Область техники, к которой относится изобретение
Изобретение относится к стереофоническому воспроизведению, и в частности, но не исключительно, к передаче и обработке данных стереофонической передаточной функции с учетом положения головы для приложений обработки аудиосигналов.
Уровень техники
Цифровое кодирование различных исходных сигналов становилось все более и более важным в последние десятилетия по мере того, как цифровое представление и передача сигнала все более и более замещали аналоговое представление и передачу. Например, аудиоконтент, такой как речь и музыка, все больше становится основанным на кодировании цифрового контента. Кроме того, потребление аудио все больше смещалось в сторону обволакивающих трехмерных переживаний с распространением, например, объемного звучания и домашних кинотеатров.
Были разработаны форматы кодирования аудиосигналов для того, чтобы обеспечить все более и более функциональные, разнообразные и гибкие аудиосервисы, и в частности были разработаны форматы аудиокодирования, поддерживающие пространственные аудиосервисы.
Известные технологии кодирования аудиосигналов, такие как DTS и Dolby Digital, производят закодированный многоканальный аудиосигнал, который представляет пространственный образ как множество каналов, которые размещаются вокруг слушателя в фиксированных положениях. Для установки динамика, которая отличается от установки, которая соответствует многоканальному сигналу, пространственный образ будет неоптимальным. Кроме того, основанные на каналах системы кодирования аудиосигналов, как правило, не способны справиться с различным количеством динамиков.
Стандарт (ISO/IEC MPEG-D) MPEG Surround обеспечивает инструмент кодирования многоканальных аудиосигналов, который позволяет расширить существующие моно- или стереокодировщики на многоканальные аудио приложения. Фиг. 1 иллюстрирует пример элементов системы MPEG Surround. Используя пространственные параметры, полученные путем анализа исходного многоканального входа, декодер MPEG Surround может воссоздать пространственный образ с помощью управляемого микширования с увеличением количества каналов моно- или стереосигнала для получения многоканального выходного сигнала.
Так как пространственный образ многоканального входного сигнала параметризован, стандарт MPEG Surround позволяет расшифровывать тот же самый многоканальный поток битов посредством воспроизводящих устройств, которые не используют многоканальную настройку динамиков. Примером этого является воспроизведение виртуального объемного звучания в наушниках, которое называется процессом стереофонического декодирования MPEG Surround. В этом режиме может быть обеспечено реалистическое объемное переживание при использовании обычных наушников. Другим примером является сокращение числа каналов в многоканальных выходах, например 7.1, до более низкого, например 5.1.
На самом деле, разнообразие и гибкость в конфигурациях воспроизведения, используемых для воспроизведения пространственного звука, значительно увеличились в последние годы, и все большее количество форматов воспроизведения становятся доступными рядовому потребителю. Это требует гибкого представления аудиосигнала. Важные шаги были сделаны с введением кодека MPEG Surround. Тем не менее, аудиоданные по-прежнему производятся и передаются для конкретной настройки громкоговорителей, например для ITU 5.1. Воспроизведение на различных настройках и на нестандартных (то есть гибких или определяемых пользователем) настройках динамиков не определено. Действительно, существует желание сделать аудиокодирование и представление все более и более независимыми от конкретных предопределенных и номинальных настроек динамиков. Все более предпочтительным становится, чтобы гибкая адаптация к широкому разнообразию различных настроек динамиков могла быть выполнена на стороне декодера/воспроизведения.
Для того, чтобы обеспечить более гибкое представление аудио, MPEG стандартизировал формат, известный как «Кодирование пространственных аудиообъектов» (ISO/IEC MPEG-D SAOC). В отличие от систем кодирования многоканальных аудиосигналов, таких как DTS, Dolby Digital и MPEG Surround, стандарт SAOC обеспечивает эффективное кодирование отдельных аудиообъектов вместо звуковых каналов. В то время как в стандарте MPEG Surround каждый канал динамика может рассматриваться как состоящий из различной смеси звуковых объектов, стандарт SAOC делает отдельные звуковые объекты доступными для интерактивной манипуляции на стороне декодирующего устройства, как проиллюстрировано на Фиг. 2. В стандарте SAOC множество звуковых объектов кодируется в моно- или стереоверсии вместе с параметрическими данными, позволяющими извлечь звуковые объекты на стороне воспроизведения, делая тем самым отдельные аудиообъекты доступными для манипуляции, например, конечным пользователем.
Действительно, аналогично стандарту MPEG Surround стандарт SAOC также создает моно или стерео версии сигнала с сокращенным количеством каналов. В дополнение к этому вычисляются и включаются параметры объекта. На стороне декодирующего устройства пользователь может манипулировать этими параметрами с тем, чтобы управлять различными признаками отдельных объектов, такими как положение, уровень, балансировка, или даже применять к ним эффекты, такие как реверберация. Фиг. 3 иллюстрирует интерактивный интерфейс, который позволяет пользователю управлять отдельными объектами, содержащимися в потоке битов SAOC. Посредством матрицы воспроизведения отдельные звуковые объекты отображаются на каналы динамиков.
Стандарт SAOC обеспечивает более гибкий подход, и в частности обеспечивает большую адаптируемость воспроизведения за счет передачи аудиообъектов в дополнение к каналам воспроизведения. Это позволяет декодирующей стороне помещать аудиообъекты в произвольных положениях в пространстве, при условии, что это пространство адекватно покрывается динамиками. Таким образом отсутствует какая-либо связь между передаваемым аудиосигналом и воспроизведением или настройкой воспроизведения, следовательно могут использоваться произвольные настройки динамиков. Это выгодно для, например, домашних кинотеатров в обычной жилой комнате, где динамики почти никогда не находятся в правильных положениях. В стандарте SAOC то, где именно объекты размещаются на звуковой сцене, решается на стороне декодирующего устройства, что часто является нежелательным с артистической точки зрения. Стандарт SAOC на самом деле обеспечивает способы передачи матрицы воспроизведения по умолчанию в потоке битов, устраняя ответственность декодера. Однако обеспечиваемые способы полагаются либо на фиксированные настройки воспроизведения, либо на неспецифицированный синтаксис. Таким образом, стандарт SAOC не обеспечивает нормативного средства для полной передачи аудиосцены независимо от настройки динамиков. Кроме того, SAOC не очень хорошо приспособлен для достоверного воспроизведения диффузных компонентов сигнала. Хотя в нем и имеется возможность включать так называемый многоканальный фоновый объект (MBO) для захвата диффузного звука, этот объект связан с одной конкретной конфигурацией динамиков.
Другая спецификация аудиоформата для трехмерного звука разрабатывается Союзом 3D-аудио (3DAA), который является промышленным альянсом. 3DAA ставит своей целью разработку стандартов для передачи трехмерного звука, которые «будут облегчать переход от текущей парадигмы питания динамиков к гибкому подходу на основе объектов». В 3DAA должен быть определен формат потока битов, который позволял бы передачу наследуемой многоканальной версии наряду с отдельными звуковыми объектами. В дополнение к этому, включаются данные о расположении объекта. Принцип формирования 3DAA аудиопотока проиллюстрирован на Фиг. 4.
В подходе 3DAA звуковые объекты получаются отдельно в расширении потока, и они могут быть извлечены из многоканальной версии. Результирующая многоканальная версия с сокращенным количеством каналов воспроизводится вместе с объектами, доступными по отдельности.
Эти объекты могут состоять из так называемых стволов. Эти стволы в основном представляют собой сгруппированные (смикшированные с уменьшением количества каналов) дорожки или объекты. Следовательно, объект может состоять из множества подобъектов, упакованных в ствол. В 3DAA многоканальное опорное микширование может быть передано с некоторым набором звуковых объектов. 3DAA передает данные о трехмерном положении для каждого объекта. Эти объекты могут быть затем извлечены с использованием данных о трехмерном положении. Альтернативно может быть передана обратная матрица микширования, описывающая соотношение между объектами и опорным микшированием.
Из описания 3DAA можно понять, что информация о звуковой сцене, вероятно, передается путем назначения угла и расстояния до каждого объекта, указывающих, где этот объект должен быть размещен относительно, например, направления вперед по умолчанию. Таким образом, информация о местонахождении передается для каждого объекта. Это является полезным для точечных источников, но не в состоянии описать широкие источники (такие как, например, хор или аплодисменты) или диффузные звуковые поля (такие как звуки окружающей среды). Когда все точечные источники извлекаются из опорного микширования, остается многоканальное микширование окружающей среды. Аналогично стандарту SAOC, остаток в 3DAA фиксируется для конкретной настройки динамиков.
Таким образом, как подход SAOC, так и подход 3DAA включают в себя передачу отдельных звуковых объектов, которыми можно манипулировать по отдельности на стороне декодирующего устройства. Разница между этими двумя подходами заключается в том, что стандарт SAOC обеспечивает информацию о звуковых объектах путем обеспечения параметров, характеризующих объекты относительно версии с сокращенным количеством каналов (то есть таким образом, что звуковые объекты формируются из версии с сокращенным количеством каналов на стороне декодирующего устройства), тогда как 3DAA обеспечивает звуковые объекты как полные и отдельные звуковые объекты (то есть, которые могут формироваться независимо от версии с сокращенным количеством каналов на стороне декодирующего устройства). Для обоих подходов могут быть сообщены данные о положении звуковых объектов.
Стереофоническая обработка, в которой пространственные переживания создаются за счет виртуального позиционирования звуковых источников с использованием отдельных сигналов для ушей слушателя, становится все более широко распространенной. Виртуальный объемный звук представляет собой способ воспроизведения звука таким образом, что источники звука воспринимаются расположенные в конкретном направлении, создавая тем самым иллюзию восприятия физически объемного звука (например, динамиков 5.1) или окружающей среды (концерт). С помощью подходящей обработки стереофонического воспроизведения могут быть вычислены сигналы, которые надо подать на барабанные перепонки слушателя для того, чтобы он воспринимал звук с любого направления, и эти сигналы воспроизводятся таким образом, что они обеспечивают желаемый эффект. Как проиллюстрировано на Фиг. 5, эти сигналы затем воссоздаются в барабанной перепонке с использованием наушников или способа устранения перекрестной связи (подходящего для воспроизведения с помощью близко расположенных динамиков).
Кроме непосредственного воспроизведения, изображенного на Фиг. 5, конкретные технологии, которые могут использоваться для воспроизведения виртуального объемного звука, включают в себя MPEG Surround и SAOC, а также планируемый этап работы по трехмерному звуку в MPEG. Эти технологии обеспечивают эффективное в вычислительном отношении воспроизведение виртуального объемного звука.
Стереофоническое воспроизведение основано на стереофонических фильтрах, которые изменяются от человека к человеку благодаря различным акустическим свойствам головы и отражающих поверхностей, таких как плечи. Например, стереофонические фильтры могут использоваться для создания стереофонической записи, моделирующей множество источников, находящихся в различных локализациях. Это может быть реализовано путем свертки каждого звукового источника с парой импульсных откликов с учетом положения головы (HRIR), которые соответствуют положению звукового источника.
Путем измерения, например, импульсных откликов от звукового источника, находящегося в конкретной локализации в двухмерном или трехмерном пространстве, с помощью микрофонов, размещенных внутри или около человеческих ушей, могут быть определены подходящие стереофонические фильтры. Как правило, такие измерения делаются, например, с использованием моделей головы человека, или в некоторых случаях измерения на самом деле могут быть сделаны путем прикрепления микрофонов вблизи от барабанных перепонок человека. Стереофонические фильтры могут использоваться для создания стереофонической записи, моделирующей множество источников, находящихся в различных локализациях. Это может быть реализовано, например, путем свертки каждого звукового источника с парой измеренных импульсных откликов для желаемого положения звукового источника. Чтобы создать иллюзию того, что звуковой источник перемещается вокруг слушателя, требуется большое количество стереофонических фильтров с соответствующим пространственным разрешением, например в 10 градусов.
Функции стереофонических фильтров могут быть представлены, например, как импульсные отклики с учетом положения головы (HRIR), или эквивалентно как передаточные функции с учетом положения головы (HRTF), или как стереофонический импульсный отклик помещения (BRIR), или как стереофоническая передаточная функция помещения (BRTF). Передаточная функция (например, оцененная или принятая) от данного положения до ушей (или барабанных перепонок) слушателя известна как стереофоническая передаточная функция с учетом положения головы. Эта функция может быть определена, например, в частотной области, и в этом случае она обычно называется HRTF или BRTF, или во временной области, и тогда она обычно упоминается как HRIR или BRIR. В некоторых сценариях стереофонические передаточные функции с учетом положения головы определяются как включающие в себя аспекты или коэффициенты свойств акустического окружения и конкретно того места, в котором делаются измерения, тогда как в других примерах рассматриваются только характеристики пользователя. Примерами первого типа функций являются функции BRIR и BRTF, а примерами второго типа функций являются функции HRIR и HRTF.
Соответственно, основная стереофоническая передаточная функция с учетом положения головы может быть представлена многими различными способами, включая HRIR, HRTF и т.д. Кроме того, для каждого из этих главных представлений существует большое количество различных способов представления конкретной функции, например с разными уровнями точности и сложности. Различные процессоры могут использовать разные подходы и таким образом могут быть основаны на различных представлениях. Таким образом, в любой аудиосистеме как правило требуется большое количество стереофонических передаточных функций с учетом положения головы. Действительно, существует большое разнообразие того, как представлять стереофонические передаточные функции с учетом положения головы, и это дополнительно усиливается большим разнообразием возможных параметров для каждой стереофонической передаточной функции с учетом положения головы. Например, функция BRIR иногда может быть представлена фильтром конечного импульсного отклика (FIR), имеющим, например, 9 выводов, но в других сценариях она может быть представлена фильтром FIR, имеющим, например, 16 выводов, и т.д. В качестве другого примера, функции HRTF могут быть представлены в частотной области с использованием параметризованного представления, где небольшой набор параметров используется для того, чтобы представить полный спектр частот.
Во многих сценариях желательно обеспечить передачу параметров желаемого стереофонического воспроизведения, таких как конкретные стереофонические передаточные функции с учетом положения головы, которые могут использоваться. Однако, благодаря большому разнообразию в возможных представлениях основной стереофонической передаточной функции с учетом положения головы может быть затруднительно гарантировать общность между порождающим и принимающим устройствами.
Технический комитет sc-02 Общества звукоинженеров (AES) недавно объявил о запуске нового проекта по стандартизации формата файла для обмена параметрами стереофонического прослушивания в форме стереофонических передаточных функций с учетом положения головы. Этот формат будет масштабируемым для того, чтобы соответствовать доступному процессу воспроизведения. Этот формат будет проектироваться так, чтобы включать исходные материалы из различных баз данных HRTF. Сложность заключается в том, как такие множество стереофонических передаточных функций с учетом положения головы могут быть наилучшим образом поддержаны, использованы и распределены в аудиосистеме.
Соответственно, желательным был бы улучшенный подход для поддержки стереофонической обработки, и особенно для передачи данных для стереофонического воспроизведения. В частности, выгодным был бы подход, обеспечивающий улучшенное представление и передачу данных стереофонического воспроизведения, уменьшенную скорость передачи данных, уменьшенные накладные расходы, облегченную реализацию и/или улучшенную эффективность.
Раскрытие изобретения
Соответственно, настоящее изобретение предпочтительно направлено на уменьшение, облегчение или устраните одного или более вышеупомянутых недостатков по отдельности или в любом их сочетании.
В соответствии с одним аспектом настоящего изобретения предложено устройство для обработки аудиосигнала, причем устройство содержит: приемник для приема входных данных, причем входные данные содержат множество наборов данных стереофонического воспроизведения, причем каждый набор данных стереофонического воспроизведения содержит данные, представляющие параметры для обработки виртуального положения стереофонического воспроизведения, причем входные данные дополнительно содержат указание представления для каждого из наборов данных стереофонического воспроизведения, указывающее на представление для набора данных стереофонического воспроизведения; селектор для выбора выбранного набора данных стереофонического воспроизведения в ответ на указания представления и возможности устройства; аудиопроцессор для обработки аудиосигнала в ответ на данные выбранного набора данных стереофонического воспроизведения.
Настоящее изобретение может обеспечить улучшенную и/или более гибкую и/или менее сложную стереофоническую обработку во многих сценариях. Данный подход может в частности обеспечить гибкий и/или простой подход для передачи и представления множества параметров стереофонического воспроизведения. Данный подход может обеспечить эффективное представление множества подходов стереофонического воспроизведения и параметров в одном и том же потоке битов/файле данных с использованием устройства, принимающего данные, способного выбирать подходящие данные и представления с низкой сложностью. В частности, подходящее стереофоническое воспроизведение, которое соответствует возможностям устройства, может быть легко идентифицировано и выбрано, не требуя полного декодирования всех данных, или на самом деле во многих вариантах осуществления вообще без какого бы то ни было декодирования данных любого набора данных стереофонического воспроизведения.
Обработка стереофонического воспроизведения виртуального положения может быть любой обработкой алгоритма или процесса, который для сигнала, представляющего звуковой источник, формирует аудиосигналы для двух ушей человека таким образом, чтобы звук воспринимался, как если бы он исходил из желаемого положения в трехмерном пространстве, и как правило из желаемого положения вне головы пользователя.
Каждый набор данных может включать в себя данные, представляющие параметры по меньшей мере одного виртуального положения для операции стереофонического воспроизведения. Каждый набор данных может относиться только к поднабору полных параметров, которые управляют или влияют на стереофоническое воспроизведение. Эти данные могут определять или описывать один или более параметров полностью, и/или могут например частично определять один или более параметров. В некоторых вариантах осуществления определенные параметры могут быть предпочтительными параметрами.
Указание представления может определять, какие параметры включаются в наборы данных и/или характеристику этих параметров, и/или как эти параметры описываются данными.
Возможности устройства могут, например, представлять собой вычислительные ограничения или ограничения ресурса памяти. Возможность устройства может определяться динамически или может быть статическим параметром.
В соответствии с признаком настоящего изобретения при необходимости наборы данных стереофонического воспроизведения включают в себя данные стереофонической передаточной функции с учетом положения головы.
Настоящее изобретение может обеспечить улучшенное и/или облегченное и более гибкое распределение стереофонических передаточных функций с учетом положения головы и/или обработку, основанную на стереофонических передаточных функциях с учетом положения головы. В частности, этот подход может позволить распределять данные, представляющие большое разнообразие стереофонических передаточных функций с учетом положения головы, с помощью отдельных обрабатывающих устройств, способных легко и эффективно идентифицировать и извлекать данные, подходящие конкретно для этого обрабатывающего устройства.
Указания представления могут представлять собой или могут содержать указания представления стереофонических передаточных функций с учетом положения головы, таких как природа стереофонической передаточной функции с учетом положения головы, а также ее отдельные параметры. Например, указание представления для данного набора данных стереофонического воспроизведения может указывать, обеспечивает ли набор данных представление стереофонической передаточной функции с учетом положения головы как функции HRTF, BRTF, HRIR или BRIR. Для представления в виде импульсного отклика указание представления может, например, указывать количество отводов (коэффициентов) для фильтра FIR, представляющего импульсный отклик, и/или количество битов, используемое для каждого отвода. Для представления в частотной области указание представления может, например, указывать количество частотных интервалов, для которых обеспечивается коэффициент, являются ли полосы частот линейны или, например, они являются полосами частот Барка, и т.д.
Обработка аудиосигнала может быть обработкой стереофонического воспроизведения виртуального положения на основании параметров стереофонической передаточной функции с учетом положения головы, восстановленной из выбранного набора данных стереофонического воспроизведения.
В соответствии с признаком настоящего изобретения при необходимости по меньшей мере один из наборов данных стереофонического воспроизведения содержит данные стереофонической передаточной функции с учетом положения головы для множества положений.
В некоторых вариантах осуществления каждый набор данных стереофонического воспроизведения может, например, определять полный набор стереофонических передаточных функций с учетом положения головы для двух- или трехмерного пространства воспроизведения источника звука. Указание представления, которое является общим для всех положений, может обеспечить эффективное представление и передачу.
В соответствии с признаком настоящего изобретения при необходимости указания представления дополнительно представляют упорядоченную последовательность набора данных стереофонического воспроизведения, упорядоченную с точки зрения по меньшей мере одного из качества и сложности стереофонического воспроизведения, представленного наборами данных стереофонического воспроизведения, и селектор выполнен с возможностью выбора выбранного набора данных стереофонического воспроизведения в ответ на положение выбранного набора данных стереофонического воспроизведения в упорядоченной последовательности.
Это может обеспечить особенно выгодную работу во многих вариантах осуществления. В частности, это может облегчить и/или улучшить процесс выбора выбранного набора данных стереофонического воспроизведения, поскольку это может быть сделано с учетом порядка указаний представления.
В некоторых вариантах осуществления порядок указаний представления представляется положениями указаний представления в потоке битов.
Это может облегчить процесс выбора. Например, указания представления могут быть оценены в соответствии с порядком, в котором они расположены в потоке битов входных данных, и набор данных выбранного подходящего указания представления может быть выбран без какого-либо рассмотрения дополнительных указаний представления. Если указания представления расположены в порядке уменьшения предпочтения (в соответствии с любым подходящим параметром), то это приведет к выбору указания предпочтительного представления и таким образом набора данных стереофонического воспроизведения.
В некоторых вариантах осуществления порядок указаний представления представляется указанием, содержащимся во входных данных. Это указание для каждого из указаний представления может содержаться в указании представления. Это указание может быть, например, указанием приоритета.
Это может облегчить процесс выбора. Например, приоритет может быть обеспечен как первые два бита каждого указания представления. Устройство может сначала просканировать поток битов для поиска максимально возможного приоритета, и может из этих указаний представления оценить, соответствуют ли они возможностям устройства. Если это так, то выбираются одно из указаний представления и соответствующий набор данных стереофонического воспроизведения. В противном случае устройство может продолжить сканировать поток битов для поиска второго максимально возможного приоритета, а затем выполнить ту же самую оценку для этих указаний представления. Этот процесс может продолжаться до тех пор, пока не будет идентифицирован подходящий набор данных стереофонического воспроизведения.
В некоторых вариантах осуществления наборы данных/указания представления могут быть упорядочены в порядке качества стереофонического воспроизведения, представленного параметрами связанного/соединенного набора данных стереофонического воспроизведения.
Этот порядок может соответствовать увеличению или уменьшению качества в зависимости от конкретных вариантов осуществления, предпочтений и приложений.
Это может обеспечить особенно эффективную систему. Например, устройство может просто обрабатывать указания представления в заданном порядке до тех пор, пока не встретится указание представления, указывающее представление набора данных стереофонического воспроизведения, которое соответствует возможностям устройства. Устройство может затем выбрать это указание представления и соответствующий набор данных стереофонического воспроизведения, поскольку это обеспечит наивысшее качество воспроизведения, возможное для конкретных данных и возможностей устройства.
В некоторых вариантах осуществления наборы данных/указания представления могут быть упорядочены в порядке сложности стереофонического воспроизведения, представленного параметрами набора данных стереофонического воспроизведения.
Этот порядок может соответствовать увеличению или уменьшению сложности в зависимости от конкретных вариантов осуществления, предпочтений и приложений.
Это может обеспечить особенно эффективную систему. Например, устройство может просто обрабатывать указания представления в заданном порядке до тех пор, пока не встретится указание представления, указывающее представление набора данных стереофонического воспроизведения, которое соответствует возможностям устройства. Устройство может затем выбрать это указание представления и соответствующий набор данных стереофонического воспроизведения, поскольку это обеспечит наименьшую сложность воспроизведения, возможную для конкретных данных и возможностей устройства.
В некоторых вариантах осуществления наборы данных/указания представления могут быть упорядочены в порядке комбинированной характеристики стереофонического воспроизведения, представленного параметрами набора данных стереофонического воспроизведения. Например, величина затрат может быть выражена как комбинация меры качества и меры сложности для каждого набора данных стереофонического воспроизведения, и указания представления могут быть упорядочены в соответствии с этой величиной затрат.
В соответствии с одним признаком настоящего изобретения при необходимости предусмотрен селектор для выбора выбранного набора данных стереофонического воспроизведения как набора данных стереофонического воспроизведения для первого указания представления в упорядоченной последовательности, который указывает обработку воспроизведения, которую может осуществить аудиопроцессор.
Это может уменьшить сложность и/или облегчить выбор.
В соответствии с одним признаком настоящего изобретения при необходимости настоящего изобретения указания представления включают в себя указание типа фильтра с учетом положения головы, представленного набором данных стереофонического воспроизведения.
В частности, указание представления для данного набора данных стереофонического воспроизведения может содержать указание, например, HRTF, BRTF, HRIR или BRIR, представленных набором данных стереофонического воспроизведения.
В соответствии с одним признаком настоящего изобретения при необходимости по меньшей мере некоторые из множества наборов данных стереофонического воспроизведения включают в себя по меньшей мере одну стереофоническую передаточную функцию с учетом положения головы, описываемую представлением, выбранным из группы, состоящей из: представления в виде импульсного отклика во временной области; представления передаточной функции фильтра в частотной области; параметрического представления; и представления фильтра в области поддиапазонов.
Это может обеспечить особенно выгодную систему во многих сценариях.
В некоторых вариантах осуществления значение указания представления является значением из набора вариантов. Входные данные могут содержать по меньшей мере два указания представления с различными значениями из набора вариантов. Эти варианты могут, например, включать в себя одно или более из: представления в виде импульсного отклика во временной области; представления передаточной функции фильтра в частотной области; параметрического представления; представления фильтра в области поддиапазонов и представления фильтра FIR.
В соответствии с одним признаком настоящего изобретения при необходимости по меньшей мере некоторые представления для наборов данных стереофонического воспроизведения соответствуют различным алгоритмам обработки стереофонических аудиосигналов, и выбор выбранного набора данных стереофонического воспроизведения зависит от алгоритма стереофонической обработки, используемого аудиопроцессором.
Это может обеспечить особенно эффективную работу во многих вариантах осуществления. Например, устройство может быть запрограммировано так, чтобы выполнять конкретный алгоритм воспроизведения на основе фильтров HRTF. В этом случае указания представления могут быть оценены для идентификации тех наборов данных стереофонического воспроизведения, которые включают в себя подходящие данные HRTF.
Аудиопроцессор выполнен с возможностью адаптации обработки аудиосигнала в зависимости от представления, используемого выбранным набором данных стереофонического воспроизведения. Например, количество коэффициентов в адаптируемом фильтре FIR, используемом для обработки HRTF, может быть адаптировано на основании указания количества коэффициентов, обеспечиваемых выбранным набором данных стереофонического воспроизведения.
В соответствии с одним признаком настоящего изобретения при необходимости по меньшей мере некоторые наборы данных стереофонического воспроизведения содержат реверберационные данные, и аудиопроцессор выполнен с возможностью адаптации обработки реверберации в зависимости от реверберационных данных выбранного набора данных стереофонического воспроизведения.
Это может обеспечить особенно выгодный стереофонический звук, и может обеспечить пользователю улучшенные переживания и восприятие звуковой сцены.
В соответствии с одним признаком настоящего изобретения при необходимости аудиопроцессор выполнен с возможностью выполнения обработки стереофонического воспроизведения, которая включает в себя формирование обработанного аудиосигнала как комбинации по меньшей мере сигнала, отфильтрованного стереофонической передаточной функцией с учетом положения головы, и реверберационного сигнала, причем реверберационный сигнал зависит от данных выбранного набора данных стереофонического воспроизведения.
Это может обеспечить особенно эффективную реализацию, и может обеспечить очень гибкую и адаптируемую обработку и предоставление данных обработки стереофонического воспроизведения.
Во многих вариантах осуществления сигнал, отфильтрованный стереофонической передаточной функцией с учетом положения головы, не зависит от данных выбранного набора данных стереофонического воспроизведения. На самом деле во многих вариантах осуществления входные данные могут включать в себя данные фильтра стереофонической передаточной функции с учетом положения головы, который является общим для множества наборов данных стереофонического воспроизведения, но с реверберационными данными, которые являются индивидуальными для отдельного набора данных стереофонического воспроизведения.
В соответствии с одним признаком настоящего изобретения при необходимости селектор выполнен с возможностью выбора выбранного набора данных стереофонического воспроизведения в ответ на указания представлений реверберационных данных, как обозначено указаниями представления.
Это может обеспечить особенно выгодный подход. В некоторых вариантах осуществления селектор может быть выполнен с возможностью выбора выбранного набора данных стереофонического воспроизведения в ответ на указания представлений реверберационных данных, обозначенные указаниями представления, но не в ответ на указания представлений фильтров стереофонической передаточной функции с учетом положения головы, обозначенных указаниями представления.
В соответствии с одним аспектом настоящего изобретения предложено устройство для формирования потока битов, причем устройство содержит: стереофоническую схему для обеспечения множества наборов данных стереофонического воспроизведения, причем каждый набор данных стереофонического воспроизведения содержит данные, представляющие параметры для обработки стереофонического воспроизведения виртуального положения, схему представления для обеспечения для каждого из наборов данных стереофонического воспроизведения указания представления, указывающего на представление набора данных стереофонического воспроизведения; и выходную схему для формирования потока битов, содержащего наборы данных стереофонического воспроизведения и указания представления.
Настоящее изобретение может обеспечить улучшенное и/или более гибкое и/или менее сложное формирование потока битов, обеспечивающего информацию о воспроизведении виртуального положения. Данный подход может в частности обеспечить гибкий и/или более простой подход для передачи и представления множества параметров стереофонического воспроизведения. Данный подход может обеспечить эффективное представление множества подходов стереофонического воспроизведения и параметров в одном и том же потоке битов/файле данных с использованием устройства, принимающего поток битов/файл данных, способного выбирать подходящие данные и представления с низкой сложностью. В частности, подходящее стереофоническое воспроизведение, которое соответствует возможностям устройства, может быть легко идентифицировано и выбрано, не требуя полного декодирования всех данных, или на самом деле во многих вариантах осуществления вообще без какого бы то ни было декодирования данных любого набора данных стереофонического воспроизведения.
Каждый набор данных может содержать данные, представляющие параметры по меньшей мере одного виртуального положения для операции стереофонического воспроизведения. Каждый набор данных может относиться только к поднабору полных параметров, которые управляют или влияют на стереофоническое воспроизведение. Эти данные могут определять или описывать один или более параметров полностью, и/или могут например частично определять один или более параметров. В некоторых вариантах осуществления определенные параметры могут быть предпочтительными параметрами.
Указание представления может определять, какие параметры включены в наборы данных, и/или характеристики этих параметров, и/или то, как эти параметры описаны данными.
В соответствии с одним признаком настоящего изобретения при необходимости выходная схема выполнена с возможностью упорядочения указаний представления в порядке меры характеристики стереофонического воспроизведения виртуального положения, представленного параметрами наборов данных стереофонического воспроизведения.
Это может обеспечить особенно выгодную работу во многих вариантах осуществления.
В соответствии с одним аспектом настоящего изобретения предложен способ обработки аудиоданных, причем способ содержит: прием входных данных, причем входные данные содержат множество наборов данных стереофонического воспроизведения, причем каждый набор данных стереофонического воспроизведения содержит данные, представляющие параметры для обработки стереофонического воспроизведения виртуального положения, причем входные данные дополнительно содержат указание представления для каждого из наборов данных стереофонического воспроизведения, указывающее на представление для набора данных стереофонического воспроизведения; выбор выбранного набора данных стереофонического воспроизведения в ответ на указания представления и возможности устройства; и обработку аудиосигнала в ответ на данные выбранного набора данных стереофонического воспроизведения.
В соответствии с одним аспектом настоящего изобретения предложен способ формирования потока битов, причем способ содержит: обеспечение множества наборов данных стереофонического воспроизведения, причем каждый набор данных стереофонического воспроизведения содержит данные, представляющие параметры для обработки стереофонического воспроизведения виртуального положения, обеспечение указания представления для каждого из наборов данных стереофонического воспроизведения, указывающего на представление набора данных стереофонического воспроизведения; и формирование потока битов, содержащего наборы данных стереофонического воспроизведения и указания представления.
Эти и другие аспекты настоящего изобретения будут объяснены и станут очевидными при обращении к варианту(ам) осуществления, описанным ниже.
Краткое описание чертежей
Далее варианты осуществления настоящего изобретения будут описаны лишь посредством примеров и с обращением к чертежам, на которых:
Фиг. 1 иллюстрирует один пример элементов системы MPEG Surround;
Фиг. 2 иллюстрирует манипуляцию звуковыми объектами, возможную в стандарте MPEG SAOC;
Фиг. 3 иллюстрирует интерактивный интерфейс, который позволяет пользователю управлять отдельными объектами, содержащимися в потоке битов стандарта SAOC;
Фиг. 4 иллюстрирует один пример принципа аудиокодирования 3DAA;
Фиг. 5 иллюстрирует один пример стереофонической обработки;
Фиг. 6 иллюстрирует один пример передатчика данных стереофонической передаточной функции с учетом положения головы в соответствии с некоторыми вариантами осуществления настоящего изобретения; и
Фиг. 7 иллюстрирует один пример приемника данных стереофонической передаточной функции с учетом положения головы в соответствии с некоторыми вариантами осуществления настоящего изобретения;
Фиг. 8 иллюстрирует один пример стереофонической передаточной функции с учетом положения головы;
Фиг. 9 иллюстрирует один пример стереофонического процессора; и
Фиг. 10 иллюстрирует один пример модифицированного ревербератора Джота.
Осуществление изобретения
Нижеследующее описание сосредоточено на вариантах осуществления настоящего изобретения, применимых к передаче данных стереофонической передаточной функции с учетом положения головы, и в частности к передаче функции HRTF. Однако, следует понимать, что настоящее изобретение не ограничивается этим применением и может быть применено к другим данным стереофонического воспроизведения.
Передача данных, описывающих стереофоническую передаточную функцию с учетом положения головы, приобретает все возрастающий интерес и, как было ранее упомянуто, AES SC инициирует новый проект, нацеленный на разработку подходящих форматов файла для передачи таких данных. Основные стереофонические передаточные функции с учетом положения головы могут быть представлены многими различными способами. Например, фильтры HRTF поступают во множестве форматов/представлений, таких как параметризованные представления, представления конечного импульсного отклика (FIR) и т.д. Поэтому выгодно иметь формат файла стереофонической передаточной функции с учетом положения головы, который поддерживает различные форматы представления для одной и той же основной стереофонической передаточной функции с учетом положения головы. Кроме того, различные декодеры могут полагаться на различные представления, и поэтому передатчику неизвестно, какие именно представления должны быть обеспечены для отдельных аудиопроцессоров. Следующее описание фокусируется на системе, в которой различные форматы представления стереофонической передаточной функции с учетом положения головы могут использоваться в пределах одного формата файла. Аудиопроцессор может выбирать из множества представлений для восстановления то представление, которое лучше всего подходит под индивидуальные требования или предпочтения данного аудиопроцессора.
Такой подход в частности допускает множество форматов представления (такие как FIR, параметрическое и т.д.) одной стереофонической передаточной функции с учетом положения головы в пределах одного файла стереофонической передаточной функции с учетом положения головы. Файл стереофонической передаточной функции с учетом положения головы может также включать в себя множество стереофонических передаточных функций с учетом положения головы, причем каждая функция может быть представлена множеством представлений. Например, множество представлений стереофонической передаточной функции с учетом положения головы может быть обеспечено для каждого множества положений. Эта система кроме того основана на файле, включающем в себя указания представления, которые идентифицируют конкретное представление, которое используется для различных наборов данных, представляющих стереофоническую передаточную функцию с учетом положения головы. Это позволяет декодеру выбирать формат представления стереофонической передаточной функции с учетом положения головы без необходимости получения доступа или обработки самих данных функции HRTF.
Фиг. 6 иллюстрирует пример передатчика для формирования и передачи потока битов, включающего в себя данные стереофонической передаточной функции с учетом положения головы.
Этот передатчик включает в себя генератор 601 функции HRTF, который формирует множество стереофонических передаточных функций с учетом положения головы, которые в конкретном примере являются функциями HRTF, но которые в других вариантах осуществления могут в качестве дополнения или альтернативы представлять собой, например, функции HRIR, BRIR или BRTF. На самом деле в последующем термин HRTF будет для краткости относиться к любому представлению стереофонической передаточной функции с учетом положения головы, включая HRIR, BRIR или BRTF, в зависимости от обстоятельств.
Каждая из функций HRTF затем представляется набором данных, причем каждый из наборов данных обеспечивает одно представление одной функции HRTF. Более подробная информация о конкретных представлениях стереофонических передаточных функций с учетом положения головы может быть найдена, например, в публикациях:
“Algazi, V.R., Duda, R.O. (2011). “Headphone-Based Spatial Sound”, IEEE Signal Processing Magazine, Vol: 28(1), 2011, Page: 33-42”, которая описывает концепции функций HRIR, BRIR, HRTF и BRTF;
“Cheng, C., Wakefield, G.H., “«Introduction to Head-Related Transfer Functions (HRTFs): Representations of HRTFs in Time, Frequency, and Space”, Journal Audio Engineering Society, Vol: 49, No. 4, April 2001.”, которая описывает различные представления стереофонической передаточной функции (во временной и частотной областях);
“Breebaart, J., Nater, F., Kohlrausch, A.(2010). “Spectral and spatial parameter resolution requirements for parametric, filter-bank-based HRTF processing“ J. Audio Eng. Soc., 58 No 3, p. 126-140.“, которая ссылается на параметрическое представление данных HRTF (используемое в стандартах MPEG Surround/SAOC);
“Menzer, F., Faller, C., “Binaural reverberation using a modified Jot reverberator with frequency-dependent interaural coherence matching”, 126th Audio Engineering Society Convention, Munich, Germany, May 7-10 2009”, которая описывает ревербератор Джота. Прямая передача коэффициентов фильтра для различных фильтров, составляющих ревербератор Джота, может быть одним способом описания параметров ревербератора Джота.
Например, для одной функции HRTF множество наборов данных стереофонического воспроизведения формируется с каждым набором данных, включающим в себя одно представление функции HRTF. Например, один набор данных может представлять функцию HRTF набором коэффициентов для фильтра FIR, тогда как другой набор данных может представлять функцию HRTF с помощью другого набора коэффициентов для фильтра FIR, например с другим количеством коэффициентов и/или с другим количеством битов для каждого коэффициента. Другой набор данных может представлять стереофонический фильтр набором коэффициентов поддиапазонов (например, БПФ) в частотной области. Еще один набор данных может представлять функцию HRTF с помощью другого набора коэффициентов поддиапазонов (БПФ), таких как коэффициенты для различных частотных интервалов и/или с различным количеством битов для каждого коэффициента. Другой набор данных может представлять HRTF набором коэффициентов фильтра QMF в частотной области. Еще один набор данных может обеспечивать параметрическое представление функции HRTF, и еще один набор данных может обеспечивать другое параметрическое представление функции HRTF. Параметрическое представление может обеспечивать набор коэффициентов в частотной области для набора фиксированных или непостоянных частотных интервалов, такого как, например, набор полос частот в соответствии со шкалой Барка или шкалой ERB.
Таким образом, генератор 601 функции HRTF формирует множество наборов данных для каждой функции HRTF с каждым набором данных, обеспечивающим представление функции HRTF. Кроме того, генератор 601 функции HRTF формирует наборы данных для множества положений. Например, генератор 601 функции HRTF может формировать наборы данных для множества функций HRTF, покрывающих набор трехмерных или двумерных положений. Комбинированные положения могут таким образом обеспечить набор функций HRTF, который может использоваться аудиопроцессором для обработки аудиосигнала с использованием алгоритма стереофонического воспроизведения виртуального позиционирования, что приводит к восприятию аудиосигнала как звукового источника в данном положении. Основываясь на желаемом положении, аудиопроцессор может извлечь подходящую функцию HRTF и применить ее в процессе воспроизведения (или может, например, извлечь две функции HRTF и сформировать функцию HRTF путем интерполяции этих извлеченных функций HRTF).
Генератор 601 функции HRTF соединен с процессором 603 указаний, который выполнен с возможностью формирования указания представления для каждого из наборов данных HRTF. Каждое из указаний представления указывает, какое представление функции HRTF используется отдельным набором данных.
Каждое указание представления в некоторых вариантах осуществления может быть сформировано так, чтобы содержаться в нескольких битах, которые определяют используемое представление, например в соответствии с предопределенным синтаксисом. Представление может, например, включать в себя несколько битов, определяющих, описывает ли набор данных функцию HRTF коэффициентами фильтра FIR, коэффициентами фильтра БПФ, коэффициентами фильтра QMF, параметрическим представлением и т.д. Указание представления может, например, в некоторых вариантах осуществления включать в себя несколько битов, определяющих, сколько значений данных используется в представлении (например, сколько отводов или коэффициентов используется для того, чтобы определить фильтр стереофонического воспроизведения). В некоторых вариантах осуществления указания представления могут включать в себя несколько битов, определяющих количество битов, используемых для каждого значения данных (например для каждого коэффициента фильтра или отвода).
Генератор 601 функции HRTF и процессор 603 указаний соединены с процессором 605 вывода, который выполнен с возможностью формирования потока битов, который включает в себя указания представления и наборы данных.
Во многих вариантах осуществления процессор 605 вывода выполнен с возможностью формирования потока битов, включающего в себя ряд указаний представления и ряд наборов данных. В других вариантах осуществления указания представления и наборы данных могут чередоваться, например с данными каждого набора данных, которым непосредственно предшествует указание представления для этого набора данных. Это может обеспечить, например, то преимущество, что не нужно никаких данных для того, чтобы указать, какое указание представления с каким набором данных связано.
Процессор 605 вывода может дополнительно содержать другие данные, заголовки, данные синхронизации, управляющие данные и т.д., известные специалисту в данной области техники.
Сформированный поток данных может быть включен в файл данных, который может быть, например, сохранен в памяти или на носителе, таком как карта памяти или DVD. В примере, изображенном на Фиг. 6, процессор 605 вывода соединен с передатчиком 607, который выполнен с возможностью передачи потока битов множеству приемников по подходящей коммуникационной сети. В частности, передатчик 607 может передавать поток битов к приемнику с использованием Интернета.
Таким образом, передатчик, изображенный на Фиг. 6, формирует поток битов, который содержит множество наборов данных стереофонического воспроизведения, которые в конкретном примере являются наборами данных HRTF. Каждый набор данных стереофонического содержит данные, представляющие параметры по меньшей мере одной обработки стереофонического воспроизведения виртуального положения. В частности, он может содержать данные, определяющие фильтр, который будет использоваться для стереофонического пространственного воспроизведения. Для каждого набора данных стереофонического воспроизведения поток битов дополнительно содержит указание представления, которое для каждого набора данных стереофонического воспроизведения указывает представление, используемое набором данных стереофонического воспроизведения.
Во многих вариантах осуществления поток битов может также содержать аудиоданные для воспроизведения, например такие, как аудиоданные стандарта MPEG Surround, MPEG SAOC или 3DAA. Эти данные могут быть затем воспроизведены с использованием стереофонических данных из наборов данных.
Фиг. 7 иллюстрирует приемное устройство в соответствии с некоторыми вариантами осуществления настоящего изобретения.
Приемное устройство содержит приемник 701, который принимает описанный выше поток битов, то есть оно может в частности принимать поток битов от передающего устройства, изображенного на Фиг. 6.
Приемник 701 соединен с селектором 703, на который подаются принятые наборы данных стереофонического воспроизведения и связанные с ними указания представления. Селектор 703 в этом примере соединен с процессором 705 возможностей, который выполнен с возможностью предоставления селектору 703 данных, которые описывают возможности аудиообработки приемного устройства. Селектор 703 выполнен с возможностью выбора по меньшей мере одного из наборов данных стереофонического воспроизведения на основании указаний представления и данных о возможностях, принимаемых от процессора 705 возможностей. Таким образом, по меньшей мере один выбранный набор данных стереофонического воспроизведения отбирается селектором 703.
Селектор 703 дополнительно соединен с аудиопроцессором 707, который принимает выбранные данные стереофонического воспроизведения. Аудиопроцессор 707, кроме того, соединен с аудиодекодером 709, который далее соединен с приемником 701.
В примере, в котором поток битов содержит аудиоданные для воспроизводимого звука, эти аудиоданные подаются к аудиодекодеру 709, который декодирует их с тем, чтобы сформировать отдельные звуковые компоненты, такие как звуковые объекты и/или звуковые каналы. Эти звуковые компоненты подаются к аудиопроцессору 707 вместе с желаемым положением источника звука для каждого звукового компонента.
Аудиопроцессор 707 выполнен с возможностью обработки одного или более аудиосигналов/компонентов на основании извлеченных стереофонических данных, и в частности в описанном примере на основании извлеченных данных функции HRTF.
В качестве примера, селектор 703 может извлекать один набор данных HRTF для каждого положения, предусмотренного в потоке битов. Получаемые функции HRTF могут быть сохранены в локальной памяти, то есть одна функция HRTF может быть сохранена для каждого из набора положений. При воспроизведении конкретного аудиосигнала аудиопроцессор 707 принимает соответствующие аудиоданные от аудиодетектора 709 вместе с желаемым положением. Аудиопроцессор 707 затем оценивает положение, чтобы увидеть, соответствует ли оно какой-либо из сохраненных функций HRTF с достаточной степенью близости. Если это так, то аудиопроцессор применяет эту функцию HRTF к аудиосигналу для того, чтобы сформировать стереофонический звуковой компонент. Если ни одна из сохраненных функций HRTF не является достаточно близкой для положения, аудиопроцессор 707 может продолжить извлечение двух самых близких функций HRTF и путем интерполяции между ними получить подходящую функцию HRTF. Этот подход может быть повторен для всех аудиосигналов/компонентов, и результирующие стереофонические выходные данные могут быть скомбинированы для того, чтобы сформировать стереофонические выходные сигналы. Эти стереофонические выходные сигналы затем могут быть поданы, например, в наушники.
Следует иметь в виду, что различные возможности могут использоваться для выбора подходящего набора (наборов) данных. Например, возможность может представлять собой по меньшей мере одно из вычислительного ресурса, ресурса памяти или требований или ограничений алгоритма воспроизведения.
Например, некоторые средства воспроизведения могут иметь существенные вычислительные возможности, которые позволяют им выполнять много операций высокой сложности. Это может позволить алгоритму стереофонического воспроизведения использовать сложное стереофоническое фильтрование. В частности, фильтры с длинными импульсными откликами (например фильтры FIR с большим количеством коэффициентов) могут быть обработаны такими устройствами. Соответственно, такое приемное устройство может извлекать функцию HRTF, которая представляется фильтром FIR с большим количеством коэффициентов и с большим количеством битов для каждого коэффициента.
Однако, другие средства воспроизведения могут иметь низкие вычислительные возможности, что препятствует тому, чтобы алгоритм стереофонического воспроизведения использовал сложное стереофоническое фильтрование. Для такого воспроизведения селектор 703 может выбрать набор данных, представляющий функцию HRTF фильтром FIR с небольшим количеством коэффициентов и с грубым разрешением (то есть с меньшим количеством битов на один коэффициент).
В качестве другого примера, некоторые средства воспроизведения могут иметь достаточную память для того, чтобы хранить большое количество данных HRTF. В этом случае селектор 703 может выбрать наборы данных HRTF, которые являются большими, например большим количеством коэффициентов и с большим количеством битов для каждого коэффициента. Однако для средств воспроизведения с малыми ресурсами памяти эти данные не могут быть сохранены, и соответственно селектор 703 может выбрать набор данных HRTF, который является намного меньшим, например с существенно меньшим количеством коэффициентов и/или меньшим количеством битов для каждого коэффициента.
В некоторых вариантах осуществления могут быть приняты во внимание возможности доступных алгоритмов стереофонического воспроизведения. Например, алгоритм как правило разрабатывается так, чтобы использоваться с функциями HRTF, которые представлены заданным образом. Например некоторые алгоритмы стереофонического воспроизведения используют стереофоническое фильтрование, основанное на данных QMF, другие используют данные импульсного отклика, третьи используют данные БПФ и т.д. Селектор 703 может учесть возможности индивидуального алгоритма, который должен использоваться, и может конкретно выбрать наборы данных для представления функций HRTF таким образом, который соответствует тому, который используется в конкретном алгоритме.
На самом деле в некоторых вариантах осуществления по меньшей мере некоторые из указаний представления/наборы данных относятся к различным алгоритмам обработки стереофонических аудиосигналов, и селектор 703 может выбирать набор (наборы) данных на основе алгоритма стереофонической обработки, используемого аудиопроцессором 707.
Например, если алгоритм стереофонической обработки основан на фильтровании в частотной области, селектор 703 может выбрать набор данных, представляющий функцию HRTF в соответствующей частотной области. Если алгоритм стереофонической обработки содержит свертку обрабатываемого сигнала с фильтром FIR, селектор 703 может выбрать набор данных, обеспечивающий подходящий фильтр FIR, и т.д.
В некоторых вариантах осуществления указания возможностей, используемые для выбора подходящего набор (наборов) данных, могут указывать на постоянные, предопределенные или статические возможности. В качестве альтернативы или дополнения к этому, указания возможностей в некоторых вариантах осуществления могут указывать на динамические / переменные возможности.
Например, вычислительный ресурс, доступный для алгоритма воспроизведения, может быть определен динамически, и набор данных может быть выбран так, чтобы соответствовать текущему доступному ресурсу. Таким образом, большой, более сложный и более требовательный к ресурсам набор данных HRTF может быть выбран тогда, когда имеется большое количество доступного вычислительного ресурса, тогда как меньший, менее сложный и менее требовательный к ресурсам набор данных HRTF может быть выбран тогда, когда количество доступного ресурса невелико. В такой системе качество стереофонического воспроизведения может быть увеличено, когда это возможно, за счет компромисса между качеством и вычислительным ресурсом, когда вычислительный ресурс необходим для других (более важных) функций.
Выбор выбранного набора данных стереофонического воспроизведения селектором 703 основан на указаниях представления, а не на самих данных. Это обеспечивает намного более простую и эффективную работу. В частности, селектор 703 не нуждается в получении доступа или восстановления каких-либо данных из наборов данных, а может просто извлечь указания представления. Поскольку эти указания обычно намного меньше, чем наборы данных, и как правило имеют намного более простую структуру и синтаксис, это может существенно упростить процесс выбора, уменьшая тем самым вычислительные требования для работы.
Данный подход таким образом обеспечивает очень гибкое распространение стереофонических данных. В частности, может распространяться один файл данных HRTF, который может поддерживать множество устройств и алгоритмов воспроизведения. Оптимизация процесса может быть выполнена локально отдельным средством воспроизведения так, чтобы отразить конкретные обстоятельства данного средства воспроизведения. Таким образом, достигаются улучшенные эффективность и гибкость распространения стереофонической информации.
Конкретный пример подходящего синтаксиса данных для потока битов предложен ниже. В этом примере поле ‘bsRepresentationID’ обеспечивает указание формата функции HRTF.
Более подробно, используются следующие поля:
ByteAlign() - до 7 заполняющих битов для байтового выравнивания относительно начала синтаксического элемента, в котором встречается ByteAlign().
bsFileSignature - строка из 4 символов ASCII, имеющая значение «HRTF».
bsFileVersion - указание версии файла.
bsNumCharName - количество символов ASCII в названии функции HRTF.
bsName - название функции HRTF.
bsNumFs - указывает, что функция HRTF передается для bsNumFs + 1 различных частот отсчетов.
bsSamplingFrequency - частота отсчетов в Гц.
bsReserved - зарезервированные биты.
Positions - указывает информацию о положении для виртуальных динамиков, передаваемую в данных HRTF.
bsNumRepresentations - количество представлений, передаваемых для функции HRTF.
bsRepresentationID - идентифицирует тип представления передаваемой функции HRTF. Каждый ID может использоваться только один раз для одной функции HRTF. Например, могут использоваться следующие доступные ID:
В этом конкретном примере следующий формат файла/синтаксис может использоваться для потока битов:
В некоторых вариантах осуществления наборы данных стереофонического воспроизведения могут содержать реверберационные данные. Селектор 703 может соответственно выбрать набор данных реверберации и передать его аудиопроцессору 707, который может адаптировать процесс, воздействуя на реверберацию аудиосигнала (сигналов), зависящего от этих реверберационных данных.
Многие стереофонические передаточные функции содержат безэховую часть, сопровождаемую реверберационной частью. Конкретные функции, которые содержат характеристики комнаты, такие как BRIR или BRTF, состоят из безэховой части, которая зависит от антропометрических характеристик субъекта (таких как размер головы, форма ушей и т.д.), (то есть из основной функции HRIR или HRTF), сопровождаемой реверберационной частью, которая характеризует комнату.
Реверберирующая часть содержит две временных области, обычно накладывающихся друг на друга. Первая область содержит так называемые ранние отражения, которые являются изолированными отражениями звукового источника от стен или препятствий в комнате до достижения барабанной перепонки (или измерительного микрофона). По мере того, как запаздывание увеличивается, количество отражений, присутствующих в фиксированном временном интервале, увеличивается, появляются вторичные отражения и т.д. Вторая область в реверберационной части является частью, где эти отражения больше не изолируются. Эту область называют диффузным или поздним реверберационным хвостом.
Реверберационная часть содержит намеки, которые дают слуховой системе информацию о расстоянии между источником и приемником (то есть положением, где были измерены функции BRIR), а также о размере и акустических свойствах комнаты. Энергия реверберационной части относительно энергии безэховой части в значительной степени определяет воспринимаемое расстояние до звукового источника. Временная плотность (ранних) отражений вносит вклад в восприятие размера комнаты. Обычно обозначаемое как T60, время реверберации представляет собой время, которое необходимо для того, чтобы энергетический уровень отражений упал на 60 дБ. Реверберация вызывается комбинацией размеров помещения и отражательными свойствами границ помещения. Хорошо отражающие стены (например, в ванной комнате) будут требовать большего количества отражений, чтобы их уровень уменьшился на 60 дБ, чем в том случае, когда имеется большое поглощение звука (например, в спальне с мебелью, ковром и шторами на окнах). Аналогичным образом большие комнаты имеют более длинные расстояния между отражениями и поэтому увеличивают время снижения уровня на 60 дБ по сравнению с меньшей комнатой с аналогичными отражающими свойствами.
Пример функции BRIR, содержащей реверберационную часть, проиллюстрирован на Фиг. 8.
Стереофоническая передаточная функция с учетом положения головы во многих вариантах осуществления может отражать как безэховую часть, так и реверберационную часть. Например, может быть обеспечена такая функция HRTF, которая отражает импульсный отклик, проиллюстрированный на Фиг. 8. Таким образом, в таких вариантах осуществления реверберационные данные являются частью функции HRTF, и реверберационная обработка является интегральным процессом фильтрования HRTF.
Однако в других вариантах осуществления реверберационные данные могут быть обеспечены по меньшей мере частично отдельно от безэховой части. На самом деле вычислительное преимущество при воспроизведении, например, функций BRIR может быть получено путем расщепления функции BRIR на безэховую часть и реверберационную часть. Более короткие безэховые фильтры могут быть применены со значительно меньшей вычислительной нагрузкой, чем длинные фильтры BRIR, и требуют существенно меньших ресурсов для хранения и передачи. Длинные реверберационные фильтры в таких вариантах осуществления могут быть осуществлены более эффективно с использованием синтетических ревербераторов.
Пример такой обработки аудиосигнала иллюстрируется на Фиг. 9. Фиг. 9 иллюстрирует подход для формирования одного сигнала из стереофонических сигналов. Вторая обработка может выполняться параллельно для формирования второго стереофонического сигнала.
В подходе, изображенном на Фиг. 9, воспроизводимый аудиосигнал подается к фильтру 901 HRTF, который применяет короткий фильтр HRTF, отражающий как правило безэховую часть и (частично) часть функции BRIR, соответствующую ранним отражениям. Таким образом, этот фильтр 901 HRTF отражает анатомические характеристики, а также некоторые ранние отражения, соответствующие конкретной комнате. В дополнение к этому, аудиосигнал подается к ревербератору 903, который формирует реверберационный сигнал из аудиосигнала.
Выходы фильтра 901 HRTF и ревербератора 903 затем комбинируются для того, чтобы сформировать выходной сигнал. В частности, эти выходы суммируются для того, чтобы сформировать комбинированный сигнал, который отражает как безэховую часть и ранние отражения, так и реверберационные характеристики.
Ревербератор 903 является в частности синтетическим ревербератором, таким как ревербератор Джота. Синтетический ревербератор как правило моделирует ранние отражения и плотный реверберационный хвост, используя сеть обратной связи. Фильтры, включенные в контуры обратной связи, управляют временем реверберации (T60) и окраской звука. Фиг. 10 иллюстрирует пример схематического описания модифицированного ревербератора Джота (с тремя контурами обратной связи), выводящего два сигнала вместо одного, так что он может использоваться для представления стереофонических ревербераций. Фильтры были добавлены для обеспечения управления корреляцией между ушами (u(z) и v(z)) и зависящим от ушей окрашиванием (hL и HR).
В этом примере стереофоническая обработка таким образом основана на двух отдельных и раздельных процессах, которые выполняются параллельно, после чего выходы этих двух процессов объединяются в стереофонический сигнал (сигналы). Эти два процесса могут управляться раздельными данными, то есть фильтр 901 HRTF может управляться данными фильтра HRTF, а ревербератор 903 может управляться реверберационными данными.
В некоторых вариантах осуществления наборы данных могут включить в себя как данные фильтра HRTF, так и реверберационные данные. Таким образом, для выбранного набора данных данные фильтра HRTF могут быть извлечены и использованы для настройки фильтра 901 HRTF, а реверберационные данные могут быть извлечены и использованы для настройки обработки ревербератора 903 с тем, чтобы обеспечить желаемую реверберацию. Таким образом, в данном примере реверберационная обработка адаптируется на основании реверберационных данных выбранного набора данных путем независимой адаптации обработки, которая формирует реверберационный сигнал.
В некоторых вариантах осуществления принятые наборы данных могут содержать данные только для одного из фильтрования HRTF и реверберационной обработки. Например, в некоторых вариантах осуществления принятые наборы данных могут содержать данные, которые определяют безэховую часть, а также начальную часть ранних отражений. Однако постоянная реверберационная обработка может использоваться независимо от того, какой набор данных выбран, и на самом деле как правило независимо от того, какое положение должно воспроизводиться (реверберация обычно является независимой от положений источников звука, поскольку она отражает много отражений в комнате). Это может привести к менее сложной обработке и работе, и может в частности быть подходящим для вариантов осуществления, в которых стереофоническая обработка может адаптироваться, например, к отдельным слушателям, но с воспроизведением, отражающим ту же самую комнату.
В других вариантах осуществления наборы данных могут содержать реверберационные данные без данных фильтрования HRTF. Например, данные фильтрования HRTF могут быть общими для множества наборов данных, или даже для всех наборов данных, и каждый набор данных может определять реверберационные данные, соответствующие различным характеристикам помещения. На самом деле в таких вариантах осуществления отфильтрованный функцией HRTF сигнал может быть независимым от данных выбранного набора данных. Этот подход может быть особенно подходящим для приложений, в которых обработка выполняется для одного и того же (например, номинального) слушателя, но с данными, обеспечивающими различные восприятия помещения.
В этих примерах селектор 703 может выбрать используемый набор данных на основании указаний представления реверберационных данных, обозначаемых указаниями представления. Таким образом, указания представления могут обеспечить указание того, как реверберационные данные представляются наборами данных. В некоторых вариантах осуществления указания представления могут содержать такие указания с указаниями фильтрования HRTF, тогда как в других вариантах осуществления указания представления могут содержать, например, только указания реверберационных данных.
Например, наборы данных могут содержать представления, соответствующие различным типам синтетических ревербераторов, и селектор 703 может быть выполнен с возможностью выбора набора данных, для которого указания представления указывают, что этот набор данных содержит данные для ревербератора, соответствующие алгоритму, который используется аудиопроцессором 707.
В некоторых вариантах осуществления указания представления представляют упорядоченную последовательность набора данных стереофонического воспроизведения. Например, наборы данных (для данного положения) могут соответствовать упорядоченной последовательности в порядке качества и/или сложности. Таким образом, последовательность может отражать увеличение (или уменьшение), качества стереофонической обработки, определяемой наборами данных. Процессор 603 указаний и/или процессор 605 вывода могут формировать или располагать указания представления так, чтобы отразить этот порядок.
Приемник может знать, какой параметр отражает упорядоченная последовательность. Например он может знать, что указания представления указывают последовательность в порядке увеличения (или уменьшения) качества или в порядке уменьшения (или увеличения) сложности. Селектор 703 может затем использовать это знание при выборе набора данных для стереофонического представления. В частности, селектор 703 может выбрать набор данных в ответ на положения набора данных в упорядоченной последовательности.
Такой подход может во многих сценариях обеспечить более низкую сложность, и может в частности облегчить выбор набора (наборов) данных для аудиообработки. В частности, если селектор 703 выполнен с возможностью оценки указаний представления в данном порядке (соответствующем рассмотрению наборов данных в той последовательности, в которой они упорядочены), это во многих вариантах осуществления и сценариях может привести к тому, что не нужно будет обрабатывать все указания представления для того, чтобы выбрать подходящий набор (наборы) данных.
На самом деле селектор 703 может быть выполнен с возможностью выбора набора данных стереофонического воспроизведения в качестве набора данных стереофонического воспроизведения для первого (самого раннего) набора данных в последовательности, для которого указание представления указывает на обработку воспроизведения, которую может выполнить аудиопроцессор.
В качестве конкретного примера, указания представления / наборы данных могут быть расположены в порядке уменьшения качества процесса воспроизведения, который представляют данные наборов данных. Оценивая указания представления в этом порядке и выбирая первый набор данных, с которым аудиопроцессор 707 в состоянии работать, селектор 703 может остановить процесс выбора, как только встретится указание представления, которое указывает, что соответствующий набор данных имеет данные, которые являются подходящими для использования аудиопроцессором 707. Селектор 703 не нуждается в рассмотрении дальнейших параметров, поскольку он будет знать, что этот набор данных приведет к воспроизведению наивысшего качества.
Аналогичным образом в системах, в которых желательна минимизация сложности, указания представления могут быть расположены в порядке увеличения сложности. Путем выбора набора данных первого указания представления, которое указывает на подходящее представление для обработки аудиопроцессором 707, селектор 703 может гарантировать, что достигается самая низкая сложность стереофонического воспроизведения.
Следует иметь в виду, что в некоторых вариантах осуществления упорядочение может быть сделано в порядке увеличения качества/уменьшения сложности. В таких вариантах осуществления селектор 703 может, например, обрабатывать указания представления в обратном порядке для того, чтобы достичь того же самого результата, как описано выше.
Таким образом, в некоторых вариантах осуществления упорядочение может быть выполнено в порядке уменьшения качества стереофонического воспроизведения, представленного наборами данных стереофонического воспроизведения, а в других вариантах осуществления упорядочение может быть выполнено в порядке увеличения качества стереофонического воспроизведения, представленного наборами данных стереофонического воспроизведения. Аналогичным образом в некоторых вариантах осуществления упорядочение может быть выполнено в порядке уменьшения сложности стереофонического воспроизведения, представленного наборами данных стереофонического воспроизведения, а в других вариантах осуществления упорядочение может быть выполнено в порядке увеличения сложности стереофонического воспроизведения, представленного наборами данных стереофонического воспроизведения.
В некоторых вариантах осуществления поток битов может содержать указание того, на каком именно параметре основано упорядочивание. Например, в поток битов может быть включен флаг, который указывает, основано ли упорядочивание на сложности или на качестве.
В некоторых вариантах осуществления упорядочивание может быть основано на комбинации параметров, такой как, например, величина, представляющая компромисс между сложностью и качеством. Следует иметь в виду, что для того, чтобы вычислить такую величину, может использоваться любой приемлемый подход.
Для представления качества в различных вариантах осуществления могут использоваться различные критерии. Например, для каждого представления может быть вычислен критерий расстояния, указывающий разность (например среднеквадратичную погрешность) между точно измеренной стереофонической передаточной функцией с учетом положения головы и передаточной функцией, которая описывается параметрами отдельного набора данных. Такая разность может содержать как эффект квантования коэффициентов фильтра, так и эффект усечения импульсного отклика. Она может также отражать эффект дискретизации во временной и/или частотной области (например, она может отражать частоту оцифровки или количество полос частот, используемых для описания диапазона звуковых частот). В некоторых вариантах осуществления указание качества может быть простым параметром, таким как, например, длина импульсного отклика фильтра FIR.
Аналогичным образом различные критерии и параметры могут использоваться для того, чтобы представить сложность стереофонической обработки, связанной с данным набором данных. В частности, сложность может быть указанием потребного вычислительного ресурса, то есть сложность может отражать то, насколько сложным может быть выполнение связанной стереофонической обработки.
Во многих сценариях параметры могут обычно указывать как увеличение качества, так и увеличение сложности. Например, длина фильтра FIR может одновременно указывать и на увеличение качества, и на увеличение сложности. Таким образом, во многих вариантах осуществления один и тот же порядок может отражать и сложность, и качество, и селектор 703 может использовать это при выборе. Например, он может выбрать набор данных высшего качества при условии, что сложность не превышает заданного уровня. Предполагая, что указания представления расположены в порядке уменьшения качества и сложности, это может быть достигнуто просто обработкой указаний представления и выбором набора данных первого указания, которое представляет сложность ниже желаемого уровня сложности (который может быть обработан аудиопроцессором).
В некоторых вариантах осуществления порядок указаний представления и связанных наборов данных может быть представлен положениями указаний представления в потоке битов. Например, для порядка, отражающего уменьшение качества, указания представления (для данного положения) могут просто быть расположены таким образом, что первое указание представления в потоке битов является тем, которое представляет набор данных с наивысшим качеством связанного стереофонического воспроизведения. Следующее указание представления в потоке битов является указанием, которое представляет набор данных со следующим наивысшим качеством связанного стереофонического воспроизведения и т.д. В таком варианте осуществления селектор 703 может просто сканировать принятый поток битов по порядку, и может для каждого указания представления определить, указывает ли оно на набор данных, который аудиопроцессор 707 способен использовать, или нет. Он может продолжать делать это до тех пор, пока не встретится подходящее указание, после чего никакие дальнейшие указания представления потока битов уже не надо обрабатывать, или на самом деле декодировать.
В некоторых вариантах осуществления порядок указаний представления и связанных наборов данных может быть представлен указанием, включенным во входные данные, и в частности указание для каждого указания представления может быть включено в само указание представления.
Например, каждое указание представления может содержать поле данных, которое указывает приоритет. Селектор 703 может сначала оценить все указания представления, которые содержат указание самого высокого приоритета, и определить, указывает ли какое-либо из них, что полезные данные включены в связанный набор данных. Если это так, то выбирается этот набор данных (если идентифицировано более одного, может быть применен вторичный критерий отбора, или например набор данных может быть выбран просто в случайном порядке). Если не найдено ни одного, можно продолжить оценивать все указания представления, указывающие на следующий самый высокий приоритет, и т.д. В качестве другого примера, каждое указание представления может указывать последовательный номер положения, и селектор 703 может обрабатывать указания представления для установления порядка последовательности.
Такие подходы могут потребовать более сложной обработки селектором 703, но могут обеспечить большую гибкость, такую как, например, обеспечение множества указаний представления, которые будут одинаково приоритезированы в последовательности. Это может также позволить свободно располагать каждое указание представления в потоке битов, и в частности может позволить включать каждое указание представления после связанного с ним набора данных.
Этот подход может таким образом обеспечить увеличенную гибкость, которая, например, облегчает формирование потока битов. Например, может быть существенно легче просто присоединить дополнительные наборы данных и связанные указания представления к существующему потоку битов, не реструктурируя весь поток.
Следует иметь в виду, что вышеупомянутое описание для ясности описывает варианты осуществления настоящего изобретения со ссылками на различные функциональные схемы, блоки и процессоры. Однако, должно быть очевидно, что может использоваться любое подходящее распределение функциональности между различными функциональными схемами, блоками или процессорами без умаления значения настоящего изобретения. Например, функциональность, проиллюстрированная как выполняемая отдельными процессорами или контроллерами, может быть выполнена одним и тем же процессором или контроллером. Следовательно, ссылки на конкретные функциональные блоки или схемы должны рассматриваться только как ссылки на подходящие средства для того, чтобы обеспечить описанную функциональность, а не как указание на жесткую логическую или физическую структуру или организацию.
Настоящее изобретение может быть осуществлено в любой подходящей форме, включая технические средства, программное обеспечение, встроенные программы или любую их комбинацию. Настоящее изобретение опционально может быть осуществлено по меньшей мере частично как программное обеспечение, выполняемое на одном или более процессорах и/или цифровых сигнальных процессорах. Элементы и компоненты варианта осуществления настоящего изобретения могут быть физически, функционально и логически осуществлены любым подходящим способом. На самом деле эта функциональность может быть осуществлена в единственном блоке, во множестве блоков или как часть других функциональных блоков. По существу настоящее изобретение может быть осуществлено в единственном блоке или может быть физически и функционально распределено между различными блоками, схемами и процессорами.
Хотя настоящее изобретение было описано в связи с некоторыми вариантами осуществления, следует понимать, что оно не ограничено конкретной формой, сформулированной в настоящем документе. Вместо этого объем настоящего изобретения ограничен только прилагаемой формулой изобретения. Кроме того, хотя какой-либо признак может представляться описываемым в связи с конкретными вариантами осуществления, специалисту в данной области техники будет понятно, что различные признаки описанных вариантов осуществления могут быть объединены в соответствии с настоящим изобретением. В формуле изобретения термин «содержащий» не исключает присутствия других элементов или этапов.
Кроме того, несмотря на перечисление в списке по отдельности, множество средств, элементов, схем или этапов способа может быть осуществлено с помощью, например, одной схемы, блока или процессора. Дополнительно к этому, хотя отдельные признаки могут быть включены в различные пункты формулы изобретения, возможно, что они могут быть с достижением преимущества скомбинированы, и включение в различные пункты формулы изобретения не подразумевает, что сочетание этих признаков не является выполнимым и/или полезным. Также включение конкретного признака в одну категорию пунктов формулы изобретения не подразумевает ограничение этой категорией, а скорее указывает, что данный признак одинаково применим к другим категориям пунктов формулы изобретения в зависимости от обстоятельств. Кроме того, порядок признаков в пунктах формулы изобретения не подразумевает какого-либо конкретного порядка, в котором эти признаки должны обрабатываться, и в частности порядок отдельных этапов в определении способа не подразумевает, что этапы должны быть выполнены именно в этом порядке. Вместо этого этапы могут быть выполнены в любом подходящем порядке. В дополнение к этому, упоминание единственного числа не исключают множества. Таким образом, использование единственного числа и терминов «первый», «второй» и т.д. не исключают множества. Условные обозначения в формуле изобретения приведены просто как поясняющий пример, и никоим образом не должны рассматриваться как ограничивающие область охвата формулы изобретения.
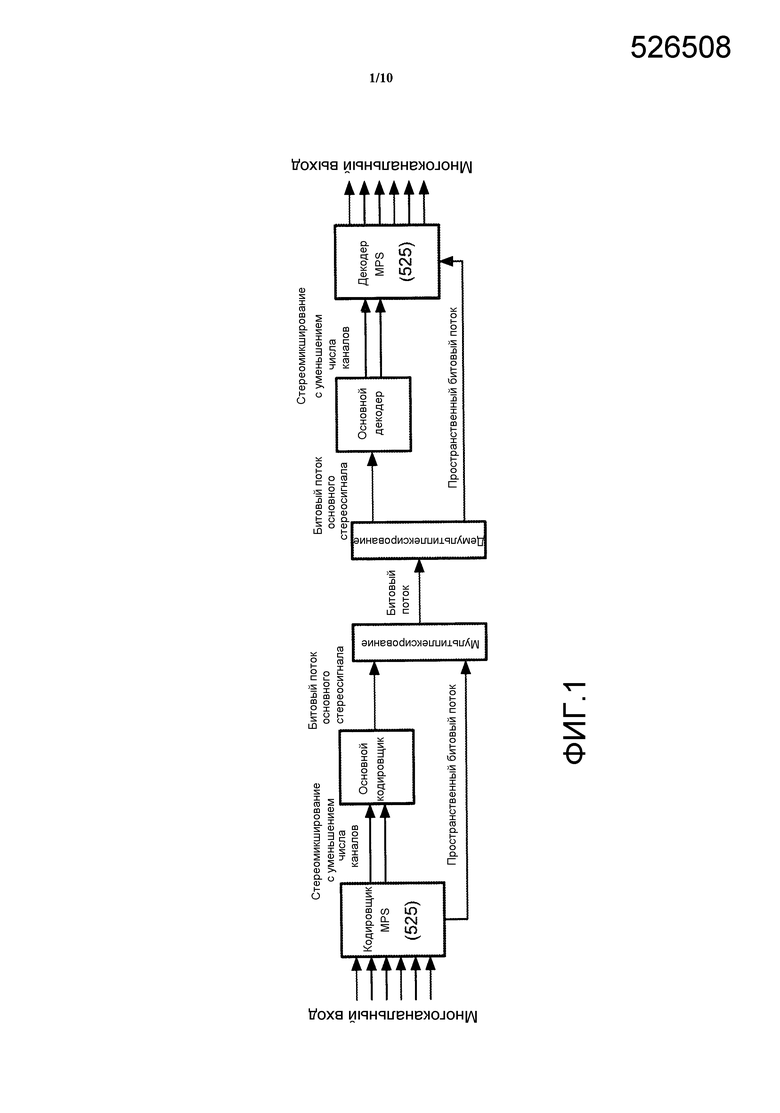
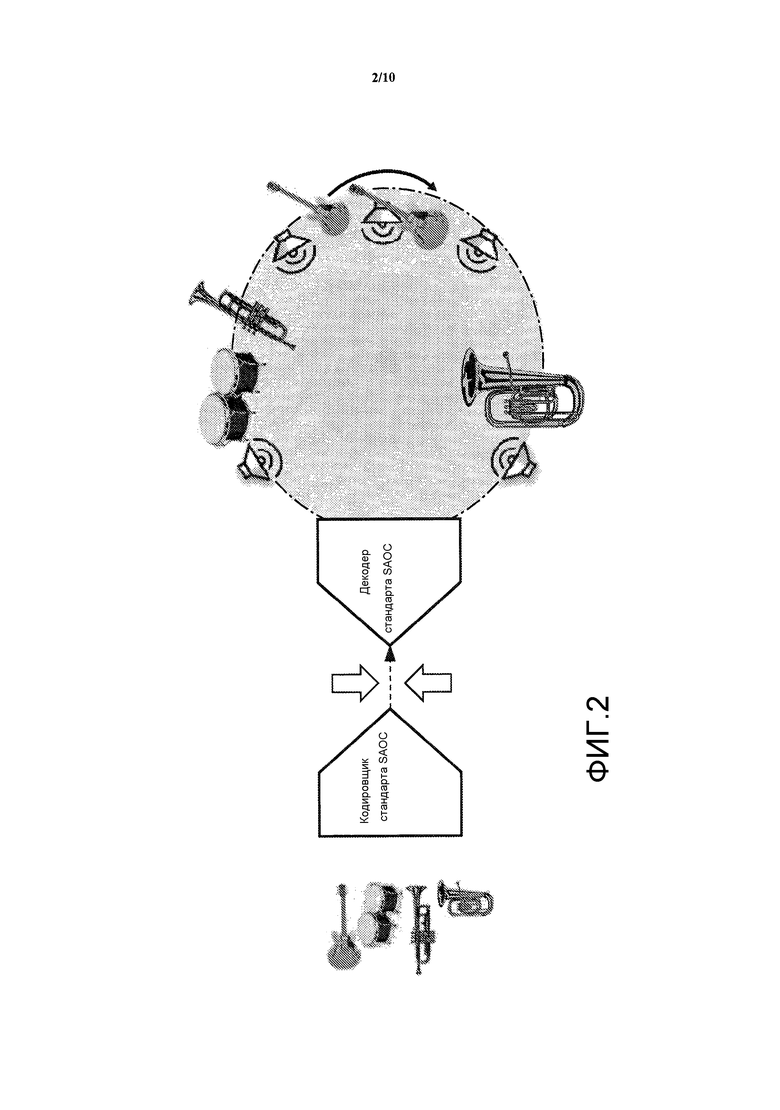
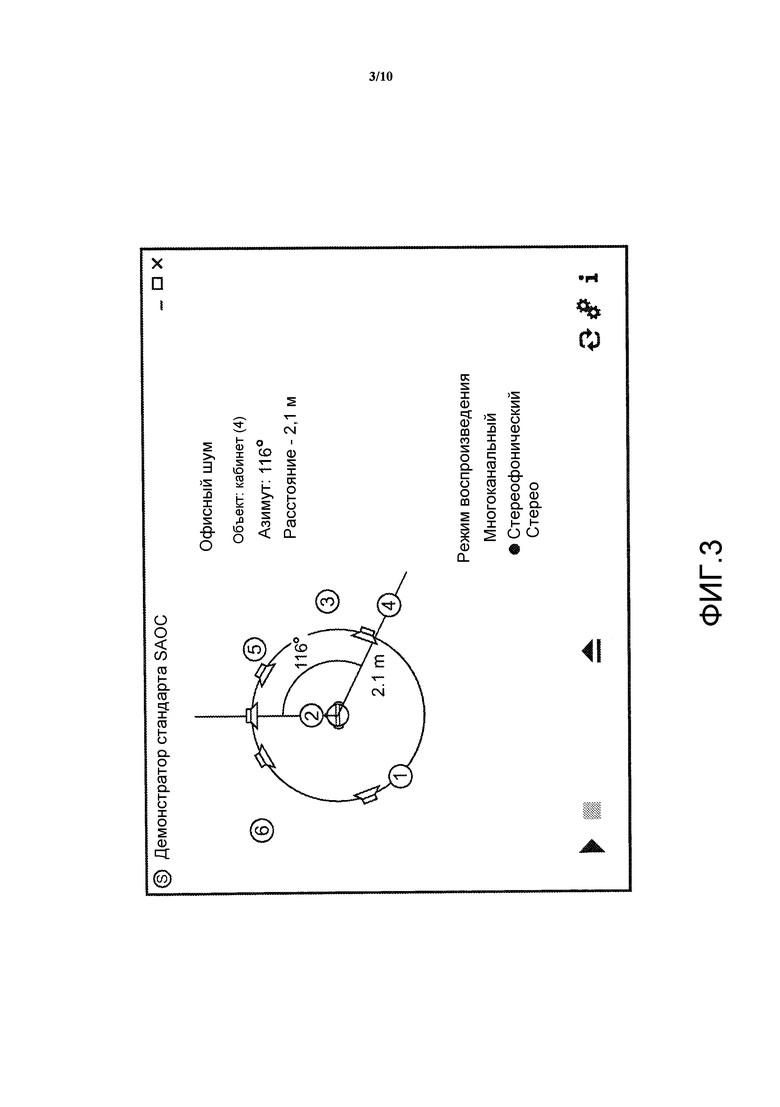
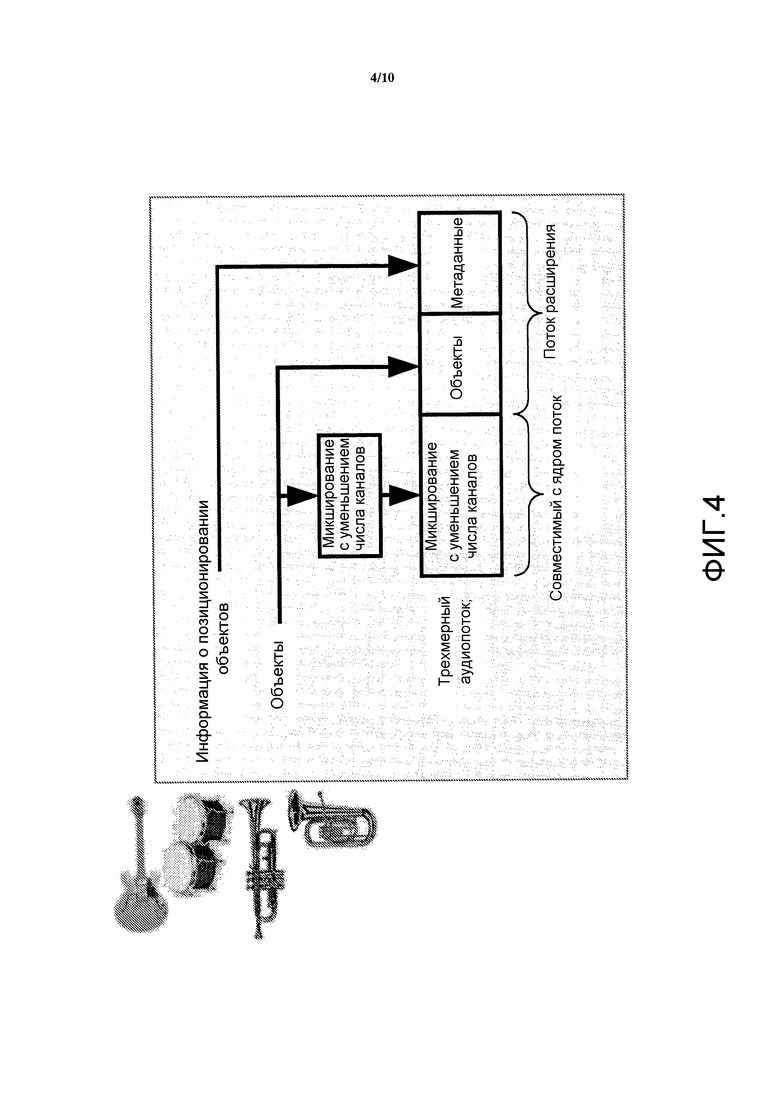
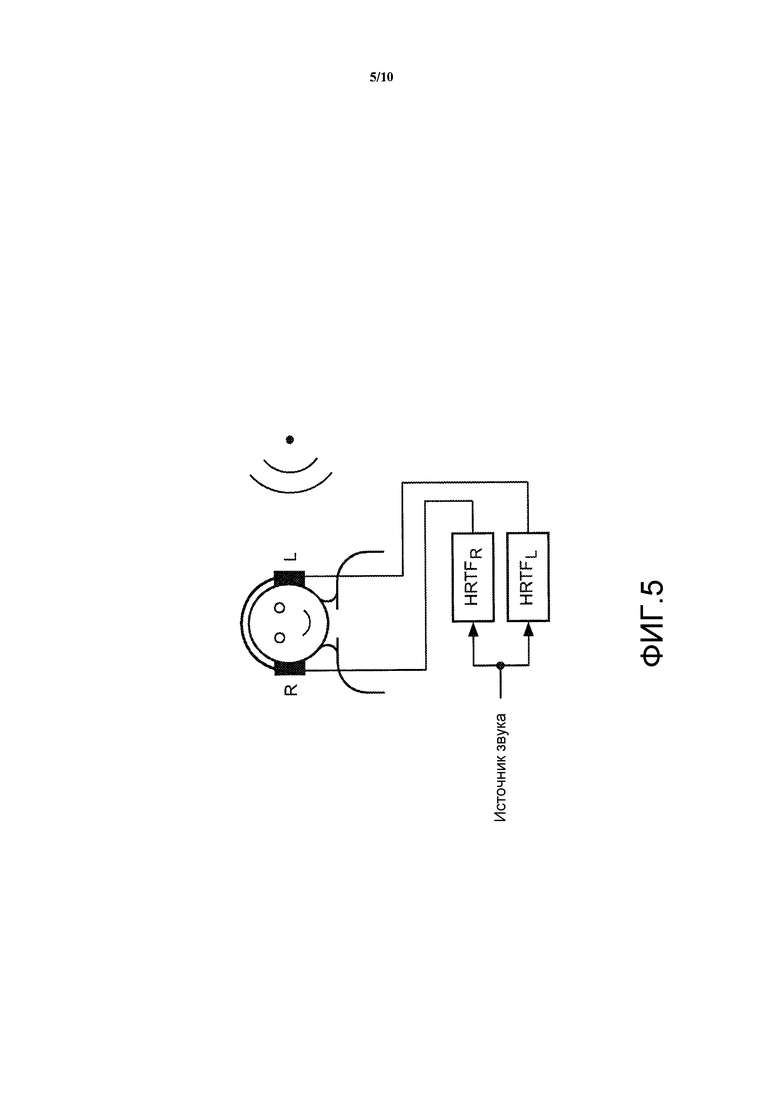
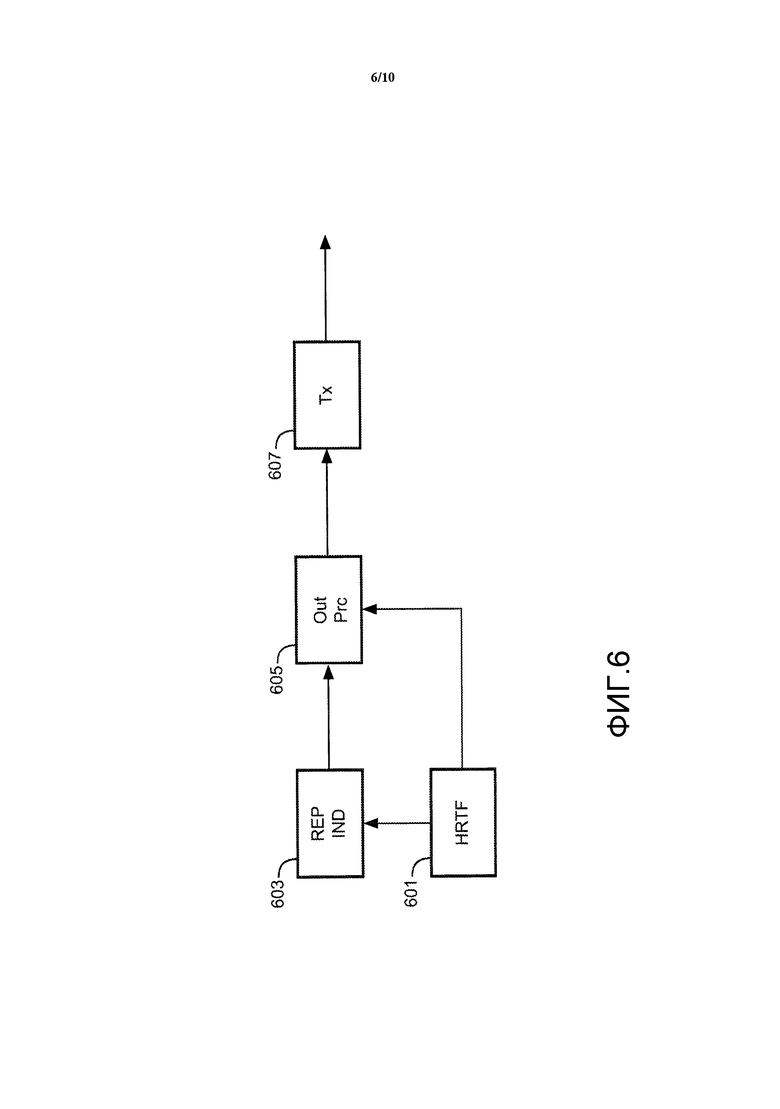
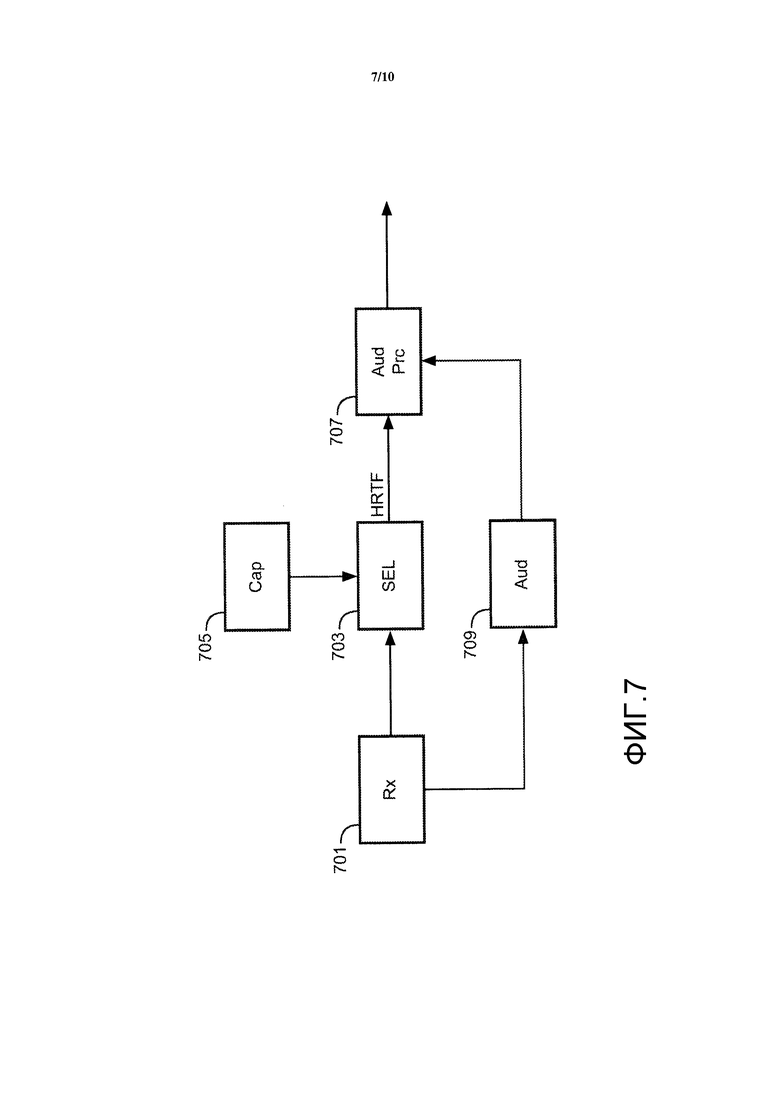
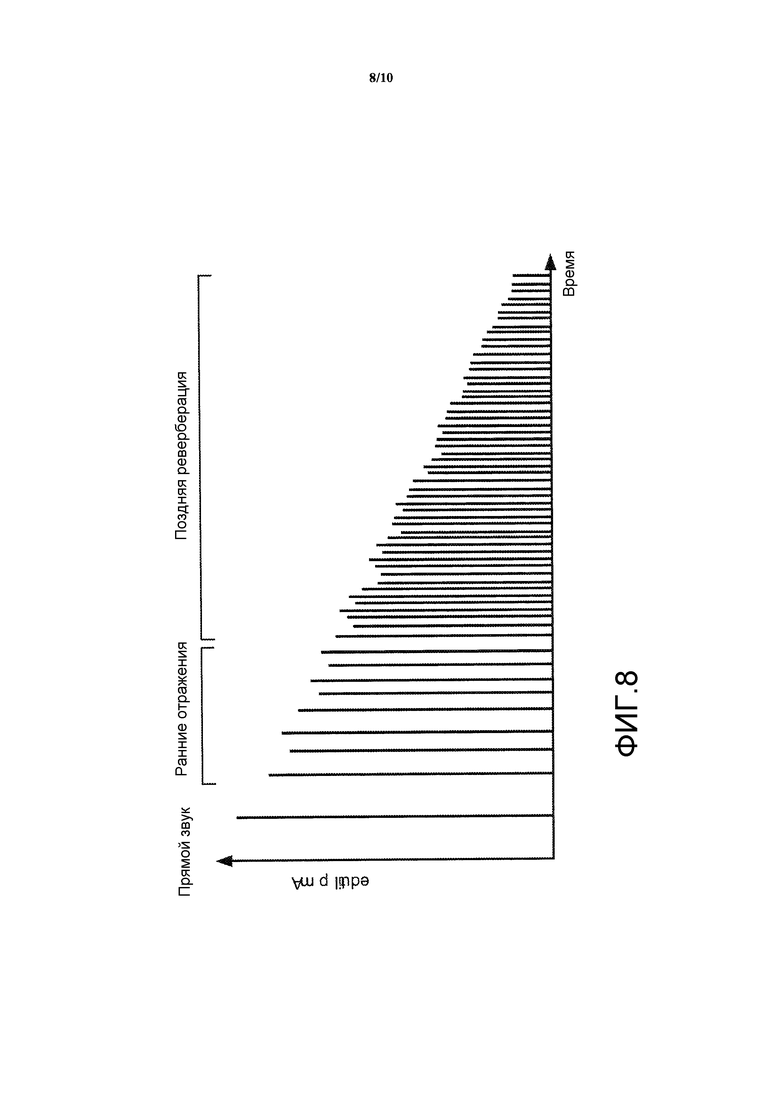
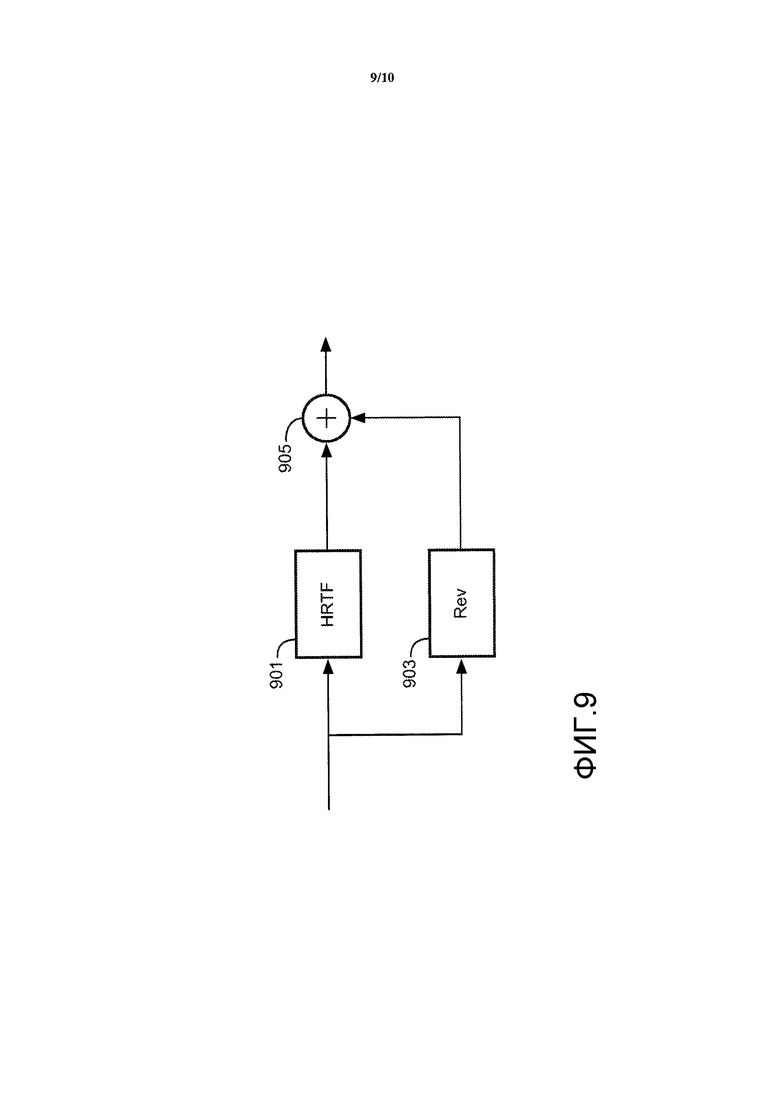
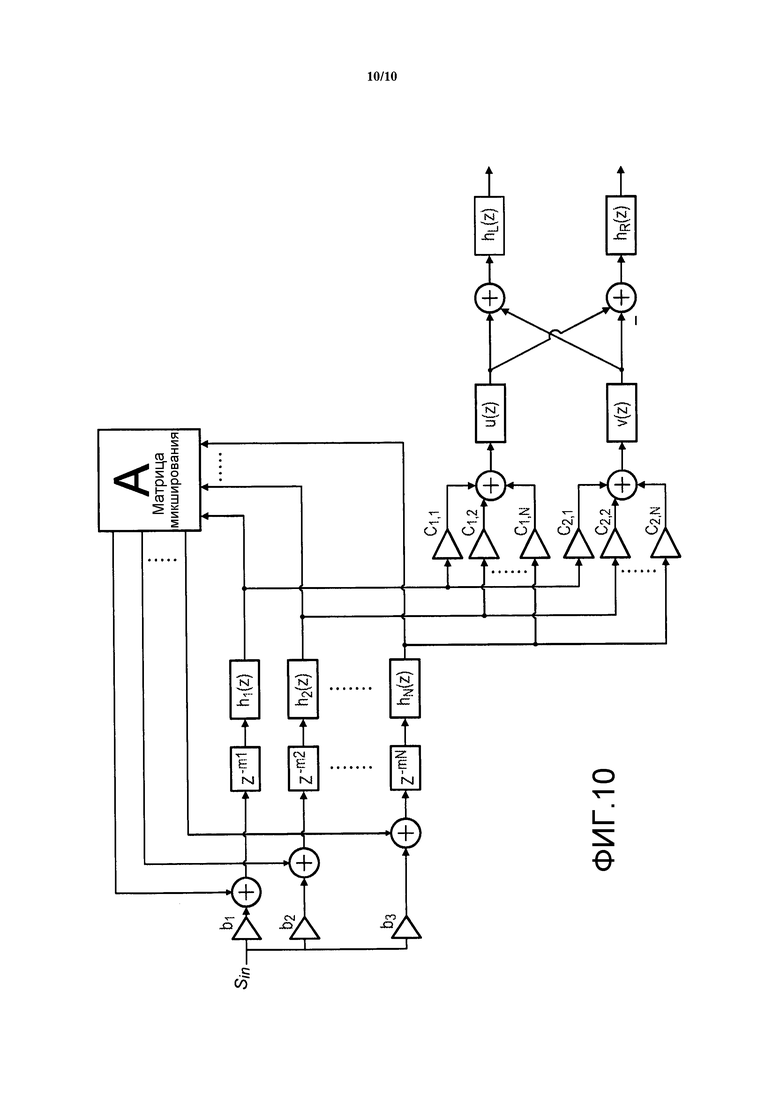
Изобретение относится к области стереофонического воспроизведения. Технический результат – обеспечение более гибкого распределения стереофонических передаточных функций с учетом положений головы. Устройство для обработки аудиосигнала содержит: приемник для приема входных данных, причем входные данные содержат множество наборов данных стереофонического воспроизведения, причем каждый набор данных стереофонического воспроизведения содержит данные, представляющие параметры для обработки стереофонического воспроизведения виртуального положения и обеспечивающие различное представление одной и той же лежащей в основе стереофонической передаточной функции с учетом положения головы, причем входные данные дополнительно содержат для каждого из наборов данных стереофонического воспроизведения указание представления, указывающее на представление для набора данных стереофонического воспроизведения; селектор для отбора выбранного набора данных стереофонического воспроизведения в ответ на указания представления и возможности устройства; и аудиопроцессор для обработки аудиосигнала в ответ на данные выбранного набора данных стереофонического воспроизведения. 4 н. и 11 з.п. ф-лы, 10 ил., 2 табл.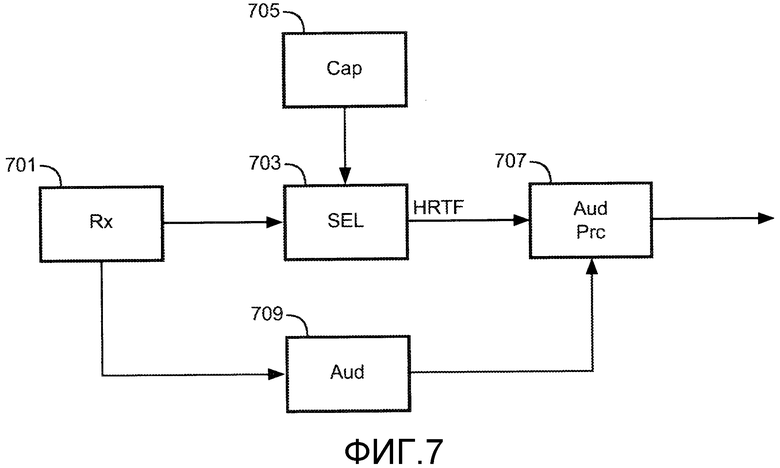
1. Устройство для обработки аудиосигнала, причем устройство содержит:
приемник для приема входных данных, причем входные данные содержат множество наборов данных стереофонического воспроизведения, причем каждый набор данных стереофонического воспроизведения содержит данные, представляющие параметры для обработки стереофонического воспроизведения виртуального положения и обеспечивающие различное представление одной и той же лежащей в основе стереофонической передаточной функции с учетом положения головы, причем входные данные дополнительно содержат для каждого из наборов данных стереофонического воспроизведения указание представления, указывающее на представление для набора данных стереофонического воспроизведения;
селектор для отбора выбранного набора данных стереофонического воспроизведения в ответ на указания представления и возможности устройства;
аудиопроцессор для обработки аудиосигнала в ответ на данные выбранного набора данных стереофонического воспроизведения.
2. Устройство по п. 1, в котором наборы данных стереофонического воспроизведения содержат данные стереофонической передаточной функции с учетом положения головы.
3. Устройство по п. 2, в котором по меньшей мере один из наборов данных стереофонического воспроизведения содержит данные стереофонической передаточной функции с учетом положения головы для множества положений.
4. Устройство по п. 1, в котором указания представления дополнительно представляют упорядоченную последовательность набора данных стереофонического воспроизведения, причем упорядоченная последовательность упорядочена с точки зрения по меньшей мере одного из качества и сложности стереофонического воспроизведения, представленного наборами данных стереофонического воспроизведения, и селектор выполнен с возможностью отбора выбранного набора данных стереофонического воспроизведения в ответ на положение выбранного набора данных стереофонического воспроизведения в упорядоченной последовательности.
5. Устройство по п. 4, в котором селектор выполнен с возможностью отбора выбранного набора данных стереофонического воспроизведения в качестве набора данных стереофонического воспроизведения для выбранного указания представления в упорядоченной последовательности, который указывает обработку воспроизведения, которую может выполнить аудиопроцессор.
6. Устройство по п. 1, в котором указания представления содержат указание типа фильтра с учетом положения головы, представленного набором данных стереофонического воспроизведения.
7. Устройство по п. 1, в котором по меньшей мере некоторые из множества наборов данных стереофонического воспроизведения включают в себя по меньшей мере одну стереофоническую передаточную функцию с учетом положения головы, описываемую представлением, выбираемым из группы, состоящей из:
представления в виде импульсного отклика во временной области;
представления передаточной функции фильтра в частотной области;
параметрического представления; и
представления фильтра в области частотных поддиапазонов.
8. Устройство по п. 1, в котором по меньшей мере некоторые представления для наборов данных стереофонического воспроизведения соответствуют различным алгоритмам обработки стереофонических аудиосигналов, и отбор выбранного набора данных стереофонического воспроизведения зависит от алгоритма стереофонической обработки, используемого аудиопроцессором.
9. Устройство по п. 1, в котором по меньшей мере некоторые наборы данных стереофонического воспроизведения содержат реверберационные данные, и аудиопроцессор выполнен с возможностью адаптации обработки реверберации в зависимости от реверберационных данных выбранного набора данных стереофонического воспроизведения.
10. Устройство по п. 9, в котором аудиопроцессор выполнен с возможностью выполнения обработки стереофонического воспроизведения, которая включает в себя формирование обработанного аудиосигнала как комбинации по меньшей мере сигнала, отфильтрованного стереофонической передаточной функцией с учетом положения головы, и реверберационного сигнала, и при этом реверберационный сигнал зависит от данных выбранного набора данных стереофонического воспроизведения.
11. Устройство по п. 9, в котором селектор выполнен с возможностью отбора выбранного набора данных стереофонического воспроизведения в ответ на указания представлений реверберационных данных, обозначенные указаниями представления.
12. Устройство для формирования потока битов, причем устройство содержит:
стереофоническую схему для обеспечения множества наборов данных стереофонического воспроизведения, причем каждый набор данных стереофонического воспроизведения содержит данные, представляющие параметры для обработки стереофонического воспроизведения виртуального положения и обеспечивающие различное представление одной и той же лежащей в основе стереофонической передаточной функции с учетом положения головы,
схему представления для обеспечения для каждого из наборов данных стереофонического воспроизведения указания представления, указывающего на представление для набора данных стереофонического воспроизведения; и
выходную схему для формирования потока битов, содержащего наборы данных стереофонического воспроизведения и указания представления.
13. Устройство по п. 12, в котором выходная схема выполнена с возможностью упорядочения указаний представления в порядке критерия характеристики стереофонического воспроизведения виртуального положения, представленной параметрами наборов данных стереофонического воспроизведения.
14. Способ обработки аудиоданных, причем способ содержит этапы, на которых:
принимают входные данные, причем входные данные содержат множество наборов данных стереофонического воспроизведения, причем каждый набор данных стереофонического воспроизведения содержит данные, представляющие параметры для обработки стереофонического воспроизведения виртуального положения и обеспечивающие различное представление одной и той же лежащей в основе стереофонической передаточной функции с учетом положения головы, причем входные данные дополнительно содержат указание представления для каждого из наборов данных стереофонического воспроизведения, указывающее на представление для набора данных стереофонического воспроизведения;
осуществляют отбор выбранного набор данных стереофонического воспроизведения в ответ на указания представления и возможности устройства; и
обрабатывают аудиосигнал в ответ на данные выбранного набора данных стереофонического воспроизведения.
15. Способ формирования потока битов, причем способ содержит этапы, на которых:
обеспечивают множество наборов данных стереофонического воспроизведения, причем каждый набор данных стереофонического воспроизведения содержит данные, представляющие параметры для обработки стереофонического воспроизведения виртуального положения и обеспечивающие различное представление одной и той же лежащей в основе стереофонической передаточной функции с учетом положения головы,
обеспечивают для каждого из наборов данных стереофонического воспроизведения указание представления, указывающее на представление для набора данных стереофонического воспроизведения;
формируют поток битов, содержащий наборы данных стереофонического воспроизведения и указание представления.
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| ИСПАРИТЕЛЬНЫЙ КУБ УСТАНОВКИ ДЛЯ ПОЛУЧЕНИЯ СПИРТА | 2000 |
|
RU2175670C1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ ФОРМИРОВАНИЯ ЗАКОДИРОВАННОГО СТЕРЕОСИГНАЛА АУДИОЧАСТИ ИЛИ ПОТОКА ДАННЫХ АУДИО | 2006 |
|
RU2376726C2 |
| ДЕКОДИРОВАНИЕ БИНАУРАЛЬНЫХ АУДИОСИГНАЛОВ | 2007 |
|
RU2409911C2 |

