ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
Настоящее изобретение относится к области техники компьютера и, в частности, к способу, устройству терминала и устройству сервера для хранения копий данных.
УРОВЕНЬ ТЕХНИКИ
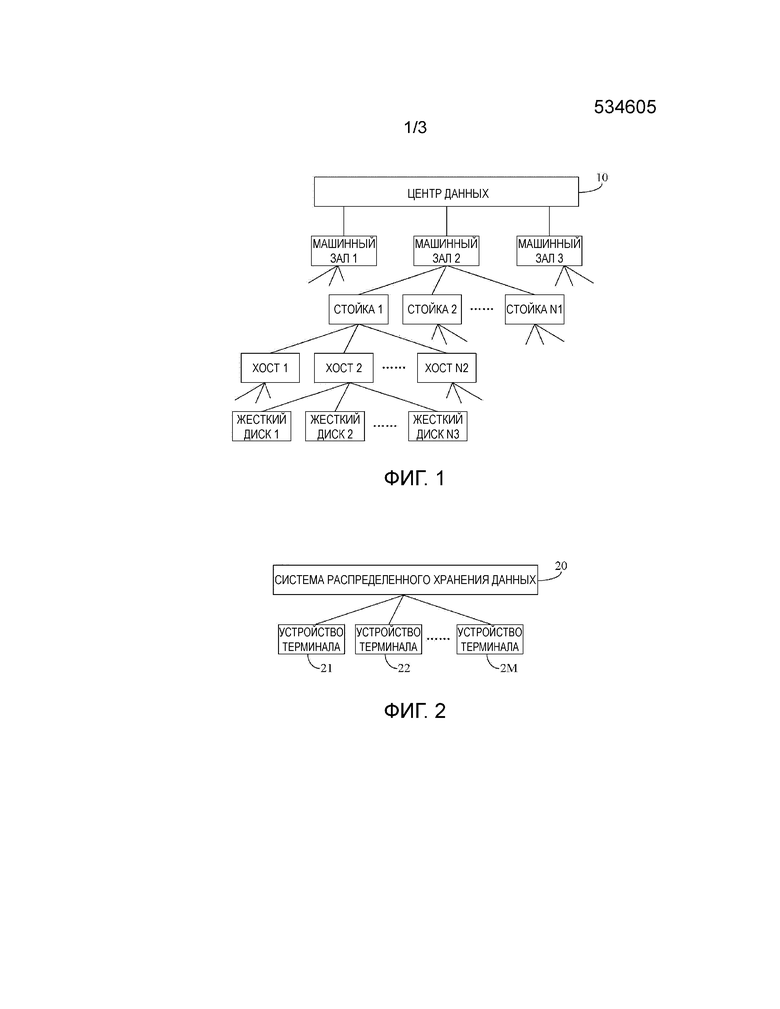
Система распределенного хранения данных в общем случае задействует режим множества копий для хранения данных с целью улучшения надежности хранения данных. Физическая топология устройства хранения в общем случае является иерархической, со ссылкой на фиг.1, которая изображает схему физической топологии устройства хранения в системе распределенного хранения данных, относящейся к настоящему изобретению. Как изображено на фиг.1, система распределенного хранения данных обеспечена в центре 10 данных, который состоит из трех машинных залов, в каждом из трех машинных залов предусмотрено несколько стоек, например в машинном зале 2 размещены стойки 1, 2, ... и N1. Кроме того, на каждой из стоек предусмотрено множество хостов (компьютеров), например хосты 1, 2, ... и N2 обеспечены на стойке 1. В каждом хосте обеспечено множество устройств хранения данных (в общем случае жестких дисков), например жесткие диски 1, 2, ... и N3 обеспечены в хосте 2. В целях ясности фиг.1 изображает только часть устройств. Можно увидеть, что система распределенного хранения данных имеет древовидную структуру, и устройства хранения данных размещены на концевых узлах, и хосты, стойки и машинные залы являются промежуточными узлами.
Системы распределенного хранения данных могут быть разделены на два режима: один с центральными узлами и другой без центральных узлов. В общем случае, в систему распределенного хранения данных с центральным узлом включены клиент, центральный узел и узел хранения, данные перерабатываются в блоки и сохраняются во множестве копий. Для позиций для хранения копий данных, позиции распределения копий данных выбираются центральным узлом согласно условиям нагрузки узла хранения и стратегии хранения копий. Центральный узел может либо быть конфигурацией резервного копирования хостов двух серверов или быть кластером серверов. В системе распределенного хранения данных без центрального узла все из узлов подключены друг к другу, данные распределяются случайным образом на устройствах хранения узлов, и позиции хранения могут быть получены узлом с использованием функции хэширования.
Для системы распределенного хранения данных с центральным узлом, когда данные считываются из нее, она сначала должна осуществить доступ к центральному узлу для того, чтобы получить позиции хранения данных, что делает центральный узел перегруженным, и эффективность обработки уменьшается, из-за чего образуется "узкое место" всей системы и уменьшается производительность системы. Кроме того, в случае, когда возникает отказ в центральном узле, "узкое место" будет усугублено, и даже вся система распределенного хранения данных становится недоступной и имеет относительно низкую надежность.
Система распределенного хранения данных без центрального узла может избежать вышеупомянутого "узкого места", но ее надежность все еще недостаточна. Например, если возникает отказ мощности или отказ сети в некоторой стойке и все копии некоторых данных находятся на жестких дисках хостов в стойках, данные не могут быть получены. Помимо этого, когда количество устройств изменяется, например, добавляется один жесткий диск или один хост, широкий диапазон перемещения данных будет неизбежно происходить в системе распределенного хранения данных без центрального узла. Это иллюстрируется следующим простым примером.
Например, система распределенного хранения данных без центрального узла имеет 5 узлов (в действительности гораздо больше чем 5), хэш-значение одних данных, которые должны быть сохранены, которое вычисляется посредством функции хэширования, равно 13, остаток его целочисленного деления на количество узлов равен 3, и тогда данные, которые должны быть сохранены, сохраняются в узле 3; когда устройства увеличиваются, чтобы сделать количество узлов равным 6, и данные считываются, остаток от целочисленного деления на количество узлов 6 хэш-значения 13 равен 2, т.е. данные считываются из узла 2. Теперь данные будут сначала перемещены из узла 3 в узел 2. Когда количество узлов изменяется, результаты остатка целочисленного деления обязательно будут различны, так что перемещение данных неизбежно будет происходить, когда данные, сохраненные до изменения количества узлов, считываются после его изменения. Следовательно, когда количество узлов изменяется, перемещение данных является частым; это будет приводить к уменьшению эффективности системы и срока службы носителя данных.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
Соответственно, настоящее изобретение обеспечивает способ, устройство терминала и устройство сервера для хранения копий данных, которые способствуют улучшению надежности системы распределенного хранения данных без центрального узла и уменьшению количества перемещаемых данных, когда количество узлов системы изменяется.
Для осуществления вышеупомянутой цели, согласно одному аспекту настоящего изобретения, обеспечен способ для сохранения копий данных.
Согласно настоящему изобретению, обеспечен способ для хранения копий данных, применяемый в системе распределенного хранения данных с древовидной структурой и без центрального узла, причем древовидная структура содержит концевые узлы, на которых находятся устройства хранения данных, и промежуточные узлы; и отличающийся тем, что способ содержит: этап A: для каждой копии данных для данных, которые должны быть сохранены, выбирают дочерний узел, причем дочерний узел выбирается от уровня к уровню от предварительно выбранного промежуточного узла древовидной структуры согласно древовидной структуре в предварительно установленном режиме выбора дочернего узла, пока дочерний узел, который выбирается, не окажется концевым узлом, и затем определяют концевой узел в качестве требуемой позиции хранения копии данных; причем режим выбора дочернего узла содержит этапы, на которых: получают значение отображения, относящееся к каждому дочернему узлу промежуточного узла согласно предварительно установленному режиму отображения путем получения каждой комбинации идентификации данных, которые должны быть сохранены, и идентификации упомянутого каждого дочернего узла в качестве предварительного образа, и выбирают один дочерний узел упомянутого промежуточного узла согласно сравнению полученного множества значений отображения; и причем для каждого промежуточного узла режим отображения перезапускается перед каждым моментом выбора его дочерних узлов; этап B: после определения требуемых позиций хранения всех копий данных для данных, которые должны быть сохранены, сохраняют все копии данных для данных, которые должны быть сохранены, в требуемых позициях хранения копий данных, соответственно.
Опционально, для одного или нескольких определенных промежуточных узлов, если промежуточный узел выбирается снова в течение определения требуемых позиций хранения всех копий данных для данных, которые должны быть сохранены, осуществляют повторный выбор из всех одноуровневых узлов промежуточного узла.
Опционально, в течение определения требуемых позиций хранения всех копий данных для данных, которые должны быть сохранены, если требуемая позиция хранения, определенная для текущей копии данных та же самая, что и для другой копии данных, повторно определяют требуемую позицию хранения текущей копии данных согласно этапу A так, чтобы требуемые позиции хранения всех копий данных для данных, которые должны быть сохранены, были различны.
Опционально, режим отображения содержит этап, на котором вычисляют уникальное значение отображения с использованием хэш-алгоритма после того, как предварительный образ отрегулирован.
Опционально, режим отображения содержит этап, на котором вычисляют хэш-значение с использованием хэш-алгоритма после того, как предварительный образ отрегулирован; получают значение отображения путем умножения хэш-значения на предварительно установленное взвешенное значение; причем предварительно установленное взвешенное значение является суммой взвешенных значений всех концевых узлов, связанных с дочерним узлом в предварительном образе, и взвешенные значения концевых узлов состоят в положительной корреляции с емкостью хранилища устройства хранения данных на концевых узлах.
Опционально, этап перезапуска отношения отображения содержит этап, на котором изменяют параметр, задействованный в течение регулирования предварительного образа.
Согласно другому аспекту настоящего изобретения, обеспечено устройство терминала.
Устройство терминала в настоящем изобретении используется для сохранения множества копий данных для данных, которые должны быть сохранены, в системе распределенного хранения данных с древовидной структурой и без центрального узла, причем древовидная структура содержит концевые узлы, на которых находятся устройства хранения данных, и промежуточные узлы. Устройство терминала содержит модуль выбора для того, чтобы для каждой копии данных для данных, которые должны быть сохранены, выбирать дочерний узел, причем дочерний узел выбирается от уровня к уровню от предварительно выбранного промежуточного узла древовидной структуры согласно древовидной структуре в предварительно установленном режиме выбора дочернего узла, пока дочерний узел, который выбирается, не окажется концевым узлом, и затем определять концевой узел в качестве требуемой позиции хранения копии данных, причем режим выбора дочернего узла содержит этапы, на которых: получают значение отображения, относящееся к каждому дочернему узлу промежуточного узла согласно предварительно установленному режиму отображения путем получения каждой комбинации идентификации данных, которые должны быть сохранены, и идентификации упомянутого каждого дочернего узла в качестве предварительного образа, и выбирают один дочерний узел упомянутого промежуточного узла согласно сравнению полученного множества значений отображения; и причем для каждого промежуточного узла режим отображения перезапускается перед каждым моментом выбора его дочерних узлов; модуль выгрузки для того, чтобы после того, как модуль выбора определяет требуемые позиции хранения всех копий данных для данных, которые должны быть сохранены, передавать все копии данных для данных, которые должны быть сохранены, и информацию требуемых позиций хранения всех копий данных для данных, которые должны быть сохранены, в компьютер в системе распределенного хранения данных так, чтобы компьютер сохранял все копии данных для данных, которые должны быть сохранены в их требуемые позиции хранения, соответственно.
Опционально, модуль выбора дополнительно используется для того, чтобы в отношении одного или нескольких определенных промежуточных узлов, если промежуточный узел выбирается снова в течение определения требуемых позиций хранения всех копий данных для данных, которые должны быть сохранены, осуществлять повторный выбор из всех одноуровневых узлов промежуточного узла.
Опционально, модуль выбора дополнительно используется для того, чтобы в течение определения требуемых позиций хранения всех копий данных для данных, которые должны быть сохранены, если требуемая позиция хранения, определенная для текущей копии данных, та же самая, что и для другой копии данных, повторно определять требуемую позицию хранению текущей копии данных, так, чтобы требуемые позиции хранения всех копий данных для данных, которые должны быть сохранены, были различны.
Опционально, режим отображения содержит этап, на котором вычисляют уникальное значение отображения с использованием хэш-алгоритма после того, как предварительный образ отрегулирован.
Опционально, режим отображения содержит этап, на котором вычисляют хэш-значение с использованием хэш-алгоритма после того, как предварительный образ отрегулирован; получают значение отображения путем умножения хэш-значения на предварительно установленное взвешенное значение; причем предварительно установленное взвешенное значение является суммой взвешенных значений всех концевых узлов, связанных с дочерним узлом в предварительном образе, и взвешенные значения концевых узлов состоят в положительной корреляции с емкостью хранилища устройства хранения данных на концевых узлах.
Согласно другому аспекту настоящего изобретения, обеспечено устройство сервера.
Устройство сервера в настоящем изобретении устанавливается внутри сервера в системе распределенного хранения данных с древовидной структурой и без центрального узла и используется для хранения множества копий данных для данных, которые должны быть сохранены, в системе распределенного хранения данных, причем древовидная структура содержит концевые узлы, на которых расположено устройство хранения данных, и промежуточные узлы. Устройство сервера содержит модуль выбора для того, чтобы в отношении каждой копии данных для данных, которые должны быть сохранены, выбирать дочерний узел, причем дочерний узел выбирается от уровня к уровню от предварительно выбранного промежуточного узла древовидной структуры согласно древовидной структуре в предварительно установленном режиме выбора дочернего узла, пока дочерний узел, который выбирается, не окажется концевым узлом, и затем определять концевой узел в качестве требуемой позиции хранения копии данных; причем режим выбора дочернего узла содержит этапы, на которых: получают значение отображения, относящееся к каждому дочернему узлу промежуточного узла согласно предварительно установленному режиму отображения путем получения каждой комбинации идентификации данных, которые должны быть сохранены, и идентификации упомянутого каждого дочернего узла в качестве предварительного образа, и выбирают один дочерний узел упомянутого промежуточного узла согласно сравнению полученного множества значений отображения; и причем для каждого промежуточного узла режим отображения перезапускается перед каждым моментом выбора его дочерних узлов; модуль сохранения для того, чтобы после определения требуемых позиций хранения всех копий данных для данных, которые должны быть сохранены, сохранять все копии данных для данных, которые должны быть сохранены, в требуемых позициях хранения копий данных, соответственно.
Опционально, модуль выбора дополнительно используется для того, чтобы в отношении одного или нескольких определенных промежуточных узлов, если промежуточный узел выбирается снова в течение определения требуемых позиций хранения всех копий данных для данных, которые должны быть сохранены, осуществлять повторный выбор из всех одноуровневых узлов промежуточного узла.
Опционально, модуль выбора дополнительно используется для того, чтобы в течение определения требуемых позиций хранения всех копий данных для данных, которые должны быть сохранены, если требуемая позиция хранения, определенная для текущей копии данных, та же самая, что и для другой копии данных, повторно определять требуемую позицию хранению текущей копии данных, так, чтобы требуемые позиции хранения всех копий данных для данных, которые должны быть сохранены, были различны.
Опционально, режим отображения содержит этап, на котором вычисляют уникальное значение отображения с использованием хэш-алгоритма после того, как предварительный образ отрегулирован.
Опционально, режим отображения содержит этап, на котором вычисляют хэш-значение с использованием хэш-алгоритма после того, как предварительный образ отрегулирован; получают значение отображения путем умножения хэш-значения на предварительно установленное взвешенное значение; причем предварительно установленное взвешенное значение является суммой взвешенных значений всех концевых узлов, связанных с дочерним узлом в предварительном образе, и взвешенные значения концевых узлов состоят в положительной корреляции с емкостью хранилища устройства хранения данных на концевых узлах.
Опционально, устройство сервера дополнительно содержит модуль подтверждения для того, чтобы инициировать модуль выбора в сервере, где одна предварительно выбранная копия соответственных данных, в текущий момент сохраненных в системе распределенного хранения данных, расположена, когда узел в системе распределенного хранения данных изменяется. Модуль выбора дополнительно используется для того, чтобы, когда он инициируется модулем подтверждения, получать предварительно выбранную копию и другие копии, идентичные этой копии, в качестве данных, которые должны быть сохранены, определять новую требуемую позицию хранения каждой копии данных для данных, которые должны быть сохранены, и затем переносить те из копий данных, у которых исходные позиции хранения не являются новыми требуемыми позициями хранения, в новые требуемые позиции хранения.
Согласно техническому решению настоящего изобретения, когда требуемые позиции хранения копий определяются, в отношении каждой копии данных для данных, которые должны быть сохранены, осуществляется выбор, из предварительно выбранного промежуточного узла в древовидной структуре системы распределенного хранения данных, дочерних узлов для каждого уровня в предварительно установленном режиме выбора дочернего узла, пока выбранный дочерний узел не окажется концевым узлом, и затем определяется концевой узел в качестве требуемой позиции хранения копии данных. Иначе говоря, осуществляется выбор, от выбранного промежуточного узла, дочерних узлов от уровня к уровню до концевого узла, где устройство хранения данных расположено, и для каждого промежуточного узла режим выбора его дочерних узлов изменяется каждый раз так, чтобы результаты выбора изменялись настолько, насколько это возможно. В условиях выбора дочерних узлов для каждого уровня такое изменение приводит к тому, что требуемые позиции хранения множества копий рассредоточиваются настолько, насколько это возможно, что помогает для улучшения устойчивости системы распределенного хранения данных, когда устройство ломается, и, таким образом, улучшает надежность системы распределенного хранения данных. Дополнительно, может определяться один или несколько промежуточных узлов и делаться так, что одни данные, которые должны быть сохранены, имеют только одну копию в устройстве хранения промежуточного узла. То есть копии данных распределяются в различных промежуточных узлах, таких как стойки или хосты; таким образом, когда один промежуточный узел становится неэффективен, например стойка или хост выходит из строя, все еще остаются другие копии, который могут обеспечивать обслуживание. Это уменьшает потерю данных и риск и вероятность недосягаемой собственности и улучшает надежность системы распределенного хранения данных. В условиях вновь увеличивающихся устройств хранения системы распределенного хранения данных значительное количество копий данных нет необходимости перемещать, количество перемещаемых данных довольно мало, эффект для эффективности системы относительно мал, и, таким образом, емкость системы распределенного хранения данных может быть легко расширена.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Чертежи обеспечены для лучшего понимания настоящего изобретения и не подразумеваются как ограничивающие, причем
фиг.1 изображает схему физической топологии устройства хранения системы распределенного хранения данных, задействованного в настоящем изобретении;
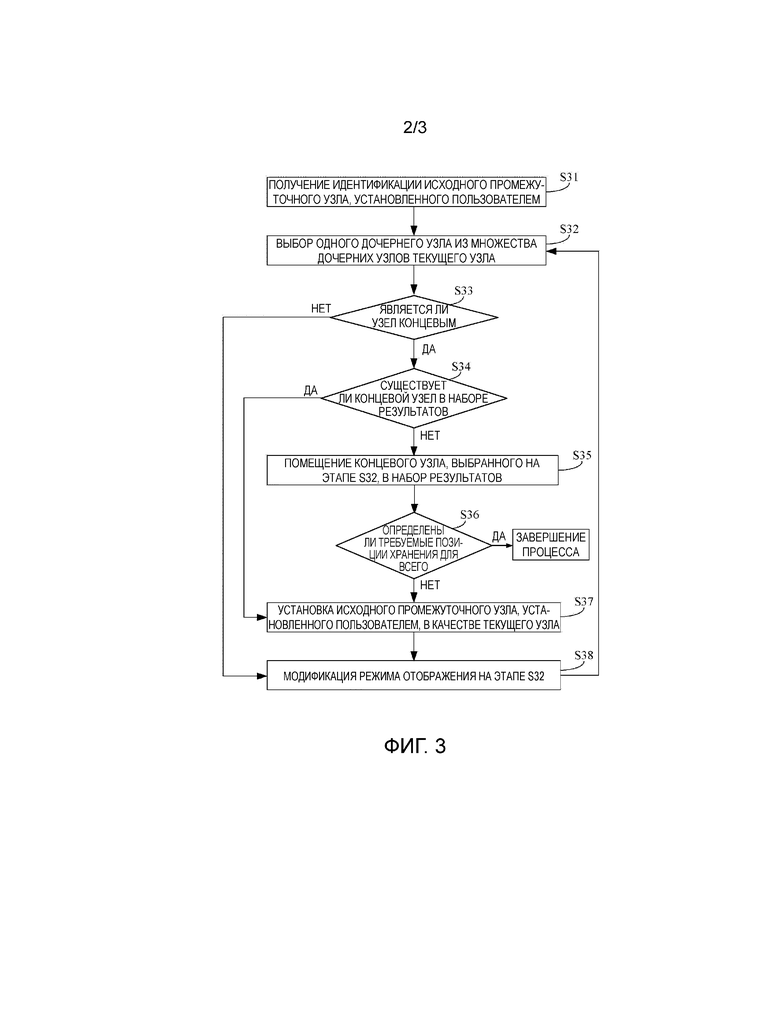
фиг.2 изображает схему состояния соединения между устройствами терминалов и системой распределенного хранения данных согласно вариантам осуществления настоящего изобретения;
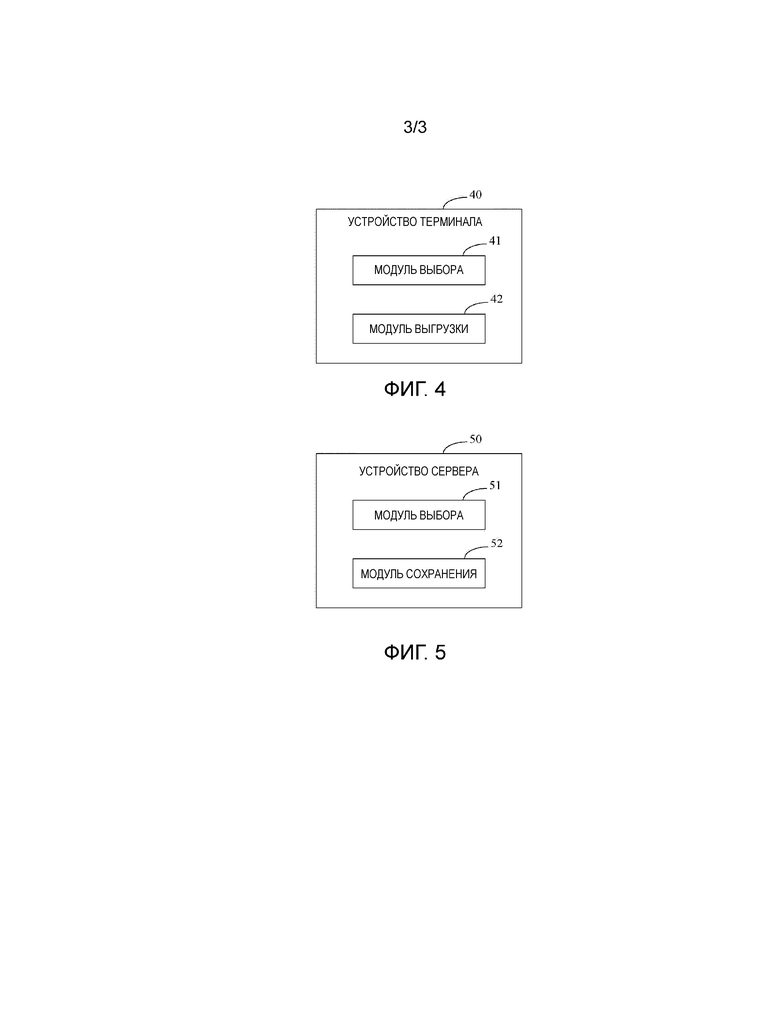
фиг.3 изображает схему способа для хранения копий данных согласно вариантам осуществления настоящего изобретения;
фиг.4 изображает схему базовой структуры устройства терминала согласно вариантам осуществления настоящего изобретения;
фиг.5 изображает схему базовой структуры устройства сервера согласно вариантам осуществления настоящего изобретения.
ОПИСАНИЕ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ
Подробное описание излагается ниже в связи с приложенными чертежами, причем различные подробности вариантов осуществления настоящего изобретения включены для того, чтобы поспособствовать в понимании изобретения, но могут учитываться как всего лишь примерные аспекты. Следовательно, специалисты в данной области техники должны понимать, что различные изменения и модификации над вариантами осуществления, описанными здесь, могут быть осуществлены без выхода за пределы сущности или объема изобретения. Подобным образом, в целях прояснения и простоты описания, объяснения общеизвестных функций и структур опускаются в последующих описаниях.
Фиг.2 изображает схему состояния соединения между устройствами терминалов и системой распределенного хранения данных согласно вариантам осуществления настоящего изобретения. Как изображено на фиг.2, множество устройств 21, 22, ..., 2M терминалов соединено с системой 20 распределенного хранения данных. В этом варианте осуществления физическая топология системы 20 распределенного хранения данных также задействует древовидную структуру, как показано на фиг.1. Каждое устройство терминала сохраняет информацию физической топологии и, таким образом, может вычислять требуемую позицию хранения каждой копии данных, которая должна быть сохранена в системе 20 распределенного хранения данных.
Для множества копий данных для данных, которые должны быть сохранены в системе 20, устройства терминалов последовательно вычисляют требуемую позицию хранения каждой из копий данных, которые должны быть сохранены в системе 20, то есть один концевой узел в системе 20 определяется для каждой копии данных, и копия данных сохраняется в устройстве носителя данных, расположенном в концевом узле. Когда концевой узел определяется, от промежуточного узла в системе 20, который определен пользователем, выбираются дочерние узлы от уровня к уровню, пока выбранный дочерний узел не окажется концевым узлом. Процесс определения требуемой позиции хранения одной копии данных показан на фиг.3, которая изображает схему способа для хранения копии данных согласно вариантам осуществления настоящего изобретения.
Этап S31: получают идентификацию исходного промежуточного узла, установленного пользователем. Из этого этапа путем циркулирующего процесса требуемая позиция хранения каждой копии данных, которые должны быть сохранены, определяется для получения набора результатов. Набор результатов является набором требуемых позиций хранения всех копий данных, которые должны быть сохранены. Со ссылкой на фиг.1, следующие этапы иллюстрируются путем использования машинного зала 2, который выполняет функцию исходного промежуточного узла, в качестве примера.
Этап S32: выбирают один из множества дочерних узлов текущего узла. Когда этот этап исполняется в первый раз, текущий узел является исходным промежуточным узлом, установленным пользователем. Когда дочерние узлы выбираются, оценка каждого дочернего узла получается, предпочтительным режимом является получение значения отображения с использованием режима отображения в стратегии на основе идентификации, например имени файла данных, для данных, которые должны быть сохранены, и идентификации дочернего узла, и значение отображения является оценкой дочернего узла для настоящих данных, которые должны быть сохранены. В вышеупомянутом режиме отображения вычисление может осуществляться путем задействования хэш-алгоритма, в частности. Поскольку режим отображения изменится на следующем этапе S36, на этом этапе комбинация идентификации данных, которые должны быть сохранены, идентификации дочернего узла и регулируемого параметра вычисляется с использованием хеш-функции для получения хэш-значения, и хэш-значение берется в качестве вышеупомянутой оценки. После того как оценка каждого дочернего узла исходного промежуточного узла получается, один дочерний узел выбирается на основе каждой оценки, например выбирается дочерний узел с наивысшей оценкой.
Другим режимом отображения, т.е. режимом вычисления вышеупомянутой оценки, является, с учетом попыток сохранить данные в устройстве носителя данных с большей емкостью, присвоение веса каждому концевому узлу. Вес состоит в положительной корреляции с емкостью хранилища устройства хранения данных на концевом узле, например вес жесткого диска в 1 Тбайт равен 1 и вес жесткого диска в 3 Тбайт равен 3. Вес промежуточного узла является суммой весов всех его дочерних узлов. Оценка узла равна умножению веса узла на вышеупомянутое хэш-значение. Таким образом, когда дочерний узел промежуточного узла выбирается согласно наивысшей оценке, узел с большей емкостью хранилища будет выбран с большей вероятностью.
Этап S33: определяют, является ли узел, выбранный на этапе S32, концевым узлом. Если да, процесс переходит к этапу S34; если нет, процесс переходит к этапу S38. Это возвращает к этапу S32 после этапа S38, и затем текущий узел на этапе S32 является узлом, определенным на этапе S33.
Этап S34: определяют, присутствует ли концевой узел, выбранный на этапе S32, в наборе результатов. Для улучшения надежности следует сделать множество копий данных, которые должны быть сохранены, распределенным в различных устройствах хранения данных. Таким образом, если результатом определения этого этапа является "да", текущий выбор концевого узла отвергается, процесс переходит к этапу S37 и требуемая позиция хранения текущей копии повторно определяется на этапе S32 для еще одного исполнения; в противном случае, текущий выбор концевого узла оставляется, и процесс переходит к этапу S35.
Этап S35: помещают концевой узел, выбранный на этапе S32, в набор результатов. Процесс переходит к этапу S36 после этапа S35.
Этап S36: определяют, были ли определены требуемые позиции хранения всех копий текущих данных, которые должны быть сохранены. Если да, процесс заканчивается; если нет, процесс переходит к этапу S37.
Этап S37: устанавливают исходный промежуточный узел, установленный пользователем, в качестве текущего узла. Затем процесс переходит к этапу S38.
Этап S38: модифицируют режим отображения на этапе S32, то есть изменяют регулируемый параметр на этапе S32. Целью является изменить оценку узла и затем изменить результат выбора узла на этапе S32. Режимы регулирования регулируемого параметра могут быть различны при условии, что они достигают цель изменения окончательной оценки. Например, можно брать генерируемое случайное число в качестве параметра или накапливать фиксированное или случайное значение больше ноля в параметре каждый раз, когда выполняется регулирование. Разумеется, режим отображения на этапе S32 может быть модифицирован посредством изменения хеш-функции. После этого этапа процесс возвращается к этапу S32.
Можно увидеть из вышеупомянутого процесса, что, когда требуемые позиции хранения копий определяются, он выбирает, из выбранного промежуточного узла, дочерние узлы от уровня к уровню до концевого узла, где устройство хранения данных расположено, и для каждого промежуточного узла режим выбора его дочерних узлов изменяется каждый раз так, чтобы результаты выбора изменялись настолько, насколько это возможно. В условиях выбора дочерних узлов для каждого уровня такое изменение делает требуемые позиции хранения множества копий настолько рассеянными, насколько это возможно, что помогает для улучшения устойчивости системы распределенного хранения данных, когда ее устройство ломается, и, таким образом, улучшает надежность системы распределенного хранения данных.
Разумеется, описанный выше режим выбора дочерних узлов каждого промежуточного узла в вышеупомянутом процессе изменяется каждый раз так, чтобы результаты выбора изменялись настолько, насколько это возможно. Однако такое изменение не абсолютно; фактически, существует маленькая вероятность того, что результаты двух моментов выборов будут одинаковы. Например, копия 1 определяется на жестком диске некоторого хоста в стойке 1, копия 2 также определяется на жестком диске некоторого хоста в стойке 1, и, соответственно, две копии станут недоступны ввиду полного отказа (например, отказа мощности или сети) стойки 1. Кроме того, в фактической системе распределенного хранения данных более идеальным режимом является распределение всех копий в различных позициях хранения некоторой иерархии, например, присутствует 10 стоек в системе и 8 копий, лучше чтобы эти восемь копий были распределены по различным стойкам. Или, ввиду некоторых фактических ситуаций, надежность некоторых стоек низка, лучше не размещать множество копий в устройствах хранения на таких стойках. Таким образом, в настоящем варианте осуществления один предпочтительный режим состоит в том, чтобы определять один или несколько промежуточных режимов, и когда процесс, показанный на фиг.3, исполняется, добавлять один этап между этапом S32 и этапом S33 и определять в добавленном этапе, выбирался ли уже дочерний узел, выбранный на этапе S32, или нет. Здесь существует два случая: один заключается в том, что для одной копии данных, обнаруживается, что другие копии данных находятся в требуемой позиции хранения, после первого раза определения ее требуемой позиции хранения (т.е. случай, в котором результатом определения является "да" на этапе S34), и в течение повторного определения требуемой позиции хранения копии данных выбранный дочерний узел тот же самый, что и выбранный в течение первого раза определения требуемой позиции хранения копии данных. Вероятность этого случая относительно мала, поскольку процессу необходимо пройти этап S38 между другими. Другой случай заключается в том, что для различных копий данных один и тот же дочерний узел выбирается в течение определения их требуемых позиций хранения, например определяется, что требуемой позицией хранения копии 1 данных является жесткий диск 2 в хосте 2, и в течение определения требуемой позиции хранения копии 2 данных также выбирается хост 2 в одном включении исполнения этапа S32. В это время на этапе, добавленном между этапом S32 и этапом S33, определяется, выбирался ли уже промежуточный узел, выбранный в текущий момент, или нет, если результатом является "да", процесс переходит к этапу S38 непосредственно, и на этапе S32, который должен быть повторно исполнен далее, родительский узел промежуточного узла, который должен быть выбран повторно, получается в качестве текущего узла, то есть осуществляется повторный выбор из одноуровневых узлов промежуточного узла, который должен быть повторно выбран. Как иллюстрируется в вышеупомянутом примере, если подтверждается, что хост 2 уже был выбран, осуществляется повторный выбор другого хоста в стойке, где хост 2 расположен. Путем вышеупомянутой обработки существует возможность сделать так, что одни данные, которые должны быть сохранены, имели только одну копию в определенном промежуточном узле, таком как стойка или хост, то есть копии данных распределяются в различных стойках или хостах так, чтобы когда одна стойка или хост не может осуществлять обслуживание, все еще оставались другие копии, которые могут обеспечивать обслуживание. Это уменьшает потерю данных и риск и вероятность недосягаемой собственности и улучшает надежность системы распределенного хранения данных.
Устройство терминала исполняет процесс, как показано на фиг.3, с возможностью определения требуемой позиции хранения каждой из копий данных одних данных, которые должны быть сохранены в системе распределенного хранения данных. Для системы распределенного хранения данных, ввиду непрерывного увеличения количества данных, новые устройства хранения часто должны добавляться в систему, например добавление жесткого диска, хоста или стойки, то есть узел будет изменяться; кроме того, некоторые из данных в существующих устройствах должны быть перемещены во вновь добавленные устройства хранения. Для этих обстоятельств в настоящем варианте осуществления хост в системе распределенного хранения данных также имеет функцию определения требуемых позиций хранения копий данных, как вышеупомянутое устройство терминала, тем самым имея возможность определения новых позиций хранения данных, уже сохраненных в системе, в условиях, когда новые устройства хранения добавляются в систему распределенного хранения данных. Необходимо заметить, что каждый из хостов будет осуществлять вычисление, чтобы сделать определение, при условии, что новые устройства хранения добавляются в систему. Разумеется, такое вычисление осуществляется только тогда, когда новые устройства хранения добавляются в систему. Можно увидеть из процесса на фиг.3, что такое вычисление является простым и занимает мало ресурсов CPU, и, таким образом, работа хоста, который повторно определяет новые позиции хранения уже сохраненных данных, не повлияет сильно на производительность системы.
Помимо этого, для одних уже сохраненных данных вышеупомянутое вычисление может исполняться только одним процессом одного хоста, хост является тем, который хранит одну копию уже сохраненных данных, и может быть установлен, когда устройство терминала определяет требуемую позицию хранения каждой из копий данных уже сохраненных данных. Например, устройство терминала определяет требуемые позиции хранения от первой до восьмой копий данных A, которые должны быть сохранены в свою очередь, причем первая копия будет сохранена на одном жестком диске четвертого хоста второй стойки, затем данные посылаются хосту, где каждая требуемая позиция хранения расположена, когда новые устройства хранения добавляются в систему распределенного хранения данных, хост, хранящий первую копию (т.е. первую копию, у которой требуемая позиция хранения определяется устройством терминала) данных A, т.е. четвертый хост второй стойки, вычисляет новые требуемые позиции хранения 8 копий данных A, и в это время четвертый хост может осуществлять исполнение согласно процессу на фиг.3. Можно увидеть из процесса на фиг.3, что для 8 копий новые требуемые позиции хранения могут быть теми же самыми, что и исходные, в частности для копий данных, позиции хранения которых в физической топологии находятся относительно далеко от вновь добавленных устройств хранения, их позиции хранения имеют гораздо меньшую вероятность изменения. Это означает, когда новые устройства хранения добавляются в систему распределенного хранения данных, что значительное количество копий данных не требует перемещения, количество перемещаемых данных довольно мало, эффект для эффективности системы относительно мал, и, таким образом, емкость системы распределенного хранения данных может быть легко расширена.
Базовая структура устройства терминала в варианте осуществления настоящего изобретения будет описана. Устройство терминала устанавливается в аппарате терминала, таком как PC, и соединено с системой распределенного хранения данных с древовидной структурой через Интернет. Фиг.4 изображает схему базовой структуры устройства терминала в вариантах осуществления настоящего изобретения. Как изображено на фиг.4, устройство 40 терминала главным образом содержит модуль 41 выбора и модуль 42 выгрузки.
Модуль 41 выбора используется для того, чтобы в отношении каждой копии данных для данных, которые должны быть сохранены, выбирать, из предварительно выбранного промежуточного узла древовидной структуры, дочерние узлы для каждого уровня в предварительно установленном режиме выбора дочернего узла, пока выбранный дочерний узел не окажется концевым узлом согласно древовидной структуре системы распределенного хранения данных, и затем определять концевой узел в качестве требуемой позиции хранения копии данных; причем режим выбора дочернего узла берет комбинацию идентификации данных, которые должны быть сохранены, и идентификации дочернего узла в качестве образа хоста, получает значение отображения, относящееся к дочернему узлу, с использованием предварительно установленного режима отображения, и выбирает дочерний узел промежуточного узла согласно множеству значений отображения всех дочерних узлов, относящихся к одному и тому же промежуточному узлу; для каждого промежуточного узла перезапускает отношение отображения перед каждым выбором его дочерних узлов.
Модуль 42 выгрузки используется для того, чтобы после того, как модуль 41 выбора определяет требуемые позиции хранения всех копий данных для данных, которые должны быть сохранены, передавать все копии данных для данных, которые должны быть сохранены, и информацию требуемых позиций хранения всех копий данных для данных, которые должны быть сохранены, в компьютер в системе распределенного хранения данных так, чтобы компьютер сохранял все копии данных для данных, которые должны быть сохранены, в их требуемые позиции хранения, соответственно.
Модуль 41 выбора дополнительно используется для того, чтобы, в отношении определенных одного или нескольких из промежуточных узлов, если промежуточный узел (узлы) выбирается (выбираются) снова в течение определения требуемых позиций хранения всех копий данных для данных, которые должны быть сохранены, осуществлять повторный выбор из всех одноуровневых узлов промежуточного узла(-ов).
Модуль 41 выбора дополнительно используется для того, чтобы в течение определения требуемых позиций хранения всех копий данных для данных, которые должны быть сохранены, если требуемая позиция хранения, определенная для текущей копии данных, та же самая, что и для другой копии данных, повторно определять требуемую позицию хранения текущей копии данных так, чтобы требуемые позиции хранения всех копий данных для данных, которые должны быть сохранены, были различны.
Фиг.5 изображает схему базовой структуры устройства сервера в вариантах осуществления настоящего изобретения. Устройство сервера устанавливается внутри сервера в системе распределенного хранения данных с древовидной структурой и используется для сохранения множества копий данных для данных, которые должны быть сохранены в системе распределенного хранения данных. Как изображено на фиг.5, устройство сервера 50 главным образом содержит модуль 51 выбора и модуль 52 сохранения, причем модуль 51 выбора может задействовать структуру, подобную структуре модуля 51 выбора; модуль 52 сохранения предназначен для сохранения всех копий данных для данных, которые должны быть сохранены, в их требуемые позиции хранения соответственно после того, как модуль выбора 51 определяет требуемые позиции хранения всех копий данных для данных, которые должны быть сохранены.
Устройство 50 сервера дополнительно содержит модуль подтверждения (не показанный на чертеже), чтобы инициировать модуль 51 выбора в сервере, где одна предварительно выбранная копия соответственных данных, в текущий момент сохраненных в системе распределенного хранения данных, расположена, когда узел в системе распределенного хранения данных изменяется. Модуль 51 выбора дополнительно используется для того, чтобы, когда он инициируется модулем подтверждения, брать предварительно выбранную копию и другие копии, идентичные этой копии, в качестве данных, которые должны быть сохранены, определять новую требуемую позицию хранения каждой копии данных для данных, которые должны быть сохранены, и затем перемещать копии данных, у которых исходные позиции хранения не являются новыми требуемыми позициями хранения, в новые требуемые позиции хранения.
Базовый принцип настоящего изобретения описывается путем комбинирования вышеупомянутых вариантов осуществления. Однако необходимо обратить внимание, что специалисты в области техники должны понять, что все или любые из этапов или частей способа и устройств в настоящем изобретении могут осуществляться в форме аппаратных средств, программно-аппаратных средств, программных средств или их комбинации в любом устройстве вычисления, включая процессоры и носители данных, или в сети устройств вычисления. Это может осуществляться специалистами в области техники с использованием их базовых навыков в программировании после прочтения объяснений настоящего изобретения.
Соответственно, цель настоящего изобретения может также быть осуществлена путем запуска одной программы или группы программ на любом устройстве вычисления, которое может быть общеизвестным универсальным устройством. Таким образом, цель настоящего изобретения может также быть осуществлена обеспечением только программного продукта, содержащего программные коды, которые могут осуществлять способ или устройство. То есть такой программный продукт также составляет настоящее изобретение, и носитель данных, хранящий программный продукт, тоже составляет настоящее изобретение. Очевидно, что носитель данных может быть либо любым общеизвестным носителем данных, либо любым носителем данных, который будет разработан.
Следует обратить внимание, что каждая часть или этап в устройствах и способе в настоящем изобретении могут быть разложены и/или скомбинированы иначе очевидным образом. Эти разложения и/или иные комбинации должны расцениваться как эквивалент решений настоящего изобретения. Кроме того, этапы исполнения вышеупомянутой последовательной обработки могут осуществляться естественным образом согласно порядку объяснения и временному порядку, но не имеют абсолютной необходимости осуществляться согласно временному порядку. Некоторые этапы могут исполняться параллельно или отдельно.
Вышеупомянутые варианты осуществления не составляют ограничения на объем охраны настоящего изобретения. Специалисты в данной области техники должны понять, что в зависимости от требования проектирования и других факторов, могут существовать различные модификации, комбинации, подкомбинации и замены. Любая модификация, эквивалентная замена, улучшение и т.п. внутри сущности и принципов настоящего изобретения должна быть охвачена внутри объема охраны настоящего изобретения.
Изобретение относится к области хранения копий данных. Техническим результатом является улучшение надежности системы распределенного хранения данных без центрального узла и уменьшение количества перемещаемых данных, когда количество узлов системы изменяется. Способ хранения копий данных содержит этапы, на которых: для каждой копии данных, которые должны быть сохранены, выбирают дочерние узлы для каждого уровня от предварительно выбранного промежуточного узла до концевого узла согласно системе древовидной структуры распределенного хранения данных без центрального узла, и определяют концевой узел в качестве требуемой позиции хранения копии данных, причем выбор дочернего узла содержит этапы, на которых: комбинируют идентификацию данных, которые должны быть сохранены, и идентификацию дочернего узла в образ хоста, получают значение отображения, относящееся к дочернему узлу, с использованием предварительно установленного режима отображения, выбирают подузел центрального узла согласно значению отображения, и перезапускают отношение отображения перед каждым разом, когда дочерний узел выбирается; и сохраняют все копии данных, которые должны быть сохранены, в требуемых позициях хранения копий данных. 3 н. и 14 з.п. ф-лы, 5 ил.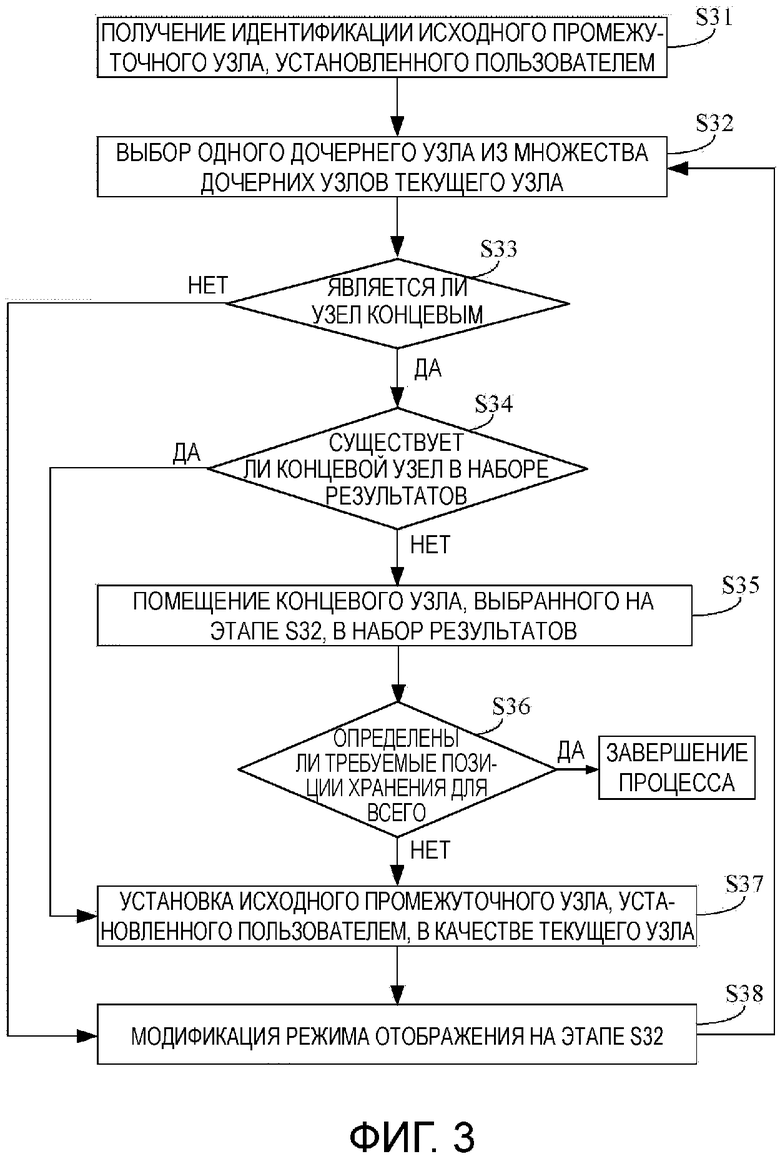
1. Способ хранения копий данных, применяемый в системе распределенного хранения данных с древовидной структурой и без центрального узла, причем древовидная структура содержит концевые узлы, на которых находятся устройства хранения данных, и промежуточные узлы; и отличающийся тем, что содержит:
этап A: для каждой копии данных для данных, которые должны быть сохранены, выбирают дочерний узел, причем дочерний узел выбирается от уровня к уровню от предварительно выбранного промежуточного узла древовидной структуры согласно древовидной структуре в предварительно установленном режиме выбора дочернего узла, пока дочерний узел, который выбирается, не окажется концевым узлом, и затем определяют концевой узел в качестве требуемой позиции хранения копии данных;
причем режим выбора дочернего узла содержит этапы, на которых: получают значение отображения, относящееся к каждому дочернему узлу промежуточного узла, согласно предварительно установленному режиму отображения путем получения каждой комбинации идентификации данных, которые должны быть сохранены, и идентификации упомянутого каждого дочернего узла в качестве предварительного образа, и выбирают один дочерний узел упомянутого промежуточного узла согласно сравнению полученного множества значений отображения; причем для каждого промежуточного узла режим отображения перезапускается перед каждым моментом выбора его дочерних узлов;
этап B: после определения требуемых позиций хранения всех копий данных для данных, которые должны быть сохранены, сохраняют все копии данных для данных, которые должны быть сохранены, в требуемых позициях хранения копий данных, соответственно.
2. Способ по п.1, отличающийся тем, что содержит этап, на котором для одного или нескольких заданных промежуточных узлов, если промежуточный узел выбирается снова в течение упомянутого определения требуемых позиций хранения всех копий данных для данных, которые должны быть сохранены, осуществляют повторный выбор из всех одноуровневых узлов промежуточного узла.
3. Способ по п.1, отличающийся тем, что содержит этап, на котором в течение упомянутого определения требуемых позиций хранения всех копий данных для данных, которые должны быть сохранены, если требуемая позиция хранения, определенная для текущей копии данных, та же самая, что и для другой копии данных, повторно определяют требуемую позицию хранения текущей копии данных согласно этапу A так, чтобы требуемые позиции хранения всех копий данных для данных, которые должны быть сохранены, были различны.
4. Способ по п.1, отличающийся тем, что режим отображения содержит этап, на котором вычисляют уникальное значение отображения с использованием хэш-алгоритма после того, как предварительный образ отрегулирован.
5. Способ по п.1, отличающийся тем, что режим отображения содержит этапы, на которых вычисляют хэш-значение с использованием хэш-алгоритма после того, как предварительный образ отрегулирован; получают значение отображения путем умножения хэш-значения на предварительно установленное взвешенное значение; причем предварительно установленное взвешенное значение является суммой взвешенных значений всех концевых узлов, связанных с дочерним узлом в предварительном образе, и взвешенные значения концевых узлов состоят в положительной корреляции с емкостью хранилища устройства хранения данных на концевых узлах.
6. Способ по п.4 или 5, отличающийся тем, что этап перезапуска отношения отображения содержит этап, на котором изменяют параметр, задействованный в течение регулирования предварительного образа.
7. Устройство терминала, используемое для сохранения множества копий данных для данных, которые должны быть сохранены, в системе распределенного хранения данных с древовидной структурой и без центрального узла, причем древовидная структура содержит концевые узлы, на которых находятся устройства хранения данных, и промежуточные узлы; и отличающееся тем, что содержит:
модуль выбора, сконфигурированный для того, чтобы в отношении каждой копии данных для данных, которые должны быть сохранены, выбирать дочерние узлы, причем дочерний узел выбирается от уровня к уровню от предварительно выбранного промежуточного узла древовидной структуры согласно древовидной структуре в предварительно установленном режиме выбора дочернего узла, пока дочерний узел, который выбирается, не окажется концевым узлом, и затем определять концевой узел в качестве требуемой позиции хранения копии данных; причем режим выбора дочернего узла содержит этапы, на которых: получают значение отображения, относящееся к каждому дочернему узлу промежуточного узла, согласно предварительно установленному режиму отображения путем получения каждой комбинации идентификации данных, которые должны быть сохранены, и идентификации упомянутого каждого дочернего узла в качестве предварительного образа, и выбирают один дочерний узел упомянутого промежуточного узла согласно сравнению полученного множества значений отображения; причем для каждого промежуточного узла режим отображения перезапускается перед каждым моментом выбора его дочерних узлов;
модуль выгрузки, сконфигурированный для того, чтобы после того, как требуемые позиции хранения всех копий данных для данных, которые должны быть сохранены, определены модулем выбора, передавать все копии данных для данных, которые должны быть сохранены, и информацию требуемых позиций хранения всех копий данных для данных, которые должны быть сохранены, в компьютер в системе распределенного хранения данных так, чтобы компьютер сохранял все копии данных для данных, которые должны быть сохранены, в их требуемые позиции хранения, соответственно.
8. Устройство терминала по п.7, отличающееся тем, что модуль выбора дополнительно используется для того, чтобы в отношении одного или нескольких определенных промежуточных узлов, если промежуточный узел выбирается снова в течение определения требуемых позиций хранения всех копий данных для данных, которые должны быть сохранены, осуществлять повторный выбор из всех одноуровневых узлов промежуточного узла.
9. Устройство терминала по п.7, отличающееся тем, что модуль выбора дополнительно используется для того, чтобы в течение определения требуемых позиций хранения всех копий данных для данных, которые должны быть сохранены, если требуемая позиция хранения, определенная для текущей копии данных, та же самая, что и для другой копии данных, повторно определять требуемую позицию хранения текущей копии данных так, чтобы требуемые позиции хранения всех копий данных для данных, которые должны быть сохранены, были различны.
10. Устройство терминала по п.7, отличающееся тем, что режим отображения содержит этап, на котором вычисляют уникальное значение отображения с использованием хэш-алгоритма после того, как предварительный образ отрегулирован.
11. Устройство терминала по п.7, отличающееся тем, что режим отображения содержит этапы, на которых вычисляют хэш-значение с использованием хэш-алгоритма после того, как предварительный образ отрегулирован; получают значение отображения путем умножения хэш-значения на предварительно установленное взвешенное значение; причем предварительно установленное взвешенное значение является суммой взвешенных значений всех концевых узлов, связанных с дочерним узлом в предварительном образе, и взвешенные значения концевых узлов состоят в положительной корреляции с емкостью хранилища устройства хранения данных на концевых узлах.
12. Устройство сервера, предусмотренное внутри сервера системы распределенного хранения данных с древовидной структурой и без центрального узла; используемое для хранения множества копий данных для данных, которые должны быть сохранены в системе распределенного хранения данных, причем древовидная структура содержит концевые узлы, на которых находятся устройства хранения данных, и промежуточные узлы; и отличающееся тем, что содержит:
модуль выбора для того, чтобы в отношении каждой копии данных для данных, которые должны быть сохранены, выбирать дочерние узлы, причем дочерний узел выбирается от уровня к уровню от предварительно выбранного промежуточного узла древовидной структуры согласно древовидной структуре в предварительно установленном режиме выбора дочернего узла, пока дочерний узел, который выбирается, не окажется концевым узлом, и затем определять концевой узел в качестве требуемой позиции хранения копии данных; причем режим выбора дочернего узла содержит этапы, на которых: получают значение отображения, относящееся к каждому дочернему узлу промежуточного узла согласно предварительно установленному режиму отображения путем получения каждой комбинации идентификации данных, которые должны быть сохранены, и идентификации упомянутого каждого дочернего узла в качестве предварительного образа, и выбирают один дочерний узел упомянутого промежуточного узла согласно сравнению полученного множества значений отображения; причем для каждого промежуточного узла режим отображения перезапускается перед каждым моментом выбора его дочерних узлов;
модуль сохранения для сохранения всех копий данных для данных, которые должны быть сохранены, в требуемых позициях хранения копий данных соответственно, после того как требуемые позиции хранения всех копий данных для данных, которые должны быть сохранены, определены модулем выбора.
13. Устройство сервера по п.12, отличающееся тем, что модуль выбора дополнительно используется для того, чтобы в отношении одного или нескольких определенных промежуточных узлов, если промежуточный узел выбирается снова в течение определения требуемых позиций хранения всех копий данных для данных, которые должны быть сохранены, осуществлять повторный выбор из всех одноуровневых узлов промежуточного узла.
14. Устройство сервера по п.12, отличающееся тем, что модуль выбора дополнительно используется для того, чтобы в течение определения требуемых позиций хранения всех копий данных для данных, которые должны быть сохранены, если требуемая позиция хранения, определенная для текущей копии данных, та же самая, что и для другой копии данных, повторно определять требуемую позицию хранения текущей копии данных так, чтобы требуемые позиции хранения всех копий данных для данных, которые должны быть сохранены, были различны.
15. Устройство сервера по п.12, отличающееся тем, что режим отображения содержит этап, на котором вычисляют уникальное значение отображения с использованием хэш-алгоритма после того, как предварительный образ отрегулирован.
16. Устройство сервера по п.12, отличающееся тем, что режим отображения содержит этапы, на которых вычисляют хэш-значение с использованием хэш-алгоритма после того, как предварительный образ отрегулирован; получают значение отображения путем умножения хэш-значения на предварительно установленное взвешенное значение; причем предварительно установленное взвешенное значение является суммой взвешенных значений всех концевых узлов, связанных с дочерним узлом в предварительном образе, и взвешенные значения концевых узлов состоят в положительной корреляции с емкостью хранилища устройства хранения данных на концевых узлах.
17. Устройство сервера по любому из пп.12-16, отличающееся тем, что дополнительно содержит модуль подтверждения для того, чтобы инициировать модуль выбора в сервере, где одна предварительно выбранная копия соответственных данных, в текущий момент сохраненных в системе распределенного хранения данных, расположена, в случае, если узел в системе распределенного хранения данных изменяется; при этом модуль выбора дополнительно используется для того, чтобы, когда он инициируется модулем подтверждения, брать предварительно выбранную копию и другие копии, идентичные этой копии, в качестве данных, которые должны быть сохранены, определять новую требуемую позицию хранения для каждой копии данных для данных, которые должны быть сохранены, и затем перемещать копии данных, у которых исходные позиции хранения не являются новыми требуемыми позициями хранения, в новые требуемые позиции хранения.
| CN 102571991 A, 11.07.2012 | |||
| CN 102916811 A, 06.02.2013 | |||
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| US 7647329 B1, 12.01.2010 | |||
| СПОСОБ УПРАВЛЕНИЯ РАСПРЕДЕЛЕННОЙ СИСТЕМОЙ ХРАНЕНИЯ | 2006 |
|
RU2411685C2 |

