Техническая отрасль
Данное изобретение относится к области связи и, в частности, кратко, к способу и устройству хранения данных для распределенной файловой системы (сокращенно DFS).
Уровень техники
Распределенное хранение достигает хранения большого объема данных и быстрого использования данных путем сохранения их на множестве дисков множества серверов распределенным образом. С помощью обновления типов устройств хранения данных новые устройства хранения данных будут непрерывно подсоединяться к кластеру диска; в результате, для этих устройств хранения данных распределенное хранение должно поддерживать принцип «включай и работай».
Разные устройства хранения данных имеют разные объемы и производительность. Как использовать пространство и производительность этих устройств хранения данных в максимальной степени является проблемой, требующей особого внимания. Первичные стратегии считывания и записи информации на диск, главным образом, касаются балансировки нагрузки между диском и файловым сервером, либо стратегии последовательного опроса и выбора. Другие технологии балансировки нагрузки в соответствующем уровне техники, главным образом, касаются выбора файлового сервера при записи файла согласно информации о нагрузке файловых серверов во время записи файла.
Однако стратегии балансировки нагрузки в соответствующем уровне техники не решают проблему нагрузки, применяемой к диску, путем доступа к активному файлу с высокой частотой при его считывании, и система имеет следующий недостаток: количество операций ввода-вывода в секунду (сокращенно IOPS), которое может поддерживаться разными устройствами хранения данных, является разным. Сперва, фрагменты для хранения файла выбирают согласно стратегии балансировки нагрузки диска либо произвольной стратегии. При той же нагрузке высокопроизводительное устройство хранения данных может работать стабильно, но на низкопроизводительном устройстве может случаться феномен задержки считывания.
В состоянии, где совместно используются высокопроизводительное и низкопроизводительное устройство хранения данных, низкопроизводительное устройство хранения данных будет составлять малую часть производительности всех распределенных устройств хранения данных и это будет представлено более явно при выполнении считывания файла. Именно в результате слабого эффекта низкопроизводительного устройства, разница в производительности между разными устройствами хранения данных будет понижать общие рабочие характеристики кластера диска, приводя к тому, что рабочие характеристики высокопроизводительного устройства хранения данных не могут использоваться по максимуму.
Краткое описание изобретения
Варианты выполнения данного изобретения предоставляют способ и устройство хранения данных для распределенной файловой системы для по меньшей мере решения проблемы нагрузки, применяемой к диску, вследствие доступа к активному файлу с высокой частотой при считывании файла в соответствующем уровне техники.
Согласно одному варианту выполнения данного изобретения предоставляется способ хранения данных для распределенной файловой системы, в котором определяют количество доступов к одному и тому же файлу в предварительно установленное время; и переносят файл в устройство хранения данных с большей производительностью, чем у текущего устройства хранения данных согласно количеству доступов.
В описанном варианте выполнения перенос файла в устройство хранения данных с большей производительностью, чем у текущего устройства хранения данных согласно количеству доступов включает определение превышения количеством доступов предварительно установленной пороговой величины, определение среди всех устройств хранения данных устройства хранения данных с большей производительностью, чем у текущего устройства хранения данных и имеющего неработающий блок, и перенос файла в определенное устройство хранения данных.
В описанном варианте выполнения, после определения превышения количеством доступов предварительно установленной пороговой величины, в способе дополнительно устанавливают атрибут заинтересованности в доступе к файлу как высокая.
В описанном варианте выполнения, перед определением количества доступов к одному и тому же файлу в предварительно установленное время, в способе дополнительно соответствующим образом определяют граничное количество операций ввода-вывода в секунду (IOPS) и поточное количество IOPS каждого устройства хранения данных в распределенной файловой системе, соответствующим образом вычисляют отношение текущего количества IOPS к граничному количеству IOPS каждого устройства хранения данных, и соответствующим образом сравнивают это отношение с предварительно установленной критической величиной, и если это отношение превышает предварительно установленную критическую величину, то определяют необходимость переноса файл с количеством доступов, превышающим предварительно установленную пороговую величину, в текущем устройстве хранения данных.
В описанном варианте выполнения после определения необходимости переноса файла с количеством доступов, превышающем предварительно установленную пороговую величину, в текущем устройстве хранения данных, в способе дополнительно принимают запрос на считывание файла и прибавляют единицу к количеству доступов к файлу.
В описанном варианте выполнения перед определением количества доступов к одному и тому же файлу в предварительно установленное время, в способе дополнительно файловый сервер вычисляет количество IOPS устройства хранения данных, соответствующего файловому серверу; и файловый сервер сообщает количество IOPS серверу метаданных согласно предварительно установленному периоду.
В описанном варианте выполнения, после переноса файла в устройство хранения данных с большей производительностью, чем у текущего устройства хранения данных согласно количеству доступов, в способе дополнительно проверяют, не превышает ли отношение текущего количества IOPS к граничному количеству IOPS каждого устройства хранения данных критическую величину согласно предварительно установленному периоду; если величина этого отношения не превышает критическую величину, то прекращают перенос файла в текущем устройстве хранения данных; и если отношение превышает критическую величину, то продолжают перенос файла с количеством доступов, превышающим пороговую величину, в текущем устройстве хранения данных.
Согласно иному варианту выполнения данного изобретения предоставляется устройство хранения данных для распределенной файловой системы, при этом устройство хранения данных применяется к серверу метаданных и содержит первый определяющий компонент, сконфигурированный для определения количества доступов к одному и тому же файлу в предварительно установленное время; и переносящий компонент, сконфигурированный для переноса файла в устройство хранения данных с большей производительностью, чем у текущего устройства хранения данных согласно количеству доступов.
В описанном варианте выполнения переносящий компонент содержит первый определяющий блок, сконфигурированный для определения превышения количеством доступов предварительно установленной пороговой величины; второй определяющий блок, сконфигурированный для определения среди всех устройств хранения данных устройства хранения данных с большей производительностью, чем у текущего устройства хранения данных и имеющего неиспользуемый блок; и переносящий блок, сконфигурированный для переноса файла в определенное устройство хранения данных.
В описанном варианте выполнения устройство дополнительно содержит второй определяющий компонент, сконфигурированный для, соответственно, определения граничной величины количества операций ввода-вывода в секунду (IOPS) и текущего количества IOPS каждого устройства хранения данных; вычислительный компонент, сконфигурированный для, соответственно, вычисления отношения текущего количества IOPS к граничному количеству IOPS каждого устройства хранения данных; сравнивающий компонент, сконфигурированный для, соответственно, сравнения этого отношения с предварительно установленной критической величиной; и третий определяющий компонент, сконфигурированный для определения необходимости переноса файла с количеством доступов, превышающим предварительно установленную пороговую величину, в текущем устройстве хранения данных, если это отношение превышает предварительно установленную критическую величину.
С помощью вариантов выполнения данного изобретения многоуровневое хранение данных выполняется на файлах в распределенной файловой системе согласно заинтересованности в доступе к файлам, то есть файл с высокой частотой доступа в предварительно установленное время переносят в устройство хранения данных с большей производительностью, а место хранения фрагмента файла связывают с заинтересованностью в доступе к фрагменту файла с помощью резервного копирования таким образом, что сжатие IOPS между устройствами хранения данных балансируется и улучшается общая производительность.
Краткое описание чертежей
Чертежи, предоставленные для дальнейшего понимания данного изобретения и формирующие часть описания, используются для разъяснения данного изобретения вместе с его вариантами выполнения, а не для ограничения данного изобретения. На сопровождающих чертежах:
Фиг. 1 изображает блок-схему способа хранения данных для распределенной файловой системы согласно варианту выполнения данного изобретения;
Фиг. 2 изображает архитектуру способа хранения данных для распределенной файловой системы согласно варианту выполнения данного изобретения;
Фиг. 3 изображает блок-схему способа хранения данных для распределенной файловой системы согласно иллюстративному варианту выполнения данного изобретения;
Фиг. 4 изображает структурную схему устройства хранения данных для распределенной файловой системы согласно варианту выполнения данного изобретения;
Фиг. 5 изображает структурную схему I устройства хранения данных для распределенной файловой системы согласно иллюстративному варианту выполнения данного изобретения; и
Фиг. 6 изображает структурную схему II устройства хранения данных для распределенной файловой системы согласно иллюстративному варианту выполнения данного изобретения.
Детальное описание вариантов выполнения
Следует отметить, что варианты выполнения и их характеристики могут сочетаться между собой, если отсутствует конфликт. Данное изобретение будет разъясняться ниже со ссылкой на чертежи и вместе с детальным описанием вариантов выполнения.
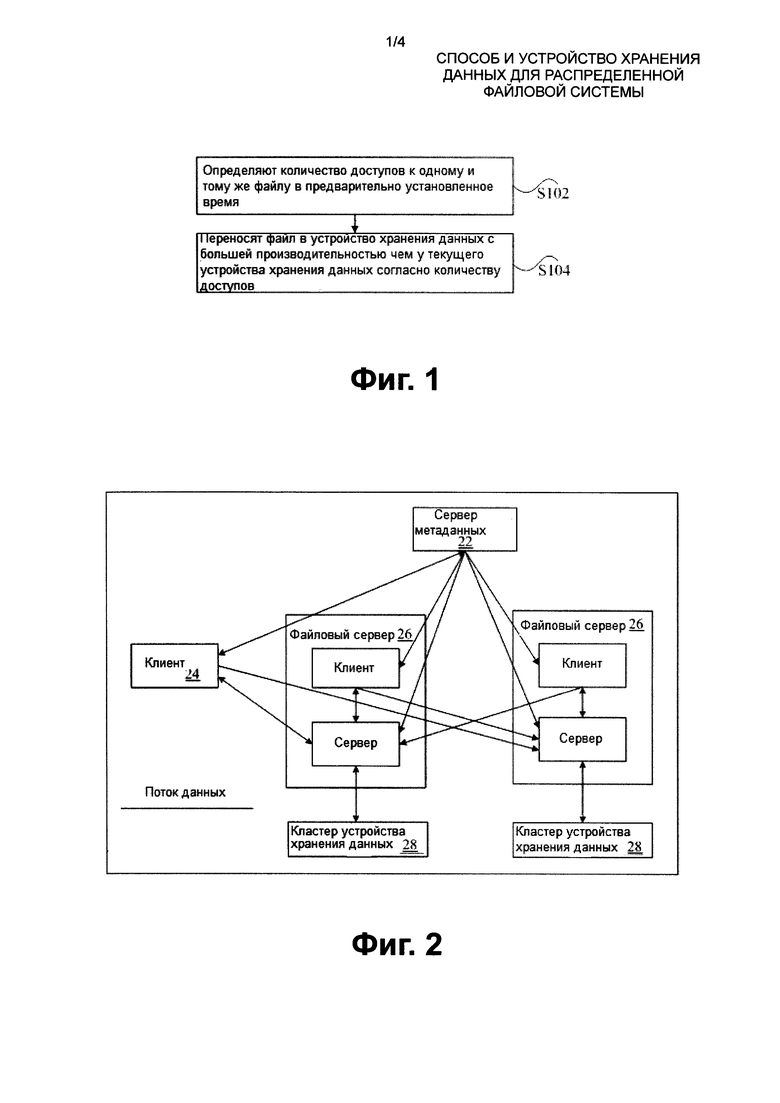
Варианты выполнения данного изобретения предоставляют способ хранения данных для распределенной файловой системы. Фиг. 1 изображает блок-схему способа хранения данных для распределенной файловой системы согласно варианту выполнения данного изобретения. Как изображено на Фиг. 1, включаются следующие этапы S102 - S104.
Этап S102: определяют количество доступов к одному и тому же файлу в предварительно установленное время.
Этап S104: файл переносят в устройство хранения данных с большей производительностью, чем у текущего устройства хранения данных согласно количеству доступов.
В соответствующем уровне техники проблема нагрузки, применяемой к диску вследствие доступа с высокой частотой к активному файлу при его считывании, не решается. В вариантах выполнения данного изобретения многоуровневое хранение данных выполняется на файлах в распределенной файловой системе согласно заинтересованности в доступе к файлам, то есть файл с высокой частотой доступа в предварительно установленное время переносится в устройство хранения данных с большей производительностью, а место хранения фрагмента файла связывают с заинтересованностью в доступе к фрагменту файла с помощью резервного копирования таким образом, что сжатие IOPS между устройствами хранения данных балансируется и улучшается общая производительность.
Следует отметить, что файл с низкой частотой доступа может также переноситься в устройство хранения данных с низкой производительностью в предварительно установленное время для избегания использования слишком большого пространства для хранения данных устройства хранения данных с высокой производительностью.
Этап S104 включает: определение превышения количеством доступов предварительно установленной пороговой величины; определение среди всех устройств хранения данных устройства хранения данных с большей производительностью, чем у текущего устройства хранения данных и имеющего неиспользуемый блок; и перенос файла в определенное устройство хранения данных с большей производительностью. В данном иллюстративном варианте выполнения, в случае, где количество доступов превышает предварительно установленную пороговую величину, определяют устройство хранения данных, которое может сохранить файл, и выполняют перенос, когда определенное устройство хранение данных имеет неиспользуемый блок, который может гарантировать точность переноса файла, избегая случая, где устройство хранения данных не имеет никакого неиспользуемого блока, но файл переносят в устройство хранения данных, что может привести к потери файла.
В иллюстративном варианте выполнения, после определения превышения количеством доступов предварительно установленной пороговой величины, атрибут заинтересованности в доступе к файлу может устанавливаться как высокая. Заинтересованность в доступе к файлу отображается в виде атрибута для облегчения проверки пользователя.
В ином иллюстративном варианте выполнения, перед определением количества доступов к одному и тому же файлу в предварительно установленное время, определяют, требует ли текущее устройство хранения данных переноса файла, то есть определяют, превысила ли нагрузка текущего устройства хранения данных критическую величину (либо предостерегающую величину), что может достигаться следующими операциями: соответственно определяют граничное количество IOPS и текущее количество IOPS каждого устройства хранения данных в распределенной файловой системе; соответственно вычисляют отношение текущего количества IOPS к граничному количеству IOPS каждого устройства хранения данных; соответственно сравнивают это отношение с предварительно установленной критической величиной; и если это отношение превышает предварительно установленную критическую величину, то определяют необходимость переноса файла с количеством доступов, превышающим предварительно установленную пороговую величину, в текущем устройстве хранения данных. В представленном варианте выполнения, определяют, нужно ли выполнять перенос согласно не только состоянию нагрузки текущего устройства хранения данных, но также и согласно заинтересованности в доступе к файлу в устройстве. Количество и частота доступа пользователя к файлу являются произвольными. Необоснованный перенос файла может понижать эффективность использования устройства хранения данных и ускорять потерю данных в устройстве хранения данных.
Вышеупомянутый процесс определения того, требуется ли перенос файла согласно нагрузке устройства хранения данных, также является условием для инициирования многоуровневого хранения данных (который может называться алгоритм получения критической величины). Существуют два главных фактора, которые влияют на инициирование переноса: (1) в зависимости от того, достигает ли количество IOPS устройства хранения данных установленной предостерегающей величины, после приближения количества IOPS к критической величине, скорость обработки данных устройства хранения данных будет значительно снижаться, и должно инициироваться многоуровневое хранение данных; и (2) имеет ли система доступный достаточный фрагмент неиспользуемого запоминающего устройства для высокопроизводительных вычислений, если нет, то игнорируют многоуровневое хранения данных.
В практических применениях определяют, нужно ли инициировать многоуровневое хранение данных согласно заинтересованности в доступе к файлу, граничному количеству IOPS и, например, статистическому количеству IOPS каждого устройства хранения данных (например, диск) и состоянию неиспользуемого блока устройства хранения данных. Например, полагая, что идентификатором того, нужно ли инициировать многоуровневое хранение данных, является у; граничным количеством IOPS диска является IOPSi; статистическим количеством текущих IOPS диска i является CIOPSi; и идентификатором того, существуют ли достаточно нерабочих блоков, является f, только, когда файл является активным файлом и величина отношения CIOPSi/IOPSi превышает критическую величину а, и целевое устройство хранения данных имеет достаточно нерабочих блоков, будет инициироваться многоуровневое хранения данных.
В иллюстративном варианте выполнения, после определения необходимости переноса файла с числом доступов, превышающим предварительно установленную пороговую величину, в текущем устройстве хранения данных, в вышеупомянутом способе дополнительно принимают запрос на считывание файла, и прибавляют единицу к количеству доступов к файлу. В представленном иллюстративном варианте выполнения, в случае определения необходимости выполнения переноса файла согласно нагрузке текущего устройства хранения данных, принимают запрос на считывание файла текущего устройства хранения данных и вычисление количества доступов к файлу может, до некоторой меры, избавить от определения статистики касательно заинтересованности доступа к файлу в каждом устройстве хранения данных, что увеличивает нагрузку сервера метаданных. В практических применениях в сервере метаданных предусматривается переключатель многоуровневого хранения данных, и переключатель включается после определения необходимости выполнения переноса, а потом выполняют статистический анализ касательно количества доступов.
В иллюстративном варианте выполнения в вышеупомянутом процессе определения необходимости выполнения переноса согласно нагрузке устройства хранения данных используют IOPS устройства хранения данных. Количество IOPS может получаться согласно следующему способу: файловый сервер вычисляет IOPS устройства хранения данных, соответствующего файловому серверу; и файловый сервер сообщает IOPS серверу метаданных согласно предварительно установленному периоду.
В практических применениях в сервисной программе файлового сервера предоставляется таймер контроля IOPS устройства хранения данных. После включения таймера, таймер вызывает интерфейс операционной системы для вычисления параметра IOPS каждого устройства хранения данных (например, диска) в данном файловом сервере и файловый сервер использует таймер для сообщения IOPS каждого диска серверу метаданных через регулярные промежутки времени.
После этапа S104 можно определить, установлена ли нагрузка начального устройства хранения файла в значение, меньшее, чем критическая величина, после переноса файла. Если нет, то заинтересованность в доступе к файлу в нем продолжают отслеживать и файл переносят, когда выполняется условие. Это может достигаться согласно следующим этапам: проверяют, не превышает ли отношение текущего количества IOPS к граничному количеству IOPS каждого устройства хранения данных критической величины согласно предварительно установленному периоду; если величина отношения не превышает критическую величину, то прекращают перенос файла в текущем устройстве хранение данных; и если это отношение превышает критическую величину, то продолжают перенос файла с количеством доступов, превышающим предварительно установленную пороговую величину, в текущем устройстве хранения данных.
Вышеупомянутый способ хранения данных для распределенной файловой системы оптимизирует решение касательно хранения данных распределенной файловой системы в соответствующем уровне техники и может рассматриваться как многоуровневое хранение фрагмента файла. Многоуровневое хранение данных относится к хранению файла с высокой частотой доступа в устройстве хранения данных с высокой производительностью, то есть устройства хранения данных делятся на два уровня: устройства хранения данных с низкой производительностью и устройства хранения данных с высокой производительностью. С помощью вышеупомянутого решения сжатие IOPS между устройствами хранения данных балансируется и улучшается общая производительность, таким образом достигая максимального использования совместимости и производительности устройств хранения данных с разными производительностями.
Для прояснения технических решений и способов реализации вариантов выполнения данного изобретения, процесс реализации описывается в деталях в комбинации с нижеприведенными иллюстративными вариантами выполнения.
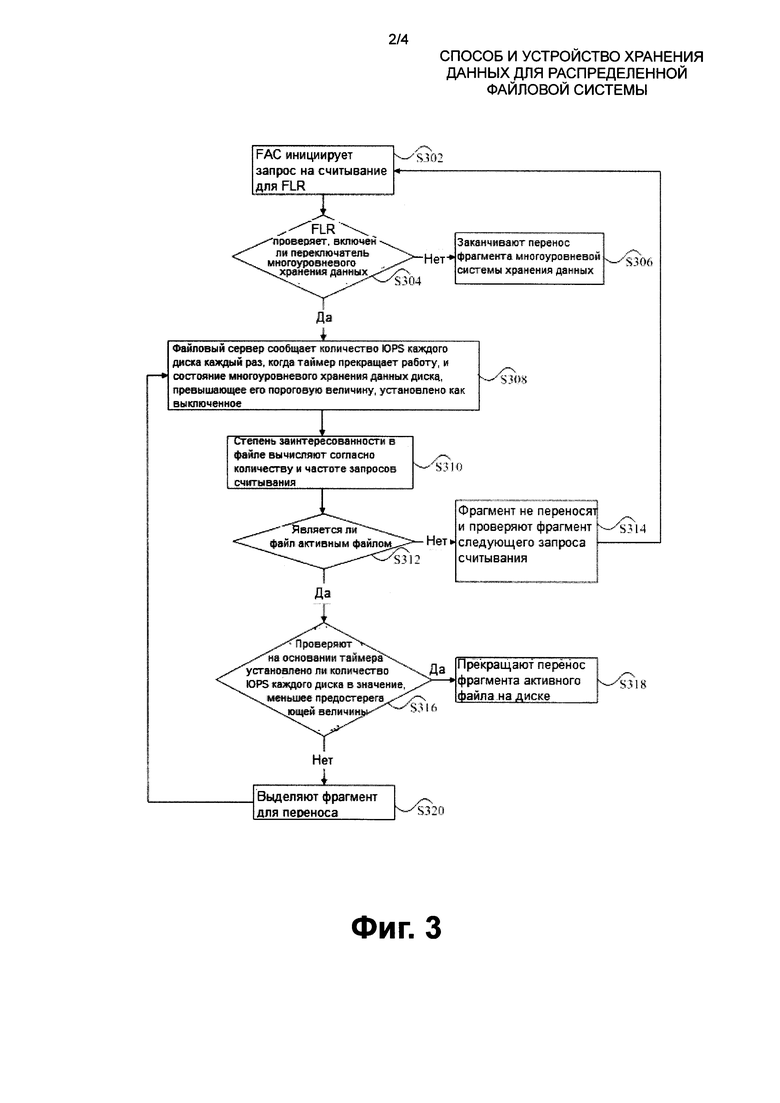
Архитектура системы для получения вышеупомянутого решения содержит сервер метаданных 22, клиента 24, файловый сервер 26 и кластер 28 устройства хранения данных, как изображено на Фиг. 2, эти компоненты будут, соответственно, описываться далее.
Сервер метаданных 22 отвечает за управление метаданными всех файлов в текущей распределенной файловой системе, такими как имена файлов, блоки данных, и за осуществление операций, таких как запись метаданных и запрос доступа к клиенту. Варианты выполнения данного изобретения прибавляют весовую величину сжатия (то есть количество доступов в предварительно установленное время) на основании списка файлов метаданных и, когда весовая величина файла превышает заданную пороговую величину, то все фрагменты файла, хранящиеся на участках низкопроизводительного устройства хранения данных, переносятся к участкам высокопроизводительного устройства хранения данных без влияния на доступ текущего пользователя.
Клиент 24 отвечает за предоставление интерфейса, вызывающего сервис, подобный стандартной файловой системе для прикладной программы, ориентированной на текущую распределенную файловую систему; инициирует запрос на доступ, получает данные, а потом возвращает их к прикладной программе; и когда сервер метаданных 22 инициирует запрос на перенос файла, переносит фрагменты файла к другим файловым серверам согласно списку фрагментов в запросе.
Файловый сервер 26 отвечает за взаимодействие с кластером 28 устройства хранения данных в текущей распределенной файловой системе и за выполнение операций практического считывания и записи на блоках данных в ответ на запрос считывания либо записи данных клиента 24, считывание данных с кластера 28 устройства хранения данных и возвращение их к клиенту 24 либо считывание данных с клиента 24 и записи их в кластере 28 устройства хранения данных. Файловый сервер 26, как изображено на Фиг. 2, включает сервер и клиента.
Кластер 28 устройства хранения данных может быть устройством хранения данных, таким как диск с низкопроизводительной интегральной электронной схемой формирования сигналов (сокращенно IDE) либо диск с интерфейсом SATA (сокращенно SATA), высокопроизводительный твердотельный диск (сокращенно SSD), SCSI с последовательным интерфейсом (сокращенно SAS, в котором SCSI является неполным) и SATA.
Фиг. 3 изображает блок-схему способа хранения данных для распределенной файловой системы согласно иллюстративному варианту выполнения данного изобретения. Как изображено на Фиг. 3, включаются следующие этапы:
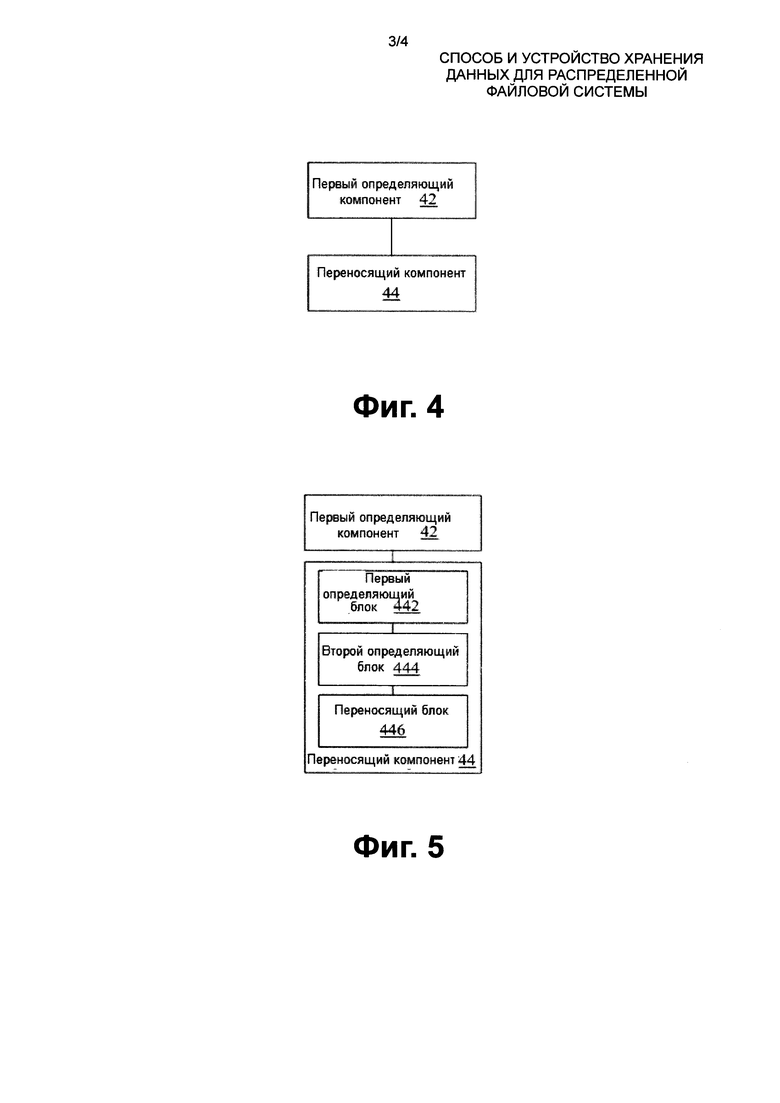
Этап S302: клиент (сокращенно FAC) инициирует запрос на считывание для регистра переноса файла (сокращенно FLR).
Этап S304: FLR проверяет, включен ли переключатель многоуровневого хранения данных. Если да, то выполняется этап S308; иначе, выполняется этап S306.
Этап S306: заканчивают перенос фрагмента файла многоуровневой системы хранения данных.
Этап S308: файловый сервер сообщает IOPS каждого диска каждый раз, когда таймер прекращает работу, и состояние многоуровневой системы хранения данных диска, превышающее ее пороговую величину, устанавливается как выключенное.
Этап S310: степень заинтересованности в файле вычисляют согласно количеству и частоте запросов на считывание.
Этап S312: оценивают, является ли файл активным. Если да, то выполняют этап S316; иначе, выполняют этап S314.
Этап S314: фрагмент не переносят, и проверяют фрагмент следующего запроса на считывание.
Этап S316: проверяют на основании таймера, установлено ли количество IOPS каждого диска в значение, меньшее, чем предостерегающая величина. Если да, то выполняю этап S318; иначе, выполняют этап S320.
Этап S318: прекращают перенос фрагмента активного файла на диске.
Этап S320: выделяют фрагмент для переноса.
Следует отметить, что по сравнению с нормальным переносом фрагмента файла, используемого для балансировки нагрузки диска, многоуровневое хранение данных, инициируемое вследствие высокой заинтересованности в доступе, осуществляется с высшим приоритетом для обеспечения плавности доступа пользователя к файлу. В ином иллюстративном варианте выполнения выполняются следующие этапы:
Этап 1: исследуют количество IOPS диска на сетевом интерфейсе и регистрируют начальную величину;
Этап 2: включают переключатель многоуровневого хранения данных на сетевом интерфейсе и незамедлительно активируют параметры;
Этап 3: устанавливают пороговое количество IOPS диска на сетевом интерфейсе и незамедлительно активируют параметры;
Этап 4: проверяют, начат ли перенос активного файла, и когда закончится перенос в протоколе; и
Этап 5: после завершения переноса, исследуют количество IOPS диска на сетевом интерфейсе, сравнивают предыдущую нагрузку, превышающую критическую величину, с нагрузкой после переноса, если количество IOPS после переноса снижается до величины, меньшей чем критическая величина, что указывает на то, что установка пороговой величины является относительно обоснованной, и если количество IOPS после переноса все еще превышает критическую величину, то повторяют этап 3 и уменьшают пороговое количество IOPS.
Следует отметить, что этапы, указанные в блок-схеме чертежей, могут выполняться, например, в компьютерной системе множеством инструкций, выполняемых компьютером, кроме того, в блок-схеме указан логический порядок, но указанные либо описанные этапы могут выполняться в другом порядке при тех же условиях.
Варианты выполнения данного изобретения также предоставляют устройство хранения данных для распределенной файловой системы, применимое для сервера метаданных, и устройство хранения данных для распределенной файловой системы может использоваться для реализации вышеупомянутого способа хранения данных для распределенной файловой системы. Фиг. 4 изображает структурную схему устройства хранения данных для распределенной файловой системы согласно варианту выполнения данного изобретения. Как изображено на Фиг. 4, устройство содержит первый определяющий компонент 42 и переносящий компонент 44. Конструкция будет описываться детально ниже.
Первый определяющий компонент 42 конфигурируют для определения количеств доступов к одному и тому же файлу в предварительно установленное время; и переносящий компонент 44 соединяют с первым определяющим компонентом и конфигурируют для переноса файла в устройство хранения данных с большей производительностью, чем у текущего устройства хранения данных согласно количеству доступов, определенного первым определяющим компонентом 42.
В соответствующем уровне техники проблема нагрузки, применяемой к диску вследствие доступа с высокой частотой к активному файлу при его считывании, не решается. В вариантах выполнения данного изобретения многоуровневое хранения данных выполняется на файлах в распределенной файловой системе согласно заинтересованности в доступе к файлам, то есть файл с высокой частотой доступа в предварительно установленное время переносят в устройство хранения данных с высокой производительностью, а место хранения фрагмента файла связывают с заинтересованностью в доступе к фрагменту файла с помощью резервного копирования таким образом, что сжатие IOPS между устройствами хранения данных балансируют и улучшают общую производительность.
Как изображено на Фиг. 5, переносящий компонент 44 содержит: первый определяющий блок 442, сконфигурированный для определения превышения количеством доступов предварительно установленной пороговой величины; второй определяющий блок 444, соединенный с первым определяющим блоком 442 и сконфигурированный для определения среди всех устройств хранения данных устройства хранения данных с большей производительностью, чем у текущего устройства хранения данных и имеющего неиспользуемый блок; и переносящий блок 446, соединенный со вторым определяющим блоком 444 и сконфигурированный для переноса файла в устройство хранения данных, определенное вторым определяющим блоком 444.
В иллюстративном варианте выполнения переносящий компонент 44 дополнительно содержит установочный блок, соединенный с первым определяющим блоком 442 и сконфигурированный для установки атрибута заинтересованности в доступе к файлу как высокая.
Как изображено на Фиг. 6, вышеупомянутое устройство дополнительно содержит: второй определяющий компонент 46, сконфигурированный для, соответственно, определения граничного количества IOPS и текущего количества IOPS каждого устройства хранения данных; вычислительный компонент 47, соединенный со вторым определяющим компонентом 46 и сконфигурированный для, соответственно, вычисления отношения текущего количества IOPS к граничному количеству IOPS каждого устройства хранения данных; сравнивающий компонент 48, соединенный с вычислительным компонентом 47 и сконфигурированный для, соответственно, сравнения этого отношения с предварительно установленной критической величиной; и третий определяющий компонент 49, соединенный со сравнивающим компонентом 48 и сконфигурированный для определения необходимости переноса файла с количеством доступов, превышающим предварительно установленную пороговую величину, в текущем устройстве хранения данных, если это отношение превышает предварительно установленную критическую величину.
В иллюстративном варианте выполнения вышеупомянутое устройство дополнительно содержит приемный компонент, соединенный с третьим определяющим компонентом 49 и сконфигурированный для приема запроса на считывание файла и прибавления единицы к количеству доступов к файлу.
В иллюстративном варианте выполнения вышеупомянутое устройство дополнительно содержит: проверочный компонент, сконфигурированный для проверки того, не превышает ли отношение текущего количества IOPS к граничному количеству IOPS каждого устройства хранения данных критическую величину согласно предварительно установленному периоду; первый обрабатывающий компонент, соединенный с проверочным компонентом и сконфигурированный для прекращения переноса файла в текущем устройстве хранения данных, если это отношение не превышает критическую величину; и второй обрабатывающий компонент, соединенный с проверочным компонентом и сконфигурированный для продолжения переноса файла с количеством доступов, превышающим предварительно установленную пороговую величину, в текущем устройстве хранения данных, если это отношение превышает критическую величину.
Следует отметить, что устройство хранения данных для распределенной файловой системы, описанной в вариантах его выполнения, соответствует вышеупомянутым вариантам выполнения способа со специальным вариантом выполнения, описанным детально в варианте выполнения способа, таким образом не требуя дальнейшего описания.
Следует отметить, что вышеупомянутое решение может применяться к распределенной файловой системе, имеющей сервер метаданных, но может не применяться к общей системе хранения данных.
В заключение, согласно вышеупомянутым вариантам выполнения данного изобретения предоставляются устройство и способ хранения данных для распределенной файловой системы. В данном изобретении многоуровневое хранение данных выполняется на файлах в распределенной файловой системе согласно заинтересованности в доступе к файлам, то есть файл с высокой частотой доступа в предварительно установленное время переносят в устройство хранения данных с большой производительностью, а место хранения фрагмента файла связывают с заинтересованностью в доступе к фрагменту файла с помощью резервного копирования таким образом, что сжатие IOPS между устройствами хранения данных балансируется и улучшается общая производительность. Достигают максимальное использование совместимости и производительности устройств хранения данных с разными производительностями. С помощью переноса файла с высокой заинтересованностью в доступе в устройство с большей производительностью в значительной степени решается проблема слабого эффекта способа хранения данных в гибридном устройстве хранения данных в соответствующем уровне техники и достигается балансировка нагрузки между различными устройствами хранения данных, таким образом улучшая общую производительность устройств хранения данных в гетерогенном режиме хранения данных.
Очевидно, специалисты в этой отрасли должны понимать, что вышеупомянутые компоненты и этапы данного изобретения могут реализовываться путем использования универсального вычислительного устройства, могут интегрироваться в одно вычислительное устройство либо распределяться по сети, которая состоит из множества вычислительных устройств. Альтернативно, компоненты и этапы данного изобретения могут реализовываться путем использования выполняемого программного кода вычислительного устройства. Поэтому, они могут храниться в устройстве хранения данных и выполняться вычислительным устройством либо они включаются, соответственно, в интегральную схему, либо множество его компонентов, либо этапов включаются в одну интегральную схему. Этим способом данное изобретение не ограничивается какой-либо конкретной комбинацией аппаратного средства и программного средства.
Вышеприведенное описание является только иллюстративными вариантами выполнения данного изобретения и не предусмотрено для ограничения данного изобретения, и данное изобретения может иметь разнообразие изменений и модификаций для специалистов в этой отрасли. Любая модификация, эквивалентная замена либо усовершенствование, выполненное в рамках данного изобретения, должно попадать в объем правовой защиты, определенный в приложенной формуле изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И УСТРОЙСТВО ДЛЯ ВОССТАНОВЛЕНИЯ ДЕДУПЛИЦИРОВАННЫХ ДАННЫХ | 2014 |
|
RU2665272C1 |
| СПОСОБ И СИСТЕМА УПРАВЛЕНИЯ МЕТАДАННЫМИ В ВЫСОКОНАГРУЖЕННЫХ ОБЛАЧНЫХ СРЕДАХ | 2024 |
|
RU2829567C1 |
| УСТРОЙСТВО ЗАПИСИ | 2012 |
|
RU2541706C2 |
| УСТРОЙСТВО ЗАПИСИ | 2012 |
|
RU2531041C2 |
| СПОСОБ УПРАВЛЕНИЯ ФАЙЛАМИ, РАСПРЕДЕЛЕННАЯ СИСТЕМА ХРАНЕНИЯ И УЗЕЛ УПРАВЛЕНИЯ | 2014 |
|
RU2658886C1 |
| КОНТЕЙНЕР ДАННЫХ ДЛЯ ДАННЫХ КОНТЕНТА ПОЛЬЗОВАТЕЛЬСКОГО ИНТЕРФЕЙСА | 2005 |
|
RU2363039C2 |
| Интегрированный программно-аппаратный комплекс | 2016 |
|
RU2646312C1 |
| ФАЙЛОВАЯ СЛУЖБА, ИСПОЛЬЗУЮЩАЯ ИНТЕРФЕЙС СОВМЕСТНОГО ФАЙЛОВОГО ДОСТУПА И ПЕРЕДАЧИ СОСТОЯНИЯ ПРЕДСТАВЛЕНИЯ | 2015 |
|
RU2686594C2 |
| СПОСОБЫ И УСТРОЙСТВО ДЛЯ КРУПНОМАСШТАБНОГО РАСПРОСТРАНЕНИЯ ЭЛЕКТРОННЫХ КЛИЕНТОВ ДОСТУПА | 2013 |
|
RU2595904C2 |
| СПОСОБ КОДИРОВАНИЯ ДАННЫХ И СИСТЕМА ХРАНЕНИЯ ДАННЫХ | 2023 |
|
RU2819584C1 |

Изобретение относится к средствам хранения данных. Технический результат заключается в оптимизации нагрузки, применяемой к устройству хранения данных вследствие доступа к активному файлу с высокой частотой при считывании файлов. Способ хранения данных для распределенной файловой системы предусматривает выполнение этапов: определяют количество доступов к одному и тому же файлу в предварительно установленное время; и переносят файл в устройство хранения данных с большей производительностью, чем у текущего устройства хранения данных согласно количеству доступов; перед определением количества доступов к одному и тому же файлу в предварительно установленное время в способе дополнительно: определяют граничное количество операций ввода-вывода в секунду (IOPS) и текущее количество IOPS каждого устройства хранения данных в распределенной файловой системе; вычисляют отношение текущего количества IOPS к граничному количеству IOPS каждого устройства хранения данных; сравнивают это отношение с предварительно установленной критической величиной; и если отношение превышает предварительно установленную критическую величину, то определяют необходимость переноса файла с количеством доступов, превышающим предварительно установленную пороговую величину, в текущем устройстве хранения данных. 2 н. и 6 з.п. ф-лы, 6 ил.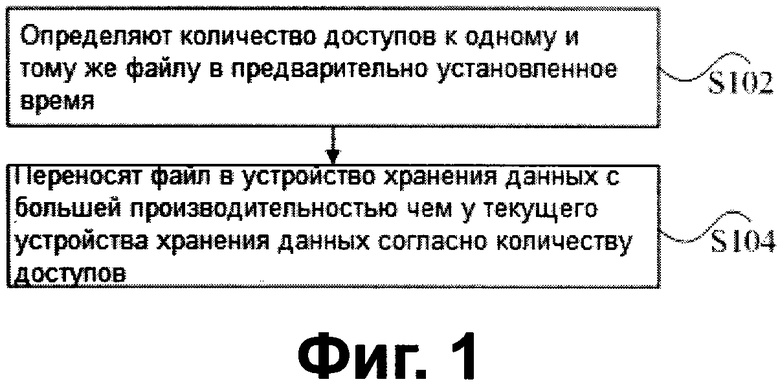
1. Способ хранения данных для распределенной файловой системы, отличающийся тем, что в нем:
определяют количество доступов к одному и тому же файлу в предварительно установленное время; и
переносят файл в устройство хранения данных с большей производительностью, чем у текущего устройства хранения данных согласно количеству доступов;
перед определением количества доступов к одному и тому же файлу в предварительно установленное время в способе дополнительно:
соответственно определяют граничное количество операций ввода-вывода в секунду (IOPS) и текущее количество IOPS каждого устройства хранения данных в распределенной файловой системе,
соответственно вычисляют отношение текущего количества IOPS к граничному количеству IOPS каждого устройства хранения данных, и
соответственно сравнивают это отношение с предварительно установленной критической величиной, и
если отношение превышает предварительно установленную критическую величину, то определяют необходимость переноса файла с количеством доступов, превышающим предварительно установленную пороговую величину, в текущем устройстве хранения данных.
2. Способ по п. 1, отличающийся тем, что перенос файла в устройство хранения данных с большей производительностью, чем у текущего устройства хранения данных согласно количеству доступов включает:
определение превышения количеством доступов предварительно установленной пороговой величины;
определение среди всех устройств хранения данных устройства хранения данных с большей производительностью, чем у текущего устройства хранения данных и имеющего неиспользуемый блок; и
перенос файла в определенное устройство хранения данных.
3. Способ по п. 2, отличающийся тем, что после определения превышения количеством доступов предварительно установленной пороговой величины, в способе дополнительно:
устанавливают атрибут заинтересованности в доступе к файлу как высокая.
4. Способ по п. 3, отличающийся тем, что после определения необходимости переноса файла с количеством доступов, превышающим предварительно установленную пороговую величину, в текущем устройстве хранения данных, в способе дополнительно:
принимают запрос на считывание файла и прибавляют единицу к количеству доступов к файлу.
5. Способ по п. 1, отличающийся тем, что перед определением количества доступов к файлу в предварительно установленное время, в способе дополнительно:
файловый сервер вычисляет количество IOPS устройства хранения данных, соответствующего файловому серверу; и
файловый сервер сообщает IOPS серверу метаданных согласно предварительно определенному периоду.
6. Способ по любому из пп. 1-5, отличающийся тем, что после переноса файла в устройство хранения данных с большей производительностью, чем у текущего устройства хранения данных согласно количеству доступов, в способе дополнительно:
проверяют, не превышает ли отношение текущего количества IOPS к граничному количеству IOPS каждого устройства хранения данных критическую величину согласно предварительно установленному периоду;
если величина этого отношения не превышает критическую величину, то прекращают перенос файла в текущем устройстве хранения данных; и
если это отношение превышает критическую величину, то продолжают перенос файла с количеством доступов, превышающим предварительно установленную пороговую величину, в текущем устройстве хранения данных.
7. Устройство хранения данных для распределенной файловой системы, отличающееся тем, что выполнено с возможностью использования для сервера метаданных и содержит:
первый определяющий компонент, сконфигурированный для определения количества доступов к одному и тому же файлу; и
переносящий компонент, сконфигурированный для переноса файла в устройство хранения данных с большей производительностью, чем у текущего устройства хранения данных согласно количеству доступов;
при этом устройство дополнительно содержит:
второй определяющий компонент, сконфигурированный для соответственно определения отношения граничного количества операций ввода-вывода в секунду (IOPS) к текущему количеству IOPS каждого устройства хранения данных;
вычислительный компонент, сконфигурированный для соответственно вычисления отношения текущего количества IOPS к граничному количеству IOPS каждого устройства хранения данных;
сравнивающий компонент, сконфигурированный для соответственно сравнения этого отношения с предварительно установленной критической величиной; и
третий определяющий компонент, сконфигурированный для определения необходимости переноса файла с количеством доступов, превышающим предварительно установленную пороговую величину, в текущем устройстве хранения данных, если это отношение превышает предварительно установленную критическую величину.
8. Устройство по п. 7, отличающееся тем, что переносящий компонент содержит:
первый определяющий блок, сконфигурированный для определения превышения количеством доступов предварительно установленной пороговой величины;
второй определяющий блок, сконфигурированный для определения среди всех устройств хранения данных устройства хранения данных с большей производительностью, чем у текущего устройства хранения данных и имеющего неиспользуемый блок; и
переносящий блок, сконфигурированный для переноса файла в определенное устройство хранения данных.
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| СИСТЕМА И СПОСОБ ЭФФЕКТИВНОГО ИСПОЛЬЗОВАНИЯ КЭШ-ПАМЯТИ В РАСПРЕДЕЛЕННОЙ ФАЙЛОВОЙ СИСТЕМЕ | 1994 |
|
RU2170454C2 |
| Прибор для очистки паром от сажи дымогарных трубок в паровозных котлах | 1913 |
|
SU95A1 |
| РАСПРЕДЕЛЕННАЯ ФАЙЛОВАЯ СИСТЕМА И СПОСОБ УПРАВЛЕНИЯ СОГЛАСОВАННОСТЬЮ БЛОКОВ ДАННЫХ В ТАКОЙ СИСТЕМЕ | 2009 |
|
RU2449358C1 |

