ОБЛАСТЬ ТЕХНИКИ
[0001] Заявленное техническое решение в общем относится к области вычислительной техники, а в частности к способу и системе хранения, именования и оперирования метаданными в облачных высоконагруженных средах.
УРОВЕНЬ ТЕХНИКИ
[0002] В настоящее время кластерные вычисления стали неотъемлемой частью многих областей, включая научные и инженерные исследования, бизнес-аналитику и обработку больших данных. Однако эффективное хранение и управление данными в кластерах остается серьезной проблемой. Традиционные локальные файловые системы не всегда подходят для таких задач из-за ограничений на масштабируемость, производительность и надежность. В связи с этим были разработаны сетевые распределенные файловые системы, способные эффективно работать в кластерах на операциях с огромным количеством данных и под высокой нагрузкой от множества клиентов.
[0003] Так, современные дата-центры используют распределенные файловые системы для управления файлами, однако, в связи с большим количеством файлов, такие системы неизбежно создают серьезные проблемы для службы метаданных. Обычно выделяют два критических этапа - разрешение пути к файлам и обработка метаданных. Так, в файловом хранилище данные хранятся в виде файлов, организованных по папкам, которые имеют определенный формат и структуру. Файлы могут содержать различные типы данных и могут быть связаны между собой через ссылки или указатели, а папки обеспечивают иерархически вложенное хранение файлов. Таким образом, файловая система обычно предоставляет клиентам иерархическое пространство имен (т.е. дерево каталогов) для управления файлами. В дереве каталогов каждый файл/каталог содержит метаданные с информацией. Соответственно, эффективность работы распределенных файловых систем сводится к эффективности доступа к данным и времени поиска путей до файлов, т.е. к управлению метаданными в таких средах.
[0004] Из уровня техники также известен подход разделения метаданных на отдельные сегменты или шарды для более эффективного хранения и обработки информации. Это позволяет распределить данные по различным узлам сети, что улучшает производительность и масштабируемость системы. Сегментирование метаданных также может использоваться для обеспечения безопасности и конфиденциальности информации, так как каждый сегмент может содержать только определенную часть метаданных.
[0005] Так, известна реализация Lustre - распределенной файловой системы массового параллелизма, используемой для кластерных вычислений. Основным принципом работы Lustre является разделение файловой системы на отдельные узлы, которые могут быть размещены на разных серверах, соединенных между собой высокопроизводительной сетью. Каждый узел отвечает за хранение и обслуживание определенной части файловой системы. Архитектурно такая система содержит централизованный активный сервер метаданных (MDS - metadata server), соединенный с одной или более целью метаданных (metadata target - MDT) в файловой системе, который хранит метаданные о пространстве имен, например, имена файлов, каталогов, права доступа, а также карту размещения файлов. Метаданные одного или нескольких MDT хранятся в единой локальной дисковой файловой системе независимо от данных, хранящихся на одном или нескольких серверах хранения объектов (object storage server - OSS) хранящих данные файлов из одного или нескольких целей хранения объектов (object storage targets - OST).
[0006] Таким образом, оптимизация хранения метаданных в указанной распределенной файловой системе заключается в возможности разделения общей метадаты файловой системы по MDS (нескольким MDT), и, при необходимости, разных ее поддеревьях, что позволяет распределить сетевую нагрузку и объем для хранения метаданных без необходимости синхронизировать файловую систему между серверами.
[0007] Недостатками указанного способа являются низкая скорость взаимодействия с метаданными при большом количестве обращений ввиду иерархической структуры вложенности каталогов, что, как следствие, повышает вычислительную нагрузку на систему и увеличивает задержки при обходе каталога для поиска требуемых метаданных и множественном одновременном обращении. Кроме того, такое решение не обеспечивает должного уровня отказоустойчивости на уровне использования нескольких MDT.
[0008] Также из уровня техники известно решение, раскрытое в патенте США № US 9886443 B1 (NUTANIX INC [US]), опубл. 06.02.2018. Указанное решение раскрывает способ работы с распределенными метаданными и реализацию сервера метаданных для распределенной среды. Так, указанное решение раскрывает возможность разделения главного сервера метаданных на множество равноправных серверов за счет дополнительной проверки сервером, перед обновлением метаданных, заключающейся в сравнении полученных метаданных с исходными метаданными, и, соответственно, обновлении метаданных только если полученные метаданные не соответствуют первоначально извлеченным метаданным.
[0009] Указанный подход позволяет решить проблемы масштабируемости системы за счет использования равноправных серверов, а также проблемы, связанные с балансировкой нагрузки и операциями между разделами.
[0010] Недостатками указанного подхода являются низкая скорость обработки запросов, ввиду необходимости обхода всего каталога метаданных при поиске требуемого файла, что, как указывалось выше, повышает вычислительную нагрузку на систему. Кроме того, такое решение подвержено взаимным блокировкам, что соответственно, недопустимо в многопользовательских средах, ввиду одновременных попыток получения доступа к ресурсу, который может быть использован только одним потоком в определенный момент времени. Это может привести к ситуации, когда каждый поток ожидает, пока другой поток освободит ресурс, что может привести к "зависанию" системы.
[0011] Общими недостатками существующих решений является отсутствие эффективного способа управления метаданными в высоконагруженных облачных средах, обеспечивающего высокую производительность системы и высокую эффективность обработки запросов файловой системы, за счет повышения скорости доступа к метаданным и сокращения времени разрешения (определения) путей расположения файлов метаданных. Кроме того, такого рода решение должно показывать высокую производительность при нагрузках, характерных для многопользовательских облачных сред, обеспечивать высокую отказоустойчивость файловой системы на уровне реализующих ее сервисов, обеспечивать эффективную балансировку сложной многопоточной нагрузки и когерентность (согласованность, актуальность) метаданных (между клиентами и сервером) для обеспечения высокой масштабируемости без внутренних перекосов/дисбалансов. Также, такое решение должно обеспечивать автоскейлинг (автоматическое масштабирование) инфраструктуры под размещение и управление метаданными при динамически меняющихся и разнотипных нагрузках на распределенную файловую систему.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[0012] В заявленном техническом решении предлагается новый подход к управлению метаданными в высоконагруженных облачных средах, который обеспечивает высокую производительность системы и высокую эффективность обработки запросов файловой системы за счет повышения скорости доступа к метаданным.
[0013] Таким образом, решается техническая проблема снижения задержки доступа к данным и сокращения вычислительной нагрузки на файловую систему.
[0014] Техническим результатом, достигающимся при решении данной проблемы, является повышение скорости доступа к метаданным распределенной системы хранения метаданных за счет распараллеливания типов метаданных при их обработке, а также разноуровнего разделения метаданных.
[0015] Указанный технический результат достигается благодаря осуществлению распределенной системы управления метаданными, содержащей:
• по меньшей мере два узла хранения данных, выполненных с возможностью распределенного хранения метаданных файловой системы;
• модуль взаимодействия с файловой системой, выполненный с возможностью:
- получения запроса пользователя на взаимодействие с файловой системой, содержащего по меньшей мере строковое имя объекта файловой системы;
- определения типа запроса пользователя, причем определение включает по меньшей мере отнесение запроса к метаданным, необходимым для ввода-вывода объекта файловой системы или метаданных, необходимых для работы с пространством имен файловой системы;
- трансляции определенного типа запроса пользователя на по меньшей мере один сервер метаданных;
- кеширования результатов выполнения запроса;
• по меньшей мере один первый сервер метаданных, предназначенный для обработки запросов связанных с пространством имен файловой системы, выполненный с возможностью:
- хранения иерархического пространства имен файловой системы, которое содержит сопоставления строковых имен объектов файловой системы с адресами метаданных объектов файловой системы, а также хранения атрибутов объектов файловой системы, связанных с состоянием объекта файловой системы;
- определения адреса расположения объекта файловой системы в пространстве имен файловой системы на основе строкового имени объекта файловой системы и извлечения адреса метаданных объекта файловой системы;
- управления состоянием объекта файловой системы;
• по меньшей мере один второй сервер метаданных, предназначенный для управления фактическим местом в по меньшей мере одном узле хранения данных, выполненный с возможностью:
- определения содержимого объекта файловой системы на основе адреса расположения объекта файловой системы;
- хранения и управления картой хранения содержимого объектов файловой системы;
- аллокации и деаллокации дискового пространства по меньшей мере одного узла хранения данных; о трансляции по меньшей мере одного адреса содержимого объекта файловой системы, включающего зарезервированное дисковое пространство, модулю взаимодействия с файловой системой.
[0016] В другом частном варианте реализации объект файловой системы представляет собой по меньшей мере одно из: файл данных, директорию, символическую ссылку, жесткую ссылку.
[0017] В другом частном варианте реализации по меньшей мере один первый и второй сервер метаданных выполнены с возможностью отказоустойчивого хранения метаданных.
[0018] В другом частном варианте реализации отказоустойчивость хранения метаданных по меньшей мере одним первым и вторым сервером реализуется с помощью по меньшей мере репликации метаданных.
[0019] В другом частном варианте реализации кеширование результатов выполнения запроса представляет собой хранение во временной памяти данных, связанных с ответом по меньшей мере одного сервера метаданных на пользовательский запрос.
[0020] В другом частном варианте реализации управление состоянием файловой системы представляет, по меньшей мере, одно из:
- резервирование части метаданных, связанных с объектом файловой системы;
- резервирование пространства в хранилище данных;
- блокировка данных, связанных с объектом файловой системы;
- блокировка метаданных, связанных с объектом файловой системы;
- изменение состояния атрибутов объектов файловой системы;
- изменение строкового имени в адресе расположения метаданных объекта файловой системы;
- изменение количества ссылок, ведущих на объект файловой системы.
[0021] В другом частном варианте реализации управление картой хранения содержимого объектов файловой системы представляет, по меньшей мере, обработку запросов по определению содержимого искомого объекта файловой системы на основе адреса метаданных объекта файловой системы.
[0022] В другом частном варианте реализации строковые имена объектов файловой системы связаны с атрибутами объектов файловой системы.
[0023] В другом частном варианте реализации определение адреса расположения объекта файловой системы в пространстве имен файловой системы выполняется с помощью, по меньшей мере, одного первого сервера метаданных на основе итеративного определения, посредством адреса метаданных родительской папки и строкового имени дочерней папки, по порядку расположения объектов файловой системы до целевого объекта файловой системы.
[0024] В другом частном варианте реализации атрибуты объекта файловой системы представляют собой, по меньшей мере:
- описание объекта файловой системы;
- права доступа к объекту файловой системы;
- информацию о владельце объекта файловой системы;
- дату последнего изменения объекта файловой системы;
- тип содержимого;
- размер содержимого.
[0025] В другом частном варианте реализации адрес расположения объекта файловой системы представляет собой структуру, состоящую из результата сопоставления строкового имени объекта с соответствующим ему адресом метаданных объекта.
[0026] В другом частном варианте реализации содержимое объекта файловой системы представляет собой по меньшей мере одну единицу данных, физически хранящуюся в распределенной системе хранения данных, составляющую информацию, которая содержится в объекте файловой системы.
[0027] В другом частном варианте реализации единица данных, физически хранящаяся в распределенной системе хранения данных представляет собой по меньшей мере одно из: блок данных, строка, цепочка блоков данных, объект объектного хранилища.
[0028] В другом частном варианте реализации кеширование результатов выполнения запроса включает, по меньшей мере, кеширование определенного адреса метаданных объекта файловой системы.
[0029] В другом частном варианте реализации запрос пользователя на взаимодействие с файловой системой дополнительно содержит адрес метаданных объекта файловой системы.
[0030] Кроме того, заявленный технический результат достигается за счет способа взаимодействия с объектом данных в распределенной системе хранения метаданных, содержащего этапы, на которых:
a) получают запрос пользователя на взаимодействие с объектом файловой системы, причем запрос содержит по меньшей мере строковое имя объекта;
b) определяют, посредством модуля взаимодействия с файловой системой, принадлежность запроса к типу метаданных, которые необходимы для работы с пространством имен файловой системы;
c) транслируют запрос в по меньшей мере один первый сервер метаданных;
d) определяют с помощью, по меньшей мере, одного первого сервера метаданных адрес расположения объекта файловой системы в пространстве имен файловой системы и извлекают адрес метаданных объекта файловой системы;
e) запрашивают, по меньшей мере у одного первого сервера метаданных на основе данных, полученных на этапе d), атрибуты объекта файловой системы для проверки возможности доступа к объекту;
f) присваивают режим работы с объектом файловой системы, на основе адреса метаданных объекта, полученного на этапе d);
g) определяют, по меньшей мере одним вторым сервером, содержимое искомого объекта файловой системы на основе адреса метаданных объекта файловой системы, полученного на этапе d);
h) определяют результирующий физический адрес размещения содержимого объекта файловой системы в по меньшей мере одном узле хранения данных на основе информации полученной на этапе g);
i) осуществляют доступ к содержимому объекта файловой системы на основе адреса размещения содержимого объекта файловой системы в по меньшей мере одном узле хранения данных на основе информации полученной на этапе h).
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0031] Признаки и преимущества настоящего изобретения станут очевидными из приводимого ниже подробного описания изобретения и прилагаемых чертежей.
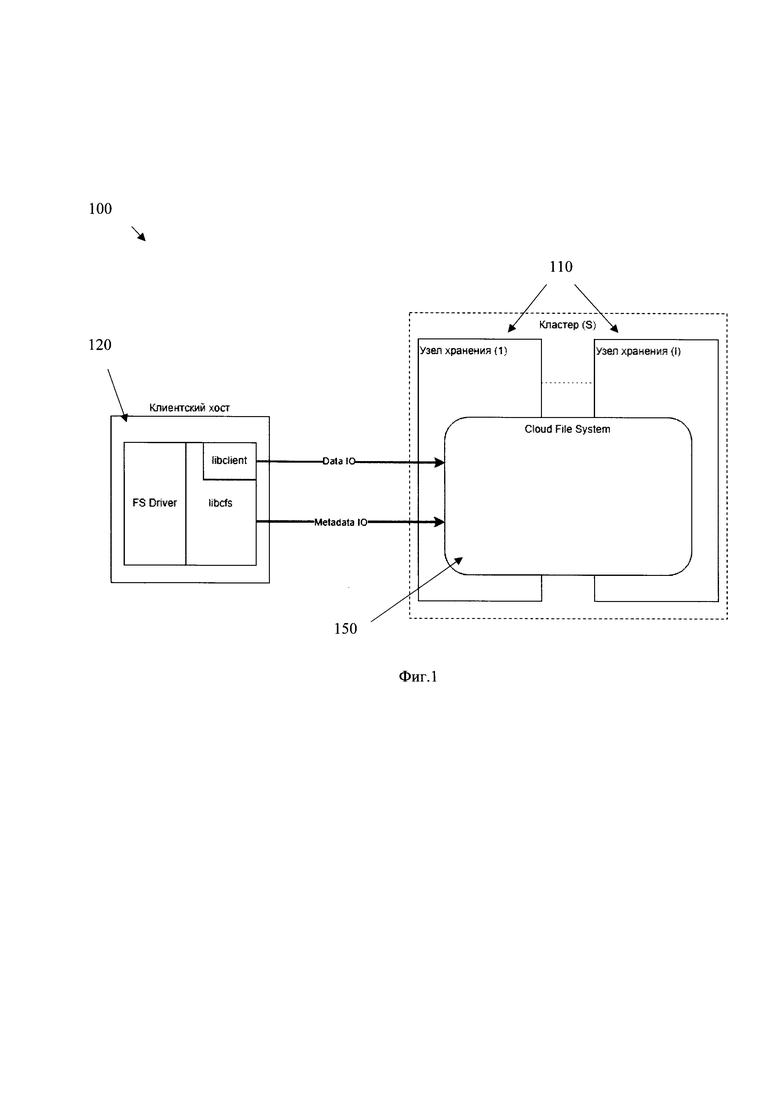
[0032] Фиг. 1 иллюстрирует блок-схему общего вида заявленной системы.
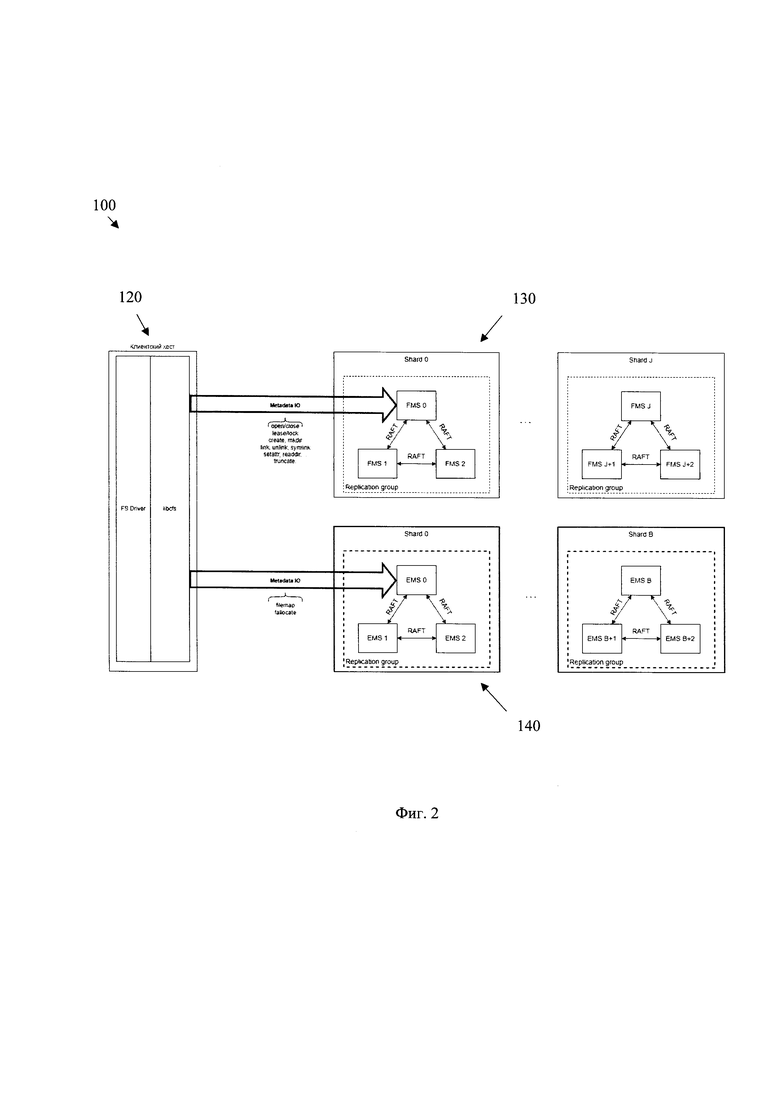
[0033] Фиг. 2 иллюстрирует блок-схему распределения метаданных.
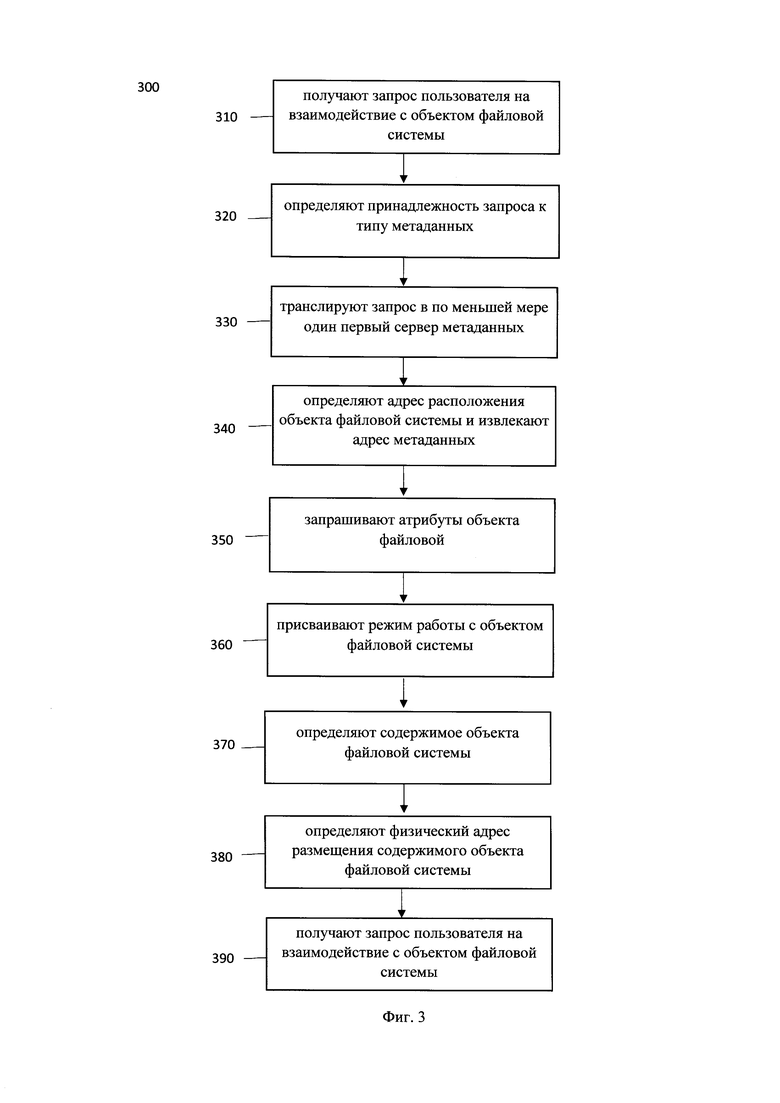
[0034] Фиг. 3 иллюстрирует блок-схему реализации заявленного способа.
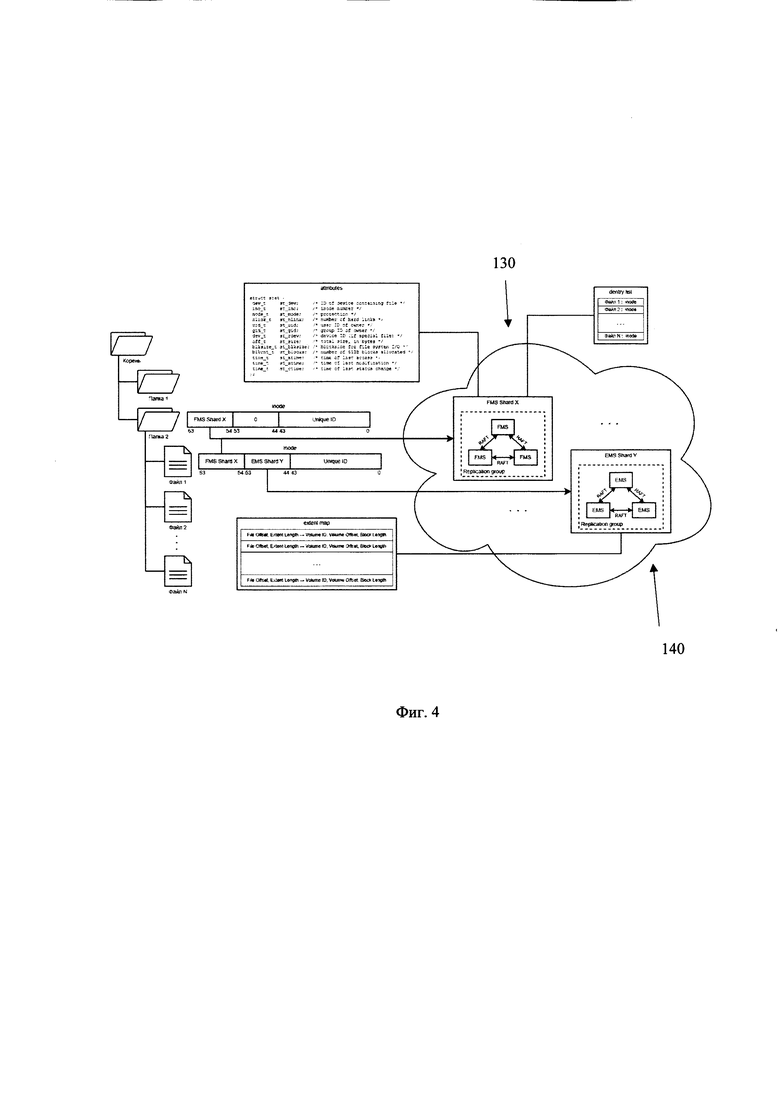
[0035] Фиг. 4 иллюстрирует пример оперирования распределенными метаданными.
[0036] Фиг. 5 иллюстрирует пример общего вида вычислительного устройства, которое обеспечивает реализацию элементов заявленного решения.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
[0037] Ниже будут описаны понятия и термины, необходимые для понимания данного технического решения.
[0038] Блок данных - единица хранения информации на, включая но не ограничиваясь, блочном, объектном устройстве хранения данных, но не конечный файл данных. Каждый блок имеет уникальный идентификатор (ID), который включает адрес, определяемый исходя из геометрии диска, для операций чтения/записи. Размер блоков данных определяется файловой системой и устройством хранения данных.
[0039] Распределенная система хранения данных (Distributed Storage) - это комплекс аппаратных и программных структур, в котором файлы разбиваются на фрагменты (состоящие из нескольких блоков) и распределяются по различным узлам (серверам), физически разнесенным в сети связи. Каждый сервер содержит только часть данных, и совместно все серверы создают единое хранилище. Это позволяет эффективно управлять большими объемами, обеспечивает отказоустойчивость и высокую скорость доступа. В одном частном варианте осуществления, распределенная система хранения данных может представлять программно-определяемую систему хранения данных (Software Defined Storage, SDS), обеспечивающую распределение данных по нескольким узлам и управление хранилищем через программное обеспечение.
[0040] Заявленное техническое решение предлагает новый подход в создании распределенной системы управления метаданными в распределенных системах хранения данных, обеспечивающей высокую производительность системы и высокую эффективность обработки запросов файловой системы, за счет повышения скорости доступа к метаданным и сокращения времени разрешения (определения) путей расположения файлов метаданных. Кроме того, такого рода решение показывает высокую производительность при нагрузках, характерных для многопользовательских облачных сред, обеспечивает высокую отказоустойчивость файловой системы на уровне реализующих ее сервисов, за счет возможности репликации блоков метаданных. Также, заявленное решение обеспечивает автоскейлинг (автоматическое масштабирование) метаданных под динамически меняющиеся и разнотипные нагрузки на распределенную файловую систему.
[0041] Техническое решение также может быть реализовано в виде распределенной компьютерной системы или вычислительного устройства.
[0042] В данном решении под системой подразумевается компьютерная система, ЭВМ (электронно-вычислительная машина), ЧПУ (числовое программное управление), ПЛК (программируемый логический контроллер), компьютеризированные системы управления и любые другие устройства, способные выполнять заданную, четко определенную последовательность вычислительных операций (действий, инструкций).
[0043] Под устройством обработки команд подразумевается электронный блок либо интегральная схема (микропроцессор), исполняющая машинные инструкции (программы).
[0044] Устройство обработки команд считывает и выполняет машинные инструкции (программы) с одного или более устройства хранения данных, например, таких устройств, как оперативно запоминающие устройства (ОЗУ) и/или постоянные запоминающие устройства (ПЗУ). В качестве ПЗУ могут выступать, но, не ограничиваясь, жесткие диски (HDD), флэш-память, твердотельные накопители (SSD), оптические носители данных (CD, DVD, BD, MD и т.п.) и др.
[0045] Термин «инструкции», используемый в этой заявке, может относиться, в общем, к программным инструкциям или программным командам, которые написаны на заданном языке программирования для осуществления конкретной функции, такой как, например, кодирование данных, обращение к памяти узла хранения данных и т.п. Инструкции могут быть осуществлены множеством способов, включающих в себя, например, объектно-ориентированные методы. Например, инструкции могут быть реализованы, посредством языка программирования Python, С, С++, Java, Go, Rust различных библиотек (например, MFC; Microsoft Foundation Classes) и т.д. Инструкции, осуществляющие процессы, описанные в этом решении, могут передаваться как по проводным, так и по беспроводным каналам передачи данных, например, Wi-Fi, Bluetooth, USB, WLAN, LAN и т.п.
[0046] На фиг. 1 приведен общий вид распределенной системы управления метаданными 100. Система 100 включает в себя основные функциональные элементы, такие как: по меньшей мере два узла хранения данных 110, модуль взаимодействия с файловой системой 120, по меньшей мере два сервера метаданных 130 и 140, которые отображены на Фиг. 2, которые являются частью файловой системы 150. Более подробно элементы заявленной системы 100 раскрыты на Фиг. 5.
[0047] Архитектура распределенной файловой системы представляет собой программно-аппаратный комплекс, реализованный по клиент-серверной технологии. Серверная часть образована из не менее чем одного кластера, который включает в себя не менее чем два узла хранения данных, таких как узлы 110 для обеспечения минимально допустимой отказоустойчивости.
[0048] Так, множество узлов хранения данных, таких как узлы 110 представляют собой серверную часть системы 100 и предназначены для размещения объектов данных файловой системы данных (файлы, папки и т.д.). Так, в одном частном варианте осуществления каждый узел 110 может представлять собой сервер, имеющий CPU/RAM и оперирующий массивами дисков. Узлы 110 связаны между собой посредством сети связи, и обеспечивают масштабируемое, отказоустойчивое и высокопроизводительное хранение данных за счет распределенной архитектуры, которая позволяет объединять несколько узлов (серверов) в кластер для обработки и хранения данных.
[0049] Распределенная файловая система, такая как система 150 представляет собой систему хранения, структурирования и управления данными на одной или нескольких распределенных системах хранения данных, например, на кластере из узлов 110. Указанная система 150 определяет, как информация будет организована и доступна для чтения и записи и организует данные в виде файлов, которые могут быть доступны для чтения или записи, а сами файлы располагаются и структурируются в иерархии папок.
[0050] Более подробно, файловые системы включают в себя блоки данных и метаданные. Блок данных - физический блок информации для хранения содержимого объектов файловой системы, например, файлов или частей файлов. Представляет собой небольшие фрагменты данных, которые могут быть прочитаны или записаны на диск. На физическом уровне блоки данных обычно имеют фиксированный размер и являются основными единицами хранения информации в файловых системах и на дисках. Метаданные - информация о размере файла, его типе, времени создания и изменения, правах доступа и других атрибутах, а также имя и уникальный идентификатор всех объектов файловой системы и информация об их расположении в каталогах (папках). Метаданные помогают системе управлять и организовывать файлы и папки, а также обеспечивают надежность и безопасность взаимодействия с файловой системой. Соответственно, под метаданными в данном решении следует понимать дополнительные данные, описывающие фактические данные. Так, например, метаданные могут использоваться в файловых системах для описания того, где хранятся соответствующие данные. Т.е. метаданные являются неотъемлемой частью файловой системы. Как указывалось, выше, кластерные файловые системы позволяют нескольким клиентским устройствам совместно использовать доступ к файлам по сети. Для многих кластерных файловых систем, особенно для приложений высокопроизводительных вычислений, серверы метаданных являются узким местом, которое снижает прирост производительности, ввиду задержек, связанных с временем поиска метаданных файлов и синхронизацией между параллельными запросами на доступ к одним и тем же данным, вызванных архитектурой таких систем. Метаданные должны сопровождать данные и нужны, как для поиска и получения детальной информации о данных (методах, сетях наблюдений и др.), так и мониторинга жизненного цикла данных.
[0051] В одном частном варианте осуществления, система 150 предполагает разделение потоков данных и метаданных файловой системы на потоки данных (Data IO) и метаданных (Metadata IO), для обеспечения эффективной параллельной работы с этими потоками. При этом, стоит отметить, что данные и связанный с ними Data IO могут размещаться, на любом известном хранилище, включая но не ограничиваясь, программно-определяемую систему хранения данных (SDS), представляющую собой кластер или набор из кластеров, реализующих предоставление сервиса блочных устройств под непосредственное размещение данных для файловой системы. Кроме того, в еще одном частном варианте осуществления файловая система выполнена с возможностью хранения данных в объектных хранилищах, например, таком как RADOS для хранения данных. Соответственно метаданные файловой системы обрабатываются и хранятся посредством системы управления метаданными, такой как система 100.
[0052] В еще одном частном варианте осуществления файловая система 150 может быть реализована на базе аппаратно-программного комплекса, содержащего физический и логический слои для обеспечения высокой производительности системы и быстроты доступа к данным. Так, система хранения данных может обеспечивать создание сети хранения данных на неспециализированном оборудовании массового класса, как правило, группе серверных узлов под управлением операционных систем общего назначения. Управление инфраструктурой хранения может осуществляться посредством виртуализации функции хранения, отделяющей аппаратное обеспечение от программного. Кроме того, система хранения данных может представлять собой систему хранения данных (СХД) на базе комплекса аппаратных и программных средств, которые предназначены для хранения и оперативной обработки данных. В качестве носителей данных используются жесткие диски, в основном SSD (системы All Flash Array), а также гибридные решения, сочетающие SSD- и HDD-накопители в одной СХД.
[0053] Узлы системы хранения данных, такие как узлы 110, с развернутым на них программно-определяемой системой хранения данных (SDS, Software Defined Storage) могут быть организованы в кластеры, объединены с помощью нескольких сетей через коммутаторы - внутреннюю высокоскоростную сеть Internal для обслуживания трафика репликации/синхронизации/кодирования данных и клиентскую сеть Public для клиентского трафика. Пропускная способность Internal сети должна быть выше пропускной сети Public для обслуживания дополнительного служебного трафика. Внутри SDS организован доступ к блочным, объектным хранилищам, распределенным относительно кластера(ов) системы хранения данных виртуальным дискам, на которых хранятся данные и происходит работа с Data IO.
[0054] Модуль взаимодействия с файловой системой 120 предназначен для связывания пользовательских запросов с облачной файловой системой, в частности с системой 150. Т.е. указанный модуль 120 является связующим звеном между DATA IO и METADATA IO. Так, модуль 120 может представлять собой программно-аппаратный модуль, реализованный на базе вычислительного устройства, связанный с системой 150 по каналам связи, например, сети Интернет. В еще одном частном варианте осуществления модуль 120 может содержать интерфейс взаимодействия с пользователем, такой как GUI. Так, в одном частном варианте осуществления, в качестве клиента для доступа к облачной файловой системе, модуль 120 реализован на базе FUSE-драйвера с оберткой libcfs. Такой подход снижает входной порог по требованиям к клиентам и не перекладывает часть нагрузки на клиентскую часть, в отличие от InfiniFS.
[0055] Модуль 120 выполнен с возможностью получения запроса пользователя на взаимодействие с файловой системой, такой как система 150. Указанный запрос может быть получен посредством сети связи или через программный интерфейс операционной системы. Так, в одном частном варианте осуществления, запрос на взаимодействие с файловой системой может содержать по меньшей мере строковое имя объекта файловой системы, с которым пользователь и/или другая система (например, внешняя система) желает взаимодействовать. Кроме того, в еще одном частном варианте осуществления, запрос может содержать адрес метаданных объекта файловой системы. Адрес метаданных объекта файловой системы (номер inode) может представлять собой результат конкатенации номеров блоков (шардов) по меньшей мере одного первого сервера метаданных 130 и по меньшей мере одного второго сервера метаданных 140 и некоторого уникального числа. Т.е. номер inode представляет собой уникальный идентификатор в файловой системе, на основе которого происходят манипуляции объектами в файловой системе. Приведем аналогию, которая поможет интерпретировать указанный термин - номер inode по своей природе схож с индексом в базе данных, т.е. предназначен для обращения к элементам с поправкой на архитектуру распределенной системы хранения метаданных. Так, в одном частном варианте осуществления указанный адрес метаданных объекта файловой системы может быть определен и/или получен по меньшей мере одним первым сервером 130 и сохранен, для последующих взаимодействий с объектом файловой системы, во временной памяти (кеш), например, модуля 120. В еще одном частном варианте осуществления временная память может являться внешней по отношению к системе 100, например, временная память системы хранения данных и т.д.
[0056] Также, модуль 120 выполнен с возможностью определения типа запроса пользователя, причем определение включает по меньшей мере отнесение запроса к метаданным, необходимым для ввода-вывода объекта файловой системы (данных) или метаданных, необходимых для работы с пространством имен файловой системы. Под объектом файловой системы в данном решении следует понимать объект, хранящийся в файловой системе. Так, объектами файловой системы могут являться, например, файл данных, директория, символическая ссылка, жесткая ссылка. Символическая («мягкая») ссылка (также «симлинк», от англ. Symbolic link) представляет собой специальный файл в файловой системе, в котором вместо пользовательских данных содержится путь к файлу, открываемому при обращении к данной ссылке (файлу). Жесткой ссылкой (англ. hard link) называется структурная составляющая файла - описывающий его элемент каталога. Так, жесткой ссылкой называется некоторое имя в иерархии каталогов ассоциируемое с уникальным идентификатором метаинформации о файле. Так, жесткая ссылка может представлять, например, для файлов - имя файла, с которым он был впервые создан. Указанные термины широко известны из уровня техники. Соответственно, метаданные объекта файловой системы - это данные, которые ассоциированы с объектом файловой системы и располагаются на сервере 130 (атрибуты и адреса расположения объекта, которые относятся к адресу метаданных объекта файловой системы) и/или на сервере 140 (карта хранения содержимого объектов файловой системы).
[0057] Как указывалось выше, распределенные файловые системы организованы посредством разделения потоков данных и метаданных. Соответственно, при получении запроса пользователя на взаимодействие с объектом (папка, файл) файловой системы, модуль 120 выполнен с возможностью определения, по типу запроса, к какому типу метаданных относится указанный запрос. Указанная особенность будет раскрыта более подробно ниже. Также, модуль 120 выполнен с возможностью трансляции определенного типа запроса пользователя на по меньшей мере один сервер метаданных и кеширования результатов выполнения запроса по меньшей мере одним сервером метаданных.
[0058] Стоит отметить, что в одном частном варианте осуществления, кэширование может выполняться как непосредственно во внутренней памяти модуля 120, так и на стороне распределенной системы хранения данных. Кроме того, в еще одном частном варианте осуществления, кеширование (хранение во временной памяти данных), может выполняться непосредственно, в операционной системе. Также, в еще одном частном варианте осуществления кеширование может выполняться на стороне клиента. Под кешированием результатов выполнения запроса понимается хранение во временной памяти данных, связанных с ответом по меньшей мере одного сервера метаданных, например, сервера 130 и/или 140 на пользовательский запрос.
[0059] Стоит отметить, что настоящие варианты реализации распределенной файловой системы и распределенной системы хранения данных не ограничиваются представленными примерами. Так, основные аспекты заявленного решения, в первую очередь, относятся к системе управления метаданными, т.е. способу работы с Metadata IO в распределенных файловых системах, который можно сочетать с различными подходами к хранению данных. Преимущества и детали осуществления заявленного решения будут ясны и изложены подробнее ниже.
[0060] Рассмотрим более подробно архитектуру системы управления метаданными.
[0061] На Фиг. 2 раскрыта блок-схема распределения метаданных.
[0062] Как видно из Фиг. 2, система 100 содержит модуль 120, по меньшей мере один первый сервер метаданных 130, по меньшей мере один второй сервер метаданных 140. Кроме того, как было описано выше, сервера 130 и 140 являются частью файловой системы 150, т.е. связаны с узлами хранения данных 110 (не показаны), которые также являются частью системы 100.
[0063] Основной особенностью заявленного технического решения является архитектура системы 100, которая является частью файловой системы 150 и принцип взаимодействия серверов 130 и 140, обеспечивающий разноуровневое разделение метаданных (потоков запросов Metadata IO) на две категории: работа с пространством имен (поиск, открытие, свойства и т.д.) и работа с дисковым пространством (операции ввода-вывода).
[0064] Как указывалось выше, при разрешении путей к файлам при запросах от множества клиентов приходится обходить дерево каталогов от корня и проверять разрешения всех промежуточных каталогов внутри путей последовательно. Это приводит к тому, что околокорневые каталоги, расположенные вблизи корня, даже при сбалансированной системе метаданных, являются причиной задержек при множественном одновременном обращении. Иными словами, так как все пути к файлам начинаются с корня, то это является причиной задержек и возникновения боттлнека (узкое место в производительности). Соответственно, за счет распараллеливания работы с разнородными типами метаданных по разным серверам 130 и 140 повышается эффективность файловой системы, повышается скорость доступа к данным, сокращается время разрешения путей до файлов.
[0065] Рассмотрим более подробно типы метаданных.
[0066] Сервер 130 представляет собой по меньшей мере один первый сервер метаданных, предназначенный для обработки запросов связанных с пространством имен файловой системы. Специалисту в данной области техники будет очевидно, что может быть использовано множество серверов 130, которые могут являться равноправными и связанными между собой. Сервер 130 и/или множество серверов 130 выполнен(ы) с возможностью хранения иерархического пространства имен файловой системы, которое содержит сопоставления строковых имен объектов файловой системы с адресами метаданных объектов файловой системы, а также хранения атрибутов объектов файловой системы, связанных с состоянием объекта файловой системы; определения адреса расположения объекта файловой системы в пространстве имен файловой системы на основе строкового имени объекта файловой системы и извлечения адреса метаданных объекта файловой системы; управления состоянием объекта файловой системы. Сервер 130 отвечает за обработку запросов связанных с пространством имен файловой системы. Под пространством имен файловой системы понимается набор метаданных, организованных в иерархическую структуру, каждый из элементов которой имеет уникальное имя, которые определяется его положением в иерархии. Пространство имен гарантирует, что все заданные объекты имеют уникальные имена, чтобы их можно было легко идентифицировать и определить их свойства (атрибуты). Так, например, к пространствам имен файловой системы относится хранение иерархии файловой системы (dentries) файлов и директорий, включая их имя и структур-идентификаторов (inodes) файлов, содержащих информацию о пути к файлам и директориям, а также свойства (аттрибуты) такие как права доступа, размер, время создания и изменения. Соответственно, dentrie - адрес расположения метаданных объекта файловой системы, структура, состоящая из сопоставления строкового имени файла с соответствующим адресом метаданных файла. Кроме того, в одном частном варианте осуществления в пространстве имен файловой системы также реализовано низкозатратное, с точки зрения использования ресурсов, хранение открытых файловых дескрипторов, механизмов блокировок.
[0067] Определение адреса расположения объекта файловой системы в пространстве имен файловой системы на основе строкового имени объекта файловой системы и извлечения адреса метаданных объекта файловой системы представляет собой итеративный этап поиска адреса метаданных объекта файловой системы (номера inode) по строковому имени объекта файловой системы. Так, адрес расположения объекта файловой системы представляет собой путь до файла, т.е. адрес метаданных файла с уже разрешенным физическими адресами размещений всех составляющих его блоков. Как указывалось выше, номер inode представляет собой уникальный идентификатор объекта, которому соответствует по меньшей мере одно строковое имя.
[0068] Для поиска адреса метаданных объекта выполняется итеративное определение, посредством адреса метаданных родительской папки и строкового имени дочерней папки, по порядку расположения объектов файловой системы до целевого объекта файловой системы. Так, номер inode одной из родительских папок всегда известен, это обеспечивается на этапе создания файловой системы, когда файловая система только подключается (монтируется) - в ней задается номер inode корневой папки. Поэтому для поиска адреса метаданных требуемого объекта, запускается итеративный процесс прохождения (нахождения) всей структуры до требуемого файла. Так, например, на фиг. 4 приведена иерархия объектов. Для поиска номера inode Файла 1 сервер 130 выполняет запрос на корневую папку со строковым именем Файла 1. Далее, из корневой папки извлекается номер inode Папки 2 и выполняется запрос со строковым именем Файла 1 на inode Папки 2. Процедура повторяет до нахождения требуемого объекта во вложенной иерархии объектов (в нашем случае до Файла 1). Финальным результатом такого запроса будет inode Файла 1. При дальнейшей работе с файлом, найденный адрес метаданных (номер inode) может храниться во временной памяти или же каждый раз итеративным способом находиться. Кроме того, при известности адреса метаданных объекта файловой системы, в одном частном варианте осуществления, этап извлечения такого адреса пропускается.
[0069] Управление состоянием объекта файловой системы представляет собой присвоение состояния объекту файловой системы. Так, состоянием объекта файловой системы может являться, например, резервирование части метаданных, связанных с объектом файловой системы; резервирование пространства в хранилище данных; блокировка данных, связанных с объектом файловой системы; блокировка метаданных, связанных с объектом файловой системы; изменение состояния атрибутов объектов файловой системы; изменение строкового имени в адресе расположения метаданных объекта файловой системы; изменение количества ссылок, ведущих на объект файловой системы.
[0070] Управление состоянием необходимо для исключения удаления объекта в момент взаимодействия пользователя с указанным объектом. Т.к. распределенная файловая система является многопользовательской, то может возникнуть ситуации, когда пользователи будут пытаться взаимодействовать с одним и тем же файлом. Соответственно присвоение правильного состояния объекту сервером 130 гарантирует, что этот объект не будет удален и/или изменен другим пользователем.
[0071] Управление состоянием объекта осуществляется на основе атрибутов объекта файловой системы. Так, атрибуты объекта файловой системы представляют собой, по меньшей мере: описание объекта файловой системы; права доступа к объекту файловой системы; информацию о владельце объекта файловой системы; дату последнего изменения объекта файловой системы; тип содержимого; размер содержимого и т.д. Как указывалось выше, атрибуты связаны с адресом метаданных объекта файловой системы, т.е. после нахождения адреса метаданных, сервер 130 может осуществить управление состоянием объекта.
[0072] Поток метаданных, обрабатываемый сервером 130 включает в себя такие операции, как операции, связанные с манипулированием самой структурой файловой системы. Так, например, к таким запросам могут относится операции lookup, open, close, readdir, lease, lock, create, mkdir, link, unlink, и т.д. Запрос Lookup выполняет поиск файлов и папок по их имени, readdir позволяет получить содержимое папки (все ее dentries). Mkdir создает новую папку, a create - новый файл. Прочие операции, такие как lease, lock, link, unlink используются для организации многопользовательского доступа к файлам и папкам, реализации ссылок и прочих управляющих операций в иерархии файловой системы. Преимуществом разделения потоков метаданных является то, что все эти операции локализованы в сервере 130, поскольку работают с одними и теми же метаданными, что в свою очередь избавляет от необходимости усложнять систему протоколами синхронизации метаданных и дополнительными сетевыми соединениями, дополнительной нагрузкой на сеть.
[0073] Т.е. операции манипулирования структурой файловой системы могут представлять операции обращения к объекту без его непосредственного изменения. Так, в качестве аналогии, приведем простой пример. Запросом пользователя, связанным с манипулированием структурой файловой системы, может являться просмотр свойства файла. Соответственно при таком сценарии заявленная система 100 обработает указанный запрос посредством сервера 130, без использования сервера 140. Сервер 130 осуществит определение расположения объекта файловой системы в пространстве имен файловой системы, с помощью уникальных идентификаторов или строковых имен запрашиваемого объекта и присвоит состояние объекта файловой системы, при этом, поскольку карта хранения объектов файловой системы расположена на сервере 140, а изменения файла не происходит, то и обхода карты расположения объектов (extent map) также не выполняется.
[0074] Сервер 140 представляет собой по меньшей мере один второй сервер метаданных, предназначенный для управления фактическим местом в по меньшей мере одном узле хранения данных, таком как узле 110. Специалисту в данной области техники будет очевидно, что может быть использовано множество серверов 140, которые могут являться равноправными и связанными между собой. Сервер 140 и/или множество серверов 140 выполнен(ы) с возможностью определения содержимого объекта файловой системы на основе адреса расположения объекта файловой системы; хранения и управления картой хранения содержимого объектов файловой системы; аллокации и деаллокации дискового пространства по меньшей мере одного узла хранения данных; трансляции по меньшей мере одного адреса содержимого объекта файловой системы, включающего зарезервированное дисковое пространство, модулю взаимодействия с файловой системой.
[0075] Так, сервер 140 отвечает за аллокацию и деаллокацию фактического места в хранилище данных (будь то виртуальное хранилище данных или объектное хранилище данных) под содержимое объекта файловой системы (файла, папки и т.д.), а также хранит экстенты файлов.
[0076] Экстент аллокатор - это механизм, который используется для управления блоками данных в файловой системе. Он группирует блоки данных в экстенты, которые представляют собой последовательности блоков, например, по 4К байт. В других частных вариантах реализации могут быть использованы блоки по 512 байт для HDD. Это позволяет оптимизировать использование дискового пространства, так как блоки данных могут быть размещены в непрерывной области диска, уменьшается фрагментация записи данных за счет крупноблочного использования, улучшается производительность операций последовательного чтения или записи. Кроме того, использование экстентов позволяет уменьшить количество метаданных, необходимых для управления данными, так как каждый экстент имеет только одну запись в таблице экстентов
[0077] Так, поток метаданных, обрабатываемый сервером 140, может включать поток запросов, связанных с изменением/созданием/удалением объекта файловой системы, т.е. запросы, связанные с управлением дисковым пространством на узлах 110. Так, например, запросы могут представлять fallocate и filemap, которые связаны с доступом к содержимому файлов. Fallocate позволяет управлять размером файла, например, увеличивать или уменьшать его. Filemap предназначен для трансляции логического адреса (смещения) внутри файла в смещение на реальном хранилище (блочном устройстве или объектном хранилище) и используется модулем 120 файловой системы для доступа к контенту файла.
[0078] Соответственно, расположение содержимого конкретного объекта (данных) в системе хранения данных называется картой хранения содержимого файловой системы или таблицей экстентов. В одном частном варианте осуществления карта хранения содержимого объектов файловой системы представляет собой В-дерево (делится на страницы), таблицу с блоками (как в HDFS) или хэш-таблицу, список или другая подходящая структура данных. Так, содержимое объекта файловой системы - цепочка блоков, экстентов или строка, составляющая содержащуюся в указанном объекте информацию. Т.е. содержимое объекта файловой системы представляет собой по меньшей мере одну единицу данных, физически хранящуюся в распределенной системе хранения данных, составляющую информацию, которая содержится в объекте файловой системы. Так, единица данных, физически хранящаяся в распределенной системе хранения данных, может представлять собой по меньшей мере одно из: блок данных, строка, цепочка блоков данных, объект объектного хранилища.
[0079] Так, данные файлов, размещаемые на виртуальных хранилищах в распределенной системе хранения данных (например, SDS) представляют собой сгруппированные цепочки подряд идущих блоков, например, по 4К байт - экстентов, которыми управляет экстент аллокатор.
[0080] Таким образом, разделение метаданных на сервера 130 и 140 обеспечивает возможность использования, для обхода иерархии файловой системы и манипулирования файлами и папками (например, переименованием, копированием, перемещением или созданием символической ссылки и т.д.), только серверов 130, а для записи и чтения данных - сервера 130 и 140. Такое разделение позволяет более тонко масштабировать кол-во так называемых шардов, требуемых для работы с данными или с метаданными, независимо друг от друга, в процессе эксплуатации файловой системы. Такое разделение снижает вычислительную нагрузку на файловую систему, ввиду исключения необходимости прохождения всего пути файла при операциях взаимодействия с файлом, касающихся манипулирования (переименование, копирование и т.д.). Кроме того, такое дополнительное разделение (шардирование) метадаты позволяет реализовать т.н. автоскейлинг (адаптивную работу), в целом, файловой системы, динамически адаптируя вычислительные ресурсы, в зависимости от меняющихся нагрузок, типов операций/запросов, их количества в единицу времени и их характера, о чем будет более подробно раскрыто далее.
[0081] В одном частном варианте осуществления пространство имен файловой системы шардируется, т.е. распределенно хранится по различным серверам 130 и 140 в пределах кластера, в зависимости от типа метаданных и сервера. В свою очередь каждый такой шард может состоять на самом деле из нескольких сервисов (по умолчанию трех) (Фиг. 2), которые отвечают за зеркалирование метаданных и бесперебойный доступ к ним, образуя группу серверов, связанных, например, RAFT протоколом или другим аналогичным протоколом консенсуса в распределенной системе.
[0082] Возвращаясь к раскрытию системы 100, деление метаданных IO на два потока по типу запросов позволяет оптимизировать обработку запросов, так как каждый поток может быть оптимизирован для выполнения определенных операций. Например, первый поток может быть оптимизирован для операций, связанных с управлением дисковым пространством, а второй поток - для операций, связанных с управлением доступом к файлам и каталогам. Это позволяет улучшить производительность системы и обеспечить более эффективную обработку запросов. К тому же, балансировка нагрузки на первый поток и второй поток может выполняться независимо: например, в сценарии с огромным числом маленьких файлов система 100 может иметь большее количество серверов 130, не увеличивая количество серверов 140.
[0083] Кроме того, такое разделение обеспечивает минимизацию взаимных блокировок, которые могут возникнуть, когда два или более запроса пытаются получить доступ к ресурсу, который может быть использован только одним потоком в определенный момент времени. Это может привести к ситуации, когда каждый поток ожидает, пока другой поток освободит ресурс, что может привести к "зависанию" системы.
[0084] На Фиг. 4 показан пример оперирования распределенными метаданными.
[0085] На Фиг. 4 приведен пример структуры файловой системы, состоящей из файлов и папок. Рассмотрим распределение метаданных объектов файловой системы в соответствии с заявленным техническим решением.
[0086] Так, как видно из фиг. 4, метаданные каждого объекта файловой системы распределены по разным серверам 130 и 140 в соответствии с типом метаданных, т.е. распределены разноуровнево. Атрибуты объекта файловой системы расположены на сервере 130. Сервер 140 хранит метаданные, относящиеся к управлению фактическим местом в узлах хранения данных 110.
[0087] Кроме того, в одном частном варианте осуществления распределение по разным серверам также происходит исходя из номера inode, в котором кодируются номера соответствующих шардов.
[0088] При получении запроса пользователя на взаимодействие с объектом файловой системы, посредством модуля 120, определяется тип запроса пользователя. Так, в одном частном варианте осуществления, запрос пользователя может представлять собой либо запрос на взаимодействие с пространством имен файловой системы, например, запрос на чтение объекта, или запрос на управление фактическим местом в узле хранения данных, например, запрос на создание объекта (создание файла). Определение типа запроса может выполняться на основе требуемой операции с объектом файловой системы, содержащейся в указанном запросе. Так, например, при запросе чтения объекта, в запросе пользователя будет содержаться операция lookup - операция поиска требуемого объекта файловой системы. Т.е. разделение запросов на типы метаданных выполняется модулем 120 посредством операции, которую необходимо выполнить с файлом. Соответственно, для сервера 130 это будут операции манипулирования самой структурой файловой системой (, lookup, open, close, readdir, lease, lock, create, mkdir, link, unlink), которые были раскрыты выше. Для сервера 140 операции будут представлять операции, характеризующие доступ к содержимому файлов (fallocate и filemap), т.е. непосредственный процесс работы с файлом (изменение, создание и т.д.).
[0089] Далее, на основе определенного типа запроса, модуль 120 транслирует указанный запрос на соответствующий сервер 130 или 140 в зависимости от типа запроса.
[0090] Так, запрос на манипулирование пространством имен файловой системы, будет содержать операцию lookup, соответственно, запрос будет отправлен на сервер 130.
[0091] Сервер 130 извлекает из запроса строковое имя объекта, к которому обращается пользователь, и выполняет сопоставление полученного имени с inode, который соответствует строковому имени. При этом, если объект с таким именем существует, то сервер 130 предоставляет модулю 120 его inode. Если объекта с таким именем не существует, то операция заканчивается неуспешно.
[0092] Так, при запросе на чтение Файла 1, будет выполняться следующая последовательность действий. Для поиска номера inode Файла 1, сервер 130 выполняет запрос на корневую папку со строковым именем Файла 1. Далее, из корневой папки извлекается номер inode Папки 2 и выполняется запрос со строковым именем Файла 1 на inode Папки 2. Процедура повторяется итеративно до нахождения требуемого объекта во вложенной иерархии объектов (в нашем случае до Файла 1). Финальным результатом такого запроса будет номер inode Файла 1.
[0093] Соответственно, после нахождения требуемого файла, сервер 130 осуществляет управление состоянием объекта файловой системы. Так, управление объектом файловой системы может представлять открытие файла (процедура чтения, резервирование файла и т.д.). В еще одном частном варианте осуществления управление объектом файловой системы представляет собой блокировку объекта в файловой системе для обеспечения возможности дальнейшей работы с файлом.
[0094] Таким образом, сервер 130 выполняет определение адреса расположения объекта файловой системы в пространстве имен файловой системы и управление состоянием объекта файловой системы. При этом, как видно, для операций манипулирования самой структурой файловой системой используется только сервер 130, вместо полного обхода карты хранения объектов файловой системы, что существенно снижает вычислительную нагрузку на систему и ускоряет поиск требуемых объектов. Т.е. за счет разделения метаданных на пространство имен файловой системы и управление объектом файловой системой, повышается локальность метаданных, т.к. все метаданные, касаемые расположения объектов хранятся и обрабатываются локально на сервере 130, без необходимости взаимодействия непосредственно с картой хранения объектов файловой системы при запросах манипулирования только структурой файловой системы, в то время как в известных решениях для выполнения указанных операций выполняется полный обход всех объектов файловой системы.
[0095] Продолжая пример, если запрос пользователя направлен на управление объектом файловой системой (управление фактическим местом в хранилище/ аллокации и деаллокации дискового пространства), например, на создание файла в директории, то в обработку запроса пользователя также подключается и сервер 140. Так, например, если запрос пользователя содержит команду fallocate, то модуль 120 на первом этапе осуществляет определение, посредством сервера 130, адреса метаданных объекта. Адрес метаданных объекта определяется посредством адреса расположения объекта, т.е. посредством аналогичной операции, как и в случае с вышеописанным сценарием, т.е. посредством поиска номера inode папки\директории. При этом, поиск может осуществляться также посредством строкового имени файла. Соответственно после нахождения требуемого номера inode сервер 130 осуществляет резервирование файла (управляет состоянием файла на основе его атрибутов, связанных с номером inode) и отправляет указанные данные на сервер 140.
[0096] Сервер 140 в свою очередь осуществляет выделение дискового пространства по меньшей мере одного узла хранения данных 110 на требуемый файл. После этого, сервер 140 транслирует по меньшей мере один адрес содержимого объекта файловой системы, содержащего зарезервированное дисковое пространство, модулю взаимодействия с файловой системой 120. Для выделения дискового пространства используется карта хранения содержимого объектов файловой системы. Т.е. посредством карты хранения содержимого определяется физическая цепочка блоков, экстентов или строка, в которую будет записан объект файловой системы. Далее, сервер 140 возвращает адрес дискового пространства (т.е. блоков или строки), куда необходимо записать файл.
[0097] В одном частном варианте осуществления сервера 130 и 140 являются отказоустойчивыми. Как видно на фиг.4, отказоустойчивость может достигаться за счет репликации блоков метаданных. Репликация может осуществляться, например, посредством RAFT протокола или любого другого протокола достижения консенсуса. Как указывалось выше, сервер 130 хранит атрибуты (attributes) и списки ентрисов (dentry list) - сопоставления файлов (имен), содержащихся, в папке Папка 2, и их номеров inode. Сервер 130 также хранит inodes. При отказоустойчивом хранении в номере inode встроены (вшиты) номер шарда сервера 130 (X) и номер шарда сервера 140 (Y) и уникальный номер inode (например, 44-битный integer) - это дает возможность не считывать структуру inode, чтобы узнать, в какой шард идти. Y равен нулю для папок, поскольку у них нет экстентов вовсе. У файлов Y всегда равен корректному номеру шарда, который отвечает за экстенты файла.
[0098] Сервер 140 занимается обслуживанием карты хранения содержимого объектов файловой системы (extent map) для каждого файла. Extent map является сущностью, оперируемой сервером 140 и ее возможно реализовать/хранить в различных вариациях и структурах, включая но не ограничиваясь - в виде таблицы с блоками (как в HDFS) или В-деревьев, хэш-таблиц, списков или другой подходящей структуры данных. На самом деле не так важен тип структуры данных, сколько то, что в реализации заявленной системы 100 указанная структура расположена внутри сервера 140 и то, что сервер, например, через API-запросы, выполняет трансляцию адресов, принимая на вход логический адрес внутри файла (File Offset) и количество запрашиваемых байт, а на выходе дает список экстентов, покрывающих требуемый диапазон, где каждый экстент характеризуется volume id, volume offset, block length (можно сказать extent length). Т.е. в моменте записи файла идет, например, запрос на сервер 140 об экстентах файла. Сервер 140 в ответ выдает адреса для записи на диске, которые могут быть в том числе распределенными, т.е. экстенты могут располагаться произвольным образом и даже на разных виртуальных дисках. Выделение места может быть физически большим, нежели фактически занятое, особенно такой сценарий характерен для записи концов файлов. Это означает, что в случае повторной дозаписи увеличившегося файла и в случае достаточно выделенного места на диске сервером 140 ранее - сервер 140 сэкономит операции для довыделения дискового пространства под запись. При этом важно отметить, что VolumeID может быть вынесен из extent map на уровень метаданных файла, к примеру, если сервер 140 всегда выделяет место для одного файла на одном и том же диске (нет смысла хранить Volume ID персонально для каждого экстента - он общий для всего файла). Это также означает, что в случае использования расширяемых по запросу Volume-ов на файловом хранилище появляется возможность управления уровнем фрагментации файла при записи, например, файл, единожды записанный на какой-то из volume-ов, уже может не переопределяться и не фрагментироваться на логическом уровне (т.е. не распределяться по нескольким volumes), при этом достаточная отказоустойчивость хранения вполне возможна к реализации на более низком физическом уровне в хранилище. Таким образом это, в свою очередь, дает, в частном случае реализации, высокую локализацию размещения данных в хранилище, таком как хранилище SDS, упрощение самого сервера 140 и оптимизацию в части снятия потребности в хранении Volume ID для каждого экстента.
[0099] Таким образом, для того чтобы прочитать уже существующий Файл 1, запрос пользователя сначала направляется на шард сервера 130 для поиска родительского каталога. Сервер 130 считывает attributes родительской Папки 2, сверяет достаточность прав для последующих операций и осуществляет поиск, посредством lookup (parent inode, "Файл 1") inode Файла 1, после чего из inode можно узнать номер шарда сервера 140, на который направляется искомый запрос filemap, чтобы получить карту размещения данных в SDS.
[0100] Также здесь важно отметить, что у папок и файлов есть возможность технически изменять по предопределенной логике в процессе работы номера шардов X и Y, перемещая соответствующую метаинформацию на другие шарды сервера 130/140, вместо того что чтобы назначать их единожды при создании файла или папки простым алгоритмом, например, Round Robin, или по хэшу. Таким образом можно перераспределять в режиме реального времени размещение папок и файлов по шардам. Это необходимо для того, чтобы реализовать решение по адаптивной работе (автоскейлингу) распределенной файловой системы, в зависимости от меняющихся во времени разнотипных облачных нагрузок на распределенную файловую систему. Например, лоадбалансер в системе обнаружит перегруженный сценарием шард (целевую папку со слишком большим количеством создаваемых файлов) и сможет выполнить перемещение части метаинформации в другой шард, меняя X и Y в битовом поле номера inode без модификации самой структуры inode, т.е. не изменяя саму метаинформацию. Таким же образом, по причине использования такой схемы нумерации inodes, становится возможным перемещение между шардами inodes и dentries.
[0101] Таким образом, за счет распараллеливания потоков метаданных по типу метаданных и возможности их дальнейшей обработки, обеспечивается снижение вычислительной нагрузки на файловую систему и повышается скорость разрешения пути до объекта файловой системы.
[0102] На фиг. 3 представлена блок схема способа 300 способа взаимодействия с объектом данных в распределенной системе хранения метаданных, такой как система 100, который раскрыт поэтапно более подробно ниже. Указанный способ 300 заключается в выполнении этапов, направленных на обработку различных цифровых данных.
[0103] На этапе 310 получают запрос пользователя на взаимодействие с объектом файловой системы, причем запрос содержит по меньшей мере строковое имя объекта.
[0104] Так, на указанном этапе 310, модуль 120 получает запрос пользователя на взаимодействие с объектом файловой системы. Как указывалось выше объект файловой системы может представлять файл данных, директорию, символическую ссылку, жесткую ссылку. Запрос пользователя может представлять действие, которое пользователь желает совершить с объектом файловой системы, например, чтение файла, просмотр свойств файла, редактирование файла и т.д.
[0105] На этапе 320 модуль 120 определяет принадлежность запроса к типу метаданных, которые необходимы для работы с пространством имен файловой системы.
[0106] Модуль 120 выполнен с возможностью извлечения метаданных, связанных с запросом, например, строкового имени и определения типа метаданных, которые необходимы для выполнения запроса. Так, при запросе поиска файла, метаданные будут отнесены к метаданным манипулирования пространством имен файловой системы. Соответственно, при запросе на редактирование файла, метаданные будут отнесены к метаданным ввода-вывода файла. В заявленном способе 300 раскрывается способ взаимодействия с объектом данных, т.е. работы с дисковым пространством узлов хранения 110. Следовательно, как указывалось выше, для взаимодействия с файлом необходимо, на первом шаге, определить его расположение, т.е. задействовать сервер 130.
[0107] Таким образом, на этапе 320, на первом шаге, модуль 120 определяет типа запроса как запрос к пространству имен.
[0108] На этапе 330 транслируют запрос в по меньшей мере один первый сервер метаданных. Указанный этап выполняется модулем 120.
[0109] На этапе 340 определяют с помощью, по меньшей мере, одного первого сервера метаданных адрес расположения объекта файловой системы в пространстве имен файловой системы и извлекают адрес метаданных объекта файловой системы.
[0110] Сервер 130 извлекает из запроса строковое имя объекта, к которому обращается пользователь и выполняет сопоставление полученного имени с номером inode, который соответствует строковому имени. При этом, если объект с таким именем существует, то сервер 130 предоставляет модулю 120 его номер inode. Если объекта с таким именем не существует, то операция заканчивается неуспешно.
[0111] Так, как указывалось выше на примере Фиг. 4 при запросе на чтение Файла 1, будет выполняться следующая последовательность действий. Для поиска inode Папки 2, сервер 130 выполняет запрос на корневую папку со строковым именем Папка 2. Далее, из корневой папки извлекается inode Папки 2 и выполняется запрос со строковым именем Файла 1 на inode Папки 2. Процедура повторяет до нахождения требуемого объекта во вложенной иерархии объектов (в нашем случае до Файла 1). Финальным результатом такого запроса будет номер inode Файла 1.
[0112] Кроме того, в одном частном варианте осуществления система 100 может иметь несколько первых и вторых серверов 130 и 140. В таком случае дополнительно необходимо определить целевой шард/сервер. Указанное определение может производиться на основании хэша имени файла, хэша адреса метаданных объекта, сервиса конфигурации и т.д.
[0113] На этапе 350 запрашивают, по меньшей мере у одного первого сервера метаданных на основе данных, полученных на этапе 340, атрибуты объекта файловой системы для проверки возможности доступа к объекту.
[0114] Так, на указанном этапе 350, сервер 130, на основе определенного адреса метаданных объекта (номера inode) получает атрибуты указанного объекта. Атрибуты объекта могут представлять собой описание объекта файловой системы, права доступа, владелец, дата последнего изменения и т.д.
[0115] На этапе 360 присваивают режим работы с объектом файловой системы, на основе адреса метаданных объекта, полученного на этапе 340.
[0116] Режим работы может представлять собой по меньшей мере один из следующих режимов: резервирование части метаданных, связанных с объектом файловой системы; резервирование пространства в хранилище узла данных; блокировка данных, связанных с объектом файловой системы; блокировка метаданных, связанных с объектом файловой системы.
[0117] На этапе 370 определяют, по меньшей мере одним вторым сервером 140, содержимое искомого объекта файловой системы на основе адреса метаданных объекта файловой системы, полученного на этапе 340.
[0118] Определенный, посредством первого сервера 130, адрес метаданных транслируется во второй сервер 140. В одном частном варианте осуществления трансляция может осуществляться посредством модуля 120. Соответственно, второй сервер 140 осуществляет определение содержимого объекта файловой системы. Содержимое объекта - цепочка блоков, экстентов или строка, составляющая содержащуюся в объекте информацию. Содержимое определяется посредством карты хранения содержимого объектов.
[0119] На этапе 380 определяют физический адрес размещения содержимого объекта файловой системы в по меньшей мере одном узле хранения данных на основе информации полученной на этапе 370.
[0120] На этапе 380, второй сервер 140, осуществляет выделение адресов содержимого объекта. Выделение адреса может представлять собой адрес расположения на физических носителях области памяти и/или цепочки блоков, куда требуется записать файл.
[0121] На этапе 390 осуществляют доступ к содержимому объекта файловой системы на основе адреса размещения содержимого объекта файловой системы в по меньшей мере одном узле хранения данных на основе информации полученной на этапе 380.
[0122] На указанном этапе 390 адрес, полученный на этапе 380, отправляется, посредством второго сервера 140 на модуль 120. Соответственно, модуль 120, на основе адреса, предоставляет доступ к объекту без участия системы 100. Т.е. когда пользователь получает адрес, где лежат данные - он просто читает их из SDS без участия метаданных.
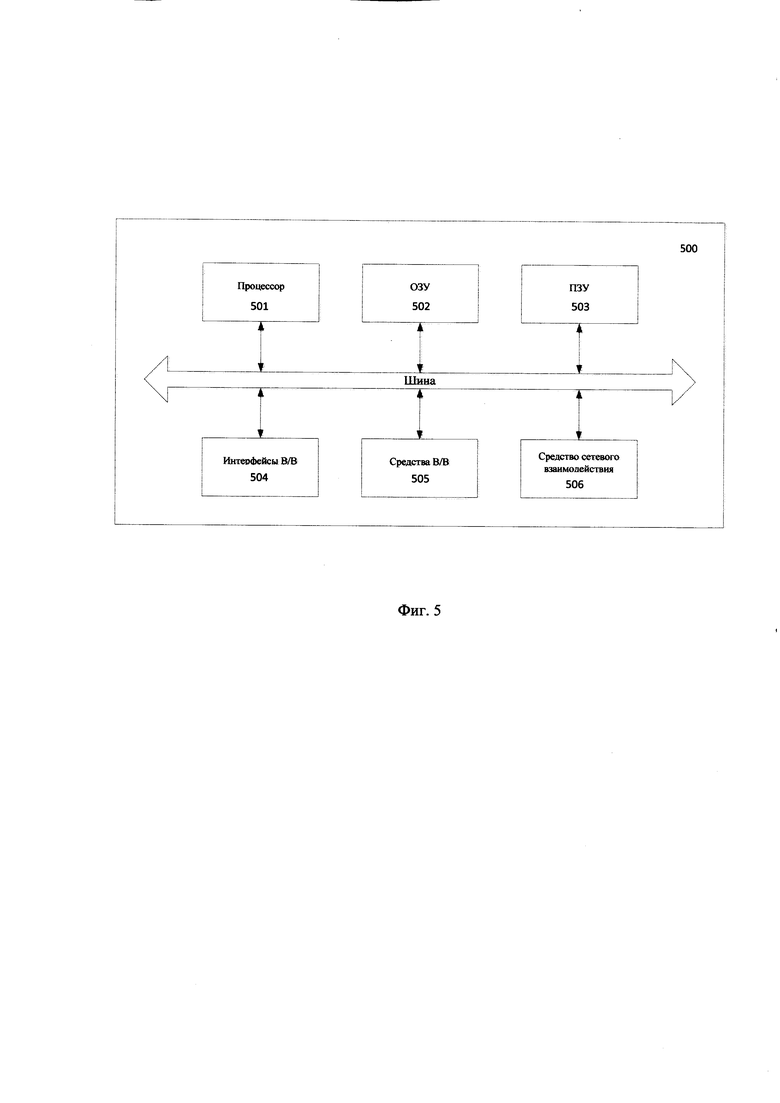
[0123] На Фиг. 5 представлен пример общего вида вычислительной системы 500, которая обеспечивает реализацию заявленной системы или является частью компьютерной системы, например, модулем 120, узлом хранения 110, частью вычислительного кластера, обрабатывающим необходимые данные для осуществления заявленного технического решения.
[0124] В общем случае система 500 содержит такие компоненты, как: один или более процессоров 501, по меньшей мере одну память 502, средство хранения данных 503, интерфейсы ввода/вывода 504, средство В/В 505, средство сетевого взаимодействия 506, которые объединяются посредством универсальной шины.
[0125] Процессор 501 выполняет основные вычислительные операции, необходимые для обработки данных при выполнении способа 300. Процессор 501 исполняет необходимые машиночитаемые команды, содержащиеся в оперативной памяти 502.
[0126] Память 502, как правило, выполнена в виде ОЗУ и содержит необходимую программную логику, обеспечивающую требуемый функционал.
[0127] Средство хранения данных 503 может выполняться в виде HDD, SSD дисков, рейд массива, флэш-памяти, оптических накопителей информации (CD, DVD, MD, Blue-Ray дисков) и т.п. Средства 503 позволяют выполнять долгосрочное хранение различного вида информации, например, блоки данных, структура данных, метаданные и т.п.
[0128] Для организации работы компонентов системы 500 и организации работы внешних подключаемых устройств применяются различные виды интерфейсов В/В 504. Выбор соответствующих интерфейсов зависит от конкретного исполнения вычислительных устройств, которые могут представлять собой, не ограничиваясь: PCI, AGP, PS/2, IrDa, FireWire, LPT, COM, SATA, IDE, Lightning, USB (2.0, 3.0, 3.1, micro, mini, type C), TRS/Audio jack (2.5, 3.5, 6.35), HDMI, DVI, VGA, Display Port, RJ45, RS232 и т.п.
[0129] Выбор интерфейсов 504 зависит от конкретного исполнения системы 500, которая может быть реализована на базе широко класса устройств, например, персональный компьютер, мейнфрейм, ноутбук, серверный кластер, тонкий клиент, смартфон, сервер и т.п.
[0130] В качестве средств В/В данных 505 может использоваться: клавиатура, джойстик, дисплей (сенсорный дисплей), монитор, сенсорный дисплей, тачпад, манипулятор мышь, световое перо, стилус, сенсорная панель, трекбол, динамики, микрофон, средства дополненной реальности, оптические сенсоры, планшет, световые индикаторы, проектор, камера, средства биометрической идентификации (сканер сетчатки глаза, сканер отпечатков пальцев, модуль распознавания голоса) и т.п.
[0131] Средства сетевого взаимодействия 506 выбираются из устройств, обеспечивающих сетевой прием и передачу данных, например, Ethernet карту, WLAN/Wi-Fi модуль, Bluetooth модуль, BLE модуль, NFC модуль, IrDa, RFID модуль, GSM модем и т.п.С помощью средств 505 обеспечивается организация обмена данными между, например, системой 500, представленной в виде сервера и вычислительным устройством пользователя, на котором могут отображаться полученные данные по проводному или беспроводному каналу передачи данных, например, WAN, PAN, ЛВС (LAN), Интранет, Интернет, WLAN, WMAN или GSM.
[0132] Конкретный выбор элементов системы 500 для реализации различных программно-аппаратных архитектурных решений может варьироваться с сохранением обеспечиваемого требуемого функционала.
[0133] Представленные материалы заявки раскрывают предпочтительные примеры реализации технического решения и не должны трактоваться как ограничивающие иные, частные примеры его воплощения, не выходящие за пределы испрашиваемой правовой охраны, которые являются очевидными для специалистов соответствующей области техники. Таким образом, объем настоящего технического решения ограничен только объемом прилагаемой формулы.
| название | год | авторы | номер документа |
|---|---|---|---|
| МНОГОПРОТОКОЛЬНОЕ УСТРОЙСТВО ХРАНЕНИЯ ДАННЫХ, РЕАЛИЗУЮЩЕЕ ИНТЕГРИРОВАННУЮ ПОДДЕРЖКУ ФАЙЛОВЫХ И БЛОЧНЫХ ПРОТОКОЛОВ ДОСТУПА | 2003 |
|
RU2302034C9 |
| СПОСОБ КОДИРОВАНИЯ ДАННЫХ И СИСТЕМА ХРАНЕНИЯ ДАННЫХ | 2023 |
|
RU2819584C1 |
| СИСТЕМА ХРАНЕНИЯ ДАННЫХ | 2023 |
|
RU2824327C1 |
| СПОСОБ И СИСТЕМА УПРАВЛЕНИЯ ОБЪЕКТАМИ И ПРОЦЕССАМИ В ВЫЧИСЛИТЕЛЬНОЙ СРЕДЕ | 2023 |
|
RU2820753C1 |
| СПОСОБ И СИСТЕМА ХРАНЕНИЯ ДАННЫХ | 2017 |
|
RU2656739C1 |
| СПОСОБ МИГРАЦИИ ВИРТУАЛЬНЫХ УСТРОЙСТВ С СОХРАНЕНИЕМ ИХ ДИНАМИЧЕСКОГО СОСТОЯНИЯ | 2024 |
|
RU2835764C1 |
| СПОСОБ И СИСТЕМА ДЛЯ СИНТЕТИЧЕСКОГО РЕЗЕРВНОГО КОПИРОВАНИЯ И ВОССТАНОВЛЕНИЯ ДАННЫХ | 2005 |
|
RU2406118C2 |
| СИСТЕМА И СПОСОБ АВТОМАТИЧЕСКОЙ МОДИФИКАЦИИ АНТИВИРУСНОЙ БАЗЫ ДАННЫХ | 2012 |
|
RU2536664C2 |
| Способ защиты данных в вычислительной системе | 2019 |
|
RU2715293C1 |
| БЕЗОПАСНОСТЬ В ПРИЛОЖЕНИЯХ СИНХРОНИЗАЦИИ РАВНОПРАВНЫХ УЗЛОВ | 2006 |
|
RU2421799C2 |
Изобретение относится к области вычислительной техники, в частности к способу и системе хранения, именования и оперирования метаданными в облачных высоконагруженных средах. Техническим результатом является повышение скорости доступа к метаданным распределенной системы хранения метаданных за счет разделения и распараллеливания типов метаданных. Распределенная система управления метаданными содержит по меньшей мере два узла хранения данных; модуль взаимодействия с файловой системой, по меньшей мере один первый сервер метаданных, предназначенный для обработки запросов, связанных с пространством имен файловой системы, по меньшей мере один второй сервер метаданных, предназначенный для управления фактическим местом в по меньшей мере одном узле хранения данных. 2 н. и 14 з.п. ф-лы, 5 ил.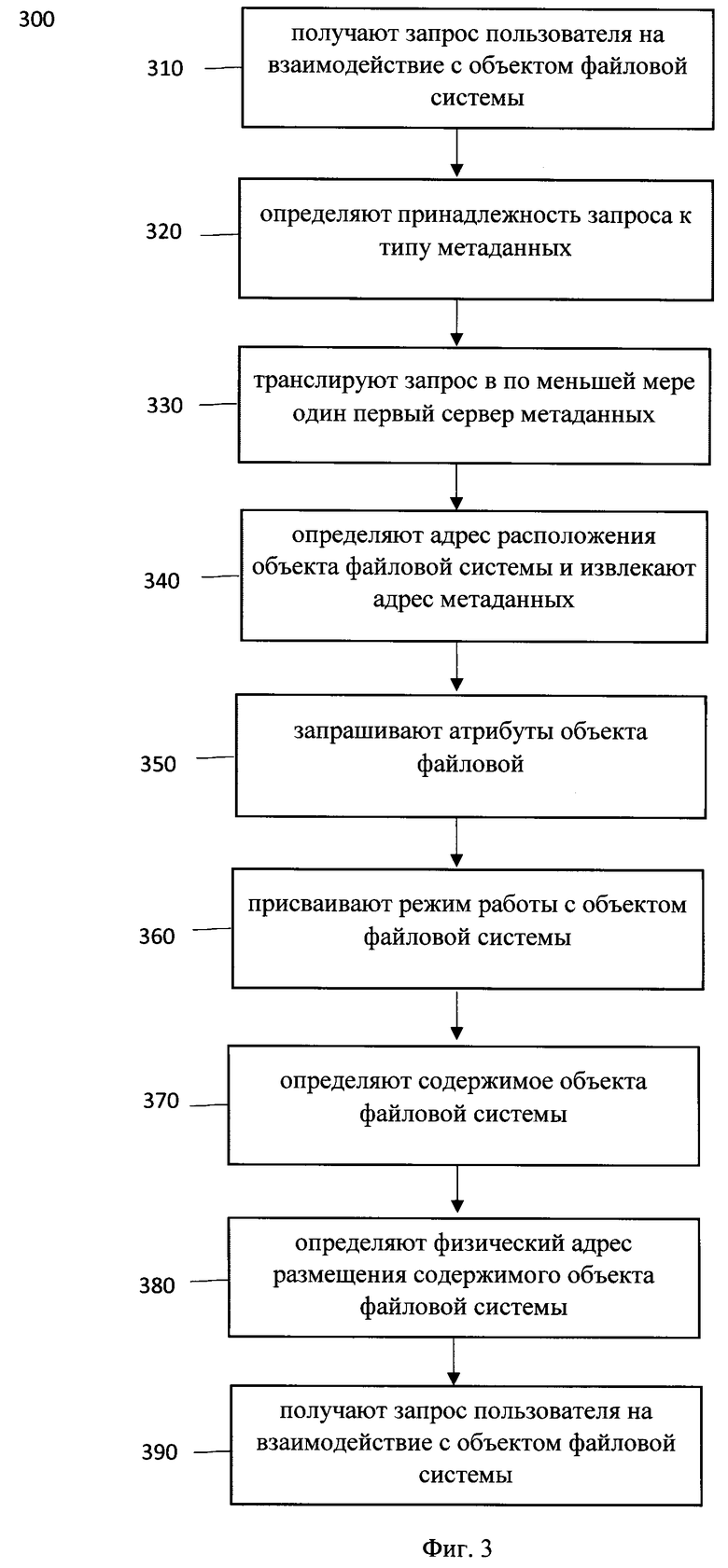
1. Распределенная система управления метаданными, содержащая:
• по меньшей мере два узла хранения данных, выполненных с возможностью распределенного хранения метаданных файловой системы;
• модуль взаимодействия с файловой системой, выполненный с возможностью:
- получения запроса пользователя на взаимодействие с файловой системой, содержащего по меньшей мере строковое имя объекта файловой системы;
- определения типа запроса пользователя, причем определение включает по меньшей мере отнесение запроса к метаданным, необходимым для ввода-вывода объекта файловой системы или метаданных, необходимых для работы с пространством имен файловой системы;
- трансляции определенного типа запроса пользователя на по меньшей мере один сервер метаданных;
- копирования результатов выполнения запроса;
• по меньшей мере один первый сервер метаданных, предназначенный для обработки запросов, связанных с пространством имен файловой системы, выполненный с возможностью:
- хранения иерархического пространства имен файловой системы, которое содержит сопоставления строковых имен объектов файловой системы с адресами метаданных объектов файловой системы, а также хранения атрибутов объектов файловой системы, связанных с состоянием объекта файловой системы;
- определения адреса расположения объекта файловой системы в пространстве имен файловой системы на основе строкового имени объекта файловой системы и извлечения адреса метаданных объекта файловой системы;
- управления состоянием объекта файловой системы;
• по меньшей мере один второй сервер метаданных, предназначенный для управления фактическим местом в по меньшей мере одном узле хранения данных, выполненный с возможностью:
- определения содержимого объекта файловой системы на основе адреса расположения объекта файловой системы;
- хранения и управления картой хранения содержимого объектов файловой системы;
- аллокации и деаллокации дискового пространства по меньшей мере одного узла хранения данных;
- трансляции по меньшей мере одного адреса содержимого объекта файловой системы, включающего зарезервированное дисковое пространство, модулю взаимодействия с файловой системой.
2. Система по п. 1, характеризующаяся тем, что объект файловой системы представляет собой по меньшей мере одно из: файл данных, директорию, символическую ссылку, жесткую ссылку.
3. Система по п. 1, характеризующаяся тем, что по меньшей мере один первый и второй сервер метаданных выполнены с возможностью отказоустойчивого хранения метаданных.
4. Система по п. 3, характеризующаяся тем, что отказоустойчивость хранения метаданных по меньшей мере одним первым и вторым сервером реализуется с помощью по меньшей мере репликации метаданных.
5. Система по п. 1, характеризующаяся тем, что кеширование результатов выполнения запроса представляет собой хранение во временной памяти данных, связанных с ответом по меньшей мере одного сервера метаданных на пользовательский запрос.
6. Система по п. 1, характеризующаяся тем, что управление состоянием файловой системы представляет по меньшей мере одно из:
- резервирование части метаданных, связанных с объектом файловой системы;
- резервирование пространства в хранилище данных;
- блокировка данных, связанных с объектом файловой системы;
- блокировка метаданных, связанных с объектом файловой системы;
- изменение состояния атрибутов объектов файловой системы;
- изменение строкового имени в адресе расположения метаданных объекта файловой системы;
- изменение количества ссылок, ведущих на объект файловой системы.
7. Система по п. 1, характеризующаяся тем, что управление картой хранения содержимого объектов файловой системы представляет по меньшей мере обработку запросов по определению содержимого искомого объекта файловой системы на основе адреса метаданных объекта файловой системы.
8. Система по п. 1, характеризующаяся тем, что строковые имена объектов файловой системы связаны с атрибутами объектов файловой системы.
9. Система по п. 1, характеризующаяся тем, что определение адреса расположения объекта файловой системы в пространстве имен файловой системы выполняется с помощью по меньшей мере одного первого сервера метаданных на основе итеративного определения, посредством адреса метаданных родительской папки и строкового имени дочерней папки, по порядку расположения объектов файловой системы до целевого объекта файловой системы.
10. Система по п. 1, характеризующаяся тем, что атрибуты объекта файловой системы представляют собой по меньшей мере:
- описание объекта файловой системы;
- права доступа к объекту файловой системы;
- информацию о владельце объекта файловой системы;
- дату последнего изменения объекта файловой системы;
- тип содержимого;
- размер содержимого.
11. Система по п. 1, характеризующаяся тем, что адрес расположения объекта файловой системы представляет собой структуру, состоящую из результата сопоставления строкового имени объекта с соответствующим ему адресом метаданных объекта.
12. Система по п. 1, характеризующаяся тем, что содержимое объекта файловой системы представляет собой по меньшей мере одну единицу данных, физически хранящуюся в распределенной системе хранения данных, составляющую информацию, которая содержится в объекте файловой системы.
13. Система по п. 11, характеризующаяся тем, что единица данных, физически хранящаяся в распределенной системе хранения данных, представляет собой по меньшей мере одно из: блок данных, строка, цепочка блоков данных, объект объектного хранилища.
14. Система по п. 1, характеризующаяся тем, что кеширование результатов выполнения запроса включает по меньшей мере кеширование определенного адреса метаданных объекта файловой системы.
15. Система по п. 1, характеризующаяся тем, что запрос пользователя на взаимодействие с файловой системой дополнительно содержит адрес метаданных объекта файловой системы.
16. Способ взаимодействия с объектом данных в распределенной системе хранения метаданных по любому из пп. 1-15, содержащий этапы, на которых:
а) получают запрос пользователя на взаимодействие с объектом файловой системы, причем запрос содержит по меньшей мере строковое имя объекта;
b) определяют, посредством модуля взаимодействия с файловой системой, принадлежность запроса к типу метаданных, которые необходимы для работы с пространством имен файловой системы;
c) транслируют запрос в по меньшей мере один первый сервер метаданных;
d) определяют с помощью по меньшей мере одного первого сервера метаданных адрес расположения объекта файловой системы в пространстве имен файловой системы и извлекают адрес метаданных объекта файловой системы;
e) запрашивают, по меньшей мере у одного первого сервера метаданных на основе данных, полученных на этапе d), атрибуты объекта файловой системы для проверки возможности доступа к объекту;
f) присваивают режим работы с объектом файловой системы, на основе адреса метаданных объекта, полученного на этапе d);
g) определяют, по меньшей мере одним вторым сервером, содержимое искомого объекта файловой системы на основе адреса метаданных объекта файловой системы, полученного на этапе d);
h) определяют результирующий физический адрес размещения содержимого объекта файловой системы в по меньшей мере одном узле хранения данных на основе информации, полученной на этапе g);
i) осуществляют доступ к содержимому объекта файловой системы на основе адреса размещения содержимого объекта файловой системы в по меньшей мере одном узле хранения данных на основе информации, полученной на этапе h).
| US 20140006465 A1, 02.01.2014 | |||
| PENG SUN и др | |||
| MetaFlow: a scalable metadata lookup service for distributed file systems in data centers, 10.11.2016, https://arxiv.org/pdf/1611.01594 | |||
| BENJAMIN CARVER и др | |||
| FS: a scalable and elastic distributed file system metadata service using serverless functions, 20.06.2023, https://arxiv.org/pdf/2306.11877 |

