Изобретение относится к устройствам для семантической классификации оцифрованных киноматериалов и информационного поиска в архивах оцифрованных киноматериалов, а именно к устройствам для анализа изображения, распознавания визуальных свойств кинофильмов, автоматического извлечения признаков из видеокадров, семантического распознавания образов и классификации сцены в оцифрованных киноматериалах, а также к устройствам для информационного поиска при условиях поиска, заданных в текстовой или категориальной форме, включающей категории обнаруженных объектов, жанров или сцен, а также при условиях поиска, заданных эталонным кинофрагментом или по крайней мере одним эталонным изображением.
Задача поиска фрагментов фондовых материалов киноархивов и телевизионных передач является актуальной при производстве новых художественных и документальных, образовательных и коммерческих фильмов, выпусков теленовостей, телевизионных передач, рекламных роликов и заставок.
Объемы хранимых в крупнейших архивах киноматериалов и телевизионных материалов огромны. Госфильмофонд РФ насчитывает около 70000 наименований фильмов; Гостелерадиофонд - около 100000. Объемы видеоматериалов на публичных интернет-порталах невообразимы. Только на видеосервис Youtube каждую минуту пользователи загружают свыше 100 часов нового видео.
Производители документальных фильмов и телевизионных передач ежедневно сталкиваются в своей работе с поиском фрагментов в видеоархивах. Качество поиска зависит от квалификации редакторов и авторов, их кругозора, культурного и исторического образования. Текстовые аннотации архивных киноматериалов в настоящее время недостаточно подробны и не позволяют эффективно использовать разработанные для Интернета стандартные поисковые системы.
Разработка системы семантической индексации киноматериалов призвана значительно повысить эффективность работы редакторов и авторов документальных фильмов и телевизионных программ по подбору фрагментов фондовых материалов. При этом потребность в ручной аннотации фондовых материалов значительно снижается.
В соответствии с международным стандартом (ISO/IEC 15938-5:2003. Информационные технологии. Интерфейс описания содержимого мультимедиа. Часть 5. Схемы описания мультимедиа. - 730 с., [1]), системы описания содержимого мультимедиа, к которым относятся и оцифрованные киноматериалы, должны обеспечивать информационный поиск по следующим видам запросов:
- Запрос по образцу на поиск близкого или идентичного представленному образцу мультимедийного материала (в частности образцу изображения и образцу кинофрагмента);
- Запрос по описанию, в котором запрос представляет собой структурированное описание в формате XML;
- Запрос в текстовой форме;
- другие виды запросов.
В технике широко известны системы для классификации изображений, т.е. системы для анализа неподвижных изображений, таких как фотографии, и присвоения им по крайней мере одной метки или текстового описания, по которым, в свою очередь, могут осуществлять поиск в базе данных изображений. Такие системы обычно используют для классификации изображений по заранее известной номенклатуре классов. Известным в технике способом классификации является применение по крайней мере одного классификатора и отнесение изображения к множеству классов, наиболее подходящих к изображению. Например, фотографию стада слонов в саванне могут отнести к классу "слон", к классу "саванна" или к множеству классов "слон, саванна".
Подобные способы классификации изображений используют различные методики технической реализации классификаторов. Например, в работе (Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks. Advances in neural information processing systems, 2012, [2]) описан классификатор на основе сверточных нейронных сетей.
Независимо от конкретной методики построения классификатора, традиционные системы классификации изображений недостаточно точны для классификации киноматериалов. Традиционные системы оптимизируют для анализа фотографий, в которых обычно уделяют значительное внимание вопросам композиции, а именно пропорциям фона и основного объекта в кадре, ракурсу съемки неподвижных объектов, отсутствию препятствий между камерой и объектом съемки, качеству освещения, экспонирования и наводки на резкость. В противоположность фотографии, кинофрагменты предназначают для восприятия зрителем целостно как последовательность кадров, в каждом из которых объект съемки может быть снят частично, в необычном ракурсе, быть смазанным из-за движения и т.п. В киносъемке применяют также ряд операторских приемов, таких как плавный ввод и вывод экспозиции, наезд или отъезд камеры и т.п.
В таких условиях классификаторы для неподвижных изображений работают с низкой точностью, и для семантической классификации киноматериалов и последующего информационного поиска применяют устройства, основанные на анализе векторов движения, гистограмм цветового фона и насыщенности, инвариантных дескрипторов особых точек изображения и др. методики.
Из уровня техники известна система для поиска по видеоархиву на основе эталонного изображения (WO 2014082288 А1, опубликована 05.06.2014). Система включает средства пользовательского интерфейса для ввода текстового запроса для поиска видеофрагмента, средства для поиска эталонных изображений на основе текстового запроса и отображения множества найденных эталонных изображений пользователю, средства для поиска видеофрагмента на основе одного выбранного пользователем эталонного изображения.
В предложенной системе поиск видеофрагмента основан на вычислении меры близости эталонного изображения и ключевого кадра видеофрагмента в архиве. Меру близости вычисляют с помощью признаков распределения цвета, типов текстур и формы контуров.
Недостатком предложенного подхода является ограничение возможностей поиска лишь одним образцом эталонного изображения, а также зависимость точности поиска от корректности выбора ключевого кадра видеофрагмента. Более полезным был бы поиск кинофрагмента по множеству эталонных фотографий требуемого образа или класса изображений. Например, если в семантическом индексе киноархива не содержится класс "Внедорожник", предпочтительно реализовать устройство для поиска фрагментов, содержащих внедорожные автомобили, на основе классификатора, обученного на множестве фотографий различных внедорожников. При сравнении фрагментов в архиве с эталонными изображениями предпочтительно использовать информацию из более чем одного эталонного изображения для обеспечения большей чувствительности информационного поиска.
Из уровня техники известны способ и система для видео поиска и формирования базы данных оцифрованных видеоматериалов для осуществления поиска на основе образцового видеофрагмента (патенте США №8515933, опубликован 15.09.2011). Способ формирования базы данных оцифрованных видеоматериалов включает шаги записи видеофайлов в базу данных, формирования метаданных для каждого видеофайла. Шаг формирования метаданных включает этап сегментации видеофайла на отдельные сцены и этап семантической индексации каждой сцены.
Сегментацию фильма на отдельные сцены осуществляют на основе обнаружения точек резкого изменения векторного расстояния между гистограммами тона и насыщенности соседних кадров.
Семантическую индексацию сцены осуществляют на основе комбинации направления вектора движения, длительности сцены и тонового угла сцены в цветовом пространстве HSV.
В системе для поиска видеофрагментов по образцу получают образцовый видеофрагмент, извлекают метаданные образцового видеофрагмента, получают кандидатуры результатов поиска по совпадению индексной метки образцового видеофрагмента, выбирают результаты поиска из кандидатур результатов поиска по критерию близости семантических векторов образцового видеофрагмента и видеофрагмента-кандидатуры.
Указанные метаданные включают комбинацию направления вектора движения, длительности сцены и тонового угла сцены в цветовом пространстве HSV. Указанные семантические векторы включают бинаризованные последовательности значений разности векторов движения между соседними кадрами.
Применение метаданных для индексации ускоряет поиск по архиву оцифрованных фильмов за счет того, что архив индексирован по значению полей метаданных (например, по тоновому углу сцены в цветовом пространстве HSV), поэтому для поиска семантически близких сцен не требуется сплошной просмотр всего архива. Однако, подбор признаков для формирования метаданных не позволяет сформировать истинно семантический индекс, т.к. предложенные в указанном патенте признаки содержат лишь общие характеристики кадра, такие как преобладающий тон цвета, преобладающее направление движения и длительность сцены. Перечисленные признаки недостаточны для семантической классификации изображений в кадре.
В качестве семантических векторов предложены бинаризованные последовательности значений разности векторов движения между соседними кадрами. Авторы сделали эмпирическое наблюдение, что указанные последовательности совпадают или близки для одинаковых видеофрагментов, записанных в различных разрешениях (размерах кадра в пикселах). Однако, предложенные семантические векторы не содержат информации, позволяющей классифицировать изображения в сценах. Поэтому возможности предложенной системы семантической индексации и поиска ограничены ситуацией, когда требуется найти фрагменты с цветовой тональностью и длительностью, близкими к заданному образцу, в которых последовательность преобладающего движения в кадре близка к заданному образцу.
Кроме того, вычисление вектора движения является вычислительно затратной процедурой, а признаки на основе гистограмм затруднительно вычислять с помощью параллельных графических ускорителей, что в совокупности ограничивает производительность системы семантической индексации и поиска.
Использование резкого изменения тональности кадров для сегментации фильма на сцены имеет недостатки, связанные с тем, что не учитывают содержательное наполнение кадра, и часто допускают ошибку разделения целостной сцены на несколько фрагментов.
Также из уровня техники известна система для семантической классификации сцен из видеофильмов (заявка США №2009208106, опубликована 20.08.2009), в которой получают видеофайл, извлекают из видеофайла подмножество кадров, исключают из указанного подмножества кадры с недостаточным уровнем яркости, определяют, принадлежит ли каждый кадр из указанного подмножества заданной общей категории, для кадров, принадлежащих к указанной общей категории, вычисляют вектор оценок принадлежности заранее заданным классам, объединяют соседние кадры с близкими векторами оценок принадлежности к заданным классам в единую сцену и индексируют указанную сцену как принадлежащую соответствующим классам. Полученный индекс используют для информационного поиска видеофильмов с требуемым содержимым.
Примером упомянутой общей категории является категория "натурная съемка". Примерами упомянутых заранее заданных классов являются "пляж", "берег", "пустыня", "лес", "луг", "автострада", "озеро", "река", "горы" и т.п.
Для определения принадлежности кадра к заданной общей категории выделяют вектор признаков из кадра и классифицируют вектор признаков с помощью классификатора общих категорий. В качестве признаков используют гистограммы распределения цветов в цветовом пространстве CIELAB, гистограммы ориентации углов, полученные с помощью фильтров Собеля, гистограммы распределения штрихов, полученные с помощью преобразования Хаффа, гистограммы распределения типов текстур, признаки формы и морфологические признаки. Классификатор общей категории реализуют с помощью машины опорных векторов.
Для вычисления вектора оценок принадлежности кадра к заранее заданным классам применяют признаки, описанные выше и ансамбли из машин опорных векторов.
В результате работы описанной системы получают индекс видеоматериалов, включающий записи, соответствующие отдельным сценам фильмов. Каждая запись включает, по меньшей мере, поля "Начало фрагмента", "Конец фрагмента", "Классы принадлежности фрагмента". При этом поля "Начало фрагмента" и "Конец фрагмента" содержат отметки времени в общем хронометраже фильма.
При информационном поиске вводят текстовый запрос, например "Автострада", находят в индексе все фрагменты, включающие в поле "Классы принадлежности фрагмента" требуемый класс "автострада", и представляют полученный перечень фрагментов пользователю.
Предложенное решение, включающее двухстадийную классификацию кадров, а именно сначала на принадлежность к общей категории, затем на принадлежность к заранее заданным классам изображения, предназначено для повышения точности семантической индексации. Благодаря первой классификации получают возможность исключить нерелевантные классификаторы, заведомо непригодные для общей категории изображения (например, для общей категории "интерьерные сцены" заведомо непригодной являются такие классы, как "земля", "трава", "лес"). Однако, такая двухстадийная классификация приводит к дополнительным затратам на обучение классификаторов, включая формирование обучающих выборок эталонных изображений для общей категории и упомянутых заранее заданных классов; вычислительные затраты на двукратное применения машины опорных векторов; потенциально двукратные затраты на извлечение векторов признаков, т.к. наборы признаков для первого и второго классификаторов обычно различаются. Кроме того, повышение точности индексации при двустадийной классификации не доказано теоретически, и при ошибочной классификации общей категории результат классификации на принадлежность заранее заданным классам будет заведомо неверным.
В описанном решении формирование сцены из отдельных кадров производят после вычисления векторов оценок принадлежности заранее заданным классам, т.е. после второй классификации. Недостатком такого подхода является тот факт, что во многих фильмах применяют операторские приемы, характерные для съемки объектов в движении. Тогда в заведомо единой сцене на отдельных кадрах могут классифицировать изображения, принадлежащие разным классам, и расстояния между соответствующими векторами оценок будут велики, поэтому сцена будет фрагментирована на несколько ложных фрагментов. Например, типичная сцена погони хищника за добычей может включать первые кадры, содержащие только животное-добычу, затем кадры, содержащие стремительно движущегося хищника, затем кадры, включающие обоих животных. Способ разбиения фильма на сцены, предложенный в прототипе, может ошибочно разделить сцену на три различных фрагмента, что может привести к ошибочным или неоптимальным результатам информационного поиска.
Также в описанном решении используют большое количество разнообразных признаков для формирования вектора признаков для классификации кадра. Значительная доля предложенных признаков носит характер гистограммы. Расчет гистограммы является алгоритмически последовательной процедурой, плохо реализуемой на современных параллельных графических ускорителях. Следовательно, производительность принципиально ограничена производительностью центрального процессора и не может быть масштабирована для ускорения расчетов. Кроме того, алгоритмы вычисления признаков разнообразны и неуниверсальны, что повышает сложность программного обеспечения и риски ошибочных вычислений. Такие признаки, как типы текстур и формы контуров, сложны в программной реализации, а их эффективность для точной классификации кадра зависит от оптимального выбора базиса, например номенклатуры типов текстур, форм контуров и масштабов сравнения.
Описанная система реализует возможности информационного поиска по архиву видеозаписей на основе текстового запроса, включающего ключевые слова. Однако, предпочтительно предоставить пользователям дополнительную возможность информационного поиска на основе эталонного фрагмента фильма. Например, пользователь мог бы выполнить первый поиск по ключевым словам, получить перечень кинофрагментов, включающих элементы требуемых классов, например выполнить поиск по ключевому слову "Слон". Далее, пользователь мог бы выбрать среди результатов первого поиска кинофрагмент с требуемыми трудноформализуемыми характеристиками, такими как масштаб и количество слонов в кадре, тип фона (лес, небо, водоем), характеристики освещенности (закатное небо или полдень) и т.п. Было бы предпочтительно, чтобы устройство для семантической индексации и поиска позволило выполнить второй поиск по образцу выбранного эталонного фрагмента, т.к. часто дать описание требований сложнее, чем предоставить визуальный образец.
Указанный источник информации выбран в качестве наиболее близкого аналога.
Таким образом, известные в технические решения для создания систем семантической индексации и информационного поиска обладают следующими недостатками. Использование разнообразных гистограмм в качестве признаков изображения ограничивает производительность системы в связи с затруднениями при параллелизации расчетов. Использование большого количества разнообразных признаков, извлекаемых из изображений, затрудняет разработку программного обеспечения. Используемые в качестве признаков гистограммы не несут семантической информации, а лишь позволяют статистически анализировать изображения на основе распределения тона, яркости, ориентации штрихов и т.п. Разделение фильма на сцены на основе вектора классификации приводит к неточной классификации из-за отсутствия усреднения между связанными кадрами, и к ложным срабатываниям, т.е. фрагментации целостных сцен. Разделение фильма на сцены на основе анализа тональности соседних кадров не учитывает содержания кадров и также приводит к ложным срабатываниям и фрагментации сцен. Применение каскадной классификации приводит к повышенным вычислительным затратам при обучении классификаторов и при классификации кадров и не устраняет ошибок классификации. Применение признаков типа текстуры и формы контуров затрудняет процесс обучения классификаторов, т.к. эффективность подобных признаков сильно зависит от оптимального выбора базиса. Применение векторов движения в качестве признаков недостаточно для семантической классификации объектов кадра. Избранная в качестве прототипа система для семантической классификации сцен в видеофильмах не позволяет осуществлять информационный поиск на основе образцового видеофрагмента и на основе эталонных изображений т.к. в индексе сохраняют только признаки принадлежности сцен к заранее заданным классам.
Настоящее изобретение направлено на решение задачи разработки устройства для семантической классификации и поиска в архивах оцифрованных киноматериалов, позволяющего: формировать индекс киноархива, позволяющего осуществлять информационный поиск кинофрагментов по текстовому запросу в формате комбинации ключевых слов, формировать индекс киноархива, позволяющего осуществлять информационный поиск кинофрагментов по структурированному запросу в формате XML, формировать индекс киноархива, позволяющего осуществлять информационный поиск кинофрагментов по образцу кинофрагмента, формировать индекс киноархива, позволяющего осуществлять информационный поиск кинофрагментов по множеству образцов неподвижных изображений, осуществлять информационный поиск кинофрагментов.
Технический результат заявленного изобретения, достигаемый при его использовании, заключается в повышении точности сегментации фильмов на сцены благодаря учету семантики содержания сцены, повышении точности классификации сцен по заранее заданному перечню классов, повышении быстродействия процесса извлечения семантических признаков из кадров кинофильма за счет эффективной реализации параллельных вычислений, сокращении дополнительных затрат на программирование при увеличении размерности вектора признаков за счет извлечения семантических признаков из кадров кинофильма на основе унифицированного алгоритма, сокращении объема данных для хранения индекса для выполнения информационного поиска кинофрагментов по текстовым запросам, запросам в структурированной форме, запросам по образцу за счет сквозного использования унифицированных векторов признаков, сокращении времени выполнения индексации за счет однократного применения операции извлечения признаков и однократного применения классификаторов, повышении точности и чувствительности информационного поиска за счет применения векторов признаков, включающих значимую семантическую информацию.
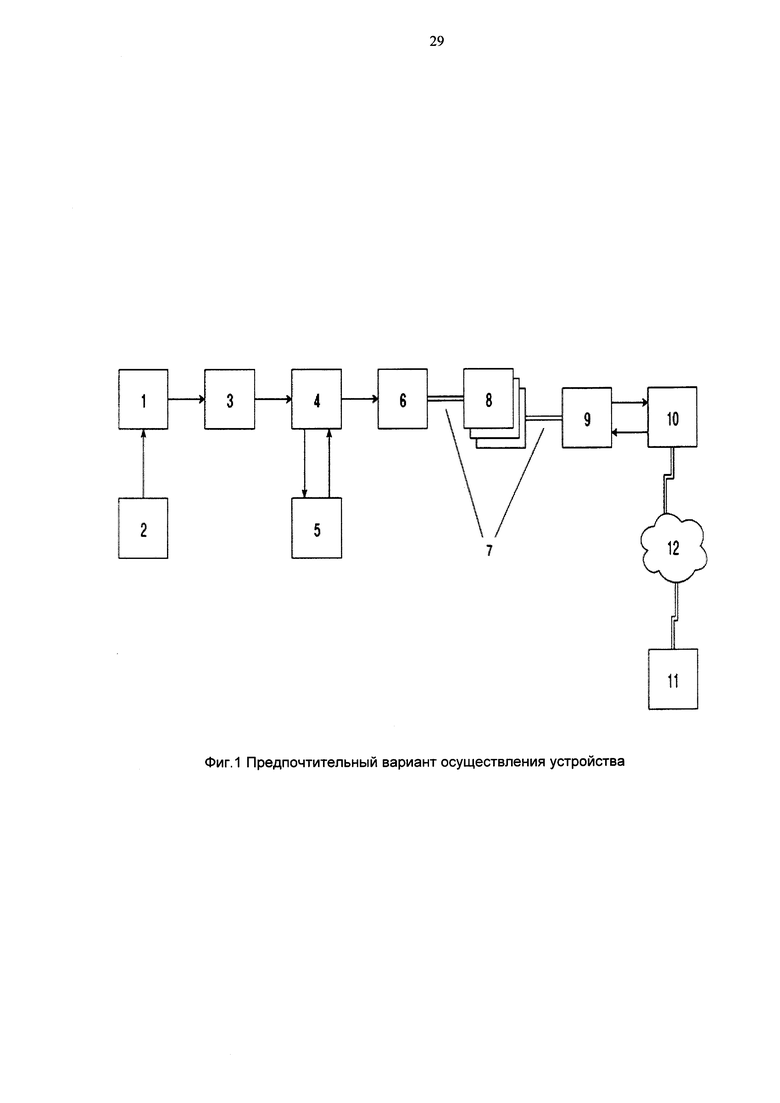
Указанный технический результат достигается за счет использования устройства для семантической классификации и поиска в архивах оцифрованных киноматериалов, которое включает последовательно соединенные средство получения оцифрованных материалов, средство извлечения выборочных кадров из оцифрованных киноматериалов, средство извлечения векторов признаков, средство сегментации и классификации, средство хранения индекса, средство для выполнения информационного поиска, серверное устройство и клиентское устройство, при этом средство извлечения выборочных кадров из оцифрованных киноматериалов выполнено с возможностью раскодировки и извлечения кадров или изображений через заданные промежутки времени, масштабирования выборочных кадров или изображений в размер, пригодный для классификации, средство извлечения векторов признаков включает по крайней мере один слой свертки, соединенный по крайней мере с одним слоем голосования и по крайней мере с одним слоем финальной классификации, причем средство извлечения векторов признаков выполнено с возможностью получения вектора признаков из слоя голосования и получения вектора классификации из слоя финальной классификации, средство сегментации и классификации выполнено с возможностью сегментации фильма на отдельные сцены посредством сравнения между собой векторов признаков соседних выборочных кадров и с возможностью усреднения векторов классификации для кадров, составляющих одну сцену, средство хранения индекса выполнено с возможностью обмена данными между средством сегментации и классификации и средством для выполнения информационного поиска посредством интерфейса локальной сети и сохранения для каждой сцены фильма по крайней мере времени начала сцены, длительности сцены и по крайней мере одного признака класса, получаемого из усредненного вектора классификации для кадров, составляющих одну сцену, серверное устройство выполнено с возможностью обмена данными со средством для выполнения информационного поиска посредством интерфейса локальной сети и с клиентским устройством посредством глобальной сети Интернет, клиентское устройство выполнено с возможностью передачи текстового запроса серверному устройству посредством глобальной сети Интернет, причем серверное устройство выполнено с возможностью формирования декларативного запроса на основании текстового запроса и передачи декларативного запроса средству для выполнения информационного поиска посредством интерфейса локальной сети, причем серверное устройство и клиентское устройство выполнены с возможностью передачи множества образцовых кинофрагментов или неподвижных изображений средству для выполнения информационного поиска, выполненному с возможностью раскодировки и извлечения кадров или изображений через заданные промежутки времени, масштабирования выборочных кадров или изображений в размер, пригодный для классификации и вычисления векторов признаков для каждого образцового изображения или каждого образцового кинофрагмента для осуществления информационного поиска по архиву оцифрованных киноматериалов на основе введенного образцового кинофрагмента или по крайней мере одного образцового неподвижного изображения.
Также средство хранения индекса выполнено с возможностью сохранения усредненных векторов признаков по крайней мере одной сцены фильма.
При этом средство извлечения векторов признаков взаимодействует с устройством графического параллельного ускорения.
Также средство для выполнения информационного поиска, выполнено с возможностью выполнения сравнения усредненного векторов признаков образцового кинофрагмента, полученного из слоя голосования, с усредненными векторами признаков, сохраненными в устройстве хранения индекса, для поиска по образцовому кинофрагменту.
Причем средство для выполнения информационного поиска выполнено с возможностью извлечения векторов признаков образцового изображения, полученными из слоя голосования, для каждого образцового изображения и выполнения обучения классификатора, и применения обученного классификатора к усредненным векторам признаков, сохраненными в устройстве хранения индекса, для поиска по множеству образцовых изображений.
Средства получения оцифрованных киноматериалов считывают цифровой фильм, выполняют операцию раскодирования и передают последовательность кадров средствам извлечения выборочных кадров. Указанные средства извлекают кадры через заданные промежутки времени, производят масштабирование выборочных кадров в размер, пригодный для классификации, и передают указанные кадры в средства извлечения векторов признаков. Указанные средства производят вычисление вектора признаков из каждого выборочного кадра, причем вектор признаков включает семантическую информацию, пригодную для классификации изображения в кадре. Это достигают за счет использования блока расчета сверточных нейронных сетей, известных в технике благодаря своим свойствам извлечение семантически значимой информации. В блок расчета сверточных нейронных сетей подают входной кадр на первый слой свертки. Выходной сигнал с первого слоя свертки подают на первый слой голосования. Известные в технике решения заключаются в чередовании нескольких слоев свертки и голосования. По крайней мере, с одного слоя голосования выходной сигнал подают на слой финальной регрессии, на выходе которого получают вектор принадлежности кадра заранее известным классам.
В отличие от ближайшего прототипа, вычисление вектора признака производят однократно для каждого кадра, поэтому затраты вычислительной мощности и электроэнергии на извлечение признаков и последующую классификацию минимальны. Средства извлечения векторов признаков также вычисляют вектор принадлежности кадра к заранее заданным классам и передают вектор признаков и вектор принадлежности кадра к заранее заданным классам на средства сегментации и классификации по заранее заданным классам.
Далее, средства сегментации и классификации по заранее заданным классам производят сравнение векторного расстояния между векторами признаков соседних кадров, и в случае превышения порога векторного расстояния производят сегментацию последовательности кадров на отдельные сцены. В отличие от известных аналогов, используемые в данном изобретении векторы признаков содержат семантическую информацию, пригодную для классификации изображения в кадре, полученные сцены содержат семантически близкие кадры, а отдельные сцены значительно различаются по своему визуальному содержимому.
Для кадров, составляющих одну сцену, средства сегментации и классификации по заранее заданным классам производят усреднение векторов принадлежности кадра к заранее заданным классам и передают полученный усредненный вектор принадлежности сцены заранее заданным классам и усредненный вектор признаков кадров, составляющих сцену, средствам хранения индекса. Благодаря усреднению векторов принадлежности, точность классификации сцены повышается по сравнению с достигнутым уровнем техники.
В отличие от ближайшего прототипа, сегментацию фильма производят не после классификации на основе векторов принадлежности отдельных кадров заранее заданным классам, а на основе векторов признаков, т.е. классификацию производят после сегментации и на основе усреднения векторов принадлежности кадров, составляющих сцену, заранее заданным классам.
Средства хранения индекса записывают информацию о сцене, включающую поля времени начала сцены, длительности сцены, усредненного вектора признаков сцены и метки принадлежности сцены по крайней мере одному из заранее заданных классов. В отличие от ближайшего прототипа, производят сохранение усредненного вектора признаков сцены, т.к. это позволяет без дополнительных вычислительных и энергетических затрат производить информационный поиск на основе запросов по образцовому кинофрагменту или по образцовым изображениям.
Для осуществления информационного поиска по архиву оцифрованных киноматериалов пользователь вводит поисковый запрос в текстовой или структурированной форме с помощью средств, для организации пользовательского интерфейса информационного поиска к которым относится серверное устройство и клиентское устройство. Указанные средства передают поисковый запрос средствам для выполнения информационного поиска. Средства для выполнения информационного поиска преобразуют поисковый запрос в декларативный формат запроса к средствам хранения индекса таким образом, чтобы выполнить поиск по меткам принадлежности сцены к заранее заданным классам. Средства для выполнения информационного поиска, обращаясь к средствам хранения индекса, выполняют поиск и формируют перечень найденных кинофрагментов. Указанный перечень передают средствам для организации пользовательского интерфейса информационного поиска для представления результатов поиска пользователю. Способы быстрого выполнения информационного поиска по декларативным запросам на основе заранее известных классов известны в технике, поэтому описываемое устройство реализует поиск по текстовому или структурированному запросу крайне быстро.
Для осуществления информационного поиска по архиву оцифрованных киноматериалов на основе образцового кинофрагмента пользователь выбирает образец из оцифрованного киноархива с помощью средств для организации пользовательского интерфейса информационного поиска. Указанные средства передают идентификационную информацию выбранного образцового кинофрагмента средствам для выполнения информационного поиска. Средства для выполнения информационного поиска получают усредненный вектор признаков первой сцены от средств хранения индекса, используя идентификационную информацию выбранного образцового кинофрагмента. Далее, средства для выполнения информационного поиска получают от средств хранения индекса по крайней мере один усредненный вектор признаков второй сцены, сравнивают с усредненным вектором признаков первой сцены и в случае близости векторов добавляют вторую сцену в перечень найденных кинофрагментов. Указанный перечень передают средствам для организации пользовательского интерфейса информационного поиска для представления результатов поиска пользователю.
В отличие от аналогов, для выполнения поиска семантически близких фрагментов не требуется повторное извлечение признаков, что приводит к экономии вычислительных и энергетических затрат, а также к ускорению поиска. Дополнительным преимуществом является высокая точность и чувствительность информационного поиска благодаря тому, что усредненный вектор признаков содержит семантически значимую информацию о визуальном содержимом кадра, в отличие от нынешнего уровня техники, в котором векторы признаков содержат информацию о распределении тона, яркости, направления штрихов и т.п.
Для осуществления информационного поиска по архиву оцифрованных киноматериалов на основе образцовых неподвижных изображений пользователь вводит по крайней мере одно образцовое неподвижное изображение с помощью средств для организации пользовательского интерфейса информационного поиска. Указанные средства передают множество образцовых неподвижных изображений средствам для выполнения информационного поиска. Средства для выполнения информационного поиска вычисляют векторы признаков для каждого образцового изображения и формируют первый набор векторов признаков. Далее, средства для выполнения информационного поиска формируют второй набор векторов признаков из усредненных векторов признаков по крайней мере одной сцены, сохраненной в устройстве хранения индекса. Затем средства для выполнения информационного поиска конфигурируют временный классификатор на основе первого и второго набора векторов признаков. Далее, средства для выполнения информационного поиска получают от средств хранения индекса усредненный вектор признаков по крайней мере одной сцены и применяют к нему указанный временный классификатор. В случае позитивного отклика классификатора добавляют сцену в перечень найденных кинофрагментов. Указанный перечень передают средствам для организации пользовательского интерфейса информационного поиска для представления результатов поиска пользователю.
В отличие от аналогов, использование множества эталонов неподвижных изображений и векторов признаков, включающих семантически значимую информацию, приводит к повышению точности и чувствительности информационного поиска.
За счет того, что в описываемом устройстве для семантической классификации и поиска сквозным образом используют однократно рассчитанные векторы признаков, включающие семантически значимую информацию, устройство имеет явные преимущества в быстродействии и энергоэффективности перед достигнутым уровнем техники. Указанные векторы признаков единообразно вычисляют с помощью унифицированных средств извлечения векторов признаков. Преимущество такого подхода в том, что при необходимости увеличения размерности векторов признаков для придания им еще большей способности семантической классификации не требуется дополнительная разработка и тестирование программного обеспечения, не требуется ручная настройка параметров или исследование в области новых методов извлечения признаков. Предложенные в данном изобретении средства извлечения векторов признаков в полной мере способны использовать преимущества параллельных вычислений для повышения производительности описываемого устройства. Применение унифицированных векторов признаков позволяет в одном устройстве объединить функции поиска по текстовому запросу, по образцовому кинофрагменту и по образцам изображений, в то время, как аналоги и ближайший прототип предлагают отдельные различающиеся устройства для реализации каждого из перечисленных способов информационного поиска.
Конструктивно, средства получения оцифрованных киноматериалов включают по крайней мере процессор и устройство долговременной памяти, например жесткий диск HDD или твердотельный диск SSD, а также устройство оперативной памяти, в котором располагают программу, управляющую процессом получения оцифрованных киноматериалов. Предпочтительно, чтобы средства получения оцифрованных киноматериалов включали по крайней мере одно устройство чтения сменных носителей, например DVD или Flash-диск.
Средства извлечения выборочных кадров из оцифрованных киноматериалов включают по крайней мере процессор и устройство оперативной памяти, в котором располагают программу извлечения выборочных кадров, а также располагают временные буферы хранения выборочных кадров. Средства извлечения выборочных кадров связаны со средствами получения оцифрованных киноматериалов с помощью локального сетевого интерфейса, например Ethernet или с помощью шины обмены данными внутри системного блока, например PCI.
Средства извлечения векторов признаков включают по крайней мере процессор и устройство оперативной памяти, в котором размещают программу управления процессом извлечения векторов признаков и временные буферы хранения выбранных кадров и векторов признаков. Предпочтительно включать в состав средств извлечения векторов признаков устройство для ускорения параллельных расчетов, например графический ускоритель CUDA, OpenCL или специализированный вычислитель на базе FPGA. Средства извлечения векторов признаков связаны со средствами извлечения выборочных кадров из оцифрованных киноматериалов с помощью локального сетевого интерфейса, например Ethernet, или с помощью шины обмены данными внутри системного блока, например PCI.
Средства сегментации и классификации по заранее заданным классам включают по крайней мере процессор и устройство оперативной памяти, в котором размещают программу управления процессом сегментации и классификации и буферы временного хранения векторов признаков и векторов принадлежности к заранее заданным классам. Средства сегментации и классификации связаны со средствами извлечения векторов признаков с помощью шины обмены данными внутри системного блока, например PCI.
Средства хранения индекса включают по крайней мере процессор и устройство долговременной памяти, например жесткий диск HDD или твердотельный диск SSD. Предпочтительно реализовать средства хранения индекса в виде кластера для распределенного хранения индекса на нескольких вычислительных узлах кластера, связанных между собой и со средствами сегментации и классификации с помощью локального сетевого интерфейса Ethernet по протоколу TCP/IP.
Средства для организации пользовательского интерфейса информационного поиска включают по крайней мере одно серверное устройство и по крайней мере одно клиентское устройство. Серверное устройство связано с клиентским устройством с помощью локального сетевого интерфейса локальной сети или, предпочтительно, глобальной сети, например Интернет, по протоколу TCP/IP. Клиентское устройство включает по крайней мере устройство графического отображения, например дисплей, и устройство текстового ввода, например, клавиатуру. Серверное устройство работает под управлением программного обеспечения, предпочтительно реализующего функции сервера HTTP и формирования форм представления информации для пользователей в формате HTML. Предпочтительно, чтобы клиентское устройство работало под управлением программы Интернет браузер, например FireFox, реализующего стандарт отображения страниц в формате HTML.
Средства для выполнения информационного поиска включают по крайней мере процессор, работающий под управлением программного обеспечения. Предпочтительный вариант средств для выполнения информационного поиска включает по крайней мере одно серверное устройство, связанное со средствами хранения индекса и средствами для организации пользовательского интерфейса информационного поиска с помощью локального сетевого интерфейса, например Ethernet.
Далее решение поясняется ссылками на фигуры, на которых изображено следующее.
Фигура 1 - предпочтительный вариант осуществления устройства для семантической классификации и поиска в архивах оцифрованных киноматериалов.
Фигура 2 - алгоритм работы средства сегментации и классификации.
Фигура 3 - алгоритм работы средства поиска в режиме поиска по образцовому видеофрагменту.
Предпочтительный вариант осуществления устройства для семантической классификации и поиска в архивах оцифрованных киноматериалов (фиг. 1) включает средства получения оцифрованных киноматериалов 1, устройство чтения сменных носителей 2, средства извлечения выборочных кадров из оцифрованных киноматериалов 3, средства извлечения векторов признаков 4, устройство графического параллельного ускорителя 5, средства сегментации и классификации по заранее заданным классам 6, интерфейс локальной сети 7, средства хранения индекса 8, средства для выполнения информационного поиска 9, серверное устройство 10 средства для организации пользовательского интерфейса информационного поиска, клиентское устройство 11 средства для организации пользовательского интерфейса информационного поиска. Серверное устройство 10 связано с клиентским устройством 11 с помощью глобальной сети Интернет 12.
При работе устройства в режиме семантической классификации носитель с записью оцифрованного фильма помещают в устройство для чтения сменных носителей 2. Например, носителем может служить DVD-диск, а устройство 2 может представлять собой DVD-дисковод. По команде оператора средства получения оцифрованных киноматериалов 1 выполняют чтение оцифрованного фильма, раскодирование (в случае записи оцифрованного фильма с компрессией) и преобразование в последовательность кадров. В описываемом варианте осуществления настоящего изобретения, средства получения оцифрованных киноматериалов 1 работают под управлением программного обеспечения на основе известной специалистам библиотеки OpenCV, обеспечивающей раскодирование большого количества форматов кодирования и компрессии оцифрованных фильмов.
Раскодированные кадры поступают в средства извлечения выборочных кадров 3, также реализованные в виде настраиваемого многофункционального средства под управлением программного обеспечения на основе библиотеки OpenCV. В описываемом варианте осуществления средства извлечения выборочных кадров 3 производят выборку кадров с интервалом около 320 мс, масштабирование без сохранения пропорций в размер 256×256 пикселей и преобразование в цветовое пространство BRG (синий - красный - зеленый).
Выборочные кадры поступают в средства извлечения векторов признаков 4, реализованные в виде настраиваемого многофункционального средства под управлением программного обеспечения на основе библиотек Caffe или Torch или аналогичных библиотек для реализации вычислений в области сверточных нейронных сетей, известных специалистам или разработанных самостоятельно. В описываемом варианте осуществления, средства извлечения векторов признаков 4 включают устройство графического параллельного ускорителя 5, реализованное по технологии CUDA, с количеством процессорных ядер около 1000, объемом глобальной памяти около 4Гб, рабочей частотой около 1,18 ГГц. Благодаря применению ускорителя 5, производительность средств извлечения векторов признаков 4 составляет не менее 25 выборочных кадров в секунду при размере кадра 256×256 пикселей. Вариант осуществления изобретения без применения ускорителя 5, обеспечивает производительность средств извлечения векторов признаков 4 составляет не более 1 выборочного кадра в секунду при размере кадра 256×256 пикселей.
В описываемом варианте осуществления средства извлечения векторов признаков 4 производят вычисление функции сверточной нейронной сети над входными данными, представляющими собой представление выборочного кадра в виде трех матриц. В каждую из матриц записывают значение уровня компонента синего, красного и зеленого цвета соответствующего пикселя кадра.
Функция сверточной нейронной сети представляет собой комбинацию по крайней мере трех типов вычислений, называемых слоями:
- свертка
- голосование
- слой финальной классификации.
Слой свертки характеризуется размером входного изображения W, размером окна Р, числом каналов K, числом фильтров F и шагом S.
Производят вычисление первого математического выражения:
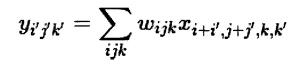
где
i', j' - координаты выходных значений в диапазоне [1, (W-P)/S+1]
i, j - координаты входных значений в диапазоне [1, W] с шагом S
k' - номер выходного фильтр-банка
k - номер входного канала
wijk - весовой коэффициент
xijk - входное значение с координатами (i, j) и номером канала k
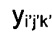 - выходное значение с координатами (i, j) и номером фильтр-банка k.
- выходное значение с координатами (i, j) и номером фильтр-банка k.
Затем выполняют второе вычисление:
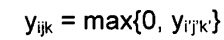 ;
;
В слое голосования производят вычисление математического выражения:
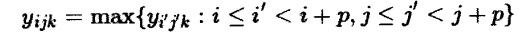 ,
,
где p - размер окна слоя голосования.
В слое финальной классификации выполняют первое вычисление:
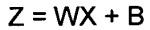 ,
,
где X - вектор входных значений; Z - вектор выходных значений; W - матрица весов; B - вектор коэффициентов смещения.
Затем выполняют второе вычисление:
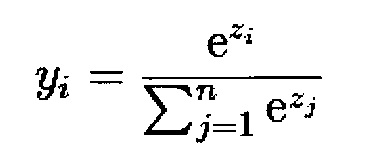
где zi - i-й компонент вектора Z, полученного в первом вычислении.
Конкретную комбинацию слоев и значения весовых коэффициентов, коэффициентов смещения, размерности окна, количества фильтров, величины шага получают методом машинного обучения, известным специалистам в данной области техники. Количество слоев свертки выбирают не менее 3, количество слоев голосования не менее 3, количество слоев финальной классификации выбирают в диапазоне [1, 2], размерности окна выбирают в диапазоне [3, 7], величину шага выбирают в диапазоне [1, 3], количество фильтров в каждом слое свертки выбирают в диапазоне [32, 4096].
В описываемом варианте осуществления данного изобретения применили количество слоев свертки 11, количество слоев голосования 5, количество слоев финальной классификации 1. В качестве вектора признаков использовали выходное значение последнего слоя голосования размерностью 1024. В качестве вектора принадлежности к заранее заданным классам использовали выходное значение последнего слоя финальной классификации размерностью 1000, т.е. номенклатура заранее известных классов составила 1000 классов. Размерность входной матрицы 224×224 при количестве каналов 3 (синий, зеленый, красный). Во входную матрицу записывают изображение центральной части выборочных кадров размером 256×256.
Специалистам в данной области техники понятно, что приведенные выше конкретные параметры осуществления средства извлечения векторов признаков 4, такие как размерность входной матрицы, количество и состав слоев сверточной нейронной сети, размерность выходного вектора не ограничивают применимость настоящего изобретения и служат для экспериментально подтверждения промышленной применимости.
Как показано в работе [2], функция сверточной нейронной сети является одной из наиболее эффективных на современном уровне техники для извлечения семантических признаков и выполнения семантической классификации изображений. Из приведенных выше математических выражений очевидно, что все вычисления производят в матричной форме и, следовательно, указанные вычисления легко поддаются параллельной реализации в устройстве графического параллельного ускорителя 5. При отсутствии устройства графического параллельного ускорителя 5 все вычисления выполняются процессорным устройством, входящим в состав средств извлечения векторов признаков 4. Независимо от способа реализации функция сверточной нейронной сети является унифицированной и заменяет собой разнородные функции извлечения признаков, предложенные в аналогах и ближайшем прототипе. Поэтому в настоящем изобретении вектор признаков, вычисляемый с помощью функции сверточной нейронной сети используют сквозным образом как для сегментации фильмов на сцены, так и для семантической классификации и для выполнения информационного поиска по образцу кинофрагмента и по образцу эталонных изображений.
Вычисленные средствами извлечения векторов признаков 4 векторы признаков и векторы принадлежности к заранее заданным классам для каждого выборочного кадра передают в средства сегментации и классификации 6.
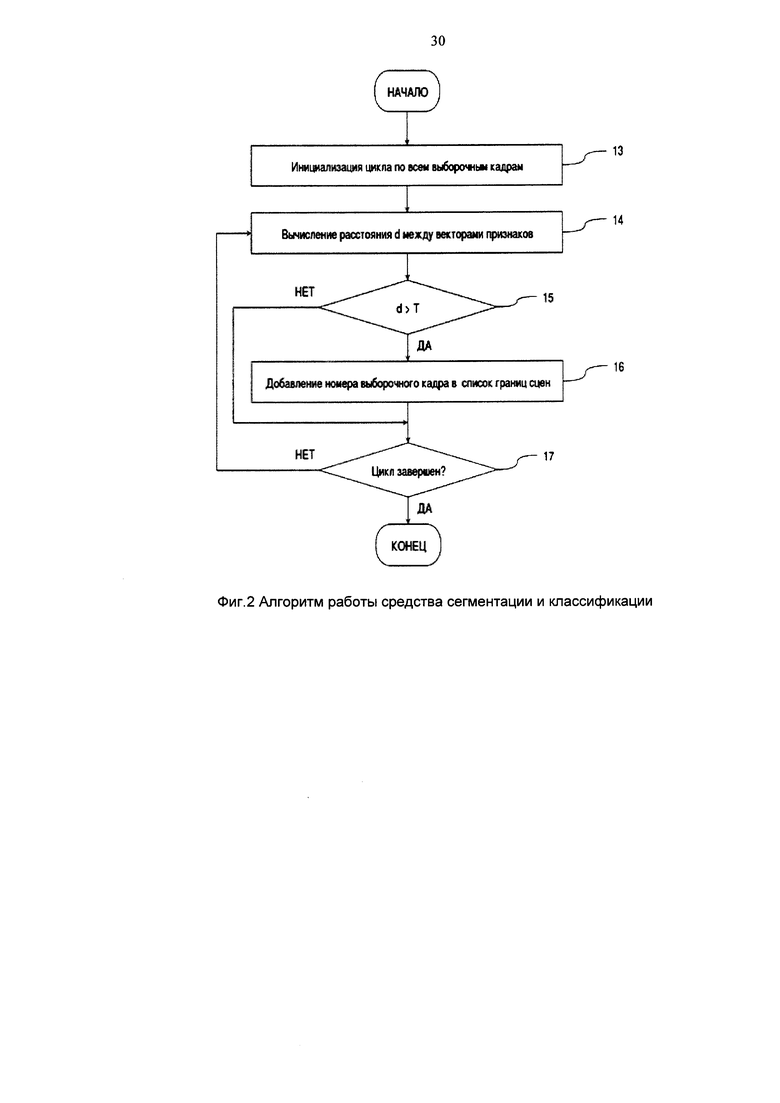
Средства сегментации и классификации 6, реализованные в виде настраиваемого многофункционального средства, выполняют первый алгоритм, изображенный на фиг. 2.
В блоке 13 первого алгоритма производят инициализацию цикла по всем выборочным кадрам.
В блоке 14 вычисляют расстояние между векторами признаков текущего выборочного кадра и предыдущего выборочного кадра. Расстояния между векторами признаков вычисляют любым способом, известным в технике, например, евклидово расстояние или косинусное расстояние. В описываемом варианте осуществления вычисляют евклидово расстояние d между векторами x, y:
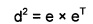
где e=x-y (вектор-строка), ет - транспонированный вектор e.
В блоке 15 сравнивают полученное пороговое значение Т, с расстоянием между векторами признаков текущего выборочного кадра и предыдущего выборочного кадра. Для векторов признаков размерности около 1000 выбирают пороговое значение Т около 85.
В блоке 16 записывают номер или временной код текущего выборочного кадра в списке границ сцен фильма.
В блоке 17 проверяют условие выхода из цикла. В случае завершения цикла формируют в оперативной памяти средств сегментации и классификации 6 структуру списка границ сцен фильма.
Далее средства сегментации и классификации 6, используя структуру списка границ сцен фильма, выполняют классификацию сцен фильма. При этом, для каждого элемента списка границ сцен фильма получают не более N векторов принадлежности к заранее заданным классам для выборочных кадров, входящих в соответствующую сцену фильма. Значение N выбирают около 10. Полученные векторы принадлежности к заранее заданным классам усредняют и выбирают М максимальных компонент усредненного вектора. Значение М выбирают около 5. Номера выбранных максимальных компонент записывают в структуру оперативной памяти средства сегментации и классификации 6 в список заранее заданных классов, которым соответствует текущая сцена. В результате обработки всех сцен фильма в оперативной памяти средства сегментации и классификации 6 формируют структуру, включающую метки начала и длительности сцены и метки принадлежности к заранее заданными классам.
Экспериментальные исследования описываемого варианта осуществления данного изобретения продемонстрировали среднее значение показателя точности F1=0,8497 (средней гармонической меры точности и чувствительности) по отношению к разбиению фильмов на сцены кодеком MPEG-4. Средняя точность классификации по пяти наиболее вероятным классам составила 0,516.
Далее в описываемом варианте осуществления метки начала, и длительности сцены и метки принадлежности к заранее заданным классам из оперативной памяти средств сегментации и классификации 6 передают через интерфейс локальной сети 7 в средства хранения индекса 8. Средства хранения индекса 8 записывают информацию о сцене, включающую поля времени начала сцены, длительности сцены, усредненного вектора признаков сцены и метки принадлежности сцены по крайней мере одному из заранее заданных классов.
Средства хранения индекса 8 могут быть реализованы в виде кластерных средств хранения баз данных или в виде встроенных средств хранения баз данных. В описываемом варианте осуществления использован кластер из трех серверных устройств, работающих под управлением программного обеспечения для распределенной базы данных Apache Cassandra.
На этом работа предложенного в данном изобретении устройства в режиме семантической классификации завершается.
При работе устройства в режиме поиска по текстовому запросу пользователь вводит по крайней мере одно ключевое слово с помощью клиентского устройства 11 средства для организации пользовательского интерфейса информационного поиска. В описываемом варианте осуществления клиентское устройство может представлять собой настольный или портативный компьютер, оснащенный программным обеспечением типа Интернет-браузер. Клиентское устройство 11 через глобальную сеть Интернет 12 передает множество ключевых слов в серверное устройство 10 с использованием протокола передачи данных HTTP или HTTPS. В другом варианте осуществления глобальную сеть Интернет 12 не используют, и передают множество ключевых слов от клиентского устройства 11 в серверное устройство 10 с помощью интерфейса локальной сети. В еще одном варианте осуществления клиентское устройство 11 и серверное устройство 10 конструктивно объединены в единые многофункциональные средства для организации пользовательского интерфейса информационного поиска, и передачу множества ключевых слов производят по внутренней шине передачи данных.
Серверное устройство 10 средства для организации пользовательского интерфейса информационного поиска передает множество из по крайней мере одного ключевого слова в средства для выполнения информационного поиска 9. Средства для выполнения информационного поиска 9 под управлением программного обеспечения, формируют декларативный запрос к средствам хранения индекса 8, используя по крайней мере одно ключевое слово. Декларативный запрос могут формировать на языке запросов SQL или других известных в технике языках декларативных запросов к системам управления базами данных. Указанный декларативный запрос передают в средства хранения индекса 8. В описываемом варианте осуществления для передачи запроса используют локальный сетевой интерфейс 7 и, предпочтительно, протокол передачи данных HTTPS.
Средства хранения индекса 8 сконфигурированы таким образом, чтобы при поступлении декларативного запроса, включающего по крайней мере одно ключевое слово, осуществить поиск в базе данных по меткам принадлежности сцен оцифрованных киноматериалов заранее заданным классам, семантически совпадающим с указанным ключевым словом. Специалистам в данной области техники понятно, что в поиск по комбинации ключевых слов, включая логическую комбинацию с использованием булевых операторов, например "И", "ИЛИ", "НЕ", "ИСКЛЮЧАЮЩЕЕ ИЛИ" не является существенным расширением и не нарушает область действия данного изобретения. В результате средства хранения индекса 8 формируют список из сцен, имеющих метки принадлежности заранее заданным классам, семантически совпадающим с указанным ключевым словом, причем указанный список включает по крайней мере идентификатор сцены, время начала сцены и длительность сцены. Специалистам в технике понятно, что в указанный список помещают не более К сцен, по причине ограниченности оперативной памяти и пропускной способности каналов связи. Значение К выбирают в диапазоне от 10 до 50.
Экспериментальные испытания описываемого варианта осуществления данного изобретения показали среднее время формирования списка из 10 сцен 0.46 секунд при общем объеме базы данных в средствах хранения индекса 8 равном от 90 до 110 Гбайт.
Средства хранения индекса 8 передают указанный список сцен серверному устройству 10 средства для организации пользовательского интерфейса информационного поиска, которое, в свою очередь, формирует на основе этого списка форму представление результатов информационного поиска для пользователя. В описываемом варианте осуществления форма представления реализована в виде HTML-страницы. В других вариантах осуществления в качестве формы представления могут использовать файлы XML, JSON, YAML или программируемые средства организации пользовательского интерфейса, например WinAPI, Qt, Java или другие известные в технике средства.
Форму представления результатов информационного поиска передают в клиентское устройство 11 средства для организации пользовательского интерфейса информационного поиска, которое отображает указанную форму на входящих в его состав средствах отображения, например цветном графическом мониторе.
При работе устройства в режиме поиска по образцовому кинофрагменту пользователь выбирает образцовый кинофрагмент с помощью клиентского устройства 11 средства для организации пользовательского интерфейса информационного поиска. В описываемом варианте осуществления клиентское устройство может представлять собой настольный или портативный компьютер, оснащенный программным обеспечением типа Интернет-браузер. Клиентское устройство 11 через глобальную сеть Интернет 12 передает идентификационные данные выбранного образцового кинофрагмента в серверное устройство 10 с использованием протокола передачи данных HTTP или HTTPS. В другом варианте осуществления глобальную сеть Интернет 12 не используют, и передают идентификационные данные выбранного образцового кинофрагмента от клиентского устройства 11 в серверное устройство 10 с помощью интерфейса локальной сети. В еще одном варианте осуществления клиентское устройство 11 и серверное устройство 10 конструктивно объединены в единые многофункциональные средства для организации пользовательского интерфейса информационного поиска, и передачу идентификационных данных выбранного образцового кинофрагмента производят по внутренней шине передачи данных.
Серверное устройство 10 средства для организации пользовательского интерфейса информационного поиска передает идентификационные данные выбранного образцового кинофрагмента в средства для выполнения информационного поиска 9.
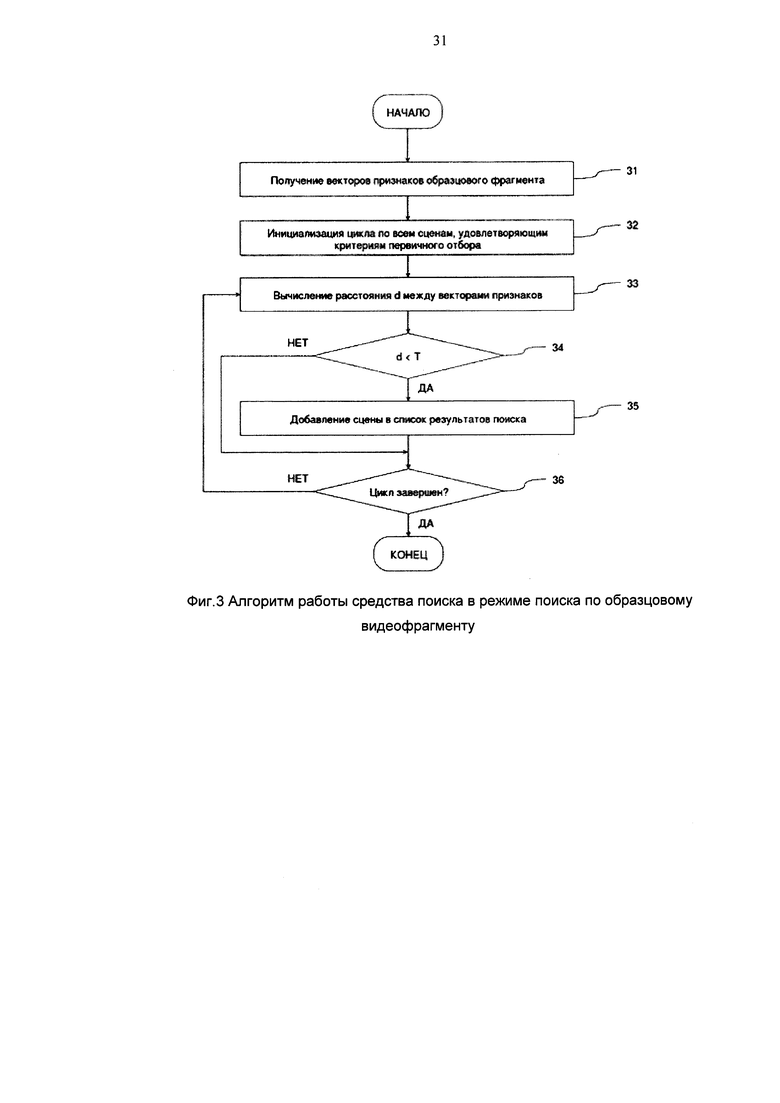
Средства для выполнения информационного поиска 9 выполняют алгоритм, изображенный на фиг. 3.
В блоке 31 средства для выполнения информационного поиска 9 передают запрос с указанием по крайней мере идентификационных данных выбранного образцового кинофрагмента средствам хранения индекса 8, и получают сохраненный в средствах хранения индекса 8 вектор признаков образцового кинофрагмента.
В блоке 32 инициализируют цикл по всем сценам, сохраненным в средствах хранения индекса 8, удовлетворяющим критериям первичного отбора. Критерии первичного отбора могут применять для сокращения объема просматриваемых сцен при информационном поиске по образцовому кинофрагменту. Специалистам в данной области техники известны различные способы первичного отбора, например метод случайных проекций вектора признаков или метод цветового дескриптора сцены. В описываемом варианте осуществления применили критерий допустимого диапазона длительности сцены, при котором в описываемом цикле просматривают все сцены, длительность которых находится в заранее заданном диапазоне, например от 5 до 20 секунд. Таким образом, цикл инициализируют методом передачи декларативного запроса средствам хранения индекса 8 на получение сцен, длительность которых находится в заранее заданном диапазоне. Специалистам в данной области понятно, что в результате такого запроса современные системы управления базами данных могут возвращать итераторы для организации цикла по записям, удовлетворяющим заданным условиям.
В блоке 33 вычисляют расстояние d между вектором признаков образцового кинофрагмента и вектором признаков текущего кинофрагмента, полученном в цикле из средств хранения индекса 8. Расстояние между векторами могут вычислять различными способами, известными в технике, например евклидово расстояние. В описываемом варианта осуществления вычисляют косинусное расстояние между векторами x, y по формуле
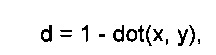
где dot - символ скалярного произведения векторов.
В блоке 34 сравнивают значение d с заранее заданным пороговым значением Т, которое выбирают в диапазоне от 0 до 1, предпочтительно от 0,2 до 0,4. Если расстояние d меньше порогового значения Т, то в блоке 35 добавляют текущую сцену к списку результатов информационного поиска в оперативной памяти средств для выполнения информационного поиска 9. Указанный список включает, по крайней мере, идентификационные данные текущей сцены, время начала сцены, длительность сцены.
В блоке 36 выполняют проверку условий окончания цикла, инициированного в блоке 32. Такими условиями могут являться достижение заранее заданного количества результатов поиска (например 10) или, предпочтительно, превышение заранее заданной длительности работы цикла, инициированного в блоке 32. Если условия окончания цикла выполнены, средства для выполнения информационного поиска 9 передают сформированный список результатов информационного поиска в серверное устройство 10 средства для организации пользовательского интерфейса информационного поиска, используя интерфейсы и протоколы передачи данных, описанные выше.
Серверное устройство 10 средства для организации пользовательского интерфейса информационного поиска формирует на основе этого списка форму представление результатов информационного поиска для пользователя. В описываемом варианте осуществления форма представления реализована в виде HTML-страницы. В других вариантах осуществления в качестве формы представления могут использовать файлы XML, JSON, YAML или программируемые средства организации пользовательского интерфейса, например WinAPI, Qt, Java или другие известные в технике средства.
Форму представления результатов информационного поиска передают в клиентское устройство 11 средства для организации пользовательского интерфейса информационного поиска, которое отображает указанную форму на входящих в его состав средствах отображения, например цветном графическом мониторе.
Экспериментальные исследования описываемого варианта осуществления данного изобретения продемонстрировали среднее значение показателя точности поиска на основе образца кинофрагмента 0.855, при этом точность оценивали как отношение числа субъективно корректных результатов поиска к общему количеству результатов поиска при выполнении информационного поиска по 42 образцовым кинофрагментам.
При работе устройства в режиме информационного поиска по архиву оцифрованных киноматериалов на основе образцовых неподвижных изображений пользователь вводит по крайней мере одно образцовое неподвижное изображение с помощью клиентского устройства 11 средства для организации пользовательского интерфейса информационного поиска. Предпочтительно, чтобы пользователь вводил от 50 до 200 образцовых изображений, включающих искомый образец для поиска, снятый с разных ракурсов, на различном фоне и т.п. В описываемом варианте осуществления клиентское устройство может представлять собой настольный или портативный компьютер, оснащенный программным обеспечением типа Интернет-браузер. Клиентское устройство 11 через глобальную сеть Интернет 12 передает множество образцовых неподвижных изображений в серверное устройство 10 с использованием протокола передачи данных HTTP или HTTPS. В другом варианте осуществления глобальную сеть Интернет 12 не используют, и передают множество образцовых неподвижных изображений от клиентского устройства 11 в серверное устройство 10 с помощью интерфейса локальной сети. В еще одном варианте осуществления клиентское устройство 11 и серверное устройство 10 конструктивно объединены в единые многофункциональные средства для организации пользовательского интерфейса информационного поиска, и передачу множества образцовых неподвижных изображений производят по внутренней шине передачи данных.
Серверное устройство 10 средства для организации пользовательского интерфейса информационного поиска передает множество образцовых неподвижных изображений в средства для выполнения информационного поиска 9.
Средства для выполнения информационного поиска 9 вычисляют векторы признаков для каждого образцового изображения и формируют первый набор векторов признаков. В описываемом варианте осуществления для вычисления вектора признаков каждого образцового изображения средства для выполнения информационного поиска 9 производят преобразование масштаба образцового изображения без сохранения пропорций в размер 256×256, преобразование цветового пространства в формат BGR, и производят вычисление функции сверточной нейронной сети над входными данными, представляющими собой представление образцового изображения в виде трех матриц в оперативной памяти средств для выполнения информационного поиска 9. В каждую из матриц записывают значение уровня компонента синего, красного и зеленого цвета соответствующего пикселя образцового изображения. Функция сверточной нейронной сети идентична описанной выше функции, которую применяют в средствах для извлечения векторов признаков 4. Полученные в результате применения функции сверточной сети векторы признаков помечают меткой позитивного обучающего примера, например "+1" и записывают в структуру в оперативной памяти или устройстве долговременного хранения средств для выполнения информационного поиска 9.
Далее средства для выполнения информационного поиска 9 формируют второй набор векторов признаков из усредненных векторов признаков по крайней мере одной сцены, сохраненной в устройстве хранения индекса 8. В описываемом варианте осуществления второй набор векторов признаков формируют из приблизительно 25000 произвольно выбранных сцен, сохраненных в устройстве хранения индекса 8. Эту операцию производят по крайней мере один раз при конфигурации средств для выполнения информационного поиска 9. Предпочтительно получать второй набор векторов признаков периодически по мере записи от 1000 до 10000 новых сцен в устройство хранения индекса. Для формирования указанного второго набора векторов признаков в случайном порядке считывают векторы признаков сцен, сохраненных в устройстве хранения индекса 8. Считанные векторы признаков помечают меткой негативного обучающего примера, например "-1" и записывают в структуру в устройстве долговременного хранения средств для выполнения информационного поиска 9.
Затем средства для выполнения информационного поиска 9 конфигурируют временный классификатор на основе первого и второго набора векторов признаков. В описываемом варианте осуществления для этого объединяют первый и второй набор векторов признаков в единый файл на устройстве долговременного хранения средств для выполнения информационного поиска 9. В качестве устройства долговременного хранения могут использовать накопитель на жестком диске HDD или накопитель на твердотельном диске SSD, или другое известное в технике устройство долговременной памяти. Затем выполняют перемешивание записей в файле, соответствующих отдельным векторам признаков. В описываемом варианте осуществления указанный файл формируют в текстовом формате, причем каждая строка файла включает один вектор признаков и одну соответствующую метку позитивного или негативного обучающего примера. Перемешивание строк файла в случайном порядке выполняют системной утилитой shuf операционной системы Linux.
Далее выполняют настройку временного классификатора на основе указанного файла, включающего обучающие примеры. В технике известны различные методы обучения классификатора, например логистическая регрессия, метод решающих деревьев, машина опорных векторов. В описываемом варианте осуществления применяют метод логистической регрессии, реализованный с помощью общедоступного программного обеспечения Vowpal Wabbit. В результате работы указанного программного обеспечения формируют в устройстве долговременной памяти средств для выполнения информационного поиска 9 временный файл классификатора.
Далее средства для выполнения информационного поиска 9 получают от средств хранения индекса 8 усредненный вектор признаков по крайней мере одной сцены и применяют к нему указанный временный классификатор. В случае позитивного отклика временного классификатора добавляют указанную сцену в структуру в оперативной памяти средств для выполнения информационного поиска 9, включающую список найденных кинофрагментов. Указанный список включает, по крайней мере, идентификационные данные сцены, время начала сцены, длительность сцены.
Описанную процедуру получения из средств хранения индекса 8 вектора признаков очередной сцены и применения временного классификатора повторяют до достижения заранее заданного количества результатов поиска (например, 10) или, предпочтительно, до превышения заранее заданной длительности работы. Если описанные условия выполнены, средства для выполнения информационного поиска 9 передают сформированный список результатов информационного поиска в серверное устройство 10 средства для организации пользовательского интерфейса информационного поиска, используя интерфейсы и протоколы передачи данных, описанные выше.
Серверное устройство 10 средства для организации пользовательского интерфейса информационного поиска формирует на основе этого списка форму представление результатов информационного поиска для пользователя. В описываемом варианте осуществления форма представления реализована в виде HTML-страницы. В других вариантах осуществления в качестве формы представления могут использовать файлы XML, JSON, YAML или программируемые средства организации пользовательского интерфейса, например WinAPI, Qt, Java или другие известные в технике средства.
Форму представления результатов информационного поиска передают в клиентское устройство 11 средства для организации пользовательского интерфейса информационного поиска, которое отображает указанную форму на входящих в его состав средствах отображения, например цветном графическом мониторе.
Экспериментальные исследования описываемого варианта осуществления данного изобретения продемонстрировали среднее значение показателя точности поиска на основе образцовых неподвижных изображений 0.64, при этом точность оценивали как отношение числа субъективно корректных результатов поиска к общему количество результатов поиска при выполнении информационного поиска по 13 запросам на основе образцовых неподвижных изображений при среднем количестве образцовых неподвижных изображений 90 на каждый запрос.
| название | год | авторы | номер документа |
|---|---|---|---|
| ОБНАРУЖЕНИЕ ОБЪЕКТОВ ИЗ ЗАПРОСОВ ВИЗУАЛЬНОГО ПОИСКА | 2017 |
|
RU2729956C2 |
| Способ обработки видео для целей визуального поиска | 2018 |
|
RU2693994C1 |
| СПОСОБ И СИСТЕМА СЕГМЕНТАЦИИ СЦЕН ВИДЕОРЯДА | 2022 |
|
RU2783632C1 |
| ФРЕЙМВОРК ПРИЕМА ВИДЕО ДЛЯ ПЛАТФОРМЫ ВИЗУАЛЬНОГО ПОИСКА | 2017 |
|
RU2720536C1 |
| РАЗРЕШЕНИЕ КОРЕФЕРЕНЦИИ В ЧУВСТВИТЕЛЬНОЙ К НЕОДНОЗНАЧНОСТИ СИСТЕМЕ ОБРАБОТКИ ЕСТЕСТВЕННОГО ЯЗЫКА | 2008 |
|
RU2480822C2 |
| ВЫСОКОУРОВНЕВАЯ ПЕРЕДАЧА СЛУЖЕБНЫХ СИГНАЛОВ ДЛЯ ВИДЕОДАННЫХ ТИПА "РЫБИЙ ГЛАЗ" | 2018 |
|
RU2767300C2 |
| СПОСОБ БИОМЕТРИЧЕСКОЙ АУТЕНТИФИКАЦИИ ПО ПАРАМЕТРАМ РЕЧИ И ГЕОМЕТРИИ ЛИЦА | 2024 |
|
RU2828618C1 |
| НАВИГАЦИЯ ПО ВИДЕОПОСЛЕДОВАТЕЛЬНОСТИ ЧЕРЕЗ МЕСТОПОЛОЖЕНИЕ ОБЪЕКТА | 2012 |
|
RU2609071C2 |
| СПОСОБ И СИСТЕМА АВТОМАТИЗИРОВАННОЙ ДИАГНОСТИКИ СОСУДИСТЫХ ПАТОЛОГИЙ НА ОСНОВАНИИ ИЗОБРАЖЕНИЯ | 2020 |
|
RU2741260C1 |
| СПОСОБ И СИСТЕМА СОЗДАНИЯ ВЕКТОРОВ АННОТАЦИИ ДЛЯ ДОКУМЕНТА | 2017 |
|
RU2720074C2 |
Изобретение относится к семантической классификации оцифрованных киноматериалов и информационного поиска в архивах оцифрованных киноматериалов. Техническими результатами являются повышение точности сегментации фильмов на сцены, повышение точности классификации сцен по заранее заданному перечню классов, повышение быстродействия процесса извлечения семантических признаков из кадров кинофильма, сокращение дополнительных затрат на программирование при увеличении размерности вектора признаков, сокращение объема данных для хранения индекса для выполнения информационного поиска кинофрагментов по текстовым запросам, запросам в структурированной форме и запросам по образцу, сокращение времени выполнения индексации и повышение точности и чувствительности информационного поиска. Устройство семантической классификации и поиска в архивах оцифрованных киноматериалов содержит последовательно соединенные средство получения оцифрованных материалов, средство извлечения выборочных кадров из оцифрованных киноматериалов, средство извлечения векторов признаков, средство сегментации и классификации, средство хранения индекса, средство для выполнения информационного поиска, серверное устройство и клиентское устройство. 4 з.п. ф-лы, 3 ил.
1. Устройство для семантической классификации и поиска в архивах оцифрованных киноматериалов, характеризующееся тем, что содержит последовательно соединенные средство получения оцифрованных материалов, средство извлечения выборочных кадров из оцифрованных киноматериалов, средство извлечения векторов признаков, средство сегментации и классификации, средство хранения индекса, средство для выполнения информационного поиска, серверное устройство и клиентское устройство,
при этом средство извлечения выборочных кадров из оцифрованных киноматериалов выполнено с возможностью раскодировки и извлечения кадров или изображений через заданные промежутки времени, масштабирования выборочных кадров или изображений в размер, пригодный для классификации,
средство извлечения векторов признаков включает по крайней мере один слой свертки, соединенный по крайней мере с одним слоем выбора максимальных значений из вектора выходных значений, полученных в слое свертки, и по крайней мере с одним слоем финальной классификации,
причем средство извлечения векторов признаков выполнено с возможностью получения вектора признаков и получения вектора классификации,
причем средство извлечения векторов признаков выполнено с возможностью параллельных вычислений для выполнения операций свертки,
средство сегментации и классификации выполнено с возможностью сегментации фильма на отдельные сцены посредством сравнения между собой векторов признаков соседних выборочных кадров и с возможностью усреднения векторов классификации для кадров, составляющих одну сцену,
средство хранения индекса выполнено с возможностью обмена данными между средством сегментации и классификации и средством для выполнения информационного поиска посредством интерфейса локальной сети и сохранения для каждой сцены фильма по крайней мере времени начала сцены и по крайней мере одного признака класса, получаемого из усредненного вектора классификации для кадров, составляющих одну сцену,
серверное устройство выполнено с возможностью обмена данными со средством для выполнения информационного поиска посредством интерфейса локальной сети и с клиентским устройством посредством глобальной сети Интернет,
клиентское устройство выполнено с возможностью передачи текстового запроса серверному устройству посредством глобальной сети Интернет, причем серверное устройство выполнено с возможностью формирования декларативного запроса на основании текстового запроса и передачи декларативного запроса средству для выполнения информационного поиска посредством интерфейса локальной сети,
причем серверное устройство и клиентское устройство выполнены с возможностью передачи множества образцовых кинофрагментов или неподвижных изображений средству для выполнения информационного поиска, выполненному с возможностью раскодировки и извлечения кадров или изображений через заданные промежутки времени, масштабирования выборочных кадров или изображений в размер, пригодный для классификации, и вычисления векторов признаков для каждого образцового изображения или каждого образцового кинофрагмента для осуществления информационного поиска по архиву оцифрованных киноматериалов на основе введенного образцового кинофрагмента или по крайней мере одного образцового неподвижного изображения.
2. Устройство по п. 1, характеризующееся тем, что средство хранения индекса выполнено с возможностью сохранения усредненных векторов признаков по крайней мере одной сцены фильма.
3. Устройство по п. 1, характеризующееся тем, что средство извлечения векторов признаков взаимодействует с устройством графического параллельного ускорения по крайней мере для выполнения операции свертки.
4. Устройство по п. 1 или 2, характеризующееся тем, что средство для выполнения информационного поиска выполнено с возможностью выполнения сравнения усредненного вектора признаков образцового кинофрагмента, полученного из слоя выбора максимальных значений из вектора выходных значений, полученных в слое свертки, с усредненными векторами признаков, сохраненными в устройстве хранения индекса, для поиска по образцовому кинофрагменту.
5. Устройство по п. 1 или 2, характеризующееся тем, что средство для выполнения информационного поиска выполнено с возможностью извлечения векторов признаков образцового изображения, полученных из слоя выбора максимальных значений из вектора выходных значений, полученных в слое свертки, для каждого образцового изображения и выполнения обучения классификатора, и применения обученного классификатора к усредненным векторам признаков, сохраненным в устройстве хранения индекса, для поиска по множеству образцовых изображений.
| Колосоуборка | 1923 |
|
SU2009A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| ИДЕНТИФИКАЦИЯ КЛЮЧЕВОГО КАДРА ВИДЕОПОСЛЕДОВАТЕЛЬНОСТИ НА ОСНОВЕ ОГРАНИЧЕННОГО КОНТЕКСТА | 2010 |
|
RU2549584C2 |

