ПЕРЕКРЕСТНАЯ ССЫЛКА НА РОДСТВЕННЫЕ ЗАЯВКИ
Настоящая заявка испрашивает приоритет предварительной заявки на патент США № 62/991 645, поданной 19 марта 2020 г., предварительной заявки на патент США № 62/840 857, поданной 30 апреля 2019 г., европейской заявки на патент № 19186491.7, поданной 16 июля 2019 г., и международной заявки № PCT/CN2020/076047, поданной 20 февраля 2020 г., которая испрашивает приоритет международной заявки № PCT/CN2019/081317, поданной 3 апреля 2019 г., все из которых полностью включены в данную заявку посредством ссылки.
ПРЕДПОСЫЛКИ ИЗОБРЕТЕНИЯ
1. Область техники
Настоящая заявка в общем относится к многосторонней связи. В частности, настоящая заявка относится к медиасерверу с масштабируемой сценой для голосовых сигналов и к способу осуществления, помимо прочего, аудиосвязи и голосовой связи.
2. Описание известного уровня техники
Системы для видео и аудио телеконференций могут позволить нескольким сторонам удаленно взаимодействовать для осуществления конференц-связи. В общем, существующие конструкции центральных медиасерверов для аудиоданных в голосовой связи используют некоторую стратегию или комбинацию стратегий в одной из двух форм.
В одной форме, путем перенаправления всех входящих аудопотоков ко всем участникам, которые будут слушать этот аудиопоток по конференц-связи, сервер способен предотвратить полную нагрузку, связанную с обработкой данных, и предоставить клиенту больше вариантов рендеринга. Однако этот подход не масштабирует и не управляет пропускной способностью в нисходящем направлении.
В другой форме, путем микширования входящих потоков в определенный микшированный сигнал или в пространственную аудиосцену, которые будут получены каждым конечным устройством, и отправки только этого микшированного сигнала, сервер может минимизировать и иметь фиксированную пропускную способность в нисходящем направлении независимо от количества клиентов, участвующих в конференц-связи. Однако этот подход требует большого объема обработки и декодирования, микширования и повторного кодирования аудиоданных на сервере, что приводит к затратам и дополнительным задержкам, вызванным обработкой. Даже в случаях, когда такие системы пытаются уменьшить и повторно использовать различные операции обработки и микширования, нагрузка остается большой. После микширования у клиента есть ограниченная возможность существенного изменения воспринимаемой аудиосцены в сцену, отличающуюся от предоставленной сервером (например, для реализации отслеживания положения головы).
Системы могут включать некоторую комбинацию двух предыдущих форм, чередуясь между использованием перенаправления для ситуаций, где активны только несколько источников речи, и использованием микширования, когда активно много источников речи. Однако такие системы могут иметь недостатки, например отсутствие возможности обеспечения достаточного увеличения эффективности, масштабируемости или управления пропускной способностью.
Соответственно, существует потребность в системах и способах для управления пиковой и средней битовой скоростью данных, отправляемых клиентам, не требующего длительного микширования аудиоданных на сервере. Кроме этого, существует потребность в системах и способах, которые могут индивидуально осуществлять рендеринг пространственного местоположения каждого потока в виде достоверной сцены, которая воспринимается непрерывной, независимо от любых операций микширования или отбора, происходящих на сервере.
КРАТКОЕ ИЗЛОЖЕНИЕ СУЩНОСТИ ИЗОБРЕТЕНИЯ
Различные аспекты настоящего изобретения относятся к электрическим схемам, системам и способам для осуществления масштабируемой многосторонней связи, включая голосовую связь.
В одном иллюстративном аспекте настоящего изобретения предоставлена система связи, содержащая медиасервер, выполненный с возможностью приема множества аудиопотоков от соответствующего множества клиентских устройств, причем медиасервер включает электронную схему, выполненную с возможностью ранжирования множества аудиопотоков на основании предопределенной метрики, объединения первой части множества аудиопотоков в первую группу, причем первая часть множества аудиопотоков представляет собой N аудиопотоков с наивысшими рангами, объединения второй части множества аудиопотоков во вторую группу, причем вторая часть множества аудиопотоков представляет собой M аудиопотоков с самыми низкими рангами, перенаправления соответствующих аудиопотоков первой группы в принимающее устройство, и удаления соответствующих аудиопотоков второй группы, причем N и M являются независимыми целыми числами.
В другом иллюстративном аспекте настоящего изобретения предоставлен способ связи, включающий прием множества аудиопотоков от соответствующего множества клиентских устройств; ранжирование множества аудиопотоков на основании предопределенной метрики; объединение первой части множества аудиопотоков в первую группу, причем первая часть множества аудиопотоков представляет собой N аудиопотоков с наивысшими рангами; объединение второй части множества аудиопотоков во вторую группу, причем вторая часть множества аудиопотоков представляет собой M аудиопотоков с самыми низкими рангами; перенаправление соответствующих аудиопотоков первой группы в принимающее устройство; и удаление соответствующих аудиопотоков второй группы, причем N и M являются независимыми целыми числами.
В другом иллюстративном аспекте настоящего изобретения предоставлен постоянный машиночитаемый носитель, на котором хранятся команды, которые при исполнении процессором медиасервера, приводят к выполнению медиасервером операций, включающих прием множества аудиопотоков от соответствующего множества клиентских устройств; ранжирование множества аудиопотоков на основании предопределенной метрики; объединение первой части множества аудиопотоков в первую группу, причем первая часть множества аудиопотоков представляет собой N аудиопотоков с наивысшими рангами; объединение второй части множества аудиопотоков во вторую группу, причем вторая часть множества аудиопотоков представляет собой M аудиопотоков с самыми низкими рангами; перенаправление соответствующих аудиопотоков первой группы в принимающее устройство; и удаление соответствующих аудиопотоков второй группы, причем N и M являются независимыми целыми числами.
Таким образом, различные аспекты настоящего изобретения обеспечивают усовершенствования по меньшей мере в области телекоммуникаций.
Настоящее изобретение может быть реализовано в различных формах, включая аппаратное обеспечение или электрические схемы, управляемые способами, реализованными с помощью компьютера, компьютерными программными продуктами, компьютерными системами и сетями, пользовательскими интерфейсами и интерфейсами прикладного программирования; а также способами, реализованными с помощью аппаратного обеспечения, схемами обработки сигналов, массивами данных в памяти, интегральными схемами специального назначения, программируемыми пользователем вентильными матрицами и т. п. Вышеизложенное краткое описание предназначено исключительно для представления общей идеи различных аспектов настоящего изобретения и не ограничивает объем изобретения каким-либо образом.
ОПИСАНИЕ ГРАФИЧЕСКИХ МАТЕРИАЛОВ
Эти и другие более детальные и специфические признаки различных вариантов осуществления более полно раскрыты в следующем описании со ссылкой на сопроводительные графические материалы, на которых:
на фиг. 1A–1C соответственно изображены иллюстративные системы связи согласно различным аспектам настоящего изобретения;
на фиг. 2 изображен график иллюстративных данных речевой активности согласно различным аспектам настоящего изобретения;
на фиг. 3A–3C соответственно изображены иллюстративные весовые функции согласно различным аспектам настоящего изобретения;
на фиг. 4 изображена другая иллюстративная система связи согласно различным аспектам настоящего изобретения;
на фиг. 5 изображена последовательность операций иллюстративного способа связи согласно различным аспектам настоящего изобретения; и
на фиг. 6A изображена последовательность операций другого иллюстративного способа связи согласно различным аспектам настоящего изобретения;
на фиг. 6B изображена последовательность операций другого иллюстративного способа связи согласно различным аспектам настоящего изобретения; и
на фиг. 7 изображена последовательность операций другого иллюстративного способа связи согласно различным аспектам настоящего изобретения.
ПОДРОБНОЕ ОПИСАНИЕ
В следующем описании изложены многочисленные подробности, например конфигурации электрических схем, временные привязки, операции и тому подобное, чтобы предоставить понимание одного или более аспектов настоящего изобретения. Специалисту в данной области техники будет очевидно, что эти конкретные подробности являются всего лишь иллюстративными и не предназначены для ограничения объема этой заявки.
Более того, хотя настоящее изобретение главным образом сосредоточено на примерах, в которых различные электрические схемы используются в голосовой связи, следует понимать, что это всего лишь один пример реализации. Также следует понимать, что описанные системы и способы могут использоваться в любом устройстве, которому необходимо создавать широкомасштабную аудиосвязь для различных источников и получателей звука; например, для глобальной связи, интернета вещей, систем виртуальной и дополненной реальности, систем альтернативной смешанной реальности, более широкого сотрудничества, роста и поддержки общества и так далее. Кроме этого, описанные системы и способы могут иметь применения, связанные только со звуком, а также вязанные со звуком в сочетании с другими видами ощущений.
Обзор
Различные аспекты настоящего изобретения предоставляют систему, в которой возможно создать высококачественное и во многих случаях неотличимое от реального впечатление сцены со многими одновременными источниками речи, в то же время передавая в любой момент времени только одну подгруппу фактических аудиопотоков. Таким образом, различные аспекты настоящего изобретения извлекают выгоду из аспектов неврологических, нейрофизиологических и перцептивных факторов человеческого слуха для создания иллюзии полной комплексной сцены голосов без всесторонней передачи или микширования данных.
Люди склонны объединять, где это возможно, компоненты звука как во временной, так и в частотной области, в меньшую группу воспринимаемых объектов. Другими словами, люди склонны перцептивно анализировать звуковые сцены применительно к потокам, где сходство пространства, спектров, временного поведения, фактуры, высоты тона, изменения высоты тона и тому подобное приводит к объединению объектов друг с другом. Кроме этого, люди способны воспринимать непрерывность элементов звукового потока, даже когда она может отсутствовать в стимуле.
Фонематическое восстановление является одним из факторов в иллюзии непрерывности и способом ее связи с высокоуровневым функционированием мозга и полным восприятием звуковой сцены. Например, когда слушатель слушает единственный источник речи и один слог скрыт или удален из звукового потока и соответствующим образом замаскирован, слушатель будет воспринимать звук там, где произошло удаление. Для осмысленного языка этот воспринимаемый звук будет представлять собой звук, который наиболее логичен в данном предложении. В данном контексте слово «замаскирован» относится не к пропуску звукового содержимого, а к перекрытию конкретного звука другим звуком или шумом. Таким образом, человеческий мозг интерпретирует отсутствие звука (тишину) иначе, чем отсутствие осмысленных звуковых сигналов (отсутствие содержимого кроме шума, заполняющего этот пробел). При маскировке контекст отсутствующей информации может быть предоставлен предварительной подготовкой и информацией, ведущей к звуковому событию (в некоторых случаях, охватывающей несколько часов перед событием), а также звуками, следующими за событием. Это явление может быть настолько сильным, что слушатель убежден в том, что слышит (или помнит, что слышал(а)) отсутствующий звук в той части предложения, где его нет. Например, слушатели, которые прослушали аудиопотоки «**eel was on cart» и «**eal was on table», (где ** обозначает слог, удаленный из потока и замаскированный), заявили, что слышали слова «wheel» и «meal» соответственно, хотя звук был идентичным до последнего слова в потоке.
Таким образом, когда отсутствующее содержимое в речи соответствующим образом замаскировано или перекрыто другим содержимым, слушатель может приспособиться или даже придумать звуки, которые подходили бы для заполнения пропущенного фрагмента. Хотя описание, представленное выше, ссылается на один источник речи, эти идеи можно расширить на ситуации, в которых происходят потери или конфликты между несколькими речевыми потоками и отсутствующие компоненты замаскированы присутствием другого речевого потока.
Невосприимчивость к изменениям является другим фактором иллюзии непрерывности. Невосприимчивость к изменениям является идеей, согласно которой слушатель менее склонен слышать искажение, изменения, отсутствующие сегменты и общие манипуляции со звуком во временной, частотной или пространственной областях, если в звуковой сцене присутствует большой объем деятельности или изменений. Это представляет собой подгруппу науки об общем восприятии, в которой исследования обычно относятся к зрительной информации; однако сдвиг внимания и происходящие из него ошибки восприятия являются подобными во многих случаях.
Невосприимчивость к изменениям является подобной и родственной смещению рассеянности. Две эти идеи слегка отличаются тем, что невосприимчивость из-за рассеянности происходит из-за активного и избирательного внимания, направленного не на изменяющиеся или ошибочные объекты, а невосприимчивость к изменениям происходит из-за ситуаций, в которых происходит много событий или большой объем деятельности, и таким образом легче скрыть изменения.
Вышеизложенное можно кратко описать как эффекты ограниченной способности к восприятию или ограниченных усилий, направленных на восприятие, доступных для функций отслеживания объектов (потокового вещания) и деятельности (изменения). Фактически, большая часть того, что люди считают слухом, в действительности является формой галлюцинации или формированием звуков по памяти, которая достоверно соответствует текущей ситуации пользователя и поступающим звуковым данным. При обработке содержимого, которое представляет собой голосовые потоки, наложенные друг на друга, эти наблюдения касательно восприятия можно применять для того, чтобы свести к минимуму количество информации, которое необходимо передать отдельным слушателям в системе связи, чтобы таким образом воссоздать пространственную сцену, состоящую из нескольких голосовых потоков.
Система связи
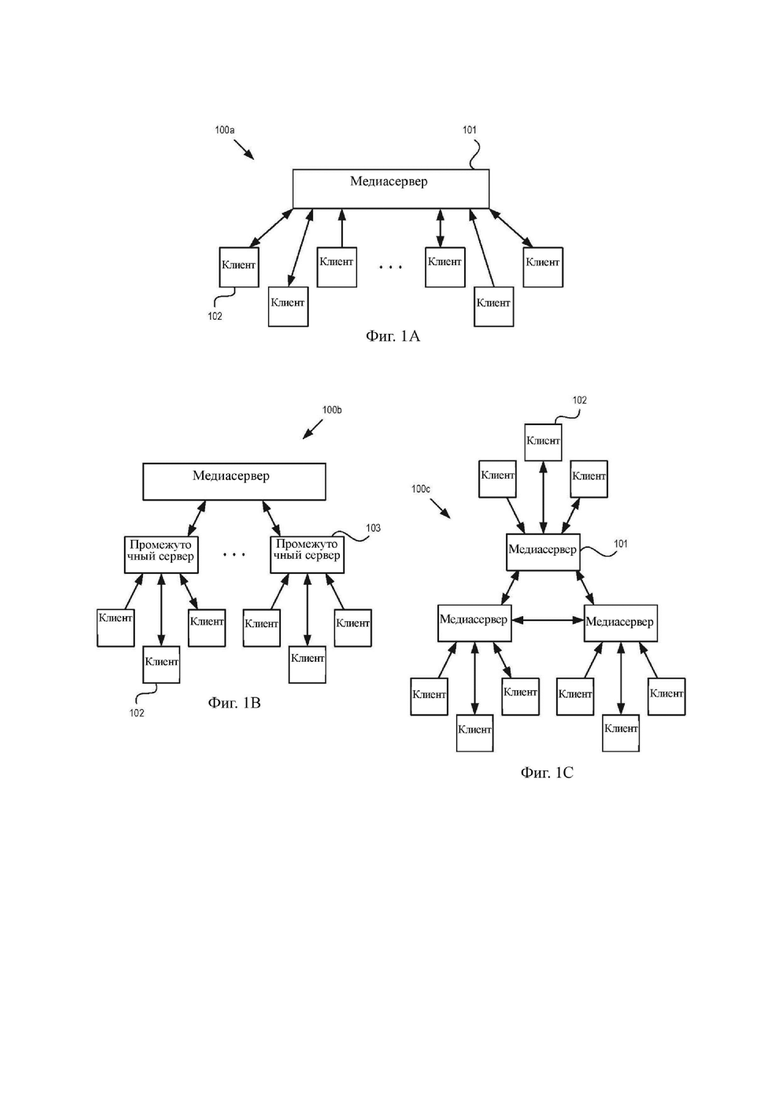
На фиг. 1A–1C изображены различные примеры системы 100a, 100b или 100c связи согласно различным аспектам настоящего изобретения. Когда разница между конкретными типами не имеет значения, эти системы могут совместно называться системой 100 связи.
На фиг. 1A изображена централизованная система 100a связи, в которой центральный медиасервер 101 принимает аудиопотоки от множества клиентских устройств 102 (в целях ясности иллюстрации обозначено только одно из них). Медиасервер 101 далее создает группу выходящих потоков по меньшей мере для части клиентских устройств 102. В системах с достаточно большим масштабом, единственный медиасервер 101 может не справляться с управлением всеми входящими аудиопотоками.
На фиг. 1B изображена группированная система 100b связи, в которой центральный медиасервер 101 принимает аудиопотоки от множества клиентских устройств 102 посредством множества промежуточных серверов 103. Промежуточный сервер 103 может перенаправлять аудиопотоки и/или выходящие потоки от различных подгрупп/к различным подгруппам множества клиентских устройств 102 с обработкой или без нее.
На фиг. 1C изображена распределенная система 100c связи, в которой множество медиасерверов 101 принимают аудиопотоки от множества клиентских устройств 102, и в которой соответствующие медиасерверы из множества медиасерверов 101 обмениваются данными друг с другом. Хотя следующее конкретно не изображено на фиг. 1C, распределенная система 100c связи может дополнительно содержать промежуточные серверы в зависимости от масштаба распределенной системы 100c связи.
В системе 100 связи, где конкретное клиентское устройство 102 предоставляет аудиопоток, но не принимает выходящий поток, линия связи изображена однонаправленной стрелкой и может называться симплексной связью. Если конкретное клиентское устройство 102 предоставляет аудиопоток, а также принимает выходящий поток, линия связи изображена двунаправленной стрелкой и может называться дуплексной связью. Хотя не изображено явным образом, настоящее изобретение также применимо к конфигурациям, в которых конкретное клиентское устройство 102 принимает выходящий поток, но не предоставляет аудиопоток.
Кроме этого, в системе 100 связи различные линии связи могут быть проводными (например, посредством токопроводящей проволоки и/или оптоволокна), беспроводными (например, посредством Wi-Fi, Bluetooth, ближней бесконтактной связи (Near-Field Communication, NFC) и т.п.) или комбинацией проводных и беспроводных (например, проводными между микрофоном и процессором клиентского устройства 102 и беспроводными между клиентским устройством 102 и медиасервером 101). Хотя на фиг. 1A–1C изображено конкретное количество клиентских устройств 102 (как общее, так и для каждого медиасервера 101 и/или промежуточного сервера 103), настоящее изобретение не ограничено таким образом и может применяться к любому количеству клиентских устройств 102, имеющих любое размещение.
В системе 100 связи аудиоданные, представляющие голос, могут включать последовательность голосовых кадров. В целях иллюстрации в настоящем документе описан пример, в котором голосовые кадры имеют либо низкий уровень шума, либо соответствующим образом обработаны с целью удаления шума. В таком случае возможно рассмотреть два признака каждого кадра: среднеквадратичное значение (root mean square, RMS) энергии кадра и спектральный пик или максимум кадра. В этом случае рассмотрение энергии в группе диапазонов, имеющих постоянное отношение пропускной способности к частоте приводит к логарифмическому интервалу между частотными диапазонами. В большей части спектра это отражает природу разделения на воспринимаемые диапазоны, например эквивалентную прямолинейную пропускную способность (ERB), шкалу Барка или интервал, выраженный в мелах. Так как пропускная способность линейно увеличивается с частотой, постоянная энергия на единицу частоты или белый шум имели бы монотонно увеличивающийся спектр мощности в таком масштабе.
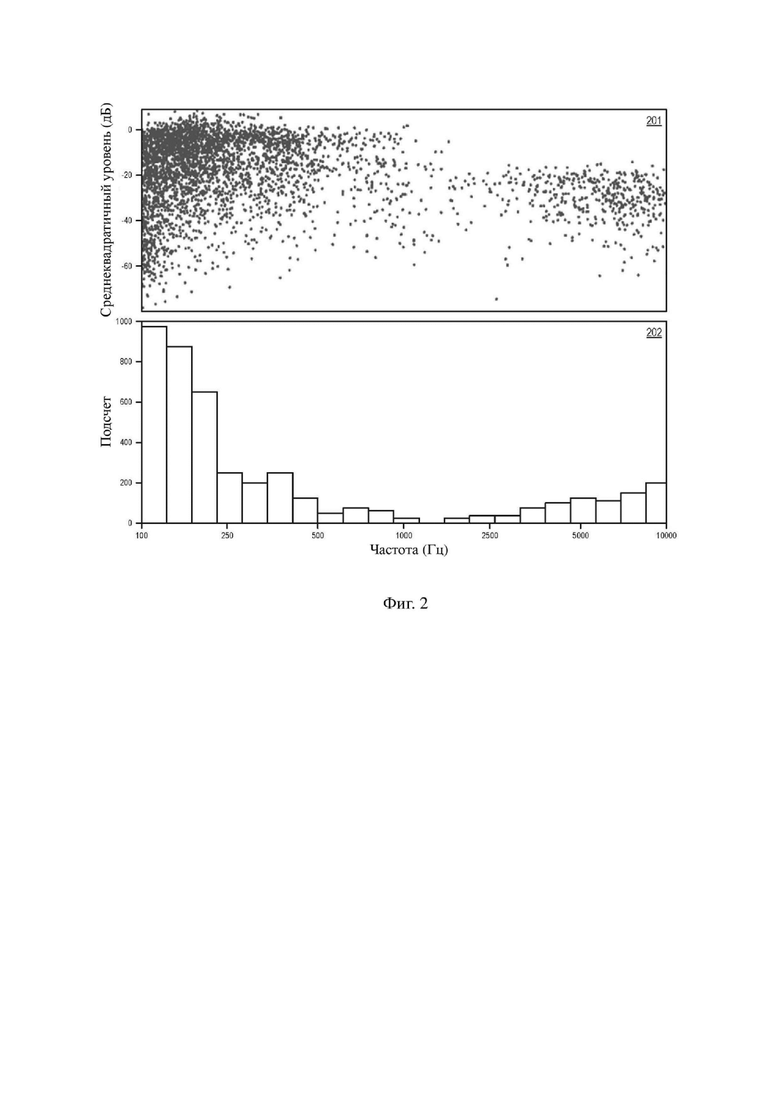
На фиг. 2 изображен график 201 разброса и столбчатая диаграмма 202 иллюстративных данных речевой деятельности согласно различным аспектам настоящего изобретения. В частности, на фиг. 1 изображены данные речевой деятельности для группы выборочных фраз для представления стандартной речевой деятельности (так называемые «гарвардские предложения»). График 201 разброса показывает среднеквадратичное значение (RMS) уровня кадра в децибелах (дБ) в зависимости от частоты в Герцах (Гц). Точнее, график 201 разброса показывает кадры величиной 20 миллисекунд (мс) гарвардских предложений со слиянием 1/3 октавы. Столбчатая диаграмма 202 показывает данные из графика 201 разброса в расчете на частотные диапазоны и только учитывает кадры с энергией выше шумового порога (приблизительно -60 дБ). Как проиллюстрировано на фиг. 2, горизонтальные оси находятся на логарифмической шкале, в то время как вертикальные оси находятся на линейной шкале (хотя дБ собственно представляет собой логарифмическую величину).
Как видно на фиг. 2, имеется большая концентрация кадров с высокой энергией на низких частотах (<500 Гц). Кадров с содержимым на более высоких частотах (>2 кГц) меньше, хотя они важны для разборчивости и локализации звука. В результате важные кадры для управления пространственным присутствием, разборчивостью и общими спектрами могут быть утрачены, если механизм микширования или отбора не будет учитывать это неравенство частот. Это соответствует идее о том, что голос является последовательностью фонем, а фонемы с пиком на более высоких частотах являются невокализованными и/или фрикативными по характеру.
Когда два или более речевых кадров перекрывают друг друга, повышается вероятность наличия в любой момент кадра с высокой энергией. Когда сервер, например вышеописанный медиасервер 100, выбирает только подгруппу активных голосовых кадров для вывода в любой момент, возможно что в выходящем микшированном сигнале будут доминировать низкочастотные кадры. В зависимости от выбранной подгруппы могут происходить различные ситуации. Например, в общем спектре микшированного сигнала может начать доминировать низкочастотная энергия и, таким образом, звук будет восприниматься как глухой или менее четкий. В некоторых случаях для слушателя это может звучать, как будто система теряет пропускную способность. Кроме этого, высокочастотные компоненты, которые важны для разборчивости (например, в фрикативных или невокализованных звуках), могут быть утрачены и сокращены из микшированного сигнала. Более того, утраченное переходное или широкополосное содержимое может привести к уменьшению ощущения пространственного присутствия и насыщенного звука с эффектом присутствия в случаях, когда рендеринг уменьшенной группы потоков пространственное осуществляется в клиентском устройстве.
Отчетливость восприятия
Для предотвращения вышеуказанных ситуаций вводится схема назначения весовых коэффициентов или другого назначения приоритетов, применяемая к речевым кадрам. Схема назначения приоритетов может быть основана на одном или более из взвешенной энергии, структурных признаков или детализации, включая их комбинацию, и тем самым предоставляет основание для определения отчетливости восприятия заданного кадра. Взвешенная энергия относится к наклону спектра или к весовой функции, введенной в вычисление энергии кадра для того, чтобы выделить более высокие частоты. Структурные признаки относятся к рассмотрению структурной и/или семантической значимости кадра и включают рассмотрение временной привязки, в которой начальным кадрам присваивают более высокий приоритет, и/или фонетической маркировки, в которой назначение приоритетов искажено таким образом, чтобы выделять кадры, которые будут иметь содержимое с более высокой частотой в спектре и меньшей энергией. Детализация относится к случаям, в которых назначение весовых коэффициентов смещено, отклонено или непосредственно опирается на объем недавней активности или детализации заданного потока, причем следует отметить, что поток, указывающий на более позднюю деятельность, скорее всего имеет высокую семантическую важность и, таким образом, с большей вероятностью на нем будет сосредоточено перцептивное внимание.
В качестве основания для назначения весовых коэффициентов рассмотрим график 201 разброса, изображенный на фиг. 2. Обычное вычисление среднеквадратичного значения этой формы будет осуществляться с использованием суммы мощности во временных выборках или в выборках элементов разрешения по частоте из преобразования в области блоков. В случае, когда система использует преобразование в частотной области, могут использоваться элементы разрешения по частоте из этого преобразования. В данном случае, разница между среднеквадратичным значением и вычислением общей мощности соответствует нормированию по размеру блоков и операции квадратного корня. Если величины выражены в дБ, проще всего с точки зрения пояснения ссылаться на среднюю (в расчете на одну выборку) или общую (в расчете на один кадр) энергию аудиосигнала, несмотря на операцию квадратного корня, без потери общности. Дополнительно, без потери общности, назначение весовых коэффициентов можно объяснить со ссылкой на единственный канал. Для n выборочных кадров, мощность кадра P может быть представлена согласно следующему выражению (1):
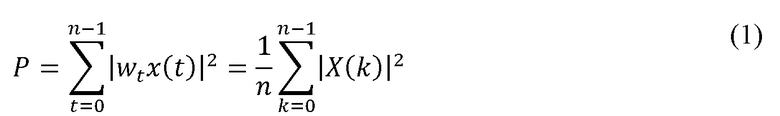
В выражении (1), x(t) (t = 0, …, n-1) является аудиосигналом; wt является функцией оконного режима, например sin(π(t+.5)/n); и X(k) может быть представлено согласно следующему выражению (2):
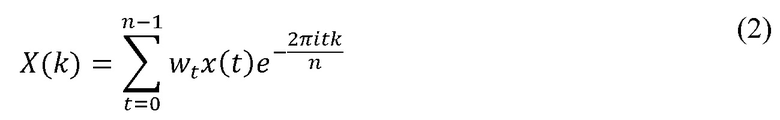
Мощность P может быть вычислена из декодированных звуковых выборок в кадре или она может непосредственно присутствовать в закодированном аудиопотоке. Кроме этого, мощность P можно извлечь из аспектов кадра кодирования аудиосигнала, например из экспоненты в преобразовании в частотной области, или из пар спектральных линий или частотной огибающей в кодеке, основанном на автоматическом регрессивном режиме. В некоторых случаях энергия, вычисленная для одного кадра, может включать некоторую обработку, например удаление очень низких (например, <100 Гц) частот, в которых часто доминирует шум.
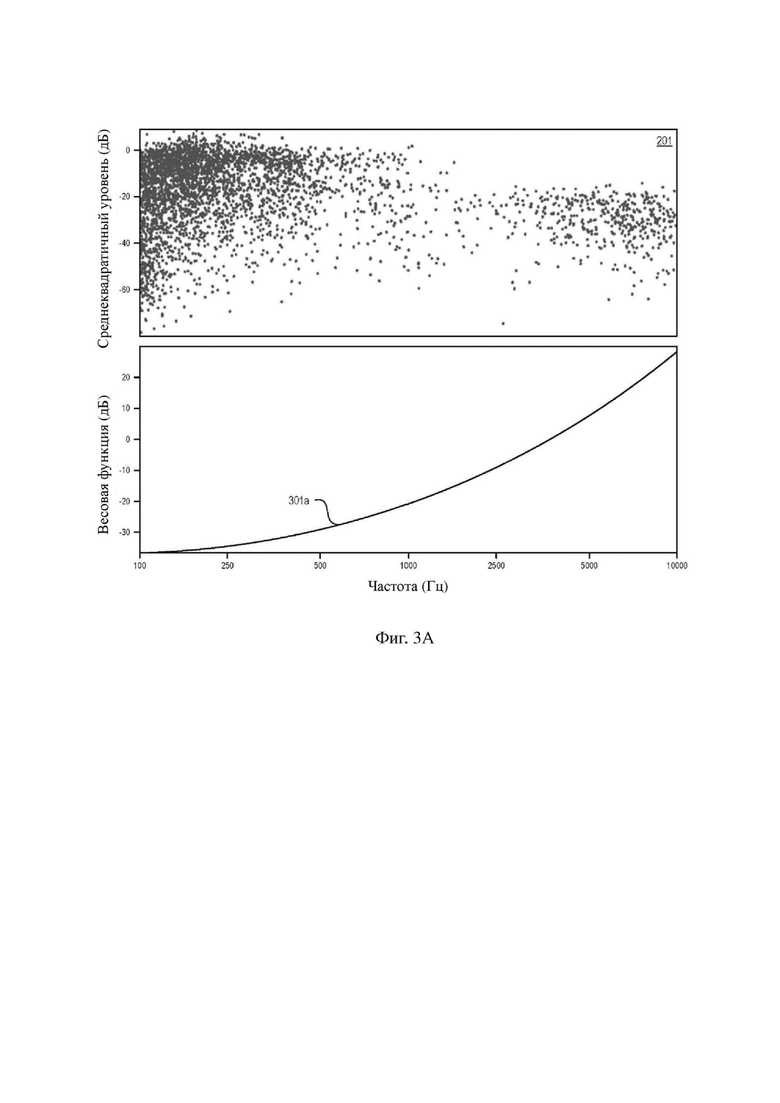
График 201 разброса содержит два кластера. Для того, чтобы сильнее выделить правый кластер точек, вводится весовая функция H(k) в частотной области. С весовой функцией H(k) вышеуказанное выражение (1) превращается в следующее выражение (3):
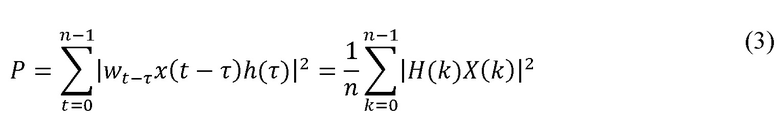
В выражении (3) весовая функция H(k) представлена следующим выражением (4):
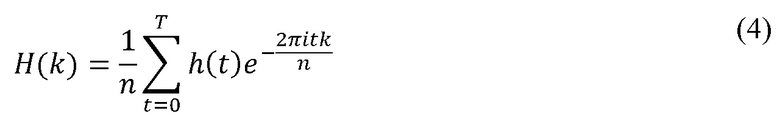
Вышеуказанная величина h(t) является реакцией на импульс во временной области. Если представить частотные весовые коэффициенты как Hk, мощность P превращается в следующее выражение (5):

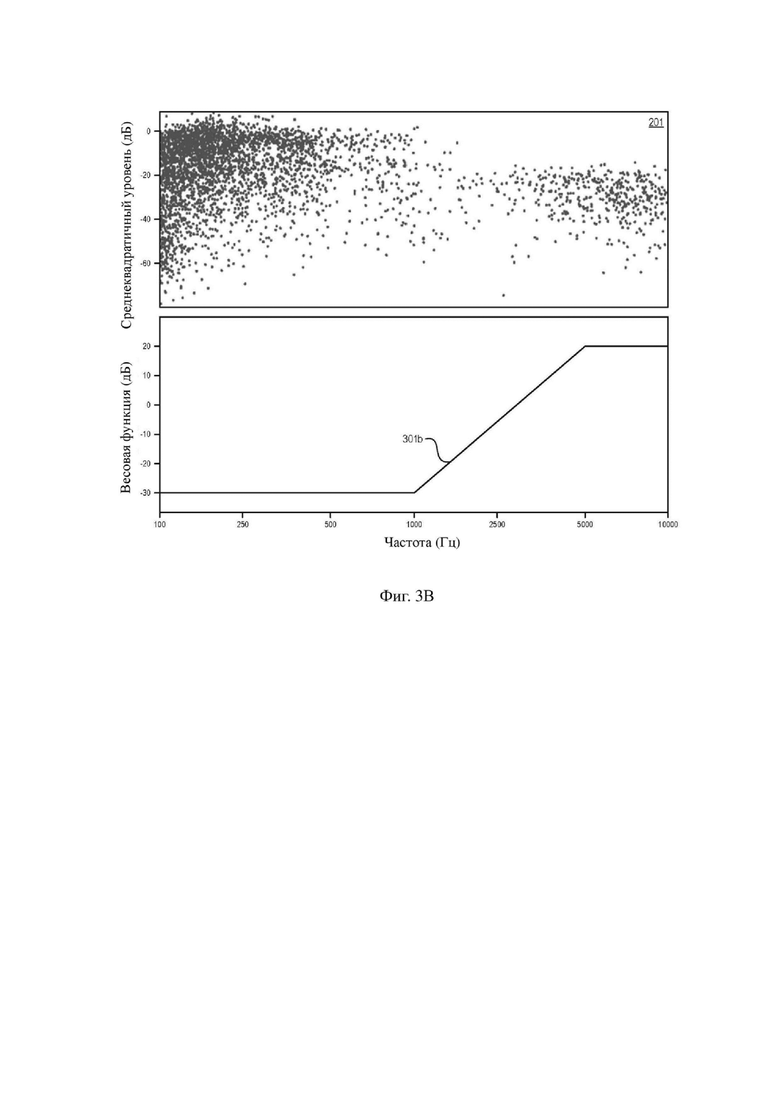
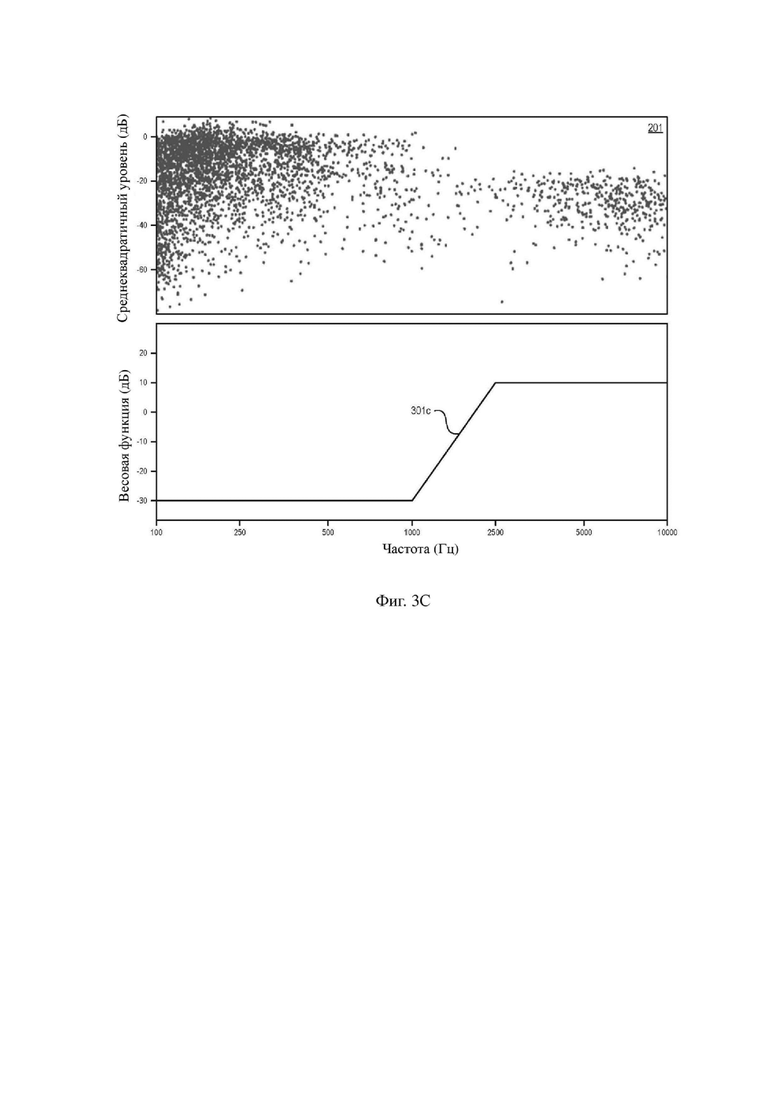
На фиг. 3A–3C изображены иллюстративные весовые функции 301a, 301b и 301c и, для ссылки, воспроизведен график 201 разброса. Когда разница между конкретными функциями не имеет значения, эти функции могут совместно называться весовой функцией 301. Для удобства весовая функция 301 будет описана частотными весовыми коэффициентами в пересчете на Гц, но следует отметить, что отношение между k и f определено размером блока и частотой выборки (например, k = (n×f)/(Fs×n)). На фиг. 3A изображена весовая функция 301a мощности, имеющая определенную форму H(f) = ((2000+f)/6000)8. Эта функция уменьшает выделение содержимого ниже 1000 Гц и выделяет содержимое с энергией 4000 Гц и выше. Этот подход обеспечивает то, что речевые кадры с меньшей энергией, относящиеся к содержимому с большим информационным наполнением, не будут потеряны при вычислении среднеквадратичного значения.
Весовая функция H(k) не ограничена функцией мощности. Например, на фиг. 3B и 3C изображены поэтапные линейные весовые функции 301b и 301c, соответственно. Поэтапная линейная весовая функция 301b по фиг. 3B применяет вес -30 дБ к содержимому ниже 1000 Гц, вес 20 дБ к содержимому свыше 5000 Гц и линейно увеличивающийся вес к содержимому между этими значениями. Поэтапная линейная весовая функция 301b по фиг. 3B применяет вес -30 дБ к содержимому ниже 1000 Гц, вес 10 дБ к содержимому свыше 2500 Гц и линейно увеличивающийся вес к содержимому между этими значениями. Реализованная поэтапная линейная весовая функция 301b будет выделять свистящие или шипящие звуки в речи. Поэтапная линейная весовая функция 301c будет выделять фрикативные звуки и переходы высоты тона. Как поэтапная линейная весовая функция 301b, так и поэтапная линейная весовая функция 301c будут преуменьшать вокализованный звук и взрывные согласные.
В любом случае весовая функция 301 влияет на обеспечение того, чтобы кластер в правой части графика 201 разброса имел большую значимость и был более предпочтительным, чем кадры с большей частотностью и более высокой энергией широкополосного диапазона в левой части графика 201 разброса. Следовательно, схема назначения приоритетов, основанная на весовой функции 301, сохраняет наиболее важные кадры для сохранения высокочастотного содержимого и впечатления голоса, разборчивости и пространственных меток, связанных с этими фрикативными звуками и переходами. Таким образом, весовая функция 301 устраняет смещение кадров от отчетливости восприятия путем преуменьшения содержимого с частотой ниже 1000 Гц и выделения содержимого с частотой выше 4000 Гц. Таким образом, весовая функция 301 не ограничена точными формами, изображенными на фиг. 3A–3C.
Вычисление отчетливости восприятия (то есть применение весовой функции 301 к аудиоданным) предпочтительно осуществляется клиентским устройством, например множеством клиентских устройств 102, описанных выше. Таким образом, множество аудиопотоков, загруженных из соответствующего множества клиентских устройств, могут включать как аудиоданные, которые обозначают содержимое аудиопотока, так и метаданные, которые обозначают назначение весовых коэффициентов и/или отчетливость восприятия содержимого аудиопотока.
В дополнение к вышеуказанной весовой функции, вычисление отчетливости восприятия может включать отношение «сигнал-шум» (SNR) в мгновенной полосе пропускания, обнаружение начала, обнаружение других событий, назначение весовых коэффициентов фонем, детализацию или их комбинации.
Отношение «сигнал-шум» (SNR) в мгновенной полосе пропускания основано на идее оценки шума и оценки мощности покадровым способом в группе полос, перцептивно удаленных друг от друга (например, логарифмически удаленных друг от друга). В принципе, энергия в кадре разделяется из группы n элементов разрешения по частоте преобразования в группу B воспринимаемых полос посредством матрицы весовых коэффициентов Wb,k. Это может быть представлено согласно следующему выражению (6):

Путем отслеживания минимума или некоторой формы оценки недавнего стационарного шума в сигнале, возможно изучить отношение присутствующего сигнала к фону. Это предоставляет измерение, в котором активность в каждой воспринимаемой полосе b имеет равную значимость независимо от абсолютной мощности в этой полосе или уровня фонового шума в этой полосе. Это может быть представлено согласно следующим выражениям (7) и (8):
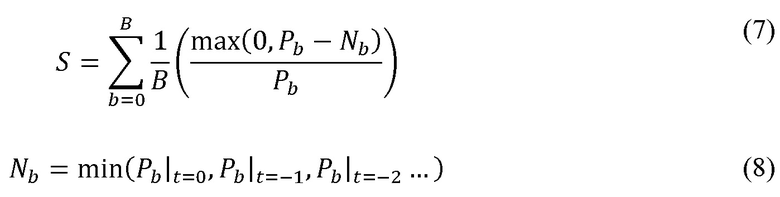
В вышеуказанных выражениях S представляет величину активности сигнала на основании воспринимаемых полос и Nb представляет недавний стационарный шум в сигнале.
Обнаружение начала основано на анализе предыдущего кадра с целью выражения деятельности применительно к количественному оцениванию положительной разницы, когда энергия в текущем кадре, скорректированная стационарным шумом, значительно больше, чем в предыдущем кадре. Это может быть включено в определение параметра Nb вышеописанного выражения (8), включая замену выражения (8) средним из нескольких недавних кадров Pb. Таким образом, активность S сигнала была бы смещена к подсчету лишь полос, в которых недавно было начало или увеличение энергии.
Другие формы обнаружения событий могут быть основаны на классификации речевой деятельности. В такой классификации дополнительные признаки, относящиеся к форме спектра и/или к среднему значению и изменению статистических параметров, можно извлечь из базовых признаков. В одном примере классификатор может быть основан на усилении признаков для создания границы принятия решения. В качестве дополнения или альтернативы классификатор может быть основан на спектральном потоке, который является мерой величины чередования кадров между низкочастотными и высокочастотными спектральными пиками с течением времени. Таким образом, спектральный поток дополнительно выделяет кадры, отсутствие которых склонен замечать слушатель, с помощью другой меры энергии.
В качестве дополнения или альтернативы клиентское устройство, например, вышеописанные клиентские устройства 102, могут обладать способностью выполнять анализ речи, что может предоставить мгновенную оценку того, какая фонема присутствует во входящем сигнале. В одном таком примере клиентское устройство может задавать весовые коэффициенты фонемам на основании их энтропии, причем фонемы, которые встречаются реже или имеют меньшую длительность, получают более высокую оценку. Это обеспечит сдвиг при выборе речи в сторону более отчетливых кадров для сохранения высокочастотного содержимого и пространственного представления.
Выбор потоков также может быть смещен в сторону сохранения потоков, которые были активными (или детализированными) позднее всех. Смещение детализации может быть измерено на основании увеличения детализации заданного потока в периоды, в течение которых он активен, а другие потоки неактивны. Один неограничивающий пример алгоритма для определения детализации V выводит значение от 0 до 1, приближенное к любому из этих граничных значений в целях нормализации. Более высокое значение указывает на то, что конечное устройство было более активно и таким образом имеет большую вероятность или больше подходит для поддержания в качестве недавно активного звукового поля в выходном микшированном сигнале. Детализация может быть модифицирована в каждом кадре или моменте времени согласно набору параметров; однако настоящее изобретение не ограничено конкретными параметрами, которые необходимо выбрать или включить. В общем, детализация V будет увеличиваться, когда конечное устройство активно, и может увеличиваться быстрее, если это единственное активное конечное устройство в заданное время. В случае отсутствия активности, можно поддерживать уровни детализации V или использовать затухание и связать затухание с постепенным исчезновением из связанного звукового поля.
В одном примере смещение или выделение, которые являются результатом высокого значения детализации V, эквивалентно 6 дБ большей мощности или взвешенной отчетливости восприятия (P) из вышеуказанных выражений. Это может быть представлено следующим выражением (9):

В выражении (9) масштабирование детализации V является иллюстративным и не ограничивающим. Вместо масштабирования, равного 6, как указано выше, масштабирование может иметь любую величину от 3 до 10 дБ.
Любая комбинация вышеуказанных вычислений может быть выполнена в клиентских устройствах, в промежуточных серверах или в медиасервере. Кроме этого, эти комбинации можно выполнять, используя комбинацию устройств. В одном примере вычисление отчетливости восприятия перед любым сдвигом детализации может выполняться в клиентском устройстве, а дальнейший сдвиг может выполняться в сервере. Назначение весовых коэффициентов может быть дополнительно закодировано в последовательности битов; например, при использовании 3-битного двоичного кода x в диапазоне от (000) до (111), назначение весовых коэффициентов может быть закодировано в виде P = -35 + 5x. Такое кодирование может помогать медиасерверу ранжировать пакеты, как будет подробнее описано ниже.
Возможно получить любые из вышеуказанных данных, например среднеквадратичное значение кадра, не анализируя весь кадр. Например, в частотной области можно извлечь среднеквадратичное значение кадра, используя только огибающую. В кодировщике речевого стиля можно вывести информацию из вектора возбуждения и параметров кодирования с линейным предсказанием (LPC).
Схемы задания весовых коэффициентов, описанные выше, в первую очередь направлены на голосовые пакеты. В случаях, когда основанное на голосе назначение весовых коэффициентов предоставляет большую чувствительность, чем это необходимо (например, в определенных случаях шума в аудиосигнале без голоса), можно применять схемы назначения весовых коэффициентов, когда устройство, выполняющее назначение весовых коэффициентов, уверено в том, что сигнал содержит голосовую активность.
Микширование и выбор потоков
Серверное устройство, например вышеописанный медиасервер 101, принимает и обрабатывает множество аудиопотоков, загруженных из соответствующего множества клиентских устройств. Такая обработка включает выбор подгруппы аудиопотоков для перенаправления и/или немедленного микширования в серверном устройстве. На основании вышеописанных принципов можно создать убедительное и иногда перцептивно неотличимое от реального представление потока, используя лишь подгруппу потенциально активных потоков.
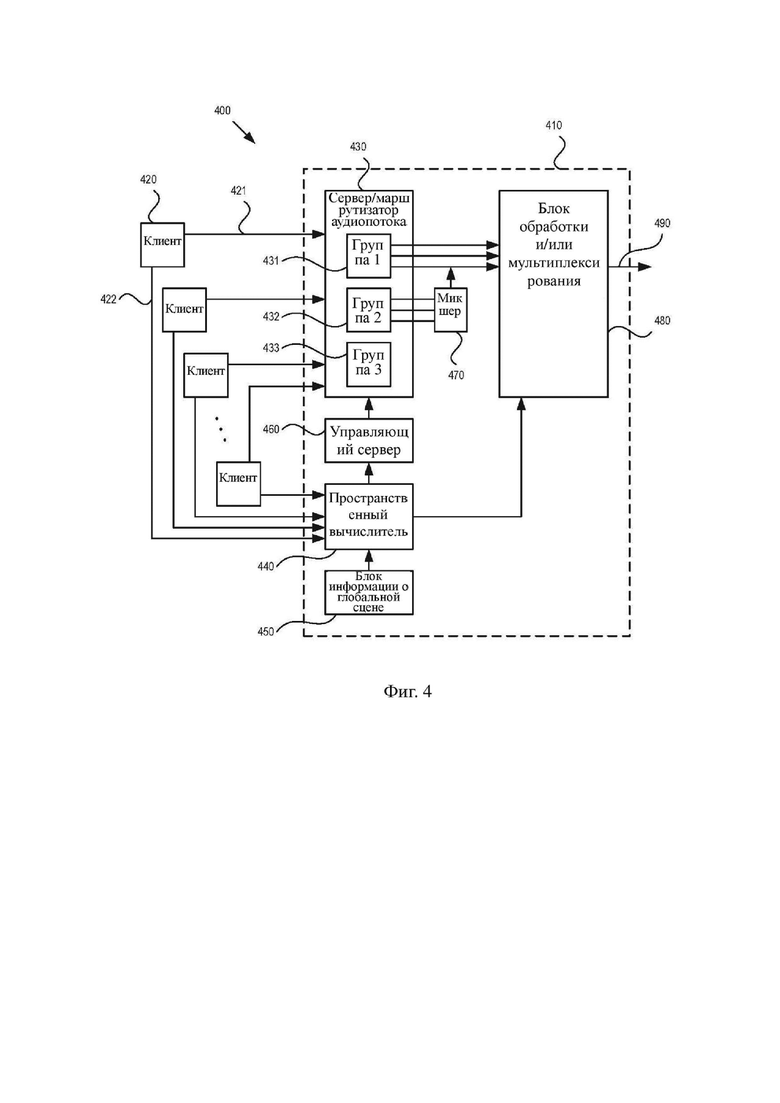
На фиг. 4 изображена иллюстративная система 400 связи согласно различным аспектам настоящего изобретения, которая может реализовывать такую обработку. Система 400 связи может быть идентичной или подобной системам 100 связи, описанным выше. Система 400 связи содержит серверное устройство 410, которое может быть идентичным или подобным медиасерверу 101, и множество клиентских устройств 420, которые могут быть идентичными или подобными клиентским устройствам 102.
Каждое из клиентских устройств 420 предоставляет серверному устройству 410 аудиопоток, содержащий аудиоданные 421 и метаданные 422. Хотя на фиг. 4 аудиоданные 421 и метаданные 422 изображены с помощью разных стрелок, на практике аудиопоток может содержать аудиоданные 421 и метаданные 422, закодированные в единый поток данных. Метаданные 422 могут включать данные, указывающие на назначение весовых коэффициентов и/или отчетливость восприятия, данные, указывающие на пространственное положение в сцене, и/или другие данные. Кроме этого, некоторые данные могут быть включены в аудиоданные 421, в то время как другие данные могут быть включены в метаданные 422. В одном неограничивающем примере аудиоданные 421 включают данные, указывающие на назначение весовых коэффициентов и/или отчетливость восприятия, в то время как метаданные 422 включают данные пространственного положения.
Серверное устройство 410 содержит сервер/маршрутизатор 430 аудиопотока, микшер 470 и блок 480 обработки и/или мультиплексирования. В случаях, когда выполняется пространственный рендеринг, серверное устройство 410 может содержать пространственный вычислитель 440, блок 450 информации о глобальной сцене и управляющий сервер 460. Сервер/маршрутизатор 430 аудиопотока принимает аудиоданные 421 из множества клиентских устройств 420 и распределяет данные по множеству групп 431–433. Распределение по группам может быть основано на данных, включенных в аудиоданные 421, метаданные 422 или как в аудиоданные, так и в метаданные. Кроме этого, хотя на фиг. 4 изображены три группы 431–433, настоящее изобретение не ограничено этим количеством. В некоторых аспектах настоящего изобретения может быть предоставлено только две группы (или четыре и более групп). Сервер/маршрутизатор 430 аудиопотока может выполнять распределение по группам, в первую очередь выполняя ранжирование множества аудиопотоков на основании предопределенной метрики, например на основании весовых коэффициентов или отчетливости восприятия, описанных выше.
В одном иллюстративном аспекте настоящего изобретения сервер/маршрутизатор 430 аудиопотока принимает L аудиопотоков из L клиентских устройств 420, объединяет N аудиопотоков с наивысшими рангами в первую группу 431, объединяет M аудиопотоков с низшими рангами в третью группу 433 и объединяет аудиопотоки с промежуточным рангом во вторую группу 432. В вышеприведенном описании L, M и N являются независимыми целыми числами, так что L ≥ M + N. Аудиопотоки первой группы 431 могут быть перенаправлены в качестве выходящего потока 490 в один или более принимающих устройств посредством блока 480 обработки и/или мультиплексирования; и аудиопотоки третьей группы 433 могут быть исключены или проигнорированы. В некоторых аспектах настоящего изобретения звуковое содержимое аудиопотоков второй группы 432 добавляют с помощью микширования в один из аудиопотоков первой группы 431, чтобы таким образом перенаправить в качестве части выходящего потока 490. Вторая группа 432 может быть добавлена посредством микширования, например, в поток с наименьшим рангом первой группы 431. Количество потоков в каждой группе не ограничено каким-либо образом. В некоторых случаях первая группа 431 может включать единственный поток; в других случаях первая группа 431 может включать множество потоков. Принимающее устройство может представлять собой любое одно или более из множества клиентских устройств 420 и/или дополнительное устройство, отдельное от множества клиентских устройств 420.
В некоторых случаях N или M может быть равно нулю. То есть, в заданный момент времени все входящие аудиопотоки могут не содержать отчетливого содержимого и в этом случае первая группа 431 будет пустой (N = 0). Такая ситуация может происходить, например, когда аудиопотоки, соответствующие всем клиентским устройствам 420, включают значимое звуковое содержимое или голосовые данные, которые необходимо перенаправить в качестве части выходящего потока 490. Кроме этого, в заданный момент времени все входящие аудиопотоки могут содержать отчетливое содержимое и в этом случае третья группа 433 будет пустой (M = 0). Такая ситуация может происходить, например, когда аудиопотоки, соответствующие всем клиентским устройствам 420, являются беззвучными или включают только неголосовые данные.
Серверное устройство 410 может принимать все аудиопотоки из множества клиентских устройств 420 и выполнять мгновенную проверку принятых потоков в каждом кадре аудиокодека, чтобы таким образом определить потоки, которые являются значимыми для принимающего устройства. Группы могут обновляться со скоростью звуковых кадров или со скоростью, которая меньше скорости звуковых кадров. Более того, в случаях, когда есть несколько принимающих устройств, серверное устройство 410 (например, с помощью управляющего сервера 460) может вычислять группы 431–433 независимо для каждого принимающего устройства. Информация из блока 430 пространственных вычислений может быть предоставлена в блок 480 обработки и/или мультиплексирования для того, чтобы включить ее в выходящий поток 490.
Соответствующие клиентские устройства 420, которые выполняют роль принимающего устройства, могут иметь несколько отдельных кодеков для того, чтобы соответствовать возможным входящим потокам. Однако в этом случае клиентские устройства 420 не обязательно должны иметь кодеки для того, чтобы охватывать все возможные источники, а вместо этого могут включать некоторое количество кодеков, достаточное для обеспечения относительной непрерывности декодированного звука и пространственный рендеринг, если/когда потоки останавливаются и запускаются путем мгновенного выбора потоков для передачи в серверном устройстве 410. Поток, который резко остановился, может требовать обработки кодеком одного-двух кадров для того, чтобы затухать или возвращаться в нейтральное состояние.
В случае кодека частотной области, это сводится к очистке буфера декодирования кадра, который содержит затухающую часть перекрываемого окна. В случае кодека, основанного на модели или глубинной нейронной сети (deep neural network, DNN), это может представлять собой короткое экстраполирование траектории модели текущего и недавнего потоков в сочетании с подходящим затуханием.
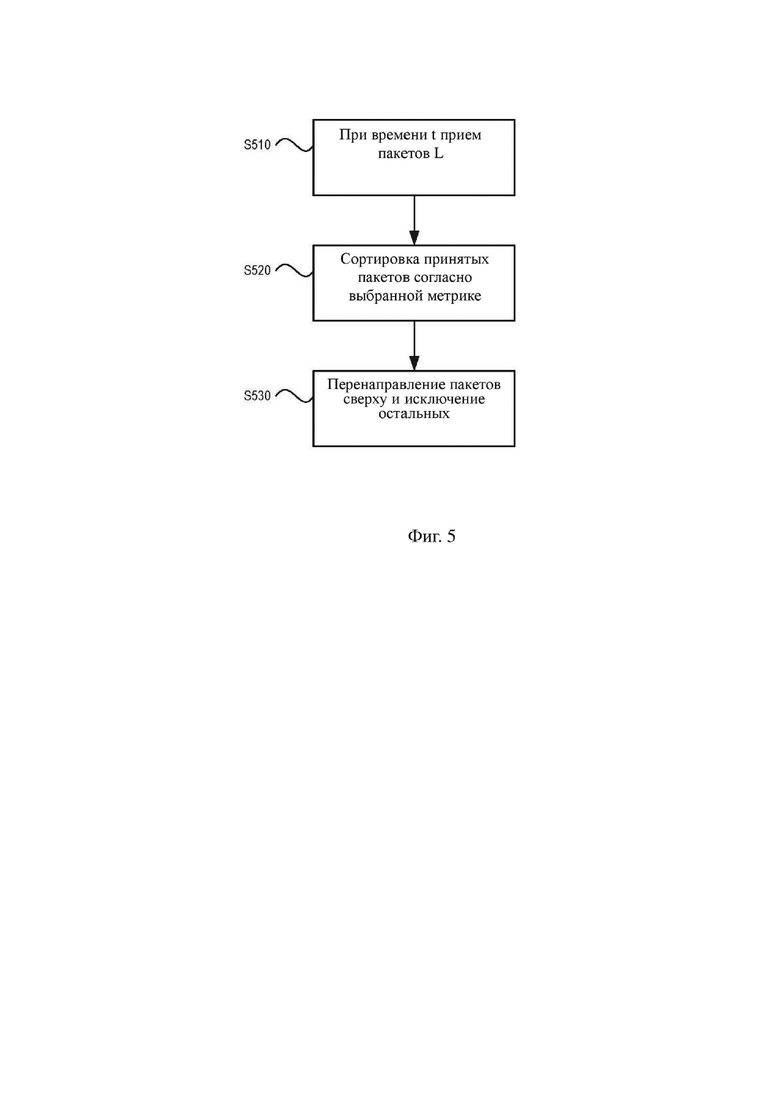
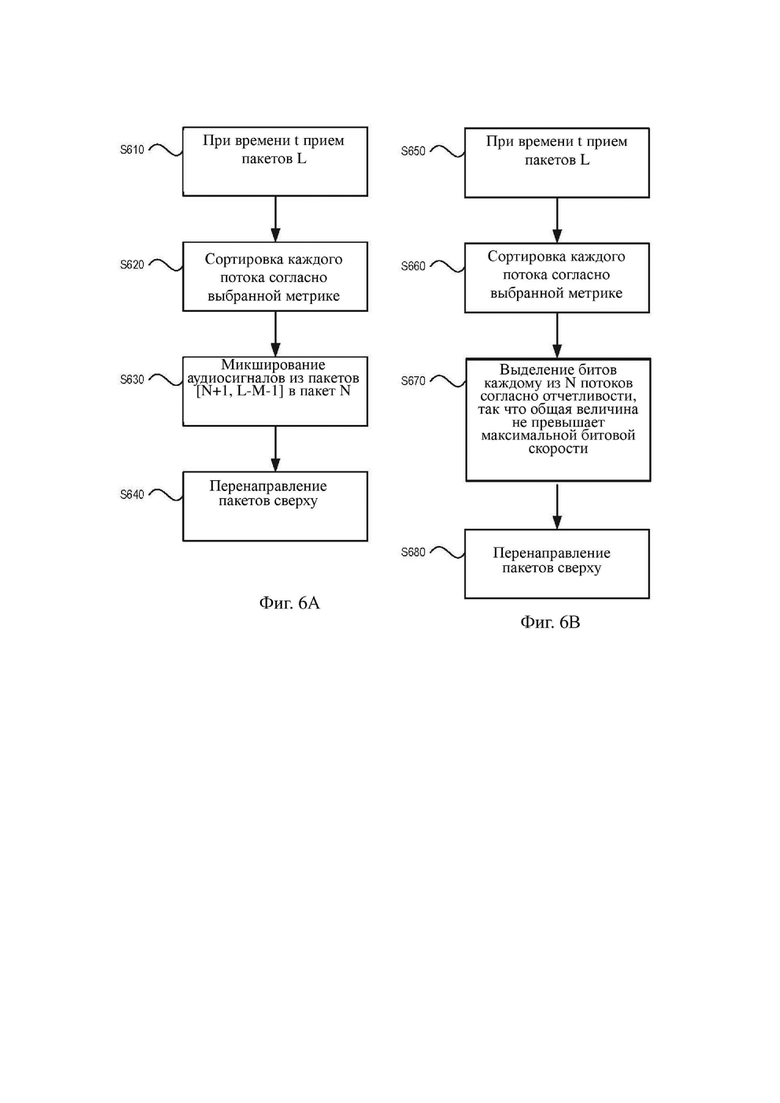
На фиг. 5 изображен иллюстративный алгоритм для определения групп, например групп 431–433, изображенных на фиг. 4. На фиг. 5 изображен иллюстративный алгоритм, с помощью которого N наиболее отчетливых потоков перенаправляются к клиентским устройствам. На этапе S510 серверное устройство, такое как серверное устройство 410, изображенное на фиг. 4, принимает несколько пакетов L. На этапе S520 серверное устройство сортирует принятые пакеты согласно выбранной метрике. Этап S520 может включать в первую очередь выполнение ранжирования множества пакетов на основании предопределенной метрики, например на основании весовых коэффициентов или отчетливости восприятия, описанных выше, и объединение аудиопотоков на основании их ранга, так что N наиболее отчетливых потоков объединяются в первую группу. На этапе S530 пакеты первой группы перенаправляют к принимающему устройству и остальные пакеты исключают или игнорируют.
На фиг. 6A изображен иллюстративный алгоритм, с помощью которого N наиболее отчетливых потоков перенаправляются к клиентским устройствам и аудиосигналы из потоков с промежуточной отчетливостью включены в качестве микшированного сигнала. На этапе S610 серверное устройство, такое как серверное устройство 410, изображенное на фиг. 4 принимает несколько пакетов L. На этапе S620 серверное устройство сортирует принятые пакеты согласно выбранной метрике. Этап S620 может включать в первую очередь выполнение ранжирования множества пакетов на основании предопределенной метрики, например на основании весовых коэффициентов или отчетливости восприятия, описанных выше, и объединение аудиопотоков на основании их ранга, так что N наиболее отчетливых потоков объединяются в первую группу, потоки с промежуточной отчетливостью объединяются во вторую группу и M наименее отчетливых потоков объединяются в третью группу. На этапе S630 аудиосигналы из потоков с промежуточной отчетливостью (то есть, потоков, которые не входят в N наиболее отчетливых и в M наименее отчетливых) добавляют посредством микширования в наименее отчетливый пакет первой группы. Если общее количество пакетов равно L, количество наиболее отчетливых пакетов равно N и количество наименее отчетливых пакетов равно M, потоки с промежуточной отчетливостью можно обозначить как группу [N+1, L-M-1] и наименее отчетливый пакет первой группы можно обозначить как пакет N. На этапе S640 пакеты первой группы, которые включают аудиосигналы из второй группы в качестве микшированного сигнала, перенаправляют к принимающему устройству и остальные M пакетов исключают или игнорируют.
Хотя, как указано выше, N и M не ограничены каким-либо образом, в некоторых аспектах настоящего изобретения N может быть равно двум или трем.
Существуют случаи, когда потоки, перенаправляемые от сервера, должны соответствовать максимальной общей битовой скорости. В этих случаях необходимо решить, как распределить биты между потоками. В предпочтительном подходе потокам с более высокой отчетливостью выделяют больше битов. На фиг. 6B изображен иллюстративный алгоритм для распределения битов между отдельными потоками, когда всего N перенаправленных потоков нужно ограничить фиксированной предопределенной максимальной битовой скоростью. В этом случае выделение битов каждому потоку осуществляется согласно метрике отчетливости, например на основании взвешенной энергии, так что каждый поток с меньшей отчетливостью получает столько же или меньше битов, чем выделено потоку с большей отчетливостью. Например, если общий «запас битовой скорости» составляет 48 кбит/сек с ограничением в три потока, то можно выделить 24 кбит/сек первому потоку и по 12 кбит/сек второму и третьему потокам. В этом случае 24 кбит/сек будет выделено потоку с наибольшей отчетливостью и по 12 кбит/сек будет выделено пакетам с наименьшей отчетливостью. На этапе S650 серверное устройство, такое как серверное устройство 410, изображенное на фиг. 4, принимает несколько пакетов L. На этапе S660 серверное устройство сортирует принятые пакеты согласно выбранной метрике. Этап S660 может включать в первую очередь выполнение ранжирования множества пакетов на основании предопределенной метрики, например на основании весовых коэффициентов или другой метрики отчетливости восприятия, описанных выше, и объединение аудиопотоков на основании их ранга, так что N наиболее отчетливых потоков объединяются в первую группу, потоки с промежуточной отчетливостью объединяются во вторую группу и M наименее отчетливых потоков объединяются в третью группу. На этапе S670 серверное устройство выделяет биты каждому из N потоков согласно отчетливости, так что общая величина не превышает максимальной битовой скорости. На этапе S680 пакеты первой группы, которые включают аудиосигналы из второй группы в качестве микшированного сигнала, перенаправляют к принимающему устройству и остальные M пакетов исключают или игнорируют.
Хотя, как указано выше, N и M не ограничены каким-либо образом, в некоторых аспектах настоящего изобретения N может быть равно двум или трем.
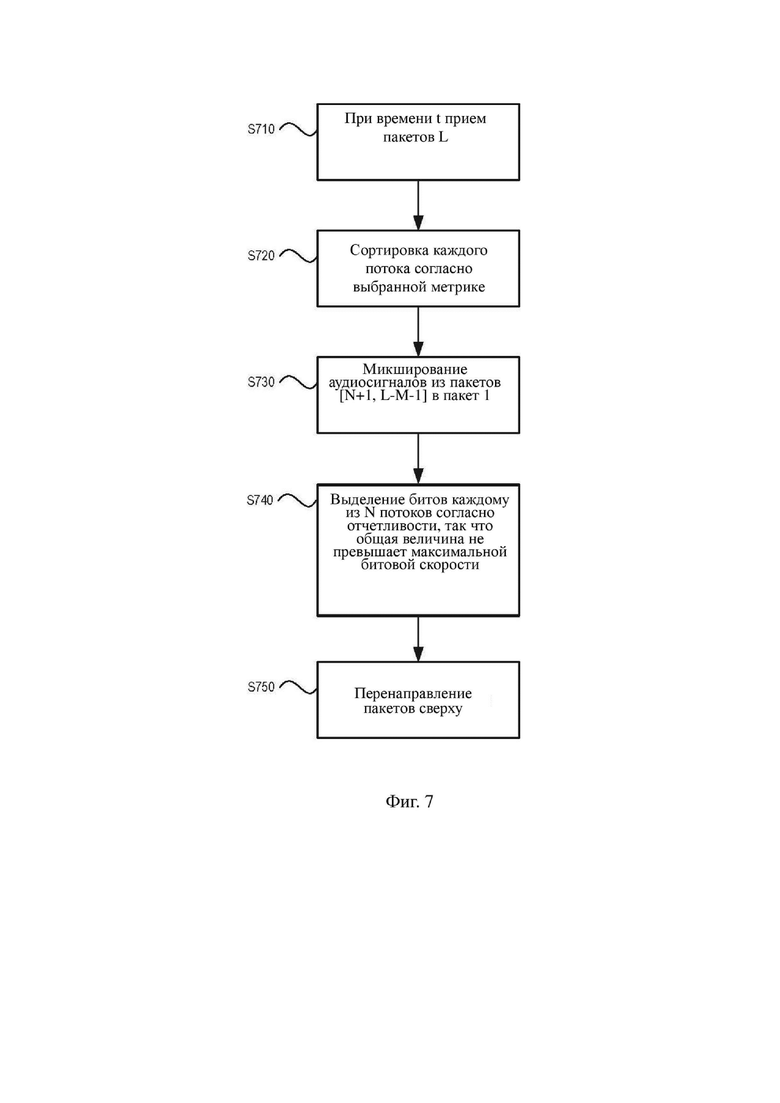
На фиг. 7 изображен другой иллюстративный алгоритм для распределения битов между отдельными потоками, когда всего N перенаправленных потоков нужно ограничить фиксированной предопределенной максимальной битовой скоростью. В этом алгоритме потоки ниже определенной пороговой величины добавляют посредством микширования в пакет с наивысшей отчетливостью и затем каждому потоку выделяют биты согласно отчетливости, причем поток с меньшей отчетливостью получает столько же или меньше битов, чем поток с большей отчетливостью. На этапе S710 серверное устройство, такое как серверное устройство 410, изображенное на фиг. 4, принимает несколько пакетов L. На этапе S720 серверное устройство сортирует принятые пакеты согласно выбранной метрике. Этап S720 может включать в первую очередь выполнение ранжирования множества пакетов на основании предопределенной метрики, например на основании весовых коэффициентов или отчетливости восприятия, описанных выше, и объединение аудиопотоков на основании их ранга, так что N наиболее отчетливых потоков объединяются в первую группу, потоки с промежуточной отчетливостью объединяются во вторую группу и M наименее отчетливых потоков объединяются в третью группу. На этапе S730 аудиосигналы из потоков с промежуточной отчетливостью (то есть, потоков, которые не входят в N наиболее отчетливых и в M наименее отчетливых) добавляют посредством микширования в пакет 1, что соответствует потоку с наибольшей отчетливостью. На этапе S7400 серверное устройство выделяет биты каждому из N потоков согласно отчетливости, так что общая величина не превышает максимальной битовой скорости. На этапе S750 пакеты первой группы, которые включают аудиосигналы из второй группы в качестве микшированного сигнала, перенаправляют к принимающему устройству и остальные M пакетов исключают или игнорируют.
Хотя, как указано выше, N и M не ограничены каким-либо образом, в некоторых аспектах настоящего изобретения N может быть равно двум или трем.
Применения
Касательно процессов, систем, способов, эвристики и т. д., описанных в настоящем документе, следует понимать, что хотя этапы таких процессов и т. д. были описаны как происходящие согласно определенной упорядоченной последовательности, такие процессы могут быть реализованы на практике с описанными этапами, выполняемыми в порядке, отличающемся от описанного в настоящем документе. Также следует понимать, что определенные этапы могут выполняться одновременно, что могут быть добавлены другие этапы или что определенные этапы, описанные в настоящем документе, могут быть пропущены. Другими словами, описания процессов в настоящем документе предоставлены с целью иллюстрации определенных вариантов осуществления и никоим образом не должны быть истолкованы как ограничение формулы изобретения.
Вышеизложенные примеры были описаны в первую очередь применительно к управлению и рендерингу сцен для голосовых сигналов; однако настоящее изобретение не следует воспринимать как применимое или характерное только для голосового содержимого. Идеи, описанные в настоящем изобретении, можно в общем расширить на любые сигналы, имеющие очень кратковременный характер, включая семантическое и потенциально интерактивное информационное содержимое. Вышеизложенные описания человеческого восприятия голоса и подобных голосу звуков предоставлены в качестве примеров, но не ограничивают использование системы.
Кроме этого, хотя в настоящем изобретении в общем упомянуты аспекты пространственной информации применительно к повторному комбинированию и рендерингу аудиосигнала в конечном клиентском устройстве, настоящее изобретение может быть расширено на ситуации, где есть аудиопотоки, которые имеют явную информацию об их предопределенном положении в потоке, идентификатор и информацию на стороне клиента или решения по поводу того, где выполнять рендеринг потока, или некоторую комбинацию перечисленного. Эта информация может дополнительно комбинироваться с дополнительной информацией управления сценой из других систем управления аудиосигналами. Таким образом, пространственное применение представляет расширенное множество, также охватывающее монофонические сигналы, где большая часть информации о направлении и/или расстоянии, предназначенной для управления рендерингом, может игнорироваться или отсутствовать. Когда рендеринг сцены выполняется с помощью технологий пространственного звука с целью создания пространственного образа пользователю, этот звук может быть доставлен многими разными способами. Например, аудиопотоки могут быть доставлены посредством наушников (бинауральный звук) и имитировать распространение звука и пространственную акустику, которые происходили бы, если бы звук на самом деле присутствовал вблизи пользователя; в качестве альтернативы можно управлять выводом нескольких положений источников речи вокруг слушателя для создания ощущения приблизительно точного или эффективно воспринимаемого звукового поля.
Настоящее изобретение ссылается на группу аудиопотоков, каждый из которых происходит из конкретного источника, который может обладать активностью, независимой от других источников. Однако каждый из этих аудиопотоков не обязательно должен представлять только один звуковой канал. Аудиопотоки собственно могут обладать характеристиками пространственного звука, которые уже частично закодированы в них; например, поток может представлять собой бинауральный звук или некоторую форму многоканального пространственного звука. Кроме этого, в заданном потоке могут быть дополнительные слои и иерархический подход для представления верности воспроизведения как применительно к точности сигнала (например, применительно к скорости битового потока), так и к пространственной точности (например, применительно к слоям или каналам).
В различных реализациях технологии, раскрытые в настоящем техническом описании, применимы, но без ограничения, к кодированию многоканального звука, где система связи может представлять собой систему кодирования звука, медиасервер может представлять собой устройство кодирования звука и клиентское устройство может представлять собой источник звука.
Различные аспекты настоящего изобретения можно понять из следующих пронумерованных примерных вариантов осуществления (ППВО):
ППВО 1. Система связи, содержащая:
медиасервер, выполненный с возможностью приема множества аудиопотоков от соответствующего множества клиентских устройств, причем медиасервер включает электронную схему, выполненную с возможностью:
ранжирования множества аудиопотоков на основании предопределенной метрики,
объединения первой части множества аудиопотоков в первую группу, причем первая часть множества аудиопотоков представляет собой N аудиопотоков с наивысшими рангами,
объединения второй части множества аудиопотоков во вторую группу, причем вторая часть множества аудиопотоков представляет собой M аудиопотоков с самыми низкими рангами,
перенаправления соответствующих аудиопотоков первой группы в принимающее устройство, и
удаления соответствующих аудиопотоков второй группы,
причем N и M являются независимыми целыми числами.
ППВО 2. Система связи по ППВО 1, при этом электронная схема дополнительно выполнена с возможностью:
объединения третьей части множества аудиопотоков в третью группу, причем третья часть множества аудиопотоков представляет собой аудиопотоки с ранжированием между первой частью и второй частью, и
добавления звукового содержимого третьей группы путем микширования в один из аудиопотоков первой группы.
ППВО 3. Система связи по ППВО 1 или 2, при этом соответствующие аудиопотоки из множества аудиопотоков включают аудиоданные и метаданные, причем метаданные включают данные, указывающие на назначение весовых коэффициентов.
ППВО 4. Система связи по ППВО 3, при этом назначение весовых коэффициентов основано на отчетливости восприятия.
ППВО 5. Система связи по ППВО 4, при этом каждому потоку выделяют биты, причем потоки с большей отчетливостью получают столько же или больше битов, чем потоки с меньшей отчетливостью.
ППВО 6. Система связи по любому из ППВО 3–5, при этом метаданные дополнительно включают данные, указывающие на пространственное положение в сцене.
ППВО 7. Система связи по любому из ППВО 3–6, при этом назначение весовых коэффициентов преуменьшает содержимое с частотой ниже 1000 Гц и выделяет содержимое с частотой выше 4000 Гц.
ППВО 8. Система связи по любому из ППВО 1–7, при этом принимающее устройство представляет собой одно из множества клиентских устройств.
ППВО 9. Способ связи, включающий:
прием множества аудиопотоков от соответствующего множества клиентских устройств;
ранжирование множества аудиопотоков на основании предопределенной метрики;
объединение первой части множества аудиопотоков в первую группу, причем первая часть множества аудиопотоков представляет собой N аудиопотоков с наивысшими рангами;
объединение второй части множества аудиопотоков во вторую группу, причем вторая часть множества аудиопотоков представляет собой M аудиопотоков с самыми низкими рангами;
перенаправление соответствующих аудиопотоков первой группы в принимающее устройство; и
удаление соответствующих аудиопотоков второй группы,
причем N и M являются независимыми целыми числами.
ППВО 10. Способ связи по ППВО 9, при этом способ дополнительно включает:
объединение третьей части множества аудиопотоков в третью группу, причем третья часть множества аудиопотоков представляет собой аудиопотоки с ранжированием между первой частью и второй частью, и
добавление звукового содержимого третьей группы путем микширования в один из аудиопотоков первой группы.
ППВО 11. Способ связи по ППВО 9 или 10, при этом соответствующие аудиопотоки из множества аудиопотоков включают аудиоданные и метаданные, причем метаданные включают данные, указывающие на назначение весовых коэффициентов.
ППВО 12. Способ связи по ППВО 11, при этом назначение весовых коэффициентов основано на отчетливости восприятия.
ППВО 13. Способ связи по ППВО 12, при этом каждому потоку выделяют биты, причем потоки с большей отчетливостью получают столько же или больше битов, чем потоки с меньшей отчетливостью.
ППВО 14. Способ связи по любому из ППВО 11–13, при этом метаданные дополнительно включают данные, указывающие на пространственное положение в сцене.
ППВО 15. Способ связи по любому из ППВО 11–14, при этом назначение весовых коэффициентов преуменьшает содержимое с частотой ниже 1000 Гц и выделяет содержимое с частотой выше 4000 Гц.
ППВО 16. Способ связи по любому из ППВО 9–15, при этом принимающее устройство представляет собой одно из множества клиентских устройств.
ППВО 17. Постоянный машиночитаемый носитель с сохраненными на нем командами, которые при их выполнении процессором медиасервера приводят к выполнению медиасервером операций, включающих:
прием множества аудиопотоков от соответствующего множества клиентских устройств;
ранжирование множества аудиопотоков на основании предопределенной метрики;
объединение первой части множества аудиопотоков в первую группу, причем первая часть множества аудиопотоков представляет собой N аудиопотоков с наивысшими рангами;
объединение второй части множества аудиопотоков во вторую группу, причем вторая часть множества аудиопотоков представляет собой M аудиопотоков с самыми низкими рангами;
перенаправление соответствующих аудиопотоков первой группы в принимающее устройство; и
удаление соответствующих аудиопотоков второй группы,
причем N и M являются независимыми целыми числами.
ППВО 18. Постоянный машиночитаемый носитель по ППВО 17, при этом дополнительно содержит:
объединение третьей части множества аудиопотоков в третью группу, причем третья часть множества аудиопотоков представляет собой аудиопотоки с ранжированием между первой частью и второй частью, и
добавление звукового содержимого третьей группы путем микширования в один из аудиопотоков первой группы.
ППВО 19. Постоянный машиночитаемый носитель по ППВО 17 или 18, при этом соответствующие аудиопотоки из множества аудиопотоков включают аудиоданные и метаданные, причем метаданные включают данные, указывающие на назначение весовых коэффициентов.
ППВО 20. Постоянный машиночитаемый носитель по ППВО 19, при этом назначение весовых коэффициентов основано на отчетливости восприятия.
ППВО 21. Постоянный машиночитаемый носитель по ППВО 20, при этом каждому потоку выделяют биты, причем потоки с большей отчетливостью получают столько же или больше битов, чем потоки с меньшей отчетливостью.
ППВО 22. Постоянный машиночитаемый носитель по любому из ППВО 19–21, при этом метаданные дополнительно включают данные, указывающие на пространственное положение в сцене.
ППВО 23. Постоянный машиночитаемый носитель по любому из ППВО 19–22, при этом назначение весовых коэффициентов преуменьшает содержимое с частотой ниже 1000 Гц и выделяет содержимое с частотой выше 4000 Гц.
Изобретение относится к средствам для осуществления аудиосвязи. Технический результат заключается в повышении эффективности осуществления аудиосвязи. Принимают множество аудиопотоков от соответствующего множества клиентских устройств. Ранжируют множество аудиопотоков на основании предопределенной метрики, причем метрика для аудиопотока включает взвешенную энергию кадра аудиопотока. Взвешенную энергию кадра аудиопотока определяют с помощью весовой функции, которая преуменьшает содержимое с частотой в спектре ниже 1000 Гц и усиливает содержимое с частотой в спектре выше 4000 Гц. Объединяют первую часть множества аудиопотоков в первую группу, причем первая часть множества аудиопотоков представляет собой N аудиопотоков с наивысшими рангами. Объединяют вторую часть множества аудиопотоков во вторую группу, причем вторая часть множества аудиопотоков представляет собой M аудиопотоков с самыми низкими рангами. Перенаправляют аудиопотоки первой группы в принимающее устройство. Удаляют аудиопотоки второй группы. N и M являются независимыми целыми числами. 3 н. и 14 з.п. ф-лы, 12 ил.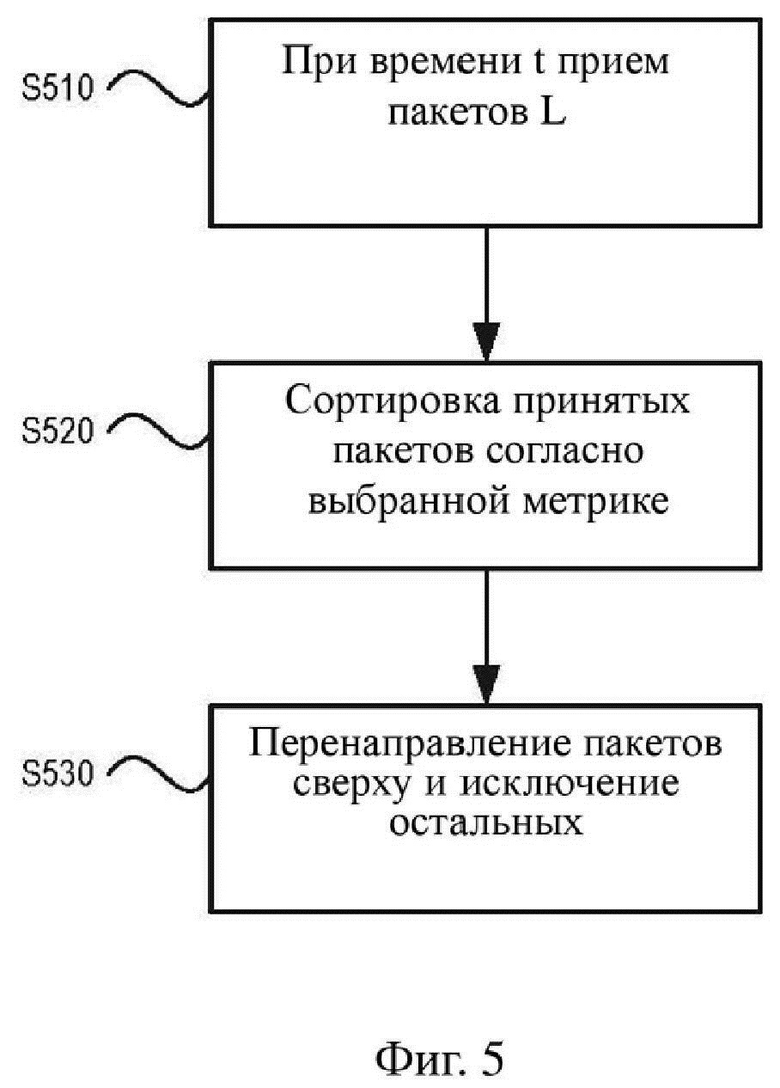
1. Система связи, содержащая:
медиасервер, выполненный с возможностью приема множества аудиопотоков от соответствующего множества клиентских устройств, причем медиасервер включает электронную схему, выполненную с возможностью:
ранжирования множества аудиопотоков на основании предопределенной метрики; причем метрика для аудиопотока включает взвешенную энергию кадра аудиопотока; причем взвешенную энергию кадра аудиопотока определяют с помощью весовой функции, которая преуменьшает содержимое с частотой в спектре ниже 1000 Гц и усиливает содержимое с частотой в спектре выше 4000 Гц,
объединения первой части множества аудиопотоков в первую группу, причем первая часть множества аудиопотоков представляет собой N аудиопотоков с наивысшими рангами,
объединения второй части множества аудиопотоков во вторую группу, причем вторая часть множества аудиопотоков представляет собой M аудиопотоков с самыми низкими рангами,
перенаправления соответствующих аудиопотоков первой группы в принимающее устройство, и
удаления соответствующих аудиопотоков второй группы,
причем N и M являются независимыми целыми числами.
2. Система связи по п. 1, отличающаяся тем, что электронная схема дополнительно выполнена с возможностью:
объединения третьей части множества аудиопотоков в третью группу, причем третья часть множества аудиопотоков представляет собой аудиопотоки с ранжированием между первой частью и второй частью, и
добавления звукового содержимого третьей группы путем микширования в один из аудиопотоков первой группы.
3. Система связи по п. 1 или 2, отличающаяся тем, что соответствующие аудиопотоки из множества аудиопотоков включают аудиоданные и метаданные, причем метаданные аудиопотока включают данные, указывающие на взвешенную энергию кадра аудиопотока.
4. Система связи по любому из пп. 1-3, отличающаяся тем, что каждому потоку, который будет перенаправлен сервером, выделяют биты, причем потоки с более высоким рангом получают столько же или больше битов, чем потоки с менее высоким рангом.
5. Система связи по п. 3 или 4, отличающаяся тем, что метаданные аудиопотока дополнительно включают данные, указывающие на пространственное положение в сцене.
6. Система связи по любому из пп. 1-5, отличающаяся тем, что принимающее устройство представляет собой одно из множества клиентских устройств.
7. Способ связи, включающий:
прием множества аудиопотоков от соответствующего множества клиентских устройств;
ранжирование множества аудиопотоков на основании предопределенной метрики; причем метрика для аудиопотока включает взвешенную энергию кадра аудиопотока; причем взвешенную энергию кадра аудиопотока определяют с помощью весовой функции, которая преуменьшает содержимое с частотой в спектре ниже 1000 Гц и усиливает содержимое с частотой в спектре выше 4000 Гц;
объединение первой части множества аудиопотоков в первую группу, причем первая часть множества аудиопотоков представляет собой N аудиопотоков с наивысшими рангами;
объединение второй части множества аудиопотоков во вторую группу, причем вторая часть множества аудиопотоков представляет собой M аудиопотоков с самыми низкими рангами;
перенаправление соответствующих аудиопотоков первой группы в принимающее устройство; и
удаление соответствующих аудиопотоков второй группы,
причем N и M являются независимыми целыми числами.
8. Способ связи по п. 7, отличающийся тем, что дополнительно включает:
объединение третьей части множества аудиопотоков в третью группу, причем третья часть множества аудиопотоков представляет собой аудиопотоки с ранжированием между первой частью и второй частью, и
добавление звукового содержимого третьей группы путем микширования в один из аудиопотоков первой группы.
9. Способ связи по п. 7 или 8, отличающийся тем, что соответствующие аудиопотоки из множества аудиопотоков включают аудиоданные и метаданные, причем метаданные аудиопотока включают данные, указывающие на взвешенную энергию кадра аудиопотока.
10. Способ связи по любому из пп. 7-9, отличающийся тем, что каждому потоку выделяют биты, причем потоки с более высоким рангом получают столько же или больше битов, чем потоки с менее высоким рангом.
11. Способ связи по п. 9 или 10, отличающийся тем, что метаданные аудиопотока дополнительно включают данные, указывающие на пространственное положение в сцене.
12. Способ связи по любому из пп. 7-11, отличающийся тем, что принимающее устройство представляет собой одно из множества клиентских устройств.
13. Постоянный машиночитаемый носитель с сохраненными на нем командами, которые при их выполнении процессором медиасервера приводят к выполнению медиасервером операций, включающих:
прием множества аудиопотоков от соответствующего множества клиентских устройств;
ранжирование множества аудиопотоков на основании предопределенной метрики; причем метрика для аудиопотока включает взвешенную энергию кадра аудиопотока; причем взвешенную энергию кадра аудиопотока определяют с помощью весовой функции, которая преуменьшает содержимое с частотой в спектре ниже 1000 Гц и усиливает содержимое с частотой в спектре выше 4000 Гц;
объединение первой части множества аудиопотоков в первую группу, причем первая часть множества аудиопотоков представляет собой N аудиопотоков с наивысшими рангами;
объединение второй части множества аудиопотоков во вторую группу, причем вторая часть множества аудиопотоков представляет собой M аудиопотоков с самыми низкими рангами;
перенаправление соответствующих аудиопотоков первой группы в принимающее устройство; и
удаление соответствующих аудиопотоков второй группы,
причем N и M являются независимыми целыми числами.
14. Постоянный машиночитаемый носитель по п. 13, отличающийся тем, что дополнительно включает:
объединение третьей части множества аудиопотоков в третью группу, причем третья часть множества аудиопотоков представляет собой аудиопотоки с ранжированием между первой частью и второй частью, и
добавление звукового содержимого третьей группы путем микширования в один из аудиопотоков первой группы.
15. Постоянный машиночитаемый носитель по п. 13 или 14, отличающийся тем, что соответствующие аудиопотоки из множества аудиопотоков включают аудиоданные и метаданные, причем метаданные аудиопотока включают данные, указывающие на взвешенную энергию кадра аудиопотока.
16. Постоянный машиночитаемый носитель по любому из пп. 13-15, отличающийся тем, что каждому потоку выделяют биты, причем потоки с более высоким рангом получают столько же или больше битов, чем потоки с менее высоким рангом.
17. Постоянный машиночитаемый носитель по любому из пп. 13-16, отличающийся тем, что метаданные аудиопотока дополнительно включают данные, указывающие на пространственное положение в сцене.
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| US 9521263 B2, 13.12.2016 | |||
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| US 9877107 B2, 23.01.2018 | |||
| ИНТЕЛЛЕКТУАЛЬНЫЙ СПОСОБ, СИСТЕМА И УЗЕЛ ОГРАНИЧЕНИЯ АУДИО | 2007 |
|
RU2398361C2 |

