Настоящее изобретение относится к кодированию аудиосигналов, например, аудиообъектов и к декодированию кодированных аудиосигналов, таких как кодированные аудиообъекты.
Введение
В данном документе описан параметрический подход для кодирования и декодирования объектно-ориентированного аудиосодержимого на низких скоростях передачи битов с использованием направленного кодирования аудио (DirAC). Представленный вариант осуществления работает в качестве части кодека 3GPP с поддержкой иммерсивных услуг передачи голоса и аудио (IVAS) и обеспечивает предпочтительную замену для низких скоростей передачи битов режима независимого потока с метаданными (ISM), подход на основе дискретного кодирования.
Уровень техники
Дискретное кодирование объектов
Самый простой подход к кодированию объектно-ориентированного аудиосодержимого заключается в кодировании и передаче объектов по отдельности наряду с соответствующими метаданными. Главный недостаток при этом подходе состоит в непозволительном расходе битов, требуемых для кодирования объектов, по мере увеличения числа объектов. Простое решение этой проблемы состоит в использовании «параметрических подходов», в которых некоторые релевантные параметры вычисляются из входного сигнала, квантуются и передаются наряду с подходящим сигналом понижающего микширования, который комбинирует несколько форм сигналов объектов.
Пространственное кодирование аудиообъектов (SAOC)
Пространственное кодирование аудиообъектов [SAOC_STD, SAOC_AES] представляет собой параметрический подход, при котором кодер вычисляет сигнал понижающего микширования на основе некоторой матрицы D понижающего микширования и набора параметров и передает означенное в декодер. Параметры представляют психоакустически релевантные свойства и взаимосвязи всех отдельных объектов. В декодере понижающее микширование подготавливается посредством рендеринга в конкретную схему размещения громкоговорителей с использованием матрицы R рендеринга.
Главный параметр SAOC представляет собой ковариационную матрицу Е объектов размера N×N, где N означает число объектов. Этот параметр транспортируется в декодер в качестве разностей уровней объектов (OLD) и при необходимости межобъектной ковариации (ЮС).
Отдельные элементы ei,j матрицы Е определяются следующим образом:
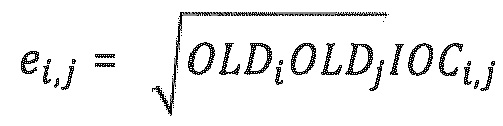
Разность уровней объектов (OLD) определяется следующим образом:
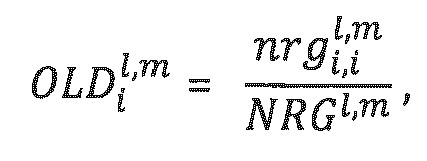 ,
,
где 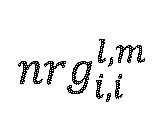 и абсолютная энергия объектов (NRG) описаны следующим образом:
и абсолютная энергия объектов (NRG) описаны следующим образом:
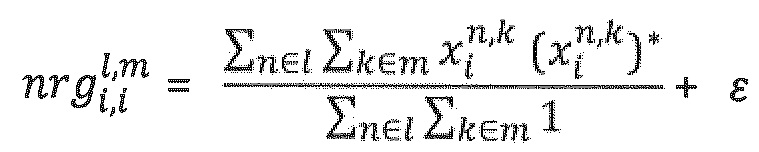 ,
,
и:
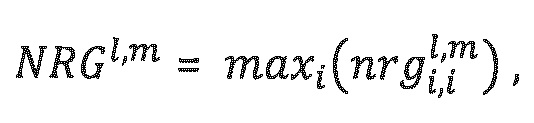
где i и j являются индексами объектов для объектов xi и xj соответственно, n указывает временной индекс, и k указывает частотный индекс. I указывает набор временный индексов, и m указывает набор частотный индексов. ε является аддитивной постоянной, чтобы не допускать деления на нуль, например, ε=10.
Показатель подобия входных объектов (IOC), например, может определяться посредством взаимной корреляции:
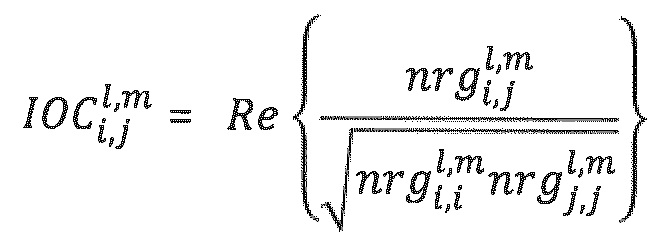
Матрица D понижающего микширования размера N_dmx × N определяется посредством элементов di, j, где i означает индекс канала сигнала понижающего микширования, и j означает индекс объекта. Для понижающего стереомикширования (N_dmx=2), di, j вычисляется из параметров DMG и DCLD следующим образом:
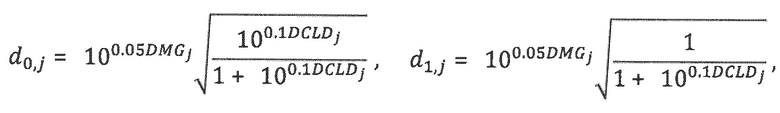
где DMGi и DCLDi определяются следующим образом:
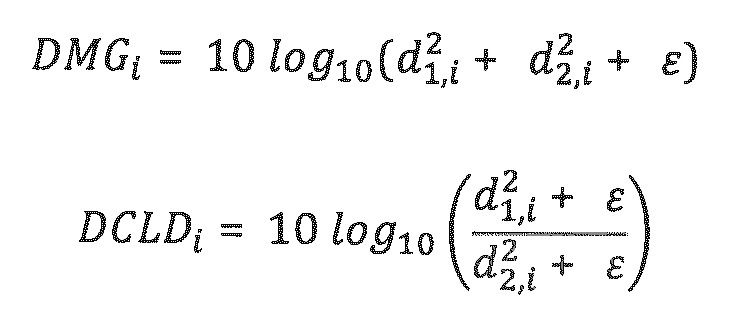
Для случая понижающего мономикширования (N_dmx=l), di, j вычисляется просто из DMG-параметров следующим образом:
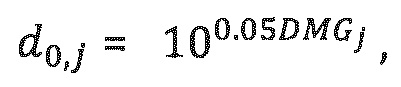
где:
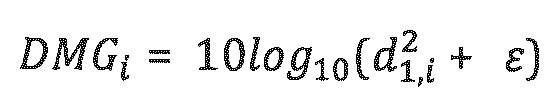
Трехмерное пространственное кодирование аудиообъектов (SAOC-3D)
Воспроизведение трехмерного аудио с пространственным кодированием аудиообъектов (SAOC-3D) [mPEGH_AES, MPEGH_IEEE, MPEGH_STD, SAOC_3D_PAT] представляет собой расширение MPEG SAOC-технологии, описанной выше, которая сжимает и подготавливает посредством рендеринга канальные и объектные сигналы очень эффективным по скорости передачи битов способом.
Существенные отличия для SAOC заключаются в следующем:
- Хотя исходное SAOC поддерживает только вплоть до двух каналов понижающего микширования, SAOC-3D может преобразовывать многообъектный ввод в произвольное число каналов понижающего микширования (и ассоциированную вспомогательную информацию).
- Рендеринг в многоканальный вывод проводится непосредственно, в отличие от классического SAOC, которое использует стандарт объемного звучания MPEG в качестве многоканального выходного процессора.
- Отброшены некоторые инструментальные средства, такие как инструментальное средство остаточного кодирования.
Несмотря на эти отличия, SAOC-3D является одинаковым с SAOC с точки зрения параметров. Декодер SAOC-3D (аналогично декодеру SAOC) принимает многоканальное понижающее микширование X, ковариационную матрицу Е, матрицу R рендеринга и матрицу D понижающего микширования.
Матрица R рендеринга определяется посредством входных каналов и входных объектов и принимается из преобразователя форматов (каналы) и модуль рендеринга объектов (объекты), соответственно.
Матрица D понижающего микширования определяется посредством элементов di, j где i означает индекс канала сигнала понижающего микширования, и j означает индекс объекта и вычисляется из усилений при понижающем микшировании (DMG):
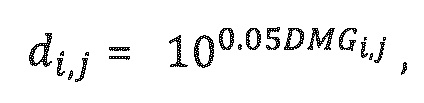
где:
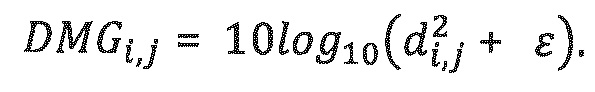
Выходная ковариационная матрица С размера N_out*N_out определяется следующим образом:
С=RER*
Связанные схемы
Существуют несколько других схем, которые являются аналогичными по своему характеру SAOC, как описано выше, с незначительными различиями:
- Бинауральное кодирование по сигнальным меткам (ВСС) для объектов описано, например, в [ВСС2001] и является предшествующим элементом технологии SAOC.
- Объединенное кодирование объектов (JOC) и усовершенствованное объединенное кодирование объектов (A-JOC) выполняют функцию, аналогичную функции SAOC при доставке примерно разделенных объектов на стороне декодера без их рендеринга в конкретную выходную схему размещения динамиков [JOC_AES, АС4_AES]. Эта технология передает элементы матрицы повышающего микширования из понижающего микширования в разделенные объекты в качестве параметров (а не OLD).
Направленное кодирование аудио (DirAC)
Другой параметрический подход представляет собой направленное кодирование аудио. DirAC [Pulkki2009] представляет собой перцепционно обусловленное воспроизведение пространственного звука. Предполагается, что в один момент времени и для одной критической полосы частот, пространственное разрешение слуховой системы человека ограничено декодированием одной сигнальной метки для направления, а другой - для интерауральной когерентности.
На основе этих допущений, DirAC представляет пространственный звук в одной полосе частот посредством плавного перехода двух потоков: ненаправленного рассеянного потока и направленного нерассеянного потока. Обработка DirAC выполняется в двух фазах: анализа и синтеза, как проиллюстрировано на фиг.12а и 12b.
В ступени анализа DirAC совпадающий микрофон первого порядка в В-формате рассматривается как ввод, и рассеянность и направление поступления звука анализируются в частотной области.
В ступени синтеза DirAC звук разделяется на два потока, нерассеянный поток и рассеянный поток. Нерассеянный поток воспроизводится в качестве точечных источников с использованием амплитудного панорамирования, которое может выполняться посредством использования векторного амплитудного панорамирования (VBAP) [Pulkki1997]. Рассеянный поток отвечает за ощущение огибания и формируется посредством передачи в громкоговорители взаимно декоррелированных сигналов.
Ступень анализа на фиг. 12а содержит полосовой фильтр 1000, модуль 1001 оценки энергии, модуль 1002 оценки интенсивности, временные усредняющие элементы 999а и 999b, модуль 1003 вычисления рассеянности и модуль 1004 вычисления направления. Вычисленные пространственные параметры представляют собой значение рассеянности между 0 и 1 для каждого частотно-временного мозаичного элемента и параметр направления поступления для каждого частотно-временного мозаичного элемента, сформированного посредством блока 1004. На фиг. 12а, параметр направления содержит угол азимута и угол места, указывающие направление поступления звука относительно опорного положения или положения прослушивания и, в частности, относительно положения, в котором расположен микрофон, из которой собираются четыре компонентных сигнала, вводимых в полосовой фильтр 1000. Эти компонентные сигналы, в иллюстрации по фиг. 12а, представляют собой компоненты амбиофонии первого порядка, которые содержат всенаправленный компонент W, направленный компонент X, другой направленный компонент Y и дополнительный направленный компонент Z.
Ступень синтеза DirAC, проиллюстрированная на фиг. 12b, содержит полосовой фильтр 1005 для формирования частотно-временного представления сигналов W, X, Y, Z микрофона в В-формате. Соответствующие сигналы для отдельных частотно-временных плиток вводятся в ступень 1006 виртуального микрофона, которая формирует для каждого канала сигнал виртуального микрофона. В частности, для формирования сигнала виртуального микрофона, например, для центрального канала, виртуальный микрофон направлен в направлении центрального канала, и результирующий сигнал представляет собой соответствующий компонентный сигнал для центрального канала. Сигнал затем обрабатывается через ветвь 1015 прямых сигналов и ветвь 1014 рассеянных сигналов. Обе ветви содержат соответствующие модули регулировки усиления или усилители, которые управляются посредством значений рассеянности, извлекаемых из исходного параметра рассеянности в блоках 1007, 1008 и дополнительно обработанных в блоках 1009, 1010, с тем чтобы получать определенную компенсацию микрофонов.
Компонентный сигнал в ветви 1015 прямых сигналов также регулируется по усилению с использованием параметра усиления, извлекаемого из параметра направления, состоящего из угла азимута и угла места. В частности, эти углы вводятся в таблицу 1011 усилений на основе VBAP (векторного амплитудного панорамирования). Результат вводится в ступень 1012 усреднения усиления громкоговорителей для каждого канала и дополнительный нормализатор 1013, и результирующий параметр усиления затем перенаправляется в усилитель или модуль регулировки усиления в ветви 1015 прямых сигналов. Рассеянный сигнал, сформированный в выводе декоррелятора 1016, и прямой сигнал или нерассеянный поток комбинируются в модуле 1017 комбинирования, и после этого другие подполосы частот добавляются в другом модуле 1018 комбинирования, который, например, может представлять собой гребенку синтезирующих фильтров. Таким образом, сигнал громкоговорителя для определенного громкоговорителя формируется, и та же процедура выполняется для других каналов для других громкоговорителей 1019 в определенной конфигурации громкоговорителей.
Высококачественная версия синтеза DirAC проиллюстрирована на фиг. 12b, в которой синтезатор принимает все сигналы в В-формате, из которых сигнал виртуального микрофона вычисляется для каждого направления громкоговорителя. Используемая диаграмма направленности типично представляет собой диполь. Сигналы виртуальных микрофонов затем модифицируются нелинейным способом в зависимости от метаданных, как пояснено относительно ветвей 1016 и 1015. Версия с низкой скоростью передачи битов DirAC не показана на фиг. 12b. Тем не менее в этой версии с низкой скоростью передачи битов, только один канал аудио передается. Различие в обработке заключается в том, что все сигналы виртуальных микрофонов должны заменяться посредством этого принимаемого одного канала аудио. Сигналы виртуальных микрофонов разделяются на два потока, рассеянный и нерассеянный потоки, которые обрабатываются отдельно. Нерассеянный звук воспроизводится в качестве точечных источников посредством использования векторного амплитудного панорамирования (VBAP). При панорамировании, монофонический звуковой сигнал применяется к поднабору громкоговорителей после умножения на конкретные для громкоговорителя коэффициенты усиления. Коэффициенты усиления вычисляются с использованием информации конфигурации громкоговорителей и указываемого направления панорамирования. В версии с низкой скоростью передачи битов, входной сигнал просто панорамируется в направления, подразумеваемые посредством метаданных. В высококачественной версии, каждый сигнал виртуального микрофона умножается на соответствующий коэффициент усиления, что формирует одинаковый эффект с панорамированием; тем не менее, он менее подвержен нелинейным артефактам.
Цель синтеза рассеянного звука состоит в том, чтобы создавать восприятие звука, который окружает слушателя. В версии с низкой скоростью передачи битов, рассеянный поток воспроизводится посредством декорреляции входного сигнала и его воспроизведения из каждого громкоговорителя. В высококачественной версии, сигналы виртуальных микрофонов рассеянных потоков являются уже некогерентными в определенной степени, и они должны декоррелироваться только немного.
Параметры DirAC, также называемые «пространственными метаданными», состоят из кортежей рассеянности и направления, которые в сферических координатах представляются посредством двух углов - азимута и угла места. Если обе ступени анализа и синтеза выполняются на стороне декодера, частотно-временное разрешение параметров DirAC может выбираться равным частотно-временному разрешению гребенки фильтров, используемой для анализа и синтеза DirAC, т.е. как отличающийся набор параметров для каждого временного кванта и частотного элемента разрешения представления на основе гребенки фильтров аудиосигнала.
Определенная работа проведена для уменьшения размера метаданных для обеспечения возможности использования парадигмы DirAC для пространственного кодирования аудио и в сценариях на основе телеконференций [Hirvonen2009].
В [WO 2019068638], введена универсальная система пространственного кодирования аудио на основе DirAC. В отличие от классического DirAC, которое проектируется с возможностью ввода в В-формате (формате амбиофонии первого или высшего порядка), эта система может разрешать амбиофонический аудиоввод первого или высшего порядка, многоканальный аудиоввод или объектно-ориентированный аудиоввод и также обеспечивает возможность микшированных входных сигналов. Все типы сигналов эффективно кодируются и передаются отдельным или комбинированным способом. Первый комбинирует различные представления в модуле рендеринга (на стороне декодера), тогда как второй использует комбинацию на стороне кодера различных аудиопредставлений в области DirAC.
Совместимость с инфраструктурой DirAC
Настоящий вариант осуществления основывается на унифицированной инфраструктуре для произвольных типов ввода, представленной в [WO 2019068638], и - аналогично тому, что [WO 2020249815] определяет для многоканального содержимого, имеет целью исключение проблемы невозможности эффективного применения параметров DirAC (направления и рассеянности) к объектному вводу. Фактически параметр рассеянности вообще не требуется, поскольку обнаружено, что одна направленная сигнальная метка в расчете на частотно-временную единицу является недостаточной для воспроизведения высококачественного объектного содержимого. Этот вариант осуществления в силу этого предлагает использовать несколько направленных меток в расчете на частотно-временную единицу и, соответственно, вводит адаптированный набор параметров, который заменяет классические параметры DirAC в случае объектного ввода.
Гибкая система на низких скоростях передачи битов
В отличие от DirAC, которое использует сцено-ориентированное представление с точки зрения слушателя, SAOC и SAOC-3D проектируются для канально- и объектно-ориентированного содержимого, в котором параметры описывают взаимосвязи между каналами/объектами. Чтобы использовать сцено-ориентированное представление для объектного ввода и в силу этого быть совместимым с модулями рендеринга DirAC, при одновременном обеспечении эффективного представления и высококачественного воспроизведения, адаптированный набор параметров требуется для обеспечения возможности передачи в служебных сигналах нескольких направленных меток.
Важная задача этого варианта осуществления заключается в нахождении способа эффективного кодирования объектного ввода с низкими скоростями передачи битов и с хорошей масштабируемостью для растущего числа объектов. Дискретное кодирование каждого объектного сигнала не может предлагать такую масштабируемость: каждый дополнительный объект приводит к тому, что полная скорость передачи битов значительно повышается. Если разрешенная скорость передачи битов превышается посредством увеличенного числа объектов, то это должно непосредственно приводить к сильно слышимому ухудшению качества выходных сигналов; это ухудшение качества представляет собой еще один аргумент в пользу этого варианта осуществления.
Задача настоящего изобретения состоит в создании усовершенствованной концепции кодирования множества аудиообъектов или декодирования кодированного аудиосигнала.
Данная задача решается устройством кодирования по пункту 1 формулы, декодером по пункту 18 формулы, способом кодирования по пункту 28 формулы, способом декодирования по пункту 29 формулы, компьютерной программой по пункту 30 формулы или кодированным аудиосигналом по пункту 31 формулы.
В одном аспекте настоящего изобретения, настоящее изобретение основано на понимании того, что для одного или более частотных элементов разрешения из множества частотных элементов разрешения, определяются по меньшей мере два релевантных аудиообъекта, и данные параметров, связанные с этими по меньшей мере двумя релевантными объектами, включаются на стороне кодера и используются на стороне декодера для получения концепции высококачественного, но эффективного кодирования/декодирования аудио.
В соответствии с дополнительным аспектом настоящего изобретения, изобретение основано на понимании того, что конкретное понижающее микширование, адаптированное к информации направления, ассоциированной с каждым объектом, выполняется таким образом, что каждый объект, который имеет ассоциированную информацию направления, допустимую для целого объекта, т.е. для всех частотных элементов разрешения во временном кадре, используется для понижающего микширования этого объекта в число транспортных каналов. Использование информации направления, например, является эквивалентным формированию транспортных каналов в качестве сигналов виртуальных микрофонов, имеющих определенные регулируемые характеристики.
На стороне декодера выполняется конкретный синтез, который базируется на ковариационном синтезе, который, в конкретных вариантах осуществления, в частности, подходит для высококачественного ковариационного синтеза, который не страдает от вводимых декоррелятором артефактов. В других вариантах осуществления, используется усовершенствованный ковариационный синтез, который базируется на конкретных улучшениях, связанных со стандартным ковариационным синтезом, чтобы повышать качество звучания и/или уменьшать объем вычислений, необходимых для вычисления матрицы микширования, используемой в ковариационном синтезе.
Тем не менее, даже в более классическом синтезе, в котором аудиорендеринг осуществляется посредством явного определения отдельных вкладов в частотно-временном элементе разрешения на основе передаваемой информации выбора, качество звучания выше относительно подходов на основе объектного кодирования или подходов на основе канального понижающего микширования из уровня техники. В такой ситуации, каждый частотно-временной элемент разрешения имеет идентификационную информацию объектов, и при выполнении рендеринга аудио, т.е. с учетом вклада в отношении направления каждого объекта, эти идентификационные данные объекта используются для выполнения поиска направления, ассоциированного с этой информацией объектов, с тем чтобы определять значения усиления для отдельных выходных каналов в расчете на частотно-временной элемент разрешения. Таким образом, когда предусмотрен только один релевантный объект в частотно-временном элементе разрешения, то только значения усиления для этого одного объекта в расчете на частотно-временной элемент разрешения определяются на основе идентификатора объекта и «таблицы кодирования» информации направления для ассоциированных объектов.
Тем не менее, когда предусмотрено более 1 релевантного объекта в частотно-временном элементе разрешения, то значения усиления для каждого релевантного объекта вычисляются таким образом, чтобы иметь распределение соответствующего частотно-временного элемента разрешения транспортного канала в соответствующие выходные каналы, отрегулированные посредством указанного пользователями выходного формата, такого как определенный формат канала, представляющий собой стереоформат, формат 5.1 и т.д. Независимо от того, используются или нет значения усиления для целей ковариационного синтеза, т.е. для целей применения матрицы микширования для микширования транспортных каналов в выходные каналы, либо от того, используются или нет значения усиления для явного определения отдельных вкладов для каждого объекта в частотно-временном элементе разрешения посредством умножения значений усиления на соответствующий частотно-временной элемент разрешения одного или более транспортных каналов и последующего суммирования вкладов для каждого выходного канала в соответствующем частотно-временном элементе разрешения, вероятно, улучшенном посредством добавления компонента рассеянного сигнала, выходное качество звучания, тем не менее, повышается вследствие гибкости, обеспечиваемой посредством определения одного или более релевантных объектов в расчете на частотный элемент разрешения.
Это определение является очень эффективно возможным, поскольку только один или более идентификаторов объектов для частотно-временного элемента разрешения должны кодироваться и передаваться в декодер вместе с информацией направления в расчете на объект, что, тем не менее, также является очень эффективно возможным. Это обусловлено этим фактом, что, для кадра, имеется только одна информация направления для всех частотных элементов разрешения.
Таким образом, независимо от того, проводится синтез с использованием предпочтительно усовершенствованного ковариационного синтеза или с использованием комбинации явных вкладов транспортных каналов в расчете на каждый объект, получается высокоэффективное и высококачественное объектное понижающее микширование, которое предпочтительно улучшается за счет использования конкретного зависимого от направления объектов понижающего микширования с базированием на весовых коэффициентах для понижающего микширования, которые отражают формирование транспортных каналов в качестве сигналов виртуальных микрофонов.
Аспект, связанный с двумя или более релевантных объектов в расчете на частотно-временной элемент разрешения, может предпочтительно комбинироваться с аспектом выполнения конкретного зависимого от направления понижающего микширования объектов в транспортные каналы. Тем не менее, оба аспекта также могут применяться независимо друг от друга. Кроме того, хотя ковариационный синтез с двумя или более релевантных объектов в расчете на частотно-временной элемент разрешения выполняется в конкретных вариантах осуществления, усовершенствованный ковариационный синтез и усовершенствованное повышающее микширование транспортных каналов в выходные каналы также могут выполняться посредством передачи только идентификационных данных одного объекта в расчете на частотно-временной элемент разрешения.
Кроме того, независимо от того, предусмотрен один или несколько релевантных объектов в расчете на частотно-временной элемент разрешения, повышающее микширование также может выполняться посредством вычисления матрицы микширования в стандартном или усовершенствованном ковариационном синтезе, или повышающее микширование может выполняться с отдельным определением вклада частотно-временного элемента разрешения на основе идентификационных данных объекта, используемых для извлечения, из «таблицы кодирования» направлений, определенной информации направления для определения значений усиления для соответствующих вкладов. Они затем суммируются таким образом, чтобы иметь полный вклад в расчете на частотно-временной элемент разрешения, в случае двух или более релевантных объектов в расчете на частотно-временной элемент разрешения. Вывод этого суммирования этапа в таком случае является эквивалентным выводу применения матрицы микширования, и выполняется конечная обработка на основе гребенки фильтров для формирования выходных канальных сигналов временной области для соответствующего выходного формата.
Ниже описаны предпочтительные варианты осуществления настоящего изобретения с обращением к сопровождаемым чертежам, на которых:
Фиг. 1а является реализацией аудиокодера в соответствии с первым аспектом наличия по меньшей мере двух релевантных объектов в расчете на частотно-временной элемент разрешения;
Фиг. 1b является реализацией кодера в соответствии со вторым аспектом наличия зависимого от направления понижающего микширования объектов;
Фиг. 2 является предпочтительной реализацией кодера в соответствии со вторым аспектом;
Фиг. 3 является предпочтительной реализацией кодера в соответствии с первым аспектом;
Фиг. 4 является предпочтительной реализацией декодера в соответствии с первым и вторым аспектом;
Фиг. 5 является предпочтительной реализацией обработки ковариационного синтеза по фиг. 4;
Фиг. 6а является реализацией декодера в соответствии с первым аспектом;
Фиг. 6b является декодером в соответствии со вторым аспектом;
Фиг. 7а является блок-схемой для иллюстрации определения информации параметров в соответствии с первым аспектом;
Фиг. 7b является предпочтительной реализацией дополнительного определения параметрических данных;
Фиг. 8а иллюстрирует частотно-временное представление на основе гребенки фильтров высокого разрешения;
Фиг. 8b иллюстрирует передачу релевантной вспомогательной информации для кадра J в соответствии с предпочтительной реализацией первого и второго аспектов;
Фиг. 8с иллюстрирует «таблицу кодирования направлений», которая включается в кодированный аудиосигнал;
Фиг. 9а иллюстрирует предпочтительный способ кодирования в соответствии со вторым аспектом;
Фиг. 9b иллюстрирует реализацию статического понижающего микширования в соответствии со вторым аспектом;
Фиг. 9с иллюстрирует реализацию динамического понижающего микширования в соответствии со вторым аспектом;
Фиг. 9d иллюстрирует дополнительный вариант осуществления второго аспекта;
Фиг. 10а иллюстрирует блок-схему предпочтительной реализации стороны декодера первого аспекта;
Фиг. 10b иллюстрирует предпочтительную реализацию вычисления выходных каналов по фиг. 10а в соответствии с вариантом осуществления, имеющим суммирование вкладов в расчете на каждый выходной канал;
Фиг. 10с иллюстрирует предпочтительный способ определения значений мощности в соответствии с первым аспектом для множества релевантных объектов;
Фиг. 10d иллюстрирует вариант осуществления вычисления выходных каналов по фиг. 10а с использованием ковариационного синтеза с базированием на вычислении и применении матрицы микширования;
Фиг.11 иллюстрирует несколько вариантов осуществления для усовершенствованного вычисления матрицы микширования для частотно-временного элемента разрешения;
Фиг. 12а иллюстрирует - кодер DirAC из уровня техники; и
Фиг. 12b иллюстрирует декодер DirAC из уровня техники.
Фиг. 1а иллюстрирует устройство для кодирования множества аудиообъектов, которое принимает, во вводе, аудиообъекты как есть и/или метаданные для аудиообъектов. Кодер содержит модуль 100 вычисления параметров объектов, который обеспечивает данные параметров по меньшей мере для двух релевантных аудиообъектов для частотно-временного элемента разрешения, и эти данные перенаправляются в выходной интерфейс 200. В частности, модуль вычисления параметров объектов вычисляет, для одного или более частотных элементов разрешения из множества частотных элементов разрешения, связанных с временным кадром, данные параметров по меньшей мере для двух релевантных аудиообъектов, при этом, в частности, число по меньшей мере двух релевантных аудиообъектов ниже общего числа множества аудиообъектов. Таким образом, модуль 100 вычисления параметров объектов фактически выполняет выбор, а не просто указывает все объекты как релевантные. В предпочтительных вариантах осуществления, выбор осуществляется посредством релевантности, и релевантность определяется посредством связанного с амплитудой показателя, такого как амплитуда, мощность, уровень громкости или другой показатель, полученный посредством возведения в амплитуды степень, отличающуюся от единицы и предпочтительно большей 1. Далее, если определенное число релевантных объектов доступно для частотно-временного элемента разрешения, объекты, имеющие самую релевантную характеристику, т.е. имеющие наибольшую мощность из всех объектов, выбираются, и данные по этим выбранным объектам включаются в данные параметров.
Выходной интерфейс 200 выполнен с возможностью вывода кодированного аудиосигнала, который содержит информацию относительно данных параметров по меньшей мере для двух релевантных аудиообъектов для одного или более частотных элементов разрешения. В зависимости от реализации, выходной интерфейс может принимать и вводить в кодированный аудиосигнал другие данные, такие как объектное понижающее микширование либо один или более транспортных каналов, представляющих объектное понижающее микширование, либо дополнительные параметры или данные форм сигналов объектов, находящиеся в микшированном представлении, в котором несколько объектов микшируются с понижением, либо другие объекты, находящиеся в отдельном представлении. В этой ситуации, объекты непосредственно вводятся или «копируются» в соответствующие транспортные каналы.
Фиг. 1b иллюстрирует предпочтительную реализацию устройства для кодирования множества аудиообъектов в соответствии со вторым аспектом, в которой аудиообъекты принимаются вместе со связанными метаданными объектов, которые указывают информацию направления относительно множества аудиообъектов, т.е. одну информацию направления для каждого объекта или для группы объектов, если группа объектов имеет ассоциированную одинаковую информацию направления. Аудиообъекты вводятся в понижающий микшер 400 для понижающего микширования множества аудиообъектов для получения одного или более транспортных каналов. Кроме того, предусмотрен кодер 300 транспортных каналов, который кодирует один или более транспортных каналов для получения одного или более кодированных транспортных каналов, которые затем вводятся в выходной интерфейс 200. В частности, понижающий микшер 400 соединяется с модулем 110 обеспечения информации направления объектов, который принимает, во вводе, любые данные, из которых могут извлекаться метаданные объектов, и выводит информацию направления, фактически используемую посредством понижающего микшера 400. Информация направления, перенаправленная из модуля 110 обеспечения информации направления объектов в понижающее микширование 400, предпочтительно представляет собой деквантованную информацию направления, т.е. одинаковую информацию направления, которая затем доступна на стороне декодера. С этой целью, модуль 110 обеспечения информации направления объектов выполнен с возможностью извлечения или вывода или поиска неквантованных метаданных объектов, затем квантования метаданных объектов для извлечения квантованных метаданных объектов, представляющих индекс квантования, который в предпочтительных вариантах осуществления передается в выходной интерфейс 200 в числе «других данных», проиллюстрированных на фиг. 1b. Кроме того, модуль 110 обеспечения информации направления объектов выполнен с возможностью деквантования квантованной информации направления объектов для получения фактической информации направления, перенаправленной из блока 110 в понижающий микшер 400.
Предпочтительно, выходной интерфейс 200 выполнен с возможностью дополнительного приема данных параметров для аудиообъектов, данные форм сигналов объектов, идентификационные данные либо несколько идентификационных данных для одного или нескольких релевантных объектов в расчете на частотно-временные элементы разрешения и, как пояснено выше, квантованные данные направления.
Далее проиллюстрированы дополнительные варианты осуществления. Представляется параметрический подход для кодирования сигналов аудиообъектов, который обеспечивает возможность эффективной передачи на низких скоростях передачи битов, а также высококачественного воспроизведения на стороне потребителя. На основе принципа DirAC для учета одной направленной метки в расчете на критическую полосу частот и момент времени (частотно-временной мозаичный элемент), наиболее доминирующий объект определяется для каждого такого частотно-временного мозаичного элемента частотно-временного представления входных сигналов. Поскольку этого оказалось недостаточным для объектного ввода, дополнительный второй наиболее доминирующий объект определяется в расчете на частотно-временной мозаичный элемент, и отношения мощностей вычисляются на основе этих двух объектов таким образом, чтобы определить влияние каждого из двух объектов на рассматриваемый частотно-временной мозаичный элемент. Примечание: Также возможно учитывать более двух наиболее доминирующих объектов в расчете на частотно-временную единицу, в частности, для растущего числа входных объектов. Для простоты, нижеприведенные описания главным образом основаны на двух доминирующих объектах в расчете на частотно-временную единицу.
Параметрическая вспомогательная информация, передаваемая в декодер, в силу этого содержит:
- Отношения мощностей, вычисленные для поднабора релевантных (доминирующих) объектов для каждого частотно-временного мозаичного элемента (или полосы частот параметров).
- Индексы объектов, которые представляют поднабор релевантных объектов для каждого частотно-временного мозаичного элемента (или полосы частот параметров).
- Информацию направления, которая ассоциирована с индексами объектов и предусмотрена для каждого кадра (при этом каждый кадр временной области содержит несколько полос частот параметров, и каждая полоса частот параметров содержит несколько частотно-временных плиток).
Информация направления определяется доступной через файлы входных метаданных, ассоциированные с сигналами аудиообъектов. Метаданные могут указываться, например, на основе кадров. Кроме вспомогательной информации, сигнал понижающего микширования, который комбинирует входные объектные сигналы, также передается в декодер.
Во ступени рендеринга передаваемая информация направления (извлекаемая через индексы объектов) используется для панорамирования передаваемого сигнала понижающего микширования (либо, обобщенно, транспортных каналов) в соответствующие направления. Сигнал понижающего микширования распределяется в два релевантных направления объектов на основе передаваемых отношений мощностей, которые используются в качестве весовых коэффициентов. Эта обработка проводится для каждого частотно-временного мозаичного элемента частотно-временного представления декодированного сигнала понижающего микширования.
В этом разделе приведена сущность обработки на стороне кодера, а далее приводится подробное описание вычисления параметров и для понижающего микширования. Аудиокодер принимает один или более сигналов аудиообъектов. С каждым сигналом аудиообъекта ассоциирован файл метаданных, описывающий свойства объектов. В этом варианте осуществления, свойства объектов, описанные в файлах ассоциированных метаданных, соответствуют информации направления, которая обеспечивается на основе кадров, при этом один кадр соответствует 20 миллисекундам. Каждый кадр идентифицируется посредством номера кадра, также содержащегося в файлах метаданных. Информация направления определяется как информация азимута и угла места, причем азимут принимает значение в [ -180, 180] градусов, и угол места принимает значение в [ -90, 90] градусов. Дополнительные свойства, приведенные в метаданных, могут включать в себя расстояние, разброс, усиление, например; эти свойства не принимаются во внимание в этом варианте осуществления.
Информация, предусмотренная в файлах метаданных, используется вместе с фактическими объектными аудиофайлами для создания набора параметров, который передается в декодер и используется для рендеринга конечных выходных аудиофайлов. Более конкретно, кодер оценивает параметры, т.е. отношения мощностей, для поднабора доминирующих объектов для каждого частотно-временного мозаичного элемента. Поднабор доминирующих объектов представляется посредством индексов объектов, которые также используются для идентификации направления объектов. Эти параметры передаются в декодер наряду с транспортными каналами и метаданными направления.
Общее представление кодера приводится на фиг. 2, на котором транспортные каналы содержат сигнал понижающего микширования, вычисленный из входных объектных файлов и информации направления, предусмотренной во входных метаданных. Число транспортных каналов всегда меньше числа входных объектных файлов. В кодере варианта осуществления, кодированный аудиосигнал представляется посредством кодированных транспортных каналов, и кодированная параметрическая вспомогательная информация указывается посредством кодированных индексов объектов, кодированных отношений мощностей и кодированной информации направления. Как кодированные транспортные каналы, трак и кодированная параметрическая вспомогательная информация вместе формируют поток битов, выводимый посредством мультиплексора 220. В частности, кодер содержит гребенку 102 фильтров, принимающую входные объектные аудиофайлы. Кроме того, файлы метаданных объектов передаются в блок 110а извлечения информации направления. Вывод блока 110а вводится в блок 110b квантования информации направления, который выводит информацию направления в понижающий микшер 400, который выполняет вычисление для понижающего микширования. Кроме того, квантованная информация направления, т.е. индекс квантования перенаправляется из блока 110b в блок 202 кодирования информации направления, который предпочтительно выполняет некоторое энтропийное кодирование для дополнительного уменьшения требуемой скорости передачи битов.
Кроме того, вывод гребенки 102 фильтров вводится в блок 104 вычисления мощности сигналов, и вывод блока 104 вычисления мощности сигналов вводится в блок 106 выбора объектов и дополнительно в блок 108 вычисления отношений мощностей. Блок 108 вычисления отношений мощностей также соединяется с блоком 106 выбора объектов для вычисления отношения мощностей, т.е. комбинированных значений только для выбранных объектов. В блоке 210, вычисленные отношения мощностей или комбинированные значения квантуются и кодируются. Как указано далее, отношения мощностей являются предпочтительными для сокращения передачи одного элемента данных мощности. Тем не менее в других вариантах осуществления, в которых это сокращение не требуется, вместо отношений мощностей, фактическая мощность сигналов или другие значения, извлеченные из мощностей сигналов, определенных посредством блока 104, могут вводиться в квантователь и кодер при выборе модуля 106 выбора объектов. Затем вычисление 108 отношений мощностей не требуется, и выбор 106 объектов удостоверяется в том, что только релевантные параметрические данные, т.е. связанные с мощностью данные для релевантных объектов вводятся в блок 210 для целей квантования и кодирования.
При сравнении фиг. 1а с фиг. 2, блоки 102, 104, 110а, 110b, 106, 108 предпочтительно включаются в модуль 100 вычисления параметров объектов по фиг. 1а, и блоки 202, 210, 220 предпочтительно включаются в выходной интерфейсный блок 200 по фиг. 1а.
Кроме того, базовый кодер 300 на фиг. 2 соответствует кодеру 300 транспортных каналов по фиг. 1b, блок 400 вычисления для понижающего микширования соответствует понижающему микшеру 400 по фиг. 1b, и модуль 110 обеспечения информации направления объектов по фиг. 1b соответствует блокам 110а, 110b по фиг. 2. Кроме того, выходной интерфейс 200 по фиг. 1b предпочтительно реализуется аналогично выходному интерфейсу 200 по фиг. 1а и содержит блоки 202, 210, 220 по фиг. 2.
Фиг. 3 показывает вариант кодера, в котором вычисление для понижающего микширования является факультативным и не основано на входных метаданных. В этой разновидности, входные аудиофайлы могут подаваться непосредственно в базовый кодер, который создает транспортные каналы из них, и число транспортных каналов в силу этого соответствует числу входных объектных файлов; это является особенно интересным, если число входных объектов равно 1 или 2. Для большего числа объектов, сигнал понижающего микширования по-прежнему используется для уменьшения объема данных, которые следует передавать.
На фиг.3, аналогичные ссылочные позиции означают аналогичные функциональности по фиг. 2. Это является только допустимым не относительно фиг. 2 и фиг. 3, но и также является допустимым для всех других чертежей, описанных в этом описании изобретения. В отличие от фиг. 2, фиг. 3 выполняет вычисление 400 для понижающего микширования вообще без информации направления. Таким образом, вычисление для понижающего микширования может представлять собой статическое понижающее микширование с использованием заранее известной матрицы понижающего микширования, например, либо может представлять собой энергозависимое понижающее микширование, которое вообще не зависит от информации направления, ассоциированной с объектами, включенными во входные объектные аудиофайлы. Тем не менее информация направления извлекается в блоке 110а и квантуется в блоке 110b, и квантованные значения перенаправляются в кодер 202 информации направления для целей наличия кодированной информации направления в кодированном аудиосигнале, который представляет собой, например, двоично кодированный аудиосигнал, формирующий поток битов.
В случае наличия не слишком высокого числа входных объектных аудиофайлов, либо в случае наличия достаточной доступной полосы пропускания передачи, также можно обходиться без блока 400 вычисления для понижающего микширования, так что входные объектные аудиофайлы непосредственно представляют транспортные каналы, которые кодируются посредством базового кодера. В такой реализации, блоки 104, 104, 106, 108, 210 также не требуются. Тем не менее предпочтительная реализация приводит к микшированной реализации, в которой некоторые объекты непосредственно вводятся в транспортные каналы, и другие объекты микшируются с понижением в один или более транспортных каналов. В такой ситуации, затем все блоки, проиллюстрированные на фиг. 3, требуются для формирования потока битов, имеющего в кодированных транспортных каналах один или более объектов непосредственно и один или более транспортных каналов, сформированных посредством понижающего микшера 400 по фиг. 2 или по фиг. 3.
Вычисление параметров
Аудиосигнал временной области, содержащий все входные объектные сигналы, преобразуется в частотно-временную область с использованием гребенки фильтров. Например: Аналитический фильтр на основе CLDFB (комплексной гребенки фильтров с низкой задержкой) преобразует кадры в 20 миллисекунд (соответствующие 960 выборкам на частоте дискретизации в 48 кГц) в частотно-временные мозаичные элементы размера 16×60 с 16 временными квантами и 60 полосами частот. Для каждой частотно-временной единицы, мгновенная мощность сигналов вычисляется следующим образом:
Pi (k, n)=|Xi (k, n)|2,
где k обозначает индекс полосы частот, n обозначает индекс временного кванта, и i обозначает индекс объекта. Поскольку передача параметров для каждого частотно-временного мозаичного элемента является очень затратной с точки зрения конечной скорости передачи битов, группировка используется таким образом, чтобы вычислять параметры для сокращенного числа частотно-временных плиток. Например: 16 временных квантов могут группироваться в один временной квант, и 60 полос частот могут группироваться на основе психоакустической шкалы в 11 полос частот. Это уменьшает начальную размерность 16×60 до 1×11, что соответствует 11 так называемым полосам частот параметров. Мгновенные значения мощности сигналов суммируются на основе группировки, с тем чтобы получать мощности сигналов в уменьшенной размерности:
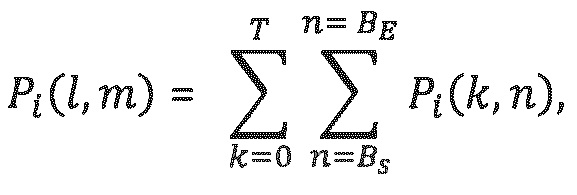
где Т соответствует 15 в этом примере, и BS и BE определяют границы полосы частот параметров.
Чтобы определять поднабор наиболее доминирующих объектов, для которых можно вычислять параметры, мгновенные значения мощности сигналов всех N входных аудиообъектов сортируется в порядке убывания. В этом варианте осуществления, определяются два наиболее доминирующих объекта, и соответствующие индексы объектов, в пределах от 0 до N-1, сохраняются в качестве части параметров, которые должны передаваться. Кроме того, вычисляются отношения мощностей, которые связывают два доминирующих объектных сигнала между собой:
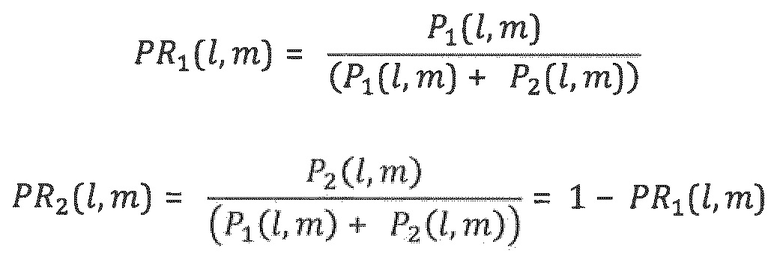
Или, в более общем выражении, которое не ограничено двумя объектами: 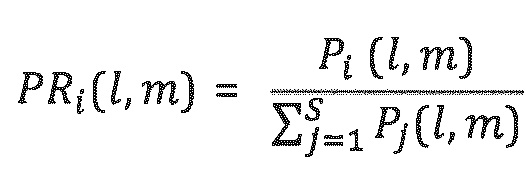 ,
,
где, в этом контексте, S обозначает число доминирующий объектов, которые должны рассматриваться, и:
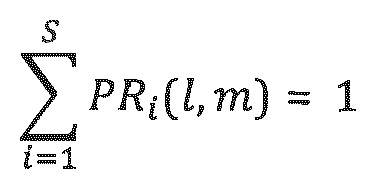
В случае двух доминирующих объектов, отношения мощностей в 0,5 для каждого из двух объектов означают то, что оба объекта одинаково присутствуют в соответствующей полосе частот параметров, тогда как отношения мощностей в 1 и 0 описывают отсутствие одного из двух объектов. Эти отношения мощностей сохраняются в качестве второй части параметров, которые должны передаваться. Поскольку отношения мощностей в сумме дают 1, достаточно передавать S-1 значений вместо S.
В дополнение к индексам объектов и значениям отношения мощностей в расчете на полосу частот параметров, должна передаваться информация направления каждого объекта, извлеченная из файлов входных метаданных. Поскольку информация первоначально обеспечивается на основе кадров, это выполняется для каждого кадра (при этом каждый кадр содержит 11 полос частот параметров или в сумме 16×60 частотно-временных плиток в описанном примере). Индексы объектов в силу этого косвенно представляют направление объектов. Примечание: Поскольку отношения мощностей в сумме дают 1, число отношений мощностей, которые должны передаваться в расчете на полосу частот параметров, может уменьшаться на 1; например: передачи 1 значения отношения мощностей достаточно в случае учета 2 релевантных объектов.
Как информация направления, так и значения отношения мощностей квантуются и комбинируются с индексами объектов, чтобы формировать параметрическую вспомогательную информацию. Эта параметрическая вспомогательная информация затем кодируется и (вместе с кодированными транспортными каналами/сигналом понижающего микширования) микшируется в конечное представление потоков битов. Хороший компромисс между выходным качеством и израсходованной скоростью передачи битов, например, достигается за счет квантования отношений мощностей с использованием 3 битов в расчете на значение. Информация направления может содержать угловое разрешение в 5 градусов и затем квантоваться с 7 битами в расчете на значение азимута и 6 битами в расчете на значение угла места в качестве практического примера.
Вычисление для понижающего микширования
Все входные сигналы аудиообъектов комбинируются в сигнал понижающего микширования, который содержит любые один или более транспортных каналов, причем число транспортных каналов меньше числа входных объектных сигналов. Примечание; В этом варианте осуществления, один транспортный канал возникает только в том случае, если предусмотрен только один входной объект, что в таком случае означает то, что вычисление для понижающего микширования пропускается.
Если понижающее микширование содержит два транспортных канала, это понижающее стереомикширование, например, может вычисляться в качестве сигнала виртуального кардиоидного микрофона. Сигнал виртуального кардиоидного микрофона определяется посредством применения информации направления, приведенной для каждого кадра в файлах метаданных (здесь, предполагается, что все значения угла места равны нулю):
wL=0,5+0,5 * cos(azimuth-pi/2)
wR=0,5+0,5 * cos(azimuth+pi/2)
Здесь, виртуальные кардиоиды расположены в 90° и -90°. Отдельные весовые коэффициенты для каждого из двух (левого и правого) транспортных каналов в силу этого определяются и применяются к соответствующему сигналу аудиообъекта:
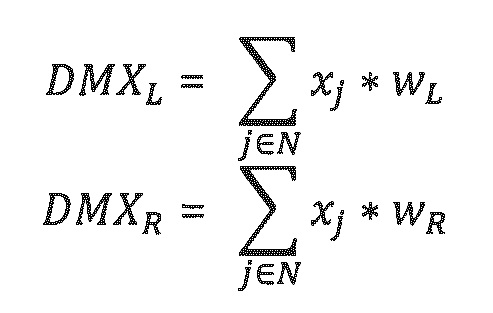
В этом контексте, N является числом входных объектов, большим или равным двум. Если весовые коэффициенты виртуальных кардиоид обновляются для каждого кадра, используется динамическое понижающее микширование, которое адаптируется к информации направления. Другая возможность состоит в том, чтобы использовать фиксированное понижающее микширование, при котором предполагается, что каждый объект расположен в статическом положении. Это статическое положение, например, может соответствовать начальному направлению объекта, что в таком случае приводит к статическим весовым коэффициентам виртуальных кардиоид, которые являются равными для всех кадров.
Если целевая скорость передачи битов разрешена, возможно более двух транспортных каналов. В случае трех транспортных каналов, кардиоиды затем могут равномерно размещаться, например, в 0°, 120° и -120°. Если используются четыре транспортных канала, четвертая кардиоида может быть обращена вверх, либо четыре кардиоиды могут снова размещаться горизонтально равномерным способом. Конфигурация также может индивидуально адаптироваться к положениям объектов, если они, например, исключительно представляют собой часть одной полусферы. Результирующий сигнал понижающего микширования обрабатывается посредством базового кодера и (вместе с кодированной параметрической вспомогательной информацией) превращается в представление потоков битов.
В качестве альтернативы, входные объектные сигналы могут подаваться в базовый кодер без комбинирования в сигнал понижающего микширования. В этом случае, число результирующих транспортных каналов соответствует числу входных объектных сигналов. Типично, обеспечивается максимальное число транспортных каналов, которое коррелируется с полной скоростью передачи битов. Сигнал понижающего микширования затем используется только в том случае, если число входных объектных сигналов превышает это максимальное число транспортных каналов.
Фиг. 6а иллюстрирует декодер для декодирования кодированного аудиосигнала, такого как сигнал, выводимый посредством фиг. 1а или фиг. 2, или фиг. 3, который содержит один или более транспортных каналов и информацию направления для множества аудиообъектов. Кроме того, кодированный аудиосигнал содержит, для одного или более частотных элементов разрешения временного кадра, данные параметров по меньшей мере для двух релевантных аудиообъектов, причем число по меньшей мере двух релевантных объектов ниже общего числа множества аудиообъектов. В частности, декодер содержит входной интерфейс для обеспечения одного или более транспортных каналов в спектральном представлении, имеющем, во временном кадре, множество частотных элементов разрешения. Это представляет сигнал, перенаправленный из входного интерфейсного блока 600 в блок 700 рендеринга аудио. В частности, модуль 700 рендеринга аудио выполнен с возможностью рендеринга одного или более транспортных каналов в определенное число аудиоканалов с использованием информации направления, включенной в кодированный аудиосигнал, число аудиоканалов предпочтительно составляет два канала для выходного стереоформата либо более двух каналов для более высокого числового выходного формата, например, 3 канала, 5 каналов, 5.1 каналов и т.д. В частности, модуль 700 рендеринга аудио выполнен с возможностью вычисления для каждого из одного или более частотных элементов разрешения вклада от одного или более транспортных каналов в соответствии с первой информацией направления, ассоциированной с первым по меньшей мере из двух релевантных аудиообъектов, и в соответствии со второй информацией направления, ассоциированной со вторым по меньшей мере из двух релевантных объектов. В частности, информация направления для множества аудиообъектов содержит первую информацию направления, ассоциированную с первым объектом, и вторую информацию направления, ассоциированную со вторым объектом.
Фиг. 8b иллюстрирует данные параметров для кадра, состоящего, в предпочтительном варианте осуществления, из информации 810 направления для множества аудиообъектов и, кроме того, отношений мощностей для каждой из определенного числа полос частот параметров, проиллюстрированных в 812, и одного, предпочтительно двух или еще более индексов объектов для каждой полосы частот параметров, указываемой в блоке 814. В частности, информация 810 направления для множества аудиообъектов проиллюстрирована подробнее на фиг. 8с. Фиг. 8с иллюстрирует таблицу с первым столбцом, имеющим определенный идентификатор объекта от 1 до N, где N является числом множества аудиообъектов. Кроме того, предусмотрен второй столбец, который имеет информацию направления для каждого объекта предпочтительно в качестве значения азимута и значения угла места либо, в случае двумерной ситуации, только значения азимута. Это проиллюстрировано в 818. Следовательно, фиг. 8с иллюстрирует «таблицу кодирования направлений», которая включается в кодированный аудиосигнал, вводимый во входной интерфейс 600 по фиг. 6а. Информация направления из столбца 818 уникально ассоциирована с определенным идентификатором объекта из столбца 816 и является допустимой для «целого» объекта в кадре, т.е. для всех полос частот в кадре. Таким образом, независимо от числа частотных элементов разрешения, будь это частотно-временные мозаичные элементы в представлении высокого разрешения или полосы частот времени/параметров в представлении более низкого разрешения, только одна информация направления должна передаваться и использоваться посредством входного интерфейса для каждых идентификационных данных объекта.
В этом контексте, фиг. 8а иллюстрирует частотно-временное представление, сформированное посредством гребенки 102 фильтров по фиг. 2 или по фиг. 3, когда эта гребенка фильтров реализуется как CLDFB (комплексная гребенка фильтров с низкой задержкой), поясненная выше. Для кадра, для которого информация направления определяется так, как пояснено выше относительно фиг. 8b и 8с, гребенка фильтров формирует 16 временных квантов, проходящих от 0 до 15, и 60 полос частот, проходящих от 0 до 59 на фиг. 8а. Таким образом, один временной квант и одна полоса частот представляют частотно-временной мозаичный элемент 802 или 804. Тем не менее, для уменьшения скорости передачи битов для вспомогательной информации предпочтительно преобразовать представление высокого разрешения в представление низкого разрешения, проиллюстрированное на фиг. 8b, в котором только один временной элемент разрешения существует, и в котором 60 полос частот преобразуются в 11 полос частот параметров, как проиллюстрировано в 812 на фиг. 8b. Таким образом, как проиллюстрировано на фиг. 10с, представление высокого разрешения указывается посредством индекса n временного кванта и индекса k полосы частот, и представление низкого разрешения определяется посредством индекса m сгруппированного временного кванта и индекса I полосы частот параметров. Тем не менее, в контексте описания изобретения, частотно-временной элемент разрешения может содержать частотно-временной мозаичный элемент 802, 804 высокого разрешения по фиг. 8а или частотно-временную единицу низкого разрешения, идентифицированную посредством индекса сгруппированного временного кванта и индекса полосы частот параметров во вводе блока 731с на фиг. 10с.
В варианте осуществления по фиг. 6а, модуль 700 рендеринга аудио выполнен с возможностью вычисления для каждого из одного или более частотных элементов разрешения вклада от одного или более транспортных каналов в соответствии с первой информацией направления, ассоциированной с первым по меньшей мере из двух релевантных аудиообъектов, и в соответствии со второй информацией направления, ассоциированной со вторым по меньшей мере из двух релевантных аудиообъектов. В варианте осуществления, проиллюстрированном на фиг. 8b, блок 814 имеет индекс объекта для каждого релевантного объекта в полосе частот параметров, т.е. имеет два или более индексов объектов, так что существуют два вклада в расчете на частотно-временной элемент разрешения.
Как указано далее относительно фиг. 10а, вычисление вкладов может осуществляться косвенно через матрицу микширования, при этом значения усиления для каждого релевантного объекта определяются и используются для вычисления матрицы микширования. В качестве альтернативы, как проиллюстрировано на фиг. 10b, вклады могут явно вычисляться снова с использованием значений усиления, и затем явно вычисленные вклады суммируются в расчете на каждый выходной канал в определенном частотно-временном элементе разрешения. Таким образом, независимо от того, вычисляются ли вклады явно или неявно, модуль рендеринга аудио, тем не менее, рендерирует один или более транспортных каналов в определенное число аудиоканалов с использованием информации направления таким образом, что, для каждого из одного или более частотных элементов разрешения, вклад из одного или более транспортных каналов в соответствии с первой информацией направления, ассоциированной с первым по меньшей мере из двух релевантных аудиообъектов, и в соответствии со второй информацией направления, ассоциированной со вторым по меньшей мере из двух релевантных аудиообъектов, включается в число аудиоканалов.
Фиг. 6b иллюстрирует декодер для декодирования кодированного аудиосигнала, содержащего один или более транспортных каналов и информацию направления для множества аудиообъектов и, для одного или более частотных элементов разрешения временного кадра, данные параметров для аудиообъекта в соответствии со вторым аспектом. С другой стороны, декодер содержит входной интерфейс 600, который принимает кодированный аудиосигнал, и декодер содержит модуль 700 рендеринга аудио для рендеринга одного или более транспортных каналов в определенное число аудиоканалов с использованием информации направления. В частности, модуль рендеринга аудио выполнен с возможностью вычисления информации прямых откликов из одного или более аудиообъектов в расчете на каждый частотный элемент разрешения из множества частотных элементов разрешения и информации направления, ассоциированной с релевантным одним или более аудиообъектов в частотных элементах разрешения. Эта информация прямых откликов предпочтительно содержит значения усиления, используемые для ковариационного синтеза или усовершенствованного ковариационного синтеза либо используемые для явного вычисления вкладов от одного или более транспортных каналов.
Предпочтительно, модуль рендеринга аудио выполнен с возможностью вычисления информации ковариационного синтеза с использованием информации прямых откликов для одного или более релевантных аудиообъектов в частотно-временной полосе частот и с использованием информации относительно числа аудиоканалов. Кроме того, информация ковариационного синтеза, которая, предпочтительно, представляет собой матрицу микширования, применяется к одному или более транспортных каналов, с тем чтобы получать число аудиоканалов. В дополнительной реализации, информация прямых откликов представляет собой вектор прямых откликов для каждого одного или более аудиообъектов, и информация ковариационного синтеза представляет собой матрицу ковариационного синтеза, и модуль рендеринга аудио выполнен с возможностью выполнения матричной операции в расчете на частотный элемент разрешения при применении информации ковариационного синтеза.
Кроме того, модуль 700 рендеринга аудио выполнен с возможностью извлечения при вычислении информации прямых откликов вектора прямых откликов для одного или более аудиообъектов и вычисления для одного или более аудиообъектов ковариационной матрицы из каждого вектора прямых откликов. Кроме того, при вычислении информации ковариационного синтеза, целевая ковариационная матрица вычисляется. Тем не менее вместо целевой ковариационной матрицы может использоваться релевантная информация для целевой ковариационной матрицы, т.е. матрица или вектор прямых откликов для одного или более наиболее доминирующих объектов и диагональная матрица прямых мощностей, указываемая как Е, как определено посредством применения отношений мощностей.
Таким образом, целевая ковариационная информация не должна обязательно представлять собой явную целевую ковариационную матрицу, но извлекается из ковариационной матрицы одного аудиообъекта либо из ковариантных матриц большего числа аудиообъектов в частотно-временном элементе разрешения, из информации мощности для соответствующего одного или более аудиообъектов в частотно-временном элементе разрешения и информации мощности, извлекаемой из одного или более транспортных каналов для одного или более частотно-временных элементов разрешения.
Представление потоков битов считывается посредством декодера, и кодированные транспортные каналы и кодированная параметрическая вспомогательная информация, содержащаяся в нем, определяются доступными для последующей обработки. Параметрическая вспомогательная информация содержит:
- информацию направления в качестве квантованных значений азимута и угла места (для каждого кадра),
- индексы объектов, обозначающие поднабор релевантных объектов (для каждой полосы частот параметров),
- квантованные отношения мощностей, связывающие релевантные объекты между собой (для каждой полосы частот параметров).
Вся обработка выполняется покадрово, причем каждый кадр содержит один или более субкадров. Кадр может состоять, например, из четырех субкадров, причем в этом случае один субкадр должен иметь длительность в 5 миллисекунд. Фиг. 4 показывает упрощенное общее представление декодера.
Фиг. 4 иллюстрирует аудиодекодер, реализующий первый и второй аспект. Входной интерфейс 600, проиллюстрированный на фиг. 6а и фиг. 6b, содержит демультиплексор 602, базовый декодер 604, декодер 608 для декодирования индексов объектов, декодер 612 для декодирования и деквантования отношения мощностей и декодер для декодирования и деквантования информации направления, указываемой в 612. Кроме того, входной интерфейс содержит гребенку 606 фильтров для обеспечения транспортных каналов в частотно-временном представлении.
Модуль 700 рендеринга аудио содержит модуль 704 вычисления прямых откликов, модуль 702 обеспечения прототипных матриц, который управляется посредством выходной конфигурации, принимаемой посредством пользовательского интерфейса, например, блок 706 для ковариационного синтеза и гребенку 708 синтезирующих фильтров, чтобы в итоге обеспечить выходной аудиофайл, содержащий число аудиоканалов в выходном формате каналов.
Таким образом, элементы 602, 604, 606, 608, 610, 612 предпочтительно включены во входной интерфейс по фиг. 6а и фиг. 6b, и элементы 702, 704, 706, 708 по фиг. 4 представляют собой часть модуля рендеринга аудио по фиг. 6а или фиг. 6b, указываемого ссылочной позицией 700.
Декодируется кодированная параметрическая вспомогательная информация, и повторно получаются квантованные значения отношения мощностей, квантованные значения азимута и угла места (информация направления) и индексы объектов. Одно значение отношения мощностей, не передаваемое, получается посредством использования того факта, что все значения отношения мощностей в сумме дают 1. Их разрешение (1, m) соответствует группировке частотно-временных плиток, используемой на стороне кодера. В ходе последующих этапов обработки, на которых используется более точное частотно-временное разрешение (k, n), параметры полосы частот параметров являются допустимыми для всех частотно-временных плиток, содержащихся в этой полосе частот параметров, согласно расширению таким образом, что (1, m)→(k, n).
Кодированные транспортные каналы декодируются посредством базового декодера. С использованием гребенки фильтров (совпадающей с гребенкой фильтров, используемой в кодере), каждый кадр такого декодированного аудиосигнала преобразуется в частотно-временное представление, разрешение которого типично является более высоким (но по меньшей мере равным), чем разрешение, используемое для параметрической вспомогательной информации.
Рендеринг/синтез выходных сигналов
Нижеприведенное описание применяется к одному кадру аудиосигнала; T обозначает оператор транспонирования:
С использованием декодированных транспортных каналов х=х(k, n)=[Х1(k, n),Х2(k, n)]т, т.е. аудиосигнала в частотно-временном представлении (в этом случае содержащего два транспортных канала) и параметрической вспомогательной информации, матрица М микширования для каждого субкадра (или кадра, с тем чтобы уменьшать вычислительную сложность) извлекается для синтеза частотно-временного выходного сигнала y=y(k,n)=[Y1(k.n),Y2(k,n),Y3(k,n),…]т, содержащий число выходных каналов (например, 5.1, 7.1, 7.1+4 и т.д.):
- Для всех (входных) объектов, с использованием передаваемых направлений объектов, определяются так называемые значения прямого отклика, которые описывают усиления панорамирования, которые должны использоваться для выходных каналов. Эти значения прямого отклика являются конкретными для целевой схемы размещения, т.е. для числа и местоположения громкоговорителей (предусмотренных в качестве части выходной конфигурации). Примеры способов панорамирования включают в себя векторное амплитудное панорамирование (VBAP) [Pulkki1997] и амплитудное панорамирование на основе краевого ослабления (EFAP) [ВогВ2014]. Каждый объект имеет вектор dri значений прямого отклика (содержащий столько элементов, сколько имеется громкоговорителей), ассоциированный с ним. Эти векторы вычисляются один раз в расчете на каждый кадр. Примечание: Если положение объекта соответствует положению громкоговорителей, вектор содержит значение 1 для этого громкоговорителя; все другие значения равны 0. Если объект расположен между двумя (или тремя) громкоговорителями, соответствующее число ненулевых векторных элементов равно двум (или трем).
- Фактический этап синтеза (в этом варианте осуществления ковариационного синтеза [Vilkamo2013]) содержит следующие подэтапы (см. фиг.5 для визуализации):
- Для каждой полосы частот параметров, индексы объектов, описывающие поднабор доминирующих объектов из входных объектов в частотно-временных мозаичных элементах, сгруппированных в эту полосу частот параметров, используются для извлечения поднабора векторов dri, необходимых для последующей обработки. Поскольку учитываются, например, только 2 релевантных объекта, требуются 2 вектора dri, ассоциированные с 2 релевантными объектами.
Для каждой полосы частот параметров, индексы объектов, описывающие поднабор доминирующих объектов из входных объектов в частотно-временных мозаичных элементах, сгруппированных в эту полосу частот параметров, используются для извлечения поднабора векторов dri, необходимых для последующей обработки. Поскольку учитываются, например, только 2 релевантных объекта, требуются 2 вектора dri, ассоциированные с 2 релевантными объектами.
- Из значений dri прямого отклика затем вычисляется ковариационная матрица Ci размерности «выходные каналы на выходные каналы» для каждого релевантного объекта:
Из значений dri прямого отклика затем вычисляется ковариационная матрица Ci размерности «выходные каналы на выходные каналы» для каждого релевантного объекта:
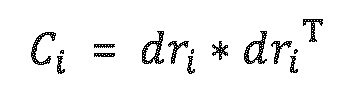
- Для каждого частотно-временного мозаичного элемента (в полосе частот параметров) определяется мощность Р(k, n) аудиосигналов. В случае двух транспортных каналов, мощность сигналов первого канала суммируется с мощностью сигналов второго канала. На эту мощность сигналов умножается каждое из значений отношения мощностей, в силу этого давая в результате одно значение прямой мощности для каждого релевантного/доминирующего объекта i:
Для каждого частотно-временного мозаичного элемента (в полосе частот параметров) определяется мощность Р(k, n) аудиосигналов. В случае двух транспортных каналов, мощность сигналов первого канала суммируется с мощностью сигналов второго канала. На эту мощность сигналов умножается каждое из значений отношения мощностей, в силу этого давая в результате одно значение прямой мощности для каждого релевантного/доминирующего объекта i:
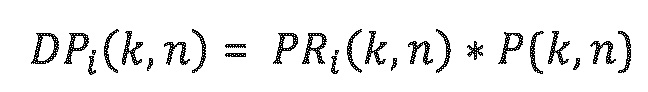
- Для каждой полосы к частот, конечная целевая ковариационная матрица Су размера «выходные каналы на выходные каналы» получается посредством суммирования по всем временным квантам n в (суб)кадре, а также суммирования по всем релевантным объектам:
Для каждой полосы к частот, конечная целевая ковариационная матрица Су размера «выходные каналы на выходные каналы» получается посредством суммирования по всем временным квантам n в (суб)кадре, а также суммирования по всем релевантным объектам:
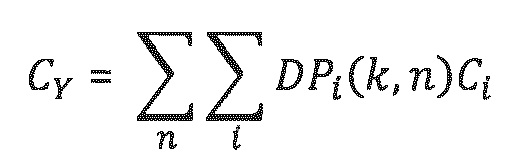
Фиг. 5 иллюстрирует подробное общее представление этапа ковариационного синтеза, выполняемого в блоке 706 по фиг. 4. В частности, вариант осуществления фиг. 5 содержит блок 721 вычисления мощности сигналов, блок 722 вычисления прямой мощности, блок 73 вычисления ковариационный матриц, блок 724 вычисления целевых ковариационный матриц, блок 726 вычисления входных ковариационный матриц, блок 725 вычисления матриц микширования и блок 727 рендеринга, который, относительно фиг. 5, дополнительно содержит блок 708 на основе гребенки фильтров по фиг. 4 таким образом, что выходной сигнал блока 727 предпочтительно соответствует выходному сигналу временной области. Тем не менее, когда блок 708 не включается в блок рендеринга по фиг. 5, то результат представляет собой представление в спектральной области соответствующих аудиоканалов.
(Следующие этапы представляют собой часть уровня техники [Vilkamo2013] и добавлены для пояснения).
- Для каждого (суб)кадра и для каждой полосы частот, входная ковариационная матрица Cx=xxT размера «транспортные каналы на транспортные каналы» вычисляется из декодированного аудиосигнала. При необходимости, могут использоваться только записи главной диагонали, причем в этом случае другие ненулевые записи устанавливаются равными нулю.
Для каждого (суб)кадра и для каждой полосы частот, входная ковариационная матрица Cx=xxT размера «транспортные каналы на транспортные каналы» вычисляется из декодированного аудиосигнала. При необходимости, могут использоваться только записи главной диагонали, причем в этом случае другие ненулевые записи устанавливаются равными нулю.
- Определяется прототипная матрица размера «выходные каналы на транспортные каналы», которая описывает преобразование транспортного канала(ов) в выходные каналы (предусмотренные в качестве части выходной конфигурации), число которых определяется посредством целевого выходного формата (например, целевой схемы размещения громкоговорителей). Эта прототипная матрица может быть статической либо изменяться на покадровой основе. Пример: Если только один транспортный канал передан, этот транспортный канал преобразуется в каждый из выходных каналов. Если два транспортных канала переданы, левый (первый) канал преобразуется во все выходные каналы, которые расположены в положениях в (+0°, +180°), т.е. в «левые» каналы. Правый (второй) канал, соответственно, преобразуется во все выходные каналы, расположенные в положениях в (-0°, -180°), т.е. в «правые» каналы. (Примечание: 0° описывает положение перед слушателем, положительные углы описывают положения слева от слушателя, и отрицательные углы описывают положения справа от слушателя. Если используется другое условное обозначение, знаки углов должны адаптироваться соответствующим образом).
Определяется прототипная матрица размера «выходные каналы на транспортные каналы», которая описывает преобразование транспортного канала(ов) в выходные каналы (предусмотренные в качестве части выходной конфигурации), число которых определяется посредством целевого выходного формата (например, целевой схемы размещения громкоговорителей). Эта прототипная матрица может быть статической либо изменяться на покадровой основе. Пример: Если только один транспортный канал передан, этот транспортный канал преобразуется в каждый из выходных каналов. Если два транспортных канала переданы, левый (первый) канал преобразуется во все выходные каналы, которые расположены в положениях в (+0°, +180°), т.е. в «левые» каналы. Правый (второй) канал, соответственно, преобразуется во все выходные каналы, расположенные в положениях в (-0°, -180°), т.е. в «правые» каналы. (Примечание: 0° описывает положение перед слушателем, положительные углы описывают положения слева от слушателя, и отрицательные углы описывают положения справа от слушателя. Если используется другое условное обозначение, знаки углов должны адаптироваться соответствующим образом).
- С использованием входной ковариационной матрицы Сх, целевой ковариационной матрицы Су и прототипной матрицы, матрица микширования вычисляется [Vilkamo2013] для каждого (суб)кадра и каждой полосы частот, приводя, например, к 60 матрицам микширования в расчете на (суб)кадр.
- Матрицы микширования (например, линейно) интерполируются между (суб)кадрами, согласно временному сглаживанию.
- В завершение, выходные каналы у синтезируются по полосам частот посредством умножения окончательного набора матриц М микширования, каждая из которых имеет размерность «выходные каналы на транспортные каналы», на соответствующую полосу частот частотно-временного представления декодированных транспортных каналов х:
у=Мх
Следует отметить, что остаточный сигнал r не используется, как описано в [Vilkamo2013].
- Выходной сигнал у преобразуется обратно в представление y(t) во временной области с использованием гребенки фильтров.
Оптимизированный ковариационный синтез
Вследствие того, как входная ковариационная матрица Сх и целевая ковариационная матрица Су вычисляются для настоящего варианта осуществления, могут достигаться определенные оптимизации для вычисления оптимальных матриц микширования с использованием ковариационного синтеза из [Vilkamo2013], которые приводят к значительному уменьшению вычислительной сложности при вычислении матриц микширования. Следует обратить внимание на то, что в этом разделе, оператор Адамара ° обозначает поэлементную операцию для матрицы, т.е. вместо соблюдения правил, например, матричного умножения, соответствующая операция проводится поэлементно. Этот оператор указывает то, что соответствующая операция проводится не для всей матрицы, а отдельно для каждого элемента. Умножение матриц А и В, например, должно соответствовать не матричному умножению АВ=С, а поэлементной операции a_ij*b_ij=c_ij.
SVD (.) обозначает разложение по сингулярным значениям. Алгоритм из [Vilkamo2013], представленный здесь в качестве функции Matlab (перечень 1), заключается в следующем (уровень техники): 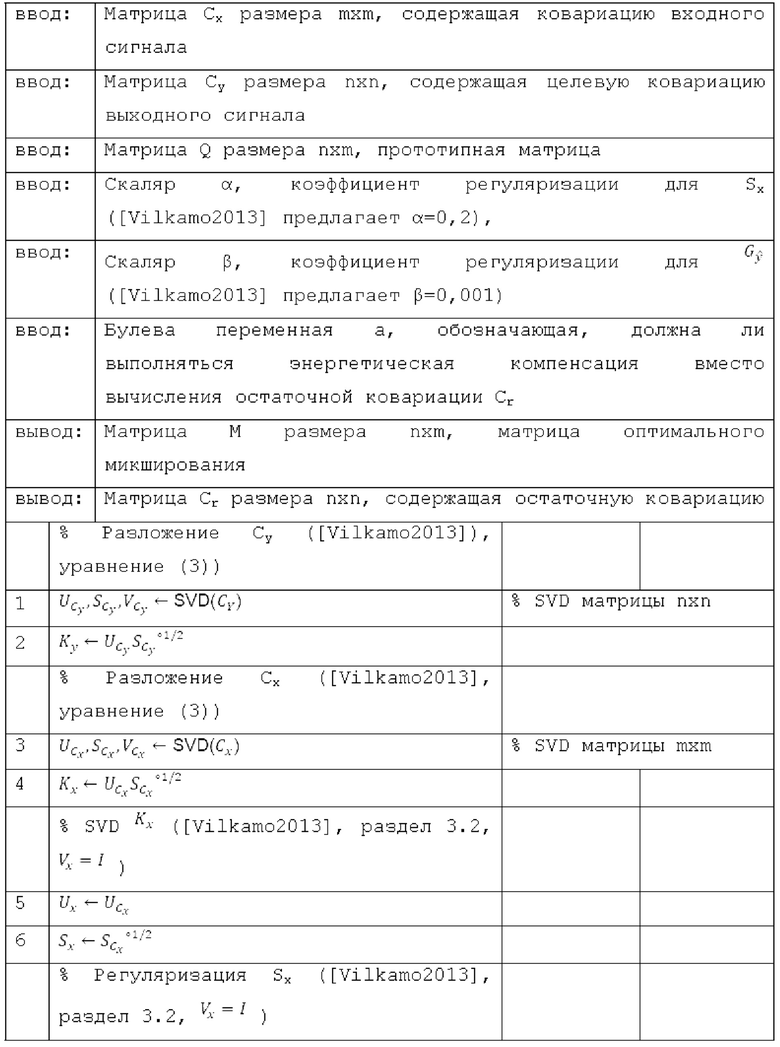


Как указано в предыдущем разделе, при необходимости используются только элементы Сх плавной диагонали, и все другие записи устанавливаются равными нулю. В этом случае, Сх представляет собой диагональную матрицу, и допустимое разложение, удовлетворяющее уравнению (3) [Vilkamo2013], является следующим:
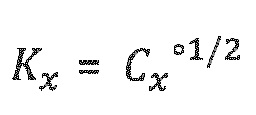
и SVD из строки 3 алгоритма из уровня техники более не требуется.
С учетом формул для формирования целевой ковариации из прямых откликов dri и прямых мощностей (или прямых энергий) из предыдущего раздела:
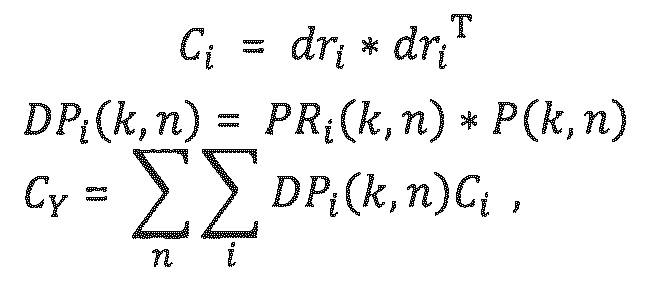
последняя формула может быть переконфигурирована и записана следующим образом:
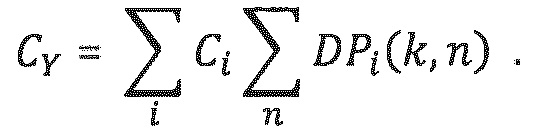
Если теперь определено:
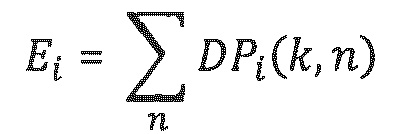 ,
,
и за счет этого получается:
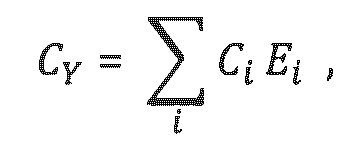
можно легко заметить, что если прямые отклики размещаются в матрице R=[dr1…drk] прямых откликов для k наиболее доминирующих объектов и создают диагональную матрицу прямых мощностей в качестве Е, где ei.i=Ei, Су также может выражаться следующим образом:

и допустимое разложение Су, удовлетворяющее уравнению (3) [Vilkamo2013], определяется следующим образом:
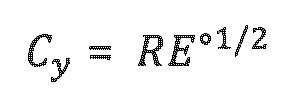 .
.
Следовательно, SVD из строки 1 алгоритма из уровня техники более не требуется.
Это приводит к оптимизированному алгоритму для ковариационного синтеза в настоящем варианте осуществления, который также принимает во внимание, что всегда используется вариант энергетической компенсации, и в силу этого не требуется остаточная целевая ковариация Cr: 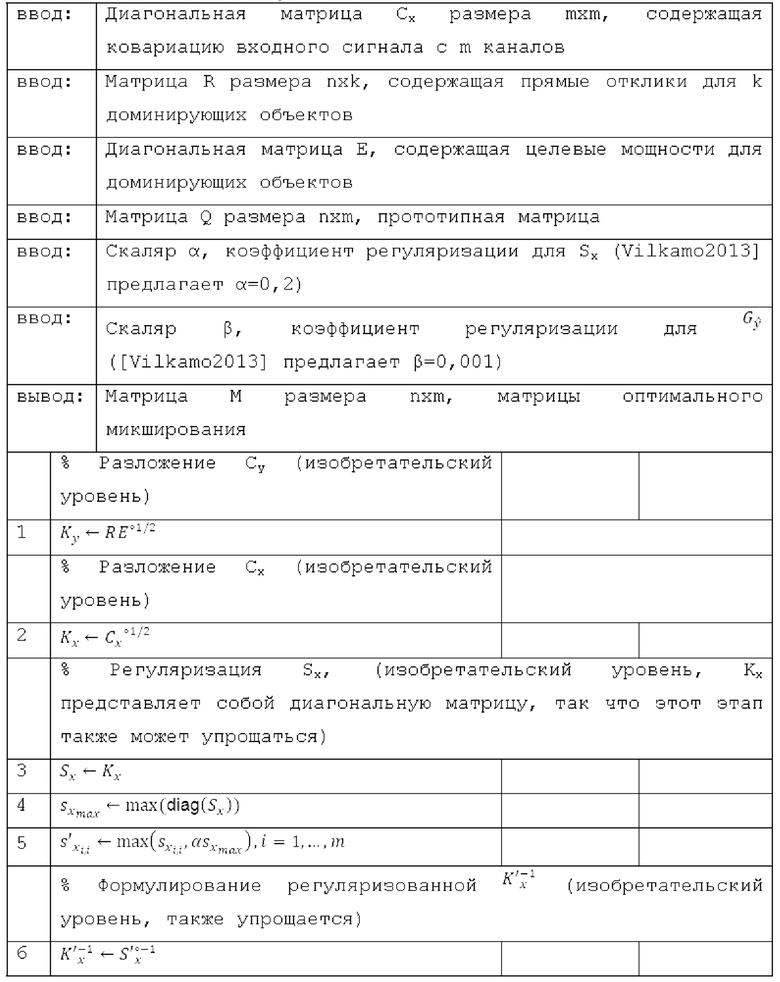

Внимательное сравнение между алгоритмом из уровня техники и предложенным алгоритмом показывает то, что первому требуются три SVD матриц с размерами mxm, nxn и mxn, соответственно, где m является числом каналов понижающего микширования, и n является числом выходных каналов, в которые подготавливаются посредством рендеринга объекты.
Предложенному алгоритму требуется только одно SVD матрицы с размером mxk, где k является числом доминирующих объектов. Кроме того, поскольку k типично гораздо меньше n, эта матрица меньше соответствующей матрицы из алгоритма из уровня техники.
Сложность стандартных реализаций SVD примерно составляет 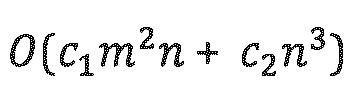 для матрицы mxn [Golub2013], где c1 и с2 являются константами, которые зависят от используемого алгоритма. Следовательно, достигается значительное снижение вычислительной сложности предложенного алгоритма по сравнению с алгоритмом из уровня техники.
для матрицы mxn [Golub2013], где c1 и с2 являются константами, которые зависят от используемого алгоритма. Следовательно, достигается значительное снижение вычислительной сложности предложенного алгоритма по сравнению с алгоритмом из уровня техники.
Далее поясняются предпочтительные варианты осуществления, связанные со стороной кодера первого аспекта, относительно фиг. 7а, 7b. Кроме того, предпочтительные реализации для реализации на стороне кодера второго аспекта поясняются относительно фиг. 9a-9d.
Фиг. 7а иллюстрирует предпочтительную реализацию модуля 100 вычисления параметров объектов по фиг. 1а. В блоке 120, аудиообъекты преобразуются в спектральное представление. Это реализуется посредством гребенки 102 фильтров по фиг. 2 или по фиг. 3. Затем, в блоке 122, информация выбора вычисляется так, как проиллюстрировано, например, в блоке 104 по фиг. 2 или по фиг. 3. С этой целью, может использоваться связанный с амплитудой показатель, такой как непосредственно амплитуда, мощность, энергия или любой другой связанный с амплитудой показатель, полученный посредством возведения амплитуды в степень, причем степень отличается от 1. Результат блока 122 представляет собой набор информации выбора для каждого объекта в соответствующем частотно-временном элементе разрешения. После этого, в блоке 124, идентификаторы объектов в расчете на частотно-временной элемент разрешения извлекаются. В первом аспекте, два или более идентификаторов объектов в расчете на частотно-временной элемент разрешения извлекаются. В соответствии со вторым аспектом, число идентификаторов объектов в расчете на частотно-временной элемент разрешения может даже представлять собой только один идентификатор объекта, так что наиболее важный или самый сильный, или наиболее релевантный объект идентифицируется в блоке 124 в числе информации, обеспечиваемой блоком 122. Блок 124 выводит информацию относительно данных параметров и включает в себя один или несколько индексов для наиболее релевантных одного или более объектов.
В случае наличия двух или более релевантных объектов в расчете на частотно-временной элемент разрешения, функциональность блока 126 является полезной для вычисления связанных с амплитудой показателей, характеризующих объекты в частотно-временном элементе разрешения. Эти связанные с амплитудой показатели могут быть равными показателям, вычисленным для информации выбора в блоке 122, либо, предпочтительно, комбинированные значения вычисляются с использованием информации, уже вычисленной посредством блока 102, как указано посредством пунктирной линии между блоком 122 и блоком 126, и связанные с амплитудой показатели и одно или более комбинированных значений затем вычисляются в блоке 126 и перенаправляются в блок 212 квантователя и кодера, с тем чтобы иметь, в качестве дополнительной параметрической вспомогательной информации, кодированные связанные с амплитудой или кодированные комбинированные значения во вспомогательной информации. В варианте осуществления по фиг. 2 или по фиг. 3, они представляют собой «кодированные отношения мощностей», которые включаются в поток битов вместе с «кодированными индексами объектов». В случае наличия только одного идентификатора объекта в расчете на частотный элемент разрешения, вычисление отношений мощностей и кодирование с квантованием не требуется, и индекс для наиболее релевантного объекта в частотно-временном элементе разрешения является достаточным для выполнения рендеринга на стороне декодера.
Фиг. 7b иллюстрирует предпочтительную реализацию вычисления 102 информации выбора по фиг. 7b. Как проиллюстрировано в блоке 123, мощности сигналов вычисляются для каждого объекта и каждого частотно-временного элемента разрешения в качестве информации выбора. После этого, в блоке 125, иллюстрирующем предпочтительную реализацию блока 124 по фиг. 7а, идентификаторы объектов для одного либо предпочтительно двух или более объектов с наибольшими мощностями извлекаются и выводятся. Кроме того, в случае двух или более релевантных объектов, отношение мощностей вычисляется так, как указано в блоке 127, в качестве предпочтительной реализации блока 126, в которой отношение мощностей вычисляется для идентификатора извлеченного объекта, связанного с мощностью всех извлеченных объектов, с соответствующими идентификаторами объектов, найденными посредством блока 125. Эта процедура является преимущественной, поскольку должно передаваться только число комбинированных значений, которое составляет число, меньшее числа объектов для частотно-временного элемента разрешения, поскольку существует правило, известное декодеру в этом варианте осуществления, указывающее то, что отношения мощностей для всех объектов должны в сумме давать единицу. Предпочтительно, функциональности блоков 120, 122, 124, 126 по фиг. 7а и/или 123, 125, 127 по фиг. 7b реализуются посредством модуля 100 вычисления параметров объектов по фиг. 1а, и функциональность блока 212 по фиг. 7а реализуется посредством выходного интерфейса 200 по фиг. 1а.
Далее подробнее поясняется устройство для кодирования в соответствии со вторым аспектом, проиллюстрированным на фиг. 1b, относительно нескольких вариантов осуществления. На этапе 110а, информация направления извлекается либо из входных сигналов, например, как проиллюстрировано относительно фиг. 12а, либо посредством считывания или синтаксического анализа информации метаданных, включенной в часть метаданных или файл метаданных. На этапе 110b, информация направления в расчете на кадр и аудиообъект квантуется, и индекс квантования в расчете на объект в расчете на кадр перенаправляется в кодер или выходной интерфейс, например, в выходной интерфейс 200 по фиг. 1b. На этапе 110с, индекс квантования направления деквантуется таким образом, что он имеет деквантованное значение, которое также может непосредственно выводиться посредством блока 110b в конкретных реализациях. Затем, на основе деквантованного индекса направления, блок 422 вычисляет весовые коэффициенты для каждого транспортного канала и для каждого объекта на основе определенной конфигурации виртуальных микрофонов. Эта конфигурация виртуальных микрофонов может содержать два сигнала виртуальных микрофонов, размещаемые в одинаковом положении и имеющие различные ориентации, либо может представлять собой конфигурацию, в которой предусмотрено два различных положения относительно опорного положения или ориентации, такого как виртуальное положение или ориентация слушателя. Конфигурация с двумя сигналами виртуальных микрофонов должна приводить к весовым коэффициентам для двух транспортных каналов для каждого объекта.
В случае формирования трех транспортных каналов, можно считать, что конфигурация виртуальных микрофонов содержит три сигнала виртуальных микрофонов из микрофонов, размещаемых в одинаковом положении и имеющих различные ориентации, либо в трех различных положениях относительно опорного положения или ориентации, причем это опорное положение или ориентация может представлять собой виртуальное положение или ориентацию слушателя.
В качестве альтернативы, четыре транспортных канала могут формироваться на основе конфигурации виртуальных микрофонов, формирующей четыре сигнала виртуальных микрофонов из микрофонов, размещаемых в одинаковом положении и имеющей различные ориентации, либо из четырех сигналов виртуальных микрофонов, размещаемых в четырех различных положениях относительно опорного положения или опорной ориентации, причем опорное положение или ориентация может представлять собой виртуальное положение слушателя или виртуальную ориентацию слушателя.
Кроме того, для целей вычисления весовых коэффициентов для каждого объекта и для каждого транспортного канала wL и wR для примера двух каналов, сигналы виртуальных микрофонов представляют собой сигналы, извлекаемые из виртуальных микрофонов первого порядка, которые представляют собой виртуальные кардиоидные микрофоны или виртуальные микрофоны в виде восьмерки, либо из депомикрофонов, которые представляют собой двунаправленные микрофоны, либо извлекаемые из виртуальных направленных микрофонов или из виртуальных субкардиоидных микрофонов, или из виртуальных однонаправленных микрофонов, или из виртуальных гиперкардиоидных микрофонов, или из виртуальных всенаправленных микрофонов.
В этом контексте, следует отметить, что для целей вычисления весовых коэффициентов любое размещение фактических микрофонов не является обязательным. Вместо этого, правила для вычисления весовых коэффициентов изменяются в зависимости от конфигурации виртуальных микрофонов, т.е. размещения виртуальных микрофонов и характеристики виртуальных микрофонов.
В блоке 404 по фиг. 9а весовые коэффициенты применяются к объектам таким образом, что для каждого объекта, вклад объекта для определенного транспортного канала получается в случае весового коэффициента, отличающегося от 0. Следовательно, блок 404 принимает, в качестве ввода, объектные сигналы. После этого, в блоке 406, вклады суммируются в расчете на каждый транспортный канал таким образом, что, например, суммируются вклады из объектов для первого транспортного канала, и суммируются вклады объектов для вторых транспортных каналов, и т.д. Как проиллюстрировано в блоке 406, затем, вывод блока 406 представляет собой транспортные каналы, например, во временной области.
Предпочтительно, объектные сигналы, вводимые в блок 404, представляют собой объектные сигналы временной области, имеющие информацию полной полосы частот, и применение в блоке 404 и суммирование в блоке 406 выполняются во временной области. Тем не менее, в других вариантах осуществления, эти этапы также могут выполняться в спектральной области.
Фиг. 9b иллюстрирует дополнительный вариант осуществления, в котором реализуется статическое понижающее микширование. С этой целью, информация направления для первого кадра извлекается в блоке 130, и весовые коэффициенты вычисляются в зависимости от первого кадра, как указано в блоке 403а. После этого, весовые коэффициенты оставляются как есть для других кадров, указываемых в блоке 408, с тем чтобы реализовывать статическое понижающее микширование.
Фиг. 9с иллюстрирует альтернативную реализацию, в которой вычисляется динамическое понижающее микширование. С этой целью, блок 132 извлекает информацию направления для каждого кадра, и весовые коэффициенты обновляются для каждого кадра, как проиллюстрировано в блоке 403b. После этого, в блоке 405, обновленные весовые коэффициенты применяются для кадров для реализации динамического понижающего микширования, которое изменяется между кадрами. Другие реализации между этими крайними случаями по фиг. 9b и 9с также являются полезными, в которых, например, весовые коэффициенты обновляются только для каждого второго, третьего или каждого n-ого кадра, и/или сглаживание весовых коэффициентов во времени выполняется таким образом, что антенная характеристика не изменяется слишком сильно время от времени для целей понижающего микширования в соответствии с информацией направления. Фиг. 9d иллюстрирует другую реализацию понижающего микшера 400, управляемого посредством модуля 110 обеспечения информации направления объектов по фиг. 1b. В блоке 410, понижающий микшер выполнен с возможностью анализа информации направления всех объектов в кадре, и в блоке 112, микрофоны для целей вычисления весовых коэффициентов wL и wR для примера стерео размещаются в соответствии с результатом анализа, при этом размещение микрофона означает местоположение микрофона и/или направленность микрофона. В блоке 414, микрофоны оставляются для других кадров аналогично статическому понижающему микшированию, поясненному относительно блока 408 по фиг. 9b, или микрофоны обновляются в соответствии с тем, что пояснено относительно блока 405 по фиг. 9с, с тем чтобы получать функциональность блока 414 по фиг. 9d. Относительно функциональности блока 412, микрофоны могут быть размещены таким образом, что получается хорошее разделение, так что первый виртуальный микрофон «смотрит» в первую группу объектов, а второй виртуальный микрофон «смотрит» во вторую группу объектов, которая отличается от первой группы объектов, и предпочтительно отличается тем, что, в максимально возможной степени, любые объекты одной группы не включаются в другую группу. В качестве альтернативы, анализ блока 410 может улучшаться за счет других параметров, и кроме того, размещение также может управляться посредством других параметров.
Далее поясняются предпочтительные реализации декодеров в соответствии с первым или вторым аспектом относительно, например, фиг. 6а, и фиг. 6b, приводятся относительно следующих фиг. 10а, 10b, 10с, 10d и 11.
В блоке 613 входной интерфейс 600 выполнен с возможностью извлечения отдельной информации направления объектов, ассоциированной с идентификаторами объектов. Эта процедура соответствует функциональности блока 612 по фиг. 4 или 5 и приводит к «таблице кодирования для кадра», как проиллюстрировано и пояснено относительно фиг. 8b и, в частности, 8с.
Кроме того, в блоке 609 один или более идентификаторов объектов в расчете на частотно-временной элемент разрешения извлекаются независимо от того, доступны ли эти данные относительно полосы частот параметров низкого разрешения или частотного мозаичного элемента высокого разрешения. Результат блока 609, который соответствует процедуре блока 608 на фиг. 4, заключается в конкретных идентификаторах в частотно-временном элементе разрешения для одного или более релевантных объектов. После этого, в блоке 611, конкретная информация направления объектов для конкретных одного или более идентификаторов для каждого частотно-временного элемента разрешения извлекается из «таблицы кодирования для кадра», т.е. из примерной таблицы, проиллюстрированной на фиг. 8с. После этого, в блоке 704, значения усиления вычисляются для одного или более релевантных объектов для отдельных выходных каналов, регулируемых посредством выходного формата, вычисляются в расчете на частотно-временной элемент разрешения. После этого, в блоке 730 или 706, 708 вычисляются выходные каналы. Функциональность вычисления выходных каналов может обеспечиваться либо в рамках явного вычисления вклада от одного или более транспортных каналов, как проиллюстрировано на фиг. 10b, либо может обеспечиваться с помощью косвенного вычисления и использования вкладов транспортных каналов, как проиллюстрировано на фиг. 10d или 11. Фиг. 10b иллюстрирует функциональность, в которой значения мощности или отношения мощностей извлекаются в блоке 610, соответствующем функциональности по фиг. 4. Затем эти значения мощности применяются к отдельным транспортным каналам в расчете на каждый релевантный объект, проиллюстрированный в блоке 733 и 735. Кроме того, эти значения мощности применяются в дополнение к значениям усиления, определенным посредством блока 704, к отдельным транспортным каналам, так что блок 733, 735 приводит к конкретным для объекта вкладам транспортных каналов, таких как транспортный канал ch1, ch2… После этого, в блоке 737, эти явно вычисленные вклады транспортных каналов суммируются для каждого выходного канала в расчете на частотно-временной элемент разрешения.
Затем, в зависимости от реализации, может быть предусмотрен модуль 741 вычисления рассеянных сигналов, который формирует рассеянный сигнал в соответствующем частотно-временном элементе разрешения для каждого выходного канала ch1, ch2…, и комбинация рассеянного сигнала и результата вклада блока 737 комбинируется таким образом, что полный вклад каналов в каждом частотно-временном элементе разрешения получается. Этот сигнал соответствует вводу в гребенку 708 фильтров по фиг. 4, когда ковариационный синтез дополнительно базируется на рассеянном сигнале. Тем не менее, когда ковариационный синтез 706 не базируется на рассеянном сигнале, а базируется только на обработке вообще без декоррелятора, то по меньшей мере энергия выходного сигнала в расчете на каждый частотно-временной элемент разрешения соответствует энергии вклада канала в выводе блока 739 по фиг. 10b. Кроме того, в случае если модуль 741 вычисления рассеянных сигналов не используется, то результат блока 739 соответствует результату блока 706 в наличии полного вклада каналов в расчете на частотно-временной элемент разрешения, которая может преобразовываться отдельно для каждого выходного канала ch1, ch2, чтобы в завершение получать выходной аудиофайл с выходными каналами временной области, которые могут сохраняться или перенаправляться в громкоговорители либо в любой вид устройства рендеринга.
Фиг. 10с иллюстрирует предпочтительную реализацию функциональности блока 610 по фиг. 10b или 4. На этапе 610а, комбинированное значение либо несколько значений (мощности) извлекаются для определенного частотно-временного элемента разрешения. В блоке 610b, соответствующее другое значение для другого релевантного объекта в частотно-временном элементе разрешения вычисляется на основе такого правила вычисления, что все комбинированные значения должны в сумме давать единицу.
В таком случае, результат предпочтительно представляет собой представление низкого разрешения, в котором имеется два отношения мощностей в расчете на сгруппированный индекс временного кванта и в расчете на индекс полосы частот параметров. Они представляют низкое частотно-временное разрешение. В блоке 610с, частотно-временное разрешение может расширяться в высокое частотно-временное разрешение таким образом, что имеются значения мощности для частотно-временных плиток с индексом n временного кванта высокого разрешения и индексом k полосы частот высокого разрешения. Расширение может содержать простое использование совершенно одинакового индекса низкого разрешения для соответствующих временных квантов в сгруппированном временном кванте и для соответствующих полос частот в полосе частот параметров.
Фиг. 10d иллюстрирует предпочтительную реализацию функциональности для вычисления информации ковариационного синтеза в блоке 706 по фиг. 4, которая представляется посредством матрицы 725 микширования, которая используется для микширования двух или более входных транспортных каналов в два или более выходных сигнала. Таким образом, когда имеется, например, два транспортных канала и шесть выходных каналов, размер матрицы микширования для каждого отдельного частотно-временного элемента разрешения должен составлять шесть строк и два столбца. В блоке 723, соответствующем функциональности блока 723 на фиг. 5, принимаются значения усиления или значения прямого отклика в расчете на объект в каждом частотно-временном элементе разрешения, и ковариационная матрица вычисляется. В блоке 722, принимаются значения или отношения мощностей, и вычисляются значения прямой мощности в расчете на объект в частотно-временном элементе разрешения, и блок 722 на фиг. 10d соответствует блоку 722 по фиг. 5.
Результат блока 721 и 722 вводится в модуль 724 вычисления целевых ковариационных матриц. Дополнительно или в качестве альтернативы, явное вычисление целевой ковариационной матрицы Су не требуется. Вместо этого, релевантная информация, включенная в целевую ковариационную матрицу, т.е. информация значений прямого отклика, указываемая в матрице R, и значения прямой мощности, указываемые в матрице Е для двух или более релевантных объектов, вводятся в блок 725а для вычисления матрицы микширования в расчете на частотно-временной элемент разрешения. Кроме того, матрица 725а микширования принимает информацию относительно прототипной матрицы Q и входной ковариационной матрицы Сх, извлекаемой из двух или более транспортных каналов, проиллюстрированных в блоке 726, соответствующем блоку 726 по фиг. 5. Матрица микширования в расчете на частотно-временной элемент разрешения и кадр может подвергаться временному сглаживанию, как проиллюстрировано в блоке 725b, и в блоке 727, соответствующем по меньшей мере части блока рендеринга по фиг. 5, матрица микширования применяется в несглаженной или сглаженной форме к транспортным каналам в соответствующих частотно-временных элементах разрешения для получения полного вклада каналов в частотно-временном элементе разрешения, практически аналогичную соответствующему полному вкладу, как пояснено выше относительно фиг. 10b в выводе блока 739. Таким образом, фиг. 10b иллюстрирует реализацию явного вычисления вклада транспортного канала, тогда как Fig. 10d иллюстрирует процедуру с неявным вычислением вкладов транспортных каналов в расчете на частотно-временной элемент разрешения и в расчете на релевантный объект в каждом частотно-временном элементе разрешения через целевую ковариационную матрицу Су или через уместную информацию R и Е блока 723 и 722, непосредственно введенную в блок 725а вычисления матриц микширования.
Далее иллюстрируется предпочтительный оптимизированный алгоритм для ковариационного синтеза относительно фиг. 11. Следует указать, что все этапы, проиллюстрированные на фиг. 11, вычисляются в ковариационном синтезе 706 по фиг. 4 или в блоке 725 вычисления матриц микширования по фиг. 5 или 725а на фиг. 10d. На этапе 751, первый результат Ky разложения вычисляется. Этот результат разложения может легко вычисляться вследствие того факта, что, как проиллюстрировано на фиг. 10d, информация полученных значений, включенных в матрицу R, и информация из двух или более релевантных объектов, в частности, информация прямой мощности, включенная в матрицу ER, непосредственно используется без явного вычисления ковариационной матрицы. Таким образом, первый результат разложения в блоке 751 может вычисляться просто и без особых усилий, поскольку конкретное разложение по сингулярным значениям более не требуется.
На этапе 752, второй результат разложения вычисляется как Kx. Этот результат разложения также может вычисляться без явного разложения по сингулярным значениям, поскольку входная ковариационная матрица трактуется в качестве диагональной матрицы, в которой недиагональные элементы игнорируются.
После этого, на этапе 753, первый регуляризованный результат на основе первого параметра α регуляризации вычисляется, и на этапе 754, второй регуляризованный результат вычисляется на основе второго параметра бета регуляризации. В отношении того, что Kx, в предпочтительной реализации, представляет собой диагональную матрицу, вычисление 753 первого регуляризованного результата упрощается относительно из уровня техники, поскольку вычисление Sx заключается просто в изменении параметров, а не в разложении, аналогично уровню техники.
Кроме того, относительно вычисления второго регуляризованного результата в блоке 754, первый этап дополнительно заключается только в переименовании параметров, а не в умножении на матрицу UxHS в уровне техники.
Кроме того, на этапе 7 55, матрица GY нормализации вычисляется, и на основе этапа 755, унитарная матрица Р вычисляется на этапе 756 на основе Kx и прототипной матрицы Q, и информации Ky, полученной посредством блока 751. Вследствие того факта, что матрица  вообще не требуется здесь, вычисление унитарной матрицы Р упрощается относительно уровня техники соответствующим образом.
вообще не требуется здесь, вычисление унитарной матрицы Р упрощается относительно уровня техники соответствующим образом.
После этого, на этапе 757, вычисляется матрица микширования без энергетической компенсации, которая представляет собой Mopt, и для этого используются унитарная матрица Р, результат блока 754 и результат блока 751. После этого, в блоке 758, энергетическая компенсация выполняется с использованием матрицы G компенсации. Энергетическая компенсация выполняется таким образом, что любой остаточный сигнал, извлекаемый из декоррелятора, не требуется. Тем не менее, вместо выполнения энергетической компенсации, в этой реализации должен быть добавлен остаточный сигнал с энергией, достаточно большой для заполнения энергетического зазора, оставляемого матрицей Mopt микширования без информации энергии. Тем не менее, для целей настоящего изобретения, декоррелированный сигнал не используется в качестве основы, чтобы не допустить артефактов, введенных декоррелятором. При этом предпочтительной является энергетическая компенсация, как показано на этапе 758.
Следовательно, оптимизированный алгоритм для ковариационного синтеза обеспечивает преимущества на этапе 751, 752, 753, 754, а также в рамках этапа 756 для вычисления унитарной матрицы Р. Следует подчеркнуть, что оптимизированный алгоритм даже обеспечивает преимущества по сравнению с уровнем техники, в котором только один из этапов 755, 752, 753, 754, 756 или только подгруппа этих этапов реализуется так, как проиллюстрировано, но соответствующие другие этапы реализуются в уровне техники. Причина состоит в том, что улучшения не базируются друг на друге, а могут применяться независимо друг от друга. Тем не менее, чем больше улучшений реализуется, тем лучше должна быть процедура относительно сложности для реализации. Таким образом, полная реализация варианта осуществления фиг. 11 является предпочтительной, поскольку она обеспечивает наибольший объем уменьшения сложности, но даже когда только один из этапов 751, 752, 753, 754, 756 реализуется в соответствии с оптимизированным алгоритмом, и другие этапы реализуются в уровне техники, получается уменьшение сложности вообще без ухудшения качества.
Варианты осуществления изобретения также могут считаться процедурой для формирования комфортного шума для стереофонического сигнала посредством микширования трех источников гауссова шума, по одному для каждого канала и третьего общего источника шума для создания коррелированного фонового шума либо, дополнительно или отдельно, управления микшированием источников шума со значением когерентности, которое передается с кадром SID.
Здесь следует отметить, что все альтернативы или аспекты, поясненные выше и ниже, и все аспекты, определяемые нижеприведенной формулой изобретения, могут использоваться по отдельности, т.е. вообще без других альтернатив или задач, отличных от предполагаемой альтернативы, задачи или независимого пункта формулы изобретения. Тем не менее, в других вариантах осуществления, две или более альтернатив или аспектов, или независимых пунктов формулы изобретения могут комбинироваться между собой, и, в других вариантах осуществления, все аспекты или альтернативы и все независимые пункты формулы изобретения могут комбинироваться между собой.
Кодированный сигнал согласно изобретению может сохраняться на цифровом носителе данных или на постоянном носителе данных либо может передаваться по среде передачи, такой как беспроводная среда передачи или проводная среда передачи, например, Интернет.
Хотя некоторые аспекты описаны в контексте устройства, очевидно, что эти аспекты также представляют описание соответствующего способа, при этом блок или устройство соответствует этапу способа либо признаку этапа способа. Аналогичным образом, аспекты, описанные в контексте этапа способа, также представляют описание соответствующего блока или элемента, или признака соответствующего устройства.
В зависимости от определенных требований к реализации, варианты осуществления изобретения могут реализовываться в аппаратных средствах или в программном обеспечении. Реализация может выполняться с использованием цифрового носителя данных, например, гибкого диска, DVD, CD, ROM, PROM, EPROM, EEPROM или флэш-памяти, имеющего сохраненные считываемые электронными средствами управляющие сигналы, которые взаимодействуют (или допускают взаимодействие) с программируемой компьютерной системой таким образом, что осуществляется соответствующий способ.
Некоторые варианты осуществления согласно изобретению содержат носитель данных, имеющий считываемые электронными средствами управляющие сигналы, которые допускают взаимодействие с программируемой компьютерной системой таким образом, что осуществляется один из способов, описанных в данном документе.
В общем, варианты осуществления настоящего изобретения могут реализовываться как компьютерный программный продукт с программным кодом, при этом программный код выполнен с возможностью осуществления одного из способов, когда компьютерный программный продукт работает на компьютере. Программный код, например, может сохраняться на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для осуществления одного из способов, описанных в данном документе, сохраненную на машиночитаемом носителе или на постоянном носителе данных.
Другими словами, вариант осуществления способа согласно изобретению представляет собой компьютерную программу, имеющую программный код для осуществления одного из способов, описанных в данном документе, когда компьютерная программа работает на компьютере.
Следовательно, дополнительный вариант осуществления способов согласно изобретению представляет собой носитель данных (цифровой носитель данных или машиночитаемый носитель), содержащий записанную компьютерную программу для осуществления одного из способов, описанных в данном документе.
Следовательно, дополнительный вариант осуществления способа согласно изобретению представляет собой поток данных или последовательность сигналов, представляющих компьютерную программу для осуществления одного из способов, описанных в данном документе. Поток данных или последовательность сигналов, например, может быть выполнена с возможностью передачи через соединение для передачи данных, например, через Интернет.
Дополнительный вариант осуществления содержит средство обработки, например, компьютер или программируемое логическое устройство, выполненное с возможностью осуществления одного из способов, описанных в данном документе.
Дополнительный вариант осуществления содержит компьютер, имеющий установленную компьютерную программу для осуществления одного из способов, описанных в данном документе.
В некоторых вариантах осуществления, программируемое логическое устройство (например, программируемая пользователем вентильная матрица) может использоваться для выполнения части или всех из функциональностей способов, описанных в данном документе. В некоторых вариантах осуществления, программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором, чтобы осуществлять один из способов, описанных в данном документе. В общем, способы предпочтительно осуществляются посредством любого аппаратного устройства.
Вышеописанные варианты осуществления являются лишь иллюстративными в отношении принципов настоящего изобретения. Следует понимать, что специалистам в данной области техники должны быть очевидны модификации и изменения конфигураций и подробностей, описанных в данном документе. Следовательно, подразумевается ограничение лишь объемом нижеприведенной формулы изобретения, но не конкретными подробностями, представленными в качестве описания и пояснения вариантов осуществления в данном документе.
Аспекты (которые используются независимо друг от друга или вместе со всеми другими аспектами, или только с подгруппой других аспектов)
Устройство или способ, или компьютерная программа, содержащая один или более нижеуказанных признаков:
Примеры изобретения в отношении аспектов новизны:
- многоволновая идея комбинируется с объектным кодированием (использованием более одной направленной метки в расчете на -мозаичный элемент T/F),
- подход на основе объектного кодирования, который является максимально близким к парадигме DirAC, для обеспечения возможности любого вида типов ввода в IVAS (объектное содержимое не охвачено до сих пор).
Примеры изобретения в отношении параметризации (кодер):
- Для каждого мозаичного элемента T/F: информация выбора для n наиболее релевантных объектов в этом мозаичном элементе T/F плюс отношения мощностей между этими вкладами n наиболее релевантных объектов
- Для каждого кадра, для каждого объекта: одно направление
Примеры изобретения в отношении рендеринга (декодер):
- Получение значений прямого отклика для каждого релевантного объекта из индексов передаваемого объекта и информации направления, и целевой выходной схемы размещения
- Получение ковариационной матрицы из прямых откликов
- Вычисление прямой мощности из мощности сигналов понижающего микширования и передаваемых отношений мощностей для каждого релевантного объекта
- Получение конечной целевой ковариационной матрицы из прямой мощности и ковариационной матрицы
- Использование только элементов диагонали входной ковариационной матрицы
Оптимизированный ковариационный синтез
Некоторые попутные примечания относительно отличий от SAOC:
- n доминирующих объектов рассматриваются вместо всех объектов
- отношения мощностей в силу этого связаны с OLD, но вычисляются по-другому
- SAOC не использует направления в кодере → информация направления вводится только в декодере (матрица рендеринга)
- декодер SAOC-3D принимает метаданные объектов для матрицы рендеринга
- SAOC использует матрицу понижающего микширования и передает усиления при понижающем микшировании
- рассеянность не рассматривается в варианте осуществления настоящего изобретения
Далее обобщаются дополнительные примеры изобретения.
1. Устройство для кодирования множества аудиообъектов и связанных метаданных, указывающих информацию направления для множества аудиообъектов, содержащее:
- понижающий микшер (400) для понижающего микширования множества аудиообъектов для получения одного или более транспортных каналов;
- кодер (300) транспортных каналов для кодирования одного или более транспортных каналов для получения одного или более кодированных транспортных каналов; и
- выходной интерфейс (200) для вывода кодированного аудиосигнала, содержащего упомянутые один или более кодированных транспортных каналов,
причем понижающий микшер (400) выполнен с возможностью понижающего микширования множества аудиообъектов в ответ на информацию направления для множества аудиообъектов.
2. Устройство по примеру 1, в котором понижающий микшер (400) выполнен с возможностью:
- формирования двух транспортных каналов в качестве двух сигналов виртуальных микрофонов, размещаемых в одинаковом положении и имеющих различные ориентации, либо в двух различных положениях относительно опорного положения или ориентации, такого как виртуальное положение или ориентация слушателя, или
- формирования трех транспортных каналов в качестве трех сигналов виртуальных микрофонов, размещаемых в одинаковом положении и имеющих различные ориентации, либо в трех различных положениях относительно опорного положения или ориентации, такого как виртуальное положение или ориентация слушателя, или
- формирования четырех транспортных каналов в качестве четырех сигналов виртуальных микрофонов, размещаемых в одинаковом положении и имеющих различные ориентации, либо в четырех различных положениях относительно опорного положения или ориентации, такого как виртуальное положение или ориентация слушателя, или
- при этом сигналы виртуальных микрофонов представляют собой сигналы виртуальных микрофонов первого порядка или сигналы виртуальных кардиоидных микрофонов, или сигналы виртуальных микрофонов в виде 8 либо дипольных микрофонов, либо двунаправленных микрофонов, или сигналы виртуальных направленных микрофонов, или сигналы виртуальных субкардиоидных микрофонов, или сигналы виртуальных однонаправленных микрофонов, или сигналы виртуальных гиперкардиоидных микрофонов, или сигналы виртуальных всенаправленных микрофонов.
3. Устройство по примеру 1 или 2, в котором понижающий микшер (400) выполнен с возможностью:
- извлечения (402) для каждого аудиообъекта из множества аудиообъектов информации взвешивания для каждого транспортного канала с использованием информации направления для соответствующего аудиообъекта;
-взвешивания (404) соответствующего аудиообъекта с использованием информации взвешивания для аудиообъекта для конкретного транспортного канала для получения вклада объекта для конкретного транспортного канала, и
- комбинирования (406) вкладов объектов для конкретного транспортного канала из множества аудиообъектов для получения конкретного транспортного канала.
4. Устройство по одному из предшествующих примеров,
- в котором понижающий микшер (400) выполнен с возможностью вычисления одного или более транспортных каналов в качестве одного или более сигналов виртуальных микрофонов, размещаемых в одинаковом положении и имеющих различные ориентации, либо в различных положениях относительно опорного положения или ориентации, такого как виртуальное положение или ориентация слушателя, с которой связана информация направления,
- при этом различные положения или ориентации определяются в левой стороне относительно центральной линии и в правой стороне относительно центральной линии, или при этом различные положения или ориентации одинаково или неодинаково распределяются в горизонтальные положения или ориентации, например, в +90 градусов или -90 градусов относительно центральной линии либо в -120 градусов, 0 градусов и +120 градусов относительно центральной линии, или при этом различные положения или ориентации содержат по меньшей мере одно положение или ориентацию, направленную вверх или вниз относительно горизонтальной плоскости, в которой находится виртуальный слушатель, при этом информация направления относительно множества аудиообъектов связана с виртуальным положением или ориентацией слушателя либо с опорным положением или ориентацией.
5. Устройство в соответствии с одним из предшествующих примеров, дополнительно содержащее:
- процессор (110) параметров для квантования метаданных, указывающих информацию направления относительно множества аудиообъектов, с тем чтобы получать квантованные элементы направления для множества аудиообъектов,
- при этом понижающий микшер (400) выполнен с возможностью работы в ответ на квантованные элементы направления в качестве информации направления, и
- при этом выходной интерфейс (200) выполнен с возможностью ввода информации о квантованных элементах направления в кодированный аудиосигнал.
6. Устройство по одному из предшествующих примеров,
- в котором понижающий микшер (400) выполнен с возможностью выполнения анализа информации направления для множества аудиообъектов и размещения одного или более виртуальных микрофонов для формирования транспортных каналов в зависимости от результата анализа.
7. Устройство по одному из предшествующих примеров,
- в котором понижающий микшер (400) выполнен с возможностью выполнения понижающего микширования (408) с использованием правила понижающего микширования, статического по множеству временных кадров, или
- при этом информация направления является переменной по множеству временных кадров, и при этом понижающий микшер (400) выполнен с возможностью выполнения понижающего микширования (405) с использованием правила понижающего микширования, переменного по множеству временных кадров.
8. Устройство по одному из предшествующих примеров,
в котором понижающий микшер (400) выполнен с возможностью понижающего микширования во временной области с использованием взвешивания по выборкам и комбинирования выборок множества аудиообъектов.
9. Устройство по одному из предшествующих примеров, дополнительно содержащее:
- модуль (100) вычисления параметров объектов, выполненный с возможностью вычисления для одного или более частотных элементов разрешения из множества частотных элементов разрешения, связанных с временным кадром, данных параметров по меньшей мере для двух релевантных аудиообъектов, при этом число по меньшей мере двух релевантных аудиообъектов меньше общего числа множества аудиообъектов, и
- при этом выходной интерфейс (200) выполнен с возможностью ввода информации о данных параметров по меньшей мере для двух релевантных аудиообъектов для одного или более частотных элементов разрешения в кодированный аудиосигнал.
10. Устройство по примеру 9, в котором модуль (100) вычисления параметров объектов выполнен с возможностью:
- преобразования (120) каждого аудиообъекта из множества аудиообъектов в спектральное представление, имеющее множество частотных элементов разрешения,
- вычисления (122) информации выбора из каждого аудиообъекта для одного или более частотных элементов разрешения, и
- извлечения (124) идентификационных данных объектов в качестве данных параметров, указывающих по меньшей мере два релевантных аудиообъекта, на основе информации выбора, и
- при этом выходной интерфейс (200) выполнен с возможностью ввода информации об идентификационных данных объектов в кодированный аудиосигнал.
11. Устройство по примеру 9 или 10, в котором модуль (100) вычисления параметров объектов выполнен с возможностью квантования и кодирования (212) одного или более связанных с амплитудой показателей или одного или более комбинированных значений, извлеченных из связанных с амплитудой показателей релевантных аудиообъектов в одном или более частотных элементах разрешения, в качестве данных параметров, и
- при этом выходной интерфейс (200) выполнен с возможностью ввода квантованных одного или более связанных с амплитудой показателей или квантованных одного или более комбинированных значений в кодированный аудиосигнал.
12. Устройство по примеру 10 или 11,
- в котором информация выбора представляет собой связанный с амплитудой показатель, такой как значение амплитуды, значение мощности или значение громкости, или амплитуда, возведенная в степень, отличающуюся от единицы, для аудиообъекта, и
- при этом модуль (100) вычисления параметров объектов выполнен с возможностью вычисления (127) комбинированного значения, такого как отношение из связанного с амплитудой показателя релевантного аудиообъекта и суммы двух или более связанных с амплитудой показателей релевантных аудиообъектов, и
- при этом выходной интерфейс (200) выполнен с возможностью ввода информации о комбинированном значении в кодированный аудиосигнал, при этом число информационных элементов в комбинированных значениях в кодированном аудиосигнале равно по меньшей мере одному и меньше числа релевантных аудиообъектов для одного или более частотных элементов разрешения.
13. Устройство по одному из примеров 10-12,
- в котором модуль (100) вычисления параметров объектов выполнен с возможностью выбора идентификационных данных объектов на основе порядка информации выбора множества аудиообъектов в одном или более частотных элементах разрешения.
14. Устройство по одному из примеров 10-13, в котором модуль (100) вычисления параметров объектов выполнен с возможностью:
- вычисления (122) мощности сигналов в качестве информации выбора,
- извлечения (124) идентификационных данных объектов для двух или более аудиообъектов, имеющих самые большие значения мощности сигналов в соответствующих одном или более частотных элементах разрешения для каждого частотного элемента разрешения по отдельности,
- вычисления (126) отношения мощностей между суммой мощностей сигналов двух или более аудиообъектов, имеющих самые большие значения мощности сигналов, и мощности сигналов по меньшей мере одного из аудиообъектов, имеющих извлеченные идентификационные данные объектов в качестве данных параметров, и
- квантования и кодирования (212) отношения мощностей, и
- при этом выходной интерфейс (200) выполнен с возможностью ввода квантованного и кодированного отношения мощностей в кодированный аудиосигнал.
15. Устройство по одному из примеров 10-14, в котором выходной интерфейс (200) выполнен с возможностью ввода в кодированный аудиосигнал одного или более кодированных транспортных каналов в качестве данных параметров двух или более кодированных идентификационных данных объектов для релевантных аудиообъектов для каждого из одного или более частотных элементов разрешения из множества частотных элементов разрешения во временном кадре и одного или более кодированных комбинированных значений или кодированных связанных с амплитудой показателей, и квантованных и кодированных данных направления для каждого аудиообъекта во временном кадре, причем данные направления являются постоянными для всех частотных элементов разрешения из одного или более частотных элементов разрешения.
16. Устройство по одному из примеров 9-15, в котором модуль (100) вычисления параметров объектов выполнен с возможностью вычисления данных параметров по меньшей мере для наиболее доминирующего объекта и второго наиболее доминирующего объекта в одном или более частотных элементах разрешения, или
- при этом число аудиообъектов из множества аудиообъектов равно трем или более, причем множество аудиообъектов содержит первый аудиообъект, второй аудиообъект и третий аудиообъект, и
- при этом модуль (100) вычисления параметров объектов выполнен с возможностью вычисления для первого из одного или более частотных элементов разрешения в качестве релевантных аудиообъектов только первой группы аудиообъектов, например первого аудиообъекта и второго аудиообъекта, и вычисления в качестве релевантных аудиообъектов для второго частотного элемента разрешения из одного или более частотных элементов разрешения только второй группы аудиообъектов, например второго аудиообъекта и третьего аудиообъекта или первого аудиообъекта и третьего аудиообъекта, при этом первая группа аудиообъектов отличается от второй группы аудиообъектов по меньшей мере в отношении одного члена группы.
17. Устройство по одному из примеров 9-16, в котором модуль (100) вычисления параметров объектов выполнен с возможностью:
- вычисления необработанных параметрических данных с первым временным или частотным разрешением и комбинирования необработанных параметрических данных в комбинированные параметрические данные, имеющие второе временное или частотное разрешение меньше первого временного или частотного разрешения, и вычисления данных параметров по меньшей мере для двух релевантных аудиообъектов в отношении комбинированных параметрических данных, имеющих второе временное или частотное разрешение, или
- определения полос частот параметров, имеющих второе временное или частотное разрешение, отличающееся от первого временного или частотного разрешения, используемого при временном или частотном разложении множества аудиообъектов, и вычисления данных параметров по меньшей мере для двух релевантных аудиообъектов для полос частот параметров, имеющих второе временное или частотное разрешение.
18. Декодер для декодирования кодированного аудиосигнала, содержащего один или более транспортных каналов и информацию направления для множества аудиообъектов и, для одного или более частотных элементов разрешения временного кадра, данные параметров для аудиообъекта, причем декодер содержит:
- входной интерфейс (600) для обеспечения одного или более транспортных каналов в спектральном представлении, имеющем, во временном кадре, множество частотных элементов разрешения; и
- модуль (700) рендеринга аудио для рендеринга одного или более транспортных каналов в определенное число аудиоканалов с использованием информации направления,
- при этом модуль (700) рендеринга аудио выполнен с возможностью вычисления информации (704) прямых откликов из одного или более аудиообъектов в расчете на каждый частотный элемент разрешения из множества частотных элементов разрешения и информации (810) направления, ассоциированной с релевантными одним или более аудиообъектами в частотных элементах разрешения.
19. Декодер по примеру 18,
- в котором модуль (700) рендеринга аудио выполнен с возможностью вычисления (706) информации ковариационного синтеза с использованием информации прямых откликов и информации (702) относительно числа аудиоканалов и применения (727) информации ковариационного синтеза к одному или более транспортным каналам таким образом, чтобы получить число аудиоканалов, или
- при этом информация (704) прямых откликов представляет собой вектор прямых откликов для каждого одного или более аудиообъектов, и при этом информация ковариационного синтеза представляет собой матрицу ковариационного синтеза, и при этом модуль (700) рендеринга аудио выполнен с возможностью выполнения матричной операции в расчете на частотный элемент разрешения при применении (727) информации ковариационного синтеза.
20. Декодер по примеру 18 или 19, в котором модуль (700) рендеринга аудио выполнен с возможностью:
- извлечения при вычислении информации (704) прямых откликов вектора прямых откликов для одного или более аудиообъектов и вычисления для одного или более аудиообъектов ковариационной матрицы из каждого вектора прямых откликов,
- извлечения (724) при вычислении информации ковариационного синтеза целевой ковариационной информации из ковариационной матрицы одного аудиообъекта или ковариантных матриц из большего количества аудиообъектов, информации мощности для соответствующих одного или более аудиообъектов и информации мощности, извлекаемой из одного или более транспортных каналов.
21. Декодер по примеру 20, в котором модуль (700) рендеринга аудио выполнен с возможностью:
- извлечения при вычислении информации прямых откликов вектора прямых откликов для одного или более аудиообъектов и вычисления (723) для каждого одного или более аудиообъектов ковариационной матрицы из каждого вектора прямых откликов,
- извлечения (726) входной ковариационной информации из транспортных каналов, и
- извлечения (725а, 725b) информации микширования из целевой ковариационной информации, входной ковариационной информации и информации относительно числа каналов, и
- применения (727) информации микширования к транспортным каналам для каждого частотного элемента разрешения во временном кадре.
22. Декодер по примеру 21, в котором результат применения информации микширования для каждого частотного элемента разрешения во временном кадре преобразуется (708) во временную область для получения числа аудиоканалов во временной области.
23. Декодер по одному из примеров 18-22, в котором модуль (700) рендеринга аудио выполнен с возможностью:
- использования только элементов главной диагонали входной ковариационной матрицы, извлекаемой из транспортных каналов, в разложении (752) входной ковариационной матрицы, или
- выполнения разложения (751) целевой ковариационной матрицы с использованием матрицы прямых откликов и матрицы мощностей объектов или транспортных каналов, или
- выполнения (752) разложения входной ковариационной матрицы посредством извлечения корня каждого элемента главной диагонали входной ковариационной матрицы, или
- вычисления (753) регуляризованной инверсии разлагаемой входной ковариационной матрицы, или
- выполнения (756) разложения по сингулярным значениям при вычислении оптимальной матрицы, которая должна использоваться в энергетической компенсации без расширенной единичной матрицы.
24. Декодер по одному из примеров 18-23, в котором данные параметров для одного или более аудиообъектов содержат данные параметров по меньшей мере для двух релевантных аудиообъектов, при этом число по меньшей мере двух релевантных аудиообъектов меньше общего числа множества аудиообъектов, и
- при этом модуль (700) рендеринга аудио выполнен с возможностью вычисления для каждого из одного или более частотных элементов разрешения вклада от одного или более транспортных каналов в соответствии с первой информацией направления, ассоциированной с первым из по меньшей мере двух релевантных аудиообъектов, и в соответствии со второй информацией направления, ассоциированной со вторым из по меньшей мере двух релевантных аудиообъектов.
25. Декодер по примеру 24,
- в котором модуль (700) рендеринга аудио выполнен с возможностью игнорирования для одного или более частотных элементов разрешения информации направления аудиообъекта, отличающегося по меньшей мере от двух релевантных аудиообъектов.
26. Декодер по примеру 24 или 25, в котором кодированный аудиосигнал содержит связанный с амплитудой показатель для каждого релевантного аудиообъекта или комбинированное значение, связанное по меньшей мере с двумя релевантными аудиообъектами в данных параметров, и
- при этом модуль (700) рендеринга аудио выполнен с возможностью работы таким образом, что учитывается вклад от одного или более транспортных каналов в соответствии с первой информацией направления, ассоциированной с первым из по меньшей мере двух релевантных аудиообъектов, и в соответствии со второй информацией направления, ассоциированной со вторым из по меньшей мере двух релевантных аудиообъектов, или определения количественного вклада одного или более транспортных каналов в соответствии со связанным с амплитудой показателем или комбинированным значением.
27. Декодер по примеру 26, в котором кодированный сигнал содержит комбинированное значение в данных параметров, и
- при этом модуль (700) рендеринга аудио выполнен с возможностью определения вклада одного или более транспортных каналов с использованием комбинированного значения для одного из релевантных аудиообъектов и информации направления для одного релевантного аудиообъекта, и
- при этом модуль (700) рендеринга аудио выполнен с возможностью определения вклада для одного или более транспортных каналов с использованием значения, извлеченного из комбинированного значения для другого из релевантных аудиообъектов в одном или более частотных элементов разрешения и информации направления другого релевантного аудиообъекта.
28. Декодер по одному из примеров 24-27, в котором модуль (700) рендеринга аудио выполнен с возможностью:
- вычисления информации (704) прямых откликов из релевантных аудиообъектов в расчете на каждый частотный элемент разрешения из множества частотных элементов разрешения и информации направления, ассоциированной с релевантными аудиообъектами в частотных элементах разрешения,
29. Декодер по примеру 28,
- в котором модуль (700) рендеринга аудио выполнен с возможностью определения (741) рассеянного сигнала в расчете на каждый частотный элемент разрешения из множества частотных элементов разрешения с использованием информации рассеянности, такой как параметр рассеянности, включенный в метаданные, или правила декорреляции, и комбинирования прямого отклика, определенного посредством информации прямых откликов и рассеянного сигнала, таким образом, чтобы получить рендерированный сигнал спектральной области для канала из определенного числа каналов.
30. Способ кодирования множества аудиообъектов и связанных метаданных, указывающих информацию направления для множества аудиообъектов, содержащий этапы, на которых:
- выполняют понижающее микширование множества аудиообъектов для получения одного или более транспортных каналов;
- кодируют один или более транспортных каналов для получения одного или более кодированных транспортных каналов; и
- выводят кодированный аудиосигнал, содержащий один или более кодированных транспортных каналов,
- при этом понижающее микширование содержит этап, на котором выполняют понижающее микширование множества аудиообъектов в ответ на информацию направления для множества аудиообъектов.
31. Способ декодирования кодированного аудиосигнала, содержащего один или более транспортных каналов и информацию направления для множества аудиообъектов и, для одного или более частотных элементов разрешения временного кадра, данные параметров для аудиообъекта, при этом способ содержит этапы, на которых:
- обеспечивают один или более транспортных каналов в спектральном представлении, имеющем во временном кадре множество частотных элементов разрешения; и
- выполняют аудиорендеринг одного или более транспортных каналов в определенное число аудиоканалов с использованием информации направления,
- при этом аудиорендеринг содержит этап, на котором вычисляют информацию прямых откликов от одного или более аудиообъектов в расчете на каждый частотный элемент разрешения из множества частотных элементов разрешения и информации направления, ассоциированной с релевантными одним или более аудиообъектов в частотных элементах разрешения.
32. Компьютерная программа для осуществления при выполнении на компьютере или в процессоре способа по примеру 30 или способа по примеру 31.
Список цитируемых источников
[Pulkki2009] V. Pulkki, M-V. Laitinen, J. Vilkamo, J. Ahonen, T. Lokki и Т. Pihlajamaki "Directional audio coding -perception-based reproduction of spatial sound", International Workshop on the Principles and Application on Spatial Hearing, ноябрь 2009 года, Зао; Мияги, Япония.
[SAOC_STD] ISO/IEC "MPEG audio technologies Part 2: Spatial Audio Object Coding (SAOC)". ISO/IEC JTC1/SC29/WG11 (MPEG) International Standard 23003-2.
[SAOC-AES] J. Herre, H. Purnhagen, J. Koppens, O. Hellmuth, J. Engdegard, J.Hilpert, L. Villemoes, L. Terentiv, C. Falch, A. Holzer, M. L. Valero, B. Resch, H. Mundt H и H. Oh "MPEG spatial audio object coding - the ISO/MPEG standard for efficient coding of interactive audio scenes", J. AES, издание 60, номер 9, стр. 655-673, сентябрь 2012 года.
[MPEGH_AES] J. Herre, J. Hilpert, A. Kuntz и J. Plogsties "MPEG-H audio - the new standard for universal spatial/3D audio coding", in Proc. 137th AES Conv., Лос-Анжелес, Калифорния, США, 2014 год.
[MPEGH_IEEE] J. Herre, J. Hilpert, A. Kuntz и J. Plogsties "MPEG-H 3D Audio - The New Standard for Coding of Immersive Spatial Audio", IEEE JOURNAL OF SELECTED TOPICS IN SIGNAL PROCESSING, издание 9, номер 5, август 2015 года.
[MPEGH_STD] Text of ISO/MPEG 23008-3/DIS 3D Audio, Саппоро, ISO/IEC JTC1/SC29/WG11 N14747, июль 2014 года.
[SAOC_3D_PAT] APPARATUS AND METHOD FOR ENHANCED SPATAL AUDIO OBJECT CODING, WO 2015/011024 A1.
[Pulkkil997] V. Pulkki "Virtual sound source positioning using vector base amplitude panning", J. Audio Eng. Soc, издание 45, номер 6, стр. 456-466, июнь 1997 года.
[DELAUNAY] С. В. Barber, D. P. Dobkin и Н. Huhdanpaa "The quickhull algorithm for convex hulls", in Proc. ACM Trans. Math. Software (TOMS), Нью-Йорк, Нью-Йорк, США, декабрь 1996 года, издание. 22, стр. 469-483.
[Hirvonen2009] Т. Hirvonen, J. Ahonen и V. Pulkki "Perceptual compression methods for metadata in Directional Audio Coding applied to audiovisual teleconference", AES 126th Convention 2009, 7-10 мая, Мюнхен, Германия.
[BorB2014] С.BorB, "A Polygon-Based Panning Method for 3D Loudspeaker Setups", AES 137th Convention 2014, 9-12 октября, Лос-Анжелес, США.
[WO 2019068638] Apparatus, method and computer program for encoding, decoding, scene processing and other procedures related to DirAC based spatial audio coding, 2018 год.
[WO 2020249815] PARAMETER ENCODING AND DECODING FOR MULTICHANNEL AUDIO USING DirAC, 2019 год.
[BCC2001] С.Faller, F. Baumgarte: "Efficient representation of spatial audio using perceptual parametrization", Proceedings of the 2001 IEEE Workshop on the Applications of Signal Processing to Audio and Acoustics (категория номер 01TH8575).
[JOC_AES] Heiko Purnhagen; Toni Hirvonen; Lars Villemoes; Jonas Samuelsson; Janusz Klejsa: "Immersive Audio Delivery Using Joint Object Coding", 140th AES Convention, номер статьи: 9587, Париж, май 2016 года.
[AC4_AES] K. Kjörling, J. Rödén, M. Wolters, J. Riedmiller, A. Biswas, P. Ekstrand, A. Gröschel, P. Hedelin, T. Hirvonen, H. Hörich, J. Klejsa, J. Koppens, K. Krauss, H-M. Lehtonen, K. Linzmeier, H. Muesch, H. Mundt, S. Norcross, J. Popp, H. Purnhagen, J. Samuelsson, M. Schug, L. Sehlström, R. Thesing, L. Villemoes и M. Vinton: "AC-4 - The Next Generation Audio Codec", 140th AES Convention, номер статьи: 9491, Париж, май 2016 года.
[Vilkamo2013] J. Vilkamo, Т. Backström, A. Kuntz, "Optimized covariance domain framework for time-frequency processing of spatial audio", Journal of the Audio Engineering Society, 2013 год.
[Golub2013] Gene H. Golub и Charles F. Van Loan "Matrix Computations", Johns Hopkins University Press, 4 издание, 2013 год.
| название | год | авторы | номер документа |
|---|---|---|---|
| УСТРОЙСТВО И СПОСОБ КОДИРОВАНИЯ МНОЖЕСТВА АУДИООБЪЕКТОВ С ИСПОЛЬЗОВАНИЕМ ИНФОРМАЦИИ НАПРАВЛЕНИЯ ВО ВРЕМЯ ПОНИЖАЮЩЕГО МИКШИРОВАНИЯ ИЛИ УСТРОЙСТВО И СПОСОБ ДЕКОДИРОВАНИЯ С ИСПОЛЬЗОВАНИЕМ ОПТИМИЗИРОВАННОГО КОВАРИАЦИОННОГО СИНТЕЗА | 2021 |
|
RU2826540C1 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ УЛУЧШЕННОГО ПРОСТРАНСТВЕННОГО КОДИРОВАНИЯ АУДИООБЪЕКТОВ | 2014 |
|
RU2660638C2 |
| КОДЕР, ДЕКОДЕР И СПОСОБЫ ДЛЯ ОБРАТНО СОВМЕСТИМОГО ПРОСТРАНСТВЕННОГО КОДИРОВАНИЯ АУДИООБЪЕКТОВ С ПЕРЕМЕННЫМ РАЗРЕШЕНИЕМ | 2013 |
|
RU2669079C2 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ ОСУЩЕСТВЛЕНИЯ ПОНИЖАЮЩЕГО МИКШИРОВАНИЯ SAOC ОБЪЕМНОГО (3D) АУДИОКОНТЕНТА | 2014 |
|
RU2666239C2 |
| ПРИНЦИП ДЛЯ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ АУДИО ДЛЯ АУДИОКАНАЛОВ И АУДИООБЪЕКТОВ | 2014 |
|
RU2641481C2 |
| ВЫДЕЛЕНИЕ АУДИООБЪЕКТА ИЗ СИГНАЛА МИКШИРОВАНИЯ С ИСПОЛЬЗОВАНИЕМ ХАРАКТЕРНЫХ ДЛЯ ОБЪЕКТА ВРЕМЕННО-ЧАСТОТНЫХ РАЗРЕШЕНИЙ | 2014 |
|
RU2646375C2 |
| УСТРОЙСТВО И СПОСОБЫ ДЛЯ АДАПТАЦИИ АУДИОИНФОРМАЦИИ ПРИ ПРОСТРАНСТВЕННОМ КОДИРОВАНИИ АУДИООБЪЕКТОВ | 2013 |
|
RU2609097C2 |
| УСТРОЙСТВО, СПОСОБ И КОМПЬЮТЕРНАЯ ПРОГРАММА ДЛЯ КОДИРОВАНИЯ, ДЕКОДИРОВАНИЯ, ОБРАБОТКИ СЦЕНЫ И ДРУГИХ ПРОЦЕДУР, ОТНОСЯЩИХСЯ К ОСНОВАННОМУ НА DirAC ПРОСТРАНСТВЕННОМУ АУДИОКОДИРОВАНИЮ | 2018 |
|
RU2759160C2 |
| УСТРОЙСТВО, СПОСОБ И КОМПЬЮТЕРНАЯ ПРОГРАММА ДЛЯ КОДИРОВАНИЯ ЗВУКОВОГО СИГНАЛА ИЛИ ДЛЯ ДЕКОДИРОВАНИЯ КОДИРОВАННОЙ АУДИОСЦЕНЫ | 2021 |
|
RU2809587C1 |
| КОДЕР, ДЕКОДЕР И СПОСОБЫ ДЛЯ ЗАВИСИМОГО ОТ СИГНАЛА ПРЕОБРАЗОВАНИЯ МАСШТАБА ПРИ ПРОСТРАНСТВЕННОМ КОДИРОВАНИИ АУДИООБЪЕКТОВ | 2013 |
|
RU2625939C2 |
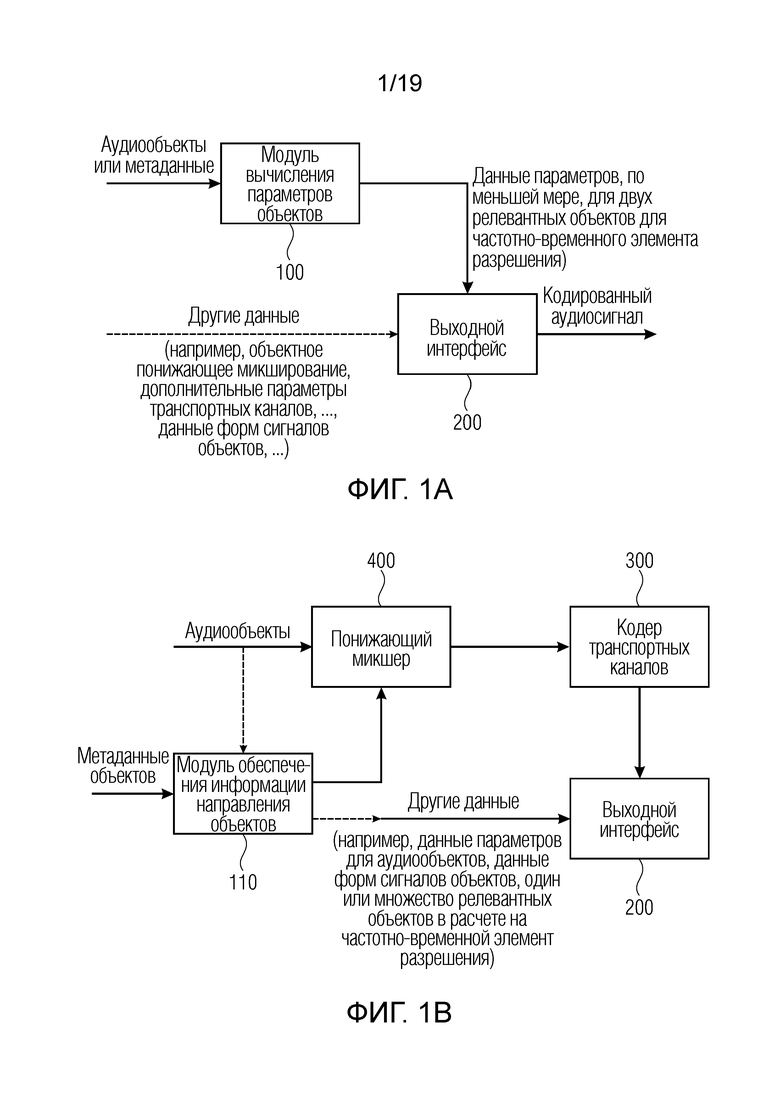
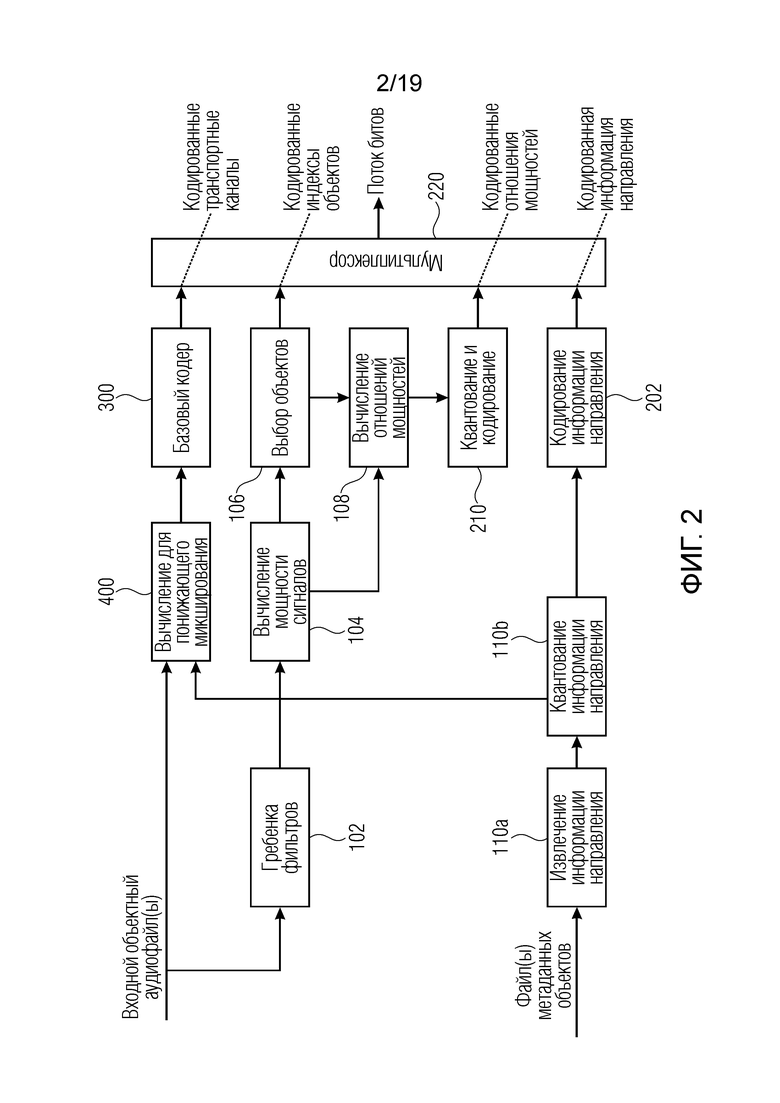
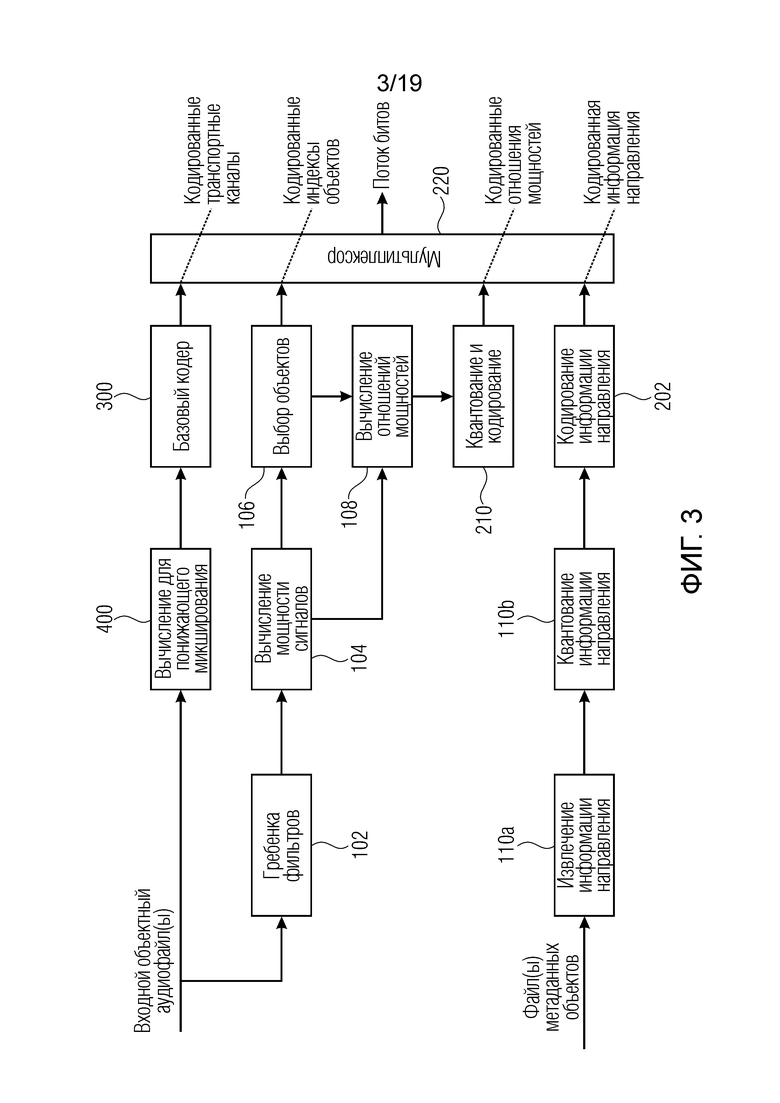
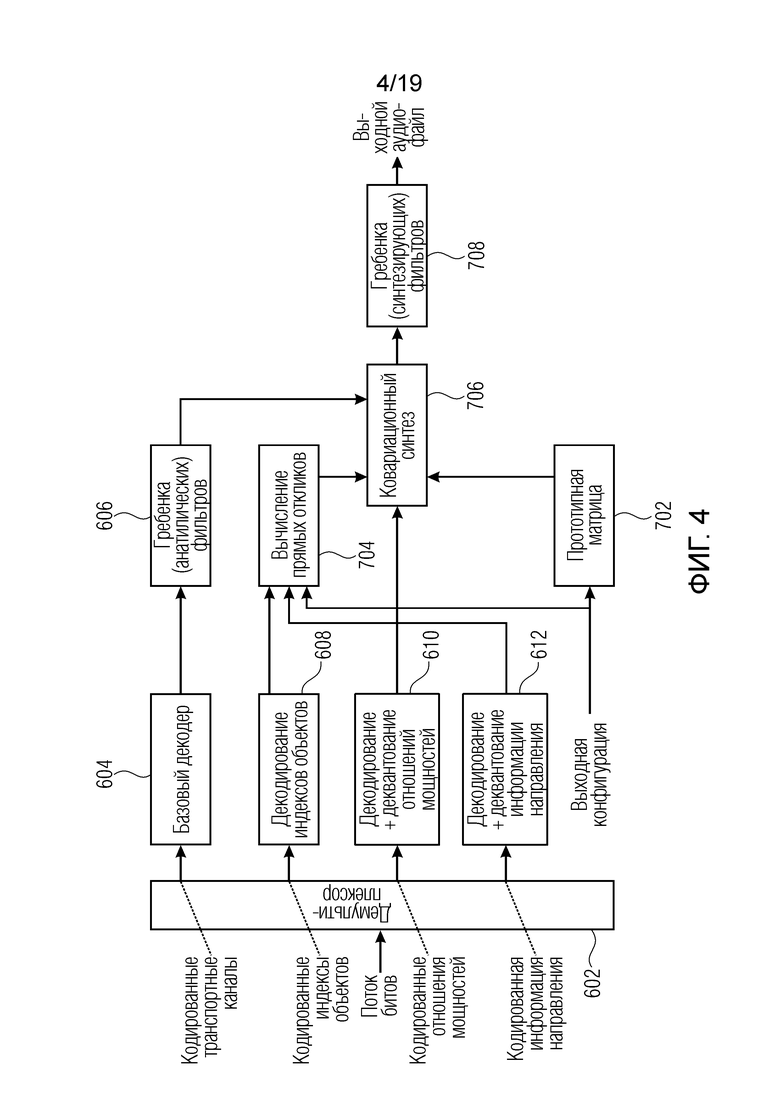
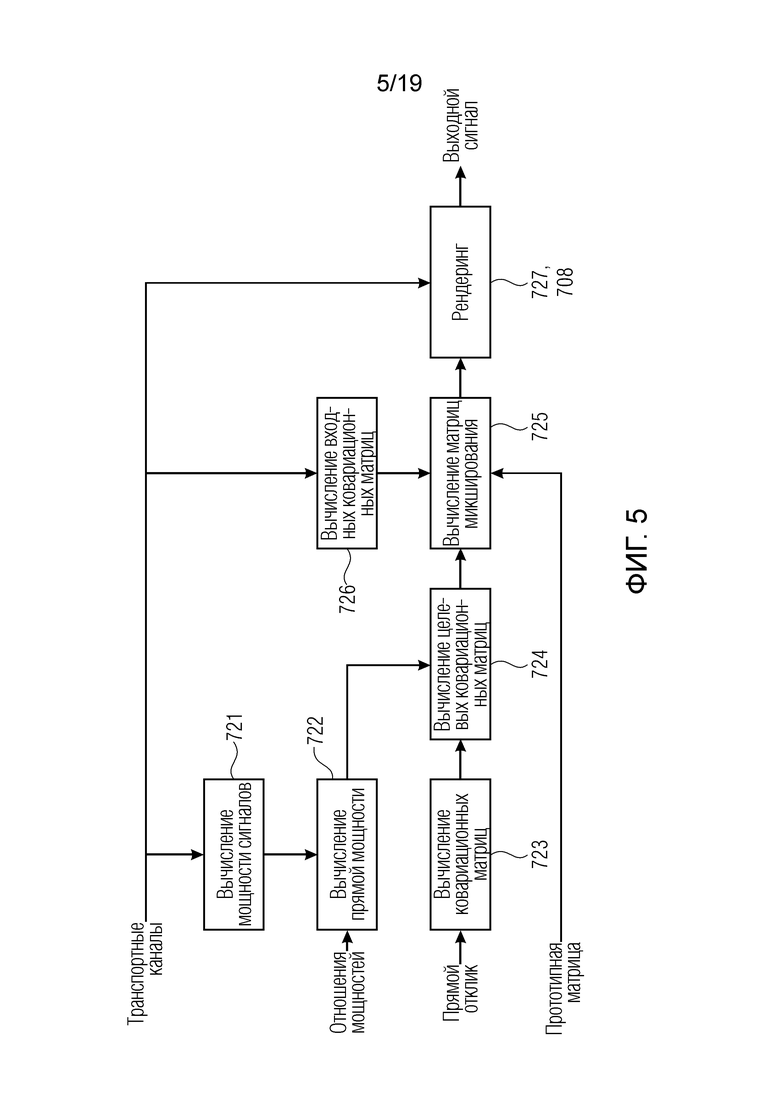
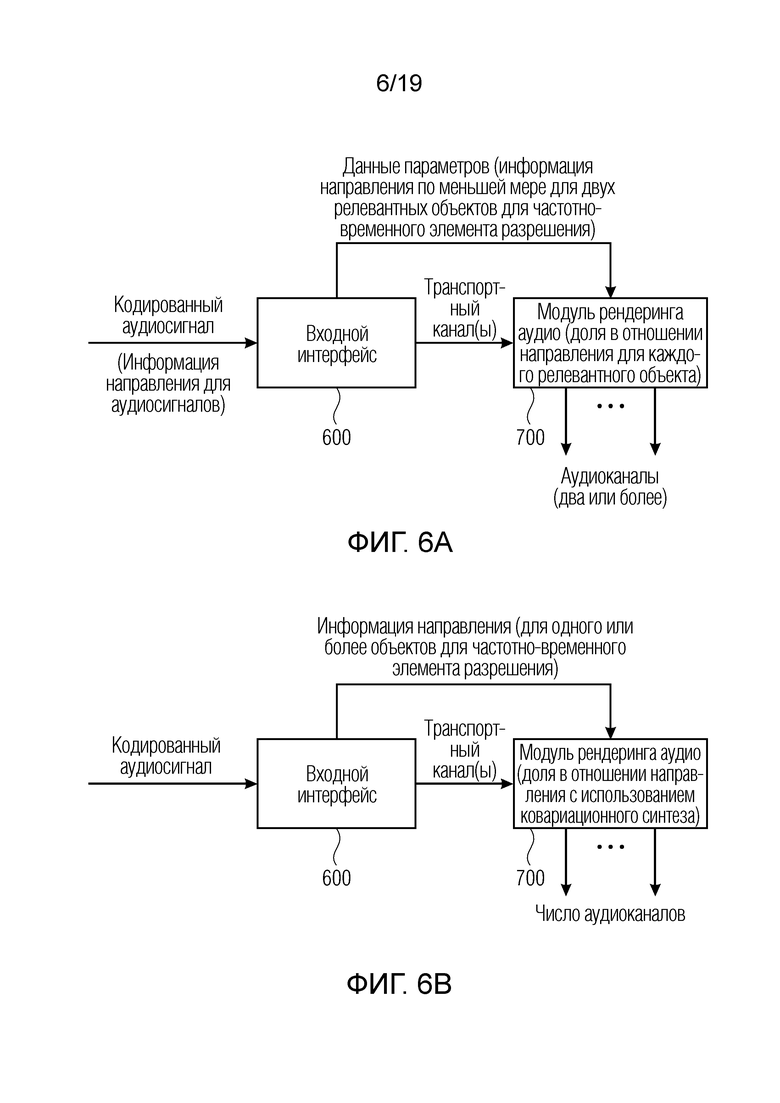
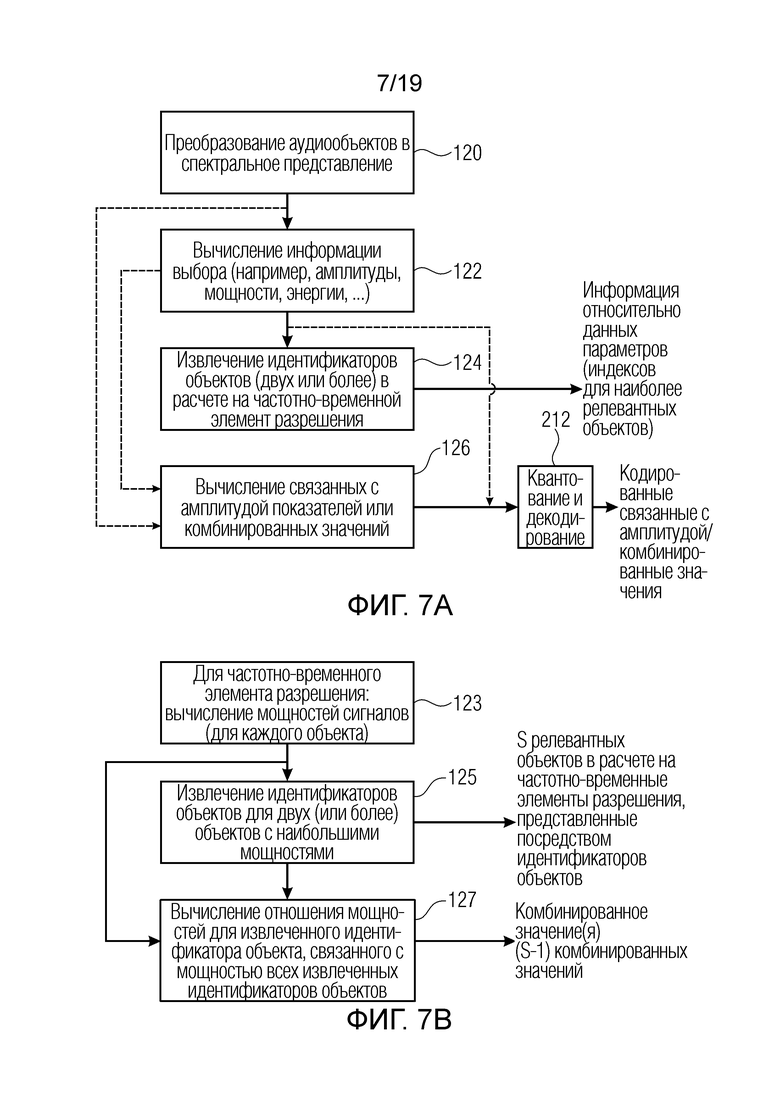
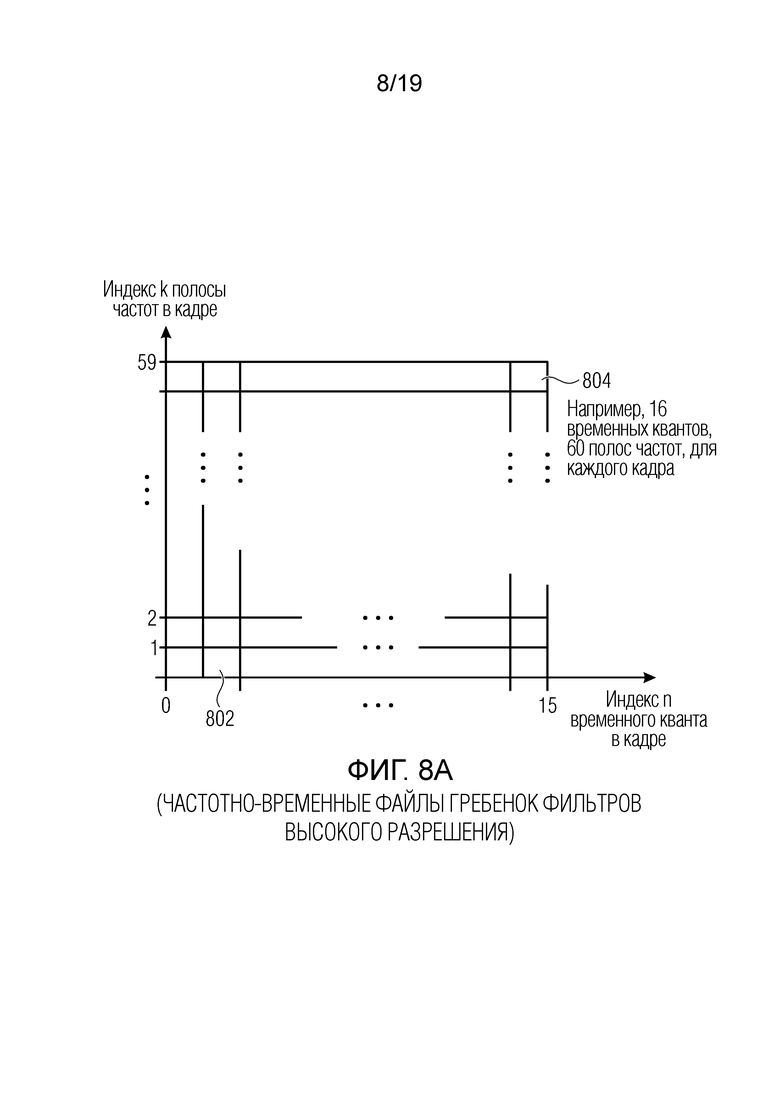
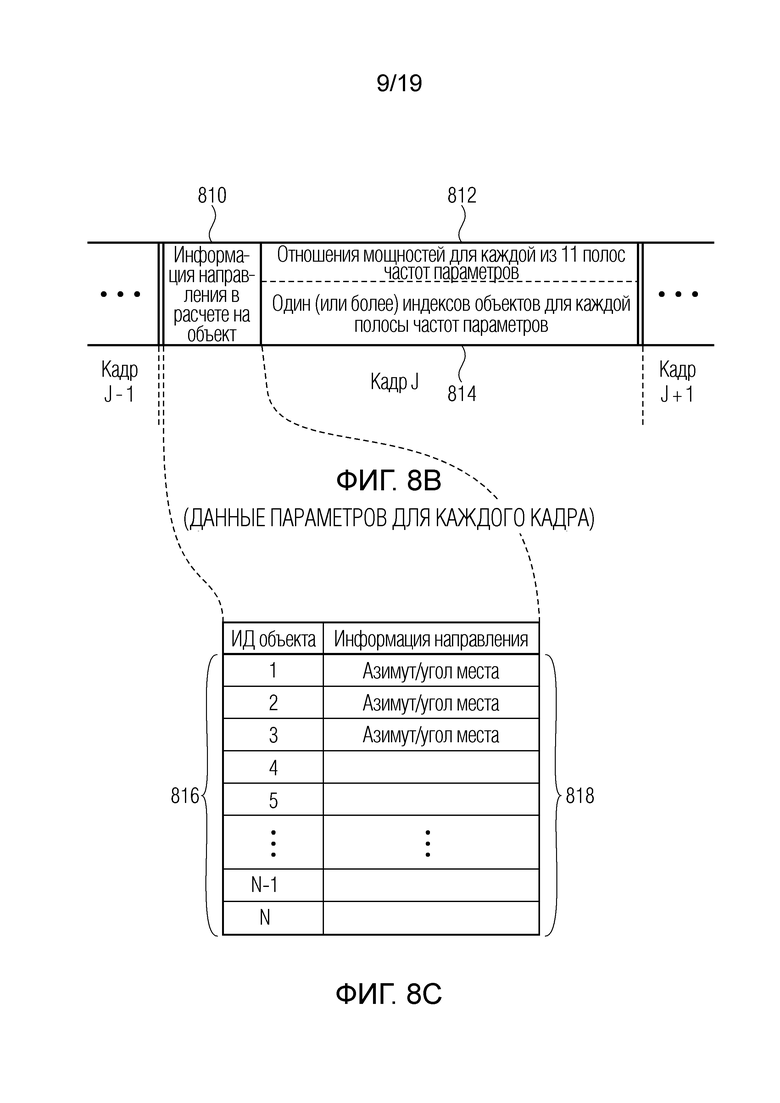
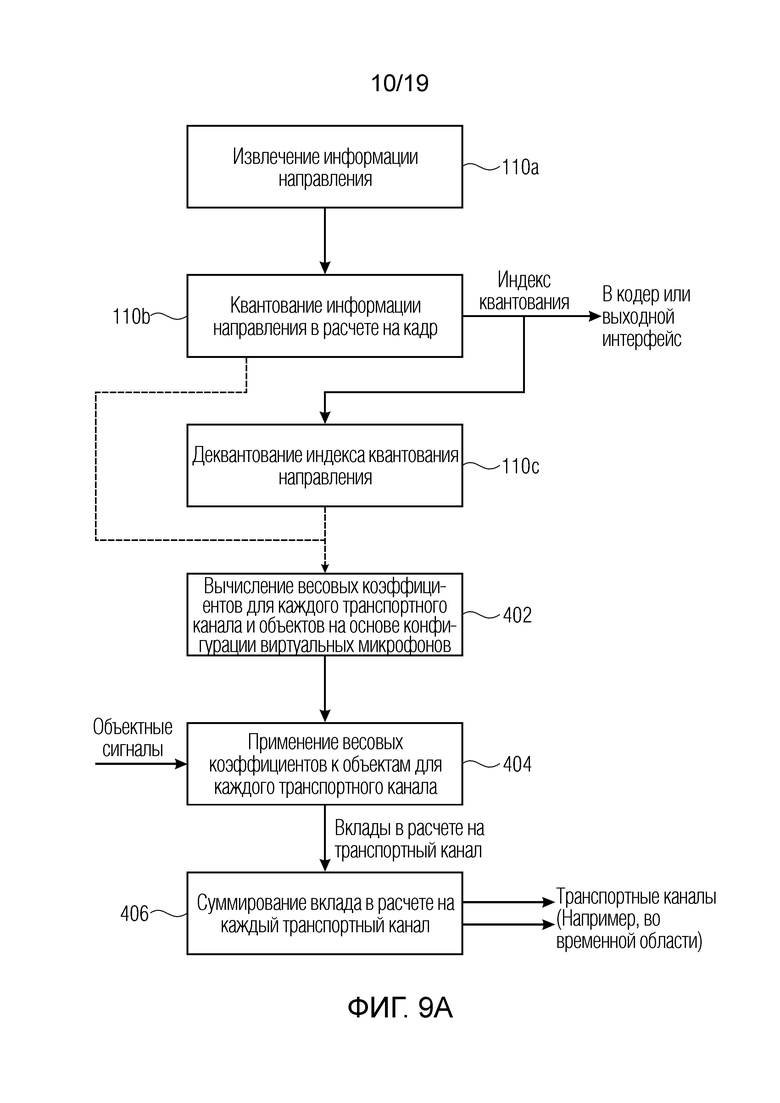
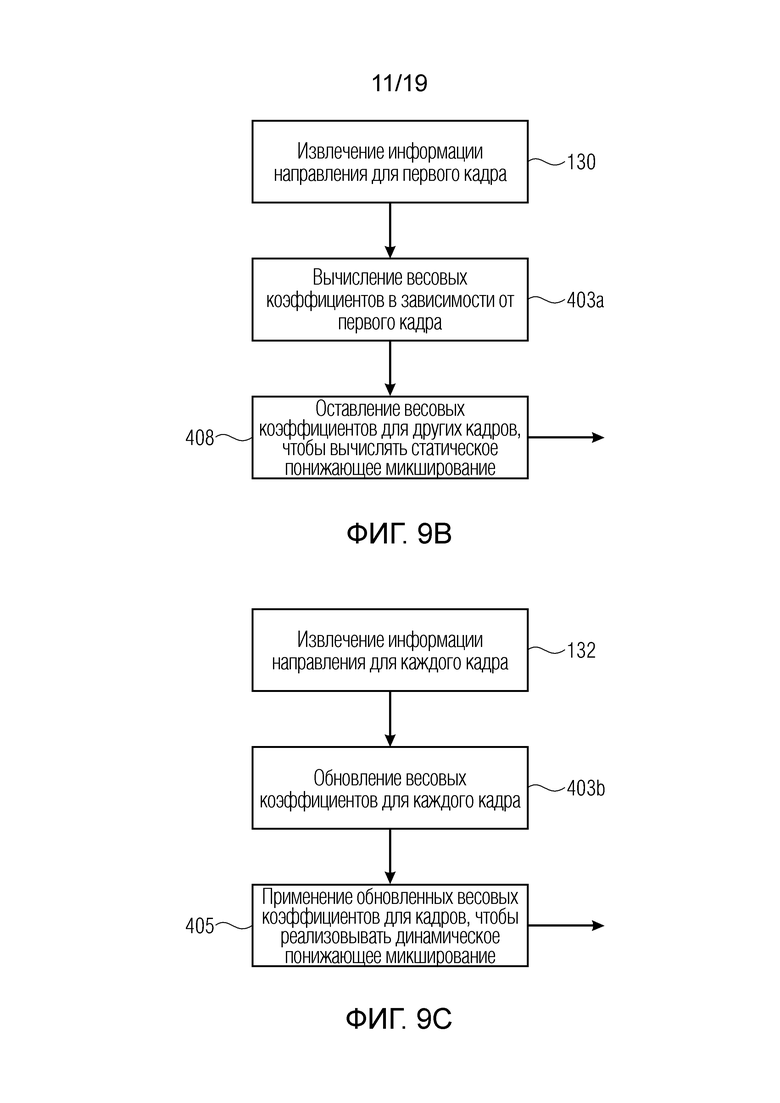
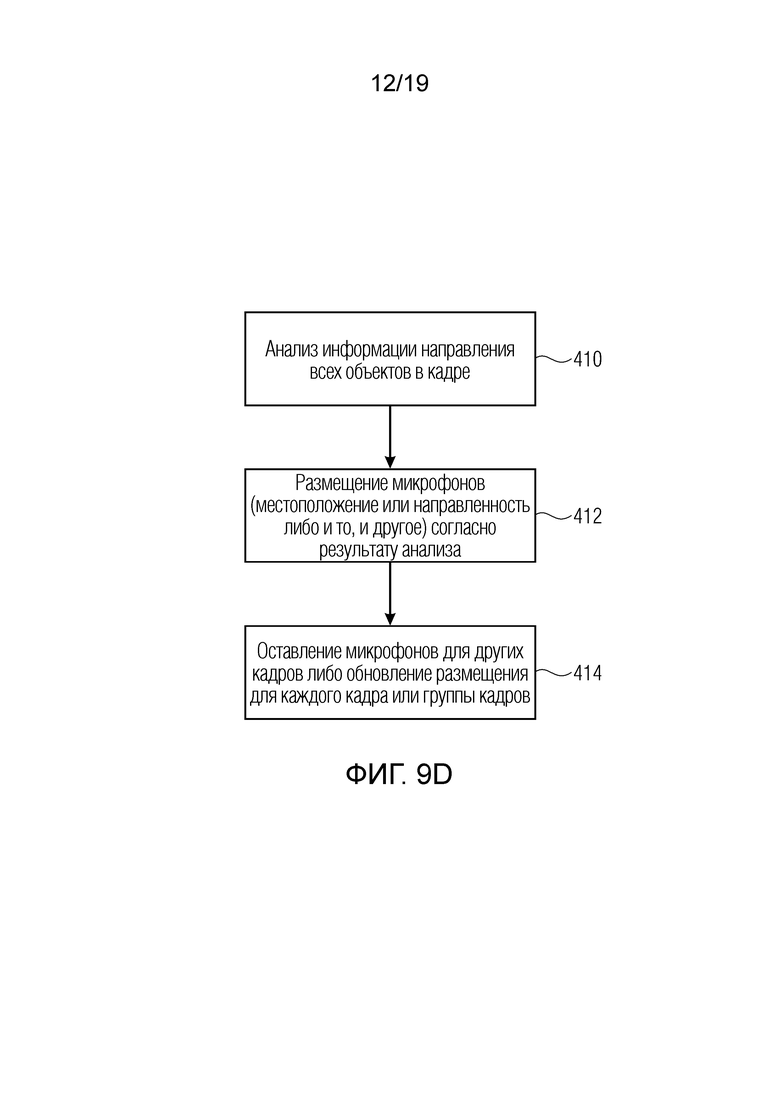
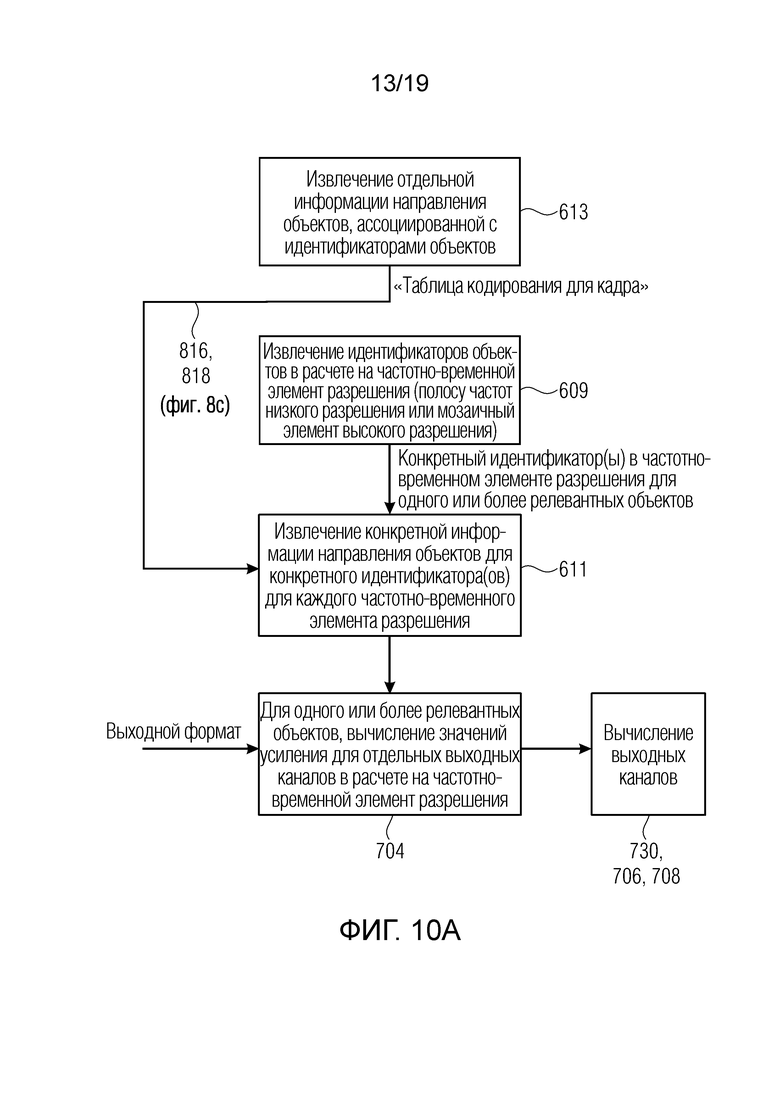
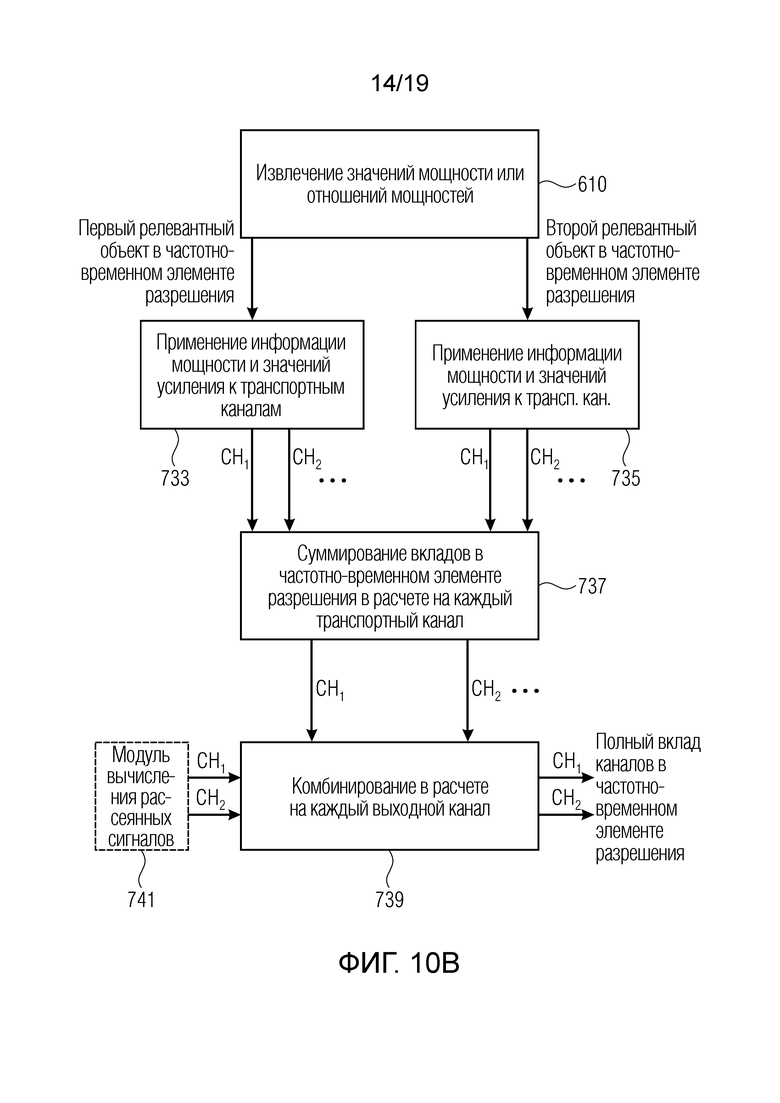
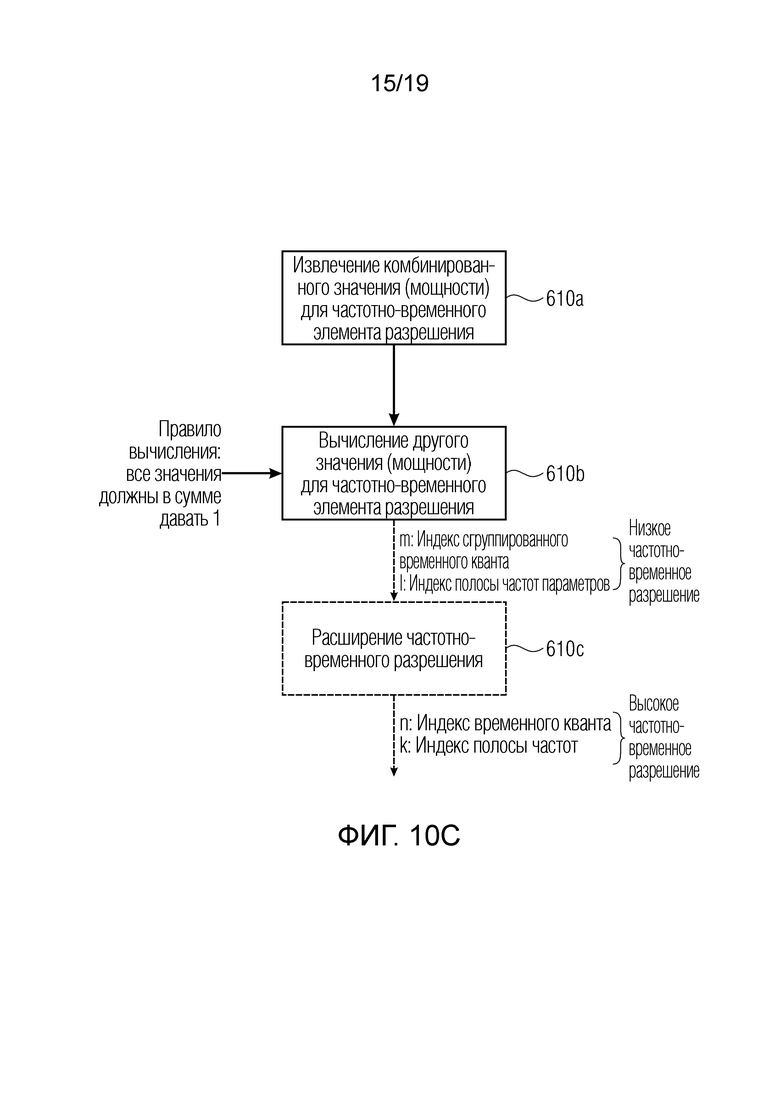
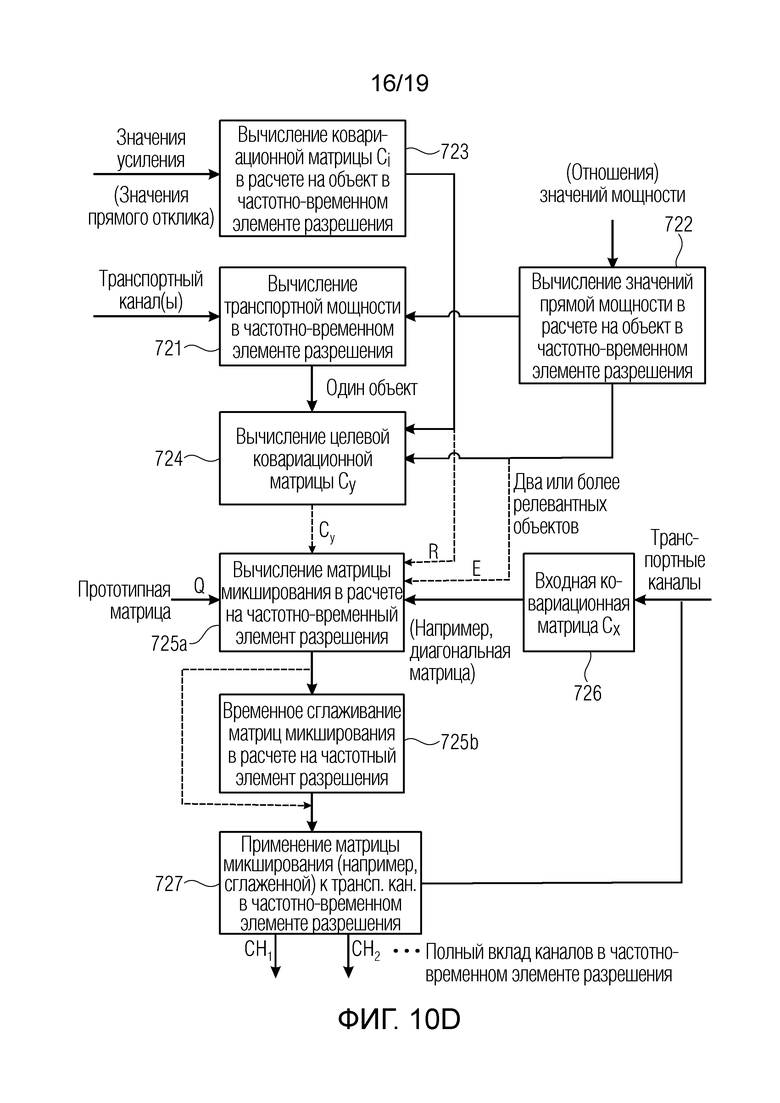
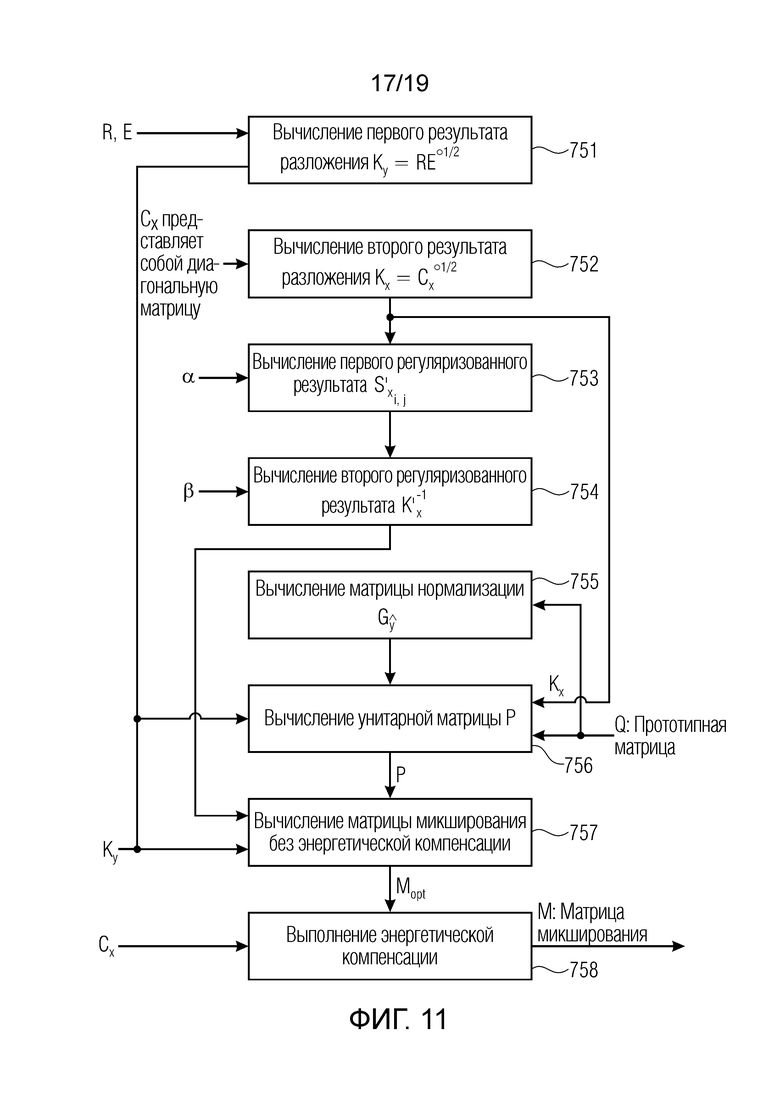
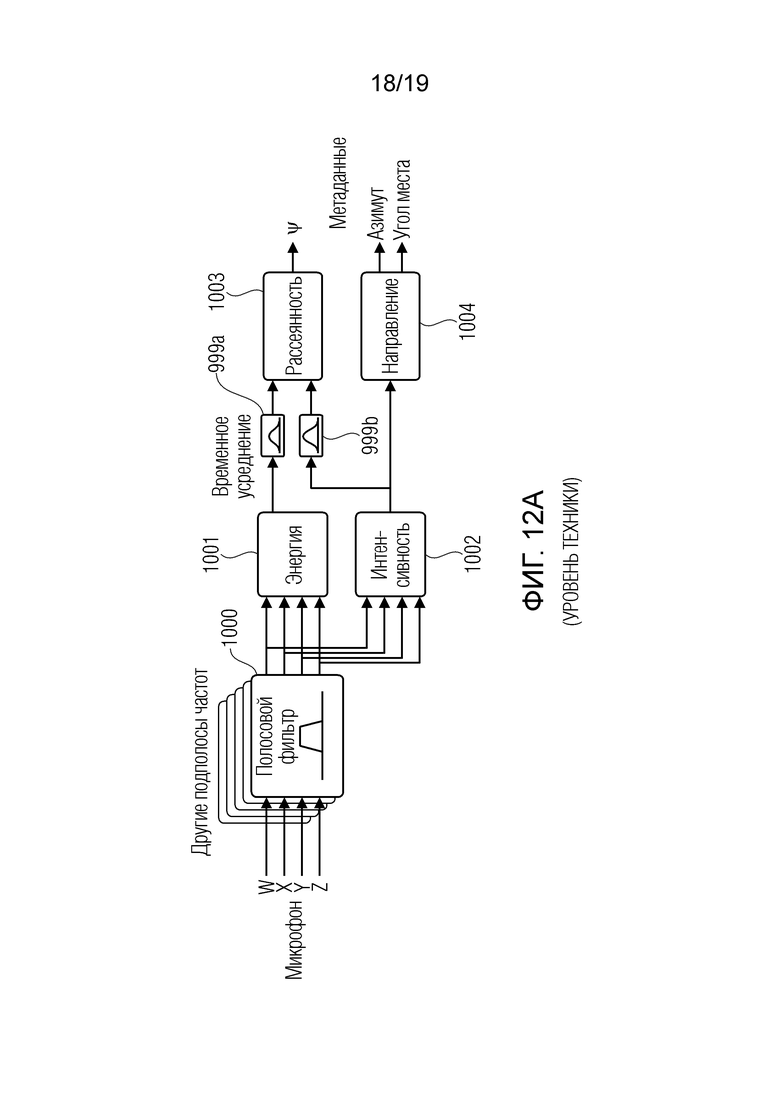
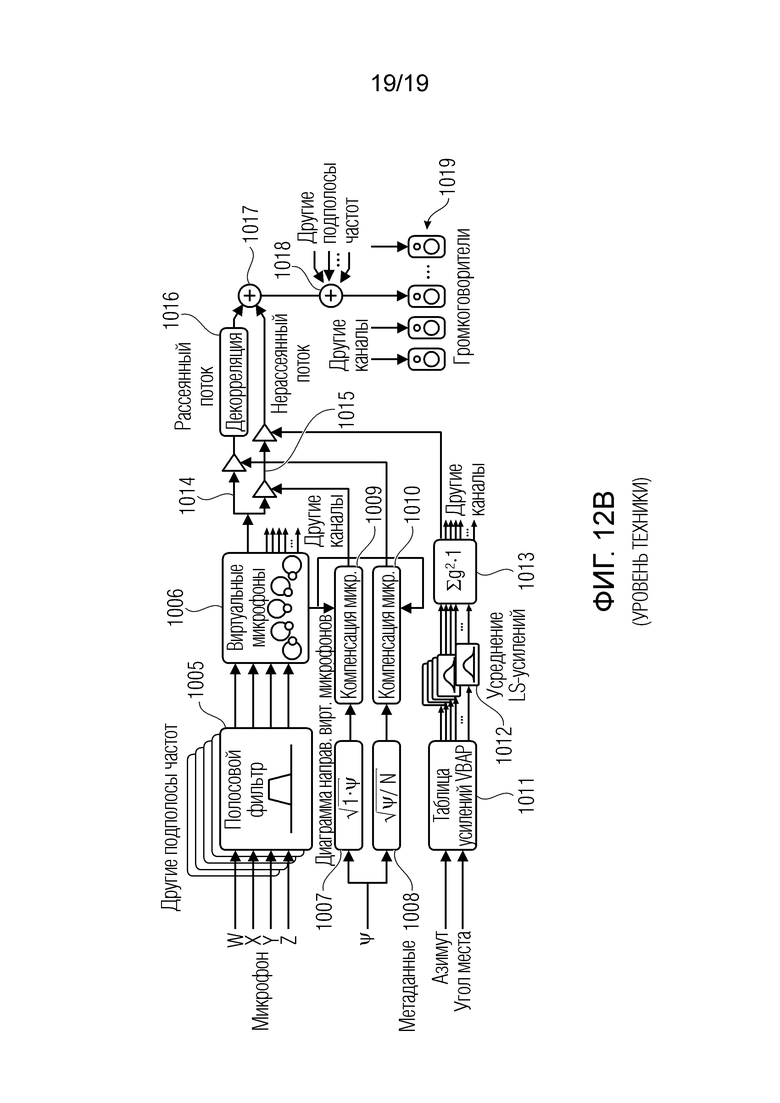
Настоящее изобретение относится к кодированию аудиосигналов, например аудиообъектов, и к декодированию кодированных аудиосигналов, таких как кодированные аудиообъекты. Устройство для кодирования множества аудиообъектов содержит модуль вычисления параметров объектов, выполненный с возможностью вычисления для одного или более частотных элементов разрешения из множества частотных элементов разрешения, связанных с временным кадром, данных параметров по меньшей мере для двух релевантных аудиообъектов, при этом число по меньшей мере двух релевантных аудиообъектов меньше общего числа множества аудиообъектов, и выходной интерфейс для вывода кодированного аудиосигнала, содержащего информацию относительно данных параметров по меньшей мере для двух релевантных аудиообъектов для одного или более частотных элементов разрешения. Технический результат заключается в усовершенствованной концепции кодирования множества аудиообъектов или декодирования кодированного аудиосигнала, с хорошей масштабируемостью для растущего числа объектов. 6 н. и 25 з.п. ф-лы, 24 ил.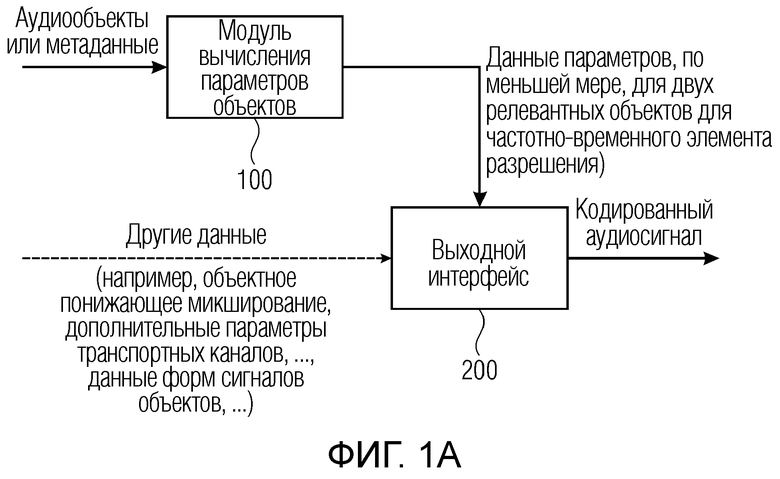
1. Устройство для кодирования множества аудиообъектов, содержащее:
- модуль (100) вычисления параметров объектов, выполненный с возможностью вычисления для одного или более частотных элементов разрешения из множества частотных элементов разрешения, связанных с временным кадром, данных параметров по меньшей мере для двух релевантных аудиообъектов, при этом число по меньшей мере двух релевантных аудиообъектов меньше общего числа множества аудиообъектов, при этом модуль (100) вычисления параметров объектов выполнен с возможностью выполнения выбора числа по меньшей мере двух релевантных аудиообъектов и неуказания общего числа аудиообъектов как релевантного, и
- выходной интерфейс (200) для вывода кодированного аудиосигнала, содержащего информацию о данных параметров по меньшей мере для двух релевантных аудиообъектов.
2. Устройство по п. 1, в котором модуль (100) вычисления параметров объектов выполнен с возможностью:
- преобразования (120) каждого аудиообъекта из множества аудиообъектов в спектральное представление, имеющее множество частотных элементов разрешения,
- вычисления (122) информации выбора из каждого аудиообъекта для одного или более частотных элементов разрешения, и
- извлечения (124) идентификационных данных объектов в качестве данных параметров, указывающих по меньшей мере два релевантных аудиообъекта, на основе информации выбора, и
- при этом выходной интерфейс (200) выполнен с возможностью ввода информации об идентификационных данных объектов в кодированный аудиосигнал.
3. Устройство по п. 1 или 2, в котором модуль (100) вычисления параметров объектов выполнен с возможностью квантования и кодирования (212) одного или более связанных с амплитудой показателей или одного или более комбинированных значений, извлеченных из связанных с амплитудой показателей релевантных аудиообъектов в одном или более частотных элементах разрешения в качестве данных параметров, и
- при этом выходной интерфейс (200) выполнен с возможностью ввода квантованных одного или более связанных с амплитудой показателей или квантованных одного или более комбинированных значений в кодированный аудиосигнал.
4. Устройство по п. 2, в котором информация выбора представляет собой связанный с амплитудой показатель, такой как значение амплитуды, значение мощности или значение громкости или амплитуда, возведенная в степень, отличающуюся от единицы, для аудиообъекта, и - при этом модуль (100) вычисления параметров объектов выполнен с возможностью вычисления (127) комбинированного значения, такого как отношение из связанного с амплитудой показателя релевантного аудиообъекта и суммы двух или более связанных с амплитудой показателей релевантных аудиообъектов, и
- при этом выходной интерфейс (200) выполнен с возможностью ввода информации о комбинированном значении в кодированный аудиосигнал, при этом число информационных элементов в комбинированных значениях в кодированном аудиосигнале равно по меньшей мере одному и меньше числа релевантных аудиообъектов для одного или более частотных элементов разрешения.
5. Устройство по одному из пп. 2 и 4,
- в котором модуль (100) вычисления параметров объектов выполнен с возможностью выбора идентификационных данных объектов на основе порядка информации выбора множества аудиообъектов в одном или более частотных элементов разрешения.
6. Устройство по одному из пп. 2, 4-5, в котором модуль (100) вычисления параметров объектов выполнен с возможностью:
- вычисления (122) мощности сигналов в качестве информации выбора,
- извлечения (124) идентификационных данных объектов для двух или более аудиообъектов, имеющих самые большие значения мощности сигналов в соответствующих одном или более частотных элементов разрешения для каждого частотного элемента разрешения отдельно,
- вычисления (126) отношений мощностей между суммой мощностей сигналов двух или более аудиообъектов, имеющих самые большие значения мощности сигналов, и мощности сигналов каждого из аудиообъектов, имеющих извлеченные идентификационные данные объектов, в качестве данных параметров, и
- квантования и кодирования (212) отношения мощностей, и
- при этом выходной интерфейс (200) выполнен с возможностью ввода квантованного и кодированного отношения мощностей в кодированный аудиосигнал.
7. Устройство по одному из пп. 1-6, в котором выходной интерфейс (200) выполнен с возможностью ввода в кодированный аудиосигнал одного или более кодированных транспортных каналов в качестве данных параметров двух или более кодированных идентификационных данных объектов для релевантных аудиообъектов для каждого из одного или более частотных элементов разрешения из множества частотных элементов разрешения во временном кадре и одно или более кодированных комбинированных значений или кодированных связанных с амплитудой показателей, и квантованных и кодированных данных направления для каждого аудиообъекта во временном кадре, причем данные направления являются постоянными для всех частотных элементов разрешения из одного или более частотных элементов разрешения.
8. Устройство по одному из пп. 1-7, в котором модуль (100) вычисления параметров объектов выполнен с возможностью вычисления данных параметров по меньшей мере для наиболее доминирующего объекта и второго наиболее доминирующего объекта в одном или более частотных элементах разрешения, или
- при этом число аудиообъектов из множества аудиообъектов равно трем или более, причем множество аудиообъектов содержат первый аудиообъект, второй аудиообъект и третий аудиообъект, и
- при этом модуль (100) вычисления параметров объектов выполнен с возможностью вычисления для первого из одного или более частотных элементов разрешения в качестве релевантных аудиообъектов только первой группы аудиообъектов, например первого аудиообъекта и второго аудиообъекта, и вычисления в качестве релевантных аудиообъектов для второго частотного элемента разрешения из одного или более частотных элементов разрешения только второй группы аудиообъектов, например второго аудиообъекта и третьего аудиообъекта или первого аудиообъекта и третьего аудиообъекта, при этом первая группа аудиообъектов отличается от второй группы аудиообъектов в отношении по меньшей мере одного члена группы.
9. Устройство по одному из пп. 1-8, в котором модуль (100) вычисления параметров объектов выполнен с возможностью:
- вычисления необработанных параметрических данных с первым временным или частотным разрешением и комбинирования необработанных параметрических данных в комбинированные
параметрические данные, имеющие второе временное или частотное разрешение меньше первого временного или частотного разрешения, и вычисления данных параметров по меньшей мере для двух релевантных аудиообъектов по отношению к комбинированным параметрическим данным, имеющим второе временное или частотное разрешение, или
- определения полос частот параметров, имеющих второе временное или частотное разрешение, отличающееся от первого временного или частотного разрешения, используемого при временном или частотном разложении множества аудиообъектов, и вычисления данных параметров по меньшей мере для двух релевантных аудиообъектов для полос частот параметров, имеющих второе временное или частотное разрешение.
10. Устройство по одному из предшествующих пунктов, в котором множество аудиообъектов содержат связанные метаданные, указывающие информацию (810) направления для множества аудиообъектов, и
- при этом устройство дополнительно содержит:
- понижающий микшер (400) для понижающего микширования множества аудиообъектов для получения одного или более транспортных каналов, при этом понижающий микшер (400) выполнен с возможностью понижающего микширования множества аудиообъектов в ответ на информацию направления для множества аудиообъектов; и
- кодер (300) транспортных каналов для кодирования одного или более транспортных каналов для получения одного или более кодированных транспортных каналов; и
- при этом выходной интерфейс (200) выполнен с возможностью ввода одного или более транспортных каналов в кодированный аудиосигнал.
11. Устройство по п. 10, в котором понижающий микшер (400) выполнен с возможностью:
- формирования двух транспортных каналов в качестве двух сигналов виртуальных микрофонов, размещаемых в одинаковом положении и имеющих различные ориентации или в двух различных положениях относительно опорного положения или ориентации, такого как виртуальное положение или ориентация слушателя, или
- формирования трёх транспортных каналов в качестве трех сигналов виртуальных микрофонов, размещаемых в одинаковом положении и имеющих различные ориентации, или в трех различных положениях относительно опорного положения или ориентации, такого как виртуальное положение или ориентация слушателя, или
- формирования четырех транспортных каналов в качестве четырех сигналов виртуальных микрофонов, размещаемых в одинаковом положении и имеющих различные ориентации, или в четырех различных положениях относительно опорного положения или ориентации, такого как виртуальное положение или ориентация слушателя, или
- при этом сигналы виртуальных микрофонов представляют собой сигналы виртуальных микрофонов первого порядка или сигналы виртуальных кардиоидных микрофонов, или сигналы виртуальных микрофонов в виде 8 либо дипольных микрофонов, либо двунаправленных микрофонов, или сигналы виртуальных направленных микрофонов, или сигналы виртуальных субкардиоидных микрофонов, или сигналы виртуальных однонаправленных микрофонов, или сигналы виртуальных гиперкардиоидных микрофонов, или сигналы виртуальных всенаправленных микрофонов.
12. Устройство по п. 10 или 11, в котором понижающий микшер (400) выполнен с возможностью:
- извлечения (402) для каждого аудиообъекта из множества аудиообъектов информации взвешивания для каждого транспортного канала с использованием информации направления для соответствующего аудиообъекта;
- взвешивания (404) соответствующего аудиообъекта с использованием информации взвешивания для аудиообъекта для конкретного транспортного канала для получения вклада объекта для конкретного транспортного канала, и
- комбинирования (406) вкладов объектов для конкретного транспортного канала из множества аудиообъектов для получения конкретного транспортного канала.
13. Устройство по одному из пп. 10-12,
- в котором понижающий микшер (400) выполнен с возможностью вычисления одного или более транспортных каналов в качестве одного или более сигналов виртуальных микрофонов, размещаемых в одинаковом положении и имеющих различные ориентации, или в различных положениях относительно опорного положения или ориентации, такого как виртуальное положение или ориентация слушателя, с которой связана информация направления,
- при этом различные положения или ориентации определяются в левой стороне относительно центральной линии и в правой стороне относительно центральной линии, или при этом различные положения или ориентации одинаково или неодинаково распределяются в горизонтальные положения или ориентации, например, в +90 градусов или -90 градусов относительно центральной линии либо в -120 градусов, 0 градусов и +120 градусов относительно центральной линии, или при этом различные положения или ориентации содержат по меньшей мере одно положение или ориентацию, направленную вверх или вниз относительно горизонтальной плоскости, в которой находится виртуальный слушатель, при этом информация направления для множества аудиообъектов связана с виртуальным положением или ориентацией слушателя либо с опорным положением или ориентацией.
14. Устройство в соответствии с одним из пп. 10-13,
дополнительно содержащее:
- процессор (110) параметров для квантования метаданных, указывающих информацию направления для множества аудиообъектов, таким образом, чтобы получить квантованные элементы направления для множества аудиообъектов,
- при этом понижающий микшер (400) выполнен с возможностью работы в ответ на квантованные элементы направления в качестве информации направления, и
- при этом выходной интерфейс (200) выполнен с возможностью ввода информации о квантованных элементах направления в кодированный аудиосигнал.
15. Устройство по одному из пп. 10-14,
- в котором понижающий микшер (400) выполнен с возможностью выполнения (410) анализа информации направления для множества аудиообъектов и размещения (412) одного или более виртуальных микрофонов для формирования транспортных каналов в зависимости от результата анализа.
16. Устройство по одному из пп. 10-15,
- в котором понижающий микшер (400) выполнен с возможностью выполнения понижающего микширования (408) с использованием правила понижающего микширования, статического по множеству временных кадров, или
- при этом информация направления является переменной по множеству временных кадров, и при этом понижающий микшер (400) выполнен с возможностью выполнения понижающего микширования (405) с использованием правила понижающего микширования, переменного по множеству временных кадров.
17. Устройство по одному из пп. 10-16, в котором понижающий микшер (400) выполнен с возможностью понижающего микширования во временной области с использованием последовательного выборочного взвешивания и комбинирования выборок множества аудиообъектов.
18. Декодер для декодирования кодированного аудиосигнала, содержащего один или более транспортных каналов и информацию направления для множества аудиообъектов и, для одного или более частотных элементов разрешения временного кадра, данные параметров по меньшей мере для двух релевантных аудиообъектов, при этом число по меньшей мере двух релевантных аудиообъектов ниже общего числа множества аудиообъектов, при этом число по меньшей мере двух релевантных аудиообъектов представляет собой выбор из общего числа аудиообъектов, при этом общее число аудиообъектов не указывается как релевантное, причем декодер содержит:
- входной интерфейс (600) для обеспечения одного или более транспортных каналов в спектральном представлении, имеющем во временном кадре множество частотных элементов разрешения; и
- модуль (700) рендеринга аудио для рендеринга одного или более транспортных каналов в определенное число аудиоканалов с использованием информации направления таким образом, что учитывается вклад от одного или более транспортных каналов в соответствии с первой информацией направления, ассоциированной с первым из по меньшей мере двух релевантных аудиообъектов, и в соответствии со второй информацией направления, ассоциированной со вторым из по меньшей мере двух релевантных аудиообъектов, или
- при этом модуль (700) рендеринга аудио выполнен с возможностью вычисления для каждого из одного или более частотных элементов разрешения вклада от одного или более транспортных каналов в соответствии с первой информацией направления, ассоциированной с первым по меньшей мере из двух релевантных аудиообъектов, и в соответствии со второй информацией направления, ассоциированной со вторым по меньшей мере из двух релевантных аудиообъектов.
19. Декодер по п. 18,
- в котором модуль (700) рендеринга аудио выполнен с возможностью игнорирования для одного или более частотных элементов разрешения информации направления аудиообъекта, отличающегося по меньшей мере от двух релевантных аудиообъектов.
20. Декодер по п. 18 или 19, в котором кодированный аудиосигнал содержит связанный с амплитудой показатель (812) для каждого релевантного аудиообъекта или комбинированное значение (812), связанное по меньшей мере с двумя релевантными аудиообъектами в данных параметров, и
- при этом модуль (700) рендеринга аудио выполнен с возможностью определения (704) количественного вклада одного или более транспортных каналов в соответствии со связанным с амплитудой показателем или комбинированным значением.
21. Декодер по п. 20, в котором кодированный сигнал содержит комбинированное значение в данных параметров, и
- при этом модуль (700) рендеринга аудио выполнен с возможностью определения (704, 733) вклада одного или более транспортных каналов с использованием комбинированного значения для одного из релевантных аудиообъектов и информации направления для одного релевантного аудиообъекта, и
- при этом модуль (700) рендеринга аудио выполнен с возможностью определения (704, 735) вклада для одного или более транспортных каналов с использованием значения, извлеченного из комбинированного значения для другого из релевантных аудиообъектов в одном или более частотных элементов разрешения и информации направления другого релевантного аудиообъекта.
22. Декодер по одному из пп. 18-21, в котором модуль (700) рендеринга аудио выполнен с возможностью:
- вычисления (704) информации прямых откликов из релевантных аудиообъектов в расчете на каждый частотный элемент разрешения из множества частотных элементов разрешения и информации направления, ассоциированной с релевантными аудиообъектами в частотных элементах разрешения.
23. Декодер по п. 22,
- в котором модуль (700) рендеринга аудио выполнен с возможностью определения (741) рассеянного сигнала в расчете на каждый частотный элемент разрешения из множества частотных элементов разрешения с использованием информации рассеянности, такой как параметр рассеянности, включенный в метаданные, или правила декорреляции, и комбинирования прямого отклика, определенного посредством информации прямых откликов и рассеянного сигнала, таким образом, чтобы получить рендерированный сигнал спектральной области для канала из определенного числа каналов, или
- вычисления (706) информации синтеза с использованием информации (704) прямых откликов и информации относительно числа аудиоканалов (702) и применять (727) информацию ковариационного синтеза к одному или более транспортных каналов таким образом, чтобы получить число аудиоканалов, или
- при этом информация (704) прямых откликов представляет собой вектор прямых откликов для каждого релевантного аудиообъекта, и при этом информация ковариационного синтеза представляет собой матрицу ковариационного синтеза, и при этом модуль (700) рендеринга аудио выполнен с возможностью выполнения матричной операции в расчете на частотный элемент разрешения при применении (727) информации ковариационного синтеза.
24. Декодер по п. 22 или 23, в котором модуль (700) рендеринга аудио выполнен с возможностью:
- извлечения при вычислении информации (704) прямых откликов вектора прямых откликов для каждого релевантного аудиообъекта и вычисления для каждого релевантного аудиообъекта ковариационной матрицы из каждого вектора прямых откликов, извлечения (724) при вычислении информации ковариационного синтеза целевой ковариационной информации из ковариационных матриц из каждого из релевантных аудиообъектов
информации мощности для соответствующего релевантного аудиообъекта и
информации мощности, извлекаемой из одного или более транспортных каналов.
25. Декодер по п. 24, в котором модуль (700) рендеринга аудио выполнен с возможностью:
- извлечения при вычислении информации (704) прямых откликов вектора прямых откликов для каждого релевантного аудиообъекта и вычисления (723) для каждого релевантного аудиообъекта ковариационной матрицы из каждого вектора прямых откликов,
- извлечения (726) входной ковариационной информации из транспортных каналов, и
- извлечения (725a, 725b) информации микширования из целевой ковариационной информации, входной ковариационной информации и информации о числе каналов, и
- применения (727) информации микширования к транспортным каналам для каждого частотного элемента разрешения во временном кадре.
26. Декодер по п. 25, в котором результат применения информации микширования для каждого частотного элемента разрешения во временном кадре преобразуется (708) во временную область для получения числа аудиоканалов во временной области.
27. Декодер по одному из пп. 22-26, в котором модуль (700) рендеринга аудио выполнен с возможностью:
- использования только элементов главной диагонали входной ковариационной матрицы, извлекаемой из транспортных каналов, в разложении (752) входной ковариационной матрицы, или
- выполнения разложения (751) целевой ковариационной матрицы с использованием матрицы прямых откликов и матрицы мощностей объектов или транспортных каналов, или
- выполнения (752) разложения входной ковариационной матрицы посредством извлечения корня каждого элемента главной диагонали входной ковариационной матрицы, или
- вычисления (753) регуляризованной инверсии разлагаемой входной ковариационной матрицы, или
- выполнения (756) разложения по сингулярным значениям при вычислении оптимальной матрицы, которая должна использоваться в энергетической компенсации без расширенной единичной матрицы.
28. Способ кодирования множества аудиообъектов, содержащий этапы, на которых:
- вычисляют для одного или более частотных элементов разрешения из множества частотных элементов разрешения, связанных с временным кадром, данные параметров по меньшей мере для двух релевантных аудиообъектов, при этом число по меньшей мере двух релевантных аудиообъектов меньше общего числа множества аудиообъектов, при этом вычисление содержит этап, на котором выполняют выбор числа по меньшей мере двух релевантных аудиообъектов, и не указывают общее число аудиообъектов как релевантное, и
- выводят кодированный аудиосигнал, содержащий информацию о данных параметров по меньшей мере для двух релевантных аудиообъектов.
29. Способ декодирования кодированного аудиосигнала, содержащего один или более транспортных каналов и информацию направления для множества аудиообъектов и, для одного или более частотных элементов разрешения временного кадра, данные параметров по меньшей мере для двух релевантных аудиообъектов, при этом число по меньшей мере двух релевантных аудиообъектов меньше общего числа множества аудиообъектов, при этом число по меньшей мере двух релевантных аудиообъектов представляет собой выбор из общего числа аудиообъектов, при этом общее число аудиообъектов не указывается как релевантное, при этом способ декодирования содержит этапы, на которых:
- обеспечивают один или более транспортных каналов в спектральном представлении, имеющем во временном кадре множество частотных элементов разрешения; и
- выполняют аудиорендеринг одного или более транспортных каналов в определенное число аудиоканалов с использованием информации направления,
- при этом аудиорендеринг содержит этап, на котором вычисляют для каждого из одного или более частотных элементов разрешения вклад от одного или более транспортных каналов в соответствии с первой информацией направления, ассоциированной с первым из по меньшей мере двух релевантных аудиообъектов, и в соответствии со второй информацией направления, ассоциированной со вторым из по меньшей мере двух релевантных аудиообъектов, таким образом, что учитывается вклад от одного или более транспортных каналов в соответствии с первой информацией направления, ассоциированной с первым из по меньшей мере двух релевантных аудиообъектов, и в соответствии со второй информацией направления, ассоциированной со вторым из по меньшей мере двух релевантных аудиообъектов.
30. Машиночитаемый носитель, содержащий компьютерную программу для осуществления при выполнении на компьютере или в процессоре способа по п. 28.
31. Машиночитаемый носитель, содержащий компьютерную программу для осуществления при выполнении на компьютере или в процессоре способа по п. 29.
| MPEG Spatial Audio Object Coding - The ISO/MPEG Standart for Efficient Coding of Interactive Audio Scenes", 01.09.2012 | |||
| US 2010169103 A1, 01.07.2010 | |||
| US 2011029113 A1, 03.02.2011 | |||
| US 2017251321 A1, 31.08.2017. |

