ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
[0001] Настоящее изобретение относится в общем плане к цифровой обработке видеосигналов и, в частности, к способу, устройству и системе для кодирования и декодирования остаточных коэффициентов единицы преобразования (TU), причем данная единица преобразования (TU) может иметь квадратную форму или неквадратную форму.
УРОВЕНЬ ТЕХНИКИ
[0002] В настоящее время существует множество приложений для кодирования видеоданных, включая приложения для передачи и хранения видеоданных. Также было разработано множество стандартов кодирования видеоданных, и в настоящий момент в стадии разработки находятся другие. Последние разработки в области стандартизации кодирования видеоданных привели к формированию группы под названием «Объединенная команда по видеокодированию (JCT-VC)». Данная объединенная команда по видеокодированию (JCT-VC) включает в себя членов исследовательской группы 16, вопроса 6 (SG16/Q6) сектора стандартизации телекоммуникаций (ITU-T) международного союза телекоммуникаций (ITU), известных как «Экспертная группа в области кодирования видеоданных (VCEG)», а также членов международных организаций по стандартизации/объединенного технического комитета 1 международной электротехнической комиссии/подкомитета 29/рабочей группы 11 (ISO/IEC JTC1/SC29/WG11), также известных как «Экспертная группа по вопросам движущегося изображения (MPEG)».
[0003] Объединенная команда по видеокодированию (JCT-VC) имеет целью выпуск нового стандарта кодирования видеоданных с целью значительно превзойти по эффективности существующий в настоящий момент стандарт кодирования видеоданных, известный как «H.264/MPEG-4 AVC». Данный стандарт H.264/MPEG-4 AVC сам по себе представляет существенное усовершенствование предшествующих стандартов кодирования видеоданных, таких как MPEG-4 и ITU-T H.263. Новый стандарт кодирования видеоданных, находящийся в стадии разработки, был назван «Высокоэффективное видеокодирование (HEVC)». Объединенная команда по видеокодированию JCT-VC также в настоящий период рассматривает проблемы осуществления, проистекающие из технологии, предложенной для высокоэффективного видеокодирования (HEVC), которые создают сложности при масштабировании осуществлений стандарта с целью функционирования с высокими разрешающими способностями или высокими скоростями передачи кадров.
[0004] Одной областью стандарта кодирования видеоданных H.264/MPEG-4 AVC, представляющей сложности для достижения высокой степени сжатия, является кодирование остаточных коэффициентов, используемых для представления видеоданных. Видеоданные формируются посредством последовательности кадров, причем каждый кадр имеет двумерный массив выборок. Обычно кадры включают в себя один канал яркости и два канала цветности. Каждый кадр раскладываeтся на один или более слайсов. Каждый слайс содержит одну или более наибольших единиц кодирования (LCU). Эти наибольшие единицы кодирования (LCU) имеют фиксированный размер, с краевыми размерностями, являющимися степенью двойки и имеющими равную ширину и высоту, например 64 выборки яркости. Одной особенностью находящегося в стадии разработки стандарта эффективного видеокодирования (HEVC) является особенность «слайсов мелкой гранулярности». Когда разрешена особенность слайсов мелкой гранулярности, границы слайсов не ограничиваются границами наибольшей единицы кодирования (LCU). Слайсы мелкой гранулярности могут быть разрешены на уровне битового потока.
[0005] Дерево кодирования разрешает подразделение каждой наибольшей единицы кодирования (LCU) на четыре области равных размеров, каждую имеющую половину ширины и высоты родительской наибольшей единицы кодирования (LCU). Каждая из областей может быть дополнительно подразделена на четыре области равных размеров. Там, где область не подразделяется дополнительно, существует единица кодирования, занимающая весь объем области. Такой процесс подразделения может применяться рекурсивно до тех пор, пока размер области не достигнет размера наименьшей единицы кодирования (SCU), и не будет выведен размер единицы кодирования (CU) наименьшей единицы кодирования (SCU). Рекурсивное подразделение наибольшей единицы кодирования на иерархию единиц кодирования имеет структуру дерева квадрантов и именуется деревом кодирования. Единицы кодирования (CU) или области имеют характеристику, известную как их «глубина», которая относится к их положению в дереве кодирования с точки зрения уровня в иерархии подразделений. Этот процесс подразделения кодируется в битовом потоке в качестве последовательности арифметически кодированных флагов. Когда разрешены слайсы медкой гранулярности, точно определяется пороговое значение, которое определяет наименьший размер единицы кодирования, при котором может существовать граница слайса.
[0006] В дереве кодирования существует набор единиц кодирования, которые не подвергаются дополнительному подразделению, являясь теми единицами кодирования, которые занимают концевые узлы дерева кодирования. На этих единицах кодирования существуют деревья преобразований. Дерево преобразований может дополнительно раскладывать единицу кодирования с использованием структуры дерева квадрантов, как это используется для дерева кодирования. На концевых узлах дерева преобразований осуществляется кодирование остаточных данных с использованием единиц преобразования (TU). В отличие от дерева кодирования, дерево преобразований может подразделять единицы кодирования на единицы преобразования, имеющие неквадратную форму. Дополнительно, структура дерева преобразований не требует, чтобы единицы преобразования (TU) занимали всю область, обеспечиваемую родительской единицей кодирования.
[0007] Каждая единица кодирования на концевых узлах деревьев кодирования подразделяется на один или более массивов выборок предсказанных данных, каждая известна как единица предсказания (PU). Каждая единица предсказания (PU) содержит предсказание части данных входного кадра, полученное посредством применения процесса интра-предсказания (внутреннего предсказания) или процесса интер-предсказания (внешнего предсказания). Для кодирования единиц предсказания (PU) внутри единицы кодирования (CU) может быть использовано несколько способов. Одна единица предсказания (PU) может занимать весь объем области единицы кодирования (CU), либо единица кодирования (CU) может быть разделена на две прямоугольных единицы предсказания (PU) равных размеров, либо горизонтальных, либо вертикальных. В дополнение к этому, единицы кодирования (CU) могут быть разделены на четыре квадратных единицы предсказания (PU) равных размеров.
[0008] Видеокодер осуществляет сжатие видеоданных в битовый поток посредством преобразования видеоданных в последовательность элементов синтаксиса. В рамках находящегося в стадии разработки стандарта эффективного видеокодирования (HEVC), с использованием схемы арифметического кодирования, идентичной схеме, определенной в стандарте сжатия видеоданных MPEG4-AVC H.264, определяется схема контекстно-зависимого адаптивного двоичного арифметического кодирования (CABAC). В находящемся в стадии разработки стандарте эффективного видеокодирования (HEVC), когда используется контекстно-зависимое адаптивное двоичное арифметическое кодирование (CABAC), каждый элемент синтаксиса выражается в качестве последовательности бинов (ячеек), где бины выбираются из набора доступных бинов. Данный набор доступных бинов получают из контекстной модели, с одним контекстом на бин. Каждый контекст удерживает вероятное значение бина («valMPS») и вероятностное состояние для операции арифметического кодирования или арифметического декодирования. Следует отметить, что бины также могут быть кодированными обходом (в режиме обхода), когда нет ассоциирования с контекстом. Кодированные обходом бины потребляют один бит в битовом потоке и, вследствие этого, приспособлены для бинов с равной вероятностью имеющих значение ноль или имеющих значение единица. Создание такой последовательности бинов из элемента синтаксиса известно как «бинаризация» (преобразование в двоичную форму) элементов синтаксиса.
[0009] В видеокодере или видеодекодере, по мере того, как отдельная информация контекста становится доступной для каждого бина, выбор контекста для бинов обеспечивает средство для улучшения эффективности кодирования. В частности, эффективность кодирования может быть улучшена посредством выбора конкретного бина, так чтобы статистические характеристики от предыдущих экземпляров бина, где была использована ассоциированная информация контекста, коррелировали со статистическими характеристиками текущего экземпляра бина. Такой выбор контекста часто использует пространственно локальную информацию для определения оптимального контекста.
[0010] В находящемся в стадии разработки стандарте эффективного видеокодирования (HEVC), а также в стандарте H.264/MPEG-4 AVC, получают предсказание для текущего блока на основе данных опорных выборок либо из других кадров, либо из соседних областей внутри текущего блока, которые были декодированы ранее. Разность между предсказанием и данными желаемой выборки известна как остаток. Представление частотной области для остатка представляет собой двумерный массив остаточных коэффициентов. Согласно правилу, остаточные коэффициенты, представляющие низкочастотную информацию, содержит верхний левый угол двумерного массива.
[0011] Один аспект производительности находящегося в стадии разработки стандарта эффективного видеокодирования (HEVC) относится к способности кодирования и декодирования видеоданных с высокими скоростями передачи битов. Схема контекстно-зависимого адаптивного двоичного арифметического кодирования (CABAC), используемая в находящемся в стадии разработки стандарте эффективного видеокодирования (HEVC), поддерживает режим работы «равной вероятности», именуемый как «кодирование обходом». В этом режиме бин не является ассоциированным с контекстом из контекстной модели, и поэтоиму не существует этапа обновления контекстной модели. В этом режиме является возможным параллельное считывание множественных смежных бинов из битового потока при условии, что каждый бин является кодированным обходом, что увеличивает производительность. Например, реализации аппаратного обеспечения могут осуществлять параллельную запись/считывание групп смежных, кодированых обходом данных с целью увеличения производительности кодирования/декодирования битового потока.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0012] Целью настоящего изобретения является, по существу, преодоление или, по меньшей мере, усовершенствование одного или более недостатков существующих компоновок.
[0013] В соответствии с одним аспектом настоящего раскрытия изобретения, обеспечивается способ декодирования множества единиц кодирования из битового потока видеоданных, причем способ содержит этапы, на которых:
определяют структуру единицы кодирования упомянутого множества единиц кодирования из первого блока данных битового потока, причем структура единицы кодирования описывает разделение единицы кодирования на множество единиц кодирования;
декодируют, согласно определенной структуре единицы кодирования, закодированные обходом данные для множества единиц кодирования из второго блока данных битового потока;
декодируют, согласно определенной структуре единицы кодирования, остаточные данные для множества единиц кодирования из третьего блока данных битового потока; и
формируют множество единиц кодирования из битового потока с использованием остаточных данных и закодированных обходом данных.
[0014] В предпочтительном варианте осуществления способ дополнительно содержит этап, на котором определяют размер второго блока данных согласно определенной структуре единицы кодирования.
[0015] В предпочтительном варианте осуществления способ дополнительно содержит этап, на котором определяют значение флага разбиения так, чтобы когда текущая единица кодирования больше, чем меньшая единица кодирования, флаг значения разбиения декодировался из битового потока, а где текущая единица кодирования равна по размеру наименьшей единице кодирования, флаг значения разбиения выводился равным нулю. Эта реализация может дополнительно содержать этап, на котором используют определенное значение флага разбиения для определения, находится ли структура единицы кодирования на концевом узле.
[0016] В другой реализации битовый поток кодирует флаг разрешения слайсов мелкой гранулярности в начале каждой наибольшей единицы кодирования, так чтобы когда слайсы мелкой гранулярности не разрешены для наибольшей единицы кодирования, способ применялся к этой наибольшей единице кодирования (LCU), а когда слайсы мелкой гранулярности разрешены для наибольшей единицы кодирования, способ применялся к каждой подразделенной единице кодирования равной по размеру пороговому значению слайса мелкой гранулярности.
[0017] В предпочтительном варианте осуществления оставшийся режим единицы кодирования упомянутого множества единиц кодирования кодируется с использованием кода с переменной длиной слова, упомянутый способ дополнительно содержит этап, на котором вычисляют минимальную длину на основе значения флага наиболее вероятного режима и размера единицы предсказания, ассоциированного с единицей кодирования.
[0018] В желательном варианте осуществления оставшиеся режимы упомянутого множества единиц кодирования кодируются с использованием кода с переменной длиной слова, упомянутый способ дополнительно содержит этап, на котором вычисляют минимальную длину на основе структуры единицы кодирования, значений флага наиболее вероятного режима и размеров единицы предсказания, ассоциированных с множеством единиц кодирования.
[0019] В преимущественном варианте, когда кодированные обходом данные имеют неизвестную длину, способ дополнительно содержит этапы, на которых осуществляют доступ к битовому потоку для определения сегмента данных, содержащего по меньшей мере некоторые кодированные обходом данные, декодируют индексы наиболее вероятного режима и оставшиеся режимы из данного сегмента данных, и устанавливают длину нарастающего итога декодированных данных, так что когда все кодированные обходом данные декодированы из сегмента данных, длина нарастающего итога затем потребляется из битового потока.
[0020] В соответствии с одним другим аспектом настоящего раскрытия изобретения, обеспечивается способ кодирования множества единиц кодирования в битовый поток видеоданных, причем способ содержит этапы, на которых:
кодируют структуру единицы кодирования упомянутого множества единиц кодирования для формирования первого блока данных битового потока, причем структура единицы кодирования описывает разделение единицы кодирования на множество единиц кодирования;
кодируют, согласно структуре единицы кодирования, закодированные обходом данные для множества единиц кодирования для формирования второго блока данных битового потока; и
кодируют, согласно структуре единицы кодирования, остаточные данные для множества единиц кодирования для формирования третьего блока данных битового потока; и
сохраняют первый, второй и третий блоки данных для кодирования множества единиц кодирования в битовый поток видеоданных.
[0021] В желательном варианте осуществления этот способ дополнительно содержит этап, на котором сохраняют флаги разбиения в первом блоке данных для кодирования структуры единицы кодирования.
[0022] В предпочтительном варианте осуществления способ дополнительно содержит этап, на котором арифметически кодируют первый блок.
[0023] В преимущественном варианте осуществления способ дополнительно содержит этап, на котором кодируют обходом второй блок.
[0024] В соответствии с одним другим аспектом раскрывается способ декодирования по меньшей мере одной единицы кодирования из битового потока видеоданных, причем способ содержит этапы, на которых:
определяют структуру единицы кодирования упомянутой по меньшей мере одной единицы кодирования из битового потока, причем структура единицы кодирования описывает разделение единицы кодирования на упомянутую по меньшей мере одну единицу кодирования и разделение упомянутой по меньшей мере одной единицы кодирования на множество единиц предсказания;
декодируют, согласно определенной структуре единицы кодирования, арифметически закодированный флаг наиболее вероятного режима для каждой из упомянутого множества единиц предсказания в упомянутой по меньшей мере одной единице кодирования из первого блока смежно кодированных данных в битовом потоке;
декодируют, согласно определенной структуре единицы кодирования, закодированные обходом данные для каждой из упомянутого множества единиц предсказания в упомянутой по меньшей мере одной единице кодирования из второго блока данных смежно кодированных данных в битовом потоке;
определяют режимы интра-предсказания для каждой из упомянутого множества единиц предсказания согласно каждому из флагов наиболее вероятного режима и закодированных обходом данных; и
декодируют упомянутую по меньшей мере одну единицу кодирования из битового потока с использованием определенных режимов интра-предсказания.
[0025] В предпочтительном варианте осуществления кодированные обходом данные содержат индекс наиболее вероятного режима. Кодированные обходом данные могут в альтернативном варианте осуществления, или в дополнение к этому, содержать значение оставшегося режима.
[0026] Также раскрываются другие аспекты.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0027] Далее будет описан по меньшей мере один вариант осуществления настоящего изобретения со ссылкой на нижеследующие чертежи, в которых:
[0028] фиг. 1 представляет собой схематическую блок-схему, демонстрирующую функциональные модули видеокодера;
[0029] фиг. 2 представляет собой схематическую блок-схему, демонстрирующую функциональные модули видеодекодера;
[0030] фиг. 3A и фиг. 3B формируют схематическую блок-схему компьютерной системы общего назначения, на которой могут применяться кодер и декодер по фиг. 1 и фиг. 2 соответственно;
[0031] фиг. 4 представляет собой схематическую блок-схему, демонстрирующую функциональные модули энтропийного кодера;
[0032] фиг. 5 представляет собой схематическую блок-схему, демонстрирующую функциональные модули энтропийного декодера;
[0033] фиг. 6A-6C представляет собой схематическую блок-схему, демонстрирующую примерную наибольшую единицу кодирования (LCU);
[0034] фиг. 7 представляет собой схематическую блок-схему, демонстрирующую стандартный битовый поток, представляющий примерную наибольшую единицу кодирования (LCU);
[0035] фиг. 8 представляет собой схематическую блок-схему, демонстрирующую битовый поток в соответствии с настоящим раскрытием изобретения, представляющий примерную наибольшую единицу кодирования (LCU);
[0036] фиг. 9 представляет собой схематическую блок-схему последовательности операций, демонстрирующую способ в соответствии с настоящим раскрытием изобретения для декодирования элементов синтаксиса наибольшей единицы кодирования (LCU) битового потока, схожего с потоком по фиг. 8;
[0037] фиг. 10 представляет собой схематическую блок-схему последовательности операций, демонстрирующую обобщенный способ в соответствии с настоящим раскрытием изобретения для декодирования элементов синтаксиса наибольшей единицы кодирования (LCU) битового потока;
[0038] фиг. 11 представляет собой схематическую блок-схему последовательности операций, демонстрирующую способ в соответствии с настоящим раскрытием изобретения для кодирования элементов синтаксиса наибольшей единицы кодирования (LCU);
[0039] фиг. 12 представляет собой схематическую блок-схему последовательности операций, демонстрирующую обобщенный способ в соответствии с настоящим раскрытием изобретения для кодирования элементов синтаксиса наибольшей единицы кодирования (LCU) битового потока;
[0040] фиг. 13 представляет собой схематическую блок-схему, демонстрирующую битовый поток, представляющий примерную наибольшую единицу кодирования (LCU), произведенную альтернативным способом, в соответствии с настоящим раскрытием изобретения, для синтаксического анализа;
[0041] фиг. 14 представляет собой схематическую блок-схему последовательности операций, демонстрирующую альтернативный способ в соответствии с настоящим раскрытием изобретения для декодирования элементов синтаксиса наибольшей единицы кодирования (LCU);
[0042] фиг. 15 представляет собой схематическую блок-схему, демонстрирующую примерную наибольшую единицу кодирования (LCU) с границей слайса внутри данной наибольшей единицы кодирования (LCU);
[0043] фиг. 16 представляет собой схематическую блок-схему, демонстрирующую битовый поток, представляющий примерную наибольшую единицу кодирования (LCU), произведенную посредством способа для синтаксического анализа с разрешенными слайсами мелкой гранулярности (FGS); и
[0044] фиг. 17 представляет собой схематическую блок-схему последовательности операций, демонстрирующую дополнительный альтернативный способ в соответствии с настоящим раскрытием изобретения для декодирования элементов синтаксиса наибольшей единицы кодирования (LCU).
ПОДРОБНОЕ ОПИСАНИЕ, ВКЛЮЧАЮЩЕЕ В СЕБЯ ЛУЧШИЕ ВАРИАНТЫ ОСУЩЕСТВЛЕНИЯ
[0045] Там, где в каком-либо одном или более из сопроводительных чертежей делается ссылка на этапы и/или признаки, имеющие одни и те же самые ссылочные позиции, эти этапы и/или признаки имеют, для целей настоящего описания, одну(и) и ту(те) же самую(ые) функцию(ии) или функционирование(ия), если только иное не следует из содержания.
[0046] Фиг. 1 представляет собой схематическую блок-схему, демонстрирующую функциональные модули видеокодера 100. Фиг. 2 представляет собой схематическую блок-схему, демонстрирующую функциональные модули соответствующего видеодекодера 200. Видеокодер 100 и видеодекодер 200 могут осуществляться с использованием компьютерной системы 300 общего назначения, как продемонстрировано на фиг. 3A и фиг. 3B, где различные функциональные модули могут быть осуществлены посредством специализированного аппаратного обеспечения внутри компьютерной системы 300, посредством программного обеспечения, выполняемого внутри компьютерной системы 300, или, в альтернативном варианте, посредством комбинации специализированного аппаратного обеспечения и программного обеспечения, выполняемого внутри компьютерной системы 300.
[0047] Как видно на фиг. 3A, компьютерная система 300 включает в себя: модуль 301 компьютера; устройства ввода, такие как клавиатура 302, устройство-манипулятор 303 типа «мышь», сканер 326, камеру 327 и микрофон 380; а устройства вывода включают в себя принтер 315, устройство 314 отображения и громкоговорители 317. Для осуществления передачи и приема информации по сети 320 связи через посредство соединения 321 модулем 301 компьютера может быть использовано внешнее приемопередающее устройство 316 модуляции-демодуляции (модем). Сеть 320 связи может представлять собой вычислительную сеть широкого охвата (WAN), такую как Интернет, сеть сотовой телефонной связи или частную WAN. Там, где соединение 321 представляет собой телефонную линию, модем 316 может представлять собой традиционный модем «с набором номера» (с коммутируемым доступом). В альтернативном варианте, там где соединение 321 представляет собой соединение с высокой пропускной способностью (например, кабельное), модем 316 может представлять собой широкополосный модем. Для беспроводного соединения с сетью 320 связи может также быть использован беспроводной модем.
[0048] Модуль 301 компьютера обычно включает в себя по меньшей мере один модуль 305 процессора и модуль 306 памяти. Например, модуль 306 памяти может иметь полупроводниковое оперативное запоминающее устройство (RAM) и полупроводниковое постоянное запоминающее устройство (ROM). Модуль 301 компьютера также включает в себя некоторое количество интерфейсов ввода/вывода (I/O), включающих в себя: интерфейс 307 для передачи аудио/видео, соединенный с устройством 314 отображения видео, громкоговорителями 317 и микрофоном 380; интерфейс 313 I/O, соединенный с клавиатурой 302, мышью 303, сканером 326, камерой 327 и, необязательно, ручкой управления типа «джойстик» или другим устройством человеко-машинного интерфейса (не проиллюстрированы); и интерфейс 308 для внешнего модема 316 и принтера 315. В некоторых осуществлениях модем 316 может быть инкорпорирован внутри модуля 301 компьютера, например, внутри интерфейса 308. Модуль 301 компьютера также имеет интерфейс 311 локальной сети, позволяющий осуществлять соединение компьютерной системы 300 через посредство соединения 323 с локальной сетью 322 связи, известной как локальная вычислительная сеть (LAN). Как проиллюстрировано на фиг. 3A, локальная сеть 322 связи может также соединяться с вычислительной сетью 320 широкого охвата через посредство соединения 324, которое может обычно включать так называемое устройство сетевой защиты «файервол» (от англ. firewall - огненная стена) или устройство со схожими функциями. Интерфейс 311 локальной сети может содержать схемную плату Ethernet™, беспроводную компоновку Bluetooth™ или беспроводную компоновку IEEE 802.11; однако для интерфейса 311 может применяться множество других типов интерфейсов.
[0049] Интерфейс 308 I/O и интерфейс 313 могут допускать любое из или оба из последовательного и параллельного соединений, причем первое из упомянутых обычно осуществляется в соответствии со стандартами универсальной последовательной шины (USB) и имеет соответствующие разъемы USB (не проиллюстрированы). Обеспечиваются устройства 309 хранения данных, которые обычно включают в себя накопитель 310 на жестком диске (HDD). Также могут быть использованы другие устройства хранения данных, такие как накопитель на гибких дисках и накопитель на магнитной ленте (не проиллюстрированы). Для работы в качестве энергонезависимого источника данных обычно обеспечивается накопитель 312 на оптических дисках. В качестве соответствующих источников данных для системы 300 могут быть использованы портативные устройства памяти, такие как, например, оптические диски (например, компакт-диск CD-ROM, диск DVD, диск Blu-ray™), USB-RAM, переносные внешние жесткие диски и гибкие магнитные диски. Обычно, в качестве источника для видеоданных, которые должны быть закодированы, или, с помощью устройства 314 отображения, в качестве адресата назначения для декодированных видеоданных, которые должны быть сохранены или воспроизведены, может быть использовано что-либо любое из накопителя 310 HDD, накопителя 312 на оптических дисках, сети 320 и сети 322, или камеры 327.
[0050] Компоненты с 305 по 313 модуля 301 компьютера обычно осуществляют связь через посредство взаимосоединенной шины 304 и способом, который в результате приводит к стандартному режиму функционирования компьютерной системы 300, известному специалистам в соответствующей области техники. Например, процессор 305 является соединенным с системной шиной 304 с использованием соединения 318. Аналогичным образом, память 306 и накопитель 312 на оптических дисках являются соединенными с системной шиной 304 посредством соединений 319. Примеры вычислительных устройств, на которых могут применяться описываемые компоновки, включают в себя компьютеры типа IBM-PC и совместимые с ними устройства, устройства Sun Sparcstation, Apple Mac™ или подобные им компьютерные системы.
[0051] В случае целесообразности и наличия желания, кодер 100 и декодер 200, а также описанные ниже способы, могут осуществляться с использованием компьютерной системы 300, в которой кодер 100, декодер 200 и процессы по фиг.10 и по фиг.11, которые будут описаны ниже по тексту, могут осуществляться в качестве одной или более прикладных программ 333 программного обеспечения, выполняемых внутри компьютерной системы 300. В частности, кодер 100, декодер 200 и этапы описываемых способов подвергаются воздействию посредством инструкций 331 (см. фиг. 3B) в программном обеспечении 333, выполняемых внутри компьютерной системы 300. Инструкции 331 программного обеспечения могут формироваться в качестве одного или более модулей кода, каждого для выполнения одной или более конкретных задач. Программное обеспечение также может быть разделенным на две отдельные части, где первая часть и соответствующие модули кода выполняют описанные способы, а вторая часть и соответствующие модули кода осуществляют управление пользовательским интерфейсом между первой частью и пользователем.
[0052] Программное обеспечение может быть сохраненным на считываемом компьютером носителе данных, включая, например, устройства хранения данных, описанные ниже. Программное обеспечение загружается в компьютерную систему 300 из считываемого компьютером носителя данных, а затем выполняется посредством компьютерной системы 300. Считываемый компьютером носитель данных, имеющий такое программное обеспечение или компьютерную программу, записанную на считываемом компьютером носителе данных, представляет собой компьютерный программный продукт. Использование данного компьютерного программного продукта в компьютерной системе 300 в предпочтительном варианте воздействует на перспективное устройство для осуществления кодера 100, декодера 200 и описываемых способов.
[0053] Программное обеспечение 333 обычно является сохраненным в накопителе 310 HDD или в памяти 306. Программное обеспечение загружается в компьютерную систему 300 из считываемого компьютером носителя информации и выполняется посредством компьютерной системы 300. Таким образом, например, программное обеспечение 333 может быть сохраненным на оптически читаемом носителе 325 информации (например, на компакт-диске CD-ROM), считываемом посредством накопителя 312 на оптических дисках.
[0054] В некоторых ситуациях прикладные программы 333 могут поставляться пользователю, будучи закодированными на одном или более компакт-дисков 325 CD-ROM, и считываться через посредство соответствующего накопителя 312, или, в альтернативном варианте, могут считываться пользователем из сети 320 или сети 322. Более того, программное обеспечение может также загружаться в компьютерную систему 300 с других считываемых компьютером носителей. Считываемыми компьютером носителями информации именуется какой-либо любой не носящий временного характера вещественный носитель информации, обеспечивающий записанные инструкции и/или данные на компьютерную систему 300 для выполнения и/или обработки. Примеры такого носителя информации включают в себя гибкие магнитные диски, магнитную пленку, компакт-диск CD-ROM, диск DVD, диск Blu-ray, накопитель на жестком диске, запоминающее устройство ROM или интегральную схему, память USB, магнитооптический диск, или считываемую компьютером карту, такую как карта PCMCIA, и тому подобное, независимо от того, расположены ли такие устройства внутри или вне модуля 301 компьютера. Примеры временных или невещественных считываемых компьютером сред передачи данных, которые также могут участвовать в предоставлении программного обеспечения, прикладных программ, инструкций и/или видеоданных или кодированных видеоданных на модуль 301 компьютера, включают в себя радиоканалы или каналы передачи данных в инфракрасном диапазоне, а также сетевое соединение с каким-либо другим вычислительным устройством или сетевым устройством, а также Интернет или внутрикорпоративные сети, включая передачи по электронной почте и информацию, записанную на веб-сайтах, и тому подобное.
[0055] Вторая часть прикладных программ 333 и соответствующих модулей кода, упомянутых выше, может выполняться с целью осуществления одного или более графических пользовательских интерфейсов (GUI) для его воспроизведения или презентации иным образом на устройстве 314 отображения. Через манипуляции, обычно, на клавиатуре 302 и с манипулятором 303 типа «мышь», пользователь компьютерной системы 300 и приложение могут осуществлять манипулирование интерфейсом функционально адаптируемым способом с целью обеспечения управляющих инструкций и/или ввода в приложения, ассоциированные с интерфейсом(ами) GUI. Также могут осуществляться другие формы функционально адаптируемых пользовательских интерфейсов, такие как аудиоинтерфейс, использующий речевой вывод подсказок через громкоговорители 317 и ввод голосовых команд пользователя через микрофон 380.
[0056] Фиг. 3B представляет собой детализированную схематическую блок-схему процессора 305 и «памяти» 334. Память 334 представляет логическое укрупнение всех модулей памяти (включая накопитель 309 HDD и полупроводниковое запоминающее устройство 306), к которым может осуществляться доступ со стороны модуля 301 компьютера по фиг. 3A.
[0057] Когда первоначально включается питание модуля 301 компьютера, выполняется программа 350 самотестирования при включении питания (POST). Данная программа 350 POST обычно сохраняется в запоминающем устройстве 349 ROM полупроводникового запоминающего устройства 306 по фиг. 3A. Устройство аппаратного обеспечения, такое как запоминающее устройство 349 ROM, сохраняющее программное обеспечение, иногда именуется как программно-аппаратное обеспечение. Программа 350 POST проверяет аппаратное оборудование внутри модуля 301 компьютера с целью обеспечения надлежащего функционирования и обычно осуществляет проверку процессора 305, памяти 334 (309, 306), а также модуля 351 программного обеспечения базовых систем ввода-вывода (BIOS), также обычно сохраняемого в запоминающем устройстве 349 ROM, для правильного функционирования. После того, как программа 350 POST была успешно выполнена, модуль 351 BIOS активирует накопитель 310 на жестком диске по фиг. 3A. Активация накопителя 310 на жестком диске побуждает к выполнению через посредство процессора 305 программы 352 начальной загрузки, постоянно хранящейся на накопителе 310 на жестком диске. Это загружает операционную систему 353 в память 306 RAM, с которой операционная система 353 начинает работать. Операционная система 353 представляет собой приложение системного уровня, выполняемое процессором 305, с целью осуществления различных функций высокого уровня, включая управление процессором, управление памятью, управление устройствами, управление сохранением, интерфейс программных приложений, а также типичный пользовательский интерфейс.
[0058] Операционная система 353 управляет памятью 334 (309, 306) с целью обеспечения того, чтобы каждый процесс или приложение, запускаемые на модуле 301 компьютера, имели достаточный объем памяти для выполнения, не вступая в конфликт с памятью, выделенной для какого-либо другого процесса. Кроме того, для того чтобы каждый процесс мог протекать эффективно, должным образом должны быть использованы различные типы памяти, доступные в системе 300 по фиг. 3A. В соответствии с этим, укрупненная память 334 не предназначена иллюстрировать, как выделяются (если только не запускаются иным образом) конкретные сегменты памяти, но скорее предназначена обеспечивать общий обзор памяти, доступной для компьютерной системы 300, и как это используется.
[0059] Как продемонстрировано на фиг. 3B, процессор 305 включает в себя некоторое количество функциональных модулей, включающих в себя модуль 339 управления, арифметико-логический модуль 340 (ALU), а также локальную или внутреннюю память 348, иногда называемую кэш-памятью. Кэш-память 348 обычно включает в себя некоторое количество запоминающих регистров 344–346 в разделе регистров. Одна или более внутренних шин 341 функционально взаимосоединяют эти функциональные модули. Процессор 305 обычно также имеет один или более интерфейсов 342 для осуществления связи с внешними устройствами через посредство системной шины 304, с использованием соединения 318. Память 334 является соединенной с шиной 304 с использованием соединения 319.
[0060] Прикладная программа 333 включает в себя последовательность инструкций 331, которая может включать в себя инструкции условного перехода и циклические инструкции. Программа 333 может также включать в себя данные 332, используемые при выполнении программы 333. Инструкции 331 и данные 332 сохраняются в ячейках 328, 329, 330 и 335, 336, 337 памяти, соответственно. В зависимости от относительного размера инструкций 331 и ячеек 328-330 памяти, конкретная инструкция может быть сохраненной в одной ячейке памяти, как это проиллюстрировано посредством инструкции, продемонстрированной в ячейке 330 памяти. С другой стороны, инструкция может быть сегментирована на некоторое количество частей, каждая из которых сохраняется в отдельной ячейке памяти, как это проиллюстрировано посредством сегментов инструкции, продемонстрированных в ячейке 328 памяти и в ячейке 329 памяти.
[0061] Обычно процессору 305 выдается набор инструкций, которые в нем выполняются. Процессор 305 ожидает последующего ввода, на который процессор 305 реагирует посредством выполнения какого-либо другого набора инструкций. Каждый ввод может обеспечиваться от одного или более из некоторого количества источников, включающих в себя данные, сгенерированные посредством одного или более из устройств ввода 302, 303, данные, принятые от внешнего источника по одной из сетей 320, 302, данные, извлеченные из одного из устройств 306, 309 хранения данных, или данные, извлеченные из носителя 325 информации, вставленного в соответствующее устройство 312 считывания, все проиллюстрированные на фиг. 3A. Выполнение набора инструкций в некоторых случаях может приводить в результате к выводу данных. Выполнение может также содержать сохранение данных или переменных величин в память 334.
[0062] Кодер 100, декодер 200 и описываемые способы используют переменные 354 ввода, сохраненные в памяти 334 в соответствующих ячейках 355, 356, 357 памяти. Кодер 100, декодер 200 и описываемые способы производят переменные 361 вывода, сохраняющиеся в памяти 334 в соответствующих ячейках 362, 363, 364 памяти. Промежуточные переменные 358 могут быть сохранены в ячейках 359, 360, 366 и 367 памяти.
[0063] Касательно процессора 305 по фиг. 3B, регистры 344, 345, 346, арифметико-логический модуль 340 (ALU), а также модуль 339 управления работают вместе для выполнения последовательностей микроопераций, необходимых для выполнения циклов «выборка - декодирование - исполнение» для каждой инструкции в наборе инструкций, составляющем программу 333. Каждый цикл «выборка - декодирование - исполнение» содержит:
(a) операцию выборки, осуществляющую выборку или считывание инструкции 331 из ячейки памяти 328, ячейки памяти 329, ячейки памяти 330;
(b) операцию декодирования, при которой модуль 339 управления определяет, выборка какой инструкции была осуществлена; и
(c) операцию исполнения, при которой модуль 339 управления и/или модуль 340 ALU выполняют данную инструкцию.
[0064] Вслед за этим, может быть выполнен дополнительный цикл «выборка - декодирование - исполнение» для следующей инструкции. Аналогичным образом, может быть выполнен цикл сохранения, посредством которого модуль 339 управления сохраняет или записывает значение в ячейку 332 памяти.
[0065] Каждый этап или подпроцесс в процессах от фиг. 1 по фиг. 17, назначенных к описанию, является ассоциированным с одним или более сегментами программы 333 и обычно выполняется посредством секции 344, 345, 347 регистров, модуля 340 ALU, а также модуля 339 управления в процессоре 305, работающих вместе для выполнения циклов «выборка - декодирование - исполнение» для каждой инструкции в наборе инструкций для указанных сегментов программы 333.
[0066] Кодер 100, декодер 200 и описываемые способы могут, в альтернативном варианте, быть осуществлены в виде специализированного аппаратного обеспечения, такого как одна или более интегральных схем, выполняющих функции или подфункции описываемых способов. Такое специализированное аппаратное оборудование может включать в себя графические процессоры, цифровые процессоры сигналов, специализированные интегральные схемы (ASIC), программируемые вентильные матрицы (FPGA) или один или более микропроцессоров и ассоциированных памятей. Совокупным эффектом от описанных систем является автоматизированное устройство, сконфигурированное с возможностью обработки единиц кодирования, ассоциированных с битовым потоком видеоданных.
[0067] Как было описано выше, видеокодер 100 может быть осуществлен в качестве одного или более модулей кода программного обеспечения прикладной программы 333 программного обеспечения, постоянно хранящейся в накопителе на жестком диске 305 и управляемой при ее выполнении посредством процессора 305. В частности, видеокодер 100 содержит модули от 102 до 112, модуль 114 и модуль 115, которые каждый могут быть осуществлены в качестве одного или более модулей кода программного обеспечения прикладной программы 333 программного обеспечения.
[0068] Хотя видеокодер 100 по фиг. 1 представляет собой пример конвейера декодирования видеоданных высокоэффективного видеокодирования (HEVC), этапы обработки, выполняемые посредством модулей от 102 до 112, модуля 114 и модуля 115, являются общими для других видеокодеков, таких как кодек стандарта VC-1 или кодек стандарта H.264/MPEG-4 AVC. Видеокодер 100 принимает некодированные данные 101 кадра в качестве последовательности кадров, включающей в себя выборки яркости и выборки цветности. Видеокодер 100 делит каждый кадр данных 101 кадра на иерархические наборы единиц кодирования (CU), представляемые, например, в качестве дерева единиц кодирования (CU).
[0069] Видеокодер 100 функционирует посредством вывода, из модуля 110 мультиплексора, массива выборок предсказанных данных, известного как единица 120 предсказания (PU). Модуль 155 разности выдает разность между единицей 120 предсказания (PU) и соответствующим массивом выборок данных, принятых от данных 101 кадра, причем данная разность известна как выборки 122 остаточных данных.
[0070] Данные выборки 122 остаточных данных от модуля 155 разности принимаются посредством модуля 102 преобразования, который осуществляет преобразование разности из пространственного представления в представление частотной области с целью создания коэффициентов 124 преобразования для каждой единицы преобразования (TU) в дереве преобразований. Для находящегося в стадии разработки стандарта эффективного видеокодирования (HEVC) преобразование в представление частотной области осуществляется с использованием усовершенствованного дискретного косинусного преобразования (DCT), при котором традиционное преобразование DCT является модифицированным с возможностью осуществления с использованием сдвигов и добавлений. Коэффициенты 124 преобразования затем вводятся в модуль 103 масштабирования и квантования и масштабируются и квантуются с целью производства остаточных коэффициентов 126. Процесс масштабирования и квантования в результате приводит к потере точности. Остаточные коэффициенты 126 принимаются в качестве ввода в модуль 105 обратного масштабирования, который осуществляет масштабирование, обратное масштабированию, выполненному посредством модуля 103 масштабирования и квантования, с целью производства повторно масштабированных коэффициентов 128 преобразования, представляющих собой повторно масштабированные варианты остаточных коэффициентов 126. Остаточные коэффициенты 126 также принимаются в качестве ввода на модуль 104 энтропийного кодера, осуществляющего кодирование остаточных коэффициентов в кодированном битовом потоке 113. По причине потери точности, происходящей от модуля 103 масштабирования и квантования, повторно масштабированные коэффициенты 128 преобразования не являются идентичными первоначальным коэффициентам 124 преобразования. Повторно масштабированные коэффициенты 128 преобразования от модуля 105 обратного масштабирования затем выводятся на модуль 106 обратного преобразования. Модуль 106 обратного преобразования выполняет обратное преобразование из частотной области в пространственную область с целью производства представления 130 пространственной области повторно масштабированных коэффициентов 128 преобразования, идентичного представлению в пространственной области, произведенному на декодере.
[0071] Модуль 107 оценки движения осуществляет производство векторов 132 движения посредством сравнения данных 101 кадра с данными предыдущего кадра, сохраненными в модуле 112 буфера кадров, сконфигурированном в памяти 306. Векторы 132 движения затем вводятся в модуль 108 компенсации движения, который производит интер-предсказанные опорные выборки 134 посредством фильтрации выборок, сохраненных в модуле 112 буфера кадров, принимая во внимание пространственный сдвиг, полученный от векторов 132 движения. Не будучи проиллюстрированными на фиг. 1, векторы 132 движения также передаются в качестве элементов синтаксиса на модуль 104 энтропийного кодера для кодирования в закодированном битовом потоке 113. Модуль 109 интра-кадрового предсказания производит интра-предсказанные опорные выборки 136 с использованием выборок 138, полученных от модуля 114 суммирования, который осуществляет суммирование вывода 120 модуля 110 мультиплексора и вывода 130 от модуля 106 обратного преобразования.
[0072] Единицы предсказания (PU) могут быть кодированными с использованием способа интра-предсказания или способа интер-предсказания. Решение по поводу того, использовать ли интра-предсказание или интер-предсказание, принимается в соответствии с компромиссом производительности (компромиссом искажения в зависимости от скорости передачи) между желаемой битовой скоростью результирующего кодированного битового потока 113 и объемом искажений качества изображений, вводимым либо посредством способа интра-предсказания, либо посредством способа интер-предсказания. Если используется интра-предсказание, из набора возможных режимов выбирается один режим интра-предсказания, также в соответствии с компромиссом производительности (искажения в зависимости от скорости передачи). Для каждой единицы предсказания выбирается один режим интра-предсказания. Экспериментальная модель 5.0 (HM-5.0) высокоэффективного видеокодирования (HEVC) поддерживает 35 режимов интра-предсказания, однако не все режимы интра-предсказания могут быть использованы для всех размеров единиц предсказания. Например, единица предсказания 8х8 может иметь 35 режимов интра-предсказания, доступных для выбора, а единица предсказания 4х4 может иметь 18 режимов интра-предсказания, доступных для выбора в некоторых реализациях, и 19 режимов, доступных для выбора в других реализациях. Модуль 110 мультиплексора выбирает либо интра-предсказанные опорные выборки 136 из модуля 109 интра-кадрового предсказания, либо интер-предсказанные опорные выборки 134 от блока 108 компенсаци движения, в зависимости от текущего режима 142 предсказания, определенного посредством логической схемы управления, не проиллюстрированной, но хорошо известной в уровне техники. Режим 142 предсказания также обеспечивается на энтропийный кодер 104 и в качестве такового используется для определения или установления иным образом порядка сканирования единиц преобразования, как он будет описан. Интер-предсказание использует только диагональный порядок сканирования, в то время как интра-предсказание может использовать диагональное сканирование, горизонтальное сканирование или вертикальный порядок сканирования.
[0073] Модуль 114 суммирования производит сумму 138, которая вводится в модуль 111 деблокирующего фильтра. Модуль 111 деблокирующего фильтра выполняет фильтрацию вдоль границ блоков, производя деблокированные выборки 140, которые записываются в модуль 112 буфера кадров, сконфигурированный в памяти 306. Модуль 112 буфера кадров представляет собой буфер с емкостью, достаточной чтобы содержать данные из множества прошлых кадров для последующих ссылок.
[0074] В видеокодере 100, выборки 122 остаточных данных внутри одной единицы преобразования (TU) определяются посредством нахождения разности между выборками данных для данных 101 входного кадра и предсказанием 120 выборок данных для данных 101 входного кадра. Разность обеспечивает пространственное представление остаточных коэффициентов единицы преобразования (TU).
[0075] Остаточные коэффициенты единицы преобразования (TU) преобразуются в двумерную карту значимости.
[0076] Карта значимости остаточных коэффициентов в единице преобразования (TU) затем сканируется в конкретном порядке, известном как порядок сканирования, для формирования одномерного списка значений флагов, называемого списком флагов значимых коэффициентов. Порядок сканирования может быть описан или иным образом определен посредством шаблона сканирования, такого как шаблон, принимаемый вместе с режимом 142 предсказания от модуля 109 интра-кадрового предсказания. Шаблон сканирования может быть горизонтальным, вертикальным, диагональным или зигзагообразным. Вариант 5 экспериментальной модели высокоэффективного видеокодирования (HEVC) выполняет сканирование в обратном направлении, однако сканирование в прямом направлении также является возможным. Для единиц преобразования (TU) 16x16, 32x32, 4x16, 16x4, 8x32 и 32x8 определяется двухуровневое сканирование, где единица преобразования (TU) разделяется на набор субблоков, причем каждый субблок имеет квадратную форму. На более высоком уровне сканирование выполняется посредством сканирования каждого более низкого уровня с использованием сканирования, такого как обратное диагональное сканирование вниз-налево. На более низком уровне, также известном как уровень субблоков, сканирование также выполняется с использованием сканирования, такого как обратное диагональное сканирование вниз-налево. В варианте 5.0 опорной модели HEVC, операция сканирования запускает один остаточныый коэффициент после последнего значимого коэффициента (где понятие «после» означает в направлении обратного сканирования остаточных коэффициентов) и протекает до тех пор, пока не будет достигнуто верхнее левое местоположение карты значимости. Операции сканирования, имеющие эту характеристику и соответствующие варианту 5.0 опорной модели HEVC, известны как «обратные сканирования». В варианте 5.0 опорного программного обеспечения HEVC местоположение последнего значимого коэффициента сигнализируется посредством кодирования координат коэффициента в единице преобразования (TU). Специалистам, знакомым с уровнем техники, будет в полной мере понятно, что использование прилагательного «последний» в данном контексте зависит от конкретного порядка сканирования. То, что может являться «последним» ненулевым остаточным коэффициентом или соответствующим флагом значимого коэффициента со значением единицы в соответствии с одним шаблоном сканирования, может не являться «последним» в соответствии с каким-либо другим шаблоном сканирования. Список флагов значимых коэффициентов, обозначающих значимость каждого остаточного коэффициента перед последним значимым коэффициентом, кодируется в битовый поток. Последнее значение флага значимого коэффициента не обязательно должно быть кодировано в битовом потоке в явной форме, поскольку предшествующее кодирование местоположения последнего флага значимого коэффициента косвенно обозначило, что этот остаточный коэффициент был значимым.
[0077] Кластеризация остаточных коэффициентов с большими значениями в направлении верхней левой части единицы преобразования (TU) приводит в результате к тому, что значимым является наибольшее количество флагов значимости, расположенных ранее по списку, в то время как позднее в списке обнаруживается малое количество флагов значимости.
[0078] Как было описано выше, видеокодер 100 также содержит модуль 104 энтропийного кодера, осуществляющй способ энтропийного кодирования. Модуль 104 энтропийного кодера производит элементы синтаксиса из поступающих данных 126 остаточных коэффициентов (или из остаточных коэффициентов), принимаемых от модуля 103 масштабирования и квантования. Модуль 104 энтропийного кодера осуществляет вывод кодированного битового потока 113 и будет более детально описан ниже. Для находящегося в стадии разработки стандарта эффективного видеокодирования (HEVC), кодированный битовый поток 113 выстраивается в единицы уровня абстракции сети (NAL). Каждый слайс кадра содержится в одной единице NAL.
[0079] Существует несколько альтернатив для способа энтропийного кодирования, осуществляемого в модуле 104 энтропийного кодера. Находящийся в стадии разработки стандарт эффективного видеокодирования (HEVC) поддерживает контекстно-зависимое адаптивное двоичное арифметическое кодирование (CABAC), один вариант контекстно-зависимого адаптивного двоичного арифметического кодирования (CABAC) присутствует в стандарте H.264/MPEG-4 AVC. Альтернативной схемой энтропийного кодирования является кодер энтропии разбиения интервала вероятности (PIPE), хорошо известный в уровне техники.
[0080] Для видеокодера 100, поддерживающего множество способов кодирования видеоданных, в соответствии с конгфигурацией кодера 100 выбирается один из поддерживаемых способов энтропийного кодирования. Дополнительно, при кодировании единиц кодирования из каждого кадра, модуль 104 энтропийного кодера осуществляет запись кодированного битового потока 113, так чтобы каждый кадр имел один или более слайсов на кадр, причем каждый слайс содержит данные изображения для части кадра. Производство одного слайса на кадр уменьшает непроизводительные затраты, ассоциированные с выстраиванием каждой границы слайса. Однако также является возможным деление кадра на множество слайсов.
[0081] Видеодекодер 200 по фиг. 2 может осуществляться в качестве одного или более модулей кода программного обеспечения прикладной программы 333 программного обеспечения, постоянно хранящейся в накопителе на жестком диске 305 и управляемой при ее выполнении посредством процесса 305. В частности, видеодекодер 200 содержит модули с 202 по 208, а также модуль 210, которые каждый могут осуществляться в качестве одного или более модулей кода программного обеспечения прикладной программы 333 программного обеспечения. Хотя видеодекодер 200 является описанным со ссылкой на конвейер декодирования видеоданных высокоэффективного видеокодирования (HEVC), этапы обработки, выполняемые посредством модулей с 202 по 208, а также посредством модуля 209, являются общими для других видеокодеков, использующих энтропийное кодирование, таких как кодек стандарта H.264/MPEG-4 AVC, кодек стандарта MPEG-2 и кодек стандарта VC-1.
[0082] Кодированный битовый поток, такой как кодированный битовый поток 113, принимается посредством видеодекодера 200. Данный кодированный битовый поток 113 может считываться из памяти 306, с накопителя 310 на жестком диске, с компакт-диска CD-ROM, с диска Blu-ray™ или с другого считываемого компьютером носителя данных. В альтернативном варианте кодированный битовый поток 113 может приниматься от внешнего источника, такого как сервер, соединенный с сетью 320 связи или радиочастотным приемником. Кодированный битовый поток 113 содержит кодированные элементы синтаксиса, представляющие данные кадра, которые должны быть декодированы.
[0083] Кодированный битовый поток 113 вводится в модуль 202 энтропийного декодера, который извлекает элементы синтаксиса из кодированного битового потока 113 и передает значения элементов синтаксиса на другие блоки в видеодекодере 200. Может существовать множество способов энтропийного декодирования, осуществляемых в модуле 202 энтропийного декодера, таких как способы, описанные со ссылкой на модуль 104 энтропийного кодера. Данные 220 элементов синтаксиса, представляющие данные остаточных коэффициентов, передаются на модуль 203 обратного масштабирования и преобразования, а данные 222 элементов синтаксиса, представляющие информацию вектора движения, передаются на модуль 204 компенсации движения. Модуль 203 обратного масштабирования и преобразования выполняет обратное масштабирование в отношении данных остаточных коэффициентов с целью создания восстановленных коэффициентов преобразования. Модуль 203 затем выполняет обратное преобразование, такое как обратное преобразование, описанное со ссылкой на модуль 106 обратного преобразования, с целью преобразования данных восстановленных коэффициентов преобразования из представления частотной области в представление пространственной области, производя остаточные выборки 224.
[0084] Модуль 204 компенсации движения использует данные 222 вектора движения от модуля 202 энтропийного декодера, комбинированные с предыдущими данными 226 кадра из блока 208 буфера кадров, сконфигурированного в памяти 306, с целью производства интер-предсказанных опорных выборок 228 для единицы предсказания (PU), представляющих собой предсказание выходных декодированных данных кадра. Когда элемент синтаксиса указывает, что текущая единица кодирования была кодирована с использованием интра-предсказания, модуль 205 интра-предсказания производит интра-предсказанные опорные выборки 230 для единицы предсказания (PU) с использованием выборок, пространственно соседствующих с единицей предсказания (PU). Данные пространственно соседствующие выборки получаются из суммы 232, выведенной из модуля 210 суммирования. Модуль 206 мультиплексора выбирает интра-предсказанные опорные выборки или интер-предсказанные опорные выборки для единицы предсказания (PU) в зависимости от текущего режима предсказания, указанного посредством элемента синтаксиса в кодированном битовом потоке 113. Массив 234 выборок, выведенных от модуля 206 мультиплексора, добавляется к остаточным выборкам 224 от модуля 203 обратного масштабирования и преобразования посредством модуля 210 суммирования с целью производства суммы 232, которая затем вводится в каждый из модуля 207 деблокирующего фильтра и модуля 205 интра-предсказания. В отличие от кодера 100, модуль 205 интра-предсказания принимает режим 236 предсказания от энтропийного декодера 202. Мультиплексор 206 принимает сигнал выбора интра-предсказания/интер-предсказания от энтропийного декодера 202. Модуль 207 деблокирующего фильтра выполняет фильтрацию вдоль границ блоков данных с целью сглаживания искажений, видимых вдоль этих границ блоков данных. Вывод от модуля 207 деблокирующего фильтра записывается в модуль 208 буфера кадров, сконфигурированный в памяти 306. Модуль 208 буфера кадров обеспечивает надлежащее хранение с целью удержания множества декодированных кадров для последующих ссылок. Декодированные кадры 209 также выводятся из модуля 208 буфера кадров.
[0085] Далее, со ссылкой на фиг. 4, будет описан энтропийный кодер 104. Элементы синтаксиса, такие как остаточные коэффициенты 401, вводятся в модуль 404 средства преобразования в двоичную форму. Размер 402 единицы преобразования (TU) вводится в модуль 404 средства преобразования в двоичную форму. Данный размер единицы преобразования (TU), обозначающий размер единицы преобразования (TU), кодируется. Шаблон 403 сканирования вводится в модуль 404 средства преобразования в двоичную форму. Модуль 404 средства преобразования в двоичную форму осуществляет преобразование в двоичную форму каждого элемента синтаксиса в последовательность бинов. Каждый бин содержит значение 406 бина и индекс 405 контекста. Значение 406 бина и индекс 405 контекста принимаются посредством контекстной модели 407, которая осуществляет вывод контекста 408, выбранного в соответствии с индексом 405 контекста. Контекст 408 обновляется в соответствии со значением 405 бина. Способ для обновления контекста 408 согласуется со способом, используемым контекстно-зависимым адаптивным двоичным арифметическим кодированием (CABAC) в стандарте H.264/MPEG-4 AVC. Двоичный арифметический кодер 409 использует контекст 408 и значение 406 бина для кодирования бина в кодированный битовый поток 113.
[0086] Далее, со ссылкой на фиг. 5, будет описан энтропийный декодер 202. Размер 502 единицы преобразования (TU) и шаблон 501 сканирования принимаются посредством модуля 503 средства преобразования из двоичной формы. Модуль 503 средства преобразования из двоичной формы осуществляет вывод остаточных коэффициентов 509 посредством выполнения обратной операции модуля 404 средства преобразования в двоичную форму. Индекс 504 контекста выводится из модуля 503 средства преобразования из двоичной формы для каждого бина, который должен быть декодирован. Контекстная модель 505 осуществляет вывод контекста 506, выбранного посредством индекса 504 контекста. Двоичный арифметический декодер 507 декодирует значение 508 бина из кодированного битового потока 113 с использованием контекста 506. Значение 508 бина принимается посредством контекстной модели 505 и используется с целью обновления контекста 506. Значение 508 бина также принимается посредством модуля 503 средства преобразования из двоичной формы.
[0087] Далее со ссылкой на фиг. 6А будет описана примерная наибольшая единица 600 кодирования (LCU). Данная наибольшая единица 600 кодирования (LGU) имеет квадратную форму выборки яркости 64x64. Наибольшая единица 600 кодирования является рекурсивно подразделенной на единицы от единицы 601 кодирования 1 по единицу 608 кодирования 10. Разделение наибольшей единицы 600 кодирования (LCU) использует иерархию уровней, разрешая рекурсивное разделение области, содержащей наибольшую единицу кодирования (LCU), на четыре равноразмерных, неперекрывающихся области в форме квадрата, причем каждая имеет размер половины вертикального и горизонтального размеров родительской области, и вместе полностью занимающих зону родительской области. Когда область далее не подразделяется на меньшие области, существует единица кодирования, которая полностью занимает область. На конкретном уровне подразделения размер области становится равным размеру, известному как наименьшая единица кодирования (SCU), на уровне которой дополнительное подразделение не является возможным или может быть иным образом запрещенным согласно правилу или целесообразности. Для находящегося в стадии разработки стандарта эффективного видеокодирования (HEVC), размер наименьшей единицы кодирования (SCU) конфигурируется как выборки яркости 8x8. Каждая единица кодирования имеет один из нескольких возможных размеров, как, например, единица 601 кодирования 1, имеющая размер 32x32, единица 602 кодирования 2, имеющая размер 16x16 и единица 603 кодирования 4, имеющая размер 8x8. Также являются возможными другие размеры единиц кодирования, в зависимости от выбранного размера наибольшей единицы кодирования (LCU) и размера наименьшей единицы кодирования (SCU), используемых в находящемся в стадии разработки стандарте эффективного видеокодирования (HEVC).
[0088] Далее со ссылкой на фиг. 6B будет дополнительно описано подразделение наибольшей единицы 600 кодирования (LCU). Здесь, в области наибольшей единицы 604 кодирования (LCU), происходит разделение, осуществляющее деление области наибольшей единицы кодирования (LCU) на четыре области равных размеров, таких как область 605. Следующее разделение используется для получения четырех дополнительных областей меньшего размера, таких как область 607. Когда размер области достигает размеров наименьшей единицы кодирования (SCU), такой как область 606, дополнительное разделение не является возможным. В каждой области, где дополнительного разделения не происходит, единицу кодирования полностью занимает область.
[0089] Наибольшая единица 604 кодирования (LCU) по фиг. 6B может также быть представленным в качестве иерархического дерева 630 кодирования, как продемонстрировано на фиг. 6C. При использовании иерархического дерева для представления наибольшей единицы кодирования (LCU), каждая из единиц кодирования будет формировать концевые узлы, в то время как области, содержащие дополнительно подразделяющиеся области, будут формировать неконцевые узлы. Корневой узел 632 дерева 630 базируется на основе области 604 по фиг. 6B и находится на уровне, представляющем выборки 64x64. Ниже корневого узла находится второй уровень, представляющий области выборок 32x32, такие как область 605. Единица кодирования 1 по фиг. 6A является представленной в качестве концевого узла 634, в то время как область, содержащая единицы кодирования с 2 по 8, является представленной посредством неконцевого узла 640. Области размером 16x16 продемонстрированы на третьем уровне дерева 630 с концевым узлом 636, представляющим единицу кодирования 2, а область 607 по фиг. 6B является представленной в качестве неконцевого узла 642. Четвертый и пятый уровень дерева 630 представляет области размером 8x8, такие как область 606, содержащая единицу 604 кодирования 4, представляемая посредством концевого узла 638. Из вышеуказанного является ясным, что размер единиц кодирования в дереве уменьшается по мере того, как увеличивается глубина дерева.
[0090] Как будет более детально описано ниже, для указания того, что область представляет собой концевой узел в наибольшей единице кодирования (LCU), используется флаг разбиения. Дерево 630 кодирования может рассматриваться как один способ представления структуры кодирования наибольшей единицы кодирования (LCU).
[0091] Далее со ссылкой на фиг. 6 и фиг. 7 будет описан битовый поток 700, кодирующий наибольшую единицу 600 кодирования (LCU) стандартным способом. Поскольку кадр видеоизображения может иметь множество наибольших единиц кодирования (LCU) на слайс, кодированный битовый поток, такой как кодированный битовый поток 113, может содержать множество экземпляров битового потока 700, продемонстрированных на фиг. 7. Фиг. 7 принимает условное обозначение для представления кодированных преобразованных в двоичную форму элементов синтаксиса, такое что сегменты, обозначенные «S», содержат арифметически закодированный флаг разбиения, сегменты, обозначенные «A», содержат один или более арифметически кодированных преобразованных в двоичную форму элементов синтаксиса или их часть(и), сегменты, обозначенные «B», содержат один или более кодированных обходом преобразованных в двоичную форму элементов синтаксиса или их часть(и), а сегменты, обозначенные «Ά, B», содержат один или более преобразованных в двоичную форму элементов синтаксиса, кодированных с использованием комбинации из арифметического кодирования и кодирования обходом. Битовый поток 700 представляет часть кодированного битового потока 113, поскольку слайсы обычно состоят из множества наибольших единиц кодирования (LCU), последовательно объединенных вместе. Для размеров кадра, не представляющих собой целые кратные размерностям LCU, получение флагов разбиения предупреждает прохождение границ кадра через единицу кодирования. Единицы кодирования, которые могут выпадать за пределы границы кадра, в битовом потоке не кодируются. Единица 601 кодирования 1 кодируется в битовом потоке 700 в компоненте 701 1 битового потока. Единицы кодирования с единицы кодирования 2 по единицу кодирования 10 аналогичным образом кодируются в битовом потоке 700 в компонентах с компонента 2 битового потока по компонент 10 битового потока.
[0092] Флаг разбиения используется для указания, что область разбивается, причем значение флага 1 указывает, что область разбивается, в то время как значение флага 0 указывает, что область не разбивается. Области, которые разбиваются, подразделяются на четыре равноразмерных неперекрывающихся меньших области, которые совместно занимают весь объем родительской области. Любая область, являющаяся равной по размеру предварительно определенной наименьшей единице кодирования (SCU), будет иметь значение 0, полученное для флага разбиения, для указания того, что область не является подразделенной. Любая область, являющаяся большей, чем размер наименьших единиц кодирования, требует, чтобы был кодирован флаг разбиения.
[0093] Флаг 709 разбиения указывает, что область 604 наибольшей единицы 600 кодирования (LCU) является разделенной на четыре области 32x32, такие как область 605. Флаг 710 разбиения указывает, что область 605 не является дополнительно разделенной. Единица 604 кодирования 4 представляет собой наименьшую единицу кодирования (SCU), поэтому дополнительное разделение не является возможным. Вследствие этого, для каждого из единиц кодирования от единицы кодирования 4 до единицы кодирования 7 флаги разбиения не кодируются. Однако имеет место флаг разбиения со значением единицы для указания того, что подразделению подвергается область 607. Флаг 711 разбиения для области 607 является расположенным перед единицей 604 кодирования 4.
[0094] Компонент 701 1 битового потока содержит элементы синтаксиса, преобразованные в двоичную форму с использованием комбинации из арифметического кодирования и кодирования обходом. Арифметически закодированный режим 703 предсказания определяет, использует ли единица 601 кодирования 1 интер-предсказание или использует интра-предсказание. Если единица кодирования использует интра-предсказание, арифметически закодированный флаг 704 наиболее вероятного режима кодирует, используется ли наиболее вероятный режим для интра-предсказания, или для кодирования режима интра-предсказания используется альтернативная схема. Если используется наиболее вероятный режим, код 705 режима интра-предсказания обходом кодирует индекс наиболее вероятного режима с длиной в один бит. Индекс наиболее вероятного режима определяет, какой один из двух предварительно определенных наиболее вероятных режимов интра-предсказания используется для единицы кодирования. Если наиболее вероятный режим не используется, код 705 режима интра-предсказания кодирует оставшийся режим, который определяет режим интра-предсказания для единицы кодирования. Код 705 режима интра-предсказания может иметь длину в 5 или 6 битов для оставшегося режима. Блок 706 данных использует арифметическое кодирование и кодирование обходом для одной или более единиц преобразования в единице 601 кодирования. Компонент 701 1 битового потока содержит все элементы синтаксиса, требуемые для декодирования единицы кодирования 1. Схожим способом, компоненты битового потока от 2 до 10 содержат требуемые элементы синтаксиса для декодирования единиц кодирования от 2 до 10, соответственно.
[0095] Далее со ссылкой на фиг. 6 и фиг. 8 будет описан битовый поток 800 в соответствии с настоящим раскрытием изобретения, кодирующий наибольшую единицу 600 кодирования (LCU). Фиг. 8 принимает условное обозначение по фиг. 7 для представления кодированных преобразованных в двоичную форму элементов синтаксиса. Битовый поток 800 представляет часть кодированного битового потока 113, кодирующего наибольшую единицу 600 кодирования (LCU). Битовый поток 800 имеет три части, которые можно видеть на первом уровне 820 детализации, представляющие собой арифметически закодированный первый блок 801 данных, который группирует информацию о структуре единицы кодирования для единиц кодирования от 1 до 10, кодированный обходом второй блок 802 данных, который группирует информацию о режимах интра-предсказания для единиц кодирования от 1 до 10, и третий блок 803 данных, который содержит как арифметически кодированные, так и закодированные обходом данные, а также группирует информацию для остаточных данных для единиц кодирования от 1 до 10. В отличие от битового потока 700, каждая из трех частей битового потока 800 может содержать информацию о единицах кодирования от 1 до 10.
[0096] Арифметически закодированный первый блок данных, в предпочтительном варианте, используется для сохранения флагов разбиения, режима предсказания, а также, когда используется интра-предсказание, информации наиболее вероятного режима для единиц кодирования от 1 до 10 по мере необходимости. Первый блок данных более детально проиллюстрирован на втором уровне 830 детализации битового потока 800 на фиг. 8. Как продемонстрировано на втором уровне 830 детализации, первый флаг 813 разбиения имеет значение 1 для указания того, что область 604 наибольшей единицы 600 кодирования (LCU) является разделенной на четыре области 32x32, таких как область 605. Флаг 807 разбиения имеет значение 0 для указания того, что область 605 не имеет дополнительных разделений. Режим 808 предсказания кодирует значение для указания того, использует ли единица кодирования 1 интер-предсказание или использует интра-предсказание. Когда единица кодирования 1 использует интра-предсказание, флаг 809 наиболее вероятного режима указывает, был ли использован либо наиболее вероятный режим, либо оставшийся режим для интра-предсказания единицы кодирования. Дополнительные экземпляры флагов разбиения, значения режимов предсказания и флаги наиболее вероятного режима кодируются в части 804 битового потока для представления единиц кодирования от 2 до 10 наибольшей единицы 600 кодирования (LCU). В первую очередь, флаг 813 разбиения, флаг 807 разбиения, режим 808 предсказания, флаг 809 наиболее вероятного режима и часть 804 битового потока все формируют часть участка 801 битового потока, которая может состоять исключительно из арифметически кодированных элементов синтаксиса.
[0097] Второй блок 802 данных содержит данные 810 обхода, присутствующие в битовом потоке 800, когда единица 601 кодирования 1 использует интра-предсказание. Когда используется интра-предсказание, и флаг 809 наиболее вероятного режима обозначает, что используется наиболее вероятный режим, данные 810 обхода представляют собой индекс, кодирующий использование одного из двух наиболее вероятных режимов. Данный индекс занимает фиксированную длину в один бит. В альтернативном варианте, когда используется интра-предсказание, а флаг 809 наиболее вероятного режима обозначает, что используется оставшийся режим, данные 810 обхода представляют собой индекс, кодирующий использование одного из 33 различных оставшихся режимов интра-предсказания (из 35 возможных режимов интра-предсказания исключаются два наиболее вероятных режима, оставляя 33 оставшихся режима). В этом случае данные 810 обхода имеют длину либо 5, либо 6 битов, в зависимости от кодированного режима интра-предсказания. Длина или размер данных 810 обхода может определяться из первых 5 битов данных 810 обхода, установленных посредством структуры единицы кодирования. После проверки первых 5 битов является возможным определение, требуется ли шестой бит из битового потока. Когда используется интер-предсказание для единицы 601 кодирования 1, данные 810 обхода опускаются из битового потока 800. Дополнительно экземпляры данных 810 обхода присутствуют для единиц кодирования от 2 до 10 в блоке 805 данных обхода, если по меньшей мере один из единиц кодирования от 2 до 10 использует интра-предсказание. Блок 802 данных обхода кодирует данные 810 обхода и блок 805 данных обхода при необходимости.
[0098] Третий блок 803 данных более детально продемонстрирован в качестве блока 811 арифметических и закодированных обходом данных. Блок 811 данных кодирует один или более единиц преобразования в единице 601 кодирования 1, который содержит остаточные коэффициенты для единиц преобразования, которые могут быть использованы вместе с информацией режима предсказания для генерирования видеоданных. Арифметически закодированный конец флага 812 слайса присутствует при тех же самых условиях, что и условия, описанные со ссылкой на фиг. 7.
[0099] Далее со ссылкой на фиг. 6, фиг. 8 и фиг. 9 будет описан способ 900 для декодирования битового потока 800. Данный способ 900 принимает битовый поток 800 и осуществляет обработку трех блоков данных с целью обеспечения возможности декодирования единиц кодирования в битовом потоке 800. Способ 900 начинается с этапа 901 определения значения флага разбиения, на котором определяют значение флага разбиения, такого как флаг 807 разбиения. Когда единица кодирования больше, чем наименьшая единица кодирования (SCU), значение флага разбиения определяют посредством декодирования флага разбиения из битового потока 800. Когда единица кодирования равна по размеру наименьшей единице кодирования (SCU), такой как единица 606 кодирования 4, тогда получают значение флага разбиения, равное нулю.
[0100] Далее значение флага разбиения используют для определения, находится ли структура единицы кодирования в текущий момент на концевом узле. Если значение флага разбиения составляет ноль, на этапе 902 тестирования концевого узла передают управление на этап 903 режима предсказания единицы кодирования. В ином случае, на этапе 902 тестирования концевого узла передают управление обратно на этап 901 определения значения флага разбиения, причем глубина дерева кодирования увеличивается с целью обозначения области на один уровень ниже текущего уровня в дереве кодирования, таком как дерево 630, описанное выше со ссылкой на фиг. 6B. Области обрабатывают в растровом порядке сканирования посредством обработки дерева кодирования способом обработки в глубину. Использование растрового порядка сканирования обеспечивает обработку единиц кодирования от 1 до 10 на фиг. 6A по порядку.
[0101] На этапе 903 режима предсказания единицы кодирования определяют значение режима предсказания. Данное значение режима предсказания определяют посредством декодирования режима предсказания, такого как режим 808 предсказания. Данный режим предсказания определяет как режим предсказания, используемый для единицы кодирования, так и режим разбиения, используемый для разделения единицы кодирования на одну или более единиц предсказания. Возможными режимами разбиения являются NxN или 2Nx2N. Если режим разбиения представляет собой NxN, тогда единица кодирования разделяется на 4 единицы предсказания, каждая с режимом предсказания. Если режим разбиения представляет собой 2Nx2N, тогда единица кодирования содержит только одну единицу предсказания. Режим разбиения NxN и режим разбиения 2Nx2N приводят в результате к тому, что единицы предсказания имеют квадратную форму. Также возможными являются другие режимы разбиения, например, режим разбиения 2NxN и режим разбиения Nx2N, приводящие в результате к единицам предсказания прямоугольной формы. Следует отметить, что интра-предсказание или интер-предсказание определяются на уровне единицы кодирования, поэтому для режима NxN, все четыре единицы предсказания будут представлять собой единицы интра-предсказания, однако каждая единица предсказания может иметь различный режим интра-предсказания, поскольку каждая единица предсказания имеет отдельные флаги наиболее вероятного режима (MPM) и режим предсказания. В то время как способ 900 является в общем плане описанным со ссылкой на то, что каждая единица кодирования имеет одну единицу предсказания, способ 900 может быть расширен до распространения на единицы кодирования, содержащие множество единиц предсказания.
[0102] Когда значение флага разбиения составляет ноль, а значение режима предсказания для единицы кодирования определяет интра-предсказание, на этапе 904 флага MPM определяют значение флага наиболее вероятного режима. Данное значение флага наиболее вероятного режима определяется посредством декодирования флага наиболее вероятного режима, такого как флаг 804 наиболее вероятного режима по фиг. 8. На этапе 905 тестирования большего количества узлов определяют, была ли обнаружена последняя единица кодирования в наибольшей единице кодирования (LCU). Если так, управление переходит к этапу 906 определения режима интра-предсказания. Если нет, управление возвращается к этапу 901 определения значения флага разбиения.
[0103] Для единицы кодирования интра-предсказания 32х32, такой как единица 601 кодирования 1 по фиг. 6, единица кодирования может содержать либо один, либо два, либо четыре единицы предсказания, в зависимости от режима разбиения единицы кодирования. На этапе 906 и этапе 907 выполняют итерацию над структурой единицы кодирования, определенной на этапах от этапа 901 по этап 905. На этапе 906 определения режима интра-предсказания определяют режим интра-предсказания для единицы предсказания, как указано ниже. Если значение флага наиболее вероятного режима для единицы предсказания указывает, что был использован наиболее вероятный режим, тогда из битового потока 800, с использованием декодирования обходом, декодируют значение индекса наиболее вероятного режима в один бит. Значение индекса наиболее вероятного режима в один бит обозначает, какой один из двух возможных наиболее вероятных режимов используется. В ином случае, значение флага наиболее вероятного режима обозначает использование оставшегося режима, и осуществляется декодирование значения оставшегося режима из битового потока 800 с использованием декодирования обходом. Количество действующих значений режима интра-предсказания, а также диапазон кода с переменной длиной слова, зависит от размера единицы предсказания. Из доступных режимов интра-предсказания для заданного размера единицы предсказания, количество оставшихся режимов является равным количеству наиболее вероятных режимов, вычтенных из количества доступных режимов. Когда количество оставшихся режимов составляет степень двойки, оставшийся режим может использовать код с фиксированной длиной слова, в ином случае используется код с переменной длиной слова. Например, интра-предсказанная единица предсказания 4х4 с 18 доступными режимами интра-предсказания и двумя наиболее вероятными режимами имеет 16 оставшихся режимов и, вследствие этого, может использовать для кодирования оставшегося режима четырехбитовый код. В альтернативном варианте, интра-предсказанная единица предсказания 4х4 с 19 доступными режимами интра-предсказания и двумя наиболее вероятными режимами имеет 17 оставшихся режимов и, вследствие этого, может использовать для кодирования оставшегося режима битовый код из четырех или пяти битов. Поскольку интра-предсказанная единица предсказания 8х8 с двумя наиболее вероятными режимами имеет 33 оставшихся режима и, вследствие этого, может для кодирования использовать код с переменной длиной слова либо в пять, либо в шесть битов, в одном осуществлении декодирование кода с переменной длиной слова осуществляется посредством считывания, по меньшей мере, надлежащего количества бинов для определения длины кода с переменной длиной слова, используемого для оставшегося режима. Для таких единиц предсказания является возможным декодирование пяти битов для определения, требуется ли декодирование шестого бита. В качестве результата, для декодирования последующей части оставшегося режима на основе декодированных в надлежащем количестве битов может выполняться второе считывание. В альтернативном осуществлении вводят флаг арифметически кодированного оставшегося режима, кодированный после флага наиболее вероятного режима, указывающий, что единица предсказания использует предварительно определенный оставшийся режим. Если предварительно определенный оставшийся режим, например «планарное интра-предсказание», не используется, осуществляется кодирование одного из других оставшийся режимов с использованием элемента синтаксиса кодированного обходом оставшегося режима. Например, если интра-предсказанная единица предсказания 4х4 имеет 19 доступных режимов, с двумя наиболее вероятными режимами и одним предварительно определенным оставшимся режимом, существует 16 других оставшихся режима, которые могут быть кодированы с использованием элемента синтаксиса оставшегося режима фиксированной длины в четыре бита. Также, если интра-предсказанная единица предсказания 8х8 имеет 35 доступных режимов, с двумя наиболее вероятными режимами и одним предварительно определенным оставшимся режимом, существует 32 других оставшихся режима, которые могут быть кодированы с использованием элемента синтаксиса оставшегося режима фиксированной длины в пять битов. Там, где количество оставшихся режимов или других оставшихся режимов составляет степень двойки, код с фиксированной длиной слова является достаточным для кодирования оставшегося режима или другого используемого оставшегося режима. Далее определяется режим интра-предсказания для единицы предсказания с использованием значения флага наиболее вероятного режима и одним из либо значения индекса наиболее вероятного режима, либо значения оставшегося режима. В альтернативном варианте, для определения режима интра-предсказания для единицы предсказания используются флаг предварительно определенного оставшегося режима и, необязательно, другой оставшийся режим. Там, где множество кодов с переменной длиной являются последовательно объединенными, является возможным выполнение считывания минимальной длины комбинированных кодов для определения, являются ли необходимыми дополнительные считывания для завершения декодирования кодов. Битовый поток 800 может кодировать каждую из частей минимальной длины оставшихся режимов переменной длины, расположенных смежно, во втором блоке 802 данных и далее кодировать какие-либо любые оставшиеся данные оставшихся режимов переменной длины во втором блоке 802 данных. Используя данное кодирование, для реализаций является возможным считывание всех частей минимальной длины за один раз и определение длины оставшихся данных с целью завершения считывания оставшихся режимов переменной длины.
[0104] На этапе 907 тестирования большего количества узлов определяют, имеются ли еще узлы дерева кодирования, для которых необходимо определение их режима интра-предсказания. Результат выполнения этапа 907 состоит в том, что этап 906 определения режима интра-предсказания выполняет итерацию над всеми узлами наибольшей единицы кодирования (LCU).
[0105] На этапе 908 декодирования остаточных данных осуществляют декодирование третьего блока 803 данных. На этапе 908 декодирования остаточных данных декодируют каждую из единиц преобразования для единиц кодирования от 1 до 10 в наибольшей единице 600 кодирования (LCU). Поскольку осуществляется декодирование каждой единицы преобразования, модуль 203 обратного масштабирования и преобразования преобразует остаточные данные из частотной области в пространственную область с целью производства остаточных выборок 224. Используя режим интра-предсказания, модуль 205 интра-предсказания определяет предсказание 234 для каждой единицы предсказания. Дополнительные этапы для декодирования наибольшей единицы 600 кодирования (LCU) согласуются с функционированием, описанным на фиг. 2.
[0106] Далее со ссылкой на фиг. 10 будет описан способ 1000 для декодирования битового потока 800. Данный способ 1000 начинается с этапа 1001 определения структуры единицы кодирования, на котором конструируют структуру единицы кодирования для представления разделения наибольшей единицы кодирования (LCU) на множество единиц кодирования на основе информации флага разбиения в арифметически кодированном первом блоке 801 данных. Другая информация о единицах кодирования также определяется из первого блока 801 данных. Данная информация включает в себя значение режима предсказания для единицы кодирования и флагов MPM для каких-либо единиц предсказания единицы кодирования. Дополнительные детали того, как это осуществляется, описаны выше, на фиг. 9, в этапе 901 определения значения флага разбиения, этапе 902 концевого узла, этапе 903 определения значения режима предсказания единицы кодирования, этапе 905 определения значения флага MPM единицы предсказания, а также в этапе 906 большего количества узлов.
[0107] Далее, на этапе 1002 декодирования закодированных обходом данных декодируют кодированный обходом второй блок 802 данных. Кодированный обходом второй блок 802 данных обеспечивает информацию касательно режимов интра-предсказания, используемых для каждой из интра-предсказанных единиц кодирования наибольшей единицы кодирования (LCU). Этап 1002 декодирования закодированных обходом данных более детально описан в этапе 906 определения режима интра-предсказания и этапе 907 большего количества узлов по фиг. 9, описанных выше.
[0108] Способ 1000 далее переходит к этапу 1003 декодирования остаточных данных, где декодируют остаточные данные от третьего блока 803 данных. Как было описано выше, третий блок 803 данных содержит данные, которые являются как арифметически кодированными, так и кодированными обходом. Этап 1003 декодирования остаточных данных более подробно описан в этапе 908 декодирования остаточных данных по фиг. 9 выше.
[0109] В довершение всего, для формирования декодированных единиц кодирования, как описано со ссылкой на фиг. 2, на этапе 1004 формирования единиц кодирования комбинируют режим интра-предсказания от этапа 1002 декодирования закодированных обходом данных и остаточные данные от этапа 1003 декодирования остаточных данных. Как только декодированная единица кодирования была сформирована, режим интра-предсказания и остаточные данные могут быть скомбинированы для формирования части декодированного видеокадра.
[0110] В то время как способ 1000 был описан со ссылкой на способ 900 по фиг. 9, данный способ также может распространяться на другие способы, такие как способ 1400 по фиг.14 и способ 1700 по фиг. 17, которые будут описаны ниже.
[0111] Далее со ссылкой на фиг. 11A будет описан способ 1100 для кодирования битового потока 800. Данный способ 1100 осуществляет кодирование битового потока 800 и производит три блока данных с целью обеспечения возможности декодирования единиц кодирования в битовом потоке 800. Способ 1100 начинается с этапа 1101 кодирования значения флага разбиения, на котором кодируют значение флага разбиения, такого как флаг 807 разбиения. Правила управления местоположением флагов разбиения более детально описаны выше со ссылкой на фиг. 6A и фиг. 6B. Когда единица кодирования больше, чем наименьшая единица кодирования (SCU), флаг разбиения кодирует соответствующее значение флага разбиения в битовый поток 800. Однако флаг разбиения не кодируется, когда единица кодирования равна по размеру наименьшей единице кодирования (SCU), такой как единица 606 кодирования 4 по фиг. 6B.
[0112] Если значение флага разбиения составляет ноль, на этапе 1102 тестирования концевого узла передают управление на этап 1103 кодирования значения режима предсказания единицы кодирования, поскольку нулевое значение флага разбиения указывает, что текущая единица кодирования является концевым узлом дерева кодирования. Если текущий узел дерева кодирования представляет собой неконцевой узел, тогда на этапе 1102 тестирования концевого узла передают управление обратно на этап 1101 кодирования значения флага разбиения, причем глубина дерева кодирования увеличивается на область на один уровень ниже текущего уровня в дереве кодирования, таком как дерево 630, описанное выше со ссылкой на фиг.6C. Как и в способе 900 по фиг. 9, области обрабатываются в растровом порядке сканирования посредством обработки дерева кодирования способом обработки в глубину. Использование растрового порядка сканирования обеспечивает обработку единиц кодирования от 1 до 10 на фиг. 6A по порядку.
[0113] На этапе 1103 режима предсказания единицы кодирования кодируют значение режима предсказания. Для слайсов, содержащих как интер-предсказанные единицы предсказания, так и интра-предсказанные единицы предсказания, режим предсказания точно определяет тип используемого предсказания. Для слайсов, содержащих только интра-предсказанные единицы предсказания, режим предсказания в кодированном битовом потоке 113 не кодируется. Способом, схожим со способом 900 по фиг. 9, режим предсказания определяет как режим предсказания, используемый для единицы кодирования, так и режим разбиения. В то время как способ 1100 является описанным со ссылкой на единицу кодирования с одной единицей предсказания, способ может быть расширен до распространения на единицы кодирования, содержащие множество единиц предсказания.
[0114] Когда значение флага разбиения составляет ноль, и значение режима предсказания для единицы кодирования определяет интра-предсказание, на этапе 1104 кодирования флага MPM кодируют значение флага наиболее вероятного режима. Модуль 109 интра-кадрового предсказания по фиг. 1 определяет режим интра-предсказания для единицы предсказания. Модуль 109 предсказания для интра-предсказания также определяет два наиболее вероятных режима для интра-предсказания. Если определенный режим интра-предсказания является равным одному из наиболее вероятных режимов, значение флага наиболее вероятного режима устанавливается на 1, указывая использование наиболее вероятного режима. В ином случае, значение флага наиболее вероятного режима устанавливается на 0, указывая использование оставшегося режима. В качестве значения флага наиболее вероятного режима кодируется флаг наиболее вероятного режима, такой как флаг 804 наиболее вероятного режима по фиг. 8. На этапе 1105 тестирования большего количества узлов определяют, была ли обнаружена последняя единица кодирования в наибольшей единице кодирования (LCU). Если так, управление переходит к этапу 1106 кодирования данных обхода. Если нет, управление возвращается к выполнению этапа 1101 кодирования значения флага разбиения.
[0115] Для единицы кодирования интра-предсказания 32х32, такой как единица 601 кодирования 1 по фиг. 6, единица кодирования может содержать либо одну, либо две, либо четыре единицы предсказания, в зависимости от режима разбиения единицы кодирования. На этапе 1106 кодирования данных обхода кодируют режим интра-предсказания для единицы предсказания, как указано ниже. Если значение флага наиболее вероятного режима для единицы предсказания указывает, что был использован наиболее вероятный режим, тогда в битовый поток 800, с использованием декодирования обходом, кодируют значение индекса наиболее вероятного режима в один бит, указывающее, какой один из двух доступных наиболее вероятных режимов был выбран. В ином случае, значение флага наиболее вероятного режима указывает использование оставшегося режима, и в битовый поток 800, с использованием кодирования обходом, кодируют значение оставшегося режима. Там, где множество значений индекса наиболее вероятного режима или значений оставшегося режима являются последовательно объединенными, возможным является выполнение записи комбинированных кодов в одной операции, вместо записи кода для каждой единицы предсказания отдельно.
[0116] На этапе 1107 тестирования большего количества узлов определяют, имеется ли еще какое-либо количество узлов дерева кодирования, для которых необходимо определение их режима интра-предсказания. Результат состоит в том, что осуществляют этап 1106 кодирования данных обхода для выполнения итерации над всеми узлами наибольшей единицы кодирования (LCU). Итерация над этапом 1106 кодирования данных обхода и этапом 1107 большего количества узлов может иметь место до записи данных обхода в кодированный битовый поток 113 в целях предварительного определения длины данных, которые должны быть записаны.
[0117] На этапе 1108 кодирования остаточных данных кодируют третий блок 803 данных. На данном этапе 1108 кодирования остаточных данных кодируют каждую из единиц преобразования для единиц кодирования от 1 до 10 в наибольшей единице 600 кодирования (LCU) в кодированный битовый поток 113. В целях кодирования каждой единицы преобразования, осуществляют преобразование остаточных выборок 122, посредством блока 102 преобразования, в коэффициенты 124 преобразования. Блок 103 масштабирования и квантования далее преобразует коэффициенты 124 преобразования в остаточные коэффициенты 126. Остаточные коэффициенты 126 кодируются, посредством энтропийного кодера 104, в кодированный битовый поток 113. Дополнительные этапы для кодирования наибольшей единицы 600 кодирования (LCU) согласуются с функционированием, описанным в видеокодере 100 по фиг. 1.
[0118] Далее со ссылкой на фиг. 12 будет описан способ 1200 для кодирования битового потока 800. Данный способ 1200 начинается с этапа 1201 кодирования структуры единицы кодирования, на котором кодируют структуру единицы кодирования для представления разделения наибольшей единицы кодирования (LCU) на множество единиц кодирования посредством информации кодирования флага разбиения в арифметически кодированном первом блоке 801 данных. Другую информацию о единицах кодирования также кодируют в первый блок 801 данных. Эта информация включает в себя значение режима предсказания для единицы кодирования и флаги MPM для каких-либо любых единиц предсказания единицы кодирования. Дополнительные детали того, как это осуществляется, описаны выше, на фиг. 11, в этапе 1101 кодирования значения флага разбиения, этапе 1102 концевого узла, этапе 1103 кодирования значения режима предсказания единицы кодирования, этапе 1104 кодирования значения флага MPM единицы предсказания, а также в этапе 1105 большего количества узлов.
[0119] Далее на этапе 1202 кодирования данных, кодированных обходом, кодируют кодированный обходом второй блок 802 данных. Кодированный обходом второй блок 802 данных осуществляет кодирование информации о режимах интра-предсказания, используемых для каждой из интра-предсказанных единиц кодирования наибольшей единицы кодирования (LCU). Этап 1202 кодирования данных, кодированных обходом, более детально описан в этапе 1106 кодирования данных обхода и этапе 1107 большего количества узлов по фиг. 11, описанных выше.
[0120] Способ 1200 далее переходит к этапу 1203 кодирования остаточных данных, на котором кодируют остаточные данные в третий блок 803 данных. Как было описано выше, третий блок 803 данных содержит данные, кодированные как арифметически, так и обходом. Этап 1203 кодирования остаточных данных более детально описан в этапе 1108 кодирования остаточных данных по фиг. 11 выше.
[0121] На этапе 1204 сохранения блоков данных сохраняют арифметически кодированные данные в блоке 801 данных, закодированные обходом данные в блоке 802 данных и комбинацию из арифметически кодированных и закодированных обходом данных в блоке 803 данных в кодированный битовый поток 113. Этап 1204 сохранения блоков данных может осуществляться в качестве одиночного этапа сохранения блоков данных или в качестве промежуточного накопления в буфере кодированных данных, по мере того как блоки данных производятся посредством соответствующих этапов в способе 1200.
[0122] В то время как способ 1200 был описан со ссылкой на способ 1100 по фиг. 11, данный способ также может распространяться на другие способы кодирования, относящиеся к декодированию, такие как способ 1400 по фиг. 14 и способ 1700 по фиг. 17, которые будут описаны ниже.
[0123] Далее со ссылкой на фиг. 13 будет описан альтернативный битовый поток 1300 для кодирования наибольшей единицы 600 кодирования (LCU). Фиг. 13 принимает условное обозначение по фиг. 7 для представления кодированных преобразованных в двоичную форму элементов синтаксиса. Битовый поток 1300 представляет часть кодированного битового потока 113, кодирующего наибольшую единицу 600 кодирования (LCU). Первый блок 1301 данных имеет структуру, схожую со структурой первого блока 801 данных, и кодирует элементы синтаксиса с использованием арифметического кодирования исключительно. Первый блок 1301 данных является схожим с первым блоком 801 данных, поскольку первый блок 1301 данных арифметически кодирует значение режима предсказания для единицы кодирования с использованием режима предсказания, такого как режим 1308 предсказания. В отличие от первого блока 801 данных, первый блок 1301 данных не кодирует флаг наиболее вероятного режима, такой как флаг 809 наиболее вероятного режима первого блока 801 данных. Вместо этого флаг наиболее вероятного режима 1309 кодируется во втором блоке 1302 данных с использованием кодирования обходом. Второй блок 1302 данных использует кодирование обходом исключительно для кодирования элементов синтаксиса, как это описано для второго блока 802 данных. Кодирование флага наиболее вероятного режима с помощью кодирования обходом может предоставлять возможность декодирования с более высокой производительностью посредством считывания больших групп бинов обхода в одной операции считывания. Схожим с данными 810 обхода способом, когда режим 1308 предсказания указывает использование интра-предсказания, битовый поток 1300 включает в себя данные 1310 обхода, которые представляют либо индекс наиболее вероятного режима, либо оставшийся режим.
[0124] Далее со ссылкой на способ 1400 по фиг. 14 будет описано альтернативное осуществление для декодирования альтернативного битового потока 1300. Этап 1401 определения значения флага разбиения, этап 1402 концевого узла, этап 1403 определения значения режима предсказания единицы кодирования, а также этап 1404 большего количества узлов, функционируют аналогично этапу 901 определения значения флага разбиения, этапу 902 концевого узла, этапу 903 определения значения режима предсказания единицы кодирования и этапу 905 большего количества узлов по фиг. 9. В отличие от способа 900, этап, соответствующий этапу 904 определения значения флага MPM единицы предсказания по фиг. 9, не является включенным в вышеуказанный набор этапов по фиг. 14. Вместо этого позднее в способе 1400 осуществляется соответствующий этап, являющийся этапом 1405. На этапе 1405 определения значения флага MPM единицы предсказания определяют значение флага MPM единицы предсказания аналогичным образом, как на этапе 904 по фиг. 9, кроме того, что кодированный обходом флаг 1309 наиболее вероятного режима кодируется из битового потока 1300. Этап 1406 определения режима интра-предсказания, этап 1407 большего количества узлов и этап 1408 декодирования остаточных данных функционируют, как описано со ссылкой на этап 906 определения режима интра-предсказания, этап 907 большего количества узлов и этап 908 декодирования остаточных данных по фиг. 9.
[0125] Далее будет описана примерная наибольшая единица 1500 кодирования (LCU) по фиг. 15. Данная наибольшая единица 1500 кодирования (LCU) имеет композицию из единиц кодирования от 1 до 10, идентичную композиции наибольшей единицы 600 кодирования (LCU) по фиг. 6. Однако, в отличие от наибольшей единицы 600 кодирования (LCU), наибольшая единица 1500 кодирования (LCU) включает в себя границу слайса между модулем 1503 кодирования 9 и модулем 1505 кодирования 10, поскольку были разрешены слайсы мелкой гранулярности. В соответствии с этим, единицы кодирования от 1 до 9 по фиг. 15 находятся в первом слайсе, в то время как единица 1505 кодирования 10 находится во втором слайсе.
[0126] Далее будет описан битовый поток 1600, продемонстрированный на фиг. 16, кодирующий наибольшую единицу 1500 кодирования (LCU). Кодирование битового потока 1600 осуществляется с разрешенными слайсами мелкой гранулярности и пороговым значением слайса мелкой гранулярности, сконфигурированным с возможностью ограничения границы слайса до границ единицы кодирования 32x32. Когда разрешаются слайсы мелкой гранулярности, наибольшая единица 1500 кодирования (LCU) может разделяться на отдельные слайсы в любой области с размером, равным или превышающим пороговое значение слайса мелкой гранулярности. Элемент синтаксиса конца слайса указывает окончание слайса. Данный элемент синтаксиса конца слайса кодируется после последней единицы кодирования в каждой области, чей размер является равным пороговому значению слайса мелкой гранулярности. На фиг. 16 имеются четыре элемента синтаксиса конца слайса, поскольку наибольшая единица кодирования (LCU) 64x64 имеет размер границы 32x32. Элемент флага синтаксиса конца слайса будет расположен после единиц кодирования 1, 8, 9 и 10. Требование состоит в том, чтобы элементы синтаксиса в одном слайсе полностью описывали единицы кодирования в этом слайсе. Когда разрешаются слайсы мелкой гранулярности, решение о разделении наибольшей единицы 1500 кодирования (LCU) на два слайса может приниматься в середине процесса кодирования битового потока 1600. В соответствии с этим, когда информация от множества единиц кодирования группируется вместе в первом, втором и третьем блоке данных, единицы кодирования группы не могут расширяться за пределы флага конца. Компонент 1601 битового потока содержит элементы синтаксиса для единицы кодирования 1. Компонент 1602 битового потока содержит первый блок 1615 данных, второй блок 1616 данных и третий блок 1607 данных, осуществляющие кодирование единиц кодирования от 2 до 8 по фиг. 15, содержащихся в области 607. Первый блок 1615 данных, второй блок 1616 данных и третий блок 1607 данных, осуществляющие кодирование единиц кодирования от 2 до 8 по фиг. 15, являются схожими с первым блоком 801 данных, вторым блоком 802 данных и третьим блоком 803 данных по фиг. 8. В отличие от битового потока 800, группирование элементов синтаксиса в первый, второй и третий блоки данных в битовом потоке 1600 ограничивается до порогового значения слайса мелкой гранулярности. Поскольку пороговое значение слайса мелкой гранулярности является установленным на 32x32, тогда единицы кодирования 1, 9 и 10 не являются сгруппированными с другими единицами кодирования, в то время как единицы кодирования от 2 до 8 являются сгруппированными вместе. Флаг 1614 конца слайса сигнализирует, что первый слайс заканчивается после единицы 1503 кодирования 9, а второй слайс начинается на единице 1505 кодирования 10 по фиг. 15.
[0127] В одном осуществлении битовый поток 1600 кодирует флаг разрешения слайсов мелкой гранулярности в начале каждой наибольшей единицы кодирования, такой как наибольшая единица 1500 кодирования (LCU). Когда для некоторой наибольшей единицы кодирования (LCU) слайсы мелкой гранулярности не разрешаются, способ 900 применяется к этой наибольшей единице кодирования (LCU). Когда разрешаются слайсы мелкой гранулярности для какой-либо наибольшей единицы кодирования (LCU), способ 900 применяется к каждой подразделенной единице кодирования равной по размеру пороговому значению слайса мелкой гранулярности.
[0128] Далее со ссылкой на способ 1700 по фиг. 17 для декодирования битового потока 800 будет описано дополнительное альтернативное осуществление. Этап 1701 определения значения флага разбиения, этап 1702 концевого узла, этап 1703 определения значения режима предсказания единицы кодирования, этап 1704 определения значения флага MPM единицы предсказания, а также этап 1705 большего количества узлов, функционируют аналогично соответствующим этапам по фиг. 9, представляющим собой этап 901 определения значения флага разбиения, этап 902 концевого узла, этап 903 определения значения режима предсказания единицы кодирования, этап 904 определения значения флага MPM единицы предсказания и этап 905 большего количества узлов. Получающаяся в результате структура единицы кодирования и информация наиболее вероятного режима используются посредством этапа 1706 считывания данных обхода с целью считывания блока 802 данных обхода. Длина блока 802 данных обхода определяется посредством структуры единицы кодирования и информации наиболее вероятного режима путем суммирования длин индексов наиболее вероятного режима и оставшихся режимов. На этапе 1706 считывания данных обхода могут считывать блок 802 данных обхода за одну операцию, или за множество операций, но это не ограничивается до считывания информации для одной единицы предсказания за один раз. Объем данных, которые должны быть считаны, составляет длину блока 802 данных обхода, которая уже является определенной.
[0129] Далее на этапе 1707 назначения режимов интра-предсказания для единицы предсказания разделяют данные обхода от этапа 1706 считывания данных обхода и определяют режим интра-предсказания для каждой единицы предсказания. Этап 1708 декодирования остаточных данных функционирует, как описано со ссылкой на этап 908 декодирования остаточных данных по фиг. 9.
[0130] Когда осуществляется кодирование оставшегося режима с использованием кода с переменной длиной слова, такого как код из пяти или из шести битов, описанный со ссылкой на фиг. 9, длина закодированных обходом данных 802 не может быть определена до этапа 1706 считывания данных обхода. Вместо этого, минимальная длина может быть вычислена на основе знания структуры единицы кодирования и значений флагов наиболее вероятного режима, а также размеров единицы предсказания. Минимальная длина может быть считана из кодированного битового потока 113 и подвергнута синтаксическому анализу для определения режима интра-предсказания по меньшей мере одной из единиц предсказания. Синтаксический анализ может применяться неоднократно до тех пор, пока не будет известна длина данных обхода. С целью считывания всего объема закодированных обходом данных 802 из кодированного битового потока 113 может выполняться одно или более последующих считываний данных обхода. В то время как метод кода с переменной длиной слова для данных обхода по описанному выше альтернативному осуществлению является описанным со ссылкой на способ 1700 по фиг. 17, данный метод может быть применен во время других способов декодирования, описанных выше, таких как способ 900 по фиг. 9.
[0131] Когда осуществляется кодирование обходом флага наиболее вероятного режима, может функционировать разновидность способа 1700 с целью удаления этапа 1704 определения значения флага MPM единицы предсказания и инкорпорирования функциональности этапа 1704 определения значения флага MPM единицы предсказания в этап 1706 считывания данных обхода.
[0132] Альтернативное осуществление для потребления закодированных обходом данных неизвестной длины функционирует с целью доступа к кодированному битовому потоку 113 для определения сегмента данных, содержащего, по меньшей мере, некоторые закодированные обходом данные. Однако, в отличие от ранее описанных подходов, данные не потребляются из битового потока. Индексы наиболее вероятного режима и оставшиеся режимы декодируются из сегмента данных, и для длины декодированных данных удерживается нарастающий итог. Когда из сегмента данных являются декодированными все закодированные обходом данные, тогда длина нарастающего итога потребляется из битового потока. Результат состоит в том, что сегмент данных осуществляет доступ к данным битового потока за пределами кодированного обходом второго блока 802 данных, но данные не потребляются, и вследствие этого, третий блок 803 арифметических данных и данных обхода является доступным для декодирования посредством этапа декодирования остаточных данных. В то время как метод декодирования кода с переменной длиной слова по описанному выше альтернативному осуществлению является описанным со ссылкой на способ 1700 по фиг. 17, данный метод может быть применен во время других способов декодирования, описанных выше, таких как способ 900 по фиг. 9.
[0133] Способы 900, 1000, 1400 и 1700, в ситуации применения к видеодекодеру 200, обеспечивают возможность осуществлений для реализации увеличения производительности синтаксического анализа кодированного битового потока, такого как кодированный битовый поток 113. Это происходит через посредство считывания больших количеств закодированных обходом данных при одной операции, по причине объединения данных, кодированных обходом. Увеличенная производительность является наиболее ощутимой для осуществлений аппаратного обеспечения, где считывание или запись закодированных обходом данных может осуществляться параллельно с целью увеличения производительности системы. Схожее преимущество реализуется для видеокодера 100, когда способы 1100, 1200, а также способы 1400 и 1700, соответствующим образом измененные для выполнения кодирования, применяются для производства кодированного битового потока.
[0134] Приложение A, следующее за данным подробным описанием, представляет модификации, которые могут быть произведены относительно экспериментальной модели 5.0 (HM-5.0) высокоэффективного видеокодирования (HEVC) для определения битового потока 800 по фиг. 8, который может быть декодирован посредством способа 900 по фиг. 9, описанного выше.
ПРОМЫШЛЕННАЯ ПРИМЕНИМОСТЬ
[0135] Описанные компоновки являются применимыми к отрасли вычислительной техники, а также к отрасли средств обработки данных, и, в частности, для цифровой обработки сигналов для кодирования декодирования сигналов, таких как видеосигналы.
[0136] Вышеизложенное описывает только некоторые варианты осуществления настоящего изобретения, и относительно них могут выполняться модификации и/или изменения, не выходя за рамки объема и сущности данного изобретения, причем данные варианты осуществления являются иллюстративными, а не ограничительными.
ПРИЛОЖЕНИЕ А
Нижеследующее представляет модификации, которые представляет модификации, которые могут быть произведены относительно экспериментальной модели 5.0 (HM-5.0) высокоэффективного видеокодирования (HEVC) для определения битового потока 800 по фиг. 8, который может быть декодирован посредством способа 900 по фиг. 9, описанного выше.
СИНТАКСИС ДЕРЕВА КОДИРОВАНИЯ


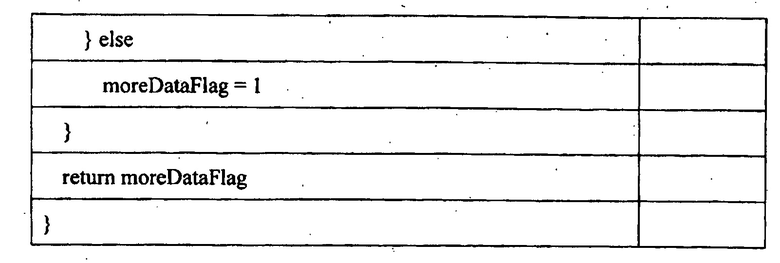
СИНТАКСИС ДЕРЕВА КОДИРОВАНИЯ ДЛЯ ФЛАГА РАЗБИЕНИЯ И ФЛАГА MPM

СИНТАКСИС ДЕРЕВА КОДИРОВАНИЯ ДЛЯ ИНТРА-РЕЖИМА ЯРКОСТИ

СИНТАКСИС ЕДИНИЦЫ КОДИРОВАНИЯ


СИНТАКСИС ЕДИНИЦЫ КОДИРОВАНИЯ ДЛЯ РЕЖИМА РАЗБИЕНИЯ И ФЛАГА MPM

СИНТАКСИС ЕДИНИЦЫ КОДИРОВАНИЯ ДЛЯ ИНТРА-РЕЖИМА ЯРКОСТИ

СИНТАКСИС ЕДИНИЦЫ ПРЕДСКАЗАНИЯ



СИНТАКСИС ЕДИНИЦЫ ПРЕДСКАЗАНИЯ ДЛЯ ФЛАГА MPM

СИНТАКСИС ЕДИНИЦЫ ПРЕДСКАЗАНИЯ ДЛЯ ИНТРА-РЕЖИМА ЯРКОСТИ

Нижеследующий синтаксис дерева кодирования иллюстрирует назначение элементов синтаксиса блокам данных в соответствии с тремя категориями, обозначенными 1, 2 и 3.
СИНТАКСИС ДЕРЕВА КОДИРОВАНИЯ


СИНТАКСИС ЕДИНИЦЫ КОДИРОВАНИЯ


СИНТАКСИС ЕДИНИЦЫ ПРЕДСКАЗАНИЯ

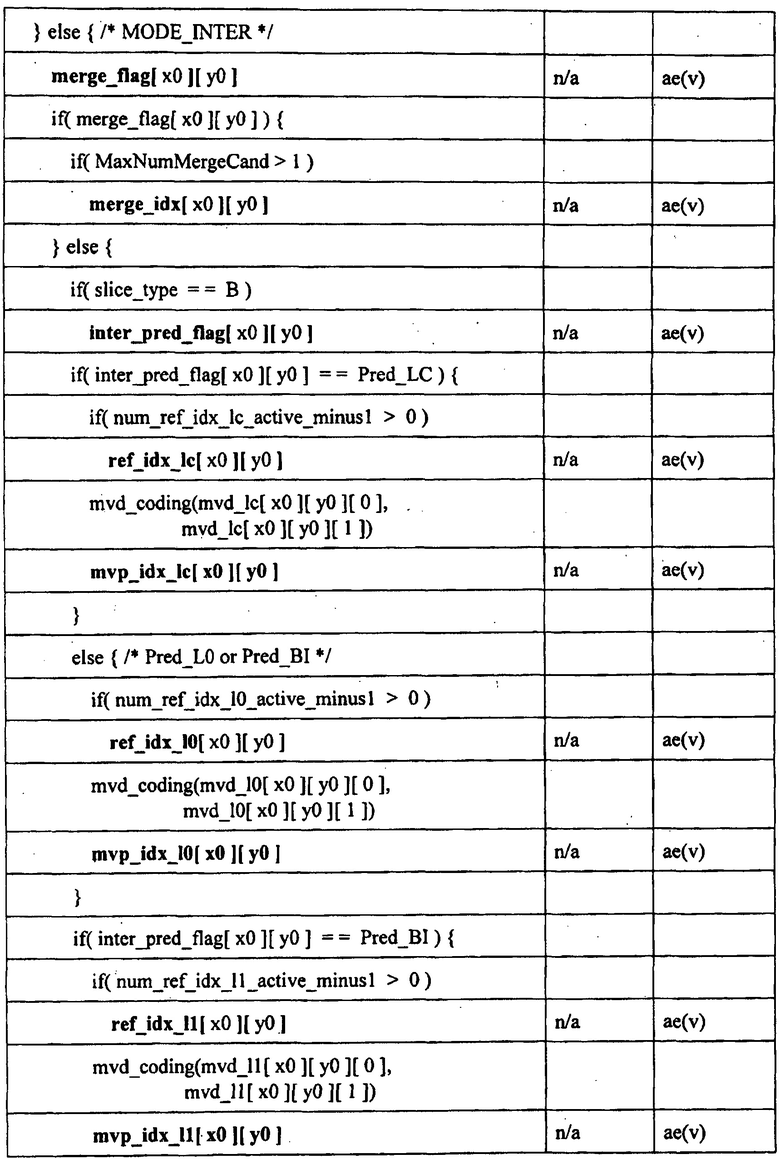
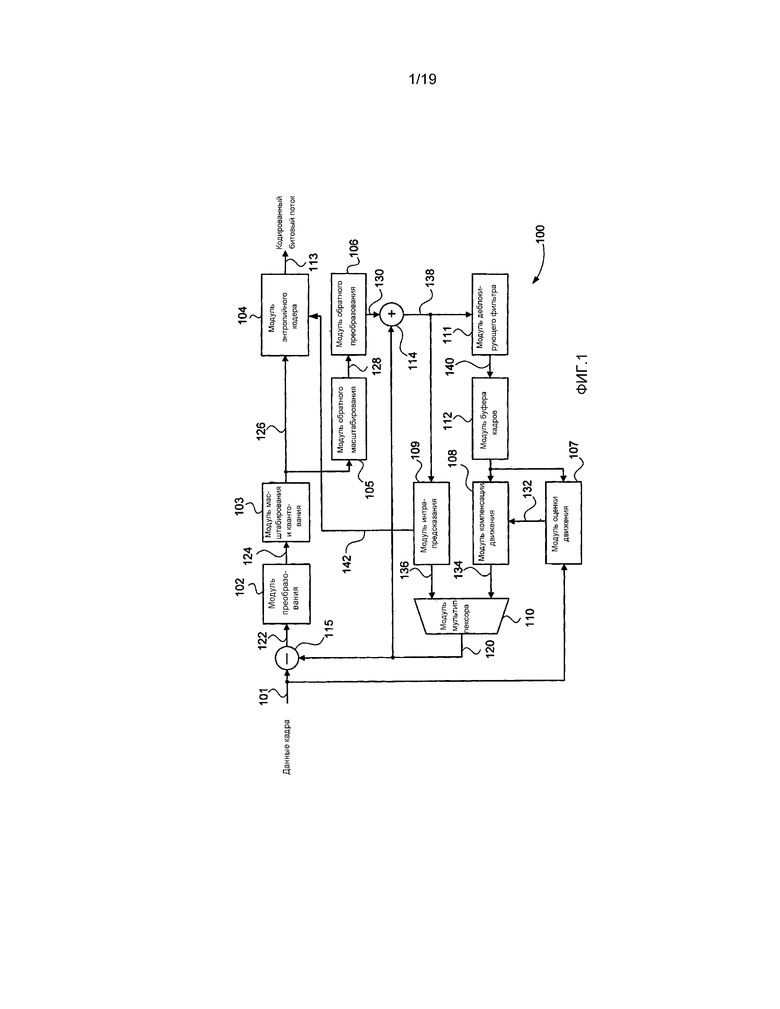
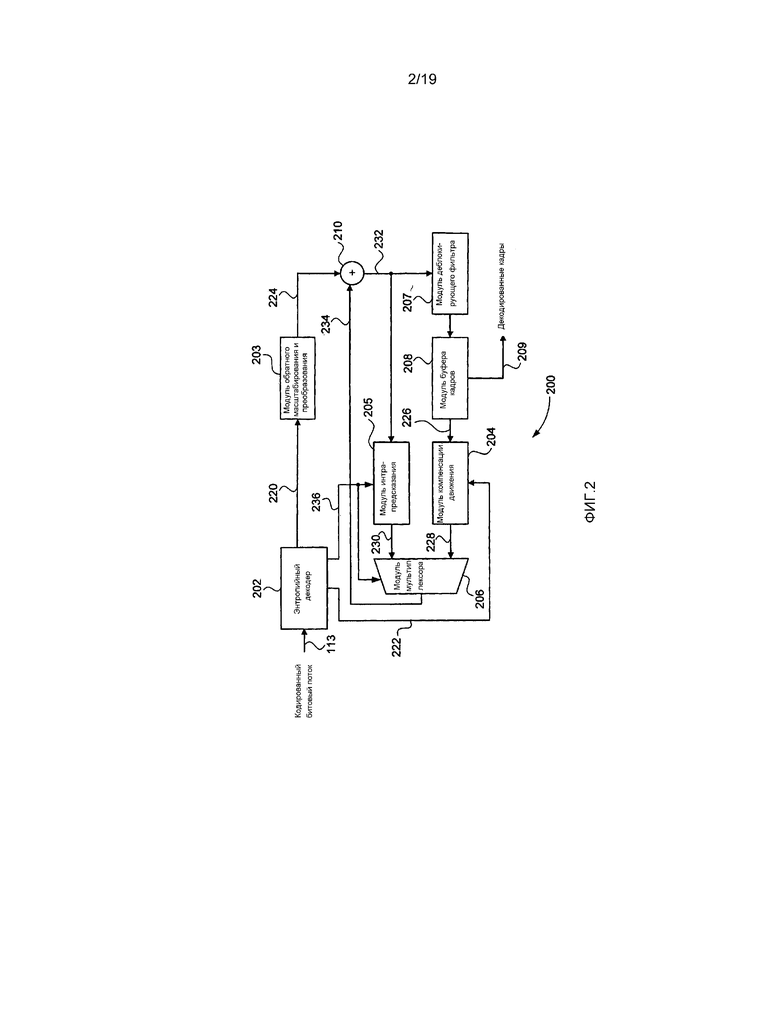
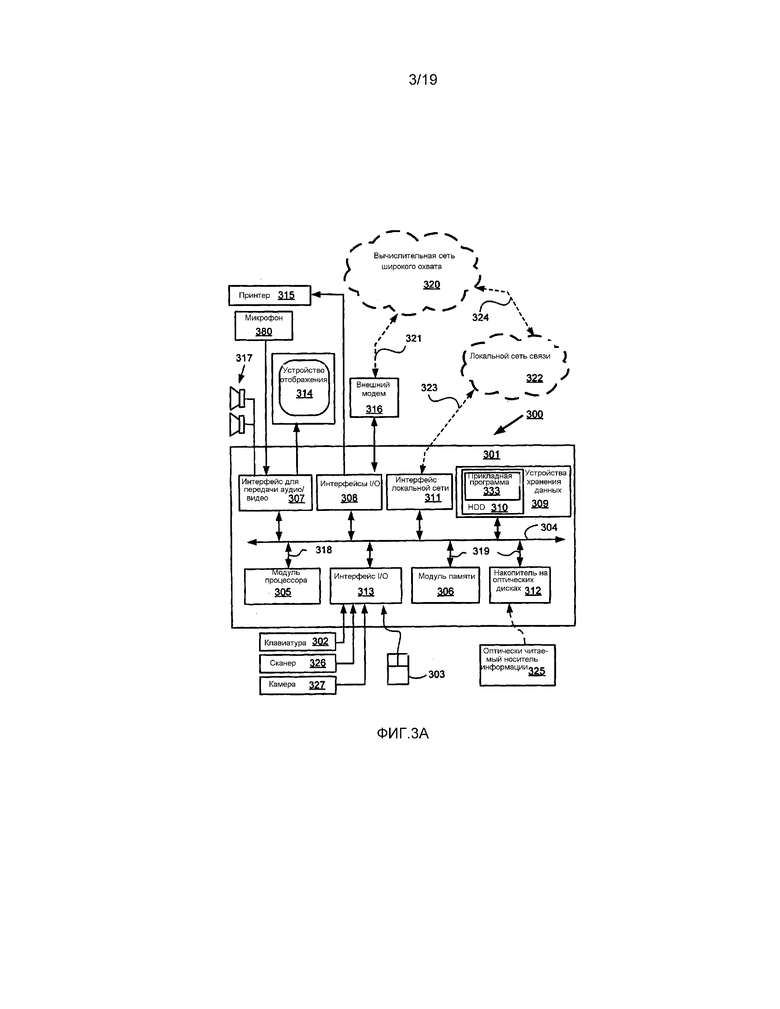
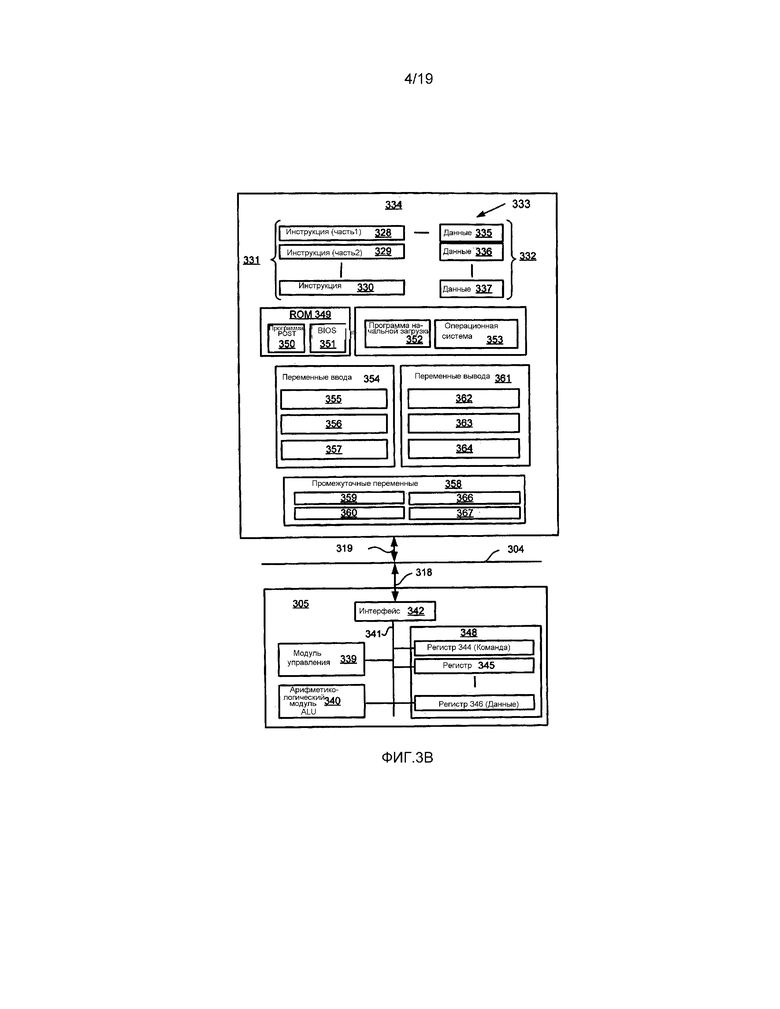
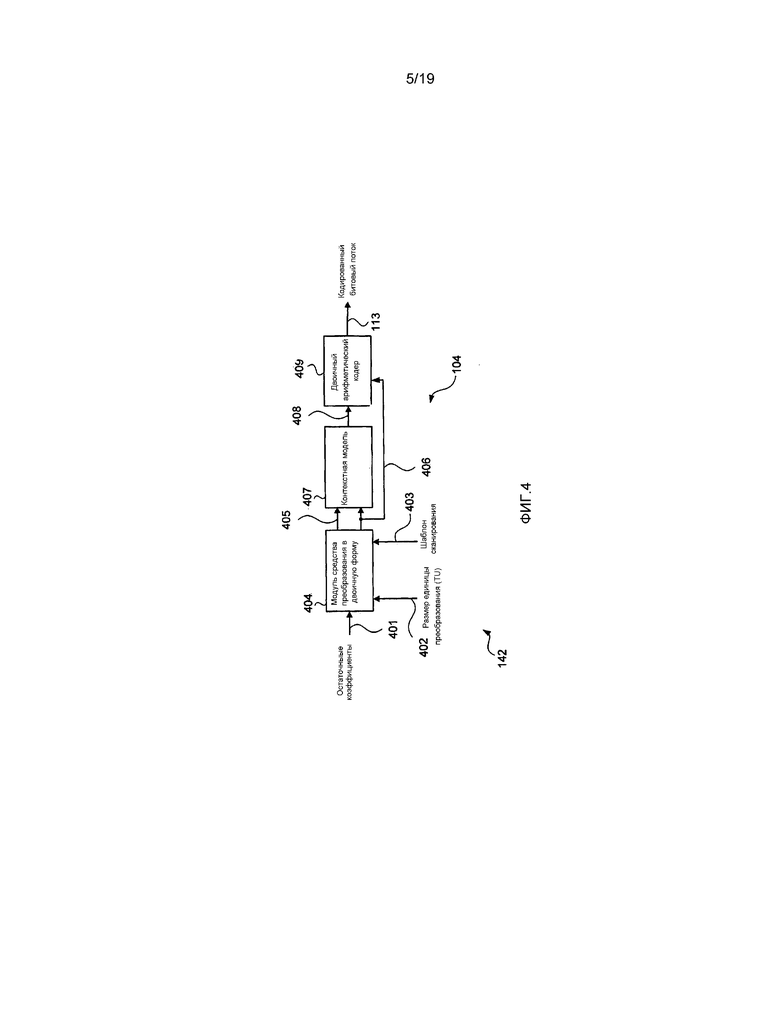
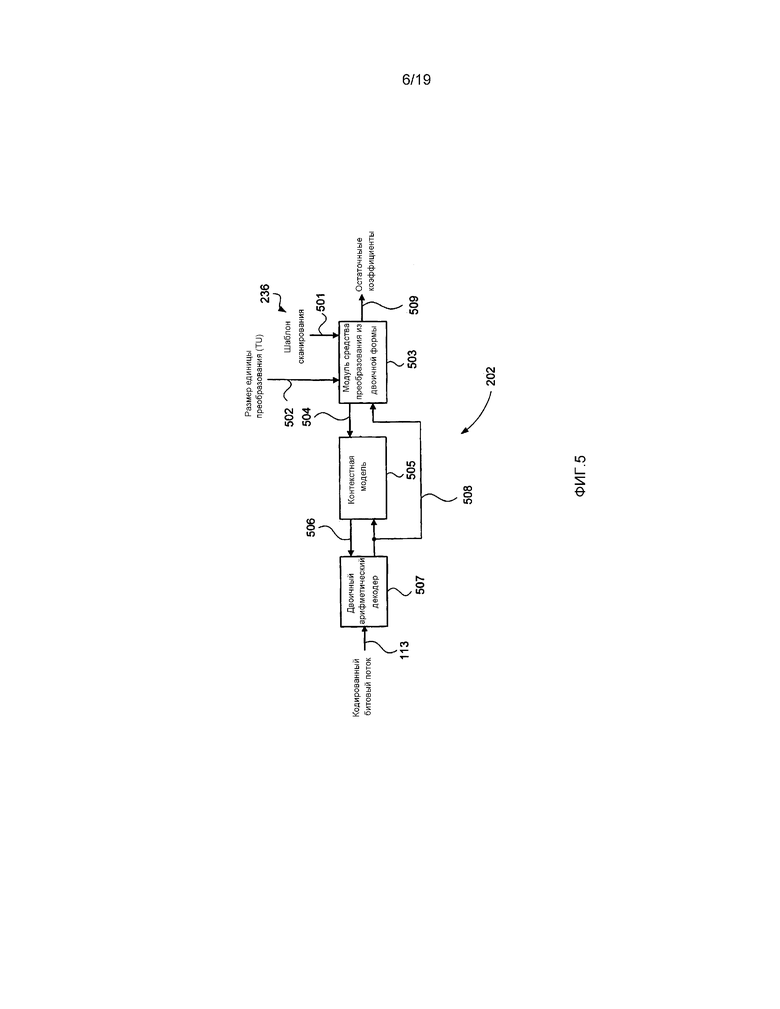
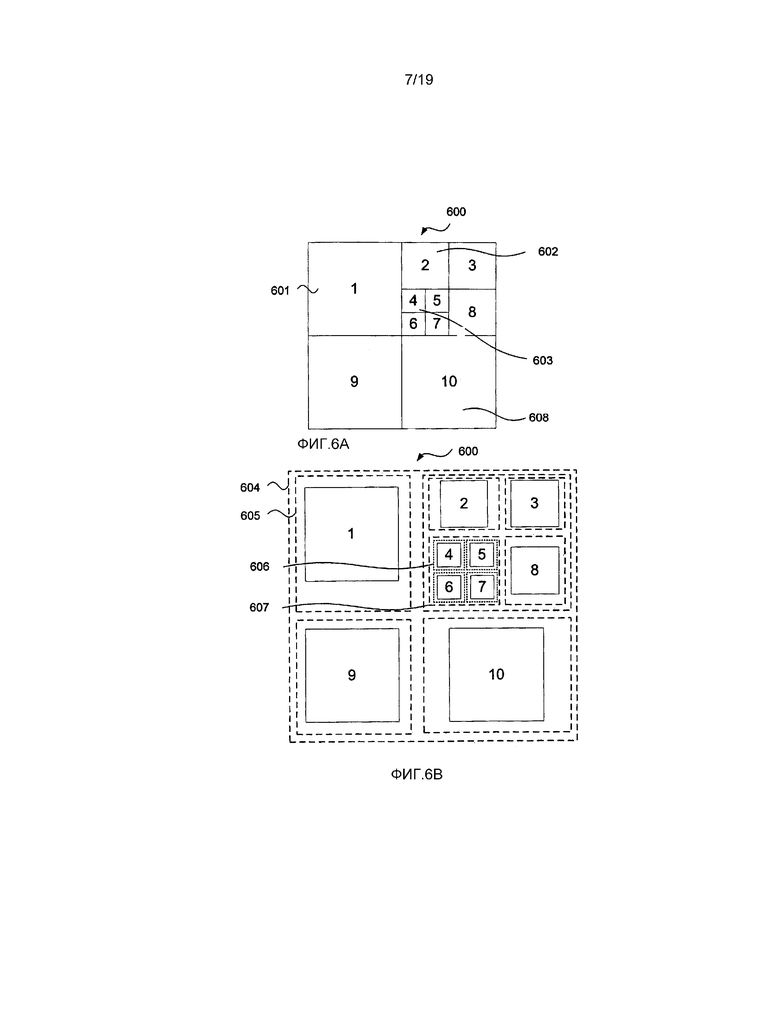
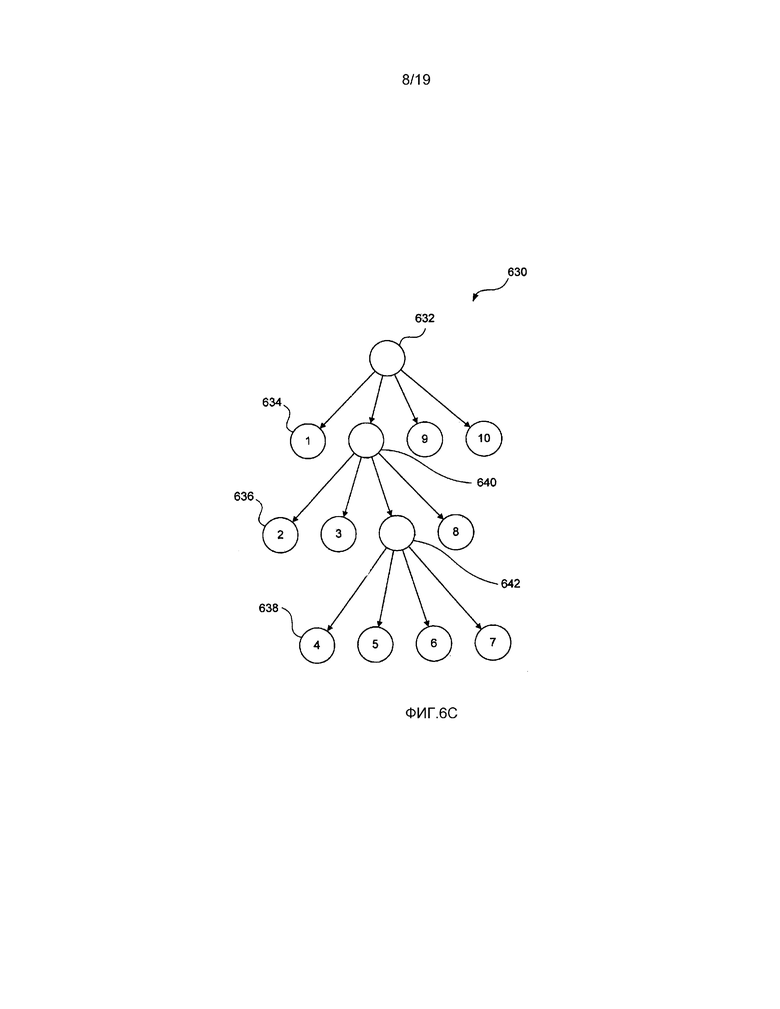
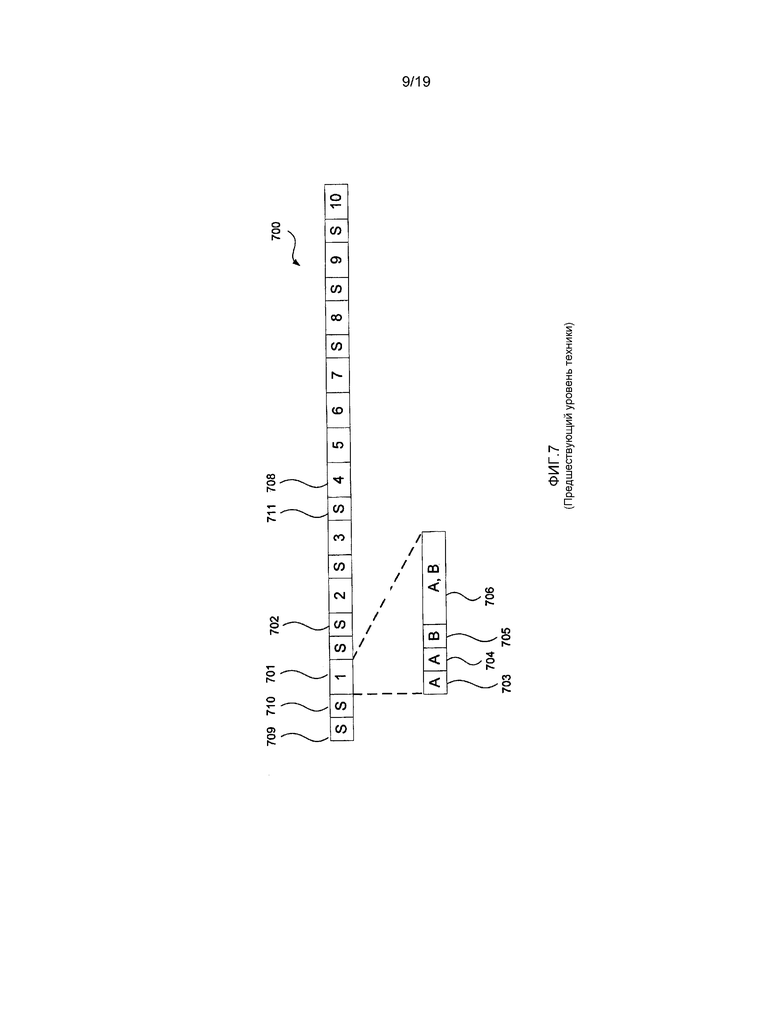
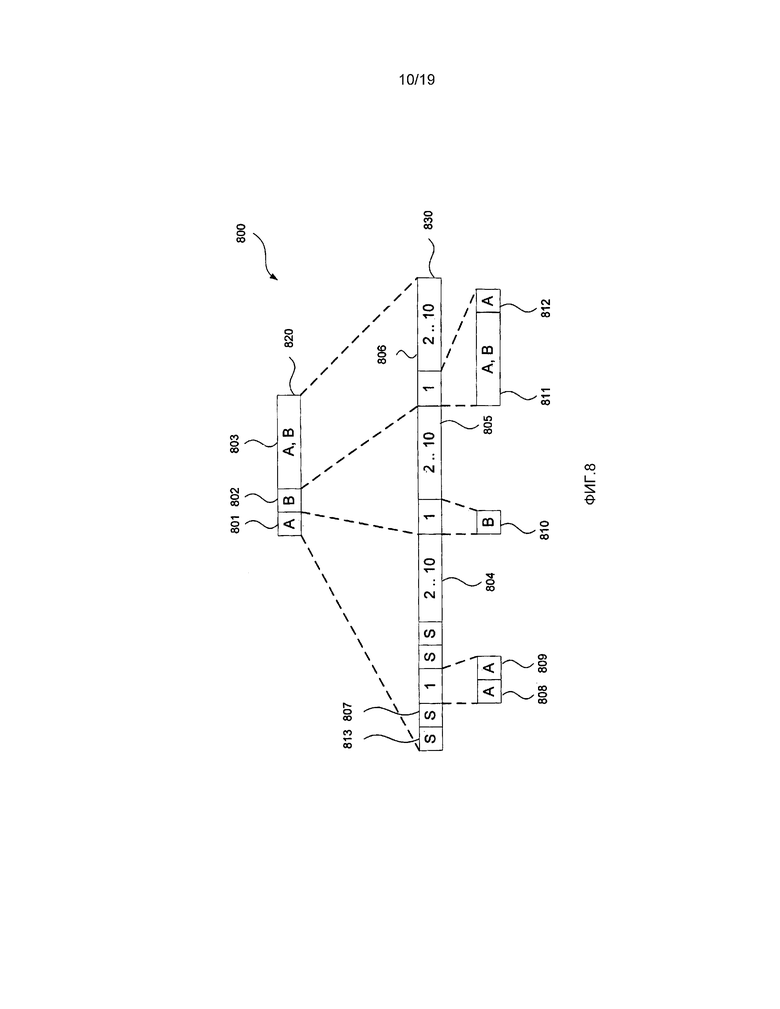
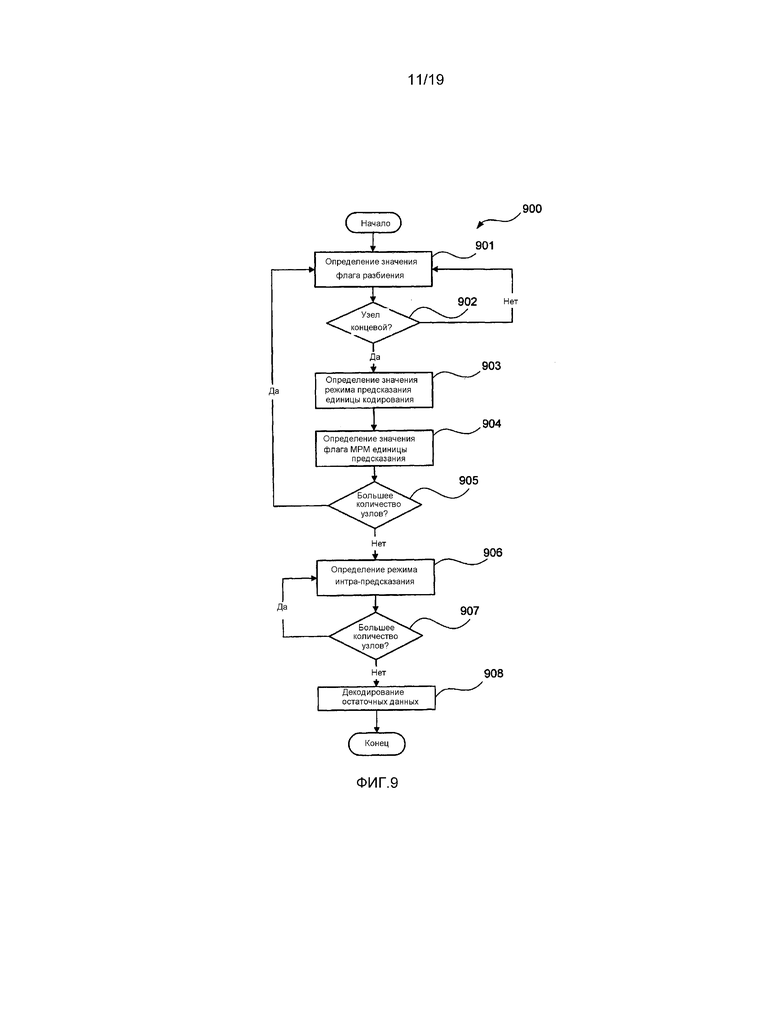
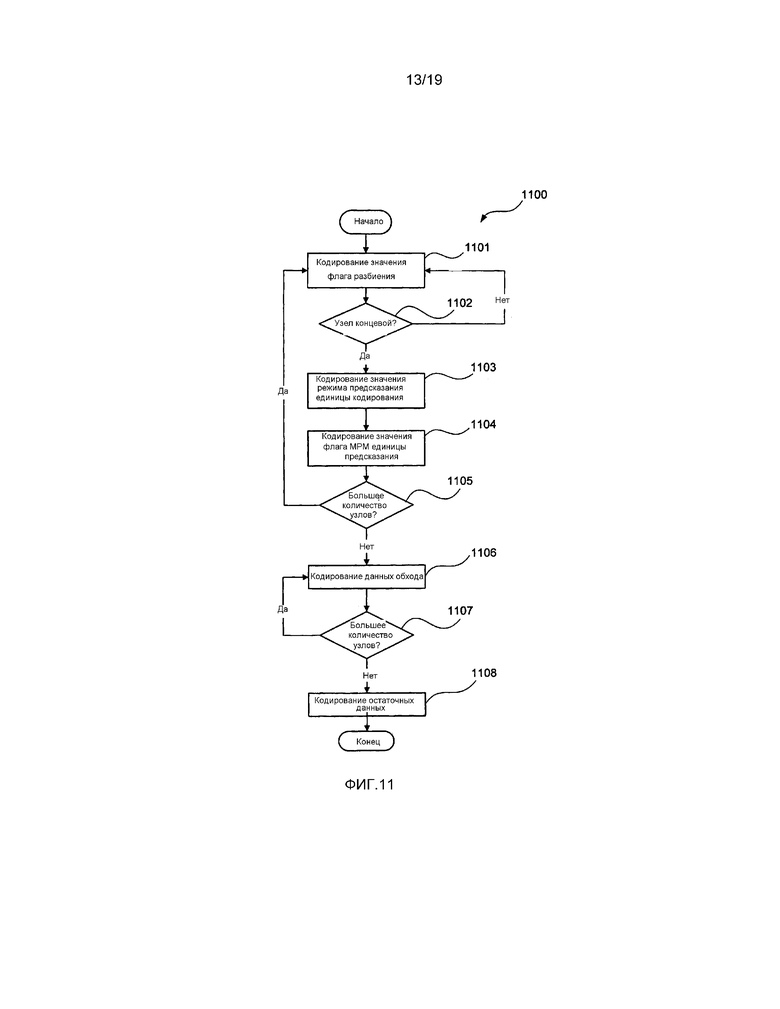
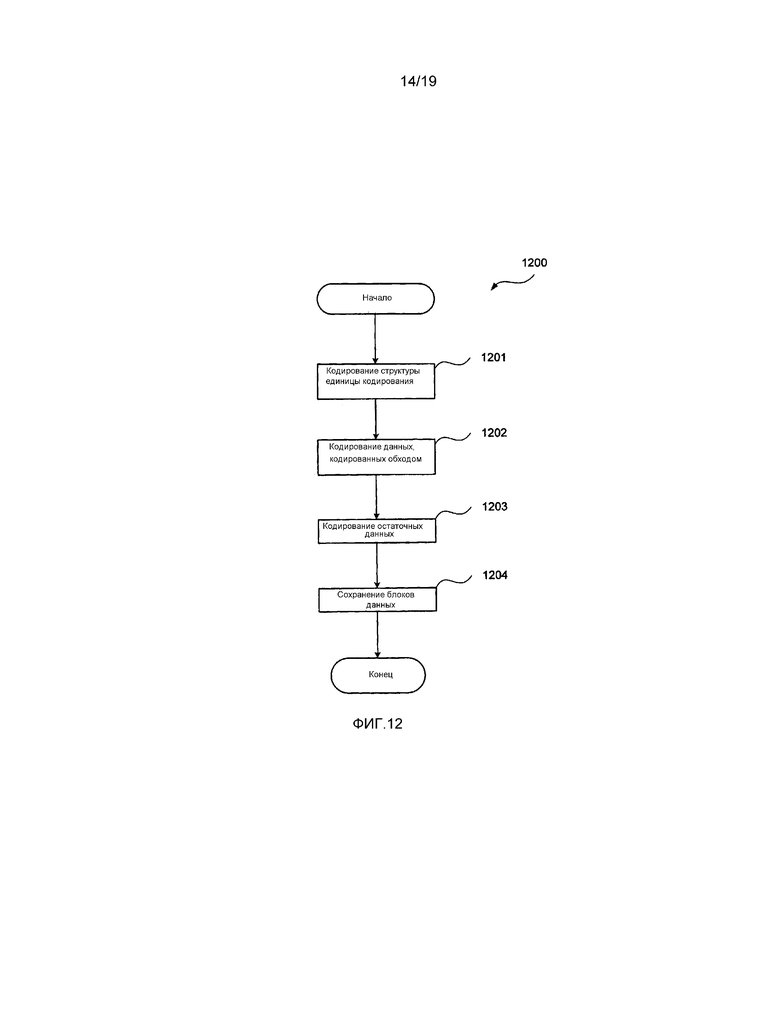
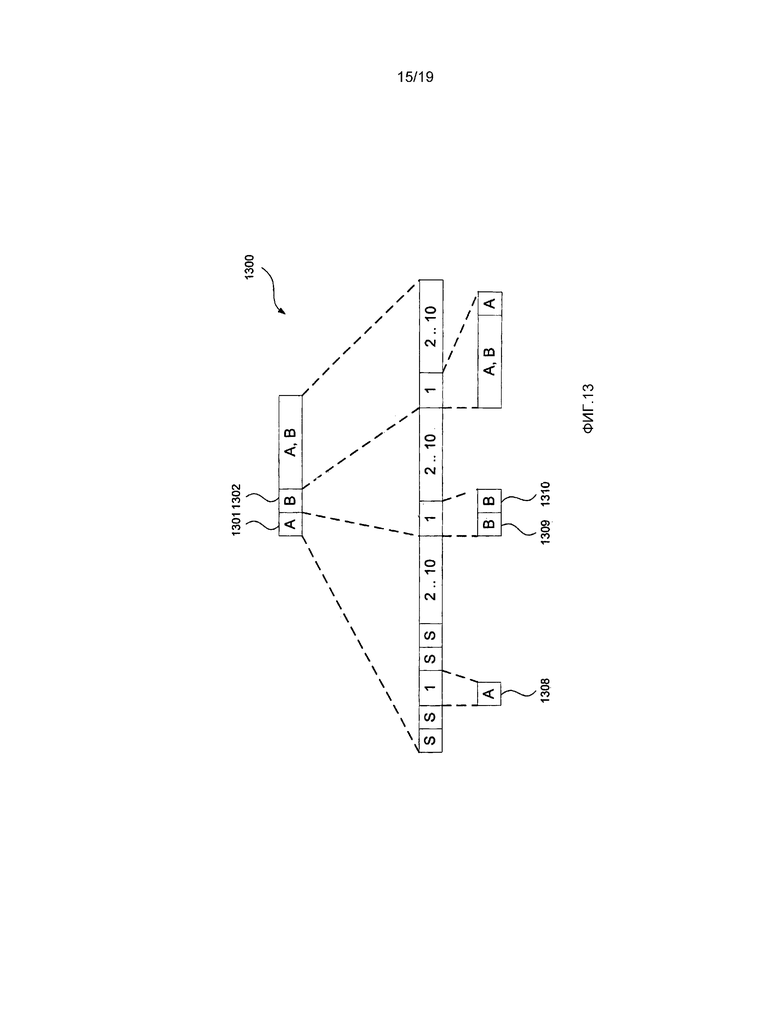
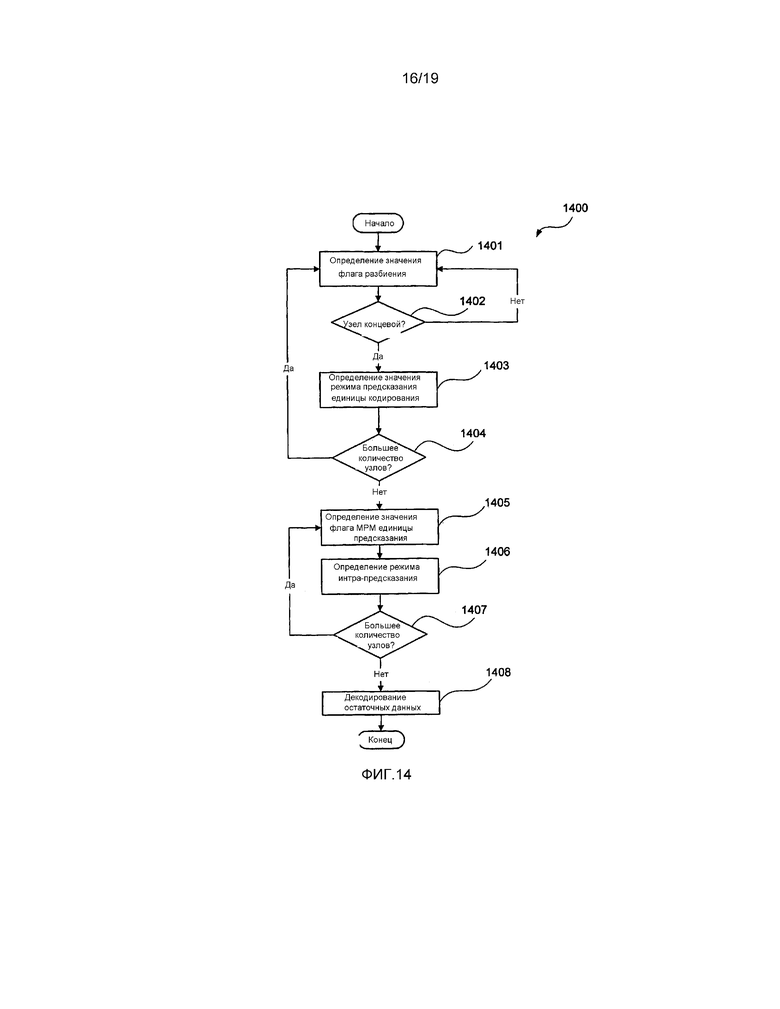
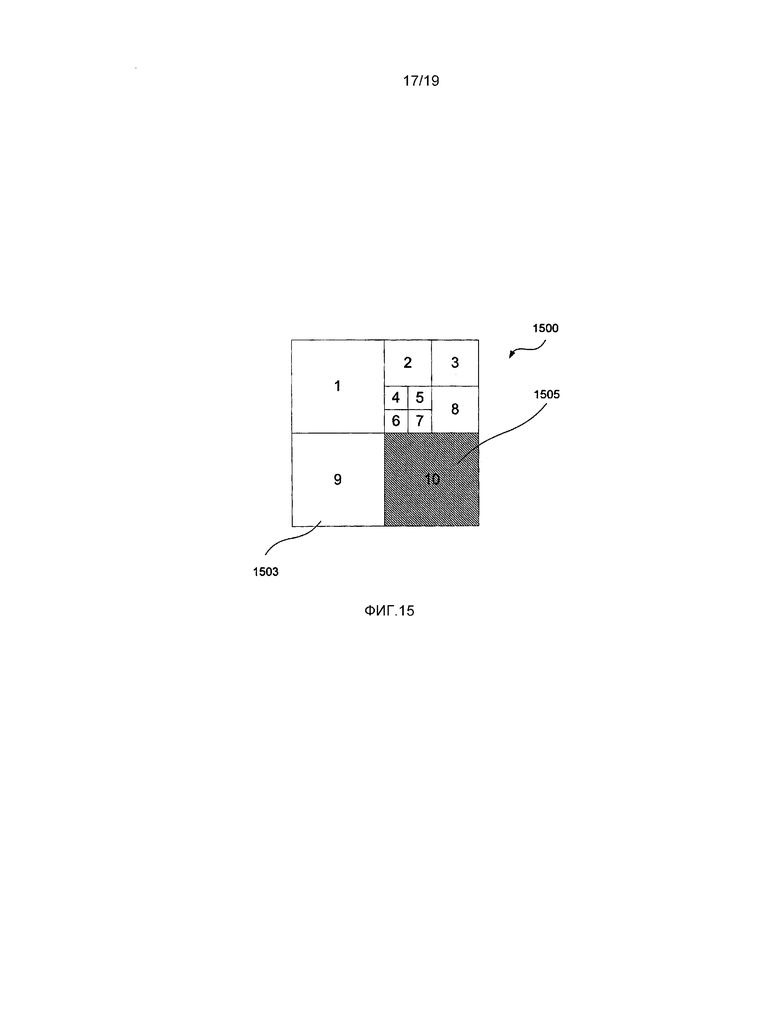
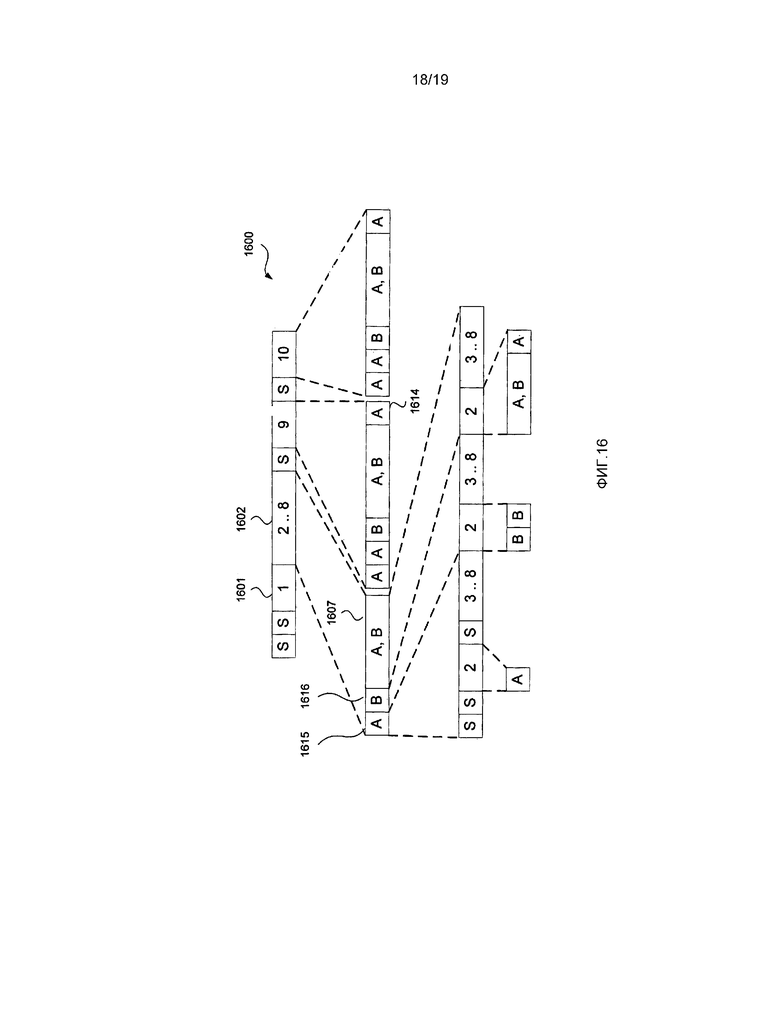
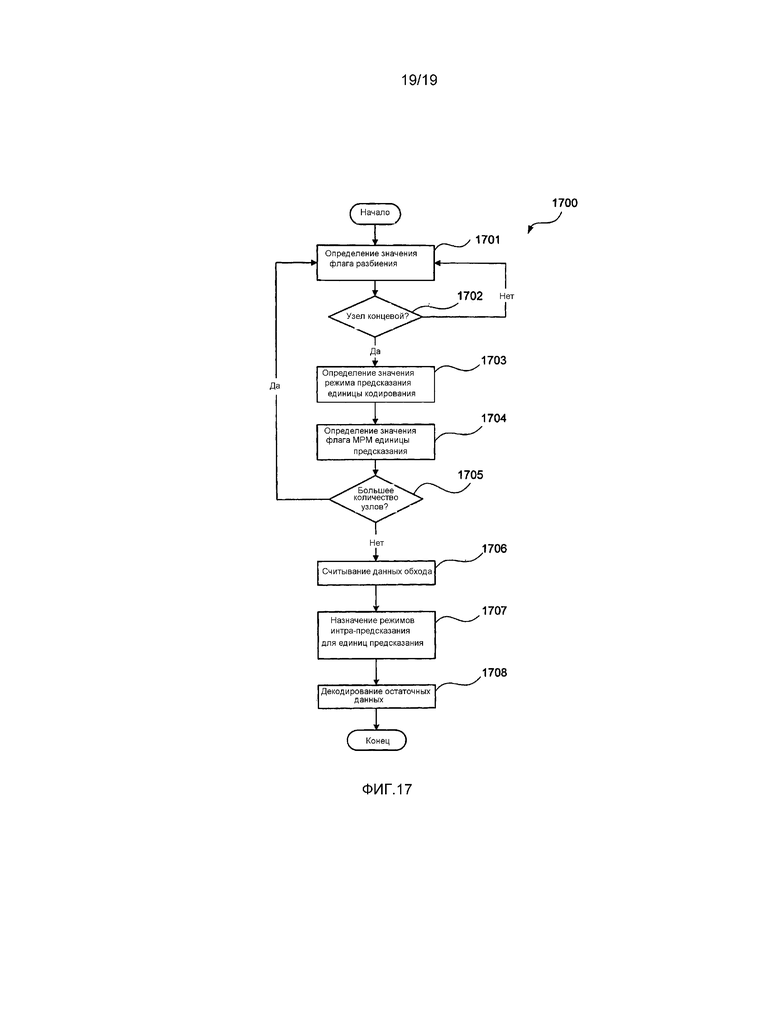
Группа изобретений относится к технологиям кодирования/декодирования видеоданных. Техническим результатом является повышение производительности обработки данных при кодировании или декодировании видеоданных за счет параллельного считывания смежных бинов из битового потока. Предложен способ декодирования по меньшей мере одной единицы кодирования. Способ включает в себя этап, на котором определяют структуру единицы кодирования упомянутой по меньшей мере одной единицы кодирования из битового потока, причем структура единицы кодирования описывает разделение единицы кодирования на упомянутую по меньшей мере одну единицу кодирования и разделение упомянутой по меньшей мере одной единицы кодирования на множество единиц предсказания. Способ также включает в себя этап, на котором декодируют, согласно определенной структуре единицы кодирования, арифметически закодированный флаг наиболее вероятного режима для каждой из упомянутого множества единиц предсказания в упомянутой по меньшей мере одной единице кодирования из первого блока смежно кодированных данных в битовом потоке. 6 н. и 4 з.п. ф-лы, 20 ил.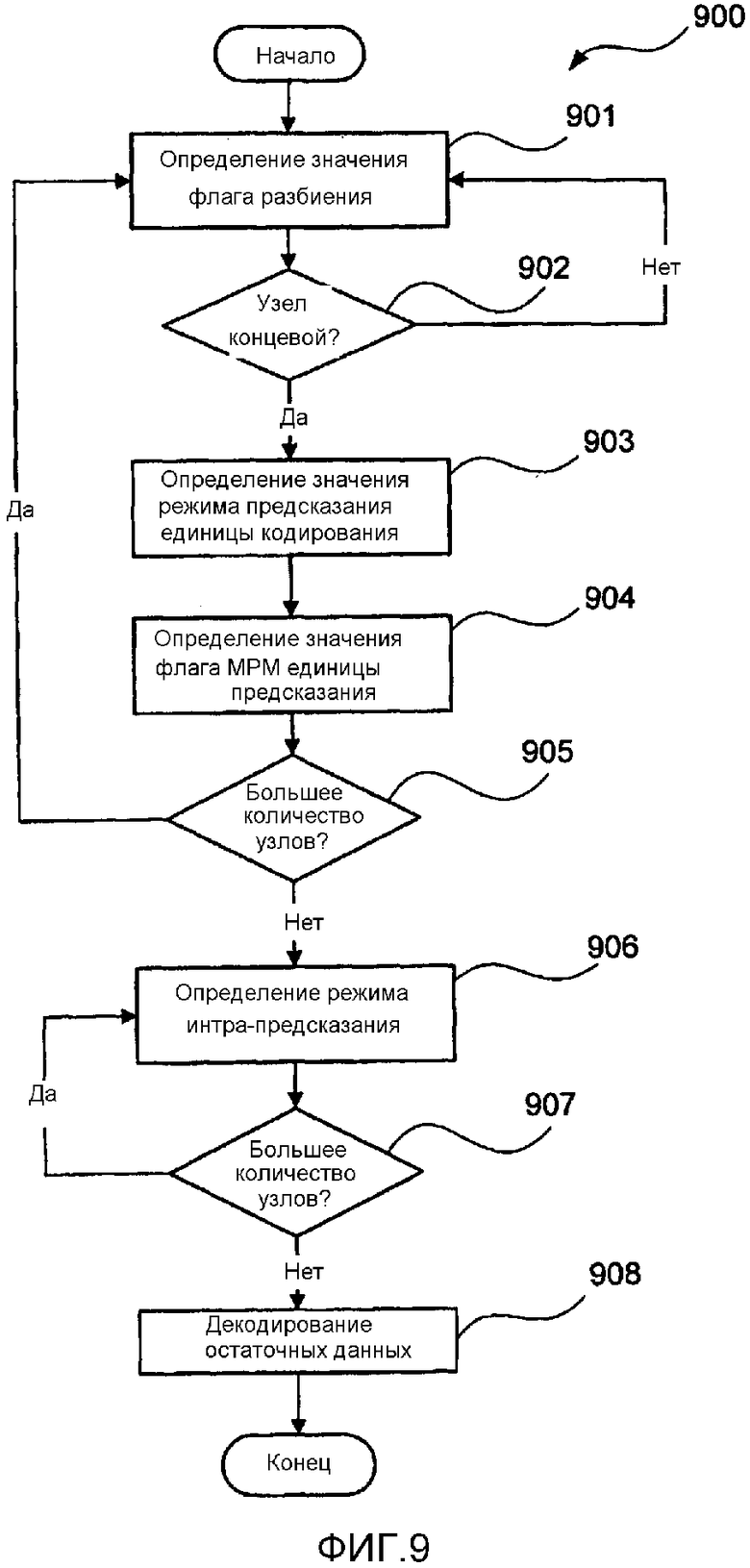
1. Способ декодирования по меньшей мере одной единицы кодирования из битового потока видеоданных, причем способ содержит этапы, на которых:
определяют структуру единицы кодирования упомянутой по меньшей мере одной единицы кодирования из битового потока, причем структура единицы кодирования описывает разделение единицы кодирования на упомянутую по меньшей мере одну единицу кодирования и разделение упомянутой по меньшей мере одной единицы кодирования на множество единиц предсказания;
декодируют, согласно определенной структуре единицы кодирования, арифметически закодированный флаг наиболее вероятного режима для каждой из упомянутого множества единиц предсказания в упомянутой по меньшей мере одной единице кодирования из первого блока данных смежно кодированных данных в битовом потоке;
декодируют, согласно определенной структуре единицы кодирования, закодированные с обходом данные для каждой из упомянутого множества единиц предсказания в упомянутой по меньшей мере одной единице кодирования из второго блока данных смежно кодированных данных в битовом потоке, при этом второй блок данных декодируется после первого блока данных;
определяют режимы интра-предсказания для каждой из упомянутого множества единиц предсказания согласно каждому из флагов наиболее вероятного режима и закодированных с обходом данных; и
декодируют упомянутую по меньшей мере одну единицу кодирования из битового потока с использованием определенных режимов интра-предсказания.
2. Способ по п. 1, в котором упомянутые кодированные с обходом данные содержат индекс наиболее вероятного режима.
3. Способ по п. 1, в котором упомянутые кодированные с обходом данные содержат значение оставшегося режима.
4. Способ кодирования по меньшей мере одной единицы кодирования в битовый поток видеоданных, причем способ содержит этапы, на которых:
кодируют структуру единицы кодирования упомянутой по меньшей мере одной единицы кодирования для формирования первого блока данных битового потока, причем структура единицы кодирования описывает разделение структуры единицы кодирования на упомянутую по меньшей мере одну единицу кодирования и разделение упомянутой по меньшей мере одной единицы кодирования на множество единиц предсказания;
арифметически кодируют наиболее вероятный флаг для каждой из упомянутого множества единиц предсказания в упомянутой по меньшей мере одной единице кодирования в смежно кодированные данные первого блока данных битового потока;
кодируют, согласно структуре единицы кодирования, кодируемые с обходом данные для каждой из упомянутого множества единиц предсказания в упомянутой по меньшей мере одной единице кодирования для формирования второго блока данных смежно кодированных данных битового потока; и
сохраняют первый и второй блоки данных для кодирования упомянутой по меньшей мере одной единицы кодирования в битовый поток видеоданных, причем первый блок данных сохраняется перед вторым блоком данных в битовом потоке.
5. Способ по п. 4, в котором кодируемые с обходом данные содержат индекс наиболее вероятного режима.
6. Способ по п. 4, в котором кодируемые с обходом данные содержат значение оставшегося режима.
7. Способ декодирования по меньшей мере одной единицы кодирования из битового потока видеоданных, причем способ содержит этапы, на которых:
определяют структуру единицы кодирования упомянутой по меньшей мере одной единицы кодирования из битового потока, причем структура единицы кодирования описывает разделение единицы кодирования на упомянутую по меньшей мере одну единицу кодирования и разделение упомянутой по меньшей мере одной единицы кодирования на множество единиц предсказания;
декодируют, согласно определенной структуре единицы кодирования, арифметически закодированный флаг наиболее вероятного режима для каждой из упомянутого множества единиц предсказания в упомянутой по меньшей мере одной единице кодирования из первого блока данных смежно кодированных данных в битовом потоке;
декодируют, согласно определенной структуре единицы кодирования, закодированные с обходом данные для каждой из упомянутого множества единиц предсказания в упомянутой по меньшей мере одной единице кодирования из второго блока данных смежно кодированных данных в битовом потоке, при этом закодированные с обходом данные для по меньшей мере двух из упомянутого множества единиц предсказания декодируются параллельно;
определяют режимы интра-предсказания для каждой из упомянутого множества единиц предсказания согласно каждому из флагов наиболее вероятного режима и закодированных с обходом данных; и
декодируют упомянутую по меньшей мере одну единицу кодирования из битового потока с использованием определенных режимов интра-предсказания.
8. Способ кодирования по меньшей мере одной единицы кодирования в битовый поток видеоданных, причем способ содержит этапы, на которых:
кодируют структуру единицы кодирования упомянутой по меньшей мере одной единицы кодирования для формирования первого блока данных битового потока, причем структура единицы кодирования описывает разделение структуры единицы кодирования на упомянутую по меньшей мере одну единицу кодирования и разделение упомянутой по меньшей мере одной единицы кодирования на множество единиц предсказания;
арифметически кодируют наиболее вероятный флаг для каждой из упомянутого множества единиц предсказания в упомянутой по меньшей мере одной единице кодирования в смежно кодированные данные первого блока данных битового потока;
кодируют, согласно структуре единицы кодирования, кодируемые с обходом данные для каждой из упомянутого множества единиц предсказания в упомянутой по меньшей мере одной единице кодирования для формирования второго блока данных смежно кодированных данных битового потока, при этом кодируемые с обходом данные для по меньшей мере двух из упомянутого множества единиц предсказания кодируются параллельно; и
сохраняют первый и второй блоки данных для кодирования упомянутой по меньшей мере одной единицы кодирования в битовый поток видеоданных, причем первый блок данных сохраняется перед вторым блоком данных в битовом потоке.
9. Компьютеризированное устройство, сконфигурированное с возможностью обработки единиц кодирования, ассоциированных с битовым потоком видеоданных, в соответствии со способом по любому одному из пп. 1-8.
10. Считываемый компьютером носитель данных, имеющий записанную на нем программу, причем данная программа является исполняемой посредством компьютеризированного устройства для выполнения способа по любому одному из пп. 1-8.
| Колосоуборка | 1923 |
|
SU2009A1 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| ОСНОВАННОЕ НА КОНТЕКСТЕ АДАПТИВНОЕ НЕРАВНОМЕРНОЕ КОДИРОВАНИЕ ДЛЯ АДАПТИВНЫХ ПРЕОБРАЗОВАНИЙ БЛОКОВ | 2003 |
|
RU2330325C2 |

