Настоящее изобретение относится к обработке аудиосигнала и, в частности, к декодеру, кодеру, системе, способам и компьютерной программе для кодирования аудиообъектов с применением адаптируемого к аудиообъекту индивидуального временно-частотного разрешения.
ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
Варианты осуществления согласно изобретению относятся к аудиодекодеру для декодирования многообъектного аудиосигнала, состоящего из сигнала понижающего микширования и связанной с объектом параметрической дополнительной информации (PSI). Дополнительные варианты осуществления согласно изобретению относятся к аудиодекодеру для обеспечения представления сигнала повышающего микширования в зависимости от представления сигнала понижающего микширования и связанной с объектом PSI. Дополнительные варианты осуществления изобретения относятся к способу декодирования многообъектного аудиосигнала, состоящего из сигнала понижающего микширования и соответствующей PSI. Дополнительные варианты осуществления согласно изобретению относятся к способу обеспечения представления сигнала повышающего микширования в зависимости от представления сигнала понижающего микширования и связанной с объектом PSI.
Дополнительные варианты осуществления изобретения относятся к аудиокодеру для кодирования множества сигналов аудиообъекта в сигнал понижающего микширования и PSI. Дополнительные варианты осуществления изобретения относятся к способу кодирования множества сигналов аудиообъекта в сигнал понижающего микширования и PSI.
Дополнительные варианты осуществления согласно изобретению относятся к компьютерной программе, соответствующей способу(ам) декодирования, кодирования и/или обеспечения сигнала повышающего микширования.
Дополнительные варианты осуществления изобретения относятся к переключению адаптируемого к аудиообъекту индивидуального временно-частотного разрешения для манипулирования смесью сигналов.
УРОВЕНЬ ТЕХНИКИ
В современных цифровых аудиосистемах, основной тенденцией является обеспечение возможности внесения модификаций, связанных с аудиообъектом, передаваемого контента на стороне приемника. Эти модификации включают в себя изменение коэффициента усиления выбранных частей аудиосигнала и/или изменение положения в пространстве конкретных аудиообъектов в случае многоканального воспроизведения посредством пространственно распределенных громкоговорителей. Этого можно добиться путем индивидуальной доставки разных частей аудиоконтента на разные громкоговорители.
Другими словами, в области обработки аудиосигнала, передачи аудиосигнала и хранения аудиосигнала, наблюдается растущая потребность в обеспечении взаимодействия с пользователем при воспроизведении объектно-ориентированного аудиоконтента, а также потребность в использовании расширенных возможностей многоканального воспроизведения для индивидуального воспроизведения аудиоконтента или его частей для улучшения слухового впечатления. Таким образом, использование многоканального аудиоконтента способствует значительным усовершенствованиям для пользователя. Например, можно получить трехмерное слуховое впечатление, которое способствует повышению удовлетворенности пользователя в развлекательных приложениях. Однако многоканальный аудиоконтент также полезен в профессиональных окружениях, например, в приложениях телефонной конференцсвязи, поскольку разборчивость речи можно повысить с использованием воспроизведения многоканального аудиосигнала. Другим возможным применением является предложение слушателю музыкального произведения индивидуально регулировать уровень воспроизведения и/или пространственное положение разных частей (также именуемых “аудиообъектами”) или дорожек, например, вокальной партии или разных инструментов. Пользователь может осуществлять такую регулировку по причинам личного вкуса, для упрощения транскрибирования одной или более частей из музыкального произведения, в образовательных целях, караоке, репетиции и т.д.
Непосредственная дискретная передача всего цифрового многоканального или многообъектного аудиоконтента, например, в форме данных импульсно-кодовой модуляции (ИКМ) или даже в форматах сжатого аудиосигнала, требует очень высоких битовых скоростей. Однако желательно также передавать и сохранять аудиоданные эффективно с точки зрения битовой скорости. Поэтому может быть желателен разумный компромисс между качеством аудиосигнала и требованиям к битовой скорости во избежание чрезмерного расходования ресурсов, обусловленного многоканальными/многообъектными приложениями.
Недавно, в области аудиокодирования, были предложены, например, Экспертной группой по вопросам движущегося изображения (MPEG) и другими, параметрические методы эффективные с точки зрения битовой скорости передачи/хранения многоканальных/многообъектных аудиосигналов. Одним примером является MPEG Surround (MPS) в качестве канально-ориентированного подхода [MPS, BCC] или пространственное кодирование аудиообъектов (SAOC) MPEG в качестве объектно-ориентированного подхода [JSC, SAOC, SAOC1, SAOC2]. Другой объектно-ориентированный подход именуется “informed source separation” [ISS1, ISS2, ISS3, ISS4, ISS5, ISS6]. Эти методы ставят своей целью реконструкцию желаемой выходной аудиосцены или желаемого объекта источника аудиосигнала на основе понижающего микширования каналов/объектов и дополнительной дополнительной информации, описывающей передаваемую/сохраненную аудиосцену и/или объекты источника аудиосигнала в аудиосцене.
Оценивание и применение дополнительной информации, связанной с каналом/объектом в таких системах осуществляется избирательно по времени и частоте. Поэтому такие системы применяют частотно-временные преобразования, например дискретное преобразование Фурье (DFT), кратковременное преобразование Фурье (STFT) или наборы фильтров наподобие наборов квадратурных зеркальных фильтров (QMF) и т.д. Основной принцип таких систем изображен на фиг. 1 на примере MPEG SAOC.
В случае STFT, временное измерение представлено количеством временных блоков и спектральное измерение захватывается количеством спектральных коэффициентов (“бинов”). В случае QMF, временное измерение представлено количеством временных слотов, и спектральное измерение захватывается количеством субполос. Если спектральное разрешение QMF повышается за счет последующего применения второго каскада фильтров, весь набор фильтров именуется гибридным QMF, и субполосы высокого разрешения именуются гибридными субполосами.
Как упомянуто выше, в SAOC общая обработка осуществляется избирательно по времени и частоте и может быть описана следующим образом в каждой полосе частот:
- осуществляется понижающее микширование N входных сигналов аудиообъектов s1 … sN в P каналах x1 … xP как часть обработки кодера с использованием матрицы понижающего микширования, состоящей из элементов d1,1 … dN,P. Кроме того, кодер извлекает дополнительную информацию, описывающую характеристики входных аудиообъектов (модуль оценивания дополнительной информации (SIE)). Для MPEG SAOC, соотношения мощностей объектов относительно друг друга являются наиболее основной формой такой дополнительной информации.
- передаются/сохраняются сигнал(ы) понижающего микширования и дополнительная информация. Для этого, аудиосигнал(ы) понижающего микширования можно сжимать, например, с использованием общеизвестных перцептивных аудиокодеров, например, MPEG-1/2 уровня II или III (иначе называемый .mp3), MPEG-2/4 Advanced Audio Coding (AAC) и т.д.
- На принимающей стороне, декодер, в принципе, пытается восстановить сигналы исходного объекта (“разделение объекта”) из (декодированных) сигналов понижающего микширования, с использованием передаваемой дополнительной информации. Затем эти приближенные сигналы ŝ1 … ŝN объекта микшируются в целевую сцену, представленную M выходными аудиоканалами ŷ1 … ŷM с использованием матрицы воспроизведения, описанной коэффициентами r1,1 … rN,M на фиг. 1. Желаемая целевая сцена, в предельном случае, может воспроизводить сигнал только одного источника из смеси (сценарий разделения источников), а также из любой другой произвольной акустической сцены, состоящей из передаваемых объектов. Например, выходом может быть одноканальной, 2-канальной стереофонической или многоканальной 5,1 целевой сценой.
Временно-частотные системы могут использовать временно-частотное (t/f) преобразование с постоянным временным и частотным разрешением. Выбор определенной сетки фиксированных t/f-разрешений обычно предусматривает компромисс между временным и частотным разрешением.
Эффект фиксированного t/f-разрешения можно продемонстрировать на примере типичных сигналов объектов в смеси аудиосигналов. Например, спектры тональных звуков демонстрируют гармонически связанную структуру с основной частотой и несколькими обертонами. Энергия таких сигналов концентрируется в определенных частотных областях. Для таких сигналов, высокое частотное разрешение используемого t/f-представления полезно для выделения узкополосных тональных спектральных областей из смеси сигналов. Напротив, переходные сигналы, например звуки барабанов, часто имеют другую временную структуру: существенная энергия присутствует только в течение коротких периодов времени и распределяется по широкому диапазону частот. Для этих сигналов, высокое временное разрешение используемого t/f-представления имеет преимущество для выделения участка переходного сигнала из смеси сигналов.
Желательно учитывать различные потребности аудиообъектов различных типов в отношении их представления во временно-частотной области при генерации и/или оценивании характерной для объекта дополнительной информации на стороне кодера или на стороне декодера, соответственно.
Это желание и/или другие желания удовлетворяются аудиодекодером для декодирования многообъектного аудиосигнала, аудиокодером для кодирования множества сигналов аудиообъекта в сигнал понижающего микширования и дополнительную информацию, способом декодирования многообъектного аудиосигнала, способом кодирования множества сигналов аудиообъекта или соответствующей компьютерной программой, которые заданы в независимых пунктах формулы изобретения.
Согласно, по меньшей мере, некоторым вариантам осуществления, предусмотрен аудиодекодер для декодирования многообъектного сигнала. Многообъектный аудиосигнал состоит из сигнала понижающего микширования и дополнительной информации. Дополнительная информация содержит характерную для объекта дополнительную информацию для, по меньшей мере, одного аудиообъекта в, по меньшей мере, одной временно-частотной области. Дополнительная информация дополнительно содержит информацию характерного для объекта временно-частотного разрешения, указывающую характерное для объекта временно-частотное разрешение характерной для объекта дополнительной информации для, по меньшей мере, одного аудиообъекта в, по меньшей мере, одной временно-частотной области. Аудиодекодер содержит блок определения характерного для объекта временно-частотного разрешения, выполненный с возможностью определения информации характерного для объекта временно-частотного разрешения из дополнительной информации для, по меньшей мере, одного аудиообъекта. Аудиодекодер дополнительно содержит блок выделения объекта, выполненный с возможностью выделения, по меньшей мере, одного аудиообъекта из сигнала понижающего микширования с использованием характерной для объекта дополнительной информации в соответствии с характерным для объекта временно-частотным разрешением.
Дополнительные варианты осуществления предусматривают аудиокодер для кодирования множества аудиообъектов в сигнал понижающего микширования и дополнительную информацию. Аудиокодер содержит временно-частотный преобразователь, выполненный с возможностью преобразования множества аудиообъектов, по меньшей мере, в первое множество соответствующих преобразований с использованием первого временно-частотного разрешения и во второе множество соответствующих преобразований с использованием второго временно-частотного разрешения. Аудиокодер дополнительно содержит блок определения дополнительной информации, выполненный с возможностью определения, по меньшей мере, первой дополнительной информации для первого множества соответствующих преобразований и второй дополнительной информации для второго множества соответствующих преобразований. Первая и вторая дополнительная информация указывают соотношение множества аудиообъектов друг с другом в первом и втором временно-частотных разрешениях, соответственно, во временно-частотной области. Аудиокодер также содержит блок выбора дополнительной информации, выполненный с возможностью выбора, для, по меньшей мере, одного аудиообъекта множества аудиообъектов, одной характерной для объекта дополнительной информации из, по меньшей мере, первой и второй дополнительной информации на основании критерия пригодности. Критерий пригодности указывает пригодность, по меньшей мере, первого или второго временно-частотного разрешения для представления аудиообъекта во временно-частотной области. Выбранная характерная для объекта дополнительная информация вставляется в дополнительную информацию, выводимую аудиокодером.
Дополнительные варианты осуществления настоящего изобретения предусматривают способ декодирования многообъектного аудиосигнала, состоящего из сигнала понижающего микширования и дополнительной информации. Дополнительная информация содержит характерную для объекта дополнительную информацию для, по меньшей мере, одного аудиообъекта в, по меньшей мере, одной временно-частотной области, и информацию характерного для объекта временно-частотного разрешения, указывающую характерное для объекта временно-частотное разрешение характерной для объекта дополнительной информации для, по меньшей мере, одного аудиообъекта в, по меньшей мере, одной временно-частотной области. Способ содержит определение информации характерного для объекта временно-частотного разрешения из дополнительной информации для, по меньшей мере, одного аудиообъекта. Способ дополнительно содержит выделение, по меньшей мере, одного аудиообъекта из сигнала понижающего микширования с использованием характерной для объекта дополнительной информации в соответствии с характерным для объекта временно-частотным разрешением.
Дополнительные варианты осуществления настоящего изобретения предусматривают способ кодирования множества аудиообъектов в сигнал понижающего микширования и дополнительную информацию. Способ содержит преобразование множества аудиообъектов, по меньшей мере, в первое множество соответствующих преобразований с использованием первого временно-частотного разрешения и во второе множество соответствующих преобразований с использованием второго временно-частотного разрешения. Способ дополнительно содержит определение, по меньшей мере, первой дополнительной информации для первого множества соответствующих преобразований и второй дополнительной информации для второго множества соответствующих преобразований. Первая и вторая дополнительная информация указывают соотношение множества аудиообъектов друг с другом в первом и втором временно-частотных разрешениях, соответственно, во временно-частотной области. Способ дополнительно содержит выбор, для, по меньшей мере, одного аудиообъекта множества аудиообъектов, одной характерной для объекта дополнительной информации из, по меньшей мере, первой и второй дополнительной информации на основании критерия пригодности. Критерий пригодности указывает пригодность, по меньшей мере, первого или второго временно-частотного разрешения для представления аудиообъекта во временно-частотной области. Характерная для объекта дополнительная информация вставляется в дополнительную информацию, выводимую аудиокодером.
Производительность выделения аудиообъекта обычно снижается, если используемое t/f-представление не согласуется с временными и/или спектральными характеристиками аудиообъекта, подлежащего выделению из смеси. Недостаточная производительность может приводить к перекрестным помехам между выделенными объектами. Упомянутые перекрестные помехи воспринимаются как опережающие или запаздывающие эхо-сигналы, изменения тембра или, в случае человеческого голоса, так называемого удвоения речи. Варианты осуществления изобретения предлагают несколько альтернативных t/f-представлений, из которых наиболее подходящее t/f-представление можно выбирать для данного аудиообъекта и данной временно-частотной области при определении дополнительной информации на стороне кодера или при использовании дополнительной информации на стороне декодера. Это обеспечивает повышенную производительность выделения для выделения аудиообъектов и повышенное субъективное качество воспроизведенного выходного сигнала по сравнению с уровнем техники.
По сравнению с другими схемами кодирования/декодирования пространственных аудиообъектов, объем дополнительной информации может быть, по существу, таким же или немного выше. Согласно вариантам осуществления изобретения, дополнительная информация используется столь же эффективно, как если бы она применялась в зависимости от объекта с учетом характерных для объекта свойств данного аудиообъекта в отношении его временной и спектральной структуры. Другими словами, t/f-представление дополнительной информации адаптируется к различным аудиообъектам.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Далее будут описаны варианты осуществления согласно изобретению со ссылкой на прилагаемые чертежи, в которых:
фиг. 1 демонстрирует упрощенную блок-схему принципиального обзора системы SAOC;
фиг. 2 демонстрирует схематическую и иллюстративную диаграмму спектрально-временного представления одноканального аудиосигнала;
фиг. 3 демонстрирует упрощенную блок-схему избирательного по времени и частоте вычисления дополнительной информации в кодере SAOC;
фиг. 4 схематически демонстрирует принцип улучшенного блока оценивания дополнительной информации согласно некоторым вариантам осуществления;
фиг. 5 схематически демонстрирует t/f-область R(tR,fR), представленную различными t/f-представлениями;
фиг. 6 – упрощенная блок-схема модуля вычисления и выбора дополнительной информации согласно вариантам осуществления;
фиг. 7 схематически демонстрирует декодирование SAOC, содержащее улучшенный (виртуальный) модуль выделения объекта (E-OS);
фиг. 8 демонстрирует упрощенную блок-схему улучшенного модуля выделение объекта (модуля EOS);
фиг. 9 – упрощенная блок-схема аудиодекодера согласно вариантам осуществления;
фиг. 10 – упрощенная блок-схема аудиодекодера, который декодирует H альтернативных t/f-представлений и затем выбирает характерные для объекта, согласно относительно простому варианту осуществления;
фиг. 11 схематически демонстрирует t/f-область R(tR,fR), представленную в различных t/f-представлениях, и их влияние на определение оцененной ковариационной матрицы E в t/f-области;
фиг. 12 схематически демонстрирует принцип выделения аудиообъекта с использованием преобразования масштабирования для осуществления выделения аудиообъекта в масштабированном временно-частотном представлении;
фиг. 13 демонстрирует упрощенную блок-схему операций способа декодирования сигнала понижающего микширования с соответствующей дополнительной информацией; и
фиг. 14 демонстрирует упрощенную блок-схему операций способа кодирования множества аудиообъектов в сигнал понижающего микширования и соответствующую дополнительную информацию.
ПОДРОБНОЕ ОПИСАНИЕ
Фиг. 1 демонстрирует общую конфигурацию кодера 10 SAOC и декодера 12 SAOC. Кодер 10 SAOC принимает в качестве входного сигнала N объектов, т.е. аудиосигналы с s1 по sN. В частности, кодер 10 содержит понижающий микшер 16, который принимает аудиосигналы с s1 по sN и осуществляет их понижающее микширование с образованием сигнала 18 понижающего микширования. Альтернативно, понижающее микширование может обеспечиваться извне (“художественное понижающее микширование”), и система оценивает дополнительную дополнительную информацию для согласования обеспеченного понижающего микширования с расчетным понижающим микшированием. На фиг. 1, сигнал понижающего микширования показан как P-канальный сигнал. Таким образом, допустима любая конфигурация монофонического (P=1), стереофонического (P=2) или многоканального (P>=2) сигнала понижающего микширования.
В случае стереофонического понижающего микширования, каналы сигнала 18 понижающего микширования обозначаются L0 и R0, в случае монофонического понижающего микширования канал обозначается просто L0. Чтобы декодер 12 SAOC мог восстанавливать отдельные объекты с s1 по sN, блок 17 оценивания дополнительной информации снабжает декодер 12 SAOC дополнительной информацией, включающей в себя параметры SAOC. Например, в случае стереофонического понижающего микширования, параметры SAOC содержат разности уровней объектов (OLD), межобъектные корреляции (IOC) (параметры межобъектной кросс-корреляции), значения коэффициента усиления при понижающем микшировании (DMG) и разности уровней каналов понижающего микширования (DCLD). Дополнительная информация 20, включающая в себя параметры SAOC, совместно с сигналом 18 понижающего микширования, образует выходной поток данных SAOC принимаемый декодером 12 SAOC.
Декодер 12 SAOC содержит повышающий микшер, который принимает сигнал 18 понижающего микширования, а также дополнительную информацию 20 для восстановления и воспроизведения аудиосигналов ŝ1 и ŝN в любой выбранный пользователем набор каналов с ŷ1 по ŷM, причем воспроизведение предписано информацией 26 воспроизведения, поступающей на декодер 12 SAOC.
Аудиосигналы с s1 по sN могут поступать на кодер 10 в любой области кодирования, например, во временной или спектральной области. В случае, когда аудиосигналы с s1 по sN поступают на кодер 10 во временной области, например ИКМ-кодированные, кодер 10 может использовать набор фильтров, например набор гибридных QMF, для преобразования сигналов в спектральную область, в которой аудиосигналы представлены в нескольких субполосах, связанных с разными спектральными участками, с конкретным разрешением набора фильтров. Если аудиосигналы с s1 по sN уже находятся в представлении, ожидаемом кодером 10, ему не нужно осуществлять спектральное разложение.
Фиг. 2 демонстрирует аудиосигнал в вышеупомянутой спектральной области. Как можно видеть, аудиосигнал представлен в виде множества субполосных сигналов. Каждый субполосный сигнал с 301 по 30K состоит из временной последовательности значений субполосы, указанных малыми прямоугольниками 32. Как можно видеть, значения 32 субполосы субполосных сигналов с 301 по 30K синхронизируются друг с другом по времени таким образом, что, для каждого из последовательных временных слотов 34 набора фильтров, каждая субполоса с 301 по 30K содержит в точности одно значение 32 субполосы. Как показано на частотной оси 36, субполосные сигналы с 301 по 30K связаны с разными частотными областями, и как показано на временной оси 38, временные слоты 34 набора фильтров последовательно размещены по времени.
Как указано выше, блок 17 извлечения дополнительной информации вычисляет параметры SAOC из входных аудиосигналов с s1 по sN. вычисляет параметры SAOC из входных аудиосигналов с s1 по sN. Согласно реализованному в настоящее время стандарту SAOC, кодер 10 осуществляет это вычисление с временным/частотным разрешением, которое может уменьшаться относительно исходного временного/частотного разрешения, которое определяется временными слотами 34 набора фильтров и разложением на субполосы, на определенную величину, причем эта определенная величина сигнализируется стороне декодера с дополнительной информацией 20. Группы последовательных временных слотов 34 набора фильтров могут образовывать кадр 41 SAOC. Количество диапазонов параметра в кадре 41 SAOC также переносится с дополнительной информацией 20. Следовательно, временно-частотная область делится на временно-частотные плитки, представленные на фиг. 2 пунктирными линиями 42. На фиг. 2 диапазоны параметра распределены одинаково в различных изображенных кадрах 41 SAOC таким образом, что получается правильное размещение временно-частотных плиток. Однако в общем случае диапазоны параметра могут изменяться от одного кадра 41 SAOC к следующему, в зависимости от разных потребностей в спектральном разрешении в соответствующих кадрах 41 SAOC. Кроме того, длина кадров 41 SAOC также может изменяться. В результате, размещение временно-частотных плиток может быть неправильным. Тем не менее, временно-частотные плитки в конкретном кадре 41 SAOC обычно имеют одинаковую длительность и выровнены во временном направлении, т.е. все t/f-плитки в упомянутом кадре 41 SAOC начинаются в начале данного кадра 41 SAOC и заканчиваются в конце упомянутого кадра 41 SAOC.
Блок 17 извлечения дополнительной информации вычисляет параметры SAOC согласно следующим формулам. В частности, блок 17 извлечения дополнительной информации вычисляет разности уровней объектов для каждого объекта i как
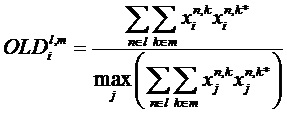
где суммы и индексы n и k, соответственно, пробегают по всем временным индексам 34, и все спектральные индексы 30, которые принадлежат определенной временно-частотной плитке 42, указаны индексами l для кадра SAOC (или временного слота обработки) и m для диапазона параметра. Таким образом, энергии всех значений субполосы xi аудиосигнала или объекта i суммируются и нормализуются к наивысшему значению энергии этой плитки из всех объектов или аудиосигналов.
Кроме того, блок 17 извлечения дополнительной информации SAOC способен вычислять меру подобия соответствующих временно-частотных плиток пар разных входных объектов с s1 по sN. Хотя понижающий микшер 16 SAOC может вычислять меру подобия между всеми парами входных объектов с s1 по sN, понижающий микшер 16 также может подавлять сигнализацию мер подобия или ограничивать вычисление мер подобия аудиообъектами с s1 по sN, которые формируют левый или правый каналы общего стереоканала. В любом случае, мера подобия называется параметром межобъектной кросс-корреляции 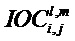
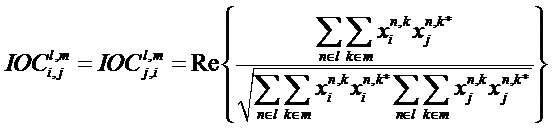
где индексы n и k, опять же, пробегают по всем значениям субполосы, принадлежащим определенной временно-частотной плитке 42, и i и j обозначают определенную пару аудиообъектов с s1 по sN.
Понижающий микшер 16 осуществляет понижающее микширование объектов с s1 по sN с использованием коэффициентов усиления, применяемых к каждому объекту с s1 по sN. Таким образом, коэффициент усиления Di применяется к объекту i и затем все взвешенные таким образом объекты с s1 по sN суммируются для получения монофонического сигнала понижающего микширования, который представлен на фиг. 1, если P=1. В другом примерном случае двухканального сигнала понижающего микширования, изображенного на фиг. 3, если P=2, коэффициент усиления D1,i применяется к объекту i, и затем все такие объекты, усиленные с коэффициентом усиления, суммируются для получения левого канала понижающего микширования L0, и коэффициенты усиления D2,i применяются к объекту i и затем усиленные таким образом с коэффициентом усиления объекты суммируются для получения правого канала понижающего микширования R0. Обработка, аналогичная вышеописанной, подлежит применению в случае многоканального понижающего микширования (P>=2).
Это предписание понижающего микширования сигнализируется стороне декодера посредством коэффициентов DMGi усиления понижающего микширования и, в случае стереосигнала понижающего микширования, разностей DCLDi уровней каналов понижающего микширования.
Коэффициенты усиления понижающего микширования вычисляются согласно:
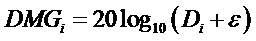
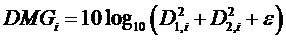
где 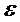 - малая величина, например 10-9.
- малая величина, например 10-9.
Для DCLD применяется следующая формула:
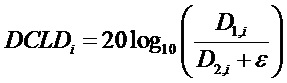
В нормальном режиме, понижающий микшер 16 генерирует сигнал понижающего микширования, согласно:
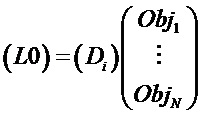
для монофонического понижающего микширования, или
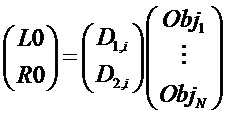
для стереофонического понижающего микширования, соответственно.
Таким образом, в вышеупомянутых формулах, параметры OLD и IOC являются функцией аудиосигналов, и параметры DMG и DCLD являются функцией D. Между прочим, заметим, что D может изменяться по времени и частоте.
Таким образом, в нормальном режиме, понижающий микшер 16 микширует все объекты с s1 по sN без предпочтений, т.е. одинаково манипулируя всеми объектами с s1 по sN.
На стороне декодера, повышающий микшер осуществляет процедуру, обратную понижающему микшированию и реализует “информацию воспроизведения” 26, представленную матрицей R (в литературе иногда также именуемый A) на одном этапе вычисления, а именно, в случае двухканального понижающего микширования
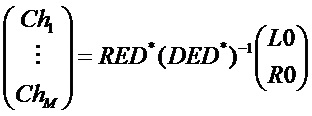
Матрица E является оцененной ковариационной матрицей аудиообъектов с s1 по sN. В современных реализациях SAOC, вычисление оцененной ковариационной матрицы E обычно осуществляется в спектральном/временном разрешении параметров SAOC, т.е. для каждого (l,m), таким образом, что оцененную ковариационную матрицу можно записать как El,m. Оцененная ковариационная матрица El,m имеет размер N x N, и ее коэффициенты заданы как
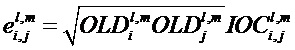
Таким образом, матрица El,m, где
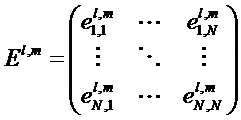
имеет по диагонали разности уровней объектов, т.е. 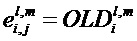 для i=j, поскольку
для i=j, поскольку 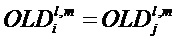 и
и 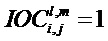 для i=j. Вне диагонали оцененная ковариационная матрица E имеет коэффициенты матрицы, представляющие среднее геометрическое разностей уровней объектов объектов i и j, соответственно, взвешенных мерой межобъектной кросс-корреляции
для i=j. Вне диагонали оцененная ковариационная матрица E имеет коэффициенты матрицы, представляющие среднее геометрическое разностей уровней объектов объектов i и j, соответственно, взвешенных мерой межобъектной кросс-корреляции 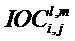
Фиг. 3 демонстрирует один возможный принцип реализации на примере блока оценки дополнительной информации (SIE) как часть кодера 10 SAOC. Кодер 10 SAOC содержит микшер 16 и блок 17 оценки дополнительной информации (SIE). SIE, в принципе, состоит из двух модулей: один модуль для вычисления t/f-представления на кратковременной основе (например, STFT или QMF) каждого сигнала. Вычисленное кратковременное t/f-представление поступает на второй модуль, модуль t/f-избирательной оценки дополнительной информации (t/f-SIE). Модуль 46 t/f-SIE вычисляет дополнительную информацию для каждой t/f-плитки. В современных реализациях SAOC, преобразование времени/частоты является фиксированным и одинаковым для всех аудиообъектов с s1 по sN. Кроме того, параметры SAOC определяются по кадрам SAOC, которые одинаковы для всех аудиообъектов и имеют одинаковое временное/частотное разрешение для всех аудиообъектов с s1 по sN, таким образом, невзирая на объектно-специфические потребности в высоком временном разрешении в ряде случаев или высоком спектральном разрешении в других случаях.
Ниже описаны некоторые ограничения принципа SAOC в нынешнем его виде: чтобы объем данных, связанных с дополнительной информацией, оставался сравнительно малым, дополнительная информация для разных аудиообъектов предпочтительно определять грубым образом для временно-частотных областей, которые занимают несколько временных слотов и несколько (гибридных) субполос входных сигналов, соответствующих аудиообъектам. Как указано выше, производительность выделения, наблюдаемая на стороне декодера, может быть близка к оптимальному, если используемое t/f-представление не адаптировано к временным или спектральным характеристикам сигнала объекта, подлежащего выделению из сигнала микширования (сигнала понижающего микширования) в каждом блоке обработки (т.е. t/f-области или t/f-плитке). Дополнительная информация для тональных частей аудиообъекта и переходных частей аудиообъекта определяются и применяется на одной и той же временно-частотной плиточной структуре, независимо от текущих характеристик объекта. Это обычно приводит к тому, что дополнительная информация для, в основном, тональных частей аудиообъекта определяется с несколько пониженным спектральным разрешением, и также дополнительная информация для, в основном, переходных частей аудиообъекта определяется с несколько пониженным временным разрешением. Аналогично, применение этой неадаптированной дополнительной информации на декодере приводит к тому, что близкие к оптимальным результаты выделения объекта ухудшаются за счет перекрестных помех объектов в форме, например, огрубления спектра и/или слышимых опережающих и запаздывающих эхо-сигналов.
Для повышения производительности выделения на стороне декодера, желательно дать возможность декодеру или соответствующему способу декодирования индивидуально адаптировать t/f-представление, используемое для обработки входных сигналов декодера (“дополнительной информации и понижающего микширования”) согласно характеристикам нужного целевого сигнала, подлежащего выделению. Для каждого целевого сигнала (объекта) наиболее подходящее t/f-представление индивидуально выбирается для обработки и выделения, например, из данного набора доступных представлений. Таким образом, декодер возбуждается дополнительной информацией, которая сигнализирует t/f-представление, подлежащее использованию для каждого индивидуального объекта в данный слот времени и данной спектральной области. Эта информация вычисляется на кодере и переносится помимо дополнительной информации уже переданной в SAOC.
- Изобретение относится к улучшенному блоку оценивания дополнительной информации (E-SIE) на кодере для вычисления дополнительной информации, обогащенной информацией, которая указывает наиболее подходящее индивидуальное t/f-представление для каждого из сигналов объектов.
- Изобретение дополнительно относится к (виртуальному) улучшенному блоку выделения объекта (E-OS) на принимающей стороне. E-OS использует дополнительную информацию, которая сигнализируют фактическое t/f-представление, которое затем применяется для оценки каждого объекта.
E-SIE может содержать два модуля. Один модуль вычисляет для каждого сигнала объекта вплоть до H t/f-представлений, отличающихся временным и спектральным разрешением и отвечающих следующему требованию: временно-частотные области R(tR,fR) могут быть заданы таким образом, чтобы контент сигнала в этих областях можно было описать любым из H t/f-представлений. Фиг. 5 демонстрирует этот принцип на примере H t/f-представлений и демонстрирует t/f-область R(tR,fR), представленную двумя различными t/f-представлениями. Контент сигнала в t/f-области R(tR,fR) можно представить с высоким спектральным разрешением, но низким временным разрешением (t/f-представление #1), с высоким временным разрешением, но низким спектральным разрешением (t/f-представление #2), или с какой-либо другой комбинацией временного и спектрального разрешения (t/f-представление #H). Количество возможных t/f-представлений не имеет ограничений.
Соответственно, предусмотрен аудиокодер для кодирования множества сигналов si аудиообъекта в сигнал X понижающего микширования и дополнительную информацию PSI. Аудиокодер содержит улучшенный блок E-SIE оценивания дополнительной информации, схематически показанный на фиг. 4. Улучшенный блок E-SIE оценивания дополнительной информации содержит временно-частотный преобразователь 52, выполненный с возможностью преобразования множества сигналов si аудиообъекта по меньшей мере, в первое множество соответствующих преобразованных сигналов s1,1(t,f) … sN,1(t,f) с использованием, по меньшей мере, первого временно-частотного разрешения TFR1 (первой временно-частотной дискретизации) и во второе множество соответствующих преобразований s1,2(t,f) … sN,2(t,f) с использованием второго временно-частотного разрешения TFR2 (второй временно-частотной дискретизации). В некоторых вариантах осуществления, временно-частотный преобразователь 52 может быть выполнен с возможностью использования более двух временно-частотных разрешений TFR1 … TFRH. Улучшенный блок оценивания дополнительной информации (E-SIE) дополнительно содержит модуль 54 вычисления и выбора дополнительной информации (SI-CS). Модуль вычисления и выбора дополнительной информации содержит (см. фиг. 6) блок определения дополнительной информации (t/f-SIE) или множество блоков 55-1 … 55-H определения дополнительной информации, выполненных с возможностью определения, по меньшей мере, первой дополнительной информации для первого множества соответствующих преобразований s1,1(t,f) … sN,1(t,f) и второй дополнительной информации для второго множества соответствующих преобразований s1,2(t,f) … sN,2(t,f), причем первая и вторая дополнительная информация указывает соотношение множества сигналов si аудиообъекта друг с другом в первом и втором временно-частотных разрешениях TFR1, TFR2, соответственно, во временно-частотной области R(tR,fR). Соотношение множества аудиосигналов si друг с другом может, например, представлять относительные энергии аудиосигналов в разных полосах частот и/или степень корреляции между аудиосигналами. Модуль 54 вычисления и выбора дополнительной информации дополнительно содержит блок 56 выбора дополнительной информации (SI-AS), выполненный с возможностью выбора, для каждого сигнала si аудиообъекта, одной характерной для объекта дополнительной информации из, по меньшей мере, первой и второй дополнительной информации на основании критерия пригодности, указывающего пригодность, по меньшей мере, первого или второго временно-частотного разрешения для представления сигнала si аудиообъекта во временно-частотной области. Затем характерная для объекта дополнительная информация вставляется в дополнительную информацию PSI, выводимую аудиокодером.
Заметим, что разбиение t/f-плоскости на t/f-области R(tR,fR) не обязательно осуществляется с эквидистантным разнесением, как указывает фиг. 5. Разбиение на области R(tR,fR) может быть, например, неоднородным с целью перцепционной адаптации. Разбиение также может согласоваться с существующими схемами кодирования аудиообъектов, например SAOC, для обеспечения обратно совместимой схемы кодирования с улучшенными возможностями оценки объектов.
Адаптация t/f-разрешения не только ограничивается указанием плиточной структуры различающихся параметров для разных объектов, но преобразование, на котором основана схема SAOC (т.е., обычно представляемое обычным временно-частотным разрешением, используемым в традиционных системах для обработки SAOC) также можно изменять для лучшей адаптации к индивидуальным целевым объектам. Это особенно полезно, например, когда требуется более высокое спектральное разрешение, чем обеспечиваемое обычным преобразованием, на котором основана схема SAOC. Например, в случае MPEG SAOC, первичное разрешение ограничено (обычным) разрешением (гибридного) банка QMF. Обработка, отвечающая изобретению позволяет повысить спектральное разрешение, но ценой некоторого снижения временного разрешения в процессе. Это осуществляется с использованием так называемого (спектрального) преобразования масштабирования, применяемого к выходным сигналам первого банка фильтров. В принципе, некоторое количество последовательных выходных выборок банка фильтров обрабатывается как сигнал временной области, и к ним применяется второе преобразование для получения соответствующего количества спектральных выборок (с одним-единственным временным слотом). Преобразование масштабирования может быть основано на банке фильтров (аналогично каскаду гибридного фильтра в MPEG SAOC), или преобразовании на основе блоков, например, DFT или комплексное модифицированное дискретное косинусное преобразование (CMDCT). Аналогичным образом, можно также повысить временное разрешение за счет спектрального разрешения (преобразование временного масштабирования): сразу несколько выходных сигналов нескольких фильтров (гибридного) банка QMF дискретизируются как сигнал частотной области, и к ним применяется второе преобразование для получения соответствующего количества временных выборок (с одной-единственной большой спектральной полосой, охватывающей спектральный диапазон нескольких фильтров).
Для каждого объекта, H t/f-представлений поступают совместно с параметры микширования во второй модуль, модуль SI-CS вычисления и выбора дополнительной информации. Модуль SI-CS определяет, для каждого из сигналов объектов, какое из H t/f-представлений следует использовать для какой t/f-области R(tR,fR) на декодере для оценивания сигнала объекта. На Фиг. 6 подробно показан принцип работы модуля SI-CS.
Для каждого из H различных t/f-представлений вычисляется соответствующая дополнительная информация (SI). Например, в SAOC можно использовать модуль t/f-SIE. Вычисленные H данных дополнительной информации поступают в модуль (SI-AS) оценивания и выбора дополнительной информации. Для каждого сигнала объекта, модуль SI-AS определяет наиболее подходящее t/f-представление для каждой t/f-области для оценивания сигнала объекта из смеси сигналов.
Помимо обычных параметров сцена микширование, SI-AS выводит, для каждого сигнала объекта и для каждой t/f-области, дополнительную информацию, которая относится к индивидуально выбранному t/f-представлению. Также может выводиться дополнительный параметр, указывающий соответствующее t/f-представление.
Рассмотрим два способа выбора наиболее подходящего t/f-представления для каждого сигнала объекта:
1. SI-AS на основании оценки источника: оценивается каждый сигнал объекта из смеси сигналов с использованием данных дополнительной информации, вычисленных на основании H t/f-представлений, в результате чего получаются H оценок источника для каждого сигнала объекта. Для каждого объекта, качество оценки в каждой t/f-области R(tR,fR) оценивается для каждого из H t/f-представлений посредством меры производительности оценивания источника. Простым примером такой меры является достигнутое отношение сигнала к искажению (SDR). Также можно использовать более сложные, перцептивные меры. Заметим, что SDR можно эффективно реализовать только на основании параметрической дополнительной информации, заданной в SAOC, не зная исходные сигналы объектов или смесь сигналов. Ниже будет описано принцип параметрической оценки SDR для случая оценки объектов на основе SAOC. Для каждой t/f-области R(tR,fR), t/f-представление, которое дает наивысшее SDR, выбирается для оценки и передачи дополнительной информации и для оценивания сигнала объекта на стороне декодера.
2. SI-AS на основании анализа H t/f-представлений: для каждого объекта в отдельности определяется разреженность каждого из H представлений сигналов объекта. Иными словами, оценивается, насколько сильно энергия сигнала объекта в каждом из разных представлений концентрируется на нескольких значениях или распределяется по всем значениям. Выбирается t/f-представление, которое представляет сигнал объекта в наиболее разреженном виде. Разреженность представлений сигнала можно оценивать, например, мерами, которые характеризуют плоскостность или пиковость представлений сигнала. Примерами таких мер являются мера спектральной плоскостности (SFM), коэффициент амплитуды (CF) и норма L0. Согласно этому варианту осуществления, критерий пригодности может быть основан на разреженности, по меньшей мере, первого временно-частотного представления и второго временно-частотного представления (и, возможно, дополнительных временно-частотных представлений) данного аудиообъекта. Блок (SI-AS) выбора дополнительной информации выполнен с возможностью выбора дополнительной информации из, по меньшей мере, первой и второй дополнительной информации, которая соответствует временно-частотному представлению, которое в наиболее разреженном виде представляет сигнал si аудиообъекта.
Ниже описана параметрическая оценка SDR для случая оценки объектов на основе SAOC.
Условные обозначения:
S - матрица N исходных сигналов аудиообъекта
X - матрица M сигналов микширования
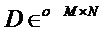
X=DS - вычисление сцены понижающего микширования
Sest - матрица N оцененных сигналов аудиообъекта
В SAOC, сигналы объектов, в принципе, оцениваются из сигналов микширования по формуле:
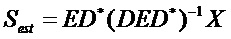
Замена X на DS дает:
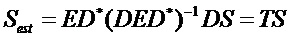
Энергия исходных частей сигнала объекта в оцененных сигналах объектов можно вычислить как:
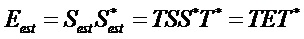
Затем члены искажения в оцененном сигнале можно вычислить по формуле:
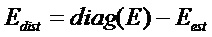
Таким образом, критерий пригодности может быть основан на оценке источника. В этом случае блок 56 выбора дополнительной информации (SI-AS) может дополнительно содержать блок оценивания источника, выполненный с возможностью оценивания, по меньшей мере, сигнала аудиообъекта, выбранного из множества сигналов si аудиообъекта с использованием сигнала X понижающего микширования и, по меньшей мере, первой информации и второй информации, соответствующей первому и второму временно-частотным разрешениям TFR1, TFR2, соответственно. Таким образом, блок оценивания источника обеспечивает, по меньшей мере, сигнал si,estim1 первого оцененного аудиообъекта и сигнал si,estim2 второго оцененного аудиообъекта (возможно, вплоть до H оцененных сигналов si,estimH аудиообъекта). Блок 56 выбора дополнительной информации также содержит блок оценивания качества, выполненный с возможностью оценивания качества, по меньшей мере, сигнала si,estim1 первого оцененного аудиообъекта и сигнала si,estim2 второго оцененного аудиообъекта. Кроме того, блок оценивания качества может быть выполнен с возможностью оценивания качества, по меньшей мере, сигнала si,estim1 первого оцененного аудиообъекта и сигнала si,estim2 второго оцененного аудиообъекта на основании отношения сигнала к искажению SDR в качестве меры производительности оценивания источника, причем отношение сигнала к искажению SDR определяется только на основании дополнительной информации PSI, в частности оцененной ковариационной матрицы Eest.
Аудиокодер согласно некоторым вариантам осуществления может дополнительно содержать процессор сигнала понижающего микширования, который выполнен с возможностью преобразования сигнала X понижающего микширования в представление, которое дискретизируется во временно-частотной области на множество временных слотов и множество (гибридных) субполос. Временно-частотная область R(tR,fR) может охватывать, по меньшей мере, две выборки сигнала X понижающего микширования. Характерное для объекта временно-частотное разрешение TFRh, указанное для, по меньшей мере, одного аудиообъекта, может быть точнее временно-частотной области R(tR,fR). Как упомянуто выше, согласно принципу неопределенности временно-частотного представления, спектральное разрешение сигнала можно повысить за счет временного разрешения, или наоборот. Хотя сигнал понижающего микширования, отправленный с аудиокодера на аудиодекодер, обычно анализируется на декодере посредством временно-частотного преобразования с фиксированным заранее определенным временно-частотным разрешением, аудиодекодер все же может преобразовывать анализируемый сигнал понижающего микширования в рассматриваемой временно-частотной области R(tR,fR) для каждого объекта в отдельности к другому временно-частотному разрешению, более подходящему для извлечения данного si аудиообъекта из сигнала понижающего микширования. Такое преобразование сигнала понижающего микширования на декодере называется в этом документе преобразованием масштабирования. Преобразование масштабирования может быть преобразованием временного масштабирования или преобразованием спектрального масштабирования.
СОКРАЩЕНИЕ ОБЪЕМА ДОПОЛНИТЕЛЬНОЙ ИНФОРМАЦИИ
в принципе, в простых вариантах осуществления системы, отвечающей изобретению, дополнительная информация для вплоть до H t/f-представлений должна передаваться для каждого объекта и для каждой t/f-области R(tR,fR), поскольку выделение на стороне декодера осуществляется путем выбора из вплоть до H t/f-представлений. Этот большой объем данных можно значительно сократить без существенного снижения воспринимаемого качества. Для каждого объекта, достаточно передавать для каждой t/f-области R(tR,fR) следующую информацию:
- один параметр, который глобально/грубо описывает контент сигнала аудиообъекта в t/f-области R(tR,fR), например, среднюю энергию сигнала объекта в области R(tR,fR).
- описание точной структуры аудиообъекта. Это описание получается из индивидуального t/f-представления, выбранного для оптимального оценивания аудиообъекта из смеси. Заметим, что информацию о точной структуре можно эффективно описывать путем параметризации различия между грубым представлением сигнала и точной структурой.
- сигнал информации, который указывает t/f-представление, подлежащее использованию для оценивания аудиообъекта.
На декодере, оценка нужных аудиообъектов из смеси на декодере может осуществляться, как описано ниже для каждой t/f-области R(tR,fR).
- вычисляется индивидуальное t/f-представление, указанное дополнительной дополнительной информацией для этого аудиообъекта.
- для выделения нужного аудиообъекта, применяется соответствующая информация (о точной структуре) сигнала объекта.
- для всех остальных аудиообъектов, т.е. аудиообъектов, создающих помехи, подлежащих подавлению, информация о точной структуре сигнала объекта используется при наличии информации для выбранного t/f-представления. В противном случае, используется грубое описание сигнала. Другой вариант состоит в использовании доступной информации о точной структуре сигнала объекта для конкретного оставшегося аудиообъекта и аппроксимации выбранного t/f-представления, например, путем усреднения доступной информации о точной структуре сигнала аудиообъекта в подобластях t/f-области R(tR,fR): таким образом, t/f-разрешение не настолько точное (высокое), как выбранное t/f-представление, но все же точнее, чем грубое t/f-представление.
ДЕКОДЕР SAOC С УЛУЧШЕННОЙ ОЦЕНКОЙ АУДИООБЪЕКТА
Фиг. 7 схематически демонстрирует декодирование SAOC, содержащее улучшенный (виртуальный) модуль выделения объекта (E-OS) и на этом примере иллюстрирует принцип работы усовершенствованного декодера SAOC, содержащего (виртуальный) улучшенный блок выделения объекта (E-OS). На декодер SAOC поступает смесь сигналов совместно с улучшенной параметрической дополнительной информацией (E-PSI). E-PSI содержит информацию об аудиообъектах, параметры микширования и дополнительную информацию. Эта дополнительная дополнительная информация сигнализирует на виртуальный E-OS, какое t/f-представление следует использовать для каждого объекта s1 … sN и для каждой t/f-области R(tR,fR). Для данной t/f-области R(tR,fR), блок выделения объекта оценивает каждый из объектов, с использованием индивидуального t/f-представления, которое сигнализируется для каждого объекта в дополнительной информации.
На Фиг. 8 подробно показан принцип работы модуля E-OS. Для данной t/f-области R(tR,fR), индивидуальное t/f-представление #h для вычисления на P сигналах понижающего микширования сигнализируется модулем 110 сигнализации t/f-представления на модуль множественных t/f-преобразований. В принципе, (виртуальный) блок 120 выделения объекта пытается оценить источник sn, на основании t/f-преобразования #h, указанного дополнительной дополнительной информацией. (Виртуальный) блок выделения объекта использует информацию о точной структуре объектов, если передается для указанного t/f-преобразования #h, и в противном случае использует переданное грубое описание сигналов источника. Заметим, что максимально возможное количество различных t/f-представлений, подлежащих вычислению для каждой t/f-области R(tR,fR), равно H. Модуль множественных временно-частотных преобразований может быть выполнен с возможностью осуществления вышеупомянутого преобразования масштабирования P сигналов понижающего микширования.
Фиг. 9 демонстрирует упрощенную блок-схему аудиодекодера для декодирования многообъектного аудиосигнала, состоящего из сигнала X понижающего микширования и дополнительной информации PSI. Дополнительная информация PSI содержит характерную для объекта дополнительную информацию PSIi, где i=1 … N для, по меньшей мере, одного аудиообъекта si в, по меньшей мере, одной временно-частотной области R(tR,fR). Дополнительная информация PSI также содержит информацию TFRIi характерного для объекта временно-частотного разрешения, где i=1 … NTF. Переменная NTF указывает количество аудиообъектов, для которых обеспечена информация характерного для объекта временно-частотного разрешения, и NTF≤N. Информация TFRIi характерного для объекта временно-частотного разрешения также может именоваться информацией характерного для объекта временно-частотного представления. В частности, термин “временно-частотное разрешение” не следует понимать как обязательно означающий однородную дискретизацию временно-частотной области, но также может означать неоднородные дискретизации в t/f-плитке или по всем t/f-плиткам полного спектра. Обычно и предпочтительно, временно-частотное разрешение выбирается таким образом, что одно из двух измерений данной t/f-плитки имеет высокое разрешение, и другое измерение имеет низкое разрешение, например, для переходных сигналов временное измерение имеет высокое разрешение, и спектральное разрешение является низким, тогда как для стационарных сигналов спектральное разрешение является высоким, и временное измерение имеет низкое разрешение. Иинформация TFRIi временно-частотного разрешения указывает характерное для объекта временно-частотное разрешение TFRh (h=1 … H) характерной для объекта дополнительной информации PSIi для, по меньшей мере, одного аудиообъекта si в, по меньшей мере, одной временно-частотной области R(tR,fR). Аудиодекодер содержит блок 110 определения характерного для объекта временно-частотного разрешения, выполненный с возможностью определения информации TFRIi характерного для объекта временно-частотного разрешения из дополнительной информации PSI для, по меньшей мере, одного аудиообъекта si. Аудиодекодер дополнительно содержит блок 120 выделения объекта, выполненный с возможностью выделения, по меньшей мере, одного аудиообъекта si из сигнала X понижающего микширования с использованием характерной для объекта дополнительной информации PSIi в соответствии с характерным для объекта временно-частотным разрешением TFRi. Это означает, что характерная для объекта дополнительная информация PSIi имеет характерное для объекта временно-частотное разрешение TFRi, указанное информацией TFRIi характерного для объекта временно-частотного разрешения, и что это характерное для объекта временно-частотное разрешение учитывается при осуществлении выделения объекта блоком 120 выделения объекта.
Характерная для объекта дополнительная информация (PSIi) может содержать характерную для объекта дополнительную информацию 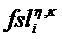
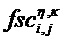
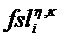
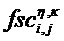
a) Характерное для объекта временно-частотное разрешение TFRi соответствует дискретности временных слотов QMF и (гибридных) субполос. В этом случае η=n и κ=k.
b) Информация TFRIi характерного для объекта временно-частотного разрешения указывает, что преобразование спектрального масштабирования нужно осуществлять во временно-частотной области R(tR,fR) или в ее участке. В этом случае, каждая (гибридная) субполоса k подразделяется на две или более (гибридных) субполосы κk, κk+1, … точной структуры, поэтому спектральное разрешение возрастает. Другими словами, (гибридные) субполосы κk, κk+1, … точной структуры являются долями исходной (гибридной) субполосы. Взамен, временное разрешение уменьшается, вследствие временно-частотной неопределенности. Следовательно, временной слот η точной структуры содержит два или более временных слотов n, n+1, ….
c) Информация TFRIi характерного для объекта временно-частотного разрешения указывает, что преобразование временного масштабирования нужно осуществлять во временно-частотной области R(tR,fR) или в ее участке. В этом случае, каждый временной слот n подразделяется на два или более временных слота ηn, ηn+1, … точной структуры, поэтому временное разрешение возрастает. Другими словами, временные слоты ηn, ηn+1, … точной структуры являются долями временного слота n. Взамен, спектральное разрешение уменьшается, вследствие временно-частотной неопределенности. Следовательно, (гибридная) субполоса κ точной структуры содержит две или более (гибридных) субполосы k, k+1, ….
Дополнительная информация может дополнительно содержать грубую характерную для объекта дополнительную информацию OLDi, IOCi,j и/или уровень абсолютной энергии NRGi для, по меньшей мере, одного аудиообъекта si в рассматриваемой временно-частотной области R(tR,fR). Грубая характерная для объекта дополнительная информация OLDi, IOCi,j и/или NRGi постоянна в, по меньшей мере, одной временно-частотной области R(tR,fR).
Фиг. 10 демонстрирует упрощенную блок-схему аудиодекодера который выполнен с возможностью приема и обработки дополнительной информации для всех N аудиообъектов во всех H t/f-представлений в одной временно-частотной плитке R(tR,fR). В зависимости от количества N аудиообъектов и количества H t/f-представлений, объем дополнительной информации, подлежащий передаче или сохранению для каждой t/f-области R(tR,fR), может становиться весьма большим, поэтому принцип показанный на фиг. 10, больше подходит для сценариев с малым количеством аудиообъектов и различных t/f-представлений. И все же, пример, представленный на фиг. 10, позволяет понять некоторые из принципов использования разных характерных для объекта t/f-представлений для разных аудиообъектов.
Иными словами, согласно варианту осуществления показанный на фиг. 10, весь набор параметров (в частности OLD и IOC) определяются и передается/сохраняется для всех H t/f-представлений, представляющих интерес. Кроме того, дополнительная информация указывает для каждого аудиообъекта, в каком именно t/f-представлении следует извлекать/синтезировать этот аудиообъект. В аудиодекодере осуществляются реконструкция Ŝh объекта во всех t/f-представлениях h. Затем окончательный аудиообъект собирается, по времени и частоте, из этих характерных для объекта плиток, или t/f-областей, сгенерированных с использованием конкретного t/f-разрешения(й), сигнализируемого(ых) в дополнительной информации для аудиообъекта, и плиток, представляющих интерес.
Сигнал X понижающего микширования поступает на множество блоков 1201 … 120H выделения объекта. Каждый из блоков 1201 … 120H выделения объекта выполнен с возможностью осуществления задачи выделения для одного конкретного t/f-представления. Для этого, каждый блок 1201 … 120H выделения объекта дополнительно принимает дополнительную информацию N разных аудиообъектов s1 … sN в конкретном t/f-представлении, с которым связан блок выделения объекта. Заметим, что фиг. 10 демонстрирует множество H блоков выделения объекта только в целях иллюстрации. В альтернативных вариантах осуществления, H задач выделения для каждой t/f-области R(tR,fR) может осуществляться меньшим количеством блоков выделения объекта, или даже единичным блоком выделения объекта. Согласно дополнительно возможным вариантам осуществления, задачи выделения могут осуществляться на многоцелевом процессоре или на многоядерном процессоре как различные потоки. Некоторые задачи выделения требуют большей вычислительной мощности, чем другие, в зависимости от того, насколько точным является соответствующее t/f-представление. Для каждой t/f-области R(tR,fR) на аудиодекодер поступает N x H наборов дополнительной информации.
Блоки 1201 … 120H выделения объекта обеспечивают N x H оцененных выделенных аудиообъектов ŝ1,1 … ŝN,H, которые могут поступать на необязательный преобразователь 130 t/f-разрешения для приведения оцененных выделенных аудиообъектов ŝ1,1 … ŝN,H к обычному t/f-представлению, если это еще не случилось. Обычно обычное t/f-разрешение или представление может быть истинным t/f-разрешением банка фильтров или преобразования, на котором основана общая обработка аудиосигналов, т.е., в случае MPEG SAOC обычное разрешение представляет собой дискретность временных слотов QMF и (гибридных) субполос. В целях иллюстрации можно предположить, что оцененные аудиообъекты временно сохраняются в виде матрицы 140. В фактической реализации, оцененные выделенные аудиообъекты, которые далее не будут использоваться, можно сразу же отбрасывать или даже не вычислять в первую очередь. Каждая строка матрицы 140 содержит H разных оценок одного и того же аудиообъекта, т.е. оцененный выделенный аудиообъект, определенный на основании H различных t/f-представлений. Средний участок матрицы 140 схематически обозначен сеткой. Каждый элемент ŝ1,1 … ŝN,H матрицы соответствует аудиосигналу оцененного выделенного аудиообъекта. Другими словами, каждый элемент матрицы содержит множество выборок временного слота/субполосы в целевой t/f-области R(tR,fR) (например, 7 временных слотов×3 субполосы=21 выборка временного слота/субполосы в примере, показанном на фиг. 11).
Аудиодекодер дополнительно выполнен с возможностью приема информации характерного для объекта временно-частотного разрешения TFRI1 … TFRIN для разных аудиообъектов и для текущей t/f-области R(tR,fR). Для каждого аудиообъекта i, информация TFRIi характерного для объекта временно-частотного разрешения указывает, какой из оцененных выделенных аудиообъектов ŝi,1 … ŝi,H следует использовать для приблизительного воспроизведения исходного аудиообъекта. Информация характерного для объекта временно-частотного разрешения обычно определяется кодером и поступает на декодер как часть дополнительной информации. На фиг. 10, пунктирные блоки и кресты в матрице 140 указывают, какое из t/f-представлений выбрано для каждого аудиообъекта. Выбор производится блоком 112 выбора, который принимает информацию TFRI1 … TFRIN характерного для объекта временно-частотного разрешения.
Блок 112 выбора выводит N выбранных сигналов аудиообъекта, которые могут быть дополнительно обработаны. Например, N выбранных сигналов аудиообъекта могут поступать на блок 150 воспроизведения, выполненный с возможностью воспроизведения выбранных сигналов аудиообъекта на доступную акустическую установку, например, стерео или 5.1 акустическую установку. Для этого, блок 150 воспроизведения может принимать заранее заданную информацию воспроизведения и/или пользовательскую информацию воспроизведения, которая описывает, как аудиосигналы оцененных выделенных аудиообъектов должны распределяться на доступные громкоговорители. Блок 150 воспроизведения является необязательным, и оцененные выделенные аудиообъекты ŝi,1 … ŝi,H на выходе блока 112 выбора можно использовать и обрабатывать напрямую. В альтернативных вариантах осуществления, блок 150 воспроизведения можно устанавливать на экстремальные настройки, например, “режим соло” или “режим караоке”. В режиме соло, для воспроизведения в выходной сигнал выбирается единичный оцененный аудиообъект. В режиме караоке, для воспроизведения в выходной сигнал выбираются все кроме одного оцененного аудиообъекта. Обычно основная вокальная партия не воспроизводится, но аккомпанемент воспроизводится. Оба режима требуют высокой производительности выделения, поскольку воспринимаются даже небольшие перекрестные помехи.
Фиг. 11 схематически демонстрирует возможную организацию дополнительной информации 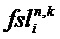
При определении дополнительной информации для аудиообъекта i на стороне аудиокодера, аудиокодер анализирует аудиообъект i в t/f-области R(tR,fR) и определяет грубую дополнительную информацию и дополнительную информацию о точной структуре. Грубая дополнительная информация может представлять собой разность уровней объекта OLDi, межобъектную ковариацию IOCi,j и/или уровень абсолютной энергии NRGi, заданные, в том числе, в стандарте SAOC ISO/IEC 23003-2. Грубая дополнительная информация задается на основе t/f-областей и обычно обеспечивает обратную совместимость, поскольку существующие декодеры SAOC используют такого рода дополнительную информацию. Характерная для объекта дополнительная информация
Характерная для объекта дополнительная информация
Нижняя часть фиг. 11 демонстрирует, что оцененная ковариационная матрица E изменяется на протяжении t/f-области R(tR,fR) в соответствии с дополнительной информацией о точной структуре для аудиообъектов i и j. Другие матрицы или значения, которые используются в задаче выделения объекта, также могут изменяться в t/f-области R(tR,fR). Блок 120 выделения объекта должен учитывать изменение ковариационной матрицы E (и, возможно, других матриц или значений). В представленном случае, для каждой выборки временного слота/субполосы t/f-области R(tR,fR) определяется отдельная ковариационная матрица E. В случае, когда точная структура спектра связана только с одним из аудиообъектов, например, объектом i, ковариационная матрица E будет постоянной в каждой из трех спектральных подобластей (в данном случае: постоянной в каждом из трех (гибридных) субполос, но, в общем случае, возможно, также в других спектральных подобластях).
Блок 120 выделения объекта может быть выполнен с возможностью определения оцененной ковариационной матрицы En,k с элементами 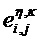
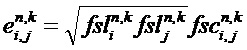
где
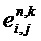
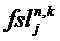
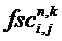
По меньшей мере, один из
Подход, альтернативный описанному выше, применяется, когда спектральное или временное разрешение возрастает по сравнению с разрешением нижележащего преобразования, например, при последующем преобразовании масштабирования. В таком случае, оценка ковариационной матрицы объекта должна осуществляться в масштабированной области, и реконструкция объекта происходит также в масштабированной области. Затем результат реконструкции может подвергаться обратному преобразованию в домен исходного преобразования, например, (гибридный) QMF, и перемежение плиток в окончательную реконструкцию происходит в этой области. В принципе, вычисления производятся таким же образом, как в случае использования плиточной структуры различающихся параметров за исключением дополнительных преобразований.
Фиг. 12 схематически демонстрирует преобразование масштабирования на примере масштабирования по спектральной оси, обработку в масштабированной области и обратное преобразование масштабирования. Рассмотрим понижающее микширование во временно-частотной области R(tR,fR) при t/f-разрешении сигнала понижающего микширования, заданном временными слотами n и (гибридными) субполосами k. В примере, показанном на фиг. 12, временно-частотная область R(tR,fR) охватывает четыре временных слота с n по n+3 и одну субполосу k. Преобразование масштабирования может осуществляться блоком 115 временно-частотного преобразования сигнала. Преобразование масштабирования может представлять собой преобразование временного масштабирования или, как показано на фиг. 12, преобразование спектрального масштабирования. Преобразование спектрального масштабирования может осуществляться посредством DFT, STFT, банка фильтров анализа на основе QMF и т.д. Преобразование временного масштабирования может осуществляться посредством обратного DFT, обратного STFT, банка фильтров синтеза на основе обратного QMF и т.д. В примере, показанном на фиг. 12, сигнал X понижающего микширования преобразуется из временно-частотное представления сигнала понижающего микширования, заданного временными слотами n и (гибридными) субполосами k, в спектрально масштабированное t/f-представление, охватывающее один-единственный характерный для объекта временной слот η, но четыре характерных для объекта (гибридных) субполосы от κ по κ+3. Следовательно, спектральное разрешение сигнала понижающего микширования во временно-частотной области R(tR,fR) повышается в 4 раза за счет временного разрешения.
Обработка осуществляется с характерным для объекта временно-частотным разрешением TFRh блоком 121 выделения объекта, который также принимает дополнительную информацию, по меньшей мере, одного из аудиообъектов в характерном для объекта временно-частотном разрешении TFRh. В примере, показанном на фиг. 12, аудиообъект i задается дополнительной информацией во временно-частотной области R(tR,fR), которая согласуется с характерным для объекта временно-частотным разрешением TFRh, т.е. одним характерным для объекта временным слотом η и четырьмя характерными для объекта (гибридными) субполосами от η по η+3. В целях иллюстрации, на фиг. 12 также схематически показана дополнительная информация для двух дополнительных аудиообъектов i+1 и i+2. Аудиообъект i+1 задается дополнительной информацией, имеющей временно-частотное разрешение сигнала понижающего микширования. Аудиообъект i+2 задается дополнительной информацией, имеющей разрешение двух характерных для объекта временных слотов и двух характерных для объекта (гибридных) субполос во временно-частотной области R(tR,fR). Для аудиообъекта i+1, блок 121 выделения объекта может рассматривать грубую дополнительную информацию во временно-частотной области R(tR,fR). Для аудиообъекта i+2 блок 121 выделения объекта может рассматривать два спектральных средних значения во временно-частотной области R(tR,fR), указанные двумя разными штриховками. В общем случае, блок 121 выделения объекта может рассматривать множество спектральных средних значений и/или множество временных средних значений, если дополнительная информация для соответствующего аудиообъекта недоступна в конкретном характерном для объекта временно-частотном разрешении TFRh, которое в данный момент обрабатывается блоком 121 выделения объекта, но дискретизируется во временном и/или спектральном измерении более точно (часто), чем временно-частотная область R(tR,fR). Таким образом, блок 121 выделения объекта пользуется доступностью характерной для объекта дополнительной информации, которая дискретизируется точнее, чем грубая дополнительная информация (например, OLD, IOC и/или NRG), хотя не обязательно столь же точно, как характерное для объекта временно-частотное разрешение TFRh, в данный момент обрабатываемое блоком 121 выделения объекта.
Блок 121 выделения объекта выводит, по меньшей мере, один извлеченный аудиообъект ŝi для временно-частотной области R(tR,fR) с характерным для объекта временно-частотным разрешением (t/f-разрешение масштабирования). Затем, по меньшей мере, один извлеченный аудиообъект ŝi подвергается преобразованию обратного масштабирования преобразователем 132 обратного масштабирования для получения извлеченного аудиообъекта ŝi в R(tR,fR) при временно-частотном разрешении сигнала понижающего микширования или при другом нужном временно-частотном разрешении. Затем извлеченный аудиообъект ŝi в R(tR,fR) объединяется с извлеченным аудиообъектом ŝi в других временно-частотных областях, например, R(tR-1,fR-1), R(tR-1,fR), … R(tR+1,fR+1), для сборки извлеченного аудиообъекта ŝi.
Согласно соответствующим вариантам осуществления, аудиодекодер может содержать временно-частотный преобразователь 115 сигнала понижающего микширования, выполненный с возможностью преобразования сигнала X понижающего микширования во временно-частотной области R(tR,fR) от временно-частотного разрешения сигнала понижающего микширования к, по меньшей мере, характерному для объекта временно-частотному разрешению TFRh, по меньшей мере, одного аудиообъекта si для получения повторно преобразованного сигнала Xη,κ понижающего микширования. Временно-частотное разрешение сигнала понижающего микширования относится к временным слотам n понижающего микширования и (гибридным) субполосам k понижающего микширования. Характерное для объекта временно-частотное разрешение TFRh относится к характерным для объекта временным слотам η и характерным для объекта (гибридным) субполосам κ. Характерные для объекта временные слоты η могут быть точнее или грубее, чем временные слоты n понижающего микширования временно-частотного разрешения понижающего микширования. Аналогично, характерные для объекта (гибридные) субполосы κ могут быть точнее или грубее, чем (гибридные) субполосы понижающего микширования временно-частотного разрешения понижающего микширования. Как объяснено выше, согласно принципу неопределенности временно-частотного представления, спектральное разрешение сигнала можно повысить за счет временного разрешения, и наоборот. Аудиодекодер может дополнительно содержать обратный временно-частотный преобразователь 132, выполненный с возможностью временно-частотного преобразования, по меньшей мере, одного аудиообъекта si во временно-частотной области R(tR,fR) от характерного для объекта временно-частотного разрешения TFRh обратно к временно-частотному разрешению сигнала понижающего микширования. Блок 121 выделения объекта выполнен с возможностью выделения, по меньшей мере, одного аудиообъекта si из сигнала X понижающего микширования с характерным для объекта временно-частотным разрешением TFRh.
В масштабированной области, оцененная ковариационная матрица Eη,κ задается для характерных для объекта временных слотов η и характерных для объекта (гибридных) субполос κ. Вышеупомянутая формула для элементов оцененной ковариационной матрицы, по меньшей мере, одного аудиообъекта si и, по меньшей мере, одного дополнительного аудиообъекта sj можно выразить в масштабированной области как:
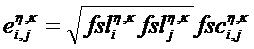
где
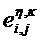
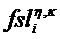
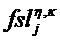
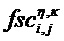
Как объяснено выше, дополнительный аудиообъект j может не задаваться дополнительной информацией, которая имеет характерное для объекта временно-частотное разрешение TFRh аудиообъекта i, поэтому параметры
Также на стороне кодера обычно рассматривается дополнительная информация о точной структуре. В аудиокодере согласно вариантам осуществления блок 55-1 … 55-H определения дополнительной информации (t/f-SIE) дополнительно выполнен с возможностью обеспечения характерной для объекта дополнительной информации 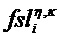
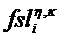
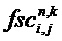
Фиг. 13 демонстрирует упрощенную блок-схему операций способа декодирования многообъектного аудиосигнала, состоящего из сигнала X понижающего микширования и дополнительной информации PSI. Дополнительная информация содержит характерную для объекта дополнительную информацию PSIi для, по меньшей мере, одного аудиообъекта si в, по меньшей мере, одной временно-частотной области R(tR,fR), и информацию TFRIi характерного для объекта временно-частотного разрешения, указывающую характерное для объекта временно-частотное разрешение TFRh характерной для объекта дополнительной информации для, по меньшей мере, одного аудиообъекта si в, по меньшей мере, одной временно-частотной области R(tR,fR). Способ содержит этап 1302 определения информации TFRIi характерного для объекта временно-частотного разрешения из дополнительной информации PSI для, по меньшей мере, одного аудиообъекта si. Способ дополнительно содержит этап 1304 выделения, по меньшей мере, одного аудиообъекта si из сигнала X понижающего микширования с использованием характерной для объекта дополнительной информации в соответствии с характерным для объекта временно-частотным разрешением TFRIi.
Фиг. 14 демонстрирует упрощенную блок-схему операций способа кодирования множества сигналов si аудиообъекта в сигнал X понижающего микширования и дополнительную информацию PSI согласно дополнительным вариантам осуществления. Аудиокодер содержит преобразование множества сигналов si аудиообъектов в, по меньшей мере, первое множество соответствующих преобразований s1,1(t,f) … sN,1(t,f) на этапе 1402. Для этого используется первое временно-частотное разрешение TFR1. Множество сигналов si аудиообъектов также преобразуется по меньшей мере, во второе множество соответствующих преобразований s1,2(t,f) … sN,2(t,f) с использованием второй временно-частотной дискретизации TFR2. На этапе 1404 определяются, по меньшей мере, первая дополнительная информация для первого множества соответствующих преобразований s1,1(t,f) … sN,1(t,f) и вторая дополнительная информация для второго множества соответствующих преобразований s1,2(t,f) … sN,2(t,f). Первая и вторая дополнительная информация указывают соотношение множества сигналов si аудиообъекта друг с другом в первом и втором временно-частотных разрешениях TFR1, TFR2, соответственно, во временно-частотной области R(tR,fR). Способ также содержит этап 1406 выбора, для каждого сигнала si аудиообъекта, одной характерной для объекта дополнительной информации из, по меньшей мере, первой и второй дополнительной информации на основании критерия пригодности, указывающего пригодность, по меньшей мере, первого или второго временно-частотного разрешения для представления сигнала si аудиообъекта во временно-частотной области, причем характерная для объекта дополнительная информация вставлена в дополнительную информацию PSI, выводимую аудиокодером.
ОБРАТНАЯ СОВМЕСТИМОСТЬ С SAOC
Преимущество предложенного решения состоит в повышении воспринимаемого качества аудиосигнала, возможно даже с полной совместимостью с декодером. Благодаря заданию t/f-областей R(tR,fR) конгруэнтными t/f-разбиению в традиционном SAOC, существующие стандартные декодеры SAOC могут декодировать обратно совместимую часть PSI и создавать реконструкции объектов на низком уровне t/f-разрешения. Если улучшенный декодер SAOC использует добавленную информацию, воспринимаемое качество реконструкций значительно повышается. Для каждого аудиообъекта, эта дополнительная дополнительная информация содержит информацию, какое индивидуальное t/f-представление следует использовать для оценивания объекта, совместно с описанием точной структуры объекта на основании выбранного t/f-представления.
Кроме того, если улучшенный декодер SAOC выполняется на ограниченных ресурсах, улучшения можно игнорировать, и, тем не менее, получать реконструкцию базового качества, требующую только низкую вычислительную сложность.
ОБЛАСТИ ПРИМЕНЕНИЯ ОБРАБОТКИ, ОТВЕЧАЮЩЕЙ ИЗОБРЕТЕНИЮ
Принцип характерных для объекта t/f-представлений и соответствующей сигнализации на декодер можно применять к любой схеме SAOC. Его можно комбинировать с любыми современными, а также будущими форматами аудиосигнала. Принцип позволяет улучшать перцептивную оценку аудиообъекта в применениях SAOC посредством адаптируемого к аудиообъекту выбора индивидуального t/f-разрешения для параметрической оценки аудиообъектов.
Хотя некоторые аспекты были описаны в контексте устройства, ясно, что эти аспекты также представляют описание соответствующего способа, где блок или устройство соответствует этапу способа или признаку этапа способа. Аналогично, аспекты, описанные в контексте этапа способа, также представляют описание соответствующего блока или элемента или признака соответствующего устройства. Некоторые или все этапы способа могут выполняться посредством (или с использованием) аппаратного устройства, например, микропроцессора, программируемого компьютера или электронной схемы. В некоторых вариантах осуществления, некоторые единичные или множественные этапы способа могут выполняться таким устройством.
Кодированный аудиосигнал, отвечающий изобретению, может храниться на цифровом носителе данных или может передаваться в среде передачи, например, беспроводной среде передачи или проводной среде передачи, например, интернете.
В зависимости от определенных требований к реализации, варианты осуществления изобретения можно реализовать аппаратными средствами или программными средствами. Реализация может осуществляться с использованием цифрового носителя данных, например, флоппи-диска, DVD, CD, ROM, PROM, EPROM, EEPROM или флэш-памяти, где хранятся электронно считываемое сигналы управления, которые взаимодействуют (или способны взаимодействовать) с программируемой компьютерной системой для осуществления соответствующего способа. Таким образом, цифровой носитель данных может быть компьютерно-считываемым.
Некоторые варианты осуществления согласно изобретению содержат носитель данных, имеющий электронно считываемое сигналы управления, которые способны взаимодействовать с программируемой компьютерной системой, благодаря чему осуществляется один из описанных здесь способов.
В общем случае, варианты осуществления настоящего изобретения можно реализовать в виде компьютерного программного продукта с программным кодом, причем программный код предназначен для осуществления одного из способов, когда компьютерный программный продукт выполняется на компьютере. Программный код может храниться, например, на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для осуществления одного из описанных здесь способов, хранящуюся на машиночитаемом носителе.
Другими словами, вариант осуществления способа, отвечающего изобретению, предусматривает компьютерную программу, имеющую программный код для осуществления одного из описанных здесь способов, когда компьютерная программа выполняется на компьютере.
Дополнительный вариант осуществления способов, отвечающих изобретению, предусматривает носитель данных (или цифровой носитель данных, или компьютерно-считываемый носитель), на котором записана компьютерная программа для осуществления одного из описанных здесь способов. Носитель данных, цифровой носитель данных или носитель записи обычно являются вещественными и/или непередающими.
Дополнительный вариант осуществления способа, отвечающего изобретению, предусматривает поток данных или последовательность сигналов, представляющих компьютерную программу для осуществления одного из описанных здесь способов. Поток данных или последовательность сигналов может быть сконфигурирован, например, для переноса через соединение для передачи данных, например через интернет.
Дополнительный вариант осуществления содержит средство обработки, например, компьютер или программируемое логическое устройство, выполненное с возможностью или адаптированное для осуществления одного из описанных здесь способов.
Дополнительный вариант осуществления содержит компьютер, на котором установлена компьютерная программа для осуществления одного из описанных здесь способов.
В некоторых вариантах осуществления, программируемое логическое устройство (например, вентильная матрица, программируемая пользователем) может использоваться для осуществления некоторых или всех функциональных возможностей описанных здесь способов. В некоторых вариантах осуществления, вентильная матрица, программируемая пользователем могут взаимодействовать с микропроцессором для осуществления одного из описанных здесь способов. В общем случае, способы, предпочтительно, осуществляются любым аппаратным устройством.
Вышеописанные варианты осуществления призваны иллюстрировать принципы настоящего изобретения. Следует понимать, что специалисты в данной области техники могут предложить модификации и вариации описанных здесь конфигураций и деталей. Поэтому они подлежат ограничению только объемом нижеследующей формулы изобретения, но не конкретными деталями, представленными посредством описания и объяснения рассмотренных здесь вариантов осуществления.
БИБЛИОГРАФИЯ
[MPS] ISO/IEC 23003-1:2007, MPEG-D (MPEG audio technologies), Part 1: MPEG Surround, 2007.
[BCC] C. Faller and F. Baumgarte, "Binaural Cue Coding- Part II: Schemes and applications," IEEE Trans. on Speech and Audio Proc., vol. 11, no. 6, Nov. 2003.
[JSC] C. Faller, "Parametric Joint-Coding of Audio Sources", 120th AES Convention, Paris, 2006.
[SAOC1] J. Herre, S. Disch, J. Hilpert, O. Hellmuth: "From SAC To SAOC – Recent Developments in Parametric Coding of Spatial Audio", 22nd Regional UK AES Conference, Cambridge, UK, April 2007.
[SAOC2] J. Engdegård, B. Resch, C. Falch, O. Hellmuth, J. Hilpert, A. Holzer, L. Terentiev, J. Breebaart, J. Koppens, E. Schuijers and W. Oomen: "Spatial Audio Object Coding (SAOC) - The Upcoming MPEG Standard on Parametric Object Based Audio Coding", l24th AES Convention, Amsterdam 2008.
[SAOC] ISO/IEC, "MPEG audio technologies - Part 2: Spatial Audio Object Coding (SAOC)", ISO/IEC JTC1/SC29/WG11 (MPEG) International Standard 23003-2.
[ISS1] M. Parvaix and L. Girin: "lnformed Source Separation of underdetermined instantaneous Stereo Mixtures using Source Index Embedding", IEEE ICASSP, 2010.
[ISS2] M. Parvaix, L. Girin, J.-M. Brassier: "A watermarking-based method for informed source separation of audio signals with a single sensor", IEEE Transactions on Audio, Speech and Language Processing, 2010.
[ISS3] A. Liutkus and J. Pinel and R. Badeau and L. Girin and G. Richard: "Informed source separation through spectrogram coding and data embedding", Signal Processing Journal, 2011.
[ISS4] A. Ozerov, A. Liutkus, R. Badeau, G. Richard: "Informed source separation: source coding meets source separation", IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, 2011.
[ISS5] Shuhua Zhang and Laurent Girin: "An Informed Source Separation System for Speech Signals", INTERSPEECH, 2011.
[ISS6] L. Girin and J. Pinel: "Informed Audio Source Separation from Compressed Linear Stereo Mixtures", AES 42nd International Conference: Semantic Audio, 2011.
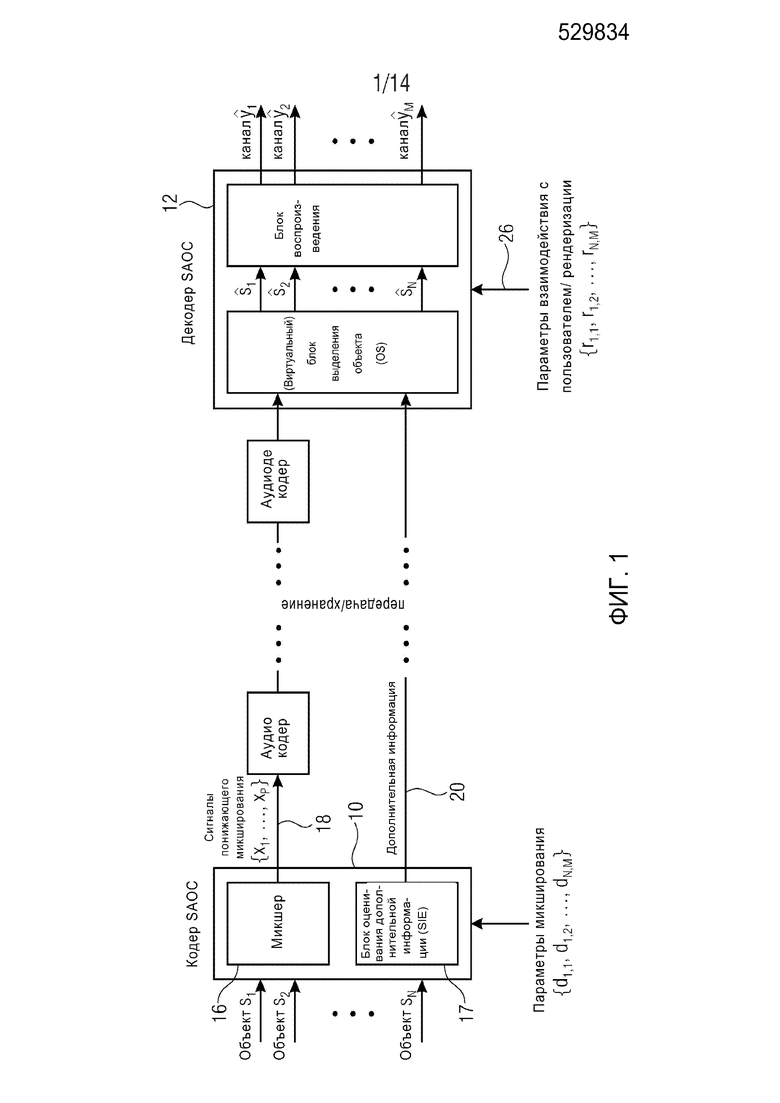
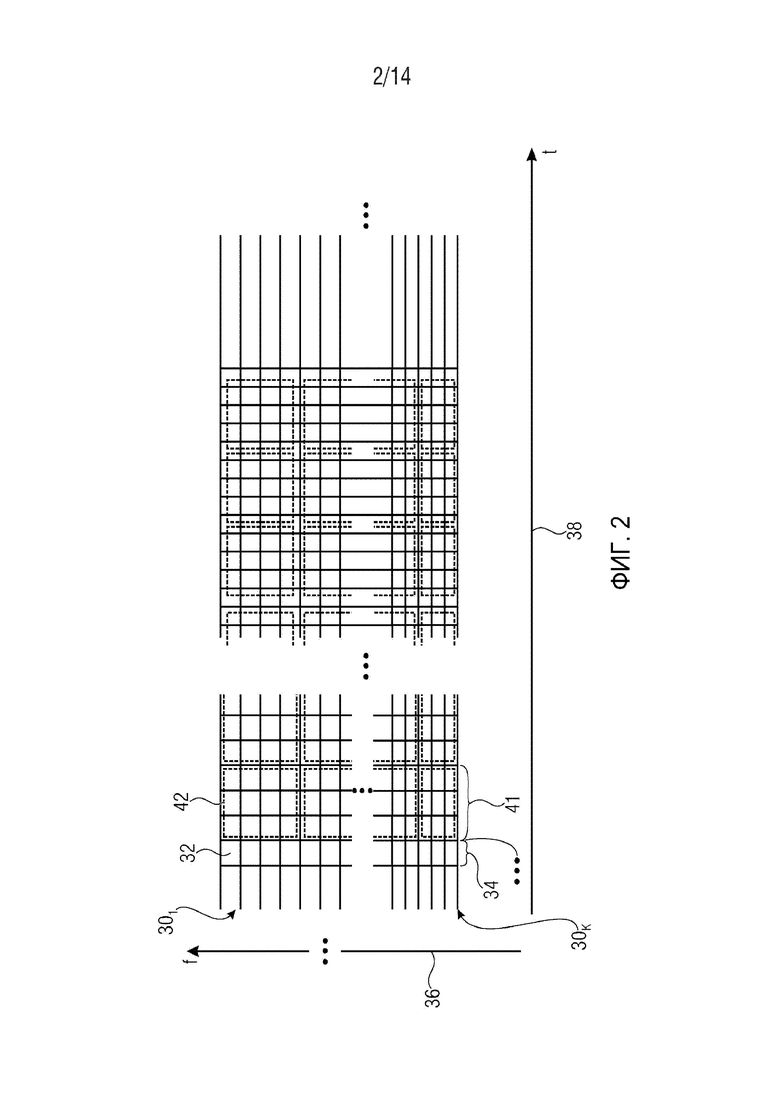
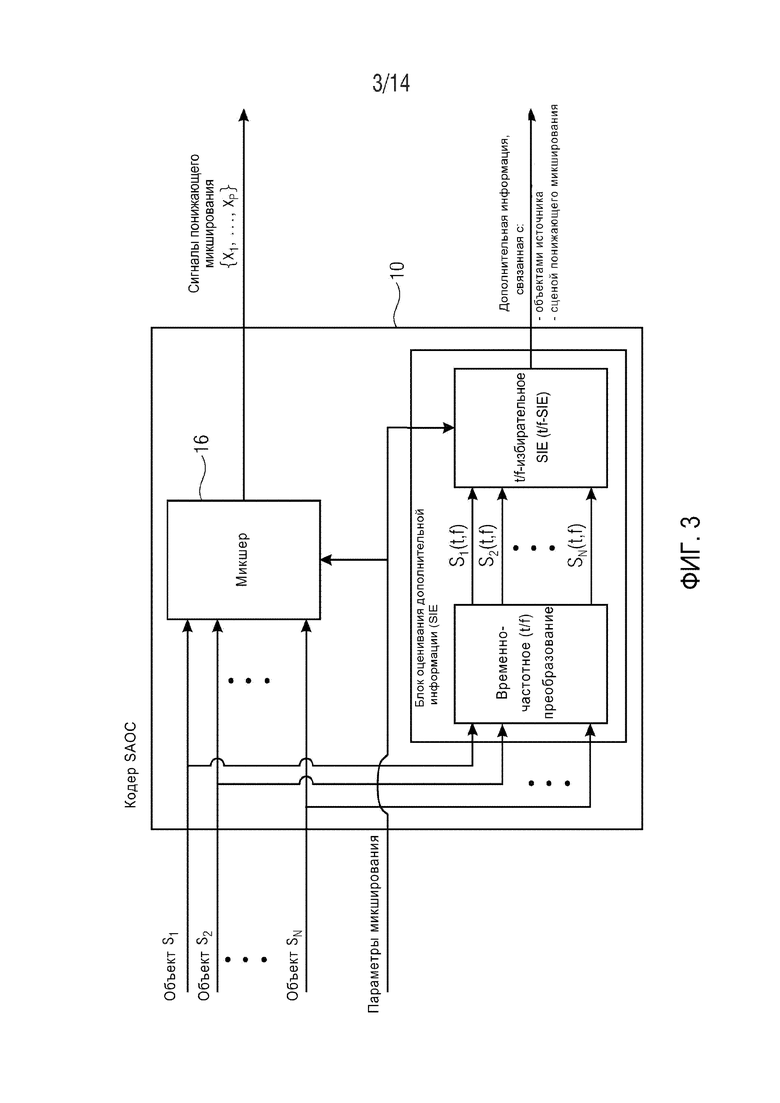
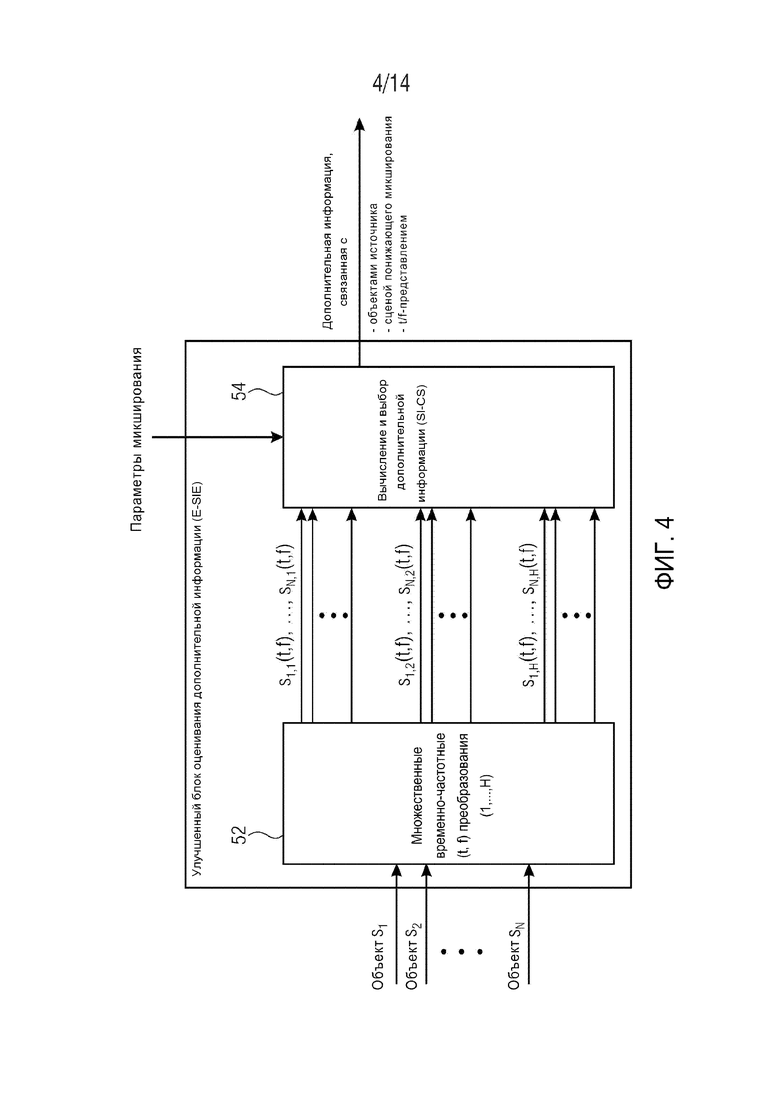
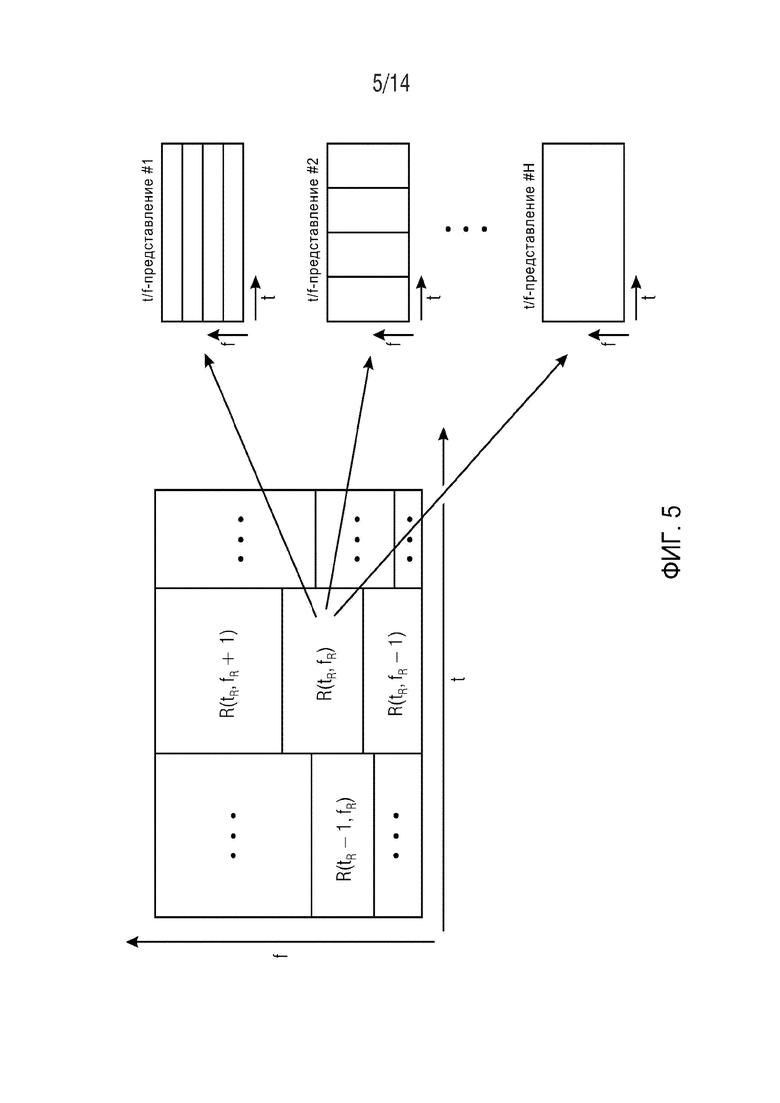
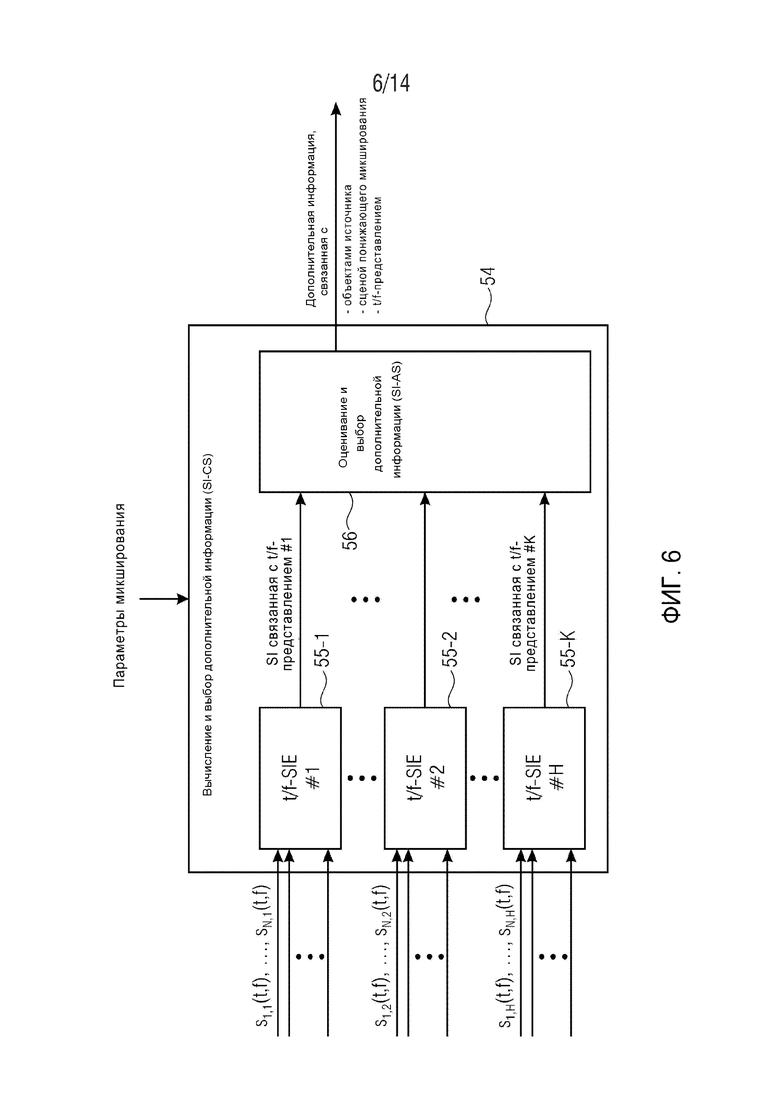
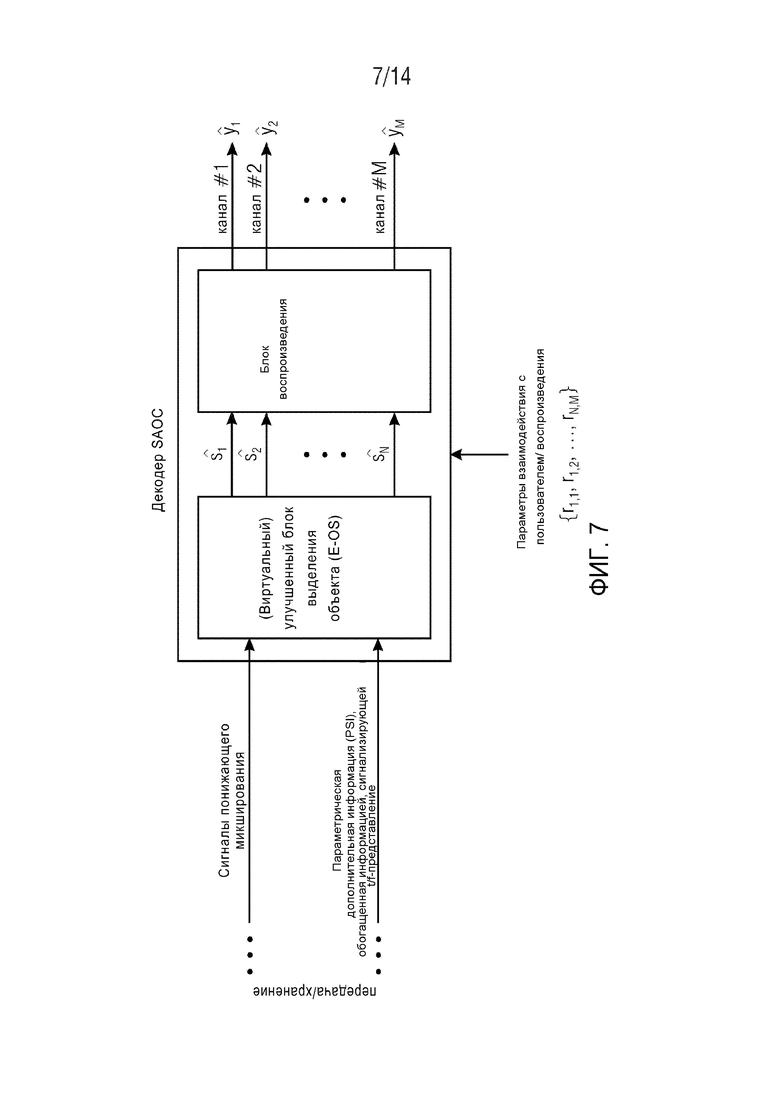
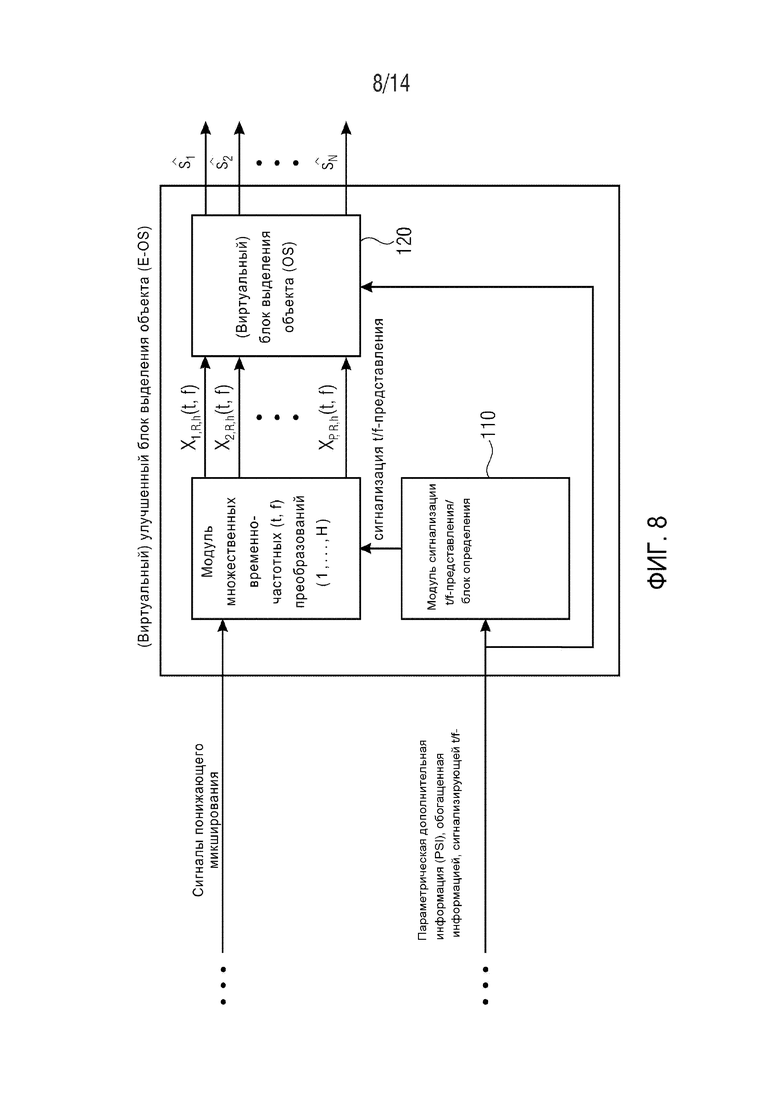
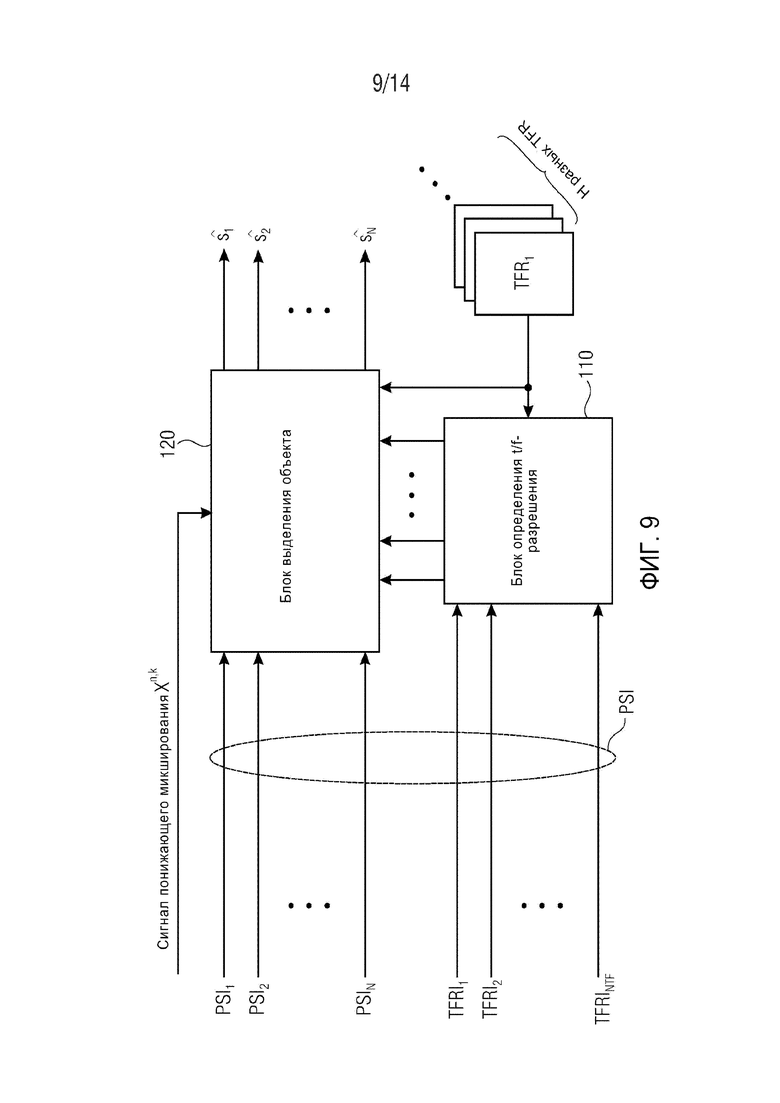
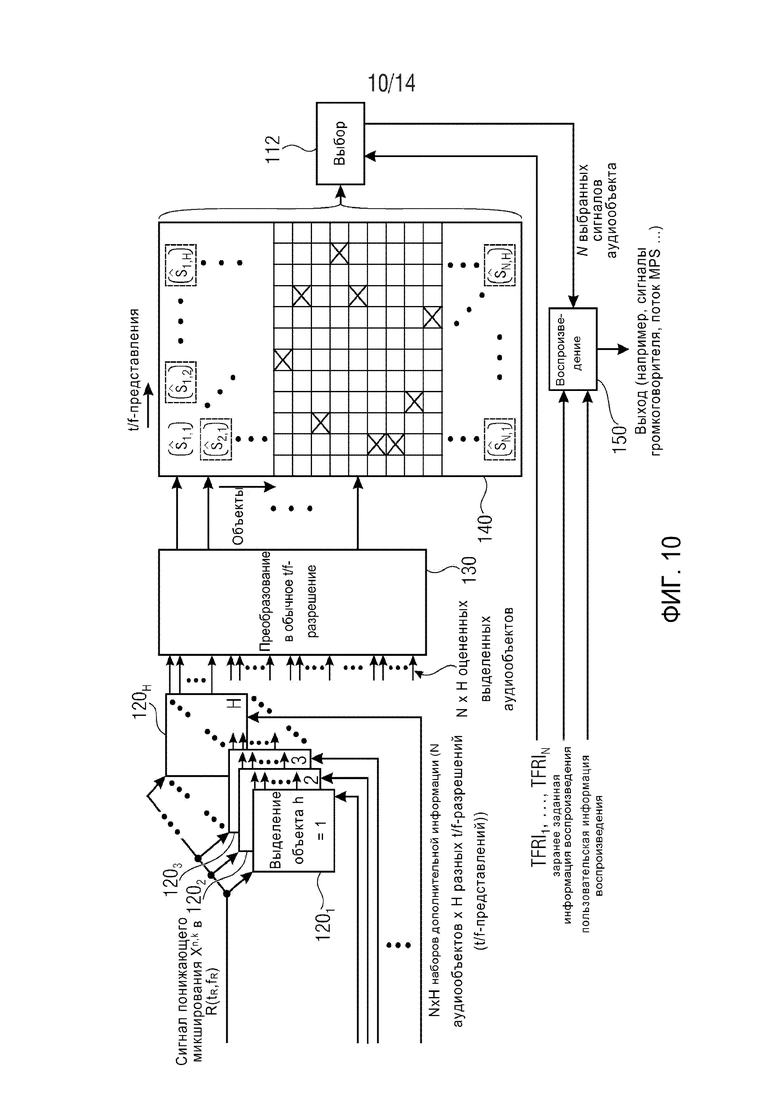
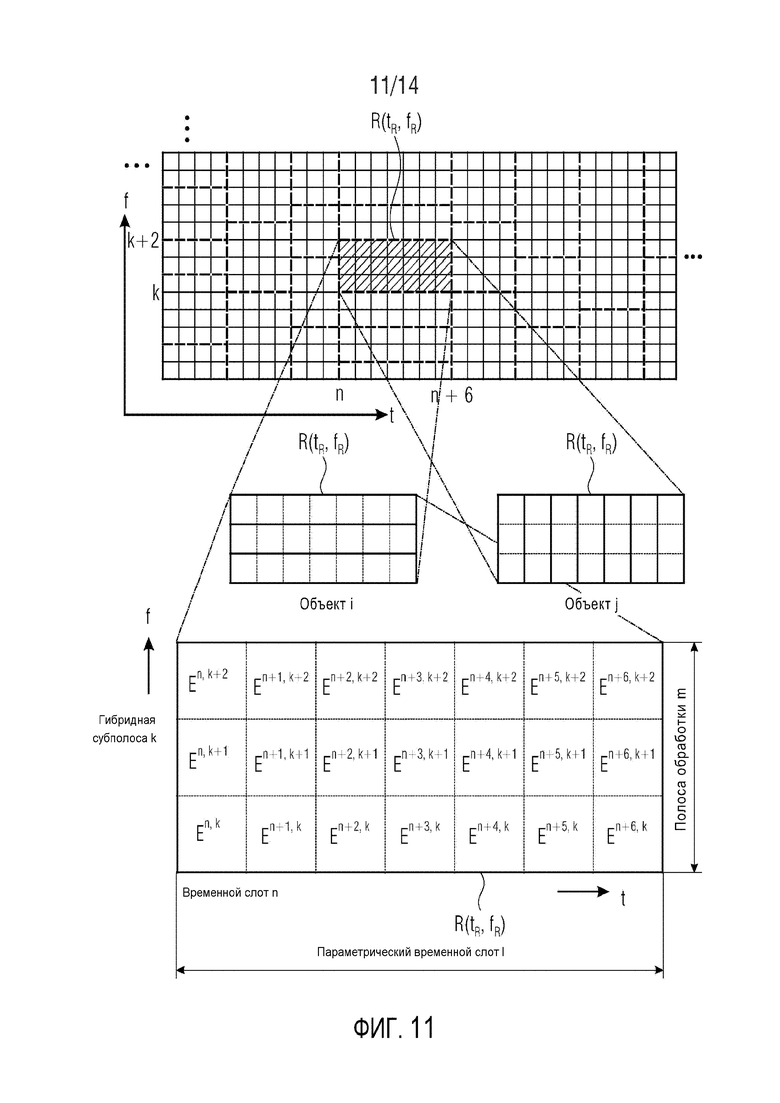
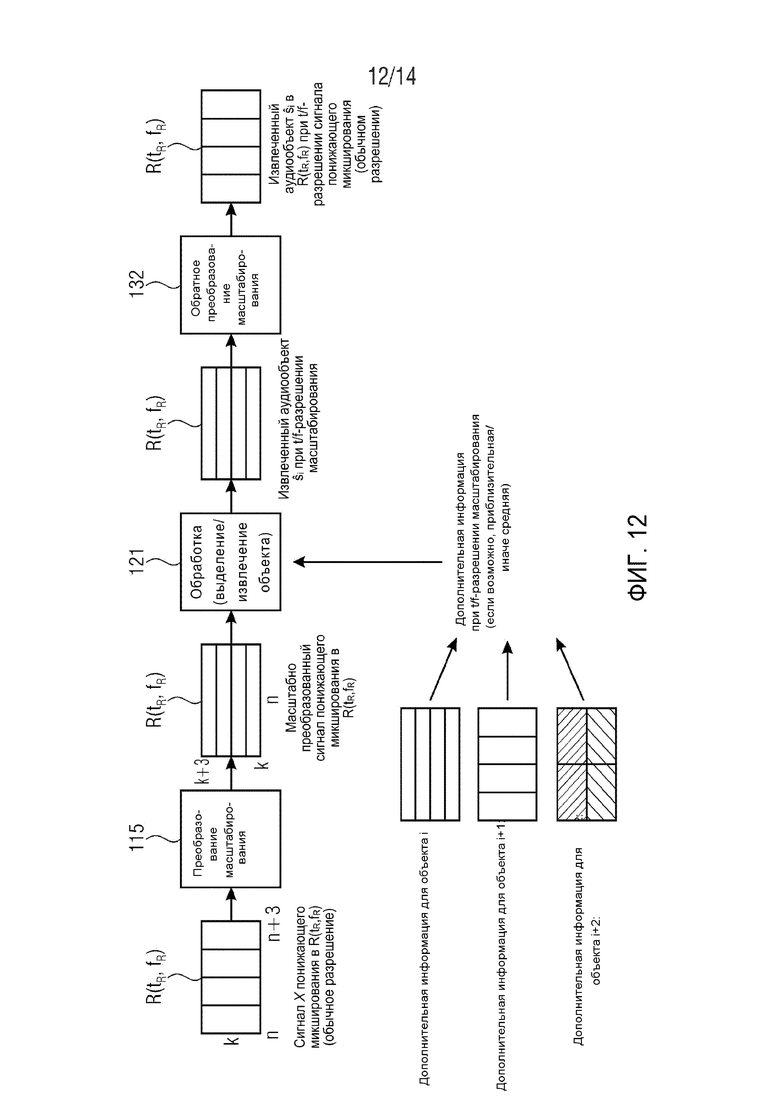
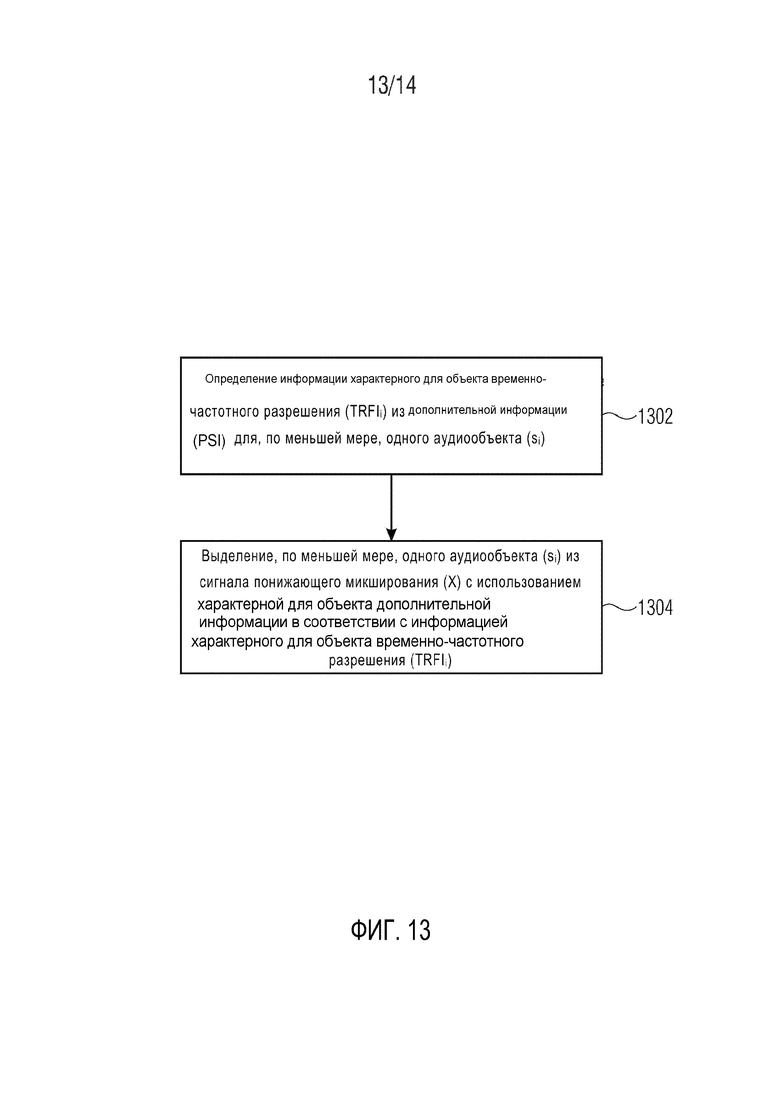
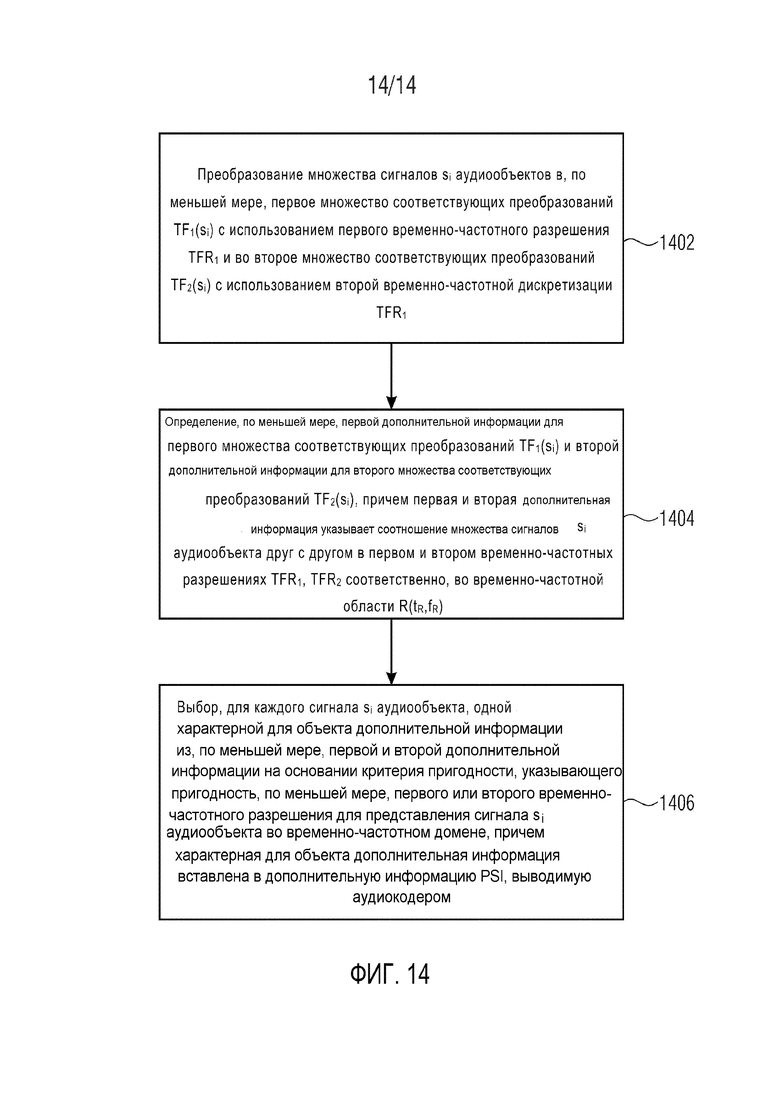
Изобретение относится к обработке аудиосигнала и предназначено для кодирования аудиообъектов с применением адаптируемого к аудиообъекту индивидуального временно-частотного разрешения. Технический результат – повышение качества воспроизводимого аудиосигнала. Аудиодекодер декодирует многообъектный аудиосигнал, состоящий из сигнала X понижающего микширования и дополнительной информации PSI. Дополнительная информация содержит дополнительную информацию PSIi для аудиообъекта si во временно-частотной области R(tR,fR) и информацию TFRIi, указывающую временно-частотное разрешение TFRh дополнительной информации для аудиообъекта si во временно-частотной области R(tR,fR). Аудиодекодер содержит блок определения временно-частотного разрешения, выполненный с возможностью определения информации TFRIi временно-частотного разрешения из дополнительной информации PSI для аудиообъекта si., блок выделения объекта, выполненный с возможностью выделения аудиообъекта si из сигнала X понижающего микширования с использованием дополнительной информации в соответствии с временно-частотным разрешением TFRIi. 11 н. и 11 з.п. ф-лы, 14 ил.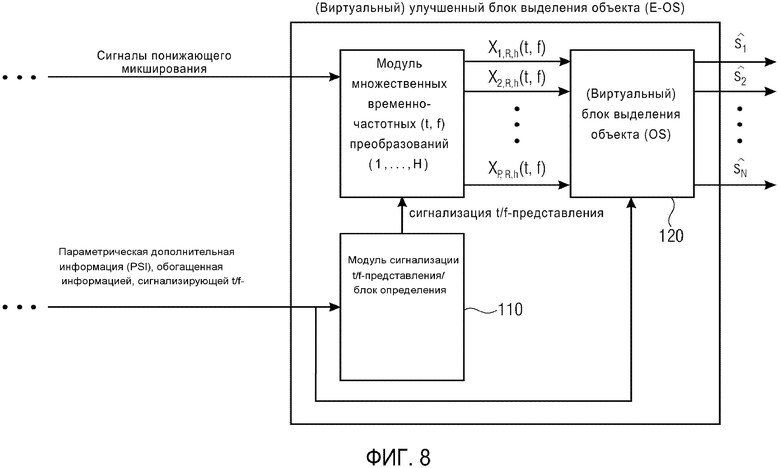
1. Аудиодекодер для декодирования многообъектного аудиосигнала, состоящего из сигнала (X) понижающего микширования и дополнительной информации (PSI), причем дополнительная информация содержит характерную для объекта дополнительную информацию (PSIi) для по меньшей мере одного аудиообъекта (si) в по меньшей мере одной временно-частотной области (R(tR,fR)) и информацию (TFRIi) характерного для объекта временно-частотного разрешения, указывающую характерное для объекта временно-частотное разрешение (TFRh) характерной для объекта дополнительной информации для по меньшей мере одного аудиообъекта (si) в по меньшей мере одной временно-частотной области (R(tR,fR)), причем аудиодекодер содержит:
блок (110) определения характерного для объекта временно-частотного разрешения, выполненный с возможностью определения информации характерного для объекта временно-частотного разрешения (TFRIi) из дополнительной информации (PSI) для по меньшей мере одного аудиообъекта (si), и
блок (120) выделения объекта, выполненный с возможностью выделения по меньшей мере одного аудиообъекта (si) из сигнала (X) понижающего микширования с использованием характерной для объекта дополнительной информации в соответствии с характерным для объекта временно-частотным разрешением (TFRIi).
2. Аудиодекодер по п. 1, в котором характерная для объекта дополнительная информация является характерной для объекта дополнительной информацией (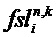
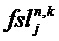
3. Аудиодекодер по п. 1, в котором характерная для объекта дополнительная информация (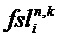
4. Аудиодекодер по п. 1, в котором сигнал (X) понижающего микширования дискретизируется во временно-частотной области на множество временных слотов и множество (гибридных) субполос, причем временно-частотная область (R(tR,fR)) распространяется на по меньшей мере две выборки сигнала (X) понижающего микширования, и при этом характерное для объекта временно-частотное разрешение (TFRh) точнее в по меньшей мере одном из двух измерений, чем временно-частотная область (R(tR,fR)).
5. Аудиодекодер по п. 1, в котором блок (120) выделения объекта выполнен с возможностью определения оцененной ковариационной матрицы (Eη,κ) с элементами 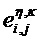
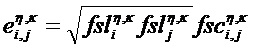
где 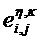
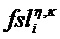
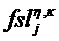
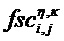
причем по меньшей мере одна из 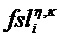
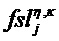
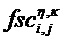
причем блок (120) выделения объекта дополнительно выполнен с возможностью выделения по меньшей мере одного аудиообъекта (si) из сигнала (X) понижающего микширования с использованием оцененной ковариационной матрицы (Eη,κ).
6. Аудиодекодер по п. 1, дополнительно содержащий:
временно-частотный преобразователь сигнала понижающего микширования, выполненный с возможностью преобразования сигнала (X) понижающего микширования во временно-частотной области (R(tR,fR)) от временно-частотного разрешения сигнала понижающего микширования к по меньшей мере характерному для объекта временно-частотному разрешению (TFRh) по меньшей мере одного аудиообъекта (si) для получения повторно преобразованного сигнала (Xη,κ) понижающего микширования;
обратный временно-частотный преобразователь, выполненный с возможностью временно-частотного преобразования по меньшей мере одного аудиообъекта (si) во временно-частотной области (R(tR,fR)) от характерного для объекта временно-частотного разрешения (TFRh) обратно в обычное t/f-разрешение или временно-частотное разрешение сигнала понижающего микширования,
причем блок (120) выделения объекта выполнен с возможностью выделения по меньшей мере одного аудиообъекта (si) из сигнала (X) понижающего микширования с характерным для объекта временно-частотным разрешением (TFRh).
7. Аудиокодер для кодирования множества аудиообъектов (si) в сигнал (X) понижающего микширования и дополнительную информацию (PSI), причем аудиокодер содержит:
временно-частотный преобразователь, выполненный с возможностью преобразования множества аудиообъектов (si) по меньшей мере в первое множество соответствующих преобразований (s1,1(t,f)…sN,1(t,f)) с использованием первого временно-частотного разрешения (TFR1) и во второе множество соответствующих преобразований (s1,2(t,f)…sN,2(t,f)) с использованием второго временно-частотного разрешения (TFR2);
блок определения дополнительной информации (t/f-SIE), выполненный с возможностью определения по меньшей мере первой дополнительной информации для первого множества соответствующих преобразований (s1,1(t,f)…sN,1(t,f)) и второй дополнительной информации для второго множества соответствующих преобразований (s1,2(t,f)…sN,2(t,f)), причем первая и вторая дополнительная информация указывает соотношение множества аудиообъектов (si) друг с другом в первом и втором временно-частотных разрешениях (TFR1, TFR2) соответственно во временно-частотной области (R(tR,fR)), и
блок (SI-AS) выбора дополнительной информации, выполненный с возможностью выбора для по меньшей мере одного аудиообъекта (si) из множества аудиообъектов одной характерной для объекта дополнительной информации из по меньшей мере первой и второй дополнительной информации на основании критерия пригодности, указывающего пригодность по меньшей мере первого или второго временно-частотного разрешения для представления аудиообъекта (si) во временно-частотной области, причем характерная для объекта дополнительная информация вставлена в дополнительную информацию (PSI), выводимую аудиокодером.
8. Аудиокодер по п. 7, в котором критерий пригодности основан на оценке источника, и при этом блок (SI-AS) выбора дополнительной информации содержит:
блок оценивания источника, выполненный с возможностью оценивания по меньшей мере выбранного аудиообъекта из множества аудиообъектов (si) с использованием сигнала (X) понижающего микширования и по меньшей мере первой информации и второй информации, соответствующих первому и второму временно-частотным разрешениям (TFR1, TFR2) соответственно, и таким образом блок оценивания источника обеспечивает по меньшей мере первый оцененный аудиообъект (si,estim1) и второй оцененный аудиообъект (si,estim2);
блок оценивания качества, выполненный с возможностью оценивания качества по меньшей мере первого оцененного аудиообъекта (si,estim1) и второго оцененного аудиообъекта (si,estim2).
9. Аудиокодер по п. 8, в котором блок оценивания качества выполнен с возможностью оценивания качества по меньшей мере первого оцененного аудиообъекта (si,estim1) и второго оцененного аудиообъекта (si,estim2) на основании отношения сигнала к искажению (SDR) в качестве меры производительности оценивания источника, причем отношение сигнала к искажению (SDR) определяется только на основании дополнительной информации (PSI).
10. Аудиокодер по п. 7, в котором критерий пригодности для по меньшей мере одного аудиообъекта (si) из множества аудиообъектов основан на степени разреженности более чем одного представления t/f-разрешения по меньшей мере одного аудиообъекта согласно по меньшей мере первому временно-частотному разрешению (TFR1) и второму временно-частотному разрешению (TFR2), и при этом блок (SI-AS) выбора дополнительной информации выполнен с возможностью выбора дополнительной информации из по меньшей мере первой и второй дополнительной информации, которая связана с наиболее разреженным t/f-представлением по меньшей мере одного аудиообъекта (si).
11. Аудиокодер по п. 7, в котором блок (t/f-SIE) определения дополнительной информации дополнительно выполнен с возможностью обеспечения характерной для объекта дополнительной информации (
12. Аудиокодер по п. 11, в котором характерная для объекта дополнительная информация (
13. Аудиокодер по п. 7, дополнительно содержащий процессор сигнала понижающего микширования, выполненный с возможностью преобразования сигнала (X) понижающего микширования в представление, которое дискретизируется во временно-частотной области на множество временных слотов и множество (гибридных) субполос, причем временно-частотная область (R(tR,fR)) распространяется на по меньшей мере две выборки сигнала (X) понижающего микширования, и при этом характерное для объекта временно-частотное разрешение (TFRh), указанное для по меньшей мере одного аудиообъекта, точнее в по меньшей мере одном из двух измерений, чем временно-частотная область (R(tR,fR)).
14. Способ декодирования многообъектного аудиосигнала, состоящего из сигнала (X) понижающего микширования и дополнительной информации (PSI), причем дополнительная информация содержит характерную для объекта дополнительную информацию (PSIi) для по меньшей мере одного аудиообъекта (si) в по меньшей мере одной временно-частотной области (R(tR,fR)) и информацию (TFRIi) характерного для объекта временно-частотного разрешения, указывающую характерное для объекта временно-частотное разрешение (TFRh) характерной для объекта дополнительной информации для по меньшей мере одного аудиообъекта (si) в по меньшей мере одной временно-частотной области (R(tR,fR)), причем способ содержит этапы, на которых:
определяют информацию (TFRIi) характерного для объекта временно-частотного разрешения из дополнительной информации (PSI) для по меньшей мере одного аудиообъекта (si), и
выделяют по меньшей мере один аудиообъект (si) из сигнала (X) понижающего микширования с использованием характерной для объекта дополнительной информации в соответствии с характерным для объекта временно-частотным разрешением (TFRIi).
15. Способ кодирования множества аудиообъектов (si) в сигнал понижающего микширования (X) и дополнительную информацию (PSI), причем способ содержит этапы, на которых:
преобразуют множество аудиообъектов (si) по меньшей мере в первое множество соответствующих преобразований (s1,1(t,f)…sN,1(t,f)) с использованием первого временно-частотного разрешения (TFR1) и во второе множество соответствующих преобразований (s1,2(t,f)…sN,2(t,f)) с использованием второго временно-частотного разрешения (TFR2);
определяют по меньшей мере первую дополнительную информацию для первого множества соответствующих преобразований (s1,1(t,f)…sN,1(t,f)) и вторую дополнительную информацию для второго множества соответствующих преобразований (s1,2(t,f) … sN,2(t,f)), причем первая и вторая дополнительная информация указывает соотношение множества аудиообъектов (si) друг с другом в первом и втором временно-частотных разрешениях (TFR1, TFR2) соответственно во временно-частотной области (R(tR,fR), и
выбирают для по меньшей мере одного аудиообъекта (si) из множества аудиообъектов одну характерную для объекта дополнительную информацию из по меньшей мере первой и второй дополнительной информации на основании критерия пригодности, указывающего пригодность по меньшей мере первого или второго временно-частотного разрешения для представления аудиообъекта (si) во временно-частотной области, причем характерная для объекта дополнительная информация вставлена в дополнительную информацию (PSI), выводимую аудиокодером.
16. Аудиодекодер для декодирования многообъектного аудиосигнала, состоящего из сигнала понижающего микширования (X) и дополнительной информации (PSI), причем дополнительная информация содержит характерную для объекта дополнительную информацию (PSIi) для по меньшей мере одного аудиообъекта (si) в по меньшей мере одной временно-частотной области (R(tR,fR)) и информацию (TFRIi) характерного для объекта временно-частотного разрешения, указывающую характерное для объекта временно-частотное разрешение (TFRh) характерной для объекта дополнительной информации для по меньшей мере одного аудиообъекта (si) в по меньшей мере одной временно-частотной области (R(tR,fR)), причем аудиодекодер содержит:
блок (110) определения характерного для объекта временно-частотного разрешения, выполненный с возможностью определения информации (TFRIi) характерного для объекта временно-частотного разрешения из дополнительной информации (PSI) для по меньшей мере одного аудиообъекта (si), и
блок (120) выделения объекта, выполненный с возможностью выделения по меньшей мере одного аудиообъекта (si) из сигнала (X) понижающего микширования с использованием характерной для объекта дополнительной информации в соответствии с характерным для объекта временно-частотным разрешением (TFRIi), причем характерная для объекта дополнительная информация для по меньшей мере одного другого аудиообъекта (sj) в сигнале понижающего микширования имеет другое характерное для объекта временно-частотное разрешение (TFR).
17. Способ декодирования многообъектного аудиосигнала, состоящего из сигнала понижающего микширования (X) и дополнительной информации (PSI), причем дополнительная информация содержит характерную для объекта дополнительную информацию (PSIi) для по меньшей мере одного аудиообъекта (si) в по меньшей мере одной временно-частотной области (R(tR,fR)) и информацию (TFRIi) характерного для объекта временно-частотного разрешения, указывающую характерное для объекта временно-частотное разрешение (TFRh) характерной для объекта дополнительной информации для по меньшей мере одного аудиообъекта (si) в по меньшей мере одной временно-частотной области (R(tR,fR)), причем способ содержит этапы, на которых:
определяют информацию (TFRIi) характерного для объекта временно-частотного разрешения из дополнительной информации (PSI) для по меньшей мере одного аудиообъекта (si), и
выделяют по меньшей мере один аудиообъект (si) из сигнала понижающего микширования (X) с использованием характерной для объекта дополнительной информации в соответствии с характерным для объекта временно-частотным разрешением (TFRIi), причем характерная для объекта дополнительная информация для по меньшей мере одного другого аудиообъекта (sj) в сигнале понижающего микширования имеет другое характерное для объекта временно-частотное разрешение (TFR).
18. Машиночитаемый носитель, имеющий сохраненный на нем программный код, который, когда выполняется на компьютере, осуществляет способ декодирования многообъектного аудиосигнала по п. 14.
19. Машиночитаемый носитель, имеющий сохраненный на нем программный код, который, когда выполняется на компьютере, осуществляет способ кодирования множества аудиообъектов по п. 15.
20. Машиночитаемый носитель, имеющий сохраненный на нем программный код, который, когда выполняется на компьютере, осуществляет способ декодирования многообъектного аудиосигнала по п. 17.
21. Аудиодекодер для декодирования многообъектного аудиосигнала, состоящего из сигнала (X) понижающего микширования и дополнительной информации (PSI), причем дополнительная информация содержит характерную для объекта дополнительную информацию (PSIi) для по меньшей мере одного аудиообъекта (si) в по меньшей мере одной временно-частотной области (R(tR,fR)) и информацию (TFRIi) характерного для объекта временно-частотного разрешения, указывающую характерное для объекта временно-частотное разрешение (TFRh) характерной для объекта дополнительной информации для по меньшей мере одного аудиообъекта (si) в по меньшей мере одной временно-частотной области (R(tR,fR)), причем аудиодекодер содержит:
блок (110) определения характерного для объекта временно-частотного разрешения, выполненный с возможностью определения информации (TFRIi) характерного для объекта временно-частотного разрешения из дополнительной информации (PSI) для по меньшей мере одного аудиообъекта (si), и
блок (120) выделения объекта, выполненный с возможностью выделения по меньшей мере одного аудиообъекта (si) из сигнала (X) понижающего микширования с использованием характерной для объекта дополнительной информации в соответствии с характерным для объекта временно-частотным разрешением (TFRIi),
причем характерная для объекта дополнительная информация является характерной для объекта дополнительной информацией (
причем характерная для объекта дополнительная информация (
22. Способ декодирования многообъектного аудиосигнала, состоящего из сигнала (X) понижающего микширования и дополнительной информации (PSI), причем дополнительная информация содержит характерную для объекта дополнительную информацию (PSIi) для по меньшей мере одного аудиообъекта (si) в по меньшей мере одной временно-частотной области (R(tR,fR)) и информацию (TFRIi) характерного для объекта временно-частотного разрешения, указывающую характерное для объекта временно-частотное разрешение (TFRh) характерной для объекта дополнительной информации для по меньшей мере одного аудиообъекта (si) в по меньшей мере одной временно-частотной области (R(tR,fR)), причем способ содержит этапы, на которых:
определяют информацию (TFRIi) характерного для объекта временно-частотного разрешения из дополнительной информации (PSI) для по меньшей мере одного аудиообъекта (si), и
выделяют по меньшей мере один аудиообъект (si) из сигнала (X) понижающего микширования с использованием характерной для объекта дополнительной информации в соответствии с характерным для объекта временно-частотным разрешением (TFRIi),
причем характерная для объекта дополнительная информация является характерной для объекта дополнительной информацией (
причем характерная для объекта дополнительная информация (
| Колосоуборка | 1923 |
|
SU2009A1 |
| АППАРАТУРА И МЕТОД МНОГОКАНАЛЬНОГО ПАРАМЕТРИЧЕСКОГО ПРЕОБРАЗОВАНИЯ | 2007 |
|
RU2431940C2 |
| СПОСОБ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ АУДИОСИГНАЛА И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2006 |
|
RU2473062C2 |
| СПОСОБ, УСТРОЙСТВО, КОДИРУЮЩЕЕ УСТРОЙСТВО, ДЕКОДИРУЮЩЕЕ УСТРОЙСТВО И АУДИОСИСТЕМА | 2005 |
|
RU2396608C2 |
| US 7756713 B2, 13.07.2010 | |||
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |

