Область техники, к которой относится изобретение
Настоящее изобретение относится к устройству обработки пакетов, которое принимает и обрабатывает пакеты пользовательских данных от мобильных терминалов, и, более конкретно, к способу распределения принятых пакетов, селектору очереди, устройству обработки пакетов и носителю информации, которые правильно распределяют пакеты пользовательских данных, поступающие извне, по множеству ядер CPU (центральный процессор), выделенных виртуальной машине.
Уровень техники
В последние годы исследовалась виртуализация мобильной сети, такой как EPC (развитое пакетное ядро), которая содержит сеть LTE (стандарт ʺДолгосрочное развитиеʺ), и т.п., путем использования NFV (виртуализация сетевых функций). В этом случае устройство обработки пакетов плоскости данных, которое принимает и обрабатывает пакеты пользовательских данных от мобильных терминалов, обеспечивается на виртуальной машине.
Здесь NFV означает способ для реализации в качестве программного обеспечения функции коммуникационного устройства, которая управляет сетью и выполняется на виртуализированной операционной системе (OS) в сервере общего назначения.
EPC обладает способностью содержания новой LTE сети доступа, продолжая содержать при этом традиционную 2G/3G сеть, которая определена в 3GPP (Проект партнерства 3-го поколения). EPC дополнительно обладает способностью содержания различных типов сетей доступа, включающих в себя не относящийся к 3GPP доступ, таких как WLAN (беспроводная локальная сеть), WiMAX (глобальная совместимость для микроволнового доступа), 3GPP2, и т.п. EPC выполнена с возможностью содержания MME (узел управления мобильностью), S-GW (сервисный шлюз) и PGW (сетевой шлюз пакетных данных) и, кроме того, может обеспечивать шлюз, в который объединяются S-GW и P-GW.
Здесь MME является узлом, который осуществляет управление мобильностью, такое как регистрация местоположения LTE терминала, обработка вызова терминала при поступлении входящего вызова и передача вызова между беспроводными базовыми станциями. S-GW является узлом, который обрабатывает пользовательские данные, такие как речь и пакеты, от мобильных терминалов, которые имеют доступ к LTE и 3G системе. P-GW является узлом, который имеет интерфейс между базовой сетью и IMS (IP мультимедийной подсистемой) или внешней сетью пакетной коммутации. IMS является подсистемой для обеспечения мультимедийных приложений, основанных на IP (Интернет протокол).
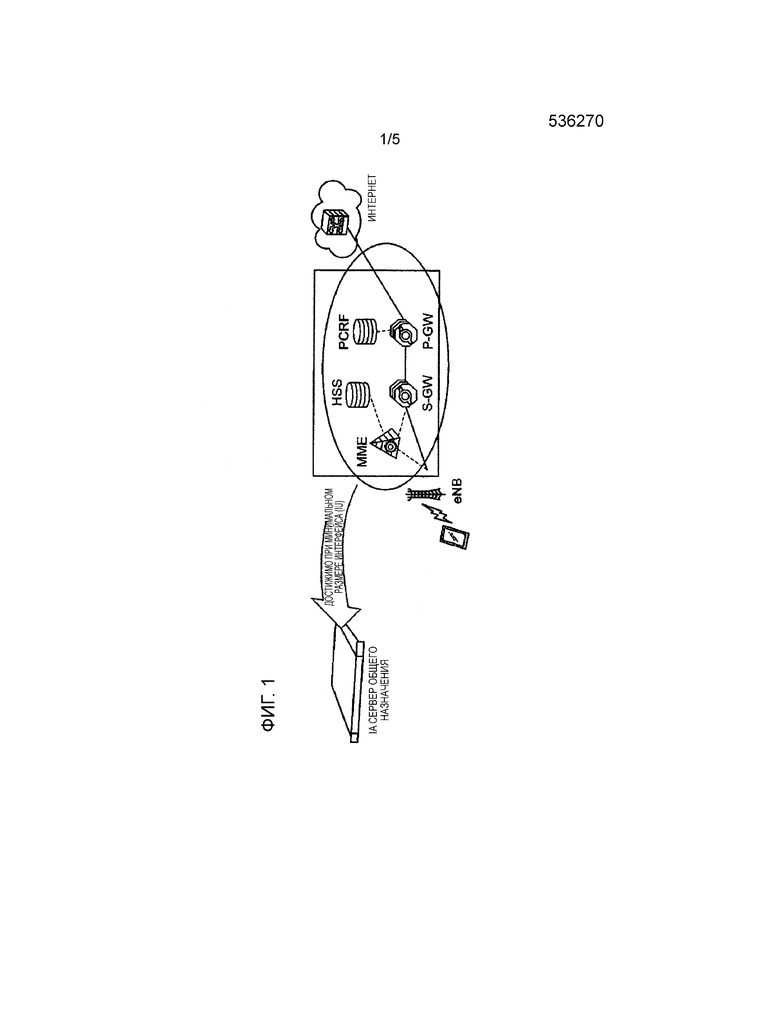
В NFV виртуализации функции MME, который отвечает за управление мобильностью, и т.п., HSS (опорный абонентский сервера), который управляет абонентской информацией, PCRF (правила и политика тарификации), который контролирует функции коммуникации в соответствии с политикой, и S/P-GW, который передает пакеты, в устройстве ядра сети мобильной связи (EPC), которое содержит LTE базовую станцию, являющуюся участком, очерченным прямоугольником на фиг. 1, обеспечиваются все вместе в виртуализированной инфраструктуре в IA сервере общего назначения (архитектура Intel®).
IA сервер является сервером, который, будучи основанным на той же архитектуре, что и обычный персональный компьютер, вмещает в себя Intel-совместимый CPU, такой как CPU (центральный процессор) серии IA-32 или IA-34, производимый Intel Corporation, или AMD® (Advanced Micro Devices, Inc.) CPU. IA сервер именуется также PC сервером. PC сервер является сервером, который проектируется и изготавливается, основываясь на персональном компьютере (PC).
На фиг. 1 eNB (развернутый узел B) является беспроводной базовой станцией (e-NodeB) в LTE. Предполагается, что мобильный терминал на чертеже является так называемым обычным мобильным телефоном, смартфоном или планшетным компьютером.
Как было сказано выше, NFV направлена на то, чтобы позволить сетям, таким как ядро сети мобильной связи, которые реализуются специализированным программным обеспечением, реализовываться программным обеспечением в сервере общего назначения. Устройство обработки пакетов плоскости данных выполняется как программное обеспечение на виртуальной машине, которая конфигурируется через виртуализацию на многоядерном CPU, установленном на сервере общего назначения. Многоядерный CPU наделяется множеством CPU-ядер.
Для того чтобы улучшить выполнение обработки в устройстве обработки пакетов плоскости данных на многоядерном CPU, требуется выполнять операции обработки пакетов на множестве CPU-ядер и к тому же масштабировать производительность в соответствии с числом CPU-ядер.
Для обеспечения масштабирования производительности в соответствии с числом CPU-ядер, которые будут использованы программной обработкой, в общем случае применяется описанный далее способ. Сначала от NIC (сетевая интерфейсная карта), которая является элементом приема пакетов в сервере общего назначения, выделенное для приема CPU-ядро на виртуальной машине забирает пакеты. Затем пакеты назначаются в соответствующие CPU-ядра (ядра обработки пакетов). После этого соответствующие CPU-ядра (ядра обработки пакетов), которые принимают пакеты, выполняют обработку пакетов.
Для улучшения производительности требуется правильно предоставлять (распределять) пакеты пользовательских данных (принятые пакеты), поступающие извне, в множество CPU-ядер, выделенных виртуальной машине.
Различные достижения предшествующего уровня техники (родственные технические приемы), относящиеся к такому способу распределения принятых пакетов, общеизвестны.
Например, в JP 2010-226275 A (PLT 1) описывается ʺкоммуникационное устройствоʺ, которое при обработке пакетов с использованием многоядерного процессора способно эффективно использовать ресурсы многоядерного процессора.
Коммуникационное устройство, описанное в PLT 1, использует способ, в котором при определении того, в какой элемент многоядерного процессора из всего множества элементов многоядерного процессора выводятся пакеты данных, определение назначенного для вывода элемента многоядерного процессора основывается на значении, вычисленном из информации, такой как ʺIP адрес назначенияʺ, ʺIP адрес источникаʺ и ʺномер протоколаʺ пакета IP данных, используя хеш-функцию. Внутри каждого элемента многоядерного процессора организовано множество ядер. Каждое ядро выполнено с возможностью обработки одновременно множества потоков. Блок управления приемом имеет функции сохранения вновь принятых пакетов данных в основной памяти и передачи обработки описанных выше пакетов в форме работы в блок управления работой, чтобы запросить блок управления работой распределить потоки для работы.
В JP 201-077746 A (PLT 2) описано ʺсетевое ретранляционное устройствоʺ, в котором каждое ядро способно обрабатывать пакеты параллельно с максимально достижимой возможностью.
Сетевое ретранляционное устройство, описанное в PLT 2, выполнено с возможностью обеспечения очереди ожидания приема, блока идентификации потока нижнего уровня, очереди ожидания идентификации потока верхнего уровня, очереди ожидания обработки переноса, блока идентификации потока верхнего уровня/обработки переноса и очереди ожидания передачи. Сетевое ретранляционное устройство, принимая пакеты, временно удерживает пакеты в очереди ожидания приема. Блок идентификации потока нижнего уровня забирает пакет из очереди ожидания приема, вычисляет хеш-функцию, используя, например, информацию заголовка, такую как IP адрес источника и IP адрес назначения в IP заголовке, в соответствии с вычисленной хеш-функцией, распределяет пакет в очередь ожидания идентификации потока верхнего уровня по отношению к каждому потоку нижнего уровня. Блок идентификации потока верхнего уровня/обработки переноса является блоком обработки, который выполняет два типа обработки, а именно, обработку идентификации потока верхнего уровня и обработку переноса, содержащихся вместе на одном ядре. Хотя в качестве примера приведен многоядерный CPU, это изобретение может быть реализовано с использованием множества CPU.
Кроме того, в JP 2009-239374 A (PLT 3) описывается ʺсистема виртуальных машинʺ, которая способна уменьшить задержки передачи пакетов в VNIC (виртуальная сетевая интерфейсная карта) множества виртуальных машин.
В системе виртуальных машин, описанной в PLT 3, множество виртуальных машин и физическая NIC связаны между собой общей шиной. Каждая из виртуальных машин имеет виртуальную сетевую интерфейсную карту (VNIC). Физическая сетевая интерфейсная карта (физическая NIC) подсоединена к общей шине и совместно используется (используется вместе) между картами VNIC. Физическая NIC обрабатывает пакеты, принятые от сети, в порядке их приема. Сетевой интерфейс (I/F), принимая данные принятых пакетов с номером 1 принятого пакета (упоминаемым далее просто как номер 1) от сети, сохраняет данные принятого пакета в буфере приема. Буфер приема извлекает IP адресные данные адресата приема из сохраненных данных принятого пакета с номером 1 и выбирает очередь приема в соответствии с IP адресом принятого пакета.
Дополнительно в JP 2011-141587 A (PLT 4) описывается ʺраспределенная система обработкиʺ, способная сократить время отклика для одной единицы данных, которая загружается в сеть и имеет большое количество информации.
Распределенная система обработки, описанная в PLT 4, выполнена с возможностью включения в себя устройства отклика на прием, устройства разделения/объединения, множества обрабатывающих устройств и одного или более устройств мониторинга очереди. Устройство отклика на прием принимает данные (загружает данные) от пользовательских терминалов через сеть. Устройство разделения/объединения получает данные, которые устройство отклика на прием считает приемлемыми, генерирует сегментные данные, разделяя данные, и затем объединяет обработанные сегментные данные. Множество обрабатывающих устройств получают сегментные данные и выполняют обработку данных. Одно или более устройств мониторинга очереди получают сегментные данные, поступающие от устройства разделения/объединения, сохраняют сегментные данные как очередь и, в ответ на запрос от обрабатывающего устройства, передают сегментные данные в обрабатывающее устройство. Обрабатывающее устройство получает сегментные данные от устройства управления очередью и выполняет заданную обработку данных применительно к полученным сегментным данным. Обрабатывающее устройство выполнено с возможностью включения в себя устройства выбора очереди, устройства получения сегментных данных, устройства обработки данных и устройства вывода результирующих сегментных данных. Устройство выбора очереди выбирает устройство управления очередью, которое становится источником получения сегментных данных. Выбор устройства управления очередью в этом случае выполняется с использованием, например, распределенного алгоритма, такого как способ кругового поиска. Устройство получения сегментных данных передает полученный запрос на сегментные данные в устройство управления очередью, выбранное устройством выбора очереди, и получает сегментные данные от устройства управления очередью.
[Перечень ссылок]
[Патентная литература]
[PLT 1] JP 2010-226275 A (параграфы [0013] и [0015]
[PLT 2] JP 2011-077746 A (параграфы [0013], [0015], [0023] и [0024]
[PLT 3] JP 2009-239374 A (фиг. 1 и 9, параграфы [0025], [0069] и [0070]
[PLT 4] JP 2011-141587 A (фиг. 1, параграфы с [0031] по [[0033] и с [0055] по [0057].
Сущность изобретения
[Техническая проблема]
Когда осуществляется виртуализация сервера общего назначения посредством NFV и устройство обработки пользовательских данных конфигурируется на виртуальной машине в виртуализированном сервере, возникает проблема производительности. Это происходит потому, что, в отличие от устройства обработки пользовательских данных, сконфигурированного конкретным сетевым аппаратным оборудованием, все функции достигаются программным обеспечением.
Например, устройство обработки пользовательских данных, сконфигурированное на виртуальной машине с использованием функций общего назначения, таких как SRIOV (Single Roof I/O Virtualization - однокорневая виртуализация ввода/вывода), и VF (виртуальная функция) функция транзитной передачи, обеспечивает возможность связи с внешним миром со стороны Guest OS (виртуальная машина) непосредственно через NIC без прохождения через главную OS. Поэтому непроизводительные издержки, требуемые для связи со стороной главной OS, могут быть исключены и, следовательно, производительность может быть улучшена. Однако существует проблема в том, что производительность не может масштабироваться в соответствии с числом CPU-ядер, если пакеты пользовательских данных, поступающие извне, не будут правильно распределены по множеству CPU-ядер, выделенных виртуальной машине. Это происходит потому, что нагрузки обработки взвешиваются применительно к конкретным CPU-ядрам, и все ресурсы CPU-ядер не могут быть полностью использованы. Хотя не существует проблемы в случае одного CPU-ядра, невозможно повысить производительность пропорционально числу CPU-ядер в многоядерном процессоре.
В родственных технологиях можно организовать специализированное для приема ядро в дополнение к множеству ядер для обработки пакетов как множеству CPU-ядер, и, как указывается, например, в упомянутой выше PLT 4, распределять принятые пакеты специализированным для приема ядром, предоставляющим принятые пакеты в соответствующие ядра для обработки пакетов, используя логику кругового поиска или другую подобную. Однако возможно, что вследствие изменения длин, и т.п., принятых пакетов длинные пакеты или короткие пакеты предоставляются в конкретные ядра обработки пакетов сосредоточенным образом. Нагрузка CPU-ядра на пакет колеблется в зависимости от размера пакета. Поэтому, с точки зрения нагрузки CPU-ядер, в результате возникает дисбаланс, и невозможно масштабировать производительность пропорционально числу CPU-ядер. Вследствие этого производительность обработки не может быть максимизирована.
Также можно предположить, что для решения таких проблем логика предоставления, используемая специализированным для приема ядром, изменяется. Однако в этом случае логика предоставления, становясь более сложной, приводит к ухудшению производительности предоставления, уменьшению числа CPU-ядер (ядер для обработки пакетов), по которым могут распределяться нагрузки, и ограничению числа CPU-ядер, которые могут масштабироваться. Вследствие этого возникает проблема в том, что производительность многоядерного процессора не может быть максимизирована.
Даже в простой логике, такой как способ кругового поиска, обработка принятых пакетов, определение назначенного для передачи CPU-ядра (ядра для обработки пакета) и передача пакета необходимы. Поэтому существует проблема, заключающаяся в том, что когда число назначенных для передачи CPU-ядер (ядер для обработки пакетов) возрастает, нагрузка на управление исключением среди соответствующих CPU-ядер (ядер для обработки пакетов), которая возникает при выполнении передачи пакетов, ядро, специализированное для приема пактов, становится ʺузким местомʺ, и производительность не может масштабироваться.
Пользовательские данные, используемые в мобильной сети, такой как EPC, инкапсулируются посредством GTP (общий протокол туннелирования), который снабжен IP адресом для межузловой связи устройств и доступен через использование IP адреса. Все IP адреса узла, представляющие устройства, которые принимают пакеты, становятся одним и тем же IP адресом назначения. Можно, используя RSS (масштабирование на стороне приема) функцию, реализованную для NIC общего назначения, распределять пакеты в соответствии с IP адресами на стороне NIC. Однако существует проблема в том, что поскольку IP адреса узлов, используемые в мобильной сети, такой как EPC, становится такой же величиной, что и IP адреса устройств обработки пакетов, по существу невозможно распределить пакеты.
Кроме того, существует проблема в том, что поскольку IP адрес пользователя, подлежащий распределению, существует в полезной нагрузке инкапсулированного пакета, RSS функция, установленная на NIC общего назначения, не способна относиться к IP адресу пользователя.
Подводя итог вышесказанному, способы распределения нагрузки для принятых пакетов в устройстве обработки пакетов, которое сконфигурировано в виртуальной среде с использованием родственных технологий, таких как NFV, имеют перечисленные ниже проблемы.
Первая проблема состоит в том, что в устройствах, соответствующих родственным технологиям, производительность обработки пакета на CPU-ядро падает из-за непроизводительных издержек, вызванных занятием ресурсов CPU-ядра, специализированного в качестве ядра для приема, и, кроме того, обменом пакетами между ядрами для обработки пакетов и ядром, специализированным для приема. Причина этой проблемы состоит в следующем. Когда множество VF создаются в NIC, используя функции, такие как SRIOV, только одна очередь приема пакетов может быть сконфигурирована в VF. Поэтому требуется организовать специализированное для приема ядро, которое забирает принятые пакеты из очереди принятых пакетов в NIC.
Вторая проблема заключается в том, что распределение пакетов по отношению к каждому мобильному терминалу не может быть достигнуто, нагрузки концентрируются в конкретных очередях принятых пакетов или в ядрах обработки пакетов, и, даже если число CPU-ядер, выполняющих обработку пакетов, возрастает, производительность обработки пакетов не может быть масштабирована в соответствии с числом CPU-ядер. Причина этой проблемы заключается в следующем. Предполагается, что множество очередей принятых пакетов образуется в VF подобно PF (физическая функция) функции в NIC, и обеспечивается NIC карта, которая способна распределять пакеты по соответствующим очередям принятых пакетов, используя RSS функции. Даже в этом случае пользовательские пакетные данные в мобильной сети, такой как EPC, инкапсулируются посредством GTP. Поэтому IP адреса мобильных терминалов содержатся внутри полезных нагрузок, и IP адрес, данный заголовку пакета, является IP адресом узла для выполнения передачи и приема среди соответствующих узлов в пределах EPC. Вследствие этого для RSS функции, нормально включенной в состав NIC, принятые пакеты могут распределяться по соответствующим очередям принятых пакетов в NIC, основываясь только на этом IP адресе узла.
Третья проблема заключается в том, что невозможно выровнять нагрузки в соответствующих ядрах для обработки пакетов в соответствии с режимами использования пользователями или характеристиками применения, и даже когда число CPU-ядер, выполняющих обработку пакетов, возрастает, невозможно масштабировать производительность обработки пакетов в соответствии с числом CPU-ядер. Причина этой проблемы заключается в следующем. Даже когда распределение пакетов, основанное на использовании IP адреса мобильного терминала, обеспечивается, длины данных пользовательских пакетов являются неоднородными, и длины пакетов различны для каждого пользователя и каждого применения. Вследствие этого, поскольку длина пакетных данных, подлежащих обработке, изменяется, нагрузки на CPU-ядра претерпевают колебания применительно к каждому пакету.
В PLT 1 просто описывается техническая идея того, как, основываясь на значении, вычисленном из информации IP пакета данных с использованием хеш-функции, определить назначенный для вывода элемент многоядерного процессора.
В PLT 2 просто описывается техническая идея того, как при приеме пакетов временно удерживать пакеты в очереди ожидания приема, извлекать пакет из очереди ожидания приема, вычислять хеш-функцию, используя информацию заголовка в IP заголовке извлеченного пакета, распределять пакет в очередь ожидания идентификации потока верхнего уровня по отношению к каждому потоку нижнего уровня, основываясь на вычисленном хеш-значении, забирать пакеты, ожидающие в очередях ожидания идентификации потока верхнего уровня, и выполнять обработку идентификации потока верхнего уровня.
В PLT 3 просто описывается техническая идея, касающаяся извлечения IP адресных данных адресата приема из данных принятого пакета и выбора очереди приема по отношению к IP адресу принятого пакета.
В PLT 4, как было сказано выше, просто описывается техническая идея, касающаяся выполнения выбора устройства управления очередью с использованием алгоритма распределения, такого как способ кругового поиска.
Задачей настоящего изобретения является обеспечение способа распределения принятых пакетов, селектора очереди, устройства обработки пакетов и носителя информации, которые способны к масштабированию производительности обработки пакетов пользовательских данных в соответствии с числом CPU-ядер.
[Решение проблемы]
Одним примерным вариантом осуществления является способ распределения принятых пакетов, относящийся к приему пакетов пользовательских данных от мобильного терминала в качестве принятых пакетов и распределению принятых пакетов в множество очередей, причем эти очереди соответствуют множеству CPU-ядер, выделенных соответственно виртуальной машине и имеющих соответствующие назначенные номера очередей. Способ включает в себя прием пакетов пользовательских данных в качестве принятых пакетов; извлечение пользовательского IP адреса, расположенного в полезной нагрузке принятого пакета; вычисление хеш-значения для извлеченного пользовательского IP адреса и выбор номера очереди, в которой принятый пакет должен быть сохранен, основываясь на хеш-значении; обращение к таблице определений, хранящей интенсивность использования CPU по отношению к каждому из множества CPU-ядер и определяющей установлен ли выбранный номер очереди как номер очереди, в которой должен быть сохранен принятый пакет, основываясь на интенсивности использования CPU; и сохранение принятого пакета в очереди с определенным номером очереди.
[Полезные эффекты изобретения}
Настоящее изобретение обеспечивает возможность масштабирования производительности обработки пакетов пользовательских данных в соответствии с числом CPU-ядер.
Краткое описание чертежей
ФИГ. 1 - схематическое представление примера виртуализации мобильной сети посредством NFV.
ФИГ. 2 - блок-схема, представляющая конфигурацию устройства обработки пакетов согласно первому примеру настоящего изобретения.
ФИГ. 3 - схема, показывающая пример таблицы определений, используемой устройством обработки пакетов, показанным на фиг. 2.
ФИГ. 4 - блок-схема, представляющая конфигурацию селектора очереди, используемого устройством обработки пакетов, показанным на фиг. 2.
ФИГ. 5 - блок-схема последовательности операций для описания работы селектора очереди, используемого устройством обработки пакетов, показанным на фиг. 2.
Описание вариантов осуществления
[Родственные технологии]
Чтобы облегчить понимание настоящего изобретения, ниже будут описаны технологии, имеющие отношение к настоящему изобретению.
Как было сказано выше, существует пример, в котором мобильная сеть, такая как EPC (развитое ядро пакетной сети), содержащая LTE (стандарт ʺДолгосрочное развитиеʺ) сеть, и т.п., подвергается виртуализации с использованием NFV (виртуализация сетевых функций), и т.п. В этом случае устройство обработки пакетов плоскости данных, которое обрабатывает пакеты пользовательских данных от мобильных терминалов, обеспечивается на виртуальной машине.
NFV направлена на достижение того, чтобы сети, такие как мобильное ядро, которые были реализованы специализированным программным обеспечением, могли быть реализованы программным обеспечением в сервере общего назначения. Устройство обработки пакетов плоскости данных реализуется как программное обеспечение на виртуальной машине, которая конфигурируется через виртуализацию на многоядерном CPU, устанавливаемом на сервере общего назначения. Многоядерный CPU обеспечивается множеством CPU-ядер.
Для обеспечения масштабируемости производительности в соответствии с числом CPU-ядер, которые будут использованы программной обработкой, обычно используется следующий способ. Сначала от NIC, которая является элементом приема пакетов в сервере общего назначения, специализированное для приема ядро на виртуальной машине забирает пакеты. Затем пакеты назначаются в соответствующие CPU-ядра (ядра обработки пакетов). После этого соответствующие CPU-ядра (ядра обработки пакетов), которые приняли пакеты, выполняют обработку пакетов.
Однако в этом способе существует проблема, заключающаяся в том, что CPU ресурс специализированного для приема ядра затрачивается больше чем необходимо, в сравнении с тем, что было до того, как CPU-ядра масштабированы, и, когда число CPU-ядер, в которые распределяются пакеты, возрастает, ядро, специализированное для приема, становится ʺузким местомʺ, препятствующим обеспечению масштабирования производительности.
[Примерный вариант осуществления]
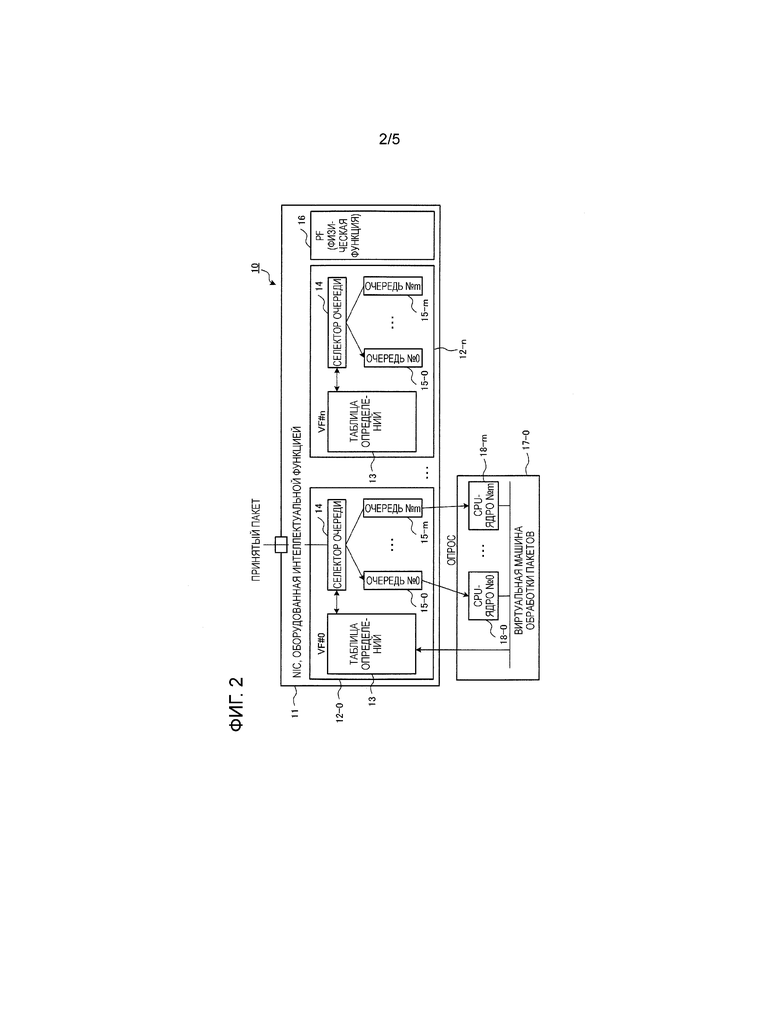
Для решения такой проблемы примерный вариант осуществления настоящего изобретения представляет устройство 10 обработки пакетов, которое использует карту сетевого интерфейса (NIC) 11, наделенную интеллектуальной функцией, как показано на фиг. 2.
Когда NIC 11, которая наделена интеллектуальной функцией и вставлена в сервер общего назначения, принимает пакеты пользовательских данных, селектор 14 очереди производит назначение пакетов и загружает пакетные данные в соответствующие очереди с 15-0 по 15-m. Здесь m - целое число от 2 и выше.
В этот момент селектор 14 очереди определяет присваиваемые назначения, основываясь на таблице 13 определений. Обращаясь к таблице 13 определений, селектор 14 очереди назначает пакетные данные в правильные очереди, основываясь на интенсивностях использования CPU, и т.п., в диапазоне от 0-го до m-го CPU-ядер с 18-0 по 18-m.
В ядре сети мобильной связи, такой как EPC, имеются два типа IP адресов, а именно, IP адрес узла, который служит с целью использования для связи между устройствами в мобильной базовой сети, такой как EPC, и IP адрес пользователя, который присваивается каждому из пользователей. Пакеты пользовательских данных инкапсулируются посредством GTP (общий протокол туннелирования) и наделяются IP адресом узла.
Физическая NIC общего назначения может обладать способностью вычисления хеш-значений IP адресов, используя RSS (масштабирование на стороне приема) функцию в VF и выполнять распределение, основываясь на хеш-значениях.
Однако в NIC к пакетам пользовательских данных в ядре сети мобильной связи, такой как EPC, в общем случае применяется назначение пакетов, основанное на хеш-значениях IP адресов. Поэтому в случае приема пакетов пользовательских данных, передаваемых от идентичного сетевого устройства, или передаваемых в идентичное сетевое устройство, пакеты пользовательских данных концентрируются на идентичном CPU-ядре, что препятствует выполнению распределенной обработки пакетов, как ожидалось.
Поскольку IP адрес пользователя располагается в полезной нагрузке пакета, назначение пакетов, основанное на хеш-значениях IP адреса пользователя, не может выполняться RSS функцией NIC общего назначения.
Поэтому в примерном варианте осуществления настоящего изобретения таблица 13 определений создает хеш-таблицу, которая определила назначенную очередь среди очередей с 15-0 по 15-m в соответствии с пользовательским IP адресом источника или пользовательским IP адресом назначения, в диапазоне от 0-го до m-го CPU-ядер с 18-0 по 18-m.
Селектор 14 очереди извлекает IP адрес пользователя, расположенный в полезной нагрузке принятого пакета, и, после вычисления хеш-значения, выбирает очередь, в которой сохраняется принятый пакет, путем обращения к таблице 13 определений. После этого селектор 14 очереди обращается к интенсивностям использования CPU в таблице 13 определений. Когда интенсивность использования CPU-ядра, назначенного выбранной очереди, больше или равна пороговому значению, селектор 14 очереди определяет очередь, назначенную CPU-ядру, имеющему наименьшую интенсивность использования CPU среди тех CPU-ядер, которые имеют интенсивность использования CPU меньше или равную пороговому значению.
Селектор 14 очереди сохраняет принятый пакет в этой определенной очереди. Когда интенсивности использования CPU всех CPU-ядер превышают или равны пороговому значению, селектор 14 очереди устанавливает новое пороговое значение в интервале между 100% и последним пороговым значением и выполняет такую же обработку выбора и определения очереди, используя новое пороговое значение. Когда все интенсивности использования CPU-ядер опять превосходят новое пороговое значение, селектор 14 очереди повторяет ту же самую переустановку и обработку выбора и определения очереди до тех пор, пока пороговое значение для интенсивностей использования не достигнет 100%.
Каждый от 0-го до m-го CPU-ядер, с 18-0 по 18-m, опрашивая одну из очередей с 15-0 по 15-m, которой CPU-ядро назначено в NIC 11, наделенной интеллектуальной функцией, забирает пакеты, как требуется, и от 0-го до m-го CPU-ядра, с 18-0 по 18-m, выполняют обработку принятых пакетов пользовательских данных.
Как было описано выше в примерном варианте осуществления настоящего изобретения, принятые пакеты пользовательских данных распределяются по соответствующим CPU-ядрам, с 18-0 по 18-m, таблицей 13 определения и селектором 14 очереди, реализованным в NIC 11, наделенной интеллектуальной функцией, и ресурсы CPU-ядер соответствующих CPU-ядер с 18-0 по 18-m сглаживаются. Поэтому можно использовать вплоть до всех ресурсов CPU-ядер, что позволяет масштабировать производительность обработки пакетов пользовательских данных в соответствии с числом CPU-ядер.
Далее со ссылкой на чертежи будут описаны примеры настоящего изобретения и принцип его работы.
[Пример 1]
На фиг. 2 показана блок-схема, представляющая конфигурацию устройства 10 обработки пакетов, соответствующую первому примеру настоящего изобретения.
Устройство 10 обработки пакетов включает в себя NIC 11, наделенную интеллектуальными функциями, и множество виртуальных машин для обработки пакетов. В приводимом примере в состав множества виртуальных машин для обработки пакетов включены, начиная от 0-й виртуальной машины 17-0 для обработки пакетов до n-й виртуальной машины для обработки пакетов (не показана), с добавлением до (n+1) виртуальных машин для обработки пакетов. Здесь n является целым числом, равным 1 или более.
На фиг. 2 NIC 11, наделенная интеллектуальными функциями, снабжена PF (физическая функция) 16 и множеством VF (виртуальная функция) с 12-0 по 12-n. В PF 16 множество VF с 12-0 по 12-n виртуально сконфигурированы, и каждая из виртуальных машин 17-0, и т.д., способна передавать и принимать пакеты, используя одну из VF с 12-0 по 12-n. В этом примере в состав множества VF включены, начиная с 0-й VF 12-0 по n-ю VF 12-n, с добавлением до (n+1) VF.
Соответствующие единицы, начиная от 0-й до n-й VF, c 12-0 по 12-n, имеют одну и ту же конфигурацию. Поэтому в последующем описании 0-я VF 12-0 будет описана как представительная VF, и описание других VF будет опущено.
0-я VF 12-0 включает в себя таблицу 13 определений, селектор 14 очереди и множество очередей с 15-0 по 15-m. В приводимом примере в состав множества очередей включены, начиная с 0-й очереди 15-0 по m-ю очередь 15-m, с добавлением до (m+1) очередей.
С другой стороны, 0-я виртуальная машина 17-0 для обработки пакетов включает в себя множество CPU-ядер с 18-0 по 18-m. В приводимом примере в состав множества CPU-ядер включены, начиная от 0-го CPU-ядра 18-0 до m-го CPU-ядра 18-m, с добавлением до (m+1) CPU-ядер.
Как показано на фиг. 2, множество очередей с 15-0 по 15-m индивидуально соответствует множеству CPU-ядер с 18-0 по 18-m, которое назначено 0-й виртуальной машине 17-0 для обработки пакетов. С 0-й по m-ю очередям с 15-0 до 15-m индивидуально назначены номера очередей с #0 по #m.
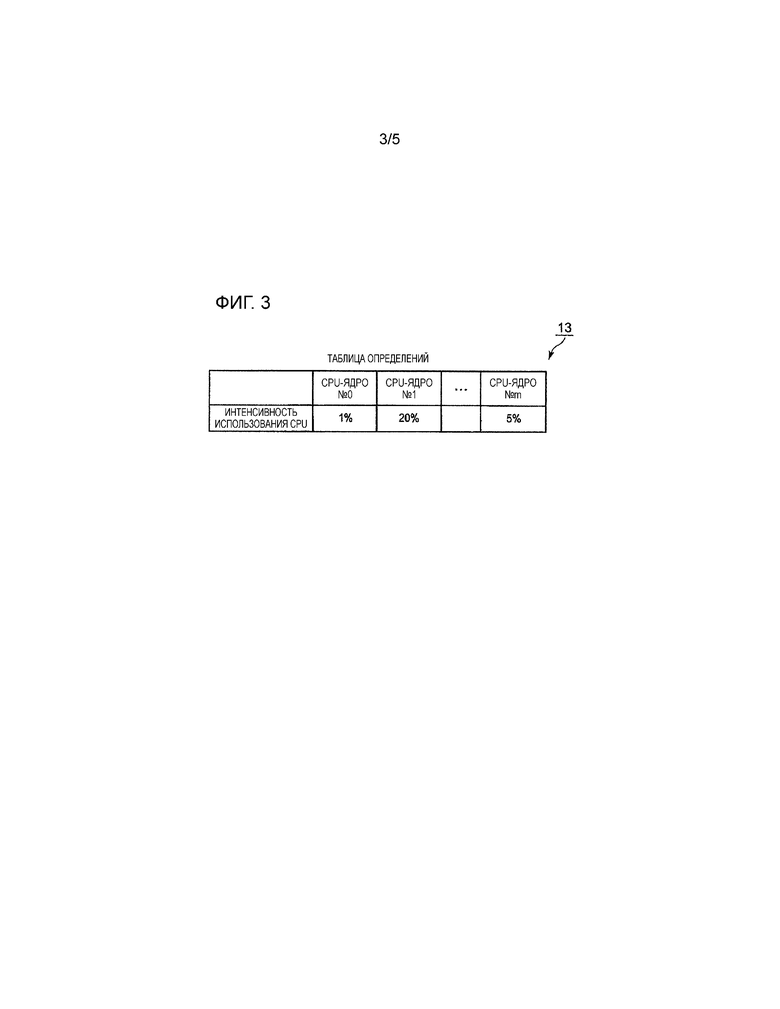
Таблица 13 определений хранит интенсивность использования CPU для каждого из множества CPU-ядер с 18-0 по 18-m, как показано на фиг. 3. В примере, представленном на фиг. 3, интенсивность использования CPU для 0-го CPU-ядра 18-0 составляет 1%, интенсивность использования CPU для 1-го CPU-ядра составляет 20%, и интенсивность использования CPU для m-го CPU-ядра 18-m составляет 5%.
В дополнение к интенсивностям использования CPU таблица 13 определений хранит, как было сказано выше, хеш-таблицу, которая определила назначенную очередь среди очередей с 15-0 по 15-m в соответствии с исходящим IP адресом пользователя или назначенным IP адресом пользователя в диапазоне из множества CPU-ядер с 18-0 по 18-m, и вызывает информацию обработки, такую как IP адрес пользователя, подлежащий обработке.
Устройство 10 обработки пакетов согласно примерному варианту осуществления настоящего изобретения при приеме пакетов пользовательских данных селектором 14 очереди в NIC 11, наделенной интеллектуальной функцией, определяет, в которой из очередей с 0-й по m-ю, с 15-0 до 15-m, должны храниться принятые пакеты, как будет описано ниже. То есть селектор 14 очереди принимает пакеты пользовательских данных от мобильных терминалов в качестве принятых пакетов и, как будет описано ниже, назначает и сохраняет пакеты в множестве очередей с 15-0 по 15-m.
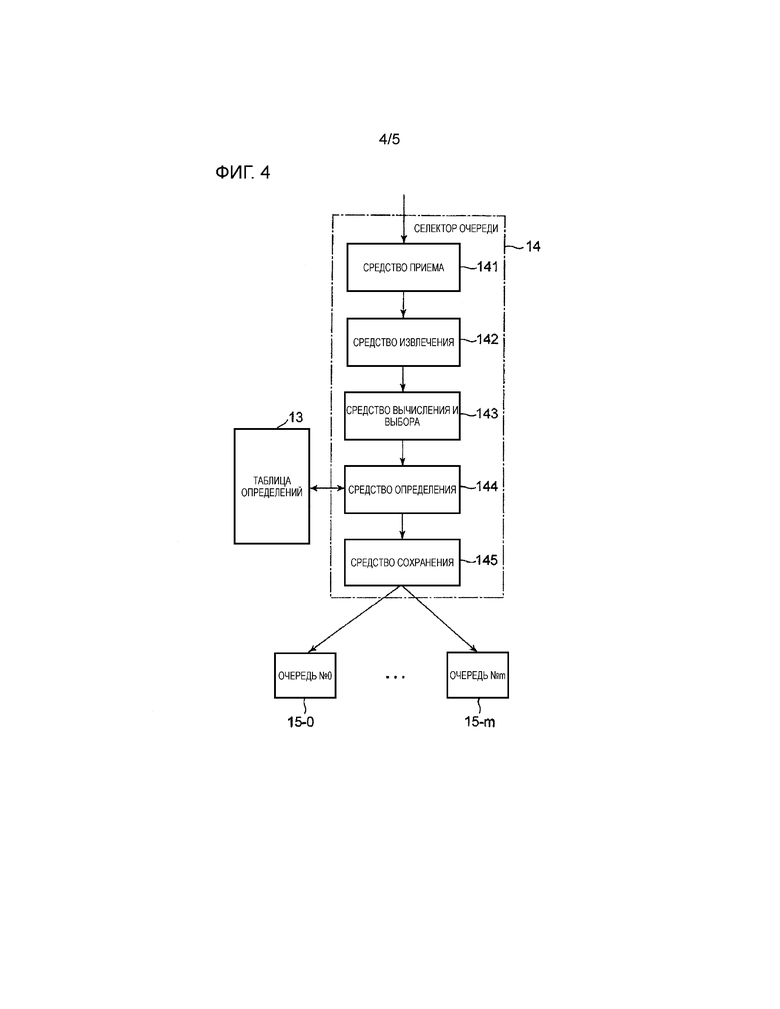
На фиг. 4 показана блок-схема, представляющая конфигурацию селектора 14 очереди. Селектор 14 очереди включает в себя средство 141 приема, средство 142 извлечения, средство 143 вычисления и выбора, средство 144 определения и средство 145 хранения.
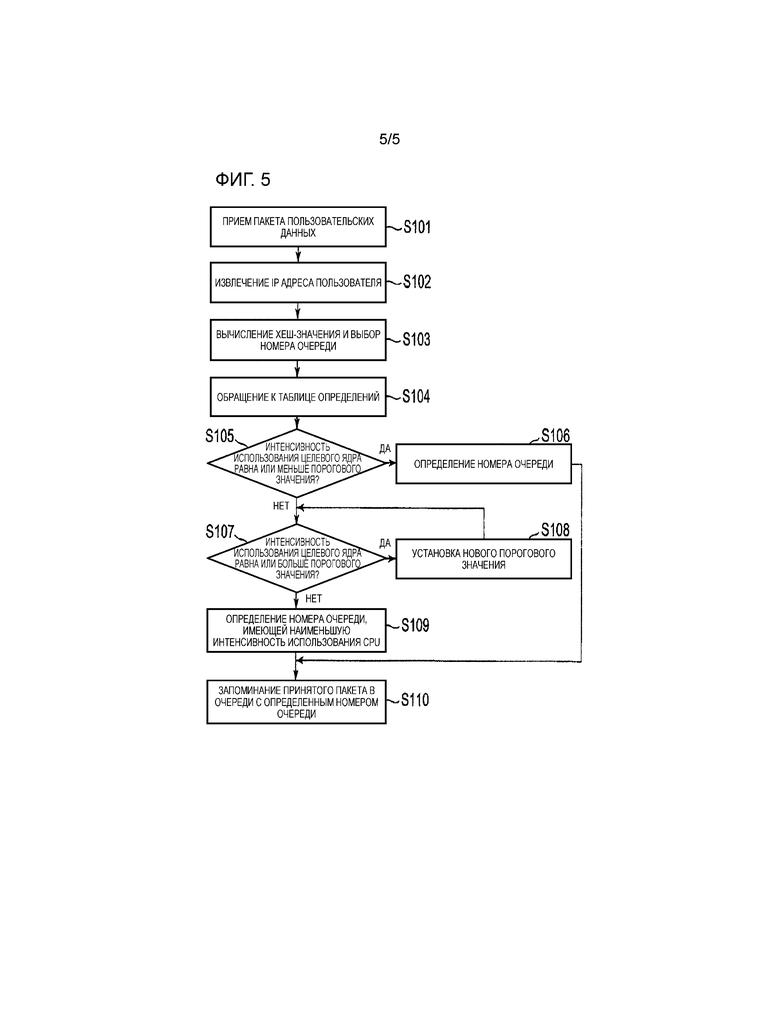
На фиг. 5 показана блок-схема или дано представление последовательности операций селектора 14 очереди.
Средство 141 приема принимает пакет пользовательских данных в качестве принятого пакета (этап S101 на фиг. 5). Средство 142 извлечения извлекает IP адрес пользователя, расположенный в полезной нагрузке принятого пакета (этап S102 на фиг. 5). Средство 143 вычисления и выбора вычисляет хеш-значение для извлеченного IP адреса пользователя и, основываясь на хеш-значении, выбирает номер очереди, в которой должны быть сохранены принятые данные (этап S103 на фиг. 5).
Средство 144 определения обращается к таблице 13 определений (этап S104 на фиг. 5) и, основываясь на интенсивности использования CPU, определяет, установлен ли выбранный номер очереди как номер очереди, в которой должен быть сохранен принятый пакет, как будет описано ниже (см. этапы с S105 по S109 на фиг. 5).
Средство 145 хранения хранит принятый пакет в очереди, имеющей определенный номер очереди (этап S110 на фиг. 5).
В примерном варианте осуществления распаковывание принятых пакетов из очереди позволяет распределять нагрузки по CPU-ядрам.
Затем, со ссылкой на фиг. 5, будет более подробно описана работа средства 144 определения.
Перед определением номера очереди, основываясь на хеш-значении, средство 144 определения обращается к таблице 13 определений (этап S104) и, после удостоверения в том, что интенсивность использования CPU-ядра, назначенного в выбранный номер очереди, меньше или равна заданному пороговому значению (ДА на этапе S105), определяет номер очереди (этап S106).
Даже когда принятые пакеты могут распределяться по очередям, используя хеш-значение на основе IP адресов пользователей, нагрузки на CPU-ядра будут неравномерными вследствие характеристик трафика, таких ка длины пакетов, и т.п. Поэтому дисбаланс в нагрузках обычно возникает по отношению к каждому CPU-ядру.
Когда определяется, что интенсивность использования CPU применительно к CPU-ядру больше или равна пороговому значению из таблицы 13 определений (НЕТ на этапе S105), средство 144 определения определяет номер очереди, назначенный CPU-ядру, имеющему интенсивность использования, которая меньше или равна пороговому значению и которая является наименьшей (НЕТ на этапе S107 и этапе S109). Средство 145 сохранения затем сохраняет принятый пакет в очереди с определенным номером очереди (этап S110).
Когда интенсивности использования CPU для всех CPU-ядер больше или равны пороговому значению (ДА на этапе S107), средство 144 определения определяет (устанавливает) новое пороговое значение (этап S108) и, основываясь на новом пороговом значении, определяет номер очереди по той же логике (этапы с S107 по S109).
В таблице 13 определений хранится информация по интенсивностям использования CPU применительно к соответствующим CPU-ядрам, которая регулярно передается от множества CPU-ядер с 18-0 по 18-m, выделенных виртуальной машине 17-0 в устройстве 10 обработки пакетов.
Таким образом, в этом примере сглаживанием нагрузок на соответствующих CPU-ядрах с 18-0 по 18-m и равномерным использованием всех ресурсов CPU-ядер можно обеспечить масштабирование производительности в соответствии с числом CPU-ядер и максимально использовать производительность CPU в аппаратном оборудовании.
Принцип действия селектора 14 будет описан со ссылкой на фиг. 5.
Селектор 14 очереди принимает пакет пользовательских данных в качестве принятого пакета (этап S101), извлекает IP адрес пользователя, сохраненный в полезной нагрузке принятого пакета (этап S102), и выполняет вычисление хеш-значения IP адреса, чтобы выбрать номер очереди, в которой должен быть сохранен принятый пакет (этап S103).
Перед определением номера очереди селектор 14 очереди обращается к таблице 13 определений (этап S104), удостоверяется в том, что интенсивность использования CPU для выбранного CPU-ядра меньше или равна пороговому значению, обращаясь к информации по интенсивностям использования CPU для соответствующих CPU-ядер, которая показана в таблице 13 определений (ДА на этапе S105), и, когда интенсивность использования CPU меньше или равна пороговому значению, определяет номер очереди (этап S106).
Когда интенсивность использования CPU больше или равна пороговому значению (НЕТ на этапе S105), селектор 14 очереди выбирает и определяет номер очереди, назначенный CPU-ядру, имеющему интенсивность использования CPU, которая меньше или равна пороговому значению и которая является наименьшей (НЕТ на этапах S107 и S109). Когда интенсивности использования всех CPU-ядер больше или равны пороговому значению (ДА на этапе S107), селектор 14 очереди опять устанавливает новое пороговое значение (этап S108) и определяет номер очереди по той же логике (этапы с S107 по S109).
Каждое из CPU-ядер с 18-0 по 18-m забирает пакет, сохраненный в одной из очередей с 15-0 по 15-m, соответствующей CPU-ядру, и выполняет обработку пакета, такую как протокольная обработка.
Как было сказано ранее, пример осуществления настоящего изобретения представляет полезные эффекты, которые будут описаны ниже.
Первый полезный эффект заключается в том, что возможно распределять принятые пакеты, не используя основные ресурсы CPU, возможно распределять принятые пакеты без специализированного для приема ядра для распределения пакетов и становится возможным предотвращать образование ʺузкого местаʺ в специализированном для приема ядре при масштабировании CPU-ядер. Это происходит потому, что информация об интенсивности использования CPU-ядер с 18-0 по 18-m, которые назначены в качестве устройств 10 обработки пакетов, и информация по обработке вызовов, такая как IP адрес пользователя, подлежащий обработке, время от времени регистрируется в таблице 13 определений в карте NIC, и очередь, в которую назначается CPU-ядро, которое обрабатывает пакет, принятый NIC 11, определяется в соответствии с таблицей 13 определений.
Вторым полезным эффектом является то, что распределение принятых пакетов по соответствующим CPU-ядрам с 18-0 по 18-m по отношению к каждому из пользователей мобильного терминала и сглаживание нагрузок на соответствующих CPU-ядрах позволяет обеспечить максимизацию производительности обработки пакетов, достижимую для устройства. Это происходит потому, что при работе селектора 14 очереди в NIC 11 обнаруживается инкапсулированный IP адрес пользователя, расположенный в полезной нагрузке принятого пакета, и, путем обращения к таблице 13 определений, очередь в NIC, в которой должен быть сохранен пакет, определяется в соответствии с хеш-значением IP адреса пользователя, и т.п.
Третьим полезным эффектом является то, что устранение дисбаланса в нагрузках на CPU-ядрах, вызываемого изменением длин пакетов и подобными изменениями пакетов пользовательских данных, и сглаживание нагрузок на соответствующих CPU-ядрах позволяет обеспечить максимизацию производительности обработки пакетов, достижимую для устройства. Это происходит потому, что CPU-ядра, интенсивности использования CPU в которых меньше или равны постоянному значению, определяются в соответствии с динамическими интенсивностями использования CPU, собираемыми от соответствующих CPU-ядер с 18-0 по 18- m, и помещаются в таблицу 13 определений, и определяется очередь в NIC 11, в которой должны сохраняться принятые пакеты.
Хотя изобретение было конкретно представлено и описано со ссылкой на примерные варианты его осуществления, изобретение не ограничивается этими вариантами осуществления. Специалистам в данной области техники должно быть понятно, что различные изменения в форме и деталях могут быть произведены без отклонения от сущности и объема настоящего изобретения, определенного формулой изобретения.
Полностью или частично примерные варианты осуществления, представленные выше, могут быть описаны, не ограничиваясь этим, следующими дополнительными пояснениями.
(Дополнительное пояснение 1)
Способ распределения принятых пакетов для приема пакетов пользовательских данных от мобильного терминала в качестве принятых пакетов и распределения принятых пакетов в множество очередей, когда эти очереди соответствуют множеству CPU-ядер, выделенных соответственно виртуальной машине и имеющих соответствующие назначенные номера очередей, причем этот способ включает в себя:
прием пакета пользовательских данных в качестве принятого пакета;
извлечение IP адреса пользователя, расположенного в полезной нагрузке принятого пакета;
вычисление хеш-значения извлеченного IP адреса пользователя и выбор номера той очереди, в которой принятый пакет должен быть сохранен, основываясь на хеш-значении;
обращение к таблице 13 определений, хранящей интенсивность использования CPU по отношению к множеству CPU-ядер и определяющей, установлен ли выбранный номер очереди как номер той очереди, в которой должен храниться принятый пакет, основываясь на интенсивности использования CPU, и
хранение принятого пакета в очереди с определенным номером очереди.
(Дополнительное пояснение 2)
Способ распределения принятых пакетов согласно дополнительному пояснению 1, в котором,
когда интенсивность использования CPU для CPU-ядра, назначенного выбранному номеру очереди, меньше или равна заданному пороговому значению, определение должно установить выбранный номер очереди как определенный номер очереди.
(Дополнительное пояснение 3)
Способ распределения принятых пакетов согласно дополнительному пояснению 2, в котором,
когда интенсивность использования CPU для CPU-ядра, назначенного выбранному номеру очереди, больше или равна пороговому значению, определение должно установить, в качестве определенного номера очереди, номер очереди, назначенный CPU-ядру с интенсивностью использования, которая меньше или равна пороговому значению и которая является наименьшей.
(Дополнительное пояснение 4)
Способ распределения принятых пакетов согласно дополнительному пояснению 3, в котором,
когда интенсивности использования CPU для всех CPU-ядер больше или равны пороговому значению, определение должно определить новое пороговое значение и определить номер очереди, в которой должен быть сохранен принятый пакет, основываясь на новом пороговом значении;
(Дополнительное пояснение 5)
Селектор очереди, который принимает пакет пользовательских данных от мобильного терминала в качестве принятого пакета и предоставляет и сохраняет принятые пакеты в множестве очередей, причем эти очереди соответствуют множеству CPU-ядер, выделенных соответственно виртуальной машине и имеющих назначенный соответствующий номер очереди, и этот селектор очереди включает в себя:
средство приема для приема пакета пользовательских данных в качестве принятого пакета;
средство извлечения для извлечения IP адреса пользователя, расположенного в полезной нагрузке принятого пакета;
средство вычисления и выбора для вычисления хеш-значения извлеченного IP адреса пользователя и выбора номера очереди для той очереди, в которой должен храниться принятый пакет, основываясь на хеш-значении;
средство определения для обращения к таблице определений, хранящей интенсивность использования CPU по отношению к каждому из множества CPU-ядер, и определения того, установлен ли выбранный номер очереди как номер той очереди, в которой должен храниться принятый пакет, основываясь на интенсивности использования CPU; и
средство сохранения для сохранения принятого пакета в очереди с определенным номером очереди.
(Дополнительное пояснение 6)
Селектор очереди согласно дополнительному пояснению 5, в котором,
когда интенсивность использования CPU для CPU-ядра назначенного выбранному номеру очереди, меньше или равна заданному пороговому значению, средство определения определяет выбранный номер очереди как определенный номер очереди.
(Дополнительное пояснение 7)
Селектор очереди согласно дополнительному пояснению 6, в котором,
когда интенсивность использования CPU для CPU-ядра назначенного выбранному номеру очереди, больше или равна пороговому значению, средство определения в качестве определенного номера очереди определяет номер очереди, назначенный CPU-ядру с интенсивностью использования, которая меньше или равна пороговому значению и которая является наименьшей.
(Дополнительное пояснение 8)
Селектор очереди согласно дополнительному пояснению 7, в котором,
когда интенсивности использования CPU для всех CPU-ядер больше или равны пороговому значению, средство определения определяет новое пороговое значение и определяет номер той очереди, в которой должен сохраниться принятый пакет, основываясь на новом пороговом значении.
(Дополнительное пояснение 9)
Устройство обработки пакетов, которое принимает и обрабатывает пакет пользовательских данных от мобильного терминала в качестве принятого пакета, причем это устройство обработки пакетов включает в себя:
множество очередей, которым назначаются соответствующие номера очередей;
множество CPU-ядер, которые выделяются виртуальной машине в соответствии с множеством очередей;
таблицу определений, которая хранит интенсивность использования CPU по отношению к каждому из CPU-ядер; и
селектор очереди, который назначает принятый пакет в соответствующую очередь среди множества очередей, обращаясь к таблице определений.
(Дополнительное пояснение 10)
Устройство обработки пакетов согласно дополнительному пояснению 9, в котором
селектор очереди включает в себя:
средство приема для приема пакета пользовательских данных в качестве принятого пакета;
средство извлечения для извлечения IP адреса пользователя, расположенного в полезной нагрузке принятого пакета;
средство вычисления и выбора для вычисления хеш-значения извлеченного IP адреса пользователя и выбора номера очереди, в которой должен сохраниться принятый пакет, основываясь на хеш-значении;
средство определения для обращения к таблице определений и определения того, установлен ли выбранный номер очереди как номер очереди, в которой должен сохраниться принятый пакет, основываясь на интенсивности использования CPU; и
средство сохранения для сохранения принятого пакета в очереди с определенным номером очереди.
(Дополнительное пояснение 11)
Устройство обработки пакетов согласно дополнительному пояснению 10, в котором,
когда интенсивность использования CPU для CPU-ядра, назначенного выбранному номеру очереди, меньше или равна заданному пороговому значению, средство определения определяет выбранный номер очереди в качестве определенного номера очереди.
(Дополнительное пояснение 12)
Устройство обработки пакетов согласно дополнительному пояснению 11, в котором,
когда интенсивность использования CPU для CPU-ядра, назначенного выбранному номеру очереди, больше или равна пороговому значению, средство определения в качестве определенного номера очереди определяет номер очереди, назначенный CPU-ядру с интенсивностью использования, которая меньше или равна пороговому значению и которая является наименьшей.
(Дополнительное пояснение 13)
Устройство обработки пакетов согласно дополнительному пояснению 12, в котором,
когда интенсивности использования всех CPU-ядер больше или равны пороговому значению, средство определения определяет новое пороговое значение и определяет номер очереди, в которой должен сохраняться принятый пакет, основываясь на новом пороговом значении.
(Дополнительное пояснение 14)
Устройство обработки пакетов согласно любому из дополнительных пояснений 10-13, в котором
множество CPU-ядер периодически передают и сохраняют соответствующие интенсивности использования CPU в таблице определений.
(Дополнительное пояснение 15)
Устройство обработки пакетов согласно любому из дополнительных пояснений 10-14, в котором
множество CPU-ядер забирают принятый пакет, сохраненный в соответствующей очереди, и выполняют соответствующую обработку пакета.
(Дополнительное пояснение 16)
Носитель информации, который является машиночитаемым носителем информации, хранящим программу, и эта программа предписывает компьютеру принимать пакеты пользовательских данных от мобильного терминала в качестве принятых пакетов и распределять принятые пакеты в множество очередей, соответствующих множеству CPU-ядер, выделенных виртуальной машине и имеющих назначенные номера очередей, причем эта программа предписывает компьютеру выполнять:
этап приема для приема пакета пользовательских данных в качестве принятого пакета;
этап извлечения для извлечения IP адреса пользователя, расположенного в полезной нагрузке принятого пакета;
этап вычисления и выбора для вычисления хеш-значения извлеченного IP адреса пользователя и выбора номера очереди, в которой должен быть сохранен принятый пакет, основываясь на хеш-значении;
этап определения для обращения к таблице определений, хранящей интенсивность использования CPU по отношению к каждому из множества CPU-ядер, и определения того, установлен ли выбранный номер очереди как номер очереди, в которой должен быть сохранен принятый пакет, основываясь на интенсивности использования CPU; и
этап сохранения для сохранения принятого пакета в очереди с определенным номером очереди.
(Дополнительное пояснение 17)
Карта сетевого интерфейса (NIC), которая принимает пакеты пользовательских данных от мобильного терминала в качестве принятых пакетов и распределяет принятые пакеты в множество CPU-ядер, которые выделены соответственно множеству виртуальных машин, при этом
карта сетевого интерфейса включает в себя множество VF (виртуальных функций) и PF (физических функций), причем множество VF виртуально сконфигурировано в PF, и каждая из виртуальных машин способна передавать и принимать пакет, используя каждую из VF, и
каждая из VF включает в себя:
множество очередей, которые соответствуют множеству CPU-ядер и соответствующим назначенным номерам очередей;
таблицу определений, которая хранит интенсивность использования CPU соответственно для множества CPU-ядер; и
селектор очереди, который назначает принятый пакет в правильную очередь среди множества очередей, обращаясь к таблице определений.
(Дополнительное пояснение 18)
Карта сетевого интерфейса согласно дополнительному пояснению 17, в которой
селектор очереди включает в себя:
средство приема для приема пакетов пользовательских данных в качестве принятых пакетов;
средство извлечения для извлечения IP адреса пользователя, расположенного в полезной нагрузке принятого пакета;
средство вычисления и выбора для вычисления хеш-значения извлеченного IP адреса пользователя и выбора номера очереди, в которой должен быть сохранен принятый пакет, основываясь на хеш-значении;
средство определения для обращения к таблице определений и определения того, установлен ли выбранный номер очереди как номер очереди, в которой должен быть сохранен принятый пакет, основываясь на интенсивности использования CPU; и
средство сохранения для сохранения принятого пакета в очереди с определенным номером очереди.
(Дополнительное пояснение 19)
Карта сетевого интерфейса согласно дополнительному пояснению 18, в которой,
когда интенсивность использования CPU для CPU-ядра, назначенного выбранному номеру очереди, меньше или равна заданному пороговому значению, средство определения определяет выбранный номер очереди как определенный номер очереди.
(Дополнительное пояснение 20)
Карта сетевого интерфейса согласно дополнительному пояснению 19, в которой,
когда интенсивность использования CPU для CPU-ядра, назначенного выбранному номеру очереди, больше или равна заданному пороговому значению, средство определения в качестве определенного номера очереди определяет номер очереди, назначенный CPU-ядру с интенсивностью использования, которая меньше или равна пороговому значению и которая является наименьшей.
(Дополнительное пояснение 21)
Карта сетевого интерфейса согласно дополнительному пояснению 20, в которой,
когда интенсивности использования всех CPU-ядер больше или равны пороговому значению, средство определения определяет новое пороговое значение и определяет номер очереди, в которой должен сохраняться принятый пакет, основываясь на новом пороговом значении.
[Перечень ссылочных позиций]
10 Устройство обработки пакетов
11 Карта сетевого интерфейса (NIC), наделенная интеллектуальной функцией
12-0 по 12-n VF (виртуальная функция)
13 Таблица определений
14 Селектор очереди
15-0 по 15-m Очередь
16 PF (физическая функция)
17-0 Виртуальная машина для обработки пакетов
18-0 по 18-m CPU-ядро.
Эта заявка основана и имеет приоритет перед японской заявкой на патент № 2014-056036, поданной 19 марта 2014 г., описание которой включено сюда полностью путем ссылки.
| название | год | авторы | номер документа |
|---|---|---|---|
| АДАПТИВНАЯ БАЛАНСИРОВКА НАГРУЗКИ ПРИ ОБРАБОТКЕ ПАКЕТОВ | 2016 |
|
RU2675212C1 |
| ИНТЕЛЛЕКТУАЛЬНЫЕ ЭЛЕКТРОННЫЕ УСТРОЙСТВА ДЛЯ СИСТЕМЫ АВТОМАТИЗАЦИИ ПОДСТАНЦИИ И СПОСОБ ЕЕ РАЗРАБОТКИ И УПРАВЛЕНИЯ | 2009 |
|
RU2504913C2 |
| СИСТЕМА БЕСПРОВОДНОЙ СВЯЗИ, БАЗОВАЯ СТАНЦИЯ, МОБИЛЬНАЯ СТАНЦИЯ И СПОСОБ ОБРАБОТКИ | 2015 |
|
RU2682420C1 |
| СПОСОБ РАСПРЕДЕЛЕНИЯ НАГРУЗКИ В МНОГОЯДЕРНОЙ СИСТЕМЕ | 2017 |
|
RU2703188C1 |
| МУЛЬТИТУННЕЛЬНЫЙ АДАПТЕР ВИРТУАЛЬНОЙ КОМПЬЮТЕРНОЙ СЕТИ | 2015 |
|
RU2675147C1 |
| Способ и устройство пересылки пакетов для гетерогенной сети | 2020 |
|
RU2822609C1 |
| СИСТЕМА И СПОСОБ ВИРТУАЛИЗАЦИИ ФУНКЦИИ МОБИЛЬНОЙ СЕТИ | 2014 |
|
RU2643451C2 |
| УСТРОЙСТВО, СПОСОБ И СИСТЕМА УПРАВЛЕНИЯ МАТРИЦАМИ | 2010 |
|
RU2491616C2 |
| Способ управления рабочим множеством виртуальных вычислителей в виртуальной сетевой системе защиты информации | 2015 |
|
RU2619716C1 |
| УСОВЕРШЕНСТВОВАННЫЙ СПОСОБ И УСТРОЙСТВО ДЛЯ ДИНАМИЧЕСКОГО СМЕЩЕНИЯ МЕЖДУ ПАКЕТАМИ МАРШРУТИЗАЦИИ И КОММУТАЦИИ В СЕТИ ПЕРЕДАЧИ ДАННЫХ | 1997 |
|
RU2189072C2 |
Изобретение относится к области виртуализации мобильной сети. Технический результат изобретения заключается в повышении производительности обработки пользовательских данных за счет распределения пакетов пользовательских данных по множеству CPU-ядер. Для того, чтобы обеспечить возможность масштабирования обработки пакетов пользовательских данных в соответствии с числом CPU-ядер, селектор очереди оборудован средством приема пакетов пользовательских данных; средством извлечения IP адресов пользователя, расположенных в полезной нагрузке пакета; средством вычисления/выбора хеш-значения для извлеченного IP адреса пользователя и, основываясь на этом хеш-значении, выбирается номер очереди, в которой должен быть сохранен принятый пакет; средством определения из таблицы определений, хранящей соответствующую интенсивность использования CPU для каждого из множества CPU-ядер, и определяется, основываясь на интенсивности использования CPU, надо ли установить выбранный номер очереди как номер очереди, в которой следует сохранить принятый пакет; и средством сохранения принятого пакета в очереди, имеющей выбранный номер очереди. 5 н. и 5 з.п. ф-лы, 5 ил.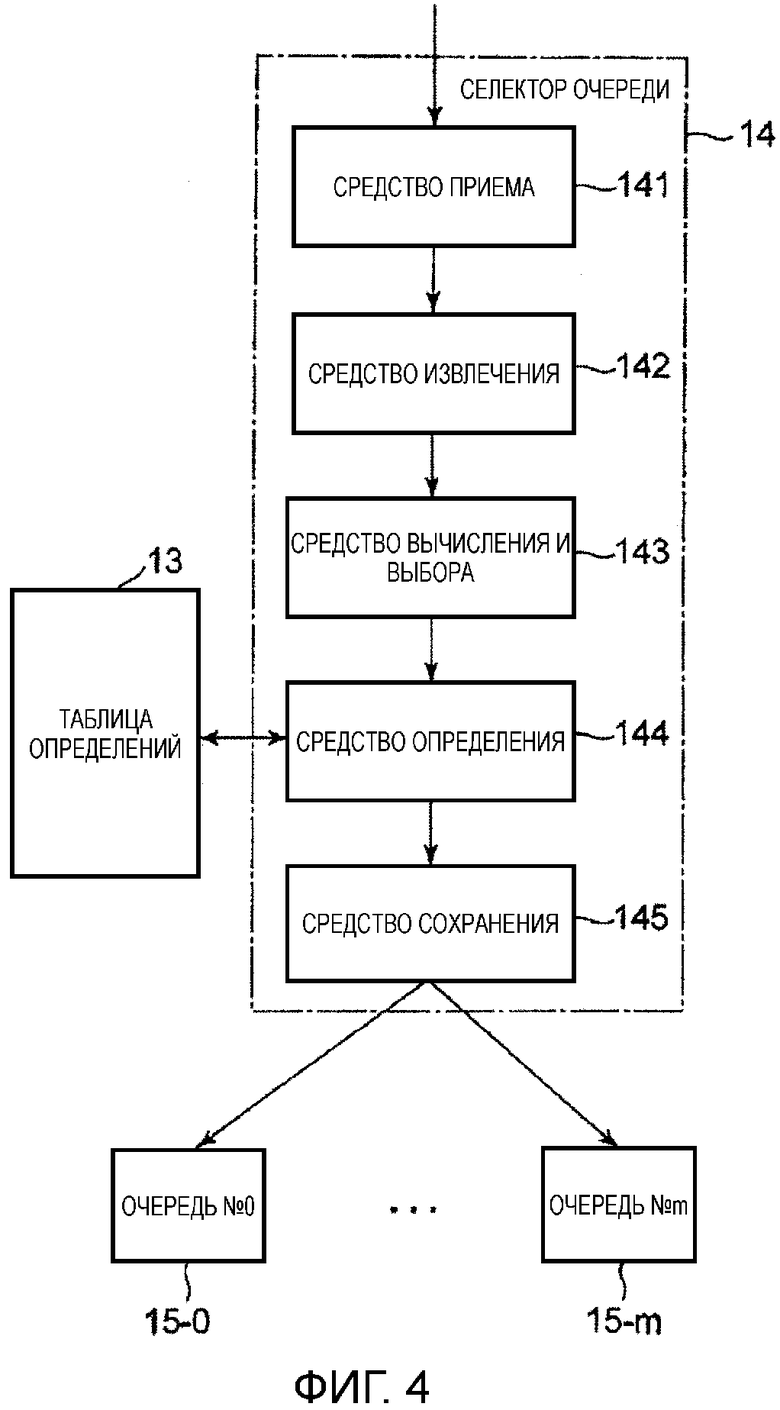
1. Способ распределения принятых пакетов для приема пакетов пользовательских данных от мобильного терминала в качестве принятых пакетов и распределения принятых пакетов во множество очередей, причем эти очереди соответствуют множеству CPU-ядер, выделенных соответственно виртуальной машине и имеющих соответствующие назначенные номера очередей, причем способ содержит:
прием пакета пользовательских данных в качестве принятого пакета;
извлечение IP адреса пользователя, расположенного в полезной нагрузке принятого пакета;
вычисление хеш-значения извлеченного IP адреса пользователя и выбор номера очереди, в которой должен быть сохранен принятый пакет, основываясь на хеш-значении;
обращение к таблице определений, хранящей интенсивность использования CPU по отношению к каждому из множества CPU-ядер, и определение того, установлен ли выбранный номер очереди как номер очереди, в которой должен сохраняться принятый пакет, основываясь на интенсивности использования CPU; и
сохранение принятого пакета в очереди с определенным номером очереди.
2. Способ распределения принятых пакетов согласно п. 1, в котором,
когда интенсивность использования CPU для CPU-ядра, назначенного выбранному номеру очереди, меньше или равна заданному пороговому значению, определение заключается в установке выбранного номера очереди как определенного номера очереди.
3. Способ распределения принятых пакетов согласно п. 2, в котором,
когда интенсивность использования CPU для CPU-ядра, назначенного выбранному номеру очереди, больше или равна пороговому значению, определение заключается в установке, в качестве определенного номера очереди, номера очереди, назначенного CPU-ядру с интенсивностью использования, которая меньше или равна пороговому значению и которая является наименьшей.
4. Способ распределения принятых пакетов согласно п. 3, в котором,
когда интенсивность использования CPU для всех CPU-ядер больше или равна пороговому значению, определение заключается в определении нового порогового значения и определении номера очереди для той очереди, в которой должен сохраняться принятый пакет, основываясь на новом пороговом значении.
5. Селектор очереди, который принимает пакеты пользовательских данных от мобильного терминала в качестве принятых пакетов и выделяет и сохраняет принятые пакеты во множестве очередей, причем эти очереди соответствуют множеству CPU-ядер, выделенных виртуальной машине, соответственно и назначенным номерам очередей соответственно, и упомянутый селектор очереди содержит:
средство приема для приема пакета пользовательских данных в качестве принятого пакета;
средство извлечения для извлечения IP адреса пользователя, расположенного в полезной нагрузке принятого пакета;
средство вычисления и выбора для вычисления хеш-значения извлеченного IP адреса пользователя и выбора номера очереди, в которой должен быть сохранен принятый пакет, основываясь на хеш-значении;
средство определения для обращения к таблице определений, хранящей интенсивность использования CPU по отношению к каждому из множества CPU-ядер, и определения того, установлен ли выбранный номер очереди как номер очереди, в которой должен сохраняться принятый пакет, основываясь на интенсивности использования CPU; и
средство хранения для хранения принятого пакета в очереди с определенным номером очереди.
6. Устройство обработки пакетов, которое принимает и обрабатывает пакеты пользовательских данных от мобильного терминала в качестве принятых пакетов, причем упомянутое устройство для обработки пакетов содержит:
множество очередей, которым назначены соответствующие номера очередей;
множество CPU-ядер, которые выделены виртуальной машине в соответствии с множеством очередей;
таблицу определений, которая хранит интенсивность использования CPU по отношению к каждому из множества CPU-ядер; и
селектор очереди, который назначает принятый пакет в правильную очередь среди множества очередей, обращаясь к таблице определений.
7. Устройство обработки пакетов согласно п. 6, в котором
множество CPU-ядер периодически передают и сохраняют соответствующие интенсивности использования CPU в таблице определений.
8. Устройство обработки пакетов согласно п. 6 или 7, в котором
множество CPU-ядер забирают принятый пакет, сохраненный в соответствующей очереди, и выполняют соответственно обработку пакета.
9. Носитель информации, который является машиночитаемым носителем информации, хранящим программу, и эта программа предписывает компьютеру принимать пакеты пользовательских данных от мобильного терминала в качестве принятых пакетов и распределять принятые пакеты во множество очередей, соответствующих CPU-ядрам, выделенным виртуальной машине и имеющим назначенные номера очередей, при этом программа предписывает компьютеру выполнять:
этап приема для приема пакета пользовательских данных в качестве принятого пакета;
этап извлечения для извлечения IP адреса пользователя, расположенного в полезной нагрузке принятого пакета;
этап вычисления и выбора для вычисления хеш-значения извлеченного IP адреса пользователя и выбора номера очереди, в которой должен быть сохранен принятый пакет, основываясь на хеш-значении;
этап определения для обращения к таблице определений, хранящей интенсивность использования CPU по отношению к каждому из множества CPU-ядер, и определения того, установлен ли выбранный номер очереди как номер очереди, в которой должен сохраняться принятый пакет, основываясь на интенсивности использования CPU; и
этап сохранения для сохранения принятого пакета в очереди с определенным номером очереди.
10. Карта сетевого интерфейса (NIC), которая принимает пакеты пользовательских данных от мобильного терминала в качестве принятых пакетов и распределяет принятые пакеты во множество CPU-ядер, которые выделены соответственно множеству виртуальных машин, при этом
карта сетевого интерфейса содержит множество VF (виртуальных функций) и PF (физических функций), причем множество VF виртуально сконфигурировано в PF, и каждая из виртуальных машин способна передавать и принимать пакет, используя каждую из VF, и
каждая из VF включает в себя:
множество очередей, которые соответствуют множеству CPU-ядер и имеют соответствующие назначенные номера очередей;
таблицу определений, которая хранит интенсивность использования CPU соответственно для множества CPU-ядер, и
селектор очереди, который назначает принятый пакет в правильную очередь среди множества очередей, обращаясь к таблице определений.
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Способ и приспособление для нагревания хлебопекарных камер | 1923 |
|
SU2003A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Аппарат для очищения воды при помощи химических реактивов | 1917 |
|
SU2A1 |

