Изобретение относится к области компьютерных систем, а именно к Интернету Вещей и организации обработки данных в Интернете Вещей.
Известны электронное передающее устройство высокопроизводительного межсоединения (патент РФ №2579140, G06F 13/42, опубл. 27.03.2016), в котором решается задача аппаратного распределения задач в многопроцессорном кластере. Устройство включает в себя синхронизирующий счетчик, предназначенный для локального выравнивания передачи сигналов определенным устройством с передачей сигналов в системе, содержащей одно или несколько других устройств, сопряженных с возможностью обмена информацией, посредством межсоединения; и многоуровневый стек, содержащий логику физического уровня, логику канального уровня и логику уровня протокола, при этом логика физического уровня по меньшей мере частично выполнена в аппаратном средстве и предназначена для синхронизирования сброса синхронизирующего счетчика с некоторым внешним детерминированным сигналом, глобально поддерживаемым для системы и синхронизирования с этим детерминированным сигналом вхождения в передающее состояние канала передачи данных на основании синхронизирующего счетчика.
Недостатками этого устройства для решения поставленной задачи предобработки данных интернета вещей для систем анализа являются:
1) Отсутствие ориентированности на конкретную решаемую задачу, и, как следствие, более низкая производительность универсальных алгоритмов при решении поставленной задачи на вычислительном кластере.
2) Отсутствие интеллектуальных средств планирования, ориентированных на предобработку данных в задачах нормализации и агрегации сообщений Интернета вещей, позволяющих избегать перегрузки системы.
Известны универсальные методы и аппаратное обеспечение для обработки данных интернета вещей, в том числе, в облачной системе (US 2014297210, G01R 21/133, US 2014303935, G01D 21/00). В обоих вариантах предложены оборудование и методы для анализа данных, поступающих из интернета вещей. В одном случае рассматриваются методы для агрегации, фильтрации и распространения данных для анализа, получая первичную информацию из интернета вещей. Согласно методу аналоговые данные интернета вещей переводятся в цифровой вид и передаются по третьим сетям с использованием соответствующих протоколов. Второй метод, ориентированный на использование облаков для анализа данных, принимает данные от датчиков (включая косвенную информацию, чем сходен с рассматриваемой системой) и анализирует ее с учетом облачных технологий. На основе анализа данных согласно рассматриваемому методу генерируется сигнал управления.
Недостатком этих методов является:
1) Низкая эффективность, выражающаяся в низкой скорости работы. Общие (универсальные) подходы методов не учитывают особенности процессов предобработки данных, таких как нормализация и агрегация информации, и связанных с ними этапов процессинга и планирования, необходимых для анализа данных интернета вещей в частности, при решении задач информационной безопасности.
2) Пониженная надежность, вызванная возможными перегрузками вычислительного кластера в силу отсутствия интеллектуальных алгоритмов планирования задач внутри самого облака, ориентированных на специфику обработки агрегируемых и нормализуемых данных.
В основу изобретения положена задача интеллектуального планирования на вычислительном кластере задач предварительной обработки данных Интернета Вещей, включая процессы нормализации и агрегации данных, для систем анализа, в котором обеспечивается повышение быстродействия обработки узлами кластера вычислительных задач и оптимизация распределения этих задач между узлами кластера путем представления вычислительных задач в виде графа задач, удобном для хранения в базе данных и получения быстрого доступа к данным; формализации интеллектуальных правил планирования задач при произвольном потоке поступающих сообщений между узлами кластера, обеспечивающих равномерную загрузку всех узлов кластера вычислительными задачами за счет автоматического направления вновь поступающих вычислительных задач на наименее загруженный узел кластера и перенаправляющих накопившиеся на узле кластера вычислительные задачи на освободившиеся узлы; задания формул весовых коэффициентов приоритетов вычислительных задач в рамках одного узла кластера, в соответствии с которыми обеспечивается приоритетное динамическое планирование вычислительных задач, при котором в каждый момент времени каждой вычислительной задаче, поступившей на узел кластера, назначается динамическое значение приоритета, тем самым, наиболее приоритетные вычислительные задачи обрабатываются раньше, вне зависимости от времени, когда они поступили на вычислительный узел кластера.
Поставленная задача решается за счет заявляемого способа планирования задач предобработки данных Интернета Вещей для систем анализа, включающего равномерное распределение и динамическое планирование вычислительных задач по предварительной обработке данных, включающей операции обработки сообщений и выделения их параметров, агрегации и нормализации параметров сообщений от устройств, агрегации параметров сообщений от разных устройств между узлами кластера и задание способа их выполнения в рамках каждого вычислительного узла кластера, в отличие от прототипа, выделяют наборы связанных задач по предварительной обработке данных, типовых для обработки каждого сообщения и представляющих собой операции обработки сообщений и выделения их параметров, агрегации и нормализации параметров сообщений от устройств, агрегации сообщений от разных устройств, затем на узлах в базе данных каждого узла выделяют промежуточные хранилища данных, представляющих собой области памяти базы данных; определяют потоки данных внутри системы при проведении вычислений, представляющих собой очередность связанных задач по предварительной обработке данных над сообщениями от устройств; выделяют среди всех узлов кластера узел-обработчик, на котором отдельно формализуют интеллектуальные правила планирования задач между узлами кластера, в соответствии с которыми вычислительные задачи равномерно поступают на наименее загруженные узлы кластера для обработки за кратчайшее время; аккумулируют на одном узле-обработчике все сообщения с каждого устройства, агрегируя значения параметров сообщений; на каждом узле кластера предлагают приоритетное планирование с динамическими приоритетами в рамках каждого узла, назначаемыми каждой вычислительной задаче предварительной обработки данных путем задания формул весовых коэффициентов приоритетов; выполняют связывание в иерархию устройств, обладающих одинаковым типом и находящихся близко друг к другу; аккумулируют сообщения связанных в иерархию устройств на одном узле-обработчике, формируя одно агрегированное сообщение от устройств иерархии вместо множества сообщений от каждого из устройств в иерархии.
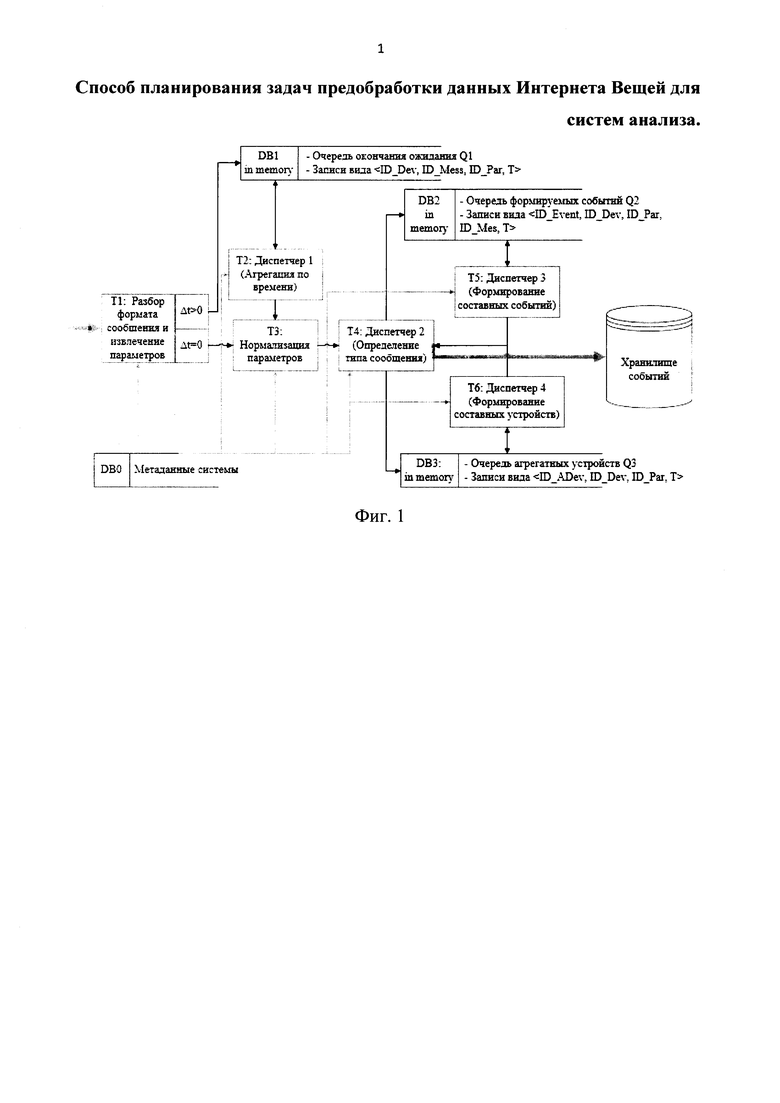
Изобретение поясняется фиг. 1, на которой приведено разбиение процесса предобработки данных на набор взаимосвязанных типовых задач и взаимодействие между этими задачами. На фиг. 1 показаны внутренние потоки данных, входной и выходной потоки данных, обращения к наборам метаданных.
Согласно разработанному способу, хранилище DB0 должно представлять собой in memory (постоянно находящийся в памяти) объект, реплицироваться и быть доступно на каждом узле кластера. Хранилища DB1-DB2 являются локальными для каждого узла кластера. Хранилище DB3 развернуто на отдельном узле и обслуживает остальные сообщения всех узлов кластера. Может быть реплицировано. Для повышения скорости работы хранилищ DB1-DB3 и минимизации обмена данными между узлами разработаны следующие правила:
1. Все сообщения с одного устройства поступают на один узел-обработчик.
2. Все сообщения связанных в иерархию устройств направляются на один узел - обработчик.
Реализация данных правил обеспечивает повышение скорости работы хранилищ и минимизацию обмена данными по следующим причинам:
1. Поскольку сообщения от одного устройства аккумулируются на одном узле-обработчике, в системе не происходит пересылки сообщений между узлами для агрегации. Следовательно, не происходит пересылки сообщений между узлами кластера, за счет этого:
а) повышается скорость процесса предварительной обработки данных в системе, потому что нет временных затрат на пересылку сообщений (минимизация обмена данными);
б) уменьшается число пересылаемых и хранимых сообщений, так как нет пересылки сообщений одного источника между узлами кластера (минимизация обмена данными и повышение скорости работы хранилищ).
2. Поскольку сообщения связанных в иерархию устройств направляются на один узел-обработчик, то агрегация сообщений от этих устройств идет уже не над отдельными сообщениями каждого устройства, а над агрегированными сообщениями каждого устройства. Таким образом, в одном агрегированном сообщении каждого устройства содержатся значения нескольких отдельных сообщений от данного устройства. При этом каждое агрегированное сообщение содержит одно значение того же типа, что и в каждом отдельном. При агрегации сообщений от иерархии устройств происходит формирование единого агрегированного сообщения от нескольких устройств вместо нескольких сообщений от каждого устройства в отдельности. Поэтому пересылка такого сообщения происходит быстрее, а размер передаваемого сообщения при этом не увеличивается, что является существенным для увеличения скорости работы обмена сообщениями и за счет чего достигается минимизация обмена данными между узлами. Кроме этого, увеличивается скорость работы хранилищ, так как осуществляется одно обращение к хранилищам за агрегированным сообщением вместо нескольких обращений для получения сообщений от каждого устройства.
При выполнении этих правил задачи распределяются между кластерами в зависимости от загруженности узлов. Загрузка узла кластера определяется по перечню привязанных к нему устройств (сначала физических, потом агрегирующих):

где Z - загрузка кластера, Nf - число физических устройств, привязанных к кластеру, Na - число агрегирующих устройств, привязанных к кластеру.
Разработаны профили задач, входящих в процесс предобработки.
Описание профилей задач включает:
1. Модуль разбора сообщений (Т1) инициируется приходом нового сообщения. Его назначение: обработка сообщения, выделение параметров. На вход ему поступает сообщение, на выходе предоставляются извлеченные параметры.
2. Диспетчер агрегации по времени (Т2) инициируется постоянно, его назначение заключается в просмотре очереди параметров и в агрегации параметров при достижении временной отметки. На вход подается выборка из Q1, на выходе предоставляется агрегированный параметр. Активация Т2 осуществляется при:
- наступлении момента времени (t);
- занесении очередного параметра в очередь (Т1).
3. Модуль нормализации (Т3) инициируется модулем Т1 (при передаче параметра) или модулем Т2 (при передаче агрегированного параметра). Его назначение в нормализации параметров. На вход поступает параметр, на выходе получается нормализованный параметр.
4. Диспетчер (Т4) предназначен для формирования агрегатных и составных событий. На вход поступает параметр (или параметры), на выходе получается событие. Т4 инициируется модулями Т3, Т5, Т6 при поступлении параметра.
5. Модуль формирования составных сообщений (Т5) предназначен для формирования составных событий из нескольких сообщений. На вход поступает выборка из Q2, на выходе предоставляется параметр. Т5 инициируется:
- модулем Т4 при поступлении параметра, последнего в цепочке для формирования составного события;
- по таймауту для проверки «зависших» событий, на которые не пришли завершающие или продолжающие сообщения.
6. Модуль формирования агрегатных (составных) устройств (Т6) предназначен для формирования параметров составных устройств. На вход поступает выборка из Q3, на выходе предоставляется параметр составного устройства. Т6 инициируется:
- модулем Т4 при поступлении параметра составного устройства;
- при истечении таймаута для составного устройства.
В соответствии с разработанным способом, интеллектуальное планирование в задаче обработки больших данных на узле кластера реализуется в виде приоритетной очереди с динамическим назначением приоритетов в зависимости от состояния системы и выполняемой задачи. Изменение приоритетов для балансировки выполнения задач должно происходить в моменты нарушения стабильности системы. Стабильность рассматриваемой системы, исходя из профиля задач, определяется следующими положениями:



где N - количество задач.
Также важными статистическими показателями работы узла являются:
1. Ni - количество задач каждого типа в системе;
2. Ti - среднее время прохождения задачи каждого типа в системе;
3. Nin0 - количество задач, поступающих в систему (Т1) за Δt (за предшествующий период)
4. Nin1 - количество задач, поступающих в систему (Т1) за Δt (за текущей период)
5. Q01-Q03 - длины очередей Q1-Q3 на момент Δt (за предшествующий период);
6. Q1-Q3 - длины очередей Q1-Q3
7. Qp1-Qp3 - пороговые значения длин.
Таким образом, профиль узла будет иметь вид: {N={N1, … N6}, Т={Т1, … Т6}, Nin0, Nin1, Q01, Q02, Q03, Q1, Q2, Q3, Qp1, Qp2, Qp3}.
На основе вышеприведенных положений были выделены следующие правила функционирования системы:
1. Количество задач каждого типа в системе за время функционирования (определенный период функционирования, определяемый по принципу сдвигаемого окна) подчиняется правилам 2-4.
2. Соотношение прироста дин очередей должно соответствовать динамике входящих сообщений.
Соотношение динамик определяется следующими правилами:




Хранилище DB0 является реплицированным по узлам кластера (и, возможно, фрагментированным в соответствии с каталогом отображения Устройство - Узел кластера).
Хранилища DB1-DB2 являются локальными для каждого кластера.
Хранилище DB3 развернуто на отдельном узле и обслуживает остальные сообщения всех узлов кластера. Может быть реплицировано.
Новизна предлагаемого решения заключается в аккумулировании сообщений от каждого устройства на одном узле-обработчике в соответствии с интеллектуальными правилами планирования, которые данный узел применяет для обеспечения быстрого равномерного распределения вычислительных задач по предварительной обработке данных между узлами кластера и уменьшения числа пересылаемых между узлами сообщений; в аккумулировании сообщений от иерархий устройств на одном узле-обработчике, за счет чего будут обеспечены получение и дальнейшая пересылка одного агрегированного сообщения, хранящего в себе значения от нескольких устройств, входящих в иерархию. Таким образом, будет обеспечена минимизация передачи сообщений между узлами кластера и будет повышена скорость работы хранилищ за счет сокращения числа обращений к ним и минимизации хранимых данных. При этом указанный способ позволит локальное ведение промежуточных хранилищ DB1-DB2.
Новизна в контексте планирования задач в рамках одного узла вычислительного кластера выражается в разработанных формулах расчета динамических приоритетов при приоритетном планировании. Использованные при разработанном способе планирования статистические показатели также применимы для установления устойчивости (устойчивого функционирования) системы.
| название | год | авторы | номер документа |
|---|---|---|---|
| Способ формирования управляемой агрегации и управления агрегацией электрической нагрузки и/или источников электрической мощности | 2020 |
|
RU2778876C2 |
| Система управления, сбора, обработки, хранения и предоставления доступа к данным устройств промышленной автоматизации и интернета вещей | 2022 |
|
RU2797756C1 |
| ЦЕНТРАЛИЗОВАННОЕ УПРАВЛЕНИЕ ПРОГРАММНО-ОПРЕДЕЛЯЕМОЙ АВТОМАТИЗИРОВАННОЙ СИСТЕМОЙ | 2016 |
|
RU2747966C2 |
| СОЗДАНИЕ ВИРТУАЛЬНЫХ СЕТЕЙ, ОХВАТЫВАЮЩИХ МНОЖЕСТВО ОБЩЕДОСТУПНЫХ ОБЛАКОВ | 2018 |
|
RU2766313C2 |
| ПРОГРАММНО-ОПРЕДЕЛЯЕМАЯ АВТОМАТИЗИРОВАННАЯ СИСТЕМА И АРХИТЕКТУРА | 2016 |
|
RU2729885C2 |
| СПОСОБ И СИСТЕМА ПОДДЕРЖКИ ПРИНЯТИЯ ВРАЧЕБНЫХ РЕШЕНИЙ НА ОСНОВАНИИ ГИБРИДНОЙ МОДЕЛИ ДИАГНОСТИКИ, ПРОГНОЗИРОВАНИЯ РИСКОВ ОСЛОЖНЕНИЙ, ПОСТАНОВКИ КЛИНИЧЕСКОГО ДИАГНОЗА, ПРОВЕДЕНИЯ ДИФФЕРЕНЦИАЛЬНОЙ ДИАГНОСТИКИ И ОПРЕДЕЛЕНИЯ ТАКТИКИ ВЕДЕНИЯ ПАЦИЕНТА | 2023 |
|
RU2828464C1 |
| Способ обнаружения скрытых взаимосвязей в Интернете Вещей | 2015 |
|
RU2654167C2 |
| СПОСОБ И КОГНИТИВНАЯ СИСТЕМА ВИДЕОАНАЛИЗА, МОНИТОРИНГА, КОНТРОЛЯ СОСТОЯНИЯ ВОДИТЕЛЯ И ТРАНСПОРТНОГО СРЕДСТВА В РЕЖИМЕ РЕАЛЬНОГО ВРЕМЕНИ | 2018 |
|
RU2684484C1 |
| ИНТЕРФЕЙС ПОЛЬЗОВАТЕЛЯ С УПРЕЖДАЮЩИМ ДЕЙСТВИЕМ | 2003 |
|
RU2353068C2 |
| СИСТЕМЫ И СПОСОБ УЛУЧШЕННОГО СОВМЕСТНОГО ИСПОЛЬЗОВАНИЯ РЕСУРСОВ В СИСТЕМЕ БЕСПРОВОДНОЙ СВЯЗИ 5G/6G | 2022 |
|
RU2808640C1 |
Изобретение относится к способу планирования задач предобработки данных Интернета Вещей для систем анализа. Технический результат заключается в автоматизации планирования задач между узлами кластера. В способе выделяют наборы связанных задач по предварительной обработке данных, представляющих собой операции обработки сообщений и выделения их параметров, агрегации и нормализации параметров сообщений от устройств, затем на узлах в базе данных каждого узла выделяют промежуточные хранилища данных; выделяют узел-обработчик, на котором формализуют интеллектуальные правила планирования задач между узлами кластера, в соответствии с которыми вычислительные задачи равномерно поступают на наименее загруженные узлы кластера; аккумулируют на одном узле-обработчике все сообщения с каждого устройства, агрегируя значения параметров сообщений; на каждом узле кластера предлагают приоритетное планирование с динамическими приоритетами в рамках каждого узла для каждой вычислительной задачи путем задания формул весовых коэффициентов приоритетов; выполняют связывание в иерархию устройств, обладающих одинаковым типом; аккумулируют сообщения связанных в иерархию устройств на одном узле-обработчике, формируя одно агрегированное сообщение от устройств иерархии вместо множества сообщений от каждого из устройств в иерархии. 1 ил.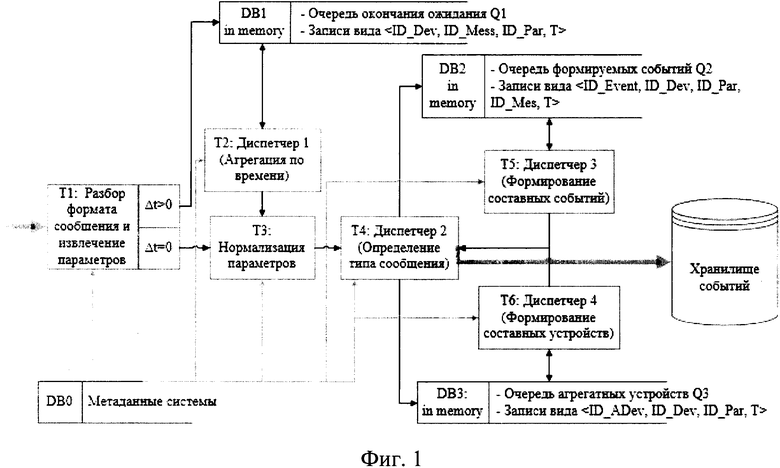
Способ планирования задач предобработки данных Интернета Вещей для систем анализа, включающий равномерное распределение и динамическое планирование вычислительных задач по предварительной обработке данных, включающей операции обработки сообщений и выделения их параметров, агрегации и нормализации параметров сообщений от устройств, агрегации параметров сообщений от разных устройств между узлами кластера и задание способа их выполнения в рамках каждого вычислительного узла кластера, отличающийся тем, что выделяют наборы связанных задач по предварительной обработке данных, типовых для обработки каждого сообщения и представляющих собой операции обработки сообщений и выделения их параметров, агрегации и нормализации параметров сообщений от устройств, агрегации сообщений от разных устройств, затем на узлах в базе данных каждого узла выделяют промежуточные хранилища данных, представляющих собой области памяти базы данных; определяют потоки данных внутри системы при проведении вычислений, представляющих собой очередность связанных задач по предварительной обработке данных над сообщениями от устройств; выделяют среди всех узлов кластера узел-обработчик, на котором отдельно формализуют интеллектуальные правила планирования задач между узлами кластера, в соответствии с которыми вычислительные задачи равномерно поступают на наименее загруженные узлы кластера для обработки за кратчайшее время; аккумулируют на одном узле-обработчике все сообщения с каждого устройства, агрегируя значения параметров сообщений; на каждом узле кластера предлагают приоритетное планирование с динамическими приоритетами в рамках каждого узла, назначаемыми каждой вычислительной задаче предварительной обработки данных путем задания формул весовых коэффициентов приоритетов; выполняют связывание в иерархию устройств, обладающих одинаковым типом и находящихся близко друг к другу; аккумулируют сообщения связанных в иерархию устройств на одном узле-обработчике, формируя одно агрегированное сообщение от устройств иерархии вместо множества сообщений от каждого из устройств в иерархии.
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| ФИЗИЧЕСКИЙ УРОВЕНЬ ВЫСОКОПРОИЗВОДИТЕЛЬНОГО МЕЖСОЕДИНЕНИЯ | 2013 |
|
RU2579140C1 |
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| EP 2977901 A2, 27.01.2016 | |||
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |

