Область техники
Изобретение относится к бинауральной аудиообработке и, в частности, но не только, к передаче и обработке данных бинауральной передаточной функции головы для вариантов применения на основе аудиообработки.
Уровень техники
В последние десятилетия все более важным становится цифровое кодирование различных исходных сигналов по мере того, как представление и передача цифровых сигналов все в большей степени заменяют аналоговое представление и передачу. Например, аудиоконтент, такой как речь и музыка, все в большей степени основывается на кодировании цифрового контента. Кроме того, потребление аудио все в большей степени становится всеобъемлющим трехмерным представлением, при этом преобладающими становятся, например, компоновки с объемным звуком и системой домашнего кинотеатра.
Разрабатываются форматы кодирования аудио для того, чтобы предоставлять все более мощные, вариативные и гибкие услуги передачи аудио, и в частности, разрабатываются форматы кодирования аудио, поддерживающие услуги передачи пространственного аудио.
Известные технологии кодирования аудио, такие как DTS и Dolby Digital, формируют кодированный многоканальный аудиосигнал, который представляет пространственное изображение в качестве числа каналов, которые размещены вокруг слушателя в фиксированных позициях. Для компоновки динамиков, которая отличается от компоновки, которая соответствует многоканальному сигналу, пространственное изображение является субоптимальным. Кроме того, системы канального кодирования аудио типично неспособны справляться с другим числом динамиков.
Стандарт объемного звучания MPEG (ISO/IEC-MPEG-D) предоставляет инструментальное средство многоканального кодирования аудио, которое обеспечивает возможность расширения существующих моно- или стереокодеров на многоканальные аудиоприложения. Фиг. 1 иллюстрирует пример элементов системы по стандарту объемного звучания MPEG. С использованием пространственных параметров, полученных посредством анализа исходного многоканального входа, декодер по стандарту объемного звучания MPEG может воссоздавать пространственное изображение посредством управляемого повышающего микширование моно- или стереосигнала, чтобы получать многоканальный выходной сигнал.
Поскольку пространственное изображение многоканального входного сигнала параметризовано, стандарт объемного звучания MPEG предоставляет возможность декодирования идентичного многоканального потока битов посредством устройств воспроизведения, которые не используют многоканальную компоновку динамиков. Пример представляет собой проигрывание с виртуальным объемным звучанием в головных наушниках, которое упоминается в качестве процесса бинаурального декодирования по стандарту объемного звучания MPEG. В этом режиме, реалистичное ощущение объемного звучания может предоставляться с использованием обычных головных наушников. Другой пример представляет собой отсечение многоканальных выходов высшего порядка, например, 7.1 каналов, до компоновок низшего порядка, например, до каналов 5.1.
Фактически, вариативность и гибкость в конфигурациях воспроизведения, используемых для воспроизведения пространственного звука, в последние годы значительно возросла, при этом все большее число форматов проигрывания становятся доступными типичному потребителю. Это требует гибкого представления аудио. Важные шаги предприняты с введением кодека по стандарту объемного звучания MPEG. Тем не менее, аудио по-прежнему формируется и передается для конкретной компоновки громкоговорителей, например, компоновки динамиков по стандарту ITU 5.1. Проигрывание в различных компоновках и в нестандартных (т.е. гибких или определяемых пользователем) компоновках динамиков не указывается. Фактически, желательно делать кодирование и представление аудио более независимым от конкретных предварительно определенных и номинальных компоновок динамиков. Более предпочтительно, если гибкая адаптация к широкому спектру различных компоновок динамиков может выполняться на стороне декодера/воспроизведения.
Чтобы предусматривать более гибкое представление аудио, MPEG стандартизирует формат, известный как "пространственное кодирование аудиообъектов' (ISO/IEC MPEG-D SAOC). В отличие от систем кодирования многоканального аудио, таких как DTS, Dolby Digital и стандарт объемного звучания MPEG, SAOC предоставляет эффективное кодирование отдельных аудиообъектов, а не аудиоканалов. Тогда как в стандарте объемного звучания MPEG, каждый канал динамика может рассматриваться как исходящий из различного микширования звуковых объектов, SAOC делает отдельные звуковые объекты доступными на стороне декодера для интерактивной обработки, как проиллюстрировано на фиг. 2. В SAOC, несколько звуковых объектов кодируются в моно- или стереосигналы посредством понижающего микширования вместе с параметрическими данными, предоставляя возможность извлечения звуковых объектов на стороне воспроизведения, за счет этого обеспечивая доступность отдельных аудиообъектов для обработки, например, конечным пользователем.
Фактически, аналогично стандарту объемного звучания MPEG, SAOC также создает моно- или стереосигналы посредством понижающего микширования. Помимо этого, параметры объекта вычисляются и включаются. На стороне декодера пользователь может обрабатывать эти параметры, чтобы управлять различными признаками отдельных объектов, такими как позиция, уровень, частотная коррекция, либо даже применять такие эффекты, как реверберация. Фиг. 3 иллюстрирует интерактивный интерфейс, который позволяет пользователю управлять отдельными объектами, содержащимися в SAOC-потоке битов. Посредством матрицы воспроизведения, отдельные звуковые объекты преобразуются в каналы динамика.
SAOC обеспечивает более гибкий подход и, в частности, обеспечивает большую адаптируемость на основе воспроизведения посредством передачи аудиообъектов, а не только каналов проигрывания. Это позволяет стороне декодера размещать аудиообъекты в произвольных позициях в пространстве при условии, что пространство адекватно покрывается динамиками. Таким образом, отсутствует взаимосвязь между передаваемым аудио и компоновкой для проигрывания или воспроизведения, и как следствие, могут использоваться произвольные компоновки динамиков. Это является преимущественным, например, для компоновок с системой домашнего кинотеатра в типичной гостиной, в которых динамики практически никогда не располагаются в намеченных позициях. В SAOC, то, где объекты размещены в звуковой сцене, определяется на стороне декодера, что зачастую является нежелательным с художественной точки зрения. SAOC-стандарт предоставляет способы передавать матрицу воспроизведения по умолчанию в потоке битов, исключая ответственность декодера. Тем не менее, предоставленные способы основываются либо на фиксированных компоновках для проигрывания, либо на неуказанном синтаксисе. Таким образом, SAOC не предоставляет нормативное средство для того, чтобы полностью передавать аудиосцену независимо от компоновки динамиков. Кроме того, SAOC не приспособлено оптимально к достоверному воспроизведению компонентов рассеянного сигнала. Хотя есть возможность включать так называемый многоканальный фоновый объект (MBO) для того, чтобы захватывать рассеянный звук, этот объект привязан к одной конкретной конфигурации динамиков.
Другие технические требования для аудиоформата для трехмерного аудио разрабатываются посредством Альянса по стандартизации в области трехмерного аудио (3DAA), который является отраслевым альянсом. 3DAA специально создан для разработки стандартов для передачи трехмерного аудио, которые "упрощают переход от текущей парадигмы прямой подачи звука в динамики к гибкому объектно-ориентированному подходу". В 3DAA, должен задаваться формат потока битов, который обеспечивает возможность передачи унаследованного многоканального понижающего микширования вместе с отдельными звуковыми объектами. Помимо этого, данные позиционирования объектов включены. Принцип формирования 3DAA-аудиопотока проиллюстрирован на фиг. 4.
В 3DAA-подходе, звуковые объекты принимаются отдельно в расширенном потоке, и они могут извлекаться из многоканального понижающего микширования. Результирующее многоканальное понижающее микширование подготовлено посредством воспроизведения вместе с доступными по отдельности объектами.
Объекты могут состоять из так называемых стемов. Эти стемы по существу представляют собой сгруппированные (микшированные с понижением) дорожки или объекты. Следовательно, объект может состоять из нескольких подобъектов, пакетированных в стем. В 3DAA, многоканальное опорное микширование может передаваться с выбором аудиообъектов. 3DAA передает трехмерные позиционные данные для каждого объекта. Объекты затем могут извлекаться с использованием трехмерных позиционных данных. Альтернативно, может передаваться обратная матрица микширования, описывающая взаимосвязь между объектами и опорным микшированием.
Из описания 3DAA, информация звуковых сцен, вероятно, передается посредством назначения угла и расстояния для каждого объекта, которые указывают то, где должен быть размещен объект относительно, например, прямого направления по умолчанию. Таким образом, позиционная информация передается для каждого объекта. Это является полезным для точечных источников, но не может описывать широкие источники (такие как, например, хор или аплодисменты) или рассеянные звуковые поля (к примеру, окружение). Когда все точечные источники извлекаются из опорного микширования, окружающее многоканальное микширование остается. Аналогично SAOC, остаток в 3DAA является фиксированным для конкретной компоновки динамиков.
Таким образом, SAOC- и 3DAA-подходы включают передачу отдельных аудиообъектов, которые могут быть по отдельности обработаны на стороне декодера. Различие между двумя подходами заключается в том, что SAOC предоставляет информацию относительно аудиообъектов посредством предоставления параметров, характеризующих объекты относительно понижающего микширования (т.е. таким образом, что аудиообъекты формируются из понижающего микширования на стороне декодера), тогда как 3DAA предоставляет аудиообъекты в качестве полных и отдельных аудиообъектов (т.е. которые могут формироваться независимо от понижающего микширования на стороне декодера). Для обоих подходов позиционные данные могут передаваться для аудиообъектов.
Бинауральная обработка, в которой пространственное восприятие создано посредством виртуального позиционирования источников звука с использованием отдельных сигналов для ушей слушателя, становится все более широко распространенной. Виртуальное объемное звучание представляет собой способ воспроизведения звука таким образом, что аудиоисточники воспринимаются как исходящие из конкретного направления, за счет этого создавая иллюзию прослушания в физической компоновке с объемным звуком (например, с динамиками 5.1) или в окружении (на концерте). За счет надлежащей обработки бинаурального воспроизведения могут вычисляться сигналы, требуемые в барабанных перепонках для восприятия слушателем звука из любого требуемого направления, и сигналы могут быть подготовлены посредством воспроизведения таким образом, что они предоставляют требуемый эффект. Как проиллюстрировано на фиг. 5, эти сигналы затем воссоздаются в барабанной перепонке либо с использованием головных наушников, либо с использованием способа подавления перекрестных помех (подходящего для воспроизведения посредством близкорасположенных динамиков).
Наряду с прямым воспроизведением по фиг. 5, конкретные технологии, которые могут использоваться для того, чтобы подготавливать посредством воспроизведения виртуальное объемное звучание, включают в себя кодирование по стандарту объемного звучания MPEG и пространственное кодирование аудиообъектов, а также объект предстоящих исследований трехмерного аудио в MPEG. Эти технологии предусматривают вычислительно эффективный рендеринг виртуального объемного звучания.
Бинауральное воспроизведение основано на бинауральных передаточных функциях головы, которые варьируются в зависимости от человека вследствие акустических свойств головы, ушей и отражающих поверхностей, таких как плечи. Например, бинауральные фильтры могут использоваться для того, чтобы создавать бинауральную запись, моделирующую несколько источников в различных местоположениях. Это может быть реализовано посредством свертки каждого источника звука с парой импульсных характеристик головы (HRIR), которые соответствуют позиции источника звука.
Посредством измерения, например, характеристик из источника звука в конкретном местоположении в двумерном или трехмерном пространстве в микрофонах, размещенных в/около человеческих ушей, могут определяться надлежащие бинауральные фильтры. Типично такие измерения выполняются, например, с использованием моделей человеческих голов, или фактически в некоторых случаях измерения могут выполняться посредством присоединения микрофонов около барабанных перепонок человека. Бинауральные фильтры могут использоваться для того, чтобы создавать бинауральную запись, моделирующую несколько источников в различных местоположениях. Это может быть реализовано, например, посредством свертки каждого источника звука с парой измеренных импульсных характеристик для требуемой позиции источника звука. Чтобы создавать иллюзию того, что источник звука перемещается вокруг слушателя, большое число бинауральных фильтров требуется с соответствующим пространственным разрешением, например, в 10 градусов.
Бинауральные передаточные функции головы могут быть представлены, например, в качестве импульсных характеристик головы (HRIR) или, эквивалентно, в качестве передаточных функций головы (HRTF), либо в качестве бинауральных импульсных характеристик в помещении (BRIR) или бинауральных передаточных функций в помещении (BRTF). (Например, оцененная или предполагаемая) передаточная функция от данной позиции в уши (или барабанные перепонки) слушателя известна как бинауральная передаточная функция головы. Эта функция, например, может задаваться в частотной области, причем в этом случае она типично упоминается в качестве HRTF или BRTF, либо во временной области, причем в этом случае она типично упоминается в качестве HRIR или BRIR. В некоторых сценариях, бинауральные передаточные функции головы определяются как включающие в себя аспекты или свойства акустического окружения и, в частности, помещения, в котором выполняются измерения, тогда как в других примерах рассматриваются только характеристики пользователя. Примеры первого типа функций представляют собой BRIR и BRTF.
Во многих сценариях желательно предоставлять возможность передачи и распределения параметров для требуемого бинаурального воспроизведения, к примеру, конкретных бинауральных передаточных функций головы, которые должны быть.
Технический комитет sc-02 Общества звукоинженеров (AES) недавно анонсировал начала нового проекта по стандартизации формата файлов для того, чтобы обмениваться параметрами бинаурального прослушивания в форме бинауральных передаточных функций головы. Формат является масштабируемым таким образом, что он соответствует доступному процессу воспроизведения. Формат проектируется с возможностью включать в себя исходные материалы из различных баз данных бинауральных передаточных функций головы. Имеется сложность в том, как такие бинауральные передаточные функции головы могут лучше всего поддерживаться, использоваться и распределяться в аудиосистеме.
Соответственно, требуется усовершенствованный подход для поддержки бинауральной обработки и, в частности, для передачи данных для бинаурального воспроизведения. В частности, должен быть преимущественным подход, обеспечивающий улучшенное представление и передачу данных бинаурального воспроизведения, меньшую скорость передачи данных, меньший объем служебной информации, упрощенную реализацию и/или повышенную производительность.
Сущность изобретения
Следовательно, изобретение предпочтительно нацелено на уменьшение, облегчение или устранение одного или более вышеуказанных недостатков по отдельности или в любой комбинации.
Согласно аспекту изобретения, предусмотрено устройство для обработки аудиосигнала, причем устройство содержит: приемное устройство для приема входных данных, причем входные данные содержат, по меньшей мере, данные, описывающие бинауральную передаточную функцию головы, содержащую раннюю часть и часть реверберации, причем данные содержат: данные ранней части, указывающие раннюю часть бинауральной передаточной функции головы, данные реверберации, указывающие часть реверберации бинауральной передаточной функции головы, индикатор синхронизации, указывающий сдвиг по времени между ранней частью и частью реверберации; схему ранней части для формирования первого аудиокомпонента посредством применения бинауральной обработки к аудиосигналу, причем бинауральная обработка, по меньшей мере, частично определяется посредством данных ранней части; ревербератор для формирования второго аудиокомпонента посредством применения реверберационной обработки к аудиосигналу, причем реверберационная обработка, по меньшей мере, частично определяется посредством данных реверберации; модуль комбинирования для формирования, по меньшей мере, первого слухового сигнала из бинаурального сигнала, причем модуль комбинирования выполнен с возможностью комбинировать первый аудиокомпонент и второй аудиокомпонент; и синхронизатор для синхронизации первого аудиокомпонента и второго аудиокомпонента в ответ на индикатор синхронизации.
Изобретение позволяет обеспечивать очень эффективную работу. При этом может достигаться очень эффективное представление и/или обработка на основе бинауральной передаточной функции головы. Подход может приводить к меньшим скоростям передачи данных и/или к обработке с меньшей сложностью, и/или к бинауральному воспроизведению.
Фактически, вместо использования простого длинного представления бинауральной передаточной функции головы, которое приводит к высокой скорости передачи данных и комплексной обработке, бинауральная передаточная функция головы может быть разделена, по меньшей мере, на две части. Представление и обработка могут быть по отдельности оптимизированы для характеристик отдельных частей бинауральной передаточной функции головы. В частности, представление и обработка могут быть оптимизированы для отдельных физических характеристик, определяющих бинауральную передаточную функцию головы в отдельных частях, и/или для перцепционных характеристик, ассоциированных с каждой из частей.
Например, представление и/или обработка ранней части может быть оптимизирована для прямого тракта распространения аудио, тогда как представление и/или обработка тракта реверберации может быть оптимизирована для отраженных трактов распространения аудио.
Кроме того, подход позволяет обеспечивать повышенное качество звука посредством предоставления возможности управления синхронизацией воспроизведения различных частей со стороны кодера. Это обеспечивает возможность тщательного управления относительной временной синхронизацией между ранней частью и частью реверберации, так чтобы предоставлять полный эффект, который соответствует исходной бинауральной передаточной функции головы. Фактически, это обеспечивает возможность управления синхронизацией различных частей на основе информации относительно информации полной бинауральной передаточной функции головы. В частности, временная синхронизация отражений и рассеянных ревербераций относительно прямого тракта зависит, например, от позиции источника звука и позиции прослушивания, а также от конкретных характеристик помещения. Эта информация отражается в измеренной бинауральной передаточной функции головы, но типично не доступна для модуля бинаурального воспроизведения. Тем не менее, подход позволяет модулю воспроизведения точно эмулировать исходную измеренную бинауральную передаточную функцию головы несмотря на то, что она представлена посредством двух различных частей.
Бинауральная передаточная функция головы, в частности, может представлять собой передаточную функцию восприятия звука в помещении, такую как BRIR или BRTF.
Синхронизатор, в частности, может быть выполнен с возможностью совмещать по времени первый и второй аудиокомпонент, при этом смещение временного совмещения определяется из индикатора синхронизации.
Синхронизатор может синхронизировать первый аудиокомпонент и второй аудиокомпонент любым подходящим способом. Таким образом, любой подход может использоваться для того, чтобы регулировать временную синхронизацию первого аудиокомпонента относительно второго аудиокомпонента до комбинирования, при этом временное регулирование определяется в ответ на индикатор синхронизации. Например, задержка может применяться к одному из аудиокомпонентов, и/или задержки, например, могут применяться к сигналам, из которых формируются первый и/или второй аудиокомпоненты.
Ранняя часть может соответствовать временному интервалу импульсной характеристики бинауральной передаточной функции головы до данного момента времени, и часть реверберации может соответствовать временному интервалу импульсной характеристики бинауральной передаточной функции головы после данного момента времени (причем два момента времени могут, но не обязательно должны, быть идентичным моментом времени). По меньшей мере, часть временного интервала импульсной характеристики для части реверберации располагается позднее временного интервала импульсной характеристики для ранней части. В большинстве вариантов осуществления и сценариев, начало части реверберации располагается позднее начала ранней части. В некоторых вариантах осуществления, временной интервал импульсной характеристики для части реверберации является временным интервалом после данного времени (импульсной характеристики), и временной интервал импульсной характеристики для ранней части является временным интервалом до данного времени.
Ранняя часть в некоторых сценариях может соответствовать или включать в себя часть бинауральной передаточной функции головы, которая соответствует прямому тракту из позиции (виртуального) источника звука бинауральной передаточной функции головы в (номинальную) позицию прослушивания. В некоторых вариантах осуществления или сценариях, ранняя часть может включать в себя часть бинауральной передаточной функции головы, которая соответствует одному или более ранним отражениям из позиции (виртуального) источника звука бинауральной передаточной функции головы в (номинальную) позицию прослушивания.
Часть реверберации в некоторых сценариях может соответствовать или включать в себя часть бинауральной передаточной функции головы, которая соответствует рассеянной реверберации в аудиоокружении, представленном посредством бинауральной передаточной функции головы. В некоторых вариантах осуществления или сценариях, часть реверберации может включать в себя часть бинауральной передаточной функции головы, которая соответствует одному или более ранним отражениям из позиции (виртуального) источника звука бинауральной передаточной функции головы в (номинальную) позицию прослушивания. Таким образом, ранние отражения могут быть распределены по ранней части и части реверберации.
Во многих вариантах осуществления и сценариях, ранняя часть может соответствовать части бинауральной передаточной функции головы, которая соответствует прямому тракту из позиции (виртуального) источника звука бинауральной передаточной функции головы в (номинальную) позицию прослушивания, и часть реверберации может соответствовать части бинауральной передаточной функции головы, которая соответствует ранним отражениям и рассеянной реверберации.
Данные ранней части могут служить признаком ранней части бинауральной передаточной функции головы посредством включения данных, которые, по меньшей мере, частично описывают раннюю часть бинауральной передаточной функции головы. В частности, они могут содержать данные, которые (прямо или косвенно), по меньшей мере, описывают бинауральную передаточную функцию головы в раннем временном интервале. Например, импульсная характеристика бинауральной передаточной функции головы в раннем временном интервале может быть, по меньшей мере, частично описана посредством данных ранней части.
Данные части реверберации могут служить признаком части реверберации бинауральной передаточной функции головы посредством включения данных, которые, по меньшей мере, частично описывают часть реверберации бинауральной передаточной функции головы. В частности, они могут содержать данные, которые (прямо или косвенно), по меньшей мере, описывают бинауральную передаточную функцию головы во временном интервале реверберации. Например, импульсная характеристика бинауральной передаточной функции головы во временном интервале реверберации может быть, по меньшей мере, частично описана посредством данных ранней части. Временной интервал реверберации заканчивается после раннего временного интервала и, во многих вариантах осуществления, также начинается после конца раннего временного интервала.
Первый аудиокомпонент может формироваться, чтобы соответствовать аудиосигналу, фильтруемому посредством ранней части бинауральной передаточной функции головы, поскольку эта функция описывается посредством данных ранней части.
Второй аудиокомпонент может соответствовать компоненту сигнала реверберации во временном интервале, соответствующем части реверберации, причем компонент сигнала реверберации формируется из аудиосигнала в соответствии с процессом, описанным (по меньшей мере, частично) посредством данных реверберации.
Бинауральная обработка может соответствовать фильтрации аудиосигнала посредством фильтра, соответствующего бинауральной передаточной функции головы в ранней части, поскольку функция определяется посредством данных ранней части.
Бинауральная обработка может формировать первый аудиокомпонент для одного сигнала из бинаурального стереосигнала (т.е. она может формировать аудиокомпонент для сигнала одного из ушей).
Процесс реверберации может представлять собой процесс формирования посредством синтетического ревербератора сигнала реверберации в части реверберации из аудиосигнала в соответствии с процессом, определенным из данных реверберации.
Процесс реверберации может соответствовать аудиосигналу, фильтруемому посредством части реверберации бинауральной передаточной функции головы, поскольку функция описывается посредством данных части реверберации.
В соответствии с необязательным признаком изобретения, синхронизатор выполнен с возможностью вводить задержку для второго аудиокомпонента относительно первого аудиокомпонента, причем задержка является зависимой от индикатора синхронизации.
Это позволяет обеспечивать эффективную работу с низкой сложностью.
В соответствии с необязательным признаком изобретения, данные ранней части служат признаком безэховой части бинауральной передаточной функции головы.
Это может приводить к сверхпреимущественной работе и типично к высокоэффективному представлению и обработке.
В соответствии с необязательным признаком изобретения, данные ранней части содержат параметры фильтрации в частотной области, и обработка ранней части представляет собой обработку в частотной области.
Это может приводить к сверхпреимущественной работе и типично к высокоэффективному представлению и обработке. В частности, фильтрация в частотной области может обеспечивать очень точную эмуляцию распространения аудио прямого тракта с низкой сложностью и использованием ресурсов. Кроме того, она может достигаться без необходимости также представления реверберации посредством фильтрации в частотной области, которая требует высокой степени сложности.
В соответствии с необязательным признаком изобретения, данные части реверберации содержат параметры для модели реверберации, и ревербератор выполнен с возможностью реализовывать модель реверберации с использованием параметров, указываемых посредством данных части реверберации.
Это может приводить к сверхпреимущественной работе и типично к высокоэффективному представлению и обработке. В частности, моделирование реверберации может обеспечивать очень точную эмуляцию отраженного аудио распределения с низкой сложностью и использованием ресурсов. Кроме того, это может достигаться без необходимости также представления прямых аудиотрактов посредством идентичной модели.
В соответствии с необязательным признаком изобретения, ревербератор содержит синтетический ревербератор, и данные части реверберации содержат параметры для синтетического ревербератора.
Это может приводить к сверхпреимущественной работе и типично к высокоэффективному представлению и обработке. В частности, синтетический ревербератор может обеспечивать очень точную эмуляцию отраженного аудио распределения с низкой сложностью и использованием ресурсов при одновременном обеспечении точного представления прямых аудиотрактов.
В соответствии с необязательным признаком изобретения, ревербератор содержит реверберационный фильтр, и данные реверберации содержат параметры для реверберационного фильтра.
Это может приводить к сверхпреимущественной работе и типично к высокоэффективному представлению и обработке.
В соответствии с необязательным признаком изобретения, бинауральная передаточная функция головы дополнительно содержит часть ранних отражений между ранней частью и частью реверберации, и данные дополнительно содержат: данные части ранних отражений, указывающие часть ранних отражений бинауральной передаточной функции головы; и второй индикатор синхронизации, указывающий сдвиг по времени между частью ранних отражений и, по меньшей мере, одной из ранней части и части реверберации; и устройство дополнительно содержит: процессор части ранних отражений для формирования третьего аудиокомпонента посредством применения обработки отражения к аудиосигналу, причем обработка отражения, по меньшей мере, частично определяется посредством данных части ранних отражений; и модуль комбинирования выполнен с возможностью формировать первый слуховой сигнал бинаурального сигнала в ответ на комбинирование, по меньшей мере, первого аудиокомпонента, второго аудиокомпонента и третьего аудиокомпонента; и синхронизатор выполнен с возможностью синхронизировать третий аудиокомпонент, по меньшей мере, с одним из первого аудиокомпонента и второго аудиокомпонента в ответ на второй индикатор синхронизации.
Это может приводить к повышенному качеству звука и/или к более эффективному представлению и/или обработке.
В соответствии с необязательным признаком изобретения, ревербератор выполнен с возможностью формировать второй аудиокомпонент в ответ на процесс реверберации, применяемый к первому аудиокомпоненту.
Это позволяет обеспечивать сверхпреимущественную реализацию в некоторых вариантах осуществления и сценариях.
В соответствии с опциональным признаком изобретения, индикатор синхронизации компенсируется в отношении задержки бинауральной обработки.
Это позволяет обеспечивать сверхпреимущественную работу в некоторых вариантах осуществления и сценариях.
В соответствии с необязательным признаком изобретения, индикатор синхронизации компенсируется в отношении задержки реверберационной обработки.
Это позволяет обеспечивать достаточно преимущественную работу в некоторых вариантах осуществления и сценариях.
Согласно аспекту изобретения, предусмотрено устройство для формирования потока битов, причем устройство содержит: процессор для приема бинауральной передаточной функции головы, содержащей раннюю часть и часть реверберации; схему обработки ранней части для формирования данных ранней части, указывающих раннюю часть бинауральной передаточной функции головы; схему реверберации для формирования данных реверберации, указывающих часть реверберации бинауральной передаточной функции головы; схему синхронизации для формирования данных синхронизации, содержащих индикатор синхронизации, указывающий сдвиг по времени между данными ранней части и данными реверберации; и выходная схема для формирования потока битов, содержащего данные ранней части, данные реверберации и данные синхронизации.
Согласно аспекту изобретения, предусмотрен способ обработки аудиосигнала, причем способ содержит: прием входных данных, причем входные данные содержат, по меньшей мере, данные, описывающие бинауральную передаточную функцию головы, содержащую раннюю часть и часть реверберации, причем данные содержат: данные ранней части, указывающие раннюю часть бинауральной передаточной функции головы, данные реверберации, указывающие часть реверберации бинауральной передаточной функции головы, индикатор синхронизации, указывающий сдвиг по времени между ранней частью и частью реверберации; формирование первого аудиокомпонента посредством применения бинауральной обработки к аудиосигналу, причем бинауральная обработка, по меньшей мере, частично определяется посредством данных ранней части; формирование второго аудиокомпонента посредством применения реверберационной обработки к аудиосигналу, причем реверберационная обработка, по меньшей мере, частично определяется посредством данных реверберации; формирование, по меньшей мере, первого слуховой сигнала из бинаурального сигнала в ответ на комбинирование первого аудиокомпонента и второго аудиокомпонента; и синхронизацию первого аудиокомпонента и второго аудиокомпонента в ответ на индикатор синхронизации.
Согласно аспекту изобретения, предусмотрен способ передачи сигнала изображения, при этом способ содержит: прием бинауральной передаточной функции головы, содержащей раннюю часть и часть реверберации; формирование данных ранней части, указывающих раннюю часть бинауральной передаточной функции головы; формирование данных реверберации, указывающих часть реверберации бинауральной передаточной функции головы; формирование данных синхронизации, содержащих индикатор синхронизации, указывающий сдвиг по времени между данными ранней части и данными реверберации; и формирование потока битов, содержащего данные ранней части, данные реверберации и данные синхронизации.
Согласно аспекту изобретения, предусмотрен поток битов, содержащий данные, представляющие бинауральную передаточную функцию головы, содержащую раннюю часть и часть реверберации, причем данные содержат: данные ранней части, указывающие раннюю часть бинауральной передаточной функции головы; данные реверберации, указывающие часть реверберации бинауральной передаточной функции головы; данные синхронизации, содержащие индикатор синхронизации, указывающий сдвиг по времени между данными ранней части и данными реверберации.
Эти и другие аспекты, признаки и преимущества изобретения должны становиться очевидными и должны истолковываться со ссылкой на описанные далее варианты осуществления.
Краткое описание чертежей
Варианты осуществления изобретения описаны далее только в качестве примера со ссылкой на чертежи, из которых:
Фиг. 1 иллюстрирует пример элементов системы по стандарту объемного звучания MPEG.
Фиг. 2 иллюстрирует обработку аудиообъектов, возможных в MPEG SAOC.
Фиг. 3 иллюстрирует интерактивный интерфейс, который позволяет пользователю управлять отдельными объектами, содержащимися в SAOC-потоке битов.
Фиг. 4 иллюстрирует пример принципа кодирования аудио 3DAA.
Фиг. 5 иллюстрирует пример бинауральной обработки.
Фиг. 6 иллюстрирует пример бинауральной импульсной характеристики в помещении.
Фиг. 7 иллюстрирует пример бинауральной импульсной характеристики в помещении.
Фиг. 8 иллюстрирует пример модуля бинаурального воспроизведения в соответствии с некоторыми вариантами осуществления изобретения.
Фиг. 9 иллюстрирует пример модифицированного ревербератора Джота.
Фиг. 10 иллюстрирует пример модуля бинаурального воспроизведения в соответствии с некоторыми вариантами осуществления изобретения.
Фиг. 11 иллюстрирует пример передающего устройства данных бинауральной передаточной функции головы в соответствии с некоторыми вариантами осуществления изобретения.
Фиг. 12 иллюстрирует пример элементов системы по стандарту объемного звучания MPEG.
Фиг. 13 иллюстрирует пример элементов системы MPEG SAOC-воспроизведения аудио.
Фиг. 14 иллюстрирует пример модуля бинаурального воспроизведения в соответствии с некоторыми вариантами осуществления изобретения.
Подробное описание некоторых вариантов осуществления изобретения
Бинауральное воспроизведение, в котором виртуальные позиции источников звука могут быть эмулированы посредством формирования отдельного звука для двух ушей слушателя, типично формирует восприятие позиции на основе бинауральных передаточных функций головы. Бинауральные передаточные функции головы типично определяются посредством измерений, при которых звук захватывается в позициях около барабанной перепонки человека или модели человека. Бинауральные передаточные функции головы включают в себя HRTF, BRTF, HRIR и BRIR.
Дополнительная информация относительно конкретных представлений бинауральных передаточных функций головы содержится, например, в следующих документах:
Algazi, V.R., Duda, R.O. (2011) "Headphone-Based Spatial Sound", IEEE Signal Processing Magazine, Vol: 28 (1), 2011 год, стр: 33-42, который описывает принципы HRIR, BRIR, HRTF, BRTF.
Cheng, C., Wakefield, G.H. "Introduction to Head-Related Transfer Functions (HRTFs): Representations of HRTFs in Time, Frequency and Space", Journal Audio Engineering Society, Vol: 49, № 4, апрель 2001 года, который описывает различные представления бинауральной передаточной функции (во времени и по частоте).
Breebaart, J., Nater, f., Kohlrausch, A. (2010 год) "Spectral and spatial parameter resolution requirements for parametric, filter-bank-based HRTF processing", J. Audio Eng. Soc., 58, номер 3, стр. 126-140, который ссылается на параметрическое представление HRTF-данных (используемое в стандарте объемного звучания MPEG/SAOC).
Примерное схематичное представление бинауральной передаточной функции головы для одного уха и, в частности, передаточной функции восприятия звука в помещении показано на фиг. 6. Пример подробно иллюстрирует BRIR.
Бинауральная обработка для того, чтобы формировать пространственное восприятие, например, из головных наушников, типично включает в себя фильтрацию аудиосигнала посредством бинауральных передаточных функций головы, которые соответствуют требуемой позиции. Чтобы выполнять такую обработку, модуль бинаурального воспроизведения, соответственно, требует сведений бинауральной передаточной функции головы.
Следовательно, желательно иметь возможность эффективно передавать и распределять информацию бинауральной передаточной функции головы. Тем не менее, одна сложность возникает в результате того факта, что бинауральные передаточные функции головы типично могут быть относительно длинными. Фактически, практическая бинауральная передаточная функция головы, например, может составлять вплоть до более 5000 выборок при типичной частоте дискретизации в 48 кГц. Это является очень существенным для сильно реверберирующих акустических окружений, например, BRIR должна иметь значительную длительность для того, чтобы захватывать полный хвост реверберации таких акустических окружений. Это приводит к высокой скорости передачи данных при обмене данными бинауральной передаточной функции головы.
Кроме того, относительно длинные бинауральные передаточные функции головы также приводят к увеличенной сложности и потребности в ресурсах обработки бинаурального воспроизведения. Например, может требоваться свертка с длинными импульсными характеристиками, что приводит к существенному увеличению числа вычислений, требуемых для каждой выборки. Кроме того, гибкость уменьшается, поскольку легко воспроизводится только конкретное акустическое окружение, захваченное посредством бинауральной передаточной функции головы.
Хотя эти проблемы могут смягчаться посредством усечения бинауральной передаточной функции головы, это оказывает существенное влияние на воспринимаемый звук. Фактически, эффекты реверберации оказывают значительное влияние на воспринимаемое звуковое ощущение, и, следовательно, усечение типично имеет значительное перцепционное влияние.
Реверберирующая часть содержит сигналы, которые предоставляют информацию слышимого восприятия человека относительно расстояния между источником и слушателем (т.е. позиции, в которой BRIR измерены) и относительно размера и акустических свойств помещения. Энергия реверберирующей части относительно энергии безэховой части в основном определяет воспринимаемое расстояние источника звука. Временная плотность (ранних) отражений способствует воспринимаемому размеру помещения.
Бинауральная передаточная функция головы может разделяться на различные части. В частности, бинауральная передаточная функция головы первоначально включает в себя долю из прямого тракта распространения из позиции источника звука в микрофон (барабанную перепонку). Эта доля, соответствующая прямому звуку, по сути, представляет кратчайшее расстояние от источника звука до микрофона и, соответственно, является первым событием в бинауральной передаточной функции головы. Эта часть бинауральной передаточной функции головы известна как безэховая часть, поскольку она представляет прямое распространение звука вообще без отражений.
После безэховой части бинауральная передаточная функция головы соответствует ранним отражениям, которые соответствуют отраженному звуку, при этом отражения типично выполняются от одной или двух стен. Первые отражения могут входить в уши через короткое время после прямого звука и могут располагаться близко друг к другу, при этом вторичные отражения (более одного отражения) следуют через относительно короткое время после этого. Во многих акустических окружениях, в частности, для неустановившихся типов звука, зачастую можно перцепционно отличать, по меньшей мере, некоторые из первых и возможно вторых отражений. Отражательная плотность увеличивается во времени, когда вводятся отражения высшего порядка (например, отражения от нескольких стен). Через некоторое время, отдельные отражения соединяются вместе в то, что известно как поздняя или рассеянная реверберация. Для этого хвоста поздней или рассеянной реверберации отдельные отражения более не могут отличаться перцепционно.
Таким образом, бинауральная передаточная функция головы включает в себя безэховый компонент, соответствующий прямому (неотраженному) тракту распространения звука. Оставшаяся (реверберирующая) часть содержит две временных области, которые обычно перекрываются. Первая область содержит так называемые ранние отражения, которые представляют собой изолированные отражения источника звука от стен или препятствий в помещении до достижения барабанной перепонки (или измерительного микрофона). По мере того, как растет запаздывание во времени, увеличивается число отражений в фиксированном временном интервале, и она начинает содержать вторичные, третичные и т.д. отражения. Последняя область в реверберирующей части представляет собой секцию, в которой эти отражения более не изолированы. Эта область зачастую называется хвостом рассеянной или поздней реверберации.
Бинауральная передаточная функция головы, в частности, может считаться превращаемой в две части, а именно, в раннюю часть, которая включает в себя безэховые компоненты, и часть реверберации, которая включает в себя хвосты поздней/рассеянной реверберации. Ранние отражения типично могут рассматриваться в качестве части для части реверберации. Тем не менее, в некоторых сценариях, одно или более ранних отражений могут рассматриваться в качестве части для ранней части.
Таким образом, бинауральная передаточная функция головы может быть разделена на раннюю часть и позднюю часть (называемую "частью реверберации"). Например, любая часть бинауральной передаточной функции головы до данного порогового значения времени может считаться частью для ранней части, и любая часть бинауральной передаточной функции головы после порогового значения времени может считаться частью для поздней части реверберации. Пороговое значение времени может быть между безэховой частью и ранними отражениями. Таким образом, в некоторых случаях, ранняя часть может быть идентичной безэховой части, и часть реверберации может включать в себя все характеристики, возникающие в результате распространения отраженного звука, включающие в себя все ранние отражения. В других вариантах осуществления, пороговое значение времени может быть таким, что одно или более ранних отражений возникают до порогового значения времени, и в силу этого такие ранние отражения считаются частью для ранней части бинауральной передаточной функции головы.
Далее описываются варианты осуществления изобретения, в которых может достигаться более эффективное представление и/или обработка на основе бинауральных передаточных функций головы. Подход основан на реализации, в которой различные части бинауральной передаточной функции головы могут иметь различные характеристики, и в которой различные части бинауральной передаточной функции головы могут обрабатываться отдельно. Фактически, в вариантах осуществления, различные части бинауральной передаточной функции головы могут обрабатываться различными способами и посредством различной функциональности, при этом результаты различных процессов затем комбинируются для того, чтобы формировать выходной сигнал, который, соответственно, отражает влияние всей бинауральной передаточной функции головы.
В частности, вычислительное преимущество в воспроизведении BRIR может получаться в примерах посредством разбиения BRIR на безэховую часть и реверберирующую часть (включающую в себя ранние отражения). Более короткие фильтры, необходимые для того, чтобы представлять безэховую часть, могут быть подготовлены посредством воспроизведения со значительно более низкой вычислительной нагрузкой, чем длинные BRIR-фильтры. Кроме того, для таких подходов, как стандарт объемного звучания MPEG и SAOC, которые используют параметризованную HRTF, отражающую безэховую часть, может достигаться очень существенное сокращение вычислительной сложности. Кроме того, длинные фильтры, требуемые для того, чтобы представлять часть реверберации, могут уменьшаться по сложности, поскольку перцепционная значимость отклонения от корректной базовой бинауральной передаточной функции головы является гораздо более низкой для части реверберации, чем для безэховой части.
Фиг. 7 иллюстрирует пример измеренной BRIR. Данные показывают прямую характеристику и первые отражения. В примере, прямая характеристика измеряется приблизительно между выборкой 410 и выборкой 500. Первые отражения начинаются примерно в выборке 520, т.е. через 120 выборок после прямой характеристики. Второе отражение возникает приблизительно через 250 выборок после начала прямой характеристики. Также можно видеть, что характеристика становится более рассеянной и с менее значительными отдельными отражениями по мере прохождения времени.
BRIR по фиг. 7, например, может быть разделена на раннюю часть, которая содержит характеристику до выборки 500 (т.е. ранняя часть соответствует безэховой прямой характеристике), и часть реверберации, которая состоит из BRIR после выборки 500. Таким образом, часть реверберации включает в себя ранние отражения и хвост рассеянной реверберации.
В этом примере, ранняя часть может быть представлена и обработана отлично от части реверберации. Например, FIR-фильтр может задаваться согласно BRIR от выборки 410 до 500, и коэффициенты отводов для этого фильтра могут использоваться для того, чтобы представлять раннюю часть BRIR. Таким образом, FIR-фильтрация может применяться к аудиосигналу, чтобы отражать влияние BRIR.
Часть реверберации может быть представлена посредством других данных. Например, она может быть представлена посредством набора параметров для синтетического ревербератора. Воспроизведение, соответственно, может включать в себя формирование сигнала реверберации посредством применения синтетического ревербератора к обрабатываемому аудиосигналу, при этом синтетический ревербератор использует предоставленные параметры. Это представление и реверберационная обработка может быть значительно менее сложной и ресурсоемкой, чем когда используется FIR-фильтр с точностью, идентичной точности для ранней части, для всей BRIR.
Данные, представляющие раннюю часть бинауральной передаточной функции головы/BRIR, например, могут задавать FIR-фильтр, который имеет импульсную характеристику, совпадающую с ранней частью бинауральной передаточной функции головы/BRIR. Данные, представляющие часть реверберации бинауральной передаточной функции головы/BRIR, например, могут задавать IIR-фильтр с импульсной характеристикой, совпадающей с частью реверберации бинауральной передаточной функции головы/BRIR. В качестве другого примера, они могут предоставлять параметры для модели реверберации, которая при выполнении предоставляет характеристику реверберации, которая совпадает с частью реверберации бинауральной передаточной функции головы/BRIR.
Бинауральный сигнал, соответственно, может формироваться посредством комбинирования двух компонентов сигнала.
Фиг. 8 иллюстрирует пример элементов модуля бинаурального воспроизведения в соответствии с вариантом осуществления изобретения. Фиг. 8 подробно иллюстрирует элементы, используемые для того, чтобы формировать сигнал для одного уха, т.е. он иллюстрирует формирование одного сигнала из двух сигналов пары на основе бинаурального сигнала. Для удобства, термин "бинауральный сигнал" используется для того, чтобы означать как бинауральный стереосигнал, содержащий сигнал для каждого уха, так и сигнал только для одного из ушей слушателя (т.е. любой из моносигналов, формирующих стереосигнал).
Устройство по фиг. 8 содержит приемное устройство 801, которое принимает поток битов. Поток битов может приниматься как поток битов для потоковой передачи в реальном времени, к примеру, из услуги или приложения для потоковой передачи по Интернету. В других сценариях, поток битов может приниматься, например, в качестве сохраненного файла данных из носителя хранения данных. Поток битов может приниматься из любого внешнего или внутреннего источника и в любом подходящем формате.
Принимаемый поток битов, в частности, содержит данные, представляющие бинауральную передаточную функцию головы, которая в конкретном случае представляет собой BRIR. Типично, поток битов должен содержать множество бинауральных передаточных функций головы, к примеру, для диапазона различных позиций, но нижеприведенное описание для ясности и краткости акцентирует внимание на обработке одной бинауральной передаточной функции головы. Кроме того, бинауральные передаточные функции головы типично предоставляются в парах, т.е. для данной позиции, бинауральная передаточная функция головы предоставляется для каждого из двух ушей. Тем не менее, поскольку нижеприведенное описание акцентирует внимание на формировании сигнала для одного уха, описание также должно акцентировать внимание на использовании одной бинауральной передаточной функции головы. Следует принимать во внимание, что идентичный подход, как описано, также может применяться для того, чтобы формировать сигнал для другого уха посредством использования бинауральной передаточной функции головы для этого уха.
Принимаемая бинауральная передаточная функция головы/BRIR представлена посредством данных, которые содержат данные ранней части и данные реверберации. Данные ранней части служат признаком ранней части BRIR, и часть реверберации служит признаком части реверберации BRIR. В конкретном примере, ранняя часть состоит из безэховой части BRIR, а часть реверберации состоит из ранних отражений и хвоста реверберации. Например, для BRIR по фиг. 7, данные ранней части описывают BRIR вплоть до выборки 500, а данные части реверберации описывают BRIR после выборки 500. В некоторых вариантах осуществления и сценариях, может быть перекрытие между частью реверберации и ранней частью. Например, данные ранней части могут описывать BRIR вплоть до выборки 525, а данные части реверберации могут описывать BRIR после выборки 475.
Описания двух частей BRIR очень отличаются в конкретном примере. Безэховая часть представлена посредством относительно короткого FIR-фильтра, тогда как часть реверберации представлена посредством параметров для синтетического ревербератора.
Кроме того, в конкретном примере, поток битов содержит аудиосигнал, который должен быть подготовлен посредством воспроизведения из позиции, связанной с бинауральной передаточной функцией головы/BRIR.
Приемное устройство 801 выполнено с возможностью обрабатывать принимаемый поток битов, чтобы извлекать, восстанавливать и разделять отдельные компоненты данных потока битов таким образом, что они могут предоставляться в надлежащую функциональность.
Приемное устройство 801 соединяется со схемой ранней части в форме процессора 803 ранней части, в который подается аудиосигнал. Помимо этого, в процессор 803 ранней части подаются данные ранней части, т.е. в него подаются данные, описывающие раннюю и, в конкретном примере, безэховую часть BRIR.
Процессор 803 ранней части выполнен с возможностью формировать первый аудиокомпонент посредством применения бинауральной обработки к аудиосигналу, при этом бинауральная обработка, по меньшей мере, частично определяется посредством данных ранней части.
В частности, аудиосигнал обрабатывается посредством применения ранней части бинауральной передаточной функции головы к аудиосигналу, за счет этого формируя первый аудиокомпонент. Таким образом, первый аудиокомпонент соответствует аудиосигналу, поскольку он должен восприниматься посредством прямого тракта, т.е. посредством безэховой части распространения звука.
Данные ранней части в конкретном примере могут описывать фильтр, соответствующий ранней части BRIR, и процессор 803 ранней части, соответственно, может быть выполнен с возможностью фильтровать аудиосигнал посредством фильтра, соответствующего ранней части BRIR. Данные ранней части, в частности, могут включать в себя данные, описывающие коэффициенты отводов FIR-фильтра, и бинауральная обработка, выполняемая посредством процессора 803 ранней части, может содержать фильтрацию аудиосигнала посредством соответствующего FIR-фильтра.
Первый аудиокомпонент, соответственно, может формироваться, чтобы соответствовать звуку, который воспринят в барабанной перепонке из прямого тракта, из требуемой позиции.
Приемное устройство 801 дополнительно соединено с задержкой 805, которая дополнительно соединена с процессором 807 реверберации. В процессор 807 реверберации также подается аудиосигнал через задержку 805. Помимо этого, в процессор 807 реверберации подаются данные части реверберации, т.е. в него подаются данные, описывающие распространение отраженного звука и, в конкретном примере, описывающие ранние отражения и хвосты рассеянной реверберации, при этом отдельные отражения не могут разделяться.
Процессор 807 реверберации выполнен с возможностью формировать второй аудиокомпонент посредством применения реверберационной обработки к аудиосигналу, при этом реверберационная обработка, по меньшей мере, частично определяется посредством данных реверберации.
В конкретном примере, процессор 807 реверберации может содержать синтетический ревербератор, который формирует сигнал реверберации на основе модели реверберации. Синтетический ревербератор типично моделирует ранние отражения и плотный хвост реверберации с использованием сети с обратной связью. Фильтры, включенные в контуры обратной связи, управляют временем реверберации (T60) и окрашиванием. Синтетический ревербератор, в частности, может представлять собой ревербератор Джота, и фиг. 9 иллюстрирует пример схематичной иллюстрации модифицированного ревербератора Джота (с тремя контурами обратной связи). В примере, ревербератор Джота модифицирован с возможностью выводить два сигнала вместо одного, так что он может использоваться для представления бинауральных ревербераций без обязательности отдельного ревербератора для каждого из бинауральных сигналов. Фильтры добавлены для того, чтобы предоставлять управление интерауральной корреляцией (u (z) и v (z)) и зависимым от уха окрашиванием (hL и hR).
Следует принимать во внимание, что множество других синтетических ревербераторов существуют и известны для специалистов в данной области техники, и что любой подходящий синтетический ревербератор может использоваться без отступления от изобретения.
Параметры синтетического ревербератора, такие как коэффициенты матрицы микширования и все или некоторые из усилений для ревербератора Джота по фиг. 9, могут предоставляться посредством данных части реверберации. Таким образом, на стороне кодера, на которой доступна полная BRIR, могут определяться наборы параметров, которые приводят к ближайшему совпадению между измеренной BRIR и эффектом ревербератора. Результирующие параметры затем кодированы и включены в данные части реверберации потока битов.
Данные части реверберации извлекаются и подаются в процессор 807 реверберации в устройстве по фиг. 8, и процессор 807 реверберации, соответственно, продолжает реализовывать ревербератор (например, Джота) с использованием принимаемых параметров. Когда результирующая модель реверберации применяется к аудиосигналу (Sin в примере по фиг. 9), формируется реверберирующий сигнал, который близко совпадает с реверберирующим сигналом, получающимся в результате применения части реверберации BRIR к аудиосигналу.
Таким образом, близкая аппроксимация исходного эффекта BRIR-характеристики достигается с использованием синтетического ревербератора с низкой сложностью, который управляется посредством параметров, предоставленных в данных части реверберации. Таким образом, второй аудиокомпонент в примере формируется в качестве сигнала реверберации, получающегося в результате применения синтетического ревербератора к аудиосигналу. Этот сигнал реверберации формируется с использованием процесса, который требует существенно меньшего объема обработки, чем для фильтра, имеющего, соответственно, длинную импульсную характеристику. Таким образом, требуются значительные меньшие вычислительные ресурсы, за счет этого, например, обеспечивая возможность выполнения процесса на устройствах с низкими ресурсами, таких как, например, портативные устройства. Сформированный сигнал реверберации во многих сценариях может не быть настолько точным представлением, как представление, которое должно достигаться, если подробная и длинная BRIR используется для того, чтобы фильтровать сигнал. Тем не менее, перцепционное влияние таких отклонений является значительно более низким для части реверберации, чем для ранней части. В большинстве сценариев и вариантов осуществления, отклонения приводят к незначительным изменениям, и типично достигается очень естественная реверберация, соответствующая исходным характеристикам реверберации.
Процессор 803 ранней части и процессор 807 реверберации соединены с модулем 809 комбинирования, который формирует первый слуховой сигнал бинаурального стереосигнала посредством комбинирования первого аудиокомпонента и второго аудиокомпонента. Следует принимать во внимание, что модуль 809 комбинирования в некоторых вариантах осуществления может включать в себя другую обработку, такую как регулирования фильтра или уровня. Кроме того, сформированный комбинированный сигнал может усиливаться, преобразовываться в область аналоговых сигналов и т.д., с тем, чтобы подаваться, например, в один вставленный в ухо наушник из головных наушников, за счет этого предоставляя звук для одного уха слушателя.
Описанный подход также может выполняться параллельно для того, чтобы формировать сигнал для другого уха слушателя. Идентичный подход может использоваться, но использует бинауральную передаточную функцию головы для другого уха слушателя.
Этот другой сигнал затем может подаваться в другой вставленный в ухо наушник из головных наушников, с тем, чтобы предоставлять бинауральное пространственное восприятие.
В конкретном примере, модуль 809 комбинирования является простым сумматором, который суммирует первый аудиокомпонент и второй аудиокомпонент таким образом, чтобы формировать бинауральный сигнал (для одного уха). Тем не менее, следует принимать во внимание, что в других вариантах осуществления могут использоваться другие модули комбинирования, такие как, например, суммирование со взвешиванием или суммирование с перекрытием, в случаях, если перекрываются части реверберации и ранние части.
Таким образом, бинауральный сигнал для одного уха формируется посредством суммирования двух аудиокомпонентов, при этом один аудиокомпонент соответствует безэховой части акустической передаточной функции от позиции источника звука в ухо, а другой аудиокомпонент соответствует отраженной части акустической передаточной функции (которая зачастую упоминается в качестве части реверберации). Комбинированный сигнал, соответственно, может представлять всю акустическую передаточную функцию/бинауральную передаточную функцию головы и, в частности, может отражать всю BRIR. Тем не менее, поскольку различные части обрабатываются отдельно, представление и обработка данных могут быть оптимизированы для отдельных характеристик отдельной части. В частности, относительно точное представление и обработка бинауральной передаточной функции головы могут использоваться для безэховой части, тогда как значительно менее точное, но значительно более эффективное представление и обработка могут использоваться для части реверберации. Например, относительно короткий, но точный FIR-фильтр может использоваться для безэховой части, и менее точная, но более длинная характеристика может использоваться для части реверберации посредством использования компактной модели реверберации.
Тем не менее, подход также приводит к некоторым сложностям. В частности, безэховый сигнал (первый аудиокомпонент) и реверберирующий сигнал (второй аудиокомпонент), в общем, должны иметь различные задержки. Обработка безэховой части посредством процессора 803 ранней части вводит задержку в формирование сигнала реверберации. Аналогично, процесс реверберации посредством процессора 807 реверберации вводит задержку в сигнал реверберации. Тем не менее, задержка, введенная посредством синтетического ревербератора, может быть ниже задержки, введенной посредством безэховой FIR-фильтрации.
Как результат, характеристика реверберации, как следствие, может возникать даже перед безэховой характеристикой в комбинированном выходном сигнале. Поскольку такой результат является инконгруэнтным с фильтрацией посредством головы, ушей и помещения в любой физической ситуации, это приводит к низкой производительности и к искаженному пространственному восприятию. Если обобщать, параллельная обработка с различными задержками должна иметь тенденцию сдвигать начало реверберации к началу безэховой характеристики по сравнению с бинауральной передаточной функцией головы и базовой акустической передаточной функцией. В общем, если отражения и рассеянная реверберация не имеют надлежащей задержки относительно безэховой части, комбинированный бинауральный сигнал может звучать неестественно.
Чтобы противостоять этому невыгодному эффекту, задержка может вводиться в тракте передачи реверберирующих сигналов, который регулируется на предмет разности в задержках обработки процессора 803 ранней части и процессора 807 реверберации. Например, если задержка обработки процессора 803 ранней части (при формировании первого аудиокомпонента/безэхового сигнала) обозначается как Tb, а задержка обработки процессора 807 реверберации (при формировании второго аудиокомпонента/сигнала реверберации) обозначается как Tr, в таком случае задержка Td=Tb-Tr может вводиться в тракте передачи сигналов реверберации. Тем не менее, такая задержка нацелена только на компенсацию задержек обработки и должна просто приводить к совмещению первого отражения реверберации с прямой характеристикой безэховой части. Такой подход не должен приводить к комбинированному эффекту, соответствующему требуемой бинауральной передаточной функции головы, поскольку первое отражение возникает не одновременно с безэховой частью, а через некоторое время после нее. Следовательно, такой подход не должен соответствовать акустическим свойствам или требуемой бинауральной передаточной функции головы. Фактически, первые отражения из синтетической реверберации должны возникать с конкретной задержкой после основного импульса безэховой характеристики. Кроме того, эта задержка зависит не просто от задержек обработки, а зависит от позиции источника и приемного устройства в помещении во время BRIR-измерения. Соответственно, задержка не может сразу извлекаться посредством устройства по фиг. 8.
Тем не менее, в системе по фиг. 8, принимаемый поток битов также содержит индикатор синхронизации, который служит признаком сдвига по времени между ранней частью и частью реверберации. Таким образом, поток битов может содержать данные синхронизации, которые могут использоваться посредством приемного устройства, чтобы синхронизировать и совмещать по времени первый и второй аудиокомпоненты (т.е. безэховый сигнал и сигнал реверберации в конкретном примере).
Индикатор синхронизации может быть основан на подходящем сдвиге по времени, таком как задержка между началом безэховой части и началом первого отражения. Эта информация может определяться на стороне кодирования/передачи на основе полной бинауральной передаточной функции головы. Например, когда полная BRIR доступна, относительный сдвиг по времени между началом безэховой части и началом первого отражения может определяться в качестве части процесса разделения BRIR на раннюю часть и часть реверберации.
Таким образом, поток битов включает в себя не только отдельные данные для ранней обработки и реверберационной обработки, но также и включает в себя информацию синхронизации, которая может использоваться для того, чтобы синхронизировать/совмещать по времени два аудиокомпонента посредством приемного устройства/модуля воспроизведения.
На фиг. 8 это реализовано посредством синхронизатора, который выполнен с возможностью синхронизировать первый аудиокомпонент и второе аудио на основе индикатора синхронизации. В частности, синхронизация может осуществляться таким образом, что первый и второй аудиокомпоненты комбинированы для того, чтобы обеспечивать сдвиг по времени между началом безэховой части и первым отражением, соответствующим сдвигу по времени, указываемому посредством индикатора синхронизации.
Следует принимать во внимание, что такая синхронизация может выполняться любым подходящим способом и фактически не должна обязательно выполняться непосредственно посредством обработки любого из первого и второго аудиокомпонентов. Наоборот, может использоваться любой процесс, который допускает результирующее изменение относительной временной синхронизации первого и второго аудиокомпонентов. Например, регулирование длины фильтров на выходе ревербератора Джота может регулировать относительную задержку.
В примере по фиг. 8, синхронизатор реализуется посредством задержки 805, которая принимает аудиосигнал и предоставляет его в процессор 807 реверберации с задержкой, которая зависит от принимаемого индикатора синхронизации. Задержка 805, соответственно, соединена с приемным устройством 801, из которого она принимает индикатор синхронизации. Например, индикатор синхронизации может указывать требуемую задержку, To, между началом безэховой части и первым отражением. В характеристике, задержка 805, в частности, может задаваться таким образом, что полная задержка тракта реверберации отклоняется от задержки тракта ранней части на эту величину, т.е. задержка Td может задаваться следующим образом:
Td=Tb-Tr+To.
Например, на конце передающего устройства, BRIR по фиг. 7 может быть проанализирована для того, чтобы идентифицировать сдвиг по времени между первыми отражениями и прямой характеристикой. В конкретном примере, первое отражение возникает через 126 выборок после начала прямой характеристики, и, соответственно, индикатор синхронизации, указывающий задержку To=126 выборок, может быть включен в поток битов. На конце приемного устройства, устройство по фиг. 8 должно знать относительные задержки ранней обработки, Tb, и реверберационной обработки, Tr. Они, например, могут выражаться с точки зрения выборок, и задержка для задержки 805 в выборках может легко вычисляться из вышеприведенного уравнения.
В вышеприведенном примере, индикатор синхронизации непосредственно отражает требуемую задержку. Тем не менее, следует принимать во внимание, что в других вариантах осуществления, могут использоваться другие индикаторы синхронизации, и, в частности, могут предоставляться другие связанные задержки.
Например, в некоторых вариантах осуществления, задержка/сдвиг по времени, указываемая посредством индикатора синхронизации, может компенсироваться в отношении, по меньшей мере, одной из задержек, ассоциированных с обработкой в приемном устройстве. В частности, индикатор синхронизации, предоставленный в потоке битов, может компенсироваться в отношении, по меньшей мере, одной из бинауральной обработки и реверберационной обработки.
Таким образом, в некоторых вариантах осуществления, кодер может иметь возможность определять или оценивать задержки, которые вызываются посредством процессора 803 ранней части и процессора 807 реверберации, а не полную требуемую задержку, индикатор синхронизации может указывать сдвиг по времени или задержку, которая модифицируется в зависимости от задержки обработки ранней части, реверберационной обработки или и того, и другого. В частности, в некоторых вариантах осуществления, индикатор синхронизации может непосредственно указывать требуемую задержку для задержки 805, которая может автоматически задаваться равной этому значению.
Например, в некоторых вариантах осуществления, безэховая часть представлена посредством FIR-фильтра данной длины, соответствующей данной задержке, вводимой посредством процессора 803 ранней части. Кроме того, может указываться конкретная реализация синтетического ревербератора, и, соответственно, результирующая задержка может быть известной в передающем устройстве. Таким образом, в таком варианте осуществления, формирование индикатора синхронизации может принимать эти значения во внимание. Например, если обозначить оцененную, предполагаемую или номинальную предполагаемую или номинальную задержку для обработки ранней части посредством как Tb, а оцененную, предполагаемую или номинальную задержку для обработки ранней части как Tr, передающее устройство может формировать индикатор синхронизации, чтобы указывать задержку, заданную следующим образом:
Td=Tb-Tr+To,
т.е. непосредственно указывать значение для задержки 805.
В других вариантах осуществления, могут передаваться другие значения задержки, такие как, например, полная задержка тракта реверберации Tcomp=Tb+To.
Следует принимать во внимание, что может использоваться любое представление синхронизации и, в частности, задержек. Например, задержки могут предоставляться в миллисекундах, выборках, единицах кадров и т.д.
В примере по фиг. 8, синхронизация безэхового аудиокомпонента и компонента реверберации достигается посредством задержки аудиосигнала, который подается в процессор 807 реверберации. Тем не менее, следует принимать во внимание, что в других вариантах осуществления может использоваться другое средство изменения относительного временного совмещения между безэховым аудиокомпонентом и компонентом реверберации. В качестве примера, задержка может применяться непосредственно к аудиокомпоненту реверберации до комбинирования (т.е. в выходе процессора 807 реверберации). В качестве другого примера, переменная задержка может вводиться в тракте обработки ранней части. Например, тракт реверберации может реализовывать фиксированную задержку, которая превышает максимальный возможный сдвиг по времени между началом безэховой характеристики и первым отражением. Вторая переменная задержка может вводиться в тракте обработки ранней части и может регулироваться на основе информации в индикаторе синхронизации, чтобы задавать требуемую относительную задержку между двумя трактами.
В примере по фиг. 8, проиллюстрированы элементы, ассоциированные с формированием сигнала для одного уха слушателя. Следует принимать во внимание, что идентичный подход может использоваться для того, чтобы формировать сигнал для другого уха. Кроме того, в некоторых вариантах осуществления, идентичная реверберационная обработка может использоваться для обоих сигналов. Такой пример проиллюстрирован на фиг. 10. В примере, принимается стереосигнал, который, например, может представлять собой микшированный с понижением звуковой стереосигнал по стандарту объемного звучания MPEG. Процессор 803 ранней части выполняет бинауральную обработку на основе ранней части BRIR, за счет этого формируя бинауральный стереовыход. Кроме того, комбинированный сигнал формируется посредством комбинирования двух сигналов входного стереосигнала, и результирующий сигнал затем задержан посредством задержки 805, и сигнал реверберации формируется из задержанного сигнала посредством процессора 807 реверберации. Результирующий сигнал реверберации добавляется в оба сигнала из бинаурального стереосигнала, сформированного посредством процессора 803 ранней части.
Таким образом, в примере, реверберация, сформированная из комбинированного сигнала, добавляется в оба бинауральных моносигнала. Ревербератор может формировать различные сигналы реверберации для различных сигналов бинаурального стереосигнала. Тем не менее, в других вариантах осуществления, сформированные сигналы реверберации могут быть идентичными для обоих сигналов, и в силу этого идентичная реверберация в некоторых вариантах осуществления может добавляться в оба бинауральных моносигнала. Это позволяет уменьшать сложность и типично является приемлемым, поскольку, в частности, более поздние отражения и хвост реверберации менее зависят от разности в позиции между ушами слушателя.
Фиг. 11 иллюстрирует пример устройства для формирования и передачи потока битов, подходящего для приемного устройства по фиг. 8.
Устройство содержит процессор/приемное устройство 1101, который принимает бинауральную передаточную функцию головы, которая должна передаваться. В конкретном примере, бинауральная передаточная функция головы представляет собой BRIR, такую как, например, BRIR по фиг. 7. Приемное устройство 1101 выполнено с возможностью разделять BRIR на раннюю часть и часть реверберации. Например, ранняя часть может составлять часть BRIR, которая возникает до данного момента времени/выборки, и часть реверберации может составлять часть BRIR, которая возникает после данного момента времени/выборки.
В некоторых вариантах осуществления, разделение на раннюю часть и часть реверберации выполняется в ответ на пользовательский ввод. Например, пользователь может вводить индикатор относительно максимальных размеров помещения. Момент времени, разделяющий две части, затем может задаваться в качестве времени начала ранней характеристики плюс время распространения звука на это расстояние.
В некоторых вариантах осуществления, разделение на раннюю часть и часть реверберации может выполняться полностью автоматически и на основе характеристик BRIR. Например, может вычисляться огибающая BRIR. Хорошее разделение на раннюю часть и часть реверберации затем задается посредством нахождения первой впадины после первого (значительного) пика временной огибающей.
Ранняя часть бинауральной передаточной функции головы подается в схему ранней части в форме формирователя 1103 данных ранней части, который соединяется с приемным устройством 1101. Формирователь 1103 данных ранней части затем переходит к формированию данных ранней части, описывающих раннюю часть бинауральной передаточной функции головы. В качестве примера, формирователь 1103 данных ранней части может подбирать FIR-фильтр данной длины, который имеет наилучшее совпадение с ранней частью бинауральной передаточной функции головы/BRIR. Например, значения коэффициентов могут определяться таким образом, чтобы максимизировать энергию и/или минимизировать среднеквадратическую ошибку между импульсной характеристикой FIR-фильтра и BRIR. Формирователь 1103 данных ранней части затем может формировать данные ранней части в качестве данных, описывающих FIR-коэффициенты. Во многих вариантах осуществления, коэффициенты FIR-фильтрации могут определяться просто в качестве выборочных значений импульсной характеристики или, во многих вариантах осуществления, в качестве субдискретизированного представления импульсной характеристики.
Параллельно, часть реверберации бинауральной передаточной функции головы подается в схему реверберации в форме формирователя 1105 данных части реверберации, который также соединяется с приемным устройством 1101. Формирователь 1105 данных части реверберации затем переходит к формированию данных части реверберации, описывающих часть реверберации бинауральной передаточной функции головы. В качестве примера, формирователь 1105 данных части реверберации может регулировать параметры для модели реверберации, такой как ревербератор Джота по фиг. 9, таким образом, что характеристика модели лучше совпадает с характеристикой поздней части BRIR. Следует принимать во внимание, что специалисты в данной области техники должны знать ряд различных подходов для сопоставления модели реверберации с измеренной BRIR, и это для краткости не описывается подробнее в данном документе. Дополнительная информация относительно ревербератора Джота содержится в работе авторов Menzer, F., Faller, C. "Binaural reverberation using the modified Jot reverberator with frequency-dependent interaural coherence matching", 126th Audio Engineering Society Convention, Мюнхен, Германия, 7-10 мая 2009 года. Прямая передача коэффициентов фильтрации различных фильтров, составляющих ревербератор Джота, может представлять собой один способ описывать параметры ревербератора Джота.
В некоторых вариантах осуществления, формирователь 1105 данных части реверберации может формировать значения коэффициентов для фильтра, имеющего импульсную характеристику, соответствующую импульсной характеристике части реверберации BRIR. Например, коэффициенты IIR-фильтра могут регулироваться таким образом, чтобы минимизировать, например, минимальную квадратическую ошибку между импульсной характеристикой IIR-фильтра и частью реверберации BRIR.
Формирователь потоков битов и передающее устройство по фиг. 11 дополнительно содержит схему синхронизации в форме формирователя 1107 индикаторов синхронизации, который соединяется с приемным устройством 1101. Приемное устройство 1101 может предоставлять информацию синхронизации, связанную с временной синхронизацией ранней части и части реверберации, в формирователь 1107 индикаторов синхронизации, который затем переходит к формированию индикатора синхронизации, который служит ее признаком.
Например, приемное устройство 1101 может предоставлять BRIR в формирователь 1107 индикаторов синхронизации. Формирователь 1107 индикаторов синхронизации затем может анализировать BRIR, чтобы определять то, когда, соответственно, возникает начало первой характеристики и первого отражения. Эта разность времен затем может быть кодирована как индикатор синхронизации.
Формирователь 1103 данных ранней части, формирователь 1105 данных части реверберации и формирователь 1107 индикаторов синхронизации соединяются с выходной схемой в форме процессора 1109 потоков битов, который переходит к формированию потока битов, содержащего данные ранней части, данные части реверберации и индикатор синхронизации.
Следует принимать во внимание, что может использоваться любой подход для размещения данных в потоке битов. Также следует принимать во внимание, что поток битов типично формируется с возможностью содержать данные, описывающие множество бинауральных передаточных функций головы, а также возможно другие типы данных. В конкретном примере, процессор 1109 потоков битов также принимает аудиоданные, включающие в себя, например, аудиосигнал для воспроизведения с использованием включенной бинауральной передаточной функции(й) головы.
Поток битов, сформированный посредством процессора 1109 потоков битов, затем может передаваться в качестве потоковой передачи в реальном времени, сохраняться в качестве файла данных в носителе хранения данных и т.д. В частности, поток битов может передаваться в приемное устройство по фиг. 8.
Преимущество описанного подхода состоит в том, что различные представления бинауральной передаточной функции головы могут использоваться для ранней части и для части реверберации. Это может обеспечивать возможность отдельной оптимизации представления для каждой отдельной части.
Во многих вариантах осуществления и для многих сценариев, должно быть очень преимущественным, если данные ранней части содержат параметры фильтрации в частотной области, и обработка ранней части представляет собой обработку в частотной области.
Фактически, ранняя часть бинауральной передаточной функции головы типично является относительно короткой и, следовательно, может эффективно реализовываться посредством относительно короткого фильтра. Такой фильтр зачастую может эффективнее реализовываться в частотной области, поскольку он требует только умножения, а не свертки. Таким образом, посредством прямого предоставления значений в частотной области, предоставляется эффективное и простое в использовании представление, которое не требует преобразования этих данных из или во временную область посредством приемного устройства.
Ранняя часть, в частности, может быть представлена посредством параметрического описания. Параметрическое представление может предоставлять набор коэффициентов частотной области для набора фиксированных или непостоянных частотных интервалов, такого как, например, набор или полосы частот согласно шкале Барка или ERB-шкале. В качестве примера, параметрическое представление может состоять из двух параметров уровня (одного для левого уха и одного для правого уха) и фазового параметра, описывающего разность фаз между левым и правым ухом для каждой полосы частот. Такое представление, например, используется в стандарте объемного звучания MPEG. Другие параметрические представления могут состоять из параметров модели, например, параметров, описывающих характеристику пользователя, например, "мужчина-женщина", или определенных антропометрических признаков, таких как расстояние между ушами. В этом случае, модель затем имеет возможность извлекать набор параметров, например, параметров амплитуды и фазы, просто на основе антропометрической информации.
В предыдущих примерах, данные реверберации предоставляют параметры для модели реверберации, и процессор 807 реверберации выполнен с возможностью формировать сигнал реверберации посредством реализации этой модели. Тем не менее, в других вариантах осуществления могут использоваться другие подходы.
Например, в некоторых вариантах осуществления, процессор 807 реверберации может реализовывать реверберационный фильтр, который типично должен иметь большую длительность, но является менее точным (например, с более приблизительным коэффициентом или квантованием по времени), чем фильтр, используемый для ранней части. В таких вариантах осуществления, данные части реверберации могут содержать параметры для реверберационного фильтра, такие как, в частности, коэффициенты частотной или временной области для реализации фильтра.
Например, данные реверберации могут формироваться в качестве FIR-фильтра с относительно низкой частотой дискретизации. FIR-фильтр может предоставлять наилучшее возможное совпадение для бинауральной передаточной функции головы для этой уменьшенной частоты дискретизации. Результирующие коэффициенты затем могут кодироваться в данных части реверберации. На приемной стороне, соответствующий FIR-фильтр может формироваться и, например, может применяться к аудиосигналу на более низкой частоте дискретизации. В этом примере, обработка ранней части и обработка части реверберации могут выполняться на различных частотах дискретизации, и, например, часть реверберационной обработки может содержать прореживание входного аудиосигнала и повышающую дискретизацию результирующего сигнала реверберации. В качестве другого примера, FIR-фильтр для более высокой частоты дискретизации может формироваться посредством формирования дополнительных FIR-коэффициентов посредством интерполяции FIR-коэффициентов с меньшей скоростью, принимаемых в качестве части данных реверберации.
Преимущество подхода состоит в том, что он может использоваться вместе с более новыми стандартами кодирования аудио, такими как стандарт объемного звучания MPEG и SAOC.
Фиг. 12 иллюстрирует пример того, как реверберация может добавляться в сигналы в соответствии со стандартом объемного звучания MPEG. Действующий стандарт обеспечивает поддержку только параметризованного воспроизведения бинауральных сигналов, и, следовательно, длинные бинауральные фильтры не могут использоваться в бинауральном воспроизведении. Тем не менее, стандарт предоставляет информативное приложение, описывающее структуру для того, чтобы добавлять реверберацию в стандарт объемного звучания MPEG в режиме бинаурального воспроизведения, как показано на фиг. 12. Описанный подход является совместимым с этим подходом и, соответственно, обеспечивает возможность предоставления эффективного и улучшенного звукового восприятия для системы по стандарту объемного звучания MPEG.
Аналогично, подход также может использоваться с SAOC. Тем не менее, SAOC не включает в себя непосредственно обработку реверберации, а поддерживает интерфейс эффектов, который может использоваться для того, чтобы выполнять параллельную бинауральную реверберацию, аналогично стандарту объемного звучания MPEG. Фиг. 13 показывает пример того, как интерфейс SAOC-эффектов используется для того, чтобы реализовывать так называемые эффекты при отправке. Для бинауральной реверберации,: интерфейс эффектов может быть выполнен с возможностью выводить канал эффектов при отправке, содержащий все объекты с относительными усилениями, аналогично бинауральному воспроизведению, который может извлекаться из матрицы воспроизведения. С использованием реверберации в качестве модуля обработки эффектов может формироваться бинауральная реверберация. В случае реверберации во временной области, такой как ревербератор Джота, канал эффектов при отправке может быть преобразован во временную область посредством гибридной гребенки синтезирующих фильтров до применения реверберации.
Предыдущее описание акцентирует внимание на вариантах осуществления, в которых бинауральная передаточная функция головы разделена на две части, причем одна из них соответствует безэховой части, а другая – отраженной части. Таким образом, в примерах, все ранние отражения представляют собой часть для части реверберации бинауральной передаточной функции головы. Тем не менее, в других вариантах осуществления, одно или более ранних отражений могут быть включены в раннюю часть, а не в часть реверберации.
Например, для BRIR по фиг. 7, момент времени, разделяющий раннюю часть и часть реверберации, может выбираться при 600 выборках, а не при 500 выборках. Это должно приводить к ранней части, включающей в себя первое отражение.
Кроме того, в некоторых вариантах осуществления, бинауральная передаточная функция головы может быть разделена более чем на две части. В частности, бинауральная передаточная функция головы может быть разделена (по меньшей мере) на раннюю часть, которая включает в себя безэховую часть, часть реверберации, которая включает в себя хвост рассеянной реверберации, и (по меньшей мере) одну часть ранних отражений, которая включает в себя одно или более ранних отражений.
В таком варианте осуществления, поток битов, соответственно, может формироваться с возможностью содержать данные ранней части, указывающие раннюю и, в частности, безэховую часть бинауральной передаточной функции головы, данные части ранних отражений, указывающие часть ранних отражений бинауральной передаточной функции головы, и данные реверберации, указывающие часть реверберации бинауральной передаточной функции головы. Кроме того, поток битов, в дополнение к первому индикатору синхронизации, который служит признаком сдвига по времени между ранней частью и частью реверберации, также может включать в себя второй индикатор синхронизации, который служит признаком сдвига по времени между частью ранних отражений и, по меньшей мере, одной из ранней части и части реверберации.
Подходы, описанные ранее для разделения бинауральной передаточной функции головы на две части, также могут использоваться для того, чтобы извлекать бинауральную передаточную функцию головы на три части. Например, первая секция, соответствующая безэховой части, может обнаруживаться посредством обнаружения первой последовательности сигналов в ограниченном временном интервале, а вторая секция, соответствующая раннему отражению, может обнаруживаться посредством обнаружения второй последовательности во временном интервале после первого интервала. Временные интервалы первой и второй частей, например, могут определяться в ответ на уровень сигнала, т.е. каждый интервал может выбираться для завершения, когда амплитуда опускается ниже данного уровня (например, относительно максимального уровня). Оставшаяся часть после второго временного интервала/часть ранних отражений может выбираться в качестве части реверберации.
Сдвиги по времени, указываемые посредством индикатора синхронизации, могут обнаруживаться из идентифицированных временных интервалов или, например, в качестве сдвигов по времени, обнаруживаемых в ответ на задержку, приводящую к максимизации корреляции между сигналами в различных временных интервалах.
В таком подходе, приемное устройство/устройство воспроизведения может включать в себя три параллельных тракта, один для ранней части, один для части ранних отражений и один для части реверберации. Обработка для ранней части, например, может быть основана на первом FIR-фильтре (представленном посредством данных ранней части), обработка части ранних отражений может быть основана на втором FIR-фильтре (представленном посредством данных части ранних отражений), и реверберационная обработка может выполняться посредством синтетического ревербератора на основе модели реверберации, для которой предоставляются параметры в данных части реверберации.
В этом подходе, три аудиокомпонента, соответственно, сформированы посредством трех различных процессов, и эти три аудиокомпонента затем комбинированы.
Кроме того, для того чтобы предоставлять временное совмещение, по меньшей мере, два из трактов (типично, тракт ранних отражений и тракт реверберации) могут включать в себя переменные задержки, которые задаются, соответственно, в ответ на первый и второй индикатор синхронизации. Таким образом, задержки задаются на основе индикаторов синхронизации таким образом, что комбинированные эффекты трех процессов соответствуют полной бинауральной передаточной функции головы.
В некоторых вариантах осуществления, процессы могут не быть полностью параллельными. Например, вместо базирования процесса реверберации на входном аудиосигнале, как проиллюстрировано на фиг. 8, он может базироваться на применении процесса реверберации к аудиокомпоненту, сформированному посредством процессора 803 ранней части. Пример такой компоновки показан на фиг. 14.
В этом примере, задержка 805 по-прежнему используется для того, чтобы совмещать по времени сигнал ранней части и сигнал реверберации, и она задается на основе принимаемого индикатора синхронизации. Тем не менее, задержка задается иным образом по сравнению с системой по фиг. 8, поскольку задержка процессора 803 ранней части теперь также представляет собой часть реверберационной обработки. Задержка, например, может задаваться следующим образом:
Td=To-Tr
Следует принимать во внимание, что вышеприведенное описание для понятности описывает варианты осуществления со ссылкой на различные функциональные схемы, модули и процессоры. Тем не менее, должно быть очевидным, что любое надлежащее распределение функциональности между различными функциональными схемами, модулями или процессорами может быть использовано без отступления от изобретения. Например, функциональность, проиллюстрированная как выполняемая посредством отдельных процессоров или контроллеров, может быть выполнена посредством одного процессора или контроллера. Следовательно, ссылки на конкретные функциональные модули или схемы должны рассматриваться только как ссылки на надлежащее средство предоставления описанной функциональности, а не обозначать точную логическую или физическую структуру либо организацию.
Изобретение может быть реализовано в любой надлежащей форме, включающей в себя аппаратные средства, программное обеспечение, микропрограммное обеспечение или любую комбинацию вышеозначенного. Необязательно, изобретение может быть реализовано, по меньшей мере, частично как вычислительное программное обеспечение, выполняемое на одном или более процессоров данных и/или процессоров цифровых сигналов. Элементы и компоненты варианта осуществления изобретения могут быть физически, функционально и логически реализованы любым надлежащим образом. Фактически, функциональность может быть реализована в одном модуле, во множестве моделей или как часть других функциональных модулей. По существу, изобретение может быть реализовано в одном модуле или может быть физически и функционально распределено между различными модулями, схемами и процессорами.
Хотя настоящее изобретение описано в связи с некоторыми вариантами осуществления, оно не имеет намерение быть ограниченным конкретной изложенной в данном документе формой. Вместо этого, объем настоящего изобретения ограничен только посредством прилагаемой формулы изобретения. Дополнительно, хотя предположительно признак описывается в данном документе в связи с конкретными вариантами осуществления, специалисты в данной области техники должны признавать, что различные признаки описанных вариантов осуществления могут быть комбинированы в соответствии с изобретением. В формуле изобретения, термин "содержащий" не исключает наличия других элементов или этапов.
Более того, хотя перечислены по отдельности, множество средств, элементов, схем или этапов способа может быть реализовано посредством, к примеру, одной схемы, модуля или процессора. Дополнительно, хотя отдельные признаки могут быть включены в различные пункты формулы изобретения, они могут быть преимущественно комбинированы, и их включение в различные пункты формулы изобретения не подразумевает, что комбинация признаков не является выполнимой и/или преимущественной. Так же, включение признака в одну категорию пунктов формулы изобретения не налагает ограничение на эту категорию, а вместо этого указывает то, что признак в равной степени применим к другим категориям пунктов формулы изобретения по мере необходимости. Более того, порядок признаков в пунктах формулы изобретения не налагает какой-либо конкретный порядок, в котором должны осуществляться признаки, и, в частности, порядок отдельных этапов в пункте формулы изобретения на способ не подразумевает, что этапы должны выполняться в этом порядке. Вместо этого, этапы могут выполняться в любом надлежащем порядке. Кроме того, ссылки в единственном числе не исключают множественность. Таким образом, ссылки на "a", "an", "первый", "второй" и т.д. не исключают множественность. Ссылки с номерами в формуле изобретения предоставлены просто в качестве поясняющего примера, и они не должны истолковываться как каким-либо образом ограничивающие объем формулы изобретения.
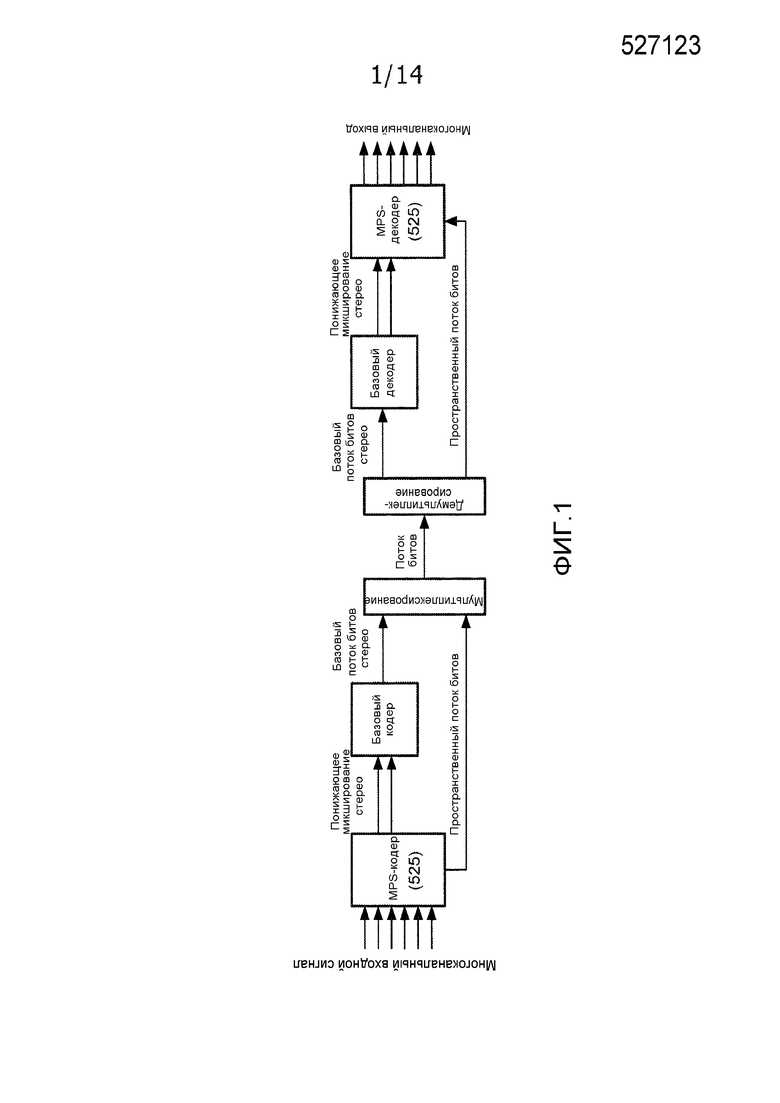
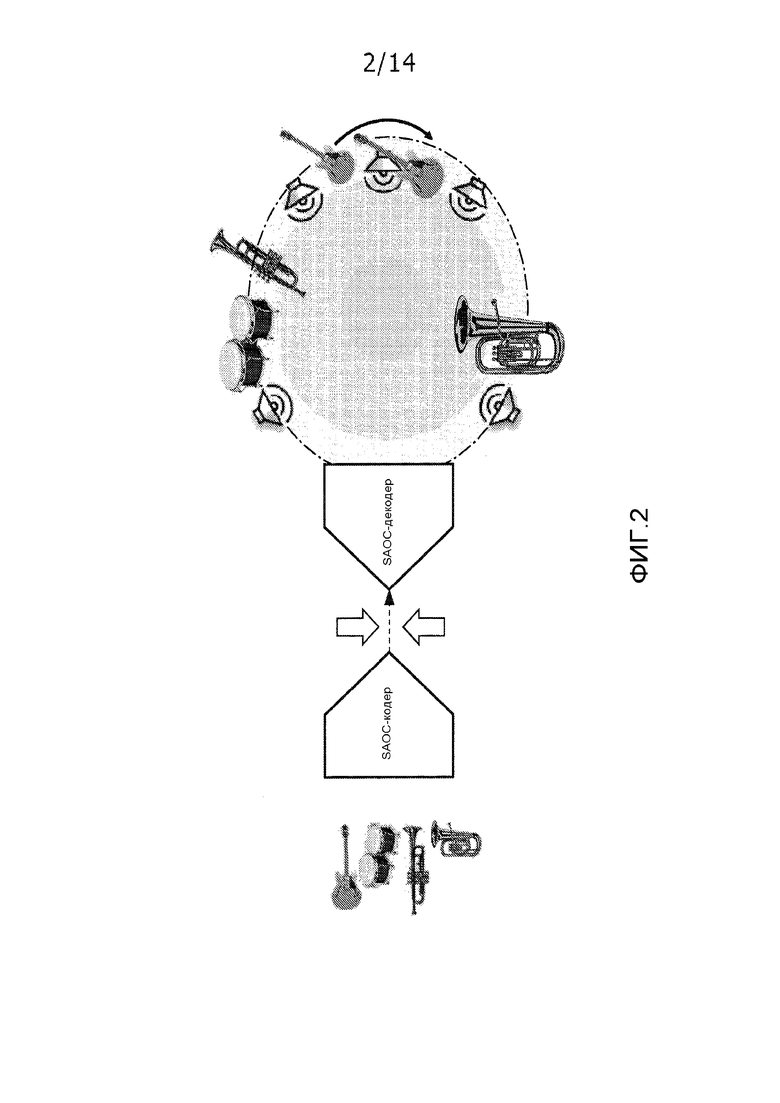
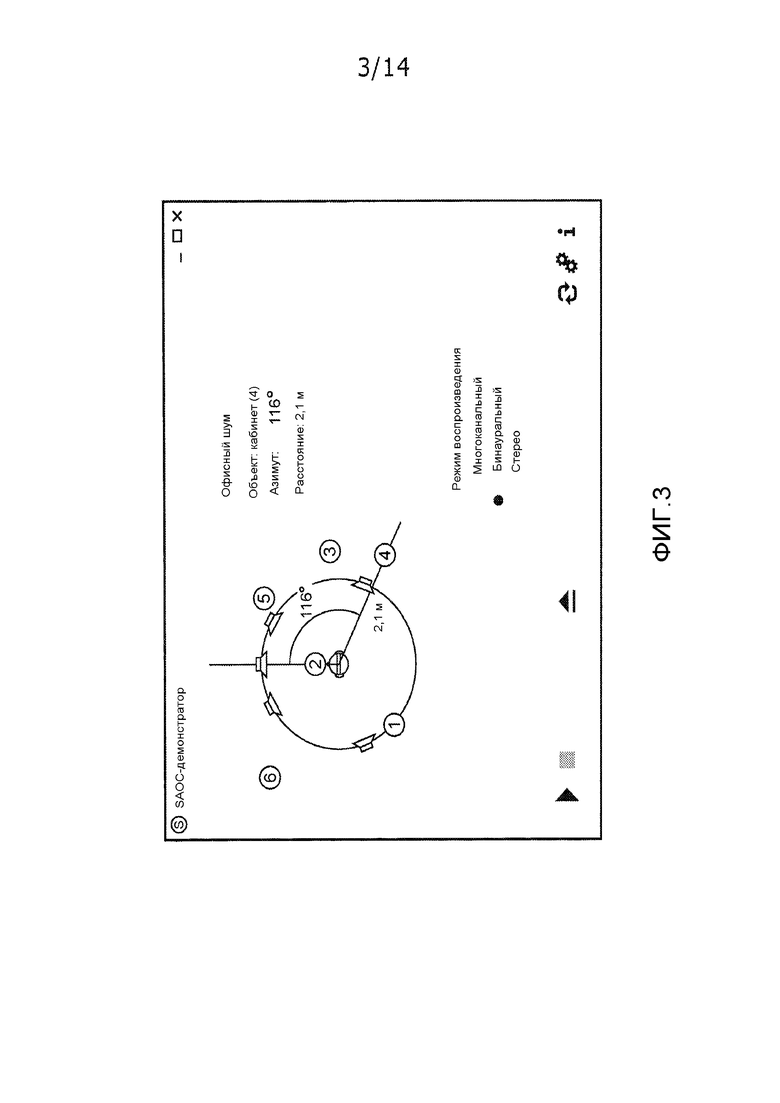
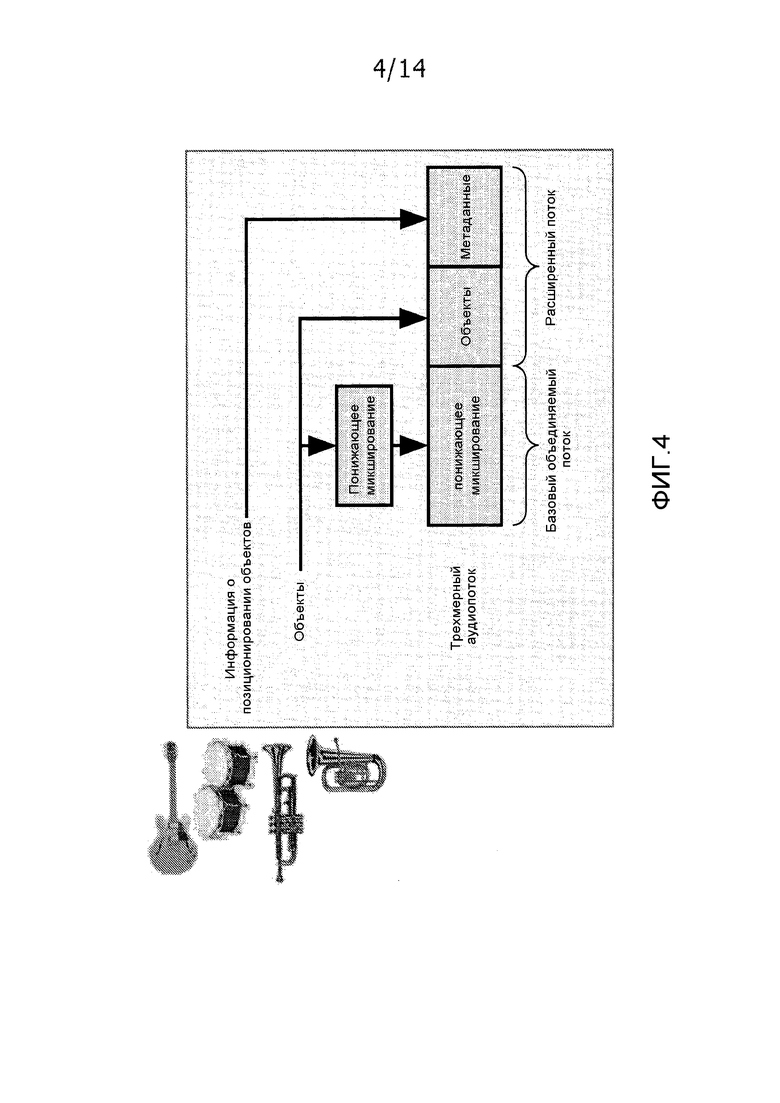
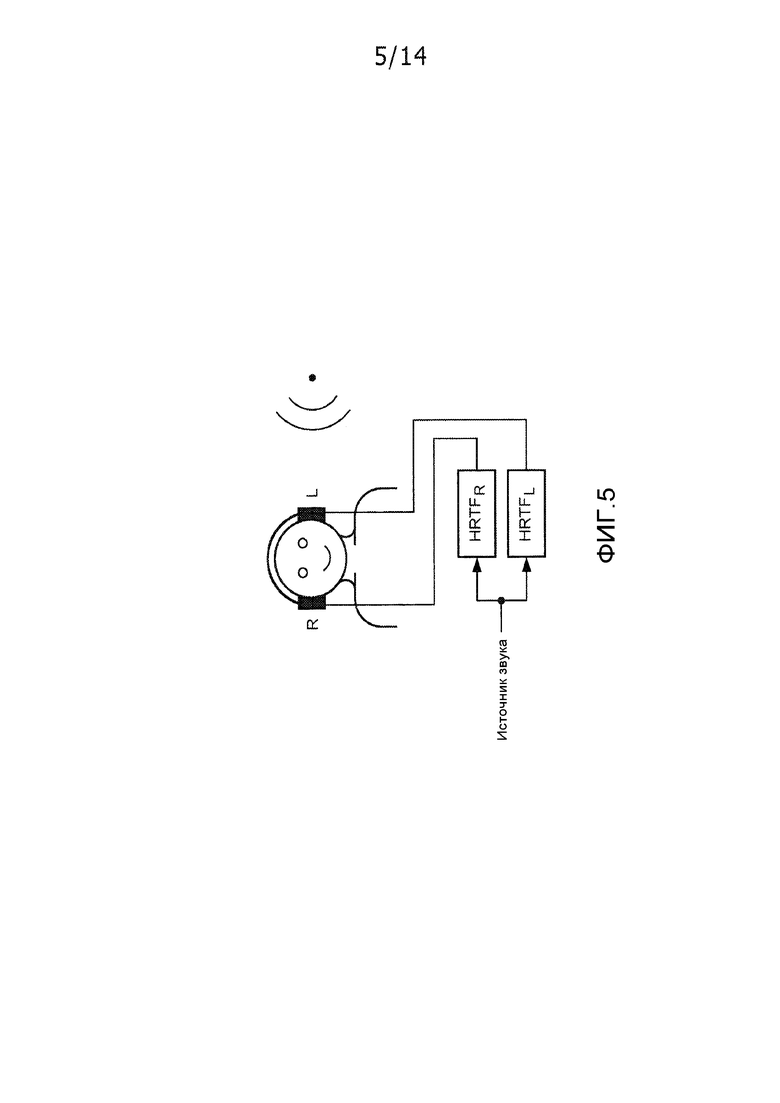
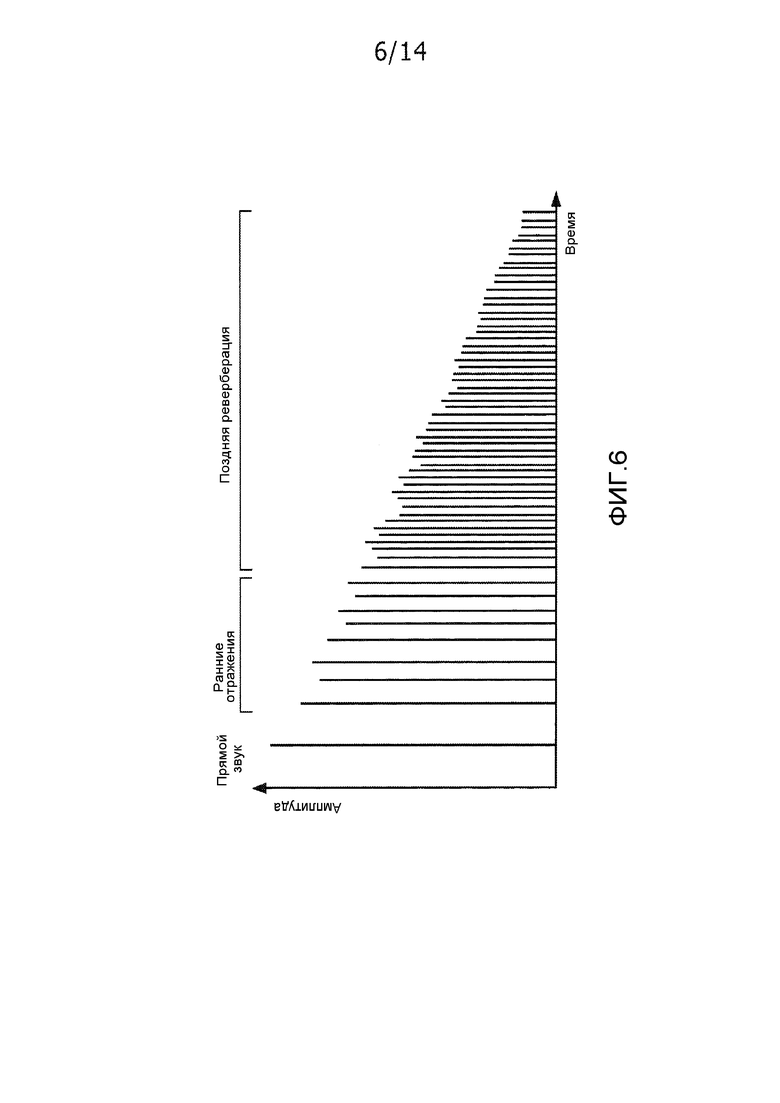

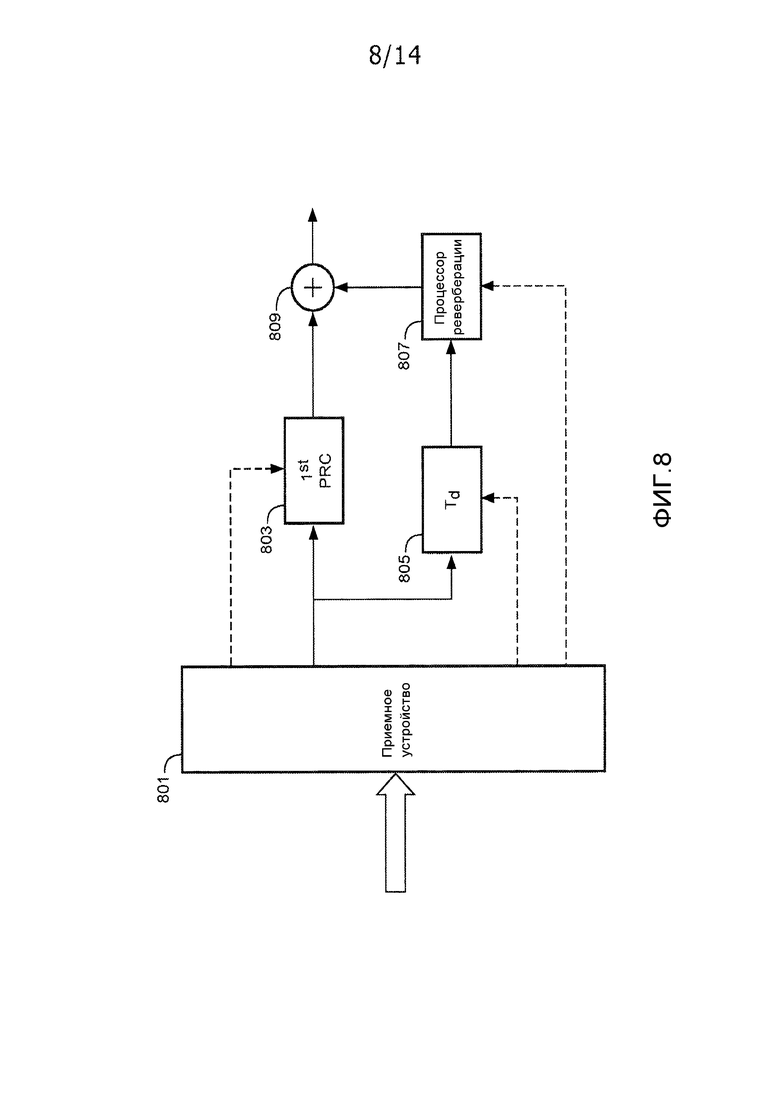
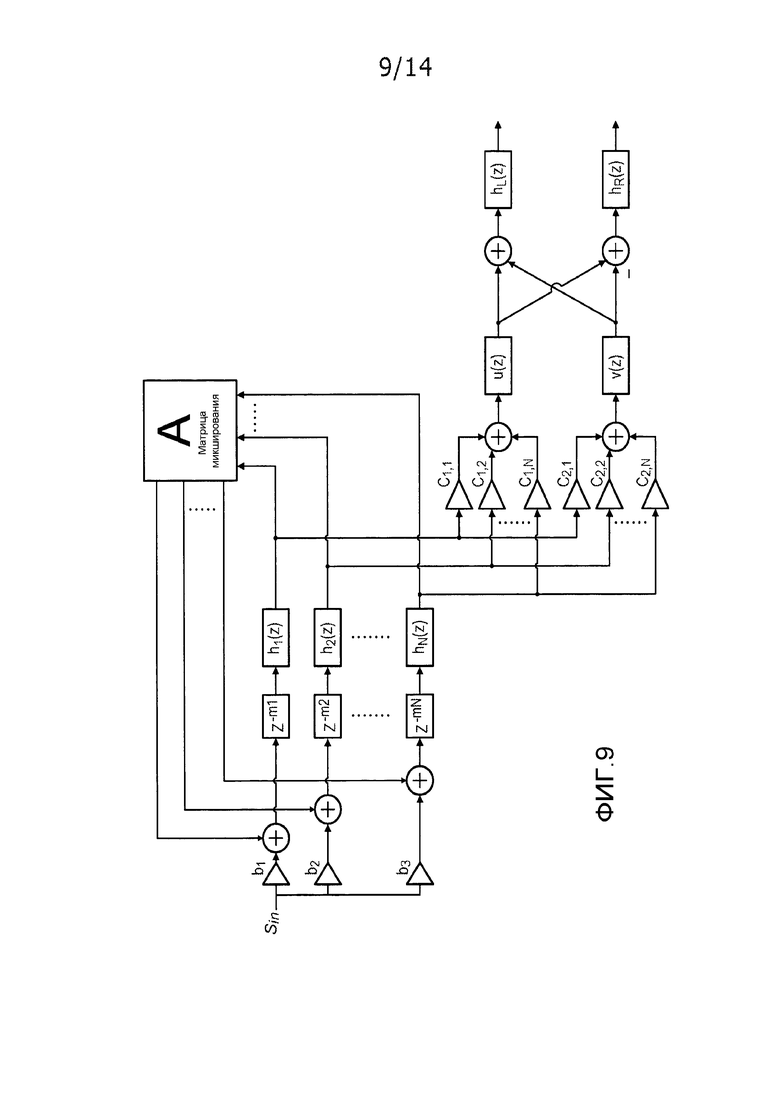
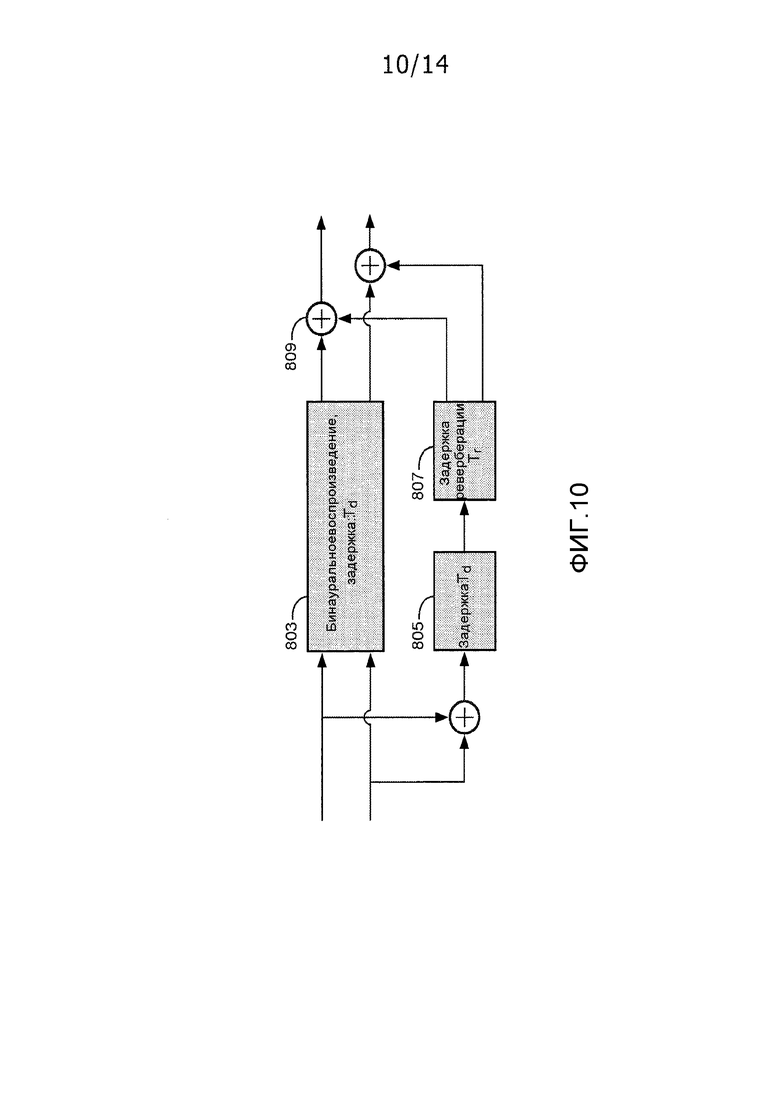
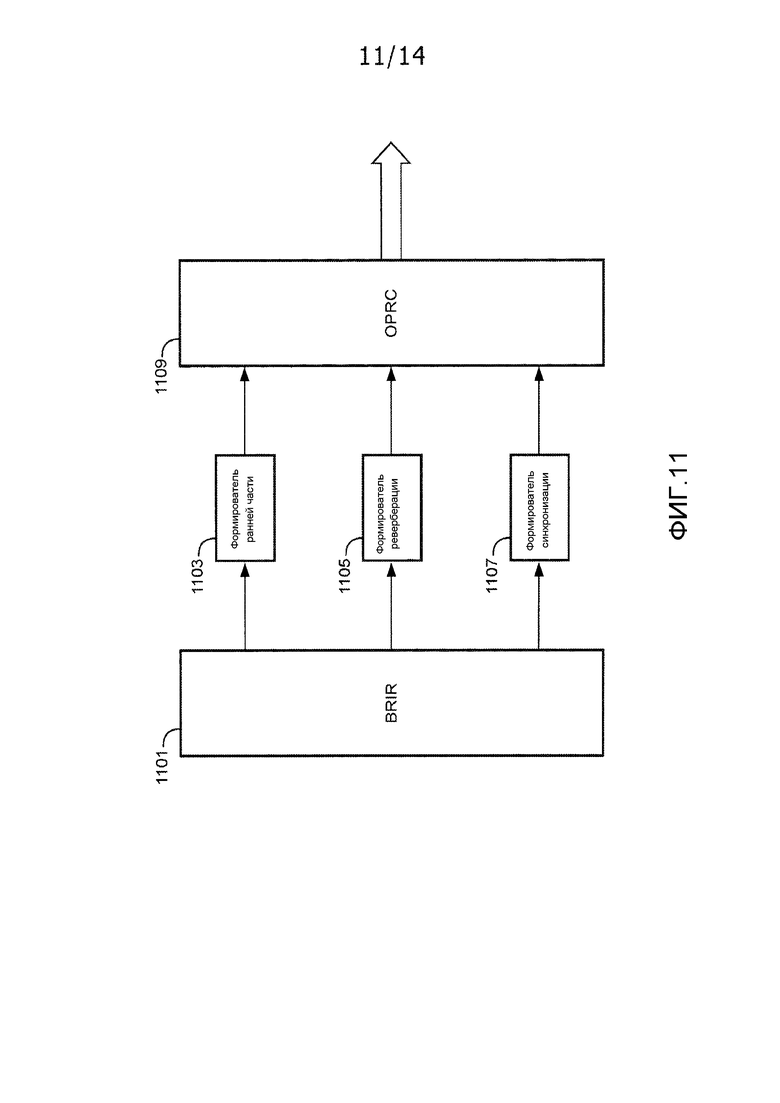
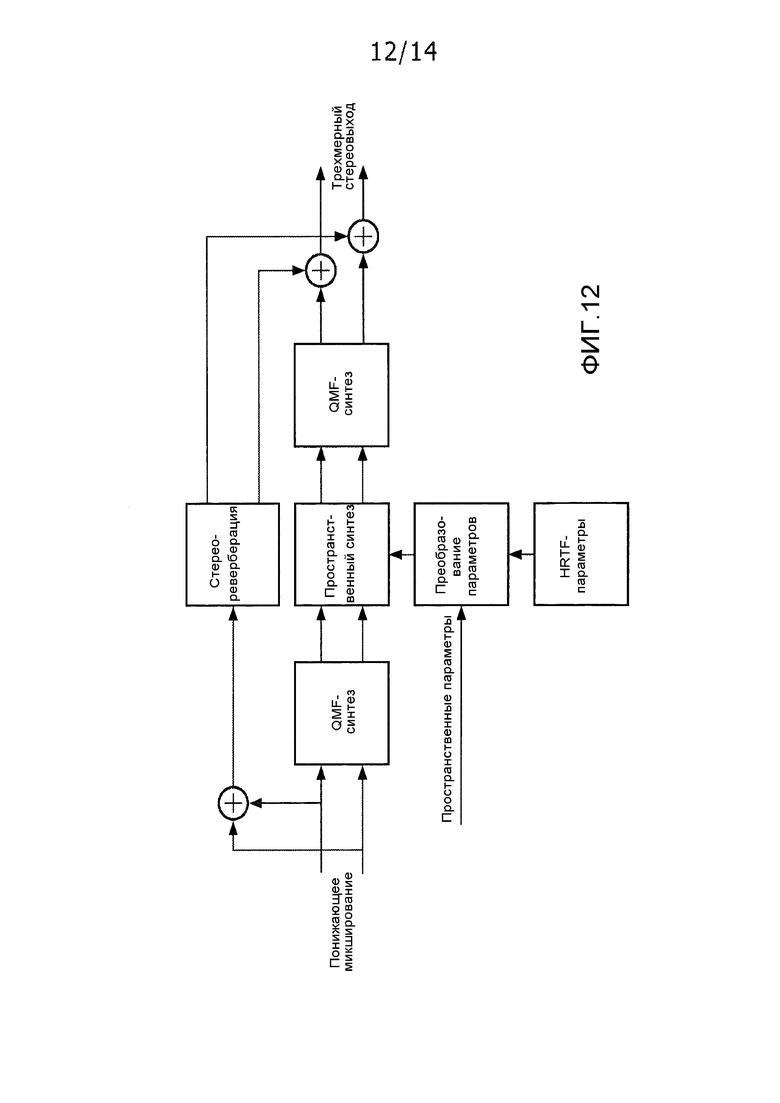
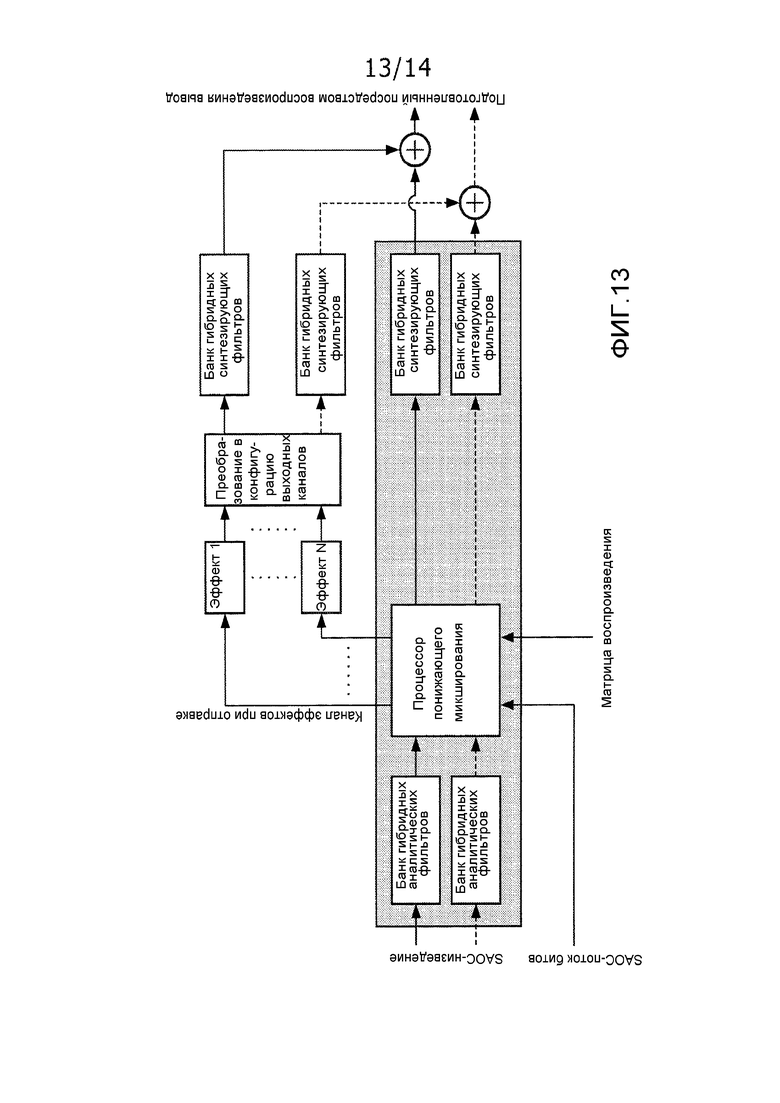
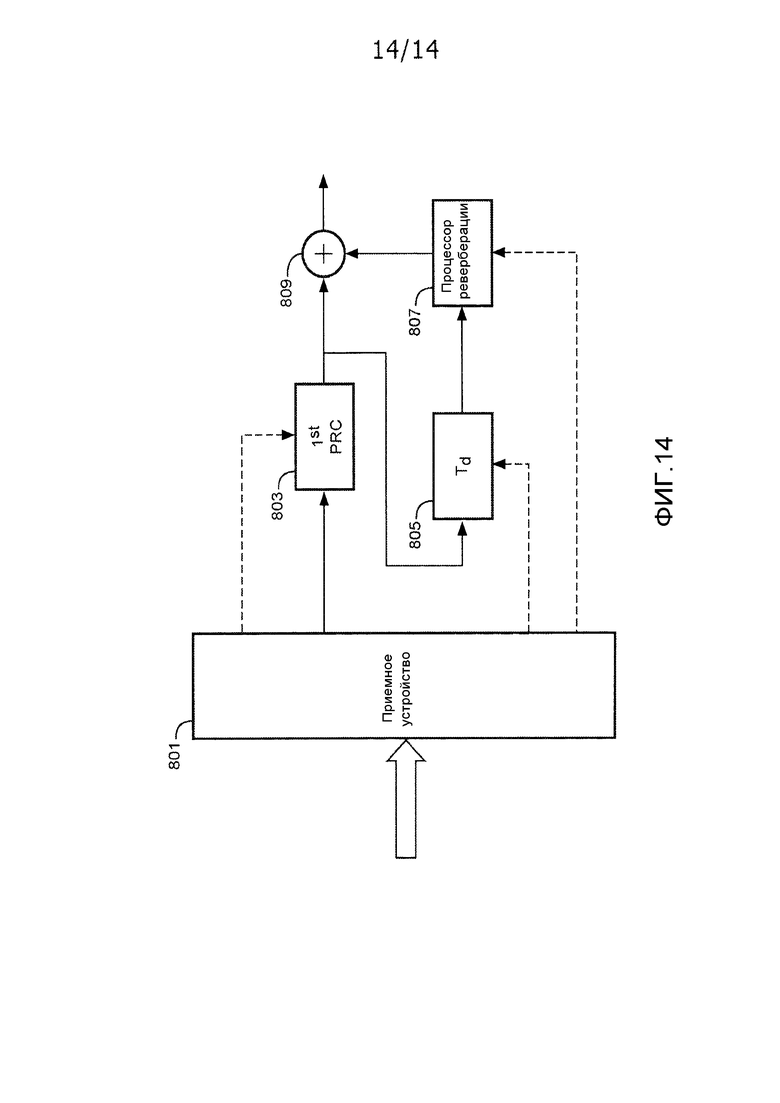
Изобретение относится к технике связи и предназначено для бинауральной аудиообработке. Технический результат – обеспечение повышенного качества звука посредством предоставления возможности управления синхронизацией воспроизведения различных частей со стороны кодера. Модуль воспроизведения аудио содержит приемное устройство, принимающее входные данные, содержащие данные ранней части, указывающие раннюю часть бинауральной передаточной функции головы; данные реверберации, указывающие часть реверберации передаточной функции; и индикатор синхронизации, указывающий сдвиг по времени между ранней частью и частью реверберации. Схема ранней части формирует аудиокомпонент посредством применения бинауральной обработки к аудиосигналу, при этом обработка зависит от данных ранней части. Ревербератор формирует второй аудиокомпонент посредством применения реверберационной обработки к аудиосигналу, при этом реверберационная обработка зависит от данных реверберации. Модуль комбинирования формирует сигнал бинаурального стереосигнала посредством комбинирования двух аудиокомпонентов. Относительная временная синхронизация аудиокомпонентов регулируется на основе индикатора синхронизации посредством синхронизатора, который, в частности, может представлять собой задержку. 6 н. и 10 з.п. ф-лы, 14 ил.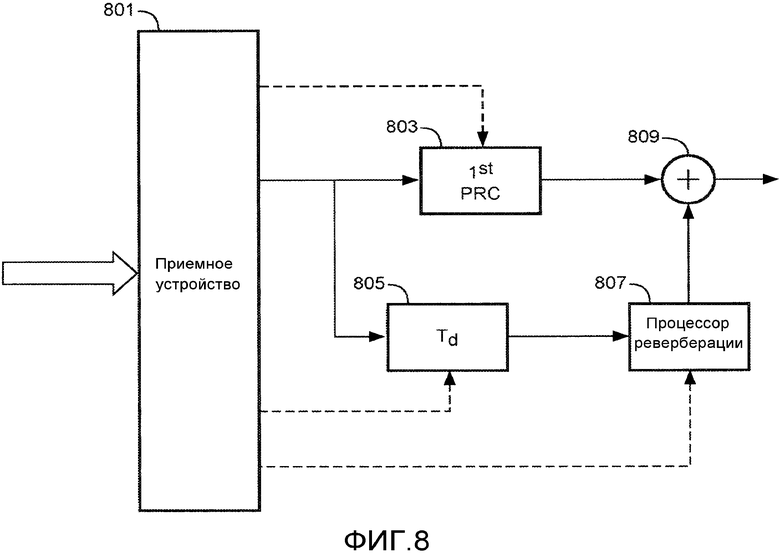
1. Устройство для обработки аудиосигнала, причем устройство содержит:
- приемное устройство (801) для приема входных данных, причем входные данные содержат, по меньшей мере, данные, описывающие бинауральную передаточную функцию головы, содержащую раннюю часть и часть реверберации, причем данные содержат:
- данные ранней части, указывающие раннюю часть бинауральной передаточной функции головы,
- данные реверберации, указывающие часть реверберации бинауральной передаточной функции головы,
- индикатор синхронизации, указывающий сдвиг по времени между ранней частью и частью реверберации;
- схему (803) ранней части для формирования первого аудиокомпонента посредством применения бинауральной обработки к аудиосигналу, причем бинауральная обработка, по меньшей мере, частично определяется посредством данных ранней части;
- ревербератор (807) для формирования второго аудиокомпонента посредством применения реверберационной обработки к аудиосигналу, причем реверберационная обработка, по меньшей мере, частично определяется посредством данных реверберации;
- модуль (809) комбинирования для формирования по меньшей мере первого слухового сигнала из бинаурального сигнала, причем модуль комбинирования выполнен с возможностью комбинировать первый аудиокомпонент и второй аудиокомпонент; и
- синхронизатор (805) для синхронизации первого аудиокомпонента и второго аудиокомпонента в ответ на индикатор синхронизации.
2. Устройство по п. 1, в котором синхронизатор (805) выполнен с возможностью вводить задержку для второго аудиокомпонента относительно первого аудиокомпонента, причем задержка является зависимой от индикатора синхронизации.
3. Устройство по п. 1, в котором данные ранней части служат признаком безэховой части бинауральной передаточной функции головы.
4. Устройство по п. 1, в котором данные ранней части содержат параметры фильтрации в частотной области, и обработка ранней части представляет собой обработку в частотной области.
5. Устройство по п. 1, в котором данные части реверберации содержат параметры для модели реверберации, и ревербератор (807) выполнен с возможностью реализовывать модель реверберации с использованием параметров, указываемых посредством данных части реверберации.
6. Устройство по п. 1, в котором ревербератор (807) содержит синтетический ревербератор, и данные части реверберации содержат параметры для синтетического ревербератора.
7. Устройство по п. 1, в котором ревербератор (807) содержит реверберационный фильтр, и данные реверберации содержат параметры для реверберационного фильтра.
8. Устройство по п. 1, в котором бинауральная передаточная функция головы дополнительно содержит часть ранних отражений между ранней частью и частью реверберации, и данные дополнительно содержат:
- данные части ранних отражений, указывающие часть ранних отражений бинауральной передаточной функции головы; и
- второй индикатор синхронизации, указывающий сдвиг по времени между частью ранних отражений и по меньшей мере одной из ранней части и части реверберации; и
устройство дополнительно содержит:
- процессор части ранних отражений для формирования третьего аудиокомпонента посредством применения обработки отражения к аудиосигналу, причем обработка отражения, по меньшей мере, частично определяется посредством данных части ранних отражений; и
- модуль (809) комбинирования выполнен с возможностью формировать первый слуховой сигнал из бинаурального сигнала в ответ на комбинирование по меньшей мере первого аудиокомпонента, второго аудиокомпонента и третьего аудиокомпонента; и
- синхронизатор (805) выполнен с возможностью синхронизировать третий аудиокомпонент по меньшей мере с одним из первого аудиокомпонента и второго аудиокомпонента в ответ на второй индикатор синхронизации.
9. Устройство по п. 1, в котором ревербератор (807) выполнен с возможностью формировать второй аудиокомпонент в ответ на процесс реверберации, применяемый к первому аудиокомпоненту.
10. Устройство по п. 1, в котором индикатор синхронизации компенсируется в отношении задержки бинауральной обработки.
11. Устройство по п. 1, в котором индикатор синхронизации компенсируется в отношении задержки реверберационной обработки.
12. Устройство для формирования потока битов, причем устройство содержит:
- процессор (1101) для приема бинауральной передаточной функции головы, содержащей раннюю часть и часть реверберации;
- схему (1103) ранней части для формирования данных ранней части, указывающих раннюю часть бинауральной передаточной функции головы;
- схему (1105) реверберации для формирования данных реверберации, указывающих часть реверберации бинауральной передаточной функции головы;
- схему (1107) синхронизации для формирования данных синхронизации, содержащих индикатор синхронизации, указывающий сдвиг по времени между данными ранней части и данными реверберации; и
- выходную схему (1109) для формирования потока битов, содержащего данные ранней части, данные реверберации и данные синхронизации.
13. Способ обработки аудиосигнала, при этом способ содержит этапы, на которых:
- принимают входные данные, причем входные данные содержат, по меньшей мере, данные, описывающие бинауральную передаточную функцию головы, содержащую раннюю часть и часть реверберации, причем данные содержат:
- данные ранней части, указывающие раннюю часть бинауральной передаточной функции головы,
- данные реверберации, указывающие часть реверберации бинауральной передаточной функции головы,
- индикатор синхронизации, указывающий сдвиг по времени между ранней частью и частью реверберации;
- формируют первый аудиокомпонент посредством применения бинауральной обработки к аудиосигналу, причем бинауральная обработка, по меньшей мере, частично определяется посредством данных ранней части;
- формируют второй аудиокомпонент посредством применения реверберационной обработки к аудиосигналу, причем реверберационную обработку, по меньшей мере, частично определяют посредством данных реверберации;
- формируют по меньшей мере первый слуховой сигнал из бинаурального сигнала в ответ на комбинирование первого аудиокомпонента и второго аудиокомпонента; и
- синхронизируют первый аудиокомпонент и второй аудиокомпонент в ответ на индикатор синхронизации.
14. Способ формирования потока битов, при этом способ содержит этапы, на которых:
- принимают бинауральную передаточную функцию головы, содержащую раннюю часть и часть реверберации;
- формируют данные ранней части, указывающие раннюю часть бинауральной передаточной функции головы;
- формируют данные реверберации, указывающие часть реверберации бинауральной передаточной функции головы;
- формируют данные синхронизации, содержащие индикатор синхронизации, указывающий сдвиг по времени между данными ранней части и данными реверберации; и
- формируют поток битов, содержащий данные ранней части, данные реверберации и данные синхронизации.
15. Процессор данных, содержащий сохраненную в нем компьютерную программу, содержащую компьютерный программный код, побуждающий процессор осуществлять способ обработки аудиосигнала по п. 13.
16. Процессор данных, содержащий сохраненную в нем компьютерную программу, содержащий компьютерный программный код, побуждающий процессор осуществлять способ формирования потока битов по п. 14.
| US 5371799 A1, 06.12.1994 | |||
| ДЕКОДИРОВАНИЕ БИНАУРАЛЬНЫХ АУДИОСИГНАЛОВ | 2007 |
|
RU2409911C2 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ ФОРМИРОВАНИЯ ЗАКОДИРОВАННОГО СТЕРЕОСИГНАЛА АУДИОЧАСТИ ИЛИ ПОТОКА ДАННЫХ АУДИО | 2006 |
|
RU2376726C2 |
| US 7715568 B2, 11.05.2010 | |||
| US 7567682 B2, 28.07/2009 | |||
| Топка с качающимися колосниковыми элементами | 1921 |
|
SU1995A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Топка с качающимися колосниковыми элементами | 1921 |
|
SU1995A1 |

