ОБЛАСТЬ ТЕХНИКИ
[0001] Настоящее решение относится к области компьютерных технологий, в частности к способу и системе для сегментации сцен видеоряда.
УРОВЕНЬ ТЕХНИКИ
[0002] В различных процессах компаний (например - продажи, разработки продуктов, и т.п.) необходимо использование коммуникаций с контрагентами (клиентами, сотрудниками других подразделений и т.п.). В рамках этих коммуникаций создаются/передаются большие объемы неструктурированной/слабоструктурированной информации, которая используется для корректировки/изменений реализации соответствующих процессов.
[0003] Одним из наиболее распространенных способов коммуникации является онлайн встреча, в рамках которой используются различные каналы передачи данных - люди видят друг друга (видео связь), общаются с помощью аудио (может быть телефонная линия) и могут демонстрировать контент (презентации, демонстрации экрана и т.п.).
[0004] Например, в процессах продаж, при коммуникациях с клиентами необходимо выявить потребность клиента и затем на основании выявленной потребности предложить соответствующие позиции из ассортимента товаров/услуг компании. Соответственно, необходимо в коммуникациях с клиентом определить промежуток времени и артефакты/объекты, относящиеся к потребностям клиента (например, описание/запрос коммерческого предложения и т.п.). Такой промежуток времени называется сценой. Определение сцен - это задача сегментации видео и другой не структурированной информации которой обмениваются стороны в процессе коммуникаций. По результатам анализа соответствующих сцен, могут совершаться определенные действия (фактически решая задачу классификации сцены по определенному набору действий/классов) - отправить покупателю соответствующие предложения из имеющегося в наличии ассортимента, рассчитать и предложить скидку на дополнительные товары и т.п.
[0005] Для сегментации видео известным и доступным (включен во многие открытые библиотеки по работе с видео, например, opencv) подходом является разбиение видеоряда на сцены по переходу между кадрами (оценивая разницу между характеристиками последовательных кадров). Такой подход не учитывает контекстную составляющую соответствующих коммуникаций (смысловое содержание видео изображений, аудио, слайдов презентаций и т.п.) и не позволяет производить классификацию сцен для получения практических результатов/действий зависящих от контекста (т.е. смысла/содержания) сцен.
[0006] В патенте RU 2628192 С2 (Акционерное общество "Творческо-производственное объединение "Центральная киностудия детских и юношеских фильмов им. М. Горького", 15.08.2017) описано средство сегментации и классификации видео, но в качестве входных признаков используется только один канал передачи данных - видеоизображение. Данный подход не подходит для формата онлайн коммуникаций, в которых видеоизображение может быть статичным долгий промежуток времени, но при этом в аудио коммуникациях может обсуждаться и затрагиваться несколько тем, относящихся к разным контекстным сценам.
[0007] В статье A Local-to-Global Approach to Multi-modal Movie Scene Segmentation (https://arxiv.org/abs/2004.02678) описан фреймворк выделения контекстных сцен в фильмах, использующий мультимодальные характеристики каждого кадра (место, актерский состав, действие и аудио). Метод извлечения признаков в этом фреймворке является наиболее близким решением, но имеет отличия в той части, что для сегментации и классификации сцен используется подход на основе «обучения с учителем» (supervised) с помощью сети BNet, предназначенный именно под художественные фильмы. Использование supervised подхода невозможно в случае различной стилистики онлайн коммуникаций (в зависимости от назначения, стиля спикеров, используемого демонстрационного материала).
[0008] В заявленном решении для преодоления недостатков, присущих решениям, известным из уровня техники, предлагается подход, позволяющий выполнять сегментацию сцен с помощью классификации по трем каналам данных, формирующих видеоряд, с помощью моделей машинного обучения.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0009] Заявленное изобретение направлено на решение технической проблемы, заключающейся в создании эффективного способа сегментации видео, содержащего демонстрацию контента.
[0010] Техническим результатом является повышение точности определения контекстных сцен для сегментации видео, за счет параллельного анализа потоков данных, формирующих видео.
[0011] Заявленный результат достигается за счет осуществления способа сегментации сцен видеоряда, выполняемого с помощью вычислительного устройства и содержащего этапы, на которых:
получают входной видеоряд, содержащий видео и речевые данные;
выполняют разделение входного видеоряда по трем потокам данных: изображения лиц, текстовые данные на основании транскрибированной речевой информации, и изображения контента, представленных в видеоряде;
определяют признаки для каждого кадра видеоряда в каждом из упомянутых потоков данных;
выполняют векторизацию упомянутых признаков в каждом из упомянутых потоков данных;
осуществляют нормализацию векторных представлений, полученных в каждом потоке, и последующую конкатенацию нормализованных векторных представлений для получения общего набора признаков для каждого кадра видеоряда в виде единого вектора;
определяют метрику расстояния для каждого потока данных, как косинусное расстояние между векторами для изображений лиц в видео, и как евклидово расстояние между векторами для текстовых данных и изображений контента;
вычисляют на основании упомянутых метрик показатель общей метрики для упомянутого единого вектора, характеризующего каждый кадр видеоряда;
выполняют сегментацию видеоряда на контекстно связанные сцены на основании сравнения получаемых единых векторных представлений кадров в векторном пространстве, при этом разделение выполняется на основании превышения порогового значения общей метрики векторных представлений единых векторов кадров видеоряда.
[0012] В одном из частных примеров осуществления способа на основании изображений лиц формируют векторные представления, характеризующие по меньшей мере одно из: лицевые характеристики, пол, возраст, направление взгляда, эмоции.
[0013] В другом частном примере осуществления способа дополнительно распознают жесты, отображаемые в видеоряде.
[0014] В другом частном примере осуществления способа дополнительно из речевых данных выделяют аудиохарактеристики голосов в видеоряде.
[0015] В другом частном примере осуществления способа аудиохарактеристики голосов включают в себя по меньшей мере одно из: тональность, интенсивность, форманты.
[0016] В другом частном примере осуществления способа демонстрируемый контент дополнительно подвергается OCR обработке для распознавания представленной информации.
[0017] Заявленное изобретение также осуществляется за счет системы сегментации сцен видеоряда, содержащая по меньшей мере один процессор и память, хранящую машиночитаемые инструкции, которые при их исполнении процессором реализуют вышеуказанный способ сегментации сцен видеоряда.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0018] Фиг. 1 иллюстрирует блок-схему заявленного способа.
[0019] Фиг. 2 иллюстрирует пример потоков данных видеоряда.
[0020] Фиг. 3 иллюстрирует пример формирования усредняющего нормализованного вектора для потока видео.
[0021] Фиг. 4 иллюстрирует общую схему вычислительного устройства.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
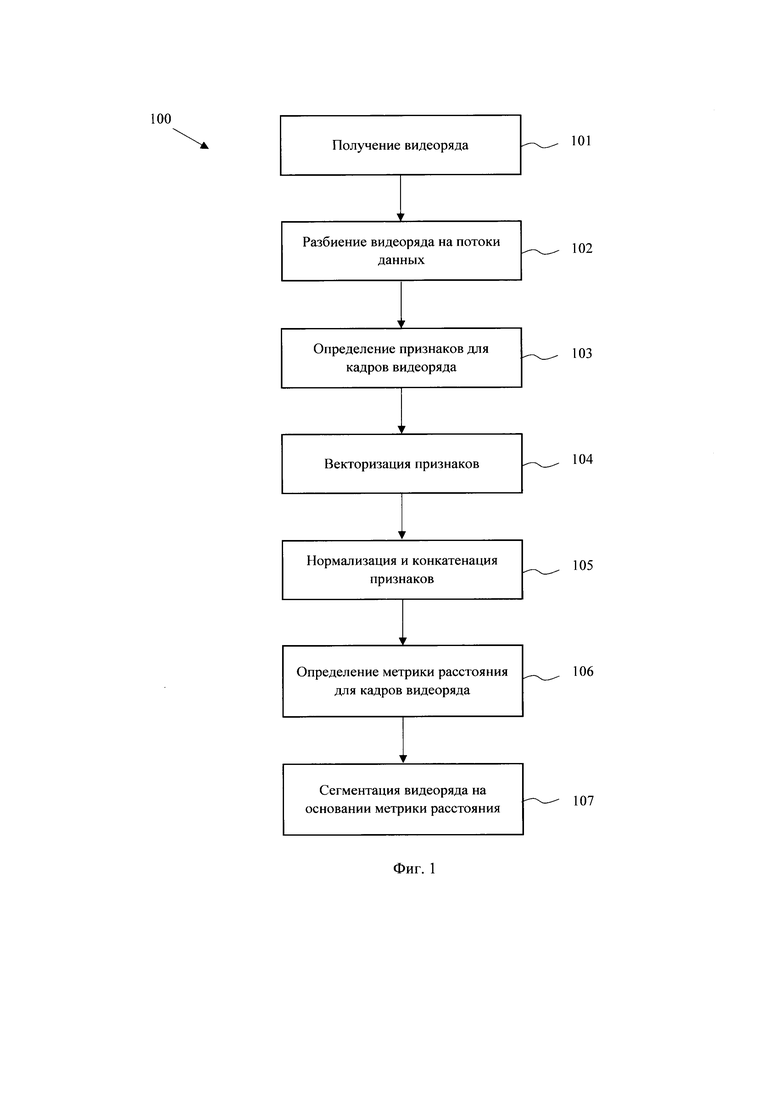
[0022] На Фиг. 1 представлена блок-схема выполнения заявленного способа (100) сегментации видеоряда. На первом этапе (101) исполняющее способ (100) устройство получает входные данные, которые представляют собой видео данные, в частности видеоряд, содержащий как изображения видео контента, так и демонстрацию сопутствующего контента в видеоряде, например, видео презентация. В качестве исполняющего устройства может применяться любой пригодный тип вычислительной техники, например, компьютер, сервер и т.п. Передача информации может осуществляться любым пригодным способ связи, например, с помощью вычислительной сети «Интернет», с помощью непосредственной загрузки данных в вычислительное устройство или любым другим известным принципом передачи цифровой информации.
[0023] Как показано на Фиг. 2 на этапе (102) из полученного видеоряда выделяется три потока данных, в каждом из которых будет происходить вычисление соответствующих признаков:
- видео данные (201);
- изображения контента, представленных в видеоряде (202);
- аудиопоток (203) и получаемые текстовые данные (2031) на основании транскрибированной речевой информации и их последующие векторные представления (2032).
[0024] Выделение потоков может выполняться с помощью известных в уровне техники подходов по выделению из кадра видеопотока контента, отображаемого в видео. Например из кадров видеоряда может выделяться область интереса (задаваемую определенной и фиксированной областью в кадре, например с помощью OpenCV алгоритмов) содержащая демонстрируемый контент. Из потока видеоданных выделяются изображения лиц людей, например, с помощью технологии распознавания лиц (алгоритмы Face recognition). Аудиопоток транскрибируется в текстовую форму для последующего анализа.
[0025] Полученные данные в каждом из потоков на этапе (103) обрабатываются для определения признаков в каждый момент времени (кадр видеоряда). В частности, для каждого потока (201-203) может устанавливаться временное окно, в котором будет происходить обработка информации (T1, Т2, Т3). Также, может определяться частота кадров для анализа кадров видеоданных (F1) и изображений контента (F3), представленного в видеоряде. Частота кадров - настраиваемый параметр, определяющие баланс между точностью и производительностью системы (рекомендуемое значение - 2 кадра в секунду, но не реже 1 кадра в 2 секунды).
[0026] Окно обработки информации в потоках данных выполняет две основные функции:
- исправление ошибок и артефактов для видеоканалов (за счет последующего отброса аномальных значений в окне и усреднения изображений) - выявляются аномалии по значению прогноз-факт на основе определения ошибки (методом Upper Control Limit) в сравнении с прогнозом модели VAR (Vector Auto-Regression) с установкой параметра max lag равным размеру окна обработки информации;
- обеспечение возможности работы с речевыми признаками для аудио потока - использование алгоритмов речь-в-текст невозможно "в моменте" (речь всегда обрабатывается за определенный промежуток времени), поэтому для того, чтобы соотнести векторное представление смысла произнесенной речи с кадром видеоряда необходима обработка аудиопотока с движущимся окном Т3.
[0027] Окна обработки (T1, Т2, Т3) - настраиваемые параметры, определяющие устойчивость (robustness) алгоритма (рекомендуемое значение для потока видео Т1=100/F1 секунд, для контента Т2=100/F3 секунд, для потока аудио Т3-30 секунд).
[0028] Для каждого потока данных определяются признаки, которые затем преобразуются в векторный вид (эмбеддинги на этапе (104) для их последующей обработки с помощью модели машинного обучения).
[0029] На каждый момент времени t (каждая секунда видео, аудио и т.п.) производится определение вектора признаков 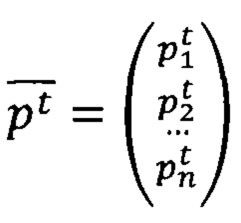 в метрическом пространстве (Р, d), где Р - множество векторов, характеризующий контекст (включающий смысловое содержание видео и демонстрируемого контента, аудио и пр.) на данный момент времени, a d - метрика, определяющая расстояние между векторами из множества Р.
в метрическом пространстве (Р, d), где Р - множество векторов, характеризующий контекст (включающий смысловое содержание видео и демонстрируемого контента, аудио и пр.) на данный момент времени, a d - метрика, определяющая расстояние между векторами из множества Р.
[0030] Например, для кадра формируется вектор признаков:

А для транслируемого контента на этом кадре:

[0031] Описанное решение позволяет работать на любых числовых признаках, но в качестве опорного перечня выбираются следующие признаки:
- видео - лицевые эмбеддинги (в том числе закодированные в них лицевых характеристики такие как направление взгляда, пол, возраст, эмоции), определение жестов, значения HSV.
- аудио - перевод речи в текст и применение языковой модели для выделения эмбедингов предложений, аудиохарактеристики голосов всех людей, находящихся в анализируемом временном окне (тональность, интенсивность, форманты).
- видео демонстрируемого контента - значения HSV, эмбеддинг изображения, детектирование (с помощью OCR) и получения эмбеддингов текста, описывающего соответствующий контент.
[0032] Далее для полученных векторов признаков в каждом из потоков (201-203) выполняется их нормализация и последующая конкатенация на этапе (105) для получения усредняющего вектора признаков для каждого потока данных. На Фиг. 3 приведен пример получения усредняющего вектора (2011) для потока видео (201).
[0033] Для потока видеоизображений (201) производится отбрасывание аномальных векторов в рамках окна и усреднение оставшихся. Аналогично для потоков контента (202) и аудио (203) выполняется нормализация признаков векторов методом Max/Min Normalization в рамках групп признаков и их конкатенирование в единый вектор (так как конкатенирование отдельных эмбеддингов без нормализации повлияет на дальнейшее вычисление расстояния).
[0034] Например, итоговый единый вектор признаков для кадра №17 будет иметь следующий вид:

[0035] Аналогично для каждого кадра видеоряда для соответствующего потока (202-203) также формируется усредненный вектор.
[0036] На основании полученного набора признаков для каждого потока данных (201-203) на этапе (106) определяется метрика расстояния, которая задает метрическое пространство, в котором каждый вектор описывает текущее состояние в момент времени. Под метрикой расстояния подразумевается числовая функция, удовлетворяющая требованиям/аксиомам определения расстояния в этом метрическом пространстве. Примерами такой метрики могут быть расстояние Хэмминга, евклидово расстояние, косинусное расстояние и т.д. Так как сравнение векторов в разных потоках данных может определяться разными метриками, то формально метрика d - это набор метрик (d1, d2, d3) и сравнение векторов выражается в применении отдельных метрик к разным потокам (201-203) и их последующее взвешенное усреднение (используя разные «веса» составляющих метрик d1, d2, d3).
[0037] Например, состав метрики d из набора метрик (d1, d2, d3) может иметь следующий вид:
- Метрика d1 для канала видео с изображениями лиц (с использованием предобученной архитектуры ResNet50 для получения эмбеддингов) представляет из себя косинусный коэффициент (косинусная близость) двух векторов;
- Метрика d2 для видео демонстрируемого контента (с использованием предобученной модели на базе ResNet50 для определения контекста сцены и модели GPT3 для получения эмбеддингов предложений) представляет из себя евклидовое расстояние между векторами;
- Метрика d3 для аудио канала (с использованием предобученной модели эмбеддингов на базе архитектуры BERT) представляет из себя евклидовое расстояние между векторами.
[0038] В результате выполнения предыдущих шагов для каждого времени Т определяется вектор в метрическом пространстве (Р, (d1, d2, d3)). Вектор признаков Р меняется во времени по ходу видеоряда (так как вектор определяется для каждого кадра видеоряда демонстрируемого в момент времени t). То есть каждый момент видеоряда представляет из себя набор векторов, привязанных ко времени.
[0039] Далее на этапе (107) выполняется сегментация входного видеоряда на сцены за счет сравнения получаемых единых векторных представлений кадров. Для выявления данных и контекста сцен с последующей сегментацией используется вышеуказанное метрическое пространство (набор признаков и соответствующая метрика расстояния) и датасет с примерами сегментации информации в каналах коммуникаций (т.е. фактически, математическое описание отдельных областей в метрическом пространстве).
[0040] Так как векторы признаков для каждого кадра видеоряда не являются независимыми, а должны быть рассмотрены как последовательность, то в отличие от применения просто методов кластеризации, применяются методы кластеризации последовательности Optimal Sequential Grouping.
[0041] Для определения последовательностей, в которых разные кадры могут сильно отличаться, но при этом контекстно содержаться в одной сцене, алгоритм проходит в два этапа.
[0042] На первом этапе для каждых последовательных кадров производится сравнение по метрике d и в случае превышения порога чувствительности L производится предварительное разделение на s сегментов, которые определяются последовательностью временных «меток» segms=[t(1), t(2), …, t(s)].
Пример результатов сравнения последовательных кадров по метрике d:
[…, 0.31, 0.25, 0.79, 0.12, 0.17, …, 0.47, 0.85, 0.14]
Соответственно для этого примера границы сцен соответствуют кадрам с расстояниями от предыдущих равными 0.79 и 0.85.
[0043] Для полученных сегментов segms производится кластеризация Optimal Sequential Grouping с помощью решения оптимизационной задачи минимизации расстояния между центроидами векторов, входящих в сегменты segms по построенной матрице попарных расстояний между сегментами. В качестве алгоритма сегментации предлагается использование методов кластеризации и использование метода локтя для определения количества кластеров.
[0044] Для калибровки и выбора параметров, используемых для сегментирования в данном подходе может использоваться калибровочная выборка. Под калибровочной выборкой понимается размеченный датасет коммуникаций в видео, с разметкой сцен (сегментов) в виде меток начала и окончания сцены. В отличие от supervised подхода, для калибровки/выбора параметров при сегментации фильмов нужно не 21000 сцен, как это представлено в A Local-to-Global Approach to Multi-modal Movie Scene Segmentation, а всего 200 сцен.
[0045] При этом с помощью калибровочной выборки возможна оптимизация и выбор параметров, используемых для сегментации. Калибруемые параметры:
- весовые коэффициенты w1, w2, w3 метрик d1,d2,d3 для расчета метрики d;
- порог чувствительности L.
[0046] Калибровка производится путем корректировки Cost функции, которая представляет сумму ошибок на калибровочной выборке (т.е. классическая задача минимизации ошибки).
[0047] Для отладки модели машинного обучения, применяемой для классификации сцен, может выполнять классификация по тэгам, которая производится на базе тех же самых единых векторов, которые получены на шаге (105), и сцен, полученных в ходе сегментации на этапе (107). Для классификации используется обучающая выборка извлекаемых объектов из сцен - тэгов. Для каждой сцены может быть несколько тэгов, то есть решается задача multilabel (множество меток) классификации.
[0048] Представлением сцены для классификации является усредненный вектор по всей сцене (под усреднением понимается вектор из сцены, который имеет наименьшее евклидово расстояние до среднего вектора). Так как вектор признаков уже подготовлен на этапе (105), то для классификации можно использовать не сложные deep learning end2end подходы, а производить обучение на обучающей выборке тэгов классическими методами машинного обучения (ML), например, с помощью метода градиентного бустинга.
[0049] Предложенный подход может найти широкое применение в части эффективной автоматизированной сегментации видеоряда с помощью применяемых технологий и алгоритмов машинного обучения, которые за счет тренировки на соответствующих датасетах могут с высокой вероятностью классифицировать контекстно связанные сцены для их выделения из общего потока данных. Например, такое применение может быть полезно для эффективного разделения блоков презентаций или конференций, в части анализа демонстрируемого контента и сегментации на основании контекстно несвязанных блоков, что может потом передаваться в качестве сегментов во внешние системы демонстрирования контента, например, системы предоставления виде по запросу (video on demand) или т.п.
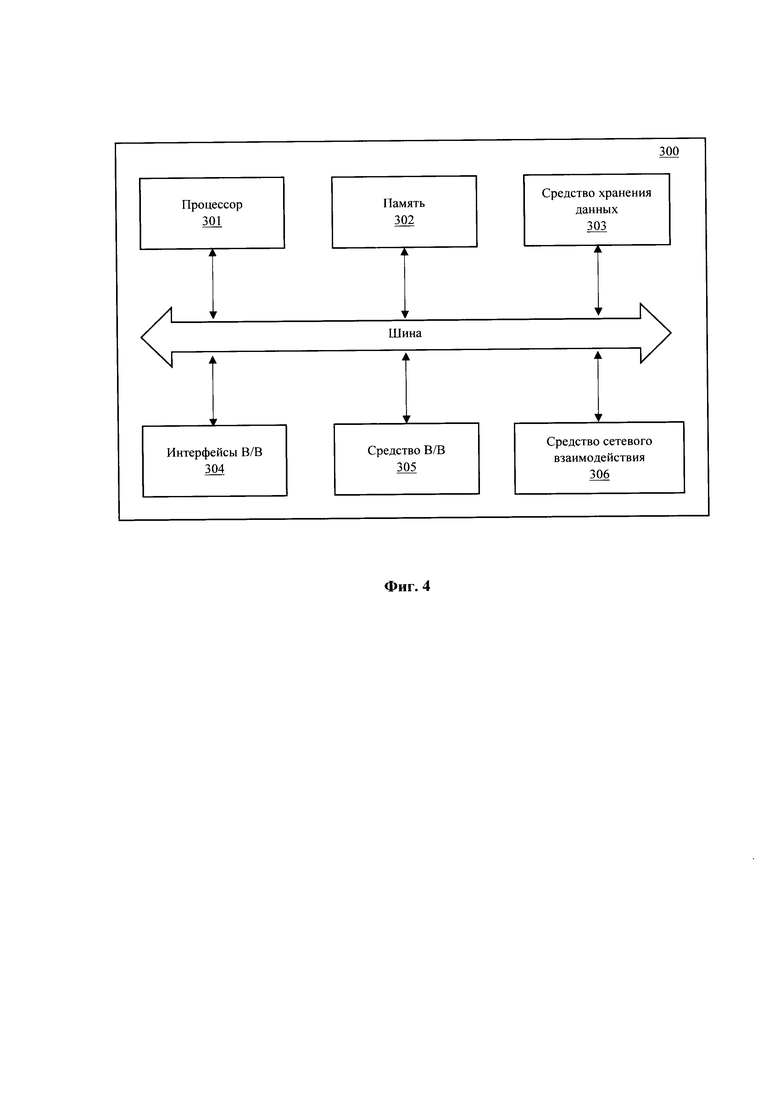
[0050] На Фиг. 4 представлен общий вид вычислительной системы на базе вычислительного устройства (300), пригодного для выполнения способа (100). Устройство (300) может представлять собой, например, сервер или иной тип вычислительного устройства, который может применяться для реализации заявленного способа.
[0051] В общем случае вычислительное устройство (300) содержит объединенные общей шиной информационного обмена один или несколько процессоров (301), средства памяти, такие как ОЗУ (302) и ПЗУ (303), интерфейсы ввода/вывода (304), устройства ввода/вывода (305), и устройство для сетевого взаимодействия (306).
[0052] Процессор (301) (или несколько процессоров, многоядерный процессор) могут выбираться из ассортимента устройств, широко применяемых в текущее время, например, компаний Intel™, AMD™, Apple™, Samsung Exynos™, MediaTEK™, Qualcomm Snapdragon™ и т.п. В качестве процессора (301) может также применяться графический процессор, например, Nvidia, AMD, Graphcore и пр.
[0053] ОЗУ (302) представляет собой оперативную память и предназначено для хранения исполняемых процессором (301) машиночитаемых инструкций для выполнение необходимых операций по логической обработке данных. ОЗУ (302), как правило, содержит исполняемые инструкции операционной системы и соответствующих программных компонент (приложения, программные модули и т.п.).
[0054] ПЗУ (303) представляет собой одно или более устройств постоянного хранения данных, например, жесткий диск (HDD), твердотельный накопитель данных (SSD), флэш-память (EEPROM, NAND и т.п.), оптические носители информации (CD-R/RW, DVD-R/RW, BlueRay Disc, MD) и др.
[0055] Для организации работы компонентов устройства (300) и организации работы внешних подключаемых устройств применяются различные виды интерфейсов В/В (304). Выбор соответствующих интерфейсов зависит от конкретного исполнения вычислительного устройства, которые могут представлять собой, не ограничиваясь: PCI, AGP, PS/2, IrDa, Fire Wire, LPT, COM, SATA, IDE, Lightning, USB (2.0, 3.0, 3.1, micro, mini, type C), TRS/Audio jack (2.5, 3.5, 6.35), HDMI, DVI, VGA, Display Port, RJ45, RS232 и т.п.
[0056] Для обеспечения взаимодействия пользователя с вычислительным устройством (300) применяются различные средства (305) В/В информации, например, клавиатура, дисплей (монитор), сенсорный дисплей, тач-пад, джойстик, манипулятор мышь, световое перо, стилус, сенсорная панель, трекбол, динамики, микрофон, средства дополненной реальности, оптические сенсоры, планшет, световые индикаторы, проектор, камера, средства биометрической идентификации (сканер сетчатки глаза, сканер отпечатков пальцев, модуль распознавания голоса) и т.п.
[0057] Средство сетевого взаимодействия (306) обеспечивает передачу данных устройством (300) посредством внутренней или внешней вычислительной сети, например, Интранет, Интернет, ЛВС и т.п. В качестве одного или более средств (306) может использоваться, но не ограничиваться: Ethernet карта, GSM модем, GPRS модем, LTE модем, 5G модем, модуль спутниковой связи, NFC модуль, Bluetooth и/или BLE модуль, Wi-Fi модуль и др.
[0058] Дополнительно могут применяться также средства спутниковой навигации в составе устройства (300), например, GPS, ГЛОНАСС, BeiDou, Galileo.
[0059] Представленные материалы заявки раскрывают предпочтительные примеры реализации технического решения и не должны трактоваться как ограничивающие иные, частные примеры его воплощения, не выходящие за пределы испрашиваемой правовой охраны, которые являются очевидными для специалистов соответствующей области техники.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ПОЛУЧЕНИЯ НИЗКОРАЗМЕРНЫХ ЧИСЛОВЫХ ПРЕДСТАВЛЕНИЙ ПОСЛЕДОВАТЕЛЬНОСТЕЙ СОБЫТИЙ | 2020 |
|
RU2741742C1 |
| Способ программной обработки видео контента с применением семантического анализа | 2024 |
|
RU2829461C1 |
| Устройство для семантической классификации и поиска в архивах оцифрованных киноматериалов | 2016 |
|
RU2628192C2 |
| КЛАССИФИКАЦИЯ КОНТЕНТА ДЛЯ ОБРАБОТКИ МУЛЬТИМЕДИЙНЫХ ДАННЫХ | 2006 |
|
RU2402885C2 |
| Способ обработки видео для целей визуального поиска | 2018 |
|
RU2693994C1 |
| Способ и устройство высокоэффективного сжатия мультимедийной информации большого объема по критериям ее ценности для запоминания в системах хранения данных | 2016 |
|
RU2654126C2 |
| УСТРОЙСТВО ДЛЯ ПЕРЕДАЧИ ПОТОКА БИТОВ ДЛЯ ЕГО ДЕКОДИРОВАНИЯ С ИСПОЛЬЗОВАНИЕМ СЕГМЕНТАЦИИ НА БЛОКИ | 2023 |
|
RU2830794C1 |
| КОДЕР, ДЕКОДЕР, СПОСОБ КОДИРОВАНИЯ, СПОСОБ ДЕКОДИРОВАНИЯ И ПРОГРАММА СЖАТИЯ КАДРОВ | 2019 |
|
RU2784381C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ОПРЕДЕЛЕНИЯ СИНТЕТИЧЕСКИ ИЗМЕНЕННЫХ ИЗОБРАЖЕНИЙ ЛИЦ НА ВИДЕО | 2021 |
|
RU2768797C1 |
| ОБНАРУЖЕНИЕ ОБЪЕКТОВ ИЗ ЗАПРОСОВ ВИЗУАЛЬНОГО ПОИСКА | 2017 |
|
RU2729956C2 |


Настоящее изобретение относится к области вычислительной техники для сегментации сцен видеоряда. Технический результат заключается в повышении точности определения контекстных сцен для сегментации видео, за счет параллельного анализа потоков данных, формирующих видео. Технический результат достигается за счет определения признаков для каждого кадра видеоряда в каждом из потоков данных; выполнения векторизации упомянутых признаков в каждом из упомянутых потоков данных; осуществления нормализации векторных представлений, полученных в каждом потоке, и последующей конкатенации нормализованных векторных представлений для получения общего набора признаков для каждого кадра видеоряда в виде единого вектора; определения метрики расстояния для каждого потока данных как косинусного расстояния между векторами для изображений лиц в видео и как евклидового расстояния между векторами для текстовых данных и изображений контента; вычисления на основании упомянутых метрик показателя общей метрики для упомянутого единого вектора, характеризующего каждый кадр видеоряда; выполнения сегментации видеоряда на контекстно-связанные сцены на основании сравнения получаемых единых векторных представлений кадров в векторном пространстве, при этом разделение выполняется на основании превышения порогового значения общей метрики векторных представлений единых векторов кадров видеоряда. 2 н. и 5 з.п. ф-лы, 4 ил.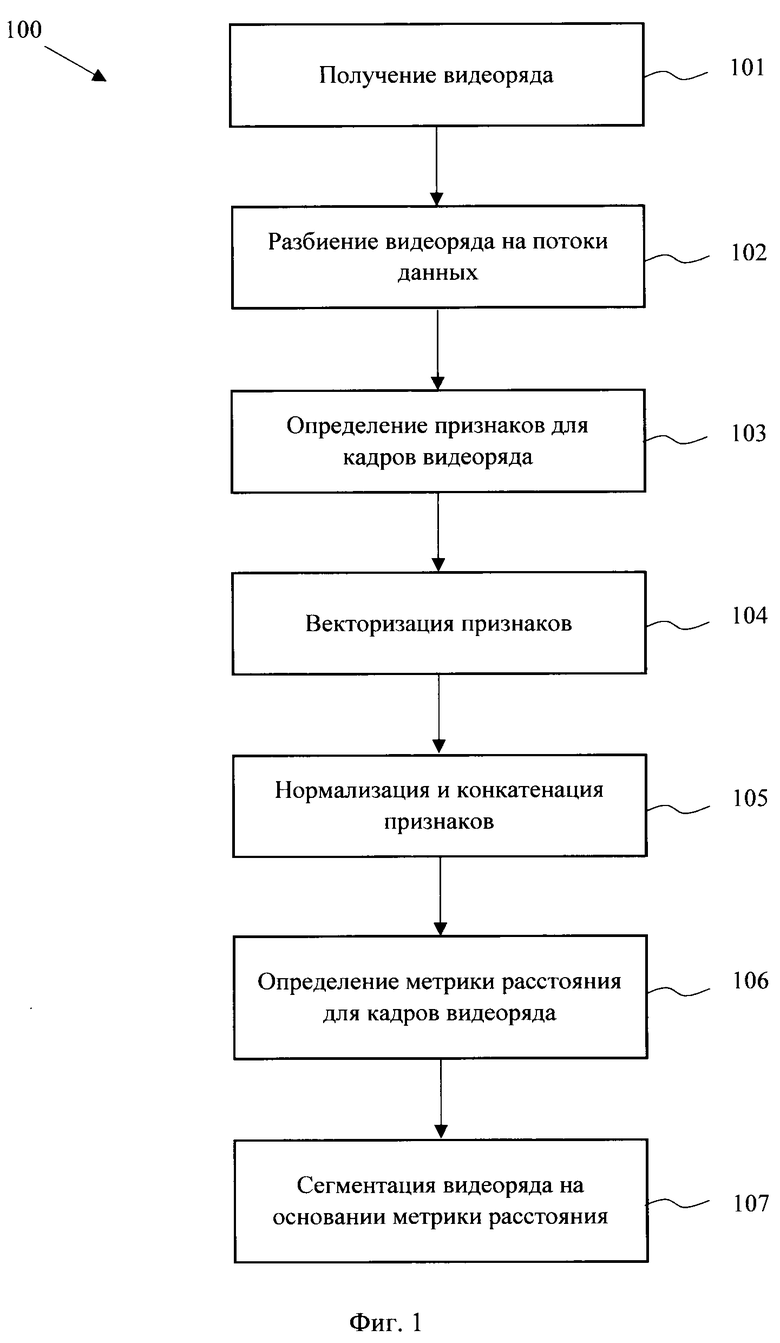
1. Способ сегментации сцен видеоряда, выполняемый с помощью вычислительного устройства и содержащий этапы, на которых:
получают входной видеоряд, содержащий видео и речевые данные;
выполняют разделение входного видеоряда по трем потокам данных: изображения лиц, текстовые данные на основании транскрибированной речевой информации и изображения контента, представленные в видеоряде;
определяют признаки для каждого кадра видеоряда в каждом из упомянутых потоков данных;
выполняют векторизацию упомянутых признаков в каждом из упомянутых потоков данных;
осуществляют нормализацию векторных представлений, полученных в каждом потоке, и последующую конкатенацию нормализованных векторных представлений для получения общего набора признаков для каждого кадра видеоряда в виде единого вектора;
определяют метрику расстояния для каждого потока данных как косинусное расстояние между векторами для изображений лиц в видео и как евклидово расстояние между векторами для текстовых данных и изображений контента;
вычисляют на основании упомянутых метрик показатель общей метрики для упомянутого единого вектора, характеризующего каждый кадр видеоряда;
выполняют сегментацию видеоряда на контекстно-связанные сцены на основании сравнения получаемых единых векторных представлений кадров в векторном пространстве, при этом разделение выполняется на основании превышения порогового значения общей метрики векторных представлений единых векторов кадров видеоряда.
2. Способ по п. 1, в котором на основании изображений лиц формируют векторные представления, характеризующие по меньшей мере одно из: лицевые характеристики, пол, возраст, направление взгляда, эмоции.
3. Способ по п. 2, в котором дополнительно распознают жесты, отображаемые в видеоряде.
4. Способ по п. 1, в котором дополнительно из речевых данных выделяют аудиохарактеристики голосов в видеоряде.
5. Способ по п. 4, в котором аудиохарактеристики голосов включают в себя по меньшей мере одно из: тональность, интенсивность, форманты.
6. Способ по п. 1, в котором демонстрируемый контент дополнительно подвергается OCR-обработке для распознавания представленной информации.
7. Система сегментации сцен видеоряда, содержащая по меньшей мере один процессор и память, хранящую машиночитаемые инструкции, которые при их исполнении процессором реализуют способ сегментации сцен видеоряда по любому из пп. 1-6.
| US 20190295302 A1, 26.09.2019 | |||
| US 20110013837 A1, 20.01.2011 | |||
| US 20130294642 A1, 07.11.2013 | |||
| US 20130272609 A1, 17.10.2013 | |||
| US 20100046830 A1, 25.02.2010 | |||
| СПОСОБ ИНТЕРАКТИВНОЙ СЕГМЕНТАЦИИ ОБЪЕКТА НА ИЗОБРАЖЕНИИ И ЭЛЕКТРОННОЕ ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО ДЛЯ ЕГО РЕАЛИЗАЦИИ | 2020 |
|
RU2742701C1 |

