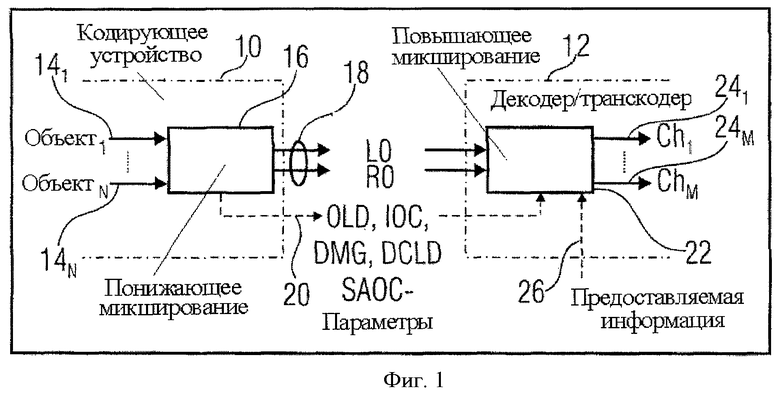
Фиг.1 показывает общую компоновку кодирующего устройства SAOC 10 и декодера SAOC 12. Кодирующее устройство SAOC 10 получает в качестве входа N объекты, то есть звуковые сигналы 141-14N. В частности, кодирующее устройство 10 включает понижающий микшер 16, который получает звуковые сигналы 141-14N и микширует с понижением их же до сигнала понижающего микширования 18. На фиг.1 сигнал понижающего микширования, например, показан как стереосигнал понижающего микширования. Однако возможен также моносигнал понижающего микширования. Каналы стереосигнала понижающего микширования 18 обозначены L0 и R0, в случае монопонижающего микширования то же самое обозначается просто L0. Чтобы обеспечить декодеру SAOC 12 возможность восстанавливать индивидуальные объекты 141-14N, понижающий микшер 16 предоставляет декодеру SAOC 12 дополнительную информацию, включая SAOC-параметры, в том числе разности уровней объекта (OLD), параметры межобъектной взаимной корреляции (IOC), коэффициенты усиления понижающего микширования (DMG) и разности уровней канала понижающего микширования (DCLD). Дополнительная информация 20, включая SAOC-параметры, наряду с сигналом понижающего микширования 18 формирует выходной поток данных SAOC, полученный декодером SAOC 12.
Декодер SAOC 12 включает повышающий микшер 22, который получает сигнал понижающего микширования 18, а также и дополнительную информацию 20, чтобы восстанавливать и передавать звуковые сигналы 141 и 14N на любой выбранный пользователем ряд каналов 241-24M с предоставлением предписанной предоставляемой информации 26, вводимой в декодер SAOC 12.
Звуковые сигналы 141-14N могут быть введены в понижающий микшер 16 в любую кодирующую область, такую как, например, временная или спектральная область. В случае, если звуковые сигналы 141-14N подаются в понижающий микшер 16 во временную область, такую как закодированный РСМ, понижающий микшер 16 использует блок фильтров, такой как гибридный блок QMF (квадратурный зеркальный фильтр), то есть блок комплексных экспоненциально смодулированных фильтров с расширением фильтра по Найквисту для самых низких частотных диапазонов, чтобы увеличить там частотное разрешение, чтобы передавать сигналы в спектральную область, в которой звуковые сигналы представлены в нескольких поддиапазонах, связанных с различными спектральными частями, при определенном разрешении блока фильтров. Если звуковые сигналы 141-14N уже находятся в представлении, ожидаемом понижающим микшером 16, спектральное разложение не должно выполняться.
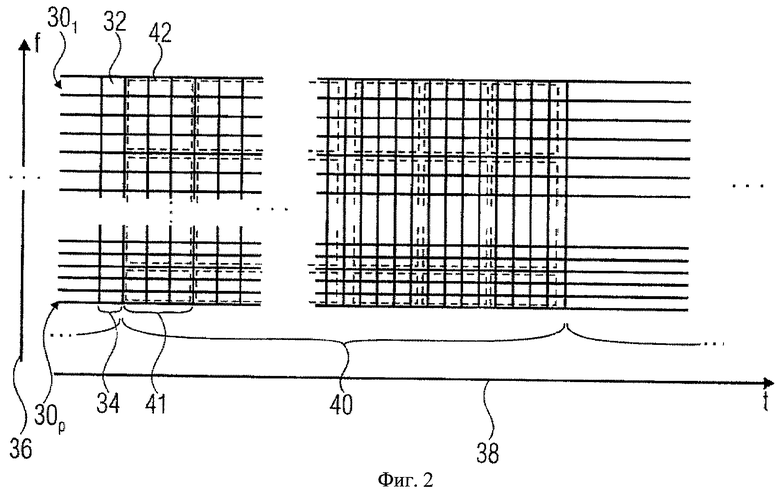
Фиг.2 показывает звуковой сигнал в только что упомянутой спектральной области. Можно заметить, что звуковой сигнал представлен как множество сигналов поддиапазона. Каждый сигнал поддиапазона 301-30P состоит из последовательности значений поддиапазонов, обозначенных маленькими прямоугольниками 32. Как видно, значения поддиапазонов 32 сигналов поддиапазонов 301-30P синхронизированы друг с другом во времени так, чтобы для каждой последовательной временной области блока фильтров 34 каждый поддиапазон 301-30P включал одно точное значение поддиапазона 32. Как показано посредством частотной оси 36, сигналы поддиапазонов 301-30P связаны с различными частотными областями и, как показано посредством временной оси 38, временные области блока фильтров 34 последовательно организованы во времени.
Как в общих чертах обрисовано выше, понижающий микшер 16 вычисляет SAOC-параметры из входных звуковых сигналов 141-14N. Понижающий микшер 16 выполняет это вычисление в частотном/временном разрешении, которое может быть уменьшено относительно оригинального частотного/временного разрешения, как определено временными областями блока фильтров 34 и разложением поддиапазона, на определенную величину, при этом эта определенная величина передается на декодер в рамках дополнительной информации 20 посредством соответствующих элементов синтаксиса bsFrameLength и bsFreqRes. Например, группы последовательных временных областей блока фильтров 34 могут сформировать структуру 40. Другими словами, звуковой сигнал может быть разделен на структуры, накладывающиеся во времени или являющиеся непосредственно смежными во времени, например. В этом случае bsFrameLength может определять число параметрических временных областей 41, то есть единиц времени, в которых параметры SAOC, такие как OLD и IOC, вычисляются в SAOC структуре 40, а bsFreqRes может определять число оперативных частотных диапазонов, для которых вычисляются SAOC параметры. Посредством этого каждая структура разделяется на частотные/временные элементы, проиллюстрированные на фиг.2 пунктирными линиями 42.
Понижающий микшер 16 вычисляет параметры SAOC в соответствии со следующими формулами. В частности, понижающий микшер 16 вычисляет разности уровней объекта для каждого объекта i как
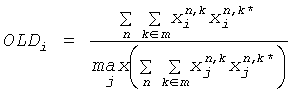
где суммы и индексы n и k соответственно проходят через все временные области блока фильтров 34, и все поддиапазоны блока фильтров 30, которые принадлежат определенному частотному/временному элементу 42. Таким образом, энергии всех значений поддиапазона xi звукового сигнала или объекта i суммируются и нормализуются до самого высокого значения энергии этого элемента среди всех объектов или звуковых сигналов.
Далее, SAOC понижающий микшер 16 может вычислять меру подобия соответствующих частотных/временных элементов пар различных входных объектов 141-14N. Хотя SAOC понижающий микшер 16 может вычислять меру подобия между всеми парами входных объектов 141-14N, понижающий микшер 16 может также подавлять передачу сигналов меры подобия или ограничивать вычисление мер подобия для звуковых объектов 141-14N, которые формируют левый или правый каналы общего стереоканала. В любом случае, мерой подобия называется параметр межобъектной взаимной корреляции IOCi,j. Вычисление выглядит следующим образом
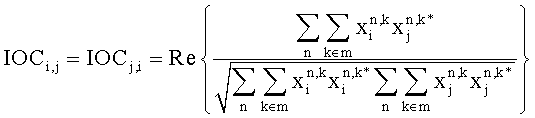
где снова индексы n и k проходят через все значения поддиапазонов, принадлежащих определенному частотному/временному элементу 42, а i и j обозначают определенную пару звуковых объектов 141-14N.
Понижающий микшер 16 микширует с понижением объекты 141-14N при помощи коэффициентов усиления, применяемых к каждому объекту 141-14N. Таким образом, коэффициент усиления Di применяется к объекту i и затем все взвешенные таким образом объекты 141-14N суммируются, чтобы получить моносигнал понижающего микширования. В случае стереосигнала понижающего микширования, как показано на фиг.1, коэффициент усиления D1, i применяется к объекту i, и затем все такие усиленные объекты суммируются, чтобы получить левый канал понижающего микширования L0, а коэффициенты усиления D2,i, применяется к объекту i, и затем усиленные таким образом объекты суммируются, чтобы получить правый канал понижающего микширования R0.
Это предписание понижающего микширования сообщается декодеру посредством коэффициентов усиления понижающего микширования DMGi, а в случае понижающего микширования стереосигнала посредством разности уровней каналов понижающего микширования DCLDi.
Коэффициенты усиления понижающего микширования вычисляются согласно:
DMGi=20log10 (Di+ε), (монопонижающее микширование),
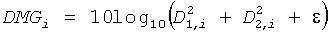 , (стереопонижающее микширование),
, (стереопонижающее микширование),
где ε - маленькое число, такое как 10-9.
Для DCLDs применяется следующая формула:
 .
.
В нормальном режиме понижающий микшер 16 производит сигнал понижающего микширования согласно:
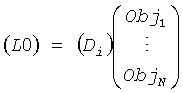
для монопонижающего микширования или
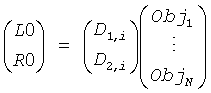
для стереопонижающего микширования соответственно.
Таким образом, в вышеупомянутых формулах параметры OLD и IOC являются функцией звуковых сигналов, а параметры DMG и DCLD - функция D. Между прочим, замечено, что D может изменяться во времени.
Таким образом, в нормальном режиме понижающий микшер 16 смешивает все объекты 141-14N без предпочтения, то есть с одинаковой обработкой всех объектов 141-14N.
Повышающий микшер 22 выполняет инверсию процедуры понижающего микширования и реализует «предоставляемую информацию», представленную матрицей А в одном этапе вычисления, а именно
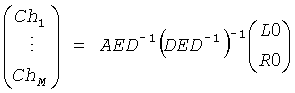 ,
,
где матрица Е является функцией параметров OLD и IOC.
Другими словами, в нормальном режиме не выполняется никакая классификация объектов 141-14N на BGO, то есть фоновый объект, или FGO, то есть объект переднего плана. Информация, относительно которой объект должен быть представлен на выходе повышающего микшера 22, должна предоставляться передающей матрицей А. Если, например, объект с индексом 1 - левый канал фонового стерео объекта, объект с индексом 2 - его правый канал, а объект с индексом 3 - объект переднего плана, то передающая матрица А будет
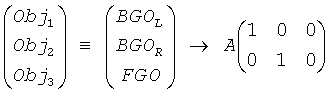
чтобы произвести выходной сигнал типа караоке.
Однако, как уже было указано выше, передавая BGO и FGO при помощи этого нормального режима, кодер-декодер SAOC не достигает приемлемых результатов.
Фиг.3 и 4 описывают осуществление данного изобретения, которое преодолевает только что описанный недостаток. Декодер и кодирующее устройство, описанное на этих Фиг., и связанные с ними функциональные возможности могут представлять дополнительный режим, такой как «расширенный режим», в который кодер-декодер SAOC фиг.1 может быть переключен. Примеры последней возможности будут представлены в дальнейшем.
Фиг.3 показывает декодер 50. Декодер 50 включает средство 52 для вычисления коэффициентов предсказания и средство 54 для повышающего микширования сигнала понижающего микширования.
Звуковой декодер 50 фиг.3 предназначен для декодирования многообъектного звукового сигнала, имеющего звуковой сигнал первого типа и звуковой сигнал второго типа, закодированные в нем. Звуковой сигнал первого типа и звуковой сигнал второго типа могут быть соответственно моно- или стереозвуковым сигналом. Звуковой сигнал первого типа, например фоновый объект, тогда как звуковой сигнал второго типа - объект переднего плана. Таким образом, осуществление фиг.3 и фиг.4 не обязательно ограничено применением в режиме Караоке/соло. Скорее декодер фиг.3 и кодирующее устройство фиг.4 могут преимущественно использоваться в где-то еще.
Многообъектный звуковой сигнал состоит из сигнала понижающего микширования 56 и дополнительной информации 58. Дополнительная информация 58 включает информацию об уровне 60, описывающую, например, спектральные энергии звукового сигнала первого типа и звукового сигнала второго типа в первом предопределенном частотном/временном разрешении, таком как, например, частотное/временное разрешение 42. В частности, информация об уровне 60 может включать нормализованное спектральное скалярное значение энергии на объект и временной/частотный элемент. Нормализация может быть связана с самым высоким спектральным значением энергии среди звуковых сигналов первого и второго типа в соответствующем временном/частотном элементе. Последняя возможность приводит к OLDs для предоставления информации об уровне, здесь также называемой информацией о разности уровней. Хотя следующие осуществления используют OLDs, они могут, хотя это не однозначно установлено, использовать иначе нормализованное спектральное представление энергии.
Дополнительная информация 58 включает также остаточный сигнал 62, определяющий остаточные значения уровня во втором предопределенном временном/частотном разрешении, которое может быть равным или может отличаться от первого предопределенного временного/частотного разрешения.
Средство 52 для вычисления коэффициентов предсказания формируется для вычисления коэффициентов предсказания на основе информации об уровне 60. Дополнительно, средство 52 может вычислять коэффициенты предсказания, далее основанные на информации о межкорреляции, также состоящей из дополнительной информации 58. Далее, средство 52 может использовать предписанную информацию о зависящем от времени понижающем микшировании, состоящую из дополнительной информации 58, чтобы вычислять коэффициенты предсказания. Коэффициенты предсказания, вычисленные средством 52, необходимы для поиска или повышающего микширования оригинальных звуковых объектов или звуковых сигналов из сигнала понижающего микширования 56.
Соответственно, средство 54 для повышающего микширования формируется для выполнения повышающего микширования сигнала понижающего микширования 56 на основе коэффициентов предсказания 64, полученных из средства 52 и остаточного сигнала 62. Используя остаточный сигнал 62, декодер 50 может лучше подавлять передачу ненужных данных от звукового сигнала одного типа к звуковому сигналу другого типа. В дополнение к остаточному сигналу 62 средство 54 может использовать зависящее от времени понижающее микширование, чтобы микшировать с повышением сигнал понижающего микширования. Далее, средство 54 для повышающего микширования может использовать пользовательский вход 66, чтобы решить, какой из звуковых сигналов восстановлен из сигнала понижающего микширования 56, который будет фактически произведен на выходе 68, или до какой степени. В качестве первого экстремального значения пользовательский вход 66 может указывать средству 54 производить только первый сигнал повышающего микширования, приближающийся к звуковому сигналу первого типа. Противоположное верно для второго экстремального значения согласно тому, какое из средств 54 должно произвести только второй сигнал повышающего микширования, приближающийся к звуковому сигналу второго типа. Возможны также промежуточные варианты согласно которым смесь обоих сигналов повышающего микширования предоставляет выход на выходе 68.
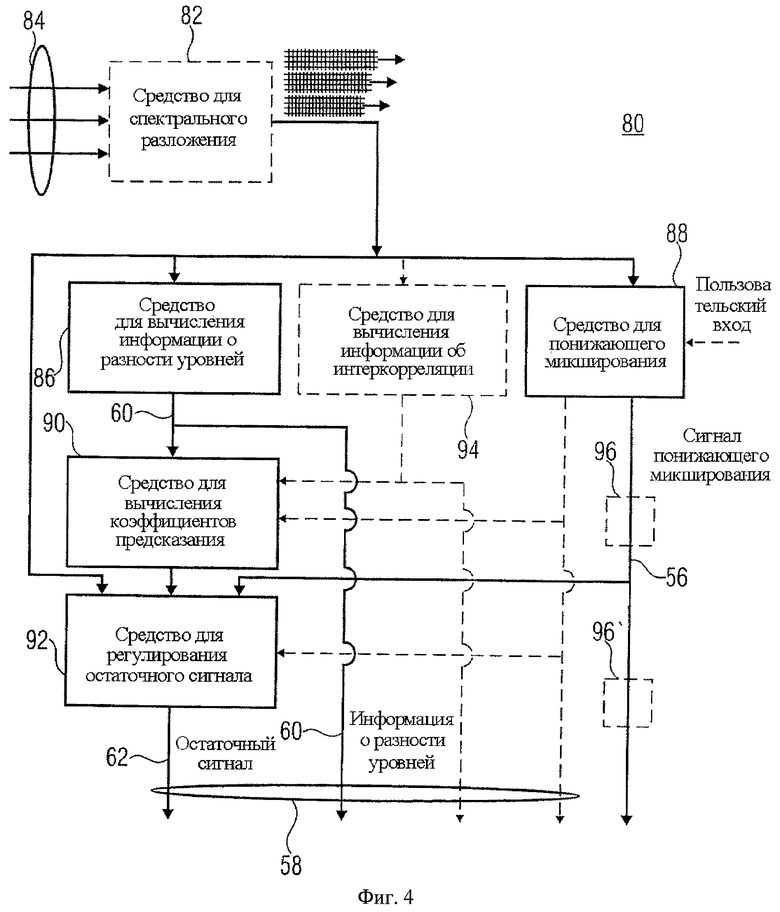
Фиг.4 показывает осуществление для звукового кодирующего устройства для производства многообъектного звукового сигнала, расшифрованного декодером фиг.3. Кодирующее устройство фиг.4, которое обозначено ссылочным номером 80, может включать средство 82 для спектрального разложения в случае, если звуковые сигналы 84 должны быть закодированы, не находятся в пределах спектральной области. Среди звуковых сигналов 84, в свою очередь, имеется, по крайней мере, один звуковой сигнал первого типа и, по крайней мере, один звуковой сигнал второго типа. Средство 82 для спектрального разложения формируется, чтобы спектрально разложить каждый из этих сигналов 84 в представлении, как показано на фиг.2, например. Таким образом, средство 82 для спектрального разложения спектрально разлагает звуковой сигнал 84 в предопределенном временном/частотном разрешении. Средство 82 может включать блок фильтров, такой как гибридный блок QMF.
Звуковое кодирующее устройство 80 далее включает средство 86 для вычисления информации об уровне, средство 88 для понижающего микширования, средство 90 для вычисления коэффициентов предсказания и средство 92 для регулирования остаточного сигнала. Дополнительно, звуковое кодирующее устройство 80 может включать средство для вычисления информации о межкорреляции, а именно средство 94. Средство 86 вычисляет информацию об уровне, описывающую уровень звукового сигнала первого типа и звукового сигнала второго типа в первом предопределенном временном/частотном разрешении из звукового сигнала как произвольно произведенное средством 82. Точно так же средство 88 микширует с понижением звуковые сигналы. Средство 88, таким образом, производит сигнал понижающего микширования 56. Средство 86 также производит информацию об уровне 60. Средство 90 для вычисления коэффициентов предсказания действует так же, как средство 52. Таким образом, средство 90 вычисляет коэффициенты предсказания из информации об уровне 60 и производит коэффициенты предсказания 64 для средства 92. Средство 92, в свою очередь, устанавливает остаточный сигнал 62, основанный на сигнале понижающего микширования 56, коэффициентах предсказания 64 и оригинальных звуковых сигналах во втором предопределенном временном/частотном разрешении таким образом, что повышающее микширование сигнала понижающего микширования 56, основанное и на коэффициентах предсказания 64 и на остаточном сигнале 62, приводит к первому звуковому сигналу повышающего микширования, приближенному к звуковому сигналу первого типа, и ко второму звуковому сигналу повышающего микширования, приближенному к звуковому сигналу второго типа; согласованное приближение сравнимо с отсутствием остаточного сигнала 62.
Остаточный сигнал 62 и информация об уровне 60 состоят из дополнительной информации 58, которая формирует, наряду с сигналом понижающего микширования 56 многообъектный звуковой сигнал, подлежащий расшифровке декодером фиг.3.
Как показано на фиг.4 и аналогично описанию фиг.3, средство 90 может дополнительно использовать информацию о межкорреляции, произведенную средством 94, и/или зависящее от времени предписание понижающего микширования, произведенное средством 88, чтобы вычислить коэффициент предсказания 64. Далее, средство 92 для регулирования остаточного сигнала 62 может дополнительно использовать зависящее от времени предписание понижающего микширования, произведенное средством 88, чтобы надлежащим образом установить остаточный сигнал 62.
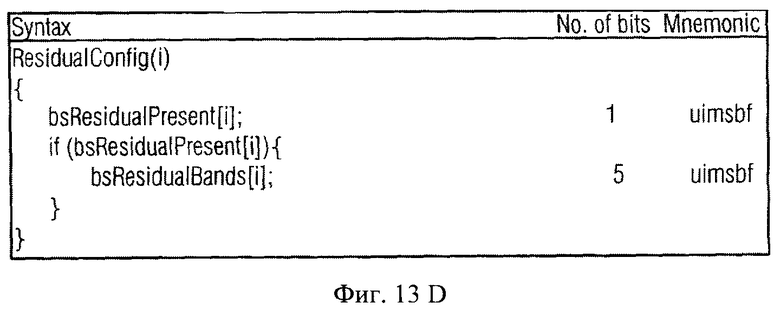
Следует снова отметить, что звуковой сигнал первого типа может быть моно- или стереозвуковым сигналом. То же самое касается звукового сигнала второго типа. Остаточный сигнал 62 может быть передан в рамках дополнительной информации в том же самом временном/частотном разрешении, поскольку параметр временного/частотного разрешения используется для вычисления, например, информации об уровне, или может использовать другое временное/частотное разрешение. Далее, вполне возможно, что передача остаточного сигнала ограничена подчастью спектрального диапазона, занятого временными/частотными элементами 42, для которых передается информация об уровне. Например, временное/частотное разрешение, в котором передается остаточный сигнал, может быть обозначено в рамках дополнительной информации 58 при помощи элементов синтаксиса bsResidualBands и bsResidualFramesPerSAOCFrame. Эти два элемента синтаксиса могут определить другое подразделение структуры на элементы времени/частоты, чем подразделение, имеющее результатом элементы 42.
Между прочим, следует заметить, что остаточный сигнал 62 может отражать, а может и не отражать потерю информации в результате потенциально используемого основного кодирующего устройства 96, используемого по выбору для кодирования сигнала понижающего микширования 56 звуковым кодирующим устройством 80. Как показано на фиг.4, средство 92 может выполнять регулирование остаточного сигнала 62 на основе версии сигнала понижающего микширования, реконструируемого из выхода основного кодирующего устройства 96 или версии из входа в основное кодирующее устройство 96'. Точно так же звуковой декодер 50 может включать основной декодер 98 для расшифровки или разворачивания сигнала понижающего микширования 56.
Способность устанавливать в пределах многообъектного звукового сигнала временное/частотное разрешение, используемое для вычисления остаточного сигнала 62, отличающегося от временного/частотного разрешения, используемого для вычисления информации об уровне 60, позволяет достигнуть хорошего компромисса между качеством звука с одной стороны и степенью сжатия многообъектного звукового сигнала с другой стороны. В любом случае, остаточный сигнал 62 позволяет обеспечить лучшее подавление выдачи ненужных данных от одного звукового сигнала до другого в пределах первого и второго сигналов повышающего микширования, которые будут произведены на выходе 68 в соответствии с пользовательским входом 66.
Как станет ясным из следующего осуществления, более одного остаточного сигнала 62 может быть передано в рамках дополнительной информации в случае, если закодировано более одного объекта переднего плана или звуковой сигнал второго типа. Дополнительная информация может учитывать индивидуальное решение относительно того, передавать ли остаточный сигнал 62 для определенного звукового сигнала второго типа или нет. Таким образом, число остаточных сигналов 62 может меняться от одного до нескольких звуковых сигналов второго типа.
В звуковом декодере Фиг.3 средство 54 для вычисления может формироваться, чтобы вычислять матрицу коэффициента предсказания С, состоящую из коэффициентов предсказания, основанных на информации об уровне (OLD), а средство 56 может формироваться, чтобы выдать первый сигнал повышающего микширования S1, и/или второй сигнал повышающего микширования S2 из сигнала понижающего микширования d согласно вычислению, представленному здесь
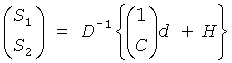 ,
,
где эти "1" обозначает - в зависимости от числа каналов d-скаляр, или матрицу идентичности, и D-1-матрица, однозначно определенная в соответствии с предписанием понижающего микширования, согласно которому звуковой сигнал первого типа и звуковой сигнал второго типа микшируются с понижением в сигнал понижающего микширования и который также состоит из дополнительной информации, и Н-член, являющийся независимым от d, но зависящий от остаточного сигнала.
Как отмечено выше и будет описано ниже, предписание понижающего микширования может изменяться во времени и/или может спектрально изменяться в рамках дополнительной информации. Если звуковой сигнал первого типа является стерео звуковым сигналом, имеющим первый (L) и второй входной канал (R), информация об уровне, например, описывает нормализованные спектральные энергии первого входного канала (L), второго входного канала (R) и звуковой сигнал второго типа, соответственно, при временном/частотном разрешении 42.
Вышеупомянутое вычисление, согласно которому средство 56 для повышающего микширования выполняет повышающее микширование, может даже быть представлено следующим образом
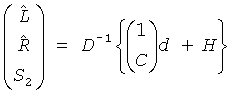 ,
,
где 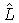 - первый канал первого сигнала повышающего микширования, приближающийся к L, и
- первый канал первого сигнала повышающего микширования, приближающийся к L, и 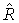 -второй канал первого сигнала повышающего микширования, приближающийся к R, и «1» - скаляр в случае, если d моно, и 2×2 матрица идентичности в случае, если d - стерео. Если сигнал понижающего микширования 56 является стерео звуковым сигналом, имеющим первый (L0) и второй выходной канал (R0), и вычисление, согласно которому средство 56 для повышающего микширования выполняет повышающее микширование, может быть представлено следующим образом
-второй канал первого сигнала повышающего микширования, приближающийся к R, и «1» - скаляр в случае, если d моно, и 2×2 матрица идентичности в случае, если d - стерео. Если сигнал понижающего микширования 56 является стерео звуковым сигналом, имеющим первый (L0) и второй выходной канал (R0), и вычисление, согласно которому средство 56 для повышающего микширования выполняет повышающее микширование, может быть представлено следующим образом
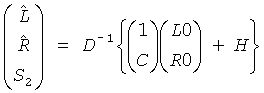 .
.
Так как член Н, зависящий от остаточного сигнала, связан с res, вычисление, согласно которому средство 56 для повышающего микширования выполняет повышающее микширование, может быть представлено следующим образом
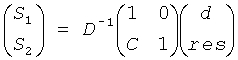 .
.
Многообъектный звуковой сигнал может даже включать множество звуковых сигналов второго типа, а дополнительная информация может включать один остаточный сигнал на звуковой сигнал второго типа. Параметр остаточного разрешения может присутствовать в дополнительной информации, определяющей спектральный диапазон, по которому остаточный сигнал передается в рамках дополнительной информации. Он может даже определять нижний и верхний предел спектрального диапазона.
Далее, многообъектный звуковой сигнал может также включать пространственную предоставляемую информацию для пространственной передачи звукового сигнала первого типа на предопределенную конфигурацию громкоговорителя. Другими словами, звуковой сигнал первого типа может быть многоканальным (больше чем два канала) MPEG Объемное звучание сигналом, смикшированным с понижением до стерео.
В дальнейшем будут описаны осуществления, которые используют вышеупомянутую передачу остаточного сигнала. Однако следует заметить, что термин «объект» часто используется в двойном смысле. Иногда объект обозначает индивидуальный монозвуковой сигнал. Таким образом, стереообъект может иметь монозвуковой сигнал, формирующий один канал стереосигнала. Однако в других ситуациях стереообъект может обозначать фактически два объекта, а именно объект относительно правого канала и далее объект относительно левого канала стерео объекта. Фактический смысл станет очевидным из контекста.
Прежде чем описать следующее осуществление, следует сказать, что то же самое мотивируется недостатками, реализованными посредством основной технологии стандарта SAOC, выбранного в качестве эталонной модели 0 (RM0) в 2007 г. RM0 позволил индивидуально управлять многими звуковыми объектами, исходя из их положения панорамирования и увеличения/ослабления. Был представлен специальный сценарий в контексте применения типа «Караоке». В этом случае
- моно, стерео или объемное звучание фонового окружения (в дальнейшем называемое Фоновым объектом, BGO) передается от ряда определенных объектов SAOC, которые воспроизводятся без изменения, то есть каждый сигнал входного канала воспроизводится через тот же самый выходной канал на неизмененном уровне, и
- определенный интересующий объект (в дальнейшем называемый Объектом переднего плана, FGO) (обычно ведущий голос), который воспроизводится с изменениями (FGO обычно размещается в середине звуковой стадии и может быть приглушен, то есть значительно уменьшен, чтобы дать возможность петь хором).
Как видно из процедур субъективной оценки и как можно было ожидать исходя из основного принципа технологии, манипулирование положением объекта приводит к высококачественным результатам, в то время как манипулирование уровнем объекта обычно является более перспективными. Как правило, чем выше дополнительное усиление/ослабление сигнала, тем больше возникает потенциальных артефактов. В этом смысле сценарий Караоке является чрезвычайно требовательным, так как необходимо предельное (идеально: общее) ослабление FGO.
Случай двойного использования - способность воспроизводить только FGO без фонового/МВО и называется в дальнейшем солорежимом.
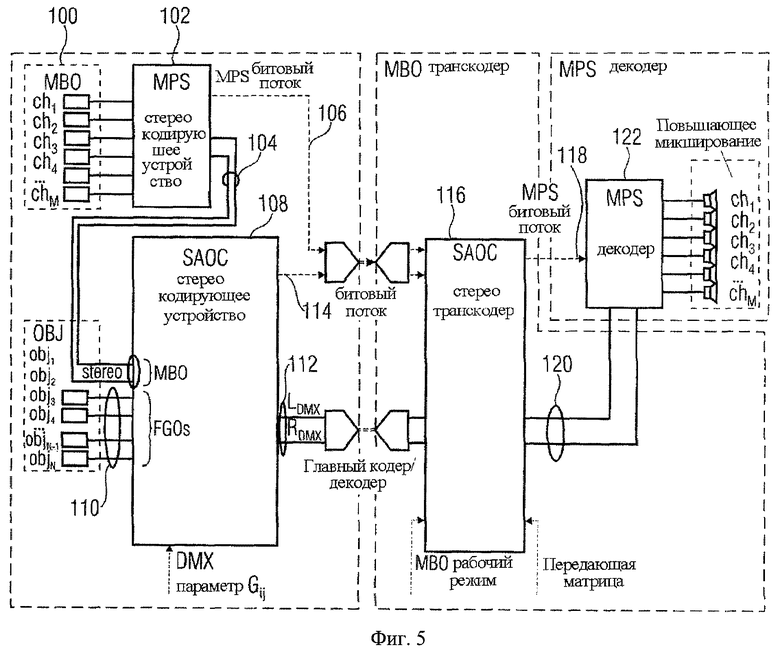
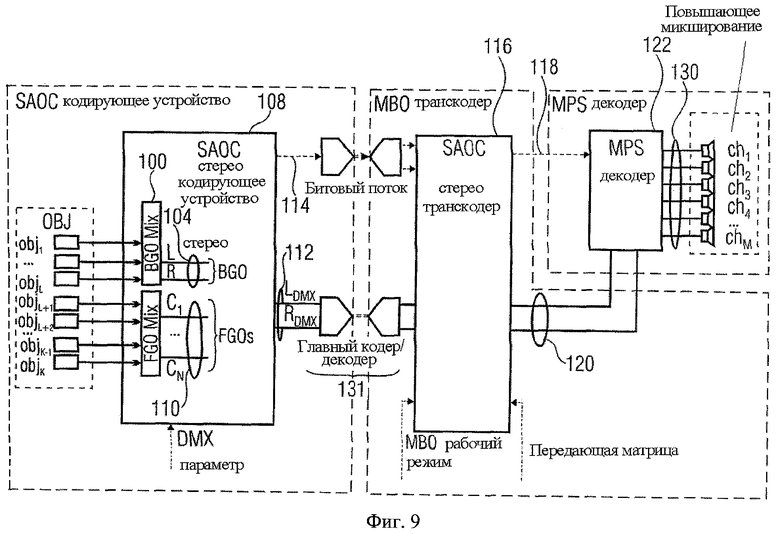
Замечено, однако, что, если включено объемное фоновое окружение, это называется Многоканальным Фоновым Объектом (МВО). Обработка МВО включает следующее, как показано на Фиг.5:
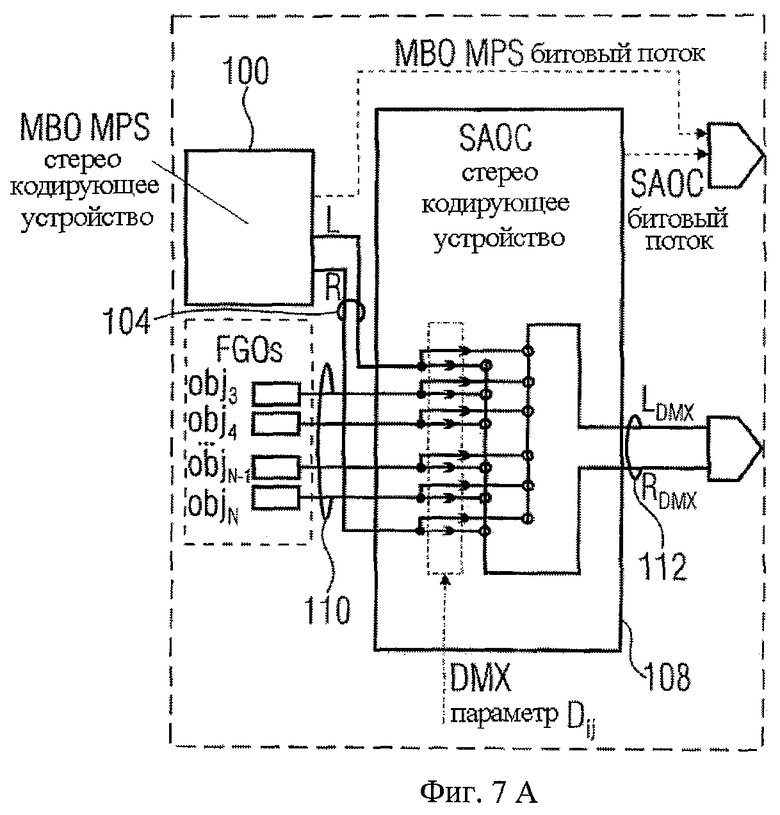
- МВО кодируется с использованием регулярного дерева 5-2-5 MPEG, Объемное звучание 102. Это приводит к формированию стерео МВО сигнала понижающего микширования 104 и МВО MPS потока дополнительной информации 106.
- МВО понижающего микширования затем кодируется последующим кодирующим устройством SAOC 108 как стереообъект (то есть разность уровней двух объектов плюс межканальная корреляция) вместе с (или несколькими) FGO 110. Это приводит к общему сигналу понижающего микширования 112 и потоку дополнительной информации SAOC 114.
В транскодере 116 сигнал понижающего микширования 112 проходит предварительную обработку, а SAOC и MPS потоки дополнительной информации 106, 114 транскодируются в единый выходной поток дополнительной информации MPS 118. Это происходит прерывистым способом, то есть или обеспечивается только полное подавление FGO (s) или полное подавление МВО.
Наконец, результирующий сигнал понижающего микширования 120 и дополнительная информация MPS 118 предоставляются декодером MPEG, Объемное звучание 122.
На фиг.5 и МВО понижающего микширования 104 и управляемый сигнал(ы) объекта 110 объединены в единый стереосигнал понижающего микширования 112. Это «загрязнение» понижающего микширования управляемым объектом 110 является причиной появления трудностей при восстановлении версии Караоке с удаленным управляемым объектом 110, который имеет достаточно высокое звуковое качество. Следующее предложение направлено на решение этой проблемы.
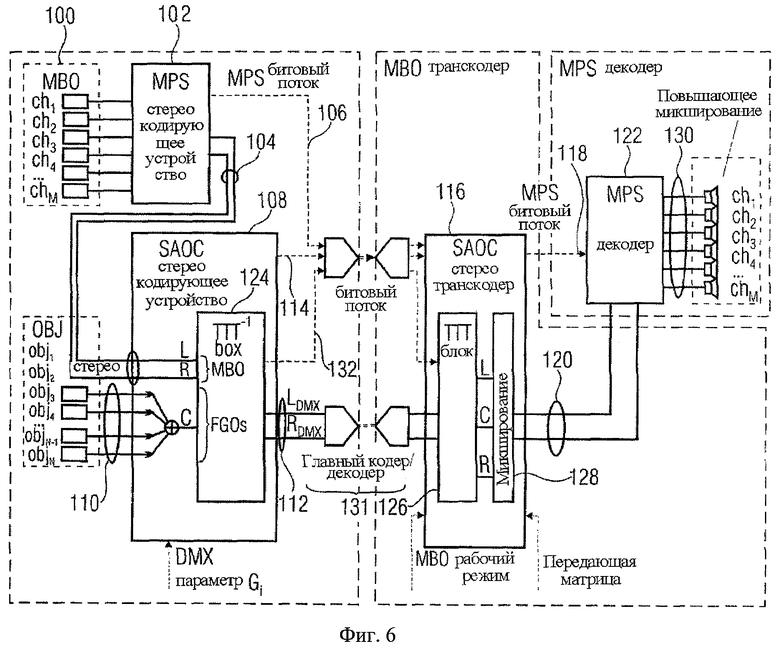
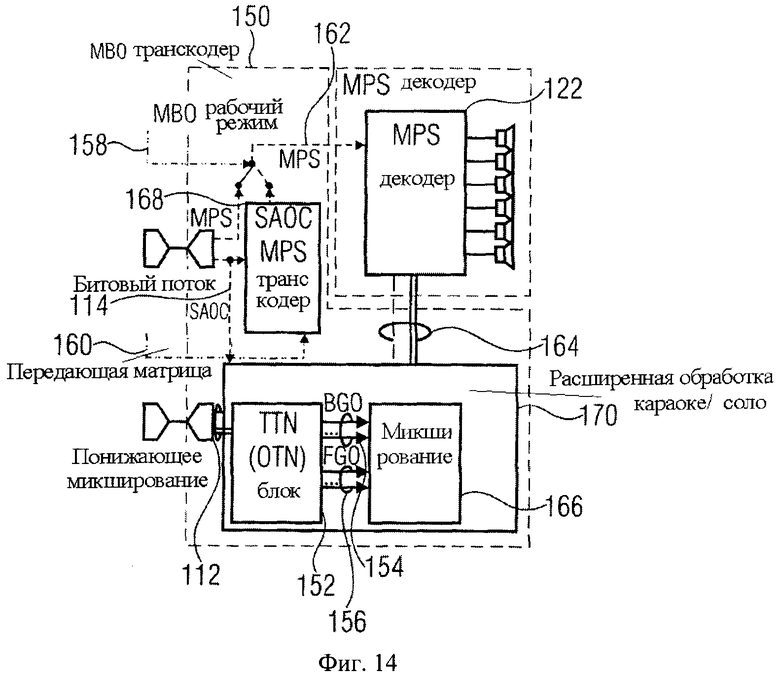
Если есть один FGO (например, один ведущий голос), ключевое наблюдение, используемое следующим осуществлением фиг.6, состоит в том, что SAOC сигнал является комбинацией сигналов BGO и FGO, то есть три звуковых сигнала микшируются с понижением и передаются через 2 канала понижающего микширования. В идеале, эти сигналы должны быть снова разделены в транскодере, чтобы произвести чистый сигнал Караоке (то есть чтобы удалить сигнал FGO) или произвести чистый соло сигнал (то есть чтобы удалить сигнал BGO). Это достигается в соответствии с осуществлением фиг.6, при использовании «два-к-трем» (ТТТ) элемента кодирующего устройства 124 (ТТТ-1, известен из спецификации MPEG, Объемное звучание) в пределах кодирующего устройства SAOC 108, чтобы объединить сигналы BGO и FGO в единый SAOC сигнал понижающего микширования в кодирующем устройстве SAOC. Здесь FGO подается на «центральный» вход сигнала блока ТТТ-1 124, в то время как BGO 104 подается на «левый/правый» ТТТ-1 входы L.R. Транскодер 116 может затем произвести приближения BGO 104 при использовании ТТТ элемента декодера 126 (ТТТ, известен из MPEG, Объемное звучание), то есть «левые/правый» ТТТ выходы L, R несут приближение BGO, тогда как «центральный» ТТТ выход С несет приближение FGO 110.
Сравнивая осуществление фиг.6 с осуществлением кодирующего устройства и декодером Фиг.3 и 4, можно заметить, что опорный признак 104 соответствует звуковому сигналу первого типа среди звуковых сигналов 84; средство 82 состоит из MPS кодирующего устройства 102; опорный признак 110 соответствует звуковым сигналам второго типа среди звукового сигнала 84; ТТТ-1 блок 124 принимает ответственность за функциональные возможности средств 88-92; функциональные возможности средств 86 и 94 реализуются в SAOC кодирующем устройстве 108; опорный признак 112 соответствует опорному признаку 56; опорный признак 114 соответствует дополнительной информации 58 меньше, чем остаточный сигнал 62; ТТТ блок 126 принимает ответственность за функциональные возможности средств 52 и 54; функциональные возможности смесителя 128 также состоят из средства 54. Наконец, сигнал 120 соответствует выходу сигнала на выходе 68. Далее, следует заметить тот факт, что фиг.6 также показывает основной путь кодера/декодера 131 для переноса понижающего микширования 112 от кодирующего устройства SAOC 108 к SAOC транскодеру 116. Этот основной путь кодера/декодера 131 соответствует факультативному основному кодеру 96 и основному декодеру 98. Как показано на фиг.6, этот основной путь кодера/декодера 131 может также кодировать/сжимать сигнал дополнительной информации, транспортируемый от кодирующего устройства 108 к транскодеру 116.
Преимущества, являющиеся результатом введения ТТТ блока фиг.6, станут ясными благодаря следующим описаниям. Например,
- простая подача «левого/правого» ТТТ выходов L.R. на MPS понижающего микширования 120 (и пересылка переданного МВО MPS битового потока 106 в поток 118), только МВО воспроизводится конечным декодером MPS. Это соответствует режиму Караоке.
- простая подача «центрального» ТТТ выхода С. в левый и правый MPS понижающего микширования 120 (и производство обычного MPS битового потока 118, который выводит FGO 110 на желательное положение и уровень), только FGO 110 воспроизводится конечным MPS декодером 122. Это соответствует режиму Соло.
Обработка трех ТТТ выходных сигналов L.R.C. выполняется в «смешивающем» блоке 128 из SAOC транскодера 116.
Обрабатывающая структура фиг.6 обеспечивает ряд очевидных преимуществ по сравнению с фиг.5:
- структура обеспечивает чистое структурное разделение фона (МВО) 100 и FGO сигнала 110
- структура ТТТ элемента 126 направлена на создание наилучшей реконструкции трех сигналов L.R.C. на основе формы волны. Таким образом, конечные MPS выходные сигналы 130 не только формируются посредством взвешивания энергии (и декорреляции) сигналов понижающего микширования, но и являются более близкими, изходя из формы волны, вследствие ТТТ обработки.
- Наряду с ТТТ блоком 126 MPEG Объемное звучание появляется возможность увеличить точность реконструкции при использовании остаточного кодирования. Таким образом, может быть достигнуто существенное повышение качества реконструкции, так как увеличивается остаточная полоса пропускания и остаточная скорость передачи битов для остаточного сигнала 132, выданного ТТТ-1 124 и используемого ТТТ блоком для повышающего микширования. В идеале (то есть для наилучшей квантизации в остаточном кодировании и кодировании сигнала понижающего микширования) прекращается интерференция между фоном (МВО) и сигналом FGO.
Обрабатывающая структура фиг.6 обладает рядом характеристик:
- двойственный режим Караоке/соло: подход фиг.6 предлагает функциональные возможности как Караоке, так и Соло при использовании тех же самых технических средств. Таким образом, параметры SAOC, например, снова используются.
- Способность к очищению: качество сигнала Караоке/соло может быть очищено так, как необходимо, посредством контроля над количеством остаточной кодирующей информации, используемой в ТТТ блоках. Например, могут использоваться параметры bsResidualSamplingFrequencyIndex, bsResidualBands и bsResidualFramesPerSAOCFrame.
- Размещение FGO в понижающем микшировании: При использовании ТТТ блока, как определено в спецификации MPEG Объемное звучание, FGO всегда будет микшироваться в центральное положение между левым и правым каналами понижающего микширования. Чтобы обеспечить большую подвижность размещения, используется обобщенный ТТТ блок кодирующего устройства, который следует тем же самым принципам, обеспечивая несимметрическое размещение сигнала, связанное с «центральными» входами/выходами.
- Множественные FGOs: В представленной конфигурации было описано использование только одного FGO (это может соответствовать случаю самого важного применения). Однако предложенная концепция также может урегулиовать несколько FGOs, используя одну или комбинацию следующих мер:
- Сгруппированные FGOs: Как показано на фиг.6, сигнал, который связан с центральным входом/выходом ТТТ блока, может фактически быть суммой нескольких сигналов FGO, а не только одного-единственного. Эти FGOs могут независимо размещаться/управляться в многоканальном выходном сигнале 130 (достигается максимальное качественное преимущество, однако, только, когда они измерены и размещены таким же образом). Они делят общее положение в стереосигнале понижающего микширования 112, и имеется только один остаточный сигнал 132. В любом случае, исключается интерференция между фоном (МВО) и управляемыми объектами (а не между самими управляемыми объектами).
- Каскадные FGOs: ограничения относительно общего положения FGO в понижающем микшировании 112 могут быть преодолены посредством расширения подхода фиг.6. Множественные FGOs могут быть приспособлены при каскадировании нескольких стадий описанной ТТТ структуры; каждая стадия соответствует одному FGO и производит остаточный кодирующий поток. Таким образом, в идеале, интерференция должна быть исключена также между каждым FGO. Конечно, эта опция требует более высокой скорости битового потока, чем используемая при подходе сгруппированных FGO. Пример будет описан позже.
- SAOC дополнительная информация: В MPEG Объемное звучание, дополнительная информация, связанная с ТТТ блоком, является парой Коэффициентов Предсказания Канала (CPCs). Напротив, SAOC параметризация и сценарий MBO/Karaoke передают энергии объекта для каждого сигнала объекта и межсигнальную корреляцию между двумя каналами МВО понижающего микширования (то есть параметризация для «стереообъекта»). Чтобы минимизировать число изменений в параметризации относительно случая без расширенного режима Караоке/соло, и таким образом, формата битового потока, CPCs могут быть вычислены из энергий сигналов понижающего микширования (МВО понижающего микширования и FGOs) и межсигнальной корреляций МВО стереообъекта понижающего микширования. Поэтому нет никакой необходимости изменять или усиливать переданную параметризацию, и CPCs могут быть вычислены из переданной параметризации SAOC в SAOC транскодере 116. Таким образом, битовый поток, использующий Расширенный режим Караоке/соло, может также быть декодирован обычным режимом декодера (без остаточного кодирования), игнорируя остаточные данные.
Таким образом, осуществление фиг.6 направлено на улучшение воспроизводства определенных выбранных объектов (или окружения без этих объектов) и расширяет современный SAOC подход к кодированию, используя стереопонижающее микширование следующим образом:
- В нормальном режиме каждый сигнал объекта взвешивается его элементами в матрице понижающего микширования (для его вклада в левый и правый канал понижающего микширования соответственно). Тогда все взвешенные вклады в левый и правый каналы понижающего микширования суммируются, чтобы сформировать левый и правый каналы понижающего микширования.
- Для улучшения работы в режиме Караоке/соло, то есть в расширенном режиме, все вклады объекта разделяются на множество вкладов объекта, которые формируют вклады Объекта Переднего плана (FGO) и вклады остальных объектов (BGO). Вклад FGO суммируется в моносигнал понижающего микширования, остальные фоновые вклады суммируются в стереосигнал понижающего микширования, и оба суммируются посредством использования обобщенного элемента ТТТ кодирующего устройства для формирования общего стерео SAOC сигнала понижающего микширования
Таким образом, регулярное суммирование заменяется «ТТТ суммированием» (которое может быть каскадным, если нужно).
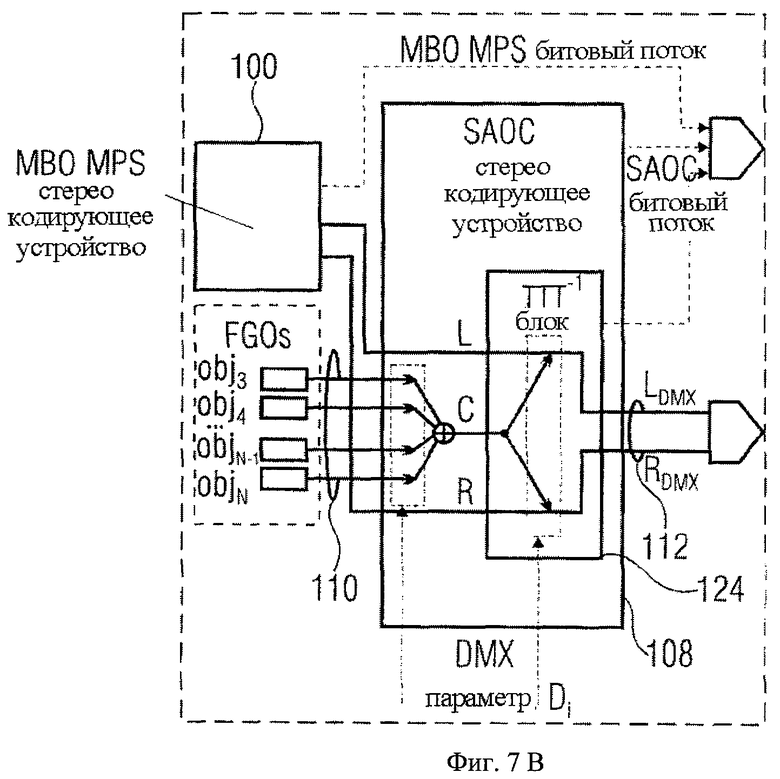
Чтобы подчеркнуть только что упомянутое различие между нормальным режимом SAOC кодирующего устройства и расширенным режимом, делается ссылка на Фиг.7а и 7b, где фиг.7а представляет нормальный режим, а фиг.7b - расширенный режим. Как можно заметить, в нормальном режиме SAOC кодирующее устройство 108 использует вышеупомянутые DMX параметры Di,j для взвешивания объектов j и добавления таким образом взвешенного объекта j к SAOC каналу i, то есть L0 или R0. В случае расширенного режима, показанного на фиг.6, необходим просто вектор DMX-параметров Di, а именно DMX-параметры Di, указывающие на то, как сформировать взвешенную сумму FGOs 110 таким образом, чтобы получить центральный канал С для ТТТ-1 блока 124, и DMX-параметры Di, инструктирующие ТТТ-1 блок о том, как распределять центральный сигнал С для левого МВО канала и для правого МВО канала соответственно, таким образом, получая LDMX или RDMX соответственно.
Проблема заключается в том, что обработка согласно фиг.6 не работает достаточно хорошо с сохраняющими кодер-декодерами без формы волны (НЕ-ААС/SBR). Решением этой проблемы может явиться обобщенный ТТТ режим, основанный на энергии, для НЕ-ААС и высоких частот. Осуществление, связанное с этой проблемой, будет описано позже.
Возможный формат битового потока для него с каскадными TTTs может быть следующим:
Дополнительно к SAOC битовому потоку, который можно было бы пропустить, если необходимо классифицировать его в «режиме постоянного декодирования»:
numTTTs int
для (ttt=0; ttt<numTTTs; ttt++)
{no_TTT_obj[ttt]int
TTT_bandwidth[ttt]; (полоса пропускания)
TTT_residual_stream [ttt] (остаточный поток)
}
Что касается требований к сложности и памяти, можно утверждать следующее. Как видно из предыдущих объяснений, расширенный режим Караоке/соло фиг.6 исполняется путем добавления стадий одного концептуального элемента в кодирующее устройство и каждый декодер/транскодер, то есть обобщенный ТТТ-1/ТТТ элемент кодирующего устройства. Оба элемента идентичны в своей сложности относительно постоянных «центрированных» ТТТ аналогов (изменение значений коэффициентов не влияет на сложность). Для предусмотренного основного применения (один FGO в качестве ведущего голоса) достаточно одного ТТТ.
Отношение этой дополнительной структуры к сложности MPEG Окружающей системы можно оценить, рассматривая структуру всего декодера MPEG Объемное звучание, который для соответствующего случая стереопонижающего микширования (конфигурация 5-2-5) состоит из одного ТТТ элемента и двух ОТТ элементов. Это уже показывает, что добавленные функциональные возможности поступают по умеренной цене исходя из сложности вычисления и потребления памяти (заметьте, что концептуальные элементы, использующие остаточное кодирование, в среднем не более сложны, чем их аналоги, которые вместо этого включают декорреляторы).
Распространение MPEG SAOC эталонной модели фиг.6 обеспечивает улучшение качества звука для специального применения режима типа соло или немой/караоке. Снова следует заметить, что описание, соответствующее Фиг.5, 6 и 7, называет МВО фоновым окружением или BGO, которое вообще не ограничено для этого типа объекта и наоборот, может быть также моно- или стереообъектом.
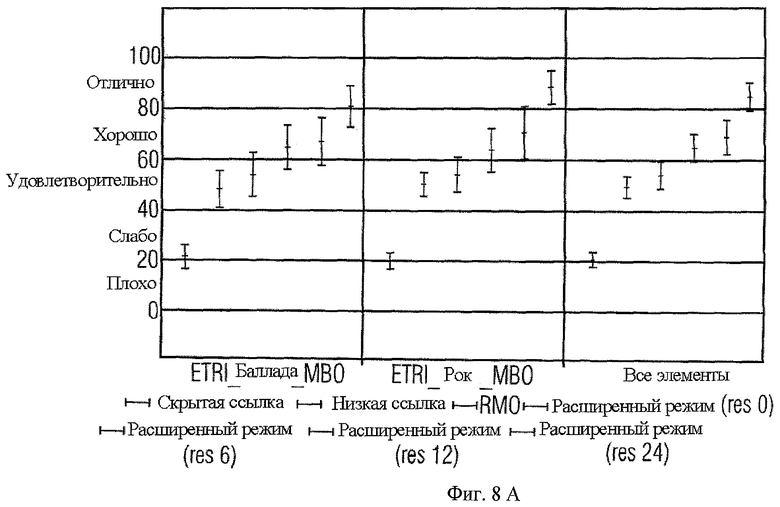
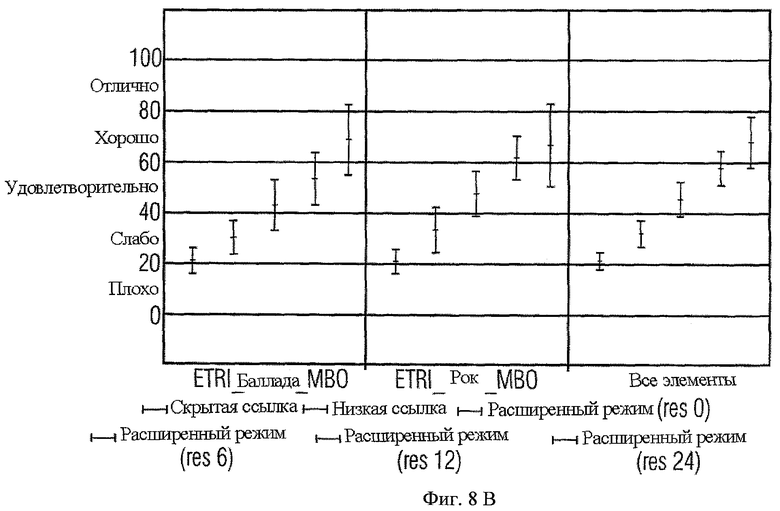
Процедура субъективной оценки показывает усовершенствование в переводе на качество звука выходного сигнала при применении для соло или Караоке. Оцениваются следующие положения:
- RM0
- Расширенный режим (res 0) (= без остаточного кодирования)
- Расширенный режим (res 6) (= с остаточным кодированием в 6 самых низких гибридных QMF диапазонах)
- Расширенный режим (res 12) (= с остаточным кодированием в 12 самых низких гибридных QMF диапазонах)
- Расширенный режим (res 24) (= с остаточным кодированием в 24 самых низких гибридных QMF диапазонах)
- Скрытая Ссылка
- Нижний якорь (ограниченная версия ссылки диапазона 3.5 кГц)
Скорость передачи битов для предложенного расширенного режима подобен RM0, если используется без остаточного кодирования. Все другие расширенные режимы требуют приблизительно 10 кбит/сек для каждых 6 диапазонов остаточного кодирования.
Иллюстрация 8а показывает результаты теста для режима немой/караоке с 10 объектами прослушивания. Предложенное решение имеет средний счет MUSHRA (Multiple Stimuli with Hidden Reference and Anchor - множественные стимулы со скрытой ссылкой и якорем), который всегда выше, чем RMO, и увеличивается с каждым шагом дополнительного остаточного кодирования. Статистически существенное усовершенствование по работе RMO можно отчетливо увидеть для режимов с 6 и большим количеством диапазонов остаточного кодирования.
Результаты для теста соло с 9 объектами на фиг.8b показывают подобные преимущества предложенного решения. Средний счет MUSHRA очевидно увеличивается при добавлении все большего остаточного кодирования. Усиление между расширенным режимом без и расширенным режимом с 24 диапазонами остаточного кодирования составляет почти 50 пунктов MUSHRA.
В целом, качество работы режима Караоке достигается за счет того, что скорость передачи битов приблизительно на 10 кбит/сек выше, чем RM0. Превосходное качество можно получить, добавляя приблизительно 40 кбит/сек к скорости передачи битов RM0. В реальном сценарии применения, где дана максимальная зафиксированная скорость передачи битов, предложенный расширенный режим прекрасно позволяет тратить «неиспользованную скорость передачи битов» для остаточного кодирования до тех пор, пока не будет достигнута допустимая максимальная скорость. Поэтому достигается самое лучшее полное звуковое качество. Возможно дальнейшее усовершенствование по представленным экспериментальным результатам вследствие более разумного использования остаточной скорости передачи битов: В то время как представленная установка всегда использовала остаточное кодирование от DC до определенной верхней граничной частоты, расширенное выполнение потратит только биты для частотного диапазона, который важен для разделения FGO и фоновых объектов.
Ранее была описана улучшенная технология SAOC для использования режимов типа караоке. Представлены дополнительные детальные осуществления применения расширенного режима Караоке/соло для многоканальной FGO обработки звукового окружения для MPEG SAOC.
В отличие от FGOs, которые воспроизводятся с изменениями, сигналы МВО должны быть воспроизведены без изменений, то есть каждый сигнал входного канала воспроизводится через тот же самый выходной канал на неизмененном уровне. Следовательно, была предложена предварительная обработка сигналов МВО посредством кодирующего устройства MPEG Объемное звучание, что привело к получению стереосигнала понижающего микширования, который служит (стерео) фоновым объектом (BGO), который будет введен в последующие стадии обработки режима Караоке/соло, включающие SAOC кодирующее устройство, МВО транскодер и MPS декодер. Фиг.9 снова показывает диаграмму полной структуры.
Как можно заметить, согласно структуре кодера режима Караоке/соло, входные объекты сортируются на стереофоновый объект (BGO) 104 и объекты переднего плана (FGO) 110.
В то время как в RM0 управление этими сценариями применения выполняется кодирующим устройством SAOC/системой транскодера, расширение фиг.6 дополнительно эксплуатирует элементарный стандартный блок структуры MPEG, Объемное звучание. Включение блока три-к-двум (ТТТ-1) в кодирующее устройство и соответствующее дополнение два-к-трем (ТТТ) в транскодер улучшает работу, когда требуется сильное повышение/ослабление специфического звукового объекта. Две основные характеристики расширенной структуры:
- лучшее разделение сигнала вследствие эксплуатации остаточного сигнала (по сравнению с RM0),
- подвижное размещение сигнала, обозначенное как центральный вход (то есть FGO) ТТТ блока посредством обобщения его спецификации микширования.
Так как прямое выполнение стандартного ТТТ блока вовлекает три входных сигнала на стороне кодирующего устройства, фиг.6 сосредоточен на обработке FGOs как (микшированный с понижением) моносигнал согласно изображению на фиг.10. Обработка многоканальных FGO сигналов также была заявлена, но будет объяснена более подробно в последующей главе.
Как видно по фиг.10, в расширенном режиме фиг.6 комбинация всех FGOs подается в центральный канал ТТТ-1 блока.
В случае FGO монопонижающего микширования, как показано на фиг.6 и фиг.10, конфигурация ТТТ-1 блока в кодирующем устройстве включает FGO, который подается к центральному входу, и BGO обеспечивающий левый и правый вход. Основная симметричная матрица выглядит:
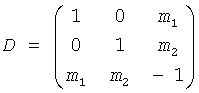 , которая обеспечивает понижающее микширование (L0 R0)Т и сигнал F0:
, которая обеспечивает понижающее микширование (L0 R0)Т и сигнал F0:
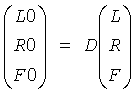 .
.
Третий сигнал, полученный посредством этой линейной системы, отбрасывается, но может быть восстановлен на стороне транскодера, включающей два коэффициента предсказания c1 и с2 (СРС) согласно:
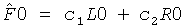 .
.
Обратный процесс в транскодере представлен:
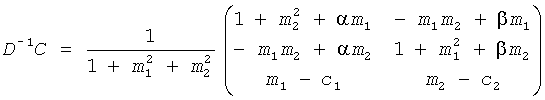 .
.
Параметры m1 и m2 соответствуют:
m1=cos(µ) и m2=sin(µ)
и µ ответственен за панорамирование FGO в общем ТТТ понижающем микшировании (L0 R0)T. Коэффициенты предсказания c1 и c2, требуемые ТТТ узлом повышающего микширования на стороне транскодера, могут быть оценены посредством использования переданных SAOC параметров, то есть разности уровней объекта (OLDs) для всех входных звуковых объектов и межобъектной корреляции (IOC) для BGO сигналов понижающего микширования (МВО). При условии статистической независимости FGO и BGO сигналов следующее отношение справедливо для оценки СРС:
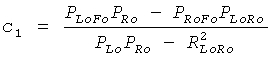 ,
, 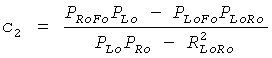 .
.
Переменные PLo, PRo, PLoRo, PLoFo и PRoFo могут быть оценены следующим образом, где параметры OLDL, OLDR и IOCLR соответствуют BGO, a OLDF является параметром FGO:
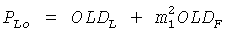 ,
,
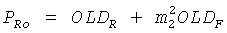 ,
,
PLoRo=IOCLR+m1m2OLDF,
PLoFo=m1(OLDL-OLDF)+m2IOCLR,
PRoFo=m2(OLDR-OLDF)+m1IOCLR.
Дополнительно, ошибка, введенная импликацией CPCs, представлена остаточным сигналом 132, который может быть передан в рамках битового потока, таким образом, что:
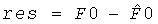 .
.
В некоторых сценариях применения ограничение одиночного моносигнала понижающего микширования всех FGOs непригодно, следовательно, оно должно быть преодолено. Например, FGOs могут быть разделены на две или больше независимых группы с различными положениями в переданном стереосигнале понижающего микширования и/или индивидуально ослаблены. Поэтому каскадная структура, показанная на фиг.11, подразумевает два или больше последовательных ТТТ-1 элементов 124а, 124b, результатом которых является постепенное понижающее микширование всех групп FGO F1, F2 на стороне кодирующего устройства, пока не будет получен желательный стереосигнал понижающего микширования 112. Каждый - или, по крайней мере, некоторые - ТТТ-1 блоки 124а, b (на фиг.11 каждый) устанавливает остаточный сигнал 132а, 132b, соответствующий определенной стадии или ТТТ-1 блок 124а, b соответственно. Наоборот, транскодер выполняет последовательное повышающее микширование посредством определенного последовательно применения ТТТ блоков 126а, b, включая соответствующие CPCs и остаточные сигналы, где возможно. Порядок обработки FGO определяется кодирующим устройством и должен рассматриваться на стороне транскодера.
Детальные расчеты, связанные с двухэтапным каскадом, показанным на фиг.11, описаны в дальнейшем.
Без потери в общности, но для простоты следующее объяснение основывается на каскаде, состоящем из двух ТТТ элементов, как показано на фиг.11. Две симметричные матрицы подобны моно FGO понижающего микширования, но должны быть применены соразмерно к соответствующим сигналам:
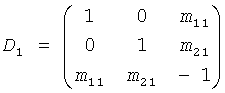 и
и 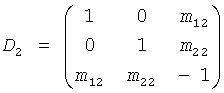 .
.
Здесь два комплекта CPCs приводят к следующей реконструкции сигнала:
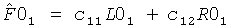 и
и 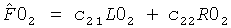 .
.
Обратный процесс представлен:
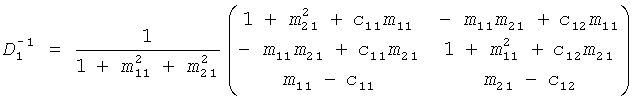 , и
, и
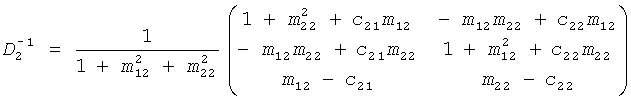 .
.
Особый случай двухэтапного каскада включает один стерео FGO, где его левый и правый каналы суммируются должным образом на соответствующие каналы BGO, в результате чего получается µ1=0 и 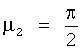 :
:
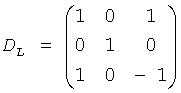 , и
, и 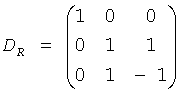 .
.
Для этого конкретного типа панорамирования и пренебрегая межобъектной корреляцией, OLDLR=0 оценку двух комплектов CPCs уменьшают до:
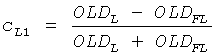 , cL2=0,
, cL2=0,
cR1=0, 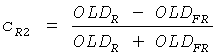 ,
,
где OLDFL и OLDFR обозначают OLDs левого и правого FGO сигнала соответственно.
Случай обычного каскада N-стадии относится к многоканальному FGO понижающего микширования согласно:
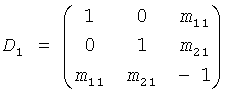 ,
, 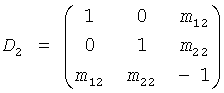 , …,
, …, 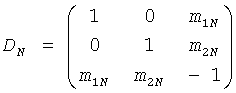 .
.
где каждая стадия показывает свои собственные CPCs и остаточный сигнал.
На стороне транскодера шаги обратного каскадирования дают:
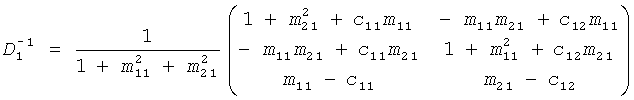 , …,
, …,
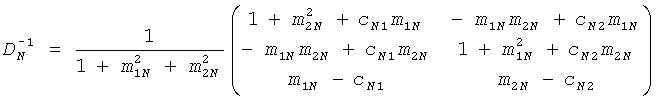 .
.
Чтобы избежать необходимости сохранять порядок ТТТ элементов, каскадная структура может быть легко преобразована в эквивалентную параллельную посредством перестройки N матриц в одну-единую симметричную TTN матрицу, таким образом, давая в результате обычный TTN тип:
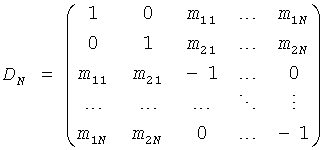 ,
,
где первые две линии матрицы обозначают стереопонижающее микширование, подлежащее передаче. С другой стороны, термин TTN - two-to-N - относится к процессу повышающего микширования на стороне транскодера.
Используя это описание, частный случай индивидуально панорамированного стерео FGO уменьшает матрицу до:
 .
.
Соответственно, этот узел может называться элементом два- к- четырем или TTF.
Также возможно получить TTF структуру, повторно используя SAOC стереомодуль препроцессора.
Для ограничения N=4 исполнение структуры два- к- четырем (TTF), которое повторно использует части существующей SAOC системы, становится допустимым. Обработка описана в следующих параграфах.
SAOC стандартный текст описывает предварительную обработку стереоповышающего микширования для «стерео- к- стереорежиму транскодирования». Строго говоря, выходной стереосигнал Y вычисляется из входного стереосигнала Х вместе с декоррелированным сигналом Xd следующим образом:
Y=GModX+P2Xd.
Декоррелированный компонент Xd - искусственное представление частей оригинального предоставленного сигнала, который уже был отклонен в процессе кодирования. Согласно фиг.12 декоррелированный сигнал заменяется остаточным сигналом, произведенным подходящим кодирующим устройством 132 для определенного частотного диапазона.
Спецификация определена как:
- D - 2×N матрица понижающего микширования
- А - 2×N передающая матрица
- Е - модель N×N ковариации входных объектов S
- GMod (соответствует G на фиг.12) - прогнозируемые 2×2 матрицы повышающего микширования.
Заметьте, что GMod - функция D, А и Е.
Чтобы вычислить остаточный сигнал XRes, необходимо воспроизвести обработку декодера в кодирующем устройстве, то есть определить GMod. В обычных сценариях А неизвестен, но в сценарии частного случая режима Караоке (например, с одним стереофоновым объектом и одним стереообъектом переднего плана, N=4) принимается, что
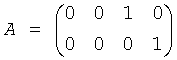 ,
,
что означает, что представлен только BGO.
Для оценки объекта переднего плана восстановленный фоновый объект вычитается из сигнала понижающего микширования X. Это и заключительное предоставление выполняется в обрабатывающем блоке «микширования». Детали представлены в дальнейшем.
Передающая матрица А установлена в
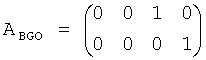 ,
,
где предполагается, что первые 2 колонки представляют 2 канала FGO, и вторые 2 колонки представляют 2 канала BGO.
BGO и FGO стереовыход вычисляется согласно следующим формулам.
YBGO=GModX+XRes
Так как весовая матрица понижающего микширования D определяется как
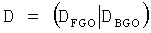
при
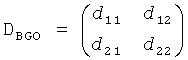
и
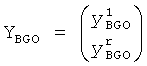
FGO объект может быть установлен в
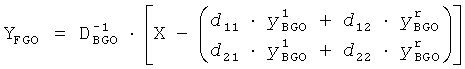
В качестве примера это уменьшается до
YFGO=X-YBGO
для матрицы понижающего микширования
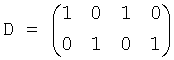
XRes - остаточные сигналы, полученные, как описано выше. Пожалуйста, заметьте, что никакие декоррелированные сигналы не добавляются. Конечный выход Y представляется:
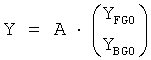
Вышеупомянутые осуществления также могут быть применены, если используется моно FGO вместо стерео FGO. Обработка тогда изменяется согласно следующему.
Передающая матрица А установлена в
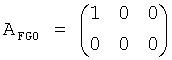
где предполагается, что первая колонка представляет моно FGO, а последующие колонки представляют 2 канала BGO.
BGO и FGO стереовыход вычисляется согласно следующим формулам.
YFGO=GModX+XRes
Так как весовая матрица понижающего микширования D определяется как
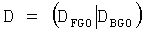
при
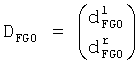
и
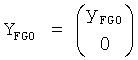
BGO объект может быть установлен в
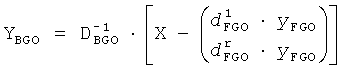
В качестве примера это уменьшается до
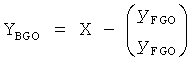
для матрицы понижающего микширования
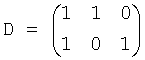
XRes - остаточные сигналы, полученные, как описано выше. Пожалуйста, заметьте, что никакие декоррелированные сигналы не добавляются.
Конечный выход Y представлен
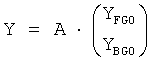
Для управления более чем 4-мя FGO объектами вышеупомянутые осуществления могут быть расширены посредством компоновки параллельных стадий шагов обработки, только что описанных.
Вышеупомянутые только что описанные осуществления обеспечили детальное описание расширенного режима Караоке/соло для случаев многоканального звукового FGO окружения. Это обобщение имеет целью увеличить класс сценариев применения режима Караоке, для которых звуковое качество MPEG SAOC эталонной модели может быть далее улучшено посредством применения расширенного режима Караоке/соло. Усовершенствование достигается посредством введения обычной NTT структуры в микшированную с понижением часть SAOC кодирующего устройства и соответствующих аналогов в SAOC для MPS транскодера. Использование остаточных сигналов увеличивало качественный результат.
Фиг.13а-13h осуществления данного изобретения показывают возможный синтаксис SAOC битового потока дополнительной информации.
Описав некоторые осуществления относительно расширенного режима для SAOC кодер-декодера, следует отметить, что некоторые осуществления касаются сценариев применения, где звуковой вход в SAOC кодирующее устройство содержит не только регулярные моно или стереозвуковые источники, но и многоканальные объекты. Это было ясно описано относительно Фиг.5-7b. Такой многоканальный фоновый объект МВО может рассматриваться как сложное звуковое окружение, вовлекающее большое и часто неизвестное число звуковых источников, для которых не требуется предоставление никаких управляемых функциональных возможностей. Индивидуально, эти звуковые источники не могут эффективно управляться архитектурой SAOC кодирующего устройства/декодера. Концепцию SAOC архитектуры можно, поэтому, рассматривать как расширенную, чтобы иметь дело с этими сложными входными сигналами, то есть МВО каналами вместе с типичными SAOC звуковыми объектами. Поэтому в только что упомянутых осуществлениях фиг.5-7b кодирующее устройство MPEG Объемное звучание рассматривается как включенное в SAOC кодирующее устройство, что обозначено пунктиром, окружающим SAOC кодирующее устройство 108 и MPS кодирующее устройство 100. Результирующее понижающее микширование 104 служит входным стереообъектом в SAOC кодирующее устройство 108 вместе с управляемым SAOC объектом 110, производящим объединенное стереопонижающее микширование 112, передаваемое на сторону транскодера. В области значений параметра и MPS битовый поток 106 и SAOC битовый поток 114 подаются в SAOC транскодер 116, который, завися от частного МВО сценария применения, обеспечивает соответствующий MPS битовый поток 118 для декодера MPEG Объемное звучание 122. Эта задача выполняется посредством использования предоставляемой информации или передающей матрицы и применения некоторой предварительной обработки понижающего микширования, чтобы преобразовать сигнал понижающего микширования 112 в сигнал понижающего микширования 120 для MPS декодера 122.
Дальнейшее осуществление для расширенного режима Караоке/соло описано ниже. Это позволяет индивидуально манипулировать несколькими звуковыми объектами исходя из усиления/ослабления уровня без существенного снижения качества результирующего звука. Специальный сценарий применения режима «типа караоке» требует полного подавления определенных объектов, обычно ведущего голоса (в дальнейшем называемом Объектом Переднего Плана, FGO) при сохранении неповрежденным перцепционного качества фонового звукового окружения. Это также влечет за собой возможность индивидуально воспроизводить определенные FGO сигналы без статического фонового звукового окружения (в дальнейшем называемое Фоновым Объектом, BGO), который не требует пользовательского управления на основе панорамирования. Этот сценарий называется режимом «Соло». Типичный случай применения содержит стерео BGO и до четырех FGO сигналов, которые могут, например, представлять два независимых стереообъекта.
Согласно этому осуществлению и фиг.14 расширенный Караоке/соло транскодер 150 включает или «два-к-N» (TTN) или «один-к-N» (OTN) элемент 152, оба представляющие обобщенную и расширенную модификацию ТТТ блока, известную из спецификации MPEG, Объемное звучание. Выбор соответствующего элемента зависит от числа переданных каналов понижающего микширования, то есть TTN блок предназначен для стереосигнала понижающего микширования, в то время как для моносигнала понижающего микширования применяется OTN блок. Соответствующий TTN-1 или OTN-1 блок в SAOC кодирующем устройстве комбинирует BGO и FGO сигналы в общий SAOC стерео- или моносигнал понижающего микширования 112 и производит битовый поток 114. Произвольное предопределенное размещение всех индивидуальных FGOs в сигнале понижающего микширования 112 поддерживается любым элементом, то есть TTN или OTN 152. На стороне транскодера BGO 154 или любая комбинация FGO сигналов 156 (в зависимости от режима работы 158 примененяемого внешне) восстанавливается из понижающего микширования 112 посредством TTN или OTN блока 152, использующего только дополнительную информацию SAOC 114 и по выбору включающего остаточные сигналы. Восстановленные звуковые объекты 154/156 и предоставляемая информация 160 используются, чтобы произвести битовый поток MPEG, Объемное звучание 162 и соответствующий предобработанный сигнал 164. Узел микширования 166 выполняет обработку сигнала понижающего микширования 112, чтобы получить MPS входное понижающее микширование 164, и MPS транскодер 168 отвечает за транскодирование SAOC параметров 114 до MPS параметров 162. TTN/OTN блок 152 и узел микширования 166 вместе выполняют обработку расширенного режима Караоке/соло 170, соответствующего средствам 52 и 54 на фиг.3 с функцией узла микширования, состоящего из средства 54.
МВО может рассматриваться так же, как было объяснено выше, то есть предварительно обрабатывается кодирующим устройством MPEG, Объемное звучание, выдавая в результате моно- или стереосигнал понижающего микширования, который служит BGO, который будет введен в последующее усиленное SAOC кодирующее устройство. В этом случае транскодер должен быть предоставлен с дополнительным битовым потоком MPEG, Объемное звучание вслед за SAOC битовым потоком.
Затем объясняется вычисление, выполненное TTN (OTN) элементом. Матрица TTN/OTN, выраженная в первом предопределенном временном/частотным разрешении 42, М., является продуктом двух матриц
М=D-1C,
где D-1 включает информацию о понижающем микшировании, и С подразумевает коэффициенты предсказания канала (CPCs) для каждого FGO канала. С вычисляется средством 52 и блоком 152, соответственно, a D-1 вычисляется и применяется наряду с С для SAOC понижающего микширования при помощи средства 54 и блока 152 соответственно. Вычисление выполнено согласно

для TTN элемента, то есть стереопонижающего микширования и
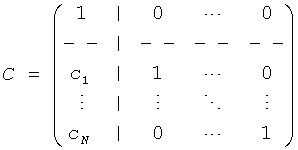
для OTN элемента, то есть монопонижающего микширования.
CPCs получаются из переданных SAOC параметров, то есть OLDs, IOCs, DMGs и DCLDs. Для одного определенного FGO канала j CPCs могут быть оценены по
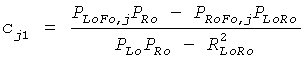 и
и 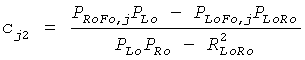 .
.
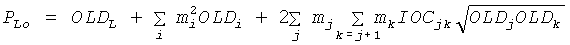 ,
,
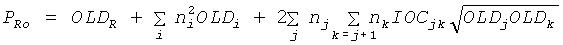 ,
,
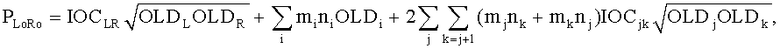
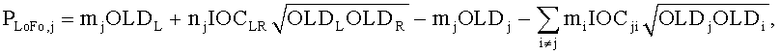
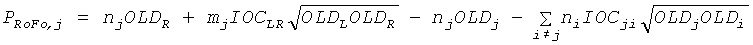 .
.
Параметры OLDL, OLDR и IOCLR соответствуют BGO, остальные являются значениями FGO.
Коэффициенты mj и nj обозначают величины понижающего микширования для каждого FGO j для правого и левого каналов понижающего микширования, и получаются из коэффициентов усиления понижающего микширования, DMG, и разностей уровней канала понижающего микширования, DCLD
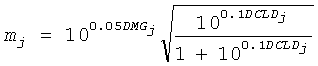 и
и 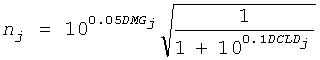 .
.
Относительно OTN элемента вычисление вторых СРС величин cj2 становится избыточным.
Чтобы восстановить две группы объекта BGO и FGO, информация о понижающем микшировании эксплуатируется обратной матрицей понижающего микширования D, которая расширена, чтобы в дальнейшем прописать линейную комбинацию для сигналов F01 к F0N, то есть
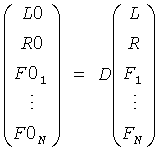 .
.
В дальнейшем будет описано понижающее микширование на стороне кодирующего устройства: В пределах TTN-1 элемента расширенная матрица понижающего микширования
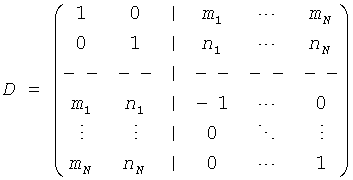 для стерео BGO,
для стерео BGO,
 для моно BGO,
для моно BGO,
и для OTN-1 элемента это
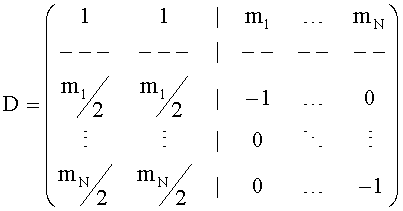 для стерео BGO,
для стерео BGO,
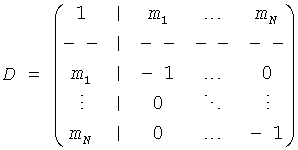 для моно ВGО.
для моно ВGО.
Выход TTN/OTN элемента дает
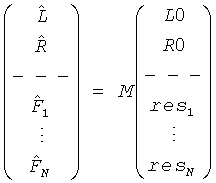
для стерео BGO и стереопонижающего микширования. В случае, если BGO и/или понижающее микширование является моносигналом, линейная система изменяется соответственно.
Остаточный сигнал resi соответствует FGO объекту i и, если не передается SAOC потоком - потому что, например, находится вне остаточного частотного диапазона, или если сообщается, что для FGO объекта i никакой остаточный сигнал не передается вообще - resi означает ноль.  - восстановленный/микшированный с повышением сигнал, приближающийся к FGO объекту i. После вычисления он может быть пропущен через синтезирующий блок фильтров, чтобы получить временной интервал, такой как РСМ закодированная версия FGO объекта i. Следует помнить, что L0 и R0 обозначают каналы SAOC сигналов понижающего микширования и являются доступными/сигнализируют об увеличенном временном/частотном разрешении по сравнению с параметрическим разрешением, лежащим в основе индексов (n, k).
- восстановленный/микшированный с повышением сигнал, приближающийся к FGO объекту i. После вычисления он может быть пропущен через синтезирующий блок фильтров, чтобы получить временной интервал, такой как РСМ закодированная версия FGO объекта i. Следует помнить, что L0 и R0 обозначают каналы SAOC сигналов понижающего микширования и являются доступными/сигнализируют об увеличенном временном/частотном разрешении по сравнению с параметрическим разрешением, лежащим в основе индексов (n, k).  и
и 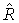 - восстановленные/микшированные с повышением сигналы, приближающиеся к левому и правому каналам BGO объекта. Наряду с MPS дополнительным битовым потоком он может быть передан на оригинальное число каналов.
- восстановленные/микшированные с повышением сигналы, приближающиеся к левому и правому каналам BGO объекта. Наряду с MPS дополнительным битовым потоком он может быть передан на оригинальное число каналов.
Согласно осуществлению следующая TTN матрица используется в энергетическом режиме.
Процедура кодирования/декодирования, основанная на энергии, разработана для сохраняющего кодирования без формы волны сигнала понижающего микширования. Таким образом, TTN матрица повышающего микширования для соответствующего энергетического режима не зависит от формы волны, а только описывает относительное распределение энергии входных звуковых объектов. Элементы этой матрицы MEnergy получены из соответствующих OLDs согласно:
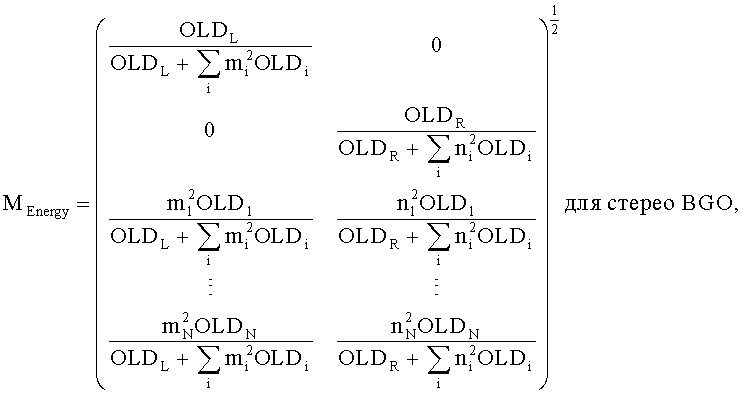
и
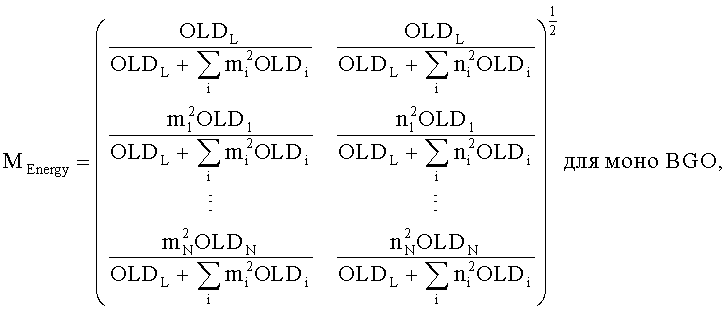
так, чтобы выход элемента TTN выдавал
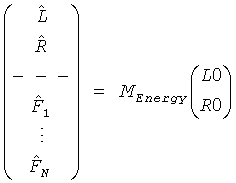 , или соответственно
, или соответственно 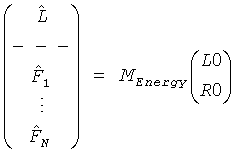 .
.
Соответственно для монопонижающего микширования основанная на энергии матрица повышающего микширования MEnergy становится
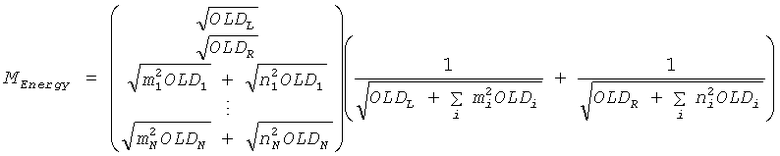
для стерео BGO, и
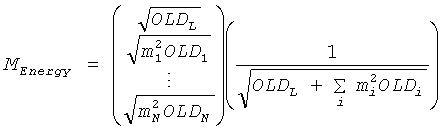 для моно BGO,
для моно BGO,
так, чтобы выход OTN элемента дал в результате
 , или соответственно
, или соответственно 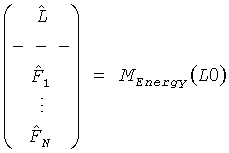 .
.
Таким образом, согласно только что упомянутому осуществлению классификация всех объектов (Obj1…ObjN) в BGO и FGO соответственно выполняется на стороне кодирующего устройства. BGO может быть моно (L) или стерео 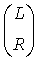 объектом. Фиксируется понижающее микширование BGO в сигнал понижающего микширования. Что касается FGOs, их число теоретически не ограничено. Однако для большинства применений в общей сложности четыре FGO объекта кажутся адекватными. Допустимы любые комбинации моно- и стереообъектов. Посредством параметров mi (взвешивание в левом/моносигнале понижающего микширования) и ni (взвешивание в правом сигнале понижающего микширования) FGO понижающего микширования является переменным. и по времени и по частоте. Как следствие, сигнал понижающего микширования может быть моно (L0) или стерео
объектом. Фиксируется понижающее микширование BGO в сигнал понижающего микширования. Что касается FGOs, их число теоретически не ограничено. Однако для большинства применений в общей сложности четыре FGO объекта кажутся адекватными. Допустимы любые комбинации моно- и стереообъектов. Посредством параметров mi (взвешивание в левом/моносигнале понижающего микширования) и ni (взвешивание в правом сигнале понижающего микширования) FGO понижающего микширования является переменным. и по времени и по частоте. Как следствие, сигнал понижающего микширования может быть моно (L0) или стерео 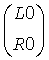 .
.
Снова, сигналы (F01…F0N)T не переданы декодеру/транскодеру. Скорее они же предсказаны на стороне декодера посредством вышеупомянутых CPCs.
В этом отношении снова следует заметить, что остаточные сигналы res могут даже игнорироваться декодером. В этом случае декодер - средство 52, например - предсказывает виртуальные сигналы, базирующиеся только на CPCs согласно:
Стереопонижающее микширование:
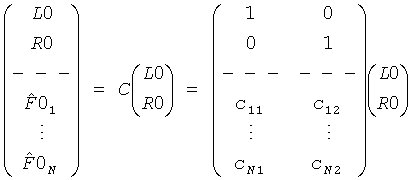
Монопонижающее микширование:
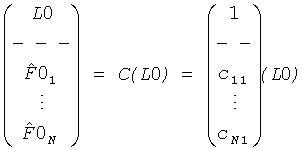 .
.
Тогда BGO и/или FGO получаются посредством - например, средства 54 - инверсии одной из четырех возможных линейных комбинаций кодирующего устройства,
например, 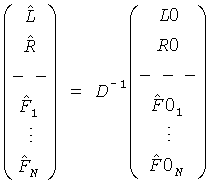 ,
,
где снова D-1 - функция параметров DMG и DCLD.
Таким образом, в конечном итоге остаточный отбрасываемый TTN (OTN) блок 152 осуществляет оба только что упомянутые шага вычисления
например: 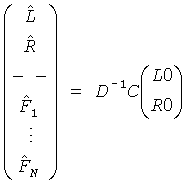 .
.
Замечено, что инверсия D может быть получена непосредственно в случае, если D является квадратным. В случае неквадратной матрицы D инверсия D должна быть псевдоинверсией, то есть pinν(D)=D*(DD*)-1 или pinν(D)=(D*D)-1D*. В любом случае существует инверсия для D.
Наконец, фиг.15 показывает дальнейшую возможность того, как установить, в рамках дополнительной информации, количество данных, потраченных на пересылку остаточных данных. Согласно этому синтаксису дополнительная информация включает bsResidualSamplingFrequencyIndex, то есть индекс к таблице, связанной, например, с частотным разрешением индекса. Альтернативно, разрешение может быть предполагаемым, чтобы быть предопределенным разрешением, таким как разрешение блока фильтров или параметрическое разрешение. Далее, дополнительная информация включает bsResidualFramesPerSAOCFrame, определяющие разрешение по времени, при котором передается остаточный сигнал. BsNumGroupsFGO, также состоящие из дополнительной информации, указывают число FGOs. Для каждого FGO элемент синтаксиса bsResidualPresent передается, указывая, передается или нет остаточный сигнал для соответствующего FGO. Если присутствует, bsResidualBands указывают число спектральных диапазонов, для которых переданы остаточные величины.
В зависимости от фактического выполнения изобретательные способы кодирования/декодирования могут быть осуществлены в аппаратных средствах или в программном обеспечении. Поэтому данное изобретение также имеет отношение к компьютерной программе, которая может быть сохранена на электронно-считываемом носителе, таком как компакт-диск, диск или любой другой носитель информации. Данное изобретение является поэтому также компьютерной программой, имеющей управляющую программу, которая, будучи реализованной на компьютере, выполняет изобретательный способ кодирования или изобретательный способ декодирования, описанный в связи с вышеупомянутыми рисунками.







Изобретение относится к вычислительной технике. Технический результат заключается в обеспечении эффективного разделения индивидуальных объектов в многообъектном звуковом сигнале. Звуковой декодер для декодирования многообъектного звукового сигнала имеет звуковой сигнал первого типа и звуковой сигнал второго типа, закодированные в нем; многообъектный звуковой сигнал состоит из сигнала понижающего микширования и дополнительной информации; дополнительная информация включает информацию об уровне звукового сигнала первого типа и звукового сигнала второго типа в первом предопределенном временном/частотном разрешении, и остаточный сигнал определяет величины остаточного уровня во втором предопределенном временном/частотном разрешении, включает средство для вычисления коэффициентов предсказания, основанное на информации об уровне; и средство для повышающего микширования сигнала понижающего микширования, основанное на коэффициентах предсказания и остаточном сигнале, для получения первого звукового сигнала повышающего микширования, приближающегося к звуковому сигналу первого типа и/или второго звукового сигнала повышающего микширования, приближающегося к звуковому сигналу второго типа. 7 н. и 18 з.п. ф-лы, 24 ил.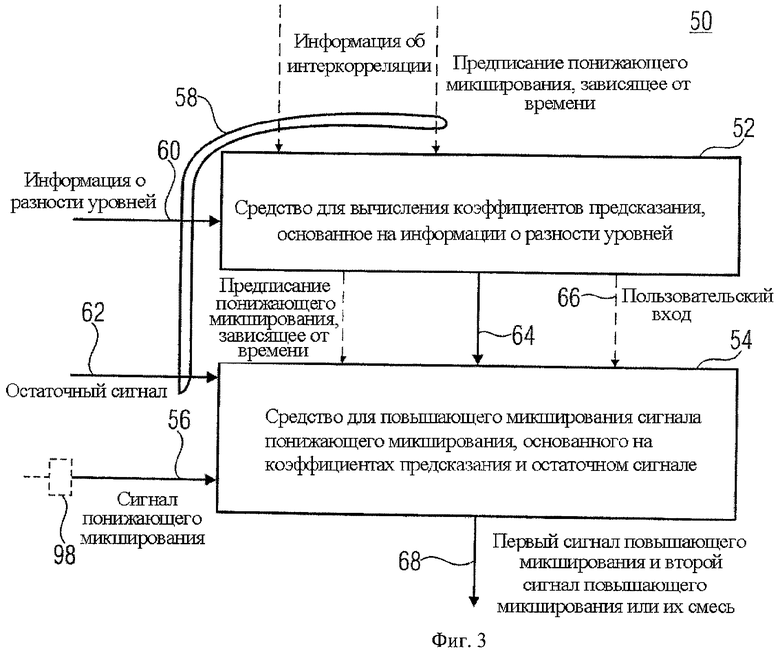
1. Звуковой декодер для декодирования многообъектного звукового сигнала, имеющий звуковой сигнал первого типа и звуковой сигнал второго типа, закодированные в нем; многообъектный звуковой сигнал состоит из сигнала понижающего микширования (56) и дополнительной информации (58); дополнительная информация включает информацию об уровне (60) звукового сигнала первого типа и звукового сигнала второго типа в первом предопределенном временном/частотном разрешении (42), и остаточный сигнал (62) определяет величины остаточного уровня во втором предопределенном временном/частотном разрешении, включает средство (52) для вычисления коэффициентов предсказания (64), основанное на информации об уровне (60); и средство (54) для повышающего микширования сигнала понижающего микширования (56), основанное на коэффициентах предсказания (64) и остаточном сигнале (62), для получения первого звукового сигнала повышающего микширования, приближающегося к звуковому сигналу первого типа и/или второго звукового сигнала повышающего микширования, приближающегося к звуковому сигналу второго типа.
2. Звуковой декодер по п.1, в котором дополнительная информация (58) далее включает предписание понижающего микширования, согласно которому звуковой сигнал первого типа и звуковой сигнал второго типа микшируются с понижением в сигнал понижающего микширования (56), где средство для повышающего микширования выполнено с возможностью далее выполнять повышающее микширование, основанное на предписании понижающего микширования.
3. Звуковой декодер по п.2, в котором предписание понижающего микширования изменяется во времени в рамках дополнительной информации.
4. Звуковой декодер по п.2, в котором предписание понижающего микширования изменяется во времени в рамках дополнительной информации, когда разрешение по времени является более крупным, чем размер структуры.
5. Звуковой декодер по п.2, в котором предписание понижающего микширования указывает взвешивание, посредством которого сигнал понижающего микширования был микширован с повышением, основываясь на звуковом сигнале первого типа и звуковом сигнале второго типа.
6. Звуковой декодер по п.1, в котором звуковой сигнал первого типа является звуковым стереосигналом, имеющим первый и второй входной канал, или монозвуковым сигналом, имеющим только первый входной канал, а сигнал понижающего микширования является звуковым стереосигналом, имеющим первый и второй выходной канал, или монозвуковым сигналом, имеющим только первый выходной канал, где информация об уровне описывает разность уровней между первым входным каналом, вторым входным каналом и звуковым сигналом второго типа соответственно в первом предопределенном временном/частотном разрешении, где дополнительная информация далее включает информацию о межкорреляции, определяющую общие черты уровней между первым и вторым входными каналами в третьем предопределенном временном/частотном разрешении, где средство для вычисления формируется, чтобы далее выполнять вычисление, основанное на информации о межкорреляции.
7. Звуковой декодер по п.6, в котором первое и третье временное/частотное разрешения определяются общим элементом синтаксиса в рамках дополнительной информации.
8. Звуковой декодер по п.6, в котором средство для вычисления и средство для повышающего микширования выполнены таким образом, что повышающее микширование представляется посредством приложения вектора, составленного из сигнала понижающего микширования и остаточного сигнала, к последовательности первой и второй матрицы; первая матрица (С) состоит из коэффициентов предсказания, а вторая матрица (D) определяется посредством предписания понижающего микширования, согласно которому звуковой сигнал первого типа и звуковой сигнал второго типа микшированы с понижением в сигнал понижающего микширования, и который также состоит из дополнительной информации.
9. Звуковой декодер по п.8, в котором средство для вычисления и средство для повышающего микширования выполнены таким образом, что первая матрица отображает вектор на промежуточном векторе, имеющем первый компонент для звукового сигнала первого типа и/или второй компонент для звукового сигнала второго типа, и определяется таким образом, что сигнал понижающего микширования отображается на первом компоненте 1-к-1, и линейная комбинация остаточного сигнала и сигнала понижающего микширования отображается на втором компоненте.
10. Звуковой декодер по п.1, в котором многообъектный звуковой сигнал включает множество звуковых сигналов второго типа, а дополнительная информация включает один остаточный сигнал на звуковой сигнал второго типа.
11. Звуковой декодер по п.1, в котором второе предопределенное временное/частотное разрешение связано с первым предопределенным временным/частотным разрешением через остаточное параметрическое разрешение, содержащееся в дополнительной информации, где звуковой декодер включает средство для получения остаточного параметрического разрешения из дополнительной информации.
12. Звуковой декодер по п.11, в котором остаточное параметрическое разрешение определяет спектральный диапазон, по которому остаточный сигнал передается в рамках дополнительной информации.
13. Звуковой декодер по п.12, в котором остаточное параметрическое разрешение определяет нижний и верхний предел спектрального диапазона.
14. Звуковой декодер по п.1, в котором средство для вычисления коэффициентов предсказания, основанное на информации об уровне, формируется, чтобы вычислять коэффициенты предсказания канала 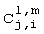 для каждого элемента времени/частоты (l, m) первого временного/частотного разрешения, для каждого выходного канала i из сигнала понижающего микширования и для каждого канала j звукового сигнала(ов) второго типа как
для каждого элемента времени/частоты (l, m) первого временного/частотного разрешения, для каждого выходного канала i из сигнала понижающего микширования и для каждого канала j звукового сигнала(ов) второго типа как
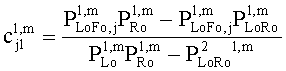 и
и 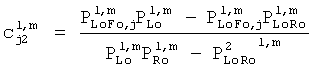
при
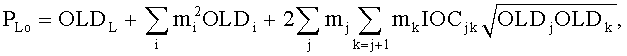
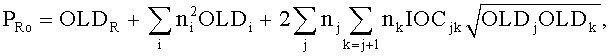
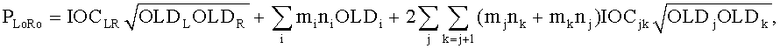
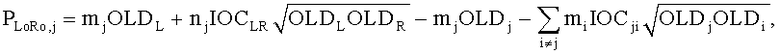
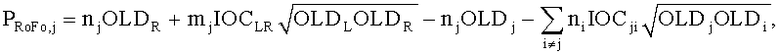
где OLDL обозначает нормализованную спектральную энергию первого входного канала звукового сигнала первого типа в соответствующем элементе времени/частоты; OLDR обозначает нормализованную спектральную энергию второго входного канала звукового сигнала первого типа в соответствующем элементе времени/частоты; и ioclr обозначает информацию о межкорреляции, определяющую спектральное подобие энергии между первым и вторым входным каналом в пределах соответствующего элемента времени/частоты в случае, если звуковой сигнал первого типа является стереосигналом или oldl обозначает нормализованную спектральную энергию звукового сигнала первого типа в соответствующем элементе времени/частоты; и OLDR и IOCLR являются нулем для случая моносигнала,
и где OLDj обозначает нормализованную спектральную энергию канала j звукового сигнала(ов) второго типа в соответствующем элементе времени/частоты, а IOCij обозначает информацию о межкорреляции, определяющую подобие спектральной энергии между каналами i и j звукового сигнала(ов) второго типа в пределах соответствующего элемента времени/частоты, где
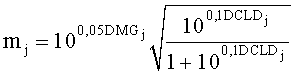 и
и 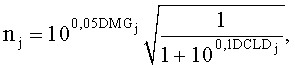
где DCLD и DMG - предписания понижающего микширования,
где средство для повышающего микширования выполнено, чтобы производить первый сигнал повышающего микширования S1 и/или второй сигнал(лы) повышающего микширования S2,i из сигнала понижающего микширования d и остаточного сигнала resi на второй сигнал повышающего микширования S2,i посредством
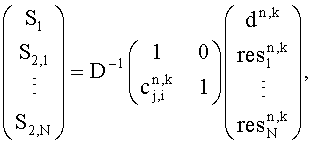
где «1» в верхнем левом углу обозначает в зависимости от числа каналов dn,k скаляр или матрицу идентичности; «1» в нижнем правом углу является матрицей идентичности размера N; «0» обозначает нулевой вектор или матрицу, также зависящую от числа каналов dn,k, a D-1 - матрица, однозначно определенная посредством предписания понижающего микширования, согласно которому звуковой сигнал первого типа и звуковой сигнал второго типа микшированы с понижением в сигнал понижающего микширования, и который также состоит из дополнительной информации, dn,k и 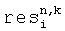 , сигнала понижающего микширования и остаточного сигнала для второго сигнала повышающего микширования S2,i в элементе времени/частоты (n, k) соответственно, где
, сигнала понижающего микширования и остаточного сигнала для второго сигнала повышающего микширования S2,i в элементе времени/частоты (n, k) соответственно, где 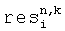 не состоят из дополнительной информации и установлены на нуль.
не состоят из дополнительной информации и установлены на нуль.
15. Звуковой декодер по п.14, где D-1 является инверсией
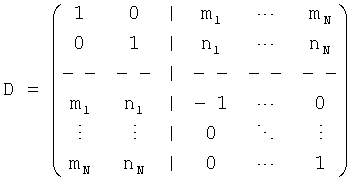
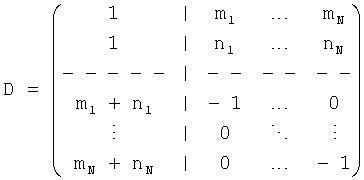
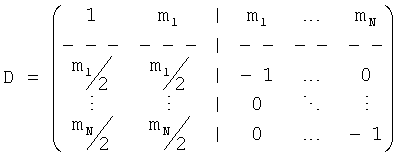

16. Звуковой декодер по п.1, в котором многообъектный звуковой сигнал включает пространственную предоставляемую информацию для пространственного представления звукового сигнала первого типа на предопределенную конфигурацию громкоговорителя.
17. Звуковой декодер по п.1, в котором средство для повышающего микширования формируется, чтобы пространственно предоставлять первый звуковой сигнал повышающего микширования, отделенный от второго звукового сигнала повышающего микширования, чтобы пространственно предоставлять второй звуковой сигнал повышающего микширования, отделенный от первого звукового сигнала повышающего микширования, или чтобы микшировать первый звуковой сигнал повышающего микширования и второй звуковой сигнал повышающего микширования, и чтобы пространственно предоставлять их микшированную версию на предопределенную конфигурацию громкоговорителя.
18. Звуковое кодирующее устройство объекта включает средство для вычисления информации об уровне звукового сигнала первого типа и звукового сигнала второго типа в первом предопределенном временном/частотном разрешении; средство для вычисления коэффициентов предсказания, основанного на информации об уровне; средство для звукового сигнала понижающего микширования первого типа и звукового сигнала второго типа, чтобы получить сигнал понижающего микширования; средство для регулирования остаточного сигнала, определяющего величину остаточного уровня во втором предопределенном временном/частотном разрешении таким образом, что повышающее микширование сигнала понижающего микширования, основывающееся и на коэффициентах предсказания и на величинах остаточного сигнала, дает в результате первый звуковой сигнал повышающего микширования, приближающийся к звуковому сигналу первого типа, и второй звуковой сигнал повышающего микширования, приближающийся к звуковому сигналу второго типа; улучшенное приближение сравнимо с отсутствием остаточного сигнала, информация об уровне и остаточный сигнал, состоявший из дополнительной информации, формируют наряду с сигналом понижающего микширования многообъектный звуковой сигнал.
19. Звуковое кодирующее устройство объекта по п.18 дополнительно включает средство для спектрального разложения звукового сигнала первого типа и звукового сигнала второго типа.
20. Способ декодирования многообъектного звукового сигнала, имеющего звуковой сигнал первого типа и звуковой сигнал второго типа, закодированные в нем; многообъектный звуковой сигнал состоит из сигнала понижающего микширования (56) и дополнительной информации (58); дополнительная информация включает информацию об уровне (60) звукового сигнала первого типа и звукового сигнала второго типа в первом предопределенном временном/частотном разрешении (42), и остаточный сигнал (62), определяющий значения остаточного уровня во втором предопределенном временном/частотном разрешении, включающий вычисление коэффициентов предсказания (64), основанное на информации об уровне (60); и повышающее микширование сигнала понижающего микширования (56), основанное на коэффициентах предсказания (64) и остаточном сигнале (62), для получения первого звукового сигнала повышающего микширования, приближающегося к звуковому сигналу первого типа и/или второго звукового сигнала повышающего микширования, приближающегося к звуковому сигналу второго типа.
21. Способ кодирования многообъектного звукового сигнала, включающий вычисление информации об уровне звукового сигнала первого типа и звукового сигнала второго типа в первом предопределенном временном/частотном разрешении; вычисление коэффициентов предсказания, основанное на информации об уровне; понижающее микширование звукового сигнала первого типа и звукового сигнала второго типа, чтобы получить сигнал понижающего микширования; регулирование остаточного сигнала, определяющее величины остаточного уровня во втором предопределенном временном/частотном разрешении таким образом, что повышающее микширование сигнала понижающего микширования, основанное и на коэффициентах предсказания и на остаточном сигнале, дает в результате первый звуковой сигнал повышающего микширования, приближающийся к звуковому сигналу первого типа, и второй звуковой сигнал повышающего микширования, приближающийся к звуковому сигналу второго типа; улучшенное приближение сравнимо с отсутствием остаточного сигнала, информация об уровне и остаточный сигнал, состоявший из дополнительной информации, формируют наряду с сигналом понижающего микширования многообъектный звуковой сигнал.
22. Машиночитаемый носитель, содержащий сохраненный на нем компьютерный программный продукт с кодом программы для выполнения способа по п.20 или 21.
23. Многообъектный звуковой сигнал, имеющий звуковой сигнал первого типа и звуковой сигнал второго типа, закодированный в нем; многообъектный звуковой сигнал, состоящий из сигнала понижающего микширования и дополнительной информации; дополнительная информации включает информацию об уровне звукового сигнала первого типа и звукового сигнала второго типа в первом предопределенном временном/частотном разрешении, и остаточный сигнал, определяющий величины остаточного уровня во втором предопределенном временном/частотном разрешении, где остаточный сигнал установлен таким образом, что вычисление коэффициентов предсказания, основанное на информации об уровне, и повышающее микширование сигнала понижающего микширования, основанное на коэффициентах предсказания и остаточном сигнале, в результате дает первый звуковой сигнал повышающего микширования, приближающийся к звуковому сигналу первого типа, и второй звуковой сигнал повышающего микширования, приближающийся к звуковому сигналу второго типа.
24. Декодер SAOC для декодирования SAOC стереосигнала понижающего микширования (112); SAOC дополнительная информация (106, 114) и остаточное кодирование (132); SAOC стереосигнал понижающего микширования, являющийся комбинацией стереосигнала объекта (104), формирующего первый и второй звуковые сигналы, и моносигнал объекта (110), формирующего третий звуковой сигнал; SAOC дополнительная информация, включающая отношения энергии объекта для каждого из трех звуковых сигналов и корреляции межсигнала между первым и вторым звуковыми сигналами; и остаточное кодирование, служащее для улучшения качества восстановления повышающего микширования; SAOC декодер включает ТТТ блок (ТТТ = два-к-трем), формируемый для вычисления (52) коэффициентов предсказания канала из энергий объекта и корреляции межсигнала, и повышающее микширование восстанавливает (54) первый и второй звуковые сигналы и/или третий звуковой сигнал на основе формы волны посредством ТТТ обработки с использованием коэффициентов предсказания канала и остаточного сигнала.
25. SAOC декодер по п.24, в котором SAOC дополнительная информация (106, 114) далее включает матрицу понижающего микширования, элементы которой указывают вес, посредством которого первый-третий звуковые сигналы вносят вклад в левый и правый каналы понижающего микширования SAOC стереосигнала понижающего микширования посредством суммирования, где первый звуковой сигнал вносит вклад в левый канал понижающего микширования, при этом не внося вклад в правый канал понижающего микширования, и второй звуковой сигнал вносит вклад в правый канал понижающего микширования, при этом не внося вклад в левый канал понижающего микширования, и третий звуковой сигнал микшируется между левым и правым каналами понижающего микширования, где ТТТ блок формируется, чтобы выполнять восстановление повышающего микширования, далее используя матрицу повышающего микширования.
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| US 6016473 A, 18.01.2000 | |||
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ КОДИРОВАНИЯ ЗВУКОВЫХ СИГНАЛОВ | 1996 |
|
RU2158478C2 |

