Настоящее изобретение относится к кодированию, декодированию и обработке аудиосигнала и, в частности, к кодеру, декодеру и способам для обратно совместимого пространственного кодирования аудиообъектов (SAOC) с переменным разрешением.
В современных цифровых аудиосистемах главной тенденцией является обеспечение относящихся к аудиообъекту модификаций передаваемого содержания на стороне приемника. Эти модификации включают в себя модификации усиления выбранных частей аудиосигнала и/или изменение пространственного положения аудиообъектов в случае многоканального воспроизведения через пространственно-распределенные громкоговорители. Это может быть достигнуто путем отдельной подачи различных частей аудио-содержания различным громкоговорителям.
Другими словами, в области обработки, передачи и хранения аудиоданных существует возрастающее желание обеспечить взаимодействие между пользователем и объектно-ориентированном воспроизведением аудио-содержания, а также запрос на использование расширенных возможностей многоканального воспроизведения для индивидуального осуществления рендеринга аудио-содержания или его части для улучшения впечатлений от прослушивания. Таким образом, использование многоканального аудио-содержания приводит к значительным улучшениям для пользователя. Например, может быть получено трехмерное впечатление от прослушивания, которое приводит к большей удовлетворенности пользователей в развлекательных приложениях. Однако многоканальное аудио-содержание также полезно в профессиональных средах, например, в приложениях телефонной конференц-связи, потому что разборчивость речи собеседников может быть улучшена при использовании многоканального аудио-воспроизведения. Другое возможное применение состоит в том, чтобы предложить слушателю музыкального произведения индивидуально регулировать уровень воспроизведения и/или пространственное положение различных частей (также называемых "аудиообъектами") или дорожек, таких как вокальная часть или различные инструменты. Пользователь может выполнять такую регулировку в связи с персональными предпочтениями, для более легкой расшифровки одной или нескольких частей музыкального произведения, с образовательными целями, для караоке, репетиции и т.д.
Прямая раздельная передача всего цифрового многоканального или многообъектного аудио-содержания, например, в форме данных импульсно-кодовой модуляции (PCM) или даже сжатых аудио-форматов требует очень высоких битовых скоростей. Однако также желательны передача и хранение аудиоданных эффективным, с точки зрения бытовой скорости, образом. Поэтому необходим приемлемый компромисс между качеством звука и требованиями битовой скорости, чтобы избежать чрезмерной загрузки ресурсов, вызванной многоканальными/многообъектными приложениями.
Недавно в области кодирования аудиосигналов были внедрены параметрические методики для эффективной с точки зрения битовой скорости передачи/хранения многоканальных/многообъектных аудиосигналов, например, экспертной группой в области движущихся изображений (MPEG) и другими. Одним из примеров является Объемный MPEG (MPS) в качестве канально-ориентированного подхода [MPS, BCC] или Пространственное кодирование аудиообъектов (SAOC) MPEG в качестве объектно-ориентированного подхода [JSC, SAOC, SAOC1, SAOC2]. Другой объектно-ориентированный подход называется "информированное разделение источников" [ISS1, ISS2, ISS3, ISS4, ISS5, ISS6]. Эти методики направлены на реконструкцию требуемой выходной аудио-сцены или требуемого объекта-источника звука на основе понижающего микширования каналов/объектов и дополнительной вспомогательной информации, описывающей переданную/сохраненную аудио сцену и/или объекты-источники звука в аудио-сцене.
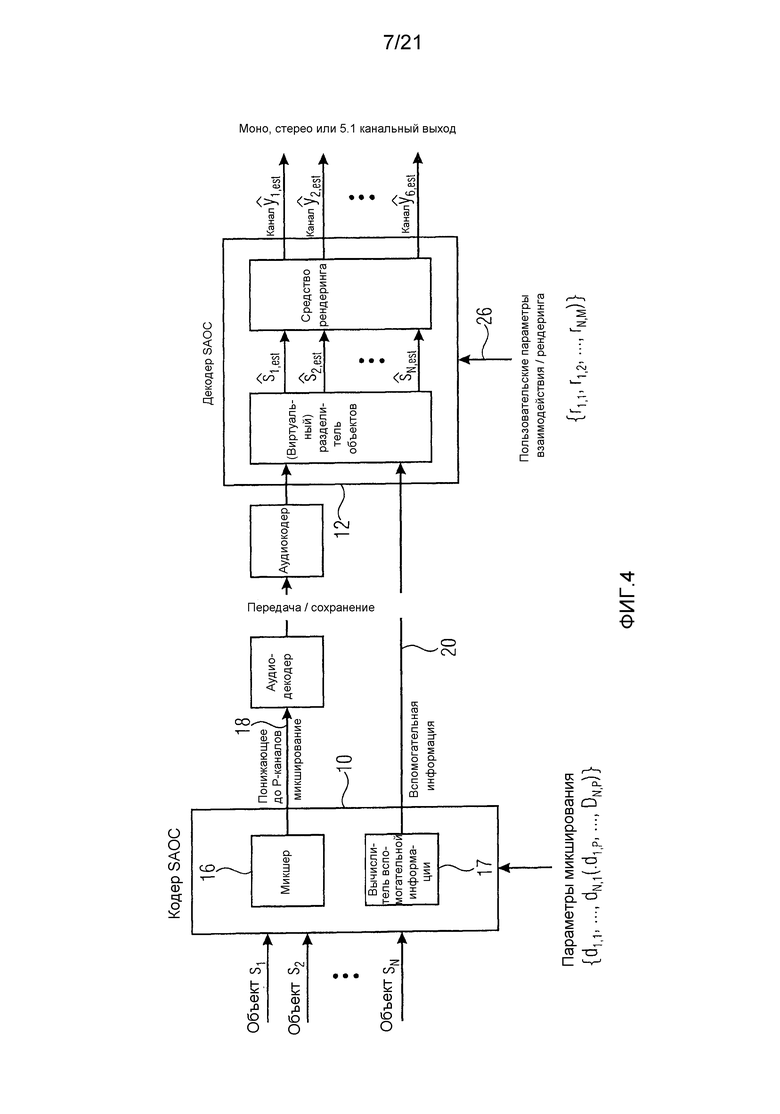
Оценка и применение относящейся к каналу/объекту вспомогательной информации в таких системах осуществляется избирательным по времени и частоте образом. Поэтому такие системы используют частотно-временные преобразования, такие как дискретное преобразование Фурье (DFT), оконное преобразование Фурье (STFT) или наборы фильтров, такие как наборы квадратурных зеркальных фильтров (QMF) и т.д. Основной принцип таких систем изображен на фиг. 4 с использованием примера SAOC MPEG.
В случае STFT временное измерение представлено номером блока времени, а спектральное измерение записано с помощью номера коэффициента спектрального разложения ("элемента"). В случае QMF временное измерение представлено номером временного интервала, а спектральное измерение записано с помощью номера поддиапазона. Если спектральное разрешение QMF улучшено путем последующего применения второго звена фильтра, то весь набор фильтров называется гибридным QMF, а поддиапазоны высокого разрешения называются гибридными поддиапазонами.
Как уже упоминалось выше, в SAOC общая обработка выполняется избирательным по времени и частоте образом, и она может быть описана следующим образом в пределах каждой полосы частот:
- N входных сигналов 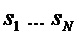
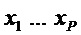
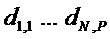
- Сигнал(ы) понижающего микширования и вспомогательная информация передаются/сохраняются. С этой целью аудиосигнал(ы) понижающего микширования могут быть сжаты, например, с использованием хорошо известных перцептивных аудио кодеров, таких как MPEG-1/2 уровень II или III (также известного как .mp3), усовершенствованное кодирование звука (AAC) МPEG-2/4 и т.д.
- На приемном конце декодер концептуально пытается восстановить исходные сигналы объектов ("разделение объектов") из (декодируемых) сигналов понижающего микширования с использованием переданной вспомогательной информации. Эти приближенные сигналы объектов 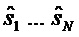
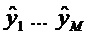
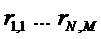
Система на частотно-временной основе могут использовать частотно-временное (t/f) преобразование с постоянным разрешением по времени и частоте. Выбор некоторой фиксированной решетки t/f-разрешения, как правило, включает в себя компромисс между разрешением по времени и по частоте.
Эффект фиксированного t/f-разрешения может быть продемонстрирован на примере типичных сигналов объектов в смеси аудиосигналов. Например, спектры тональных звуков демонстрируют связанную с гармониками структуру с основной частотой и несколькими обертонами. Энергия таких сигналов концентрируется в некоторых областях частот. Для таких сигналов высокочастотное разрешение используемого t/f-представления является выгодным для отделения узкополосных тональных спектральных областей из смеси сигналов. И наоборот, транзиентные (импульсные) сигналы, например барабанные звуки, часто имеют четко выраженную временную структуру: существенная энергия присутствует только в течение коротких промежутков времени и простирается на широкий диапазон частот. Для этих сигналов высокое временное разрешение используемого t/f-представления является выгодным для отделения транзиентной (переходной) части сигнала от смеси сигналов.
Разрешение по частоте, полученное из стандартного представления SAOC, ограничено числом параметрических полос, имея максимальное значение, равное 28 в стандартном SAOC. Они получаются из набора гибридных QMF, состоящего из 64-полосного QMF-анализа с дополнительным звеном гибридной фильтрации на самых низких полосах, дополнительно делящим их на вплоть до 4 комплексных поддиапазонов. Полученные полосы частот группируются в параметрические полосы, имитирующие критическое разрешение полос слуховой системы человека. Группировка позволяет уменьшить требуемую скорость передачи вспомогательной информации до размера, который может эффективно обрабатываться в практических применениях.
Существующие схемы кодирования аудиообъектов предлагают лишь ограниченную варьируемость в частотно-временной избирательности обработки SAOC. Например, SAOC MPEG [SAOC] [SAOC1] [SAOC2] ограничено частотно-временным разрешением, которое может быть получено путем использования так называемого набора гибридных квадратурных зеркальных фильтров (гибридный-QMF) и его последующей группировки в параметрические полосы. Поэтому восстановление объектов в стандартном SAOC часто страдает от низкого разрешения по частоте гибридного-QMF, что приводит к слышимым модулированным перекрестным помехам от других аудиообъектов (например, артефакты одновременного разговора в речи или артефакты акустических шероховатостей в музыке).
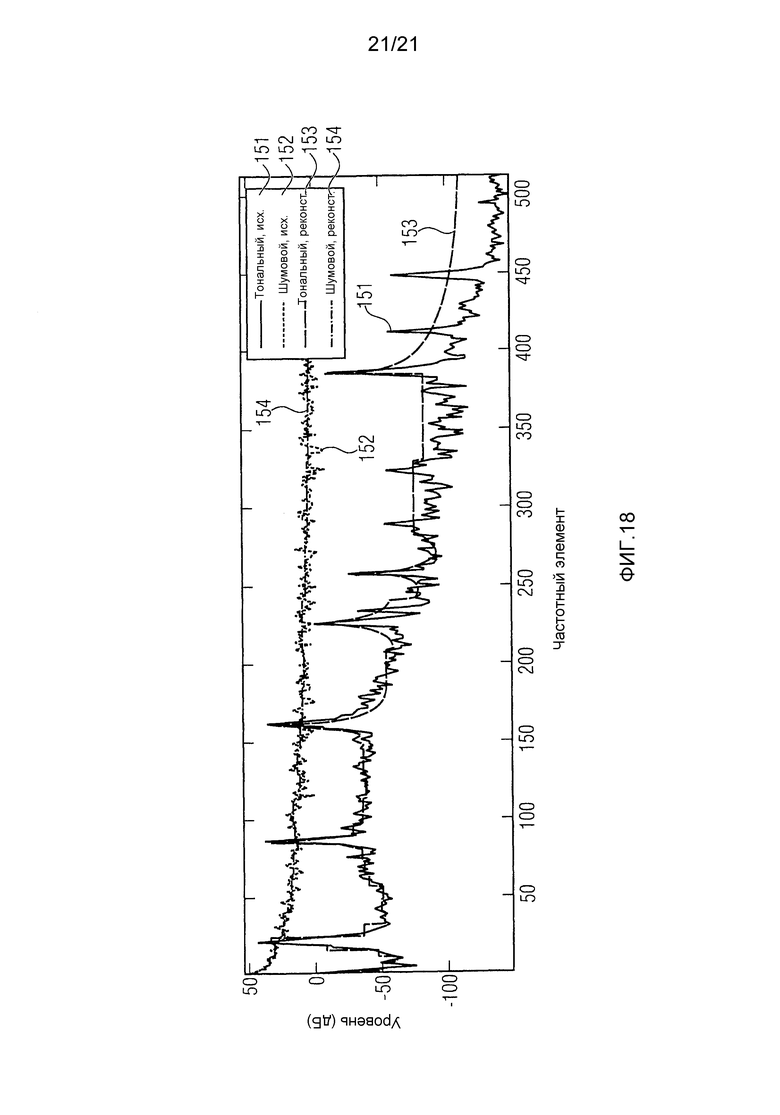
Существующая система производит приемлемое качество разделения, учитывая достаточно низкую скорость передачи данных. Основной проблемой является недостаточное разрешение по частоте для чистого разделения тональных звуков. Это выражается в виде "гало" других объектов, окружающего тональные компоненты объекта. Перцептивно это наблюдается как шероховатость или вокодеро-подобный артефакт. Вредное воздействие этого гало может быть уменьшено путем увеличения параметрического разрешения по частоте. Было отмечено, что разрешение равное или большее 512 полос (при частоте дискретизации 44.1 кГц) является достаточным, чтобы произвести перцептивно значительно улучшенное разделение в тестовых сигналах. Проблема с таким высоким параметрическим разрешением состоит в том, что значительно, до непрактичных величин, увеличивается количество необходимой вспомогательной информации. Кроме того, будет потеряна совместимость с существующими системами стандартного SAOC.
Поэтому было бы очень полезно, если бы можно было обеспечить концепции, которые учат, как преодолеть вышеописанные ограничения существующего уровня техники.
Задачей настоящего изобретения является обеспечение таких улучшенных концепций для кодирования аудиообъектов. Задача настоящего изобретения решается с помощью декодера по п. 1 формулы изобретения, с помощью кодера по п. 9 формулы изобретения, с помощью закодированного аудиосигнала по п. 14 формулы изобретения, с помощью системы по п. 15 формулы изобретения, с помощью способа для декодирования по п. 16 формулы изобретения, с помощью способа для кодирования по п. 17 формулы изобретения и с помощью компьютерной программы по п. 18 формулы изобретения.
В отличие от SAOC существующего уровня техники, варианты воплощения настоящего изобретения обеспечивают такую спектральную параметризацию, что
- битовые потоки параметров SAOC, происходящие от стандартного кодера SAOC, могут по-прежнему декодироваться усовершенствованным декодером с качеством восприятия, сопоставимым с таковым, полученным с помощью стандартного декодера,
- битовые потоки параметров усовершенствованного SAOC могут быть декодированы с помощью стандартного декодера SAOC с качеством, сопоставимым с получаемым с помощью битовых потоков стандартного SAOC,
- битовые потоки параметров усовершенствованного SAOC могут декодироваться с оптимальным качеством с помощью усовершенствованного декодера,
- усовершенствованный декодер SAOC может динамически регулировать уровень улучшения, например, в зависимости от доступных вычислительных ресурсов,
- битовые потоки параметров стандартного и усовершенствованного SAOC могут смешиваться, например, в случае многоточечного блока управления (MCU), в один общий битовый поток, который может быть декодирован с помощью стандартного или усовершенствованного декодера с качеством, обеспечиваемым декодером, и
- дополнительная параметризация является компактной.
Для упомянутых выше свойств предпочтительно иметь параметризацию, которая понятна стандартному декодеру SAOC, но также позволяет осуществлять эффективную доставку информации с более высоким разрешением по частоте. Разрешение лежащего в основе частотно-временного представления определяет максимальную производительность улучшений. Изобретение в настоящем документе определяет способ для доставки расширенной высокочастотной информации способом, который является компактным и позволяет осуществлять обратно совместимое декодирование.
Качество восприятия усовершенствованного SAOC может быть получено, например, с помощью динамической адаптации разрешения по времени/частоте набора фильтров или преобразования, которое используется для оценки или синтеза признаков аудиообъектов для конкретных свойств входного аудиообъекта. Например, если аудиообъект является квазистационарным в течение некоторого интервала времени, оценка и синтез параметров предпочтительно выполняются с низким разрешением по времени и высоким разрешением по частоте. Если аудиообъект содержит транзиенты (короткие одиночные импульсы) или нестационарности в течение некоторого интервала времени, оценка параметров и синтез предпочтительно делаются с использованием высокого разрешения по времени и низкого разрешения по частоте. Таким образом, динамическая адаптация набора фильтров или преобразования позволяет обеспечить
- высокую частотную избирательность в спектральном разделении квазистационарных сигналов, чтобы избежать перекрестных помех между объектами, и
- высокую точность по времени для начал объектов или транзиентных событий для минимизации опережающего и запаздывающего эха.
В то же время, качество традиционного SAOC может быть получено путем отображения данных стандартного SAOC на частотно-временную решетку, обеспеченную обратно совместимым адаптивным преобразованием сигнала согласно изобретению, которое зависит от вспомогательной информации, описывающей характеристики сигнала объекта.
Возможность декодировать данные и стандартного, и усовершенствованного SAOC с использованием одного общего преобразования обеспечивает прямую обратную совместимость для приложений, которые охватывают смешивание данных стандартного и нового усовершенствованного SAOC. Это также позволяет обеспечить избирательное по частоте и времени улучшение стандартного качества.
Обеспеченные варианты воплощения не ограничиваются никаким конкретным частотно-временным преобразованием, и могут применяться с любым преобразованием, обеспечивающим в достаточной мере высокое разрешение по частоте. Документ описывает применение к основанному на дискретном преобразовании Фурье (DFT) набору фильтров с переключаемым частотно-временным разрешением. В этом подходе сигналы временной области подразделяются на более короткие блоки, которые могут также перекрываться. Сигнал в каждом более коротком блоке умножается на весовой коэффициент в виде оконной функции (обычно имеющей большие значения в середине и уменьшающуюся до нуля на обоих концах). Наконец, умноженный на весовой коэффициент сигнал преобразуется в частотную область с помощью выбранного преобразования, в данном описании путем применения DFT.
Обеспечен декодер для генерации размикшированного (“un-mixed”) аудиосигнала, содержащий множество размикшированных аудиоканалов. Декодер содержит определитель информации размикширования для определения информации размикширования путем приема первой параметрической вспомогательной информации о по меньшей мере одном сигнале аудиообъекта и второй параметрической вспомогательной информации о по меньшей мере одном сигнале аудиообъекта, при этом разрешение по частоте второй параметрической вспомогательной информации выше, чем разрешение по частоте первой параметрической вспомогательной информации. Кроме того, декодер содержит модуль размикширования для применения информации размикширования к сигналу понижающего микширования, указывающим понижающее микширование по меньшей мере одного сигнала аудиообъекта, для получения размикшированного аудиосигнала, содержащего упомянутое множество размикшированных аудиоканалов. Определитель информации размикширования сконфигурирован определять информацию размикширования путем модификации первой параметрической информации и второй параметрической информации для получения модифицированной параметрической информации так, что модифицированная параметрическая информация имеет разрешение по частоте, которое выше, чем первое разрешение по частоте.
Кроме того, обеспечен кодер для кодирования одного или нескольких входных сигналов аудиообъектов. Кодер содержит блок понижающего микширования для понижающего микширования упомянутого одного или нескольких входных сигналов аудиообъектов для получения одного или нескольких сигналов понижающего микширования. Кроме того, кодер содержит генератор параметрической вспомогательной информации для генерации первой параметрической вспомогательной информации о по меньшей мере одном сигнале аудиообъекта и второй параметрической вспомогательной информации о по меньшей мере одном сигнале аудиообъекта так, что разрешение по частоте второй параметрической вспомогательной информации выше, чем разрешение по частоте первой параметрической вспомогательной информации.
Кроме того, обеспечен закодированный аудиосигнал. Закодированный аудиосигнал содержит часть понижающего микширования, указывающую понижающее микширование одного или нескольких входных сигналов аудиообъектов, и часть параметрической вспомогательной информации, содержащую первую параметрическую вспомогательную информацию о по меньшей мере одном сигнале аудиообъекта и вторую параметрическую вспомогательную информацию о по меньшей мере одном сигнале аудиообъекта. Разрешение по частоте второй параметрической вспомогательной информации выше, чем разрешение по частоте первой параметрической вспомогательной информации.
Кроме того, обеспечена система. Система содержит кодер, описанный выше, и декодер, описанный выше. Кодер сконфигурирован кодировать один или несколько входных сигналов аудиообъектов путем получения одного или нескольких сигналов понижающего микширования, указывающих понижающее микширование одного или нескольких входных сигналов аудиообъектов, путем получения первой параметрической вспомогательной информации о по меньшей мере одном сигнале аудиообъекта и получения второй параметрической вспомогательной информации о по меньшей мере одном сигнале аудиообъекта, при этом разрешение по частоте второй параметрической вспомогательной информации выше, чем разрешение по частоте первой параметрической вспомогательной информации. Декодер сконфигурирован генерировать размикшированный аудиосигнал на основании одного или нескольких сигналов понижающего микширования и на основании первой параметрической вспомогательной информации и второй параметрической вспомогательной информации.
Кодер сконфигурирован кодировать один или несколько входных сигналов аудиообъектов путем получения одного или нескольких сигналов понижающего микширования, указывающих понижающее микширование одного или нескольких входных сигналов аудиообъектов, путем получения первой параметрической вспомогательной информации о по меньшей мере одном сигнале аудиообъекта и путем получения второй параметрической вспомогательной информации о по меньшей мере одном сигнале аудиообъекта, при этом разрешение по частоте второй параметрической вспомогательной информации выше, чем разрешение по частоте первой параметрической вспомогательной информации. Декодер сконфигурирован генерировать выходной аудиосигнал на основании одного или нескольких сигналов понижающего микширования и на основании первой параметрической вспомогательной информации и второй параметрической вспомогательной информации.
Кроме того, обеспечен способ для генерации размикшированного аудиосигнала, содержащего множество размикшированных аудиоканалов. Способ содержит этапы, на которых:
- определяют информацию размикширования путем приема первой параметрической вспомогательной информации о по меньшей мере одном сигнале аудиообъекта и второй параметрической вспомогательной информации о по меньшей мере одном сигнале аудиообъекта, при этом разрешение по частоте второй параметрической вспомогательной информации выше, чем разрешение по частоте первой параметрической вспомогательной информации; и:
- применяют информацию размикширования к сигналу понижающего микширования, указывающему понижающее микширование по меньшей мере одного сигнала аудиообъекта, для получения размикшированного аудиосигнала, содержащего упомянутое множество размикшированных аудиоканалов.
Этап, на котором определяют информацию размикширования, содержит этап, на котором модифицируют первую параметрическую информацию и вторую параметрическую информацию для получения модифицированной параметрической информации так, что модифицированная параметрическая информация имеет разрешение по частоте, которое выше, чем первое разрешение по частоте.
Кроме того, обеспечен способ для кодирования одного или нескольких входных сигналов аудиообъектов. Способ содержит этапы, на которых:
- осуществляют понижающее микширование одного или нескольких входных сигналов аудиообъектов для получения одного или нескольких сигналов понижающего микширования; и
- генерируют первую параметрическую вспомогательную информацию о по меньшей мере одном сигнале аудиообъекта и вторую параметрическую вспомогательную информацию о по меньшей мере одном сигнале аудиообъекта так, что разрешение по частоте второй параметрической вспомогательной информации выше, чем разрешение по частоте первой параметрической вспомогательной информации.
Кроме того, обеспечена компьютерная программа для реализации одного из описанных выше способов при исполнении на компьютере или сигнальном процессоре.
Предпочтительные варианты воплощения будут обеспечены в зависимых пунктах формулы изобретения.
Далее более подробно описываются варианты воплощения настоящего изобретения со ссылкой на фигуры, на которых:
фиг. 1a иллюстрирует декодер в соответствии с вариантом воплощения,
фиг. 1b иллюстрирует декодер в соответствии с другим вариантом воплощения,
фиг. 2a иллюстрирует кодер в соответствии с вариантом воплощения,
фиг. 2b иллюстрирует кодер в соответствии с другим вариантом воплощения,
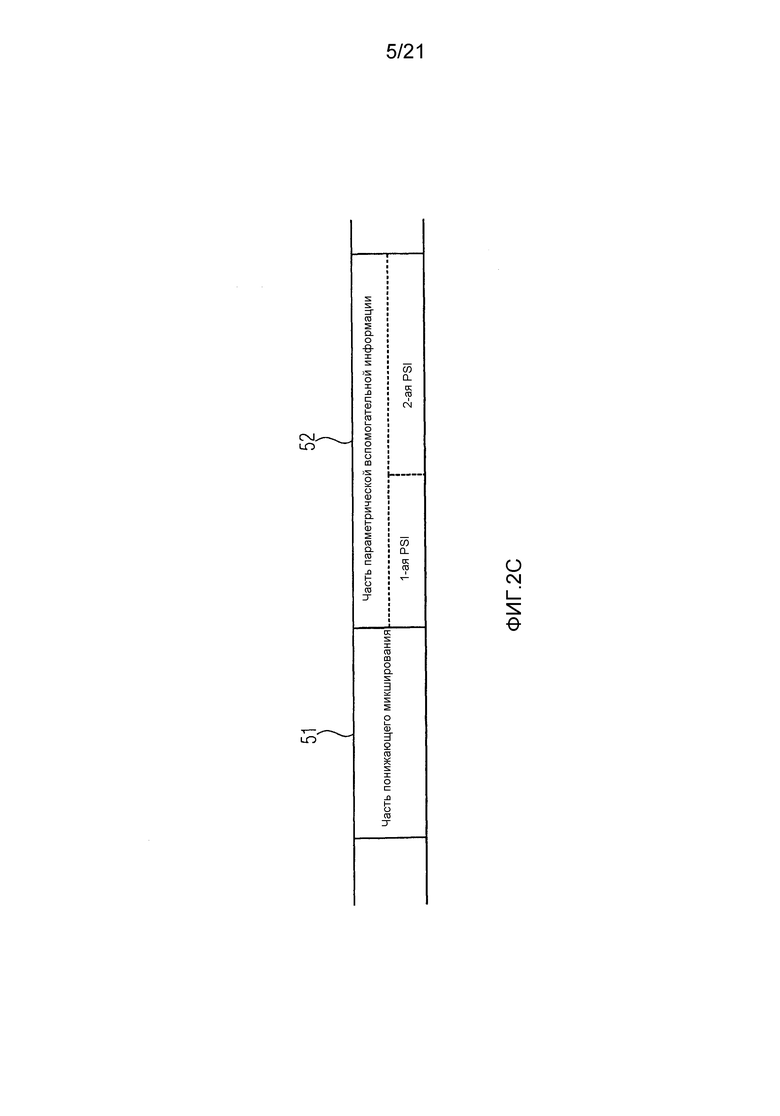
фиг. 2c иллюстрирует закодированный аудиосигнал в соответствии с вариантом воплощения,
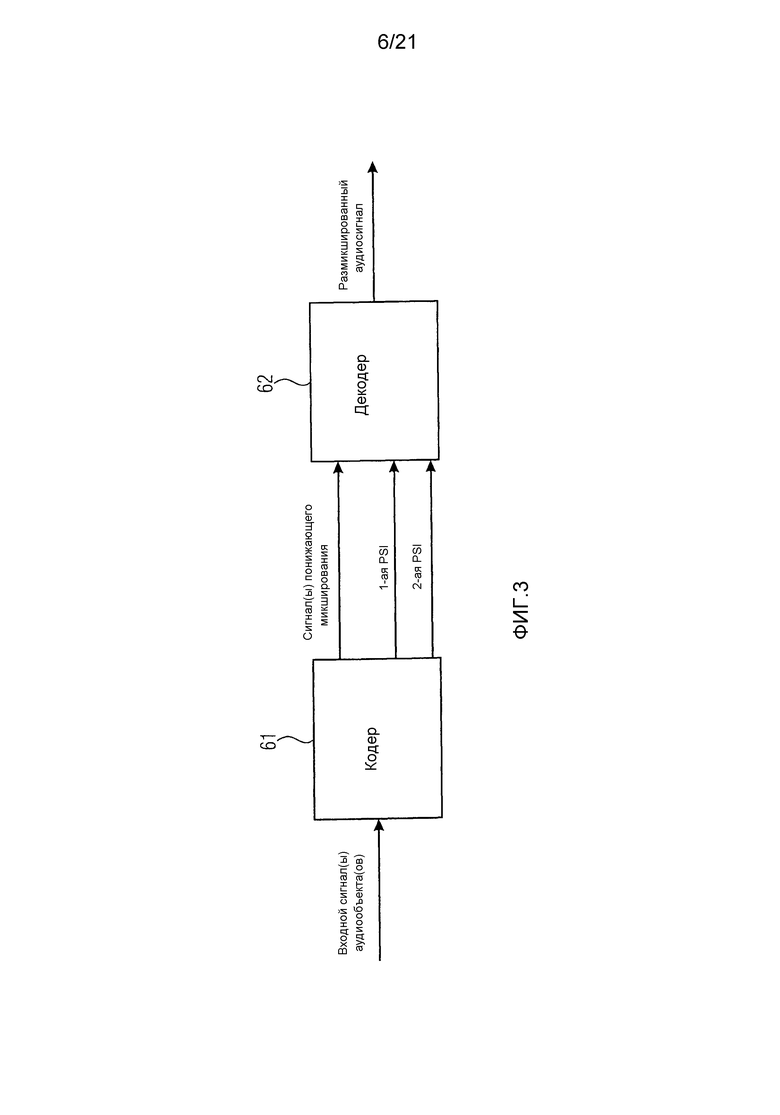
фиг. 3 иллюстрирует систему в соответствии с вариантом воплощения,
фиг. 4 показывает блок-схему концептуального общего вида системы SAOC,
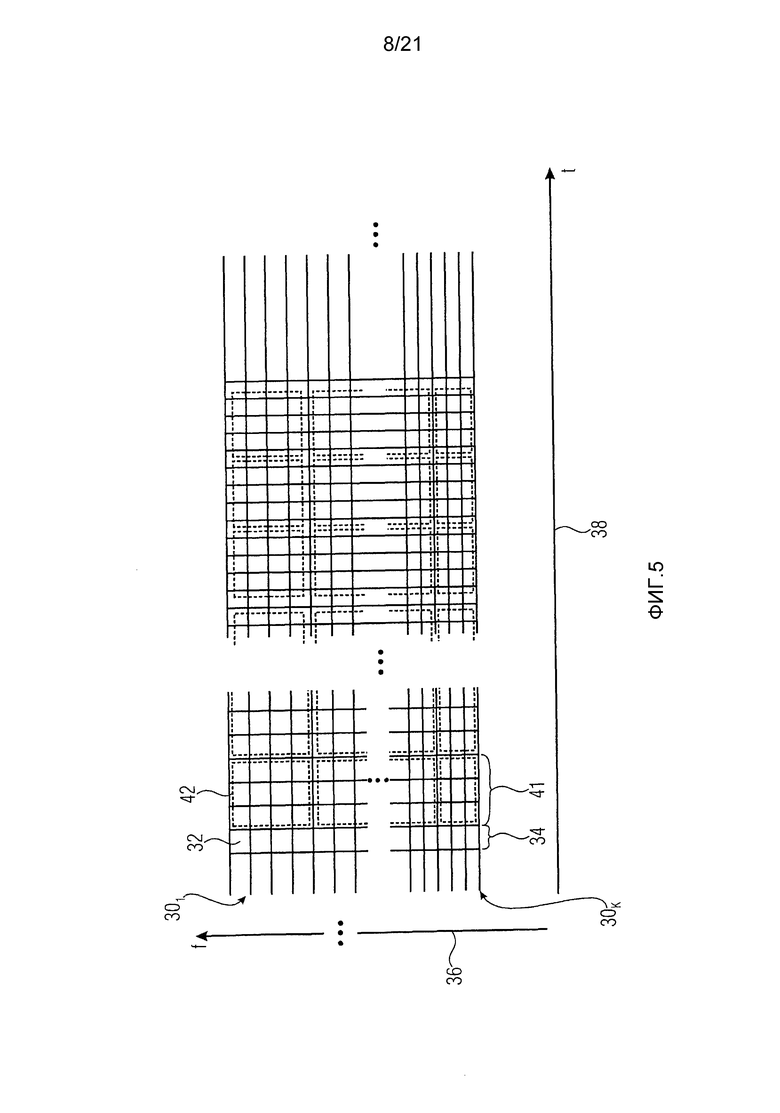
фиг. 5 показывает схематическую и иллюстративную диаграмму спектрально-временного представления одноканального аудиосигнала,
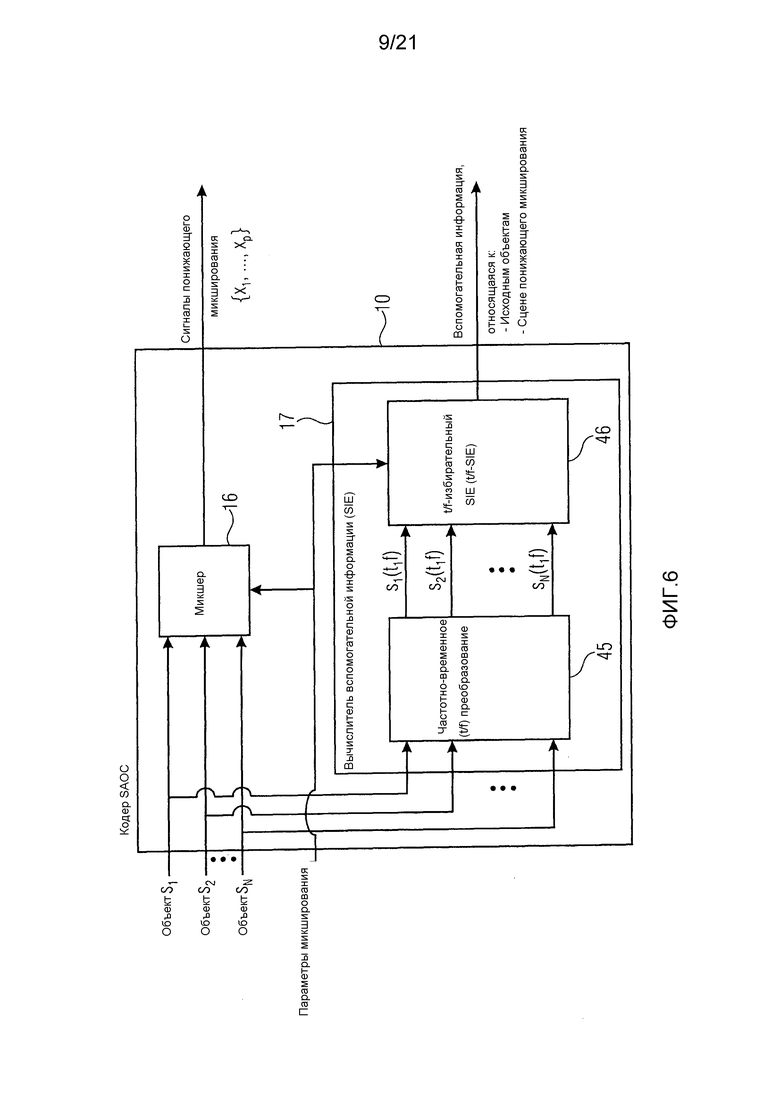
фиг. 6 показывает блок-схему избирательного по времени и частоте вычисления вспомогательной информации в кодере SAOC,
фиг. 7 иллюстрирует обратно совместимое представление в соответствии с вариантами воплощения,
фиг. 8 иллюстрирует кривую разности между истинным значением параметра и средним значением с низким разрешением в соответствии с вариантом воплощения,
фиг. 9 изображает высокоуровневую иллюстрацию усовершенствованного кодера, обеспечивающего обратно совместимый битовый поток с улучшениями в соответствии с вариантом воплощения,
фиг. 10 иллюстрирует блок-схему кодера в соответствии с конкретным вариантом воплощения, реализующим параметрический путь кодера,
фиг. 11 изображает высокоуровневую блок-схему усовершенствованного декодера в соответствии с вариантом воплощения, который способен декодировать и стандартный, и улучшенный битовые потоки,
фиг. 12 иллюстрирует блок-схему, иллюстрирующую вариант воплощения блока усовершенствованного PSI-декодирования,
фиг. 13 изображает блок-схему декодирования битовых потоков стандартного SAOC с помощью усовершенствованного декодера SAOC в соответствии с вариантом воплощения,
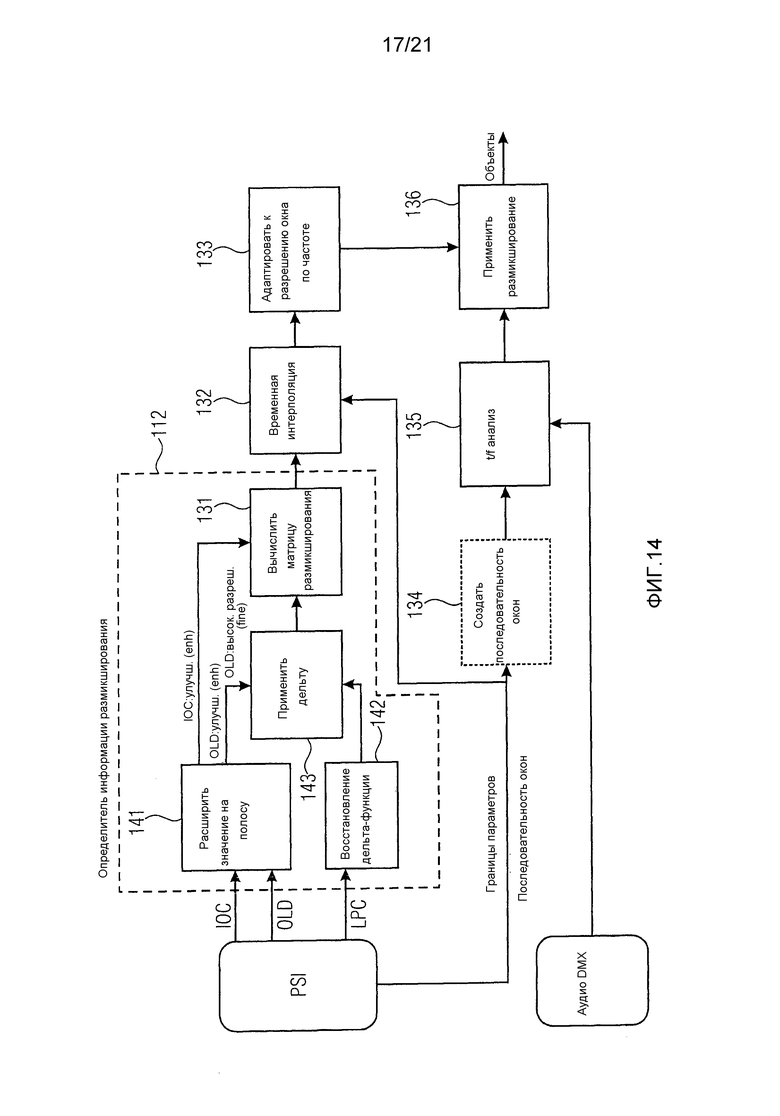
фиг. 14 изображает основные функциональные блоки декодера в соответствии с вариантом воплощения,
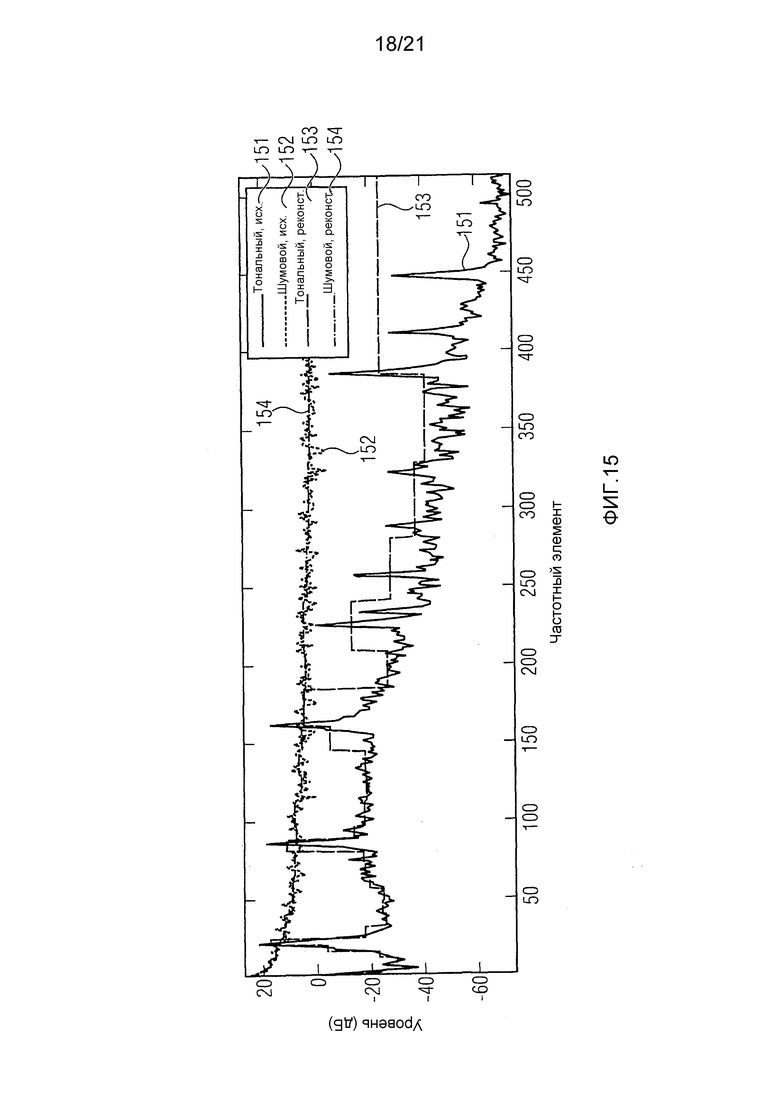
фиг. 15 иллюстрирует тональный и шумовой сигналы и, в частности, энергетические спектры с высоким разрешением и соответствующие приблизительные реконструкции,
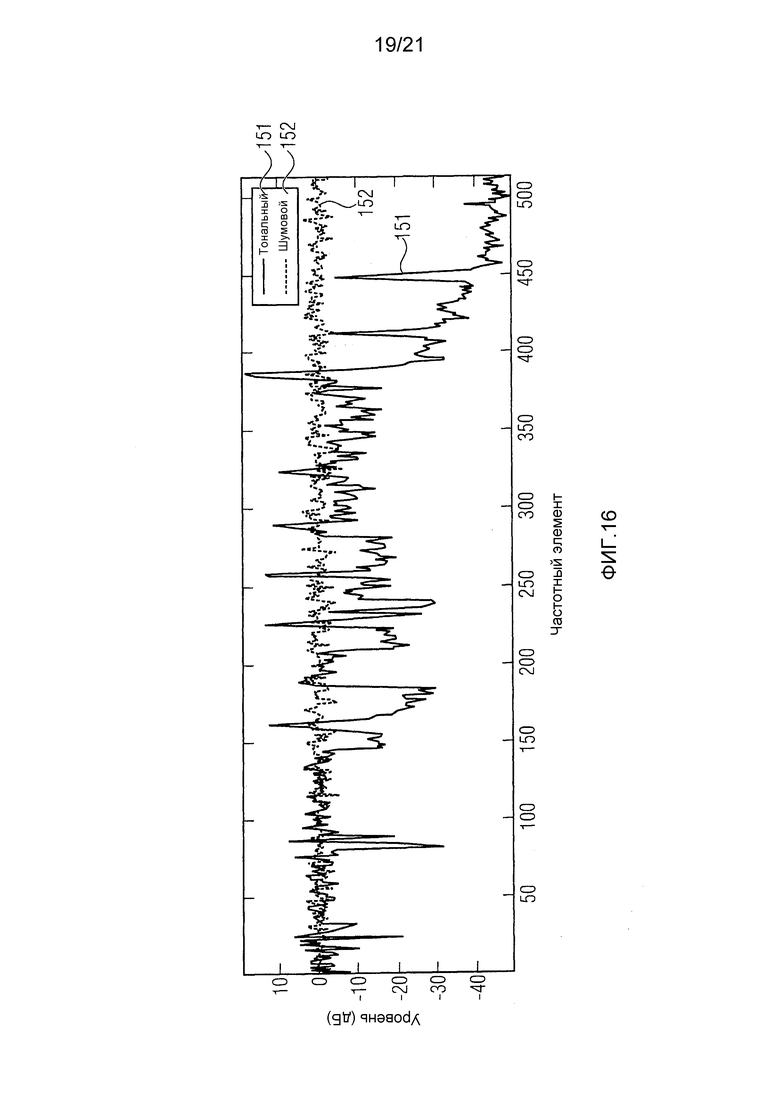
фиг. 16 иллюстрирует модификацию для обоих иллюстративных сигналов, в частности, поправочные коэффициенты для иллюстративных сигналов,
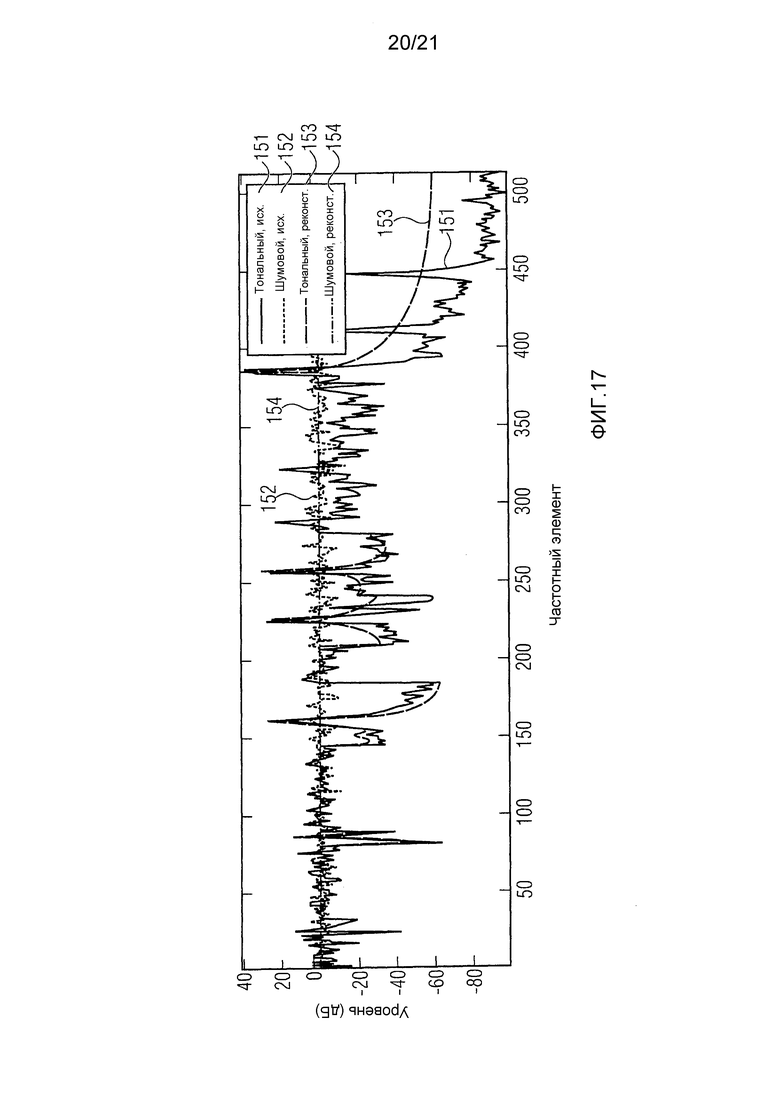
фиг. 17 иллюстрирует исходные поправочные коэффициенты и аппроксимации на основе линейного предсказания приведенного порядка для обоих иллюстративных сигналов, и
фиг. 18 иллюстрирует результат применения смоделированных поправочных коэффициентов к приблизительной реконструкции.
Прежде чем приступить к описанию вариантов воплощения настоящего изобретения, обеспечено более подробное описание существующего уровня техники для систем SAOC.
Фиг. 4 показывает общий вид кодера 10 SAOC и декодера 12 SAOC. Кодер 10 SAOC принимает в качестве входа N объектов, то есть аудиосигналы 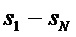
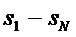
В случае понижающего до стерео микширования каналы сигнала 18 понижающего микширования обозначены как L0 и R0, в случае понижающего до моно микширования то же самое обозначено просто как L0. Чтобы декодер 12 SAOC мог восстановить отдельные объекты
Декодер 12 SAOC содержит повышающий микшер, который принимает сигнал 18 понижающего микширования, а также вспомогательную информацию 20, чтобы восстановить и осуществить рендеринг аудиосигналов 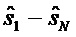
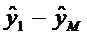
Аудиосигналы
Фиг. 5 показывает аудиосигнал в только что упомянутой спектральной области. Как можно видеть, аудиосигнал представлен как множество сигналов поддиапазонов. Каждый сигнал 301 - 30K поддиапазона состоит из временной последовательности значений поддиапазона, обозначенных маленькими квадратами 32. Как можно видеть, значения 32 поддиапазонов сигналов 301-30K поддиапазонов синхронизированы друг с другом во времени, так что в течение каждого из последовательных временных интервалов 34 набора фильтров каждый поддиапазон 301-30K содержит точно одно значение 32 поддиапазона. Как иллюстрируется осью 36 частот, сигналы 301-30K поддиапазонов ассоциированы с различными областями частот, и, как иллюстрируется осью 38 времени, временные интервалы 34 набора фильтров расположены последовательно во времени.
Как было отмечено выше, экстрактор 17 вспомогательной информации на фиг. 4, вычисляет SAOC-параметры из входных аудиосигналов
Экстрактор 17 вспомогательной информации, изображенный на фиг. 4, вычисляет параметры SAOC в соответствии со следующими формулами. В частности, экстрактор 17 вспомогательной информации вычисляет разности уровней объектов для каждого объекта 
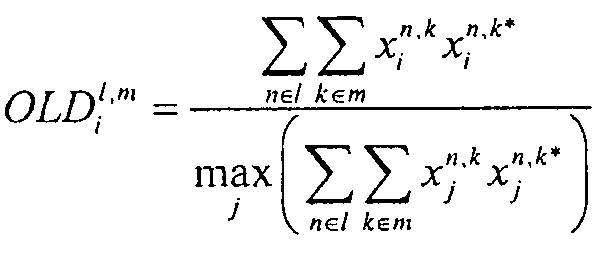
где суммы и индексы 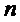
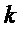
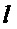
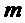
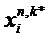
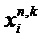
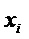
Далее экстрактор 17 вспомогательной информации SAOC может вычислить меру подобия соответствующих частотно-временных ячеек пар различных входных объектов 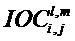
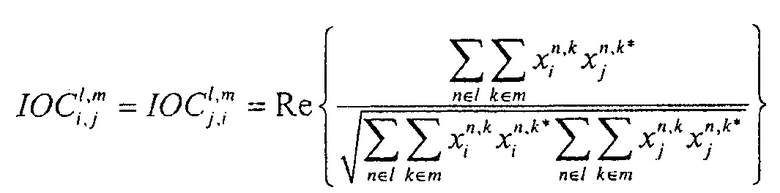
где опять же индексы 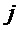
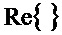
Понижающий микшер 16 на фиг. 4 подвергает понижающему микшированию объекты 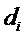
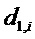
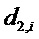
Этот рецепт понижающего микширования сообщается стороне декодера посредством усилений 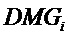
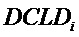
Усиления понижающего микширования вычисляются в соответствии со следующими формулами:
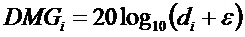
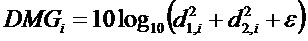
где 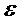
Для DCLD применима следующая формула:
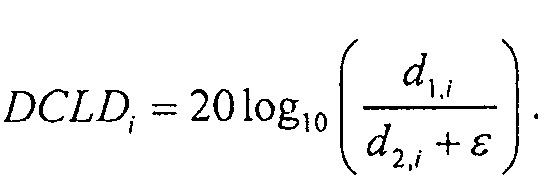
В нормальном режиме понижающий микшер 16 генерирует сигнал понижающего микширования в соответствии с:
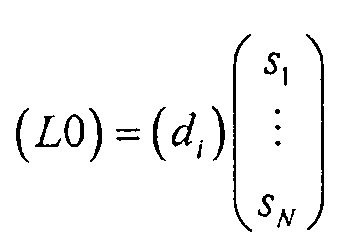
для понижающего до моно микширования, или
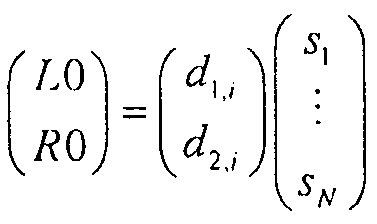
для понижающего до стерео микширования, соответственно.
Таким образом, в упомянутых выше формулах параметры OLD и IOC являются функцией аудиосигналов, а параметры DMG и DCLD являются функциями коэффициентов 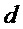
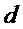
Таким образом, в нормальном режиме понижающий микшер 16 микширует все объекты
На стороне декодера повышающий микшер выполняет процедуру, обратную процедуре понижающего микширования, и вариант осуществления "информации о рендеринге" 26, представленный матрицей R (в литературе, иногда также называемой A) в одном этапе вычисления, а именно, в случае понижающего до двух каналов микширования

где матрица E является функцией параметров OLD и IOC, а матрица D содержит коэффициенты понижающего микширования в виде
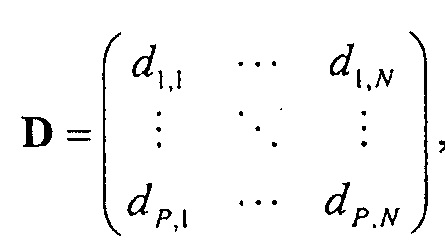
и где D* обозначает комплексно-транспонированную D. Матрица E является оценочной ковариационной матрицей аудиообъектов 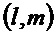
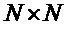
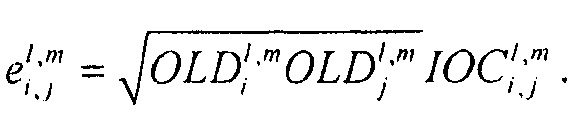
Таким образом, матрица
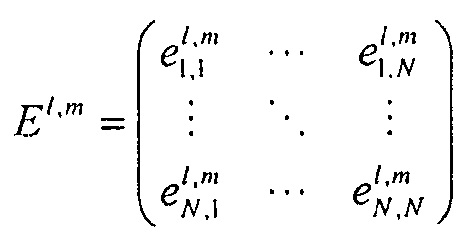
имеет вдоль ее диагонали разности уровней объектов, то есть 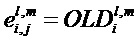
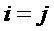
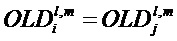
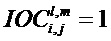
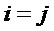
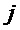
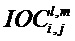
Фиг. 6 показывает один возможный принцип варианта осуществления на примере вычислителя вспомогательной информации (SIE) как части кодера 10 SAOC. Кодер 10 SAOC содержит микшер 16 и вычислитель 17 вспомогательной информации (SIE). SIE концептуально состоит из двух модулей: один модуль 45 для вычисления оконного t/f-представления (например, STFT или QMF) каждого сигнала. Вычисленное оконное t/f-представление подается во второй модуль 46, t/f-избирательный модуль оценки вспомогательной информации (t/f-SIE). t/f-SIE модуль 46 вычисляет вспомогательную информацию для каждой t/f-ячейки. В существующих вариантах осуществления SAOC частотно-временное преобразование является фиксированным и одинаковым для всех аудиообъектов
Далее описываются варианты воплощения настоящего изобретения.
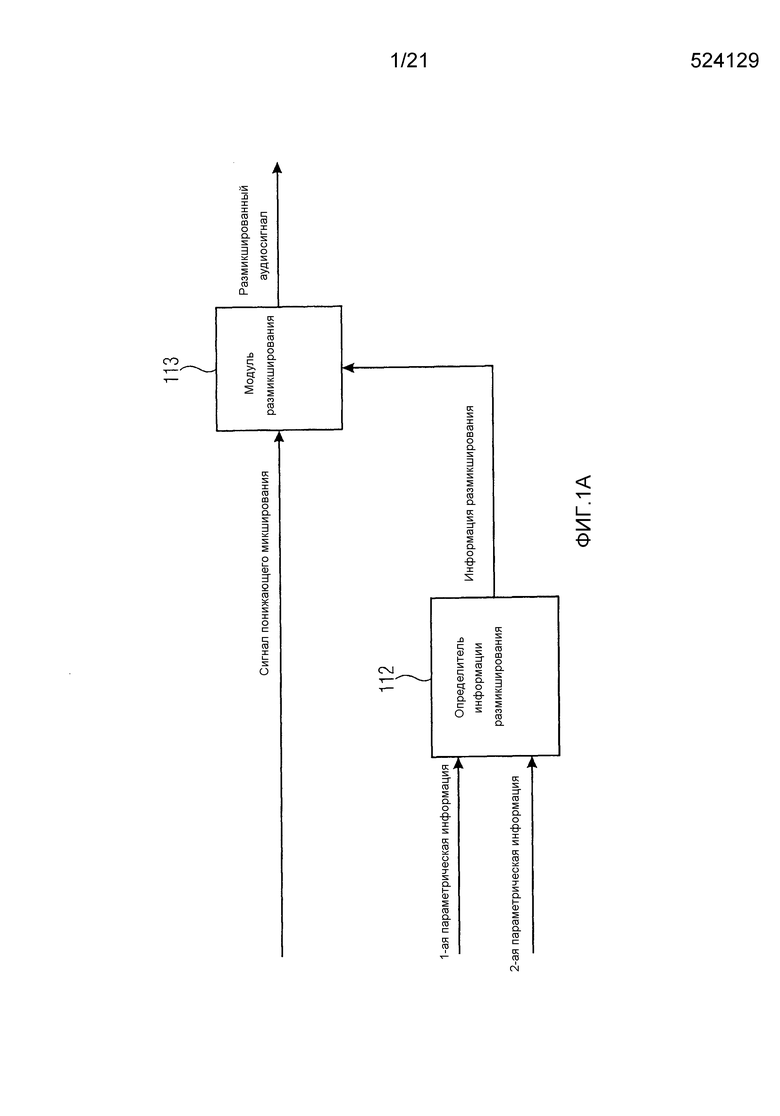
Фиг. 1a иллюстрирует декодер для генерации размикшированного аудиосигнала, содержащего множество размикшированных аудиоканалов в соответствии с вариантом воплощения.
Декодер содержит определитель 112 информации размикширования для определения информации размикширования путем приема первой параметрической вспомогательную информацию о по меньшей мере одном сигнале аудиообъекта и второй параметрической вспомогательной информации о по меньшей мере одном сигнале аудиообъекта, при этом разрешение по частоте второй параметрической вспомогательной информации выше, чем разрешение по частоте первой параметрической вспомогательной информации.
Кроме того, декодер содержит модуль 113 размикширования для применения информации размикширования к сигналу понижающего микширования, указывающему понижающее микширование по меньшей мере одного сигнала аудиообъекта, для получения размикшированного аудиосигнала, содержащего упомянутое множество размикшированных аудиоканалов.
Определитель 112 информации размикширования сконфигурирован определять информацию размикширования путем модификации первой параметрической информации и второй параметрической информации для получения модифицированной параметрической информации, такой что эта модифицированная параметрическая информация имеет более высокое разрешение по частоте, чем первое разрешение по частоте.
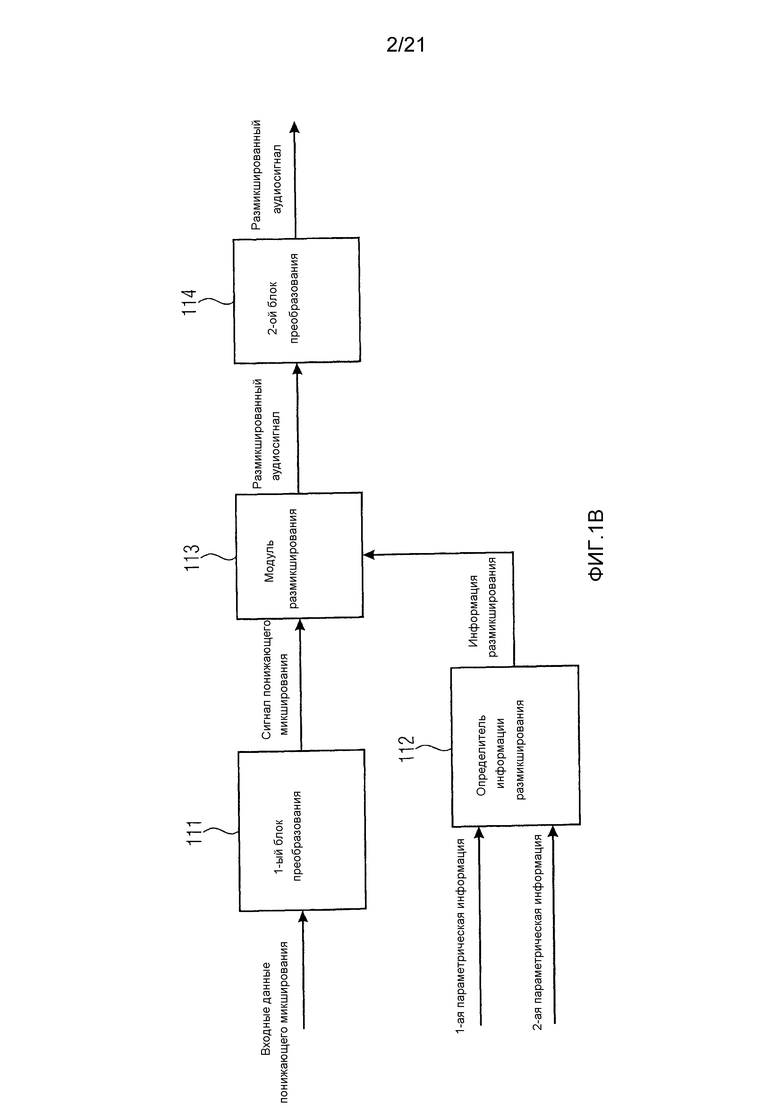
Фиг. 1b иллюстрирует декодер для генерации размикшированного аудиосигнала, содержащего множество размикшированных аудиоканалов в соответствии с другим вариантом воплощения. Декодер на фиг. 1b дополнительно содержит первый блок 111 преобразования для преобразования входных данных понижающего микширования, представленных во временной области, для получения сигнала понижающего микширования, представленного в частотно-временной области. Кроме того, декодер на фиг. 1b содержит второй блок 114 преобразования для преобразования размикшированного аудиосигнала из частотно-временной области во временную область.
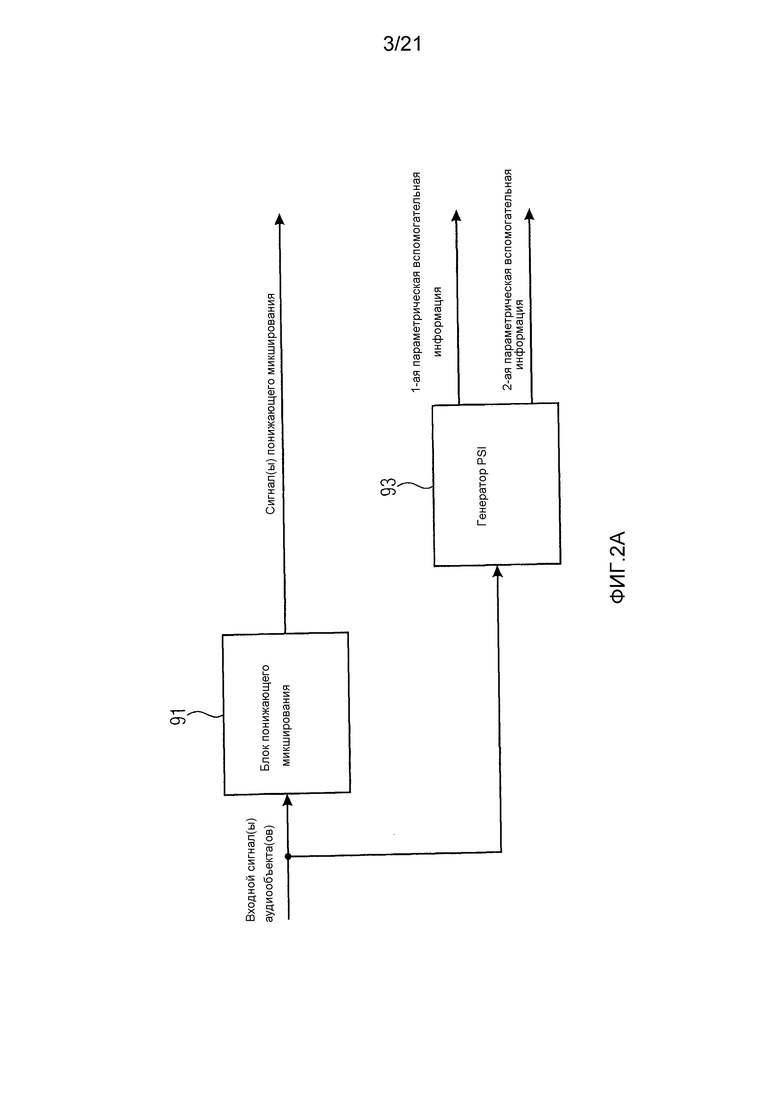
Фиг. 2a иллюстрирует кодер для кодирования одного или нескольких входных сигналов аудиообъектов в соответствии с вариантом воплощения.
Кодер содержит блок 91 понижающего микширования для понижающего микширования одного или нескольких входных сигналов аудиообъектов для получения одного или нескольких сигналов понижающего микширования.
Кроме того, кодер содержит генератор 93 параметрической вспомогательной информации для генерации первой параметрической вспомогательной информации о по меньшей мере одном сигнале аудиообъекта и второй параметрической вспомогательной информации о по меньшей мере одном сигнале аудиообъекта, так что разрешение по частоте второй параметрической вспомогательной информации выше, чем разрешение по частоте первой параметрической вспомогательной информации.
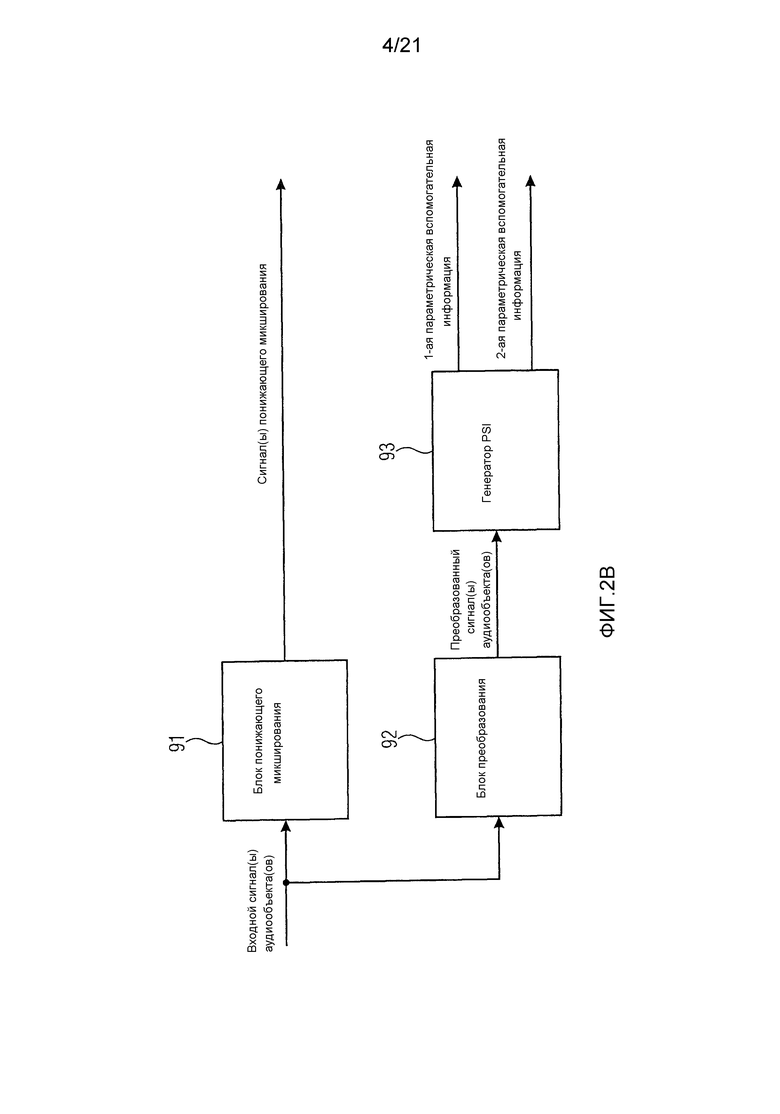
Фиг. 2b иллюстрирует кодер для кодирования одного или нескольких входных сигналов аудиообъектов в соответствии с другим вариантом воплощения. Кодер на фиг. 2b дополнительно содержит блок 92 преобразования для преобразования одного или нескольких входных сигналов аудиообъектов из временной области в частотно-временную область для получения одного или нескольких преобразованных сигналов аудиообъектов. В варианте воплощения на фиг. 2b генератор 93 параметрической вспомогательной информации сконфигурирован генерировать первую параметрическую вспомогательную информацию и вторую параметрическую вспомогательную информацию на основании упомянутого одного или нескольких преобразованных сигналов аудиообъектов.
Фиг. 2c иллюстрирует закодированный аудиосигнал в соответствии с вариантом воплощения. Закодированный аудиосигнал содержит часть 51 понижающего микширования, указывающую понижающее микширование одного или нескольких входных сигналов аудиообъекта, и часть 52 параметрической вспомогательной информации, содержащую первую параметрическую вспомогательную информацию о по меньшей мере одном сигнале аудиообъекта и вторую параметрическую вспомогательную информацию о по меньшей мере одном сигнале аудиообъекта. Разрешение по частоте второй параметрической вспомогательной информации выше, чем разрешение по частоте первой параметрической вспомогательной информации.
Фиг. 3 иллюстрирует систему в соответствии с вариантом воплощения. Система содержит кодер 61, описанный выше, и декодер 62, описанный выше.
Кодер 61 сконфигурирован кодировать один или несколько входных сигналов аудиообъектов для получения одного или нескольких сигналов понижающего микширования, указывающих понижающее микширование одного или нескольких входных сигналов аудиообъектов, путем получения сначала параметрической вспомогательной информации о по меньшей мере одном сигнале аудиообъекта и получения второй параметрической вспомогательной информации о по меньшей мере одном сигнале аудиообъекта, при этом разрешение по частоте второй параметрической вспомогательной информации выше, чем разрешение по частоте первой параметрической вспомогательной информации.
Декодер 62 сконфигурирован генерировать размикшированный аудиосигнал на основании одного или нескольких сигналов понижающего микширования и на основании первой параметрической вспомогательной информации и второй параметрической вспомогательной информации.
Далее описывается усовершенствованный SAOC, использующий обратно совместимое улучшение разрешающей способности по частоте.
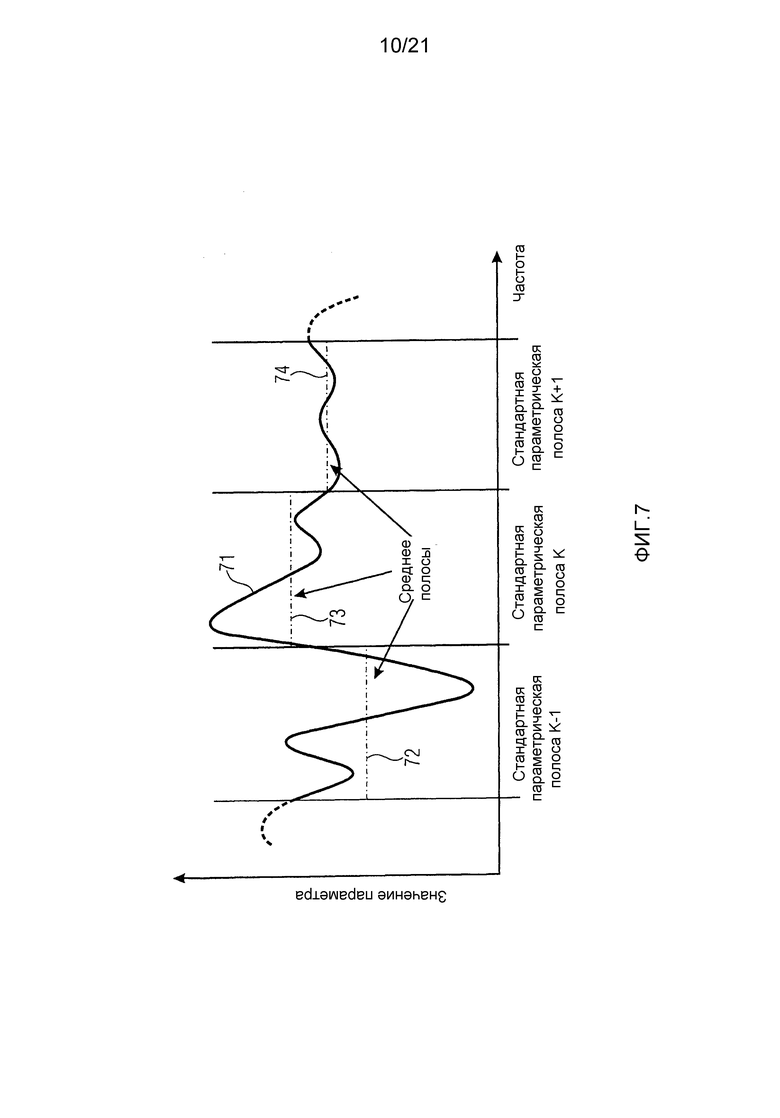
Фиг. 7 иллюстрирует обратно-совместимое представление в соответствии с вариантами воплощения. Свойство сигнала, которое должно быть представлено, например, огибающая 71 спектральной мощности, варьируется в зависимости от частоты. Ось частот разделена на параметрические полосы, и для каждого поддиапазона присвоен один набор дескрипторов сигнала. Используя их вместо обеспечения описания, для каждого частотного элемента отдельно позволяет уменьшить количество необходимой вспомогательной информации без значительной потери в качестве восприятия. В стандартном SAOC единственным дескриптором для каждой полосы является среднее значение 72, 73, 74 поэлементных дескрипторов. Как можно понять, это может привести к потере информации, величина которой зависит от свойств сигнала. На фиг. 7 полосы 
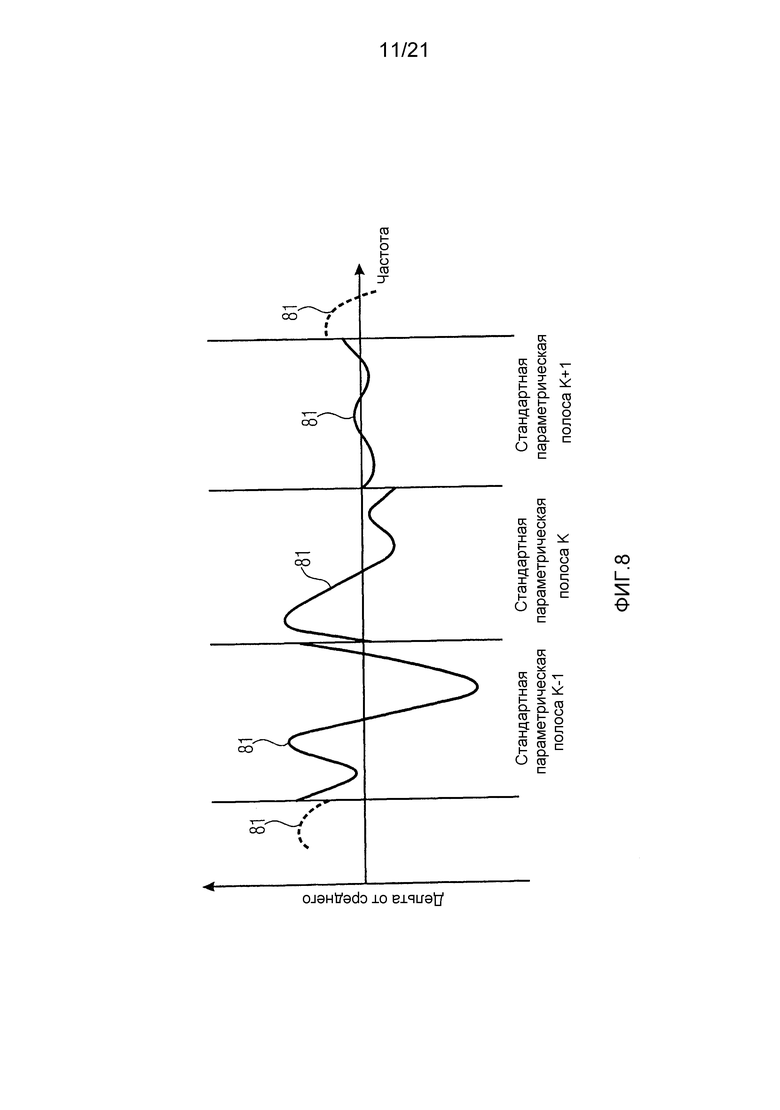
Фиг. 8 иллюстрирует кривую 81 разности между истинным значением параметра и средним значением с низким разрешением в соответствии с вариантом воплощения, например, информацию о мелкоразмерных структурах, теряющуюся в стандартной параметризации SAOC. Мы описываем способ для параметризации и передачи кривых 81 разности между средними значениями 72, 73, 74 (например, стандартным дескриптором SAOC) и истинными значениями с высоким разрешением эффективным образом, позволяющим обеспечить аппроксимацию структуры с высоким разрешением в декодере.
Следует отметить, что добавление улучшающей информации к одному объекту в смеси улучшает результирующее качество не только этого конкретного объекта, но и качество всех объектов, имеющих одинаковое приблизительное пространственное местоположение и имеющих некоторое спектральное перекрытие.
Далее описывается обратно совместимое усовершенствованное кодирование SAOC с усовершенствованным кодером, в частности, усовершенствованный кодер SAOC, который создает битовый поток, содержащий обратно совместимую вспомогательную часть информации и дополнительные улучшения. Добавленная информация может быть вставлена в битовый поток стандартного SAOC таким образом, что старые, совместимые со стандартом декодеры просто игнорируют добавленные данные, в то время как усовершенствованные декодеры используют их. Существующие стандартные декодеры SAOC могут декодировать обратно совместимую часть параметрической вспомогательной информации (PSI) и создавать реконструкции объектов, в то время как добавленная информация, используемая усовершенствованным декодером SAOC, в большинстве случаев улучшает качество восприятия реконструкций. Кроме того, если усовершенствованный декодер SAOC работает с ограниченными ресурсами, улучшения могут игнорироваться, и при этом по-прежнему получается реконструкция с базовым качеством. Следует отметить, что реконструкции из стандартного SAOC и усовершенствованного SAOC декодеров с использованием только PSI, совместимой со стандартным SAOC, отличаются, но по восприятию очень похожи (разница имеет аналогичную природу, что и в декодировании битовых потоков стандартного SAOC с помощью усовершенствованного декодера SAOC).
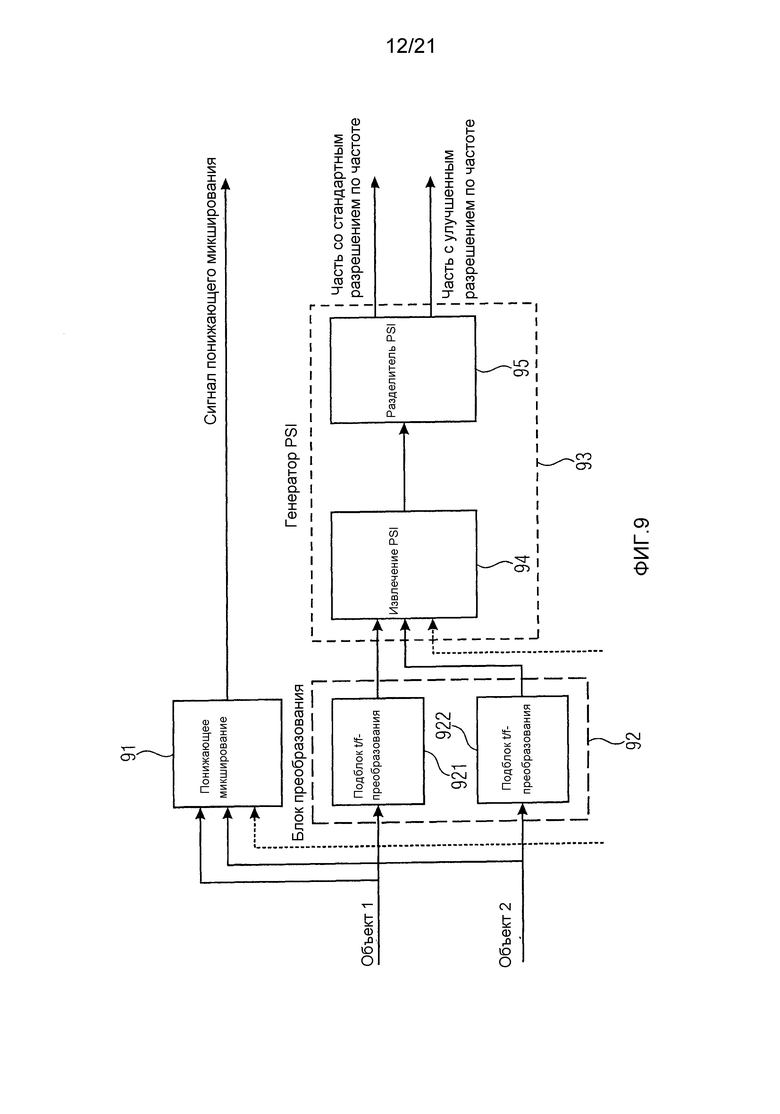
Фиг. 9 изображает высокоуровневую иллюстрацию усовершенствованного кодера, обеспечивающего обратно совместимый битовый поток с улучшениями в соответствии с вариантом воплощения.
Кодер содержит блок 91 понижающего микширования для понижающего микширования множества сигналов аудиообъектов для получения одного или нескольких сигналов понижающего микширования. Например, сигналы аудиообъектов (например, отдельные (аудио) объекты) используются блоком 91 понижающего микширования для создания сигнала понижающего микширования. Это может происходить во временной области, частотной области, или даже может использоваться обеспеченное извне понижающее микширование.
В PSI-пути сигналы (аудио) объектов преобразуются блоком 92 преобразования из временной области в частотную область, частотно-временную область или спектральную область (например, блоком 92 преобразования, включающим в себя один или несколько подблоков 921, 922 t/f-преобразования).
Кроме того, кодер содержит генератор 93 параметрической вспомогательной информации для генерации параметрической вспомогательной информации. В варианте воплощения на фиг. 9 генератор 93 параметрической вспомогательной информации может, например, содержать блок 94 извлечения PSI и разделитель 95 PSI. В соответствии с таким вариантом воплощения в частотной области PSI извлекается блоком 94 извлечения PSI. Разделитель 95 PSI затем используется для разделения PSI на две части: часть со стандартным разрешением по частоте, которая может быть декодирована с помощью любого совместимого со стандартом SAOC-декодера, и часть с улучшенным разрешением по частоте. Последняя может быть "скрыта" в элементах битового потока, так что она будет игнорироваться стандартными декодерами, но будет использоваться усовершенствованными декодерами.
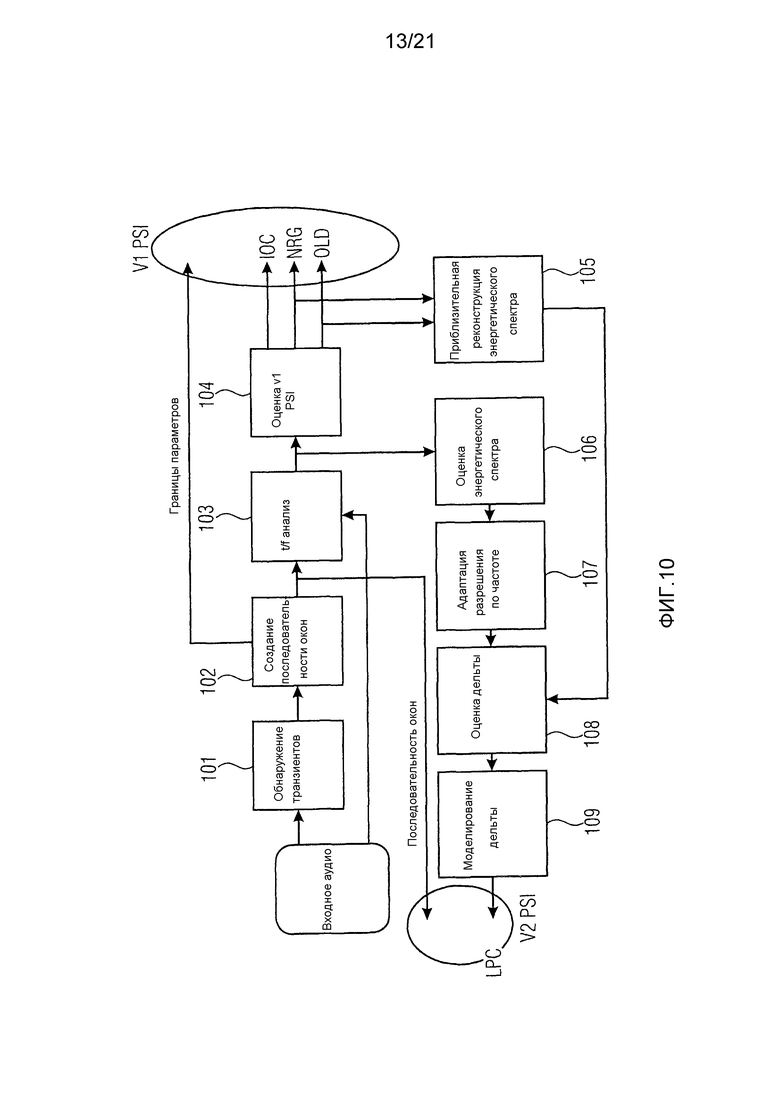
Фиг. 10 иллюстрирует блок-схему кодера в соответствии с конкретным вариантом воплощения, реализующим параметрический путь кодера, описанного выше. Жирные черные функциональные блоки (102, 105, 106, 107, 108, 109) указывают основные компоненты обработки согласно изобретению. В частности, фиг. 10 иллюстрирует блок-схему двухступенчатого кодирования, создающего обратно совместимый битовый поток с улучшениями для декодеров, имеющих бóльшие возможности. Кодер сконфигурирован создавать PSI, которая может быть декодирована с помощью обеих версий декодера. Блок 92 преобразования на фиг. 9 реализован с помощью блока 101 обнаружения транзиентов, блока 102 создания последовательности окон, и блока 103 t/f-анализа на фиг. 10. Другие блоки 104, 105, 106, 107, 108, 109 на фиг. 10 реализуют генератор 93 параметрической вспомогательной информации (например, блоки 104, 105, 106, 107, 108, 109 могут реализовывать функциональность комбинации блока 94 извлечения PSI и разделителя 95 PSI).
Вначале сигнал делится на кадры анализа, которые затем преобразуются в частотную область. Несколько кадров анализа группируются в кадр параметров фиксированной длины, например, в стандартном SAOC часто используются длины в 16 и 32 кадров анализа. Предполагается, что свойства сигнала остаются квазистационарными во время кадра параметров и могут, таким образом, быть охарактеризованы только одним набором параметров. Если характеристики сигнала изменяются в пределах кадра параметров, происходит ошибка моделирования, и было бы полезно подразделить более длинный кадр параметров на части, в которых снова выполняется допущение о квазистационарности. С этой целью необходимо обнаружение транзиентов.
В варианте воплощения блок 92 преобразования сконфигурирован преобразовывать один или несколько входных сигналов аудиообъектов из временной области в частотно-временную область в зависимости от длины окна блока преобразования сигнала, содержащего значения сигнала по меньшей мере одного из упомянутого одного или нескольких входных сигналов аудиообъектов. Блок 92 преобразования содержит блок 101 обнаружения транзиентов для определения результата обнаружения транзиента, указывающего, присутствует ли транзиент в одном или нескольких из по меньшей мере одного сигнала аудиообъекта, при этом транзиент указывает изменение сигнала в одном или нескольких из по меньшей мере одного сигнала аудиообъекта. Кроме того, блок 92 преобразования дополнительно содержит блок 102 последовательности окон для определения длины окна в зависимости от результата обнаружения транзиента.
Например, транзиенты могут быть обнаружены блоком 101 обнаружения транзиентов во всех входных объектах по отдельности, и когда имеется транзиентное событие только в одном из объектов, это место объявляется глобальным местом транзиента. Информация о местах транзиентов используется для создания соответствующей последовательности разбиения на окна. Создание может быть основано, например, на следующей логике:
- Установить длину окна по умолчанию, то есть, длину по умолчанию блока преобразования сигнала, равной, например, 2048 сэмплам.
- Установить длину кадра параметров равной, например, 4096 сэмплам, что соответствует 4 окнам по умолчанию с 50%-м перекрытием. Кадры параметров группируют несколько окон вместе, и используется один набор дескрипторов сигнала для всего блока вместо того, чтобы иметь дескрипторы для каждого окна по отдельности. Это позволяет уменьшить количество PSI.
- Если транзиент не был обнаружен, использовать окна по умолчанию и полную длину кадра параметров.
- Если транзиент обнаружен, адаптировать разбиение на окна для обеспечения лучшего временного разрешения в месте транзиента.
Блок 102 создания последовательности окон создает последовательность разбиения на окна. Одновременно он также создает подкадры параметров из одного или нескольких окон анализа. Каждое подмножество анализируется как единое целое, и только один набор PSI-параметров передается для каждого подблока. Для обеспечения PSI, совместимой со стандартным SAOC, используется определенная длина блока параметра в качестве основной длины блока параметров, а возможные расположенные в пределах этого блока транзиенты определяют подмножества параметров.
Созданная последовательность окон выводится для частотно-временного анализа входных аудиосигналов, проводимого блоком 103 t/f-анализа, и передается в части улучшенной PSI усовершенствованного SAOC.
PSI состоит из наборов разностей уровней объектов (OLD), межобъектных корреляций (IOC) и информации матрицы D понижающего микширования, использованной для создания сигнала понижающего микширования из отдельных объектов в кодере. Каждый набор параметров ассоциирован с границей параметров, которая определяет временную область, с которой параметры ассоциированы.
Спектральные данные каждого окна анализа используются блоком 104 оценки PSI для оценки PSI для части стандартного SAOC. Это делается путем группировки спектральных элементов в параметрические полосы стандартного SAOC и оценки IOC, OLD и абсолютных энергий объектов (NRG) в полосах. Следуя приблизительно обозначениям стандартного SAOC, нормированное произведение двух спектров 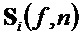
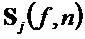
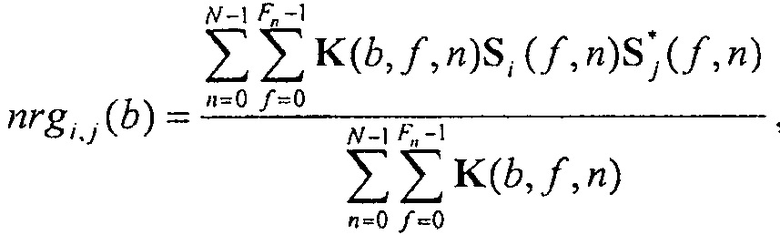
где матрица 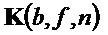
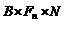
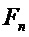
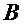
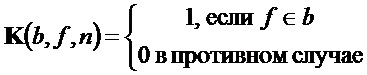
Спектральное разрешение может варьироваться между кадрами в пределах одного параметрического блока, таким образом матрица отображения преобразует данные в базис с обычным разрешением. Максимальная энергия объекта в этой ячейке параметризации определяется как максимальная энергия объекта 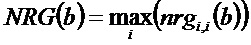
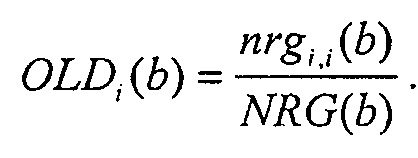
И, наконец, IOC может быть получен из перекрестных энергий как
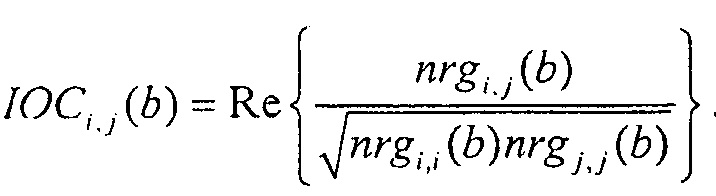
Это завершает оценку совместимых со стандартным SAOC частей битового потока.
Блок 105 приблизительной реконструкции энергетического спектра сконфигурирован использовать OLD и NRG для реконструкции грубой оценки огибающей спектра в анализируемом блоке параметров. Огибающая конструируется с самым высоким разрешением по частоте, используемым в этом блоке.
Исходный спектр каждого окна анализа используется блоком 106 оценки энергетического спектра для вычисления энергетического спектра в этом окне.
Полученные энергетические спектры преобразуются в обычное представление с высоким разрешением по частоте блоком 107 адаптации разрешения по частоте. Это может быть сделано, например, путем интерполяции значений энергетических спектров. Затем вычисляется средний профиль энергетических спектров путем усреднения спектров в пределах блока параметров. Это примерно соответствует OLD-оценке, опускающему агрегирование параметрической полосы. Полученный спектральный профиль рассматривается как OLD с высоким разрешением.
Кодер дополнительно содержит блок 108 оценки дельты для оценки множества поправочных коэффициентов путем деления каждой из множества OLD одного из по меньшей мере одного сигнала аудиообъекта на значение реконструкции энергетического спектра упомянутого одного из по меньшей мере одного сигнала аудиообъекта для получения второй параметрической вспомогательной информации, при этом упомянутое множество OLD имеет более высокое разрешение по частоте, чем упомянутая реконструкция энергетического спектра.
В варианте воплощения блок 108 оценки дельты сконфигурирован рассчитывать множество поправочных коэффициентов на основании множества параметрических значений, зависящих от по меньшей мере одного сигнала аудиообъекта, для получения второй параметрической вспомогательной информации. Например, блок 108 оценки дельты может быть сконфигурирован рассчитывать поправочный коэффициент, "дельту", например, путем деления OLD с высоким разрешением на приблизительную реконструкцию энергетического спектра. В результате это обеспечивает для каждого частотного элемента (например, мультипликативный) поправочный коэффициент, который может использоваться для аппроксимации OLD с высоким разрешением данных приблизительных спектров.
Наконец, блок 109 моделирования дельты сконфигурирован эффективным образом моделировать оценочный поправочный коэффициент для передачи. Одна возможность для моделирования с использованием коэффициентов линейного предсказания (LPC) описывается ниже в дальнейшем.
Эффективно, модификации усовершенствованного SAOC состоят из добавления информации о последовательности разбиения на окна и параметров для передачи "дельты" к битовому потоку.
ДАЛЕЕ ОПИСЫВАЕТСЯ УСОВЕРШЕНСТВОВАННЫЙ ДЕКОДЕР.
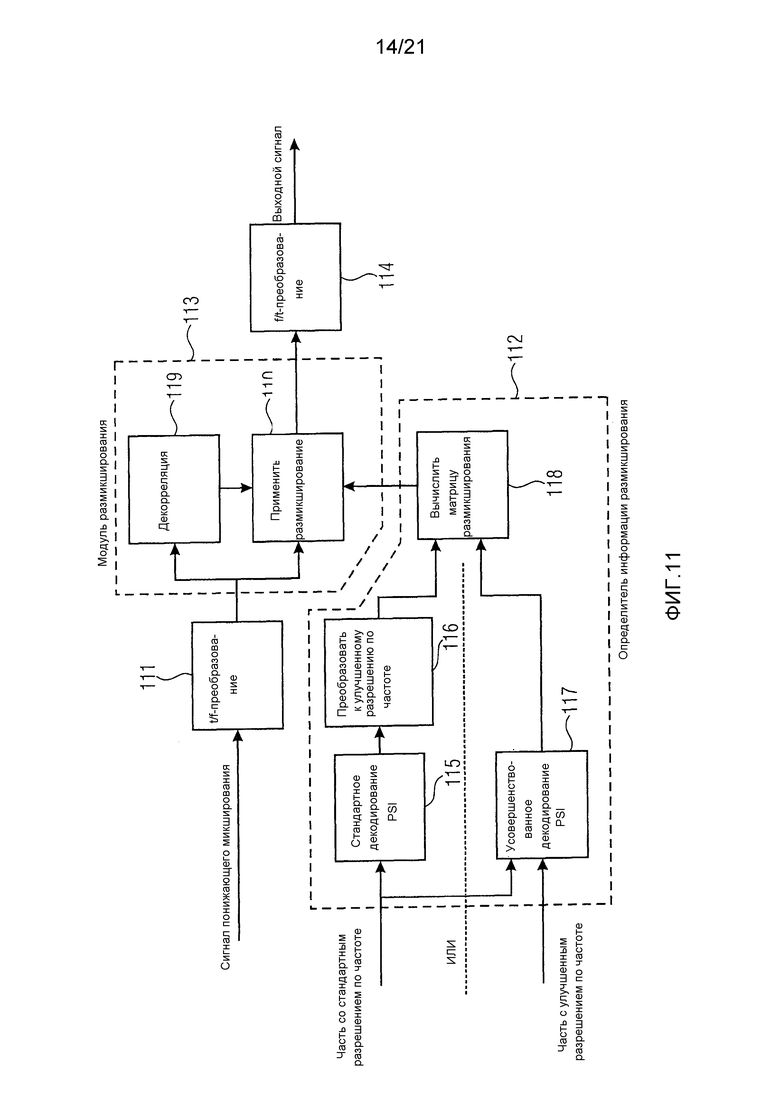
Фиг. 11 изображает высокоуровневую блок-схему усовершенствованного декодера в соответствии с вариантом воплощения, который способен декодировать и стандартный, и расширенный битовые потоки. В частности, фиг. 11 иллюстрирует операционную блок-схему усовершенствованного декодера, который способен декодировать и стандартные битовые потоки, и битовые потоки, включающие в себя улучшения разрешения по частоте.
Входной сигнал понижающего микширования преобразуется в частотную область блоком 111 t/f-преобразования.
Оценочная матрица размикширования применяется к преобразованному сигналу понижающего микширования блоком 110 размикширования для генерации выхода размикширования.
Кроме того, имеется путь декорреляции, чтобы позволить более качественное пространственное управление объектами при размикшировании. Блок 119 декорреляции выполняет декорреляцию над преобразованным сигналом понижающего микширования, и результат декорреляции подается в блок 110 размикширования. Блок 110 размикширования использует результат декорреляции для генерации выхода размикширования.
Выход размикширования затем преобразуется обратно во временную область блоком 114 f/t-преобразования.
Путь параметрической обработки может брать PSI стандартного разрешения в качестве входных данных, в этом случае декодированная PSI, которая генерируется блоком 115 стандартного декодирования PSI, адаптируется блоком 116 преобразования разрешения по частоте к разрешению по частоте, используемому в t/f-преобразованиях.
Альтернативные входные данные комбинируют часть PSI со стандартным разрешением по частоте с частью с увеличенным разрешением по частоте, и вычисления включают в себя информацию с увеличенным разрешением по частоте. Более подробно, блок 117 усовершенствованного декодирования PSI генерирует декодированную PSI, демонстрирующую увеличенное разрешение по частоте.
Генератор 118 матрицы размикширования генерирует матрицу размикширования на основании декодированной PSI, принятой из блока 116 преобразования разрешения по частоте или из блока 117 усовершенствованного декодирования PSI. Генератор 118 матрицы размикширования может также генерировать матрицу размикширования на основании информации о рендеринге, например, на основании матрицы рендеринга. Блок 110 размикширования сконфигурирован генерировать Выход размикширования путем применения этой матрицы размикширования, сгенерированной генератором 118 матрицы размикширования, к преобразованному сигналу понижающего микширования.
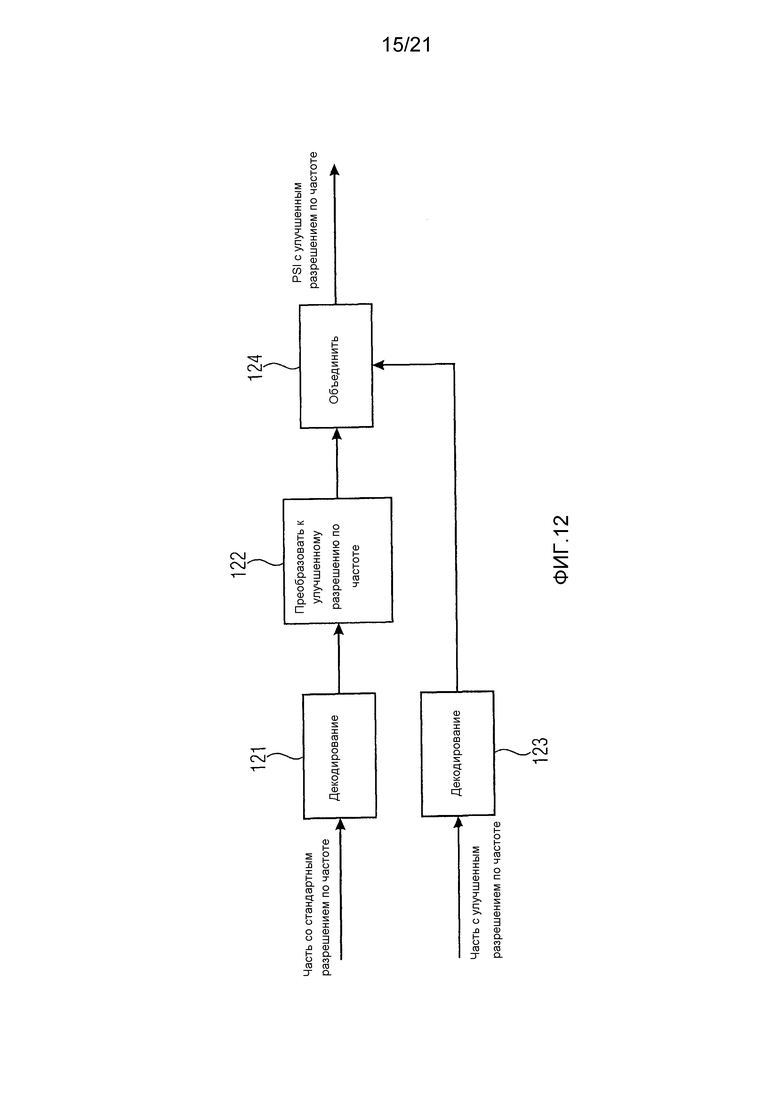
Фиг. 12 иллюстрирует блок-схему, иллюстрирующую вариант воплощения блока 117 усовершенствованного декодирования PSI на фиг. 11.
Первая параметрическая информация содержит множество первых значений параметров, при этом вторая параметрическая информация содержит множество вторых значений параметров. Определитель 112 информации размикширования содержит подблок 122 преобразования разрешения по частоте и объединитель 124. Блок 112 преобразования разрешения по частоте сконфигурирован генерировать дополнительные значения параметров, например, путем репликации первых значений параметров, при этом первые значения параметров и дополнительные значения параметров вместе формируют множество первых обработанных значений параметров. Объединитель 124 сконфигурирован объединять первые обработанные значения параметров и вторые значения параметра для получения множества модифицированных значений параметров в качестве модифицированной параметрической информации.
В соответствии с вариантом воплощения часть со стандартным разрешением по частоте декодируется подблоком 121 декодирования и преобразуется подблоком 122 преобразования разрешения по частоте в разрешение по частоте, используемое улучшающей частью. Декодированная улучшающая часть, сгенерированная подблоком 123 усовершенствованного декодирования PSI, объединяется объединителем 124 с преобразованной частью со стандартным разрешением.
Далее более подробно описываются два режима декодирования с возможными вариантами осуществления.
Сначала описывается декодирование битовых потоков стандартного SAOC с помощью усовершенствованного декодера.
Усовершенствованный декодер SAOC спроектирован так, что он способен декодировать битовые потоки от стандартных кодеров SAOC с хорошим качеством. Декодирование ограничивается только параметрической реконструкцией, и возможные остаточные потоки игнорируются.
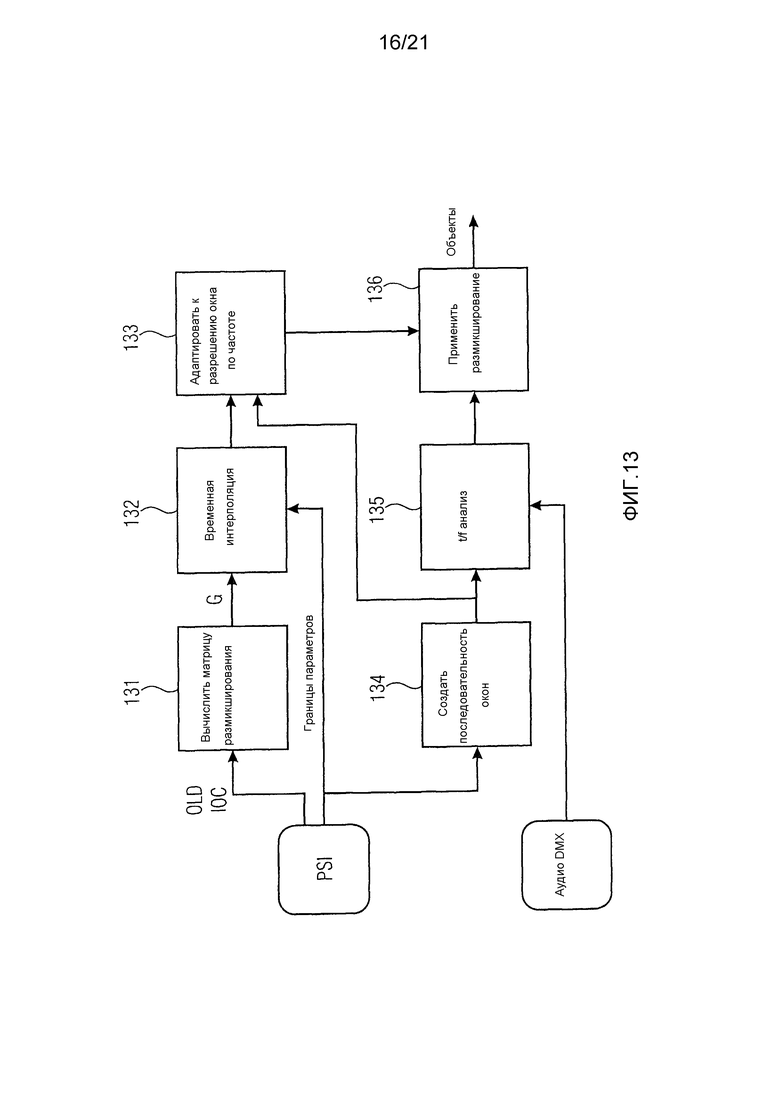
Фиг. 13 изображает блок-схему декодирования битовых потоков стандартного SAOC с помощью усовершенствованного декодера SAOC, иллюстрирующую процесс декодирования в соответствии с вариантом воплощения. Жирные черные функциональные блоки (131, 132, 133, 135) указывают основную часть обработки согласно изобретению.
Вычислитель 131 матрицы размикширования, временной интерполятор 132 и блок 133 адаптации к разрешению окна по частоте реализуют функциональность блока 115 стандартного декодирования PSI, блока 116 преобразования разрешения по частоте и генератора 118 матрицы размикширования на фиг. 11. Генератор 134 последовательности окон и модуль 135 t/f-анализа реализуют блок 111 t/f-преобразования на фиг. 11.
Обычно частотные элементы лежащего в основе частотно-временного представления сгруппированы в параметрические полосы. Расстояние между полосами имеет сходство с расстоянием между критическими полосами в слуховой системе человека. Кроме того, несколько кадров t/f-представления могут быть сгруппированы в кадр параметров. Обе эти операции обеспечивают уменьшение количества требуемой вспомогательной информации за счет неточностей моделирования.
Как описано в стандарте SAOC, OLD и IOC используются для вычисления матрицы размикширования 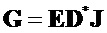
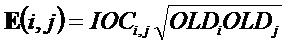
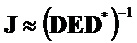
Матрица размикширования затем линейно интерполируется временным интерполятором 132 из матрицы размикширования предыдущего кадра на кадр параметров до границы параметров, на которой достигаются оценочные значения, согласно стандартному SAOC. Результатом этого является матрица размикширования для каждого частотно-временного окна анализа и параметрической полосы.
Разрешение по частоте параметрической полосы матриц размикширования расширяется до разрешения частотно-временного представления в этом окне анализа блоком 133 адаптации к разрешению окна по частоте. Когда интерполированная матрица размикширования для параметрической полосы 
Генератор 134 последовательности окон сконфигурирован использовать информацию о диапазоне набора параметров из PSI для определения соответствующей последовательности разбиения на окна для анализа входного аудиосигнала понижающего микширования. Основным требованием является то, что когда есть граница набора параметров в PSI, точка пересечения между последовательными окнами анализа должна совпадать с ней. Разбиение на окна также определяет разрешение по частоте данных в пределах каждого окна (используемое в расширении данных размикширования, как было описано выше).
Разбитые на окна данные затем преобразуются модулем 135 t/f-анализа в представление в частотной области с использованием подходящего частотно-временного преобразования, например, дискретного преобразования Фурье (DFT), комплексного модифицированного дискретного косинусного преобразования (CMDCT) или нечетное дискретное преобразование Фурье (ODFT).
Наконец, блок 136 размикширования применяет покадровые, для каждого частотного элемента матрицы размикширования к спектральному представлению сигнала X понижающего микширования для получения параметрических рендерингов Y. Выходной канал 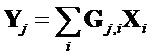
Качество, которое может быть получено с помощью этого процесса, для большинства целей на восприятие неотличимо от результата, получаемого с помощью стандартного декодера SAOC.
Следует отметить, что вышеупомянутый текст описывает реконструкцию отдельных объектов, но в стандартном SAOC рендеринг включен в матрицу размикширования, то есть он включен в параметрическую интерполяцию. Так как это линейная операция, порядок операций не имеет значения, но разницу стоит отметить.
Далее описывается декодирование битовых потоков усовершенствованного SAOC с помощью усовершенствованного декодера.
Основная функциональность усовершенствованного декодера SAOC уже была описана выше при декодировании битовых потоков стандартного SAOC. Эта секция детализирует, как добавленные улучшения в PSI усовершенствованного SAOC могут использоваться для получения более высокого качества восприятия.
Фиг. 14 изображает основные функциональные блоки декодера в соответствии с вариантом воплощения, иллюстрирующим декодирование улучшений разрешения по частоте. Жирные черные функциональные блоки (141, 142, 143) указывают основную часть обработки согласно изобретению. Блок 141 расширения значений на полосу, блок 142 восстановления дельта-функции, блок 143 применения дельты, вычислитель 131 матрицы размикширования, временной интерполятор 132 и блок 133 адаптации к разрешению окна по частоте реализуют функциональность блока 117 усовершенствованного декодирования PSI и генератора 118 матрицы размикширования на фиг. 11.
Декодер на фиг. 14 содержит определитель 112 информации размикширования. Среди прочего, определитель 112 информации размикширования содержит блок 142 восстановления дельта функции и блок 143 применения дельты. Первая параметрическая информация содержит множество параметрических значений, зависящих от по меньшей мере одного сигнала аудиообъекта, например, значений разности уровней объектов. Вторая параметрическая информация содержит параметризацию поправочных коэффициентов. Блок 142 восстановления дельта-функции сконфигурирован инвертировать параметризацию поправочных коэффициентов для получения дельта-функции. Блок 143 применения дельты сконфигурирован применять дельта-функцию к параметрическим значениям, например, к значениям разности уровней объектов для определения информации размикширования. В варианте воплощения параметризация поправочных коэффициентов содержит множество коэффициентов линейного предсказания, и блок 142 восстановления дельта-функции сконфигурирован инвертировать параметризацию поправочных коэффициентов путем генерации множества поправочных коэффициентов в зависимости от упомянутого множества коэффициентов линейного предсказания и сконфигурирован генерировать дельта-функцию на основании упомянутого множества поправочных коэффициентов.
Например, сначала блок 141 расширения значений на полосу адаптирует значения OLD и IOC для каждой параметрической полосы к разрешению по частоте, используемому в улучшениях, например, к 1024 элементам. Это делается путем репликации значения на частотные элементы, которые соответствуют параметрической полосе. Это приводит к новым OLD 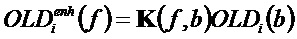
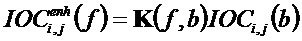
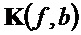
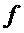
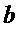
Параллельно этому блок 142 восстановления дельта-функции инвертирует параметризацию поправочных коэффициентов для получения дельта-функции 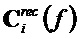
Затем блок 143 применения дельты применяет дельту к расширенным значениям OLD, и полученные значения OLD c высоким разрешением получаются с помощью 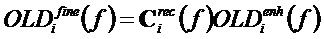
В конкретном варианте воплощения вычисление матриц размикширования может, например, выполняться вычислителем 131 матрицы размикширования, как и при декодировании битового потока стандартного SAOC: 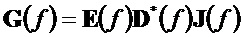
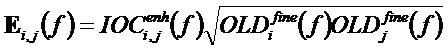
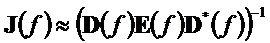
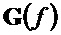
Поскольку разрешение по частоте в каждом окне может отличаться (быть ниже) от номинального высокого разрешения по частоте, блок 133 адаптации к разрешению окна по частоте должен адаптировать матрицы размикширования, чтобы они соответствовали разрешению спектральных данных из аудио, чтобы их можно было применить. Это может быть сделано, например, путем передискретизации коэффициентов по оси частот до правильного разрешения. Или если разрешения являются кратными, путем простого усреднения в данных с высоким разрешением показателей, которые соответствуют одному частотному элементу с более низким разрешением 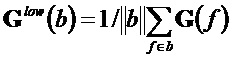
Информация о последовательности разбиения на окна из битового потока может использоваться для получения полностью дополняющего частотно-временного анализа к используемому в кодере, или последовательность разбиения на окна может быть сконструирована на основании границ параметров, как делается в стандартном декодировании битовых потоков SAOC. Для этого может использоваться генератор 134 последовательности окон.
Частотно-временной анализ аудио понижающего микширования затем выполняется модулем 135 t/f-анализа с использованием данных окон.
Наконец, интерполированные во времени и спектрально (возможно) адаптированные матрицы размикширования применяются блоком 136 размикширования к частотно-временному представлению входного аудио, и выходной канал 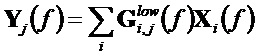
Далее описывается конкретные аспекты вариантов воплощения.
В варианте воплощения блок 109 моделирования дельты на фиг. 10 сконфигурирован определять коэффициенты линейного предсказания из множества поправочных коэффициентов (дельта) путем выполнения линейного предсказания.
Теперь описывается процесс оценки поправочного коэффициента, дельты и возможной альтернативы моделирования с использованием коэффициентов линейного предсказания (LPC) в соответствии с таким вариантом воплощения.
Сначала описывается оценка дельты в соответствии с вариантом воплощения.
Входные данные для оценки состоят из оценочных профилей энергетических спектров высокого разрешения для блока параметров и из приблизительной реконструкции профиля энергетического спектра на основании параметров OLD и NRG. Профили энергетических спектров высокого разрешения вычисляются следующим образом. 
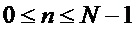
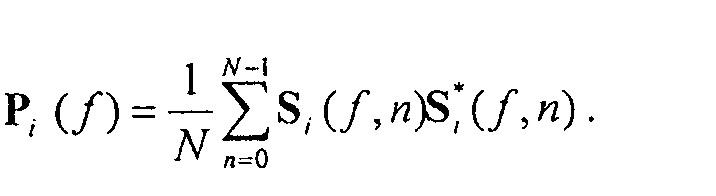
Приблизительная реконструкция вычисляется по (де-квантованным) OLD и NRG с помощью
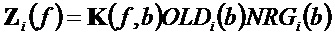
где 
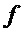
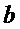
В этой секции в качестве примеров будут использоваться два сигнала с отличающимися спектральными свойствами: первый является (розовым) шумом с практически плоским спектром (игнорируя наклона спектра), и второй является тоном от инструмента металлофон, который имеет высокотональный, то есть с резким пиком, спектр.
Фиг. 15 иллюстрирует энергетические спектры тонального и шумового сигналов. Их энергетические спектры высокого разрешения ("исх.") и соответствующие приблизительные реконструкции на основании OLD и NRG ("реконст."). В частности, фиг. 15 иллюстрирует приближенный и высокого разрешения энергетические спектры обоих сигналов. В частности, показаны энергетические спектры исходного тонального сигнала 151 и исходного шумового сигнала 152, и реконструированные энергетические спектры тонального сигнала 153 и шумового сигнала. Следует отметить, что на последующих фигурах, для сигналов 153 и 154 изображены масштабные коэффициенты (реконструированный параметр энергетических спектров), а не полностью реконструированные сигналы.
Можно легко заметить, что в случае шумового сигнала средняя разница между точным и приблизительными значениями довольно небольшая, в то время как в тональном сигнале различия являются очень большими. Эти различия вызывают перцептивные ухудшения в параметрической реконструкции всех объектов.
Поправочный коэффициент получается путем деления кривой высокого разрешения на кривую приблизительной реконструкции:
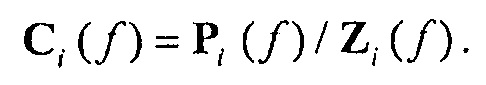
Это позволяет восстановить мультипликативный фактор, который может быть применен к приблизительной реконструкции для получения кривой высокого разрешения:
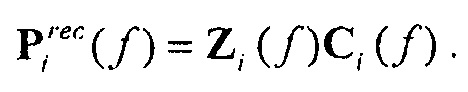
Фиг. 16 иллюстрирует модификацию для обоих иллюстративных сигналов, в частности, поправочные коэффициенты для иллюстративных сигналов. В частности, показаны поправочные коэффициенты для тонального сигнала 151 и шумового сигнала 152.
ДАЛЕЕ ОПИСЫВАЕТСЯ МОДЕЛИРОВАНИЕ ДЕЛЬТЫ.
Кривая 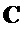
1. Спектральный поправочный коэффициент 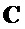
Когда длина блока моделирования является нечетной, псевдоспектр, который должен быть преобразован, определяется как

Когда блок моделирования является четным, псевдоспектр определяется как
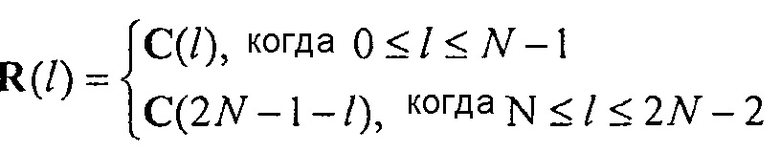
Результат трансформирования тогда равен 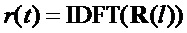
2. Результат усекается до первой половины: 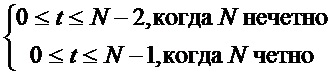
3. Применяются рекурсии Левинсона-Дербина к автокорреляционной последовательности 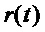
4. Опционально: На основании остаточной дисперсии e моделирования отбросить все моделирование (поскольку не было получено никакого усиления) или выбрать соответствующий порядок.
5. Параметры модели квантуются для передачи.
Возможно принять решение, должна ли быть передана дельта, для каждой t-f ячейки (стандартной параметрической полосы, определяющей диапазон частот, и блока параметров, определяющего временной диапазон) независимо. Решение может быть принято на основании, например,
- Проверки остаточной энергии моделирования дельты. Если остаточная энергия моделирования не превышает определенный порог, улучшающая информация не передается.
- Измерения "насколько много максимумов"/степени неровности смоделированного параметрического описания высокого разрешения, моделирования дельты или огибающей энергетического спектра сигнала аудиообъекта. В зависимости от измеренной величины параметры моделирования дельты, которые описывают высокое спектральное разрешение, передаются или нет, или вообще вычисляются в зависимости от степени неровности огибающей энергетического спектра сигнала аудиообъекта. Соответствующими измерениями являются, например, спектральный коэффициент амплитуды, мера ровности спектра или отношение минимума к максимуму.
- Получается качество восприятия реконструкции. Кодер вычисляет реконструкции рендеринга с и без улучшений и определяет увеличение качества для каждого улучшения. Затем находится точка надлежащего баланса между сложностью моделирования и увеличением качества, и указанные улучшения передаются. Например, для решения может использоваться отношение искажения к сигналу с весовыми коэффициентами восприятия или усовершенствованные критерии восприятия. Решение может приниматься для каждой (приблизительной) параметрической полосы отдельно (то есть локальная оптимизация качества), но также и с учетом смежных полос для учета искажений сигнала, вызванных переменными во времени и по частоте манипуляциями частотно-временных коэффициентов (то есть, глобальная оптимизация качества).
ТЕПЕРЬ ОПИСЫВАЕТСЯ РЕКОНСТРУКЦИЯ И ПРИМЕНЕНИЕ ДЕЛЬТЫ.
Реконструкция кривой коррекции следует следующим этапам:
1. Принятые коэффициенты k отражения (вектор длины L-1) де-квантуются и преобразуются в коэффициенты a длины L IIR-фильтра, в синтаксисе псевдо-кода (где функция X = diag(x) выводит матрицу X, диагональные элементы которой равны x, а все недиагональные элементы X равны нулю):
A=diag(k)
for ii=1 to L
for l=1 to ii-1
A(l,ii)=A(l,ii-1)+k(ii) * A(ii-l, ii-1)
end
end
a=[1; A(1 to end, end)]
2. Частотная характеристика 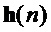
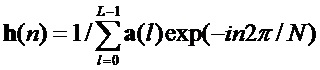
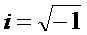
3. Реконструкция функции коррекции получается из этого с помощью 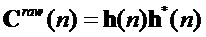
4. Ответ нормируется, чтобы иметь среднее равное единице, так что общая энергия смоделированного блока не изменяется 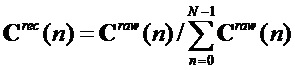
5. Поправочные коэффициенты применяются к OLD, которые были расширены до высокого разрешения 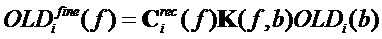
Фиг. 17 иллюстрирует исходные поправочные коэффициенты и основанные на LPC аппроксимации приведенного порядка (после моделирования) для обоих иллюстративных сигналов. В частности, показаны исходные поправочные коэффициенты тонального сигнала 151, исходного шумового сигнала 152 и оценки реконструированных поправочных коэффициентов тонального сигнала 153 и шумового сигнала 154.
Фиг. 18 иллюстрирует результат применения смоделированных поправочных коэффициентов к приблизительным реконструкциям, изображенным на фиг. 15. В частности, показаны энергетические спектры исходного тонального сигнала 151, исходного шумового сигнала 152 и оценки реконструированных энергетических спектров тонального сигнала 153 и шумового сигнала 154. Эти кривые могут теперь использоваться вместо OLD в дальнейших вычислениях, в частности, реконструированных энергетических спектров высокого разрешения после применения смоделированных поправочных коэффициентов. Здесь информация об абсолютных энергиях включена, чтобы сделать сравнение лучше видным, но тот же самый принцип работает также без них.
Способ и устройство согласно изобретению уменьшают упомянутые выше недостатки обработки SAOC существующего уровня техники с использованием набора фильтров или частотно-временного преобразования с высоким разрешением по частоте и обеспечивают эффективную параметризацию дополнительной информации. Кроме того, можно передавать эту дополнительную информацию таким образом, что стандартные декодеры SAOC могут декодировать обратно совместимую часть информации c качеством, сопоставимым с тем, которое получают с использованием кодера, совместимого со стандартным SAOC, и тем не менее позволять усовершенствованным декодерам использовать дополнительную информацию для лучшего качества восприятия. И самое главное, дополнительная информация может быть представлена в очень компактной форме для эффективной передачи или хранения.
Представленный метод согласно изобретению может быть применен к любой схеме SAOC. Он может объединяться с любыми существующим, а также будущими аудиоформатами. Способ согласно изобретению позволяет обеспечить улучшенное качество восприятия звука в приложениях SAOC путем двухуровневого представления спектральной вспомогательной информации.
Та же идея может использоваться также в сочетании с Объемным MPEG при замене концепции OLD разностями уровней каналов (CLD).
Обеспечены аудиокодер или способ аудиокодирования или соответствующая компьютерная программа согласно описанному выше. Кроме того, обеспечены аудиокодер или способ декодирования аудиосигнала или соответствующая компьютерная программа согласно описанному выше. Кроме того, обеспечен закодированный аудиосигнал или носитель данных, хранящий закодированный аудиосигнал, согласно описанному выше.
Хотя некоторые аспекты были описаны в контексте устройства, очевидно, что эти аспекты также представляют описание соответствующего способа, где блок или устройство соответствуют этапу способа или признаку этапа способа. Аналогично, аспекты, описанные в контексте этапа способа, также представляют собой описание соответствующего блока, элемента или признака соответствующего устройства.
Разложенный сигнал согласно изобретению может быть сохранен на цифровом носителе данных или может быть передан через передающую среду, такую как беспроводная среда передачи или проводная среда передачи, такая как Интернет.
В зависимости от некоторых требований реализации, варианты воплощения изобретения могут быть реализованы с помощью аппаратных средств или программного обеспечения. Реализация может быть выполнена с использованием цифрового носителя данных, например, гибкого диска, DVD, CD, ROM, PROM, EPROM, EEPROМ или флэш-памяти, имеющих сохраненные на них электронно-считываемые управляющие сигналы, которые взаимодействуют (или могут взаимодействовать) с программируемой компьютерной системой так, что выполняется соответствующий способ.
Некоторые варианты воплощения в соответствии с изобретением содержат долговременный носитель данных, имеющий электронно-считываемые управляющие сигналы, которые могут взаимодействовать с программируемой компьютерной системой так, что выполняется один из способов, описанных здесь.
В общем, варианты воплощения настоящего изобретения могут быть реализованы как компьютерный программный продукт с программным кодом, который исполняется для выполнения одного из способов, когда компьютерный программный продукт запущен на компьютере. Программный код может быть, например, сохранен на машиночитаемом носителе.
Другие варианты воплощения содержат компьютерную программу для выполнения одного из способов, описанных здесь, сохраненную на машиночитаемом носителе.
Поэтому, другими словами, вариантом воплощения способа согласно изобретению является компьютерная программа, имеющая программный код для выполнения одного из способов, описанных здесь, когда компьютерная программа запущена на компьютере.
Поэтому дополнительным вариантом воплощения способов согласно изобретению является носитель данных (или цифровой носитель данных или машиночитаемый носитель), содержащий записанную на нем компьютерную программу для выполнения одного из способов, описанных здесь.
Поэтому дополнительным вариантом воплощения способа согласно изобретению является поток данных или последовательность сигналов, представляющая собой компьютерную программу для выполнения одного из способов, описанных здесь. Поток данных или последовательность сигналов может быть, например, сконфигурирована для передачи через соединение для передачи данных, например, через Интернет.
Дополнительный вариант воплощения содержит средство обработки, например, компьютер или программируемое логическое устройство, сконфигурированное или адаптированное для выполнения одного из способов, описанных здесь.
Дополнительный вариант воплощения содержит компьютер с установленной на нем компьютерной программой для выполнения одного из способов, описанных здесь.
В некоторых вариантах воплощения может использоваться программируемое логическое устройство (например программируемая пользователем вентильная матрица) для выполнения некоторых или всех функциональных возможностей способов, описанных здесь. В некоторых вариантах воплощения программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором для выполнения одного из способов, описанных здесь. В общем, способы предпочтительно выполняются любым аппаратным устройством.
Описанные выше варианты воплощения являются просто иллюстрацией принципов настоящего изобретения. Понято, что модификации и вариации конструкций и подробностей, описанных здесь, будут очевидны для специалистов в области техники. Таким образом, изобретение ограничено только объемом прилагаемой формулы изобретения, а не конкретными подробностями, представленными с помощью описания и объяснения вариантов воплощения в настоящем описании.
ССЫЛКИ
[BCC] C. Faller and F. Baumgarte, "Binaural Cue Coding - Part II: Schemes and applications," IEEE Trans. on Speech and Audio Proc., vol. 11, no. 6, Nov. 2003.
[JSC] C. Faller, "Parametric Joint-Coding of Audio Sources", 120th AES Convention, Paris, 2006.
[SAOC1] J. Herre, S. Disch, J. Hilpert, O. Hellmuth: "From SAC To SAOC - Recent Developments in Parametric Coding of Spatial Audio", 22nd Regional UK AES Conference, Cambridge, UK, April 2007.
[SAOC2] J. Engdegård, B. Resch, C. Falch, O. Hellmuth, J. Hilpert, A. Hölzer, L. Terentiev, J. Breebaart, J. Koppens, E. Schuijers and W. Oomen: " Spatial Audio Object Coding (SAOC) - The Upcoming MPEG Standard on Parametric Object Based Audio Coding", 124th AES Convention, Amsterdam, 2008.
[SAOC] ISO/IEC, "MPEG audio technologies - Part 2: Spatial Audio Object Coding (SAOC)," ISO/IEC JTC1/SC29/WG11 (MPEG) International Standard 23003-2:2010.
[AAC] M. Bosi, K. Brandenburg, S. Quackenbush, L. Fielder, K. Akagiri, H. Fuchs, M. Dietz, "ISO/IEC MPEG-2 Advanced Audio Coding", J. Audio Eng. Soc, vol. 45, no 10, pp. 789-814, 1997.
[ISS1] M. Parvaix and L. Girin: "Informed Source Separation of underdetermined instantaneous Stereo Mixtures using Source Index Embedding", IEEE ICASSP, 2010.
[ISS2] M. Parvaix, L. Girin, J.-M. Brossier: "A watermarking-based method for informed source separation of audio signals with a single sensor", IEEE Transactions on Audio, Speech and Language Processing, 2010.
[ISS3] A. Liutkus and J. Pinel and R. Badcau and L. Girin and G. Richard: "Informed source separation through spectrogram coding and data embedding", Signal Processing Journal, 2011.
[ISS4] A. Ozerov, A. Liutkus, R. Badeau, G. Richard: "Informed source separation: source coding meets source separation", IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, 2011.
[ISS5] S. Zhang and L. Girin: "An Informed Source Separation System for Speech Signals", INTERSPEECH, 2011.
[ISS6] L. Girin and J. Pinel: "Informed Audio Source Separation from Compressed Linear Stereo Mixtures", AES 42nd International Conference: Semantic Audio, 2011.
[ISS7] A. Nesbit, E. Vincent, and M. D. Plumbley: "Benchmarking flexible adaptive time-frequency transforms for underdetermined audio source separation", IEEE International Conference on Acoustics, Speech and Signal Processing, pp. 37-40, 2009.
Изобретение относится к средствам кодирования и декодирования аудиосигнала. Технический результат заключается в повышении качества кодированного аудиосигнала. Декодер содержит определитель информации размикширования для определения информации размикширования путем приема первой параметрической вспомогательной информации об одном сигнале аудиообъекта и второй параметрической вспомогательной информации об одном сигнале аудиообъекта, при этом разрешение по частоте второй параметрической вспомогательной информации выше, чем разрешение по частоте первой параметрической вспомогательной информации. Кроме того, декодер содержит модуль размикширования для применения информации размикширования к сигналу понижающего микширования, указывающему понижающее микширование одного сигнала аудиообъекта, для получения размикшированного аудиосигнала, содержащего упомянутое множество размикшированных аудиоканалов. Определитель информации размикширования сконфигурирован определять информацию размикширования путем модификации первой параметрической информации и второй параметрической информации для получения модифицированной параметрической информации. 7 н. и 11 з.п. ф-лы, 21 ил.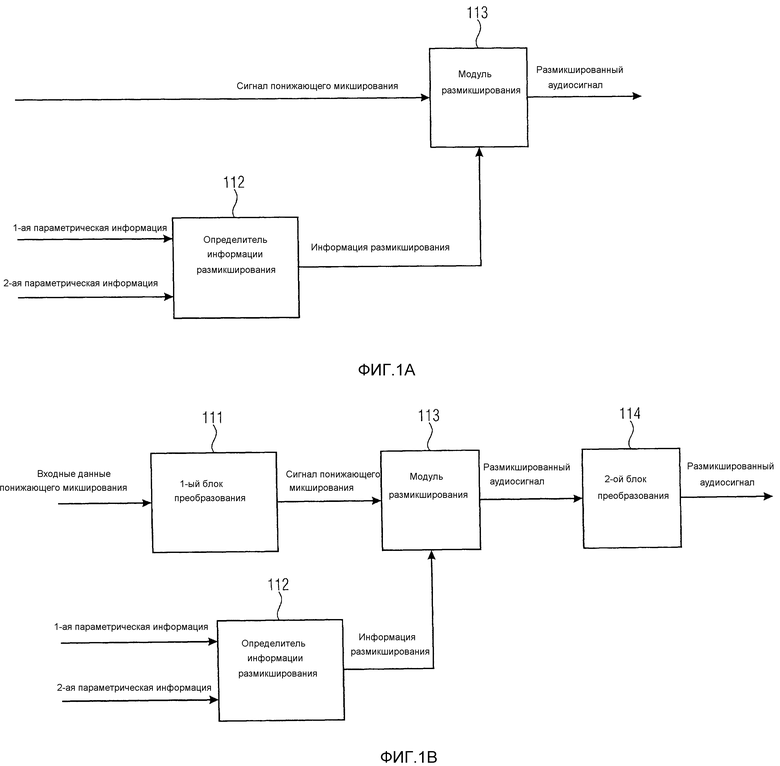
1. Декодер для генерации размикшированного аудиосигнала, содержащего множество размикшированных аудиоканалов, при этом декодер содержит:
определитель (112) информации размикширования для определения информации размикширования путем приема первой параметрической вспомогательной информации о по меньшей мере одном сигнале аудиообъекта и второй параметрической вспомогательной информации о по меньшей мере одном сигнале аудиообъекта, при этом разрешение по частоте второй параметрической вспомогательной информации выше, чем разрешение по частоте первой параметрической вспомогательной информации, и
модуль (113) размикширования для применения информации размикширования к сигналу понижающего микширования, указывающему понижающее микширование по меньшей мере одного сигнала аудиообъекта, для получения размикшированного аудиосигнала, содержащего упомянутое множество размикшированных аудиоканалов,
при этом определитель (112) информации размикширования сконфигурирован определять информацию размикширования путем модификации первой параметрической информации и второй параметрической информации для получения модифицированной параметрической информации, так что модифицированная параметрическая информация имеет разрешение по частоте, которое выше, чем первое разрешение по частоте.
2. Декодер по п. 1,
при этом декодер дополнительно содержит первый блок (111) преобразования для преобразования входных данных понижающего микширования, представленных во временной области, для получения сигнала понижающего микширования, представленного в частотно-временной области, и
при этом декодер содержит второй блок (114) преобразования для преобразования размикшированного аудиосигнала из частотно-временной области во временную область.
3. Декодер по п. 1, в котором определитель (112) информации размикширования сконфигурирован определять информацию размикширования путем объединения первой параметрической информации и второй параметрической информации для получения модифицированной параметрической информации так, что модифицированная параметрическая информация имеет разрешение по частоте, которое равно второму разрешению по частоте.
4. Декодер по п. 1,
в котором первая параметрическая информация содержит множество первых значений параметров, в котором вторая параметрическая информация содержит множество вторых значений параметров,
в котором определитель (112) информации размикширования содержит подблок (122) преобразования разрешения по частоте и объединитель (124),
в котором блок (112) преобразования разрешения по частоте сконфигурирован генерировать дополнительные значения параметров, при этом первые значения параметров и дополнительные значения параметров вместе формируют множество первых обработанных значений параметров, и
в котором объединитель (124) сконфигурирован объединять первые обработанные значения параметров и вторые значения параметров для получения множества модифицированных значений параметров в качестве модифицированной параметрической информации.
5. Декодер по п. 1,
в котором определитель (112) информации размикширования содержит блок (142) восстановления дельта-функции и блок (143) применения дельты,
в котором первая параметрическая информация содержит множество первых значений, зависящих от упомянутого по меньшей мере одного сигнала аудиообъекта, и в котором вторая параметрическая информация содержит множество вторых значений,
при этом блок (142) восстановления дельта-функции сконфигурирован инвертировать множество вторых значений для получения дельта-функции, и
при этом блок (143) применения дельты сконфигурирован применять дельта-функцию к первым значениям для определения информации размикширования.
6. Декодер по п. 5,
в котором множество вторых значений содержит множество коэффициентов линейного предсказания,
при этом блок (142) восстановления дельта-функции сконфигурирован инвертировать множество вторых значений путем генерации множества вторых значений в зависимости от упомянутого множества коэффициентов линейного предсказания, и
при этом блок (142) восстановления дельта-функции сконфигурирован генерировать дельта-функцию на основании упомянутого множества вторых значений.
7. Декодер по п. 1,
при этом декодер дополнительно содержит генератор (118) матрицы размикширования для генерации матрицы размикширования в зависимости от первой параметрической вспомогательной информации, в зависимости от второй параметрической вспомогательной информации и в зависимости от информации о рендеринге, и
при этом модуль (113) размикширования сконфигурирован применять матрицу размикширования к преобразованному понижающему микшированию для получения размикшированного аудиосигнала.
8. Декодер по п. 1,
в котором модуль (113) размикширования содержит блок (119) декорреляции и блок (110) размикширования,
при этом блок (119) декорреляции сконфигурирован производить декорреляцию преобразованного понижающего микширования для получения результата декорреляции,
и при этом блок (110) размикширования сконфигурирован использовать результат декорреляции для получения размикшированного аудиосигнала.
9. Кодер для кодирования одного или нескольких входных сигналов аудиообъектов, содержащий:
блок (91) понижающего микширования для понижающего микширования упомянутого одного или нескольких входных сигналов аудиообъектов для получения одного или нескольких сигналов понижающего микширования, и
генератор (93) параметрической вспомогательной информации для генерации первой параметрической вспомогательной информации о по меньшей мере одном сигнале аудиообъекта и второй параметрической вспомогательной информации о по меньшей мере одном сигнале аудиообъекта, так что разрешение по частоте второй параметрической вспомогательной информации выше, чем разрешение по частоте первой параметрической вспомогательной информации.
10. Кодер по п. 9,
при этом кодер дополнительно содержит блок (92) преобразования для преобразования упомянутого одного или нескольких входных сигналов аудиообъектов из временной области в частотно-временную область для получения одного или нескольких преобразованных сигналов аудиообъектов, и
при этом генератор (93) параметрической вспомогательной информации сконфигурирован генерировать первую параметрическую вспомогательную информацию и вторую параметрическую вспомогательную информацию на основании упомянутого одного или нескольких преобразованных сигналов аудиообъектов.
11. Кодер по п. 10,
в котором блок (92) преобразования сконфигурирован преобразовывать упомянутый один или несколько входных сигналов аудиообъектов из временной области в частотно-временную область в зависимости от длины окна блока преобразования сигнала, содержащего множество третьих значений по меньшей мере одного из упомянутого одного или нескольких входных сигналов аудиообъектов,
при этом блок (92) преобразования содержит блок (101) обнаружения транзиентов для определения результата обнаружения транзиента, указывающего, присутствует ли транзиент в одном или нескольких из упомянутого по меньшей мере одного сигнала аудиообъекта, при этом транзиент указывает изменение сигнала в одном или нескольких из упомянутого по меньшей мере одного сигнала аудиообъекта, и
при этом блок (92) преобразования дополнительно содержит блок (102) последовательности окон для определения длины окна в зависимости от результата обнаружения транзиента.
12. Кодер по п. 9, при этом кодер дополнительно содержит блок (108) оценки дельты для оценки множества вторых значений на основании множества первых значений, зависящих от упомянутого по меньшей мере одного сигнала аудиообъекта, для получения второй параметрической вспомогательной информации.
13. Кодер по п. 12, при этом кодер дополнительно содержит блок (109) моделирования дельты для определения коэффициентов линейного предсказания по множеству вторых значений путем выполнения линейного предсказания.
14. Система для кодирования одного или нескольких входных сигналов аудиообъектов и для генерации размикшированного аудиосигнала, содержащая:
кодер (61) по п. 9 для кодирования упомянутого одного или нескольких входных сигналов аудиообъектов путем получения одного или нескольких сигналов понижающего микширования, указывающих понижающее микширование одного или нескольких входных сигналов аудиообъектов, путем получения первой параметрической вспомогательной информации о по меньшей мере одном сигнале аудиообъекта и путем получения второй параметрической вспомогательной информации о по меньшей мере одном сигнале аудиообъекта, при этом разрешение по частоте второй параметрической вспомогательной информации выше, чем разрешение по частоте первой параметрической вспомогательной информации, и
декодер (62) по п. 1 для генерации размикшированного аудиосигнала на основании упомянутого одного или нескольких сигналов понижающего микширования и на основании первой параметрической вспомогательной информации и второй параметрической вспомогательной информации.
15. Способ для генерации размикшированного аудиосигнала, содержащего множество размикшированных аудиоканалов, при этом способ содержит этапы, на которых:
определяют информацию размикширования путем приема первой параметрической вспомогательной информации о по меньшей мере одном сигнале аудиообъекта и второй параметрической вспомогательной информации о по меньшей мере одном сигнале аудиообъекта, при этом разрешение по частоте второй параметрической вспомогательной информации выше, чем разрешение по частоте первой параметрической вспомогательной информации, и
применяют информацию размикширования к сигналу понижающего микширования, указывающему понижающее микширование по меньшей мере одного сигнала аудиообъекта, для получения размикшированного аудиосигнала, содержащего упомянутое множество размикшированных аудиоканалов,
при этом определение информации размикширования содержит модифицирование первой параметрической информации и второй параметрической информации для получения модифицированной параметрической информации, так что модифицированная параметрическая информация имеет разрешение по частоте, которое выше, чем первое разрешение по частоте.
16. Способ для кодирования одного или нескольких входных сигналов аудиообъектов, содержащий этапы, на которых:
выполняют понижающее микширование одного или нескольких входных сигналов аудиообъектов для получения одного или нескольких сигналов понижающего микширования, и
генерируют первую параметрическую вспомогательную информацию о по меньшей мере одном сигнале аудиообъекта и вторую параметрическую вспомогательную информацию о по меньшей мере одном сигнале аудиообъекта, так что разрешение по частоте упомянутой второй параметрической вспомогательной информации выше, чем разрешение по частоте упомянутой первой параметрической вспомогательной информации.
17. Машиночитаемый носитель, содержащий компьютерную программу для реализации способа по п. 15, при ее исполнении на компьютере или сигнальном процессоре.
18. Машиночитаемый носитель, содержащий компьютерную программу для реализации способа по п. 16, при ее исполнении на компьютере или сигнальном процессоре.
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| ЭФФЕКТИВНОЕ КОДИРОВАНИЕ ОГИБАЮЩЕЙ СПЕКТРА С ИСПОЛЬЗОВАНИЕМ ПЕРЕМЕННОГО РАЗРЕШЕНИЯ ПО ВРЕМЕНИ И ПО ЧАСТОТЕ И ПЕРЕКЛЮЧЕНИЯ ВРЕМЯ/ЧАСТОТА | 2000 |
|
RU2236046C2 |

