Область техники, к которой относится изобретение
Изобретение относится к области обработки данных, в частности, к области распределения вычислительных ресурсов многоядерной системы обработки пакетов данных.
Уровень техники
Эффективное использование системы обработки данных напрямую влияет на затраты ресурсов, необходимых для функционирования этой системы. В частности, эффективное использование ядер процессора влияет на энергопотребление. Таким образом, существует потребность в том, чтобы при выполнении задач по обработке пакетов данных в многоядерной системе использовалось с одной стороны достаточное, а с другой стороны не избыточное количество ядер процессора.
Необходимое количество ядер процессора определяется количеством пакетов, которые необходимо обрабатывать в единицу времени. Поскольку количество обрабатываемых пакетов данных может меняться в широких пределах, имеется необходимость отслеживать это изменение и изменять количество ядер соответствующим образом.
Существует два подхода к решению задачи реагирования на необходимость изменения количества обрабатывающих средств: горизонтальное масштабирование, при котором изменяется количество обрабатывающих средств, и вертикальное масштабирование, при котором изменяется вычислительная мощность обрабатывающего средства (средств).
В данной заявке будут рассмотрены подходы к вертикальному масштабированию. При этом порядок следования пакетов в рамках клиентских сессий не должен нарушаться.
Известно устройство коммутации пакетов данных и балансировки нагрузки сервера (US 6,272,522 B1, опубл. 2001-08-07), которое реализовано на основе вычислительной системы на базе процессора общего назначения. Вычислительная система на базе процессора общего назначения включает в себя множество симметричных процессоров, соединенных друг с другом с помощью общей шины данных, основную память, используемую совместно с процессорами, а также множество сетевых интерфейсов, каждый из которых адаптирован для присоединения к соответствующим внешним сетям для приема и отправки пакетов данных, с помощью определенных протоколов связи, таких как, например, TCP и UDP. Первый из процессоров выполнен с возможностью выполнять роль управляющего процессора, а остальные из процессоров адаптированы выполнять роль процессоров коммутации пакетов данных. Каждый процессор коммутации пакетов данных соединен по меньшей мере с одним из множества сетевых интерфейсов. Процессор управления получает необработанные данные о состоянии нагрузки от внешних сетей и генерирует данные конфигурации распределения нагрузки. Данные конфигурации распределения нагрузки сохраняются в основной памяти для доступа со стороны процессоров коммутации пакетов данных. Процессоры коммутации направляют принятые пакеты данных в выбранную внешнюю сеть в соответствии с информацией, включенной в часть заголовка пакетов данных и данных конфигурации распределения нагрузки. Процессоры коммутации выполняют периодический опрос соответствующих сетевых интерфейсов для обнаружения принятых в них пакетов данных. Кроме того, процессоры коммутации переписывают информацию о маршрутизации, включенную в часть заголовка пакетов данных, для отражения выбранной внешней сети.
Однако в данном решении ничего не говорится о том, как реагировать на увеличение или уменьшение количества пакетов данных, поступающих в систему.
Известно решение (US 9,396,154 B2, опубл. 2016-07-19), в котором раскрывается система, содержащая многоядерный процессор, буфер данных, аппаратный ускоритель, контроллер прерываний. Контроллер прерываний передает первый сигнал прерывания на первое одно из ядер на основе первого аппаратного сигнала, принятого от аппаратного ускорителя. Первое ядро создает копию дескрипторов буфера (BD) кольца дескрипторов буфера, которое соответствует пакетам данных в буфере данных в первой виртуальной очереди, и указывает аппаратному ускорителю, что пакеты данных обработаны. Если имеются дополнительные пакеты данных, контроллер прерываний передает второй сигнал прерывания на второе ядро, которое выполняет те же действия, что и первое ядро. Первое и второе ядро одновременно обрабатывают пакеты данных, связанных с BD в первой и второй виртуальных очередях, соответственно.
Однако в данном решении ничего не говорится о том, как реагировать на увеличение или уменьшение количества пакетов данных, поступающих в систему.
Известно выбранное в качестве прототипа решение, в котором описывается способ динамической балансировки очереди приема с помощью верхнего и нижнего порогов (US 8,346,999 B2, опубл. 2013-01-01), в котором осуществляют этапы, на которых назначают сетевое приложение по меньшей мере одному первому обрабатывающему блоку ядра из множества обрабатывающих блоков ядра, назначают первую очередь приема первому обрабатывающему блоку ядра, причем первая очередь приема выполнена с возможностью принимать поток пакетов, связанных с сетевым приложением, задающим верхний порог для первой очереди приема, отслеживают поток пакетов в первой очереди приема и сравнивают уровень потока пакетов в первой очереди приема с верхним порогом, причем если уровень потока пакетов превышает порог, формируют сообщение состояния очереди, указывающее, что уровень потока пакетов в первой очереди превысил верхний порог очереди, формируют в ответ на сообщение состояния очереди назначение нового ядра для назначения сетевого приложения второму обрабатывающему блоку ядра.
Однако в данном решении речь идет лишь о переводе конкретного приложения с одного ядра на другое, что с высокой долей вероятности приведет к неравномерности нагрузки и неоптимальности загрузки ядер, что понизит эффективность работы.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
В одном аспекте раскрыт способ обработки пакетов данных множеством ядер процессора, содержащий этапы, на которых:
- обрабатывают пакеты данных множеством ядер процессора;
- отслеживают очереди на обработку у множества ядер процессора и загруженность процессорных ядер посредством блока масштабирования;
если средний размер очереди на обработку меньше первой предварительно заданной нижней пороговой величины среднего размера очереди и загруженность процессорных ядер меньше первой предварительно заданной нижней пороговой величины загруженности процессорных ядер, то блок масштабирования блокирует добавление пакетов данных в очереди на обработку, проверяет опустошение очереди на обработку у каждого обрабатывающего ядра процессора, после опустошения очереди на обработку у каждого обрабатывающего ядра процессора уменьшает количество обрабатывающих ядер процессора на одно, если это обрабатывающее ядро не единственное, и инициирует обработку пакетов данных, используя уменьшенное количество ядер;
если по меньшей мере одно из среднего размера очереди на обработку и загруженности процессорных ядер превышает первую предварительно заданную верхнюю пороговую величину среднего размера очереди и первую предварительно заданную верхнюю пороговую величину загруженности процессорных ядер, соответственно, то блок масштабирования направляет все данные из очереди на обработку у каждого обрабатывающего ядра процессора в буфер памяти, увеличивает количество обрабатывающих ядер процессора на одно, если не достигнуто максимальное число ядер, и инициирует обработку пакетов данных, используя увеличенное количество ядер.
В дополнительных аспектах раскрыто, что если средний размер очереди на обработку меньше второй предварительно заданной нижней пороговой величины, то блок масштабирования уменьшает количество обрабатывающих ядер процессора на два; блок масштабирования дополнительно отслеживает время, в течение которого по меньшей мере одно из среднего размера очереди на обработку и загруженности процессорных ядер меньше первой предварительно заданной нижней пороговой величины среднего размера очереди и первой предварительно заданной нижней пороговой величины загруженности процессорных ядер, соответственно, и уменьшает количество обрабатывающих ядер процессора, если упомянутое время превышает предварительно заданную величину; если средний размер очереди на обработку превышает вторую предварительно заданную верхнюю пороговую величину, то блок масштабирования увеличивает количество обрабатывающих ядер процессора на два; блок масштабирования дополнительно отслеживает время, в течение которого по меньшей мере одно из среднего размера очереди на обработку и загруженности процессорных ядер больше первой предварительно заданной верней пороговой величины среднего размера очереди и первой предварительно заданной верхней пороговой величины загруженности процессорных ядер, соответственно, и увеличивает количество обрабатывающих ядер процессора, если упомянутое время превышает предварительно заданную пороговую величину; блок масштабирования дополнительно определяет скорость изменения среднего размера очереди на обработку, и если скорость изменения среднего размера очереди на обработку превышает заранее заданную пороговую величину, то дополнительно добавляет заранее заданное количество обрабатывающих ядер; блок масштабирования задает значение пороговой величины для упомянутого времени в зависимости от загруженности процессорных ядер, причем чем выше загруженность процессорных ядер, тем меньше значение пороговой величины для упомянутого времени.
В другом аспекте раскрыто устройство для обработки пакетов данных, содержащее:
- входной интерфейс, выполненный с возможностью приема пакетов данных;
- множество ядер, выполненных с возможностью обработки пакетов данных;
- память, выполненную с возможностью хранения данных;
- выходной интерфейс, выполненный с возможностью передачи обработанных пакетов данных;
- блок масштабирования, выполненный с возможностью перенаправлять пакетные данные и задавать количество ядер;
причем множество ядер содержит
множество приемных ядер, выполненных с возможностью обрабатывать поступающие с входного интерфейса пакеты данных в своих очередях, и направлять пакеты данных в очереди обрабатывающих ядер;
множество обрабатывающих ядер, выполненных с возможностью обрабатывать пакеты данных в своих очередях и направлять обработанные пакеты данных в очереди передающих ядер;
множество передающих ядер, выполненных с возможностью обрабатывать пакеты данных в своих очередях и отправлять их в выходной интерфейс;
причем устройство для обработки пакетов данных выполнено с возможностью осуществлять описанный выше способ и его варианты.
Основной задачей, решаемой заявленным изобретением, являются оптимизация использования вычислительных ресурсов, использование оптимального по критерию энергоэффективности количества ядер, осуществляющих обработку пакетов данных.
Сущность изобретения заключается в том, что предлагается способ обработки в многоядерной системе обработки пакетов, в котором осуществляется масштабирование (увеличение/уменьшение) количества ядер, не нарушающее порядка следования пакетов в рамках клиентских сессий. Для этой цели отслеживают очереди на обработку у обрабатывающих ядер, и если средний размер очереди на обработку меньше предварительно заданной величины, то блокируют добавление пакетов данных в очередь на обработку, после опустошения очереди на обработку у каждого обрабатывающего ядра уменьшают количество обрабатывающих ядер процессора и возобновляют обработку; если же размер очереди на обработку превышает предварительно заданную величину, то направляют все данные из очереди на обработку у каждого обрабатывающего ядра в буфер памяти, увеличивают количество обрабатывающих ядер и возобновляют обработку.
Технический результат, достигаемый данным решением, заключается в оптимизации нагрузки на обрабатывающие ядра посредством динамического масштабирования количества ядер с сохранением порядка следования пакетов в рамках клиентских сессий, что приводит к оптимизации использования вычислительных ресурсов обрабатывающей пакеты данных системы, уменьшает энергопотребление обрабатывающей пакеты данных системы.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
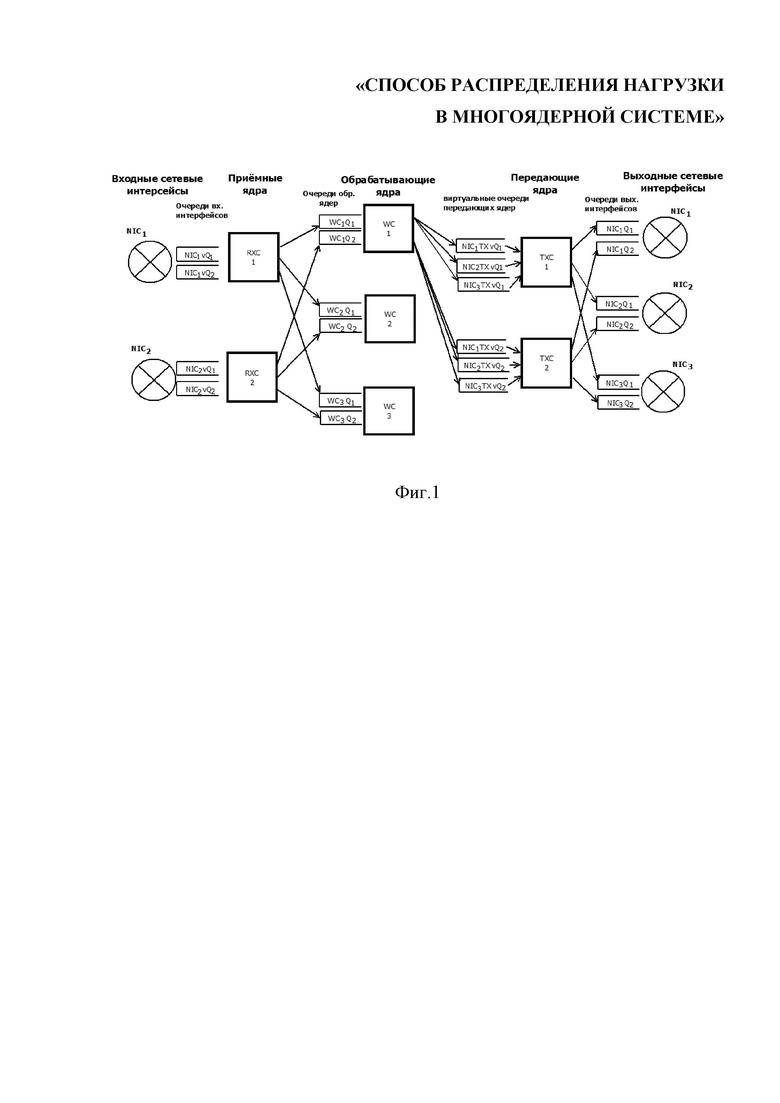
Фиг.1 показывает архитектуру системы многоядерной обработки пакетов.
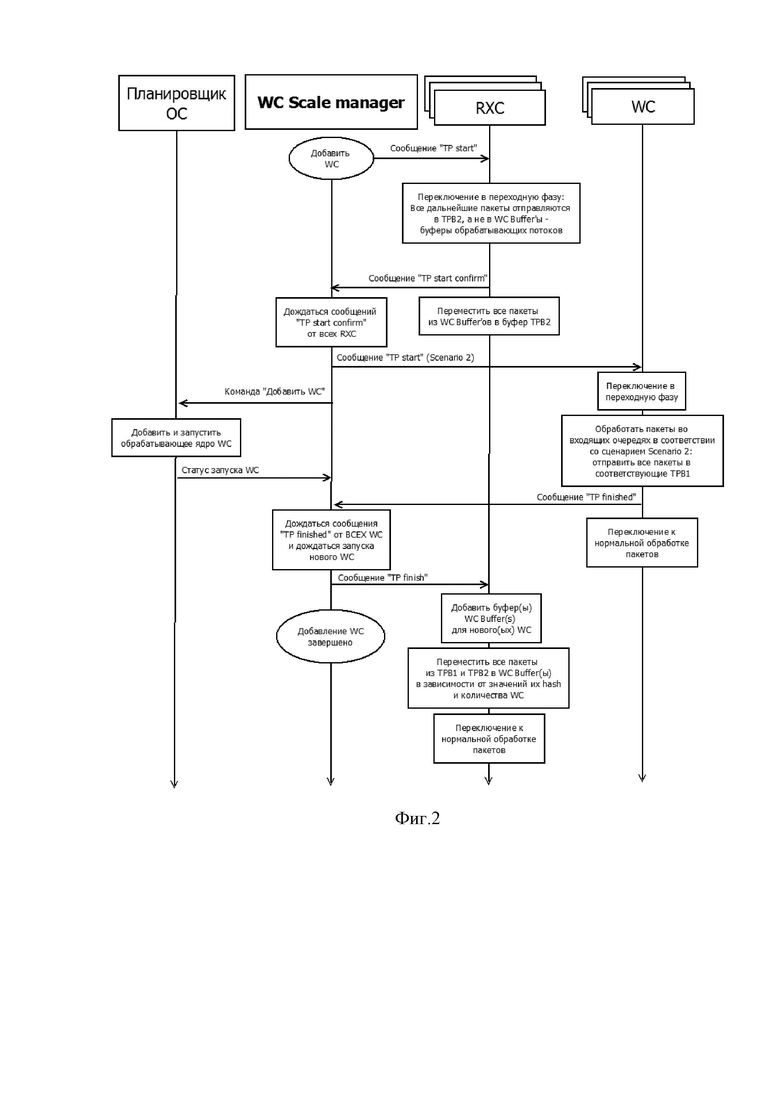
Фиг.2 показывает временную диаграмму работы ядер при увеличении количества обрабатывающих ядер.
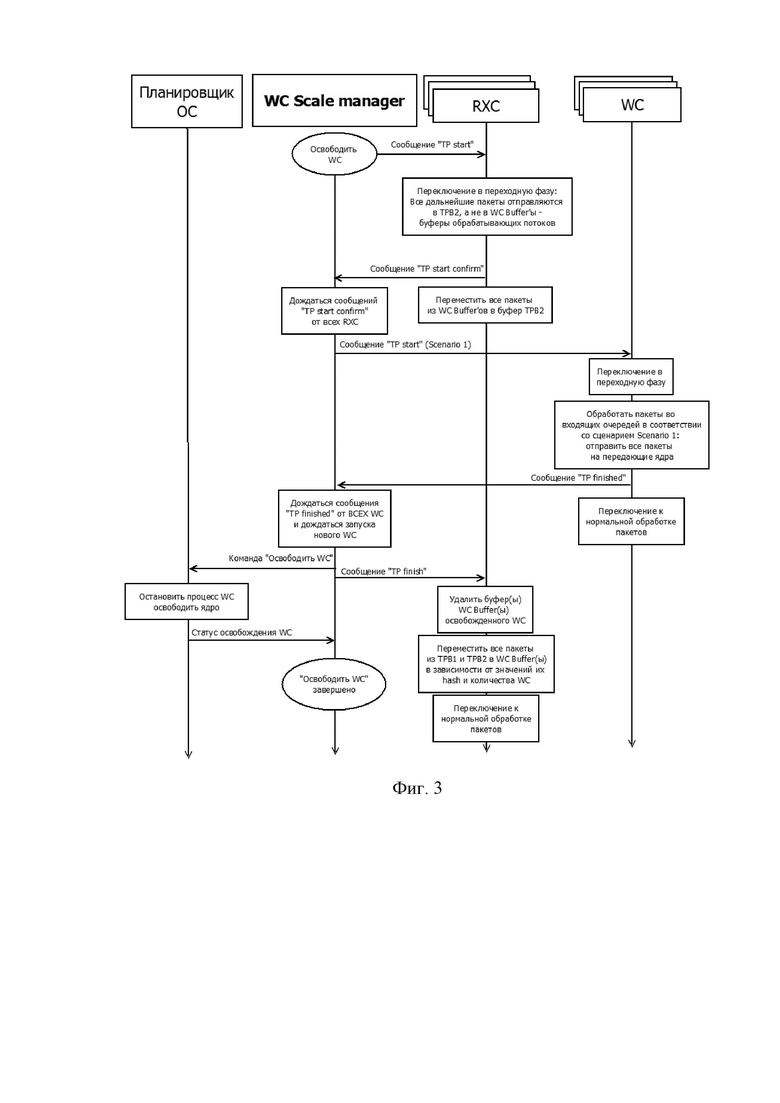
Фиг.3 показывает временную диаграмму работы ядер при уменьшении количества обрабатывающих ядер.
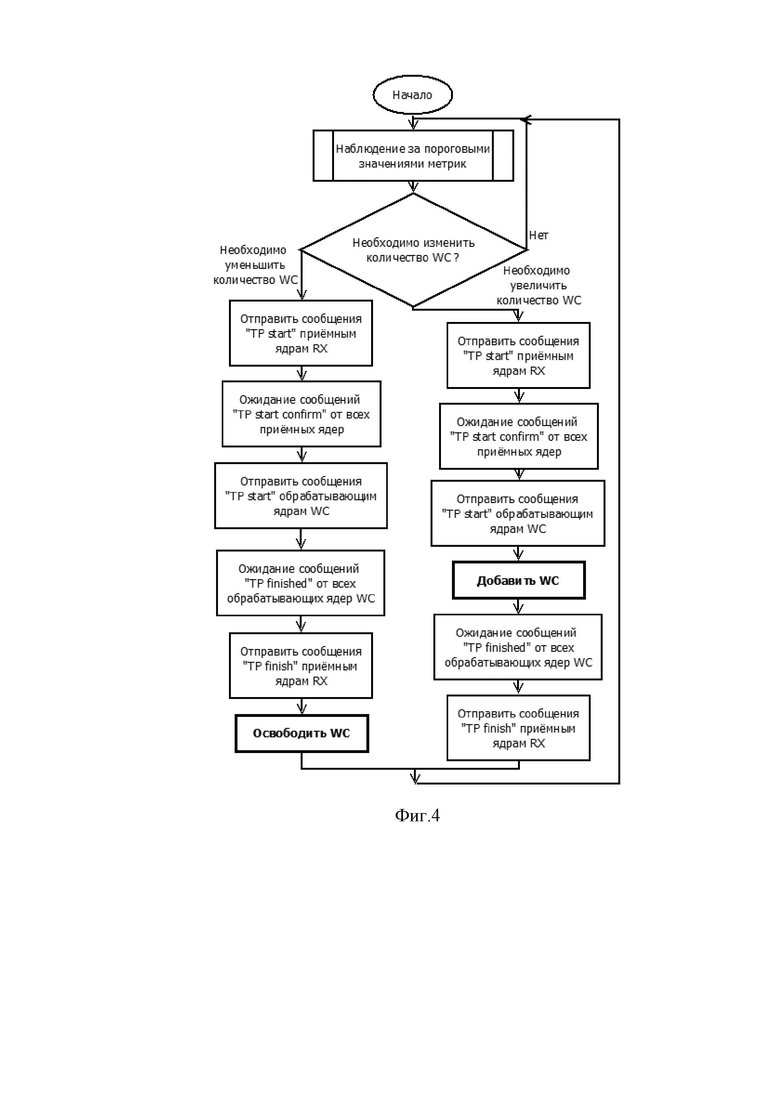
Фиг.4 показывает алгоритм работы блока масштабирования (WCScaleManager).
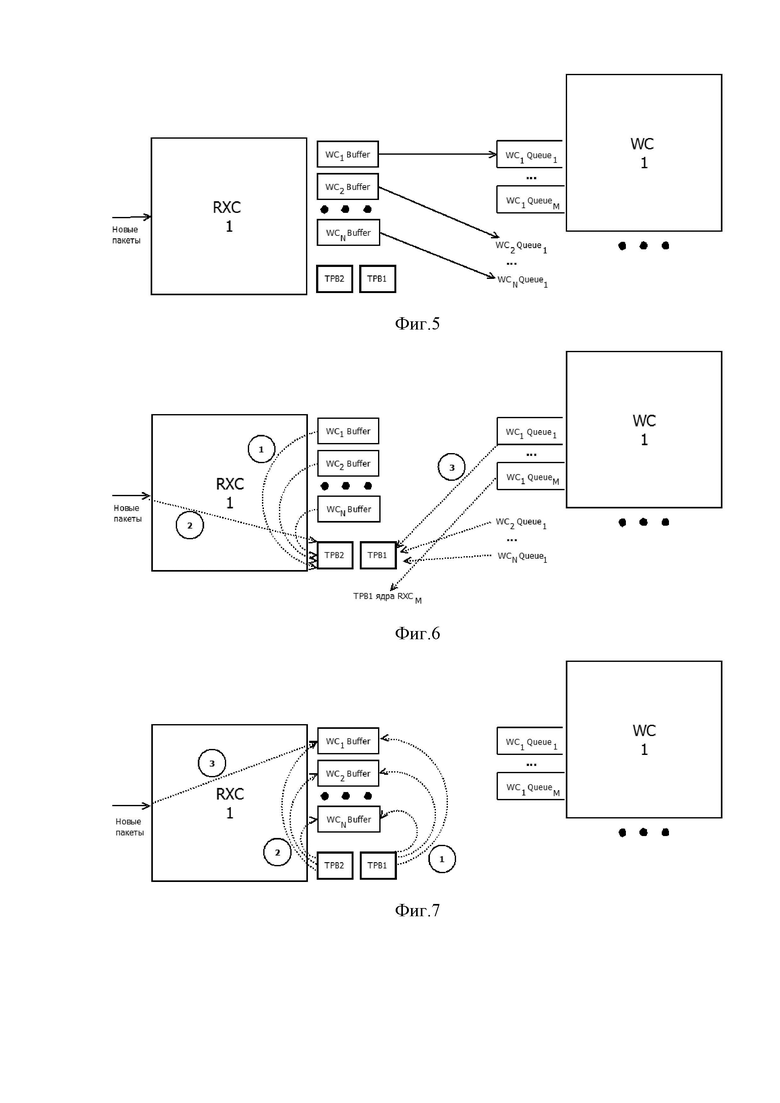
Фиг.5 показывает буферы и очереди, использующиеся при обмене между приёмным ядром (RXC) и обрабатывающим ядром (WC).
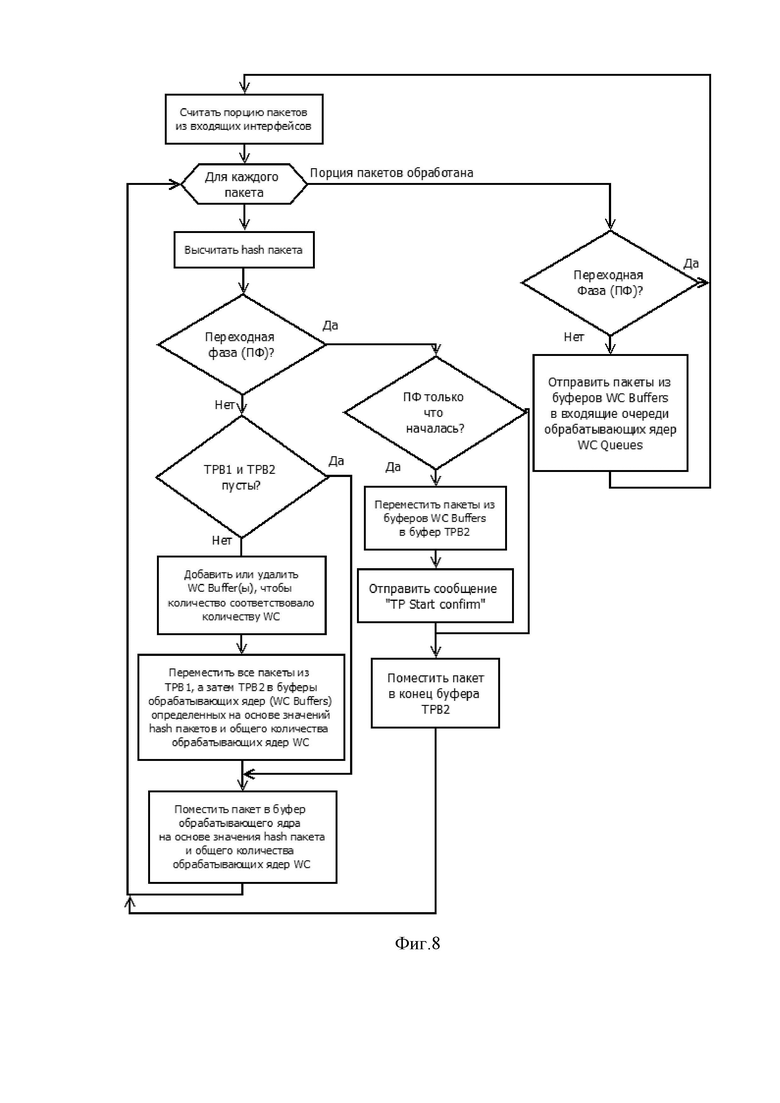
Фиг.6 показывает последовательность заполнения буферов переходной фазы при начале переходной фазы.
Фиг.7 показывает последовательность освобождения буферов переходной фазы после окончания переходной фазы.
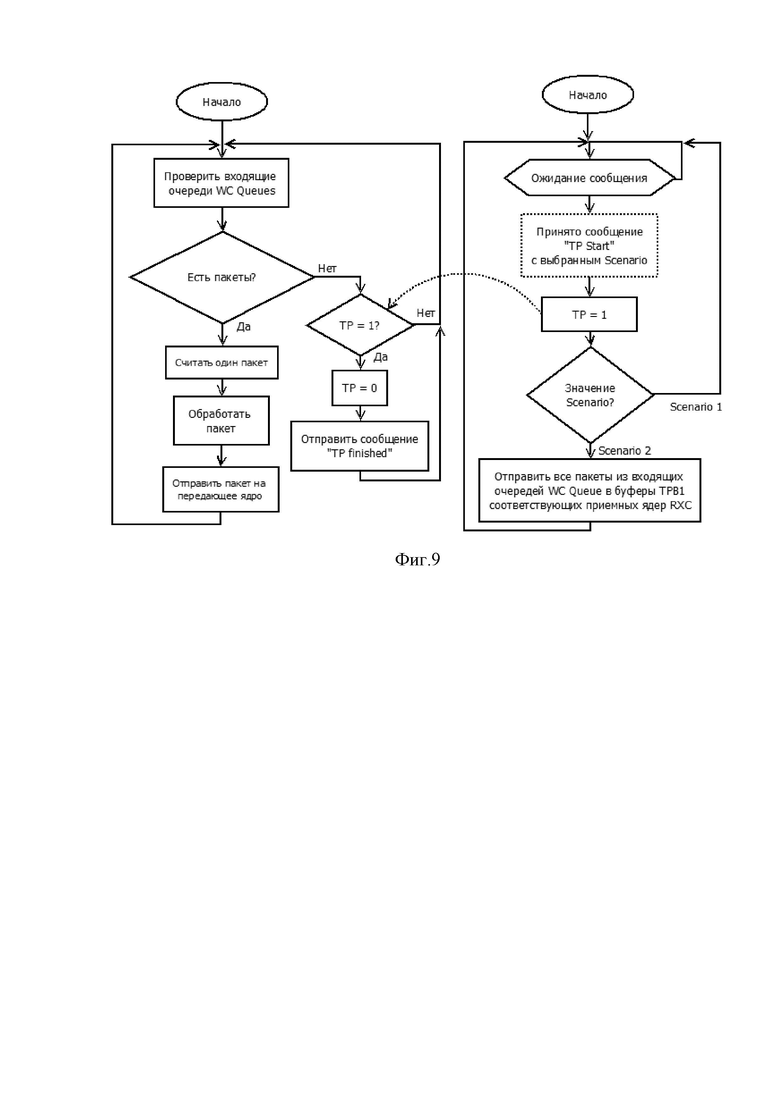
Фиг.8 показывает алгоритм работы приемного ядра (RXC).
Фиг.9 показывает алгоритм работы обрабатывающего ядра.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
Задачей заявленного решения является обеспечение оптимального количества обрабатывающих ядер процессора в аспекте использования вычислительных ресурсов и уменьшения энергопотребления.
Для решения этой задачи предлагается архитектура многоядерной системы обработки пакетов данных, изображенная на фиг. 1, и способ масштабирования (увеличения/уменьшения) количества ядер, не нарушающий порядка следования пакетов в рамках клиентских сессий.
Система обработки пакетов данных на фиг.1 содержит входной интерфейс, в который поступают входные пакеты данных. Этот интерфейс связан линиями связи с по меньшей мере одним приемным ядром (RXC), из которого принятые приёмным ядром пакеты данных направляются в блоки очередей обрабатывающих ядер (WC). Блоки очередей обрабатывающих ядер связаны со своими обрабатывающими ядрами, обрабатывающими пакеты данных и направляющими их в блоки очередей передающих ядер (TXC), откуда они направляются на ядра TXC. С ядер TXC информация направляется на выходной интерфейс.
Таким образом, в предлагаемой системе есть 3 вида ядер:
1. Приёмные ядра (RXC), обрабатывающие очереди пакетов, поступающих с входных сетевых интерфейсов, и направляющие пакеты в очереди обрабатывающих ядер (WC).
2. Обрабатывающие ядра (WC), которые обрабатывают пакеты в своих входных очередях и отправляют их в очереди передающих ядер (TXC).
3. Передающие ядра (TXC), которые обрабатывают пакеты в своих входных очередях и отправляют их в очереди выходных сетевых интерфейсов.
Количество ядер любого вида может быть изменено для более эффективного использования их ресурсов. Так, при увеличившемся потоке пакетов, количество ядер должно быть увеличено, а при уменьшившемся потоке пакетов может быть уменьшено для меньшего потребления энергии.
Если входные очереди какого-либо из видов ядер (RXC, WC, TXC) начинают увеличиваться, или средний размер очередей какого-либо из видов ядер превышает пороговое значение, то инициируется увеличение количества ядер данного вида в системе. Так же изменение количества ядер какого-либо вида может быть инициировано при переходе порогового значения по загруженности ядер.
В предложенной системе очереди, которые обслуживают RXC, и очереди, которые обслуживают TXC, не зависят от количества соответствующих ядер и привязываются к сетевым интерфейсам, принимающим и передающим, соответственно. Очереди, которые обслуживают обрабатывающие ядра WC, создаются вместе с обрабатывающими ядрами WC.
Приемные ядра RXC и передающие ядра TXC при обработке пакетов обращаются только к данным обрабатываемого пакета, в то время как обрабатывающие ядра WC в процессе работы могут создавать, считывать и модифицировать данные клиентской сессии, то есть данные, общие для более чем одного пакета.
Ядра RXC и TXC могут быть добавлены/освобождены без каких-либо проблем.
Ядра WC не могут быть добавлены или освобождены без дополнительных действий, так как при простом уменьшении или увеличении числа ядер пакеты клиентских сессий начинают сразу поступать на новые ядра, но пакеты, уже попавшие в очереди, также будут обрабатываться, то есть пакеты одной клиентской сессии могут обрабатываться одновременно на двух ядрах: определенном по-старому, и определенном по-новому. Это приведет либо к потенциальным ошибкам из-за обращения к общим данным сессии из разных ядер, что подробнее раскрыто ниже, либо к необходимости использования архитектуры с блокировками для избегания ошибок (такая архитектура более медленная). Помимо этого, за счёт возможной одновременной обработки на двух ядрах пакетов одной клиентской сессии возможно нарушение порядка следования пакетов.
Для быстрой обработки пакетов в многоядерных системах наиболее эффективными оказываются системы, в которых нет блокировок (архитектура данных выстроена таким образом, что ядра обращаются только к своим данным). При обработке пакетов в предложенной системе быстрая обработка достигается тем, что пакеты с одинаковым набором (source IP (IP источника), source port (порт источника), destination IP (IP адресата), destination port (порт адресата), протокол) обрабатываются одним WC. Обычно распределение пакетов по WC происходит в соответствии со значением hash-функции от вышеуказанного набора и количеством WC.
После изменения количества WC, пакеты, ранее (до изменения количества WC) предназначавшиеся для обработки на одном ядре, должны будут обрабатываться на другом ядре. Таким образом, пакеты, находящиеся в очередях на обработку WC на момент изменения количества WC, будут создавать опасность обращения к одним данным из разных ядер, в случае если пакет с тем же набором, содержащим любую подходящую комбинацию из следующих элементов, использующихся для вычисления hash-функции: (source IP, source port, destination IP, destination port, протокол), начнёт обрабатываться на другом WC.
Возможны следующие варианты функционирования системы на время переходного периода после изменения количества WC до обработки всех пакетов из всех очередей WC, присутствовавших в них на момент изменения количества WC:
Вариант 1 (Scenario 1): не добавлять новые пакеты в очереди на обработку WC до тех пор, пока на всех WC пакеты, попавшие в очереди до изменения количества WC, не будут обработаны.
Вариант 2 (Scenario 2): все пакеты, находящиеся в очередях на обработку WC, вернуть на приёмное ядро, поставив в начало очереди на отправку на WC.
Вариант 1 наиболее целесообразно применять в случае изменения количества WC в меньшую сторону.
Вариант 2 наиболее целесообразно применять в случае изменения количества WC в большую сторону.
Целесообразно, чтобы переходный период, во время которого меняется число ядер, прошел наиболее быстро, для того чтобы система могла возобновить прием и обработку пакетов и начала работать в штатном режиме. Понятно, что чем больше ядер обрабатывают пакеты во время переходного периода, тем быстрее они их обработают. Таким образом, необходимо выбирать для каждого случая (уменьшение/увеличение числа ядер) такой сценарий, при котором в переходном периоде будет работать наибольшее количество ядер. То есть, для уменьшения количества ядер – это Сценарий 1 (сначала все обработать, а потом уменьшить число ядер), а для увеличения количества ядер – Сценарий 2 (нарастить число ядер, а затем начать обрабатывать).
На фиг. 2 приведена временная диаграмма работы ядер при увеличении количества обрабатывающих ядер.
WCScaleManager (блок масштабирования ядер WC) – программный блок, который следит за триггерами переключения количества ядер.
Когда возникает необходимость увеличить количество обрабатывающих ядер, WCScaleManager управляет процессом согласно схеме на фиг.2.Когда возникает необходимость уменьшить количество обрабатывающих ядер, WCScaleManager управляет процессом согласно схеме на фиг.3.
До того как возникает необходимость изменить количество обрабатывающих ядер, система работает в нормальном режиме (NormalPacketProcessing). При изменении количества обрабатывающих ядер WCScaleManager на некоторое время переводит приёмные ядра и обрабатывающие ядра в переходную фазу (TransitionPhase), а после выполнения всех необходимых действий ядра возвращаются в нормальный режим работы.
При определении блоком масштабирования, что необходимо добавить обрабатывающее ядро или уменьшить количество обрабатывающих ядер, он направляет на приемные ядра команду начала переходной фазы (Фиг. 2, Фиг. 3).
В результате каждое приемное ядро переходит в переходную фазу: все пакеты, которые будут обработаны приёмным ядром во время переходной фазы, направляются не в буферы WC (WCBuffer на Фиг. 5), а в буфер переходной фазы приёмного ядра (TPB2 на Фиг. 5).В начале буферов TPB2 предварительно резервируется место для размещения пакетов из буферов WC. После этого каждое приемное ядро направляет команду подтверждения перехода в переходную фазу на блок масштабирования. Затем приемное ядро отправляет в начало буфера TPB2 пакеты из буферов WC, которые были распределены для отправки в очереди соответствующих WC (WCQueue на Фиг. 5), это обеспечит неизменность порядка следования пакетов в рамках клиентских сессий после возобновления обработки пакетов в нормальном режиме.
Блок масштабирования ожидает приема подтверждения о переходе в переходную фазу от всех приёмных ядер и направляет на обрабатывающие ядра WC сигнал начала переходной фазы с типом сценария перехода (Scenario 1 или Scenario 2, описанные выше).
При получении сигнала о начале переходной фазы каждое ядро WC переходит в переходную фазу: обрабатывает пакеты в очереди согласно сценарию переходной фазы, по завершению направляет на блок масштабирования сигнал подтверждения завершения обработки согласно сценарию переходной фазы и переключается в нормальный режим работы.
В случае увеличения количества обрабатывающих ядер (Фиг. 2) блок масштабирования после отправки команды начала переходной фазы в ядра WC, не дожидаясь подтверждения окончания переходной фазы в них, отправляет команду Планировщику ОС (операционной системы) (Scheduler) добавить одно или более WC.
В случае уменьшения количества обрабатывающих ядер (Фиг. 3) блок масштабирования дожидается подтверждения окончания переходной фазы в обрабатывающих ядрах WC и только после этого отправляет команду Планировщику ОС убрать одно или более обрабатывающих ядер WC.
Когда Планировщику ОС, занимающемуся распределением задач между ядрами, отправляется сигнал о добавлении WC, он распределяет задачи так, что определенное ядро процессора будет использоваться исключительно для выполнения процесса WC. В этом случае процесс WC работает на отдельном ядре процессора. При получении сигнала об уменьшении количества обрабатывающих ядер, Планировщик ОС освобождает ядра.
Когда блок масштабирования получает сигналы подтверждения завершения обработки согласно сценарию переходной фазы от всех WC, он направляет команду завершения переходной фазы в приемное ядро для переключения в нормальный режим работы.
В результате вышеописанных действий в многоядерной системе добавляется в работу по меньшей мере одно ядро WC (Фиг. 2), или количество WC уменьшается на одно или более (Фиг. 3). При этом исключается возможность обработки пакетов данных из одной клиентской сессии одновременно на нескольких ядрах, а также гарантируется сохранение порядка следования пакетов данных в рамках клиентских сессий.
В одном варианте осуществления задается несколько пороговых значений, выход за которые предполагает изменение количества ядер на соответствующие величины. Например, при выходе очереди за первое пороговое значение количество ядер изменяется на одно, при выходе за второе пороговое значение количество ядер изменяется на два и т.д.
WCScaleManager (блок масштабирования) может быть реализован в виде отдельного программного потока на одном из ядер.
Алгоритм работы WCScaleManager представлен на фиг. 4, детальное описание алгоритма дано ниже.
Блок WCScaleManager отслеживает значения метрик и при переходе пороговых значений инициирует изменение числа ядер WC.
Пороговые значения для изменения количества ядер
Блок масштабирования должен автоматически принимать решения об изменении количества обрабатывающих ядер.
Для принятия решений об изменении количества ядер блок масштабирования должен наблюдать за метриками. В качестве метрик могут быть использованы различные величины, относящиеся к загруженности WC, в том числе:
1) Средняя загруженность процессорных ядер, на которых происходит выполнение WC – CU (CPUCoreUtilization);
2) Средняя загруженность входных очередей WC – QU (QueueUtilization).
Для переключения могут быть использованы различные стратегии, среди них:
1) Простые пороговые значения. В этом случае для каждой метрики могут быть заданы верхнее пороговое значение с интервалом времени и нижнее пороговое значение с интервалом времени. При переходе какой-либо метрикой верхнего или нижнего порогового значения на протяжении заданного интервала времени принимается решение об изменении количества WC;
2) Сложные пороговые значения. В этом случае решение об изменении количества WC принимается при одновременном пребывании нескольких метрик за пределами пороговых значений в течение заданного интервала времени. Могут быть составлены сложные правила с участием логических операторов AND, OR.
В каждом случае величина, на которую должно быть изменено количество WC, может быть как абсолютной (например, 1, 2 – изменение количества WC на 1, 2), так и относительной, то есть зависеть от общего количества активных в данный момент WC (например, 10% –изменение количества WC на 10%). В случае указания относительной величины также должно быть указано (или задано по умолчанию), в какую сторону должно происходить округление: в большую (например, имеется всего 12 WC, изменение на 20% составит 12 * 20% = (2.4) = 3), в меньшую (12 * 20% = (2.4) = 2), или по математическим правилам округления (12 * 20% = (2.4) = 2).
Например, правила могут быть выражены в следующем виде:
<метрика> <тип порога> <значение порога> [<интервал_времени>] = <тип изменения> <величина изменения>
Где:
<метрика> – одна из перечисленных выше: CU, QU
<тип порога> – одно из значений “<” или “>”, где “>” обозначает верхний порог, а “<” - нижний
<значение порога> – пороговое значение метрики с единицами измерения метрики (например: 60%)
<интервал времени> – интервал времени в единицах времени. s – секунды, ms – миллисекунды, и т.д.
<тип изменения> – увеличение или уменьшение количества WC, обозначается “+” или “–“
<величина изменения> – количество WC или процент от текущего количества WC
Например:
• CU > 80% [10 s] = +1
Если средняя загруженность процессорных ядер, обслуживающих WC, превышает 80% в течение 10 секунд, то увеличить число WC на 1.
• QU < 20% [5 s] = -20%
Если средняя загруженность входных очередей WC меньше 20% в течение 5 секунд, то уменьшить число WC на 20%.
• CU > 80% [10 s] AND QU > 70% [10 s] = +1
Если средняя загруженность ядер превышает 80% в течение 10 секунд и при этом загруженность входных очередей WC превышает 70% в течение 10 секунд, то увеличить количество WC на 1.
Случай, в котором необходимо добавить ядро WC (левая ветвь на фиг.4).
Блок WCScaleManager сообщает ядрам RXC, что начинается переходная фаза, ожидает, пока все ядра RXС подтвердят, что они получили сигнал начала переходной фазы, сообщает всем WC, что начинается переходная фаза (TP), добавляет одно или более ядер WC, ожидает, пока все ядра WC завершат переходную фазу, сообщает ядрам RXС, что переходная фаза завершена, и затем инициирует нормальную работу с увеличенным количеством ядер WC.
Случай, в котором необходимо освободить ядро WC (правая ветвь на фиг.4).
Блок WCScaleManager сообщает ядрам RXC, что начинается переходная фаза, ожидает, пока все ядра RXС подтвердят, что они получили сигнал начала переходной фазы, сообщает всем WC, что начинается переходная фаза (TP), ожидает, пока все WC завершат переходную фазу, сообщает ядрам RXС, что переходная фаза завершена, освобождает одно или более ядер WC и затем инициирует нормальную работу с увеличенным количеством ядер WC.
На фиг. 5 изображены буферы и очереди, использующиеся при обмене между приёмным ядром и обрабатывающим ядром. Буферы обрабатывающих ядер (WC1Buffer…WCNBuffer, где N – общее число обрабатывающих ядер WC) используются для хранения пакетов до момента их передачи приёмным ядром в очереди обрабатывающих ядер (WC1Queue1 …WCNQueue1, где N – общее число обрабатывающих ядер WC). Передача пакетов в очереди обрабатывающих ядер осуществляется периодически, после нескольких циклов получения пакетов из сетевых интерфейсов, например RX1 отправляет пакеты из буфера WC1Buffer в очередь WC1Queue1 обрабатывающего ядра WC1, а пакеты из буфера WCkBuffer – в очередь WCkQueue1 обрабатывающего ядра WCk, где k – номер обрабатывающего ядра. Буферы переходной фазы TransitionPhaseBuffers (TPB) TPB1 и TPB2 используются для хранения пакетов во время переходной фазы. Во время переходной фазы в TPB1 будут помещены пакеты из очередей обрабатывающих ядер (WC1Queue1 …WCNQueue1, где N – общее число обрабатывающих ядер WC), а в TPB2 – пакеты из буферов обрабатывающих ядер (WC1Buffer…WCNBuffer, где N – общее число обрабатывающих ядер WC), а также в TPB2 будут помещаться пакеты, считываемые из входного сетевого интерфейса.
На фиг.6 изображена последовательность размещения пакетов, находящихся в буферах обрабатывающих ядер (WC1Buffer…WCNBuffer, где N – общее число обрабатывающих ядер WC) и очередях обрабатывающих ядер (WC1Queue1 …WCNQueue1, где N – общее число обрабатывающих ядер WC) в буферах переходной фазы TPB1 и TPB2 во время начала переходной фазы. Во время начала переходной фазы приемное ядро RXС1 переместит в начало своего буфера TPB2 все пакеты из буферов обрабатывающих ядер (WC1Buffer…WCNBuffer, где N – общее число обрабатывающих ядер WC). Все пакеты, считываемые приемным ядром RXС1 из входного сетевого интерфейса во время переходной фазы, будут отправляться в буфер TPB2. После получения сигнала о начале переходной фазы все обрабатывающие ядра WC1 …WCN переместят все пакеты из своих входных очередей WC Queue в буферы TPB1 соответствующих приемных ядер RXС. В TPB1 приёмного ядра RXС1 будут отправлены пакеты из очередей WC1Queue1… WCNQueue1, в TPB1 приёмного ядра RXСК будут отправлены пакеты из очередей WC1Queuek…WCNQueuek (k – номер приёмного ядра, N – общее количество обрабатывающих ядер WC).
На Фиг. 7 изображена последовательность обработки пакетов приёмным ядром после окончания переходной фазы. После окончания переходной фазы приёмное ядро RXС1 сначала отправляет в буферы WC1Buffer…WCNBuffer все пакеты из буфера TPB1, затем все пакеты из буфера TPB2, а после этого переходит в нормальный режим работы, отправляя пакеты, считываемые из входного сетевого интерфейса, в буферы WC1Buffer…WCNBuffer. Пакеты отправляются в буферы WC1Buffer…WCNBuffer в зависимости от значения hash каждого пакета и количества обрабатывающих ядер. Такой порядок отправки пакетов из буферов переходной фазы обеспечивает сохранение последовательности пакетов в рамках клиентской сессии.
На фиг. 8 более подробно изображён алгоритм работы приёмного ядра (RXC) с учётом переходной фазы TransitionPhase (TP).
Приемное ядро непрерывно выполняет следующие действия: считывает порцию пакетов из входного сетевого интерфейса, далее для считанной порции пакетов циклически берет очередной пакет и вычисляет hash для данного пакета. Проверяет, имеет ли место переходная фаза, если нет, то проверяет, пусты ли буферы переходной фазы. Если буферы не пусты (это означает, что переходная фаза только что завершилась), то сначала освобождает ненужные или добавляет новые буферы обрабатывающих ядер WC Buffer (в зависимости от того, было ли количество обрабатывающих ядер, соответственно, уменьшено или увеличено), а затем перемещает все пакеты из TPB1 и TPB2 в буферы WC, выбранные на основании значения hash пакетов и числа обрабатывающих ядер WC. Далее приемное ядро помещает пакет в один из буферов WC на основании ранее вычисленного значения hash пакета и общего числа ядер WC. Далее цикл повторяется для всех оставшихся пакетов.
Если на этапе проверки того, имеет ли место переходная фаза, обнаруживается, что она имеет место, то проверяется, началась ли переходная фаза только что, и если да, то пакеты из всех буферов WC перемещаются в буфер переходной фазы TPB2, далее подтверждается начало переходной фазы приемным ядром, и обрабатываемый пакет помещается в конец буфера переходной фазы TPB2. Если же при проверке обнаруживается, что переходная фаза началась не только что, то обрабатываемый пакет сразу помещается в конец буфера переходной фазы TPB2.
По завершению цикла для считанной из входного сетевого интерфейса порции пакетов проверяется, идет ли переходная фаза, и если нет, то помещают пакеты из буферов WC в соответствующую очередь WC и снова считывают очередную порцию пакетов из входного сетевого интерфейса. Если переходная фаза идет, то сразу начинают считывать очередную порцию пакетов из входного сетевого интерфейса.
На фиг. 9 изображен алгоритм работы обрабатывающего ядра.
Обрабатывающее ядро WC проверяет пакеты в очереди WC, и если пакеты присутствуют, то считывает их из очереди, обрабатывает, отправляет на ядро TXС. Если пакетов нет, то проверяет, имеет ли место переходная фаза (проверяет условие TP=1, которое могло быть выставлено слушающим потоком, который подробнее будет описан ниже), и если имеет место, то устанавливает значение TP=0, сообщает, что переходная фаза завершена и возвращается к проверке пакетов в очереди WC, если же проверка показала, что переходная фаза не имеет место, то сразу переходит к проверке пакетов в очереди WC.
При этом система постоянно ожидает поступления сообщения о начале переходной фазы. Это может быть реализовано в отдельном слушающем потоке. При поступлении сообщения слушающий поток устанавливает признак переходной фазы (TP=1), который будет затем считан обрабатывающим ядром. После этого, в зависимости от номера сценария, полученного в сообщении (описаны выше: Вариант (сценарий) 1, Вариант (сценарий) 2), слушающий поток либо в случае сценария 1 (Scenario 1) возвращается к ожиданию новых сообщений, либо в случае сценария 2 (Scenario 2) отправляет все пакеты из всех своих входных очередей WC1Queue1… WC1QueueM в буферы переходной фазы TPB1 соответствующих приёмных ядер RXС1 … RXСM, где M – общее количество приёмных ядер RXC.
В одном из вариантов осуществления блок WCScaleManager дополнительно отслеживает скорость изменения размера очереди на по меньшей мере одном ядре WC и, в случае превышения скоростью изменения порогового значения в течение заданного времени, инициирует дополнительное изменение числа ядер WC. Таким образом, если определено, что средний размер очереди на обработку превышает первую предварительно заданную пороговую величину и что скорость изменения размера очереди в сторону увеличения превышает пороговое значение, то добавляется дополнительное ядро WC.
В одном из вариантов осуществления, если скорость изменения размера очереди в сторону увеличения превышает вторую предварительно заданную пороговую величину, до дополнительно добавляется 2 ядра WC.
Причем пороговое значение для скорости изменения в сторону увеличения размера очереди на по меньшей мере одном ядре WC может быть задано больше порогового значения для скорости изменения в сторону уменьшения размера очереди для обеспечения более быстрой обработки данных при сохранении энергоэффективности.
Пороговое значение может быть задано как для размера очереди одного ядра, так и для среднего размера очереди всех ядер WC.
Пример работы решения
Система может быть развёрнута на сервере общего назначения с многоядерным процессором, например, имеющим архитектуру x86. На сервере должны быть установлены одна или более сетевых карт (NIC – NetworkInterfaceController).
Планировщику ОС отдаются команды для распределения RXС, TXС, WC по отдельным ядрам процессора. Каждый RXС, TXС, WC работает исключительно на своём процессорном ядре. WCScaleManager запускается на каком-либо процессорном ядре, не занятом RXС, TXС или WC.
Предположим, что система работает с 2 RXС, 2 TXС и 2 WC.
WCScale Manager – запущен на ядре Core1.
RXС1 – запущен на ядре Core2.
RXС2 – запущен на ядре Core3.
TXС1 – запущен на ядре Core4.
TXС2 – запущен на ядре Core5.
WC1 – запущен на ядре Core6.
WC2 – запущен на ядре Core7.
WCScaleManager конфигурируется правилами изменения количества WC. Возможные варианты составления правил изменения количества WC описаны в разделе «Пороговые значения для изменения количества ядер».
Предположим, что заданы следующие правила (Rule):
Rule1 : CU > 80% [10 s] = +1
Rule2 : CU < 20% [10 s] = -1
WCScaleManager начинает наблюдать за метриками, указанными в его наборе правил. Перечень метрик, за которыми может наблюдать WCScaleManager, приведен в разделе «Пороговые значения для изменения количества ядер». Способ наблюдения за метриками находится вне области данной заявки.
В приведенном примере WCScaleManager наблюдает за CU – средней загруженностью процессорных ядер, на которых работают WC.
Если среднее арифметическое загруженности ядер Core6 и Core7 больше 80% в течение 10 секунд подряд, то это вызовет срабатывание правила Rule1. По этому правилу в систему необходимо добавить 1 WC.
WCScaleManager посылает сигнал “TPStart” (начало переходного периода) на RXС1 и RXС2.
RXС1 и RXС2 перемещают все пакеты из буферов WC в свои буферы переходного периода RXС1:TPB2 и RXС2:TPB2. После этого они отправляют сигнал “TPStartConfirm” (подтверждение TPStart) на WCScaleManager. RXС1 и RXС2 продолжают получать пакеты из соответствующих буферов сетевых интерфейсов (NIC), но после получения отправляют их не в соответствующие буферы обрабатывающих ядер WCBuffer, а в буфер переходного периода TPB2.
WCScaleManager ожидает получения сигналов “TPStartConfirm” от RXС1 и RXС2. После того, как оба сигнала получены, он отправляет сигнал “TPStart” на WC1 и WC2 со значением Scenario 2 (добавление WC). После этого отправляет команду Планировщику ОС о запуске нового WC на отдельном ядре и ждёт результата выполнения команды.
После получения сигнала “TPStart” WC1 и WC2 используют Scenario 2 (добавление WC) – отправляют все пакеты из своих WCQueue в буфер переходного периода TPB1 соответствующего RXС, отправляют сигнал “TPFinished” (переходный период завершен) на WCScaleManager и возвращаются к работе в нормальном режиме, ожидая, когда в их очередях WCQueue появятся новые пакеты для обработки.
WCScaleManager ожидает получения сигналов “TPFinished” от WC1 и WC2, а также статус выполнения задачи по добавлению нового WC от Планировщика ОС.
Планировщик ОС запускает новое обрабатывающее ядро WC3 на процессорном ядре Core8.
После получения всех сигналов WCScaleManager отправляет сигнал “TPFinished” на RXС1 и RXС2.
После получения сигнала “TPFinished” RXС1 и RXС2 добавляют себе буферы WC3Buffer для нового обрабатывающего ядра. Затем обрабатывают последовательно пакеты в буферах переходного периода TPB: сначала TPB1, затем TPB2, под обработкой понимается отправка пакетов в соответствующий WCBuffer в зависимости от значения hash пакета и общего количества WC, которых теперь становится 3. После обработки своих TPB1 и TPB2 RXС1 и RXС2 возвращаются к своему нормальному режиму функционирования.
Аналогичным образом осуществляется освобождение одного из ядер.
WCScaleManager наблюдает за CU – средней загруженностью процессорных ядер, на которых работают WC, и если среднее арифметическое загруженности ядер Core6 и Core7 меньше 20% в течение 10 секунд подряд, то это вызовет срабатывание правила Rule2. По этому правилу из системы необходимо освободить 1 WC.
Далее последовательность действий аналогична описанной выше.
Варианты осуществления не ограничиваются описанными здесь вариантами осуществления, специалисту в области техники на основе информации, изложенной в описании, и знаний уровня техники станут очевидны и другие варианты осуществления изобретения, не выходящие за пределы сущности и объема данного изобретения.
Элементы, упомянутые в единственном числе, не исключают множественности элементов, если отдельно не указано иное.
Под функциональной связью элементов следует понимать связь, обеспечивающую корректное взаимодействие этих элементов друг с другом и реализацию той или иной функциональности элементов. Частными примерами функциональной связи может быть связь с возможностью обмена информацией, связь с возможностью передачи электрического тока, связь с возможностью передачи механического движения, связь с возможностью передачи света, звука, электро-магнитных или механических колебаний и т.д. Конкретный вид функциональной связи определяется характером взаимодействия упомянутых элементов, и, если не указано иное, обеспечивается широко известными средствами, используя широко известные в технике принципы.
Способы, раскрытые здесь, содержат один или несколько этапов или действий для достижения описанного способа. Этапы и/или действия способа могут заменять друг друга, не выходя за пределы объема формулы изобретения. Другими словами, если не определен конкретный порядок этапов или действий, порядок и/или использование конкретных этапов и/или действий может изменяться, не выходя за пределы объема формулы изобретения.
В заявке не указано конкретное программное и аппаратное обеспечение для реализации блоков на чертежах, но специалисту в области техники должно быть понятно, что сущность изобретения не ограничена конкретной программной или аппаратной реализацией, и поэтому для осуществления изобретения могут быть использованы любые программные и аппаратные средства, известные в уровне техники. Так, аппаратные средства могут быть реализованы в одной или нескольких специализированных интегральных схемах, цифровых сигнальных процессорах, устройствах цифровой обработки сигналов, программируемых логических устройствах, программируемых пользователем вентильных матрицах, процессорах, контроллерах, микроконтроллерах, микропроцессорах, электронных устройствах, других электронных модулях, выполненных с возможностью осуществлять описанные в данном документе функции, компьютер либо комбинации вышеозначенного.
Хотя отдельно не упомянуто, но следует понимать, что, когда речь идет о хранении данных, программ и т.п., подразумевается наличие машиночитаемого носителя данных. Примеры машиночитаемых носителей данных включают в себя постоянное запоминающее устройство, оперативное запоминающее устройство, регистр, кэш-память, полупроводниковые запоминающие устройства, магнитные носители, такие как внутренние жесткие диски и съемные диски, магнитооптические носители и оптические носители, такие как диски CD-ROM и цифровые универсальные диски (DVD), а также любые другие известные в уровне техники носители данных.
Несмотря на то, что примерные варианты осуществления были подробно описаны и показаны на сопроводительных чертежах, следует понимать, что такие варианты осуществления являются лишь иллюстративными и не предназначены ограничивать более широкое изобретение, и что данное изобретение не должно ограничиваться конкретными показанными и описанными компоновками и конструкциями, поскольку различные другие модификации могут быть очевидны специалистам в соответствующей области.
Признаки, упомянутые в различных зависимых пунктах формулы, а также реализации, раскрытые в различных частях описания, могут быть скомбинированы с достижением полезных эффектов, даже если возможность такого комбинирования не раскрыта явно.
| название | год | авторы | номер документа |
|---|---|---|---|
| Способ управления рабочим множеством виртуальных вычислителей в виртуальной сетевой системе защиты информации | 2015 |
|
RU2619716C1 |
| АРХИТЕКТУРА НАКРИСТАЛЬНОГО МЕЖСОЕДИНЕНИЯ | 2015 |
|
RU2625558C2 |
| СПОСОБ РАСПРЕДЕЛЕНИЯ ПРИНИМАЕМЫХ ПАКЕТОВ, СЕЛЕКТОР ОЧЕРЕДИ, УСТРОЙСТВО ОБРАБОТКИ ПАКЕТОВ И НОСИТЕЛЬ ИНФОРМАЦИИ | 2015 |
|
RU2643626C1 |
| Малогабаритный высокопроизводительный вычислительный модуль на базе многопроцессорной Системы-на-Кристалле | 2021 |
|
RU2778213C1 |
| ФИЗИЧЕСКИЙ УРОВЕНЬ ВЫСОКОПРОИЗВОДИТЕЛЬНОГО МЕЖСОЕДИНЕНИЯ | 2013 |
|
RU2579140C1 |
| ФИЗИЧЕСКИЙ УРОВЕНЬ ВЫСОКОПРОИЗВОДИТЕЛЬНОГО МЕЖСОЕДИНЕНИЯ | 2013 |
|
RU2599971C2 |
| СПОСОБ ПАРАЛЛЕЛЬНОЙ ОБРАБОТКИ ИНФОРМАЦИИ В ГЕТЕРОГЕННОЙ МНОГОПРОЦЕССОРНОЙ СИСТЕМЕ НА КРИСТАЛЛЕ (СнК) | 2022 |
|
RU2790094C1 |
| ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО ПРОГРАММНО-АППАРАТНОГО КОМПЛЕКСА | 2016 |
|
RU2618367C1 |
| Специализированная вычислительная система, предназначенная для вывода в глубоких нейронных сетях, основанная на потоковых процессорах | 2022 |
|
RU2793084C1 |
| ИНТЕЛЛЕКТУАЛЬНЫЕ ЭЛЕКТРОННЫЕ УСТРОЙСТВА ДЛЯ СИСТЕМЫ АВТОМАТИЗАЦИИ ПОДСТАНЦИИ И СПОСОБ ЕЕ РАЗРАБОТКИ И УПРАВЛЕНИЯ | 2009 |
|
RU2504913C2 |
Изобретение относится к средствам распределения вычислительных ресурсов многоядерной системы обработки пакетов данных. Технический результат заключается в оптимизации нагрузки на обрабатывающие ядра посредством динамического масштабирования количества ядер, что приводит к оптимизации использования вычислительных ресурсов обрабатывающей пакеты данных системы и уменьшению энергопотребления обрабатывающей пакеты данных системы. Отслеживают очереди на обработку у множества ядер процессора и загруженность процессорных ядер, если средний размер очереди на обработку меньше предварительно заданной нижней пороговой величины, то блок масштабирования блокирует добавление пакетов данных в очереди на обработку. Проверяют опустошение очереди на обработку у каждого обрабатывающего ядра процессора. После опустошения очереди на обработку у каждого обрабатывающего ядра процессора уменьшают количество обрабатывающих ядер процессора. Если по меньшей мере одно из среднего размера очереди на обработку превышает первую предварительно заданную верхнюю пороговую величину, то блок масштабирования направляет все данные из очереди на обработку в буфер памяти, увеличивает количество обрабатывающих ядер процессора. 2 н. и 6 з.п. ф-лы, 9 ил.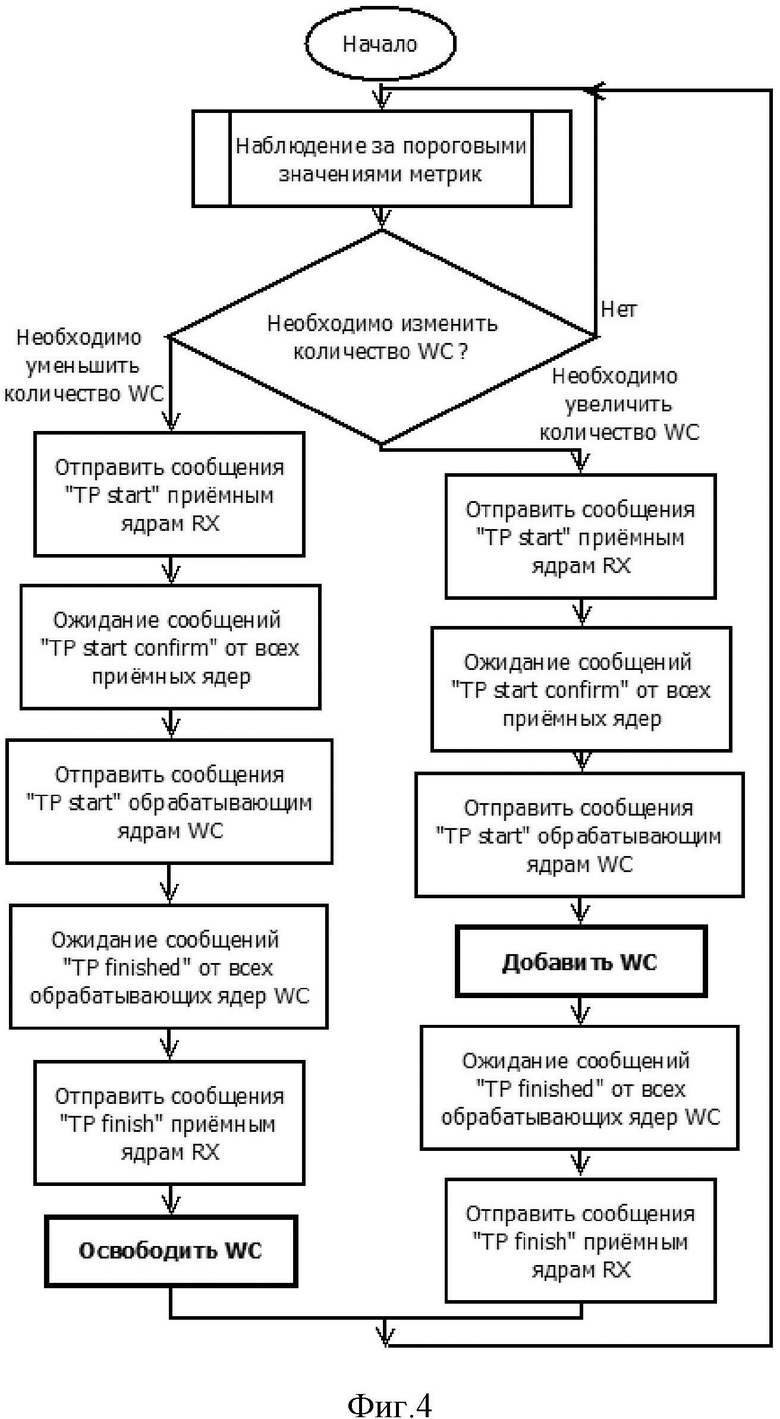
1. Способ обработки пакетов данных множеством ядер процессора, содержащий этапы, на которых:
- обрабатывают пакеты данных множеством ядер процессора;
- отслеживают очереди на обработку у множества ядер процессора и загруженность процессорных ядер посредством блока масштабирования;
если средний размер очереди на обработку меньше первой предварительно заданной нижней пороговой величины среднего размера очереди и загруженность процессорных ядер меньше первой предварительно заданной нижней пороговой величины загруженности процессорных ядер, то блок масштабирования блокирует добавление пакетов данных в очереди на обработку, проверяет опустошение очереди на обработку у каждого обрабатывающего ядра процессора, после опустошения очереди на обработку у каждого обрабатывающего ядра процессора уменьшает количество обрабатывающих ядер процессора на одно, если это обрабатывающее ядро не единственное, и инициирует обработку пакетов данных, используя уменьшенное количество ядер;
если по меньшей мере одно из среднего размера очереди на обработку и загруженности процессорных ядер превышает первую предварительно заданную верхнюю пороговую величину среднего размера очереди и первую предварительно заданную верхнюю пороговую величину загруженности процессорных ядер, соответственно, то блок масштабирования направляет все данные из очереди на обработку у каждого обрабатывающего ядра процессора в буфер памяти, увеличивает количество обрабатывающих ядер процессора на одно, если не достигнуто максимальное число ядер, и инициирует обработку пакетов данных, используя увеличенное количество ядер.
2. Способ по п. 1, в котором, если средний размер очереди на обработку меньше второй предварительно заданной нижней пороговой величины, то блок масштабирования уменьшает количество обрабатывающих ядер процессора на два.
3. Способ по п. 1, в котором блок масштабирования дополнительно отслеживает время, в течение которого по меньшей мере одно из среднего размера очереди на обработку и загруженности процессорных ядер меньше первой предварительно заданной нижней пороговой величины среднего размера очереди и первой предварительно заданной нижней пороговой величины загруженности процессорных ядер, соответственно, и уменьшает количество обрабатывающих ядер процессора, если упомянутое время превышает предварительно заданную величину.
4. Способ по п. 1, в котором, если средний размер очереди на обработку превышает вторую предварительно заданную верхнюю пороговую величину, то блок масштабирования увеличивает количество обрабатывающих ядер процессора на два.
5. Способ по п. 1, в котором блок масштабирования дополнительно отслеживает время, в течение которого по меньшей мере одно из среднего размера очереди на обработку и загруженности процессорных ядер больше первой предварительно заданной верней пороговой величины среднего размера очереди и первой предварительно заданной верхней пороговой величины загруженности процессорных ядер, соответственно, и увеличивает количество обрабатывающих ядер процессора, если упомянутое время превышает предварительно заданную пороговую величину.
6. Способ по п. 1, в котором блок масштабирования дополнительно определяет скорость изменения среднего размера очереди на обработку, и если скорость изменения среднего размера очереди на обработку превышает заранее заданную пороговую величину, то дополнительно добавляет заранее заданное количество обрабатывающих ядер.
7. Способ по п.5, в котором блок масштабирования задает значение пороговой величины для упомянутого времени в зависимости от загруженности процессорных ядер, причем чем выше загруженность процессорных ядер, тем меньше значение пороговой величины для упомянутого времени.
8. Устройство для обработки пакетов данных, содержащее:
- входной интерфейс, выполненный с возможностью приема пакетов данных;
- множество ядер, выполненных с возможностью обработки пакетов данных;
- память, выполненную с возможностью хранения данных;
- выходной интерфейс, выполненный с возможностью передачи обработанных пакетов данных;
- блок масштабирования, выполненный с возможностью перенаправлять пакетные данные и задавать количество ядер;
причем множество ядер содержит
множество приемных ядер, выполненных с возможностью обрабатывать поступающие с входного интерфейса пакеты данных в своих очередях и направлять пакеты данных в очереди обрабатывающих ядер;
множество обрабатывающих ядер, выполненных с возможностью обрабатывать пакеты данных в своих очередях и направлять обработанные пакеты данных в очереди передающих ядер;
множество передающих ядер, выполненных с возможностью обрабатывать пакеты данных в своих очередях и отправлять их в выходной интерфейс;
причем устройство для обработки пакетов данных выполнено с возможностью осуществлять способ по одному из пп.1-7.
| US 8346999 B2, 01.01.2013 | |||
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| ЭНЕРГОСБЕРЕГАЮЩЕЕ ПЛАНИРОВАНИЕ ПОТОКОВ И ДИНАМИЧЕСКОЕ ИСПОЛЬЗОВАНИЕ ПРОЦЕССОРОВ | 2009 |
|
RU2503987C2 |

