Область техники
[0001] Настоящая технология относится к области хранения данных и, более конкретно, к системе и способу дублирования файлов на клиентских устройствах для хранения на серверах облачного хранилища.
Уровень техники
[0002] Обычно сервисы персональных облачных хранилищ используют алгоритмы дублирования файлов, позволяющие серверу облачного хранилища идентифицировать файлы на пользовательском устройстве, которые уже сохранены на сервере, чтобы не загружать их снова с пользовательского устройства. Когда пользователь загружает файл в облачное хранилище с пользовательского устройства, файл на самом деле не сохраняется в системе. Пользовательское устройство, с которого загружается файл, определяет уникальный идентификатор файла, который обычно основан на значении хэша или на комбинации нескольких значений хэш. Пользовательское устройство затем отправляет этот идентификатор на сервер облачного хранилища и, при условии, что файл с таким же идентификатором уже существует на сервере, сервер не загружает сам файл с пользовательского устройства, а создает визуальное представление файла в персональной папке пользователя в облачном хранилище. Это визуальное представление (например, символьная ссылка) связано с оригинальном файлом, хранящимся на сервере облачного хранилища.
[0003] Когда файл для загрузки на сервер облачного хранилища очень велик, определение уникального идентификатора файла на пользовательском устройстве может требовать много времени и ресурсов. Следовательно, существует необходимость в более эффективном механизме дублирования файлов на пользовательском устройстве.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[0004] Предметами настоящей технологии являются системы, способы и компьютерные устройства для дублирования файлов на клиентском устройстве для сохранения на сервере облачного хранилища. В одном варианте осуществления настоящей технологии способ включает в себя: получение пользовательским устройством запроса на загрузку файла, сохраненного локально на пользовательском устройстве, на сервер облачного хранилища; определение времени, которое требуется на создание уникального идентификатора файла для указанного файла, и времени, требуемого на загрузку указанного файла на сервер облачного хранилища; в ответ на превышение временем, которое требуется на создание уникального идентификатора файла для указанного файла, времени, требуемого на загрузку указанного файла на сервер облачного хранилища, инициацию загрузки файла на сервер облачного хранилища; в ответ на превышение временем, требуемым на загрузку указанного файла на сервер облачного хранилища, времени которое требуется на создание уникального идентификатора файла для указанного файла, создание указанного уникального идентификатора файла и передача уникального идентификатора файла на сервер облачного устройства.
[0005] В одном варианте осуществления настоящей технологии уникальный идентификатор файла включает в себя один или несколько хэшей.
[0006] В другом варианте осуществления настоящей технологии определение времени, требуемого на загрузку указанного файла на сервер облачного хранилища, включает в себя анализ одной или нескольких полос пропускания сетевого соединения между пользовательским устройством и устройством облачного хранилища, текущих вычислительных ресурсов, доступных на пользовательском устройстве, характеристик пользовательского устройства и размера и типа файла.
[0007] В другом варианте осуществления настоящей технологии способ также включает в себя сохранение в локальном хранилище пользовательского устройства информации о вычислительных ресурсах пользовательского устройства после анализа, чтобы не анализировать их снова в следующий раз.
[0008] В другом варианте осуществления настоящей технологии способ также включает в себя определение размера файла; и в ответ на превышение размером файла предварительно определенного размера осуществление этапов определения, загрузки и создания.
[0009] В другом варианте осуществления настоящей технологии способ может быть реализован в одном или нескольких из: в коде браузера, выполняемом на пользовательском устройстве, в коде «родного» приложения облачного хранилища, запущенного на пользовательском устройстве, и в коде веб-сайта, выполняемого на пользовательском устройстве.
[0010] В другом варианте осуществления настоящей технологии способ также включает в себя начало определения уникального идентификатора файла практически одновременно с загрузкой файла на сервер облачного хранилища.
[0011] В другом варианте осуществления настоящей технологии способ также включает в себя, при завершении загрузки файла на сервер облачного хранилища раньше, чем завершится создание уникального идентификатора файла, прекращение создания уникального идентификатора файла; и при завершении создания уникального идентификатора файла раньше, чем завершится загрузка файла на сервер облачного хранилища, передачу уникального идентификатора файла на сервер облачного хранилища, и: при условии, что файл уникален, продолжение загрузки файла на сервер облачного хранилища; а при условии, что файл не уникален, завершение загрузки файла на сервер облачного хранилища.
[0012] В другом варианте осуществления настоящей технологии коэффициент вероятности, обозначающий среднюю вероятность уникальности файла, определяется с использованием следующего неравенства:
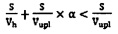 ,
,
где S - размер файла,
Vh - скорость создания идентификатора уникального файла на пользовательском устройстве,
Vupl - скорость загрузки файла на сервер облачного хранилища,
α - средняя вероятность уникальности файла на сервере облачного хранилища.
[0013] В другом варианте осуществления настоящей технологии неравенство упрощается до th<tupl*(1-α), где время t определяется как, и при условии, что неравенство верно, на пользовательском устройстве создается уникальный идентификатор файла.
[0014] В другом варианте осуществления настоящей технологии система дублирования файлов на пользовательском устройстве включает в себя процессор пользовательского устройства, выполненный с возможность осуществлять: получение пользовательским устройством запроса на загрузку файла, сохраненного локально на пользовательском устройстве, на сервер облачного хранилища; определение времени, которое требуется на создание уникального идентификатора файла для указанного файла, и времени, требуемого на загрузку указанного файла на сервер облачного хранилища; в ответ на превышение временем, которое требуется на создание уникального идентификатора файла для указанного файла, времени, требуемого на загрузку указанного файла на сервер облачного хранилища, инициацию загрузки файла на сервер облачного хранилища; в ответ на превышение временем, требуемым на загрузку указанного файла на сервер облачного хранилища, времени которое требуется на создание уникального идентификатора файла для указанного файла, создание указанного уникального идентификатора файла и передача уникального идентификатора файла на сервер облачного устройства.
[0015] В другом варианте осуществления настоящей технологии постоянный машиночитаемый носитель хранит выполняемые компьютером инструкции дублирования файлов на пользовательском устройстве, включающие в себя инструкции для: получения пользовательским устройством запроса на загрузку файла, сохраненного локально на пользовательском устройстве, на сервер облачного хранилища; определения времени, которое требуется на создание уникального идентификатора файла для указанного файла, и времени, требуемого на загрузку указанного файла на сервер облачного хранилища; в ответ на превышение временем, которое требуется на создание уникального идентификатора файла для указанного файла, времени, требуемого на загрузку указанного файла на сервер облачного хранилища, инициации загрузки файла на сервер облачного хранилища; в ответ на превышение временем, требуемым на загрузку указанного файла на сервер облачного хранилища, времени которое требуется на создание уникального идентификатора файла для указанного файла, создания указанного уникального идентификатора файла и передача уникального идентификатора файла на сервер облачного устройства.
[0016] Представленное выше описание упрощенных вариантов осуществления предметов технологии служит для понимания основных ее предметов. Это описание не является полным для всех рассматриваемых предметов, и не предназначено для определения ключевых или важнейших элементов всех предметов или для ограничения объема любого или всех предметов технологии. Единственной его целью является представление одного или нескольких предметов в упрощенной форме перед более подробным описанием, которое следует ниже. Для выполнения вышеизложенной задачи один или несколько предметов технологии включают в себя признаки, описанные и конкретно указанные в формуле изобретения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0017] Прилагаемые чертежи включены в данное описание и составляют его часть, иллюстрируют один или несколько вариантов осуществления предметов технологии вместе с подробным описанием и служат для пояснения принципов и вариантов осуществления технологии.
На Фиг. 1 представлена схема примера сетевой архитектуры для дублирования файлов на клиентском устройстве для сохранения на сервере облачного хранилища.
На Фиг. 2А и 2Б представлены таблицы приведенных для примера тестовых данных дублирования файлов на клиентском устройстве для сохранения на сервере облачного хранилища.
На Фиг. 3 представлена схема примера способа дублирования файлов на клиентском устройстве для сохранения на сервере облачного хранилища.
На Фиг. 4 представлена схема, иллюстрирующая пример неспециализированной компьютерной системы, на которой реализованы системы и способы проверки веб-страниц.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
[0018] Примеры предметов настоящей технологии, описанные здесь в контексте систем, способов и компьютерных программных продуктов для дублирования файлов на клиентском устройстве для сохранения на сервере облачного хранилища. Специалистам в данной области техники будет понятно, что следующее описание является исключительно иллюстративным и не предназначено для установления каких-либо ограничений. Другие предметы будут очевидны специалистам в данной области техники, обладающим преимуществами от прочтения настоящего описания. Теперь подробнее будут описаны варианты осуществления предметов, проиллюстрированных в прилагаемых чертежах. На всех чертежах и в нижеследующем описании одни и те же элементы по возможности будут пронумерованы одинаково.
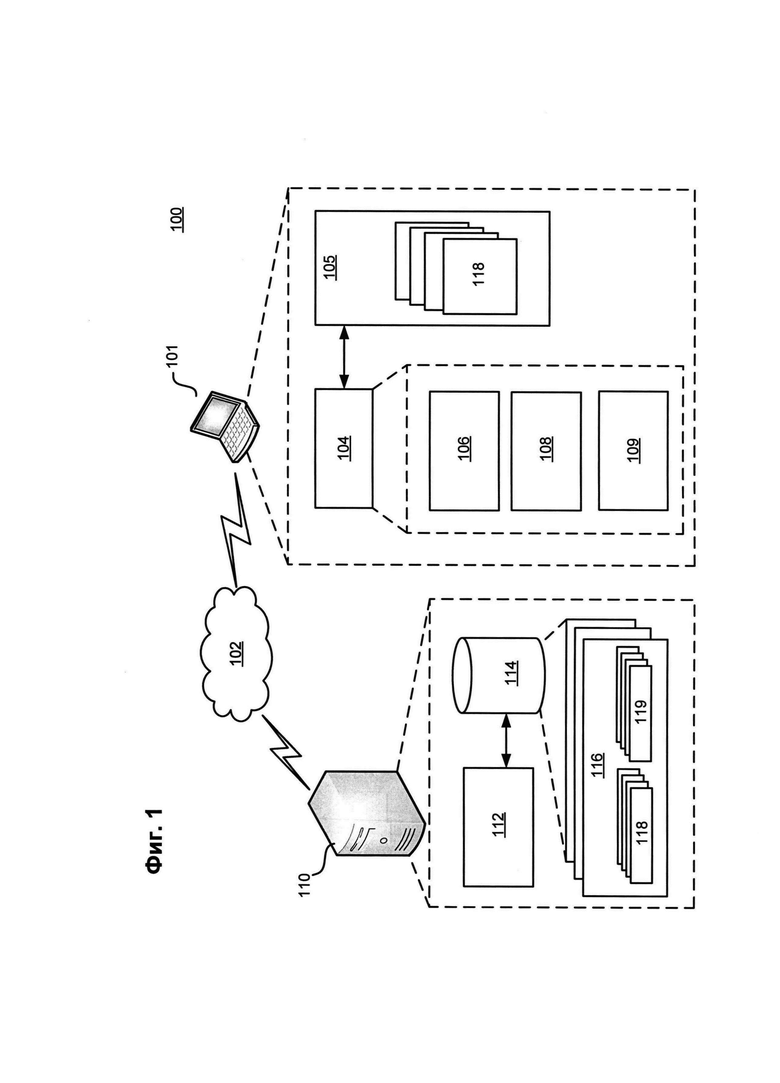
[0019] На Фиг. 1 представлен пример системы для дублирования файлов на клиентском устройстве для сохранения на сервере облачного хранилища. Система 100 включает в себя пользовательское устройство 101 (также может упоминаться как клиентское устройство), которое обменивается данными с сервером 110 сетевого хранилища по сети 102 передачи данных, например, по Интернету. Пользовательское устройство 101 может представлять собой персональный компьютер, ноутбук, планшет, мобильный телефон или устройства обработки данных другого типа. Пользовательское устройство 101 может выполнять программу 104 резервного копирования, которая осуществляет дублирование (или резервное копирование) файлов 118, сохраненных в локальном хранилище 105 пользовательского устройства 101 на сервер 110 облачного хранилища. Программа 104 резервного копирования может включать в себя, не ограничиваясь, приложение резервного копирования данных, приложение системы безопасности, мобильное приложение, веб-браузер, приложение облачного хранилища, запущенное на пользовательском устройстве и HTML-код или сценарий, выполняемый веб-браузером клиентского устройства.
[0020] Как было кратко описано выше, сервисы персональных облачных хранилищ, как, например, тот, что предоставляется сервером 110 сетевого хранилища, используют алгоритмы дублирования файлов, позволяющие серверу 110 облачного хранилища идентифицировать файлы на пользовательском устройстве, которые уже сохранены на сервере, чтобы не загружать их снова с пользовательского устройства 101. Когда пользователь загружает файл 118 на сервер 110 облачного хранилища с пользовательского устройства 101, файл 118 на самом деле не сохраняется на сервере 110. Пользовательское устройство 101, с которого загружается файл 118, определяет уникальный идентификатор файла, который обычно основан на значении хэша или на комбинации нескольких значений хэш-файла. Пользовательское устройство 101 затем отправляет этот идентификатор на сервер 110 облачного хранилища и, при условии, что файл с таким же идентификатором уже существует на сервере 110, сервер 110 не загружает сам файл 118 с пользовательского устройства 101, а создает визуальное представление (символьную ссылку) 119 файла 118 в персональной папке 116 пользователя в облачном хранилище. Символьная ссылка 119 связана с оригинальным файлом 118, который также может быть сохранен на сервере 110 облачного хранилища.
[0021] В случаях, когда файл 118 для загрузки на сервер 110 облачного хранилища велик (например, несколько сотен мегабайт или гигабайт, как в случае с фотографиями с высоким разрешением, большими видеофайлами и т.д.), может возникнуть ситуация, когда определение уникального идентификатора файла на пользовательском устройстве 101 занимает больше времени, чем сама загрузка файла на сервер 110 облачного хранилища, поскольку определение хэшей для больших файлов является ресурсозатратной задачей и может быть неэффективно для мобильного пользовательского устройства с низким количеством ресурсов для обработки данных и ограниченными ресурсами памяти.
[0022] Чтобы решить эту проблему, программа 104 резервного копирования может реализовать расширенный алгоритм дублирования файлов на пользовательском устройстве 101 для сохранения на сервере 110 облачного хранилища. В соответствии с одним вариантом осуществления настоящей технологии, когда пользователь инициирует процесс загрузки файла 118, сохраненного в локальном хранилище 105 пользовательского устройства 101, на сервер 110 облачного хранилища, программа 104 резервного копирования оценивает время, необходимое на определение уникального идентификатора файла 118 и время, необходимое для непосредственной загрузки файла 118 на сервер 110 облачного хранилища. Если время, необходимое для определения идентификатора, меньше, чем время загрузки, программа 104 резервного копирования оценивает уникальный идентификатор для файла 118 и отправляет его на сервер 110 облачного хранилища. Модуль 112 обработки файлов сервера 110 облачного хранилища использует полученный идентификатор файла, чтобы проверить, содержится ли копия соответствующего файла 118 в базе данных 114 файлов. Если файл 118 не обнаружен в базе данных 114 сервера, модуль 112 обработки файлов инициирует загрузку файла 118 с клиентского устройства 101 в базу данных 114 файлов. Если сервер 110 содержит копию файла 118, модуль 112 обработки файлов создает символьную ссылку 119 файла 118 и сохраняет ее в персональной папке 116 пользователя в базе данных 114 файлов. Если время, необходимое для определения уникального идентификатора файла, превышает время, необходимое для загрузки файла 118 на сервер 110 облачного хранилища, программа 104 резервного копирования не определяет уникальный идентификатор файла и начинает загрузку файла 118 на сервер 110 облачного хранилища. После того, как файл 118 загружен на сервер 110 облачного хранилища, модуль 112 обработки файлов определяет уникальный идентификатор для файла 118 и, после этого, запускает процесс дублирования.
[0023] Описанный как пример расширенный алгоритм дублирования файлов на пользовательском устройстве для хранения на сервере облачного хранилища предлагает ряд преимуществ. Механизм дублирования файлов предлагает такой баланс между вычислениями хэш-сервером и клиентом, при котором время загрузки для пользователя минимально. Он также предлагает гибкое переключение между вычислениями хэш-сервером и клиентом, причем задачей этого переключения является удобство пользователя. Следует отметить, что для повышения эффективности алгоритма, логические схемы решения могут выборочно использоваться только для файлов, превышающих определенный размер. Так, например, программа 104 резервного копирования может автоматически определить хэши небольших файлов (например, менее 10 КБ размером) на пользовательском устройстве 101 и отправить их на сервер 110 облачного хранилища, потому что это не требует слишком много вычислительных ресурсов.
[0024] Более конкретно, чтобы реализовать описанный выше алгоритм, программа 104 резервного копирования может включать в себя множество программных модулей, которые могут быть реализованы процессором пользовательского устройства 101, включая модуль 106 определения уникального идентификатора файла, модуль 108 определения времени передачи и модуль 109 решений. Термин «модуль» в данном контексте означает физическое устройство, компонент или множество компонентов, выполненных с использованием аппаратного обеспечения, например, с помощью, интегральной схемы специального назначения (ASIC) или программируемой логической интегральной схемы (FPGA), или же комбинации аппаратного и программного обеспечения, например, с помощью микропроцессорной системы и набора инструкций, реализующих функционал модуля, которые (при выполнении) трансформируют микропроцессорную систему в устройство специального назначения. Модуль также может быть реализован в виде комбинации обоих, причем некоторые конкретные функции реализуются за счет аппаратного обеспечения, а другие функции реализуются комбинацией аппаратного и программного обеспечения. В некоторых конкретных вариантах осуществления технологии по меньшей мере часть модулей (а в некоторых случаях - все) могут быть выполнены на процессоре компьютера общего назначения (например, подобном тому, который подробно описан ниже и изображен на Фиг. 4). Соответственно, каждый модуль программы 104 резервного копирования может быть реализован в виде множества различных конфигураций и не ограничивается конкретным вариантом осуществления, приведенным здесь в качестве примера.
[0025] В одном варианте осуществления настоящей технологии модуль 106 программы 104 резервного копирования выполнен с возможностью определять время, требуемое на создание уникального идентификатора файла 118 на пользовательском устройстве 101, и непосредственно создавать уникальный идентификатор файла 118. При оценке времени, требуемого на создание уникального идентификатора файла 118, модуль 106 может принимать во внимание размер и тип файла, тип уникального идентификатора файла, текущие вычислительные ресурсы, доступные на пользовательском устройстве 101, характеристики пользовательского устройства 101 и другие параметры.
[0026] Например, размер файла может значительно влиять на время, которое необходимо для создания хэша (например, SHA-256) этого файла. Например, пользовательское устройство с процессором Intel Core i5 может затратить примерно 0,921 секунд на создание хэша SHA-256 файла размером 10 КБ; и примерно 18,28 секунд на создание хэша SHA-256 файла размером 1 ГБ, что в 20 раз дольше.
[0027] В другом примере тип уникального идентификатора файла может указывать тип алгоритма хэширования, используемый для создания идентификатора, например, SHA-256, SHA-512, MD5 или другие, а также может быть использован модулем 106 определения идентификатора файла при оценке времени хэширования. Различные типы алгоритмов хэширования имеют различные вычислительные сложности, как известно специалистам в данной области компьютерной и программной разработки; что означает, что время определения хэша файла с использованием различных алгоритмов хэширования будет различным.
[0028] В другом варианте осуществления настоящей технологии характеристики пользовательского устройства 101 и доступных вычислительных ресурсов пользовательского устройства 101 могут также влиять на время, требуемое на определение хэша файла 118 на пользовательском устройстве 101. Например, пользовательское устройство с многоядерным процессором будет определять хэш файла быстрее, чем пользовательское устройство с одноядерным процессором, потому что многоядерные процессоры обладают большей вычислительной мощностью, чем одноядерные. В другом варианте осуществления настоящей технологии на пользовательском устройстве 101 уже запущена ресурсоемкая задача, например, видеоигра, или антивирусная программа сканирует его жесткий диск; в таком случае его вычислительные ресурсы, доступные для определения хэша файла, ограничены, что повышает время хэширования.
[0029] В одном варианте осуществления настоящей технологии модуль 106 определения идентификатора файла может сохранить информацию о вычислительных ресурсах и характеристики пользовательского устройства в локальном хранилище 105, чтобы не анализировать его в следующий раз снова, при запросе на дублирование другого файла. Модуль 106 определения идентификатора файла может позже использовать хранящуюся информацию для оценки времени для создания уникальных идентификаторов файлов на пользовательском устройстве 101.
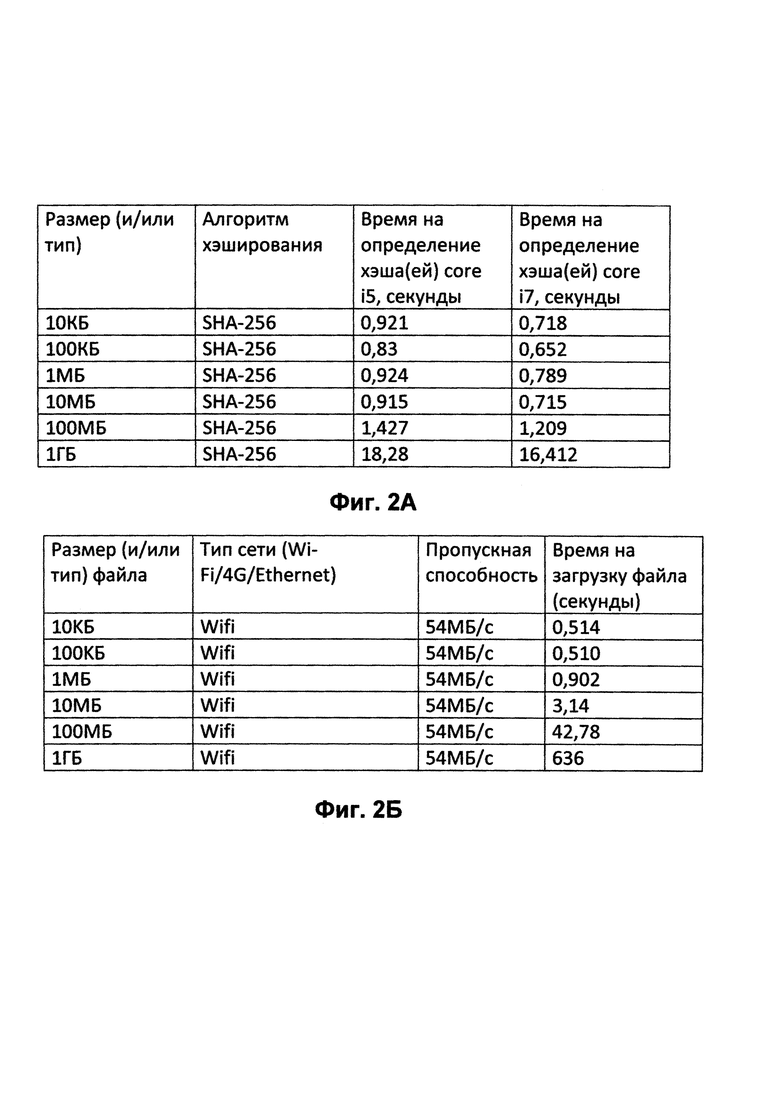
[0030] В таблице на Фиг. 2А приведены несколько примеров оценок времени модулем 106 определения идентификатора файла для определения хэша SHA-256 файлов различных размеров на двух различных типах пользовательских устройств. В одном варианте осуществления настоящей технологии модуль 106 определения идентификатора файла может использовать эту таблицу для оценки времени для определения уникального идентификатора файла для файла 118 при запросе загрузки. Например, в соответствии с таблицей, определение хэша SHA-256 файла размером 10 КБ занимает 0,921 секунд на пользовательском устройстве с процессором Intel Core i5; и примерно 0,718 секунд для файла такого же размера на пользовательском устройстве с процессором Intel Core i7. В другом примере определение хэша SHA-256 файла размером 1 ГБ занимает 18,28 секунд на пользовательском устройстве с процессором Intel Core i5; и примерно 16,412 секунд для файла такого же размера на пользовательском устройстве с процессором Intel Core i7.
[0031] В одном варианте осуществления настоящей технологии модуль 108 программы 104 резервного копирования выполнен с возможностью оценки времени, требуемого на загрузку файла 118 на сервер 110 облачного хранилища. При оценке времени загрузки файла модуль 108 может принимать во внимание размер и тип файла, пропускную способность сетевого соединения между пользовательским устройством 101 и сервером 110, текущие вычислительные ресурсы, доступные на пользовательском устройстве 101, характеристики пользовательского устройства 101 и другие параметры. Например, чем меньше размер файла, тем быстрее он будет загружен пользовательским устройством 101 на сервер 110 облачного хранилища. В другом примере чем больше пропускная способность канала обмена данными между пользовательским устройство 101 и сервером 110 облачного хранилища, тем больше будет скорость загрузки файла. В другом примере если пользовательское устройство 101 осуществляет или планирует осуществить передачу большого объема данных по сети передачи данных, то загрузка файла 118 может быть отложена и эта отсрочка может быть добавлена к оценке времени загрузки, осуществляемой модулем 108 оценки времени передачи.
[0032] В одном варианте осуществления настоящей технологии модуль 108 определения времени передачи может сохранить в локальном хранилище 105 информацию о времени загрузки файлов различных размеров в разных сетях, чтобы не анализировать его в следующий раз снова при запросе на дублирование другого файла. Сохраненная информация может быть использована позже для оценки времени загрузки файлов на сервер 110. В таблице на Фиг. 2Б представлены различные примеры сохраненных оценок времени загрузки для файлов различного размера. В одном варианте осуществления настоящей технологии модуль 108 определения времени передачи может использовать эту таблицу для оценки времени, требуемого на загрузку файла на сервер 110 облачного хранилища. Например, в соответствии с этой таблицей, для загрузки файла размером 10 КБ по сети Wi-Fi со скоростью передачи 54 МБ/с требуется примерно 0,514 секунд, а для загрузки файла размером 1 ГБ по тому же сетевому соединению требуется примерно 636 секунд.
[0033] В одном варианте осуществления настоящей технологии модуль 109 программы 104 резервного копирования выполнен с возможностью сравнивать оценку времени создания уникального идентификатора файла с оценкой времени загрузки файла на сервер 110 облачного хранилища. Затем, в ответ на превышение временем, требуемым для создания уникального идентификатора файла, времени, требуемого для загрузки указанного файла на сервер 110 облачного хранилища, модуль 109 решений выполнен с возможностью инициировать загрузку файла 118 на сервер 110 облачного хранилища. Однако, в ответ на превышение временем, требуемым для загрузки указанного файла на сервер 110 облачного хранилища, времени, требуемого для создания уникального идентификатора файла, модуль 109 создает уникальный идентификатор файла и передает его на сервер 110 облачного хранилища.
[0034] Например, как в таблицах на Фиг. 2А и 2Б, если модуль 109 решений определяет, что оценка времени для определения хэша SHA-256 для файла 100 КБ на пользовательском устройстве 101 с процессором Intel Core i5 составляет 0,83 секунды, а время, чтобы загрузить тот же самый файл на сервер 110 облачного хранилища составляет 0,51 секунду, то модуль 109 решений дает команду программе 104 резервного копирования загрузить файл на сервер 110 хранилища, потому что это займет меньше времени, чем определение хэш-функции файла на пользовательском устройстве 101. Однако, если модуль 109 решений определяет, что оценка времени для определения хэша SHA-256 для файла 10 МБ на пользовательском устройстве 101 с процессором Intel Core i7 составляет 0,715 секунды, а время, чтобы загрузить тот же самый файл на сервер 110 облачного хранилища составляет 3,14 секунд, то модуль 109 решений дает команду программе 104 резервного копирования определить хэш-функцию файла на пользовательском устройстве 101 и отправить ее на сервер 110 облачного хранилища, потому что определение хэша для этого файла на пользовательском устройстве 101 займет меньше времени, чем загрузка файла на сервер 110. Если непосредственный размер файла не обнаружен в таблицах 2А и 2Б, модуль 109 решений может найти самое близкое значение размера файла и использовать его для оценки времени хэширования и времени загрузки. Так, например, если непосредственный размер файла равен приблизительно 120 КБ, то модуль 109 решений может использовать оценки времени хэширования и времени загрузки для файла размером 100 КБ из таблиц 2А и 2Б.
[0035] В другом варианте осуществления настоящей технологии модуль 109 решений использует эвристическую информацию о доступных вычислительных ресурсах пользовательского устройства, характеристиках пользовательского устройства, типе и размере файла и другую доступную информацию для установления того, нужно ли определить уникальный идентификатор файла на пользовательском устройстве 101 или на сервере 110 облачного хранилища. Например, если пользовательское устройство 101 является мобильным устройством (например, смартфоном или планшетом), которое обычно обладает низкой вычислительной мощностью, модуль 109 решений может не определять хэши на устройствах такого типа, а сразу начинать загрузку файла на сервер 110 облачного хранилища. В другом примере, если нагрузка процессора пользовательского устройства 101 превышает определенный порог, модуль 109 решений может принять решение не определять хэши на пользовательском устройстве, а сразу начать загрузку. В другом примере, если заряд аккумулятора мобильного пользовательского устройства 101 низкий, модуль 109 решений может принять решение не определять хэши на пользовательском устройстве, а сразу начать загрузку. Альтернативно, если файл велик (например, файл размером 1 ГБ), а заряд аккумулятора настолько низок, что загрузка с таким зарядом, очевидно, невозможна, модуль 109 решений может дать команду программе 104 резервного копирования определить хэш и отправить его на сервер 110, поскольку это дает возможность по меньшей мере иметь файл в хранилище, в случае, если это дубликат, что лучше, чем ничего не осуществить.
[0036] В одном варианте осуществления настоящей технологии модуль 109 решений в процессе принятия решения о том, загружать или не загружать файл в облачное хранилище, может также принять во внимание фактор уникальности различных типов файла (например, изображений, видео или PDF). Например, существует большая вероятность, что фактор уникальности загруженных фото больше, чем у загруженных файлов PDF, причем в этом случае, если файл определен как уникальный, модуль 109 загрузит файл на сервер 110 облачного хранилища, где будет определен хэш файла; если файл не определен как уникальный, то хэш файла будет определен на пользовательском устройстве 101 и отправлен на сервер 110 облачного хранилища.
[0037] В другом варианте осуществления настоящей технологии модуль 109 решений может дополнительно использовать в процессе принятия решения о том, загружать или не загружать файл на сервер облачного хранилища, коэффициент вероятности, означающий среднюю вероятность того, что файл уникален. Этот коэффициент вероятности может быть описан следующим неравенством:

S - размер файла,
Vh - скорость создания идентификатора уникального файла на пользовательском устройстве (например, скорость хэширования 60 МБ/с),
Vupl - скорость загрузки файла на сервер облачного хранилища (например, 6 МБ/с),
α - средняя вероятность того, что файл уникален на сервере облачного хранилища, определенная как среднее для всего сервера облачного хранилища; может варьировать от 0 - все файлы не уникальны, до 1 - все файлы уникальны.
[0038] В одном варианте осуществления настоящей технологии неравенство (1) может быть упрощено до th<tupl*(1-α), где время t определяется как размер файла, поделенный на скорость загрузки файла или скорость создания идентификатора файла, и при условии, что неравенство верно, на пользовательском устройстве создают идентификатор файла. Таким образом, если упрощенное неравенство верно (т.е. время хэширования меньше, чем время загрузки), уникальные идентификаторы могут быть определены на пользовательском устройстве 101. И, если упрощенное неравенство неверно (т.е. время хэширования больше, чем время загрузки), уникальные идентификаторы файла могут быть определены на сервере 110 облачного хранилища.
[0039] В другом варианте осуществления настоящей технологии модуль 109 решений может начать определение хэшей для файла 118 определение хэшей файла 118 практически одновременно с загрузкой файла 118 на сервер 110. И, в зависимости от того, какой процесс завершится ранее, модулем 109 решений может быть выполнена следующая логическая схема: при завершении загрузки файла на сервер 110 облачного хранилища раньше, чем завершится создание уникального идентификатора файла на пользовательском устройстве 101, модуль 109 решений прекращает создание уникального идентификатора файла; а при завершении создания уникального идентификатора файла раньше, чем завершится загрузка файла на сервер 110 облачного хранилища, модуль 109 решений передает уникальный идентификатор файла на сервер 110 облачного хранилища, и затем: при условии, что файл уникален, загрузка файла на сервер 110 облачного хранилища продолжается; а при условии, что файл не уникален, загрузка файла на сервер 110 облачного хранилища завершается.
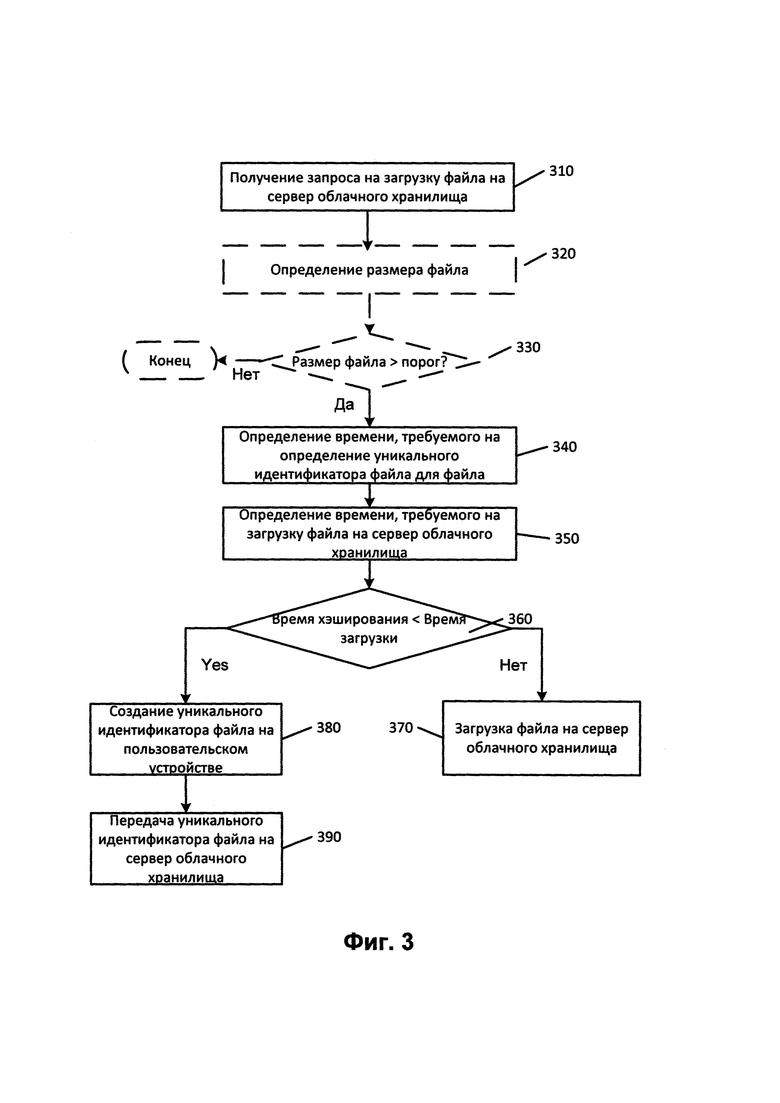
[0040] На Фиг. 3 представлена схема примера способа дублирования файлов на клиентском устройстве для сохранения на сервере облачного хранилища. На этапе 310 программа 104 резервного копирования получает запрос от пользователя или сервера облачного хранилища на загрузку файла на сервер 110 облачного хранилища. Далее на этапах 320 и 330, которые опциональны в одном варианте осуществления настоящей технологии, программа 104 резервного копирования определяет размер файла и, на основе размера файла, определяет, продолжать ли процесс дублирования. Если размер файла превышает определенный порог, например, 10 КБ, способ продолжается и переходит на этап 340, на котором модуль 106 определения идентификатора файла определяет время, требуемое на создание уникального идентификатора файла для файла. На этапе 350 модуль 108 определения времени передачи определяет время, требуемое на загрузку указанного файла на сервер 110 облачного хранилища. Далее, на этапе 360 модуль 109 решения сравнивает оценки времени хэширования и времени загрузки. Далее на этапе 370, в ответ на превышение временем, требуемым для создания уникального идентификатора файла, времени, требуемого для загрузки указанного файла на сервер облачного хранилища, модуль 109 решений инициирует загрузку файла на сервер облачного хранилища. Альтернативно на этапах 380 и 390, соответственно, в ответ на превышение временем, требуемым для загрузки файла на сервер облачного хранилища, времени, требуемого для создания уникального идентификатора файла, модуль 109 создает уникальный идентификатор файла на пользовательском устройстве 101 и передает его на сервер 110 облачного хранилища.
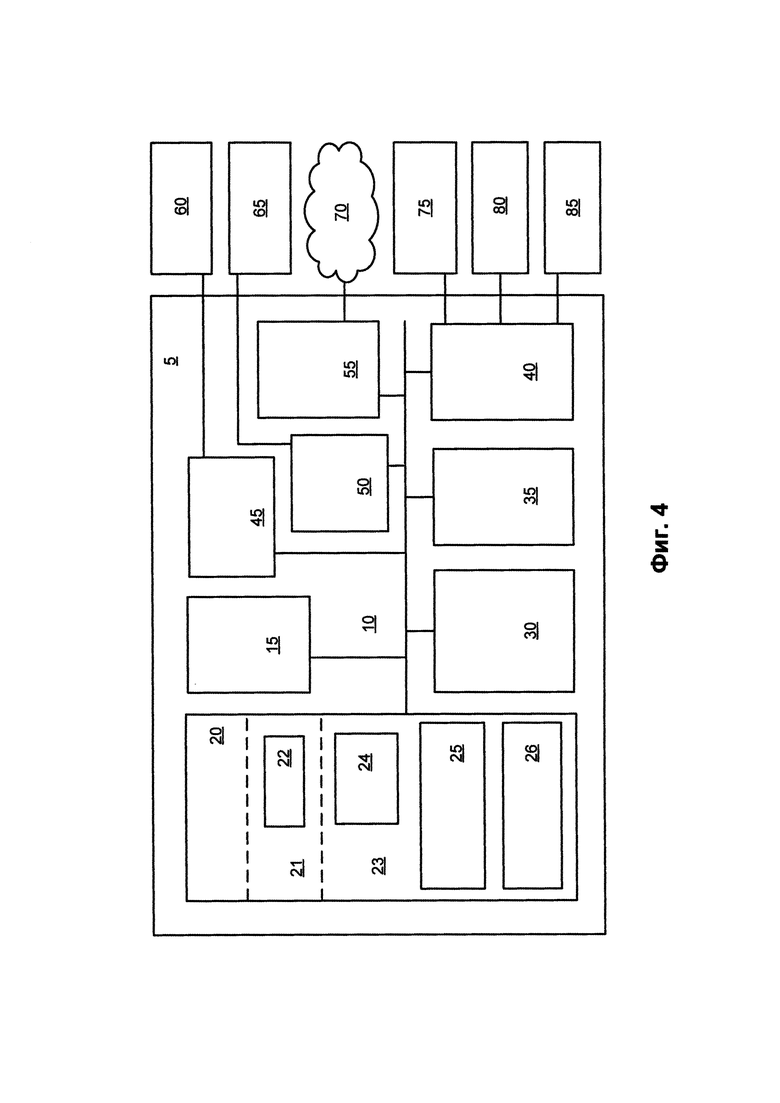
[0041] На Фиг. 4 представлен один пример варианте осуществления компьютерной системы 5, которая может быть использована для реализации описанных систем и способов дублирования файлов на клиентском устройстве для сохранения на сервере облачного хранилища. Компьютерная система 5 может включать (без введения ограничений) сервер (например, сервер 210) приложений, веб-сервер, персональный компьютер, ноутбук, настольный компьютер, смартфон или другой тип устройства обработки данных. Как показано, компьютерная система 5 может включать в себя один или несколько аппаратных процессоров 15, память 20, один или несколько жестких дисков 30, оптических приводов 35, последовательных портов 40, графическую карту 45, звуковую карту 50 и сетевую(ые) карту(ы) 55, соединенную с системной шиной 10. Системная шина 10 может представлять собой шинную структуру любого типа, который включает в себя шину памяти, контроллер памяти, периферическую шину и локальную шину, использующую любой из множества известных шинных архитектур. Процессор 15 может включать в себя одно или несколько процессоров Intel® Core 2 Quad 2.33 ГГц или другой тип микропроцессоров.
[0042] Системная память 20 может включать в себя постоянную память (ПЗУ) 21 и оперативную память (ОЗУ) 23. Память 20 может быть реализована как динамическое ОЗУ, стираемое программируемое ПЗУ, электрически стираемое программируемое ПЗУ, флэш-память или любая другая архитектура памяти. ПЗУ 21 хранит базовую систему ввода/вывода (BIOS), содержащую основные процедуры, которые помогают передавать информацию между модулями компьютерной системы 5, например во время запуска. ОЗУ 23 хранит операционную систему 24 (ОС), например, Windows® 7 Professional или другой тип операционной системы, который отвечает за управление и координацию процессов и распределения аппаратных ресурсов в компьютерной системе 5. Память 20 также хранит приложения и программы 25. Память 20 также сохраняет различные данные 26 этапа исполнения, используемые программами 25.
[0043] Компьютерная система 5 может дополнительно включать в себя жесткий(е) диск(и) 30, например SATA HDD, и оптический(е) привод(ы) 35 для чтения или записи съемного оптического диска, например CD-ROM, DVD-ROM или другого оптического носителя. Диски 30 и 35 и связанные с ними машиночитаемые носители обеспечивают энергонезависимое хранение машиночитаемых инструкций, структур данных, приложений и программных модулей/подпроцедур, которые реализуют описанные здесь алгоритмы и способы. Несмотря на то, что примерная компьютерная система 5 использует магнитные и оптические диски, специалисты в данной области техники понимают, что в альтернативных аспектах компьютерной системы 5 также могут быть использованы другие типы машиночитаемых носителей, способные хранить данные, доступные компьютерной системе 5, например магнитные кассеты, флэш-карты памяти, цифровые видеодиски, ОЗУ, ПЗУ, стираемое программируемое ПЗУ и другие типы памяти.
[0044] Компьютерная система 5 дополнительно включает в себя множество последовательных портов 40 например, универсальную последовательную шину (USB), для подключения устройств(а) 75 ввода данных, таких как клавиатура, мышь, сенсорная панель и прочие. Последовательные порты 40 также могут быть использованы для подключения устройств(а) 80 вывода данных, таких как принтер, сканер и другие, а также других периферийных устройств(а) 85, например внешних устройств хранения данных и т.п. Система 5 также может включать в себя видеокарту 45, например nVidia® GeForce® GT 240М или другую видеокарту, для взаимодействия с экраном 60 или другим устройством воспроизведения видео, например, сенсорным экраном. Система 5 также может включать в себя звуковую карту 50 для воспроизведения звука через внутренние или внешние динамики 65. Кроме того, система 5 может включать в себя сетевую(ые) карту(ы) 55, такие как Ethernet, WiFi, GSM, Bluetooth или другой проводной, беспроводной или сотовый сетевой интерфейс для подключения компьютерной системы 5 к сети 70, например, к сети интернет.
[0045] В различных вариантах осуществления настоящей технологии, системы и способы, описанные здесь, могут быть реализованы на аппаратном обеспечении, прикладном программном обеспечении, системном программном обеспечении или любой из их комбинаций. При реализации в виде прикладного программного обеспечения, способы могут быть сохранены в виде одной или нескольких инструкций или кода на постоянном машиночитаемом носителе. Машиночитаемый носитель включает в себя хранилище данных. В качестве примера, а не ограничения, подобный машиночитаемый носитель может представлять собой ОЗУ, ПЗУ, электрически стираемое программируемое ПЗУ, флэш-память или любой другой тип электрического, магнитного или оптического носителя, или любой другой носитель, который может быть использован для переноса или хранения желаемого программного кода в форме инструкций или структур данных, к которым может обращаться процессор компьютера общего назначения.
[0046] Для ясности стоит отметить, что здесь описаны не все обычные характеристики предметов настоящей технологии. Следует иметь в виду, что при модификации какого-либо фактического варианта осуществления технологии необходимо принять ряд специфичных для варианта осуществления решений для достижения конкретных целей разработчика, и эти конкретные цели будут отличаться для различных вариантов осуществления и для различных разработчиков. Следует иметь в виду, что подобная разработка может быть сложной и затратной по времени, но, тем не менее, не будет представлять сложности для опытных специалистов в данной области техники, обладающих преимуществом от прочтения настоящего описания.
[0047] Кроме того, следует иметь в виду, что термины и сочетания терминов используются здесь в целях описания, а не ограничения, таким образом, термины и сочетание терминов настоящего описания должны интерпретироваться специалистами в данной области техники с учетом представленных здесь указаний и руководства в сочетании со знаниями специалистов в соответственной(ых) области(ях) техники. Более того, ни одному термину в описании или формуле не следует приписывать особого или специального смысла, если явно не указано иное.
[0048] Различные описанные здесь предметы технологии охватывают нынешние и будущие известные эквиваленты известных модулей, указанных в данном описании в целях иллюстрации. Кроме того, несмотря на представленные и описанные варианты осуществления технологии и приложения, специалистам в данной области техники, обладающим преимуществом от прочтения настоящего описания, будет очевидно, что возможна реализация многих других вышеописанных модификаций без отступления от представленной здесь концепции технологии.
Изобретение относится к технологиям сетевой связи. Технический результат заключается в повышении безопасности передачи данных. Способ содержит: получение процессором пользовательского устройства запроса на загрузку файла, сохраненного локально на пользовательском устройстве, на сервер облачного хранилища; определение процессором времени, требуемого на создание идентификатора файла для указанного файла, и времени, требуемого на загрузку указанного файла на сервер облачного хранилища; в ответ на превышение временем, требуемым на создание идентификатора файла для указанного файла, времени, требуемого на загрузку указанного файла на сервер облачного хранилища, загрузка процессором пользовательского устройством файла на сервер облачного хранилища; создание сервером идентификатора файла и проверка на основании идентификатора файла наличия на сервере копии файла и в ответ на обнаружение на сервере копии файла, создание сервером визуального представления файла, ассоциированного с копией файла; в ответ на отсутствие на сервере копии файла сохранение файла на сервере; в ответ на превышение временем, требуемым на загрузку указанного файла на сервер облачного хранилища, времени, требуемого на создание идентификатора файла для указанного файла. 2 н. и 14 з.п. ф-лы, 4 ил.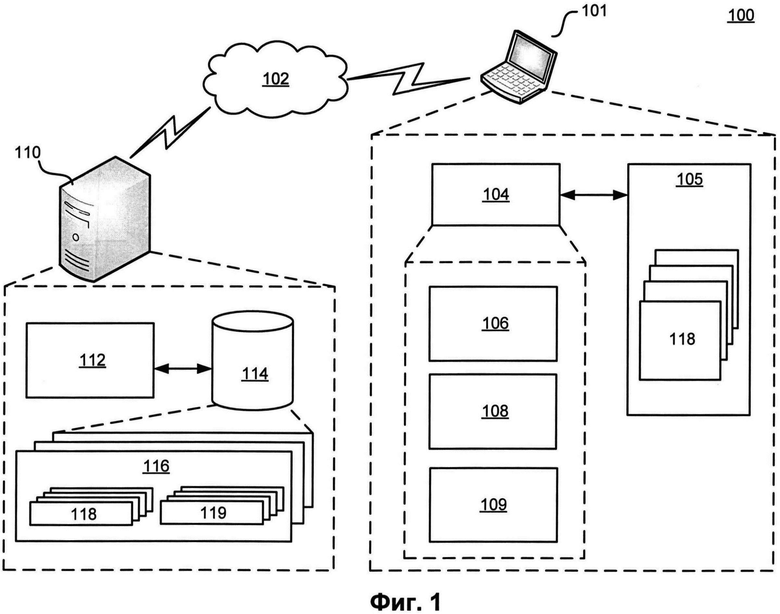
1. Способ дублирования файлов пользовательского устройства, включающий: получение процессором пользовательского устройства запроса на загрузку файла, сохраненного локально на пользовательском устройстве, на сервер облачного хранилища; определение процессором времени, требуемого на создание идентификатора файла для указанного файла, и времени, требуемого на загрузку указанного файла на сервер облачного хранилища; в ответ на превышение временем, требуемым на создание идентификатора файла для указанного файла, времени, требуемого на загрузку указанного файла на сервер облачного хранилища, загрузка процессором пользовательского устройством файла на сервер облачного хранилища; создание сервером идентификатора файла и проверка на основании идентификатора файла наличия на сервере копии файла и в ответ на обнаружение на сервере копии файла, создание сервером визуального представления файла, ассоциированного с копией файла; в ответ на отсутствие на сервере копии файла, сохранение файла на сервере; в ответ на превышение временем, требуемым на загрузку указанного файла на сервер облачного хранилища, времени, требуемого на создание идентификатора файла для указанного файла, создание процессором пользовательского устройства указанного идентификатора файла и передачу идентификатора файла на сервер облачного хранилища проверка на основании идентификатора файла наличия на сервере копии файла и в ответ на обнаружение на сервере копии файла создание сервером визуального представления файла, ассоциированного с копией файла; в ответ на отсутствие на сервере копии файла загрузка файла на сервер и сохранение файла на сервере.
2. Способ по п. 1, в котором идентификатор файла включает в себя по меньшей мере один хэш файла.
3. Способ по п. 1, в котором при определении времени, требуемого на загрузку указанного файла на сервер облачного хранилища, выполняют анализ одной или нескольких полос пропускания сетевого соединения между пользовательским устройством и устройством облачного хранилища текущих вычислительных ресурсов, доступных на пользовательском устройстве, характеристик пользовательского устройства и размера и типа файла.
4. Способ по п. 3, в котором дополнительно выполняют: сохранение в локальном хранилище пользовательского устройства информации о вычислительных ресурсах пользовательского устройства после анализа, чтобы не анализировать их снова в следующий раз.
5. Способ по п. 1, в котором дополнительно выполняют: определение размера файла; и в ответ на превышение файлом предварительно определенного размера осуществление этапов определения процессором времени, требуемого для создания идентификатора для указанного файла, и времени, требуемого на загрузку указанного файла на сервер облачного хранилища, загрузки процессором файла на сервер и создания процессором идентификатора файла.
6. Способ по п. 1, в котором этапы определения процессором времени, требуемого для создания идентификатора для указанного файла, и времени, требуемого на загрузку указанного файла на сервер облачного хранилища, загрузки процессором файла на сервер и создания процессором идентификатора файла реализуют в одном или нескольких из: в коде браузера, выполняемом на пользовательском устройстве, в коде «родного» приложения облачного хранилища, запущенного на пользовательском устройстве, и в коде веб-сайта, выполняемого на пользовательском устройстве.
7. Способ по п. 1, в котором дополнительно выполняют начало определения уникального идентификатора файла практически одновременно с загрузкой файла на сервер облачного хранилища.
8. Способ по п. 7, в котором дополнительно выполняют: при завершении загрузки файла на сервер облачного хранилища раньше, чем завершится создание идентификатора файла, прекращение создания идентификатора файла; и при завершении создания идентификатора файла раньше, чем завершится загрузка файла на сервер облачного хранилища, передачу идентификатора файла на сервер облачного хранилища, и: при условии, что файл уникален, продолжение загрузки файла на сервер облачного хранилища; а при условии, что файл не уникален, завершение загрузки файла на сервер облачного хранилища.
9. Способ по п. 1, в котором коэффициент вероятности, обозначающий среднюю вероятность уникальности файла, определяют с использованием следующего неравенства:
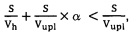
где S - размер файла,
Vh - скорость создания идентификатора файла на пользовательском устройстве,
Vupl - скорость загрузки файла на сервер облачного хранилища,
α - средняя вероятность уникальности файла на сервере облачного хранилища.
10. Способ по п. 9, в котором неравенство 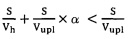 упрощается до th<tupl*(1-α), где время t определяется как размер файла, поделенный на скорость загрузки файла или скорость создания идентификатора файла, и при условии, что неравенство верно, на пользовательском устройстве создают идентификатор файла.
упрощается до th<tupl*(1-α), где время t определяется как размер файла, поделенный на скорость загрузки файла или скорость создания идентификатора файла, и при условии, что неравенство верно, на пользовательском устройстве создают идентификатор файла.
11. Система дублирования файлов пользовательского устройства, включающая в себя: процессор пользовательского устройства, выполненный с возможностью осуществлять: получение запроса на загрузку файла, сохраненного локально на пользовательском устройстве, на сервер облачного хранилища; определение времени, требуемого на создание идентификатора файла для указанного файла, и времени, требуемого на загрузку указанного файла на сервер облачного хранилища; в ответ на превышение временем, требуемым на создание идентификатора файла для указанного файла, времени, требуемого на загрузку указанного файла на сервер облачного хранилища, инициацию загрузки файла на сервер облачного хранилища; в ответ на превышение временем, требуемым на загрузку указанного файла на сервер облачного хранилища, времени, требуемого на создание идентификатора файла для указанного файла, создание указанного идентификатора файла и передача идентификатора файла на сервер облачного хранилища; сервер, выполненный с возможностью осуществлять: в ответ на получение от пользовательского устройства файла создание идентификатора файла и проверку на основании идентификатора файла наличия на сервере копии файла и в ответ на обнаружение на сервере копии файла, создание визуального представления файла, ассоциированного с копией файла; в ответ на отсутствие на сервере копии файла, сохранение файла на сервере; в ответ на получение от пользовательского устройства идентификатора файла проверку на основании идентификатора файла наличия на сервере копии файла и в ответ на обнаружение на сервере копии файла создание визуального представления файла, ассоциированного с копией файла; в ответ на отсутствие на сервере копии файла загрузка файла на сервер и сохранение файла на сервере
12. Система по п. 11, в которой процессор выполнен с дополнительной возможностью осуществлять: при определении времени, требуемого на загрузку указанного файла на сервер облачного хранилища, выполнять анализ одной или нескольких полос пропускания сетевого соединения между пользовательским устройством и устройством облачного хранилища, текущих вычислительных ресурсов, доступных на пользовательском устройстве, характеристик пользовательского устройства, размера и типа файла.
13. Система по п. 11, в которой процессор выполнен с дополнительной возможностью: сохранять в локальном хранилище пользовательского устройства информацию о вычислительных ресурсах пользовательского устройства после анализа.
14. Система по п. 11, в которой процессор выполнен с дополнительной возможностью: определять размер файла; и в ответ на превышение файлом предварительно определенного размера осуществлять этапы определения времени, требуемого для создания идентификатора для указанного файла, и времени, требуемого на загрузку указанного файла на сервер облачного хранилища, загрузки файла на сервер и создания идентификатора файла
15. Система по п. 11, в которой процессор выполнен с дополнительной возможностью: начинать определение идентификатора файла практически одновременно с загрузкой файла на сервер облачного хранилища.
16. Система по п. 15, в которой процессор выполнен с дополнительной возможностью: при завершении загрузки файла на сервер облачного хранилища раньше, чем завершится создание идентификатора файла, прекращать создание идентификатора файла; и при завершении создания идентификатора файла раньше, чем завершится загрузка файла на сервер облачного хранилища, передавать идентификатор файла на сервер облачного хранилища, и: при условии, что файл уникален, продолжать загрузку файла на сервер облачного хранилища; а при условии, что файл не уникален, завершать загрузку файла на сервер облачного хранилища.
| US 8903838 B2, 02.12.2014 | |||
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ПЕРЕДАЧИ ЭНЕРГИИ НА СНАРЯД | 2011 |
|
RU2535825C2 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| ЗАЩИЩЕННОЕ И КОНФИДЕНЦИАЛЬНОЕ ХРАНЕНИЕ И ОБРАБОТКА РЕЗЕРВНЫХ КОПИЙ ДЛЯ ДОВЕРЕННЫХ СЕРВИСОВ ВЫЧИСЛЕНИЯ И ДАННЫХ | 2010 |
|
RU2531569C2 |

