Область техники
Изобретение относится к антивирусным технологиям, а более конкретно к системам и способам обнаружения вредоносных файлов.
Уровень техники
Бурное развитие компьютерных технологий в последнее десятилетие, а также широкое распространение разнообразных вычислительных устройств (персональных компьютеров, ноутбуков, планшетов, смартфонов и т.д.) стали мощным стимулом для использования упомянутых устройств в разнообразных сферах деятельности и для огромного количества задач (от интернет-серфинга до банковских переводов и ведения электронного документооборота). Параллельно с ростом количества вычислительных устройств и программного обеспечения, работающего на этих устройствах, быстрыми темпами росло и количество вредоносных программ.
В настоящий момент существует огромное количество разновидностей вредоносных программ. Одни крадут с устройств пользователей их персональные и конфиденциальные данные (например, логины и пароли, банковские реквизиты, электронные документы). Другие формируют из устройств пользователей так называемые бот-сети (англ. botnet) для таких атак, как отказ в обслуживании (англ. DDoS - Distributed Denial of Service), или для перебора паролей методом грубой силы (англ. bruteforce) на другие компьютеры или компьютерные сети. Третьи предлагают пользователям платный контент через навязчивую рекламу, платные подписки, отправку CMC на платные номера и т.д.
Для борьбы с вредоносными программами, включающей в себя обнаружение вредоносных программ, предотвращение заражения и восстановление работоспособности вычислительных устройств, зараженных вредоносными программами, применяются специализированные программы-антивирусы. Для обнаружения всего многообразия вредоносных программ антивирусные программы используют разнообразные технологии, такие как:
 статический анализ - анализ программ на вредоносность, исключающий запуск или эмуляцию работы анализируемых программ, на основании данных содержащихся в файлах, составляющих анализируемые программы, при этом при статистическом анализе могут использоваться:
статический анализ - анализ программ на вредоносность, исключающий запуск или эмуляцию работы анализируемых программ, на основании данных содержащихся в файлах, составляющих анализируемые программы, при этом при статистическом анализе могут использоваться:
 сигнатурный анализ - поиск соответствий какого-либо участка кода анализируемых программ известному коду (сигнатуре) из базы данных сигнатур вредоносных программ;
сигнатурный анализ - поиск соответствий какого-либо участка кода анализируемых программ известному коду (сигнатуре) из базы данных сигнатур вредоносных программ;
белые и черные списки - поиск вычисленных контрольных сумм от анализируемых программ (или их частей) в базе данных контрольных сумм вредоносных программ (черные списки) или базе данных контрольных сумм безопасных программ (белые списки);
динамический анализ - анализ программ на вредоносность на основании данных, полученных в ходе исполнения или эмуляции работы анализируемых программ, при этом при динамическом анализе могут использоваться:
эвристический анализ - эмуляция работы анализируемых программ, создание журналов эмуляции (содержащих данные по вызовам API-функций, переданным параметрам, участкам кода анализируемых программ и т.д.) и поиск соответствий данных из созданных журналов с данными из базы данных поведенческих сигнатур вредоносных программ;
проактивная защита - перехват вызовов API-функций запущенных анализируемых программ, создания журналов поведения анализируемых программ (содержащих данные по вызовам API-функций, переданным параметрам, участкам кода анализируемых программ и т.д.) и поиск соответствий данных из созданных журналов с данными из базы данных вызовов вредоносных программ.
И статический, и динамический анализ обладают своими плюсами и минусами. Статический анализ менее требователен к ресурсам вычислительного устройства, на котором выполняется анализ, а поскольку он не требует исполнения или эмуляции анализируемой программы, статистический анализ более быстрый, но при этом менее эффективен, т.е. имеет более низкий процент обнаружения вредоносных программ и более высокий процент ложных срабатываний (т.е. вынесения решения о вредоносности файла, анализируемого средствами программы-антивируса, при том, что анализируемый файл является безопасным). Динамический анализ из-за того, что использует данные, получаемые при исполнении или эмуляции работы анализируемой программы, более медленный и предъявляет более высокие требования к ресурсам вычислительного устройства на котором выполняется анализ, но при этом и более эффективен. Современные антивирусные программы используют комплексный анализ, включающий в себя как элементы статического, так и динамического анализа.
Поскольку современные стандарты информационной безопасности требуют оперативного реагирования на вредоносные программы (в особенности на новые), на первый план выходят автоматические средства обнаружения вредоносных программ. Для эффективной работы упомянутых средств зачастую применяются элементы искусственного интеллекта и разнообразные методы машинного обучения моделей обнаружения вредоносных программ (т.е. совокупности правил принятия решения о вредоносности файла на основании некоторого набора входных данных, описывающих вредоносный файл), позволяющие эффективно обнаруживать не только хорошо известные вредоносные программы или вредоносные программы с хорошо известным вредоносным поведением, но и новые вредоносные программы, обладающие неизвестным или слабо исследованным вредоносным поведением, а также оперативно адоптироваться (обучаться) к обнаружению новых вредоносных программ.
В патентной публикации US 9288220B2 описана технология обнаружения вредоносного ПО в сетевом трафике. С этой целью из данных, выбранных из сетевого трафика, выделяют характерные признаки (признаки, характеризующие тип исполняемого файла, поведение исполняемого файла, тип передаваемых по компьютерной сети данных, например тип и размер передаваемых по компьютерной сети данных, команды, выполняемые при исполнении файла, наличие заранее заданных сигнатур в файле и т.д.), в качестве которых может выступать признаковое описание выбранных данных, т.е. вектор (англ. feature vector), составленный из значений, соответствующих некоторому набору признаков для объекта, содержащего выбранные данные. Применяя модели обнаружения безопасных файлов, обнаружения вредоносных файлов и определения типов вредоносных файлов, предварительно обученные с использованием методов машинного обучения на основании шаблонов, составленных из схожих с упомянутыми характерных признаков, определяют, с каким весом и к какому типу вредоносного ПО относятся выбранные данные, и выносят решение об обнаружении вредоносного ПО в сетевом трафике.
Хотя описанная выше технология хорошо справляется с обнаружением вредоносных файлов, обладающих некоторыми характерными признаками (т.е. данными, описывающими некоторые особенности файлов из некоторой совокупности файлов, например, наличие графического интерфейса, шифрования данных, передачи данных по компьютерной сети и т.д.), схожими с характерными признаками уже известных вредоносных файлов, она не способна справиться с обнаружением вредоносных файлов, имеющих отличные характерные признаки (хотя и схожее поведение) от характерных признаков уже известных вредоносных файлов, кроме того описанная выше технология не раскрывает такие аспекты машинного обучения моделей, как тестирование и переобучение моделей, а также формирование и переформирование (в зависимости от результатов упомянутого выше тестирования) характерных признаков.
Настоящее изобретение позволяет решать задачу обнаружения вредоносных файлов.
Раскрытие изобретения
Изобретение предназначено для антивирусной проверки файлов.
Технический результат настоящего изобретения заключается в обнаружении вредоносных файлов с использованием обученной модели обнаружения вредоносных файлов.
Еще один технический результат настоящего изобретения заключается в повышении точности обнаружения вредоносных файлов за счет использования нескольких моделей обнаружения вредоносных файлов, каждая из которых обучена для обнаружения вредоносных файлов с уникальными заранее заданными характерными признаками.
Еще один технический результат настоящего изобретения заключается в повышении скорости обнаружения вредоносных файлов за счет использования нескольких моделей обнаружения вредоносных файлов, каждая из которых обучена для обнаружения вредоносных файлов с уникальными заранее заданными характерными признаками.
Данные результаты достигаются с помощью использования системы обнаружения вредоносных файлов с использованием обученной модели обнаружения вредоносных файлов, которая содержит средство анализа журнала поведения, предназначенное для формирования по меньшей мере одного шаблона поведения на основании команд и параметров, выбранных из журнала поведения исполняемого файла, при этом шаблон поведения представляет собой набор из по меньшей мере одной команды и такого параметра, который описывает все команды из упомянутого набора; вычисления свертки от всех сформированных шаблонов поведения; передачи сформированной свертки средству вычисления степени вредоносности; средство выбора моделей обнаружения, предназначенное для выборки из базы моделей обнаружения по меньшей мере двух моделей обнаружения вредоносных файлов на основании команд и параметров, выбранных из журнала поведения исполняемого файла, при этом модель обнаружения вредоносных файлов представляет собой решающее правило определения степени вредоносности; передачи всех выбранных моделей обнаружения вредоносных файлов средству вычисления степени вредоносности; средство вычисления степени вредоносности, предназначенное для вычисления степени вредоносности исполняемого файла на основании анализа полученной свертки с помощью каждой полученной модели обнаружения вредоносных файлов; передачи каждой вычисленной степени вредоносности средству анализа; средство анализа, предназначенное для формирования на основании полученных степени вредоносности шаблона решения; признания исполняемого файла вредоносным, в случае, когда степень схожести между сформированным шаблоном решения и по меньшей мере одним из заранее заданных шаблонов решения из базы шаблонов решения, предварительно сформированных на основании анализа вредоносных файлов, превышает заранее заданное пороговое значение.
В другом частном случае реализации системы система обнаружения вредоносных файлов с использованием обученной модели обнаружения вредоносных файлов дополнительно содержит средство формирования журналов поведения исполняемого файла, предназначенное для перехвата по меньшей мере одной команды по меньшей мере во время исполнения файла, эмуляции исполнения файла; определения для каждой перехваченной команды по меньшей мере одного параметра, описывающего упомянутую команду; формирования на основании перехваченных команд и определенных параметров журнала поведения упомянутого файла; передачи сформированного журнала поведения средству анализа журнала поведения и средству выбора моделей обнаружения.
Еще в одном частном случае реализации системы журнал поведения представляет собой совокупность исполняемых команд (далее - команда) из файла, где каждой команде соответствует по меньшей мере один параметр, описывающий упомянутую команду (далее - параметр).
В другом частном случае реализации системы вычисление свертки от сформированных шаблонов поведения выполняется на основании заранее заданной функции свертки, такой что обратная функция свертки от результата упомянутой функции свертки над всеми сформированными шаблонами поведения имеет степень схожести с упомянутым шаблоном поведения больше заданного значения.
Еще в одном частном случае реализации системы модель обнаружения вредоносных файлов была предварительно обучена методом машинного обучения на по меньшей мере одном безопасном файле и вредоносном файле.
В другом частном случае реализации системы в качестве метода машинного обучения модели обнаружения выступает по меньшей мере метод: градиентный бустинг на деревьях принятия решений; деревья принятия решений; ближайших соседей kNN; опорных векторов.
Еще в одном частном случае реализации системы метод обучения модели обнаружения обеспечивает монотонность изменения степени вредоносности файла в зависимости от изменения количества шаблонов поведения, сформированных на основании анализа журнала поведения.
В другом частном случае реализации системы шаблон решения представляет собой композицию степеней вредоносности.
Еще в одном частном случае реализации системы каждая выбранная из базы моделей обнаружения модель обнаружения вредоносных файлов обучена для обнаружения вредоносных файлов с уникальными заранее заданными характерными признаками.
В другом частном случае реализации системы дополнительно средство анализа предназначено для переобучения по меньшей мере одной модели обнаружения из базы моделей обнаружения на основании команд и параметров, выбранных из журнала поведения исполняемого файла, в случае, когда степень схожести между сформированным шаблоном решения и по меньшей мере одним из заранее заданных шаблонов решения из базы шаблонов решения превышает заранее заданное пороговое значение, а степени вредоносности, вычисленные с помощью упомянутых моделей обнаружения вредоносного файла, не превышают заранее заданного порогового значения.
Данные результаты достигаются с помощью использования способа обнаружения вредоносных файлов с использованием обученной модели обнаружения вредоносных файлов, при этом способ содержит этапы, которые реализуются с помощью средств из системы обнаружения вредоносных файлов с использованием обученной модели обнаружения вредоносных файлов и на которых формируют по меньшей мере один шаблон поведения на основании команд и параметров, выбранных из журнала поведения исполняемого файла, при этом шаблон поведения представляет собой набор из по меньшей мере одной команды и такого параметра, который описывает все команды из упомянутого набора; вычисляют свертку от всех сформированных на предыдущем этапе шаблонов поведения; выбирают из базы моделей обнаружения по меньшей мере две модели обнаружения вредоносных файлов на основании команд и параметров, выбранных из журнала поведения исполняемого файла, при этом модель обнаружения вредоносных файлов представляет собой решающее правило определения степени вредоносности; вычисляют степень вредоносности исполняемого файла на основании анализа вычисленной на предыдущем этапе свертки с помощью каждой выбранной на предыдущем этапе модели обнаружения вредоносных файлов; формируют на основании полученных на предыдущем этапе степеней вредоносности шаблона решения; признают исполняемый файл вредоносным, в случае, когда степень схожести между сформированным на предыдущем этапе шаблоном решения и по меньшей мере одним из заранее заданных шаблонов решения из базы шаблонов решения превышает заранее заданное пороговое значение.
В другом частном случае реализации способа дополнительно перехватывают по меньшей мере одну команду по меньшей мере во время исполнения файла, эмуляции исполнения файла; определяют для каждой перехваченной команды по меньшей мере один параметр, описывающий упомянутую команду; формируют на основании перехваченных команд и определенных параметров журнала поведения упомянутого файла.
Еще в одном частном случае реализации способа журнал поведения представляет собой совокупность исполняемых команд (далее - команда) из файла, где каждой команде соответствует по меньшей мере один параметр, описывающий упомянутую команду (далее - параметр).
В другом частном случае реализации способа вычисляют свертку от сформированных шаблонов поведения на основании заранее заданной функции свертки, такой что обратная функция свертки от результата упомянутой функции свертки над всеми сформированными шаблонами поведения имеет степень схожести с упомянутым шаблоном поведения больше заданного значения
Еще в одном частном случае реализации способа модель обнаружения вредоносных файлов была предварительно обучена методом машинного обучения на по меньшей мере одном безопасном файле и вредоносном файле.
В другом частном случае реализации способа в качестве метода машинного обучения модели обнаружения выступает по меньшей мере метод: градиентный бустинг на деревьях принятия решений; деревья принятия решений; ближайших соседей kNN; опорных векторов.
Еще в одном частном случае реализации способа метод обучения модели обнаружения обеспечивает монотонность изменения степени вредоносности файла в зависимости от изменения количества шаблонов поведения, сформированных на основании анализа журнала поведения.
В другом частном случае реализации способа шаблон решения представляет собой композицию степеней вредоносности.
Еще в одном частном случае реализации способа каждая выбранная из базы моделей обнаружения модель обнаружения вредоносных файлов обучена для обнаружения вредоносных файлов с уникальными заранее заданными характерными признаками.
В другом частном случае реализации способа переобучают по меньшей мере одну модель обнаружения из базы моделей обнаружения на основании команд и параметров, выбранных из журнала поведения исполняемого файла, в случае, когда степень схожести между сформированным шаблоном решения и по меньшей мере одним из заранее заданных шаблонов решения из базы шаблонов решения превышает заранее заданное пороговое значение, а степени вредоносности, вычисленные с помощью упомянутых моделей обнаружения вредоносного файла, не превышают заранее заданного порогового значения.
Краткое описание чертежей
Фиг. 1 представляет структурную схему системы машинного обучения модели обнаружения вредоносных файлов.
Фиг. 2 представляет структурную схему способа машинного обучения модели обнаружения вредоносных файлов.
Фиг. 3 представляет примеры динамики изменения степени вредоносности от количества шаблонов поведения.
Фиг. 4 представляет пример схемы связей между элементами шаблонов поведения.
Фиг. 5 представляет структурную схему системы обнаружения вредоносных файлов с использованием обученной модели обнаружения вредоносных файлов.
Фиг. 6 представляет структурную схему способа обнаружения вредоносных файлов с использованием обученной модели обнаружения вредоносных файлов.
Фиг. 7 представляет пример компьютерной системы общего назначения, персональный компьютер или сервер.
Хотя изобретение может иметь различные модификации и альтернативные формы, характерные признаки, показанные в качестве примера на чертежах, будут описаны подробно. Следует понимать, однако, что цель описания заключается не в ограничении изобретения конкретным его воплощением. Наоборот, целью описания является охват всех изменений, модификаций, входящих в рамки данного изобретения, как это определено приложенной формуле.
Описание вариантов осуществления изобретения
Объекты и признаки настоящего изобретения, способы для достижения этих объектов и признаков станут очевидными посредством отсылки к примерным вариантам осуществления. Однако настоящее изобретение не ограничивается примерными вариантами осуществления, раскрытыми ниже, оно может воплощаться в различных видах. Сущность, приведенная в описании, является ничем иным, как конкретными деталями, необходимыми для помощи специалисту в области техники в исчерпывающем понимании изобретения, и настоящее изобретение определяется в объеме приложенной формулы.
Введем ряд определений и понятий, которые будут использоваться при описании вариантов осуществления изобретения.
Вредоносный файл - файл, исполнение которого заведомо способно привести к несанкционированному уничтожению, блокированию, модификации, копирования компьютерной информации или нейтрализации средств защиты компьютерной информации.
Вредоносное поведение исполняемого файла - совокупность действий, которые могут быть выполнены при исполнении упомянутого файла и которые заведомо способны привести к несанкционированному уничтожению, блокированию, модификации, копированию информации или нейтрализации средств защиты компьютерной информации.
Вредоносная активность исполняемого файла - совокупность действий, выполненных упомянутым файлом в соответствии с его вредоносным поведением.
Вычислительное устройство среднестатистического пользователя - гипотетическое (теоретическое) вычислительное устройство, обладающее усредненными характеристиками вычислительных устройств заранее выбранной группы пользователей, на котором исполняются те же приложения, что и на вычислительных устройствах упомянутых пользователей.
Команда, исполняемая вычислительным устройством, - совокупность машинных инструкций или инструкций сценариев, исполняемых вычислительным устройством на основании параметров упомянутых инструкций, называемых параметрами команды или параметрами, описывающими упомянутую команду.
Лексический анализ («токенизация», от англ. tokenizing) - процесс аналитического разбора входной последовательности символов на распознанные группы (далее - лексемы) с целью формирования на выходе идентификационных последовательностей (далее - токены).
Токен - идентификационная последовательность, формируемая из лексемы в процессе лексического анализа.
Фиг. 1 представляет структурную схему системы машинного обучения модели обнаружения вредоносных файлов.
Структурная схема системы машинного обучения состоит из средства подготовки обучающих выборок 111, средства формирования журналов поведения 112, средства формирования шаблонов поведения 121, средства формирования функций свертки 122, средства создания модели обнаружения 131, средства машинного обучения модели обнаружения 132, средства вычисления степени вредоносности 142, средства управления ресурсами 143.
В одном из вариантов реализации системы упомянутая система машинного обучения модели обнаружения представляет собой клиент-серверную архитектуру, в которой средство подготовки обучающих выборок 111, средство формирования журналов поведения 112, средство формирования шаблонов поведения 121, средство формирования функций свертки 122, средство создания модели обнаружения 131 и средство машинного обучения модели обнаружения 132 работают на стороне сервера, а средство формирования шаблонов поведения 121, средство вычисления степени вредоносности 142 и средство управления ресурсами 143 работают на стороне клиента.
Например, в качестве клиента могут выступать вычислительные устройства пользователя такие, как персональный компьютер, ноутбук, смартфон и т.д., а в качестве сервера могут выступать вычислительные устройства антивирусной компании такие, как распределенные системы серверов, с помощью которых кроме всего прочего предварительно осуществляют сбор и антивирусный анализ файлов, создание антивирусных записей и т.д., при этом система машинного обучения модели обнаружения вредоносных файлов будет использована для обнаружения вредоносных файлов на клиенте, тем самым повышая эффективность антивирусной защиты упомянутого клиента.
Еще в одном примере в качестве как клиента, так и сервера могут выступать вычислительные устройства только антивирусной компании, при этом система машинного обучения модели обнаружения вредоносных файлов будет использована для автоматизированного антивирусного анализа файлов и создания антивирусных записей, тем самым повышая эффективность работы антивирусной компании.
Средство подготовки обучающих выборок 111 предназначено для:
 выборки по меньшей мере одного файла из базы файлов согласно заранее заданным правилам формирования обучающей выборки файлов, впоследствии на основании анализа выбранных файлов средство машинного обучения модели обнаружения 132 будет выполнять обучение модели обнаружения;
выборки по меньшей мере одного файла из базы файлов согласно заранее заданным правилам формирования обучающей выборки файлов, впоследствии на основании анализа выбранных файлов средство машинного обучения модели обнаружения 132 будет выполнять обучение модели обнаружения;
передачи выбранных файлов средству формирования журналов поведения 112.
В одном из вариантов реализации системы в базе файлов хранится по меньшей мере один безопасный файл и один вредоносный файл.
Например, в базе файлов в качестве безопасных файлов могут храниться файлы операционной системы «Windows», а в качестве вредоносных - файлы бэкдоров (англ. backdoor), приложений, осуществляющих несанкционированный доступ к данным и удаленному управлению операционной системой и компьютером в целом. При этом обученная на упомянутых файлах с помощью методов машинного обучения модель обнаружения вредоносных файлов будет способна с высокой точностью (точность тем выше, чем больше файлов было использовано для обучения упомянутой модели обнаружения) обнаруживать вредоносные файлы, обладающие функционалом, схожим с функционалом упомянутых выше бэкдоров.
Еще в одном из вариантов реализации системы дополнительно в базе файлов хранятся по меньшей мере:
подозрительные файлы (англ. riskware) - файлы, не являющиеся вредоносными, но способные выполнять вредоносные действия;
неизвестные файлы - файлы, вредоносность которых не была определена и остается неизвестной (т.е. файлы, не являющиеся безопасными, вредоносными, подозрительными и т.д.).
Например, в базе файлов в качестве подозрительных файлов могут выступать файлы приложений удаленного администрирования (к примеру, RAdmin), архивации или шифрования данных (к примеру, WinZip) и т.д.
Еще в одном из вариантов реализации системы в базе файлов хранятся файлы по меньшей мере:
собранные антивирусными поисковыми роботами (англ. web crawler);
переданные пользователями.
При этом упомянутые файлы анализируются антивирусными экспертами, в том числе с помощью автоматических средств анализа файлов, для последующего вынесения решение о вредоносности упомянутых файлов.
Например, в базе файлов могут храниться файлы, переданные пользователями со своих вычислительных устройств антивирусным компаниям для проверки на вредоносность, при этом переданные файлы могут быть как безопасными, так и вредоносными, при этом распределение между количеством упомянутых безопасных и вредоносных файлов близко к распределению между количеством всех безопасных и вредоносных файлов, расположенных на вычислительных устройствах упомянутых пользователей (т.е. отношение количества упомянутых безопасных к количеству упомянутых вредоносных файлов отличается от отношения количества всех безопасных к количеству всех вредоносных файлов, расположенных на вычислительных устройствах упомянутых пользователей на величину меньше заданного порогового значения

). В отличие от файлов, переданных пользователями (т.е. файлов, субъективно подозрительных), файлы, собранные антивирусными поисковыми роботами, созданными для поиска подозрительных и вредоносных файлов, чаще оказываются вредоносными.
Еще в одном из вариантов реализации системы в качестве критериев, согласно которым выбираются файлы из базы файлов, выступает по меньшей мере одно из условий:
распределение между безопасными и вредоносными файлами, выбранными из базы файлов, соответствует распределению между безопасными и вредоносными файлами, расположенными на вычислительном устройстве среднестатистического пользователя;
распределение между безопасными и вредоносными файлами, выбранными из базы файлов, соответствует распределению между безопасными и вредоносными файлами, собранными с помощью антивирусных поисковых роботов;
параметры файлов, выбранных из базы файлов, соответствуют параметрам файлов, расположенных на вычислительном устройстве среднестатистического пользователя;
количество выбранных файлов соответствует заранее заданному значению, а сами файлы выбраны случайным образом.
Например, база файлов содержит 100000 файлов, среди которых 40% безопасных файлов и 60% вредоносных файлов. Из базы файлов выбирают 15000 файлов (15% от общего количества файлов, хранящихся в базе файлов) таким образом, чтобы распределение между выбранными безопасными и вредоносными файлами соответствовало распределению между безопасными и вредоносными файлами, расположенными на вычислительном устройстве среднестатистического пользователя и составляло 95 к 5. С этой целью из базы файлов случайным образом выбирают 14250 безопасных файлов (35,63% от общего числа безопасных файлов) и 750 вредоносных файлов (1,25% от общего числа вредоносных файлов).
Еще в одном примере база файлов содержит 1250000 файлов, среди которых 95% безопасных файлов и 5% вредоносных файлов, т.е. распределение между безопасными и вредоносными файлами, хранящимися в базе файлов, соответствует распределению между безопасными и вредоносными файлами, расположенными на вычислительном устройстве среднестатистического пользователя. Среди упомянутых файлов случайным образом выбирают 5000 файлов, среди которых с большой вероятностью окажется ~4750 безопасных файлов и ~250 вредоносных файлов.
Еще в одном из вариантов реализации системы в качестве параметров файла выступает по меньшей мере:
вредоносность файла, характеризующая, является ли файл безопасным, вредоносным, потенциально опасным или поведение вычислительной системы при исполнении файла не определено и т.д.;
количество команд, выполненных вычислительным устройством во время исполнения файла;
размер файла;
приложения, использующие файл.
Например, из базы файлов выбирают вредоносные файлы, представляющие собой сценарии на языке «ActionScript», выполняемые приложением «Adobe Flash», и не превышающие размер в 5КБ.
Еще в одном из вариантов реализации системы дополнительно средство подготовки обучающих выборок 111 предназначено для:
выборки по меньшей мере еще одного файла из базы файлов согласно заранее заданным правилам формирования тестовой выборки файлов, при этом впоследствии на основании анализа выбранных файлов средство машинного обучения модели обнаружения 132 будет выполнять проверку обученной модели обнаружения;
передачи выбранных файлов средству формирования журналов поведения 112.
Например, база файлов содержит 75000 файлов, среди которых 20% безопасных файлов и 80% вредоносных файлов. Изначально из базы файлов выбирают 12500 файлов, среди которых 30% безопасных файлов и 70% вредоносных файлов, при этом впоследствии на основании анализа выбранных файлов средство машинного обучения модели обнаружения 132 будет выполнять обучение модели обнаружения, затем из оставшихся 62500 файлов выбирают 2500 файлов, среди которых 60% безопасных файлов и 40% вредоносных файлов, при этом впоследствии на основании анализа выбранных файлов средство машинного обучения модели обнаружения 132 будет выполнять проверку обученной модели обнаружения. Данные, сформированные описанным выше образом, называется набором данных для перекрестной проверки (англ. cross-validation set of data).
Средство формирования журналов поведения 112 предназначено для:
перехвата по меньшей мере одной исполняемой команды по меньшей мере во время:
 исполнения полученного файла,
исполнения полученного файла,
эмуляции исполнения полученного файла, при этом эмуляция исполнения файла включает в том числе открытие упомянутого файла (например, открытие сценария интерпретатором);
определения для каждой перехваченной команды по меньшей мере одного параметра, описывающего упомянутую команду;
формирования на основании перехваченных команд и определенных параметров журнала поведения полученного файла, при этом журнал поведения представляет собой совокупность перехваченных команд (далее - команда) из файла, где каждой команде соответствует по меньшей мере один определенный параметр, описывающий упомянутую команду (далее - параметр).
Например, перехваченные во время исполнения вредоносного файла, собирающего пароли и передающего их по компьютерной сети, команды и вычисленные параметры упомянутых команд могут иметь вид:
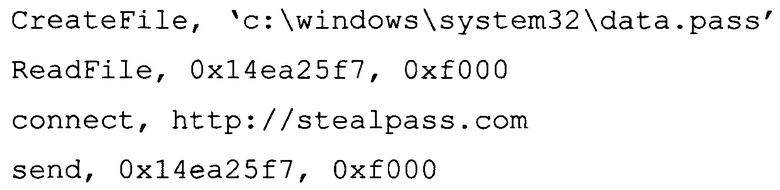
В одном из вариантов реализации системы перехват команд из файла осуществляется с помощью по меньшей мере:
специализированного драйвера;
средства отладки (англ. debugger);
гипервизора (англ. hypervisor).
Например, перехват команд при исполнении файла и определение их параметров осуществляется с помощью драйвера, использующего перехват сплайсингом (англ. splicing) точки входа (англ. entry point) WinAPI-функции.
Еще в одном примере перехват команд при эмуляции работы файла осуществляется непосредственно средствами эмулятора, выполняющего упомянутую эмуляцию, который определяет параметры команды, которую требуется эмулировать.
Еще в одном примере перехват команд при исполнении файла на виртуальной машине осуществляется средствами гипервизора, который определяет параметры команды, которую требуется эмулировать.
Еще в одном из вариантов реализации системы в качестве перехваченных команд из файла выступают по меньшей мере:
API-функции;
совокупности машинных инструкций, описывающих заранее заданный набор действий (макрокоманд).
Например, очень часто вредоносные программы осуществляют поиск некоторых файлов и модификацию их атрибутов, для чего выполняется последовательность команд, таких как:

, что может быть в свою очередь описано лишь одной командой
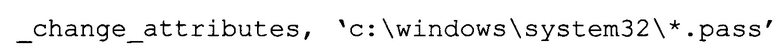
Еще в одном из вариантов реализации системы каждой команде ставится в соответствие свой уникальный идентификатор.
Например, всем WinAPI функциям могут быть поставлены в соответствие числа в диапазоне от 0×0000 до 0×8000, при этом каждой WinAPI-функции соответствует свое уникальное число (к примеру, ReadFile→0×00f0, ReadFileEx→0×00f1, connect→0×03A2).
Еще в одном из вариантов реализации системы нескольким командам, описывающим схожие действия, ставится в соответствие единый идентификатор.
Например, всем командам, таким как ReadFile, ReadFileEx, ifstream, getline, getchar и т.д., описывающим чтение данных из файла, ставится в соответствие идентификатор _read_data_file (0×70F0).
Средство формирования шаблонов поведения 121 предназначено для:
 формирования по меньшей мере одного шаблона поведения на основании команд и параметров, выбранных из журнала поведения, при этом журнал поведения представляет собой совокупность исполняемых команд (далее - команда) из файла, где каждой команде соответствует по меньшей мере один параметр, описывающий упомянутую команду (далее - параметр), шаблон поведения представляет собой набор из по меньшей мере одной команды и такого параметра, который описывает все команды из упомянутого набора (далее - элементы шаблона поведения);
формирования по меньшей мере одного шаблона поведения на основании команд и параметров, выбранных из журнала поведения, при этом журнал поведения представляет собой совокупность исполняемых команд (далее - команда) из файла, где каждой команде соответствует по меньшей мере один параметр, описывающий упомянутую команду (далее - параметр), шаблон поведения представляет собой набор из по меньшей мере одной команды и такого параметра, который описывает все команды из упомянутого набора (далее - элементы шаблона поведения);
передачи сформированных шаблонов поведения средству формирования функций свертки 122.
Например, из журнала поведения выбирают следующие команды ci (от англ. command) и параметры pi (от англ. parameter):
{c1,p1, p2, p3},
{c2, p1, p4},
{c3, p5},
{c2, p5},
{c1,p5, p6},
{с3, p2}.
На основании выбранных команд и параметров формируют шаблоны поведения, содержащие по одной команде и одному параметру, описывающему упомянутую команду:
{c1, p1}, {с1, р2}, {с1, р3}, {c1, p5}, {с1, p6},
{c2, p1}, {c2, p4}, {c2, p5},
{c3, p2}, {с3, p5}.
Затем на основании сформированных шаблонов дополнительно формируют шаблоны поведения, содержащие по одному параметру и все команды, описываемые упомянутым параметром:
{c1, c2, p3},
{c1, c3, p2},
{c1, c2, c3, p5},
Затем на основании сформированных шаблонов дополнительно формируют шаблоны поведения, содержащие по несколько параметров и все команды, одновременно описываемые упомянутыми параметрами:
{c1, c2, p1, p5}.
В одном из вариантов реализации системы команды и параметры из журнала поведения выбирают на основании правил, по которым по меньшей мере выбирают:
 последовательно каждую i-ю команду и описывающие ее параметры, при этом шаг i является заранее заданным;
последовательно каждую i-ю команду и описывающие ее параметры, при этом шаг i является заранее заданным;
команды, выполненные через заранее заданный промежуток времени (например, каждую десятую секунду) после предыдущей выбранной команды, и описывающие их параметры;
команды и описывающие их параметры, выполненные в заранее заданном временном диапазоне с начала исполнения файла;
команды из заранее заданного списка и описывающие их параметры;
параметры из заранее заданного списка и описываемые упомянутыми параметрами команды;
первые или случайные k параметров команд, в случае, когда количество параметров команд больше заранее заданного порогового значения.
Например, из журнала поведения выбирают все команды для работы с жестким диском (такие как CreateFile, ReadFile, WriteFile, DeleteFile, GetFileAttribute и т.д.) и все параметры, описывающие выбираемые команды.
Еще в одном примере из журнала поведения выбирают каждую тысячную команду и все параметры, описывающие выбираемые команды.
В одном из вариантов реализации системы журналы поведения заранее сформированы из по меньшей мере двух файлов, один из которых - безопасный файл, а другой - вредоносный файл.
Еще в одном из вариантов реализации системы каждому элементу шаблона поведения ставится в соответствие такая характеристика, как тип элемента шаблона поведения. В качестве типа элемента шаблона поведения (команды или параметра) выступает по меньшей мере:
в случае, если элемент шаблона поведения может быть выражен в виде числа - «численный диапазон»
например, для элемента шаблона поведения, представляющего собой параметр porthtml = 80 команды connect, тип упомянутого элемента шаблона поведения может быть «численное значение от 0×0000 до 0×FFFF»,
в случае, если элемент шаблона поведения может быть выражен в виде строки - «строка»
например, для элемента шаблона поведения, представляющего собой команду connect, тип упомянутого элемента шаблона поведения может быть «строка размером менее 32 символов»,
в случае, если элемент шаблона поведения может быть выражен в виде данных, описываемых заранее заданной структурой данных, тип упомянутого элемента шаблона поведения может быть «структура данных»
например, для элемента шаблона поведения, представляющего собой параметр src=0×336b9a480d490982cdd93e2e49fdeca7 команды find_record, тип упомянутого элемента шаблона поведения может быть «структура данных MD5».
Еще в одном из вариантов реализации системы дополнительно в шаблон поведения в качестве элементов шаблона поведения включаются токены, сформированные на основании лексического анализа упомянутых элементов шаблона поведения с использованием по меньшей мере:
заранее заданных правил формирования лексем,
заранее обученной рекурсивной нейронной сети (англ. recurrent neural network).
Например, с помощью лексического анализа параметра
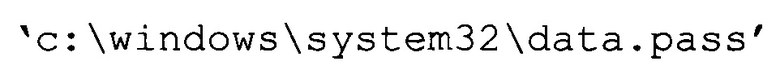
на основании правил формирования лексем:
если строка содержит путь к файлу, определить диск, на котором расположен файл;
если строка содержит путь к файлу, определить папки, в которых расположен файл;
если строка содержит путь к файлу, определить расширение файла;
где в качестве лексем выступают:
пути к файлу;
папки, в которых расположены файлы;
имена файлов;
расширения файлов;
могут быть сформированы токены:
«пути к файлу» →
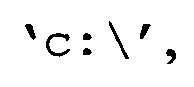
«папки, в которых расположены файлы» →

«расширения файлов» →
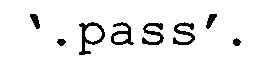
Еще в одном примере с помощью лексического анализа параметров
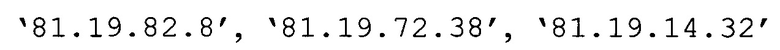
на основании правила формирования лексемы:
если параметры представляют собой IP-адреса, определить битовую маску (или ее аналог, выраженный через метасимволы), описывающую упомянутые IP-адреса (т.е. такую битовую маску М, для которой верно равенство М∧IP=const для всех упомянутых IP);
может быть сформирован токен:
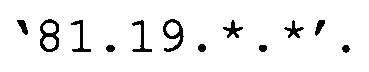
Еще в одном примере из всех доступных параметров, в качестве которых выступают числа, формируют токены чисел в заранее заданных диапазонах:
23, 16, 7224, 6125152186, 512, 2662162, 363627632, 737382, 52, 2625, 3732, 812, 3671, 80, 3200
сортируют по диапазонам чисел:

Еще в одном из вариантов реализации системы токены формируются из элементов шаблона поведения, в качестве которых выступают строки.
Например, шаблон поведения представляет собой путь к файлу, содержащему названия диска, директории, файла, расширения файла и т.д. В этом случае токен может представлять собой название диска и расширение файла.

Средство формирования функций свертки 122 предназначено для:
 формирования такой функции свертки от шаблона поведения, что обратная функция свертки от результата такой функции свертки над полученным шаблоном поведения будет иметь степень схожести с полученным шаблоном поведения больше заданного значения, т.е.
формирования такой функции свертки от шаблона поведения, что обратная функция свертки от результата такой функции свертки над полученным шаблоном поведения будет иметь степень схожести с полученным шаблоном поведения больше заданного значения, т.е.
r~g-1(g(r))
где:
ri - шаблон поведения,
g - функция свертки,
g-1 - обратная функция свертки.
передачи сформированной функции свертки средству машинного обучения модели обнаружения 132.
В одном из вариантов реализации системы средство формирования функций свертки дополнительно предназначено для:
вычисления признакового описания (англ. feature vector) шаблона поведения на основании полученного шаблона поведения, при этом признаковое описание шаблона поведения может быть выражено как сумма хэш-сумм от элементов шаблона поведения;
формирования функции свертки от признакового описания шаблона поведения, при этом функция свертки представляет собой хэш-функцию, такую, что степень схожести вычисленного признакового описания и результата обратной хэш-функции от результата упомянутой хэш-функции от вычисленного признакового описания больше заранее заданного значения.
Еще в одном из вариантов реализации системы функция свертки формируется методом метрического обучения (англ. metric learning), т.е. таким образом, что расстояние между свертками, полученными с помощью упомянутой функции свертки для шаблонов поведения имеющих степень схожести больше заранее заданного порогового значения было меньше заранее заданного порогового значения, а для шаблонов поведения имеющих степень схожести менее заранее заданного порогового значения - больше заранее заданного порогового значения.
Например, признаковое описание шаблона поведения может вычисляться следующим образом:
предварительно создают пустой битовый вектор, состоящий из 100000 элементов (где для каждого элемента вектора зарезервирован один бит информации);
для хранения данных о командах ci из шаблона поведения r отводят 1000 элементов, оставшиеся 99000 элементов отводят для параметров ci из шаблона поведения r, при этом для строковых параметров отводят 50000 элементов (с 1001 элемента по 51000 элемент), для численных - 25000 элементов (с 51001 элемента по 76000 элемент);
каждой команде c1 из шаблона поведения r ставят в соответствие некоторое число xi от 0 до 999, и устанавливают соответствующий бит в созданном векторе
ν[xi]=true;
для каждого параметра pi из шаблона поведения r вычисляют хэш-сумму по формуле:
 для строк: yi=1001+crc32(pi) (mod 50000)
для строк: yi=1001+crc32(pi) (mod 50000)
для чисел: yi=51001+crc32(pi) (mod 25000)
для остального: yi=76001+crc32(pi) (mod 24000)
и в зависимости от вычисленной хэш-суммы устанавливают соответствующий бит в созданном векторе
ν[yi]=true;
Описанный битовый вектор с установленными элементами представляет собой признаковое описание шаблона поведения r.
Еще в одном из вариантов реализации системы признаковое описание шаблона поведения вычисляется согласно формуле:
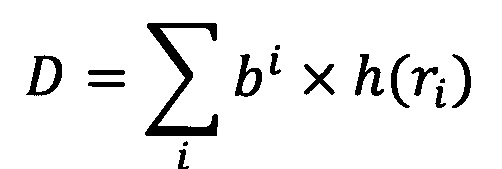
где:
b - основание позиционной системы счисления (например, для бинарного вектора b=2, для вектора, представляющего собой строку, т.е. совокупность символов, b=8),
ri - i-й элемент шаблона поведения,
h - хэш-функция, при этом 0≤h(ri)<b.
Например, признаковое описание шаблона поведения может вычисляться следующим образом:
предварительно создают еще один (отличный от предыдущего примера) пустой битовый вектор, состоящий из 1000 элементов (где для каждого элемента вектора зарезервирован один бит информации);
для каждого элемента шаблона ri из шаблона поведения r вычисляют хэш-сумма по формуле:
хi=2crc32(ri) (mod 1000)
и в зависимости от вычисленной хэш-суммы устанавливают соответствующий бит в созданном векторе
ν[xi]=true;
Еще в одном из вариантов реализации системы признаковое описание шаблона поведения представляет собой фильтр Блума.
Например, признаковое описание шаблона поведения может вычисляться следующим образом:
предварительно создают еще один (отличный от предыдущих примеров) пустой вектор, состоящий из 100000 элементов;
для каждого элемента шаблона ri из шаблона поведения r вычисляют по меньшей мере две хэш-суммы с помощью набора хэш-функций {hj} по формуле:
xij=hj(ri)
где:
hj(ri)=crc32(ri),
hj(0)=constj
и в зависимости от вычисленных хэш-сумм устанавливают соответствующие элементы в созданном векторе
ν[xij]=true.
Еще в одном из вариантов реализации системы размер результата сформированной функции свертки от признакового описания шаблона поведения меньше размера упомянутого признакового описания шаблона поведения.
Например, признаковое описание представляет собой битовый вектор, содержащий 100000 элементов, и тем самым имеет размер 12500 байт, а результат функции свертки от упомянутого признакового описания представляет собой набор из 8 MD5 хэш-сумм и тем самым имеет размер 256 байт, т.е. ~2% от размера признакового описания.
Еще в одном из вариантов реализации системы степень схожести признакового описания и результата обратной хэш-функции от результата упомянутой хэш-функции от вычисленного признакового описания представляет собой численное значение в диапазоне от 0 до 1 и вычисляется согласно формуле:
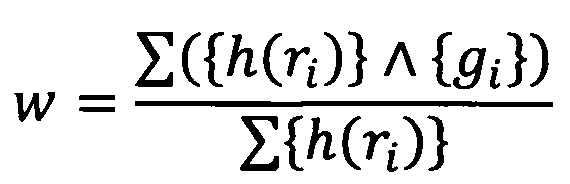
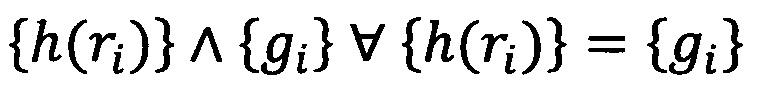
где:
h(ri)∧gi обозначает совпадение h(ri) с gi
и
{h(ri)} совокупность результатов хэш-функций от элементов шаблона поведения,
{gi} - совокупность результатов обратной хэш-функции от результата хэш-функции от элементов шаблона поведения,
ri - i-й элемент шаблона поведения,
h - хэш-функция,
w - степень схожести.
Например, вычисленное признаковое описание представляет собой битовый вектор

результат функции свертки от упомянутого признакового описания
а результат обратной функции свертки от полученного выше результата

(где жирным шрифтом отмечены элементы, отличные от признакового описания). Таким образом, схожесть признакового описания и результата обратной функции свертки составляет 0,92.
Еще в одном из вариантов реализации системы упомянутая хэш-функция, принимающая в качестве параметра элемент шаблона поведения, зависит от типа элемента шаблона поведения:
h(ri)=hri(ri)
Например, для вычисления хэш-суммы от параметра из шаблона поведения, представляющего собой строку, содержащую путь к файлу, используется хэш-функция CRC32, любую другую строку - алгоритм Хаффмана, набор данных - хэш-функция MD5.
Еще в одном из вариантов реализации системы формирование функции свертки от признакового описания шаблона поведения выполняется через автокодировщик (англ. autoencoder), при этом в качестве входных данных выступают элементы упомянутого признакового описания шаблона поведения, а в качестве выходных данных - данных, имеющие коэффициент схожести с входными данными выше заранее заданного порогового значения.
Средство создания модели обнаружения 131 предназначено для:
 создания модели обнаружения вредоносных файлов, которое включает в себя по меньшей мере:
создания модели обнаружения вредоносных файлов, которое включает в себя по меньшей мере:
 выбор метода машинного обучения модели обнаружения;
выбор метода машинного обучения модели обнаружения;
инициализации параметров модели обучения, при этом параметры модели обучения, проинициализированные до начала машинного обучения модели обнаружения, называются гиперпараметрами (англ. hyperparameter);
в зависимости от параметров файлов, выбранных средством подготовки обучающих выборок 111;
передачи созданной модели обучения средству машинного обучения модели обнаружения 132.
Например, при выборе метода машинного обучения модели обнаружения вначале выносится решение следует ли использовать в качестве модели обнаружения искусственную нейронную сеть или случайные леса (англ. random forest), затем, в случае выбора случайного леса, выбирается разделяющий критерий для узлов случайного леса; или в случае выбора искусственной нейронной сети, выбирается метод численной оптимизации параметров искусственной нейронной сети. При этом решение о выборе того или иного метода машинного обучения принимается на основании эффективности упомянутого метода при обнаружении вредоносных файлов (т.е. количества ошибок первого и второго рода, возникающих при обнаружении вредоносных файлов) с использованием входных данных (шаблонов поведения) заранее заданного вида (т.е. структуры данных, количества элементов шаблонов поведения, производительности вычислительного устройства на котором выполняется поиск вредоносных файлов, доступных ресурсов вычислительного устройства и т.д.).
Еще в одном примере метод машинного обучения модели обнаружения выбирают на основании по меньшей мере:
перекрестной проверки, скользящего контроля, кросс-валидации (англ. cross-validation, CV);
математического обоснования критериев AIC, BIC и т.д.;
А/В тестирования (англ. А/В testing, split testing);
стекинга.
Еще в одном примере в случае невысокой производительности вычислительного устройства выбирают случайные леса, в противном случае - искусственную нейронную сеть.
В одном из вариантов реализации системы выполняется машинное обучение заранее созданной необученной модели обнаружения (т.е. модели обнаружения, у которой параметры упомянутой модели не позволяют получить на основании анализа входных данных выходных данных с точностью выше заранее заданного порогового значения).
Еще в одном из вариантов реализации системы в качестве метода машинного обучения модели обнаружения выступает по меньшей мере метод:
градиентный бустинг на деревьях принятия решений (англ. decision-tree-based gradient boosting);
деревья принятия решений (англ. decision trees);
ближайших соседей kNN (англ. K-nearest neighbor method);
опорных векторов (англ. support vector machine, SVM).
Еще в одном из вариантов реализации системы дополнительно средство создания модели обнаружения 131 предназначено для создания модели обнаружения по запросу от средства машинного обучения 132, при этом определенные гиперпараметры и методы машинного обучения выбираются отличными от гиперпараметров и методов машинного обучения, выбранных для предыдущей модели обнаружения.
Средство машинного обучения модели обнаружения 132 предназначено для обучения модели обнаружения, в которой параметры модели обнаружения вычисляются с использованием полученной функции свертки над полученными шаблонами поведения, где модель обнаружения представляет собой совокупность правил вычисления степени вредоносности файла на основании по меньшей мере одного шаблона поведения с использованием вычисленных параметров упомянутой модели обнаружения.
Например, модель обнаружения обучают на известном наборе файлов, выбранных средством подготовки обучающих выборок 111, при этом упомянутый набор файлов содержит 60% безопасных файлов и 40% вредоносных файлов.
В одном из вариантов реализации системы степень вредоносности файла представляет собой численное значение от 0 до 1, при этом 0 означает, что упомянутый файл безопасный, 1 - вредоносный.
Еще в одном из вариантов реализации системы выбирается метод обучения модели обнаружения, обеспечивающий монотонность изменения степени вредоносности файла в зависимости от изменения количества шаблонов поведения, сформированных на основании анализа журнала поведения.
Например, монотонное изменение степени вредоносности файла приводит к тому, что при анализе каждого последующего шаблона поведения, вычисленная степень вредоносности оказывается не меньше чем, вычисленная ранее степень вредоносности (к примеру, после анализа 10-го шаблона поведения вычисленная степень вредоносности равна 0,2 после анализа 50-го шаблона поведения - 0,4, а после анализа 100-го шаблона поведения - 0,7).
Еще в одном из вариантов реализации системы дополнительно средство машинного обучения модели обнаружения 132 предназначено для:
выполнения проверки обученной модели обнаружения на полученных журналах поведения, сформированных на основании анализа файлов из тестовой выборки файлов, с целью определить корректность определения вредоносности файлов из тестовой выборки файлов;
в случае отрицательного результата проверки передачи запроса по меньшей мере:
 средству подготовки обучающих выборок 111 для подготовки выборки файлов, отличной от текущей, на которой производилось обучение модели обнаружения;
средству подготовки обучающих выборок 111 для подготовки выборки файлов, отличной от текущей, на которой производилось обучение модели обнаружения;
средству создания модели обнаружения 131 для создания новой модели обнаружения, отличной от текущей.
При этом проверка обученной модели обнаружения заключается в следующем. Упомянутая модель обнаружения была обучена на основании набора выбранных средством подготовки обучающих выборок 111 файлов, для которых было известно, являются ли они безопасными или вредоносными. Для того, чтобы проверить, что модель обнаружения вредоносных файлов была обучена корректно, т.е. упомянутая модель обнаружения сможет обнаруживать вредоносные файлы и пропускать безопасные файлы, выполняется проверка упомянутой модели. С этой целью с помощью упомянутой модели обнаружения определяют, являются ли файлы из другого набора выбранных средством подготовки обучающих выборок 111 файлов вредоносными, при этом, являются ли упомянутые файлы вредоносными, известно заранее. Таким образом, определяют, сколько вредоносных файлов было «пропущено» и сколько безопасных файлов было обнаружено. Если количество пропущенных вредоносных и обнаруженных безопасных файлов больше заранее заданного порогового значения, то упомянутая модель обнаружения считается некорректно обученной и требуется выполнить ее повторное машинное обучение (например, на другой обучающей выборке файлов, с использованием отличных от предыдущих значений параметров модели обнаружения и т.д.).
Например, при выполнении проверки обученной модели проверяется количество ошибок первого и второго рода при обнаружении вредоносных файлов из тестовой выборки файлов. Если количество упомянутых ошибок превышает заранее заданное пороговое значение, то выбирается новая обучающая и тестовая выборка файлов и создается новая модель обнаружения.
Еще в одном примере обучающая выборка файлов содержала 10000 файлов, из которых 8500 было вредоносными, а 1500 - безопасными. После того как модель обнаружения была обучена, ее проверили на тестовой выборке файлов, содержащей 1200 файлов, из которых 350 было вредоносными, а 850 - безопасными. По результатам выполненной проверки 15 из 350 вредоносных файлов обнаружить не удалось (4%), в то же время 102 из 850 безопасных файлов (12%) ошибочно было признано вредоносными. В случае, когда количество не обнаруженных вредоносных файлов превышает 5% или случайно обнаруженных безопасных файлов превышает 0,1%, обученная модель обнаружения признается некорректно обученной.
В одном из вариантов реализации системы дополнительно журнал поведения системы формируется на основании ранее сформированного журнала поведения системы и команд, перехваченных после формирования упомянутого журнала поведения системы.
Например, после начала исполнения файла, для которого требуется вынести вердикт о вредоносности или безопасности упомянутого файла, перехваченные выполняемые команды и описывающие их параметры записываются в журнал поведения. На основании анализа упомянутых команд и параметров вычисляется степень вредоносности упомянутого файла. Если по результатам анализа решения о признании файла вредоносным или безопасным вынесено не было, перехват команд может быть продолжен. Перехваченные команды и описывающие их параметры дописываются в старый журнал поведения или в новый журнал поведения. В первом случае степень вредоносности вычисляется на основании анализа всех команд и параметров, записанных в журнале поведения, т.е. и тех, которые ранее использовались для вычисления степени вредоносности.
Средство вычисления степени вредоносности 142 предназначено для:
 вычисления степени вредоносности на основании полученного от средства формирования журнала поведения 142 журнала поведения и от средства машинного обучения модели обнаружения 132 модели обнаружения, при этом степень вредоносности файла представляет собой количественную характеристику (например, лежащую в диапазоне от 0 - файл обладает исключительно безопасным поведением до 1 - упомянутый файл обладает заранее заданным вредоносным поведением), описывающую вредоносное поведение исполняемого файла;
вычисления степени вредоносности на основании полученного от средства формирования журнала поведения 142 журнала поведения и от средства машинного обучения модели обнаружения 132 модели обнаружения, при этом степень вредоносности файла представляет собой количественную характеристику (например, лежащую в диапазоне от 0 - файл обладает исключительно безопасным поведением до 1 - упомянутый файл обладает заранее заданным вредоносным поведением), описывающую вредоносное поведение исполняемого файла;
передачи вычисленного степени вредоносности средству управления ресурсами 143.
Средство управления ресурсами 143 предназначено для, на основании анализа полученной степени вредоносности выделения вычислительных ресурсов компьютерной системы, использования их при обеспечении безопасности компьютерной системы.
В одном из вариантов реализации системы в качестве вычислительных ресурсов компьютерной системы выступают по меньшей мере:
объем свободной оперативной памяти;
объем свободного места на жестких дисках;
свободное процессорное время (кванты процессорного времени), которое может быть потрачено на антивирусную проверку (например, с большей глубиной эмуляции).
Еще в одном из вариантов реализации системы анализ степени вредоносности заключается в определении динамики изменения значения степени вредоносности после каждого из предыдущих вычислений степени вредоносности и в случае по меньшей мере:
увеличение значения степени вредоносности - выделения дополнительных ресурсов компьютерной системы;
уменьшение значения степени вредоносности - освобождение ранее выделенных ресурсов компьютерной системы.
Фиг. 2 представляет структурную схему способа машинного обучения модели обнаружения вредоносных файлов.
Структурная схема способа машинного обучения модели обнаружения вредоносных файлов содержит этап 211, на котором подготавливают обучающие выборки файлов, этап 212, на котором формируют журналы поведения, этап 221, на котором формируют шаблоны поведения, этап 222, на котором формируют функции свертки, этапа 231, на котором создают модель обнаружения, этапа 232, на котором обучаю модель обнаружения, этапа 241, на котором отслеживают поведение компьютерной системы, этапа 242, на котором вычисляют степень вредоносности, этап 243, на котором управляют ресурсами компьютерной системы.
На этапе 211 с помощью средства подготовки обучающих выборок 111 выбирают по меньшей мере один файл из базы файлов согласно заранее заданным критериям, при этом на основании выбранных файлов на этапе 232 будут выполнять обучение модели обнаружения.
На этапе 212 с помощью средства формирования журналов поведения 112:
перехватывают по меньшей мере одну команду по меньшей мере во время:
 исполнения выбранного на этапе 211 файла,
исполнения выбранного на этапе 211 файла,
эмуляции работы выбранного на этапе 211 файла;
определяют для каждой перехваченной команды по меньшей мере один параметр, описывающий упомянутую команду;
формируют на основании перехваченных команд и определенных параметров журнал поведения полученного файла, при этом журнал поведения представляет собой совокупность перехваченных команд (далее - команда) из файла, где каждой команде соответствует по меньшей мере один определенный параметр, описывающий упомянутую команду (далее - параметр).
На этапе 221 с помощью средства формирования шаблонов поведения 121 формируют по меньшей мере один шаблон поведения на основании команд и параметров, выбранных из журнала поведения, сформированного на этапе 212, при этом журнал поведения представляет собой совокупность исполняемых команд (далее - команда) из файла, где каждой команде соответствует по меньшей мере один параметр, описывающий упомянутую команду (далее - параметр), шаблон поведения представляет собой набор из по меньшей мере одной команды и такого параметра, который описывает все команды из упомянутого набора.
На этапе 222 с помощью средства формирования функций свертки 122 формируют такую функцию свертки от шаблона поведения, сформированного на этапе 221, что обратная функция свертки от результата такой функции свертки над упомянутым шаблоном поведения будет иметь степень схожести с упомянутым шаблоном поведения больше заданного значения.
На этапе 231 с помощью средства создания модели обнаружения 131 создают модель обнаружения для чего по меньшей мере:
выбирают метод машинного обучения модели обнаружения;
инициализируют параметры модели обучения, при этом параметры модели обучения, проинициализированные до начала машинного обучения модели обнаружения, называются гиперпараметрами (англ. hyperparameter),
в зависимости от параметров файлов, выбранных на этапе 211.
На этапе 232 с помощью средства машинного обучения модели обнаружения 132 обучают модель обнаружения, созданную на этапе 231, в которой параметры упомянутой модели обнаружения вычисляются с использованием функции свертки, сформированной на этапе 222, над шаблонами поведения, сформированными на этапе 221, где модель обнаружения представляет собой совокупность правил вычисления степени вредоносности файла на основании по меньшей мере одного шаблона поведения с использованием вычисленных параметров упомянутой модели обнаружения.
На этапе 241 с помощью средства отслеживания поведения 141:
перехватывают по меньшей мере одну команду, исполняемую файлами, работающими в компьютерной системе;
формируют на основании перехваченных команд журнал поведения системы.
На этапе 242 с помощью средства вычисления степени вредоносности 142 вычисляют степень вредоносности на основании журнала поведения системы, сформированного на этапе 241, и модели обнаружения, обученной на этапе 232.
На этапе 243 с помощью средства управления ресурсами 143 на основании анализа степени вредоносности, вычисленного на этапе 242, выделяют вычислительные ресурсы для использования их при обеспечении безопасности компьютерной системы.
Фиг. 3 представляет примеры динамики изменения степени вредоносности от количества шаблонов поведения.
Примеры динамики изменения степени вредоносности от количества шаблонов поведения содержат график динамики произвольного изменения степени вредоносности от количества шаблонов поведения, сформированных во время исполнения вредоносного файла 311, график динамики монотонного изменения степени вредоносности от количества шаблонов поведения, сформированных во время исполнения вредоносного файла 312, график динамики произвольного изменения степени вредоносности от количества шаблонов поведения, сформированных во время исполнения безопасного файла 321, график динамики монотонного изменения степени вредоносности от количества шаблонов поведения, сформированных во время исполнения безопасного файла 322.
В одном из вариантов реализации системы степень вредоносности исполняемого файла принимает значение в диапазоне от 0 (упомянутый файл обладает исключительно безопасным поведением) до 1 (упомянутый файл обладает заранее заданным вредоносным поведением).
На графике 311 изображена динамика произвольного изменения степени вредоносности от количества шаблонов поведения, сформированных во время исполнения вредоносного файла.
Изначально, при исполнении упомянутого файла количество сформированных шаблонов поведения невелико, вдобавок вредоносная активность исполняемого файла может отсутствовать или быть минимальной (например, выполняется инициализация данных, свойственная многим, в том числе и безопасным файлам), поэтому вычисленная степень вредоносности незначительно отличается от 0 и не превышает заранее заданного порогового значения (далее - критерия безопасности), при превышении которого поведение исполняемого файла перестанет считаться безопасным (на графике упомянутое пороговое значение обозначается пунктирной линией).
Однако со временем вредоносная активность исполняемого файла возрастает и степень вредоносности начинает стремиться к 1, превышая критерий безопасности, при этом степень вредоносности может не достигать заранее заданного порогового значения (далее - критерий вредоносности), при превышении которого поведение исполняемого файла будет считаться вредоносным (на графике упомянутое пороговое значение обозначается штриховой линией).
После периода роста вредоносная активность может прекращаться и степень вредоносности опять будет стремиться к 0 (момент А). В определенный момент степень вредоносности становится больше критерия вредоносности (момент В) и поведение исполняемого файла признается вредоносным и как следствие сам файл признается вредоносным.
При этом момент признания файла вредоносным может произойти значительно позже начала роста вредоносной активности, поскольку описанный подход хорошо реагирует на резкий рост степени вредоносности, что происходит чаще всего при длительной, явно выраженной вредоносной активности исполняемого файла.
В случае, когда вредоносная активность возникает эпизодически (левая сторона графика 311), вычисленная степень вредоносности может не достигать значения, после которого выносится решение о вредоносности поведения исполняемого файла и, следовательно, вредоносности самого исполняемого файла.
В случае, когда степень вредоносности вычисляется не на основании каждого сформированного шаблона поведения (например, из-за того, что производительность вычислительного устройства является невысокой), возможна ситуация, когда степень вредоносности будет вычислена в момент А (когда начинается вредоносная активность) и момент С (когда завершается вредоносная активность) и не будет вычислена в момент В (когда происходит вредоносная активность), из-за чего вычисленные степени вредоносности не превысят критерия вредоносности, активность исполняемого файла не будет признана вредоносной и, следовательно, вредоносный файл не будет обнаружен.
На графике 312 изображена динамика монотонного изменения степени вредоносности от количества шаблонов поведения, сформированных во время исполнения вредоносного файла.
Изначально, при исполнении упомянутого файла количество сформированных шаблонов поведения невелико, вдобавок вредоносная активность исполняемого файла может отсутствовать или быть минимальной (например, выполняется инициализация данных, свойственная многим, в том числе и безопасным файлам), поэтому вычисленная степень вредоносности незначительно отличается от 0 и не превышает заранее заданного порогового значения (далее - критерия безопасности), при превышении которого поведение исполняемого файла перестанет считаться безопасным (на графике упомянутое пороговое значение обозначается пунктирной линией).
Однако со временем вредоносная активность исполняемого файла возрастает и степень вредоносности начинает стремиться к 1, превышая критерий безопасности, при этом степень вредоносности может не достигать заранее заданного порогового значения (далее - критерий вредоносности), при превышении которого поведение исполняемого файла будет считаться вредоносным (на графике упомянутое пороговое значение обозначается штриховой линией).
После периода роста (моменты А-В) вредоносная активность может прекращаться (моменты В-А), но степень вредоносности уменьшаться уже не будет, а при любой вредоносной активности исполняемого файла будет только продолжать расти. В определенный момент степень вредоносности становится больше критерия вредоносности (момент D) и поведение исполняемого файла признается вредоносным и как следствие сам файл признается вредоносным.
При этом момент признания файла вредоносным может произойти сразу после выявления вредоносной активности, поскольку описанный подход хорошо реагирует на плавный рост степени вредоносности, что происходит как при длительной, явно выраженной вредоносной активности исполняемого файла, так и при частых эпизодической слабовыраженной вредоносной активности.
В случае, когда вредоносная активность возникает эпизодически (левая сторона графика 312), вычисленная степень вредоносности со временем может достигать значения, после которого выносится решение о вредоносности поведения исполняемого файла и вредоносности самого исполняемого файла.
В случае, когда степень вредоносности вычисляется не на основании каждого сформированного шаблона поведения (например, из-за того, что производительность вычислительного устройства является невысокой), возможна ситуация, когда степень вредоносности будет вычислена в момент А (когда начинается вредоносная активность) и момент С (когда завершается вредоносная активность) и не будет вычислена в момент В (когда происходит вредоносная активность), тем не менее, поскольку степень вредоносности меняется монотонно, вычисленные степени вредоносности только увеличивают свои значения и в момент С степень вредоносности превысит критерий вредоносности, активность исполняемого файла будет признана вредоносной и, следовательно, вредоносный файл будет обнаружен.
На графике 321 изображена динамика произвольного изменения степени вредоносности от количества шаблонов поведения, сформированных во время исполнения безопасного файла.
Изначально, при исполнении упомянутого файла количество сформированных шаблонов поведения невелико, вдобавок вредоносная активность как таковая у исполняемого файла отсутствует, но могут выполняться «подозрительные» команды, выполняемые также и при исполнении вредоносных файлов (например, удаление файлов, передача данных по компьютерной сети и т.д.), поэтому вычисленная степень вредоносности отличается от 0 и не превышает заранее заданного порогового значения (далее - критерия безопасности), при превышении которого поведение исполняемого файла перестанет считаться безопасным (на графике упомянутое пороговое значение обозначается пунктирной линией).
Однако со временем вредоносная активность исполняемого файла из-за выполнения большого количества «подозрительных» команд возрастает и степень вредоносности начинает стремиться к 1, при этом степень вредоносности может не достигать заранее заданного порогового значения (далее - критерий вредоносности), при превышении которого поведение исполняемого файла будет считаться вредоносным (на графике упомянутое пороговое значение обозначается штриховой линией), но может превышать критерий безопасности, таким образом файл может перестать считаться безопасным и стать «подозрительным».
После периода роста вредоносная активность может прекращаться и степень вредоносности опять будет стремиться к 0 (момент С).
В случае, когда степень вредоносности вычисляется не на основании каждого сформированного шаблона поведения (например, из-за того, что производительность вычислительного устройства является невысокой), возможна ситуация, когда степень вредоносности будет вычислена в момент В (когда активность наиболее схожа с вредоносной, т.е. становится «подозрительной») и не будет вычислена в момент А (когда «подозрительная» активность увеличивается) и в момент С (когда «подозрительная активность» уменьшается), из-за чего вычисленная степень вредоносности превысит критерий безопасности, активность исполняемого файла будет признана «подозрительной» (не будет признана безопасной) и, следовательно, безопасный файл не будет признан безопасным.
На графике 322 изображена динамика монотонного изменения степени вредоносности от количества шаблонов поведения, сформированных во время исполнения безопасного файла.
Изначально, при исполнении упомянутого файла количество сформированных шаблонов поведения невелико, вдобавок вредоносная активность как таковая у исполняемого файла отсутствует, но могут выполняться «подозрительные» команды, выполняемые также и при исполнении вредоносных файлов (например, удаление файлов, передача данных по компьютерной сети и т.д.), поэтому вычисленная степень вредоносности отличается от 0 и не превышает заранее заданного порогового значения (далее - критерия безопасности), при превышении которого поведение исполняемого файла перестанет считаться безопасным (на графике упомянутое пороговое значение обозначается пунктирной линией).
Однако со временем вредоносная активность исполняемого файла из-за выполнения большого количества «подозрительных» команд возрастает и степень вредоносности начинает стремиться к 1, при этом степень вредоносности может не достигать заранее заданного порогового значения (далее - критерий вредоносности), при превышении которого поведение исполняемого файла будет считаться вредоносным (на графике упомянутое пороговое значение обозначается штриховой линией), а также может не превышать критерий безопасности, таким образом файл будет продолжать считаться безопасным.
После периода роста (моменты А-В) вредоносная активность может прекращаться (моменты В-А), но степень вредоносности уменьшаться уже не будет, а при любой вредоносной активности исполняемого файла будет только продолжать расти, но при этом не превышать коэффициент безопасности, таким образом активность исполняемого файла будет считаться безопасной и, следовательно, упомянутый файл будет считаться безопасным.
В случае, когда степень вредоносности вычисляется не на основании каждого сформированного шаблона поведения (например, из-за того, что производительность вычислительного устройства является невысокой), возможна ситуация, когда степень вредоносности будет вычислена в момент В (когда активность наиболее схожа с вредоносной, т.е. становится «подозрительной») и не будет вычислена в момент А (когда «подозрительная» активность увеличивается) и в момент С (когда «подозрительная активность» уменьшается), тем не менее, поскольку степень вредоносности меняется монотонно, вычисленные степени вредоносности только увеличивают свои значения, в моменты А, В, С степени вредоносности не превысят критерия безопасности, активность исполняемого файла будет признана безопасной и, следовательно, безопасный файл будет признан безопасным.
При этом момент признания файла «подозрительным» может не произойти после выявления «подозрительной» активности, поскольку описанный подход обеспечивает на плавный рост степени вредоносности, что позволяет избежать резких пиков при росте степени вредоносности.
Фиг. 4 представляет пример схемы связей между элементами шаблонов поведения.
Пример схемы связей между элементами шаблонов поведения содержит команды 411 (пустые кружки), параметры 412 (штрихованные кружки), пример шаблона поведения с одним параметром 421, пример шаблона поведения с одной командой 422.
Во время исполнения файла были перехвачены команды 411 и определены описывающие им параметры 412:

На основании упомянутых команд 411 и параметров 412 формируют шаблоны поведения (421, 422) и определяют связи между элементами шаблонов поведения.
На первом этапе формируют шаблоны, содержащие одну команду 411 и один параметр 412, описывающий упомянутую команду:
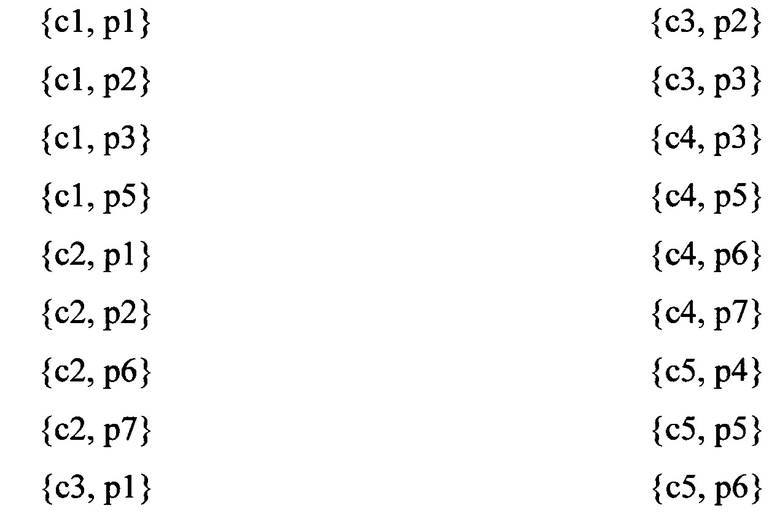
В приведенном примере на основании 8 перехваченных команд (с описывающими их параметрами) было сформировано 19 шаблонов поведения.
На втором этапе формируют шаблоны, содержащие один параметр 412 и все команды 411, описываемые упомянутым параметром 412:

В приведенном примере на основании 8 перехваченных команд (с описывающими их параметрами) было дополнительно сформировано 7 шаблонов поведения.
На третьем этапе формируют шаблоны, содержащие несколько параметров 412 и все команды 411, описываемые упомянутыми шаблонами 412:

В приведенном примере на основании 8 перехваченных команд (с описывающими их параметрами) было дополнительно сформировано 3 шаблона поведения.
Фиг. 5 представляет структурную схему системы обнаружения вредоносных файлов с использованием обученной модели обнаружения вредоносных файлов.
Структурная схема системы обнаружения вредоносных файлов с использованием обученной модели обнаружения вредоносных файлов состоит из анализируемого файла 501, средства формирования журналов поведения 112, средства выбора моделей обнаружения 520, базы моделей обнаружения 521, средства анализа журнала поведения 530, средства вычисления степени вредоносности 540, базы шаблонов решений 541 и средства анализа 550.
В одном из вариантов реализации системы упомянутая система дополнительно содержит средство формирования журналов поведения 112 исполняемого файла, предназначенное для:
перехвата по меньшей мере одной команды по меньшей мере во время:
 исполнения файла 501,
исполнения файла 501,
эмуляции исполнения файла 501;
определения для каждой перехваченной команды по меньшей мере одного параметра, описывающего упомянутую команду;
формирования на основании перехваченных команд и определенных параметров журнала поведения упомянутого файла, при этом перехваченные команды и описывающие их параметры записываются в журнал поведения в хронологическом порядке от более ранней перехваченной команды к более поздней перехваченной команды (далее - запись в журнале поведения);
передачи сформированного журнала поведения средству анализа журнала поведения 530 и средству выбора моделей обнаружения 520.
Еще в одном из вариантов реализации системы журнал поведения представляет собой совокупность исполняемых команд (далее - команда) из файла 501, где каждой команде соответствует по меньшей мере один параметр, описывающий упомянутую команду (далее - параметр).
Еще в одном из вариантов реализации системы перехват команд исполняемого файла 501 и определение параметров перехваченных команд осуществляется на основании анализа производительности вычислительного устройства, на котором работает система обнаружения вредоносных файлов с использованием обученной модели обнаружения вредоносных файлов, что включает в себя по меньшей мере:
 определения, возможно ли проанализировать исполняемый файл 501 на вредоносность (осуществляемое с помощью средства анализа журнала поведения 530, средства вычисления степени вредоносности 540 и средства анализа 550) до момента, когда будет перехвачена следующая команда;
определения, возможно ли проанализировать исполняемый файл 501 на вредоносность (осуществляемое с помощью средства анализа журнала поведения 530, средства вычисления степени вредоносности 540 и средства анализа 550) до момента, когда будет перехвачена следующая команда;
определения, не приведет ли анализ исполняемого файла 501 на вредоносность к снижению вычислительных ресурсов упомянутого вычислительного устройства ниже заранее заданного порогового значения, при этом в качестве ресурсов вычислительного устройства выступает по меньшей мере:
производительность упомянутого вычислительного устройства;
объем свободной оперативной памяти упомянутого вычислительного устройства;
объем свободного места на носителях информации упомянутого вычислительного устройства (например, жестких дисках);
пропускная способность компьютерной сети, к которой подключено упомянутое вычислительное устройство.
Для повышения производительности системы обнаружения вредоносных файлов с использованием обученной модели обнаружения вредоносных файлов может потребоваться анализировать журнал поведения, содержащего не все выполняемые команды исполняемого файла 501, поскольку вся последовательность действий, выполняемых для анализа файла 501 на вредоносность, занимает времени больше, чем промежуток времени между двумя последовательно выполняемыми командами исполняемого файла 501.
Например, команды исполняемого файла 501 выполняются (а, следовательно, и перехватываются) каждую 0,001 сек, но анализ файла 501 на вредоносность занимает 0,15 сек, таким образом все команды, перехваченные в течении упомянутого промежутка времени, будут проигнорированы, таким образом достаточно перехватывать лишь каждую 150 команду.
Средство выбора моделей обнаружения 520 предназначено для:
выборки из базы моделей обнаружения 521 по меньшей мере двух моделей обнаружения вредоносных файлов на основании команд и параметров, выбранных из журнала поведения исполняемого файла 501, при этом модель обнаружения вредоносных файлов представляет собой решающее правило определения степени вредоносности;
передачи всех выбранных моделей обнаружения вредоносных файлов средству вычисления степени вредоносности 540.
В одном из вариантов реализации системы модели обнаружения вредоносных файлов, хранящиеся в базе моделей обнаружения 521, были предварительно обучены методом машинного обучения на по меньшей мере одном безопасном файле и вредоносном файле.
Более подробно модель обнаружения вредоносных файлов описана на Фиг. 1 - Фиг. 4.
Еще в одном из вариантов реализации системы в качестве метода машинного обучения модели обнаружения выступает по меньшей мере метод:
градиентный бустинг на деревьях принятия решений;
деревья принятия решений;
ближайших соседей kNN;
опорных векторов.
Еще в одном из вариантов реализации системы метод обучения модели обнаружения обеспечивает монотонность изменения степени вредоносности файла в зависимости от изменения количества шаблонов поведения, сформированных на основании анализа журнала поведения.
Например, вычисленная степень вредоносности файла 501 может только монотонно возрастать или не изменяться в зависимости от количества шаблонов поведения, сформированных на основании анализа журнала поведения упомянутого файла 501. В начале исполнения файла 501 количество сформированных шаблонов поведения незначительно, а вычисленная степень вредоносности упомянутого файла 501 незначительно отличается от 0, со временем количество сформированных шаблонов растет и вычисленная степень вредоносности упомянутого файла 501 также растет или если вредоносная активность упомянутого файла 501 отсутствует - вычисленная степень вредоносности остается неизменной, таким образом в какой бы момент исполнения вредоносного файла 501 (или с какой бы записи из журнала поведения ни началось бы формирование шаблонов поведения) ни была бы вычислена степень вредоносности файла, она будет отражать, имела ли место вредоносная активность файла 501 или нет до момента вычисления упомянутой степени вредоносности.
Еще в одном из вариантов реализации системы каждая выбранная из базы моделей обнаружения 521 модель обнаружения вредоносных файлов обучена для обнаружения вредоносных файлов с заранее заданными уникальными характерными признаками.
Например, модели обнаружения, хранящиеся в базе моделей обнаружения 521, могут быть обучены для обнаружения файлов:
обладающих графическим интерфейсом (англ. GUI - graphical user interface);
обменивающиеся данными по компьютерной сети;
шифрующих файлы (например, вредоносные файлы семейства «Trojan-Cryptors»);
использующие для распространения сетевые уязвимости (например, вредоносные файлы семейства «Net-Worms»), Р2Р сети (например, вредоносные файлы семейства «P2P-Worms») и т.д.
Таким образом, вредоносный файл может быть обнаружен с использованием нескольких обученных моделей обнаружения вредоносных файлов. Например, вредоносный файл «WannaCry.exe» во время своего исполнения шифрующий данные на вычислительном устройстве пользователя и пересылающий свои копии другим вычислительным устройствам, подключенным к той же компьютерной сети, что и упомянутое вычислительное устройство пользователя, на котором исполняется упомянутый файл, может быть обнаружен с помощью модели обнаружения #1, обученной для обнаружения файлов, использующих уязвимости, модели обнаружения #2, обученной для обнаружения файлов, предназначенных для шифрования файлов и модели обнаружения #3, обученной для обнаружения файлов, содержащих текстовую информацию, интерпретируемую как выдвигаемые требования (например, о форме оплаты, денежных суммах и т.п.). При этом степени вредоносности, вычисленная с помощью упомянутых моделей, а также моменты времени, когда вычисленные степени вредоносности превысят заранее заданное пороговое значение, могут различаться. Например, результаты использования моделей обнаружения вредоносных файлов, с помощью которых удалось обнаружить вредоносный файл 501, могут быть выражены в следующей таблице:
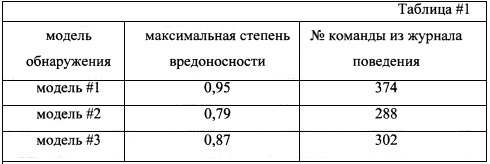
Файл 501 признается вредоносным в случае, когда вычисленная степень вредоносности превосходит 0,78. При этом степень вредоносности (например, 0,78) характеризует вероятность того, что файл для которого вычислена степень вредоносности может оказаться вредоносным (78%) или безопасным (22%). Если файл 501 может быть признан вредоносным с использованием нескольких моделей обнаружения вредоносных файлов, то вероятность того, что файл 501 окажется вредоносным возрастает. Например, для моделей обнаружения вредоносных файлов, по которым приведены данные в Таблице #1, итоговая степень вредоносности может быть вычислена по формуле
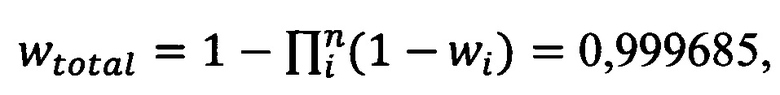
где
wtotal - итоговая степень вредоносности,
wi - степень вредоносности, вычисленная с использованием с модели i,
n - количество моделей обнаружения вредоносных файлов, использованных для вычисления итоговой степени вредоносности.
Таким образом, полученная итоговая степень вредоносности (0,999685) значительно выше, чем заранее заданное пороговое значение, при превышении вычисленной степенью вредоносности которого (0,78) файл признается вредоносным. Т.е. использование нескольких моделей обнаружения вредоносных файлов позволяет значительно повысить точность определения вредоносных файлов, уменьшить ошибки первого и второго рода, возникающие при обнаружении вредоносных файлов.
Еще в одном примере использование нескольких моделей обнаружения вредоносных файлов позволяет итоговой степени вредоносности достичь заранее заданное пороговое значение, при превышении вычисленной степенью вредоносности которого файл признается вредоносным, гораздо раньше, чем при использовании каждой из моделей обнаружения вредоносных файлов по отдельности. Например, для моделей обнаружения вредоносных файлов, по которым приведены данные в Таблице #1, при условии, что вычисляемые степени вредоносности монотонно изменяются, № команды из журнала поведения, после которого файл будет признан вредоносным, может быть вычислен по формуле
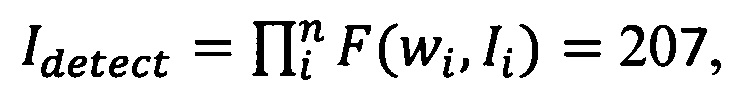
где
Idetect - № команды из журнала поведения, после анализа которой файл признается вредоносным,
Ii - № команды из журнала поведения, после анализа которой с использованием с модели i файл признается вредоносным,
wi - степень вредоносности, вычисленная с использованием с модели i,
n - количество моделей обнаружения вредоносных файлов, использованных для вычисления № команды из журнала поведения, после анализа которой файл признается вредоносным.
Таким образом полученный итоговый № команды из журнала поведения (207) значительно меньше, чем самый ранний № команды из журнала поведения (288), после анализа которой файл был признан вредоносным одной из моделей обнаружения вредоносных файлов (модель #2). Т.е. использование нескольких моделей обнаружения вредоносных файлов позволяет значительно повысить скорость (т.е. оперативность) определения вредоносных файлов.
Еще в одном примере разные модели обнаружения, хранящиеся в базе моделей обнаружения 521, могут быть обучены для обнаружения вредоносных файлов с несколькими не обязательно уникальными заранее заданными характерными признаками, т.е. модель обнаружения #1, может обнаруживать файлы, обладающие графическим интерфейсом и обменивающиеся данными по компьютерной сети, а модель #2, может обнаруживать файлы, обменивающиеся данными по компьютерной сети и распространяющиеся по упомянутой компьютерной сети с использованием сетевых уязвимостей. Обе упомянутые модели обнаружения могут обнаружить упомянутый вредоносный файл «WannaCry.exe» за счет общего характерного признака распространения файла по компьютерной сети с использованием сетевых уязвимостей.
Еще в одном из вариантов реализации системы выбирают из базы моделей обнаружения 521 такую модель обнаружения вредоносных файлов, которая обучалась на файлах, при исполнении которых по меньшей мере:
выполнялись те же команды, что и команды, выбранные из журнала поведения исполняемого файла 501;
использовались те же параметры, что и параметры, выбранные из журнала поведения исполняемого файла 501.
Например из журнала поведения были выбраны команды «CreateFileEx», «ReadFile», «WriteFile», «CloseHandle», которые используются для модификации файлов, в том числе для шифрования файлов. Из базы моделей обнаружения 521 выбирают модель обнаружения, обученную для использования для обнаружения вредоносных файлов семейства «Trojan-Cryptors».
Еще в одном примере из журнала поведения были выбраны параметры «8080», «21», описывающие команды работы с компьютерной сетью (например, connect, где описанные выше параметры представляют собой порты соединения к электронному адресу). Из базы моделей обнаружения 521 выбирают модель обнаружения, обученную для использования для обнаружения файлов, обеспечивающих обмен данными по компьютерной сети.
Средство анализа журнала поведения 530 предназначено для:
формирования по меньшей мере одного шаблона поведения на основании команд и параметров, выбранных из журнала поведения исполняемого файла 501, при этом шаблон поведения представляет собой набор из по меньшей мере одной команды и такого параметра, который описывает все команды из упомянутого набора;
вычисления свертки от всех сформированных шаблонов поведения;
передачи сформированной свертки средству вычисления степени вредоносности 540 исполняемого файла.
В одном из вариантов реализации системы вычисление свертки от сформированных шаблонов поведения выполняется на основании заранее заданной функции свертки, такой что обратная функция свертки от результата упомянутой функции свертки над всеми сформированными шаблонами поведения имеет степень схожести с упомянутым шаблоном поведения больше заданного порогового значения.
Более подробно формирование и использование функций свертки (вычисление свертки) описаны на Фиг. 1, Фиг. 2.
Средство вычисления степени вредоносности 540 предназначено для:
вычисления степени вредоносности исполняемого файла 501 на основании анализа полученной свертки с помощью каждой полученной модели обнаружения вредоносных файлов;
передачи каждой вычисленной степени вредоносности средству анализа 550.
В одном из вариантов реализации системы шаблон решения представляет собой композицию степеней вредоносности.
Например, композиция степеней вредоносности, вычисленных на основании моделей #1, #2, #3, описанных выше, может быть представлена в виде совокупности пар {0.95, 374}, {0.79, 288}, {0.87, 302}.
Еще в одном примере композиция степеней вредоносности, вычисленных на основании моделей #1, #2, #3, описанных выше, может представлять меру центральной тенденции вычисленных степеней вредоносности (например, среднее арифметическое, в данном случае 0,87).
Еще в одном примере композиция степеней вредоносности представляет собой зависимость изменения степеней вредоносности от времени или количества шаблонов поведения, используемых для вычисления степени вредоносности.
Средство анализа 550 предназначено для:
формирования на основании полученных степеней вредоносности шаблона решения;
признания исполняемого файла 501 вредоносным, в случае, когда степень схожести между сформированным шаблоном решения и по меньшей мере одним из заранее заданных шаблонов решения из базы шаблонов решения 541, предварительно сформированных на основании анализа вредоносных файлов, превышает заранее заданное пороговое значение.
В одном из вариантов реализации системы шаблон решения представляет собой совокупность степеней вредоносности, полученных от средства вычисления степеней вредоносности 540.
Еще в одном из вариантов реализации системы шаблон решения представляет собой зависимость степени вредоносности от времени или количества шаблонов поведения, используемых для вычисления упомянутой степени вредоносности.
Еще в одном из вариантов реализации системы шаблонов решения из базы шаблонов решения 541 формируются на основании анализа вредоносных файлов, использованных для обучения моделей из базы моделей обнаружения 521.
Например, на основании 100000 файлов, из которых 75000 безопасных файлов и 25000 вредоносных файлов обучают (включая тестирование) модели обнаружения, которые затем сохраняют в базу моделей обнаружения 521. После того как модели обнаружения вредоносных файлов были обучены, они используются для формирования шаблонов решений для некоторых (или всех) из 25000 упомянутых вредоносных файлов, которые затем записывают в базу шаблонов решений 541. Т.е. первоначально на обучающей и тестовой выборке файлов выполняют машинное обучение моделей обнаружения вредоносных файлов. В итоге может быть обучено несколько моделей обнаружения вредоносных файлов, каждая из которых будет обучена для обнаружения вредоносных файлов с уникальными заранее заданными характерными признаками. После того, как все модели обнаружения будут обучены, определяют, какие из обученных моделей обнаружения вредоносных файлов обнаруживают те или иные вредоносные файлы (из описанного выше примера - 25000 вредоносных файлов), может оказаться, что один вредоносный файл может быть обнаружен с использованием одного набора моделей обнаружения вредоносных файлов, другой - с использованием другого набора моделей обнаружения вредоносных файлов, третий - с использованием некоторых моделей обнаружения вредоносных файлов из упомянутых выше наборов моделей обнаружения вредоносных файлов. На основании полученных данных о том, с помощью каких моделей обнаружения вредоносных файлов какие вредоносные файлы могут быть обнаружены, формируются шаблоны решения.
Еще в одном из вариантов реализации системы дополнительно средство анализа 550 предназначено для переобучения по меньшей мере одной модели обнаружения из базы моделей обнаружения 521 на основании команд и параметров, выбранных из журнала поведения исполняемого файла 501, в случае, когда степень схожести между сформированным шаблоном решения и по меньшей мере одним из заранее заданных шаблонов решения из базы шаблонов решения 541 превышает заранее заданное пороговое значение, а степени вредоносности, вычисленные с помощью упомянутых моделей обнаружения вредоносного файла, не превышают заранее заданного порогового значения.
Фиг. 6 представляет структурную схему способа обнаружения вредоносных файлов с использованием обученной модели обнаружения вредоносных файлов.
Структурная схема способа обнаружения вредоносных файлов с использованием обученной модели обнаружения вредоносных файлов содержит этап 610, на котором исполняют анализируемый файл, этап 620, на котором формируют журнал поведения, этап 630, на котором формируют шаблоны поведения, этап 640, на котором вычисляют свертку, этап 650, на котором выбирают модель обнаружения, этап 660, на котором вычисляют степень вредоносности, этап 670, на котором формируют шаблон решения, этап 680, на котором признают файл вредоносным и этап 690, на котором переобучают модель обнаружения.
На этапе 610 с помощью средства формирования журналов поведения 112 по меньшей мере:
исполняют анализируемый файл 501;
 эмулируют исполнение анализируемого файла 501.
эмулируют исполнение анализируемого файла 501.
На этапе 620 с помощью средства формирования журналов поведения 112 формируют журнал поведения для анализируемого файла 501 для чего:
перехватывают по меньшей мере одну выполняемую команду;
определяют для каждой перехваченной команды по меньшей мере один параметр, описывающий упомянутую команду;
формируют на основании перехваченных команд и определенных параметров журнала поведения упомянутого файла 501.
На этапе 630 с помощью средства анализа журнала поведения 530 формируют по меньшей мере один шаблон поведения на основании команд и параметров, выбранных из журнала поведения исполняемого файла 501, при этом шаблон поведения представляет собой набор из по меньшей мере одной команды и такого параметра, который описывает все команды из упомянутого набора.
На этапе 640 с помощью средства анализа журнала поведения 530 вычисляют свертку от всех сформированных на этапе 630 шаблонов поведения.
На этапе 650 с помощью средства выбора моделей обнаружения 520 выбирают из базы моделей обнаружения 521 по меньшей мере две модели обнаружения вредоносных файлов на основании команд и параметров, выбранных из журнала поведения исполняемого файла 501, при этом модель обнаружения вредоносных файлов представляет собой решающее правило определения степени вредоносности.
На этапе 660 с помощью средства вычисления степени вредоносности 540 вычисляют степень вредоносности исполняемого файла 501 на основании анализа вычисленной на этапе 640 свертки с помощью каждой выбранной на этапе 650 модели обнаружения вредоносных файлов.
На этапе 670 с помощью средства анализа 550 формируют на основании полученных на этапе 660 степеней вредоносности шаблон решения.
На этапе 680 с помощью средства анализа 550 признают исполняемый файл 501 вредоносным, в случае, когда степень схожести между сформированным на этапе 670 шаблоном решения и по меньшей мере одним из заранее заданных шаблонов решения из базы шаблонов решения 541 превышает заранее заданное пороговое значение.
На этапе 690 с помощью средства анализа 550 переобучают по меньшей мере одну модель обнаружения из базы моделей обнаружения 521 на основании команд и параметров, выбранных из журнала поведения исполняемого файла, в случае, когда степень схожести между сформированным шаблоном решения и по меньшей мере одним из заранее заданных шаблонов решения из базы шаблонов решения 541 превышает заранее заданное пороговое значение, а степени вредоносности, вычисленные с помощью упомянутых моделей обнаружения вредоносного файла, не превышают заранее заданного порогового значения.
Фиг. 7 представляет пример компьютерной системы общего назначения, персональный компьютер или сервер 20, содержащий центральный процессор 21, системную память 22 и системную шину 23, которая содержит разные системные компоненты, в том числе память, связанную с центральным процессором 21. Системная шина 23 реализована, как любая известная из уровня техники шинная структура, содержащая в свою очередь память шины или контроллер памяти шины, периферийную шину и локальную шину, которая способна взаимодействовать с любой другой шинной архитектурой. Системная память содержит постоянное запоминающее устройство (ПЗУ) 24, память с произвольным доступом (ОЗУ) 25. Основная система ввода/вывода (BIOS) 26, содержит основные процедуры, которые обеспечивают передачу информации между элементами персонального компьютера 20, например, в момент загрузки операционной системы с использованием ПЗУ 24.
Персональный компьютер 20 в свою очередь содержит жесткий диск 27 для чтения и записи данных, привод магнитных дисков 28 для чтения и записи на сменные магнитные диски 29 и оптический привод 30 для чтения и записи на сменные оптические диски 31, такие как CD-ROM, DVD-ROM и иные оптические носители информации. Жесткий диск 27, привод магнитных дисков 28, оптический привод 30 соединены с системной шиной 23 через интерфейс жесткого диска 32, интерфейс магнитных дисков 33 и интерфейс оптического привода 34 соответственно. Приводы и соответствующие компьютерные носители информации представляют собой энергонезависимые средства хранения компьютерных инструкций, структур данных, программных модулей и прочих данных персонального компьютера 20.
Настоящее описание раскрывает реализацию системы, которая использует жесткий диск 27, сменный магнитный диск 29 и сменный оптический диск 31, но следует понимать, что возможно применение иных типов компьютерных носителей информации 56, которые способны хранить данные в доступной для чтения компьютером форме (твердотельные накопители, флеш карты памяти, цифровые диски, память с произвольным доступом (ОЗУ) и т.п.), которые подключены к системной шине 23 через контроллер 55.
Компьютер 20 имеет файловую систему 36, где хранится записанная операционная система 35, а также дополнительные программные приложения 37, другие программные модули 38 и данные программ 39. Пользователь имеет возможность вводить команды и информацию в персональный компьютер 20 посредством устройств ввода (клавиатуры 40, манипулятора «мышь» 42). Могут использоваться другие устройства ввода (не отображены): микрофон, джойстик, игровая консоль, сканер и т.п. Подобные устройства ввода по своему обычаю подключают к компьютерной системе 20 через последовательный порт 46, который в свою очередь подсоединен к системной шине, но могут быть подключены иным способом, например, при помощи параллельного порта, игрового порта или универсальной последовательной шины (USB). Монитор 47 или иной тип устройства отображения также подсоединен к системной шине 23 через интерфейс, такой как видеоадаптер 48. В дополнение к монитору 47, персональный компьютер может быть оснащен другими периферийными устройствами вывода (не отображены), например, колонками, принтером и т.п.
Персональный компьютер 20 способен работать в сетевом окружении, при этом используется сетевое соединение с другим или несколькими удаленными компьютерами 49. Удаленный компьютер (или компьютеры) 49 являются такими же персональными компьютерами или серверами, которые имеют большинство или все упомянутые элементы, отмеченные ранее при описании существа персонального компьютера 20, представленного на Фиг. 7. В вычислительной сети могут присутствовать также и другие устройства, например, маршрутизаторы, сетевые станции, пиринговые устройства или иные сетевые узлы.
Сетевые соединения могут образовывать локальную вычислительную сеть (LAN) 50 и глобальную вычислительную сеть (WAN). Такие сети применяются в корпоративных компьютерных сетях, внутренних сетях компаний и, как правило, имеют доступ к сети Интернет. В LAN- или WAN-сетях персональный компьютер 20 подключен к локальной сети 50 через сетевой адаптер или сетевой интерфейс 51. При использовании сетей персональный компьютер 20 может использовать модем 54 или иные средства обеспечения связи с глобальной вычислительной сетью, такой как Интернет. Модем 54, который является внутренним или внешним устройством, подключен к системной шине 23 посредством последовательного порта 46. Следует уточнить, что сетевые соединения являются лишь примерными и не обязаны отображать точную конфигурацию сети, т.е. в действительности существуют иные способы установления соединения техническими средствами связи одного компьютера с другим.
В заключение следует отметить, что приведенные в описании сведения являются примерами, которые не ограничивают объем настоящего изобретения, определенного формулой.
| название | год | авторы | номер документа |
|---|---|---|---|
| Система и способ обнаружения вредоносного файла | 2018 |
|
RU2739865C2 |
| Система и способ управления вычислительными ресурсами для обнаружения вредоносных файлов | 2017 |
|
RU2659737C1 |
| Система и способ машинного обучения модели обнаружения вредоносных файлов | 2017 |
|
RU2673708C1 |
| Система и способ классификации объектов вычислительной системы | 2018 |
|
RU2724710C1 |
| Система и способ классификации объектов | 2017 |
|
RU2679785C1 |
| Система и способ выбора средства обнаружения вредоносных файлов | 2019 |
|
RU2739830C1 |
| Система и способ обучения модели обнаружения вредоносных контейнеров | 2018 |
|
RU2697955C2 |
| Способ обнаружения вредоносных файлов, противодействующих анализу в изолированной среде | 2018 |
|
RU2708355C1 |
| Система и способ обнаружения вредоносных файлов с использованием элементов статического анализа | 2017 |
|
RU2654146C1 |
| Система и способ обнаружения вредоносной активности на компьютерной системе | 2018 |
|
RU2697958C1 |


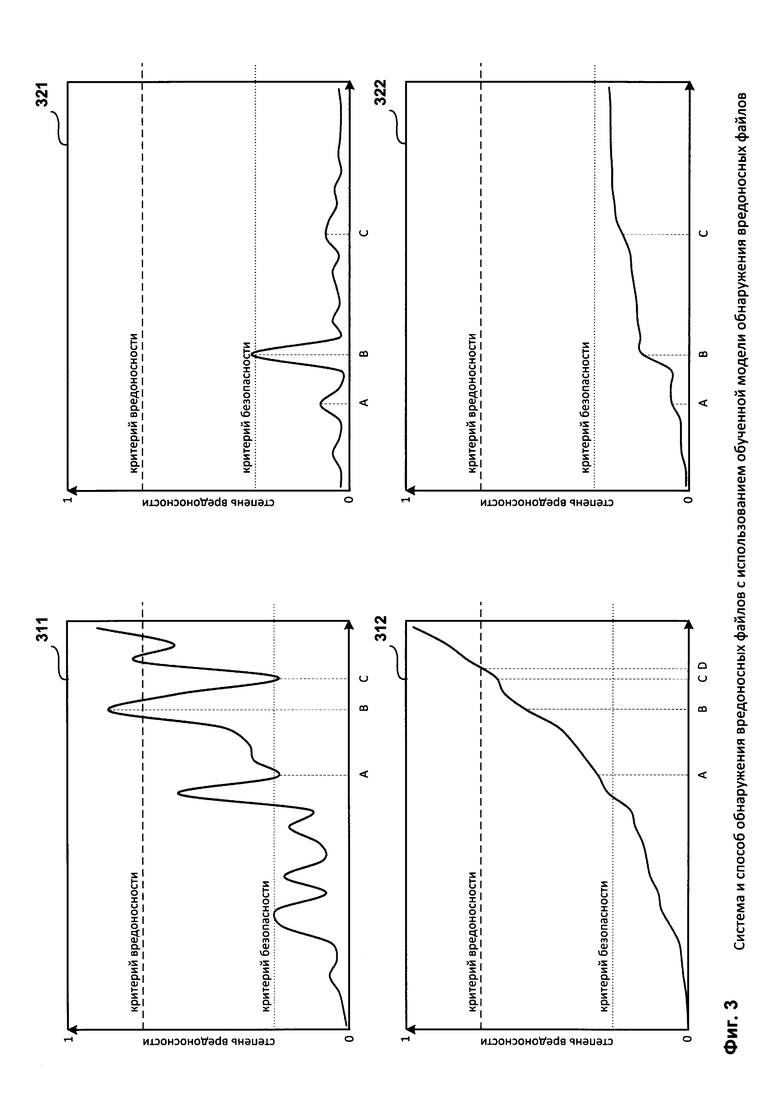
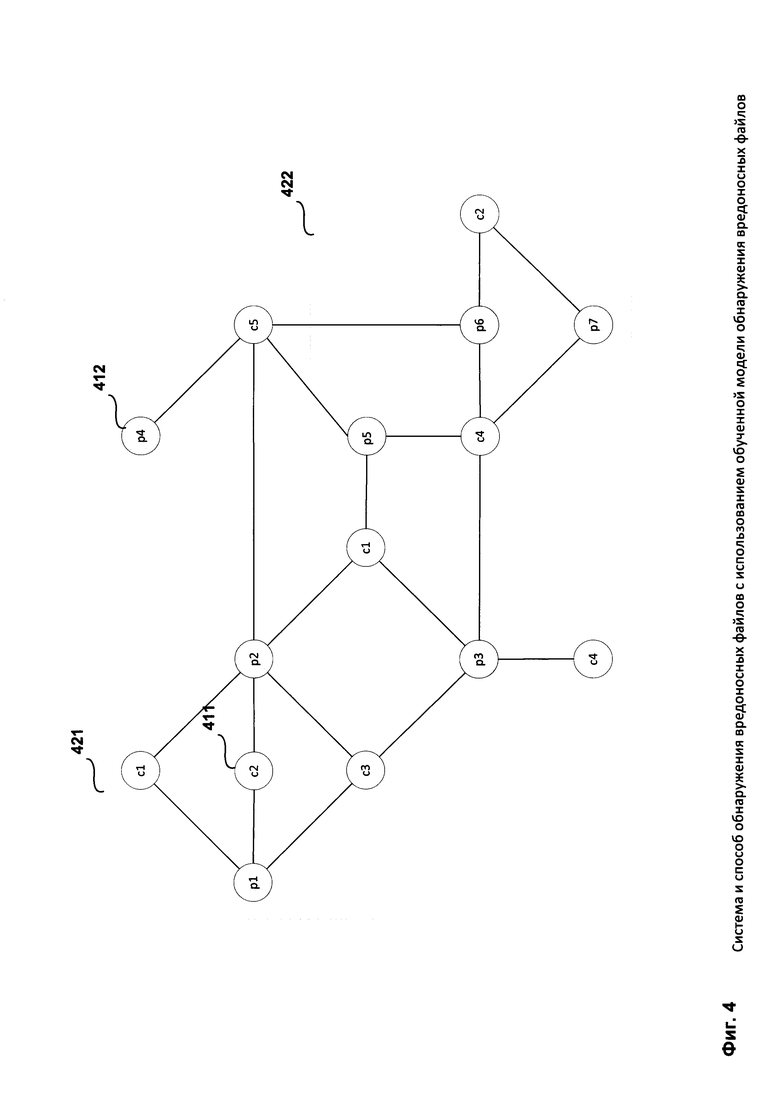
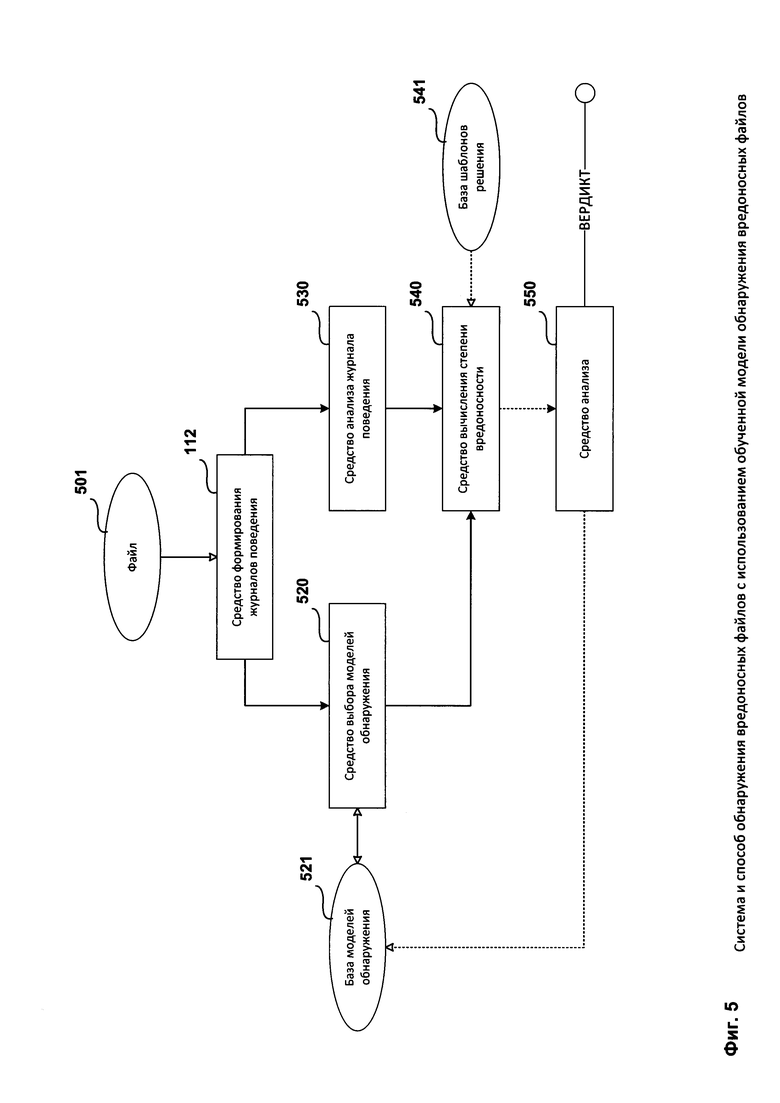
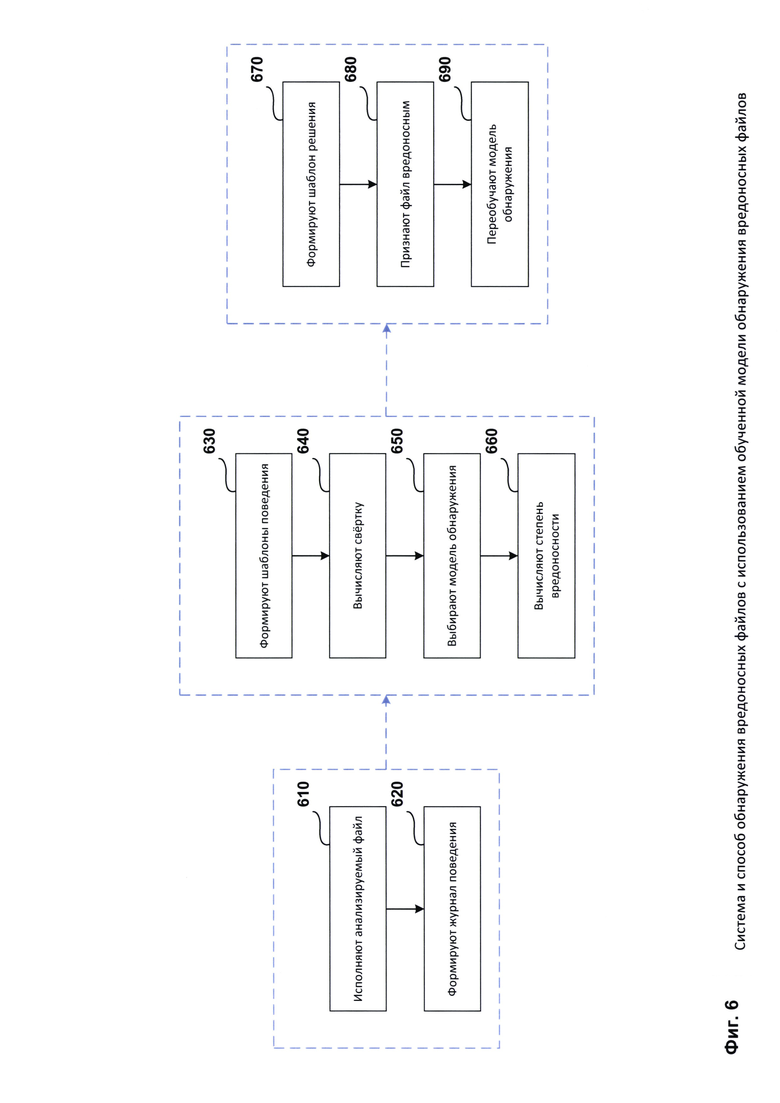
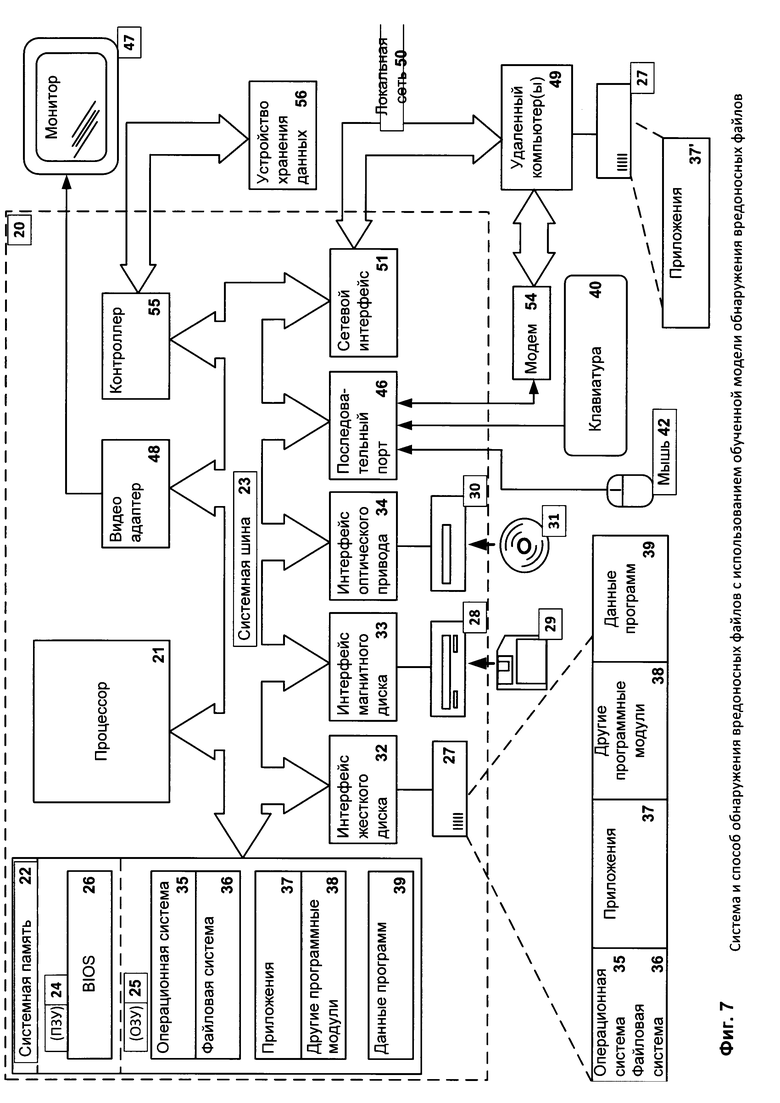
Изобретение предназначено для антивирусной проверки файлов. Технический результат заключается в обнаружении вредоносных файлов с использованием обученной модели обнаружения вредоносных файлов. Система обнаружения вредоносных файлов содержит средство анализа журнала поведения, предназначенное для формирования шаблона поведения на основании команд и параметров, выбранных из журнала; вычисления свертки от всех сформированных шаблонов поведения; средство выбора моделей обнаружения, предназначенное для выборки из базы моделей обнаружения по меньшей мере двух моделей обнаружения вредоносных файлов на основании команд и параметров, выбранных из журнала поведения; средство вычисления степени вредоносности, предназначенное для вычисления степени вредоносности исполняемого файла на основании анализа полученной свертки с помощью каждой полученной модели обнаружения; средство анализа, предназначенное для формирования на основании полученной степени вредоносности шаблона решения; признания исполняемого файла вредоносным, в случае, когда степень схожести между сформированным шаблоном решения и по меньшей мере одним из заранее заданных шаблонов решения из базы шаблонов решения превышает заранее заданное пороговое значение. 2 н. и 18 з.п. ф-лы, 7 ил.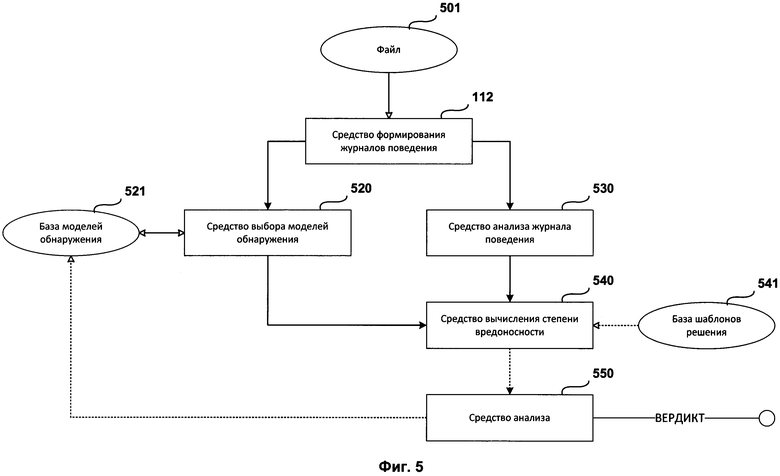
1. Система обнаружения вредоносных файлов с использованием обученной модели обнаружения вредоносных файлов, которая содержит:
а) средство анализа журнала поведения, предназначенное для:
• формирования по меньшей мере одного шаблона поведения на основании команд и параметров, выбранных из журнала поведения исполняемого файла, при этом шаблон поведения представляет собой набор из по меньшей мере одной команды и такого параметра, который описывает все команды из упомянутого набора;
• вычисления свертки от всех сформированных шаблонов поведения;
• передачи сформированной свертки средству вычисления степени вредоносности;
б) средство выбора моделей обнаружения, предназначенное для:
• выборки из базы моделей обнаружения по меньшей мере двух моделей обнаружения вредоносных файлов на основании команд и параметров, выбранных из журнала поведения исполняемого файла, при этом модель обнаружения вредоносных файлов представляет собой решающее правило определения степени вредоносности;
• передачи всех выбранных моделей обнаружения вредоносных файлов средству вычисления степени вредоносности;
в) средство вычисления степени вредоносности, предназначенное для:
• вычисления степени вредоносности исполняемого файла на основании анализа полученной свертки с помощью каждой полученной модели обнаружения вредоносных файлов;
• передачи каждой вычисленной степени вредоносности средству анализа;
г) средство анализа, предназначенное для:
• формирования на основании полученных степеней вредоносности шаблона решения;
• признания исполняемого файла вредоносным, в случае, когда степень схожести между сформированным шаблоном решения и по меньшей мере одним из заранее заданных шаблонов решения из базы шаблонов решения, предварительно сформированных на основании анализа вредоносных файлов, превышает заранее заданное пороговое значение.
2. Система по п. 1, которая дополнительно содержит средство формирования журналов поведения исполняемого файла, предназначенное для:
• перехвата по меньшей мере одной команды по меньшей мере во время:
 исполнения файла,
исполнения файла,
эмуляции исполнения файла;
• определения для каждой перехваченной команды по меньшей мере одного параметра, описывающего упомянутую команду;
• формирования на основании перехваченных команд и определенных параметров журнала поведения упомянутого файла;
• передачи сформированного журнала поведения средству анализа журнала поведения и средству выбора моделей обнаружения.
3. Система по п. 1, в которой журнал поведения представляет собой совокупность исполняемых команд (далее - команда) из файла, где каждой команде соответствует по меньшей мере один параметр, описывающий упомянутую команду (далее - параметр).
4. Система по п. 1, в которой вычисление свертки от сформированных шаблонов поведения выполняется на основании заранее заданной функции свертки, такой что обратная функция свертки от результата упомянутой функции свертки над всеми сформированными шаблонами поведения имеет степень схожести с упомянутым шаблоном поведения больше заданного значения.
5. Система по п. 1, в которой модель обнаружения вредоносных файлов была предварительно обучена методом машинного обучения на по меньшей мере одном безопасном файле и вредоносном файле.
6. Система по п. 5, в которой в качестве метода машинного обучения модели обнаружения выступает по меньшей мере метод:
• градиентный бустинг на деревьях принятия решений;
• деревья принятия решений;
• ближайших соседей kNN;
• опорных векторов.
7. Система по п. 5, в которой метод обучения модели обнаружения обеспечивает монотонность изменения степени вредоносности файла в зависимости от изменения количества шаблонов поведения, сформированных на основании анализа журнала поведения.
8. Система по п. 1, в которой шаблон решения представляет собой композицию степеней вредоносности.
9. Система по п. 1, в которой каждая выбранная из базы моделей обнаружения модель обнаружения вредоносных файлов обучена для обнаружения вредоносных файлов с уникальными заранее заданными характерными признаками.
10. Система по п. 9, в которой дополнительно средство анализа предназначено для переобучения по меньшей мере одной модели обнаружения из базы моделей обнаружения на основании команд и параметров, выбранных из журнала поведения исполняемого файла, в случае, когда степень схожести между сформированным шаблоном решения и по меньшей мере одним из заранее заданных шаблонов решения из базы шаблонов решения превышает заранее заданное пороговое значение, а степени вредоносности, вычисленные с помощью упомянутых моделей обнаружения вредоносного файла, не превышают заранее заданного порогового значения.
11. Способ обнаружения вредоносных файлов с использованием обученной модели обнаружения вредоносных файлов, при этом способ содержит этапы, которые реализуются с помощью средств из системы по п. 1 и на которых:
а) формируют по меньшей мере один шаблон поведения на основании команд и параметров, выбранных из журнала поведения исполняемого файла, при этом шаблон поведения представляет собой набор из по меньшей мере одной команды и такого параметра, который описывает все команды из упомянутого набора;
б) вычисляют свертку от всех сформированных на предыдущем этапе шаблонов поведения;
в) выбирают из базы моделей обнаружения по меньшей мере две модели обнаружения вредоносных файлов на основании команд и параметров, выбранных из журнала поведения исполняемого файла, при этом модель обнаружения вредоносных файлов представляет собой решающее правило определения степени вредоносности;
г) вычисляют степень вредоносности исполняемого файла на основании анализа вычисленной на этапе б) свертки с помощью каждой выбранной на этапе в) модели обнаружения вредоносных файлов;
д) формируют на основании полученных на предыдущем этапе степеней вредоносности шаблон решения;
е) признают исполняемый файл вредоносным, в случае, когда степень схожести между сформированным на предыдущем этапе шаблоном решения и по меньшей мере одним из заранее заданных шаблонов решения из базы шаблонов решения превышает заранее заданное пороговое значение.
12. Способ по п. 11, по которому дополнительно:
• перехватывают по меньшей мере одну команду по меньшей мере во время:
исполнения файла,
эмуляции исполнения файла;
• определяют для каждой перехваченной команды по меньшей мере один параметр, описывающий упомянутую команду;
• формируют на основании перехваченных команд и определенных параметров журнал поведения упомянутого файла.
13. Способ по п. 11, по которому журнал поведения представляет собой совокупность исполняемых команд (далее - команда) из файла, где каждой команде соответствует по меньшей мере один параметр, описывающий упомянутую команду (далее - параметр).
14. Способ по п. 11, по которому вычисляют свертку от сформированных шаблонов поведения на основании заранее заданной функции свертки, такой что обратная функция свертки от результата упомянутой функции свертки над всеми сформированными шаблонами поведения имеет степень схожести с упомянутым шаблоном поведения больше заданного значения.
15. Способ по п. 11, по которому модель обнаружения вредоносных файлов была предварительно обучена методом машинного обучения на по меньшей мере одном безопасном файле и вредоносном файле.
16. Способ по п. 15, по которому в качестве метода машинного обучения модели обнаружения выступает по меньшей мере метод:
• градиентный бустинг на деревьях принятия решений;
• деревья принятия решений;
• ближайших соседей kNN;
• опорных векторов.
17. Способ по п. 15, по которому метод обучения модели обнаружения обеспечивает монотонность изменения степени вредоносности файла в зависимости от изменения количества шаблонов поведения, сформированных на основании анализа журнала поведения.
18. Способ по п. 11, по которому шаблон решения представляет собой композицию степеней вредоносности.
19. Способ по п. 11, по которому каждая выбранная из базы моделей обнаружения модель обнаружения вредоносных файлов обучена для обнаружения вредоносных файлов с уникальными заранее заданными характерными признаками.
20. Способ по п. 19, по которому переобучают по меньшей мере одну модель обнаружения из базы моделей обнаружения на основании команд и параметров, выбранных из журнала поведения исполняемого файла, в случае, когда степень схожести между сформированным шаблоном решения и по меньшей мере одним из заранее заданных шаблонов решения из базы шаблонов решения превышает заранее заданное пороговое значение, а степени вредоносности, вычисленные с помощью упомянутых моделей обнаружения вредоносного файла, не превышают заранее заданного порогового значения.
| US 7487544 B2, 03.02.2009 | |||
| US 9652617 B1, 16.05.2017 | |||
| СИСТЕМА И СПОСОБ СОЗДАНИЯ ГИБКОЙ СВЕРТКИ ДЛЯ ОБНАРУЖЕНИЯ ВРЕДОНОСНЫХ ПРОГРАММ | 2013 |
|
RU2580036C2 |
| СИСТЕМА И СПОСОБ ПОВЫШЕНИЯ ЭФФЕКТИВНОСТИ ОБНАРУЖЕНИЯ НЕИЗВЕСТНЫХ ВРЕДОНОСНЫХ ОБЪЕКТОВ | 2010 |
|
RU2454714C1 |
| Мешалка для перемешивания вина в акратофоре | 1954 |
|
SU101223A1 |

