УРОВЕНЬ ТЕХНИКИ
[0001] Производительность компьютерной операционной системы часто характеризуется максимальной скоростью операций ввода/вывода (I/O) (также называемой "I/O-производительностью"), которую операционная система может поддерживать в течение некоторого заданного интервала времени. В результате операционные системы задействуют множество различных широко известных механизмов для повышения I/O-производительности.
[0002] Операционные системы традиционно пишутся с использованием неуправляемых языков (таких как язык ассемблера, C, C++), которые обеспечивают программистам системы очень точное управление тем, как осуществляются манипуляции с памятью. Использование непроверяемых указателей может быть использовано с целью минимизировать служебное сигнализирование операционной системы и обеспечить возможность увеличенной пропускной способности или уменьшенной задержки. Недостаток использования этих непроверяемых указателей состоит в том, что их сложно создавать и обуславливать, что приводит к ненадежным программным средствам и к уязвимостям безопасности.
[0003] Написание программных средств на управляемом языке программирования обеспечивает существенные преимущества в точности и эффективность по времени разработки. Эти управляемые языки предотвращают то, что программисты создают множество видов программных дефектов, что приводит к улучшенному качеству программных средств и уменьшенному времени разработки. Точность операционной системы является важной составляющей для обеспечения надежного и безопасного вычислительного процесса. Таким образом, использование управляемых языков для создания операционных систем является привлекательным предложением, поскольку может быть улучшена надежность операционной системы и могут быть уменьшены издержки разработки.
[0004] Для достижения этих преимуществ управляемые языки программирования добавляют уровень абстракции между исходным кодом, составленным программистом, и необработанными машинными ресурсами физической компьютерной системы. Этот уровень абстракции в общем случае служит для ограничения того, что программисты имеют возможность писать, и, таким образом, для устранения целых категорий потенциальных дефектов. К сожалению, этот уровень абстракции создает служебное сигнализирование, которое может повредить выполнению создаваемых программных средств. В результате, общераспространенное мнение состоит в том, что управляемые языки заменяют дефекты точности дефектами производительности. Таким образом, программные средства, написанные на управляемых языках, часто считаются по существу медленнее, чем программные средства, написанные на неуправляемых языках.
[0005] Конкретной проблемой, которая влияет на операционные системы управляемого кода, является свойственная им необходимость копировать данные между слоями, когда данные перемещаются через систему. Это вызвано тем фактом, что отдельные компоненты системы существуют в различных контекстах изоляции и не существует четкого механизма для ухода от этих контекстов изоляции.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0006] В соответствии с по меньшей мере одним вариантом осуществления, описанным здесь, система имеет управляемую память, в которой каждая из множества вычислительных сущностей имеет соответствующую специализированную для сущности часть управляемой памяти, которая подвергается сборке мусора. Неизменяемый буфер расположен вне управляемой памяти. Для некоторой заданной вычислительной сущности соответствующая часть управляемой памяти содержит один или несколько специализированных для сущности объектов, к которым может осуществляться доступ конкретной вычислительной сущностью, но не множеством других вычислительных сущностей, которые имеют свои собственные специализированные для сущности части управляемой памяти.
[0007] Для одной или нескольких из специализированных для сущности частей управляемой памяти часть также включает в себя ссылку на совместно используемую (разделяемую) память. В одном варианте осуществления эта совместно используемая память может быть неизменяемым буфером. Ссылка структурирована так, чтобы ее игнорировала программа сборки мусора, хотя ссылка может иметь вид просто обычного объекта в части управляемой памяти. Например, возможно, что ссылка является элементом массива. Программа сборки мусора, однако, может отличать ссылку от других объектов. В качестве примера, программа сборки мусора может искать адрес в массиве, и если этот адрес является местоположением вне управляемой памяти, программа сборки мусора не выполняет сборку мусора в отношении ссылки.
[0008] Таким образом, обеспечивается возможность унифицированной модели доступа к памяти, в которой способы для того, чтобы вычислительная сущность осуществляла доступ к обычному объекту в управляемой памяти, подобны тому, как вычислительная сущность осуществляет доступ к совместно используемой памяти. Это краткое описание сущности изобретения не предназначено ни для определения ключевых признаков или существенных признаков заявляемого изобретения, ни для использования в качестве помощи в определении объема заявляемого изобретения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0009] С целью описания того, как вышеперечисленные и другие преимущества и признаки могут быть получены, более конкретное описание различных вариантов осуществления будет обеспечено путем ссылки на приложенные чертежи. С пониманием, что эти чертежи изображают только примерные варианты осуществления и, таким образом, не должны расцениваться как ограничивающие объем изобретения, варианты осуществления будут описаны и объяснены с дополнительной конкретностью и подробностями посредством использования сопроводительных чертежей, на которых:
[0010] фиг. 1 абстрактно изображает вычислительную систему, в которой некоторые варианты осуществления, описанные здесь, могут быть задействованы;
[0011] фиг. 2 изображает блок-схему способа для обеспечения неизменяемого буфера;
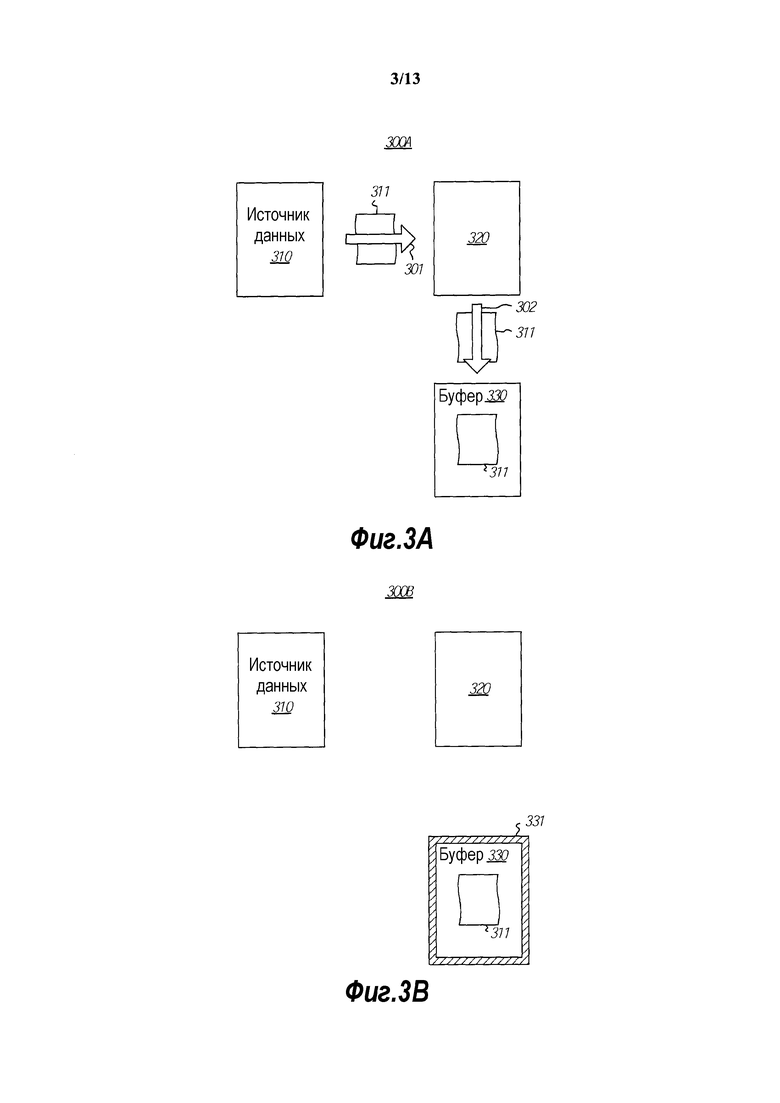
[0012] фиг. 3A изображает среду, в которой происходит процесс заполнения буфера;
[0013] фиг. 3B изображает среду, в которой заполненный буфер делается неизменяемым;
[0014] фиг. 4 изображает блок-схему способа для использования неизменяемого буфера;
[0015] фиг. 5 изображает среду, в которой различные вычислительные сущности имеют различные представления для неизменяемого буфера;
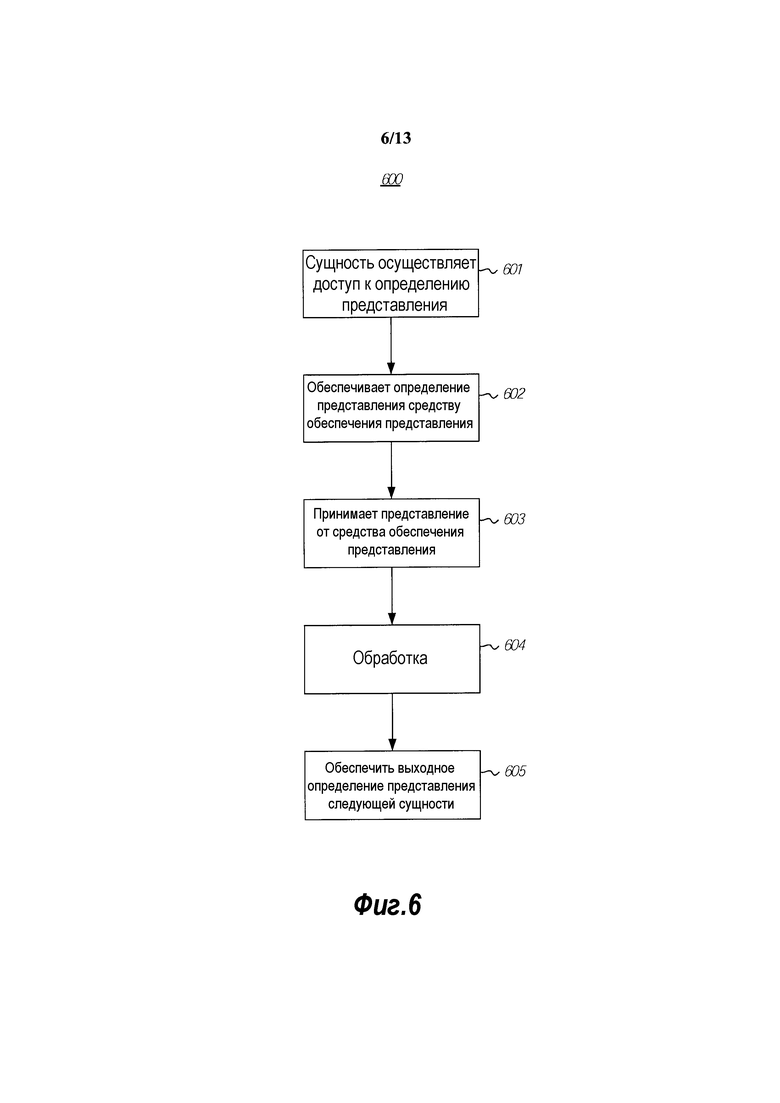
[0016] фиг. 6 изображает блок-схему способа для передачи неизменяемых данных от одной вычислительной сущности к следующей;
[0017] фиг. 7 изображает потоковую среду, в которой поток данных обеспечен из источника потока буферу потока и затем обеспечен из буфера потребителю потока;
[0018] фиг. 8 изображает среду, в которой вторая вычислительная сущность получает кэш посредством кэша первой вычислительной сущности;
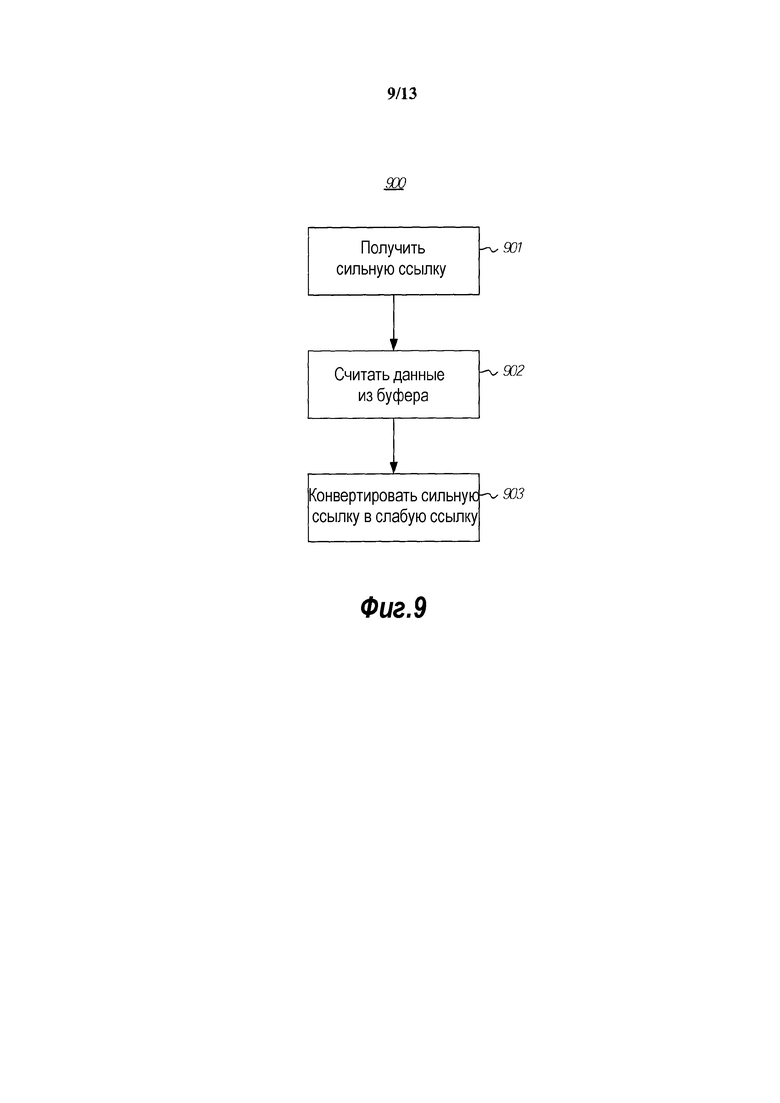
[0019] фиг. 9 изображает блок-схему способа, которым вторая вычислительная сущность сначала осуществляет считывание из кэша, поддерживаемого первой вычислительной сущностью;
[0020] фиг. 10 изображает блок-схему способа, которым вторая вычислительная сущность после этого осуществляет считывание из кэша, поддерживаемого первой вычислительной сущностью;
[0021] фиг. 11 изображает блок-схему способа, которым первая вычислительная сущность (или резервный кэш) выполняет высвобождение;
[0022] фиг. 12 изображает примерную систему управляемого кода; и
[0023] фиг. 13 изображает обычный управляемый массив байтов, который имеет два отдельных интервала, указывающих на него и обеспечивающих возможность приложению просматривать части массива в качестве различных типов.
ПОДРОБНОЕ ОПИСАНИЕ
[0024] В соответствии с вариантами осуществления, описанными здесь, описаны механизмы, которые продвигают семантику ввода/вывода (I/O) с нулевым копированием в управляемых операционных системах. Некоторые из таких механизмов могут быть использованы в операционных системах неуправляемого кода, а также в операционных системах управляемого кода. Механизмы не являются взаимно-исключающими, поскольку один, некоторые или даже все из механизмов могут быть скомбинированы, чтобы еще лучше способствовать I/O-семантике нулевого копирования.
[0025] "Нулевое копирование" означает архитектуру, спроектированную для обеспечения возможности данным входить в систему путем записи в память и распространения через множество уровней абстракции без необходимости копировать данные. Архитектура нулевого копирования не гарантирует, что никакого копирования данных не происходит. В действительности, она всего лишь устанавливает механизм для обеспечения того, что большинство I/O-операций может быть осуществлено без копирования. В этом описании и в формуле изобретения "память" определена как любая оперативная память, которая обычно является энергозависимой памятью, но может также включать в себя энергонезависимые части или, возможно, может целиком являться энергонезависимой. В этом описании и в формуле "память" определена как первичный носитель данных вычислительной системы, состоящей из отдельных местоположений с возможностью адресации, доступных микропроцессорам вычислительной системы и доступных аппаратным устройствам, таким как графические средства управления или средства управления сетевыми интерфейсами посредством механизмов DMA (непосредственного доступа к памяти).
[0026] Во-первых, будут описаны механизмы неизменяемых коллективных данных с возможностью совместного использования нулевого копирования, которые используют неизменяемый буфер совместно используемых данных. Такие механизмы обеспечивают возможность переноса больших буферов данных по всей вычислительной системе без копирования. Механизмы будут дополнительно расширены на совместное использование потоков данных внутри вычислительной системы с полным управлением потоков для обеспечения возможности эффективного использования ресурсов, при этом поддерживая полную семантику нулевого копирования. В то время как текущий тип безопасности систем управляемого кода обеспечивает возможность более непосредственного осуществления этих механизмов, использование этих механизмов внутри систем неуправляемого кода также может быть задействовано.
[0027] Во-вторых, будет описан механизм для кэширования с нулевым копированием. Такое кэширование с нулевым копированием может быть задействовано как в системах неуправляемого кода, так и в системах управляемого кода. Кэширование с нулевым копированием обеспечивает возможность создания универсальной архитектуры кэширования, которая представляет семантику нулевого копирования для данных, входящих в кэш, а также данных, возвращаемых из кэша.
[0028] В-третьих, будет описано несколько механизмов, которые дополнительно улучшают производительность систем управляемого кода независимо от того, применяют эти системы неизменяемый буфер или совместно используемые данные. Такие механизмы управляемого кода включают в себя унифицированный доступ к памяти и безопасное по типам приведение типов. Унифицированный доступ к памяти обеспечивает возможность управляемому коду унифицированным образом осуществлять доступ как к управляемой памяти, так и к неуправляемой памяти (используемой для I/O-буферов) с использованием стабильного и компонуемого подхода. Безопасное по типам приведение типов обеспечивает возможность управляемому коду выполнять приведение указателей для обеспечения возможности того, чтобы некоторая заданная область памяти рассматривалась как обособленные типы, при этом сохраняя полную безопасность по типам.
[0029] Некоторое вступительное рассмотрение вычислительной системы будет описано в отношении фиг. 1. Затем вышеперечисленные механизмы будут описаны в порядке, обеспеченном выше, в отношении фиг. 2-13.
[0030] Сейчас вычислительные системы все чаще принимают широкое множество различных форм. Вычислительные системы могут, например, быть карманными устройствами, приборами, компьютерами-ноутбуками, настольными компьютерами, мейнфреймами, распределенными вычислительными системами или даже устройствами, которые стандартно не рассматривались как вычислительная система. В этом описании и в формуле изобретения термин "вычислительная система" определен широко, как включающий в себя любое устройство или систему (или их комбинацию), которые включают в себя по меньшей мере один физический и материальный процессор, и физическую и материальную память с возможностью иметь машиноисполняемые инструкции, которые могут исполняться процессором. Память может принимать любую форму и может зависеть от природы и формы вычислительной системы. Вычислительная система может быть распределенной по сетевой среде и может включать в себя множество составляющих вычислительных систем.
[0031] Как изображено на фиг. 1, в ее самой базовой конфигурации вычислительная система 100 включает в себя по меньшей мере один обрабатывающий блок 102 и машиночитаемые носители 104. Машиночитаемые носители 104 концептуально могут рассматриваться как включающие в себя физическую системную память, которая может быть энергозависимой, энергонезависимой или некоторой комбинацией этих двух типов. Машиночитаемые носители 104 также концептуально включают в себя энергонезависимое массовое хранилище. Если вычислительная система является распределенной, возможность обработки, памяти и/или хранения также может быть распределенной.
[0032] Используемый здесь термин "исполняемый модуль" или "исполняемый компонент" может обозначать программные объекты, маршрутизации или способы, которые могут исполняться на вычислительной системе. Различные компоненты, модули, подсистемы и службы, описанные здесь, могут осуществляться как объекты или процессы, которые исполняются на вычислительной системе (например, в качестве отдельных потоков). Такие исполняемые модули могут быть управляемым кодом в случае исполнения в управляемой среде, в которой внедряется безопасность по типам и в которой процессам выделяются их собственные отдельные объекты памяти. Такие исполняемые модули могут также быть неуправляемым кодом в случае, когда исполняемые модули разрабатываются на внутреннем коде, таком как C или C++.
[0033] В описании, которое следует далее, варианты осуществления описаны со ссылками на действия, которые выполняются одной или несколькими вычислительными системами. Если такие действия осуществляются в программных средствах, один или несколько процессоров ассоциированной вычислительной системы, которая выполняет действие, управляют операцией вычислительной системы в ответ на исполнение машиноисполняемых инструкций. Например, такие машиноисполняемые инструкции могут осуществляться на одном или нескольких машиночитаемых носителях, которые формируют компьютерный программный продукт. Пример такой операции включает в себя манипуляцию данными. Машиноисполняемые инструкции (и манипулируемые данные) могут сохраняться в памяти 104 вычислительной системы 100. Вычислительная система 100 может также содержать каналы 108 связи, которые обеспечивают возможность вычислительной системе 100 осуществлять связь с другими процессорами через, например, сеть 110.
[0034] Варианты осуществления, описанные здесь, могут содержать или задействовать специализированный или универсальный компьютер, включающий в себя компьютерные аппаратные средства, такие как, например, один или несколько процессоров и системная память, как рассмотрено более подробно ниже. Варианты осуществления, описанные здесь, также включают в себя физические и другие машиночитаемые носители для переноса или хранения машиноисполняемых инструкций и/или структур данных. Такие машиночитаемые носители могут быть любыми доступными носителями, к которым может осуществляться доступ универсальной или специализированной компьютерной системой. Машиночитаемые носители, которые хранят машиноисполняемые инструкции, являются физическими носителями памяти. Машиночитаемые носители, которые переносят машиноисполняемые инструкции, являются носителями передачи. Таким образом, в качестве примера и не ограничения, варианты осуществления изобретения могут содержать по меньшей мере два раздельных различных вида машиночитаемых носителей: компьютерные носители памяти и носители передачи.
[0035] Компьютерные носители памяти включают в себя RAM, ROM, EEPROM, CD-ROM или другой накопитель на оптических дисках, накопитель на магнитных дисках или другие магнитные устройства хранения, или любой другой материальный носитель данных, который может быть использован для хранения желаемых средств программного кода в форме машиноисполняемых инструкций или структур данных и к которому может осуществлять доступ универсальный или специализированный компьютер.
[0036] "Сеть" определяется как одна или несколько линий передачи данных, которые обеспечивают возможность переноса электронных данных между компьютерными системами, и/или модулями, и/или другими электронными устройствами. Когда информация переносится или обеспечивается по сети или другому соединению связи (либо жестко замонтированному, либо беспроводному, либо комбинации жестко замонтированного или беспроводного) компьютеру, компьютер надлежащим образом рассматривает соединение как носитель передачи. Носители передачи могут включать в себя сеть и/или линии передачи данных, которые могут быть использованы для переноса желаемых средств программного кода в форме машиноисполняемых инструкций или структур данных и к которым может осуществлять доступ универсальный или специализированный компьютер. Комбинации вышеописанного должны также включаться в объем машиночитаемых носителей.
[0037] Кроме того, при достижении различных компонентов компьютерной системы средства программного кода в форме машиноисполняемых инструкций или структур данных могут быть перенесены автоматически с носителей передачи на компьютерные носители памяти (или наоборот). Например, машиноисполняемые инструкции или структуры данных, принимаемые по сети или линии передачи данных, могут буферизоваться в RAM внутри средства управления сетевого интерфейса (например, "NIC") и затем в какой-то момент переноситься в RAM компьютерной системы и/или в менее энергозависимую компьютерную среду хранения в компьютерной системе. Таким образом, следует понимать, что компьютерные носители памяти могут быть включены в компоненты компьютерной системы, которые также (или даже в первую очередь) задействуют носители передачи.
[0038] Машиноисполняемые инструкции содержат, например, инструкции и данные, которые при исполнении в процессоре побуждают универсальный компьютер, специализированный компьютер или специализированное обрабатывающее устройство выполнять некоторую функцию или группу функций. Машиноисполняемыми инструкциями могут быть, например, двоичные файлы, инструкции промежуточного формата, такого как язык ассемблера, или даже исходный код. Хотя изобретение было описано на языке, характерном для структурных признаков и/или методологических действий, следует понимать, что изобретение, определенное в прилагаемой формуле изобретения, не обязательно ограничивается описанными признаками или действиями, описанными выше. В действительности, описанные признаки и действия раскрываются в качестве примерных форм осуществления формулы.
[0039] Специалисты в данной области техники поймут, что изобретение может осуществляться на практике в сетевых вычислительных средах с множеством типов конфигураций компьютерной системы, включающих в себя персональные компьютеры, настольные компьютеры, компьютеры-ноутбуки, процессоры сообщений, портативные устройства, многопроцессорные системы, основанную на микропроцессоре или программируемую бытовую электронику, сетевые PC, миникомпьютеры, компьютеры-мейнфреймы, мобильные телефоны, PDA, пейджеры, маршрутизаторы, переключатели и т.п. Изобретение может также осуществляться на практике в распределенных системных средах, где локальные и удаленные компьютерные системы, которые связываются (либо посредством жестко замонтированных линий передачи данных, либо посредством беспроводных линий передачи данных, либо посредством комбинации жестко замонтированных и беспроводных линий передачи данных) через сеть, вместе выполняют задачи. В распределенной системной среде программные модули могут быть расположены как в локальных, так и в удаленных устройствах хранения памяти.
Неизменяемые коллективные данные нулевого копирования с возможностью совместного использования
[0040] Большой сложностью для поддержки нулевого копирования были I/O-интерфейсы в традиционных системах, которые определяются как операции копирования между различными слоями в системе. Интерфейс прикладных программ (API) считывания принимает буфер приложения в качестве входных данных и заполняет его данными из некоторого источника данных. Подобным образом API записи берет буфер приложения и записывает его содержимое в некоторую цель данных. Семантика API считывания/записи обеспечивает приложению полную свободу для выравнивания буфера, пространства выделения и удерживания. Эта простая модель имеет несколько характерных ограничений, заключающихся в том, что модель не имеет возможности выразить несмежные буферы или уменьшить количество операций копирования данных.
[0041] Множество операционных систем поддерживают файлы, отображаемые в память, как механизм для совместного использования страниц в буферном кэше файловой системы с приложениями и избегания операций копирования, ассоциированных с интерфейсом считывания/записи. Специальные API были добавлены к сетевому интерфейсу, чтобы непосредственно посылать данные от буферного кэша файловой системы с использованием отображения в памяти файлов для ускорения сетевого трафика.
[0042] Абстракции файлов, отображаемых в память, не достает поддержки для скрывания базового выравнивания и разреженного формата буферов и требуется, чтобы приложения обрабатывали и управляли виртуальными отображениями и представлениями логических данных непосредственно. Например, приложению, осуществляющему доступ к файлу на смещении 10, необходимо применить арифметику указателей на виртуальном адресе базы отображения для выведения верного адреса. Расширение файла, когда он отображается, требует, чтобы приложение управляло дополнительными представлениями, которые не обязательно являются смежными в адресном пространстве, и доступы между представлениями должны обрабатываться приложением.
[0043] Избегание копий данных посредством файлов, отображаемых в память, имеет другие недостатки. Обеспечение семантической непротиворечивости между файлами, отображаемыми в память, и операциями считывания/записи требует сложной координации между I/O, памятью и файловыми системами. I/O, отображаемый в память, вносит служебное сигнализирование синхронного завершения, поскольку пропуск ошибки страницы на виртуальном адресе, который отображается в файловую область, задерживает поток, пока страница не будет доступна в физической памяти.
[0044] Методики виртуальной памяти копирования при записи также использовались для скрывания издержек от операций копирования. Эти методики копирования при записи назначают псевдоним приложению и страницам буферного кэша на основе предположения, что является редкостью то, что приложения модифицируют входные буферы на месте. Это дает файловой системе возможность кэшировать одни и те же физические страницы без копирования. Для некоторых рабочих загрузок эта оптимизация может избегать операции копирования ценой существенной сложности, в особенности, когда приложение и стеки памяти находятся в различных областях защиты. Другие методики, такие как повторное отображение страницы виртуальной памяти, были полезны для сетевых путей приема при определенных условиях, когда буферы приложения надлежащим образом выровнены.
[0045] Фиг. 2 изображает блок-схему способа 200 для обеспечения неизменяемого буфера. Фиг. 3A изображает среду 300A, в которой происходит процесс заполнения буфера. Фиг. 3B изображает среду 300B, в которой заполненный буфер становится неизменяемым. Соответственно способ 200 с фиг. 2 далее будет описан с частыми ссылками на фиг. 3A и 3B. Среды 300A и 300B могут возникать внутри вычислительной системы 100 с фиг. 1, хотя не обязательно. Среды 300A и 300B могут быть распределенными или находящимися в одной вычислительной системе.
[0046] К исходным данным, которые должны быть использованы для заполнения буфера, сначала осуществляется доступ получающей вычислительной сущностью (действие 210). Исходные данные могут быть любыми данными, но в одном варианте осуществления исходные данные включают в себя большое количество коллективных данных, которые требуют существенных вычислительных ресурсов для генерирования. В этом описании и в формуле изобретения "вычислительной сущностью" является любой компонент, модуль, метод, функция, процесс, процессор или любая их комбинация, которые имеют возможность обрабатывать данные в вычислительной системе. Такая вычислительная сущность может быть распределенной или располагаться на одном компьютере.
[0047] Получающая вычислительная сущность может генерировать все или некоторые из исходных данных (действие 211). В качестве альтернативы или дополнения, получающая вычислительная сущность может получать все или некоторые из исходных данных из источника данных (действие 212). Например, со ссылкой на фиг. 3A, получающая вычислительная сущность 320 получает (как представлено стрелкой 301) исходные данные 311 из источника 310 данных. Источником данных может быть, например, сеть или энергонезависимое устройство хранения, такое как диск.
[0048] Получающая вычислительная сущность также получает буфер (действие 220). Это получение буфера (220) показано параллельно с получением исходных данных (действие 210), поскольку самый широкий аспект принципов, описанных здесь, не требует того, чтобы какое-либо из действий происходило первым. Однако в некоторых системах одно может требоваться перед другим и/или эти действия могут по меньшей мере частично происходить параллельно. Со ссылкой на фиг. 3A, получающая вычислительная сущность 320 получает буфер 330 в той степени, что получающая вычислительная сущность может затем заполнять буфер 330 данными.
[0049] Независимо от того, генерирует ли получающая вычислительная сущность исходные данные или же принимает исходные данные из источника данных, или и то, и другое, получающая вычислительная сущность заполняет буфер данными (действие 230). Со ссылкой на фиг. 3A, например, получающая вычислительная сущность 320 заполняет (как представлено стрелкой 302) данными 311 буфер 330.
[0050] Буфер затем классифицируется как неизменяемый (действие 240). Фиг. 3B изображает среду 300B, которая подобна среде 300A с фиг. 3A за исключением того, что данные 311 изображены защищенными внутри буфера 330, который изображен как имеющий заштрихованную границу 331, абстрактно представляющую, что буфер 330 теперь неизменяемый. Эта классификация защищает данные (например, данные 311), заполняющие неизменяемый буфер (например, буфер 330 на фиг. 3B), от изменения в течение времени существования неизменяемого буфера и также защищает неизменяемый буфер от изменения его физического адреса в течение времени существования неизменяемого буфера. Ввиду этой неизменяемой характеристики, доступ к неизменяемым данным может быть предоставлен произвольному количеству вычислительных сущностей без риска конфликта, поскольку каждая из этих вычислительных сущностей может только просматривать данные.
[0051] В среде собственного языка (такого как C или C++) эта неизменяемость может достигаться путем записи в блок управления памяти (MMU) процессора для ограничения процессора в записи в конкретные диапазоны памяти. Это может быть довольно затратно, и ограничение на доступы к памяти не очень детализировано, будучи часто достигаемым на относительно большом страничном уровне. Кроме того, это может быть затратной операцией и не избегает ситуаций, в которых копирование выполняется для того, чтобы скрыть данные от других уровней со степенью детализации, меньшей чем страничный уровень.
[0052] В управляемой среде (среде, которая включает в себя управляемое время выполнения) программные средства используются для объявления памяти неизменяемой и для введения неизменяемости. Кроме того, время существования буфера памяти может обслуживаться посредством счетчика использования, который увеличивает значение, когда сущности предоставляется новый указатель на память, и уменьшает значение, когда указатель на память больше не используется сущностью. Когда счетчик использования возвращается на ноль, буфер недоступен и может быть возвращен средством управления памятью. В одном варианте осуществления ядро предоставляет права различным сущностям для осуществления доступа к памяти и обслуживает счетчик использования, в то время как управляемое время выполнения обеспечивает представления неизменяемой памяти, вводит неизменяемость и обеспечивает ограничения для данных. Дополнительные подробности, касающиеся управляемых сред, описаны ниже в отношении фиг. 12.
[0053] Фиг. 4 изображает блок-схему способа для использования неизменяемого буфера. Прежде всего компонент представления предлагает гибкие представления для неизменяемого буфера (действие 401) и затем обеспечивает представления надлежащим образом различным потребителям неизменяемого буфера (действие 402). Вычислительная сущность затем может осуществлять доступ к неизменяемому буферу только через его соответственное представление (действие 403). Например, со ссылкой на среду 500 с фиг. 5, первая вычислительная сущность 501 осуществляет доступ к (что представлено стрелкой 521) неизменяемому буферу 330 через первое представление 511, и вторая вычислительная сущность 502 осуществляет доступ к (что представлено стрелкой 522) неизменяемому буферу 330 через второе представление 512. Эллипсы 513 показывают, что это может быть продолжено для большего количества, чем только эти две вычислительные сущности 501 и 502. Представления 511 и 512 могут быть различными представлениями, но могут также быть одним и тем же представлением. Так или иначе, компонент 520 представления имеет возможность обеспечения различных представлений базового неизменяемого буфера 330. В этом описании термины "первый" и "второй" используются исключительно для отличия одного элемента от другого и не подразумевают какой-либо последовательности, приоритета, позиции или важности.
[0054] В некоторых вариантах осуществления вычислительные сущности, которые потребляют данные из неизменяемого буфера, находятся с различных сторон границы защиты или процесса. Например, фиг. 5 изображает, что вычислительные сущности 501 и 502, которые потребляют данные через их соответственные представления 511 и 512, в действительности разделены границей 530. Например, вычислительные сущности 501 и 502 могут быть раздельными процессами, в случае чего граница 530 представляет границу между процессами. Граница 530 может также быть границей защиты, в случае чего можно не обеспечивать данные непосредственно другому без копирования. Например, вычислительная сущность 501 может быть компонентом ядра внутри операционной системы, в то время как вычислительная сущность 502 может быть компонентом пользовательского режима, таким как компонент приложения.
[0055] Обычно данные не используются совместно между процессами и границами защиты, если только данные не копируются. Такое копирование может тратить существенное количество вычислительных ресурсов, в особенности если количество копируемых данных очень большое или если различные части данных должны часто совместно использоваться между такими границами. Принципы, описанные здесь, обеспечивают удобный и гибкий механизм для совместного использования данных между процессами и границами защиты без копирования. Таким образом, это улучшает производительность операционной системы.
[0056] Представления, обеспечиваемые средством 520 обеспечения представления, могут быть мелкоструктурными. Например, предположим, что неизменяемые данные, которые должны быть считаны из неизменяемого буфера, являются сетевыми данными. Каждый из различных слоев пакета протоколов может быть заинтересован в различных частях этих сетевых данных. Компоненты сетевого уровня (такие как компонент протокола Интернета) могут быть заинтересованы в заголовках сетевого уровня, в то время как компонент уровня приложений может быть попросту заинтересован в необработанной полезной нагрузке. Между этими двумя слоями существуют различные компоненты, которые заинтересованы в различных частях сетевых данных.
[0057] Принципы, описанные здесь, могут быть эффективно применены к обработке этих сетевых данных без необходимости копирования сетевых данных. Например, самый нижний уровень пакета протоколов может иметь возможность просматривать весь сетевой пакет. Этот самый нижний уровень может обрабатывать самый внешний заголовок этого пакета и возвращать определение представления следующему компоненту более высокого уровня в стеке протоколов. Определение представления определяет весь объем сетевого пакета, кроме самого внешнего пакета. Этот второй компонент обеспечивает определение представления средству 520 обеспечения представления, которое обеспечивает это представление второму компоненту. Таким образом, самый нижний компонент видит весь пакет, в то время как следующий компонент видит тот же самый пакет без самого внешнего заголовка. Это было осуществлено без какого-либо копирования данных. Вместо этого данные остались внутри неизменяемого буфера. Это может повторяться до тех пор, пока самому верхнему слою приложения не будет обеспечено определение представления, которое определяет только полезную информацию пакета.
[0058] Фиг. 6 изображает блок-схему способа 600 для передачи неизменяемых данных от одной вычислительной сущности к следующей. Первая вычислительная сущность осуществляет доступ к определению представления (действие 601) и обеспечивает это определение представления средству обеспечения представления (действие 602). Средство обеспечения представления затем обеспечивает представление к первой вычислительной сущности (действие 603). После того как первая вычислительная сущность выполняет свою логическую операцию (действие 604), она может затем обеспечивать другое определение представления к следующей вычислительной сущности (действие 605), которое предназначено для обработки данных от неизменяемого буфера. Следующая вычислительная сущность может затем повторять этот способ 600, и, таким образом, процесс может продолжаться для множества слоев системы.
[0059] Несмотря на то, что выше описано потребление буферов/потоков способом нулевого копирования, принципы, описанные выше, могут также применяться к созданию буферов и потоков средством создания данных. В случае средства создания данных также существует гибкость для приложения, чтобы посылать его собственные буферы (назначаются отдельно) или запрашивать у средства создания данных обеспечить представления с возможностью записи (интервалы) в его собственном внутреннем буфере. Это потенциально не только устраняет копирование, но также улучшает использование буфера путем устранения необходимости посылать полузаполненные буферы.
Потоковая передача данных с нулевым копированием
[0060] Коллективное перемещение данных через операционную систему часто моделируется с использованием потоковой архитектуры. Поток представляет логический модуль обмена между источником данных и потребителем данных, обеспечивая возможность данным, создаваемым источником, быть доставленными по назначению. Потоки обычно осуществляют буферизацию для того, чтобы предусмотреть несоответствие пропускной способности между создателем и потребителем.
[0061] Например, фиг. 7 изображает потоковую среду 700, в которой поток 711 данных обеспечивается (как представлено стрелкой 701) из источника 710 потока в буфер 720 потока и затем обеспечивается (как представлено стрелкой 702) из буфера 720 потребителю 730 потока. Среда 700 также включает в себя средство 740 управления (диспетчер) потоком, которое выполняет управление потоком. Средство 740 управления потоком побуждает подачу частей потока потребителю 730 потока из буфера 720 (как представлено стрелкой 702) с удовлетворительной скоростью для потребителя 730 потока. Кроме того, средство 730 управления потоком выполняет надлежащее упреждающее считывание потока (как представлено стрелкой 701), чтобы удостовериться в том, что количество частей потока внутри буфера 720 потока не настолько мало, что для потребителя 730 потока имеется риск иссякания частей потока, и не настолько велико, что занимается избыточное количество памяти буфера 720 потока. Средство 740 управления потоком также управляет временем существования частей потока внутри буфера 720 потока так, чтобы память, занятая частью потока, могла быть восстановлена, когда часть потока потреблена.
[0062] Потоки часто логически пересекают множество процессов и/или границ защиты. Например, когда приложение считывает данные из файла, данные часто считываются с физического диска под управлением драйвера устройства в защищенном режиме. Данные затем проходят через слой файловой системы и затем, наконец, делаются доступны коду приложения. Часто пересечение слоя может включать в себя копирование данных, которое влияет на производительность и расход мощности.
[0063] Однако, принципы неизменяемого буфера нулевого копирования, описанные выше, могут быть использованы для формирования буфера потока (такого как буфер 720 потока), в котором необходимость копировать части потока между процессами или границами защиты устранена.
[0064] Конкретным образом, предположим, что неизменяемый буфер (такой как описан в отношении фиг. 2-6) установлен для каждой из множества частей потока в потоке. Кроме того, предположим, что способ с фиг. 2 и процессы с фиг. 3A и 3B выполняются для создания ассоциированного неизменяемого буфера, содержащего единственную часть потока, каждый раз, когда принимается часть потока.
[0065] Такой неизменяемый буфер обеспечивает возможность любым данным, включающим в себя части потока, проходить через различные слои и компоненты системы, обеспечивая возможность каждому иметь свое собственное конкретное представление для данных, без требования копировать данные, как описано в отношении общих данных на фиг. 5 и 6. Буфер 720 потока в таком случае будет всего лишь набором неизменяемых буферов, каждый из которых имеет соответствующую часть потока, содержащуюся в нем в качестве данных. По мере того, как каждая часть потока потребляется, для памяти соответствующего неизменяемого буфера обеспечивается возможность возврата. Таким образом, потоковая передача данных нулевого копирования возможна с использованием принципов, описанных здесь.
Кэширование с нулевым копированием
[0066] Кэширование является важным аспектом I/O-подсистемы любой операционной системы. Задержка уменьшается и эффективная пропускная способность увеличивается путем влияния на тот факт, что схемы доступа к данным имеют тенденцию объединяться в группы, и одни и те же данные часто извлекаются множество раз. Традиционное кэширование выполняется путем наличия специализированных накопителей памяти в варьирующихся слоях операционной системы, управляемых независимо, каждый с ортогональными политиками удержания и замещения. Осуществление доступа к данным из кэша часто включает в себя копирование данных из буферов кэша в буферы приложения.
[0067] Принципы, описанные выше в отношении фиг. 2-6, обеспечивают возможность совместного использования неизменяемых буферов между процессами и между границами защиты, через которые вызовы функций не могут осуществляться, но вместо этого гораздо более затратная межпроцессная связь или пересекающая границы защиты связь должна быть использована для связи между границами.
[0068] Эти принципы могут быть использованы для реализации кэша. По мере потоковой передачи данных из операций непосредственного доступа к памяти (DMA) данные входят в систему в качестве неизменяемых буферов (таких как неизменяемый буфер 330 с фиг. 3A, 3B и 5). Неизменяемые буферы могут циркулировать по системе для передачи новых данных, и в то же время может быть сделан их снимок в кэш для дальнейшего повторного использования. Когда возникает дальнейший запрос на данные, один и тот же неизменяемый буфер может извлекаться из кэша и повторно использоваться - без какого-либо копирования или, в действительности, даже осуществления доступа к базовым данным. Это приводит к существенным преимуществам по эффективности.
[0069] Когда вычислительная сущность удерживает кэш, который основан на базовых данных в неизменяемом буфере, вычислительная сущность имеет "сильную" ссылку на базовые данные в неизменяемом буфере и может использовать эту сильную ссылку для осуществления доступа к данным неизменяемого буфера. Использование термина "сильная" для модификации ссылки всего лишь используется для отличия ссылки от того, что будет названо "мягкой" и "слабой" ссылками ниже. Схожим образом, использование терминов "слабая" и "мягкая" для модификации ссылки всего лишь используется для отличия ссылок друг от друга и от сильной ссылки.
[0070] До тех пор, пока какая-либо сущность имеет сильную ссылку на неизменяемый буфер внутри кэша, неизменяемый буфер и его данные гарантированно продолжают существовать в течение по меньшей мере продолжительности сильной ссылки для каждой сущности, которая имеет сильную ссылку. "Мягкая" ссылка на неизменяемый буфер не может быть использована для осуществления доступа к данным из неизменяемого буфера без того, чтобы сначала преобразовать мягкую ссылку в сильную ссылку. Сильная ссылка может быть преобразована в мягкую ссылку, когда доступ к данным завершается.
[0071] Мягкая ссылка может быть использована в качестве формы подсказки управления памятью. Если существуют только мягкие ссылки на некоторый заданный неизменяемый буфер какой-либо вычислительной сущностью и в системе заканчивается память, система может принять решение возвратить память, резервирующую этот неизменяемый буфер. Если это происходит, то следующая попытка преобразовать мягкую ссылку в сильную ссылку потерпит неудачу. Содержимое буфера потеряно, и вычислительная сущность должна будет повторно сгенерировать содержимое другого неизменяемого буфера из источника данных.
[0072] Эта мягкая ссылка является ценным способом для использования максимально большой части системной памяти для кэшей без необходимости высокой точности для настройки размеров кэшей в системе. Например, кэш может избрать удерживание большой части своих данных в виде мягких, а не сильных ссылок. Использование памяти другого процесса может затем импульсивно повышаться достаточно сильно для приведения системы к состоянию низкой памяти. Система может затем реагировать быстро и освобождать память от этих мягких ссылок без необходимости делать какой-либо выбор в отношении того, сколько памяти выдать какому процессу.
[0073] Вычислительная сущность может также удерживать "слабую" ссылку на некоторый заданный неизменяемый буфер. Как и с мягкой ссылкой, слабая ссылка должна быть преобразована в "сильную" ссылку для обеспечения возможности доступа к данным внутри неизменяемого буфера. Сильная ссылка может также быть преобразована в слабую ссылку. Слабая ссылка обеспечивает вторую форму управления памяти для этих буферов. Она используется для сохранения потенциального доступа к неизменяемому буферу без назначения вычислительной сущности, которая удерживает слабую ссылку, памяти, используемой этим буфером. Если существуют только слабые ссылки на некоторый заданный неизменяемый буфер со стороны какого-либо процесса, то базовый буфер может быть немедленно высвобожден.
[0074] Слабые ссылки на неизменяемые буферы могут быть использованы для смягчения издержек межпроцессной и пересекающей границу защиты связи, которая требовалась бы для извлечения сильной ссылки на неизменяемый буфер от другого процесса, который имеет сильную ссылку на неизменяемый буфер. То есть кэш слабых ссылок может быть создан в одной вычислительной сущности (например, одном процессе) для смягчения издержек извлечения этих буферов из другой вычислительной сущности (например, другого процесса), даже если они уже были кэшированы этой другой вычислительной сущностью.
[0075] Фиг. 9 изображает блок-схему способа 900, которым вторая вычислительная сущность сначала осуществляет считывание из кэша, поддерживаемого первой вычислительной сущностью. Фиг. 10 изображает блок-схему способа 1000, которым вторая вычислительная сущность впоследствии осуществляет считывание из кэша, поддерживаемого первой вычислительной сущностью. Вместе способы 900 и 1000 обеспечивают возможность второй вычислительной сущности выстраивать локальный кэш на основе кэша, удерживаемого первой вычислительной сущностью. Способы 900 и 1000 могут выполняться в контексте среды 800 с фиг. 8 и, таким образом, будут описаны с частой ссылкой на фиг. 8.
[0076] Сначала со ссылками на среду 800 с фиг. 8, первая вычислительная сущность 810 имеет кэш 811 данных, поддерживаемых неизменяемым буфером 801. Вторая вычислительная сущность 820 также предназначена для получения данных из неизменяемого буфера. Вторая вычислительная сущность 820 также должна обслуживать кэш 812 данных, найденных из неизменяемого буфера 801. Однако кэш 812 является слабым кэшем в том смысле, что не может ожидать команды высвобождения от второй вычислительной сущности, прежде чем прекратить существовать. Таким образом, вторая вычислительная сущность 820 не имеет управления над тем, когда ее кэш 812 высвобождается.
[0077] Граница 830 (межпроцессорная или граница защиты) находится между первой вычислительной сущностью 810 и второй вычислительной сущностью 820. В одном примерном осуществлении предположим, что первая вычислительная сущность является файловой системой, и вторая вычислительная сущность является веб-сервером, который раздает и/или обрабатывает файлы, обеспеченные файловой системой.
[0078] Когда первая вычислительная сущность получает кэш (например, файловый кэш в случае файловой системы), первая вычислительная сущность получает более быстрый и более локальный доступ к данным (отсюда термин "кэш"), но также получает сильную ссылку на неизменяемый буфер, который поддерживает кэш. Сильная ссылка обеспечивает гарантию, что неизменяемый буфер (и его данные) будет продолжать существовать по меньшей мере до тех пор, пока первая вычислительная система продолжает удерживать сильную ссылку (и потенциально дольше, если другие сущности также удерживают сильные ссылки на неизменяемый буфер). В этом состоянии мы переходим к описанию с фиг. 9, которая изображает способ 900 для того, чтобы вторая вычислительная сущность (например, вторая вычислительная сущность 820) изначально осуществляла считывание из кэша (например, кэша 811), поддерживаемого первой вычислительной сущностью (например, первой вычислительной сущностью 810).
[0079] Вторая вычислительная сущность связывается с первой вычислительной сущностью для получения сильной ссылки на неизменяемые данные (действие 901). Это является межпроцессной или пересекающей границу защиты связью и, таким образом, является затратной связью. Однако она легко может быть только пересекающей границу защиты связью, требуемой до тех пор, пока неизменяемый буфер, который поддерживает кэш, продолжает существовать. Например, предположим, что веб-сервер принял первый запрос на файл, содержащийся внутри кэша. Этот исходный запрос может побуждать веб-сервер выполнить эту исходную связь и получить сильную ссылку на неизменяемый буфер от файловой системы. С использованием этой сильной ссылки вторая вычислительная сущность может считывать данные из неизменяемого буфера (действие 902). При или после считывания данных из кэша вторая вычислительная сущность понижает сильную ссылку на неизменяемый буфер в слабую ссылку на неизменяемый буфер (действие 903).
[0080] Фиг. 10 изображает блок-схему способа 1000 для того, чтобы вторая вычислительная сущность впоследствии осуществляла считывание из кэша, поддерживаемого первой вычислительной сущностью, если кэш второй вычислительной сущности не имеет данных. При приеме запроса на считывание из кэша, в то время как слабая ссылка на кэш все еще существует (действие 1001), вторая вычислительная сущность определяет, существует ли все еще неизменяемый буфер (блок 1002 принятия решений). Если неизменяемый буфер все еще существует ("Да" в блоке 1002 принятия решений), вторая вычислительная сущность преобразует свою слабую ссылку в сильную ссылку на неизменяемый буфер (действие 1011), осуществляет считывание из буфера (действие 1012) (и локальным образом кэширует эти данные в локальном кэше 812) и после этого преобразует сильную ссылку обратно в слабую ссылку (действие 1013). Это выполняется без выполнения межпроцессной или пересекающей границу защиты связи с первой вычислительной сущностью. В действительности, вторая вычислительная сущность просто получает представление для неизменяемого буфера и осуществляет считывание из неизменяемого буфера.
[0081] Если неизменяемый буфер все еще не существуют ("Нет" в блоке 1002 принятия решений). Межпроцессная или пересекающая границы защиты связь выполняется с первой вычислительной сущностью, чтобы тем самым побудить первую вычислительную сущность повторно получить данные и повторно создать новый неизменяемый буфер (действие 1021). Затем, возвращаясь к способу 900, вторая вычислительная сущность может затем получать сильную ссылку на новый неизменяемый буфер (действие 901) и осуществлять считывание из буфера (действие 902).
[0082] Таким образом, вторая вычислительная сущность может рассматриваться как имеющая слабый кэш (тот, который может иметь необходимость воссоздания перед тем, как вторая вычислительная сущность заканчивает использование слабого кэша), который находится из сильного кэша первой вычислительной сущности (того, который остается на месте при управлении первой вычислительной сущностью). Построение этого второго "слабого" кэша вдобавок к другому сильному кэшу влечет некоторые проблемы с политикой замещения (или высвобождения) резервного кэша. Высвобождением называется механизм, в котором менее используемые данные (т.е. "холодные" данные) удаляются (или высвобождаются) из кэша, чтобы обеспечить место для более часто используемых данных (т.е. "горячих" данных). Высвобождение основано на статистике, касающейся частоты, с которой к конкретным элементам данных осуществляется доступ. Слабый кэш 812 и сильный кэш 811 имеют различную статистику, касающуюся частоты доступа к частям кэша, поскольку они видят различные запросы на данные.
[0083] Конкретным образом, слабый кэш 812 будет использован для обслуживания запросов второй вычислительной сущности 820 сначала перед возвращением к резервному кэшу 811. Этот слабый кэш, таким образом, вберет в себя все, кроме исходной, ссылки на горячие данные, скрывая их полезность в резервный кэш 811. Таким образом, когда резервный кэш 811 принимает запросы на новые элементы, без решения этой проблемы резервный кэш может заставить данные, которые являются "горячими" согласно статистике слабого кэша 812, заменить элементы, которые все еще удерживаются слабым кэшем 812. Это замещение может удалять последнюю долговременную сильную/слабую ссылку на базовый буфер, высвобождая буфер, соответствующий слабой ссылке в слабом кэше. После этого следующий запрос на этот элемент в отношении слабого кэша будет неуспешным.
[0084] В соответствии с вариантами осуществления, описанными здесь, эта проблема решается путем передачи полезности горячих данных (что видно по слабому кэшу 812) резервному кэшу 811. Система может обеспечивать этот механизм в качестве побочного эффекта, когда вторая вычислительная сущность преобразует слабую ссылку на данные в сильную ссылку на данные. Система подсчитывает, сколько раз это происходит для каждого базового буфера, и выдает это количество в качестве свойства метаданных для самого буфера. Резервный кэш может затем запрашивать это значение и определять количество ссылок, которые произошли между любыми двумя моментами времени. Эта информация может быть использована алгоритмом замещения резервного кэша для удержания этого элемента в обоих кэшах.
[0085] Фиг. 11 изображает блок-схему способа 1100 для первой вычислительной сущности (или резервного кэша) для выполнения высвобождения. Прежде всего, резервный кэш использует свою собственную статистику для того, чтобы определить кандидатов для высвобождения (действие 1101). Первый резервный кэш затем сверяет со второй статистикой слабого кэша эти идентифицированные кандидаты (действие 1102). Решение о высвобождении, касающееся идентифицированных кандидатов, затем осуществляется (действие 1103) после сверки со второй статистикой так, чтобы, если вторая статистика указывает более частый доступ идентифицированного кандидата, идентифицированный кандидат мог на настоящий момент остаться внутри кэша.
[0086] Эти первые три концепции (а именно неизменяемые совместно используемые коллективные данные с нулевым копированием, потоковая передача данных с нулевым копированием и кэширование с нулевым копированием) могут применяться в системах неуправляемого кода, а также в системе управляемого кода. Однако, поскольку представления, обеспечиваемые управляемыми системами, могут быть созданы быстрее и сделаны гораздо более детектированными, чем в неуправляемых системах, принципы могут быть наиболее эффективно использованы с управляемыми системами.
[0087] Фиг. 12 изображает примерную систему 1200 управляемого кода. Управляемая система 1200 включает в себя управляемую память 1201. Управляемая система 1200 имеет множество компонентов 1230 управляемого кода, каждый из которых имеет исключительный доступ к специализированной для сущности памяти. Например, запущенные компоненты 1230 управляемого кода изображаются как включающие в себя семь компонентов 1231-1237, хотя эллипсы 1238 представляют большую гибкость в этом количестве. Например, компоненты 1231-1237 могут быть процессами.
[0088] Каждый из семи запущенных компонентов 1231-1237 имеет соответствующую специализированную для сущности память 1211-1217. Управляемый компонент не может осуществлять доступ к специализированной для сущности памяти другой специализированной для сущности памяти. Таким образом, существует защищенность изоляции между элементами специализированной для сущности памяти так, чтобы только соответствующий управляемый компонент мог осуществлять доступ к этой специализированной для сущности памяти. Например, компонент 1231 осуществляет доступ к части 1211 специализированной для сущности памяти, но не к частям 1212-1217 специализированной для сущности памяти; компонент 1232 осуществляет доступ к части 1212 специализированной для сущности памяти, но не к части 1211 специализированной для сущности памяти или частям 1213-1217 специализированной для сущности памяти, и так далее.
[0089] Память 1210 управляемого кода также включает в себя совместно используемую память 1219. Эта совместно используемая память 1219 является примером неизменяемого буфера 330 с фиг. 3A, 3B и 5. При этом вышеописанные принципы вовсе не полагаются на систему управляемого кода. Однако последние две концепции, описанные здесь, ограничены для управляемых сред. Несколько дополнительных элементов с фиг. 12 будет описано в отношении описания этих последних двух концепций (а именно унифицированного доступа к памяти и безопасного по типам приведения типов).
Унифицированный доступ к памяти
[0090] Память в среде управляемого языка потенциально является очень динамической. Объекты выделяются из кучи, и ими осуществляется управление программой сборки мусора. Со ссылкой на фиг. 12, управляемая система 1200 включает в себя программу 1221 сборки мусора. На основе эвристики программа сборки мусора обычно выполняет обслуживание кучи путем сжимания объектов вместе для того, чтобы вернуть ранее используемое пространство. Сжимание объектов вместе подразумевает, что адрес памяти объекта по существу нестабилен, подвержен изменениям со стороны программы сборки мусора. Программа сборки мусора зависит от конкретных схем генерирования кода и от поддержки со стороны операционной системы для возможности перемещения объектов тем образом, который прозрачен для кода уровня приложения.
[0091] I/O-подсистема операционной системы отвечает за перемещение больших количеств данных через системную память. При считывании данные обычно получаются от внешнего устройства и помещаются в память посредством операции DMA, управляемой самим устройством с минимальным взаимодействием с процессором. Подобным образом, при выписывании данных операции памяти DMA могут автоматически считывать содержимое из памяти.
[0092] Операции DMA не могут состязаться с содержимым памяти, перемещаемым в течение операции. Это потребовало бы высокоточной координации между процессором и устройствами, что существенно скажется на производительности и эффективности по мощности. В результате этого ограничения существует два широких варианта для поддержки DMA в управляемой операционной системе:
[0093] Специальные операции закрепления используются над областями памяти для инструктирования программы сборки мусора не перемещать определенные объекты. Это обеспечивает возможность операциям DMA видеть устойчивый снимок памяти, подвергающейся воздействию, в то время как они исполняются.
[0094] Операции DMA происходят в специальных областях памяти, которые не подвергаются сборке мусора.
[0095] Первый подход может существенно понизить эффективность программы сборки мусора, поскольку взаимодействие с закрепленными областями памяти усложняет процесс сжатия и уменьшает его эффективность. Второй подход избегает этой проблемы, но может легко приводить к избыточному копированию памяти, поскольку специализированная логика необходима для переноса данных между обычными областями памяти и специальными дружественными для DMA областями памяти.
[0096] Архитектура унифицированного доступа к памяти обеспечивает систематический способ осуществления ссылок на память независимо от того, обычная это управляемая память или же специальные дружественные для DMA области памяти. Это обеспечивает возможность для программистов манипулировать данными в дружественных для DMA областях памяти непосредственно полностью безопасным образом, избегающим необходимости как закреплять объекты, так и осуществлять копирование между обычной памятью и дружественной для DMA памятью.
[0097] В среде управляемого языка коллективные данные обычно удерживаются в массивах. Среда управляемого языка (например, управляемая система 1200) непосредственно понимает массивы, обеспечивая возможность доступа к отдельным элементам массива и обеспечивая то, что программисты не могут превысить ограничений массива. Будучи управляемыми языковой средой, массивы ограничены расположением в управляемой куче.
[0098] В управляемой системе 1200 с фиг. 12 неизменяемый буфер 1219 расположен вне управляемой кучи и, таким образом, при обычных условиях не будет непосредственно доступен со стороны управляемых программ. Считывание и запись из I/O-памяти обычно были бы выполнены с использованием классического пакета программ I/O с явными операциями считывания и записи, которые вызывают неявное копирование между обычной памятью в управляемой куче и I/O-памятью.
[0099] Управляемая система включает в себя абстракцию (называемую здесь "интервал" ("span")), которая обеспечивает механизм для непосредственного доступа к неизменяемому буферу 1219 от компонента управляемого кода. Со ссылкой на фиг. 12, часть 1211 управляемой памяти включает в себя множество различных объектов, включающих в себя абстрактно представленную абстракцию 1240 интервала. Интервалы могут безопасным образом создаваться для обеспечения непосредственного доступа к любой области I/O-буфера способом, очень подобным тому, как работают массивы. Кроме того, интервалы могут быть построены так, чтобы ссылаться на управляемую память. Программные абстракции, построенные вдобавок к интервалам, могут, таким образом, не быть осведомленными о местоположении базовой памяти интервала. Это обеспечивает окончательную область композиции, обеспечивая возможность абстракциям быть спроектированными натуральным образом для оперирования над управляемой памятью (например, частями памяти 1211-1218) или неизменяемым буфером 1219.
[0100] Интервалы создаются путем взаимодействия с базовым хранилищем для интервала. Например, неизменяемый буфер 1219 может обеспечивать вызовы методов для возвращения интервалов, которые ссылаются на неизменяемые буферы, управляемые интервалом непосредственно. Подобным образом массивы обеспечивают способы, которые возвращают интервалы, которые указывают на них или на их части. Как только интервал был реализован, он может передаваться и использоваться, по большому счету, как используются массивы в обычных управляемых языках.
[0101] Особенная точность с интервалами относится к управлению временем существования базового хранилища. Одно из первичных преимуществ управляемой среды программирования состоит в том, что программа сборки мусора берет на себя обязательство обнаружения, когда на объекты больше не делается ссылка и их хранилище может быть возвращено в использование. Это происходит, когда массивы более не являются полезными, например.
[0102] Когда память, лежащая в основе интервала, находится вне обычной кучи сборки мусора, управление временем существования этой памяти должно осуществляться осторожно, чтобы созданные интервалы, которые ссылаются на память, не существовали дольше, чем сам буфер памяти. Это может быть обеспечено некоторым количеством способов, например, посредством счетчиков ссылок в базовой памяти или ограничения времени существования самих интервалов.
[0103] В одном варианте осуществления объект интервала хранит специально помеченный указатель на область памяти, которую он представляет. Программа сборки мусора распознает эти специальные указатели и обрабатывает их специальным образом. В течение операции сборки мусора, если программа сборки мусора встречает специальный указатель, она анализирует адрес, который указатель хранит. Если программа сборки мусора обнаруживает, что указатель указывает место вне управляемой кучи, программа сборки мусора в дальнейшем полностью игнорирует указатель. Если вместо этого обнаружено, что указатель указывает точку внутри управляемой кучи, программа сборки мусора обрабатывает указатель как ссылку на управляемый объект и, следовательно, автоматически регулирует значение указателя в случае, если базовый объект перемещен.
[0104] Интервалы могут создаваться для представления подобластей других интервалов. Это делает интервалы очень удобным способом вырезания части из большей области памяти безопасным и низкозатратным образом без создания копий. Получающийся в итоге интервал выглядит как любой другой интервал, даже несмотря на то, что ему назначен псевдоним поднабора памяти другого интервала.
Безопасное по типам приведение (casting) типов
[0105] Основной ролью управляемых языков программирования является обеспечение безопасности по типам, которая препятствует программам в получении произвольного адреса в памяти и манипулировании им как объектом. Например, управляемая система 1200 с фиг. 12 включает в себя систему 1222 типов, которая обеспечивает безопасность по типам. Все объекты получаются явным образом, и управление адресом каждого объекта осуществляется исключительно программой сборки мусора (например, программой 1221 сборки мусора). В такой системе память не под непосредственным управлением программы сборки мусора не может быть использована непосредственно кодом приложения. Вместо этого память в итоге оказывается необходимо копировать из специальной памяти обратно в память, управляемую программой сборки мусора, прежде чем она сможет быть использована, что неэффективно.
[0106] По мере потоковой передачи данных в и из системы через операции DMA, данные, манипулируемые устройствами DMA, обычно имеют некоторую характерную форму. Например, при выписывании данных через DMA некоторая структура данных в куче сборки мусора обычно удерживает данные, которые должны быть выписаны. Этап "преобразования в последовательную форму" затем используется для преобразования данных в этих структурах в форму, необходимую для операции DMA. Этот этап преобразования в последовательную форму является трудоемким, подверженным ошибкам и неэффективным. Преобразования в последовательную форму и преобразования из последовательной формы обычно являются неотъемлемой частью управляемых языков программирования.
[0107] Путем влияния на абстракцию интервала универсальная модель обеспечивает возможность программистам непосредственно взаимодействовать с областями памяти DMA с использованием объектно-ориентированной семантики. Поддержка специального приведения типов обеспечивает возможность для программистов просматривать области памяти DMA как объекты и, таким образом, непосредственно считывать и записывать память естественным образом, максимизируя эффективность, улучшая точность и упрощая задачу программистам. Модель не ограничивается одной лишь DMA-памятью и поддерживает также расширенную семантику приведения типов для обычной памяти сборки мусора.
[0108] Для поддержания безопасности по типам невозможно и нежелательно допускать приведение типов между произвольными типами. Вместо этого существуют конкретные правила, которые ограничивают набор допустимых типов, которые могут быть задействованы в этом расширенном приведении типов. Однако правила довольно широки и в итоге работают идеально для того рода данных, который обычно задействуется в операциях DMA.
[0109] В управляемом языке программирования, всегда, когда память выделяется, ей назначается некоторый заданный тип. Тип определяет значимость различных частей блока памяти и операций, которые могут выполняться над блоком памяти. Тип не может быть изменен для блока памяти, пока память не становится неактивной и не возвращается в использование посредством процесса сборки мусора. На всех этапах языковая среда отвечает за выделение, типизацию и возвращение в использование блоков памяти.
[0110] Приведение типов является возможностью рассматривать некоторую память как тип, отличный от того типа, каким она известна управляемой среде. Приведение типов является распространенным во внутренних языках программирования, но управляемые языки в общем случае не предлагают приведения типов. Вместо этого управляемые среды обеспечивают механизмы преобразования типов, которые обеспечивают возможность копировать один тип значения в другой тип. Например, существует возможность преобразования целого значения в значение с плавающей запятой. Однако это всегда выполняется посредством копирования - исходное местоположение памяти остается неизменным.
[0111] В соответствии с принципами, описанными здесь, приведение типов вводится как универсальное средство в управляемых языках. Ограничения применяются для обеспечения того, чтобы сохранялась безопасность по типам, как объясняется позже.
[0112] В управляемой операционной системе память, используемая для I/O-операций, должна либо быть закрепленными объектами, либо быть областями памяти, специализированными для I/O. Как упомянуто ранее, закрепление объектов в памяти для предотвращения их перемещения является затратным и приводит к множеству проблем со средой сборки мусора. Принципы, описанные здесь, используют специализированную I/O память под видом неизменяемых буферов (таких как неизменяемый буфер 330 с фиг. 3A, 3B и 5).
[0113] I/O-память находится вне досягаемости от подсистемы управляемой памяти. Управляемая среда не управляет типом этой памяти, и, следовательно, не существует возможности осуществить непосредственный доступ к этому виду памяти со стороны управляемой программы. Вместо этого код специального соединения (т.е. связующий код) был бы в обычной ситуации использован для того, чтобы обеспечить возможность этой памяти быть считанной или записанной с использованием явных вызовов. Осуществление доступа к любого вида структурированным данным внутри этих I/O-буферов включает в себя чрезвычайно неэффективный код или включает в себя копирование данных в и из I/O-памяти в обычную управляемую память, что также неэффективно.
[0114] Рассмотрим неизменяемый буфер, полученный от сетевого устройства. В этом буфере есть заголовок TCP, содержащий информацию сетевого протокола. Существует, по существу, два способа, которыми данные в заголовке TCP могут быть использованы в управляемом языке программирования. Таблица ниже изображает оба подхода и этапы, задействованные в каждом.
[0115] Получение объекта заголовка TCP с возможностью его использования существенно быстрее с приведением типов, чем с традиционным подходом. Новый подход имитирует то, что происходит в собственной операционной системе, где математика указателей возможна и часто используется для получения преимуществ в сценарии такого вида. Математика указателей недоступна в управляемых языках программирования, но безопасное по типам приведение типов обеспечивает те же самые функциональные возможности.
[0116] Возможны вариации над традиционным подходом, которые приводят к большему или меньшему служебному сигнализированию. Например, возможно, что рассматриваемый буфер памяти непосредственно доступен программисту, и, таким образом, к нему может осуществляться доступ более эффективно, чем посредством способов считывания/записи. Однако в таком случае программист все еще отвечает за преобразование последовательности байтов в объект более высокого уровня, что трудоемко, подвержено ошибкам и плохо по производительности.
[0117] Что делает приведение типов возможным и обеспечивает то, что безопасность по типам сохраняется, так это то, что приведение типов возможно только с типами, которые выполнены для обеспечения этой возможности. Для того чтобы принять участие в приведении типов, типы: 1) являются типами значений (в отличие от типов ссылок), 2) составлены только из других типов, которые поддерживают приведение типов, 3) не состоят из ссылок, 4) определяются с использованием конкретного формата памяти и 5) допускают любую битовую схему в любом из своих полей.
[0118] Эти ограничения означают, что для того, чтобы быть использованным для приведения типов, тип не может содержать ссылок на другие объекты. Оказывается, что эти ограничения идеально описывают характеристики типов, определенные для представления форматов данных, таких как заголовки TCP и широкий набор других таких структур данных.
[0119] Как описано, безопасное по типам приведение типов может быть использовано для считывания или записи в I/O-буферы, которые находятся вне досягаемости для среды управляемой памяти, и может также быть использовано для просмотра управляемой памяти в качестве другого типа. В частности, эта методика полезна для просмотра массивов байтов в качестве экземпляров одного или нескольких более насыщенных типов вместо этого.
[0120] Фиг. 13 изображает обычный управляемый массив байтов, который имеет два отдельных интервала, указывающих на него и обеспечивающих возможность приложению просматривать части массива в виде различных типов. Любое количество интервалов может быть создано таким образом, где каждый имеет отдельные типы. Интервалы могут свободно накладываться, ссылаясь потенциально на одну и ту же область памяти в качестве различных типов.
[0121] Правило, которое говорит, что любая битовая схема должна быть приемлема в любом из ее полей, важно для надежности модели. При использовании приведения типов экземпляры объектов, которые в других случаях выглядят обычно, вводятся в среду без исполнения конструктора типа. Обычно конструктор выполняет подтверждение достоверности входных аргументов и служит для окончательного ограничения набора допустимых значений, которые составляют объект. Но при приведении типов существует возможность создания объекта на пустом месте путем просмотра существующего интервала памяти, как если бы он был другим типом.
[0122] Традиционный подход копирования данных в отдельный объект в управляемой куче обеспечивает возможность подтвердить достоверность данных, когда они подаются в конструктор управляемого объекта. Это означает, что в системе реального мира недостоверных версий управляемого объекта никогда не существует внутри системы, конструктор обеспечивает то, что только достоверные версии могут быть созданы. В этом состоит отличие от приведения типов, где может возникнуть любая битовая схема. Если существуют значения, которые семантически недействительны, они не могут быть обнаружены, поскольку не происходит построения объекта.
[0123] Решением для проблемы корректности является представление дополнительного уровня абстракции в программных средствах. В частности, если мы снова берем пример считывания заголовка TCP, можно представить, что разработчик определил два отдельных типа: RawTcpHeader (НеобработанныйЗаголовокTCP) и ValidTcpHeader (ДостоверныйЗаголовокTCP).
[0124] Данные во входном буфере будут приведены по типу к RawTcpHeader (НеобработанныйЗаголовокTCP). При наличии этого объекта затем может быть инициирован метод AcquireValidTcpHeader (ПолучитьДостоверныйЗаголовокTCP). Этот метод проверит достоверность полей в RawTcpHeader (НеобработанныйЗаголовокTCP) и вернет новый экземпляр ValidTcpHeader (ДостоверныйЗаголовокTCP), который будет выполнять функцию тривиальной оболочки, заключающей в себе RawTcpHeader (НеобработанныйЗаголовокTCP), и сообщит удерживающему элементу (holder), что у него в наличии гарантированно достоверный заголовок. Это все выполняется без какого-либо копирования, исключительно с созданием объекта сквозного использования, который имеет тип значения ValidTcpHeader.
[0125] Настоящее изобретение может осуществляться в других конкретных формах без выхода за пределы его сущности или существенных характеристик. Описанные варианты осуществления должны расцениваться во всех отношениях только как иллюстративные и неограничительные. Объем изобретения, таким образом, определяется прилагаемой формулой изобретения, а не вышеприведенным описанием. Все изменения, которые находятся в пределах значения и диапазона соответствия пунктов формулы изобретения, должны быть охвачены определяемым ею объемом.
| название | год | авторы | номер документа |
|---|---|---|---|
| ТЕХНОЛОГИИ ДЛЯ ОБЕСПЕЧЕНИЯ ПРОВЕРКИ ПРАВИЛЬНОСТИ И ПЕРЕДАЧИ ИНФОРМАЦИИ | 2006 |
|
RU2420007C2 |
| ТРАНСЛЯЦИЯ АДРЕСОВ ВВОДА-ВЫВОДА В АДРЕСА ЯЧЕЕК ПАМЯТИ | 2010 |
|
RU2547705C2 |
| ОПРЕДЕЛЕНИЕ ФОРМАТОВ ТРАНСЛЯЦИИ ДЛЯ ФУНКЦИЙ АДАПТЕРА ВО ВРЕМЯ ВЫПОЛНЕНИЯ | 2010 |
|
RU2556418C2 |
| ЖУРНАЛИРУЕМОЕ ХРАНЕНИЕ БЕЗ БЛОКИРОВОК ДЛЯ НЕСКОЛЬКИХ СПОСОБОВ ДОСТУПА | 2014 |
|
RU2672719C2 |
| КЭШИРОВАНИЕ ГЕНЕРИРУЕМОГО ВО ВРЕМЯ ВЫПОЛНЕНИЯ КОДА | 2009 |
|
RU2520344C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ВИРТУАЛИЗАЦИИ ГОСТЕВОГО ФИЗИЧЕСКОГО АДРЕСА В СРЕДЕ ВИРТУАЛЬНОЙ МАШИНЫ | 2006 |
|
RU2393534C2 |
| АКТИВАЦИЯ/ДЕАКТИВАЦИЯ АДАПТЕРОВ ВЫЧИСЛИТЕЛЬНОЙ СРЕДЫ | 2010 |
|
RU2562372C2 |
| КОНФИГУРАЦИЯ ИЗОЛИРОВАННЫХ РАСШИРЕНИЙ И ДРАЙВЕРОВ УСТРОЙСТВ | 2006 |
|
RU2443012C2 |
| ИЗМЕРИТЕЛЬНОЕ СРЕДСТВО ДЛЯ ФУНКЦИЙ АДАПТЕРА | 2010 |
|
RU2523194C2 |
| ПРЕОБРАЗОВАНИЕ ИНИЦИИРУЕМОГО СООБЩЕНИЯМИ ПРЕРЫВАНИЯ В УВЕДОМЛЕНИЕ О ГЕНЕРИРОВАННОМ АДАПТЕРОМ ВВОДА-ВЫВОДА СОБЫТИИ | 2010 |
|
RU2546561C2 |










Изобретение относится к области управления памятью. Технический результат заключается в повышении надежности вычислительного процесса. Предложен способ выполнения сборки мусора, содержащий действие просмотра конкретной части управляемой памяти, действие обнаружения множества объектов при просмотре этой конкретной части управляемой памяти, включая ссылку на неизменяемый буфер. При обнаружении упомянутой ссылки, определение того, что данная ссылка соответствует элементу вне управляемой памяти, и в случае, если ссылка не соответствует, отказ от выполнения сборки мусора в отношении данного элемента, соответствующего ссылке. 2 н. и 8 з.п. ф-лы, 14 ил.
1. Система выполнения сборки мусора, содержащая:
управляемую память, имеющую множество частей управляемой памяти, каждая из которых соответствует управляемой вычислительной сущности;
неизменяемый буфер, расположенный вне управляемой памяти, причем конкретная часть управляемой памяти из данного множества частей управляемой памяти включает в себя один или несколько объектов, в отношении которых выполняется сборка мусора и которые являются доступными для соответствующей конкретной управляемой вычислительной сущности, но не для других вычислительных сущностей, причем эта конкретная часть управляемой памяти также включает в себя одну или несколько ссылок на неизменяемый буфер; и
компонент сборки мусора, сконфигурированный для управления упомянутыми одним или несколькими объектами, в отношении которых может выполняться сборка мусора, в упомянутой конкретной части управляемой памяти, но также сконфигурированный не выполнять каких-либо действий над упомянутыми одной или несколькими ссылками на неизменяемый буфер.
2. Система по п. 1, в которой управляемая память является управляемой кучей.
3. Система по п. 1, в которой неизменяемый буфер защищен от того, чтобы его данные изменялись в течение времени существования неизменяемого буфера.
4. Система по п. 1, в которой неизменяемый буфер защищен от того, чтобы его физический адрес изменялся в течение времени существования неизменяемого буфера.
5. Система по п. 1, в которой по меньшей мере одна из упомянутых одной или нескольких ссылок является элементом массива.
6. Система по п. 1, в которой по меньшей мере одна из упомянутых одной или нескольких ссылок включает в себя адрес по меньшей мере части неизменяемого буфера.
7. Система по п. 1, в которой упомянутая конкретная часть управляемой памяти является первой частью управляемой памяти и упомянутая конкретная вычислительная сущность является первой вычислительной сущностью из упомянутого множества вычислительных сущностей, вторая часть управляемой памяти из упомянутого множества частей управляемой памяти также включает в себя один или несколько объектов, в отношении которых может выполняться сборка мусора и которые доступны для соответствующей второй вычислительной сущности, но не для других вычислительных сущностей, причем вторая часть управляемой памяти также включает в себя одну или несколько ссылок на неизменяемый буфер.
8. Способ выполнения сборки мусора, содержащий:
действие просмотра конкретной части управляемой памяти, соответствующей конкретной вычислительной сущности, причем управляемая память включает в себя множество частей управляемой памяти, причем каждая часть управляемой памяти соответствует вычислительной сущности;
действие обнаружения множества объектов при просмотре этой конкретной части управляемой памяти, включая ссылку на неизменяемый буфер, который находится вне управляемой памяти;
при обнаружении упомянутой ссылки действие определения того, что данная ссылка соответствует элементу вне управляемой памяти, и,
в результате упомянутого действия определения, действие отказа от выполнения сборки мусора в отношении данного элемента, соответствующего ссылке.
9. Способ по п. 8, в котором другие части управляемой памяти из управляемой памяти также включают в себя ссылку на упомянутый элемент вне управляемой памяти.
10. Способ по п. 8, дополнительно содержащий действие выполнения сборки мусора в отношении объектов, которые не ссылаются на элементы вне части управляемой памяти.
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| US 6167434, 26.12.2000 | |||
| EA 200400068 A1, 30.06.2005 | |||
| RU 2005126821 A, 20.01.2008. | |||

